Pandora3D: A Comprehensive Framework for High-Quality 3D Shape and Texture Generation
Pandora3D: 高质量3D形状与纹理生成的综合框架
Abstract
摘要
This report presents a comprehensive framework for generating high-quality 3D shapes and textures from diverse input prompts, including single images, multi-view images, and text descriptions. The framework consists of 3D shape generation and texture generation. (1). The 3D shape generation pipeline employs a Variation al Auto encoder (VAE) to encode implicit 3D geometries into a latent space and a diffusion network to generate latents conditioned on input prompts, with modifications to enhance model capacity. An alternative Artist-Created Mesh (AM) generation approach is also explored, yielding promising results for simpler geometries. (2). Texture generation involves a multi-stage process starting with frontal images generation followed by multi-view images generation, RGB-to-PBR texture conversion, and high-resolution multi-view texture refinement. A consistency scheduler is plugged into every stage, to enforce pixel-wise consistency among multi-view textures during inference, ensuring seamless integration.
本报告提出了一个从多样化输入提示(包括单张图像、多视角图像和文本描述)生成高质量3D形状和纹理的综合框架。该框架包括3D形状生成和纹理生成两部分。(1) 3D形状生成流程采用变分自编码器 (VAE) 将隐式3D几何编码到潜在空间中,并使用扩散网络生成基于输入提示的潜在表示,同时通过修改增强了模型容量。此外,还探索了一种替代的艺术家创建网格 (AM) 生成方法,在简单几何体上取得了良好的效果。(2) 纹理生成涉及多阶段过程,首先生成正面图像,然后生成多视角图像,进行RGB到PBR纹理转换,并进行高分辨率多视角纹理优化。在每个阶段都引入了一致性调度器,以确保推理过程中多视角纹理之间的像素级一致性,从而实现无缝集成。
The pipeline demonstrates effective handling of diverse input formats, leveraging advanced neural architectures and novel methodologies to produce high-quality 3D content. This report details the system architecture, experimental results, and potential future directions to improve and expand the framework. The source code and pretrained weights are released at: https://github.com/Tencent/Tencent-XR-3DGen.
该流程展示了系统在处理多样化输入格式时的有效性,利用先进的神经网络架构和新颖的方法生成高质量的3D内容。本报告详细介绍了系统架构、实验结果以及未来改进和扩展框架的潜在方向。源代码和预训练权重已发布在:https://github.com/Tencent/Tencent-XR-3DGen。
1. Introduction
1. 引言
Automated generation of high-quality digital 3D assets has drawn more and more attention in recent years. Digital 3D assets have become deeply ingrained in modern life and production. These assets vividly express the imaginations of creators across various fields, including gaming and film, bringing joy and creating immersive experiences for both players and audiences alike. Meanwhile, 3D assets also serve as essential building blocks in the domains of physical simulation and embodied AI, enabling machines and robots to understand the elements in the real world. However, the creation of 3D assets is far from simple; it is often a complex, time-consuming, and expensive process. Taking text prompts or an image as input, the digital 3D asset production pipeline commonly involves stages of 3D shape generation and texture generation, each requiring a high level of expertise and proficiency in digital content creation software.
近年来,高质量数字3D资产的自动化生成引起了越来越多的关注。数字3D资产已深深融入现代生活和生产。这些资产生动地表达了游戏、电影等多个领域创作者的想象力,为玩家和观众带来了欢乐,并创造了沉浸式体验。同时,3D资产也是物理模拟和具身AI领域的重要组成部分,帮助机器和机器人理解现实世界中的元素。然而,3D资产的创建并不简单,通常是一个复杂、耗时且昂贵的过程。以文本提示或图像为输入,数字3D资产的生产流程通常包括3D形状生成和纹理生成两个阶段,每个阶段都需要在数字内容创作软件中具备高水平的专业知识和熟练度。
In this report, we present Pandora3D, a framework designed for high-quality 3D shape and texture generation. The framework consists of two main components: 3D shape generation and texture generation.
在本报告中,我们介绍了Pandora3D,一个专为高质量3D形状和纹理生成设计的框架。该框架主要由两个核心部分组成:3D形状生成和纹理生成。<|end▁of▁sentence|>
The pipeline demonstrates effective handling of diverse input formats, leverages advanced neural architectures, and incor porates novel methodologies to produce high-quality 3D content. This report details the system architecture, experimental results, and potential future directions to improve and expand the framework.
该流程展示了有效处理多种输入格式的能力,利用先进的神经架构,并采用新颖的方法来生成高质量的 3D 内容。本报告详细介绍了系统架构、实验结果以及未来改进和扩展框架的潜在方向。
2. 3D Shape Generation
2. 3D 形状生成<|end▁of▁sentence|>
2.1. 3D Latent Space Diffusion
2.1. 3D 潜在空间扩散
The process begins by generating a 3D shape from a single image, multiple images, or a text prompt. This involves the following steps:
该过程从单张图像、多张图像或文本提示生成3D形状开始,涉及以下步骤:
· Variation al Auto encoder (VAE): Compresses 3D geometries into a latent space, enabling efficient representation and processing. · Diffusion Network: Generates latent representations conditioned on the input prompts. This network is adapted from CLAY [43] / Craftsman [16] / LAM3D [4], with modifications to improve the capacity and performance of the model.
· 变分自编码器 (VAE, Variation al Auto encoder):将3D几何压缩到潜在空间,实现高效表示和处理。
· 扩散网络 (Diffusion Network):根据输入提示生成潜在表示。该网络基于 CLAY [43] / Craftsman [16] / LAM3D [4] 进行了改进,以提升模型的容量和性能。
2.1.1 Effcient 3D Geometry Auto encoder
2.1.1 高效的三维几何自动编码器<|end▁of▁sentence|>
For 3D geometry compression model, we build upon CraftsMan [16], which adopts structures introduced in 3 D Shape 2 Vec Set [4 and Michelangelo [44]. Furthermore, we leverage the multi-resolution training strategy proposed in CLAY [43]. This approach encodes 3D geometry into latent space by progressively sampling additional points from a 3D point cloud, which increment ally extends and refines the latent representation of the shape. Progressive sampling allows the model to focus on areas of higher geometric complexity, capturing both global structure and intricate details. The primary goal of our VAE is to generate expressive latent embeddings that effectively guide the diffusion process in subsequent stages. To enhance the efficiency of this process, we propose a more advanced point sampling strategy. This method is designed to maximize the utility of the 3D point-cloud data by prioritizing points that contribute the most to capturing fine-grained features and spatial relationships. This enhancement not only increases the model's capacity to handle large-scale data for improved s cal ability but also preserves the fine-grained details of 3D geometry.
对于3D几何压缩模型,我们基于CraftsMan [16]构建,它采用了3D Shape 2 Vec Set [4]和Michelangelo [44]中引入的结构。此外,我们还利用了CLAY [43]提出的多分辨率训练策略。该方法通过逐步从3D点云中采样额外的点,将3D几何编码到潜在空间中,逐步扩展和细化形状的潜在表示。渐进采样使模型能够专注于几何复杂度较高的区域,捕捉全局结构和精细细节。我们VAE的主要目标是生成具有表达力的潜在嵌入,以有效指导后续阶段的扩散过程。为了提高这一过程的效率,我们提出了一种更先进的点采样策略。该方法旨在通过优先选择对捕捉细粒度特征和空间关系贡献最大的点,最大化3D点云数据的效用。这一增强不仅提高了模型处理大规模数据的能力,以改善可扩展性,还保留了3D几何的细粒度细节。
The design options of our VAE are illustrated in Fig. 1. We employ the model structure introduced in 3 D Shape 2 Vec Set as our base model. This approach involves embedding the input point cloud, augmented with normal information $X\in\mathbb{R}^{N\times6}$ which is sampled from a mesh $M$ , into a latent code using a learnable embedding function and a cross-attention encoding module:
我们的VAE设计选项如图1所示。我们采用3D Shape 2 Vec Set中介绍的模型结构作为基础模型。该方法通过可学习的嵌入函数和交叉注意力编码模块,将输入点云(从网格$M$中采样并增强了法线信息$X\in\mathbb{R}^{N\times6}$)嵌入到潜在代码中:

Where $q\in\mathbb{R}^{m\times d}$ represents a set of learnable queries that compress the sampled points into a latent embedding. The cross-attention mechanism ensures effective integration of geometric and positional features into the latent space. The VAE's decoder is composed of successive self-attention layers followed by a cross-attention layer. The cross-attention layer maps the latent embeddings back into 3D geometry, enabling reconstruction:
其中 $q\in\mathbb{R}^{m\times d}$ 表示一组可学习的查询,将采样点压缩为潜在嵌入。交叉注意力机制确保了几何和位置特征在潜在空间中的有效整合。VAE的解码器由连续的自注意力层和交叉注意力层组成。交叉注意力层将潜在嵌入映射回3D几何,实现重建:

where $p$ denotes random query points in 3D space, these points query with the latent and output occupancy logits. This base VAE implementation is illustrated in Fig. 1 (A).
其中 $p$ 表示三维空间中的随机查询点,这些点与潜在变量进行查询并输出占用 logits。这个基础的 VAE 实现如图 1 (A) 所示。
Following the approach outlined in CLAY [43], we adopt a multi-resolution training strategy to progressively upscale the model's capacity. Specifically, we increment ally increase the number of sampled points from 4096 to 32768 while simultan e ou sly extending the latent embedding dimensionality from 256 to 2048. This progressive training scheme gradually introduces more detailed input information to the model, enabling it to capture finer geometric details. At the same time, the expanded latent embedding length increases the model's capacity to represent complex features. Together, these enhancements enrich the latent space, thereby providing a more robust foundation for the subsequent diffusion model training. This multi-resolution approach ensures an efficient and scalable training process, optimizing both the model's performance and its ability to generalize across diverse 3D geometries.
遵循 CLAY [43] 中概述的方法,我们采用了多分辨率训练策略,逐步提升模型的容量。具体来说,我们逐步将采样点的数量从 4096 增加到 32768,同时将潜在嵌入维度从 256 扩展到 2048。这种渐进式训练方案逐步向模型引入更详细的输入信息,使其能够捕捉更精细的几何细节。同时,扩展的潜在嵌入长度增加了模型表示复杂特征的能力。这些增强共同丰富了潜在空间,从而为后续的扩散模型训练提供了更稳健的基础。这种多分辨率方法确保了一个高效且可扩展的训练过程,优化了模型的性能及其在多样化 3D 几何中的泛化能力。
Recall that the primary objective of our VAE is to generate expressive latent embeddings. While the previously mentioned approach progressively increases the number of sampling points, each object contains a total of $500\mathrm{k}$ points, leaving many points unsampled. This results in inevitable information loss, as not all geometric details are captured in the latent representation. Furthest point sampling [24] has the potential to mitigate this issue by selecting more representative points. However, this method is significantly slower compared to random sampling, making it less practical for large-scale training scenarios. This residual information loss can pose challenges during the diffusion process, as it may hinder the generation of high-quality latent embeddings. Consequently, the decoder is tasked with reconstructing fine-grained 3D details that might not be adequately represented in the latent embedding, potentially limiting the overall quality and fidelity of the reconstructed geometry.
回想一下,我们的 VAE 的主要目标是生成具有表现力的潜在嵌入。虽然前面提到的方法逐步增加了采样点的数量,但每个对象总共包含 $500\mathrm{k}$ 个点,许多点未被采样。这导致了不可避免的信息丢失,因为并非所有几何细节都被捕捉到潜在表示中。最远点采样 [24] 有潜力通过选择更具代表性的点来缓解这一问题。然而,与随机采样相比,这种方法明显更慢,使其在大规模训练场景中不太实用。这种剩余信息丢失可能对扩散过程构成挑战,因为它可能会妨碍高质量潜在嵌入的生成。因此,解码器的任务是重建潜在嵌入中可能未充分表示的精细 3D 细节,这可能会限制重建几何的整体质量和保真度。<|end▁of▁sentence|>
We have developed an enhancement to our Variation al Auto encoder (VAE) model that allows it to operate without sampling, while still retaining all data points. A straightforward approach might involve utilizing PointNet+ $^{\cdot+}$ [24] to compress features from a point cloud into a few "centroid points"’ through the use of cascaded convolutional layers. However, this method demands a substantial amount of memory, especially when managing point cloud data consisting of millions of points. To address this, our model optimizes the processing of large-scale point clouds more efficiently, reducing the memory burden without compromising the integrity and richness of the data. Alternatively, we opt to sample a set of centroid points $M\in\mathbb{R}^{m\times6}$ and employ a Q-former [15] style module to compress the raw point cloud data onto these centroids. The core component of the Q-former, the cross-attention mechanism, exhibits a computational complexity $O(2M N d)$ ,where $M$ is the amount of centroids and $N$ is the size of the input point cloud and $d$ is feature dimension. Although utilizing a memory-efficient attention method such as Flash Attention [5] helps, it remains resource-intensive and slow for processing large point clouds directly without sampling. To overcome these challenges, we propose the adoption of a linear attention mechanism [26, 25] for implementing cross-attention within our Q-former module. The theoretical complexity of this approach is $O(M d^{2}+N d^{2})$ . Given that $N>>N>>d$ , the computational load of linear cross-attention is significantly reduced compared to traditional cross-attention methods. During the training of our VAE, we randomly select points from the original point clouds to serve as centroid points. These centroids, which have a dimension larger than 6, act as queries in the Q-former and compress geometric information from the raw point cloud. Subsequently, these centroid points are processed by the VAE encoder to generate latent embeddings. This extended VAE is depicted in Fig. 1 (B).
我们开发了一种变分自编码器 (Variational Autoencoder, VAE) 模型的增强版本,使其能够在无需采样的同时保留所有数据点。一种直接的方法可能是利用 PointNet+$^{\cdot+}$ [24],通过级联卷积层将点云特征压缩为几个“质心点”。然而,这种方法需要大量内存,尤其是在处理包含数百万个点的点云数据时。为了解决这个问题,我们的模型优化了大规模点云的处理效率,减少了内存负担,同时不损害数据的完整性和丰富性。或者,我们选择采样一组质心点 $M\in\mathbb{R}^{m\times6}$,并采用 Q-former [15] 风格的模块将原始点云数据压缩到这些质心上。Q-former 的核心组件——交叉注意力机制,其计算复杂度为 $O(2M N d)$,其中 $M$ 是质心数量,$N$ 是输入点云的大小,$d$ 是特征维度。尽管使用内存高效的注意力方法(如 Flash Attention [5])有所帮助,但在不进行采样的情况下直接处理大规模点云仍然资源密集且速度较慢。为了克服这些挑战,我们提出在线性注意力机制 [26, 25] 的基础上实现 Q-former 模块中的交叉注意力。这种方法的理论复杂度为 $O(M d^{2}+N d^{2})$。考虑到 $N>>N>>d$,线性交叉注意力的计算负载相比传统的交叉注意力方法显著降低。在训练我们的 VAE 时,我们从原始点云中随机选择点作为质心点。这些维度大于 6 的质心点作为 Q-former 中的查询,压缩来自原始点云的几何信息。随后,这些质心点由 VAE 编码器处理以生成潜在嵌入。这种扩展的 VAE 如图 1 (B) 所示。
Similarly, we still adopt multi-reolustion training strategy to progressively increase the centroid points amount and latent embedding length to enlarge the latent embedding capacity. In addition, we empirically find that progressively increasing the training data amount can accelerate model convergence. Methods like 3 D Shape 2 Vec Set and CLAY, which derive latents from sampled points of the original point cloud, inevitably suffer from detail loss. Our extension effectively addresses this issue of information loss and maximizes the utilization of high-resolution point clouds, thereby preserving more detailed and accurate representations.
同样,我们仍然采用多分辨率训练策略,逐步增加中心点数量和潜在嵌入长度,以扩大潜在嵌入容量。此外,我们通过实验发现,逐步增加训练数据量可以加速模型收敛。像 3D Shape 2 Vec Set 和 CLAY 这样的方法,从原始点云的采样点中提取潜在特征,不可避免地会遭受细节损失。我们的扩展有效地解决了信息丢失的问题,并最大限度地利用了高分辨率点云,从而保留了更详细和准确的表示。
2.1.2 Diffusion Pipeline
2.1.2 扩散管道 (Diffusion Pipeline)
The diffusion pipeline is illustrated in Fig. 2. We employ Multimodel Diffusion Transformer(MMDiT) [9] as our diffusion backbone, utilizing two pretrained models, specifically, CLIP-ViT-L/14 [27] as the global image feature extractor, and DinoV2-Large [20] for local image feature extraction. Instead of employing DDPM, we utilize the flow matching schedule. Following CLAY [43] methodology, the diffusion model is trained in coarse-to-fine manner.
扩散流程如图 2 所示。我们采用 Multimodel Diffusion Transformer (MMDiT) [9] 作为扩散主干,利用两个预训练模型,具体来说,CLIP-ViT-L/14 [27] 作为全局图像特征提取器,DinoV2-Large [20] 用于局部图像特征提取。我们没有采用 DDPM,而是使用了流匹配调度。遵循 CLAY [43] 的方法,扩散模型以从粗到细的方式进行训练。
To enhance the image control effect, we use both global and local image feature as condition features of diffusion model. Global condition feature $z_{g l o b a l}\in\mathbb{R}^{L}$ is extracted with ClIP vision encoder, meanwhile, local detail condition feature $z_{l o c a l}\in\mathbb{R}^{L\times1024}$ is extracted with Dino vision encoder. The global condition and local condition are integrated into the diffusion model through MMDiT Block following Stable Diffusion 3 [9]. The diffusion model we use has 2.3B parameters and 28 layers MMDiT block.
为了增强图像控制效果,我们使用全局和局部图像特征作为扩散模型的条件特征。全局条件特征 $z_{g l o b a l}\in\mathbb{R}^{L}$ 通过 ClIP 视觉编码器提取,同时,局部细节条件特征 $z_{l o c a l}\in\mathbb{R}^{L\times1024}$ 通过 Dino 视觉编码器提取。全局条件和局部条件通过 MMDiT 块集成到扩散模型中,遵循 Stable Diffusion 3 [9]。我们使用的扩散模型具有 28 层 MMDiT 块和 23 亿参数。
To enhance practical utility in 3D design workflows, we have extended our geometry generation framework to accept multi-view conditional inputs. This architectural advancement enables finer-grained geometric control through multi-view visual guidance. The system accommodates variable numbers of reference images (stochastic ally sampled from 1 to 4 views per instance) within a unified architecture, eliminating requirement for fixed-size input configurations. All synthesized geometries maintain spatial alignment with the primary view's coordinate system (defined by the first input image). Input images must be arranged in ascending azimuth order ${\theta_{1},\theta_{2},\ldots,\theta_{n}}$ where $\theta_{i}\in\left[0^{\circ},360^{\circ}\right)$ .Multiview feature representations are aggregated through ordered concatenation along the sequence dimension, preserving relative spatial-semantic correspondence across views. Accelerated convergence is achieved via progressive transfer learning, where parameters initialized from our single-view conditioned model undergo fine-tuning using multiview datasets while maintaining pretrained backbone weights during initial phases.
为了增强在3D设计工作流程中的实用性,我们扩展了几何生成框架以支持多视角条件输入。这一架构进步通过多视角视觉指导实现了更精细的几何控制。该系统在统一架构中适应可变数量的参考图像(每个实例随机采样1到4个视角),消除了对固定大小输入配置的需求。所有合成几何体均保持与主视角坐标系的空间对齐(由第一个输入图像定义)。输入图像必须按升序方位角排列 ${\theta_{1},\theta_{2},\ldots,\theta_{n}}$,其中 $\theta_{i}\in\left[0^{\circ},360^{\circ}\right)$。多视角特征表示通过序列维度上的有序连接进行聚合,保留了跨视角的相对空间语义对应关系。通过渐进式迁移学习加速收敛,其中从单视角条件模型初始化的参数在使用多视角数据集进行微调的同时,在初始阶段保持预训练的主干权重。
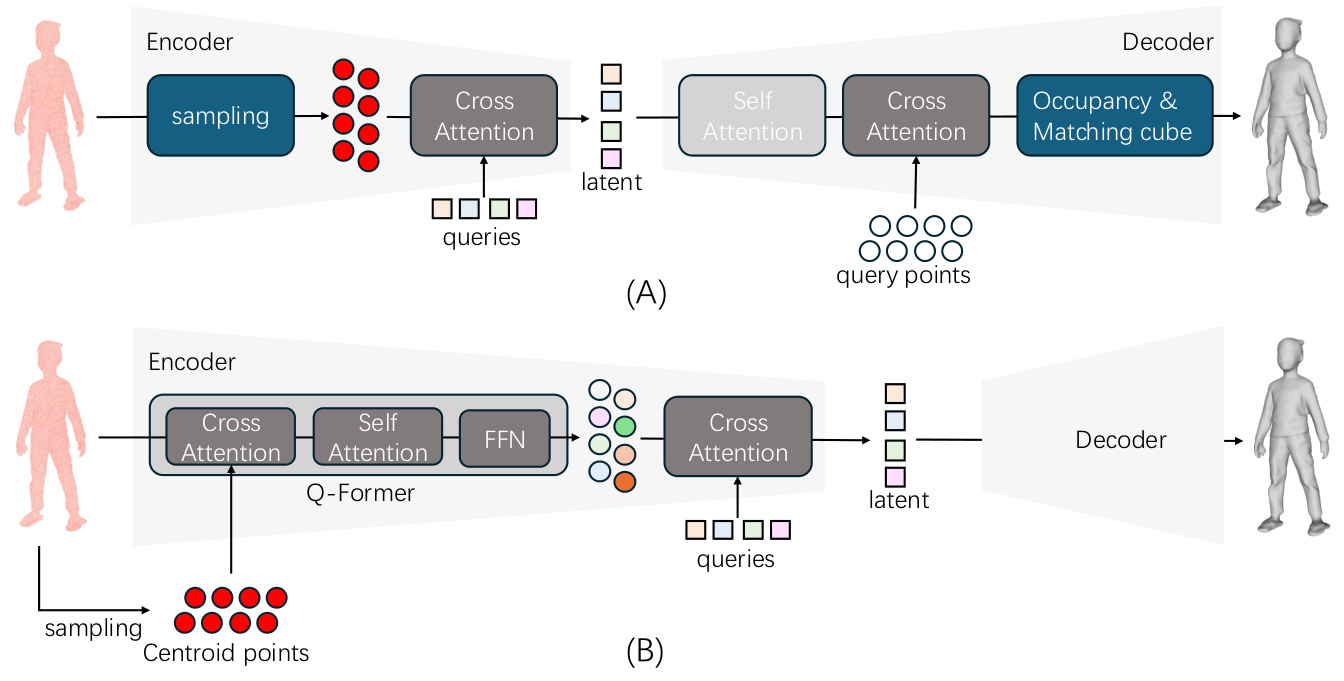
Figure 1. 3D Geometry variation al auto encoder. (A): Our base VAE for 3D geometry compression. (B) Extended VAE for efficient 3I geometry compression.
图 1: 3D 几何变化自动编码器。(A): 我们用于 3D 几何压缩的基础 VAE。(B) 用于高效 3I 几何压缩的扩展 VAE。
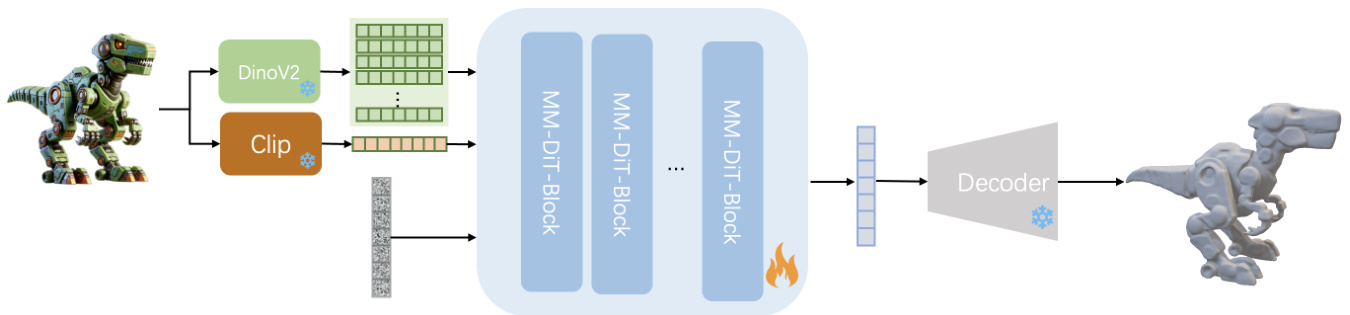
Figure 2. Diffusion pipline. In the process of training a diffusion model, the DinoV2, CLIP, and VAE Decoder components are kept frozen
图 2. 扩散流程。在训练扩散模型的过程中,DinoV2、CLIP 和 VAE 解码器组件保持冻结状态
2.2. Meshing and UV Unwrapping
2.2. 网格划分与UV展开
Once the 3D geometry is generated, it undergoes isosurface extraction, remeshing and UV unwrapping so that a textureready triangle mesh is produced.
生成 3D 几何体后,会进行等值面提取、重新网格化和 UV 展开,从而生成可用于纹理处理的三角网格。
2.2.1 Isosurface extraction
2.2.1 等值面提取
We perform a modifed version of marching cubes algorithm [17, 19] to effciently extract a watertight mesh from geometry tokens.
我们执行了一种改进版本的 Marching Cubes 算法 [17, 19],以高效地从几何 Token 中提取出封闭的网格。
Marching cubes traditionally require a dense occupancy grid of $D\times D\times D$ occupancy values. Directly computing such a dense grid with Eq. (2) incurs a $O(D^{3})$ time complexity that is prohibitively expensive at high resolutions $D$ . To improve efficiency, we adopt a coarse to fine strategy: starting from a coarse grid resolution $d_{0}\ll D$ , we iterative ly build a sparse finer grid of resolution $d_{i+1}=2d_{i}$ whose cells are subdivided from active cells in the coarser grid of resolution $d_{i}$ that are close to the isosurface. This strategy ensures that most occupancy queries of Eq. (2) are confined within a small margin around the isosurface and significantly reduces the number of queries required for isosurface extraction, achieving two to three orders faster mesh extraction.
传统的 Marching cubes 算法需要一个密集的 $D\times D\times D$ 占用值网格。直接使用公式 (2) 计算这样的密集网格会带来 $O(D^{3})$ 的时间复杂度,在高分辨率 $D$ 下代价过高。为了提高效率,我们采用了从粗到细的策略:从粗网格分辨率 $d_{0}\ll D$ 开始,逐步构建一个稀疏的细网格,其分辨率为 $d_{i+1}=2d_{i}$ ,该网格的单元是从分辨率 $d_{i}$ 的粗网格中靠近等值面的活跃单元细分而来。该策略确保公式 (2) 中的大多数占用查询都限制在等值面附近的小范围内,并显著减少了等值面提取所需的查询数量,使网格提取速度提高了两个到三个数量级。
To guarantee a watertight mesh, at the highest level $d_{n}=D$ , we expand the sparse active cells along the isosurface to eliminate holes and perform Lewiner's topology check [14] to ensure manifold ness. We implement the sparse marching cubes as a custom CUDA kernel function to maximize efficiency.
为了确保网格的严密性,在最高层级 $d_{n}=D$ 下,我们沿着等值面扩展稀疏的活跃单元以消除孔洞,并执行 Lewiner 的拓扑检查 [14] 以确保流形性。我们将稀疏行进立方体实现为自定义的 CUDA 内核函数,以最大化效率。
2.3. Remesh and UV unwrap
2.3. 重新网格化和 UV 展开<|end▁of▁sentence|>
The triangle meshes extracted from Marching cubes may contain poorly constructed elements such as collapsed faces or slivers. Furthermore, they often exhibit a high face count that could create problems for downstream applications. We overcome these issues with an optional remeshing step using either an off-the-shelf quad-remesher' or isotropic remeshing [21] followed by QEM triangle decimation [10].
从 Marching cubes 提取的三角网格可能包含构造不良的元素,例如塌陷面或薄片。此外,它们通常表现出较高的面数,这可能会给下游应用带来问题。我们通过可选的重新网格化步骤来克服这些问题,使用现成的四边形重新网格化工具或各向同性重新网格化 [21],然后进行 QEM 三角网格简化 [10]。
In addition, we use the open source project UV-Atlas [45]for UV charting and packing. At this point, we obtain a polygon mesh that is ready for texture generation.
此外,我们使用开源项目 UV-Atlas [45] 进行 UV 图表和打包。此时,我们获得了一个准备进行纹理生成的多边形网格。
2.4. Alternative Approach: Artist-Created Meshes Generation
2.4 替代方法:艺术家创建的网格生成<|end▁of▁sentence|>
An alternative approach we explored involves directly generating the mesh, bypassing the initial generation of geometry as an implicit function followed by mesh extraction. This method effectively produces meshes with reasonable topology, akin to those crafted by artists for simple shapes. However, it encounters difficulties when applied to complex geometries, where maintaining structural integrity and topological accuracy becomes challenging.
我们探索的另一种方法涉及直接生成网格,绕过作为隐式函数生成几何形状的初始步骤,随后进行网格提取。该方法有效地生成了具有合理拓扑结构的网格,类似于艺术家为简单形状制作的网格。然而,当应用于复杂几何形状时,保持结构完整性和拓扑准确性变得具有挑战性。
2.4.1 Mesh Compression
2.4.1 网格压缩
Direct regression of vertex coordinates results in substantial memory consumption, which consequently limits the number of faces the model can handle. To mitigate this issue, we adopt the methodology proposed by BPT [38], which involves compressing the original vertex coordinates using block index compression and patchified aggregation. Specifically, for a vertex $\boldsymbol{v}{i}=\left(x{i},y_{i},z_{i}\right)$ ,the block-wise indexing $(b_{i},o_{i})$ is formulated as follows:
直接回归顶点坐标会导致内存消耗大量增加,从而限制了模型可以处理的面数。为了解决这个问题,我们采用了 BPT [38] 提出的方法,该方法通过使用块索引压缩和分块聚合来压缩原始顶点坐标。具体来说,对于顶点 $\boldsymbol{v}{i}=\left(x{i},y_{i},z_{i}\right)$,块索引 $(b_{i},o_{i})$ 的公式如下:

In this formulation, the symbols $|$ and $%$ represent division without remainder and the modulo operation, respectively. This approach segments the coordinates along each axis into $B$ blocks, each of length $O$ . To further enhance the compression ratio, we employ the patchified aggregation technique as described in [38]. This technique aggregates the faces connected to the same vertex into a non-overlapping patch and utilizes dual-block indices to denote the starting point of a patch. Consequently, the offset vocabulary is shared between the center vertex and the surrounding vertices. The center patch is formulated as follows:
在此公式中,符号 $|$ 和 $%$ 分别表示无余数除法和取模运算。该方法将沿每个轴的坐标分割为 $B$ 个块,每个块的长度为 $O$。为了进一步提高压缩比,我们采用了 [38] 中描述的 patchified aggregation 技术。该技术将连接到同一顶点的面聚合成一个不重叠的 patch,并使用双块索引表示 patch 的起点。因此,中心顶点和周围顶点之间共享偏移量词汇表。中心 patch 的公式如下:

In this context, $b_{c}^{\prime}$ and $O_{C}$ denote the blocking index and the offset index of the center patch, respectively. These indices are critical for accurately referencing the spatial configuration of the patch within the compressed data structure.
在此上下文中,$b_{c}^{\prime}$ 和 $O_{C}$ 分别表示中心区块的阻塞索引和偏移索引。这些索引对于准确引用压缩数据结构中区块的空间配置至关重要。<|end▁of▁sentence|>
To achieve this, we initially convert vertex coordinates into discrete values with a resolution of $R$ .Subsequently,we encode the mesh information, including vertices and faces, into a discrete token sequence. This sequence can be decoded back into a mesh using the same technique. It is important to note that this encoding and decoding process is governed by predefined rules and does not involve any learnable parameters.
为实现这一目标,我们首先将顶点坐标转换为分辨率为 $R$ 的离散值。随后,我们将包括顶点和面在内的网格信息编码为离散的 Token 序列。该序列可以使用相同的技术解码回网格。需要注意的是,该编码和解码过程由预定义的规则控制,不涉及任何可学习的参数。
2.4.2 Auto regressive Model for Mesh Generation
2.4.2 用于网格生成的自回归模型
In this section, we describe the methodology for generating novel shapes from various modalities using the compression technique outlined in the preceding sections. Fig. 3 illustrates the pipeline of our approach. Initially, a mesh is encoded into discrete token sequences utilizing the method detailed previously. Subsequently, a decoder-only auto regressive model is employed to predict subsequent tokens based on preceding ones. To facilitate multi-modality condition control, a pre-trained condition encoder network is utilized to encode condition information, such as images, text, and point clouds, into latent features. These features serve as the contextual input for the decoder-only model. The resulting token sequence can then be decoded back into the final mesh using a mesh decoder. It is important to note that both the mesh encoder and mesh decoder are purely rule-based, as previously explained, and do not involve any learnable parameters.
在本节中,我们描述了使用前几节概述的压缩技术从各种模态生成新形状的方法。图3展示了我们方法的流程。首先,使用先前详述的方法将网格编码为离散的token序列。随后,使用仅解码的自回归模型来预测基于前序token的后续token。为了支持多模态条件控制,使用预训练的条件编码器网络将条件信息(如图像、文本和点云)编码为潜在特征。这些特征作为仅解码器模型的上下文输入。最终的token序列可以通过网格解码器解码回最终网格。需要注意的是,网格编码器和网格解码器都是基于规则的,如前所述,不涉及任何可学习参数。<|end▁of▁sentence|>
Fig. 4 visualizes the meshes generated by our model, which exhibit superior topology consistency with a minimal numbel of faces.
图 4: 展示了我们模型生成的网格,其拓扑一致性优异且面数最少。
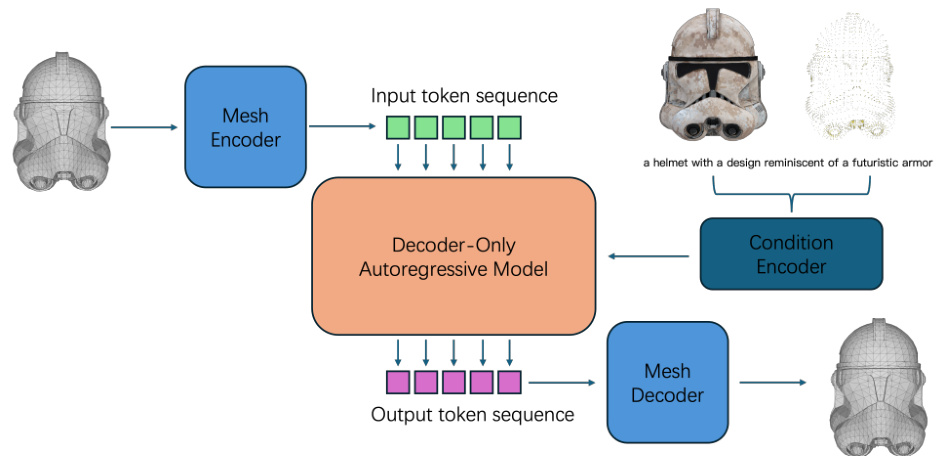
Figure 3. Pipeline for Artist-Created Mesh Generation. Initially, meshes are encoded into discrete token sequences. These sequences are then processed through a decoder-only auto regressive model that utilizes a Transformer network architecture. To enforce multi-modality condition control, a pretrained condition encoder network is employed. This network effectively integrates diverse modalities, ensuring that the generated meshes adhere to specified conditions.
图 3: 艺术家创建的网格生成流程。首先,网格被编码为离散的序列。这些序列随后通过一个仅包含解码器的自回归模型进行处理,该模型采用了Transformer网络架构。为了实现多模态条件控制,使用了一个预训练的条件编码器网络。该网络有效地整合了多种模态,确保生成的网格符合指定的条件。<|end▁of▁sentence|>
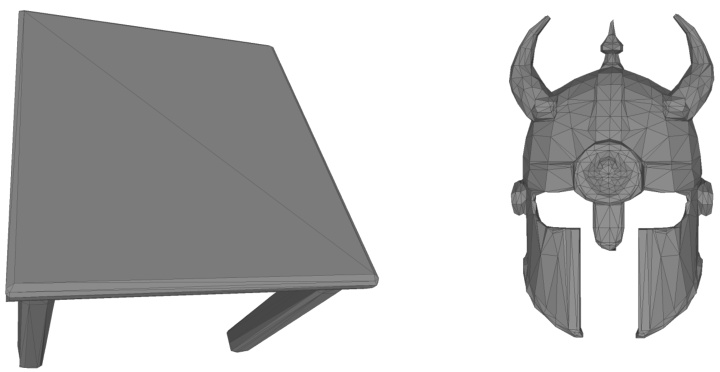
Figure 4. Example Meshes Generated by Our Artist-Created Mesh Generation Model. The meshes produced by our model demonstrate superior performance in maintaining topological consistency, showcasing the effectiveness of our approach in generating high-quality artistic meshes.
图 4: 由我们的艺术家创建的网格生成模型生成的示例网格。我们的模型生成的网格在保持拓扑一致性方面表现出色,展示了我们在生成高质量艺术网格方面的有效性。<|end▁of▁sentence|>
3. Texture Generation
- 纹理生成
The proposed texture generation pipeline consists of several stages, each contributing to the generation of consistent and high-quality textures. Fig. 5 illustrates the texture generation pipeline. The pipeline begins with a 3D mesh without texture. Below we introduce each stage in detail.
所提出的纹理生成管道由多个阶段组成,每个阶段都贡献于生成一致且高质量的纹理。图 5 展示了纹理生成管道。该管道从没有纹理的 3D 网格开始。下面我们详细介绍每个阶段。
3.1. Frontal Image Generation
3.1. 正面图像生成
If the input prompt is text, a frontal image is initially generated conditioned on a depth map derived from the 3D geometry. This process involves rendering the 3D mesh into a depth map and utilizing depth-conditioned diffusion models [42] to produce the frontal image. Alternatively, if the input is an image, we integrate the IP-Adapter [39] and ControlNet [42] to generate the frontal image. As illustrated in Fig. 6, both text and image prompts are converted into a geometry-aligned frontal image, which serves as the input for subsequent texture generation.
如果输入提示是文本,首先会根据从3D几何体生成的深度图生成正面图像。该过程包括将3D网格渲染为深度图,并利用深度条件扩散模型 [42] 生成正面图像。如果输入是图像,我们会集成 IP-Adapter [39] 和 ControlNet [42] 来生成正面图像。如图6所示,文本和图像提示都被转换为与几何体对齐的正面图像,作为后续纹理生成的输入。

Figure 5. Texture Generation Pipeline (input image and mesh from Trellis3D)
图 5: 纹理生成流程(输入图像和网格来自 Trellis3D)

Figure 6. Both textual and visual prompts are transformed into a frontal image that is aligned with the frontal-view geometry.
图 6: 文本和视觉提示都被转换为与正面视图几何对齐的正面图像。
3.2. Multi-view RGB Image Generation
3.2. 多视角 RGB 图像生成
A single-view to multi-view image generator creates multi-view RGB images conditioned on the multi-view position maps and the frontal image. Please note that normal and depth maps can also be used here. We first train a multi-view image generator with a network structure similar with Zero $123\mathrm{+}\mathrm{+}$ [30], then, we combine the ControlNet [42] with Zero $123\mathrm{+}\mathrm{+}$ [30] conditioned on the position (XYZ coordinate) maps, enabling the generation of position-aligned multi-view images. Whether the frontal image originates from text and depth or is provided as input, the multi-view image generator generates six multiviewimages (each $512\times512$ 0 starting from random Gaussian noise, with geometric conditions and photometric modules. An example is shown in the first image in Fig. 7.
单视角到多视角图像生成器根据多视角位置图和正面图像生成多视角 RGB 图像。请注意,这里也可以使用法线图和深度图。我们首先训练了一个与 Zero $123\mathrm{+}\mathrm{+}$ [30] 网络结构相似的多视角图像生成器,然后将 ControlNet [42] 与 Zero $123\mathrm{+}\mathrm{+}$ [30] 结合,基于位置(XYZ 坐标)图进行条件生成,从而实现位置对齐的多视角图像生成。无论正面图像是来自文本和深度还是作为输入提供,多视角图像生成器都会生成六幅多视角图像(每幅 $512\times512$),从随机高斯噪声开始,结合几何条件和光度模块。图 7 中的第一张图展示了一个示例。
3.3. Multi-view PBR Image Generation
3.3. 多视角 PBR 图像生成
After obtaining multi-view rgb image conditioned on multi-view position maps, we generate the corresponding multi-view PBR (Physically Based Rendering) image via a image-2-image diffusion model [28]. Specially, taking multi-view rgb image as input, we train image-2-image diffusion models to generate corresponding multi-view PBR image. This stage includes generating multi-view albedo, metallic, and roughness maps (each sub image with resolution of $512\times512$ 0.Please kindly note that we train two models in multi-view PBR image generation process, where one model estimate multi-view albedo image, and one model estimate multi-view metallic and roughness maps. Examples of the generated albedo, metallic and roughness images are shown in Fig. 7.
在获得基于多视角位置图的多视角RGB图像后,我们通过图像到图像的扩散模型生成相应的多视角物理渲染(PBR)图像[28]。具体来说,我们以多视角RGB图像作为输入,训练图像到图像的扩散模型,以生成相应的多视角PBR图像。这一阶段包括生成多视角的漫反射、金属度和粗糙度图(每个子图像的分辨率为$512 \times 512$)。请注意,我们在多视角PBR图像生成过程中训练了两个模型,其中一个模型用于估计多视角漫反射图,另一个模型用于估计多视角金属度和粗糙度图。图7展示了生成的漫反射、金属度和粗糙度图的示例。<|end▁of▁sentence|>

Figure 7. Multi-view RGB, albedo, metallic and roughness images.
图 7: 多视角 RGB、反射率、金属度和粗糙度图像。<|end▁of▁sentence|>

Figure 8. High-resolution albedo images.
图 8: 高分辨率反照率图像<|end▁of▁sentence|>
3.4. High-Resolution Refinement
3.4. 高分辨率优化
To further enhance visual quality, we upscale the albedo multi-view images by several iterative upscaling steps. Firstly, we apply two steps of image repainting, utilizing a pre-trained SDXL [22] model conditioned on albedo, depth, XYZ coordinate maps, and the frontal image to upscale the albedo multi-view images to resolutions of $768\times768$ and $1024\times1024$ ,introducing finer details. We then use Real-ESRGAN [36] to further enhances the multi-view textures to generate detailed high-resolution albedomaps $(3072\times3072)$ ,seeFig.8.
为了进一步提升视觉质量,我们通过多次迭代的上采样步骤来放大反照率多视角图像。首先,我们使用预训练的 SDXL [22] 模型,基于反照率、深度、XYZ 坐标图和正面图像进行两步图像修复,将反照率多视角图像上采样到 $768\times768$ 和 $1024\times1024$ 的分辨率,引入更精细的细节。然后,我们使用 Real-ESRGAN [36] 进一步提升多视角纹理,生成详细的高分辨率反照率图 $(3072\times3072)$,见图 8。
3.5. Pixel-Wise Consistency Enforcement
3.5. 像素级一致性增强
The multi-view generation stages may produce inconsistencies at the pixel level across different views. To address this, we implement a consistent scheduler similar to TexPainter [41], which enforces pixel-wise consistency. Specifically, the multi-view textures are firstly baked onto the 3D mesh, and a Poisson system is solved to produce seamless textures. Then, multi-view images are re-rendered and resampled into each view, ensuring consistency across different views and lighting conditions. The resampled views are used as the updated $z_{0}$ , which is plugged into the noise scheduler of the diffusion model similar to [41].
多视图生成阶段可能会在不同视图之间产生像素级的不一致。为了解决这个问题,我们实现了一个类似于 TexPainter [41] 的一致性调度器,它强制执行像素级一致性。具体来说,首先将多视图纹理烘焙到 3D 网格上,并求解泊松系统以生成无缝纹理。然后,重新渲染多视图图像并将其重新采样到每个视图中,确保不同视图和光照条件下的一致性。重新采样的视图被用作更新的 $z_{0}$ ,并将其插入到与 [41] 类似的扩散模型的噪声调度器中。
4. 3D Model Data Processing
4. 3D 模型数据处理<|end▁of▁sentence|>
We collect assets (mostly 3D models) from multiple sources and preprocess them to be training compatible, including converting mesh geometry to discrete sampling of implicit functions, multi-view image generation, and PBR rendering. Our
我们从多个来源收集资产(主要是 3D 模型),并对其进行预处理以使其兼容训练,包括将网格几何体转换为隐函数的离散采样、多视图图像生成和 PBR 渲染。

Figure 9. Data processing pipline. The procedures marked in red are one-off implementations, while the green-boxed elements demand tailored development according to the algorithmic modules deployed on the dataset, we thereby provide exampled steps for jobs described in Section 2 and Section 3.2.
图 9: 数据处理流程。红色标记的步骤是一次性实施的,而绿色框中的元素需要根据数据集中部署的算法模块进行定制开发,我们因此为第 2 节和第 3.2 节中描述的工作提供了示例步骤。
data processing pipeline is demonstrated in Fig. 9. We will detail each step in the processing pipeline in the following contents of this section.
数据处理流程如图9所示。我们将在本节后续内容中详细介绍处理流程中的每个步骤。<|end▁of▁sentence|>
4.1. Data Origins
4.1. 数据来源<|end▁of▁sentence|>
The main data sources are:
主要数据来源包括:<|end▁of▁sentence|>
4.2. Filter Mesh
4.2. 过滤网格
We first filter mesh using the following mesh prop rie ties, which are modified from the standards used in MeshXL [2]:
我们首先使用以下网格属性进行过滤,这些属性是从 MeshXL [2] 中使用的标准修改而来的:
· Objects cannot be of pure color i.e. pure red or pure blue. This can be checked by checking object's material graph in Blender.
· 物体不能是纯色的,例如纯红或纯蓝。这可以通过在 Blender 中检查物体的材质图来验证。<|end▁of▁sentence|>

Figure 10. Typical images of scanned objects in Objaverse dataset [7]. (A) and (C) are rendered images of the two objects; (B) and (D) are corresponding object demonstration in blender.
图 10: Objaverse 数据集中扫描对象的典型图像 [7]。(A) 和 (C) 是两个对象的渲染图像;(B) 和 (D) 是 Blender 中对应的对象展示。
4.3. Format Conversion
4.3. 格式转换
For convenience of usage, we convert all 3D mesh formats to $\mathrm{OBJ^{4}}$ . This is because most processing pipelines that are not part of DCC software i.e. Digital Content Creation software, cannot support read full information of complex 3D formats like $\mathrm{GLB^{5}}$ and $\mathrm{FBX^{6}}$ . If we wish to scale-up for future learning-based algorithms that need to directly read information from meshes, we have to convert 3D format to OBJ. However, directly converting 3D models to OBJ format often fails, mostly because default format conversion function in Blender cannot correctly deal with file path of texture images. We thus need some extra care of some certain file types.
为了方便使用,我们将所有 3D 网格格式转换为 $\mathrm{OBJ^{4}}$。这是因为大多数不属于 DCC(数字内容创作)软件的处理流程无法支持读取复杂 3D 格式(如 $\mathrm{GLB^{5}}$ 和 $\mathrm{FBX^{6}}$)的全部信息。如果我们希望扩展未来需要直接从网格读取信息的学习算法,必须将 3D 格式转换为 OBJ 格式。然而,直接将 3D 模型转换为 OBJ 格式通常会失败,主要是因为 Blender 中的默认格式转换函数无法正确处理纹理图像的文件路径。因此,我们需要对某些特定文件类型进行额外处理。<|end▁of▁sentence|>
· MAX to OBJ cannot be done directly, as MAX file is only supported by $3\mathrm{DSMax^{7}}$ and OBJ exporting function in that software cannot correctly handle objects with multiple complex materials. This is because we use an extension of OBJ that supports PBR formats developed by Carla [8], which is not properly supported in 3DSMax. We thus first convert MAX files to FBX formats using 3DSMax, and convert FBX to OBJ using blender.
· MAX 转 OBJ 无法直接完成,因为 MAX 文件仅受 $3\mathrm{DSMax^{7}}$ 支持,且该软件中的 OBJ 导出功能无法正确处理具有多个复杂材质的对象。这是因为我们使用了 Carla [8] 开发的扩展 OBJ 格式,该格式支持 PBR(基于物理的渲染),而 3DSMax 并未完全支持此格式。因此,我们首先使用 3DSMax 将 MAX 文件转换为 FBX 格式,然后再使用 Blender 将 FBX 转换为 OBJ。
· GLB to OBJ can be done in blender, but to get correct textures extra care is needed in rebuilding material graph structure. This is because GLB specification has embedded texture images within mesh files. We first convert all GLB files to GLTF formats which extract texture files to disk; then we go through the material graph of GLTF format and rebuild connections in new mesh.
· GLB 转 OBJ 可以在 Blender 中进行,但要获得正确的纹理,需要在重建材质图结构时格外小心。这是因为 GLB 规范在网格文件中嵌入了纹理图像。我们首先将所有 GLB 文件转换为 GLTF 格式,将纹理文件提取到磁盘;然后我们遍历 GLTF 格式的材质图,并在新网格中重建连接。
· PMX to OBJ can be done in blender using codes derived from Cats plugin?. $\mathrm{{PMX^{9}}}$ is often used by some creators of the anime industry.
· PMX 转 OBJ 可以在 Blender 中使用来自 Cats 插件的代码实现?$\mathrm{{PMX^{9}}}$ 常被一些动漫行业的创作者使用。
4.4. Classify Mesh
4.4. 网格分类
The propose of this step is to eliminate low-quality mesh as thoroughly as posible, and to mark object of distinctive types. This provides the following advantages:
此步骤的目的是尽可能彻底地消除低质量网格,并标记不同类型的对象。这具有以下优势:
The filtering process descirbed in this section is modified from the process used in MeshXL [2], as shown in Fig. 11. Aftel this process, we render 9 images surrounding the mesh, and use the HunYuan vision model1° to filter the mesh by thest rendered images. Note that you can substitute this vision model with any other vLLM models, such as GPT-4Vll . As showr
本节描述的过滤过程是对 MeshXL [2] 中使用的过程进行修改后的版本,如图 11 所示。在此过程之后,我们渲染了围绕网格的 9 张图像,并使用 HunYuan 视觉模型1° 通过这些渲染的图像来过滤网格。需要注意的是,你可以用任何其他 vLLM 模型(如 GPT-4Vll)替换此视觉模型。

Figure 11. Classify mesh using vLLM by making the vLLM model to describe the model using 9 rendered images. Some parts of the structured data (marked with red box) can be used to classify mesh; the aggregated full sentence can be used as the caption of the mesh.
图 11. 通过让 vLLM 模型使用 9 张渲染图像描述模型来分类网格。结构化数据的某些部分(用红色框标记)可用于分类网格;聚合的完整句子可用作网格的标题。
in Fig. 11, the text prompt guides the vLLM to describe the appearance of the object, and check if the object is of certain classes. Then, we use LLM [33] to convert unstructured text into a structured format with structures similar to JSON. Labels in these structured texts can be used as the object's class.
在图 11 中,文本提示引导 vLLM 描述对象的外观,并检查对象是否属于某些类别。然后,我们使用大语言模型 (LLM) [33] 将非结构化文本转换为类似于 JSON 的结构化格式。这些结构化文本中的标签可以用作对象的类别。
4.5. Generate watertight mesh
4.5. 生成防水网格
Generating watertight mesh, which is essential for 3D-DiT training, is generating an envelope tightly conforming to the model's exterior geometry, rather than using both interior and exterior geometry. The latter, like Manifold [11, 12] and other works [23] that can provide similar results,is not suitable for 3D-DiT training.
生成水密网格(watertight mesh),这对于3D-DiT训练至关重要,是指生成一个紧密贴合模型外部几何形状的外壳,而不是同时使用内部和外部几何形状。后者,如Manifold [11, 12]和其他能够提供类似结果的工作 [23],并不适用于3D-DiT训练。
We use similar watertight mesh generation method from 3 D Shape 2 Vec Set [40], which is adopted from Stutz's work [32] and used in occupancy networks $[18]^{12}$ . The method is based on TSDF fusion of a group of depth map rendering around the object. However, this method will slightly vary the exterior shape of the mesh due to the following reasons:
我们采用了与3D Shape 2 Vec Set [40]中类似的防水网格生成方法,该方法源自Stutz的工作 [32] 并用于占用网络 $[18]^{12}$ 。该方法基于围绕物体的一组深度图渲染的TSDF融合。然而,由于以下原因,该方法会略微改变网格的外部形状:
However, increasing the definition of the SDF volume will lead to a mesh with particularly large face number, which requires the pipeline to provide a decimated mesh. It's worth noticing that most decimating methods in DCC software uses QEM triangle decimation [10], which will sometimes provide ill-formed faces i.e. the shape of the face may not be suitable for further developments. We therefore also recommend using ACVD [1, 35, 34] in the decimating step. We have also developed a baking tool based on baking function in Blender to provide texture for watertight mesh.
然而,增加 SDF 体积的定义将导致网格面数特别大,这需要流程提供简化后的网格。值得注意的是,DCC 软件中的大多数简化方法都使用 QEM 三角简化 [10],这种方法有时会产生不规则的网格面,即面的形状可能不适合进一步开发。因此,我们建议在简化步骤中使用 ACVD [1, 35, 34]。我们还基于 Blender 中的烘焙功能开发了一个烘焙工具,为水密网格提供纹理。
4.6. Rendering and Sampling
4.6. 渲染与采样
All meshes are normalized to a tightly coupled (radius is 1) bounding sphere using Welzl's algorithm [37]. We prefer not to use bounding boxes because arbitrarily rotating objects within them may cause the objects to extend beyond the confines of the box. Rendering is done in Blender using EEVEE13 renderer, while sampling is done using trimesh14. We sample three groups of points,each with $500k$ points, which is similar to sampling approach used by For 3D geometry compression model, we build upon CraftsMan [16], who adopts structures introduced in 3 D Shape 2 Vec Set [40]:
所有网格均使用 Welzl 的算法 [37] 归一化为紧密耦合(半径为 1)的包围球。我们更倾向于不使用包围盒,因为在其内部任意旋转对象可能导致对象超出盒子的范围。渲染在 Blender 中使用 EEVEE13 渲染器完成,而采样使用 trimesh14 完成。我们采样三组点,每组包含 $500k$ 个点,这与 3D 几何压缩模型所采用的采样方法类似,我们基于 CraftsMan [16] 构建,后者采用了 3D Shape 2 Vec Set [40] 中引入的结构:
· We perform uniformly random sampling within the circumscribed cube of the bounding sphere, yielding SPACE points. · We sample a group of points just on surface of the watertight mesh, yielding SURFACE points. We compute Gaussian curvature of each vertex on the mesh and use this curvature as importance of each area on the mesh: more points will be sampled on areas with higher curvature.
· 我们在包围球的立方体内进行均匀随机采样,得到 SPACE 点。
· 我们在水密网格的表面上采样一组点,得到 SURFACE 点。我们计算网格上每个顶点的高斯曲率,并将此曲率作为网格上每个区域的重要性:在曲率较高的区域将采样更多的点。

Figure 12. Visual results with color image as input, the green areas show the rendered multi-view images without textures and the red areas show the rendered multi-view images with textures.
图 12. 以彩色图像作为输入的视觉结果,绿色区域显示未带纹理的渲染多视图图像,红色区域显示带纹理的渲染多视图图像。
· We perform uniformly random sampling on the surface of the mesh, and add a small bias to coordinates of each sampled point, yielding NEAR-SURFACE points.
我们在网格表面进行均匀随机采样,并对每个采样点的坐标添加一个小偏差,生成近表面点。
5. Experiments
5. 实验<|end▁of▁sentence|>
Fig. 12 and Fig. 13 illustrate the results of 3D generation with the prompt and the image as input. As shown in these figures, which shows that our Pandora3D system could faithfully recover the shape and texture with fine-grained details and produce neat space without any floaters.
图 12 和图 13 展示了以提示词和图像作为输入的 3D 生成结果。如图所示,我们的 Pandora3D 系统能够忠实恢复具有精细细节的形状和纹理,并生成整洁的空间,没有任何漂浮物。
6. Conclusion
6. 结论
In this report, we present Pandora3D, a framework designed for high-quality 3D shape and texture generation. 3D shape generation and texture generation are proposed in Pandora3D. In specific, the 3D shape generation utilizes a Variation al Autoencoder (VAE) to encode implicit 3D geometries into a latent space; then, a diffusion network is used to generate latents conditioned on input prompts, with modifications aimed at enhancing the model's capacity. Meanwhile, we also explore an alternative Artist-Created Mesh (AM) generation approach, which shows promising results for simpler geometries. The texture generation process is multi-staged, starting with the generation of frontal images, followed by multi-view images generation, RGB-to-PBR texture conversion, and high-resolution multi-view texture refinement. A novel consistency scheduler is integrated into every stage of this process to ensure pixel-wise consistency among multi-view textures during inference, leading to seamless integration. Experiment results demonstrate the effectiveness of Pandora3D handling of diverse input formats to produce high-quality 3D content.
在本报告中,我们介绍了Pandora3D,这是一个专为高质量3D形状和纹理生成设计的框架。Pandora3D提出了3D形状生成和纹理生成的方案。具体而言,3D形状生成利用变分自编码器(VAE)将隐式3D几何体编码到潜在空间中;然后,使用扩散网络根据输入提示生成潜在变量,并通过改进增强模型的能力。同时,我们还探索了一种替代的艺术家创建网格(AM)生成方法,该方法在简单几何体上表现出色。纹理生成过程是多阶段的,首先生成正面图像,然后生成多视角图像,接着进行RGB到PBR纹理的转换,最后进行高分辨率多视角纹理的细化。整个过程每个阶段都集成了新颖的一致性调度器,以确保推理过程中多视角纹理之间的像素级一致性,从而实现无缝集成。实验结果证明了Pandora3D在处理多种输入格式以生成高质量3D内容方面的有效性。
References
参考文献
[1] M Audette, D Riviere, M Ewend, A En quo bah rie, and S Valette. Approach-guided controlled resolution brain meshing for fe-based interactive neurosurgery simulation. In Workshop on Mesh Processing in Medical Image Analysis, in conjunction with MICCAI 2011, pages 176-186, 2011. 11
[1] M Audette, D Riviere, M Ewend, A En quo bah rie, 和 S Valette. 基于有限元交互式神经外科模拟的方法引导可控分辨率脑网格生成. 在 MICCAI 2011 的医学图像分析中的网格处理研讨会中, 第 176-186 页, 2011.

Figure 13. Visual results with prompt as input, the green areas show the rendered multi-view images without textures and the red area show the rendered multi-view images with textures.
图 13: 以提示词为输入的可视化结果,绿色区域显示无纹理渲染的多视角图像,红色区域显示带纹理渲染的多视角图像。