CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset
CrossWOZ: 一个大规模中文跨领域任务导向对话数据集
Qi Zhu1, Kaili Huang2, Zheng Zhang1, Xiaoyan $\mathbf{Zhu^{1}}$ , Minlie Huang1
Qi Zhu1, Kaili Huang2, Zheng Zhang1, Xiaoyan $\mathbf{Zhu^{1}}$ , Minlie Huang1
1Dept. of Computer Science and Technology, 1Institute for Artificial Intelligence, 1Beijing National Research Center for Information Science and Technology, 2Dept. of Industrial Engineering, Tsinghua University, Beijing, China {zhu-q18,hkl16,z-zhang15}@mails.tsinghua.edu.cn{zxy-dcs,aihuang}@tsinghua.edu.cn
1清华大学计算机科学与技术系,1清华大学人工智能研究院,1北京信息科学与技术国家研究中心,2清华大学工业工程系,北京,中国 {zhu-q18,hkl16,z-zhang15}@mails.tsinghua.edu.cn{zxy-dcs,aihuang}@tsinghua.edu.cn
Abstract
摘要
To advance multi-domain (cross-domain) dialogue modeling as well as alleviate the shortage of Chinese task-oriented datasets, we propose CrossWOZ, the first large-scale Chinese Cross-Domain Wizard-of-Oz taskoriented dataset. It contains 6K dialogue sessions and 102K utterances for 5 domains, including hotel, restaurant, attraction, metro, and taxi. Moreover, the corpus contains rich annotation of dialogue states and dialogue acts at both user and system sides. About $60%$ of the dialogues have cross-domain user goals that favor interdomain dependency and encourage natural transition across domains in conversation. We also provide a user simulator and several benchmark models for pipelined taskoriented dialogue systems, which will facilitate researchers to compare and evaluate their models on this corpus. The large size and rich annotation of CrossWOZ make it suitable to investigate a variety of tasks in cross-domain dialogue modeling, such as dialogue state tracking, policy learning, user simulation, etc.
为了推进多领域(跨领域)对话建模并缓解中文任务导向数据集的短缺问题,我们提出了 CrossWOZ,这是第一个大规模的中文跨领域 Wizard-of-Oz 任务导向数据集。它包含 6K 个对话会话和 102K 个话语,涵盖 5 个领域,包括酒店、餐厅、景点、地铁和出租车。此外,该语料库还包含丰富的对话状态和对话行为标注,涵盖用户和系统两端。大约 $60%$ 的对话具有跨领域的用户目标,这些目标有利于领域间的依赖关系,并鼓励对话中跨领域的自然过渡。我们还提供了一个用户模拟器和几个用于管道式任务导向对话系统的基准模型,这将有助于研究人员在该语料库上比较和评估他们的模型。CrossWOZ 的大规模和丰富标注使其适用于研究跨领域对话建模中的各种任务,如对话状态跟踪、策略学习、用户模拟等。
2017), WOZ 2.0 (Wen et al., 2017) and M2M (Shah et al., 2018).
2017), WOZ 2.0 (Wen et al., 2017) 和 M2M (Shah et al., 2018).
Despite the significant contributions to the community, these datasets are still limited in size, language variation, or task complexity. Furthermore, there is a gap between existing dialogue corpora and real-life human dialogue data. In real-life conversations, it is natural for humans to transition between different domains or scenarios while still maintaining coherent contexts. Thus, real-life dialogues are much more complicated than those dialogues that are only simulated within a single domain. To address this issue, some multi-domain corpora have been proposed (Bud zia now ski et al., 2018b; Rastogi et al., 2019). The most notable corpus is MultiWOZ (Bud zia now ski et al., 2018b), a large-scale multi- domain dataset which consists of crowd sourced human-to-human dialogues. It contains 10K dialogue sessions and 143K utterances for 7 domains, with annotation of system-side dialogue states and dialogue acts. However, the state annotations are noisy (Eric et al., 2019), and user-side dialogue acts are missing. The dependency across domains is simply embodied in imposing the same prespecified constraints on different domains, such as requiring both a hotel and an attraction to locate in the center of the town.
尽管这些数据集对社区做出了重要贡献,但其在规模、语言多样性或任务复杂性方面仍然存在局限。此外,现有对话语料库与现实生活中的对话数据之间存在差距。在现实生活中,人类在不同领域或场景之间自然切换,同时保持连贯的上下文是很常见的。因此,现实生活中的对话比仅在单一领域内模拟的对话要复杂得多。为了解决这个问题,一些多领域语料库被提出(Budzianowski et al., 2018b; Rastogi et al., 2019)。其中最著名的语料库是 MultiWOZ(Budzianowski et al., 2018b),这是一个大规模的多领域数据集,包含众包的人类对话。它包含 10K 个对话会话和 143K 个话语,涵盖 7 个领域,并标注了系统端的对话状态和对话行为。然而,状态标注存在噪声(Eric et al., 2019),且用户端的对话行为缺失。领域之间的依赖关系仅体现在对不同领域施加相同的预设约束上,例如要求酒店和景点都位于城镇中心。
1 Introduction
1 引言
Recently, there have been a variety of taskoriented dialogue models thanks to the prosperity of neural architectures (Yao et al., 2013; Wen et al., 2015; Mrksic et al., 2017; Peng et al., 2017; Lei et al., 2018; Gür et al., 2018). However, the research is still largely limited by the availability of large-scale high-quality dialogue data. Many corpora have advanced the research of task-oriented dialogue systems, most of which are single domain conversations, including ATIS (Hemphill et al., 1990), DSTC 2 (Henderson et al., 2014), Frames (El Asri et al., 2017), KVRET (Eric et al.,
近年来,得益于神经架构的繁荣,出现了多种面向任务的对话模型 (Yao et al., 2013; Wen et al., 2015; Mrksic et al., 2017; Peng et al., 2017; Lei et al., 2018; Gür et al., 2018)。然而,研究仍然在很大程度上受到大规模高质量对话数据可用性的限制。许多语料库推动了面向任务的对话系统的研究,其中大多数是单领域对话,包括 ATIS (Hemphill et al., 1990)、DSTC 2 (Henderson et al., 2014)、Frames (El Asri et al., 2017)、KVRET (Eric et al.,
In comparison to the abundance of English dialogue data, surprisingly, there is still no widely recognized Chinese task-oriented dialogue corpus. In this paper, we propose CrossWOZ, a largescale Chinese multi-domain (cross-domain) taskoriented dialogue dataset. An dialogue example is shown in Figure 1. We compare CrossWOZ to other corpora in Table 1 and 2. Our dataset has the following features comparing to other corpora (particularly MultiWOZ (Bud zia now ski et al., 2018b)):
与丰富的英语对话数据相比,令人惊讶的是,目前仍然没有广泛认可的中文任务导向对话语料库。本文提出了CrossWOZ,一个大规模的中文多领域(跨领域)任务导向对话数据集。图1展示了一个对话示例。我们将CrossWOZ与其他语料库进行了比较,如表1和表2所示。与其他语料库(特别是MultiWOZ (Budzianowski et al., 2018b))相比,我们的数据集具有以下特点:
- The dependency between domains is more challenging because the choice in one domain will affect the choices in related domains in CrossWOZ. As shown in Figure 1 and Table 2, the hotel must be near the attraction chosen by the user in previous turns, which requires more accurate context understanding.
- 领域之间的依赖关系更具挑战性,因为在 CrossWOZ 中,一个领域的选择会影响相关领域的选择。如图 1 和表 2 所示,酒店必须靠近用户在前几轮选择的景点,这需要更准确的上下文理解。

Figure 1: A dialogue example. The user state is initialized by the user goal: finding an attraction and one of its nearby hotels, then book a taxi to commute between these two places. In addition to expressing pre-specified informable slots and filling in request able slots, users need to consider and modify cross-domain informable slots (bold) that vary through conversation. We only show a few turns (turn number on the left), each with either user or system state of the current domain which are shown above each utterance.
图 1: 对话示例。用户状态由用户目标初始化:找到一个景点及其附近的一家酒店,然后预订一辆出租车在这两个地点之间通勤。除了表达预先指定的可告知槽位和填写可请求槽位外,用户还需要考虑和修改跨域的可告知槽位(加粗),这些槽位在对话过程中会发生变化。我们只展示了几轮对话(左侧的轮次编号),每轮对话中当前域的用户或系统状态显示在每个话语上方。
- It is the first Chinese corpus that contains large-scale multi-domain task-oriented dialogues, consisting of 6K sessions and 102K utterances for 5 domains (attraction, restaurant, hotel, metro, and taxi).
- 这是首个包含大规模多领域任务导向对话的中文语料库,由 6K 个会话和 102K 个话语组成,涵盖 5 个领域(景点、餐厅、酒店、地铁和出租车)。
- Annotation of dialogue states and dialogue acts is provided for both the system side and user side. The annotation of user states enables us to track the conversation from the user’s perspective and can empower the development of more elaborate user simulators.
- 对话状态和对话行为的标注同时提供了系统端和用户端的信息。用户状态的标注使我们能够从用户的角度跟踪对话,并有助于开发更精细的用户模拟器。
In this paper, we present the process of dialogue collection and provide detailed data analysis of the corpus. Statistics show that our cross-domain dialogues are complicated. To facilitate model comparison, benchmark models are provided for different modules in pipelined task-oriented dialogue systems, including natural language understanding, dialogue state tracking, dialogue policy learning, and natural language generation. We also provide a user simulator, which will facilitate the development and evaluation of dialogue models on this corpus. The corpus and the benchmark models are publicly available at https://github. com/thu-coai/CrossWOZ.
在本文中,我们介绍了对话收集的过程,并提供了对语料库的详细数据分析。统计数据显示,我们的跨领域对话较为复杂。为了便于模型比较,我们为流水线式任务导向对话系统中的不同模块提供了基准模型,包括自然语言理解、对话状态跟踪、对话策略学习和自然语言生成。我们还提供了一个用户模拟器,这将有助于在该语料库上开发和评估对话模型。语料库和基准模型可在 https://github.com/thu-coai/CrossWOZ 公开获取。
2 Related Work
2 相关工作
According to whether the dialogue agent is human or machine, we can group the collection methods of existing task-oriented dialogue datasets into three categories. The first one is human-tohuman dialogues. One of the earliest and wellknown ATIS dataset (Hemphill et al., 1990) used this setting, followed by El Asri et al. (2017), Eric et al. (2017), Wen et al. (2017), Lewis et al. (2017), Wei et al. (2018) and Bud zia now ski et al. (2018b). Though this setting requires many human efforts, it can collect natural and diverse dialogues. The second one is human-to-machine dialogues, which need a ready dialogue system to converse with humans. The famous Dialogue State Tracking Challenges provided a set of humanto-machine dialogue data (Williams et al., 2013;
根据对话代理是人类还是机器,我们可以将现有任务导向对话数据集的收集方法分为三类。第一类是人类与人类之间的对话。最早且知名的ATIS数据集(Hemphill等,1990)采用了这种设置,随后是El Asri等(2017)、Eric等(2017)、Wen等(2017)、Lewis等(2017)、Wei等(2018)和Budzianowski等(2018b)。尽管这种设置需要大量的人力投入,但它能够收集到自然且多样化的对话。第二类是人类与机器之间的对话,这需要一个现成的对话系统来与人类进行交流。著名的对话状态跟踪挑战赛提供了一组人类与机器对话的数据(Williams等,2013;
Table 1: Comparison of CrossWOZ to other task-oriented corpora (training set). H2H, H2M, M2M represent human-to-human, human-to-machine, machine-to-machine respectively. The average numbers of domains and turns are for each dialogue.
表 1: CrossWOZ 与其他面向任务的语料库(训练集)的对比。H2H、H2M、M2M 分别表示人-人、人-机、机-机。平均领域数和轮次数为每个对话的平均值。
| 类型 | 单领域目标 | 单领域目标 | 单领域目标 | 单领域目标 | 单领域目标 | 多领域目标 | 多领域目标 | 多领域目标 |
|---|---|---|---|---|---|---|---|---|
| 数据集 | DSTC2 | WOZ2.0 | Frames | KVRET | M2M | MultiWOZ | Schema | CrossWOZ |
| 语言 | EN | EN | EN | EN | EN | EN | EN | CN |
| 说话者 | H2M | H2H | H2H | H2H | M2M | H2H | M2M | H2H |
| 领域数 | 1 | 1 | 1 | 3 | 2 | 7 | 16 | 5 |
| 对话数 | 1,612 | 600 | 1,369 | 2,425 | 1,500 | 8,438 | 16,142 | 5,012 |
| 轮次数 | 23,354 | 4,472 | 19,986 | 12,732 | 14,796 | 115,424 | 329,964 | 84,692 |
| 平均领域数 | 1 | 1 | 1 | 1 | 1 | 1.80 | 1.84 | 3.24 |
| 平均轮次数 | 14.5 | 7.5 | 14.6 | 5.3 | 9.9 | 13.7 | 20.4 | 16.9 |
| 槽位数 | 8 | 4 | 61 | 13 | 14 | 25 | 214 | 72 |
| 值数 | 212 | 99 | 3,871 | 1,363 | 138 | 4,510 | 14,139 | 7,871 |
Table 2: Cross-domain dialog examples in MultiWOZ, Schema, and CrossWOZ. The value of cross-domain constraints(bold) are underlined. Some turns are omitted to save space. Names of hotels are replaced by A,B,C for simplicity. Cross-domain constraints are pre-specified in MultiWOZ and Schema, while determined dynamically in CrossWOZ. In CrossWOZ, the choice in one domain will greatly affect related domains.
表 2: MultiWOZ、Schema 和 CrossWOZ 中的跨领域对话示例。跨领域约束的值(加粗)已用下划线标出。为节省空间,部分对话轮次已省略。酒店名称简化为 A、B、C。跨领域约束在 MultiWOZ 和 Schema 中是预先指定的,而在 CrossWOZ 中是动态确定的。在 CrossWOZ 中,一个领域的选择会极大地影响相关领域。
| MultiWOZ | CrossWoZ |
|---|---|
| usr: 我在寻找一个学院类型的景点。usr: 我想参观市中心的景点。sys: 天安门城楼、算街小吃和北京欢乐谷都是很不错的地方。 | usr:你好,可以帮我推荐一个评分是 4.5 分以上的景点吗?Hello, could you recommend an attraction with a rating of 4.5 or higher? Tiananmen, Gui Street, and Beijing Happy Valley are very nice places. usr:我喜欢北京欢乐谷,你知道这个景点周边的酒店都是什么吗?I like Beijing Happy Valley. What hotels are around this attraction? sys: 那可多了,有 A 酒店,B 酒店,C 酒店。There are many, such as hotel A, hotel B, and hotel C. |
| usr: 你能帮我找一家也在市中心的印度餐厅吗? | |
| Schema usr: 我想在圣地亚哥找一家酒店,并且我想在下周四退房。usr: 太好了,我正打算在景点附近找个酒店住宿呢,知道哪家评分 |
Henderson et al., 2014). The performance of the dialogue system will largely influence the quality of dialogue data. The third one is machine-tomachine dialogues. It needs to build both user and system simulators to generate dialogue outlines, then use templates (Peng et al., 2017) to generate dialogues or further employ people to paraphrase the dialogues to make them more natural (Shah et al., 2018; Rastogi et al., 2019). It needs much less human effort. However, the complexity and diversity of dialogue policy are limited by the simulators. To explore dialogue policy in multidomain scenarios, and to collect natural and diverse dialogues, we resort to the human-to-human setting.
Henderson 等人, 2014)。对话系统的性能将在很大程度上影响对话数据的质量。第三种是机器对机器对话。它需要构建用户和系统模拟器来生成对话大纲,然后使用模板 (Peng 等人, 2017) 生成对话,或者进一步雇佣人员对对话进行改写,使其更加自然 (Shah 等人, 2018; Rastogi 等人, 2019)。这种方法需要的人力较少。然而,对话策略的复杂性和多样性受到模拟器的限制。为了在多领域场景中探索对话策略,并收集自然且多样化的对话,我们采用了人机对话的设置。
Most of the existing datasets only involve single domain in one dialogue, except MultiWOZ (Bud zia now ski et al., 2018b) and Schema (Rastogi et al., 2019). MultiWOZ dataset has attracted much attention recently, due to its large size and multi-domain characteristics. It is at least one order of magnitude larger than previous datasets, amounting to 8,438 dialogues and 115K turns in the training set. It greatly promotes the research on multi-domain dialogue modeling, such as policy learning (Takanobu et al., 2019), state tracking (Wu et al., 2019), and context-to-text gen- eration (Bud zia now ski et al., 2018a). Recently the Schema dataset is collected in a machine-tomachine fashion, resulting in 16,142 dialogues and 330K turns for 16 domains in the training set. However, the multi-domain dependency in these two datasets is only embodied in imposing the same pre-specified constraints on different domains, such as requiring a restaurant and an attraction to locate in the same area, or the city of a hotel and the destination of a flight to be the same (Table 2).
大多数现有的数据集仅涉及单一领域的对话,除了 MultiWOZ (Budzianowski et al., 2018b) 和 Schema (Rastogi et al., 2019)。MultiWOZ 数据集由于其规模大和多领域特性,最近引起了广泛关注。它比之前的数据集至少大一个数量级,训练集中包含 8,438 个对话和 115K 轮次。它极大地推动了多领域对话建模的研究,例如策略学习 (Takanobu et al., 2019)、状态跟踪 (Wu et al., 2019) 和上下文到文本生成 (Budzianowski et al., 2018a)。最近,Schema 数据集以机器对机器的方式收集,训练集中包含 16,142 个对话和 330K 轮次,涵盖 16 个领域。然而,这两个数据集中的多领域依赖性仅体现在对不同领域施加相同的预定义约束上,例如要求餐厅和景点位于同一区域,或酒店所在城市与航班目的地相同 (表 2)。
Table 1 presents a comparison between our dataset with other task-oriented datasets. In comparison to MultiWOZ, our dataset has a comparable scale: 5,012 dialogues and 84K turns in the training set. The average number of domains and turns per dialogue are larger than those of MultiWOZ, which indicates that our task is more complex. The cross-domain dependency in our dataset is natural and challenging. For example, as shown in Table 2, the system needs to recommend a hotel near the attraction chosen by the user in previous turns. Thus, both system recommendation and user selection will dynamically impact the dialogue. We also allow the same domain to appear multiple times in a user goal since a tourist may want to go to more than one attraction.
表 1 展示了我们的数据集与其他面向任务的数据集之间的比较。与 MultiWOZ 相比,我们的数据集具有相当的规模:训练集中有 5,012 个对话和 84K 轮次。每个对话的平均领域数和轮次均大于 MultiWOZ,这表明我们的任务更为复杂。我们数据集中的跨领域依赖性是自然且具有挑战性的。例如,如表 2 所示,系统需要推荐一个靠近用户在前几轮选择的景点的酒店。因此,系统推荐和用户选择都会动态影响对话。我们还允许同一领域在用户目标中多次出现,因为游客可能希望参观多个景点。
To better track the conversation flow and model user dialogue policy, we provide annotation of user states in addition to system states and dialogue acts. While the system state tracks the dialogue history, the user state is maintained by the user and indicates whether the sub-goals have been completed, which can be used to predict user actions. This information will facilitate the construction of the user simulator.
为了更好地跟踪对话流程和模拟用户对话策略,我们除了提供系统状态和对话行为的标注外,还提供了用户状态的标注。系统状态跟踪对话历史,而用户状态由用户维护,指示子目标是否已完成,这可用于预测用户行为。这些信息将有助于构建用户模拟器。
To the best of our knowledge, CrossWOZ is the first large-scale Chinese dataset for task-oriented dialogue systems, which will largely alleviate the shortage of Chinese task-oriented dialogue corpora that are publicly available.
据我们所知,CrossWOZ 是第一个面向任务型对话系统的大规模中文数据集,它将极大地缓解公开可用的中文任务型对话语料库的短缺问题。
two ways. One is to constrain two targets that locate near each other. The other is to use a taxi or metro to commute between two targets in HAR domains mentioned in the context. To make workers understand the task more easily, we crafted templates to generate natural language descriptions for each structured goal.
有两种方式。一种是对彼此靠近的两个目标进行约束。另一种是在上下文中提到的HAR领域内使用出租车或地铁在两个目标之间通勤。为了让工作者更容易理解任务,我们设计了模板,为每个结构化目标生成自然语言描述。
- Dialogue Collection: before the formal data collection starts, we required the workers to make a small number of dialogues and gave them feedback about the dialogue quality. Then, well-trained workers were paired to converse according to the given goals. The workers were also asked to annotate both user states and system states.
- 对话收集:在正式数据收集开始之前,我们要求工作人员进行少量对话,并就对话质量给予反馈。然后,经过良好培训的工作人员被配对,根据给定的目标进行对话。工作人员还被要求标注用户状态和系统状态。
- Dialogue Annotation: we used some rules to automatically annotate dialogue acts according to user states, system states, and dialogue histories. To evaluate the quality of the annotation of dialogue acts and states, three experts were employed to manually annotate dialogue acts and states for 50 dialogues. The results show that our annotations are of high quality. Finally, each dialogue contains a structured goal, a task description, user states, system states, dialogue acts, and utterances.
- 对话标注:我们使用了一些规则,根据用户状态、系统状态和对话历史自动标注对话行为。为了评估对话行为和状态标注的质量,我们聘请了三位专家对50个对话的对话行为和状态进行手动标注。结果表明,我们的标注质量很高。最终,每个对话都包含一个结构化目标、任务描述、用户状态、系统状态、对话行为和话语。
3 Data Collection
3 数据收集
Our corpus is to simulate scenarios where a traveler seeks tourism information and plans her or his travel in Beijing. Domains include hotel, attraction, restaurant, metro, and taxi. The data collec- tion process is summarized as below:
我们的语料库旨在模拟旅行者在北京寻求旅游信息并规划行程的场景。涉及的领域包括酒店、景点、餐厅、地铁和出租车。数据收集过程总结如下:
- Database Construction: we crawled travel information in Beijing from the Web, including Hotel, Attraction, and Restaurant domains (hereafter we name the three domains as HAR domains). Then, we used the metro information of entities in HAR domains to build the metro database. For the taxi domain, there is no need to store the information. Instead, we can call the API directly if necessary.
- 数据库构建:我们从网络上爬取了北京的旅游信息,包括酒店、景点和餐厅领域(以下简称HAR领域)。然后,我们使用HAR领域中实体的地铁信息构建了地铁数据库。对于出租车领域,不需要存储信息,而是在必要时直接调用API。
- Goal Generation: a multi-domain goal generator was designed based on the database. The relation across domains is captured in
- 目标生成:基于数据库设计了一个多领域目标生成器。跨领域的关系被捕捉在
3.1 Database Construction
3.1 数据库构建
We collected 465 attractions, 951 restaurants, and 1,133 hotels in Beijing from the Web. Some statistics are shown in Table 3. There are three types of slots for each entity: common slots such as name and address; binary slots for hotel services such as wake-up call; nearby attractions/restaurants/hotels
我们从网上收集了北京465个景点、951家餐厅和1,133家酒店。部分统计数据如表3所示。每个实体有三种类型的槽位:常见槽位,如名称和地址;酒店服务的二元槽位,如叫醒服务;附近的景点/餐厅/酒店
| 领域 | 景点 | 餐厅 | 酒店 |
|---|---|---|---|
| 实体数量 | 465 | 951 | 1133 |
| 槽位数量 | 9 | 10 | 8+37* |
| 平均附近景点数量 | 4.7 | 3.3 | 0.8 |
| 平均附近餐厅数量 | 6.7 | 4.1 | 2.0 |
| 平均附近酒店数量 | 2.1 | 2.4 |
Table 3: Database statistics. ∗ indicates that there are 37 binary slots for hotel services such as wake-up call. The last three rows show the average number of nearby attractions/restaurants/hotels for each entity. We did not collect nearby hotels information for the hotel domain.
表 3: 数据库统计信息。∗ 表示有 37 个用于酒店服务(如叫醒服务)的二进制槽位。最后三行显示了每个实体附近的平均景点/餐厅/酒店数量。我们没有收集酒店领域的附近酒店信息。
Table 4: A user goal example (translated into English). Slots with bold/italic/blank value are crossdomain informable slots, common informable slots, and request able slots. In this example, the user wants to find an attraction and one of its nearby hotels, then book a taxi to commute between these two places.
表 4: 用户目标示例(翻译成英文)。粗体/斜体/空白值的槽位是跨域可告知槽位、通用可告知槽位和可请求槽位。在此示例中,用户希望找到一个景点及其附近的一家酒店,然后预订一辆出租车在这两个地点之间通勤。
| PI | 领域 | 槽位 | 值 |
|---|---|---|---|
| 1 | 景点 | 费用 | 免费 |
| 1 | 景点 | 名称 | |
| 1 | 景点 | 附近酒店 | |
| 2 | 酒店 | 名称 | 附近 (id=1) |
| 2 | 酒店 | 叫醒服务 | 是 |
| 2 | 酒店 | 评分 | |
| 3 | 出租车 | 出发地 | (id=1) |
| 3 | 出租车 | 目的地 | (id=2) |
| 3 | 出租车 | 车型 | |
| 3 | 出租车 | 车牌号 |
slots that contain nearby entities in the attraction, restaurant, and hotel domains. Since it is not usual to find another nearby hotel in the hotel domain, we did not collect such information. This nearby relation allows us to generate natural cross-domain goals, such as "find another attraction near the first one" and "find a restaurant near the attraction". Nearest metro stations of HAR entities form the metro database. In contrast, we provided the pseudo car type and plate number for the taxi domain.
包含附近实体的槽位,涉及景点、餐厅和酒店领域。由于在酒店领域通常不会找到另一家附近的酒店,因此我们没有收集此类信息。这种邻近关系使我们能够生成自然的跨领域目标,例如“找到第一个景点附近的另一个景点”和“找到景点附近的餐厅”。HAR实体的最近地铁站构成了地铁数据库。相比之下,我们为出租车领域提供了伪装的车型和车牌号。
3.2 Goal Generation
3.2 目标生成
To avoid generating overly complex goals, each goal has at most five sub-goals. To generate more natural goals, the sub-goals can be of the same domain, such as two attractions near each other. The goal is represented as a list of (sub-goal id, domain, slot, value) tuples, named as semantic tuples. The sub-goal id is used to distinguish subgoals which may be in the same domain. There are two types of slots: informable slots which are the constraints that the user needs to inform the system, and request able slots which are the information that the user needs to inquire from the system. As shown in Table 4, besides common informable slots (italic values) whose values are determined before the conversation, we specially design crossdomain informable slots (bold values) whose values refer to other sub-goals. Cross-domain informable slots utilize sub-goal id to connect different sub-goals. Thus the actual constraints vary according to the different contexts instead of being pre-specified. The values of common informable slots are sampled randomly from the database. Based on the informable slots, users are required to gather the values of request able slots (blank values in Table 4) through conversation.
为避免生成过于复杂的目标,每个目标最多包含五个子目标。为了使目标更加自然,子目标可以属于同一领域,例如彼此靠近的两个景点。目标表示为(子目标ID、领域、槽位、值)元组的列表,称为语义元组。子目标ID用于区分可能属于同一领域的子目标。槽位有两种类型:可告知槽位(informable slots),即用户需要告知系统的约束条件;以及可请求槽位(requestable slots),即用户需要从系统查询的信息。如表4所示,除了值在对话前确定的常见可告知槽位(斜体值)外,我们还特别设计了跨领域可告知槽位(粗体值),其值引用其他子目标。跨领域可告知槽位利用子目标ID连接不同的子目标。因此,实际约束条件根据不同的上下文而变化,而不是预先指定的。常见可告知槽位的值从数据库中随机抽取。基于可告知槽位,用户需要通过对话收集可请求槽位的值(表4中的空白值)。
There are four steps in goal generation. First, we generate independent sub-goals in HAR domains. For each domain in HAR domains, with the same probability $\mathcal{P}$ we generate a sub-goal, while with the probability of $1-\mathcal{P}$ we do not generate any sub-goal for this domain. Each subgoal has common informable slots and request able slots. As shown in Table 5, all slots of HAR domains can be request able slots, while the slots with an asterisk can be common informable slots.
目标生成分为四个步骤。首先,我们在HAR领域生成独立的子目标。对于HAR领域中的每个领域,以相同的概率 $\mathcal{P}$ 生成一个子目标,而以 $1-\mathcal{P}$ 的概率不为该领域生成任何子目标。每个子目标都有可告知的公共槽位和可请求的槽位。如表5所示,HAR领域的所有槽位都可以是可请求的槽位,而带有星号的槽位可以是可告知的公共槽位。
Second, we generate cross-domain sub-goals in HAR domains. For each generated sub-goal (e.g., the attraction sub-goal in Table 4), if its requestable slots contain "nearby hotels", we generate an additional sub-goal in the hotel domain (e.g., the hotel sub-goal in Table 4) with the probability of $\mathcal{P}{a t t r a c t i o n\rightarrow h o t e l}$ . Of course, the selected hotel must satisfy the nearby relation to the attraction entity. Similarly, we do not generate any additional sub-goal in the hotel domain with the probability of $1\textrm{--}\mathcal{P}{a t t r a c t i o n{\rightarrow}h o t e l}$ . This also works for the attraction and restaurant domains. $\mathcal{P}_{h o t e l\rightarrow h o t e l}=0$ since we do not allow the user to find the nearby hotels of one hotel.
其次,我们在HAR领域生成跨域子目标。对于每个生成的子目标(例如表4中的景点子目标),如果其可请求的槽位包含“附近酒店”,我们以概率$\mathcal{P}{a t t r a c t i o n\rightarrow h o t e l}$在酒店领域生成一个额外的子目标(例如表4中的酒店子目标)。当然,所选的酒店必须满足与景点实体的附近关系。同样地,我们以概率$1\textrm{--}\mathcal{P}{a t t r a c t i o n{\rightarrow}h o t e l}$不在酒店领域生成任何额外的子目标。这也适用于景点和餐厅领域。$\mathcal{P}_{h o t e l\rightarrow h o t e l}=0$,因为我们不允许用户查找一个酒店的附近酒店。
Third, we generate sub-goals in the metro and taxi domains. With the probability of $\mathcal{P}{t a x i}$ , we generate a sub-goal in the taxi domain (e.g., the taxi sub-goal in Table 4) to commute between two entities of HAR domains that are already generated. It is similar for the metro domain and we set $\mathcal{P}{m e t r o}=\mathcal{P}_{t a x i}$ . All slots in the metro or taxi domain appear in the sub-goals and must be filled. As shown in Table 5, from and to slots are always cross-domain informable slots, while others are always request able slots.
第三,我们在地铁和出租车领域生成子目标。以概率 $\mathcal{P}{t a x i}$ 生成出租车领域的子目标(例如表 4 中的出租车子目标),用于在已生成的 HAR 领域的两个实体之间通勤。地铁领域的情况类似,我们设置 $\mathcal{P}{m e t r o}=\mathcal{P}_{t a x i}$。地铁或出租车领域的所有槽位都会出现在子目标中,并且必须被填充。如表 5 所示,from 和 to 槽位始终是跨领域的可告知槽位,而其他槽位始终是可请求槽位。
Last, we rearrange the order of the sub-goals to generate more natural and logical user goals. We require that a sub-goal should be followed by its referred sub-goal as immediately as possible.
最后,我们重新排列子目标的顺序,以生成更自然和逻辑的用户目标。我们要求一个子目标应尽可能紧随其引用的子目标。
To make the workers aware of this cross-domain feature, we additionally provide a task description for each user goal in natural language, which is generated from the structured goal by hand-crafted templates.
为了让工作者意识到这种跨领域特性,我们额外为每个用户目标提供了自然语言的任务描述,这些描述是通过手工制作的模板从结构化目标生成的。
Compared with the goals whose constraints are all pre-specified, our goals impose much more dependency between different domains, which will significantly influence the conversation. The exact values of cross-domain informable slots are finally determined according to the dialogue context.
与所有约束条件都预先指定的目标相比,我们的目标在不同领域之间施加了更多的依赖关系,这将显著影响对话。跨领域信息槽的确切值最终根据对话上下文确定。
Table 5: All slots in each domain (translated into English). Slots in bold can be cross-domain informable slots. Slots with asterisk are informable slots. All slots are request able slots except "from" and "to" slots in the taxi and metro domains. The "nearby attractions/restaurants/hotels" slots and the "dishes" slot can be multiple valued (a list). The value of each "service" is either yes or no.
表 5: 每个领域的所有槽位(翻译成英文)。加粗的槽位可以是跨领域的可告知槽位。带星号的槽位是可告知槽位。除了出租车和地铁领域的 "from" 和 "to" 槽位外,所有槽位都是可请求槽位。"nearby attractions/restaurants/hotels" 槽位和 "dishes" 槽位可以是多值的(列表)。每个 "service" 的值是 yes 或 no。
| 景点领域 | 名称*, 评分*, 费用*, 时长*, 地址, 电话, 附近景点, 附近餐厅, 附近酒店 |
| 餐厅领域 | 名称*, 评分*, 费用*, 菜品*, 地址, 电话, 营业时间, 附近景点, 附近餐厅, 附近酒店 |
| 酒店领域 | 名称*, 评分*, 价格*, 类型*, 37 项服务*, 电话, 地址, 附近景点, 附近餐厅 |
| 出租车领域 | 出发地, 目的地, 车型, 车牌号 |
| 地铁领域 | 出发地, 目的地, 出发站, 到达站 |
3.3 Dialogue Collection
3.3 对话收集
We developed a specialized website that allows two workers to converse synchronously and make annotations online. On the website, workers are free to choose one of the two roles: tourist (user) or system (wizard). Then, two paired workers are sent to a chatroom. The user needs to accomplish the allocated goal through conversation while the wizard searches the database to provide the neces- sary information and gives responses. Before the formal data collection, we trained the workers to complete a small number of dialogues by giving them feedback. Finally, 90 well-trained workers are participating in the data collection.
我们开发了一个专门的网站,允许两名工作人员同步对话并在线进行标注。在该网站上,工作人员可以自由选择两个角色之一:游客(用户)或系统(向导)。然后,两名配对的工作人员被送入一个聊天室。用户需要通过对话完成分配的目标,而向导则搜索数据库以提供必要的信息并给出回应。在正式数据收集之前,我们通过反馈训练工作人员完成少量对话。最终,90名经过良好培训的工作人员参与了数据收集。
In contrast, MultiWOZ (Bud zia now ski et al., 2018b) hired more than a thousand workers to converse asynchronously. Each worker received a dialogue context to review and need to respond for only one turn at a time. The collected dialogues may be incoherent because workers may not understand the context correctly and multiple workers contributed to the same dialogue session, possibly leading to more variance in the data quality. For example, some workers expressed two mutually exclusive constraints in two consecutive user turns and failed to eliminate the system’s confusion in the next several turns. Compared with MultiWOZ, our synchronous conversation setting may produce more coherent dialogues.
相比之下,MultiWOZ (Budzianowski et al., 2018b) 雇佣了超过一千名工作人员进行异步对话。每个工作人员都会收到一个对话上下文进行审阅,并且每次只需要回应一个回合。收集到的对话可能不连贯,因为工作人员可能无法正确理解上下文,并且多个工作人员参与了同一个对话会话,可能导致数据质量的更大差异。例如,一些工作人员在两个连续的用户回合中表达了两个相互排斥的约束,并且在接下来的几个回合中未能消除系统的困惑。与 MultiWOZ 相比,我们的同步对话设置可能会产生更连贯的对话。
3.3.1 User Side
3.3.1 用户端
The user state is the same as the user goal before a conversation starts. At each turn, the user needs to 1) modify the user state according to the system response at the preceding turn, 2) select some semantic tuples in the user state, which indicates the dialogue acts, and 3) compose the utterance according to the selected semantic tuples. In addition to filling the required values and updating cross-domain informable slots with real values in the user state, the user is encouraged to modify the constraints when there is no result under such constraints. The change will also be recorded in the user state. Once the goal is completed (all the values in the user state are filled), the user can terminate the dialogue.
用户状态在对话开始前与用户目标相同。在每一轮对话中,用户需要:1) 根据上一轮的系统响应修改用户状态,2) 从用户状态中选择一些语义元组,这些元组表示对话行为,3) 根据选定的语义元组生成话语。除了填充所需的值并在用户状态中用真实值更新跨域可告知槽位外,鼓励用户在约束条件下没有结果时修改约束条件。这些更改也会记录在用户状态中。一旦目标完成(用户状态中的所有值都已填充),用户可以终止对话。
3.3.2 Wizard Side
3.3.2 Wizard 端
We regard the database query as the system state, which records the constraints of each domain till the current turn. At each turn, the wizard needs to 1) fill the query according to the previous user response and search the database if necessary, 2) select the retrieved entities, and 3) respond in natural language based on the information of the selected entities. If none of the entities satisfy all the constraints, the wizard will try to relax some of them for a recommendation, resulting in multiple queries. The first query records original user constraints while the last one records the constraints relaxed by the system.
我们将数据库查询视为系统状态,它记录了每个领域到当前轮次的约束条件。在每一轮中,向导需要:1) 根据先前的用户响应填写查询,并在必要时搜索数据库;2) 选择检索到的实体;3) 基于所选实体的信息以自然语言进行响应。如果没有实体满足所有约束条件,向导将尝试放宽部分约束以进行推荐,这会导致多次查询。第一次查询记录原始用户约束,而最后一次查询记录系统放宽的约束。
3.4 Dialogue Annotation
3.4 对话标注
After collecting the conversation data, we used some rules to annotate dialogue acts automatically. Each utterance can have several dialogue acts. Each dialogue act is a tuple that consists of intent, domain, slot, and value. We pre-define 6 types of intents and use the update of the user state and system state as well as keyword matching to obtain dialogue acts. For the user side, dialogue acts are mainly derived from the selection of semantic tuples that contain the informa- tion of domain, slot, and value. For example, if (1, Attraction, fee, free) in Table 4 is selected by the user, then (Inform, Attraction, fee, free) is labelled. If (1, Attraction, name, ) is selected, then (Request, Attraction, name, none) is labelled. If (2, Hotel, name, near $(\mathrm{id}{=}1)$ ) is selected, then (Select, Hotel, src_domain, Attraction) is labelled. This intent is specially designed for the "nearby" constraint. For the system side, we mainly applied keyword matching to label dialogue acts. Inform intent is derived by matching the system utterance with the information of selected entities. When the wizard selects multiple retrieved entities and recommend them, Recommend intent is labeled. When the wizard expresses that no result satisfies user constraints, NoOffer is labeled. For General intents such as "goodbye", "thanks" at both user and system sides, keyword matching is applied.
在收集对话数据后,我们使用了一些规则来自动标注对话行为。每个话语可以有多个对话行为。每个对话行为是一个由意图、领域、槽位和值组成的元组。我们预定义了6种意图类型,并使用用户状态和系统状态的更新以及关键词匹配来获取对话行为。对于用户端,对话行为主要来源于包含领域、槽位和值信息的语义元组的选择。例如,如果表4中的 (1, Attraction, fee, free) 被用户选中,则标注为 (Inform, Attraction, fee, free)。如果 (1, Attraction, name, ) 被选中,则标注为 (Request, Attraction, name, none)。如果 (2, Hotel, name, near $(\mathrm{id}{=}1)$ ) 被选中,则标注为 (Select, Hotel, src_domain, Attraction)。这个意图是专门为“附近”约束设计的。对于系统端,我们主要应用关键词匹配来标注对话行为。Inform意图是通过将系统话语与所选实体的信息进行匹配得出的。当向导选择多个检索到的实体并推荐它们时,标注为Recommend意图。当向导表示没有结果满足用户约束时,标注为NoOffer。对于用户和系统端的通用意图,如“再见”、“谢谢”,则应用关键词匹配。
We also obtained a binary label for each semantic tuple in the user state, which indicates whether this semantic tuple has been selected to be expressed by the user. This annotation directly illustrates the progress of the conversation.
我们还为用户状态中的每个语义元组获取了一个二元标签,该标签指示此语义元组是否已被用户选择表达。此注释直接说明了对话的进展。
To evaluate the quality of the annotation of dialogue acts and states (both user and system states), three experts were employed to manually annotate dialogue acts and states for the same 50 dialogues (806 utterances), 10 for each goal type (see Section 4). Since dialogue act annotation is not a clas- sification problem, we didn’t use Fleiss’ kappa to measure the agreement among experts. We used dialogue act F1 and state accuracy to measure the agreement between each two experts’ annotations. The average dialogue act F1 is $94.59%$ and the average state accuracy is $93.55%$ . We then compared our annotations with each expert’s annotations which are regarded as gold standard. The average dialogue act F1 is $95.36%$ and the average state accuracy is $94.95%$ , which indicates the high quality of our annotations.
为了评估对话行为(dialogue acts)和状态(包括用户和系统状态)标注的质量,我们聘请了三位专家对相同的50个对话(806个话语)进行手动标注,每个目标类型10个对话(见第4节)。由于对话行为标注不是分类问题,我们没有使用Fleiss' kappa来衡量专家之间的一致性。我们使用对话行为F1和状态准确率来衡量每两位专家标注之间的一致性。平均对话行为F1为$94.59%$,平均状态准确率为$93.55%$。然后,我们将我们的标注与每位专家的标注(视为黄金标准)进行了比较。平均对话行为F1为$95.36%$,平均状态准确率为$94.95%$,这表明我们的标注质量很高。
4 Statistics
4 统计
After removing uncompleted dialogues, we collected 6,012 dialogues in total. The dataset is split randomly for training/validation/test, where the statistics are shown in Table 6. The average number of sub-goals in our dataset is 3.24, which is much larger than that in MultiWOZ (1.80) (Bud zia now ski et al., 2018b) and Schema (1.84) (Rastogi et al., 2019). The average number of turns (16.9) is also larger than that in MultiWOZ
在移除未完成的对话后,我们总共收集了6,012个对话。数据集被随机分为训练/验证/测试集,统计数据如表6所示。我们数据集中子目标的平均数量为3.24,远高于MultiWOZ (1.80) (Budzianowski et al., 2018b) 和Schema (1.84) (Rastogi et al., 2019)。平均对话轮次 (16.9) 也高于MultiWOZ。
| 训练集 | 验证集 | 测试集 | |
|---|---|---|---|
| 对话数量 | 5,012 | 500 | 500 |
| 轮次数量 | 84,692 | 8,458 | 8,476 |
| Token 数量 | 1,376,033 | 137,736 | 137,427 |
| 词汇量 | 12,502 | 5,202 | 5,143 |
| 平均子目标数 | 3.24 | 3.26 | 3.26 |
| 平均 STs | 14.8 | 14.9 | 15.0 |
| 平均轮次 | 16.9 | 16.9 | 17.0 |
| 平均 Token 数 | 16.3 | 16.3 | 16.2 |
Table 6: Data statistics. The average numbers of subgoals, turns, and STs (semantic tuples) are for each dialogue. The average number of tokens is for each turn.
表 6: 数据统计。每个对话的子目标、轮次和语义元组 (ST) 的平均数量。每个轮次的平均 Token 数量。
(13.7). These statistics indicate that our dialogue data are more complex.
(13.7)。这些统计数据表明,我们的对话数据更为复杂。
According to the type of user goal, we group the dialogues in the training set into five categories:
根据用户目标的类型,我们将训练集中的对话分为五类:
Single-domain (S) 417 dialogues have only one sub-goal in HAR domains.
单领域 (S) 417 个对话在 HAR 领域中只有一个子目标。
Independent multi-domain (M) 1573 dialogues have multiple sub-goals $(2\sim3)$ in HAR domains. However, these sub-goals do not have cross-domain informable slots.
独立多领域 (M) 1573 个对话在 HAR 领域中有多个子目标 $(2\sim3)$。然而,这些子目标没有跨领域的可信息槽。
Independent multi-domain $^+$ traffic $(\mathbf+\mathbf)$
独立多域 $^+$ 流量 $(\mathbf+\mathbf)$
691 dialogues have multiple sub-goals in HAR domains and at least one sub-goal in the metro or taxi domain $3\sim5$ sub-goals). The sub-goals in HAR domains do not have cross-domain informable slots.
691 个对话在 HAR 领域中有多个子目标,并且在地铁或出租车领域中至少有一个子目标($3\sim5$ 个子目标)。HAR 领域中的子目标没有跨领域的可信息槽。
Cross multi-domain (CM) 1,759 dialogues have multiple sub-goals $(2{\sim}5)$ in HAR domains with cross-domain informable slots.
跨多领域 (CM) 1,759 个对话在 HAR 领域中具有跨领域可信息槽的多个子目标 $(2{\sim}5)$。
Cross multi-domain $^+$ traffic ( $\mathbf{\widetilde{CM}}\mathbf{+T})$ 572 dialogues have multiple sub-goals in HAR domains with cross-domain informable slots and at least one sub-goal in the metro or taxi domain ( $3{\sim}5$ sub-goals).
跨多领域 $^+$ 交通 ( $\mathbf{\widetilde{CM}}\mathbf{+T})$ 572 个对话在 HAR 领域中有多个子目标,涉及跨领域可告知槽位,并且至少有一个子目标在地铁或出租车领域 ( $3{\sim}5$ 个子目标)。
The data statistics are shown in Table 7. As mentioned in Section 3.2, we generate independent multi-domain, cross multi-domain, and traf-fic domain sub-goals one by one. Thus in terms of the task complexity, we have $\mathbf{S}{<}\mathbf{M}{<}\mathbf{CM}$ and $\mathbf{M}{<}\mathbf{M}{+}\mathbf{T}{<}\mathbf{C}\mathbf{M}{+}\mathbf{T}$ , which is supported by the average number of sub-goals, semantic tuples, and turns per dialogue in Table 7. The average number of tokens also becomes larger when the goal becomes more complex. About $60%$ of dialogues $\mathbf{(M+T}$ , CM, and $\mathbf{CM}+\mathbf{T},$ have cross-domain informable slots. Because of the limit of maximal sub-goals number, the ratio of dialogue number of $\mathbf{CM}{+}\mathbf{T}$ to CM is smaller than that of $\mathbf{M}+\mathbf{T}$ to M.
数据统计如表 7 所示。如第 3.2 节所述,我们依次生成独立多领域、跨多领域和交通领域的子目标。因此,在任务复杂性方面,我们有 $\mathbf{S}{<}\mathbf{M}{<}\mathbf{CM}$ 和 $\mathbf{M}{<}\mathbf{M}{+}\mathbf{T}{<}\mathbf{C}\mathbf{M}{+}\mathbf{T}$,这由表 7 中每个对话的平均子目标数、语义元组数和轮次数支持。当目标变得更复杂时,平均 Token 数也会增加。大约 $60%$ 的对话 $\mathbf{(M+T}$、CM 和 $\mathbf{CM}+\mathbf{T},$ 具有跨领域可信息槽。由于最大子目标数的限制,$\mathbf{CM}{+}\mathbf{T}$ 与 CM 的对话数比例小于 $\mathbf{M}+\mathbf{T}$ 与 M 的比例。
Table 7: Statistics for dialogues of different goal types in the training set. NoOffer rate and Goal change rate are for each dialogue. Multi-query rate is for each system turn. The average number of dialogue acts is for each turn.
表 7: 训练集中不同目标类型对话的统计信息。NoOffer 率和目标变化率是针对每个对话的。多查询率是针对每个系统轮次的。平均对话行为数是针对每个轮次的。
| 目标类型 | S | M | M+T | CM | CM+T |
|---|---|---|---|---|---|
| # 对话数 | 417 | 1573 | 691 | 1759 | 572 |
| NoOffer 率 | 0.10 | 0.22 | 0.22 | 0.61 | 0.55 |
| 多查询率 | 0.06 | 0.07 | 0.07 | 0.14 | 0.12 |
| 目标变化率 | 0.10 | 0.28 | 0.31 | 0.69 | 0.63 |
| 平均对话行为数 | 1.85 | 1.90 | 2.09 | 2.06 | 2.11 |
| 平均子目标数 | 1.00 | 2.49 | 3.62 | 3.87 | 4.57 |
| 平均 STs | 4.5 | 11.3 | 15.8 | 18.2 | 20.7 |
| 平均轮次数 | 6.8 | 13.7 | 16.0 | 21.0 | 21.6 |
CM and $\mathbf{CM}{+}\mathbf{T}$ are much more challenging than other tasks because additional cross-domain constraints in HAR domains are strict and will result in more "NoOffer" situations (i.e., the wizard finds no result that satisfies the current constraints). In this situation, the wizard will try to relax some constraints and issue multiple queries to find some results for a recommendation while the user will compromise and change the original goal. The negotiation process is captured by "NoOffer rate", "Multi-query rate", and "Goal change rate" in Table 7. In addition, "Multi-query rate" suggests that each sub-goal in M and $\mathbf{M}+\mathbf{T}$ is as easy to finish as the goal in S.
CM 和 $\mathbf{CM}{+}\mathbf{T}$ 比其他任务更具挑战性,因为 HAR 领域中的额外跨域约束非常严格,会导致更多的“无推荐”情况(即,向导找不到满足当前约束的结果)。在这种情况下,向导会尝试放宽一些约束并发出多个查询以找到一些推荐结果,而用户则会妥协并改变原始目标。这一协商过程通过表 7 中的“无推荐率”、“多查询率”和“目标变更率”来捕捉。此外,“多查询率”表明 M 和 $\mathbf{M}+\mathbf{T}$ 中的每个子目标与 S 中的目标一样容易完成。
The distribution of dialogue length is shown in Figure 2, which is an indicator of the task complexity. Most single-domain dialogues terminate within 10 turns. The curves of M and $\mathbf{M}+\mathbf{T}$ are almost of the same shape, which implies that the traffic task requires two additional turns on average to complete the task. The curves of CM and $\mathbf{CM}{+}\mathbf{T}$ are less similar. This is probably because CM goals that have 5 sub-goals (about $22%$ ) can not further generate a sub-goal in traffic domains and become $\mathbf{CM}{+}\mathbf{T}$ goals.
对话长度的分布如图 2 所示,这是任务复杂度的指标。大多数单领域对话在 10 轮内结束。M 和 $\mathbf{M}+\mathbf{T}$ 的曲线形状几乎相同,这意味着交通任务平均需要额外两轮才能完成。CM 和 $\mathbf{CM}{+}\mathbf{T}$ 的曲线相似度较低。这可能是因为具有 5 个子目标的 CM 目标(约 $22%$)无法在交通领域中生成进一步的子目标,从而变成 $\mathbf{CM}{+}\mathbf{T}$ 目标。
5 Corpus Features
5 语料库特征
Our corpus is unique in the following aspects:
我们的语料库在以下方面具有独特性:
• Complex user goals are designed to favor inter-domain dependency and natural transition between multiple domains. In return, the collected dialogues are more complex and natural for cross-domain dialogue tasks.
• 复杂的用户目标设计旨在促进跨领域依赖性和多个领域之间的自然过渡。因此,收集的对话在跨领域对话任务中更加复杂和自然。
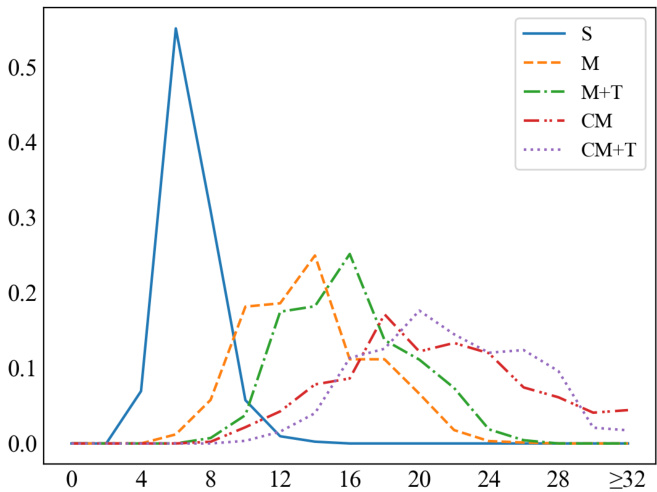
Figure 2: Distributions of dialogue length for different goal types in the training set.
图 2: 训练集中不同目标类型的对话长度分布。
• A well-controlled, synchronous setting is applied to collect human-to-human dialogues. This ensures the high quality of the collected dialogues.
• 采用一个控制良好、同步的环境来收集人与人之间的对话,以确保收集到的对话具有高质量。
Explicit annotations are provided at not only the system side but also the user side. This feature allows us to model user behaviors or develop user simulators more easily.
系统端和用户端都提供了显式注释。这一特性使我们能够更容易地建模用户行为或开发用户模拟器。
6 Benchmark and Analysis
6 基准测试与分析
CrossWOZ can be used in different tasks or settings of a task-oriented dialogue system. To facilitate further research, we provided benchmark models for different components of a pipelined task-oriented dialogue system (Figure 3), including natural language understanding (NLU), dialogue state tracking (DST), dialogue policy learning, and natural language generation (NLG). These models are implemented using ConvLab-2 (Zhu et al., 2020), an open-source task-oriented dialog system toolkit. We also provided a rule-based user simulator, which can be used to train dialogue policy and generate simulated dialogue data. The benchmark models and simulator will greatly facilitate researchers to compare and evaluate their models on our corpus.
CrossWOZ 可用于面向任务对话系统的不同任务或设置。为了促进进一步研究,我们为流水线式面向任务对话系统的不同组件提供了基准模型(图 3),包括自然语言理解 (NLU)、对话状态跟踪 (DST)、对话策略学习和自然语言生成 (NLG)。这些模型使用 ConvLab-2 (Zhu et al., 2020) 实现,这是一个开源的面向任务对话系统工具包。我们还提供了一个基于规则的用户模拟器,可用于训练对话策略并生成模拟对话数据。这些基准模型和模拟器将极大地帮助研究人员在我们的语料库上比较和评估他们的模型。
6.1 Natural Language Understanding
6.1 自然语言理解
Task: The natural language understanding component in a task-oriented dialogue system takes an
任务:面向任务的对话系统中的自然语言理解组件
| S | M | M+T | CM | CM+T | Overall | |
|---|---|---|---|---|---|---|
| BERTNLU -context | ||||||
| Dialogue act F1 | 96.69 | 96.01 | 96.15 | 94.99 | 95.38 | 95.53 |
| 94.55 | 93.05 | 93.70 | 90.66 | 90.82 | 91.85 | |
| RuleDST TRADE | ||||||
| Joint state accuracy (single turn) Jointstate accuracy | 84.17 71.67 | 78.17 45.29 | 81.93 | 63.38 | 67.86 | 71.33 |
| SL policy | ||||||
| 37.98 | 30.77 | 25.65 | 36.08 | |||
| Dialogue act F1 Dialogue act F1 (delex) | 50.28 67.96 | 44.97 67.35 | 54.01 | 41.65 | 44.02 | 44.92 |
| Simulator | ||||||
| Joint state accuracy (single turn) | 63.53 | 48.79 | 73.94 | 62.27 | 66.29 | 66.02 |
| ** | ||||||
| Dialogue act F1 (single turn) | 85.99 | 81.39 | 50.26 80.82 | 40.66 75.27 | 41.76 77.23 | 45.00 |
| 49.4 | 78.39 | |||||
| DA Sim NL Sim (Template) | ||||||
| Task finish rate | 76.5 67.4 | 33.3 | 33.7 29.1 | 17.2 | 15.7 | 34.6 |
| NL Sim (SC-LSTM) | ||||||
| 60.6 | 27.1 | 23.1 | 10.0 8.8 | 10.0 9.0 | 23.6 19.7 |
Table 8: Performance of Benchmark models. "Single turn" means having the gold information of the last turn. Task finish rate is evaluated on 1000 times simulations for each goal type. It’s worth noting that "task finish" does not mean the task is successful, because the system may provide wrong information. Results show that cross multi-domain dialogues (CM and $\mathbf{CM+T},$ ) is challenging for these tasks.
表 8: 基准模型的性能。"单轮"表示拥有最后一轮的黄金信息。任务完成率是基于每种目标类型的 1000 次模拟进行评估的。值得注意的是,"任务完成"并不意味着任务成功,因为系统可能提供错误信息。结果表明,跨多领域对话(CM 和 $\mathbf{CM+T},$)对这些任务具有挑战性。
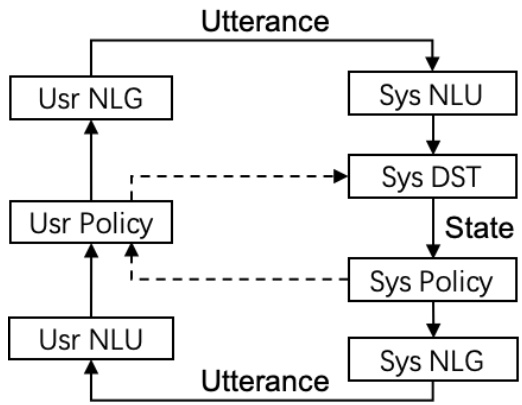
Figure 3: Pipelined user simulator (left) and Pipelined task-oriented dialogue system (right). Solid connections are for natural language level interaction, while dashed connections are for dialogue act level. The connections without comments represent dialogue acts.
图 3: 流水线用户模拟器(左)和流水线任务导向对话系统(右)。实线连接表示自然语言级别的交互,而虚线连接表示对话行为级别。未标注的连接表示对话行为。
utterance as input and outputs the corresponding semantic representation, namely, a dialogue act. The task can be divided into two sub-tasks: intent classification that decides the intent type of an utterance, and slot tagging which identifies the value of a slot.
将话语作为输入并输出相应的语义表示,即对话行为。该任务可以分为两个子任务:意图分类(决定话语的意图类型)和槽位标注(识别槽位的值)。
Model: We adapted BERTNLU from ConvLab2. BERT (Devlin et al., 2019) has shown strong performance in many NLP tasks. We use Chinese pre-trained BERT∗ (Cui et al., 2019) for initialization and then fine-tune the parameters on Cross-
模型:我们从 ConvLab2 中适配了 BERTNLU。BERT (Devlin et al., 2019) 在许多 NLP 任务中表现出色。我们使用中文预训练的 BERT∗ (Cui et al., 2019) 进行初始化,然后在 Cross- 上微调参数。
WOZ. We obtain word embeddings and the sentence representation (embedding of [CLS]) from BERT. Since there may exist more than one intent in an utterance, we modify the traditional method accordingly. For dialogue acts of inform and recommend intents such as (intent=Inform, domain $\v u_{1}=\v u_{2}$ Attraction, slot=fee, value=free) whose values appear in the sentence, we perform sequential labeling using an MLP which takes word embeddings ("free") as input and outputs tags in BIO schema ("B-Inform-Attraction-fee"). For each of the other dialogue acts (e.g., (intent $\risingdotseq$ Request, domain $\v u_{1}=\v u_{2}$ Attraction, slot=fee)) that do not have actual values, we use another MLP to perform binary classification on the sentence representation to predict whether the sentence should be labeled with this dialogue act. To incorporate context information, we use the same BERT to get the embedding of last three utterances. We separate the utterances with [SEP] tokens and insert a [CLS] token at the beginning. Then each original input of the two MLP is concatenated with the context embedding (embedding of [CLS]), serving as the new input. We also conducted an ablation test by removing context information. We trained models with both system-side and user-side utterances.
WOZ。我们从BERT中获取词嵌入和句子表示([CLS]的嵌入)。由于一个话语中可能存在多个意图,我们相应地修改了传统方法。对于诸如(intent=Inform, domain $\v u_{1}=\v u_{2}$ Attraction, slot=fee, value=free)这样的inform和recommend意图的对话行为,其值出现在句子中,我们使用一个多层感知机(MLP)进行序列标注,该MLP以词嵌入("free")作为输入,并输出BIO格式的标签("B-Inform-Attraction-fee")。对于其他没有实际值的对话行为(例如(intent $\risingdotseq$ Request, domain $\v u_{1}=\v u_{2}$ Attraction, slot=fee)),我们使用另一个MLP对句子表示进行二分类,以预测该句子是否应标记为此对话行为。为了融入上下文信息,我们使用相同的BERT获取最后三个话语的嵌入。我们用[SEP]标记分隔话语,并在开头插入一个[CLS]标记。然后,两个MLP的原始输入与上下文嵌入([CLS]的嵌入)连接,作为新的输入。我们还通过移除上下文信息进行了消融测试。我们使用系统端和用户端的话语训练了模型。
Result Analysis: The results of the dialogue act prediction (F1 score) are shown in Table 8. We further tested the performance on different intent types, as shown in Table 9. In general, BERTNLU performs well with context information. The performance on cross multi-domain dialogues (CM and $\mathbf{CM}+\mathbf{T},$ drops slightly, which may be due to the decrease of "General" intent and the increase of "NoOffer" as well as "Select" intent in the dialogue data. We also noted that the F1 score of "Select" intent is remarkably lower than those of other types, but context information can improve the performance significantly. Since recognizing domain transition is a key factor for a cross-domain dialogue system, natural language understanding models need to utilize context information more effectively.
结果分析:对话行为预测(F1 分数)的结果如表 8 所示。我们进一步测试了不同意图类型的性能,如表 9 所示。总体而言,BERTNLU 在上下文信息下表现良好。跨多领域对话(CM 和 $\mathbf{CM}+\mathbf{T},$)的性能略有下降,这可能是由于对话数据中“General”意图的减少以及“NoOffer”和“Select”意图的增加所致。我们还注意到,“Select”意图的 F1 分数明显低于其他类型,但上下文信息可以显著提高性能。由于识别领域转换是跨领域对话系统的关键因素,自然语言理解模型需要更有效地利用上下文信息。
Table 9: F1 score of different intent type. "Recom." represents "Recommend".
表 9: 不同意图类型的 F1 分数。"Recom." 代表 "Recommend"。
| GeneralInform | n | Request | Recom 1 | NoOffer | Select |
|---|---|---|---|---|---|
| BERTNLU | 99.45 | 99.69 | 94.67 | 90.80 | 96.57 |
6.2 Dialogue State Tracking
6.2 对话状态追踪
Task: Dialogue state tracking is responsible for recognizing user goals from the dialogue context and then encoding the goals into the pre-defined system state. Traditional state tracking models take as input user dialogue acts parsed by natural language understanding modules, while recently there are joint models obtaining the system state directly from the context.
任务:对话状态跟踪负责从对话上下文中识别用户目标,然后将这些目标编码为预定义的系统状态。传统的状态跟踪模型以自然语言理解模块解析的用户对话行为作为输入,而最近出现了直接从上下文中获取系统状态的联合模型。
Model: We implemented a rule-based model (RuleDST) and adapted TRADE (Transferable Dialogue State Generator)† (Wu et al., 2019) in this experiment. RuleDST takes as input the previous system state and the last user dialogue acts. Then, the system state is updated according to hand-crafted rules. For example, If one of user dialogue acts is (intent=Inform, domain $\equiv.$ Attraction, slot=fee, value $:=$ free), then the value of the "fee" slot in the attraction domain will be filled with "free". TRADE generates the system state directly from all the previous utterances using a copy mechanism. As mentioned in Section 3.3.2, the first query of the system often records full user constraints, while the last one records relaxed constraints for recommendation. Thus the last one involves system policy, which is out of the scope of state tracking. We used the first query for these models and left state tracking with recommendation for future work.
模型:我们在本实验中实现了一个基于规则的模型(RuleDST)并适配了TRADE(可转移对话状态生成器)†(Wu et al., 2019)。RuleDST将先前的系统状态和最后的用户对话行为作为输入。然后,系统状态根据手工制定的规则进行更新。例如,如果用户对话行为之一是(intent=Inform, domain $\equiv.$ Attraction, slot=fee, value $:=$ free),那么景点领域的“fee”槽位将被填充为“free”。TRADE通过复制机制直接从所有先前的对话中生成系统状态。如第3.3.2节所述,系统的第一个查询通常记录完整的用户约束,而最后一个查询记录用于推荐的宽松约束。因此,最后一个查询涉及系统策略,这超出了状态跟踪的范围。我们使用第一个查询来训练这些模型,并将推荐的状态跟踪留待未来工作。
Result Analysis: We evaluated the joint state accuracy (percentage of exact matching) of these two models (Table 8). TRADE, the state-of-theart model on MultiWOZ, performs poorly on our dataset, indicating that more powerful state trackers are necessary. At the test stage, RuleDST can access the previous gold system state and user dialogue acts, which leads to higher joint state accuracy than TRADE. Both models perform worse on cross multi-domain dialogues (CM and $\mathbf{CM}{+}\mathbf{T}$ . To evaluate the ability of modeling cross-domain transition, we further calculated joint state accuracy for those turns that receive "Select" intent from users (e.g., "Find a hotel near the attraction"). The performances are $11.6%$ and $12.0%$ for RuleDST and TRADE respectively, showing that they are not able to track domain transition well.
结果分析:我们评估了这两个模型的联合状态准确率(精确匹配的百分比)(表 8)。MultiWOZ 上的最先进模型 TRADE 在我们的数据集上表现不佳,这表明需要更强大的状态跟踪器。在测试阶段,RuleDST 可以访问之前的黄金系统状态和用户对话行为,因此其联合状态准确率高于 TRADE。两个模型在跨多领域对话(CM 和 $\mathbf{CM}{+}\mathbf{T}$)上的表现都较差。为了评估跨领域转换的建模能力,我们进一步计算了用户发出“选择”意图(例如“在景点附近找一家酒店”)时的联合状态准确率。RuleDST 和 TRADE 的表现分别为 $11.6%$ 和 $12.0%$,表明它们在跟踪领域转换方面表现不佳。
6.3 Dialogue Policy Learning
6.3 对话策略学习
Task: Dialogue policy receives state $s$ and outputs system action $a$ at each turn. Compared with the state given by a dialogue state tracker, $s$ may have more information, such as the last user dialogue acts and the entities provided by the backend database.
任务:对话策略在每个回合接收状态 $s$ 并输出系统动作 $a$。与由对话状态跟踪器提供的状态相比,$s$ 可能包含更多信息,例如上一次的用户对话动作以及后端数据库提供的实体。
Model: We adapted a vanilla policy trained in a supervised fashion from ConvLab-2 (SL policy). The state $s$ consists of the last system dialogue acts, last user dialogue acts, system state of the current turn, the number of entities that satisfy the constraints in the current domain, and a terminal signal indicating whether the user goal is completed. The action $a$ is de lexical i zed dialogue acts of current turn which ignores the exact values of the slots, where the values will be filled back after prediction.
模型:我们采用了从 ConvLab-2 中经过监督训练的普通策略(SL 策略)。状态 $s$ 包括上一轮的系统对话行为、上一轮的用户对话行为、当前轮次的系统状态、当前域中满足约束的实体数量,以及一个指示用户目标是否完成的终止信号。动作 $a$ 是当前轮次的去词化对话行为,忽略槽位的具体值,这些值将在预测后填充回去。
Result Analysis: As illustrated in Table 8, there is a large gap between F1 score of exact dialogue act and F1 score of de lexical i zed dialogue act, which means we need a powerful system state tracker to find correct entities. The result also shows that cross multi-domain dialogues (CM and $\mathbf{CM+T}$ are harder for system dialogue act prediction. Additionally, when there is "Select" intent in preceding user dialogue acts, the F1 score of exact dialogue act and de lexical i zed dialogue act are $41.53%$ and $54.39%$ respectively. This shows that the policy performs poorly for cross-domain transition.
结果分析:如表 8 所示,精确对话行为 (exact dialogue act) 的 F1 分数与去词汇化对话行为 (de lexicalized dialogue act) 的 F1 分数之间存在较大差距,这意味着我们需要一个强大的系统状态跟踪器来找到正确的实体。结果还表明,跨多域对话 (CM 和 $\mathbf{CM+T}$) 对系统对话行为预测来说更具挑战性。此外,当用户前序对话行为中存在 "Select" 意图时,精确对话行为和去词汇化对话行为的 F1 分数分别为 $41.53%$ 和 $54.39%$。这表明策略在跨域转换方面表现较差。
6.4 Natural Language Generation
6.4 自然语言生成
Task: Natural language generation transforms a structured dialogue act into a natural language sentence. It usually takes de lexical i zed dialogue acts as input and generates a template-style sentence that contains placeholder s for slots. Then, the placeholder s will be replaced by the exact values, which is called lexical iz ation.
任务:自然语言生成将结构化的对话行为转化为自然语言句子。通常以去词汇化的对话行为作为输入,生成包含占位符的模板式句子。然后,占位符将被具体的值替换,这一过程称为词汇化。
Model: We provided a template-based model (named Template N LG) and SC-LSTM (Semantically Conditioned LSTM) (Wen et al., 2015) for natural language generation. For Template N LG, we extracted templates from the training set and manually added some templates for infrequent dialogue acts. For SC-LSTM we adapted the implementation‡ on MultiWOZ and trained two SC-LSTM with system-side and user-side utterances respectively.
模型:我们提供了一个基于模板的模型(名为 Template N LG)和 SC-LSTM(语义条件 LSTM)(Wen et al., 2015) 用于自然语言生成。对于 Template N LG,我们从训练集中提取了模板,并手动添加了一些用于不常见对话行为的模板。对于 SC-LSTM,我们调整了在 MultiWOZ 上的实现‡,并分别训练了两个 SC-LSTM,分别用于系统端和用户端的语句。
Result Analysis: We calculated corpus-level BLEU as used by Wen et al. (2015). We took all utterances with the same de lex cali zed dialogue acts as references (100 references on average), which results in high BLEU score. For user-side utterances, the BLEU score for Template N LG is 0.5780, while the BLEU score for SC-LSTM is 0.7858. For system-side, the two scores are 0.6828 and 0.8595. As exemplified in Table 10, the gap between the two models can be attributed to that SC-LSTM generates common pattern while TemplateNLG retrieves original sentence which has more specific information. We do not provide BLEU scores for different goal types (namely, S, M, CM, etc.) because BLEU scores on different corpus are not comparable.
结果分析:我们计算了Wen等人(2015)使用的语料库级BLEU。我们将所有具有相同去词汇化对话行为的语句作为参考(平均100个参考),这导致了较高的BLEU分数。对于用户侧的语句,Template NLG的BLEU分数为0.5780,而SC-LSTM的BLEU分数为0.7858。对于系统侧,这两个分数分别为0.6828和0.8595。如表10所示,这两个模型之间的差距可以归因于SC-LSTM生成了常见模式,而TemplateNLG检索了具有更具体信息的原始句子。我们没有提供不同目标类型(即S、M、CM等)的BLEU分数,因为不同语料库上的BLEU分数不可比。
6.5 User Simulator
6.5 用户模拟器
Task: A user simulator imitates the behavior of users, which is useful for dialogue policy learning and automatic evaluation. A user simulator at dialogue act level (e.g., the "Usr Policy" in Figure 3) receives the system dialogue acts and outputs user dialogue acts, while a user simulator at natural language level (e.g., the left part in Figure 3) directly takes system’s utterance as input and
任务:用户模拟器模仿用户的行为,这对对话策略学习和自动评估非常有用。对话行为级别的用户模拟器(例如图 3 中的 "Usr Policy")接收系统对话行为并输出用户对话行为,而自然语言级别的用户模拟器(例如图 3 中的左侧部分)直接以系统的发言作为输入。
Input: (Inform, Restaurant, name, \$name) (Inform, Restaurant, cost, \$cost)
输入:(Inform, Restaurant, name, \$name) (Inform, Restaurant, cost, \$cost)
SC-LSTM: 为您推荐\$name,人均消费\$cost。I Recommend you \$name. It costs $\$\mathrm{cost}.$
SC-LSTM: 为您推荐\$name,人均消费\$cost。我推荐您\$name,人均消费$\$\mathrm{cost}.$
Template N LG:
模板 N LG:
Table 10: Comparison of SC-LSTM and TemplateNLG. The input is de lexical i zed dialogue acts, where the actual values are replaced with $\$1\$ name and \$cost. Two retrieved results are shown for TemplateNLG.
表 10: SC-LSTM 和 TemplateNLG 的对比。输入是去词汇化的对话行为 (de-lexicalized dialogue acts),其中实际值被替换为 $\$1\$ 名称和 \$cost。TemplateNLG 展示了两个检索结果。
outputs user’s utterance.
输出用户的语句。
Model: We built a rule-based user simulator that works at dialogue act level. Different from agenda-based (Schatzmann et al., 2007) user simulator that maintains a stack-like agenda, our simulator maintains the user state straightforwardly (Section 3.3.1). The simulator will generate a user goal as described in Section 3.2. At each user turn, the simulator receives system dialogue acts, modifies its state, and outputs user dialogue acts according to some hand-crafted rules. For example, if the system inform the simulator that the attraction is free, then the simulator will fill the "fee" slot in the user state with "free", and ask for the next empty slot such as "address". The simulator terminates when all request able slots are filled, and all cross-domain informable slots are filled by real values.
模型:我们构建了一个基于规则的用户模拟器,该模拟器在对话行为级别工作。与基于议程(Schatzmann 等人,2007)的用户模拟器不同,后者维护一个类似堆栈的议程,我们的模拟器直接维护用户状态(第 3.3.1 节)。模拟器将生成如第 3.2 节所述的用户目标。在每个用户回合中,模拟器接收系统对话行为,修改其状态,并根据一些手工制定的规则输出用户对话行为。例如,如果系统告知模拟器某个景点是免费的,那么模拟器将在用户状态中将“费用”槽填充为“免费”,并询问下一个空槽,例如“地址”。当所有可请求的槽都被填满,并且所有跨域的可通知槽都被真实值填满时,模拟器终止。
Result Analysis: During the evaluation, we initialized the user state of the simulator using the previous gold user state. The input to the simulator is the gold system dialogue acts. We used joint state accuracy (percentage of exact matching) to evaluate user state prediction and F1 score to evaluate the prediction of user dialogue acts. The results are presented in Table 8. We can observe that the performance on complex dialogues (CM and $\mathbf{CM+T}$ ) is remarkably lower than that on simple ones (S, M, and $\mathbf{M}{+}\mathbf{T}.$ ). This simple rule-based simulator is provided to facilitate dialogue policy learning and automatic evaluation, and our corpus supports the development of more elaborated simulators as we provide the annotation of user-side dialogue states and dialogue acts.
结果分析:在评估过程中,我们使用之前的黄金用户状态初始化了模拟器的用户状态。模拟器的输入是黄金系统对话行为。我们使用联合状态准确率(完全匹配的百分比)来评估用户状态预测,并使用F1分数来评估用户对话行为的预测。结果如表8所示。我们可以观察到,复杂对话(CM和$\mathbf{CM+T}$)的性能明显低于简单对话(S、M和$\mathbf{M}{+}\mathbf{T}.$)。这个简单的基于规则的模拟器旨在促进对话策略学习和自动评估,我们的语料库支持开发更精细的模拟器,因为我们提供了用户侧对话状态和对话行为的注释。
6.6 Evaluation with User Simulation
6.6 用户模拟评估
In addition to corpus-based evaluation for each module, we also evaluated the performance of a whole dialogue system using the user simulator as described above. Three configurations were explored:
除了对每个模块进行基于语料库的评估外,我们还使用上述用户模拟器评估了整个对话系统的性能。探索了三种配置:
DA Sim Simulation at dialogue act level. As shown by the dashed connections in Figure 3, we used the aforementioned simulator at the user side and assembled the dialogue system with RuleDST and SL policy.
DA Sim 在对话行为层面的模拟。如图 3 中的虚线连接所示,我们在用户端使用了上述模拟器,并使用 RuleDST 和 SL 策略组装了对话系统。
NL Sim (Template) Simulation at natural language level using Template N LG. As shown by the solid connections in Figure 3, the simulator and the dialogue system were equipped with BERTNLU and Template N LG additionally.
NL Sim (模板) 使用模板 N LG 在自然语言级别进行模拟。如图 3 中的实线连接所示,模拟器和对话系统还配备了 BERTNLU 和模板 N LG。
NL Sim (SC-LSTM) Simulation at natural language level using SC-LSTM. Template N LG was replaced with SC-LSTM in the second configuration.
NL Sim (SC-LSTM) 使用 SC-LSTM 在自然语言级别进行模拟。在第二个配置中,模板 N LG 被替换为 SC-LSTM。
When all the slots in a user goal are filled by real values, the simulator terminates. This is regarded as "task finish". It’s worth noting that "task finish" does not mean the task is success, because the system may provide wrong information. We calculated "task finish rate" on 1000 times simulations for each goal type (See Table 8). Findings are summarized below:
当用户目标中的所有槽位都被真实值填充时,模拟器终止。这被视为“任务完成”。值得注意的是,“任务完成”并不意味着任务成功,因为系统可能提供错误的信息。我们计算了每种目标类型在1000次模拟中的“任务完成率”(见表8)。以下是主要发现:
- Cross multi-domain tasks (CM and $\mathbf{CM}{+}\mathbf{T},$ ) are much harder to finish. Comparing M and $\mathbf{M}+\mathbf{T}$ , although each module performs well in traffic domains, additional sub-goals in these domains are still difficult to accomplish.
- 跨多领域任务(CM 和 $\mathbf{CM}{+}\mathbf{T},$)更难完成。比较 M 和 $\mathbf{M}+\mathbf{T}$,尽管每个模块在交通领域表现良好,但这些领域中的额外子目标仍然难以实现。
- The system-level performance is largely limited by RuleDST and SL policy. Although the corpus-based performance of NLU and NLG modules is high, the two modules still harm the performance. Thus more powerful models are needed for all components of a pipelined dialogue system.
- 系统级性能主要受限于 RuleDST 和 SL 策略。尽管 NLU 和 NLG 模块在语料库上的表现很高,但这两个模块仍然对性能产生了负面影响。因此,流水线对话系统的所有组件都需要更强大的模型。
- Template N LG has a much lower BLEU score but performs better than SC-LSTM in natural language level simulation. This may be attributed to that BERTNLU prefers templates retrieved from the training set.
- 模板 N LG 的 BLEU 分数较低,但在自然语言层面的模拟中表现优于 SC-LSTM。这可能归因于 BERTNLU 更倾向于从训练集中检索模板。
7 Conclusion
7 结论
In this paper, we present the first large-scale Chinese Cross-Domain task-oriented dialogue dataset, CrossWOZ. It contains 6K dialogues and 102K utterances for 5 domains, with the annotation of dialogue states and dialogue acts at both user and system sides. About $60%$ of the dialogues have cross-domain user goals, which encourage natural transition between related domains. Thanks to the rich annotation of dialogue states and dialogue acts at both user side and system side, this corpus provides a new testbed for a wide range of tasks to investigate cross-domain dialogue modeling, such as dialogue state tracking, policy learning, etc. Our experiments show that the cross-domain constraints are challenging for all these tasks. The transition between related domains is especially challenging to model. Besides corpus-based component-wise evaluation, we also performed system-level evaluation with a user simulator, which requires more powerful models for all components of a pipelined crossdomain dialogue system.
在本文中,我们提出了首个大规模的中文跨领域任务导向对话数据集 CrossWOZ。该数据集包含 6K 个对话和 102K 条话语,涵盖 5 个领域,并在用户和系统两侧标注了对话状态和对话行为。约 $60%$ 的对话具有跨领域的用户目标,这鼓励了相关领域之间的自然过渡。得益于用户和系统两侧丰富的对话状态和对话行为标注,该语料库为研究跨领域对话建模的多种任务提供了新的测试平台,例如对话状态跟踪、策略学习等。我们的实验表明,跨领域约束对所有任务都具有挑战性。相关领域之间的过渡尤其难以建模。除了基于语料库的组件评估外,我们还使用用户模拟器进行了系统级评估,这要求流水线式跨领域对话系统的所有组件都需要更强大的模型。
Acknowledgments
致谢
This work was supported by the National Science Foundation of China (Grant No. 61936010/61876096) and the National Key R&D Program of China (Grant No. 2018 Y FC 0830200). We would like to thank THUNUS NExT JointLab for the support. We would also like to thank Ryuichi Takanobu and Fei Mi for their constructive comments. We are grateful to our action editor, Bonnie Webber, and the anonymous reviewers for their valuable suggestions and feedback.
本工作得到了国家自然科学基金 (资助号: 61936010/61876096) 和国家重点研发计划 (资助号: 2018YFC0830200) 的支持。我们感谢 THUNUS NExT JointLab 的支持。同时,我们感谢 Ryuichi Takanobu 和 Fei Mi 的建设性意见。我们感谢我们的行动编辑 Bonnie Webber 以及匿名评审员提供的宝贵建议和反馈。
References
参考文献
Pawel Bud zia now ski, Iñigo Casanueva, Bo- Hsiang Tseng, and Milica Gasic. 2018a. Towards end-to-end multi-domain dialogue mod- elling.
Pawel Budzianowski, Iñigo Casanueva, Bo-Hsiang Tseng, 和 Milica Gasic. 2018a. 面向端到端多领域对话建模。
Paweł Bud zia now ski, Tsung-Hsien Wen, Bo- Hsiang Tseng, Iñigo Casanueva, Stefan Ultes,
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes,
Osman Ramadan, and Milica Gasic. 2018b. MultiWOZ - a large-scale multi-domain wizard-of-Oz dataset for task-oriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 5016–5026, Brussels, Belgium. Association for Computational Linguistics.
Osman Ramadan 和 Milica Gasic. 2018b. MultiWOZ - 一个用于任务导向对话建模的大规模多领域 Wizard-of-Oz 数据集。在 2018 年自然语言处理经验方法会议论文集 (Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing) 中,第 5016–5026 页,比利时布鲁塞尔。计算语言学协会 (Association for Computational Linguistics)。
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, and Guoping Hu. 2019. Pre-training with whole word masking for chinese bert. arXiv preprint arXiv:1906.08101.
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, 和 Guoping Hu. 2019. 中文 BERT 的全词掩码预训练. arXiv 预印本 arXiv:1906.08101.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin, Ming-Wei Chang, Kenton Lee 和 Kristina Toutanova. 2019. BERT: 用于语言理解的深度双向 Transformer 预训练. 在 2019 年北美计算语言学协会会议: 人类语言技术论文集, 第 1 卷 (长篇和短篇论文), 第 4171–4186 页, 明尼苏达州明尼阿波利斯. 计算语言学协会.
Layla El Asri, Hannes Schulz, Shikhar Sharma, Jeremie Zumer, Justin Harris, Emery Fine, Rahul Mehrotra, and Kaheer Suleman. 2017. Frames: a corpus for adding memory to goaloriented dialogue systems. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 207–219, Saarbr cken, Germany. Association for Computational Linguistics.
Layla El Asri, Hannes Schulz, Shikhar Sharma, Jeremie Zumer, Justin Harris, Emery Fine, Rahul Mehrotra, and Kaheer Suleman. 2017. Frames: 为目标导向对话系统添加记忆的语料库。在第十八届SIGdial话语与对话年会论文集 (Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue) 中,第207-219页,德国萨尔布吕肯。计算语言学协会 (Association for Computational Linguistics)。
Mihail Eric, Rahul Goel, Shachi Paul, Abhishek Sethi, Sanchit Agarwal, Shuyag Gao, and Dilek Hakkani-Tur. 2019. Multiwoz 2.1: Multi-domain dialogue state corrections and state tracking baselines. arXiv preprint arXiv:1907.01669.
Mihail Eric, Rahul Goel, Shachi Paul, Abhishek Sethi, Sanchit Agarwal, Shuyag Gao, and Dilek Hakkani-Tur. 2019. MultiWOZ 2.1: 多领域对话状态修正与状态跟踪基线. arXiv 预印本 arXiv:1907.01669.
Mihail Eric, Lakshmi Krishnan, Francois Charette, and Christopher D. Manning. 2017. Key-value retrieval networks for task-oriented dialogue. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 37–49, Saarbr cken, Germany. Association for Computational Linguistics.
Mihail Eric、Lakshmi Krishnan、Francois Charette 和 Christopher D. Manning。2017。面向任务对话的键值检索网络。载于第18届SIGdial话语与对话年会论文集,第37-49页,德国萨尔布吕肯。计算语言学协会。
Izzeddin Gür, Dilek Hakkani-Tür, Gokhan Tür, and Pararth Shah. 2018. User modeling for task oriented dialogues. In 2018 IEEE Spoken Language Technology Workshop (SLT), pages 900– 906. IEEE.
Izzeddin Gür, Dilek Hakkani-Tür, Gokhan Tür, and Pararth Shah. 2018. 面向任务型对话的用户建模。在2018年IEEE口语语言技术研讨会 (SLT) 上,第900-906页。IEEE。
Charles T. Hemphill, John J. Godfrey, and George R. Doddington. 1990. The ATIS spoken language systems pilot corpus. In Speech and Natural Language: Proceedings of a Workshop Held at Hidden Valley, Pennsylvania, June 24-27,1990.
Charles T. Hemphill, John J. Godfrey, 和 George R. Doddington. 1990. ATIS 口语系统试点语料库. 收录于《语音与自然语言:1990年6月24-27日在宾夕法尼亚州Hidden Valley举行的研讨会论文集》.
Matthew Henderson, Blaise Thomson, and Jason D. Williams. 2014. The second dialog state tracking challenge. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), pages 263–272, Philadelphia, PA, U.S.A. Association for Computational Linguistics.
Matthew Henderson, Blaise Thomson, 和 Jason D. Williams. 2014. 第二届对话状态跟踪挑战赛. 在《第15届话语与对话特别兴趣小组年会论文集》(SIGDIAL) 中, 第263-272页, 美国宾夕法尼亚州费城. 计算语言学协会.
Wenqiang Lei, Xisen Jin, Min-Yen Kan, Zhaochun Ren, Xiangnan He, and Dawei Yin. 2018. Sequicity: Simplifying task-oriented dialogue systems with single sequence-tosequence architectures. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1437–1447, Melbourne, Australia. Association for Computational Linguistics.
Wenqiang Lei, Xisen Jin, Min-Yen Kan, Zhaochun Ren, Xiangnan He, 和 Dawei Yin. 2018. Sequicity: 使用单一序列到序列架构简化任务导向对话系统. 在《第56届计算语言学协会年会论文集(第1卷:长论文)》中, 第1437–1447页, 澳大利亚墨尔本. 计算语言学协会.
Mike Lewis, Denis Yarats, Yann Dauphin, Devi Parikh, and Dhruv Batra. 2017. Deal or no deal? end-to-end learning of negotiation dialogues. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2443–2453, Copenhagen, Denmark. Association for Computational Linguistics.
Mike Lewis, Denis Yarats, Yann Dauphin, Devi Parikh, 和 Dhruv Batra. 2017. 成交还是不成交?端到端的谈判对话学习。在《2017年自然语言处理实证方法会议论文集》中,第2443-2453页,丹麦哥本哈根。计算语言学协会。
Nikola Mrksic, Diarmuid O Séaghdha, TsungHsien Wen, Blaise Thomson, and Steve Young. 2017. Neural belief tracker: Data-driven dialogue state tracking. In Proceedings of the $55t h$ Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1777–1788, Vancouver, Canada. Association for Computational Linguistics.
Nikola Mrksic、Diarmuid O Séaghdha、TsungHsien Wen、Blaise Thomson 和 Steve Young。2017。神经信念跟踪器:数据驱动的对话状态跟踪。在第 55 届计算语言学协会年会(第 1 卷:长论文)中,第 1777–1788 页,加拿大温哥华。计算语言学协会。
Baolin Peng, Xiujun Li, Lihong Li, Jianfeng Gao, Asli Cel i kyi l maz, Sungjin Lee, and Kam-Fai Wong. 2017. Composite task-completion dialogue policy learning via hierarchical deep rein for cement learning. In Proceedings of the
Baolin Peng, Xiujun Li, Lihong Li, Jianfeng Gao, Asli Celikyilmaz, Sungjin Lee, 和 Kam-Fai Wong. 2017. 通过分层深度强化学习进行复合任务完成对话策略学习。发表于
2017 Conference on Empirical Methods in Natural Language Processing, pages 2231–2240, Copenhagen, Denmark. Association for Computational Linguistics.
2017年自然语言处理实证方法会议,第2231-2240页,丹麦哥本哈根。计算语言学协会。
Abhinav Rastogi, Xiaoxue Zang, Srinivas Sunkara, Raghav Gupta, and Pranav Khaitan. 2019. Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset. arXiv preprint arXiv:1909.05855.
Abhinav Rastogi, Xiaoxue Zang, Srinivas Sunkara, Raghav Gupta, 和 Pranav Khaitan. 2019. 迈向可扩展的多领域对话系统:模式引导对话数据集. arXiv 预印本 arXiv:1909.05855.
Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, and Steve Young. 2007. Agenda-based user simulation for bootstrapping a POMDP dialogue system. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers, pages 149–152, Rochester, New York. Association for Computational Linguistics.
Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, 和 Steve Young. 2007. 基于议程的用户模拟用于引导 POMDP 对话系统. 收录于《2007年人类语言技术:北美计算语言学协会会议;配套卷,短论文》, 第149-152页, 纽约州罗切斯特. 计算语言学协会.
Pararth Shah, Dilek Hakkani-Tür, Gokhan Tür, Abhinav Rastogi, Ankur Bapna, Neha Nayak, and Larry Heck. 2018. Building a conversational agent overnight with dialogue self-play. arXiv preprint arXiv:1801.04871.
Pararth Shah, Dilek Hakkani-Tür, Gokhan Tür, Abhinav Rastogi, Ankur Bapna, Neha Nayak, and Larry Heck. 2018. 通过对话自我对弈在一夜之间构建对话智能体。arXiv 预印本 arXiv:1801.04871.
Ryuichi Takanobu, Hanlin Zhu, and Minlie Huang. 2019. Guided dialog policy learning: Reward estimation for multi-domain taskoriented dialog. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 100–110, Hong Kong, China. Association for Computational Linguistics.
Ryuichi Takanobu, Hanlin Zhu 和 Minlie Huang. 2019. 引导式对话策略学习:面向多领域任务型对话的奖励估计. 在 2019 年自然语言处理经验方法会议和第 9 届自然语言处理国际联合会议 (EMNLP-IJCNLP) 论文集, 第 100–110 页, 中国香港. 计算语言学协会.
Zhongyu Wei, Qianlong Liu, Baolin Peng, Huaixiao Tou, Ting Chen, Xuanjing Huang, Kamfai Wong, and Xiangying Dai. 2018. Taskoriented dialogue system for automatic diagnosis. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 201–207, Melbourne, Australia. Association for Computational Linguistics.
Zhongyu Wei, Qianlong Liu, Baolin Peng, Huaixiao Tou, Ting Chen, Xuanjing Huang, Kamfai Wong, 和 Xiangying Dai. 2018. 面向任务的自动诊断对话系统. 在《第56届计算语言学协会年会论文集(第2卷:短论文)》中,第201-207页,澳大利亚墨尔本. 计算语言学协会.
Tsung-Hsien Wen, Milica Gasic, Nikola Mrksic, Pei-Hao Su, David Vandyke, and Steve Young. 2015. Semantically conditioned LSTM-based natural language generation for spoken dialogue systems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1711–1721, Lisbon, Portugal. Association for Computational Linguistics.
Tsung-Hsien Wen, Milica Gasic, Nikola Mrksic, Pei-Hao Su, David Vandyke, 和 Steve Young. 2015. 基于语义条件的 LSTM 自然语言生成在口语对话系统中的应用. 在 2015 年自然语言处理经验方法会议论文集 (Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing) 中, 第 1711–1721 页, 葡萄牙里斯本. 计算语言学协会 (Association for Computational Linguistics).
Tsung-Hsien Wen, David Vandyke, Nikola Mrksic, Milica Gasic, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. 2017. A network-based end-to-end trainable task-oriented dialogue system. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 438–449, Valencia, Spain. Association for Computational Linguistics.
Tsung-Hsien Wen, David Vandyke, Nikola Mrksic, Milica Gasic, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, 和 Steve Young. 2017. 一种基于网络的端到端可训练任务导向对话系统. 在《第15届欧洲计算语言学协会会议论文集:第一卷,长论文》中,第438-449页,西班牙瓦伦西亚. 计算语言学协会.
Jason Williams, Antoine Raux, Deepak Ramachandran, and Alan Black. 2013. The dialog state tracking challenge. In Proceedings of the SIGDIAL 2013 Conference, pages 404– 413, Metz, France. Association for Computational Linguistics.
Jason Williams, Antoine Raux, Deepak Ramachandran, and Alan Black. 2013. 对话状态跟踪挑战. 在 SIGDIAL 2013 会议论文集, 第 404–413 页, 法国梅斯. 计算语言学协会.
Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher, and Pascale Fung. 2019. Transferable multidomain state generator for task-oriented dialogue systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 808–819, Florence, Italy. Association for Computational Linguistics.
Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher, 和 Pascale Fung. 2019. 面向任务对话系统的可迁移多领域状态生成器. 在《第57届计算语言学协会年会论文集》中, 第808–819页, 意大利佛罗伦萨. 计算语言学协会.
Kaisheng Yao, Geoffrey Zweig, Mei-Yuh Hwang, Yangyang Shi, and Dong Yu. 2013. Recurrent neural networks for language understanding. In Inter speech, pages 2524–2528.
Kaisheng Yao, Geoffrey Zweig, Mei-Yuh Hwang, Yangyang Shi, 和 Dong Yu. 2013. 用于语言理解的循环神经网络 (Recurrent Neural Networks for Language Understanding). 在 Inter speech, 第 2524–2528 页.
Qi Zhu, Zheng Zhang, Yan Fang, Xiang Li, Ryuichi Takanobu, Jinchao Li, Baolin Peng, Jianfeng Gao, Xiaoyan Zhu, and Minlie Huang. 2020. Convlab-2: An open-source toolkit for building, evaluating, and diagnosing dialogue systems. arXiv preprint arXiv:2002.04793.
Qi Zhu, Zheng Zhang, Yan Fang, Xiang Li, Ryuichi Takanobu, Jinchao Li, Baolin Peng, Jianfeng Gao, Xiaoyan Zhu, and Minlie Huang. 2020. Convlab-2: 一个用于构建、评估和诊断对话系统的开源工具包。arXiv preprint arXiv:2002.04793.