SEAL: Semantic Aware Image Watermarking
SEAL:语义感知图像水印
Kasra Arabi, R. Teal Witter, Chinmay Hegde, Niv Cohen New York University
Kasra Arabi, R. Teal Witter, Chinmay Hegde, Niv Cohen 纽约大学
Abstract
摘要
Generative models have rapidly evolved to generate realistic outputs. However, their synthetic outputs increasingly challenge the clear distinction between natural and AI-generated content, necessitating robust watermarking techniques. Watermarks are typically expected to preserve the integrity of the target image, withstand removal attempts, and prevent unauthorized replication onto unrelated images. To address this need, recent methods embed persistent watermarks into images produced by diffusion models using the initial noise. Yet, to do so, they either distort the distribution of generated images or rely on searching through a long dictionary of used keys for detection.
生成式模型已迅速发展,能够生成逼真的输出。然而,它们的合成输出日益挑战自然内容与AI生成内容之间的明确区分,因此需要强大的水印技术。水印通常需要保持目标图像的完整性,抵御移除尝试,并防止未经授权的复制到无关图像上。为了满足这一需求,最近的方法通过使用初始噪声将持久水印嵌入到扩散模型生成的图像中。然而,这些方法要么会扭曲生成图像的分布,要么依赖于在长字典中搜索使用的密钥进行检测。
In this paper, we propose a novel watermarking method that embeds semantic information about the generated image directly into the watermark, enabling a distortion-free watermark that can be verified without requiring a database of key patterns. Instead, the key pattern can be inferred from the semantic embedding of the image using localitysensitive hashing. Furthermore, conditioning the watermark detection on the original image content improves robustness against forgery attacks. To demonstrate that, we consider two largely overlooked attack strategies: (i) an attacker extracting the initial noise and generating a novel image with the same pattern; (ii) an attacker inserting an unrelated (potentially harmful) object into a watermarked image, possibly while preserving the watermark. We empirically validate our method’s increased robustness to these attacks. Taken together, our results suggest that content-aware watermarks can mitigate risks arising from image-generative models. Our code is available at https://github.com/Kasraarabi/SEAL.
在本文中,我们提出了一种新颖的水印方法,该方法将生成图像的语义信息直接嵌入到水印中,从而实现了一种无需密钥模式数据库即可验证的无失真水印。相反,密钥模式可以通过使用局部敏感哈希从图像的语义嵌入中推断出来。此外,将水印检测条件设定为原始图像内容可以提高对伪造攻击的鲁棒性。为了证明这一点,我们考虑了两种被广泛忽视的攻击策略:(i) 攻击者提取初始噪声并生成具有相同模式的新图像;(ii) 攻击者在可能保留水印的情况下,将无关(可能有害)的对象插入到带水印的图像中。我们通过实验验证了我们的方法对这些攻击的增强鲁棒性。总的来说,我们的结果表明,内容感知水印可以减轻图像生成模型带来的风险。我们的代码可在 https://github.com/Kasraarabi/SEAL 获取。
1. Introduction
1. 引言
The growing capabilities of generative models pose risks to society, including misleading public opinion, violating privacy or intellectual property, and fabricating legal evidence [5, 14, 22]. Watermarking methods aim to mitigate such risks by allowing the detection of generated contents.
生成模型日益增长的能力对社会构成了风险,包括误导公众舆论、侵犯隐私或知识产权,以及伪造法律证据 [5, 14, 22]。水印方法旨在通过检测生成内容来减轻此类风险。
Yet, many conventional watermarking techniques lack robustness against adversaries who attempt to remove them using regeneration attacks powered by recent generative models [9, 18, 24]. To address this, new watermarking techniques leveraging advances in generative models offer increased robustness against such attacks [4, 25, 27]. Namely, these methods embed a watermarking pattern in the initial noise used by a diffusion model. These patterns have been shown to be more robust against existing removal attacks.
然而,许多传统的水印技术在面对使用最新生成模型驱动的再生攻击的对手时,缺乏鲁棒性 [9, 18, 24]。为了解决这一问题,利用生成模型进展的新水印技术提供了更强的抗攻击能力 [4, 25, 27]。具体来说,这些方法在扩散模型使用的初始噪声中嵌入水印模式。这些模式已被证明对现有的去除攻击更具鲁棒性。
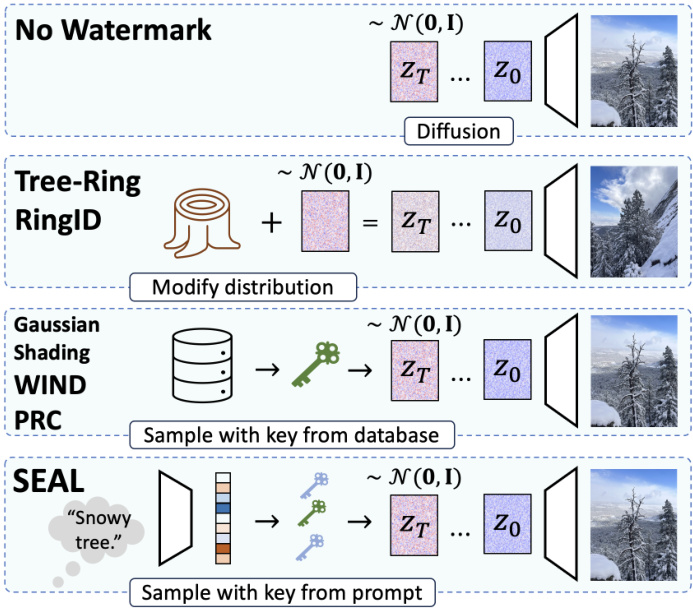
Figure 1. Illustration of different watermarking frameworks using the initial noise of diffusion models. No Watermark: A diffusion model maps pure Gaussian noise to an image. Tree-Ring: A pattern is added to the initial noise, modifying the distribution of generated images in a detectable way. Key-Based Watermarking: A key is sampled to generate distortion-free images linked to the key. Ours (SEAL): The initial noise is conditioned on multiple keys derived from the image’s semantic embedding, with each key influencing a different patch.
图 1: 使用扩散模型初始噪声的不同水印框架示意图。无水印:扩散模型将纯高斯噪声映射到图像。Tree-Ring:在初始噪声中添加模式,以可检测的方式修改生成图像的分布。基于密钥的水印:采样密钥以生成与密钥相关的无失真图像。我们的方法 (SEAL):初始噪声以从图像语义嵌入派生的多个密钥为条件,每个密钥影响不同的图像块。
However, existing watermarks that utilize the diffusion model initial noise tend to be vulnerable to other attacks aiming to “steal” the watermark and apply it to images unrelated to the watermark owners. Some of these watermark forgery attacks can be evaded by using a distortion-free watermark - generating watermarked images from a similar distribution to the distribution of non-watermarked images; therefore exposing less information about the watermark identity. Even so, using an extensively large number of watermark identities requires maintaining a database of used noises, and might still be forgeable by other attacks.
然而,现有的利用扩散模型初始噪声的水印往往容易受到其他攻击,这些攻击旨在“窃取”水印并将其应用于与水印所有者无关的图像。其中一些水印伪造攻击可以通过使用无失真水印来避免——从与非水印图像相似的分布中生成水印图像;因此暴露的水印身份信息较少。即便如此,使用大量水印身份需要维护一个已使用噪声的数据库,并且可能仍然会被其他攻击伪造。
To address these challenges, we introduce SEAL - Semantic Embedding for AI Lineage, a method that embeds watermark patterns directly tied to image semantics. Our approach enables direct watermark detection from image samples and offers the following key properties: (i) Distortionfree: As in previous works, we utilize pseudo-random hash functions to generate an initial noise that is similar to the noise used by non-watermarked models, ensuring a similar distribution of generated images. (ii) Robust to regeneration attacks: Similar to prior watermarking methods based on DDIM inversion, our approach demonstrates resilience against regeneration-based removal attempts [28]. (iii) Correlated with image semantics: The applied watermark encodes semantic information from the image. (iv) Independent of a historical database: Unlike previous methods that rely on a database of past generations, our approach embeds watermarks without requiring access to such a database, making detection possible without prior stored data.
为了解决这些挑战,我们引入了 SEAL - 语义嵌入的 AI 溯源方法,该方法将水印模式直接嵌入到图像语义中。我们的方法能够直接从图像样本中检测水印,并提供以下关键特性:(i) 无失真:与之前的工作一样,我们利用伪随机哈希函数生成初始噪声,该噪声与非水印模型使用的噪声相似,确保生成的图像具有相似的分布。(ii) 对再生攻击具有鲁棒性:与之前基于 DDIM 反演的水印方法类似,我们的方法展示了对抗基于再生的移除尝试的韧性 [28]。(iii) 与图像语义相关:应用的水印编码了图像的语义信息。(iv) 独立于历史数据库:与之前依赖过去生成数据库的方法不同,我们的方法在嵌入水印时不需要访问此类数据库,使得在没有预先存储数据的情况下也能进行检测。
Our key insight is that we can encode semantic information about the image content in a distortion-free watermark by embedding the semantic encoding directly into the initial noise. We use projections of the user prompt embedding to seed different pseudo-random patches that compose the initial noise. We ensure the encoded embedding correlates strongly with the resulting image content, not just with the prompt, which is important since the prompt is not available during detection. At detection time, our approach identifies an image as watermarked only when the watermark pattern is both present and properly correlated with the image semantics. We describe in detail our watermarking technique in Section 3.
我们的关键洞察是,通过将语义编码直接嵌入到初始噪声中,可以在无失真的水印中编码图像内容的语义信息。我们使用用户提示嵌入的投影来生成构成初始噪声的不同伪随机补丁。我们确保编码的嵌入与生成的图像内容强相关,而不仅仅与提示相关,这一点很重要,因为在检测时提示不可用。在检测时,我们的方法仅在存在水印模式且与图像语义正确相关时,才将图像识别为带有水印。我们将在第3节详细描述我们的水印技术。
Correlating our watermarking algorithm to the image semantics also allows us to resist forgery attacks that are challenging for many existing approaches. An attacker attempting to forge such a watermark onto unauthorized content would alter the image’s semantic embedding, breaking its correlation with the embedded pattern and rendering the watermark invalid.
将我们的水印算法与图像语义相关联,还能帮助我们抵御许多现有方法难以应对的伪造攻击。攻击者试图在未经授权的内容上伪造此类水印时,会改变图像的语义嵌入,破坏其与嵌入模式的相关性,从而使水印失效。
One mostly overlooked attack involves an adversary altering only small portions of a watermarked image while preserving the rest of its content. In such cases, the attacker can manipulate the image to be offensive, illegal, or damaging to the watermark owner’s reputation, all while the original watermark remains detectable. We term this attack the CAT ATTACK, as the attacker may add an object to the image (e.g., a cat) and expect the watermark to persist. We evaluate the potential damage of such attacks and demonstrate that our method uniquely provides robustness against both the CAT ATTACK and forgery attempts by adversaries who obtain accurate copies of our initial noise. Our experiments confirm our method’s effectiveness against these novel threats as well as previously studied attack vectors.
一种大多被忽视的攻击方式涉及对手仅改变水印图像的一小部分,同时保留其余内容。在这种情况下,攻击者可以操纵图像使其具有冒犯性、非法性或损害水印所有者的声誉,而原始水印仍然可被检测到。我们将这种攻击称为 CAT ATTACK,因为攻击者可能会在图像中添加一个对象(例如,一只猫),并期望水印仍然存在。我们评估了此类攻击的潜在损害,并证明我们的方法独特地提供了对 CAT ATTACK 和对手获取我们初始噪声的准确副本的伪造尝试的鲁棒性。我们的实验证实了我们的方法对这些新威胁以及先前研究的攻击向量的有效性。
Our contributions are as follows:
我们的贡献如下:
2. Related works
2. 相关工作
Recent research on image watermarking can be broadly categorized into post-processing and in-processing approaches, each offering distinct trade-offs between quality, robustness, and deployment practicality [2]. We cover here InProcessing Methods, and for Post-Processing Methods refer to Appendix 8.
最近的图像水印研究大致可以分为后处理 (post-processing) 和处理中 (in-processing) 方法,每种方法在质量、鲁棒性和部署实用性之间提供了不同的权衡 [2]。我们在这里介绍处理中方法,后处理方法请参见附录 8。
In-Processing Methods. In-processing approaches integrate watermark embedding directly within the image generation process. These methods are often used in diffusion models to achieve minimal perceptual impact. Some methods modify the generative model entirely by fine-tuning specific components, as demonstrated in Stable Signature [10]. An alternative class of techniques manipulates the initial noise of the generation process, thereby embedding the watermark without extensive model retraining. For example, Tree-Ring [25] embeds a Fourier-domain pattern into the initial noise, which can be detected through DDIM inversion [23], while RingID [7] extends this idea to support multiple keys. Other notable methods include Gaussian Shading, which produces a unique key for each watermark owner [27], PRC that leverages pseudo-random error-correcting codes for computational un detect ability [12], and WIND, which employs a two-stage detection process to enables a very large number of keys [4].
处理中方法。处理中方法将水印嵌入直接集成到图像生成过程中。这些方法通常用于扩散模型,以实现最小的感知影响。一些方法通过微调特定组件完全修改生成模型,如 Stable Signature [10] 所示。另一类技术则操纵生成过程的初始噪声,从而在不进行大量模型重新训练的情况下嵌入水印。例如,Tree-Ring [25] 将傅里叶域模式嵌入到初始噪声中,可以通过 DDIM 反演 [23] 检测到,而 RingID [7] 则扩展了这一思路以支持多个密钥。其他值得注意的方法包括 Gaussian Shading,它为每个水印所有者生成唯一的密钥 [27],PRC 利用伪随机纠错码实现计算不可检测性 [12],以及 WIND,它采用两阶段检测过程以支持大量密钥 [4]。
Locally Sensitive Hashing in High-Dimensional Spaces.
高维空间中的局部敏感哈希 (Locally Sensitive Hashing)
Recent advances in approximate nearest neighbor (ANN) search have increasingly relied on the power of Locally Sensitive Hashing (LSH) to address the challenges inherent in high-dimensional data. Originally introduced by Indyk and Motwani [13] and further refined by Gionis et al. [11], LSH employs randomized hash functions that ensure similar data points are mapped to the same bucket with high probability. Formally, for a hash family $\mathcal{H}$ , the collision probability is
最近在近似最近邻 (ANN) 搜索方面的进展越来越依赖于局部敏感哈希 (Locally Sensitive Hashing, LSH) 的能力,以应对高维数据中固有的挑战。LSH 最初由 Indyk 和 Motwani [13] 提出,并由 Gionis 等人 [11] 进一步改进,它采用随机哈希函数,确保相似的数据点以高概率映射到同一个桶中。形式上,对于哈希族 $\mathcal{H}$,碰撞概率为
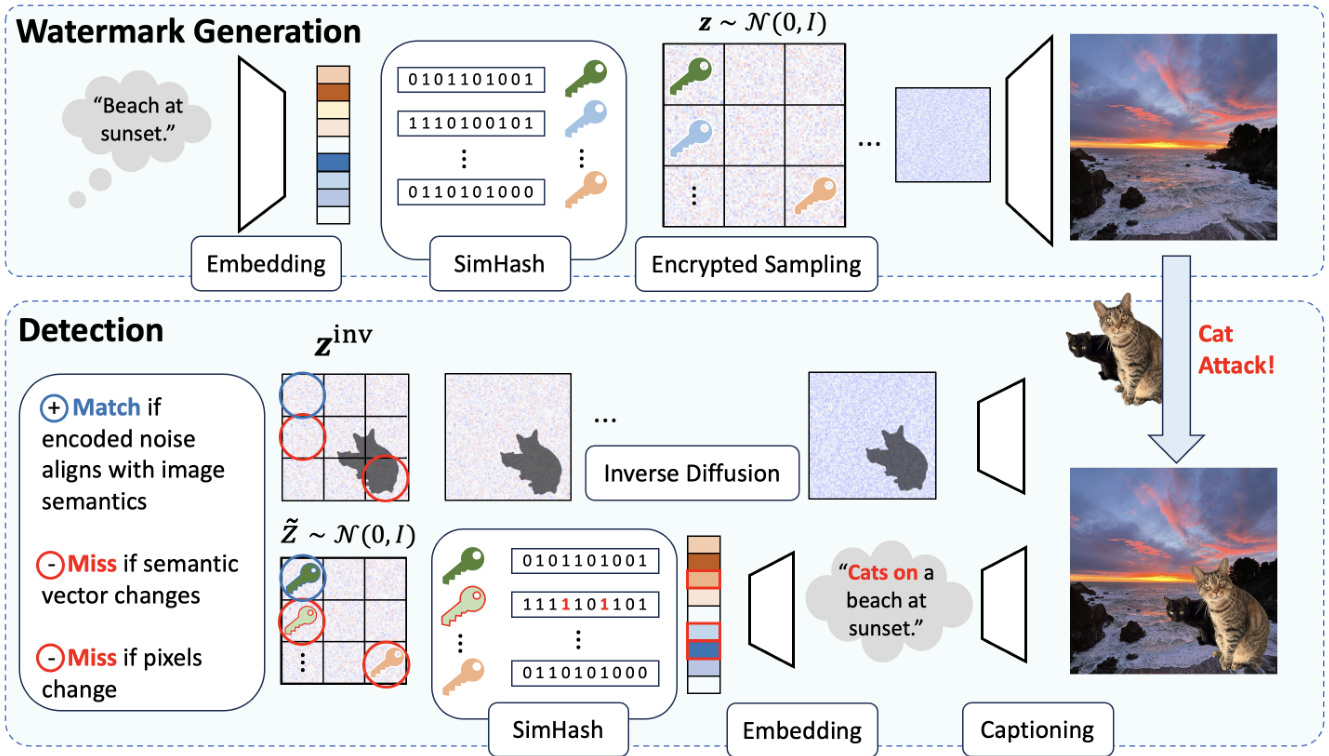
Figure 2. Illustration of the SEAL watermarking framework for diffusion models using semantic-aware noise patterns. Watermark Generation: A textual prompt (e.g., “Beach at sunset.”) is first embedded into a semantic space. The embedding is then processed using SimHash to generate discrete keys, which are used in Encrypted Sampling to choose the initial noise $\mathbf{z}\sim\mathcal{N}(0,I)$ . The watermarked noise then undergoes standard diffusion to generate the final image. Detection: The image is captioned to obtain an embedding, which is then processed by SimHash to generate a reference noise, similar to watermark generation. This noise remains correlated with the initial noise used during generation as long as the image semantics remain unchanged. The image is also processed through Inverse Diffusion to estimate the actual initial noise used during its generation. If there are insufficient matches between the reference noise and the noise obtained from inversion, the watermarking framework flags the image as non-watermarked. If a key match is found but the image is still deemed suspicious, a detailed inspection of the patches can be performed to identify local edits.
图 2: 使用语义感知噪声模式的扩散模型 SEAL 水印框架示意图。水印生成:首先将文本提示(例如,“日落时的海滩”)嵌入到语义空间中。然后使用 SimHash 处理嵌入以生成离散密钥,这些密钥在加密采样中用于选择初始噪声 $\mathbf{z}\sim\mathcal{N}(0,I)$。带水印的噪声随后经过标准扩散生成最终图像。检测:对图像进行描述以获得嵌入,然后通过 SimHash 处理生成参考噪声,类似于水印生成。只要图像语义保持不变,该噪声仍与生成过程中使用的初始噪声相关。图像还通过逆扩散处理以估计生成过程中使用的实际初始噪声。如果参考噪声与逆扩散获得的噪声之间匹配不足,水印框架会将图像标记为未加水印。如果找到密钥匹配但图像仍被视为可疑,则可以对图像块进行详细检查以识别局部编辑。
given by
给定

Subsequent improvements by Datar et al. [8] and Andoni and Indyk [3] have enhanced both the efficiency and robustness of LSH methods, making them key for large-scale, highdimensional search tasks.
Datar 等人 [8] 以及 Andoni 和 Indyk [3] 的后续改进提升了 LSH 方法的效率和鲁棒性,使其成为大规模高维搜索任务的关键。
3. SEAL: Semantic Aware Watermarking
3. SEAL: 语义感知水印
3.1. Motivation
3.1. 动机
Watermarking methods suffer from an inherent trade-off: a watermark that is harder to remove is also easier to attach to unrelated generations, compromising the reputation of the watermark owner [5]. One suggested solution to overcome this trade-off, might be maintaining a database of past generations, such that the owner could compare a seemingly watermarked image to the actual past generations. Yet, this solution is not without its problems. First, maintaining and searching a rapidly growing database, which expands with each new generation, can be challenging. Second, safeguarding the database itself may pose security risks. Finally, in various use cases, the watermark owner may not only wish to detect if an image is watermarked but also provide to a third party evidence that it is. We therefore turn to suggest a watermarking scheme that is hard to remove, hard to forge, and does not rely on maintaining a database of past generations.
水印方法面临一个固有的权衡:更难去除的水印也更容易附加到不相关的生成内容上,从而损害水印所有者的声誉 [5]。为了克服这一权衡,一种建议的解决方案可能是维护一个过去生成内容的数据库,使得所有者可以将看似带有水印的图像与实际过去的生成内容进行比较。然而,这一解决方案并非没有问题。首先,维护和搜索一个随着每次新生成而迅速增长的数据库可能具有挑战性。其次,保护数据库本身可能会带来安全风险。最后,在各种使用场景中,水印所有者可能不仅希望检测图像是否带有水印,还希望向第三方提供证据证明其带有水印。因此,我们转而建议一种难以去除、难以伪造且不依赖于维护过去生成内容数据库的水印方案。
Our core idea is to use a distortion-free initial noise pattern not only to indicate the origin of the image but also to encode which semantic information the image may contain. We do so in three stages (see also Figure 2): (i) Semantic Embedding – we predict a vector representing the expected semantic content in each generated image (ii) SimHash Encoding – we encode the semantic vector using a set of multibit hash functions (iii) Encrypted Sampling – The pseudorandom outputs of these functions are combined to produce the initial noise for the denoising process. Taken together, these steps set an initial noise that is both distortion-free with respect to standard random initialization and correlated with the semantics of the input prompt (see Section 3.3). We describe our watermarking method in detail below.
我们的核心思想是使用无失真的初始噪声模式,不仅用于指示图像的来源,还用于编码图像可能包含的语义信息。我们通过三个阶段实现这一目标(参见图 2):(i) 语义嵌入——我们预测一个向量,表示每个生成图像中预期的语义内容;(ii) SimHash 编码——我们使用一组多比特哈希函数对语义向量进行编码;(iii) 加密采样——这些函数的伪随机输出被组合起来,生成去噪过程的初始噪声。综合来看,这些步骤设置的初始噪声既相对于标准随机初始化是无失真的,又与输入提示的语义相关联(参见第 3.3 节)。我们将在下面详细描述我们的水印方法。

Figure 3. Effect of the Cat Attack on SEAL. (Left) A cat image is pasted onto a watermarked image at a random position and scale. (Right) Our method detects this modification by identifying elevated $\ell_{2}$ norms in affected patches.
图 3: 猫攻击对 SEAL 的影响。(左) 一张猫的图像被随机位置和缩放粘贴到带有水印的图像上。(右) 我们的方法通过识别受影响区域中升高的 $\ell_{2}$ 范数来检测这种修改。
3.2. Method
3.2. 方法
Formally, our method first creates a semantic vector $\mathbf{v}$ and uses it to sample the initial noise $\mathbf{z}$ for the watermarked image. During detection, we aim to verify the connection between the used initial noise $\mathbf{z}$ and the semantic embedding of the image. When approximating $\mathbf{z}$ from the generated image during detection and verifying it, we consider the following error sources:
形式上,我们的方法首先创建一个语义向量 $\mathbf{v}$,并使用它来为水印图像采样初始噪声 $\mathbf{z}$。在检测过程中,我们的目标是验证所使用的初始噪声 $\mathbf{z}$ 与图像的语义嵌入之间的联系。在检测过程中从生成的图像中近似 $\mathbf{z}$ 并验证它时,我们考虑以下误差来源:
We would ideally like for $\mathbf{z}^{\mathrm{inv}}$ to align with $\tilde{\mathbf{z}}$ but this is not guaranteed because both differ from $\mathbf{z}$ due to the error sources mentioned above. Instead, we separate each noise vector into patches and compare them. Our method provides a high likelihood that even if some patches do not match because of the challenges discussed above, many of the patches will match as long as the suspect image is watermarked.
我们理想情况下希望 $\mathbf{z}^{\mathrm{inv}}$ 与 $\tilde{\mathbf{z}}$ 对齐,但这并不能保证,因为两者都由于上述错误源而与 $\mathbf{z}$ 不同。相反,我们将每个噪声向量分成小块并进行比较。我们的方法提供了很高的可能性,即使由于上述挑战导致某些小块不匹配,只要嫌疑图像被水印,许多小块仍将匹配。
Semantic Patterns with SimHash
使用 SimHash 的语义模式
The core subroutine of our watermarking method is SimHash [6], used to generate initial noise maps correlated to a given vector (Algorithm 1). SimHash takes a vector $\mathbf{v}$ and generates an initial noise $\mathbf{z}{i}$ for patch $i$ , allowing a verifier to later determine, with some probability, whether $\mathbf{z}{i}$ is related to $\mathbf{v}$ Namely, the semantic vector $\mathbf{v}$ is passed through a localitysensitive hashing method that generates representations of $\mathbf{v}$ in terms of its projections in random directions.
我们水印方法的核心子程序是 SimHash [6],用于生成与给定向量相关的初始噪声图(算法 1)。SimHash 接受一个向量 $\mathbf{v}$,并为补丁 $i$ 生成初始噪声 $\mathbf{z}{i}$,使得验证者能够以一定概率确定 $\mathbf{z}{i}$ 是否与 $\mathbf{v}$ 相关。具体来说,语义向量 $\mathbf{v}$ 通过一种局部敏感哈希方法,生成其在随机方向上的投影表示。
Specifically, SimHash projects $\mathbf{v}$ onto a set of random vectors. The input to the hash function is determined by the
具体来说,SimHash 将 $\mathbf{v}$ 投影到一组随机向量上。哈希函数的输入由以下决定:
Algorithm 1 SimHash
算法 1 SimHash
1: Input: v: semantic vector, $i$ : patch index, salt: secret salt, $b$ : number of bits, hash: cryptographic hash function 2: Output: Semantic, secure, normally distributed noise 3: bit $\mathbf{\Lambda}\subset\mathbf{0}$ // Initialize hash input 4: for $j=1,\ldots,b$ do 5: // Re prod uci bly sample random vector 6: $s\gets\mathtt{h a s h}(i,j,s\mathtt{a l t})$ 7: Sample $\mathbf{r}{j}^{(i)}\overset{s}{\sim}\mathcal{N}(\mathbf{0},\mathbf{I})$ 8: b $\mathbf{\nabla}{\mathbf{\eta}}\mathbf{\cdot}\mathbf{c}\mathbf{s}[j]\gets\mathrm{sign}(\langle\mathbf{v},\mathbf{r}{j}^{(i)}\rangle)$ // Random projection 9: end for 10: $s{i}\gets\mathtt{h a s h}(\mathtt{b i t s},i,\mathtt{s a l t})$ 11: return $\mathbf{z}{i}\overset{s{i}}{\sim}N(\mathbf{0},\mathbf{I})$
1: 输入: v: 语义向量, $i$: 补丁索引, salt: 秘密盐值, $b$: 位数, hash: 加密哈希函数
2: 输出: 语义安全、正态分布的噪声
3: bit $\mathbf{\Lambda}\subset\mathbf{0}$ // 初始化哈希输入
4: for $j=1,\ldots,b$ do
5: // 可重复采样随机向量
6: $s\gets\mathtt{h a s h}(i,j,s\mathtt{a l t})$
7: 采样 $\mathbf{r}{j}^{(i)}\overset{s}{\sim}\mathcal{N}(\mathbf{0},\mathbf{I})$
8: b $\mathbf{\nabla}{\mathbf{\eta}}\mathbf{\cdot}\mathbf{c}\mathbf{s}[j]\gets\mathrm{sign}(\langle\mathbf{v},\mathbf{r}{j}^{(i)}\rangle)$ // 随机投影
9: end for
10: $s{i}\gets\mathtt{h a s h}(\mathtt{b i t s},i,\mathtt{s a l t})$
11: return $\mathbf{z}{i}\overset{s{i}}{\sim}N(\mathbf{0},\mathbf{I})$
sign of the projection, ensuring that similar vectors yield similar hash values. For $i\in{1,\ldots,k}$ , the seed and the noise for patch $i$ are:
投影的符号确保相似的向量产生相似的哈希值。对于 $i\in{1,\ldots,k}$,补丁 $i$ 的种子和噪声为:
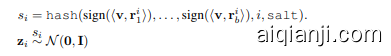
Having repetitive patches in the initial noise may distort image generation. Therefore, we include the patch index in the hash function input to ensure that $s_{i}\neq s_{j}$ even when the input bits are identical (see Figure 8 for a visualization of what happens to the noise without the patch-dependent input). For cryptographic security, we also hash a secret salt.
初始噪声中的重复补丁可能会扭曲图像生成。因此,我们在哈希函数输入中包含补丁索引,以确保即使输入位相同,$s_{i}\neq s_{j}$(参见图 8,了解在没有补丁相关输入的情况下噪声的变化情况)。为了加密安全,我们还对秘密盐值进行哈希处理。
Watermark Generation
水印生成
Algorithm 2 Watermark Generation
算法 2 水印生成
The first step of the generation process is to find a semantic vector describing the image that will be generated. Ideally, the semantic vector depends only on the prompt and correlates exclusively with images generated from it. Yet, in practice, predicting the image semantics based on the prompt is difficult.
生成过程的第一步是找到描述将要生成图像的语义向量。理想情况下,语义向量仅依赖于提示词,并且仅与由其生成的图像相关。然而,在实践中,基于提示词预测图像语义是困难的。
Our solution begins by generating a proxy image ${\bf x}^{\mathrm{pre}}$ . Then, we use a captioning model to achieve a text description of the generated image. The caption is embedded into a latent semantic space, resulting in a semantic vector v, which captures the high-level semantics of the generated image by the prompt. Next, we generate the watermarked noise $\mathbf{z}$ in patches using the semantic vector $\mathbf{v}$ and SimHash. Finally, we apply diffusion to the watermarked initial noise.
我们的解决方案首先通过生成一个代理图像 ${\bf x}^{\mathrm{pre}}$。然后,我们使用一个描述模型来获取生成图像的文本描述。该描述被嵌入到一个潜在语义空间中,生成一个语义向量 v,它捕捉了提示生成图像的高级语义。接下来,我们使用语义向量 $\mathbf{v}$ 和 SimHash 以分块的方式生成带水印的噪声 $\mathbf{z}$。最后,我们对带水印的初始噪声进行扩散处理。
Embedding Optimization. During detection, the generated image will be captioned to obtain a semantic vector $\tilde{\bf{v}}$ . To make sure that v correlates to $\tilde{\bf{v}}$ and not to unrelated vectors, we fine-tune the embedding model to improve the similarity between the embedding of different images generated from the same prompt.
嵌入优化。在检测过程中,生成的图像将被标注以获得语义向量 $\tilde{\bf{v}}$。为了确保 v 与 $\tilde{\bf{v}}$ 相关,而不是与不相关的向量相关,我们对嵌入模型进行微调,以提高从同一提示生成的不同图像的嵌入之间的相似性。
Algorithm 3 Watermark Detection
算法 3 水印检测
1: Input: x: suspect image, $\tau$ : patch distance threshold, $n$ : number of patches, $m^{\mathrm{match}}$ : match threshold, $b$ number of bits, salt: secret salt 2: Output: Watermark detection (True/False) 3: $\Tilde{\mathbf{v}}\gets$ Embed(Caption $\left(\tilde{\mathbf{x}}\right)$ )4: $\mathbf{z}^{\mathrm{inv}}\gets$ Inverse Diffusion $(\tilde{\mathbf{x}})$ 5: $m\gets0$ 6: for $i=1,\ldots,n$ do 7: $\widetilde{\mathbf z}{i}\gets\mathrm{SimHash}(\widetilde{\mathbf v},i,\mathrm{salt})$ 8: if $|\tilde{\mathbf{z}}{i}-\mathbf{z}{i}^{\mathrm{inv}}|{2}<\tau$ then 9: $m++$ 10: end if 11: end for 12: return m ≥ mmatch
1: 输入: x: 可疑图像, $\tau$: 块距离阈值, $n$: 块数量, $m^{\mathrm{match}}$: 匹配阈值, $b$: 位数, salt: 秘密盐值
2: 输出: 水印检测 (True/False)
3: $\Tilde{\mathbf{v}}\gets$ 嵌入(描述 $\left(\tilde{\mathbf{x}}\right)$ )
4: $\mathbf{z}^{\mathrm{inv}}\gets$ 逆扩散 $(\tilde{\mathbf{x}})$
5: $m\gets0$
6: for $i=1,\ldots,n$ do
7: $\widetilde{\mathbf z}{i}\gets\mathrm{SimHash}(\widetilde{\mathbf v},i,\mathrm{salt})$
8: if $|\tilde{\mathbf{z}}{i}-\mathbf{z}{i}^{\mathrm{inv}}|{2}<\tau$ then
9: $m++$
10: end if
11: end for
12: return m ≥ mmatch
Watermark Detection
水印检测
For detection, we generate noise based on the semantic content of the image and check how well it corresponds to the reconstructed noise obtained through DDIM inversion (Algorithm 3). We begin by embedding the image to get a semantic vector $\tilde{\bf{v}}$ that captures the content of the image. SimHash is then applied to this vector as in the watermark generation process, generating an estimated initial noise $\tilde{\mathbf{z}}$ . Finally, we use inverse diffusion (e.g., DDIM [23]) to approximately reconstruct the initial noise $\mathbf{z}^{\mathrm{inv}}$ from the image.
对于检测,我们基于图像的语义内容生成噪声,并检查其与通过DDIM反演(算法3)获得的重构噪声的对应程度。我们首先嵌入图像以获得捕捉图像内容的语义向量 $\tilde{\bf{v}}$ 。然后像水印生成过程一样,对该向量应用SimHash,生成估计的初始噪声 $\tilde{\mathbf{z}}$ 。最后,我们使用逆扩散(例如,DDIM [23])从图像中近似重构初始噪声 $\mathbf{z}^{\mathrm{inv}}$ 。
Since $\mathbf{v}$ and $\tilde{\bf{v}}$ may differ, $\mathbf{z}$ and $\tilde{\mathbf{z}}$ are not necessarily the same. However, by the similarity property of SimHash, $\mathbf{z}$ and $\tilde{\mathbf{z}}$ will be identical on some patches as long as $\mathbf{v}$ and $\tilde{\bf{v}}$ are close. On the patches $i$ where $\widetilde{\mathbf{z}}{i}=\mathbf{z}{i}$ ,
由于 $\mathbf{v}$ 和 $\tilde{\bf{v}}$ 可能不同,$\mathbf{z}$ 和 $\tilde{\mathbf{z}}$ 不一定相同。然而,根据 SimHash 的相似性特性,只要 $\mathbf{v}$ 和 $\tilde{\bf{v}}$ 接近,$\mathbf{z}$ 和 $\tilde{\mathbf{z}}$ 在某些局部区域上将是相同的。在 $\widetilde{\mathbf{z}}{i}=\mathbf{z}{i}$ 的局部区域 $i$ 上,
$$
|\widetilde{\mathbf z}{i}-\mathbf z{i}^{\mathrm{inv}}|{2}=|{\mathbf z}{i}-{\mathbf z}{i}^{\mathrm{inv}}|{2}.
$$
$$
|\widetilde{\mathbf z}{i}-\mathbf z{i}^{\mathrm{inv}}|{2}=|{\mathbf z}{i}-{\mathbf z}{i}^{\mathrm{inv}}|{2}.
$$
For such $i$ , the only error stems from the diffusion and inverse diffusion processes. Empirically, we find that there is a threshold $\tau$ so that two patches have $\ell_{2}$ -norm difference at most $\tau$ it is likely that they were generated from the same random seed.
对于这样的 $i$,唯一的误差来源于扩散和逆扩散过程。经验上,我们发现存在一个阈值 $\tau$,使得两个补丁的 $\ell_{2}$ 范数差异最多为 $\tau$,它们很可能是由相同的随机种子生成的。
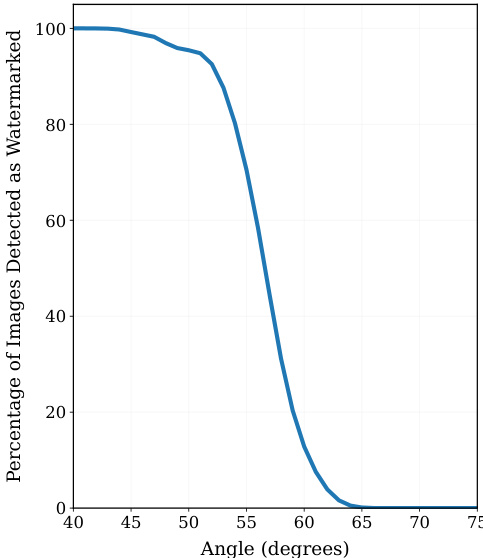
Figure 4. Watermark Detection vs. Semantic Similarity. We plot the empirical probability of declaring an image as watermarked as a function of the angle between the semantic embedding used for watermark generation $(n=1024$ and $b=7.$ ) and that of the inspected image. Our use of locally-sensitive hashing allows us to constrain the semantic embedding of the image we deem watermarked according to the initial noise used.
图 4: 水印检测与语义相似性。我们绘制了将图像声明为带水印的经验概率,作为用于生成水印的语义嵌入与检查图像的语义嵌入之间角度的函数 $(n=1024$ 和 $b=7.$)。我们使用局部敏感哈希的方法,能够根据初始噪声限制我们认为带水印的图像的语义嵌入。
Semantic Similarity Detection. In order to detect whether an image was initially generated with our watermark, we count the number of patches that match (i.e., their $\ell_{2}$ -norm distance is at most $\tau$ ). If the number of matches is above a set threshold $n^{\mathrm{match}}$ then we declare the image is watermarked. In Section 3.3, we analyze the probability of correctly identifying a watermarked image.
语义相似性检测。为了检测图像最初是否使用我们的水印生成,我们计算匹配的补丁数量(即它们的 $\ell_{2}$ 范数距离最多为 $\tau$)。如果匹配数量超过设定的阈值 $n^{\mathrm{match}}$,则我们声明该图像带有水印。在第 3.3 节中,我们分析了正确识别带水印图像的概率。
Tampering Detection. In addition to the association between the watermark and the semantic embedding, edits such as object addition, removal, or modification are likely to alter the estimated initial noise in the affected image regions. This enables our watermark to provide localized information about edits that might have been made to the image. Consequently, even if the semantic embedding $\tilde{\bf{v}}$ aligns well with the initial embedding $\mathbf{v}$ after edits, such tampering can still be detected by identifying localized patches in the reconstructed initial noise that neither match the expected noise nor any other valid input to the hash function. Inspecting the patches one by one, the model owner may recover the $b$ input bits for each patch with an exhaustive search over the $2^{b}$ options per patch, and recover a matching initial noise.
篡改检测。除了水印与语义嵌入之间的关联外,对象添加、移除或修改等编辑操作可能会改变受影响图像区域的估计初始噪声。这使得我们的水印能够提供有关图像可能被编辑的局部信息。因此,即使编辑后的语义嵌入 $\tilde{\bf{v}}$ 与初始嵌入 $\mathbf{v}$ 对齐良好,通过识别重建的初始噪声中既不匹配预期噪声也不匹配哈希函数任何其他有效输入的局部区域,仍然可以检测到此类篡改。通过逐一检查这些区域,模型所有者可以通过对每个区域的 $2^{b}$ 种选项进行穷举搜索,恢复每个区域的 $b$ 输入比特,并恢复匹配的初始噪声。
Comparing this reconstructed noise to the inverted noise $\mathbf{z}^{\mathrm{inv}}$ allows us to detect which patches may have been modified. The total time for this search scales as $n\cdot2^{b}$ (which is much faster than naively searching over all $2^{(b\cdot n)}$ possible initial noise). After obtaining a per patch map (see Figure 3b), we may apply a spatial test as the one described
将此重建噪声与反转噪声 $\mathbf{z}^{\mathrm{inv}}$ 进行比较,可以检测出哪些图像块可能被修改。此搜索的总时间与 $n\cdot2^{b}$ 成正比(这比在所有 $2^{(b\cdot n)}$ 种可能的初始噪声中进行朴素搜索要快得多)。在获得每个图像块的映射后(见图 3b),我们可以应用空间测试,如所述
in Section 10.
在第10节中。
In any case, the local patch inspection is only required when an image is deemed watermarked by semantic similarity detection; but the watermark owner would like to have a finer understanding of the edits that might have been applied to it. This inspection is especially useful against the CAT ATTACK, described in Section 4.
在任何情况下,只有当图像被语义相似性检测判定为带有水印时,才需要进行局部补丁检查;但水印所有者可能希望更细致地了解可能对其进行的编辑。这种检查对于应对第4节中描述的CAT ATTACK尤其有用。
3.3. Analysis
3.3. 分析
Before formally analyzing our watermarking scheme, we state a simplifying assumption on the distance between the initial and reconstructed noise patches. We assume the noise patches are close if and only if the suspect image was produced from the same noise as the one given by our watermarking scheme. The impact of low-likelihood events, where unrelated patches end up close after noise reconstruction, remains part of our empirical analysis in Section 5.
在正式分析我们的水印方案之前,我们对初始噪声块与重建噪声块之间的距离做一个简化假设。我们假设噪声块接近当且仅当可疑图像是由与水印方案提供的相同噪声生成的。低概率事件(即不相关的噪声块在噪声重建后最终接近)的影响仍然是我们第5节实证分析的一部分。
Assumption 3.1 (Patch Distance Separation). There is a threshold $\tau^{\mathrm{dist}}$ so that, for all generation noises z, inverted noises $\mathbf{z}^{\mathrm{inv}}$ , and patches $i\in[k]$ ,
假设 3.1 (Patch Distance Separation)。存在一个阈值 $\tau^{\mathrm{dist}}$,使得对于所有生成噪声 z、反演噪声 $\mathbf{z}^{\mathrm{inv}}$ 和 patch $i\in[k]$,
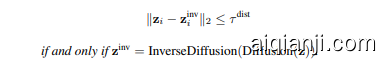
if and only $i f z^{\mathrm{inv}}=\dot{}$ Inverse Diffusion(Diffusion(z)).
当且仅当 $z^{\mathrm{inv}}=\dot{}$ 逆扩散 (Diffusion(z))。
An immediate consequence of the patch distance separation assumption is that we never declare an image as watermarked if its initial noise was not generated using our watermarking scheme. In practice, such unrelated images can match with a few patches; however, it is highly unlikely for them to match with the $n^{\mathrm{match}}$ needed for our method to declare a detection.
补丁距离分离假设的一个直接后果是,如果图像的初始噪声不是使用我们的水印方案生成的,我们永远不会将其声明为带有水印。在实践中,这些无关的图像可能会与少数补丁匹配;然而,它们与我们方法所需的 $n^{\mathrm{match}}$ 匹配的可能性极低。
Unrelated prompts. A key property of our watermarking approach is its resistance to forgeries generated from unrelated prompts. Prior watermarking methods declare an image as watermarked as long as the pattern is embedded in the initial noise and the diffusion and inverse diffusion processes remain reasonably accurate. However, this creates vulnerabilities - an adversary could take an existing watermark and apply it to an unrelated, potentially offensive, or misleading prompt.
无关提示。我们水印方法的一个关键特性是它对来自无关提示生成的伪造内容的抵抗力。先前的水印方法只要初始噪声中嵌入了模式,并且扩散和逆扩散过程保持合理准确,就会声明图像为水印图像。然而,这带来了漏洞——攻击者可以获取现有的水印,并将其应用于无关的、可能具有冒犯性或误导性的提示。
In contrast, our approach strengthens watermark integrity by requiring that the new prompt remains semantically close to the original. This ensures that watermarks are not erroneously detected in entirely unrelated images.
相比之下,我们的方法通过要求新提示在语义上接近原始提示来增强水印的完整性。这确保了在完全不相关的图像中不会错误地检测到水印。
Lemma 3.2 (Detection Probability). Consider a suspect image× produced from our watermarking scheme with initial semantic vector v. Let $\tilde{\bf{v}}$ be the (possibly quite different) semantic embedding of $\tilde{\mathbf{x}},$ , and $\theta\in[-90^{\circ},90^{\circ}]$ be the angle between v and $\tilde{\bf{v}}$ . Set $\theta^{m i d}$ as the threshold between related and unrelated semantic vectors. The probability that we identify the image as watermarked is
引理 3.2 (检测概率)。考虑由我们的水印方案生成的嫌疑图像×,其初始语义向量为 v。设 $\tilde{\bf{v}}$ 为 $\tilde{\mathbf{x}}$ 的(可能非常不同的)语义嵌入,$\theta\in[-90^{\circ},90^{\circ}]$ 为 v 和 $\tilde{\bf{v}}$ 之间的角度。设 $\theta^{m i d}$ 为相关和不相关语义向量之间的阈值。我们将图像识别为带水印的概率为
Table 1. Watermark Detection Probabilities. Example detection probabilities for suspect images generated by our watermarking scheme with an angle threshold of $\theta^{m i d}=70^{\circ}$ , $n=1024$ patches, and $b=4$ bits. For images with angles deviating by more than $5^{\circ}$ from the threshold, our method distinguishes between related and unrelated watermarked images.
表 1: 水印检测概率。我们使用角度阈值为 $\theta^{m i d}=70^{\circ}$、$n=1024$ 个补丁和 $b=4$ 位的水印方案生成的嫌疑图像的检测概率示例。对于角度偏离阈值超过 $5^{\circ}$ 的图像,我们的方法能够区分相关和不相关的水印图像。
| 语义角度: 0(v,) | 检测概率 |
|---|---|
| 80 | 3.06 × 10-6 |
| 75 | 0.0111 |
| 70 | 0.507 |
| 65 | 0.992 |
| 60 | 1.0 |

where $\begin{array}{r}{\rho(\theta)=\left(1-\frac{\theta}{180^{\circ}}\right)^{b}}\end{array}$
其中 $\begin{array}{r}{\rho(\theta)=\left(1-\frac{\theta}{180^{\circ}}\right)^{b}}\end{array}$
We illustrate in the example below the sharp detection thresholds Lemma 3.2 implies; specifically how watermark detection probability varies with semantic similarity between the original and a potentially modified image. We delay the proof of Lemma 3.2 to the appendix.
我们在下面的示例中展示了引理 3.2 所隐含的尖锐检测阈值;具体来说,水印检测概率如何随原始图像与可能修改后的图像之间的语义相似性而变化。我们将引理 3.2 的证明推迟到附录中。
Example 3.3 (Sharp Detection Thresholds). Our watermarking scheme embeds a semantic vector v into an image at generation time. When evaluating a suspect image that was generated via our watermark, we extract its current semantic vector $\tilde{\bf{v}}$ . The probability of a watermark detection depends on the semantic angle $\theta({\boldsymbol{\mathbf{v}}},{\tilde{\mathbf{v}}})$ between v and $\tilde{\bf{v}}$ .
例 3.3 (尖锐检测阈值). 我们的水印方案在生成时将语义向量 v 嵌入到图像中。当评估通过我们的水印生成的嫌疑图像时,我们提取其当前的语义向量 $\tilde{\bf{v}}$。水印检测的概率取决于 v 和 $\tilde{\bf{v}}$ 之间的语义角度 $\theta({\boldsymbol{\mathbf{v}}},{\tilde{\mathbf{v}}})$。
For instance, Figure $5c$ illustrates a separation between vectors associated with the original image and those that are unrelated, occurring at a threshold of approximately $\theta^{m i d}\approx$ $70^{\circ}$ . When our watermarking scheme is run with $\theta^{m i d}=70^{\circ}$ $n=1024$ , and $b=4$ , Table 1 quantifies the probability of a watermark detection. For images with angles beyond $5^{\circ}$ of the threshold, we almost always correctly distinguish between related and unrelated watermarked images (under assumption 3.1; see Figure 4 for the empirical curve).
例如,图 $5c$ 展示了与原始图像相关的向量和无关向量之间的分离,分离发生在约 $\theta^{m i d}\approx$ $70^{\circ}$ 的阈值处。当我们的水印方案以 $\theta^{m i d}=70^{\circ}$、$n=1024$ 和 $b=4$ 运行时,表 1 量化了水印检测的概率。对于角度超过阈值 $5^{\circ}$ 的图像,我们几乎总能正确区分相关和无关的水印图像(在假设 3.1 下;参见图 4 中的经验曲线)。
4. The CAT ATTACK- Harmful Image Edits
4. CAT ATTACK - 有害图像编辑
Commonly evaluated forgery attacks typically aim to forge the entire image. The forged image in that case may have no semantic connection to the image (or group of images) from which the watermark was stolen. Yet, even when such attacks are not possible, the model owner’s security might still be compromised. Here, we explore one such case, where the attacker locally modifies an existing watermarked image. Adding new content to a watermarked image may pose reputation al risks to the model owner, even if the rest of the image remains unchanged. Such editing attacks are expected to be most effective against watermarks that are relatively resilient to removal attacks - a watermark that is removed after small edits will typically be removed even after edits that do not change the content.
通常评估的伪造攻击通常旨在伪造整个图像。在这种情况下,伪造的图像可能与从中窃取水印的图像(或图像组)没有语义联系。然而,即使这种攻击不可能,模型所有者的安全性仍可能受到威胁。在这里,我们探讨了一种情况,即攻击者本地修改现有的带水印图像。向带水印的图像添加新内容可能会对模型所有者的声誉造成风险,即使图像的其余部分保持不变。这种编辑攻击预计对相对抗移除攻击的水印最为有效——在小幅编辑后移除的水印通常也会在内容未改变的编辑后被移除。

(a) Image Feature Vector. Direct use of image feature embedding fails to separate related from unrelated images.
图 1:
(a) 图像特征向量。直接使用图像特征嵌入无法区分相关和不相关的图像。

Figure 5. Ablation of Embedding Strategies for Watermark Detection. Comparison of angle separation between related and unrelated images using different embedding approaches. The raw image feature vector (left) fails to distinguish semantic relationships, while caption embeddings (center) substantially improve separation. Fine-tuning the embedding model (right) yields additional gains in detection accuracy.
图 5: 水印检测嵌入策略的消融实验。使用不同嵌入方法时,相关图像与不相关图像之间的角度分离比较。原始图像特征向量(左)无法区分语义关系,而标题嵌入(中)显著改善了分离效果。微调嵌入模型(右)进一步提高了检测精度。

(b) Caption Embeddings. Employing caption embeddings from blip2-flan-t5-xl and paraphrasempnet-base $\nu2$ yields improved separation. (c) Fine-tuned Caption Embeddings. Fine-tuning the embedding model on $10\mathrm{k\Omega}$ caption pairs further enhances separation.
(b) 标题嵌入。使用来自 blip2-flan-t5-xl 和 paraphrasempnet-base $\nu2$ 的标题嵌入可以改善分离效果。(c) 微调后的标题嵌入。在 $10\mathrm{k\Omega}$ 标题对上进行嵌入模型的微调进一步增强了分离效果。
Here, we consider an attack where a cropped object is pasted into a watermarked image. We refer to it as the CAT ATTACK. Our watermark method can detect such edits, and declare the image non-watermarked (or watermarked and edited) in two different ways: global Semantic Similarity Detection and local Tampering Detection (both described in Section 3). In practice, we recommend starting with Semantic Similarity Detection as a faster approach that would catch most conventional attacks. When further inspection is needed, a more local Tampering Detection can be used.
在这里,我们考虑一种攻击方式,即将裁剪的对象粘贴到带有水印的图像中。我们称之为 CAT ATTACK。我们的水印方法可以检测到此类编辑,并通过两种不同的方式声明图像未加水印(或已加水印并编辑):全局语义相似性检测和局部篡改检测(两者在第 3 节中均有描述)。在实际应用中,我们建议首先使用语义相似性检测,作为一种更快的方法,可以捕捉到大多数常规攻击。当需要进一步检查时,可以使用更局部的篡改检测。
and can invert the generated image using the same model that produced it. The attacker’s access to the private model is taken as an upper bound for the attacker’s capability in a forgery attack [4, 17].
并且可以使用生成图像的同一模型对生成的图像进行反转。攻击者对私有模型的访问被视为攻击者在伪造攻击中的能力上限 [4, 17]。
In our experiment, we first generate an image using watermarked noise. We then perform an inversion with the same model to recover an approximate initial noise, which is subsequently used to generate a second image. Because the attack prompt differs from the original prompt, the semantic embedding of the image $\tilde{\bf{v}}$ changes to $\mathbf{v}{a t t a c k}$ . The detection algorithm, therefore compares the estimated noise to a reference derived from $\mathbf{v}{a t t a c k}$ (and not $\tilde{\bf{v}}$ ). The noise based on $\mathbf{v}_{a t t a c k}$ is less likely to correlate to the pattern embedded in the image, enabling the detection algorithm to declare the image as ‘not watermarked’ and evade the attack. As can be seen in Table 3, our method uniquely provides non-trivial robustness in this setting.
在我们的实验中,我们首先使用带有水印的噪声生成一张图像。然后,我们使用相同的模型进行反演,以恢复一个近似的初始噪声,该噪声随后用于生成第二张图像。由于攻击提示词与原始提示词不同,图像的语义嵌入 $\tilde{\bf{v}}$ 变为 $\mathbf{v}{a t t a c k}$。因此,检测算法将估计的噪声与基于 $\mathbf{v}{a t t a c k}$ 的参考值进行比较(而不是 $\tilde{\bf{v}}$)。基于 $\mathbf{v}_{a t t a c k}$ 的噪声不太可能与图像中嵌入的模式相关联,从而使检测算法能够将图像声明为“未加水印”并规避攻击。如表 3 所示,我们的方法在这种设置下提供了独特的非平凡鲁棒性。
5. Empirical Analysis
5. 实证分析
In this section, we evaluate the robustness of SEAL.
在本节中,我们评估 SEAL 的鲁棒性。
Setting. To ensure a fair comparison with prior work [4, 7, 25], we use Stable Diffusion-v2 [20] with 50 inference steps for both generation and inversion for all methods. Evaluations were conducted on a set of prompts sourced from [21]. We set $n=1024$ and $b=7$ for all experiments. An ablation study on the effects of $n$ and $b$ is available in Section 11.
设置。为了确保与之前的工作 [4, 7, 25] 进行公平比较,我们使用 Stable Diffusion-v2 [20],在所有方法的生成和反演过程中均采用 50 步推理。评估基于一组来自 [21] 的提示词进行。我们在所有实验中设置 $n=1024$ 和 $b=7$。关于 $n$ 和 $b$ 影响的消融研究见第 11 节。
Regeneration with the Private Model. Prior works assume that the attacker lacks access to the model weights (which are needed for accurate DDIM noise inversion) and that the noise used during generation cannot be forged or approximated with sufficient accuracy. Going beyond previous studies, we consider here a more challenging scenario in which the attacker has full access to the model weights
使用私有模型进行再生。先前的研究假设攻击者无法访问模型权重(这些权重是进行精确 DDIM 噪声反演所必需的),并且生成过程中使用的噪声无法被伪造或以足够的精度近似。超越以往的研究,我们在此考虑一个更具挑战性的场景,即攻击者完全访问模型权重。
Cat Attack. In this experiment, we explore the resilience of our watermarking method by pasting a cat image onto a watermarked image. The cat image is randomly resized to between $30%$ and $60%$ of the watermarked image’s dimensions and placed at a random location, as exemplified in Figure 3a (We use here a cat to avoid dealing with not-safe-for-work material). Unlike previous watermarking techniques, which overlook semantic content and thus fail to detect such alterations, our approach identifies modifications by observing elevated $\ell_{2}$ norms in the patches where the cat is overlaid, as shown in Figure 3b. However, since our method hinges on counting patches with an $\ell_{2}$ similarity to the reference pattern norm below a given threshold, it may occasionally miss these changes.
猫攻击。在本实验中,我们通过在带有水印的图像上粘贴一张猫的图像来探索水印方法的鲁棒性。猫的图像被随机调整大小为水印图像尺寸的 $30%$ 到 $60%$,并放置在随机位置,如图 3a 所示(我们在这里使用猫的图像是为了避免处理不适合工作场所的内容)。与之前的水印技术不同,这些技术忽略了语义内容,因此无法检测到此类修改,而我们的方法通过观察猫覆盖区域的 $\ell_{2}$ 范数升高来识别修改,如图 3b 所示。然而,由于我们的方法依赖于计算与参考模式范数的 $\ell_{2}$ 相似度低于给定阈值的补丁,因此有时可能会错过这些变化。
To increase our robustness to such attacks, we use the Tampering Detection technique detailed in Section 3. The results in Table 2 reveal that, while our method offers some robustness even without the spatial test, integrating it significantly improves detection. Other methods are vulnerable to this type of attack, as they strive not to be easily removed by small edits. Since our robustness here is in tension with our resistance to watermark removal attacks, we next analyze our method performance against these types of attacks.
为了提高我们对这类攻击的鲁棒性,我们使用了第3节中详细介绍的篡改检测技术。表2中的结果显示,尽管我们的方法在没有空间测试的情况下也提供了一定的鲁棒性,但将其集成后显著提高了检测效果。其他方法对这种类型的攻击较为脆弱,因为它们力求不被小规模的编辑轻易移除。由于我们在此的鲁棒性与我们对水印移除攻击的抵抗性之间存在矛盾,接下来我们分析了我们的方法在这些类型攻击下的表现。
Table 2. Detection AUC Under the Cat Attack. AUC of detecting edits in generated images, as described in Section 4.
表 2: Cat Attack 下的检测 AUC。检测生成图像中编辑的 AUC,如第 4 节所述。
| 方法 | AUC |
|---|---|
| WIND | 0.000 |
| Tree-Ring | 0.000 |
| Gaussian Shading | 0.000 |
| SEAL SEAL+Spatial Test | 0.551 0.982 |
Table 3. Robustness to Private Model-Based Regeneration Attack. An attacker with access to the private model weights can approximate the watermarked initial noise by inverting a watermarked image using the private model. We evaluate how accurately different methods evade the false identification of unrelated images, generated with this initial noise, as watermarked.
表 3: 对基于私有模型的重建攻击的鲁棒性。攻击者可以通过访问私有模型的权重,使用私有模型对水印图像进行反演,从而近似水印的初始噪声。我们评估了不同方法在避免将使用此初始噪声生成的不相关图像错误识别为水印图像时的准确性。
| 方法 | AUC |
|---|---|
| WIND | 0.000 |
| Tree-Ring | 0.000 |
| Gaussian Shading | 0.000 |
| SEAL | 0.708 |
Image Transformation Attacks. We evaluated the robustness of SEAL under a standard suite of image transformations (see Section 12). As shown in Figure 6, SEAL achieves an average detection rate of 0.896 under these conditions. This is comparable to some watermarking and somewhat lower than others [25]. Yet, our method is uniquely resistant to forgery. Further enhancements, such as incorporating rotation search or sliding-window search during detection, could improve its robustness against removal.
图像变换攻击。我们在标准图像变换套件下评估了SEAL的鲁棒性(见第12节)。如图6所示,SEAL在这些条件下的平均检测率为0.896。这与某些水印方法相当,但略低于其他方法[25]。然而,我们的方法在防伪造方面具有独特的优势。进一步的增强,例如在检测过程中加入旋转搜索或滑动窗口搜索,可能会提高其抗移除的鲁棒性。
Ablation of Captioning and Embedding Models. A straightforward approach for our method would be to use the feature vector from the first generated image rather than the embedding of its caption. However, as illustrated in Figure 5a, this approach fails to yield a clear separation between related and unrelated images. Consequently, we employ the blip2-flan-t5-xl [15] model for caption generation and the paraphrase-mpnet-base-v2 [19] for deriving caption embeddings, which results in a more distinct separation as shown in Figure 5. To further enhance our method’s accuracy, we fine-tuned the embedding model using 10k pairs of related captions, leading to additional improvements ( Figure $5\mathrm{c}^{1}$ ).
标题消融实验:字幕生成与嵌入模型
我们方法的一个直接思路是使用第一张生成图像的特征向量,而非其字幕的嵌入。然而,如图 5a 所示,这种方法未能清晰地区分相关与不相关的图像。因此,我们采用 blip2-flan-t5-xl [15] 模型进行字幕生成,并使用 paraphrase-mpnet-base-v2 [19] 来获取字幕嵌入,从而实现了更明显的区分,如图 5 所示。为了进一步提升方法的准确性,我们使用 10k 对相关字幕对嵌入模型进行了微调,带来了额外的改进(图 $5\mathrm{c}^{1}$)。
St eg analysis Attack. We evaluate the robustness of our method against a st eg analysis attack [26] that attempts to approximate the watermark by subtracting non-watermarked images from watermarked ones. As shown in App. Table 4, SEAL maintains high performance under this attack.
隐写分析攻击。我们评估了我们的方法在面对隐写分析攻击 [26] 时的鲁棒性,该攻击试图通过从带水印图像中减去未带水印的图像来近似水印。如附录表 4 所示,SEAL 在此攻击下仍保持高性能。
Generation Quality. Our method is distortion-free at the single-image level, as the noise is drawn from a pseudo-random Gaussian distribution. Consequently, all single-image quality metrics are identical to those of nonwatermarked images (see also Section 14).
生成质量。我们的方法在单图像级别是无失真的,因为噪声是从伪随机高斯分布中提取的。因此,所有单图像质量指标与非水印图像的指标相同(参见第14节)。
6. Limitation and Discussion
6. 局限性与讨论
Stronger Forgery Attacks. Although we evaluated a stronger set of forgery attacks compared to prior work, other types of forgery attacks might still potentially compromise our watermark. For example, a highly persistent attacker might attempt to gather information about the correlation between individual initial noise patches and the image semantics. While not theoretically impossible, an attacker would face several practical limitations in carrying out such an attack. Among them, are the lack of access to the private model weights, the inherent stochastic it y of the watermark, and the watermark owner’s ability to deploy multiple instances of the hash function.
更强的伪造攻击。尽管我们评估了比之前工作更强的伪造攻击集,但其他类型的伪造攻击仍可能危及我们的水印。例如,一个高度持久的攻击者可能会尝试收集有关单个初始噪声块与图像语义之间关联的信息。虽然理论上并非不可能,但攻击者在实施此类攻击时将面临几个实际限制。其中包括缺乏对私有模型权重的访问权限、水印固有的随机性,以及水印所有者部署多个哈希函数实例的能力。
Attacker Advantage and Removal Attacks. Our method is more vulnerable to removal attacks than some existing methods. However, we believe that a sufficiently persistent attacker can remove most current watermarks. Nonetheless, increasing the robustness of watermarks holds significant societal value. It helps reduce misleading content and makes forgery attacks more difficult, which is crucial for their practical deployment.
攻击者优势与移除攻击。我们的方法相比现有的一些方法更容易受到移除攻击的影响。然而,我们相信足够执着的攻击者可以移除大多数当前的水印。尽管如此,提高水印的鲁棒性具有重要的社会价值。它有助于减少误导性内容,并使伪造攻击更加困难,这对于水印的实际部署至关重要。
Additional limitations and discussion points can be found in Section 13.
其他限制和讨论点可以在第13节中找到。
7. Conclusion
7. 结论
We introduce the first initial noise-based watermarking method for diffusion models that is both database-free and semantic-aware. Our suggested watermark is uniquely robust against a new class of stronger forgery attacks. We hope our work highlights the potential of semantic-aware watermarking and helps pave the way forward for further research in this area.
我们首次引入了一种基于初始噪声的水印方法,该方法无需数据库且具有语义感知能力。我们提出的水印在面对一类新型更强的伪造攻击时表现出独特的鲁棒性。我们希望我们的工作能够凸显语义感知水印的潜力,并为进一步研究这一领域铺平道路。
SEAL: Semantic Aware Image Watermarking
SEAL: 语义感知图像水印
Supplementary Material
补充材料

Figure 6. Robustness of Watermark Detection Against Image Transformations. Comparison of correct watermark detection accuracy of SEAL under various image transformations.
图 6: 水印检测对图像变换的鲁棒性。SEAL 在各种图像变换下的正确水印检测准确率比较。
8. Additional Related Works
8. 其他相关工作
Post-Processing Methods. Post-processing techniques embed watermarks after the image generation stage, providing model-agnostic flexibility at the cost of potential quality degradation. Frequency-domain methods, such as methods using the Discrete Wavelet Transform (DWT) and Discrete Cosine Transform (DCT) [1, 18], embed watermarks in the transformed domains and offer robustness against operations like resizing and translation. Complementing these, deep encoder-decoder frameworks such as HiDDeN [29] and StegaStamp [24] utilize end-to-end neural training for watermark embedding and extraction. Despite these advancements, however, these methods are vulnerable to regeneration attacks [28]. Alternative strategies operating in latent spaces have also been proposed [9], though they also remain susceptible to sophisticated removal attacks.
后处理方法。后处理技术在图像生成阶段之后嵌入水印,提供了模型无关的灵活性,但可能会牺牲一定的质量。频域方法,例如使用离散小波变换 (DWT) 和离散余弦变换 (DCT) [1, 18] 的方法,在变换域中嵌入水印,并提供了对调整大小和平移等操作的鲁棒性。作为补充,深度编码-解码框架,如 HiDDeN [29] 和 StegaStamp [24],利用端到端的神经训练进行水印嵌入和提取。尽管有这些进展,这些方法仍然容易受到再生攻击 [28] 的影响。在潜在空间中操作的其他策略也被提出 [9],但它们仍然容易受到复杂的去除攻击。
9. Proof of Lemma 3.2
9. 引理 3.2 的证明
Proof of Lemma 3.2. The angle between the original semantic vector $\mathbf{v}$ used to generate the watermark and extracted semantic vector $\tilde{\bf{v}}$ of the suspect image is
引理 3.2 的证明。用于生成水印的原始语义向量 $\mathbf{v}$ 与嫌疑图像的提取语义向量 $\tilde{\bf{v}}$ 之间的角度为

By the property of $\mathrm{SimHash}^{2}$ and Assumption 3.1, the
根据 $\mathrm{SimHash}^{2}$ 的性质和假设 3.1,

Figure 7. Ablation Study of the Number of Patches $(n)$ and Bits (b) on Watermark Detection Performance.
图 7: 补丁数量 $(n)$ 和比特数 (b) 对水印检测性能的消融研究。
probability 3 that the ith patch aligns is
第 i 个补丁对齐的概率为 3

Since each SimHash instance is independent, the number of matches $m$ is distributed like a Binomial with $n$ trials and success probability $\rho(\theta)$ . During watermark detection, we count the number of patches that match, declaring an image watermarked if the number of matches exceeds the threshold $m^{\mathrm{match}}$ . Setting $m^{\mathrm{match}}=\lfloor n\rho(\theta^{\mathrm{mid}})\rfloor$ yields the lemma statement. 口
由于每个 SimHash 实例是独立的,匹配数 $m$ 服从二项分布,试验次数为 $n$,成功概率为 $\rho(\theta)$。在水印检测过程中,我们统计匹配的补丁数量,如果匹配数超过阈值 $m^{\mathrm{match}}$,则声明图像带有水印。设置 $m^{\mathrm{match}}=\lfloor n\rho(\theta^{\mathrm{mid}})\rfloor$ 即可得到引理陈述。
10. Spatial Test
10. 空间测试
To better analyze potential image tampering, we examine the structural organization of high-intensity regions in the patch correspondence heatmaps (see Section 3, Tampering Detection). Specifically, we threshold the heatmap data at the 80th percentile and identify connected components. The extracted parameter, the number of distinct clusters detected at this threshold, provides insight into the fragmentation of high-intensity regions. A higher number of clusters indicates a more dispersed distribution, while a lower number suggests more contiguous structures, which may be indicative of image tampering.
为了更好地分析潜在的图像篡改,我们检查了补丁对应热图中高强度区域的结构组织(见第3节,篡改检测)。具体来说,我们将热图数据在第80百分位数处进行阈值处理,并识别连通组件。提取的参数,即在此阈值下检测到的不同簇的数量,提供了高强度区域碎片化的洞察。簇的数量越多,表示分布越分散;而簇的数量越少,则表明结构越连续,这可能暗示图像篡改。
11. Ablation of Number of Patches and Bits.
11. 分块数量和比特数的消融实验
To investigate the impact of the number of patches $(n)$ and the number of bits $(b)$ used to generate the initial noise, we
为了研究生成初始噪声时使用的补丁数量 $(n)$ 和位数 $(b)$ 的影响,我们
$$
\mathop{\mathrm{Pr}}_{{\bf r}\sim\mathcal{N}({\bf0},{\bf I})}(\mathrm{sign}(\langle{\bf v},{\bf r}\rangle)=\mathrm{sign}(\langle\tilde{\bf v},{\bf r}\rangle))=1-\frac{\theta}{180^{\circ}}.
$$
$$
\mathop{\mathrm{Pr}}_{{\bf r}\sim\mathcal{N}({\bf0},{\bf I})}(\mathrm{sign}(\langle{\bf v},{\bf r}\rangle)=\mathrm{sign}(\langle\tilde{\bf v},{\bf r}\rangle))=1-\frac{\theta}{180^{\circ}}.
$$
Table 4. Robustness of St eg analysis-Based Removal. Comparison of performance metrics (AUC for SEAL, Tree-Ring, and, WIND and bit accuracy for Gaussian Shading) under various levels of averaging.
表 4. 基于隐写分析的去除鲁棒性。在不同平均水平下的性能指标比较(SEAL、Tree-Ring 和 WIND 的 AUC,以及高斯阴影的比特精度)。
| 方法 | 5 | 10 | 20 | 50 | 100 | 200 | 500 | 1000 | 2000 | 5000 |
|---|---|---|---|---|---|---|---|---|---|---|
| 高斯阴影 (比特精度) | 0.490 | 0.469 | 0.537 | 0.488 | 0.486 | 0.479 | 0.461 | 0.463 | 0.465 | 0.462 |
| Tree-Ring (AUC) | 0.293 | 0.267 | 0.314 | 0.275 | 0.214 | 0.228 | 0.211 | 0.224 | 0.224 | 0.241 |
| WIND (AUC) | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| SEAL (AUC) | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
conducted an exhaustive ablation study across various parameter combinations. The results are presented in Figure 7.
对各种参数组合进行了详尽的消融研究。结果如图 7 所示。
12. Transformations for the Removal Attack
12. 移除攻击的变换
We use a standard suit of transformations, including a $75^{\circ}$ rotation, $25%$ JPEG compression, $75%$ random cropping and scaling (C & S), Gaussian blur using an $8\times8$ filter, Gaussian noise with $\sigma=0.1$ , and color jitter with a brightness factor uniformly sampled between 0 and 6.
我们使用了一套标准的变换操作,包括 $75^{\circ}$ 旋转、$25%$ 的 JPEG 压缩、$75%$ 的随机裁剪和缩放 (C & S)、使用 $8\times8$ 滤波器的高斯模糊、$\sigma=0.1$ 的高斯噪声,以及亮度因子在 0 到 6 之间均匀采样的颜色抖动。
13. Additional Limitations and Discussion
13. 其他限制与讨论
Distortion-Free Property for Sets of Images Our watermarking scheme securely generates the noise for each patch from a normal distribution, ensuring that each individual noise is distributed from a normal distribution. However, multiple watermarked images corresponding to related prompts may leak information about the noise i.e., the noise in some patches will match while the noise in other patches does not. This leakage arises from our design choice to make similar prompts produce similar watermarks, a feature that enhances consistency but comes at the cost of some information exposure.
图像集的无失真特性
我们的水印方案安全地从正态分布中为每个图像块生成噪声,确保每个单独的噪声都来自正态分布。然而,与相关提示对应的多个加水印图像可能会泄露噪声信息,即某些图像块中的噪声会匹配,而其他图像块中的噪声则不会。这种泄露源于我们的设计选择,即让相似的提示生成相似的水印,这一特性增强了一致性,但以信息暴露为代价。
In contrast, some prior works do not exhibit this property and instead maintain a stronger sense of distribution-free randomness. Ignoring cases where the exact same noise is reused, such as when multiple images are generated by the same user in [27], these methods ensure that each image is independently sampled from a normal distribution. This fundamental difference highlights a trade-off between ensuring independent randomness and enabling structured watermark consistency across related prompts. A user concerned about the distortion-free property for sets may vary the secret salt for different generations. This will allow the user to enjoy the best of both worlds, At the cost of searching through possible salts that may have been used during detection time.
相比之下,一些先前的工作并不具备这一特性,而是保持了更强的无分布随机性。忽略重复使用完全相同噪声的情况(例如在[27]中同一用户生成多张图像时),这些方法确保每张图像都是从正态分布中独立采样的。这一根本差异突显了在确保独立随机性和实现相关提示之间的结构化水印一致性之间的权衡。关注集合的无失真属性的用户可以为不同的生成过程改变秘密盐值。这将使用户能够同时享受两者的优势,代价是在检测时搜索可能使用的盐值。
Further Possible Improvement. We made an initial attempt to find a semantic vector that is both known before generation and recoverable from the generated image. Yet, we believe this is a promising direction for future research. Improved semantic embedding methods, as well as approaches that jointly optimize image generation and semantic descriptor generation, could enhance the correspondence between the embedded watermark and the image’s semantics. Such advancements may enable much stricter bounds on detecting when a watermarked image has been tampered with and how.
进一步可能的改进。我们初步尝试寻找一个在生成前已知且能从生成图像中恢复的语义向量。然而,我们相信这是未来研究的一个有前景的方向。改进的语义嵌入方法,以及联合优化图像生成和语义描述符生成的方法,可以增强嵌入水印与图像语义之间的对应关系。这些进展可能会在检测水印图像是否被篡改以及如何被篡改时,提供更严格的界限。

Figure 8. Impact of Repetitive Patches in the Initial Noise on Image Generation.
图 8: 初始噪声中重复补丁对图像生成的影响
14. Image Quality Results
14. 图像质量结果
Table 5. CLIP Score Evaluation. Comparison of CLIP scores before and after watermarking for images generated using prompts from the Stable-Diffusion-Prompts [21] and COCO [16] dataset.
表 5. CLIP 分数评估。使用 Stable-Diffusion-Prompts [21] 和 COCO [16] 数据集生成的图像在水印前后的 CLIP 分数对比。
| Stable-Diffusion-Prompts | COCO |
|---|---|
| CLIP (before) | CLIP (after) |
| 32.378 | 32.401 |

Figure 9. Watermarked images generated using SEAL.
图 9: 使用 SEAL 生成的水印图像。