Revisiting Adversarial Training under Long-Tailed Distributions
重新审视长尾分布下的对抗训练
Xinli Yue, Ningping Mou, Qian Wang, Lingchen Zhao* Key Laboratory of Aerospace Information Security and Trusted Computing, Ministry of Education, School of Cyber Science and Engineering, Wuhan University, Wuhan 430072, China {xinliyue,ning ping mou,qianwang,lczhaocs}@whu.edu.cn
岳新立, 牟宁平, 王倩, 赵凌琛* 航空航天信息安全与可信计算教育部重点实验室, 网络空间安全学院, 武汉大学, 武汉 430072, 中国 {xinliyue,ningpingmou,qianwang,lczhaocs}@whu.edu.cn
Abstract
摘要
Deep neural networks are vulnerable to adversarial attacks, often leading to erroneous outputs. Adversarial training has been recognized as one of the most effective methods to counter such attacks. However, existing adversarial training techniques have predominantly been tested on balanced datasets, whereas real-world data often exhibit a long-tailed distribution, casting doubt on the efficacy of these methods in practical scenarios.
深度神经网络容易受到对抗攻击的影响,通常会导致错误输出。对抗训练已被认为是对抗此类攻击的最有效方法之一。然而,现有的对抗训练技术主要在平衡数据集上进行测试,而现实世界的数据往往呈现长尾分布,这引发了对这些方法在实际场景中有效性的质疑。
In this paper, we delve into adversarial training under long-tailed distributions. Through an analysis of the previous work “RoBal”, we discover that utilizing Balanced Softmax Loss alone can achieve performance comparable to the complete RoBal approach while significantly reducing training overheads. Additionally, we reveal that, similar to uniform distributions, adversarial training under longtailed distributions also suffers from robust over fitting. To address this, we explore data augmentation as a solution and unexpectedly discover that, unlike results obtained with balanced data, data augmentation not only effectively alleviates robust over fitting but also significantly improves robustness. We further investigate the reasons behind the improvement of robustness through data augmentation and identify that it is attributable to the increased diversity of examples. Extensive experiments further corroborate that data augmentation alone can significantly improve robustness. Finally, building on these findings, we demonstrate that compared to RoBal, the combination of BSL and data augmentation leads to a $+6.66%$ improvement in model robustness under AutoAttack on CIFAR-10-LT. Our code is available at: https://github.com/NISPLab/AT-BSL.
本文深入探讨了长尾分布下的对抗训练。通过对先前工作“RoBal”的分析,我们发现仅使用平衡 Softmax 损失 (Balanced Softmax Loss) 即可实现与完整 RoBal 方法相当的性能,同时显著减少训练开销。此外,我们揭示出,与均匀分布类似,长尾分布下的对抗训练也存在鲁棒过拟合问题。为了解决这一问题,我们探索了数据增强作为解决方案,并意外地发现,与平衡数据下的结果不同,数据增强不仅能有效缓解鲁棒过拟合,还能显著提高鲁棒性。我们进一步研究了数据增强提高鲁棒性的原因,并确定这是由于样本多样性的增加。大量实验进一步证实,仅使用数据增强即可显著提高鲁棒性。最后,基于这些发现,我们证明了与 RoBal 相比,BSL 和数据增强的结合在 CIFAR-10-LT 上的 AutoAttack 下使模型鲁棒性提高了 $+6.66%$。我们的代码可在以下网址获取:https://github.com/NISPLab/AT-BSL。
1. Introduction
1. 引言
It is well-known that deep neural networks (DNNs) are vulnerable to adversarial attacks, where attackers can induce errors in DNNs’ recognition results by adding perturbations that are imperceptible to the human eye [12, 39]. Many researchers have focused on defending against such attacks. Among the various defense methods proposed, adversarial training is recognized as one of the most effective approaches. It involves integrating adversarial examples into the training set to enhance the model’s generalization capability against these examples [20, 31, 42, 45, 53, 54]. In recent years, significant progress has been made in the field of adversarial training. However, we note that almost all studies on adversarial training utilize balanced datasets like CIFAR-10, CIFAR-100 [23], and Tiny-ImageNet [24] for performance evaluation. In contrast, real-world datasets often exhibit an imbalanced, typically long-tailed distribution. Hence, the efficacy of adversarial training in practical systems should be reassessed using long-tailed datasets [14, 40].
众所周知,深度神经网络(DNNs)容易受到对抗攻击的影响,攻击者可以通过添加人眼难以察觉的扰动来诱导 DNNs 的识别结果出错 [12, 39]。许多研究者致力于防御此类攻击。在提出的各种防御方法中,对抗训练被认为是最有效的方法之一。它通过将对抗样本整合到训练集中,以增强模型对这些样本的泛化能力 [20, 31, 42, 45, 53, 54]。近年来,对抗训练领域取得了显著进展。然而,我们注意到,几乎所有关于对抗训练的研究都使用 CIFAR-10、CIFAR-100 [23] 和 Tiny-ImageNet [24] 等平衡数据集进行性能评估。相比之下,现实世界的数据集通常表现出不平衡的长尾分布。因此,对抗训练在实际系统中的有效性应使用长尾数据集重新评估 [14, 40]。
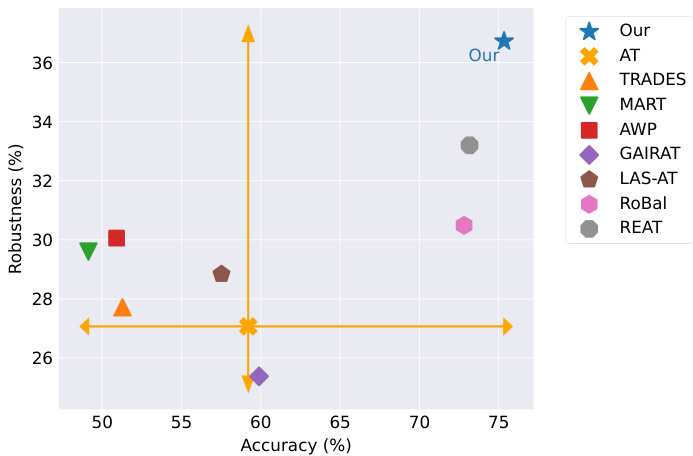
Figure 1. The clean accuracy and robustness under AutoAttack (AA) [5] of various adversarial training methods using WideResNet-34-10 [51] on CIFAR-10-LT [23]. Our method, building upon AT [31] and BSL [36], leverages data augmentation to improve robustness, achieving a $+6.66%$ improvement over the SOTA method RoBal [46]. REAT [26] is a concurrent work with ours, yet to be published.
图 1: 使用 WideResNet-34-10 [51] 在 CIFAR-10-LT [23] 上,各种对抗训练方法在 AutoAttack (AA) [5] 下的干净精度和鲁棒性。我们的方法基于 AT [31] 和 BSL [36],利用数据增强来提高鲁棒性,相比 SOTA 方法 RoBal [46] 提升了 $+6.66%$。REAT [26] 是与我们同时期的工作,尚未发表。
To the best of our knowledge, RoBal [46] is the sole published work that investigates the adversarial robustness under the long-tailed distribution. However, due to its complex design, RoBal demands extensive training time and GPU memory, which somewhat limits its practicality. Upon revisiting the design and principles of RoBal, we find that its most critical component is the Balanced Softmax Loss (BSL) [36]. We observe that combining AT [31] with BSL to form AT-BSL can match RoBal’s effectiveness while significantly reducing training overhead. Following Occam’s Razor principle, where entities should not be multiplied without necessity [19], we advocate using AT-BSL as a substitute for RoBal. In this paper, we base our studies on ATBSL.
据我们所知,RoBal [46] 是唯一一篇研究长尾分布下对抗鲁棒性的已发表工作。然而,由于其复杂的设计,RoBal 需要大量的训练时间和 GPU 内存,这在一定程度上限制了其实用性。在重新审视 RoBal 的设计和原理后,我们发现其最关键的部分是 Balanced Softmax Loss (BSL) [36]。我们观察到,将 AT [31] 与 BSL 结合形成 AT-BSL 可以匹配 RoBal 的效果,同时显著减少训练开销。根据奥卡姆剃刀原则,即若无必要,勿增实体 [19],我们提倡使用 AT-BSL 作为 RoBal 的替代方案。在本文中,我们的研究基于 AT-BSL。
In the course of our study on the robustness of models under long-tailed distribution, we encounter another significant finding: adversarial training with long-tailed distribution data, similar to training on balanced datasets, also leads to the issue of robust over fitting [37]. Previous works on balanced datasets often employed data augmentation to mitigate this robust over fitting [4, 13, 35, 37, 45]. Hence, a straightforward approach is to attempt the use of data augmentation to alleviate the robust over fitting issue in adversarial training with long-tailed distribution. Our results align with findings on balanced datasets, indicating that data augmentation can mitigate robust over fitting. However, contrary to findings on balanced datasets where it was concluded that data augmentation alone can not improve robustness [35, 37, 45], we find that data augmentation techniques, including MixUp [52], Cutout [9], CutMix [50], AugMix [17], Auto Augment (AuA) [6], RandAugment (RA) [7] and Trivial Augment (TA) [33], can significantly improve robustness. Hence, we introduce the following query: Why does data augmentation improve robustness? We hypothesize that data augmentation augments example diversity, enabling the model to learn richer representations thereby improving its robustness. Subsequently, we validate our hypothesis through ablation studies on RA.
在我们研究长尾分布下模型鲁棒性的过程中,我们遇到了另一个重要发现:使用长尾分布数据进行对抗训练,与在平衡数据集上训练类似,也会导致鲁棒过拟合问题 [37]。之前关于平衡数据集的工作通常采用数据增强来缓解这种鲁棒过拟合 [4, 13, 35, 37, 45]。因此,一个直接的方法是尝试使用数据增强来缓解长尾分布对抗训练中的鲁棒过拟合问题。我们的结果与平衡数据集上的发现一致,表明数据增强可以缓解鲁棒过拟合。然而,与平衡数据集上的发现相反,后者得出结论认为仅靠数据增强无法提高鲁棒性 [35, 37, 45],我们发现数据增强技术,包括 MixUp [52]、Cutout [9]、CutMix [50]、AugMix [17]、Auto Augment (AuA) [6]、RandAugment (RA) [7] 和 Trivial Augment (TA) [33],可以显著提高鲁棒性。因此,我们提出了以下问题:为什么数据增强能提高鲁棒性?我们假设数据增强增加了样本多样性,使模型能够学习更丰富的表示,从而提高了其鲁棒性。随后,我们通过对 RA 的消融研究验证了我们的假设。
Our contributions are summarized as follows:
我们的贡献总结如下:
2. Related Works
- 相关工作
Long-Tailed Recognition. Long-tailed distributions refer to a common imbalance in training set where a small portion of classes (head) have massive examples, while other classes (tail) have very few examples [14, 40]. Models trained under such distribution tend to exhibit a bias towards the head classes, resulting in poor performance for the tail classes. Traditional rebalancing techniques aim at addressing the long-tailed recognition problem include re-sampling [21, 38, 41, 56] and cost-sensitive learning [8, 29], which often improve the performance of tail classes at the expense of head classes. To mitigate these adverse effects, some methods handle class-specific attributes through perspectives such as margins [43] and biases [36]. Recently, more advanced techniques like class-conditional sharpness-aware minimization [57], feature clusters compression [27], and global-local mixture consistency cumulative learning [10] have been introduced, further improving the performance of long-tailed recognition. However, these works have been devoted to improving clean accuracy, and investigations into the adversarial robustness of long-tailed recognition remain scant.
长尾识别
Adversarial Training. The philosophy of adversarial training involves integrating adversarial examples into the training set, thereby improving the model’s general iz ability to such examples. Adversarial training addresses a min-max problem, with the inner maximization dedicated to generating the strongest adversarial examples and the outer minimization aimed at optimizing the model parameters. The quintessential method of adversarial training is AT [31], which can be mathematically represented as follows:
对抗训练。对抗训练的理念是将对抗样本整合到训练集中,从而提高模型对这类样本的泛化能力。对抗训练解决的是一个极小极大问题,其中内层最大化致力于生成最强的对抗样本,而外层最小化则旨在优化模型参数。对抗训练的典型方法是 AT [31],其数学表示如下:

where $x^{\prime}$ is an adversarial example constrained by $\ell_{p}$ norm for clean examples $x,y$ is the label of $x$ , $\theta_{m}$ is the parameter of the model $m$ , $\epsilon$ is the perturbation size, $\mathcal{L}{\mathrm{max}}$ is the internal maximization loss, and $\mathcal{L}{\mathrm{min}}$ is the external minimization loss.
其中 $x^{\prime}$ 是由 $\ell_{p}$ 范数约束的对抗样本,$x,y$ 是 $x$ 的标签,$\theta_{m}$ 是模型 $m$ 的参数,$\epsilon$ 是扰动大小,$\mathcal{L}{\mathrm{max}}$ 是内部最大化损失,$\mathcal{L}{\mathrm{min}}$ 是外部最小化损失。
Building upon the foundation of AT [31], subsequent works developed advanced adversarial training techniques such as TRADES [53], MART [42], AWP [45], GAIRAT [54], and LAS-AT [20]. However, these adversarial training methods were predominantly experimented with on balanced datasets like CIFAR-10 and CIFAR-100. Robustness under Long-Tailed Distribution. Previous adversarial training works were concentrated mainly on balanced datasets. However, data in the real world are seldom balanced; they are more commonly characterized by long-tailed distributions [14, 40]. Therefore, a critical criterion for assessing the practical utility of adversarial training should be its performance on long-tailed distributions. To our knowledge, RoBal [46] is the only work that investigates adversarial training on long-tailed datasets. In Section 3, we delve into the components of RoBal, improv- ing the efficacy of long-tailed adversarial training based on our findings. Moreover, some works [30, 44, 47, 49] have already indicated that adversarial training on balanced datasets can lead to significant robustness disparities across classes. Whether this disparity is exacerbated on long-tailed datasets remains an open question for further exploration.
在 AT [31] 的基础上,后续研究开发了诸如 TRADES [53]、MART [42]、AWP [45]、GAIRAT [54] 和 LAS-AT [20] 等先进的对抗训练技术。然而,这些对抗训练方法主要是在 CIFAR-10 和 CIFAR-100 等平衡数据集上进行实验的。长尾分布下的鲁棒性。之前的对抗训练工作主要集中在平衡数据集上。然而,现实世界中的数据很少是平衡的;它们更常见的是长尾分布 [14, 40]。因此,评估对抗训练实际效用的一个关键标准应该是其在长尾分布上的表现。据我们所知,RoBal [46] 是唯一一个研究长尾数据集上对抗训练的工作。在第 3 节中,我们深入探讨了 RoBal 的组成部分,并根据我们的发现改进了长尾对抗训练的效果。此外,一些研究 [30, 44, 47, 49] 已经表明,在平衡数据集上进行对抗训练会导致不同类别之间的显著鲁棒性差异。这种差异在长尾数据集上是否会加剧,仍然是一个有待进一步探索的开放性问题。
Data Augmentation. In standard training regimes, data augmentation has been validated as an effective tool to mitigate over fitting and improve model generalization, regardless of whether the data distribution is balanced or longtailed [2, 10, 48, 55]. The most commonly utilized augmentation techniques for image classification tasks include random flips, rotations, and crops [15]. More sophisticated augmentation methods like MixUp [52], Cutout [9], and CutMix [50] have been shown to yield superior results in standard training contexts. Furthermore, augmentation strategies such as Augmix [17], AuA [6], RA [7], and TA [33], which employ a learned or random combination of multiple augmentations, have elevated the efficacy of data augmentation to new heights, heralding the advent of the era of automated augmentation.
数据增强 (Data Augmentation)。在标准的训练机制中,数据增强已被验证为一种有效的手段,能够缓解过拟合并提升模型的泛化能力,无论数据分布是平衡的还是长尾的 [2, 10, 48, 55]。在图像分类任务中,最常用的增强技术包括随机翻转、旋转和裁剪 [15]。更为复杂的增强方法如 MixUp [52]、Cutout [9] 和 CutMix [50] 在标准训练场景中已显示出更优越的效果。此外,像 Augmix [17]、AuA [6]、RA [7] 和 TA [33] 这样的增强策略,通过使用学习或随机的多种增强组合,将数据增强的效果提升到了新的高度,预示着自动化增强时代的到来。
3. Analysis of RoBal
3. RoBal 分析
3.1. Preliminaries
3.1. 预备知识
RoBal [46], in comparison to AT [31], incorporates four additional components: 1) cosine classifier; 2) Balanced Softmax Loss [36]; 3) class-aware margin; 4) TRADES regu- larization [53].
RoBal [46] 与 AT [31] 相比,引入了四个额外组件:1) 余弦分类器;2) 平衡Softmax损失 (Balanced Softmax Loss) [36];3) 类别感知边界;4) TRADES 正则化 [53]。
Cosine Classifier. In basic classification tasks employing a standard linear classifier, the predicted logit for class $i$ can be represented as:
余弦分类器。在采用标准线性分类器的基本分类任务中,类别 $i$ 的预测逻辑值可以表示为:

where $g(\cdot)$ is the liner classifer. In this formulation, the prediction depends on three factors: 1) the magnitude of the weight vector $\Vert W_{i}\Vert$ and the feature vector $|f(x)|$ ; 2) the angle between them, expressed as $\cos\theta_{i}$ ; and 3) the bias of the classifier $b_{i}$ .
其中 $g(\cdot)$ 是线性分类器。在此公式中,预测结果取决于三个因素:1) 权重向量 $\Vert W_{i}\Vert$ 和特征向量 $|f(x)|$ 的幅度;2) 它们之间的夹角,表示为 $\cos\theta_{i}$ ;以及 3) 分类器的偏差 $b_{i}$ 。
The above decomposition illustrates that simply by scaling the norm of examples in feature space, the predictions of the examples can be altered. In linear class if i ers, the scale of the weight vector $|W_{i}|$ often diminishes in tail classes, thereby impacting the recognition performance for tail classes. Consequently, [46] endeavors to utilize a cosine classifier [34] to mitigate the scale effects of features and weights. And in the cosine classifier, the predicted logit for class $i$ can be represented as:
上述分解说明,仅通过缩放特征空间中样本的范数,就可以改变样本的预测结果。在线性分类器中,权重向量 $|W_{i}|$ 的尺度在尾部类别中通常减小,从而影响尾部类别的识别性能。因此,[46] 尝试利用余弦分类器 [34] 来减轻特征和权重的尺度影响。在余弦分类器中,类别 $i$ 的预测值可以表示为:

where $h(\cdot)$ is the cosine classifier, $|\cdot|$ denotes the $\ell_{2}$ norm of the vector, $s$ is the scaling factor.
其中 $h(\cdot)$ 是余弦分类器,$|\cdot|$ 表示向量的 $\ell_{2}$ 范数,$s$ 是缩放因子。
Balanced Softmax Loss. An intuitive and widely adopted approach to addressing class imbalance is to assign classspecific biases during training for the cross-entropy (CE) loss. [46] employs the formulation by [32, 36], denoted as $b_{i}=\tau_{b}\log\left(n_{i}\right)$ , where the modified cross-entropy loss, namely Balanced Softmax Loss (BSL), becomes:
Balanced Softmax Loss。一种直观且广泛采用的解决类别不平衡问题的方法是在训练时为交叉熵(Cross-Entropy, CE)损失分配类别特定的偏差。[46] 采用了 [32, 36] 的公式,表示为 $b_{i}=\tau_{b}\log\left(n_{i}\right)$,修改后的交叉熵损失,即 Balanced Softmax Loss (BSL),变为:

where $n_{i}$ is the number of examples in the $i$ -th class, and $\tau_{b}$ is a hyper parameter controling the calculation of bias. BSL adapts to the label distribution shift between training and testing by adding specific biases to each class based on the number of examples in each class to improve long-tailed recognition performance [36].
其中 $n_{i}$ 是第 $i$ 类中的样本数量,$\tau_{b}$ 是控制偏差计算的超参数。BSL 通过根据每个类中的样本数量为每个类添加特定的偏差来适应训练和测试之间的标签分布偏移,从而提高长尾识别的性能 [36]。
Class-Aware Margin. However, when considering the margin representation, the margin from the true class $y$ to class $i$ , denoted by $\tau_{b}\log{(n_{i}/n_{y})}$ , becomes negative when $n_{y}>n_{i}$ , leading to poorer disc rim i native representations and classifier learning for head classes. To address this, [46] introduces a class-aware margin term [34], which assigns a larger margin value to head classes as compensation:
类感知边界。然而,在考虑边界表示时,从真实类别 $y$ 到类别 $i$ 的边界 $\tau_{b}\log{(n_{i}/n_{y})}$ 在 $n_{y}>n_{i}$ 时会变为负值,导致头部类别的判别表示和分类器学习效果变差。为了解决这个问题,[46] 引入了一个类感知边界项 [34],该边界项为头部类别分配了更大的边界值作为补偿:

The first term increases with $n_{i}$ and reaches its minimum of zero when $n_{i}={\ensuremath{n_{\mathrm{min}}}}$ , with $\tau_{m}$ as the hyper parameter controlling the trend. The second term, $m_{0}>0$ , is a uniform boundary for all classes, a common strategy in networks based on cosine class if i ers. Add this class-aware margin $m_{i}$ to $\mathcal{L}{0}$ to become $\mathcal{L}{1}$ :
第一项随着 $n_{i}$ 的增加而增加,当 $n_{i}={\ensuremath{n_{\mathrm{min}}}}$ 时达到最小值零,其中 $\tau_{m}$ 是控制趋势的超参数。第二项 $m_{0}>0$ 是所有类的统一边界,这是基于余弦分类器的网络中的常见策略。将这个类感知边距 $m_{i}$ 添加到 $\mathcal{L}{0}$ 中,得到 $\mathcal{L}{1}$:

TRADES Regular iz ation. [46] incorporates a $\mathrm{KL}$ regularization term following TRADES [53], thereby modifying the overall loss function to:
TRADES 正则化。[46] 在 TRADES [53] 的基础上引入了一个 $\mathrm{KL}$ 正则化项,从而将整体损失函数修改为:

where $\beta$ serves as a hyper parameter to control the intensity of the TRADES regular iz ation.
其中,$\beta$ 作为超参数用于控制 TRADES 正则化的强度。
Table 1. The clean accuracy, robustness, time (average per epoch) and memory (GPU) using ResNet-18 [15] on CIFAR-10-LT following the integration of components from RoBal [46] into AT [31]. The best results are bolded. The second best results are underlined. Cos: Cosine Classifier; BSL: Balanced Softmax Loss [36]; CM: Class-aware Margin [46]; TRADES: TRADES Regular iz ation [53].
表 1. 使用 ResNet-18 [15] 在 CIFAR-10-LT 上,将 RoBal [46] 的组件集成到 AT [31] 后,得到的准确率、鲁棒性、时间(每个 epoch 的平均值)和内存(GPU)的对比。最佳结果加粗,次佳结果加下划线。Cos: 余弦分类器;BSL: 平衡 Softmax 损失 [36];CM: 类别感知边界 [46];TRADES: TRADES 正则化 [53]。
| 方法 | 组件 | 准确率 | 效率 |
|---|---|---|---|
| Cos BSL | CM | TRADES | |
| AT [31] | |||
| AT-BSL | |||
| AT-BSL-Cos | √ | √ | |
| AT-BSL-Cos-TRADES | √ | 人 | |
| RoBal [46] |
3.2. Ablation Studies of RoBal
3.2. RoBal 的消融研究
To investigate the role of each component in RoBal [46], we conduct ablation studies on it. Specifically, we incrementally add each component of RoBal to AT [31] and then evaluate the method’s clean accuracy, robustness, training time per epoch, and memory usage. The results are summarized in Table 1. Note that the parameters utilized in Table 1 adhere strictly to the default settings of [46], and the details about adversarial attacks are in Section 5.1. We observe that the AT-BSL method outperforms AT [31] in terms of clean accuracy and adversarial robustness. However, upon integrating a cosine classifier with AT-BSL, while the robustness under PGD [31] significantly improves, robustness under adaptive attacks like CW [3], LSA [18], and AA [5] notably decreases. This aligns with observations in REAT [26], suggesting that the cosine classifier (scaleinvariant classifier) used in RoBal may lead to gradient vanishing when generating adversarial examples with crossentropy loss. This is attributed to the normalization of weights and features in the classification layer, which substantially reduces the gradient scale, impeding the generation of potent adversarial examples [26]. Further additions of TRADES regular iz ation [53] and class-aware margin do not yield substantial improvements in robustness under AA, yet markedly increase training time and memory consumption. In fact, AT-BSL alone can match the complete RoBal in terms of clean accuracy and robustness under AA. Therefore, in line with Occam’s Razor [19], we advocate using AT-BSL, which renders adversarial training more efficient without sacrificing significant performance. The $\mathcal{L}_{m i n}$ formula of AT-BSL is as follows:
为了探究 RoBal [46] 中每个组件的作用,我们对其进行了消融研究。具体而言,我们逐步将 RoBal 的各个组件添加到 AT [31] 中,然后评估该方法的干净准确率、鲁棒性、每轮训练时间和内存使用情况。结果总结在表 1 中。请注意,表 1 中使用的参数严格遵循 [46] 的默认设置,关于对抗攻击的详细信息见第 5.1 节。我们观察到,AT-BSL 方法在干净准确率和对抗鲁棒性方面优于 AT [31]。然而,在将余弦分类器与 AT-BSL 结合后,虽然 PGD [31] 下的鲁棒性显著提高,但在 CW [3]、LSA [18] 和 AA [5] 等自适应攻击下的鲁棒性却显著下降。这与 REAT [26] 中的观察结果一致,表明 RoBal 中使用的余弦分类器(尺度不变分类器)在使用交叉熵损失生成对抗样本时可能会导致梯度消失。这是由于分类层中权重和特征的归一化,显著降低了梯度规模,阻碍了强对抗样本的生成 [26]。进一步添加 TRADES 正则化 [53] 和类感知边界并未在 AA 下的鲁棒性上带来显著提升,却显著增加了训练时间和内存消耗。事实上,仅使用 AT-BSL 即可在干净准确率和 AA 下的鲁棒性方面与完整的 RoBal 相匹配。因此,根据奥卡姆剃刀原则 [19],我们提倡使用 AT-BSL,它使对抗训练更高效,而不会显著牺牲性能。AT-BSL 的 $\mathcal{L}_{m i n}$ 公式如下:

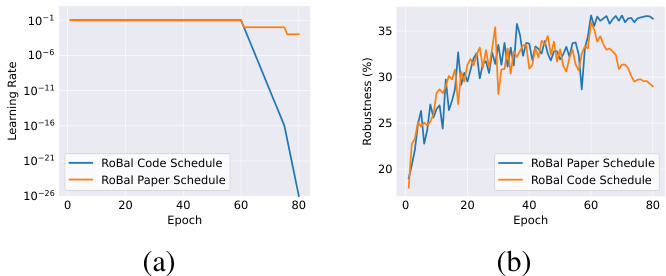
Figure 2. Learning rate scheduling analysis of RoBal [46]. (a) comparison of the learning rate schedules: ‘RoBal Code Schedule’ from the source code and ‘RoBal Paper Schedule’ as described in the publication. (b) the evolution of test robustness under PGD20 [31] using ResNet-18 on CIFAR-10-LT across training epochs.
图 2: RoBal [46] 的学习率调度分析。(a) 学习率调度比较:来自源代码的‘RoBal Code Schedule’和出版物中描述的‘RoBal Paper Schedule’。(b) 在 CIFAR-10-LT 上使用 ResNet-18 进行 PGD20 [31] 测试鲁棒性随训练周期的演变。
3.3. Robust Over fitting and Unexpected Discovery
3.3. 鲁棒过拟合与意外发现
Discrepancy in Learning Rate Scheduling: Paper Description vs. Code Implementation. RoBal [46] asserts that early stopping is not employed, and the results reported are from the final epoch, the 80th epoch. The declared learning rate schedule is an initial rate of 0.1, with decays at the 60th and 70th epochs, each by a factor of 0.1. After executing the source code of RoBal, we observe, as depicted by the blue line in Fig. 2(b), that test robustness remains essentially unchanged after the first learning rate decay (60th epoch), indicating an absence of robust over fitting. It is well-known that adversarial training on CIFAR-10 exhibits significant robust over fitting [37], and given that CIFAR10-LT has less data than CIFAR-10, the absence of robust over fitting on CIFAR-10-LT is contradictory to the assertion that additional data can alleviate robust over fitting in [35].
学习率调度中的差异:论文描述与代码实现。RoBal [46] 声称未采用早停策略,报告的结果来自最后一个 epoch,即第 80 个 epoch。声明的学习率调度方案是初始学习率为 0.1,在第 60 和第 70 个 epoch 时分别衰减 0.1 倍。在执行 RoBal 的源代码后,我们观察到,如图 2(b) 中的蓝线所示,第一次学习率衰减(第 60 个 epoch)后,测试鲁棒性基本保持不变,这表明没有出现鲁棒过拟合现象。众所周知,在 CIFAR-10 上进行对抗训练会表现出显著的鲁棒过拟合 [37],而 CIFAR10-LT 的数据量少于 CIFAR-10,因此在 CIFAR-10-LT 上未出现鲁棒过拟合与 [35] 中关于额外数据可以缓解鲁棒过拟合的断言相矛盾。
Upon a meticulous examination of the official code provided by RoBal [46], we discover inconsistencies between the implemented learning rate schedule and what is claimed in the paper. The official code uses a learning rate schedule starting at 0.1, with a decay of 0.1 per epoch after the 60th epoch and 0.01 per epoch after the 75th epoch (the blue line in Fig. 2(a)). This leads to a learning rate as low as 1e26 by the 80th epoch, potentially limiting learning after the 60th epoch and contributing to the similar performance of models at the 60th and 80th epochs as shown in Fig. 2(b).
在对 RoBal [46] 提供的官方代码进行仔细检查后,我们发现实现的学习率调度与论文中声称的不一致。官方代码使用的学习率调度从 0.1 开始,在第 60 个 epoch 后每 epoch 衰减 0.1,在第 75 个 epoch 后每 epoch 衰减 0.01(图 2(a) 中的蓝色线)。这导致在第 80 个 epoch 时学习率低至 1e26,可能限制了第 60 个 epoch 之后的学习,并导致了图 2(b) 中第 60 和第 80 个 epoch 模型性能相似的结果。
Subsequently, we adjust the learning rate schedule to what is declared in [46] (the orange line in Fig. 2(a)) and redraw the robustness curve, represented by the orange line in Fig. 2(b). Post-adjustment, a continuous decline in test robustness following the first learning rate decay is observed, aligning with the robust over fitting phenomenon typically seen on CIFAR-10.
随后,我们将学习率调整至 [46] 中声明的值(图 2(a) 中的橙色线),并重新绘制了鲁棒性曲线,如图 2(b) 中的橙色线所示。调整后,观察到第一次学习率衰减后测试鲁棒性持续下降,这与 CIFAR-10 上常见的鲁棒过拟合现象一致。
Therefore, adversarial training under long-tailed distributions exhibits robust over fitting, similar to balanced distributions. So, how might we resolve this problem? Several works [4, 13, 35, 37, 45] have attempted to use data augmentation to alleviate robust over fitting on balanced datasets.
因此,长尾分布下的对抗训练表现出与平衡分布相似的鲁棒过拟合。那么,我们该如何解决这个问题?一些研究 [4, 13, 35, 37, 45] 尝试使用数据增强来缓解平衡数据集上的鲁棒过拟合。
Testing MixUp. [35, 37, 45] suggest that on CIFAR-10, MixUp [52] can alleviate robust over fitting. Therefore, we posit that on the long-tailed version of CIFAR-10, CIFAR10-LT, MixUp would also mitigate robust over fitting. In Fig. 3(a), it is evident that AT-BSL-MixUp, which utilizes MixUp, significantly alleviates robust over fitting compared to AT-BSL. Furthermore, we unexpectedly discover that MixUp markedly improves robustness. This observation is inconsistent with previous findings in balanced datasets [35, 37, 45], where it was concluded that data augmentation alone does not improve robustness.
测试 MixUp。[35, 37, 45] 表明在 CIFAR-10 上,MixUp [52] 可以缓解鲁棒过拟合。因此,我们假设在 CIFAR-10 的长尾版本 CIFAR10-LT 上,MixUp 也能缓解鲁棒过拟合。在图 3(a) 中,明显可以看出,使用 MixUp 的 AT-BSL-MixUp 相比 AT-BSL 显著缓解了鲁棒过拟合。此外,我们意外地发现 MixUp 显著提高了鲁棒性。这一观察结果与之前在平衡数据集上的发现 [35, 37, 45] 不一致,之前的研究结论是单独的数据增强并不能提高鲁棒性。
Exploring data augmentation. Following the validation of the MixUp hypothesis, our investigation expands to assess whether other augmentation techniques could alleviate robust over fitting and improve robustness. This includes augmentations like Cutout [9], CutMix [50], AugMix [17], TA [33], AuA [6], and RA [7]. Analogous to our analysis of MixUp, we report the robustness achieved by these augmentation techniques during training in Fig. 3. Firstly, our findings indicate that each augmentation technique mitigated robust over fitting, with CutMix, AuA, RA, and TA exhibiting almost negligible instances of this phenomenon. Furthermore, we observe that robustness attained by each augmentation surpasses that of the vanilla AT-BSL, further corroborating that data augmentation alone can improve robustness.
探索数据增强。在验证了MixUp假设后,我们的研究进一步评估了其他增强技术是否能够缓解鲁棒过拟合并提高鲁棒性。这包括Cutout [9]、CutMix [50]、AugMix [17]、TA [33]、AuA [6]和RA [7]等增强技术。与我们对MixUp的分析类似,我们在图3中报告了这些增强技术在训练期间实现的鲁棒性。首先,我们的研究结果表明,每种增强技术都缓解了鲁棒过拟合,其中CutMix、AuA、RA和TA几乎完全消除了这种现象。此外,我们观察到每种增强技术实现的鲁棒性都超过了普通的AT-BSL,进一步证实了仅通过数据增强就可以提高鲁棒性。
4. Why Data Augmentation Can Improve Robustness
4. 为什么数据增强可以提高鲁棒性
Formulating Hypothesis. We postulate that data augmentation improves robustness by increasing example diversity, thereby allowing models to learn richer representations. Taking RA [7] as an illustrative example, for each training image, RA randomly selects a series of augmentations from a search space consisting of 14 augmentations, namely Identity, ShearX, ShearY, TranslateX, TranslateY, Rotate, Brightness, Color, Contrast, Sharpness, Posterize, Solarize, Auto Contrast, and Equalize, to apply to the image. We initiate an ablation study on RA, testing the impact of each augmentation individually. Specifically, we narrow the search space of RA to a single augmentation, meaning RA is restricted to using only this one augmentation to augment all training examples. From Fig. 4(a), it can be observed that except for Contrast, none of the augmentations alone improve robustness; in fact, augmentations such as Solarize, Auto Contrast, and Equalize significantly underperform compared to AT-BSL. We surmise that this is due to the limited example diversity provided by a single augmentation, thereby resulting in no substantial improvement in robustness.
提出假设。我们假设数据增强通过增加样本多样性来提高鲁棒性,从而使模型能够学习到更丰富的表示。以 RA [7] 为例,对于每个训练图像,RA 会从包含 14 种增强操作的搜索空间中随机选择一系列增强操作,这些操作包括 Identity、ShearX、ShearY、TranslateX、TranslateY、Rotate、Brightness、Color、Contrast、Sharpness、Posterize、Solarize、Auto Contrast 和 Equalize,并将其应用于图像。我们对 RA 进行了消融研究,分别测试了每种增强操作的影响。具体来说,我们将 RA 的搜索空间缩小到单一增强操作,即 RA 只能使用这一种增强操作来增强所有训练样本。从图 4(a) 可以看出,除了 Contrast 之外,单独使用任何一种增强操作都无法提高鲁棒性;实际上,像 Solarize、Auto Contrast 和 Equalize 这样的增强操作在性能上显著低于 AT-BSL。我们推测这是由于单一增强操作提供的样本多样性有限,从而导致鲁棒性没有显著提升。
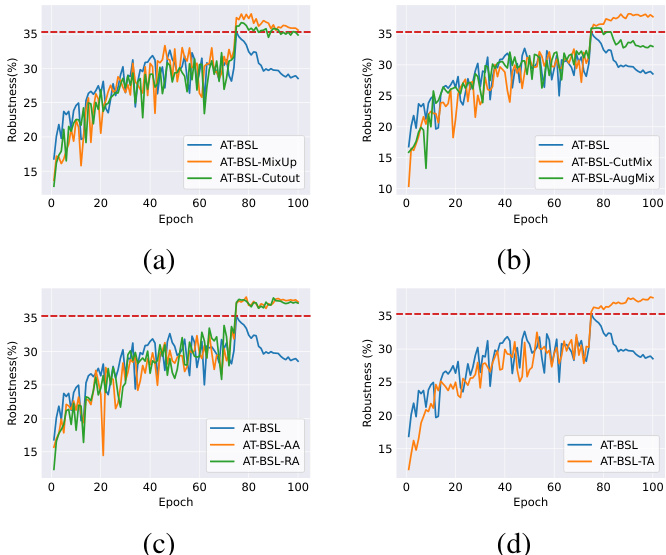
Figure 3. The evolution of test robustness under PGD-20 using ResNet-18 on CIFAR-10-LT for AT-BSL using different data augmentation strategies across training epochs. For reference, the red dashed lines in each panel represent the robustness of the best checkpoint of AT-BSL. Due to the density of the illustrations, the results have been compartmentalized into four distinct panels: (a), (b), (c), and (d).
图 3: 在 CIFAR-10-LT 数据集上使用 ResNet-18 进行 PGD-20 攻击测试时,AT-BSL 在使用不同数据增强策略下的测试鲁棒性随训练轮次的演变。作为参考,每个面板中的红色虚线表示 AT-BSL 最佳检查点的鲁棒性。由于图示密度较大,结果被分为四个独立的面板:(a)、(b)、(c) 和 (d)。
Validating Hypothesis. Subsequently, we explore the impact of the number of types of augmentations on robustness. Specifically, for each trial, we randomly selected $n$ types of augmentations to constitute the search space of RA, with $n\in{2,14}$ . Each experiment is repeated five times. As shown in Fig. 4(b), we reveal that robustness progressively improves with the addition of more augmentation methods in the search space of RA. This indicates that as the number of types of augmentations in the search space increases, the variety of augmentations available to examples also grows, leading to greater example diversity. Consequently, the represent at ions learned by the model become more comprehensive, thereby improving robustness. This validates our hypothesis.
验证假设。随后,我们探讨了增强类型数量对鲁棒性的影响。具体而言,对于每次试验,我们随机选择 $n$ 种增强类型来构成 RA 的搜索空间,其中 $n\in{2,14}$ 。每个实验重复五次。如图 4(b) 所示,我们发现随着 RA 搜索空间中增强方法的增加,鲁棒性逐渐提高。这表明随着搜索空间中增强类型数量的增加,样本可用的增强方式也增多,从而导致样本多样性增加。因此,模型学习到的表示更加全面,从而提高了鲁棒性。这验证了我们的假设。
Moreover, to further substantiate our hypothesis, we conduct an ablation study on the three types of augmentations—Solarize, Auto Contrast, and Equalize—which, when used individually, impair robustness. Specifically, we eliminate these three and employ the remaining 11 augmentations as the baseline: RA-11. We then increment ally add
此外,为了进一步验证我们的假设,我们对三种类型的增强(Solarize、Auto Contrast 和 Equalize)进行了消融研究,这些增强在单独使用时会影响鲁棒性。具体来说,我们剔除这三种增强,并使用剩下的 11 种增强作为基线:RA-11。然后我们逐步添加
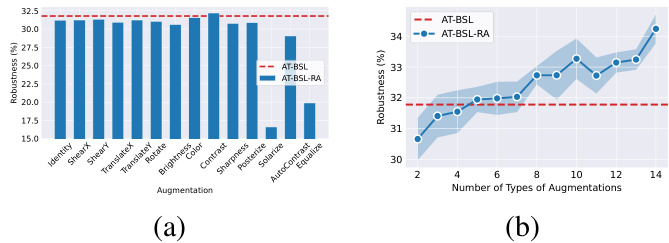
Figure 4. The robustness under AA for AT-BSL with different augmentations using ResNet-18 on CIFAR-10-LT. (a) Change the augmentation space of RA [7] to a single augmentation, and the horizontal axis represents the name of the single augmentation. (b) The horizontal axis represents the number of types of augmentations in the search space of RA.
图 4: 在 CIFAR-10-LT 上使用 ResNet-18 进行不同增强的 AT-BSL 在 AA 下的鲁棒性。(a) 将 RA [7] 的增强空间更改为单一增强,横轴表示单一增强的名称。(b) 横轴表示 RA 搜索空间中增强类型的数量。
Table 2. The clean accuracy and robustness under AA for AT-BSL with different augmentations using ResNet-18 on CIFAR-10-LT. The best results are bolded. RA-11 means only using the first 11 augmentations in the search space of RA. The lines below RA-11 indicate additional augmentations based on RA-11, and the last line uses the complete search space of RA. SO: Solarize; AC: AutoContrast; EQ: Equalize.
表 2. 在 CIFAR-10-LT 上使用 ResNet-18 的 AT-BSL 在不同增强下的干净准确性和 AA 鲁棒性。最佳结果以粗体显示。RA-11 表示仅使用 RA 搜索空间中的前 11 种增强。RA-11 下方的行表示基于 RA-11 的额外增强,最后一行使用 RA 的完整搜索空间。SO: 曝光; AC: 自动对比; EQ: 均衡。
| 方法 | Clean | FGSM | PGD | CW | LSA | AA |
|---|---|---|---|---|---|---|
| RA-11 | 67.80 | 40.68 | 35.88 | 34.01 | 33.89 | 32.12 |
| 67.60 | 41.43 | 37.04 | 34.52 | 34.05 | 32.76 | |
| SO AC | 68.57 | 41.20 | 34.24 | |||
| 36.60 | 34.07 | 32.51 | ||||
| EQ SO+AC | 68.33 | 41.64 | 36.80 | 34.33 | 34.17 | 32.59 |
| 68.43 | 42.10 | 37.23 | 34.62 | 34.37 | 33.02 | |
| SO+EQ | 68.53 | 41.89 | 37.42 | 35.07 | 34.83 | 33.49 |
| 34.91 | 34.49 | 33.15 | ||||
| AC+EQ | 68.36 | 41.88 | 37.42 | |||
| SO+AC+EQ | 70.86 | 43.06 | 37.94 | 36.24 | 36.04 | 34.24 |
one to three of the negative augmentations, with the results outlined in Table 2. It is discovered that the more types of augmentations added, the more significant the improvement in robustness. Despite the negative impact of these three augmentations when used in isolation, their inclusion in the search space of RA still contributes to robustness improvement, further validating our hypothesis that data augmentation increases example diversity and thereby improves ro- bustness.
表 2 中概述了使用一到三种负增强的结果。研究发现,添加的增强类型越多,鲁棒性的提升越显著。尽管这三种增强在单独使用时会产生负面影响,但将它们包含在 RA 的搜索空间中仍然有助于提高鲁棒性,这进一步验证了我们的假设,即数据增强增加了样本的多样性,从而提高了鲁棒性。
5. Experiments
5. 实验
5.1. Settings
5.1. 设置
Datasets. Following [46], we conduct experiments on CIFAR-10-LT and CIFAR-100-LT [23]. Due to space constraints, partial results for CIFAR-100-LT are included in the appendix. In our main experiments, the imbalance ratio (IR) of CIFAR-10-LT is set to 50. Table 6 also provides results for various IRs.
数据集。遵循 [46],我们在 CIFAR-10-LT 和 CIFAR-100-LT [23] 上进行实验。由于篇幅限制,CIFAR-100-LT 的部分结果包含在附录中。在我们的主要实验中,CIFAR-10-LT 的不平衡比率 (IR) 设置为 50。表 6 也提供了不同 IR 的结果。
Evaluation Metrics. When assessing model robustness, the $l_{\infty}$ norm-bounded perturbation is $\epsilon=8/255$ . The attacks carried out include the single-step attack FGSM [12] and several iterative attacks, such as PGD [31], CW [3] and LSA [18], performed over 20 steps with a step size of 2/255. We also employ AutoAttack (AA) [5], considered the strongest attack so far. For all methods, the evaluations are based on both the best checkpoint (selected based on robustness under PGD-20) and the final checkpoint.
评估指标。在评估模型鲁棒性时,$l_{\infty}$ 范数有界扰动的 $\epsilon=8/255$。所进行的攻击包括单步攻击 FGSM [12] 和几种迭代攻击,如 PGD [31]、CW [3] 和 LSA [18],这些攻击在 20 步内进行,步长为 2/255。我们还使用了 AutoAttack (AA) [5],它被认为是目前最强的攻击。对于所有方法,评估均基于最佳检查点(根据 PGD-20 下的鲁棒性选择)和最终检查点。
Comparison Methods. We consider adversarial training methods under long-tailed distributions: RoBal [46] and REAT [26], as well as defenses under balanced distributions: AT [31], TRADES [53], MART [42], AWP [45], GAIRAT [54], and LAS-AT [20].
对比方法。我们考虑了长尾分布下的对抗训练方法:RoBal [46] 和 REAT [26],以及平衡分布下的防御方法:AT [31]、TRADES [53]、MART [42]、AWP [45]、GAIRAT [54] 和 LAS-AT [20]。
Training Details. We train the models using the Stochastic Gradient Descent (SGD) optimizer with an initial learning rate of 0.1, momentum of 0.9, and weight decay of 5e-4. We set the batch size to 128. We set the total number of training epochs to 100, and the learning rate is divided by 10 at the 75th and 90th epoch following [53]. During generating adversarial examples, we enforce a maximum perturbation of 8/255 and a step size of $2/255$ . The number of iterations for internal maximization is fixed at 10, denoting PGD-10, and the impact of PGD steps on robustness is investigated in Table 15. For all experiments related to AT-BSL, we adopt $\tau_{b}=1$ , and the results for different $\tau_{b}$ are provided in Fig. 7. Note that the AT-BSL presented in Tables 3 and 4 represents our own implementation, which differs in training parameters from RoBal [46]. Detailed discussions regarding these discrepancies are provided in the appendix.
训练细节。我们使用随机梯度下降 (Stochastic Gradient Descent, SGD) 优化器训练模型,初始学习率为 0.1,动量为 0.9,权重衰减为 5e-4。我们将批量大小设置为 128,总训练轮数设置为 100,并在第 75 轮和第 90 轮时将学习率除以 10,遵循 [53]。在生成对抗样本时,我们设置最大扰动为 8/255,步长为 $2/255$。内部最大化的迭代次数固定为 10,记为 PGD-10,PGD 步骤对鲁棒性的影响在表 15 中进行了研究。对于所有与 AT-BSL 相关的实验,我们采用 $\tau_{b}=1$,不同 $\tau_{b}$ 的结果在图 7 中提供。请注意,表 3 和表 4 中所示的 AT-BSL 是我们自己的实现,其训练参数与 RoBal [46] 不同。有关这些差异的详细讨论在附录中提供。
5.2. Main Results
5.2. 主要结果
As evident from Tables 3 and 4, on CIFAR-10-LT, ATBSL with data augmentation achieves the highest clean accuracy and adversarial robustness on both ResNet-18 and WideResNet-34-10. Note that on WideResNet-34-10, our method, AT-BSL-AuA, demonstrates a significant improvement of $+6.66%$ robustness under AA compared to the SOTA method RoBal. Moreover, in terms of robustness at the final checkpoint, our method significantly outperforms others, demonstrating that data augmentation mitigates robust over fitting.
从表 3 和表 4 可以看出,在 CIFAR-10-LT 上,使用数据增强的 ATBSL 在 ResNet-18 和 WideResNet-34-10 上均实现了最高的干净准确率和对抗鲁棒性。值得注意的是,在 WideResNet-34-10 上,我们的方法 AT-BSL-AuA 在 AA 下的鲁棒性相比 SOTA 方法 RoBal 有显著提升,达到了 $+6.66%$。此外,在最终检查点的鲁棒性方面,我们的方法显著优于其他方法,表明数据增强缓解了鲁棒过拟合问题。
We present the robustness of different methods across each class in Fig. 5. It is observable that, except for a few classes, our method improves robustness in almost every class, particularly in tail classes (5 to 9 classes) where the improvements are more pronounced. Furthermore, consistent with observations on balanced datasets [30, 44, 47, 49], there is a significant disparity in class-wise robustness. Class 3 remains the least robust despite its example numbers far exceeding that of subsequent classes, which may be attributable to the intrinsic properties of class 3 [46].
我们在图 5 中展示了不同方法在每个类别上的鲁棒性。可以看出,除了少数类别外,我们的方法在几乎所有类别上都提高了鲁棒性,尤其是在尾类(5 到 9 类)中,改进更为显著。此外,与在平衡数据集上的观察结果一致 [30, 44, 47, 49],类别之间的鲁棒性存在显著差异。尽管类别 3 的样本数量远远超过后续类别,但它仍然是最不鲁棒的,这可能是由于类别 3 的内在属性所致 [46]。
5.3. Futher Analysis
5.3. 进一步分析
Effect of Augmentation Strategies and Parameters. We present in both Table 5 and Fig. 6 the impact of different augmentation strategies and parameters on robustness. Specifically, we conduct experiments using ResNet-18 on CIFAR-10-LT, comparing robustness at the best checkpoint. In addition, in Table 5, we use the best hyper-parameters: mixing rate $\alpha~=~0.3$ for Mixup, window length 17 for Cutout, mixing rate $\alpha=0.1$ for CutMix, and magnitude 8 for RA. As shown in Table 5, various augmentation strategies improve robustness compared to vanilla AT-BSL, with AuA and RA also achieving gains in clean accuracy. Fig. 6 indicates that for MixUp and CutMix, smaller values of $\alpha$ yield better robustness; for Cutout, longer window lengths generally correlate with better robustness; for RA, a moderate magnitude of transformation improves robustness, peaking at magnitude $=8$ , highlighting that excessive augmentation is not always beneficial.
数据增强策略和参数的影响。我们在表5和图6中展示了不同数据增强策略和参数对鲁棒性的影响。具体来说,我们在 CIFAR-10-LT 数据集上使用 ResNet-18 进行实验,并比较了最佳检查点的鲁棒性。此外,在表5中,我们使用了最佳超参数:Mixup的混合率 $\alpha~=~0.3$,Cutout的窗口长度为17,CutMix的混合率 $\alpha=0.1$,以及 RA 的强度为8。如表5所示,与原始的 AT-BSL 相比,各种数据增强策略都提高了鲁棒性,其中 AuA 和 RA 在干净准确率上也取得了提升。图6表明,对于 MixUp 和 CutMix,较小的 $\alpha$ 值会带来更好的鲁棒性;对于 Cutout,较长的窗口长度通常与更好的鲁棒性相关;对于 RA,适度的变换强度可以提高鲁棒性,并在强度 $=8$ 时达到峰值,这表明过度的数据增强并不总是有益的。
Table 3. The clean accuracy and robustness for various algorithms using ResNet-18 on CIFAR-10-LT. The best results are bolded.
表 3: 使用 ResNet-18 在 CIFAR-10-LT 上的各种算法的干净准确率和鲁棒性。最佳结果已加粗。
| 方法 | 最佳检查点 | 最后检查点 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clean | FGSM | PGD | CW | LSA | AA | Clean | FGSM | PGD | CW | LSA | AA | |
| AT [31] | 49.35 | 30.09 | 27.30 | 26.93 | 27.08 | 25.76 | 52.91 | 29.29 | 25.15 | 25.58 | 27.13 | 24.23 |
| TRADES [53] | 43.61 | 29.18 | 27.81 | 26.73 | 26.58 | 26.41 | 43.75 | 29.06 | 27.05 | 26.10 | 25.93 | 25.78 |
| MART [42] | 48.61 | 32.75 | 30.29 | 28.82 | 28.46 | 27.73 | 48.80 | 32.60 | 29.78 | 28.45 | 28.12 | 27.30 |
| AWP [45] | 49.29 | 33.78 | 31.20 | 30.53 | 30.36 | 29.53 | 47.75 | 32.77 | 30.83 | 30.01 | 29.68 | 29.12 |
| GAIRAT [54] | 50.83 | 30.20 | 27.46 | 21.65 | 21.23 | 20.41 | 50.66 | 28.44 | 25.60 | 19.68 | 19.22 | 18.26 |
| LAS-AT [20] | 52.81 | 33.35 | 30.32 | 29.57 | 29.15 | 28.53 | 53.50 | 33.14 | 30.09 | 29.13 | 28.84 | 28.30 |
| RoBal [46] | 70.34 | 40.50 | 35.93 | 31.05 | 31.10 | 29.54 | 70.00 | 36.18 | 29.00 | 27.67 | 26.98 | 25.63 |
| REAT [26] | 67.38 | 40.13 | 35.83 | 33.88 | 33.66 | 32.20 | 67.58 | 36.99 | 30.93 | 30.83 | 31.62 | 28.61 |
| AT-BSL | 68.89 | 40.08 | 35.27 | 33.47 | 33.46 | 31.78 | 67.63 | 35.20 | 28.65 | 28.91 | 31.35 | 26.97 |
| AT-BSL-RA | 70.86 | 43.06 | 37.94 | 36.24 | 36.04 | 34.24 | 71.83 | 42.62 | 37.15 | 35.37 | 35.50 | 33.44 |
Table 4. The clean accuracy and robustness for various algorithms using WideResNet-34-10 on CIFAR-10-LT. The best results are bolded.
表 4: 使用 WideResNet-34-10 在 CIFAR-10-LT 上各种算法的清洁准确率和鲁棒性。最佳结果已加粗。
| Method | Best Checkpoint | Last Checkpoint | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clean | FGSM | PGD | cW | LSA | AA | Clean | FGSM | PGD | CW | LSA | AA | |
| AT [31] | 59.21 | 31.88 | 27.88 | 28.19 | 29.81 | 27.07 | 58.25 | 29.77 | 25.29 | 25.71 | 29.83 | 24.94 |
| TRADES [53] | 51.28 | 31.58 | 28.70 | 28.45 | 28.36 | 27.72 | 53.85 | 30.44 | 26.23 | 26.57 | 26.77 | 25.59 |
| MART [42] | 49.13 | 34.33 | 32.32 | 30.73 | 30.13 | 29.60 | 52.48 | 33.95 | 31.09 | 29.64 | 29.43 | 28.67 |
| AWP [45] | 50.91 | 34.28 | 31.85 | 31.23 | 31.01 | 30.06 | 48.65 | 33.21 | 31.07 | 30.33 | 30.14 | 29.40 |
| GAIRAT [54] | 59.89 | 33.47 | 30.40 | 26.69 | 26.71 | 25.38 | 56.37 | 29.41 | 27.25 | 23.94 | 23.95 | 23.15 |
| LAS-AT [20] | 57.52 | 33.66 | 29.86 | 29.60 | 29.44 | 28.84 | 58.19 | 32.98 | 28.89 | 28.75 | 28.58 | 27.90 |
| RoBal [46] | 72.82 | 41.34 | 36.42 | 32.48 | 31.95 | 30.49 | 70.85 | 35.95 | 27.74 | 27.59 | 26.76 | 25.71 |
| REAT [26] | 73.16 | 41.32 | 35.94 | 35.28 | 35.67 | 33.20 | 67.76 | 34.51 | 27.75 | 28.17 | 31.82 | 26.66 |
| AT-BSL | 73.19 | 41.84 | 35.60 | 34.86 | 35.99 | 32.80 | 65.95 | 33.29 | 27.23 | 27.87 | 31.00 | 26.45 |
| AT-BSL-AuA | 75.17 | 46.18 | 40.84 | 38.82 | 39.23 | 37.15 | 77.27 | 44.73 | 38.06 | 37.14 | 39.05 | 35.11 |
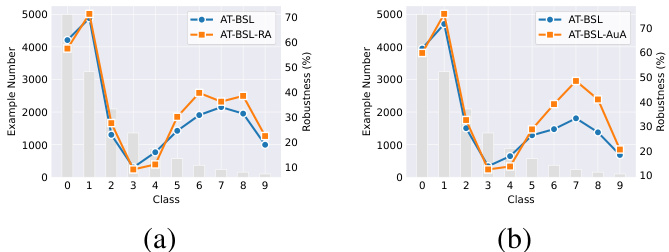
Figure 5. The class-wise example number and robustness under AA for various algorithms on CIFAR-10-LT at the best checkpoint. (a) ResNet-18; (b) WideResNet-34-10.
图 5: 在 CIFAR-10-LT 数据集上,不同算法在最佳检查点下的类别样本数量及在 AA (AutoAttack) 下的鲁棒性。(a) ResNet-18;(b) WideResNet-34-10。
Table 5. The clean accuracy and robustness for AT-BSL with different augmentations using ResNet-18 on CIFAR-10-LT. The best results are bolded.
表 5: 使用ResNet-18在CIFAR-10-LT上不同增强方法的AT-BSL的干净准确性和鲁棒性。最佳结果加粗显示。
| 方法 | Clean | FGSM | PGD | cW | LSA | AA |
|---|---|---|---|---|---|---|
| Vanilla | 68.89 | 40.08 | 35.27 | 33.47 | 33.46 | 31.78 |
| MixUp [52] | 65.82 | 41.33 | 38.05 | 34.29 | 33.63 | 32.92 |
| Cutout [9] | 65.12 | 40.25 | 36.68 | 34.81 | 34.51 | 33.35 |
| CutMix [50] | 64.54 | 41.13 | 37.86 | 34.10 | 33.46 | 32.83 |
| AugMix [17] | 67.12 | 40.31 | 35.95 | 34.19 | 34.02 | 32.51 |
| TA [33] | 67.14 | 41.56 | 37.75 | 34.34 | 33.90 | 32.62 |
Effect of Hyper parameter $\tau_{b}$ . To investigate the sensitivity of AT-BSL to $\tau_{b}$ , we evaluate the performance of AT-BSL under varying $\tau_{b}$ values. Specifically, we utilize
超参数 $\tau_{b}$ 的影响
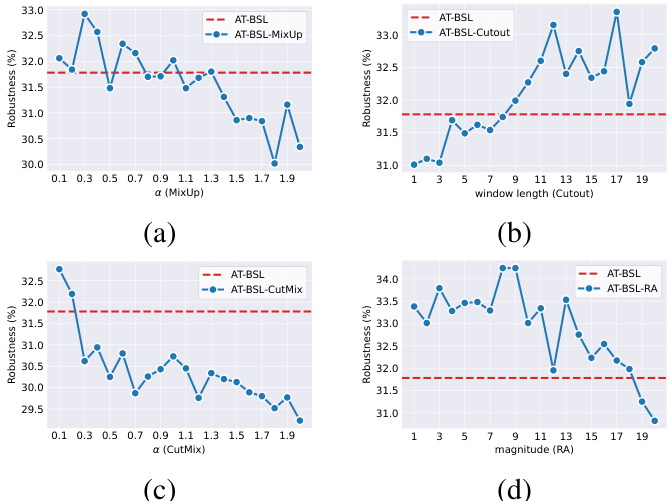
Figure 6. The robustness under AA using ResNet-18 on CIFAR10-LT as we vary (a) the mixing rate $\alpha$ for MixUp, (b) the window length for Cutout, (c) the mixing rate $\alpha$ for CutMix, and (d) the magnitude of transformations for RA.
图 6. 在 CIFAR10-LT 上使用 ResNet-18 时,随着 (a) MixUp 的混合率 $\alpha$、(b) Cutout 的窗口长度、(c) CutMix 的混合率 $\alpha$ 和 (d) RA 的变换幅度的变化,AA 下的鲁棒性。
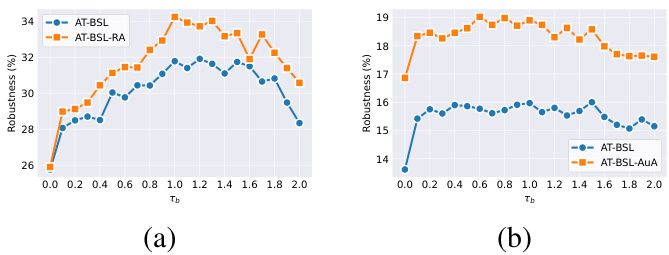
Figure 7. The robustness under AA for various algorithms with different $\tau_{b}$ using ResNet-18. (a): CIFAR-10-LT; (b): CIFAR100-LT.
图 7: 使用 ResNet-18 时,不同算法在不同 $\tau_{b}$ 下的 AA 鲁棒性。(a): CIFAR-10-LT; (b): CIFAR100-LT.
ResNet-18 with $\tau_{b}$ ranging from 0 to 20. Note that at $\tau_{b}=0$ , the bias $b_{i}=\tau_{b}\log\left(n_{i}\right)$ added by AT-BSL becomes zero, and Eq.8 reverts to the vanilla CE loss, transforming ATBSL into vanilla AT [31]. The results, depicted in Fig. 7, reveal that on CIFAR10-LT, AT-BSL is quite sensitive to $\tau_{b}$ , achieving optimal robustness at $\tau_{b}=1$ . Conversely, on CIFAR-100-LT, AT-BSL shows less sensitivity to $\tau_{b}$ . Additionally, across tested datasets and $\tau_{b}$ values, AT-BSL with additional data augmentation consistently exhibits significantly higher robustness than vanilla AT-BSL, underscoring the substantial benefits of data augmentation in adversarial training under long-tailed distributions.
ResNet-18 中 $\tau_{b}$ 的取值范围为 0 到 20。需要注意的是,当 $\tau_{b}=0$ 时,AT-BSL 添加的偏置 $b_{i}=\tau_{b}\log\left(n_{i}\right)$ 变为零,公式 8 恢复到原始的 CE 损失,AT-BSL 也就变成了原始的 AT [31]。图 7 中的结果显示,在 CIFAR10-LT 上,AT-BSL 对 $\tau_{b}$ 非常敏感,当 $\tau_{b}=1$ 时达到最佳的鲁棒性。相反,在 CIFAR-100-LT 上,AT-BSL 对 $\tau_{b}$ 的敏感性较低。此外,在测试的数据集和 $\tau_{b}$ 取值范围内,使用额外数据增强的 AT-BSL 始终表现出比原始 AT-BSL 显著更高的鲁棒性,这突显了在长尾分布下进行对抗训练时数据增强的巨大优势。
Effect of Imbalance Ratio. We further construct longtailed datasets with varying IRs following the protocol of [8, 46] to evaluate the performance of our method. Table 6 illustrates that RA consistently improves the robustness of AT-BSL across various IR settings, further substantiating the finding that data augmentation can improve robustness. Effect of PGD Step Size. To delve into the impact of PGD step size on robustness, we fine-tune the PGD step size from $2/255$ to $1/255$ and $0.5/255$ , while also increasing the PGD steps from 10 to 20 and 40. As depicted in Table 7, it is evident that RA consistently improves the robustness of AT
不平衡比例的影响
表 6 表明,RA 在各种 IR 设置下始终能提升 AT-BSL 的鲁棒性,进一步证实了数据增强可以提高鲁棒性的发现。
PGD 步长的影响
为了探讨 PGD 步长对鲁棒性的影响,我们将 PGD 步长从 $2/255$ 微调到 $1/255$ 和 $0.5/255$,同时将 PGD 步数从 10 增加到 20 和 40。如表 7 所示,RA 始终能提升 AT 的鲁棒性。
Table 6. The clean accuracy and robustness for various algorithms using ResNet-18 on CIFAR-10-LT with different imbalance ratios. Better results are bolded.
表 6. 使用 ResNet-18 在 CIFAR-10-LT 上不同不平衡比率下各种算法的干净准确率和鲁棒性。更好的结果以粗体显示。
| IR | Method Clean FGSM PGD CW LSA AA |
|---|---|
| AT-BSL 10 AT-BSL-RA | 73.29 47.33 42.04 40.77 41.05 39.12 79.00 50.98 44.19 42.82 43.10 40.56 |
| 20 | AT-BSL 71.89 44.76 39.40 38.47 38.68 36.74 AT-BSL-RA7 75.84 47.62 41.68 39.92 39.82 37.78 |
| AT-BSL 50 AT-BSL-RA | 68.89 40.08 35.27 33.47 33.46 31.78 70.86 43.06 37.94 36.24 36.04 34.24 |
| AT-BSL 62.03 100 AT-BSL-RA66.85 | 35.06 30.95 29.41 29.56 28.01 38.75 33.69 31.77 31.50 30.00 |
Table 7. The clean accuracy and robustness for various algorithms using ResNet-18 on CIFAR-10-LT training with different PGD step sizes. Better results are bolded.
表 7: 使用 ResNet-18 在 CIFAR-10-LT 训练上不同 PGD 步长下各种算法的干净准确率和鲁棒性。更好的结果加粗。
| Size | Method Clean | FGSM | PGD | CW | LSA | AA |
|---|---|---|---|---|---|---|
| 0.5 | AT-BSL | 68.57 | 39.65 | 35.10 | 32.92 | 32.97 |
| 0.5 | AT-BSL-RA | 68.68 | 41.97 | 37.60 | 34.81 | 34.36 |
| 1 | AT-BSL | 68.63 | 39.98 | 35.09 | 33.02 | 33.00 |
| 1 | AT-BSL-RA | 68.93 | 42.71 | 37.85 | 35.30 | 34.79 |
| 2 | AT-BSL | 68.89 | 40.08 | 35.27 | 33.47 | 33.46 |
| 2 | AT-BSL-RA | 70.86 | 43.06 | 37.94 | 36.24 | 36.04 |
BSL regardless of the PGD step size. However, we also note a decrease in robustness when compared to the baseline robustness at a PGD step size of 2/255.
BSL 无论在 PGD 步长如何,都表现出稳定的表现。然而,我们也注意到与 PGD 步长为 2/255 时的基线鲁棒性相比,鲁棒性有所下降。
6. Conclusion
6. 结论
In this paper, we first dissect the components of RoBal, identifying BSL as a critical component. We then address the issue of robust over fitting in adversarial training under long-tailed distributions and attempt to mitigate it using data augmentation. Surprisingly, we find that data augmentation not only mitigates robust over fitting but also significantly improves robustness. We hypothesize that the improved robustness is due to increased example diversity brought about by data augmentation, and we validate this hypothesis through experiments. Finally, we conduct extensive experiments with different data augmentation strategies, model architectures, and datasets, affirming the generaliz ability of our findings. Our findings advance adversarial training a step further towards real-world scenarios.
本文首先剖析了 RoBal 的组成,确定 BSL 为关键组件。随后,我们解决了长尾分布下对抗训练中的鲁棒过拟合问题,并尝试通过数据增强来缓解该问题。令人惊讶的是,我们发现数据增强不仅缓解了鲁棒过拟合,还显著提高了鲁棒性。我们推测,这种鲁棒性的提升源于数据增强带来的样本多样性增加,并通过实验验证了这一假设。最后,我们针对不同的数据增强策略、模型架构和数据集进行了广泛的实验,证实了我们发现的普适性。我们的发现将对抗训练向实际应用场景推进了一步。
Acknowledgements
致谢
This work was partially supported by the NSFC under Grants U20B2049, U21B2018, and 62302344, and the Fundamental Research Funds for the Central Universities, 2042023kf0122.
本研究得到国家自然科学基金(项目编号:U20B2049、U21B2018 和 62302344)以及中央高校基本科研业务费专项资金(项目编号:2042023kf0122)的部分资助。
References
参考文献
[57] Zhipeng Zhou, Lanqing Li, Peilin Zhao, Pheng-Ann Heng, and Wei Gong. Class-conditional sharpness-aware minimization for deep long-tailed recognition. In CVPR, 2023. 2
[57] Zhipeng Zhou, Lanqing Li, Peilin Zhao, Pheng-Ann Heng, and Wei Gong. 面向深度长尾识别的类条件锐度感知最小化. In CVPR, 2023. 2
Revisiting Adversarial Training under Long-Tailed Distributions
重新审视长尾分布下的对抗训练
Supplementary Material
补充材料
A. Implementation Details of Experiments
A. 实验实现细节
A.1. Details of Table 1
A.1. 表 1 的详细信息
All parameters in the experiments presented in Table 1 are consistent with those used in RoBal [46]. Specifically, the initial learning rate is set at 0.1, with a decay factor of 10 applied at the 60th and 75th epochs, for a total training duration of 80 epochs. An SGD momentum optimizer is employed with a weight decay of $2\times10^{-4}$ . The batch size is maintained at 64. For adversarial training, we adopt a maximum perturbation of $8/255$ and a step size of $2/255$ , with the number of iterations for internal maximization set at 5, corresponding to PGD-5. For CIFAR-10-LT, we utilize $m_{0}~=0.1$ , $s=~10$ , $\tau_{b}~=~1.5$ , and $\tau_{m}~=~0.3$ ; for CIFAR-100-LT, the parameters are set as $m_{0}=0.3$ , $s=10$ , $\tau_{b}=1.5$ , and $\tau_{m}=0.3$ . The specific hyper parameters for each experiment are detailed in Table 8.
表 1 中实验的所有参数均与 RoBal [46] 中使用的参数一致。具体而言,初始学习率设置为 0.1,并在第 60 和第 75 个 epoch 时应用衰减因子 10,总训练时长为 80 个 epoch。采用 SGD 动量优化器,权重衰减为 $2\times10^{-4}$ 。批量大小保持为 64。对于对抗训练,我们采用最大扰动 $8/255$ 和步长 $2/255$ ,内部最大化的迭代次数设置为 5,对应 PGD-5。对于 CIFAR-10-LT,我们使用 $m_{0}~=0.1$ 、 $s=~10$ 、 $\tau_{b}~=~1.5$ 和 $\tau_{m}~=~0.3$ ;对于 CIFAR-100-LT,参数设置为 $m_{0}=0.3$ 、 $s=10$ 、 $\tau_{b}=1.5$ 和 $\tau_{m}=0.3$ 。每个实验的具体超参数详见表 8。
A.2. Details of Data Augment a ions
A.2. 数据增强的细节
Data augmentation techniques such as MixUp [52], Cutout [9], CutMix [50], Augmix [17], Auto Augment (AuA) [6], Rand Augment (RA) [7], and Trivial Aug men (TA) [33] are employed utilizing the implementations provided in torch vision $0.16.0^{1}$ . Regarding the integration of data augmentation into the adversarial training pipeline, we follow the approach outlined in [35], whereby data augmentation precedes the generation of adversarial examples through adversarial attacks. It is observed that reversing this order, i.e., performing data augmentation after adversarial attacks, leads to the disruption of adversarial perturbations, significantly diminishing the effectiveness of the adversarial attacks.
数据增强技术如 MixUp [52]、Cutout [9]、CutMix [50]、Augmix [17]、Auto Augment (AuA) [6]、Rand Augment (RA) [7] 和 Trivial Augment (TA) [33] 均采用 torch vision $0.16.0^{1}$ 提供的实现。关于将数据增强集成到对抗训练流程中,我们遵循 [35] 中概述的方法,即在通过对抗攻击生成对抗样本之前进行数据增强。观察到如果颠倒这一顺序,即在对抗攻击之后进行数据增强,会导致对抗扰动被破坏,从而显著降低对抗攻击的有效性。
A.3. Code References
A.3. 代码引用
For the defense methods compared in our paper, we utilize the official code releases, including AT $[31]^{2}$ , TRADES $[53]^{3}$ , MART $[42]^{4}$ , AWP $[45]^{5}$ , GAIRAT $[54]^{6}$ , LAS-AT $[20]^{7}$ , RoBal $[46]^{8}$ , and REAT $[26]^{9}$ . Regarding the attacks used for evaluation, we implement them by referring to several official code repositories and the original papers, encompassing FGSM [12], PGD [31], CW [3], and AutoAttack $[5]^{10}$ .
对于论文中比较的防御方法,我们使用了官方发布的代码,包括AT [31] 、TRADES [53] 、MART [42] 、AWP [45] 、GAIRAT [54] 、LAS-AT [20] 、RoBal [46] 和REAT [26] 。至于用于评估的攻击方法,我们通过参考多个官方代码库和原始论文来实现,包括FGSM [12]、PGD [31]、CW [3] 和AutoAttack [5] 。
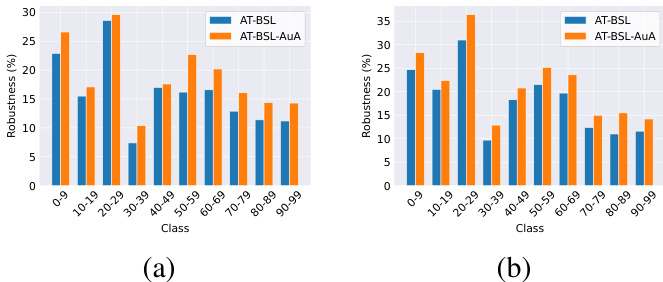
Figure 8. The class-wise robustness under AA for various algorithms on CIFAR-100-LT at the best checkpoint. (a) ResNet-18; (b) WideResNet-34-10.
图 8. 在 CIFAR-100-LT 数据集上,不同算法在最佳检查点下的 AA 分类鲁棒性。(a) ResNet-18; (b) WideResNet-34-10。
B. Extensive Experiments
B. 广泛实验
B.1. More Ablation Studies of RoBal
B.1. RoBal 的更多消融实验
In addition to the experiments conducted with ResNet-18 and CIFAR-10-LT as presented in Table 1, we extend our ablation studies to include WideResNet-34-10 and CIFAR100-LT, as illustrated in Tables 9, 10, and 11. The data acquired from these additional experiments align with the conclusions drawn from Table 1, demonstrating that the ATBSL alone achieves comparable performance in terms of clean accuracy and robustness to the complete RoBal framework. Moreover, a significant advantage is observed regarding training time and memory consumption.
除了表 1 中展示的使用 ResNet-18 和 CIFAR-10-LT 进行的实验外,我们还扩展了消融研究,包括 WideResNet-34-10 和 CIFAR100-LT,如表 9、表 10 和表 11 所示。这些额外实验获得的数据与表 1 得出的结论一致,表明单独的 ATBSL 在干净准确性和鲁棒性方面与完整的 RoBal 框架表现相当。此外,在训练时间和内存消耗方面也观察到了显著优势。
B.2. Experiments on CIFAR-100-LT
B.2. CIFAR-100-LT 上的实验
Tables 12 and 13 reveal that on CIFAR-100-LT, AT-BSL with data augmentation achieves the highest clean accuracy and adversarial robustness on both ResNet-18 and WideResNet-34-10. Compared to the improvement observed on CIFAR-10-LT, the improvements on CIFAR-100- LT are less pronounced, likely due to CIFAR-100-LT’s more significant number of classes and fewer examples per class, making advancements more challenging.
表 12 和表 13 显示,在 CIFAR-100-LT 上,使用数据增强的 AT-BSL 在 ResNet-18 和 WideResNet-34-10 上均实现了最高的干净准确率和对抗鲁棒性。与在 CIFAR-10-LT 上观察到的改进相比,CIFAR-100-LT 上的改进不太明显,这可能是由于 CIFAR-100-LT 的类别数量更多且每个类别的样本较少,使得进展更具挑战性。
In Fig. 8, we illustrate the robustness of different methods across each class. Given the extremely low robustness in most classes on CIFAR-100-LT and the presence of only 50 images per class in the test set, we report the average values for every 10 classes. Notably, AuA universally improves the robustness across all class groups.
在图 8 中,我们展示了不同方法在各个类别上的鲁棒性。鉴于 CIFAR-100-LT 上大多数类别的鲁棒性极低,且测试集中每个类别只有 50 张图像,我们报告了每 10 个类别的平均值。值得注意的是,AuA 在所有类别组中都普遍提高了鲁棒性。
B.3. Experiments on Tiny-ImageNet-LT
B.3. Tiny-ImageNet-LT 上的实验
To see if BSL and data augmentation are as important for higher resolution datasets as they are for low resolution datasets (such as CIFAR-10-LT and CIFAR-100-LT), we conduct experiments on Tiny-ImageNet [24]. Firstly, TinyImageNet is a dataset consisting of 200 classes, with images sized $64^{*}64$ pixels, making it four times the resolution of CIFAR-10/100. We derive Tiny-ImageNet-LT using an IR of 0.1 from Tiny-ImageNet. Following [20, 25], we employ the Pre Act Res Net-18 model [16]. Apart from the model, the experimental setup for Tiny-ImageNet-LT remains largely similar to that of CIFAR-10-LT. As observed from the Table 14, both BSL and data augmentation prove to be crucial for Tiny-ImageNet-LT.
为了验证BSL和数据增强对于高分辨率数据集(如Tiny-ImageNet)是否与低分辨率数据集(如CIFAR-10-LT和CIFAR-100-LT)同样重要,我们在Tiny-ImageNet [24]上进行了实验。首先,TinyImageNet是一个包含200个类别的数据集,图像尺寸为$64^{*}64$像素,分辨率为CIFAR-10/100的四倍。我们使用IR为0.1的Tiny-ImageNet生成了Tiny-ImageNet-LT。根据[20, 25],我们采用了Pre Act Res Net-18模型 [16]。除了模型外,Tiny-ImageNet-LT的实验设置与CIFAR-10-LT基本相同。从表14中可以看出,BSL和数据增强对于Tiny-ImageNet-LT同样至关重要。
Table 8. The specific hyper parameters for each experiment following the integration of components from RoBal [46] into AT [31]. Cos: Cosine Classifier; BSL: Balanced Softmax Loss [36]; CM: Class-aware Margin [46]; TRADES: TRADES Regular iz ation [53].
表 8. 将 RoBal [46] 的组件集成到 AT [31] 后,每个实验的具体超参数。Cos:余弦分类器;BSL:平衡 Softmax 损失 [36];CM:类感知间隔 [46];TRADES:TRADES 正则化 [53]。
| 方法 | Cos | BSL | CM | TRADES | CIFAR-10-LT | CIFAR-100-LT |
|---|---|---|---|---|---|---|
| AT [31] | 0 | 1 | ||||
| AT-BSL | √ | 0 | 1 | |||
| AT-BSL-Cos | √ | √ | 0.1 | 10 | ||
| AT-BSL-Cos-TRADES | √ | √ | 0.1 | 10 | ||
| RoBal [46] | √ | √ | √ | √ | 0.1 | 10 |
Table 9. The clean accuracy, robustness, time (average per epoch), and memory (GPU) using WideResNet-34-10 [51] on CIFAR-10-LT following the integration of components from RoBal [46] into AT [31]. The best results are bolded. The second best results are underlined. Cos: Cosine Classifier; BSL: Balanced Softmax Loss [36]; CM: Class-aware Margin [46]; TRADES: TRADES Regular iz ation [53].
表 9. 在 CIFAR-10-LT 上使用 WideResNet-34-10 [51] 将 RoBal [46] 的组件集成到 AT [31] 后的清洁准确率、鲁棒性、时间(每轮平均)和内存(GPU)。最佳结果以粗体显示。次佳结果以下划线显示。Cos:余弦分类器;BSL:平衡 Softmax 损失 [36];CM:类感知边距 [46];TRADES:TRADES 正则化 [53]。
| 方法 | 组件 | 准确率 | 效率 |
|---|---|---|---|
| CosBSLCM | TRADES | Clean | |
| AT [31] | |||
| AT-BSL | |||
| AT-BSL-CoS | √ | ||
| AT-BSL-Cos-TRADES | √ | ||
| RoBal [46] |
B.4. Different PGD Steps
B.4. 不同PGD步骤
To investigate the impact of PGD steps on robustness, we assess the robustness achieved using different PGD steps following [46]. Table 15 indicates that RA consistently improves the robustness of AT-BSL regardless of PGD steps, and the clean accuracy also experiences improvement. Moreover, there is a trade-off between clean accuracy and robustness: as the PGD step increases, clean accuracy decreases while robustness improves. The optimal trade-off is attained at PGD-10. Hence, we employ PGD-10 in our experiments involving AT-BSL.
为了研究PGD步骤对鲁棒性的影响,我们根据[46]评估了使用不同PGD步骤所实现的鲁棒性。表15表明,无论PGD步骤如何,RA都能持续提升AT-BSL的鲁棒性,同时干净准确率也有所提升。此外,干净准确率与鲁棒性之间存在权衡:随着PGD步骤的增加,干净准确率下降而鲁棒性提高。最优权衡在PGD-10时达到。因此,我们在涉及AT-BSL的实验中使用PGD-10。
B.5. Different Weight Decay
B.5. 不同的权重衰减
During our replication of the experiments of REAT [26], we observe a discrepancy in the weight decay parameters used: REAT employed a weight decay of $5\times10^{-4}$ , contrasting with $2\times10^{-4}$ used by RoBal [46]. This leads us to conduct experiments using varying values of weight decay. The results, depicted in Fig. 9, indicate that a weight decay of $5\times10^{-4}$ offers a significant improvement over $2\times10^{-4}$ in terms of both accuracy and robustness. However, further increasing the weight decay beyond $5\times10^{-4}$ results in a noticeable decline in accuracy. Therefore, we employ a weight decay of $5\times10^{-4}$ in our experiments.
在复现 REAT [26] 的实验时,我们观察到使用的权重衰减参数存在差异:REAT 使用了 $5\times10^{-4}$ 的权重衰减,而 RoBal [46] 使用的是 $2\times10^{-4}$。这促使我们使用不同的权重衰减值进行实验。结果如图 9 所示,表明 $5\times10^{-4}$ 的权重衰减在准确性和鲁棒性方面均优于 $2\times10^{-4}$。然而,进一步将权重衰减增加到超过 $5\times10^{-4}$ 会导致准确性显著下降。因此,我们在实验中使用 $5\times10^{-4}$ 的权重衰减。

Figure 9. The clean accuracy and robustness under AA for various algorithms with different weight decay using ResNet-18 on CIFAR-10-LT at the best checkpoint.
图 9: 在 CIFAR-10-LT 数据集上,使用 ResNet-18 模型在不同权重衰减下的各种算法在最佳检查点时的干净准确率和鲁棒性 (AA) 表现。
B.6. Different Batch Sizes
B.6. 不同批处理大小
While replicating the experiments of REAT [26], we note an inconsistency in the batch size settings: REAT utilized a batch size of 128, whereas RoBal utilized 64. To address this, we conduct experiments with different batch sizes, and the results are presented in Table 16. The findings indicate that the performance with batch sizes 64 and 128 are comparable, and both outperform larger batch sizes; however,
在复现 REAT [26] 的实验时,我们注意到批次大小设置存在不一致:REAT 使用了 128 的批次大小,而 RoBal 使用了 64。为了解决这一问题,我们进行了不同批次大小的实验,结果如表 16 所示。研究结果表明,批次大小为 64 和 128 的性能相当,且均优于更大的批次大小;然而,
Table 10. The clean accuracy, robustness, time (average per epoch) and memory (GPU) using ResNet-18 [15] on CIFAR-100-LT following the integration of components from RoBal [46] into AT [31]. The best results are bolded. The second best results are underlined. Cos: Cosine Classifier; BSL: Balanced Softmax Loss [36]; CM: Class-aware Margin [46]; TRADES: TRADES Regular iz ation [53].
表 10: 在 CIFAR-100-LT 上使用 ResNet-18 [15],将 RoBal [46] 的组件集成到 AT [31] 后的清洁准确率、鲁棒性、时间(每轮平均)和内存(GPU)。最佳结果加粗,次佳结果加下划线。Cos: 余弦分类器;BSL: 平衡 Softmax 损失 [36];CM: 类感知边际 [46];TRADES: TRADES 正则化 [53]。
| 方法 | 组件 | 准确率 | 效率 |
|---|---|---|---|
| CosBSLCM | TRADES | 清洁 | |
| AT [31] | |||
| AT-BSL | |||
| AT-BSL-CoS | |||
| AT-BSL-Cos-TRADES | √ | ||
| RoBal [46] |
Table 11. The clean accuracy, robustness, time (average per epoch), and memory (GPU) using WideResNet-34-10 [51] on CIFAR-100-LT following the integration of components from RoBal [46] into AT [31]. The best results are bolded. The second best results are underlined. Cos: Cosine Classifier; BSL: Balanced Softmax Loss [36]; CM: Class-aware Margin [46]; TRADES: TRADES Regular iz ation [53].
表 11: 在 CIFAR-100-LT 上使用 WideResNet-34-10 [51] 进行实验,将 RoBal [46] 的组件集成到 AT [31] 后,得到的干净准确率、鲁棒性、时间(每轮平均)和内存(GPU)结果。最佳结果加粗,次佳结果加下划线。Cos:余弦分类器;BSL:平衡 Softmax 损失 [36];CM:类感知边界 [46];TRADES:TRADES 正则化 [53]。
| 方法 | Cos BSL | CM | TRADES | Clean | FGSM | PGD | cW | LSA | AA | 时间 (s) | 内存 (MiB) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AT [31] | 48.87 | 21.14 | 17.20 | 17.61 | 21.23 | 16.27 | 319.33 | ||||
| AT-BSL | 49.68 | 23.08 | 19.81 | 19.47 | 21.19 | 17.84 | 323.66 | ||||
| AT-BSL-CoS | √ | 48.29 | 20.25 | 16.34 | 16.43 | 17.90 | 15.09 | 327.17 | |||
| AT-BSL-Cos-TRADES | √ | √ | 44.37 | 18.94 | 15.48 | 15.70 | 17.02 | 14.43 | 603.99 | ||
| RoBal [46] | 50.08 | 23.04 | 18.84 | 19.30 | 21.87 | 17.90 | 617.73 |
128 is more commonly used and helps speed up training. Consequently, we employ a batch size of 128 in our experiments.
128 是更常用的批量大小,有助于加速训练。因此,我们在实验中使用批量大小为 128。
B.7. Different Training Epochs
B.7. 不同训练轮次
As indicated in Table 17, without data augmentation, the results between 80 and 100 training epochs show little difference. However, with data augmentation, we observe that a higher number of training epochs leads to increased robustness. This improvement is likely attributable to the augmented diversity of examples, necessitating a more extended learning period for the model.
如表 17 所示,在没有数据增强的情况下,80 到 100 个训练 epoch 之间的结果差异不大。然而,在数据增强的情况下,我们观察到更高的训练 epoch 数量会带来更强的鲁棒性。这一改进可能归因于样本的多样性增加,使得模型需要更长的学习时间。
B.8. Hyper parameter Tuning of RoBal
B.8. RoBal 的超参数调优
Through hyper parameter tuning similar to those done for AT-BSL using ResNet-18 on CIFAR-10-LT, we find that RoBal achieve the best results with PGD-10, weight decay of $2\times10^{-4}$ , batch size of 64, epochs of 60, and $\tau_{b}=1.5$ . The robustness under AA reach $31.61%$ , which is close to the performance of AT-BSL.
通过在 CIFAR-10-LT 上使用 ResNet-18 进行类似于 AT-BSL 的超参数调优,我们发现 RoBal 在使用 PGD-10、权重衰减为 $2\times10^{-4}$、批量大小为 64、训练轮数为 60 以及 $\tau_{b}=1.5$ 时取得了最佳结果。在 AA 下的鲁棒性达到了 $31.61%$,接近 AT-BSL 的表现。
B.9. Retraining RoBal and REAT
B.9. 重新训练 RoBal 和 REAT
Compared to RoBal [46], our primary experiments employ different experimental settings, including previously discussed variables like PGD steps, weight decay, batch size, and training epochs. To facilitate a fairer comparison, we adapt these settings in our main experiments: changing PGD-5 to PGD-10, weight decay from $2\times10^{-4}$ to $5\times10^{-4}$ , batch size from 64 to 128, and increasing training epochs from 80 to 100, and then we retrain RoBal under these settings, referred to as RoBal (retraining). Compared with REAT [26], the only discrepancy is in the training epochs. Therefore, we adjusted REAT’s training epochs to 100 and conduct a retraining called REAT (retraining). The results are presented in Table 18. The retrained RoBal is observed to achieve improved robustness, albeit at a slight cost to accuracy. Conversely, the retrained REAT displays even lower robustness than its initial version. Through this comparison, we note that the robustness achieved by the retrained RoBal and REAT is similar to that of the vanilla AT-BSL.
与 RoBal [46] 相比,我们的主要实验采用了不同的实验设置,包括先前讨论的变量,如 PGD 步数、权重衰减、批量大小和训练周期。为了进行更公平的比较,我们在主要实验中调整了这些设置:将 PGD-5 改为 PGD-10,权重衰减从 $2\times10^{-4}$ 改为 $5\times10^{-4}$,批量大小从 64 改为 128,并将训练周期从 80 增加到 100,然后在这些设置下重新训练 RoBal,称为 RoBal(重新训练)。与 REAT [26] 相比,唯一的差异在于训练周期。因此,我们将 REAT 的训练周期调整为 100,并进行了重新训练,称为 REAT(重新训练)。结果如表 18 所示。观察到重新训练的 RoBal 提高了鲁棒性,尽管略微降低了准确性。相反,重新训练的 REAT 显示出比初始版本更低的鲁棒性。通过这一比较,我们注意到重新训练的 RoBal 和 REAT 的鲁棒性与普通 AT-BSL 相似。
B.10. Other Data Augmentations
B.# # # 1.# 非正式沟通与正式沟通# Issue 23400: Fix unpickling of square and other special matrices
archive/issues_023163.json:
# Base<pr>Title: Add github actions
Q: How to get the first 10 words of a string in PHP?# MyApp
---
# 第4章 循环队列和循环链表
# BIDDING# SMB2 (SMB<issue_start><issue_# # 중간고사 대비 C++ 문제 정리
<issue_start><issue_comment>Title: Move all# rds-cluster
# Changel# Release Notes
All---
title: "Cute Hand Tattoos For Females : 40+ Spectacular Cherry# Deleting a topic
To delete a topic:
# springQ1.
# E-Ticaret Sitesi - Back-End Development
# 3.0.0 (unreleased# 2018年セカイのカガクプロジェクト
## プロジェクトの説明
# golib
<issue_start><issue_comment>Title: Add---
title: "코스트코상품권 판매순위 - [20~40대# Module 1 Challenge: Ref<issue_start><issue_comment>Title: Update stable version# 计算机体系结构
## 计算机组成与体系结构
计算机组成(Computer Organization) 是指计算机的硬件实现# Star# Tarea de Red#!# google code
Here# 1.26.11 - Add support for additional SMB share path in NAS fileset
## 5.2.3.# What is the difference between a process# 6.0.0.1.2.3.4
**#!The official blog of the U.S. Coast Guard
# Tag Archives: Hurricane
## Coast# The LongThe official blog of the U.S. Coast# The CoastThe official blog of the U.S.# The official blog of the U.S. Coast# The official blog of the U.S. Coast
Yii2 项目结构
Giles Coren to be the next Doctor Who
## The day I almost died
I was in the middle
Hallo, ich bin ein Test!# _This is my first project_
This is my **first/*This is my first project*/
This is my **first** project
**Project Title: Library Management System**
**# Install OpenShift
# Docker
### Setup# GettingGuy S. Sterling
T he M ilit a r y in P o lit ic s
By Morris Janowitz
# The Military in Politics# The Military in Politics
# The Military in Politics# The Military in Politics
# The Military in Politics
# The Military in Politics
# The Military on the United States
The Military in the United States is a complex and multifaceted institution that plays a crucial role in the nation# Odes to the Sea: A Poetic Exploration of the Ocean’s Majesty
The sea has# Odes to the Sea: A Poetic Exploration of the Ocean’s Majesty
The sea hasThe official blog of the U.S. Coast Guard
# Tag: Reserve
By Petty Officer 3rd Class
## The Secret
### 题目
<http://codeforces.com/# /contest/1/problem/A>Problem A</a>
Data Augmentations Designed for Long-Tailed Recognition. CUDA \$[2]^{11}\$ initially explored the relationship between the degree of augmentation and class performance, discovering that an appropriate level of augmentation needs to be allocated for each class to mitigate class imbalance issues. Inspired by this finding, [2] introduces a simple yet efficient novel curriculum to identify the appropriate data augmentation strength for each class, called CUDA: CUrriculum of Data Augmentation for long-tailed recognition. To assess CUDA’s performance in adversarial train- ing under long-tailed distributions, we augment AT-BSL with CUDA, referred to as AT-BSL-CUDA, and compared it with the vanilla AT-BSL, as shown in the Table 19. The results suggest that CUDA’s performance in adversarial training under long-tailed distributions appears less effective than RA.
为长尾识别设计的数据增强。CUDA [2] 最初探索了增强程度与类别性能之间的关系,发现需要为每个类别分配适当水平的增强,以缓解类别不平衡问题。受此启发,[2] 引入了一种简单而高效的新课程,称为 CUDA:用于长尾识别的数据增强课程,以确定每个类别的适当数据增强强度。为了评估 CUDA 在长尾分布下的对抗训练中的表现,我们用 CUDA 增强 AT-BSL,称为 AT-BSL-CUDA,并将其与原始的 AT-BSL 进行比较,如表 19 所示。结果表明,CUDA 在长尾分布下的对抗训练中的表现似乎不如 RA 有效。
Table 12. The clean accuracy and robustness for various algorithms using ResNet-18 on CIFAR-100-LT. The best results are bolded.
<html><body><table><tr><td rowspan="2">Method</td><td colspan="6">Best Checkpoint</td><td colspan="6">Last Checkpoint</td></tr><tr><td>Clean</td><td>FGSM</td><td>PGD</td><td>CW</td><td>LSA</td><td>AA</td><td>Clean</td><td>FGSM</td><td>PGD</td><td>CW</td><td>LSA</td><td>AA</td></tr><tr><td>AT [31]</td><td>41.20</td><td>17.42</td><td>14.59</td><td>14.51</td><td>16.49</td><td>13.62</td><td>41.44</td><td>17.21</td><td>13.89</td><td>14.17</td><td>16.40</td><td>13.10</td></tr><tr><td>TRADES [53]</td><td>38.12</td><td>19.60</td><td>17.89</td><td>15.96</td><td>15.91</td><td>15.59</td><td>38.71</td><td>19.43</td><td>17.27</td><td>15.83</td><td>15.87</td><td>15.28</td></tr><tr><td>MART [42]</td><td>38.46</td><td>23.04</td><td>21.36</td><td>18.59</td><td>18.36</td><td>17.51</td><td>39.58</td><td>22.38</td><td>20.51</td><td>18.40</td><td>18.42</td><td>17.27</td></tr><tr><td>AWP [45]</td><td>41.53</td><td>23.47</td><td>21.79</td><td>19.68</td><td>19.73</td><td>18.61</td><td>43.57</td><td>22.91</td><td>20.72</td><td>19.11</td><td>19.30</td><td>17.82</td></tr><tr><td>GAIRAT [54]</td><td>38.99</td><td>19.73</td><td>18.05</td><td>16.59</td><td>16.80</td><td>15.61</td><td>39.70</td><td>14.66</td><td>11.87</td><td>11.57</td><td>12.28</td><td>10.48</td></tr><tr><td>LAS-AT [20]</td><td>44.33</td><td>22.02</td><td>19.59</td><td>17.18</td><td>17.11</td><td>16.15</td><td>44.70</td><td>22.11</td><td>19.23</td><td>16.93</td><td>17.03</td><td>15.77</td></tr><tr><td>RoBal [46]</td><td>45.93</td><td>21.35</td><td>17.40</td><td>17.80</td><td>19.14</td><td>16.42</td><td>45.78</td><td>19.97</td><td>15.37</td><td>15.75</td><td>18.67</td><td>14.51</td></tr><tr><td>REAT [26]</td><td>46.28</td><td>21.55</td><td>18.85</td><td>18.07</td><td>18.95</td><td>16.54</td><td>45.99</td><td>19.62</td><td>16.29</td><td>16.04</td><td>18.22</td><td>14.79</td></tr><tr><td>AT-BSL</td><td>45.59</td><td>21.14</td><td>18.05</td><td>17.34</td><td>18.14</td><td>15.97</td><td>45.35</td><td>18.96</td><td>15.52</td><td>15.59</td><td>17.78</td><td>14.41</td></tr><tr><td>AT-BSL-AuA</td><td>48.39</td><td>25.81</td><td>22.96</td><td>20.73</td><td>21.30</td><td>18.90</td><td>50.66</td><td>25.89</td><td>22.43</td><td>20.62</td><td>21.43</td><td>18.79</td></tr></table></body></html>
表 12: 使用 ResNet-18 在 CIFAR-100-LT 上各种算法的干净准确率和鲁棒性。最佳结果加粗显示。
| 方法 | Best Checkpoint | | | | | | Last Checkpoint | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| | Clean | FGSM | PGD | CW | LSA | AA | Clean | FGSM | PGD | CW | LSA | AA |
| AT [31] | 41.20 | 17.42 | 14.59 | 14.51 | 16.49 | 13.62 | 41.44 | 17.21 | 13.89 | 14.17 | 16.40 | 13.10 |
| TRADES [53] | 38.12 | 19.60 | 17.89 | 15.96 | 15.91 | 15.59 | 38.71 | 19.43 | 17.27 | 15.83 | 15.87 | 15.28 |
| MART [42] | 38.46 | 23.04 | 21.36 | 18.59 | 18.36 | 17.51 | 39.58 | 22.38 | 20.51 | 18.40 | 18.42 | 17.27 |
| AWP [45] | 41.53 | 23.47 | 21.79 | 19.68 | 19.73 | 18.61 | 43.57 | 22.91 | 20.72 | 19.11 | 19.30 | 17.82 |
| GAIRAT [54] | 38.99 | 19.73 | 18.05 | 16.59 | 16.80 | 15.61 | 39.70 | 14.66 | 11.87 | 11.57 | 12.28 | 10.48 |
| LAS-AT [20] | 44.33 | 22.02 | 19.59 | 17.18 | 17.11 | 16.15 | 44.70 | 22.11 | 19.23 | 16.93 | 17.03 | 15.77 |
| RoBal [46] | 45.93 | 21.35 | 17.40 | 17.80 | 19.14 | 16.42 | 45.78 | 19.97 | 15.37 | 15.75 | 18.67 | 14.51 |
| REAT [26] | 46.28 | 21.55 | 18.85 | 18.07 | 18.95 | 16.54 | 45.99 | 19.62 | 16.29 | 16.04 | 18.22 | 14.79 |
| AT-BSL | 45.59 | 21.14 | 18.05 | 17.34 | 18.14 | 15.97 | 45.35 | 18.96 | 15.52 | 15.59 | 17.78 | 14.41 |
| AT-BSL-AuA | 48.39 | 25.81 | 22.96 | 20.73 | 21.30 | 18.90 | 50.66 | 25.89 | 22.43 | 20.62 | 21.43 | 18.79 |
Table 13. The clean accuracy and robustness for various algorithms using WideResNet-34-10 on CIFAR-100-LT. The best results are bolded.
<html><body><table><tr><td rowspan="2">Method</td><td colspan="6">Best Checkpoint</td><td colspan="6">Last Checkpoint</td></tr><tr><td>Clean</td><td>FGSM</td><td>PGD</td><td>cW</td><td>LSA</td><td>AA</td><td>Clean</td><td>FGSM</td><td>PGD</td><td>cW</td><td>LSA</td><td>AA</td></tr><tr><td>AT [31]</td><td>45.18</td><td>19.25</td><td>16.36</td><td>16.43</td><td>19.00</td><td>15.60</td><td>44.86</td><td>19.01</td><td>15.65</td><td>15.89</td><td>19.12</td><td>15.08</td></tr><tr><td>TRADES [53]</td><td>41.71</td><td>21.91</td><td>19.85</td><td>18.46</td><td>18.39</td><td>17.91</td><td>43.22</td><td>20.28</td><td>17.46</td><td>17.34</td><td>17.56</td><td>16.69</td></tr><tr><td>MART [42]</td><td>41.32</td><td>25.01</td><td>23.27</td><td>20.89</td><td>20.77</td><td>19.98</td><td>43.67</td><td>22.84</td><td>19.88</td><td>18.80</td><td>19.45</td><td>17.77</td></tr><tr><td>AWP [45]</td><td>45.66</td><td>25.89</td><td>23.88</td><td>21.87</td><td>22.10</td><td>20.56</td><td>48.18</td><td>24.75</td><td>21.81</td><td>20.30</td><td>21.19</td><td>18.67</td></tr><tr><td>GAIRAT[54]</td><td>36.41</td><td>18.87</td><td>17.31</td><td>16.07</td><td>16.13</td><td>14.77</td><td>45.11</td><td>19.49</td><td>16.31</td><td>15.85</td><td>16.71</td><td>14.75</td></tr><tr><td>LAS-AT[20]</td><td>45.86</td><td>23.30</td><td>20.02</td><td>18.67</td><td>18.79</td><td>17.35</td><td>46.54</td><td>22.84</td><td>19.65</td><td>18.18</td><td>18.38</td><td>17.01</td></tr><tr><td>RoBal [46]</td><td>50.08</td><td>23.04</td><td>18.84</td><td>19.30</td><td>21.87</td><td>17.90</td><td>46.34</td><td>19.99</td><td>15.17</td><td>15.87</td><td>20.06</td><td>14.77</td></tr><tr><td>REAT [26]</td><td>50.29</td><td>23.99</td><td>20.82</td><td>20.25</td><td>21.93</td><td>18.65</td><td>49.22</td><td>20.89</td><td>16.57</td><td>17.08</td><td>20.89</td><td>15.49</td></tr><tr><td>AT-BSL</td><td>50.04</td><td>23.37</td><td>19.66</td><td>19.60</td><td>21.66</td><td>18.04</td><td>48.56</td><td>20.88</td><td>16.83</td><td>17.09</td><td>20.13</td><td>15.76</td></tr><tr><td>AT-BSL-AuA</td><td>53.08</td><td>28.55</td><td>25.40</td><td>23.39</td><td>24.48</td><td>21.43</td><td>55.55</td><td>26.74</td><td>22.18</td><td>21.88</td><td>24.28</td><td>19.68</td></tr></table></body></html>
表 13: 使用 WideResNet-34-10 在 CIFAR-100-LT 上的各种算法的清洁准确率和鲁棒性。最佳结果以粗体显示。
| Method | Best Checkpoint | | | | | | Last Checkpoint | | | | | |
|--------------|-----------------|-------|-------|-------|-------|-------|-----------------|-------|-------|-------|-------|-------|
| | Clean | FGSM | PGD | cW | LSA | AA | Clean | FGSM | PGD | cW | LSA | AA |
| AT [31] | 45.18 | 19.25 | 16.36 | 16.43 | 19.00 | 15.60 | 44.86 | 19.01 | 15.65 | 15.89 | 19.12 | 15.08 |
| TRADES [53] | 41.71 | 21.91 | 19.85 | 18.46 | 18.39 | 17.91 | 43.22 | 20.28 | 17.46 | 17.34 | 17.56 | 16.69 |
| MART [42] | 41.32 | 25.01 | 23.27 | 20.89 | 20.77 | 19.98 | 43.67 | 22.84 | 19.88 | 18.80 | 19.45 | 17.77 |
| AWP [45] | 45.66 | 25.89 | 23.88 | 21.87 | 22.10 | 20.56 | 48.18 | 24.75 | 21.81 | 20.30 | 21.19 | 18.67 |
| GAIRAT[54] | 36.41 | 18.87 | 17.31 | 16.07 | 16.13 | 14.77 | 45.11 | 19.49 | 16.31 | 15.85 | 16.71 | 14.75 |
| LAS-AT[20] | 45.86 | 23.30 | 20.02 | 18.67 | 18.79 | 17.35 | 46.54 | 22.84 | 19.65 | 18.18 | 18.38 | 17.01 |
| RoBal [46] | 50.08 | 23.04 | 18.84 | 19.30 | 21.87 | 17.90 | 46.34 | 19.99 | 15.17 | 15.87 | 20.06 | 14.77 |
| REAT [26] | 50.29 | 23.99 | 20.82 | 20.25 | 21.93 | 18.65 | 49.22 | 20.89 | 16.57 | 17.08 | 20.89 | 15.49 |
| AT-BSL | 50.04 | 23.37 | 19.66 | 19.60 | 21.66 | 18.04 | 48.56 | 20.88 | 16.83 | 17.09 | 20.13 | 15.76 |
| AT-BSL-AuA | 53.08 | 28.55 | 25.40 | 23.39 | 24.48 | 21.43 | 55.55 | 26.74 | 22.18 | 21.88 | 24.28 | 19.68 |
Table 14. The robustness for various algorithms with different training epochs using Pre Act Res Net-18 on Tiny-ImageNet-LT at the best checkpoint. Better results are bolded.
<html><body><table><tr><td>Method</td><td>Clean FGSM PGD cW LSA AA</td></tr><tr><td>AT 36.30</td><td>16.58 14.52 12.65 13.16 11.37</td></tr><tr><td></td><td></td></tr><tr><td>RoBal 36.27</td><td>13.66 10.98 10.18 9.84 8.98</td></tr><tr><td>AT-BSL 38.83 AT-BSL-RA 39.00</td><td>17.47 15.34 13.35 14.08 11.83 18.82 16.94 14.26 14.60 12.73</td></tr></table></body></html>
表 14: 使用 Pre Act Res Net-18 在 Tiny-ImageNet-LT 上对不同训练周期的最佳检查点的各种算法的鲁棒性。更好的结果以粗体显示。
| Method | Clean | FGSM | PGD | cW | LSA | AA |
|--------------|-------|------|-----|----|-----|----|
| AT | 36.30 | 16.58 | 14.52 | 12.65 | 13.16 | 11.37 |
| RoBal | 36.27 | 13.66 | 10.98 | 10.18 | 9.84 | 8.98 |
| AT-BSL | 38.83 | 17.47 | 15.34 | 13.35 | 14.08 | 11.83 |
| AT-BSL-RA | 39.00 | 18.82 | 16.94 | 14.26 | 14.60 | 12.73 |
Data Augmentations Designed for Adversarial Training. DAJAT \$[1]^{12}\$ proposes a data augmentation technique designed explicitly for adversarial training. [1] initially conceptualizes data augmentation as a domain generalization problem during the training process. Subsequently, they introduce Diverse Augmentation-based Joint Adversarial Training (DAJAT), effectively integrating data augmentation into adversarial training. Since DAJAT’s experiments are based on TRADES [53], it cannot be directly applied to augment AT-BSL. We conduct comparative analyses between vanilla TRADES and DAJAT. The comparison in Table 19 reveals that DAJAT still contributes to improved robustness in long-tailed adversarial training, showing comparable effectiveness to TRADES-RA.
专为对抗训练设计的数据增强方法。DAJAT [1]^12 提出了一种专为对抗训练设计的数据增强技术。[1] 首先将数据增强概念化为训练过程中的领域泛化问题,随后引入了基于多样化增强的联合对抗训练 (DAJAT),有效将数据增强融入对抗训练。由于 DAJAT 的实验基于 TRADES [53],因此无法直接应用于增强 AT-BSL。我们对原始的 TRADES 和 DAJAT 进行了对比分析。表 19 中的对比显示,DAJAT 在长尾对抗训练中仍有助于提升鲁棒性,表现出与 TRADES-RA 相当的效果。
IDBH [28]13 is another data augmentation technique that is specifically formulated for adversarial training. [28] discovers that the diversity and hardness of data augmentation play a crucial role in combating adversarial over fitting. Overall, diversity enhances both accuracy and robustness, while hardness can improve robustness to a certain extent, but at the expense of accuracy and beyond a certain threshold, it diminishes both. [28] introduces a novel cropping transformation method called Cropshift to mitigate robust over fitting. Building on Cropshift, [28] proposes a new augmentation scheme called Improved Diversity and Balanced Hardness (IDBH). We utilize IDBH to augment AT
IDBH [28] 是另一种专门为对抗训练设计的数据增强技术。[28] 发现数据增强的多样性和硬度在对抗过拟合中起着至关重要的作用。总体而言,多样性可以提高准确性和鲁棒性,而硬度可以在一定程度上提高鲁棒性,但会以牺牲准确性为代价,超过一定阈值后,两者都会下降。[28] 引入了一种名为 Cropshift 的新型裁剪变换方法,以缓解鲁棒过拟合。在 Cropshift 的基础上,[28] 提出了一种新的增强方案,称为改进多样性和平衡硬度(IDBH)。我们利用 IDBH 来增强对抗训练(AT)。
Table 15. The clean accuracy and robustness for various algorithms using ResNet-18 on CIFAR-10-LT training with different PGD steps. Better results are bolded.
<html><body><table><tr><td>Steps</td><td>sMethodClean FGSM PGDCWLSAAA</td></tr><tr><td>1</td><td>AT-BSL77.1523.1512.0513.0624.8011.27 AT-BSL-RA82.1628.2814.2515.3426.3013.21</td></tr><tr><td>3</td><td></td></tr><tr><td>S</td><td></td></tr><tr><td>7</td><td>AT-BSL-RA68.7942.4537.7835.3134.9833.57</td></tr><tr><td>10</td><td>AT-BSL-RA70.8643.0637.9436.2436.0434.24</td></tr><tr><td>11</td><td></td></tr><tr><td>13</td><td>AT-BSL69.0739.8235.1933.1232.9131.44 AT-BSL-RA68.9042.1837.8934.9334.5833.35</td></tr></table></body></html>
表 15: 使用 ResNet-18 在 CIFAR-10-LT 训练中不同 PGD 步数下各种算法的干净准确率和鲁棒性。更好的结果已加粗。
| Steps | sMethodClean | FGSM | PGDCW | LSAAA |
|-------|--------------|------|-------|-------|
| 1 | AT-BSL | 77.15 | 23.15 | 12.05 | 13.06 | 24.80 | 11.27 | AT-BSL-RA | 82.16 | 28.28 | 14.25 | 15.34 | 26.30 | 13.21 |
| 3 | | | | | | | | | | | | | | |
| S | | | | | | | | | | | | | | |
| 7 | AT-BSL-RA | 68.79 | 42.45 | 37.78 | 35.31 | 34.98 | 33.57 | | | | | | | |
| 10 | AT-BSL-RA | 70.86 | 43.06 | 37.94 | 36.24 | 36.04 | 34.24 | | | | | | | |
| 11 | | | | | | | | | | | | | | |
| 13 | AT-BSL | 69.07 | 39.82 | 35.19 | 33.12 | 32.91 | 31.44 | AT-BSL-RA | 68.90 | 42.18 | 37.89 | 34.93 | 34.58 | 33.35 |
Table 16. The robustness for various algorithms with different batch sizes using ResNet-18 on CIFAR-10-LT at the best checkpoint. Better results are bolded. BS: Batch Size.
<html><body><table><tr><td>BS</td><td>Method Clean FGSM PGD</td></tr><tr><td>AT-BSL-RA66.70 41.85 37.8735.3434.8333.78</td></tr><tr><td>AT-BSL 68.89 40.08 35.2733.4733.4631.78 128 AT-BSL-RA 70.86 43.06 37.94 36.24 36.0434.24</td></tr><tr><td>AT-BSL 66.72 37.66 33.0831.5531.4229.98 256 AT-BSL-RA 67.93 41.05 36.6033.78 33.43 31.97</td></tr><tr><td>AT-BSL 60.01 35.45 32.2729.4429.0228.15 512 AT-BSL-RA63.25 37.6634.3831.14 30.5929.53</td></tr></table></body></html>
表 16: 使用 ResNet-18 在 CIFAR-10-LT 数据集上,不同批量大小下各种算法在最佳检查点时的鲁棒性。更好的结果加粗显示。BS: 批量大小。
| BS | Method Clean FGSM PGD |
| --- | --------------------- |
| 128 | AT-BSL-RA 66.70 41.85 37.87 35.34 34.83 33.78 |
| 128 | AT-BSL 68.89 40.08 35.27 33.47 33.46 31.78 |
| 128 | AT-BSL-RA 70.86 43.06 37.94 36.24 36.04 34.24 |
| 256 | AT-BSL 66.72 37.66 33.08 31.55 31.42 29.98 |
| 256 | AT-BSL-RA 67.93 41.05 36.60 33.78 33.43 31.97 |
| 512 | AT-BSL 60.01 35.45 32.27 29.44 29.02 28.15 |
| 512 | AT-BSL-RA 63.25 37.66 34.38 31.14 30.59 29.53 |
Table 17. The robustness for various algorithms with different training epochs using ResNet-18 on CIFAR-10-LT at the best checkpoint. Better results are bolded.
<html><body><table><tr><td>Method</td><td>Clean FGSM PGD cW LSA AA</td></tr><tr><td>AT-BSL-80 AT-BSL</td><td>66.68 40.18 36.1133.8733.6431.95 68.89 40.08 35.2733.47 33.46 31.78</td></tr><tr><td>AT-BSL-RA-8069.39 AT-BSL-RA</td><td>41.93 37.2034.8234.3632.92 70.86 43.06 37.9436.24 36.04 34.24</td></tr></table></body></html>
表 17: 使用 ResNet-18 在 CIFAR-10-LT 上不同训练周期的最佳检查点的各种算法的鲁棒性。更好的结果以粗体显示。
| 方法 | Clean | FGSM | PGD | cW | LSA | AA |
| --- | --- | --- | --- | --- | --- | --- |
| AT-BSL-80 | 66.68 | 40.18 | 36.11 | 33.87 | 33.64 | 31.95 |
| AT-BSL | 68.89 | 40.08 | 35.27 | 33.47 | 33.46 | 31.78 |
| AT-BSL-RA-80 | 69.39 | 41.93 | 37.20 | 34.82 | 34.36 | 32.92 |
| AT-BSL-RA | 70.86 | 43.06 | 37.94 | 36.24 | 36.04 | 34.24 |
Table 18. The robustness for various algorithms using ResNet18 on CIFAR-10-LT at the best checkpoint. The best results are bolded.
<html><body><table><tr><td>Method</td><td>CleanFGSM IPGD CW LSA AA</td></tr><tr><td>RoBal RoBal (retraining) 67.46 REAT REAT (retraining) 67.38 AT-BSL</td><td>70.3440.5035.93 31.05 31.1029.54 41.613 38.0432.7533.0831.26 67.38 40.13 35.8333.8833.6632.20 339.51 35.1533.5333.3131.77 68.89 40.08 :35.2733.4733.4631.78</td></tr></table></body></html>
表 18: 在 CIFAR-10-LT 上使用 ResNet18 的最佳检查点下,各种算法的鲁棒性。最佳结果已加粗。
| 方法 | Clean | FGSM | IPGD | CW | LSA | AA |
| --- | --- | --- | --- | --- | --- | --- |
| RoBal | 70.34 | 40.50 | 35.93 | 31.05 | 31.10 | 29.54 |
| RoBal (retraining) | 67.46 | 41.61 | 38.04 | 32.75 | 33.08 | 31.26 |
| REAT | 67.38 | 40.13 | 35.83 | 33.88 | 33.66 | 32.20 |
| REAT (retraining) | 67.38 | 40.13 | 35.83 | 33.88 | 33.66 | 32.20 |
| AT-BSL | 68.89 | 40.08 | 35.27 | 33.47 | 33.46 | 31.78 |
Table 19. The robustness for various algorithms with different data augmentations using ResNet-18 on CIFAR-10-LT at the best checkpoint. The best results are bolded.
<html><body><table><tr><td>Method</td><td>Clean FGSM PGD CW LSA AA</td></tr><tr><td>TRADES DAJAT TRADES-RA</td><td>43.61 29.18 27.81 26.73 326.5826.41 42.04 29.34 27.70 26.47 26.36 26.27 44.45 29.18 27.61 26.51 26.47 26.27</td></tr><tr><td>AT-BSL AT-BSL-CUDA AT-BSL-IDBH AT-BSL-RA</td><td>68.89 40.08 35.2733.47 33.4631.78 68.05 40.06 36.48 33.07 32.75 31.49 70.80 39.54 33.30 032.56 33.01 31.24 70.86 43.06 37.9436.2436.0434.24</td></tr></table></body></html>
表 19. 在 CIFAR-10-LT 上使用 ResNet-18 进行不同数据增强的各种算法在最佳检查点处的鲁棒性。最佳结果以粗体显示。
| Method | Clean | FGSM | PGD | CW | LSA | AA |
| --- | --- | --- | --- | --- | --- | --- |
| TRADES | 43.61 | 29.18 | 27.81 | 26.73 | 26.58 | 26.41 |
| DAJAT | 42.04 | 29.34 | 27.70 | 26.47 | 26.36 | 26.27 |
| TRADES-RA | 44.45 | 29.18 | 27.61 | 26.51 | 26.47 | 26.27 |
| AT-BSL | 68.89 | 40.08 | 35.27 | 33.47 | 33.46 | 31.78 |
| AT-BSL-CUDA | 68.05 | 40.06 | 36.48 | 33.07 | 32.75 | 31.49 |
| AT-BSL-IDBH | 70.80 | 39.54 | 33.30 | 32.56 | 33.01 | 31.24 |
| AT-BSL-RA | 70.86 | 43.06 | 37.94 | 36.24 | 36.04 | 34.24 |
Table 20. The robustness for various algorithms with different training epochs using ResNet-18 on CIFAR-10-LT at the best checkpoint. Better results are bolded.
<html><body><table><tr><td>Method Clean FGSM PGD cW LSA AA</td></tr><tr><td>AT-BSL</td></tr><tr><td>68.89 40.08 35.2733.4733.4631.78</td></tr><tr><td>AT-BSL-RA 70.86 43.06 37.9436.2436.04 34.24</td></tr><tr><td>AT-BSL-DM 72.61 47.09 42.01 41.56 41.89 39.48</td></tr></table></body></html>
表 20: 使用 ResNet-18 在 CIFAR-10-LT 数据集上不同训练周期的最佳检查点下各种算法的鲁棒性。更好的结果已加粗。
| Method | Clean | FGSM | PGD | cW | LSA | AA |
|-------------|-------|------|-----|----|-----|----|
| AT-BSL | 68.89 | 40.08 | 35.27 | 33.47 | 33.46 | 31.78 |
| AT-BSL-RA | 70.86 | 43.06 | 37.94 | 36.24 | 36.04 | 34.24 |
| AT-BSL-DM | 72.61 | 47.09 | 42.01 | 41.56 | 41.89 | 39.48 |
BSL, referred to as AT-BSL-IDBH. Upon comparison in Table 19, it is found that IDBH’s effectiveness is less pronounced than RA on long-tailed datasets.
在表 19 的对比中,发现 IDBH 在长尾数据集上的有效性不如 RA。
# B.11. Using Data Generated by Diffusion Models
B.11. 使用扩散模型生成的数据
To investigate the potential of leveraging data generated by diffusion models to improve the robustness of AT-BSL, we train a diffusion model, \$\mathrm{DDPM++}\$ , for CIFAR-10-LT, se- lecting the version with the best Fréchet Inception Distance (FID) of 6.92 after 18 sampling steps following [11, 22]. For the generation of 1 million data points, we produce 100,000 images per class, culminating in a total of 1 million images. Following [11], we set the proportion of unsupervised data to 0.7 and train a ResNet-18 using AT-BSL, which we refer to as AT-BSL-DM. The results presented in Table 20 clearly demonstrate the significant improvement in robustness afforded by incorporating data generated by diffusion models.
为了研究利用扩散模型生成的数据来提高 AT-BSL 鲁棒性的潜力,我们为 CIFAR-10-LT 训练了一个扩散模型 \$\mathrm{DDPM++}\$,在 18 次采样步骤后选择了 Fréchet Inception Distance (FID) 为 6.92 的最佳版本 [11, 22]。为了生成 100 万个数据点,我们为每个类别生成了 10 万张图像,最终总共生成了 100 万张图像。根据 [11],我们将无监督数据的比例设置为 0.7,并使用 AT-BSL 训练了一个 ResNet-18,我们将其称为 AT-BSL-DM。表 20 中的结果清楚地表明,通过引入扩散模型生成的数据,鲁棒性得到了显著提升。
# B.12. Different Adversarial Training Methods
B.12. 不同的对抗训练方法
To further validate the hypothesis that data augmentation alone improves robustness under long-tailed distributions, we conduct experiments across various adversarial training methods, employing AuA or RA. As evidenced in Table 21, with few exceptions, data augmentation is beneficial for robustness. This effect is particularly common on CIFAR100-LT, likely due to the reduced number of training examples per class in this dataset, leading to a more substantial reliance on data augmentation techniques.
为了进一步验证数据增强本身是否能提高长尾分布下的鲁棒性这一假设,我们在多种对抗训练方法中进行了实验,采用了 AuA 或 RA。如表 21 所示,除了少数例外,数据增强对鲁棒性是有益的。这种效果在 CIFAR100-LT 上尤为常见,可能是因为该数据集中每类的训练样本数量较少,导致对数据增强技术的依赖更为显著。
# B.13. Standard Deviation
B.13. 标准差
We repeat AT-BSL and AT-BSL-RA five times using ResNet-18 on CIFAR-10-LT. Their mean and standard deviation of robustness under AA are \$31.65\pm0.45\$ and \$34.12\pm\$ 0.51, respectively. The relatively small variance indicates the stability of our training process.
我们在 CIFAR-10-LT 上使用 ResNet-18 重复了 AT-BSL 和 AT-BSL-RA 五次。它们在 AA 下的鲁棒性均值和标准差分别为 \$31.65\pm0.45\$ 和 \$34.12\pm0.51\$。较小的方差表明我们的训练过程具有稳定性。
# B.14. Computational Cost Comparison
# B.14. 计算成本对比
In this section, we compare the computational costs of ATBSL and AT-BSL-RA/AuA regarding average training time per epoch and GPU memory usage. The detailed results are summarized in Table 22. The comparison indicates that the introduction of data augmentation incurs a negligible increase in time cost without imposing additional memory overhead.
在本节中,我们比较了ATBSL和AT-BSL-RA/AuA在每轮平均训练时间和GPU内存使用方面的计算成本。详细结果总结在表22中。对比表明,数据增强的引入在时间成本上仅带来了可忽略的增加,且未增加额外的内存开销。
# C. Comparison with Concurrent Works
# C. 与同期工作的对比
Concurrently and independently from our work, REAT [26] has also explored adversarial training under long-tailed distributions. [26] identifies that compared to conventional adversarial training on balanced datasets, this process tends to produce imbalanced adversarial examples and feature embedding spaces, resulting in reduced robustness on tail data. To address this issue, [26] introduces a novel adversarial training framework: Re-balancing Adversarial Training (REAT). This framework comprises two key components: (1) a new training strategy inspired by the concept of effective numbers, guiding the model to generate more balanced and informative adversarial examples, and (2) a meticulously designed penalty function aimed at enforcing a satisfactory feature space. Notably, the experimental settings utilized in our paper are fundamentally consistent with those employed in REAT. Moreover, as shown in Tables 3, 4, 12, and 13, the robustness achieved by our implemented vanilla AT-BSL is comparable to that of REAT.
与我们的工作并行且独立地,REAT [26] 也探索了长尾分布下的对抗训练。 [26] 指出,与在平衡数据集上进行传统对抗训练相比,这一过程往往会产生不平衡的对抗样本和特征嵌入空间,从而导致尾部数据的鲁棒性降低。为了解决这一问题, [26] 提出了一种新的对抗训练框架:Re-balancing Adversarial Training (REAT)。该框架包含两个关键组成部分: (1) 一种受有效数量概念启发的新训练策略,指导模型生成更平衡且信息丰富的对抗样本, (2) 一个精心设计的惩罚函数,旨在强制执行令人满意的特征空间。值得注意的是,本文中使用的实验设置与 REAT 中的设置基本一致。此外,如表 3、表 4、表 12 和表 13 所示,我们实现的 vanilla AT-BSL 所达到的鲁棒性与 REAT 相当。
Table 21. The robustness for various algorithms with/without data augmentations at the best checkpoint. On the combination of ResNet-18 and CIFAR-10-LT, RA is employed, whereas, for other model and dataset combinations, AuA is utilized. Better results are bolded.
<html><body><table><tr><td rowspan="2">Method</td><td colspan="6">CIFAR-10-LT</td><td colspan="6">CIFAR-100-LT</td></tr><tr><td colspan="3">ResNet-18</td><td colspan="3">WideResNet-34-10</td><td colspan="3">ResNet-18</td><td colspan="3">WideResNet-34-10</td></tr><tr><td></td><td>Clean</td><td>PGD</td><td>AA</td><td>Clean</td><td>PGD</td><td>AA</td><td>Clean</td><td>PGD</td><td>AA</td><td>Clean</td><td>PGD</td><td>AA</td></tr><tr><td>AT [31]</td><td>49.35</td><td>27.30</td><td>25.76</td><td>59.21</td><td>27.88</td><td>27.07 31.64</td><td>41.20 45.17</td><td>14.59 19.78</td><td>13.62 17.22</td><td>45.18 50.00</td><td>16.36 21.87</td><td>15.60 19.44</td></tr><tr><td>AT-RA/AuA</td><td>44.31</td><td>27.81</td><td>25.90</td><td>62.98</td><td>33.40</td><td></td><td></td><td></td><td></td><td></td><td></td><td></td></tr><tr><td>TRADES [53] TRADES-RA/AuA</td><td>43.61 44.45</td><td>27.81 27.61</td><td>26.41 26.27</td><td>51.28 55.89</td><td>28.70 31.53</td><td>27.72 29.77</td><td>38.12 42.14</td><td>17.89 19.69</td><td>15.59 16.12</td><td>41.71 46.23</td><td>19.85 22.78</td><td>17.91 19.52</td></tr><tr><td></td><td></td><td></td><td>27.73</td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td></tr><tr><td>MART [42] MART-RA/AuA</td><td>48.61 43.76</td><td>30.29 29.86</td><td>26.77</td><td>49.13 48.07</td><td>32.32 31.93</td><td>29.60 28.31</td><td>38.46 38.01</td><td>21.36 22.64</td><td>17.51 18.68</td><td>41.32 43.43</td><td>23.27 25.41</td><td>19.98 21.26</td></tr><tr><td>AWP [45]</td><td>49.29</td><td>31.20</td><td>29.53</td><td>50.91</td><td>31.85</td><td>30.06</td><td>41.53</td><td>21.79</td><td>18.61</td><td></td><td></td><td></td></tr><tr><td>AWP-RA/AuA</td><td>45.28</td><td>30.56</td><td>28.73</td><td>44.06</td><td>29.91</td><td>27.81</td><td>41.07</td><td>23.02</td><td>19.37</td><td>45.66 45.27</td><td>23.88 25.76</td><td>20.56 21.60</td></tr><tr><td>GAIRAT [54]</td><td>50.83</td><td>27.46</td><td>20.41</td><td>59.89</td><td>30.40</td><td>25.38</td><td>38.99</td><td>18.05</td><td>15.61</td><td>36.41</td><td>17.31</td><td>14.77</td></tr><tr><td>GAIRAT-RA/AuA</td><td>43.56</td><td>27.34</td><td>17.82</td><td>66.43</td><td>37.96</td><td>25.53</td><td>41.94</td><td>19.18</td><td>14.82</td><td>49.75</td><td>22.19</td><td>18.24</td></tr><tr><td>LAS-AT [20]</td><td>52.81</td><td>30.32</td><td>28.53</td><td>57.52</td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td></tr><tr><td>LAS-AT-RA/AuA</td><td>51.20</td><td>31.20</td><td>29.18</td><td>59.14</td><td>29.86 34.51</td><td>28.84 32.54</td><td>44.33 45.18</td><td>19.59 22.78</td><td>16.15 18.61</td><td>45.86 49.73</td><td>20.02 24.09</td><td>17.35 20.79</td></tr><tr><td>RoBal [46]</td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td></tr><tr><td>RoBal-RA/AuA</td><td>70.34 68.66</td><td>35.93 37.50</td><td>29.54 30.06</td><td>72.82 72.57</td><td>36.42 40.54</td><td>30.49 31.87</td><td>45.93 47.75</td><td>17.40 19.93</td><td>16.42 18.04</td><td>50.08 54.12</td><td>18.84 21.41</td><td>17.90 19.66</td></tr><tr><td>REAT [26]</td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td><td></td></tr><tr><td>REAT-RA/AuA</td><td>67.38</td><td>35.83</td><td>32.20</td><td>73.16</td><td>35.94</td><td>33.20</td><td>46.28</td><td>18.85</td><td>16.54</td><td>50.29</td><td>20.82</td><td>18.65</td></tr><tr><td></td><td>66.64</td><td>36.97</td><td>31.84</td><td>72.05</td><td>40.05</td><td>35.74</td><td>47.65</td><td>22.86</td><td>18.48</td><td>50.10</td><td>25.07</td><td>20.81</td></tr><tr><td>AT-BSL</td><td>68.89</td><td>35.27</td><td>31.78</td><td>73.19</td><td>35.60</td><td>32.80</td><td>45.59</td><td>18.05</td><td>15.97</td><td>50.04</td><td>19.66</td><td>18.04</td></tr><tr><td>AT-BSL-RA/AuA</td><td>70.86</td><td>37.94</td><td>34.24</td><td>75.17</td><td>40.84</td><td>37.15</td><td>48.39</td><td>22.96</td><td>18.90</td><td>53.08</td><td>25.40</td><td>21.43</td></tr></table></body></html>
表 21: 不同算法在最佳检查点处有无数据增强的鲁棒性。在 ResNet-18 和 CIFAR-10-LT 的组合中,使用了 RA,而在其他模型和数据集的组合中,使用了 AuA。更好的结果用粗体表示。
| 方法 | CIFAR-10-LT | CIFAR-10-LT | CIFAR-10-LT | CIFAR-10-LT | CIFAR-10-LT | CIFAR-10-LT | CIFAR-100-LT | CIFAR-100-LT | CIFAR-100-LT | CIFAR-100-LT | CIFAR-100-LT | CIFAR-100-LT |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| | ResNet-18 | ResNet-18 | ResNet-18 | WideResNet-34-10 | WideResNet-34-10 | WideResNet-34-10 | ResNet-18 | ResNet-18 | ResNet-18 | WideResNet-34-10 | WideResNet-34-10 | WideResNet-34-10 |
| | Clean | PGD | AA | Clean | PGD | AA | Clean | PGD | AA | Clean | PGD | AA |
| AT [31] | 49.35 | 27.30 | 25.76 | 59.21 | 27.88 | 27.07 | 31.64 | 41.20 | 14.59 | 13.62 | 45.18 | 16.36 |
| AT-RA/AuA | 44.31 | 27.81 | 25.90 | 62.98 | 33.40 | | | | | | | |
| TRADES [53] | 43.61 | 27.81 | 26.41 | 51.28 | 28.70 | 27.72 | 38.12 | 17.89 | 15.59 | 41.71 | 19.85 | 17.91 |
| TRADES-RA/AuA | 44.45 | 27.61 | 26.27 | 55.89 | 31.53 | 29.77 | 42.14 | 19.69 | 16.12 | 46.23 | 22.78 | 19.52 |
| MART [42] | 48.61 | 30.29 | 26.77 | 49.13 | 32.32 | 29.60 | 38.46 | 21.36 | 17.51 | 41.32 | 23.27 | 19.98 |
| MART-RA/AuA | 43.76 | 29.86 | | 48.07 | 31.93 | 28.31 | 38.01 | 22.64 | 18.68 | 43.43 | 25.41 | 21.26 |
| AWP [45] | 49.29 | 31.20 | 29.53 | 50.91 | 31.85 | 30.06 | 41.53 | 21.79 | 18.61 | | | |
| AWP-RA/AuA | 45.28 | 30.56 | 28.73 | 44.06 | 29.91 | 27.81 | 41.07 | 23.02 | 19.37 | 45.66 | 23.88 | 20.56 |
| GAIRAT [54] | 50.83 | 27.46 | 20.41 | 59.89 | 30.40 | 25.38 | 38.99 | 18.05 | 15.61 | 36.41 | 17.31 | 14.77 |
| GAIRAT-RA/AuA | 43.56 | 27.34 | 17.82 | 66.43 | 37.96 | 25.53 | 41.94 | 19.18 | 14.82 | 49.75 | 22.19 | 18.24 |
| LAS-AT [20] | 52.81 | 30.32 | 28.53 | 57.52 | | | | | | | | |
| LAS-AT-RA/AuA | 51.20 | 31.20 | 29.18 | 59.14 | 29.86 | 28.84 | 44.33 | 19.59 | 16.15 | 45.86 | 20.02 | 17.35 |
| RoBal [46] | | | | | | | | | | | | |
| RoBal-RA/AuA | 70.34 | 35.93 | 29.54 | 72.82 | 36.42 | 30.49 | 45.93 | 17.40 | 16.42 | 50.08 | 18.84 | 17.90 |
| REAT [26] | | | | | | | | | | | | |
| REAT-RA/AuA | 67.38 | 35.83 | 32.20 | 73.16 | 35.94 | 33.20 | 46.28 | 18.85 | 16.54 | 50.29 | 20.82 | 18.65 |
| AT-BSL | 68.89 | 35.27 | 31.78 | 73.19 | 35.60 | 32.80 | 45.59 | 18.05 | 15.97 | 50.04 | 19.66 | 18.04 |
| AT-BSL-RA/AuA | 70.86 | 37.94 | 34.24 | 75.17 | 40.84 | 37.15 | 48.39 | 22.96 | 18.90 | 53.08 | 25.40 | 21.43 |
Table 22. The time and memory for various algorithms. On the combination of ResNet-18 and CIFAR-10-LT, RA is employed, whereas, for other model and dataset combinations, AuA is utilized. All experiments are run on NVIDIA RTX 3090.
<html><body><table><tr><td rowspan="2">Dataset</td><td rowspan="2">Method</td><td colspan="2">ResNet-18</td><td colspan="2">WideResNet-34-10</td></tr><tr><td>Time (s)</td><td>Memory (MiB)</td><td>Time (s)</td><td>Memory (MiB)</td></tr><tr><td rowspan="2">CIFAR-10-LT</td><td>AT-BSL</td><td>22.37</td><td>1345</td><td>200.70</td><td>4293</td></tr><tr><td>AT-BSL-RA/AuA</td><td>22.43</td><td>1345</td><td>201.42</td><td>4293</td></tr><tr><td rowspan="2">CIFAR-100-LT</td><td>AT-BSL</td><td>30.94</td><td>1347</td><td>277.82</td><td>4293</td></tr><tr><td>AT-BSL-RA/AuA</td><td>31.25</td><td>1347</td><td>279.66</td><td>4293</td></tr></table></body></html>
表 22. 不同算法的时间和内存。在 ResNet-18 和 CIFAR-10-LT 的组合中,使用了 RA,而在其他模型和数据集的组合中,使用了 AuA。所有实验均在 NVIDIA RTX 3090 上运行。
| 数据集 | 方法 | ResNet-18 时间 (s) | ResNet-18 内存 (MiB) | WideResNet-34-10 时间 (s) | WideResNet-34-10 内存 (MiB) |
| --- | --- | --- | --- | --- | --- |
| CIFAR-10-LT | AT-BSL | 22.37 | 1345 | 200.70 | 4293 |
| CIFAR-10-LT | AT-BSL-RA/AuA | 22.43 | 1345 | 201.42 | 4293 |
| CIFAR-100-LT | AT-BSL | 30.94 | 1347 | 277.82 | 4293 |
| CIFAR-100-LT | AT-BSL-RA/AuA | 31.25 | 1347 | 279.66 | 4293 |