Knowledge Graphs and Pre-trained Language Models enhanced Representation Learning for Conversational Recommend er Systems
知识图谱与预训练语言模型增强的对话推荐系统表征学习
Abstract—Conversational recommend er systems (CRS) utilize natural language interactions and dialogue history to infer user preferences and provide accurate recommendations. Due to the limited conversation context and background knowledge, existing CRSs rely on external sources such as knowledge graphs to enrich the context and model entities based on their interrelations. However, these methods ignore the rich intrinsic information within entities. To address this, we introduce the Knowledge-Enhanced Entity Representation Learning (KERL) framework, which leverages both the knowledge graph and a pretrained language model to improve the semantic understanding of entities for CRS. In our KERL framework, entity textual descriptions are encoded via a pre-trained language model, while a knowledge graph helps reinforce the representation of these entities. We also employ positional encoding to effectively capture the temporal information of entities in a conversation. The enhanced entity representation is then used to develop a recommend er component that fuses both entity and contextual representations for more informed recommendations, as well as a dialogue component that generates informative entity-related information in the response text. A high-quality knowledge graph with aligned entity descriptions is constructed to facilitate our study, namely the Wiki Movie Knowledge Graph (WikiMKG). The experimental results show that KERL achieves state-of-theart results in both recommendation and response generation tasks. Our code is publicly available at the link: https://github. com/icedpanda/KERL.
摘要—对话推荐系统(CRS)利用自然语言交互和对话历史推断用户偏好并提供精准推荐。由于对话上下文和背景知识有限,现有CRS依赖知识图谱等外部资源来丰富上下文,并基于实体间关系建模。然而这些方法忽略了实体内部丰富的固有信息。为此,我们提出知识增强的实体表示学习(KERL)框架,通过结合知识图谱和预训练语言模型来提升CRS对实体的语义理解。在KERL框架中,实体文本描述通过预训练语言模型编码,知识图谱则用于强化实体表示。我们还采用位置编码来有效捕捉对话中实体的时序信息。增强后的实体表示被用于开发两个组件:融合实体与上下文表示以生成更明智推荐的推荐组件,以及在回复文本中生成信息性实体相关内容的对话组件。为支持研究,我们构建了包含对齐实体描述的高质量知识图谱Wiki Movie Knowledge Graph(WikiMKG)。实验结果表明,KERL在推荐和回复生成任务上均达到最先进水平。代码已开源:https://github.com/icedpanda/KERL。
Index Terms—Pre-trained language model, conversational recommend er system, knowledge graph, representation learning.
索引术语—预训练语言模型、对话推荐系统、知识图谱、表征学习。
I. INTRODUCTION
I. 引言
This research was supported in part by the Australian Research Council (ARC) under grants FT 210100097 and DP 240101547, and the CSIRO – National Science Foundation (US) AI Research Collaboration Program. Zhangchi Qiu is supported by the Griffith University Postgraduate Research Scholarship. Manuscript received xx; revised xxx; accepted xxx. Date of publication xxx; date of current version xxx. (Corresponding author: Alan Wee-Chung Liew.)
本研究部分获得澳大利亚研究理事会(ARC) FT 210100097和DP 240101547项目资助,以及CSIRO-美国国家科学基金会人工智能研究合作计划支持。张驰秋获得格里菲斯大学研究生研究奖学金资助。稿件收稿日期xx;修改日期xxx;录用日期xxx。出版日期xxx;当前版本日期xxx。(通讯作者:Alan Wee-Chung Liew。)
Zhangchi Qiu, Ye Tao, Shirui Pan, and Alan Wee-Chung Liew are with the School of Information and Communication Technology, Griffith University, Gold Coast, Queensland 4222, Australia (e-mail: {zhangchi.qiu, griffith uni.edu.au; {s.pan, a.liew}@griffith.edu.au).
张驰邱、叶涛、潘世瑞和Alan Wee-Chung Liew就职于澳大利亚昆士兰州黄金海岸4222格里菲斯大学信息与通信技术学院 (e-mail: {zhangchi.qiu, griffithuni.edu.au; {s.pan, a.liew}@griffith.edu.au)。
TABLE I: An illustrative example of a chatbot-user conversation on movie recommendations, with items (movies) in italic blue font and entities (e.g., movie genres) in italic red font.
表 1: 电影推荐场景下的聊天机器人与用户对话示例,其中项目(电影)以蓝色斜体显示,实体(如电影类型)以红色斜体显示。
| 用户 | 你好,我特别喜欢喜剧片。能推荐一部吗?比如《油脂》(1978)这种风格的? |
| 聊天机器人 | 你看过《非亲兄弟》(2008)吗?这部非常搞笑。 |
| 用户 | 看过,很棒!或许再来部音乐剧?比如《芝加哥》(2002)? |
| 聊天机器人 | 如果你喜欢这种类型,应该会爱看《婚礼傲客》(2005)。风格很相似。 |
| 用户 | 这部还没看过呢。听起来太完美了!谢谢! |
these methods encounter several drawbacks. They may yield recommendations misaligned with the user’s current interests, often suggesting items that are similar to those previously interacted with. Furthermore, they are not adept at capturing sudden changes in user preferences, rendering them less responsive to the user’s evolving interests.
这些方法存在若干缺陷。它们可能产生与用户当前兴趣不符的推荐,往往建议与之前交互过的物品相似的内容。此外,它们不擅长捕捉用户偏好的突然变化,导致对用户兴趣演变的响应能力不足。
These drawbacks motivated the development of conversational recommend er systems (CRSs) [6]–[10], which seek to address the limitations of traditional recommendation systems by employing natural language processing (NLP) techniques to engage users in multi-turn dialogues, allowing CRS to elicit their preferences, and provide personalized recommendations that are better aligned with their current situations, along with accompanying explanations. As an example shown in Table I, a CRS aims to recommend a movie suitable for the user. To accomplish this, the CRS initially offers a recommendation based on the user’s expressed preferences. As the user provides feedback, the CRS refines its understanding of the user’s current interests and adjusts its recommendations accordingly, ensuring a more personalized and relevant suggestion.
这些缺点推动了对话式推荐系统 (CRS) [6]–[10] 的发展,其通过采用自然语言处理 (NLP) 技术让用户参与多轮对话,从而解决传统推荐系统的局限性。这使得 CRS 能够获取用户偏好,并提供更符合其当前情境的个性化推荐及相应解释。如表 1 所示,CRS 的目标是为用户推荐合适的电影。为此,CRS 首先根据用户表达的偏好提供推荐。随着用户给出反馈,CRS 会不断细化对用户当前兴趣的理解,并相应调整推荐,确保建议更加个性化和相关。
To develop an effective CRS, existing studies [8], [9], [11] have explored the integration of external data sources, such as knowledge graphs (KGs) and relevant reviews [10], to supplement the limited contextual information in dialogues and backgrounds. These systems extract entities from the conversational history and search for relevant candidate items in the knowledge graph to make recommendations.
为开发有效的对话推荐系统(CRS),现有研究[8]、[9]、[11]探索了整合外部数据源(如知识图谱(KGs)和相关评论[10])的方法,以补充对话和背景中有限的上下文信息。这些系统从对话历史中提取实体,并在知识图谱中搜索相关候选项目以进行推荐。
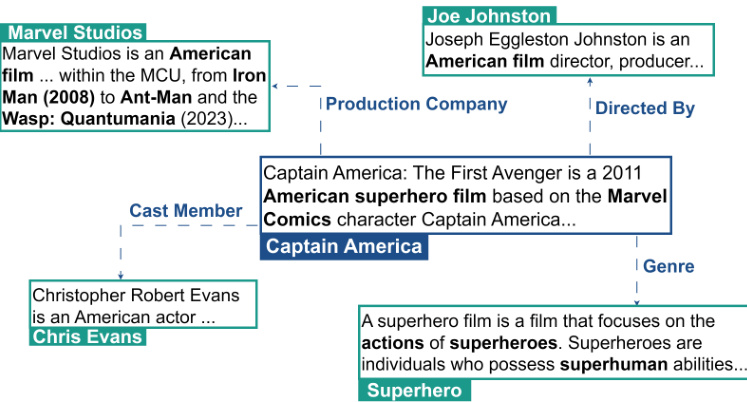
Fig. 1: Example of a KG that incorporates entity descriptions. The figure suggests that descriptions contain rich information and can help improve the semantic understanding of entities
图 1: 融合实体描述的知识图谱示例。该图表明描述包含丰富信息,有助于提升实体的语义理解
Despite the advances made by these studies, three main challenges remain to be addressed:
尽管这些研究取得了进展,仍有三个主要挑战亟待解决:
To address these issues, we propose a novel framework that leverages KGs and pre-trained language models (PLMs) for enhanced representation learning in CRSs. This framework, which we refer to as KERL, stands for Knowledge-enhanced Entity Representation Learning framework. Firstly, we use a PLM to directly encode the textual descriptions of entities into embeddings, which are then used in combination with graph neural networks to learn entity embeddings that incorporate both topological and textual information. This results in a more comprehensive representation of the entities and their relationships (challenge 1). Secondly, we adopt a positional encoding inspired by the Transformer [12] to account for the sequence order of entities in the context history (challenge 2), along with a conversational history encoder to capture contextual information in the conversation. By combining these two components, we are able to gain a better understanding of the user’s preferences from both entity and contextual perspectives. This leads to more informed and tailored recommendations that better align with the user’s current interests and context. However, as these two user preference embeddings are from two different embedding spaces, we employ the contrastive learning [13] method to bring together the same users with different perspectives, such as entity-level user preferences and contextual-level user preferences, while simultaneously distancing irrelevant ones. Lastly, we integrate the knowledge-enhanced entity representation with the pre-trained BART [14] model as our dialogue generation module. This allows us to leverage the capability of the BART model while also incorporating entity knowledge to generate more diverse and informative responses (challenge 3), providing a more comprehensive and engaging experience for the user.
为解决这些问题,我们提出了一种新颖的框架,该框架利用知识图谱(KG)和预训练语言模型(PLM)来增强对话推荐系统(CRS)中的表示学习。我们称该框架为KERL(知识增强的实体表示学习框架)。首先,我们使用PLM直接将实体的文本描述编码为嵌入向量,然后结合图神经网络学习融合拓扑和文本信息的实体嵌入。这能生成更全面的实体及其关系表示(挑战1)。其次,我们采用受Transformer [12]启发的 positional encoding 来建模上下文历史中的实体序列顺序(挑战2),并通过对话历史编码器捕捉对话中的上下文信息。通过结合这两个组件,我们能从实体和上下文两个视角更全面地理解用户偏好,从而生成更贴合用户当前兴趣和情境的个性化推荐。由于这两个用户偏好嵌入来自不同的嵌入空间,我们采用对比学习[13]方法拉近同一用户在不同视角(如实体级用户偏好和上下文级用户偏好)的表示,同时疏离无关表示。最后,我们将知识增强的实体表示与预训练的BART [14]模型集成作为对话生成模块,在保留BART模型能力的同时融入实体知识,生成更多样且信息丰富的回复(挑战3),为用户提供更全面、更具吸引力的体验。
The contributions can be summarized as follows: (1) We construct a movie knowledge graph (WikiMKG) with entity description information. (2) We use a knowledgeenhanced entity representation learning approach to enrich the representation of entities that captures both topological and textual information. (3) We utilize positional encoding to accurately capture the order of appearance of entities in a conversation. This allows for a more precise understanding of the user’s current preferences. (4) We adopt a contrastive learning scheme to bridge the gap between entity-level user preferences and contextual-level user preferences. (5) We integrate entity descriptions and a pre-trained BART model to improve the system’s ability to compensate for limited contextual information and enable the generation of informative responses.
本研究的贡献可总结如下:(1) 我们构建了包含实体描述信息的电影知识图谱(WikiMKG);(2) 采用知识增强的实体表示学习方法,通过融合拓扑结构与文本信息来丰富实体表征;(3) 利用位置编码技术精准捕捉对话中实体的出现顺序,从而更准确地理解用户当前偏好;(4) 通过对比学习方案弥合实体级用户偏好与上下文级用户偏好之间的差异;(5) 整合实体描述与预训练BART模型,增强系统在有限上下文条件下的补偿能力,实现信息丰富的响应生成。
II. RELATED WORK
II. 相关工作
A. Conversational Recommend er System
A. 对话式推荐系统
With the rapid development of dialogue systems [15]– [19], there has been growing interest in utilizing interactive conversations to better understand users’ dynamic intent and preferences. This has led to the rapidly expanding area of conversational recommend er systems [6], [20], [21], which aim to provide personalized recommendations to users through natural language interactions.
随着对话系统[15]-[19]的快速发展,人们越来越关注利用交互式对话来更好地理解用户动态意图和偏好。这推动了对话推荐系统[6]、[20]、[21]领域的迅速扩展,其目标是通过自然语言交互为用户提供个性化推荐。
In the realm of CRS, one approach involves the use of predefined actions, such as item attributes and intent slots [6], [20], [22], [23], for interaction with users. This category of CRS primarily focuses on efficiently completing the recommendation task within a limited number of conversational turns. To achieve this objective, they have adopted reinforcement learning [20], [23]–[25], multi-armed bandit [6] to help the system in finding the optimal interaction strategy. However, these methods still struggle to generate human-like conversations, which is a crucial aspect of a more engaging and personalized CRS.
在CRS领域,一种方法涉及使用预定义动作(如物品属性和意图槽位)[6], [20], [22], [23]与用户交互。这类CRS主要关注在有限对话轮次内高效完成推荐任务。为实现该目标,它们采用了强化学习[20], [23]–[25]、多臂老虎机[6]等技术帮助系统寻找最优交互策略。然而这些方法仍难以生成类人对话,而这正是构建更具吸引力和个性化CRS的关键要素。
Another category of CRS focuses on generating both accurate recommendations and human-like responses, by incorporating a generation-based dialogue component in their design. Li et al. [21] proposed a baseline HREDbased [7] model and released the CRS dataset in a movie recommendation scenario. However, the limited contextual information in dialogues presents a challenge in accurately capturing user preferences. To address this issue, existing studies introduce the entity-oriented knowledge graph [8], [11], the word-oriented knowledge graph [9], and review information [10]. This information is also used in text generation to provide knowledge-aware responses. Although these integration s have enriched the system’s knowledge, the challenge of effectively fusing this information into the recommendation and generation process still remains. Therefore, Zhou et al. [26] proposed the contrastive learning approach to better fuse this external information to enhance the performance of the system. Additionally, instead of modeling entity representation with KG, Yang et al. [27] constructed entity metadata into text sentences to reflect the semantic representation of items. However, such an approach lacks the capability to capture multi-hop information.
另一类CRS通过在设计中加入基于生成的对话组件,专注于同时提供精准推荐和拟人化回应。Li等人[21]提出了基于HRED[7]的基线模型,并发布了电影推荐场景下的CRS数据集。然而,对话中有限的上下文信息对准确捕捉用户偏好提出了挑战。为解决这一问题,现有研究引入了面向实体的知识图谱[8][11]、面向词汇的知识图谱[9]以及评论信息[10]。这些信息也被用于文本生成以提供知识感知的回应。虽然这些整合丰富了系统知识,但如何有效融合这些信息到推荐与生成过程中仍是挑战。为此,Zhou等人[26]提出对比学习方法以更好地融合外部信息来提升系统性能。此外,Yang等人[27]摒弃了用知识图谱建模实体表示的方法,转而将实体元数据构造成文本来反映物品的语义表征,但该方法缺乏捕捉多跳信息的能力。
Inspired by the success of PLMs, Wang et al. [28] combined DialogGPT [17] with an entity-oriented KG to seamlessly integrate recommendation into dialogue generation using a vocabulary pointer. Furthermore, Wang et al. [29] introduced the knowledge-enhanced prompt learning approach based on a fixed DialogGPT [17] to perform both recommendation and conversation tasks. These studies do not exploit the information present in the textual description of entities and their sequence order in the dialogue. In contrast, our proposed KERL incorporates a PLM for encoding entity descriptions and uses positional encoding to consider sequence order, leading to a more comprehensive understanding of entities and conversations.
受PLM成功的启发,Wang等人[28]将DialogGPT[17]与面向实体的知识图谱(KG)相结合,通过词汇指针将推荐无缝整合到对话生成中。此外,Wang等人[29]基于固定版DialogGPT[17]提出了知识增强的提示学习方法,可同时执行推荐和对话任务。这些研究未充分利用实体文本描述信息及其在对话中的序列顺序。相比之下,我们提出的KERL采用PLM编码实体描述,并利用位置编码考虑序列顺序,从而实现对实体和对话更全面的理解。
B. Knowledge Graph Embedding
B. 知识图谱嵌入 (Knowledge Graph Embedding)
Knowledge graph embedding (KGE) techniques have evolved to map entities and relations into low-dimensional vector spaces, extending beyond simple structural information to include rich semantic contexts. These embeddings are vital for tasks such as graph completion [30]–[32], question answering [33], [34], and recommendation [35], [36]. Conventional KGE methods such as TransE [37], RotatE [38] and DistMult [39] focus on KGs’ structural aspects, falling into translation-based or semantic matching categories based on their unique scoring functions [40], [41]. Recent research capitalizes on the advancements in NLP to encode rich textual information of entities and relations. DKRL [30] were early adopters, encoding entity descriptions using convolutional neural networks. PretrainKGE [42] further advanced this approach by employing BERT [43] as an encoder and initializes additional learnable knowledge embeddings, then discarding the PLM after finetuning for efficiency. Subsequent developments, including KEPLER [44] and JAKET [45], have utilized PLMs to encode textual descriptions as entity embeddings. These methods optimize both knowledge embedding objectives and masked language modeling tasks. Additionally, LMKE [46] introduced a contrastive learning method, which significantly improves the learning of embeddings generated by PLMs for KGE tasks. In comparison to these existing methods, our work enhances conversational recommend er systems by integrating a PLM with a KG to produce enriched knowledge embeddings. We then align these embeddings with user preferences based on the conversation history. This method effectively tailors the recommendation and generation tasks in CRS.
知识图谱嵌入 (Knowledge Graph Embedding, KGE) 技术已发展至将实体和关系映射到低维向量空间,不仅涵盖简单结构信息,还扩展至丰富语义上下文。这些嵌入对于图谱补全 [30]–[32]、问答系统 [33][34] 以及推荐系统 [35][36] 等任务至关重要。传统 KGE 方法如 TransE [37]、RotatE [38] 和 DistMult [39] 聚焦知识图谱的结构特性,根据其独特评分函数可分为基于翻译或语义匹配的类别 [40][41]。近期研究利用自然语言处理 (NLP) 进展来编码实体与关系的丰富文本信息:DKRL [30] 率先采用卷积神经网络编码实体描述,PretrainKGE [42] 则通过 BERT [43] 作为编码器进一步优化,初始化额外可学习知识嵌入后为提升效率在微调阶段舍弃预训练语言模型 (PLM)。后续发展如 KEPLER [44] 和 JAKET [45] 利用 PLM 将文本描述编码为实体嵌入,同时优化知识嵌入目标和掩码语言建模任务。此外,LMKE [46] 引入对比学习方法,显著提升了 PLM 生成嵌入在 KGE 任务中的学习效果。相较于现有方法,本研究通过整合 PLM 与知识图谱生成增强型知识嵌入,进而基于对话历史将这些嵌入与用户偏好对齐,有效优化了对话式推荐系统 (CRS) 中的推荐与生成任务。
III. METHODOLOGY
III. 方法论
In this section, we present KERL with its overview shown in Figure 2, which consists of three main modules: knowledge graph encoding module, recommendation module, and response generation module. We first formalize the conversational recommendation task in Section III-A, followed by a brief architecture overview in Section III-B, we then introduce the process of encoding entity information (Section III-C), followed by our approach to both recommendation (Section III-D) and conversation tasks (Section III-E). Finally, we present our training algorithm of KERL in Section III-F.
在本节中,我们将介绍KERL,其整体架构如图2所示,包含三个主要模块:知识图谱编码模块、推荐模块和响应生成模块。我们首先在III-A节形式化定义了对话推荐任务,随后在III-B节简要概述了整体架构,接着介绍了实体信息编码过程(III-C节),之后分别阐述了推荐任务(III-D节)和对话任务(III-E节)的处理方法。最后,我们在III-F节介绍了KERL的训练算法。
A. Problem Formulation
A. 问题表述
Formally, let $C={c_{1},c_{2},...,c_{m}}$ denote the history context of a conversation, where $c_{m}$ represents the utterance $c$ at the $m$ -th round of a conversation. Each utterance $c_{m}$ is either from the seeker (i.e., user) or from the recommend er (i.e., system). At the $m$ -th round, the recommendation module will select items $\mathscr{T}{m+1}$ from a set of candidate items $\mathcal{T}$ based on the estimated user preference, and the response generation module will generate a response $c_{m+1}$ to prior utterances. Note that $\mathcal{T}_{t}$ can be empty when there is no need for a recommendation (i.e., chit-chat).
形式上,令 $C={c_{1},c_{2},...,c_{m}}$ 表示对话的历史上下文,其中 $c_{m}$ 代表第 $m$ 轮对话中的语句 $c$。每条语句 $c_{m}$ 来自提问者(即用户)或推荐者(即系统)。在第 $m$ 轮时,推荐模块会根据预估的用户偏好从候选物品集 $\mathcal{T}$ 中选择物品 $\mathscr{T}{m+1}$,响应生成模块则会针对先前的语句生成响应 $c_{m+1}$。注意当无需推荐时(即闲聊场景),$\mathcal{T}_{t}$ 可能为空集。
For the knowledge graph, let $\mathcal{G}={(h,r,t)|h,t\in\mathcal{E},r\in$ $\scriptstyle{\mathcal{R}}}$ denote the knowledge graph, where each triplet $(h,r,t)$ describes a relationship $r$ between the head entity $h$ and the tail entity $t$ . The entity set $\mathcal{E}$ contains all movie items in $\mathcal{T}$ and other non-item entities that are movie properties (i.e., director, production company).
对于知识图谱,令 $\mathcal{G}={(h,r,t)|h,t\in\mathcal{E},r\in$ $\scriptstyle{\mathcal{R}}}$ 表示知识图谱,其中每个三元组 $(h,r,t)$ 描述了头实体 $h$ 和尾实体 $t$ 之间的关系 $r$。实体集 $\mathcal{E}$ 包含 $\mathcal{T}$ 中的所有电影条目以及其他非条目实体(即导演、制片公司等电影属性)。
B. Architecture Overview
B. 架构概述
This section elaborates on the workflow integrating the knowledge graph encoding module, the knowledgeenhanced recommendation module, and the knowledgeenhanced response generation module, as shown in Figure 2. These components work together to process user inputs and generate personalized recommendations, as demonstrated in scenarios such as suggesting a superhero movie.
本节详细阐述了知识图谱编码模块、知识增强推荐模块和知识增强响应生成模块的集成工作流程,如图 2 所示。这些组件协同处理用户输入并生成个性化推荐,例如在推荐超级英雄电影等场景中有所体现。
• Knowledge Graph Encoding Module: This module integrates textual descriptions and entity relationships from the WikiMKG. When a user mentions an interest in superhero films and watched Avengers: Infinity War, this module engages by extracting and encoding relevant entity information (e.g. actors, directors, and movie characteristics). This process ensures a rich understanding of the entities, laying the foundation for con textually aware recommendations. • Knowledge-enhanced Recommendation Module: This module synthesizes the encoded entity information with the user’s conversational history, capturing the essence of the ongoing dialogue. For instance, when a user, after discussing Avengers: Infinity War, seeks something different, this module can suggest a new superhero movie, aligning with their current preferences.
• 知识图谱编码模块 (Knowledge Graph Encoding Module):该模块整合来自 WikiMKG 的文本描述和实体关系。当用户提到对超级英雄电影感兴趣并观看了《复仇者联盟3:无限战争》时,该模块通过提取和编码相关实体信息(如演员、导演和电影特征)进行交互。这一过程确保了对实体的深入理解,为基于上下文的推荐奠定了基础。
• 知识增强推荐模块 (Knowledge-enhanced Recommendation Module):该模块将编码后的实体信息与用户的对话历史相结合,捕捉当前对话的核心。例如,当用户在讨论《复仇者联盟3:无限战争》后寻求不同的内容时,该模块可以根据其当前偏好推荐一部新的超级英雄电影。
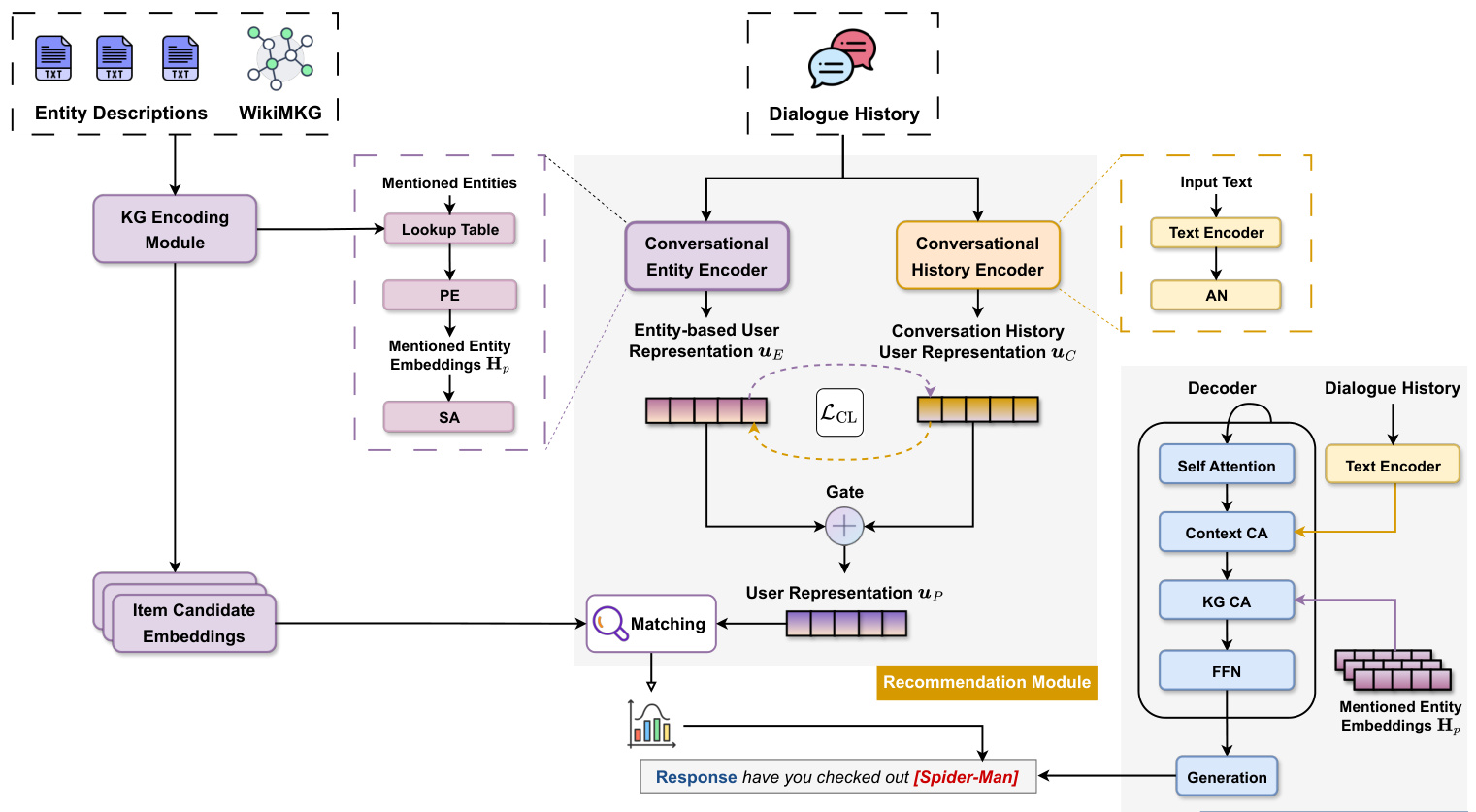
Fig. 2: The overview of the framework of the proposed KERL in a movie recommendation scenario. The Attention Network (AN) selectively focuses on relevant tokens. Positional Encoding (PE) and Self-Attention (SA) mechanisms preserve the sequence order and context, respectively. Context Cross-Attention (CA) and KG Cross-Attention integrate conversational and knowledge graph cues. The Recommendation Module matches items to user preferences, and the Response Generation Module formulates natural language suggestions.
图 2: 电影推荐场景中提出的KERL框架概览。注意力网络(AN)选择性关注相关Token。位置编码(PE)和自注意力(SA)机制分别保留序列顺序和上下文。上下文交叉注意力(CA)与知识图谱交叉注意力整合对话线索和知识图谱信息。推荐模块将物品与用户偏好匹配,响应生成模块形成自然语言建议。
• Knowledge-enhanced Response Generation Module: This final module brings together the insights from the KG and the conversational context to formulate coherent and engaging responses. In our superhero movie scenario, it would generate a natural language suggestion that not only aligns with the user’s expressed interest, but also fits seamlessly into the flow of the conversation. For example, the system suggests “Have you checked out Spider-Man?” as a fresh yet relevant choice.
• 知识增强的响应生成模块 (Knowledge-enhanced Response Generation Module):该最终模块整合知识图谱 (KG) 和对话上下文的洞察,以生成连贯且引人入胜的响应。在我们的超级英雄电影场景中,它会生成一个自然语言建议,不仅符合用户表达的兴趣,还能无缝融入对话流程。例如,系统会建议"你看过《蜘蛛侠》吗?"作为一个新颖且相关的选择。
C. Knowledge Graph Encoding Module
C. 知识图谱编码模块
The Knowledge Graph Encoding Module is central to the proposed framework, as illustrated in detail in Figure 3, designed to integrate rich textual descriptions with complex entity relationships from the KG. This integration is crucial, as it ensures that the system captures both the semantic and structural nuances of entities, providing a solid foundation for the CRS’s contextual awareness and recommendation mechanisms.
知识图谱编码模块是该框架的核心,如图 3 所示,其设计目的是将丰富的文本描述与知识图谱 (KG) 中的复杂实体关系相整合。这种整合至关重要,因为它确保系统能捕捉实体的语义和结构细微差别,为 CRS 的上下文感知和推荐机制奠定坚实基础。
- PLM for Entity Encoding: Previous studies focused on modeling entity representations based on their relationships with other entities, without taking into account the rich information contained in the text description of entities. To address this limitation, we propose to leverage the textual descriptions of entities to encode entities into vector representations. Our innovative approach builds upon the capabilities of PLMs such as BERT [43], BART [14] and GPT2 [47]. Within our framework, a domain-specific or generic PLM serves as a fundamental component for encoding textual information. These PLMs have demonstrated superior performance on various tasks in natural language processing. In our architecture, the entity text encoder is designed to be adaptable and customizable, ensuring its compatibility with a range of PLMs. For the purpose of this study, we use a pretrained distillation BERT [48] as our entity text encoder to capture the contextual word representations, underlining the adaptability and efficacy of our approach.
- 用于实体编码的预训练语言模型 (PLM) :先前研究主要基于实体间关系建模实体表示,未充分利用实体文本描述中的丰富信息。为解决这一局限,我们提出利用实体文本描述将实体编码为向量表示。这一创新方法基于 BERT [43]、BART [14] 和 GPT2 [47] 等预训练语言模型的能力构建。在我们的框架中,领域专用或通用预训练语言模型作为编码文本信息的基础组件,这些模型已在自然语言处理多项任务中展现卓越性能。该架构中的实体文本编码器设计为可适配定制,确保与多种预训练语言模型兼容。本研究采用预训练蒸馏 BERT [48] 作为实体文本编码器以捕获上下文词表征,体现了该方法的适应性与高效性。
In the entity descriptions, different words carry varying degrees of significance in representing the entity. Therefore, computing the average of hidden word representations, which assigns equal weight to all words, may lead to a loss of crucial information. Thus, we adopt an attention network that integrates multi-head self-attention [12], and an attention-pooling block [49]. This approach allows the model to selectively focus on the important words in entity descriptions, facilitating the learning of more informative entity representations. More specifically, for a given entity description text denoted as $[w_{1},w_{2},...,w_{k}]$ , with $k$ representing the total number of words in the description, we first transform the words into embeddings using the BERT model. These embeddings are fed into multiple Transformer [12] layers to produce hidden word representations. We then use an attention network and a feed-forward network to summarize the hidden word representations into a unified entity embedding. The attention weights are calculated as follows:
在实体描述中,不同词语对表征实体具有不同程度的重要性。因此,若对所有词语赋予同等权重计算隐藏词表征的平均值,可能导致关键信息丢失。为此,我们采用融合多头自注意力 [12] 和注意力池化模块 [49] 的注意力网络。该方法使模型能选择性聚焦实体描述中的重要词语,从而学习信息更丰富的实体表征。具体而言,对于给定实体描述文本 $[w_{1},w_{2},...,w_{k}]$ (其中 $k$ 表示描述中的总词数),我们首先通过BERT模型将词语转换为嵌入向量,将这些嵌入输入多层Transformer [12] 以生成隐藏词表征,随后使用注意力网络和前馈网络将隐藏词表征汇总为统一实体嵌入。注意力权重计算公式如下:
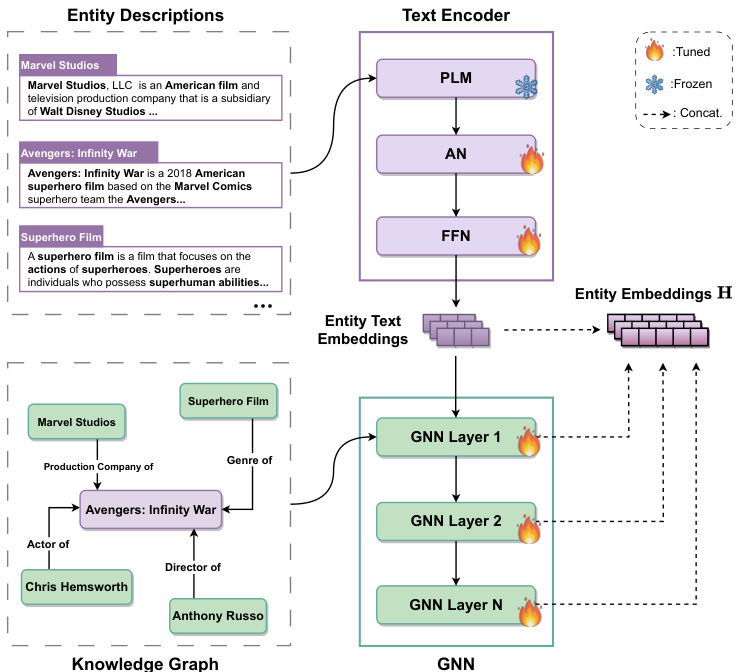
Fig. 3: The Knowledge Graph Encoding Module employs a PLM for textual semantics and a GNN for structural relations. It generates entity embeddings that include item embeddings, which are a subset used for recommendations. “AN” denotes the attention network.
图 3: 知识图谱编码模块采用PLM处理文本语义,GNN处理结构关系。生成的实体嵌入包含用于推荐的物品嵌入子集。"AN"表示注意力网络。
$$
\alpha_{i}^{w}=\frac{\exp(\pmb q_{w}^{\top}\cdot\sigma(\mathbf V_{w}\mathbf w_{i}+\mathbf v_{w})}{\sum_{j=1}^{k}\exp(\pmb q_{w}^{\top}\cdot\sigma(\mathbf V_{w}\mathbf w_{j}+\mathbf v_{w})}
$$
$$
\alpha_{i}^{w}=\frac{\exp(\pmb q_{w}^{\top}\cdot\sigma(\mathbf V_{w}\mathbf w_{i}+\mathbf v_{w})}{\sum_{j=1}^{k}\exp(\pmb q_{w}^{\top}\cdot\sigma(\mathbf V_{w}\mathbf w_{j}+\mathbf v_{w})}
$$
where $\pmb{\alpha}{i}^{w}$ denotes the attention weights of the $i$ -th word in the entity descriptions, $\mathbf{w}{i}$ denotes the word representations obtained from the top layer of BERT, $\sigma$ is tanh activation function, ${\bf V}{w}$ and ${\bf v}{w}$ are projection parameters, and $\pmb{q}_{w}$ is the query vector. To generate the entity embeddings, we aggregate the representation of these word representations by employing the weighted summation of the contextual word representation and a feed-forward network, formulated as:
其中 $\pmb{\alpha}{i}^{w}$ 表示实体描述中第 $i$ 个词的注意力权重,$\mathbf{w}{i}$ 表示从BERT顶层获得的词表征,$\sigma$ 是tanh激活函数,${\bf V}{w}$ 和 ${\bf v}{w}$ 是投影参数,$\pmb{q}_{w}$ 是查询向量。为生成实体嵌入,我们通过加权求和上下文词表征与前馈网络来聚合这些词表征,其公式为:
$$
\mathbf{h}{e}^{d}=\mathrm{FFN}\left(\sum_{i=1}^{k}\alpha_{i}\mathbf{x}_{i}\right)
$$
$$
\mathbf{h}{e}^{d}=\mathrm{FFN}\left(\sum_{i=1}^{k}\alpha_{i}\mathbf{x}_{i}\right)
$$
where $\mathrm{FFN}(\cdot)$ denotes a fully connected feed-forward network, consisting of two linear transformations with an activation layer, $\mathbf{h}_{e}^{d}$ represents the entity embedding that captures the rich information contained in its textual description. We omit equations related to BERT and multi-head attention.
其中 $\mathrm{FFN}(\cdot)$ 表示全连接前馈网络,由两个线性变换和一个激活层组成,$\mathbf{h}_{e}^{d}$ 代表捕获其文本描述中丰富信息的实体嵌入。我们省略了与BERT和多头注意力相关的方程。
- Knowledge Graph Embedding: In addition to the textual descriptions of entities, semantic relationships between entities can provide valuable information and context. To capture this information, we adopt Relational Graph Convolutional Networks (R-GCNs) [8], [26], [50] to encode structural and relational information between entities. Formally, the representation of the entity $e$ at the $(\ell{+}1)$ -th layer is calculated as follows:
- 知识图谱嵌入 (Knowledge Graph Embedding): 除了实体的文本描述外,实体的语义关系也能提供有价值的信息和上下文。为了捕捉这类信息,我们采用关系图卷积网络 (Relational Graph Convolutional Networks, R-GCNs) [8], [26], [50] 来编码实体的结构和关系信息。形式上,实体 $e$ 在第 $(\ell{+}1)$ 层的表征计算如下:
$$
\mathbf{h}{e}^{(\ell+1)}=\sigma\left(\sum_{r\in\mathcal{R}}\sum_{e^{\prime}\in\mathcal{E}{e}^{r}}\frac{1}{Z_{e,r}}\mathbf{W}{r}^{(\ell)}\mathbf{h}{e^{\prime}}^{(\ell)}+\mathbf{W}{e}^{(\ell)}\mathbf{h}_{e}^{(\ell)}\right)
$$
$$
\mathbf{h}{e}^{(\ell+1)}=\sigma\left(\sum_{r\in\mathcal{R}}\sum_{e^{\prime}\in\mathcal{E}{e}^{r}}\frac{1}{Z_{e,r}}\mathbf{W}{r}^{(\ell)}\mathbf{h}{e^{\prime}}^{(\ell)}+\mathbf{W}{e}^{(\ell)}\mathbf{h}_{e}^{(\ell)}\right)
$$
where $\mathbf{h}{e}^{\ell}$ is the embedding of entity $e$ at the $\ell$ -th layer and $h_{e}^{0}$ is the textual embedding of the entity derived from the text encoder described in Equation 2. The set $\mathcal{E}{e}^{r}$ consists of neighboring entities that are connected to the entity $e$ through the relation $r.\mathbf{W}{r}^{(\ell)}$ and $\mathbf{W}{e}^{(\ell)}$ are learnable model parameters matrices, $Z_{e,r}$ serves as a normalization factor, and $\sigma$ is the activation function. As the output of different layers represents information from different hops, we use the layer-aggregation mechanism [51] to concatenate the representations from each layer into a single vector as:
其中 $\mathbf{h}{e}^{\ell}$ 是实体 $e$ 在第 $\ell$ 层的嵌入表示,$h_{e}^{0}$ 是由公式2所述文本编码器生成的实体文本嵌入。集合 $\mathcal{E}{e}^{r}$ 包含通过关系 $r$ 与实体 $e$ 相连的相邻实体。$\mathbf{W}{r}^{(\ell)}$ 和 $\mathbf{W}{e}^{(\ell)}$ 是可学习的模型参数矩阵,$Z_{e,r}$ 是归一化因子,$\sigma$ 为激活函数。由于不同层的输出代表不同跳数的信息,我们采用层聚合机制 [51] 将各层表示拼接为单个向量:
$$
{\bf h}{e}^{*}={\bf h}{e}^{(0)}\vert\vert\cdot\cdot\cdot\vert\vert{\bf h}_{e}^{(\ell)}
$$
$$
{\bf h}{e}^{*}={\bf h}{e}^{(0)}\vert\vert\cdot\cdot\cdot\vert\vert{\bf h}_{e}^{(\ell)}
$$
where $||$ is the concatenation operation. By doing so, we can enrich the entity embedding by performing the propagation operations as well as control the propagation strength by adjusting $\ell$ . Finally, we can obtain the hidden representation of all entities in $\mathcal{G}$ , which can be further used for user modeling and candidate matching.
其中 $||$ 表示拼接操作。通过这种方式,我们既可以通过传播操作丰富实体嵌入,又能通过调整 $\ell$ 来控制传播强度。最终,我们可以获得 $\mathcal{G}$ 中所有实体的隐藏表示,这些表示可进一步用于用户建模和候选匹配。
To preserve the relational reasoning within the structure of the knowledge graph, we employ the TransE [37] scoring function as our knowledge embedding objective to train our knowledge graph embedding. This widely used method learns to embed each entity and relation by optimizing the translation principle of $h+r\approx t$ for a valid triple $(h,r,t)$ . Formally, the score function $d_{r}$ for a triplet $(h,r,t)$ in the knowledge graph $\mathcal{G}$ is defined as follows:
为了保持知识图谱结构中的关系推理能力,我们采用TransE [37]评分函数作为知识嵌入目标来训练知识图谱嵌入。这一广泛使用的方法通过优化有效三元组$(h,r,t)$的平移原理$h+r\approx t$,学习嵌入每个实体和关系。形式上,知识图谱$\mathcal{G}$中三元组$(h,r,t)$的评分函数$d_{r}$定义如下:
$$
d_{r}(h,t)=||\mathbf{e}{h}+\mathbf{r}-\mathbf{e}{t}||_{p}
$$
$$
d_{r}(h,t)=||\mathbf{e}{h}+\mathbf{r}-\mathbf{e}{t}||_{p}
$$
where $h$ and $t$ represent the head and tail entities, respectively. $\mathbf{e}{h}$ and $\mathbf{e}_{t}$ are the new entity embeddings from Equation 4, and $\mathbf{r}\in\mathbb{R}^{|\mathcal{R}|\times d}$ are the embeddings of the relation, $d$ is the embedding dimension, and $p$ is the normalization factor. The training process of knowledge graph embeddings prioritizes the relative order between valid and broken triplets and encourages their discrimination through margin-based ranking loss [38]:
其中 $h$ 和 $t$ 分别表示头实体和尾实体。$\mathbf{e}{h}$ 和 $\mathbf{e}_{t}$ 是来自公式4的新实体嵌入,$\mathbf{r}\in\mathbb{R}^{|\mathcal{R}|\times d}$ 是关系的嵌入表示,$d$ 为嵌入维度,$p$ 是归一化因子。知识图谱嵌入的训练过程优先考虑有效三元组与破坏三元组之间的相对顺序,并通过基于间隔的排序损失 [38] 鼓励它们之间的区分性:
$$
\begin{array}{l}{\displaystyle\mathcal{L}{\mathrm{KE}}=-\log\sigma(\gamma-d_{r}(h,t))}\ {\displaystyle-\sum_{i=1}^{k}\frac{1}{k}\log\sigma(d_{r}(h_{i}^{'},t_{i}^{'})-\gamma)}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\mathcal{L}{\mathrm{KE}}=-\log\sigma(\gamma-d_{r}(h,t))}\ {\displaystyle-\sum_{i=1}^{k}\frac{1}{k}\log\sigma(d_{r}(h_{i}^{'},t_{i}^{'})-\gamma)}\end{array}
$$
where $\gamma$ is a fixed margin, $\sigma$ is the sigmoid function, and $(h_{i}^{'},r,t_{i}^{'})$ are broken triplets that are constructed by randomly corrupting either the head or tail entity of the positive triples $k$ times.
其中 $\gamma$ 是固定边界值,$\sigma$ 是 sigmoid 函数,$(h_{i}^{'},r,t_{i}^{'})$ 是通过随机破坏正样本三元组的头实体或尾实体 $k$ 次而构建的损坏三元组。
D. Knowledge-enhanced Recommendation Module
D. 知识增强推荐模块
The Knowledge-enhanced Recommendation Module synthesizes entity-based user representation with contextual dialogue history to deliver precise and context-aware recommendations. This module employs a conversational entity encoder, integrating positional encoding with selfattention to reflect the sequential significance of entities in dialogue. Complementing this, a conversational history encoder captures the textual nuances of user interactions. A contrastive learning strategy harmonizes these dual representations, sharpening the system’s ability to discern and align with user preferences for more personalized recommendations.
知识增强推荐模块通过融合基于实体的用户表征与上下文对话历史,提供精准且情境感知的推荐。该模块采用对话实体编码器,将位置编码与自注意力机制相结合,以反映对话中实体的时序重要性。同时,对话历史编码器负责捕捉用户交互的文本细微特征。通过对比学习策略协调这两种表征,增强系统识别和适应用户偏好的能力,从而实现更个性化的推荐。
- Conversational Entity Encoder: To effectively capture user preferences with respect to the mentioned entities, we employ positional encoding and a self-attention mechanism [52]. First, we extract non-item entities and item entities in the conversation history $C$ that are matched to the entity set $\mathcal{E}$ . Here, item entities refer to movie items, while non-item entities pertain to movie properties such as the director and production company. Then, we can represent a user as a set of entities ${\bf E}{u}={e_{1},e_{2},...,e_{i}}$ , where $e_{i}\in{\mathcal{E}}$ . After looking up the entities in ${\bf E}{u}$ from the entity representation matrix $\mathbf{H}$ (as shown in Equation 4), we obtain the respective embeddings $\mathbf{H}{u}=(\mathbf{h}{1}^{},\mathbf{h}{2}^{},...,\mathbf{h}_{i}^{*})$ .
- 对话实体编码器:为有效捕捉用户对提及实体的偏好,我们采用位置编码和自注意力机制[52]。首先,我们从对话历史$C$中提取与实体集$\mathcal{E}$匹配的非物品实体和物品实体。此处物品实体指电影条目,非物品实体则涉及导演、制作公司等电影属性。随后,用户可表示为实体集合${\bf E}{u}={e_{1},e_{2},...,e_{i}}$,其中$e_{i}\in{\mathcal{E}}$。通过从实体表示矩阵$\mathbf{H}$(如公式4所示)查找${\bf E}{u}$中的实体,我们获得对应嵌入表示$\mathbf{H}{u}=(\mathbf{h}{1}^{},\mathbf{h}{2}^{},...,\mathbf{h}_{i}^{*})$。
Previous research [8]–[10] has primarily relied on the selfattention mechanism [52] to summarize the user’s preference over the mentioned entities. However, such an approach ignores the order of entities within a conversation, which can significantly affect the topic of a conversation, leading to different conversational trajectories. Therefore, we use the learnable positional encoding inspired by the Transformer [12] architecture. This approach is commonly used in NLP to encode information about the position of a token in a sentence, allowing the model to understand the relationship between tokens based on their position in a sentence. We first utilize it to capture the order of entity appearance within the conversation, ensuring more accurate summaries of user preferences. Formally, the entity-level representation of the user that includes positional information can be formulated as follows:
先前的研究 [8]–[10] 主要依赖自注意力机制 [52] 来总结用户对提及实体的偏好。然而,这种方法忽略了对话中实体的顺序,这会显著影响对话主题,导致不同的对话轨迹。因此,我们采用了受 Transformer [12] 架构启发的可学习位置编码。这种方法在自然语言处理 (NLP) 中常用于编码 token 在句子中的位置信息,使模型能够根据 token 在句子中的位置理解它们之间的关系。我们首先利用它来捕捉对话中实体出现的顺序,从而更准确地总结用户偏好。形式上,包含位置信息的用户实体级表示可以表述如下:
$$
\mathbf{H}{p}=\mathbf{H}{u}+\mathbf{E}_{p o s},
$$
$$
\mathbf{H}{p}=\mathbf{H}{u}+\mathbf{E}_{p o s},
$$
where $\mathbf{H}{p}$ denotes the entity-level representation of the user that considers entity positional information. The positional encoding matrix, denoted as ${\bf{E}}{p o s}$ , has dimensions $\in\mathbb{R}^{|P|\times d}$ . Here, $|P|$ corresponds to the length of the entity sequence, and $d$ denotes the embedding dimension. The positional encoding matrix is added to the user entity representation set $\mathbf{H}{u}$ based on the corresponding order of appearance of the entity. Then, we adopt the self-attention mechanism [52] to summarize the entity-based user representation $\pmb{u}_{E}$ as follows:
其中 $\mathbf{H}{p}$ 表示考虑实体位置信息的用户实体级表示。位置编码矩阵 ${\bf{E}}{p o s}$ 的维度为 $\in\mathbb{R}^{|P|\times d}$ ,其中 $|P|$ 对应实体序列长度, $d$ 表示嵌入维度。该位置编码矩阵会根据实体出现顺序叠加到用户实体表示集 $\mathbf{H}{u}$ 上。随后,我们采用自注意力机制 [52] 来汇总基于实体的用户表示 $\pmb{u}_{E}$ ,计算方式如下:
$$
\begin{array}{r l}&{{\bf{\boldsymbol{\mathscr{u}}}}{E}={\bf{\boldsymbol{\mathrm{\mathbf{H}}}}}{p}\cdot{\boldsymbol{\alpha}}^{e}}\ &{{\boldsymbol{\alpha}}^{e}=\operatorname{softmax}({\boldsymbol{b}}{e}^{\top}\cdot{\boldsymbol{\sigma}}({\bf W}{p}{\bf H}_{p}))}\end{array}
$$
$$
\begin{array}{r l}&{{\bf{\boldsymbol{\mathscr{u}}}}{E}={\bf{\boldsymbol{\mathrm{\mathbf{H}}}}}{p}\cdot{\boldsymbol{\alpha}}^{e}}\ &{{\boldsymbol{\alpha}}^{e}=\operatorname{softmax}({\boldsymbol{b}}{e}^{\top}\cdot{\boldsymbol{\sigma}}({\bf W}{p}{\bf H}_{p}))}\end{array}
$$
where $\alpha^{e}$ denotes the attention weight vector that reflects the importance of each interacted entity, and $\mathbf{W}{p}$ and $b_{e}$ are learnable parameter matrix and vector, and $\sigma$ is the tanh activation function. Finally, we can derive the entity-based user representation $\pmb{u}_{E}$ that considers the importance of each interacted entity and their chronological context within the conversation history, providing a nuanced and temporallyinformed representation of user preferences at the entity level.
其中 $\alpha^{e}$ 表示反映每个交互实体重要性的注意力权重向量,$\mathbf{W}{p}$ 和 $b_{e}$ 是可学习的参数矩阵和向量,$\sigma$ 是 tanh 激活函数。最终,我们可以得到基于实体的用户表示 $\pmb{u}_{E}$,该表示考虑了每个交互实体的重要性及其在对话历史中的时序上下文,从而在实体层面提供了一种细致且具有时序信息的用户偏好表征。
- Conversational History Encoder: Despite the capability of knowledge-enhanced entity-based user representation to model user preferences based on entities mentioned in context $C$ , it can lead to misinterpretations of user preferences, as it did not take into account the actual textual content of the conversation. For example, consider a scenario where a user states “I am not a fan of the movie A”. This negative sentiment towards “movie A” cannot be accurately captured using only entity-level representation. Therefore, we employ a conversational history encoder to obtain a representation that encompasses the textual content of the conversation. Specifically, a conversation history $C$ is composed of $m$ utterances that are generated by the user and the recommend er. We concatenate the dialogue utterance $c_{m}$ in chronological order to create an extended sentence ${c_{1};c_{m}}$ . To compute the contextual word representation, we employ the BART [14] encoder as our conversational history encoder and denote it as:
- 对话历史编码器:尽管基于知识增强的实体用户表示能够根据上下文 $C$ 中提及的实体建模用户偏好,但由于未考虑对话的实际文本内容,可能导致对用户偏好的误判。例如,当用户表示"我不喜欢电影A"时,仅通过实体级表示无法准确捕捉这种对"电影A"的负面情绪。因此,我们采用对话历史编码器来获取包含对话文本内容的表示。具体而言,对话历史 $C$ 由用户和推荐系统生成的 $m$ 条语句组成。我们按时间顺序连接对话语句 $c_{m}$ 以构建扩展语句 ${c_{1};c_{m}}$。为计算上下文词表示,我们使用BART[14]编码器作为对话历史编码器,其表示形式为:
$$
\mathcal{F}^{\mathcal{C}}=\mathtt{B A R T–E n c}(c_{1};c_{m})
$$
$$
\mathcal{F}^{\mathcal{C}}=\mathtt{B A R T–E n c}(c_{1};c_{m})
$$
where ${\mathcal{F}}^{\mathcal{C}}$ represents contextual word representations. Next, we utilize the same attention network as in Equation 1 and Equation 2 to derive the conversation history user representation $\pmb{u}_{C}$ . This approach enables us to capture the contextual-level user preferences, which can complement entity-level preferences.
其中 ${\mathcal{F}}^{\mathcal{C}}$ 表示上下文词表征。接着,我们采用与公式1和公式2相同的注意力网络来推导会话历史用户表征 $\pmb{u}_{C}$。这种方法使我们能够捕捉上下文级别的用户偏好,从而补充实体级别的偏好。
- Semantic Alignment via Contrastive Learning: To effectively leverage both conversation history user representation and entity-based user representation, it is important to fuse them in a way that captures the user’s preferences from both perspectives.
- 通过对比学习实现语义对齐:为了有效利用对话历史用户表征和基于实体的用户表征,需要以能够同时捕捉用户在这两个维度上偏好的方式进行融合。
Previous works [9], [26] have shown that aligning the different types of representations can significantly improve the performance of the CRS. Therefore, we adopt the contrastive learning framework [13], [26] to bridge the gap between the conversation history user representation $\pmb{u}{C}$ and the entitybased user representation ${\pmb u}{E}$ . More specifically, we take pairs $({\pmb u}{C},{\pmb u}_{E})$ as positive samples, representing the same user’s preferences from two distinct views: the conversational context and their entity interactions. In contrast, the representations from different users in the same batch are treated as negative examples. We compute the contrastive loss as:
先前的研究[9]、[26]表明,对齐不同类型的表征能显著提升CRS的性能。为此,我们采用对比学习框架[13]、[26]来弥合对话历史用户表征$\pmb{u}{C}$与基于实体的用户表征${\pmb u}{E}$之间的差异。具体而言,我们将成对的$({\pmb u}{C},{\pmb u}_{E})$作为正样本,它们从两个不同视角(对话上下文和实体交互)反映同一用户的偏好;而同一批次中不同用户的表征则被视为负样本。对比损失的计算公式为:
$$
\mathcal{L}{\mathrm{CL}}=\log\frac{\exp(\sin(\mathbf{z},\mathbf{z}^{+})/\tau)}{\sum_{\mathbf{z}{i}^{-}\in{\mathbf{z}^{-}}}\exp(\sin(\mathbf{z},\mathbf{z}_{i}^{-})/\tau)}
$$
$$
\mathcal{L}{\mathrm{CL}}=\log\frac{\exp(\sin(\mathbf{z},\mathbf{z}^{+})/\tau)}{\sum_{\mathbf{z}{i}^{-}\in{\mathbf{z}^{-}}}\exp(\sin(\mathbf{z},\mathbf{z}_{i}^{-})/\tau)}
$$
where $\mathbf{z}$ and $\mathbf{z}^{+}$ are positive pairs, is the negative example set for $\mathbf{z}$ , $\mathrm{sim}(\cdot)$ is the cosine similarity function, and $\tau$ is a temperature hyper parameter. By leveraging contrastive learning objectives, we can pull together representations from different views, and enable them to mutually improve and contribute to a more comprehensive representation of the user’s preferences.
其中 $\mathbf{z}$ 和 $\mathbf{z}^{+}$ 为正样本对,为 $\mathbf{z}$ 的负样本集,$\mathrm{sim}(\cdot)$ 为余弦相似度函数,$\tau$ 为温度超参数。通过对比学习目标,我们可以拉近不同视角的表征,使其相互促进并共同构建更全面的用户偏好表征。
- Entity-Context Fusion for Recommendation: To incorporate both entity-based user preferences and conversation history user representation, we utilize a gate mechanism to derive the preference representation ${\pmb u}_{P}$ of the user $u$ :
- 推荐中的实体-上下文融合:为了结合基于实体的用户偏好和对话历史用户表征,我们采用门控机制来推导用户 $u$ 的偏好表征 ${\pmb u}_{P}$:
$$
\begin{array}{r l}&{\pmb{u}{P}=\beta\cdot\pmb{u}{E}+(1-\beta)\cdot\pmb{u}{C}}\ &{\quad\beta=\mathrm{sigmoid}\Big(\mathbf{W}{\mathrm{gate}}(\pmb{u}{E}\parallel\pmb{u}_{C}\Big)}\end{array}
$$
$$
\begin{array}{r l}&{\pmb{u}{P}=\beta\cdot\pmb{u}{E}+(1-\beta)\cdot\pmb{u}{C}}\ &{\quad\beta=\mathrm{sigmoid}\Big(\mathbf{W}{\mathrm{gate}}(\pmb{u}{E}\parallel\pmb{u}_{C}\Big)}\end{array}
$$
where $\beta$ represents the gating probability, $\mathbf{W}_{\mathrm{gate}}$ is learnable parameters matrix. Finally, the probability of recommending an item $i$ from the item set $\mathcal{T}$ to the user $u$ is calculated as follows:
其中 $\beta$ 表示门控概率,$\mathbf{W}_{\mathrm{gate}}$ 为可学习参数矩阵。最终,向用户 $u$ 推荐物品集 $\mathcal{T}$ 中物品 $i$ 的概率计算如下:
$$
\mathbf{P}{\mathrm{rec}}(i)=\mathrm{softmax}(\pmb{u}{P}^{\top}\cdot\mathbf{H}_{i}),
$$
$$
\mathbf{P}{\mathrm{rec}}(i)=\mathrm{softmax}(\pmb{u}{P}^{\top}\cdot\mathbf{H}_{i}),
$$
where $\mathbf{H}_{i}$ is the learned item embedding for item $i$ . To learn the parameters, we use cross-entropy loss as the optimization objective:
其中 $\mathbf{H}_{i}$ 是物品 $i$ 的学习嵌入向量。为优化参数,我们采用交叉熵损失作为目标函数:
$$
\mathcal{L}{\mathrm{rec}}=-\sum_{j=1}^{M}\sum_{i=1}^{N}y_{i j}\cdot\log\Bigl(\mathrm{P}_{\mathrm{rec}}^{(j)}(i)\Bigr)
$$
$$
\mathcal{L}{\mathrm{rec}}=-\sum_{j=1}^{M}\sum_{i=1}^{N}y_{i j}\cdot\log\Bigl(\mathrm{P}_{\mathrm{rec}}^{(j)}(i)\Bigr)
$$
where $M$ is the number of conversations, $j$ is the index of the current conversation, $N$ is the number of items, and $i$ is the index of items. $y_{i j}$ denotes the ground-truth label.
其中 $M$ 为对话总数,$j$ 为当前对话索引,$N$ 为项目总数,$i$ 为项目索引。$y_{i j}$ 表示真实标签。
E. Knowledge-enhanced Response Generation Module
E. 知识增强的响应生成模块
In this section, we study how to fine-tune the proposed response generation module to produce informative responses, utilizing the BART [14] model. The BART model is a pretrained language model that is built upon on Transformer [12] architecture and trained using denosing objectives. It has been demonstrated to be effective in many natural language generation tasks, including sum maris ation, machine translation, and abstract ive QA. Our implementation of the encoder adheres to the standard BART Transformer architecture, and we devote our attention to introducing the knowledge-enhanced decoder.
在本节中,我们研究如何利用BART [14]模型微调所提出的响应生成模块以生成信息丰富的响应。BART模型是一种基于Transformer [12]架构构建、通过去噪目标训练的预训练语言模型,已被证明在摘要生成、机器翻译和抽象问答等多种自然语言生成任务中表现优异。我们的编码器实现遵循标准BART Transformer架构,重点将介绍知识增强的解码器设计。
To enhance response generation during decoding, we adopt a approach similar to KGSF [9]. Specifically, we integrate knowledge-enhanced representation of entities, as described in Equation 7, and fused via attention layers as follows:
为提升解码阶段的响应生成质量,我们采用类似KGSF [9]的方法。具体而言,我们整合了如公式7所述的知识增强实体表征,并通过如下注意力层进行融合:
$$
\begin{array}{r l}&{{\bf A}{0}^{l}=\mathrm{MHA}({\bf Y}^{l-1},{\bf Y}^{l-1},{\bf Y}^{l-1})}\ &{{\bf A}{1}^{l}=\mathrm{MHA}({\bf A}{0}^{l},{\bf X},{\bf X})}\ &{{\bf A}{2}^{l}=\mathrm{MHA}({\bf A}{1}^{l},{\bf H}{p},{\bf H}{p})}\ &{{\bf Y}^{l}=\mathrm{FFN}({\bf A}_{2}^{l}),}\end{array}
$$
$$
\begin{array}{r l}&{{\bf A}{0}^{l}=\mathrm{MHA}({\bf Y}^{l-1},{\bf Y}^{l-1},{\bf Y}^{l-1})}\ &{{\bf A}{1}^{l}=\mathrm{MHA}({\bf A}{0}^{l},{\bf X},{\bf X})}\ &{{\bf A}{2}^{l}=\mathrm{MHA}({\bf A}{1}^{l},{\bf H}{p},{\bf H}{p})}\ &{{\bf Y}^{l}=\mathrm{FFN}({\bf A}_{2}^{l}),}\end{array}
$$
where $\mathbf{MHA}(\mathbf{Q},\mathbf{K},\mathbf{V})$ denotes the multi-head attention function [12], which takes a query matrix $\mathbf{Q}$ , key matrix $\mathbf{K}$ and value matrix $\mathbf{V}$ as input. $\mathrm{FFN}(\cdot)$ represents a fully connected feed-forward network. $\mathbf{X}$ represents the context token embeddings from the BART encoder, and $\mathbf{H}{p}$ corresponds to the knowledge-enhanced entity embeddings obtained from the recommendation module. ${\bf A}{0}^{l}$ , ${\bf A}{1}^{l}$ , ${\bf A}_{2}^{l}$
其中 $\mathbf{MHA}(\mathbf{Q},\mathbf{K},\mathbf{V})$ 表示多头注意力函数 [12],它以查询矩阵 $\mathbf{Q}$、键矩阵 $\mathbf{K}$ 和值矩阵 $\mathbf{V}$ 作为输入。$\mathrm{FFN}(\cdot)$ 代表全连接前馈网络。$\mathbf{X}$ 表示来自 BART 编码器的上下文 token 嵌入,$\mathbf{H}{p}$ 对应从推荐模块获得的知识增强实体嵌入。${\bf A}{0}^{l}$、${\bf A}{1}^{l}$、${\bf A}_{2}^{l}$
This can be attributed to its effectiveness in capturing and utilizing straightforward, structural patterns inherent in the KG. For example, the model can quickly learn to recognize and recommend based on simply yet significant patterns, such as users’ preferences for movies by specific directors. This early advantage likely arises because these structural patterns are more readily discern able and simpler to model. However, when training surpasses a specific epoch threshold, the model overfits the relationship information, leading to a marginal performance improvement. This indicates a ceiling effect where relational data alone is no longer sufficient for continued performance gains. Conversely, integrating both relationship information and entity descriptions initially resulted in worse performance, implying an increase in complexity in handling multiple data modalities, as the model must learn to effectively combine both types of information. However, as training progresses, this integrative approach begins to yield better results. This improvement over time shows the model’s evolving capability to interpret entity characteristics and their interrelationships more effectively. Ultimately, this comprehensive understanding of entities and their relationships can produce superior performance, as the model fully leverages the richness of the combined data.
这可以归因于其有效捕捉和利用知识图谱(KG)中固有的简单结构性模式。例如,该模型能快速学习识别并基于简单却显著的模式进行推荐,比如用户偏好特定导演的电影。这种早期优势可能源于这些结构模式更易识别且建模更简单。但当训练超过特定周期阈值时,模型会过度拟合关系信息,导致性能提升边际递减,表明仅靠关系数据已无法持续提升性能。相反,整合关系信息和实体描述最初会导致性能下降,意味着处理多模态数据的复杂性增加,因为模型需要学习有效结合两类信息。但随着训练推进,这种整合方法开始产生更好效果,表明模型解释实体特征及其相互关系的能力在逐步增强。最终,这种对实体及其关系的全面理解能带来更优性能,因为模型充分挖掘了组合数据的丰富信息。
TABLE VII: The effect of entity description length on the recommendation and conversation tasks for the ReDial dataset. Bold indicates the best results, and the second-best results are underlined.
表 VII: 实体描述长度对ReDial数据集的推荐和对话任务的影响。加粗表示最佳结果,次佳结果带下划线。
| Length | Recommendation | Conversation | ||||
|---|---|---|---|---|---|---|
| R@1 | R@10 | R@50 | Dist@2 | Dist@3 | Dist@4 | |
| 20 | 0.047 | 0.215 | 0.425 | 0.566 | 1.085 | 1.545 |
| 30 | 0.049 | 0.210 | 0.425 | 0.695 | 1.275 | 1.706 |
| 40 | 0.056 | 0.217 | 0.426 | 0.764 | 1.430 | 1.919 |
| 50 | 0.050 | 0.215 | 0.430 | 0.733 | 1.323 | 1.792 |
- Influence of Entity Description Length: To study the impact of entity description length on both recommendation and conversation tasks, we conduct experiments by varying the maximum number of tokens allowed in entity descriptions. As shown in Table VII, most evaluation metrics achieved the best results at a maximum length of 40 tokens. While longer descriptions generally provide more information about the entity and can improve the performance of the CRS, excessive length may introduce noise and hinder the model’s ability to effectively capture the key features of the entity, leading to a reduction in performance. Furthermore, excessive length can increase computational costs. Thus, in our approach, if an entity description exceeds 40 tokens, only the initial 40 tokens are utilized, with the rest being disregarded. Despite the potential loss of valuable information through this process, the conducted experiments confirm that this approach achieves a good balance between performance and efficiency.
- 实体描述长度的影响:为研究实体描述长度对推荐和对话任务的影响,我们通过改变实体描述允许的最大token数量进行实验。如表 VII 所示,大多数评估指标在最大长度为40个token时取得最佳结果。虽然更长的描述通常能提供更多实体信息并可能提升CRS性能,但过长描述会引入噪声并阻碍模型有效捕捉实体关键特征,导致性能下降。此外,过长描述还会增加计算成本。因此在本方法中,若实体描述超过40个token,仅使用前40个token并舍弃其余部分。尽管此过程可能丢失有价值信息,实验证实该方法在性能与效率间取得了良好平衡。
D. Case Study
D. 案例研究
In this section, we present a case study using two conversation examples displayed in Table VIII to demonstrate the quality of generated responses and recommended items by
在本节中,我们通过表 VIII 展示的两个对话案例,分析生成式回复与推荐内容的质量表现

Fig. 5: Performance comparison of different KERL variants on recommendation tasks on the ReDial Dataset. D, KE and CL refer to entity description, knowledge embedding method and contrastive learning.
图 5: 不同KERL变体在ReDial数据集推荐任务上的性能对比。D、KE和CL分别表示实体描述、知识嵌入方法和对比学习。
TABLE VIII: Case Study showcasing generated responses from different models on movie item recommendation. Italic blue font indicates the movie item and red font indicates the entity.
表 8: 电影推荐案例研究展示不同模型生成的响应。斜体蓝色字体表示电影条目,红色字体表示实体。
| 推荐系统: 用户: | 你喜欢哪种类型的电影?我想找一部电影推荐。小时候我特别喜欢《猛鬼街》(1984)。 |
| UniCRS: C2CRS: KERL(我们的) | 我也超爱那部!是啊,确实很棒。我真的很喜欢那部电影! |
| 用户: | 我还爱看《杀人不分左右》(1972)。最近看的一些新恐怖片也不错。 |
| UniCRS: C?CRS KERL(我们的) | 我没看过那部。不过《罗斯玛丽的婴儿》(1968)是经典中的经典杀人狂电影。《小丑回魂》(2017)是部充满反转的经典恐怖片。 |
| 推荐系统: 用户: 推荐系统: 用户: | 你好。想找些好电影?今晚想独自看部不错的电影。有偏好的类型吗?可能悬疑类吧。 |
| UniCRS: C2CRS: KERL(我们的): | 《东方快车谋杀案》(2017)很不错。看过《汉尼拔》(2001)吗?好的,那《七宗罪》(1995)呢?这是部经典。 |
| 用户: | 我也喜欢犯罪片,《汉尼拔》(2001)超棒!《沉默的羔羊》(1991)也很不错。 |
| UniCRS: C2CRS: KERL(我们的): | 那《十二宫》(2007)是另一部经典。如果喜欢犯罪惊悚片,《禁闭岛》(2010)会是个好选择。 |
our proposed model, KERL, in comparison to UniCRS and $\mathrm{{C^{2}C R S}}$ .
我们提出的模型KERL,与UniCRS和$\mathrm{{C^{2}C R S}}$的对比。
Our model effectively integrates dialogue context and background knowledge to generate informative responses and appropriate recommendations, thereby enhancing the user experience. For instance, in the first example, when the user expresses their preferences, KERL identifies the user’s interest in horror movies and recommends “It (2017)”, a newer film that combines intense horror scenes with violent supernatural elements. This recommendation aligns with the user’s favored films, “A Nightmare on Elm Street (1984)” and “The Last House on the Left (1972)”, both known for similar thematic content. In contrast, $\mathrm{{C^{2}C R S}}$ recommends “Rosemary’s Baby (1968)”, a film that, while also a horror, primarily focuses on psychological horror and does not cater to the user’s preference for slasher-style horror, and is also older. Moreover, in the second example, KERL initially suggests “Seven (1995)”, a highly-regarded mystery movie, in response to the user’s request. When the user reveals their appreciation for crime movies and mentions “Hannibal (2001)”, KERL adapts by recommending “Shutter Island (2010)”. This film, a psychological thriller within the crime genre, mirrors the elements appreciated in “Hannibal (2001)” and reflects KERL’s ability to incorporate new information from the conversation and adjust its recommendations accordingly. Conversely, $\mathrm{{C^{2}C R S}}$ , while providing genreappropriate recommendations, lacks depth in adapting to the user’s psychological preferences. UniCRS, after learning the user’s enjoyment of “Hannibal (2001)”, recommends “The Silence of the Lambs (1991)”, which, although relevant, does not expand on the psychological depth or introduce diverse themes.
我们的模型有效整合对话上下文和背景知识,生成信息丰富的回复与精准推荐,从而提升用户体验。例如第一个案例中,当用户表达偏好时,KERL识别出其对恐怖片的兴趣,推荐了融合激烈恐怖场景与超自然暴力元素的新片《小丑回魂(2017)》。该推荐与用户喜爱的《猛鬼街(1984)》和《杀人不分左右(1972)》主题高度契合。相比之下,$\mathrm{{C^{2}C R S}}$推荐的《罗斯玛丽的婴儿(1968)》虽同属恐怖片,但侧重心理惊悚且年代久远,未能满足用户对砍杀式恐怖片的偏好。第二个案例中,KERL根据用户初始请求推荐了高分悬疑片《七宗罪(1995)》,当用户表明喜爱犯罪片并提及《汉尼拔(2001)》后,系统立即调整为推荐同属犯罪题材的心理惊悚片《禁闭岛(2010)》,既呼应《汉尼拔(2001)》的核心元素,也展现了KERL动态整合对话新信息的能力。反观$\mathrm{{C^{2}C R S}}$虽能匹配类型却缺乏心理偏好洞察,而UniCRS在获知用户喜欢《汉尼拔(2001)》后推荐的《沉默的羔羊(1991)》虽有关联性,但未拓展心理深度或引入多元主题。
This case study emphasizes the superiority of our proposed model in comprehending user preferences and providing context-aware recommendations and informative responses. In contrast, $\mathrm{{C^{2}C R S}}$ occasionally faces difficulties in delivering fluent responses and may generate repeated tokens, as seen in the first example, resulting in a degraded user experience. On the other hand, UniCRS tends to generate generic responses with less item-related information.
本案例研究强调了我们提出的模型在理解用户偏好、提供情境感知推荐和信息丰富响应方面的优越性。相比之下,$\mathrm{{C^{2}C R S}}$ 偶尔在生成流畅响应时遇到困难,并可能产生重复 token (如第一个示例所示),导致用户体验下降。另一方面,UniCRS 倾向于生成通用性较强且物品相关信息较少的响应。
VI. CONCLUSION
VI. 结论
In this paper, we presented a novel framework, KnowledgeEnhanced Entity Representation Learning, for conversational recommendation systems. Specifically, our approach leverages a knowledge graph with entity descriptions to better understand the intrinsic information in each entity, and employs an entity encoder to construct entity embeddings from textual descriptions. We then used positional encoding to capture the temporal information of entities in the conversation to ensure more accurate summaries of user preferences. By merging entity information into knowledge-enhanced BART model and copy mechanism, we were able to generate fluent and informative responses. Moreover, we constructed a highquality KG, namely WikiMKG, to facilitate our study.
本文提出了一种用于对话推荐系统的新框架——知识增强实体表征学习(KnowledgeEnhanced Entity Representation Learning)。具体而言,该方法利用带有实体描述的知识图谱来更好地理解每个实体的内在信息,并采用实体编码器从文本描述中构建实体嵌入。随后通过位置编码捕捉对话中实体的时序信息,以确保更准确地总结用户偏好。通过将实体信息融入知识增强的BART模型和复制机制,我们能够生成流畅且信息丰富的响应。此外,我们还构建了高质量的知识图谱WikiMKG以支持本研究。
As future work, we intend to focus on improving the interpret ability and explain ability of generated recommendations. This involves developing techniques to provide transparent reasoning for each recommendation, which is crucial for mitigating potential inaccuracies and biases, thereby ensuring more reliable and user-focused results. Subsequently, the exploration will extend to the utilization of pre-trained user profiles for CRSs. Learning from pre-trained profiles can be more realistic and common in the real world, as users often provide explicit preferences or have a history of interactions with the system that can be leveraged to personalize recommendations.
作为未来的工作,我们计划重点提升生成推荐的可解释性。这包括开发能为每条推荐提供透明推理的技术,这对减少潜在错误和偏见至关重要,从而确保结果更可靠且以用户为中心。后续研究将扩展到利用预训练用户画像构建对话推荐系统(CRS)。从预训练画像中学习更贴近现实场景,因为用户通常会提供明确偏好或存在可被用于个性化推荐的历史交互记录。