GPT4All: An Ecosystem of Open Source Compressed Language Models
GPT4All: 开源压缩语言模型的生态系统
Abstract
摘要
Large language models (LLMs) have recently achieved human-level performance on a range of professional and academic benchmarks. The accessibility of these models has lagged behind their performance. State-of-the-art LLMs require costly infrastructure; are only accessible via rate-limited, geo-locked, and censored web interfaces; and lack publicly available code and technical reports.
大语言模型 (LLMs) 最近在一系列专业和学术基准测试中达到了人类水平的表现。然而,这些模型的可访问性却落后于其性能。最先进的大语言模型需要昂贵的基础设施;只能通过速率受限、地理位置锁定和审查的网络界面访问;并且缺乏公开可用的代码和技术报告。
In this paper, we tell the story of GPT4All, a popular open source repository that aims to democratize access to LLMs. We outline the technical details of the original GPT4All model family, as well as the evolution of the GPT4All project from a single model into a fully fledged open source ecosystem. It is our hope that this paper acts as both a technical overview of the original GPT4All models as well as a case study on the subsequent growth of the GPT4All open source ecosystem.
在本文中,我们讲述了 GPT4All 的故事,这是一个旨在普及大语言模型 (LLM) 访问的流行开源项目。我们概述了原始 GPT4All 模型系列的技术细节,以及 GPT4All 项目从单一模型发展为一个成熟的开源生态系统的历程。我们希望本文既能作为原始 GPT4All 模型的技术概述,也能作为 GPT4All 开源生态系统后续发展的案例研究。
variety of queries, responding only with the now infamous "As an AI Language Model, I cannot..." prefix (Vincent, 2023). These transparency and accessibility concerns spurred several developers to begin creating open source large language model (LLM) alternatives. Several grassroots efforts focused on fine tuning Meta’s open code LLaMA model (Touvron et al., 2023; McMillan, 2023), whose weights were leaked on BitTorrent less than a week prior to the release of GPT-4 (Verge, 2023). GPT4All started as one of these variants.
面对各种查询,仅以现在臭名昭著的“作为一个AI语言模型,我不能……”前缀回应 (Vincent, 2023)。这些透明度和可访问性问题促使一些开发者开始创建开源的大语言模型 (LLM) 替代品。一些草根努力集中在微调 Meta 的开源代码 LLaMA 模型 (Touvron et al., 2023; McMillan, 2023),其权重在 GPT-4 发布前不到一周在 BitTorrent 上泄露 (Verge, 2023)。GPT4All 就是这些变体之一。
In this paper, we tell the story of GPT4All. We comment on the technical details of the original GPT4All model (Anand et al., 2023), as well as the evolution of GPT4All from a single model to an ecosystem of several models. We remark on the impact that the project has had on the open source community, and discuss future directions. It is our hope that this paper acts as both a technical overview of the original GPT4All models as well as a case study on the subsequent growth of the GPT4All open source ecosystem.
在本文中,我们讲述了 GPT4All 的故事。我们评论了原始 GPT4All 模型 (Anand et al., 2023) 的技术细节,以及 GPT4All 从单一模型演变为多个模型生态系统的过程。我们评价了该项目对开源社区的影响,并讨论了未来的发展方向。我们希望本文既能作为原始 GPT4All 模型的技术概述,也能作为 GPT4All 开源生态系统后续发展的案例研究。
1 Introduction
1 引言
On March 14 2023, OpenAI released GPT-4, a large language model capable of achieving human level performance on a variety of professional and academic benchmarks. Despite the popularity of the release, the GPT-4 technical report (OpenAI, 2023) contained virtually no details regarding the architecture, hardware, training compute, dataset construction, or training method used to create the model. Moreover, users could only access the model through the internet interface at chat.openai.com, which was severely rate limited and unavailable in several locales (e.g. Italy) (BBC News, 2023). Additionally, GPT-4 refused to answer a wide
2023年3月14日,OpenAI发布了GPT-4,这是一个能够在各种专业和学术基准上达到人类水平表现的大语言模型。尽管发布广受欢迎,但GPT-4技术报告(OpenAI, 2023)几乎没有包含有关模型架构、硬件、训练计算、数据集构建或训练方法的详细信息。此外,用户只能通过chat.openai.com的互联网界面访问该模型,该界面受到严格的速率限制,并且在多个地区(例如意大利)不可用(BBC News, 2023)。此外,GPT-4拒绝回答广泛的问题。
2 The Original GPT4All Model
2 原始 GPT4All 模型
2.1 Data Collection and Curation
2.1 数据收集与整理
To train the original GPT4All model, we collected roughly one million prompt-response pairs using the GPT-3.5-Turbo OpenAI API between March 20, 2023 and March 26th, 2023. In particular, we gathered GPT3.5-Turbo responses to prompts of three publicly available datasets: the unified chip2 subset of LAION OIG, a random sub-sample of Stack overflow Questions, and a sub-sample of Bigscience/P3 (Sanh et al., 2021). Following the approach in Stanford Alpaca (Taori et al., 2023), an open source LLaMA variant that came just before GPT4All, we focused substantial effort on dataset curation.
为了训练原始的 GPT4All 模型,我们在 2023 年 3 月 20 日至 2023 年 3 月 26 日期间,使用 GPT-3.5-Turbo OpenAI API 收集了大约一百万个提示-响应对。具体来说,我们收集了 GPT3.5-Turbo 对三个公开可用数据集的提示的响应:LAION OIG 的 unified chip2 子集、Stack Overflow 问题的随机子样本以及 Bigscience/P3 的子样本 (Sanh et al., 2021)。我们遵循了 Stanford Alpaca (Taori et al., 2023) 的方法,这是一个在 GPT4All 之前发布的开源 LLaMA 变体,我们在数据集整理上投入了大量精力。
The collected dataset was loaded into Atlas (AI, 2023)—a visual interface for exploring and tagging massive unstructured datasets —for data curation. Using Atlas, we identified and removed subsets of the data where GPT-3.5-Turbo refused to respond, had malformed output, or produced a very short response. This resulted in the removal of the entire Bigscience/P3 subset of our data, as many P3 prompts induced responses that were simply one word. After curation, we were left with a set of 437,605 prompt-response pairs, which we visualize in Figure 1a.
收集到的数据集被加载到 Atlas (AI, 2023) 中——这是一个用于探索和标记大规模非结构化数据的可视化界面——用于数据整理。通过 Atlas,我们识别并删除了 GPT-3.5-Turbo 拒绝响应、输出格式错误或生成非常简短响应的数据子集。这导致我们删除了整个 Bigscience/P3 数据子集,因为许多 P3 提示引发的响应仅为一个单词。整理后,我们保留了 437,605 个提示-响应对,如图 1a 所示。
2.2 Model Training
2.2 模型训练
The original GPT4All model was a fine tuned variant of LLaMA 7B. In order to train it more efficiently, we froze the base weights of LLaMA, and only trained a small set of LoRA (Hu et al., 2021) weights during the fine tuning process. Detailed model hyper-parameters and training code can be found in our associated code repository 1.
最初的 GPT4All 模型是基于 LLaMA 7B 的微调变体。为了更高效地训练它,我们冻结了 LLaMA 的基础权重,并在微调过程中仅训练了一小部分 LoRA (Hu et al., 2021) 权重。详细的模型超参数和训练代码可以在我们的相关代码库中找到。
2.3 Model Access
2.3 模型访问
We publicly released all data, training code, and model weights for the community to build upon. Further, we provided a 4-bit quantized version of the model, which enabled users to run it on their own commodity hardware without transferring data to a 3rd party service.
我们公开了所有数据、训练代码和模型权重,供社区在此基础上进行构建。此外,我们还提供了模型的4位量化版本,使用户能够在自己的普通硬件上运行,而无需将数据传输到第三方服务。
Our research and development costs were dominated by $\mathord{\sim}\$800$ in GPU spend (rented from Lambda Labs and Paperspace) and $\mathord{\sim}\$500$ in OpenAI API spend. Our final GPT4All model could be trained in about eight hours on a Lambda Labs DGX $\mathrm{A1008x80GB}$ for a total cost of ${\sim}\$100$ .
我们的研发成本主要由约800美元的GPU支出(从Lambda Labs和Paperspace租用)和约500美元的OpenAI API支出构成。我们最终的GPT4All模型可以在Lambda Labs DGX A1008x80GB上训练约八小时,总成本约为100美元。
2.4 Model Evaluation
2.4 模型评估
We performed a preliminary evaluation of our model using the human evaluation data from the Self Instruct paper (Wang et al., 2023). We reported the ground truth perplexity of our model against what was, to our knowledge, the best openly available alpaca-lora model at the time, provided by user chainyo on Hugging Face. Both models had very large perplexities on a small number of tasks, so we reported perplexities clipped to a maximum of 100. We found that GPT4All produces stochastic ally lower ground truth perplexities than alpaca-lora (Anand et al., 2023).
我们使用 Self Instruct 论文 (Wang et al., 2023) 中的人类评估数据对我们的模型进行了初步评估。我们报告了我们的模型在已知的最佳公开可用 alpaca-lora 模型(由 Hugging Face 上的用户 chainyo 提供)上的真实困惑度 (ground truth perplexity)。两个模型在少量任务上都有非常大的困惑度,因此我们报告了困惑度的上限为 100。我们发现,GPT4All 在真实困惑度上比 alpaca-lora 随机更低 (Anand et al., 2023)。
3 From a Model to an Ecosystem
3 从模型到生态系统
3.1 GPT4All-J: Repository Growth and the implications of the LLaMA License
3.1 GPT4All-J:代码库增长与LLaMA许可证的影响
The GPT4All repository grew rapidly after its release, gaining over 20000 GitHub stars in just one week, as shown in Figure 2. This growth was supported by an in-person hackathon hosted in New York City three days after the model release, which attracted several hundred participants. As the Nomic discord, the home of online discussion about GPT4All, ballooned to over 10000 people, one thing became very clear - there was massive demand for a model that could be used commercially.
GPT4All 仓库在发布后迅速增长,仅一周内就获得了超过 20000 个 GitHub star,如图 2 所示。这一增长得益于模型发布三天后在纽约市举办的线下黑客马拉松,吸引了数百名参与者。随着 Nomic discord(GPT4All 在线讨论的主要场所)的成员数量激增至超过 10000 人,一个事实变得非常清晰——市场对可用于商业用途的模型有着巨大的需求。
The LLaMA model that GPT4All was based on was licensed for research only, which severely limited the set of domains that GPT4All could be applied in. As a response to this, the Nomic team repeated the model training procedure of the original GPT4All model, but based on the already open source and commercially licensed GPT-J model (Wang and Komatsu zak i, 2021). GPT4All-J also had an augmented training set, which contained multi-turn QA examples and creative writing such as poetry, rap, and short stories. The creative writing prompts were generated by filling in schemas such as "Write a [CREATIVE STORY TYPE] about [NOUN] in the style of [PERSON]." We again employed Atlas to curate the prompt-response pairs in this data set.
GPT4All 所基于的 LLaMA 模型仅授权用于研究,这严重限制了 GPT4All 的应用领域。为此,Nomic 团队重复了原始 GPT4All 模型的训练过程,但基于已经开源且具有商业许可的 GPT-J 模型 (Wang and Komatsuzaki, 2021)。GPT4All-J 还拥有一个增强的训练集,其中包含多轮问答示例以及诗歌、说唱和短篇小说等创意写作内容。创意写作提示通过填充诸如“以 [PERSON] 的风格写一篇关于 [NOUN] 的 [CREATIVE STORY TYPE]”等模板生成。我们再次使用 Atlas 来整理该数据集中的提示-响应对。
Our evaluation methodology also evolved as the project grew. In particular, we began evaluating GPT4All models using a suite of seven reasoning tasks that were used for evaluation of the Databricks Dolly (Conover et al., 2023b) model, which was released on April 12, 2023. Unfortunately, GPT4All-J did not outperform other prominent open source models on this evaluation. As a result, we endeavour ed to create a model that did.
我们的评估方法也随着项目的发展而演变。特别是,我们开始使用一套七项推理任务来评估 GPT4All 模型,这些任务曾用于评估 Databricks Dolly (Conover et al., 2023b) 模型,该模型于 2023 年 4 月 12 日发布。遗憾的是,GPT4All-J 在此次评估中并未超越其他知名的开源模型。因此,我们努力创建了一个能够超越这些模型的模型。
3.2 GPT4All-Snoozy: the Emergence of the GPT4All Ecosystem
3.2 GPT4All-Snoozy: GPT4All 生态系统的崛起
GPT4All-Snoozy was developed using roughly the same procedure as the previous GPT4All models, but with a few key modifications. First, GPT4All-Snoozy used the LLaMA-13B base model due to its superior base metrics when compared to GPT-J. Next, GPT4All-Snoozy incorporated the Dolly’s training data into its train mix. After data curation and de duplication with Atlas, this yielded a training set of 739,259 total prompt-response pairs. We dubbed the model that resulted from training on this improved dataset GPT4All-Snoozy. As shown in Figure 1, GPT4All-Snoozy had the best average score on our evaluation benchmark of any model in the ecosystem at the time of its release.
GPT4All-Snoozy 的开发过程与之前的 GPT4All 模型大致相同,但有一些关键修改。首先,GPT4All-Snoozy 使用了 LLaMA-13B 基础模型,因为与 GPT-J 相比,它的基础指标更优。其次,GPT4All-Snoozy 将 Dolly 的训练数据纳入了其训练混合中。经过 Atlas 的数据整理和去重后,最终得到了一个包含 739,259 个提示-响应对的训练集。我们将在这一改进数据集上训练得到的模型命名为 GPT4All-Snoozy。如图 1 所示,GPT4All-Snoozy 在发布时在我们的评估基准上获得了生态系统内所有模型中的最佳平均分数。
Concurrently with the development of GPT4All, several organizations such as LMSys, Stability AI, BAIR, and Databricks built and deployed open source language models. We heard increasingly from the community that they wanted quantized versions of these models for local use. As we realized that organizations with ever more resources were developing source language models, we decided to pivot our effort away from training increasingly capable models and towards providing easy access to the plethora of models being produced by the open source community. Practically, this meant spending our time compressing open source models for use on commodity hardware, providing stable and simple high level model APIs, and supporting a GUI for no code model experimentation.
与 GPT4All 开发的同时,LMSys、Stability AI、BAIR 和 Databricks 等组织构建并部署了开源语言模型。我们越来越多地听到社区反馈,他们希望这些模型的量化版本能够在本地使用。当我们意识到越来越多的资源组织正在开发源语言模型时,我们决定将工作重心从训练能力越来越强的模型转向为开源社区提供的众多模型提供便捷访问。实际上,这意味着我们将时间花在压缩开源模型以在普通硬件上使用、提供稳定且简单的高级模型 API,以及支持无代码模型实验的 GUI 上。
3.3 The Current State of GPT4All
3.3 GPT4All 的现状
Today, GPT4All is focused on improving the accessibility of open source language models. The repository
今天,GPT4All 致力于提高开源语言模型的可访问性。该仓库
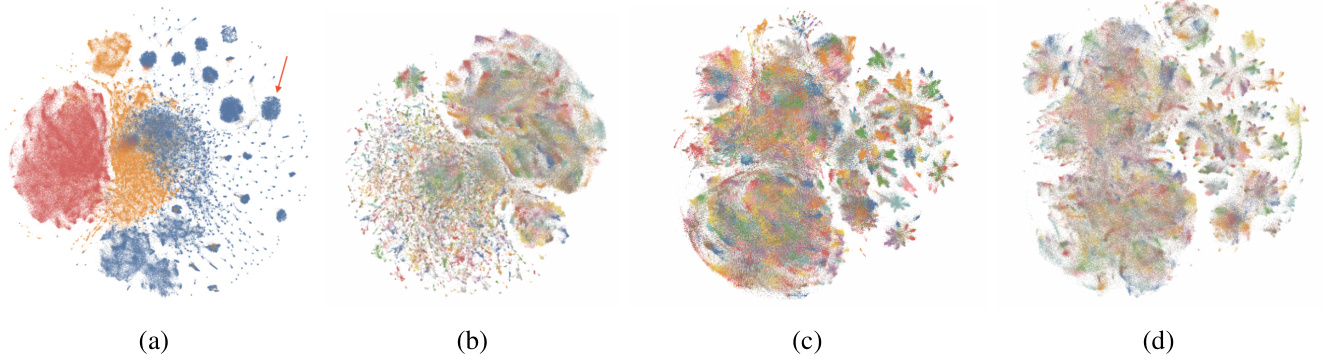
Figure 1: TSNE visualization s showing the progression of the GPT4All train set. Panel (a) shows the original uncurated data. The red arrow denotes a region of highly homogeneous prompt-response pairs. The coloring denotes which open dataset contributed the prompt. Panel (b) shows the original GPT4All data after curation. This panel, as well as panels (c) and (d) are 10 colored by topic, which Atlas automatically extracts. Notice that the large homogeneous prompt-response blobs no longer appearl. Panel (c) shows the GPT4All-J dataset. The "starburst" clusters introduced on the right side of the panel correspond to the newly added creative data. Panel (d) shows the final GPT4All-snoozy dataset. All datasets have been released to the public, and can be interactively explored online. In the web version of this article, you can click on a panel to be taken to its interactive visualization.
图 1: TSNE 可视化展示了 GPT4All 训练集的进展。图 (a) 显示了原始的未筛选数据。红色箭头表示高度同质的提示-响应对区域。颜色表示提示来自哪个开放数据集。图 (b) 显示了经过筛选后的原始 GPT4All 数据。此图以及图 (c) 和图 (d) 按主题着色,主题由 Atlas 自动提取。请注意,大的同质提示-响应块不再出现。图 (c) 显示了 GPT4All-J 数据集。图右侧引入的“星爆”簇对应于新添加的创意数据。图 (d) 显示了最终的 GPT4All-snoozy 数据集。所有数据集均已公开发布,并可以在线进行交互式探索。在本文的网页版本中,您可以点击图以进入其交互式可视化。
| 模型 | BoolQ | PIQA | HellaSwag | WinoG. | ARC-e | ARC-c | OBQA | 平均 |
|---|---|---|---|---|---|---|---|---|
| GPT4All-J6B v1.0* | 73.4 | 74.8 | 63.4 | 64.7 | 54.9 | 36 | 40.2 | 58.2 |
| GPT4All-J v1.1-breezy* | 74 | 75.1 | 63.2 | 63.6 | 55.4 | 34.9 | 38.4 | 57.8 |
| GPT4All-J v1.2-jazzy* | 74.8 | 74.9 | 63.6 | 63.8 | 56.6 | 35.3 | 41 | 58.6 |
| GPT4All-J v1.3-gro0vy* | 73.6 | 74.3 | 63.8 | 63.5 | 57.7 | 35 | 38.8 | 58.1 |
| GPT4All-J Lora 6B* | 68.6 | 75.8 | 66.2 | 63.5 | 56.4 | 35.7 | 40.2 | 58.1 |
| GPT4All LLaMa Lora 7B* | 73.1 | 77.6 | 72.1 | 67.8 | 51.1 | 40.4 | 40.2 | 60.3 |
| GPT4All 13B snoozy* | 83.3 | 79.2 | 75 | 71.3 | 60.9 | 44.2 | 43.4 | 65.3 |
| GPT4All Falcon | 77.6 | 79.8 | 74.9 | 70.1 | 67.9 | 43.4 | 42.6 | 65.2 |
| Nous-Hermes (Nous-Research, 2023b) | 79.5 | 78.9 | 80 | 71.9 | 74.2 | 50.9 | 46.4 | 68.8 |
| Nous-Hermes2 (Nous-Research,2023c) | 83.9 | 80.7 | 80.1 | 71.3 | 75.7 | 52.1 | 46.2 | 70.0 |
| Nous-Puffin (Nous-Research, 2023d) | 81.5 | 80.7 | 80.4 | 72.5 | 77.6 | 50.7 | 45.6 | 69.9 |
| Dolly 6B*(Conover et al.,2023a) | 68.8 | 77.3 | 67.6 | 63.9 | 62.9 | 38.7 | 41.2 | 60.1 |
| Dolly 12B* (Conover et al., 2023b) | 56.7 | 75.4 | 71 | 62.2 | 64.6 | 38.5 | 40.4 | 58.4 |
| Alpaca 7B* (Taori et al.,2023) | 73.9 | 77.2 | 73.9 | 66.1 | 59.8 | 43.3 | 43.4 | 62.5 |
| Alpaca Lora 7B* (Wang, 2023) | 74.3 | 79.3 | 74 | 68.8 | 56.6 | 43.9 | 42.6 | 62.8 |
| GPT-J* 6.7B (Wang and Komatsuzaki, 2021) | 65.4 | 76.2 | 66.2 | 64.1 | 62.2 | 36.6 | 38.2 | 58.4 |
| LLama 7B* (Touvron et al., 2023) | 73.1 | 77.4 | 73 | 66.9 | 52.5 | 41.4 | 42.4 | 61.0 |
| LLama 13B*(Touvron et al.,2023) | 68.5 | 79.1 | 76.2 | 70.1 | 60 | 44.6 | 42.2 | 63.0 |
| Pythia 6.7B* (Biderman et al.,2023) | 63.5 | 76.3 | 64 | 61.1 | 61.3 | 35.2 | 37.2 | 56.9 |
| Pythia 12B*(Biderman et al.,2023) | 67.7 | 76.6 | 67.3 | 63.8 | 63.9 | 34.8 | 38 | 58.9 |
| Fastchat T5* (Zheng et al., 2023) | 81.5 | 64.6 | 46.3 | 61.8 | 49.3 | 33.3 | 39.4 | 53.7 |
| Fastchat Vicuna* 7B (Zheng et al., 2023) | 76.6 | 77.2 | 70.7 | 67.3 | 53.5 | 41.2 | 40.8 | 61.0 |
| Fastchat Vicuna 13B* (Zheng et al., 2023) | 81.5 | 76.8 | 73.3 | 66.7 | 57.4 | 42.7 | 43.6 | 63.1 |
| StableVicuna RLHF* (Stability-AI, 2023) | 82.3 | 78.6 | 74.1 | 70.9 | 61 | 43.5 | 44.4 | 65.0 |
| StableLMTuned*(Stability-AI,2023) | 62.5 | 71.2 | 53.6 | 54.8 | 52.4 | 31.1 | 33.4 | 51.3 |
| StableLM Base*(Stability-AI, 2023) | 60.1 | 67.4 | 41.2 | 50.1 | 44.9 | 27 | 32 | 46.1 |
| Koala 13B* (Geng et al., 2023) | 76.5 | 77.9 | 72.6 | 68.8 | 54.3 | 41 | 42.8 | 62.0 |
| Open AssistantPythia 12B* | 67.9 | 78 | 68.1 | 65 | 64.2 | 40.4 | 43.2 | 61.0 |
| Mosaic MPT7B (MosaicML-Team, 2023) | 74.8 | 79.3 | 76.3 | 68.6 | 70 | 42.2 | 42.6 | 64.8 |
| Mosaic mpt-instruct (MosaicML-Team, 2023) | 74.3 | 80.4 | 77.2 | 67.8 | 72.2 | 44.6 | 43 | 65.6 |
| Mosaic mpt-chat (MosaicML-Team, 2023) | 77.1 | 78.2 | 74.5 | 67.5 | 69.4 | 43.3 | 44.2 | 64.9 |
| Wizard 7B (Xu et al., 2023) | 78.4 | 77.2 | 69.9 | 66.5 | 56.8 | 40.5 | 42.6 | 61.7 |
| Wizard 7B Uncensored (Xu et al., 2023) | 77.7 | 74.2 | 68 | 65.2 | 53.5 | 38.7 | 41.6 | 59.8 |
| Wizard 13B Uncensored (Xu et al., 2023) | 78.4 | 75.5 | 72.1 | 69.5 | 57.5 | 40.4 | 44 | 62.5 |
| GPT4-x-Vicuna-13b (Nous-Research,2023a) | 81.3 | 75 | 75.2 | 65 | 58.7 | 43.9 | 43.6 | 63.2 |
| Falcon 7b (Almazrouei et al.,2023) | 73.6 | 80.7 | 76.3 | 67.3 | 71 | 43.3 | 44.4 | 65.2 |
| Falcon 7b instruct (Almazrouei et al.,2023) | 70.9 | 78.6 | 69.8 | 66.7 | 67.9 | 42.7 | 41.2 | 62.5 |
| text-davinci-003 | 88.1 | 83.8 | 83.4 | 75.8 | 83.9 | 63.9 | 51.0 | 75.7 |
Table 1: Evaluations of all language models in the GPT4All ecosystem as of August 1, 2023. Code models are not included. OpenAI’s text-davinci-003 is included as a point of comparison. The best overall performing model in the GPT4All ecosystem, Nous-Hermes2, achieves over $92%$ of the average performance of text-davinci-003. Models marked with an asterisk were available in the ecosystem as of the release of GPT4All-Snoozy. Note that at release, GPT4All-Snoozy had the best average performance of any model in the ecosystem. Bolded numbers indicate the best performing model as of August 1, 2023.
表 1: 截至2023年8月1日,GPT4All生态系统中所有语言模型的评估结果。代码模型未包含在内。OpenAI的text-davinci-003作为对比基准包含在内。GPT4All生态系统中整体表现最佳的模型Nous-Hermes2,达到了text-davinci-003平均性能的92%以上。标有星号的模型在GPT4All-Snoozy发布时已在生态系统中可用。请注意,在发布时,GPT4All-Snoozy在生态系统中的所有模型中具有最佳的平均性能。加粗的数字表示截至2023年8月1日表现最佳的模型。
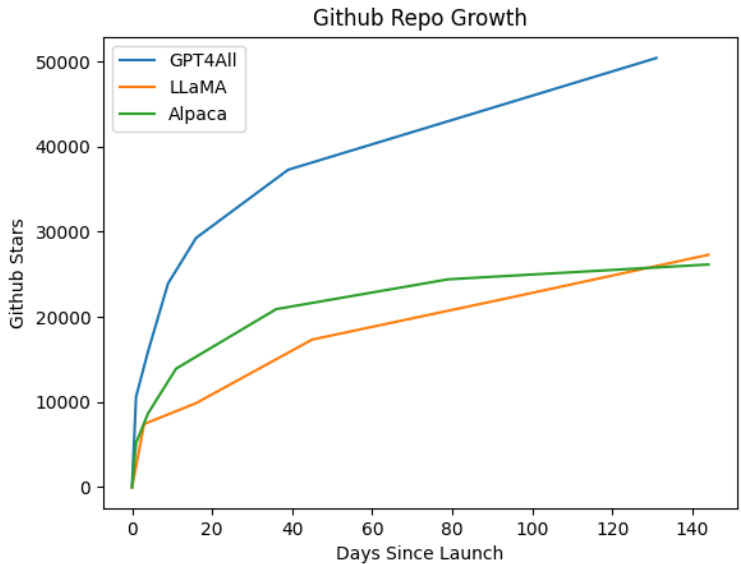
Figure 2: Comparison of the github start growth of GPT4All, Meta’s LLaMA, and Stanford’s Alpaca. We conjecture that GPT4All achieved and maintains faster ecosystem growth due to the focus on access, which allows more users to meaningfully participate.
图 2: GPT4All、Meta 的 LLaMA 和 Stanford 的 Alpaca 在 GitHub 上的 star 增长对比。我们推测 GPT4All 之所以能够实现并保持更快的生态系统增长,是因为其专注于访问性,这使得更多用户能够有意义地参与其中。
provides compressed versions of open source models for use on commodity hardware, stable and simple high level model APIs, and a GUI for no code model experi ment ation. The project continues to increase in popularity, and as of August 1 2023, has garnered over 50000 GitHub stars and over 5000 forks.
提供了开源模型的压缩版本,可在普通硬件上使用,稳定且简单的高级模型API,以及一个无需代码的模型实验GUI。该项目持续受到欢迎,截至2023年8月1日,已获得超过50000个GitHub星标和超过5000个分支。
GPT4All currently provides native support and benchmark data for over 35 models (see Figure 1), and includes several models co-developed with industry partners such as Replit and Hugging Face. GPT4All also provides high level model APIs in languages including Python, Typescript, Go, C#, and Java, among others. Furthermore, the GPT4All no code GUI currently supports the workflows of over 50000 monthly active users, with over $25%$ of users coming back to the tool every day of the week. (Note that all GPT4All user data is collected on an opt in basis.) GPT4All has become the top language model integration in the popular open source AI orchestration library LangChain (Chase, 2022), and powers many popular open source projects such as PrivateGPT (imartinez, 2023), Quiver (StanGirard, 2023), and MindsDB (MindsDB, 2023), among others. GPT4All is the 3rd fastest growing GitHub repository of all time (Leo, 2023), and is the 185th most popular repository on the platform, by star count.
GPT4All 目前为超过 35 个模型提供原生支持和基准测试数据(见图 1),并包括与 Replit 和 Hugging Face 等行业合作伙伴共同开发的多个模型。GPT4All 还提供了 Python、Typescript、Go、C# 和 Java 等多种语言的高级模型 API。此外,GPT4All 的无代码 GUI 目前支持超过 50000 名月活跃用户的工作流程,其中超过 $25%$ 的用户每周每天都返回使用该工具。(请注意,所有 GPT4All 用户数据都是在用户同意的基础上收集的。)GPT4All 已成为流行的开源 AI 编排库 LangChain (Chase, 2022) 中的顶级语言模型集成,并为许多流行的开源项目提供支持,如 PrivateGPT (imartinez, 2023)、Quiver (StanGirard, 2023) 和 MindsDB (MindsDB, 2023) 等。GPT4All 是有史以来增长第三快的 GitHub 仓库 (Leo, 2023),并且按星标数计算,是该平台上第 185 个最受欢迎的仓库。
4 The Future of GPT4All
4 GPT4All 的未来
In the future, we will continue to grow GPT4All, supporting it as the de facto solution for LLM accessibility. Concretely, this means continuing to compress and distribute important open-source language models developed by the community, as well as compressing and distributing increasingly multimodal AI models. Furthermore, we will expand the set of hardware devices that GPT4All models run on, so that GPT4All models “just work" on any machine, whether it comes equipped with Apple Metal silicon, NVIDIA, AMD, or other edgeaccelerated hardware. Overall, we envision a world where anyone, anywhere, with any machine, can access and contribute to the cutting edge of AI.
未来,我们将继续发展 GPT4All,使其成为大语言模型 (LLM) 可访问性的实际解决方案。具体来说,这意味着我们将继续压缩和分发社区开发的重要开源语言模型,以及压缩和分发日益多模态的 AI 模型。此外,我们将扩展 GPT4All 模型运行的硬件设备集,使 GPT4All 模型在任何机器上都能“即插即用”,无论是配备 Apple Metal 芯片、NVIDIA、AMD 还是其他边缘加速硬件。总的来说,我们设想一个世界,任何人、任何地方、使用任何机器,都能访问并贡献于 AI 的前沿。
Limitations
局限性
By enabling access to large language models, the GPT4All project also inherits many of the ethical concerns associated with generative models. Principal among these is the concern that unfiltered language models like GPT4All enable malicious users to generate content that could be harmful and dangerous (e.g., instructions on building bioweapons). While we recognize this risk, we also acknowledge the risk of concentrating this technology in the hands of a limited number of increasingly secretive research groups. We believe that the risk of focusing on the benefits of language model technology significantly outweighs the risk of misuse, and hence we prefer to make the technology as widely available as possible.
通过提供对大语言模型的访问,GPT4All 项目也继承了与生成式模型相关的许多伦理问题。其中最主要的问题是,像 GPT4All 这样未经过滤的语言模型可能被恶意用户用来生成有害和危险的内容(例如,关于制造生物武器的指导)。虽然我们认识到这一风险,但我们也意识到将这项技术集中在少数日益隐秘的研究团队手中的风险。我们认为,关注语言模型技术带来的益处远远超过滥用的风险,因此我们更倾向于尽可能广泛地推广这项技术。
Finally, we realize the challenge in assigning credit for large-scale open source initiatives. We make a first attempt at fair credit assignment by explicitly including the GPT4All open source developers as authors on this work, but recognize that this is insufficient fully characterize everyone involved in the GPT4All effort. Furthermore, we acknowledge the difficulty in citing open source works that do not necessarily have standardized citations, and do our best in this paper to provide URLs to projects whenever possible. We encourage further research in the area of open source credit assignment, and hope to be able to support some of this research ourselves in the future.
最后,我们意识到在大规模开源项目中分配贡献的挑战。我们首次尝试通过明确将 GPT4All 开源开发者列为本文作者来进行公平的贡献分配,但也认识到这不足以全面涵盖参与 GPT4All 项目的所有人。此外,我们承认引用没有标准化引用的开源作品的困难,并尽可能在本文中提供项目链接。我们鼓励在开源贡献分配领域进行进一步研究,并希望未来能够支持其中的一些研究。
References
参考文献
Nomic AI. 2023. Atlas. https://atlas.nomic.ai/.
Nomic AI. 2023. Atlas. https://atlas.nomic.ai/.
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Merouane Debbah, Etienne Goffinet, Daniel Heslow, Julien Launay, Quentin Malartic, Badreddine Noune, Baptiste Pannier, and Guilherme Penedo. 2023. Falcon-40B: an open large language model with state-of-the-art performance.
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Merouane Debbah, Etienne Goffinet, Daniel Heslow, Julien Launay, Quentin Malartic, Badreddine Noune, Baptiste Pannier, 和 Guilherme Penedo. 2023. Falcon-40B: 一个具有最先进性能的开放大语言模型。
Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. 2023. Gpt4all: Training an assistant-style chatbot with large scale data distillation from gpt-3.5-turbo. https://github.com/nomic-ai/gpt4all.
Yuvanesh Anand、Zach Nussbaum、Brandon Duderstadt、Benjamin Schmidt 和 Andriy Mulyar。2023。Gpt4all:通过从 GPT-3.5-turbo 进行大规模数据蒸馏训练助手风格聊天机器人。https://github.com/nomic-ai/gpt4all。
BBC News. 2023. Chatgpt banned in italy over privacy concerns. BBC News.
BBC News. 2023. 意大利因隐私问题禁止使用ChatGPT。BBC News.
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hal- lahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. 2023. Pythia: A suite for analyzing large language models across training and scaling.
Stella Biderman、Hailey Schoelkopf、Quentin Anthony、Herbie Bradley、Kyle O’Brien、Eric Hallahan、Mohammad Aflah Khan、Shivanshu Purohit、USVSN Sai Prashanth、Edward Raff、Aviya Skowron、Lintang Sutawika 和 Oskar van der Wal。2023。Pythia:一套用于分析大语言模型在训练和扩展中的工具套件。
Harrison Chase. 2022. langchain. https://github. com/langchain-ai/langchain.
Harrison Chase. 2022. langchain. https://github.com/langchain-ai/langchain.
Mike Conover, Matt Hayes, Ankit Mathur, Xiangrui Meng, Jianwei Xie, Jun Wan, Ali Ghodsi, Patrick Wendell, and Matei Zaharia. 2023a. Hello dolly: Democratizing the magic of chatgpt with open models.
Mike Conover, Matt Hayes, Ankit Mathur, Xiangrui Meng, Jianwei Xie, Jun Wan, Ali Ghodsi, Patrick Wendell, 和 Matei Zaharia. 2023a. Hello Dolly: 用开放模型普及 ChatGPT 的魔力。
Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. 2023b. Free dolly: Introducing the world’s first truly open instructiontuned llm.
Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, 和 Reynold Xin. 2023b. Free dolly: 推出世界上第一个真正开放的指令调优大语言模型。
Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace, Pieter Abbeel, Sergey Levine, and Dawn Song. 2023. Koala: A dialogue model for academic research. Blog post.
Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace, Pieter Abbeel, Sergey Levine, 和 Dawn Song. 2023. Koala: 学术研究的对话模型. 博客文章.
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models.
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: 大语言模型的低秩适应 (Low-rank adaptation of large language models).
imartinez. 2023. privategpt. https://github.com/ imartinez/privateGPT.
imartinez. 2023. privategpt. https://github.com/imartinez/privateGPT.
Oscar Leo. 2023. GitHub: The Fastest Growing Repositories of All Time.
Oscar Leo. 2023. GitHub: 有史以来增长最快的仓库。
Robert McMillan. 2023. A meta platforms leak put powerful ai in the hands of everyone. The Wall Street Journal.
Robert McMillan. 2023. Meta平台泄露事件让强大的人工智能落入众人之手。《华尔街日报》。
MindsDB. 2023. Mindsdb. https://github.com/ mindsdb/mindsdb. GitHub repository.
MindsDB. 2023. Mindsdb. https://github.com/mindsdb/mindsdb. GitHub 仓库。
MosaicML-Team. 2023. Introducing mpt-7b: A new standard for open-source, commercially usable llms. Accessed: 2023-08-07.
MosaicML-Team. 2023. 介绍 MPT-7B:开源、商业可用的大语言模型新标准。访问日期:2023-08-07。
Nous-Research. 2023a. gpt4-x-vicuna-13b. https://hugging face.co/Nous Research/ gpt4-x-vicuna-13b. Model on Hugging Face.
Nous-Research. 2023a. gpt4-x-vicuna-13b. https://huggingface.co/NousResearch/gpt4-x-vicuna-13b. Hugging Face 上的模型。
Nous-Research. 2023b. Nous-hermes-13b. https://hugging face.co/Nous Research/ Nous-Hermes-13b. Model on Hugging Face.
Nous-Research. 2023b. Nous-hermes-13b. https://hugging face.co/Nous Research/ Nous-Hermes-13b. Hugging Face 上的模型。
Nous-Research. 2023c. Nous-hermes-llama-2-7b. https://hugging face.co/Nous Research/ Nous-Hermes-llama-2-7b. Model on Hugging Face.
Nous-Research. 2023c. Nous-hermes-llama-2-7b. https://hugging face.co/Nous Research/ Nous-Hermes-llama-2-7b. Hugging Face 上的模型。
Nous-Research. 2023d. Redmond-puffin-13b. https://hugging face.co/Nous Research/ Redmond-Puffin-13B. Model on Hugging Face.
Nous-Research. 2023d. Redmond-puffin-13b. https://huggingface.co/NousResearch/Redmond-Puffin-13B. Hugging Face 上的模型。
OpenAI. 2023. Gpt-4 technical report.
OpenAI. 2023. GPT-4 技术报告
Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Ab- heesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Stella Biderman, Leo Gao, Tali Bers, Thomas Wolf, and Alexander M. Rush. 2021. Multitask prompted training enables zero-shot task generalization.
Victor Sanh、Albert Webson、Colin Raffel、Stephen H. Bach、Lintang Sutawika、Zaid Alyafeai、Antoine Chaffin、Arnaud Stiegler、Teven Le Scao、Arun Raja、Manan Dey、M Saiful Bari、Canwen Xu、Urmish Thakker、Shanya Sharma Sharma、Eliza Szczechla、Taewoon Kim、Gunjan Chhablani、Nihal Nayak、Debajyoti Datta、Jonathan Chang、Mike Tian-Jian Jiang、Han Wang、Matteo Manica、Sheng Shen、Zheng Xin Yong、Harshit Pandey、Rachel Bawden、Thomas Wang、Trishala Neeraj、Jos Rozen、Abheesht Sharma、Andrea Santilli、Thibault Fevry、Jason Alan Fries、Ryan Teehan、Stella Biderman、Leo Gao、Tali Bers、Thomas Wolf 和 Alexander M. Rush。2021。多任务提示训练实现零样本任务泛化。
Stability-AI. 2023. Stablelm. https://github.com/ Stability-AI/StableLM. GitHub repository.
Stability-AI. 2023. Stablelm. https://github.com/Stability-AI/StableLM. GitHub 仓库。
StanGirard. 2023. quivr. https://github.com/ StanGirard/quivr. GitHub repository.
StanGirard. 2023. quivr. https://github.com/StanGirard/quivr. GitHub 仓库。
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. github.com/tatsu-lab/stanford alpaca.
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, 和 Tatsunori B. Hashimoto. 2023. Stanford Alpaca: 一个遵循指令的 LLaMA 模型. https://github.com/tatsu-lab/stanford_alpaca.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: Open and efficient foundation language models.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: 开放且高效的基础语言模型。
The Verge. 2023. Meta’s powerful ai language model has leaked online — what happens now? The Verge.
The Verge. 2023. Meta 的强大 AI 语言模型已在线泄露——接下来会发生什么?The Verge.
James Vincent. 2023. As an ai generated language model: The phrase that shows how ai is polluting the web. The Verge.
James Vincent. 2023. 作为AI生成的语言模型:揭示AI如何污染网络的短语。The Verge。