YOLOE: Real-Time Seeing Anything
Abstract
摘要
Object detection and segmentation are widely employed in computer vision applications, yet conventional models like YOLO series, while efficient and accurate, are limited by predefined categories, hindering adaptability in open scenarios. Recent open-set methods leverage text prompts, visual cues, or prompt-free paradigm to overcome this, but often compromise between performance and efficiency due to high computational demands or deployment complexity. In this work, we introduce YOLOE, which integrates detection and segmentation across diverse open prompt mechanisms within a single highly efficient model, achieving real-time seeing anything. For text prompts, we propose Re-parameter iz able Region-Text Alignment (RepRTA) strategy. It refines pretrained textual embeddings via a re-parameter iz able lightweight auxiliary network and enhances visual-textual alignment with zero inference and transferring overhead. For visual prompts, we present Semantic-Activated Visual Prompt Encoder (SAVPE). It employs decoupled semantic and activation branches to bring improved visual embedding and accuracy with minimal complexity. For prompt-free scenario, we introduce Lazy Region-Prompt Contrast (LRPC) strategy. It utilizes a builtin large vocabulary and specialized embedding to identify all objects, avoiding costly language model dependency. Extensive experiments show YOLOE’s exceptional zero-shot performance and transfer ability with high inference efficiency and low training cost. Notably, on LVIS, with $3\times$ less training cost and $I.4\times$ inference speedup, YOLOE $\nu\delta{-}S$ surpasses YOLO-Worldv2-S by $3.5~A P.$ When transferring to COCO, YOLOE-v8-L achieves $O.6A P^{b}$ and 0.4 $A P^{m}$ gains over closed-set $Y O L O\nu\delta\ –L$ with nearly $4\times$ less training time. Code and models are available at https: //github.com/THU-MIG/yoloe.
目标检测与分割在计算机视觉应用中被广泛采用,然而传统的模型如 YOLO 系列虽然高效且准确,但受限于预定义类别,在开放场景中的适应性较差。最近的开放集方法利用文本提示、视觉线索或无提示范式来克服这一问题,但由于高计算需求或部署复杂性,往往在性能与效率之间做出妥协。在本工作中,我们提出了 YOLOE,它将检测与分割整合到单一高效的模型中,支持多样化的开放提示机制,实现了实时“看到任何东西”。对于文本提示,我们提出了可重参数化的区域-文本对齐策略(RepRTA)。它通过可重参数化的轻量级辅助网络优化预训练的文本嵌入,并在零推理和迁移开销的情况下增强视觉-文本对齐。对于视觉提示,我们提出了语义激活的视觉提示编码器(SAVPE)。它采用解耦的语义和激活分支,以最小的复杂度带来改进的视觉嵌入和准确性。对于无提示场景,我们引入了惰性区域-提示对比策略(LRPC)。它利用内置的大词汇量和专用嵌入来识别所有对象,避免了对昂贵语言模型的依赖。大量实验表明,YOLOE 在零样本性能和迁移能力方面表现出色,具有高推理效率和低训练成本。值得注意的是,在 LVIS 上,YOLOE $\nu\delta{-}S$ 以 $3\times$ 的训练成本减少和 $I.4\times$ 的推理加速,超越了 YOLO-Worldv2-S,提升了 $3.5~A P.$。在迁移到 COCO 时,YOLOE-v8-L 在封闭集 $Y O L O\nu\delta\ –L$ 的基础上实现了 $O.6A P^{b}$ 和 0.4 $A P^{m}$ 的提升,训练时间减少了近 $4\times$。代码和模型可在 https://github.com/THU-MIG/yoloe 获取。
1. Introduction
1. 引言
Object detection and segmentation are foundational tasks in computer vision [15, 48], with widespread applications spanning autonomous driving [2], medical analyses [55], and robotics [8], etc. Traditional approaches like YOLO series [1, 3, 21, 47], have leveraged convolutional neural networks to achieve real-time remarkable performance. However, their dependence on predefined object categories constrains flexibility in practical open scenarios. Such scenarios increasingly demand models capable of detecting and segmenting arbitrary objects guided by diverse prompt mechanisms, such as texts, visual cues, or without prompt.
目标检测与分割是计算机视觉中的基础任务 [15, 48],其应用广泛覆盖自动驾驶 [2]、医学分析 [55] 和机器人技术 [8] 等领域。传统方法如 YOLO 系列 [1, 3, 21, 47] 利用卷积神经网络实现了显著的实时性能。然而,它们对预定义目标类别的依赖限制了在实际开放场景中的灵活性。这些场景越来越需要能够通过多种提示机制(如文本、视觉提示或无提示)检测和分割任意目标的模型。
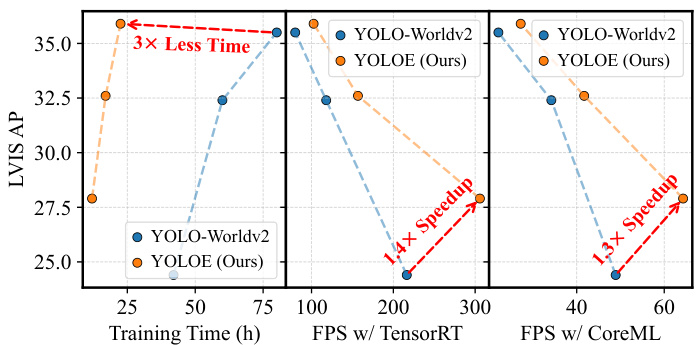
Figure 1. Comparison of performance, training cost, and inference efficiency between YOLOE (Ours) and advanced YOLO-Worldv2 in terms of open text prompts. LVIS AP is evaluated on minival set and FPS w/ TensorRT and w/ CoreML is measured on T4 GPU and iPhone 12, respectively. The results highlight our superiority.
图 1: YOLOE (Ours) 与先进的 YOLO-Worldv2 在开放文本提示下的性能、训练成本和推理效率对比。LVIS AP 在 minival 集上评估,FPS w/ TensorRT 和 w/ CoreML 分别在 T4 GPU 和 iPhone 12 上测量。结果凸显了我们的优势。
Given this, recent efforts have shifted towards enabling models to generalize for open prompts [5, 20, 49, 80]. They target single prompt type, e.g., GLIP [32], or multiple prompt types in a unified way, e.g., DINO-X [49]. Specifically, with region-level vision-language pre training [32, 37, 65], text prompts are usually processed by text encoder to serve as contrastive objectives for region features [20, 49], achieving recognition for arbitrary categories, e.g., YOLOWorld [5]. For visual prompts, they are often encoded as class embeddings tied to specified regions for identifying similar objects, by the interaction with image features or language-aligned visual encoder [5, 19, 30, 49], e.g., TRex2 [20]. In prompt-free scenario, existing methods typically integrate language models, finding all objects and generating the corresponding category names conditioned on region features sequentially [49, 62], e.g., GenerateU [33].
因此,最近的研究工作转向了使模型能够对开放提示进行泛化 [5, 20, 49, 80]。它们针对单一提示类型,例如 GLIP [32],或以统一的方式处理多种提示类型,例如 DINO-X [49]。具体而言,通过区域级视觉语言预训练 [32, 37, 65],文本提示通常由文本编码器处理,作为区域特征的对比目标 [20, 49],实现对任意类别的识别,例如 YOLOWorld [5]。对于视觉提示,它们通常被编码为与指定区域绑定的类别嵌入,通过与图像特征或语言对齐的视觉编码器的交互来识别相似对象 [5, 19, 30, 49],例如 TRex2 [20]。在无提示场景中,现有方法通常集成语言模型,依次找到所有对象并根据区域特征生成相应的类别名称 [49, 62],例如 GenerateU [33]。
Despite notable advancements, a single model that supports diverse open prompts for arbitrary objects with high efficiency and accuracy is still lacking. For example, DINO
尽管取得了显著进展,但能够高效且准确地支持任意对象多样化开放提示的单一模型仍然缺乏。例如,DINO
X [49] features a unified architecture, which, however, incurs resource-intensive training and inference overhead. Additionally, individual designs for different prompts in separate works exhibit suboptimal trade-offs between performance and efficiency, making it difficult to directly combine them into one model. For example, text-prompted approaches often incur substantial computational overhead when incorporating large vocabularies, due to complexity of cross-modality fusion [5, 32, 37, 49]. Visual-prompted methods usually compromise deploy ability on edge devices owing to the transformer-heavy design or reliance on additional visual encoder [20, 30, 67]. Prompt-free ways, meanwhile, depend on large language models, introducing considerable memory and latency costs [33, 49].
X [49] 采用了一种统一架构,然而,这带来了资源密集型的训练和推理开销。此外,不同工作中针对不同提示的独立设计在性能和效率之间表现出次优的权衡,使得很难将它们直接结合到一个模型中。例如,文本提示方法在融合大词汇量时,由于跨模态融合的复杂性,通常会带来大量的计算开销 [5, 32, 37, 49]。视觉提示方法通常由于 Transformer 密集型设计或依赖额外的视觉编码器而在边缘设备上的部署能力上做出妥协 [20, 30, 67]。与此同时,无提示方法依赖大语言模型,引入了相当大的内存和延迟成本 [33, 49]。
In light of these, in this paper, we introduce YOLOE(ye), a highly efficient, unified, and open object detection and segmentation model, like human eye, under different prompt mechanisms, like texts, visual inputs, and promptfree paradigm. We begin with YOLO models with widely proven efficacy. For text prompts, we propose a Reparameter iz able Region-Text Alignment (RepRTA) strat- egy, which employs a lightweight auxiliary network to improve pretrained textual embeddings for better visualsemantic alignment. During training, pre-cached textual embeddings require only the auxiliary network to process text prompts, incurring low additional cost compared with closed-set training. At inference and transferring, auxiliary network is seamlessly re-parameterized into the classification head, yielding an architecture identical to YOLOs with zero overhead. For visual prompts, we design a SemanticActivated Visual Prompt Encoder (SAVPE). By formalizing regions of interest as masks, SAVPE fuses them with multi-scale features from PAN to produce grouped promptaware weights in low dimension in an activation branch and extract prompt-agnostic semantic features in a semantic branch. Prompt embeddings are derived through aggregation of them, resulting in favorable performance with min- imal complexity. For prompt-free scenario, we introduce Lazy Region-Prompt Contrast (LRPC) strategy. Without relying on costly language models, LRPC leverages a specialized prompt embedding to find all objects and a built-in large vocabulary for category retrieval. By matching only anchor points with identified objects against the vocabulary, LRPC ensures high performance with low overhead.
基于这些,本文中我们提出了YOLOE(ye),一种高效、统一且开放的目标检测与分割模型,它能够像人眼一样在不同的提示机制下工作,如文本、视觉输入以及无提示范式。我们从已被广泛验证有效的YOLO模型出发。针对文本提示,我们提出了一种可重参数化的区域-文本对齐(RepRTA)策略,该策略采用轻量级辅助网络来优化预训练的文本嵌入,以实现更好的视觉语义对齐。训练期间,预缓存的文本嵌入仅需辅助网络处理文本提示,相比闭集训练,额外成本较低。在推理和迁移时,辅助网络无缝地重参数化到分类头中,生成与YOLO结构相同且无额外开销的架构。对于视觉提示,我们设计了语义激活视觉提示编码器(SAVPE)。通过将感兴趣区域形式化为掩码,SAVPE将其与PAN的多尺度特征融合,在激活分支中生成低维度的分组提示感知权重,并在语义分支中提取与提示无关的语义特征。提示嵌入通过它们的聚合得出,以最小的复杂度实现优异的性能。对于无提示场景,我们引入了惰性区域-提示对比(LRPC)策略。LRPC不依赖于成本高昂的语言模型,而是利用专门的提示嵌入来寻找所有对象,并内置大词汇表用于类别检索。通过仅将锚点与识别出的对象与词汇表匹配,LRPC确保了高性能与低开销。
Thanks to them, YOLOE excels in detection and segmentation across diverse open prompt mechanisms within one model, enjoying high inference efficiency and low training cost. Notably, as shown in Fig. 1, under $3\times$ less training cost, YOLOE-v8-S significantly outperforms YOLOWorldv2-S [5] by 3.5 AP on LVIS [14], with $1.4\times$ and $1.3\times$ inference speedups on T4 and iPhone 12, respectively. In visual-prompted and prompt-free settings, YOLOE-v8-L outperforms T-Rex2 by $3.3\mathrm{AP}_{r}$ and GenerateU by 0.4 AP with $2\times$ less training data and $6.3\times$ fewer parameters, respectively. For transferring to COCO [34], YOLOE-v8-M $/\mathrm{L}$ outperforms $\mathrm{YOLOv8{-}M/\Omega L}$ by $0.4/0.6\mathrm{AP}^{b}$ and $0.4~/$ $0.4~{\mathrm{AP}}^{m}$ with nearly $4\times$ less training time. We hope that YOLOE can establish a strong baseline and inspire further advancements in real-time open prompt-driven vision tasks.
得益于它们,YOLOE 在单一模型内跨多种开放提示机制中表现出色,具备高推理效率和低训练成本。值得注意的是,如图 1 所示,在训练成本减少 $3\times$ 的情况下,YOLOE-v8-S 在 LVIS [14] 上显著优于 YOLOWorldv2-S [5],AP 高出 3.5,并且在 T4 和 iPhone 12 上的推理速度分别提升了 $1.4\times$ 和 $1.3\times$。在视觉提示和无提示设置下,YOLOE-v8-L 分别以 $3.3\mathrm{AP}_{r}$ 和 0.4 AP 优于 T-Rex2 和 GenerateU,同时训练数据减少 $2\times$,参数减少 $6.3\times$。在迁移到 COCO [34] 时,YOLOE-v8-M $/\mathrm{L}$ 以 $0.4/0.6\mathrm{AP}^{b}$ 和 $0.4~/$ $0.4~{\mathrm{AP}}^{m}$ 优于 $\mathrm{YOLOv8{-}M/\Omega L}$,且训练时间减少近 $4\times$。我们希望 YOLOE 能够建立一个强大的基线,并激发实时开放提示驱动视觉任务的进一步进展。
2. Related Work
2. 相关工作
Traditional detection and segmentation. Traditional approaches for object detection and segmentation primarily operate under closed-set paradigms. Early two-stage frameworks [4, 12, 15, 48], exemplified by Faster RCNN [48], introduce region proposal networks (RPNs) followed by region-of-interest (ROI) classification and regression. Meanwhile, single-stage detectors [10, 35, 38, 56, 72] prioritizes speed through grid-based predictions within a single network. The YOLO series [1, 21, 27, 47, 59, 60] plays a significant role in this paradigm and are widely used in real world. Moreover, DETR [28] and its variants [28, 69, 77] mark a major shift by removing heuristicdriven components with transformer-based architectures. To achieve finer-grained results, existing instance segmentation methods predict pixel-level masks rather than bounding box coordinates [15]. For this, YOLACT [3] facilitates real-time instance segmentation through integration of prototype masks and mask coefficients. Based on DINO [69], MaskDINO [29] utilizes query embeddings and a highresolution pixel embedding map to produce binary masks.
传统检测与分割。传统的目标检测和分割方法主要在封闭集范式下运行。早期的两阶段框架 [4, 12, 15, 48],以 Faster RCNN [48] 为例,引入了区域提议网络 (RPNs),随后进行感兴趣区域 (ROI) 的分类和回归。与此同时,单阶段检测器 [10, 35, 38, 56, 72] 通过在单一网络中进行基于网格的预测来优先考虑速度。YOLO 系列 [1, 21, 27, 47, 59, 60] 在这一范式中扮演了重要角色,并在现实世界中得到广泛应用。此外,DETR [28] 及其变体 [28, 69, 77] 通过使用基于 Transformer 的架构移除启发式驱动的组件,标志着一个重大转变。为了获得更细粒度的结果,现有的实例分割方法预测像素级掩码而非边界框坐标 [15]。为此,YOLACT [3] 通过整合原型掩码和掩码系数实现了实时实例分割。基于 DINO [69],MaskDINO [29] 利用查询嵌入和高分辨率像素嵌入图生成二进制掩码。
Text-prompted detection and segmentation. Recent advancements in open-vocabulary object detection [13, 25, 61, 68, 74–76] have focused on detecting novel categories by aligning visual features with textual embeddings. Specifically, GLIP [32] unifies object detection and phrase grounding through grounded pre-training on largescale image-text pairs, demonstrating robust zero-shot performance. DetCLIP [65] facilitates open-vocabulary learning by enriching the concepts with descriptions. Besides, Grounding DINO [37] enhances this by integrating crossmodality fusion into DINO, improving alignment between text prompts and visual representations. YOLO-World [5] further shows the potential of pre training small detectors with open recognition capabilities based on the YOLO architecture. YOLO-UniOW [36] builds upon YOLO-World by leveraging the adaptive decision-learning strategy. Similarly, several open-vocabulary instance segmentation models [11, 18, 26, 45, 63] learn rich visual-semantic knowledge from advanced foundation models to perform segmentation on novel object categories. For example, X-Decoder [79] and OpenSeeD [71] explore both the open-vocabulary detection and segmentation tasks. APE [54] introduces a universal visual perception model that aligns and prompts all objects in image using various text prompts.
文本提示的检测与分割。最近在开放词汇目标检测领域的进展[13, 25, 61, 68, 74-76]主要集中在通过将视觉特征与文本嵌入对齐来检测新类别。具体来说,GLIP[32]通过在大规模图像-文本对上进行基于预训练的统一,展示了强大的零样本性能。DetCLIP[65]通过用描述丰富概念来促进开放词汇学习。此外,Grounding DINO[37]通过将跨模态融合集成到DINO中,提高了文本提示与视觉表示之间的对齐。YOLO-World[5]进一步展示了基于YOLO架构的小型检测器在开放识别能力方面的预训练潜力。YOLO-UniOW[36]在YOLO-World的基础上,利用了自适应决策学习策略。同样,一些开放词汇实例分割模型[11, 18, 26, 45, 63]从先进的基础模型中学习丰富的视觉-语义知识,以对新对象类别进行分割。例如,X-Decoder[79]和OpenSeeD[71]探索了开放词汇检测和分割任务。APE[54]引入了一个通用视觉感知模型,使用各种文本提示对齐和提示图像中的所有对象。
Visual-prompted detection and segmentation. While text prompts offer a generic description, certain objects can be challenging to describe with language alone, such as those requiring specialized domain knowledge. In such cases, visual prompts can guide detection and segmentation more flexibly and specifically, complementing text prompts [19, 20]. OV-DETR [67] and OWL-ViT [41] leverage CLIP encoders to process text and image prompts. MQDet [64] augments text queries with class-specific visual information from query images. DINOv [30] explores visual prompts as in-context examples for generic and referring vision tasks. T-Rex2 [20] integrates visual and text prompts by region-level contrastive alignment. For segmentation, based on large-scale data, SAM [23] presents a flexible and strong model that can be prompted interactively and iteratively. SEEM [80] further explores segmenting objects with more various prompt types. Semantic-SAM [31] excels in semantic comprehension and granularity detection, handling both panoptic and part segmentation tasks.
视觉提示检测与分割。尽管文本提示提供了通用的描述,但某些对象可能难以仅用语言描述,例如那些需要专业领域知识的对象。在这种情况下,视觉提示可以更灵活和具体地指导检测和分割,与文本提示形成互补 [19, 20]。OV-DETR [67] 和 OWL-ViT [41] 利用 CLIP 编码器处理文本和图像提示。MQDet [64] 通过从查询图像中提取特定类别的视觉信息来增强文本查询。DINOv [30] 探索了将视觉提示作为通用和引用视觉任务的上下文示例。T-Rex2 [20] 通过区域级别的对比对齐整合了视觉和文本提示。在分割方面,基于大规模数据,SAM [23] 提出了一个灵活且强大的模型,可以交互式和迭代地进行提示。SEEM [80] 进一步探索了使用更多样化的提示类型来分割对象。Semantic-SAM [31] 在语义理解和粒度检测方面表现出色,能够处理全景和部分分割任务。
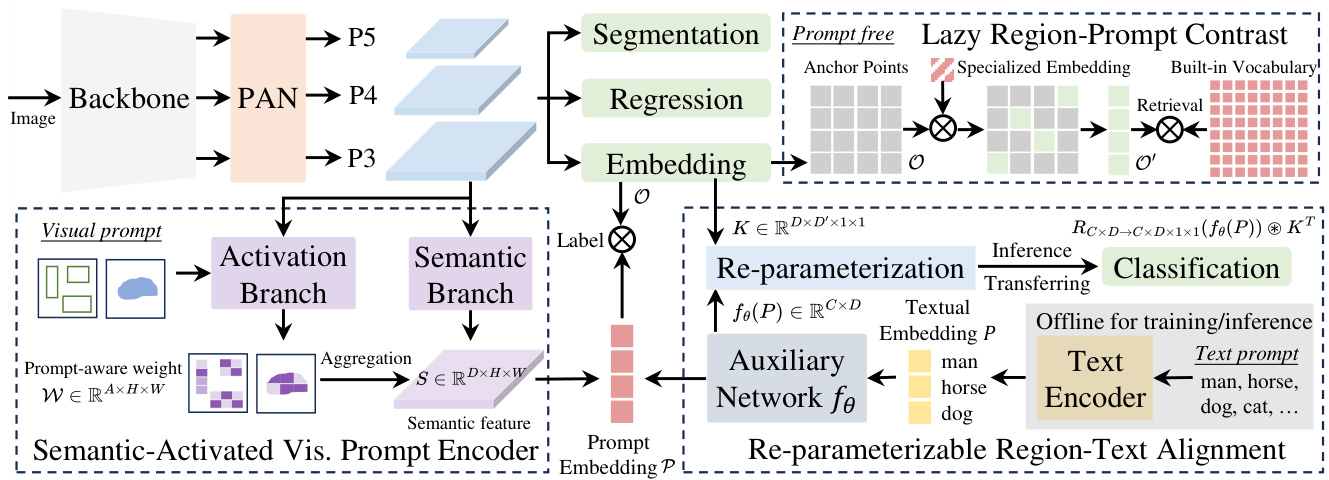
Figure 2. The overview of YOLOE, which supports detection and segmentation for diverse open prompt mechanisms. For text prompts, We design a re-parameter iz able region-text alignment strategy to improve performance with zero inference and transferring overhead. For visual prompts, SAVPE is employed to encode visual cues with enhanced prompt embedding under minimal cost. For prompt-free setting, we introduce lazy region-prompt contrast strategy to provide category names for all identified objects efficiently by retrieval.
图 2: YOLOE 的概述,支持多种开放提示机制的检测和分割。对于文本提示,我们设计了一种可重参数化的区域-文本对齐策略,以在零推理和迁移开销下提高性能。对于视觉提示,SAVPE 被用于在最小成本下编码视觉提示,并增强提示嵌入。对于无提示设置,我们引入了惰性区域-提示对比策略,通过检索高效地为所有识别对象提供类别名称。
Prompt-free detection and segmentation. Existing approaches still depend on explicit prompts during inference for open-set detection and segmentation. To address this limitation, several works [33, 40, 49, 62, 66] explore integrating with generative language models to produce object descriptions for all found objects. For instance, GRiT [62] employs a text decoder for both dense captioning and object detection tasks. DetCLIPv3 [66] trains an object captioner on large-scale data, enabling model to generate rich label information. GenerateU [33] leverages the language model to generate object names in a free-form way.
无提示检测与分割。现有方法在开放集检测和分割的推理过程中仍然依赖显式提示。为了解决这一限制,一些工作 [33, 40, 49, 62, 66] 探索了与生成式语言模型(Generative Language Model)的集成,为所有发现的对象生成描述。例如,GRiT [62] 在密集字幕生成和对象检测任务中使用了一个文本解码器。DetCLIPv3 [66] 在大规模数据上训练了一个对象字幕生成器,使模型能够生成丰富的标签信息。GenerateU [33] 则利用语言模型以自由形式生成对象名称。
Closing remarks. To the best of our knowledge, aside from DINO-X [49], few efforts have achieved object detection and segmentation across various open prompt mecha- nisms within a single architecture. However, DINO-X entails extensive training cost and notable inference overhead, severely constraining the practicality for real-world edge deployments. In contrast, our YOLOE aims to deliver an efficient and unified model that enjoys real-time performance and efficiency with easy deploy ability.
结语。据我们所知,除了 DINO-X [49] 之外,很少有研究在单一架构内实现了跨多种开放提示机制的目标检测和分割。然而,DINO-X 需要大量的训练成本和显著的推理开销,严重限制了其在现实世界边缘部署中的实用性。相比之下,我们的 YOLOE 旨在提供一个高效且统一的模型,具备实时性能和高效的部署能力。
3. Methodology
3. 方法论
In this section, we detail designs of YOLOE. Building upon YOLOs (Sec. 3.1), YOLOE supports text prompts through RepRTA (Sec. 3.2), visual prompts via SAVPE (Sec. 3.3), and prompt-free scenario with LRPC (Sec. 3.4).
在本节中,我们详细介绍了 YOLOE 的设计。基于 YOLOs(第 3.1 节),YOLOE 通过 RepRTA(第 3.2 节)支持文本提示,通过 SAVPE(第 3.3 节)支持视觉提示,并在 LRPC(第 3.4 节)中支持无提示场景。
3.1. Model architecture
3.1. 模型架构
As shown in Fig. 2, YOLOE adopts the typical YOLOs’ architecture [1, 21, 47], consisting of backbone, PAN, regression head, segmentation head, and object embedding head. The backbone and PAN extracts multi-scale features for the image. For each anchor point, the regression head predicts the bounding box for detection, and the segmentation head produces the prototype and mask coefficients for segmentation [3]. The object embedding head follows the structure of classification head in YOLOs, except that the output channel number of last $1\times$ convolution layer is changed from the class number in closed-set scenario to the embedding dimension. Meanwhile, given text and visual prompts, we employ RepRTA and SAVPE to encode them as normalized prompt embeddings $\mathcal{P}$ , respectively. They serve as the classification weights and contrast with the anchor points’ object embeddings $\mathcal{O}$ to obtain category labels. The process can be formalized as
如图 2 所示,YOLOE 采用了典型的 YOLOs 架构 [1, 21, 47],包括骨干网络、PAN、回归头、分割头和物体嵌入头。骨干网络和 PAN 提取图像的多尺度特征。对于每个锚点,回归头预测检测的边界框,分割头生成分割的原型和掩码系数 [3]。物体嵌入头遵循 YOLOs 中分类头的结构,只是将最后一层 $1\times$ 卷积层的输出通道数从封闭场景中的类别数更改为嵌入维度。同时,给定文本和视觉提示,我们使用 RepRTA 和 SAVPE 将它们分别编码为归一化的提示嵌入 $\mathcal{P}$。它们作为分类权重,并与锚点的物体嵌入 $\mathcal{O}$ 进行对比以获得类别标签。该过程可以形式化为
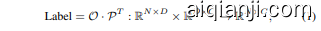
where $N$ denotes the number of anchor points, $C$ indicates the number of prompts, and $D$ means the feature dimension of embeddings, respectively.
其中 $N$ 表示锚点数量,$C$ 表示提示数量,$D$ 表示嵌入的特征维度。
3.2. Re-parameter iz able region-text alignment
3.2. 可重参数化的区域-文本对齐
In open-set scenarios, the alignment between textual and object embeddings determines the accuracy of identified categories. Prior works usually introduce complex crossmodality fusion to improve the visual-textual representation for better alignment [5, 37]. However, these ways incur notable computational overhead, especially with large number of texts. Given this, we present Re-parameter iz able RegionText Alignment (RepRTA) strategy, which improves pretrained textual embeddings during training through the reparameter iz able lightweight auxiliary network. The alignment between textual and anchor points’ object embeddings can be enhanced with zero inference and transferring cost.
在开放集场景中,文本嵌入与物体嵌入的对齐决定了识别类别的准确性。先前的工作通常引入复杂的跨模态融合来改进视觉-文本表示,以实现更好的对齐 [5, 37]。然而,这些方法会带来显著的计算开销,尤其是在文本数量较多时。鉴于此,我们提出了可重参数化的区域文本对齐 (RepRTA) 策略,该策略通过可重参数化的轻量级辅助网络在训练过程中改进预训练的文本嵌入。文本嵌入与锚点物体嵌入的对齐可以在零推理和迁移成本的情况下得到增强。
Specifically, with the text prompts of $T$ with length of $C$ , we first employ the CLIP text encoder [44, 57] to obtain pretrained textual embedding $P=\mathrm{TextEncoder}(T)$ . Before training, we cache all embeddings of texts in datasets in advance and the text encoder can be removed with no extra training cost. Meanwhile, as shown in Fig. 3.(a), we introduce a lightweight auxiliary network $f_{\theta}$ with only one feed forward block [53, 58], where $\theta$ indicates the trainable parameters and introduces low overhead compared with closed-set training. It derives the enhanced textual embedding $\mathcal{P}=f_{\theta}(P)\stackrel{\cdot}{\in}\mathbb{R}^{C\times D}$ for contrasting with the anchor points’ object embedding during training, leading to improved visual-semantic alignment. Let K ∈ RD×D′×1×1 be the kernel parameters of last convolution layer with input features $\overset{\cdot}{I}\in\mathbb{R}^{D^{\prime}\times H\times W}$ in the object embedding head, $\circledast$ be the convolution operator, and $R$ be the reshape function, we have
具体来说,对于长度为 $C$ 的文本提示 $T$,我们首先使用 CLIP 文本编码器 [44, 57] 获得预训练的文本嵌入 $P=\mathrm{TextEncoder}(T)$。在训练之前,我们预先缓存了数据集中所有文本的嵌入,因此文本编码器可以在不增加额外训练成本的情况下移除。同时,如图 3(a) 所示,我们引入了一个轻量级的辅助网络 $f_{\theta}$,它仅包含一个前馈块 [53, 58],其中 $\theta$ 表示可训练参数,与闭集训练相比,引入的开销较低。它生成增强的文本嵌入 $\mathcal{P}=f_{\theta}(P)\stackrel{\cdot}{\in}\mathbb{R}^{C\times D}$,用于在训练过程中与锚点的对象嵌入进行对比,从而改善视觉-语义对齐。设 K ∈ RD×D′×1×1 为对象嵌入头中最后一个卷积层的核参数,输入特征为 $\overset{\cdot}{I}\in\mathbb{R}^{D^{\prime}\times H\times W}$,$\circledast$ 为卷积运算符,$R$ 为重塑函数,我们有

Moreover, after training, the auxiliary network can be reparameterized with the object embedding head into the identical classification head of YOLOs. The new kernel parameters $K^{\prime}\in\mathbb{R}^{C\times D^{\prime}\times1\times1}$ for last convolution layer after re-parameter iz ation can be derived by
此外,训练完成后,辅助网络可以通过目标嵌入头重新参数化为 YOLOs 相同的分类头。重新参数化后,最后一层卷积层的新内核参数 $K^{\prime}\in\mathbb{R}^{C\times D^{\prime}\times1\times1}$ 可以通过以下方式得出:
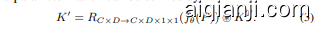
The final predication can be obtained by $\mathrm{Label}=I\circledast K^{\prime}$ , which is identical to the original YOLO architecture, leading to zero overhead for deployment and transferring to downstream closed-set tasks.
最终的预测可以通过 $\mathrm{Label}=I\circledast K^{\prime}$ 获得,这与原始的 YOLO 架构相同,因此在部署和迁移到下游闭集任务时不会产生额外开销。
3.3. Semantic-activated visual prompt encoder
3.3. 语义激活的视觉提示编码器
Visual prompts are designed to indicate the object category of interest through visual cues, e.g., box and mask. To produce the visual prompt embedding, prior works often employ transformer-heavy design [20, 30], e.g., deformable attention [78], or additional CLIP vision encoder [44, 67]. These ways, however, introduce challenges in deployment and efficiency due to complex operators or high computational demands. Considering this, we introduce Semantic-Activated Visual Prompt Encoder (SAVPE) for efficiently processing visual cues. It features two decoupled lightweight branches: (1) Semantic branch outputs prompt-agnostic semantic features in $D$ channels without overhead of fusing visual cues, and (2) Activation branch produces grouped prompt-aware weights by interacting visual cues with image features in much fewer channels under low costs. Their aggregation then leads to informative prompt embedding under minimal complexity.
视觉提示旨在通过视觉线索(例如框和掩码)指示感兴趣的对象类别。为了生成视觉提示嵌入,先前的工作通常采用基于 Transformer 的设计 [20, 30],例如可变形注意力 [78],或额外的 CLIP 视觉编码器 [44, 67]。然而,由于复杂的操作或高计算需求,这些方法在部署和效率方面带来了挑战。考虑到这一点,我们引入了语义激活视觉提示编码器 (SAVPE) 来高效处理视觉线索。它具有两个解耦的轻量级分支:(1) 语义分支在没有融合视觉线索的开销下输出与提示无关的语义特征,通道数为 $D$;(2) 激活分支通过在较少通道中以低成本将视觉线索与图像特征交互,生成分组的提示感知权重。它们的聚合在最小复杂度下产生信息丰富的提示嵌入。
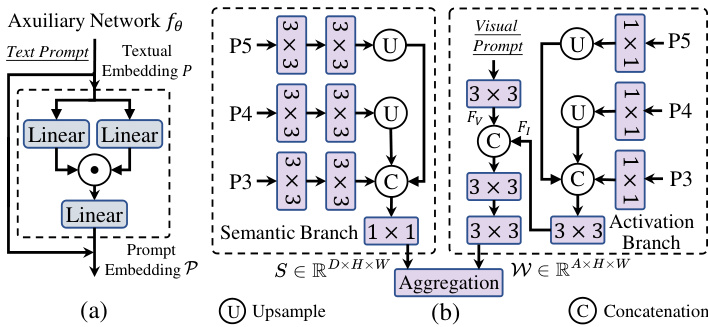
Figure 3. (a) The structure of lightweight auxiliary network in RepRTA, which consists of one SwiGLU FFN block [53]. (b) The structure of SAVPE, which consists of semantic branch to generate prompt-agnostic semantic features and activation branch to provide grouped prompt-aware weights. Visual prompt embedding can thus be efficiently derived by their aggregation.
图 3: (a) RepRTA 中的轻量级辅助网络结构,由一个 SwiGLU FFN 块 [53] 组成。(b) SAVPE 的结构,由语义分支和激活分支组成,语义分支生成与提示无关的语义特征,激活分支提供分组提示感知权重。通过它们的聚合,可以高效地生成视觉提示嵌入。
As shown in Fig. 3.(b), in the semantic branch, we adopt the similar structure as object embedding head. With multiscale features ${P_{3},P_{4},P_{5}}$ from PAN, we employ two $3\times3$ convs for each scale, respectively. After upsampling, features are concatenated and projected to derive semantic features $S~\in~\mathbb{R}^{D\times H\times W}$ . In the activation branch, we formalize visual prompt as mask with 1 for indicated region and 0 for others. We downsample it and leverage $3\times3$ conv to derive prompt feature $F_{V}\in\mathbb{R}^{A\times H\times W}$ . Besides, we obtain image features $F_{I}\in\mathbb{R}^{A\times H\times W}$ for fusion with it from ${P_{3},P_{4},P_{5}}$ by convs. $F_{V}$ and $F_{I}$ are then concatenated and utilized to output prompt-aware weights $\mathcal{W}\in\mathbb{R}^{A\times H\times W}$ , which is normalized using softmax within prompt-indicated region. Moreover, we divide the channels of $S$ into $A$ groups with $\textstyle{\frac{D}{A}}$ channels in each. The channels in the $i$ -th group share the weight $\mathcal{W}_{i:i+1}$ from the $i\cdot$ - th channel of $\mathcal{W}$ . With $A\ll D$ , we can process visual cues with image features in low dimension, bringing minimal cost. Furthermore, prompt embedding can be derived with aggregation of two branches by
如图 3(b) 所示,在语义分支中,我们采用了与对象嵌入头相似的结构。利用 PAN 提供的多尺度特征 ${P_{3},P_{4},P_{5}}$,我们分别为每个尺度使用了两个 $3\times3$ 卷积。上采样后,特征被拼接并投影以得到语义特征 $S~\in~\mathbb{R}^{D\times H\times W}$。在激活分支中,我们将视觉提示形式化为掩码,指示区域为 1,其他区域为 0。我们对其进行下采样,并利用 $3\times3$ 卷积得到提示特征 $F_{V}\in\mathbb{R}^{A\times H\times W}$。此外,我们从 ${P_{3},P_{4},P_{5}}$ 通过卷积获得图像特征 $F_{I}\in\mathbb{R}^{A\times H\times W}$,用于与其融合。$F_{V}$ 和 $F_{I}$ 随后被拼接并用于输出提示感知权重 $\mathcal{W}\in\mathbb{R}^{A\times H\times W}$,该权重在提示指示区域内使用 softmax 进行归一化。此外,我们将 $S$ 的通道分为 $A$ 组,每组有 $\textstyle{\frac{D}{A}}$ 个通道。第 $i$ 组中的通道共享来自 $\mathcal{W}$ 第 $i\cdot$ 个通道的权重 $\mathcal{W}_{i:i+1}$。由于 $A\ll D$,我们可以在低维度下处理视觉线索,带来最小的成本。此外,提示嵌入可以通过两个分支的聚合得到。

It can thus contrast with anchor points’ object embeddings to identify objects with category of interest.
因此,它可以与锚点的对象嵌入进行对比,以识别具有感兴趣类别的对象。
3.4. Lazy region-prompt contrast
3.4. 惰性区域提示对比
In prompt-free scenario without explicit guidance, models are expected to identity all objects with names in the image. Prior works usually formulate such setting as a generative problem, where language model is employed to generate categories for dense found objects [33, 49, 62]. However, this introduces notable overhead, where language models, e.g., FlanT5-base [6] with 250M parameters in GenerateU [33] and OPT-125M [73] in DINO-X [49], are far from meeting high efficiency requirement. Given this, we reformulate such setting as a retrieval problem and present Lazy Region-Prompt Contrast (LRPC) strategy. It lazily retrieves category names from a built-in large vocabulary for anchor points with objects in the cost-effective way. Such paradigm enjoys zero dependency on language models, meanwhile with favorable efficiency and performance.
在没有明确指导的无提示场景中,模型需要识别图像中所有命名的对象。先前的工作通常将此类场景形式化为生成问题,即使用大语言模型为密集找到的对象生成类别 [33, 49, 62]。然而,这引入了显著的开销,例如 GenerateU [33] 中使用的 FlanT5-base [6](具有 2.5 亿参数)和 DINO-X [49] 中的 OPT-125M [73],远未满足高效率要求。鉴于此,我们将此类场景重新形式化为检索问题,并提出了惰性区域提示对比(LRPC)策略。它以成本效益高的方式从内置的大词汇表中惰性检索带有对象的锚点的类别名称。这种范式完全不依赖大语言模型,同时具有良好的效率和性能。
Specifically, with pretrained YOLOE, we introduce a specialized prompt embedding and train it exclusively to find all objects, where objects are treated as one category. Meanwhile, we follow [16] to collect a large vocabulary which covers various categories and serve as the built-in data source for retrieval. One may directly leverage the large vocabulary as text prompts for YOLOE to identify all objects, which, however, incurs notable computational cost by contrasting abundant anchor points’ object embeddings with numerous textual embeddings. Instead, we employ the specialized prompt embedding $\mathcal{P}_{s}$ to find the set $\mathcal{O}^{\prime}$ of anchor points corresponding to objects by
具体来说,借助预训练的 YOLOE,我们引入了一个专门的提示嵌入 (prompt embedding),并对其进行专门训练以找到所有对象,这些对象被视为一个类别。同时,我们遵循 [16] 的方法收集了一个覆盖各类别的大词汇表,并将其作为检索的内置数据源。可以直接利用这个大词汇表作为 YOLOE 的文本提示来识别所有对象,但这会通过将大量锚点的对象嵌入与众多文本嵌入进行对比而带来显著的计算成本。相反,我们采用专门的提示嵌入 $\mathcal{P}_{s}$ 来找到对应于对象的锚点集合 $\mathcal{O}^{\prime}$。

where $\mathcal{O}$ denotes all anchor points and $\delta$ is the threshold hyper parameter for filtering. Then, only anchor points in $\mathcal{O}^{\prime}$ are lazily matched against the built-in vocabulary to retrieve category names, bypassing the cost for irrelevant anchor points. This further improves efficiency without performance drop, facilitating the real world application.
其中 $\mathcal{O}$ 表示所有锚点,$\delta$ 是用于过滤的阈值超参数。然后,仅对 $\mathcal{O}^{\prime}$ 中的锚点进行懒匹配,以检索类别名称,从而避免了对不相关锚点的开销。这进一步提高了效率且不会导致性能下降,有助于实际应用。
3.5. Training objective
3.5. 训练目标
During training, we follow [5] to obtain an online vocabulary for each mosaic sample with the texts involved in the images as positive labels. Following [21], we leverage taskaligned label assignment to match predictions with ground truths. The binary cross entropy loss is employed for classification, with IoU loss and distributed focal loss adopted for regression. For segmentation, we follow [3] to utilize binary cross-entropy loss for optimizing masks.
在训练过程中,我们遵循 [5] 为每个马赛克样本获取在线词汇表,并将图像中的文本作为正标签。根据 [21],我们利用任务对齐的标签分配将预测与真实值匹配。分类采用二元交叉熵损失,回归采用 IoU 损失和分布式焦点损失。对于分割,我们遵循 [3] 使用二元交叉熵损失来优化掩码。
4. Experiments
4. 实验
4.1. Implementation details
4.1. 实现细节
Model. For fair comparison with [5], we employ the same YOLOv8 architecture [21] for YOLOE. Besides, to verify its good general iz ability on other YOLOs, we also experiment with YOLO11 architecture [21]. For both of them, we provide three model scales, i.e., small (S), medium (M), and large (L), to suit various application needs. Text prompts are encoded using the pretrained MobileCLIP-B(LT) [57] text encoder. We empirically use $A=16$ in SAVPE, by default.
模型。为了与[5]进行公平比较,我们在YOLOE中采用了相同的YOLOv8架构[21]。此外,为了验证其在其他YOLO架构上的良好泛化能力,我们还使用了YOLO11架构[21]进行实验。对于这两种架构,我们提供了三种模型规模,即小型(S)、中型(M)和大型(L),以适应不同的应用需求。文本提示使用预训练的MobileCLIP-B(LT)[57]文本编码器进行编码。默认情况下,我们经验性地在SAVPE中使用$A=16$。
Data. We follow [5] to utilize detection and grounding datasets, including Objects365 (V1) [52], GoldG [22] (includes GQA [17] and Flickr30k [43]), where images from COCO [34] are excluded. Beside, we leverage advanced SAM-2.1 [46] model to generate pseudo instance masks using ground truth bounding boxes from the detection and grounding datasets for segmentation data. These masks undergo filtering and simplification to eliminate noise [9]. For visual prompt data, we follow [20] to leverage ground truth bounding boxes for visual cues. In prompt-free tasks, we reuse the same datasets, but annotate all objects as a single category to learn a specialized prompt embedding.
数据。我们遵循 [5] 使用检测和定位数据集,包括 Objects365 (V1) [52]、GoldG [22](包含 GQA [17] 和 Flickr30k [43]),其中排除了来自 COCO [34] 的图像。此外,我们利用先进的 SAM-2.1 [46] 模型,通过检测和定位数据集中的真实边界框生成伪实例掩码,用于分割数据。这些掩码经过过滤和简化以消除噪声 [9]。对于视觉提示数据,我们遵循 [20] 利用真实边界框作为视觉提示。在无提示任务中,我们复用相同的数据集,但将所有对象标注为单一类别以学习专门的提示嵌入。
Training. Due to limited computational resource, unlike YOLO-World’s training for 100 epochs, we first train YOLOE with text prompts for 30 epochs. Then, we only train the SAVPE for merely 2 epochs with visual prompts, which avoids additional significant training cost that comes with supporting visual prompts. At last, we train the specialized prompt embedding for only 1 epoch for promptfree scenarios. During the text prompt training stage, we adopt the same settings as [5]. Notably, YOLOE-v8-S / M $/\mathrm{L}$ can be trained on 8 Nvidia RTX4090 GPUs in $12.0~/$ $17.0/22.5$ hours, with $3\times$ less cost compared with YOLOWorld. For visual prompt training, we freeze all other parts and adopt the same setting as in text prompt training. To enable prompt-free capability, we leverage the same data to train a specialized embedding. We can see that YOLOE not only enjoys low training costs but also show exceptional zero-shot performance. Besides, to verify YOLOE’s good transfer ability on downstream tasks, we fine-tune our YOLOE on COCO [34] for closed-set detection and segmentation. We experiment with two distinct practical finetuning strategies: (1) Linear probing: Only the classification head is learnable and (2) Full tuning: All parameters are trainable. For Linear probing, we train all models for only 10 epochs. For Full tuning, we train small scale models including YOLOE-v8-S / 11-S for 160 epochs, and medium and large scale models including YOLOE-v8-M / L and YOLOE-11-M / L for 80 epochs, respectively.
训练。由于计算资源有限,与 YOLO-World 的 100 轮训练不同,我们首先使用文本提示训练 YOLOE 30 轮。然后,我们仅使用视觉提示训练 SAVPE 2 轮,这避免了支持视觉提示带来的额外显著训练成本。最后,我们仅为无提示场景训练专用提示嵌入 1 轮。在文本提示训练阶段,我们采用与 [5] 相同的设置。值得注意的是,YOLOE-v8-S / M $/\mathrm{L}$ 可以在 8 个 Nvidia RTX4090 GPU 上分别训练 $12.0~/$ $17.0/22.5$ 小时,与 YOLOWorld 相比,成本减少了 $3\times$ 。对于视觉提示训练,我们冻结所有其他部分并采用与文本提示训练相同的设置。为了实现无提示能力,我们利用相同的数据训练专用嵌入。我们可以看到,YOLOE 不仅训练成本低,而且表现出出色的零样本性能。此外,为了验证 YOLOE 在下游任务中的良好迁移能力,我们在 COCO [34] 上微调 YOLOE 以进行闭集检测和分割。我们实验了两种不同的实际微调策略:(1)线性探测:仅分类头可学习;(2)完全微调:所有参数可训练。对于线性探测,我们仅训练所有模型 10 轮。对于完全微调,我们训练包括 YOLOE-v8-S / 11-S 的小规模模型 160 轮,训练包括 YOLOE-v8-M / L 和 YOLOE-11-M / L 的中大规模模型 80 轮。
Metric. For text prompt evaluation, we utilize all category names from the benchmark as inputs, adhering to the standard protocol for open-vocabulary object detection tasks. For visual prompt evaluation, following [20], for each category, we randomly sample $N$ training images $N{=}16$ by default), extract visual embeddings using their ground truth bounding boxes, and compute the average prompt embedding. For prompt-free evaluation, we employ the same protocol as [33]. A pretrained text encoder [57] is employed to map open-ended predictions to semantically similar category names within the benchmark. In contrast to [33], we streamline the mapping process by selecting the most confident prediction, and eliminating the need for top $\mathbf{\nabla\cdotk}$ selection and beam search. We use the tag list from [16] as the built-in large vocabulary with total 4585 category names, and empirically use $\delta=0.001$ for LRPC, by default. For all three prompt types, following [5, 20, 33], evaluations are conducted on LVIS [14] in a zero-shot manner, which contains 1,203 categories. By default, Fixed AP [7] on LVIS minival subset is reported. For transferring to COCO, standard AP is evaluated, following [1, 21]. Besides, we measure the FPS for all models on Nvidia T4 GPU with TensorRT and mobile device iPhone 12 with CoreML.
评估指标。对于文本提示的评估,我们利用基准测试中的所有类别名称作为输入,遵循开放词汇对象检测任务的标准协议。对于视觉提示的评估,遵循 [20],对于每个类别,我们默认随机采样 $N$ 张训练图像 ($N{=}16$),使用其真实边界框提取视觉嵌入,并计算平均提示嵌入。对于无提示的评估,我们采用与 [33] 相同的协议。使用预训练的文本编码器 [57] 将开放预测映射到基准测试中的语义相似类别名称。与 [33] 不同的是,我们通过选择最具信心的预测来简化映射过程,无需进行 top $\mathbf{\nabla\cdotk}$ 选择和束搜索。我们使用 [16] 中的标签列表作为内置的大词汇表,总共有 4585 个类别名称,并默认使用 $\delta=0.001$ 进行 LRPC。对于所有三种提示类型,遵循 [5, 20, 33],在 LVIS [14] 上进行零样本评估,其中包含 1,203 个类别。默认情况下,报告在 LVIS 小验证子集上的 Fixed AP [7]。对于迁移到 COCO,遵循 [1, 21] 评估标准 AP。此外,我们在 Nvidia T4 GPU 上使用 TensorRT 和在 iPhone 12 移动设备上使用 CoreML 测量所有模型的 FPS。
Table 1. Zero-shot detection evaluation on LVIS. For fair comparisons, Fixed $A P$ is reported on LVIS minival set in a zero-shot manner. The training time is for text prompts, based on 8 Nvidia V100 GPUs for [32, 65] and 8 RTX4090 GPUs for YOLO-World and YOLOE. The FPS is measured on Nvidia T4 GPU using TensorRT and on iPhone 12 using CoreML, respectively. Results are provided with text prompt (T) and visual prompt (V) type. For training data, OI, HT, and CH indicates OpenImages [24], HierText [39], and CrowdHuman [51], respectively. OG indicates Objects365 [52] and GoldG [22], and G-20M represents Grounding-20M [50].
表 1: LVIS 上的零样本检测评估。为了公平比较,Fixed $A P$ 在 LVIS minival 集上以零样本方式报告。训练时间基于 8 个 Nvidia V100 GPU 用于 [32, 65] 和 8 个 RTX4090 GPU 用于 YOLO-World 和 YOLOE。FPS 分别在 Nvidia T4 GPU 上使用 TensorRT 和在 iPhone 12 上使用 CoreML 进行测量。结果提供了文本提示 (T) 和视觉提示 (V) 类型。对于训练数据,OI、HT 和 CH 分别表示 OpenImages [24]、HierText [39] 和 CrowdHuman [51]。OG 表示 Objects365 [52] 和 GoldG [22],G-20M 表示 Grounding-20M [50]。
| 模型 | 提示类型 | 参数量 | 训练数据 | 训练时间 | FPS T4 /iPhone | AP | APr | APc | APf |
|---|---|---|---|---|---|---|---|---|---|
| GLIP-T [32] | T | 232M | OG,Cap4M | 1337.6h | - / - | 26.0 | 20.8 | 21.4 | 31.0 |
| GLIPv2-T [70] | T | 232M | OG,Cap4M | - | - / - | 29.0 | |||
| GDINO-T[37] | T | 172M | OG,Cap4M | - / - | 27.4 | 18.1 | 23.3 | 32.7 | |
| DetCLIP-T [65] | T | 155M | OG | 250.0h | - / - | 34.4 | 26.9 | 33.9 | 36.3 |
| G-1.5 Edge [50] | T | G-20M | - / - | 33.5 | 28.0 | 34.3 | 33.9 | ||
| T-Rex2 [20] | V | 0365,OI,HT CH,SA-1B | - / - | 37.4 | 29.9 | 33.9 | 41.8 | ||
| YWorldv2-S [5] | T | 13M | OG | 41.7h | 216.4 / 48.9 | 24.4 | 17.1 | 22.5 | 27.3 |
| YWorldv2-M [5] | T | 29M | OG | 60.0h | 117.9/34.2 | 32.4 | 28.4 | 29.6 | 35.5 |
| YWorldv2-L [5] | T | 48M | OG | 80.0h | 80.0/22.1 | 35.5 | 25.6 | 34.6 | 38.1 |
| YOLOE-v8-S | T/V | 12M/13M | OG | 12.0h | 305.8 / 64.3 | 27.9/26.2 | 22.3/21.3 | 27.8/27.7 | 29.0 /25.7 |
| YOLOE-v8-M | T/V | 27M/30M | OG | 17.0h | 156.7/ 41.7 | 32.6/31.0 | 26.9/27.0 | 31.9/31.7 | 34.4 /31.1 |
| YOLOE-v8-L | T/V | 45M/50M | OG | 22.5h | 102.5/27.2 | 35.9/34.2 | 33.2/33.2 | 34.8 / 34.6 | 37.3 /34.1 |
| YOLOE-11-S | T/V | 10M/12M | OG | 13.0h | 301.2/73.3 | 27.5/26.3 | 21.4 /22.5 | 26.8 / 27.1 | 29.3 / 26.4 |
| YOL0E-11-M | T/V | 21M/27M | OG | 18.5h | 168.3 / 39.2 | 33.0/31.4 | 26.9 / 27.1 | 32.5 /31.9 | 34.5 / 31.7 |
| YOLOE-11-L | T/V | 26M/32M | OG | 23.5h | 130.5 / 35.1 | 35.2 /33.7 | 29.1 / 28.1 | 35.0 / 34.6 | 36.5 / 33.8 |
4.2. Text and visual prompt evaluation
4.2. 文本与视觉提示评估
As shown in Tab. 1, for detection on LVIS, YOLOE exhibits favorable trade-offs between efficiency and zero-shot performance across different model scales. We also note that such results are achieved under much less training time, e.g., $3\times$ faster than YOLO-Worldv2. Specifically, YOLOE $\mathrm{v}8\mathrm{-}\mathrm{S}/\mathrm{M}/\mathrm{L}$ outperforms YOLOv8-Worldv2-S / M / L by $3.5/0.2/0.4$ AP, along with $1.4\times\textit{/}1.3\times\textit{/}1.3\times$ and $1.3\times\textit{/}1.2\times\textit{/}1.2\times$ inference speedups on T4 and iPhone 12, respectively. Besides, for rare category which is challenging, our YOLOE-v8-S and YOLOE-v8-L obtains significant improvements of $5.2%$ and $7.6%$ $\mathrm{AP}{r}$ . Besides, compared with YOLO-Worldv2, while YOLOE-v8-M / L achieves lower $\operatorname{AP}{f}$ , this performance gap primarily stems from YOLOE’s integration of both detection and segmentation in one model. Such multi-task learning introduces a trade-off that adversely impact detection performance on frequent categories, as shown in Tab. 5. Besides, YOLOE with YOLO11 architecture also exhibits favorable performance and efficiency. For example, YOLOE-11-L achieves comparable AP with YOLO-Worldv2-L, but with notably $1.6\times$ inference speedups on T4 and iPhone 12, highlighting the strong general iz ability of our YOLOE.
如表 1 所示,在 LVIS 上的检测任务中,YOLOE 在不同模型规模下展现了效率与零样本性能之间的良好权衡。我们还注意到,这些结果是在更短的训练时间内实现的,例如比 YOLO-Worldv2 快 $3\times$。具体而言,YOLOE $\mathrm{v}8\mathrm{-}\mathrm{S}/\mathrm{M}/\mathrm{L}$ 在 AP 上分别优于 YOLOv8-Worldv2-S / M / L $3.5/0.2/0.4$,同时在 T4 和 iPhone 12 上的推理速度分别提升了 $1.4\times\textit{/}1.3\times\textit{/}1.3\times$ 和 $1.3\times\textit{/}1.2\times\textit{/}1.2\times$。此外,对于具有挑战性的稀有类别,我们的 YOLOE-v8-S 和 YOLOE-v8-L 在 $\mathrm{AP}{r}$ 上分别取得了 $5.2%$ 和 $7.6%$ 的显著提升。另外,与 YOLO-Worldv2 相比,虽然 YOLOE-v8-M / L 的 $\operatorname{AP}{f}$ 较低,但这一性能差距主要源于 YOLOE 在一个模型中同时集成了检测和分割任务。这种多任务学习引入了一种权衡,对频繁类别的检测性能产生了不利影响,如表 5 所示。此外,采用 YOLO11 架构的 YOLOE 也展现了良好的性能和效率。例如,YOLOE-11-L 的 AP 与 YOLO-Worldv2-L 相当,但在 T4 和 iPhone 12 上的推理速度显著提升了 $1.6\times$,凸显了我们 YOLOE 的强大泛化能力。
Moreover, the inclusion of visual prompts further amplifies YOLOE’s versatility. Compared with T-Rex2, YOLOEv8-L yield the improvements of $3.3\mathrm{AP}{r}$ and $0.9\mathrm{AP}{c}$ , with $2\times$ less training data $(3.1\mathrm{M}$ vs. Our: $1.4\mathrm{M},$ ) and much lower training resource (16 Nvidia A100 GPUs vs. Our: 8 Nvidia RTX4090 GPUs). Besides, for visual prompts, while we only train SAVPE with other parts frozen for 2 epochs, we note that it can achieve comparable $\mathrm{AP}{r}$ and $\mathrm{AP}{c}$ with the text prompts for various model scales. This shows the efficacy of visual prompts in less frequent objects that text prompts often struggle to accurately describe, which is similar to the observation in [20].
此外,视觉提示的加入进一步增强了 YOLOE 的多功能性。与 T-Rex2 相比,YOLOEv8-L 在 $3.3\mathrm{AP}{r}$ 和 $0.9\mathrm{AP}{c}$ 上取得了提升,同时使用了 $2\times$ 更少的训练数据 $(3.1\mathrm{M}$ vs. 我们的: $1.4\mathrm{M},$ ) 和更低的训练资源 (16 张 Nvidia A100 GPU vs. 我们的: 8 张 Nvidia RTX4090 GPU)。此外,对于视觉提示,虽然我们只训练了 SAVPE,其他部分冻结了 2 个 epoch,但我们注意到它在各种模型规模上可以达到与文本提示相当的 $\mathrm{AP}{r}$ 和 $\mathrm{AP}{c}$。这表明视觉提示在文本提示难以准确描述的较少出现的物体上的有效性,这与 [20] 中的观察结果类似。
Furthermore, for segmentation, we present the evaluation results on the LVIS val set with the standard $\mathbf{A}\mathbf{P}^{m}$ reported in Tab. 2. It shows that YOLOE exhibits strong performance by leveraging both text prompts and visual prompts. Specifically, YOLOE-v8-M / L achieves 20.8 and $23.5~\mathrm{AP}^{m}$ in the zero-shot manner, significantly outperforming YOLO-Worldv2-M $/\mathrm{L}$ that is fine-tuned on LVIS-Base dataset, by 3.0 and $3.7\mathrm{AP}^{m}$ , respectively. These results well show the superiority of YOLOE.
此外,对于分割任务,我们在 LVIS 验证集上展示了评估结果,标准 $\mathbf{A}\mathbf{P}^{m}$ 如表 2 所示。结果表明,YOLOE 通过结合文本提示和视觉提示,展现出强大的性能。具体而言,YOLOE-v8-M / L 在零样本方式下分别达到了 20.8 和 $23.5~\mathrm{AP}^{m}$,显著优于在 LVIS-Base 数据集上微调的 YOLO-Worldv2-M $/\mathrm{L}$,分别提升了 3.0 和 $3.7\mathrm{AP}^{m}$。这些结果充分展示了 YOLOE 的优越性。
4.3. Prompt-free evaluation
4.3. 无提示评估
As shown in Tab. 3, for prompt-free scenario, YOLOE also exhibits superior performance and efficiency. Specifically,
如表 3 所示,在无提示(prompt-free)场景下,YOLOE 也表现出卓越的性能和效率。具体来说,
Table 2. Segmentation evaluation on LVIS. We evaluate all models on LVIS val set with the standard $\mathbf{A}\mathbf{P}^{m}$ reported. YOLOE supports both text (T) and visual cues (V) as inputs. $^\dagger$ indicates that the pretrained models are fine-tuned on LVIS-Base data for segmentation head. In contrast, we evaluate YOLOE in a zero-shot manner without utilizing any images from LVIS during training.
表 2: LVIS 上的分割评估。我们在 LVIS val 集上评估所有模型,并报告标准的 $\mathbf{A}\mathbf{P}^{m}$。YOLOE 支持文本 (T) 和视觉线索 (V) 作为输入。$^\dagger$ 表示预训练模型在 LVIS-Base 数据上进行了分割头的微调。相比之下,我们在零样本方式下评估 YOLOE,在训练过程中没有使用任何来自 LVIS 的图像。
| 模型 | 提示 | APm | APm | APm C | APm |
|---|---|---|---|---|---|
| YWorld-M | T | 16.7 | 12.6 | 14.6 | 20.8 |
| YWorld-Lt | T | 19.1 | 14.2 | 17.2 | 23.5 |
| YWorldv2-Mt | T | 17.8 | 13.9 | 15.5 | 22.0 |
| YWorldv2-Lt | T | 19.8 | 17.2 | 17.5 | 23.6 |
| YOLOE-v8-S | T/V | 17.7/16.8 | 15.5/13.5 | 16.3/16.7 | 20.3/18.2 |
| YOLOE-v8-M | T/V | 20.8/20.3 | 17.2/17.0 | 19.2/20.1 | 24.2/22.0 |
| YOLOE-v8-L | T/V | 23.5/22.0 | 21.9/16.5 | 21.6/22.1 | 26.4/24.3 |
| YOLOE-11-S | T/V | 17.6/17.1 | 16.1/14.4 | 15.6/16.8 | 20.5/18.6 |
| YOLOE-11-M | T/V | 21.1/21.0 | 17.2/18.3 | 19.6/20.6 | 24.4/22.6 |
| YOLOE-11-L | T/V | 22.6/22.5 | 19.3/20.5 | 20.9/21.7 | 26.0/24.1 |
Table 3. Prompt-free evaluation on LVIS. Fixed $A P$ is reported on the LVIS minival set, following the protocol in [33]. The FPS is measured on Nvidia T4 GPU with Pytorch [42].
表 3. LVIS 上的无提示评估。按照 [33] 中的协议,在 LVIS minival 集上报告了固定的 $AP$。FPS 是在 Nvidia T4 GPU 上使用 Pytorch [42] 测量的。
| 模型 | Backbone | Params | AP | APr | APc | APf | FPS |
|---|---|---|---|---|---|---|---|
| GenerateU [33] | Swin-T | 297M | 26.8 | 320.0 | 24.9 | 29.8 | 0.48 |
| GenerateU [33] | Swin-L | 467M | 27.9 | 22.3 | 25.2 | 31.4 | 0.40 |
| YOLOE-v8-S | YOLOv8-S | 13M | 21.0 | 19.1 | 21.3 | 21.0 | 95.8 |
| YOLOE-v8-M | YOLOv8-M | 29M | 24.7 | 22.2 | 24.5 | 525.3 | 45.9 |
| YOLOE-v8-L | YOLOv8-L | 47M | 27.2 | 23.5 | 27.0 | 28.0 | - |
| YOLOE-11-S | YOLO11-S | 11M | 25.3 | 20.6 | 18.4 | 20.2 | 21.3 |
| YOL0E-11-M | YOL011-M | 24M | 25.5 | 21.6 | 525.5 | 26.1 | 42.5 |
YOLO-v8-L achieves 27.2 AP and $23.5\mathrm{AP}{r}$ , outperforming GenerateU with Swin-T backbone by $0.4~\mathrm{AP}$ and 3.5 $\mathrm{AP}{r}$ , along with $6.3\times$ fewer parameters and $53\times$ inference speedups. It shows the effectiveness of YOLOE by reformulating the open-ended problem as the retrieval task for a built-in large vocabulary and underscores its potential in generalizing across a wide range of categories without replying on explicit prompts. Such functionality also enhances YOLOE’s practicality, enabling its application in a broader range of real-world scenarios.
YOLO-v8-L 实现了 27.2 AP 和 $23.5\mathrm{AP}{r}$,以 $0.4~\mathrm{AP}$ 和 3.5 $\mathrm{AP}{r}$ 的优势超越了使用 Swin-T 骨干的 GenerateU,同时参数减少了 $6.3\times$,推理速度提升了 $53\times$。它通过将开放性问题重新表述为内置大词汇库的检索任务,展示了 YOLOE 的有效性,并强调了其在无需依赖显式提示的情况下跨广泛类别泛化的潜力。这种功能还增强了 YOLOE 的实用性,使其能够在更广泛的现实场景中应用。
4.4. Downstream transferring
4.4. 下游迁移
As shown in Tab. 4, when transferring to COCO for downstream closed-set detection and segmentation, YOLOE exhibits favorable performance under limited training epochs in both two fine-tuning strategies. Specifically, for Linear probing, with less than $2%$ of the training time, YOLOE $11{-}\mathbf{M}/\mathrm{L}$ can achieve over $80%$ of the performance of YOLO11-M $/\mathrm{L}$ , respectively. This highlights the strong transfer ability of YOLOE. For Full tuning, YOLOE can further enhance the performance under limited training cost. For example, with nearly $4\times$ less training epochs, YOLOE $\mathbf{v}8\mathbf{-M_{\mu}/\mathrm{L}}$ outperforms $\mathrm{YOLOv8–M/\OmegaL}$ by $0.4\mathrm{AP}^{m}$ and 0.6 $\mathbf{A}\mathbf{P}^{b}$ , respectively. Under $3\times$ less training time, YOLO-v8- S also obtains better performance compared with YOLOv8- S for both detection and segmentation. These results well demonstrate that YOLOE can serve as a strong starting point for transferring to downstream task.
如表 4 所示,当迁移到 COCO 进行下游闭集检测和分割时,YOLOE 在两种微调策略下都表现出在有限训练轮次中的良好性能。具体而言,对于线性探测 (Linear probing),在不到 $2%$ 的训练时间内,YOLOE $11{-}\mathbf{M}/\mathrm{L}$ 分别可以达到 YOLO11-M $/\mathrm{L}$ 超过 $80%$ 的性能。这凸显了 YOLOE 强大的迁移能力。对于完全微调 (Full tuning),YOLOE 可以在有限的训练成本下进一步提升性能。例如,在训练轮次减少近 $4\times$ 的情况下,YOLOE $\mathbf{v}8\mathbf{-M_{\mu}/\mathrm{L}}$ 分别以 $0.4\mathrm{AP}^{m}$ 和 0.6 $\mathbf{A}\mathbf{P}^{b}$ 优于 $\mathrm{YOLOv8–M/\OmegaL}$。在训练时间减少 $3\times$ 的情况下,YOLO-v8- S 在检测和分割方面也比 YOLOv8- S 获得了更好的性能。这些结果充分证明了 YOLOE 可以作为迁移到下游任务的强大起点。
Table 4. Downstream transfer on COCO. We fine-tune YOLOE on COCO and report the standard AP for both detection and segmentation. We experiment with two practical fine-tuning strategies, i.e., Linear probing and Full tuning.
表 4. COCO上的下游迁移。我们在COCO上对YOLOE进行微调,并报告检测和分割的标准AP。我们实验了两种实用的微调策略,即线性探测和全调优。
| 模型 | 训练轮数 | AP' | AP'o | AP75 | APm | AP | AP% |
|---|---|---|---|---|---|---|---|
| 从头训练 | YOLOv8-S | 500 | 44.7 | 61.4 | 48.7 | 36.6 | 58.0 |
| 从头训练 | YOLOv8-M | 300 | 50.0 | 66.8 | 54.8 | 40.5 | 63.4 |
| 从头训练 | YOLOv8-L | 300 | 52.4 | 69.3 | 57.2 | 42.3 | 66.0 |
| 从头训练 | YOLO11-S | 500 | 46.6 | 63.3 | 50.6 | 37.8 | 59.7 |
| 从头训练 | YOLO11-M | 600 | 51.5 | 68.5 | 55.7 | 41.5 | 65.0 |
| 从头训练 | YOLO11-L | 600 | 53.3 | 70.1 | 58.2 | 42.8 | 66.8 |
| 线性探测 | YOLOE-v8-S | 10 | 35.6 | 51.5 | 38.9 | 30.3 | 48.2 |
| 线性探测 | YOLOE-v8-M | 10 | 42.2 | 59.2 | 46.3 | 35.5 | 55.6 |
| 线性探测 | YOLOE-v8-L | 10 | 45.4 | 63.3 | 50.0 | 38.3 | 59.6 |
| 线性探测 | YOLOE-11-S | 10 | 37.0 | 52.9 | 40.4 | 31.5 | 49.7 |
| 线性探测 | YOLOE-11-M | 10 | 43.1 | 60.6 | 47.4 | 36.5 | 56.9 |
| 线性探测 | YOLOE-11-L | 10 | 45.1 | 62.8 | 49.5 | 38.0 | 59.2 |
| 全调优 | YOLOE-v8-S | 160 | 45.0 | 61.6 | 49.1 | 36.7 | 58.3 |
| 全调优 | YOLOE-v8-M | 80 | 50.4 | 67.0 | 55.2 | 40.9 | 63.7 |
| 全调优 | YOLOE-v8-L | 80 | 53.0 | 69.8 | 57.9 | 42.7 | 66.5 |
| 全调优 | YOLOE-11-S | 160 | 46.2 | 62.9 | 50.0 | 37.6 | 59.3 |
| 全调优 | YOLOE-11-M | 80 | 51.3 | 68.3 | 56.0 | 41.5 | 64.8 |
| 全调优 | YOLOE-11-L | 80 | 52.6 | 69.7 | 57.5 | 42.4 | 66.2 |
Table 5. Roadmap to YOLOE in terms of text prompts. The standard AP is reported on LVIS minival set in the zero-shot manner. The FPS is is measured on Nvidia T4 GPU and iPhone 12 with TensorRT (T) and CoreML (C), respectively.
表 5: YOLOE 在文本提示方面的路线图。标准 AP 是在 LVIS minival 数据集上以零样本方式报告的。FPS 分别在 Nvidia T4 GPU 和 iPhone 12 上使用 TensorRT (T) 和 CoreML (C) 进行测量。
| 模型 | Epochs | 6AP | APr | APc | APf | FPS (T/C) |
|---|---|---|---|---|---|---|
| YOLO-Worldv2-L | 100 | 33.0 | 22.6 | 32.0 | 35.8 | 80.0/22.1 |
| + Fewer train.epochs | 30 | 31.0 | 22.6 | 28.8 | 34.2 | 80.0/22.1 |
| + Global negative dict. | 30 | 31.9 | 22.8 | 31.0 | 34.4 | 80.0/22.1 |
| -Cross-modal.fusion | 30 | 30.0 | 19.1 | 28.0 | 33.9 | 102.5/27.2 |
| +MobileCLIPencoder | 30 | 31.5 | 20.2 | 30.5 | 34.4 | 102.5/27.2 |
| + RepRTA | 30 | 33.5 | 29.5 | 32.0 | 35.5 | 102.5/27.2 |
| 30 | 33.3 | 30.8 | 32.2 | 34.6 | 102.5/27.2 | |
| + Segment. (YOLOE) |
4.5. Ablation study
4.5. 消融研究
We further provide extensive analyses for the effectiveness of designs in our YOLOE. Experiments are conducted on YOLOE-v8-L and standard AP is reported on LVIS minival set for zero-shot evaluation, by default.
我们进一步对YOLOE中设计的有效性进行了广泛分析。默认情况下,实验在YOLOE-v8-L上进行,并在LVIS minival集上报告了标准AP,用于零样本评估。
Roadmap to YOLOE. We outline the stepwise progression from the baseline model YOLOv8-Worldv2-L to our
YOLOE 路线图。我们概述了从基线模型 YOLOv8-Worldv2-L 到我们的逐步进展。

Figure 4. (a) Zero-shot inference on LVIS. (b) Results with customized text prompt, where “white hat, red hat, white car, sunglasses, mustache, tie” are provided as text prompts. (c) Results with visual prompt, where the red dashed bounding box serves as the visual cues. (d) Results in prompt-free scenario, where no explicit prompt is provided. Please refer to the supplementary for more examples.
图 4. (a) LVIS 上的零样本推理。 (b) 使用自定义文本提示的结果,其中提供了“白色帽子、红色帽子、白色汽车、太阳镜、胡须、领带”作为文本提示。 (c) 使用视觉提示的结果,其中红色虚线边界框作为视觉线索。 (d) 无提示场景下的结果,其中未提供明确的提示。更多示例请参见补充材料。
Table 6. Effective. of SAVPE. Table 7. Effective. of LRPC.
| Model | AP | AP APc APf |
| Mask pool 30.4 | 27.6 31.3 30.2 | |
| SAVPE | 31.9 | 29.432.5 31.7 |
| A = 1 | 30.92 | 28.231.930.4 |
| A =16 | 31.9 | 29.432.531.7 |
| A=32 | 31.9 | 28.233.031.7 |
表 6: SAVPE 的效果。表 7: LRPC 的效果。
| Model | AP | AP APc APf |
|---|---|---|
| Mask pool | 30.4 | 27.6 31.3 30.2 |
| SAVPE | 31.9 | 29.4 32.5 31.7 |
| A = 1 | 30.92 | 28.2 31.9 30.4 |
| A =16 | 31.9 | 29.4 32.5 31.7 |
| A=32 | 31.9 | 28.2 33.0 31.7 |
| 模型 | LRPC | AP APr APcAPf FPS |
|---|---|---|
| v8-S | =1e-3 =1e-4 6: = 1e | 21.0 19.1 21.4 21.0 56.5 21.0 19.1 21.3 21.0 95.8 21.0 19.1 21.3 21.0 66.1 20.8 19.1 21.2 20.8 106 |
| v8-L | x 8=1e 3 | 27.2 23.5 27.0 28.0 19.9 27.2 23.5 27.0 28.0 25.3 |
YOLOE-v8-L in terms of text prompts in Tab. 5. With the initial baseline metric of $33.0%$ AP, due to limited computational resource, we first reduce the training epochs to 30, leading to $31.0%$ AP. Besides, instead of using empty string as negative texts for grounding data, we follow [65] by maintaining a global dictionary to sample more diverse negative prompts. The global dictionary is constructed by selecting category names that appear more than 100 times in the training data. This leads to $0.9%$ AP improvement. Next, we remove the cross-modality fusion to avoid costly visual-textual feature interaction, which results in $1.9%$ AP degradation but with $1.28\times$ and $1.23\times$ inference speedups on T4 and iPhone 12, respectively. To address this drop, we utilize stronger MobileCLIP-B(LT) text encoder [57] to obtain better pretrained textual embeddings, which recovers AP to $31.5%$ . Furthermore, we employ RepRTA to enhance the alignment between anchor points’ object and textual embeddings, which leads to notable $2.3%$ AP enhancement with zero inference overhead, showing its effectiveness. At last, we introduce the segmentation head and train YOLOE for detection and segmentation simultaneously. Although this leads to $0.2%$ AP and $0.9\mathrm{AP}_{f}$ drop due to multi-task learning, YOLOE gains ability to segment arbitrary objects.
在表 5 中的文本提示方面,YOLOE-v8-L 的初始基线指标为 $33.0%$ AP。由于计算资源有限,我们首先将训练周期减少到 30,导致 AP 降至 $31.0%$。此外,我们没有使用空字符串作为 grounding data 的负样本文本,而是遵循 [65],通过维护一个全局字典来采样更多样化的负样本提示。该全局字典是通过选择训练数据中出现超过 100 次的类别名称构建的。这带来了 $0.9%$ AP 的提升。接下来,我们移除了跨模态融合以避免昂贵的视觉-文本特征交互,这导致 AP 下降了 $1.9%$,但在 T4 和 iPhone 12 上的推理速度分别提高了 $1.28\times$ 和 $1.23\times$。为了解决这一下降,我们使用了更强的 MobileCLIP-B(LT) 文本编码器 [57] 以获得更好的预训练文本嵌入,将 AP 恢复到 $31.5%$。此外,我们采用 RepRTA 来增强锚点对象和文本嵌入之间的对齐,这带来了显著的 $2.3%$ AP 提升,且没有推理开销,显示了其有效性。最后,我们引入了分割头,并同时训练 YOLOE 进行检测和分割。尽管由于多任务学习导致 AP 下降了 $0.2%$ 和 $0.9\mathrm{AP}_{f}$,但 YOLOE 获得了分割任意对象的能力。
Effectiveness of SAVPE. To verify the effectiveness of SAVPE for visual inputs, we remove the activation branch and simply leverage mask pooling to aggregate semantic features with the formulated visual prompt mask. As shown in Tab. 6, SAVPE significantly outperforms “Mask pool” by 1.5 AP. This is because “Mask pool” neglects the varying semantic importance at different positions within promptindicated region, while our activation branch effectively models such difference, leading to improved aggregation of semantic features and better prompt embedding for contrast. We also examine the impact of different group numbers, i.e., $A$ , in the activation branch. As shown in Tab. 6, performance can also be enhanced with only a group, i.e., $A=1$ . Besides, we can achieve the strong performance of 31.9 AP under $A=16$ , obtaining the favorable balance, where more groups lead to marginal performance difference.
SAVPE的有效性。为了验证SAVPE在视觉输入上的有效性,我们移除了激活分支,并简单地利用掩码池化(mask pooling)来聚合语义特征与生成的视觉提示掩码。如表 6 所示,SAVPE显著优于“Mask pool”,AP值高出1.5。这是因为“Mask pool”忽略了提示区域内不同位置的语义重要性差异,而我们的激活分支有效建模了这种差异,从而改进了语义特征的聚合,并生成更好的对比提示嵌入。我们还研究了激活分支中不同组数,即 $A$ 的影响。如表 6 所示,即使只有一组(即 $A=1$),性能也能得到提升。此外,在 $A=16$ 下,我们可以达到31.9 AP的强劲性能,取得了良好的平衡,更多组数带来的性能差异较小。
Effectiveness of LRPC. To verify the effectiveness of LRPC for prompt-free setting, we introduce the baseline that directly leverage the built-in large vocabulary as text prompts for YOLOE to identify all objects. Tab. 7 presents the comparison results. We observe that with the same performance, our LRPC obtains notably $1.7\times\textit{/}1.3\times$ inference speedups for YOLOE-v8-S / L, respectively, by lazily retrieving the categories for anchor points with found objects and skipping the numerous irrelevant ones. These results well highlight its efficacy and practicality. Besides, with different threshold $\delta$ for filtering, LRPC can achieve different performance and efficiency trade-offs, e.g., enabling $1.9\times$ speedup for YOLOE-v8-S with only $0.2\mathrm{AP}$ drop.
LRPC的有效性。为了验证LRPC在无提示设置下的有效性,我们引入了一个基线方法,该方法直接利用内置的大词汇表作为文本提示,让YOLOE识别所有对象。表7展示了对比结果。我们观察到,在相同的性能下,我们的LRPC通过懒加载检索带有已发现对象的锚点类别,并跳过大量不相关的类别,分别为YOLOE-v8-S/L带来了显著的$1.7\times\textit{/}1.3\times$推理加速。这些结果充分凸显了其有效性和实用性。此外,通过不同的过滤阈值$\delta$,LRPC可以实现不同的性能与效率权衡,例如,在仅下降$0.2\mathrm{AP}$的情况下,为YOLOE-v8-S实现了$1.9\times$的加速。
4.6. Visualization analyses
4.6. 可视化分析
We conduct visualization analyses for YOLOE in four scenarios: (1) Zero-shot inference on LVIS in Fig. 4.(a), where its category names are text prompts, (2) Text prompts in Fig. 4.(b), where arbitrary texts can be input as prompts, (3) Visual prompts in Fig. 4.(c), where visual cues can be drawn as prompts, and (4) No explicit prompt in Fig. 4.(d), where model identifies all objects. We can see that YOLOE performs well and can accurately detect and segment various objects in these diverse scenarios, further showing its efficacy and practicality in various applications.
我们在四种场景下对 YOLOE 进行了可视化分析:(1) 图 4(a) 中对 LVIS 的零样本推理,其类别名称作为文本提示,(2) 图 4(b) 中的文本提示,可以输入任意文本作为提示,(3) 图 4(c) 中的视觉提示,可以绘制视觉线索作为提示,(4) 图 4(d) 中无明确提示,模型识别所有对象。我们可以看到,YOLOE 在这些多样化场景中表现良好,能够准确检测和分割各种对象,进一步展示了其在各种应用中的有效性和实用性。
5. Conclusion
5. 结论
In this paper, we present YOLOE, a single highly efficient model that seamlessly integrates object detection and segmentation across diverse open prompt mechanisms. Specifically, we introduce RepRTA, SAVPE, and LRPC to enable YOLOs to process textual prompt, visual cues, and prompt-free paradigm with favorable performance and low cost. Thanks to them, YOLOE enjoys strong capabilities and high efficiency for various prompt ways, enabling realtime seeing anything. We hope that it can serve as a strong baseline to inspire further advancements.
本文提出 YOLOE,一个高效的单模型,能够无缝集成目标检测和分割,适用于多种开放式提示机制。具体来说,我们引入了 RepRTA、SAVPE 和 LRPC,使 YOLO 能够处理文本提示、视觉线索和无提示范式,具有优异的性能和低成本。得益于这些技术,YOLOE 在各种提示方式下具备强大的能力和高效率,实现了实时感知。我们希望它能作为一个强大的基线,激发进一步的研究进展。
References
参考文献
A. More Implementation Details
A. 更多实现细节
Data. We employ Objects365[52], GoldG [22] (including GQA[17] and Flickr30k [43]) for training YOLOE. Tab. 8 present their details. We utilize SAM-2.1-Hiera-Large [46] to generate high-quality pseudo labeling of segmentation masks with ground truth bounding boxes as prompts. We filter out ones with too few areas. To enhance the smoothness of mask edges, we apply Gaussian kernel to masks, using $3\times3$ and $7\times7$ kernels for small and large ones, respectively. Besides, we refine the masks following [9], which iterative ly simplifies the mask contours. This reduces noise pixels while preserving overall structure.
数据。我们使用 Objects365 [52]、GoldG [22](包括 GQA [17] 和 Flickr30k [43])来训练 YOLOE。表 8 展示了它们的详细信息。我们利用 SAM-2.1-Hiera-Large [46] 生成高质量的分割掩码伪标签,并使用真实边界框作为提示。我们过滤掉面积过小的掩码。为了增强掩码边缘的平滑度,我们对掩码应用高斯核,分别使用 $3\times3$ 和 $7\times7$ 核来处理小掩码和大掩码。此外,我们按照 [9] 的方法对掩码进行优化,迭代简化掩码轮廓。这减少了噪声像素,同时保留了整体结构。
Table 8. Data details for YOLOE training.
| Dataset | Type | Box | Mask | Images | Anno. |
| Objects365[52] | Detection | √ | √ | 609k | 8,530k |
| GQA[17] | Grounding | √ | 621k | 3,662k | |
| Flickr [43] | Grounding | √ | √ | 149k | 638k |
表 8. YOLOE 训练数据详情。
| 数据集 | 类型 | 框 | 掩码 | 图像 | 标注 |
|---|---|---|---|---|---|
| Objects365[52] | 检测 | √ | √ | 609k | 8,530k |
| GQA[17] | 基础 | √ | 621k | 3,662k | |
| Flickr[43] | 基础 | √ | √ | 149k | 638k |
Training. For all models, we adopt AdamW optimizer with an initial learning rate of 0.002. The batch size and weight decay are set to 128 and 0.025, respectively. The data augmentation includes color jittering, random affine transformations, random horizontal flipping, and mosaic augmentation. During transferring to COCO, for both Linear probing and Full tuning, we utilize the AdamW optimizer with an initial learning rate of 0.001, setting the batch size and weight decay to 128 and 0.025, respectively.
训练。对于所有模型,我们采用 AdamW 优化器,初始学习率为 0.002。批量大小 (batch size) 和权重衰减 (weight decay) 分别设置为 128 和 0.025。数据增强包括颜色抖动、随机仿射变换、随机水平翻转和马赛克增强。在迁移到 COCO 时,对于线性探测 (Linear probing) 和完全微调 (Full tuning),我们使用 AdamW 优化器,初始学习率为 0.001,批量大小和权重衰减分别设置为 128 和 0.025。
B. More Analyses for LRPC
B. LRPC 的更多分析
To qualitatively show the efficacy of LRPC strategy, we visualize the number of anchor points retained for category retrieval after filtering. We present their average count under varying filtering threshold $\delta$ on the LVIS minival set in Fig. 5. It reveals that as $\delta$ increases, the number of retained anchor points decreases substantially across different models. This reduction significantly lowers computational overhead compared with the baseline scenario, which employs a total of 8400 anchor points. For example, for YOLOEv8-S, with $\delta=0.001$ , the number of valid anchor points is reduced by $80%$ , enjoying $1.7\times$ inference speedup with the same performance (see Tab. 7 in the paper). The results further confirm the notably redundancy of anchor points for category retrieval and verify the efficacy of LRPC.
为了定性展示 LRPC 策略的有效性,我们可视化了过滤后保留的用于类别检索的锚点数量。我们在图 5 中展示了在 LVIS minival 数据集上不同过滤阈值 $\delta$ 下的平均数量。结果表明,随着 $\delta$ 的增加,不同模型保留的锚点数量大幅减少。与基线场景相比,这种减少显著降低了计算开销,基线场景使用了总共 8400 个锚点。例如,对于 YOLOEv8-S,当 $\delta=0.001$ 时,有效锚点数量减少了 $80%$,在相同性能下实现了 $1.7\times$ 的推理加速(参见论文中的表 7)。这些结果进一步证实了类别检索中锚点的显著冗余,并验证了 LRPC 的有效性。
C. More Visualization Results
C. 更多可视化结果
To qualitatively show the efficacy of YOLOE, we present more visualization results for it in various scenarios.
为了定性地展示YOLOE的有效性,我们在多种场景下展示了更多的可视化结果。
Zero-shot inference on LVIS. In Fig. 6, we present the zero-shot inference capabilities of YOLOE on the LVIS. By leveraging the 1203 category names as text prompts, the model demonstrates its ability to detect and segment diverse objects across various images.
Zero-shot 推理在 LVIS 上的表现。在图 6 中,我们展示了 YOLOE 在 LVIS 上的零样本推理能力。通过利用 1203 个类别名称作为文本提示,模型展示了其在不同图像中检测和分割多样化对象的能力。

Figure 5. The count of retained anchor points under different filtering thresholds in LRPC. The dashed line means the total number.
图 5: LRPC 中不同过滤阈值下保留的锚点数量。虚线表示总数。
Prompt with customized texts. Fig. 7 presents the results with customized text prompts. We can see that YOLOE can interpret both generic and specific textual inputs, enabling precise object detection and fine-grained segmentation. Such capability allows users to tailor the model’s behavior to meet specific requirements by defining input prompts at varying levels of granularity.
使用自定义文本的提示。图 7 展示了使用自定义文本提示的结果。我们可以看到 YOLOE 能够解释通用和特定的文本输入,实现精确的目标检测和细粒度分割。这种能力允许用户通过定义不同粒度的输入提示来定制模型的行为,以满足特定需求。
Prompt with visual inputs. In Fig. 8, we present the results of YOLOE with visual inputs as prompt. The visual inputs can take various forms, such as bounding box, point, or handcrafted shape. It can also be provided across the images. We can see that with visual prompt indicating the target object, YOLOE can accurately find other instances of the same category. Beside, it performs well across different objects and images, exhibiting robust capability.
带有视觉输入的提示。在图 8 中,我们展示了 YOLOE 使用视觉输入作为提示的结果。视觉输入可以采取多种形式,例如边界框、点或手工绘制形状。它还可以在图像之间提供。我们可以看到,通过指示目标对象的视觉提示,YOLOE 能够准确找到同一类别的其他实例。此外,它在不同对象和图像之间表现良好,展现了强大的能力。
Prompt-free inference. Fig. 9 shows the results of YOLOE with the prompt-free paradigm. We can see that in such setting, YOLOE achieves effective identification for diverse objects. This highlights its practicality in scenarios where predefined inputs are unavailable or impractical.
无提示推理。图 9 展示了 YOLOE 在无提示范式下的结果。可以看出,在这种情况下,YOLOE 能够有效识别多种物体。这突显了其在无法或不适合使用预定义输入的场景中的实用性。


Figure 6. Zero-Shot inference on LVIS. The categories of LVIS are provided as text prompts.
图 6: LVIS 上的零样本推理。LVIS 的类别作为文本提示提供。

Figure 7. Prompt with customized texts. YOLOE adapts to both generic and specific text prompts for flexible usage. Figure 8. Prompt with visual inputs. YOLOE demonstrates the ability to identify objects guided by various visual prompts, like boundin box (top left), point (top right), handcrafted shape (bottom left). The visual prompt can also be applied across images (bottom right).
图 7: 带有自定义文本的提示。YOLOE 能够适应通用和特定的文本提示,实现灵活使用。
图 8: 带有视觉输入的提示。YOLOE 展示了在各种视觉提示下识别物体的能力,例如边界框(左上)、点(右上)、手工绘制的形状(左下)。视觉提示还可以跨图像应用(右下)。

Figure 9. Prompt-free inference (omitting segmentation masks for clearer visualization). YOLOE can find diverse objects without prompt
图 9: 无提示推理(省略分割掩码以便更清晰地可视化)。YOLOE 可以在没有提示的情况下找到多样化的对象