MonSter: Marry Monodepth to Stereo Unleashes Power
MonSter: 融合单目深度与立体视觉释放潜力
Junda Cheng1, Longliang Liu1, Gangwei $\mathrm{Xu^{1}}$ , Xianqi Wang1, Zhaoxing Zhang1, Yong Deng2, Jinliang Zang2, Yurui Chen2, Zhipeng Cai3, Xin Yang1† 1 Huazhong University of Science and Technology 2 Autel Robotics 3 Intel Labs {jundacheng, longliangl, gwxu, xianqiw, zzx, x in yang 2014}@hust.edu.cn, czptc2h@gmail.com
Junda Cheng1, Longliang Liu1, Gangwei $\mathrm{Xu^{1}}$ , Xianqi Wang1, Zhaoxing Zhang1, Yong Deng2, Jinliang Zang2, Yurui Chen2, Zhipeng Cai3, Xin Yang1† 1 华中科技大学 2 道通智能 3 英特尔实验室 {jundacheng, longliangl, gwxu, xianqiw, zzx, x in yang 2014}@hust.edu.cn, czptc2h@gmail.com

Figure 1. Zero-shot generalization comparison: all models are trained on Scene Flow and tested directly on KITTI. Compared to the baseline IGEV [38], our method MonSter shows significant improvement in challenging regions such as reflective surfaces, texture less areas, fine structures, and distant objects.
图 1: 零样本泛化对比:所有模型均在 Scene Flow 上训练,并直接在 KITTI 上测试。与基线 IGEV [38] 相比,我们的方法 MonSter 在反射表面、无纹理区域、精细结构和远距离物体等具有挑战性的区域表现出显著改进。
Abstract
摘要
Stereo matching recovers depth from image correspondences. Existing methods struggle to handle ill-posed regions with limited matching cues, such as occlusions and texture less areas. To address this, we propose MonSter, a novel method that leverages the complementary strengths of monocular depth estimation and stereo matching. MonSter integrates monocular depth and stereo matching into a dual-branch architecture to iterative ly improve each other. Confidence-based guidance adaptively selects reliable stereo cues for monodepth scale-shift recovery. The refined monodepth is in turn guides stereo effectively at illposed regions. Such iterative mutual enhancement enables MonSter to evolve monodepth priors from coarse objectlevel structures to pixel-level geometry, fully unlocking the potential of stereo matching. As shown in Fig. 2, MonSter ranks $1^{s t}$ across five most commonly used leader boards — SceneFlow, KITTI 2012, KITTI 2015, Middlebury, and ETH3D. Achieving up to $49.5%$ improvements (Bad 1.0 on ETH3D) over the previous best method. Comprehensive analysis verifies the effectiveness of MonSter in illposed regions. In terms of zero-shot generalization, MonSter significantly and consistently outperforms state-of-theart across the board. The code is publicly available at: https://github.com/Junda24/MonSter.
立体匹配从图像对应关系中恢复深度。现有方法难以处理匹配线索有限的病态区域,例如遮挡和无纹理区域。为了解决这个问题,我们提出了 MonSter,这是一种利用单目深度估计和立体匹配互补优势的新方法。MonSter 将单目深度和立体匹配集成到双分支架构中,以迭代地相互改进。基于置信度的指导自适应地选择可靠的立体线索用于单目深度尺度偏移恢复。改进后的单目深度反过来在病态区域有效地引导立体匹配。这种迭代的相互增强使 MonSter 能够将单目深度先验从粗略的对象级结构演变为像素级几何,充分释放立体匹配的潜力。如图 2 所示,MonSter 在五个最常用的排行榜上排名第一 —— SceneFlow、KITTI 2012、KITTI 2015、Middlebury 和 ETH3D。与之前的最佳方法相比,实现了高达 49.5% 的改进(ETH3D 上的 Bad 1.0)。综合分析验证了 MonSter 在病态区域的有效性。在零样本泛化方面,MonSter 在各个领域都显著且持续地超越了最先进的方法。代码公开在:https://github.com/Junda24/MonSter。
1. Introduction
1. 引言
Stereo matching estimates a disparity map from rectified stereo images, which can be subsequently converted into metric depth. It is the core of many applications such as self-driving, robotic navigation, and 3D reconstruction.
立体匹配从校正后的立体图像中估计视差图,随后可以将其转换为度量深度。它是自动驾驶、机器人导航和3D重建等许多应用的核心。
Deep learning based methods [4, 14, 16, 20, 35, 48] have demonstrated promising performance on standard benchmarks. These methods can be roughly categorized into cost filtering-based methods and iterative optimization-based methods. Cost filtering-based methods [4, 14, 15, 22, 37, 39, 41, 43] construct 3D/4D cost volume using CNN features, followed by a series of 2D/3D convolutions for regularization and filtering to minimize mismatches. Iterative optimization-based methods [10, 16, 20, 38, 49] initially construct an all-pairs correlation volume, then index a local cost to extract motion features, which guide the recurrent units (ConvGRUs) [9] to iterative ly refine the disparity map.
基于深度学习的方法 [4, 14, 16, 20, 35, 48] 在标准基准测试中展示了出色的性能。这些方法大致可分为基于成本过滤的方法和基于迭代优化的方法。基于成本过滤的方法 [4, 14, 15, 22, 37, 39, 41, 43] 使用CNN特征构建3D/4D成本体积,然后通过一系列2D/3D卷积进行正则化和过滤以最小化不匹配。基于迭代优化的方法 [10, 16, 20, 38, 49] 首先构建全对相关体积,然后索引局部成本以提取运动特征,这些特征指导循环单元 (ConvGRUs) [9] 迭代地优化视差图。
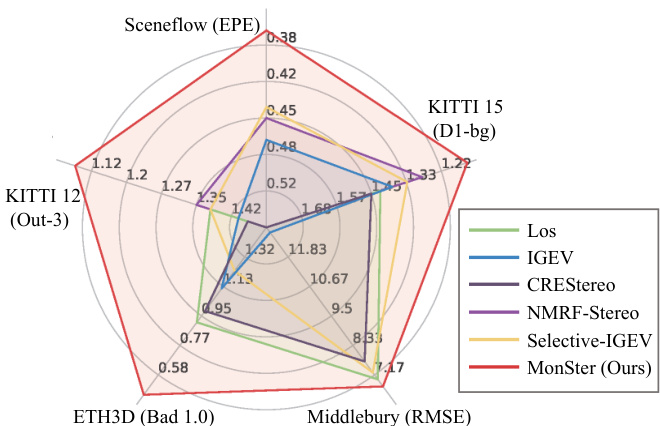
Figure 2. Leader board performance. Our method ranks $1^{s t}$ across 5 leader boards, advancing SOTA by a large margin.
图 2: 排行榜表现。我们的方法在 5 个排行榜中排名第 1,大幅推进了 SOTA。
Both types of methods essentially derive disparity from similarity matching, assuming visible correspondences in both images. This poses challenges in ill-posed regions with limited matching cues, e.g., occlusions, textureless areas, repetitive/thin structures, and distant objects with low pixel representation. Existing methods [4, 31, 33, 37, 42, 44, 49] address this issue by enhancing matching with stronger feature representations during feature extraction or cost aggregation: GMStereo [42] and STTR [18] employ transformer as feature extractors; IGEV [38] and ACVNet [37] incorporate geometric information into the cost volume using attention mechanisms to strengthen matching information; Selective-IGEV [35] and DLNR [49] further improve performance by introducing high-frequency information during the iterative refinement stage. However, these methods still struggle to fundamentally resolve the issue of mismatching, limiting their practical performance.
两种方法本质上都是从相似性匹配中推导视差,假设两幅图像中存在可见的对应关系。这在匹配线索有限的病态区域中带来了挑战,例如遮挡、无纹理区域、重复/细长结构以及像素表示较少的远距离物体。现有方法 [4, 31, 33, 37, 42, 44, 49] 通过在特征提取或成本聚合阶段使用更强的特征表示来增强匹配以解决这个问题:GMStereo [42] 和 STTR [18] 使用 Transformer 作为特征提取器;IGEV [38] 和 ACVNet [37] 通过注意力机制将几何信息融入成本体积以增强匹配信息;Selective-IGEV [35] 和 DLNR [49] 在迭代优化阶段引入高频信息以进一步提高性能。然而,这些方法仍然难以从根本上解决误匹配问题,限制了其实际表现。
Unlike stereo matching, monocular depth estimation directly recovers 3D from a single image, which does not encounter the challenge of mismatching. While monocular depth provides complementary structural information for stereo, pre-trained models often yield relative depth with scale and shift ambiguities. As shown in Fig.3, the prediction of monodepth models differ heavily from the ground- truth. Even after global scale and shift alignment, substantial errors still persist, complicating pixel-wise fusion of monocular depth and stereo disparity. Based on these insights, we propose MonSter, a novel approach that decomposes stereo matching into monocular depth estimation and per-pixel scale-shift recovery, which fully combines the strengths of monocular and stereo algorithms and overcomes the limitations from the lack of matching cues.
与立体匹配不同,单目深度估计直接从单张图像中恢复3D信息,不会遇到不匹配的挑战。虽然单目深度为立体提供了互补的结构信息,但预训练模型通常会产生带有尺度和偏移模糊的相对深度。如图3所示,单目深度模型的预测与真实值存在很大差异。即使在全局尺度和偏移对齐之后,仍然存在大量误差,这使单目深度和立体视差的像素级融合变得复杂。基于这些观察,我们提出了 MonSter,这是一种将立体匹配分解为单目深度估计和像素级尺度-偏移恢复的新方法,它充分结合了单目和立体算法的优势,并克服了缺乏匹配线索的局限性。
MonSter constructs separate branches for monocular depth estimation and stereo matching, and adaptively fuses them through Stereo Guided Alignment (SGA) and Mono Guided Refinement (MGR) modules. SGA first rescales monodepth into a “monocular disparity” by aligning globally with stereo disparity. Then it uses condition-guided GRUs to adaptively select reliable stereo cues for updating the per-pixel monocular disparity shift. Symmetric to SGA, MGR uses the optimized monocular disparity as the condition to adaptively refine the stereo disparity in regions where matching fails. Through multiple iterations, the two branches effectively complement each other: 1) Though beneficial at coarse object-level, directly and uni directionally fuse monodepth into stereo suffers from scale-shift ambiguities, which often introduces noise in complex regions such as slanted or curved surfaces. Refining monodepth with stereo resolves this issue effectively, ensuring the robustness of MonSter. 2) The refined monodepth in turn provides strong guidance to stereo in challenging regions. E.g., the depth perception ability of stereo matching degrades with distance due to smaller pixel proportions and the increased matching difficulty. Monodepth models pretrained on large-scale datasets are less affected by such issues, which can effectively improve stereo disparity in the corresponding region.
MonSter 为单目深度估计和立体匹配构建了独立的分支,并通过 Stereo Guided Alignment (SGA) 和 Mono Guided Refinement (MGR) 模块自适应地融合它们。SGA 首先通过全局对齐立体视差将单目深度重新缩放为“单目视差”。然后,它使用条件引导的 GRU 自适应地选择可靠的立体线索来更新每个像素的单目视差偏移。与 SGA 对称,MGR 使用优化后的单目视差作为条件,在匹配失败的区域自适地细化立体视差。通过多次迭代,这两个分支有效地互补:1) 尽管在粗略的对象级别上有益,但直接将单目深度单向融合到立体中会遭受尺度偏移的模糊性,这通常在复杂区域(如倾斜或弯曲表面)引入噪声。用立体细化单目深度有效地解决了这个问题,确保了 MonSter 的鲁棒性。2) 优化后的单目深度反过来在具有挑战性的区域为立体提供了强有力的指导。例如,由于像素比例较小和匹配难度增加,立体匹配的深度感知能力随着距离的增加而下降。在大规模数据集上预训练的单目深度模型受此类问题的影响较小,可以有效地改善相应区域的立体视差。
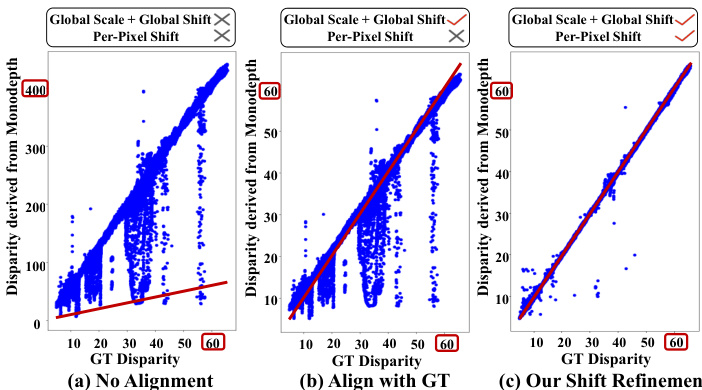
Figure 3. Distance between GT disparity and the disparity derived from monocular depth [46] on KITTI dataset. The red line indicates identical disparity maps. (a): Without any alignment. (b) Align depth with GT using global scale and global shift values (same for all pixels). (c) The monocular disparity produced by MonSter, with per-pixel shift refinement. Even globally aligned with GT, SOTA monocular depth models still exhibit severe noise. Our method MonSter effectively addresses this issue by refining monocular depth with per-pixel shift, which fully unlocks the power of monocular depth priors for stereo matching.
图 3. KITTI 数据集中 GT 视差与单目深度 [46] 导出的视差之间的距离。红线表示相同的视差图。(a): 未进行任何对齐。(b) 使用全局尺度和全局平移值(所有像素相同)将深度与 GT 对齐。(c) MonSter 生成的单目视差,带有逐像素平移优化。即使与 GT 全局对齐,SOTA 单目深度模型仍然表现出严重的噪声。我们的方法 MonSter 通过逐像素平移优化单目深度,有效解决了这一问题,充分释放了单目深度先验在立体匹配中的潜力。
Our main contributions can be summarized as follows:
我们的主要贡献可总结如下:
• We propose a novel stereo-matching method MonSter, fully leveraging the pixel-level monocular depth priors to significantly improve the depth perception performance of stereo matching in ill-posed regions and fine structures. • As shown in Fig. 2, MonSter ranks $1^{s t}$ across 5 widelyused leader boards: KITTI 2012 [11], KITTI 2015 [23], Scene Flow [22], Middlebury [27] and ETH3D [28]. Ad- vancing SOTA by up to $49.5%$ .
• 我们提出了一种新颖的立体匹配方法 MonSter,充分利用像素级单目深度先验,显著提升了立体匹配在病态区域和精细结构中的深度感知性能。
• 如图 2 所示,MonSter 在 5 个广泛使用的排行榜上排名第一:KITTI 2012 [11]、KITTI 2015 [23]、Scene Flow [22]、Middlebury [27] 和 ETH3D [28]。相比现有最佳方法 (SOTA) 提升了高达 49.5%。
• Compared to SOTA methods, MonSter achieves the best zero-shot generalization consistently across diverse datasets. MonSter trained solely on synthetic data demonstrates strong performance across diverse realworld datasets (see Fig.1).
• 与 SOTA 方法相比,MonSter 在各种数据集上始终表现出最佳的零样本泛化能力。仅使用合成数据训练的 MonSter 在多样化的真实世界数据集中表现出色(见图 1)。
2. Related Work
2. 相关工作
Matching based Methods. Mainstream stereo matching methods recover disparity from matching costs. These methods can generally be divided into two categories: cost filtering-based methods and iterative optimization-based methods. Cost filtering-based methods [5, 6, 12, 14, 22, 29, 43] typically construct a 3D/4D cost volume using feature maps and subsequently employing 2D/3D CNN to filter the volume and derive the final disparity map. Constructing a cost volume with strong representational capacity and accurately regressing disparity from a noisy cost volume are key challenges. PSMNet [4] proposes a stacked hourglass 3D CNN for better cost regular iz ation. [14, 30, 37] propose the group-wise correlation volume, the attention concatenation volume, and the pyramid warping volume respectively to improve the expressiveness of the matching cost. Recently, a novel class of methods based on iterative optimization [16, 20, 35, 38, 49] has achieved state-of-the-art performance in both accuracy and efficiency. These methods use ConvGRUs to iterative ly update the disparity by leveraging local cost values retrieved from the all-pairs correlation volume. Similarly, iterative optimization-based methods also primarily focus on improving the matching cost construction and the iterative optimization stages. CREStereo [16] proposes a cascaded recurrent network to update the disparity field in a coarse-to-fine manner. IGEV [38] proposes a Geometry Encoding Volume that encodes geometry and context information for a more robust matching cost. Both types of methods essentially derive depth from matching costs, which are inherently limited by ill-posed regions.
基于匹配的方法。主流的立体匹配方法从匹配代价中恢复视差。这些方法通常可以分为两类:基于代价滤波的方法和基于迭代优化的方法。基于代价滤波的方法 [5, 6, 12, 14, 22, 29, 43] 通常使用特征图构建 3D/4D 代价体,随后使用 2D/3D CNN 对代价体进行滤波并得到最终的视差图。构建具有强表示能力的代价体并从噪声代价体中准确回归视差是关键挑战。PSMNet [4] 提出了一种堆叠沙漏结构的 3D CNN 以实现更好的代价正则化。[14, 30, 37] 分别提出了分组相关体、注意力连接体和金字塔扭曲体,以提高匹配代价的表达能力。最近,基于迭代优化的方法 [16, 20, 35, 38, 49] 在精度和效率上都达到了最先进的性能。这些方法使用 ConvGRU 通过从全对相关体中检索局部代价值来迭代更新视差。同样,基于迭代优化的方法也主要集中在改进匹配代价构建和迭代优化阶段。CREStereo [16] 提出了一种级联循环网络,以从粗到细的方式更新视差场。IGEV [38] 提出了一种几何编码体,用于编码几何和上下文信息以实现更鲁棒的匹配代价。这两类方法本质上都是从匹配代价中推导深度,而这些代价在本质上受到不适定区域的限制。
Stereo Matching with Structural Priors. Matching in illposed regions is challenging, previous methods [7, 17, 19, 31, 44, 47] tried to leverage structural priors to address this issue. EdgeStereo [31] enhances performance in edge regions by incorporating edge detection cues into the disparity estimation pipeline. SegStereo [44] utilizes semantic cues from a segmentation network as guidance for stereo matching, improving performance in texture less regions. However, semantic and edge cues only provide object-level priors, which are insufficient for pixel-level depth perception. Consequently, they are not effective in challenging scenes with large curved or slanted surfaces. Therefore, some methods incorporate monocular depth priors to provide perpixel guidance for stereo matching through dense relative depth. CLStereo [47] introduces a monocular branch that serves as a contextual constraint, transferring geometric priors from the monocular to the stereo branch. Los [17] uses monocular depth as local structural prior to generating the slant plane, which can explicitly leverage structure information for updating disparities. However, monocular depth estimation suffers from severe scale and shift ambiguities as shown in Fig.3. Directly using it as a structural prior to constrain stereo matching can introduce heavy noise. Our MonSter adaptively selects reliable stereo disparity to correct the scale and shift of monodepth, which fully leverages the monocular depth priors while avoiding noise, thereby significantly enhancing stereo performance in ill-posed regions.
基于结构先验的立体匹配
3. Method
3. 方法
As shown in Fig. 4, MonSter consists of 1) a monocular depth branch, 2) a stereo matching branch and 3) a mutual refinement module. The two branches estimate initial monocular depth and the stereo disparity, which are fed into mutual refinement to iterative ly improve each other.
如图 4 所示,MonSter 由 1) 单目深度分支、2) 立体匹配分支和 3) 互优化模块组成。这两个分支分别估计初始的单目深度和立体视差,然后输入到互优化模块中,通过迭代相互优化。
3.1. Monocular and Stereo Branches
3.1. 单目与立体分支
The monocular depth branch can leverage most monocular depth models to achieve non-trivial performance improvements (see Sec.4.5 for analysis). Our best empirical configuration uses pretrained Depth Anything V 2 [46] as the monocular depth branch, which uses DINOv2 [24] as the encoder and DPT [26] as the decoder. The stereo matching branch follows IGEV [38] to obtain the initial stereo disp, with modifications only to the feature extraction component, as shown in Fig. 4. To efficiently and fully leverage the pretrained monocular model, the stereo branch shares the ViT encoder in DINOv2 with the monocular branch, with parameters frozen to prevent the stereo matching training from affecting its generalization ability. Moreover, the ViT architecture extracts feature at a single resolution, while recent stereo matching methods commonly utilize multiscale features at four scales (1/32, 1/16, 1/8, and 1/4 of the original image resolution ). To fully align with IGEV, we employ a stack of 2D convolutional layers, denoted as the feature transfer network, to downsample and transform the ViT feature into a collection of pyramid features $\mathcal{F}={F_{0},F_{1},F_{2},F_{3}}$ , where $\begin{array}{r}{F_{k}\in\mathbb{R}^{\frac{H}{2^{5}-k}\times\frac{W}{2^{5}-k}\times c_{k}}}\end{array}$ . We follow IGEV to construct Geometry Encoding Volume and use the same ConvGRUs for iterative optimization. To balance accuracy and efficiency, we perform only $N_{1}$ iterations to obtain a initial stereo disparity with reasonable quality.
单目深度分支可以利用大多数单目深度模型来实现显著的性能提升(详细分析见第4.5节)。我们最佳的实验配置使用预训练的 Depth Anything V 2 [46] 作为单目深度分支,该分支使用 DINOv2 [24] 作为编码器,DPT [26] 作为解码器。立体匹配分支遵循 IGEV [38] 来获取初始的立体视差,仅对特征提取组件进行了修改,如图 4 所示。为了高效且充分地利用预训练的单目模型,立体分支与单目分支共享 DINOv2 中的 ViT 编码器,并冻结其参数,以防止立体匹配训练影响其泛化能力。此外,ViT 架构在单一分辨率下提取特征,而最近的立体匹配方法通常利用四个尺度(原始图像分辨率的 1/32、1/16、1/8 和 1/4)的多尺度特征。为了完全与 IGEV 对齐,我们使用一系列二维卷积层(称为特征转移网络)对 ViT 特征进行下采样,并将其转换为金字塔特征集合 $\mathcal{F}={F_{0},F_{1},F_{2},F_{3}}$,其中 $\begin{array}{r}{F_{k}\in\mathbb{R}^{\frac{H}{2^{5}-k}\times\frac{W}{2^{5}-k}\times c_{k}}}\end{array}$。我们遵循 IGEV 构建几何编码体积,并使用相同的 ConvGRU 进行迭代优化。为了平衡精度和效率,我们仅进行 $N_{1}$ 次迭代以获得具有合理质量的初始立体视差。
3.2. Mutual Refinement
3.2. 双向优化
Once the initial (relative) monocular depth and stereo disparity are obtained, they are fed into the mutual refinement module to iterative ly refine each other. We first perform global scale-shift alignment, which converts monocular depth into a disparity map and aligns it coarsely with stereo outputs. Then we iterative ly perform a dual-branched refinement: Stereo guided alignment (SGA) leverages stereo cues to update the per-pixel shift of the monocular dispar- ity; Mono guided refinement (MGR) leverages the aligned monocular prior to further refine stereo disparity.
一旦获得了初始的(相对)单目深度和立体视差,它们会被输入到相互精炼模块中,以迭代地相互精炼。我们首先执行全局尺度-位移对齐,将单目深度转换为视差图,并将其与立体输出进行粗略对齐。然后我们迭代执行双分支精炼:立体引导对齐(SGA)利用立体线索更新单目视差的每像素位移;单目引导精炼(MGR)利用对齐的单目先验进一步精炼立体视差。
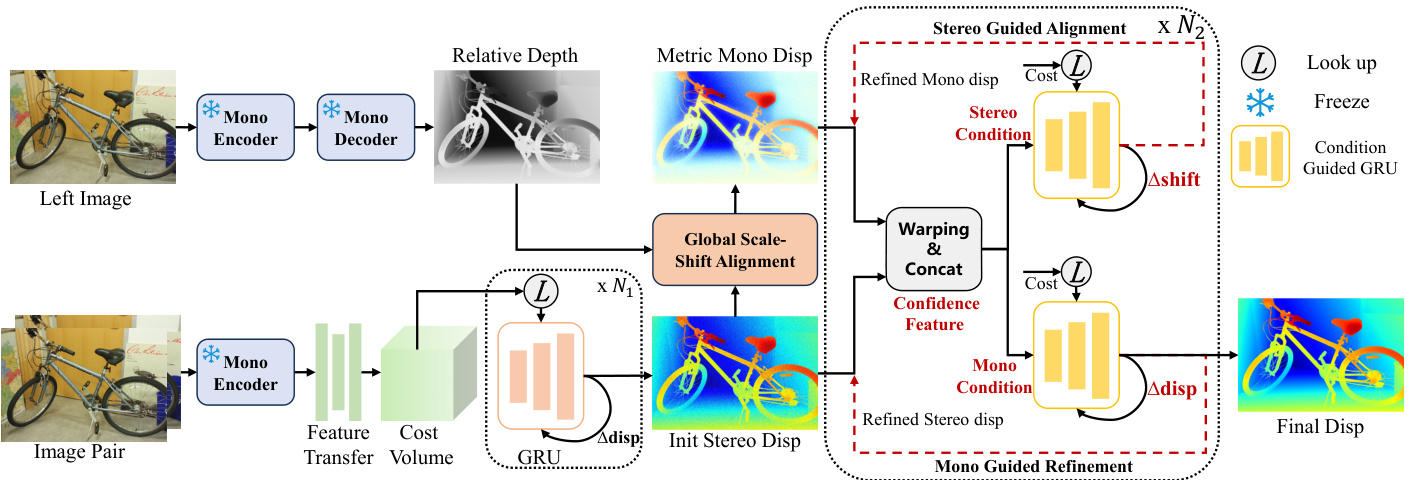
Figure 4. Overview of MonSter. MonSter consists of a monocular depth estimation branch, a stereo matching branch, and a mutua refinement module. It iterative ly improves one branch with priors from the other, effectively resolving the ill-posedness in stereo matching.
图 4: MonSter 概述。MonSter 由一个单目深度估计分支、一个立体匹配分支和一个相互优化模块组成。它通过从一个分支中获取先验信息来迭代改进另一个分支,从而有效解决立体匹配中的不适定问题。
Global Scale-Shift Alignment. Global Scale-Shift Alignment performs least squares optimization over a global scale $s_{G}$ and a global shift $t_{G}$ to coarsely align the inverse monocular depth with the stereo disparity:
全局尺度-位移对齐

where $D_{M}(i)$ and $D_{S}^{0}(i)$ are the inverse monocular depth and stereo disparity at the i-th pixel. $\Omega$ represents the region where stereo disparity values fall between $20%$ to $90%$ sorting in ascending order, which helps to filter unreliable regions such as the sky, extremely distant areas, and closerange outliers. Intuitively, this step converts the inverse monocular depth into a disparity map coarsely aligned with the stereo disparity, enabling effective mutual refinement in the same space. We call this aligned disparity map $D_{M}^{0}$ the monocular disparity in the remainder of the paper.
其中 $D_{M}(i)$ 和 $D_{S}^{0}(i)$ 分别表示第 i 个像素的单目深度逆值和立体视差值。$\Omega$ 表示立体视差值按升序排序后落在 $20%$ 到 $90%$ 之间的区域,这有助于过滤掉不可靠的区域,如天空、极远区域和近距离的异常值。直观上,这一步将单目深度逆值转换为与立体视差粗略对齐的视差图,从而在同一空间内实现有效的相互优化。我们在本文的后续部分将这种对齐后的视差图 $D_{M}^{0}$ 称为单目视差。
Stereo Guided Alignment (SGA). Though coarsely aligned, a unified shift $t_{G}$ is not sufficient to recover accurate monocular disparity at different pixels. To fully release the potential of monocular depth prior, SGA leverages intermediate stereo cues to further estimate a per-pixel residual shift. To avoid introducing noisy stereo cues, SGA uses confidence based guidance. In each update step $j$ , we compute the confidence using the flow residual map ${\bf\bar{\Delta}}{\cal F}{S}^{j}$ , which is obtained by warping and subtracting features based on the stereo disparity $\pmb{D}{S}^{j}$ as:
立体引导对齐 (SGA)。虽然粗略对齐,但统一的偏移量 $t_{G}$ 不足以恢复不同像素处的准确单目视差。为了充分发挥单目深度先验的潜力,SGA 利用中间立体线索进一步估计每个像素的残差偏移。为了避免引入噪声立体线索,SGA 使用基于置信度的引导。在每次更新步骤 $j$ 中,我们使用流残差图 ${\bf\bar{\Delta}}{\cal F}{S}^{j}$ 计算置信度,该残差图通过基于立体视差 $\pmb{D}{S}^{j}$ 的扭曲和特征相减得到:

where $F_{3}^{L},F_{3}^{R}$ represent the quarter-resolution features of left and right images in $\mathcal{F}$ respectively. For each iteration, we also use the current stereo disparity $D_{S}^{j}$ to index from the Geometry Encoding Volume to obtain geometry features of stereo branch $G_{S}^{j}$ follow IGEV. Concatenated with $F_{S}^{j}$ and $D_{S}^{j}$ , we obtain the stereo condition as:
其中 $F_{3}^{L},F_{3}^{R}$ 分别表示 $\mathcal{F}$ 中左右图像的四分之一分辨率特征。对于每次迭代,我们还使用当前的立体视差 $D_{S}^{j}$ 从几何编码卷中索引,以获取立体分支的几何特征 $G_{S}^{j}$,遵循 IGEV。与 $F_{S}^{j}$ 和 $D_{S}^{j}$ 连接后,我们得到立体条件为:

where $\operatorname{En}{g}$ and $\mathrm{En}{d}$ are two convolutional layers for feature encoding. We feed $x_{S}^{j}$ into condition-guided ConvGRUs to update the hidden state $h_{m}^{i-1}$ of monocular branch as:
其中 $\operatorname{En}{g}$ 和 $\mathrm{En}{d}$ 是两个用于特征编码的卷积层。我们将 $x_{S}^{j}$ 输入到条件引导的 ConvGRU 中,以更新单目分支的隐藏状态 $h_{m}^{i-1}$:

where $c_{k},c_{r},c_{h}$ are context features. Based on the hidden state $h_{M}^{j}$ , we decode a residual shift $\Delta t$ through two convolutional layers to update the monocular disparity:
其中 $c_{k},c_{r},c_{h}$ 是上下文特征。基于隐藏状态 $h_{M}^{j}$,我们通过两个卷积层解码出一个残差位移 $\Delta t$ 来更新单目视差:

Mono Guided Refinement (MGR). Symmetric to SGA, MGR leverages the aligned monocular disparity to address stereo deficiencies in ill-posed regions, thin structures, and distant objects. Specifically, we employ the same conditionguided GRU architecture with independent parameters to refine stereo disparity. We simultaneously calculate the flow residual maps $\bar{F}{M}^{j}$ , $\overset{\cdot}{F}{S}^{j}$ and geometric features $G_{M}^{j},G_{S}^{j}$ for both the monocular and stereo branches, providing a comprehensive stereo refinement guidance:
单目引导优化 (MGR)。与SGA对称,MGR利用对齐的单目视差来解决不适定区域、薄结构和远距离物体中的立体视差缺陷。具体来说,我们采用具有独立参数的相同条件引导GRU架构来优化立体视差。我们同时计算单目和立体分支的流残差图 $\bar{F}{M}^{j}$ 、 $\overset{\cdot}{F}{S}^{j}$ 以及几何特征 $G_{M}^{j},G_{S}^{j}$,提供全面的立体优化指导:


Figure 5. Qualitative results on ETH3D. MonSter outperforms IGEV in challenging areas with strong reflectance, fine structures etc.
图 5: ETH3D 上的定性结果。MonSter 在具有强反射、精细结构等挑战性区域中优于 IGEV。
where $G_{M}^{j}$ is the geometry features of the monocular branch obtained by indexing from the Geometry Encoding Volume using the monocular disparity DjM . xjM represents the monocular condition for ConvGRUs, and we use the Eq. (4) to update the hidden state $h_{S}^{i}$ similarly, with only the condition input changed from xiS to $x_{M}^{i}$ . We use the same two convolutional layers to decode the residual disparity $\triangle d$ and update the current stereo disparity following Eq. (5). After $N_{2}$ rounds of dual-branched refinement, the disparity of the stereo branch is the final output of MonSter.
其中 $G_{M}^{j}$ 是通过使用单目视差 $D_{j}^{M}$ 从几何编码体积中索引获得的单目分支的几何特征。$x_{j}^{M}$ 表示 ConvGRUs 的单目条件,我们使用公式 (4) 来类似地更新隐藏状态 $h_{S}^{i}$,仅将条件输入从 $x_{i}^{S}$ 更改为 $x_{M}^{i}$。我们使用相同的两个卷积层来解码残差视差 $\triangle d$,并按照公式 (5) 更新当前立体视差。经过 $N_{2}$ 轮双分支细化后,立体分支的视差是 MonSter 的最终输出。
3.3. Loss Function
3.3. 损失函数
We use the L1 loss to supervise the output from two branches. We denote the set of disparities from the first $N_{1}$ iterations of the stereo branch as ${\dot{d}{i}}{i=0}^{N_{1}-1}$ and follow [20] to exponentially increase the weights as the number of iterations increases. The total loss is defined as the sum of the monocular branch loss $\mathcal{L}{M o n o}$ and the stereo branch loss $\mathcal{L}{S t e r e o}$ as follows:
我们使用 L1 损失来监督两个分支的输出。我们将立体分支前 $N_{1}$ 次迭代的视差集表示为 ${\dot{d}{i}}{i=0}^{N_{1}-1}$,并按照 [20] 的方法,随着迭代次数的增加指数级增加权重。总损失定义为单目分支损失 $\mathcal{L}{M o n o}$ 和立体分支损失 $\mathcal{L}{S t e r e o}$ 的总和,如下所示:

where $\gamma=0.9$ , and $d_{g t}$ is the ground truth.
其中 $\gamma=0.9$,$d_{gt}$ 是真实值。
4. Experiment
4. 实验
4.1. Implementation Details
4.1. 实现细节
We implement MonSter with PyTorch and perform experiments using NVIDIA RTX 3090 GPUs. We use the AdamW [21] optimizer and clip gradients to the range [-1, 1] following baseline [38]. We use the one-cycle learning rate schedule with a learning rate of 2e-4 and train MonSter with a batch size of 8 for 200k steps as the pretrained model. For the monocular branch, we use the ViT-large version of Depth Anything V 2 [46] and freeze its parameters to prevent training of stereo-matching tasks from affecting its generalization and accuracy.
我们使用 PyTorch 实现 MonSter,并在 NVIDIA RTX 3090 GPU 上进行实验。我们使用 AdamW [21] 优化器,并将梯度裁剪到 [-1, 1] 范围内,遵循基线 [38] 的设置。我们采用 one-cycle 学习率调度策略,学习率为 2e-4,并以 batch size 为 8 训练 MonSter 20 万步作为预训练模型。对于单目分支,我们使用 Depth Anything V 2 [46] 的 ViT-large 版本,并冻结其参数,以防止立体匹配任务的训练影响其泛化能力和准确性。
Following the standard [16, 17, 35], we pretrain MonSter on Scene Flow [22] for most experiments. For finetuning on ETH3D and Middlebury, we follow SOTA methods [16, 17, 35] to create the Basic Training Set (BTS) from various public datasets for pre training, including Scene Flow [22], CREStereo [16], Tartan Air [34], Sintel Stereo [3], Falling Things [32] and InStereo2k [2].
遵循标准 [16, 17, 35],我们在 Scene Flow [22] 上对 MonSter 进行预训练以进行大多数实验。对于 ETH3D 和 Middlebury 的微调,我们遵循 SOTA 方法 [16, 17, 35] 从各种公共数据集创建基础训练集(BTS)进行预训练,包括 Scene Flow [22]、CREStereo [16]、Tartan Air [34]、Sintel Stereo [3]、Falling Things [32] 和 InStereo2k [2]。
4.2. Benchmark Performance
4.2. 基准性能
To demonstrate the outstanding performance of our method, we evaluate MonSter on the five most commonly used benchmarks: KITTI 2012 [11], KITTI 2015 [23], ETH3D [28], Middlebury [27] and Scene Flow [22].
为了展示我们方法的出色性能,我们在五个最常用的基准数据集上评估了 MonSter:KITTI 2012 [11]、KITTI 2015 [23]、ETH3D [28]、Middlebury [27] 和 Scene Flow [22]。
Scene Flow [22]. As shown in Tab. 1, we achieve a new state-of-the-art performance with an EPE metric of 0.37 on Scene Flow, surpassing our baseline [38] by $21.28%$ and outperforming the SOTA method [35] by $15.91%$ .
场景流 (Scene Flow) [22]。如表 1 所示,我们在场景流上实现了新的最先进性能,EPE 指标为 0.37,超过了我们的基线 [38] 21.28%,并且优于 SOTA 方法 [35] 15.91%。
ETH3D[28]. Following the SOTA methods [16, 17, 35,
ETH3D [28]。遵循SOTA方法 [16, 17, 35,
Table 1. Quantitative evaluation on Scene Flow test set. The best result is bolded, and the second-best result is underscored.
表 1: Scene Flow 测试集上的定量评估。最佳结果加粗,次佳结果加下划线。
| Method | GwcNet[14] | LEAStereo[8] | ACVNet[37] | IGEV[38] | Selective-IGEV[35] | MonSter (Ours) |
|---|---|---|---|---|---|---|
| EPE (px)↓ | 0.76 | 0.78 | 0.48 | 0.47 | 0.44 | 0.37 (-15.91%) |
Table 2. Results on four popular benchmarks. All results are derived from official leader board publications or corresponding papers. All metrics are presented in percentages, except for RMSE, which is reported in pixels. For testing masks, “All” denotes being tested with all pixels while “Noc” denotes being tested with a non-occlusion mask. The best and second best are marked with colors.
| 方法 | ETH3D[28] | Middlebury[27] | KITTI2015[11] | KITTI2012[11] |
|---|---|---|---|---|
| Bad1.0 | Bad1.0 | RMSE | Bad2.0 | |
| Noc | All | Noc | Noc | |
| GwcNet[14] | 6.42 | 6.95 | 0.69 | |
| GANet[48] | 6.22 | 6.86 | 0.75 | |
| LEAStereo[8] | 7.15 | |||
| ACVNet[37] | 2.58 | 2.86 | 0.45 | 13.70 |
| RAFT-Stereo[20] | 2.44 | 2.60 | 0.36 | 4.74 |
| CREStereo[16] | 0.98 | 1.09 | 0.28 | 3.71 |
| IGEV[38] | 1.12 | 1.51 | 0.34 | 4.83 |
| CroCo-Stereo[36] | 0.99 | 1.14 | 0.30 | 7.29 |
| DLNR[49] | 3.20 | |||
| Selective-IGEV[35] | 1.23 | 1.56 | 0.29 | 2.51 |
| LoS[17] | 0.91 | 1.03 | 0.31 | 4.20 |
| NMRF-Stereo[13] | ||||
| MonSter(我们的) | 0.46 | 0.72 | 0.20 | 2.64 |
表 2. 四个流行基准上的结果。所有结果均来自官方排行榜发布或相应的论文。除RMSE以像素为单位外,所有指标均以百分比表示。对于测试掩码,“All”表示在所有像素上进行测试,而“Noc”表示在非遮挡掩码上进行测试。最佳和次佳结果用颜色标记。
40, 42], the full training set is composed of the BTS and ETH3D training set. Our MonSter ranks 1st on the ETH3D leader board. As shown in Tab. 2, MonSter achieves the best performance among all published methods for all metrics. Compared with baseline IGEV, we achieve improvements of $58.93%$ , $52.32%$ , and $41.18%$ in the three reported metrics, respectively. Qualitative comparisons shown in Fig.5 exhibit a similar trend. Notably, even compared with the previous best method LoS, we improved the Bad 1.0 (Noc) metric from 0.91 to 0.46, achieving a $49.45%$ improvement.
我们的 MonSter 在 ETH3D 排行榜上排名第一。如表 2 所示,MonSter 在所有已发布的方法中,所有指标均达到了最佳性能。与基线 IGEV 相比,我们在三个报告的指标上分别实现了 $58.93%$、$52.32%$ 和 $41.18%$ 的提升。图 5 中的定性比较也显示出类似的趋势。值得注意的是,即使与之前的最佳方法 LoS 相比,我们也将 Bad 1.0 (Noc) 指标从 0.91 提升至 0.46,实现了 $49.45%$ 的改进。
Middlebury. Also following [16, 17, 35, 42], the training set of Middlebury is the combination of the BTS and Middlebury training set. As shown in Tab. 2, MonSter outperforms all existing methods in terms of RMSE metric. Compared with baseline [38], we achieved an improvement of $45.34%$ on the Bad 2.0 (Noc) metric.
Middlebury。同样遵循 [16, 17, 35, 42],Middlebury 的训练集是 BTS 和 Middlebury 训练集的组合。如表 2 所示,MonSter 在 RMSE 指标上优于所有现有方法。与基线 [38] 相比,我们在 Bad 2.0 (Noc) 指标上实现了 $45.34%$ 的提升。
KITTI. Following the training of SOTA methods [13, 16, 35], we finetuned Scene Flow pretrained model on the mixed dataset of KITTI 2012 and KITTI 2015 for 50k steps. At the time of writing, MonSter ranks $1^{s t}$ simultaneously on both the KITTI 2012 and KITTI 2015 leader boards. As shown in Tab. 2, we achieve the best performance for all metrics. On KITTI 2015, MonSter surpasses CREStereo [16] and Selective-IGEV [35] by $16.57%$ and $9.03%$ on D1- all metric of all regions, respectively. As for KITTI 2012, we significantly outperform the existing SOTA by a large margin. Compared to the current highest-precision method, NMRF-Stereo [13] and Selective-IGEV [35], we achieve a $19.26%$ improvement and a $21.01%$ improvement respectively in the Out-3 metric across all regions.
KITTI。根据 SOTA 方法 [13, 16, 35] 的训练,我们在 KITTI 2012 和 KITTI 2015 的混合数据集上对 Scene Flow 预训练模型进行了 50k 步的微调。在撰写本文时,MonSter 同时在 KITTI 2012 和 KITTI 2015 排行榜上排名第 1。如表 2 所示,我们在所有指标上均取得了最佳性能。在 KITTI 2015 上,MonSter 在 D1-所有区域指标上分别比 CREStereo [16] 和 Selective-IGEV [35] 高出 16.57% 和 9.03%。对于 KITTI 2012,我们显著超越了现有的 SOTA。与当前最高精度的方法 NMRF-Stereo [13] 和 Selective-IGEV [35] 相比,我们在所有区域的 Out-3 指标上分别实现了 19.26% 和 21.01% 的提升。
Table 3. Results of the reflective regions on KITTI 2012 leaderboard. The best and second best are marked with colors.
表 3. KITTI 2012 排行榜上反射区域的结果。最佳和次佳结果用颜色标记。
| 方法 | KITTI 2012 反射区域 | |||||
|---|---|---|---|---|---|---|
| Out-2 Noc | Out-2 All | Out-3 Noc | Out-3 All | Out-4 Noc | Out-4 All | |
| ACVNet[37] | 11.42 | 13.53 | 7.03 | 8.67 | 5.18 | 6.48 |
| CREStereo[16] | 9.71 | 11.26 | 6.27 | 7.27 | 4.93 | 5.55 |
| IGEV[38] | 7.57 | 8.80 | 4.35 | 5.00 | 3.16 | 3.57 |
| Selective-IGEV[35] | 6.73 | 7.84 | 3.79 | 4.38 | 2.66 | 3.05 |
| LoS[17] | 6.31 | 7.84 | 3.47 | 4.45 | 2.41 | 3.01 |
| NMRF-Stereo[13] | 10.02 | 12.34 | 6.35 | 8.11 | 4.80 | 6.09 |
| MonSter(Ours) | 5.66 | 6.81 | 2.75 | 3.38 | 1.73 | 2.13 |
Table 4. Comparison on SceneFlow test set in different regions.
表 4: 不同区域的SceneFlow测试集对比。
| 方法 | 边 | 非边 |
|---|---|---|
| EPE | >1px | |
| IGEV[38] | 2.23 | 20.42 |
| Selective-IGEV[35] | 2.18 | 20.01 |
| MonSter (Ours) | 1.91 | 18.59 |
4.3. Performance in Ill-posed Regions
4.3. 病态区域的性能
MonSter fully leverages the advantages of monocular depth priors, effectively overcoming challenges in ill-posed regions. To validate this, we conduct comparisons on several representative ill-posed regions, such as reflective areas, edge and non-edge regions, and distant backgrounds:
MonSter 充分利用了单目深度先验的优势,有效克服了不适定区域的挑战。为了验证这一点,我们在几个具有代表性的不适定区域上进行了比较,例如反射区域、边缘与非边缘区域以及远距离背景:
Table 5. Zero-shot generalization benchmark. The top half is generalization comparisons only trained on Scene Flow. The bottom half compares generalizations for models trained on a combination of Scene Flow, CREStereo, and TartanAir datasets.
表 5: 零样本泛化基准。上半部分为仅在 Scene Flow 上训练的泛化比较。下半部分比较了在 Scene Flow、CREStereo 和 TartanAir 数据集组合上训练的模型的泛化效果。
| 方法 | KITTI-12 (>3px) | KITTI-15 (>2px) | Middlebury (>1px) | ETH3D (>3px) |
|---|---|---|---|---|
| 训练集 | SceneFlow | |||
| CFNet [29] | 4.72 | 5.81 | 9.80 | 5.80 |
| RAFT-Stereo [20] | 5.12 | 5.74 | 9.36 | 3.28 |
| CREStereo [16] | 5.03 | 5.79 | 12.88 | 8.98 |
| Selective-IGEV [35] | 5.64 | 6.05 | 12.04 | 5.40 |
| NMRF-Stereo [13] | 4.23 | 5.10 | 7.54 | 3.82 |
| IGEV [38] | 4.84 | 6.23 | 3.62 | |
| MonSter (Ours) | 3.62 | 5.51 | 3.97 | 2.03 |
| 5.17 | ||||
| 训练集 | SceneFlow+CREStereo+TartanAir | |||
| IGEV [38] | 3.95 | 4.30 | 5.56 | |
| MonSter (Ours) | 2.95 | 3.23 | 2.38 | 2.94 |
• Reflective Regions: We conducted comparisons on the reflective regions of KITTI 2012 benchmark. MonSter ranks $1^{s t}$ on the KITTI 2012 leader board for all metrics of reflective regions. As shown in Tab.3, we have elevated the existing SOTA to a new level. MonSter surpasses Selective-IGEV and LoS by $30.16%$ and $29.24%$ on Out-4(All) metric, respectively. Notably, compared to the SOTA method NMRF-Stereo, we achieved significant improvements of $58.32%$ and $65.02%$ in the Out-3(All) and Out-4(All) metrics respectively.
反射区域:我们在KITTI 2012基准的反射区域上进行了比较。MonSter在KITTI 2012排行榜的反射区域所有指标上排名第1。如表3所示,我们将现有的SOTA提升到了一个新的水平。MonSter在Out-4(All)指标上分别超越了Selective-IGEV和LoS 30.16%和29.24%。值得注意的是,与SOTA方法NMRF-Stereo相比,我们在Out-3(All)和Out-4(All)指标上分别实现了58.32%和65.02%的显著提升。
• Edge $&$ Non-edge Regions: Stereo matching faces challenges in edge and low-texture regions, which our method addresses by leveraging the strengths of monocular depth. To evaluate MonSter in these areas, we divide the Scene Flow test set into edge and non-edge regions using the Canny operator following [35]. As shown in Tab. 4, MonSter outperforms the baseline [38] by $14.35%$ and $24.39%$ in edge regions and non-edge regions. Even when compared to [35], which is specifically designed to address edge and texture less regions, our method achieves improvements of $12.39%$ and $18.42%$ in two types of regions on EPE metric, respectively.
• 边缘与非边缘区域:立体匹配在边缘和低纹理区域面临挑战,我们的方法通过利用单目深度的优势来应对这些问题。为了在这些区域评估 MonSter,我们按照 [35] 使用 Canny 算子将 Scene Flow 测试集划分为边缘和非边缘区域。如表 4 所示,MonSter 在边缘区域和非边缘区域分别比基线 [38] 提高了 14.35% 和 24.39%。即使与专门设计用于处理边缘和纹理较少区域的 [35] 相比,我们的方法在 EPE 指标上分别在两类区域实现了 12.39% 和 18.42% 的提升。
• Distant Backgrounds: Stereo matching struggles with depth perception for distant objects, we improve it by incorpora ting our SGA and MGR modules. As shown in Tab.2, MonSter improves the D1-bg metric by $18.12%$ compared to the baseline on KITTI 2015 benchmark. The D1-bg metric reflects the percentage of stereo disparity outliers averaged specifically over background regions.
• 远距离背景:立体匹配在远距离物体的深度感知方面存在困难,我们通过引入SGA和MGR模块来改进这一点。如表2所示,MonSter在KITTI 2015基准测试中相比基线将D1-bg指标提升了18.12%。D1-bg指标反映了背景区域中立体视差异常点的平均百分比。

Figure 6. Visual comparisons on our captured real-world zeroshot data provide a more comprehensive assessment of generalization capability. All models are trained solely on the synthetic SceneFlow dataset. MonSter significantly outperforms IGEV in texture less regions, reflective areas and fine structures, etc.
图 6: 在我们捕捉的真实世界零样本数据上的视觉比较,提供了对泛化能力的更全面评估。所有模型仅在合成的 SceneFlow 数据集上进行训练。MonSter 在无纹理区域、反射区域和精细结构等方面显著优于 IGEV。
els were trained on the same synthetic datasets and then tested directly on real-world datasets: KITTI[11, 23], Middlebury[27], and ETH3D[28] training sets. We conducted a more thorough generalization comparison by training with different datasets:
模型在相同的合成数据集上进行了训练,然后直接在真实世界的数据集上进行了测试:KITTI[11, 23]、Middlebury[27] 和 ETH3D[28] 的训练集。我们通过使用不同的数据集进行训练,进行了更全面的泛化比较:
Scene Flow: We compared with SOTA methods which are only trained on the Scene Flow training set. As shown in the top half of Tab. 5, MonSter achieves the best generalization performance across four datasets. MonSter even surpasses CFNet and CREStereo, both of which are specifically designed for cross-domain generalization.
场景流:我们与仅在场景流训练集上训练的SOTA方法进行了比较。如Tab. 5上半部分所示,MonSter在四个数据集上实现了最佳的泛化性能。MonSter甚至超过了CFNet和CREStereo,这两种方法都是专门为跨域泛化设计的。
Mix 3 datasets: Interestingly, only adding CREStereo and TartanAir to the training set, the generalization of MonSter improves significantly. This is because the SceneFlow dataset differs substantially from real-world distributions, whereas the virtual data in TartanAir more closely resemble real-world scenes. This similarity helps our SGA and MGR modules better in learning how to effectively integrate monocular and stereo cues. As shown in the bottom half of Tab. 5, we surpass the baseline[38] by $47.12%$ and $49.16%$ on Middlebury and ETH3D respectively.
混合3个数据集:有趣的是,仅仅将CREStereo和TartanAir添加到训练集中,MonSter的泛化能力就显著提高。这是因为SceneFlow数据集与现实世界的分布差异较大,而TartanAir中的虚拟数据更接近现实世界的场景。这种相似性有助于我们的SGA和MGR模块更好地学习如何有效地整合单目和立体线索。如Tab. 5下半部分所示,我们在Middlebury和ETH3D上分别比基线[38]高出$47.12%$和$49.16%$。
The strong sim-to-real generalization of MonSter is highly encouraging. In the future, we plan to scale up the size and diversity of simulation training data to further boost the performance of MonSter.
MonSter 的强大仿真到现实泛化能力非常令人鼓舞。我们计划在未来扩大仿真训练数据的规模和多样性,以进一步提升 MonSter 的性能。
4.4. Zero-shot Generalization
4.4. 零样本泛化
Our method not only improves the accuracy of in-domain datasets but also enhances generalization ability. We evaluate the generalization performance of MonSter from synthetic datasets to unseen real-world scenes. All mod
我们的方法不仅提高了领域内数据集的准确性,还增强了泛化能力。我们评估了MonSter从合成数据集到未见过的真实场景的泛化性能。
4.5. Ablation Study
4.5. 消融研究
To demonstrate the effectiveness of each component of MonSter, we ablation on Scene Flow [22] and the following strategies are discussed:
为了展示MonSter每个组件的有效性,我们在Scene Flow [22]上进行了消融实验,并讨论了以下策略:
• Disparity Fusion: Monocular depth often carries substantial noise, which complicates its fusion with the stereo branch’s disparity. To demonstrate the efficiency of our Mono Guided Refinement (MGR) fusion method, we replaced the MGR module with a convolution-based hourglass network of equal parameter numbers, directly concatenating the monocular and stereo disparities for fusion, denoted as Mono $^+$ Conv. As shown in Tab.6, compared with ‘Mono $+\mathrm{Conv}'$ , ‘Mono $+\mathbf{M}\mathrm{GR}^{}$ ’ improves the EPE metric by $6.52%$ .
• 视差融合:单目深度通常带有大量噪声,这使其与立体分支的视差融合变得复杂。为了展示我们的单目引导优化 (Mono Guided Refinement, MGR) 融合方法的效率,我们将 MGR 模块替换为具有相同参数数量的基于卷积的 hourglass 网络,直接连接单目和立体视差进行融合,记为 Mono $^+$ Conv。如表 6 所示,与 ‘Mono $+\mathrm{Conv}’$ 相比,‘Mono $+\mathbf{M}\mathrm{GR}^{}$’ 将 EPE 指标提升了 $6.52%$。
Table 6. Ablation study of the effectiveness of proposed modules on the Scene Flow test set.
表 6. 在 Scene Flow 测试集上对提出模块有效性的消融研究。
| 模型 | 单目深度 | 视差融合 | 缩放&平移精调 | 特征共享 | EPE (px) | >1px (%) | 运行时间 (S) |
|---|---|---|---|---|---|---|---|
| Baseline (IGEV) | 0.47 | 5.21 | 0.37 | ||||
| Mono+Conv | √ | Conv | 0.46 | 5.12 | 0.64 | ||
| Mono+MGR | √ | MGR | 0.43 | 4.96 | 0.65 | ||
| Mono+MGR+Conv | √ | MGR | Conv | 0.42 | 4.82 | 0.65 | |
| Mono+MGR+SGA | √ | MGR | SGA | 0.39 | 4.43 | 0.66 | |
| Full model (MonSter) | √ | MGR | SGA | √ | 0.37 | 4.25 | 0.64 |
Table 7. Efficiency and universality of MonSter.
表 7: MonSter 的效率和通用性
| 模型 | MonoDepth 模型 | 数量 | (EPE) | IterationSceneflow 运行时间 (S) |
|---|---|---|---|---|
| IGEV[38] | 32 | 0.47 | 0.37 | |
| Fullmodel | DepthAnythingV2[46] | 32 | 0.37 | 0.64 |
| Fullmodel-4iter | DepthAnythingV2[46] | 4 | 0.42 | 0.34 |
| Fullmodel-V1 | DepthAnythingV1[45] | 32 | 0.39 | 0.64 |
| Fullmodel-midas | MiDaS[25] | 32 | 0.41 | 0.51 |
• Scale $&$ Shift Refinement: As shown in Fig.3, even after global scale-shift alignment, the monocular depth still suffers from significant scale and shift ambiguities. Therefore, leveraging high-confidence regions from the stereo branch to correct the scale and shift of the monocular disparity is essential. We incorporated our Stereo Guided Refinement module (SGA) to optimize the scale and shift based on $\scriptstyle\mathbf{\dot{M}o n o+M G R}^{\mathrm{}},$ ’. As shown in Tab.6, compared with ‘Mono $+\mathbf{M}\mathbf{G}\mathbf{R}^{\star}$ , our SGA module achieves improvements of $9.30%$ in EPE and $10.69%$ in 1-pixel error, demonstrating that monocular depth with accurate scale and shift can provide further enhancements to stereo matching. Similarly, we validated that our SGA module is more effective than direct convolution-based fusion. Compared to $\mathrm{^Mono+MGR{+}C o n v}^{\prime}$ , our SGA still achieves an $8.09%$ improvement in 1-pixel error.
• 尺度与偏移优化:如图 3 所示,即使在全局尺度-偏移对齐后,单目深度仍然存在显著的尺度和偏移模糊性。因此,利用立体分支中的高置信区域来校正单目视差的尺度和偏移是至关重要的。我们引入了立体引导优化模块 (SGA) 来基于 $\scriptstyle\mathbf{\dot{M}o n o+M G R}^{\mathrm{}}$ 优化尺度和偏移。如表 6 所示,与“Mono $+\mathbf{M}\mathbf{G}\mathbf{R}^{\star}$”相比,我们的 SGA 模块在 EPE 上实现了 9.30% 的提升,在 1 像素误差上实现了 10.69% 的提升,这表明具有准确尺度和偏移的单目深度可以进一步提升立体匹配的效果。同样,我们验证了我们的 SGA 模块比直接基于卷积的融合更有效。与 $\mathrm{^Mono+MGR{+}C o n v}^{\prime}$ 相比,我们的 SGA 在 1 像素误差上仍然实现了 8.09% 的提升。
• Feature Sharing: The feature extraction component of monocular depth estimation models, pre-trained on large datasets, contains rich contextual information that can be shared with the stereo branch. We employ a feature transfer network to map these features, transforming them into a representation compatible with stereo matching. As shown in the last 2 rows of Tab.6, feature sharing improved the EPE metric by $5.13%$ .
• 特征共享:在大规模数据集上预训练的单目深度估计模型的特征提取组件包含丰富的上下文信息,这些信息可以与立体分支共享。我们采用特征迁移网络来映射这些特征,将其转换为与立体匹配兼容的表示。如表 6 的最后两行所示,特征共享使 EPE 指标提高了 $5.13%$。
Compatibility with Other Monocular Models. To validate the general iz ability of MonSter to different depth models, we replace the monocular branch with the ViTlarge version of [45] and the dpt beit large version of MiDaS [25]. As shown in Tab.7, all MonSter variants consistently outperform the baseline [38]. This demonstrates the versatility of MonSter and its potential to benefit from future advancements in monocular depth models.
与其他单目模型的兼容性
Efficiency. We use the ViT-large version of DepthAnythingV2 [46] as the monocular branch, which introduces time and memory overheads. Compared to the baseline [38], our inference time increases from 0.37s to 0.64s. With the monocular branch containing 335.3M parameters, the stereo branch having 12.6M parameters, and the SGA and MGR modules having 8.2M parameters, our full model has a total of 356.1M parameters. Existing methods [1, 36] also use ViT-based encoders with a large number of parameters. For example, CroCo-Stereo [36] has 437.4M parameters, larger than MonSter, yet its performance is inferior, as shown in Tab.2, this demonstrates that the number of parameters does not determine the final effectiveness. Our research focuses on the accuracy and generalization capabilities, given the significant improvement in accuracy and generalization (as shown in Tab.2 and Tab.5), the additional inference cost is acceptable. Notably, our approach simplifies stereo matching and enables us to achieve SOTA performance with only 4 iterations $\scriptstyle N_{1}=N_{2}=2)$ . As shown in Tab.7, while the baseline requires 32 iterations, our method achieves a $10.64%$ improvement in EPE with just 4 iterations, achieving a better accuracy-speed trade-off. Further memory reduction can be achieved through encoder quantization or distillation, which we leave as future work.
效率。我们使用 DepthAnythingV2 [46] 的 ViT-large 版本作为单目分支,这引入了时间和内存开销。与基线 [38] 相比,我们的推理时间从 0.37 秒增加到 0.64 秒。单目分支包含 335.3M 参数,立体分支有 12.6M 参数,SGA 和 MGR 模块有 8.2M 参数,我们的完整模型总共有 356.1M 参数。现有方法 [1, 36] 也使用基于 ViT 的编码器,具有大量参数。例如,CroCo-Stereo [36] 有 437.4M 参数,比 MonSter 更大,但其性能较差,如 Tab.2 所示,这表明参数数量并不决定最终效果。我们的研究集中在准确性和泛化能力上,考虑到准确性和泛化能力的显著提升(如 Tab.2 和 Tab.5 所示),额外的推理成本是可以接受的。值得注意的是,我们的方法简化了立体匹配,并且仅需 4 次迭代 ($\scriptstyle N_{1}=N_{2}=2$) 即可实现 SOTA 性能。如 Tab.7 所示,基线需要 32 次迭代,而我们的方法仅需 4 次迭代即可在 EPE 上实现 $10.64%$ 的提升,实现了更好的精度-速度权衡。通过编码器量化或蒸馏可以进一步减少内存占用,我们将其留作未来的工作。
5. Conclusion
5. 结论
We propose MonSter, a novel pipeline that decouples the stereo matching task into a simpler paradigm of recovering scale and shift from relative depth. This approach fully leverages the contextual and geometric priors provided by monocular methods while avoiding issues such as noise and scale ambiguity. As a result, our method significantly enhances the accuracy and robustness of stereo matching in ill-posed regions. MonSter achieves substantial improvements over the state-of-the-art on five widely used benchmarks. Additionally, MonSter also demonstrates the best generalization performance, and experimental results show that there is still considerable room for improvement. Therefore, our future work will focus on scaling up MonSter to serve as a stereo foundation model, enabling a wide range of downstream applications that require metric depth.
我们提出了 MonSter,这是一种新颖的流程,它将立体匹配任务解耦为从相对深度中恢复尺度和位移的简单范式。该方法充分利用了单目方法提供的上下文和几何先验,同时避免了噪声和尺度模糊等问题。因此,我们的方法显著提高了在不适定区域中立体匹配的准确性和鲁棒性。MonSter 在五个广泛使用的基准测试中相比现有技术取得了显著改进。此外,MonSter 还展示了最佳的泛化性能,实验结果表明仍有相当大的改进空间。因此,我们未来的工作将集中在扩展 MonSter,使其成为立体基础模型,从而支持各种需要度量深度的下游应用。
References
参考文献