Better Combine Them Together! Integrating Syntactic Constituency and Dependency Representations for Semantic Role Labeling
更好的结合方式!整合句法成分与依存表示以提升语义角色标注
Abstract
摘要
Structural syntax knowledge has been proven effective for semantic role labeling (SRL), while existing works mostly use only one singleton syntax, such as either syntactic dependency or constituency tree. In this paper, we explore the integration of heterogeneous syntactic representations for SRL. We first consider a TreeLSTM-based integration, collaboratively learning the phrasal boundaries from the constituency and the semantic relations from dependency. We further introduce a labelaware GCN solution for simultaneously modeling the syntactic edges and labels. Experimental results demonstrate that by effectively combining the heterogeneous syntactic representations, our methods yield task improvements on both span-based and dependencybased SRL. Also our system achieves new state-of-the-art SRL performances, meanwhile bringing explain able task improvements.
结构句法知识已被证明对语义角色标注(SRL)有效,而现有工作大多仅使用单一语法结构,例如句法依存树或成分树。本文探索了异构句法表示在SRL中的融合应用。我们首先提出基于TreeLSTM的融合方法,协同学习成分树的短语边界和依存树的语义关系。进一步引入标签感知(labelaware)的图卷积网络(GCN)方案,同时建模句法边和标签。实验结果表明,通过有效结合异构句法表示,我们的方法在基于跨度和基于依存的SRL任务上均取得提升。同时,我们的系统实现了新的SRL最先进性能,并带来可解释的任务改进。
1 Introduction
1 引言
Semantic role labeling (SRL) aims to disclose the predicate-argument structure of a given sentence. Such shallow semantic structures have been shown highly useful for a wide range of downstream tasks in natural language processing (NLP), such as information extraction (Fader et al., 2011; Bastia nell i et al., 2013), machine translation (Xiong et al., 2012; Shi et al., 2016) and question answering (Maqsud et al., 2014; Xu et al., 2020). Based on whether to recognize the constituent phrasal span or the syntactic dependency head token of an argument, prior works categorize SRL into two types: the span-based SRL popularized in CoNLL05/12 shared tasks (Carreras and Marquez, 2005; Pradhan et al., 2013), and the dependency-based SRL introduced in CoNLL08/09 shared tasks (Surdeanu et al., 2008; Hajic et al., 2009). By adopting various neural network methods, two types of SRL have achieved significant performances in recent years (FitzGerald et al., 2015; He et al., 2017; Fei et al., 2021a)
语义角色标注 (SRL) 旨在揭示给定句子的谓词-论元结构。这种浅层语义结构已被证明对自然语言处理 (NLP) 中的广泛下游任务非常有用,例如信息抽取 (Fader et al., 2011; Bastia nell i et al., 2013)、机器翻译 (Xiong et al., 2012; Shi et al., 2016) 和问答系统 (Maqsud et al., 2014; Xu et al., 2020)。根据是识别论元的成分短语跨度还是句法依存中心词 token,先前工作将 SRL 分为两种类型:在 CoNLL05/12 共享任务中流行的基于跨度的 SRL (Carreras and Marquez, 2005; Pradhan et al., 2013),以及在 CoNLL08/09 共享任务中引入的基于依存关系的 SRL (Surdeanu et al., 2008; Hajic et al., 2009)。通过采用各种神经网络方法,这两种 SRL 近年来都取得了显著性能 (FitzGerald et al., 2015; He et al., 2017; Fei et al., 2021a)
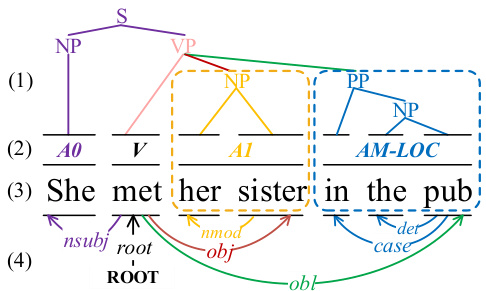
Figure 1: The mutual benefit to integrate both the (1) syntactic constituency and (4) dependency structures for (2) SRL, based on (3) an example sentence.
图 1: 基于 (3) 示例句子,(1) 句法成分结构和 (4) 依存结构对 (2) 语义角色标注 (SRL) 的协同增效作用。
Syntactic features have been extensively verified to be highly effective for SRL (Pradhan et al., 2005; Punyakanok et al., 2008; March egg ian i and Titov, 2017; Strubell et al., 2018; Zhang et al., 2019). In particular, syntactic dependency features have gained a majority of attention, especially for the dependency-based SRL, considering their close relevance with the dependency structure (Roth and Lapata, 2016; He et al., 2018; Xia et al., 2019; Fei et al., 2021b). Most existing works focus on designing various methods for modeling the dependency representations into the SRL learning, such as TreeLSTM (Li et al., 2018; Xia et al., 2019) and graph convolutional networks (GCN) (Marcheggiani and Titov, 2017; Li et al., 2018). On the other hand, some efforts try to encode the constituency representations for facilitating the span-based SRL (Wang et al., 2019; March egg ian i and Titov, 2020).
句法特征已被广泛验证对语义角色标注(SRL)非常有效(Pradhan et al., 2005; Punyakanok et al., 2008; Marcheggiani and Titov, 2017; Strubell et al., 2018; Zhang et al., 2019)。其中,句法依存特征因其与依存结构的紧密关联性(Roth and Lapata, 2016; He et al., 2018; Xia et al., 2019; Fei et al., 2021b),尤其对基于依存的语义角色标注获得了最多关注。现有研究主要聚焦于设计各种方法将依存表征建模融入SRL学习,例如TreeLSTM(Li et al., 2018; Xia et al., 2019)和图卷积网络(GCN)(Marcheggiani and Titov, 2017; Li et al., 2018)。另一方面,也有研究尝试编码成分句法表征来辅助基于跨度的语义角色标注(Wang et al., 2019; Marcheggiani and Titov, 2020)。
Yet almost all the syntax-based SRL methods use one standalone syntactic tree, i.e., either dependency or constituency tree. Constituent and dependency syntax actually depict the syntactic structure from different perspectives, and integrating these two heterogeneous representations can intuitively bring complementary advantages (Farkas et al., 2011; Yoshikawa et al., 2017; Zhou and Zhao, 2019). As exemplified in Figure 1, the dependency edges represent the inter-relations between arguments and predicates, while the constituency structure1 locates more about phrase boundaries of argument spans, and then directs the paths to the predicate globally. Interacting these two structures can better guide the system to focus on the most proper granularity of phrasal spans (as circled by the dotted box), while also ensuring the route consistency between predicate-argument pairs. Unfortunately, we find that there are very limited explorations of the heterogeneous syntax integration in SRL. For instance, Li et al. (2010) manually craft two types of discrete syntax features for statistical model, and recently Fei et al. (2020a) implicitly distill two heterogeneous syntactic representations into one unified neural model.
然而,几乎所有基于句法的语义角色标注 (SRL) 方法都使用单一的句法树,即依存树或成分树。成分句法和依存句法实际上从不同角度描绘了句法结构,整合这两种异构表示可以直观地带来互补优势 (Farkas et al., 2011; Yoshikawa et al., 2017; Zhou and Zhao, 2019)。如图 1 所示,依存边表示论元与谓词之间的相互关系,而成分结构1更多定位论元跨度的短语边界,并全局引导路径指向谓词。交互这两种结构能更好地引导系统关注最合适的短语跨度粒度(如虚线框标注部分),同时确保谓词-论元对的路径一致性。遗憾的是,我们发现当前针对 SRL 的异构句法整合研究非常有限。例如,Li et al. (2010) 为统计模型手工设计了两类离散句法特征,而近期 Fei et al. (2020a) 将两种异构句法表示隐式蒸馏到一个统一的神经模型中。
In this paper, we present two innovative neural methods for explicitly integrating two kinds of syntactic features for SRL. As shown in Figure 2, in our framework, the syntactic constituent and dependency encoders are built jointly as a unified block (i.e., Heterogeneous Syntax Fuser, namely HeSyFu), and work closely with each other. In the first architecture of HeSyFu (cf. Figure 3), we take two separate TreeLSTMs as the structure encoders for two syntactic trees. Based on our framework, we try to answer the following questions:
本文提出了两种创新性的神经方法,用于显式整合两种句法特征以实现语义角色标注(SRL)。如图2所示,在我们的框架中,句法成分编码器和依存关系编码器被联合构建为一个统一模块(即异构句法融合器HeSyFu),并紧密协作。在HeSyFu的第一种架构中(见图3),我们采用两个独立的TreeLSTM分别作为两种句法树的结构编码器。基于该框架,我们试图回答以下问题:
$\blacktriangleright$ Q1. Whether the combination of constituent and dependency syntax can really improve SRL? $\blacktriangleright$ Q2. If yes, how much will such improvements be for the dependency- and span-based SRL?
$\blacktriangleright$ Q1. 成分句法和依存句法的结合是否真的能提升语义角色标注 (SRL) 性能?
$\blacktriangleright$ Q2. 若有效,这种改进对基于依存和基于跨度的语义角色标注分别有多大提升?
We further propose Const GCN and Dep GCN encoders to enhance the syntax encoding in HeSyFu, where the syntactic labels (i.e., dependent arc types and constituency node types) are modeled in a unified manner within the label-aware GCN, as illustrated in Figure 4. With this, we can dig deeper:
我们进一步提出Const GCN和Dep GCN编码器来增强HeSyFu中的句法编码,其中句法标签(即依存弧类型和成分节点类型)在标签感知GCN中以统一方式建模,如图4所示。通过这种方式,我们可以进行更深入的挖掘:
▶ Q3. How different will the results be by employing the TreeLSTM or GCN encoder? ▶ Q4. Can SRL be further improved by leveraging syntactic labels? ▶ Q5. What kind of associations can be discovered between SRL structures and these heterogeneous syntactic structures?
▶ Q3. 使用TreeLSTM或GCN编码器会使结果产生多大差异?
▶ Q4. 通过利用句法标签能否进一步提升语义角色标注(SRL)效果?
▶ Q5. 在语义角色标注结构与异构句法结构之间能发现何种关联?
To find the answers, we conduct extensive experiments on both span- and dependency-based SRL benchmarks (i.e., CoNLL05/12 and CoNLL09). The results and analyses show that,
为了找到答案,我们在基于跨度和依存关系的语义角色标注基准测试(即CoNLL05/12和CoNLL09)上进行了大量实验。结果表明,
▶A1. combining two types of syntax information is more helpful than just using either one of them; ▶A2. the improvement for span-based SRL is more obvious than dependency-based one; ▶A3. GCN performs better than TreeLSTM; ▶A4. syntactic labels are quite helpful for SRL; ▶A5. SRL and both kinds of syntactic structures have strong associations and should be exploited for mutual benefits.
▶A1. 结合两种句法信息比仅使用其中一种更有帮助;
▶A2. 基于跨度的语义角色标注 (SRL) 比基于依赖的改进更明显;
▶A3. 图卷积网络 (GCN) 的表现优于树结构长短期记忆网络 (TreeLSTM);
▶A4. 句法标签对语义角色标注非常有用;
▶A5. 语义角色标注与两种句法结构存在强关联性,应相互促进利用。
In our experiments, our SRL framework with two proposed HeSyFu encoders achieves better results than current best-performing systems, and yield more explain able task improvements.
在我们的实验中,采用两种新型HeSyFu编码器的SRL框架取得了优于当前最佳系统的结果,并带来了更具可解释性的任务改进。
2 Related Work
2 相关工作
The SRL task, uncovering the shallow semantic structure (i.e. ‘who did what to whom where and when’) is pioneered by Gildea and Jurafsky (2000), and popularized from PropBank (Palmer et al., 2005) and FrameNet (Baker et al., 1998). SRL is typically divided into the span-based one and dependency-based one on the basis of the granularity of arguments (e.g., phrasal spans or dependency heads). Earlier efforts focus on designing hand-crafted features with machine learning methods (Pradhan et al., 2005; Punyakanok et al., 2008; Zhao et al., 2009b,a). Later, SRL works mostly employ neural networks with distributed features for the task improvements (FitzGerald et al., 2015; Roth and Lapata, 2016; March egg ian i and Titov, 2017; Strubell et al., 2018). Most high-performing systems model the task as a sequence labeling problem with BIO tagging scheme for both two types of SRL (He et al., 2017; Ouchi et al., 2018; Fei et al., 2020c,b).
语义角色标注 (SRL) 任务由 Gildea 和 Jurafsky (2000) 开创,旨在揭示浅层语义结构(即"谁在何时何地对谁做了什么"),随后通过 PropBank (Palmer et al., 2005) 和 FrameNet (Baker et al., 1998) 得到普及。根据论元粒度(如短语跨度或依存中心词),SRL通常分为基于跨度的和基于依存的两类。早期研究主要集中于利用机器学习方法设计人工特征 (Pradhan et al., 2005; Punyakanok et al., 2008; Zhao et al., 2009b,a)。后来,SRL工作大多采用具有分布式特征的神经网络来改进任务 (FitzGerald et al., 2015; Roth and Lapata, 2016; March egg ian i and Titov, 2017; Strubell et al., 2018)。大多数高性能系统将这两类SRL任务建模为采用BIO标记方案的序列标注问题 (He et al., 2017; Ouchi et al., 2018; Fei et al., 2020c,b)。
On the other hand, syntactic features are a highly effective SRL performance enhancer, according to numbers of empirical verification in prior works (March egg ian i et al., 2017; He et al., 2018; S way am dip ta et al., 2018; Zhang et al., 2019), as intuitively SRL shares much underlying structure with syntax. Basically, the syntactic dependent feature is more preferred to be injected into the dependency-based SRL (Roth and Lapata, 2016; March egg ian i and Titov, 2017; He et al., 2018; Kasai et al., 2019), while other consider the constituent syntax for the span-based SRL (Wang et al., 2019; March egg ian i and Titov, 2020).
另一方面,句法特征能显著提升语义角色标注(SRL)性能,这一点已被多项先前研究的实证结果所验证(March egg ian i et al., 2017; He et al., 2018; S way am dip ta et al., 2018; Zhang et al., 2019),因为直观上SRL与句法存在大量底层结构关联。通常,基于依存关系的SRL更倾向于融入依存句法特征(Roth and Lapata, 2016; March egg ian i and Titov, 2017; He et al., 2018; Kasai et al., 2019),而基于跨度的SRL则多采用成分句法(Wang et al., 2019; March egg ian i and Titov, 2020)。
Actually, the constituent and dependency syntax depict the structural features from different angles, while they can share close linguistic relevance. Related works have revealed the mutual benefits on integrating these two heterogeneous syntactic representations for various NLP tasks (Collins, 1997; Charniak, 2000; Charniak and Johnson, 2005; Farkas et al., 2011; Yoshikawa et al., 2017; Zhou and Zhao, 2019; Strzyz et al., 2019; Kato and Matsubara, 2019). Unfortunately, there are very limited explorations for SRL. For example, Li et al. (2010) construct discrete heterogeneous syntactic features for SRL. More recent work in Fei et al. (2020a) leverage knowledge distillation method to inject the heterogeneous syntax representations from various tree encoders into one model for enhancing the span-based SRL. In this work, we consider an explicit integration of these two syntactic structures via two neural solutions. To our knowledge, we are the first attempt performing thorough investigations on the impacts of the heterogeneous syntax combination to the SRL task.
实际上,成分句法和依存句法从不同角度描述了结构特征,但它们之间存在紧密的语言学关联。相关研究表明,将这两种异构句法表示整合到各类NLP任务中能产生相互增益 (Collins, 1997; Charniak, 2000; Charniak and Johnson, 2005; Farkas et al., 2011; Yoshikawa et al., 2017; Zhou and Zhao, 2019; Strzyz et al., 2019; Kato and Matsubara, 2019)。然而针对语义角色标注(SRL)的探索却非常有限:Li等人(2010)为SRL构建了离散的异构句法特征;Fei等人(2020a)近期工作则利用知识蒸馏方法,将来自不同树编码器的异构句法表示注入单一模型以增强基于跨度的SRL。本文通过两种神经架构实现这两种句法结构的显式整合。据我们所知,这是首次系统研究异构句法组合对SRL任务影响的尝试。
Various neural models have been proposed for encoding the syntactic structures, such as attention mechanism (Strubell et al., 2018; Zhang et al., 2019), TreeLSTM (Li et al., 2018; Xia et al., 2019), GCN (March egg ian i and Titov, 2017; Li et al., 2018; March egg ian i and Titov, 2020), etc. In this work, we take the advantages of the TreeLSTM and GCN models for encoding the constituent and dependency trees, as two solutions of our HeSyFu encoders. It is worth noticing that prior works using GCN to encode dependency (March egg ian i and Titov, 2017) and constituent (March egg ian i and Titov, 2020), where however the syntactic labels are not managed in a unified manner. We thus consider enhancing the syntax GCN by simultaneously modeling the syntactic labels within the structure.
为编码句法结构,研究者提出了多种神经模型,例如注意力机制 (attention mechanism) [Strubell et al., 2018; Zhang et al., 2019]、TreeLSTM [Li et al., 2018; Xia et al., 2019]、图卷积网络 (GCN) [March egg ian i and Titov, 2017; Li et al., 2018; March egg ian i and Titov, 2020] 等。本文结合TreeLSTM与GCN的优势,分别对成分树和依存树进行编码,作为HeSyFu编码器的两种实现方案。值得注意的是,此前使用GCN编码依存 [March egg ian i and Titov, 2017] 和成分 [March egg ian i and Titov, 2020] 的研究均未统一处理句法标签。为此,我们提出通过在结构中同步建模句法标签来增强语法图卷积网络。
3 SRL Model
3 SRL模型
3.1 Task Modeling
3.1 任务建模
Following prior works (Tan et al., 2018; Marcheggiani and Titov, 2020), our system aims to identify and classify the arguments of a predicate into semantic roles, such as $A O,A l,A M–L O C,$ , etc. We denote the complete role set as $\mathcal{R}$ . We adopt the $B I O$ tagging scheme. And given a sentence $s={w_{1},\cdot\cdot\cdot,w_{n}}$ and a predicate $w_{p}$ , the model assigns each word $w_{i}$ a label $\hat{y}\in\mathcal{V}$ where $\mathcal{V}\overline{{=}}({B,I}\times\mathcal{R})\cup{O}$ .2 Note that each semantic argument corresponds to a word span of ${w_{j},\cdot\cdot\cdot,w_{k}}$ $(1{\le}j{\le}k{\le}n)$ .3
遵循先前的研究 (Tan et al., 2018; Marcheggiani and Titov, 2020),我们的系统旨在识别谓词的论元并将其分类为语义角色,例如 $A O,A l,A M–L O C,$ 等。我们将完整角色集表示为 $\mathcal{R}$。采用 $B I O$ 标注方案。给定句子 $s={w_{1},\cdot\cdot\cdot,w_{n}}$ 和谓词 $w_{p}$,模型为每个词 $w_{i}$ 分配标签 $\hat{y}\in\mathcal{V}$,其中 $\mathcal{V}\overline{{=}}({B,I}\times\mathcal{R})\cup{O}$。2 注意每个语义论元对应一个词跨度 ${w_{j},\cdot\cdot\cdot,w_{k}}$ $(1{\le}j{\le}k{\le}n)$。3
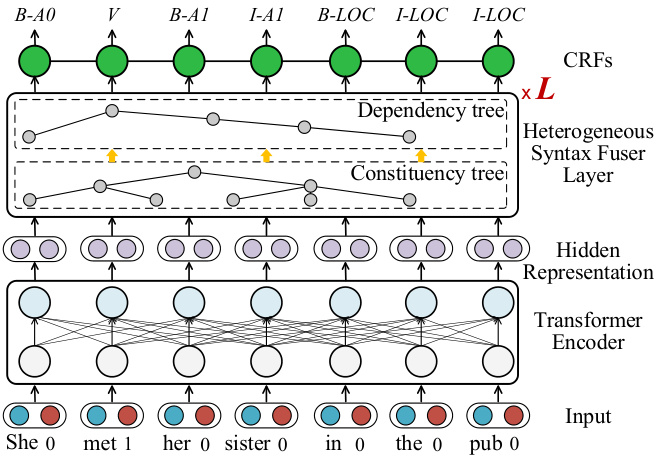
Figure 2: Overview of our SRL framework.
图 2: 我们的语义角色标注 (SRL) 框架概览。
3.2 Framework
3.2 框架
As illustrated in Figure 2, our SRL framework consists of four components, including input representations, Transformer encoder, heterogeneous syntax fuser layer and CRFs decoding layer.
如图 2 所示,我们的 SRL (Semantic Role Labeling) 框架包含四个组件,包括输入表示、Transformer 编码器、异构语法融合层和 CRFs (Conditional Random Fields) 解码层。
Given an input sentence $s$ and a predicate word $w_{p}$ $\mathrm{\check{\rho}}$ is the position), the input representations $\mathbf{\nabla}{x}$ are the concatenation $(\oplus)$ of word embeddings ${\bf\nabla}x_{w_{i}}$ and predicate binary embeddings ${\pmb x}{(i==p)}$ indicating the presence or absence of $w_{p}$ :
给定输入句子 $s$ 和谓词 $w_{p}$ ($\mathrm{\check{\rho}}$ 表示位置),输入表征 $\mathbf{\nabla}{x}$ 是词嵌入 ${\bf\nabla}x_{w_{i}}$ 与谓词二值嵌入 ${\pmb x}{(i==p)}$ (用于指示 $w_{p}$ 是否出现) 的拼接 $(\oplus)$:
$$
\pmb{x}{i}=\pmb{x}{w_{i}}\oplus\pmb{x}_{(i==p)}.
$$
$$
\pmb{x}{i}=\pmb{x}{w_{i}}\oplus\pmb{x}_{(i==p)}.
$$
Afterwards, we adopt Transformer (Vaswani et al., 2017) as our base encoder for yielding contextualized word representations. Transformer $(T r m)$ works with multi-head self-attention mechanism:
随后,我们采用 Transformer (Vaswani et al., 2017) 作为基础编码器来生成上下文相关的词表征。Transformer $(T r m)$ 采用多头自注意力机制:
$$
\mathrm{Softmax}(\frac{Q\cdot K^{\mathrm{T}}}{\sqrt{d_{k}}})\cdot V,
$$
$$
\mathrm{Softmax}(\frac{Q\cdot K^{\mathrm{T}}}{\sqrt{d_{k}}})\cdot V,
$$
where $Q,K$ and $V$ are the linear projections from the input representation $\boldsymbol{x}_{i}$ . We simplify the flow:
其中 $Q,K$ 和 $V$ 是输入表示 $\boldsymbol{x}_{i}$ 的线性投影。我们简化流程:
$$
{\pmb{r}{1},\cdot\cdot\cdot,\pmb{r}{n}}=\operatorname{Trm}({\pmb{x}{1},\cdot\cdot\cdot,\pmb{x}_{n}}).
$$
$$
{\pmb{r}{1},\cdot\cdot\cdot,\pmb{r}{n}}=\operatorname{Trm}({\pmb{x}{1},\cdot\cdot\cdot,\pmb{x}_{n}}).
$$
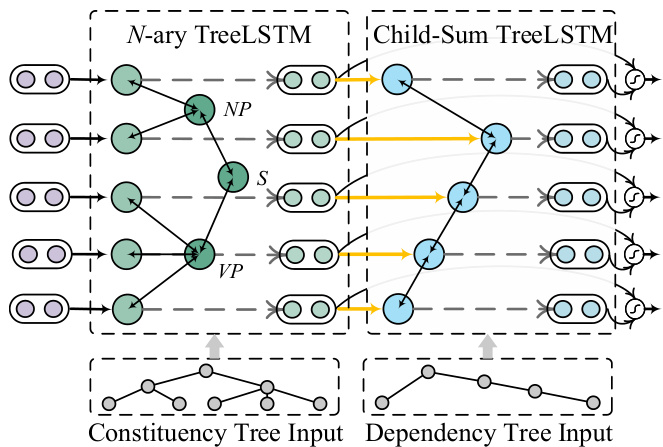
Figure 3: TreeLSTM-based HeSyFu layer.
图 3: 基于TreeLSTM的HeSyFu层。
Based on the syntax-aware hidden representation $s_{i}$ , we use CRFs (Lafferty et al., 2001) to compute the probability of each candidate output $\pmb{y}={y_{1},\dots,y_{n}}$ :
基于语法感知的隐藏表示 $s_{i}$,我们使用条件随机场 (CRFs) [20] 来计算每个候选输出 $\pmb{y}={y_{1},\dots,y_{n}}$ 的概率:
$$
p(y|s)=\frac{\exp{\sum_{i}(W s_{n}+T_{y_{i-1},y_{i}})}}{Z},
$$
$$
p(y|s)=\frac{\exp{\sum_{i}(W s_{n}+T_{y_{i-1},y_{i}})}}{Z},
$$
where $W$ and $\mathbf{\delta}_{\mathbf{\delta}\mathbf{T}}$ are the parameters and $Z$ is a normalization factor. The Viterbi algorithm is used to search for the highest-scoring tag sequence $\hat{y}$ .
其中 $W$ 和 $\mathbf{\delta}_{\mathbf{\delta}\mathbf{T}}$ 是参数,$Z$ 是归一化因子。使用 Viterbi 算法搜索最高分的标签序列 $\hat{y}$。
4 Integration of Syntactic Constituency and Dependency Structure
4 句法成分与依存结构的整合
We present two neural heterogeneous syntax fusers (a.k.a., HeSyFu), including a TreeLSTM-based HeSyFu (cf. Figure 3), and a label-aware GCNbased HeSyFu (cf. Figure 4). HeSyFu is stacked with total $L$ layers for a full syntax interaction. We design the architecture with the constituency (denoted as const.) encoding in front of the dependency (denoted as dep.) encoding, based on the intuition that the boundary recognition helped by const. syntax should go before the semantic relation determination aided by dep. syntax.
我们提出了两种神经异构语法融合器(即HeSyFu),包括基于TreeLSTM的HeSyFu(见图3)和基于标签感知GCN的HeSyFu(见图4)。HeSyFu共堆叠了$L$层以实现完整的语法交互。基于成分句法(constituency,简称const.)辅助的边界识别应先于依存句法(dependency,简称dep.)辅助的语义关系判定这一直觉,我们在架构设计上将成分编码置于依存编码之前。
4.1 TreeLSTM Heterogeneous Syntax Fuser
4.1 TreeLSTM异构语法融合器
Our TreeLSTM-based HeSyFu (Tr-HeSyFu) is comprised of the $N$ -ary TreeLSTM for const. trees and the Child-Sum TreeLSTM for dep. trees motivated by Tai et al. (2015).
我们基于TreeLSTM的HeSyFu (Tr-HeSyFu) 由针对const.树的$N$元TreeLSTM和针对dep.树的Child-Sum TreeLSTM组成,其设计灵感来自Tai等人 (2015) 的研究。
Constituency tree encoding The flow in TreeLSTM is bidirectional, i.e., bottom-up and top-down, for a full information interaction. For each node $u$ in the tree, we denote the hidden state and memory cell of its $v$ -th $(v\in[1,M])$ branching child as $\boldsymbol{h}{u v}^{\dagger}$ and $c{u v}$ . The bottom-up one computes the representation $\boldsymbol{h}_{u}^{\dagger}$ from its children hierarchically:
成分树编码
TreeLSTM中的信息流是双向的,即自底向上和自顶向下,以实现完整的信息交互。对于树中的每个节点$u$,我们将其第$v$个$(v\in[1,M])$分支子节点的隐藏状态和记忆单元记为$\boldsymbol{h}{u v}^{\dagger}$和$c{u v}$。自底向上的方式通过层级计算从其子节点得到表示$\boldsymbol{h}_{u}^{\dagger}$:
$$
\begin{array}{r l}&{\quad i_{u}=\sigma(W^{(i)}r_{u}+\sum_{v=1}^{M}U_{v}^{(i)}h_{u v}^{\dagger}+b^{(i)}),}\ &{f_{u k}=\sigma(W^{(f)}r_{u}+\sum_{v=1}^{M}U_{k v}^{(f)}h_{u v}^{\dagger}+b^{(f)}),}\ &{o_{u}=\sigma(W^{(o)}r_{u}+\sum_{v=1}^{M}U_{v}^{(o)}h_{u v}^{\dagger}+b^{(o)}),}\ &{u_{u}=\mathrm{Tanh}(W^{(u)}r_{u}+\sum_{v=1}^{M}U_{v}^{(u)}h_{u v}^{\dagger}+b^{(u)}),}\ &{c_{u}=i_{u}\odot u_{u}+\sum_{k=1}^{M}f_{u k}\odot c_{u k},}\ &{h_{u}^{\dagger}=o_{u}\odot\operatorname{tanh}(c_{u}),}\end{array}
$$
$$
\begin{array}{r l}&{\quad i_{u}=\sigma(W^{(i)}r_{u}+\sum_{v=1}^{M}U_{v}^{(i)}h_{u v}^{\dagger}+b^{(i)}),}\ &{f_{u k}=\sigma(W^{(f)}r_{u}+\sum_{v=1}^{M}U_{k v}^{(f)}h_{u v}^{\dagger}+b^{(f)}),}\ &{o_{u}=\sigma(W^{(o)}r_{u}+\sum_{v=1}^{M}U_{v}^{(o)}h_{u v}^{\dagger}+b^{(o)}),}\ &{u_{u}=\mathrm{Tanh}(W^{(u)}r_{u}+\sum_{v=1}^{M}U_{v}^{(u)}h_{u v}^{\dagger}+b^{(u)}),}\ &{c_{u}=i_{u}\odot u_{u}+\sum_{k=1}^{M}f_{u k}\odot c_{u k},}\ &{h_{u}^{\dagger}=o_{u}\odot\operatorname{tanh}(c_{u}),}\end{array}
$$
where $W,U$ and $^b$ are parameters. $\pmb{r}{u},\pmb{i}{u}$ , $\mathbf{)}{u}$ and $f_{u v}$ are the input token representation, input gate, output gate and forget gate. Analogously, the top-down $N$ -ary TreeLSTM calculates the representation $h_{u}^{\downarrow}$ the same way. We concatenate the represent at ions of two directions: $h_{u}^{c o n s t}=h_{u}^{\uparrow}\oplus h_{u}^{\downarrow}$ Note that the constituent tree nodes include terminal word nodes and non-terminal constituent nodes, and we only take the representations (i.e., $h_{i}^{c o n s t})$ corresponding to the word node $w_{i}$ for any usage.
其中 $W,U$ 和 $^b$ 是参数。$\pmb{r}{u},\pmb{i}{u}$、$\mathbf{)}{u}$ 和 $f_{u v}$ 分别表示输入token表征、输入门、输出门和遗忘门。类似地,自上而下的 $N$ 元TreeLSTM以相同方式计算表征 $h_{u}^{\downarrow}$。我们将双向表征拼接为:$h_{u}^{c o n s t}=h_{u}^{\uparrow}\oplus h_{u}^{\downarrow}$。注意成分树节点包含终端词节点和非终端成分节点,我们仅提取词节点 $w_{i}$ 对应的表征(即 $h_{i}^{c o n s t}$)供后续使用。
Dependency tree encoding Slightly different from $N$ -ary TreeLSTM for const. tree, the nonterminal nodes in dep. tree encoded by Child-Sum TreeLSTM are all the word nodes. We also consider the bidirectional calculation here. The bottomup TreeLSTM obtains $h_{i}^{\uparrow}$ of the word $w_{i}$ via:
依存树编码
与针对常量树的 $N$ 叉 TreeLSTM 略有不同,依存树中由 Child-Sum TreeLSTM 编码的非终结节点均为词节点。此处我们同样考虑双向计算:自底向上的 TreeLSTM 通过以下公式获得词 $w_{i}$ 的 $h_{i}^{\uparrow}$:
$$
\begin{array}{r l}&{\overline{{h}}{i}^{\uparrow}=\sum_{j\in C(i)}h_{j}^{\uparrow},}\ &{\begin{array}{r l}&{i_{i}=\sigma(W^{(i)}r_{i}^{\prime}+U^{(i)}\overline{{h}}{i}^{\uparrow}+b^{(i)}),}\ &{f_{i j}=\sigma(W^{(f)}r_{i}^{\prime}+U^{(f)}\overline{{h}}{j}^{\uparrow}+b^{(f)}),}\end{array}}\ &{\begin{array}{r l}&{o_{i}=\sigma(W^{(o)}r_{i}^{\prime}+U^{(o)}\overline{{h}}{i}^{\uparrow}+b^{(o)}),}\ &{u_{i}=\boldsymbol{\mathrm{Tanh}}(W^{(u)}r_{i}^{\prime}+U^{(u)}\overline{{h}}{i}^{\uparrow}+b^{(u)}),}\end{array}}\ &{\begin{array}{r l}&{c_{i}=i_{\mathrm{\Gamma}}\sigma_{u i}+\sum_{j\in C(i)}f_{i j}\odot c_{j},}\ &{h_{i}^{\uparrow}=o_{i}\odot\operatorname{tanh}(c_{i}),}\end{array}}\end{array}
$$
$$
\begin{array}{r l}&{\overline{{h}}{i}^{\uparrow}=\sum_{j\in C(i)}h_{j}^{\uparrow},}\ &{\begin{array}{r l}&{i_{i}=\sigma(W^{(i)}r_{i}^{\prime}+U^{(i)}\overline{{h}}{i}^{\uparrow}+b^{(i)}),}\ &{f_{i j}=\sigma(W^{(f)}r_{i}^{\prime}+U^{(f)}\overline{{h}}{j}^{\uparrow}+b^{(f)}),}\end{array}}\ &{\begin{array}{r l}&{o_{i}=\sigma(W^{(o)}r_{i}^{\prime}+U^{(o)}\overline{{h}}{i}^{\uparrow}+b^{(o)}),}\ &{u_{i}=\boldsymbol{\mathrm{Tanh}}(W^{(u)}r_{i}^{\prime}+U^{(u)}\overline{{h}}{i}^{\uparrow}+b^{(u)}),}\end{array}}\ &{\begin{array}{r l}&{c_{i}=i_{\mathrm{\Gamma}}\sigma_{u i}+\sum_{j\in C(i)}f_{i j}\odot c_{j},}\ &{h_{i}^{\uparrow}=o_{i}\odot\operatorname{tanh}(c_{i}),}\end{array}}\end{array}
$$
where $C(i)$ is the set of child nodes of $w_{i}$ . $\pmb{r}{i}^{'}$ is the input token representation consulting the foregoing constituent output representation: $\pmb{r}{i}^{\prime}=\pmb{r}{i}+\pmb{h}{i}^{c o n s t}$ The top-down one yields $h_{i}^{\downarrow}$ , which is concatenated with the bottom-up one: $\pmb{h}{i}^{\dot{d e}p}=\pmb{h}{i}^{\uparrow}\oplus\pmb{h}_{i}^{\downarrow}$ .
其中 $C(i)$ 是 $w_{i}$ 的子节点集合。$\pmb{r}{i}^{'}$ 是通过参考前述成分输出表示得到的输入token表示:$\pmb{r}{i}^{\prime}=\pmb{r}{i}+\pmb{h}{i}^{c o n s t}$。自上而下的过程生成 $h_{i}^{\downarrow}$,与自下而上的表示进行拼接:$\pmb{h}{i}^{\dot{d e}p}=\pmb{h}{i}^{\uparrow}\oplus\pmb{h}_{i}^{\downarrow}$。
Integration To fully make use of the heterogeneous syntactic knowledge, we fuse these two resulting syntactic representations. We apply a fusion gate to flexibly coordinate their contributions:
集成
为了充分利用异构句法知识,我们将这两种生成的句法表示进行融合。我们采用一个融合门来灵活协调它们的贡献:
$$
\begin{array}{r l}&{{\pmb g}{i}=\sigma({\pmb W}^{(g_{1})}{\pmb h}{i}^{c o n s t}+{\pmb W}^{(g_{2})}{\pmb h}{i}^{d e p}+{\pmb b}^{(g)}),}\ &{{\pmb s}{i}={\pmb g}{i}\odot{\pmb h}{i}^{c o n s t}+(1-{\pmb g}{i})\odot{\pmb h}_{i}^{d e p}.}\end{array}
$$
$$
\begin{array}{r l}&{{\pmb g}{i}=\sigma({\pmb W}^{(g_{1})}{\pmb h}{i}^{c o n s t}+{\pmb W}^{(g_{2})}{\pmb h}{i}^{d e p}+{\pmb b}^{(g)}),}\ &{{\pmb s}{i}={\pmb g}{i}\odot{\pmb h}{i}^{c o n s t}+(1-{\pmb g}{i})\odot{\pmb h}_{i}^{d e p}.}\end{array}
$$
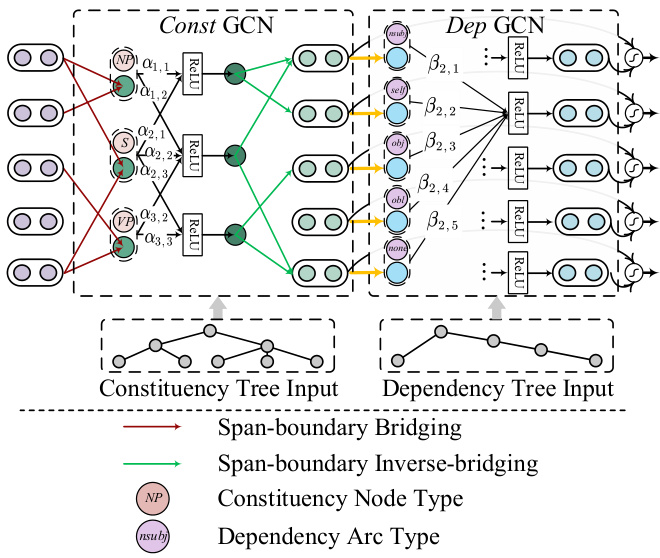
Figure 4: Label-aware GCN-based HeSyFu layer.
图 4: 基于标签感知的GCN HeSyFu层。
4.2 Label-aware GCN-based Heterogeneous Syntax Fuser
4.2 基于标签感知GCN的异构语法融合器
Compared with TreeLSTM, GCN is more comput ation ally efficient on performing the structural propagation among nodes, i.e., with O(1) complexity. On the other hand, it is also crucial to leverage the syntactic labels (i.e., dependent arc types, and constituent phrasal types) into the SRL learning. For example, within the dependency tree, the information from the neighboring nodes under distinct types of arcs can contribute in different degrees. However we note that current popular syntax GCNs (March egg ian i and Titov, 2017, 2020) do not en- code the dependent or constituent labels with the nodes in a unified manner, which could be inaccurate to describe the syntactic connecting attributes between the neighbor nodes. Based on their syntax GCNs, we newly propose label-aware constituency and dependency GCNs which are able to explicitly formalize the structure edges with syntactic labels simultaneously, and normalize them unitedly.4 As illustrated in Figure 4, our label-aware GCN-based $\mathrm{He}\mathrm{Sy}\mathrm{E}\mathrm{u}$ (denoted as LG-HeSyFu) has a similar assembling architecture to TreeLSTMbased $\mathrm{He}\mathrm{Sy}\mathrm{E}\mathrm{u}$ , and will finally be navigated via the gate mechanism as in Eq. (8).
与TreeLSTM相比,GCN在节点间执行结构传播时计算效率更高(即复杂度为O(1))。另一方面,将句法标签(即依存弧类型和成分短语类型)融入语义角色标注(SRL)学习也至关重要。例如,在依存树中,不同类型弧下相邻节点的信息贡献程度可能不同。但我们注意到当前流行的句法GCN (Marcheggiani和Titov, 2017, 2020)并未以统一方式将依存或成分标签与节点编码,这可能无法准确描述相邻节点间的句法连接属性。基于这些句法GCN,我们新提出了标签感知成分GCN和依存GCN,能够同时显式地将带句法标签的结构边形式化并进行统一归一化。如图4所示,我们基于标签感知GCN的$\mathrm{He}\mathrm{Sy}\mathrm{E}\mathrm{u}$(记为LG-HeSyFu)具有与基于TreeLSTM的$\mathrm{He}\mathrm{Sy}\mathrm{E}\mathrm{u}$相似的组装架构,最终将通过公式(8)中的门控机制进行导航。
Constituency tree encoding The constituent tree is modeled as a graph $G^{(c)}{=}(U^{(c)},E^{(c)})$ , where $U^{(c)}$ is the node set and $E^{(c)}$ is the edge set. We denote e(ucv) =1 if there is an edge between node u and node $v$ , and $e_{u v}{=}0$ vice versa. We enable the edges to be bidirectional. $\mu_{u}$ represents the constituent label of node $u$ , such as $S,N P$ and $V P$ , etc. We take the vectorial embedding $\mathbf{\Delta}\mathbf{v}{u}^{(c)}$ for the node label $\mu_{u}$ . Our constituent GCN (denoted as Const GCN) yields the node representations $\boldsymbol{h}_{u}^{(c)}$ :
成分树编码
成分树被建模为图 $G^{(c)}{=}(U^{(c)},E^{(c)})$ ,其中 $U^{(c)}$ 是节点集, $E^{(c)}$ 是边集。若节点 $u$ 与节点 $v$ 之间存在边,则记为 $e(ucv) =1$ ,否则 $e_{u v}{=}0$ 。我们允许边为双向。 $\mu_{u}$ 表示节点 $u$ 的成分标签,例如 $S,N P$ 和 $V P$ 等。我们为节点标签 $\mu_{u}$ 获取向量化嵌入 $\mathbf{\Delta}\mathbf{v}_{u}^{(c)}$ 。我们的成分GCN(记为Const GCN)生成节点表示 $\boldsymbol{h}_{u}^{(c)}$ :
$\begin{array}{r}{\pmb{h}{\pmb{u}}^{(c)}=\mathrm{ReLU}{\sum_{v=1}^{M}\alpha_{u v}(\pmb{W}^{(c_{1})}\cdot\pmb{r}{v}^{b}+\pmb{W}^{(c_{2})}\cdot\pmb{v}{v}^{(c)}+b^{(c)})},}\end{array}$ (9) where $r_{v}^{b}$ is the initial node representation of the node $v$ via span-boundary bridging operation, i.e., adding the start and end token representation of the phrasal span, $\pmb{r}{v}^{b}=\pmb{r}{s t a r t}+\pmb{r}{e n d}$ . And $\alpha_{u v}$ is the constituent connecting distribution:
其中 $r_{v}^{b}$ 是通过跨边界桥接操作获得的节点 $v$ 的初始节点表示,即添加短语跨度的起始和结束 token 表示:$\pmb{r}{v}^{b}=\pmb{r}{start}+\pmb{r}{end}$。而 $\alpha_{uv}$ 是成分连接分布:
$$
\alpha_{u v}=\frac{e_{u v}^{(c)}\cdot\exp{{(z_{u}^{(c)})^{T}\cdot z_{v}^{(c)}}}}{\sum_{v^{'}=1}^{M}e_{u v^{'}}^{(c)}\cdot\exp{{(z_{u}^{(c)})^{T}\cdot z_{v^{'}}^{(c)}}}},
$$
$$
\alpha_{u v}=\frac{e_{u v}^{(c)}\cdot\exp{{(z_{u}^{(c)})^{T}\cdot z_{v}^{(c)}}}}{\sum_{v^{'}=1}^{M}e_{u v^{'}}^{(c)}\cdot\exp{{(z_{u}^{(c)})^{T}\cdot z_{v^{'}}^{(c)}}}},
$$
where z(uc) $\pmb{z}{u}^{(c)}=\pmb{v}{u}+\pmb{v}{u}^{(c)}$ . This distribution $\alpha_{u v}$ encodes both the syntactic edge and label information, and thus comprehensively reflects the connecting strengths between neighbors. We then perform span-boundary inverse-bridging to restore the token node representation $h_{i}^{c o n s t}$ for each word wi, i.e., hiconst = h(c) + h(c) .
其中 z(uc) $\pmb{z}{u}^{(c)}=\pmb{v}{u}+\pmb{v}{u}^{(c)}$。该分布 $\alpha_{u v}$ 同时编码了句法边和标签信息,从而全面反映邻居节点间的连接强度。接着我们通过跨边界逆桥接恢复每个单词 wi 的 token 节点表示 $h_{i}^{c o n s t}$,即 hiconst = h(c) + h(c)。
Dependency tree encoding Likewise, the dependent tree is modeled as a graph $G^{(d)}{=}(U^{(d)},\\\hat{E^{(d)}})$ . $e_{i j}^{(d)}{=}1/0$ denotes the dependency arc existence. $\pi_{i j}^{\leftrightarrow}$ represents the edge label between $w_{i}$ and $w_{j}$ , which is also bidirectional. Besides of the pre-defined dependency labels, we additionally add a ‘self ’ label as the self-loop edge $\pi_{i i}^{\leftrightarrow}$ , and a ‘none’ label representing no edge between $w_{i}$ and $w_{j}$ . We use the embedding form ${\pmb v}{i j}^{(d)}$ for $\pi_{i j}^{\leftrightarrow}$ . The update in dependent GCN (denoted as Dep GCN) is written as:
依存树编码
同样地,依存树被建模为图 $G^{(d)}{=}(U^{(d)},\\\hat{E^{(d)}})$。$e_{i j}^{(d)}{=}1/0$ 表示依存弧的存在性。$\pi_{i j}^{\leftrightarrow}$ 表示 $w_{i}$ 和 $w_{j}$ 之间的边标签,该标签也是双向的。除了预定义的依存标签外,我们还额外添加了表示自循环边 $\pi_{i i}^{\leftrightarrow}$ 的“self”标签,以及表示 $w_{i}$ 和 $w_{j}$ 之间无边连接的“none”标签。我们使用嵌入形式 ${\pmb v}{i j}^{(d)}$ 来表示 $\pi_{i j}^{\leftrightarrow}$。依存图卷积网络(记为 Dep GCN)的更新公式为:
(11) 其中 ${\pmb r}{j}^{\prime}={\pmb r}{j}+{\pmb h}{i}^{c o n s t}$。$\beta_{i j}$ 表示邻居连接强度分布:
$$
\beta_{i j}=\frac{e_{i j}^{(d)}\cdot\exp{(z_{i}^{(d)})^{T}\cdot z_{j}^{(d)}}}{\sum_{j^{\prime}=1}^{n}e_{i j^{\prime}}^{(d)}\cdot\exp{(z_{i}^{(d)})^{T}\cdot z_{j^{\prime}}^{(d)}}},
$$
$$
\beta_{i j}=\frac{e_{i j}^{(d)}\cdot\exp{(z_{i}^{(d)})^{T}\cdot z_{j}^{(d)}}}{\sum_{j^{\prime}=1}^{n}e_{i j^{\prime}}^{(d)}\cdot\exp{(z_{i}^{(d)})^{T}\cdot z_{j^{\prime}}^{(d)}}},
$$
where zi $z_{i}^{(d)}={\pmb r}{i}^{\prime}+{\pmb v}{i j}^{(d)}$ Here hi(d) also can be denoted as $h_{i}^{d e p}$ , whicijh navigates the dependent arc and label information in a more unified way.
其中 $z_{i}^{(d)}={\pmb r}{i}^{\prime}+{\pmb v}{i j}^{(d)}$ 。此处 hi(d) 也可表示为 $h_{i}^{d e p}$ ,以更统一的方式引导依赖弧和标签信息。
5 Experiments
5 实验
5.1 Setups
5.1 设置
We conduct experiments on the span-based SRL datasets (CoNLL05 & CoNLL12), and dependency-based SRL dataset (CoNLL09). Each dataset has its own training, development, and test sets. We convert the constituency syntax annotations in CoNLL05&12 into dependency annotations by following the standard of Stanford Typed Dependency (v3.3.0).5 We obtain the constituency annotations for CoNLL09 from the PTB data. We adopt the CoNLL05 evaluation scripts6 to evaluate the performances, with precision (P), recall (R) and F1 score as the metrics. We conduct significance tests via Dan Bikel’s evaluation comparer.7 The Transformer hidden size is 768. The hidden sizes in TreeLSTM and GCN encoders are in [250,300,350]. We adopt the Adam optimizer with an initial learning rate of 2e-5. We train the model8 by mini-batch size in [16,24,32] with early-stop strategy. We also load the pre-trained parameters 9 from the RoBERTa language model (Liu et al., 2019) to our Transformer encoder for boosting the performance. The environment is with Intel i9 CPU and NVIDIA RTX 3090Ti GPU.
我们在基于跨度的语义角色标注数据集(CoNLL05和CoNLL12)和基于依存关系的语义角色标注数据集(CoNLL09)上进行实验。每个数据集都有独立的训练集、开发集和测试集。我们按照Stanford Typed Dependency(v3.3.0)标准将CoNLL05&12中的成分句法标注转换为依存关系标注。从PTB数据中获取CoNLL09的成分句法标注。采用CoNLL05评估脚本来评估性能,使用精确率(P)、召回率(R)和F1值作为指标。通过Dan Bikel的评估比较器进行显著性检验。Transformer隐藏层维度为768。TreeLSTM和GCN编码器的隐藏层维度在[250,300,350]之间。采用初始学习率为2e-5的Adam优化器。通过[16,24,32]的mini-batch大小训练模型,并采用早停策略。我们还从RoBERTa语言模型(Liu et al., 2019)加载预训练参数到Transformer编码器以提升性能。实验环境为Intel i9 CPU和NVIDIA RTX 3090Ti GPU。
Table 1: Results on span-based SRL datasets. Values with $^*$ are from our re-implementations, while others are retrieved from the raw papers. Scores with $\dagger$ are presented after significant test $(\mathtt{p}{\le}0.05)$ .
| CoNLL05 WSJ | CoNLL05 Brown | CoNLL12 OntoNotes | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| Without Syntax | |||||||||
| He et al. (2017) | 85.00 | 84.30 | 84.60 | 74.90 | 72.40 | 73.60 | 83.50 | 83.30 | 83.40 |
| Tan et al. (2018) | 84.50 | 85.20 | 84.80 | 73.50 | 74.60 | 74.10 | 81.90 | 83.60 | 82.70 |
| Li et al. (2020a)+RoBERTa | 88.05 | 88.00 | 88.03 | 80.04 | 79.56 | 79.80 | 86.40 | 86.83 | 86.61 |
| Trm+RoBERTat | 87.41 | 87.72 | 87.60 | 79.78 | 79.86 | 79.82 | 86.28 | 86.67 | 86.40 |
| With Dependency Syntax | |||||||||
| Strubell et al. (2018) | 84.70 | 84.24 | 84.47 | 73.89 | 72.39 | 73.13 | 83.30 | 81.38 | 82.33 |
| Xia et al. (2020) | 85.12 | 85.00 | 85.06 | 76.30 | 75.42 | 75.86 | = | ||
| Child-Sum TreeLSTM | 84.94 | 85.80 | 85.40 | 74.60 | 74.10 | 74.36 | 83.42 | 83.56 | 83.47 |
| Dep GCNt | 86.03 | 86.52 | 86.22 | 75.38 | 75.89 | 75.62 | 84.32 | 84.88 | 84.61 |
| Dep GCN+RoBERTat | 88.21 | 87.82 | 88.07 | 80.73 | 79.82 | 80.13 | 86.58 | 86.99 | 86.82 |
| With ConstituencySyntax | |||||||||
| Wang et al. (2019)* | 85.40 | 85.02 | 85.23 | 75.48 | 75.23 | 75.36 | 84.35 | 84.11 | 84.21 |
| Marcheggiani and Titov (2020) | 85.80 | 85.10 | 85.40 | 76.20 | 74.70 | 75.50 | 84.50 | 84.30 | 84.40 |
| Marcheggiani and Titov (2020)+RoBERTa | 87.70 | 88.10 | 87.90 | 80.50 | 80.70 | 80.60 | 86.50 | 87.10 | 86.80 |
| N-ary TreeLSTMt | 85.91 | 85.27 | 85.58 | 75.22 | 75.06 | 75.12 | 84.12 | 83.85 | 84.02 |
| Const GCNt | 86.68 | 86.38 | 86.52 | 76.54 | 76.21 | 76.36 | 85.51 | 84.96 | 85.25 |
| Const GCN+RoBERTat | 88.71 | 88.94 | 88.81 | 81.52 | 81.05 | 81.27 | 87.33 | 87.42 | 87.35 |
| With Dependency & Constituency Syntax | |||||||||
| Fei et al. (2020a)* | 86.82 | 86.50 | 86.72 | 76.67 | 76.35 | 76.48 | 85.86 | 85.30 | 85.50 |
| Tr-HeSyFut | 86.27 | 86.52 | 86.64 | 76.95 | 76.50 | 76.87 | 85.91 | 85.48 | 85.66 |
| LG-HeSyFut | 87.16 | 87.63 | 87.32 | 78.72 | 77.35 | 78.12 | 86.51 | 85.92 | 86.20 |
| LG-HeSyFu w/o Syn.Labelt | 86.93 | 87.21 | 86.98 | 77.61 | 76.85 | 77.48 | 85.93 | 85.68 | 85.79 |
| LG-HeSyFu+RoBERTat | 88.86 | 89.28 | 89.04 | 83.52 | 83.75 | 83.67 | 88.09 | 88.83 | 88.59 |
表 1: 基于跨度的语义角色标注数据集结果。带 $^*$ 的数值来自我们的复现结果,其余数据引自原论文。标有 $\dagger$ 的分数表示通过显著性检验 $(\mathtt{p}{\le}0.05)$。

Figure 5: HeSyFu with different layers.
图 5: 不同层数的HeSyFu。
5.2 Development Experiments
5.2 开发实验
We first perform preliminary experiments based on the development sets.
我们首先基于开发集进行初步实验。
Layer of syntax encoder From Figure 5 we see that either too larger or fewer layers of HeSyFu does no benefits to the overall performances. When $L{=}2$ for Tr-/LG-HeSyFu, the performances become universally the best.
语法编码器层数
从图 5 可以看出,HeSyFu 的层数过多或过少都对整体性能无益。当 Tr-/LG-HeSyFu 的 $L{=}2$ 时,性能普遍达到最佳。
Table 2: Influences of the syntax encoding order.
表 2: 句法编码顺序的影响
| CoNLL05 | CoNLL12 | CoNLL09 | ||||
|---|---|---|---|---|---|---|
| F1 | △ | F1 | △ | F1 | △ | |
| Tr-HeSyFu | ||||||
| Dep.→Const. Const.→Dep. | 84.5 85.7 | -1.2 | 83.3 84.3 | -1.0 | 91.2 91.5 | -0.3 |
| LG-HeSyFu | ||||||
| Dep.→Const. Const.→Dep. | 85.3 86.7 | -1.4 | 84.3 85.1 | -0.8 | 92.1 92.5 | -0.4 |
Order of the heterogeneous syntax encoding We design the architecture with constituency encoding before dependency encoding, as described earlier. If we exchange this encoding order, we see from Table 2 that the drops come out. Also the drops are more severe on the span-based SRL data. This verifies the correctness of our model design.
异构句法编码顺序
我们按照前文所述,设计了先进行成分句法编码再进行依存句法编码的架构。若调换这两种编码顺序,从表2可以看出性能出现下降,其中基于跨度的语义角色标注(SRL)数据性能下降更为显著。这验证了我们模型设计的正确性。
5.3 Main Results
5.3 主要结果
Our aim is to answer the research questions as listed in Section $\S1$ , based on the main experimental results in Table 1 and Table 3. [⋆ Answer to Q1] Our first observation is that leveraging syntax knowledge, e.g. either the dependency or constituency, benefits both the span-based and dependency-based SRL, while the integration of two heterogeneous syntax contributes the most, more than any one of the standalone syntax.
我们的目标是根据表1和表3中的主要实验结果,回答$\S1$节中列出的研究问题。[⋆ Q1答案] 我们首先观察到,利用句法知识(例如依存句法或成分句法)对基于跨度和基于依存关系的语义角色标注(SRL)均有提升,而两种异构句法的整合贡献最大,效果超过任何单一句法。
However we see that the improvements from this syntax integration is slightly different between span-based and dependency-based SRL. [⋆ Answer to Q2] In particular, the improvements for span-based SRL are more notable than dependency-based SRL, which can be learned by the comparisons between ‘Trm+RoBERTa’ and ‘LG-HeSyFu+RoBERTa’ on two tables. Our conjecture is that the the constituent structure knowledge will additionally help the span boundary detection of span-based SRL, compared with dependency-based SRL. Also we find that using only constituency syntax contributes more spanbased SRL, while the dependency-based SRL benefits more from dependency syntax.
然而我们发现,这种句法整合对基于跨度(span-based)和基于依存(dependency-based)的语义角色标注(SRL)的改进略有不同。[⋆ Q2答案] 具体而言,基于跨度的SRL改进比基于依存的SRL更为显著,这可以通过两个表格中"Trm+RoBERTa"与"LG-HeSyFu+RoBERTa"的对比看出。我们的推测是,与基于依存的SRL相比,成分结构知识会额外帮助基于跨度的SRL进行跨度边界检测。此外,我们发现仅使用成分句法对基于跨度的SRL贡献更大,而基于依存的SRL则更多受益于依存句法。
Looking into the specific results, within the scope of heterogeneous syntax integration methods, our systems (both Tr-HeSyFu and LG-HeSyFu) outperform Fei et al. (2020a), demonstrating the advances of our heterogeneous syntax integrating methods. Overall, our LG-HeSyFu model wins the new state-of-the-art performances on the used datasets, and with the help of the RoBERTa language model, the superiority is still maintained.
具体来看,在异构语法整合方法范围内,我们的系统(包括Tr-HeSyFu和LG-HeSyFu)均优于Fei等人 (2020a) 的研究成果,这证明了我们异构语法整合方法的先进性。总体而言,LG-HeSyFu模型在所用数据集上取得了新的最优性能,且在RoBERTa语言模型的辅助下,其优势依然得以保持。
Table 3: Results on dependency-based SRL CoNLL09 dataset.
表 3: 基于依存关系的语义角色标注 (SRL) CoNLL09 数据集结果。
| P | R | F1 | |
|---|---|---|---|
| Without Syntax He et al. (2018) | |||
| Li et al. (2020b) Trm+RoBERTat | 89.50 | 87.90 | 88.70 90.26 |
| WithDependencySyntax | 91.34 | 91.12 | 91.25 |
| Li et al. (2018) | 90.30 | 89.30 | 89.80 |
| He et al. (2019) | |||
| Child-Sum TreeLSTMT | 89.96 | 89.96 | 89.96 |
| 90.67 | 90.60 | 90.63 | |
| Dep GCNt | 90.98 | 90.85 | 90.91 |
| Dep GCN+RoBERTat | 92.45 | 92.05 | 92.23 |
| With ConstituencySyntax | |||
| N-ary TreeLSTM+ | 89.56 | 89.21 | 89.42 |
| Const GCNt | 90.48 | 90.19 | 90.35 |
| Const GCN+RoBERTat | |||
| 91.33 | 91.87 | 91.65 | |
| With Dependency & Constituency Syntax | |||
| Fei et al. (2020a)* | 90.78 | 90.92 | 90.88 |
| Tr-HeSyFut | 91.02 | 91.22 | 91.10 |
| LG-HeSyFut | 92.24 | 92.53 | 92.45 |
| LG-HeSyFu w/o Syn. Labelt | 91.85 | 92.15 | 92.05 |
| LG-HeSyFu+RoBERTat | 92.89 | 92.80 | 92.83 |
[⋆ Answer to Q3] Also we show that our LGHeSyFu based system consistently outperforms Tr-HeSyFu based one. Even LG-HeSyFu without using the syntax label features can still keep better. It is also clear that the GCN based encoders show consistently higher scores than the TreeLSTM based ones, verifying the effectiveness of leveraging GCN encoding syntax (March egg ian i and Titov, 2017; Li et al., 2018). $[\star$ Answer to Q4] Meanwhile, the ablation of syntax label information reveals the importance of its leverage for the SRL learning.
[⋆ Q3回答] 我们还证明了基于LGHeSyFu的系统始终优于基于Tr-HeSyFu的系统。即使不使用语法标签特征的LG-HeSyFu仍能保持更好表现。显然,基于GCN的编码器持续获得比基于TreeLSTM更高的分数,验证了利用GCN编码语法的有效性 (March egg ian i and Titov, 2017; Li et al., 2018)。
$[\star$ Q4回答] 同时,语法标签信息的消融实验揭示了其对语义角色标注(SRL)学习的重要性。
5.4 Analysis and Discussion
5.4 分析与讨论
Correlations between SRL and syntax structures We explore the correlations between the SRL structure and the two syntax structures. We reach this by analyzing the SRL prediction with the neighbor connecting weights, i.e., $\alpha_{u v}$ of Const GCN and $\beta_{i j}$ of Dep GCN. We visualize the results (on CoNLL05) in Figure 6. [⋆ Answer to Q5] We learn that our framework indeed has captured the underlying inter-dependency between the SRL structures and the syntactic structure from the diversified visualization s. By accurately modeling such correlations, our LG-HeSyFu system naturally yields prominent meanwhile explain able SRL performances. Also some interesting patterns can be observed. Actually, not all the syntactic elements contribute the SRL learning. For example, the semantic roles A0, A1 and A2 relates more to the dependent edge nsubj and csubj, and more to the constituent phrase NP. We believe this can lay a crucial foundation for the direction of unsupervised semantic role labeling that relies on the syntactic structures.
语义角色标注(SRL)与句法结构的关联性分析
我们探究了语义角色标注结构与两种句法结构之间的关联。通过分析带有邻接连接权重的SRL预测结果(即Const GCN的$\alpha_{u v}$和Dep GCN的$\beta_{i j}$),我们在图6中展示了CoNLL05数据集上的可视化结果。[⋆ Q5答案] 从多样化的可视化呈现中可以发现,我们的框架确实捕捉到了SRL结构与句法结构之间潜在的相互依存关系。通过精确建模这种关联性,LG-HeSyFu系统自然能同时实现优异且可解释的SRL性能。
我们还观察到一些有趣的现象:并非所有句法元素都对SRL学习有贡献。例如,语义角色A0、A1和A2更依赖于依存边nsubj/csubj,且与成分短语NP关联更强。这一发现为基于句法结构的无监督语义角色标注研究方向奠定了重要基础。

Figure 6: Discovered correlations of (1) SRL vs. dependent structure, (2) SRL vs. constituent structure.
图 6: 发现的关联性:(1) 语义角色标注 (SRL) 与依存结构的关系,(2) 语义角色标注 (SRL) 与成分结构的关系。
Span boundary detection We now investigate the influences of the heterogeneous syntax integration to the span boundary match10 on span-based SRL, i.e., on CoNLL05/12 data. From Figure 7 we learn that the heterogeneous syntax integration can improve the boundary detection over any standalone syntax leverage, while actually the constituency syntax contributes more significantly than dependency feature. And our LG-HeSyFu shows the best helpfulness than Tr-HeSyFu.
跨度边界检测
我们现在研究异构句法整合对基于跨度的语义角色标注 (SRL) 中跨度边界匹配的影响,即在 CoNLL05/12 数据上的表现。从图 7 可以看出,异构句法整合相比任何单一句法利用都能提升边界检测效果,实际上成分句法的贡献比依存特征更显著。我们的 LG-HeSyFu 方法相比 Tr-HeSyFu 展现出最佳辅助效果。
Label prediction We next evaluate the role label prediction. We only measure the correctly extracted arguments on whether its label further matches the gold annotation. We show the F1 score in Figure 8. Similar to the span boundary identification, the heterogeneous syntax integration can con- tribute the most than that with any single syntax usage. Interestingly, the standalone dependency syntax shows more improvements on the dependencybased SRL, while the phrasal constituency features benefit more the span-based SRL.
标签预测
接下来我们评估角色标签预测的效果。我们仅测量正确提取的论元,判断其标签是否进一步匹配黄金标注。图8展示了F1分数。与跨度边界识别类似,异构句法整合的贡献最大,超过任何单一句法的使用。有趣的是,独立依存句法在基于依存的语义角色标注(SRL)上表现更优,而短语成分特征对基于跨度的语义角色标注提升更明显。

Figure 7: F1 scores for span boundary detection.
图 7: 片段边界检测的 F1 分数。

Figure 8: Results on the argument role label prediction.
图 8: 论元角色标签预测结果。
Error breakdown To analyze which error types different syntax-aided SRL models tend to make, we follow prior works (He et al., 2017; Strubell et al., 2018), manually fixing the errors by applying oracle transformations increment ally based on CoNLL05.11 The analysis is shown in Figure 9. Specifically, constituency syntax methods perform better than dependency-aided methods, w.r.t. the span boundary errors (‘Merge Spans’, ‘Split Spans’ and ‘Fix Span Boundary’). Most importantly, it is quite clear that our heterogeneous syntax integrated systems (Tr-HeSyFu and LG-HeSyFu) makes fewer errors than baseline standalone syntaxaware methods, demonstrating the necessity to combine both two types of syntax.
错误分类分析
为探究不同句法辅助语义角色标注(SRL)模型的错误倾向类型,我们参照前人工作[20][21],基于CoNLL05数据集逐步应用标准修正进行人工错误标注。具体分析结果如图9所示:
- 在跨度边界错误("合并跨度"、"拆分跨度"和"修正跨度边界")方面,成分句法方法优于依存句法方法
- 最关键的是,我们的异构句法融合系统(Tr-HeSyFu和LG-HeSyFu)比基线单一句法方法的错误率显著降低,印证了融合两种句法的必要性
(注:根据要求保留CoNLL05、Tr-HeSyFu、LG-HeSyFu等专业术语及文献引用格式[20][21],将Figure 9转换为"图9",并调整了中文语序。w.r.t.按语境译为"方面",oracle transformations根据NLP领域惯例译为"标准修正"。)
Syntax distribution By observing the gate values ${\bf{\it{g}}}_{i}$ (in Eq. 8) we can analyze the distributions of dependency and constituency features required by span-based and dependency-based SRL. From Figure 10 we see that span-SRL relies more on constituency feature, while dependency-SRL needs more dependency-aware feature. Such finding quite coincides with the foregoing quantitative analysis, as well as our intuition.
句法分布
通过观察门控值 ${\bf{\it{g}}}_{i}$ (式8) ,我们可以分析基于跨度和基于依存关系的语义角色标注 (SRL) 所需的依存与成分特征分布。从图 10 可见,跨度式 SRL 更依赖成分特征,而依存式 SRL 需要更多依存感知特征。这一发现与前述定量分析及我们的直觉高度吻合。

Figure 9: Performances after error corrections.
图 9: 纠错后的性能表现。

Figure 10: Heterogeneous syntax distribution. Level ${\ge}0.5$ means more reliance upon constituent syntax, otherwise for dependency
图 10: 异构句法分布。层级 ${\ge}0.5$ 表示更依赖成分句法,反之则依赖依存句法
6 Conclusion and Future Work
6 结论与未来工作
We investigated the integration of constituency and dependency syntax for the SRL task. We first introduced TreeLSTM-based heterogeneous syntax fusing encoders, and further proposed innovative label-aware syntax GCN encoders for the integration. Experimental results showed that combin- ing the heterogeneous syntax brought better results on both span-based and dependency-based SRL, than any one standalone syntax knowledge. As future work, we investigate other kinds of structural knowledge integration besides syntax, such as Semantic Dependency Structure, Abstract Meaning Representation (AMR), and explore the possibility of extending our model to incorporating such structured information. Besides, integrating the heterogeneous syntax knowledge into pre-training language models will be a promising direction.
我们研究了将成分句法和依存句法整合用于语义角色标注(SRL)任务的方法。首先提出了基于TreeLSTM的异构句法融合编码器,进一步创新性地设计了标签感知的句法图卷积网络(GCN)编码器来实现整合。实验结果表明,相比单独使用任何一种句法知识,结合异构句法能在基于跨度和基于依存的SRL任务上都取得更好效果。未来工作将探索除句法外其他结构化知识的整合,如语义依存结构(Semantic Dependency Structure)、抽象意义表示(Abstract Meaning Representation, AMR),并研究扩展模型以融合此类结构化信息的可能性。此外,将异构句法知识整合到预训练语言模型中也将是颇具前景的研究方向。