MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask
MaskNet: 通过实例引导的掩码将特征乘法引入CTR排序模型
Zhiqiang Wang, Qingyun She, Junlin Zhang Sina Weibo Corp Beijing, China roky2813@sina.com,qing yun she@163.com,junlin6@staff.weibo.com
王智强,佘青云,张俊林
新浪微博公司,中国北京
roky2813@sina.com, qingyun.she@163.com, junlin6@staff.weibo.com
ABSTRACT
摘要
Click-Through Rate(CTR) estimation has become one of the most fundamental tasks in many real-world applications and it’s important for ranking models to effectively capture complex high-order features. Shallow feed-forward network is widely used in many state-of-the-art DNN models such as FNN, DeepFM and xDeepFM to implicitly capture high-order feature interactions. However, some research has proved that addictive feature interaction, particular feed-forward neural networks, is inefficient in capturing common feature interaction. To resolve this problem, we introduce specific multiplicative operation into DNN ranking system by proposing instance-guided mask which performs element-wise product both on the feature embedding and feed-forward layers guided by input instance. We also turn the feed-forward layer in DNN model into a mixture of addictive and multiplicative feature interactions by proposing MaskBlock in this paper. MaskBlock combines the layer normalization, instance-guided mask, and feed-forward layer and it is a basic building block to be used to design new ranking model under various configurations. The model consisting of MaskBlock is called MaskNet in this paper and two new MaskNet models are proposed to show the effectiveness of MaskBlock as basic building block for composing high performance ranking systems. The experiment results on three real-world datasets demonstrate that our proposed MaskNet models outperform state-of-the-art models such as DeepFM and xDeepFM significantly, which implies MaskBlock is an effective basic building unit for composing new high performance ranking systems.
点击率(CTR)预估已成为许多实际应用中最基础的任务之一,对于排序模型来说,有效捕捉复杂的高阶特征至关重要。浅层前馈网络在许多最先进的深度神经网络(DNN)模型中被广泛使用,例如FNN、DeepFM和xDeepFM,以隐式捕捉高阶特征交互。然而,一些研究已经证明,加性特征交互,特别是前馈神经网络,在捕捉常见特征交互方面效率低下。为了解决这个问题,我们通过在DNN排序系统中引入特定的乘法操作,提出了实例引导的掩码(instance-guided mask),该掩码在输入实例的引导下对特征嵌入层和前馈层执行逐元素乘积。我们还将DNN模型中的前馈层转变为加性和乘法特征交互的混合体,提出了本文中的MaskBlock。MaskBlock结合了层归一化、实例引导的掩码和前馈层,它是一个基本构建块,可用于在各种配置下设计新的排序模型。由MaskBlock组成的模型在本文中被称为MaskNet,并提出了两种新的MaskNet模型,以展示MaskBlock作为构建高性能排序系统的基本构建块的有效性。在三个实际数据集上的实验结果表明,我们提出的MaskNet模型显著优于DeepFM和xDeepFM等最先进的模型,这表明MaskBlock是构建新的高性能排序系统的有效基本单元。
ACM Reference Format:
ACM 参考格式:
Zhiqiang Wang, Qingyun She, Junlin Zhang. 2021. MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask. In Proceedings of DLP-KDD 2021. ACM, New York, NY, USA, 9 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn
Zhiqiang Wang, Qingyun She, Junlin Zhang. 2021. MaskNet: 通过实例引导的掩码将特征乘法引入CTR排序模型。在DLP-KDD 2021会议论文集中。ACM, 纽约, 纽约州, 美国, 9页。https://doi.org/10.1145/nnnnnnn.nnnnnnn
1 INTRODUCTION
1 引言
Click-through rate (CTR) prediction is to predict the probability of a user clicking on the recommended items. It plays important role in personalized advertising and recommend er systems. Many models have been proposed to resolve this problem such as Logistic Regression (LR) [16], Polynomial-2 (Poly2) [17], tree-based models [7], tensor-based models [12], Bayesian models [5], and Field-aware Factorization Machines (FFMs) [11]. In recent years, employing DNNs for CTR estimation has also been a research trend in this field and some deep learning based models have been introduced such as Factorization-Machine Supported Neural Networks(FNN)[24], Attentional Factorization Machine (AFM)[3], wide & deep(W&D)[22], DeepFM[6], xDeepFM[13] etc.
点击率 (CTR) 预测是预测用户点击推荐项的概率。它在个性化广告和推荐系统中起着重要作用。许多模型已被提出以解决此问题,例如逻辑回归 (LR) [16]、多项式-2 (Poly2) [17]、基于树的模型 [7]、基于张量的模型 [12]、贝叶斯模型 [5] 和场感知因子分解机 (FFMs) [11]。近年来,使用深度神经网络 (DNN) 进行 CTR 估计也成为该领域的研究趋势,一些基于深度学习的模型已被引入,例如因子分解机支持神经网络 (FNN) [24]、注意力因子分解机 (AFM) [3]、宽深模型 (W&D) [22]、DeepFM [6]、xDeepFM [13] 等。
Feature interaction is critical for CTR tasks and it’s important for ranking model to effectively capture these complex features. Most DNN ranking models such as FNN , W&D, DeepFM and xDeepFM use the shallow MLP layers to model high-order interactions in an implicit way and it’s an important component in current state-ofthe-art ranking systems.
特征交互对于CTR任务至关重要,排名模型有效捕捉这些复杂特征非常重要。大多数DNN排名模型,如FNN、W&D、DeepFM和xDeepFM,使用浅层MLP层以隐式方式建模高阶交互,这是当前最先进排名系统中的一个重要组成部分。
However, Alex Beutel et.al [2] have proved that addictive feature interaction, particular feed-forward neural networks, is inefficient in capturing common feature crosses. They proposed a simple but effective approach named "latent cross" which is a kind of multiplicative interactions between the context embedding and the neural network hidden states in RNN model. Recently, Rendle et.al’s work [18] also shows that a carefully configured dot product baseline largely outperforms the MLP layer in collaborative filtering. While a MLP can in theory approximate any function, they show that it is non-trivial to learn a dot product with an MLP and learning a dot product with high accuracy for a decently large embedding dimension requires a large model capacity as well as many training data. Their work also proves the inefficiency of MLP layer’s ability to model complex feature interactions.
然而,Alex Beutel 等人 [2] 已经证明,成瘾性特征交互,特别是前馈神经网络,在捕捉常见特征交叉方面效率低下。他们提出了一种简单但有效的方法,称为“潜在交叉”(latent cross),这是一种在 RNN 模型中上下文嵌入与神经网络隐藏状态之间的乘法交互。最近,Rendle 等人的工作 [18] 也表明,精心配置的点积基线在协同过滤中大大优于 MLP 层。虽然 MLP 理论上可以逼近任何函数,但他们表明,用 MLP 学习点积并非易事,并且对于较大的嵌入维度,高精度地学习点积需要较大的模型容量以及大量的训练数据。他们的工作也证明了 MLP 层在建模复杂特征交互方面的低效性。
Inspired by "latent cross"[2] and Rendle’s work [18], we care about the following question: Can we improve the DNN ranking systems by introducing specific multiplicative operation into it to make it efficiently capture complex feature interactions?
受 "latent cross" [2] 和 Rendle 的工作 [18] 启发,我们关注以下问题:能否通过引入特定的乘法操作来改进 DNN 排序系统,使其能够高效捕捉复杂的特征交互?
In order to overcome the problem of inefficiency of feed-forward layer to capture complex feature cross, we introduce a special kind of multiplicative operation into DNN ranking system in this paper. First, we propose an instance-guided mask performing elementwise production on the feature embedding and feed-forward layer. The instance-guided mask utilizes the global information collected from input instance to dynamically highlight the informative elements in feature embedding and hidden layer in a unified manner. There are two main advantages for adopting the instance-guided mask: firstly, the element-wise product between the mask and hidden layer or feature embedding layer brings multiplicative operation into DNN ranking system in unified way to more efficiently capture complex feature interaction. Secondly, it’s a kind of finegained bit-wise attention guided by input instance which can both weaken the influence of noise in feature embedding and MLP layers while highlight the informative signals in DNN ranking systems.
为了克服前馈层在捕捉复杂特征交叉时效率低下的问题,本文在深度神经网络(DNN)排序系统中引入了一种特殊的乘法操作。首先,我们提出了一种实例引导的掩码(instance-guided mask),该掩码对特征嵌入和前馈层执行逐元素乘积操作。实例引导的掩码利用从输入实例中收集的全局信息,以统一的方式动态突出特征嵌入和隐藏层中的信息元素。采用实例引导的掩码有两个主要优势:首先,掩码与隐藏层或特征嵌入层之间的逐元素乘积操作以统一的方式将乘法操作引入DNN排序系统,从而更有效地捕捉复杂的特征交互。其次,这是一种由输入实例引导的细粒度位级注意力机制,既能减弱特征嵌入和多层感知机(MLP)层中噪声的影响,又能突出DNN排序系统中的信息信号。
By combining instance-guided mask, a following feed-forward layer and layer normalization, MaskBlock is proposed by us to turn the commonly used feed-forward layer into a mixture of addictive and multiplicative feature interactions. The instance-guided mask introduces multiplicative interactions and the following feedforward hidden layer aggregates the masked information in order to better capture the important feature interactions. While the layer normalization can ease optimization of the network.
通过结合实例引导的掩码、后续的前馈层和层归一化,我们提出了MaskBlock,将常用的前馈层转变为加性和乘性特征交互的混合体。实例引导的掩码引入了乘性交互,而后续的前馈隐藏层则聚合了掩码信息,以更好地捕捉重要的特征交互。同时,层归一化可以简化网络的优化过程。
MaskBlock can be regarded as a basic building block to design new ranking models under some kinds of configuration. The model consisting of MaskBlock is called MaskNet in this paper and two new MaskNet models are proposed to show the effectiveness of MaskBlock as basic building block for composing high performance ranking systems.
MaskBlock 可以被视为一种基础构建模块,用于在某些配置下设计新的排序模型。由 MaskBlock 组成的模型在本文中被称为 MaskNet,并且提出了两种新的 MaskNet 模型,以展示 MaskBlock 作为构建高性能排序系统的基础模块的有效性。
The contributions of our work are summarized as follows:
我们工作的贡献总结如下:
The rest of this paper is organized as follows. Section 2 introduces some related works which are relevant with our proposed model. We introduce our proposed models in detail in Section 3. The experimental results on three real world datasets are presented and discussed in Section 4. Section 5 concludes our work in this paper.
本文的其余部分组织如下。第2节介绍了一些与我们提出的模型相关的工作。我们在第3节详细介绍了我们提出的模型。第4节展示并讨论了在三个真实世界数据集上的实验结果。第5节总结了本文的工作。
2 RELATED WORK
2 相关工作
2.1 State-Of-The-Art CTR Models
2.1 最先进的CTR模型
Many deep learning based CTR models have been proposed in recent years and it is the key factor for most of these neural network based models to effectively model the feature interactions.
近年来,许多基于深度学习的点击率(CTR)模型被提出,而这些基于神经网络模型的关键因素在于有效建模特征交互。
Factorization-Machine Supported Neural Networks (FNN)[24] is a feed-forward neural network using FM to pre-train the embedding layer. Wide & Deep Learning[22] jointly trains wide linear models and deep neural networks to combine the benefits of memorization and generalization for recommend er systems. However, expertise feature engineering is still needed on the input to the wide part of Wide & Deep model. To alleviate manual efforts in feature engineering, DeepFM[6] replaces the wide part of Wide & Deep model with FM and shares the feature embedding between the FM and deep component.
因子分解机支持的神经网络 (FNN) [24] 是一种使用因子分解机 (FM) 预训练嵌入层的前馈神经网络。Wide & Deep Learning [22] 联合训练宽线性模型和深度神经网络,以结合记忆和泛化的优势,用于推荐系统。然而,Wide & Deep 模型的宽部分输入仍然需要专业的特征工程。为了减轻特征工程中的手动工作量,DeepFM [6] 用 FM 替换了 Wide & Deep 模型的宽部分,并在 FM 和深度组件之间共享特征嵌入。
While most DNN ranking models process high-order feature interactions by MLP layers in implicit way, some works explicitly introduce high-order feature interactions by sub-network. Deep & Cross Network (DCN)[21] efficiently captures feature interactions of bounded degrees in an explicit fashion. Similarly, eXtreme Deep Factorization Machine (xDeepFM) [13] also models the loworder and high-order feature interactions in an explicit way by proposing a novel Compressed Interaction Network (CIN) part. AutoInt[19] uses a multi-head self-attentive neural network to explicitly model the feature interactions in the low-dimensional space. FiBiNET[9] can dynamically learn feature importance via the Squeeze-Excitation network (SENET) mechanism and feature interactions via bilinear function.
虽然大多数 DNN 排序模型通过 MLP 层以隐式方式处理高阶特征交互,但一些工作通过子网络显式引入高阶特征交互。Deep & Cross Network (DCN)[21] 以显式方式高效地捕捉有界阶数的特征交互。类似地,eXtreme Deep Factorization Machine (xDeepFM)[13] 也通过提出一种新颖的压缩交互网络 (CIN) 部分,以显式方式建模低阶和高阶特征交互。AutoInt[19] 使用多头自注意力神经网络在低维空间中显式建模特征交互。FiBiNET[9] 可以通过 Squeeze-Excitation 网络 (SENET) 机制动态学习特征重要性,并通过双线性函数学习特征交互。
2.2 Feature-Wise Mask Or Gating
2.2 特征级掩码或门控
Feature-wise mask or gating has been explored widely in vision [8, 20], natural language processing [4] and recommendation system[14, 15]. For examples, Highway Networks [20] utilize feature gating to ease gradient-based training of very deep networks. Squeezeand-Excitation Networks[8] re calibrate feature responses by explicitly multiplying each channel with learned sigmoidal mask values. Dauphin et al.[4] proposed gated linear unit (GLU) to utilize it to control what information should be propagated for predicting the next word in the language modeling task. Gating or mask mechanisms are also adopted in recommendation systems. Ma et al. [15] propose a novel multi-task learning approach, Multi-gate Mixture-of-Experts (MMoE), which explicitly learns to model task relationships from data. Ma et al.[14] propose a hierarchical gating network (HGN) to capture both the long-term and short-term user interests. The feature gating and instance gating modules in HGN select what item features can be passed to the downstream layers from the feature and instance levels, respectively.
特征层面的掩码或门控机制在视觉 [8, 20]、自然语言处理 [4] 和推荐系统 [14, 15] 领域得到了广泛探索。例如,Highway Networks [20] 利用特征门控来简化基于梯度的深度网络训练。Squeeze-and-Excitation Networks [8] 通过显式地将每个通道与学习到的 sigmoidal 掩码值相乘来重新校准特征响应。Dauphin 等人 [4] 提出了门控线性单元 (GLU),用于在语言建模任务中控制哪些信息应该传播以预测下一个词。门控或掩码机制也被应用于推荐系统中。Ma 等人 [15] 提出了一种新颖的多任务学习方法,即多门混合专家 (MMoE),该方法显式地从数据中学习任务关系建模。Ma 等人 [14] 提出了一种分层门控网络 (HGN),以捕捉用户的长期和短期兴趣。HGN 中的特征门控和实例门控模块分别从特征层面和实例层面选择哪些项目特征可以传递到下游层。
2.3 Normalization
2.3 归一化
Normalization techniques have been recognized as very effective components in deep learning. Many normalization approaches have been proposed with the two most popular ones being BatchNorm [10] and LayerNorm [1] . Batch Normalization (Batch Norm or BN)[10] normalizes the features by the mean and variance computed within a mini-batch. Another example is layer normalization (Layer Norm or LN)[1] which was proposed to ease optimization of recurrent neural networks. Statistics of layer normalization are not computed across the $N$ samples in a mini-batch but are estimated in a layer-wise manner for each sample independently. Normalization methods have shown success in accelerating the training of deep networks.
归一化技术在深度学习中已被认为是非常有效的组成部分。许多归一化方法被提出,其中最流行的两种是 BatchNorm [10] 和 LayerNorm [1]。批量归一化 (Batch Normalization 或 BN) [10] 通过在小批量内计算的均值和方差对特征进行归一化。另一个例子是层归一化 (Layer Normalization 或 LN) [1],它被提出以简化循环神经网络的优化。层归一化的统计量不是在小批量的 $N$ 个样本中计算,而是以逐层的方式独立地为每个样本估计。归一化方法在加速深度网络的训练方面取得了成功。
3 OUR PROPOSED MODEL
3 我们提出的模型
In this section, we first describe the feature embedding layer. Then the details of the instance-guided mask, MaskBlock and MaskNet structure we proposed will be introduced. Finally the log loss as a loss function is introduced.
在本节中,我们首先描述特征嵌入层。然后介绍我们提出的实例引导掩码、MaskBlock 和 MaskNet 结构的细节。最后介绍作为损失函数的对数损失。
3.1 Embedding Layer
3.1 嵌入层
The input data of CTR tasks usually consists of sparse and dense features and the sparse features are mostly categorical type. Such features are encoded as one-hot vectors which often lead to excessively high-dimensional feature spaces for large vocabularies. The common solution to this problem is to introduce the embedding layer. Generally, the sparse input can be formulated as:
CTR任务的输入数据通常由稀疏特征和密集特征组成,稀疏特征大多为类别型特征。这些特征通常被编码为独热向量,对于大规模词汇表来说,这往往会导致特征空间维度过高。解决这一问题的常见方法是引入嵌入层。通常,稀疏输入可以表示为:

where $f$ denotes the number of fields, and $x_{i}\in\mathbb{R}^{n}$ denotes a onehot vector for a categorical field with $n$ features and $x_{i}\in\mathbb{R}^{n}$ is vector with only one value for a numerical field. We can obtain feature embedding $e_{i}$ for one-hot vector $x_{i}$ via:
其中 $f$ 表示字段的数量,$x_{i}\in\mathbb{R}^{n}$ 表示具有 $n$ 个特征的分类字段的独热向量,$x_{i}\in\mathbb{R}^{n}$ 是数值字段的仅包含一个值的向量。我们可以通过以下方式获得独热向量 $x_{i}$ 的特征嵌入 $e_{i}$:

where $W_{e}\in\mathbb{R}^{k\times n}$ is the embedding matrix of $n$ features and $k$ is the dimension of field embedding. The numerical feature $x_{j}$ can also be converted into the same low-dimensional space by:
其中 $W_{e}\in\mathbb{R}^{k\times n}$ 是 $n$ 个特征的嵌入矩阵,$k$ 是字段嵌入的维度。数值特征 $x_{j}$ 也可以通过以下方式转换为相同的低维空间:

where $V_{j}\in\mathbb{R}^{k}$ is the corresponding field embedding with size $k$
其中 $V_{j}\in\mathbb{R}^{k}$ 是对应的字段嵌入,大小为 $k$
Through the aforementioned method, an embedding layer is applied upon the raw feature input to compress it to a low dimensional, dense real-value vector. The result of embedding layer is a wide concatenated vector:
通过上述方法,在原始特征输入上应用嵌入层,将其压缩为低维、密集的实值向量。嵌入层的结果是一个宽连接向量:

where $f$ denotes the number of fields, and $\mathrm{e}_{i}\in\mathbb{R}^{k}$ denotes the embedding of one field. Although the feature lengths of input instances can be various, their embedding are of the same length $f\times k$ , where $k$ is the dimension of field embedding.
其中 $f$ 表示字段的数量,$\mathrm{e}_{i}\in\mathbb{R}^{k}$ 表示一个字段的嵌入。尽管输入实例的特征长度可能各不相同,但它们的嵌入长度相同,均为 $f\times k$,其中 $k$ 是字段嵌入的维度。
We use instance-guided mask to introduce the multiplicative operation into DNN ranking system and here the so-called "instance" means the feature embedding layer of current input instance in the following part of this paper.
我们使用实例引导的掩码将乘法操作引入到DNN排序系统中,这里的“实例”指的是本文后续部分中当前输入实例的特征嵌入层。
3.2 Instance-Guided Mask
3.2 实例引导掩码
We utilize the global information collected from input instance by instance-guided mask to dynamically highlight the informative elements in feature embedding and feed-forward layer. For feature embedding, the mask lays stress on the key elements with more information to effectively represent this feature. For the neurons in hidden layer, the mask helps those important feature interactions to stand out by considering the contextual information in the input instance. In addition to this advantage, the instance-guided mask also introduces the multiplicative operation into DNN ranking system to capture complex feature cross more efficiently.
我们利用通过实例引导的掩码从输入实例中收集的全局信息,动态突出特征嵌入和前馈层中的信息丰富元素。对于特征嵌入,掩码强调具有更多信息的关键元素,以有效表示该特征。对于隐藏层中的神经元,掩码通过考虑输入实例中的上下文信息,帮助那些重要的特征交互脱颖而出。除了这一优势外,实例引导的掩码还将乘法操作引入DNN排序系统,以更高效地捕捉复杂的特征交叉。
As depicted in Figure 1, two fully connected (FC) layers with identity function are used in instance-guided mask. Notice that the input of instance-guided mask is always from the input instance, that is to say, the feature embedding layer.
如图 1 所示,实例引导掩码中使用了两个具有恒等函数的全连接 (FC) 层。需要注意的是,实例引导掩码的输入始终来自输入实例,即特征嵌入层。
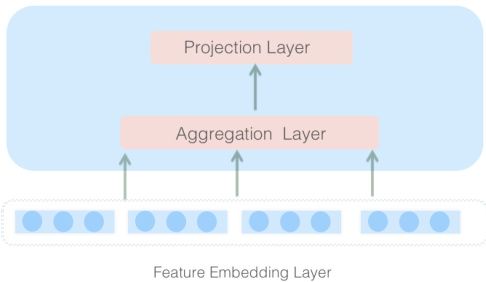
Figure 1: Neural Structure of Instance-Guided Mask
图 1: 实例引导掩码的神经结构
The first FC layer is called "aggregation layer" and it is a relatively wider layer compared with the second FC layer in order to better collect the global contextual information in input instance. The aggregation layer has parameters $W_{d1}$ and here $d$ denotes the $d$ -th mask. For feature embedding and different MLP layers, we adopt different instance-guided mask owning its parameters to learn to capture various information for each layer from input instance.
第一个全连接层(FC)被称为“聚合层”,与第二个全连接层相比,它是一个相对较宽的层,以便更好地收集输入实例中的全局上下文信息。聚合层具有参数 $W_{d1}$,其中 $d$ 表示第 $d$ 个掩码。对于特征嵌入和不同的多层感知机(MLP)层,我们采用不同的实例引导掩码,每个掩码都有自己的参数,以学习从输入实例中捕获每层的各种信息。
The second FC layer named "projection layer" reduces dimensionality to the same size as feature embedding layer $V_{e m b}$ or hidden layer $V_{h i d d e n}$ with parameters $W_{d2}$ , Formally,
第二个全连接层(FC)名为“投影层”,通过参数 $W_{d2}$ 将维度降低到与特征嵌入层 $V_{e m b}$ 或隐藏层 $V_{h i d d e n}$ 相同的大小。形式上,

where $V_{e m b}\in\mathbb{R}^{m=f\times k}$ refers to the embedding layer of input instance, $W_{d1}\in\mathbb{R}^{t\times m}$ and $W_{d2}\in\mathbb{R}^{z\times t}$ are parameters for instance- guided mask, $t$ and $z$ respectively denotes the neural number of aggregation layer and projection layer, $f$ denotes the number of fields and $k$ is the dimension of field embedding. $\beta_{d1}\in\mathbb{R}^{t\times m}$ and $\beta_{d2}\in\mathbb{R}^{z\times t}$ are learned bias of the two FC layers. Notice here that the aggregation layer is usually wider than the projection layer because the size of the projection layer is required to be equal to the size of feature embedding layer or MLP layer. So we define the size $r=t/z$ as reduction ratio which is a hyper-parameter to control the ratio of neuron numbers of two layers.
其中 $V_{e m b}\in\mathbb{R}^{m=f\times k}$ 表示输入实例的嵌入层,$W_{d1}\in\mathbb{R}^{t\times m}$ 和 $W_{d2}\in\mathbb{R}^{z\times t}$ 是实例引导掩码的参数,$t$ 和 $z$ 分别表示聚合层和投影层的神经元数量,$f$ 表示字段数量,$k$ 是字段嵌入的维度。$\beta_{d1}\in\mathbb{R}^{t\times m}$ 和 $\beta_{d2}\in\mathbb{R}^{z\times t}$ 是两个全连接层的学习偏置。需要注意的是,聚合层通常比投影层更宽,因为投影层的大小需要与特征嵌入层或MLP层的大小相等。因此,我们定义大小 $r=t/z$ 为缩减比,这是一个控制两层神经元数量比例的超参数。
Element-wise product is used in this work to incorporate the global contextual information aggregated by instance-guided mask into feature embedding or hidden layer as following:
在本工作中,使用逐元素乘积将实例引导掩码聚合的全局上下文信息融入特征嵌入或隐藏层,如下所示:

where $\mathrm{V}{e m b}$ denotes embedding layer and $\mathrm{V}{h i d d e n}$ means the feedforward layer in DNN model, $\odot$ means the element-wise production between two vectors as follows:
其中 $\mathrm{V}{e m b}$ 表示嵌入层,$\mathrm{V}{h i d d e n}$ 表示 DNN 模型中的前馈层,$\odot$ 表示两个向量之间的逐元素乘积,如下所示:

here $u$ is the size of vector $V_{i}$ and $V_{j}$
这里 $u$ 是向量 $V_{i}$ 和 $V_{j}$ 的大小
The instance-guided mask can be regarded as a special kind of bitwise attention or gating mechanism which uses the global context information contained in input instance to guide the parameter optimization during training. The bigger value in $V_{m a s k}$ implies that the model dynamically identifies an important element in feature embedding or hidden layer. It is used to boost the element in vector $V_{e m b}$ or $V_{h i d d e n}$ . On the contrary, small value in $V_{m a s k}$ will suppress the uninformative elements or even noise by decreasing the values in the corresponding vector $V_{e m b}$ or $V_{h i d d e n}$ .
实例引导的掩码可以被视为一种特殊的按位注意力或门控机制,它利用输入实例中包含的全局上下文信息来指导训练期间的参数优化。$V_{m a s k}$ 中的较大值意味着模型动态识别出特征嵌入或隐藏层中的重要元素。它用于增强向量 $V_{e m b}$ 或 $V_{h i d d e n}$ 中的元素。相反,$V_{m a s k}$ 中的较小值将通过减少相应向量 $V_{e m b}$ 或 $V_{h i d d e n}$ 中的值来抑制无信息元素甚至噪声。
The two main advantages in adopting the instance-guided mask are: firstly, the element-wise product between the mask and hidden layer or feature embedding layer brings multiplicative operation into DNN ranking system in unified way to more efficiently capture complex feature interaction. Secondly, this kind of fine-gained bit-wise attention guided by input instance can both weaken the influence of noise in feature embedding and MLP layers while highlight the informative signals in DNN ranking systems.
采用实例引导掩码的两个主要优势是:首先,掩码与隐藏层或特征嵌入层之间的逐元素乘积以统一的方式将乘法操作引入DNN排序系统,从而更有效地捕捉复杂的特征交互。其次,这种由输入实例引导的细粒度位级注意力既可以减弱特征嵌入和MLP层中噪声的影响,同时又能突出DNN排序系统中的信息信号。
3.3 MaskBlock
3.3 MaskBlock
To overcome the problem of the inefficiency of feed-forward layer to capture complex feature interaction in DNN models, we propose a basic building block named MaskBlock for DNN ranking systems in this work, as shown in Figure 2 and Figure 3. The proposed MaskBlock consists of three key components: layer normalization module ,instance-guided mask, and a feed-forward hidden layer. The layer normalization can ease optimization of the network. The instance-guided mask introduces multiplicative interactions for feed-forward layer of a standard DNN model and feed-forward hidden layer aggregate the masked information in order to better capture the important feature interactions. In this way, we turn the widely used feed-forward layer of a standard DNN model into a mixture of addictive and multiplicative feature interactions.
为了解决前馈层在深度神经网络 (DNN) 模型中捕捉复杂特征交互效率低下的问题,我们在本工作中提出了一种名为 MaskBlock 的基本构建模块,用于 DNN 排序系统,如图 2 和图 3 所示。所提出的 MaskBlock 由三个关键组件组成:层归一化模块、实例引导掩码和前馈隐藏层。层归一化可以简化网络的优化过程。实例引导掩码为标准 DNN 模型的前馈层引入了乘法交互,而前馈隐藏层则聚合了掩码信息,以便更好地捕捉重要的特征交互。通过这种方式,我们将标准 DNN 模型中广泛使用的前馈层转变为加性和乘法特征交互的混合体。
First, we briefly review the formulation of LayerNorm.
首先,我们简要回顾一下 LayerNorm 的公式。
Layer Normalization:
Layer Normalization:
In general, normalization aims to ensure that signals have zero mean and unit variance as they propagate through a network to reduce "covariate shift" [10]. As an example, layer normalization (Layer Norm or LN)[1] was proposed to ease optimization of recurrent neural networks. Specifically, let $x=(x_{1},x_{2},...,x_{H})$ denotes the vector representation of an input of size $H$ to normalization layers. LayerNorm re-centers and re-scales input $_\mathrm{xas~}$
一般来说,归一化的目的是确保信号在网络中传播时具有零均值和单位方差,以减少“协变量偏移” [10]。例如,层归一化(Layer Norm 或 LN)[1] 被提出以简化循环神经网络的优化。具体来说,设 $x=(x_{1},x_{2},...,x_{H})$ 表示大小为 $H$ 的输入到归一化层的向量表示。LayerNorm 对输入 $_\mathrm{xas~}$ 进行重新中心化和重新缩放。

where $h$ is the output of a LayerNorm layer. $\odot$ is an element-wise production operation. $\mu$ and $\delta$ are the mean and standard deviation of input. Bias b and gain g are parameters with the same dimension $H$ .
其中 $h$ 是 LayerNorm 层的输出。$\odot$ 是逐元素乘法操作。$\mu$ 和 $\delta$ 是输入的均值和标准差。偏置 b 和增益 g 是维度为 $H$ 的参数。
As one of the key component in MaskBlock, layer normalization can be used on both feature embedding and feed- forward layer. For the feature embedding layer, we regard each feature’s embedding as a layer to compute the mean, standard deviation, bias and gain of LN as follows:
作为 MaskBlock 的关键组件之一,层归一化 (Layer Normalization) 可以同时应用于特征嵌入层和前馈层。对于特征嵌入层,我们将每个特征的嵌入视为一个层,计算层归一化的均值、标准差、偏置和增益,如下所示:

As for the feed-forward layer in DNN model, the statistics of $L N$ are estimated among neurons contained in the corresponding hidden layer as follows:
至于 DNN 模型中的前馈层,$L N$ 的统计量是在相应隐藏层中包含的神经元之间估计的,如下所示:

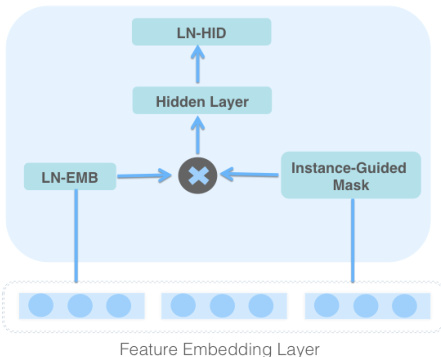
Figure 2: MaskBlock on Feature Embedding
图 2: 特征嵌入上的 MaskBlock
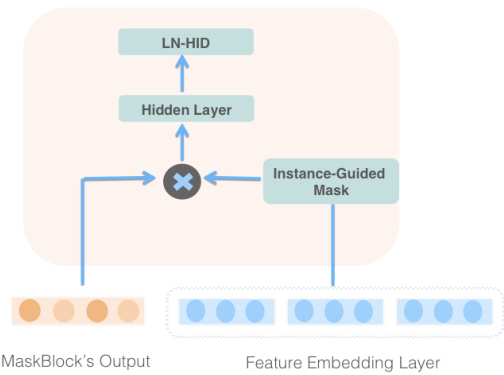
Figure 3: MaskBlock on MaskBlock
图 3: MaskBlock 上的 MaskBlock
where $\mathrm{X}\in\mathbb{R}^{t}$ refers to the input of feed-forward layer, $\mathrm{W}_{i}\in\mathbb{R}^{m\times t}$ are parameters for the layer, $t$ and $m$ respectively denotes the size of input layer and neural number of feed-forward layer. Notice that we have two places to put normalization operation on the MLP: one place is before non-linear operation and another place is after non-linear operation. We find the performance of the normalization before non-linear consistently outperforms that of the normalization after non-linear operation. So all the normalization used in MLP part is put before non-linear operation in our paper as formula (4) shows.
其中 $\mathrm{X}\in\mathbb{R}^{t}$ 表示前馈层的输入,$\mathrm{W}_{i}\in\mathbb{R}^{m\times t}$ 是该层的参数,$t$ 和 $m$ 分别表示输入层的大小和前馈层的神经元数量。需要注意的是,我们在 MLP 中有两个地方可以放置归一化操作:一个是在非线性操作之前,另一个是在非线性操作之后。我们发现,在非线性操作之前进行归一化的性能始终优于在非线性操作之后进行归一化。因此,在我们的论文中,MLP 部分使用的所有归一化操作都放在非线性操作之前,如公式 (4) 所示。
MaskBlock on Feature Embedding:
MaskBlock 在特征嵌入上的应用:
We propose MaskBlock by combining the three key elements: layer normalization, instance-guided mask and a following feed-forward layer. MaskBlock can be stacked to form deeper network. According to the different input of each MaskBlock, we have two kinds of MaskBlocks: MaskBlock on feature embedding and MaskBlock on Maskblock. We will firstly introduce the MaskBlock on feature embedding as depicted in Figure 2 in this subsection.
我们通过结合三个关键元素提出了 MaskBlock:层归一化、实例引导掩码和随后的前馈层。MaskBlock 可以堆叠形成更深的网络。根据每个 MaskBlock 的不同输入,我们有两种 MaskBlock:基于特征嵌入的 MaskBlock 和基于 MaskBlock 的 MaskBlock。我们将首先介绍基于特征嵌入的 MaskBlock,如图 2 所示。
The feature embedding $\mathrm{V}{e m b}$ is the only input for MaskBlock on feature embedding. After the layer normalization operation on embedding $\mathrm{V}{e m b}$ . MaskBlock utilizes instance-guided mask to highlight the informative elements in $\mathrm{V}_{e m b}$ by element-wise product, Formally,
特征嵌入 $\mathrm{V}{e m b}$ 是 MaskBlock 在特征嵌入上的唯一输入。在对嵌入 $\mathrm{V}{e m b}$ 进行层归一化操作后,MaskBlock 利用实例引导的掩码通过逐元素乘积来突出 $\mathrm{V}_{e m b}$ 中的信息元素。形式上,

where $\odot$ means an element-wise production between the instanceguided mask and the normalized vector $L N_{E}M B(\mathrm{V}{e m b})$ , V𝑚𝑎𝑠𝑘𝑒𝑑𝐸𝑀𝐵 denote the masked feature embedding. Notice that the input of instance-guided mask $\mathrm{V}{m a s k}$ is also the feature embedding $V_{e m b}$ .
其中 $\odot$ 表示实例引导掩码与归一化向量 $L N_{E}M B(\mathrm{V}{e m b})$ 之间的逐元素乘积,V𝑚𝑎𝑠𝑘𝑒𝑑𝐸𝑀𝐵 表示掩码后的特征嵌入。注意,实例引导掩码 $\mathrm{V}{m a s k}$ 的输入也是特征嵌入 $V_{e m b}$。

Figure 4: Structure of Serial Model and Parallel Model
图 4: 串行模型与并行模型的结构
We introduce a feed-forward hidden layer and a following layer normalization operation in MaskBlock to better aggregate the masked information by a normalized non-linear transformation. The output of MaskBlock can be calculated as follows:
我们在 MaskBlock 中引入了一个前馈隐藏层和随后的层归一化操作,以通过归一化的非线性变换更好地聚合掩码信息。MaskBlock 的输出可以按如下方式计算:

where $\mathrm{W}{i}\in\mathbb{R}^{q\times n}$ are parameters of the feed-forward layer in the $i$ -th MaskBlock, $n$ denotes the size of $\mathrm{V}{m a s k e d E M B}$ and $q$ means the size of neural number of the feed-forward layer.
其中,$\mathrm{W}{i}\in\mathbb{R}^{q\times n}$ 是第 $i$ 个 MaskBlock 中前馈层的参数,$n$ 表示 $\mathrm{V}{m a s k e d E M B}$ 的大小,$q$ 表示前馈层的神经元数量。
The instance-guided mask introduces the element-wise product into feature embedding as a fine-grained attention while normalization both on feature embedding and hidden layer eases the network optimization. These key components in MaskBlock help the feedforward layer capture complex feature cross more efficiently.
实例引导的掩码将逐元素乘积引入特征嵌入中,作为一种细粒度的注意力机制,同时对特征嵌入和隐藏层进行归一化,简化了网络优化。MaskBlock 中的这些关键组件帮助前馈层更高效地捕捉复杂的特征交叉。
MaskBlock on MaskBlock:
MaskBlock on MaskBlock:
In this subsection, we will introduce MaskBlock on MaskBlock as depicted in Figure 3. There are two different inputs for this MaskBlock: feature embedding $V_{e m b}$ and the output 𝑉𝑜𝑝𝑢𝑡𝑝𝑢𝑡 of the previous MaskBlock. The input of instance-guided mask for this kind of MaskBlock is always the feature embedding $V_{e m b}$ . MaskBlock utilizes instance-guided mask to highlight the important feature interactions in previous MaskBlock’s output 𝑉𝑜𝑝𝑢𝑡𝑝𝑢𝑡 by element-wise product, Formally,
在本小节中,我们将介绍图 3 中所示的 MaskBlock。该 MaskBlock 有两个不同的输入:特征嵌入 $V_{e m b}$ 和前一个 MaskBlock 的输出 𝑉𝑜𝑝𝑢𝑡𝑝𝑢𝑡。这种 MaskBlock 的实例引导掩码输入始终是特征嵌入 $V_{e m b}$。MaskBlock 通过逐元素乘积的方式利用实例引导掩码来突出前一个 MaskBlock 输出 𝑉𝑜𝑝𝑢𝑡𝑝𝑢𝑡 中的重要特征交互。

where $\odot$ means an element-wise production between the instanceguided mask $V_{m a s k}$ and the previous MaskBlock’s output $V_{o u t p u t}^{p}$ $V_{m a s k e d H I D}$ denote the masked hidden layer.
其中,$\odot$ 表示实例引导掩码 $V_{mask}$ 与前一个 MaskBlock 的输出 $V_{output}^{p}$ 之间的逐元素乘积,$V_{maskedHID}$ 表示掩码后的隐藏层。
In order to better capture the important feature interactions, another feed-forward hidden layer and a following layer normalization are introduced in MaskBlock . In this way, we turn the widely used feed-forward layer of a standard DNN model into a mixture of addictive and multiplicative feature interactions to avoid the ineffectiveness of those addictive feature cross models. The output of MaskBlock can be calculated as follows:
为了更好地捕捉重要的特征交互,MaskBlock 中引入了另一个前馈隐藏层和随后的层归一化。通过这种方式,我们将标准 DNN 模型中广泛使用的前馈层转变为加性和乘性特征交互的混合,以避免那些加性特征交叉模型的无效性。MaskBlock 的输出可以按如下方式计算:

where $W_{i}\in\mathbb{R}^{q\times n}$ are parameters of the feed-forward layer in the $i$ -th MaskBlock, $n$ denotes the size of $\mathrm{V}_{m a s k e d H I D}$ and $q$ means the size of neural number of the feed-forward layer.
其中 $W_{i}\in\mathbb{R}^{q\times n}$ 是第 $i$ 个 MaskBlock 中前馈层的参数,$n$ 表示 $\mathrm{V}_{m a s k e d H I D}$ 的大小,$q$ 表示前馈层的神经元数量。
3.4 MaskNet
3.4 MaskNet
Based on the MaskBlock, various new ranking models can be designed according to different configurations. The rank model consisting of MaskBlock is called MaskNet in this work. We also propose two MaskNet models by utilizing the MaskBlock as the basic building block.
基于 MaskBlock,可以根据不同的配置设计各种新的排序模型。由 MaskBlock 组成的排序模型在本工作中被称为 MaskNet。我们还利用 MaskBlock 作为基本构建块,提出了两种 MaskNet 模型。
Serial MaskNet:
Serial MaskNet:
We can stack one MaskBlock after another to build the ranking system , as shown by the left model in Figure 4. The first block is a MaskBlock on feature embedding and all other blocks are MaskBlock on Maskblock to form a deeper network. The prediction layer is put on the final MaskBlock’s output vector. We call MaskNet under this serial configuration as SerMaskNet in our paper. All inputs of instance-guided mask in every MaskBlock come from the feature embedding layer $\mathrm{V}_{e m b}$ and this makes the serial MaskNet model look like a RNN model with sharing input at each time step.
我们可以将一个 MaskBlock 堆叠在另一个 MaskBlock 之后来构建排序系统,如图 4 左侧模型所示。第一个块是基于特征嵌入的 MaskBlock,其他所有块都是基于 MaskBlock 的 MaskBlock,以形成更深的网络。预测层放置在最终 MaskBlock 的输出向量上。我们在论文中将这种串行配置下的 MaskNet 称为 SerMaskNet。每个 MaskBlock 中实例引导掩码的所有输入都来自特征嵌入层 $\mathrm{V}_{e m b}$,这使得串行 MaskNet 模型看起来像一个在每个时间步共享输入的 RNN 模型。
Parallel MaskNet:
Parallel MaskNet:
We propose another MaskNet by placing several MaskBlocks on feature embedding in parallel on a sharing feature embedding layer, as depicted by the right model in Figure 4. The input of each block is only the shared feature embedding $\mathrm{V}_{e m b}$ under this configuration. We can regard this ranking model as a mixture of multiple experts just as MMoE[15] does. Each MaskBlock pays attention to specific kind of important features or feature interactions. We collect the information of each expert by concatenating the output of each MaskBlock as follows:
我们提出了另一种MaskNet,通过在共享特征嵌入层上并行放置多个MaskBlock来实现,如图4右侧模型所示。在这种配置下,每个块的输入仅为共享特征嵌入 $\mathrm{V}_{e m b}$。我们可以将这个排序模型视为多个专家的混合体,就像MMoE[15]所做的那样。每个MaskBlock关注特定类型的重要特征或特征交互。我们通过将每个MaskBlock的输出连接起来来收集每个专家的信息,如下所示:

where $\mathrm{V}_{o u t p u t}^{i}\in\mathbb{R}^{q}$ is the output of the $i$ -th MaskBlock and $q$ means size of neural number of feed-forward layer in MaskBlock, $u$ is the MaskBlock number.
其中 $\mathrm{V}_{o u t p u t}^{i}\in\mathbb{R}^{q}$ 是第 $i$ 个 MaskBlock 的输出,$q$ 表示 MaskBlock 中前馈层的神经元数量,$u$ 是 MaskBlock 的数量。
To further merge the feature interactions captured by each expert, multiple feed-forward layers are stacked on the concatenation information $\mathrm{V}{m e r g e}$ . Let $\mathrm{H}{\mathrm{0}}=\mathrm{V}_{m e r g e}$ denotes the output of the
为了进一步融合每个专家捕获的特征交互,多个前馈层被堆叠在连接信息 $\mathrm{V}{m e r g e}$ 上。设 $\mathrm{H}{\mathrm{0}}=\mathrm{V}_{m e r g e}$ 表示输出。
concatenation layer, then $\mathrm{H}_{\mathrm{0}}$ is fed into the deep neural network and the feed forward process is:
连接层,然后将 $\mathrm{H}_{\mathrm{0}}$ 输入深度神经网络,前馈过程如下:

where $l$ is the depth and ReLU is the activation function. $\mathrm{W}{t},\beta{t},\mathrm{H}_{l}$ are the model weight, bias and output of the $l$ -th layer. The prediction layer is put on the last layer of multiple feed-forward networks. We call this version MaskNet as "Para Mask Net" in the following part of this paper.
其中 $l$ 是深度,ReLU 是激活函数。$\mathrm{W}{t},\beta{t},\mathrm{H}_{l}$ 分别是模型权重、偏置和第 $l$ 层的输出。预测层被放置在多个前馈网络的最后一层。在本文的后续部分,我们将这个版本的 MaskNet 称为 "Para Mask Net"。
3.5 Prediction Layer
3.5 预测层
To summarize, we give the overall formulation of our proposed model’ s output as:
总结来说,我们提出的模型输出整体公式为:

where $\hat{y}\in(0,1)$ is the predicted value of CTR, $\delta$ is the sigmoid function, $n$ is the size of the last MaskBlock’s output(SerMaskNet) or feed-forward layer(Para Mask Net), $x_{i}$ is the bit value of feedforward layer and $w_{i}$ is the learned weight for each bit value.
其中 $\hat{y}\in(0,1)$ 是点击率 (CTR) 的预测值,$\delta$ 是 sigmoid 函数,$n$ 是最后一个 MaskBlock 输出 (SerMaskNet) 或前馈层 (Para Mask Net) 的大小,$x_{i}$ 是前馈层的比特值,$w_{i}$ 是每个比特值的学习权重。
For binary classifications, the loss function is the log loss:
对于二分类问题,损失函数为对数损失 (log loss):

where $N$ is the total number of training instances, $y_{i}$ is the ground truth of $i$ -th instance and $\hat{y}_{i}$ is the predicted CTR. The optimization process is to minimize the following objective function:
其中 $N$ 是训练实例的总数,$y_{i}$ 是第 $i$ 个实例的真实值,$\hat{y}_{i}$ 是预测的点击率 (CTR)。优化过程是最小化以下目标函数:

where $\lambda$ denotes the regular iz ation term and $\Theta$ denotes the set of parameters, including those in feature embedding matrix, instanceguided mask matrix, feed-forward layer in MaskBlock, and prediction part.
其中,$\lambda$ 表示正则化项,$\Theta$ 表示参数集,包括特征嵌入矩阵、实例引导掩码矩阵、MaskBlock 中的前馈层以及预测部分的参数。
4 EXPERIMENTAL RESULTS
4 实验结果
In this section, we evaluate the proposed approaches on three realworld datasets and conduct detailed ablation studies to answer the following research questions:
在本节中,我们在三个真实世界的数据集上评估了所提出的方法,并进行了详细的消融研究,以回答以下研究问题:
In the following, we will first describe the experimental settings, followed by answering the above research questions.
以下我们将首先描述实验设置,然后回答上述研究问题。
4.1 Experiment Setup
4.1 实验设置
4.1.1 Datasets. The following three data sets are used in our experiments:
4.1.1 数据集
我们在实验中使用了以下三个数据集:
We randomly split instances by $8:1:1$ for training , validation and test while Table 1 lists the statistics of the evaluation datasets.
我们按照 $8:1:1$ 的比例随机划分实例用于训练、验证和测试,而表 1 列出了评估数据集的统计信息。
Table 1: Statistics of the evaluation datasets
表 1: 评估数据集的统计信息
| 数据集 | 实例数 | 字段数 | 特征数 |
|---|---|---|---|
| Criteo | 45M | 39 | 30M |
| Avazu | 40.43M | 23 | 9.5M |
| Malware | 8.92M | 82 | 0.97M |
4.1.2 Evaluation Metrics. AUC (Area Under ROC) is used in our experiments as the evaluation metric. AUC’s upper bound is 1 and larger value indicates a better performance.
4.1.2 评估指标。在我们的实验中,使用 AUC (ROC 曲线下面积) 作为评估指标。AUC 的上限为 1,值越大表示性能越好。
RelaImp is also as work [23] does to measure the relative AUC improvements over the corresponding baseline model as another evaluation metric. Since AUC is 0.5 from a random strategy, we can remove the constant part of the AUC score and formalize the RelaImp as:
RelaImp 也如工作 [23] 所做的那样,通过测量相对于相应基线模型的相对 AUC 改进作为另一个评估指标。由于随机策略的 AUC 为 0.5,我们可以去除 AUC 分数的常数部分,并将 RelaImp 形式化为:

4.1.3 Models for Comparisons. We compare the performance of the following CTR estimation models with our proposed approaches: FM, DNN, DeepFM, Deep&Cross Network(DCN), xDeepFM and AutoInt Model, all of which are discussed in Section 2. FM is considered as the base model in evaluation.
4.1.3 对比模型。我们将以下CTR预估模型的性能与我们提出的方法进行比较:FM、DNN、DeepFM、Deep&Cross Network (DCN)、xDeepFM和AutoInt模型,这些模型在第2节中均有讨论。FM在评估中被视为基准模型。
4.1.4 Implementation Details. We implement all the models with Tensorflow in our experiments. For optimization method, we use the Adam with a mini-batch size of 1024 and a learning rate is set to 0.0001. Focusing on neural networks structures in our paper, we make the dimension of field embedding for all models to be a fixed value of 10. For models with DNN part, the depth of hidden layers is set to 3, the number of neurons per layer is 400, all activation function is ReLU. For default settings in MaskBlock, the reduction ratio of instance-guided mask is set to 2. We conduct our experiments with 2 Tesla 𝐾40 GPUs.
4.1.4 实现细节。我们在实验中使用 Tensorflow 实现了所有模型。对于优化方法,我们使用 Adam,小批量大小为 1024,学习率设置为 0.0001。由于本文重点关注神经网络结构,我们将所有模型的字段嵌入维度固定为 10。对于包含 DNN 部分的模型,隐藏层的深度设置为 3,每层的神经元数量为 400,所有激活函数均为 ReLU。在 MaskBlock 的默认设置中,实例引导掩码的缩减比例设置为 2。我们使用 2 块 Tesla K40 GPU 进行实验。
Table 2: Overall performance (AUC) of different models on three datasets(feature embedding size $\mathbf{\mu}_{:=10}$ ,our proposed two models both have 3 MaskBlocks with same default settings.)
表 2: 不同模型在三个数据集上的整体性能 (AUC) (特征嵌入大小 $\mathbf{\mu}_{:=10}$,我们提出的两个模型都有 3 个 MaskBlocks,且使用相同的默认设置。)
| Criteo | Malware | Avazu | ||||
|---|---|---|---|---|---|---|
| AUC | Relalmp | AUC | Relalmp | AUC | Relalmp | |
| FM | 0.7895 | 0.00% | 0.7166 | 0.00% | 0.7785 | 0.00% |
| DNN | 0.8054 | +5.35% | 0.7246 | +3.70% | 0.7820 | +1.26% |
| DeepFM | 0.8057 | +5.46% | 0.7293 | +5.86% | 0.7833 | +1.72% |
| DCN | 0.8058 | +5.49% | 0.7300 | +6.19% | 0.7830 | +1.62% |
| xDeepFM | 0.8064 | +5.70% | 0.7310 | +6.65% | 0.7841 | +2.01% |
| AutoInt | 0.8051 | +5.39% | 0.7282 | +5.36% | 0.7824 | +1.40% |
| SerMaskNet | 0.8119 | +7.74% | 0.7413 | +11.40% | 0.7877 | +3.30% |
| ParaMaskNet | 0.8124 | +7.91% | 0.7410 | +11.27% | 0.7872 | +3.12% |
4.2 Performance Comparison (RQ1)
4.2 性能对比 (RQ1)
The overall performances of different models on three evaluation datasets are show in the Table 2. From the experimental results, we can see that:
不同模型在三个评估数据集上的整体性能如表 2 所示。从实验结果可以看出:
4.3 Ablation Study of MaskBlock (RQ2)
4.3 MaskBlock 消融研究 (RQ2)
In order to better understand the impact of each component in MaskBlock, we perform ablation experiments over key components of MaskBlock by only removing one of them to observe the performance change, including mask module, layer normalization(LN) and feed-forward network(FFN). Table 3 shows the results of our two full version MaskNet models and its variants removing only one component.
为了更好地理解 MaskBlock 中每个组件的影响,我们通过对 MaskBlock 的关键组件进行消融实验,仅移除其中一个组件以观察性能变化,包括掩码模块、层归一化 (LN) 和前馈网络 (FFN)。表 3 展示了我们两个完整版本的 MaskNet 模型及其仅移除一个组件的变体的结果。
From the results in Table 3, we can see that removing either instance-guided mask or layer normalization will decrease model’s performance and this implies that both the instance-guided mask and layer normalization are necessary components in MaskBlock for its effectiveness. As for the feed-forward layer in MaskBlock, its effect on serial model or parallel model shows difference. The
从表 3 的结果可以看出,移除实例引导掩码 (instance-guided mask) 或层归一化 (layer normalization) 都会降低模型的性能,这表明实例引导掩码和层归一化都是 MaskBlock 中必要的组成部分。至于 MaskBlock 中的前馈层 (feed-forward layer),其对串行模型或并行模型的影响有所不同。
Serial model’s performance dramatically degrades while it seems do no harm to parallel model if we remove the feed-forward layer in MaskBlock. We deem this implies that the feed-forward layer in MaskBlock is important for merging the feature interaction information after instance-guided mask. For parallel model, the multiple feed-forward layers above parallel MaskBlocks have similar function as feed-forward layer in MaskBlock does and this may produce performance difference between two models when we remove this component.
串行模型的性能显著下降,而如果我们移除 MaskBlock 中的前馈层,似乎对并行模型没有影响。我们认为这意味着 MaskBlock 中的前馈层在实例引导掩码后合并特征交互信息方面非常重要。对于并行模型,并行 MaskBlock 上方的多个前馈层与 MaskBlock 中的前馈层具有类似的功能,这可能导致在移除该组件时两种模型之间的性能差异。
Table 3: Overall performance (AUC) of MaskNet models removing different component in MaskBlock on Criteo dataset(feature embedding size $=10$ , MaskNet model has 3 MaskBlocks.)
| Model Name | SerMaskNet | ParaMaskNet |
| Full | 0.8119 | 0.8124 |
| -w/oMask | 0.8090 | 0.8093 |
| -w/oLN | 0.8106 | 0.8103 |
| -w/oFFN | 0.8085 | 0.8122 |
表 3: 在 Criteo 数据集上移除 MaskBlock 中不同组件的 MaskNet 模型的整体性能 (AUC) (特征嵌入大小 $=10$,MaskNet 模型有 3 个 MaskBlocks。)
| 模型名称 | SerMaskNet | ParaMaskNet |
|---|---|---|
| Full | 0.8119 | 0.8124 |
| -w/oMask | 0.8090 | 0.8093 |
| -w/oLN | 0.8106 | 0.8103 |
| -w/oFFN | 0.8085 | 0.8122 |
4.4 Hyper-Parameter Study(RQ3)
4.4 超参数研究 (RQ3)
In the following part of the paper, we study the impacts of hyperparameters on two MaskNet models, including 1) the number of feature embedding size; 2) the number of MaskBlock; and 3) the reduction ratio in instance-guided mask module. The experiments are conducted on Criteo dataset via changing one hyper-parameter while holding the other settings. The hyper-parameter experiments show similar trend in other two datasets.
在论文的以下部分,我们研究了超参数对两个MaskNet模型的影响,包括:1) 特征嵌入大小的数量;2) MaskBlock的数量;3) 实例引导掩码模块中的缩减比例。实验在Criteo数据集上进行,通过改变一个超参数而保持其他设置不变。超参数实验在其他两个数据集中也显示出相似的趋势。
Number of Feature Embedding Size. The results in Table 4 show the impact of the number of feature embedding size on model performance. It can be observed that the performances of both models increase when embedding size increases at the beginning. However, model performance degrades when the embedding size is set greater than 50 for SerMaskNet model and 30 for Para Mask Net model. The experimental results tell us the models benefit from larger feature embedding size.
特征嵌入维度数量。表 4 中的结果显示特征嵌入维度数量对模型性能的影响。可以观察到,当嵌入维度增加时,两个模型的性能最初都会提升。然而,当嵌入维度设置为大于 50(对于 SerMaskNet 模型)和 30(对于 Para Mask Net 模型)时,模型性能会下降。实验结果表明,模型受益于更大的特征嵌入维度。
Table 4: Overall performance (AUC) of different feature embedding size of MaskNet Models on Criteo dataset(the number of MaskBlock is 3)
表 4: 不同特征嵌入大小的 MaskNet 模型在 Criteo 数据集上的整体性能 (AUC) (MaskBlock 数量为 3)
| 嵌入大小 | 10 | 20 | 30 | 50 | 80 |
|---|---|---|---|---|---|
| SerMaskNet | 0.8119 | 0.8123 | 0.8121 | 0.8125 | 0.8121 |
| ParaMaskNet | 0.8124 | 0.8128 | 0.8131 | 0.8129 | 0.8129 |
Table 5: Overall performance (AUC) of different numbers of MaskBlocks in MaskNet model on Criteo dataset(embedding size $=10$ )
表 5: 不同数量的 MaskBlocks 在 Criteo 数据集 (嵌入大小 $=10$ ) 上 MaskNet 模型的整体性能 (AUC)
| Block Number | 1 | 3 | 5 | 7 | 6 |
|---|---|---|---|---|---|
| SerMaskNet | 0.8110 | 0.8119 | 0.8126 | 0.8117 | 0.8115 |
| ParaMaskNet | 0.8113 | 0.8124 | 0.8127 | 0.8128 | 0.8132 |
Table 6: Overall performance (AUC) of different size of Hidden Layer in Mask Module of MastBlock on Criteo dataset.(embedding size $=10$ , number of MaskBlock is 3)
表 6: 在 Criteo 数据集上,MastBlock 的 Mask Module 中不同大小的隐藏层的整体性能 (AUC) (嵌入大小 $=10$,MaskBlock 数量为 3)
| 缩减比例 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| SerMaskNet | 0.8118 | 0.8119 | 0.8120 | 0.8117 | 0.8119 |
| ParaMaskNet | 0.8124 | 0.8124 | 0.8122 | 0.8122 | 0.8124 |
Number of MaskBlock. For understanding the influence of the number of MaskBlock on model’s performance, we conduct experiments to stack MaskBlock from 1 to 9 blocks for both MaskNet models. The experimental results are listed in the Table 5. For SerMaskNet model, the performance increases with more blocks at the beginning until the number is set greater than 5. While the performance slowly increases when we continually add more MaskBlock into Para Mask Net model. This may indicates that more experts boost the Para Mask Net model’s performance though it’s more time consuming.
MaskBlock 数量。为了理解 MaskBlock 数量对模型性能的影响,我们对 MaskNet 模型进行了实验,将 MaskBlock 从 1 块堆叠到 9 块。实验结果列在表 5 中。对于 SerMaskNet 模型,性能在开始时随着块数的增加而提高,直到块数超过 5。而在 Para Mask Net 模型中,当我们继续增加更多 MaskBlock 时,性能缓慢提升。这可能表明更多的专家提升了 Para Mask Net 模型的性能,尽管这更耗时。
Reduction Ratio in Instance-Guided Mask. In order to explore the influence of the reduction ratio in instance-guided mask, We conduct some experiments to adjust the reduction ratio from 1 to 5 by changing the size of aggregation layer. Experimental results are shown in Table 6 and we can observe that various reduction ratio has little influence on model’s performance. This indicates that we can adopt small reduction ratio in aggregation layer in real life applications for saving the computation resources.
实例引导掩码中的缩减比例。为了探索实例引导掩码中缩减比例的影响,我们进行了一些实验,通过改变聚合层的大小将缩减比例从1调整到5。实验结果如表6所示,我们可以观察到不同的缩减比例对模型性能的影响很小。这表明在实际应用中,我们可以采用较小的缩减比例来节省计算资源。
4.5 Instance-Guided Mask Study(RQ4)
4.5 实例引导的掩码研究 (RQ4)
As discussed in Section in 3.2, instance-guided mask can be regarded as a special kind of bit-wise attention mechanism to highlight important information based on the current input instance. We can utilize instance-guided mask to boost the informative elements and suppress the uninformative elements or even noise in feature embedding and feed-forward layer.
如第3.2节所述,实例引导的掩码可以被视为一种特殊的逐位注意力机制,用于根据当前输入实例突出重要信息。我们可以利用实例引导的掩码来增强特征嵌入和前馈层中的信息元素,并抑制无信息元素甚至噪声。
To verify this, we design the following experiment: After training the SerMaskNet with 3 blocks, we input different instances into the model and observe the outputs of corresponding instance-guided masks.
为了验证这一点,我们设计了以下实验:在使用3个模块训练SerMaskNet后,我们将不同的实例输入模型,并观察相应的实例引导掩码的输出。

Figure 5: Distribution of Mask Values
图 5: 掩码值分布

Figure 6: Mask Values of Two Expamples
图 6: 两个示例的掩码值
Firstly, we randomly sample 100000 different instances from Criteo dataset and observe the distributions of the produced values by instance-guided mask from different blocks. Figure 5 shows the result. We can see that the distribution of mask values follow normal distribution. Over $50%$ of the mask values are small number near zero and only little fraction of the mask value is a relatively larger number. This implies that large fraction of signals in feature embedding and feed-forward layer is uninformative or even noise which is suppressed by the small mask values. However, there is some informative information boosted by larger mask values through instance-guided mask.
首先,我们从Criteo数据集中随机抽取100000个不同的实例,并观察不同块中由实例引导的掩码生成的值分布。图5展示了结果。我们可以看到,掩码值的分布遵循正态分布。超过$50%$的掩码值是接近零的小数,只有一小部分掩码值是相对较大的数。这意味着特征嵌入和前馈层中的大部分信号是无信息或甚至是噪声,这些信号被较小的掩码值抑制。然而,通过实例引导的掩码,较大的掩码值增强了一些信息量。
Secondly, we randomly sample two instances and compare the difference of the produced values by instance-guided mask. The results are shown in Figure 6. We can see that: As for the mask values for feature embedding, different input instances lead the mask to pay attention to various areas. The mask outputs of instance A pay more attention to the first few features and the mask values of instance B focus on some bits of other features. We can observe the similar trend in the mask values in feed-forward layer. This indicates the input instance indeed guide the mask to pay attention to the different part of the feature embedding and feed-forward layer.
其次,我们随机抽取两个实例,并通过实例引导的掩码比较生成值的差异。结果如图 6 所示。我们可以看到:对于特征嵌入的掩码值,不同的输入实例导致掩码关注不同的区域。实例 A 的掩码输出更关注前几个特征,而实例 B 的掩码值则集中在其他特征的一些位上。在前馈层的掩码值中,我们也可以观察到类似的趋势。这表明输入实例确实引导掩码关注特征嵌入和前馈层的不同部分。
5 CONCLUSION
5 结论
In this paper, we introduce multiplicative operation into DNN ranking system by proposing instance-guided mask which performs element-wise product both on the feature embedding and feedforward layers. We also turn the feed-forward layer in DNN model into a mixture of addictive and multiplicative feature interactions by proposing MaskBlock by bombing the layer normalization, instanceguided mask, and feed-forward layer. MaskBlock is a basic building block to be used to design new ranking model. We also propose two specific MaskNet models based on the MaskBlock. The experiment results on three real-world datasets demonstrate that our proposed models outperform state-of-the-art models such as DeepFM and xDeepFM significantly.
在本文中,我们通过提出实例引导的掩码 (instance-guided mask) 将乘法操作引入到 DNN 排序系统中,该掩码在特征嵌入层和前馈层上执行逐元素乘积。我们还通过提出 MaskBlock,将 DNN 模型中的前馈层转变为加性和乘性特征交互的混合体,该模块结合了层归一化 (layer normalization)、实例引导的掩码和前馈层。MaskBlock 是一个基本构建块,可用于设计新的排序模型。我们还基于 MaskBlock 提出了两种具体的 MaskNet 模型。在三个真实世界数据集上的实验结果表明,我们提出的模型显著优于 DeepFM 和 xDeepFM 等最先进的模型。