3D CoCa: Contrastive Learners are 3D Captioners
3D CoCa: 对比学习器实现三维场景描述
Abstract
摘要
3D captioning, which aims to describe the content of 3D scenes in natural language, remains highly challenging due to the inherent sparsity of point clouds and weak cross-modal alignment in existing methods. To address these challenges, we propose 3D CoCa, a novel unified framework that seamlessly combines contrastive visionlanguage learning with 3D caption generation in a single architecture. Our approach leverages a frozen CLIP vision-language backbone to provide rich semantic priors, a spatially-aware 3D scene encoder to capture geometric context, and a multi-modal decoder to generate descriptive captions. Unlike prior two-stage methods that rely on explicit object proposals, 3D CoCa jointly optimizes contrastive and captioning objectives in a shared feature space, eliminating the need for external detectors or handcrafted proposals. This joint training paradigm yields stronger spatial reasoning and richer semantic grounding by aligning 3D and textual representations. Extensive experiments on the ScanRefer and Nr3D benchmarks demonstrate that 3D CoCa significantly outperforms current stateof-the-arts by $10.2%$ and $5.76%$ in CIDEr $\ @0.5\mathrm{IoU}$ , respectively. Code will be available at https://github.com/A I Geeks Group/3DCoCa.
3D字幕生成(3D captioning)旨在用自然语言描述3D场景内容,由于点云固有的稀疏性和现有方法中跨模态对齐能力较弱,该任务仍极具挑战性。为解决这些问题,我们提出3D CoCa——一种将对比式视觉语言学习与3D字幕生成无缝结合的统一框架。该方法采用冻结的CLIP视觉语言主干网络提供丰富语义先验,通过空间感知的3D场景编码器捕捉几何上下文,并利用多模态解码器生成描述性字幕。与依赖显式物体提案的两阶段方法不同,3D CoCa在共享特征空间中联合优化对比和字幕生成目标,无需外部检测器或人工提案。这种联合训练范式通过对齐3D与文本表征,实现了更强的空间推理能力和更丰富的语义基础。在ScanRefer和Nr3D基准测试上的大量实验表明,3D CoCa在CIDEr@0.5IoU指标上分别以10.2%和5.76%显著超越当前最优方法。代码将在https://github.com/AIGeeksGroup/3DCoCa发布。
CCS Concepts
CCS概念
• Computing methodologies $\rightarrow$ Scene understanding;
• 计算方法 $\rightarrow$ 场景理解;
Keywords
关键词
3D Captioning, Contrastive Learning, Multimodal Vision-Language Model
3D字幕生成、对比学习、多模态视觉-语言模型
1 Introduction
1 引言
In recent years, 3D learning research has been increasing, driven by various practical applications such as robotics, autonomous driving, and augmented reality [14, 15, 24, 39]. Within this burgeoning field, the intersection of computer vision (CV) and natural language processing (NLP) has prompted researchers to strive to bridge the gap between visual perception and language expression, thus promoting the rise of cross-modal tasks such as visual captioning. The emergence of large-scale vision-language models has brought unprecedent ed breakthroughs in the generation of captions for 2D images. With the development of 3D vision-language datasets, 3D captions have also shown promising prospects. 3D captioning extends 2D image captioning and aims to accurately perceive the 3D structure of objects and generate reasonable descriptions by leveraging a comprehensive set of attribute details and contextual interaction information between objects and their surroundings. However, due to the sparsity of point clouds and the cluttered distribution of objects, describing objects within a 3D scene remains a particularly challenging endeavor.
近年来,3D学习研究在机器人、自动驾驶和增强现实等多种实际应用的推动下不断增长[14, 15, 24, 39]。在这一新兴领域中,计算机视觉(CV)与自然语言处理(NLP)的交叉促使研究者努力弥合视觉感知与语言表达之间的鸿沟,从而推动了视觉描述等跨模态任务的兴起。大规模视觉语言模型的出现为2D图像描述生成带来了前所未有的突破。随着3D视觉语言数据集的发展,3D描述也展现出广阔前景。3D描述延伸了2D图像描述的任务范畴,旨在通过利用全面的属性细节以及物体与其周围环境的上下文交互信息,准确感知物体的3D结构并生成合理描述。然而,由于点云的稀疏性和物体分布的杂乱性,描述3D场景中的物体仍是一项极具挑战性的任务。
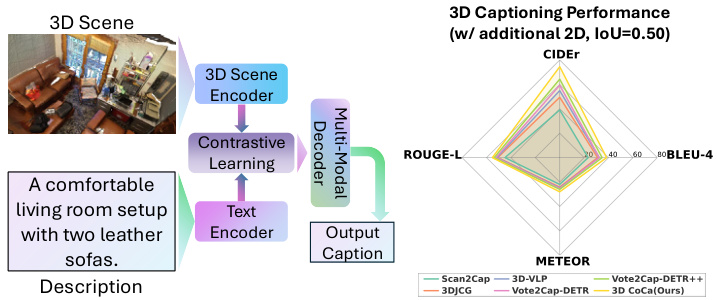
Figure 1: Conceptual homepage figure for 3D CoCa, highlighting its architecture (left) and performance (right). Left: The 3D CoCa model unifies contrastive learning and multimodal captioning in one framework. Right:Radar chart comparison of 3D CoCa and previous methods Scan2Cap [6], 3DJCG [3], 3D-VLP [43], Vote2Cap-DETR [12], Vote2Cap-DETR $^{++}$ [13] on the ScanRefer [8] benchmark.
图 1: 3D CoCa概念首页图,展示其架构(左)与性能(右)。左:3D CoCa模型将对比学习(contrastive learning)和多模态字幕生成统一在单一框架中。右:雷达图对比3D CoCa与先前方法Scan2Cap [6]、3DJCG [3]、3D-VLP [43]、Vote2Cap-DETR [12]、Vote2Cap-DETR$^{++}$[13]在ScanRefer [8]基准测试中的表现。
Early approaches to 3D dense captioning adopted a two-stage “detect-then-describe” paradigm, where object proposals were first detected from point clouds and then described individually. For example, Scan2Cap [6] is the first attempt to integrate 3D object detection and caption generation into 3D scenes in a cascade manner. [21] introduced a novel 3D language pre-training approach that uses context-aware alignment and mutual masking to learn generic representations for 3D dense captioning tasks. Although effective, a two-stage pipeline can suffer from significant performance degradation. First, the detection stage usually produces redundant bounding boxes, and thus careful tuning using the Non-Maximum Suppression (NMS) [29] operation is required, which introduces additional hyper parameters and increases computational overhead. Second, the cascade design of the “detect-then-describe” process makes caption generation highly dependent on the quality of the detection stage. In this context, the exploration of one-stage endto-end 3D dense captioning models has attracted widespread attention. Vote2Cap-DETR [12] and its advanced version Vote2Cap $\mathrm{DETR++}$ [13] are notable examples, using the Transformer framework to simultaneously locate and describe objects during inference in a single forward pass, improving both efficiency and performance. Other recent approaches, such as BiCA [23] introduced a Bi-directional Contextual Attention mechanism to disentangle object localization from contextual feature aggregation in 3D scenes and See-It-All (SIA) model [22] adopted a late aggregation strategy to capture both local object details and global contextual information with a novel aggregator. Moreover, TOD3Cap [20] employed a Bird’s Eye View (BEV) representation for the generation of object proposals and integrated the Q-Former Relation with the LLaMAAdapter to generate descriptive sentences, particularly for outdoor environments.
早期3D密集描述方法采用了两阶段"检测-描述"范式,即先检测点云中的物体候选框再单独生成描述。例如Scan2Cap [6]首次尝试以级联方式将3D物体检测与描述生成整合到3D场景中。[21]提出了一种新颖的3D语言预训练方法,通过上下文感知对齐和互掩码学习来获取3D密集描述任务的通用表征。尽管有效,两阶段流程存在明显性能缺陷:首先检测阶段通常会产生冗余边界框,需要采用非极大值抑制(NMS) [29]进行精细调参,这会引入额外超参数并增加计算开销;其次"检测-描述"的级联设计使描述生成高度依赖检测阶段质量。在此背景下,单阶段端到端3D密集描述模型研究受到广泛关注,Vote2Cap-DETR [12]及其升级版Vote2Cap-DETR++ [13]是典型代表,它们利用Transformer框架在单次前向传播中同步完成物体定位与描述,提升了效率与性能。其他最新方法如BiCA [23]采用双向上下文注意力机制解耦3D场景中的物体定位与上下文特征聚合,See-It-All(SIA)模型 [22]则通过新型聚合器实施延迟聚合策略来捕获局部物体细节与全局上下文信息。此外TOD3Cap [20]采用鸟瞰图(BEV)表征生成物体候选框,并整合Q-Former关系模块与LLaMAAdapter来生成描述性语句,尤其适用于室外环境。
Despite progress, 3D captioning remains very challenging, especially in modeling spatial relations and aligning 3D visual data with textual semantics. Describing complex spatial arrangements requires the model to understand 3D geometry and relative object positions, which is non-trivial to encode and reason about. Bridging the gap between the 3D modality and language is also difficult. Existing methods treat vision and language as separate stages with weak cross-modal interaction. This leads to suboptimal alignment between visual and textual representations.
尽管取得了进展,3D描述生成仍面临巨大挑战,尤其是在建模空间关系以及对齐3D视觉数据与文本语义方面。描述复杂的空间布局需要模型理解3D几何和物体相对位置,这对编码和推理而言并非易事。弥合3D模态与语言之间的鸿沟同样困难。现有方法将视觉与语言视为两个独立阶段,跨模态交互薄弱,导致视觉表征与文本表征的对齐效果欠佳。
These challenges point to the need for a unified framework that can enhance spatial reasoning and cross-modal alignment using strong visual-linguistic priors. Foundation models in visionlanguage research CoCa [40] have shown that contrastive pretraining on large image-text corpora yields representations with rich semantics and excellent alignment between modalities. Inspired by this, we hypothesize that bringing such powerful priors into 3D captioning will significantly improve performance and generalization. This insight motivates us to design a 3D captioning approach that jointly learns spatially-grounded captions and visual-text alignments within a single end-to-end model, leveraging knowledge from large-scale vision-language training.
这些挑战表明需要一个统一框架,利用强大的视觉-语言先验来增强空间推理和跨模态对齐。视觉语言研究中的基础模型CoCa [40]已证明,在大规模图文语料上进行对比预训练能获得具有丰富语义和出色模态对齐的表征。受此启发,我们假设将这种强大先验引入3D描述任务将显著提升性能和泛化能力。这一洞见促使我们设计了一种端到端的3D描述方法,通过联合学习空间锚定描述和视觉-文本对齐,并利用大规模视觉语言训练的知识。
In this paper, we introduce 3D CoCa (Contrastive Captioner for 3D), as illustrated in Figure 1, a novel approach that integrates contrastive learning and caption generation into a unified model for 3D scenes. The core idea is to train a 3D scene encoder and a text encoder together with a shared contrastive learning objective, while simultaneously training a multi-modal decoder to generate captions. By coupling these tasks, 3D CoCa learns a joint feature space where 3D representations and captions are deeply aligned. The model leverages rich semantic knowledge from large-scale pretraining: we build on a vision-language backbone initialized with learned visual and linguistic features, injecting strong priors about objects and language into the 3D domain. This allows the model to recognize a wide range of concepts in the scene and associate them with the correct words. Furthermore, 3D CoCa is designed to be spatially aware – the 3D scene encoder preserves geometric structure, and the decoder’s attention mechanism can attend to specific regions when wording the description. As a result, the generated captions capture not only object attributes, but also their precise spatial context, directly addressing the core difficulty of 3D captioning. In essence, our approach marries a powerful contrastive learner with a captioning model, demonstrating that contrastive learners are effective 3D captioners.
本文介绍了3D CoCa (3D对比字幕生成器),如图 1所示,这是一种将对比学习和字幕生成整合到统一3D场景模型中的创新方法。其核心思想是通过共享对比学习目标联合训练3D场景编码器和文本编码器,同时训练多模态解码器生成描述文字。通过耦合这些任务,3D CoCa学习到一个3D表征与字幕深度对齐的联合特征空间。该模型利用来自大规模预训练的丰富语义知识:我们基于具有预训练视觉和语言特征的视觉语言主干网络进行构建,将关于物体和语言的强先验知识注入3D领域。这使得模型能够识别场景中的广泛概念并将其与正确词汇关联。此外,3D CoCa具有空间感知能力——3D场景编码器保留几何结构,解码器的注意力机制在生成描述时可关注特定区域。因此,生成的字幕不仅能捕捉物体属性,还能精确描述其空间上下文关系,直接解决了3D字幕生成的核心难点。本质上,我们的方法将强大的对比学习模型与字幕生成模型相结合,证明了对比学习模型可以作为高效的3D字幕生成器。
In summary, the main contributions of this work include:
总结而言,本研究的主要贡献包括:
• We propose 3D CoCa, the first end-to-end framework to unify contrastive vision-language learning with 3D captioning. This design eliminates the need for external 3D object detectors by jointly learning to localize and describe from point clouds. • We demonstrate how to leverage strong visual-linguistic priors from large-scale image-text pre training within a 3D captioner. By integrating a contrastive alignment objective, our model attains improved semantic understanding and
• 我们提出了3D CoCa,首个将对比式视觉-语言学习与3D描述生成统一起来的端到端框架。该设计通过联合学习点云定位与描述,消除了对外部3D物体检测器的依赖。
• 我们展示了如何在大规模图文预训练中获取的强视觉-语言先验知识应用于3D描述生成器。通过整合对比对齐目标,我们的模型获得了更强的语义理解能力...
cross-modal alignment, enabling richer and more accurate captions for complex 3D scenes. • Extensive evaluations on benchmark datasets show that 3D CoCa achieves state-of-the-art captioning performance on Nr3D [1] $\langle52.84%:\mathrm{C}@0.5)$ and Scanrefer [8] $(77.13%:\mathrm{C}@0.5)$ .
跨模态对齐,为复杂3D场景生成更丰富、更准确的描述。• 在基准数据集上的大量评估表明,3D CoCa在Nr3D [1] $\langle52.84%:\mathrm{C}@0.5)$ 和Scanrefer [8] $(77.13%:\mathrm{C}@0.5)$ 上实现了最先进的描述性能。
2 Related Works
2 相关工作
3D Dense Captioning. 3D dense captioning involves localizing objects in a 3D scene and describing them in natural language. Early work like Scan2Cap [6] pioneered this task by leveraging point cloud data with spatial reasoning, marking a departure from conventional 3D detection pipelines focused only on classification and bounding boxes [4, 5, 44, 45]. Subsequent methods were built on this foundation with improved relational modeling. For example, the Multi-Order Relation Extraction (MORE) framework [19] introduced higher-order relationship reasoning, showing that richer spatial context leads to more informative and accurate captions.
3D密集描述。3D密集描述涉及在3D场景中定位物体并用自然语言描述它们。Scan2Cap [6]等早期工作通过利用点云数据和空间推理开创了这一任务,标志着与仅关注分类和边界框的传统3D检测流程 [4, 5, 44, 45] 的不同。后续方法在此基础上改进了关系建模。例如,多阶关系提取 (MORE) 框架 [19] 引入了高阶关系推理,表明更丰富的空间上下文可以生成信息量更大且更准确的描述。
The introduction of Transformer architectures further accelerated progress in 3D captioning. SpaCap3D [36] employed a Transformerbased encoder–decoder with a spatially guided encoder to capture geometric context and an object-centric decoder for attributerich descriptions. $\chi$ -Trans2Cap [42] extended this idea by distilling knowledge from 2D vision-language models into a 3D captioner, effectively transferring semantic understanding from images to point clouds. Recent works strive for unified architectures that handle multiple tasks: 3DJCG [3] uses shared Transformers to jointly optimize 3D captioning and visual grounding, and UniT3D [7] demonstrates that pre-training a Transformer on large-scale point cloud–text pairs can yield state-of-the-art results across diverse 3D scene understanding benchmarks.
Transformer架构的引入进一步加速了3D描述生成领域的进展。SpaCap3D [36] 采用了基于Transformer的编码器-解码器结构,其中空间引导编码器用于捕捉几何上下文,而面向对象的解码器则生成富含属性的描述。$\chi$-Trans2Cap [42] 通过从2D视觉-语言模型中蒸馏知识到3D描述生成器,将语义理解从图像有效迁移至点云数据。近期研究致力于构建统一的多任务架构:3DJCG [3] 使用共享Transformer同时优化3D描述生成与视觉定位任务,UniT3D [7] 则证明在大规模点云-文本对上预训练Transformer能在多种3D场景理解基准测试中取得最先进成果。
Despite these advances, most approaches still follow a two-stage “detect-then-describe” paradigm [3, 6, 36, 42], where an object detector provides regions that are then described. This separation can cause error propagation and misalignment between the vision and language components. To overcome this limitation, end-toend paradigms have been explored. Vote2Cap-DETR [12] and its improved variant Vote2Cap-DETR $^{++}$ [13] reformulate dense captioning as a direct set-prediction task, similar to DETR in 2D vision. They jointly localize and caption objects in one stage, eliminating dependence on pre-trained detectors. Through a Transformer encoder–decoder with learnable queries and iterative refinement, these one-stage models achieve competitive performance while simplifying the pipeline.
尽管取得了这些进展,大多数方法仍遵循两阶段的"检测-描述"范式 [3, 6, 36, 42],即先由物体检测器提供区域,再对这些区域进行描述。这种分离会导致视觉与语言组件之间的错误传播和错位。为克服这一局限,研究者开始探索端到端范式。Vote2Cap-DETR [12] 及其改进版 Vote2Cap-DETR$^{++}$ [13] 将密集描述任务重新定义为直接集合预测任务,类似于二维视觉中的 DETR。它们通过单阶段联合定位物体并生成描述,消除了对预训练检测器的依赖。借助可学习查询和迭代优化的 Transformer 编码器-解码器结构,这些单阶段模型在简化流程的同时实现了具有竞争力的性能。
3D Pre-training and Vision-Language Foundations. Another line of work has focused on pre-training 3D representations to provide stronger foundations for downstream tasks. Unsupervised 3D represent ation learning techniques can be categorized into global contrastive methods [28, 35] that learn holistic point cloud embeddings, local contrastive methods [37, 38] that distinguish fine-grained geometric structures or multi-view correspondences, and masked point modeling approaches [30, 41] that adapt masked auto encoding to 3D data. These approaches learn powerful geometric features; however, they operate purely on 3D geometry and lack grounding in natural language semantics.
3D预训练与视觉-语言基础。另一研究方向聚焦于预训练3D表征,为下游任务提供更强基础。无监督3D表征学习技术可分为三类:学习整体点云嵌入的全局对比方法 [28, 35] 、区分细粒度几何结构或多视角对应关系的局部对比方法 [37, 38] ,以及将掩码自编码适配到3D数据的掩码点建模方法 [30, 41] 。这些方法能学习强大的几何特征,但仅基于3D几何数据运作,缺乏自然语言语义的关联基础。
To bridge this gap, researchers have explored 3D vision-language pre-training. For example, 3D-VLP [43] uses contrastive learning to align point cloud segments with text descriptions, yielding representations that improve 3D dense captioning and visual grounding performance by injecting semantic knowledge. Similarly, UniT3D [7] showed that training on large-scale point cloud–caption pairs endows a unified model with strong multi-task 3D understanding capabilities. Such findings underscore the value of learning joint 3D–language representations as a foundation for captioning.
为弥补这一差距,研究者们探索了3D视觉-语言预训练。例如,3D-VLP [43] 采用对比学习将点云片段与文本描述对齐,通过注入语义知识获得能提升3D密集描述和视觉定位性能的表征。类似地,UniT3D [7] 证明在大规模点云-描述对上训练可使统一模型具备强大的多任务3D理解能力。这些发现凸显了学习联合3D-语言表征作为描述基础的价值。
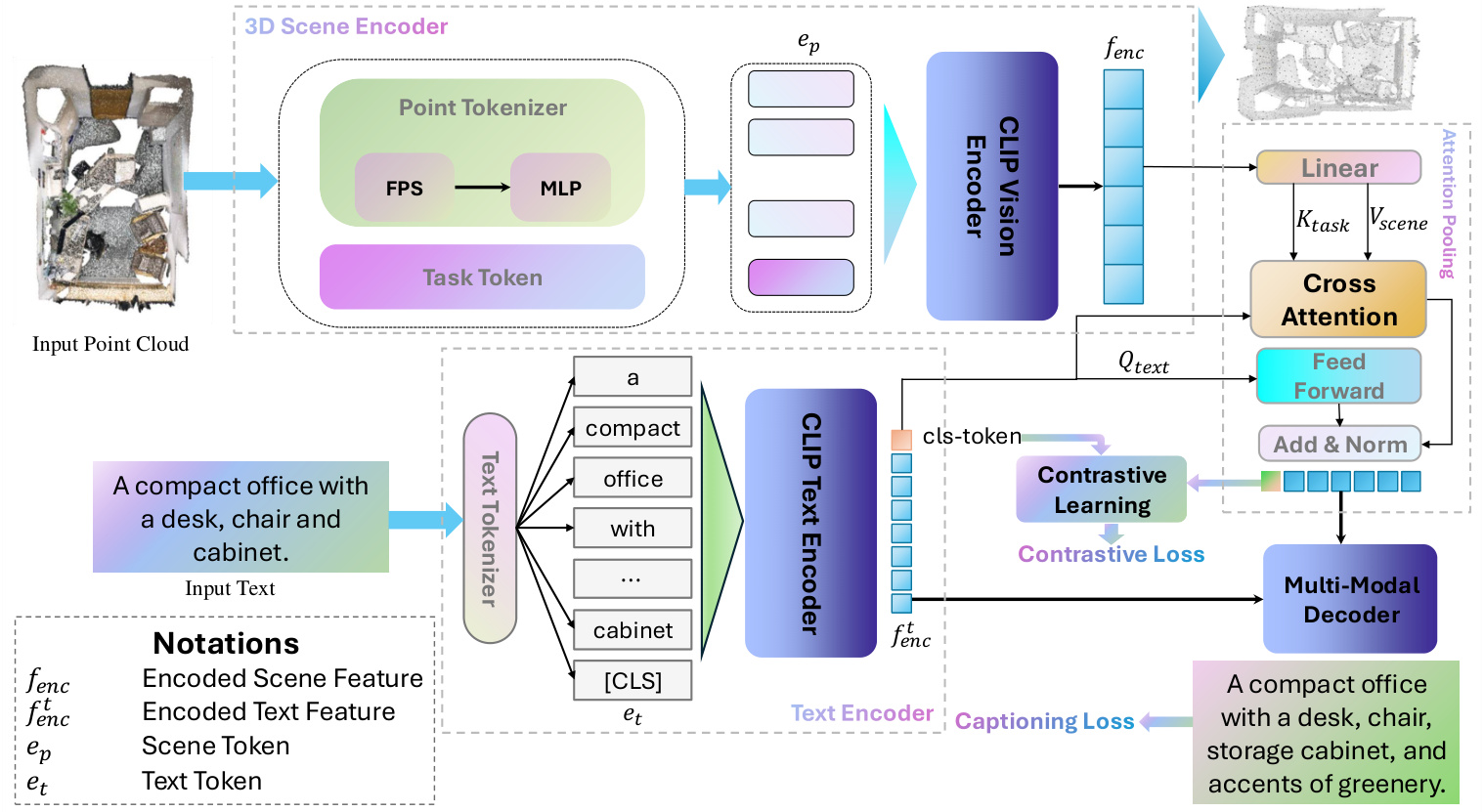
Figure 2: Illustration of a multi-modal Transformer architecture for 3D vision-language understanding. The input point cloud and textual description are processed by CLIP Vision and Text Encoders, respectively. Cross-attention mechanisms fuse these features within a Multi-Modal Decoder, enabling the generation of descriptive captions. The model training is guided by contrastive and captioning losses, promoting effective alignment between visual and textual modalities.
图 2: 面向3D视觉-语言理解的多模态Transformer架构示意图。输入点云和文本描述分别通过CLIP视觉编码器和文本编码器处理。多模态解码器中的交叉注意力机制融合这些特征,实现描述性文本生成。模型训练通过对比损失和描述损失进行优化,促进视觉与文本模态的有效对齐。
Multimodal Large Language Models for 3D Scenes. Recently, the success of large language models in vision-language tasks has sparked interest in extending them to 3D scene understanding. A representative example is LL3DA [11], a “Large Language 3D Assistant” that combines 3D visual inputs with an LLM, allowing the model to follow natural-language instructions and generate responses about a 3D scene. This enables interactive tasks such as 3D captioning, visual grounding, and question answering by leveraging the reasoning ability of LLMs. Similarly, Chat-3D [17] aligns point cloud features directly with a pretrained language model’s embedding space, demonstrating impressive conversational capabilities to describe 3D environments. Such systems illustrate the promise of MLLMs for 3D grounding, dense captioning, and dialogue-based interaction.
面向3D场景的多模态大语言模型。近期,大语言模型在视觉-语言任务中的成功激发了将其扩展至3D场景理解的研究热潮。典型代表是LL3DA [11],这个"大语言3D助手"将3D视觉输入与大语言模型结合,使模型能够遵循自然语言指令并生成关于3D场景的响应。通过利用大语言模型的推理能力,该系统可实现3D场景描述、视觉定位和问答等交互式任务。类似地,Chat-3D [17] 将点云特征直接对齐到预训练语言模型的嵌入空间,展现出描述3D环境的卓越对话能力。这些系统展示了多模态大语言模型在3D场景理解、密集描述和基于对话的交互方面的潜力。
However, these LLM-driven frameworks typically rely on an external language model and complex alignment procedures, treating captioning as just one of many tasks rather than a dedicated end-to-end objective. Consequently, fine-grained spatial details can be difficult to handle without additional tricks. In contrast, 3D CoCa takes a different route: it directly integrates multimodal pre-training into a unified captioning architecture. By jointly training a 3D scene encoder and a text decoder with a contrastive vision-language objective, 3D CoCa harnesses rich semantic priors from foundation models while remaining end-to-end trainable for the captioning task. This design eliminates the need for separate detection modules or post-hoc LLM integration; to our knowledge, 3D CoCa is the first to unify contrastive vision-language pre-training with 3D dense captioning in a single model, marking a novel paradigm in 3D captioning within the evolving MLLM-centered landscape.
然而,这些大语言模型驱动的框架通常依赖外部语言模型和复杂的对齐流程,将描述生成视为众多任务之一而非专门的端到端目标。因此,若不借助额外技巧,细粒度空间细节往往难以处理。相比之下,3D CoCa采用了不同路径:它直接将多模态预训练整合到统一的描述生成架构中。通过联合训练3D场景编码器与基于对比视觉语言目标的文本解码器,3D CoCa既能利用基础模型丰富的语义先验,又能保持端到端可训练的特性。这一设计省去了独立检测模块或事后大语言模型集成的需求;据我们所知,3D CoCa是首个在单一模型中统一对比视觉语言预训练与3D密集描述生成的方法,在以多模态大语言模型为中心的发展图景中,标志着3D描述生成的新范式。
3 The Proposed Method
3 所提出的方法
3.1 Overview
3.1 概述
In this section, we present the proposed 3D CoCa, a framework that bridges the gap between 3D point cloud representation learning and natural language understanding for captioning. Our approach builds on principles of contrastive alignment and multi-modal captioning, inspired by the successes of CLIP-style image-text models [33] and the Contrastive Captioner (CoCa) paradigm [40]. As illustrated in Figure 2, 3D CoCa consists of four key components: a 3D Scene Encoder, a Text Encoder, a Contrastive Learning module, and a Multi-Modal Fusion Decoder.
在本节中,我们提出了3D CoCa框架,该框架弥合了3D点云表示学习与自然语言理解在描述生成方面的差距。我们的方法基于对比对齐和多模态描述生成原则,其灵感来自CLIP风格的图文模型[33]和对比描述生成器(CoCa)范式[40]的成功。如图2所示,3D CoCa包含四个关键组件:3D场景编码器、文本编码器、对比学习模块和多模态融合解码器。
Unlike traditional methods that focus on either 2D images or purely 3D data, 3D CoCa leverages knowledge distilled from largescale 2D-text pre-training and adapts it to the complexities of point cloud data. Most of CLIP’s pre-trained weights are frozen in our framework to preserve the robust visual and linguistic representations, introducing only minimal additional parameters for 3D processing. The following subsections describe each component in detail. We conclude this section with the joint training objectives that bind these components into a unified model for generating captions from 3D scenes.
与传统方法仅关注2D图像或纯3D数据不同,3D CoCa利用了从大规模2D文本预训练中提取的知识,并将其适应于点云数据的复杂性。在我们的框架中,CLIP的大部分预训练权重被冻结以保留强大的视觉和语言表征,仅引入极少量额外参数用于3D处理。以下小节将详细描述每个组件。本节最后介绍了将这些组件结合为统一模型的联合训练目标,用于从3D场景生成描述。
3.2 3D Scene Encoder
3.2 3D场景编码器
The role of the 3D scene encoder is to transform an unstructured point cloud into a set of latent tokens that capture the scene’s geometric and semantic content. We build our scene encoder based on the EPCL architecture [18], a design that integrates point-based processing with a frozen 2D CLIP visual backbone. The encoder comprises three parts: (i) a point cloud tokenizer that groups points into patch tokens, (ii) a set of learnable task tokens that inject 3Dcaptioning context, and (iii) a frozen CLIP vision transformer that encodes the combined token sequence. Figure 2 (top-left) depicts how raw point clouds are converted into tokens and fed into the encoder.
3D场景编码器的作用是将非结构化的点云转换为一系列潜在token,以捕捉场景的几何和语义内容。我们的场景编码器基于EPCL架构[18]构建,该设计将基于点的处理与冻结的2D CLIP视觉主干相结合。编码器包含三部分:(i) 点云分词器,将点分组为patch token;(ii) 一组可学习的任务token,用于注入3D描述上下文;(iii) 冻结的CLIP视觉Transformer,用于编码组合后的token序列。图2(左上)展示了原始点云如何被转换为token并输入编码器。
3.2.1 Point cloud tokenizer. Given an input point cloud 𝑃 ∈ R𝑁 ×(3+𝐹 ) (with $N$ points, each described by 3D coordinates $(x,y,z)$ and $F$ additional features such as color, normal, height or multiview feature), we first convert it into a discrete token sequence. We sample $M$ representative points as patch centers using farthest point sampling (FPS) to ensure even coverage of the scene. FPS reduces redundancy in dense regions while preserving structure in sparse areas. Next, for each sampled center, we group its $K$ nearest neighbor points to form a local patch. This yields $M$ patches $P_{1},P_{2},\dots,P_{M}$ , each containing $K$ points that are spatially proximate. We then pass each patch through a small point-wise network (a series of Multi-Layer Perce ptr on s, MLPs) to encode local geometry and appearance features. This produces a set of $M$ point tokens (one per patch), each a $D_{p}$ -dimensional embedding:
3.2.1 点云分词器 (Point cloud tokenizer)。给定输入点云 𝑃 ∈ R𝑁 ×(3+𝐹 ) (包含 $N$ 个点,每个点由3D坐标 $(x,y,z)$ 和 $F$ 个附加特征如颜色、法线、高度或多视图特征描述),我们首先将其转换为离散的token序列。采用最远点采样 (FPS) 选取 $M$ 个代表点作为块中心,以确保场景的均匀覆盖。FPS能减少密集区域的冗余,同时保留稀疏区域的结构。接着,为每个采样中心分组其 $K$ 个最近邻点形成局部块,最终得到 $M$ 个块 $P_{1},P_{2},\dots,P_{M}$ ,每个块包含 $K$ 个空间邻近的点。随后,每个块通过小型逐点网络 (一系列多层感知器 MLPs) 编码局部几何和外观特征,生成 $M$ 个点token (每个块对应一个),每个token为 $D_{p}$ 维嵌入向量:
$$
E_{\boldsymbol{\ P}}(\boldsymbol{P})=[\mathbf e_{\boldsymbol{\ p}{1}},\mathbf e_{\boldsymbol{\rho}{2}},\dots,\mathbf e_{\boldsymbol{\rho}{M}}]\in\mathbb{R}^{M\times D_{\boldsymbol{P}}},
$$
$$
E_{\boldsymbol{\ P}}(\boldsymbol{P})=[\mathbf e_{\boldsymbol{\ p}{1}},\mathbf e_{\boldsymbol{\rho}{2}},\dots,\mathbf e_{\boldsymbol{\rho}{M}}]\in\mathbb{R}^{M\times D_{\boldsymbol{P}}},
$$
where $\mathbf{e}{\phi_{i}}$ is the embedding of the $i$ -th patch. By treating each local patch as a token, the continuous 3D data is converted into a structured sequence of vectors. This token iz ation balances fine local detail (within each patch of $K$ points) and global coverage (through the $M$ sampled patches) of the scene.
其中 $\mathbf{e}{\phi_{i}}$ 是第 $i$ 个局部块的嵌入向量。通过将每个局部块视为一个token,连续的3D数据被转换为结构化的向量序列。这种token化处理在场景的精细局部细节(每个包含 $K$ 个点的块内)和全局覆盖(通过采样的 $M$ 个块)之间实现了平衡。
3.2.2 Task token mechanism. While the above point tokens capture visual elements of the scene, the model still needs guidance that the task is 3D captioning (describing the scene in words). To provide this context, we introduce a small set of learnable task tokens. Each task token is an embedding vector (implemented as part of the model parameters) that is prepended to the sequence of point tokens. Following the prompt tuning approach in [26], we initialize these task token embeddings with distinct fixed values (e.g. enumerated numbers) and allow them to be learned. The task tokens act as a high-level prompt or query that informs the model about the captioning task. By attending over the entire point cloud, these tokens learn to pull out global semantic information (e.g. the overall scene context or salient objects) that is useful for generating descriptive text. In essence, the task tokens provide a shared contextual bias for the 3D scene, helping the encoder emphasize elements relevant to language description.
3.2.2 任务Token机制
虽然上述点Token捕捉了场景的视觉元素,但模型仍需明确当前任务是3D描述(用文字描述场景)。为此,我们引入了一小组可学习的任务Token。每个任务Token是一个嵌入向量(作为模型参数的一部分实现),会被预置到点Token序列之前。遵循[26]中的提示调优方法,我们用不同的固定值(例如枚举数字)初始化这些任务Token嵌入,并允许它们被学习。这些任务Token充当高级提示或查询,告知模型当前是描述任务。通过关注整个点云,这些Token学会提取对生成描述性文本有用的全局语义信息(例如整体场景上下文或显著物体)。本质上,任务Token为3D场景提供了共享的上下文偏置,帮助编码器强调与语言描述相关的元素。
3.2.3 Frozen CLIP vision encoder. After obtaining the $M$ point tokens and $m_{t}$ task tokens, we concatenate them into a single sequence:
3.2.3 冻结CLIP视觉编码器。在获得$M$个点token和$m_{t}$个任务token后,我们将它们拼接成单一序列:
$$
\lbrack{\bf e}{p_{1}},\ldots,{\bf e}{p_{M}};{\bf t}{1},\ldots,{\bf t}{m_{t}}],
$$
$$
\lbrack{\bf e}{p_{1}},\ldots,{\bf e}{p_{M}};{\bf t}{1},\ldots,{\bf t}{m_{t}}],
$$
where $\mathbf{t}{j}$ denotes the $j$ -th task token embedding. This combined sequence of length $M+m_{t}$ is then fed into the CLIP visual Transformer encoder [33]. We adopt the CLIP image encoder architecture and keep its weights frozen to leverage the rich visual features it learned from massive image-text data. Freezing the CLIP vision backbone preserves its robust representation power and stabilizes training – we avoid updating a large number of parameters, thus preventing “catastrophic forgetting” of prior knowledge. It also improves efficiency: with most parameters fixed, memory usage, and training time are significantly reduced.
其中 $\mathbf{t}{j}$ 表示第 $j$ 个任务token嵌入。这个长度为 $M+m_{t}$ 的组合序列随后被输入到CLIP视觉Transformer编码器 [33]。我们采用CLIP图像编码器架构并保持其权重冻结,以利用其从海量图文数据中学到的丰富视觉特征。冻结CLIP视觉主干网络可保留其强大的表征能力并稳定训练——我们避免更新大量参数,从而防止对先前知识的"灾难性遗忘"。这种做法还提升了效率:由于大部分参数固定,内存占用和训练时间显著降低。
The CLIP vision encoder processes the token sequence and outputs a sequence of latent features in a high-dimensional space. This output encodes both the 3D geometry and the task context. From these outputs, we can derive a global scene representation that will be used for downstream alignment with text. In practice, we obtain the global 3D scene feature $f_{e n c}$ from the CLIP encoder’s output. This feature $f_{e n c}\in\mathbb{R}^{D}$ with $D$ the encoder output dimension is a compact, semantically rich summary of the entire 3D scene conditioned on the captioning task. It encapsulates the visual content in a form suitable for aligning with language and will serve as the 3D scene embedding for the contrastive learning module.
CLIP视觉编码器处理token序列,并在高维空间中输出一系列潜在特征。该输出同时编码了3D几何结构和任务上下文。从这些输出中,我们可以提取出全局场景表征,用于后续与文本的对齐。实际操作中,我们从CLIP编码器的输出中获取全局3D场景特征$f_{enc}$。该特征$f_{enc}\in\mathbb{R}^{D}$(其中$D$为编码器输出维度)是基于描述任务生成的整个3D场景的紧凑且语义丰富的摘要。它以适合与语言对齐的形式封装了视觉内容,并将作为对比学习模块的3D场景嵌入。
3.3 Text Encoder
3.3 文本编码器
While the 3D scene encoder encodes visual information from point clouds, the text encoder processes natural language descriptions into a compatible embedding space. We use the text encoder branch of CLIP [33] to obtain language features. This text encoder is a Transformer-based model that we also keep frozen, so as to exploit the linguistic knowledge gained from large-scale pre-training. By using a fixed pre-trained text encoder, we ensure that our captions are encoded in the same semantic space as the CLIP representations, which facilitates alignment with the 3D scene features.
当3D场景编码器从点云中编码视觉信息时,文本编码器将自然语言描述处理为兼容的嵌入空间。我们采用CLIP [33]的文本编码器分支来获取语言特征。该文本编码器是基于Transformer的模型,同样保持冻结状态,以利用从大规模预训练中获得的语言知识。通过使用固定的预训练文本编码器,我们确保生成的标题与CLIP表征处于同一语义空间,从而促进与3D场景特征的对齐。
3.3.1 Text tokenizer. Given an input sentence $T$ , we first tokenize it into a sequence of $L$ tokens. Each token $w_{i}$ is mapped to an embedding vector in $\mathbb{R}^{D_{t}}$ using a learned embedding table. This produces a sequence of text token embeddings:
3.3.1 文本分词器。给定输入句子 $T$,我们首先将其分词为包含 $L$ 个 token 的序列。每个 token $w_{i}$ 通过预训练的嵌入表映射为 $\mathbb{R}^{D_{t}}$ 空间中的嵌入向量,最终生成文本 token 嵌入序列:
$$
E_{t}(T)=[{\mathbf e}{t_{1}},{\mathbf e}{t_{2}},\ldots,{\mathbf e}{t_{L}},]\in\mathbb{R}^{L\times D_{t}},
$$
$$
E_{t}(T)=[{\mathbf e}{t_{1}},{\mathbf e}{t_{2}},\ldots,{\mathbf e}{t_{L}},]\in\mathbb{R}^{L\times D_{t}},
$$
where $\mathbf{e}{t_{i}}$ corresponds to the $i$ -th token in the sentence. We prepend a special beginning-of-sequence token to this sequence, which will be used to aggregate the sentence-level information. We also add positional encodings to each token embedding $E_{t}(T)$ to preserve the order of words, which is crucial to capture the syntactic structure and meaning of the caption. We employ a subword tokenizer to handle out-of-vocabulary words by breaking them into known subunits, ensuring that any arbitrary caption can be represented by the token sequence.
其中 $\mathbf{e}{t_{i}}$ 对应句子中的第 $i$ 个 token。我们在该序列前添加一个特殊的起始序列 token,用于聚合句子级信息。同时,我们为每个 token 嵌入 $E_{t}(T)$ 添加位置编码以保留单词顺序,这对捕捉标题的句法结构和语义至关重要。我们采用子词分词器处理未登录词,将其拆分为已知子单元,确保任意标题都能通过 token 序列表示。
3.3.2 Frozen CLIP text encoder. The sequence of text embeddings $E_{t}(T)$ is then passed through the CLIP text Transformer encoder, which has $N_{t e}$ layers of multi-head self-attention and feed-forward networks. We denote the hidden states at layer $l$ as $H^{l}$ with $H^{0}=$
3.3.2 冻结CLIP文本编码器。文本嵌入序列 $E_{t}(T)$ 随后通过CLIP文本Transformer编码器,该编码器包含 $N_{t e}$ 层多头自注意力和前馈网络。我们将第 $l$ 层的隐藏状态表示为 $H^{l}$,其中 $H^{0}=$
$E_{t}(T)$ being the input. The Transformer applies its layers successively:
$E_{t}(T)$ 作为输入。Transformer 会逐层应用其结构:
$$
H^{l}=\mathrm{TransformerBlock}^{l}(H^{l-1}),l\in[1,\ldots,N t e],
$$
$$
H^{l}=\mathrm{TransformerBlock}^{l}(H^{l-1}),l\in[1,\ldots,N t e],
$$
comprising self-attention, layer normalization, and MLP sublayers in each block. We keep all weights of this text encoder frozen during training to preserve the rich language understanding it acquired through pre-training on image-text pairs. Freezing also mitigates over fitting, given that 3D captioning datasets are relatively small compared to general text corpora.
由自注意力机制、层归一化和每个模块中的MLP子层组成。在训练过程中,我们保持该文本编码器的所有权重冻结,以保留其通过图像-文本对预训练获得的丰富语言理解能力。冻结权重还能缓解过拟合问题,因为3D字幕数据集相对于通用文本语料库规模较小。
From the final layer of the text Transformer, we extract the output corresponding to the special [CLS] token, which we treat as the global text representation for the caption. Denote this vector as $\bar{f_{e n c}^{t}}\in\mathbb{R}^{D_{t}}$ . This vector encodes the semantic content of the entire description $T$ in a single feature. It will be used in our contrastive learning module to align with the 3D scene feature $f_{e n c}$ from the scene encoder. By using CLIP’s text encoder and keeping it fixed, we ensure $f_{e n c}^{t}$ lies in a language embedding space that is directly comparable to CLIP visual features, aiding the multimodal alignment.
从文本Transformer的最后一层,我们提取出与特殊[CLS] token对应的输出,将其视为标题的全局文本表示。记该向量为$\bar{f_{e n c}^{t}}\in\mathbb{R}^{D_{t}}$。该向量将整个描述$T$的语义内容编码为单一特征,它将用于我们的对比学习模块中与场景编码器提取的3D场景特征$f_{e n c}$进行对齐。通过使用CLIP的文本编码器并保持其固定,我们确保$f_{e n c}^{t}$位于可直接与CLIP视觉特征比较的语言嵌入空间中,从而辅助多模态对齐。
3.4 Contrastive Learning Paradigm
3.4 对比学习范式
To bridge the heterogeneous modalities of 3D point clouds and text, we adopt a contrastive learning strategy for feature alignment. The core idea is to project both the 3D scene feature $f_{e n c}$ and the text feature $f_{e n c}^{t}$ into a shared latent space where corresponding 3Dscenes and captions are pulled closer together, while non-matching pairs are pushed farther apart. This follows in the same spirit as the CLIP multimodal training objective, encouraging the model to learn cross-modal associations. We describe the feature projection and normalization, followed by the contrastive loss formulation.
为了弥合3D点云与文本的异构模态差异,我们采用对比学习策略进行特征对齐。其核心思想是将3D场景特征$f_{e n c}$和文本特征$f_{e n c}^{t}$映射到共享的潜在空间,在该空间中对应的3D场景与描述文本会被拉近,而不匹配的样本对则会被推远。这与CLIP多模态训练目标的设计理念一致,旨在促使模型学习跨模态关联。接下来我们将阐述特征投影与归一化操作,以及对比损失的构建方式。
3.4.1 Feature alignment. Before computing the similarity between $f_{e n c}$ and $f_{e n c}^{t}$ , we transform them into a common embedding space using learnable projection heads. In particular, we apply two small MLPs to map the features to a shared dimension. Specifically, we use a two-layer MLP to project the features:
3.4.1 特征对齐。在计算 $f_{e n c}$ 和 $f_{e n c}^{t}$ 之间的相似度之前,我们使用可学习的投影头将它们转换到一个共同的嵌入空间。具体来说,我们应用两个小型 MLP 将特征映射到共享维度。更详细地,我们使用一个两层的 MLP 来投影特征:
$$
\tilde{f}{e n c}=\mathrm{MLP}{v}\left(\boldsymbol{f}{e n c}\right),\qquad\tilde{f}{e n c}^{t}=\mathrm{MLP}{t}\left(f_{e n c}^{t}\right),
$$
$$
\tilde{f}{e n c}=\mathrm{MLP}{v}\left(\boldsymbol{f}{e n c}\right),\qquad\tilde{f}{e n c}^{t}=\mathrm{MLP}{t}\left(f_{e n c}^{t}\right),
$$
where $\mathrm{MLP}{v}$ and $\mathrm{MLP}_{t}$ are two-layer perce ptr on s for the 3D scene feature and text feature respectively. Each MLP consists of a linear layer, a ReLU activation, and a second linear layer. These learned projections ensure that the 3D and text embeddings are not only of the same dimension but also tuned for maximal alignment. After projection, we L2-normalize each feature vector to unit length:
其中 $\mathrm{MLP}{v}$ 和 $\mathrm{MLP}_{t}$ 分别是针对3D场景特征和文本特征的两层感知器。每个MLP包含一个线性层、ReLU激活函数和第二个线性层。这些学习到的投影确保3D和文本嵌入不仅维度相同,还经过调整以实现最大对齐。投影后,我们对每个特征向量进行L2归一化至单位长度:
$$
\hat{f}{e n c}=\frac{\Tilde{f}{e n c}}{\left\lVert\Tilde{f}{e n c}\right\rVert_{2}},\qquad\hat{f}{e n c}^{t}=\frac{\Tilde{f}{e n c}^{t}}{\left\lVert\Tilde{f}{e n c}^{t}\right\rVert_{2}}.
$$
$$
\hat{f}{e n c}=\frac{\Tilde{f}{e n c}}{\left\lVert\Tilde{f}{e n c}\right\rVert_{2}},\qquad\hat{f}{e n c}^{t}=\frac{\Tilde{f}{e n c}^{t}}{\left\lVert\Tilde{f}{e n c}^{t}\right\rVert_{2}}.
$$
This normalization enables direct comparison via cosine similarity during loss computation.
这种归一化使得在损失计算过程中可以通过余弦相似度进行直接比较。
3.4.2 Contrastive loss function. With the features projected and normalized, we employ a contrastive loss to train the model to align the correct 3D-text pairs. We follow the InfoNCE loss formulation popularized by CLIP. Consider a training batch of $N$ pairs of 3D scenes and their corresponding captions. We first compute the pairwise cosine similarities between all scene–caption pairs in the batch. For the $i$ -th scene and $j$ -th text in the batch, the similarity is defined as:
3.4.2 对比损失函数。通过投影和归一化特征后,我们采用对比损失来训练模型以对齐正确的3D-文本对。我们遵循CLIP推广的InfoNCE损失公式。考虑一个包含$N$对3D场景及其对应描述的训练批次,首先计算批次中所有场景-描述对之间的成对余弦相似度。对于批次中第$i$个场景和第$j$个文本,相似度定义为:
$$
\sin\left(\hat{f}{e n c,i},\hat{f}{e n c,j}^{t}\right)=\frac{\hat{f}{e n c,i}\cdot\hat{f}{e n c,j}^{t}}{\left|\hat{f}{e n c,i}\right|\left|\hat{f}_{e n c,j}^{t}\right|},
$$
$$
\sin\left(\hat{f}{e n c,i},\hat{f}{e n c,j}^{t}\right)=\frac{\hat{f}{e n c,i}\cdot\hat{f}{e n c,j}^{t}}{\left|\hat{f}{e n c,i}\right|\left|\hat{f}_{e n c,j}^{t}\right|},
$$
which is simply the dot product of the two unit-normalized feature vectors. The contrastive learning objective then maximizes the similarity of each scene with its matched caption (where $i=j$ ) while minimizing its similarity with unmatched captions $(i\neq j)$ . Specifically, for each scene 𝑖, we define the contrastive loss using a softmax over the $N$ captions:
这仅仅是两个单位归一化特征向量的点积。对比学习的目标是最大化每个场景与其匹配字幕的相似度(其中 $i=j$),同时最小化其与非匹配字幕的相似度 $(i\neq j)$。具体来说,对于每个场景 𝑖,我们使用 $N$ 个字幕的 softmax 定义对比损失:
$$
\mathcal{L}{\mathrm{Con}}=-\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp{\left(\sin(\hat{f}{e n c,i},\hat{f}{e n c,i}^{t})/\tau\right)}}{\sum_{j=1}^{N}\exp{\left(\sin(\hat{f}{e n c,i},\hat{f}_{e n c,j}^{t})/\tau\right)}},
$$
$$
\mathcal{L}{\mathrm{Con}}=-\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp{\left(\sin(\hat{f}{e n c,i},\hat{f}{e n c,i}^{t})/\tau\right)}}{\sum_{j=1}^{N}\exp{\left(\sin(\hat{f}{e n c,i},\hat{f}_{e n c,j}^{t})/\tau\right)}},
$$
where $\tau$ is a learnable temperature parameter that scales the logits before softmax. This InfoNCE loss encourages $\sin(f_{e n c,i},f_{e n c,i}^{t})$ to be larger than $s\mathrm{im}(f_{e n c,i},f_{e n c,j}^{t})$ for any $j\neq i$ , thereby aligning the $i$ -th 3D scene only with its correct description. In summary, the contrastive loss $\mathcal{L}_{\mathrm{Con}}$ provides a strong supervisory signal that couples the 3D scene features and text features, driving the model to produce a joint embedding space where cross-modal correspondences are captured.
其中 $\tau$ 是一个可学习的温度参数,用于在 softmax 之前对 logits 进行缩放。该 InfoNCE 损失函数促使 $\sin(f_{e n c,i},f_{e n c,i}^{t})$ 大于 $s\mathrm{im}(f_{e n c,i},f_{e n c,j}^{t})$(对于任意 $j\neq i$),从而仅将第 $i$ 个 3D 场景与其正确描述对齐。总之,对比损失 $\mathcal{L}_{\mathrm{Con}}$ 提供了一个强大的监督信号,将 3D 场景特征和文本特征耦合起来,驱动模型生成一个能捕获跨模态对应关系的联合嵌入空间。
3.5 Multi-Modal Fusion Decoder
3.5 多模态融合解码器
The final component of 3D CoCa is the multi-modal fusion decoder, which generates natural language descriptions for the input 3D scene. This decoder takes the aligned 3D-text representations and fuses them to produce fluent, con textually grounded sentences. We design the decoder as an auto regressive Transformer that uses cross-attention to incorporate visual context at each step of generation. In essence, the decoder serves as a conditional language model: it outputs a caption word-by-word, while attending to the 3D scene features to ensure the caption accurately describes the scene. By leveraging the aligned features from the contrastive stage, the decoder can inject detailed 3D scene information into the generation process, producing descriptions that are both coherent and faithful to the visual input.
3D CoCa的最后一个组件是多模态融合解码器,它为输入的3D场景生成自然语言描述。该解码器接收对齐的3D-文本表征,并将其融合以生成流畅且符合上下文的句子。我们将解码器设计为自回归Transformer,利用交叉注意力在生成的每一步融入视觉上下文。本质上,解码器充当条件语言模型:它逐词输出描述,同时关注3D场景特征以确保描述准确反映场景。通过利用对比阶段对齐的特征,解码器能将详细的3D场景信息注入生成过程,产生既连贯又忠实于视觉输入的描述。
The decoder operates in an auto regressive manner. It begins with a special start-of-sequence token and generates the caption one token at a time. At each time step $t$ , the decoder has access to all previously generated words $y<t$ as context, and predicts the next word $y_{t}$ . This causal self-attention mechanism within the decoder allows it to capture intra-sentence dependencies, ensuring that the resulting sentence is grammatically correct and con textually consistent. In parallel, at every decoding step, the decoder is conditioned on the 3D scene representation, so that what it writes is grounded in the scene content. We achieve this through a cross-attention mechanism.
解码器以自回归方式运行。它从一个特殊的序列起始token开始,每次生成一个token作为描述内容。在每个时间步$t$,解码器可以访问之前生成的所有单词$y<t$作为上下文,并预测下一个单词$y_{t}$。解码器内部的因果自注意力机制使其能够捕捉句子内部的依赖关系,确保生成的句子语法正确且上下文一致。同时,在每一步解码过程中,解码器都以3D场景表示为条件,从而使其生成内容基于场景内容。这一过程通过交叉注意力机制实现。
3.5.1 Cross-Attention mechanism. To integrate visual information from the 3D scene into the captioning process, the decoder incorporates cross-modal attention layers. In each decoder layer, a cross-attention layer allows the decoder to attend to the encoded 3D scene tokens (the output of the 3D scene encoder from Section 3.2). Formally, let $Q_{\mathrm{text}}$ be the query matrix containing the decoder’s current hidden states (for each position in the sequence at that layer), and let $K_{\mathrm{task}}$ and $V_{\mathrm{scene}}$ be the key and value matrices derived from the set of 3D scene token embeddings. The cross-attention is computed as:
3.5.1 跨模态注意力机制 (Cross-Attention mechanism)
为将3D场景的视觉信息整合到字幕生成过程中,解码器引入了跨模态注意力层。在每个解码器层中,跨注意力层使解码器能够关注编码后的3D场景token(即3.2节所述3D场景编码器的输出)。形式上,设 $Q_{\mathrm{text}}$ 为包含解码器当前隐藏状态的查询矩阵(对应该层序列中的每个位置),$K_{\mathrm{task}}$ 和 $V_{\mathrm{scene}}$ 为从3D场景token嵌入集合导出的键矩阵与值矩阵。跨注意力计算方式为:
$$
\mathrm{ntion}\left(Q_{\mathrm{text}},K_{\mathrm{task}},V_{\mathrm{scene}}\right)=\mathrm{softmax}\left(\frac{Q_{\mathrm{text}}K_{\mathrm{task}}^{\top}}{\sqrt{d_{k}}}\right)V_{\mathrm{scene}},
$$
$$
\mathrm{ntion}\left(Q_{\mathrm{text}},K_{\mathrm{task}},V_{\mathrm{scene}}\right)=\mathrm{softmax}\left(\frac{Q_{\mathrm{text}}K_{\mathrm{task}}^{\top}}{\sqrt{d_{k}}}\right)V_{\mathrm{scene}},
$$
where $d_{k}$ is the dimensionality of the keys. This operation produces an attention output for the decoder at each position, which is essentially a weighted sum of the 3D scene value vectors $V_{\mathrm{scene}}$ , with weights determined by the compatibility of queries $Q_{\mathrm{text}}$ with keys $K_{\mathrm{task}}$ . In this way, the decoder can retrieve the relevant visual information needed to accurately describe that object. The crossattention mechanism ensures that the caption not only reflects the overall context of the scene, but also captures important local details by looking at the appropriate regions in the 3D data.
其中 $d_{k}$ 是键向量的维度。该操作为解码器在每个位置生成注意力输出,本质上是3D场景值向量 $V_{\mathrm{scene}}$ 的加权求和,权重由查询向量 $Q_{\mathrm{text}}$ 与键向量 $K_{\mathrm{task}}$ 的匹配度决定。通过这种方式,解码器能够检索准确描述目标物体所需的相关视觉信息。这种交叉注意力机制不仅确保生成的描述反映场景整体上下文,还能通过关注3D数据中的恰当区域来捕捉重要局部细节。
The cross-attention layers are interleaved with the self-attention layers in the decoder, allowing for a continuous exchange of information between the textual and visual modalities. This iterative process of fusing self-attention and cross-attention enables the model to build a refined understanding of the scene context while preserving the grammatical and sequential coherence of the generated text.
解码器中的交叉注意力层(cross-attention)与自注意力层(self-attention)交错排列,实现了文本模态与视觉模态间的持续信息交互。这种自注意力与交叉注意力的迭代融合机制,使模型能够在保持生成文本语法连贯性与序列性的同时,逐步构建对场景上下文的精确理解。
3.5.2 Training objectives and joint optimization. Training the multimodal decoder is accomplished with a combination of captioning loss and the previously introduced contrastive loss. We jointly optimize these objectives so that the model learns to generate accurate captions and maintain cross-modal alignment at the same time. The contrastive loss $\mathcal{L}_{\mathrm{Con}}$ (Eq. (8)) applied to the encoder outputs encourages the 3D and text features to stay aligned, which provides a good initialization and constraint for the decoder’s cross-attention. Meanwhile, the decoder itself is primarily supervised by a captioning loss that measures how well its generated text matches the reference description.
3.5.2 训练目标与联合优化
多模态解码器的训练通过结合标题生成损失和先前引入的对比损失来完成。我们联合优化这些目标,使模型学会生成准确的标题,同时保持跨模态对齐。应用于编码器输出的对比损失 $\mathcal{L}_{\mathrm{Con}}$ (式 (8)) 促使3D与文本特征保持对齐,这为解码器的交叉注意力提供了良好的初始化和约束。同时,解码器本身主要由标题生成损失监督,该损失衡量其生成文本与参考描述的匹配程度。
For the caption generation task, we use the standard crossentropy loss between the predicted caption and the ground-truth caption. Given a generated caption $\hat{Y}=(\hat{y}{1},\hat{y}{2},\cdot\cdot\cdot,\hat{y}{L})$ and the corresponding ground truth $Y=\left(y_{1},\cdot\cdot\cdot\mathbf{\mu},y_{L}\right)$ , the captioning loss is defined as:
在标题生成任务中,我们使用预测标题与真实标题之间的标准交叉熵损失。给定生成标题 $\hat{Y}=(\hat{y}{1},\hat{y}{2},\cdot\cdot\cdot,\hat{y}{L})$ 和对应的真实标题 $Y=\left(y_{1},\cdot\cdot\cdot\mathbf{\mu},y_{L}\right)$ ,标题生成损失定义为:
$$
\mathcal{L}{\mathrm{Cap}}=-\sum_{t=1}^{L}\log P\left(\hat{y}{t}=y_{t}:\mid\hat{y}{<t},f_{e n c}\right),
$$
$$
\mathcal{L}{\mathrm{Cap}}=-\sum_{t=1}^{L}\log P\left(\hat{y}{t}=y_{t}:\mid\hat{y}{<t},f_{e n c}\right),
$$
where $f_{e n c}$ is the conditioning global 3D feature, ensuring that the generated sentence is tightly linked to the visual content of the scene.
其中 $f_{e n c}$ 是全局三维条件特征,确保生成的句子与场景视觉内容紧密关联。
This captioning loss is jointly optimized with the contrastive loss described in the previous section 3.4. The total loss function is expressed as:
字幕生成损失与前一节3.4中描述的对比损失联合优化。总损失函数表示为:
$$
\mathcal{L}{\mathrm{Total}}=\mathcal{L}{\mathrm{Con}}+\lambda\cdot\mathcal{L}_{\mathrm{Cap}},
$$
$$
\mathcal{L}{\mathrm{Total}}=\mathcal{L}{\mathrm{Con}}+\lambda\cdot\mathcal{L}_{\mathrm{Cap}},
$$
where $\lambda$ is a scalar hyper parameter that balances the two terms. By tuning $\lambda$ , we regulate the trade-off between enforcing multimodal feature alignment and producing accurate natural-language output. In our experiments, we set $\lambda$ to give roughly the same importance to both objectives.
其中 $\lambda$ 是一个标量超参数,用于平衡这两项。通过调整 $\lambda$ ,我们可以调节强制多模态特征对齐与生成准确自然语言输出之间的权衡。在我们的实验中,我们将 $\lambda$ 设置为使两个目标具有大致相同的重要性。
This joint optimization scheme causes the two parts of the model to reinforce each other. The contrastive alignment ensures that the visual encoder produces features that are readily attended to by the text decoder. Conversely, the act of captioning provides feedback that can refine the shared embedding space - the decoder will only succeed if the visual features $f_{e n c}$ encode the information needed for generation, which in turn pressures the encoder to capture fine-grained, caption-relevant details. Overall, the combined loss drives the model to generate captions that are not only linguistically fluent and descriptive, but also correspond closely to the 3D scene content. Jointly training 3D CoCa in this manner leads to improved integration of visual context into the language output, and a tighter cross-modal correspondence between the 3D scenes and their generated captions.
这种联合优化方案使模型的两部分相互增强。对比对齐确保视觉编码器生成的特征易于被文本解码器关注。反过来,描述行为提供了可优化共享嵌入空间的反馈——只有当视觉特征$f_{enc}$编码了生成所需信息时,解码器才能成功,这反过来促使编码器捕获细粒度的、与描述相关的细节。总体而言,联合损失驱动模型生成的描述不仅在语言上流畅且具有描述性,还与3D场景内容高度对应。通过这种方式联合训练3D CoCa,可以更好地将视觉上下文整合到语言输出中,并实现3D场景与其生成描述之间更紧密的跨模态对应。
4 Experiments
4 实验
4.1 Datasets and Evaluation Metrics
4.1 数据集与评估指标
4.1.1 Datasets. We analyze the performance of 3D captioning using two benchmark datasets: ScanRefer [8] and $\mathrm{Nr}3\mathrm{D}$ [1]. These datasets provide extensive descriptions of 3D scenes and objects generated by humans. ScanRefer contains 36,665 descriptions covering 7,875 objects in 562 scenes, while Nr3D contains 32,919 descriptions of 4,664 objects in 511 scenes. The training data for both datasets come from the ScanNet [16] database, which contains 1,201 3D scenes. For evaluation, we use 9,508 descriptions of 2,068 objects in 141 scenes from ScanRefer and 8,584 descriptions of 1,214 objects in 130 scenes from Nr3D, all of which are from the 312 3D scenes in the ScanNet validation set.
4.1.1 数据集。我们使用两个基准数据集分析3D描述生成性能:ScanRefer [8] 和 $\mathrm{Nr}3\mathrm{D}$ [1]。这些数据集包含人工生成的大规模3D场景和物体描述。ScanRefer包含562个场景中7,875个物体的36,665条描述,Nr3D包含511个场景中4,664个物体的32,919条描述。两个数据集的训练数据均来自包含1,201个3D场景的ScanNet [16]数据库。评估阶段使用ScanRefer中141个场景2,068个物体的9,508条描述,以及Nr3D中130个场景1,214个物体的8,584条描述,这些数据均来自ScanNet验证集的312个3D场景。
4.1.2 Evaluation metrics. We use four metrics to evaluate model performance: CIDEr [34] measures human-like consensus via TFIDF weighted n-gram similarity, BLEU-4 [31] evaluates the accuracy of n-gram overlap between generated and reference captions, METEOR [2] evaluates semantic alignment by considering synonyms and paraphrases, and ROUGE-L [25] evaluates structural similarity based on the longest common sub sequence, denoted as C, B-4, M, and R, respectively. Following previous studies [3, 6, 12, 19, 36], Non-Maximum Suppression (NMS) is initially applied to filter out duplicate object predictions in the proposals. In order to accurately evaluate the model’s caption generation capabilities, we adopt the $m@k I O U$ metric and set the IoU thresholds to 0.25 and 0.5 in our experiments, following [6]:
4.1.2 评估指标。我们采用四项指标评估模型性能:CIDEr [34] 通过TFIDF加权的n-gram相似度衡量类人共识,BLEU-4 [31] 评估生成描述与参考描述间n-gram重叠的准确性,METEOR [2] 通过考虑同义词和转述来评估语义对齐,ROUGE-L [25] 基于最长公共子序列评估结构相似性,分别记为C、B-4、M、R。遵循先前研究[3, 6, 12, 19, 36],我们首先应用非极大值抑制(NMS)过滤提议框中的重复物体预测。为准确评估模型描述生成能力,采用$m@k I O U$指标,并参照[6]将IoU阈值设为0.25和0.5:
Table 1: Comparison of various methods on the ScanRefer dataset [8]. We evaluate the performance of each method, with and without additional 2D input, at IoU thresholds of 0.25 and 0.5. Metrics include CIDEr (C) [34], BLEU-4 (B-4) [31], METEOR (M) [2], and ROUGE-L (R) [25]. Our proposed 3D CoCa achieves state-of-the-art results across all settings.
表 1: ScanRefer数据集[8]上各方法对比。我们在IoU阈值为0.25和0.5时评估了各方法在有无额外2D输入情况下的性能,指标包括CIDEr(C)[34]、BLEU-4(B-4)[31]、METEOR(M)[2]和ROUGE-L(R)[25]。我们提出的3D CoCa在所有设置中都达到了最先进的性能。
| 方法 | w/o 额外2D输入 (IoU=0.25) | w/o 额外2D输入 (IoU=0.50) | w/ 额外2D输入 (IoU=0.25) | w/ 额外2D输入 (IoU=0.50) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C↑ | B-4↑ | M↑ | R↑ | C↑ | B-4↑ | M↑ | R↑ | C↑ | B-4↑ | M↑ | R↑ | C↑ | B-4↑ | M↑ | R↑ | |
| Scan2Cap[6] | 53.73 | 34.25 | 26.14 | 54.95 | 35.20 | 22.36 | 21.44 | 43.57 | 56.82 | 34.18 | 26.29 | 55.27 | 39.08 | 23.32 | 21.97 | 44.78 |
| MORE[19] | 58.89 | 35.41 | 26.36 | 55.41 | 38.98 | 23.01 | 21.65 | 44.33 | 62.91 | 36.25 | 26.75 | 56.33 | 40.94 | 22.93 | 21.66 | 44.42 |
| SpaCap3d[36] | 58.06 | 35.30 | 26.16 | 55.03 | 42.76 | 25.38 | 22.84 | 45.66 | 63.30 | 36.46 | 26.71 | 55.71 | 44.02 | 25.26 | 22.33 | 45.36 |
| 3DJCG[3] | 60.86 | 39.67 | 27.45 | 59.02 | 47.68 | 31.53 | 24.28 | 51.80 | 64.70 | 40.17 | 27.66 | 59.23 | 49.48 | 31.03 | 24.22 | 50.80 |
| D3Net[9] | - | - | - | - | - | - | - | - | - | - | - | - | 46.07 | 30.29 | 24.35 | 51.67 |
| 3D-VLP[43] | 64.09 | 39.84 | 27.65 | 58.78 | 50.02 | 31.87 | 24.53 | 51.17 | 70.73 | 41.03 | 28.14 | 59.72 | 54.94 | 32.31 | 24.83 | 51.51 |
| Vote2Cap-DETR[12] | 71.45 | 39.34 | 28.25 | 59.33 | 61.81 | 34.46 | 26.22 | 54.40 | 72.79 | 39.17 | 28.06 | 59.23 | 59.32 | 32.42 | 25.28 | 52.53 |
| Unit3D[7] | - | - | - | - | - | - | - | - | - | - | - | - | 46.69 | 27.22 | 21.91 | 45.98 |
| Vote2Cap-DETR++[13] | 76.36 | 41.37 | 28.70 | 60.00 | 67.58 | 37.05 | 26.89 | 55.64 | 77.03 | 40.99 | 28.53 | 59.59 | 64.32 | 34.73 | 26.04 | 53.67 |
| 3D CoCa (Ours) | 85.42 | 45.56 | 30.95 | 61.98 | 77.13 | 41.23 | 28.52 | 57.40 | 86.12 | 44.79 | 30.75 | 61.45 | 74.52 | 38.42 | 28.03 | 55.23 |
where $N$ represents the total number of annotated objects in the evaluation dataset, $\hat{c}{i}$ is the generated caption, $C_{i}$ is the groundtruth caption, and $m$ can be any natural language generation metric, such as CIDEr [34], METEOR [2], BLEU-4 [31], and ROUGE-L [25].
其中 $N$ 表示评估数据集中标注对象的总数,$\hat{c}{i}$ 是生成的描述,$C_{i}$ 是真实描述,$m$ 可以是任何自然语言生成指标,例如 CIDEr [34]、METEOR [2]、BLEU-4 [31] 和 ROUGE-L [25]。
4.2 Implementation Details
4.2 实现细节
We provide implementation details of different baselines. “w/o additional $2\mathrm{D}^{\mathrm{s}}$ means that the input $\mathcal{P}\in\mathbb{R}^{40,000\times10}$ contains the absolute positions of 40, 000 points representing the 3D scene, as well as color, normal, and height. “additional $2\mathrm{D}^{\mathfrak{s}}$ means that we replace the color information with 128-dimensional multiview features extracted from 2D images by ENet [10] following [6]. The 3D scene encoder backbone is based on EPCL [18], integrated with the frozen CLIP visual encoder [33], and the text embedding is obtained by the frozen CLIP text encoder.
我们提供不同基线的实现细节。"w/o additional $2\mathrm{D}^{\mathrm{s}}$"表示输入$\mathcal{P}\in\mathbb{R}^{40,000\times10}$包含代表3D场景的40,000个点的绝对位置,以及颜色、法线和高度信息。"additional $2\mathrm{D}^{\mathfrak{s}}$"表示我们使用ENet [10] 从2D图像提取的128维多视角特征(遵循[6]的方法)替换颜色信息。3D场景编码器主干基于EPCL [18],集成冻结的CLIP视觉编码器 [33],文本嵌入通过冻结的CLIP文本编码器获取。
We train the models for 1,080 epochs using the standard crossentropy loss and contrastive loss on ScanRefer [8] and $\mathrm{Nr}3\mathrm{D}$ [1], using the AdamW optimizer [27] with a learning rate of 0.1, a batch size of 4, and a cosine annealing learning rate scheduler. All experiments mentioned above are conducted on a single RTX4090 GPU.
我们使用标准交叉熵损失和对比损失在ScanRefer [8] 和 $\mathrm{Nr}3\mathrm{D}$ [1] 上训练模型1,080个周期,采用AdamW优化器 [27],学习率为0.1,批大小为4,并配合余弦退火学习率调度器。上述所有实验均在单块RTX4090 GPU上完成。
4.3 Comparative Study
4.3 对比研究
In this section, we compare the performance with existing works on metrics C, M, B-4, R as abbreviations for CIDEr [34], METEOR [2], BLEU-4 [31], Rouge-L [25] under IoU thresholds of 0.25, 0.5 for ScanRefer (Table 1) and 0.5 for $\mathrm{Nr}3\mathrm{D}$ (Table 2). In both tables, "-" indicates that neither the original paper nor any follow-up works provide such results.
在本节中,我们比较了现有工作在指标 C (CIDEr [34])、M (METEOR [2])、B-4 (BLEU-4 [31])、R (Rouge-L [25]) 上的性能,其中 ScanRefer 在 IoU 阈值为 0.25 和 0.5 时的结果见 (表 1),$\mathrm{Nr}3\mathrm{D}$ 在 IoU 阈值为 0.5 时的结果见 (表 2)。两个表格中 "-" 表示原始论文或后续工作均未提供相关结果。
4.3.1 Scanrefer. The description in ScanRefer includes the attributes of the object and its spatial relationship with surrounding objects.
4.3.1 Scanrefer。ScanRefer中的描述包含对象的属性及其与周围物体的空间关系。
Table 2: Comparison on Nr3D [1] at $\mathbf{IoU}{=}\mathbf{0.5}$ . Our model outperforms existing methods, demonstrating higher CIDEr (C) [34], BLEU-4 (B-4) [31], METEOR (M) [2], and ROUGE-L (R) [25] scores.
As shown in Table 1, our method outperforms the existing methods in all data settings and IoU thresholds.
表 2: Nr3D [1] 在 $\mathbf{IoU}{=}\mathbf{0.5}$ 下的对比。我们的模型优于现有方法,展现出更高的 CIDEr (C) [34]、BLEU-4 (B-4) [31]、METEOR (M) [2] 和 ROUGE-L (R) [25] 分数。
| 方法 | C@0.5 | B-4@0.5 | M@0.5 | R@0.5↑ |
|---|---|---|---|---|
| Scan2Cap [6] | 27.47 | 17.24 | 21.80 | 49.06 |
| SpaCap3d[36] | 33.71 | 19.92 | 22.61 | 50.50 |
| D3Net [9] | 33.85 | 20.70 | 23.13 | 53.38 |
| 3DJCG [3] | 38.06 | 22.82 | 23.77 | 52.99 |
| Vote2Cap-DETR[12] | 43.84 | 26.68 | 25.41 | 54.43 |
| Vote2Cap-DETR++ [13] | 47.08 | 27.70 | 25.44 | 55.22 |
| 3D CoCa(我们的) | 52.84 | 29.29 | 25.55 | 56.43 |
如表 1 所示,我们的方法在所有数据设置和 IoU 阈值下均优于现有方法。
4.3.2 Nr3D. The $\mathrm{Nr}3\mathrm{D}$ dataset evaluates the model’s ability to interpret human-spoken, free-form object descriptions. As shown in Table 2, our approach achieves significant performance improvements over existing models in generating diverse descriptions.
4.3.2 Nr3D。$\mathrm{Nr}3\mathrm{D}$数据集评估模型对人类口语化自由形式物体描述的解析能力。如表 2 所示,我们的方法在生成多样化描述方面较现有模型实现了显著性能提升。
4.4 Ablation Study
4.4 消融实验
Table 3: The impact of Contrastive Learning Loss weight 𝜆 on the model description performance. Four evaluation indicators, CIDEr(C) [34], BLEU-4(B-4) [31], METEOR(M) [2], and ROUGE-L(R) [25] are listed.
表 3: 对比学习损失权重 𝜆 对模型描述性能的影响。列出了四个评估指标:CIDEr(C) [34]、BLEU-4(B-4) [31]、METEOR(M) [2] 和 ROUGE-L(R) [25]。
| (对比权重) | C@0.5↑ | B-4@0.5↑ | M@0.5↑ | R@0.5↑ |
|---|---|---|---|---|
| 0 | 74.12 | 40.98 | 27.45 | 58.76 |
| 0.1 | 77.30 | 41.80 | 28.10 | 59.60 |
| 0.5 | 79.55 | 42.55 | 28.75 | 60.40 |
| 1.0 | 85.42 | 45.56 | 30.95 | 61.98 |
| 2.0 | 76.89 | 41.50 | 28.00 | 59.30 |
4.4.1 Contrastive learning loss impact analysis. We first investigate the impact of using contrastive learning loss and the sensitivity to different weight coefficients(𝜆). By controlling the contrastive loss weight coefficient $\lambda={0,0.1,0.5,1.0,2.0}$ , the performance of the model was compared without contrastive learning and with different strength contrastive learning strategies. As shown in Table 3, it can be seen that when contrastive loss is not used, the model performs the worst in all indicators; the performance is significantly improved after moderate introduction of contrastive learning. For
4.4.1 对比学习损失影响分析。我们首先研究了使用对比学习损失的影响以及不同权重系数(𝜆)的敏感性。通过控制对比损失权重系数$\lambda={0,0.1,0.5,1.0,2.0}$,比较了不使用对比学习与采用不同强度对比学习策略时的模型性能。如表3所示,当不使用对比损失时,模型在所有指标上表现最差;适度引入对比学习后性能显著提升。对于

Figure 3: A visual comparison on the ScanRefer [8] dataset showcasing indoor scenes described by Vote2Cap-DETR $^{++}$ [13], our method (Ours), and the ground truth (GT), highlighting differences in descriptive accuracy and style.
图 3: ScanRefer [8] 数据集的视觉对比,展示了 Vote2Cap-DETR$^{++}$ [13]、我们的方法 (Ours) 和真实标注 (GT) 描述的室内场景,突出了描述准确性和风格上的差异。
example, when $\lambda$ increases from 0 to 0.5, CIDEr increases from $74.12%$ to $79.55%$ , and the best performance is achieved when $\lambda{=}1$ . However, after increasing the weight to 2.0, the indicator dropped slightly, which is still better than in the case without contrast loss. The above results show that an appropriate amount of contrast learning objectives can improve the model’s ability to align and capture the semantics of 3D scenes, thereby improving the description quality.
例如,当$\lambda$从0增加到0.5时,CIDEr从$74.12%$提升至$79.55%$,且在$\lambda{=}1$时达到最佳性能。然而,当权重增至2.0后,指标略有下降,但仍优于未使用对比损失的情况。上述结果表明,适量的对比学习目标能增强模型对齐和捕捉3D场景语义的能力,从而提升描述质量。
Table 4: Comparison of the impact of different 3D point cloud encoder architectures on description performance. “EPCL” is the encoder proposed in this paper, and “PointNet++” is the traditional point cloud encoder.
表 4: 不同3D点云编码器架构对描述性能的影响对比。"EPCL"是本文提出的编码器,"PointNet++"是传统点云编码器。
| 编码器架构 | C@0.5↑ | B-4@0.5↑ | M@0.5↑ | R@0.5↑ |
|---|---|---|---|---|
| PointNet++ (基线) | 72.48 | 38.95 | 26.80 | 56.30 |
| EPCL (本文提出) | 85.42 | 45.56 | 30.95 | 61.98 |
4.4.2 Point cloud encoder structure analysis. We compared the performance difference between the proposed EPCL point cloud encoder fused with CLIP features and the traditional PointNet $^{++}$ [32] point cloud encoder under the same settings. From Table 4, it can be seen that when using our EPCL-based encoder, the model performance is significantly better than that of $\mathrm{PointNet++}$ , for example, CIDEr exceeds PointNe $^{\cdot++}$ by $12.94%$ . The comprehensive improvement of various indicators shows that the EPCL framework combined with the pre-trained CLIP visual features effectively enhances the semantic expression and spatial modeling capabilities of point clouds and can capture richer scene information, thereby generating more accurate and detailed descriptions.
4.4.2 点云编码器结构分析。我们在相同设置下比较了融合CLIP特征的EPCL点云编码器与传统PointNet++ [32]点云编码器的性能差异。从表4可以看出,当使用基于EPCL的编码器时,模型性能明显优于PointNet++,例如CIDEr指标超过PointNet++达12.94%。各项指标的综合提升表明,结合预训练CLIP视觉特征的EPCL框架有效增强了点云的语义表达与空间建模能力,能够捕捉更丰富的场景信息,从而生成更准确细致的描述。
Table 5: The impact of different caption generation decoders on model performance. Comparison of the description indicators of the original GPT-2 generator and the CoCa-style multimodal decoder in this paper under the same visual features.
表 5: 不同标题生成解码器对模型性能的影响。在相同视觉特征下,原始 GPT-2 生成器与本文提出的 CoCa 风格多模态解码器的描述指标对比。
| 标题解码器 | C@0.5↑ | B-4@0.5↑ | M@0.5↑ | R@0.5↑ |
|---|---|---|---|---|
| GPT-2Captioner (基线) | 76.20 | 41.00 | 27.80 | 59.50 |
| CoCa Transformer (本文方案) | 85.42 | 45.56 | 30.95 | 61.98 |
4.4.3 Decoder architecture comparison. Finally, we analyze the impact of the caption generation decoder structure on performance while keeping the output features of the visual encoder unchanged. We replace the CoCa-style multimodal Transformer decoder with the traditional GPT-2 text generation model. As shown in Table 5, it can be seen that the model description quality is significantly reduced when using the GPT-2 captioner. This demonstrates that the CoCa-style Transformer decoder in our approach can more effectively incorporate contrastive ly learned aligned visual features into the language generation process, resulting in descriptions that are more semantically rich and more closely related to the scene.
4.4.3 解码器架构对比。最后,在保持视觉编码器输出特征不变的情况下,我们分析了描述生成解码器结构对性能的影响。我们将CoCa风格的多模态Transformer解码器替换为传统的GPT-2文本生成模型。如表5所示,使用GPT-2描述生成器时模型描述质量显著下降。这表明我们方法中的CoCa风格Transformer解码器能更有效地将对比学习对齐的视觉特征融入语言生成过程,从而生成语义更丰富、与场景关联更紧密的描述。
4.5 Qualitative Results
4.5 定性结果
We compare qualitative results with the state-of-the-art Vote2Cap $\mathrm{DETR++}$ model [13] in Figure 3. It can be seen that our method can accurately describe the attributes and categories of 3D scenes.
我们在图 3 中与最先进的 Vote2Cap $\mathrm{DETR++}$ 模型 [13] 进行了定性结果对比。可以看出,我们的方法能够准确描述 3D 场景的属性和类别。
5 Conclusion
5 结论
In this work, we propose 3D CoCa, a unified contrastive-captioning framework for 3D vision-language tasks. By jointly learning contrastive 3D-text representations and caption generation within a single model, 3D CoCa eliminates the need for any explicit 3D object detectors or proposal stages. This unified approach enables direct 3D-to-text alignment in a shared feature space, leading to improved spatial reasoning and more precise semantic grounding compared to previous methods. Experiments on two widely used datasets validate that our proposed 3D CoCa model significantly outperforms existing methods across standard captioning metrics and proves the benefits of our contrastive learning strategy.
在本工作中,我们提出了3D CoCa,一个用于3D视觉语言任务的统一对比-描述框架。通过在一个单一模型中联合学习对比式3D-文本表征和描述生成,3D CoCa消除了对任何显式3D物体检测器或提案阶段的需求。这种统一方法能够在共享特征空间中实现直接的3D到文本对齐,与先前方法相比,带来了改进的空间推理和更精确的语义基础。在两个广泛使用的数据集上的实验验证了我们提出的3D CoCa模型在标准描述指标上显著优于现有方法,并证明了我们对比学习策略的优势。