The First Cadenza Signal Processing Challenge: Improving Music for Those With a Hearing Loss
首届Cadenza信号处理挑战赛:为听障人士改善音乐体验
Abstract
摘要
The Cadenza project aims to improve the audio quality of music for those who have a hearing loss. This is being done through a series of signal processing challenges, to foster better and more inclusive technologies. In the first round, two common listening scenarios are considered: listening to music over headphones, and with a hearing aid in a car. The first scenario is cast as a demixing-remixing problem, where the music is decomposed into vocals, bass, drums and other components. These can then be intelligently remixed in a personalized way, to increase the audio quality for a person who has a hearing loss. In the second scenario, music is coming from car loudspeakers, and the music has to be enhanced to overcome the masking effect of the car noise. This is done by taking into account the music, the hearing ability of the listener, the hearing aid and the speed of the car. The audio quality of the submissions will be evaluated using the Hearing Aid Audio Quality Index (HAAQI) for objective assessment and by a panel of people with hearing loss for subjective evaluation.
Cadenza项目旨在通过一系列信号处理挑战,提升听障人士的音乐音频质量,以推动更具包容性的技术创新。首轮研究聚焦两种常见聆听场景:耳机听歌和车内助听器使用。第一场景被定义为音轨分离-重混问题,音乐将被分解为人声、贝斯、鼓点及其他组分,随后进行个性化智能重混以优化听障用户的听觉体验。第二场景针对车载扬声器播放的音乐,需通过综合考量音乐本身、听者听力水平、助听器参数及车速等因素,克服行车噪音的掩蔽效应进行音质增强。参赛方案将采用助听器音频质量指数(HAAQI)进行客观评估,并由听障人士组成评审团进行主观评价。
Keywords
关键词
hearing loss, hearing aids, inclusive music, music quality, machine learning, signal processing, challenge
听力损失、助听器、包容性音乐、音乐质量、机器学习、信号处理、挑战
1. Introduction
1. 引言
There are many causes of hearing loss, including congenital hearing loss, chronic middle ear infections, noise exposure and age-related hearing loss [1]. The World Health Organization estimates that over 1.5 billion people worldwide have hearing loss. This is projected to rise to 2.5 billion by 2050. In the UK, nearly 12 million people – 1 in 5 – have hearing loss, with more than $40%$ of cases affecting people over 50 years old, and this figure rises to more than $70%$ for people over 70 years old [2].
听力损失的成因众多,包括先天性听力损失、慢性中耳炎、噪声暴露及年龄相关性听力损失 [1]。世界卫生组织估计全球有超过15亿人存在听力障碍,预计到205年这一数字将增至25亿。在英国,近1200万人(占总人口1/5)患有听力损失,其中40%以上病例为50岁以上人群,70岁以上人群的患病比例更是超过70% [2]。
Hearing loss can have a major impact on a person’s quality of life, making it difficult to communicate, participate in social activities, and enjoy music. Despite this, only $40%$ of people who could benefit from hearing aids actually have them and use them often enough. This is partly because people perceive hearing aids as performing poorly [3, 4, 5, 6] or find little benefit in using them [7, 8]. Historically, hearing aids have focused on speech communication. However, music listening is also important as it benefits health and well-being. Music is a universal human phenomenon that exists in many contexts and has a powerful impact on our emotions [9]. Hearing loss can make it difficult to appreciate music. To take two examples, it can affect the ability of listeners to pick out the lyrics and melody lines, as well as to hear the high frequencies that give the music its richness and detail. As a result, music can sound dull, which can lead to disengagement from music.
听力损失会严重影响一个人的生活质量,导致沟通困难、难以参与社交活动及欣赏音乐。然而,仅有40%的潜在助听器受益者实际拥有并经常使用助听器。部分原因在于人们认为助听器性能不佳 [3, 4, 5, 6] 或使用收益有限 [7, 8]。传统上,助听器主要聚焦于语音交流功能。但音乐聆听同样重要,因其对健康与幸福感具有积极影响 [9]。作为人类社会的普遍现象,音乐存在于多元场景中,并对情绪产生深刻影响。听力损失会削弱音乐欣赏能力:例如导致听众难以辨识歌词与旋律线条,或听不见赋予音乐丰富细节的高频成分,从而使音乐显得沉闷,最终降低音乐参与度。
There are several spectro-temporal differences between speech and music that makes hearing aids optimised for speech perform poorly for music [10]. Although manufacturers have been developing special programs for music listening, the effectiveness has been mixed, with $68%$ of users reporting difficulty listening to music through their hearing aids [11]. There is a pressing need for better and more inclusive technology to enhance music accessibility to people with hearing loss.
语音和音乐在频谱和时间维度上存在诸多差异,导致针对语音优化的助听器在音乐场景下表现不佳 [10]。尽管制造商已开发专用音乐聆听程序,但效果参差不齐——约68%用户反馈通过助听器欣赏音乐存在困难 [11]。当前亟需开发更优质、更具包容性的技术来提升听障人士的音乐可及性。
The Cadenza project aims to improve the audio quality of music for people with hearing loss who wear hearing aids, using signal processing and machine learning challenges. These challenges are designed to bring together various research communities to make music more accessible to everyone, taking into consideration the diversity of listeners and making it more inclusive. In the first round (CAD1), we focused on two common scenarios for listening to music: over headphones and in a car in the presence of noise. Firstly, we introduce the general structure and design of CAD1 challenge. Sections 3 and 4 describe the specifics of Task 1 and Task 2. We conclude in Section 6. More details can be found on the challenge website1.
Cadenza项目旨在通过信号处理和机器学习挑战,提升佩戴助听器的听力受损人群的音乐音质。这些挑战旨在汇聚不同研究群体,让音乐更具包容性,同时兼顾听众的多样性。在第一轮挑战(CAD1)中,我们聚焦于两种常见音乐聆听场景:耳机聆听和车载环境下的噪声场景。首先介绍CAD1挑战的整体架构与设计,第3、4节分别详述任务1与任务2的具体内容,第6节进行总结。更多细节可查阅挑战官网1。
2. Overview of the Challenge Tasks
2. 挑战任务概述
In the first scenario (Task 1), a person with hearing loss listens to music through headphones without using their hearing aids. In the second scenario (Task 2), the listener is inside a moving car, listening to the music that is coming from the car stereo in the presence of noise, while wearing their hearing aids. Entrants to the challenges are tasked with personalizing the music signals to improve the audio quality.
在第一种场景(Task 1)中,听力损失者在不使用助听器的情况下通过耳机听音乐。在第二种场景(Task 2)中,听者佩戴助听器坐在行驶的汽车内,通过车载音响在噪声环境中聆听音乐。挑战赛参与者需要对音乐信号进行个性化处理以提升音质。
Figure 1 shows a diagram with the general structure of the challenges. Entrants must develop a Music Enhancer that takes in clean music and listener characteristics as input. The Evaluation Processor then takes the improved music signals, applying any acoustic conditions that are relevant to the task. Finally, the signals are evaluated using the Hearing Aid Audio Quality Index (HAAQI) [12] and a listener panel.
图 1: 展示了挑战赛总体结构示意图。参赛者需开发一个音乐增强器 (Music Enhancer),其输入为纯净音乐和听者特征。评估处理器 (Evaluation Processor) 随后接收优化后的音乐信号,并施加与任务相关的声学条件。最终使用助听器音频质量指数 (HAAQI) [12] 和听者小组对信号进行评价。
2.1. Listener character is ation databases
2.1. 监听器特征化数据库
Listeners are characterised by bilateral pure-tone audiograms. This give the audible thresholds at standardised frequencies ([250, 500, 1000, 2000, 3000, 4000, 6000, 8000] Hz) as measured by an audiometer [13]. While a wider frequency range might have been useful for music, we were restricted to this range because these are the standard frequencies that have been tested in the available databases.
听者的特征表现为双侧纯音听力图。该图表通过听力计[13]测量标准化频率([250, 500, 1000, 2000, 3000, 4000, 6000, 8000] Hz)下的可听阈值。虽然更宽的频率范围可能对音乐更有用,但我们仅限于此范围,因为这些是现有数据库中测试过的标准频率。
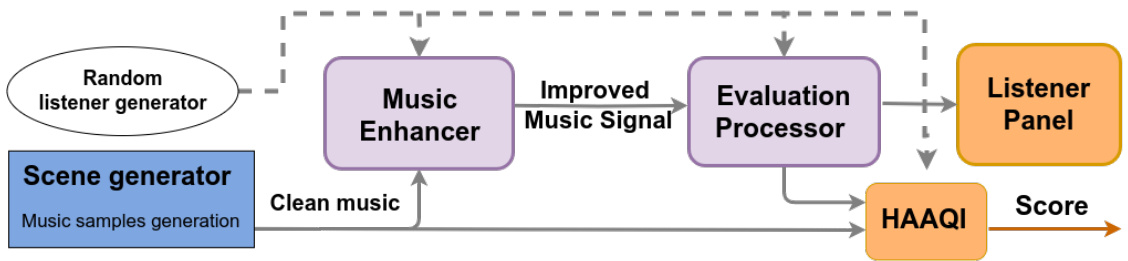
Figure 1: Diagram of the structural design of the first challenge
图 1: 第一个挑战的结构设计示意图
For the training (train) set, we used the 83 audiograms employed by the 2nd Clarity Enhancement Challenge [14] from the Clarity Project . These correspond to anonymised examples of real audiograms drawn from the Scottish Section of Hearing Sciences at the University of Nottingham dataset.
在训练集(train set)中,我们使用了Clarity项目第二届清晰度增强挑战赛[14]提供的83份听力图。这些数据来自诺丁汉大学听力科学苏格兰分部的真实匿名听力图样本。
For the development (dev) set, we selected 50 audiograms from [15]. We first filtered the audiograms to better-ear 4-frequency hearing loss between 20 and 75 dB. We then randomly chose the necessary number of audiograms to maintain the same distribution per band as in the original Clarity dataset. This dev set has an equal male-female distribution.
在开发(dev)集构建中,我们从[15]中选取了50份听力图。首先筛选出较好耳四频平均听阈介于20至75分贝的听力图,随后按原始Clarity数据集各频段分布比例随机抽取对应数量的样本。该开发集保持了男女比例均衡的特征。
For the evaluation (eval) set, we recruited 52 bilateral hearing aid users, with symmetric or asymmetric hearing loss. The listeners were recruited via the University of Leeds. Hearing loss severity was mild for 15 listeners, moderate for 17 listeners, moderately severe for 18 listeners and severe for 2 listeners. In the train, dev and eval sets, hearing loss levels, at each frequency, were limited to 80 dB Hearing Level (HL).
在评估(eval)集中,我们招募了52名双侧助听器使用者,包括对称性和非对称性听力损失患者。受试者通过利兹大学招募。听力损失程度为轻度15人、中度17人、中重度18人、重度2人。在训练集(train)、开发集(dev)和评估集中,各频率的听力损失水平均限制在80分贝听力级(dB HL)以内。
2.2. Challenge Evaluations
2.2. 挑战评估
Both scenarios will be subjected to two evaluation processes. The first is an objective evaluation using HAAQI. This is an intrusive metric in which the processed and reference signals are compared. In the evaluation, the HAAQI function is configured so that the reference signal has an amplification applied to it, so that all frequency bands contribute equally to its loudness. This amplification is the NAL-R hearing aid prescription [16]. This prescribes the gain to apply based on the individual’s audiogram thresholds (in dB HL). This linear amplification improves audibility; there is no dynamic range compression.
两种场景都将经过两个评估流程。首先是使用HAAQI (Hearing Aid Audio Quality Index) 进行的客观评估。这是一种侵入式指标,通过比较处理后的信号与参考信号来实现。评估中配置了HAAQI函数,使参考信号应用了NAL-R助听器处方 [16] 规定的增益放大,确保所有频段对响度的贡献均等。该增益基于个体听力图阈值 (以dB HL为单位) 进行线性放大以提升可听度,不涉及动态范围压缩。
The second evaluation consists of a listener panel of 52 listeners (the eval listeners) who will rate the audio quality of the music samples. The panel will use a number of scales: clarity, harshness, distortion, frequency balance, overall audio quality, and liking. Overall audio quality captures whether the audio quality is poor or good, and liking is how much the listener liked the specific piece they just listened to. These dimensions have been developed for this purpose, through a sensory evaluation study [17].
第二次评估由52名听众(评估听众)组成的小组对音乐样本的音频质量进行评分。该小组将使用多个维度:清晰度、刺耳度、失真度、频率平衡、整体音频质量和喜好度。整体音频质量反映音频质量的好坏,喜好度则是听众对刚听过的特定曲目的喜爱程度。这些维度是通过感官评估研究[17]专门开发的。
Overall audio quality captures whether the audio quality is poor / good, and liking is how much the participant liked the specific piece they just listened to
整体音质 (audio quality) 反映音频质量的好坏程度,喜好度 (liking) 表示参与者对刚听完的特定片段的喜爱程度
3. Design of Task 1
3. 任务1的设计
This is presented as a demixing-remixing problem. The demixing stage follows the same design as previous music separation challenges [18, 19]. The goal is to decompose stereo music into vocal, drums, bass, and other (VDBO). However, unlike past demixing challenges, we use HAAQI for the evaluation instead of the signal-to-distortion ratio. In the remixing stage, the separated VDBO components allow for personalised remixing for each listener. For example, for some music, the vocals could be amplified to improve the audibility of the lyrics. In Task 1, for Figure 1, the Evaluation Processor only focuses on computing HAAQI.
这被视为一个分离-重混问题。分离阶段沿用了以往音乐分离挑战赛的设计 [18, 19],目标是将立体声音乐分解为人声 (vocal)、鼓组 (drums)、贝斯 (bass) 和其他元素 (other,简称 VDBO)。但与以往分离挑战不同的是,本次采用 HAAQI 而非信噪比作为评估指标。在重混阶段,分离出的 VDBO 组件可为每位听众实现个性化混音,例如在某些音乐中增强人声以提高歌词清晰度。在任务1中,图1所示的评估处理器仅专注于计算 HAAQI。
We use the MUSDB18-HQ music dataset [20]. This contains 150 tracks where 86 are for train, 14 for dev and 50 for eval. For training data augmentation, entrants are allowed to use the BACH10 [21], FMA-Small [22] and MedleydB versions 1 [23] and 2 [24].
我们使用MUSDB18-HQ音乐数据集[20]。该数据集包含150条音轨,其中86条用于训练,14条用于开发,50条用于评估。为进行训练数据增强,参赛者允许使用BACH10[21]、FMA-Small[22]以及MedleydB 1.0[23]和2.0[24]版本。
The eval set includes 49 tracks, after removing one track where the lyrics might cause offence. For the objective evaluation, 30-second segments of music were selected at random. For the listening panel, 15-second segments were selected at random, ensuring that no explicit language was present.
评估集包含49首曲目,其中移除了1首可能因歌词引发不适的曲目。在客观评估中,随机选取了30秒的音乐片段。听审环节则随机选取15秒片段,并确保不包含任何敏感语言。
4. Design of Task 2
4. 任务2的设计
The goal is to process music emitted by a car stereo, while accounting for the presence of simulated car noise. However, this is not a denoising problem, as participants do not have access to the exact noise signal. The evaluator processor, for Figure 1, adds the car acoustic conditions (head-related impulse responses (HRIRs) and simulated car noise) and applies the fixed hearing aid processing algorithms to the enhanced signals before computing the HAAQI score.
目标是处理车载音响播放的音乐,同时考虑模拟汽车噪声的存在。然而,这并不是一个去噪问题,因为参与者无法获取确切的噪声信号。对于图 1,评估处理器会添加汽车声学条件(头相关脉冲响应 (HRIRs) 和模拟汽车噪声),并在计算 HAAQI 分数前对增强信号应用固定的助听器处理算法。
The music datasets for task 2 are based on the FMA-Small [22] and the MTG Jamendo datasets [25]. FMA-Small contains 30-second music segments from eight genres; however, we only included the genres ‘Hip-Hop’, ‘Instrumental’, ‘International’, ‘Pop’ and ‘Rock’ as they are the most likely to be found in a car listening environment for our target listeners. We also included samples from the ‘classical’ and ‘orchestral’ genres from the MTG-Jamendo dataset, as people with hearing loss are more likely to be older and listeners to classical music [26].
任务2的音乐数据集基于FMA-Small [22] 和MTG Jamendo数据集 [25]。FMA-Small包含来自八种流派的30秒音乐片段,但我们仅纳入"嘻哈"、"器乐"、"国际"、"流行"和"摇滚"流派,因为这些最可能出现在目标听众的汽车收听环境中。我们还从MTG-Jamendo数据集中加入了"古典"和"管弦乐"流派的样本,因为听力受损人群更可能年龄较大且是古典音乐听众 [26]。
This process resulted in 7000 30-second tracks distributed as follows: 5600 train, 700 dev, and 700 eval. However, as the eval samples will be listened to by the listener panel, the eval set was reduced to 70 samples by randomly selecting 10 samples per genre. HAAQI will be computed over the whole 30-second segments but, only 15 seconds will be scored by the panel.
这一过程最终生成了7000段30秒的音频,分布如下:5600段用于训练,700段用于开发,700段用于评估。不过由于评估样本将由听众小组进行聆听,评估集被缩减至70个样本,即每个流派随机选取10个样本。HAAQI指标将基于完整的30秒片段计算,但评分小组仅对其中15秒进行打分。
We simulate the different components of the car noise based on a car speed and gear as follows: (i) a mono complex tone corresponding to the engine noise, (ii) two mono signals generated by filtering a white noise by a lowpass filter with a 6-dB/octave slope corresponding to aerodynamic and rolling noise from the left and right side of the car.
我们基于车速和档位模拟了汽车噪声的不同组成部分如下:(i) 对应发动机噪声的单声道复合音,(ii) 通过6-dB/octave斜率的低通滤波器过滤白噪声生成的两个单声道信号,分别对应汽车左右两侧的空气动力学噪声和滚动噪声。
HRIRs were drawn from the eBrIRD - ELOSPHERES database [27]. Each scene contains 74 measurements from $-90^{\circ}$ to $90^{\circ}$ azimuth in $2.5^{\circ}$ steps. Anechoic HRIRs are used for the car noise, and in-car HRIRs are used for the enhanced signals.
HRIRs来自eBrIRD - ELOSPHERES数据库[27]。每个场景包含74次测量,方位角从$-90^{\circ}$到$90^{\circ}$,步长为$2.5^{\circ}$。汽车噪声使用消声HRIRs,增强信号则使用车内HRIRs。
Table 1 Baseline HAAQI scores for Task 1 and Task 2 of the First Cadenza Challenge.
表 1: 首届 Cadenza 挑战赛任务 1 和任务 2 的基线 HAAQI 分数。
| 任务 | 系统 | 平均HAAQI | 标准差HAAQI |
|---|---|---|---|
| 任务 1 | 基线 1 - Demucs | 0.2548 | 0.0403 |
| 任务 1 | 基线 2 - OpenUnmix | 0.2253 | 0.0290 |
| 任务 2 | 基线 | 0.1256 | 0.0321 |
5. Baseline Details and Results
5. 基线详情与结果
Two baseline systems were proposed for Task 1. The first baseline, ‘Baseline 1 - Demucs’, utilizes the out-of-the-box hybrid-demucs source separation model [28] to estimate the VDBO components of the music. This hybrid architecture leverages both time-domain and spec tr ogrambased approaches. The second baseline, ‘Baseline 2 - OpenUnmix’, employs the OpenUmix source separation model [29]. OpenUnmix is a purely spec tr ogram-based approach and served as the baseline for the SiSEC 2018 challenge [18].
任务1提出了两个基线系统。第一个基线"Baseline 1 - Demucs"采用开箱即用的hybrid-demucs源分离模型[28]来估计音乐的VDBO成分。这种混合架构同时利用了时域和频谱图方法。第二个基线"Baseline 2 - OpenUnmix"使用了OpenUnmix源分离模型[29]。OpenUnmix是纯频谱图方法,曾作为SiSEC 2018挑战赛的基线[18]。
For Task 2, a single baseline was proposed, which applies a level constraint to the mixture at the hearing aid microphones to prevent clipping caused by the NAL-R hearing aid amplification. Table 1 shows the baseline HAAQI scores for Task 1 and Task 2. For Task 1, the results correspond to the mean and standard deviation (std) of all eight left and right VDBO signals. In Task 2, the scores represent the mean and std of the scores per genre.
对于任务2,提出了单一基线方法,该方法在助听器麦克风处对混合信号施加电平约束,以防止NAL-R助听器放大导致的削波。表1展示了任务1和任务2的基线HAAQI分数。在任务1中,结果对应于所有八个左右VDBO信号的平均值和标准差(std)。任务2中的分数则代表每类音乐风格得分的平均值和标准差。
6. Conclusion and Future Work
6. 结论与未来工作
The Cadenza project aims to improve the audio quality of music for those who have a hearing loss. It consists of two common music listening scenarios; Task 1, listening to music over headphones and, in Task 2, listening to music in a car. While Task 1 presents a demixingremixing problem, Task 2 presents a near-end music enhancement problem. Both scenarios will be evaluated using HAAQI for objective evaluation and a listener panel for subjective evaluation in autumn/winter 2023. The project team will run an online workshop in December 2023 where entrants will outline their approaches, and the results of the evaluations will be presented. Currently, we are running an ICASSP 2024 Grand Challenge and the CAD2 challenge will launch in 2024.
Cadenza项目旨在为听力受损人群提升音乐音频质量。该项目包含两种常见音乐聆听场景:任务1通过耳机聆听音乐,任务2在车内聆听音乐。任务1属于音源分离-重混音问题,任务2属于近端音乐增强问题。两个场景都将在2023年秋冬季采用HAAQI进行客观评估,并通过听众小组进行主观评估。项目团队将于2023年12月举办在线研讨会,参赛团队将阐述其技术方案,评估结果也将在会上公布。目前我们正在开展ICASSP 2024国际挑战赛,CAD2挑战赛将于2024年启动。
Acknowledgments
致谢
The Cadenza project is supported by the Engineering and Physical Sciences Research Council (EPSRC) [grant number: EP/W019434/1]. We thank our partners: BBC, Google, Logitech, RNID, Sonova, Universit t Oldenburg.
Cadenza项目由工程与物理科学研究理事会 (EPSRC) [资助号: EP/W019434/1] 支持。我们感谢合作伙伴:BBC、Google、Logitech、RNID、Sonova、Universit t Oldenburg。