深度研究的不同之处:解析深度研究的三种形态
在人工智能前沿实验室中,最近掀起了一股“深度研究(Deep Research)”的浪潮。2024年12月,谷歌发布了其Gemini 1.5深度研究模型;2025年2月,OpenAI紧随其后推出了自己的深度研究系统;Perplexity也在不久之后推出了其版本的深度研究功能。与此同时,DeepSeek、阿里巴巴的通义千问(Qwen)以及埃隆·马斯克的xAI也为其聊天机器人助手推出了搜索和深度搜索功能。此外,在GitHub上还涌现了数十个模仿这些功能的开源实现。这似乎表明,“深度研究”已经成为2025年的“检索增强生成(RAG)”,一切都被重新包装并贴上了“深度研究”的标签,但其具体内涵却并不明确。
这种现象听起来熟悉吗?它让人联想到2023年RAG的炒作热潮,以及近几个月关于代理(agents)和代理型RAG的关注。为了拨开迷雾,本文从技术实现的角度剖析各种形式的“深度研究”。
深度研究、深度搜索还是仅仅是搜索?
以下是几家主要公司对深度研究的定义:
- 谷歌:“深度研究利用人工智能为你探索复杂主题,并提供一份全面且易于阅读的报告。这是Gemini在处理复杂任务方面变得更好的初步展示,能够为你节省时间。”
- OpenAI:“深度研究是OpenAI的下一个代理工具,它能够独立完成工作。你只需给它一个提示,ChatGPT就会查找、分析并整合数百个在线资源,生成相当于研究分析师水平的详细报告。”
- Perplexity:“当你提出一个深度研究问题时,Perplexity会执行数十次搜索,阅读数百个来源,并通过对材料的推理自主生成一份全面的报告。”
去除营销术语后,深度研究的简洁定义为:
“深度研究是一种报告生成系统,它接受用户的查询,使用大型语言模型(LLMs)作为代理迭代搜索和分析信息,最终生成一份详细的报告作为输出。”
在自然语言处理(NLP)领域,这一过程被称为“报告生成”。
技术实现方式
自ChatGPT发布以来,报告生成(或称为“深度研究”)一直是人工智能工程领域的焦点。我自己在2023年初的黑客松活动中也进行过相关实验,当时人工智能工程刚刚起步。LangChain、AutoGPT、GPT-Researcher等工具以及无数次在Twitter和LinkedIn上的演示引起了广泛关注。然而,真正的挑战在于实现细节。以下我们将探讨常见的报告生成系统构建模式,指出它们之间的差异,并对不同厂商的产品进行分类。
未训练方法:有向无环图(DAG)
早期,人工智能工程师发现直接让像GPT-3.5这样的大模型从头生成报告并不现实。因此,他们采用了复合模式(Composite Patterns),将多个大模型调用串联起来形成流程。
典型步骤如下:
- 分解用户查询:有时使用“回退提示法”(step back prompting)创建报告大纲。
- 信息检索与摘要:针对每个部分,从搜索引擎或知识库中检索相关信息并进行总结。
- 生成连贯报告:最后,利用大模型将各部分缝合成一份完整的报告。
一个典型的例子是GPT-Researcher。在这种系统中,每个提示都经过精心的手动调整(即“提示工程”)。评估完全依赖于主观判断,导致报告质量参差不齐。
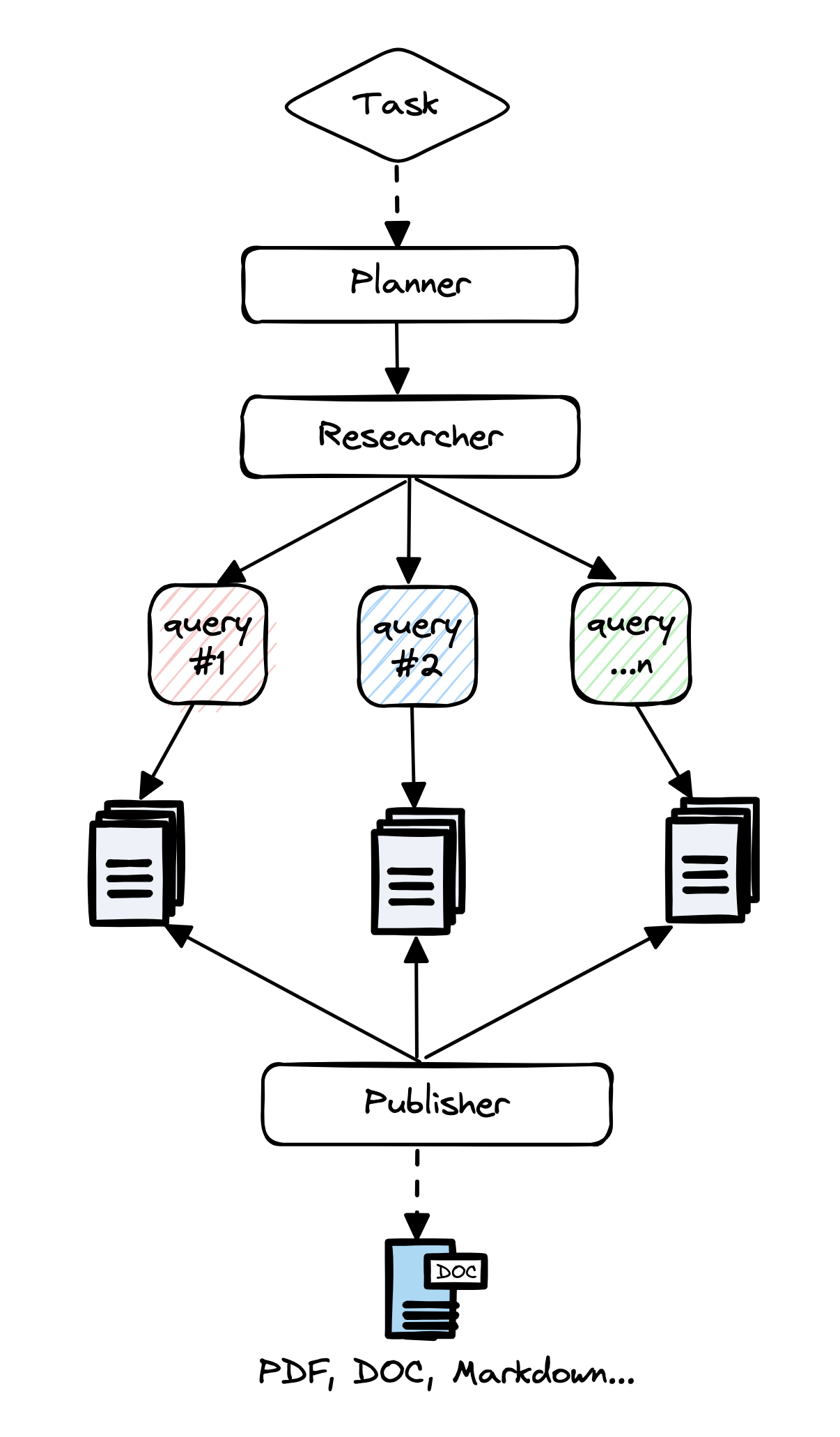
虽然这种方法效果不错,但其一致性和可靠性仍有待提高。
未训练方法:有限状态机(FSM)
为了提升报告质量,工程师们在DAG基础上增加了复杂性,引入了如“反思”(reflexion)和“自我反思”机制,让大模型审查并优化自身输出。这种方式将简单的DAG转变为有限状态机(FSM),大模型在一定程度上指导状态转换。
例如,Jina.ai的一个示意图很好地展示了这一方法:
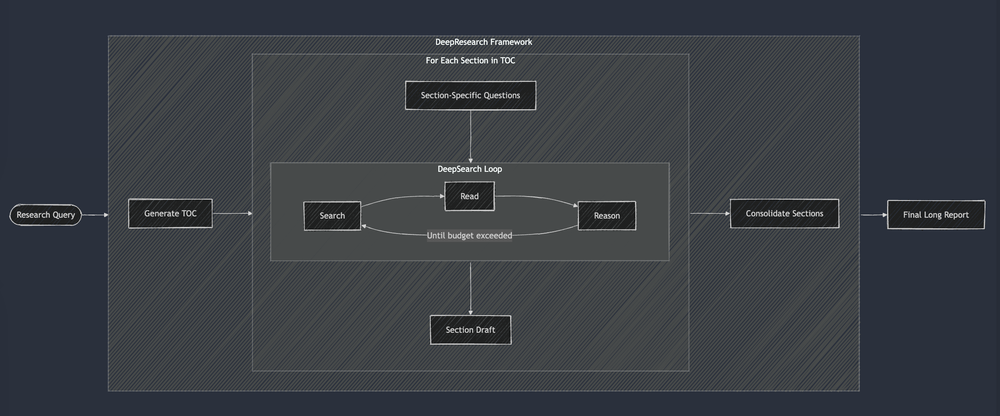
与DAG方法类似,FSM中的每个提示也需要手动设计,评估仍然主观化,系统质量因手调参数而波动较大。
训练方法:端到端
为解决前两种方法中提示工程混乱且缺乏可衡量评估标准的问题,研究人员尝试转向端到端优化。斯坦福大学的STORM项目[Shao et al, 2024]通过DSPy[Khattab et al, 2023]实现了这一目标。
以下是STORM的流程示意图:
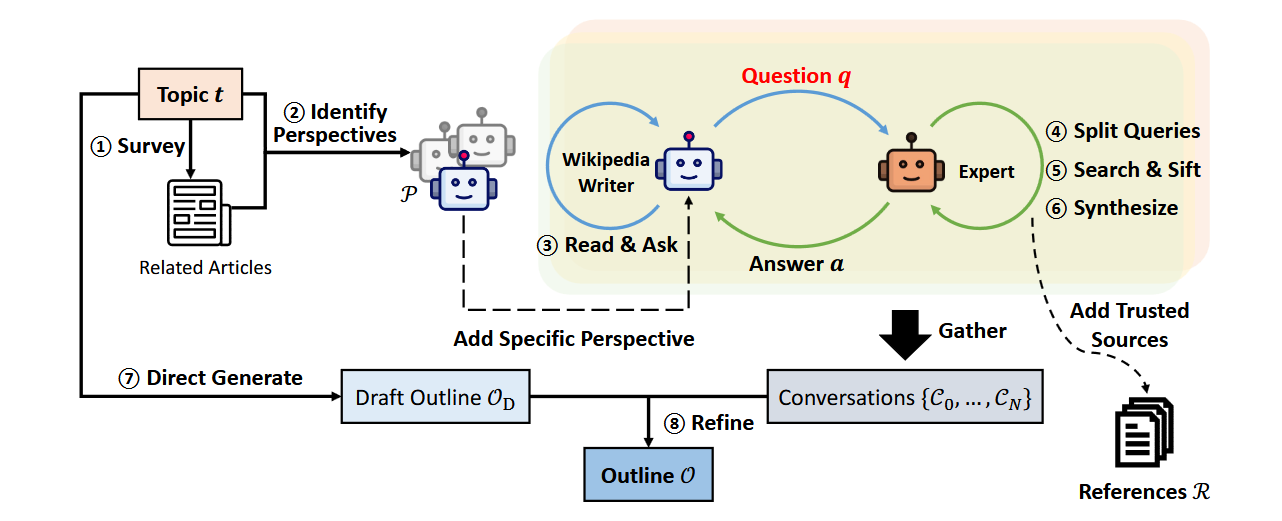
结果显示,STORM生成的报告质量接近维基百科文章水平。
训练方法:大型推理模型
随着大模型推理能力的提升,大规模推理模型成为深度研究的一种有力选择。例如,OpenAI描述了其深度研究模型的训练过程,其中包括使用“大模型作为评判员”[LLM-as-a-judge]和评分标准来评估输出质量。
以下是其流程示意图:

谷歌的Gemini和Perplexity的聊天助手也提供了“深度研究”功能,但两者均未公开如何优化模型或系统的文献资料,也没有进行实质性定量评估。不过,谷歌深度研究的产品经理在一次播客采访中提到:“我们有一些特殊权限。基本上还是同一个模型(Gemini 1.5),当然我们也做了些后续训练工作。”我们可以假设这些微调工作并不显著。
相比之下,xAI的Grok在报告生成方面表现出色,尽管其搜索通常不超过两次迭代——大纲部分几次,每部分内容再分别搜索几次。
竞争格局
我们绘制了一个概念地图,用于评估多种热门服务的深度研究能力。纵轴表示研究深度,定义为基于先前结果进行额外信息收集的迭代次数;横轴则评估训练水平,从手动调优的系统(如手工设计提示)到完全基于机器学习技术的训练系统。
以下是一些训练系统的示例:
- OpenAI深度研究:通过强化学习专门优化以满足研究任务需求。
- DeepSeek:训练用于通用推理和工具使用,适应研究需求。
- 谷歌Gemini:指令微调的大语言模型(LLMs),训练广泛但未专为研究优化。
- 斯坦福STORM:一个训练以端到端简化整个研究过程的系统。
这个框架突出了不同服务在研究深度和训练复杂度之间的平衡,有助于更清晰地了解它们在深度研究方面的优势。

结论
深度研究领域正以前所未有的速度发展。那些六个月前失败或未广泛推广的技术现在可能已取得成功。然而,命名规则仍不明晰,进一步加剧了混乱局面。希望本文能够帮助您澄清这些技术差异,摆脱营销术语的困扰。
参考资料
- Shao, Yijia et al. (2024). Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models. arXiv:2402.14207
- OpenAI (2025). Deep Research System Card. PDF
- GPT Researcher. GitHub Repository
- Jina AI. A practical guide to implementing DeepSearch/DeepResearch. Link
- Latent Space. The inventors of deep research. Link
作者简介:
韩乐(Hanchung Lee),专注于机器学习工程、复合AI系统、搜索与信息检索以及推荐系统。他曾在多个初创企业和企业级项目中深入探索机器学习、大语言模型代理及数据科学应用。