Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Spark-TTS: 基于大语言模型的高效文本转语音模型,采用单流解耦语音Token
Abstract
摘要
Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multistage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce SparkTTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic con- tent and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chainof-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github. com/SparkAudio/Spark-TTS.
大语言模型 (LLM) 的最新进展推动了零样本文本到语音 (TTS) 合成的显著进步。然而,现有的基础模型依赖于多阶段处理或复杂架构来预测多个码本,限制了效率和集成灵活性。为了克服这些挑战,我们引入了 SparkTTS,这是一个由 BiCodec 驱动的新系统,BiCodec 是一种单流语音编解码器,将语音分解为两种互补的 Token 类型:用于语言内容的低比特率语义 Token 和用于说话者属性的固定长度全局 Token。这种解耦表示,结合 Qwen2.5 大语言模型和思维链 (CoT) 生成方法,实现了粗粒度控制(例如性别、说话风格)和细粒度调整(例如精确的音高值、说话速率)。为了促进可控 TTS 的研究,我们引入了 VoxBox,这是一个精心策划的 100,000 小时数据集,带有全面的属性注释。大量实验表明,Spark-TTS 不仅实现了最先进的零样本语音克隆,还生成了高度可定制的声音,超越了基于参考的合成的限制。源代码、预训练模型和音频样本可在 https://github.com/SparkAudio/Spark-TTS 获取。
1 Introduction
1 引言
Recent advances in speech token iz ation have revolutionized text-to-speech (TTS) synthesis by bridging the fundamental gap between continuous speech signals and discrete token-based large language models (LLMs) (A nast as sio u et al., 2024; Zhu et al., 2024; Wang et al., 2024c). Through sophisticated quantization techniques, particularly Vector Quantization (VQ) (Van Den Oord et al., 2017) and Finite Scalar Quantization (FSQ) (Mentzer et al., 2023), codec-based LLMs have emerged as the predominant paradigm for zero-shot TTS. The integration of extensive training data with large-scale model architectures has enabled these systems to achieve unprecedented levels of naturalness, often rendering synthetic speech indistinguishable from human speech (A nast as sio u et al., 2024; Du et al., 2024b; Chen et al., 2024b; Ye et al., 2024a).
语音 Token 化的最新进展通过弥合连续语音信号和基于离散 Token 的大语言模型之间的根本差距,彻底改变了文本到语音 (TTS) 合成 (Anastassio u et al., 2024; Zhu et al., 2024; Wang et al., 2024c)。通过复杂的量化技术,特别是矢量量化 (VQ) (Van Den Oord et al., 2017) 和有限标量量化 (FSQ) (Mentzer et al., 2023),基于编解码器的大语言模型已成为零样本 TTS 的主导范式。通过将大量训练数据与大规模模型架构相结合,这些系统实现了前所未有的自然度,通常使合成语音与人类语音难以区分 (Anastassio u et al., 2024; Du et al., 2024b; Chen et al., 2024b; Ye et al., 2024a)。
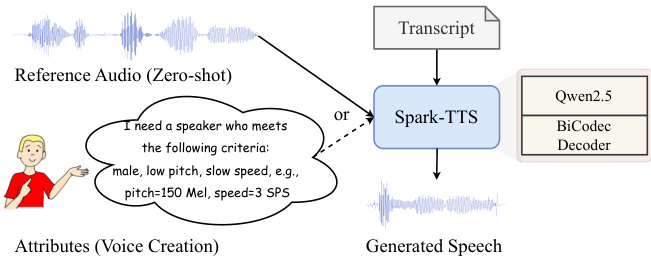
Figure 1: Spark-TTS enables zero-shot voice cloning from reference audio while also generating new speakers through coarse- or fine-grained attribute control. The final waveform is directly reconstructed from the predicted speech tokens using BiCodec’s decoder.
图 1: Spark-TTS 支持从参考音频中进行零样本语音克隆,同时通过粗粒度或细粒度属性控制生成新的说话者。最终波形是使用 BiCodec 的解码器直接从预测的语音 Token 重建的。
Despite the remarkable progress in LLM-based zero-shot TTS, several fundamental challenges persist. Current codec-based TTS architectures exhibit significant complexity, requiring either dual generative models (Wang et al., 2023a; A nast as sio u et al., 2024) or intricate parallel multi-stream code prediction mechanisms (Kreuk et al., 2023; Le Lan et al., 2024) that deviate substantially from conventional text LLM frameworks. This divergence stems from inherent limitations in existing audio codecs - while semantic tokens provide compactness, they necessitate additional models for acoustic feature prediction (Du et al., 2024a; Huang et al., 2023) and lack integrated timbre control capabilities. Acoustic tokens, meanwhile, rely on complex codebook architectures like group-VQ (Défossez et al., 2022; Van Den Oord et al., 2017). The field also struggles with the creation of novel voices, as current systems are predominantly limited to reference-based generation (Zhang et al., 2023b; Chen et al., 2024a), lacking the capability to synthesize voices with precisely specified characteristics. This limitation is further compounded by insufficient granularity in attribute control, especially for fine-grained charact eris tics such as pitch modulation, despite recent advances in instruction-based generation (Du et al., 2024b). Furthermore, the prevalent use of proprietary datasets in current research creates significant challenges for standardized evaluation and meaningful comparison of methods (A nast as sio u et al., 2024; Ye et al., 2024a). These limitations collec- tively underscore the need for a unified approach that can simplify architecture, enable flexible voice creation with comprehensive attribute control, and establish reproducible benchmarks through open data resources.
尽管基于大语言模型的零样本 TTS 取得了显著进展,但仍存在一些基本挑战。当前的基于编解码器的 TTS 架构表现出显著的复杂性,需要双生成模型(Wang et al., 2023a; Anastas siou et al., 2024)或复杂的并行多流代码预测机制(Kreuk et al., 2023; Le Lan et al., 2024),这与传统的文本大语言模型框架大相径庭。这种差异源于现有音频编解码器的固有局限性——虽然语义Token提供了紧凑性,但它们需要额外的模型来进行声学特征预测(Du et al., 2024a; Huang et al., 2023),并且缺乏集成的音色控制能力。与此同时,声学Token依赖于复杂的代码本架构,如 group-VQ(Défossez et al., 2022; Van Den Oord et al., 2017)。该领域还在新声音的创建方面面临困难,因为当前系统主要局限于基于参考的生成(Zhang et al., 2023b; Chen et al., 2024a),缺乏合成具有精确指定特征的声音的能力。尽管最近在基于指令的生成方面取得了进展(Du et al., 2024b),但属性控制的粒度不足进一步加剧了这一限制,特别是在音高调制等细粒度特征方面。此外,当前研究中普遍使用专有数据集,这给标准化评估和方法的有效比较带来了重大挑战(Anastas siou et al., 2024; Ye et al., 2024a)。这些局限性共同强调了对统一方法的需求,该方法可以简化架构,实现具有全面属性控制的灵活声音创建,并通过开放数据资源建立可复现的基准。
To address these fundamental limitations, we introduce Spark-TTS, a unified system that achieves zero-shot TTS with comprehensive attribute control through a single codec LLM, maintaining archit ect ural alignment with conventional text LLMs. In addition, we present VoxBox, a meticulously curated and annotated open-source speech dataset that establishes a foundation for reproducible research in speech synthesis. Specifically, we introduce BiCodec, a novel token iz ation framework that preserves the efficiency of semantic tokens while enabling fine-grained control over timbrerelated attributes. BiCodec achieves this through combining low-bitrate semantic tokens with fixedlength global tokens, effectively capturing both linguistic content and time-invariant acoustic charact eris tics. Building upon BiCodec, we leverage Qwen2.5 (Yang et al., 2024) through targeted finetuning, seamlessly integrating TTS capabilities within the text LLM paradigm. To enable comprehensive voice control, we implement a hierarchical attribute system combining coarse-grained labels (gender, pitch, speaking speed) with fine-grained numerical values, orchestrated through a chain-ofthought (CoT) prediction framework.
为了解决这些根本性限制,我们引入了 Spark-TTS,这是一个通过单一编解码大语言模型实现零样本 TTS 并具备全面属性控制的统一系统,保持了与传统文本大语言模型的架构一致性。此外,我们推出了 VoxBox,这是一个精心策划和标注的开源语音数据集,为语音合成领域的可重复研究奠定了基础。具体来说,我们引入了 BiCodec,这是一种新颖的 Token 化框架,它在保持语义 Token 效率的同时,实现了对音色相关属性的细粒度控制。BiCodec 通过将低比特率语义 Token 与固定长度的全局 Token 相结合,有效地捕捉了语言内容和时不变声学特征。基于 BiCodec,我们通过对 Qwen2.5 (Yang et al., 2024) 进行针对性微调,将 TTS 能力无缝集成到文本大语言模型范式中。为了实现全面的语音控制,我们实现了一个分层属性系统,将粗粒度标签(性别、音高、语速)与细粒度数值相结合,并通过思维链 (CoT) 预测框架进行协调。
Our primary contributions encompass:
我们的主要贡献包括:
• New Token iz ation: We present BiCodec, a unified speech token iz ation that generates a hybrid token stream combining semantic and global tokens. This approach maintains linguistic fidelity while enabling sophisticated attribute control through LM-based mechanisms.
新 Token 化:我们提出了 BiCodec,一种统一的语音 Token 化方法,生成结合语义和全局 Token 的混合 Token 流。该方法在保持语言保真度的同时,通过基于 LM 的机制实现了精细的属性控制。
• Coarse- and Fine-Grained Voice Control: Spark-TTS implements a comprehensive attribute control system that seamlessly integrates both categorical and continuous parameters within a text LLM-compatible architecture. As demonstrated in Fig. 1, this innovation transcends traditional reference-based approaches to zero-shot TTS.
• 粗粒度与细粒度的语音控制:Spark-TTS 实现了一个全面的属性控制系统,将分类参数和连续参数无缝集成在一个与大语言模型兼容的架构中。如图 1 所示,这一创新超越了传统的基于参考的零样本 TTS 方法。
• Benchmark Dataset: We introduce VoxBox, a rigorously curated 100,000-hour speech corpus, developed through systematic data collection, cleaning, and attribute annotation. This resource establishes a standardized benchmark for TTS research and evaluation.
• 基准数据集:我们推出了VoxBox,这是一个经过严格筛选的10万小时语音语料库,通过系统化的数据收集、清理和属性标注开发而成。该资源为TTS研究和评估建立了标准化基准。
2 Related Work
2 相关工作
2.1 Single-Stream Speech Tokenizer
2.1 单流语音 Tokenizer
Early single-stream speech tokenizers primarily focused on extracting semantic tokens (Huang et al., 2023; Du et al., 2024a; Tao et al., 2024). While pure semantic tokens enable low-bitrate encoding, they necessitate an additional acoustic feature prediction module in semantic token-based speech synthesis (Du et al., 2024a,b).
早期的单流语音 Tokenizer 主要关注提取语义 Token (Huang et al., 2023; Du et al., 2024a; Tao et al., 2024)。虽然纯语义 Token 支持低比特率编码,但在基于语义 Token 的语音合成中,它们需要一个额外的声学特征预测模块 (Du et al., 2024a,b)。
Recently, single-stream-based acoustic tokenization has gained considerable attention (Xin et al., 2024; Wu et al., 2024). Wav Token ize r (Ji et al., 2024a) employs a convolution-based decoder to improve reconstruction quality, while X-codec2 (Ye et al., 2025) enlarges the code space with FSQ. Instead of following a pure encoder-VQ-decoder paradigm, decoupling speech content has proven effective in reducing bitrate using a single codebook (Li et al., 2024a; Zheng et al., 2024).
最近,基于单流的声学Token化方法受到了广泛关注 (Xin et al., 2024; Wu et al., 2024)。Wav Tokenizer (Ji et al., 2024a) 采用基于卷积的解码器来提高重建质量,而 X-codec2 (Ye et al., 2025) 则通过 FSQ 扩展了编码空间。与纯编码器-VQ-解码器范式不同,解耦语音内容已被证明在使用单码本的情况下能有效降低比特率 (Li et al., 2024a; Zheng et al., 2024)。
Among these methods, TiCodec (Ren et al., 2024) is the most similar to our approach in handling global information. However, unlike TiCodec, the proposed BiCodec employs semantic tokens as its time-variant tokens. Instead of using group GVQ (Ren et al., 2024), we propose a novel global embedding quantization method based on FSQ with learnable queries and a cross-attention mechanism. This approach enables the generation of a relatively longer token sequence, offering a more expressive and flexible representation.
在这些方法中,TiCodec (Ren et al., 2024) 在处理全局信息方面与我们的方法最为相似。然而,与 TiCodec 不同,我们提出的 BiCodec 使用语义 Token 作为其时间变化的 Token。我们没有使用分组 GVQ (Ren et al., 2024),而是提出了一种基于 FSQ 的全局嵌入量化方法,该方法具有可学习的查询和交叉注意力机制。这种方法能够生成相对较长的 Token 序列,提供了更具表现力和灵活性的表示。
2.2 LLM-based Zero-Shot TTS
2.2 基于大语言模型的零样本TTS
Prevalent codec LLMs zero-shot TTS predomi- nantly fall into two categories. The first type involves predicting single-stream codes using LLMs, followed by the generation of codes enriched with detailed acoustic or continuous semantic features through another LLM (Zhang et al., 2023b; Chen et al., 2024a; Wang et al., 2024a) or generative diffusion models (A nast as sio u et al., 2024; Casanova et al., 2024). The second type involves predicting multi-stream codes using carefully designed parallel strategies (Le Lan et al., 2024; Copet et al., 2024) or masked generative patterns (Garcia et al., 2023; Ziv et al., 2024; Li et al., 2024b).
常见的编解码器大语言模型零样本 TTS 主要分为两类。第一类涉及使用大语言模型预测单流代码,然后通过另一个大语言模型(Zhang et al., 2023b; Chen et al., 2024a; Wang et al., 2024a)或生成式扩散模型(Anastasiou et al., 2024; Casanova et al., 2024)生成包含详细声学或连续语义特征的代码。第二类涉及使用精心设计的并行策略(Le Lan et al., 2024; Copet et al., 2024)或掩码生成模式(Garcia et al., 2023; Ziv et al., 2024; Li et al., 2024b)预测多流代码。
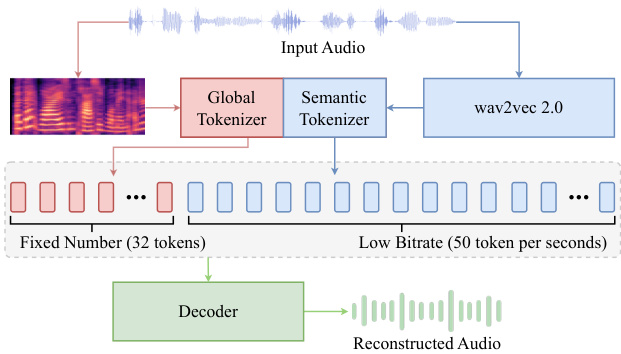
Figure 2: Illustration of the BiCodec. The Global Tokenizer processes the Mel spec tr ogram to produce global tokens with fixed length, while the Semantic Tokenizer adopts features from wav2vec 2.0 to produce 50 TPS semantic tokens. The decoder reconstructs the waveform from the generated tokens. The detailed structure of BiCodec is provided in Appendix A.
图 2: BiCodec 的示意图。Global Tokenizer 处理梅尔频谱图以生成固定长度的全局 Token,而 Semantic Tokenizer 采用 wav2vec 2.0 的特征来生成 50 TPS 的语义 Token。解码器从生成的 Token 中重建波形。BiCodec 的详细结构见附录 A。
By leveraging the single-stream tokens produced by the proposed BiCodec, Spark-TTS simplifies the modeling of speech tokens within an LLM framework that is fully unified with text LLMs. The most comparable work is the concurrent TTS model Llasa (Ye et al., 2025), which employs an FSQ-based tokenizer to encode speech into singlestream codes with a codebook size of 65,536, followed by LLaMA (Touvron et al., 2023) for speech token prediction. In contrast, Spark-TTS extends beyond zero-shot TTS by integrating speaker attribute labels, enabling controllable voice creation. Additionally, Spark-TTS achieves higher zero-shot TTS performance while using fewer model parameters, enhancing both efficiency and flexibility.
通过利用所提出的 BiCodec 生成的单流 Token,Spark-TTS 简化了在完全与文本大语言模型统一的大语言模型框架内的语音 Token 建模。最具可比性的工作是并行的 TTS 模型 Llasa (Ye et al., 2025),它采用基于 FSQ 的 Tokenizer 将语音编码为单流代码,代码本大小为 65,536,随后使用 LLaMA (Touvron et al., 2023) 进行语音 Token 预测。相比之下,Spark-TTS 通过集成说话者属性标签,超越了零样本 TTS,实现了可控的语音生成。此外,Spark-TTS 在使用更少模型参数的同时,实现了更高的零样本 TTS 性能,从而提升了效率和灵活性。
3 BiCodec
3 BiCodec
To achieve both the compact nature and semantic relevance of semantic tokens, while also enabling acoustic attribute control within an LM, we propose BiCodec, which disc ret ize s input audio into: (i) Semantic tokens at 50 tokens per second (TPS), capturing linguistic content, and (ii) Fixedlength global tokens, encoding speaker attributes and other global speech characteristics.
为了实现语义Token的紧凑性和语义相关性,同时在语言模型中实现声学属性控制,我们提出了BiCodec,它将输入音频离散化为:(i) 以每秒50个Token (TPS) 的语义Token,捕获语言内容;(ii) 固定长度的全局Token,编码说话者属性和其他全局语音特征。
3.1 Overview
3.1 概述
As shown in Fig. 2, BiCodec includes a Global Tokenizer and a Semantic Tokenizer. The former extracts global tokens from the Mel spectrogram of input audio. The latter uses features from wav2vec 2.0 (Baevski et al., 2020) as input to extract semantic tokens.
如图 2 所示,BiCodec 包含一个全局分词器 (Global Tokenizer) 和一个语义分词器 (Semantic Tokenizer)。前者从输入音频的梅尔频谱图中提取全局 Token,后者使用 wav2vec 2.0 (Baevski et al., 2020) 的特征作为输入来提取语义 Token。
The BiCodec architecture follows a standard VQVAE encoder-decoder framework, augmented with a global tokenizer. The decoder reconstructs discrete tokens back into audio. For an input audio signal $\pmb{x}\in[-1,1]^{T}$ , with sample number of $T$ , BiCodec functions as follows:
BiCodec 架构遵循标准的 VQVAE 编码器-解码器框架,并增加了全局分词器。解码器将离散的 Token 重建为音频。对于输入音频信号 $\pmb{x}\in[-1,1]^{T}$ ,样本数为 $T$ ,BiCodec 的工作原理如下:

where $E_{s}(\cdot)$ is the encoder of the semantic tokenizer, $F(\cdot)$ is the pre-trained wav2vec $2.0^{1}$ , $E_{g}(\cdot)$ is the encoder of the global tokenizer, $\mathrm{Mel}(\cdot)$ is to extract Mel spec tr ogram from $x,h$ is a sequence of learnable queries matching the length of the final global token sequence, $Q_{s}(\cdot)$ is a quantization layer with VQ, $Q_{g}(\cdot)$ is a quantization layer with FSQ, $A_{g}(\cdot)$ is an aggregation module with a pooling layer, and $G(\cdot)$ is the decoder that reconstructs the time-domain signal $\hat{\pmb x}$ .
其中 $E_{s}(\cdot)$ 是语义分词器的编码器,$F(\cdot)$ 是预训练的 wav2vec $2.0^{1}$,$E_{g}(\cdot)$ 是全局分词器的编码器,$\mathrm{Mel}(\cdot)$ 是从 $x$ 中提取梅尔频谱图,$h$ 是与最终全局token序列长度匹配的可学习查询序列,$Q_{s}(\cdot)$ 是带有 VQ 的量化层,$Q_{g}(\cdot)$ 是带有 FSQ 的量化层,$A_{g}(\cdot)$ 是带有池化层的聚合模块,$G(\cdot)$ 是重建时域信号 $\hat{\pmb x}$ 的解码器。
3.2 Model Structure
3.2 模型结构
Encoder and Decoder The encoder of the semantic tokenizer $E_{s}$ and the decoder $G$ are fully convolutional neural networks built with ConvNeXt (Liu et al., 2022) blocks. To effectively capture semantic information, based on the relationship between different layer features of wav2vec 2.0 (XLSR-53) and semantics (Pasad et al., 2023), we select features from the 11th, 14th, and 16th layers, averaging them to obtain the semantic feature, which serves as the input for the semantic tokenizer. The features from the first two layers show a strong correlation with words, while the features from the 16th layer exhibit the strongest correlation with phonemes.
编码器与解码器
语义分词器的编码器 $E_{s}$ 和解码器 $G$ 是由 ConvNeXt (Liu et al., 2022) 块构建的全卷积神经网络。为了有效捕捉语义信息,基于 wav2vec 2.0 (XLSR-53) 不同层特征与语义的关系 (Pasad et al., 2023),我们选择了第 11、14 和 16 层的特征,通过平均化处理得到语义特征,作为语义分词器的输入。前两层的特征与词汇表现出强相关性,而第 16 层的特征则与音素的相关性最强。
The global tokenizer’s encoder, $E_{g}$ , uses the ECAPA-TDNN architecture (Des plan ques et al., 2020) following the implementation by Wespeaker (Wang et al., 2023b) up to the final pooling layer. After encoding, the global tokenizer extracts a fixed-length sequence representation $g_{f}$ using a cross-attention mechanism with a set of learnable queries.
全局分词器的编码器 $E_{g}$ 采用了 ECAPA-TDNN 架构 (Des plan ques et al., 2020),并遵循 Wespeaker (Wang et al., 2023b) 的实现方式,直至最后的池化层。编码后,全局分词器通过一组可学习的查询使用交叉注意力机制提取固定长度的序列表示 $g_{f}$。
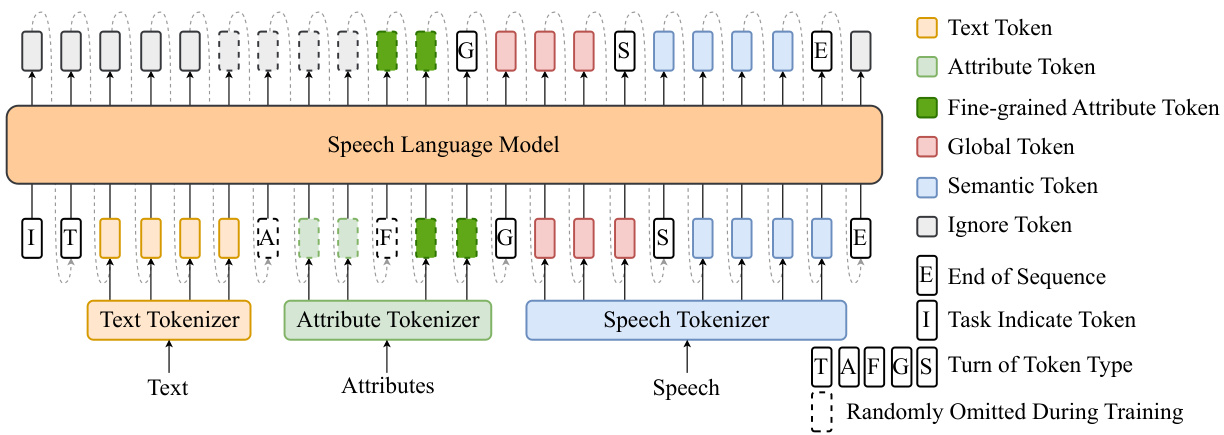
Figure 3: Speech language model of Spark-TTS. During inference, if the input contains attribute tokens representing gender, pitch level, and speed level, the model can predict the corresponding fine-grained attribute tokens, global tokens, and semantic tokens without requiring reference audio in a CoT manner. Otherwise, global tokens can be derived from the reference audio for zero-shot TTS.
图 3: Spark-TTS 的语音语言模型。在推理过程中,如果输入包含表示性别、音调水平和速度水平的属性 Token,模型可以以 CoT 的方式预测相应的细粒度属性 Token、全局 Token 和语义 Token,而无需参考音频。否则,全局 Token 可以从参考音频中导出,用于零样本 TTS。
Quantization The semantic tokenizer employs single-codebook vector quantization for quantization. Inspired by DAC (Kumar et al., 2024), we use factorized codes to project the encoder’s output into a low-dimensional latent variable space prior to quantization.
量化 语义分词器采用单码本向量量化进行量化。受DAC (Kumar et al., 2024)的启发,我们在量化之前使用分解码将编码器的输出投影到低维潜变量空间。
Considering that the global tokenizer requires a set of discrete tokens to represent time-independent global information, FSQ is employed rather than VQ to mitigate the potential risk of training collapse associated with VQ. Details about the model structure can be seen in Appendix A.
考虑到全局分词器 (tokenizer) 需要一组离散的 Token 来表示时间无关的全局信息,因此使用 FSQ 而非 VQ,以减轻 VQ 可能带来的训练崩溃风险。有关模型结构的详细信息请参见附录 A。
3.3 Training objective
3.3 训练目标
Loss Functions BiCodec is trained end-to-end employing a Generative Adversarial Network (GAN) methodology (Goodfellow et al., 2020) to minimize reconstruction loss, together with L1 feature matching loss (via disc rim in at or s) (Kumar et al., 2019, 2024) while simultaneously optimizing the VQ codebook.
损失函数 BiCodec 采用生成对抗网络 (Generative Adversarial Network, GAN) 方法 (Goodfellow et al., 2020) 进行端到端训练,以最小化重建损失,同时结合 L1 特征匹配损失 (通过判别器) (Kumar et al., 2019, 2024),并在优化 VQ 码本的同时进行训练。
Following (Kumar et al., 2024), we compute the frequency domain reconstruction loss using L1 loss on multi-scale mel-spec tro grams. Multi-period disc rim in at or (Kong et al., 2020; Engel et al., 2020; Gritsenko et al., 2020) and multi-band multi-scale STFT disc rim in at or (Kumar et al., 2024) are used for waveform discrimination and frequency domain discrimination, respectively.
遵循 (Kumar et al., 2024),我们使用 L1 损失在多尺度梅尔频谱图上计算频域重建损失。多周期判别器 (Kong et al., 2020; Engel et al., 2020; Gritsenko et al., 2020) 和多频带多尺度 STFT 判别器 (Kumar et al., 2024) 分别用于波形判别和频域判别。
VQ codebook learning incorporates both a codebook loss and a commitment loss. Following the approach in (Xin et al., 2024), the codebook loss is calculated as the L1 loss between the encoder output and the quantized results, employing stopgradients. Additionally, the straight-through estimator (Bengio et al., 2013) is used to enable the back propagation of gradients.
VQ 码本学习结合了码本损失和约束损失。根据 (Xin et al., 2024) 的方法,码本损失通过计算编码器输出和量化结果之间的 L1 损失,并应用 stopgradients 来获得。此外,使用直通估计器 (Bengio et al., 2013) 来实现梯度的反向传播。
To ensure training stability, in the initial stages, the global embedding derived from the averaged $g_{q}$ is not integrated into the decoder. Instead, this embedding is obtained directly from the pooling of $g_{f}$ . Meanwhile, the FSQ codebook is updated using an L1 loss between embedding obtained from $g_{f}$ and that from pool $\left({\pmb g}_{q}\right)$ . As training progresses and stabilizes, this teacher-student form will be omitted after a specific training step.
为了确保训练稳定性,在初始阶段,不会将从平均 $g_{q}$ 获得的全局嵌入集成到解码器中。相反,该嵌入直接从 $g_{f}$ 的池化中获得。同时,FSQ 码本通过 $g_{f}$ 获得的嵌入与池化 $\left({\pmb g}_{q}\right)$ 获得的嵌入之间的 L1 损失进行更新。随着训练的进行和稳定,这种师生形式将在特定训练步骤后被省略。
To further ensure semantic relevance, following X-Codec (Ye et al., 2024b), a wav2vec 2.0 recon- struction loss is applied after quantization, with ConvNeXt-based blocks serving as the predictor.
为进一步确保语义相关性,遵循 X-Codec (Ye et al., 2024b),在量化后应用了 wav2vec 2.0 重构损失,并使用基于 ConvNeXt 的模块作为预测器。
4 Language Modeling of Spark-TTS
4 Spark-TTS 的语言建模
4.1 Overview
4.1 概述
As illustrated in Fig. 3, the Spark-TTS speech language model adopts a decoder-only transformer architecture, unified with a typical textual language model. We employ the pre-trained textual LLM Qwen $2.5{-}0.5\mathrm{B}^{2}$ (Yang et al., 2024) as the backbone of the speech language model. Unlike CosyVoice2 (Du et al., 2024a), Spark-TTS does not require flow matching to generate acoustic features. Instead, BiCodec’s decoder directly processes the LM’s output to produce the final audio, significantly simplifying the textual LLM-based speech generation pipeline.
如图 3 所示,Spark-TTS 语音语言模型采用了仅解码器的 Transformer 架构,与典型的文本语言模型统一。我们使用预训练的文本大语言模型 Qwen $2.5{-}0.5\mathrm{B}^{2}$ (Yang et al., 2024) 作为语音语言模型的主干。与 CosyVoice2 (Du et al., 2024a) 不同,Spark-TTS 不需要流匹配来生成声学特征。相反,BiCodec 的解码器直接处理大语言模型的输出来生成最终音频,极大地简化了基于文本大语言模型的语音生成流程。
In addition to zero-shot TTS, Spark-TTS supports voice creation using various attribute labels.
除了零样本 TTS,Spark-TTS 还支持使用多种属性标签进行语音创建。
During inference, if attribute labels for gender, pitch level, and speed level are provided, the language model can predict fine-grained pitch values, speed values, global tokens, and semantic tokens through a chain-of-thought (CoT) manner. If no attribute labels are provided, global tokens are extracted from the reference audio, enabling zeroshot TTS.
在推理过程中,如果提供了性别、音高水平和速度水平的属性标签,语言模型可以通过思维链 (CoT) 方式预测细粒度的音高值、速度值、全局 Token 和语义 Token。如果未提供属性标签,则从参考音频中提取全局 Token,从而实现零样本 TTS。
4.2 Tokenizer
4.2 Tokenizer
Text Tokenizer Similar to textual LLMs, SparkTTS employs a byte pair encoding (BPE)-based tokenizer to process raw text. Here, we adopt the Qwen2.5 tokenizer (Yang et al., 2024), which supports multiple languages.
文本分词器
与文本大语言模型类似,SparkTTS 采用基于字节对编码 (BPE) 的分词器来处理原始文本。这里,我们采用了 Qwen2.5 分词器 (Yang et al., 2024),它支持多种语言。
Attribute Tokenizer To enable voice creation based on speech attributes, Spark-TTS encodes attribute information at two levels: (i) CoarseGrained: Attribute labels representing high-level speech characteristics, including gender, pitch (categorized into five discrete levels), and speed (categorized into five discrete levels); (ii) Fine-Grained: Attribute values enabling precise control over pitch and speed, which are quantized by rounding to the nearest integer during token iz ation.
属性 Tokenizer 为了根据语音属性进行语音生成,Spark-TTS 在以下两个层次对属性信息进行编码:(i) 粗粒度:表示高级语音特征的属性标签,包括性别、音高(分为五个离散级别)和语速(分为五个离散级别);(ii) 细粒度:允许对音高和语速进行精确控制的属性值,这些值在 Token 化过程中通过四舍五入量化为最接近的整数。
Speech Tokenizer The speech tokenizer consists of a global tokenizer and a semantic tokenizer. Using both global and semantic tokens, the BiCodec decoder reconstructs the waveform signal.
语音 Tokenizer
语音 Tokenizer 由全局 Tokenizer 和语义 Tokenizer 组成。使用全局和语义 Token,BiCodec 解码器重建波形信号。
4.3 Training Objective
4.3 训练目标
The decoder-only language model is trained by minimizing the negative log-likelihood of token predictions. Let $\tau$ represent the tokenized textual prompt and $\mathcal{G}$ denote the global speech token prompt; the optimization for zero-shot TTS is defined as follows:
仅解码器语言模型通过最小化 Token 预测的负对数似然进行训练。令 $\tau$ 表示 Token 化的文本提示,$\mathcal{G}$ 表示全局语音 Token 提示;零样本 TTS 的优化定义如下:

where $\sigma\in\mathbb{N}{o}^{T}$ represents the semantic tokens to be predicted in the zero-shot TTS scenario, and $\theta{L M}$ denotes the parameters of the language model.
其中,$\sigma\in\mathbb{N}{o}^{T}$ 表示在零样本 TTS 场景中要预测的语义 Token,$\theta{L M}$ 表示大语言模型的参数。
For the case of voice creation, the optimization is defined as follows:
在语音生成案例中,优化定义如下:

where $\mathcal{A}$ represents the attribute label prompt, and the output $^c$ encompasses ${\mathcal{F}},{\mathcal{G}}$ , and $s$ . Here, $\mathcal{F}$ denotes the fine-grained attribute value prompt, and $s$ is speech semantic tokens.
其中 $\mathcal{A}$ 表示属性标签提示,输出 $^c$ 包含 ${\mathcal{F}},{\mathcal{G}}$ 和 $s$。这里,$\mathcal{F}$ 表示细粒度属性值提示,$s$ 是语音语义 Token。
In practice, $\mathcal{L}{z s t}$ and $\mathcal{L}{c o n t r o l}$ are mixed during training. Specifically, each audio example is structured into two training samples according to $\mathcal{L}{z s t}$ and $\mathcal{L}{c o n t r o l}$ respectively.
在实践中,$\mathcal{L}{z s t}$ 和 $\mathcal{L}{c o n t r o l}$ 在训练过程中是混合使用的。具体来说,每个音频样本根据 $\mathcal{L}{z s t}$ 和 $\mathcal{L}{c o n t r o l}$ 分别被构建为两个训练样本。
5 VoxBox
5 VoxBox
5.1 Overview
5.1 概述
To facilitate voice creation and establish a fair comparison benchmark for future research, we introduce VoxBox, a well-annotated dataset for both English and Chinese. All data sources in VoxBox originate from open-source datasets, ensuring broad accessibility. To enhance data diversity, we collect not only common TTS datasets, but also datasets used for speech emotion recognition. Each audio file in VoxBox is annotated with gender, pitch, and speed. Additionally, we also perform data cleaning on datasets with lower text quality. After data cleaning, VoxBox comprises 4.7 million audio files, sourced from 29 open datasets, totaling $102.5\mathrm{k}$ hours of speech data. Details about VoxBox and the source datasets can be found in Appendix E.
为促进语音创作并建立公平的比较基准,我们引入了VoxBox,这是一个针对英语和中文的详细标注数据集。VoxBox中的所有数据源均来自开源数据集,确保了广泛的可访问性。为了增强数据的多样性,我们不仅收集了常见的TTS数据集,还收集了用于语音情感识别的数据集。VoxBox中的每个音频文件都标注了性别、音高和速度。此外,我们还对文本质量较低的数据集进行了数据清理。经过数据清理后,VoxBox包含470万个音频文件,来自29个开源数据集,总计102.5k小时的语音数据。有关VoxBox和源数据集的详细信息可在附录E中找到。
5.2 Clean and Annotation
5.2 清洗与标注
Gender Annotation Given the strong performance of pre-trained WavLM in speaker-related tasks (Li et al., 2024c), we fine-tune the WavLM-large model for gender classification using datasets that contain explicit gender labels (detailed in Appendix E.2). Our fine-tuned model achieves $99.4%$ accuracy on the AISHELL-3 test set. We then use this gender classification model to annotate datasets previously lacking gender labels.
性别标注
Pitch Annotation We extract the average pitch value from each audio clip using PyWorld3, rounding it to the nearest integer to obtain fine-grained pitch value tokens. For the definition of pitch levels, we first convert the average pitch of each audio clip to the Mel scale. We then conduct a statistical analysis of all Mel scale pitch for all males and females separately. Based on the 5th, 20th, 70th, and 90th percentiles, we establish boundaries for five pitch levels: very low, low, moderate, high, and very high (detailed in Appendix E.1).
音高标注
Speed Annotation Compared to characterbased (Vyas et al., 2023), word-based (Ji et al., 2024b), or phoneme-based (Lyth and King, 2024) speaking rate calculations, syllable-based measurements provide a more direct correlation with speaking rate. Here, we initially apply Voice Activity Detection (VAD) to eliminate silent segments at both ends. Subsequently, we calculate the syllables per second (SPS), which is then rounded to the nearest integer to serve as the fine-grained speed value token. Using the 5th, 20th, 80th, and 95th percentiles, we establish boundaries for five distinct speed levels: very slow, slow, moderate, fast, and very fast (detailed in Appendix E.1).
速度标注
Data Cleaning For datasets exhibiting lower text quality, we conduct an additional cleaning process. Specifically, for Emilia (He et al., 2024), the original transcripts were obtained using the Whisperbased (ASR) system (Radford et al., 2023), employing the whisper-medium model, which occasionally resulted in inaccuracies. To address this, we employ another ASR model, FunASR (Gao et al., $2023)^{4}$ , to re-recognize the audio. We then use the original scripts as ground truth to calculate the Word Error Rate (WER) and excluded samples with a WER exceeding 0.05. For the MLS-English, Libri Speech, LibriTTS-R, and datasets originally designed for emotion recognition, we employ the whisper-large $\mathbf{\nabla}\cdot\mathbf{V}3^{5}$ model for speech recognition, comparing the recognition results with the original scripts. Samples exhibiting insertions or deletions are excluded from the dataset.
数据清洗
6 Experiments
6 实验
6.1 Implementation Details
6.1 实现细节
BiCodec is trained on the full training set of the Libri Speech dataset, comprising 960 hours of English speech data. Additionally, we include 1,000 hours of speech data from both Emilia-CN and Emilia-EN, bringing the total training data to approximate ly 3,000 hours. All audio samples are resampled to $16\mathrm{kHz}$ . The global token length is set as 32. For optimization, we use the AdamW optimizer with moving average coefficients coefficients $\beta_{1}=0.8$ and $\beta_{2}=0.9$ . The model converges within approximately $800\mathrm{k\Omega}$ training steps using a batch size with 614.4 seconds of speech.
BiCodec 在 Libri Speech 数据集的完整训练集上进行训练,该数据集包含 960 小时的英语语音数据。此外,我们还加入了来自 Emilia-CN 和 Emilia-EN 的 1,000 小时语音数据,使得总训练数据量接近 3,000 小时。所有音频样本均被重采样至 $16\mathrm{kHz}$。全局 Token 长度设置为 32。为了优化,我们使用了 AdamW 优化器,其移动平均系数为 $\beta_{1}=0.8$ 和 $\beta_{2}=0.9$。模型在使用 614.4 秒语音的批量大小时,大约在 $800\mathrm{k\Omega}$ 训练步数内收敛。
The Spark-TTS language model is trained using the entire VoxBox training set. If a dataset lacks predefined train/test splits, we use the entire processed dataset for training. The training employs the AdamW optimizer with $\beta_{1}=0.9$ and $\beta_{2}=0.96$ . The model undergoes training over 3 epochs, using a batch size of 768 samples.
Spark-TTS 语言模型使用整个 VoxBox 训练集进行训练。如果数据集没有预定义训练/测试划分,我们使用整个处理后的数据集进行训练。训练采用 AdamW 优化器,$\beta_{1}=0.9$ 和 $\beta_{2}=0.96$。模型经过 3 个周期的训练,使用 768 个样本的批次大小。
6.2 Reconstruction Performance of BiCodec
6.2 BiCodec 重构性能
Comparsion with Other Methods The reconstruction performance of BiCodec compared to other methods is presented in Table 1. As can be seen, within the low-bitrate range ${\bf\zeta}_{<1}$ kbps), BiCodec surpasses all methods on most metrics, except for UTMOS, where it ranks second to Stable Codec, and SIM, where it ranks second to X-Codec2, thereby achieving a new state-of-the-art (SOTA) performance.
与其他方法的比较
BiCodec 与其他方法的重建性能对比见表 1。可以看出,在低比特率范围 ${\bf\zeta}_{<1}$ kbps) 内,BiCodec 在大多数指标上超越了所有方法,除了在 UTMOS 上排名第二,仅次于 Stable Codec,以及在 SIM 上排名第二,仅次于 X-Codec2,因此实现了新的最先进 (SOTA) 性能。
Notably, BiCodec’s semantic tokens are extracted from wav2vec 2.0 rather than raw audio, resulting in stronger semantic alignment compared to codecs that directly process waveform-based representations. Further experimental results and analyses are provided in Appendix A.3.
值得注意的是,BiCodec 的语义 Token 是从 wav2vec 2.0 中提取的,而不是原始音频,因此与直接处理基于波形的表示的编解码器相比,语义对齐更强。进一步的实验结果和分析见附录 A.3。
Effectiveness of Global Tokenizer We first evaluate the optimal length for the global token sequence. As shown in Table 2, we compare the impact of different sequence lengths on reconstruction quality. The results without FSQ quantization serve as a benchmark reference. Notably, increasing the global token sequence length consistently improves reconstruction quality, with performance approaching the benchmark at the length of 32.
全局 Tokenizer 的有效性
Furthermore, Table 2 compares our proposed quantization method—which incorporates learnable queries and FSQ—against the GVQ-based method introduced by Ren et al. (Ren et al., 2024) for time-invariant codes. Our approach demonstrates a substantial performance improvement over the GVQ-based method, highlighting the effectiveness of FSQ with learnable queries in enhancing global token representation.
此外,表 2 将我们提出的量化方法(结合了可学习查询和 FSQ)与 Ren 等人 (Ren et al., 2024) 提出的基于 GVQ 的时不变编码方法进行了比较。我们的方法相比于基于 GVQ 的方法展现出显著的性能提升,凸显了 FSQ 与可学习查询在增强全局 Token 表示方面的有效性。
6.3 Control Capabilities of Spark-TTS
6.3 Spark-TTS 的控制能力
Spark-TTS enables controllable generation by inputting attribute labels or fine-grained attribute values. In label-based control, the model automatically generates the corresponding attribute values (e.g., pitch and speed). However, when these values are manually specified, the system switches to fine-grained control.
Spark-TTS 通过输入属性标签或细粒度的属性值来实现可控生成。在基于标签的控制中,模型会自动生成相应的属性值(例如音高和速度)。然而,当手动指定这些值时,系统会切换到细粒度控制。
Gender To assess Spark-TTS’s capability in gender control, we compare it with textual promptbased controllable TTS models, including VoxInstruct(Zhou et al., 2024b) and Parler-TTS(Lyth and King, 2024). For evaluation, we reorganize the test prompts of real speech from PromptTTS (Guo et al., 2023) based on the prompt structures used in
性别
为了评估 Spark-TTS 在性别控制方面的能力,我们将其与基于文本提示的可控 TTS 模型进行比较,包括 VoxInstruct(Zhou 等人,2024b)和 Parler-TTS(Lyth 和 King,2024)。为了进行评估,我们根据 PromptTTS(Guo 等人,2023)中使用的提示结构,重新组织了真实语音的测试提示。
Table 1: Comparisons of various codec models for speech reconstruction on the Libri Speech test-clean datase Detailed information about these models can be found in Appendix A.2.
表 1: 在 Libri Speech test-clean 数据集上各种编解码模型语音重建的对比。这些模型的详细信息见附录 A.2。
| 模型 | 码本大小 | bN | Token 速率 (TPS) | 带宽 (bps) | STOI↑ | PESQ NB↑ | PESQ WB↑ | UTMOS↑ | SIM↑ |
|---|---|---|---|---|---|---|---|---|---|
| Encodec | 1024 | 8 | 600 | 6000 | 0.94 | 3.17 | 2.75 | 3.07 | 0.89 |
| DAC | 1024 | 12 | 600 | 6000 | 0.95 | 4.15 | 4.01 | 4.00 | 0.98 |
| Encodec | 1024 | 2 | 150 | 1500 | 0.84 | 1.94 | 1.56 | 1.58 | 0.6 |
| Mimi | 2048 | 8 | 100 | 1100 | 0.91 | 2.8 | 2.25 | 3.56 | 0.73 |
| BigCodec | 8192 | 1 | 80 | 1040 | 0.94 | 3.27 | 2.68 | 4.11 | 0.84 |
| DAC | 1024 | 2 | 100 | 1000 | 0.73 | 1.4 | 1.14 | 1.29 | 0.32 |
| SpeechTokenizer | 1024 | 2 | 100 | 1000 | 0.77 | 1.59 | 1.25 | 2.28 | 0.36 |
| X-codec | 1024 | 2 | 100 | 1000 | 0.86 | 2.88 | 2.33 | 4.21 | 0.72 |
| WavTokenizer | 4096 | 1 | 75 | 900 | 0.89 | 2.64 | 2.14 | 3.94 | 0.67 |
| X-codec2 | 65536 | 1 | 50 | 800 | 0.92 | 3.04 | 2.43 | 4.13 | 0.82 |
| StableCodec | 15625 | 2 | 50 | 697 | 0.91 | 2.91 | 2.24 | 4.23 | 0.62 |
| Single-Codec | 8192 | 1 | 23.4 | 304 | 0.86 | 2.42 | 1.88 | 3.72 | 0.60 |
| BiCodec | 8192 | 1 | 50 | 650 | 0.92 | 3.13 | 2.51 | 4.18 | 0.80 |
Table 2: Performance of BiCodec with varying global token lengths for reconstruction on the Libri Speech testclean dataset, where "w/o" indicates the omission of FSQ-based quantization, and gvq-32 means the global tokenizer is implemented with group VQ. For performance results on the LibriTTS test-clean dataset, refer to Appendix A.3.
表 2: BiCodec 在 Libri Speech testclean 数据集上不同全局 Token 长度的重建性能,其中 "w/o" 表示省略基于 FSQ 的量化,gvq-32 表示全局 Token 器使用 group VQ 实现。关于 LibriTTS test-clean 数据集的性能结果,请参见附录 A.3。
| Global Token | STO1↑ | PESQ NB↑ | PESQ WB↑ | UTMOS↑ SIM↑ |
|---|---|---|---|---|
| w/oFSQ | 0.915 | 3.14 | 2.52 | 4.15 |
| gvq-32 | 0.912 | 2.91 | 2.30 | 4.06 |
| 8 | 0.916 | 3.04 | 2.41 | 4.16 |
| 16 | 0.919 | 3.08 | 2.45 | 4.15 |
| 32 | 0.922 | 3.13 | 2.51 | 4.18 |
Table 3: Gender control performance of various models.
表 3: 不同模型的性别控制性能。
| Method | VoxInstruct | Parler-tts | Spark-TTS |
|---|---|---|---|
| Acc (%)↑ | 82.99 | 98.12 | 99.77 |
Vox Instruct and Parler-TTS. The gender accuracy (Acc) of the generated speech is measured using our gender predictor, which is specifically trained for gender annotation. The results, presented in Table 3, show that Spark-TTS significantly outperforms other controllable TTS systems in gender control, demonstrating its strong capability in attribute-based voice generation.
Vox Instruct 和 Parler-TTS。生成的语音的性别准确率 (Acc) 使用我们专门为性别标注训练的性别预测器进行测量。结果如表 3 所示,Spark-TTS 在性别控制方面显著优于其他可控 TTS 系统,展示了其在基于属性的语音生成方面的强大能力。
Pitch and Speed Spark-TTS enables control- lable generation by inputting attribute labels or fine-grained attribute values. In label-based control, the model automatically generates the corresponding attribute values (e.g., pitch and speed). However, when these values are manually specified, the system switches to fine-grained control. Fig. 4 illustrates the control confusion matrices for pitch and speaking rate based on coarse-grained labels, while Fig. 5 presents the fine-grained control performance for pitch and speed. As shown, SparkTTS accurately generates speech that aligns with the specified attribute labels, demonstrating precise control over both coarse-grained and fine-grained attributes.
音高和速度
Spark-TTS 支持通过输入属性标签或细粒度属性值进行可控生成。在基于标签的控制中,模型会自动生成相应的属性值(例如音高和速度)。然而,当这些值被手动指定时,系统会切换到细粒度控制。图 4 展示了基于粗粒度标签的音高和语速控制混淆矩阵,而图 5 则展示了音高和速度的细粒度控制性能。如图所示,Spark-TTS 能够准确生成与指定属性标签一致的语音,展现出对粗粒度和细粒度属性的精确控制。
6.4 Zero-shot TTS Performance
6.4 零样本 TTS 性能
To evaluate Spark-TTS’s zero-shot TTS capabil- ity, we assess its performance on Seed-TTS-eval and compare it with existing zero-shot TTS models. The results are presented in Table 4, where speech intelligibility is evaluated using the Character Error Rate (CER) for Chinese and the WER for English, following the Seed-TTS-eval6. As can been seen, Spark-TTS demonstrates significant superiority in intelligibility for zero-shot TTS scenarios. On test-zh, Spark-TTS achieves a CER second only to the closed-source model Seed-TTS, while it ranks second only to F5-TTS (Chen et al., 2024b) for English WER. This high intelligibility is partly attributed to the semantic feature-based BiCodec and further validates the high quality of our VoxBox dataset in terms of transcripts. In terms of speaker similarity, while Spark-TTS is relatively weaker than multi-stage or NAR-based methods, it significantly outperforms the single-stage model Llasa (Ye et al., 2025). Notably, Spark-TTS, with just 0.5B model parameters and $100\mathrm{k}$ hours of training data, surpasses Llasa, which has 8B parameters and is trained on $250\mathrm{k\Omega}$ hours of data.
为了评估 Spark-TTS 的零样本 TTS 能力,我们在 Seed-TTS-eval 上对其性能进行了评估,并与现有的零样本 TTS 模型进行了比较。结果如表 4 所示,其中语音清晰度使用中文的字符错误率 (CER) 和英语的单词错误率 (WER) 进行评估,遵循 Seed-TTS-eval6。可以看出,Spark-TTS 在零样本 TTS 场景中的清晰度表现出显著优势。在 test-zh 上,Spark-TTS 的 CER 仅次于闭源模型 Seed-TTS,而在英语 WER 上,它仅次于 F5-TTS (Chen et al., 2024b)。这种高清晰度部分归功于基于语义特征的 BiCodec,并进一步验证了我们的 VoxBox 数据集在转录方面的高质量。在说话人相似度方面,虽然 Spark-TTS 相对于多阶段或基于 NAR 的方法较弱,但它显著优于单阶段模型 Llasa (Ye et al., 2025)。值得注意的是,Spark-TTS 仅使用 0.5B 模型参数和 $100\mathrm{k}$ 小时的训练数据,就超越了具有 8B 参数并在 $250\mathrm{k\Omega}$ 小时数据上训练的 Llasa。
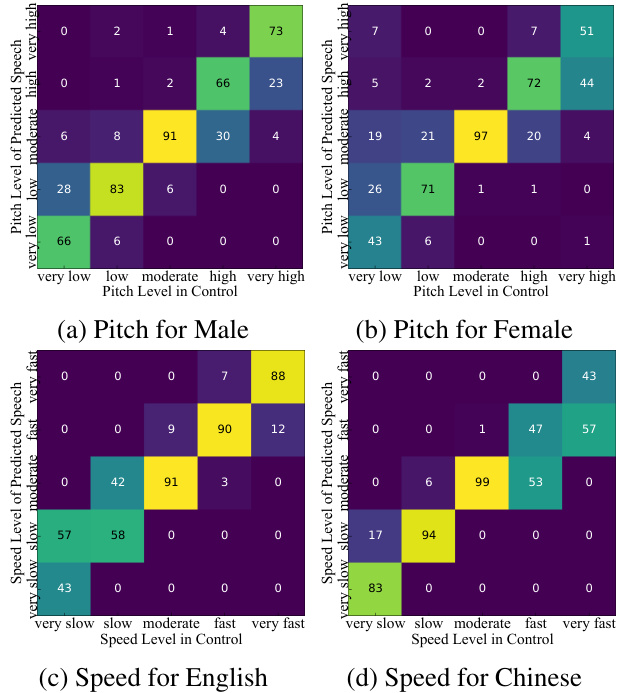
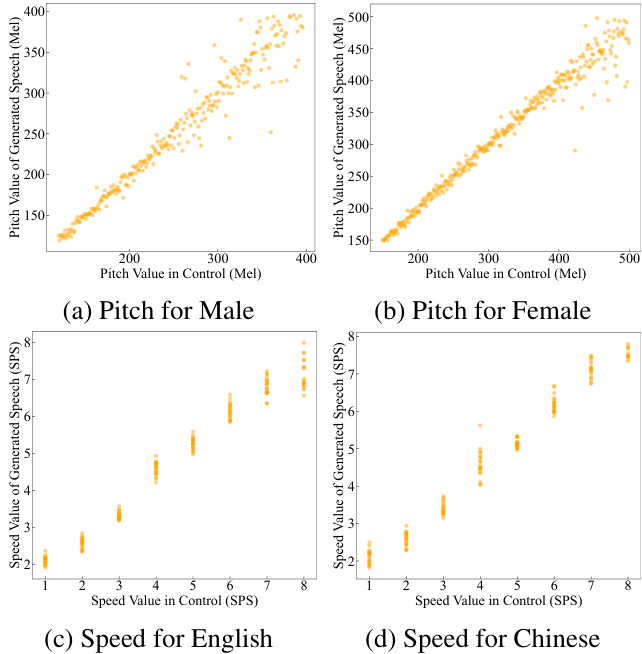
Figure 4: Confusion matrix of coarse-grained pitch and speed control results. In pitch-controllable generation, each label’s generated samples consist of 50 Chinese and 50 English samples. In speed-controllable generation, each label’s generated samples consist of 50 male and 50 female samples. Figure 5: Fine-grained pitch and speed control results. For pitch-controllable generation, each generated value includes one Chinese sample and one English sample. For speed-controllable generation, each generated value includes 10 male samples and 10 female samples.
图 4: 粗粒度音高和速度控制结果的混淆矩阵。在音高可控生成中,每个标签的生成样本包含 50 个中文样本和 50 个英文样本。在速度可控生成中,每个标签的生成样本包含 50 个男性样本和 50 个女性样本。图 5: 细粒度音高和速度控制结果。对于音高可控生成,每个生成值包含一个中文样本和一个英文样本。对于速度可控生成,每个生成值包含 10 个男性样本和 10 个女性样本。
Following CosyVoice2 (Du et al., 2024b), we evaluate the quality of the generated speech on the Libri Speech test-clean set. As shown in Table 5, our method produces audio of significantly higher quality than the original and outperforms CosyVoice2, the SOTA open-source TTS model with multi-stage modeling. This demonstrates the strong performance of Spark-TTS in terms of
继 CosyVoice2 (Du et al., 2024b) 之后,我们在 Libri Speech 测试集上评估生成语音的质量。如表 5 所示,我们的方法生成的音频质量显著高于原始版本,并且优于采用多阶段建模的 SOTA 开源 TTS 模型 CosyVoice2。这证明了 Spark-TTS 在性能方面的强大表现。
speech quality.
语音质量
Table 4: Results of Spark-TTS and recent TTS models on the Seed test sets (test-zh for Chinese and test-en for English). $\dagger$ denotes closed-sourced models.
表 4: Spark-TTS 和近期 TTS 模型在 Seed 测试集上的结果(test-zh 为中文,test-en 为英文)。$\dagger$ 表示闭源模型。
| 模型 | test-zh CER↓ | test-zh SIM↑ | test-en WER↓ | test-en SIM↑ |
|---|---|---|---|---|
| 多阶段或非自回归方法 | ||||
| Seed-TTS FireRedTTS MaskGCT | 1.12 1.51 2.27 | 0.796 0.635 0.774 | 2.25 3.82 2.62 | 0.762 0.460 0.714 |
| E2 TTS (32 NFE) | 1.97 | 0.730 | 2.19 | 0.710 |
| F5-TTS (32NFE) | 1.56 | 0.741 | 1.83 | 0.647 |
| CosyVoice | 3.63 1.45 | 0.723 0.748 | 4.29 | 0.609 |
| CosyVoice2 | 2.57 | 0.652 | ||
| 单阶段自回归方法 | ||||
| Llasa-1B-250k | 1.89 | 0.669 | 3.22 | 0.572 |
| Llasa-3B-250k | 1.60 | 0.675 | 3.14 | 0.579 |
| Llasa-8B-250k | 1.59 | 0.684 | 2.97 | 0.574 |
| Spark-TTS | 1.20 | 0.672 | 1.98 | 0.584 |
Table 5: Quality comparison of zero-shot TTS audio generation on the Libri Speech test-clean set. GT represents ground truth.
表 5: Libri Speech test-clean 数据集上零样本 TTS 音频生成的质量对比。GT 表示真实值。
| 方法 | GT | CosyVoice | Cosy Voice2 | Spark-TTS |
|---|---|---|---|---|
| UTMOS↑ | 4.08 | 4.09 | 4.23 | 4.35 |
7 Conclusion
7 结论
This paper introduces BiCodec, which retains the advantages of semantic tokens, including high compression efficiency and high intelligibility, while addressing the limitation of traditional semantic tokens, which cannot control timbre-related attributes within an LM, by incorporating global tokens. BiCodec achieves a new SOTA reconstruction quality, operating at $50\mathrm{TPS}$ with a bit rate of $0.65\mathrm{kbps}$ , surpassing other codecs within the sub-1 kbps range. Building on BiCodec, we develop Spark-TTS, a text-to-speech model that integrates the textual language model Qwen2.5. Spark-TTS enables voice generation based on specified attributes and supports zero-shot synthesis. To our knowledge, this is the first TTS model to offer fine-grained control over both pitch and speaking rate, while simultaneously supporting zero-shot TTS. Additionally, to facilitate comparative research, we introduce VoxBox, an open-source dataset designed for controllable speech synthesis. VoxBox not only filters out low-quality textual data but also provides comprehensive annotations, including gender, pitch, and speaking rate, significantly enhancing training for controlled generation tasks.
本文介绍了 BiCodec,它在保留语义 Token 高压缩效率和高可理解性优点的同时,通过引入全局 Token 解决了传统语义 Token 无法在 LM 内控制音色相关属性的局限性。BiCodec 在 $50\mathrm{TPS}$ 的速率下以 $0.65\mathrm{kbps}$ 的比特率运行,实现了新的 SOTA 重建质量,超越了其他低于 1 kbps 的编解码器。基于 BiCodec,我们开发了 Spark-TTS,这是一个集成了文本语言模型 Qwen2.5 的文本到语音模型。Spark-TTS 支持基于指定属性的语音生成,并支持零样本合成。据我们所知,这是第一个能够同时精细控制音高和语速,并支持零样本 TTS 的 TTS 模型。此外,为了促进比较研究,我们引入了 VoxBox,这是一个专为可控语音合成设计的开源数据集。VoxBox 不仅过滤了低质量的文本数据,还提供了包括性别、音高和语速在内的全面标注,显著增强了可控生成任务的训练。
Limitation
局限性
Despite its advantages, Spark-TTS also has notable limitations. Similar to Llasa (Ye et al., 2025), which relies on a single codebook and a textual language model, Spark-TTS exhibits relatively lower speaker similarity metrics in zero-shot TTS compared to multi-stage or NAR methods. This may be due to the greater speaker variability introduced by the AR language model during inference. Currently, Spark-TTS does not impose additional disentanglement constraints between global tokens and semantic tokens. In future work, we aim to enhance global token control over timbre by introducing perturbations to formants or pitch in the semantic token input. This approach will promote better disentanglement of timbre information, allowing BiCodec’s decoder to exert absolute control over timbre. By doing so, we aim to reduce randomness introduced by the AR model, improving the speaker similarity in zero-shot synthesis.
尽管 Spark-TTS 具有优势,但它也存在显著的局限性。与 Llasa (Ye et al., 2025) 类似,Spark-TTS 依赖于单个码本和文本语言模型,在零样本 TTS 中,与多阶段或 NAR 方法相比,说话人相似性指标相对较低。这可能是由于在推理过程中,AR 语言模型引入了更大的说话人变异性。目前,Spark-TTS 并未在全局 token 和语义 token 之间施加额外的解耦约束。在未来的工作中,我们计划通过对语义 token 输入中的共振峰或音高引入扰动来增强全局 token 对音色的控制。这种方法将促进音色信息的更好解耦,使 BiCodec 的解码器能够对音色施加绝对控制。通过这种方式,我们旨在减少 AR 模型引入的随机性,从而提高零样本合成中的说话人相似性。
References
参考文献
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432.
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. 2013. 通过随机神经元估计或传播梯度以进行条件计算。arXiv preprint arXiv:1308.3432.
Jiaqi Li, Peiyang Shi, et al. 2024. Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 885–890. IEEE.
Jiaqi Li, Peiyang Shi 等. 2024. Emilia: 一个用于大规模语音生成的广泛、多语言且多样化的语音数据集. 在 2024 IEEE 口语语言技术研讨会 (SLT) 中, 页码 885–890. IEEE.
Zhichao Huang, Chutong Meng, and Tom Ko. 2023. Repcodec: A speech representation codec for speech token iz ation. arXiv preprint arXiv:2309.00169.
Zhichao Huang, Chutong Meng, 和 Tom Ko. 2023. Repcodec: 一种用于语音 Token 化的语音表示编解码器. arXiv 预印本 arXiv:2309.00169.
Philip Jackson and SJUoSG Haq. 2014. Surrey audiovisual expressed emotion (savee) database. University of Surrey: Guildford, UK.
Philip Jackson 和 SJUoSG Haq. 2014. 萨里视听情感表达 (SAVEE) 数据库. 萨里大学: 吉尔福德, 英国.
Jesin James, Li Tian, and Catherine Watson. 2018. An open source emotional speech corpus for human robot interaction applications. Inter speech 2018.
Jesin James, Li Tian, 和 Catherine Watson. 2018. 用于人机交互应用的开源情感语音语料库. Inter speech 2018.
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, et al. 2024a. Wavtok- enizer: an efficient acoustic discrete codec tokenizer for audio language modeling. arXiv preprint arXiv:2408.16532.
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, et al. 2024a. Wavtokenizer: 一种用于音频语言建模的高效声学离散编解码器分词器. arXiv preprint arXiv:2408.16532.
Shengpeng Ji, Jialong Zuo, Minghui Fang, Ziyue Jiang, Feiyang Chen, Xinyu Duan, Baoxing Huai, and Zhou Zhao. 2024b. Text r ol speech: A text style control speech corpus with codec language text-to-speech models. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 10301–10305. IEEE.
Shengpeng Ji, Jialong Zuo, Minghui Fang, Ziyue Jiang, Feiyang Chen, Xinyu Duan, Baoxing Huai, and Zhou Zhao. 2024b. 文本到语音:基于编解码器语言模型的文本风格控制语音语料库。在 ICASSP 2024-2024 IEEE 国际声学、语音和信号处理会议 (ICASSP) 上,第 10301–10305 页。IEEE。
Zeyu Jin, Jia Jia, Qixin Wang, Kehan Li, Shuoyi Zhou, Songtao Zhou, Xiaoyu Qin, and Zhiyong Wu. 2024. Speech craft: A fine-grained expressive speech dataset with natural language description. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 1255–1264.
Zeyu Jin, Jia Jia, Qixin Wang, Kehan Li, Shuoyi Zhou, Songtao Zhou, Xiaoyu Qin, 和 Zhiyong Wu. 2024. Speech craft:一个带有自然语言描述的细粒度表达性语音数据集。在第32届ACM国际多媒体会议论文集,1255–1264页。
Yuma Koizumi, Heiga Zen, Shigeki Karita, Yifan Ding, Kohei Yatabe, Nobuyuki Morioka, Michiel Bacchiani, Yu Zhang, Wei Han, and Ankur Bapna. 2023. Libritts-r: A restored multi-speaker text-to-speech corpus. arXiv preprint arXiv:2305.18802.
Yuma Koizumi, Heiga Zen, Shigeki Karita, Yifan Ding, Kohei Yatabe, Nobuyuki Morioka, Michiel Bacchiani, Yu Zhang, Wei Han, and Ankur Bapna. 2023. Libritts-r: 一个修复的多说话人文本到语音 (Text-to-Speech) 语料库. arXiv 预印本 arXiv:2305.18802.
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. 2020. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in neural information processing systems, 33:17022– 17033.
Jungil Kong, Jaehyeon Kim, Jaekyoung Bae. 2020. Hifi-gan: 用于高效高保真语音合成的生成对抗网络. Advances in neural information processing systems, 33:17022–17033.
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. 2023. Audiogen: Tex- tually guided audio generation. In The Eleventh Inter national Conference on Learning Representations.
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, 和 Yossi Adi. 2023. Audiogen: 文本引导的音频生成. 在第十一届国际学习表示会议中.
Kundan Kumar, Rithesh Kumar, Thibault De Boissiere, Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexan- dre De Brebisson, Yoshua Bengio, and Aaron C Courville. 2019. Melgan: Generative adversarial networks for conditional waveform synthesis. Advances in neural information processing systems, 32.
Kundan Kumar, Rithesh Kumar, Thibault De Boissiere, Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexandre De Brebisson, Yoshua Bengio, 和 Aaron C Courville. 2019. MelGAN: 用于条件波形生成的生成对抗网络. 神经信息处理系统进展, 32.
Rithesh Kumar, Prem See th a raman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar. 2024. Highfidelity audio compression with improved rvqgan. Advances in Neural Information Processing Systems, 36.
Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, 和 Kundan Kumar. 2024. 基于改进的RVQGAN的高保真音频压缩. Advances in Neural Information Processing Systems, 36.
Gael Le Lan, Varun Nagaraja, Ernie Chang, David Kant, Zhaoheng Ni, Yangyang Shi, Forrest Iandola, and Vikas Chandra. 2024. Stack-and-delay: a new codebook pattern for music generation. In ICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 796– 800. IEEE.
Gael Le Lan、Varun Nagaraja、Ernie Chang、David Kant、Zhaoheng Ni、Yangyang Shi、Forrest Iandola 和 Vikas Chandra。2024。Stack-and-delay:一种用于音乐生成的新码本模式。在 ICASSP 2024 - 2024 IEEE 国际声学、语音和信号处理会议 (ICASSP) 中,第 796–800 页。IEEE。
Keon Lee, Kyumin Park, and Daeyoung Kim. 2023. Dailytalk: Spoken dialogue dataset for conversational text-to-speech. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE.
Keon Lee, Kyumin Park, 和 Daeyoung Kim. 2023. Dailytalk: 用于对话式文本到语音的口语对话数据集. 在 ICASSP 2023-2023 IEEE 国际声学、语音和信号处理会议 (ICASSP) 上, 第 1-5 页. IEEE.
Hanzhao Li, Liumeng Xue, Haohan Guo, Xinfa Zhu, Yuanjun Lv, Lei Xie, Yunlin Chen, Hao Yin, and Zhifei Li. 2024a. Single-codec: Single-codebook speech codec towards high-performance speech generation. arXiv preprint arXiv:2406.07422.
Hanzhao Li, Liumeng Xue, Haohan Guo, Xinfa Zhu, Yuanjun Lv, Lei Xie, Yunlin Chen, Hao Yin, 和 Zhifei Li. 2024a. Single-codec: 面向高性能语音生成的单码本语音编解码器. arXiv 预印本 arXiv:2406.07422.
Xu Li, Qirui Wang, and Xiaoyu Liu. 2024b. Masksr: Masked language model for full-band speech restoration. arXiv preprint arXiv:2406.02092.
Xu Li, Qirui Wang, 和 Xiaoyu Liu. 2024b. Masksr: 用于全频带语音恢复的掩码语言模型. arXiv 预印本 arXiv:2406.02092.
Yue Li, Xinsheng Wang, Li Zhang, and Lei Xie. 2024c. Scdnet: Self-supervised learning featurebased speaker change detection. arXiv preprint arXiv:2406.08393.
Yue Li, Xinsheng Wang, Li Zhang, 和 Lei Xie. 2024c. Scdnet: 基于自监督学习的说话人变化检测. arXiv 预印本 arXiv:2406.08393.
Zheng Lian, Haiyang Sun, Licai Sun, Kang Chen, Mngyu Xu, Kexin Wang, Ke Xu, Yu He, Ying Li, Jinming Zhao, et al. 2023. Mer 2023: Multi-label learning, modality robustness, and semi-supervised learning. In Proceedings of the 31st ACM International Conference on Multimedia, pages 9610–9614.
Zheng Lian, Haiyang Sun, Licai Sun, Kang Chen, Mngyu Xu, Kexin Wang, Ke Xu, Yu He, Ying Li, Jinming Zhao, 等. 2023. Mer 2023: 多标签学习、模态鲁棒性和半监督学习. 在《第31届ACM国际多媒体会议论文集》中,第9610–9614页。
Rui Liu, Yifan Hu, Yi Ren, Xiang Yin, and Haizhou Li. 2024. Generative expressive conversational speech synthesis. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 4187–4196.
Rui Liu, Yifan Hu, Yi Ren, Xiang Yin, and Haizhou Li. 2024. 生成式表达性对话语音合成。在《第32届ACM国际多媒体会议论文集》中,页码4187–4196。
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Fe- i chten hofer, Trevor Darrell, and Saining Xie. 2022. A convnet for the 2020s. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986.
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, 和 Saining Xie. 2022. 2020年代的卷积网络。在IEEE/CVF计算机视觉与模式识别会议论文集上,页码11976–11986。
Steven R Livingstone and Frank A Russo. 2018. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english. PloS one, 13(5):e0196391.
Steven R Livingstone 和 Frank A Russo. 2018. 瑞尔森情感语音和歌曲视听数据库 (RAVDESS): 一个动态、多模态的北美英语面部和声音表达数据集. PloS one, 13(5):e0196391.
Dan Lyth and Simon King. 2024. Natural language guidance of high-fidelity text-to-speech with synthetic annotations. arXiv preprint arXiv:2402.01912.
Dan Lyth 和 Simon King. 2024. 使用合成注释进行高保真文本到语音的自然语言引导. arXiv 预印本 arXiv:2402.01912.
Linhan Ma, Dake Guo, Kun Song, Yuepeng Jiang, Shuai Wang, Liumeng Xue, Weiming Xu, Huan
Linhan Ma, Dake Guo, Kun Song, Yuepeng Jiang, Shuai Wang, Liumeng Xue, Weiming Xu, Huan
Zhao, Binbin Zhang, and Lei Xie. 2024. Wenet- speech4tts: A 12,800-hour mandarin tts corpus for large speech generation model benchmark. arXiv preprint arXiv:2406.05763.
Zhao, Binbin Zhang, 和 Lei Xie. 2024. Wenet-speech4tts: 一个用于大规模语音生成模型基准的12,800小时普通话TTS语料库. arXiv 预印本 arXiv:2406.05763.
Ziyang Ma, Zhisheng Zheng, Jiaxin Ye, Jinchao Li, Zhifu Gao, Shiliang Zhang, and Xie Chen. 2023. emotion 2 vec: Self-supervised pre-training for speech emotion representation. arXiv preprint arXiv:2312.15185.
Ziyang Ma, Zhisheng Zheng, Jiaxin Ye, Jinchao Li, Zhifu Gao, Shiliang Zhang, and Xie Chen. 2023. emotion 2 vec: 语音情感表示的自监督预训练. arXiv preprint arXiv:2312.15185.
MagicData. 2019. Magicdata mandarin chinese read speech corpus.
MagicData. 2019. MagicData 普通话朗读语音库。
Luz Martinez, Mohammed Abdelwahab, and Carlos Busso. 2020. The msp-conversation corpus. Inter- speech 2020.
Luz Martinez、Mohammed Abdelwahab 和 Carlos Busso. 2020. The msp-conversation corpus. Interspeech 2020.
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. 2023. Finite scalar quan- tization: Vq-vae made simple. arXiv preprint arXiv:2309.15505.
Fabian Mentzer, David Minnen, Eirikur Agustsson, 和 Michael Tschannen. 2023. 有限标量量化:简化的 VQ-VAE. arXiv 预印本 arXiv:2309.15505.
Tu Anh Nguyen, Wei-Ning Hsu, Antony d’Avirro, Bowen Shi, Itai Gat, Maryam Fazel-Zarani, Tal Remez, Jade Copet, Gabriel Synnaeve, Michael Has- sid, et al. 2023. Expresso: A benchmark and analysis of discrete expressive speech re synthesis. arXiv preprint arXiv:2308.05725.
Tu Anh Nguyen, Wei-Ning Hsu, Antony d’Avirro, Bowen Shi, Itai Gat, Maryam Fazel-Zarani, Tal Remez, Jade Copet, Gabriel Synnaeve, Michael Has- sid, 等. 2023. Expresso: 离散表达语音重合成的基准与分析. arXiv 预印本 arXiv:2308.05725.
Kari Ali Noriy, Xiaosong Yang, and Jian Jun Zhang. 2023. Emns/imz/corpus: An emotive singlespeaker dataset for narrative storytelling in games, television and graphic novels. arXiv preprint arXiv:2305.13137.
Kari Ali Noriy, Xiaosong Yang, 和 Jian Jun Zhang. 2023. Emns/imz/corpus: 用于游戏、电视和图像小说中叙事故事的情感单说话者数据集. arXiv 预印本 arXiv:2305.13137.
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Libri speech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE.
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Libri speech: 基于公共领域有声读物的自动语音识别语料库. 在 2015 年 IEEE 国际声学、语音与信号处理会议 (ICASSP) 上, 页码 5206–5210. IEEE.
Julian D Parker, Anton Smirnov, Jordi Pons, CJ Carr, Zack Zukowski, Zach Evans, and Xubo Liu. 2024. Scaling transformers for low-bitrate high-quality speech coding. arXiv preprint arXiv:2411.19842.
Julian D Parker, Anton Smirnov, Jordi Pons, CJ Carr, Zack Zukowski, Zach Evans, and Xubo Liu. 2024. 面向低比特率高音质语音编码的 Transformer 扩展. arXiv preprint arXiv:2411.19842.
Ankita Pasad, Bowen Shi, and Karen Livescu. 2023. Comparative layer-wise analysis of self-supervised speech models. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE.
Ankita Pasad, Bowen Shi 和 Karen Livescu. 2023. 自监督语音模型的层次比较分析. 在 ICASSP 2023-2023 IEEE 国际声学、语音和信号处理会议 (ICASSP) 上, 页码 1–5. IEEE.
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. 2018. Meld: A multimodal multi-party dataset for emotion recognition in conversations. arXiv preprint arXiv:1810.02508.
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, 和 Rada Mihalcea. 2018. Meld: 用于对话中情感识别的多模态多方数据集. arXiv 预印本 arXiv:1810.02508.
Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. 2020. Mls: A largescale multilingual dataset for speech research. ArXiv, abs/2012.03411.
Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, 和 Ronan Collobert. 2020. MLS: 一个用于语音研究的大规模多语言数据集. ArXiv, abs/2012.03411.
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR.
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, 和 Ilya Sutskever. 2023. 通过大规模弱监督实现鲁棒的语音识别. 在国际机器学习会议上, 页码 28492–28518. PMLR.
Yong Ren, Tao Wang, Jiangyan Yi, Le Xu, Jianhua Tao, Chu Yuan Zhang, and Junzuo Zhou. 2024. Fewertoken neural speech codec with time-invariant codes. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12737–12741. IEEE.
Yong Ren, Tao Wang, Jiangyan Yi, Le Xu, Jianhua Tao, Chu Yuan Zhang, 和 Junzuo Zhou. 2024. 使用时间不变编码的少Token神经语音编解码器. 在 ICASSP 2024-2024 IEEE 国际声学、语音和信号处理会议 (ICASSP), 页码 12737–12741. IEEE.
Antony W Rix, John G Beerends, Michael P Hollier, and Andries P Hekstra. 2001. Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs. In 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), volume 2, pages 749–752. IEEE.
Antony W Rix, John G Beerends, Michael P Hollier, 和 Andries P Hekstra. 2001. 语音质量感知评估 (PESQ) — 一种用于电话网络和编解码器语音质量评估的新方法. 在 2001 年 IEEE 国际声学、语音和信号处理会议. 论文集 (Cat. No. 01CH37221), 第 2 卷, 第 749–752 页. IEEE.
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2022. Utmos: Utokyo-sarulab sys- tem for voicemos challenge 2022. arXiv preprint arXiv:2204.02152.
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, 和 Hiroshi Saruwatari. 2022. Utmos: Utokyo-sarulab 系统用于 voicemos 挑战 2022. arXiv 预印本 arXiv:2204.02152.
Yao Shi, Hui Bu, Xin Xu, Shaoji Zhang, and Ming Li. 2020. Aishell-3: A multi-speaker mandarin tts corpus and the baselines. arXiv preprint arXiv:2010.11567.
Yao Shi, Hui Bu, Xin Xu, Shaoji Zhang, and Ming Li. 2020. Aishell-3: 多说话人普通话 TTS 语料库及基线。arXiv 预印本 arXiv:2010.11567。
Dehua Tao, Daxin Tan, Yu Ting Yeung, Xiao Chen, and Tan Lee. 2024. Toneunit: A speech disc ret iz ation approach for tonal language speech synthesis. arXiv preprint arXiv:2406.08989.
Dehua Tao, Daxin Tan, Yu Ting Yeung, Xiao Chen, 和 Tan Lee. 2024. Toneunit: 一种面向声调语言的语音合成离散化方法. arXiv 预印本 arXiv:2406.08989.
Jianhua Tao, Fangzhou Liu, Meng Zhang, and Huibin Jia. 2008. Design of speech corpus for mandarin text to speech. In The blizzard challenge 2008 workshop.
Jianhua Tao, Fangzhou Liu, Meng Zhang, 和 Huibin Jia. 2008. 普通话文本到语音的语音语料库设计. 在 The blizzard challenge 2008 workshop 中.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, 等. 2023. Llama: 开放且高效的基础语言模型. arXiv 预印本 arXiv:2302.13971.
Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural discrete representation learning. Advances in neural information processing systems, 30.
Aaron Van Den Oord, Oriol Vinyals 等. 2017. 神经离散表示学习. 神经信息处理系统进展, 30.
Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, et al. 2023. Audiobox: Unified audio generation with natural language prompts. arXiv preprint arXiv:2312.15821.
Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan 等. 2023. Audiobox: 使用自然语言提示的统一音频生成. arXiv 预印本 arXiv:2312.15821.
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. 2023a. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111.
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. 2023a. 神经编解码语言模型是零样本文本到语音合成器。arXiv预印本 arXiv:2301.02111。
Hongji Wang, Chengdong Liang, Shuai Wang, Zhengyang Chen, Binbin Zhang, Xu Xiang, Yanlei Deng, and Yanmin Qian. 2023b. Wespeaker: A research and production oriented speaker embedding learning toolkit. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE.
Hongji Wang, Chengdong Liang, Shuai Wang, Zhengyang Chen, Binbin Zhang, Xu Xiang, Yanlei Deng, and Yanmin Qian. 2023b. Wespeaker: 面向研究和生产的说话人嵌入学习工具包. In ICASSP 2023-2023 IEEE 国际声学、语音和信号处理会议 (ICASSP), pages 1–5. IEEE.
Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. 2020. Mead: A large-scale audiovisual dataset for emotional talking-face generation. In European Conference on Computer Vision, pages 700–717. Springer.
Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. 2020. Mead: 用于情感对话面部生成的大规模视听数据集。In European Conference on Computer Vision, pages 700–717. Springer.
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, and Takuya Yoshioka. 2024a. Speechx: Neural codec language model as a versatile speech transformer. IEEE/ACM Transactions on Audio, Speech, and Language Processing.
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, and Takuya Yoshioka. 2024a. Speechx: 作为多功能语音Transformer的神经编解码语言模型。IEEE/ACM Transactions on Audio, Speech, and Language Processing。
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Jiachen Zheng, Qiang Zhang, Xueyao Zhang, Shunsi Zhang, and Zhizheng Wu. 2024b. Maskgct: Zero-shot text-to-speech with masked generative codec transformer. arXiv preprint arXiv:2409.00750.
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Jiachen Zheng, Qiang Zhang, Xueyao Zhang, Shunsi Zhang, and Zhizheng Wu. 2024b. Maskgct: Zero-shot text-to-speech with masked generative codec transformer. arXiv preprint arXiv:2409.00750.
Zhichao Wang, Yuanzhe Chen, Xinsheng Wang, Lei Xie, and Yuping Wang. 2024c. Stream voice+: Evolving into end-to-end streaming zero-shot voice conversion. IEEE Signal Processing Letters.
王智超, 陈元哲, 王新胜, 谢磊, 王玉平. 2024c. Stream voice+: 迈向端到端流式零样本语音转换. IEEE Signal Processing Letters.
Haibin Wu, Naoyuki Kanda, Sefik Emre Eskimez, and Jinyu Li. 2024. Ts3-codec: Transformer-based simple streaming single codec. arXiv preprint arXiv:2411.18803.
Haibin Wu, Naoyuki Kanda, Sefik Emre Eskimez, and Jinyu Li. 2024. Ts3-codec: 基于Transformer的简单流式单编解码器。arXiv preprint arXiv:2411.18803.
Detai Xin, Xu Tan, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2024. Bigcodec: Pushing the limits of low-bitrate neural speech codec. arXiv preprint arXiv:2409.05377.
Detai Xin, Xu Tan, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2024. Bigcodec: 突破低比特率神经语音编解码器的极限。arXiv预印本 arXiv:2409.05377。
Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald. 2019. CSTR VCTK Corpus: English multispeaker corpus for CSTR voice cloning toolkit (version 0.92).
Junichi Yamagishi、Christophe Veaux 和 Kirsten MacDonald. 2019. CSTR VCTK 语料库:用于 CSTR 语音克隆工具包的英语多说话人语料库(版本 0.92)。
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. 2024. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115.
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, 等. 2024. Qwen2. 5 技术报告. arXiv 预印本 arXiv:2412.15115.
Zhen Ye, Zeqian Ju, Haohe Liu, Xu Tan, Jianyi Chen, Yiwen Lu, Peiwen Sun, Jiahao Pan, Weizhen Bian, Shulin He, et al. 2024a. Flash speech: Efficient zeroshot speech synthesis. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 6998–7007.
Zhen Ye, Zeqian Ju, Haohe Liu, Xu Tan, Jianyi Chen, Yiwen Lu, Peiwen Sun, Jiahao Pan, Weizhen Bian, Shulin He 等. 2024a. Flash speech: 高效的零样本语音合成. 在第32届ACM国际多媒体会议论文集, 第6998-7007页.
Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, et al. 2024b. Codec does matter: Exploring the semantic shortcoming of codec for audio language model. arXiv preprint arXiv:2408.17175.
Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qiuqiang Liu, 等. 2024b. 编解码器的重要性:探索音频语言模型中编解码器的语义缺陷. arXiv 预印本 arXiv:2408.17175.
Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi DAI, et al. 2025. Llasa: Scaling train-time and inference-time compute for llama-based speech synthesis. arXiv preprint arXiv:2502.04128.
Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi DAI, 等. 2025. Llasa: 基于 LLaMA 的语音合成的训练和推理计算扩展. arXiv 预印本 arXiv:2502.04128.
style captioning and stylistic speech synthesis. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 7513–7522.
风格字幕和风格语音合成。在第32届ACM国际多媒体会议论文集上,第7513-7522页。
Alon Ziv, Itai Gat, Gael Le Lan, Tal Remez, Felix Kreuk, Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2024. Masked audio generation using a single non-auto regressive transformer. arXiv preprint arXiv:2401.04577.
Alon Ziv, Itai Gat, Gael Le Lan, Tal Remez, Felix Kreuk, Alexandre Défossez, Jade Copet, Gabriel Synnaeve, 和 Yossi Adi. 2024. 使用单个非自回归 Transformer 进行掩码音频生成. arXiv 预印本 arXiv:2401.04577.
A BiCodec
双编码器 (BiCodec)
The model structure of BiCodec is illustrated in Fig. 6. BiCodec primarily consists of three components:
BiCodec 的模型结构如图 6 所示。BiCodec 主要由三个组件组成:
• Semantic Tokenizer • Global Tokenizer • Decoder
• 语义分词器 (Semantic Tokenizer)
• 全局分词器 (Global Tokenizer)
• 解码器 (Decoder)
Additionally, to compute the feature loss with the input wav2vec 2.0 features, an extra ConvNeXt block is incorporated to predict wav2vec 2.0 features, to further ensure the semantic relevance.
此外,为了计算输入 wav2vec 2.0 特征的特征损失,引入了一个额外的 ConvNeXt 模块来预测 wav2vec 2.0 特征,以进一步确保语义相关性。
A.1 Model Configurations
A.1 模型配置
The semantic tokenizer consists of 12 ConvNeXt blocks and 2 down sampling blocks. The downsampling blacks is only for semantic codes with lower than 50 TPS. The codebook size of VQ is 8192. The ECAPA-TDNN in the global tokenizer features an embedding dimension of 512. Meanwhile, the vector number of the learnable queries in the global tokenizer equal to the final goal token sequence length. For the FSQ module, the FSQ dimension is set to 6, with each dimension having 4 levels, resulting in a codebook size of 4096.
语义分词器由12个ConvNeXt块和2个下采样块组成。下采样块仅用于语义代码,且TPS低于50。VQ的码本大小为8192。全局分词器中的ECAPA-TDNN的嵌入维度为512。同时,全局分词器中可学习查询的向量数量等于最终目标Token序列长度。对于FSQ模块,FSQ维度设置为6,每个维度有4个级别,因此码本大小为4096。
The upsampling rates in the Transposed Convolution Blocks are set to [8, 5, 4, 2] for $16\mathrm{kHz}$ sampled audio and [8, 5, 4, 3] for $24\mathrm{kHz}$ sampled audio. The reconstruction performance of BiCodec with $24\mathrm{kHz}$ sampled audio is presented in Table 9.
转置卷积块中的上采样率对于 16kHz 采样的音频设置为 [8, 5, 4, 2],对于 24kHz 采样的音频设置为 [8, 5, 4, 3]。BiCodec 在 24kHz 采样音频下的重建性能如表 9 所示。
A.2 Compared Methods
A.2 对比方法
• Encodec (Défossez et al., 2022): An RVQ- based codec designed for universal audio compression.
• Encodec (Défossez et al., 2022): 一种基于 RVQ 的编解码器,专为通用音频压缩而设计。
• DAC (Kumar et al., 2024): An RVQ-based codec for universal audio. • Mimi (Défossez et al., 2024): An RVQ-based codec with semantic constraint for speech. • Single-Codec (Li et al., 2024a): A single- stream Mel codec that incorporates speaker embeddings. The reconstruction results for this method are provided by the authors. • BigCodec (Xin et al., 2024): A VQ-based single-stream codec for speech.
• DAC (Kumar et al., 2024): 一种基于 RVQ 的通用音频编解码器。
• Mimi (Défossez et al., 2024): 一种基于 RVQ 的带有语义约束的语音编解码器。
• Single-Codec (Li et al., 2024a): 一种结合说话人嵌入的单流 Mel 编解码器。该方法的重建结果由作者提供。
• BigCodec (Xin et al., 2024): 一种基于 VQ 的单流语音编解码器。
A.3 Additional Experiment
A.3 附加实验
To evaluate the performance of BiCodec at lower bitrates, we apply a down sampling operation in the semantic encoder, reducing the semantic token rate to 25 TPS. We compare BiCodec with SingleCodec (Li et al., 2024a), which operates at a similar bitrate, on the Libri Speech test-clean and LibriTTS test-clean datasets. The results are presented in Table 6 and Table 7.
为了评估 BiCodec 在低比特率下的性能,我们在语义编码器中应用了下采样操作,将语义 token 速率降低到 25 TPS。我们在 Libri Speech test-clean 和 LibriTTS test-clean 数据集上将 BiCodec 与在相似比特率下运行的 SingleCodec (Li et al., 2024a) 进行了比较。结果如表 6 和表 7 所示。
Global Token Length The reconstruction performance of BiCodec with varying global token lengths on the LibriTTS test-clean dataset is presented in Table 8.
全局 Token 长度 BiCodec 在 LibriTTS test-clean 数据集上不同全局 Token 长度的重建性能如表 8 所示。
Performance on Other Datasets To evaluate the generalization ability of BiCodec, we conducted experiments on a broader range of diverse datasets. The results are presented in Table 9.
在其他数据集上的性能
B Inference of Spark-TTS
B Spark-TTS 推理
Zero-shot TTS There are two inference strategies for zero-shot TTS:
零样本 TTS
• Using the text to be synthesized along with the global tokens from a reference audio as the prompt to generate speech, e.g., [
• 使用待合成的文本以及参考音频的全局Token作为提示生成语音,例如:[<内容文本> <全局Token> $\rightarrow$ <语义Token>]。
• 将参考音频的转录文本和语义Token作为提示的前缀进行结合,例如:[<内容文本> <参考文本> <全局Token> <参考语义Token> $\rightarrow$ <语义Token>]。
Among these, the second approach achieves higher speaker similarity. The results reported in Table 4 are based on this second inference strategy. A comparison between the two inference methods is provided in Table 10.
其中,第二种方法实现了更高的说话人相似度。表4中报告的结果基于这种第二种推理策略。表10中提供了两种推理方法的对比。

Figure 6: Model Structure of BiCodec
图 6: BiCodec 的模型结构
Table 6: Performance of BiCodec with lower bitrate on the Libri Speech test-clean dataset.
表 6: BiCodec 在 Libri Speech test-clean 数据集上的低比特率性能。
| 模型 | 码本大小 | bN | Token 率 | 带宽 STOI↑ | PESQ NB↑ | PESQ WB↑ | UTMOS↑ SIM↑ |
|---|---|---|---|---|---|---|---|
| Single-Codec | 8192 | 1 | 23.4 | 304 | 0.86 | 2.42 | 1.88 |
| BiCodec-4096-25 | 4096 | 1 | 25 | 300 | 0.88 | 2.53 | 1.97 |
| BiCodec-8192-25 | 8192 | 1 | 25 | 325 | 0.89 | 2.62 | 2.05 |
| BiCodec-4096-50 | 4096 | 1 | 50 | 600 | 0.92 | 3.03 | 2.42 |
Voice Creation Controllable TTS includes two levels of control for inference:
语音创建可控TTS包括两层推理控制:
• Coarse-grained control: The prompt consists of the text to be synthesized along with attribute labels, e.g., [
• 粗粒度控制:提示词包含待合成的文本及其属性标签,例如 [<内容文本> <属性标签> $\rightarrow$ <属性值> <全局Token> <语义Token>]。在此过程中,首先预测细粒度的属性值,然后以 CoT 方式生成全局Token,最后生成语义Token。
• 细粒度控制:提示词包含待合成的文本、属性层级和精确的属性值,例如 [<内容文本> <属性标签> <属性值> $\rightarrow$ <全局Token> <语义Token>]。
C Compared Zero-shot Methods
C 对比零样本方法
• Seed-TTS (A nast as sio u et al., 2024): A twostage model that employs an AR LM for semantic token prediction and flow matching for acoustic feature generation.
• Seed-TTS (A nast as sio u et al., 2024):一种两阶段模型,使用自回归语言模型(AR LM)进行语义Token预测,并使用流匹配进行声学特征生成。
Table 7: Reconstruction performance of BiCodec with various bitrates on the LibriTTS test-clean dataset.
表 7: BiCodec 在 LibriTTS test-clean 数据集上不同比特率的重建性能。
| 码本大小 | Nq | Token 率 | 带宽 | STOI↑ | PESQ NB↑ | PESQ WB↑ | UTMOS↑ | SIM↑ |
|---|---|---|---|---|---|---|---|---|
| 4096 | 1 | 25 | 300 | 0.88 | 2.47 | 1.91 | 3.88 | 0.67 |
| 8192 | 1 | 25 | 325 | 0.88 | 2.56 | 1.98 | 4.02 | 0.68 |
| 4096 | 1 | 50 | 600 | 0.91 | 2.96 | 2.36 | 4.10 | 0.75 |
| 8192 | 1 | 50 | 650 | 0.92 | 3.08 | 2.46 | 4.11 | 0.78 |
Table 8: Performance of BiCodec with varying global token lengths for reconstruction on the LibriTTS testclean dataset, where "w/o" indicates the omission of FSQ-based quantization, and gvq-32 means the global tokenizer is implemented with group VQ.
表 8: BiCodec在不同全局Token长度下在LibriTTS testclean数据集上的重建性能,其中"w/o"表示省略基于FSQ的量化,gvq-32表示全局分词器使用分组VQ实现。
| Global Token | PESQ NB↑ | PESQ WB↑ | STOI↑ | UTMOS↑ | SIM↑ |
|---|---|---|---|---|---|
| w/o | 0.923 | 3.1 | 2.48 | 4.09 | 0.81 |
| gvq-32 | 0.913 | 2.91 | 2.30 | 4.06 | 0.71 |
| 8 | 0.916 | 2.97 | 2.34 | 4.10 | 0.72 |
| 16 | 0.918 | 3.03 | 2.40 | 4.08 | 0.74 |
| 32 | 0.921 | 3.08 | 2.46 | 4.11 | 0.78 |
diction and flow matching for acoustic feature generation.
声学特征生成的预测与流匹配
• CosyVoice2 (Du et al., 2024b): An improved version of CosyVoice, maintaining the twostage structure with an AR LM for semantic tokens and flow matching for acoustic features.
CosyVoice2 (Du et al., 2024b): CosyVoice 的改进版本,保留了两阶段结构,使用 AR LM 生成语义 Token,并使用流匹配生成声学特征。
• Llasa (Ye et al., 2025): A single-stream codecbased TTS model that uses a single AR language model for direct single-stream code prediction.
Llasa (Ye et al., 2025): 一种基于单流编解码器的TTS模型,使用单个自回归(AR)语言模型进行直接单流代码预测。
D Objective Metircs
D 目标指标
• STOI (Andersen et al., 2017): A widely used metric for assessing speech intelligibility. Scores range from 0 to 1, with higher values indicating better intelligibility.
STOI (Andersen et al., 2017):一种广泛用于评估语音清晰度的指标。得分范围从0到1,数值越高表示清晰度越好。
• PESQ (Rix et al., 2001): A speech quality assessment metric that compares the reconstructed speech to a reference speech signal. We evaluate using both wide-band (WB) and narrow-band (NB) settings.
• PESQ (Rix et al., 2001):一种语音质量评估指标,将重建的语音与参考语音信号进行比较。我们使用了宽带(WB)和窄带(NB)设置进行评估。
• UTMOS (Saeki et al., 2022): An automatic Mean Opinion Score (MOS) predictor, providing an estimate of overall speech quality.
• UTMOS (Saeki et al., 2022): 一种自动的Mean Opinion Score (MOS)预测器,提供整体语音质量的估计。
• SIM: A speaker similarity metric, computed as the cosine similarity between the speaker embeddings of the reconstructed speech (generated speech in TTS) and the original input speech (prompt speech in TTS). We extract speaker embeddings using WavLM-large, finetuned on the speaker verification task (Chen et al., 2022).
• SIM: 一种说话人相似度度量,计算为重建语音(TTS 中的生成语音)和原始输入语音(TTS 中的提示语音)的说话人嵌入之间的余弦相似度。我们使用 WavLM-large 提取说话人嵌入,并在说话人验证任务上进行了微调 (Chen et al., 2022)。
E VoxBox
E VoxBox
E.1 Criteria for Pitch and Speed Categorization
E.1 音高和速度分类标准
• Speed The adoption of the 5th, 20th, 80th, and 95th percentiles to segment speech rates into distinct categories is founded on the need to accurately reflect the natural distribution of speech tempo variations within the population. These percentiles help to capture the extremes and the more central values of speech rate, ensuring that each category is meaningful and representative of specific vocal characteristics.
• 速度 采用第5、20、80和95百分位将语速划分为不同类别,是基于需要准确反映人群中语速变化的自然分布。这些百分位有助于捕捉语速的极端值和更中心值,确保每个类别都具有意义,并能代表特定的语音特征。
• Pitch Similar to the segmentation of speech rate, the division of pitch also starts from human subjective perception and the actual distribution characteristics. However, because humans are more sensitive to higher frequencies within the range of human fundamental frequencies, the 5th, 20th, 70th, and 90th percentiles are used as the division boundaries.
• 音高 与语速的划分类似,音高的划分也是从人类的主观感知和实际分布特征出发。但由于人类对人类基频范围内的较高频率更为敏感,因此使用第5、20、70和90百分位数作为划分界限。
Pitch Group for Male
男性音高组
Very Low: < 145 Mel Low: 145–164 Mel Moderate: 164–211 Mel High: 211–250 Mel Very High: >= 250 Mel
极低:< 145 Mel 低:145–164 Mel 中等:164–211 Mel 高:211–250 Mel 极高:>= 250 Mel
Table 9: Reconstruction performance on various datasets: Data-P comprises low-quality Chinese recordings made by internal staff using mobile phones; Data-S consists of expressive Chinese data recorded in a professional studio; and Data-M is a multilingual dataset collected from in-the-wild sources.
表 9: 不同数据集上的重建性能:Data-P 包含内部员工使用手机录制的低质量中文录音;Data-S 包含在专业录音室录制的富有表现力的中文数据;Data-M 是从野外收集的多语言数据集。
| 数据 | 方法 | 码本大小 | 训练数据 | STOI↑ | PESQ NB↑ | PESQ WB↑ | UTMOS↑ | SIM↑ |
|---|---|---|---|---|---|---|---|---|
| Data-P | X-codec2 | 65536 | 150k | 0.89 | 2.69 | 2.10 | 3.16 | 0.73 |
| BiCodec | 8192 | 3k | 0.90 | 2.80 | 2.22 | 3.22 | 0.78 | |
| BiCodec-24k | 8192 | 20k | 0.90 | 2.80 | 2.19 | 3.20 | 0.78 | |
| Data-S | X-codec2 | 65536 | 150k | 0.92 | 2.81 | 2.30 | 3.16 | 0.69 |
| BiCodec | 8192 | 3k | 0.93 | 3.04 | 2.50 | 3.28 | 0.82 | |
| BiCodec-24k | 8192 | 20k | 0.93 | 3.00 | 2.44 | 3.24 | 0.82 | |
| Data-M | X-codec2 | 65536 | 150k | 0.84 | 2.43 | 1.87 | 2.17 | 0.75 |
| BiCodec | 8192 | 3k | 0.85 | 2.56 | 1.91 | 2.17 | 0.76 | |
| BiCodec-24k | 8192 | 20k | 0.85 | 2.57 | 1.91 | 2.28 | 0.76 |
Table 10: Zero-shot performance of Spark-TTS with and without reference audio as a prefix.
| Model | test-zh | test-en |
| CER↓ SIM↑WER↓ SIM↑ | ||
| Spark-TTS Spark-TTS w/o prefix | 1.20 0.678 0.98 0.628 | 1.98 0.584 1.32 0.474 |
表 10: Spark-TTS 在有无参考音频作为前缀时的零样本性能
| 模型 | test-zh | test-en |
|---|---|---|
| Spark-TTS Spark-TTS w/o prefix | 1.20 0.678 0.98 0.628 | 1.98 0.584 1.32 0.474 |
Pitch Group for Female
女性音高分组
Very Low: < 225 Mel Low: 225–258 Mel Moderate: 258–314 Mel High: 314–353 Mel Very High: $>=353\mathrm{Mel}$
极低:< 225 Mel 低:225–258 Mel 中等:258–314 Mel 高:314–353 Mel 极高:$>=353\mathrm{Mel}$
Speaking Rate Group for Chinese
中文语速组
Very Slow: < 2.7 SPS Slow: 2.7–3.6 SPS Moderate: 3.6–5.2 SPS Fast: 5.2–6.1 SPS Very Fast: $>=6.1$ SPS
非常慢:< 2.7 SPS 慢:2.7–3.6 SPS 中等:3.6–5.2 SPS 快:5.2–6.1 SPS 非常快:$>=6.1$ SPS
Speaking Rate Group for English
英语语速分组
Very Slow: < 2.6 SPS Slow: 2.6–3.4 SPS Moderate: 3.4–4.8 SPS Fast: 4.8–5.5 SPS Very Fast: >= 5.5 SPS
非常慢:< 2.6 SPS
慢:2.6–3.4 SPS
中等:3.4–4.8 SPS
快:4.8–5.5 SPS
非常快:>= 5.5 SPS
E.2 Data for Gender Predictor Training
E.2 性别预测器训练数据
We fine-tune the WavLM-large model for gender classification using datasets that contain explicit gender labels, including VCTK (Yamagishi et al., 2019), AISHELL-3 (Shi et al., 2020), MLS- English (Pratap et al., 2020), MAGICDATA (MagicData, 2019), and Common Voice (Ardila et al., 2019).
我们使用包含明确性别标签的数据集对 WavLM-large 模型进行微调,用于性别分类,这些数据集包括 VCTK (Yamagishi et al., 2019)、AISHELL-3 (Shi et al., 2020)、MLS-English (Pratap et al., 2020)、MAGICDATA (MagicData, 2019) 和 Common Voice (Ardila et al., 2019)。
E.3 Annotation
E.3 标注
In addition to the attributes involved in the experiments of this paper, to make VoxBox applicable to a wider range of scenarios, we have also annotated more information for each sample of VoxBox, including age and emotion. Similar to the gender annotations, we fine-tune the WavLM-large model based on AISHELL-3, VCTK, MAGICDATA, Common Voice, and HQ-Conversations to predict five age ranges: Child, Teenager, Young Adult, Middle-aged, and Elderly. The performance metrics for both the gender and age predictors are presented in Table 11, where both Wav2vec 2.0- ft (Burkhardt et al., 2023) and Speech Craft (Jin et al., 2024) are based on the pre-trained Wav2vec 2.0 model.
除了本文实验涉及的属性外,为了使 VoxBox 适用于更广泛的场景,我们还为 VoxBox 的每个样本标注了更多信息,包括年龄和情绪。与性别标注类似,我们基于 AISHELL-3、VCTK、MAGICDATA、Common Voice 和 HQ-Conversations 微调 WavLM-large 模型,以预测五个年龄段:儿童、青少年、青年、中年和老年。性别和年龄预测器的性能指标如表 11 所示,其中 Wav2vec 2.0-ft (Burkhardt et al., 2023) 和 Speech Craft (Jin et al., 2024) 均基于预训练的 Wav2vec 2.0 模型。
Table 11: Comparison of different models on attribute predictions: All evaluations are conducted on the AISHELL-3 test dataset.
表 11: 不同模型在属性预测上的对比:所有评估均在 AISHELL-3 测试数据集上进行。
| 模型 | 年龄准确率↑ | 性别准确率↑ |
|---|---|---|
| wav2vec 2.0-ft | 80.2 | 98.8 |
| SpeechCraft | 87.7 | 97.7 |
| Our | 95.6 | 99.4 |
For datasets without emotion labels in the original metadata, we assign various emotion labels, sourced from different models, to the relevant samples. Specifically, we provide the following tags:
对于原始元数据中没有情感标签的数据集,我们从不同模型中为相关样本分配了各种情感标签。具体来说,我们提供了以下标签:
Prompt for Text Emotion Tag (English)
文本情感标签提示(英文)
E.4 Data Statistics
E.4 数据统计
The distributions of speaking rate, duration, and pitch are shown in Fig 7, while the distributions of gender and age are presented in Fig 8.
说话速率、时长和音高的分布如图 7 所示,而性别和年龄的分布如图 8 所示。
E.5 Source Data
E.5 源数据
• AISHELL-3: A multi-speaker Mandarin speech corpus for TTS. Source: www.openslr.org/93/ • CASIA: An emotional multi-speaker Mandarin speech corpus containing six emotions for TTS. Source: gitcode.com/ open-source-toolkit/bc5e6 CREMA-D: An emotional multi-speaker multilingual speech corpus containing six emotions and four intensity levels for TTS. Source:github.com/ Cheyney Computer Science/CREMA-D
• AISHELL-3:一个多说话者的中文语音语料库,用于TTS。来源:https://www.openslr.org/93/
• CASIA:一个包含六种情感的多说话者中文语音语料库,用于TTS。来源:https://gitcode.com/open-source-toolkit/bc5e6
• CREMA-D:一个包含六种情感和四种强度级别的多说话者多语言语音语料库,用于TTS。来源:https://github.com/CheyneyComputerScience/CREMA-D
• Dailytalk: A multi-speaker English speech corpus with conversational style for TTS. Source:https: //github.com/keon lee 9420/DailyTalk
• Dailytalk: 面向TTS的多说话人对话风格英语语音语料库。来源:https: //github.com/keon lee 9420/DailyTalk

Figure 7: Data distribution of VoxBox.
图 7: VoxBox 的数据分布。

Figure 8: Gender and age distribution of VoxBox.
图 8: VoxBox 的性别和年龄分布。
• Libri speech: A mutli-speaker English speech corpus with reading style for TTS. Source: https://tensorflow.google.cn/ datasets/catalog/libri speech
• Libri speech: 一个多说话人英语语音语料库,适用于 TTS (Text-to-Speech) 的阅读风格。来源:https://tensorflow.google.cn/datasets/catalog/librispeech
• LibriTTS-R: Sound quality improved version of the LibriTTS (Zen et al., 2019) corpus which is a large-scale corpus of English speech for TTS. Source: https://www. openslr.org/141/
• LibriTTS-R:LibriTTS (Zen et al., 2019) 语料库的音质改进版本,该语料库是一个用于 TTS 的大规模英语语音语料库。来源:https://www.openslr.org/141/
• M3ED: An emotional mutli-speaker Mandarin speech corpus containing seven emotions for TTS. Source: https://github. com/aim3-ruc/rucm3ed
• M3ED:一个包含七种情感的多说话人中文普通话语音语料库,用于TTS。来源:https://github.com/aim3-ruc/rucm3ed
• MAGICDATA: A mutli-speaker Mandarin speech corpus with conversational style for TTS. Source: https://openslr.org/68/
• MAGICDATA: 一个用于 TTS 的多说话人普通话对话风格语音语料库。来源: https://openslr.org/68/
• MEAD: An emotional mutli-speaker English speech corpus containing eight emotions and three intensity levels for TTS. Source: https: //github.com/uniBruce/Mead
• MEAD:一个包含八种情感和三种强度级别的多说话人英语语音语料库,用于TTS。来源:https: //github.com/uniBruce/Mead
• MELD: An emotional mutli-speaker English speech corpus containing seven emotions for TTS. Source: https://affective-meld. github.io/
• MELD:一个包含七种情感的多说话者英语语音语料库,用于 TTS。来源:https://affective-meld.github.io/
• MER2023: An emotional mutli-speaker Mandarin speech corpus containing six emotions for TTS. Source: http://www. mer challenge.cn/datasets
• MER2023:一个包含六种情感的多说话人普通话语音语料库,用于TTS。来源:http://www.merchallenge.cn/datasets
• MLS-English: A mutli-speaker English speech corpus for TTS. Source: www.openslr.org/94/
• MLS-English:用于TTS的多说话人英语语音语料库。来源:https://www.openslr.org/94/
• MSP-Podcast: An emotional mutli-speaker English speech corpus containing eight emotions for TTS. Source: https://ecs. utdallas.edu/research/research labs/ msp-lab/MSP-Podcast.html
MSP-Podcast:一个包含八种情感的多说话人英语语音语料库,用于TTS。来源:https://ecs.utdallas.edu/research/researchlabs/msp-lab/MSP-Podcast.html
• NCSSD-CL: A mutli-speaker bilingual speech corpus for TTS. Source: github.com/uniBruce/Mead
• NCSSD-CL:一个用于TTS的多说话人双语语音语料库。来源: github.com/uniBruce/Mead
• NCSSD-RL: A mutli-speaker bilingual speech corpus for TTS. Source: github.com/uniBruce/Mead
• NCSSD-RL: 一个用于TTS的多说话人双语语音语料库。来源: https://github.com/uniBruce/Mead
• RAVDESS: An emotional mutli-speaker English speech corpus containing eight emotions and two intensity levels for TTS. Source: https://www. kaggle.com/datasets/uw rf ka gg ler/ ravdess-emotional-speech-audio
• RAVDESS: 一个包含八种情绪和两种强度级别的多说话者英语语音语料库,用于语音合成 (TTS)。来源:https://www.kaggle.com/datasets/uwrfkaggler/ravdess-emotional-speech-audio
F SparkVox: A Toolkit for Speech Related Tasks
F SparkVox:语音相关任务工具包
The training code for Spark-TTS will be integrated into the open-source SparkVox framework. SparkVox is a training framework designed for speech-related tasks, supporting a variety of applications, including: vocoder, codec, TTS, and speech understanding. Additionally, SparkVox provides various file processing tools for both text and speech data, facilitating efficient data handling. Its simplified framework structure is illustrated in Fig. 9.
Spark-TTS 的训练代码将被集成到开源的 SparkVox 框架中。SparkVox 是一个专为语音相关任务设计的训练框架,支持多种应用,包括:声码器 (vocoder)、编解码器 (codec)、TTS 和语音理解。此外,SparkVox 提供了多种文件和语音数据的处理工具,便于高效的数据处理。其简化的框架结构如图 9 所示。

Figure 9: Framework of SparkVox.
图 9: SparkVox 框架。
Table 12: VoxBox Statistics
表 12: VoxBox 统计数据
| 数据 | 语言 #Utterance | 时长 (h) | |||
|---|---|---|---|---|---|
| 男性 | 女性 | 总计 | |||
| AISHELL-3 (Shi et al., 2020) | 中文 | 88,035 | 16.01 | 69.61 | 85.62 |
| CASIA (Ta0 et al., 2008) | 中文 | 857 | 0.25 | 0.2 | 0.44 |
| Emilia-CN (He et al., 2024) | 中文 | 15,629,241 22,017.56 | 12.741.89 | 34,759.45 | |
| ESD (Zhou et al., 2021) | 中文 | 16,101 | 6.69 | 7.68 | 14.37 |
| HQ-Conversations (Zhou et al., 2024a) | 中文 | 50,982 | 35.77 | 64.23 | 100 |
| M3ED (Zha0 et al., 2022) | 中文 | 253 | 0.04 | 0.06 | 0.1 |
| MAGICDATA (MagicData, 2019) | 中文 | 609,474 | 360.31 | 393.81 | 754.13 |
| MER2023 (Lian et al., 2023) | 中文 | 1,667 | 0.86 | 1.07 | 1.93 |
| NCSSD-CL-CN (Liu et al., 2024) | 中文 | 98,628 | 53.83 | 59.21 | 113.04 |
| NCSSD-RC-CN (Liu et al., 2024) | 中文 | 21,688 | 7.05 | 22.53 | 29.58 |
| WenetSpeech4TTS (Ma et al., 2024) | 中文 | 8,856,480 | 7,504.19 | 4,264.3 | 11,768.49 |
| 总计 | 中文 | 25,373,406 | 30,002.56 | 17,624.59 | 47,627.15 |
| CREMA-D (Ca0 et al., 2014) | 英文 | 809 | 0.3 | 0.27 | 0.57 |
| Dailytalk (Lee et al., 2023) | 英文 | 23,754 | 10.79 | 10.86 | 21.65 |
| EmiliaEN (He et al., 2024) | 英文 | 8,303,103 | 13,724.76 | 6,573.22 | 20,297.98 |
| EMNS (Noriy et al., 2023) | 英文 | 918 | 0 | 1.49 | 1.49 |
| EmoV-DB (Adigwe et al.,2018) | 英文 | 3,647 | 2.22 | 2.79 | 5 |
| Expresso (Nguyen et al., 2023) | 英文 | 11,595 | 5.47 | 5.39 | 10.86 |
| Gigaspeech (Chen et al., 2021) | 英文 | 6,619,339 | 4,310.19 | 2,885.66 | 7,195.85 |
| Hi-Fi TTS (Bakhturina et al., 2021) | 英文 | 323,911 | 133.31 | 158.38 | 291.68 |
| IEMOCAP (Busso et al.,2008) | 英文 | 2,423 | 1.66 | 1.31 | 2.97 |
| JL-Corpus (James et al., 2018) | 英文 | 893 | 0.26 | 0.26 | 0.52 |
| Librispeech (Panayotov et al., 2015) | 英文 | 230,865 | 393.95 | 367.67 | 761.62 |
| LibriTTS-R (Koizumi et al., 2023) | 英文 | 363,270 | 277.87 | 283.03 | 560.9 |
| MEAD (Wang et al.,2020) | 英文 | 3,767 | 2.26 | 2.42 | 4.68 |
| MELD (Poria et al., 2018) | 英文 | 5,100 | 2.14 | 1.94 | 4.09 |
| MLS-English (Pratap et al., 2020) | 英文 | 6,319,002 | 14,366.25 | 11,212.92 | 225,579.18 |
| MSP-Podcast (Martinez et al., 2020) | 英文 | 796 | 0.76 | 0.56 | 1.32 |
| NCSSD-CL-EN (Liu et al., 2024) | 英文 | 62,107 | 36.84 | 32.93 | 69.77 |
| NCSSD-RL-EN (Liu et al., 2024) | 英文 | 10,032 | 4.18 | 14.92 | 19.09 |
| RAVDESS (Livingstone and Russo, 2018) | 英文 | 950 | 0.49 | 0.48 | 0.97 |
| SAVEE (Jackson and Haq, 2014) | 英文 | 286 | 0.15 | 0.15 | 0.31 |
| TESS (Yu et al., 2021) | 英文 | 1,956 | 0 | 1.15 | 1.15 |
| VCTK (Yamagishi et al., 2019) | 英文 | 44,283 | 16.95 | 24.51 | 41.46 |
| 总计 | 英文 | 22,332,806 33,290.8 | 21,582.31 | 54,873.11 | |
| 总计 | 47,706,212 63,293.36 | 539,206.9 | 102,500.26 |