Visual-RFT: Visual Reinforcement Fine-Tuning
Visual-RFT: 视觉强化微调
{liuziyu77, szy2023}@sjtu.edu.cn, {zangyuhang, wangjiaqi}@pjlab.org.cr https://github.com/Liuziyu77/Visual-RFT
{liuziyu77, szy2023}@sjtu.edu.cn, {zangyuhang, wangjiaqi}@pjlab.org.cr https://github.com/Liuziyu77/Visual-RFT
Abstract
摘要
Reinforcement Fine-Tuning (RFT) in Large Reasoning Models like OpenAI o1 learns from feedback on its answers, which is especially useful in applications when fine-tuning data is scarce. Recent open-source work like DeepSeekR1 demonstrates that reinforcement learning with verifiable reward is one key direction in reproducing ol. While the Rl-style model has demonstrated success in language models,its application in multi-modal domains remains under-explored.This work introduces Visual Reinforcement Fine-Tuning (Visual-RFT), which further extends the application areas of RFT on visual tasks. Specifically, VisualRFT first uses Large Vision-Language Models (LVLMs) to generate multiple responses containing reasoning tokens and final answers for each input, and then uses our proposed visual perception verifiable reward functions to update the model via the policy optimization algorithm such as Group Relative Policy Optimization (GRPO). We design different verifiable reward functions for different perception tasks,such as the Intersection over Union (loU) reward for object detection.Experimental results on finegrained image classification, few-shot object detection, reasoning grounding,as well as open-vocabulary object detec tion benchmarks show the competitive performance and advanced generalization ability ofVisual-R FT compared with Supervised Fine-tuning (SFT). For example, VisualRFT improves accuracy by $24.3%$ over the baselinein oneshot fine-grained image classification with around 100 samples. In few-shot object detection, Visual-RFT also exceeds the baseline by 21.9 on COcO's two-shot setting and 15.4 on LVIS. Our Visual-RFT represents a paradigm shift in fine-tuning LVLMs, offering a data-efficient, rewarddriven approach that enhances reasoning and adaptability for domain-specific tasks.
在大型推理模型中的强化微调 (Reinforcement Fine-Tuning, RFT) 如 OpenAI o1 通过对其答案的反馈进行学习,这在微调数据稀缺的应用中尤为有用。最近的开源工作如 DeepSeekR1 表明,带有可验证奖励的强化学习是重现 ol 的一个关键方向。虽然 Rl 风格的模型在语言模型中已取得成功,但其在多模态领域的应用仍未被充分探索。本文介绍了视觉强化微调 (Visual Reinforcement Fine-Tuning, Visual-RFT),进一步扩展了 RFT 在视觉任务中的应用领域。具体而言,Visual-RFT 首先使用大型视觉语言模型 (Large Vision-Language Models, LVLMs) 为每个输入生成包含推理 Token 和最终答案的多个响应,然后使用我们提出的视觉感知可验证奖励函数通过策略优化算法(如 Group Relative Policy Optimization, GRPO)更新模型。我们为不同的感知任务设计了不同的可验证奖励函数,例如用于目标检测的交并比 (Intersection over Union, IoU) 奖励。在细粒度图像分类、少样本目标检测、推理定位以及开放词汇目标检测基准上的实验结果表明,与监督微调 (Supervised Fine-tuning, SFT) 相比,Visual-RFT 具有竞争性的性能和先进的泛化能力。例如,在仅有约 100 个样本的单样本细粒度图像分类中,Visual-RFT 的准确率比基线提高了 24.3%。在少样本目标检测中,Visual-RFT 在 COCO 的双样本设置上比基线高出 21.9,在 LVIS 上高出 15.4。我们的 Visual-RFT 代表了微调 LVLMs 的范式转变,提供了一种数据高效、奖励驱动的方法,增强了领域特定任务的推理和适应能力。
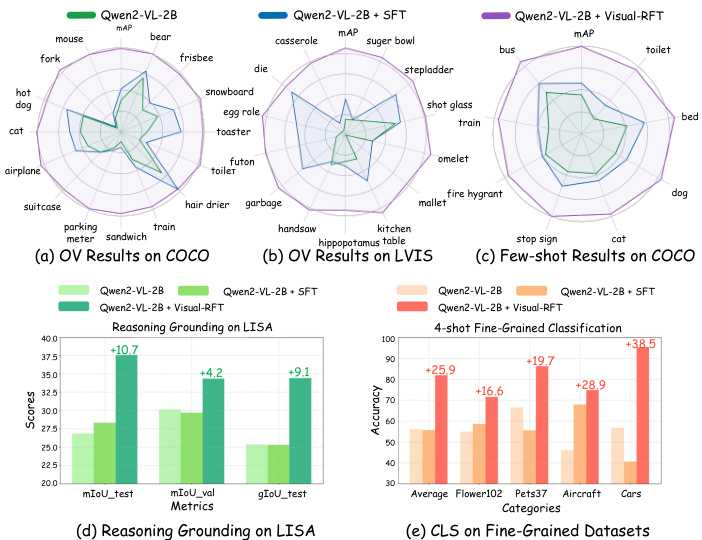
Figure 1. Our Visual Reinforcement Fine-Tuning (Visual-RFT) performs better than previous Supervised Fine-Tuning (SFT) on a variety of tasks, such as Open Vocabulary(OV)/Few-shot Detection, Reasoning Grounding, and Fine-grained Classification.
图 1: 我们的视觉强化微调 (Visual-RFT) 在多种任务上表现优于之前的监督微调 (SFT),例如开放词汇 (OV)/少样本检测、推理定位和细粒度分类。
1. Introduction
1. 引言
Large Reasoning Models (LRMs) such as OpenAI o1 [7] represent frontier AI models designed to spend more time "thinking" before answering, and achieving excellent reasoning abilities. One impressive capability of OpenAI o1 is Reinforcement Fine-Tuning (RFT) ', which efficiently fine-tune the model with merely dozens to thousands of samples to excel at domain-specific tasks. Although the implementation details of o1 are not publicly available, recent open-source studies like DeepSeek R1 [4] reveal one promising direction in reproducing ol is Verifiable Rewards [4, 12, 37]: the reward score in reinforcement learning is directly determined by pre-defined rules, rather than predicted by the separate reward model [17, 26, 45] trained on preference data.
大型推理模型 (Large Reasoning Models, LRMs) 如 OpenAI o1 [7] 代表了前沿的 AI 模型,旨在回答前花费更多时间“思考”,并具备卓越的推理能力。OpenAI o1 的一个令人印象深刻的能力是强化微调 (Reinforcement Fine-Tuning, RFT),它能够仅用几十到几千个样本高效地微调模型,使其在特定领域任务中表现出色。尽管 o1 的实现细节尚未公开,但最近的开源研究如 DeepSeek R1 [4] 揭示了重现 o1 的一个有前景的方向是可验证奖励 (Verifiable Rewards) [4, 12, 37]:强化学习中的奖励分数直接由预定义的规则决定,而不是通过基于偏好数据训练的单独奖励模型 [17, 26, 45] 来预测。
A primary distinction between the RFT and Previous Supervised Fine-Tuning (SFT) lies in data efficiency. Previous
RFT 与之前的监督微调 (SFT) 之间的主要区别在于数据效率。
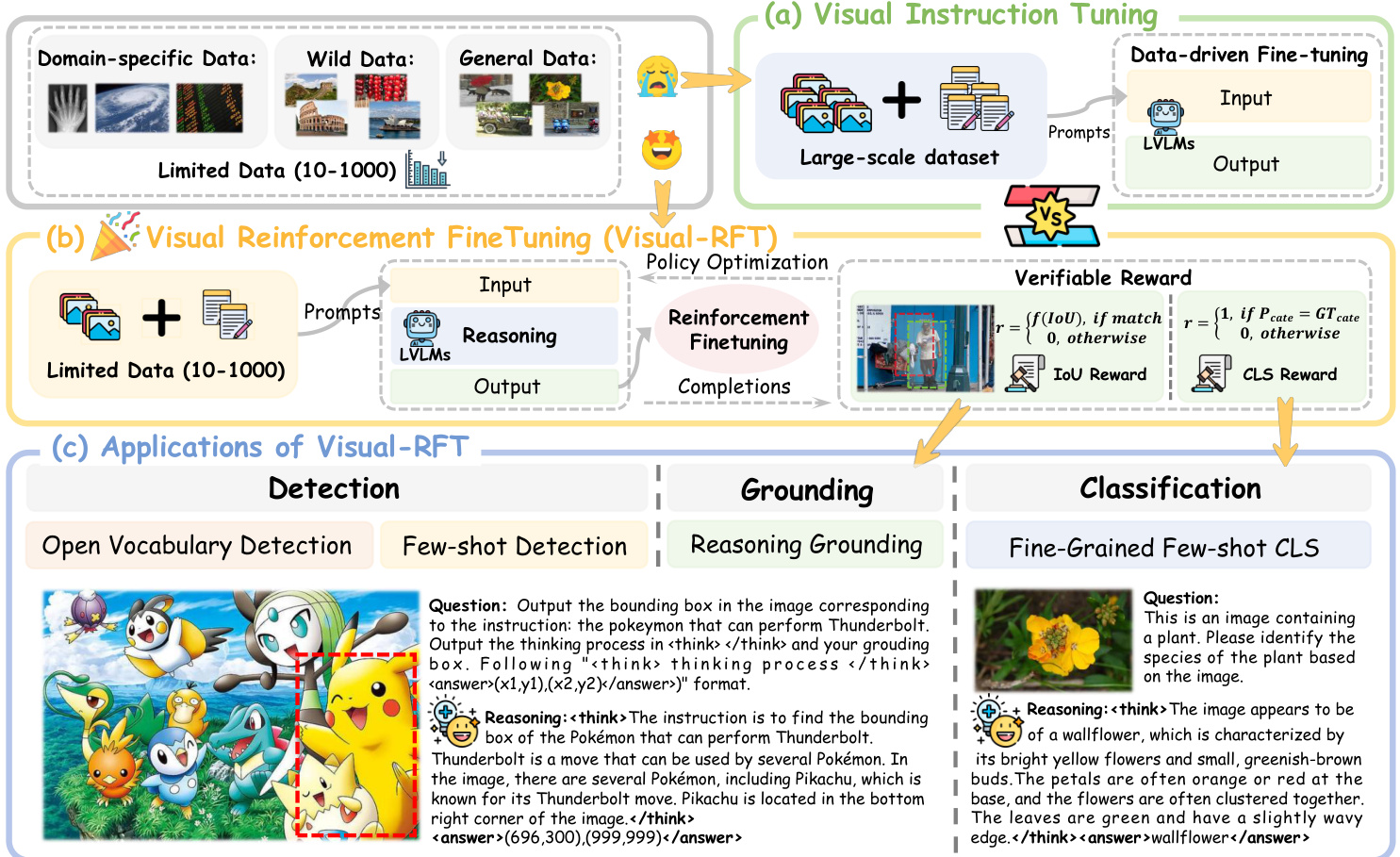
Figure 2. Overview of Visual-RFT. Compared to the (a) Visual Instruction Tuning that is data-hungry, (b) our Visual Reinforcement Fine-Tuning (Visual-RFT) is more data efficient with limited data. (c) We successfully empower Large Vision-Language Models (LVLMs) with RFT on a series of multi-modal tasks, and present examples of the model's reasoning process at the bottom.
图 2: Visual-RFT 概览。与 (a) 数据需求量大的视觉指令微调相比,(b) 我们的视觉强化微调 (Visual-RFT) 在数据有限的情况下更加高效。(c) 我们成功通过 RFT 在一系列多模态任务中增强了大视觉语言模型 (LVLMs) 的能力,并在底部展示了模型的推理过程示例。
SFT paradigm (see Fig. 2 (a)) directly imitates the “groundtruth" answers provided in the high-quality, curated data, thus relying on a large amount of training data. By contrast, RFT evaluates the model's responses and adjusts based on whether they're correct, helping it learn through trial and error. Thus, RFT is particularly useful in domains where data is scarce [7, 24]. However, a previous common sense is that RFT is applied merely in tasks like scientific (e.g., mathematics) and code generation. That's because math and coding exhibit clear and objective final answers or test cases, making their rewards relatively straightforward to verify. In this paper, we demonstrate that RFT can be applied beyond math and code domains to visual perception tasks. Specifically, we introduce Visual Reinforcement Fine-Tuning (Visual-RFT), which successfully extends RFT to empower Large Vision-Language Models (LVLMs) in various multi-modal tasks (see Fig. 1), such as few-shot classification and open-vocabulary object detection.
SFT 范式 (见图 2 (a)) 直接模仿高质量、精选数据中提供的“真实”答案,因此依赖于大量的训练数据。相比之下,RFT 评估模型的响应并根据其是否正确进行调整,帮助其通过试错学习。因此,RFT 在数据稀缺的领域特别有用 [7, 24]。然而,之前的普遍认知是 RFT 仅适用于科学 (如数学) 和代码生成等任务。这是因为数学和编码具有明确且客观的最终答案或测试用例,使得其奖励相对容易验证。在本文中,我们展示了 RFT 可以应用于数学和代码领域之外的视觉感知任务。具体来说,我们引入了视觉强化微调 (Visual-RFT),成功地将 RFT 扩展到赋能大视觉语言模型 (LVLMs) 在各种多模态任务中 (见图 1),例如少样本分类和开放词汇对象检测。
To extend RFT on visual tasks, we present the implementation details of Visual-RFT in Fig. 2 (b). For each input, Visual-RFT uses Large Vision-Language Models (LVLMs) to generate multiple responses (trajectories) that contain the reasoning tokens and final answers. Crucially, we define task-specific, rule-based verifiable reward functions to guide policy optimization, such as GRPO [31], in updating the model. For instance, we propose the Intersection over Union (IoU) reward for the object detection task. Our Visual-RFT contrasts with SFT, which relies on memorizing correct answers. Instead, our approach explores different possible solutions and learns to optimize for a desired outcome defined by our verified reward function. It's about discovering what works best, not just mimicking predefined answers. Our approach shifts the training paradigm from data scaling in SFT to the strategic design of variable reward functions tailored to specific multi-modal tasks. As shown in Fig. 2 (c), the synergistic combination of verifiable rewards and visual perception abilities (e.g., detection, grounding, classification) allows our model to achieve rapid and data-efficient mastery of new concepts, facilitated by a detailed reasoning process.
为了将 RFT 扩展到视觉任务上,我们在图 2 (b) 中展示了 Visual-RFT 的实现细节。对于每个输入,Visual-RFT 使用大型视觉语言模型 (LVLMs) 生成包含推理 Token 和最终答案的多个响应(轨迹)。关键的是,我们定义了特定于任务的、基于规则的可验证奖励函数,以指导策略优化(如 GRPO [31])来更新模型。例如,我们为目标检测任务提出了交并比 (IoU) 奖励。我们的 Visual-RFT 与 SFT 形成对比,后者依赖于记忆正确答案。相反,我们的方法探索了不同的可能解决方案,并学习优化由我们验证的奖励函数定义的期望结果。这是关于发现什么最有效,而不仅仅是模仿预定义的答案。我们的方法将训练范式从 SFT 中的数据扩展转变为针对特定多模态任务设计的可变奖励函数的战略设计。如图 2 (c) 所示,可验证奖励和视觉感知能力(例如检测、定位、分类)的协同组合使我们的模型能够通过详细的推理过程快速且高效地掌握新概念。
We validate the effectiveness of Visual-RFT on the following tasks. In fine-grained image classification, the model utilizes its advanced reasoning capabilities to analyze fine-grained categories with high precision. In the oneshot setting with extremely limited data (e.g., around 100 samples), Visual-RFT boosts the accuracy with $24.3%$ over the baseline, while SFT dropped by $4.3%$ . In few-shot experiments, Visual-RFT also demonstrates exceptional performance with minimal training data, showcasing superior few-shot learning capabilities compared to SFT. In reasoning grounding, Visual-RFT excels in the LISA [11] dataset, which heavily relies on reasoning, outperforming specialized models like Grounded SAM [18]. Furthermore, in open vocabulary object detection, Visual-RFT quickly transfers recognition capabilities to new categories, including rare categories in LVIS [5], showing strong generaliza- tion. Specifically, the 2B model achieves mAP improve- ments from 9.8 to 31.3 on new classes of COCO [15] and from 2.7 to 20.7 on selected rare classes of LVIS [5]. These diverse visual perception tasks not only highlight VisualRFT's robust generalization capabilities in visual recognition but also underscore the crucial role of reinforcement learning in enhancing visual perception and reasoning.
我们验证了 Visual-RFT 在以下任务中的有效性。在细粒度图像分类中,该模型利用其先进的推理能力,以高精度分析细粒度类别。在数据极其有限(例如约 100 个样本)的单样本设置中,Visual-RFT 的准确率比基线提高了 $24.3%$,而 SFT 则下降了 $4.3%$。在少样本实验中,Visual-RFT 在极少的训练数据下也表现出色,展示了比 SFT 更优越的少样本学习能力。在推理基础任务中,Visual-RFT 在 LISA [11] 数据集上表现出色,该数据集高度依赖推理,超越了 Grounded SAM [18] 等专用模型。此外,在开放词汇目标检测中,Visual-RFT 能够快速将识别能力转移到新类别,包括 LVIS [5] 中的稀有类别,展示了强大的泛化能力。具体而言,2B 模型在 COCO [15] 的新类别上实现了 mAP 从 9.8 到 31.3 的提升,在 LVIS [5] 的选定稀有类别上实现了从 2.7 到 20.7 的提升。这些多样化的视觉感知任务不仅凸显了 Visual-RFT 在视觉识别中的强大泛化能力,还强调了强化学习在增强视觉感知和推理中的关键作用。
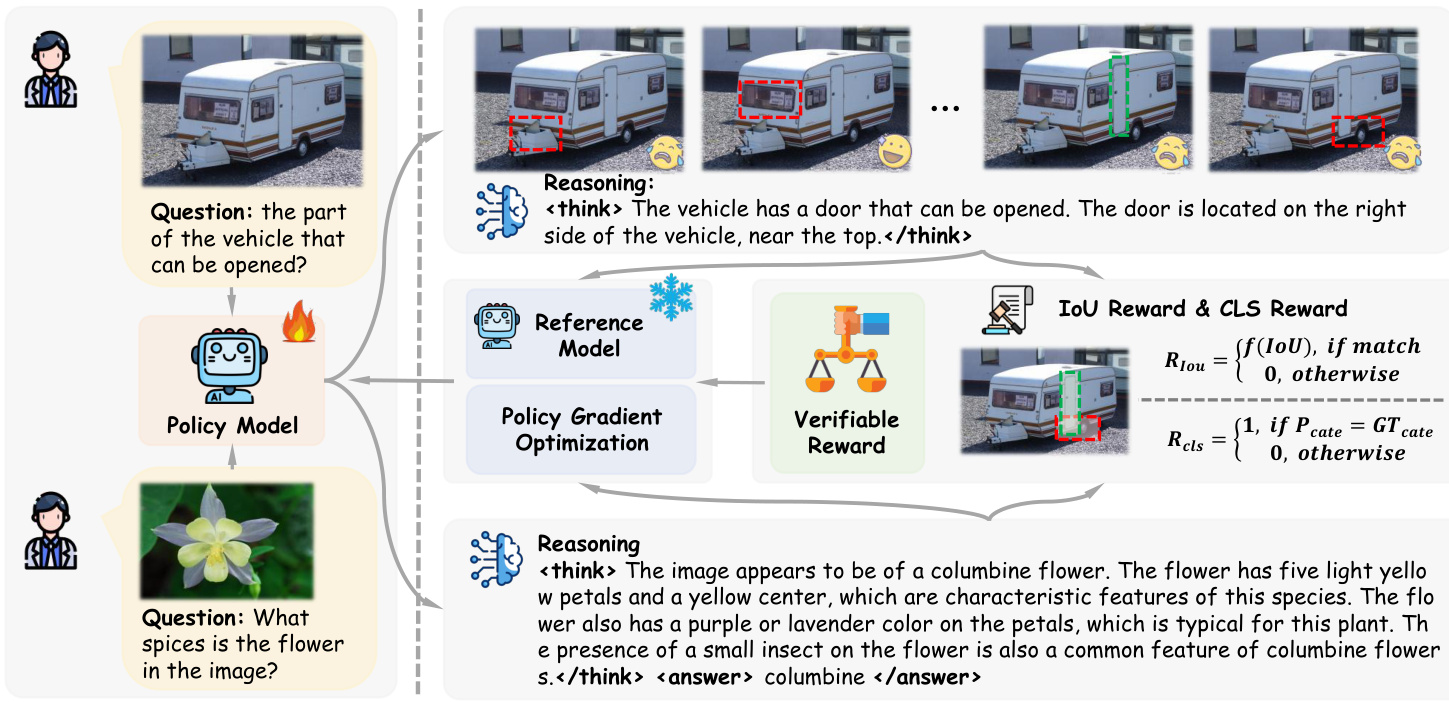
Figure 3. Framework of Visual-RFT. Given the question and visual image inputs,the policy model generates multiple responses containing reasoning steps. Then the verifiable reward such as IoU reward and CLS reward is used with the policy gradient optimization algorithm to update the policy model.
图 3: Visual-RFT 框架。给定问题和视觉图像输入,策略模型生成包含推理步骤的多个响应。然后使用可验证的奖励(如 IoU 奖励和 CLS 奖励)与策略梯度优化算法来更新策略模型。
In summary, our key contributions are as follows:
总结来说,我们的主要贡献如下:
(1) We introduce Visual Reinforcement Fine-tuning (Visual-RFT), which extends reinforcement learning with verifiable rewards on visual perception tasks that are effective with limited data for fine-tuning. (2) We design different verifiable rewards for different visual tasks that enable efficient, high-quality reward computation at a negligible cost. This allows the seamless transfer of DeepSeek R1's style reinforcement learning to LVLMs. (3) We conduct extensive experiments on various visual perception tasks, including fine-grained image classification, few-shot object detection, reasoning grounding, and open vocabulary object detection. On all the settings, VisualRFT achieves remarkable performance improvements, significantly surpassing the supervised fine-tuning baselines.
(1) 我们引入了视觉强化微调 (Visual-RFT),它通过视觉感知任务上的可验证奖励扩展了强化学习,这些任务在有限的数据下进行微调时非常有效。(2) 我们为不同的视觉任务设计了不同的可验证奖励,这些奖励能够以可忽略的成本实现高效、高质量的奖励计算。这使得 DeepSeek R1 的风格强化学习能够无缝地转移到 LVLMs 上。(3) 我们在各种视觉感知任务上进行了广泛的实验,包括细粒度图像分类、少样本目标检测、推理基础和开放词汇目标检测。在所有设置中,Visual-RFT 都取得了显著的性能提升,显著超越了监督微调的基线。
(4) We fully open-source the training code, training data, and evaluation scripts on Github to facilitate further research.
(4) 我们在 Github 上完全开源了训练代码、训练数据和评估脚本,以促进进一步的研究。
2. Related Work
2. 相关工作
Large Vision Language Models (LVLMs) like GPT40 [23] achieves excellent visual understanding ability by integrating both visual and textual data. This integration enhances the models’ ability to understand complex multi-modal inputs and enables more advanced AI systems [13, 16, 38, 47] capable of processing and responding to both images and text. Generally, the training of LVLMs involves two steps: (a) pre-training and (b) posttraining which contains supervised fine-tuning and reinforcement learning. Post-training is crucial in improving the model's response quality, instruction following, and reasoning abilities. While there has been significant research on using reinforcement learning to enhance LLMs during post-training [1,3,25,28,32,33, 36,40,44, 52,53], the progress for LVLMs has been slower. In this paper, we propose Visual-RFT, which used GRPO-based reinforcement algorithms and verifiable reward during the post-training phase to enhance the model's visual perception and reasoning capabilities.
像 GPT40 [23] 这样的大型视觉语言模型 (Large Vision Language Models, LVLMs) 通过整合视觉和文本数据,实现了卓越的视觉理解能力。这种整合增强了模型理解复杂多模态输入的能力,并使得更先进的 AI 系统 [13, 16, 38, 47] 能够处理和响应图像和文本。通常,LVLMs 的训练分为两个步骤:(a) 预训练和 (b) 后训练,后训练包括监督微调和强化学习。后训练对于提高模型的响应质量、指令遵循和推理能力至关重要。尽管在利用强化学习增强大语言模型 (LLMs) 的后训练方面已有大量研究 [1,3,25,28,32,33,36,40,44,52,53],但 LVLMs 的进展相对较慢。在本文中,我们提出了 Visual-RFT,它在后训练阶段使用基于 GRPO 的强化算法和可验证的奖励,以增强模型的视觉感知和推理能力。
Reinforcement Learning Recently, with the emergence of reasoning models like OpenAI's o1 [7], the research focus in Large Language Models (LLMs) has increasingly shifted towards enhancing the models′ reasoning capabilities through reinforcement learning (RL) techniques. Studies have explored improving LLMs’ performance in reasoning tasks such as solving mathematical problems [2, 20, 31, 39, 41] and coding [6, 8, 46, 48]. A notable breakthrough in this area is Deepseek-R1-Zero [4], which introduced a new approach to achieving robust reasoning capabilities using RL merely, eliminating the supervised fine-tuning (SFT) stage. However, current research on RL-based reasoning has largely been confined to the language domain, with limited exploration of its application in multi-modal settings. For LVLMs, RL has primarily been used for tasks like mitigating hallucinations and aligning models with human preference [19, 34, 35, 42, 43, 49-51], but there remains a significant gap in research focusing on enhancing reasoning and visual perception of Large Vision Language Models. To address this gap, our work introduces a novel reinforcement fine-tuning strategy Visual-RFT, applying verifiable rewards with GRPO-based [31] RL to a broad range of visual perception tasks. Our approach aims to improve the performance of LVLMs in processing various visual tasks, especially when the fine-tuning data is limited.
强化学习
近年来,随着 OpenAI 的 o1 [7] 等推理模型的出现,大语言模型 (LLMs) 的研究重点逐渐转向通过强化学习 (RL) 技术提升模型的推理能力。研究探索了如何提升 LLMs 在解决数学问题 [2, 20, 31, 39, 41] 和编程 [6, 8, 46, 48] 等推理任务中的表现。Deepseek-R1-Zero [4] 是该领域的一个显著突破,它引入了一种仅通过 RL 实现强大推理能力的新方法,消除了监督微调 (SFT) 阶段。然而,当前基于 RL 的推理研究主要局限于语言领域,对其在多模态环境中的应用探索有限。对于大视觉语言模型 (LVLMs),RL 主要用于减少幻觉和使模型与人类偏好对齐 [19, 34, 35, 42, 43, 49-51] 等任务,但在提升大视觉语言模型的推理和视觉感知能力方面的研究仍存在显著空白。为填补这一空白,我们的工作引入了一种新颖的强化微调策略 Visual-RFT,将基于 GRPO [31] 的 RL 与可验证奖励应用于广泛的视觉感知任务。我们的方法旨在提升 LVLMs 在处理各种视觉任务中的表现,尤其是在微调数据有限的情况下。
Table 1. Prompts used to construct the dataset. We have listed the detection prompt and classification prompt separately.
表 1: 用于构建数据集的提示。我们分别列出了检测提示和分类提示。
| 检测提示: 检测图像中属于类别“{category}”的所有对象,并提供边界框(介于0和1000之间的整数)和置信度(介于0和1之间,保留两位小数)。如果图像中没有属于类别“{category}”的对象,则返回“无对象”。在
| 分类提示: 这是一张包含植物的图像。请根据图像识别植物的种类。在
3. Methodology
3. 方法论
3.1. Preliminary
3.1. 初步准备
Reinforcement Learning with Verifiable Rewards. Rein for cement Learning with Verifiable Rewards (RLVR) [4, 12, 37] is a novel training approach designed to enhance language models in tasks with objectively verifiable outcomes, such as math and coding. Unlike previous Reinforcement Learning from Human Feedback (RLHF) [17, 26, 45], which relies on a trained reward model, RLVR instead uses a direct verification function to assess correctness. This approach simplifies the reward mechanism while maintaining strong alignment with the task's inherent correctness criteria. Given the input question $q$ ,the policy model $\pi_{\theta}$ generates responses $o$ and receives the verifiable reward. More specifically, RLVR optimizes the following objective:
可验证奖励的强化学习。可验证奖励的强化学习 (Reinforcement Learning with Verifiable Rewards, RLVR) [4, 12, 37] 是一种新颖的训练方法,旨在增强语言模型在具有客观可验证结果的任务(如数学和编程)中的表现。与之前依赖训练奖励模型的基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) [17, 26, 45] 不同,RLVR 使用直接验证函数来评估正确性。这种方法简化了奖励机制,同时保持了与任务固有正确性标准的强一致性。给定输入问题 $q$,策略模型 $\pi_{\theta}$ 生成响应 $o$ 并接收可验证的奖励。更具体地说,RLVR 优化以下目标:

where $\pi_{\mathrm{ref}}$ is the reference model before optimization, $R$ is the verifiable reward function, and $\beta$ is the hyper parameters to control the KL-divergence. The verifiable reward function $R$ takes the question and output pair $(q,o)$ as inputs, and checks if the ground-truth answer remains the same as the prediction $o$
其中 $\pi_{\mathrm{ref}}$ 是优化前的参考模型,$R$ 是可验证的奖励函数,$\beta$ 是控制 KL 散度的超参数。可验证的奖励函数 $R$ 以问题和输出对 $(q,o)$ 作为输入,并检查真实答案是否与预测 $o$ 一致。

DeepSeek R1-Zero and GRPO. The DeepSeek R1-Zero algorithm eliminates dependence on supervised fine-tuning (SFT) by employing reinforcement learning for training, specifically through its Group Relative Policy Optimization (GRPO) framework. Different from reinforcement learning algorithms such as PPO [30] that require a critic model to evaluate policy performance, GRPO compares groups of candidate responses directly, eliminating the need for an additional critic model. For a given question $q$ ,GRPO first generates $G$ distinct responses ${o_{1},o_{2},...,o_{G}}$ from the current policy $\pi_{\theta_{\mathrm{old}}}$ . Then GRPO takes actions based on these responses and denotes the obtained rewards as ${r_{1},r_{2},...,r_{G}}$ . By computing their mean and standard deviation for normalization, GRPO determines the relative quality of these responses:
DeepSeek R1-Zero 和 GRPO。DeepSeek R1-Zero 算法通过采用强化学习进行训练,特别是通过其组相对策略优化 (Group Relative Policy Optimization, GRPO) 框架,消除了对监督微调 (Supervised Fine-Tuning, SFT) 的依赖。与 PPO [30] 等需要批评模型来评估策略性能的强化学习算法不同,GRPO 直接比较候选响应组,从而消除了对额外批评模型的需求。对于给定的问题 $q$,GRPO 首先从当前策略 $\pi_{\theta_{\mathrm{old}}}$ 生成 $G$ 个不同的响应 ${o_{1},o_{2},...,o_{G}}$。然后 GRPO 基于这些响应采取行动,并将获得的奖励表示为 ${r_{1},r_{2},...,r_{G}}$。通过计算它们的均值和标准差进行归一化,GRPO 确定了这些响应的相对质量:

where $A_{i}$ represents the relative quality of the $i$ -thanswer. GRPO encourages the model to favor better answers with a high reward value within the group.
其中 $A_{i}$ 表示第 $i$ 个答案的相对质量。GRPO 鼓励模型在组内选择具有高奖励值的更好答案。
3.2. Visual-RFT
3.2. Visual-RFT
The framework of Visual-RFT is shown in Fig. 3. The multi-modal input data from the user consists of images and questions. The policy model $\pi_{\theta}$ outputs a reasoning process and generates a group of responses based on the input. Each response is passed through a verifiable reward function to compute the reward. After group computation of the rewards for each output, the quality of each response is evaluated and used to update the policy model. To ensure the stability of the policy model training, Visual-RFT uses KL divergence to limit the difference between the policy model and the reference model. We will further discuss how to design the verifiable reward for visual tasks in Sec. 3.2.1, and the data preparation steps in Sec. 3.2.2
Visual-RFT 的框架如图 3 所示。用户的多模态输入数据包括图像和问题。策略模型 $\pi_{\theta}$ 输出推理过程,并基于输入生成一组响应。每个响应通过可验证的奖励函数计算奖励。在对每个输出的奖励进行组计算后,评估每个响应的质量并用于更新策略模型。为了确保策略模型训练的稳定性,Visual-RFT 使用 KL 散度来限制策略模型与参考模型之间的差异。我们将在第 3.2.1 节进一步讨论如何为视觉任务设计可验证的奖励,并在第 3.2.2 节讨论数据准备步骤。
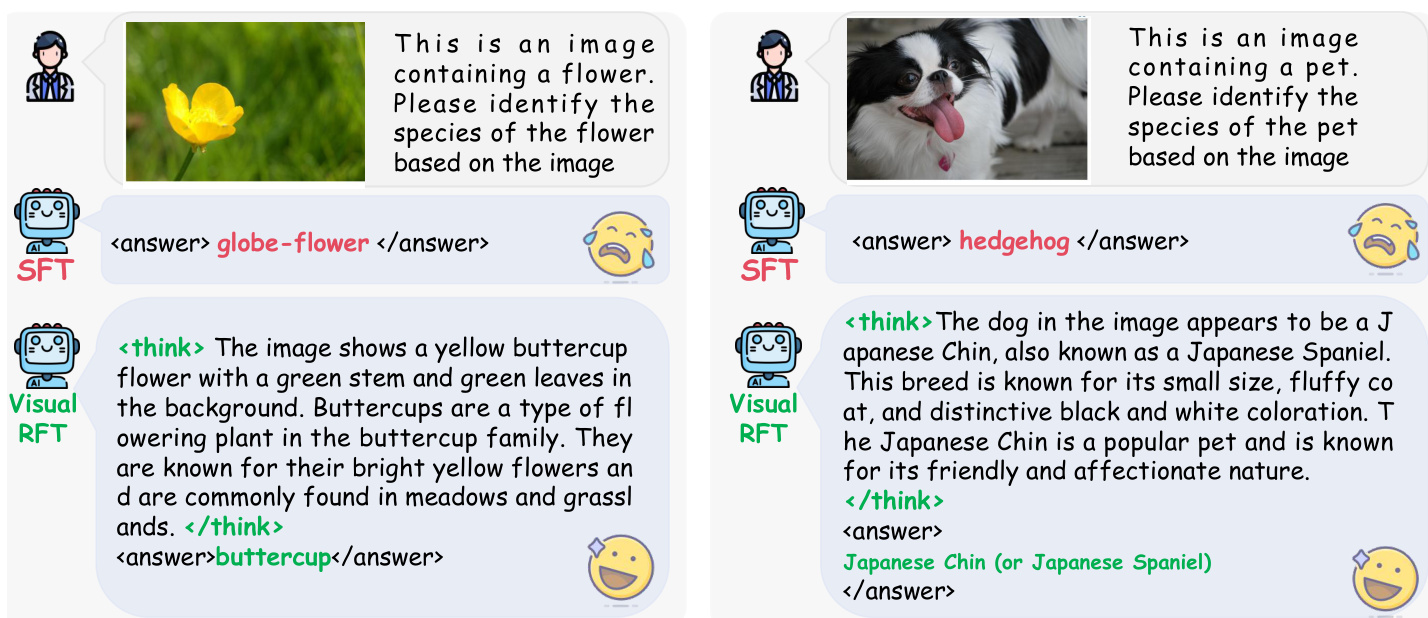
Figure 4. Qualitative results of Fine-Grained Image Classification. The thinking process significantly improves the reasoning ability of LVLMs, leading to higher image classification performance.
图 4: 细粒度图像分类的定性结果。思考过程显著提升了 LVLMs 的推理能力,从而提高了图像分类性能。
3.2.1. Verifiable Reward in Visual Perception
3.2.1 视觉感知中的可验证奖励
The reward model is a key step in reinforcement learning (RL) that aligns models with preference alignment algorithms, which can be as straightforward as a verification function that checks for exact matches between predictions and ground-truth answers. The RL training process in the recent DeepSeek-R1 [4] model achieves a significant improvement in the model's reasoning ability through the verifiable reward design. To transfer this strategy to the visual domain, we design different rule-based verifiable reward functions for various visual perception tasks.
奖励模型是强化学习 (RL) 中的关键步骤,它将模型与偏好对齐算法对齐,这可能像检查预测与真实答案之间完全匹配的验证函数一样简单。最近的 DeepSeek-R1 [4] 模型中的 RL 训练过程通过可验证的奖励设计显著提高了模型的推理能力。为了将这一策略转移到视觉领域,我们为各种视觉感知任务设计了不同的基于规则的可验证奖励函数。
IoU Reward in Detection Tasks. For the detection task, the model's output consists of bounding boxes (bbox) and corresponding confidences. The reward function for the detection task should adequately consider the Intersectionover-Union (IoU) metric, which is used to compute the mean Average Precision (mAP) in evaluation. Therefore, we design an IoU and confidence-based reward function $R_{d}$ .First, for the model's output box and confidence, we sort these boxes based on their confidence, denoted as ${b_{1},b_{2},...,b_{n}}$ . We then match each $b_{i}$ with the ground truth bbox, ${b_{1}^{g},b_{2}^{g},...,b_{m}^{g}}$ , and calculate the IoU, while setting an IoU threshold $\tau$ . Bounding boxes with an IoU below this threshold $\tau$ are considered invalid, and unmatched bboxes have an IoU of O. After matching, we obtain the IoU and confidence for each box from the initial set, denoted as $\left{i o u_{1}:c_{1},i o u_{2}:c_{2},...,i o u_{n}:c_{n}\right},$
检测任务中的IoU奖励。对于检测任务,模型的输出包括边界框(bbox)和相应的置信度。检测任务的奖励函数应充分考虑交并比(IoU)指标,该指标用于在评估中计算平均精度(mAP)。因此,我们设计了一个基于IoU和置信度的奖励函数 $R_{d}$。首先,对于模型输出的框和置信度,我们根据置信度对这些框进行排序,记为 ${b_{1},b_{2},...,b_{n}}$。然后,我们将每个 $b_{i}$ 与真实边界框 ${b_{1}^{g},b_{2}^{g},...,b_{m}^{g}}$ 进行匹配,并计算IoU,同时设置一个IoU阈值 $\tau$。IoU低于此阈值 $\tau$ 的边界框被视为无效,未匹配的边界框的IoU为0。匹配后,我们从初始集合中获取每个框的IoU和置信度,记为 $\left{i o u_{1}:c_{1},i o u_{2}:c_{2},...,i o u_{n}:c_{n}\right},$
We then use these IoU results and confidence to construct our reward $R_{d}$ . Our reward $R_{d}$ consists of three parts, including the IoU reward, Confidence reward, and Format
然后我们使用这些 IoU 结果和置信度来构建我们的奖励 $R_{d}$。我们的奖励 $R_{d}$ 由三部分组成,包括 IoU 奖励、置信度奖励和格式奖励。
reward:
奖励:

The IoU reward $R_{\mathrm{IoU}}$ is the average IoU of all the bounding boxes in the model's output,
IoU奖励 $R_{\mathrm{IoU}}$ 是模型输出中所有边界框的平均IoU。

The confidence reward $R_{\mathrm{conf}}$ is related to IoU. For each bounding box, if the $i o u_{i}$ is non-zero, indicating a successful match, the confidence reward for this single box $r_{c}$ as the predicted confidence in computed as:
置信度奖励 $R_{\mathrm{conf}}$ 与 IoU 相关。对于每个边界框,如果 $iou_{i}$ 不为零,表示匹配成功,则该单框的置信度奖励 $r_{c}$ 计算为预测置信度:

This means that for successfully matched boxes, the higher the confidence, the better. If the $i o u_{i}$ is zero, indicating a failed match, the lower the confidence reward $r_{c}$ for this box, the better. The overall confidence reward $R_{\mathrm{conf}}$ for the model's output is the average of the confidence rewards of all the bounding boxes in that output,
这意味着对于成功匹配的框,置信度越高越好。如果 $iou_{i}$ 为零,表示匹配失败,则该框的置信度奖励 $r_{c}$ 越低越好。模型输出的总体置信度奖励 $R_{\mathrm{conf}}$ 是该输出中所有边界框的置信度奖励的平均值。

The format reward $R_{\mathrm{format}}$ is used to force the model prediction to meet the required HTML tag format of <think $\textgreater$ and
格式奖励 $R_{\mathrm{format}}$ 用于强制模型预测满足所需的 HTML 标签格式,即 <think $\textgreater$> 和
CLS Reward in Classification Tasks. In classification tasks, the reward function we use consists of two parts: accuracy reward $R_{\mathrm{acc}}$ and format reward $R_{\mathrm{format}}$ .The accuracy
分类任务中的 CLS 奖励。在分类任务中,我们使用的奖励函数由两部分组成:准确率奖励 $R_{\mathrm{acc}}$ 和格式奖励 $R_{\mathrm{format}}$ 。
Figure 5. Qualitative results of reasoning grounding on LISA [11]. Thinking process significantly improves reasoning grounding ability withVisual-RFT.
图 5: 基于 LISA [11] 的推理定性结果。思考过程显著提升了 Visual-RFT 的推理基础能力。
reward is determined by comparing the model's output class with the ground truth class, yielding a value of 1 for correct classification and O for incorrect classification:
奖励是通过将模型的输出类别与真实类别进行比较来确定的,正确分类时值为1,错误分类时值为0:
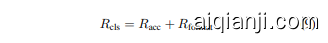
3.2.2. Data Preparation
3.2.2 数据准备
To train the Visual-RFT on various visual perception tasks, we need to construct the multi-modal training dataset. Similar to DeepSeek-R1, to enhance the model's reasoning ability and apply this ability to improve visual perception, Visual-RFT designed a prompt format to guide the model to output its reasoning process before providing the final answer. The prompts used for detection and classification tasks are shown in Tab 1.
为了在各种视觉感知任务上训练 Visual-RFT,我们需要构建多模态训练数据集。与 DeepSeek-R1 类似,为了增强模型的推理能力并将这种能力应用于提升视觉感知,Visual-RFT 设计了一种提示格式,以引导模型在提供最终答案之前输出其推理过程。用于检测和分类任务的提示如表 1 所示。
During the training process, we use the format reward to guide the model to output its reasoning process and the final answer in a structured format. The reasoning process is key to the model's self-learning and improvement during reinforcement fine-tuning, while the reward determined by the answer directs the model's optimization.
在训练过程中,我们使用格式奖励来引导模型以结构化格式输出其推理过程和最终答案。推理过程是模型在强化微调过程中自我学习和改进的关键,而由答案决定的奖励则指导模型的优化。
4. Experiments
4. 实验
4.1. Experimental Setup
4.1. 实验设置
Implementation Details Our method is adaptable to various visual perception tasks. We employ a few-shot learning approach, providing the model with a minimal number of samples for training. For the image classification and object detection task, we adopt a few-shot setting to evaluate the model's fine-grained disc rim i native and recognition capability, applying reinforcement learning on limited data. Then, for the LISA [11] dataset focusing on reasoning grounding, which demands strong reasoning abilities, we train the model using Visual-RFT and assess its reasoning and perception performance. Lastly, for openvocabulary object detection, we evaluate the model's genera liz ation capability by training the Qwen2-VL-2/7B [38] using Visual-RFT on a subdivided COCO dataset containing 65 base classes. We then test it on 15 novel classes from COCO and 13 rare classes from LVIS [5]. The model's visual perception and reasoning abilities are assessed in an open-vocabulary detection setting. In our detection experiments, we first prompt the model to check whether the category is present in the image, then predict bound boxes for categories that exist in the images.
实现细节
我们的方法适用于各种视觉感知任务。我们采用少样本学习方法,为模型提供少量样本进行训练。对于图像分类和目标检测任务,我们采用少样本设置来评估模型的细粒度判别和识别能力,在有限数据上应用强化学习。然后,针对需要强推理能力的 LISA [11] 数据集,我们使用 Visual-RFT 训练模型,并评估其推理和感知性能。最后,对于开放词汇目标检测,我们在包含 65 个基础类别的细分 COCO 数据集上使用 Visual-RFT 训练 Qwen2-VL-2/7B [38],并在 COCO 的 15 个新类别和 LVIS [5] 的 13 个稀有类别上进行测试,评估模型的视觉感知和推理能力。在我们的检测实验中,我们首先提示模型检查图像中是否存在该类别,然后为图像中存在的类别预测边界框。
Table 2. Few-shot results on Fine-grained Classification dataset. We evaluated four fine-grained image classification datasets.
表 2: 细粒度分类数据集的少样本结果。我们评估了四个细粒度图像分类数据集。
| Flower10 | Pets37 | FGVC | Cars196 | ||
|---|---|---|---|---|---|
| Qwen2-VL-2B | 56.0 | 54.8 | 66.4 | 45.9 | |
| one-shot | |||||
| + SFT | 51.7 | 56.6 | 54.7 | 65.3 | 30.0 |
| + Visual-RFT | 80.3 | 70.8 | 84.1 | 72.5 | 93.8 |
| △ | +24.3 | +16.0 | +17.7 | +26.6 | +37.0 |
| 2-shot | |||||
| + SFT | 58.8 | 60.3 | 65.6 | 68.9 | 40.2 |
| + Visual-RFT | 83.5 | 75.8 | 87.5 | 75.3 | 95.4 |
| △ | +27.5 | +21.0 | +21.1 | +29.4 | +38.6 |
| 4-shot | |||||
| + SFT | 55.6 | 58.5 | 55.5 | 67.9 | 40.5 |
| + Visual-RFT | 81.9 | 71.4 | 86.1 | 74.8 | 95.3 |
| △ | +25.9 | +16.6 | +19.7 | +28.9 | +38.5 |
| 8-shot | |||||
| + SFT | 60.3 | 59.6 | 71.4 | 69.2 | 40.9 |
| + Visual-RFT | 85.1 | 77.7 | 90.2 | 75.9 | 96.5 |
| △ | +29.1 | +22.9 | +23.8 | +30.0 | +39.7 |
| 16-shot | |||||
| + SFT | 64.0 | 66.8 | 71.6 | 76.1 | 41.5 |
| + Visual-RFT | 85.3 | 79.2 | 87.1 | 79.4 | 95.3 |
| △ | +29.3 | +24.4 | +20.7 | +33.5 | +38.5 |
4.2. Few-Shot Classification
4.2. 少样本分类
To demonstrate the extensive generalization ability of Visual-RFT in the visual domain, we conduct few-shot experiments on fine-grained image classification. We selected four datasets: Flower102 [22], Pets37 [27], FGVCAircraft [21], and Car196 [10], which contain dozens to hundreds of similar categories, adding significant difficulty
为了展示 Visual-RFT 在视觉领域的广泛泛化能力,我们在细粒度图像分类上进行了少样本实验。我们选择了四个数据集:Flower102 [22]、Pets37 [27]、FGVCAircraft [21] 和 Car196 [10],这些数据集包含数十到数百个相似类别,增加了显著的难度。
Table 3. Few-Shot results on COCO dataset of 8 categories. We conducted one-shot, 2-shot, 4-shot, 8-shot, and 16-shot experiments on 8 categories from the COCO dataset.
表 3: COCO 数据集中 8 个类别的少样本 (Few-Shot) 结果。我们在 COCO 数据集的 8 个类别上进行了 1-shot、2-shot、4-shot、8-shot 和 16-shot 实验。
| mAP | bus | hydrant fire | sign stop | bed | toilet | |||
|---|---|---|---|---|---|---|---|---|
| Qwen2-VL-2B | ||||||||
| Baseline | 19.6 | 19.0 | 15.8 | 25.8 | 18.4 | 29.9 | 23.2 | 14.6 |
| 1-shot | ||||||||
| + SFT | 19.5 | 18.3 | 17.4 | 23.1 | 18.2 | 28.0 | 23.4 | 17.3 |
| + Visual-RFT | 33.6 | 23.4 | 35.7 | 39.1 | 23.8 | 54.3 | 42.5 | 19.5 |
| △ | +14.0 | +4.4 | +19.9 | +13.3 | +5.4 | +24.4 | +19.3 | +4.9 |
| 2-shot | ||||||||
| + SFT | 21.0 | 22.1 | 15.8 | 29.8 | 19.0 | 28.9 | 26.5 | 15.5 |
| + Visual-RFT | 41.5 | 28.8 | 39.6 | 38.2 | 48.0 | 63.8 | 52.7 | 25.9 |
| △ | +21.9 | +9.8 | +23.8 | +12.4 | +29.6 | +33.9 | +29.5 | +11.3 |
| 4-shot | ||||||||
| + SFT | 25.2 | 25.4 | 23.6 | 26.6 | 21.5 | 35.6 | 30.6 | 18.4 |
| + Visual-RFT | 40.6 | 30.0 | 40.6 | 45.7 | 35.0 | 60.9 | 44.9 | 24.6 |
| △ | +21.0 | +11.0 | +24.8 | +19.9 | +16.6 | +31.0 | +21.7 | +10.0 |
| 8-shot | ||||||||
| + SFT | 30.2 | 25.8 | 35.1 | 29.4 | 21.9 | 44.5 | 39.0 | 22.6 |
| + Visual-RFT | 47.4 | 36.2 | 47.9 | 50.4 | 47.7 | 65.2 | 57.0 | 30.4 |
| △ | +27.8 | +17.2 | +32.1 | +24.6 | +29.3 | +35.3 | +33.8 | +15.8 |
| 16-shot | ||||||||
| + SFT | 31.3 | 24.0 | 35.9 | 32.0 | 23.6 | 39.8 | 40.6 | 27.5 |
| + Visual-RFT | 46.8 | 36.2 | 44.4 | 51.4 | 48.5 | 66.6 | 56.2 | 27.6 |
| △ | +27.2 | +17.2 | +28.6 | +25.6 | +30.1 | +36.7 | +33.0 | +13.0 |
| Qwen2-VL-7B | ||||||||
| Baseline | 43.0 | 35.0 | 43.3 | 37.1 | 36.7 | 57.3 | 50.3 | 37.4 |
| 4-shot | ||||||||
| + SFT | 44.1 | 41.4 | 51.7 | 35.6 | 30.8 | 60.5 | 52.7 | 38.5 |
| + Visual-RFT | 54.3 | 44.3 | 59.8 | 52.0 | 46.0 | 72.7 | 62.8 | 41.9 |
| △ | +11.3 | +9.3 | +16.5 | +14.9 | +9.3 | +15.4 | +12.5 | +4.5 |
to the classification task.
分类任务。
As shown in Tab. 2, with just one-shot of data, VisualRFT already delivers a significant performance boost $(+24.3%)$ .In contrast, SFT shows a noticeable decline $(-4.3%)$ with the same minimal amount of data. Under the 4-shot setting, the performance of SFT is still slightly lower than the baseline, while the reinforcement fine-tuned model with Visual-RFT achieves an average performance improvement of 25.9. Under the 8-shot and 16-shot settings, as the amount of data increases, SFT's performance slightly exceeds the baseline. However, SFT still lags significantly behind the performance of the Visual-RFT. In Fig.4, we present some inference cases of the model after reinforcement fine-tuning when handling fine-grained classification tasks. These results not only demonstrate the strong generalization ability of Visual-RFT and its capacity to learn from limited data but also confirm that reinforcement fine-tuning, compared to SFT, leads to a genuine under standing of the task and deeper learning from reasoning.
如表 2 所示,仅使用一次数据,VisualRFT 就带来了显著的性能提升 $(+24.3%)$。相比之下,SFT 在相同的最小数据量下表现出明显的下降 $(-4.3%)$。在 4-shot 设置下,SFT 的性能仍然略低于基线,而使用 Visual-RFT 进行强化微调的模型平均性能提升了 25.9。在 8-shot 和 16-shot 设置下,随着数据量的增加,SFT 的性能略微超过了基线。然而,SFT 仍然显著落后于 Visual-RFT 的性能。在图 4 中,我们展示了模型在处理细粒度分类任务时经过强化微调后的一些推理案例。这些结果不仅证明了 Visual-RFT 的强大泛化能力及其从有限数据中学习的能力,还证实了与 SFT 相比,强化微调能够真正理解任务并从推理中进行更深入的学习。
Table 4. Few-shot results on LVIS dataset of 6 rare categories. We conducted 10-shot experiments on 6 rare categories from the LVIS dataset.
表 4: LVIS 数据集中 6 个稀有类别的少样本结果。我们在 LVIS 数据集的 6 个稀有类别上进行了 10-shot 实验。
| 模型 | horse | die | table chen kitcl | omel | papaya | stepladder |
|---|---|---|---|---|---|---|
| Qwen2-VL-2B | 2.9 | 1.2 | 13.4 | 4.7 | 1.5 | 0.0 |
| + SFT | 7.0 | 7.6 | 34.1 | 4.7 | 6.3 | 0.0 |
| + Visual-RFT | 9.1 | 19.6 | 42.2 | 20.4 | 14.5 | 10.9 |
| △ | +6.2 | +18.4 | +29.2 | +15.7 | +13.0 | +10.9 |
| Qwen2-VL-7B | 19.7 | 21.9 | 14.5 | 18.1 | 18.5 | 0.0 |
| + SFT | 26.9 | 21.9 | 49.7 | 29.2 | 25.2 | 12.7 |
| + Visual-RFT | 26.2 | 27.8 | 70.6 | 23.5 | 21.2 | 29.3 |
| △ | +6.5 | +5.9 | +56.1 | +5.4 | +2.7 | +29.3 |
Table 5. Few-shot results on MG dataset of 5 categories. By introducing out-of-domain data, we increased the difficulty of model recognition and reasoning, further demonstrating the strong generalization ability of reinforcement fine-tuning in visual perception tasks.
Table 6. Reasoning Grounding Results on LISA [11]. VisualRFT surpasses SFT in reasoning grounding with 239 training images.
表 6. LISA [11] 上的推理基础结果。VisualRFT 在 239 张训练图像的情况下,在推理基础上超越了 SFT。
| 模型 | mIoUtest | mIoUval | gloUtest |
|---|---|---|---|
| OV-Seg [14] | 28.4 | 30.5 | 26.1 |
| X-Decoder [54] | 28.5 | 29.1 | 24.3 |
| GroundedSAM [18] | 26.2 | 28.6 | 21.3 |
| Qwen2-VL-2B | 26.9 | 30.1 | 25.3 |
| + SFT | 28.3 | 29.7 | 25.3 |
| + Visual-RFT | 37.6 | 34.4 | 34.4 |
| △ | +10.7 | +4.3 | +9.1 |
| Qwen2-VL-7B | 40.4 | 45.2 | 38.0 |
| + SFT | 39.1 | 43.9 | 37.2 |
| + Visual-RFT | 43.9 | 47.1 | 43.7 |
| △ | +3.5 | +1.9 | +5.6 |
4.3. Few-Shot Object Detection
4.3. 少样本目标检测
Few-shot learning has always been one of the core challenges faced by traditional visual models and large-scale vision-language models (LVLMs). Reinforcement finetuning provides a new solution to this problem by enabling the model to quickly learn and understand with a small amount of data. We selected eight categories from the COCO dataset, with 1, 2, 4, 8, and 16 images per category, to construct training sets with limited data. For the LVIS dataset, we select 6 rare categories. Since the training images for these rare categories are very sparse, with each category having between 1 and 10 images, we approximated this as a 10-shot setting. We then train the Qwen2-VL-2/7B model for 200 steps using both reinforcement fine-tuning and SFT, to evaluate the model's learning ability with lim
少样本学习一直是传统视觉模型和大规模视觉语言模型 (LVLMs) 面临的核心挑战之一。强化微调通过使模型能够快速学习和理解少量数据,为这一问题提供了新的解决方案。我们从 COCO 数据集中选择了八个类别,每个类别有 1、2、4、8 和 16 张图像,以构建有限数据的训练集。对于 LVIS 数据集,我们选择了 6 个稀有类别。由于这些稀有类别的训练图像非常稀疏,每个类别有 1 到 10 张图像,我们将其近似为 10-shot 设置。然后,我们使用强化微调和 SFT 对 Qwen2-VL-2/7B 模型进行 200 步训练,以评估模型在有限数据下的学习能力。
Table 7. Open Vocabulary Object Detection Results on COCO dataset. We trained on 65 base categories and tested on 15 novel categories.
表 7: COCO 数据集上的开放词汇目标检测结果。我们在 65 个基础类别上进行训练,并在 15 个新类别上进行测试。
| 模型 | mAP | mAPb | mAPall |
|---|---|---|---|
| Qwen2-VL-2B | 9.8 | 6.0 | 6.7 |
| + SFT | 13.6 | 7.8 | 8.9 |
| + Visual-RFT | 31.3 | 20.6 | 22.6 |
| △ | +21.5 | +14.6 | +15.9 |
| Qwen2-VL-7B | 26.3 | 17.5 | 19.2 |
| + SFT | 25.7 | 17.5 | 19.0 |
| + Visual-RFT | 35.8 | 25.4 | 27.4 |
| △ | +9.5 | +7.9 | +8.2 |
ited data.
受限数据
As shown in Tab. 3 and Tab. 4, although both SFT and reinforcement fine-tuning can improve the model's recognition accuracy under the few-shot setting, the model after reinforcement fine-tuning consistently outperforms the SFT model by a large margin, maintaining a significant lead. On the COCO [15] categories, as the training data increases, the SFT model reaches an average mAP of approximately 31, while the reinforcement fine-tuned model approaches 47. In the LVIS [5] few-shot experimental results shown in Tab. 4, for the six more challenging rare categories in LVIS, reinforcement fine-tuning still outperforms SFT. The results in Tab. 3 and Tab. 4 clearly demonstrate the exceptional performance of reinforcement fine-tuning in the few-shot setting, where the model achieves a significant improvement in visual perception capabilities through reinforcement learning with only a small amount of data.
如表 3 和表 4 所示,尽管 SFT 和强化微调都能提高模型在少样本设置下的识别准确率,但经过强化微调的模型始终大幅优于 SFT 模型,保持显著领先。在 COCO [15] 类别中,随着训练数据的增加,SFT 模型的平均 mAP 达到约 31,而经过强化微调的模型接近 47。在表 4 所示的 LVIS [5] 少样本实验结果中,对于 LVIS 中六个更具挑战性的稀有类别,强化微调仍然优于 SFT。表 3 和表 4 的结果清楚地展示了强化微调在少样本设置中的卓越性能,模型通过少量数据的强化学习在视觉感知能力上实现了显著提升。
able 8. Open Vocabulary Object Detection Results on LVIS dataset. We trained on the 65 base categories of the COCO dataset and ested on the 13 rare categories of the LVIS dataset.
表 8: LVIS 数据集上的开放词汇目标检测结果。我们在 COCO 数据集的 65 个基础类别上进行训练,并在 LVIS 数据集的 13 个稀有类别上进行测试。
| 模型 | mAP | sserole cass | roll | futon | garbag | dsaw hanc | opotamus 0 P | table hen kitche | malle | omele | glass shot | epladde | bowl igar |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GroudingDINO-B [18] | 23.9 | 17.1 | 0.0 | 2.4 | 47.5 | 27.7 | 13.4 | 15.2 | 92.5 | 0.0 | 26.6 | 16.0 | 41.0 |
| Qwen2-VL-2B | 2.7 | 1.6 | 1.2 | 0.0 | 2.4 | 0.0 | 10.0 | 0.0 | 13.4 | 0.2 | 4.7 | 2.1 | 0.0 |
| + SFT | 7.6 | 3.9 | 21.2 | 0.0 | 0.0 | 10.7 | 9.0 | 11.6 | 19.4 | 0.0 | 11.7 | 6.3 | 0.0 |
| + Visual-RFT | 20.7 | 24.5 | 23.4 | 2.0 | 16.0 | 27.7 | 20.2 | 14.4 | 45.8 | 11.1 | 22.7 | 6.0 | 6.0 |
| △ | +18.0 | +22.9 | +22.2 | +2.0 | +13.6 | +27.7 | +10.2 | +14.4 | +32.4 | +10.9 | +18.0 | +3.9 | +6.0 |
| Qwen2-VL-7B | 15.7 | 3.7 | 21.9 | 0.7 | 24.5 | 15.3 | 19.2 | 13.1 | 14.5 | 11.9 | 18.1 | 27.9 | 0.0 |
| + SFT | 24.0 | 20.8 | 25.4 | 0.6 | 41.8 | 12.2 | 19.2 | 18.8 | 42.5 | 11.9 | 15.3 | 27.9 | 28.1 |
| + Visual-RFT | 30.4 | 19.7 | 27.8 | 4.3 | 41.8 | 17.4 | 35.1 | 20.0 | 70.6 | 16.7 | 23.5 | 29.8 | 29.3 |
| △ | +14.7 | +16.0 | +5.9 | +3.6 | +17.3 | +2.1 | +15.9 | +6.9 | +56.1 | +4.8 | +5.4 | +1.9 | +29.3 |
We further test on some abstract out-of-domain datasets. We selected the MG (Monster Girls) dataset, which contains different types of anime-style monster girls. By using out-of-domain data, we increased the difficulty of both model recognition and reasoning, and conducted experiments under 4-shot and 16-shot settings. The results, shown in Tab. 5, indicate that reinforcement fine-tuning achieved a significant performance improvement, surpassing supervised fine-tuning (SFT).
我们进一步在一些抽象的领域外数据集上进行了测试。我们选择了MG(Monster Girls)数据集,该数据集包含不同类型的动漫风格怪物女孩。通过使用领域外数据,我们增加了模型识别和推理的难度,并在4-shot和16-shot设置下进行了实验。结果如表5所示,表明强化微调取得了显著的性能提升,超过了监督微调(SFT)。
4.4. Reasoning Grounding
4.4. 推理基础
Another crucial aspect of vision-language intelligence is grounding the exact object according to user needs. Previous specialized detection systems lack reasoning abilities and fail to fully understand the user's intentions. Pioneered by LISA [11], there have been works done to enable large language models (LLMs) to output control tokens for other models (such as SAM [9]) or directly predict bounding box coordinates [29, 38] through supervised fine-tuning. In our work, we explore the use of Visual-RFT in this task and find that reinforcement learning (RL) leads to significant improvements over supervised fine-tuning.
We finetune Qwen2-VL 2B/7B model [38] using VisualRFT and supervised fine-tuning (SFT) on the LISA training set, which consists of 239 images with reasoning grounding objects. We follow the same test setting with LISA and compare the results of SFT and our method, both with 500 fine-tuning steps. As shown in Tab. 6, Visual-RFT significantly improves the final results in terms of bounding box IoU compared to SFT. Additionally, we prompt SAM [9] with the Qwen2-VL predicted bounding box to generate the segmentation mask (evaluated using gIoU). Visual-RFT significantly enhances grounding ability and outperforms previous specialized detection systems. Qualitative results are visualized in Fig. 5, where the thinking process significantly improves the ability to reason and grounding accuracy. Through Visual-RFT, Qwen2-VL learns to think critically and carefully examine the image to produce accurate grounding results.
我们使用 VisualRFT 和监督微调 (SFT) 在 LISA 训练集上对 Qwen2-VL 2B/7B 模型 [38] 进行微调,该训练集包含 239 张带有推理基础对象的图像。我们遵循与 LISA 相同的测试设置,并比较了 SFT 和我们的方法的结果,两者都进行了 500 步微调。如表 6 所示,与 SFT 相比,Visual-RFT 在边界框 IoU 方面显著提高了最终结果。此外,我们使用 Qwen2-VL 预测的边界框提示 SAM [9] 以生成分割掩码(使用 gIoU 进行评估)。Visual-RFT 显著增强了基础能力,并优于之前的专用检测系统。定性结果如图 5 所示,其中思考过程显著提高了推理能力和基础准确性。通过 Visual-RFT,Qwen2-VL 学会了批判性思考并仔细检查图像以产生准确的基础结果。
4.5. Open Vocabulary Object Detection
4.5. 开放词汇目标检测
The advantage of Visual-RFT over SFT arises from the former's true deep understanding of the task, rather than merely memorizing the data. To further demonstrate the powerful generalization ability of reinforcement finetuning, we conduct open vocabulary object detection experiments. We first randomly sampled 6K annotations from the COCO dataset, which included 65 base categories. We perform Visual-RFT and SFT on the Qwen2-VL-2/7B model [38] using this data, and test the model on 15 new categories it has never seen before. To increase the difficulty, we further test 13 rare categories from the LVIS [5] dataset.
Visual-RFT 相较于 SFT 的优势在于前者对任务有真正的深入理解,而不仅仅是记忆数据。为了进一步展示强化微调的强大泛化能力,我们进行了开放词汇目标检测实验。我们首先从 COCO 数据集中随机抽取了 6K 个标注,其中包含 65 个基础类别。我们使用这些数据对 Qwen2-VL-2/7B 模型 [38] 进行 Visual-RFT 和 SFT,并在模型从未见过的 15 个新类别上进行测试。为了增加难度,我们进一步测试了来自 LVIS [5] 数据集的 13 个稀有类别。
As shown in Tab. 7 and Tab. 8, after reinforcement finetuning, the Qwen2-VL-2/7B model achieves an average mAP increase of 21.5 and 9.5 on 15 new categories from the COCO dataset. On the more challenging rare categories of the LVIS [5] dataset, mAP increased by 18.0 and 14.7. The Visual-RFT not only transfers its detection capabilities from the COCO base categories to the new COCO categories but also achieves significant improvements on the more challenging rare categories of LVIS. Notably, for some rare LVIS categories in Tab. 8, the original or SFT-trained models cannot recognize these categories, resulting in O AP. However, after reinforcement fine-tuning, the model shows a qualitative leap from O to 1 in recognizing these previously unidentifiable categories (such as egg roll and futon). This demonstrates that Visual-RFT has a significant impact on improving the performance and generalization ability in visual recognition for LVLMs.
如表 7 和表 8 所示,经过强化微调后,Qwen2-VL-2/7B 模型在 COCO 数据集的 15 个新类别上平均 mAP 分别提升了 21.5 和 9.5。在更具挑战性的 LVIS [5] 数据集的稀有类别上,mAP 分别提升了 18.0 和 14.7。Visual-RFT 不仅将其检测能力从 COCO 基础类别迁移到了新的 COCO 类别,还在更具挑战性的 LVIS 稀有类别上取得了显著提升。值得注意的是,在表 8 中的一些 LVIS 稀有类别中,原始模型或经过 SFT 训练的模型无法识别这些类别,导致 AP 为 0。然而,经过强化微调后,模型在识别这些之前无法识别的类别(如蛋卷和蒲团)时,表现出从 0 到 1 的质的飞跃。这表明 Visual-RFT 对提升 LVLM 在视觉识别中的性能和泛化能力具有显著影响。
5. Conclusion
5. 结论
In this paper, we introduce Visual Reinforcement Finetuning (Visual-RFT), the first approach to adapt the GRPObased reinforcement learning strategy for enhancing the visual perception and grounding ability of LVLMs. By using a rule-based verifiable reward system, Visual-RFT reduces the need for manual labeling and simplifies reward computation, achieving significant improvements across various visual perception tasks. Extensive experiments show that Visual-RFT excels in fine-grained classification, open vocabulary detection, reasoning grounding and few-shot learning tasks. It outperforms supervised fine-tuning (SFT) with minimal data and shows strong generalization. This work demonstrates the potential of reinforcement learning to enhance the capabilities of LVLMs, making them more efficient and effective in visual perception tasks.
在本文中,我们介绍了视觉强化微调(Visual-RFT),这是首个基于GRPO的强化学习策略,用于增强大视觉语言模型(LVLM)的视觉感知和基础能力。通过使用基于规则的可验证奖励系统,Visual-RFT减少了对人工标注的需求,并简化了奖励计算,在各种视觉感知任务中实现了显著改进。大量实验表明,Visual-RFT在细粒度分类、开放词汇检测、推理基础和少样本学习任务中表现出色。它在少量数据下优于监督微调(SFT),并展现出强大的泛化能力。这项工作展示了强化学习在增强LVLM能力方面的潜力,使它们在视觉感知任务中更加高效和有效。
References
参考文献
[54] Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, et al. Generalized decoding for pixel, image, and language. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15116-15127, 2023.8
[54] Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, 等. 广义解码用于像素、图像和语言. 在 IEEE/CVF 计算机视觉与模式识别会议论文集, 第 15116-15127 页, 2023.