Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-R1: 通过强化学习训练大语言模型进行推理并利用搜索引擎
Bowen ${\bf{J i n}}^{1}$ , Hansi Zeng2, Zhenrui $\mathbf{Y}\mathbf{u}\mathbf{e}^{1}$ , Dong Wang1, Hamed Zamani2, Jiawei Han1 1 Department of Computer Science, University of Illinois at Urbana-Champaign 2 Center for Intelligent Information Retrieval, University of Massachusetts Amherst {bowenj4,zhenrui3,dwang24,hanj}@illinois.edu, {hzeng, zamani}@cs.umass.edu
Bowen ${\bf{J i n}}^{1}$, Hansi Zeng2, Zhenrui $\mathbf{Y}\mathbf{u}\mathbf{e}^{1}$, Dong Wang1, Hamed Zamani2, Jiawei Han1
1 伊利诺伊大学厄巴纳-香槟分校计算机科学系
2 马萨诸塞大学阿默斯特分校智能信息检索中心
{bowenj4,zhenrui3,dwang24,hanj}@illinois.edu, {hzeng, zamani}@cs.umass.edu
Abstract
摘要
Efficiently acquiring external knowledge and up-to-date information is essential for effective reasoning and text generation in large language models (LLMs). Retrieval augmentation and tool-use training approaches where a search engine is treated as a tool lack complex multi-turn retrieval flexibility or require large-scale supervised data. Prompting advanced LLMs with reasoning capabilities during inference to use search engines is not optimal, since the LLM does not learn how to optimally interact with the search engine. This paper introduces SEARCH-R1, an extension of the DeepSeek-R1 model where the LLM learns—solely through reinforcement learning (RL)— to autonomously generate (multiple) search queries during step-by-step reasoning with real-time retrieval. SEARCH-R1 optimizes LLM rollouts with multi-turn search interactions, leveraging retrieved token masking for stable RL training and a simple outcome-based reward function. Experiments on seven question-answering datasets show that SEARCH-R1 improves performance by $26%$ (Qwen2.5-7B), $21%$ (Qwen2.5-3B), and $10%$ (LLaMA3.2-3B) over SOTA baselines. This paper further provides empirical insights into RL optimization methods, LLM choices, and response length dynamics in retrieval-augmented reasoning. The code and model checkpoints are available at https://github.com/Peter Griffin J in/Search-R1.
高效获取外部知识和最新信息对于大语言模型 (LLMs) 的有效推理和文本生成至关重要。将搜索引擎视为工具的检索增强和工具使用训练方法缺乏复杂的多轮检索灵活性,或者需要大规模的监督数据。在推理过程中提示具有推理能力的先进大语言模型使用搜索引擎并不是最佳选择,因为大语言模型没有学会如何与搜索引擎进行最佳交互。本文介绍了 SEARCH-R1,它是 DeepSeek-R1 模型的扩展,其中大语言模型仅通过强化学习 (RL) 学会在逐步推理过程中自主生成(多个)搜索查询,并实时检索。SEARCH-R1 通过多轮搜索交互优化大语言模型的 rollout,利用检索到的 token 掩码进行稳定的 RL 训练,并使用基于结果的简单奖励函数。在七个问答数据集上的实验表明,SEARCH-R1 的性能比 SOTA 基线提高了 $26%$ (Qwen2.5-7B)、$21%$ (Qwen2.5-3B) 和 $10%$ (LLaMA3.2-3B)。本文进一步提供了关于 RL 优化方法、大语言模型选择和检索增强推理中响应长度动态的实证见解。代码和模型检查点可在 https://github.com/Peter Griffin J in/Search-R1 获取。
1 Introduction
1 引言
In recent years, large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding and generation (Hendrycks et al., 2020; Clark et al., 2018). Despite these achievements, LLMs often encounter challenges when tasked with complex reasoning (Wei et al., 2022) and retrieving up-to-date information from external sources (Jin et al., 2024). Addressing these limitations necessitates integrating advanced reasoning abilities (Huang & Chang, 2022) and the capability to interact effectively with search engines (Schick et al., 2023).
近年来,大语言模型 (LLMs) 在自然语言理解和生成方面展现了显著的能力 (Hendrycks et al., 2020; Clark et al., 2018)。尽管取得了这些成就,大语言模型在处理复杂推理 (Wei et al., 2022) 和从外部来源检索最新信息 (Jin et al., 2024) 时仍然面临挑战。解决这些限制需要整合先进的推理能力 (Huang & Chang, 2022) 以及与搜索引擎有效交互的能力 (Schick et al., 2023)。
Existing approaches for integrating LLMs with search engines typically fall into two categories: (1) retrieval-augmented generation (RAG) (Gao et al., 2023; Lewis et al., 2020) and (2) treating the search engine as a tool (Yao et al., 2023; Schick et al., 2023). RAG retrieves relevant passages based on the input query and incorporates them into the LLM’s context for generation (Lewis et al., 2020). This allows the LLM to leverage external knowledge when answering questions. However, RAG is constrained by retrieval inaccuracy (Jin et al., 2024) and lacks the flexibility for multi-turn, multi-query retrieval, which is essential for complex reasoning tasks (Yang et al., 2018). Alternatively, LLMs can be prompted or trained to utilize tools, including search engines, as part of their reasoning process (Qu et al., 2025; Trivedi et al., 2022a). However, prompting-based approaches often struggle with generalization, as certain tasks may not have been encountered during LLM pre training. On the other hand, training-based approaches provide greater adaptability but rely on large-scale, high-quality annotated trajectories of search-and-reasoning interactions, making them difficult to scale effectively (Schick et al., 2023).
现有将大语言模型与搜索引擎集成的方法通常分为两类:(1) 检索增强生成 (RAG) (Gao et al., 2023; Lewis et al., 2020) 和 (2) 将搜索引擎视为工具 (Yao et al., 2023; Schick et al., 2023)。RAG 根据输入查询检索相关段落,并将其整合到大语言模型的上下文中进行生成 (Lewis et al., 2020)。这使得大语言模型在回答问题时能够利用外部知识。然而,RAG 受限于检索的不准确性 (Jin et al., 2024),并且缺乏多轮、多查询检索的灵活性,而这对于复杂推理任务至关重要 (Yang et al., 2018)。另一种方法是,大语言模型可以通过提示或训练来使用工具,包括搜索引擎,作为其推理过程的一部分 (Qu et al., 2025; Trivedi et al., 2022a)。然而,基于提示的方法通常难以泛化,因为某些任务可能在大语言模型预训练期间未被遇到。另一方面,基于训练的方法提供了更大的适应性,但依赖于大规模、高质量的搜索与推理交互的标注轨迹,这使得它们难以有效扩展 (Schick et al., 2023)。
Reinforcement Learning (RL) (Sutton et al., 1999; Kaelbling et al., 1996) has emerged as a potent paradigm for enhancing the reasoning capabilities of LLMs (Guo et al., 2025; Hou et al., 2025; Xie et al., 2025; Kumar et al., 2024). Notably, models like OpenAI-o1 (Jaech et al., 2024) and DeepSeek-R1 (Guo et al., 2025) have leveraged RL techniques (e.g., PPO (Schulman et al., 2017) and GRPO (Shao et al., 2024)) to improve logical inference and problem-solving skills by learning from experience and feedback. After RL, even when trained solely on the outcome rewards, the models learn complex reasoning capabilities, including self-verification (Weng et al., 2022) and self-correction (Kumar et al., 2024).
强化学习 (Reinforcement Learning, RL) (Sutton et al., 1999; Kaelbling et al., 1996) 已成为增强大语言模型 (LLMs) 推理能力的有效范式 (Guo et al., 2025; Hou et al., 2025; Xie et al., 2025; Kumar et al., 2024)。值得注意的是,像 OpenAI-o1 (Jaech et al., 2024) 和 DeepSeek-R1 (Guo et al., 2025) 这样的模型已经利用 RL 技术 (例如 PPO (Schulman et al., 2017) 和 GRPO (Shao et al., 2024)) 通过从经验和反馈中学习来提升逻辑推理和问题解决能力。经过 RL 训练后,即使仅基于结果奖励进行训练,模型也能学习到复杂的推理能力,包括自我验证 (Weng et al., 2022) 和自我纠正 (Kumar et al., 2024)。
However, applying reinforcement learning (RL) to search-and-reasoning scenarios presents three key challenges: (1) RL Framework and Stability – It remains unclear how to effectively integrate the search engine into the LLM RL framework while ensuring stable optimization, particularly when incorporating retrieved context. (2) Multi-Turn Interleaved Reasoning and Search – Ideally, the LLM should be capable of iterative reasoning and search engine calls, dynamically adjusting its retrieval strategy based on the complexity of the problem. (3) Reward Design – Designing an effective reward function for search-and-reasoning tasks is nontrivial, as traditional reward formulations may not generalize well to this new paradigm.
然而,将强化学习 (RL) 应用于搜索和推理场景面临三个关键挑战:(1) RL 框架和稳定性——目前尚不清楚如何有效地将搜索引擎集成到大语言模型 RL 框架中,同时确保稳定的优化,特别是在结合检索上下文时。(2) 多轮交错推理和搜索——理想情况下,大语言模型应该能够进行迭代推理和搜索引擎调用,根据问题的复杂性动态调整其检索策略。(3) 奖励设计——为搜索和推理任务设计有效的奖励函数并非易事,因为传统的奖励公式可能无法很好地推广到这种新范式。
To address these challenges, we introduce SEARCH-R1, a novel reinforcement learning (RL) framework that enables LLMs to interact with search engines in an interleaved manner with their own reasoning. Specifically, SEARCH-R1 introduces the following key innovations: (1) We model the search engine as part of the environment, enabling rollout sequences that interleave LLM token generation with search engine retrievals. SEARCH-R1 is compatible with various RL algorithms, including PPO and GRPO, and we apply retrieved token masking to ensure stable optimization. (2) SEARCH-R1 supports multi-turn retrieval and reasoning, where search calls are explicitly triggered by
为了解决这些挑战,我们引入了 SEARCH-R1,这是一个新颖的强化学习 (RL) 框架,使大语言模型能够以交错的方式与搜索引擎交互并进行自己的推理。具体来说,SEARCH-R1 引入了以下关键创新:(1) 我们将搜索引擎建模为环境的一部分,使得大语言模型的 Token 生成与搜索引擎的检索能够交错进行。SEARCH-R1 兼容多种 RL 算法,包括 PPO 和 GRPO,并且我们应用了检索 Token 掩码以确保稳定的优化。(2) SEARCH-R1 支持多轮检索和推理,其中搜索调用通过 <search> 和 </search> Token 显式触发。检索到的内容被包裹在 <information> 和 </information> Token 中,而大语言模型的推理步骤则被包裹在 <think> 和 </think> Token 中。最终答案使用 <answer> 和 </answer> Token 进行格式化,从而实现结构化的迭代决策。(3) 我们采用了一种简单的结果导向奖励函数,避免了基于过程的奖励的复杂性。我们的结果表明,这种最小化的奖励设计在搜索和推理场景中是有效的。SEARCH-R1 可以被视为 DeepSeek-R1 (Guo et al., 2025) 的扩展,后者主要通过引入搜索增强的 RL 训练来增强检索驱动的决策,主要关注参数化推理。
In summary, our key contributions are threefold:
总结来说,我们的主要贡献有三点:
• We identify the challenges of applying RL to LLM reasoning with search engine calling. • We propose SEARCH-R1, a novel reinforcement learning framework that supports LLM rollout and RL optimization with a search engine, including retrieved token masking to stabilize RL training, multi-turn interleaved reasoning and search to support complex task-solving and a simple yet effective outcome reward function. • We conduct systematic experiments to demonstrate the effectiveness of SEARCH-R1 with $26%$ , $21%$ , and $10%$ average relative improvement with three LLMs over SOTA baselines. In addition, we provide insights on RL for reasoning and search settings, including RL methods selection, different LLM choices and response length study.
• 我们识别了将强化学习(RL)应用于大语言模型(LLM)推理并结合搜索引擎调用时的挑战。
• 我们提出了 SEARCH-R1,这是一个新颖的强化学习框架,支持通过搜索引擎进行 LLM 展开和 RL 优化,包括检索到的 Token 掩码以稳定 RL 训练、多轮交替推理和搜索以支持复杂任务解决,以及一个简单但有效的结果奖励函数。
• 我们进行了系统性实验,证明了 SEARCH-R1 的有效性,在三种 LLM 上分别实现了 $26%$、$21%$ 和 $10%$ 的平均相对改进,优于 SOTA 基线。此外,我们还提供了关于 RL 在推理和搜索设置中的见解,包括 RL 方法选择、不同 LLM 选择以及响应长度研究。
2 Related Works
2 相关工作
2.1 Large Language Models and Retrieval
2.1 大语言模型与检索
Although large language models (LLMs) (Zhao et al., 2023; Team, 2024; Achiam et al., 2023) have demonstrated remarkable reasoning (Guo et al., 2025) and coding (Guo et al., 2024) capabilities, they still lack domain-specific knowledge (Peng et al., 2023; Li et al., 2023) and are prone to hallucinations (Zhang et al., 2023). To address these limitations, search engines (Zhao et al., 2024) are widely used to provide external information. There are two primary ways to integrate search engines with LLMs: (1) retrieval-augmented generation (RAG) (Gao et al., 2023) and (2) treating the search engine as a tool (Schick et al., 2023). RAG (Lewis et al., 2020; Yue et al., 2024; Xiong et al., 2025) typically follows a one-round retrieval and sequential generation pipeline, where a search engine fetches relevant information based on the input query, which is then concatenated with the query and fed into the LLM. However, this pipeline struggles with issues such as retrieving irrelevant information (Jin et al., 2024) and failing to provide sufficiently useful context (Jiang et al., 2023). An alternative approach is search-as-a-tool, where LLMs are prompted or fine-tuned to interact with the search engine. IRCoT (Trivedi et al., 2022a) and ReAct (Yao et al., 2023) use prompting to guide iterative reasoning and search engine calls, while Toolformer (Schick et al., 2023) leverages supervised fine-tuning to enhance search capabilities. However, these methods rely on high-quality labeled trajectories, which are difficult to scale. Recent work (Guo et al., 2025) suggests that reinforcement learning can enable LLMs to develop advanced reasoning skills using only outcome rewards, yet its potential in search engine calling scenarios remains under-explored.
尽管大语言模型 (LLMs) (Zhao et al., 2023; Team, 2024; Achiam et al., 2023) 已经展示了卓越的推理 (Guo et al., 2025) 和编码 (Guo et al., 2024) 能力,但它们仍然缺乏特定领域的知识 (Peng et al., 2023; Li et al., 2023) 并且容易产生幻觉 (Zhang et al., 2023)。为了解决这些限制,搜索引擎 (Zhao et al., 2024) 被广泛用于提供外部信息。将搜索引擎与大语言模型集成的主要方式有两种:(1) 检索增强生成 (RAG) (Gao et al., 2023) 和 (2) 将搜索引擎视为工具 (Schick et al., 2023)。RAG (Lewis et al., 2020; Yue et al., 2024; Xiong et al., 2025) 通常遵循一轮检索和顺序生成的流程,搜索引擎根据输入查询获取相关信息,然后将其与查询连接并输入到大语言模型中。然而,这种流程在处理检索到不相关信息 (Jin et al., 2024) 和未能提供足够有用的上下文 (Jiang et al., 2023) 等问题时存在困难。另一种方法是搜索即工具,通过提示或微调大语言模型与搜索引擎进行交互。IRCoT (Trivedi et al., 2022a) 和 ReAct (Yao et al., 2023) 使用提示来引导迭代推理和搜索引擎调用,而 Toolformer (Schick et al., 2023) 则利用监督微调来增强搜索能力。然而,这些方法依赖于高质量的标注轨迹,难以扩展。最近的研究 (Guo et al., 2025) 表明,强化学习可以使大语言模型仅通过结果奖励发展出高级推理能力,但其在搜索引擎调用场景中的潜力仍有待探索。
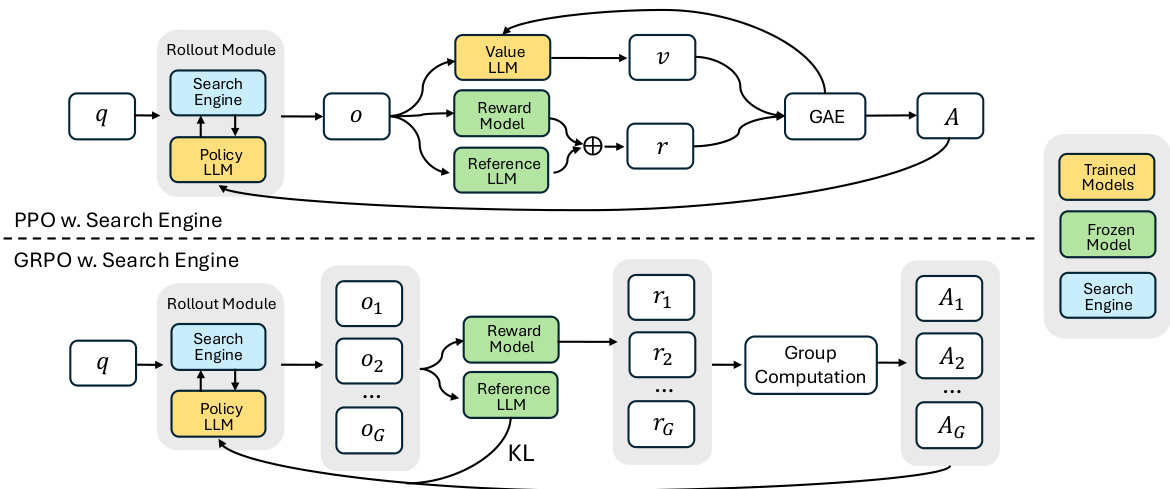
Figure 1: Demonstration of PPO and GRPO training with the search engine (SEARCH-R1).
图 1: 使用搜索引擎 (SEARCH-R1) 进行 PPO 和 GRPO 训练的演示。
2.2 Large Language Models and Reinforcement Learning
2.2 大语言模型与强化学习
Reinforcement learning (RL) (Kaelbling et al., 1996) is a learning paradigm where an agent learns to make sequential decisions by interacting with an environment and receiving feedback in the form of rewards, aiming to maximize cumulative reward over time (Sutton et al., 1999). RL was introduced to LLM tuning by Ouyang et al. (2022) through reinforcement learning from human feedback (RLHF) (Kaufmann et al., 2023). This approach first trains a reward model using human preference data (Lambert et al., 2024), which then guides RL-based tuning of the policy LLM, typically via the Proximal Policy Optimization (PPO) algorithm. However, PPO involves multiple rounds of LLM optimization, making it challenging to implement. To simplify RL-based tuning, direct optimization methods such as Direct Preference Optimization (DPO) (Rafailov et al., 2023) and SimPO (Meng et al., 2024) have been proposed. While these methods offer computational efficiency, they suffer from off-policy issues (Pang et al., 2024) and do not consistently match the performance of pure RL approaches. Alternative solutions include Group Relative Policy Optimization (GRPO) (Shao et al., 2024), which eliminates the need for a critic model by estimating baselines from group scores, and RLOO (Ahmadian et al., 2024), which introduces a simplified REINFORCE-style (Williams, 1992) optimization framework. Despite these advances, the application of RL to LLM-driven search engine interactions and reasoning remains largely unexplored.
强化学习 (Reinforcement Learning, RL) (Kaelbling et al., 1996) 是一种学习范式,其中智能体通过与环境的交互和以奖励形式接收反馈来学习做出序列决策,旨在最大化随时间累积的奖励 (Sutton et al., 1999)。Ouyang 等人 (2022) 通过基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) (Kaufmann et al., 2023) 将 RL 引入大语言模型的调优中。该方法首先使用人类偏好数据训练奖励模型 (Lambert et al., 2024),然后通过近端策略优化 (Proximal Policy Optimization, PPO) 算法指导基于 RL 的策略大语言模型调优。然而,PPO 涉及多轮大语言模型优化,实现起来具有挑战性。为了简化基于 RL 的调优,提出了直接优化方法,如直接偏好优化 (Direct Preference Optimization, DPO) (Rafailov et al., 2023) 和 SimPO (Meng et al., 2024)。尽管这些方法提供了计算效率,但它们存在离策略问题 (Pang et al., 2024),并且无法始终匹配纯 RL 方法的性能。替代解决方案包括组相对策略优化 (Group Relative Policy Optimization, GRPO) (Shao et al., 2024),它通过从组分数估计基线来消除对评论模型的需求,以及 RLOO (Ahmadian et al., 2024),它引入了简化的 REINFORCE 风格 (Williams, 1992) 优化框架。尽管取得了这些进展,RL 在大语言模型驱动的搜索引擎交互和推理中的应用仍然很大程度上未被探索。
3 Search-R1
3 搜索-R1
In the following sections, we present the detailed design of SEARCH-R1, covering (1) reinforcement learning with a search engine; (2) text generation with an interleaved multiturn search engine call; (3) the training template; and (4) reward model design.
在以下部分中,我们将详细介绍 SEARCH-R1 的设计,涵盖:(1) 使用搜索引擎的强化学习;(2) 通过交错多轮搜索引擎调用的文本生成;(3) 训练模板;以及 (4) 奖励模型设计。
3.1 Reinforcement Learning with a Search Engine
3.1 使用搜索引擎的强化学习
We formulate the reinforcement learning framework with a search engine $\mathcal{R}$ as follows:
我们将强化学习框架与搜索引擎 $\mathcal{R}$ 表述如下:

where $\pi_{\theta}$ is the policy LLM, $\pi_{\mathrm{ref}}$ is the reference LLM, $r_{\phi}$ is the reward function and $\mathbb{D}{\mathrm{KL}}$ is the KL-divergence. Unlike prior LLM reinforcement learning methods that primarily rely on the policy LLM $\pi{\boldsymbol{\theta}}(\cdot\mid x)$ to generate rollout sequences (Rafailov et al., 2023; Ouyang et al., 2022), our framework explicitly incorporates retrieval interleaved reasoning via $\pi_{\boldsymbol{\theta}}(\cdot\mid x;\mathcal{R})$ , which can be seen as $\pi_{\boldsymbol{\theta}}(\cdot\mid x)\otimes^{\lambda}\mathcal{R},$ where $\otimes$ denotes interleaved retrievaland-reasoning. This enables more effective decision-ma king in reasoning-intensive tasks that require external information retrieval. A detailed illustration of the rollout process is provided in Section 3.2.
其中 $\pi_{\theta}$ 是策略大语言模型,$\pi_{\mathrm{ref}}$ 是参考大语言模型,$r_{\phi}$ 是奖励函数,$\mathbb{D}{\mathrm{KL}}$ 是 KL 散度。与之前主要依赖策略大语言模型 $\pi{\boldsymbol{\theta}}(\cdot\mid x)$ 生成 rollout 序列的大语言模型强化学习方法 (Rafailov et al., 2023; Ouyang et al., 2022) 不同,我们的框架通过 $\pi_{\boldsymbol{\theta}}(\cdot\mid x;\mathcal{R})$ 显式地结合了检索交错推理,可以将其视为 $\pi_{\boldsymbol{\theta}}(\cdot\mid x)\otimes^{\lambda}\mathcal{R}$,其中 $\otimes$ 表示检索与推理的交错。这使得在需要外部信息检索的推理密集型任务中能够更有效地进行决策。第 3.2 节提供了 rollout 过程的详细说明。
Our approach builds upon two well-established policy gradient RL methods: Proximal Policy Optimization (PPO) (Schulman et al., 2017) and Group Relative Policy Optimization (GRPO) (Shao et al., 2024; Guo et al., 2025), leveraging their respective advantages to optimize retrieval-augmented reasoning.
我们的方法基于两种成熟的策略梯度强化学习方法:近端策略优化 (Proximal Policy Optimization, PPO) (Schulman et al., 2017) 和群体相对策略优化 (Group Relative Policy Optimization, GRPO) (Shao et al., 2024; Guo et al., 2025),利用它们各自的优势来优化检索增强推理。
Loss Masking for Retrieved Tokens. In both PPO and GRPO, the token-level loss is computed over the entire rollout sequence. In SEARCH-R1, the rollout sequence consists of both LLM-generated tokens and retrieved tokens from external passages. While optimizing LLM-generated tokens enhances the model’s ability to interact with the search engine and perform reasoning, applying the same optimization to retrieved tokens can lead to unintended learning dynamics. To address this, we introduce loss masking for retrieved tokens, ensuring that the policy gradient objective is computed only over LLM-generated tokens, while excluding retrieved content from the optimization process. This approach stabilizes training while preserving the flexibility of search-augmented generation.
检索Token的损失掩码。在PPO和GRPO中,Token级别的损失是在整个生成序列上计算的。在SEARCH-R1中,生成序列既包括大语言模型生成的Token,也包括从外部段落中检索到的Token。虽然优化大语言模型生成的Token可以增强模型与搜索引擎交互和进行推理的能力,但对检索到的Token应用相同的优化可能会导致意外的学习动态。为了解决这个问题,我们引入了检索Token的损失掩码,确保策略梯度目标仅在大语言模型生成的Token上计算,同时将检索到的内容排除在优化过程之外。这种方法在保持搜索增强生成灵活性的同时,稳定了训练过程。
PPO $^+$ Search Engine. Proximal Policy Optimization (PPO) (Schulman et al., 2017) is a popular actor-critic reinforcement learning algorithm commonly used for fine-tuning large language models (LLMs) during the RL stage (Ouyang et al., 2022). In our reasoning plus search engine calling scenario, it optimizes LLMs by maximizing the following objective:
PPO$^+$ 搜索引擎。近端策略优化 (Proximal Policy Optimization, PPO) (Schulman et al., 2017) 是一种流行的演员-评论家强化学习算法,通常用于在强化学习 (RL) 阶段微调大语言模型 (LLMs) (Ouyang et al., 2022)。在我们的推理加搜索引擎调用场景中,它通过最大化以下目标来优化大语言模型:
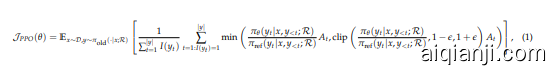
where $\pi_{\theta}$ and $\pi_{\mathrm{ref}}$ represent the current and reference policy models, respectively. The variable $x$ denotes input samples drawn from the dataset $\mathcal{D}$ , while $y$ represents the model’s generated outputs interleaved with search engine calling results, sampled from the reference policy $\pi_{\mathrm{ref}}(y\mid x;\mathcal{R})$ and retrieved from the search engine $\mathcal{R}$ . $I(y_{t})$ is the token loss masking operation. $I(y_{t})=1$ if $y_{t}$ is a LLM generated token and $I(y_{t})\overset{}{=}0$ if $y_{t}$ is a retrieved token. The term $\epsilon$ is a clipping-related hyper parameter introduced in PPO to stabilize training. The advantage estimate $A_{t}$ is computed using Generalized Advantage Estimation (GAE) (Schulman et al., 2015), based on future rewards ${r_{\geq t}}$ and a learned value function $V_{\phi}$ .
其中 $\pi_{\theta}$ 和 $\pi_{\mathrm{ref}}$ 分别表示当前策略模型和参考策略模型。变量 $x$ 表示从数据集 $\mathcal{D}$ 中抽取的输入样本,而 $y$ 表示模型生成的输出与搜索引擎调用结果的交错,这些输出是从参考策略 $\pi_{\mathrm{ref}}(y\mid x;\mathcal{R})$ 中采样并从搜索引擎 $\mathcal{R}$ 中检索得到的。$I(y_{t})$ 是 Token 损失掩码操作。如果 $y_{t}$ 是大语言模型生成的 Token,则 $I(y_{t})=1$;如果 $y_{t}$ 是检索到的 Token,则 $I(y_{t})\overset{}{=}0$。$\epsilon$ 是 PPO 中引入的与裁剪相关的超参数,用于稳定训练。优势估计 $A_{t}$ 使用广义优势估计 (GAE) (Schulman et al., 2015) 计算,基于未来奖励 ${r_{\geq t}}$ 和学习到的价值函数 $V_{\phi}$。
GRPO $^+$ Search Engine. To improve policy optimization stability and avoid the need for an additional value function approximation, Group Relative Policy Optimization (GRPO) is introduced in Shao et al. (2024). GRPO differs from Proximal Policy Optimization (PPO) by leveraging the average reward of multiple sampled outputs as a baseline rather than relying on a learned value function. Specifically, for each input question $x_{,}$ , GRPO samples a group of responses ${y_{1},y_{2},\dots,y_{G}}$ from the reference policy $\pi_{\mathrm{ref}}$ . The policy model is then optimized by maximizing the following objective function:
GRPO$^+$搜索引擎。为了提高策略优化的稳定性并避免额外的价值函数近似需求,Shao等人(2024)提出了组相对策略优化(Group Relative Policy Optimization,GRPO)。GRPO与近端策略优化(Proximal Policy Optimization,PPO)的不同之处在于,它利用多个采样输出的平均奖励作为基线,而不是依赖于学习到的价值函数。具体来说,对于每个输入问题$x_{,}$,GRPO从参考策略$\pi_{\mathrm{ref}}$中采样一组响应${y_{1},y_{2},\dots,y_{G}}$。然后通过最大化以下目标函数来优化策略模型:

where $\epsilon$ and $\beta$ are hyper parameters, and $\hat{A}{i,t}$ represents the advantage, which is computed based on the relative rewards of outputs within each group. This approach avoids introducing additional complexity in the computation of $\hat{A{i,t}}$ . $I(y_{i,t})$ is the token loss masking operation. $I(y_{i,t})=1$ if $y_{i,t}$ is a LLM generated token and $\overset{\cdot}{I}(\overset{\cdot}{y}{i,t})=0$ if $y{i,t}$ is a retrieved token. Additionally, instead of incorporating KL divergence as a penalty within the reward function, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss function. The retrieved token masking is also applied when calculating the KL divergence loss $\mathbb{D}_{K L}$ .
其中 $\epsilon$ 和 $\beta$ 是超参数,$\hat{A}{i,t}$ 表示优势值,它是基于每组输出中的相对奖励计算的。这种方法避免了在计算 $\hat{A{i,t}}$ 时引入额外的复杂性。$I(y_{i,t})$ 是 Token 损失掩码操作。如果 $y_{i,t}$ 是大语言模型生成的 Token,则 $I(y_{i,t})=1$;如果 $y_{i,t}$ 是检索到的 Token,则 $\overset{\cdot}{I}(\overset{\cdot}{y}{i,t})=0$。此外,GRPO 不是将 KL 散度作为惩罚项加入奖励函数中,而是通过直接将训练策略与参考策略之间的 KL 散度添加到损失函数中进行正则化。在计算 KL 散度损失 $\mathbb{D}{K L}$ 时,也会应用检索到的 Token 掩码。
3.2 Text Generation with Interleaved Multi-turn Search Engine Call
3.2 多轮交错搜索引擎调用的文本生成
In this section, we describe the rollout process for LLM response generation with interleaved multi-turn search engine calls, formulated as: $y\sim\pi_{\boldsymbol{\theta}}(\cdot\mid\dot{\boldsymbol{x}};\mathcal{R})\stackrel{\sim}{=}\pi_{\boldsymbol{\theta}}(\cdot\mid\boldsymbol{x})\otimes\mathcal{R}$ .
在本节中,我们描述了通过交错多轮搜索引擎调用生成大语言模型 (LLM) 响应的 rollout 过程,其公式为:$y\sim\pi_{\boldsymbol{\theta}}(\cdot\mid\dot{\boldsymbol{x}};\mathcal{R})\stackrel{\sim}{=}\pi_{\boldsymbol{\theta}}(\cdot\mid\boldsymbol{x})\otimes\mathcal{R}$。
Our approach follows an iterative framework where the LLM alternates between text generation and external search engine queries. Specifically, the system instruction guides the LLM to encapsulate its search query between two designated search call tokens,
我们的方法遵循一个迭代框架,其中大语言模型 (LLM) 在文本生成和外部搜索引擎查询之间交替进行。具体来说,系统指令引导 LLM 在需要外部检索时,将其搜索查询封装在两个指定的搜索调用 Token 之间,即 <search> 和 </search>。当在生成的序列中检测到这些 Token 时,系统会提取搜索查询,向搜索引擎发出查询,并检索相关结果。检索到的信息随后被封装在特殊的检索 Token 中,即 <information> 和 </information>,并附加到正在进行的序列中,作为下一步生成的额外上下文。这个过程会持续迭代,直到满足以下条件之一:(1) 搜索引擎调用预算耗尽,或 (2) 模型生成最终响应,该响应被封装在指定的答案 Token 之间,即 <answer> 和 </answer>。完整的工作流程如算法 1 所示。
3.3 Training Template
3.3 训练模板
To train SEARCH-R1, we start by crafting a simple template that directs the initial LLM to follow our predefined instructions. As shown in Table 1, this template structures the model’s output into three parts in an iterative fashion: first, a reasoning process, then a search engine calling function, and finally, the answer. We deliberately limit our constraints to this structural format, avoiding any content-specific biases, such as enforcing reflective reasoning and search engine calling or endorsing specific problem-solving approaches. This ensures that the model’s natural learning dynamics during the RL process remain observable and unbiased.
为了训练 SEARCH-R1,我们首先设计了一个简单的模板,指导初始的大语言模型遵循我们预定义的指令。如表 1 所示,该模板以迭代的方式将模型的输出结构化为三个部分:首先是推理过程,然后是搜索引擎调用函数,最后是答案。我们特意将约束限制在这种结构格式上,避免任何内容特定的偏见,例如强制进行反思性推理和搜索引擎调用,或支持特定的问题解决方法。这确保了模型在强化学习过程中的自然学习动态保持可观察且无偏见。
Table 1: Template for SEARCH-R1. question will be replaced with the specific question during training and inference.
表 1: SEARCH-R1 的模板。在训练和推理过程中,question 将被替换为具体的问题。
Algorithm 1 LLM Response Rollout with Multi-Turn Search Engine Calls
算法 1 多轮搜索引擎调用的大语言模型响应展开
3.4 Reward Modeling
3.4 奖励建模
The reward function serves as the primary training signal, guiding the optimization process in reinforcement learning. To train SEARCH-R1, we adopt a rule-based reward system that consists solely of final outcome rewards, which assess the correctness of the model’s response. For instance, in factual reasoning tasks, correctness can be evaluated using rule-based criteria such as exact string matching.
奖励函数作为主要的训练信号,在强化学习中指导优化过程。为了训练 SEARCH-R1,我们采用了一个基于规则的奖励系统,该系统仅包含最终结果奖励,用于评估模型响应的正确性。例如,在事实推理任务中,可以使用基于规则的准则(如精确字符串匹配)来评估正确性。

where $a_{\mathrm{pred}}$ is the extracted final answer from response $y$ and $a_{\mathrm{gold}}$ is the ground truth answer. Unlike Guo et al. (2025), we do not incorporate format rewards, as our learned model already demonstrates strong structural adherence. We leave the exploration of more complex format rewards for future work. Furthermore, we deliberately avoid training neural reward models for either outcome or process evaluation, following Guo et al. (2025). This decision is motivated by the susceptibility of neural reward models to reward hacking in large-scale reinforcement learning, as well as the additional computational cost and complexity introduced by retraining these models.
其中 $a_{\mathrm{pred}}$ 是从响应 $y$ 中提取的最终答案,$a_{\mathrm{gold}}$ 是真实答案。与 Guo 等人 (2025) 不同,我们没有引入格式奖励,因为我们的学习模型已经表现出很强的结构遵循性。我们将更复杂的格式奖励探索留给未来的工作。此外,我们有意避免为结果或过程评估训练神经奖励模型,遵循 Guo 等人 (2025) 的做法。这一决定是由于神经奖励模型在大规模强化学习中容易受到奖励攻击的影响,以及重新训练这些模型带来的额外计算成本和复杂性。
4 Main results
4 主要结果
4.1 Datasets
4.1 数据集
We evaluate SEARCH-R1 on seven benchmark datasets, categorized as follows:
我们在七个基准数据集上评估了 SEARCH-R1,分类如下:
General Question Answering: NQ (Kwiatkowski et al., 2019), TriviaQA (Joshi et al., 2017), and PopQA (Mallen et al., 2022).
通用问答:NQ (Kwiatkowski et al., 2019)、TriviaQA (Joshi et al., 2017) 和 PopQA (Mallen et al., 2022)。
Multi-Hop Question Answering: HotpotQA (Yang et al., 2018), 2 Wiki Multi Hop QA (Ho et al., 2020), Musique (Trivedi et al., 2022b), and Bamboogle (Press et al., 2022).
多跳问答:HotpotQA (Yang et al., 2018), 2 Wiki Multi Hop QA (Ho et al., 2020), Musique (Trivedi et al., 2022b), 以及 Bamboogle (Press et al., 2022).
These datasets encompass a diverse range of search with reasoning challenges, enabling a comprehensive evaluation of SEARCH-R1 across both single-turn and multi-hop retrieval scenarios.
这些数据集涵盖了多样化的搜索与推理挑战,能够全面评估 SEARCH-R1 在单轮和多跳检索场景中的表现。
4.2 Baselines
4.2 基线
To evaluate the effectiveness of SEARCH-R1, we compare it against the following baseline methods:
为了评估 SEARCH-R1 的有效性,我们将其与以下基线方法进行比较:
Inference without Retrieval: Direct inference and Chain-of-Thought (CoT) reasoning (Wei et al., 2022).
无需检索的推理:直接推理与思维链 (Chain-of-Thought, CoT) 推理 (Wei et al., 2022)。
Inference with Retrieval: Retrieval-Augmented Generation (RAG) (Lewis et al., 2020), IRCoT (Trivedi et al., 2022a), and Search-o1 (Li et al., 2025).
推理与检索:检索增强生成 (Retrieval-Augmented Generation, RAG) (Lewis et al., 2020)、IRCoT (Trivedi et al., 2022a) 和 Search-o1 (Li et al., 2025)。
Fine-Tuning-Based Methods: Supervised fine-tuning (SFT) (Chung et al., 2024) and reinforcement learning-based fine-tuning without a search engine (R1) (Guo et al., 2025).
基于微调的方法:监督微调 (SFT) (Chung et al., 2024) 和基于强化学习的微调 (R1) (Guo et al., 2025)。
These baselines cover a broad spectrum of retrieval-augmented and fine-tuning approaches, allowing for a comprehensive assessment of SEARCH-R1 in both zero-shot and learned retrieval settings.
这些基线涵盖了广泛的检索增强和微调方法,使得我们能够在零样本和已学习的检索设置中对 SEARCH-R1 进行全面评估。
To make a fair comparison between different methods, we use the same retriever, knowledge corpus, training data and LLMs. More details can be found in Section 4.3.
为了在不同方法之间进行公平比较,我们使用了相同的检索器、知识库、训练数据和大语言模型。更多细节可以在第4.3节中找到。
4.3 Experimental Setup
4.3 实验设置
We conduct experiments using three types of models: Qwen-2.5-3B (Base/Instruct) and Qwen-2.5-7B (Base/Instruct) (Yang et al., 2024), as well as Llama-3.2-3B (Base/Instruct) (Dubey et al., 2024). For retrieval, we use the 2018 Wikipedia dump (Karpukhin et al., 2020) as the knowledge source and E5 (Wang et al., 2022) as the retriever. To ensure fair comparison, we follow Lin et al. (2023) and set the number of retrieved passages to three across all retrieval-based methods.
我们使用三种类型的模型进行实验:Qwen-2.5-3B (Base/Instruct) 和 Qwen-2.5-7B (Base/Instruct) (Yang et al., 2024),以及 Llama-3.2-3B (Base/Instruct) (Dubey et al., 2024)。对于检索,我们使用 2018 年的 Wikipedia 数据转储 (Karpukhin et al., 2020) 作为知识源,并使用 E5 (Wang et al., 2022) 作为检索器。为了确保公平比较,我们遵循 Lin et al. (2023) 的方法,在所有基于检索的方法中将检索到的段落数量设置为三。
For training, we merge the training sets of NQ and HotpotQA to form a unified dataset for SEARCH-R1 and other fine-tuning-based baselines. Evaluation is conducted on the test or validation sets of all seven datasets to assess both in-domain and out-of-domain performance. Exact Match (EM) is used as the evaluation metric, following Yu et al. (2024). For inferencestyle baselines, we use instruct models, as base models fail to follow instructions. For RL tuning methods, experiments are conducted on both base and instruct models.
为了训练,我们将 NQ 和 HotpotQA 的训练集合并,形成一个统一的数据集,用于 SEARCH-R1 和其他基于微调的基线模型。评估在所有七个数据集的测试集或验证集上进行,以评估域内和域外性能。遵循 Yu 等人 (2024) 的方法,使用精确匹配 (Exact Match, EM) 作为评估指标。对于推理风格的基线模型,我们使用指令模型,因为基础模型无法遵循指令。对于强化学习调优方法,实验在基础模型和指令模型上进行。
For SEARCH-R1 training, in PPO Training, the policy LLM learning rate is set to 1e-6, and value LLM learning rate to 1e-5. The Generalized Advantage Estimation (GAE) parameters are $\lambda=1$ and $\gamma=\mathrm{\check{1}}$ . In GRPO Training, the policy LLM learning rate is set to 1e-6, with five sampled responses per prompt. We use exact match (EM) to calculate the outcome reward. Unless stated otherwise, PPO is used as the default RL method, and a detailed comparison between PPO and GRPO is provided in Section 5.1.
在 SEARCH-R1 的训练中,PPO 训练的策略大语言模型 (LLM) 学习率设置为 1e-6,价值大语言模型学习率设置为 1e-5。广义优势估计 (GAE) 参数为 $\lambda=1$ 和 $\gamma=\mathrm{\check{1}}$。在 GRPO 训练中,策略大语言模型学习率设置为 1e-6,每个提示生成五个采样响应。我们使用精确匹配 (EM) 来计算结果奖励。除非另有说明,PPO 被用作默认的强化学习方法,PPO 和 GRPO 的详细对比见第 5.1 节。
4.4 Performance
4.4 性能
The main results comparing SEARCH-R1 with baseline methods across the seven datasets are presented in Table 2. From the results, we make the following key observations:
表 2 展示了 SEARCH-R1 与基线方法在七个数据集上的主要结果对比。从结果中,我们得出以下关键观察:
SEARCH-R1 consistently outperforms strong baseline methods. We achieve $26%$ , $21%$ , and $10%$ average relative improvement with Qwen2.5-7B, Qwen2.5-3B, and LLaMA3.2- 3B, respectively. These gains hold across both in-distribution evaluation (i.e., NQ and HotpotQA) and out-of-distribution evaluation (i.e., TriviaQA, PopQA, 2 Wiki Multi Hop QA, Musique, and Bamboogle).
SEARCH-R1 始终优于强基线方法。我们使用 Qwen2.5-7B、Qwen2.5-3B 和 LLaMA3.2-3B 分别实现了 26%、21% 和 10% 的平均相对改进。这些改进在分布内评估(即 NQ 和 HotpotQA)和分布外评估(即 TriviaQA、PopQA、2 Wiki Multi Hop QA、Musique 和 Bamboogle)中均保持一致。
SEARCH-R1 surpasses RL-based training for LLM reasoning without retrieval (R1) (Guo et al., 2025). This aligns with expectations, as incorporating search into LLM reasoning provides access to relevant external knowledge, improving overall performance.
SEARCH-R1 在没有检索 (R1) 的情况下超越了基于强化学习 (RL) 的大语言模型推理训练 (Guo et al., 2025)。这与预期一致,因为将搜索引入大语言模型推理可以提供相关的外部知识,从而提高整体性能。
SEARCH-R1 is effective for both base and instruction-tuned models. This demonstrates that DeepSeek-R1-Zero-style RL with outcome-based rewards (Guo et al., 2025) can be successfully applied to reasoning with search, extending beyond its previously established effectiveness in pure reasoning scenarios.
SEARCH-R1 对基础模型和指令调优模型均有效。这表明,基于结果的奖励的 DeepSeek-R1-Zero 风格强化学习 (Guo et al., 2025) 可以成功应用于搜索推理,超越了其在纯推理场景中已确立的有效性。
Table 2: Main results. The best performance is set in bold, and the second best is set in underline.
表 2: 主要结果。最佳性能以粗体显示,次佳性能以下划线显示。
| 方法 | NQ | TriviaQA | PopQA | HotpotQA | 2wiki | Musique | Bamboogle | 平均 |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-7b-Base/Instruct | ||||||||
| 直接推理 | 0.134 | 0.408 | 0.140 | 0.183 | 0.250 | 0.031 | 0.120 | 0.181 |
| CoT | 0.048 | 0.185 | 0.054 | 0.092 | 0.111 | 0.022 | 0.232 | 0.106 |
| IRCoT | 0.224 | 0.478 | 0.301 | 0.133 | 0.149 | 0.072 | 0.224 | 0.239 |
| Search-o1 | 0.151 | 0.443 | 0.131 | 0.187 | 0.176 | 0.058 | 0.296 | 0.206 |
| RAG | 0.349 | 0.585 | 0.392 | 0.299 | 0.235 | 0.058 | 0.208 | 0.304 |
| SFT | 0.318 | 0.354 | 0.121 | 0.217 | 0.259 | 0.066 | 0.112 | 0.207 |
| R1-base | 0.297 | 0.539 | 0.202 | 0.242 | 0.273 | 0.083 | 0.296 | 0.276 |
| R1-instruct | 0.270 | 0.537 | 0.199 | 0.237 | 0.292 | 0.072 | 0.293 | 0.271 |
| Search-R1-base | 0.412 | 0.568 | 0.428 | 0.356 | 0.322 | 0.142 | 0.384 | 0.373 |
| Search-R1-instruct | 0.397 | 0.606 | 0.404 | 0.380 | 0.326 | 0.168 | 0.408 | 0.384 |
| Qwen2.5-3b-Base/Instruct | ||||||||
| 直接推理 | 0.106 | 0.288 | 0.108 | 0.149 | 0.244 | 0.020 | 0.024 | 0.134 |
| CoT | 0.023 | 0.032 | 0.005 | 0.021 | 0.021 | 0.002 | 0.000 | 0.015 |
| IRCoT | 0.111 | 0.312 | 0.200 | 0.164 | 0.171 | 0.067 | 0.240 | 0.181 |
| Search-o1 | 0.238 | 0.472 | 0.262 | 0.221 | 0.218 | 0.054 | 0.320 | 0.255 |
| RAG | 0.348 | 0.544 | 0.387 | 0.255 | 0.226 | 0.047 | 0.080 | 0.270 |
| SFT | 0.249 | 0.292 | 0.104 | 0.186 | 0.248 | 0.044 | 0.112 | 0.176 |
| R1-base | 0.226 | 0.455 | 0.173 | 0.201 | 0.268 | 0.055 | 0.224 | 0.229 |
| R1-instruct | 0.210 | 0.449 | 0.171 | 0.208 | 0.275 | 0.060 | 0.192 | 0.224 |
| Search-R1-base | 0.341 | 0.513 | 0.362 | 0.263 | 0.273 | 0.076 | 0.211 | 0.292 |
| Search-R1-instruct | 0.323 | 0.537 | 0.364 | 0.308 | 0.336 | 0.105 | 0.315 | 0.327 |
| LLaMA3.2-3b-Base/Instruct | ||||||||
| 直接推理 | 0.139 | 0.368 | 0.124 | 0.122 | 0.107 | 0.015 | 0.064 | 0.134 |
| CoT | 0.246 | 0.487 | 0.166 | 0.051 | 0.083 | 0.006 | 0.024 | 0.152 |
| IRCoT | 0.363 | 0.566 | 0.428 | 0.238 | 0.236 | 0.072 | 0.208 | 0.301 |
| Search-o1 | 0.107 | 0.203 | 0.093 | 0.132 | 0.117 | 0.035 | 0.176 | 0.123 |
| RAG | 0.317 | 0.551 | 0.337 | 0.234 | 0.118 | 0.034 | 0.064 | 0.237 |
| SFT | 0.320 | 0.341 | 0.122 | 0.206 | 0.257 | 0.064 | 0.120 | 0.204 |
| R1-base | 0.290 | 0.514 | 0.237 | 0.234 | 0.279 | 0.055 | 0.146 | 0.251 |
| R1-instruct | 0.384 | 0.549 | 0.228 | 0.238 | 0.269 | 0.074 | 0.315 | 0.294 |
| Search-R1-base | 0.394 | 0.596 | 0.437 | 0.280 | 0.264 | 0.056 | 0.105 | 0.305 |
| Search-R1-instruct | 0.357 | 0.578 | 0.378 | 0.314 | 0.233 | 0.090 | 0.306 | 0.322 |
SEARCH-R1 generalizes across different base LLMs, including Qwen2.5 and LLaMA3.2. This contrasts with findings in RL for mathematical reasoning, where RL has been observed to work effectively only for certain base LLMs (Zeng et al., 2025). Our results indicate that search-augmented RL is more broadly applicable across model families.
SEARCH-R1 能够泛化到不同的基础大语言模型 (LLM),包括 Qwen2.5 和 LLaMA3.2。这与数学推理中的强化学习 (RL) 研究结果形成对比,后者观察到 RL 仅对某些基础大语言模型有效 (Zeng et al., 2025)。我们的结果表明,搜索增强的强化学习在模型家族中具有更广泛的适用性。
5 Analysis
5 分析
5.1 Different RL methods: PPO vs. GRPO
5.1 不同的强化学习方法:PPO 与 GRPO
We evaluate SEARCH-R1 using both PPO and GRPO as the base RL method, conducting experiments on LLaMA3.2-3B and Qwen2.5-3B models. The training dynamics comparison is presented in Figure 2, revealing the following insights:
我们使用 PPO 和 GRPO 作为基础的强化学习方法对 SEARCH-R1 进行评估,并在 LLaMA3.2-3B 和 Qwen2.5-3B 模型上进行了实验。训练动态的比较如图 2 所示,揭示了以下见解:
GRPO converges faster than PPO across all cases. This is because PPO relies on a critic model, which requires several warm-up steps before effective training begins.
GRPO 在所有情况下都比 PPO 收敛得更快。这是因为 PPO 依赖于一个评论家模型 (critic model),该模型在有效训练开始之前需要几个预热步骤。
PPO demonstrates greater training stability. As shown in Figure 2(b), GRPO leads to reward collapse when applied to the LLaMA3.2-3B-Instruct model, whereas PPO remains stable across different LLM architectures.
PPO 表现出更强的训练稳定性。如图 2(b) 所示,当应用于 LLaMA3.2-3B-Instruct 模型时,GRPO 会导致奖励崩溃,而 PPO 在不同的 LLM 架构中保持稳定。
The final training rewards of PPO and GRPO are comparable. Despite differences in convergence speed and stability, both methods achieve similar final reward values, indicating that both are viable for optimizing SEARCH-R1.
PPO 和 GRPO 的最终训练奖励相当。尽管收敛速度和稳定性存在差异,但两种方法都达到了相似的最终奖励值,表明两者都适用于优化 SEARCH-R1。

Figure 2: Training dynamics of SEARCH-R1 with PPO and GRPO as the base RL method across four LLMs. GRPO generally converges faster but may exhibit instability in certain cases (e.g., LLaMA3.2-3B-Instruct), whereas PPO provides more stable optimization but converges at a slower rate.
图 2: 使用 PPO 和 GRPO 作为基础强化学习方法的 SEARCH-R1 在四个大语言模型上的训练动态。GRPO 通常收敛更快,但在某些情况下可能表现出不稳定性(例如 LLaMA3.2-3B-Instruct),而 PPO 提供了更稳定的优化,但收敛速度较慢。
Table 3: The performance results of SEARCH-R1 with PPO and GRPO on seven datasets.
表 3: SEARCH-R1 在 PPO 和 GRPO 下在七个数据集上的性能结果。
| 方法 | NQ | TriviaQA | PopQA | HotpotQA | 2wiki | Musique | Bamboogle | 平均值 |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-3b-Base/Instruct | ||||||||
| SEARCH-R1-base (GRPO) | 0.396 | 0.582 | 0.390 | 0.283 | 0.266 | 0.054 | 0.113 | 0.298 |
| SEARCH-R1-instruct(GRPO) | 0.409 | 0.552 | 0.405 | 0.345 | 0.369 | 0.154 | 0.320 | 0.365 |
| SEARCH-R1-base (PPO) | 0.341 | 0.513 | 0.362 | 0.263 | 0.273 | 0.076 | 0.211 | 0.292 |
| SEARCH-R1-instruct(PPO) | 0.323 | 0.537 | 0.364 | 0.308 | 0.336 | 0.105 | 0.315 | 0.327 |
| LLaMA3.2-3b-Base/Instruct | ||||||||
| SEARCH-R1-base (GRPO) | 0.431 | 0.612 | 0.458 | 0.300 | 0.297 | 0.067 | 0.104 | 0.324 |
| SEARCH-R1-instruct(GRPO) | 0.333 | 0.524 | 0.329 | 0.229 | 0.190 | 0.047 | 0.192 | 0.263 |
| SEARCH-R1-base (PPO) | 0.394 | 0.596 | 0.437 | 0.280 | 0.264 | 0.056 | 0.105 | 0.305 |
| SEARCH-R1-instruct (PPO) | 0.357 | 0.578 | 0.378 | 0.314 | 0.233 | 0.090 | 0.306 | 0.322 |
The evaluation results are presented in Table 3, revealing the following key findings:
评估结果如表 3 所示,揭示了以下关键发现:
GRPO generally outperforms PPO. Across both Qwen2.5-3B and LLaMA3.2-3B, GRPO achieves higher average performance, demonstrating its effectiveness in optimizing retrievalaugmented reasoning.
GRPO 通常优于 PPO。在 Qwen2.5-3B 和 LLaMA3.2-3B 上,GRPO 实现了更高的平均性能,证明了其在优化检索增强推理方面的有效性。
Instruct variants perform better than base variants. For Qwen2.5-3B, SEARCH-R1-Instruct (GRPO) achieves the highest overall average score (0.365), outperforming all other configurations. For LLaMA3.2-3B, the best-performing variant is SEARCH-R1-Base (GRPO) with an average score of 0.324, followed closely by SEARCH-R1-Instruct (PPO) at 0.322.
Instruct 变体表现优于基础变体。对于 Qwen2.5-3B,SEARCH-R1-Instruct (GRPO) 获得了最高的总体平均分 (0.365),优于所有其他配置。对于 LLaMA3.2-3B,表现最好的变体是 SEARCH-R1-Base (GRPO),平均得分为 0.324,紧随其后的是 SEARCH-R1-Instruct (PPO),得分为 0.322。
5.2 Base vs. Instruct LLMs
5.2 基础大语言模型 vs. 指令大语言模型
We analyze the training dynamics of SEARCH-R1 across both base LLMs and instructiontuned LLMs. Experiments are conducted on three model variants: LLaMA3.2-3B, Qwen2.5- 3B, and Qwen2.5-7B. As shown in Figure 3, we observe that instruction-tuned models converge faster and start from a higher initial performance compared to base models. However, the final performance of both model types remains highly similar after training. This finding suggests that while general post-training accelerates learning in reasoning-plussearch scenarios, reinforcement learning can effectively bridge the gap over time, enabling base models to achieve comparable performance.
我们分析了 SEARCH-R1 在基础大语言模型和指令微调大语言模型上的训练动态。实验在三个模型变体上进行:LLaMA3.2-3B、Qwen2.5-3B 和 Qwen2.5-7B。如图 3 所示,我们观察到指令微调模型相比基础模型收敛更快,并且从更高的初始性能开始。然而,训练后两种模型类型的最终性能仍然非常相似。这一发现表明,虽然通用的训练后加速在推理加搜索场景中加快了学习速度,但强化学习能够随着时间的推移有效弥合差距,使基础模型能够达到相当的性能。
5.3 Response Length Study
5.3 响应长度研究
We conduct an experiment using SEARCH-R1 with the LLaMA3.2-3b-base model, training on NQ to analyze the dynamics of training reward and response length over the course of training. The results are presented in Figure 4(a), revealing the following key trends:
我们使用 SEARCH-R1 和 LLaMA3.2-3b-base 模型进行实验,在 NQ 数据集上进行训练,以分析训练过程中奖励和响应长度的动态变化。结果如图 4(a) 所示,揭示了以下关键趋势:
(1) Early Stage (First 100 Steps): The response length sharply decreases, while the training reward exhibits a slight increase. During this phase, the base model learns to eliminate excessive filler words and begins adapting to the task requirements.
(1) 早期阶段 (前 100 步):响应长度急剧下降,而训练奖励略有增加。在此阶段,基础模型学会消除过多的填充词,并开始适应任务要求。

Figure 3: Study of SEARCH-R1 on base and instruct LLMs. The instruction model converges faster and starts from a better initial performance. However, the final performance of both models is very similar.
图 3: SEARCH-R1 在基础大语言模型和指令大语言模型上的研究。指令模型收敛速度更快,并且初始性能更好。然而,两个模型的最终性能非常相似。

Figure 4: (a) Response Length Study: The response length exhibits a decrease-increasestabilize trend throughout training, aligning with the overall performance trajectory of the LLM. (b) Retrieved Token Loss Masking Study: Implementing retrieved token masking leads to greater LLM improvements, mitigating unintended optimization effects and ensuring more stable training dynamics.
图 4: (a) 响应长度研究:响应长度在整个训练过程中呈现出下降-上升-稳定的趋势,与大语言模型的整体性能轨迹一致。 (b) 检索 Token 损失掩码研究:实施检索 Token 掩码会带来更大的大语言模型改进,减轻意外的优化效果并确保更稳定的训练动态。
(2) Mid Stage (100–130 Steps): Both response length and training reward increase significantly. At this point, the LLM learns to call the search engine, resulting in longer responses due to retrieved passages. The training reward improves substantially, as the model becomes more effective at leveraging search results.
(2) 中期阶段 (100–130 步):响应长度和训练奖励显著增加。此时,大语言模型学会了调用搜索引擎,由于检索到的段落,响应变得更长。训练奖励大幅提升,因为模型在利用搜索结果方面变得更加有效。
(3) Late Stage (After 130 Steps): The response length stabilizes, and the training reward continues to increase slightly. At this stage, the model has learned to use the search engine effectively and focuses on refining its search queries. Given that NQ is a relatively simple task, the response length stabilizes at approximately 500 tokens, indicating convergence.
(3) 后期阶段 (130 步之后):响应长度趋于稳定,训练奖励继续小幅增加。在此阶段,模型已经学会有效使用搜索引擎,并专注于优化其搜索查询。由于 NQ 是一个相对简单的任务,响应长度稳定在约 500 个 token,表明模型已经收敛。
5.4 Study of Retrieved Tokens Loss Masking
5.4 检索 Token 损失掩码研究
In Section 3.1, we introduced token-level loss masking for retrieved tokens to prevent unintended optimization behaviors. Here, we empirically evaluate its effectiveness by analyzing its impact on training stability and model performance.
在第3.1节中,我们介绍了检索到的Token的Token级损失掩码,以防止意外的优化行为。在这里,我们通过分析其对训练稳定性和模型性能的影响,实证评估其有效性。
We conduct experiments on the LLaMA3.2-3b-base model, comparing training dynamics with and without retrieved token loss masking. As shown in Figure 4(b), applying retrieved token masking results in greater LLM improvements, mitigating unintended optimization effects and ensuring more stable training dynamics.
我们在 LLaMA3.2-3b-base 模型上进行了实验,比较了有无检索 Token 损失掩码的训练动态。如图 4(b) 所示,应用检索 Token 掩码带来了更大的大语言模型改进,减轻了意外的优化效果,并确保了更稳定的训练动态。
The performance comparison is provided in Table 4, demonstrating that SEARCH-R1 trained with retrieved token loss masking consistently outperforms the variant without masking.
性能对比见表 4,结果表明,使用检索到的 token 损失掩码训练的 SEARCH-R1 始终优于未使用掩码的变体。
5.5 Case Studies
5.5 案例研究
To gain deeper insights into SEARCH-R1, we conduct a case study using Qwen2.5-7B-Base, comparing its behavior with RL without a search engine (Guo et al., 2025). The results are presented in Table 5, revealing the following key observations:
为了更深入地了解 SEARCH-R1,我们使用 Qwen2.5-7B-Base 进行了一项案例研究,将其行为与没有搜索引擎的 RL (Guo et al., 2025) 进行了比较。结果如表 5 所示,揭示了以下关键观察结果:
Table 4: The performance of SEARCH-R1 with and without retrieved token loss masking. The LLM trained with retrieved token loss masking achieves consistently better performance. (LLM: LLaMA3.2-3b-base)
表 4: SEARCH-R1 在使用和不使用检索 token 损失掩码时的性能对比。使用检索 token 损失掩码训练的大语言模型 (LLM) 始终表现更好。(LLM: LLaMA3.2-3b-base)
| 方法 | NQ | TriviaQA | PopQA | HotpotQA | 2wiki | Musique | Bamboogle | 平均 |
|---|---|---|---|---|---|---|---|---|
| SEARCH-R1 使用掩码 | 0.394 | 0.596 | 0.437 | 0.280 | 0.264 | 0.056 | 0.105 | 0.305 |
| SEARCH-R1 不使用掩码 | 0.124 | 0.360 | 0.152 | 0.131 | 0.211 | 0.017 | 0.032 | 0.147 |
Table 5: A case study of R1 and SEARCH-R1.
表 5: R1 和 SEARCH-R1 的案例研究
| Ground Truth: McComb, Mississippi |
Interleaved Reasoning and Retrieval Enhances Problem Analysis: SEARCH-R1 enables the LLM to perform in-depth reasoning with multi-turn retrieval, whereas RL without search relies solely on the model’s internal knowledge. By incorporating retrieved passages, SEARCH-R1 allows the LLM to iterative ly refine its reasoning, leading to more informed and accurate responses.
交错推理与检索增强问题分析:SEARCH-R1 使大语言模型能够通过多轮检索进行深入推理,而无检索的 RL 仅依赖模型的内部知识。通过整合检索到的段落,SEARCH-R1 使大语言模型能够迭代优化其推理,从而产生更明智和准确的响应。
Self-Verification through Iterative Retrieval: We observe that after the second retrieval round, the LLM has already gathered sufficient information to answer the question. However, SEARCH-R1 performs an additional retrieval step to self-verify its conclusion, further reinforcing its confidence in the final response. This phenomenon aligns with findings from LLM reasoning RL without retrieval (Guo et al., 2025), highlighting how reinforcement learning can encourage verification-driven reasoning even in search-augmented settings.
通过迭代检索进行自我验证:我们观察到,在第二轮检索后,大语言模型已经收集了足够的信息来回答问题。然而,SEARCH-R1 执行了额外的检索步骤以自我验证其结论,进一步增强了其对最终回答的信心。这一现象与无需检索的大语言模型推理强化学习(Guo et al., 2025)的研究结果一致,强调了即使在搜索增强的环境中,强化学习也能促进验证驱动的推理。
6 Conclusion
6 结论
In this work, we introduced SEARCH-R1, a novel reinforcement learning framework that enables large language models (LLMs) to interleave self-reasoning with real-time search engine interactions. Unlike existing retrieval-augmented generation (RAG) approaches, which lack flexibility for multi-turn retrieval, or tool-use methods that require large-scale supervised training data, SEARCH-R1 optimizes LLM rollouts through reinforcement learning, allowing autonomous query generation and strategic utilization of retrieved information. Through extensive experiments on seven datasets, we demonstrated that SEARCH-R1 significantly enhances LLMs’ ability to tackle complex reasoning tasks requiring real-time external knowledge. Our analysis also provides key insights into RL training strategies for search-augmented reasoning. Looking ahead, future work can explore expanding SEARCHR1 to support broader search strategies, including more sophisticated reward mechanisms, dynamic retrieval adjustments based on uncertainty, and integration with diverse information sources beyond web search. It is also promising to investigate its applicability to multimodal reasoning tasks.
在本工作中,我们介绍了 SEARCH-R1,这是一种新颖的强化学习框架,使大语言模型 (LLMs) 能够在自我推理与实时搜索引擎交互之间交替进行。与现有的检索增强生成 (RAG) 方法(缺乏多轮检索的灵活性)或需要大规模监督训练数据的工具使用方法不同,SEARCH-R1 通过强化学习优化 LLM 的 rollout,允许自主生成查询并战略性地利用检索到的信息。通过在七个数据集上的广泛实验,我们证明了 SEARCH-R1 显著增强了 LLMs 处理需要实时外部知识的复杂推理任务的能力。我们的分析还为搜索增强推理的强化学习训练策略提供了关键见解。展望未来,未来的工作可以探索扩展 SEARCH-R1 以支持更广泛的搜索策略,包括更复杂的奖励机制、基于不确定性的动态检索调整,以及与网络搜索之外的多样化信息源的集成。研究其在多模态推理任务中的适用性也很有前景。
Acknowledgments
致谢
This research was supported in part by Apple PhD Fellowship, in part by US DARPA INCAS Program No. HR0011-21-C0165 and BRIES Program No. HR0011-24-3-0325, in part by the Office of Naval Research contract number N 000142412612, in part by NSF grant numbers IIS19-56151 and 2402873, in part by the Molecule Maker Lab Institute: An AI Research Institutes program supported by NSF under Award No. 2019897 and the Institute for Geospatial Understanding through an Integrative Discovery Environment (I-GUIDE) by NSF under Award No. 2118329, in part by Cisco, and in part by the Center for Intelligent Information Retrieval. Any opinions, findings, and conclusions or recommendations expressed herein are those of the authors and do not necessarily represent the views, either expressed or implied, of the sponsors or the U.S. Government.
本研究部分由 Apple PhD Fellowship 支持,部分由美国 DARPA INCAS 计划(编号 HR0011-21-C0165)和 BRIES 计划(编号 HR0011-24-3-0325)支持,部分由海军研究办公室合同(编号 N 000142412612)支持,部分由 NSF 资助(编号 IIS19-56151 和 2402873)支持,部分由 NSF 资助的分子制造实验室研究所(编号 2019897)和 NSF 资助的通过综合发现环境的空间理解研究所(I-GUIDE,编号 2118329)支持,部分由 Cisco 支持,部分由智能信息检索中心支持。本文所表达的任何观点、发现、结论或建议均为作者的观点,并不一定代表赞助方或美国政府的观点。
References
参考文献
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2, 2023.
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang, 和 Haofen Wang. 大语言模型的检索增强生成:综述. arXiv 预印本 arXiv:2312.10997, 2, 2023.
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. Reward bench: Evaluating reward models for language modeling. arXiv preprint arXiv:2403.13787, 2024.
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, 等. Reward bench: 评估语言建模的奖励模型. arXiv 预印本 arXiv:2403.13787, 2024.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, 和 Oleg Klimov. 近端策略优化算法. arXiv 预印本 arXiv:1707.06347, 2017.