LEARNING EFFICIENT ONLINE 3D BIN PACKING ON PACKING CONFIGURATION TREES
基于装箱配置树的高效在线三维装箱学习
Hang $\mathbf{Zhao^{1,2*}}$ ,Yang $\mathbf{Y}\mathbf{u}^{2}$ ,Kai $\mathbf{X}\mathbf{u}^{1\dagger}$ 1School of Computer Science, National University of Defense Technology, China 2National Key Lab for Novel Software Technology, Nanjing University, China {alex.hang.zhao, kevin.kai.xu}@gmail.com, yuy@nju.edu.cn
Hang $\mathbf{Zhao^{1,2*}}$,Yang $\mathbf{Y}\mathbf{u}^{2}$,Kai $\mathbf{X}\mathbf{u}^{1\dagger}$
1 国防科技大学计算机学院,中国
2 南京大学软件新技术国家重点实验室,中国
{alex.hang.zhao, kevin.kai.xu}@gmail.com, yuy@nju.edu.cn
ABSTRACT
摘要
Online 3D Bin Packing Problem (3D-BPP) has widespread applications in industrial automation and has aroused enthusiastic research interest recently. Existing methods usually solve the problem with limited resolution of spatial discretization, and/or cannot deal with complex practical constraints well. We propose to enhance the practical applicability of online 3D-BPP via learning on a novel hierarchical representation ——- packing configuration tree (PCT). PCT is a full-fedged description of the state and action space of bin packing which can support packing policy learning based on deep reinforcement learning (DRL). The size of the packing action space is proportional to the number of leaf nodes, i.e.candidate placements, making the DRL model easy to train and well-performing even with continuous solution space. During training, PCT expands based on heuristic rules, however, the DRL model learns a much more effective and robust packing policy than heuristic methods. Through extensive evaluation, we demonstrate that our method outperforms all existing online BPP methods and is versatile in terms of incorporating various practical constraints.
在线三维装箱问题(3D-BPP)在工业自动化中有着广泛的应用,并且最近引起了广泛的研究兴趣。现有方法通常通过有限的空间离散化分辨率来解决该问题,并且/或者无法很好地处理复杂的实际约束。我们提出通过一种新颖的分层表示——装箱配置树(PCT)——来增强在线3D-BPP的实际适用性。PCT是对装箱状态和动作空间的完整描述,可以支持基于深度强化学习(DRL)的装箱策略学习。装箱动作空间的大小与叶子节点(即候选放置位置)的数量成正比,使得DRL模型即使在连续解空间中也易于训练且表现良好。在训练过程中,PCT基于启发式规则进行扩展,然而,DRL模型学习到的装箱策略比启发式方法更为有效和鲁棒。通过广泛的评估,我们证明了我们的方法优于所有现有的在线BPP方法,并且在整合各种实际约束方面具有广泛的适用性。
1 INTRODUCTION
1 引言
As one of the most classic combinatorial optimization problems, the 3D bin packing problem usually refers to packing a set of cuboid-shaped items $i\in\mathcal{T}$ with sizes $s_{i}^{x},s_{i}^{y},s_{i}^{z}$ along $x,y,z$ axes, respectively, into the minimum number of bins with sizes $S^{x},S^{y},S^{z}$ , in an axis-aligned fashion. Traditional 3D-BPP assumes that all the items to be packed are known a priori (Martello et al., 2000), which is also called offline BPP. The problem is known to be strongly NP-hard (De Castro Silva et al., 2003). However, in many real-world application scenarios, e.g., logistics or warehousing (Wang & Hauser, 2019a), the upcoming items cannot be fully observed; only the current item to be packed is observable. Packing items without the knowledge of all upcoming items is referred to as online BPP (Seiden, 2002).
作为最经典的组合优化问题之一,三维装箱问题 (3D bin packing problem) 通常指将一组长方体形状的物品 $i\in\mathcal{T}$ 沿 $x,y,z$ 轴分别以尺寸 $s_{i}^{x},s_{i}^{y},s_{i}^{z}$ 装入尺寸为 $S^{x},S^{y},S^{z}$ 的箱子中,且要求箱子数量最少。传统的三维装箱问题假设所有待装箱的物品都是预先已知的 (Martello et al., 2000),这也被称为离线装箱问题 (offline BPP)。该问题被证明是强 NP 难问题 (De Castro Silva et al., 2003)。然而,在许多实际应用场景中,例如物流或仓储 (Wang & Hauser, 2019a),即将到来的物品无法完全观察到;只有当前待装箱的物品是可见的。在不知道所有即将到来的物品的情况下进行装箱被称为在线装箱问题 (online BPP) (Seiden, 2002)。
Due to its obvious practical usefulness, online 3D-BPP has received increasing attention recently. Given the limited knowledge, the problem cannot be solved by usual search-based methods. Different from offline 3D-BPP where the items can be placed in an arbitrary order, online BPP must place items following their coming order, which imposes additional constraints. Online 3D-BPP is usually solved with either heuristic methods (Ha et al., 2017) or learning-based ones (Zhao et al., 2021), with complementary pros and cons. Heuristic methods are generally not limited by the size of action space, but they find difficulties in handling complex practical constraints such as packing stability or specific packing preferences. Learning-based approaches usually perform better than heuristic methods, especially under various complicated constraints. However, the learning is hard to converge with a large action space, which has greatly limited the applicability of learning-based methods due to, e.g., the limited resolution of spatial disc ret iz ation (Zhao et al., 2021).
由于其明显的实用性,在线3D-BPP(三维装箱问题)最近受到了越来越多的关注。由于知识有限,该问题无法通过常规的基于搜索的方法解决。与离线3D-BPP不同,离线3D-BPP可以按任意顺序放置物品,而在线BPP必须按照物品到达的顺序进行放置,这增加了额外的约束。在线3D-BPP通常通过启发式方法(Ha et al., 2017)或基于学习的方法(Zhao et al., 2021)来解决,这两种方法各有优缺点。启发式方法通常不受动作空间大小的限制,但在处理复杂的实际约束(如包装稳定性或特定的包装偏好)时存在困难。基于学习的方法通常比启发式方法表现更好,尤其是在各种复杂约束下。然而,由于动作空间较大,学习难以收敛,这极大地限制了基于学习方法的适用性,例如空间离散化的有限分辨率(Zhao et al., 2021)。
We propose to enhance learning-based online 3D-BPP towards practical applicability through learning with a novel hierarchical representation -— packing configuration tree (PCT). PCT is a dynamically growing tree where the internal nodes describe the space configurations of packed items and leaf nodes the packable placements of the current item. PCT is a full-fledged description of the state and action space of bin packing which can support packing policy learning based on deep reinforcement learning (DRL). We extract state features from PCT using graph attention networks (Velickovic et al., 2018) which encodes the spatial relations of all space configuration nodes. The state feature is input into the actor and critic networks of the DRL model. The actor network, designed based on pointer mechanism, weighs the leaf nodes and outputs the action (the final placement).
我们提出通过一种新颖的层次表示——装箱配置树(PCT)来增强基于学习的在线3D-BPP(三维装箱问题)的实际应用性。PCT是一棵动态增长的树,其中内部节点描述已装箱物品的空间配置,叶节点描述当前物品的可装箱位置。PCT是对装箱状态和动作空间的完整描述,能够支持基于深度强化学习(DRL)的装箱策略学习。我们使用图注意力网络(Velickovic et al., 2018)从PCT中提取状态特征,该网络编码了所有空间配置节点的空间关系。状态特征被输入到DRL模型的actor和critic网络中。基于指针机制设计的actor网络对叶节点进行加权,并输出动作(最终放置位置)。
During training, PCT grows under the guidance of heuristics such as Corner Point (Martello et al., 2000), Extreme Point (Crainic et al., 2008), and Empty Maximal Space (Ha et al., 2017). Although PCT is expanded with heuristic rules, confining the solution space to what the heuristics could explore, our DRL model learns a discriminant fitness function (the actor network) for the candidate placements, resulting in an effective and robust packing policy exceeding the heuristic methods. Furthermore, the size of the packing action space is proportional to the number of leaf nodes, making the DRL model easy to train and well-performing even with continuous solution space where the packing coordinates are continuous values. Through extensive evaluation, we demonstrate that our method outperforms all existing online 3D-BPP methods and is versatile in terms of incorporating various practical constraints such as isle friendliness and load balancing (Gzara et al., 2020). Our work is, to our knowledge, the first that deploys the learning-based method on solving online 3DBPP with continuous solution space successfully.
在训练过程中,PCT 在 Corner Point (Martello et al., 2000)、Extreme Point (Crainic et al., 2008) 和 Empty Maximal Space (Ha et al., 2017) 等启发式方法的指导下增长。尽管 PCT 通过启发式规则扩展,将解空间限制在启发式方法所能探索的范围内,但我们的 DRL 模型学习了候选放置的判别适应度函数(即演员网络),从而产生了一种超越启发式方法的有效且稳健的装箱策略。此外,装箱动作空间的大小与叶节点的数量成正比,这使得 DRL 模型即使在装箱坐标为连续值的连续解空间中也能轻松训练并表现出色。通过广泛的评估,我们证明了我们的方法优于所有现有的在线 3D-BPP 方法,并且在结合各种实际约束(如通道友好性和负载平衡 (Gzara et al., 2020))方面具有通用性。据我们所知,我们的工作是首次成功地将基于学习的方法应用于解决具有连续解空间的在线 3DBPP 问题。
2 RELATED WORK
2 相关工作
Offline 3D-BPP The early interest of 3D-BPP mainly focused on its offline setting. Offline 3DBPP assumes that all items are known as a priori and can be placed in an arbitrary order. Martello et al. (2000) first solved this problem with an exact branch-and-bound approach. Limited by exponential worst-case complexity of exact approaches, lots of heuristic and meta-heuristic algorithms are proposed to get an approximate solution quickly, such as guided local search (Faroe et al., 2003), tabu search (Crainic et al., 2009), and hybrid genetic algorithm (Kang et al., 2012). Hu et al. (2017) decompose the offline 3D-BPP into packing order decisions and online placement decisions. The packing order is optimized with an end-to-end DRL agent and the online placement policy is a handdesigned heuristic. This two-step fashion is widely accepted and followed by Duan et al. (2019), Hu et al. (2020), and Zhang et al. (2021).
离线 3D-BPP
早期对 3D-BPP 的研究主要集中在离线设置上。离线 3D-BPP 假设所有物品都是已知的,并且可以按任意顺序放置。Martello 等人 (2000) 首次使用精确的分支定界方法解决了这个问题。由于精确方法的最坏情况复杂度呈指数级增长,许多启发式和元启发式算法被提出以快速获得近似解,例如引导局部搜索 (Faroe 等人, 2003)、禁忌搜索 (Crainic 等人, 2009) 和混合遗传算法 (Kang 等人, 2012)。Hu 等人 (2017) 将离线 3D-BPP 分解为装箱顺序决策和在线放置决策。装箱顺序通过端到端的深度强化学习 (DRL) 智能体进行优化,而在线放置策略则采用手工设计的启发式方法。这种两步法被广泛接受,并被 Duan 等人 (2019)、Hu 等人 (2020) 和 Zhang 等人 (2021) 所沿用。
Heuristics for Online 3D-BPP Although offline 3D-BPP has been well studied, their searchbased approaches cannot be directly transferred to the online setting. Instead, lots of heuristic methods have been proposed to solve this problem. For reasons of simplicity and good performance, the deep-bottom-left (DBL) heuristic (Karabulut & Inceoglu, 2004) has long been a favorite. Ha et al. (2017) sort the empty spaces with this DBL order and place the current item into the first fit one. Wang & Hauser (2019b) propose a Heightmap-Minimization method to minimize the volume increase of the packed items as observed from the loading direction. Hu et al. (2020) optimize the empty spaces available for the packing future with a Maximize-Accessible-Convex-Space method.
在线三维装箱问题(3D-BPP)的启发式方法
尽管离线三维装箱问题已经得到了广泛研究,但其基于搜索的方法无法直接应用于在线场景。因此,许多启发式方法被提出以解决这一问题。由于简单性和良好的性能,深底左(DBL)启发式方法(Karabulut & Inceoglu, 2004)长期以来备受青睐。Ha 等人(2017)使用这种 DBL 顺序对空置空间进行排序,并将当前物品放入第一个合适的空间。Wang & Hauser(2019b)提出了一种高度图最小化方法,以最小化从装载方向观察到的已装物品的体积增加。Hu 等人(2020)通过最大化可访问凸空间方法优化了可用于未来装箱的空置空间。
DRL for Online 3D-BPP The heuristic methods are intuitive to implement and can be easily applied to various scenarios. However, the price of good fexibility is that these methods perform mediocrely, especially for online 3D-BPP with specific constraints. Designing new heuristics for specific classes of 3D-BPP is heavy work since this problem has an NP-hard solution space, many situations need to be premeditated manually by trial and error. Substantial domain knowledge is also necessary to ensure safety and reliability. To automatically generate a policy that works well on specified online 3D-BPP, Verma et al. (2020); Zha0 et al. (2021) employ the DRL method on solving this problem, however, their methods only work in small discrete coordinate spaces. Despite their limitations, these works are soon followed by Hong et al. (2020); Yang et al. (2021); Zhao et al. (2022) for logistics robot implementation. Zhang et al. (2021) adopt a similar online placement policy for offline packing needs referring to Hu et al. (2017). All these learning-based methods only work in a grid world with limited disc ret iz ation accuracy, which reduces their practical applicability.
DRL 用于在线 3D-BPP 的启发式方法直观且易于实现,可以轻松应用于各种场景。然而,良好灵活性的代价是这些方法表现平庸,特别是对于具有特定约束的在线 3D-BPP。为特定类别的 3D-BPP 设计新的启发式方法是一项繁重的工作,因为该问题的解空间是 NP 难的,许多情况需要通过试错手动预先考虑。此外,还需要大量的领域知识来确保安全性和可靠性。为了自动生成在指定在线 3D-BPP 上表现良好的策略,Verma 等人 (2020);Zha0 等人 (2021) 采用 DRL 方法来解决此问题,然而,他们的方法仅适用于小型离散坐标空间。尽管存在这些限制,这些工作很快被 Hong 等人 (2020);Yang 等人 (2021);Zhao 等人 (2022) 用于物流机器人实现。Zhang 等人 (2021) 参考 Hu 等人 (2017) 采用类似的在线放置策略来满足离线包装需求。所有这些基于学习的方法仅在具有有限离散化精度的网格世界中有效,这降低了它们的实际适用性。
Practical Constraints The majority of literature for 3D-BPP (Martello et al., 2000) only considers the basic non-overlapping constraint 1 and containment constraint 2:
实际约束
大多数关于3D-BPP(Martello等,2000)的文献仅考虑基本的非重叠约束1和包含约束2:
$$
\begin{array}{r l}{p_{i}^{d}+s_{i}^{d}\leq p_{j}^{d}+S^{d}(1-e_{i j}^{d})}&{i\not=j,i,j\in\mathbb{Z},d\in{x,y,z}}\ {0\leq p_{i}^{d}\leq S^{d}-s_{i}^{d}}&{i\in\mathbb{Z},d\in{x,y,z}}\end{array}
$$
$$
\begin{array}{r l}{p_{i}^{d}+s_{i}^{d}\leq p_{j}^{d}+S^{d}(1-e_{i j}^{d})}&{i\not=j,i,j\in\mathbb{Z},d\in{x,y,z}}\ {0\leq p_{i}^{d}\leq S^{d}-s_{i}^{d}}&{i\in\mathbb{Z},d\in{x,y,z}}\end{array}
$$
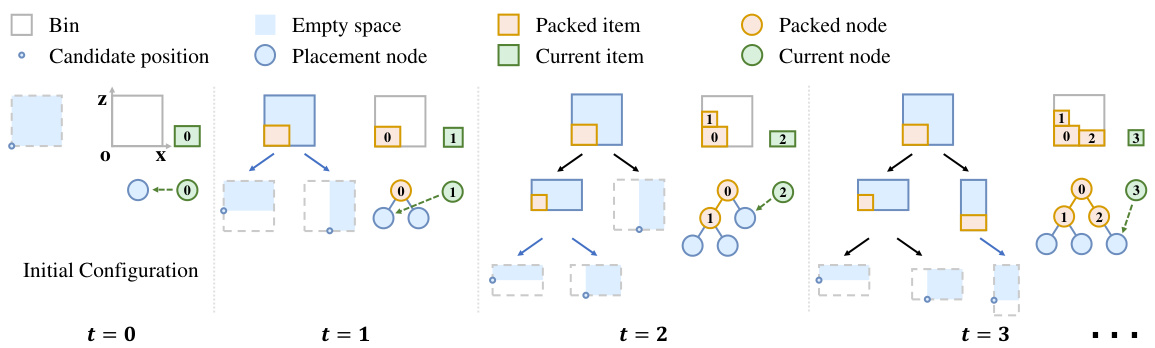
Figure 1: PCT expansion illustrated using a 2D example (in $x o z$ plane) for simplicity and the number of allowed O orientations $|\mathbf{O}|$ is 1 (see Appendix B for the 3D version). A newly added item introduces a series of empty spaces and new candidate placements are generated, e.g., the left-bottom corner of the empty space.
图 1: 使用二维示例(在 $x o z$ 平面中)简化说明 PCT 扩展,允许的 O 方向数量 $|\mathbf{O}|$ 为 1(3D 版本见附录 B)。新添加的物品引入了一系列空的空间,并生成了新的候选放置位置,例如空空间的左下角。
Where $p_{i}$ means the front-left-bottom coordinate of item $i$ and $d$ the coordinate axis, $e_{i j}$ takes value 1 otherwise O if item $i$ precedes item $j$ along $d$ .The algorithms for 3D-BPP are of limited practical applicability if no even basic real-world constraints, e.g., stability (Ramos et al., 2016), are considered. Zhao et al. (2022) propose a fast stability estimation method for DRL training and test their learned policies with real logistics boxes. The flaw of their work is the heightmap (the upper frontier of packed items) state representation like Zhang et al. (2021) is still used, while the underlying constraints between packed items are missed. The un availability of underlying spatial information makes their problem a partially observable Markov Decision Process (Spaan, 2012) which is not conducive to DRL training and limits the performance on 3D-BPP instances with more complex practical constraints, like isle friendliness and load balancing (Gzara et al., 2020).
其中 $p_{i}$ 表示物品 $i$ 的前-左-下坐标,$d$ 表示坐标轴,$e_{i j}$ 在物品 $i$ 沿 $d$ 轴先于物品 $j$ 时取值为 1,否则为 0。如果不考虑基本的现实约束(例如稳定性 (Ramos et al., 2016)),3D-BPP 算法的实际应用性将受到限制。Zhao 等人 (2022) 提出了一种用于深度强化学习 (DRL) 训练的快速稳定性估计方法,并使用真实的物流箱测试了他们学习到的策略。他们工作的缺陷在于仍然使用了类似于 Zhang 等人 (2021) 的高度图(已打包物品的上边界)状态表示,而忽略了已打包物品之间的底层约束。底层空间信息的缺失使得他们的问题成为一个部分可观测的马尔可夫决策过程 (Spaan, 2012),这不利于 DRL 训练,并限制了在具有更复杂实际约束(如通道友好性和负载平衡 (Gzara et al., 2020))的 3D-BPP 实例中的性能。
3 METHOD
3 方法
In this section, we first introduce our PCT concept in Section 3.1 for describing the online packing process. The parameter iz ation of the tree structure and the leaf node selection policy are introduced in Section 3.2 and Section 3.3 respectively. In Section 3.4, we formulate online 3D-BPP as Markov Decision Process based on PCT, followed by the description of the training method.
在本节中,我们首先在第3.1节中介绍了用于描述在线装箱过程的PCT概念。树结构的参数化以及叶节点选择策略分别在第3.2节和第3.3节中介绍。在第3.4节中,我们基于PCT将在线3D-BPP(三维装箱问题)表述为马尔可夫决策过程,随后描述了训练方法。
3.1 PACKING CONFIGURATION TREE
3.1 包装配置树
When a rectangular item $n_{t}$ is added to a given packing with position $(p_{n}^{x},p_{n}^{y},p_{n}^{z})$ at time step $t$ , it introduces a series of new candidate positions where future items can be accommodated, as illustrated in Figure 1. Combined with the axis-aligned orientation $o\in{\bf O}$ for $n_{t}$ based on existing positions, we get candidate placements (i.e. position and orientation). The packing process can be seen as a placement node being replaced by a packed item node, and new candidate placement nodes are generated as children. As the packing time step $t$ goes on, these nodes are iterative ly updated and a dynamic packing configuration tree is formed, denoted as $\tau$ . The internal node set $\mathbf{B}{t}\in\mathcal{T}{t}$ represents the space configurations of packed items, and the leaf node set $\mathbf{L}{t}\in\mathcal{T}{t}$ the packable candidate placements. During the packing, leaf nodes that are no longer feasible, e.g., covered by packed items, will be removed from $\mathbf{L}{t}$ . When there is no packable leaf node that makes $n{t}$ satisfy the constraints of placement, the packing episode ends. Without loss of generality, we stipulate a vertical top-down packing within a single bin (Wang & Hauser, 2019b).
当一个矩形物品 $n_{t}$ 在时间步 $t$ 被添加到给定的装箱中,位置为 $(p_{n}^{x},p_{n}^{y},p_{n}^{z})$ 时,它会引入一系列新的候选位置,未来的物品可以放置在这些位置,如图 1 所示。结合基于现有位置的轴对齐方向 $o\in{\bf O}$ 为 $n_{t}$ 确定方向,我们得到候选放置(即位置和方向)。装箱过程可以看作是一个放置节点被一个已装箱物品节点替换,并生成新的候选放置节点作为子节点。随着装箱时间步 $t$ 的进行,这些节点会迭代更新,形成一个动态装箱配置树,记为 $\tau$。内部节点集 $\mathbf{B}{t}\in\mathcal{T}{t}$ 表示已装箱物品的空间配置,叶节点集 $\mathbf{L}{t}\in\mathcal{T}{t}$ 表示可装箱的候选放置。在装箱过程中,不再可行的叶节点(例如被已装箱物品覆盖的节点)将从 $\mathbf{L}{t}$ 中移除。当没有可装箱的叶节点使得 $n{t}$ 满足放置约束时,装箱过程结束。在不失一般性的情况下,我们规定在单个箱子内进行垂直自上而下的装箱 (Wang & Hauser, 2019b)。
Traditional 3D-BPP literature only cares about the remaining placements for accommodating the current item $n_{t}$ , their packing policies can be written as $\pi({\bf L}{t}|{\bf L}{t},n_{t})$ . If we want to promote this problem for practical demands, 3D-BPP needs to satisfy more complex practical constraints which also act on $\mathbf{B}{t}$ . Taking packing stability for instance, a newly added item $n{t}$ has possibly force and torque effect on the whole item set $\mathbf{B}{t}$ (Ramos et al., 2016). The addition of $n{t}$ should make $\mathbf{B}{t}$ a more stable spatial distribution so that more items can be added in the future. Therefore, our packing policy over $\mathbf{L}{t}$ is defined as $\pi(\mathbf{L}{t}|\mathcal{T}{t},n_{t})$ , which means probabilities of selecting leaf nodes from $\mathbf{L}{t}$ given $\mathcal{T}{t}$ and $n_{t}$ . For online packing, we hope to find the best leaf node selection policy to expand the PCT with more relaxed constraints so that more future items can be appended.
传统的3D-BPP文献仅关注于容纳当前物品 $n_{t}$ 的剩余放置位置,其打包策略可以表示为 $\pi({\bf L}{t}|{\bf L}{t},n_{t})$ 。如果我们希望将这一问题推广到实际需求中,3D-BPP需要满足更多复杂的实际约束,这些约束也作用于 $\mathbf{B}{t}$ 。以打包稳定性为例,新添加的物品 $n{t}$ 可能对整个物品集 $\mathbf{B}{t}$ 产生力和扭矩效应 (Ramos et al., 2016) 。添加 $n{t}$ 应使 $\mathbf{B}{t}$ 的空间分布更加稳定,以便未来可以添加更多物品。因此,我们对 $\mathbf{L}{t}$ 的打包策略定义为 $\pi(\mathbf{L}{t}|\mathcal{T}{t},n_{t})$ ,这意味着在给定 $\mathcal{T}{t}$ 和 $n{t}$ 的情况下,从 $\mathbf{L}_{t}$ 中选择叶节点的概率。对于在线打包,我们希望找到最佳的叶节点选择策略,以扩展PCT并放宽约束,以便未来可以添加更多物品。
Leaf Node Expansion Schemes The performance of online 3D-BPP policies has a strong relationship with the choice of leaf node expansion schemes ——- which increment ally calculate new candidate placements introduced by the just placed item $n_{t}$ . A good expansion scheme should reduce the number of solutions to be explored while not missing too many feasible packings. Meanwhile, polynomial ly computability is also expected. Designing such a scheme from scratch is non-trivial. Fortunately, several placement rules independent from particular packing problems have been proposed, such as Corner Point (Martello et al., 2000), Extreme Point (Crainic et al., 2008), and Empty Maximal Space (Ha et al., 2017). We extend these schemes which have proven to be accurate and efficient to our PCT expansion. The performance of learned policies will be reported in Section 4.1.
叶节点扩展方案
在线 3D-BPP 策略的性能与叶节点扩展方案的选择密切相关——这些方案逐步计算由刚刚放置的物品 $n_{t}$ 引入的新候选放置位置。一个好的扩展方案应减少需要探索的解的数量,同时不遗漏太多可行的装箱方案。此外,还需要具备多项式可计算性。从头设计这样的方案并非易事。幸运的是,已经提出了一些与特定装箱问题无关的放置规则,例如角点 (Corner Point) (Martello et al., 2000)、极点 (Extreme Point) (Crainic et al., 2008) 和最大空空间 (Empty Maximal Space) (Ha et al., 2017)。我们将这些已被证明准确且高效的方案扩展到我们的 PCT 扩展中。学习策略的性能将在第 4.1 节中报告。
3.2 TREE REPRESENTATION
3.2 树表示
Given the bin configuration $\mathcal{T}{t}$ and the current item $n{t}$ , the packing policy can be parameterized as $\pi(\mathbf{L}{t}|\mathcal{T}{t},n_{t})$ . The tuple $(\mathcal{T}{t},n{t})$ can be treated as a graph and encoded by Graph Neural Networks (GNNs) (Gori et al., 2005). Specifically, the PCT keeps growing with time step $t$ and cannot be embedded by spectral-based approaches (Bruna et al., 2014) which require a fixed graph structure. We adopt non-spectral Graph Attention Networks (GATs) (Velickovic et al., 2018), which require no priori on graph structures.
给定箱子配置 $\mathcal{T}{t}$ 和当前物品 $n{t}$,打包策略可以参数化为 $\pi(\mathbf{L}{t}|\mathcal{T}{t},n_{t})$。元组 $(\mathcal{T}{t},n{t})$ 可以被视为一个图,并通过图神经网络 (GNNs) (Gori et al., 2005) 进行编码。具体来说,PCT 随着时间的推移 $t$ 不断增长,无法通过基于谱的方法 (Bruna et al., 2014) 进行嵌入,因为这些方法需要固定的图结构。我们采用非谱图注意力网络 (GATs) (Velickovic et al., 2018),这些网络不需要图结构的先验知识。
The raw space configuration nodes $\mathbf{B}{t},\mathbf{L}{t},n_{t}$ are presented by descriptors in different formats. We use three independent node-wise Multi-Layer Perceptron (MLP) blocks to project these heterogeneous descriptors into the homogeneous node features: $\hat{\textbf{h}}={\phi_{\theta_{B}}(\mathbf{B}{t}),\phi{\theta_{L}}(\mathbf{L}{t}),\phi{\theta_{n}}(n_{t})}\in$ $\mathbf{\check{\mathbb{R}}}^{d_{h}\times N}$ , $d_{h}$ is the dimension of each node feature and $\phi_{\theta}$ is an MLP block with its parameters $\theta$ The feature number $N$ should be $\left|{\bf B}{t}\right|+\left|{\bf L}{t}\right|+1$ , which is a variable. The GAT layer is used to transform $\hat{\mathbf{h}}$ into high-level node features. The Scaled Dot-Product Attention (Vaswani et al., 2017) is applied to each node for calculating the relation weight of one node to another. These relation weights are normalized and used to compute the linear combination of features h. The feature of node $i$ embedded by the GAT layer can be represented as:
原始空间配置节点 $\mathbf{B}{t},\mathbf{L}{t},n_{t}$ 由不同格式的描述符表示。我们使用三个独立的节点级多层感知器 (MLP) 块将这些异构描述符投影为同构节点特征:$\hat{\textbf{h}}={\phi_{\theta_{B}}(\mathbf{B}{t}),\phi{\theta_{L}}(\mathbf{L}{t}),\phi{\theta_{n}}(n_{t})}\in$ $\mathbf{\check{\mathbb{R}}}^{d_{h}\times N}$,其中 $d_{h}$ 是每个节点特征的维度,$\phi_{\theta}$ 是一个带有参数 $\theta$ 的 MLP 块。特征数量 $N$ 应为 $\left|{\bf B}{t}\right|+\left|{\bf L}{t}\right|+1$,这是一个变量。GAT 层用于将 $\hat{\mathbf{h}}$ 转换为高级节点特征。缩放点积注意力 (Vaswani et al., 2017) 应用于每个节点,以计算一个节点与另一个节点的关系权重。这些关系权重被归一化并用于计算特征 h 的线性组合。由 GAT 层嵌入的节点 $i$ 的特征可以表示为:

Where $W^{Q}\in\mathbb{R}^{d_{k}\times d_{h}}$ , $W^{K}\in\mathbb{R}^{d_{k}\times d_{h}}$ , $W^{V}\in\mathbb{R}^{d_{v}\times d_{h}}$ 2 and $W^{O}\in\mathbb{R}^{d_{h}\times d_{v}}$ are projection matrices, $d_{k}$ and $d_{v}$ are dimensions of projected features. The softmax operation normalizes the relation weight between node $i$ and node $j$ . The initial feature $\hat{\mathbf{h}}$ is embedded by a GAT layer and the skip-connection operation (Vaswani et al., 2017) is followed to get the final output features $\mathbf{h}$
其中 $W^{Q}\in\mathbb{R}^{d_{k}\times d_{h}}$ , $W^{K}\in\mathbb{R}^{d_{k}\times d_{h}}$ , $W^{V}\in\mathbb{R}^{d_{v}\times d_{h}}$ 和 $W^{O}\in\mathbb{R}^{d_{h}\times d_{v}}$ 是投影矩阵, $d_{k}$ 和 $d_{v}$ 是投影特征的维度。softmax 操作对节点 $i$ 和节点 $j$ 之间的关系权重进行归一化。初始特征 $\hat{\mathbf{h}}$ 通过 GAT 层嵌入,并采用跳跃连接操作 (Vaswani et al., 2017) 来获得最终输出特征 $\mathbf{h}$ 。

Where $\phi_{F F}$ is a node-wise Feed-Forward MLP with output dimension $d_{h}$ and $\mathbf{h}^{\prime}$ is an intermediate variable. Equation 4 can be seen as an independent block and be repeated multiple times with different parameters. We don't extend GAT to employ the multi-head attention mechanism (Vaswani et al., 2017) since we find that additional attention heads cannot help the final performance. We execute Equation 4 once and we set $d_{v}=d_{k}$ . More implementation details are provided in Appendix A.
其中 $\phi_{F F}$ 是一个节点级的前馈 MLP (Feed-Forward MLP),输出维度为 $d_{h}$,$\mathbf{h}^{\prime}$ 是一个中间变量。公式 4 可以看作一个独立的模块,并且可以使用不同的参数重复多次。我们没有将 GAT 扩展到使用多头注意力机制 (Vaswani et al., 2017),因为我们发现额外的注意力头并不能帮助提升最终性能。我们执行公式 4 一次,并设置 $d_{v}=d_{k}$。更多实现细节见附录 A。
3.3LEAF NODE SELECTION
3.3 叶子节点选择
Given the node features $\mathbf{h}$ , we need to decide the leaf node indices for accommodating the current item $n_{t}$ . Since the leaf nodes vary as the PCT keeps growing over time step $t$ , we use a pointer mechanism (Vinyals et al., 2015) which is context-based attention over variable inputs to select a leaf node from $\mathbf{L}{t}$ . We still adopt Scaled Dot-Product Attention for calculating pointers, the global context feature $\bar{h}$ is aggregated by a mean operation on $\mathbf{h}$ $\begin{array}{r}{\bar{h}=\frac{1}{N}\sum{i=1}^{N}h_{i}}\end{array}$ . The global feature $\bar{h}$ .s projected to a query $q$ by matrix $W^{q}\in\mathbb{R}^{d_{k}\times d_{h}}$ and the leaf node features $\mathbf{h}{\mathbf{L}}$ are utilized to calculate a set of keys $k{\mathbf{L}}$ by $\dot{W}^{k}\in\mathbb{R}^{d_{k}\times d_{h}}$ . The compatibility $\mathbf{u_{L}}$ of the query with all keys are:
给定节点特征 $\mathbf{h}$,我们需要决定用于容纳当前项目 $n_{t}$ 的叶节点索引。由于叶节点随着 PCT 在时间步 $t$ 的不断增长而变化,我们使用了一种指针机制 (Vinyals et al., 2015),该机制基于上下文对可变输入进行注意力选择,以从 $\mathbf{L}{t}$ 中选择一个叶节点。我们仍然采用缩放点积注意力 (Scaled Dot-Product Attention) 来计算指针,全局上下文特征 $\bar{h}$ 通过对 $\mathbf{h}$ 进行均值操作来聚合:$\begin{array}{r}{\bar{h}=\frac{1}{N}\sum{i=1}^{N}h_{i}}\end{array}$。全局特征 $\bar{h}$ 通过矩阵 $W^{q}\in\mathbb{R}^{d_{k}\times d_{h}}$ 投影为查询 $q$,叶节点特征 $\mathbf{h}{\mathbf{L}}$ 通过 $\dot{W}^{k}\in\mathbb{R}^{d{k}\times d_{h}}$ 计算一组键 $k_{\mathbf{L}}$。查询与所有键的兼容性 $\mathbf{u_{L}}$ 为:

Here $h_{i}$ only comes from $\mathbf{h}{\mathbf{L}}$ . The compatibility vector $\mathbf{u}{\mathbf{L}}\in\mathbb{R}^{|\mathbf{L}{t}|}$ represents the leaf node selection logits. The probability distribution over the PCT leaf nodes $\mathbf{L}{t}$ is:
这里 $h_{i}$ 仅来自 $\mathbf{h}{\mathbf{L}}$ 。兼容性向量 $\mathbf{u}{\mathbf{L}}\in\mathbb{R}^{|\mathbf{L}{t}|}$ 表示叶节点选择的 logits。PCT 叶节点 $\mathbf{L}{t}$ 上的概率分布为:

Following Bello et al. (2017), the compatibility logits are clipped with tanh, where the range is controlled by hyper parameter $c_{c l i p}$ , and finally normalized by a softmax operation.
根据 Bello et al. (2017) 的研究,兼容性 logits 通过 tanh 进行裁剪,其范围由超参数 $c_{c l i p}$ 控制,最后通过 softmax 操作进行归一化。
3.4 MARKOV DECISION PROCESS FORMULATION
3.4 马尔可夫决策过程 (Markov Decision Process) 公式化
The online 3D-BPP decision at time step $t$ only depends on the tuple $(\mathcal{T}{t},n{t})$ and can be formulated as Markov Decision Process, which is constructed with state $s$ action $\mathcal{A}$ , transition $\mathcal{P}$ , and reward $R$ . We solve this MDP with an end-to-end DRL agent. The MDP model is formulated as follows.
在线 3D-BPP 决策在时间步 $t$ 仅依赖于元组 $(\mathcal{T}{t},n{t})$ ,可以表述为马尔可夫决策过程 (Markov Decision Process, MDP) ,该过程由状态 $s$ 、动作 $\mathcal{A}$ 、转移 $\mathcal{P}$ 和奖励 $R$ 构成。我们通过一个端到端的深度强化学习 (Deep Reinforcement Learning, DRL) 智能体来解决这个 MDP。MDP 模型表述如下。
State The state $s_{t}$ at time step $t$ is represented as $s_{t}=(\mathcal{T}{t},n{t})$ , where $\tau_{t}$ consists of the internal nodes $\mathbf{B}{t}$ and the leaf nodes $\mathbf{L}{t}$ . Each internal node $b\in\mathbf{B}{t}$ is a spatial configuration of sizes $\left(s{b}^{x},s_{b}^{y},s_{b}^{z}\right)$ and coordinates $(p_{b}^{x},p_{b}^{y},p_{b}^{z})$ corresponding to a packed item. The current item $n_{t}$ is a size tuple (sn, sn, $\left(s_{n}^{x},s_{n}^{y},s_{n}^{z}\right)$ Extra proper tis will b appended t $b$ and $n_{t}$ for specific packing preferences, such as density, item category, etc. The descriptor for leaf node $l\in\mathbf{L}{t}$ is a placement vector of sizes $\left(s{o}^{x},s_{o}^{y},s_{o}^{z}\right)$ and position coordinates $(p^{x},p^{y},p^{z})$ , where $\left(s_{o}^{x},s_{o}^{y},s_{o}^{z}\right)$ indicates the sizes of $n_{t}$ along each dimension after an axis-aligned orientation $o\in{\bf O}$ . Only the packable leaf nodes which satisfy placement constraints are provided.
状态 时间步 $t$ 的状态 $s_{t}$ 表示为 $s_{t}=(\mathcal{T}{t},n{t})$,其中 $\tau_{t}$ 由内部节点 $\mathbf{B}{t}$ 和叶节点 $\mathbf{L}{t}$ 组成。每个内部节点 $b\in\mathbf{B}{t}$ 是一个空间配置,大小为 $\left(s{b}^{x},s_{b}^{y},s_{b}^{z}\right)$,坐标为 $(p_{b}^{x},p_{b}^{y},p_{b}^{z})$,对应于一个已打包的物品。当前物品 $n_{t}$ 是一个大小元组 (sn, sn, $\left(s_{n}^{x},s_{n}^{y},s_{n}^{z}\right)$。额外的属性将被附加到 $b$ 和 $n_{t}$ 上,以满足特定的打包偏好,例如密度、物品类别等。叶节点 $l\in\mathbf{L}{t}$ 的描述符是一个放置向量,大小为 $\left(s{o}^{x},s_{o}^{y},s_{o}^{z}\right)$,位置坐标为 $(p^{x},p^{y},p^{z})$,其中 $\left(s_{o}^{x},s_{o}^{y},s_{o}^{z}\right)$ 表示 $n_{t}$ 在轴对齐方向 $o\in{\bf O}$ 后沿每个维度的大小。仅提供满足放置约束的可打包叶节点。
Action The action $a_{t}\in\mathcal{A}$ is the index of the selected leaf node $l$ , denoted as $a_{t}=i n d e x(l)$ The action space $\mathcal{A}$ has the same size as $\mathbf{L}{t}$ . A surge of learning-based methods (Zhao et al., 2021) directly learn their policy on a grid world through disc ret i zing the full coordinate space, where $|{\mathcal{A}}|$ grows explosively with the accuracy of the disc ret iz ation. Different from existing works, our action space solely depends on the leaf node expansion scheme and the packed items $\mathbf{B}{t}$ . Therefore, our method can be used to solve online 3D-BPP with continuous solution space. We also find that even if only an intercepted subset $\mathbf{L}{s u b}\in\mathbf{L}{t}$ is provided, our method can still maintain a good performance.
动作 $a_{t}\in\mathcal{A}$ 是所选叶子节点 $l$ 的索引,表示为 $a_{t}=index(l)$。动作空间 $\mathcal{A}$ 的大小与 $\mathbf{L}{t}$ 相同。基于学习的方法(Zhao 等,2021)通过将整个坐标空间离散化,直接在网格世界上学习其策略,其中 $|{\mathcal{A}}|$ 随着离散化精度的提高而爆炸性增长。与现有工作不同,我们的动作空间仅取决于叶子节点扩展方案和打包物品 $\mathbf{B}{t}$。因此,我们的方法可用于解决具有连续解空间的在线 3D-BPP。我们还发现,即使只提供截取的子集 $\mathbf{L}{sub}\in\mathbf{L}{t}$,我们的方法仍然可以保持良好的性能。
Transition The transition $\mathcal{P}(s_{t+1}|s_{t})$ is jointly determined by the current policy $\pi$ and theprobability distribution of sampling items. Our online sequences are generated on-the-fly from an item set $\mathcal{T}$ in a uniform distribution. The generalization performance of our method on item sampling distributions different from the training one is discussed in Section 4.4.
转移概率 $\mathcal{P}(s_{t+1}|s_{t})$ 由当前策略 $\pi$ 和采样项的概率分布共同决定。我们的在线序列是从一个均匀分布的项集 $\mathcal{T}$ 中动态生成的。关于我们的方法在不同于训练分布的项采样分布上的泛化性能,将在第 4.4 节中讨论。
Reward Our reward function $R$ is defined as $\boldsymbol{r}{t}=\boldsymbol{c}{r}\cdot\boldsymbol{w}{t}$ once $n{t}$ is inserted into PCT as an internal node successfully, otherwise, $r_{t}=0$ and the packing episode ends. Here $c_{r}$ is a constant and $w_{t}$ is the weight of $n_{t}$ . The choice of $w_{t}$ depends on the customized needs. For simplicity and clarity, unless otherwise noted, we set $w_{t}$ as the volume occupancy $v_{t}$ f $n_{t}$ , where $v_{t}=s_{n}^{x}\cdot s_{n}^{y}\cdot s_{n}^{z}$
奖励 我们的奖励函数 $R$ 定义为 $\boldsymbol{r}{t}=\boldsymbol{c}{r}\cdot\boldsymbol{w}{t}$,当 $n{t}$ 成功插入 PCT 作为内部节点时,否则 $r_{t}=0$,并且打包过程结束。这里 $c_{r}$ 是一个常数,$w_{t}$ 是 $n_{t}$ 的权重。$w_{t}$ 的选择取决于定制需求。为了简单和清晰起见,除非另有说明,我们将 $w_{t}$ 设置为 $n_{t}$ 的体积占用 $v_{t}$,其中 $v_{t}=s_{n}^{x}\cdot s_{n}^{y}\cdot s_{n}^{z}$。
Training Method A DRL agent seeks for a policy $\pi(\boldsymbol{a}{t}|\boldsymbol{s}{t})$ to maximize the accumulated discounted reward. Our DRL agent is trained with the ACKTR method (Wu et al., 2017). The actor weighs the leaf nodes $\mathbf{L}{t}$ and outputs the policy distribution $\pi{\boldsymbol{\theta}}(\mathbf{L}{t}|\mathcal{T}{t},n_{t})$ . The critic maps the global context h into a state value prediction to predict how much accumulated discount reward the agent can get from $t$ and helps the training of the actor. The action $a_{t}$ is sampled from the distribution $\pi_{\theta}(\bar{\mathbf{L}{t}}|\mathcal{T}{t},n_{t})$ for training and we take the argmax of the policy for the test.
训练方法
一个 DRL 智能体寻求策略 $\pi(\boldsymbol{a}{t}|\boldsymbol{s}{t})$ 以最大化累积折扣奖励。我们的 DRL 智能体使用 ACKTR 方法进行训练 (Wu et al., 2017)。执行者 (actor) 对叶节点 $\mathbf{L}{t}$ 进行加权,并输出策略分布 $\pi{\boldsymbol{\theta}}(\mathbf{L}{t}|\mathcal{T}{t},n_{t})$。评论者 (critic) 将全局上下文 h 映射为状态值预测,以预测智能体从 $t$ 开始可以获得多少累积折扣奖励,并帮助执行者的训练。动作 $a_{t}$ 从分布 $\pi_{\theta}(\bar{\mathbf{L}{t}}|\mathcal{T}{t},n_{t})$ 中采样用于训练,而在测试时我们取策略的 argmax。
ACKTR runs multiple parallel processes for gathering on-policy training samples. The node number $N$ of each sample varies with the time step $t$ and the packing sequence of each process. For batch calculation, we fullfill PCT to a fixed length with dummy nodes, as illustrated by Figure 2 (a). These redundant nodes are eliminated by masked attention (Velickovic et al., 2018) during the feature calculation of GAT. The aggregation of h only happens on the eligible nodes. For preserving node spatial relations, state $s_{t}$ is embedded by GAT as a fully connected graph as Figure 2 (b), without any inner mask operation. More implementation details are provided in Appendix A.
ACKTR 运行多个并行进程来收集策略内训练样本。每个样本的节点数 $N$ 随时间步 $t$ 和每个进程的打包顺序而变化。为了进行批量计算,我们用虚拟节点将 PCT 填充到固定长度,如图 2 (a) 所示。这些冗余节点在 GAT 的特征计算过程中通过掩码注意力 (Velickovic et al., 2018) 被消除。h 的聚合仅发生在符合条件的节点上。为了保留节点的空间关系,状态 $s_{t}$ 通过 GAT 嵌入为一个全连接图,如图 2 (b) 所示,没有任何内部掩码操作。更多实现细节见附录 A。
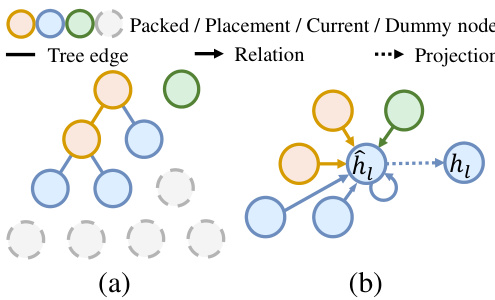
Figure 2: Batch calculation for PCT.
图 2: PCT 的批量计算。
4 EXPERIMENTS
4 实验
In this section, we first report the performance of our PCT model combined with different leaf node expansion schemes. Then we will demonstrate the benefits of the PCT structure: better node spatial relation representations as well as more fexible action space. Finally, we test the generalization performance of our method and extend it to other online 3D-BPP with complex practical constraints.
在本节中,我们首先报告了我们的 PCT 模型结合不同叶节点扩展方案的性能。然后我们将展示 PCT 结构的优势:更好的节点空间关系表示以及更灵活的动作空间。最后,我们测试了我们方法的泛化性能,并将其扩展到具有复杂实际约束的其他在线 3D-BPP 问题。
Baselines Although there are very few online packing implementations publicly available, we still do our best to collect or reproduce various online 3D-BPP algorithms, both heuristic and learningbased, from potentially relevant literature. We help the heuristic methods to make a pre-judgment of placement constraints, e.g., stability, in case of premature downtime. The learning-based agents are trained until there are no significant performance gains. Although both Zhao et al. (2022) and Zhao et al. (2021) are learning-based methods recently proposed, we only compare with the former since it is the upgrade of the latter. We also compare with the reported results of Zhang et al. (2021) under the same condition. All methods are implemented in Python and tested on 2oo0 instances with a desktop computer equipped with a Gold 5117 CPU and a GeForce TITAN V GPU. We publish the source code of our method along with related baselines at Github1.
基线方法
尽管公开可用的在线装箱实现非常少,我们仍然尽力从相关文献中收集或复现各种在线3D-BPP(三维装箱问题)算法,包括启发式方法和基于学习的方法。我们帮助启发式方法在提前停机的情况下对放置约束(例如稳定性)进行预判。基于学习的AI智能体则训练到性能不再显著提升为止。尽管Zhao等人 (2022) 和Zhao等人 (2021) 都是最近提出的基于学习的方法,但我们仅与前者进行比较,因为它是后者的升级版本。我们还在相同条件下与Zhang等人 (2021) 的报告结果进行了比较。所有方法均使用Python语言实现,并在配备Gold 5117 CPU和GeForce TITAN V GPU的台式计算机上对2000个实例进行了测试。我们在Github上发布了我们方法的源代码及相关基线方法。
Datasets Some baselines like Karabulut & Inceoglu (2004) need to traverse the entire coordinate space to find the optimal solution, and the running costs explode as the spatial disc ret iz ation accuracy increases. To ensure that all algorithms are runnable within a reasonable period, we use the discrete dataset proposed by Zhao et al. (2021) without special declaration. The bin sizes $S^{d}$ areset to 10 With $d\in{x,y,z}$ and the item sizes $s^{d}\in\mathbb{Z}^{+}$ are not greater than $S^{d}/2$ to avoid over-simplified scenarios. Our performance on a more complex continuous dataset will be reported in Section 4.3. Considering that there are many variants of 3D-BPP, we choose three representative settings:
数据集
一些基线方法如 Karabulut & Inceoglu (2004) 需要遍历整个坐标空间以找到最优解,随着空间离散化精度的提高,运行成本会急剧增加。为了确保所有算法在合理的时间内可运行,我们在没有特殊声明的情况下使用了 Zhao 等人 (2021) 提出的离散数据集。bin 的大小 $S^{d}$ 设置为 10,其中 $d\in{x,y,z}$,且物品大小 $s^{d}\in\mathbb{Z}^{+}$ 不超过 $S^{d}/2$,以避免过于简化的场景。我们在更复杂的连续数据集上的表现将在第 4.3 节中报告。考虑到 3D-BPP 有许多变体,我们选择了三种具有代表性的设置:
Setting 1: Following Zhao et al. (2022), the stability of the $\mathbf{B}{t}$ is checked when $n{t}$ is placed. Only two horizontal orientations ( $|\mathbf{O}|=2)$ are permitted for robot manipulation convenience. Setting 2: Following Martello et al. (2000), item $n_{t}$ only needs to satisfy Constraint 1 and 2. Arbitrary orientation ( $|\mathbf{0}|=6\$ is allowed here. This is the most common setting in 3D-BPP literature. Setting 3: Inherited from setting 1, each item $n_{t}$ has an additional density property $\rho$ sampled from $(0,1]$ uniformly. This information is appended into the descriptors of $\mathbf{B}{t}$ and $n{t}$
设置 1: 按照 Zhao 等人 (2022) 的方法,当放置 $n_{t}$ 时,检查 $\mathbf{B}{t}$ 的稳定性。为了方便机器人操作,只允许两种水平方向 ($|\mathbf{O}|=2$)。
设置 2: 按照 Martello 等人 (2000) 的方法,物品 $n{t}$ 只需要满足约束 1 和 2。这里允许任意方向 ($|\mathbf{0}|=6$)。这是 3D-BPP 文献中最常见的设置。
设置 3: 继承自设置 1,每个物品 $n_{t}$ 都有一个额外的密度属性 $\rho$,从 $(0,1]$ 中均匀采样。此信息被附加到 $\mathbf{B}{t}$ 和 $n{t}$ 的描述符中。
4.1 PERFORMANCE OF PCT POLICIES
4.1 PCT 策略的性能
We first report the performance of our PCT model combined with different leaf node expansion schemes. Three existing schemes which have proven to be both efficient and effective are adopted here: Corner Point (CP), Extreme Point (EP), and Empty Maximal Space (EMS). These schemes are all related to boundary points of a packed item along $d$ axis. We combine the start/end points of $n_{t}$ with the boundary points of $b\in\mathbf{B}{t}$ to get the superset, namely Event Point (EV). See Appendix B for details and learning curves. We extend these schemes to our PCT model. Although the number of leaf nodes generated by these schemes is within a reasonable range, we only randomly intercept a subset $\mathbf{L}{s u b_{t}}$ from $\mathbf{L}{t}$ if $\left\vert\dot{\mathbf{L}}{t}\right\vert$ exceeds a certain length, for saving computing resources. The interception length is a constant during training and determined by a grid search (GS) during the test. See Appendix A for implementation details. The performance comparisons are summarized in Table 1.
我们首先报告了我们的 PCT 模型结合不同叶节点扩展方案的性能。这里采用了三种已被证明既高效又有效的现有方案:角点 (Corner Point, CP)、极点 (Extreme Point, EP) 和空最大空间 (Empty Maximal Space, EMS)。这些方案都与沿 $d$ 轴的打包物品的边界点相关。我们将 $n_{t}$ 的起点/终点与 $b\in\mathbf{B}{t}$ 的边界点结合,得到超集,即事件点 (Event Point, EV)。详见附录 B 中的细节和学习曲线。我们将这些方案扩展到我们的 PCT 模型中。尽管这些方案生成的叶节点数量在合理范围内,但如果 $\left\vert\dot{\mathbf{L}}{t}\right\vert$ 超过一定长度,我们仅从 $\mathbf{L}{t}$ 中随机截取一个子集 $\mathbf{L}{s u b_{t}}$,以节省计算资源。截取长度在训练期间为常数,并在测试期间通过网格搜索 (Grid Search, GS) 确定。详见附录 A 中的实现细节。性能比较总结在表 1 中。
Table 1: Performance comparisons. Uti. and Num. mean the average space utilization and the average number of packed items separately.Var. $(\times10^{-3})$ is the variance of Uti. and Gap is w.r.t. the best Uti. across all methods. Random and Random & EV randomly pick placements from full coordinates and full EV nodes respectively. DBL, LSAH, MACS, and BR are heuristic methods proposed by Karabulut & Inceoglu (2004), Hu et al. (2017), Hu et al. (2020), and Zhao et al. (2021). Ha et al. (2017), LSAH, and BR are heuristics based on EMS.
'https://github.com/alex from 0815/Online-3D-BPP-PCT
表 1: 性能对比。Uti. 和 Num. 分别表示平均空间利用率和平均打包物品数量。Var. $(\times10^{-3})$ 是 Uti. 的方差,Gap 是与所有方法中最佳 Uti. 的差距。Random 和 Random & EV 分别从完整坐标和完整 EV 节点中随机选择放置位置。DBL、LSAH、MACS 和 BR 是 Karabulut & Inceoglu (2004)、Hu et al. (2017)、Hu et al. (2020) 和 Zhao et al. (2021) 提出的启发式方法。Ha et al. (2017)、LSAH 和 BR 是基于 EMS 的启发式方法。
| 方法 | 随机 | Setting1 Uti. | Var. Num. | Gap | Uti. | Var. Num. | Gap | Uti. | Var. Num. | Gap |
|---|---|---|---|---|---|---|---|---|---|---|
| 随机 | 36.7% | 10.3 | 14.9 | 51.7% | 38.6% | 8.3 | 15.7 | 55.1% | 36.8% | 10.6 |
| BR | 22.6 | 34.1% | 48.9% | 10.7 | 19.5 | 35.4% | ||||
| Ha et al. | 49.0% | 52.1% | 10.8 | 20.1 | 19.6 | 20.6 | 35.5% | 31.4% | 56.7% | 59.9% |
| LSAH | 52.5% | 12.2 | 20.8 | 30.9% | 65.0% | 6.1 | 25.6 | 24.4% | 52.4% | 12.2 |
| Wang&Hauser | 57.6% | 11.5 | 24.1 | 24.2% | 66.1% | 8.4 | 25.9 | 23.1% | 56.5% | 11.2 |
| MACS | 57.7% | 10.5 | 22.6 | 24.1% | 50.8% | 8.8 | 20.1 | 40.9% | 57.7% | 10.6 |
| DBL | 60.5% | 8.8 | 23.8 | 20.4% | 70.6% | 7.9 | 27.8 | 17.9% | 60.5% | 8.9 |
| Zhao et al. | 70.9% | 6.2 | 27.5 | 6.7% | 70.3% | 4.3 | 27.4 | 18.3% | 59.6% | 5.4 |
| PCT&CP | 69.4% | 5.4 | 26.7 | 8.7% | 81.8% | 2.0 | 31.3 | 4.9% | 69.5% | 5.4 |
| PCT&EP | 71.9% | 6.6 | 27.8 | 5.4% | 78.1% | 3.8 | 30.3 | 9.2% | 72.2% | 5.8 |
| PCT&FC | 72.4% | 4.7 | 28.0 | 4.7% | 76.9% | 3.3 | 29.7 | 10.6% | 69.8% | 5.3 |
| PCT&EMS | 75.8% | 4.4 | 29.3 | 29.4 | 0.3% | 86.0% | 85.3% | 1.9 | 2.1 | 33.0 |
| PCT&EV | 76.0% | 75.7% | 4.2 | 4.8 | 29.2 | 0.0% | 0.4% | 80.5% | 2.9 | 32.8 |
| PCT&EVF | 75.8% | 4.7 | 29.2 | 0.3% | 84.8% | 2.1 | 32.6 | 1.4% | 75.5% | 4.8 |
| PCT&EV/GS | 13.5 | 18.4 | 39.9% | 51.0% | 20.4 | 40.7% | ||||
| Random&EV | 45.7% | 8.3 | 45.1% |
Although PCT grows under the guidance of heuristics, the combinations of PCT with EMS and EV still learn effective and robust policies outperforming all baselines by a large margin regarding all settings. Note that the closer the space utilization is to 1, the more difficult online 3D-BPP is. It is interesting to see that policies guided by EMS and EV even exceed the performance of the full coordinate space (FC) which is expected to be optimal. This demonstrates that a good leaf node expansion scheme reduces the complexity of the problem and helps DRL agents learn better performance. To prove that the interception of $\mathbf{L}{t}$ will not harm the final performance, we train agents with full leaf nodes derived from the EV scheme (EVF) and the test performance is slightly worse than the intercepted cases. We conjecture that the interception keeps the final performance may be caused by two reasons. First, sub-optimal solutions for online 3D-BPP may exist even in the intercepted leaf node set $\mathbf{L}{s u b}$ . In addition, the randomly chosen leaf nodes force the agent to make new explorations in case the policy $\pi$ falls into the local optimum. We remove GS from EV cases to prove its effectiveness. The performance of Zhao et al. (2022) deteriorates quickly in setting 2 and setting 3 due to the multiplying orientation space and insufficient state representation separately. Running costs, s cal ability performance, behavior understanding, visualized results, and the implementation details of our real-world packing system can all be found in Appendix C.
尽管 PCT 在启发式指导下增长,但 PCT 与 EMS 和 EV 的组合仍然学习到了有效且稳健的策略,在所有设置下都大幅超越了所有基线。需要注意的是,空间利用率越接近 1,在线 3D-BPP 问题就越困难。有趣的是,由 EMS 和 EV 指导的策略甚至超过了预期为最优的全坐标空间 (FC) 的性能。这表明,良好的叶节点扩展方案降低了问题的复杂性,并帮助 DRL 智能体学习到更好的性能。为了证明截取 $\mathbf{L}{t}$ 不会损害最终性能,我们使用由 EV 方案 (EVF) 导出的完整叶节点训练智能体,测试性能略低于截取的情况。我们推测,截取保持最终性能的原因可能有两个。首先,即使在截取的叶节点集 $\mathbf{L}{s u b}$ 中,也可能存在在线 3D-BPP 的次优解。此外,随机选择的叶节点迫使智能体在策略 $\pi$ 陷入局部最优时进行新的探索。我们从 EV 案例中移除 GS 以证明其有效性。Zhao 等人 (2022) 的性能在设置 2 和设置 3 中迅速下降,分别由于倍增的定向空间和不足的状态表示。运行成本、可扩展性性能、行为理解、可视化结果以及我们现实世界包装系统的实现细节都可以在附录 C 中找到。
We also repeat the same experiment as Zhang et al. (2021) which pack items sampled from a predefined item set $|\mathcal{T}|=64$ in setting 2. While Zhang et al. (2021) packs on average 15.6 items and achieves $67.0%$ space utilization, our method packs 19.7 items with a space utilization of $83.0%$
我们还重复了 Zhang 等人 (2021) 的实验,该实验在设置 2 中打包从预定义项目集 $|\mathcal{T}|=64$ 中采样的项目。虽然 Zhang 等人 (2021) 平均打包 15.6 个项目并实现了 $67.0%$ 的空间利用率,我们的方法打包了 19.7 个项目,空间利用率为 $83.0%$。
4.2 BENEFITS OF TREE PRESENTATION
4.2 树形表示的优势
Here we verify that the PCT representation does help online 3D-BPP tasks. For this, we embed each space configuration node independently like PointNet (Qi et al., 2017) to prove the node spatial relations help the final performance. We also deconstruct the tree structure into node sequences and embed them with Ptr-Net (Vinyals et al., 2015), which selects a member from serialized inputs, for indicating that the graph embedding fashion fits our tasks well. We have verified that an appropriate choiceof $\mathbf{L}{t}$ makes DRL agents easy to train, then we remove the internal nodes $\mathbf{B}{t}$ from $\mathcal{T}{t}$ ,along with its spatial relations with other nodes, to prove $\mathbf{B}{t}$ is also a necessary part. We choose EV as the leaf node expansion scheme here. The comparison results are summarized in Table 2.
我们在此验证 PCT 表示确实有助于在线 3D-BPP 任务。为此,我们像 PointNet (Qi et al., 2017) 那样独立嵌入每个空间配置节点,以证明节点空间关系有助于最终性能。我们还将树结构解构为节点序列,并使用 Ptr-Net (Vinyals et al., 2015) 嵌入它们,Ptr-Net 从序列化输入中选择一个成员,以表明图嵌入方式非常适合我们的任务。我们已经验证了适当选择 $\mathbf{L}{t}$ 使得 DRL 智能体易于训练,然后我们从 $\mathcal{T}{t}$ 中移除内部节点 $\mathbf{B}{t}$ 及其与其他节点的空间关系,以证明 $\mathbf{B}{t}$ 也是一个必要的部分。我们在此选择 EV 作为叶节点扩展方案。比较结果总结在表 2 中。
Table 2: A graph embedding for complete PCT helps the final performance.
表 2: 完整的 PCT 图嵌入有助于最终性能。
| 表示方法 | 利用率 | 设置1 | 设置2 | 设置3 |
|---|---|---|---|---|
| 变量 | 数量 | 差距 | ||
| PointNet | 69.2% | 6.7 | 26.9 | 8.9% |
| Ptr-Net | 64.1% | 10.0 | 25.1 | 15.7% |
| PCT (T /B) | 70.9% | 5.9 | 27.5 | 6.7% |
| PCT (T) | 76.0% | 4.2 | 29.4 | 0.0% |
If we ignore the spatial relations between the PCT nodes or only treat the state input as a flattened sequence, the performance of the learned policies will be severely degraded. The presence of $\mathbf{B}$ functions more on setting 1 and setting 3 since setting 2 allows items to be packed in any empty spaces without considering constraints with internal nodes. This also confirms that a complete PCT representation is essential for online 3D-BPP of practical needs.
如果我们忽略 PCT 节点之间的空间关系,或者仅将状态输入视为扁平序列,学习到的策略性能将严重下降。$\mathbf{B}$ 在设置 1 和设置 3 中的作用更为显著,因为设置 2 允许物品被装入任何空余空间,而无需考虑与内部节点的约束。这也证实了完整的 PCT 表示对于实际需求的在线 3D-BPP 至关重要。
4.3 PERFORMANCE ON CONTINUOUS DATASET
4.3 连续数据集上的性能
The most concerning issue about online 3D-BPP is their solution space limit. Given that most learning-based methods can only work in a limited discrete coordinate space, we directly test our method in a continuous bin with sizes $S^{d}=1$ to prove our superiority. Due to the lack of public datasets for online 3D-BPP issues, we generate item sizes through a uniform distribution $s^{d}\sim$ $U(a,S^{d}/2)$ $a$ is set to O.1 in case endless items are generated. Specifically, for 3D-BPP instances where stability is considered, the diversity of item size $s^{z}$ needs to be controlled. If all subsets of $\mathbf{B}_{t}$ meet:
在线 3D-BPP 最令人关注的问题是其解决方案空间的限制。鉴于大多数基于学习的方法只能在有限的离散坐标空间中工作,我们直接在大小为 $S^{d}=1$ 的连续箱子中测试我们的方法,以证明我们的优越性。由于缺乏公开的在线 3D-BPP 问题数据集,我们通过均匀分布 $s^{d}\sim$ $U(a,S^{d}/2)$ 生成物品尺寸,$a$ 设置为 0.1,以防止生成无限数量的物品。具体来说,对于考虑稳定性的 3D-BPP 实例,需要控制物品尺寸 $s^{z}$ 的多样性。如果 $\mathbf{B}_{t}$ 的所有子集都满足:

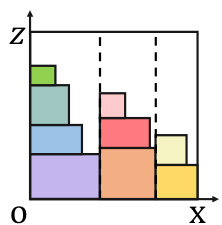
This means any packed items cannot form a new plane for providing support in the direction of gravity and the available packing areas shrink. Excessive diversity of $s^{z}$ will degenerate 3D-BPP into 1D-BPP as shown in the toy demo. To prevent this degradation from leading to the under utilization of the bins, we sample $s^{z}$ from a finite set ${0.1,0.2,\ldots,0.5}$ on setting 1 and setting 3.
这意味着任何已打包的物品无法在重力方向上形成新的支撑平面,可用的打包区域会缩小。$s^{z}$ 的过度多样性会导致 3D-BPP 退化为 1D-BPP,如示例所示。为了防止这种退化导致容器的利用率不足,我们在设置 1 和设置 3 中从有限集合 ${0.1,0.2,\ldots,0.5}$ 中采样 $s^{z}$。
Table 3: Online 3D-BPP with continuous solution space.
表 3: 在线 3D-BPP 连续解空间。
| 方法 | 设置1 | 设置2 | 利用率 | 设置3 | 差距 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 利用率 | 变量 | 数量差距 | 利用率 | 变量 | 数量 | 利用率 | 变量 | 数量 | |||||
| eu | BR | 40.9% | 7.4 | 16.1 | 37.5% | 45.3% | 5.2 | 17.8 | 31.7% | 40.9% | 7.3 | 16.1 | 38.6% |
| Ha et al. | 43.9% | 14.2 | 17.2 | 32.9% | 46.1% | 6.8 | 18.1 | 30.5% | 43.9% | 14.2 | 17.2 | 34.1% | |
| LSAH | 48.3% | 12.1 | 18.7 | 26.1% | 58.7% | 4.6 | 22.8 | 11.5% | 48.4% | 12.2 | 18.8 | 27.3% | |
| GD | 5.6% | 2.2 | 91.4% | 7.5% | 2.9 | 88.7% | 5.2% | 2.1 | 92.2% | ||||
| PCT&EMS | 65.3% | 4.4 | 24.9 | 0.2% | 66.3% | 2.3 | 27.0 | 0.0% | 66.6% | 3.3 | 25.3 | 0.0% | |
| PCT&EV | 65.4% | 3.3 | 25.0 | 0.0% | 65.0% | 2.6 | 26.4 | 2.0% | 65.8% | 3.6 | 25.1 | 2.7% |
We find that some heuristic methods (Ha et al., 2017) also have the potential to work in the continuous domain. We improve these methods as our baselines. Another intuitive approach for solving online 3D-BPP with continuous solution space is driving a DRL agent to sample actions from a gaussian distribution (GD) and output continuous coordinates directly. The test results are summarized in Table 3. Although the continuous-size item set is infinite ( $|{\mathcal{I}}|=\infty)$ which increases the difficulty of the problem and reduces the performance of all methods, our method still performs better than all competitors. The DRL agent which outputs continuous actions directly cannot even converge and their variance is not considered. Our work is, to our knowledge, the first that deploys the learning-based method on solving online 3D-BPP with continuous solution space successfully.
我们发现一些启发式方法 (Ha et al., 2017) 在连续域中也有潜力。我们改进了这些方法作为基线。另一种解决具有连续解空间的在线 3D-BPP 的直观方法是驱动 DRL 智能体从高斯分布 (GD) 中采样动作并直接输出连续坐标。测试结果总结在表 3 中。尽管连续尺寸物品集是无限的 ( $|{\mathcal{I}}|=\infty)$ ,这增加了问题的难度并降低了所有方法的性能,但我们的方法仍然优于所有竞争对手。直接输出连续动作的 DRL 智能体甚至无法收敛,且未考虑其方差。据我们所知,我们的工作是首次成功部署基于学习的方法来解决具有连续解空间的在线 3D-BPP。
4.4 GENERALIZATION ON DIFFERENT DISTRIBUTIONS
4.4 不同分布上的泛化
The generalization ability of learning-based methods has always been a concern. Here we demonstrate that our method has a good generalization performance on item size distributions different from the training one. We conduct this experiment with continuous solution space. We sample $s^{d}$ from normal distributions $N(\mu,\sigma^{2})$ for generating test sequences where $\mu$ and $\sigma$ are the expectation and the standard deviation. Three normal distributions are adopted here, namely $N(0.3,\dot{0}.1^{2})$ , $N(0.1,0.2^{2})$ , and $N(0.5,0.2^{2})$ , as shown in Figure 3. The larger $\mu$ of the normal distribution, the larger the average size of sampled items. We still control $s^{d}$ within the range of [0.1, 0.5]. If the sampled item sizes are not within this range, we will resample until it meets the condition.
基于学习的方法的泛化能力一直是一个关注点。在这里,我们展示了我们的方法在与训练分布不同的物品尺寸分布上具有良好的泛化性能。我们在连续解空间中进行此实验。我们从正态分布 $N(\mu,\sigma^{2})$ 中采样 $s^{d}$ 以生成测试序列,其中 $\mu$ 和 $\sigma$ 分别是期望和标准差。这里采用了三种正态分布,即 $N(0.3,\dot{0}.1^{2})$ 、 $N(0.1,0.2^{2})$ 和 $N(0.5,0.2^{2})$ ,如图 3 所示。正态分布的 $\mu$ 越大,采样物品的平均尺寸越大。我们仍然将 $s^{d}$ 控制在 [0.1, 0.5] 的范围内。如果采样的物品尺寸不在此范围内,我们将重新采样,直到满足条件。
Table 4: Generalization performance on different kinds of item sampling distributions.
表 4: 不同项目采样分布下的泛化性能
| 测试分布 | 方法 | Setting1 | Setting2 | Setting3 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Uti. | Var. | Num. | Uti. | Var. | Num. | Uti. | Var. | Num. | ||
| sd ~ U(0.1,0.5) | LSAH PCT&EMS PCT&EV | 48.3% 65.3% 65.4% | 12.1 4.4 3.3 | 18.7 24.9 25.0 | 58.7% 66.3% 65.0% | 4.6 2.3 2.6 | 22.8 27.0 26.4 | 48.4% 66.6% 65.8% | 12.2 3.3 3.6 | 18.8 25.3 25.1 |
| sd ~ N(0.3, 0.12) | LSAH PCT&EMS PCT&EV | 49.2% 66.1% 65.1% | 11.1 3.6 2.8 | 18.9 25.1 24.7 | 60.0% 64.3% 63.7% | 4.1 3.5 2.6 | 22.9 25.6 25.3 | 49.2% 66.4% 66.2% | 11.0 3.0 2.9 | 18.9 25.2 25.1 |
| ~ N(0.1, 0.22) S | LSAH PCT&EMS PCT&EV | 52.4% 68.5% 66.5% | 8.9 2.5 2.7 | 30.3 39.0 38.0 | 62.9% 66.4% 64.9% | 2.4 3.0 2.7 | 44.3 49.7 48.3 | 52.3% 69.2% 67.4% | 8.9 2.5 2.4 | 30.2 39.4 38.5 |
| sd ~ N(0.5,0.2) | LSAH PCT&EMS PCT&EV | 47.3% 63.5% 65.1% | 12.6 5.0 3.3 | 13.0 17.3 17.7 | 56.0% 64.5% 64.5% | 5.5 2.8 2.8 | 12.9 15.4 15.3 | 47.3% 65.2% 65.1% | 12.6 3.8 3.7 | 13.0 17.7 17.7 |
We directly transfer our policies trained on $U(0.1,0.5)$ to these new datasets without any fine-tuning. We use the best-performing heuristic method LSAH (Hu et al., 2017) in Section 4.3 as a baseline. The test results are summarized in Table 4. Our method performs well on the distributions different from the training one and always surpasses the LSAH method. See Appendix C for more results about the generalization ability of our method on disturbed distributions and unseen items.
我们直接将训练在 $U(0.1,0.5)$ 上的策略迁移到这些新数据集上,无需任何微调。我们使用第4.3节中表现最佳的启发式方法 LSAH (Hu et al., 2017) 作为基线。测试结果总结在表4中。我们的方法在与训练分布不同的分布上表现良好,并且始终优于 LSAH 方法。更多关于我们方法在扰动分布和未见项目上的泛化能力的结果,请参见附录 C。
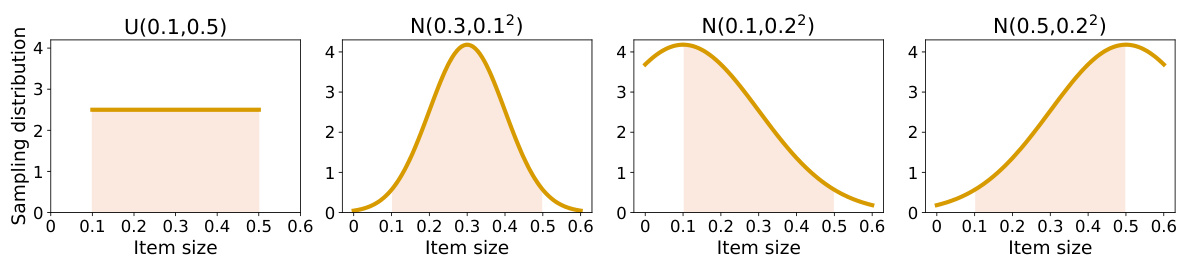
Figure 3: The probability distribution for sampling item sizes. The area of the colored zone is normalized to 1.
图 3: 采样项目大小的概率分布。彩色区域的面积被归一化为 1。
4.5 MORE COMPLEX PRACTICAL CONSTRAINTS
4.5 更复杂的实际约束
To further prove that our method fits 3D-BPP with complex constraints well, we give two demonstrations about extending our method to online 3D-BPP with additional practical constraints: isle friendliness and load balancing (Gzara et al., 2020):
为了进一步证明我们的方法适用于具有复杂约束的3D-BPP(三维装箱问题),我们展示了如何将我们的方法扩展到具有额外实际约束的在线3D-BPP:通道友好性和负载均衡性 (Gzara et al., 2020):
3D-BPP with Isle Friendliness Isle friendliness refers to that items belonging to the same category should be packed as closely as possible. The item weight is set as $w_{t}=m a x(0,v_{t}-c\cdot$ $d i s t(n_{t},\mathbf{B}{t}))$ $c$ is a constant. The additional object function $d i s t(n{t},\mathbf{B}{t})$ means the average distance between $n{t}$ and the items of the same category in $\mathbf{B}{t}$ . The additional category information is appended into the descriptors of $\mathbf{B}{t}$ and $n_{t}$ . Four item categories are tested here.
3D-BPP 与岛屿友好性
岛屿友好性指的是属于同一类别的物品应尽可能紧密地打包。物品权重设置为 $w_{t}=m a x(0,v_{t}-c\cdot$ $d i s t(n_{t},\mathbf{B}{t}))$,其中 $c$ 是一个常数。附加的目标函数 $d i s t(n{t},\mathbf{B}{t})$ 表示 $n{t}$ 与 $\mathbf{B}{t}$ 中同一类别物品的平均距离。附加的类别信息被添加到 $\mathbf{B}{t}$ 和 $n_{t}$ 的描述符中。这里测试了四种物品类别。
3D-BPP with Load Balancing Load balancing dictates that the packed items should have an even mass distribution within the bin. The item weight is set as $w_{t}=m a x(0,v_{t}-c\cdot v a r(n_{t},\mathbf{B}{t}))$ .Object $v a r(n{t},\mathbf{B}_{t})$ is the variance of the mass distribution of the packed items on the bottom of the bin.
带负载均衡的3D-BPP
负载均衡要求装箱物品在箱内应具有均匀的质量分布。物品重量设置为 $w_{t}=m a x(0,v_{t}-c\cdot v a r(n_{t},\mathbf{B}{t}))$ 。对象 $v a r(n{t},\mathbf{B}_{t})$ 是箱底已装箱物品质量分布的方差。
Table 5: Online 3D-BPP with practical constraints. Obj. means the task-specific objective score, the smaller the better. Setting 2 involves no mass property and the load balancing is not considered.
表 5: 带有实际约束的在线 3D-BPP。Obj. 表示任务特定的目标分数,越小越好。设置 2 不涉及质量属性,且不考虑负载均衡。
We choose the learning-based method Zhao et al. (2022) as our baseline since heuristic methods only take space utilization as their objects. The results are summarized in Table 5. Compared with the baseline algorithm, our method better achieves the additional object while still taking into account the space utilization as the primary.
我们选择基于学习的方法 Zhao 等人 (2022) 作为基线,因为启发式方法仅以空间利用率为目标。结果总结在表 5 中。与基线算法相比,我们的方法在仍然以空间利用率为主要目标的同时,更好地实现了额外目标。
5 DISCUSSION
5 讨论
We formulate the online 3D-BPP as a novel hierarchical representation -- packing configuration tree. PCT is a full-fledged description of the state and action space of bin packing which makes the DRL agent easy to train and well-performing. We extract state feature from PCT using graph attention networks which encodes the spatial relations of all space configuration nodes. The graph representation of PCT helps the agent with handling online 3D-BPP with complex practical constraints, while the finite leaf nodes prevent the action space from growing explosively. Our method surpasses all other online 3D-BPP algorithms and is the first learning-based method that solves online 3D-BPP with continuous solution space successfully. Our method performs well even on item sampling distributions different from the training one. We also give demonstrations to prove that our method is versatile in terms of incorporating various practical constraints. For future research, we are extremely interested in applying our method to the more difficult irregular shape packing (Wang & Hauser, 2019a), where the sampling costs for training DRL agents are more expensive and the solution space will be far more complex. A good strategy for balancing exploration and exploitation for learning agents is eagerly needed in this situation. Finding other alternatives for better representing 3D-BPP with different packing constraints and designing better leaf node expansion schemes for PCT are also interesting directions.
我们将在线三维装箱问题 (3D-BPP) 表述为一种新颖的层次化表示——装箱配置树 (PCT)。PCT 是对装箱问题的状态和动作空间的完整描述,这使得深度强化学习 (DRL) 智能体易于训练且表现良好。我们使用图注意力网络从 PCT 中提取状态特征,该网络编码了所有空间配置节点的空间关系。PCT 的图表示帮助智能体处理具有复杂实际约束的在线 3D-BPP,而有限的叶节点防止了动作空间的爆炸性增长。我们的方法超越了所有其他在线 3D-BPP 算法,并且是第一个成功解决具有连续解空间的在线 3D-BPP 的学习方法。即使在与训练分布不同的物品采样分布上,我们的方法也表现良好。我们还通过演示证明,我们的方法在结合各种实际约束方面具有多功能性。对于未来的研究,我们非常有兴趣将我们的方法应用于更困难的不规则形状装箱问题 (Wang & Hauser, 2019a),在这种情况下,训练 DRL 智能体的采样成本更高,解空间也将更加复杂。在这种情况下,迫切需要一种平衡探索和利用的良好策略。寻找其他替代方案以更好地表示具有不同装箱约束的 3D-BPP,以及为 PCT 设计更好的叶节点扩展方案,也是有趣的研究方向。
ACKNOWLEDGEMENTS
致谢
We thank Zhan Shi, Wei Yu, and Lintao Zheng for helpful discussions. We would also like to thank anonymous reviewers for their insightful comments and valuable suggestions. This work is supported by the National Natural Science Foundation of China (62132021, 61876077).
我们感谢 Zhan Shi、Wei Yu 和 Lintao Zheng 的有益讨论。同时,我们也感谢匿名评审的深刻评论和宝贵建议。本研究得到了国家自然科学基金 (62132021, 61876077) 的支持。
ETHICS STATEMENT
伦理声明
We believe the broader impact of this research is significant. BPP is considered one of the most needed academic problems due to its wide applicability in our daily lives (Skiena, 1997). Providing a good solution to online 3D-BPP yields direct and profound impacts beyond academia. We note that online packing setups have been already widely deployed in logistics hubs and manufacturing plants. A good online 3D-BPP policy benefits all the downstream operations like package wrapping, transportation, warehousing, and distribution.
我们相信这项研究的广泛影响是显著的。由于其在日常生活中的广泛应用,BPP(装箱问题)被认为是最需要的学术问题之一(Skiena, 1997)。为在线3D-BPP提供一个良好的解决方案,将产生超越学术界的直接而深远的影响。我们注意到,在线装箱设置已经在物流中心和制造工厂中广泛部署。一个良好的在线3D-BPP策略将惠及所有下游操作,如包装、运输、仓储和配送。
Our method can also be treated as a separate decision module and utilized to solve other variants of 3D-BPP issues, such as multi-bin online 3D-BPP, online 3D-BPP with lookahead (Zhao et al., 2021), online placement decision for offline 3D-BPP (Hu et al., 2017), and the logistics robot implementation for online packing (Zhao et al., 2022), which have been well studied in previous works. We give demonstrations about applying our method to solving online 3D-BPP with various complex practical constraints, the similar idea can also be adopted to meet other customized desires.
我们的方法也可以被视为一个独立的决策模块,用于解决其他变体的3D-BPP问题,例如多箱在线3D-BPP (Zhao et al., 2021)、带前瞻的在线3D-BPP (Zhao et al., 2021)、离线3D-BPP的在线放置决策 (Hu et al., 2017),以及在线装箱的物流机器人实现 (Zhao et al., 2022),这些问题在之前的研究中已经得到了充分的研究。我们展示了如何应用我们的方法来解决具有各种复杂实际约束的在线3D-BPP问题,类似的想法也可以用于满足其他定制需求。
REPRODUCIBILITY
可复现性
Our real-world video demo is submitted with the supplemental material. The source code of our method and related baselines is published at https : / /github. com/alex from 0815/ On1ine-3D-BPP-PCT.
我们的真实世界视频演示已随补充材料提交。我们方法的源代码及相关基线已发布在 https://github.com/alexfrom0815/Online-3D-BPP-PCT。
REFERENCES
参考文献
Oluf Faroe, David Pisinger, and Martin Zacharias en. Guided local search for the three-dimensional bin-packing problem. INFORMS J. Comput., 15(3):267-283, 2003. doi: 10.1287/ijoc.15.3.267. 16080.
Oluf Faroe, David Pisinger 和 Martin Zachariasen. 三维装箱问题的引导局部搜索. INFORMS J. Comput., 15(3):267-283, 2003. doi: 10.1287/ijoc.15.3.267. 16080.
Antonio Galrao Ramos, José Fernando Oliveira, and Manuel Pereira Lopes. A physical packing sequence algorithm for the container loading problem with static mechanical equilibrium conditions. Int. Trans. Oper. Res., 23(1-2):215-238, 2016. doi: 10.1111/itor.12124.
Antonio Galrao Ramos, José Fernando Oliveira 和 Manuel Pereira Lopes. 一种用于静态机械平衡条件下的集装箱装载问题的物理装箱序列算法. Int. Trans. Oper. Res., 23(1-2):215-238, 2016. doi: 10.1111/itor.12124.
Steven S. Seiden. On the online bin packing problem. J. ACM, 49(5):640-671, 2002. doi: 10.1145/ 585265.585269.
Steven S. Seiden. 在线装箱问题研究. J. ACM, 49(5):640-671, 2002. doi: 10.1145/585265.585269.
In this appendix, we provide more details and statistical results of our PCT method. Our real-world packing demo is also submitted with the supplemental material.
在本附录中,我们提供了关于 PCT 方法的更多细节和统计结果。我们的实际装箱演示也随补充材料一并提交。
· Section A gives more descriptions about training methods, which include the implementation of the deep reinforcement learning method, specific GAT network designs for extracting problem features from PCT, and recommendations for finding suitable PCT length. · Section B elaborates the concept of the leaf node expansion schemes adopted for finding candidate placements in our method. Learning curves and the computational complexity analysis of these schemes are also provided in this section. · Section C reports more statistical results of our method, including further discussions on generalization ability, running costs, and s cal ability. The understanding of model behaviors, the visualized results, and details of our real-world packing system are also provided.
· 第 A 节详细介绍了训练方法,包括深度强化学习方法的实现、用于从 PCT 中提取问题特征的特定 GAT 网络设计,以及寻找合适 PCT 长度的建议。
· 第 B 节详细阐述了在我们的方法中用于寻找候选放置位置的叶节点扩展方案的概念。本节还提供了这些方案的学习曲线和计算复杂度分析。
· 第 C 节报告了我们方法的更多统计结果,包括对泛化能力、运行成本和可扩展性的进一步讨论。还提供了对模型行为的理解、可视化结果以及我们现实世界包装系统的详细信息。
A IMPLEMENTATION DETAILS
实现细节
Deep Reinforcement Learning We formulate online 3D-BPP as Markov Decision Process and solve it with the deep reinforcement learning method. A DRL agent seeks for a policy $\pi$ to maximize the accumulated discounted reward:
深度强化学习
我们将在线3D-BPP(三维装箱问题)建模为马尔可夫决策过程,并使用深度强化学习方法来解决。一个DRL(深度强化学习)智能体寻找策略 $\pi$ 以最大化累积折扣奖励:

Where $\gamma\in[0,1]$ is the discount factor, and ${\boldsymbol{\tau}}=\left(s_{0},a_{0},s_{1},\ldots\right)$ is a trajectory sampled based on the policy $\pi$ . We extract the feature of state $s_{t}=(\mathcal{T}_{t},n_{t})$ using graph attention networks (Velickovic et al., 2018) for encoding the spatial relations of all space configuration nodes. The context feature is fed to two key components of our pipeline: an actor network and a critic network. The actor network, designed based on pointer mechanism, weighs the leaf nodes of PCT, which is written as $\pi(\boldsymbol{a}_{t}|\boldsymbol{s}_{t})$ . The action $a_{t}$ is an index of selected leaf node $l\in\mathbf{L}_{t}$ , denoted as $a_{t}=i n d e x(l)$ . The critic network maps the context feature into a state value prediction $V(s_{t})$ which helps the training of actor network. The whole network is trained via a composite loss ${\dot{L}}={\alpha}\cdot{L_{a c t o r}}+\beta\cdot{L_{c r i t i c}}$ $(\alpha=\beta=1$ in our implementation), which consists of actor loss $L_{a c t o r}$ and critic loss $L_{c r i t i c}$ These two loss functions are defined as:
其中 $\gamma\in[0,1]$ 是折扣因子,${\boldsymbol{\tau}}=\left(s_{0},a_{0},s_{1},\ldots\right)$ 是基于策略 $\pi$ 采样的轨迹。我们使用图注意力网络 (Velickovic et al., 2018) 提取状态 $s_{t}=(\mathcal{T}_{t},n_{t})$ 的特征,以编码所有空间配置节点的空间关系。上下文特征被输入到我们管道的两个关键组件:一个演员网络和一个评论家网络。演员网络基于指针机制设计,对 PCT 的叶节点进行加权,表示为 $\pi(\boldsymbol{a}_{t}|\boldsymbol{s}_{t})$。动作 $a_{t}$ 是所选叶节点 $l\in\mathbf{L}_{t}$ 的索引,记为 $a_{t}=i n d e x(l)$。评论家网络将上下文特征映射为状态值预测 $V(s_{t})$,这有助于演员网络的训练。整个网络通过复合损失 ${\dot{L}}={\alpha}\cdot{L_{a c t o r}}+\beta\cdot{L_{c r i t i c}}$ 进行训练(在我们的实现中 $\alpha=\beta=1$),该损失由演员损失 $L_{a c t o r}$ 和评论家损失 $L_{c r i t i c}$ 组成。这两个损失函数定义如下:

Where $r_{t}=c_{r}\cdot w_{t}$ is our reward signal and we set $\gamma$ as 1 since the packing episode is finite. We adopt a step-wise reward $r_{t}=c_{r}\cdot w_{t}$ once $n_{t}$ is inserted into PCT as an internal node successfully. Otherwise, $r_{t}:=:0$ and the packing episode ends. The choice of item weight $w_{t}$ depends on the packing preferences. In the general sense, we set $w_{t}$ as the volume occupancy $v_{t}=s_{n}^{x}\cdot s_{n}^{y}\cdot s_{n}^{z}$ f $n_{t}$ ,, and the constant $c_{r}$ is $10/(S^{x}\cdot S^{y}\cdot S^{z})$ . For online 3D-BPP with additional packing constraints, this weight can be set as $w_{t}=m a x(0,v_{t}-c\cdot O(s_{t},a_{t}))$ . While term $v_{t}$ ensures that space utilization is still the primary concern, the objective function $\dot{O}(s_{t},a_{t})$ guides the agent to satisfy additional constraints like isle friendliness and load balancing. We adopt ACKTR (Wu et al., 2017) method for training our DRL agent, which iterative ly updates an actor and a critic using Kronecker-factored approximate curvature (K-FAC) (Martens $&$ Grosse, 2015) with trust region. Zhao et al. (2021) have demonstrated that this method has a surprising superiority on online 3D packing problems over other model-free DRL algorithms like SAC (Haarnoja et al., 2018).
其中 $r_{t}=c_{r}\cdot w_{t}$ 是我们的奖励信号,由于装箱过程是有限的,我们将 $\gamma$ 设为 1。一旦 $n_{t}$ 成功插入 PCT 作为内部节点,我们采用逐步奖励 $r_{t}=c_{r}\cdot w_{t}$。否则,$r_{t}:=:0$,装箱过程结束。物品权重 $w_{t}$ 的选择取决于装箱偏好。在一般情况下,我们将 $w_{t}$ 设为体积占用率 $v_{t}=s_{n}^{x}\cdot s_{n}^{y}\cdot s_{n}^{z}$,常数 $c_{r}$ 为 $10/(S^{x}\cdot S^{y}\cdot S^{z})$。对于具有额外装箱约束的在线 3D-BPP,此权重可以设置为 $w_{t}=m a x(0,v_{t}-c\cdot O(s_{t},a_{t}))$。虽然项 $v_{t}$ 确保空间利用率仍然是主要关注点,但目标函数 $\dot{O}(s_{t},a_{t})$ 引导智能体满足额外的约束条件,如通道友好性和负载平衡。我们采用 ACKTR (Wu et al., 2017) 方法来训练我们的 DRL 智能体,该方法使用 Kronecker-factored 近似曲率 (K-FAC) (Martens $&$ Grosse, 2015) 和信任区域迭代更新 actor 和 critic。Zhao 等人 (2021) 已经证明,这种方法在在线 3D 装箱问题上比其他无模型 DRL 算法(如 SAC (Haarnoja et al., 2018))具有显著的优势。
Feature extraction Specifically, ACKTR runs multiple parallel processes (64 here) to interact with their respective environments and gather samples. The different processes may have different packing time step $t$ and deal with different packing sequences, the space configuration nodes number N also changes. To combine these data with irregular shapes into one batch, we fullfill $\mathbf{B}{t}$ and $\mathbf{L}{t}$ to fixed lengths, 80 and $25\cdot|\mathbf{O}|$ respectively, with dummy nodes. The descriptors for dummy nodes are all-zero vectors and have the same size as the internal nodes or the leaf nodes. The relation weight logits $u_{i j}$ of dummy node $j$ to arbitrary node $i$ is replaced with $-i n f$ to eliminate these dummy nodes during the feature calculation of GAT. The global context feature $\bar{h}$ is aggregated only on the eligible nodes $\mathbf{h}$ $\begin{array}{r}{\bar{h}=\frac{1}{N}\sum_{i=1}^{N}h_{i}}\end{array}$ Alspace con igu ration node are embeded by GTAT as a flly connected graph as Figure 2 (b), without any inner mask operation.
特征提取
具体来说,ACKTR 运行多个并行进程(此处为 64 个)以与其各自的环境交互并收集样本。不同的进程可能具有不同的打包时间步长 $t$,并处理不同的打包序列,空间配置节点数 N 也会变化。为了将这些形状不规则的数据合并为一个批次,我们用虚拟节点将 $\mathbf{B}{t}$ 和 $\mathbf{L}{t}$ 填充到固定长度,分别为 80 和 $25\cdot|\mathbf{O}|$。虚拟节点的描述符是全零向量,并且与内部节点或叶节点的大小相同。虚拟节点 $j$ 到任意节点 $i$ 的关系权重 logits $u_{i j}$ 被替换为 $-i n f$,以在 GAT 的特征计算过程中消除这些虚拟节点。全局上下文特征 $\bar{h}$ 仅在符合条件的节点 $\mathbf{h}$ 上聚合:$\begin{array}{r}{\bar{h}=\frac{1}{N}\sum_{i=1}^{N}h_{i}}\end{array}$。空间配置节点通过 GTAT 嵌入为一个全连接图,如图 2 (b) 所示,没有任何内部掩码操作。
We only provide the packable leaf nodes which satisfy placement constraints for DRL agents. For setting 2, we check in advance if a candidate placement satisfies Constraint 1 and 2. For setting 1 and setting 3 where the mass of item $n_{t}$ is $v_{t}$ and $\rho\cdot v_{t}$ respectively, we will additionally check if one placement meets the constraints of packing stability. Benefits from the fast stability estimation method proposed by Zhao et al. (2022), this pre-checking process can be completed in a very short time, and our DRL agent samples data at a frequency of more than 400 FPS.
我们仅提供满足DRL智能体放置约束的可打包叶节点。对于设置2,我们提前检查候选放置是否满足约束1和2。对于设置1和设置3,其中物品$n_{t}$的质量分别为$v_{t}$和$\rho\cdot v_{t}$,我们还将额外检查一个放置是否满足打包稳定性约束。得益于Zhao等人(2022)提出的快速稳定性估计方法,这一预检查过程可以在极短的时间内完成,我们的DRL智能体以超过400 FPS的频率采样数据。
The node-wise MLPs $\phi_{\theta_{B}},\phi_{\theta_{L}}$ , and $\phi_{\theta_{n}}$ used to embed raw space configuration nodes are two-layer linear networks with LeakyReLU activation function. $\phi_{F F}$ is a two-layer linear structure activated by ReLU. The feature dimensions $d_{h},d_{k}$ , and $d_{v}$ are 64. The hyper parameter $c_{c l i p}$ used to control the range of clipped compatibility logits is set to 10 in our GAT implementation.
节点级别的多层感知机 (MLP) $\phi_{\theta_{B}},\phi_{\theta_{L}}$ 和 $\phi_{\theta_{n}}$ 用于嵌入原始空间配置节点,它们是带有 LeakyReLU 激活函数的两层线性网络。$\phi_{F F}$ 是一个由 ReLU 激活的两层线性结构。特征维度 $d_{h},d_{k}$ 和 $d_{v}$ 均为 64。在我们的 GAT 实现中,用于控制裁剪兼容性 logits 范围的超参数 $c_{c l i p}$ 设置为 10。
Choice of PCT Length Since PCT allows discarding some valid leaf nodes and this will not harm our performance, we randomly intercept a subset $\mathbf{L}{s u b{t}}$ from $\mathbf{L}{t}$ if $\left|{{\mathbf{L}}{t}}\right|$ exceeds a certain length. Determining the suitable PCT length for different bin configurations is important, we give our recommendations for finding this hyper parameter. For training, we find that the performance of learned policies is more sensitive to the number of allowed orientations $|\mathbf{O}|$ . Thus we set the PCT length as $c\cdot|\mathbf{O}|$ where $c$ can be determined by a grid search nearby $c=25$ for different bin configurations. For our experiments, $c=25$ works quite well. During the test, the PCT length can be different from the training one, we suggest searching this interception length with a validation dataset via a grid search which ranges from 50 to 300 with step length 10.
PCT 长度的选择
由于 PCT 允许丢弃一些有效的叶节点且不会影响性能,如果 $\left|{{\mathbf{L}}{t}}\right|$ 超过一定长度,我们会从 $\mathbf{L}{t}$ 中随机截取一个子集 $\mathbf{L}{s u b{t}}$。确定不同箱子配置的合适 PCT 长度非常重要,我们给出了寻找此超参数的建议。对于训练,我们发现学习策略的性能对允许的方向数量 $|\mathbf{O}|$ 更为敏感。因此,我们将 PCT 长度设置为 $c\cdot|\mathbf{O}|$,其中 $c$ 可以通过在 $c=25$ 附近进行网格搜索来确定,适用于不同的箱子配置。在我们的实验中,$c=25$ 效果很好。在测试期间,PCT 长度可以与训练时不同,我们建议通过网格搜索在验证数据集上搜索此截取长度,范围从 50 到 300,步长为 10。
B LEAF NODE EXPANSION SCHEMES
B 叶节点扩展方案
We introduce the leaf node expansion schemes adopted in our PCT implementation here. These schemes are used to increment ally calculate new candidate placements introduced by the just placed item $n_{t}$ . A good expansion scheme should reduce the number of solutions to be explored while not missing too many feasible packings. Meanwhile, polynomial ly computability is also expected. As shown in Figure 4, the policies guided by suitable leaf node expansion schemes outperform the policy trained on a full coordinate (FC) space in the whole training process. We extend three existing heuristic placement rules which have proven to be both accurate and efficient to our PCT expansion, i.e. Corner Point, Extreme Point, and Empty Maximal Space. Since all these schemes are related to boundary points of packed items, we combine the start/end points of $n_{t}$ with these boundary points as a superset, namely Event Point.
我们在此介绍PCT实现中采用的叶节点扩展方案。这些方案用于增量计算由刚放置的物品$n_{t}$引入的新候选位置。一个好的扩展方案应减少需要探索的解的数量,同时不遗漏太多可行的包装方案。此外,还期望具有多项式可计算性。如图4所示,在整个训练过程中,由合适的叶节点扩展方案指导的策略优于在全坐标(FC)空间上训练的策略。我们将三种现有的启发式放置规则扩展到PCT扩展中,这些规则已被证明既准确又高效,即角点、极点和最大空空间。由于所有这些方案都与已包装物品的边界点相关,我们将$n_{t}$的起点/终点与这些边界点结合为一个超集,即事件点。

Figure 4: Learning curves on setting 1. A good expansion scheme for PCT reduces the complexity and helps DRL methods for more efficient learning and better performance. EVF means the full EV leaf node set without an interception.
图 4: 设置 1 上的学习曲线。PCT 的良好扩展方案降低了复杂性,并帮助 DRL 方法实现更高效的学习和更好的性能。EVF 表示没有截断的完整 EV 叶节点集。
Corner Point Martello et al. (2000) first introduce the concept of Corner Point (CP) for their branch-and-bound methods. Given 2D packed items in the coy plane, the corner points can be found where the envelope of the items in the bin changes from vertical to horizontal, as shown in Figure 5 (a). The past corner points which no longer meet this condition will be deleted. Extend this 2D situation to 3D cases, the new candidate 3D positions introduce by the just placed item $n_{t}$ are a subset of $\left\lbrace(p_{n}^{x}+s_{n}^{x},p_{n}^{y},p_{n}^{z}),(p_{n}^{x},p_{n}^{y}+s_{n}^{y},p_{n}^{\bar{z}}),(p_{n}^{x},p_{n}^{y},p_{n}^{z}+s_{n}^{z})\right\rbrace$ if the envelope of the corresponding 2D plane, i.e. coy, $y o z$ and $x o z$ , is changed by $n_{t}$ . The time complexity of finding 3D corner points increment ally is $O(c)$ with an easy-to-maintained bin height map data structure to detect the change of envelope on each plane, $c$ is a constant here.
Corner Point Martello 等人 (2000) 首次为他们的分支定界方法引入了 Corner Point (CP) 的概念。给定二维平面上的打包物品,可以在物品的包络从垂直变为水平的地方找到角点,如图 5 (a) 所示。不再满足此条件的过去角点将被删除。将这种二维情况扩展到三维情况,由刚刚放置的物品 $n_{t}$ 引入的新候选三维位置是 $\left\lbrace(p_{n}^{x}+s_{n}^{x},p_{n}^{y},p_{n}^{z}),(p_{n}^{x},p_{n}^{y}+s_{n}^{y},p_{n}^{\bar{z}}),(p_{n}^{x},p_{n}^{y},p_{n}^{z}+s_{n}^{z})\right\rbrace$ 的子集,如果对应的二维平面(即 $xoy$、$yoz$ 和 $xoz$)的包络被 $n_{t}$ 改变。通过易于维护的箱体高度图数据结构来检测每个平面上的包络变化,增量地找到三维角点的时间复杂度为 $O(c)$,其中 $c$ 是一个常数。
Extreme Point Crainic et al. (2008) extend the concept of Corner Point to Extreme Point (EP) and claim their method reaches the best offine performance of that era. Its insight is to provide the means to exploit the free space defined inside a packing by the shapes of the items that already exist.When the current item $n_{t}$ is added, new EPs are increment ally generated by projecting the coordinates $\left\lbrace(p_{n}^{x}+s_{n}^{x},p_{n}^{y},p_{n}^{z}),(p_{n}^{x},p_{n}^{y}+s_{n}^{y},p_{n}^{z}),(p_{n}^{x},p_{n}^{y},p_{n}^{z}+s_{n}^{y})\right\rbrace$ on the orthogonal axes, e.. project $(p_{n}^{x}+s_{n}^{x},p_{n}^{y},p_{n}^{z})$ in the directions of the $y$ and $z$ axes to find intersections with all items lying between item $n_{t}$ and the boundary of the bin. The nearest intersection in the respective direction is an extreme point. Since we stipulate a vertical top-down loading direction, the 3D extreme points in the strict sense may exist a large item blocking the loading direction. So we find the 2D extreme points (see Figure 5 (b)) in the coy plane and repeat this operation on each distinct $p^{z}$ value (i.e. start/end $z$ coordinate of a packed item) which satisfies $p_{n}^{z}\leq p^{z}\leq p_{n}^{z}+s_{n}^{z}$ . The time complexity of this method is $O(m\cdot|\bar{\bf B}{2D}|)$ , where ${\bf{B}}{2D}$ is the packed items that exist in the corresponding $z$ plane and $m$ is the number of related $z$ scans.
极端点 (Extreme Point) Crainic 等人 (2008) 将角点 (Corner Point) 的概念扩展到极端点 (Extreme Point, EP),并声称他们的方法达到了当时的最佳离线性能。其核心思想是通过已存在物品的形状来利用包装内部定义的自由空间。当当前物品 $n_{t}$ 被添加时,通过将坐标 $\left\lbrace(p_{n}^{x}+s_{n}^{x},p_{n}^{y},p_{n}^{z}),(p_{n}^{x},p_{n}^{y}+s_{n}^{y},p_{n}^{z}),(p_{n}^{x},p_{n}^{y},p_{n}^{z}+s_{n}^{y})\right\rbrace$ 投影到正交轴上,逐步生成新的极端点。例如,将 $(p_{n}^{x}+s_{n}^{x},p_{n}^{y},p_{n}^{z})$ 在 $y$ 和 $z$ 轴方向上投影,以找到与物品 $n_{t}$ 和箱子边界之间的所有物品的交点。在各自方向上最近的交点即为极端点。由于我们规定了垂直自上而下的装载方向,严格意义上的 3D 极端点可能会存在一个大型物品阻挡装载方向。因此,我们在 coy 平面中找到 2D 极端点(见图 5 (b)),并在每个满足 $p_{n}^{z}\leq p^{z}\leq p_{n}^{z}+s_{n}^{z}$ 的不同 $p^{z}$ 值(即已包装物品的起始/结束 $z$ 坐标)上重复此操作。该方法的时间复杂度为 $O(m\cdot|\bar{\bf B}{2D}|)$,其中 ${\bf{B}}{2D}$ 是相应 $z$ 平面中存在的已包装物品,$m$ 是相关 $z$ 扫描的次数。

Figure 5: Full candidate positions generated by different PCT expansion schemes (all in coy plane). The gray dashed lines are the boundaries of the bin. Circles in (a) and (b) represent corner points and extreme points respectively. (c): The candidate positions (circles) introduced by different EMSs are rendered with different colors. All intersections of two dashed lines in (d) constitute event points.
图 5: 不同 PCT 扩展方案生成的全部候选位置(均在 coy 平面)。灰色虚线表示 bin 的边界。(a) 和 (b) 中的圆圈分别表示角点和极值点。(c): 不同 EMS 引入的候选位置(圆圈)用不同颜色渲染。(d) 中所有两条虚线的交点构成事件点。
Empty Maximal Space Empty Maximal Spaces (EMSs) (Ha et al., 2017) are the largest empty orthogonal spaces whose sizes cannot extend more along the coordinate axes from its front-leftbottom (FLB) corner. This is a simple and effective placement rule. An EMS $e$ is presented by its FLB corner $(p_{e}^{x},p_{e}^{y},p_{e}^{z})$ and sizes $\left(s_{e}^{x},s_{e}^{y},s_{e}^{z}\right)$ When the current item $n_{t}$ is placed into $e$ on its FLB corner, this EMS is split into three smaller EMSs with positions $(p_{e}^{x}+s_{n}^{x},p_{e}^{y},p_{e}^{z})$ , $(p_{e}^{x},p_{e}^{y}+$ $s_{n}^{y},p_{e}^{z})$ , $\left(p_{e}^{x},p_{e}^{y},p_{e}^{z}+s_{n}^{z}\right)$ and sizes $\left(s_{e}^{x}-s_{n}^{x},s_{e}^{y},s_{e}^{z}\right)$ , $\left(s_{e}^{x},s_{e}^{y}-s_{n}^{y},s_{e}^{z}\right)$ $\left(s_{e}^{x},s_{e}^{y},s_{e}^{z}-s_{n}^{z}\right)$ , respectively. If the item $n_{t}$ only partially intersects with $e$ , we can apply a similar volume subtraction to the intersecting part for splitting $e$ .For each ems, we define the left-up $\left(p_{e}^{x},p_{e}^{y}+s_{e}^{y},p_{e}^{z}\right)$ , right-up $(p_{e}^{x}+s_{e}^{x},p_{e}^{y}+s_{e}^{y},p_{e}^{z})$ , left-bottom $(p_{e}^{x},p_{e}^{y},p_{e}^{z})$ , and right-bottom $(p_{e}^{x}+s_{e}^{x},p_{e}^{y},p_{e}^{z})$ corners of its vertical bottom as candidate positions, as shown in Figure 5 (c). These positions also need to be converted to the FLB corner coordinate for placing item $n_{t}$ . The left-up, right-up, left-bottom and right-bottom corners of $e$ should be converted to $\left(p_{e}^{x},p_{e}^{y}+s_{e}^{y}-s_{n}^{y},p_{e}^{z}\right)$ , $\left(p_{e}^{x}+s_{e}^{x}-s_{n}^{x},p_{e}^{y}+s_{e}^{y}-s_{n}^{y},p_{e}^{z}\right)$ , $(p_{e}^{x},p_{e}^{y},p_{e}^{z})$ , and $(p_{e}^{x}+s_{e}^{x}-s_{n}^{x},p_{e}^{y},p_{e}^{z})$ respectively. Since all EMSs ${e\in{\bf E}}$ in the bin needs to detect intersection with $n_{t}$ , the time complexity of finding 3D EMSs increment ally is $O(|\mathbf{E}|)$ .A 3D schematic diagram of PCT expansion guided by EMSs is provided in Figure 6.
空最大空间 (Empty Maximal Spaces, EMSs) (Ha et al., 2017) 是指从其前左下角 (FLB) 沿坐标轴方向无法再扩展的最大空正交空间。这是一个简单而有效的放置规则。一个 EMS $e$ 由其 FLB 角 $(p_{e}^{x},p_{e}^{y},p_{e}^{z})$ 和尺寸 $\left(s_{e}^{x},s_{e}^{y},s_{e}^{z}\right)$ 表示。当当前物品 $n_{t}$ 被放置到 $e$ 的 FLB 角时,这个 EMS 被分割成三个较小的 EMS,位置分别为 $(p_{e}^{x}+s_{n}^{x},p_{e}^{y},p_{e}^{z})$ , $(p_{e}^{x},p_{e}^{y}+s_{n}^{y},p_{e}^{z})$ , $\left(p_{e}^{x},p_{e}^{y},p_{e}^{z}+s_{n}^{z}\right)$ ,尺寸分别为 $\left(s_{e}^{x}-s_{n}^{x},s_{e}^{y},s_{e}^{z}\right)$ , $\left(s_{e}^{x},s_{e}^{y}-s_{n}^{y},s_{e}^{z}\right)$ , $\left(s_{e}^{x},s_{e}^{y},s_{e}^{z}-s_{n}^{z}\right)$ 。如果物品 $n_{t}$ 仅部分与 $e$ 相交,我们可以对相交部分应用类似的体积减法来分割 $e$ 。对于每个 EMS,我们定义其垂直底部的左上角 $\left(p_{e}^{x},p_{e}^{y}+s_{e}^{y},p_{e}^{z}\right)$ ,右上角 $(p_{e}^{x}+s_{e}^{x},p_{e}^{y}+s_{e}^{y},p_{e}^{z})$ ,左下角 $(p_{e}^{x},p_{e}^{y},p_{e}^{z})$ ,右下角 $(p_{e}^{x}+s_{e}^{x},p_{e}^{y},p_{e}^{z})$ 作为候选位置,如图 5 (c) 所示。这些位置也需要转换为 FLB 角坐标以放置物品 $n_{t}$ 。$e$ 的左上角、右上角、左下角和右下角应分别转换为 $\left(p_{e}^{x},p_{e}^{y}+s_{e}^{y}-s_{n}^{y},p_{e}^{z}\right)$ , $\left(p_{e}^{x}+s_{e}^{x}-s_{n}^{x},p_{e}^{y}+s_{e}^{y}-s_{n}^{y},p_{e}^{z}\right)$ , $(p_{e}^{x},p_{e}^{y},p_{e}^{z})$ ,和 $(p_{e}^{x}+s_{e}^{x}-s_{n}^{x},p_{e}^{y},p_{e}^{z})$ 。由于箱子中的所有 EMS ${e\in{\bf E}}$ 都需要检测与 $n_{t}$ 的相交,因此增量查找 3D EMS 的时间复杂度为 $O(|\mathbf{E}|)$ 。图 6 提供了一个由 EMS 引导的 PCT 扩展的 3D 示意图。

Figure 6: A 3D PCT expansion schematic diagram. This PCT grows under the guidance of the EMS expansion scheme. For simplicity, we only choose the bottom-right-up corners of each EMS as candidate positions and weset $|\mathbf{O}|=1$ here.
图 6: 3D PCT 扩展示意图。该 PCT 在 EMS 扩展方案的指导下生长。为简化起见,我们仅选择每个 EMS 的右下上角作为候选位置,并在此设置 $|\mathbf{O}|=1$。
Event Point It's not difficult to find that all schemes mentioned above are related to boundary points of a packed item along $d\in{x,y}$ axes (we assume the initial empty bin is also a special packed item here). When the current item $n_{t}$ is packed, we update the existing PCT leaf nodes by scanning all distinct $p^{z}$ values which satisfy $p_{n}^{z}\leq p^{z}\leq p_{n}^{z}+s_{n}^{z}$ and combine the start/end points of $n_{t}$ with the boundary points that exist in this $z$ plane to get the superset (see Figure 5 (d), which is called Event Points. The time complexity for detecting event points is $O(m\cdot|\bar{B_{2D}}|^{2})$
事件点
不难发现,上述所有方案都与沿 $d\in{x,y}$ 轴的打包物品的边界点相关(我们假设初始的空箱子也是一个特殊的打包物品)。当当前物品 $n_{t}$ 被打包时,我们通过扫描所有满足 $p_{n}^{z}\leq p^{z}\leq p_{n}^{z}+s_{n}^{z}$ 的不同 $p^{z}$ 值来更新现有的 PCT 叶节点,并将 $n_{t}$ 的起点/终点与该 $z$ 平面中存在的边界点结合,得到超集(见图 5 (d),称为事件点。检测事件点的时间复杂度为 $O(m\cdot|\bar{B_{2D}}|^{2})$。
C MORE RESULTS
C 更多结果
In this section, we report more results of our method. Section C.1 further discusses the generalization ability of our method on disturbed item sampling distributions and unseen items. Section C.2 reports the running cost of each method. Section C.3 scales our method to a larger problem and reports the performance. Section C.4 visualizes packing sequences to analyze model behavior and more visualized results are provided in Section C.5. Section C.6 introduces our real-world packing system.
在本节中,我们报告了更多关于我们方法的结果。C.1 节进一步讨论了我们的方法在受干扰的物品采样分布和未见物品上的泛化能力。C.2 节报告了每种方法的运行成本。C.3 节将我们的方法扩展到更大的问题并报告了性能。C.4 节可视化了打包序列以分析模型行为,C.5 节提供了更多的可视化结果。C.6 节介绍了我们的现实世界打包系统。
C.1 FURTHER DISCUSSIONS ON GENERALIZATION
C.1 关于泛化的进一步讨论
We have verified in Section 4.4 that our method has good generalization performance on item sampling distributions different from the training one. Now we further analyze the generalization ability of our method. Firstly, we demonstrate that our algorithm has a good generalization performance on disturbed item sampling distributions. We conduct this experiment in the discrete setting where the item set is finite $\langle\mathcal{Z}|=125\rangle$ . For each item $i\in\mathcal{T}$ , we add a random non-zero disturbance $\delta_{i}$ on its original sample probability $p_{i}$ , e.g.. $p_{i}=p_{i}\cdot\left(1-\delta_{i}\right)$ . We normalize the disturbed $p_{i}$ as the final item sampling probability. Note that $\delta_{i}$ is fixed during sampling one complete sequence. The state transition of DRL $\mathcal{P}(s_{t+1}|s_{t})$ which is partly determined by the probabilities of sampling items will be different from the training transition where the uniform distribution sample items with equal probabilities. Generalizing to a new transition is a classic challenge for reinforcement learning (Taylor & Stone, 2009). We test different ranges of $\delta_{i}$ and the results are summarized in Table 6.
我们在第4.4节中验证了我们的方法在与训练分布不同的物品采样分布上具有良好的泛化性能。现在,我们进一步分析我们方法的泛化能力。首先,我们证明了我们的算法在受扰动的物品采样分布上具有良好的泛化性能。我们在离散设置下进行此实验,其中物品集是有限的 $\langle\mathcal{Z}|=125\rangle$。对于每个物品 $i\in\mathcal{T}$,我们在其原始采样概率 $p_{i}$ 上添加一个随机的非零扰动 $\delta_{i}$,例如 $p_{i}=p_{i}\cdot\left(1-\delta_{i}\right)$。我们将受扰动的 $p_{i}$ 归一化为最终的物品采样概率。注意,$\delta_{i}$ 在采样一个完整序列时是固定的。DRL 的状态转移 $\mathcal{P}(s_{t+1}|s_{t})$ 部分由采样物品的概率决定,将与训练转移不同,训练转移中均匀分布以相等概率采样物品。泛化到新的转移是强化学习中的一个经典挑战 (Taylor & Stone, 2009)。我们测试了不同范围的 $\delta_{i}$,结果总结在表6中。
Table 6: Transfer the best-performing PCT policies directly to the disturbed item sampling distributions. Dif. means how much the generalization performance drops from the undisturbed case $\boldsymbol{\cdot}\delta_{i}=0$
表 6: 将表现最佳的 PCT 策略直接转移到受干扰的项目采样分布中。Dif. 表示泛化性能相对于未受干扰情况下的下降程度 $\boldsymbol{\cdot}\delta_{i}=0$
| 干扰 | Setting1 效用 | 变量数 | Dif. | Setting2 效用 | 变量数 | Dif. | Setting3 效用 | 变量数 | Dif. | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0=0 | 76.0% | 4.2 | 29.4 | 0.0% | 86.0% | 1.9 | 33.0 | 0.0% | 75.7% | 4.6 | 29.2 | |
| E[-20%,20%] | 75.6% | 4.6 | 29.1 | 0.5% | 85.7% | 2.1 | 32.8 | 0.3% | 75.3% | 4.5 | 29.0 | |
| OiE | [-40%,40%] | 75.5% | 4.5 | 29.0 | 0.7% | 85.6% | 2.1 | 32.8 | 0.5% | 75.6% | 4.8 | 29.3 |
| Oi E | [-60%,60%] | 75.5% | 4.3 | 28.9 | 0.7% | 85.8% | 2.1 | 32.8 | 0.2% | 75.5% | 4.8 | 28.9 |
| SE | [-80%,80%] | 75.7% | 4.5 | 29.2 | 0.4% | 85.6% | 2.2 | 32.9 | 0.5% | 75.4% | 4.9 | 29.3 |
| ∈ [-100%,100%] | 75.8% | 4.4 | 29.0 | 0.3% | 85.5% | 2.2 | 32.6 | 0.6% | 75.3% | 4.7 | 29.3 |
Benefits from the efficient guidance of heuristic leaf node expansion schemes, our method maintains its performance under various amplitude disturbances. Our method even behaves well with a strong disturbance $\delta_{i}\in[-100%,100%]$ applied, which means some items may never be sampled by some distributions when $\delta_{i}=1$ and $\dot{p_{i}\cdot(1-\delta_{i})}=0$ in a specific sequence.
得益于启发式叶节点扩展方案的高效指导,我们的方法在各种幅度扰动下保持了其性能。即使施加了强扰动 $\delta_{i}\in[-100%,100%]$ ,我们的方法依然表现良好,这意味着在某些序列中,当 $\delta_{i}=1$ 且 $\dot{p_{i}\cdot(1-\delta_{i})}=0$ 时,某些项目可能永远不会被某些分布采样到。
Beyond experiments on generalization to disturbed distributions, we also test our method with unseen items. We conduct this experiment in the discrete setting. We randomly delete 25 items from $\mathcal{T}$ and train PCT policies with $\left|\mathcal{T}_{s u b}^{-}\right|=100$ . Then we test the trained policies on full $\mathcal{T}$ .See Table 7 for results. Our method still performs well on datasets where unseen items exist regarding all settings.
除了对扰动分布的泛化实验外,我们还用未见过的物品测试了我们的方法。我们在离散设置下进行此实验。我们从 $\mathcal{T}$ 中随机删除 25 个物品,并使用 $\left|\mathcal{T}_{s u b}^{-}\right|=100$ 训练 PCT 策略。然后我们在完整的 $\mathcal{T}$ 上测试训练好的策略。结果见表 7。在所有设置中,我们的方法在存在未见物品的数据集上仍然表现良好。
Table 7: Generalization performance on unseen items. All policies are trained with the EV scheme.
表 7: 未见项目的泛化性能。所有策略均使用 EV 方案进行训练。
| 训练 | 测试 | 效用 | 方差 | 数量 | 效用 | 方差 | 数量 | 效用 | 方差 | 数量 |
|---|---|---|---|---|---|---|---|---|---|---|
| [ | = 125 | Z | =125 | 76.0% | 4.2 | 29.4 | 85.3% | 2.1 | 32.8 | 75.7% |
| Lsub = 100 | Zsub | = 100 | 74.4% | 5.1 | 29.4 | 86.3% | 1.7 | 33.8 | 74.2% | 4.7 |
| Lsub = 100 | Z | =125 | 74.6% | 5.4 | 28.9 | 85.6% | 2.6 | 33.0 | 74.4% | 5.2 |
C.2 RUNNING COSTS
C.2 运行成本
For 3D-BPP of online needs, the running cost for placing each item is especially important. We count the running costs of the experiments in Section 4.1 and Section 4.3 and summarize them in Table 8. Each running cost at time step $t$ is counted from putting down the previous item $n_{t-1}$ until the current item $n_{t}$ is placed, which includes the time to make placement decisions, the time to check placement feasibility, and the time to interact with the packing environment. The running cost of our method is comparable to most baselines. Our method can meet real-time packing requirements in both discrete solution space and continuous solution space.
对于在线需求的3D-BPP问题,放置每个物品的运行成本尤为重要。我们统计了第4.1节和第4.3节实验的运行成本,并将其总结在表8中。每个时间步$t$的运行成本从放下前一个物品$n_{t-1}$开始计算,直到当前物品$n_{t}$被放置为止,这包括做出放置决策的时间、检查放置可行性的时间以及与打包环境交互的时间。我们方法的运行成本与大多数基线方法相当。我们的方法在离散解空间和连续解空间中都能满足实时打包需求。
Table 8: Running costs (seconds) tested on online 3D-BPP with discrete solution space (Section 4.1) and continuous solution space (Section 4.3). The running costs of the latter are usually more expensive since checking Constraint 1 and 2 in the continuous domain is more time-consuming.
表 8: 在线 3D-BPP 的运行成本(秒),测试了离散解空间(第 4.1 节)和连续解空间(第 4.3 节)。后者的运行成本通常更高,因为在连续域中检查约束 1 和 2 更耗时。
| 方法 | 离散 | 设置1 连续 | 设置2 离散 连续 | 设置3 离散 连续 |
|---|---|---|---|---|
| Random DBL BR | Wang&Hauser | 2.03 × 10^-2 | ||
| 4.59 × 10^-2 | 3.01 × 10^-2 | |||
| 4.76 × 10^-2 | 1.87 × 10^-2 | |||
| 5.58 × 10^-2 | ||||
| 1.50 × 10^-2 | 1.69 × 10^-2 | 1.74 × 10^-2 | 1.76 × 10^-2 | |
| 5.89 × 10^-3 1.22 × 10^-2 | 1.48 × 10^-2 1.44 × 10^-2 | 3.39 × 10^-3 4.98 × 10^-3 | 7.17 × 10^-3 7.02 × 10^-3 | |
| MACS Zhao et al. | 2.68 × 10^-2 | 一 | 3.00 × 10^-2 | 一 |
| 5.51 × 10^-2 | 1.33 × 10^-2 | |||
| PCT &CP | 8.43 × 10^-3 | 1.61 × 10^-2 | 7.36 × 10^-3 | 1.52 × 10^-2 |
| PCT&EP | 1.22 × 10^-2 | 3.73 × 10^-2 | 1.13 × 10^-2 | 1.57 × 10^-2 |
| 1.77 × 10^-2 | 9.49 × 10^-3 | 2.36 × 10^-2 | ||
| PCT&EMS PCT&EV | 2.66 × 10^-2 | 4.11 × 10^-2 4.46 × 10^-2 | 1.25 × 10^-2 | 3.21 × 10^-2 |
C.3 S CAL ABILITY
C.3 可扩展性
The number of PCT nodes changes constantly with the generation and removal of leaf nodes during the packing process. To verify whether our method can solve packing problems with a larger scale $|\mathbf{B}|$ , we conduct a stress test on setting 2 where the most orientations are allowed and the most leaf nodes are generated. We limit the maximum item sizes $s^{d}$ to $S^{d}/5$ so that more items can be accommodated. We transfer the best-performing policies on setting 2 (trained with EMS) to these new datasets without any fine-tuning. The results are summarized in Table 9.
在打包过程中,PCT节点的数量随着叶节点的生成和移除而不断变化。为了验证我们的方法是否能够解决更大规模 $|\mathbf{B}|$ 的打包问题,我们在设置2上进行了压力测试,该设置允许最多的方向并生成最多的叶节点。我们将最大物品尺寸 $s^{d}$ 限制为 $S^{d}/5$,以便容纳更多的物品。我们将设置2上表现最佳的策略(使用EMS训练)转移到这些新数据集上,无需任何微调。结果总结在表9中。
Table 9: S cal ability on larger packing problems. $|\mathbf{L}|$ is the average number of leaf nodes per step. Run.is the running cost. $|\mathbf{L}|$ will not increase exponentially with $|\mathbf{B}|$ since invalid leaf nodes will be removed.
表 9: 更大规模装箱问题的可扩展性。$|\mathbf{L}|$ 是每一步的平均叶子节点数。Run.is 是运行成本。$|\mathbf{L}|$ 不会随着 $|\mathbf{B}|$ 的增加而指数级增长,因为无效的叶子节点会被移除。

PCT size will not grow exponentially with packing scale $\mathbf{\left|B\right|}$ since invalid leaf nodes will be removed from leaf nodes $\mathbf{L}$ during the packing process, both discrete and continuous cases. For continuous cases, $|\mathbf{L}|$ is more sensitive to $|\mathbf{B}|$ due to the diversity of item sizes (i.e. $|{\mathcal{T}}|=\infty,$ , however, $|\mathbf{L}|$ still doesn't explode with $|\mathbf{B}|$ and it grows in a sub-linear way. Our method can execute packing decisions at a real-time speed with controllable PCT sizes even if the item scale is around two hundred.
PCT 大小不会随着装箱规模 $\mathbf{\left|B\right|}$ 呈指数增长,因为在装箱过程中,无效的叶节点会从叶节点 $\mathbf{L}$ 中移除,无论是离散还是连续情况。对于连续情况,$|\mathbf{L}|$ 对 $|\mathbf{B}|$ 更敏感,因为物品尺寸的多样性(即 $|{\mathcal{T}}|=\infty$),然而,$|\mathbf{L}|$ 仍然不会随着 $|\mathbf{B}|$ 爆炸式增长,而是以次线性方式增长。即使物品规模在两百左右,我们的方法也能以实时速度执行装箱决策,且 PCT 大小可控。
C.4 UNDERSTANDING OF MODEL BEHAVIORS
C.4 模型行为的理解
The qualitative understanding of model behaviors is important, especially for practical concerns. We visualize our packing sequences to give our analysis. The behaviors of learned models differ with the packing constraints. If there is no specific packing preference, our learned policies will start packing nearby a fixed corner (Figure 7 (a)). The learned policies tend to combine items of different heights together to form a plane for supporting future ones (Figure 7 (b)). Meanwhile, it prefers to assign little items to gaps and make room (Figure 7 (c)) for future large ones (Figure 7 (d)). If additional packing preference is considered, the learned policies behave differently. For online 3DBPP with load balancing, the model will keep the maximum height in the bin as low as possible and pack items layer by layer (Figure 7(e)). For online 3D-BPP with isle friendliness, our model tends to pack the same category of items nearby the same bin corner (Figure 7 (f)).
对模型行为的定性理解非常重要,尤其是在实际应用中。我们通过可视化打包序列来进行分析。学习到的模型行为会随着打包约束的不同而变化。如果没有特定的打包偏好,学习到的策略会从固定的角落附近开始打包(图 7 (a))。学习到的策略倾向于将不同高度的物品组合在一起,形成一个平面以支持后续物品(图 7 (b))。同时,它更倾向于将小物品分配到间隙中,为未来的大物品腾出空间(图 7 (c))(图 7 (d))。如果考虑了额外的打包偏好,学习到的策略会表现出不同的行为。对于具有负载均衡的在线 3D-BPP,模型会尽可能保持箱子的最大高度较低,并逐层打包物品(图 7 (e))。对于具有通道友好性的在线 3D-BPP,我们的模型倾向于将同一类别的物品打包到箱子的同一角落附近(图 7 (f))。
C.5 VISUALIZED RESULTS
C.5 可视化结果
We visualize the experimental results of Section 4.1 in Figure 8. Each plot is about a randomly generated item sequence packed by our best-performing policies (PCT & EV on setting 1 and setting 3, PCT & EMS on setting 2).
我们在图 8 中可视化了第 4.1 节的实验结果。每个图都是关于由我们表现最佳的策略(在设置 1 和设置 3 上为 PCT & EV,在设置 2 上为 PCT & EMS)打包的随机生成的物品序列。

Figure7: $(\mathbf{a}){\sim}(\mathbf{d})$ : Different packing stages of the same sequence. The learned policies assign little items (colored in blue) to gaps and save room for future uncertainty. (e): Online 3D-BPP where load balancing is considered. (f): Online 3D-BPP with isle-friendliness, different color means different item categories.
图7: $(\mathbf{a}){\sim}(\mathbf{d})$:同一序列的不同装箱阶段。学习到的策略将小物品(蓝色)分配到间隙中,为未来的不确定性预留空间。(e):考虑负载均衡的在线3D-BPP。(f):考虑通道友好性的在线3D-BPP,不同颜色表示不同物品类别。

Figure 8: Visualized results of our method.
图 8: 我们方法的可视化结果。
C.6 REAL-WORLD PACKING SYSTEM
C.6 现实世界的包装系统
We follow the online autonomous bin packing system implementation of Zhao et al. (2022) in a logistics warehouse to validate our PCT method. As shown in Figure 9, the conveyor belt transports items to the robot arm (STEP $^\mathrm{\textregistered}$ SR20E) at a fixed speed. The onconveyor RGB-D camera (PhoXi 3D Scanner XL) recognizes the size and location of the current item. This information is sent to the robot arm for picking the current item and our PCT model for the placement decision. We align the bin coordinate with the robot coordinate and transform the packing decision to a real-world position. Then the robot arm places the current item into the bin which is a table trolley with sizes $S^{x}=110c m,S^{y}=90c m$ ,and $S^{z}=80c m$ We record sizes and positions of packed items as descriptors of internal nodes B.
我们遵循 Zhao 等人 (2022) 在物流仓库中实现的在线自主装箱系统来验证我们的 PCT 方法。如图 9 所示,传送带以固定速度将物品运送到机械臂 (STEP $^\mathrm{\textregistered}$ SR20E) 处。传送带上的 RGB-D 相机 (PhoXi 3D Scanner XL) 识别当前物品的尺寸和位置。这些信息被发送到机械臂以拾取当前物品,并发送到我们的 PCT 模型以进行放置决策。我们将箱子坐标与机械臂坐标对齐,并将装箱决策转换为现实世界中的位置。然后,机械臂将当前物品放入箱子中,箱子是一个尺寸为 $S^{x}=110c m,S^{y}=90c m$ 和 $S^{z}=80c m$ 的台车。我们记录已装箱物品的尺寸和位置作为内部节点 B 的描述符。

Figure 9: Our packing system. The on-conveyor camera detects packing targets. The on-bin camera monitors possible drifts of packed items.
图 9: 我们的包装系统。传送带上的摄像头检测包装目标。箱子上的摄像头监控已包装物品可能的偏移。
Different from the original implementation of Zhao et al. (2022) where only one on-conveyor camera is used for detecting the target item to be packed, we add one more on-bin RGB-D camera and adopt Mask R-CNN (He et al., 2017) for instance segmentation of input depth image, for monitoring possible drift of packed items. If a packed item deviates from the position of the PCT decision and this drift is detected, we will correct the descriptor of the corresponding internal node $b\in{\mathbf B}$ with the offset position. We use items with $s^{x}$ and $s^{y}$ ranging from $20\mathrm{cm}$ to $40\mathrm{cm}$ , and $s^{z}$ ranging from $10\mathrm{cm}$ to $25\mathrm{cm}$ . We fill items with paddings of the same density and train PCT policies on setting 1 with the EV scheme and the load balancing constraint. We test our system with 50 random sequences and our method achieves $78.6%$ space utilization with 50.9 items packed. Our real-world packing video demo is also submitted with the supplemental material.
与 Zhao 等人 (2022) 的原始实现不同,他们仅使用一个传送带上的摄像头来检测要打包的目标物品,我们增加了一个箱内 RGB-D 摄像头,并采用 Mask R-CNN (He 等人, 2017) 对输入的深度图像进行实例分割,以监控已打包物品可能的偏移。如果已打包的物品偏离了 PCT 决策的位置并且检测到这种偏移,我们将使用偏移位置来校正相应内部节点 $b\in{\mathbf B}$ 的描述符。我们使用的物品尺寸为 $s^{x}$ 和 $s^{y}$ 在 $20\mathrm{cm}$ 到 $40\mathrm{cm}$ 之间,$s^{z}$ 在 $10\mathrm{cm}$ 到 $25\mathrm{cm}$ 之间。我们使用相同密度的填充物填充物品,并在设置 1 中使用 EV 方案和负载平衡约束训练 PCT 策略。我们使用 50 个随机序列测试了我们的系统,我们的方法实现了 $78.6%$ 的空间利用率,打包了 50.9 件物品。我们的真实世界打包视频演示也随补充材料一起提交。