Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
Comet: 专家混合模型中的细粒度计算-通信重叠
1ByteDance Seed, 2Shanghai Jiao Tong University
1字节跳动种子,2上海交通大学
◦Equal Contribution, ∗Work done at ByteDance Seed, †Corresponding authors
◦同等贡献,∗工作完成于字节跳动Seed部门,†通讯作者
Abstract
摘要
Mixture-of-experts (MoE) has been extensively employed to scale large language models to trillionplus parameters while maintaining a fixed computational cost. The development of large MoE models in the distributed scenario encounters the problem of large communication overhead. The inter-device communication of a MoE layer can occupy $47%$ time of the entire model execution with popular models and frameworks. Therefore, existing methods suggest the communication in a MoE layer to be pipelined with the computation for overlapping. However, these coarse grained overlapping schemes introduce a notable impairment of computational efficiency and the latency concealing is sub-optimal.
专家混合 (Mixture-of-experts, MoE) 已被广泛用于将大语言模型扩展到万亿级参数,同时保持固定的计算成本。在分布式场景中开发大型 MoE 模型时,会遇到通信开销大的问题。在流行的模型和框架中,MoE 层的设备间通信可能占据整个模型执行时间的 $47%$。因此,现有方法建议将 MoE 层的通信与计算进行流水线化以实现重叠。然而,这些粗粒度的重叠方案会显著降低计算效率,并且延迟隐藏效果并不理想。
To this end, we present Comet, an optimized MoE system with fine-grained communicationcomputation overlapping. Leveraging data dependency analysis and task rescheduling, Comet achieves precise fine-grained overlapping of communication and computation. Through adaptive workload assignment, Comet effectively eliminates fine-grained communication bottlenecks and enhances its adaptability across various scenarios. Our evaluation shows that Comet accelerates the execution of a single MoE layer by $1.96\times$ and for end-to-end execution, Comet delivers a $1.71\times$ speedup on average. Comet has been adopted in the production environment of clusters with ten-thousand-scale of GPUs, achieving savings of millions of GPU hours.
为此,我们提出了 Comet,一个具有细粒度通信计算重叠的优化 MoE 系统。通过数据依赖分析和任务重新调度,Comet 实现了通信和计算的精确细粒度重叠。通过自适应工作负载分配,Comet 有效消除了细粒度通信瓶颈,并增强了其在各种场景中的适应性。我们的评估显示,Comet 将单个 MoE 层的执行速度提高了 $1.96\times$,并且在端到端执行中,Comet 平均实现了 $1.71\times$ 的加速。Comet 已在拥有数万 GPU 的集群生产环境中得到采用,节省了数百万 GPU 小时。
Correspondence: Ningxin Zheng, Haibin Lin, Quan Chen, Xin Liu Project Page: https://github.com/bytedance/flux
通讯:Ningxin Zheng, Haibin Lin, Quan Chen, Xin Liu
项目页面:https://github.com/bytedance/flux
Introduction
引言
Recent advancements in large language models have revolutionized multiple domains, including natural language processing [35, 36], computer vision [16] and multi-modal perception [3, 14]. These achievements demonstrate that scaling up model size can significantly enhance model capacity. However, the growth in model parameters poses substantial challenges for the deployment of such giant models, as computational resources increasingly constrain model
近年来,大语言模型的进展已经彻底改变了多个领域,包括自然语言处理 [35, 36]、计算机视觉 [16] 以及多模态感知 [3, 14]。这些成就表明,扩大模型规模可以显著提升模型能力。然而,模型参数的增长为这类巨型模型的部署带来了巨大挑战,因为计算资源越来越成为模型的限制因素。
capacity [28].
容量 [28]。
To this end, Mixture-of-Experts (MoE) [29] introduces a sparse structure, within which only part of the parameters is activated. Instead of interacting with all parameters in dense models, MoE models allow each input to interact with only a few experts. For example, the Mixtral-8x7B model [12] comprises 45 billion parameters in total, while only 14 billion parameters are active during runtime. Nowadays, MoE has emerged as a key architecture for scaling models to trillion-plus parameters.
为此,专家混合模型 (Mixture-of-Experts, MoE) [29] 引入了一种稀疏结构,其中只有部分参数被激活。与密集模型中所有参数交互不同,MoE 模型允许每个输入仅与少数专家交互。例如,Mixtral-8x7B 模型 [12] 总共包含 450 亿个参数,但在运行时只有 140 亿个参数是活跃的。如今,MoE 已成为将模型扩展到万亿级以上参数的关键架构。
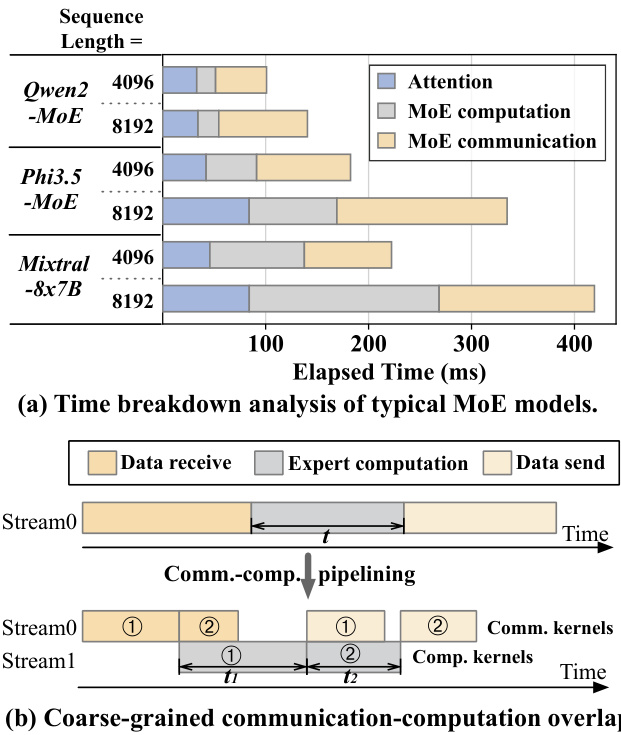
Figure 1 Analysis of the execution of MoE. (a) Time breakdown of MoE models executed on 8 H800 GPUs using Megatron-LM. (b) An illustration of communicationcomputation overlap by partitioning an expert computation kernel into two.
图 1: MoE 执行分析。(a) 使用 Megatron-LM 在 8 个 H800 GPU 上执行的 MoE 模型的时间分解。(b) 通过将专家计算内核分成两部分来说明通信计算重叠。
The increase in parameter size in MoE models allows for the integration of greater amounts of information, but it poses challenges in expert placement. A typical approach is to distribute the experts across different GPUs as a single GPU cannot store all experts [13]. Consequently, during the execution of MoE layers, there is an intensive need for data exchange among GPUs. In the forward pass of several popular MoE models, the communication among devices accounts for 47% of the total execution time on average, as shown in Figure 1(a).
MoE模型中参数规模的增加使得可以集成更多的信息,但也带来了专家放置的挑战。典型的方法是将专家分布在不同的GPU上,因为单个GPU无法存储所有专家 [13]。因此,在执行MoE层时,GPU之间需要大量的数据交换。在几个流行的MoE模型的前向传播中,设备间的通信平均占总执行时间的47%,如图1(a)所示。
In a distributed environment, executing an MoE layer involves data reception, expert computation, and data transmission, as depicted in in Figure 1(b). To reduce communication overhead, one effective strategy is to pipeline the process, overlapping communication with expert computation [8, 10, 31, 32]. This approach involves partitioning input data into smaller data chunks, allowing decomposed communication and computation phases to overlap. In the example in Figure 1(b), the received input data is divided into two chunks, and this coarse-grained overlapping reduces the overall execution time relative to non-pipelined execution.
在分布式环境中,执行 MoE 层涉及数据接收、专家计算和数据传输,如图 1(b) 所示。为了减少通信开销,一种有效的策略是流水线化处理,使通信与专家计算重叠 [8, 10, 31, 32]。这种方法将输入数据划分为较小的数据块,允许分解的通信和计算阶段重叠。在图 1(b) 的示例中,接收到的输入数据被分成两个块,这种粗粒度的重叠相对于非流水线执行减少了整体执行时间。
The overlapping in existing mechanisms remains suboptimal due to two primary inefficiencies. First, the efficiency of partitioned experts declines as the data chunks assigned to each expert become smaller, potentially leading to under-utilization of GPU computational resources (e.g., the total compute time of experts after partitioning $t_{1}+t_{2}$ exceeds the original time $t$ ). The coarse-grained partitioning results in unavoidable GPU idle time during the initial and final communication phases, such as when receiving data for chunk 1 and sending data for chunk 2, which do not overlap with computation. Consequently, minimizing the non-overlapping time in these phases while maintaining computational efficiency is crucial. This is challenging because the data dependency between communication and computation is complex and it is hard to be overlapped in a fine-grained granularity efficiently. Second, due to the dynamic nature of MoE, the input shapes for experts are various at runtime, thereby posing diverse communication and computation burdens on GPUs. Encapsulating communication and computation tasks into separate kernels on different streams, like almost all the prior researches do, restricts control over hardware resources and results in non-deterministic kernel performance, thereby hindering seamless overlap (e.g., the computation of chunk 1 and the receiving of chunk 2 are misaligned). The second challenge, therefore, is to dynamically ensure precise allocation of hardware resources between computation and communication workloads at runtime.
现有机制中的重叠仍然不够理想,主要由于两个低效问题。首先,随着分配给每个专家的数据块变小,分区专家的效率下降,可能导致 GPU 计算资源的利用不足(例如,分区后专家的总计算时间 $t_{1}+t_{2}$ 超过了原始时间 $t$)。粗粒度的分区在初始和最终通信阶段(例如接收块 1 的数据和发送块 2 的数据时)会导致不可避免的 GPU 空闲时间,这些阶段与计算不重叠。因此,在保持计算效率的同时,最小化这些阶段中的非重叠时间至关重要。这具有挑战性,因为通信和计算之间的数据依赖性复杂,难以在细粒度上高效重叠。其次,由于 MoE 的动态特性,专家在运行时的输入形状各不相同,从而给 GPU 带来了不同的通信和计算负担。像几乎所有先前研究那样,将通信和计算任务封装到不同流上的单独内核中,限制了对硬件资源的控制,并导致内核性能的不确定性,从而阻碍了无缝重叠(例如,块 1 的计算和块 2 的接收未对齐)。因此,第二个挑战是在运行时动态确保计算和通信工作负载之间硬件资源的精确分配。
The complex data dependency, and the dynamic computation and communication workloads in MoE impede existing systems to realize efficient communication-computation overlap. We therefore propose Comet, a system that enables fine-grained communication-computation overlapping for efficient MoE execution. Comet introduces two key designs: 1) A dependency resolving method that identifies complex data dependencies between communication and computation operations in MoE, enabling optimized computation-communication pipeline structuring. 2) An adaptive workload assignment method that dynamically allocates GPU thread blocks to different workloads within a kernel, balancing communication and computation to improve latency concealment.
MoE中复杂的数据依赖关系以及动态的计算和通信工作负载阻碍了现有系统实现高效的通信-计算重叠。因此,我们提出了Comet,一个能够实现细粒度通信-计算重叠以高效执行MoE的系统。Comet引入了两个关键设计:1) 一种依赖关系解析方法,用于识别MoE中通信和计算操作之间的复杂数据依赖关系,从而优化计算-通信流水线结构。2) 一种自适应工作负载分配方法,动态地将GPU线程块分配给内核中的不同工作负载,平衡通信和计算以提高延迟隐藏能力。
Comet facilitates fine-grained overlapping in MoE by analyzing shared data buffers between communication and computation operations, referred to as shared tensor. By decomposing the shared tensors along specific dimensions and reorganizing tensor data along with intra-operator execution order,
Comet 通过分析通信和计算操作之间的共享数据缓冲区(称为共享张量),在 MoE 中实现了细粒度的重叠。通过沿特定维度分解共享张量,并重新组织张量数据以及操作内部的执行顺序,
Comet eliminates the granularity mismatches between communication and computation, thereby enabling fine-grained overlapping. To ensure precise resource allocation and effective latency concealment, Comet integrates communication and computation tasks within fused GPU kernels. Through thread block specialization, Comet isolates the impact of communication on computation performance , maintaining high computational efficiency. By adjusting the number of thread blocks allocated to each workload, Comet effectively balances communication and computation latencies and reduces bubbles in overlapping.
Comet 消除了通信与计算之间的粒度不匹配,从而实现了细粒度的重叠。为了确保精确的资源分配和有效的延迟隐藏,Comet 将通信和计算任务集成在融合的 GPU 内核中。通过线程块专门化,Comet 隔离了通信对计算性能的影响,保持了高计算效率。通过调整分配给每个工作负载的线程块数量,Comet 有效地平衡了通信和计算延迟,并减少了重叠中的气泡。
We have integrated Comet into Megatron-LM [33] and verified the capability of Comet with various parallel strategies. Our extensive experiments on Nvidia H800 and L20 clusters show that Comet delivers $1.96\times$ speedup for typical MoE layers, and 1.71 $\times$ speedup for end-to-end MoE model execution (Mixtral-8x7B [12], Qwen2-MoE [2], Phi3.5-MoE [1]) on average, compared with the SOTA MoE systems. Comet has been deployed to accelerate training and inference of large MoE models in production clusters comprising over ten thousand GPUs, achieving savings of millions of GPU hours. Comet introduces a fine-grained pipelined programming model for computation and communication. We will open-source COMET, aiming to inspire further optimization s, such as implementing the programming model in Comet using compilers like Triton [26] or TVM [6].
我们将 Comet 集成到了 Megatron-LM [33] 中,并通过多种并行策略验证了 Comet 的能力。我们在 Nvidia H800 和 L20 集群上进行的大量实验表明,与最先进的 MoE 系统相比,Comet 在典型的 MoE 层上实现了 $1.96\times$ 的加速,在端到端 MoE 模型执行(Mixtral-8x7B [12]、Qwen2-MoE [2]、Phi3.5-MoE [1])上平均实现了 1.71 $\times$ 的加速。Comet 已被部署到包含超过一万个 GPU 的生产集群中,用于加速大型 MoE 模型的训练和推理,节省了数百万 GPU 小时。Comet 引入了细粒度的流水线编程模型,用于计算和通信。我们将开源 COMET,旨在激发进一步的优化,例如使用 Triton [26] 或 TVM [6] 等编译器实现 Comet 中的编程模型。
2 Background and Motivation
2 背景与动机
2.1 MoE Structure
2.1 MoE 结构
Table 1 Description of symbols.
表 1: 符号描述
| 符号 | 描述 |
|---|---|
| L | Transformer层数 |
| E | 专家总数 |
| topk | 每个Token路由到的专家数量 |
| TP | 张量并行大小 |
| EP | 专家并行大小 |
| M | 总并行世界大小 (TP x EP) |
| M | 输入Token长度 × 批量大小 |
| N | Token的嵌入大小 |
| K | 专家中前馈层的隐藏大小 |
Mixture of Experts (MoE) is critical for efficiently scaling models. By enabling sparse activation of parameters, MoE allows for the integration of more parameters without increasing execution costs, thereby enhancing performance. The key idea of MoE is that it consists of multiple small models, namely experts and tokens are only routed to partial experts for computation. Figure 2 shows the typical execution flow of an MoE layer and Table 1 explains symbols to describe the execution of an MoE model.
专家混合 (Mixture of Experts, MoE) 对于高效扩展模型至关重要。通过实现参数的稀疏激活,MoE 可以在不增加执行成本的情况下集成更多参数,从而提升性能。MoE 的核心思想在于它由多个小型模型组成,即专家 (experts),而 token 仅被路由到部分专家进行计算。图 2 展示了 MoE 层的典型执行流程,表 1 解释了描述 MoE 模型执行过程的符号。
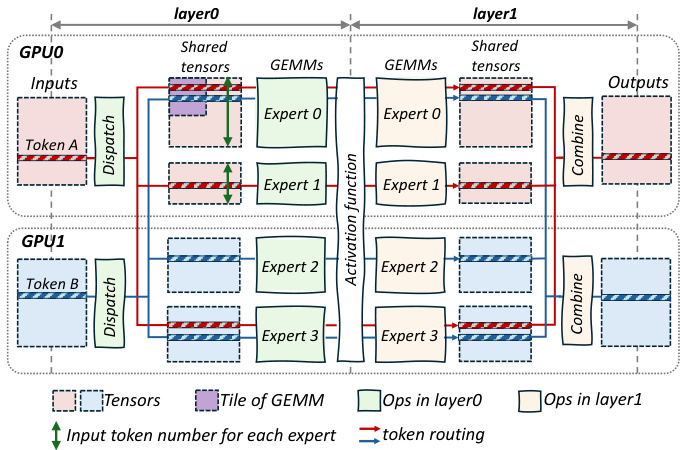
Figure 2 Example of an MoE layer across two GPUs, with two experts reside on GPU0 and two reside on GPU1. The MoE layer is composed of two feed-forward layers. In this example, for each token in the input buffer, it is dispatched to three experts ( $t o p k=3$ ) in layer0 and then the results are combined in layer1. The shape of experts is $N\times K$ in layer0 and $K\times N$ in layer1.
图 2 跨两个 GPU 的 MoE 层示例,其中两个专家位于 GPU0,两个专家位于 GPU1。MoE 层由两个前馈层组成。在此示例中,输入缓冲区中的每个 token 被分配到 layer0 中的三个专家 ( $t o p k=3$ ),然后在 layer1 中组合结果。专家的形状在 layer0 中为 $N\times K$,在 layer1 中为 $K\times N$。
Each input token is assigned to one or more experts for computation, with assignments determined by various algorithms [15, 40, 41]. A common method involves a gate network [29] that selects the topk experts for each token, as shown in Figure 2, where token A is routed to Expert0, Expert1 and Expert3. After passing through two feed-forward layers of General Matrix Multiply (GEMM), the topk outputs are gathered and reduced to produce the final result.
每个输入 Token 会被分配到一个或多个专家进行计算,分配由多种算法决定 [15, 40, 41]。常见的方法是通过一个门控网络 [29] 为每个 Token 选择 topk 专家,如图 2 所示,其中 Token A 被路由到 Expert0、Expert1 和 Expert3。在通过通用矩阵乘法 (GEMM) 的两个前馈层后,topk 输出被收集并缩减以生成最终结果。
The operations in MoE’s layer0 comprise token communication (dispatch) across GPUs and the first layer of expert computations (GEMM operations), thereby establishing a communication-computation pipeline. MoE’s layer1 includes the second layer of expert computations, token undispatch and the topk reduction (combine), forming a computation-communication pipeline.
MoE的layer0操作包括跨GPU的Token通信(分发)和第一层专家计算(GEMM操作),从而建立了一个通信-计算管道。MoE的layer1包括第二层专家计算、Token反分发和topk归约(合并),形成了一个计算-通信管道。
MoE employs two primary parallel iz ation strategies: Expert parallelism [13] and Tensor parallelism [33]. In expert parallelism, the weights of different experts are distributed across separate GPUs, with each expert’s weights being fully intact. Tokens are routed to the corresponding devices of their respective experts. Figure 2 shows a case for expert parallelism, with Expert0 and Expert1 reside on GPU0 and others reside on GPU1. In contrast, tensor parallelism partitions the weights of all experts along the hidden dimension, with each GPU hosting a portion of the weights from all experts. Both expert and tensor parallelism are essential for the efficient execution of MoE. In practical deployment of MoE models, a hybrid parallelism approach combining both expert and tensor parallelism is often applied.
MoE 采用两种主要的并行化策略:专家并行 (Expert parallelism) [13] 和张量并行 (Tensor parallelism) [33]。在专家并行中,不同专家的权重分布在不同的 GPU 上,每个专家的权重保持完整。Token 会被路由到其对应专家的设备上。图 2 展示了一个专家并行的案例,其中 Expert0 和 Expert1 位于 GPU0 上,其他专家位于 GPU1 上。相比之下,张量并行将所有专家的权重沿隐藏维度进行分割,每个 GPU 承载所有专家的一部分权重。专家并行和张量并行对于 MoE 的高效执行都至关重要。在实际部署 MoE 模型时,通常会结合专家并行和张量并行的混合并行方法。
2.2 Computation and Communication Overlapping
2.2 计算与通信重叠
As the MoE architecture grows larger and sparser, the proportion of time spent on communication in MoE models becomes increasingly significant, as shown in Figure 1(a). As illustrated in section 1, coarsegrained overlapping of computation and communication offers limited optimization potential, and kernel- level scheduling is not efficient for dynamic workloads. Thus, it is more efficient to perform the overlapping at a fine-grained granularity (such as token-wise) and integrates computation and communication workloads into fused GPU kernels. Adopting such a finergrained overlapping could extremely unleash further optimization opportunities. However, achieving such fine-grained overlapping in MoE is non-trivial and there are two primary obstacles in our observation.
随着MoE架构变得更大且更稀疏,MoE模型中通信所占时间的比例变得越来越显著,如图1(a)所示。如第1节所述,计算和通信的粗粒度重叠提供的优化潜力有限,而内核级调度对于动态工作负载并不高效。因此,在细粒度(例如Token级别)进行重叠并将计算和通信工作负载集成到融合的GPU内核中更为高效。采用这种细粒度的重叠可以极大地释放进一步的优化机会。然而,在MoE中实现这种细粒度的重叠并非易事,根据我们的观察,存在两个主要障碍。
2.2.1 Granularity mismatch between computation and communication
2.2.1 计算与通信之间的粒度不匹配
In MoE systems, the token serves as the fundamental unit of data movement, illustrated by the movement of Token A in Figure 2. To maximize GPU compute efficiency, high-performance GEMM(GroupGEMM) kernels typically organize rows into tiles for processing. The purple block in Figure 2 represents such a computation tile in GEMM kernels, exemplified by a 128x128 tile. Therefore, the GEMM computations associated with a single expert may require 128 tokens distributed across multiple GPUs. When fusing computation and communication at fine granularity, the disparity between token-level data transfer and tilelevel computation introduces considerable challenges: The complex data dependency adversely affects the efficiency of overlap, prompting the use of fine-grained communication, while integrating fine-grained communication with computation within fused kernels is also challenging.
在 MoE 系统中,Token 作为数据移动的基本单位,如图 2 中 Token A 的移动所示。为了最大化 GPU 计算效率,高性能的 GEMM(GroupGEMM)内核通常将行组织成块进行处理。图 2 中的紫色块代表了 GEMM 内核中的计算块,例如一个 128x128 的块。因此,与单个专家相关的 GEMM 计算可能需要分布在多个 GPU 上的 128 个 Token。在细粒度上融合计算和通信时,Token 级别的数据传输与块级别的计算之间的差异带来了相当大的挑战:复杂的数据依赖性对重叠效率产生了不利影响,促使使用细粒度通信,同时在融合内核中将细粒度通信与计算集成也具有挑战性。
Complex data dependency. The tokens needed for each computation tile, determined by the MoE’s gate at runtime, are randomly distributed across multiple devices. Computation for a tile cannot start until all required tokens are available. As shown in Figure 2, Expert0’s tile does not initiate processing until both
复杂的数据依赖性。每次计算所需的Token,由MoE的门控在运行时决定,这些Token随机分布在多个设备上。只有在所有必需的Token都可用时,计算才能开始。如图2所示,Expert0的区块直到所有必需的Token都可用时才开始处理。
Token A and Token B are received. Thus, with coarsegrained data communication, data preparation time for each computational tile may be prolonged because of this irregular and complicated data dependency. To mitigate this, we should employ fine-grained communication, where each computational tile reads or writes only the data it requires directly through the Unified Virtual Address [18], and leverage the data reorganization and rescheduling to hide it with computation efficiently.
接收到 Token A 和 Token B。因此,由于这种不规则且复杂的数据依赖性,粗粒度的数据通信可能会延长每个计算块的数据准备时间。为了缓解这一问题,我们应该采用细粒度的通信方式,即每个计算块仅通过统一虚拟地址 [18] 直接读取或写入所需的数据,并利用数据重组和重新调度来有效地将其与计算隐藏。
Fine-grained communication. The integration of token-wise communication with tile-wise computation for overlapping is non-trivial. Remote I/O operations between GPUs exhibit significantly higher latency compared to local GPU memory access. Therefore, executing numerous fine-grained read and write operations on remote data tokens within computation thread blocks can block subsequent computational tasks, leading to a significant decline in kernel efficiency. This challenge is especially evident in the Hopper architecture, where computation kernels leverage Tensor Memory Accelerator (TMA) hardware instructions [20] to establish asynchronous compute pipelines. The integration of long-latency remote I/O operations within these asynchronous pipelines can considerably prolong the overall execution time, adversely affecting performance. Thus, it is critical to constrain the impact of fine-grained communication on computation kernels.
细粒度通信。将基于Token的通信与基于Tile的计算集成以实现重叠并非易事。GPU之间的远程I/O操作相比本地GPU内存访问具有显著更高的延迟。因此,在计算线程块内对远程数据Token执行大量细粒度的读写操作会阻塞后续的计算任务,导致内核效率显著下降。这一挑战在Hopper架构中尤为明显,计算内核利用Tensor Memory Accelerator (TMA)硬件指令[20]来建立异步计算管道。在这些异步管道中集成高延迟的远程I/O操作会显著延长整体执行时间,对性能产生不利影响。因此,限制细粒度通信对计算内核的影响至关重要。
Our first insight is that resolving the granularity mismatch between computation and communication in MoE models is the key to enable efficient overlap of these two processes.
我们的第一个见解是,解决 MoE 模型中计算与通信之间的粒度不匹配问题是实现这两个过程高效重叠的关键。
2.2.2 Diverse loads of computation and communication
2.2.2 计算和通信的多样化负载
Another characteristic of MoE is the dynamic routing of tokens to different experts, resulting in varying input shapes for experts at runtime (e.g., the token number received by Expert0 and Expert1 are different as shown in Figure 2). This variability imposes differing communication and computation demands on GPUs. Besides, the hardware environments can also have various compute architectures or network topologies, providing different compute capacities and communication bandwidths. Achieving seamless overlap between computation and communication thus requires dynamically adjusting the allocation of GPU resources to different workloads, which is hard to be realized through wrapping workloads into separate kernels.
MoE 的另一个特点是 Token 动态路由到不同的专家,导致运行时专家的输入形状不同(例如,Expert0 和 Expert1 接收到的 Token 数量不同,如图 2 所示)。这种变化性对 GPU 的通信和计算需求提出了不同的要求。此外,硬件环境也可能具有不同的计算架构或网络拓扑,提供不同的计算能力和通信带宽。因此,要实现计算和通信之间的无缝重叠,需要动态调整 GPU 资源对不同工作负载的分配,这很难通过将工作负载封装到单独的内核中来实现。
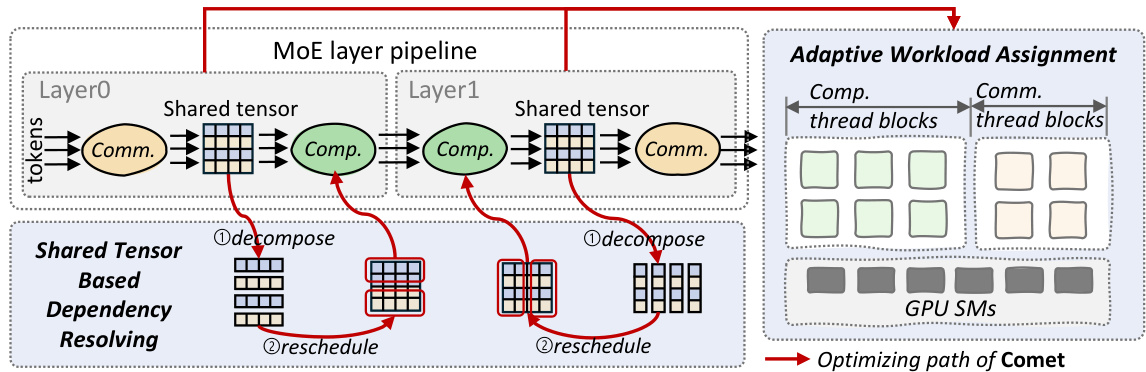
Figure 3 Design overview of Comet. Comet is composed of a shared tensor-based dependency resolving method and an adaptive workload assignment mechanism.
图 3: Comet 的设计概览。Comet 由一个基于张量的共享依赖解析方法和一个自适应工作负载分配机制组成。
Our second insight is that the resource allocation should be adaptive within kernels at runtime to further achieve seamless communication-computation overlapping.
我们的第二个见解是,资源分配应在运行时在内核内自适应,以进一步实现无缝的通信-计算重叠。
3 Design of Comet
3 Comet 的设计
In this section, we present the core design of Comet, a Mixture of Experts (MoE) system optimized for efficient execution of MoE layers through pipelined execution and fine-grained overlapping of communication and computation. Our analysis reveals that the MoE architecture has two distinct producer-consumer pipelines: the communication-computation pipeline and the computation-communication pipeline, as illustrated in Figure 3. Tokens traverse the pipelines as depicted and the operations within each pipeline are linked through a shared buffer, referred to as the shared tensor, serving as both the producer’s output buffer and the consumer’s input buffer. To minimize overall latency and enhance pipeline performance, Comet introduces two key mechanisms aimed at overlapping computation and communication workloads effectively.
在本节中,我们介绍了 Comet 的核心设计,这是一个专为通过流水线执行和通信与计算的细粒度重叠来高效执行 MoE (Mixture of Experts) 层而优化的系统。我们的分析表明,MoE 架构有两个不同的生产者-消费者流水线:通信-计算流水线和计算-通信流水线,如图 3 所示。Token 按照图示遍历这些流水线,每个流水线中的操作通过一个共享缓冲区(称为共享张量)连接,该缓冲区既作为生产者的输出缓冲区,也作为消费者的输入缓冲区。为了最小化总体延迟并提高流水线性能,Comet 引入了两个关键机制,旨在有效地重叠计算和通信工作负载。
- Shared tensor based dependency resolving: As previously mentioned, the intricate data dependencies between communication and computation pose a challenge to achieving seamless overlap between these operations. To address this, we examine the data dependencies by analyzing the shared tensor. Our analysis reveals that the shared tensor can be decomposed, and the associated computations can be rescheduled to overlap more effectively with communication. Accordingly, the dependency resolving process employs two key optimization strategies on the shared tensors as shown in Figure 3: $\textcircled{1}$ Decomposing the shared tensors along specific dimensions to break the coarse-grained data dependencies and, $\textcircled{2}$ rescheduling the computations to enhance efficiency while ensuring effective overlapping.
- 基于共享张量的依赖解析:如前所述,通信与计算之间复杂的数据依赖关系对实现这些操作的无缝重叠提出了挑战。为了解决这个问题,我们通过分析共享张量来检查数据依赖关系。我们的分析表明,共享张量可以被分解,并且相关的计算可以重新调度,以更有效地与通信重叠。因此,依赖解析过程在共享张量上采用了两个关键的优化策略,如图 3 所示:$\textcircled{1}$ 沿特定维度分解共享张量以打破粗粒度的数据依赖关系,以及 $\textcircled{2}$ 重新调度计算以提高效率,同时确保有效的重叠。
- Adaptive workload assignment: Following pipeline optimization by the dependency resolving, the pattern of communication-computation overlap becomes more consistent and regular. To effectively hide the fine-grained communication latency, it is essential to allocate appropriate hardware resources to both communication and computation workloads. Given that these workloads exhibit different performance characteristics depending on input shapes, model config u rations, and hardware environments, the adaptive workload assignment scheme dynamically balances computation and communication. This approach generates highly efficient horizontally-fused kernels for the MoE system, thereby optimizing latency concealment.
- 自适应工作负载分配:在通过依赖关系解析进行流水线优化后,通信-计算重叠的模式变得更加一致和规律。为了有效隐藏细粒度的通信延迟,必须为通信和计算工作负载分配适当的硬件资源。鉴于这些工作负载根据输入形状、模型配置和硬件环境表现出不同的性能特征,自适应工作负载分配方案动态平衡计算和通信。这种方法为MoE系统生成高效的水平融合内核,从而优化延迟隐藏。
As shown in Figure 3, Comet first leverages the shared tensor based dependency resolving method to optimize the pipelines in the MoE structure by decomposing and rescheduling the shared tensors. According to the reformed pipelines, Comet then provides highly-efficient fused kernels through the adaptive workload assignment mechanism.
如图 3 所示,Comet 首先利用基于共享张量的依赖解析方法来优化 MoE 结构中的流水线,通过分解和重新调度共享张量来实现。根据重构后的流水线,Comet 随后通过自适应工作负载分配机制提供高效融合的内核。
3.1 Shared Tensor Based Dependency Resolving
3.1 基于共享张量的依赖解析
We now introduce how to resolve the complex data dependency between computation and communication in MoE. It aims to bridge the granularity of communication and computation operations to sustain high efficiency by decomposing and rescheduling shared tensors.
我们现在介绍如何在MoE中解决计算和通信之间的复杂数据依赖问题。其目标是通过分解和重新调度共享张量,来桥接通信和计算操作的粒度,以保持高效率。
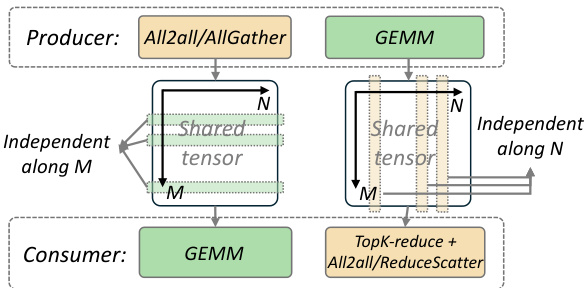
Figure 4 The producer-consumer modeling of layer0 (left) and layer1 (right) of an MoE layer. The global size of the shared tensor is $(M\times t o p k,N)$ for both layer0 and layer1.
图 4: MoE 层的 layer0 (左) 和 layer1 (右) 的生产者-消费者模型。layer0 和 layer1 的共享张量的全局大小为 $(M\times t o p k,N)$。
3.1.1 How to decompose the shared tensor?
3.1.1 如何分解共享张量?
Shared tensors, as the bridge between the producer operator and the consumer operator, is the key to enable overlapping. Notably, overlapping can occur only when the producer and consumer operate on independent data within the shared tensor, as illustrated in Figure 4. Thus, we analyze the access pattern of operators on the shared tensor and decompose it along a specific dimension where data remain independent for the consumer operator.
共享张量作为生产者操作和消费者操作之间的桥梁,是实现重叠的关键。值得注意的是,只有当生产者和消费者在共享张量中操作独立数据时,重叠才会发生,如图 4 所示。因此,我们分析了操作在共享张量上的访问模式,并沿着消费者操作数据保持独立的特定维度对其进行分解。
For example, in the communication-computation pipeline in layer0, the consumer operator is a GEMM, with the shared tensor serving as its input matrix. In this case, tokens are independent with each other alongside the $M$ (token) dimension, allowing for decomposition of the shared tensor along $M$ . However, since the computation of a GEMM tile involves multip li cation and reduction along the token embedding dimension to produce the final outputs, decomposing the shared tensor along this dimension is not feasible.
例如,在 layer0 的通信-计算流水线中,消费者操作符是一个 GEMM (General Matrix Multiply),共享张量作为其输入矩阵。在这种情况下,Token 在 $M$ (Token) 维度上是相互独立的,因此可以沿 $M$ 维度对共享张量进行分解。然而,由于 GEMM 图块的计算涉及沿 Token 嵌入维度的乘法和归约以生成最终输出,因此沿此维度分解共享张量是不可行的。
As for the computation-communication pipeline in layer1, the consumer operator contains a top-K reduction, which reduces tokens along the $M$ dimension, leading to significant interdependencies between tokens along this dimension. Thus, the shared tensor can only be decomposed along the $N$ dimension where elements are independent.
至于层1中的计算-通信管道,消费者操作符包含一个top-K归约,它沿着$M$维度减少token,导致该维度上的token之间存在显著的相互依赖性。因此,共享张量只能沿着元素独立的$N$维度进行分解。
3.1.2 How to reschedule the decomposed shared tensor?
3.1.2 如何重新调度分解后的共享张量?
At the finest granularity, the shared tensor can be split into individual rows or columns, enabling the consumer to begin computation as soon as a single row or column is received. However, this level of granularity results in low computational efficiency, particularly in pipelines involving compute-intensive GEMMs, which are typically organized and processed in tiles to achieve high utilization. Therefore, after decomposing shared tensors along specific dimensions, the resulting sub-tensors must be reorganized and rescheduled into tiles for computation. The rescheduling of shared tensors follows two principles: $\textcircled{1}$ Rescheduled sub-tensors should align with the original computation tile granularity for computational efficiency. $\textcircled{2}$ The scheduling policy should prioritize portions of the producer that can be immediately used by the consumer, allowing the consumer to begin execution as early as possible.
在最细粒度上,共享张量可以拆分为单独的行或列,使得消费者在接收到单一行或列后即可开始计算。然而,这种粒度会导致计算效率低下,特别是在涉及计算密集型GEMM(通用矩阵乘法)的流水线中,这些计算通常以分块形式组织和处理,以实现高利用率。因此,在沿特定维度分解共享张量后,生成的子张量必须重新组织并重新调度为分块进行计算。共享张量的重新调度遵循两个原则:$\textcircled{1}$ 重新调度的子张量应与原始计算分块粒度对齐,以提高计算效率。$\textcircled{2}$ 调度策略应优先考虑生产者中消费者可立即使用的部分,以便消费者尽早开始执行。
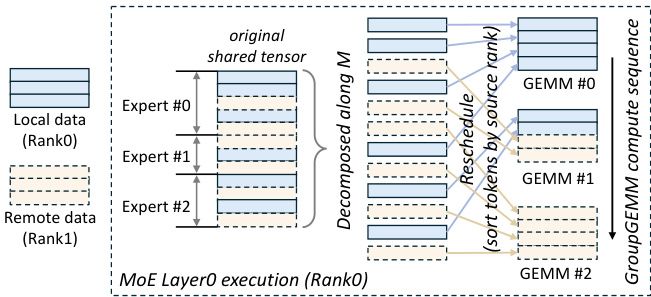
Figure 5 Decompose and reschedule the shared tensor in MoE layer0. In this illustration, three experts are located on Rank 0, each requiring both local and remote data for computation.
图 5: 在 MoE 层 0 中分解并重新调度共享张量。在此图示中,三个专家位于 Rank 0 上,每个专家都需要本地和远程数据进行计算。
Comet leverages GroupGEMM to perform the computations for all experts on current rank. In the communication-computation pipeline (MoE layer0), the shared tensor, consumed by GroupGEMM, is decomposed along the $M$ dimension. To enable early computation by the experts, tokens are sorted based on their source rank, as shown in Figure 5. The compute sequence of tiles in the GroupGEMM is then designed to minimize dependency on remote data, with computation beginning from tiles containing local tokens while the transfer of other remote tokens proceeds concurrently.
Comet 利用 GroupGEMM 在当前节点上执行所有专家的计算。在通信-计算流水线(MoE 层0)中,GroupGEMM 消耗的共享张量沿 $M$ 维度分解。为了使专家能够尽早开始计算,Token 会根据其来源节点进行排序,如图 5 所示。GroupGEMM 中的计算块序列设计旨在最小化对远程数据的依赖,计算从包含本地 Token 的块开始,同时其他远程 Token 的传输并行进行。
In the computation-communication pipeline (MoE layer1), the shared tensor undergoes a top-k reduction after processing by the GroupGEMM of experts. As analyzed previously, the shared tensor is decomposed along the $N$ dimension. The tile computation sequence is adjusted (Figure 6) to enable the consumer operator to start processing before expert computations are fully completed. Instead of computing each expert sequentially, GroupGEMM operations are executed column-wise. This approach allows the reduction and communicate operations to proceed as soon as the first $T_{N}$ columns of the shared tensors are computed. Without rescheduling, tokens could only be reduced after all experts have completed their computations.
在计算-通信流水线(MoE layer1)中,共享张量在经过专家组的 GroupGEMM 处理后,会进行 top-k 缩减。如前所述,共享张量沿着 $N$ 维度进行分解。为了使得消费者操作符能够在专家计算完全完成之前开始处理,我们对瓦片计算序列进行了调整(图 6)。GroupGEMM 操作不是按顺序计算每个专家,而是按列执行。这种方法使得一旦共享张量的前 $T_{N}$ 列计算完成,缩减和通信操作就可以立即进行。如果不进行重新调度,Token 只能在所有专家完成计算后才能进行缩减。
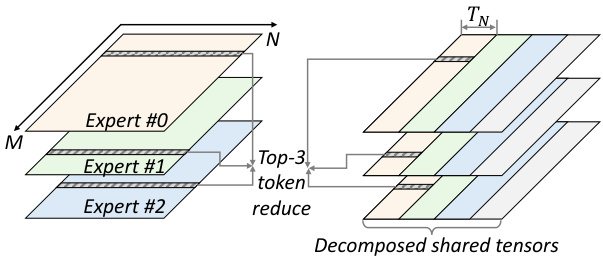
Figure 6 Rescheduled compute sequence for MoE layer1 ( $E=3$ and $t o p k=3$ ). The execution order of the GroupGEMM is indicated by color (yellow $\rightarrow$ green $\rightarrow$ blue $\rightarrow$ grey). Here, $T_{N}$ denotes the tile size of a GroupGEMM along the $N$ dimension.
图 6: MoE 层 1 的重新调度计算序列 ( $E=3$ 和 $topk=3$ )。GroupGEMM 的执行顺序由颜色表示 (黄色 $\rightarrow$ 绿色 $\rightarrow$ 蓝色 $\rightarrow$ 灰色)。其中,$T_{N}$ 表示 GroupGEMM 沿 $N$ 维度的分块大小。
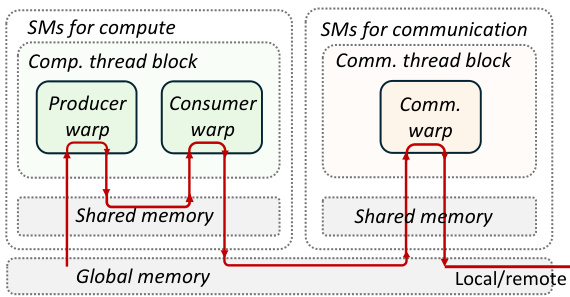
Figure 7 Kernel design for the MoE layer1 on Hopper architecture. Each SM only accommodate one thread block. The red arrows indicates the route of data movement.
图 7: Hopper 架构上 MoE layer1 的核设计。每个 SM 仅容纳一个线程块。红色箭头表示数据移动的路径。
3.2 Adaptive Workload Assignment
3.2 自适应工作负载分配
With the decomposition and rescheduling of shared tensors, the pipelines in MoE can now achieve finegrained overlap. To ensure effective latency hiding, the durations of fine-grained communication and computation must be closely aligned to minimize pipeline bubbles. Achieving this requires adaptive resource allocation for both computation and communication, tailored to specific tasks involved.
通过对共享张量的分解和重新调度,MoE中的管道现在可以实现细粒度的重叠。为了确保有效的延迟隐藏,细粒度的通信和计算持续时间必须紧密对齐,以最小化管道气泡。实现这一点需要根据具体任务自适应地分配计算和通信资源。
3.2.1 Thread block specialization
3.2.1 线程块特化
A straightforward approach to achieve communication-computation overlap in Mixture of Experts (MoE) is to encapsulate the entire pipeline within homogeneous thread blocks, integrating communication I/O into the prologue or epilogue of the computation (GEMM), a strategy referred to here as vertical fusion. Through vertical fusion, thread blocks execute concurrently, but the overlap occurs irregularly, leading to non-deterministic latencies of communication and computation, making it challenging to balance their durations for latency hiding. Furthermore, token-level fine-grained I/O in MoE can significantly reduce the computational efficiency of the underlying kernels, particularly on advanced architectures such as Hopper. To address this, we implement thread block-level isolation between communication and computation workloads. This isolation enables precise control over hardware resource allocation for each workload, facilitating a balanced distribution between computation and communication that maximizes latency hiding.
在专家混合模型 (Mixture of Experts, MoE) 中实现通信-计算重叠的一种直接方法是将整个流水线封装在均匀的线程块中,将通信 I/O 集成到计算 (GEMM) 的前导或后记中,这种策略在此称为垂直融合。通过垂直融合,线程块并发执行,但重叠发生不规则,导致通信和计算的延迟不确定性,使得平衡它们的持续时间以隐藏延迟变得具有挑战性。此外,MoE 中的 Token 级细粒度 I/O 会显著降低底层内核的计算效率,尤其是在 Hopper 等先进架构上。为了解决这个问题,我们在通信和计算工作负载之间实现了线程块级别的隔离。这种隔离使得能够精确控制每个工作负载的硬件资源分配,促进计算和通信之间的平衡分配,从而最大化延迟隐藏。
Figure 7 depicts the details of the thread block specialized kernel on Hopper, with the critical data path highlighted in red. Due to the isolation between communication and computation, the GEMM thread blocks in Comet utilize the same implementation as the default GEMM before fusion. In the scenario depicted in Figure 7, where the GEMM is compiled using CUTLASS on the Hopper architecture, the GEMM execution is distributed across different warps. Specifically, the producer warp loads data from global memory into a shared memory buffer with the async TMA instructions, while the consumer warp initiates tensor core MMA operations [21]. The communication thread blocks subsequently read the results produced by the consumer warp from global memory. Following the top-K reduction, the warps within the communication blocks either write tokens to the local global memory or transmit them to remote destinations. This thread block-specialized programming model is easily portable to other architectures, such as Ampere and Volta, requiring only a substitution of the respective compute thread block implementation.
图 7 展示了 Hopper 上线程块专用内核的细节,关键数据路径以红色突出显示。由于通信和计算之间的隔离,Comet 中的 GEMM 线程块在融合前使用了与默认 GEMM 相同的实现。在图 7 描述的场景中,GEMM 在 Hopper 架构上使用 CUTLASS 编译,GEMM 的执行分布在不同的 warp 上。具体来说,生产者 warp 使用异步 TMA 指令将数据从全局内存加载到共享内存缓冲区,而消费者 warp 则启动张量核心 MMA 操作 [21]。通信线程块随后从全局内存中读取消费者 warp 生成的结果。在 top-K 归约之后,通信块内的 warp 要么将 token 写入本地全局内存,要么将它们传输到远程目的地。这种线程块专用编程模型很容易移植到其他架构,例如 Ampere 和 Volta,只需要替换相应的计算线程块实现即可。
Hardware resource restriction. The proposed thread block-specialized kernel is designed with the primary objective of minimizing data movement costs. However, this design must also contend with hardware resource limitations. For instance, it is theoretically feasible to integrate communication warps with computation warps within the same thread block to eliminate redundant global memory accesses. However, the thread number restriction of warps constrict the communication operator to fully utilize the communication bandwidth. From another perspective, the warps for communication also interfere with the computation warps within the same thread block.
硬件资源限制。提出的线程块专用内核设计的主要目标是尽量减少数据移动成本。然而,这种设计还必须应对硬件资源的限制。例如,理论上可以在同一个线程块内将通信 warp 与计算 warp 集成,以消除冗余的全局内存访问。然而,warp 的线程数限制使得通信操作符无法充分利用通信带宽。从另一个角度来看,用于通信的 warp 也会干扰同一线程块内的计算 warp。
3.2.2 Adaptive thread block assignment
3.2.2 自适应线程块分配
Suppose that there are $n$ thread blocks for the fused kernel, within which $n_{p}$ blocks serve as producers in the pipeline and $n_{c}$ blocks serve as consumers. Identifying an optimal division point $n_{p}/n_{c}$ is crucial for maximizing overall efficiency. We demonstrate that the optimal division point is influenced by the shape of input and specific model configurations in an MoE layer. To investigate this, we measure the duration of MoE layer1 across various input sequence lengths and parallel iz ation strategies, as shown in Figure 8. It is observed that there exist an optimal division point under different configurations.
假设融合内核中有 $n$ 个线程块,其中 $n_{p}$ 个块作为流水线中的生产者,$n_{c}$ 个块作为消费者。确定一个最优的分割点 $n_{p}/n_{c}$ 对于最大化整体效率至关重要。我们证明了最优分割点受输入形状和 MoE 层中特定模型配置的影响。为了研究这一点,我们测量了不同输入序列长度和并行化策略下 MoE 层1的持续时间,如图 8 所示。观察到在不同配置下存在一个最优的分割点。

Figure 8 Duration of the MoE layer1 kernel with varying number of thread blocks assigned for communication $(n_{c})$ . The total number of thread blocks is identical to the number of SMs on Hopper(132). The figure shows four cases with different parallelisms.
图 8: 不同通信线程块数量 $(n_{c})$ 下 MoE 层1内核的持续时间。线程块总数与 Hopper (132) 上的 SM 数量相同。图中展示了四种不同并行度的情况。
When the input token length changes, although the data sizes processed by communication and computation operations both scale with input length, the s cal ability of the respective resource requirements differs. Consequently, the optimal division point shifts with changes in input length. For example, when $T P=8$ , the optimal $n_{c}$ changes from 18 to 26 when $M$ is changed from 4096 to 16384. When the model configuration (parallel strategy) is modified, the optimal division point undergoes a significant alteration. For instance, when $T P$ is adjusted from 8 to 4, the optimal $n_{c}$ is transformed from 26 to 46 with $M=16384$ .
当输入 token 长度变化时,尽管通信和计算操作处理的数据量都随输入长度扩展,但各自资源需求的可扩展性不同。因此,最优划分点会随着输入长度的变化而移动。例如,当 $T P=8$ 时,最优的 $n_{c}$ 从 18 变为 26,当 $M$ 从 4096 变为 16384 时。当模型配置(并行策略)被修改时,最优划分点会发生显著变化。例如,当 $T P$ 从 8 调整为 4 时,最优的 $n_{c}$ 从 26 变为 46,当 $M=16384$ 时。
Comet’s library comprises multiple pre-compiled kernels, each with a distinct division point. Prior to deployment, the optimal configuration for each setup is profiled and stored as metadata. During runtime, Comet utilizes this metadata to select the optimal kernel for execution.
Comet 的库包含多个预编译的内核,每个内核都有不同的划分点。在部署之前,每个设置的最佳配置会被分析并存储为元数据。在运行时,Comet 利用这些元数据来选择最佳的内核进行执行。
4 Implementation
4 实现
Comet consists of approximately 12k lines of $\mathrm{C}++$ and CUDA code and 2k lines of Python. Comet provides a suite of user-friendly Python APIs and developers can seamlessly integrate the APIs into their frameworks. In production environment, Comet has been implemented in Megatron-LM for large-scale
Comet 由大约 12k 行 $\mathrm{C}++$ 和 CUDA 代码以及 2k 行 Python 代码组成。Comet 提供了一套用户友好的 Python API,开发者可以无缝地将这些 API 集成到他们的框架中。在生产环境中,Comet 已在 Megatron-LM 中实现,用于大规模
Table 2 Configuration of MoE models used in experiments. The models are open-sourced on Hugging Face [9]. The meaning of symbols are explained in Table 1.
表 2 实验中使用的 MoE 模型配置。这些模型已在 Hugging Face [9] 上开源。符号的含义在表 1 中解释。
| L | E | topk | N | K | |
|---|---|---|---|---|---|
| Mixtral 8x7B | 32 | 8 | 2 | 4096 | 14336 |
| Qwen2-MoE-2.7B | 24 | 64 | 4 | 2048 | 1408 |
| Phi-3.5-MoE | 32 | 16 | 2 | 4096 | 6400 |
MoE training. The source code will be available on GitHub.
MoE 训练。源代码将在 GitHub 上提供。
Optimized GEMM kernels for MoE. Comet extensively utilizes the programming templates provided by CUTLASS to generate highly efficient GEMM kernels. Additionally, it incorporates various optimizations to minimize data movement overhead. For instance, in MoE layer 0, the row indices of the input matrix for GEMM operations must be accessed from global memory at each K iteration. By caching these row indices in registers, Comet significantly reduces the global memory access cost.
为MoE优化的GEMM内核。Comet广泛利用CUTLASS提供的编程模板来生成高效的GEMM内核。此外,它还结合了各种优化技术,以最小化数据移动开销。例如,在MoE的第0层,GEMM操作的输入矩阵的行索引必须在每次K迭代时从全局内存中访问。通过将这些行索引缓存在寄存器中,Comet显著降低了全局内存访问成本。
NVSHMEM as communication library. We employ NVSHMEM [24] within kernels to support finegrained communication. NVSHMEM is a communication library designed for NVIDIA GPUs. It creates a global address space for data that spans the memory of multiple GPUs and can be accessed with finegrained GPU-initiated operations and CPU-initiated operations. Unlike NCCL [23], which targets highlevel communication operations, NVSHMEM offers a more composable, low-level API that facilitates finer data access granularity within kernels.
NVSHMEM 作为通信库。我们在内核中使用 NVSHMEM [24] 来支持细粒度的通信。NVSHMEM 是一个为 NVIDIA GPU 设计的通信库。它为跨越多个 GPU 内存的数据创建了一个全局地址空间,可以通过 GPU 发起的细粒度操作和 CPU 发起的操作进行访问。与针对高层通信操作的 NCCL [23] 不同,NVSHMEM 提供了一个更具可组合性的底层 API,便于在内核中实现更细粒度的数据访问。
5 Evaluation
5 评估
5.1 Experimental Setup
5.1 实验设置
Testbed. We evaluate Comet on a server equipped with 8 Nvidia H800 GPUs (80 GB memory each). These GPUs are interconnected through NVLink. Our software environment includes CUDA 12.3, NVSHMEM 2.11, Pytorch 2.4.0 and Megatron-LM (git-hash 6dbe4c).
测试平台。我们在配备8块Nvidia H800 GPU(每块80 GB内存)的服务器上评估Comet。这些GPU通过NVLink互连。我们的软件环境包括CUDA 12.3、NVSHMEM 2.11、Pytorch 2.4.0和Megatron-LM(git-hash 6dbe4c)。
Comparing targets. We then compare Comet with several baselines. All baselines are implemented on Megatron-LM, which is a widely adopted framework for high-performance model execution, integrating hybrid parallel strategies.
比较目标。我们随后将 Comet 与多个基线进行比较。所有基线均在 Megatron-LM 上实现,这是一个广泛采用的高性能模型执行框架,集成了混合并行策略。
The baselines are: (a) Megatron-Cutlass: Megatron with MoE experts that are implemented through CUTLASS grouped GEMM [22]. (b) MegatronTE: Megatron with experts that use transformer engine [25]. Transformer Engine is Nvidia’s library for accelerating transformer models on NVIDIA GPUs. (c) FasterMoE [7, 8]: FasterMoE is an MoE system that customizes All-to-All communication to overlap the communication and computation operations of experts. (d) Tutel [10]: Tutel delivers several optimization techniques for efficient and adaptive MoE, including adaptive parallelism, the 2-dimensional hierarchical All-to-All algorithm and fast encode/decode with sparse computation on GPU.
基线方法包括:
(a) Megatron-Cutlass:使用通过 CUTLASS 分组 GEMM [22] 实现的 MoE 专家的 Megatron。
(b) MegatronTE:使用 Transformer Engine [25] 的专家的 Megatron。Transformer Engine 是 Nvidia 的库,用于在 NVIDIA GPU 上加速 Transformer 模型。
(c) FasterMoE [7, 8]:FasterMoE 是一个 MoE 系统,通过定制 All-to-All 通信来重叠专家的通信和计算操作。
(d) Tutel [10]:Tutel 提供了多种优化技术,以实现高效且自适应的 MoE,包括自适应并行性、二维分层 All-to-All 算法以及在 GPU 上使用稀疏计算的快速编码/解码。

Figure 9 End-to-end MoE model latency. For the computation of MoE layers, the number of token on each device before permutation is $M\times W/T P$ . The hatched region represents the identical duration of non-MoE (attention) layers in different mechanisms. Note that FasterMoE only supports expert parallelism for MoE layers.
图 9: 端到端 MoE 模型延迟。对于 MoE 层的计算,每个设备在置换前的 token 数量为 $M\times W/T P$。阴影区域表示不同机制中非 MoE(注意力)层的相同持续时间。请注意,FasterMoE 仅支持 MoE 层的专家并行。
5.2 Overall Performance
5.2 整体性能
We evaluate the end-to-end performance of Comet in multiple large MoE models, including Mixtral 8x7B [12], Qwen2-MoE [2] and Phi3.5-MoE [1]. The configurations of these models are shown in Table 2. The experiment is conducted with various input token lengths and diverse hybrid parallel strategies. The experimental details and results are shown in Figure 9. Note that when $T P<W$ , Megatron-LM enables data parallelism for non-MoE layers to improve overall throughput and the data parallel size is $W/T P$ . The computation of attention layers are identical with different mechanisms using Megatron-LM, and only the MoE layer is implemented differently with diverse mechanisms.
我们在多个大型 MoE 模型中评估了 Comet 的端到端性能,包括 Mixtral 8x7B [12]、Qwen2-MoE [2] 和 Phi3.5-MoE [1]。这些模型的配置如表 2 所示。实验在不同的输入 token 长度和多种混合并行策略下进行。实验细节和结果如图 9 所示。需要注意的是,当 $T P<W$ 时,Megatron-LM 会对非 MoE 层启用数据并行以提高整体吞吐量,数据并行的大小为 $W/T P$。使用 Megatron-LM 时,注意力层的计算在不同机制下是相同的,只有 MoE 层在不同机制下的实现方式不同。
As observed, the end-to-end latencies of the benchmarks are reduced by $34.1%$ , $42.6%$ , $44.4%$ and $31.8%$ with Comet compared with Megatron-Cutlass, Megatron-TE, FasterMoE and Tutel respectively. The performance gain is more prominent with the identical attention computation apart. Comet outperforms other baselines in all configurations because it realizes sufficient overlapping and the scheduling inside high-performance fused kernels greatly reduce the the overhead at CPU side.
正如观察到的,与 Megatron-Cutlass、Megatron-TE、FasterMoE 和 Tutel 相比,Comet 的基准测试端到端延迟分别减少了 $34.1%$、$42.6%$、$44.4%$ 和 $31.8%$。在相同的注意力计算部分,性能提升更为显著。Comet 在所有配置中都优于其他基线,因为它实现了充分的重叠,并且高性能融合内核内部的调度大大减少了 CPU 端的开销。
Besides, we can also observe that MegatronCutlass and Megatron-TE perform similar. This is because they are identical except from the imple ment ation of GEMM/GroupGEMM. Neither of them supports overlapping, while Megatron-TE performs worse in some cases because of the overhead in transformer engine API calls. Tutel performs better than other baselines because it incorporates communication into experts’ computation through delicate scheduling and adaptive parallelism. Although communication and computation is overlapped partially, when the number of experts is large (Qwen2), the advantage of Tutel diminishes because of the large scheduling overhead. FasterMoE only supports expert parallelism ( $E P=W$ ) and it also does not perform well on Qwen2 because the experts are small in Qwen2 and the kernel invoking time for experts dominates the MoE layer.
此外,我们还可以观察到 MegatronCutlass 和 Megatron-TE 的表现相似。这是因为它们除了 GEMM/GroupGEMM 的实现外,其他部分完全相同。两者都不支持重叠,而 Megatron-TE 在某些情况下表现较差,因为 transformer engine API 调用的开销较大。Tutel 比其他基线表现更好,因为它通过精细的调度和自适应并行性将通信融入专家的计算中。尽管通信和计算部分重叠,但当专家数量较大时(如 Qwen2),Tutel 的优势因调度开销较大而减弱。FasterMoE 仅支持专家并行($E P=W$),并且在 Qwen2 上表现不佳,因为 Qwen2 中的专家规模较小,专家内核调用时间主导了 MoE 层的性能。
5.3 Detailed Evaluation on a Single MoE Layer
5.3 单个MoE层的详细评估
We then conduct an in-depth examination of a single MoE layer to perform a detailed analysis.
然后我们对单个MoE层进行深入检查,以进行详细分析。
Handling varying input token lengths. The latency of a single MoE layer with varying input token lengths is shown in Figure 10. With the input token number varying, Comet experiences a shorter duration compared with baselines and the improvement is stable. Comet achieves a $1.28\times$ to $2.37\times$ speedup compared with the baselines on average. It is noted that the advantage of Comet is prominent especially when $M$ is small. This is because the scheduling time on the host side predominates the overall duration when $M$ is small and Comet reduces such overhead through kernel scheduling within the fused kernel. The scheduling overhead increases with topk and $E$ for mechanisms with kernel-level scheduling (FasterMoE and Tutel) because the experts to manage become more complicated, inducing more kernels to be scheduled.
处理不同输入 Token 长度的变化。图 10 展示了单个 MoE 层在不同输入 Token 长度下的延迟情况。随着输入 Token 数量的变化,Comet 相比基线方法表现出更短的持续时间,并且这种改进是稳定的。Comet 相比基线方法平均实现了 $1.28\times$ 到 $2.37\times$ 的加速。值得注意的是,Comet 的优势在 $M$ 较小时尤为显著。这是因为当 $M$ 较小时,主机端的调度时间占据了整体持续时间的主导地位,而 Comet 通过融合内核中的内核调度减少了这种开销。对于具有内核级调度的机制(如 FasterMoE 和 Tutel),调度开销随着 topk 和 $E$ 的增加而增加,因为需要管理的专家变得更加复杂,导致需要调度更多的内核。

Figure 10 Single MoE layer duration with expert parallelism $E P=8$ ). The x-axis represents the total input token length $M$ . Each device has $M/W$ tokens before token dispatching. The shape of experts are identical to that of Mixtral 8x7B.
图 10: 专家并行 (EP=8) 下的单个 MoE 层持续时间。x 轴表示总输入 token 长度 (M)。每个设备在 token 分发前有 M/W 个 token。专家的形状与 Mixtral 8x7B 相同。
Time breakdown analysis of an MoE layer. The time breakdown of a specific MoE layer is shown in Figure 11. Note that the communication part only consists of the GPU-to-GPU communication time, and the operations of token indexing, dispatching and combining on local device are regarded as the computation part. As revealed, Megatron-TE and Megatron-cutlass experience no overlapping between communication and computation. FasterMoE reduces the communication latency through customized Scatter and Gather operators, while the introduced local indexing extends the computation time. Tutel reduces the communication overhead through the optimized all-to-all primitive design. However, its optimized all-to-all also exacerbates the burden of local computation. Megatron-TE has no communication overlapped. Comet hides $86.5%$ of communication latency on average and the computational efficiency of experts is not influenced, while FasterMoE and Tutel hide only $29.2%$ and $68.6%$ respectively.
MoE层的时间分解分析。图11展示了一个特定MoE层的时间分解。需要注意的是,通信部分仅包含GPU到GPU的通信时间,而本地设备上的Token索引、分发和组合操作被视为计算部分。如图所示,Megatron-TE和Megatron-cutlass在通信和计算之间没有重叠。FasterMoE通过定制的Scatter和Gather操作符减少了通信延迟,但引入的本地索引延长了计算时间。Tutel通过优化的all-to-all原语设计减少了通信开销。然而,其优化的all-to-all也加剧了本地计算的负担。Megatron-TE没有通信重叠。Comet平均隐藏了86.5%的通信延迟,且专家的计算效率不受影响,而FasterMoE和Tutel分别仅隐藏了29.2%和68.6%。
Parallelism within the MoE layer. Because of the introduction of expert parallelism, the parallel strategy within the MoE layer can be different from the model’s overall parallel strategy. Figure 12 shows the performance of methods applying diverse parallel strategies. Among all baselines, FasterMoE unfortunately does not support tensor parallelism. For other baselines (Megatron-TE, MegatronCutlass and Tutel), the MoE layer latency increases when $T P$ grows. This is because that tensor parallelism splits each expert onto multiple devices, triggering more fragmented small GEMMs for experts and resulting in a degradation of computational efficiency. Nevertheless, Comet maintains low latency in diverse parallelisms as the shared tensor is rescheduled to maintain computational efficiency and the weight switching overhead is eliminated.
MoE层内的并行性。由于引入了专家并行性,MoE层内的并行策略可能与模型的整体并行策略不同。图12展示了应用不同并行策略的方法的性能。在所有基线中,遗憾的是FasterMoE不支持张量并行。对于其他基线(Megatron-TE、MegatronCutlass和Tutel),当$TP$增加时,MoE层的延迟会增加。这是因为张量并行将每个专家拆分到多个设备上,触发了更多碎片化的小型GEMM(通用矩阵乘法)操作,导致计算效率下降。然而,Comet在各种并行性中保持了低延迟,因为共享张量被重新调度以保持计算效率,并且消除了权重切换的开销。

Figure 11 Time breakdown of an MoE layer with expert parallelism. ( $E P=8$ $8,T P=1,E=8,t o p k=2$ and $M=16384.$ ).
图 11: 使用专家并行化的 MoE 层的时间分解。( $E P=8$ , $T P=1$ , $E=8$ , $t o p k=2$ , 以及 $M=16384$ )。

Figure 12 Single MoE layer duration under various parallelism strategies with $E=8,t o p k=2,M=$ 8192, $E P\times T P=8$ .
图 12: 不同并行策略下单个 MoE 层的持续时间,其中 $E=8, topk=2, M=8192, EP\times TP=8$。
5.4 Adaptive ness to Different Configurations
5.4 对不同配置的适应性
We further inquire into the performance of Comet when adapting different model configurations, runtime workloads and system environments.
我们进一步探讨了Comet在不同模型配置、运行时工作负载和系统环境下的性能表现。
Performance with various MoE parameters. We adjust the number of experts $E$ as well as topk to evaluate the performance of Comet in various MoE structures. The results are shown in Figure 13. With the increasing of topk, the duration of the MoE layer is increased because the computation amount at runtime is scaled up. Comet consistently demonstrates superior performance across different values of topk and $E$ , yielding a speedup in the range of $1.16\times$ to $1.83\times$ compared to baseline implementations.
不同MoE参数下的性能表现。我们调整专家数量$E$以及topk值,以评估Comet在不同MoE结构中的性能。结果如图13所示。随着topk值的增加,MoE层的持续时间也随之增加,因为运行时的计算量相应增大。Comet在不同topk值和$E$值下始终展现出卓越的性能,相较于基线实现,其加速比在$1.16\times$至$1.83\times$之间。

Figure 13 Duration of a single MoE layer $M=$ 16384, $E P=8$ , $T P=1$ ) with various number of experts $E$ and topk.
图 13: 单个 MoE 层的持续时间 ($M=16384$, $EP=8$, $TP=1$) 在不同专家数量 $E$ 和 topk 下的表现

Figure 14 Performance of a MoE layer when scal- ing to different scenarios. Left: Duration with vari- ous token distribution with expert parallelism ( $\mathrm{\textit{E}~}=$ $8,t o p k=2,M=8192,T P=1,E P=8)$ . Right: Duration on a L20 Cluster with diverse parallelisms $\mathit{\Pi}^{\prime}E=8,t o p k=4,M=8192$ , $E P\times T P=8$ ).
图 14: MoE层在不同场景下的性能表现。左图:在不同Token分布下使用专家并行($\mathrm{\textit{E}~}=8, topk=2, M=8192, TP=1, EP=8$)的持续时间。右图:在L20集群上使用不同并行策略($\mathit{\Pi}^{\prime}E=8, topk=4, M=8192$, $EP\times TP=8$)的持续时间。
Performance with varying token distribution. When using expert parallelism, the number of tokens routed to different devices varies. We evaluate the performance of Comet in scenarios with imbalanced token distribution. The standard deviation of the token distribution across different experts is denoted as std. As shown in the left panel of Figure 14, 8192 tokens are distributed across various experts with differing distributions. When $s t d=0$ , tokens are uniformly distributed and each expert receives $M\times t o p k/E=2048$ tokens. At $s t d=0.05$ , the leastloaded expert is assigned only a few hundred tokens. In a typical training job in production, the average std is 0.032. When the load imbalance problem is exacerbated, the latency of the MoE layer in all systems is prolonged. Comet consistently outperforms other MoE systems.
不同Token分布下的性能表现。在使用专家并行时,路由到不同设备的Token数量会有所不同。我们评估了Comet在Token分布不均衡场景下的性能表现。不同专家之间Token分布的标准差用std表示。如图14左侧所示,8192个Token以不同的分布方式分布在各个专家中。当$std=0$时,Token均匀分布,每个专家接收$M\times topk/E=2048$个Token。当$std=0.05$时,负载最轻的专家仅分配了几百个Token。在生产环境的典型训练任务中,平均std为0.032。当负载不均衡问题加剧时,所有系统中MoE层的延迟都会延长。Comet始终优于其他MoE系统。
Scaling to distinct clusters. We carry out the experiments on another distinct cluster with a different network environment. The cluster is equipped with 8 Nvidia L20 GPUs (46 GB memory) and the GPUs are connected via PCIe bridges. The GPU-to-GPU bandwidth is around 25 GB/s as tested, which is much lower than the H800 cluster. The experiments on the L20 cluster represents a bandwidth-limited environment. As shown in the right panel of Figure 14, the average speedup of Comet compared with other baselines is from $1.19\times$ to $1.46\times$ . The results manifest the superiority of Comet under different cluster environments.
扩展到不同集群。我们在另一个具有不同网络环境的集群上进行了实验。该集群配备了8个Nvidia L20 GPU(46 GB内存),GPU通过PCIe桥连接。测试显示,GPU到GPU的带宽约为25 GB/s,远低于H800集群。L20集群上的实验代表了带宽受限的环境。如图14右侧所示,Comet与其他基线相比的平均加速比从$1.19\times$到$1.46\times$。结果表明,Comet在不同集群环境下均表现出优越性。
Table 3 Required device memory size for NVSHMEM.
| Mem(MB) | Mixtral8x7B | Qwen2-MoE | Phi3.5-MoE |
| M=4096 | 32 | 16 | 32 |
| M=8192 | 64 | 32 | 64 |
表 3 NVSHMEM 所需的设备内存大小
| Mem(MB) | Mixtral8x7B | Qwen2-MoE | Phi3.5-MoE |
|---|---|---|---|
| M=4096 | 32 | 16 | 32 |
| M=8192 | 64 | 32 | 64 |
5.5 Overhead Analysis
5.5 开销分析
Comet leverages NVSHMEM to allocate a shared memory buffer for communication on each device. The buffer size is dependent on the model configuration and equals to $M N$ , where $M$ is the input sequence length and $N$ is the model hidden size. For datatype of BF16 or FP16, the allocated memory size is $2M N$ . The communication buffer is global for the execution of the entire model, which means that it is shared across layers and experts. We list the device memory consumption of Comet in Table 3, and it is negligible compared with the large device memory on current GPUs.
Comet 利用 NVSHMEM 在每个设备上分配一个共享内存缓冲区用于通信。缓冲区大小取决于模型配置,等于 $M N$,其中 $M$ 是输入序列长度,$N$ 是模型隐藏大小。对于 BF16 或 FP16 数据类型,分配的内存大小为 $2M N$。通信缓冲区在整个模型的执行过程中是全局的,这意味着它在各层和各专家之间共享。我们在表 3 中列出了 Comet 的设备内存消耗,与当前 GPU 上的大容量设备内存相比,这是可以忽略不计的。
Related Work
相关工作
With the successful application of MoE in large-scale distributed training and inference, there are plenty of works focusing on the system-level optimization s of reducing the communication overhead inherited in the MoE structure.
随着 MoE 在大规模分布式训练和推理中的成功应用,许多工作集中在系统级优化上,以减少 MoE 结构中固有的通信开销。
Communication optimization. To reduce the communication overhead in MoE execution, a straightforward approach is to leverage efficient communication algorithms [19, 30] for faster data transmission. Recent works [10, 17, 27] also propose the 2D-hierarchical all-to-all algorithm to better utilize intra-node bandwidth and accelerate MoE communication. Some other works propose to reduce communication volume by data compression. For example, ScheMoE [32] and Zhou et al., [39] propose to apply data compression technologies to reduce the all-to-all communication volume while preserving the model convergence.
通信优化。为了减少MoE执行中的通信开销,一种直接的方法是利用高效的通信算法 [19, 30] 来加速数据传输。最近的研究 [10, 17, 27] 还提出了2D层次化的全对全算法,以更好地利用节点内带宽并加速MoE通信。其他一些研究则提出通过数据压缩来减少通信量。例如,ScheMoE [32] 和 Zhou 等人 [39] 提出应用数据压缩技术来减少全对全通信量,同时保持模型收敛性。
Computation-communication overlapping. The techniques of overlapping of computation and communication for dense models have been extensively employed in distributed training and inference [4, 5, 11, 34, 37, 38]. For the MoE structure, recent studies also try to identify the pipelining opportunities for communication tasks of all-to-all operations and computing tasks of GEMMs. FasterMoE [8] allows a pipeline degree of 2 to pipeline the expert computations and all-to-all communications. Tutel [10] enables a manually set degree of pipelining or a heuristic search under limited searching space, which may be suboptimal. PipeMoE [31] and ScheMoE [32] aim to schedule MoE operators to better utilize intra- and inter-connect bandwidths. These solutions realize overlapping through kernel-level scheduling and do not fully resolve the fine-grained data dependency in MoE.
计算-通信重叠。密集模型的计算和通信重叠技术已广泛应用于分布式训练和推理 [4, 5, 11, 34, 37, 38]。对于 MoE 结构,最近的研究也尝试为全对全操作的通信任务和 GEMM 的计算任务寻找流水线机会。FasterMoE [8] 允许流水线度为 2,以流水线化专家计算和全对全通信。Tutel [10] 允许手动设置流水线度或在有限搜索空间内进行启发式搜索,这可能不是最优的。PipeMoE [31] 和 ScheMoE [32] 旨在调度 MoE 操作符以更好地利用内部和互连带宽。这些解决方案通过内核级调度实现重叠,但并未完全解决 MoE 中的细粒度数据依赖问题。
7 Conclusion
7 结论
In this paper, we propose Comet, a MoE system that aims to achieve fine-grained communication and computation overlapping for MoE. Comet features two key designs to achieve seamless overlapping without impact the computational efficiency: Shared tensor based dependency resolving that enables fine-grained overlapping, while eliminating the bottleneck caused by fine-grained communication I/O; The workload assignment mechanism that promises precise and adaptive overlapping of operators, inducing maximal latency concealing. Comet achieves $1.96\times$ speedup in a single MoE layer and 1.71 $\times$ speedup in the end-to-end execution of MoE models, compared with existing literature.
在本文中,我们提出了 Comet,一种旨在为 MoE 实现细粒度通信与计算重叠的 MoE 系统。Comet 具有两个关键设计,以实现无缝重叠而不影响计算效率:基于共享张量的依赖关系解析,支持细粒度重叠,同时消除由细粒度通信 I/O 引起的瓶颈;工作负载分配机制,确保算子的精确和自适应重叠,从而实现最大延迟隐藏。与现有文献相比,Comet 在单个 MoE 层中实现了 $1.96\times$ 的加速,在 MoE 模型的端到端执行中实现了 1.71 $\times$ 的加速。