Highly Optimized Kernels and Fine-Grained Codebooks for LLM Inference on Arm CPUs
针对 Arm CPU 上大语言模型推理的高度优化内核与细粒度码本
Abstract
摘要
Large language models (LLMs) have transformed the way we think about language understanding and generation, enthralling both researchers and developers. However, deploying these models for inference has been a significant challenge due to their unprecedented size and resource requirements. Facilitating the efficient execution of LLMs on commodity Arm CPUs will expand their reach to billions of compact devices such as smartphones and other small devices. While quantizing model weights to sub-byte precision (for example, 4 bits per weight or less) has emerged as a promising solution to ease memory pressure, the group quantization formats commonly used for LLM quantization have significant compute overheads and a resource-intensive de quantization process. As a result, a higher proportion of compute instructions do not perform multiplies, i.e., real work, rendering them unsuitable for meeting the required latency requirements for LLM variants deployed on commodity CPUs. In addition, CPU-based LLM inference has received far less attention in previous efforts. In this work, we propose a set of highly optimized kernels to accelerate LLM inference, demonstrate the best possible performance, and unleash the full potential of CPUs, particularly Arm CPUs. These kernels amortize the cost of loading the operands and the cost of weight unpacking across multiple output rows. This, along with the introduction of an optimized interleaved group data layout format for weights and decompression path optimization s to reduce unnecessary operations and de quantization overhead while maximizing the use of vector and matrix multiply operations, significantly improves the efficiency of MAC operations. Furthermore, we present a groupwise non-uniform codebook-based quantization method for ultra-low-precision quantization of LLMs to better match non-uniform patterns in their weight distributions, allowing large-scale LLMs to fit on smaller devices and demonstrating better throughput during token generation while ensuring better quality than the state-of-the-art. Experiments show that applying these improvements to LLMs with 4-bit and 2-bit quantization results in at least $3-3.2\times$ improvement in prompt processing and $2\times$ improvement in auto regressive decoding on a single Arm CPU core, compared to LLaMA.cpp-based solution. The optimized kernels are available at https://github.com/ggerganov/llama.cpp.
大语言模型 (LLMs) 已经彻底改变了我们对语言理解和生成的思考方式,吸引了研究人员和开发者的广泛关注。然而,由于这些模型的空前规模和资源需求,部署它们进行推理一直是一个重大挑战。在商用 Arm CPU 上高效执行大语言模型将使其能够扩展到数十亿台紧凑设备,如智能手机和其他小型设备。虽然将模型权重量化为亚字节精度(例如,每个权重 4 比特或更少)已成为缓解内存压力的一个有前景的解决方案,但通常用于大语言模型量化的分组量化格式具有显著的计算开销和资源密集的解量化过程。因此,较高比例的计算指令不执行乘法运算,即实际工作,这使得它们无法满足在商用 CPU 上部署的大语言模型变体所需的延迟要求。此外,基于 CPU 的大语言模型推理在以往的研究中受到的关注较少。在本工作中,我们提出了一组高度优化的内核来加速大语言模型推理,展示最佳性能,并释放 CPU,特别是 Arm CPU 的全部潜力。这些内核通过在多行输出中分摊操作数加载和权重解包的代价,以及引入优化的交错组数据布局格式和优化解压缩路径以减少不必要的操作和解量化开销,同时最大化向量和矩阵乘法运算的使用,显著提高了 MAC 操作的效率。此外,我们提出了一种基于分组非均匀码本的超低精度量化方法,以更好地匹配大语言模型权重分布中的非均匀模式,使大规模大语言模型能够适应更小的设备,并在生成 Token 时展示出比现有技术更好的吞吐量,同时确保更好的质量。实验表明,与基于 LLaMA.cpp 的解决方案相比,将这些改进应用于 4 比特和 2 比特量化的大语言模型,在单个 Arm CPU 核心上,提示处理至少提高了 $3-3.2\times$,自回归解码提高了 $2\times$。优化后的内核可在 https://github.com/ggerganov/llama.cpp 获取。
1 Introduction
1 引言
Generative Large Language Models (LLMs) have demonstrated remarkable results for a wide range of tasks. A language model can predict the next word given a context or a question. LLMs are trained with massive amounts of data to learn language patterns. They can perform tasks ranging from summarizing and translating texts to responding in chatbot conversations. As a result, facilitating their efficient execution on Arm CPUs will expand their reach to billions of Arm devices. LLMs are often memory-bandwidth and memory capacity-bound, with memory accesses dominated by weights, allowing CPUs the opportunity to achieve competitive performance and outperform other processors and accelerators in terms of overall inference/cost. Furthermore, Arm CPUs are pervasive, providing portability and flexibility, so a new LLM compression scheme can work seamlessly on Arm CPUs without much effort. Given all the advantages, this work attempts to unlock the full potential of LLMs on Arm CPUs deployed in data cene ter s, smartphones, and edge devices.
生成式大语言模型 (Generative Large Language Models, LLMs) 在广泛的任务中展现了卓越的表现。语言模型能够根据上下文或问题预测下一个词。大语言模型通过海量数据进行训练,以学习语言模式。它们能够执行从文本摘要、翻译到聊天机器人对话回应的多种任务。因此,促进其在 Arm CPU 上的高效执行将使其能够扩展到数十亿台 Arm 设备。大语言模型通常受限于内存带宽和内存容量,内存访问主要由权重主导,这使得 CPU 有机会在整体推理/成本方面实现竞争性性能,并超越其他处理器和加速器。此外,Arm CPU 无处不在,提供了可移植性和灵活性,因此新的 LLM 压缩方案可以无缝地在 Arm CPU 上运行,而无需太多努力。鉴于所有这些优势,本研究试图在部署于数据中心、智能手机和边缘设备的 Arm CPU 上充分释放大语言模型的潜力。
Deploying these LLMs for inference has been a significant challenge due to their unprecedented size and resource requirements. One of the primary performance bottlenecks in LLM inference for generative tasks is memory bandwidth. Quantization has been an effective approach to converting high-precision (16 or 32-bit) model weights to lower-precision values without significantly affecting accuracy. It lowers the model’s memory and computational requirements, making it better suited for deployment on devices with limited resources. While 8-bit quantization reduces LLM storage requirements by half, the large scale size of LLMs necessitates quantizing them to even lower precisions (for example, 4, or even lower bit-widths). When quantized to 2 bits, the Llama3 70B-like large-scale foundation model requires less than $20\mathrm{GB}$ of memory. As a result, there has been a significant research interest in achieving even greater compression through ultra-low-precision (e.g., 2 bits per weight) quantization, non-uniform quantization, and complex compression schemes. While quantization has emerged as a promising solution to the memory bandwidth problem, expensive decoding schemes and large model footprint access of existing quantization methods continue to have a significant impact on runtime performance. With this advancement in quantization formats and compression algorithms targeting LLMs, a major obstacle still to be overcome is providing effective system support for these compressed numerical formats for extreme compression regimes (4 or fewer bits per weight) so that LLMs can be executed quickly and accurately on end devices such as GPUs or CPUs. This motivates the development of faster inference kernels as well as runtime-friendly, fast, and accurate quantization methods.
由于大语言模型前所未有的规模和资源需求,部署这些模型进行推理一直是一个重大挑战。生成任务中大语言模型推理的主要性能瓶颈之一是内存带宽。量化是一种有效的方法,可以将高精度(16 或 32 位)模型权重转换为低精度值,而不会显著影响准确性。它降低了模型的内存和计算需求,使其更适合在资源有限的设备上部署。虽然 8 位量化将大语言模型的存储需求减少了一半,但大语言模型的庞大规模需要将其量化为更低的精度(例如 4 位,甚至更低的位宽)。当量化为 2 位时,类似 Llama3 70B 的大规模基础模型所需的内存不到 $20\mathrm{GB}$。因此,通过超低精度(例如,每个权重 2 位)量化、非均匀量化和复杂压缩方案实现更大压缩的研究兴趣显著增加。虽然量化已成为解决内存带宽问题的一种有前景的解决方案,但现有量化方法的昂贵解码方案和大模型占用访问仍然对运行时性能有重大影响。随着针对大语言模型的量化格式和压缩算法的进步,仍需克服的一个主要障碍是为这些极端压缩方案(每个权重 4 位或更少)的压缩数值格式提供有效的系统支持,以便大语言模型可以在 GPU 或 CPU 等终端设备上快速准确地执行。这推动了更快推理内核以及运行时友好、快速且准确的量化方法的开发。
While much of the prior research has focused on GPU-based inference as the primary target scenario [18, 21, 26, 17, 15], CPU-based inference has received significantly less attention. Although open-source CPU-based inference frameworks, such as LLaMA.cpp [14], can offer decent timeto-first-token and generative performance on off-the-shelf CPUs, in this work, we investigate the possibility of achieving significantly better runtime performance by designing optimized matrixvector multiplications (GEMV) and matrix-matrix multiplications (GEMM) kernels targeting LLM inference of varying low-bitwidths on Arm CPUs.
尽管之前的研究大多集中在基于 GPU 的推理作为主要目标场景 [18, 21, 26, 17, 15],但基于 CPU 的推理受到的关注明显较少。虽然开源的基于 CPU 的推理框架,如 LLaMA.cpp [14],可以在现成的 CPU 上提供不错的首次 Token 时间和生成性能,但在本工作中,我们通过设计优化的矩阵向量乘法 (GEMV) 和矩阵矩阵乘法 (GEMM) 内核,研究了在 Arm CPU 上实现显著更好的运行时性能的可能性,这些内核针对不同低位宽的大语言模型推理进行了优化。
Furthermore, existing quantization methods do not perform well at extreme compression ratios, such as 2-bit quantization, and result in either poor runtime performance despite advanced kernel optimization s or notable degradation in quality. We then propose a novel non-uniform codebookbased post-training quantization method that enables ultra-low-precision quantization of LLMs while outperforming the state-of-the-art in terms of text generation quality and runtime performance. This is accomplished through the innovation of applying non-uniform codebook-based quantization over group-wise structured LLM weight matrices, fine-grained codebook assignment to weight groups, in conjunction with identifying and using as few codebooks for all LLM layers as possible, so that the codebooks for all of them can be stored in an Arm CPU’s register file (for example, a single 128-bit vector register). This, combined with Arm CPU-optimized codebook-based group-wise quantized matrix multiply kernels, results in significantly improved runtime performance for foundation models in the domain of LLM. While we consider ARM CPU-based generative inference as the motivating setup for our work, our techniques are general and should be extensible to other settings as well.
此外,现有的量化方法在极端压缩比(如2位量化)下表现不佳,尽管进行了高级内核优化,但要么导致运行时性能较差,要么导致质量显著下降。我们提出了一种新颖的基于非均匀码本的后训练量化方法,该方法能够实现大语言模型的超低精度量化,同时在文本生成质量和运行时性能方面优于现有技术。这是通过在分组结构化的LLM权重矩阵上应用非均匀码本量化、对权重组进行细粒度码本分配,并结合识别和使用尽可能少的码本来实现的,以便所有LLM层的码本都可以存储在Arm CPU的寄存器文件中(例如,单个128位向量寄存器)。这与针对Arm CPU优化的基于码本的分组量化矩阵乘法内核相结合,显著提高了大语言模型领域基础模型的运行时性能。虽然我们将基于Arm CPU的生成推理作为我们工作的动机设置,但我们的技术是通用的,应该也可以扩展到其他设置。
The key contributions of this work are as follows:
本工作的主要贡献如下:
• We develop a set of highly optimized GEMV and GEMM kernels for various low bitwidth group-wise quantized LLMs. With the help of SIMD-aware weight packing and fast decompression path optimization s, these kernels can fully take advantage of available vector and matrix multiply instructions to maximize MAC unit utilization, minimize overhead and memory accesses, and achieve the best possible performance (to date) on Arm CPUs. Our optimized 4-bit group-wise quantization kernels enable $3-3.2\times$ faster throughput in the compute-bound time-to-first-token (prefill) and $2\times$ higher throughput in the memory-bound token generation (auto regressive decoding) stages of LLM inference on Arm CPUs when compared to the state-of-the-art. We also present highly optimized kernels for various non-uniform quantization methods, such as scalar and vector quantization types, as well as narrower 2-bit quantization, and demonstrate the effectiveness of off-the-shelf Arm CPUs in offering high throughput performance for them.
• 我们为各种低比特宽度分组量化的大语言模型开发了一套高度优化的 GEMV 和 GEMM 内核。通过 SIMD 感知的权重打包和快速解压缩路径优化,这些内核能够充分利用可用的向量和矩阵乘法指令,最大化 MAC 单元利用率,最小化开销和内存访问,并在 Arm CPU 上实现迄今为止最佳的性能。我们优化的 4 位分组量化内核在计算受限的首个 Token 生成时间(预填充)阶段实现了 $3-3.2\times$ 的吞吐量提升,在内存受限的 Token 生成(自回归解码)阶段实现了 $2\times$ 的吞吐量提升,相较于当前最先进的技术。我们还为各种非均匀量化方法(如标量和向量量化类型)以及更窄的 2 位量化提供了高度优化的内核,并展示了现成 Arm CPU 在提供高吞吐量性能方面的有效性。
• We propose a group-wise codebook-based quantization method for ultra-low-precision quantization of LLMs to better match non-uniform patterns in their weight distributions. Our fine-grained non-uniform quantization technique not only achieves better LLM quality than the current state-of-the-art (about a 0.9-point improvement in perplexity at similar bits per weight for the LLaMA-3 8B model) but also demonstrates a high throughput comparable to low-decompression overhead uniform quantization techniques during token generation. We present a pareto-optimal solution in terms of model quality and runtime performance for low bit-width quantization, outperforming state-of-the-art 2-3-bit quantization techniques in terms of LLM quality while requiring similar bits per weight and no additional finetuning.
• 我们提出了一种基于分组码书的量化方法,用于大语言模型的超低精度量化,以更好地匹配其权重分布中的非均匀模式。我们的细粒度非均匀量化技术不仅在大语言模型质量上优于当前的最先进技术(在LLaMA-3 8B模型上,每权重相似比特数的情况下,困惑度提高了约0.9点),而且在Token生成过程中展示了与低解压缩开销的均匀量化技术相当的高吞吐量。我们提出了一种在模型质量和运行时性能方面达到帕累托最优的低比特宽度量化解决方案,在大语言模型质量上优于最先进的2-3比特量化技术,同时需要相似的每权重比特数且无需额外的微调。
2 Related work
2 相关工作
Quantization of LLMs. Due to the massive size of LLMs, post-training quantization (PTQ) methods have emerged as an essential technique for accelerating LLMs during inference and running them efficiently. There has been a surge of interest and an increasing body of work in developing accurate PTQ methods targeting LLMs in recent times, as doing so can directly lower the cost of running them. By reducing the precision of pre-trained LLMs, PTQ methods save memory and speed up LLM inference while preserving most of the model quality at scale when compared to the performance and compute requirements of other compression techniques such as pruning and quantization-aware training (QAT). Early PTQ works on LLMs such as ZeroQuant [33], LLM.int8() [7], and nuQmm [24] demonstrate the potential to use fine-grained quantization (i.e., group-wise quantization) for model weights to achieve better accuracy while at the cost of slightly less compression in comparison to standard coarser-grained quantization methods. Subsequent quantization works, such as GPTQ [13], compress LLM weights more aggressively to 3 or 4 bits, unlocking the possibility of running massive LLMs on consumer hardware. GPTQ employs layer-wise quantization in conjunction with Optimal Brain Quantization (OBQ) [12], in which the easiest weights are quantized first, and all remaining non-quantized weights are adjusted to compensate for the precision loss. This, combined with finegrained group-wise quantization, results in high compression rates while maintaining high quality. QuIP [2] and QuIP# [28] apply incoherence processing to further quantize LLMs to 2 bits per weight, recognizing that quantization benefits from incoherent weights and corresponding proxy Hessian matrices. SqueezeLLM [16], AWQ [20], and SpQR [9] lines of work observe that a small subset of LLM model weights produce noticeably large quantization errors, therefore storing them with higher precision to counteract the accuracy degradation caused by their weight quantization and demonstrating improved PTQ accuracy over previous works. While aggressive weight quantization is critical for LLMs to reduce inference costs, activation quantization is less of an issue due to their smaller memory footprint, so activation s are typically quantized to 8 bits. The presence of activation outliers can sometimes pose a challenge to weight-activation co-quantization, and subsequent works such as Smooth Quant [32], Outlier Suppression [30, 31], and OmniQuant [25] addressed this by introducing a per-channel scaling transformation that shifts the quantization difficulty from activation s to weights, allowing activation s to be quantized to 8 bits.
大语言模型的量化。由于大语言模型的规模庞大,训练后量化(PTQ)方法已成为加速大语言模型推理并高效运行的关键技术。近年来,针对大语言模型开发精确的PTQ方法的研究兴趣激增,相关成果也越来越多,因为这样做可以直接降低运行成本。通过降低预训练大语言模型的精度,PTQ方法节省了内存并加速了大语言模型的推理,同时与剪枝和量化感知训练(QAT)等其他压缩技术相比,在大规模模型质量上保留了大部分性能。早期的PTQ工作,如ZeroQuant [33]、LLM.int8() [7]和nuQmm [24],展示了使用细粒度量化(即分组量化)对模型权重进行量化以实现更好精度的潜力,尽管与标准粗粒度量化方法相比,压缩率稍低。随后的量化工作,如GPTQ [13],将大语言模型权重更激进地压缩到3或4比特,从而解锁了在消费级硬件上运行大规模大语言模型的可能性。GPTQ采用分层量化与最优脑量化(OBQ)[12]相结合的方法,其中最容易量化的权重首先被量化,所有剩余未量化的权重被调整以补偿精度损失。这与细粒度分组量化相结合,实现了高压缩率的同时保持了高质量。QuIP [2]和QuIP# [28]应用非相干处理进一步将大语言模型量化到每权重2比特,认识到量化受益于非相干权重和相应的代理Hessian矩阵。SqueezeLLM [16]、AWQ [20]和SpQR [9]系列工作观察到,大语言模型权重的一小部分会产生明显的量化误差,因此以更高精度存储这些权重以抵消其量化引起的精度下降,并展示了比之前工作更高的PTQ精度。虽然激进的权重量化对于降低大语言模型的推理成本至关重要,但由于激活的内存占用较小,激活量化问题较少,因此激活通常被量化为8比特。激活异常值的存在有时会对权重-激活共同量化构成挑战,随后的工作如Smooth Quant [32]、Outlier Suppression [30, 31]和OmniQuant [25]通过引入每通道缩放变换来解决这一问题,将量化难度从激活转移到权重,从而使激活能够量化为8比特。
In general, most previous LLM PTQ studies have used group-wise quantization, along with some advanced techniques to handle outliers [36, 34, 1, 23, 19, 22]. The open-source inference framework LLaMA.cpp [14] also employs group-wise quantization in conjunction with higher precisions for critical layers, such as 4-bits for the vast majority of layers and higher precisions for a few.
总体而言,大多数先前的大语言模型 (LLM) 后训练量化 (PTQ) 研究都采用了分组量化 (group-wise quantization),并结合一些先进技术来处理异常值 [36, 34, 1, 23, 19, 22]。开源推理框架 LLaMA.cpp [14] 也采用了分组量化,并对关键层使用更高的精度,例如大多数层使用 4 位精度,少数层使用更高的精度。
System support for low-bit quantized LLMs. The majority of the aforementioned quantization techniques focused on GPU inference as their primary target scenario. For group-wise quantized LLMs, GPTQ-for-LLaMA offers 4-bit (INT4) Triton kernels, while GPTQ provides 3-bit (INT3) CUDA kernels. vLLM [18] implements optimized CUDA kernels for INT4, INT8, and FP8 data types for both Nvidia and AMD GPUs, and it also enhances memory efficiency by using Paged Attention to manage attention key and value memory effectively. Nvidia’s TensorRT-LLM inference library integrates optimized GPU kernels from Faster Transformer and employs tensor parallelism to enable scalable inference across multiple GPUs. Flash Attention [6, 5] combines all of the attention operations into a single kernel and tiles the weight matrices into smaller blocks to better fit the small SRAM, reducing the number of memory accesses between GPU high-bandwidth memory (HBM) and GPU on-chip SRAM. LUT-GEMM [24] uses lookup tables to perform bitwise computations on GPU CUDA cores.
低比特量化大语言模型的系统支持。上述大多数量化技术主要针对GPU推理场景。对于分组量化的大语言模型,GPTQ-for-LLaMA提供了4比特(INT4)的Triton内核,而GPTQ则提供了3比特(INT3)的CUDA内核。vLLM [18] 为Nvidia和AMD GPU实现了针对INT4、INT8和FP8数据类型的优化CUDA内核,并通过使用分页注意力(Paged Attention)有效管理注意力键和值的内存,进一步提升了内存效率。Nvidia的TensorRT-LLM推理库集成了来自Faster Transformer的优化GPU内核,并利用张量并行性实现跨多个GPU的可扩展推理。Flash Attention [6, 5] 将所有注意力操作合并到一个内核中,并将权重矩阵分块以适应较小的SRAM,从而减少GPU高带宽内存(HBM)与GPU片上SRAM之间的内存访问次数。LUT-GEMM [24] 使用查找表在GPU CUDA核心上执行位运算。
On the other hand, CPU-based LLM inference and running modes locally on end devices equipped with CPUs have received far less attention [35]. The open-source inference framework LLaMA.cpp can offer reasonable generative performance on end devices. Our work develops the most optimized kernels for group-quantized LLMs to date, demonstrating significantly improved performance over LLaMA.cpp for a variety of low bit-widths on Arm CPUs.
另一方面,基于 CPU 的大语言模型推理和在配备 CPU 的终端设备上本地运行的模式受到的关注要少得多 [35]。开源推理框架 LLaMA.cpp 可以在终端设备上提供合理的生成性能。我们的工作开发了迄今为止针对分组量化大语言模型的最优化内核,展示了在 Arm CPU 上各种低比特宽度下性能显著优于 LLaMA.cpp。
Non-uniform quantization. In addition to uniform quantization techniques as mentioned above, post-training non-uniform quantization techniques have recently received a lot of attention in order to better match the non-uniform patterns commonly found in LLM weight distributions. SqueezeLLM [16] applies $\mathbf{k}$ -means clustering to LLM weights to closely approximate the nonuniform distribution and encodes the clusters using codebooks. Recent work on GPTVQ [29], QuIP# [28], and AQLM [11] extends the potential of non-uniform quantization to vector quantization, which quantizes a vector of weights together using codebooks and thus captures the shape of the source distribution more accurately than SqueezeLLM-like scalar quantization approaches. However, the high overhead of accessing codebooks, combined with the complex decompression path of the above studies, results in poor runtime performance. In contrast, our group-wise codebook-based quantization ensures not only faster throughput but also better quality than these state-of-the-art approaches under extreme compression scenarios (e.g., 2-bit quantization). There are works employing a differentiable k-means approach [3] as an alternative to performing non-uniform codebook-based quantization on pre-trained models. This approach allows codebooks to be fine-tuned using SGD with the original loss function to better recover the network accuracy.
非均匀量化。除了上述的均匀量化技术外,为了更好匹配大语言模型权重分布中常见的非均匀模式,训练后非均匀量化技术最近受到了广泛关注。SqueezeLLM [16] 对大语言模型权重应用 $\mathbf{k}$ 均值聚类,以紧密逼近非均匀分布,并使用码本对聚类进行编码。最近关于 GPTVQ [29]、QuIP# [28] 和 AQLM [11] 的研究将非均匀量化的潜力扩展到向量量化,通过码本一起量化权重向量,从而比类似 SqueezeLLM 的标量量化方法更准确地捕捉源分布的形态。然而,访问码本的高开销与上述研究的复杂解压缩路径相结合,导致运行时性能较差。相比之下,我们的基于分组码本的量化不仅在极端压缩场景(例如 2 位量化)下确保了更快的吞吐量,而且比这些最先进的方法具有更好的质量。有研究采用可微分 k 均值方法 [3] 作为对预训练模型执行基于非均匀码本量化的替代方案。这种方法允许使用 SGD 和原始损失函数对码本进行微调,以更好地恢复网络精度。
3 Background and motivation
3 背景与动机
LLM inference. LLMs are made of transformer layers. Given an input prompt, each round through this LLM network generates a new token, and the new token is fed into the LLM for generating the token in the next round. Ideally, for the next round, the LLM should need the initial prompt and the answer generated so far as the input context to generate the next token. However, since all the tokens except the last generated token remain the same as the previous round, in order to save on redundant computation, the LLM stores the embeddings for them in KV caches when they are generated for the first time. So in the next round, the LLM simply retrieves the history, state, or embeddings of the previous tokens and processes the last generated token in conjunction with the previous embeddings to generate the next token. The LLM updates the history with the last token and repeats the process until a complete answer is generated. Except for the first round, because the text generation at each step primarily depends on the last generated token, i.e., a single row of input or activation, the text generation phase for a single inference case mainly involves GEMV operations. On the other hand, processing the initial multi-token prompt or text generation for batched inference cases (i.e., many concurrent users) involves many rows of input or activation, necessitating GEMM operations.
大语言模型推理。大语言模型由Transformer层组成。给定一个输入提示,每次通过这个大语言模型网络都会生成一个新的Token,这个新Token会被输入到大语言模型中用于生成下一轮的Token。理想情况下,对于下一轮,大语言模型应该需要初始提示和迄今为止生成的答案作为输入上下文来生成下一个Token。然而,由于除了最后生成的Token之外的所有Token都与上一轮相同,为了节省冗余计算,大语言模型在首次生成这些Token时会将它们的嵌入存储在KV缓存中。因此,在下一轮中,大语言模型只需检索之前Token的历史、状态或嵌入,并结合之前的嵌入处理最后生成的Token以生成下一个Token。大语言模型会用最后一个Token更新历史,并重复这个过程,直到生成完整的答案。除了第一轮之外,由于每一步的文本生成主要依赖于最后生成的Token,即单行输入或激活,单个推理案例的文本生成阶段主要涉及GEMV操作。另一方面,处理初始的多Token提示或批量推理案例(即许多并发用户)的文本生成涉及多行输入或激活,因此需要进行GEMM操作。
Group-wise quantization. For typical operators in LLMs, weight matrices are significantly larger than activation matrices. As a result, compression of the weight matrix is critical to reducing memory and bandwidth consumption, so they are typically quantized to 4 or fewer bits. Typically, tensor-wise uniform quantization is used for 8-bit quantization with 256 distinct quantized values, where a single floating-point scale for the entire tensor can convert the quantized values to actual weights with very low quantization noise. However, quantizing a 16- or 32-bit float value to a 4-bit integer (INT4) or even fewer bits is complex, as an INT4 can only represent 16 distinct values, compared to the vast range of the FP32. One issue with this tensor-wide quantization approach is that LLM weight tensors can feature “outliers” having much larger magnitude than the other weights; a scale factor chosen to accommodate the outliers results in the remaining weights being represented much less accurately, lowering the quantized model’s accuracy. As a result, when the weight matrix is quantized to 4 or fewer bits, it is typically quantized using group-wise quantization. Group-wise quantization has a finer granularity than standard tensor-wise or channel-wise quantization [4], allowing it to reduce quantization noise natively while approaching the full-precision (floating point) quality of a foundation model. Group-wise quantization quantizes in groups, whereby weights are divided into groups of 32, 64, or 256, as shown in Figure 1. Each group is then quantized individually to mitigate the effect of outliers and increase precision.
分组量化 (Group-wise quantization)。在大语言模型中,权重矩阵通常远大于激活矩阵。因此,权重矩阵的压缩对于减少内存和带宽消耗至关重要,通常会被量化为4位或更少位数。通常情况下,8位量化使用张量级别的均匀量化,具有256个不同的量化值,其中单个浮点比例因子可以将量化值转换为实际权重,量化噪声非常低。然而,将16位或32位浮点值量化为4位整数 (INT4) 或更少位数则较为复杂,因为INT4只能表示16个不同的值,而FP32的范围则非常广泛。这种张量级别的量化方法的一个问题是,大语言模型的权重张量可能包含“异常值”,其幅度远大于其他权重;为适应这些异常值而选择的比例因子会导致其余权重的表示精度大幅下降,从而降低量化模型的准确性。因此,当权重矩阵被量化为4位或更少位数时,通常使用分组量化。分组量化比标准的张量级别或通道级别量化具有更细的粒度 [4],使其能够自然地减少量化噪声,同时接近基础模型的全精度(浮点)质量。分组量化按组进行,权重被分为32、64或256个组,如图1所示。然后每个组单独量化,以减轻异常值的影响并提高精度。
For example, the Q4_0 group quantization format from LLaMA.cpp considers a group size (V) of 32 and uses an FP16 scale factor to quantize weight values to 4 bits before interleaving the top and bottom halves of the 32 4-bit weights into 16 bytes. In the case of activation s, size and bandwidth are less important, so they are typically quantized to 8-bit integer values and the corresponding Q8_0 format groups and quantizes them to 8 bits using FP16 scale factors. This weight quantization and interleaving format is chosen to optimize space and bandwidth, as well as to make the decompression process easier during inference, whereas the activation quantization format is chosen to facilitate subsequent integer dot product computation with group-quantized weights, as discussed in the following sections.
例如,LLaMA.cpp 中的 Q4_0 分组量化格式考虑了一个组大小 (V) 为 32,并使用 FP16 比例因子将权重值量化为 4 位,然后将 32 个 4 位权重的上半部分和下半部分交错排列为 16 字节。对于激活值,大小和带宽不那么重要,因此它们通常被量化为 8 位整数值,并使用 FP16 比例因子进行分组和量化为 8 位的 Q8_0 格式。选择这种权重量化和交错格式是为了优化空间和带宽,并使推理过程中的解压缩过程更容易,而选择激活量化格式是为了便于后续与分组量化权重进行整数点积计算,如下文所述。
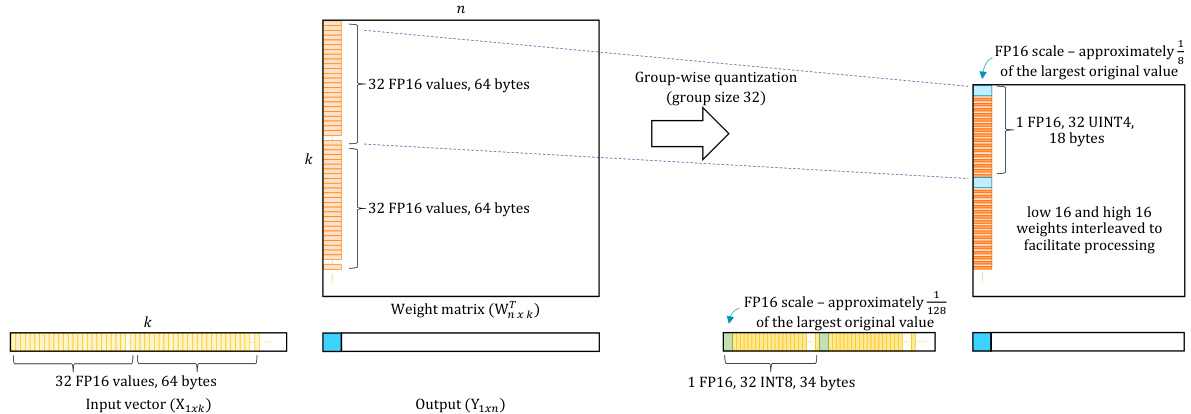
Figure 1: Group-wise quantization, in which weights are divided into groups, each with V elements and its own scale factor. We use a group size (V) of 32 here. Given a weight tensor, a group of 32 floating-point weights is quantized into 4-bit integer values using a local scale factor. The next set of 32 consecutive weights are then quantized to 4 bits using a different scale factor, and this process is repeated until the entire weight tensor is covered. We use FP16 precision for scale factors.
图 1: 分组量化,其中权重被分成若干组,每组包含 V 个元素,并拥有自己的缩放因子。这里我们使用的组大小 (V) 为 32。给定一个权重张量,一组 32 个浮点权重使用局部缩放因子量化为 4 位整数值。然后,接下来的 32 个连续权重使用不同的缩放因子量化为 4 位,重复此过程直到覆盖整个权重张量。我们使用 FP16 精度来表示缩放因子。
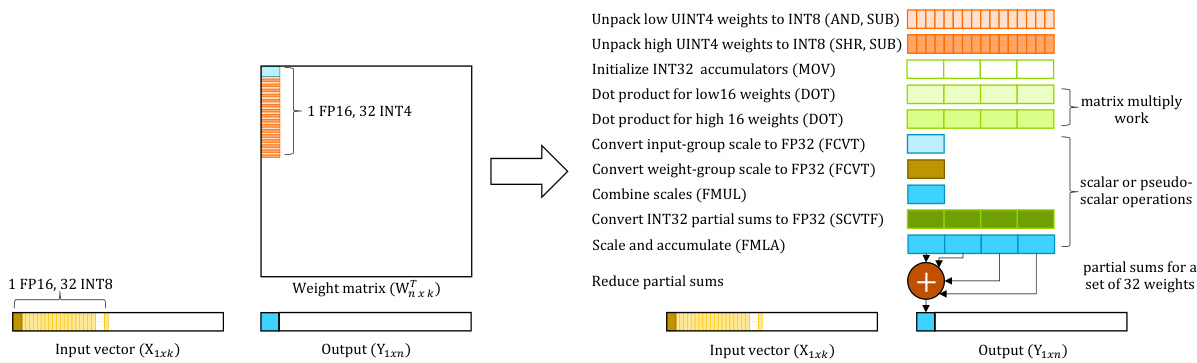
Figure 2: Group processing steps in a reference baseline group-wise quantized dot product kernel.
图 2: 参考基线组量化点积内核中的组处理步骤。
Motivation. Because the weights are in a 4-bit group-quantized format, a matrix-multiply kernel involving group-quantized 4-bit weights must incur an overhead when de quant i zing them, as shown in Figure 2. In particular, they need to be first unpacked and expanded from 4-bit weights to signed 8-bit values before computing dot-products between 8-bit integer weights and activation s. Aside from that, the FP16 scale factors of weights and activation s for a group must be expanded to FP32 values before being combined and used to scale a group’s integer dot product result (INT32 partial sum), as well as contributing to the final FP32 dot product value for a weight column. This process is repeated until the scaled dot product results of all quantized groups in an entire weight column are combined to obtain the weight column’s final dot product value against an activation row.
动机。由于权重采用4位组量化格式,涉及组量化4位权重的矩阵乘法内核在反量化时必然会产生开销,如图2所示。具体来说,在计算8位整数权重与激活值之间的点积之前,需要先将4位权重解包并扩展为有符号的8位值。此外,权重和激活值的FP16比例因子在组合并用于缩放组的整数点积结果(INT32部分和)之前,必须扩展为FP32值,同时贡献于权重列的最终FP32点积值。这一过程会重复进行,直到整个权重列中所有量化组的缩放点积结果被组合起来,得到权重列与激活行的最终点积值。
Due to typically considering a single weight column at a time by the reference kernels of CPUbased LLM inference frameworks, such as LLaMA.cpp, as shown in Figure 2, there is no reuse of activation s (input vector) for GEMV kernels or activation s and weights for GEMM kernels. This leads to a large number of redundant loads. There is no reuse of the activation’s FP16 scale factors or corresponding FP32 converted values. Furthermore, because only one weight column is considered at a time, vector instructions cannot be used to convert FP16 scale factors to FP32 values for a group of weight columns or to combine FP32 scale factors of weights and activation s, resulting in a large number of scalar operations.
由于基于 CPU 的大语言模型推理框架(如 LLaMA.cpp)的参考内核通常一次只考虑一个权重列,如图 2 所示,GEMV 内核的激活值(输入向量)或 GEMM 内核的激活值和权重没有重用。这导致了大量的冗余加载。激活值的 FP16 缩放因子或相应的 FP32 转换值也没有重用。此外,由于一次只考虑一个权重列,无法使用向量指令将一组权重列的 FP16 缩放因子转换为 FP32 值,也无法组合权重和激活值的 FP32 缩放因子,从而导致大量的标量操作。
Additionally, there are quite a few “pseudo-scalar” operations, which operate on a vector of values that is actually one true value split across vector lanes, and are significantly less efficient than “true” vector operations. This essentially means that, while fused multiply-accumulate (dot product) vector operations, such as the ARM dot product operation, v dot q lane q s 32, of the reference matrix multiply kernel operate on vectors of values, they still operate on a single weight column. This, in turn, necessitates additional reduction operations to reduce scaled partial dot products or partial sums from different vector lanes (4 vector lanes as shown in Figure 2) in order to obtain the final FP32 dot product result for a weight group and accumulate it to the weight column’s overall dot product value. In summary, many compute instructions do not perform useful matrix multiplication work.
此外,还存在相当多的“伪标量”操作,这些操作作用于一个实际上是一个真实值分散在向量通道中的值向量,并且效率远低于“真正的”向量操作。这本质上意味着,虽然融合乘加(点积)向量操作(如参考矩阵乘法内核中的ARM点积操作v dot q lane q s 32)作用于值向量,但它们仍然作用于单个权重列。这反过来又需要额外的归约操作,以减少来自不同向量通道(如图2所示的4个向量通道)的缩放部分点积或部分和,以获得权重组的最终FP32点积结果,并将其累加到权重列的整体点积值中。总之,许多计算指令并未执行有用的矩阵乘法工作。
4 Arm CPU architecture optimized kernel design for LLMs
4 针对大语言模型优化的 Arm CPU 架构内核设计
To this end, we present the design of GEMV and GEMM kernels for group-quantized LLMs optimized for various families of Arm CPU architectures. We consider weights and activation s to be quantized to 4 and 8 bits, respectively, before delving into optimization s for ultra-low-precision weights (e.g., 2 bits per weight) and non-uniform quantization. Matrix-multiply kernels (GEMV and GEMM) of QKV, output projections, and FFN layers of an LLM operate on 4-bit weights and 8-bit activation inputs, primarily carrying out efficient integer computation and generating FP32 outputs. Attention layers perform computations in higher-precision, such as FP16 or FP32. Prior to performing GEMV and GEMM for a LLM layer, FP32 outputs from a previous layer undergo group-wise, dynamic quantization instead of per-tensor, static quantization (i.e., scaling factors computed offline) to produce 8-bit activation inputs. Dynamic quantization ensures low quantization noise and high accuracy.
为此,我们展示了针对各种 Arm CPU 架构优化的组量化大语言模型的 GEMV 和 GEMM 内核设计。在深入研究超低精度权重(例如,每个权重 2 比特)和非均匀量化的优化之前,我们考虑将权重和激活量化为 4 比特和 8 比特。大语言模型的 QKV、输出投影和 FFN 层的矩阵乘法内核(GEMV 和 GEMM)在 4 比特权重和 8 比特激活输入上运行,主要执行高效的整数计算并生成 FP32 输出。注意力层以更高精度(如 FP16 或 FP32)执行计算。在执行大语言模型层的 GEMV 和 GEMM 之前,前一层的 FP32 输出会进行组动态量化,而不是逐张量静态量化(即离线计算的缩放因子),以生成 8 比特激活输入。动态量化确保了低量化噪声和高精度。
4.1 Optimized GEMV for auto regressive decoding phase
4.1 针对自回归解码阶段的优化 GEMV
To increase the reuse of the input activation vector as well as the use of MAC and vector operations, the GEMV kernel considers a series of consecutive weight columns of an LLM weight matrix at a time, as shown in Figure 3. The use of multiple weight columns in the GEMV kernel leads to increased reuse of the quantized activation vector and associated scale factor, as well as fewer load operations. Furthermore, our optimized GEMV kernel uses vector instructions for weight scale factor conversions, enabling it to convert FP16 scale factors of multiple quantized weight groups from different weight columns to FP32 values using a single vector operation. While multiple weight columns improve the reuse of the input vector and the use of vector operations in a GEMV kernel, the overhead from reduction operations and de quantization operations pose a significant challenge to group-quantized GEMVs in achieving good MAC unit utilization and thus a high percentage of useful work. We address the overhead of reduction operations through SIMD-aware weight packing, which interleaves weights from multiple weight columns prior to performing GEMV, and we reduce de quantization overhead by saving signed values directly into group-quantized weights.
为了增加输入激活向量的重用以及 MAC 和向量操作的使用,GEMV 内核一次考虑大语言模型权重矩阵的一系列连续权重列,如图 3 所示。在 GEMV 内核中使用多个权重列可以增加量化激活向量和相关缩放因子的重用,并减少加载操作。此外,我们优化的 GEMV 内核使用向量指令进行权重缩放因子转换,使其能够使用单个向量操作将来自不同权重列的多个量化权重组的 FP16 缩放因子转换为 FP32 值。虽然多个权重列提高了 GEMV 内核中输入向量的重用和向量操作的使用,但归约操作和反量化操作的开销对分组量化的 GEMV 实现良好的 MAC 单元利用率以及高比例的有用工作构成了重大挑战。我们通过 SIMD 感知的权重打包来解决归约操作的开销,该打包在执行 GEMV 之前交错多个权重列的权重,并通过直接将有符号值保存到分组量化权重中来减少反量化开销。
4.1.1 SIMD-aware weight packing
4.1.1 SIMD感知的权重打包
Before decompressing quantized operands and performing the necessary arithmetic operations of a matrix multiply kernel, the operands must be loaded from memory into the register file. Naive loading of 4-bit consecutive weight elements from a quantized group of a single output channel requires the fused multiply-accumulate (dot product) instruction v dot q lane q s 32 to perform additional reduction operations. Reduction operations must be performed on partial dot products from different vector lanes to obtain the final dot product result for a quantized weight group, as discussed in Section 3 and Figure 2. This can be avoided if different vector lanes of the v dot q lane q s 32 instruction operate on weight elements from different output channels. This ensures that the accumulators for the v dot q lane q s 32 instruction’s various vector lanes can accumulate results from different output channels rather than multiple parts of the same output channel. This in turn necessitates a strided weight layout for each vector lane in computation, as illustrated in Figure 3 (middle). A naive weight loading scheme would necessitate loading the corresponding quantized group from multiple output channels, incurring additional overhead from pointer arithmetic operations and address calculation for each output channel. Furthermore, non-contiguous access patterns of quantized groups across channels in memory prevent achieving the best possible DRAM bandwidth.
在解压缩量化操作数并执行矩阵乘法内核的必要算术操作之前,必须将操作数从内存加载到寄存器文件中。从单个输出通道的量化组中加载连续的4位权重元素时,需要使用融合乘加(点积)指令 v dot q lane q s 32 来执行额外的归约操作。如第3节和图2所述,必须对不同向量通道的部分点积结果进行归约操作,以获得量化权重组的最终点积结果。如果 v dot q lane q s 32 指令的不同向量通道操作来自不同输出通道的权重元素,则可以避免这种情况。这确保了 v dot q lane q s 32 指令的各个向量通道的累加器可以累积来自不同输出通道的结果,而不是同一输出通道的多个部分。这反过来要求在计算中为每个向量通道使用跨步权重布局,如图3(中间)所示。简单的权重加载方案需要从多个输出通道加载相应的量化组,这会因每个输出通道的指针算术操作和地址计算而产生额外的开销。此外,内存中跨通道的量化组的非连续访问模式阻碍了实现最佳DRAM带宽。
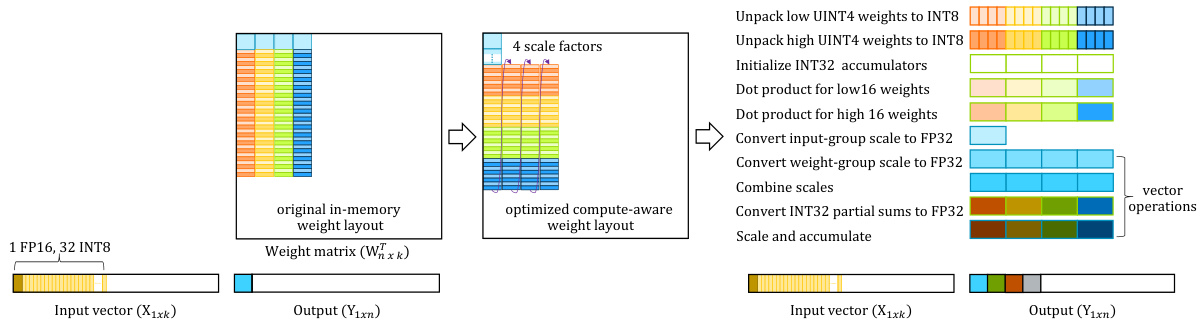
Figure 3: SIMD-aware weight reorder to minimize scalar operations in GEMV and GEMM kernels.
图 3: SIMD感知的权重重排序,以最小化GEMV和GEMM内核中的标量操作。
We solved this problem by storing the group-quantized weights from consecutive output channels in memory in the same order that they are used during computation. Instead of permuting weights each time, we reformat them beforehand to match the compute order and store them in memory in reordered format. This reordering has no runtime overhead because it is performed permanently on weights before they are used for inference. In order to perform compute-aware weight reordering, we first store the scale factor of the quantized groups of several consecutive output channels, then reorder and store the corresponding quantized elements from them. For example, when reordering quantized weight groups with a group size of 32 from four output channels, the first four bytes of the four quantized groups are stored one after the other from four output channels, followed by the next four bytes of the quantized groups. This process is repeated until all of the bytes from these groups are stored in the reordered format. After the first four groups from these four output channels are reordered, the next four groups from these output channels are considered and reordered in the same manner. This process continues until all of the quantized groups from these output channels are reordered before proceeding to the next set of four output weight channels.
我们通过将连续输出通道的分组量化权重按计算时使用的顺序存储在内存中来解决这个问题。我们不再每次计算时重新排列权重,而是预先将它们重新格式化以匹配计算顺序,并以重新排序的格式存储在内存中。这种重新排序没有运行时开销,因为它是在权重用于推理之前永久执行的。为了实现计算感知的权重重新排序,我们首先存储几个连续输出通道的量化组的比例因子,然后重新排序并存储来自它们的相应量化元素。例如,当重新排序来自四个输出通道的组大小为32的量化权重组时,首先存储来自四个输出通道的四个量化组的前四个字节,接着是量化组的下四个字节。这个过程重复进行,直到这些组的所有字节都以重新排序的格式存储。在重新排序完这四个输出通道的前四个组之后,接着考虑并重新排序这些输出通道的下四个组。这个过程持续进行,直到这些输出通道的所有量化组都被重新排序,然后再继续处理下一组四个输出权重通道。
This reordering is space-neutral, with the same data stored in a different order. In addition to improving the locality of reference and bandwidth of memory transactions, as well as lowering pointer arithmetic overhead, it improves the alignment properties of quantized groups in memory. For a group size of 32, 4-bit quantized weights, and the FP16 scale factor, this ensures that no more 18-byte structures are stored in memory. Instead, better-aligned, reordered weight groups from consecutive channels (e.g., an 8-way grouped structure of 144 bytes for weight groups from eight channels) are stored. It also simplifies scale factor handling by eliminating the need to assemble vectors from multiple locations.
这种重排序是空间中立的,相同的数据以不同的顺序存储。除了提高内存事务的引用局部性和带宽,以及降低指针算术开销外,它还改善了内存中量化组的对齐属性。对于组大小为32、4位量化权重和FP16比例因子的情况,这确保了内存中不会存储超过18字节的结构。相反,存储的是来自连续通道的更好对齐的重排序权重组(例如,来自八个通道的权重组的8路分组结构,大小为144字节)。它还通过消除从多个位置组装向量的需求,简化了比例因子的处理。
4.1.2 Fast de quantization
4.1.2 快速反量化
Because the current Arm CPU architectures do not support multiplication of 4-bit and 8-bit values, or 4-bit and 4-bit values, for quantized layers, de quant i zing operands to 8-bit within the GEMV and GEMM kernels is required prior to performing matrix multiply computation. Our proposed matrix multiply kernels for Arm CPUs fuse de quantization kernels with matrix multiplication kernels to avoid writing de quantized values to DRAM. In the case of 4-bit weight quantization, unsigned 4-bit integers should be unpacked into unsigned 8-bit integers before being converted to signed 8-bit integers within a matrix multiply kernel.
由于当前的 Arm CPU 架构不支持 4 位和 8 位值或 4 位和 4 位值的乘法运算,因此在执行矩阵乘法计算之前,需要在 GEMV 和 GEMM 内核中将量化层的操作数反量化为 8 位。我们提出的 Arm CPU 矩阵乘法内核将反量化内核与矩阵乘法内核融合,以避免将反量化值写入 DRAM。在 4 位权重量化的情况下,无符号 4 位整数应在矩阵乘法内核中转换为有符号 8 位整数之前解包为无符号 8 位整数。
For 4-bit group quantization formats, typically the top and bottom halves of the 4-bit weights of a group are interleaved in memory. For a group size of 32, the 4-bit weights $w_{0},w_{1},w_{2},w_{3},...,w_{31}$ are reordered into $w_{0}$ , $w_{16}$ , $w_{1}$ , $w_{17}$ , ..., $w_{15}$ , $w_{31}$ sequence and stored in 16 bytes. Furthermore, to avoid sign extension issues, signed 4-bit values are stored as unsigned after adding an 8-bit bias value [20]. The same ordering within each group is preserved when group-quantized weights from multiple channels are interleaved to match the compute order, as described in the previous section. This weight packing format was specifically chosen to efficiently unpack them into unsigned 8-bit values using a few SIMD operations (bitwise AND and shift operations), and then subtract 8 to restore true signed values and sign bits of the 4-bit nibbles during the de quantization path. Although simple, this method adds a significant overhead to the de quantization process.
对于4位组量化格式,通常组内4位权重的上半部分和下半部分在内存中是交错存储的。对于组大小为32的情况,4位权重 $w_{0},w_{1},w_{2},w_{3},...,w_{31}$ 会被重新排序为 $w_{0}$ , $w_{16}$ , $w_{1}$ , $w_{17}$ , ..., $w_{15}$ , $w_{31}$ 的序列,并存储在16个字节中。此外,为了避免符号扩展问题,有符号的4位值在添加8位偏置值后以无符号形式存储 [20]。当多个通道的组量化权重交错以匹配计算顺序时,每个组内的相同顺序会被保留,如前一节所述。这种权重打包格式被特别选择,以便使用少量SIMD操作(按位与和移位操作)高效地将它们解包为无符号8位值,然后在反量化路径中减去8以恢复4位半字节的真实有符号值和符号位。虽然简单,但这种方法在反量化过程中增加了显著的开销。
Instead, we employ a more efficient approach for storing signed values directly, significantly reducing the de quantization overhead of converting them to signed 8-bit values during matrix multiplication operations, as illustrated in Figure 4. This is accomplished by toggling the most significant bit (MSB)
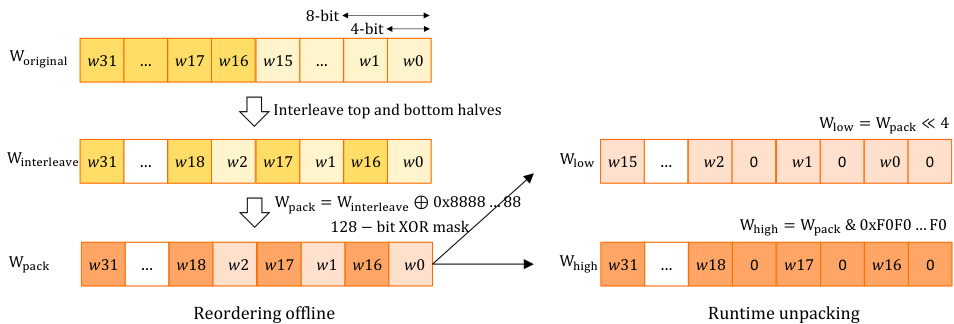
Figure 4: Fast decompression path for unpacking 4-bit nibbles into signed 8-bit weights in GEMV and GEMM kernels.
图 4: 在 GEMV 和 GEMM 内核中将 4 位半字节解压为有符号 8 位权重的快速解压缩路径。
of each nibble stored in the byte (stored as unsigned after adding an 8-bit bias value, as previously stated) during the weight reordering stage. After this operation, the two nibbles represent the four most significant bits of the original signed nibble values after being converted to signed 8-bit values and multiplied by 16. Therefore, at runtime, we can simply use an arithmetic shift left to get the low nibble (bits 0-3) and a 0xF0 mask to get the high nibble (bits 4-7) of a byte, because the arithmetic shift left fills the empty bits with zeros. Because these weight values are scaled up by 16, we must scale down the subsequent partial dot product value that uses them to obtain the correct result. We accomplish this by dividing the partial product by 16 using either an implicit shift right (as part of the required integer-to-floating-point convert instruction in group-quantized matrix multiply kernels to update the floating-point master accumulator) or an explicit floating-point exponent adjustment operation. It is significantly less expensive than having to subtract 8 from each vector of weights and saves eight subtraction operations, requiring only one scale operation on the accumulator at most.
在权重重排序阶段,每个字节中存储的半字节(在添加8位偏置值后存储为无符号数,如前所述)经过处理后,两个半字节表示原始有符号半字节值转换为有符号8位值并乘以16后的四个最高有效位。因此,在运行时,我们可以简单地使用算术左移来获取字节的低半字节(位0-3),并使用0xF0掩码来获取字节的高半字节(位4-7),因为算术左移会用零填充空位。由于这些权重值被放大了16倍,我们必须将使用它们的后续部分点积值缩小以获得正确的结果。我们通过将部分积除以16来实现这一点,可以使用隐式右移(作为组量化矩阵乘法内核中更新浮点主累加器所需的整数到浮点转换指令的一部分)或显式浮点指数调整操作。这比必须从每个权重向量中减去8要便宜得多,并且节省了八个减法操作,最多只需要对累加器进行一次缩放操作。
4.2 Optimized GEMM for prompt phase (time-to-first-token)
4.2 针对提示阶段(首Token时间)优化的GEMM
While GEMV operations make up the majority of the computations in the decode stage for a single inference case (i.e., a request from a single user), GEMM operations dominate the prompt phase (prefill stage) for both single and batched inference cases. Furthermore, for batched inference cases, GEMM consumes the majority of the computation for the decode stage as well.
虽然 GEMV 操作在单次推理(即单个用户的请求)的解码阶段占据了大部分计算量,但在单次和批量推理的提示阶段(预填充阶段),GEMM 操作占据了主导地位。此外,对于批量推理的情况,GEMM 在解码阶段也消耗了大部分计算量。
We apply the same optimization s to developing Arm CPU architecture optimized GEMM kernels as we do for GEMV kernels. In particular, in order to increase compute throughput further, maximize the use of vector operations, and avoid pseudo-scalar operations, we make use of the matrix-matrix multiply-accumulate (MMLA) instruction. The MMLA instruction can perform twice as many MAC operations when compared to an equivalent SIMD dot product instruction (for example, 128-bit DOT) used in the GEMV kernel. An 128-bit MMLA instruction performs double operations by processing multiple rows of activation s at once. It multiplies a $2\mathrm{x}8$ matrix of 8-bit integer values in the first source vector by an $\mathrm{8x2}$ matrix of 8-bit integer values in the second source vector to produce a $2\mathrm{x}2$ matrix of 32-bit integer product values.
我们在开发针对Arm CPU架构优化的GEMM(通用矩阵乘法)内核时,采用了与GEMV(通用矩阵向量乘法)内核相同的优化策略。特别是为了进一步提高计算吞吐量、最大化向量操作的使用并避免伪标量操作,我们利用了矩阵-矩阵乘加(MMLA)指令。与GEMV内核中使用的等效SIMD点积指令(例如128位DOT)相比,MMLA指令可以执行两倍的MAC(乘加)操作。128位MMLA指令通过同时处理多行激活值来执行双倍操作。它将第一个源向量中的8位整数值的$2\mathrm{x}8$矩阵与第二个源向量中的8位整数值的$\mathrm{8x2}$矩阵相乘,生成一个32位整数值的$2\mathrm{x}2$矩阵。
However, this requires reordering activation s from multiple input rows to correspond to the weight reordering and value ordering required by the MMLA operation. Because each matrix multiply kernel is always preceded by a dynamic re-quantization kernel for FP32 activation s, the reorder kernel for activation s can be fused into it with minimal latency overhead. Furthermore, a larger number of input activation rows and output weight channels creates high pressure on vector register files for storing partial dot products, causing large GEMM kernels to be register-bound on Arm CPUs due to the nature of the output stationary dataflow. As a result, the size of the vector register file for an Arm processor architecture type influences the number of concurrently processed rows and columns and the design of a GEMM kernel. In particular, we design three types of group-quantized GEMV and GEMM kernels based on specifications such as the availability of SDOT or MMLA instructions, weight channel interleaving patterns, SIMD vector widths, and register file sizes of different available Arm CPU types.
然而,这需要重新排序来自多个输入行的激活值,以对应MMLA操作所需的权重重新排序和值排序。由于每个矩阵乘法内核之前总是有一个用于FP32激活值的动态重新量化内核,因此可以将激活值的重新排序内核融合到其中,且延迟开销最小。此外,更多的输入激活行和输出权重通道对存储部分点积的向量寄存器文件造成了巨大压力,导致大型GEMM内核在Arm CPU上由于输出静态数据流的特性而受限于寄存器。因此,Arm处理器架构类型的向量寄存器文件大小会影响并发处理的行数和列数以及GEMM内核的设计。特别是,我们根据SDOT或MMLA指令的可用性、权重通道交错模式、SIMD向量宽度以及不同可用Arm CPU类型的寄存器文件大小等规格,设计了三种类型的组量化GEMV和GEMM内核。
4.3 Turning intrinsics into assembly
4.3 将内在函数转换为汇编
While we can generally rely on the compiler and use regular intrinsics for the group-quantized GEMV and GEMM kernels, we always find that the compiler does not generate fully optimized code, especially when there is high register pressure while running GEMMs during the prefill stage for single inferences and the prefill and decode stages for batched inferences. As a result, we convert intrinsics into assembly code to maximize the use of available vector registers and MAC units, avoid spilling of register values to memory and associated restore code, and improve instruction-level parallelism, leading to improved compute efficiency.
虽然我们通常可以依赖编译器并使用常规的 intrinsics 来处理分组量化的 GEMV 和 GEMM 内核,但我们发现编译器生成的代码并不总是完全优化的,尤其是在单次推理的预填充阶段和批量推理的预填充与解码阶段运行 GEMM 时存在高寄存器压力的情况下。因此,我们将 intrinsics 转换为汇编代码,以最大限度地利用可用的向量寄存器和 MAC 单元,避免寄存器值溢出到内存以及相关的恢复代码,并提高指令级并行性,从而提升计算效率。
5 Group-wise non-uniform codebook-based quantization
5 基于分组非均匀码本的量化
Uniform quantization divides the range of weight values into equal intervals and assigns a quantization level to each interval. It distributes quantized values uniformly and equidistant ly. As a result, despite being commonly used in conjunction with group-wise quantization for LLMs, it is not very flexible in matching the non-uniform patterns typically found in LLM weight distributions [16], resulting in suboptimal accuracy, especially for low-precision LLM quantization. Non-uniform quantization with a codebook allows for a more flexible allocation of high-precision weight values. Given a weight distribution, non-uniform codebook-based quantization can identify $k$ centroids that best represent the weight values and map weights to them. For example, when quantizing a weight distribution to 4-bits, state-of-the-art codebook-based quantization techniques aim to determine the 16 centroid values that best represent the values. Each high-precision weight can then be represented by the 4-bit index of a centroid in the codebook instead of its original bit-width. In addition, non-uniform codebook-based quantization requires storing the codebook itself and incurring associative overhead. While there are a few recent non-uniform codebook-based quantization techniques for LLMs in the literature [16, 29, 2, 28], they either do not exhibit good runtime for both phases (prompt processing and auto regressive decoding) of LLM inference under ultra-low-bit precision scenarios or do not extend well to achieving extreme degrees of compression, as discussed below.
均匀量化将权重值的范围划分为相等的区间,并为每个区间分配一个量化级别。它均匀且等距地分布量化值。因此,尽管它通常与大语言模型的分组量化结合使用,但在匹配大语言模型权重分布中常见的非均匀模式时并不灵活 [16],导致精度不理想,尤其是在低精度大语言模型量化中。基于码本的非均匀量化允许更灵活地分配高精度权重值。给定一个权重分布,基于码本的非均匀量化可以识别最能代表权重值的 $k$ 个中心点,并将权重映射到这些中心点。例如,当将权重分布量化为4位时,最先进的基于码本的量化技术旨在确定最能代表这些值的16个中心点值。然后,每个高精度权重可以由码本中某个中心点的4位索引表示,而不是其原始位宽。此外,基于码本的非均匀量化需要存储码本本身,并产生关联开销。尽管文献中有一些最近针对大语言模型的基于码本的非均匀量化技术 [16, 29, 2, 28],但它们要么在超低位精度场景下的大语言模型推理的两个阶段(提示处理和自回归解码)中表现不佳,要么在实现极端压缩程度时扩展性不佳,如下所述。
5.1 Challenges of prior non-uniform quantization techniques
5.1 先前非均匀量化技术的挑战
SqueezeLLM [16]. In order to be more sensitive to the importance of the weights, SqueezeLLM quantization first clusters the weights using a weighted $\mathbf{k}$ -means clustering algorithm where the centroids of the cluster (codebook) are chosen to be close to the sensitive weights. In other words, rather than scaling high-precision weights group-wise into the range provided by a given number of bits, SqueezeLLM uses weighted $\mathbf{k}$ -means clustering on all weights in a tensor row, mapping weights to codebooks with the number of codebooks determined by the bit per weight a quantization scheme wishes to spend. However, the improvement in representation of the weight distribution by the SqueezeLLM quantization comes at the cost of loading the codebook for each row of a weight matrix along with the index assignments for the weights. This, combined with FP16 values for the per-row codebook entries, results in inefficient floating-point computation and significantly slows down LLM inference, as observed in our evaluations. Furthermore, before using the SqueezeLLM quantization, the codebooks for each layer of an LLM must be determined; the same codebook entries will not work for an unseen LLM. In addition, SqueezeLLM does not support low-precision quantization below 4-bits, which is required to fit large-scale LLMs to resource-constrained devices and is thus the primary focus of our proposed method.
SqueezeLLM [16]。为了更敏感地处理权重的重要性,SqueezeLLM量化首先使用加权 $\mathbf{k}$ 均值聚类算法对权重进行聚类,其中聚类中心(码本)被选择为接近敏感权重。换句话说,SqueezeLLM不是将高精度权重按组缩放到给定比特数提供的范围内,而是对张量行中的所有权重使用加权 $\mathbf{k}$ 均值聚类,将权重映射到码本,码本的数量由量化方案希望使用的每权重比特数决定。然而,SqueezeLLM量化对权重分布表示的改进是以加载权重矩阵每行的码本以及权重索引分配为代价的。这与每行码本条目的FP16值相结合,导致了低效的浮点计算,并显著减慢了大语言模型的推理速度,正如我们在评估中观察到的那样。此外,在使用SqueezeLLM量化之前,必须确定大语言模型每一层的码本;相同的码本条目不适用于未见过的模型。此外,SqueezeLLM不支持低于4比特的低精度量化,而这是将大规模大语言模型适配到资源受限设备上所需的,因此也是我们提出的方法的主要关注点。
GPTVQ [29]. Recent work GPTVQ extends the potential of non-uniform quantization for higher levels of compression (for example, 2-bit and 3-bit quantization) and outperforms its uniform counterpart. Notably, it makes use of vector quantization, which involves quantizing multiple weights together and mapping them to a single centroid in a codebook rather than representing each quantized value with a centroid in the codebook, resulting in a more versatile quantization grid across multiple dimensions. It also performs codebook quantization to 8-bits and shares the codebook across multiple rows/columns of an LLM layer. While it demonstrates the potential of codebook-based quantization for ultra-low-precision quantization, the accuracy of the resulting LLMs suffers noticeably (for example, for 2-bit quantization).
GPTVQ [29]。最近的工作 GPTVQ 扩展了非均匀量化在更高压缩级别(例如 2 位和 3 位量化)上的潜力,并优于其均匀量化对应方法。值得注意的是,它利用了向量量化,即将多个权重一起量化并将它们映射到码本中的单个质心,而不是用码本中的质心表示每个量化值,从而在多个维度上形成更通用的量化网格。它还执行 8 位码本量化,并在大语言模型层的多行/列之间共享码本。虽然它展示了基于码本的量化在超低精度量化中的潜力,但生成的大语言模型的准确性明显下降(例如,对于 2 位量化)。
QuIP# [28]. State-of-the-art 2-bit quantization technique QuIP# improves upon previous work by leveraging lattice codebooks for vector quantization and incoherence processing for superior outlier suppression. E8 lattice codebooks encode the magnitude of quantized values in a group of eight. Besides, QuIP# forces an even number of positive (or negative) signs of quantized values in a group of eight. This enables the use of seven bits to record the sign of eight quantized values. While the combination of these optimization s allows QuIP# to achieve good LLM quality in extreme compression regimes (for example, 2 bits per weight), the resultant complexity of the decompression path in converting 2-bit quantized weight values to 8-bit significantly slows down LLM inference, as found in our evaluations.
QuIP# [28]。最先进的2位量化技术QuIP#通过利用格码本进行向量量化和不相干处理来改进先前的工作,以实现更好的异常值抑制。E8格码本将量化值的大小编码为一组八个。此外,QuIP#强制在一组八个量化值中具有偶数个正(或负)符号。这使得可以使用七位来记录八个量化值的符号。虽然这些优化的组合使QuIP#能够在极端压缩情况下(例如,每个权重2位)实现良好的大语言模型质量,但在我们的评估中发现,将2位量化权重值转换为8位的解压缩路径的复杂性显著减慢了大语言模型的推理速度。
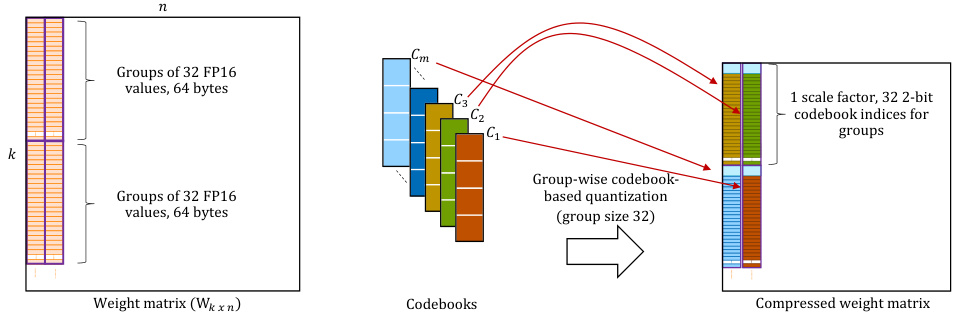
Figure 5: Fine-grained assignment of codebooks to various groups in group-wise codebook-based quantization. Each group finds the closest codebook of the $C$ codebooks $(C_{1},C_{2},...,C_{m})$ that best represents its values and quantizes its high-precision values to the codebook centroids using 2-bit indices.
图 5: 基于分组码本的量化中,码本到各个组的细粒度分配。每个组找到最能代表其值的 $C$ 个码本 $(C_{1},C_{2},...,C_{m})$ 中最接近的一个,并使用 2-bit 索引将其高精度值量化为码本中心点。
Our proposal addresses limitations in prior non-uniform quantization techniques and attempts to fill the void by not only ensuring faster throughput but also better quality than the current state-of-the-art under extreme compression scenarios (e.g., 2-bit quantization) for LLMs.
我们的提案解决了先前非均匀量化技术的局限性,并试图填补这一空白,不仅确保在极端压缩场景(例如,2-bit量化)下比当前最先进技术更快的吞吐量,还提供更好的质量。
5.2 The group-wise codebook-based quantization method
5.2 基于分组码本的量化方法
Our innovation is motivated by the following observations and insights: For LLM weight matrices, which are commonly quantized group-wise, there may be some variations in the shape of the Gaussian distribution of values between groups. However, after being scaled by the group-wise scale factors, the Gaussian distributions of various groups with different shapes should be clustered into a small set of shapes, each of which can be represented with its own codebook.
我们的创新基于以下观察和见解:对于通常按组量化的LLM权重矩阵,不同组之间值的正态分布形状可能存在一些差异。然而,在按组比例因子缩放后,具有不同形状的各组正态分布应聚集为少量形状,每种形状都可以用其自己的码本表示。
Motivated by these insights, we apply a group-wise structure to divide the high bit-width floating point weights into groups and scale each group separately first, using its own scale factor. The scale factor is chosen so that the ranges of values after scaling can be represented by codebook’s bit-width. For example, if the required bit-width of centroid values in a codebook is a signed 8-bit integer, the scale factor for a group scales the group’s weights to the $-128$ to 127 range. We then use a two-phase clustering algorithm (constraint-satisfaction-guided clustering algorithm) to cluster the scaled group of weight values into a small number of codebooks, each with a few centroid values. In phase 1, similar weight groups or groups of scaled weight values with similar Gaussian distributions are divided into $C$ clusters by converting each group of scaled weight values to a probability distribution. This is accomplished by finding the histogram of the scaled weight values and normalizing it, converting the discrete distribution of intensities into a discrete distribution of probabilities, and then applying $\mathbf{k}$ -means clustering to these probability distributions, which now represent the different groups, to cluster the similar groups. Phase 2 then applies $\mathrm{k\Omega}$ -means clustering analysis to each clustered group of values (created in phase 1) to identify a few centroid values that best represent the probability distribution of weight values within each and repeats it for $C$ clustered groups of values to create $C$ codebooks to find the different non-uniform weight distributions present in the high-precision weights. The clustering of similar groups into the same codebook aids a weight group later during post-training quantization in locating the closest codebook of the $C$ codebooks that best represents its values, as shown in Figure 5, while the small number of centroid values for each codebook ensures that high-precision centroid values, such as four 8-bit signed centroids in a codebook, can be encoded using a lower bit-width index (2-bit indices here) in the codebook.
基于这些见解,我们采用分组结构将高比特宽度的浮点权重划分为若干组,并首先使用各自的缩放因子分别对每组进行缩放。选择缩放因子是为了确保缩放后的值范围可以用码本的比特宽度表示。例如,如果码本中质心值所需的比特宽度为有符号8位整数,则组的缩放因子将该组的权重缩放到$-128$到127的范围内。然后,我们使用两阶段聚类算法(约束满足引导的聚类算法)将缩放的权重值组聚类为少量码本,每个码本包含少量质心值。在第一阶段,通过将每组缩放的权重值转换为概率分布,将具有相似高斯分布的权重组或缩放权重值组划分为$C$个聚类。这是通过找到缩放权重值的直方图并对其进行归一化,将强度的离散分布转换为概率的离散分布,然后对这些概率分布应用$\mathbf{k}$均值聚类来实现的,这些概率分布现在代表不同的组,以聚类相似的组。第二阶段则对每个聚类组(在第一阶段创建的)应用$\mathrm{k\Omega}$均值聚类分析,以识别最能代表每组权重值概率分布的少量质心值,并对$C$个聚类组重复此过程,以创建$C$个码本,从而找到高精度权重中存在的不同非均匀权重分布。将相似组聚类到同一码本中有助于在训练后量化过程中,权重组能够找到最能代表其值的$C$个码本中最接近的码本,如图5所示,而每个码本中少量的质心值确保了高精度质心值(例如码本中的四个8位有符号质心)可以使用较低比特宽度的索引(此处为2位索引)在码本中进行编码。
For extreme compression cases, we observe that quantization bit-width and associated number of distinct values or quantization bins (e.g., 16 distinct values for 4-bit quantization) have the greatest impact on LLM accuracy. Changes in the bit-precision of scale factors, on the other hand, have less of an impact on LLM accuracy. The various codebooks in group-wise codebook-based quantization essentially help in adapting a group to choose a subset of relatively higher-precision data type while using low bit-width indices (4 most important quantization bins of a distribution for a group here
在极端压缩情况下,我们观察到量化比特宽度及其相关的不同值或量化区间数量(例如,4 位量化有 16 个不同值)对大语言模型 (LLM) 的准确性影响最大。另一方面,比例因子的比特精度变化对 LLM 准确性的影响较小。基于分组码本的量化中的各种码本本质上帮助一个组选择相对较高精度数据类型的子集,同时使用低比特宽度索引(这里一个分布中一个组的 4 个最重要的量化区间)。
15: end for
15: 结束循环
Output $C$ codebooks, $F P16$ scale factor, codebook index, and corresponding centroid indices for each group of high-precision input weight values
输出 $C$ 个码本、$F P16$ 比例因子、码本索引以及每组高精度输入权重值对应的质心索引
Algorithm 2 Fine-grained codebook-based quantization: Inference
算法 2:基于细粒度码本的量化:推理
using 2-bit indices). This results in closely following the distribution of quantization bins of a higher-precision data type and bridging the accuracy gap with it.
使用2位索引)。这使得量化箱的分布与更高精度数据类型的分布紧密跟随,并缩小了与高精度数据类型之间的准确度差距。
Furthermore, our codebook-based quantization scheme keeps the decompression path in converting low-bit codebook indices to high-precision centroid values simple when compared to prior schemes, resulting in improved throughput. Given high-precision weight values of a LLM, Algorithm 1 describes how to generate a predetermined number of codebooks and subsequently use them in post-training quantization of the LLM, while Algorithm 2 describes fast inference with a group-wise codebook-based quantized layer.
此外,与之前的方案相比,我们基于码本的量化方案在将低位码本索引转换为高精度质心值的解压缩路径上保持了简单性,从而提高了吞吐量。给定大语言模型的高精度权重值,算法 1 描述了如何生成预定数量的码本,并随后将其用于大语言模型的后训练量化,而算法 2 描述了基于分组码本的量化层的快速推理。
5.3 Example group-wise codebook-based quantization for 2-bit width
5.3 基于组别码本的2比特宽度量化示例
We apply our codebook-based quantization technique to compress LLMs to about 2, 3, or 4 bits per weight. Our 2-bit codebook-based quantization scheme uses a small number of codebooks, such as four, eight, or sixteen, depending on the required compression size and accuracy. As demonstrated in Algorithm 1, they are discovered by first applying a group-wise structure and scale factors to LLM weight matrices, followed by dividing and clustering similar groups (groups with similar distributions) into a small number. The small number of clustered groups then use a clustering algorithm individually to cluster values in them into an equal number of codebooks, each with four centroids. Later, during post-training quantization of a group-wise structured LLM, the various groups choose one of the codebooks that best matches their distribution with the lowest reconstruction MSE (mean square error). As a result, each group typically requires two to four bits to encode the selected codebook’s index, as well as two bits for each of its elements to encode one of the codebook’s four centroids.
我们应用基于码本的量化技术将大语言模型压缩至每权重约2、3或4比特。我们的2比特基于码本的量化方案使用少量码本,如四个、八个或十六个,具体取决于所需的压缩大小和精度。如算法1所示,首先对大语言模型权重矩阵应用分组结构和比例因子,然后将相似组(具有相似分布的组)划分并聚类为少量组。这些少量聚类组随后分别使用聚类算法将其中的值聚类为等量的码本,每个码本有四个中心点。之后,在对分组结构的大语言模型进行训练后量化时,各组选择与其分布最匹配且重建均方误差(MSE)最低的码本之一。因此,每组通常需要2到4比特来编码所选码本的索引,以及每个元素2比特来编码码本的四个中心点之一。
For example, for some 2-bit linear layers in LLMs, our 2-bit codebook-based quantization technique has four codebooks, each with four signed 8-bit integer centroids. It has a group size of 256, divided into 16 sub-groups of 16 2-bit quantized elements, each with their own local scale factor. Each sub-group also has a 2-bit codebook index, which is used to index into one of the four codebooks and extract centroid values corresponding to the 2-bit index elements. It also has an FP16 superblock scale factor for the 256-wide group. Our codebook-based quantization scheme is also extended for other bit-widths, such as 3- and 4-bit quantization, by dividing similar groups into a few clusters (for example, four, eight, or sixteen) and then encoding each clustered group with an 8- (for 3-bit index) or 16-entry (for 4-bit index) codebook.
例如,对于大语言模型中的一些2-bit线性层,我们的基于2-bit码本的量化技术有四个码本,每个码本包含四个带符号的8-bit整数中心点。它的组大小为256,分为16个子组,每个子组包含16个2-bit量化元素,每个子组都有自己的局部缩放因子。每个子组还有一个2-bit码本索引,用于索引四个码本中的一个,并提取与2-bit索引元素对应的中心点值。它还有一个FP16的超块缩放因子,用于256宽的组。我们的基于码本的量化方案也扩展到其他比特宽度,例如3-bit和4-bit量化,通过将类似的组分成几个簇(例如四个、八个或十六个),然后用8-entry(用于3-bit索引)或16-entry(用于4-bit索引)的码本对每个簇进行编码。
Table 1: Comparison of the prefill rate and token generation throughput (tokens/sec) of the LLaMA-3 8B and LLaMA-3.2 3B models for the reference llama.cpp 4-bit uniform quantization kernel (Q4_0) and our corresponding optimized kernel (Q4_0_8_8) on Arm Graviton3 CPUs (64 cores).
表 1: LLaMA-3 8B 和 LLaMA-3.2 3B 模型在 Arm Graviton3 CPU (64 核) 上使用参考 llama.cpp 4-bit 均匀量化内核 (Q4_0) 和我们相应的优化内核 (Q4_0_8_8) 的预填充率和 Token 生成吞吐量 (tokens/sec) 对比。
| Batch Size | Q4_0 (llama.cpp) Prefill | Token Gen. | Q4_0_8_8 (Optimized) Prefill | Token Gen. | Q4_0 (llama.cpp) Prefill | Token Gen. | Q4_0_8_8 (Optimized) Prefill | Token Gen. |
|---|---|---|---|---|---|---|---|---|
| 1 | 190.4 | 46.0 | 570.9 | 46.8 | 409.8 | 84.3 | 1137.2 | 87.7 |
| 4 | 204.2 | 112.1 | 650.2 | 149.8 | 473.0 | 195.7 | 1472.5 | 270.6 |
| 8 | 223.8 | 139.1 | 683.2 | 199.5 | 538.7 | 268.3 | 1588.8 | 371.4 |
| 16 | 222.8 | 157.5 | 678.5 | 315.8 | 538.8 | 313.1 | 1579.3 | 535.4 |
| 32 | 222.2 | 166.8 | 665.0 | 342.9 | 533.7 | 339.0 | 1550.0 | 585.0 |
6 Experiments
6 实验
6.1 Evaluation setup
6.1 评估设置
We compare our optimized kernels and codebook-based quantization method to LLaMA.cpp, both in terms of inference throughput (tokens generated / second) as well as in terms of accuracy of the resulting models, measured in terms of perplexity (PPL). LLaMA.cpp lowers the entire computation graph to $\mathrm{C}{+}{+}$ to minimize overhead on CPUs. We use a prompt sequence length of 128 and an output token generation length of 128, and Flash Attention is enabled for all throughput measurement experiments.
我们将优化的内核和基于码本的量化方法与LLaMA.cpp进行比较,比较内容包括推理吞吐量(每秒生成的Token)以及生成模型的准确性(通过困惑度(PPL)衡量)。LLaMA.cpp将整个计算图降级为$\mathrm{C}{+}{+}$,以最小化CPU上的开销。我们使用128的提示序列长度和128的输出Token生成长度,并且在所有吞吐量测量实验中启用了Flash Attention。
6.2 Inference throughput for 4-bit uniform quantization
6.2 4位均匀量化的推理吞吐量
Table 1 compares the runtime performance of our optimized 4-bit group-wise quantized kernel (Q4_0_8_8) to that of LLaMA.cpp’s 4-bit kernel (Q4_0) on Graviton3 processors with $64~\mathrm{Arm}$ Neoverse V1 CPU cores for different batch sizes (number of users). For the LLaMA-3 8B model, Q4_0_8_8 improves inference throughput (tokens per second) by $3-3.2\times$ during the prefill stage and by up to $2\times$ during the auto regressive decoding or token generation stage. The token generation phase for a bath size of one at high core (thread) counts is memory bound, so our optimized GEMV kernels for it, while offering a significant speedup1 for a smaller number of cores, cannot provide a tangible improvement at 64 cores over LLaMA.cpp’s reference Q4_0 kernel. In the case of the LLaMA.cpp FP16 implementation, the prefill rate and token generation throughput increase from 123.5 tokens/s to 136.2 tokens/s and 16.9 tokens/s to 106.4 tokens/s, respectively, as batch size increases from 1 to 32. While the LLaMA.cpp’s reference Q4_0 kernels can offer some improvement in throughput over their FP16 implementation, our 4-bit optimized kernels improved end-to-end throughput significantly over FP16 and Q4_0, as shown in Table 1.
表 1 比较了我们在 Graviton3 处理器上优化的 4 位分组量化内核 (Q4_0_8_8) 与 LLaMA.cpp 的 4 位内核 (Q4_0) 在不同批量大小(用户数量)下的运行时性能。对于 LLaMA-3 8B 模型,Q4_0_8_8 在预填充阶段将推理吞吐量(每秒 token 数)提高了 $3-3.2\times$,在自回归解码或 token 生成阶段提高了最多 $2\times$。在高核心(线程)数量下,批量大小为 1 的 token 生成阶段受内存限制,因此我们为其优化的 GEMV 内核虽然在较少数量的核心上提供了显著的加速,但在 64 核心上无法提供相对于 LLaMA.cpp 的参考 Q4_0 内核的实质性改进。在 LLaMA.cpp 的 FP16 实现中,随着批量大小从 1 增加到 32,预填充率和 token 生成吞吐量分别从 123.5 tokens/s 增加到 136.2 tokens/s 和从 16.9 tokens/s 增加到 106.4 tokens/s。虽然 LLaMA.cpp 的参考 Q4_0 内核在吞吐量上比其 FP16 实现有所改进,但我们的 4 位优化内核在端到端吞吐量上显著优于 FP16 和 Q4_0,如表 1 所示。
We also develop different variants of our 4-bit optimized kernels based on their weight interleaving patterns, the use of various vector iz ation techniques, and advanced matrix-matrix multiply (MMLA) operations when designing a CPU kernel. Table 2 compares the performance of different variants of our optimized 4-bit group-wise quantized kernels. The Q4_0_8_8 and $Q4_0_4_8$ kernels are designed with MMLA operations, whereas the Q4_0_4_4 kernels do not include any MMLA instructions. The performance of LLaMA models with Q4_0_4_8 kernels is measured on a Graviton4 processor with 64 Neoverse V2 cores, while Q4_0_4_4 kernels without MMLA operations are run on a Graviton2 processor with 64 Neoverse N1 cores that lack MMLA support.
我们还基于权重交错模式、各种向量化技术的使用以及设计CPU内核时的高级矩阵-矩阵乘法(MMLA)操作,开发了不同变体的4位优化内核。表2比较了我们优化的4位分组量化内核的不同变体的性能。Q4_0_8_8和$Q4_0_4_8$内核设计时使用了MMLA操作,而Q4_0_4_4内核则不包含任何MMLA指令。使用Q4_0_4_8内核的LLaMA模型性能在具有64个Neoverse V2核心的Graviton4处理器上测量,而不使用MMLA操作的Q4_0_4_4内核则在缺乏MMLA支持的64个Neoverse N1核心的Graviton2处理器上运行。
Table 2: Comparison of the prefill rate and token generation throughput of the LLaMA-3 8B and LLaMA-3.2 3B models for the reference 4-bit Q4_0 quantization kernel and our optimized Q4_0_4_4, Q4_0_8_8, and Q4_0_4_8 kernels on Arm Graviton2, Graviton3, and Graviton4 CPUs (64 cores), respectively.
表 2: LLaMA-3 8B 和 LLaMA-3.2 3B 模型在 Arm Graviton2、Graviton3 和 Graviton4 CPU (64 核) 上,参考 4-bit Q4_0 量化内核与我们的优化 Q4_0_4_4、Q4_0_8_8 和 Q4_0_4_8 内核的预填充率和 Token 生成吞吐量对比。
| Batch Size | LLaMA-38B | LLaMA-3.23B |
|---|---|---|
| Prefill | Q4_4_8 (优化) TokenGen. | |
| 1 | 643.6 | 66.2 |
| 4 | 756.8 | 192.9 |
| 8 | 779.5 | 246.2 |
| 16 | 767.9 | 341.4 |
| 32 | 767.3 | 375.7 |

Figure 6: Comparison of the prefill rate and token generation throughput of the LLaMA-3 8B, LLaMA-3.2 3B, and LLaMA-3.2 1B models on the Redmi K60 mobile device powered by Arm Cortex-series CPUs (4 cores). The batch size is set to one for inference on the mobile device.
图 6: LLaMA-3 8B、LLaMA-3.2 3B 和 LLaMA-3.2 1B 模型在搭载 Arm Cortex 系列 CPU (4 核) 的 Redmi K60 移动设备上的预填充率和 Token 生成吞吐量对比。在移动设备上进行推理时,批量大小设置为 1。
The design of Q4_0_4_8 and Q4_0_8_8 kernels has good similarity; the difference primarily lies in the weight interleaving patterns between them. In the case of the Q4_0_4_8 and Q4_0_8_8 kernels, we perform SIMD-aware weight packing from consecutive four and eight channels, respectively, and the subsequent vector operations on them produce the results of four and eight output channels at once. To create an interleaved weight layout, Q4_0_8_8 interleaves eight channels in a group of eight bytes or 16 4-bit quantized elements from each, whereas Q4_0_4_8 interleaves four channels in a group of eight bytes. The improved throughput for $Q4_0_4_8$ in Table 2 in comparison to Q4_0_8_8 in Table 1 is primarily attributed to changes in Neoverse V2 cores relative to Neoverse V1 and increased memory bandwidth of Graviton4 processors. Q4_0_4_4 interleaves four channels in a group of four bytes. It is worth noting that even without the use of advanced matrix multiply MMLA operations, Q4_0_4_4 achieves significantly better performance in comparison to LLaMA.cpp’s reference Q4_0 kernels.
Q4_0_4_8 和 Q4_0_8_8 内核的设计具有较高的相似性,主要区别在于它们之间的权重交错模式。对于 Q4_0_4_8 和 Q4_0_8_8 内核,我们分别从连续的四个和八个通道执行 SIMD 感知的权重打包,随后对它们进行的向量操作会一次性生成四个和八个输出通道的结果。为了创建交错的权重布局,Q4_0_8_8 在每组八个字节或每组 16 个 4 位量化元素中交错八个通道,而 Q4_0_4_8 则在每组八个字节中交错四个通道。表 2 中 $Q4_0_4_8$ 相对于表 1 中 Q4_0_8_8 的吞吐量提升主要归因于 Neoverse V2 核心相对于 Neoverse V1 的变化以及 Graviton4 处理器内存带宽的增加。Q4_0_4_4 在每组四个字节中交错四个通道。值得注意的是,即使没有使用高级矩阵乘法 MMLA 操作,Q4_0_4_4 的性能也显著优于 LLaMA.cpp 的参考 Q4_0 内核。
Figure 6 compares the prefill rate and token generation throughput of LLaMA models with parameter sizes ranging from 1B to 8B on the Redmi K60 mobile device, which is powered by four Arm Cortex-series CPU cores. For inference on mobile devices, the batch size is set to one. For the LLaMA-3.2 1B parameter model, we improve the inference speed for the prefill phase from 104 tokens/s to 255.6 tokens/s and the token generation phase from 43.4 tokens/s to 47.8 tokens/s through our 4-bit optimized kernels.
图 6 比较了在 Redmi K60 移动设备上,参数规模从 1B 到 8B 的 LLaMA 模型的预填充速率和 Token 生成吞吐量。该设备由四个 Arm Cortex 系列 CPU 核心驱动。在移动设备上进行推理时,批量大小设置为 1。对于 LLaMA-3.2 1B 参数模型,我们通过 4 位优化内核将预填充阶段的推理速度从 104 Token/s 提升到 255.6 Token/s,并将 Token 生成阶段的推理速度从 43.4 Token/s 提升到 47.8 Token/s。
Table 3: Comparison of the prefill rate and token generation throughput of the LLaMA-3 8B and LLaMA-3.2 3B models for the reference llama.cpp 4-bit non-uniform quantization kernel (IQ4_NL) and our corresponding optimized kernel on Arm Graviton3 CPUs (64 cores).
表 3: LLaMA-3 8B 和 LLaMA-3.2 3B 模型在参考 llama.cpp 4-bit 非均匀量化内核 (IQ4_NL) 和我们在 Arm Graviton3 CPU (64 核) 上优化的内核的预填充率和 Token 生成吞吐量对比。
| Batch | LLaMA-38B | LLaMA-38B | LLaMA-38B | LLaMA-38B | LLaMA-3.23B | LLaMA-3.23B | LLaMA-3.23B | LLaMA-3.23B |
|---|---|---|---|---|---|---|---|---|
| IQ4_NL (llama.cpp) Prefill | IQ4_NL (llama.cpp) Token Gen. | IQ4_NL (Optimized) Prefill | IQ4_NL (Optimized) Token Gen. | IQ4_NL (llama.cpp) Prefill | IQ4_NL (llama.cpp) Token Gen. | IQ4_NL (Optimized) Prefill | IQ4_NL (Optimized) Token Gen. | |
| 1 | 132.6 | 45.5 | 470.1 | 45.5 | 282.2 | 83.2 | 1015.7 | 87.6 |
| 4 | 138.3 | 90.1 | 520.5 | 142.0 | 327.8 | 180.3 | 1274.0 | 264.7 |
| 8 | 145.7 | 105.0 | 531.1 | 184.8 | 356.1 | 217.7 | 1357.3 | 356.4 |
| 16 | 145.5 | 114.0 | 527.7 | 282.9 | 355.6 | 242.0 | 1349.5 | 506.3 |
| 32 | 145.0 | 118.5 | 522.8 | 304.9 | 351.7 | 254.6 | 1333.6 | 554.0 |
6.3 Inference throughput for 4-bit non-uniform quantization
6.3 4位非均匀量化的推理吞吐量
We extend our proposed SIMD-aware weight packing and fast decompression path optimization s to 4-bit non-uniform codebook-based quantization methods, such as LLaMA.cpp’s IQ4_NL [14]. IQ4_NL employs a single 16-entry 8-bit integer codebook with a non-uniform distribution, similar to a Normal Float- [8] or Student Float-like [10] normal distribution, to map 4-bit quantized indices into 8-bit integer values. In addition to the aforementioned optimization s, our optimized IQ4_NL kernel for Arm CPUs can take advantage of existing vector table lookup instructions (vtbl). vtbl can perform a vector read to access multiple byte values at once corresponding to quantized indexes in the input vector from a codebook table during inference. Because IQ4_NL only has a single 16-entry codebook, all of its entries can fit in a vector register and be accessed from there during inference. This, in turn, enables faster throughput in both the compute-bound prefill and small-batch-sized memory-bound token generation stages when compared to the LLaMA.cpp’s reference IQ4_NL kernel, as illustrated in Table 3. Furthermore, the inference speed of our optimized IQ4_NL on Graviton3 CPUs in Table 3 is comparable to that of the optimized Q4_0_8_8 kernel in Table 1. This also confirms the seamless support of off-the-shelf Arm CPUs in efficiently running non-uniform codebook-based quantization methods along with uniform quantization.
我们将提出的SIMD感知权重打包和快速解压缩路径优化扩展到4位非均匀码本量化方法,例如LLaMA.cpp的IQ4_NL [14]。IQ4_NL采用了一个16条目的8位整数码本,其分布类似于正态浮点 [8] 或学生浮点 [10] 的正态分布,将4位量化索引映射为8位整数值。除了上述优化外,我们为Arm CPU优化的IQ4_NL内核可以利用现有的向量表查找指令(vtbl)。vtbl可以在推理期间执行向量读取,从码本表中一次访问多个字节值,这些值对应于输入向量中的量化索引。由于IQ4_NL只有一个16条目的码本,其所有条目都可以放入向量寄存器中,并在推理期间从中访问。这使得在计算受限的预填充阶段和小批量内存受限的Token生成阶段,与LLaMA.cpp的参考IQ4_NL内核相比,我们的优化内核具有更快的吞吐量,如表3所示。此外,表3中我们优化的IQ4_NL在Graviton3 CPU上的推理速度与表1中优化的Q4_0_8_8内核相当。这也证实了现成的Arm CPU在高效运行非均匀码本量化方法以及均匀量化方面的无缝支持。
6.4 Inference throughput for narrower 2-bit quantization
6.4 2位窄量化下的推理吞吐量
Figure 7 shows the runtime performance of our optimized, narrower bit-width group-quantized kernels on Arm CPUs, specifically 2-bit uniform and non-uniform quantization methods, such as Q2_K and IQ2_S from LLaMA.cpp [14]. Q2_K is a group-wise 2-bit uniform quantization technique, whereas IQ2_S is a 2-bit non-uniform codebook-based technique. The IQ2 family of quantization methods from LLaMA.cpp adopts some of the key compression techniques proposed in the QuIP# [28] work, especially the E8 lattice-based codebook for vector quantization and its symmetric properties of an even number of positive (or negative) signs in quantized vectors, in conjunction with a group-wise structure over LLM weight matrices. We report the performance of the token generation stage in LLM inference for varying thread counts. For a small number of threads, the token generation stage is compute bound. To better understand the comparative performance of the various 2-bit schemes, we compare them to the runtime performance (tokens/sec) of 4-bit quantization schemes. For the compute-bound token generation stage with lower thread counts, as well as the prefill stage, the decompression overhead for a 2-bit quantization scheme in converting 2-bit quantized weights to 8-bit values should be low enough to avoid de quantization becoming a bottleneck. The uniform Q2_K quantization method has a low de quantization overhead, which helps bridge the performance gap between Arm CPU-optimized Q2_K and Arm CPU-optimized Q4_0_8_8 at lower thread counts. For the memory-bound token generation phase at higher thread counts, the decompression overhead has no effect on actual speedup, and the low memory bandwidth pressure of 2-bit quantization methods helps to achieve better overall performance than 4-bit methods. On the other hand, the non-uniform codebook-based method, IQ2_S, incurs a high de quantization overhead in constructing codebook indices from compressed weights and then accessing codebooks, so even our highly optimized IQ2_S (Arm CPU-optimized IQ2_S) performs poorly when compared to the optimized Q2_K’s (Arm CPU-optimized Q2_K) throughput at lower thread counts, as shown in Figure 7.
图 7 展示了我们在 Arm CPU 上优化的、更窄位宽的组量化内核的运行时性能,特别是 2 位均匀和非均匀量化方法,例如来自 LLaMA.cpp [14] 的 Q2_K 和 IQ2_S。Q2_K 是一种基于组的 2 位均匀量化技术,而 IQ2_S 是一种基于 2 位非均匀码本的技术。LLaMA.cpp 的 IQ2 系列量化方法采用了 QuIP# [28] 工作中提出的一些关键压缩技术,特别是基于 E8 格子的码本用于向量量化及其在量化向量中偶数个正(或负)符号的对称特性,结合大语言模型权重矩阵的组结构。我们报告了在不同线程数下大语言模型推理中 Token 生成阶段的性能。对于较少的线程数,Token 生成阶段是计算受限的。为了更好地理解各种 2 位量化方案的性能对比,我们将它们与 4 位量化方案的运行时性能(Token/秒)进行了比较。对于计算受限的 Token 生成阶段(线程数较少)以及预填充阶段,2 位量化方案在将 2 位量化权重转换为 8 位值时的解压缩开销应该足够低,以避免反量化成为瓶颈。均匀的 Q2_K 量化方法具有较低的反量化开销,这有助于在较低线程数下缩小 Arm CPU 优化的 Q2_K 和 Arm CPU 优化的 Q4_0_8_8 之间的性能差距。对于较高线程数下的内存受限的 Token 生成阶段,解压缩开销对实际加速没有影响,2 位量化方法的低内存带宽压力有助于实现比 4 位方法更好的整体性能。另一方面,基于非均匀码本的方法 IQ2_S 在从压缩权重构建码本索引并访问码本时会产生较高的反量化开销,因此即使是我们高度优化的 IQ2_S(Arm CPU 优化的 IQ2_S)在较低线程数下的吞吐量也比不上优化的 Q2_K(Arm CPU 优化的 Q2_K),如图 7 所示。

Figure 7: Comparison of the token generation throughput of the LLaMA-3 8B model for different quantization schemes of varying bit-widths. Performance was measured for different numbers of threads (cores) on Arm Graviton3 CPUs.
图 7: LLaMA-3 8B 模型在不同比特宽度量化方案下的 Token 生成吞吐量对比。性能测试在 Arm Graviton3 CPU 上针对不同线程(核心)数量进行。
The poor performance of existing codebook-based methods for low bit-widths like IQ2_S motivates the development of our group-wise fine-grained codebook-based quantization, a simple yet effective method for low-bit non-uniform quantization. Our group-wise codebook-based quantization is built around fast inference, not only to ensure high throughput during memory-bound token generation phases at higher thread counts but also to minimize de quantization overhead and achieve high throughput during compute-bound LLM inference phases at lower thread counts while achieving better accuracy.
现有基于码本的方法在低比特宽度(如 IQ2_S)上的表现不佳,这促使我们开发了基于分组细粒度码本的量化方法,这是一种简单但有效的低比特非均匀量化方法。我们的分组码本量化方法围绕快速推理构建,不仅确保在高线程数下内存受限的Token生成阶段的高吞吐量,还在低线程数下计算受限的大语言模型推理阶段最小化解量化开销并实现高吞吐量,同时获得更好的精度。
6.5 Accuracy evaluation for group-wise codebook-based quantization
6.5 基于分组码书的量化精度评估
We evaluate the quantized models on token perplexity for the WikiText2 validation set. Table 4 reports the perplexity metric numbers for WikiText2. We compare our group-wise non-uniform codebook-based quantization approach against several recent state-of-the-art post-training uniform and non-uniform quantization methods targeting LLMs, including the IQ2 and IQ3 family of models, Q2K from LLaMA.cpp [14], and SqueezeLLM [16] on the LLaMA family of models with varying parameters [27]. As previously mentioned, the IQ2 and IQ3 quantization approaches closely adopt the quantization techniques from the state-of-the-art QuIP# [28]. Additional accuracy results for other models, centroid value distributions of different codebooks, and ablation studies for group-wise codebook quantization are provided in the Appendix.
我们在 WikiText2 验证集上评估量化模型的 Token 困惑度。表 4 报告了 WikiText2 的困惑度指标数值。我们将基于分组非均匀码本的量化方法与几种最近的最先进的后训练均匀和非均匀量化方法进行了比较,这些方法针对大语言模型,包括 IQ2 和 IQ3 系列模型、LLaMA.cpp [14] 的 Q2K 以及针对不同参数的 LLaMA 系列模型的 SqueezeLLM [16]。如前所述,IQ2 和 IQ3 量化方法紧密采用了最先进的 QuIP# [28] 的量化技术。其他模型的额外准确性结果、不同码本的质心值分布以及分组码本量化的消融研究在附录中提供。
Activation s are quantized using 8-bit group-wise uniform quantization across all experiments for various weight quantization methods. For each LLM layer, the Q2_K quantization method quantizes the majority of weight matrices to 2-bit while a few of them to 3-bit. To ensure a fair comparison with a uniform quantization technique such as Q2_K with similar bits per weight, all 2-bit and 3-bit uniform quantized weight matrices of it are compressed using group-wise codebook-based quantization. For both 2-bit and 3-bit quantized layers, a handful of 4-entry and 8-entry 8-bit codebooks, respectively, are found using Algorithm 1 and used during PTQ. Furthermore, there is no need to determine the codebook entries for a new, unseen LLM. For accuracy evaluation in Table 4, the codebooks found for the LLaMA2 7B model weights using Algorithm 1 are used during PTQ for the LLaMA3 8B model. This ensures the generalization performance of codebooks found using Algorithm 1 after scaling weight values to codebook bit-width via group-wise quantization. It is worth noting that, while the majority of the codebooks found for 2-bit and 3-bit quantized layers using Algorithm 1 capture mostly symmetric distributions of various shapes, a few also capture asymmetric distributions found in group-wise quantized LLM weights. As shown in Table 4, our fine-grained codebook-based quantization technique outperforms both the most effective uniform quantization technique, Q2_K, and the non-uniform quantization technique, IQ2_S, in terms of perplexity while requiring similar bits per weight. For the LLaMA3 8B model, the uniform quantization method $\mathbf{Q}2_\mathbf{K}$ achieves a perplexity of 8.65, whereas our group-wise codebook quantization offers a better perplexity of 7.77 at similar bits per weight (3.15 − 3.2 bits).
在所有实验中,激活值使用8-bit分组均匀量化进行量化,适用于各种权重量化方法。对于每个大语言模型层,Q2_K量化方法将大部分权重矩阵量化为2-bit,少数量化为3-bit。为了确保与类似每权重比特数的均匀量化技术(如Q2_K)进行公平比较,所有2-bit和3-bit均匀量化的权重矩阵都使用基于分组码本的量化进行压缩。对于2-bit和3-bit量化的层,分别使用算法1找到少量4-entry和8-entry的8-bit码本,并在PTQ(后训练量化)过程中使用。此外,无需为新的大语言模型确定码本条目。在表4的精度评估中,使用算法1为LLaMA2 7B模型权重找到的码本在PTQ过程中用于LLaMA3 8B模型。这确保了通过分组量化将权重值缩放到码本比特宽度后,使用算法1找到的码本的泛化性能。值得注意的是,虽然使用算法1为2-bit和3-bit量化层找到的大部分码本捕捉了各种形状的对称分布,但也有一些捕捉到了分组量化大语言模型权重中的非对称分布。如表4所示,我们的细粒度基于码本的量化技术在困惑度方面优于最有效的均匀量化技术Q2_K和非均匀量化技术IQ2_S,同时需要类似的每权重比特数。对于LLaMA3 8B模型,均匀量化方法$\mathbf{Q}2_\mathbf{K}$的困惑度为8.65,而我们的分组码本量化在类似的每权重比特数(3.15 − 3.2 bits)下提供了更好的困惑度7.77。
Table 4: Comparison of the perplexity score on WikiText2 for a sequence length of 512. Results for SqueezeLLM [16] were obtained using the released codebase for LLaMA.cpp. 2-bit quantization is unsupported by the SqueezeLLM codebase.
表 4: WikiText2 上序列长度为 512 时的困惑度 (perplexity) 分数对比。SqueezeLLM [16] 的结果是使用 LLaMA.cpp 的发布代码库获得的。SqueezeLLM 代码库不支持 2-bit 量化。
| 方法 | 平均每权重比特数 (激活值: 8-bit) | 量化类型 | LLaMA-27B | LLaMA-38B |
|---|---|---|---|---|
| FP16 | 16 | 5.79 | 6.23 | |
| SqueezeLLM | 4.04 | 非均匀 | 5.97 | - |
| Q8_0 | 8.50 | 均匀 | 5.80 | 6.23 |
| Q6_K | 6.56 | 均匀 | 5.81 | 6.25 |
| Q5_K_M | 5.70 | 均匀 | 5.83 | 6.29 |
| Q5_0 | 5.58 | 均匀 | 5.83 | 6.36 |
| Q4_K_M | 4.89 | 均匀 | 5.87 | 6.38 |
| Q4_0 | 4.65 | 均匀 | 5.96 | 6.70 |
| IQ4_NL | 4.65 | 非均匀 | 5.87 | 6.45 |
| Q3_K_M | 3.99 | 均匀 | 6.00 | 6.73 |
| IQ3_M | 3.76 | 非均匀 | 6.02 | 6.89 |
| IQ3_XS | 3.49 | 非均匀 | 6.12 | 7.16 |
| Q3_K_S | 3.64 | 均匀 | 6.21 | 7.60 |
| Q2_K | 3.15 | 均匀 | 6.68 | 8.65 |
| Q2_K_S | 2.96 | 均匀 | 7.21 | 9.32 |
| IQ2_M | 2.92 | 非均匀 | 6.59 | 8.60 |
| IQ2_S | 2.74 | 非均匀 | 7.01 | 9.65 |
| IQ2_XS | 2.58 | 非均匀 | 7.52 | 10.76 |
| 分组码本 | 3.2 | 非均匀 | 6.39 | 7.77 |
The fewer number of 4- or 8-entry codebooks for our group-wise codebook quantization ensures that all the codebooks can fit in the vector register file of Arm CPU cores during the course of inference as opposed to fitting in L1 cache in case of IQ2_S-like techniques. In other words, there is no need to load the codebook entries to the register file for different weight rows or LLM layers; once loaded from memory, the register file can store the entire codebook. The same codebook essentially applies to all layers of an LLM. In contrast, for IQ2_S-like techniques using E8 lattice-based codebooks from QuIP# [28], while the entire codebook can fit in L1 cache, it cannot fit in the register file of CPU cores to enable fast access to codebooks. For our group-wise codebook quantization, the codebook index for a group and the centroid indices that specify particular centroid values from the assigned codebook can be combined using bitwise vector operations before using specialized vector table lookup operations vtbl to retrieve centroid values from register file resident codebooks. The simple de quantization path, akin to Q2_K-like uniform quantization techniques, and low overhead in accessing register file resident codebooks using vtbl in our group-wise codebook-based quantization ensures fast inference and comparable throughput to that of Q2_K, whereas the fine-grained assignment of codebooks to each group in a weight tensor ensures better accuracy than Q2_K. For the memory-bound decode stage with large thread counts (for example, 64 threads), both quantization schemes, Q2_K and our group-wise codebook-based quantization, can achieve higher throughput due to their reduced model footprint and the consequent ease of memory bandwidth, as observed in our experiments. It is worth noting that, like IQ2, the 3-bit IQ3 quantization schemes have a high decompression overhead when creating codebook indices and accessing codebooks, resulting in poor runtime performance.
我们组级码本量化中较少的4或8条目码本数量确保了在推理过程中所有码本都能适配到Arm CPU核心的向量寄存器文件中,而不是像IQ2_S类似技术那样适配到L1缓存中。换句话说,无需为不同的权重行或大语言模型层将码本条目加载到寄存器文件中;一旦从内存中加载,寄存器文件就可以存储整个码本。相同的码本基本上适用于大语言模型的所有层。相比之下,对于使用QuIP# [28]中基于E8格点码本的IQ2_S类似技术,虽然整个码本可以适配到L1缓存中,但它无法适配到CPU核心的寄存器文件中以实现对码本的快速访问。对于我们的组级码本量化,组的码本索引和指定特定质心值的质心索引可以在使用专门的向量表查找操作vtbl从寄存器文件驻留的码本中检索质心值之前,通过位向量操作进行组合。类似于Q2_K的统一量化技术的简单反量化路径,以及使用vtbl访问寄存器文件驻留码本的低开销,确保了快速推理和与Q2_K相当的吞吐量,而权重张量中每个组的码本细粒度分配确保了比Q2_K更好的准确性。对于具有大线程数(例如64个线程)的内存受限解码阶段,Q2_K和我们的组级码本量化方案都可以由于模型占用空间减少和内存带宽的便利性而实现更高的吞吐量,正如我们在实验中所观察到的那样。值得注意的是,与IQ2类似,3位IQ3量化方案在创建码本索引和访问码本时具有较高的解压缩开销,导致运行时性能较差。
To summarize, our group-wise, non-uniform codebook-based quantization scheme not only outperforms the state-of-the-art in terms of quality by matching the underlying distribution of weight values with codebooks, but it also ensures comparable throughput performance to an equivalent uniform quantization scheme with low decompression overhead for both compute-bound and memory-bound stages in LLM inference. In other words, it presents a pareto-optimal solution in terms of model quality and runtime performance for narrow bit-widths such as 2-bit and 3-bit quantization. While we apply our fine-grained codebook-based quantization technique to 2 and 3 bit-widths, it can also be used to find group-wise codebooks for other bit-widths, such as 4-bit quantization.
总结来说,我们基于分组的非均匀码本量化方案不仅在质量上超越了现有技术,通过将权重值的底层分布与码本匹配,还确保了在大语言模型推理的计算密集型和内存密集型阶段中,与等效的均匀量化方案相比具有可比的吞吐量性能,且解压缩开销较低。换句话说,它在模型质量和运行时性能方面为窄位宽(如2位和3位量化)提供了一个帕累托最优解。虽然我们将细粒度的基于码本的量化技术应用于2位和3位宽,但它也可以用于为其他位宽(如4位量化)找到分组码本。
7 Conclusion
7 结论
In this work, we propose highly optimized matrix multiply kernels to accelerate LLM inference on CPUs. Our optimized kernels for Arm CPU-based inference for LLaMA models can deliver a $3-3.2\times$ improvement in prompt processing and an approximately $2\times$ improvement in token generation runtime for 4-bit quantized LLMs, significantly enhancing both memory efficiency and inference speed over the best existing LLaMA.cpp-based open-source solution for CPUs. Furthermore, we present highly efficient kernels for 4-bit non-uniformly quantized and narrower 2-bit uniformly and non-uniformly quantized LLMs, demonstrating the efficacy of off-the-shelf CPUs, particularly Arm CPUs, in supporting non-uniform and narrower bit-width quantization s. However, the complex decompression path of existing non-uniform codebook-based quantization schemes for narrower bit-widths, such as 2 bits per weight, presents a significant challenge to achieving good runtime performance even with sophisticated kernel optimization s. We address this through the introduction of a group-wise fine-grained codebook-based quantization scheme, which can better match the different non-uniform distribution patterns existing across different groups in LLM weights. It outperforms state-of-the-art non-uniform and uniform quantization methods, achieving higher accuracy at similar bits per weight while potentially ensuring significantly faster runtime than non-uniform quantization methods and comparable runtime to light-weight uniform quantization methods. There are other group-wise quantization schemes for various bit-widths, and the kernel optimization s and fine-grained codebooks proposed here should be extended to other schemes as well.
在本工作中,我们提出了高度优化的矩阵乘法内核,以加速 CPU 上的大语言模型推理。我们针对基于 Arm CPU 的 LLaMA 模型推理进行了优化,能够在 4 位量化的大语言模型上实现提示处理速度提升 $3-3.2\times$,并在 Token 生成运行时提升约 $2\times$,显著提高了内存效率和推理速度,超越了现有的基于 LLaMA.cpp 的最佳开源 CPU 解决方案。此外,我们还展示了针对 4 位非均匀量化和更窄的 2 位均匀与非均匀量化大语言模型的高效内核,证明了现成 CPU(尤其是 Arm CPU)在支持非均匀和更窄位宽量化方面的有效性。然而,现有的基于非均匀码本的量化方案在更窄位宽(如每个权重 2 位)下的复杂解压路径,即使通过复杂的内核优化,也仍然对实现良好的运行时性能构成了重大挑战。我们通过引入一种基于组级细粒度码本的量化方案来解决这一问题,该方案能够更好地匹配大语言模型权重中不同组之间存在的不同非均匀分布模式。它在每个权重相似位数的情况下,优于最先进的非均匀和均匀量化方法,实现了更高的精度,同时可能确保比非均匀量化方法显著更快的运行时,并与轻量级均匀量化方法的运行时相当。还有其他针对各种位宽的组级量化方案,本文提出的内核优化和细粒度码本也应扩展到其他方案中。
Acknowledgments
致谢
We would like to thank Eric Biscondi, Milos Puzovic, Gian Marco Iodice, Ronan Naughton, Ashok Bhat, Ravi Malhotra, Pavan Gorti, Masoud Koleini, Adnan AlSinan, Mariusz Czyz, and Sandeep Singh from Arm for their insightful discussions, feedback, and support.
我们要感谢来自 Arm 的 Eric Biscondi、Milos Puzovic、Gian Marco Iodice、Ronan Naughton、Ashok Bhat、Ravi Malhotra、Pavan Gorti、Masoud Koleini、Adnan AlSinan、Mariusz Czyz 和 Sandeep Singh,感谢他们的深入讨论、反馈和支持。
References
参考文献
[10] Jordan Dotzel, Yuzong Chen, Bahaa Kotb, Sushma Prasad, Gang Wu, Sheng Li, Mohamed S Abdel fat tah, and Zhiru Zhang. Learning from students: Applying t-distributions to explore accurate and efficient formats for LLMs. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 11573–11591. PMLR, 21–27 Jul 2024. URL https://proceedings.mlr.press/v235/dotzel24a.html.
[10] Jordan Dotzel, Yuzong Chen, Bahaa Kotb, Sushma Prasad, Gang Wu, Sheng Li, Mohamed S Abdel fat tah, 和 Zhiru Zhang. 向学生学习:应用 t 分布探索大语言模型的准确和高效格式。在第 41 届国际机器学习会议论文集,第 235 卷,机器学习研究论文集,第 11573–11591 页。PMLR,2024 年 7 月 21–27 日。URL https://proceedings.mlr.press/v235/dotzel24a.html.