IDOL: Indicator-oriented Logic Pre-training for Logical Reasoning
IDOL: 面向指标的逻辑预训练推理框架
Abstract
摘要
In the field of machine reading comprehension (MRC), existing systems have surpassed the average performance of human beings in many tasks like SQuAD. However, there is still a long way to go when it comes to logical reasoning. Although some methods for it have been put forward, they either are designed in a quite complicated way or rely too much on external structures. In this paper, we proposed IDOL (InDicator-Oriented Logic Pre-training), an easy-to-understand but highly effective further pre-training task which logically strengthens the pre-trained models with the help of 6 types of logical indicators and a logically rich dataset LGP (LoGic Pre-training). IDOL achieves state-of-the-art performance on ReClor and LogiQA, the two most representative benchmarks in logical reasoning MRC, and is proven to be capable of generalizing to different pre-trained models and other types of MRC benchmarks like RACE and $\mathrm{SQuAD}2.0$ while keeping competitive general language under standing ability through testing on tasks in GLUE. Besides, at the beginning of the era of large language models, we take several of them like ChatGPT into comparison and find that IDOL still shows its advantage.1
在机器阅读理解(MRC)领域,现有系统已在SQuAD等多项任务中超越人类平均水平。然而在逻辑推理方面,现有研究仍存在明显差距。虽然已有部分方法被提出,但这些方案要么设计过于复杂,要么过度依赖外部结构。本文提出IDOL(InDicator-Oriented Logic Pre-training),这是一种通过6类逻辑指示符和富含逻辑的数据集LGP(LoGic Pre-training)来增强预训练模型逻辑能力的方案。IDOL在逻辑推理MRC领域最具代表性的两个基准测试ReClor和LogiQA上取得了最先进性能,并被证实能泛化至不同预训练模型及其他类型MRC基准(如RACE和$\mathrm{SQuAD}2.0$),同时通过GLUE任务测试保持了具有竞争力的通用语言理解能力。此外,在大语言模型时代初期,我们将ChatGPT等模型纳入对比,发现IDOL仍具优势。[20]
1 Introduction
1 引言
With the development of pre-trained language models, a large number of tasks in the field of natural language understanding have been dealt with quite well. However, those tasks emphasize more on assessing basic abilities like word-pattern recognition of the models while caring less about advanced abilities like reasoning over texts (Helwe et al., 2021).
随着预训练语言模型的发展,自然语言理解领域的大量任务已得到较好处理。然而这些任务更侧重于评估模型的基础能力(如词形识别),而较少关注高级能力(如文本推理) (Helwe et al., 2021)。
In recent years, an increasing number of challenging tasks have been brought forward gradually. At sentence-level reasoning, there is a great variety of benchmarks for natural language inference like
近年来,逐渐涌现出越来越多具有挑战性的任务。在句子级推理方面,自然语言推理领域存在多种基准测试,如
QNLI (Demszky et al., 2018) and MNLI (Williams et al., 2018). Although the construction processes are different, nearly all these datasets evaluate models with binary or three-way classification tasks which need reasoning based on two sentences. At passage-level reasoning, the most difficult benchmarks are generally recognized as the ones related to logical reasoning MRC which requires questionanswering systems to fully understand the whole passage, extract information related to the question and reason among different text spans to generate new conclusions in the logical aspect. In this area, the most representative benchmarks are some machine reading comprehension datasets like ReClor (Yu et al., 2020) and LogiQA (Liu et al., 2020).
QNLI (Demszky等人, 2018) 和 MNLI (Williams等人, 2018)。虽然构建过程不同,但这些数据集几乎都通过需要基于双句推理的二分类或三分类任务来评估模型。在篇章级推理领域,最困难的基准测试通常被认为是与逻辑推理机器阅读理解 (MRC) 相关的任务,这类任务要求问答系统完整理解整个篇章,提取与问题相关的信息,并在不同文本片段间进行逻辑层面的推理以生成新结论。该领域最具代表性的基准测试包括ReClor (Yu等人, 2020) 和LogiQA (Liu等人, 2020) 等机器阅读理解数据集。
Considering that there are quite few optimization strategies for the pre-training stage and that it is difficult for other researchers to follow and extend the existing methods which are designed in rather complex ways, we propose an easy-to-understand but highly effective pre-training task named IDOL which helps to strengthen the pre-trained models in terms of logical reasoning. We apply it with our customized dataset LGP which is full of logical information. Moreover, we experimented with various pre-trained models and plenty of different downstream tasks and proved that IDOL is competitive while keeping models and tasks agnostic.
考虑到预训练阶段的优化策略相对较少,且现有方法设计复杂使得其他研究者难以跟进和扩展,我们提出了一种易于理解但高效的预训练任务IDOL,旨在增强预训练模型的逻辑推理能力。我们将其应用于自定义数据集LGP,该数据集富含逻辑信息。此外,我们在多种预训练模型和大量不同下游任务上进行了实验,证明IDOL在保持模型与任务无关性的同时仍具有竞争力。
Recently, ChatGPT attracts a lot of attention all over the world due to its amazing performance in question answering. Thus, we also arranged an experiment to let IDOL compete with a series of LLMs (large language models) including it.
近期,ChatGPT 因其在问答领域的惊人表现而受到全球广泛关注。为此,我们也设计了一项实验,让 IDOL 与包括它在内的一系列大语言模型 (LLM) 展开较量。
The contributions of this paper are summarized as follows:
本文的贡献总结如下:
• Put forward the definitions of 5 different types of logical indicators. Based on these we construct the dataset LGP for logical pre-training and we probe the impact of different types of logical indicators through a series of ablation experiments.
• 提出5种不同类型逻辑指标的定义。基于这些定义,我们构建了用于逻辑预训练的数据集LGP,并通过一系列消融实验探究了不同类型逻辑指标的影响。
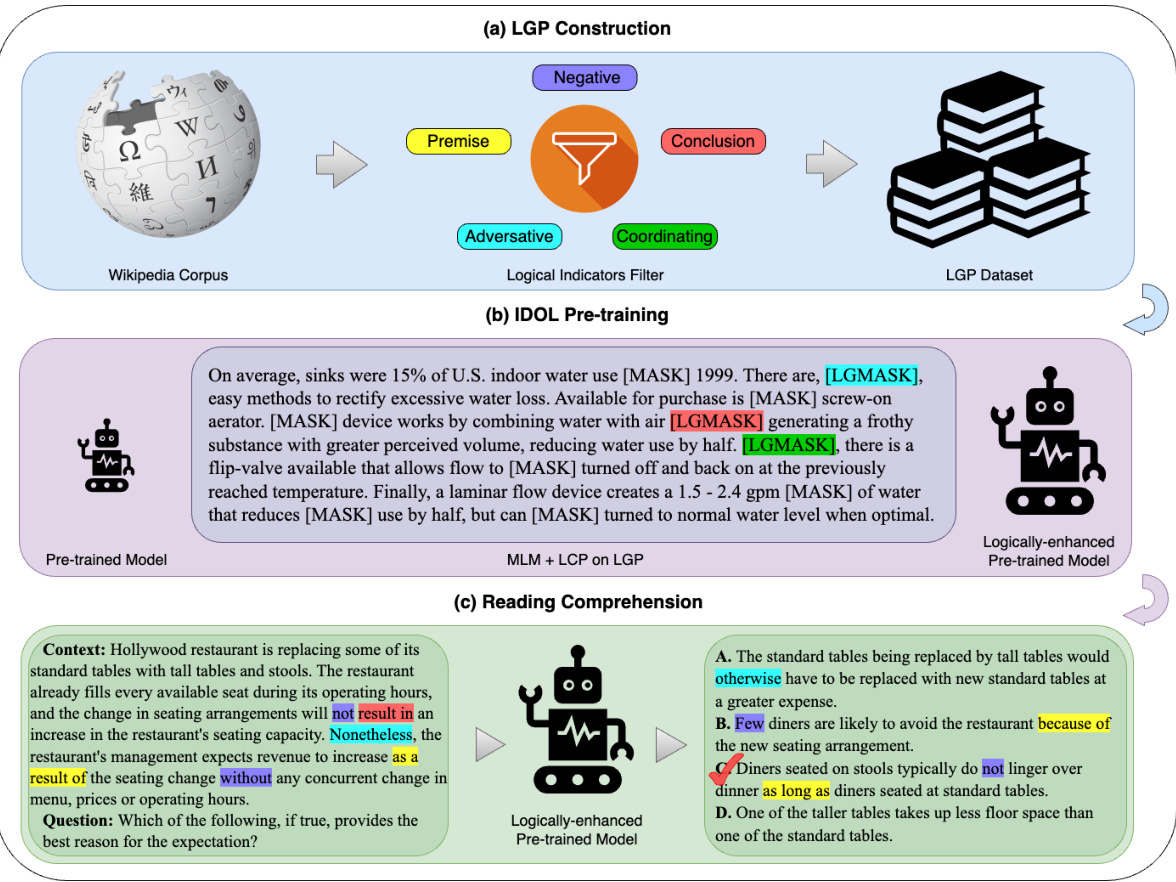
Figure 1: A diagram illustrating the three steps of our method: (a) construct the logically rich dataset LGP from Wikipedia, (b) further pre-train models to improve logical reasoning ability, and (c) answer logical reasoning MRC questions with the help of logical indicators appeared both in context and choices. See Section 4 for more details on our method.
图 1: 展示我们方法三个步骤的示意图:(a) 从维基百科构建逻辑丰富的数据集LGP,(b) 进一步预训练模型以提升逻辑推理能力,(c) 借助上下文和选项中同时出现的逻辑指示符来回答逻辑推理MRC问题。关于我们方法的更多细节请参见第4节。
• Design an indicator-oriented further pretraining method named IDOL, which aims to enhance the logical reasoning ability of pretrained models. It achieves state-of-the-art performance in logical reasoning MRC and shows progress in general MRC and general understanding ability evaluation.
• 设计了一种面向指标的进一步预训练方法IDOL,旨在增强预训练模型的逻辑推理能力。该方法在逻辑推理机器阅读理解(MRC)任务中实现了最先进的性能,并在通用MRC和通用理解能力评估方面取得了进展。
• The first to provide a pilot test about the comparison between fine-tuning traditional pretrained models and prompting LLMs in the field of logical reasoning MRC.
• 首个在逻辑推理MRC领域对微调传统预训练模型和提示大语言模型进行对比的试点测试。
In the aspect of pre-training, to the best of our knowledge, there are only two approaches presented in published papers called MERIt and LogiGAN. MERIt team generated a dataset from the one provided by Qin et al. (2021) which contains passages from Wikipedia with annotations about entities and relations. And then optimize the model on that with the help of contrastive learning (Jiao et al., 2022). The researchers behind LogiGAN use a task about statement recovery to enhance the logic understanding ability of generative pretrained language models like T5 (Pi et al., 2022).
在预训练方面,据我们所知,目前仅有MERIt和LogiGAN两种方法在已发表的论文中被提出。MERIt团队基于Qin等人(2021)提供的维基百科段落数据集(包含实体与关系标注)生成新数据集,并借助对比学习(Jiao等人,2022)优化模型。LogiGAN的研究人员则采用陈述恢复任务来增强T5等生成式预训练语言模型(Pi等人,2022)的逻辑理解能力。
2 Related Work
2 相关工作
2.1 Logical Reasoning
2.1 逻辑推理
In order to help reasoning systems perform better on reading comprehension tasks focusing on logical reasoning, there have been a great many methods put forward by research institutions from all over the world. Un surprisingly, the majority of the optimization approaches put forward revolve around the fine-tuning phase while there are far fewer methods designed for further pre-training.
为了帮助推理系统在侧重逻辑推理的阅读理解任务中表现更优,全球研究机构已提出大量方法。不出所料,大多数优化方案围绕微调阶段展开,而为进一步预训练设计的方法则少得多。
For optimizing models at the fine-tuning phase, there are dozens of methods proposed as far as we know. For example, LReasoner put forward a context extension framework with the help of logical equivalence laws including contra position and transitive laws (Wang et al., 2022a). Another example is Logiformer which introduced a twostream architecture containing a syntax branch and a logical branch to better model the relationships among distant logical units (Xu et al., 2022).
在微调阶段优化模型的方法,据我们所知已有数十种。例如,LReasoner 提出了一个借助逻辑等价律(包括逆否律和传递律)的上下文扩展框架 (Wang et al., 2022a)。另一个例子是 Logiformer,它引入了包含语法分支和逻辑分支的双流架构,以更好地建模远距离逻辑单元之间的关系 (Xu et al., 2022)。
Table 1: Libraries and examples of all types of logical indicators.
| Type | Library | Example |
| PMI | given that, seeing that, for the reason that, owing to, as indicated by, on thegrounds that,on account of,considering,because of, due to, now that, may be inferred from, by virtue of, in view of, for the sake of, thanks to, as long as, based on that, as a result of, considering that, inasmuch as, if and only if, according to, in | The real world contains no political entity exer- cising literally total control over even one such aspect. This is because anysystemof control is inefficient, and, therefore, its degree of control is partial. |
| conclude that, entail that, infer that, that is why, therefore, thereby, wherefore, accordingly, hence, thus, consequently, whence, so that, it follows that, imply that, as a result, suggest that, prove that, as a conclusion, conclusively, for this reason, as a consequence, on that account, in conclusion, to that end, because of this, that being so, ergo, in this way, in this manner, eventually | In the United States, each bushel of corn pro- duced might result in the loss of as much as two bushels of topsoil. Moreover, in the last 100 years, the topsoil in many states, which once was about fourteen inches thick, has been eroded to only six or eight inches. | |
| NTI | not, neither, none of, unable, few, little, hardly, merely, seldom, without, never, nobody, nothing, nowhere, rarely, scarcely, barely, no longer, isn't, aren't,wasn't, weren't, can't, cannot, couldn't, won't,wouldn't,don't,doesn't,didn't,haven't,hasn't | A high degree of creativity and a high level of artistic skill are seldom combined in the cre- ation of a work of art. |
| ATI | although, though, but, nevertheless, however, instead of, nonethe- This advantage accruing to the sentinel does not less, yet, rather, whereas, otherwise, conversely, on the contrary, even, nevertheless, despite, in spite of, in contrast, even if, even though, unless, regardless of, reckless of | /, mean that its watchful behavior is entirely self- interested. On the contrary , the sentinel's be- havior is an example of animal behavior moti- vated at least in part by altruism. |
| CNI | and, or, nor, also, moreover, in addition, on the other hand, meanwhile, further, afterward, next, besides, additionally, mean- to serve in the presidential cabinet. time, furthermore, as well, simultaneously, either, both, similarly, likewise | l,A graduate degree in policymaking is necessary In addition everyone in the cabinet must pass a security clearance. |
表 1: 各类逻辑指示词库及示例
| 类型 | 词库 | 示例 |
|---|---|---|
| PMI | given that, seeing that, for the reason that, owing to, as indicated by, on the grounds that, on account of, considering, because of, due to, now that, may be inferred from, by virtue of, in view of, for the sake of, thanks to, as long as, based on that, as a result of, considering that, inasmuch as, if and only if, according to, in | 现实世界中不存在对任何一个方面实施完全控制的政体。这是因为任何控制系统都存在效率问题,因此其控制程度都是局部的。 |
| conclude that, entail that, infer that, that is why, therefore, thereby, wherefore, accordingly, hence, thus, consequently, whence, so that, it follows that, imply that, as a result, suggest that, prove that, as a conclusion, conclusively, for this reason, as a consequence, on that account, in conclusion, to that end, because of this, that being so, ergo, in this way, in this manner, eventually | 在美国,每生产一蒲式耳玉米可能导致多达两蒲式耳表土流失。此外在过去100年间,许多州原本约14英寸厚的表土层已被侵蚀至仅剩6-8英寸。 | |
| NTI | not, neither, none of, unable, few, little, hardly, merely, seldom, without, never, nobody, nothing, nowhere, rarely, scarcely, barely, no longer, isn't, aren't, wasn't, weren't, can't, cannot, couldn't, won't, wouldn't, don't, doesn't, didn't, haven't, hasn't | 在艺术创作中,高度创造力与精湛艺术技巧很少能同时体现在同一件作品中。 |
| ATI | although, though, but, nevertheless, however, instead of, nonetheless, yet, rather, whereas, otherwise, conversely, on the contrary, even, nevertheless, despite, in spite of, in contrast, even if, even though, unless, regardless of, reckless of | 哨兵获得的这种优势并不意味着其警戒行为完全出于自私。相反,哨兵的行为是动物行为至少部分利他动机的例证。 |
| CNI | and, or, nor, also, moreover, in addition, on the other hand, meanwhile, further, afterward, next, besides, additionally, meantime, furthermore, as well, simultaneously, either, both, similarly, likewise | 获得政策制定研究生学位是进入总统内阁的必要条件。此外,所有内阁成员都必须通过安全审查。 |
2.2 Pre-training Tasks
2.2 预训练任务
As NLP enters the era of pre-training, more and more researchers are diving into the design of pre-training tasks, especially about different masking strategies. For instance, in Cui et al. (2020), the authors apply Whole Word Masking (WWM) on Chinese BERT and achieved great progress. WWM changes the masking strategy in the original masked language modeling (MLM) into masking all the tokens which constitute a word with complete meaning instead of just one single token. In addition, Lample and Conneau (2019) extends MLM to parallel data as Translation Language Modeling (TLM) which randomly masks tokens in both source and target sentences in different languages simultaneously. The results show that TLM is beneficial to improve the alignment among different languages.
随着NLP进入预训练时代,越来越多的研究者投入到预训练任务的设计中,特别是关于不同的掩码策略。例如,在Cui等人(2020)的研究中,作者将全词掩码(WWM)应用于中文BERT并取得了显著进展。WWM将原始掩码语言建模(MLM)中的掩码策略改为掩码构成完整意义单词的所有token,而非单个token。此外,Lample和Conneau(2019)将MLM扩展到并行数据,提出了翻译语言建模(TLM),该方法会同时随机掩码不同语言的源句和目标句中的token。结果表明,TLM有助于提升不同语言之间的对齐效果。
3 Preliminary
3 初步准备
3.1 Text Logical Unit
3.1 文本逻辑单元
It is admitted that a single word is the most basic unit of a piece of text but its meaning varies with different contexts. In $\mathrm{Xu}$ et al. (2022), the authors refer logical units to the split sentence spans that contain independent and complete semantics. In this paper, since much more abundant logical indicators with different types that link not only clauses but also more fine-grained text spans are introduced, we extend this definition to those shorter text pieces like entities.
承认单个词是文本最基本的单元,但其含义会随上下文变化。在Xu等人 (2022) 的研究中,作者将逻辑单元定义为包含独立完整语义的切分句段。本文由于引入了更丰富的多类型逻辑指示符(不仅连接从句还关联更细粒度文本片段),我们将该定义扩展至实体等更短的文本片段。
3.2 Logical Indicators
3.2 逻辑指标
By analyzing the passages in logical reasoning MRC and reasoning-related materials like debate scripts, we found that the relations between logic units (like entities or events) can be summarized into 5 main categories as follows and all these relations are usually expressed via a series of logical indicators. After consulting some previous work like Pi et al. (2022) and Penn Discourse TreeBank 2.0 (PDTB 2.0) (Prasad et al., 2008), we managed to construct an indicator library for each category. As for the examples of indicators we used in detail, please refer to Table 1.
通过分析逻辑推理机器阅读理解(MRC)中的段落及辩论脚本等推理相关材料,我们发现逻辑单元(如实体或事件)之间的关系可归纳为以下5大类,这些关系通常通过一系列逻辑指示词来表达。参考Pi等人(2022)和宾夕法尼亚话语树库2.0(PDTB 2.0)(Prasad等人,2008)等前人工作后,我们为每类关系构建了指示词库。具体使用的指示词示例请见表1:
• Premise/Conclusion Indicator (PMI/CLI) The first two types of logical indicators pertain to premises and conclusions. These indicators signal the logical relationship between statements. For instance, premise expressions such as “due to” indicate that the logic unit following the keyword serves as the reason or explanation for the unit preceding it. Conversely, conclusion phrases like “result in” suggest an inverse relationship, implying that the logic unit after the keyword is a consequence or outcome of the preceding unit.
• 前提/结论指示词 (PMI/CLI)
前两类逻辑指示词涉及前提和结论。这些指示词标志着陈述之间的逻辑关系。例如,"due to"等前提表达式表明关键词后的逻辑单元是其前面单元的原因或解释。相反,"result in"等结论短语则暗示相反的关系,即关键词后的逻辑单元是前面单元的结果或后果。
• Negative Indicator (NTI) Negative indicators, such as “no longer”, play a crucial role in text logic by negating affirmative logic units. They have the power to significantly alter the meaning of a statement. For example, consider the sentences “Tom likes hamburgers.” and “Tom no longer likes hamburgers.” These two sentences have nearly opposite meanings, solely due to the presence of the indicator “no longer”.
• 否定性指标 (NTI) 否定性指标(如"不再")通过否定肯定性逻辑单元,在文本逻辑中起着至关重要的作用。它们能够显著改变语句的含义。例如,比较句子"Tom喜欢汉堡。"和"Tom不再喜欢汉堡。"这两个句子的含义几乎相反,仅仅因为存在"不再"这一指标。
• Ad vers at ive Indicator (ATI) Certain expressions, such as “however”, are commonly employed between sentences to signify a shift or change in the narrative. They serve as valuable tools for indicating the alteration or consequence of a preceding event, which helps to cover this frequent kind of relation among logic units.
• 对抗性指标 (Adversarial Indicator, ATI) 某些表达方式(如"however")通常用于句子之间,表示叙述的转变或变化。它们是指示前文事件变化或结果的重要工具,有助于覆盖逻辑单元间这种常见的关系类型。
• Coordinating Indicator (CNI) The coordinating relation is undoubtedly the most prevalent type of relationship between any two logic units. Coordinating indicators are used to convey that the units surrounding them possess the same logical status or hold equal importance. These indicators effectively demonstrate the coordination or parallelism between the connected logic units.
• 协调性指示词 (CNI) 协调关系无疑是任意两个逻辑单元之间最普遍的关系类型。协调性指示词用于表明其连接的逻辑单元具有同等地位或重要性,这些指示词能有效体现被连接逻辑单元之间的并列或平行关系。
4 Methodology
4 方法论
4.1 LGP Dataset Construction
4.1 LGP数据集构建
For the sake of further pre-training models with IDOL, we constructed the dataset LGP (LoGic Pretraining) based on the most popular un annotated corpus English Wikipedia.2 We first split the articles into paragraphs and abandoned those whose lengths (after token iz ation) were no longer than 5. In order to provide as much logical information as possible, we used the logical indicators listed in Table 1 to filter the Wiki paragraphs. During this procedure, we temporarily removed those indicators with extremely high frequency like “and”, otherwise, there would be too many paragraphs whose logical density was unacceptably low. Then, we iterated every logical keyword and replaced it with our customized special token [LGMASK] under the probability of $70%$ .
为了进一步用IDOL进行模型预训练,我们基于最流行的未标注语料库英文维基百科构建了数据集LGP(逻辑预训练)。首先将文章分割为段落,并舍弃分词后长度不超过5的段落。为了提供尽可能多的逻辑信息,我们使用表1列出的逻辑指示词对维基百科段落进行筛选。在此过程中,我们暂时移除了"and"等出现频率过高的指示词,否则会导致大量段落的逻辑密度过低。接着遍历每个逻辑关键词,并以70%的概率将其替换为自定义的特殊token [LGMASK]。
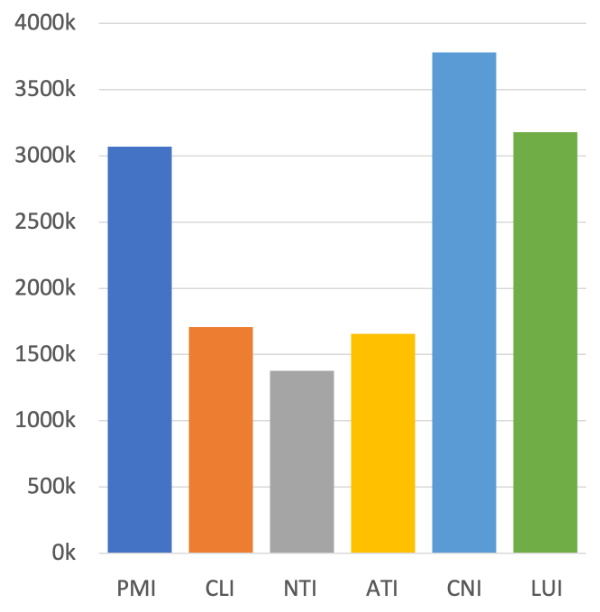
Figure 2: The numbers of 6 types of logical indicators in LGP for RoBERTa.
图 2: RoBERTa 在 LGP 中 6 种逻辑指标的数量。
For the purpose of modeling the ability to distinguish whether a certain masked place is logicrelated or not, we introduced the sixth logical indicator type - Logic Unrelated Indicator (LUI). Based on this, we then randomly replaced $0.6%$ tokens other than logical indicators with [LGMASK]. Afterward, the labels for the logical category prediction (LCP) task were generated based on the corresponding logic types of all the [LGMASK]s. In the end, take RoBERTa (Liu et al., 2019) for example, our logic dataset LGP contains over 6.1 million samples and as for the quantities of logical indicators in each type please refer to Figure 2.
为了建模区分某个被遮蔽位置是否与逻辑相关的能力,我们引入了第六种逻辑指示符类型——逻辑无关指示符(LUI)。基于此,我们随机将除逻辑指示符外$0.6%$的token替换为[LGMASK]。随后,根据所有[LGMASK]对应的逻辑类型生成逻辑类别预测(LCP)任务的标签。最终以RoBERTa (Liu et al., 2019)为例,我们的逻辑数据集LGP包含超过610万个样本,各类型逻辑指示符的数量请参见图2。
4.2 IDOL Pre-training
4.2 IDOL 预训练
4.2.1 Logical Category Prediction
4.2.1 逻辑类别预测
As introduced in section 3.2 and section 4.1, we defined a logic-related special mask token [LGMASK] and it will take the place of 6 types of logical indicators - PMI, CLI, NTI, ATI, CNI, and LUI. During the forward process of fine-tuning the pre-trained models, the corresponding logical categories need to be predicted by them like what will be done in the token classification task of the standard Masked Language Modeling (MLM) (Devlin et al., 2019).
如第3.2节和第4.1节所述,我们定义了一个与逻辑相关的特殊掩码token [LGMASK],它将替代6种逻辑指示符——PMI、CLI、NTI、ATI、CNI和LUI。在前置训练模型的微调前向过程中,需要像标准掩码语言建模(MLM) [20]的token分类任务那样预测对应的逻辑类别。
When the models are trying to predict the correct logical type of a certain [LGMASK], they will learn to analyze the relationship among the logical units around the current special token and whether there is some kind of logical relations with the help of the whole context. Therefore, the pre-trained models will be equipped with a stronger ability of reasoning over texts gradually.
当模型试图预测某个[LGMASK]的正确逻辑类型时,它们会学习分析当前特殊token周围逻辑单元之间的关系,并借助整个上下文判断是否存在某种逻辑关联。因此,预训练模型会逐步具备更强的文本推理能力。
Moreover, we use Cross-Entropy Loss (CELoss) to evaluate the performance of predicting the logical categories. The loss function for LCP is as described in Equation (1) where $n$ is the number of samples, $m$ is the number of $\mathsf{L L G M A S K]}$ in the $i_{t h}$ sample, $y_{i,j}$ indicates the model prediction result for the $j_{t h}$ [LGMASK] in the $i_{t h}$ sample and $\hat{y}_{i,j}$ denote the corresponding ground truth value.
此外,我们使用交叉熵损失 (CELoss) 来评估逻辑类别预测的性能。LCP 的损失函数如公式 (1) 所示,其中 $n$ 为样本数量,$m$ 为第 $i_{t h}$ 个样本中 $\mathsf{L L G M A S K]}$ 的数量,$y_{i,j}$ 表示模型对第 $i_{t h}$ 个样本中第 $j_{t h}$ 个 [LGMASK] 的预测结果,$\hat{y}_{i,j}$ 表示对应的真实值。

Figure 3: An example of pre-training with IDOL. The model needs to recover the tokens replaced by [MASK] (MLM) and predict the category of each logical indicator masked by [LGMASK] (LCP) in the meantime.
图 3: IDOL预训练示例。模型需要同时恢复被[MASK]替换的token (MLM) 并预测每个被[LGMASK]遮盖的逻辑指示符类别 (LCP)。
$$
\mathcal{L}{\mathrm{LCP}}=\sum_{i=1}^{n}\frac{1}{m}\sum_{j=1}^{m}\mathbf{CELoss}(y_{i,j},\hat{y}_{i,j})
$$
$$
\mathcal{L}{\mathrm{LCP}}=\sum_{i=1}^{n}\frac{1}{m}\sum_{j=1}^{m}\mathbf{CELoss}(y_{i,j},\hat{y}_{i,j})
$$
4.2.2 IDOL
4.2.2 IDOL
To avoid catastrophic forgetting, we combine the classic MLM task with the LCP introduced above to become IDOL, a multi-task learning pre-training method for enhancing the logical reasoning ability of pre-trained models. For the purpose of balancing the effects of the two pre-training tasks, we introduced a hyper-parameter $\lambda$ as the weight of the loss of LCP (the proper $\lambda$ depends on the pre-trained language model used and the empirical range is between 0.7 and 0.9). Thus, for the IDOL pre-training loss function, please refer to Equation (2). Figure 3 presented an example of IDOL pre-training where predicting tokens and the classes of logical indicators simultaneously.
为避免灾难性遗忘,我们将经典MLM任务与上述LCP结合形成IDOL,这是一种增强预训练模型逻辑推理能力的多任务学习预训练方法。为平衡两个预训练任务的影响,引入超参数$\lambda$作为LCP损失的权重(具体$\lambda$值取决于所用预训练语言模型,经验范围在0.7至0.9之间)。因此,IDOL预训练损失函数请参见公式(2)。图3展示了IDOL预训练中同时预测token和逻辑指示符类别的示例。
$$
\mathcal{L}{\mathrm{IDOL}}=\lambda\cdot\mathcal{L}{\mathrm{LCP}}+(1-\lambda)\cdot\mathcal{L}_{\mathrm{MLM}}
$$
$$
\mathcal{L}{\mathrm{IDOL}}=\lambda\cdot\mathcal{L}{\mathrm{LCP}}+(1-\lambda)\cdot\mathcal{L}_{\mathrm{MLM}}
$$
5 Experiments
5 实验
5.1 Baselines
5.1 基线方法
With the rapid development of pre-training technology these years, we have various choices for backbone models. In this paper, we decide to apply IDOL on BERT-large (Devlin et al., 2019), RoBERTa-large (Liu et al., 2019), ALBERTxxlarge (Lan et al., 2020) and DeBERTa-v2-xxlarge (He et al., 2021) and will evaluate the models in
近年来,随着预训练(pre-training)技术的快速发展,我们在主干模型选择上有了多种方案。本文决定将IDOL应用于BERT-large (Devlin等人,2019)、RoBERTa-large (Liu等人,2019)、ALBERTxxlarge (Lan等人,2020)和DeBERTa-v2-xxlarge (He等人,2021)等模型,并将对这些模型进行...
In terms of logical reasoning MRC, we will compare IDOL with several previous but still competitive methods for logical reasoning MRC including DAGN (Huang et al., 2021), AdaLoGN (Li et al., 2022), LReasoner (Wang et al., 2022b), Logiformer (Xu et al., 2022) and MERIt (Jiao et al., 2022). Much more interesting, we let IDOL compete with ChatGPT in a small setting.
在逻辑推理机器阅读理解 (MRC) 方面,我们将 IDOL 与几种先前但仍具竞争力的逻辑推理 MRC 方法进行比较,包括 DAGN (Huang et al., 2021)、AdaLoGN (Li et al., 2022)、LReasoner (Wang et al., 2022b)、Logiformer (Xu et al., 2022) 和 MERIt (Jiao et al., 2022)。更有趣的是,我们在小规模设置中让 IDOL 与 ChatGPT 进行竞争。
5.2 Datasets
5.2 数据集
First and foremost, the aim of IDOL is to improve the logical reasoning ability of pre-trained models, thus, the two most representative benchmarks - ReClor and LogiQA will act as the primary examiners.
首先,IDOL的目标是提升预训练模型的逻辑推理能力,因此最具代表性的两个基准测试——ReClor和LogiQA将作为主要评估工具。
Following this, RACE (Lai et al., 2017) and SQuAD 2.0 (Rajpurkar et al., 2018), two classic machine reading comprehension datasets that are not targeted at assessing reasoning ability, will come on stage, which will be beneficial to conclude whether IDOL helps with other types of reading comprehension abilities.
随后登场的是RACE (Lai et al., 2017)和SQuAD 2.0 (Rajpurkar et al., 2018)这两个不针对推理能力评估的经典机器阅读理解数据集,这将有助于验证IDOL是否对其他类型的阅读理解能力有所提升。
Last but not least, we also tested the models pre-trained with IDOL on MNLI (Williams et al.,
最后但同样重要的是,我们还测试了在MNLI (Williams et al., [20]) 上使用IDOL预训练的模型。
- and STS-B (Cer et al., 2017), two tasks of GLUE (Wang et al., 2018), to make sure that the general language understanding abilities are retained to a great extent during the process of logical enhancement. The evaluation metrics on STS-B are the Pearson correlation coefficient (Pear.) and Spearman’s rank correlation coefficient (Spear.) on the development set. And we use the accuracy of MNLI-m and MNLI-mm development sets for evaluation on MNLI.
- 和 STS-B (Cer 等人, 2017), 这两个 GLUE (Wang 等人, 2018) 任务, 以确保在逻辑增强过程中通用语言理解能力得到较大程度保留。STS-B 的评估指标是开发集上的皮尔逊相关系数 (Pear.) 和斯皮尔曼等级相关系数 (Spear.)。对于 MNLI, 我们使用 MNLI-m 和 MNLI-mm 开发集的准确率进行评估。
ReClor The problems in this dataset are collected from two American standardized tests - LSAT and GMAT, which guarantee the difficulty of answering the questions. Moreover, ReClor covers 17 classes of logical reasoning including main idea inference, reasoning flaws detection, sufficient but unnecessary conditions, and so forth. Each problem consists of a passage, a question, and four answer candidates, like the one shown in the green section of Figure 1. There are 4638, 500, and 1000 data points in the training set, development set, and test set respectively. The accuracy is used to evaluate the system’s performance.
ReClor
该数据集中的问题收集自美国两项标准化考试——LSAT和GMAT,确保了答题难度。此外,ReClor涵盖17类逻辑推理题型,包括主旨推断、推理缺陷检测、充分非必要条件等。每道题由一篇短文、一个问题及四个候选答案组成,如图1绿色区域所示。训练集、开发集和测试集分别包含4638、500和1000个数据点,采用准确率作为系统性能评估指标。
LogiQA The main difference compared with ReClor is that the problems in LogiQA are generated based on the National Civil Servants Examination of China. Besides, it incorporates 5 main reasoning types such as categorical reasoning and d is jun ct ive reasoning. And 7376, 651, and 651 samples are gathered for the training set, development set, and test set individually.
LogiQA
与ReClor的主要区别在于,LogiQA中的问题基于中国国家公务员考试生成。此外,它融合了5种主要推理类型,如分类推理和析取推理。训练集、开发集和测试集分别收集了7376、651和651个样本。
5.3 Implementation Detail
5.3 实现细节
5.3.1 IDOL
5.3.1 IDOL
During the process of pre-training with IDOL, we implemented the experiments on 8 Nvidia A100 GPUs. Since IDOL was applied on multiple different pre-trained models, we provide a range for some main hyper parameters. The whole training process consists of $10\mathrm{k}{\sim}20\mathrm{k}$ steps while the warmup rate keeps 0.1. The learning rate is warmed up to a peak value between $5\mathrm{e}{-6}{\sim}3\mathrm{e}{-5}$ for different models, and then linearly decayed. As for batch size, we found that 1024 or 2048 is more appropriate for most models. Additionally, we use AdamW (Loshchilov and Hutter, 2017) as our optimizer with a weight decay of around 1e-3. For the software packages we used in detail, please see Appendix.
在使用IDOL进行预训练的过程中,我们在8块Nvidia A100 GPU上完成了实验。由于IDOL被应用于多个不同的预训练模型,我们为部分主要超参数提供了范围。整个训练过程包含$10\mathrm{k}{\sim}20\mathrm{k}$步,同时保持0.1的热身率。学习率会热身至峰值,不同模型介于$5\mathrm{e}{-6}{\sim}3\mathrm{e}{-5}$之间,随后线性衰减。至于批量大小,我们发现1024或2048对大多数模型更为合适。此外,我们采用AdamW (Loshchilov and Hutter, 2017)作为优化器,权重衰减约为1e-3。关于我们使用的详细软件包,请参阅附录。
With respect to the hyper parameters for finetuning models on downstream tasks, we follow the configurations provided in the original paper of either the corresponding model or the dataset.
在下游任务上微调模型的超参数设置方面,我们遵循对应模型或数据集原始论文中提供的配置。
Table 2: Results on logical reasoning MRC benchmarks - ReClor and LogiQA. In each block, the previous methods listed for comparison and IDOL take the pre-trained model in the first line as their backbone model. $\spadesuit$ : reproduced by ourselves.
表 2: 逻辑推理MRC基准测试结果 - ReClor和LogiQA。每个区块中列出的对比方法和IDOL均以第一行的预训练模型作为主干模型。 $\spadesuit$ : 我们自行复现的结果。
| 模型 | ReClor Dev | ReClor Test | LogiQA Dev | LogiQA Test |
|---|---|---|---|---|
| BERT IDOL | 53.8 56.8 | 49.8 53.3 | 35.3 36.9 | 33.0* 34.3 |
| RoBERTa DAGN | 62.6 65.2 | 55.6 58.2 | 37.0* 35.5 | 36.6 38.7 |
| AdaLoGN LReasoner | 65.2 66.2 | 60.2 62.4 | 39.9 38.1 | 40.7 40.6 |
| MERIt | 67.8 | 60.7 | 42.4 | 41.5 |
| Logiformer | 68.4 | 63.5 | 42.2 | 42.6 |
| IDOL | 70.2 | 63.9 | 42.5 | 41.8 |
| ALBERT | 70.4 | 67.3 | 41.2 | 41.3 |
| LReasoner | 73.2 | 70.7 | 41.6 | 41.2 |
| MERIT | 73.2 | 71.1 | 43.9 | 45.3 |
| IDOL | 74.6 | 70.9 | 44.7 | 43.8 |
5.3.2 LLM
5.3.2 大语言模型 (LLM)
For the purpose of comparing IDOL with LLMs, we randomly sampled 30 pieces of data in the development sets of ReClor and LogiQA separately (named Dev-30). As for models, we choose GPT $3.5^{4}$ , ChatGPT5 and GLM-130B (Zeng et al., 2022) for this pilot test.
为了比较IDOL与大语言模型(LLM)的性能,我们分别在ReClor和LogiQA的开发集中随机抽取了30条数据(命名为Dev-30)。模型方面,我们选择了GPT $3.5^{4}$、ChatGPT5和GLM-130B (Zeng et al., 2022)进行本次试点测试。
To better evaluate the performance of LLMs, we tested them in the following three settings: zeroshot prompting, few-shot prompting, and chain-ofthought prompting. For zero-shot prompting, we designed the following template to wrap up the MRC problem.
为了更好地评估大语言模型 (LLM) 的性能,我们在以下三种设置下对其进行了测试:零样本 (zero-shot) 提示、少样本 (few-shot) 提示和思维链 (chain-of-thought) 提示。对于零样本提示,我们设计了以下模板来封装 MRC 问题。
The passage is [PASSAGE]. The question is [QUESTION]. Here are 4 choices for it and they are [CHOICES]. Which one should I choose? Thanks.
文章是[PASSAGE]。问题是[QUESTION]。这里有4个选项[CHOICES]。我该选哪个?谢谢。
As for few-shot prompting, we insert 3 examples in the same template but with correct answers ahead of the target question. When testing with chain-of-thought prompting, the template is similar to the one presented above. But there is only one example ahead and sentences describing the process of the way how humans reason to solve the problem are provided before giving the right answer to the example. For more details about the templates and the test example, please refer to Table 6 and Figure 4.
至于少样本提示,我们在同一模板中插入3个带有正确答案的示例,并置于目标问题之前。在使用思维链提示进行测试时,模板与上述类似,但仅在前方提供一个示例,并在给出正确答案前添加描述人类推理解决问题过程的语句。有关模板和测试示例的更多细节,请参阅表6和图4。
Table 3: Results of IDOL with DeBERTa and other publicly available data. ♣: top results from the official leader board of ReClor (as of January 19, 2023). ♡: the performance of the original DeBERTa from Jiao et al. (2022) for reference (the majority of the top submissions and IDOLs in this table take DeBERTa as the backbone model).
表 3: IDOL 与 DeBERTa 及其他公开数据的对比结果。♣: ReClor 官方排行榜的顶级结果 (截至 2023 年 1 月 19 日)。♡: Jiao 等人 (2022) 原始 DeBERTa 的参考性能 (本表中大多数顶级提交模型和 IDOL 均以 DeBERTa 作为主干模型)。
| 模型 | ReClor | ||
|---|---|---|---|
| Test | Test-E | Test-H | |
| DeBERTa | 75.3 | 84.0 | 68.4 |
| LReasoner* | 76.1 | 87.1 | 67.5 |
| Knowledge Model* | 79.2 | 91.8 | 69.3 |
| MERIt* | 79.3 | 85.2 | 74.6 |
| AMR-LE* | 80.0 | 87.7 | 73.9 |
| IDOL | 80.6 | 87.7 | 75.0 |
5.4 Main Results
5.4 主要结果
5.4.1 Logical Reasoning MRC
5.4.1 逻辑推理机器阅读理解 (Logical Reasoning MRC)
Fine-tuning To evaluate the model performance on logical reasoning MRC, we experimented with the baseline models mentioned above on ReClor and LogiQA, the two most representative benchmarks in this field. The majority of previous researchers focus on applying their method to RoBERTa, IDOL meets the most competitors in this setting as shown in Table 2. In spite of this, IDOL surpassed all the existing strong systems by an obvious margin in nearly every evaluation metric except the accuracy on the LogiQA test set. Apparently, from the results on BERT and ALBERT in Table 2 and results on DeBERTa in Table 3, we can see that IDOL has significant advantages over other opponents as well. In summary, IDOL is highly effective in logical reasoning MRC with state-of-the-art performance and this benefit can be generalized to different pretrained models even to the recent large-scale and strong ones.
微调
为评估模型在逻辑推理机器阅读理解 (MRC) 上的性能,我们在该领域最具代表性的两个基准数据集 ReClor 和 LogiQA 上对上述基线模型进行了实验。此前大多数研究者专注于将他们的方法应用于 RoBERTa,如表 2 所示,IDOL 在此设置下遇到了最多的竞争对手。尽管如此,除了 LogiQA 测试集的准确率外,IDOL 在几乎所有评估指标上都以明显优势超越了现有所有强系统。显然,从表 2 中 BERT 和 ALBERT 的结果以及表 3 中 DeBERTa 的结果可以看出,IDOL 相比其他对手也具有显著优势。总之,IDOL 在逻辑推理 MRC 中非常高效,具备最先进的性能,并且这一优势可以推广到不同的预训练模型,甚至包括近期的大规模强模型。
Prompting Although the scale of Dev-30 for the pilot test on LLM is small, the results displayed in Table 5 inspired us to some extent. Generally, IDOL is still competitive in the era of LLM. On ReClor, it achieved an accuracy of $80%$ while the best result from LLMs is $70%$ (ChatGPT with Chain-ofThought prompting). Even though GLM-130B realizes an accuracy of $50%$ on LogiQA in Zero-Shot setting surprisingly (slightly higher than $43.3%$ by IDOL), IDOL has an obvious advantage compared with other settings and other LLMs. Additionally, there is an interesting phenomenon that chain-ofthought prompting brings negative effects on LLMs except for ChatGPT on ReClor, which is not consistent with the findings in Wei et al. (2022).
提示
尽管用于大语言模型 (LLM) 试点测试的 Dev-30 规模较小,但表 5 中显示的结果在一定程度上给了我们启发。总体而言,IDOL 在 LLM 时代仍具竞争力。在 ReClor 上,其准确率达到 $80%$,而 LLM 的最佳结果为 $70%$(ChatGPT 结合思维链提示)。尽管 GLM-130B 在零样本 (Zero-Shot) 设置下于 LogiQA 上意外实现了 $50%$ 的准确率(略高于 IDOL 的 $43.3%$),但与其他设置及其他 LLM 相比,IDOL 仍具有明显优势。此外,一个有趣的现象是:除 ChatGPT 在 ReClor 上的表现外,思维链提示对其他 LLM 产生了负面影响,这与 Wei 等人 (2022) [20] 的研究发现不一致。

Figure 4: An example of ChatGPT answering an MRC question.
图 4: ChatGPT 回答 MRC (机器阅读理解) 问题的示例。
5.4.2 Other MRC Datasets
5.4.2 其他 MRC 数据集
For testing whether IDOL could also benefit on types of MRC tasks or maintain the original abilities, we conducted a series of experiments based on RoBERTa as the backbone model. The results are displayed in the middle part of Table 4 where we compare the original model, the model further pre-trained with only MLM on LGP and the model further pre-trained with IDOL. We evaluate the models in each setting with 4 different seeds and report the average value. It is apparent that IDOL performs better on both RACE and SQuAD 2.0 in each evaluation metric (although the effects are not as big as those on ReClor or LogiQA), which implies that IDOL indeed helps on general MRC tasks while achieving significant improvement in logical reasoning ability.
为了测试IDOL是否也能在其他类型的机器阅读理解(MRC)任务中受益或保持原有能力,我们以RoBERTa作为主干模型进行了一系列实验。结果如表4中间部分所示,其中我们比较了原始模型、仅在LGP上使用MLM继续预训练的模型以及使用IDOL继续预训练的模型。我们在每种设置下用4个不同的随机种子评估模型,并报告平均值。显然,IDOL在RACE和SQuAD 2.0的每个评估指标上都表现更好(尽管效果不如在ReClor或LogiQA上显著),这表明IDOL确实有助于提升通用MRC任务性能,同时在逻辑推理能力上实现了显著改进。
5.4.3 General Understanding Ability
5.4.3 通用理解能力
Following the experiment configuration in section 5.4.2, we planned to find out what kind of effect would IDOL have on other types of natural language understanding tasks which help to reflect the general understanding ability of pre-trained language models. We evaluate the models in each setting with 4 different seeds and report the average value. From the results presented in the right part of Table 4, we can easily find that although IDOL falls behind on MNLI and exceeds the other two competitors on STS-B, the differences in all the evaluation metrics are quite small. Therefore, we could conclude that IDOL retains the general language understanding ability from the original pre-trained model successfully during the process of becoming stronger in logical reasoning.
按照第5.4.2节的实验配置,我们计划探究IDOL对其他类型自然语言理解任务的影响,这些任务有助于反映预训练语言模型的通用理解能力。我们在每种设置下使用4个不同种子评估模型,并报告平均值。从表4右侧呈现的结果可以明显看出,虽然IDOL在MNLI上稍逊一筹,但在STS-B上超越了另外两个竞争对手,所有评估指标的差异都非常小。因此,我们可以得出结论:IDOL在增强逻辑推理能力的过程中,成功保留了原始预训练模型的通用语言理解能力。
Table 4: Results of RoBERTa with different pre-training tasks on logical reasoning MRC, other types of MRC and other types of NLU tasks.
| 模型 | ReClor 开发集 | ReClor 测试集 | LogiQA 开发集 | LogiQA 测试集 | RACE 开发集 | RACE 测试集 | SQuAD 2.0 F1 | SQuAD 2.0 EM | STS-B 皮尔逊 | STS-B 斯皮尔曼 | MNLI 匹配集 | MNLI 不匹配集 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RoBERTa | 62.7 | 55.2 | 36.2 | 37.1 | 85.2 | 84.4 | 89.0 | 86.1 | 92.6 | 92.5 | 89.5 | 89.3 |
| +MLM | 65.0 | 58.4 | 37.9 | 36.6 | 85.4 | 84.5 | 89.0 | 86.1 | 92.2 | 92.1 | 89.5 | 89.5 |
| +LCP (IDOL) | 66.8 | 60.6 | 39.4 | 38.8 | 85.6 | 84.8 | 89.2 | 86.2 | 92.3 | 92.2 | 89.7 | 89.5 |
表 4: RoBERTa在不同预训练任务下在逻辑推理MRC、其他类型MRC和其他类型NLU任务上的结果。
Table 5: Results on ReClor and LogiQA from LLMs and IDOL. ZS: Zero-Shot prompting. FS: Few-Shot prompting. CoT: Chain-of-Thought prompting. FT: Fine-Tuning.
表 5: 大语言模型和IDOL在ReClor和LogiQA上的结果。ZS: 零样本提示。FS: 少样本提示。CoT: 思维链提示。FT: 微调。
| 模型 | ZS | FS | CoT FT |
|---|---|---|---|
| ReClor | |||
| GPT-3.5 | 56.7 | 50.0 46.7 | |
| ChatGPT | 63.3 | 63.3 70.0 | |
| GLM-130B | 46.7 | 40.0 23.3 | |
| IDOL | 80.0 | ||
| LogiQA | |||
| GPT-3.5 | 30.0 | 10.0 13.3 | |
| ChatGPT | 33.3 | 36.7 23.3 | |
| GLM-130B | 50.0 | 36.7 26.6 | |
| IDOL | 43.3 |
6 Ablation Study
6 消融研究
In this section, we conducted a series of ablation experiments about the multiple logical indicators we used in both fine-tuning and pre-training phases. We evaluate the models based on RoBERTa with 4 different seeds and report the average value.
在本节中,我们针对微调和预训练阶段使用的多项逻辑指标进行了一系列消融实验。我们基于RoBERTa模型评估了4组不同随机种子的结果,并报告了平均值。
6.1 Indicators in Fine-tuning
6.1 微调中的指标
As introduced in section 3.2, we defined 5 classes of logical indicators that reflect various logical relations among text logical units and we make use of all of them in IDOL. To figure out whether the 5 types are of equal importance in logical reasoning MRC, we conducted a set of controlled experiments where certain types of indicators are removed from the ReClor train set as the fine-tuning train dataset in each setting.
如第3.2节所述,我们定义了5类反映文本逻辑单元间不同逻辑关系的逻辑指示符,并在IDOL中全部采用。为探究这5类指示符在逻辑推理MRC任务中的重要性是否等同,我们设计了一组对照实验:在每种实验设置中,从ReClor训练集中移除特定类型的指示符作为微调训练数据集。
From the results displayed in Table 7, it is obvious from the last column that logical indicators indeed play an important role in logical reasoningrelated text understanding since the loss of all indicators decreases accuracy by 4 to 7 points. In detail, we can conclude that the negative and adversative indicators influence the most by comparing the gaps between pre-training on the original LGP and the dataset without individual types of indicators.
从表7展示的结果可以明显看出,最后一列数据表明逻辑指示词在逻辑推理相关的文本理解中确实起着重要作用,因为去除所有指示词会使准确率下降4到7个百分点。具体而言,通过比较原始LGP预训练数据与去除单类指示词数据集的性能差距,我们可以得出否定类和转折类指示词的影响最为显著。
6.2 Indicators in Pre-training
6.2 预训练指标
Now that logical indicators have been proven to be effective in fine-tuning stage, we believe they also help with the pre-training stage. Therefore, we arranged a series of experiments on gradually incorpora ting more logical indicators from not leveraging any indicators (MLM), only making use of PMI and CLI (LCP-2), adding LUI to LCP-2 (LCP3), to taking advantage of all 6 types of logical indicators (LCP).
既然逻辑指标在微调阶段已被证明有效,我们相信它们对预训练阶段同样有帮助。因此,我们设计了一系列实验,逐步引入更多逻辑指标:从不使用任何指标(MLM)、仅利用PMI和CLI(LCP-2)、在LCP-2基础上增加LUI(LCP3)、到全面采用6类逻辑指标(LCP)。
From the lines displayed in Figure 5, it is clear that models perform better while leveraging a greater variety of logical indicators since the red line (IDOL) is positioned significantly higher than green and yellow lines representing pre-training tasks that utilize fewer types of logical indicators. According to the results in Table 7, PMI and CLI brought the least difference in the model performance on ReClor. The LCP-2 and LCP-3 mainly rely on the two types, and introducing a new special token [LGMASK] inevitably brings noise during model training and further widens the gap between pre-training and down-stream tasks, so that they perform even not better than the original MLM. Additionally, in the aspect of overall trends, the model pre-trained with IDOL is becoming stronger gradually during the process of pre-training, which certifies the effectiveness of our designed task targeted at logical indicators.
从图5显示的曲线可以明显看出,模型在利用更多样化的逻辑指示符时表现更优,因为红色线(IDOL)的位置显著高于代表使用较少类型逻辑指示符的预训练任务的绿色和黄色线。根据表7的结果,PMI和CLI对ReClor数据集上的模型性能影响最小。LCP-2和LCP-3主要依赖这两种类型,而引入新的特殊token [LGMASK]不可避免地会在模型训练过程中带来噪声,并进一步拉大预训练与下游任务之间的差距,因此它们的表现甚至不如原始MLM。此外,从整体趋势来看,使用IDOL预训练的模型在预训练过程中逐渐变强,这验证了我们针对逻辑指示符设计的任务的有效性。
Table 6: Templates and examples for LLM prompting in different settings.
表 6: 不同场景下的大语言模型提示模板及示例
| 场景 | 模板 |
|---|---|
| 零样本 (Zero-Shot) | 文章是[PASSAGE]。问题是[QUESTION]。这里有4个选项[CHOICES]。我该选哪个?谢谢。 |
| 少样本 (Few-Shot) | [示例A][示例B][示例C]文章是[PASSAGE]。问题是[QUESTION]。这里有4个选项[CHOICES]。我该选哪个?谢谢。 |
| 思维链 (Chain-of-Thought) | 文章是[PASSAGE]。问题是[QUESTION]。这里有4个选项[CHOICES]。你可以这样分析:[Thought Process]。所以答案是[Answer]。文章是[PASSAGE]。问题是[QUESTION]。这里有4个选项[CHOICES]。我该选哪个?谢谢。 |
Table 7: Results of fine-tuning with datasets obtained by removing certain types of logical indicators in the original ReClor train set and testing on the development set. The first row under “ReClor Train set” in each column indicates what indicators are removed from LGP. “—”: the original LGP. “PMI&CLI”: both premise and conclusion indicators are removed. “ALL”: no logical indicators left.
表 7: 在原始ReClor训练集中移除特定类型逻辑指示符后获得的数据集上进行微调,并在开发集上测试的结果。每列"ReClor Train set"下的第一行表示从LGP中移除了哪些指示符。"—": 原始LGP。"PMI&CLI": 同时移除前提和结论指示符。"ALL": 无逻辑指示符保留。
| Models | ReClorTrainSet | PMI&CLI | NTI | ATI | CNI ALL |
|---|---|---|---|---|---|
| RoBERTa | 62.7 | 64.0 | 59.7 | 61.7 | 63.7 |
| + MLM | 65.0 | 64.9 | 61.8 | 61.5 | 64.5 |
| + LCP | 66.8 | 63.8 | 62.7 | 63.4 | 64.2 |
7 Conclusion and Future Work
7 结论与未来工作
In this paper, we proposed an easy-to-understand further pre-training method IDOL which fully exploits the logical information provided by 6 types of logical indicators and is proven effective on different pre-trained language models while keeping them competitive on many other kinds of downstream tasks. Particularly, IDOL achieves state-ofthe-art performance on logical reasoning machine reading comprehension tasks.
本文提出了一种易于理解的进一步预训练方法IDOL,该方法充分利用6种逻辑指示器提供的逻辑信息,并在不同预训练语言模型上验证了其有效性,同时保持这些模型在其他多种下游任务中的竞争力。特别地,IDOL在逻辑推理机器阅读理解任务上实现了最先进的性能。
With respect to future work, we plan to leverage the sentence-level or passage-level logical features in the meantime and integrate it with IDOL to generate a stronger multi-task further pre-training method for improving the logical reasoning ability of pre-trained language models. Moreover, we decide to redesign the IDOL task and find out whether logical indicators also play an important role in those generative pre-trained models as well. Furthermore, we will explore the way of combining IDOL with prompting to find a better method to elicit the reasoning abilities of LLMs.
关于未来的工作,我们计划同时利用句子级或段落级的逻辑特征,并将其与IDOL结合,生成一种更强的多任务进一步预训练方法,以提升预训练语言模型的逻辑推理能力。此外,我们决定重新设计IDOL任务,探究逻辑指示词在生成式预训练模型中是否同样发挥重要作用。进一步地,我们将探索IDOL与提示(prompting)结合的途径,以找到更好的方法来激发大语言模型的推理能力。

Figure 5: The results on ReClor development set of models with different tasks on RoBERTa during the pre-training. LCP-2: LCP only with PMI and CLI. LCP-3: LCP only with PMI, CLI, and LUI. Baseline: fine-tuning with the original RoBERTa.
图 5: RoBERTa预训练阶段不同任务在ReClor开发集上的结果。LCP-2: 仅使用PMI和CLI的LCP。LCP-3: 仅使用PMI、CLI和LUI的LCP。Baseline: 原始RoBERTa微调结果。
8 Limitations
8 局限性
First of all, IDOL relies on a customized dataset that is filtered out from Wikipedia pages with the help of many pre-defined logical indicators. Inevitably, this will introduce a certain amount of artificial bias. If an automatic method for logical indicator extraction based on something like hidden representations from neural network models is put forward, it would be beneficial to narrow the gap between the dataset preparation and logical pre-training.
首先,IDOL依赖于一个从维基百科页面中通过多个预定义的逻辑指示器筛选出的定制数据集。这不可避免地会引入一定程度的人为偏差。如果能提出一种基于神经网络模型的隐藏表示等方法的逻辑指示器自动提取方法,将有助于缩小数据集准备与逻辑预训练之间的差距。
In addition, in the field of pre-training task design, there have been a lot of different but effective approaches proposed. For example, in Cui et al.
此外,在预训练任务设计领域,研究者们提出了许多不同但有效的方法。例如,在Cui等人的研究中[20]。
(2022), the authors presented a pre-training task named PERT which requires the models to recover the original token sequences under the background of that different token permutation within a certain range would not affect Chinese text understanding. This method only depends on the original texts, but IDOL introduces one more special token, which widens the gap between pre-training and fine-tuning to some extent.
(2022) 的研究者提出了一种名为 PERT 的预训练任务,该任务要求模型在一定范围内的 token 排列不影响中文文本理解的背景下,恢复原始 token 序列。这种方法仅依赖于原始文本,而 IDOL 引入了额外的特殊 token,在一定程度上扩大了预训练与微调之间的差距。