ViDoRAG: Visual Document Retrieval-Augmented Generation via Dynamic Iterative Reasoning Agents
ViDoRAG: 基于动态迭代推理AI智能体的视觉文档检索增强生成
Abstract
摘要
Understanding information from visually rich documents remains a significant challenge for traditional Retrieval-Augmented Generation (RAG) methods. Existing benchmarks predominantly focus on image-based question answering (QA), overlooking the fundamental challenges of efficient retrieval, comprehension, and reasoning within dense visual documents. To bridge this gap, we introduce ViDoSeek, a novel dataset designed to evaluate RAG performance on visually rich documents requiring complex reasoning. Based on it, we identify key limitations in current RAG approaches: (i) purely visual retrieval methods struggle to effectively integrate both textual and visual features, and (ii) previous approaches often allocate insufficient reasoning tokens, limiting their effectiveness. To address these challenges, we propose ViDoRAG, a novel multi-agent RAG framework tailored for complex reasoning across visual documents. ViDoRAG employs a Gaussian Mixture Model (GMM)-based hybrid strategy to effectively handle multi-modal retrieval. To further elicit the model’s reasoning capabilities, we introduce an iterative agent workflow incorporating exploration, sum mari z ation, and reflection, providing a framework for investigating test-time scaling in RAG domains. Extensive experiments on ViDoSeek validate the effectiveness and generalization of our approach. Notably, ViDoRAG outperforms existing methods by over $10%$ on the competitive ViDoSeek benchmark.
理解视觉丰富文档中的信息对于传统的检索增强生成 (Retrieval-Augmented Generation, RAG) 方法仍然是一个重大挑战。现有的基准测试主要集中在基于图像的问答 (QA) 上,忽视了在密集视觉文档中进行高效检索、理解和推理的基本挑战。为了弥补这一差距,我们引入了 ViDoSeek,这是一个旨在评估 RAG 在需要复杂推理的视觉丰富文档上的性能的新数据集。基于此,我们识别了当前 RAG 方法的关键局限性:(i) 纯视觉检索方法难以有效整合文本和视觉特征,(ii) 先前的方法通常分配不足的推理 Token,限制了其有效性。为了解决这些挑战,我们提出了 ViDoRAG,这是一个专为跨视觉文档的复杂推理而设计的新型多智能体 RAG 框架。ViDoRAG 采用基于高斯混合模型 (Gaussian Mixture Model, GMM) 的混合策略,有效处理多模态检索。为了进一步激发模型的推理能力,我们引入了一个迭代的智能体工作流程,结合探索、总结和反思,为研究 RAG 领域的测试时扩展提供了一个框架。在 ViDoSeek 上的大量实验验证了我们方法的有效性和泛化能力。值得注意的是,ViDoRAG 在竞争性 ViDoSeek 基准测试中比现有方法高出超过 10%。
1 Introduction
1 引言
Retrieval-Augmented Generation (RAG) enhances Large Models (LMs) by enabling them to use external knowledge to solve problems. As the expression of information becomes increasingly diverse, we often work with visually rich documents that contain diagrams, charts, tables, etc. These visual elements make information easier to understand and are widely used in education, finance, law, and other fields. Therefore, researching RAG within visually rich documents is highly valuable.
检索增强生成 (Retrieval-Augmented Generation, RAG) 通过使大模型 (Large Models, LMs) 能够利用外部知识来解决问题,从而增强其能力。随着信息表达方式日益多样化,我们经常处理包含图表、表格等视觉元素的文档。这些视觉元素使信息更易于理解,并广泛应用于教育、金融、法律等领域。因此,在视觉丰富的文档中研究 RAG 具有很高的价值。
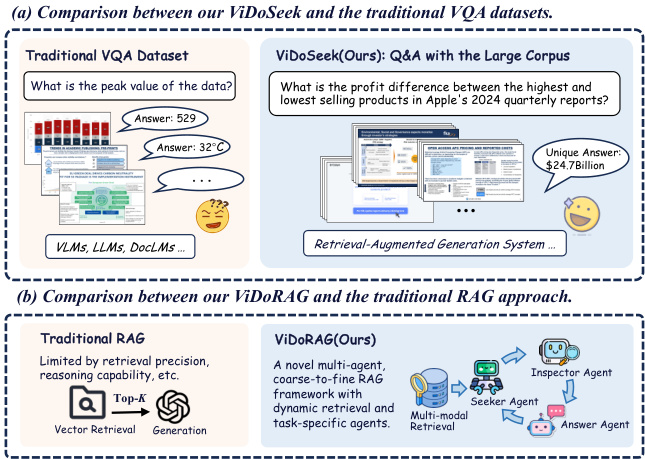
Figure 1: Comparison of our work with the existing datasets and methods. (a) In traditional datasets, each query must be paired with specific images or documents. In our ViDoSeek, each query can obtain a unique answer within the large corpus. (b) Our ViDoRAG is a multiagent, coarse-to-fine framework specifically optimized for visually rich documents.
图 1: 我们的工作与现有数据集和方法的对比。(a) 在传统数据集中,每个查询必须与特定的图像或文档配对。在我们的 ViDoSeek 中,每个查询都可以在大语料库中获得唯一的答案。(b) 我们的 ViDoRAG 是一个多智能体、由粗到细的框架,专门针对视觉丰富的文档进行了优化。
In practical applications, RAG systems often need to retrieve information from a large collection consisting of hundreds of documents, amounting to thousands of pages. As shown in Fig. 1, existing Visual Question Answering (VQA) benchmarks aren’t designed for such large corpus. The queries in these benchmarks are typically paired with one single image(Methani et al., 2020; Masry et al., 2022; Li et al., 2024; Mathew et al., 2022) or docu- ment(Ma et al., 2024), which is used for evaluating Q&A tasks but not suitable for evaluating RAG systems. The answers to queries in these datasets may not be unique within the whole corpus.
在实际应用中,RAG系统通常需要从由数百个文档组成的庞大数据集中检索信息,这些文档总页数可达数千页。如图 1 所示,现有的视觉问答(VQA)基准测试并未针对如此大规模的数据集进行设计。这些基准测试中的查询通常与单个图像(Methani et al., 2020; Masry et al., 2022; Li et al., 2024; Mathew et al., 2022)或文档(Ma et al., 2024)配对,这些设计适用于问答任务的评估,但不适合评估RAG系统。在这些数据集中,查询的答案在整个数据集中可能并不唯一。
To address this gap, we introduce ViDoSeek, a novel dataset designed for visually rich document retrieval-reason-answer. In ViDoSeek, each query has a unique answer and specific reference pages. It covers the diverse content types and multi-hop reasoning that most VQA datasets include. This specificity allows us to better evaluate retrieval and generation performance separately.
为了解决这一差距,我们引入了 ViDoSeek,这是一个专为视觉丰富的文档检索-推理-回答设计的新数据集。在 ViDoSeek 中,每个查询都有唯一的答案和特定的参考页面。它涵盖了大视觉问答数据集中的多样化内容类型和多跳推理。这种特异性使我们能够更好地分别评估检索和生成性能。
Moreover, to enable models to effectively reason over a large corpus, we propose ViDoRAG, a multi-agent, coarse-to-fine retrieval-augmented generation framework tailored for visually rich documents. Our approach is based on two critical observations: (i) Inefficient and Variable Retrieval Performance. Traditional OCR-based retrieval struggles to capture visual information. With the development of vision-based retrieval, it is easy to capture visual information(Faysse et al., 2024; Yu et al., 2024a; Zhai et al., 2023). However, there lack of an effective method to integrate visual and textual features, resulting in poor retrieval of relevant content. (ii) Insufficient Activation of Reasoning Capabilities during Generation. Previous studies on inference scaling for RAG focus on expanding the length of retrieved documents(Jiang et al., 2024; Shao et al., 2025; Xu et al., 2023). However, due to the characteristics of VLMs, only emphasizing on the quantity of knowledge without providing further reasoning guidance presents certain limitations. There is a need for an effective inference scale-up method to efficiently utilize specific action spaces, such as resizing and filtering, to fully activate reasoning capabilities.
此外,为了使模型能够有效地在大规模语料库上进行推理,我们提出了ViDoRAG,这是一个专为视觉丰富文档设计的多智能体、由粗到细的检索增强生成框架。我们的方法基于两个关键观察:(i) 检索性能低效且不稳定。传统的基于OCR的检索难以捕捉视觉信息。随着基于视觉的检索技术的发展,捕捉视觉信息变得容易(Faysse et al., 2024; Yu et al., 2024a; Zhai et al., 2023)。然而,缺乏一种有效的方法来整合视觉和文本特征,导致相关内容检索效果不佳。(ii) 生成过程中推理能力激活不足。之前关于RAG推理扩展的研究主要集中在扩展检索文档的长度(Jiang et al., 2024; Shao et al., 2025; Xu et al., 2023)。然而,由于VLM的特性,仅强调知识的数量而不提供进一步的推理指导存在一定的局限性。需要一种有效的推理扩展方法,以高效利用特定的操作空间(如调整大小和过滤)来充分激活推理能力。
Building upon these insights, ViDoRAG introduces improvements in both retrieval and generation. We propose Multi-Modal Hybrid Retrieval, which combines both visual and textual features and dynamically adjusts results distribution based on Gaussian Mixture Models (GMM) prior. This approach achieves the optimal retrieval distribution for each query, enhancing generation efficiency by reducing unnecessary computations. During generation, our framework comprises three agents: the seeker, inspector, and answer agents. The seeker rapidly scans thumbnails and selects relevant images with feedback from the inspector. The inspector reviews, then provides reflection and offers preliminary answers. The answer agent ensures consistency and gives the final answer. This framework reduces exposure to irrelevant information and ensures consistent answers across multiple scales.
基于这些洞察,ViDoRAG 在检索和生成方面均提出了改进。我们提出了多模态混合检索 (Multi-Modal Hybrid Retrieval),它结合了视觉和文本特征,并基于高斯混合模型 (GMM) 先验动态调整结果分布。这种方法为每个查询实现了最优检索分布,通过减少不必要的计算来提升生成效率。在生成过程中,我们的框架包含三个 AI智能体:搜索者、检查者和回答者。搜索者快速浏览缩略图,并根据检查者的反馈选择相关图像。检查者进行审查,随后提供反思并给出初步答案。回答者确保一致性并给出最终答案。该框架减少了与无关信息的接触,并确保了跨多个尺度的一致性答案。
Our major contributions are as follows:
我们的主要贡献如下:
• We introduce ViDoSeek, a benchmark specifically designed for visually rich document retrieval-reason-answer, fully suited for evaluation of RAG within large document corpus. • We propose ViDoRAG, a novel RAG framework that utilizes a multi-agent, actor-critic paradigm for iterative reasoning, enhancing the noise robustness of generation models. • We introduce a GMM-based multi-modal hybrid retrieval strategy to effectively integrate visual and textual pipelines. • Extensive experiments demonstrate the effectiveness of our method. ViDoRAG significantly outperforms strong baselines, achieving over $10%$ improvement, thus establishing a new state-of-the-art on ViDoSeek.
• 我们推出了 ViDoSeek,这是一个专为视觉丰富的文档检索-推理-回答设计的基准,完全适合在大文档语料库中评估 RAG。
• 我们提出了 ViDoRAG,这是一个新颖的 RAG 框架,利用多智能体、演员-评论家范式进行迭代推理,增强生成模型的噪声鲁棒性。
• 我们引入了一种基于 GMM 的多模态混合检索策略,以有效整合视觉和文本管道。
• 大量实验证明了我们方法的有效性。ViDoRAG 显著优于强基线,实现了超过 $10%$ 的提升,从而在 ViDoSeek 上建立了新的最先进水平。
2 Related Work
2 相关工作
Visual Document Q&A Benchmarks. Visual Document Question Answering is focused on answering questions based on the visual content of documents(Antol et al., 2015; Ye et al., 2024; Wang et al., 2024). While most existing research (Methani et al., 2020; Masry et al., 2022; Li et al., 2024; Mathew et al., 2022) has primarily concentrated on question answering from single images, recent advancements have begun to explore multi-page document question answering, driven by the increasing context length of modern models (Mathew et al., 2021; Ma et al., 2024; Tanaka et al., 2023). However, prior datasets were not wellsuited for RAG tasks involving large collections of documents. To fill this gap, we introduce ViDoSeek, the first large-scale document collection QA dataset, where each query corresponds to a unique answer across a collection of $\sim6k$ images.
视觉文档问答基准。视觉文档问答专注于基于文档的视觉内容回答问题 (Antol et al., 2015; Ye et al., 2024; Wang et al., 2024)。虽然大多数现有研究 (Methani et al., 2020; Masry et al., 2022; Li et al., 2024; Mathew et al., 2022) 主要集中在单张图像的问答上,但最近的进展已经开始探索多页文档的问答,这是由现代模型不断增长的上下文长度驱动的 (Mathew et al., 2021; Ma et al., 2024; Tanaka et al., 2023)。然而,之前的数据集并不太适合涉及大量文档的 RAG 任务。为了填补这一空白,我们引入了 ViDoSeek,这是第一个大规模文档集合问答数据集,其中每个查询对应 $\sim6k$ 张图像集合中的唯一答案。
Retrieval-augmented Generation. With the advancement of large models, RAG has enhanced the ability of models to incorporate external knowledge (Lewis et al., 2020; Chen et al., 2024b; Wu et al., 2025). In prior research, retrieval often followed the process of extracting text via OCR technology (Chen et al., 2024a; Lee et al., 2024; Robertson et al., 2009). Recently, the growing interest in multimodal embeddings has greatly improved image retrieval tasks (Faysse et al., 2024; Yu et al., 2024a). Additionally, there are works that focus on In-Context Learning in RAG(Agarwal et al., 2025; Yue et al., 2024; Team et al., 2024; Weijia et al.,
检索增强生成。随着大模型的进步,RAG 增强了模型整合外部知识的能力 (Lewis et al., 2020; Chen et al., 2024b; Wu et al., 2025)。在先前的研究中,检索通常遵循通过 OCR 技术提取文本的过程 (Chen et al., 2024a; Lee et al., 2024; Robertson et al., 2009)。最近,对多模态嵌入的兴趣日益增长,极大地改善了图像检索任务 (Faysse et al., 2024; Yu et al., 2024a)。此外,还有专注于 RAG 中的上下文学习的工作 (Agarwal et al., 2025; Yue et al., 2024; Team et al., 2024; Weijia et al.,
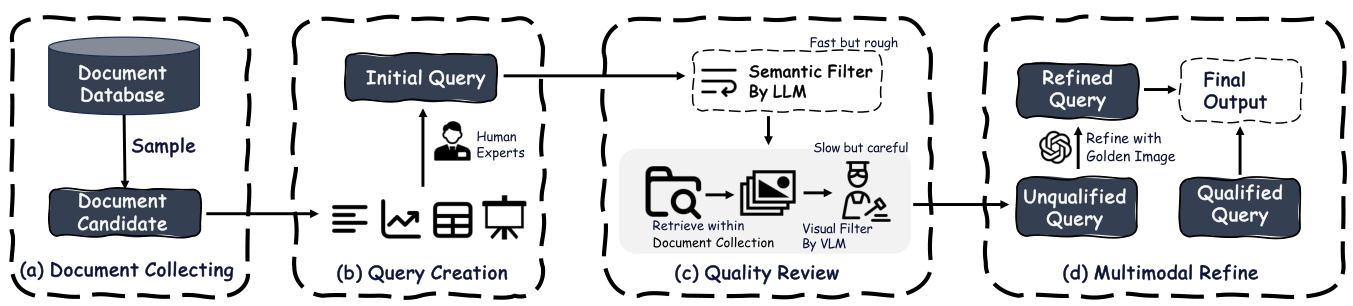
Figure 2: Data Construction pipeline. (a) We sample and filter documents according to the requirements to obtain candidates. (b) Then experts construct the initial query from different contents. (c) After that, we prompt GPT-4 to directly determine whether the query is a general query. The remaining queries are carefully reviewed with top $\cdot K$ recall images. (d) Finally, unqualified queries are refined paired with golden image by GPT-4o.
图 2: 数据构建流程。(a) 我们根据需求对文档进行采样和过滤,以获得候选文档。(b) 然后专家从不同内容中构建初始查询。(c) 之后,我们提示 GPT-4 直接判断查询是否为通用查询。剩余的查询会与 top $\cdot K$ 召回图像一起进行仔细审查。(d) 最后,不合格的查询会由 GPT-4o 与黄金图像配对进行优化。
2023). Our work builds upon these developments by combining multi-modal hybrid retrieval with a coarse-to-fine multi-agent generation framework, seamlessly integrating various embedding and generation models into a scalable framework.
2023)。我们的工作在这些进展的基础上,通过将多模态混合检索与从粗到细的多智能体生成框架相结合,无缝整合了各种嵌入和生成模型,构建了一个可扩展的框架。
3 Problem Formulation
3 问题表述
Given a query as $q$ , and we have a collection of documents $\mathcal{C}={\mathcal{D}{1},\mathcal{D}{2},\ldots,\mathcal{D}{M}}$ which contains $M$ documents. Each document $\mathcal{D}{m}$ consists of $N$ pages, each image representing an individual page, defined as $\mathcal{D}_{m}={\mathbf{I}_{1},\mathbf{I}_{2},\ldots,\mathbf{I}_{N}}$ . The to- tal number of images included in the collection is $\textstyle\sum_{m=1}^{M}|{\mathcal{D}}_{m}|$ . We aim to retrieve the most relevant information efficiently and accurately and generate the final answer $a$ to the query $q$ .
给定查询 $q$,我们有一个文档集合 $\mathcal{C}={\mathcal{D}{1},\mathcal{D}{2},\ldots,\mathcal{D}{M}}$,其中包含 $M$ 个文档。每个文档 $\mathcal{D}{m}$ 由 $N$ 页组成,每张图像代表一个单独的页面,定义为 $\mathcal{D}_{m}={\mathbf{I}_{1},\mathbf{I}_{2},\ldots,\mathbf{I}_{N}}$。集合中包含的图像总数为 $\textstyle\sum_{m=1}^{M}|{\mathcal{D}}_{m}|$。我们的目标是高效且准确地检索最相关的信息,并生成对查询 $q$ 的最终答案 $a$。
4 ViDoSeek Dataset
4 ViDoSeek 数据集
Existing VQA datasets typically consist of queries paired with a single image or a few images. However, in practical application scenarios, users often pose questions based on a large-scale corpus rather than targeting an individual document or image. To better evaluate RAG systems, we prefer questions that have unique answers when retrieving from a large corpus. To address this need, we introduce a novel Visually rich Document dataset specifically designed for RAG systems, called ViDoSeek. Below we provide the pipeline for constructing the dataset(§4.1) and a detailed analysis of the dataset(§4.2).
现有的 VQA 数据集通常由与单个图像或少数图像配对的查询组成。然而,在实际应用场景中,用户通常基于大规模语料库提出问题,而不是针对单个文档或图像。为了更好地评估 RAG 系统,我们更倾向于在从大规模语料库中检索时具有唯一答案的问题。为了满足这一需求,我们引入了一个专门为 RAG 系统设计的视觉丰富文档数据集,称为 ViDoSeek。下面我们提供了构建数据集的流程 (§4.1) 和数据集的详细分析 (§4.2)。
4.1 Dataset Construction.
4.1 数据集构建
To construct the ViDoSeek dataset, we developed a four-step pipeline to ensure that the queries meet our stringent requirements. As illustrated in Figure 2, our dataset comprises two parts: one annotated from scratch by our AI researchers, and the other derived from refining queries in the existing opensource dataset SlideVQA (Tanaka et al., 2023). For the open-source dataset, we initiate the query refinement starting from the third step of our pipeline. For the dataset we build from scratch, we follow the entire pipeline beginning with document collection. The following outlines our four-step pipeline:
为了构建 ViDoSeek 数据集,我们开发了一个四步流程,以确保查询符合我们的严格要求。如图 2 所示,我们的数据集由两部分组成:一部分由我们的 AI 研究人员从头开始标注,另一部分源自对现有开源数据集 SlideVQA (Tanaka et al., 2023) 中查询的优化。对于开源数据集,我们从流程的第三步开始进行查询优化。对于从头构建的数据集,我们从文档收集开始,遵循整个流程。以下是我们的四步流程:
Step 1. Document Collecting. As slides are a widely used medium for information transmission today, we selected them as our document source. We began by collecting English-language slides containing 25 to 50 pages, covering 12 domains such as economics, technology, literature, and geography. And we filtered out 300 slides that simultan e ou sly include text, charts, tables, and twodimensional layouts which refer to flowcharts, diagrams, or any visual elements composed of various components and are a distinctive feature of slides.
步骤 1:文档收集。由于幻灯片是当今广泛使用的信息传播媒介,我们选择其作为文档来源。我们首先收集了包含 25 至 50 页的英文幻灯片,涵盖经济、技术、文学和地理等 12 个领域。然后我们筛选出 300 份同时包含文本、图表、表格和二维布局的幻灯片,其中二维布局指的是流程图、示意图或由各种组件组成的视觉元素,这也是幻灯片的显著特征。
Step 2. Query Creation. To make the queries more suitable for RAG over a large-scale collection, our experts were instructed to construct queries that are specific to the document. Additionally, we encouraged constructing queries in various forms and with different sources and reasoning types to better reflect real-world scenarios.
步骤2:查询创建
Step 3. Quality Review. In large-scale retrieval and generation tasks, relying solely on manual annotation is challenging due to human brain limitations. To address this, we propose a review module that automatically identifies problematic queries.
第3步:质量审查。在大规模检索和生成任务中,由于人脑的局限性,仅依赖人工标注具有挑战性。为了解决这一问题,我们提出了一个自动识别问题查询的审查模块。
Step 4. Multimodal Refine. In this final step, we refine the queries that did not meet our standards during the quality review. We use carefully designed VLM-based agents to assist us throughout the entire dataset construction pipeline.
步骤 4:多模态优化。在此最终步骤中,我们对在质量审查中未达标的查询进行优化。我们使用精心设计的基于 VLM 的 AI智能体来协助我们完成整个数据集构建流程。
Table 1: Comparison of existing dataset with ViDoSeek.
表 1: 现有数据集与ViDoSeek的对比
| DATASET | DOMAIN | CONTENTTYPE | REFERENCETYPE | LARGEDOCUMENT COLLECTION |
|---|---|---|---|---|
| PlotQA (Methani et al., 2020) | Academic | Chart | Single-Image | x |
| ChartQA (Masry et al., 2022) | Academic | Chart | Single-Image | × |
| ArxivQA (Li et al., 2024) | Academic | Chart | Single-Image | |
| InfoVQA (Mathew et al., 2022) | Open-Domain | Text, Chart, Layout | Single-Image | xxxx |
| DocVQA (Mathew et al., 2021) | Open-Domain | Text, Chart, Table | Single-Document | |
| MMLongDoc (Ma et al., 2024) | Open-Domain | Text, Chart, Table, Layout | Single-Document | |
| SlideVQA (Tanaka et al., 2023) | Open-Domain | Text, Chart, Table, Layout | Single-Document | x |
| ViDoSeek (Ours) | Open-Domain | Text, Chart, Table, Layout | Multi-Documents |
4.2 Dataset Analysis
4.2 数据集分析
Dataset Statistics. ViDoSeek is the first dataset specifically designed for question-answering over large-scale document collections. It comprises approximate ly $\sim1.2k$ questions across a wide array of domains, addressing four key content types: Text, Chart, Table, and Layout. Among these, the Layout type poses the greatest challenge and represents the largest portion of the dataset. Additionally, the queries are categorized into two reasoning types: single-hop and multi-hop. Further details of the dataset can be found in the Appendix B and C.
数据集统计。ViDoSeek 是首个专门为大规模文档集合上的问答任务设计的数据集。它包含了约 $\sim1.2k$ 个问题,覆盖了多个领域,涉及四种关键内容类型:文本、图表、表格和布局。其中,布局类型最具挑战性,并且占据了数据集中最大的比例。此外,查询被分为两种推理类型:单跳和多跳。数据集的更多详细信息可以在附录 B 和 C 中找到。
Comparative Analysis. Table 1 highlights the limitations of existing datasets, which are predominantly tailored for scenarios involving single images or documents, lacking the capacity to handle the intricacies of retrieving relevant information from large collections. ViDoSeek bridges this gap by offering a dataset that more accurately mirrors real-world scenarios. This facilitates a more robust and scalable evaluation of RAG systems.
对比分析。表1突出了现有数据集的局限性,这些数据集主要针对涉及单张图像或文档的场景,缺乏处理从大型集合中检索相关信息的复杂性的能力。ViDoSeek 通过提供一个更准确反映现实世界场景的数据集来弥合这一差距。这有助于对 RAG 系统进行更稳健和可扩展的评估。
as the most relevant nodes are not always ranked at the top. Conversely, a larger $\kappa$ can slow down inference and introduce inaccuracies due to noise. Additionally, manually tuning $\kappa$ for different scenarios is troublesome.
由于最相关的节点并不总是排在前面。相反,较大的 $\kappa$ 会减慢推理速度并由于噪声引入不准确性。此外,手动为不同场景调整 $\kappa$ 也很麻烦。
Our objective is to develop a straightforward yet effective method to automatically determine $\kappa$ for each modality, without the dependency on a fixed value. We utilize the similarity $s$ of the embedding $E$ to quantify the relevance between the query and the document collection $\mathcal{C}$ :
我们的目标是开发一种简单而有效的方法来自动确定每个模态的 $\kappa$,而不依赖于固定值。我们利用嵌入 $E$ 的相似度 $s$ 来量化查询与文档集合 $\mathcal{C}$ 之间的相关性:

where $s_{i}$ represents the cosine similarity between the query $\mathcal{Q}$ and page $p_{i}$ . In the visual pipeline, a page corresponds to an image, whereas in the textual pipeline, it corresponds to chunks of OCR text. We propose that the distribution of $s$ follows a GMM and we consider they are sampled from a bimodal distribution $\mathcal{P}(s)$ shown in Fig.3:
其中 $s_{i}$ 表示查询 $\mathcal{Q}$ 与页面 $p_{i}$ 之间的余弦相似度。在视觉管道中,页面对应于图像,而在文本管道中,页面对应于 OCR 文本块。我们提出 $s$ 的分布遵循 GMM (Gaussian Mixture Model),并认为它们是从图 3 所示的双峰分布 $\mathcal{P}(s)$ 中采样的:

5 Method
5 方法
In this section, drawing from insights and foundational ideas, we present a comprehensive description of our ViDoRAG framework, which integrates two modules: Multi-Modal Hybrid Retrieval (§5.1) and Multi-Scale View Generation (§5.2).
在本节中,基于见解和基础思想,我们全面描述了 ViDoRAG 框架,该框架集成了两个模块:多模态混合检索 (Multi-Modal Hybrid Retrieval) (§5.1) 和多尺度视图生成 (Multi-Scale View Generation) (§5.2)。
5.1 Multi-Modal Hybrid Retrieval
5.1 多模态混合检索
For each query, our approach involves retrieving information through both textual and visual pipelines, dynamically determining the optimal value of topK using a Gaussian Mixture Model (GMM), and merging the retrieval results from both pipelines.
对于每个查询,我们的方法包括通过文本和视觉管道检索信息,使用高斯混合模型(GMM)动态确定 topK 的最佳值,并合并来自两个管道的检索结果。
Adaptive Recall with Gaussian Mixture Model. Traditional methods rely on a static hyper para meter, $\kappa$ , to retrieve the top $\cdot K$ images or text chunks from a corpus. A smaller $\kappa$ might fail to capture sufficient references needed for accurate responses, where $\mathcal{N}$ represents a Gaussian distribution, with $w,\mu,\sigma^{2}$ indicating the weight, mean, and variance, respectively. The subscripts $T$ and $F$ refer to the distributions of pages with high and low similarity. The distribution with higher similarity is deemed valuable for generation. The ExpectationMaximization (EM) algorithm is utilized to estimate the prior probability $\mathcal{P}(T|s,\mu_{T},\sigma_{T}^{2})$ for each modality. The dynamic value of $\kappa$ is defined as:
基于高斯混合模型的自适应召回。传统方法依赖于静态超参数 $\kappa$ 从语料库中检索前 $\cdot K$ 张图片或文本块。较小的 $\kappa$ 可能无法捕捉到准确响应所需的足够参考,其中 $\mathcal{N}$ 表示高斯分布,$w,\mu,\sigma^{2}$ 分别表示权重、均值和方差。下标 $T$ 和 $F$ 分别表示高相似度和低相似度的页面分布。具有较高相似度的分布被认为对生成有价值。期望最大化 (EM) 算法用于估计每种模态的先验概率 $\mathcal{P}(T|s,\mu_{T},\sigma_{T}^{2})$。$\kappa$ 的动态值定义为:

Considering that the similarity score distribution for different queries within a document collection may not strictly follow a standard distribution, we establish upper and lower bounds to manage outliers. The EM algorithm is employed sparingly, less than $\sim1%$ of the time. Dynamically adjusting $\kappa$ enhances generation efficiency compared to a static setting. Detailed analysis is available in $\S7.2$
考虑到文档集中不同查询的相似度得分分布可能不严格遵循标准分布,我们建立了上下限来管理异常值。EM算法使用得较少,不到 $\sim1%$ 的时间。与静态设置相比,动态调整 $\kappa$ 提高了生成效率。详细分析见 $\S7.2$
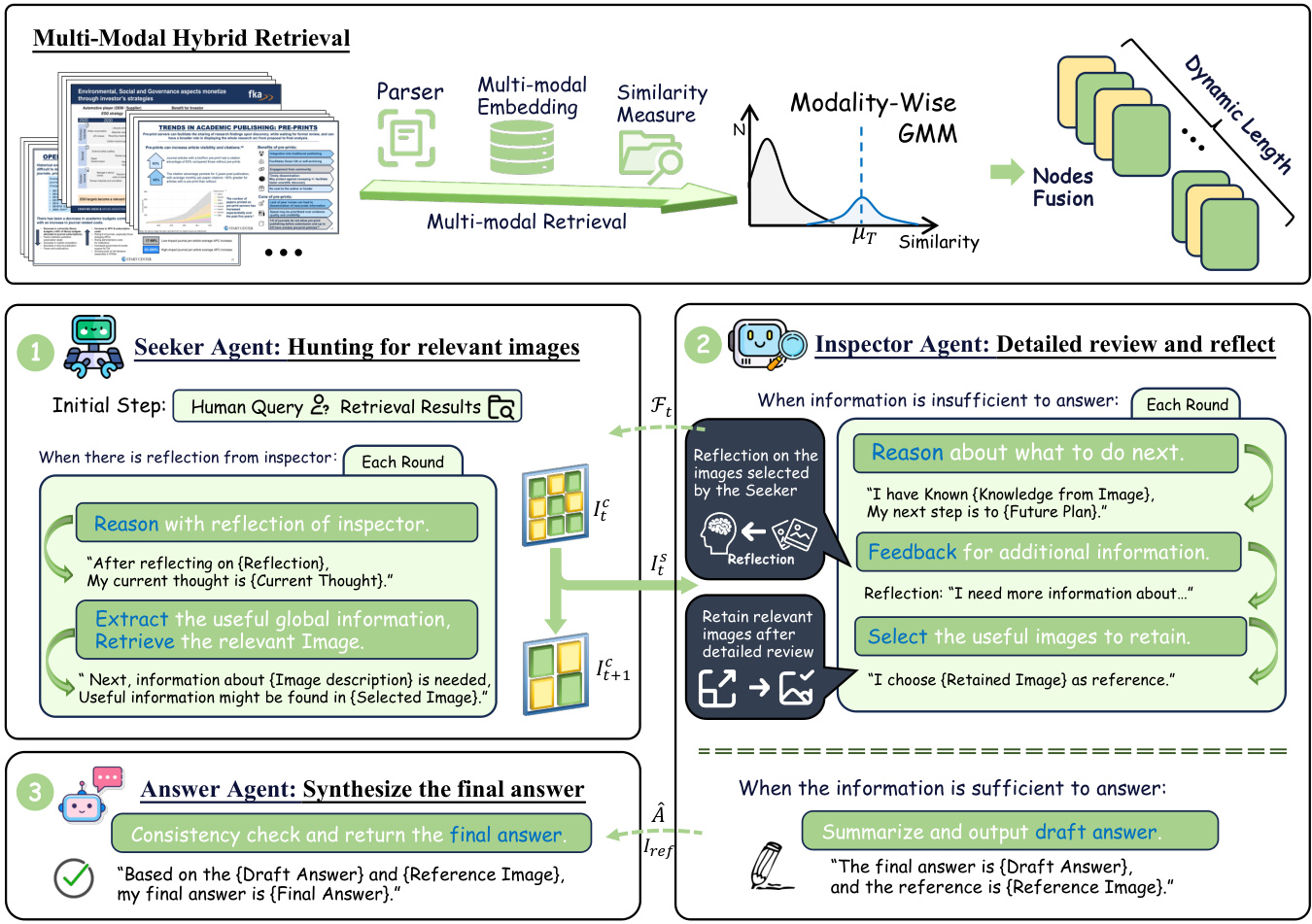
Figure 3: ViDoRAG Framework.
图 3: ViDoRAG 框架。
Textual and Visual Hybrid Retrieval. In the previous step, nodes were retrieved from both pipelines. In this phase, we integrate them:
文本与视觉混合检索。在上一步中,节点从两个流程中被检索出来。在这一阶段,我们将它们整合在一起:

where ${\mathcal{R}}{T e x t}$ and ${\mathcal{R}}{V i s u a l}$ denote the retrieval results from the textual and visual pipelines, respectively. The function ${\mathcal{F}}(\cdot)$ signifies a union operation, and $S o r t(\cdot)$ arranges the nodes in their original sequence, as continuous pages often exhibit correlation (Yu et al., 2024b).
其中 ${\mathcal{R}}{T e x t}$ 和 ${\mathcal{R}}{V i s u a l}$ 分别表示文本和视觉管道的检索结果。函数 ${\mathcal{F}}(\cdot)$ 表示并集操作,而 $S o r t(\cdot)$ 将节点按原始序列排列,因为连续页面通常表现出相关性 (Yu et al., 2024b)。
The textual and visual retrieval pipelines demonstrate varying levels of performance for different features. Without adaptive recall, the combined retrieval $\mathcal{R}_{h y b r i d}$ can become excessive. Adaptive recall ensures that effective retrievals are concise, while traditional pipelines yield longer recall results. This strategy optimizes performance relative to context length, underscoring the value of adaptive recall in hybrid retrieval.
文本和视觉检索管道在不同特征上表现出不同水平的性能。在没有自适应召回的情况下,组合检索 $\mathcal{R}_{h y b r i d}$ 可能会变得过度。自适应召回确保了有效的检索是简洁的,而传统的管道则会产生更长的召回结果。该策略相对于上下文长度优化了性能,强调了自适应召回在混合检索中的价值。
5.2 Multi-Agent Generation with Iterative Reasoning
5.2 基于迭代推理的多智能体生成
During the generation, we introduce a multi-agent framework which consists of three types of agents:
在生成过程中,我们引入了一个多智能体框架,该框架由三种类型的智能体组成:
the Seeker Agent, the Inspector Agent, and the Answer Agent. As illustrated in Fig. 3, this framework extracts clues, reflects, and answers in a coarse-tofine manner from a multi-scale perspective. More details are provided in Appendix D.
Seeker Agent、Inspector Agent 和 Answer Agent。如图 3 所示,该框架从多尺度角度以从粗到细的方式提取线索、反思和回答。更多细节见附录 D。
Seeker Agent: Hunting for relevant images.
Seeker Agent:寻找相关图像
The Seeker Agent is responsible for selecting from a coarse view and extracting global cues based on the query and reflection from the Inspector Agent. We have made some improvements to ReAct(Yao et al., 2022) to facilitate better memory management. The action space is defined as the selection of the images. Initially, the agent will reason only based on the query $\mathcal{Q}$ and select the most relevant images $\mathbf{I}{0}^{\mathrm{s}}$ from the candidate images $\mathbf{I}{0}^{\mathrm{c}}$ , while the initial memory $\mathcal{M}{0}$ is empty. In step $t$ , the candidate images $\mathbf{I}{t+1}^{\mathrm{c}}$ are the complement of previously selected images $\mathbf{I}{t}^{\mathrm{s}}$ , defined as $\mathbf{I}{t+1}^{\mathrm{c}}=\mathbf{I}{t}^{\mathrm{c}}\setminus\mathbf{I}{t}^{\mathrm{s}}$ . The seeker has received the reflection $\mathcal{F}{t-1}$ from the inspector, which includes an evaluation of the selected images and a more detailed description of the requirements for the images. The Seeker integrates feedback $\mathcal{F}{t-1}$ from the Inspector, which includes an evaluation of the selected images and a description of image requirements, to further refine the selection $\mathbf{I}{t}^{s}$ and update the memory $\mathcal{M}{t+1}$ :
Seeker Agent 负责从粗略视图中选择并根据 Inspector Agent 的查询和反思提取全局线索。我们对 ReAct(Yao et al., 2022) 进行了一些改进,以便更好地管理内存。动作空间被定义为图像的选择。最初,智能体将仅根据查询 $\mathcal{Q}$ 进行推理,并从候选图像 $\mathbf{I}{0}^{\mathrm{c}}$ 中选择最相关的图像 $\mathbf{I}{0}^{\mathrm{s}}$,而初始内存 $\mathcal{M}{0}$ 为空。在步骤 $t$ 中,候选图像 $\mathbf{I}{t+1}^{\mathrm{c}}$ 是先前选择的图像 $\mathbf{I}{t}^{\mathrm{s}}$ 的补集,定义为 $\mathbf{I}{t+1}^{\mathrm{c}}=\mathbf{I}{t}^{\mathrm{c}}\setminus\mathbf{I}{t}^{\mathrm{s}}$。Seeker 从 Inspector 接收到反思 $\mathcal{F}{t-1}$,其中包括对所选图像的评估以及对图像需求的更详细描述。Seeker 整合来自 Inspector 的反馈 $\mathcal{F}{t-1}$,其中包括对所选图像的评估和图像需求的描述,以进一步优化选择 $\mathbf{I}{t}^{s}$ 并更新内存 $\mathcal{M}{t+1}$:

where $\mathcal{M}_{t+1}$ represents the model’s thought content in step $t$ under the ReAct paradigm, maintaining a constant context length. The process continues until the Inspector determines that sufficient information is available to answer the query, or the Seeker concludes that no further relevant images exist among the candidates.
其中 $\mathcal{M}_{t+1}$ 代表模型在 ReAct 范式下第 $t$ 步的思考内容,保持上下文长度不变。该过程将持续到 Inspector 确定有足够的信息来回答查询,或者 Seeker 得出结论认为候选图像中不再存在相关图像。
Inspector Agent: Review in detail and Reflect. In baseline scenarios, increasing the top $\mathcal{K}$ value improves recall $ @K$ , but accuracy initially rises and then falls. This is attributed to interference from irrelevant images, referred to as noise, affecting model generation. To address this, we use Inspector to perform a more fine-grained inspection of the images. In each interaction with the Seeker, the Inspector’s action space includes providing feedback or drafting a preliminary answer. At step $t$ , the inspector reviews images at high resolution, denoted as $\Theta(\mathbf{I}{t}^{c}\cup\mathbf{I}{t-1}^{r},\mathcal{Q})$ where $\mathbf{I}{t-1}^{r}$ are images retained from the previous step and $\mathbf{I}{t}^{c}$ are from the Seeker. If the current information is sufficient to answer the query, a draft answer $\hat{\boldsymbol A}$ is provided, alongside a reference to the relevant image:
审查员智能体:详细审查与反思。在基线场景中,增加 top $\mathcal{K}$ 值可以提高召回率 $ @K$,但准确率会先上升后下降。这是由于不相关图像(称为噪声)的干扰影响了模型生成。为了解决这个问题,我们使用审查员对图像进行更细粒度的审查。在与搜寻者的每次交互中,审查员的动作空间包括提供反馈或起草初步答案。在第 $t$ 步,审查员以高分辨率审查图像,记为 $\Theta(\mathbf{I}{t}^{c}\cup\mathbf{I}{t-1}^{r},\mathcal{Q})$,其中 $\mathbf{I}{t-1}^{r}$ 是前一步保留的图像,$\mathbf{I}{t}^{c}$ 来自搜寻者。如果当前信息足以回答查询,则提供草稿答案 $\hat{\boldsymbol A}$,并引用相关图像:

Conversely, if more information is needed, the Inspector offers feedback $\mathcal{F}{t}$ to guide the Seeker in better image selection and identifies images $\mathbf{I}{t}^{r}$ to retain for further review in the next step $t+1$ :
相反,如果需要更多信息,检查器会提供反馈 $\mathcal{F}{t}$,以指导搜索者更好地选择图像,并识别图像 $\mathbf{I}{t}^{r}$,以便在下一步 $t+1$ 中进一步审查。

The number of images the Inspector reviews is typically fewer than the Seeker’s, ensuring robustness in reasoning, particularly for Visual Language Models with moderate reasoning abilities.
检查员审查的图像数量通常少于搜索者,这确保了推理的稳健性,特别是对于具有中等推理能力的视觉语言模型。
Answer Agent: Synthesize the final answer. In our framework, the Seeker and Inspector engage in a continuous interaction, and the answer agent provides the answer in the final step. To balance accuracy and efficiency, the Answer Agent verifies the consistency of the Inspector’s draft answer Aˆ. If the reference image matches the Inspector’s input, the draft answer is accepted as the final answer $\bar{\mathcal{A}}=\hat{\mathcal{A}}$ . If the reference image is a subset of the input image, the answer agent should check for consistency between the draft answer $\hat{\boldsymbol A}$ and the reference image, then give the final answer $\mathcal{A}$ : If the reference image is a subset of Inspector’s the input, the Answer Agent ensures consistency between the draft answer $\hat{\boldsymbol A}$ and the reference image before finalizing the answer $\mathcal{A}$ :
答案生成器:合成最终答案。在我们的框架中,探索者和检查者持续互动,答案生成器在最后一步提供答案。为了平衡准确性和效率,答案生成器验证检查者草稿答案 Aˆ 的一致性。如果参考图像与检查者的输入匹配,则草稿答案被接受为最终答案 $\bar{\mathcal{A}}=\hat{\mathcal{A}}$。如果参考图像是输入图像的子集,答案生成器应检查草稿答案 $\hat{\boldsymbol A}$ 与参考图像之间的一致性,然后给出最终答案 $\mathcal{A}$:如果参考图像是检查者输入的子集,答案生成器在最终确定答案 $\mathcal{A}$ 之前确保草稿答案 $\hat{\boldsymbol A}$ 与参考图像之间的一致性:

The Answer Agent utilizes the draft answer as prior knowledge to refine the response from coarse to fine. The consistency check between the Answer Agent and Inspector Agent enhances the depth and comprehensiveness of the final answer.
答案智能体利用草稿答案作为先验知识,从粗到细地精炼回答。答案智能体与审查智能体之间的一致性检查增强了最终答案的深度和全面性。
6 Experiments
6 实验
6.1 Experimental Settings
6.1 实验设置
Evaluation Metric For our end-to-end evaluation, we employed a model-based assessment using GPT-4o, which involved assigning scores from 1 to 5 by comparing the reference answer with the final answer. Answers receiving scores of 4 or above were considered correct, and we subsequently calculate accuracy as the evaluation metric. For retrieval evaluation, we use recall as the metric.
评估指标
对于我们的端到端评估,我们采用了基于 GPT-4o 的模型评估方法,通过将参考答案与最终答案进行比较,给出 1 到 5 的评分。得分为 4 及以上的答案被视为正确,随后我们计算准确率作为评估指标。对于检索评估,我们使用召回率作为指标。
Baselines and Oracle. We selecte Nv-embedV2(Lee et al., 2024) and ColQwen2(Faysse et al., 2024) as the retrievers for the TextRAG and VisualRAG baselines, respectively. Based on their original settings, we choose the top-5 recall results as the generation input, which equals the average length of dynamic recall results. This ensures a fair comparison and highlights the advantages of our method. The Oracle serves as the upper bound performance, where the model responds based on the golden page without retrieval or other operations.
基线与 Oracle。我们选择 Nv-embedV2 (Lee et al., 2024) 和 ColQwen2 (Faysse et al., 2024) 分别作为 TextRAG 和 VisualRAG 基线的检索器。根据其原始设置,我们选择前 5 个召回结果作为生成输入,这等于动态召回结果的平均长度。这确保了公平的比较,并突出了我们方法的优势。Oracle 作为性能的上限,模型在没有任何检索或其他操作的情况下基于黄金页面进行响应。
6.2 Main Results
6.2 主要结果
As shown in Table. 2, we conducted experiments on both closed-source and open-source models: GPT-4o, Qwen2.5-7B-Instruct, Qwen2.5-VL7B(Yang et al., 2024)-Instruct, Llama3.2-Vision90B-Instruct. Closed-source models generally outperform open-source models performance. It is worth mentioning that the qwen2.5-VL-7B has shown excellent instruction-following and reasoning capabilities within our framework. In contrast, we found that the llama3.2-VL requires 90B parameters to accomplish the same instructions, which may be related to the model’s pre-training domain. The results suggest that while API-based models offer strong baseline performance, our method is also effective in enhancing the performance of opensource models, offering promising potential for future applications. To further demonstrate the robustness of the framework, we constructed a pipeline using data to rewrite queries from SlideVQA(Tanaka et al., 2023), making the queries suitable for scenarios involving large corpora. The experimental results are presented the analysis.
如表 2 所示,我们对闭源和开源模型进行了实验:GPT-4o、Qwen2.5-7B-Instruct、Qwen2.5-VL7B (Yang et al., 2024)-Instruct、Llama3.2-Vision90B-Instruct。闭源模型通常优于开源模型的性能。值得一提的是,qwen2.5-VL-7B 在我们的框架中表现出色,具备优秀的指令执行和推理能力。相比之下,我们发现 llama3.2-VL 需要 90B 参数才能完成相同的指令,这可能与模型的预训练领域有关。结果表明,虽然基于 API 的模型提供了强大的基线性能,但我们的方法也能有效提升开源模型的性能,为未来应用提供了广阔的前景。为了进一步证明框架的鲁棒性,我们使用数据构建了一个管道,从 SlideVQA (Tanaka et al., 2023) 中重写查询,使查询适用于涉及大规模语料的场景。实验结果展示了分析。
Table 2: Overall Generation performance.
表 2: 总体生成性能
| METHOD | REASONINGTYPE Single-hop | Multi-hop | ANSWER TYPE Text | Table | Chart | Layout | OVERALL |
|---|---|---|---|---|---|---|---|
| Llama3.2-Vision-90B-Instruct | |||||||
| Upper Bound | 83.1 | 78.7 | 88.7 | 73.1 | 68.1 | 85.1 | 81.1 |
| TextRAG | 42.6 | 45.7 | 67.6 | 41.8 | 25.4 | 45.9 | 43.9 |
| VisualRAG | 61.8 | 60.5 | 82.5 | 48.5 | 52.2 | 63.9 | 61.2 |
| ViDoRAG (Ours) | 73.3 | 68.5 | 85.1 | 65.6 | 56.1 | 74.7 | 71.2 |
| Qwen2.5-VL-7B-Instruct | |||||||
| Upper Bound | 77.5 | 78.2 | 88.4 | 77.1 | 69.4 | 78.8 | 77.9 |
| TextRAG | 59.6 | 55.7 | 78.7 | 53.8 | 40.7 | 60.5 | 57.6 |
| VisualRAG | 66.8 | 64.3 | 84.9 | 61.1 | 52.8 | 67.5 | 65.7 |
| ViDoRAG (Ours) | 70.4 | 67.3 | 81.9 | 65.2 | 57.7 | 71.3 | 69.1 |
| GPT-4o(Closed-SourcedModels) | |||||||
| Upper Bound | 88.8 | 86.3 | 97.5 | 85.7 | 77.1 | 89.4 | 87.7 |
| TextRAG | 64.3 | 62.6 | 78.7 | 61.0 | 48.4 | 66.1 | 63.5 |
| VisualRAG | 75.7 | 66.1 | 90.1 | 62.4 | 58.5 | 75.4 | 72.1 |
| ViDoRAG (Ours) | 83.5 | 74.1 | 88.5 | 73.6 | 76.4 | 80.4 | 79.4 |
Table 3: Retrieval Performance on ViDoSeek.
表 3: ViDoSeek 检索性能
| Retriever | Recall@1 | Recall@3 | Recall@5 | MRR@5 |
|---|---|---|---|---|
| BM25 | 55.2 | 77.4 | 84.5 | 66.5 |
| BGE-M3 (Chen et al., 2024a) | 60.2 | 79.3 | 87.6 | 70.5 |
| NV-Embed-V2 (Lee et al., 2024) | 64.1 | 83.5 | 90.3 | 74.7 |
| VisRAG-Ret (Yu et al., 2024a) | 64.4 | 84.1 | 91.2 | 75.2 |
| ColPali (Faysse et al., 2024) | 70.6 | 87.9 | 92.8 | 79.6 |
| ColQwen2 (Faysse et al., 2024) | 75.4 | 89.7 | 95.1 | 83.3 |

Figure 4: Retrieval performance across different retrievers and hybrid retrieval, along with ablations on GMM.
图 4: 不同检索器和混合检索的检索性能,以及对 GMM 的消融实验。
retrieval across queries, we use the average length of results for analysis. Our goal is to incorporate more relevant information within a shorter context while minimizing the impact of noise and reducing computational cost without losing valuable information. Dynamic retrieval can achieve better recall performance with a smaller context length, while hybrid retrieval combines the results of two pipelines achieving state-of-the-art performance.
在查询检索中,我们使用结果的平均长度进行分析。我们的目标是在较短的上下文中融入更多相关信息,同时尽量减少噪声的影响并降低计算成本,而不丢失有价值的信息。动态检索能够在较短的上下文长度下实现更好的召回性能,而混合检索则结合了两条管道的结果,实现了最先进的性能。
7 Analysis
7 分析
7.1 Ablations
7.1 消融实验
Table 4 presents the impact of different retrievers and generation methods on performance. We have decomposed the dynamic retrieval into two components, Dynamic and Hybrid. Naive refers to the method of direct input, which is most commonly used as baselines. Dynamic indicates using GMM to fit the optimal recall distribution based solely on the visual pipeline. Hybrid refers to merging the visual and the textual retrieval results directly, which leads to suboptimal results due to long contexts. Experiments demonstrate that the effectiveness and s cal ability of our improvements on retrieval and generation modules, as well as their combination, can comprehensively enhance end-to-end performance from various perspectives.
表 4 展示了不同检索器和生成方法对性能的影响。我们将动态检索分解为两个部分,动态(Dynamic)和混合(Hybrid)。朴素(Naive)指的是直接输入的方法,通常作为基线使用。动态(Dynamic)表示仅基于视觉管道使用 GMM 拟合最佳召回分布。混合(Hybrid)指的是直接将视觉和文本检索结果合并,由于长上下文的存在,会导致次优结果。实验表明,我们在检索和生成模块上的改进及其组合的有效性和可扩展性,可以从多个角度全面提升端到端性能。
6.3 Retrieval Evaluation
6.3 检索评估
In Table 3, we report the detailed performance for various retrievers, including OCR-based and visual-based. Due to the uncertainty of dynamical
表 3: 各种检索器的详细性能对比(包括基于 OCR 和基于视觉的检索器)。由于动态性不确定性
7.2 Time Efficiency
7.2 时间效率
How does dynamic retrieval balance latency and accuracy? In traditional RAG systems, using a small top-K value may result in missing critical information, whereas employing a larger value can introduce noise and increase computational overhead. ViDoRAG dynamically determines the number of documents to retrieve based on the similarity distribution between the query and the corpus. This approach ensures that only the most relevant documents are retrieved, thereby reducing unnecessary computations from overly long contexts and accelerating the generation process. As shown in Table 5, we compare retrieval with and without GMM based on the Naive method. The experiments indicate that GMM may reduce recall due to distribution bias. However, because it significantly shortens the generation context, it effectively improves performance in end-to-end evaluations.
动态检索如何平衡延迟与准确性?在传统的 RAG 系统中,使用较小的 top-K 值可能导致遗漏关键信息,而使用较大的值则可能引入噪声并增加计算开销。ViDoRAG 根据查询与语料库之间的相似度分布动态决定检索的文档数量。这种方法确保仅检索最相关的文档,从而减少因上下文过长带来的不必要计算,并加速生成过程。如表 5 所示,我们基于 Naive 方法对比了使用和不使用 GMM 的检索。实验表明,由于分布偏差,GMM 可能会降低召回率。然而,因为它显著缩短了生成上下文,因此在端到端评估中有效提升了性能。
Table 4: Ablation study on ViDoSeek benchmark.
表 4: ViDoSeek 基准的消融研究。
| 检索 | 生成 | 准确率 |
|---|---|---|
| Naive | Dynamic | Hybrid |
| √ |
Table 5: Evaluation of Dynamic Retrieval Methods.
表 5: 动态检索方法评估。
| 方法 | 准确率↑ | 平均页数↓ |
|---|---|---|
| w/oGMM | 72.1 | 10 |
| w/ GMM | 72.8 | 6.76 |
Latency Analysis of the Multi-Agent Generation. There is an increase in delay due to the iterative nature of the multi-agent system, as shown in Fig. 5. Each agent performs specific tasks in a sequential manner, which adds a small overhead compared to traditional straightforward RAG. However, despite the increase in latency, the overall performance improves due to the higher quality of generated answers, making the trade-off between latency and accuracy highly beneficial for complex RAG tasks.
多智能体生成的延迟分析

Figure 5: Latency Analysis on Generation.
图 5: 生成延迟分析
7.3 Modalities and Strategies of Generation
7.3 生成模态与策略
As shown in Fig. 6, the vision-based pipeline outperforms the text-based pipeline across all types, even for queries related to text content. Generally speaking, due to models’ inherent characteristics, the reasoning ability of LLMs is stronger than that of VLMs. However, the lack of visual information makes it difficult for models to identify the intrinsic connections between pieces of information. This also poses a challenge for the generation of content based on visually rich documents. While obtaining visual information, VidoRAG further enhances the reasoning capabilities of VLMs, striking a balance between accuracy and computational load.
如图 6 所示,基于视觉的管道在所有类型上都优于基于文本的管道,即使是与文本内容相关的查询也是如此。一般来说,由于模型的固有特性,大语言模型的推理能力比视觉语言模型更强。然而,缺乏视觉信息使得模型难以识别信息之间的内在联系。这也为基于视觉丰富的文档生成内容带来了挑战。在获取视觉信息的同时,VidoRAG 进一步增强了视觉语言模型的推理能力,在准确性和计算负载之间取得了平衡。

Figure 6: Performance across different types of queries on our ViDoSeek and the refined SlideVQA datasets.
图 6: 在我们的 ViDoSeek 和优化后的 SlideVQA 数据集上,不同类型查询的性能表现。

Figure 7: Scaling behavior with ViDoRAG.
图 7: 使用 ViDoRAG 的扩展行为。
7.4 Performance with Test-time Scaling
7.4 测试时缩放性能
Fig. 7 illustrates the number of interaction rounds between the seeker and inspector within ViDoRAG based on different models. Due to the limited instruction capabilities of some models, we sampled 200 queries for the experiment. Models with stronger performance require fewer reasoning iterations, while weaker models often need additional time to process and reach a conclusion. Conditioning the model on a few demonstrations of the task at inference time has been proven to be a computationally efficient approach to enhance model performance(Brown et al., 2020; Min et al., 2021). The results indicate that pre defining tasks and breaking down complex tasks into simpler ones is an effective method for scaling inference.
图 7 展示了基于不同模型的 ViDoRAG 中 seeker 和 inspector 之间的交互轮数。由于部分模型的指令能力有限,我们采样了 200 个查询用于实验。性能更强的模型需要的推理迭代次数更少,而较弱的模型通常需要额外的时间来处理并得出结论。在推理时基于少量任务演示对模型进行调节已被证明是一种计算高效的方法,可以提升模型性能 (Brown et al., 2020; Min et al., 2021)。结果表明,预定义任务并将复杂任务分解为简单任务是扩展推理的有效方法。
8 Conclusion
8 结论
In this work, we introduced ViDoRAG, a novel multi-agent RAG framework tailored for visually rich documents. By proposing a coarse-to-fine reasoning process and a multi-modal retrieval strategy, ViDoRAG significantly outperforms existing methods, achieving new SOTA on the ViDoSeek benchmark. Future work will focus on further optimizing the framework’s efficiency while maintaining high accuracy, and exploring its potential in diverse realworld applications, such as education and finance, where visually rich document RAG is crucial.
在本工作中,我们介绍了 ViDoRAG,这是一种专为视觉丰富文档设计的新型多智能体 RAG 框架。通过提出从粗到精的推理过程和多模态检索策略,ViDoRAG 显著优于现有方法,在 ViDoSeek 基准上达到了新的 SOTA。未来的工作将集中在进一步优化框架效率的同时保持高准确性,并探索其在教育和金融等视觉丰富文档 RAG 至关重要的多样化现实应用中的潜力。
Limitations
局限性
In addition to the advanced improvements mentioned above, our work has several limitations: (1) Potential Bias in Query Construction. The queries in ViDoSeek were constructed by human experts, which may introduce bias in the types of questions and the way they are phrased. This could affect the model’s ability to handle more diverse and natural language queries from real-world users. (2) Computational Overhead of ViDoRAG. The multi-agent framework, while effective in enhancing reasoning capabilities, introduces additional computational overhead due to the iterative interactions between the seeker, inspector, and answer agents. This may limit the s cal ability of the framework in scenarios with strict latency requirements. (3) Model Hallucinations. Despite the improvements in retrieval and reasoning, the models used in ViDoRAG can still generate hallucinated answers that are not grounded in the retrieved information. This issue can lead to incorrect or misleading responses, especially when the model is overconfident in its generated content.
除了上述高级改进之外,我们的工作还存在一些局限性:(1) 查询构建中的潜在偏差。ViDoSeek 中的查询是由人类专家构建的,这可能会在问题的类型和表述方式上引入偏差。这可能会影响模型处理来自现实世界中用户的更多样化和自然语言查询的能力。(2) ViDoRAG 的计算开销。多智能体框架虽然在增强推理能力方面有效,但由于搜索者、检查者和答案智能体之间的迭代交互,引入了额外的计算开销。这可能会限制框架在具有严格延迟要求的场景中的可扩展性。(3) 模型幻觉。尽管在检索和推理方面有所改进,但 ViDoRAG 中使用的模型仍然可能生成未基于检索信息的幻觉答案。这个问题可能会导致错误或误导性的响应,尤其是当模型对其生成的内容过于自信时。
In summary, while ViDoRAG demonstrates significant improvements in visually rich document retrieval and reasoning, there are still areas for further enhancement, particularly in terms of generalization to diverse document types, reducing potential biases in query construction, optimizing the computational efficiency of the multi-agent framework, and addressing the issue of model hallucinations. Future work will focus on addressing these limitations to further improve the robustness and applicability of the model.
总之,尽管 ViDoRAG 在视觉丰富的文档检索和推理方面展示了显著的改进,但仍有一些方面需要进一步优化,特别是在泛化到多样化文档类型、减少查询构建中的潜在偏见、优化多智能体框架的计算效率以及解决模型幻觉问题方面。未来的工作将集中在解决这些限制,以进一步提高模型的鲁棒性和适用性。
Ethical Considerations
伦理考量
Our data does not contain any private or sensitive information, and all content is derived from publicly available sources. Additionally, the construction and refinement of the dataset were conducted in a manner that respects copyright and intellectual property rights.
我们的数据不包含任何私人或敏感信息,所有内容均来源于公开可获取的资源。此外,数据集的构建和优化过程均遵循版权和知识产权保护的原则。
A Additional Experiments Details
A 额外实验细节
Backbones. To thoroughly validate the effectiveness of ViDoRAG, we conducted experiments on various models across various baselines, including both closed-source and open-source models: GPT-4o, Qwen2.5-7B, Llama3.2-3B, Qwen2.5-VL- 7B(Yang et al., 2024), Llama3.2-Vision-90B. For OCR-based pipelines, we use PPOCR(Ma et al., 2019) to recognize text within documents. Optionally, VLMs can also be employed for text recognition, as their OCR capabilities are quite strong.
骨干模型。为了全面验证 ViDoRAG 的有效性,我们在各种基线模型上进行了实验,包括闭源和开源模型:GPT-4o、Qwen2.5-7B、Llama3.2-3B、Qwen2.5-VL-7B (Yang et al., 2024)、Llama3.2-Vision-90B。对于基于 OCR 的流程,我们使用 PPOCR (Ma et al., 2019) 来识别文档中的文本。可选地,视觉语言模型 (VLMs) 也可以用于文本识别,因为它们的 OCR 能力非常强大。
Experimental Environments. We conducted our experiments on a server equipped with 8 A100 GPUs and 96 CPU cores. Open-source models require substantial computational resources.
实验环境。我们在配备8块A100 GPU和96个CPU核心的服务器上进行实验。开源模型需要大量的计算资源。
Retrieval Implementation Details. Due to the context length limitations of the model, we use the Top $2K$ pages to fit the GMM and we restrict the output chunks of the GMM algorithm to be between $K/2$ and $K$ , we set $K=10$ in practice.
检索实现细节。由于模型的上下文长度限制,我们使用前 $2K$ 页来拟合 GMM,并将 GMM 算法的输出块限制在 $K/2$ 到 $K$ 之间,实践中我们设置 $K=10$。
B More Details on Datasets
B 数据集更多细节
B.1 Annotation Case
B.1 标注案例
Annotated Data Format
标注数据格式

Figure 8: Annotation case in ViDoSeek.
图 8: ViDoSeek 中的标注案例。
B.2 Details on ViDoSeek
B.2 ViDoSeek 详情
More Dataset Statistics. The statistical about ViDoSeek is presented in Table 7. We categorize queries from a logical reasoning perspective into single-hop and multi-hop. Text, Table, Chart and Layout represent different sources of reference.
更多数据集统计。ViDoSeek 的统计数据如表 7 所示。我们从逻辑推理的角度将查询分为单跳和多跳。文本 (Text)、表格 (Table)、图表 (Chart) 和布局 (Layout) 代表不同的参考来源。
Dataset Difficulty. ViDoSeek sets itself apart with its heightened difficulty level, attributed to the multi-document context and the intricate nature of its content types, particularly the Layout category. The dataset contains both single-hop and multihop queries, presenting a diverse set of challenges. Consequently, ViDoSeek serves as a more comprehensive and demanding benchmark for RAG systems compared to previous works.
数据集难度。ViDoSeek 以其更高的难度水平脱颖而出,这归因于其多文档上下文和内容类型的复杂性,尤其是布局类别。该数据集包含单跳和多跳查询,呈现出多样化的挑战。因此,与之前的工作相比,ViDoSeek 为 RAG 系统提供了一个更全面且更具挑战性的基准。
Table 6: Statistics of ViDoSeek.
表 6: ViDoSeek 的统计信息
| STATISTIC | NUMBER |
|---|---|
| Total Questions | 1142 |
| Single-Hop Multi-Hop | 645 497 |
| Pure Text Chart | 80 |
| 157 | |
| Table | 175 730 |
| Layout |
B.3 Details on SlideVQA-Refined
B.3 SlideVQA-Refined 的详细信息
Dataset Statistics. We supplemented our experiments with the SlideVQA dataset to demonstrate the s cal ability of our method. SlideVQA categorizes queries from a logical reasoning perspective into single-hop and multi-hop. Non-span, singlespan, and multi-span respectively refer to answers derived from a single information-dense sentence, reference information that is sparse but located on the same page, and reference information distributed across different pages. The statistical information about dataset is presented in Table 7.
数据集统计。我们使用SlideVQA数据集补充了实验,以展示我们方法的可扩展性。SlideVQA从逻辑推理的角度将查询分为单跳和多跳。非跨度、单跨度和多跨度分别指从单个信息密集的句子、稀疏但位于同一页面的参考信息以及分布在不同页面的参考信息中得到的答案。数据集统计信息如表7所示。
Table 7: Statistics of SlideVQA-Refined.
表 7: SlideVQA-Refined 统计
| STATISTIC | NUMBER |
|---|---|
| TotalQuestions | 2020 |
| Single-Hop Multi-Hop | 1486 534 |
| Non-Span | 358 |
| Single-Spin Multi-Span | 1347 315 |
Dataset Difficulty. The SlideVQA dataset focuses on evaluating the RAG system’s ability to understand both visually sparse and visually dense information. When multi-hop questions involve reference information spread across different pages, it presents a significant challenge to the RAG system, further demonstrating the effectiveness of our approach.
数据集难度。SlideVQA 数据集专注于评估 RAG 系统对视觉稀疏和视觉密集信息的理解能力。当多跳问题涉及分布在多个页面的参考信息时,这对 RAG 系统提出了重大挑战,进一步证明了我们方法的有效性。
C Data Construction Details
C 数据构建细节
To construct the ViDoSeek dataset, we developed a four-step pipeline to ensure that the queries meet our requirements.
为了构建 ViDoSeek 数据集,我们开发了一个四步流程,以确保查询满足我们的要求。
Step 1. Document Collecting. We collected English-language slides containing 25 to 50 pages, covering 12 domains such as economics, technology, literature, and geography, etc.
第一步:文档收集。我们收集了包含25至50页的英文幻灯片,涵盖经济学、技术、文学和地理等12个领域。
Step 2. Query Creation. To make the queries more suitable for RAG over a large-scale collection, our experts constructed queries based on the following requirements: (i) Each query must have a unique answer when paired with the document. (ii) The query must include unique keywords that point to the specific document and pages. (iii) The query should require external knowledge. Additionally, we encouraged constructing queries in various forms and with different sources and reasoning types to better reflect real-world scenarios. Our queries not only focus on types of references, including text, tables, charts, and layouts, but also provide a classification of reasoning types, including single-hop and multi-hop.
步骤 2:查询创建。为了使查询更适合在大规模集合上进行 RAG (Retrieval-Augmented Generation),我们的专家根据以下要求构建了查询:(i) 每个查询与文档配对时必须有一个唯一的答案。(ii) 查询必须包含指向特定文档和页面的唯一关键词。(iii) 查询应需要外部知识。此外,我们鼓励构建各种形式、不同来源和推理类型的查询,以更好地反映现实场景。我们的查询不仅关注参考文献的类型,包括文本、表格、图表和布局,还提供了推理类型的分类,包括单跳和多跳。
Step 3. Quality Review. To effectively evaluate the generation and retrieval quality of our RAG system, we require queries that yield unique answers, preferably located on a specific page or within a few pages. However, in large-scale retrieval and generation tasks, relying solely on manual annotation is challenging due to human cognitive limitations. To address this, we propose a review module that automatically identifies problematic queries. This module consists of two steps: (i) We prompt LLMs to filter out queries that may have multiple answers across the document collection; for example, the question What is the profit for this company in 2024? might have a unique answer within a single document but could yield multiple answers in a multi-document setting. (ii) For the remaining queries, we retrieve the top $k$ slides for each query and use a VLM to determine whether each slide can answer the query. If only the golden page can answer the question, we consider it to meet the requirements. If pages other than the golden page can answer the query, we have experts manually evaluate and refine them.
步骤 3:质量审查。为了有效评估 RAG 系统的生成和检索质量,我们需要能够产生唯一答案的查询,最好位于特定页面或少数页面内。然而,在大规模检索和生成任务中,由于人类认知的限制,仅依赖人工标注是具有挑战性的。为了解决这一问题,我们提出了一个自动识别问题查询的审查模块。该模块包括两个步骤:(i) 我们提示大语言模型过滤掉可能在文档集合中有多个答案的查询;例如,问题“2024 年该公司的利润是多少?”在单个文档中可能有唯一答案,但在多文档环境中可能会产生多个答案。(ii) 对于剩余的查询,我们为每个查询检索前 $k$ 张幻灯片,并使用视觉语言模型 (VLM) 确定每张幻灯片是否能回答查询。如果只有黄金页面能回答问题,我们认为它符合要求。如果黄金页面以外的页面能回答查询,我们会请专家手动评估并完善它们。
Step 4. Multimodal Refine. In this final step, we refine the queries that did not meet our standards during the quality review. The goal is to adjust these queries so they satisfy the following requirements: (i) The refined query should point to specific pages within the large collection with minimal additional information; (ii) The refined query must retain its original meaning. We use carefully designed VLM-based agents to assist us throughout the entire dataset construction pipeline. The prompt is presented in Fig. 9 and Fig. 10, respectively. We will first perform filtering based on semantics, and then conduct a fine-grained review using a multimodal reviewer.
第4步:多模态优化。在这一最后步骤中,我们对在质量审查中未达标的查询进行优化。目标是调整这些查询,使其满足以下要求: (i) 优化后的查询应指向大集合中的特定页面,且附加信息最少; (ii) 优化后的查询必须保留其原始含义。我们在整个数据集构建流程中使用精心设计的基于VLM的智能体来辅助。提示分别如图9和图10所示。我们将首先基于语义进行过滤,然后使用多模态审查员进行细粒度审查。
D More Details about Multi-Agent Generation with Iterative Reasoning
D 多智能体生成与迭代推理的更多细节
We designed prompts to drive VLMs-based agents, and through our experiments, we found that some open-source models require the design of few-shot examples to learn specific thought patterns. See detailed prompts in Fig. 12, Fig.13 and Fig.14.
我们设计了提示词来驱动基于 VLMs 的 AI智能体,并通过实验发现,某些开源模型需要设计少样本示例来学习特定的思维模式。详见 图 12、图 13 和图 14 中的详细提示词。
System Prompt:
系统提示:
Multi-Modal Reviewer Prompt.
多模态评审提示
System Prompt:
系统提示:
Please check the image, tell me whether the image can answer my question.
请检查图像,告诉我图像是否能回答我的问题。
User Prompt:
用户提示:
Query: {Query Description} Image: {Relevant Image}
查询: {查询描述} 图像: {相关图像}
System Prompt:
系统提示:
Task
任务
Rewrite the following question so that it contains specific keywords that clearly point to the provided document, ensuring that it would likely match this document alone within a larger corpus.
根据提供的文档,重写以下问题,使其包含特定关键词,确保在更大语料库中仅匹配该文档。
Instruction
指令
Examples
示例
- Original question: GIS data integration is part of which process? - Rewritten question: Citizen Science shows which process the GIS data integration is part of?
- 原始问题:GIS数据集成是哪个过程的一部分?- 改写问题:公民科学展示了GIS数据集成是哪个过程的一部分?
- Original question: What directly follows "conduct market research to refine" in the figure? - Rewritten question: What directly follows "conduct market research to refine" in the figure within the Social Velocity Strategic Plan Process?
- 原问题:图中“conduct market research to refine”后面直接跟随什么?- 重写的问题:在社会速度战略计划流程中,图中“conduct market research to refine”后面直接跟随什么?
- Original question: How can the company which details 24 countries in the report be contacted? - Rewritten question: How can the company which details 24 countries in the Global Digital Statistics 2014 report, be contacted?
- 原问题:如何联系报告中详细列出24个国家的公司?
- 改写后的问题:如何联系在《2014年全球数字统计》报告中详细列出24个国家的公司?
- Original question: What substances are involved in the feeding of substrates? - Rewritten question: What substances are involved in the feeding of substrates during the production of penicillin?
原始问题:底物进料中涉及哪些物质?
改写后问题:青霉素生产过程中底物进料涉及哪些物质?
User Prompt:
用户提示:
Query: {Query Description} Document: {Document Description} Image: {Image File}
查询: {查询描述} 文档: {文档描述} 图像: {图像文件}
System Prompt:
系统提示:
Character Introduction
角色介绍
You are an artificial intelligence assistant with strong ability to find references to problems through images. The images are numbered in order, starting from zero and numbered as 0, 1, 2 ... Now please tell me what information you can get from all the images first, then help me choose the number of the best picture that can answer the question.
你是一个具备通过图像查找问题参考信息强大能力的人工智能助手。图像按顺序编号,从零开始,编号为0、1、2……现在请先告诉我你能从所有图像中获得什么信息,然后帮我选出最能回答问题的图片编号。
Response Format
响应格式
The number of the image is starting from zero, and counting from left to right and top to bottom, and you should response with the image number in the following format:
图片编号从零开始,从左到右、从上到下计数,响应时应使用以下格式的图片编号:
" reason ": Evaluate the relevance of the image to the question step by step , " summary ": Extract the information related to the problem , " choice ": List [ int ]
原因:逐步评估图像与问题的相关性
总结:提取与问题相关的信息
选择:列出 [int]
System Prompt:
系统提示:
Character Introduction
角色介绍
Images: {Images Pending Review.}
图像:{图像待审核。}
System Prompt:
系统提示:
Character Introduction
角色介绍
You are an artificial intelligence assistant with strong ability to answer questions through images. Please provide the answer to the question based on the information provided and tell me which pictures are your references.
你是一位具备通过图像回答问题能力的强大人工智能助手。请根据提供的信息回答问题,并告诉我你参考了哪些图片。
Response Format
响应格式
Please provide the answer in JSON format:
请以 JSON 格式提供答案:

Figure 14: Prompt of Answer Agent.
图 14: Answer Agent 的 Prompt。