SAM2MOT: A Novel Paradigm of Multi-Object Tracking by Segmentation
SAM2MOT: 基于分割的多目标跟踪新范式
Abstract
摘要
Segment Anything 2 (SAM2) enables robust single-object tracking using segmentation. To extend this to multiobject tracking (MOT), we propose SAM2MOT, introducing a novel Tracking by Segmentation paradigm. Unlike Tracking by Detection or Tracking by Query, SAM2MOT directly generates tracking boxes from segmentation masks, reducing reliance on detection accuracy. SAM2MOT has two key advantages: zero-shot generalization, allowing it to work across datasets without fine-tuning, and strong object association, inherited from SAM2. To further improve performance, we integrate a trajectory manager system for precise object addition and removal, and a crossobject interaction module to handle occlusions. Experiments on DanceTrack, UAVDT, and BDD100K show stateof-the-art results. Notably, SAM2MOT outperforms existing methods on DanceTrack by $+2.1$ HOTA and $+4.5I D F I$ , highlighting its effectiveness in MOT. Code is available at https://github.com/TripleJoy/SAM2MOT.
Segment Anything 2 (SAM2) 通过分割实现了稳健的单目标跟踪。为将其扩展至多目标跟踪 (MOT),我们提出 SAM2MOT,引入了一种新颖的"基于分割的跟踪"范式。不同于"基于检测的跟踪"或"基于查询的跟踪",SAM2MOT 直接从分割掩码生成跟踪框,降低了对检测精度的依赖。SAM2MOT 具备两大关键优势:继承自 SAM2 的零样本泛化能力(无需微调即可跨数据集工作)和强大的目标关联能力。为进一步提升性能,我们集成了轨迹管理系统以实现精准的目标增删,以及跨目标交互模块以处理遮挡问题。在 DanceTrack、UAVDT 和 BDD100K 上的实验展示了最先进的结果。值得注意的是,SAM2MOT 在 DanceTrack 上以 HOTA $+2.1$ 和 IDF1 $+4.5$ 的优势超越现有方法,凸显了其在 MOT 任务中的有效性。代码已开源:https://github.com/TripleJoy/SAM2MOT。
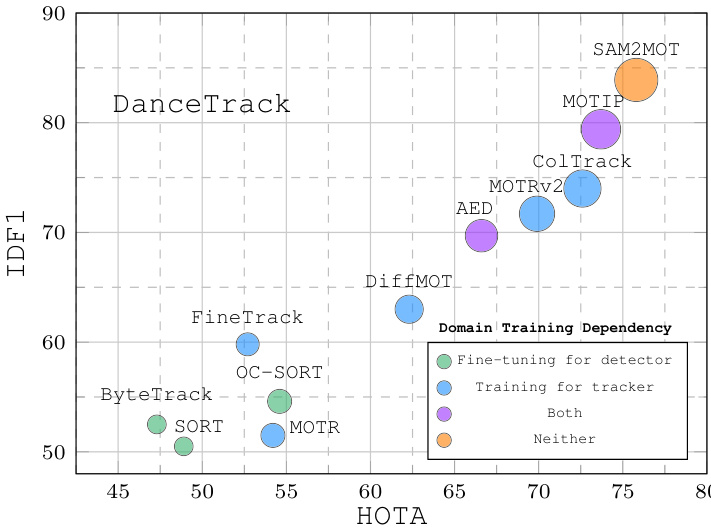
Figure 1. IDF1-HOTA-AssA comparisons of different trackers on the test set of DanceTrack, where the horizontal axis represents HOTA, the vertical axis represents IDF1, and the circle radius indicates AssA. This comparison highlights our method’s superior capability in associating objects across frames, surpassing all previous trackers. Details are given in Table 1.
图 1: 不同跟踪器在DanceTrack测试集上的IDF1-HOTA-AssA对比,其中横轴代表HOTA,纵轴代表IDF1,圆圈半径表示AssA。该对比凸显了我们方法在跨帧关联目标方面的卓越能力,超越了所有先前跟踪器。具体细节见表1。
1. Introduction
1. 引言
Multi-object tracking (MOT) methods typically adopt a two-stage pipeline: object detection followed by interframe association[1, 2, 4, 29, 40]. However, this pipeline heavily relies on detector performance, often requiring dataset-specific training and fine-tuning to improve generalization. Recently, Tracking by Query (TBQ)[17, 19, 24, 28, 38] has been proposed to enhance identity consistency via learned association networks. Nevertheless, the reliance on large-scale annotated tracking data limits the practicality of TBQ in data-scarce scenarios.
多目标跟踪 (MOT) 方法通常采用两阶段流程:目标检测后进行帧间关联 [1, 2, 4, 29, 40]。然而该流程高度依赖检测器性能,通常需要针对特定数据集进行训练和微调以提升泛化能力。近期提出的查询式跟踪 (TBQ) [17, 19, 24, 28, 38] 通过学习的关联网络增强了身份一致性,但对大规模标注跟踪数据的依赖限制了 TBQ 在数据稀缺场景中的实用性。
To overcome these limitations, we propose SAM2MOT, a novel Tracking by Segmentation paradigm that extends SAM2[20] from single-object to multi-object tracking. SAM2MOT decouples detection from tracking by generating tracking boxes directly from segmentation masks, using object detection only for initial prompt generation. This design reduces dependence on detection accuracy and eliminates the need for annotated tracking data, enabling: (1) Strong zero-shot generalization across datasets without retraining or fine-tuning. (2) Improved object association through segmentation-based tracking.
为克服这些限制,我们提出了SAM2MOT——一种新颖的基于分割的跟踪范式,将SAM2[20]从单目标跟踪扩展到多目标跟踪。SAM2MOT通过直接从分割掩码生成跟踪框,将检测与跟踪解耦,仅使用目标检测进行初始提示生成。该设计降低了对检测精度的依赖,并消除了对标注跟踪数据的需求,从而实现了:(1) 跨数据集的强大零样本泛化能力,无需重新训练或微调。(2) 通过基于分割的跟踪改进目标关联。
Despite SAM2’s effectiveness in single-object tracking, extending it to MOT presents two key challenges: (1) the lack of automatic object addition and removal, and (2) memory error accumulation due to brute-force selection in the memory bank. SAM2MOT addresses these issues with two novel modules: Trajectory Manager System and Crossobject Interaction. Trajectory Manager System utilizes an object detector to generate prompt information, enabling dynamic object addition, removal, and quality reconstruction. Cross-object Interaction Module models inter-object relationships to mitigate association errors caused by occlusions.
尽管SAM2在单目标跟踪中表现出色,但将其扩展到多目标跟踪(MOT)面临两大挑战:(1) 缺乏自动目标增减机制;(2) 记忆库暴力选择导致的内存误差累积。SAM2MOT通过两个创新模块解决这些问题:轨迹管理系统(Trajectory Manager System)和跨目标交互模块(Crossobject Interaction Module)。轨迹管理系统利用目标检测器生成提示信息,实现动态目标增删与质量重建;跨目标交互模块通过建模目标间关系,缓解遮挡导致的关联错误。
Experiments on DanceTrack, UAVDT, BDD100K and demonstrate SAM2MOT’s state-of-the-art performance, particularly excelling in object association without requiring dataset-specific training.
在DanceTrack、UAVDT和BDD100K数据集上的实验表明,SAM2MOT实现了最先进的性能,尤其在无需针对特定数据集训练的情况下,其目标关联表现尤为出色。
In conclusion, our contributions are as follows:
综上所述,我们的贡献如下:
2. Related Works
2. 相关工作
2.1. Tracking-by-Detection
2.1. 检测跟踪 (Tracking-by-Detection)
Traditional tracking-by-detection methods, such as SORT[2] and DeepSORT[26], associate detections across frames using motion priors and the Hungarian algorithm. SORT is known for its real-time efficiency, while DeepSORT improves upon this by integrating deep re-identification (ReID) features, enabling more accurate appearance-based matching and robust identity management.
传统的基于检测的跟踪方法,如 SORT[2] 和 DeepSORT[26],利用运动先验和匈牙利算法 (Hungarian algorithm) 进行跨帧检测关联。SORT 以实时效率著称,而 DeepSORT 通过整合深度重识别 (ReID) 特征进一步优化,实现了更精准的基于外观匹配和鲁棒的身份管理。
FairMOT[39] advances this approach by combining detection and ReID into a unified architecture, achieving high performance with a simple end-to-end framework. OC-SORT[4] integrates a Kalman filter to handle occlusions, improving tracking continuity in challenging scenarios. ByteTrack[40] enhances robustness by reintroducing low-confidence detections, yielding better performance in dense scenes. StrongSORT[8] builds on DeepSORT by adding camera displacement compensation, improving tracking stability under camera motion.
FairMOT[39] 通过将检测和ReID整合到统一架构中推进了该方法,以简单的端到端框架实现高性能。OC-SORT[4] 集成卡尔曼滤波器处理遮挡问题,提升了复杂场景下的跟踪连续性。ByteTrack[40] 通过重新引入低置信度检测增强鲁棒性,在密集场景中表现更优。StrongSORT[8] 在DeepSORT基础上增加相机位移补偿,提升了相机运动时的跟踪稳定性。
However,these methods fail to decouple detection from association, which means that fluctuations in detection accuracy directly affect the reliability of IoU-based matching. As a result, this fragile relationship leads to a high dependence on domain-specific fine-tuning, severely restricting the development of these methods.
然而,这些方法未能将检测与关联解耦,这意味着检测精度的波动会直接影响基于交并比(IoU)匹配的可靠性。因此,这种脆弱的关系导致了对领域特定微调的高度依赖,严重限制了这些方法的发展。
2.2. Tracking-by-Query
2.2. 基于查询的跟踪 (Tracking-by-Query)
Tracking-by-query methods redefine multi-object tracking by introducing detect queries for new objects and track queries for existing ones. These methods can be divided into parallel and serial approaches. Parallel methods, such as VisTR[28] and SeqFormer[30], process short video clips in a single pass, but incur substantial memory costs, limiting their application to brief sequences. Serial methods—including Track Former[19], MOTR[38], and TransTrack[24]—iterative ly update track queries on a frame-by-frame basis. For example, TransTrack uses IoU matching for new detections, while MOTR relies on an endto-end pipeline that handles irregular motion effectively.
基于查询的跟踪方法通过引入新物体检测查询和现有物体跟踪查询,重新定义了多目标跟踪。这类方法可分为并行和串行两种实现方式。并行方法如VisTR[28]和SeqFormer[30]能单次处理短视频片段,但内存消耗较大,仅适用于短序列场景。串行方法包括Track Former[19]、MOTR[38]和TransTrack[24],通过逐帧迭代更新跟踪查询:例如TransTrack采用交并比(IoU)匹配新检测目标,而MOTR依靠端到端管道有效处理不规则运动。
To leverage temporal context, MeMOT[3] and MeMOTR[11] integrate memory banks or long-term feature injection to reinforce inter-frame associations. However, most methods still prioritize adjacent-frame cues and under utilize long-range temporal information. Solutions like CO-MOT[17] and MOTRv3[36] refine supervision to resolve conflicts between newly detected and established objects.
为利用时序上下文信息,MeMOT[3]和MeMOTR[11]通过集成记忆库或长期特征注入来增强帧间关联。然而,大多数方法仍优先考虑相邻帧线索,未能充分利用长程时序信息。CO-MOT[17]和MOTRv3[36]等方案通过优化监督机制来解决新检测目标与已跟踪目标间的冲突。
However, in real-world scenarios, due to the lack of large-scale annotated tracking data, these methods often perform poorly, limiting their development.
然而,在实际场景中,由于缺乏大规模标注的跟踪数据,这些方法往往表现不佳,限制了其发展。
2.3. SAM/SAM2
2.3. SAM/SAM2
SAM [13], the Segment Anything Model, revolutionizes object segmentation with its flexible, prompt-based framework. By leveraging SAM’s capabilities, MASA [14] trains an adapter that enables zero-shot object matching across video frames on open-vocabulary MOT benchmarks.
SAM [13](Segment Anything Model)通过其灵活的基于提示(prompt)的框架彻底改变了对象分割技术。借助SAM的强大功能,MASA [14]训练了一个适配器,能够在开放词汇多目标跟踪(MOT)基准测试中实现视频帧间的零样本对象匹配。
SAM2 [20] extends SAM’s functionality by incorporating a memory bank that retains object-specific information throughout video sequences, making it effective for singleobject tracking over time. Concretely, SAM2’s tracking is based on historical mask-level features that implicitly encode both object appearance and positional information. In each frame, beyond predicting the target object’s segmentation mask, SAM2 also provides a logits score, whose magnitude correlates approximately linearly with the object’s appearance quality. Building on this foundation, SAM2- Long[6] enhances long-range tracking via a decision-tree memory structure, while SAMURAI[33] introduces a memory cleaning module that discards irrelevant information to further improve tracking performance.
SAM2 [20] 通过引入一个记忆库来扩展SAM的功能,该记忆库能在整个视频序列中保留特定对象的信息,从而实现对单一对象的长期有效跟踪。具体而言,SAM2的跟踪基于历史掩码级别的特征,这些特征隐式编码了对象的外观和位置信息。在每一帧中,除了预测目标对象的分割掩码外,SAM2还提供一个逻辑分数(logits score),其大小与对象外观质量大致呈线性相关。在此基础上,SAM2-Long[6]通过决策树记忆结构增强了长距离跟踪能力,而SAMURAI[33]引入了记忆清理模块,通过丢弃无关信息进一步提升跟踪性能。
Inspired by these advancements, we expand SAM2 from single-object tracking to multi-object tracking (MOT) by leveraging detector outputs as prompts. Moreover, we incorporate object interactions to improve occlusion handling, thereby enhancing robustness under diverse conditions.
受这些进展的启发,我们通过利用检测器输出作为提示,将SAM2从单目标跟踪扩展到多目标跟踪(MOT)。此外,我们引入目标交互机制来提升遮挡处理能力,从而增强不同条件下的鲁棒性。
3. Method
3. 方法
3.1. Overview
3.1. 概述
We propose SAM2MOT, a novel Tracking by Segmentation paradigm for multi-object tracking. As shown in Fig- ure 2, unlike traditional methods that rely on high-precision detections for inter-frame association, SAM2MOT uses detection only for initialization and performs self-tracking of individual object using SAM2. Tracking boxes are directly derived from segmentation masks, reducing dependence on detection accuracy. To address SAM2’s limitations in multi-object tracking, SAM2MOT introduces two key modules: (1) Trajectory Manager System, which dynamically manages object addition, removal, and quality reconstruction. (2) Cross-object Interaction, which enhances memory selection through inter-object information exchange, effectively filtering out erroneous memories and improving tracking performance.
我们提出SAM2MOT,一种基于分割的新型多目标跟踪范式。如图2所示,与传统方法依赖高精度检测进行帧间关联不同,SAM2MOT仅用检测进行初始化,并利用SAM2实现目标自跟踪。跟踪框直接从分割掩码生成,降低了对检测精度的依赖。针对SAM2在多目标跟踪中的局限性,SAM2MOT引入两个关键模块:(1) 轨迹管理系统,动态管理目标新增、移除和质量重建;(2) 跨目标交互,通过目标间信息交换增强记忆选择,有效过滤错误记忆并提升跟踪性能。
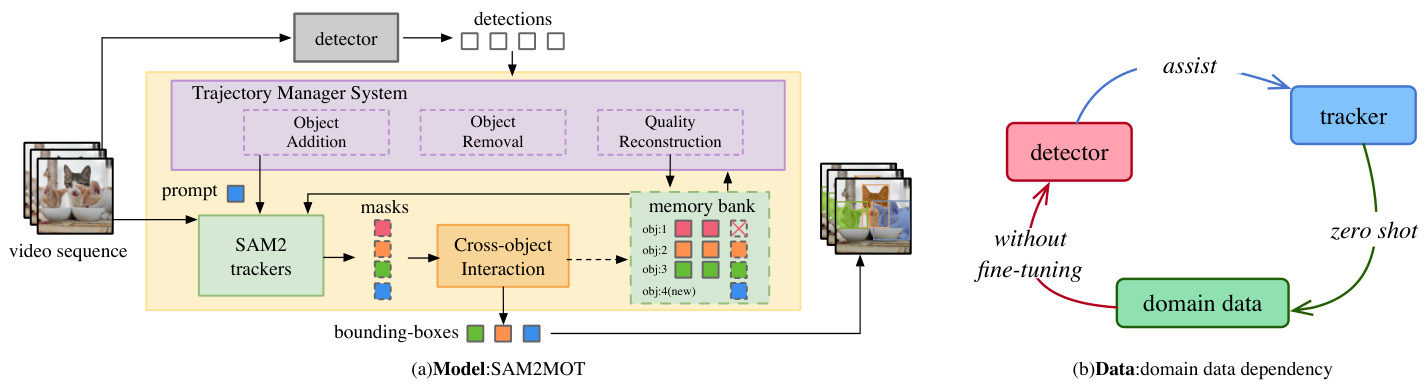
Figure 2. Overview of our Tracking-by-Segmentation MOT framework, consisting of: (a) an adapted method, SAM2MOT, extending SAM2[20] for multi-object tracking. (b) shows our original motivation and the data dependencies of this approach.
图 2: 我们的基于分割的跟踪(Tracking-by-Segmentation)多目标跟踪框架概述,包含:(a) 改进方法SAM2MOT,将SAM2[20]扩展用于多目标跟踪。(b) 展示我们最初的动机和该方法的数据依赖关系。
3.2. Trajectory Manager System
3.2. 轨迹管理系统
SAM2, as an interactive tracker, requires user-provided prompts for object initialization. While a single prompt suffices for single-object tracking, multi-object tracking (MOT) involves dynamic object appearances and disappearances, making static initialization inadequate. To address this limitation, we introduce the Trajectory Manager System, which enables object addition, removal, and quality reconstruction, significantly enhancing SAM2’s adaptability and robustness in MOT.
SAM2作为交互式追踪器,需要用户提供提示(prompt)进行目标初始化。虽然单目标追踪仅需单个提示,但多目标追踪(MOT)涉及动态目标出现与消失,使得静态初始化不再适用。为解决这一局限,我们引入了轨迹管理系统(Trajectory Manager System),支持目标添加、移除和质量重建,显著提升了SAM2在多目标追踪中的适应性与鲁棒性。
Object Addition in multi-object tracking requires auto mati call y generating reliable initial prompts for objects while simultaneously preventing persistent tracking errors that stem from low-quality appearance features. To achieve this, SAM2MOT integrates an object detection model to generate initialization prompts and employs a three-stage filtering process to ensure their accuracy and stability.
多目标跟踪中的物体新增需要自动生成可靠的物体初始提示,同时防止因低质量外观特征导致的持续跟踪错误。为此,SAM2MOT集成了一个物体检测模型来生成初始化提示,并采用三阶段过滤流程确保其准确性和稳定性。
At each frame, SAM2 generates segmentation masks and tracking bounding boxes for currently tracked objects, while the object detection model provides new bounding box proposals. High-confidence detections are first selected, and the Hungarian matching algorithm is applied to associate them with existing tracked objects. Unmatched detections are considered as candidate new objects.
在每一帧中,SAM2会为当前追踪的目标生成分割掩码和追踪边界框,而目标检测模型则提供新的边界框提议。首先筛选出高置信度的检测结果,再通过匈牙利匹配算法将其与现有追踪目标关联。未匹配的检测结果将被视为候选新目标。
To further refine selection, an untracked region mask $M_{n o n}$ is computed by aggregating and inverting all tracked object masks, as shown in Equation 1. For each candidate, the overlap $p$ between its detection bounding box and $M_{n o n}$ is measured, and if the ratio of $p$ to the bounding box area exceeds a predefined threshold, the detection is confirmed as a new object.
为了进一步优化选择,通过聚合并反转所有被追踪物体的掩码来计算未追踪区域掩码 $M_{n o n}$ ,如公式 1 所示。对于每个候选检测,测量其检测边界框与 $M_{n o n}$ 之间的重叠度 $p$ ,若该重叠度占边界框面积的比例超过预设阈值,则将该检测确认为新物体。
This ensures that newly initialized objects are both visually reliable and occupy untracked regions, reducing redundancy and improving tracking robustness. Finally, the selected detections serve as initialization prompts for SAM2, enabling automatic and adaptive object addition.
这确保了新初始化的对象既具有视觉可靠性,又位于未跟踪区域,从而减少冗余并提高跟踪鲁棒性。最后,所选检测结果作为SAM2的初始化提示,实现自动且自适应的对象添加。
$$
{\mathcal{M}}{\mathrm{non}}=I-\bigcup_{i=1}^{n}{\mathcal{M}}_{i}
$$
$$
{\mathcal{M}}{\mathrm{non}}=I-\bigcup_{i=1}^{n}{\mathcal{M}}_{i}
$$
Object Removal is achieved by setting a tolerance frame count, meaning that an object is removed when its lost status persists beyond the tolerance threshold. The challenge lies in accurately determining the lost status. SAM2 assigns logits scores to objects in each frame, representing their tracking confidence. Based on these scores, we define three thresholds, $\tau_{r},\tau_{p}$ , and $\tau_{s}$ , to classify objects into four levels: reliable, pending, suspicious, and lost, as shown in Equation 2. When an object moves out of the camera’s field of view, its logits score drops significantly and remains low. If this condition persists beyond the tolerance frame count, the object is considered permanently lost and is removed from tracking.
物体移除通过设置容忍帧数实现,即当物体丢失状态持续超过容忍阈值时将被移除。关键在于准确判定丢失状态。SAM2为每帧中的物体分配logits分数以表示跟踪置信度。基于这些分数,我们定义了三个阈值$\tau_{r},\tau_{p}$和$\tau_{s}$,将物体分为四个等级:可靠(reliable)、待定(pending)、可疑(suspicious)和丢失(lost),如公式2所示。当物体移出摄像机视野时,其logits分数会显著下降并持续低位。若此状态持续超过容忍帧数,该物体将被判定为永久丢失并从跟踪系统中移除。
$$
\mathrm{State}=\left{\begin{array}{l l}{\mathrm{reliable},}{\mathrm{logits}>\tau_{r},}\ {\mathrm{pending},}{\tau_{p}<\mathrm{logits}\leq\tau_{r},}\ {\mathrm{suspicious},}&{\tau_{s}<\mathrm{logits}\leq\tau_{p},}\ {\mathrm{lost},}&{\mathrm{logits}\leq\tau_{s}.}\end{array}\right.
$$
Quality Reconstruction addresses the gradual degradation of an object’s prompt information due to changes in size, shape, appearance, and position caused by motion and viewpoint variations. While SAM2 relies on manual prompt updates, SAM2MOT integrates an object detection model to automate this process using redundant detection information. To reduce computational complexity, reconstruction is performed only when necessary and follows two key conditions to ensure reliability. First, reconstruction is triggered only if an object’s logits score decreases but remains within a high-confidence range, meaning its trajectory is in Pending state. Second, during object addition, the object must successfully match a high-confidence detection box, ensuring that low-quality appearance features are not mistakenly used for reconstruction. If both conditions are met, the matched detection box is used as new prompt information for re initialization, allowing SAM2MOT to maintain accurate and robust tracking over time.
质量重建 (Quality Reconstruction) 解决了物体因运动和视角变化导致尺寸、形状、外观及位置改变时提示信息逐渐退化的问题。SAM2依赖手动更新提示,而SAM2MOT通过整合物体检测模型,利用冗余检测信息实现自动化更新。为降低计算复杂度,系统仅在满足两个关键条件时执行重建以确保可靠性:首先,仅当物体logits分数下降但仍处于高置信区间(即轨迹处于Pending状态)时触发重建;其次,在物体新增阶段,必须成功匹配高置信检测框,避免误用低质量外观特征进行重建。若同时满足条件,系统将匹配的检测框作为新提示信息重新初始化,使SAM2MOT能够持续保持精准稳健的跟踪。
3.3. Cross-object Interaction
3.3. 跨对象交互
Occlusion remains a key challenge in object tracking. When an object A of the same category occludes object B, SAM2 may mis associate the occluded object B with object A, leading to persistent tracking errors that prevent object B from being recovered. This happens because SAM2’s memory bank uses a fixed selection mechanism, storing one conditional frame with the user-provided prompt and six recent non-conditional frames. These frames are fused to generate historical tracking features. However, once a mistake occurs, incorrect information gets stored and affects future frames, causing cumulative errors.
遮挡仍是目标跟踪领域的关键挑战。当同类物体A遮挡物体B时,SAM2可能错误地将被遮挡物体B与物体A关联,导致持续跟踪错误且无法恢复物体B。这是因为SAM2的记忆库采用固定选择机制:存储一帧用户提供提示的条件帧和六帧最近的非条件帧,通过融合这些帧生成历史跟踪特征。但一旦发生错误,错误信息会被存储并影响后续帧,从而产生累积误差。
In single-object tracking, methods such as SAMURAI reduce errors by discarding historical memory with low logits scores. However, this approach is limited in multi-object tracking scenarios. A fixed threshold lacks flexibility—if set too high, valuable historical information may be prematurely discarded; if too low, erroneous memory persists, reducing overall tracking accuracy. Tracking errors also occur during partial occlusions, where the fixed threshold fails to distinguish between valid and erroneous information, reducing the adaptability of the tracking framework.
在单目标跟踪中,SAMURAI等方法通过丢弃对数概率(logits)得分较低的历史记忆来减少误差。然而,这种方法在多目标跟踪场景中存在局限性。固定阈值缺乏灵活性——若设置过高,可能过早丢弃有价值的历史信息;若设置过低,错误记忆会持续存在,降低整体跟踪精度。在部分遮挡情况下也会出现跟踪误差,此时固定阈值无法区分有效信息与错误信息,从而降低了跟踪框架的适应性。
Unlike single-object tracking, SAM2MOT can track multiple objects in a frame at once. Leveraging this capability, we introduce a Cross-Object Interaction module, enabling objects A and B to interact when occlusion occurs. This interaction facilitates the dynamic identification of erroneously tracked objects and the removal of corrupted memory information, thereby enhancing tracking accuracy and robustness.
与单目标跟踪不同,SAM2MOT可同时追踪帧中的多个目标。基于这一能力,我们引入了跨目标交互模块,使目标A与B在遮挡发生时能够交互。这种交互机制可动态识别错误追踪目标并清除受损记忆信息,从而提升追踪精度与鲁棒性。
Specifically, to determine the occlusion relationship between objects A and B, we use mask Intersection over Union (mIoU) to quantify the degree of overlap between their segmentation masks, as shown in Equation 3. If the mIoU exceeds 0.8, it indicates significant overlap, suggesting occlusion and potential tracking errors. To further identify the incorrectly tracked object caused by occlusion, we propose a two-stage approach.
具体而言,为确定物体A和B之间的遮挡关系,我们使用掩码交并比(mIoU)来量化它们分割掩码之间的重叠程度,如公式3所示。若mIoU超过0.8,则表明存在显著重叠,意味着发生遮挡并可能导致跟踪错误。为进一步识别由遮挡引起的错误跟踪物体,我们提出了一种两阶段方法。
$$
\mathrm{mIoU}\big(\mathcal{M}{a},\mathcal{M}{b}\big)=\frac{\big|\mathcal{M}{a}\cap\mathcal{M}{b}\big|}{\big|\mathcal{M}{a}\cup\mathcal{M}_{b}\big|},
$$
$$
\mathrm{mIoU}\big(\mathcal{M}{a},\mathcal{M}{b}\big)=\frac{\big|\mathcal{M}{a}\cap\mathcal{M}{b}\big|}{\big|\mathcal{M}{a}\cup\mathcal{M}_{b}\big|},
$$
Assuming object $\mathbf{B}$ is occluded, we first compare the logits scores of objects A and B. If object A’s score is significantly higher, it suggests object $\mathbf{B}$ is occluded. If their logits scores are similar, we need to distinguish between two possibilities: object A’s score has gradually decreased due to lack of re initialization, or object B’s score has suddenly dropped due to occlusion. To clarify this, we compute the variance of their logits scores over the past $N$ frames, as shown in Equation 4. Typically, object A will show lower variance because its score decline is gradual, while object B’s drop is abrupt. By analyzing this variance, we can identify object B as the occluded object.
假设物体 $\mathbf{B}$ 被遮挡,我们首先比较物体A和B的logits分数。若物体A的分数显著更高,则表明物体 $\mathbf{B}$ 被遮挡。若两者的logits分数相近,需区分两种可能性:物体A的分数因缺乏重新初始化而逐渐下降,或物体B的分数因遮挡而突然降低。为明确判断,我们计算过去 $N$ 帧内两者logits分数的方差(如公式4所示)。通常情况下,物体A的方差较低,因其分数下降是渐进的,而物体B的分数下降是突发的。通过分析该方差,我们可判定物体B为被遮挡对象。
$$
\sigma_{\mathrm{logits}}^{2}=\frac{1}{N}\sum_{i=1}^{N}(\mathrm{logits}_{i}-\mathrm{lo\bar{j}t s})^{2}
$$
$$
\sigma_{\mathrm{logits}}^{2}=\frac{1}{N}\sum_{i=1}^{N}(\mathrm{logits}_{i}-\mathrm{lo\bar{j}t s})^{2}
$$
Once object $\mathbf{B}$ is recognized as incorrectly tracked, its memory information is removed from the memory bank to avoid propagating errors. This strategy significantly enhances SAM2MOT’s ability to handle occlusion and improves its tracking robustness in complex scenarios.
一旦物体 $\mathbf{B}$ 被识别为错误跟踪,其记忆信息会从记忆库中移除,以避免错误传播。这一策略显著增强了 SAM2MOT 处理遮挡的能力,并提升了其在复杂场景中的跟踪鲁棒性。
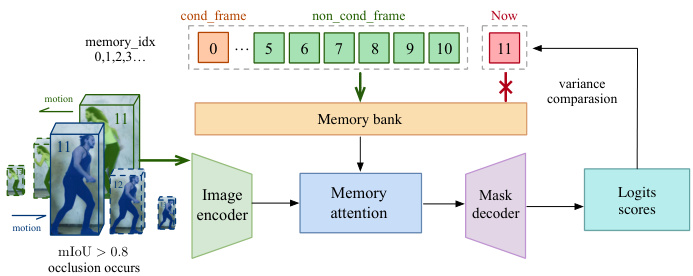
Figure 3. Cross-object interaction pipeline. During motion, when objects experience severe occlusion exceeding a predefined threshold, we utilize the variance of their logits scores to identify the occluded target, remove its memory entry for the current frame, and rely on the adjacent seven memory frames for subsequent calculations.The effectiveness of this approach is verified by our results in Table 7.
图 3: 跨物体交互流程。在运动过程中,当物体遭遇超过预设阈值的严重遮挡时,我们利用其logits分数的方差来识别被遮挡目标,移除当前帧的内存条目,并依赖相邻的七帧内存数据进行后续计算。该方法的有效性由表 7 中的实验结果验证。
4. Experiments
4. 实验
4.1. Benchmarks
4.1. 基准测试
In this study, we evaluate SAM2MOT on three benchmark datasets: DanceTrack[25], UAVDT[7] and BDD100K[37]. These datasets encompass a diverse range of tracking challenges, including occlusions, complex object motion, and high inter-object similarity. Additionally, they cover various real-world scenarios, providing a comprehensive assessment of the model’s adaptability and robustness.
在本研究中,我们在三个基准数据集上评估了SAM2MOT:DanceTrack[25]、UAVDT[7]和BDD100K[37]。这些数据集涵盖了多样化的跟踪挑战,包括遮挡、复杂物体运动和高物体间相似性。此外,它们覆盖了多种现实场景,为模型的适应性和鲁棒性提供了全面评估。
DanceTrack is a large-scale dataset designed for multiobject tracking in dance scenarios, where the primary challenges include high inter-object similarity and frequent occlusions. The dataset consists of 100 video sequences, with 65 used for training and validation and 35 for testing. The video resolution ranges from $720\mathrm{p}$ to $1080\mathrm{p}$ , with a frame rate of 20 frames per second.
DanceTrack是一个专为舞蹈场景中多目标追踪设计的大规模数据集,其主要挑战包括目标间高度相似性及频繁遮挡。该数据集包含100段视频序列,其中65段用于训练和验证,35段用于测试。视频分辨率介于$720\mathrm{p}$到$1080\mathrm{p}$之间,帧率为每秒20帧。
UAVDT-MOT is a multi-object tracking dataset based on a drone perspective, covering various typical scenes such as squares, main roads, toll stations, highways, and T-junctions. It primarily focuses on vehicle targets, including cars, trucks, and buses. The dataset consists of 50 video sequences, with 30 used for training and validation and 20 for testing. All videos have a resolution of $1080{\times}540$ and a frame rate of 30 frames per second.
UAVDT-MOT是一个基于无人机视角的多目标跟踪数据集,涵盖广场、主干道、收费站、高速公路、丁字路口等多种典型场景,主要关注车辆目标,包括轿车、卡车和公交车。该数据集包含50个视频序列,其中30个用于训练和验证,20个用于测试。所有视频的分辨率为$1080{\times}540$,帧率为每秒30帧。
BDD100K-MOT is a multi-object tracking dataset for autonomous driving scenarios, covering various driving environments such as urban roads, highways, and suburban areas, while also incorporating different weather conditions and lighting variations. The dataset focuses on eight common objects in autonomous driving, including pedestrians, riders, cars, trucks, buses, trains, motorcycles, and bicycles. It consists of 1,600 video sequences, with 1,400 used for training and 200 for validation. All videos have a resolution of $1280\times1080$ and a frame rate of 30 frames per second.
BDD100K-MOT是一个面向自动驾驶场景的多目标跟踪数据集,涵盖城市道路、高速公路和郊区等多种驾驶环境,同时包含不同天气条件和光照变化。该数据集聚焦自动驾驶中的八类常见物体,包括行人、骑行者、汽车、卡车、公交车、火车、摩托车和自行车。数据集包含1,600个视频序列,其中1,400个用于训练,200个用于验证。所有视频分辨率均为$1280\times1080$,帧率为每秒30帧。
Evaluation Metrics. We use HOTA, MOTA, and IDF1 as the primary evaluation metrics to comprehensively analyze the tracking performance of the model. On the DanceTrack dataset, we additionally consider the DetA and AssA sub-metrics to evaluate object detection and association performance at a finer granularity. For the BDD100K-MOT and UAVDT-MOT datasets, due to the constraints of the official evaluation scripts, we report only MOTA and IDF1 to ensure fair comparison.
评估指标。我们采用HOTA、MOTA和IDF1作为核心评估指标,全面分析模型的跟踪性能。在DanceTrack数据集上,额外引入DetA和AssA子指标,以更细粒度评估目标检测与关联性能。针对BDD100K-MOT和UAVDT-MOT数据集,由于官方评估脚本的限制,为确保公平比较仅报告MOTA和IDF1指标。
4.2. Implementation Details
4.2. 实现细节
SAM2MOT employs Co-DINO-l and Grounding-DINO-l, mainly pre-trained on the COCO dataset, as object detectors. The detectors are directly applied to the test sets of all datasets without additional training. Since they are not fine-tuned, their confidence distribution varies across different video sequences. Therefore, we dynamically adjust the detection threshold for each sequence to achieve optimal detection performance under limited conditions. Additionally, the segmentation model utilizes the pre-trained SAM2.1-large weights to ensure high-quality segmentation.
SAM2MOT采用Co-DINO-l和Grounding-DINO-l作为目标检测器,这两个模型主要在COCO数据集上进行了预训练。检测器直接应用于所有数据集的测试集,无需额外训练。由于未进行微调,其置信度分布在不同视频序列间存在差异。因此,我们动态调整每个序列的检测阈值,以在有限条件下实现最佳检测性能。此外,分割模型使用了预训练的SAM2.1-large权重,以确保高质量的分割效果。
In all datasets, the object addition phase sets the threshold for the ratio $r$ of untracked region pixels $p$ to the detection bounding box area at 0.5. In the object removal phase, the tolerance frame count is set to 25, meaning lost trajectories are retained for 25 frames to prevent d is association if the object reappears. For trajectory state classification, thresholds are set as $\tau_{r}=8.0$ , $\tau_{p}=6.0$ , and $\tau_{s}=2.0$ to distinguish different trajectory levels. In Cross-Object Interaction module, $N=10$ frames are used to compute the variance of the object logits score to assess trajectory stability.
在所有数据集中,物体添加阶段将未跟踪区域像素$p$与检测边界框面积的比率$r$阈值设为0.5。在物体移除阶段,容错帧数设置为25,意味着丢失的轨迹会保留25帧以防止物体重现时发生解关联。对于轨迹状态分类,设定阈值$\tau_{r}=8.0$、$\tau_{p}=6.0$和$\tau_{s}=2.0$以区分不同轨迹级别。在跨物体交互模块中,使用$N=10$帧计算物体logits得分的方差来评估轨迹稳定性。
4.3. State-of-the-Art Comparison
4.3. 最先进技术对比
DanceTrack. We report SAM2MOT’s results on DanceTrack test set in Table 1, and compare them with other popular methods. The results demonstrate that SAM2MOT significantly surpasses existing baselines in nonlinear object motion scenarios, establishing a new state-of-the-art.
DanceTrack。我们在表 1 中报告了 SAM2MOT 在 DanceTrack 测试集上的结果,并与其他流行方法进行了对比。结果表明,在非线性物体运动场景中,SAM2MOT 显著超越了现有基线,创造了新的最优性能。
When using Co-DINO-l as the detector, SAM2MOT achieves HOTA of 75.5, MOTA of 89.2, and IDF1 of 83.4. When using Grounding-DINO-l, the corresponding values are 75.8, 88.5, and 83.9, respectively. Compared to previous best-performing methods, SAM2MOT exhibits a substantial advantage in object association, with HOTA increasing by 2.1, IDF1 improving by 4.5, and AssA rising by 6.3.
当使用Co-DINO-l作为检测器时,SAM2MOT实现了75.5的HOTA、89.2的MOTA和83.4的IDF1。使用Grounding-DINO-l时,对应数值分别为75.8、88.5和83.9。与先前性能最佳的方法相比,SAM2MOT在目标关联方面展现出显著优势:HOTA提升2.1,IDF1提高4.5,AssA增长6.3。
UAVDT-MOT. In UAVDT-MOT dataset, we observe that not all visible vehicles are annotated. Small-sized or stationary vehicles parked on the roadside are typically excluded from the ground truth (GT) using ignore region annotations. Additionally, among the 20 video sequences in the test set, four exhibit a noticeable decline in annotation quality. To ensure a fair comparison, we do not modify the GT annotations but instead add additional ignore regions following the annotation logic of the UAVDT dataset.
UAVDT-MOT。在UAVDT-MOT数据集中,我们观察到并非所有可见车辆都被标注。使用忽略区域标注时,通常会将停靠在路边的小型或静止车辆排除在真实标注 (GT) 之外。此外,在测试集的20个视频序列中,有四个序列的标注质量明显下降。为确保公平比较,我们未修改GT标注,而是遵循UAVDT数据集的标注逻辑额外增加了忽略区域。
Moreover, UAVDT-MOT contains a significant number of small objects, and visual analysis reveals that the GT bounding boxes often deviate from the actual vehicle contours, generally being larger than the vehicles themselves. This discrepancy may cause correctly tracked results to fail to match the GT under the $\mathrm{IoU=0.5}$ criterion, leading to false positives. To address this issue, we compute MOTA and IDF1 using both $\mathrm{IoU=0.5}$ and $\mathrm{IoU=0.4}$ .
此外,UAVDT-MOT数据集中包含大量小物体,视觉分析显示其真实标注框(GT)常偏离车辆实际轮廓,普遍大于车辆本身。这种偏差可能导致正确跟踪结果在$\mathrm{IoU=0.5}$标准下无法匹配GT,产生误判。为解决该问题,我们同时采用$\mathrm{IoU=0.5}$和$\mathrm{IoU=0.4}$计算MOTA与IDF1指标。
We report SAM2MOT’s results on UAVDT-MOT test set in Table 2, and compare them with other popular methods. Wen using Co-DINO-l as the detector, SAM2MOT achieves MOTA of 55.6 and IDF1 of 74.4 under $\mathrm{IoU=0.5}$ . Under $\mathrm{IoU}=0.4$ , MOTA and IDF1 improve to 66.1 and 79.4, respectively.
我们在表2中报告了SAM2MOT在UAVDT-MOT测试集上的结果,并与其他流行方法进行了比较。当使用Co-DINO-l作为检测器时,在$\mathrm{IoU=0.5}$条件下,SAM2MOT实现了55.6的MOTA和74.4的IDF1。在$\mathrm{IoU}=0.4$条件下,MOTA和IDF1分别提升至66.1和79.4。
The results demonstrate that even with the $\mathrm{IoU}=0.5$ evaluation standard, SAM2MOT achieves the best MOTA and IDF1. Under $\mathrm{IoU=0.4}$ , the evaluation results more accurately reflect SAM2MOT’s actual tracking performance, with both MOTA and IDF1 significantly improving, showcasing a higher level of tracking capability.
结果表明,即使在 $\mathrm{IoU}=0.5$ 的评估标准下,SAM2MOT仍取得了最优的MOTA和IDF1指标。当 $\mathrm{IoU=0.4}$ 时,评估结果更真实反映了SAM2MOT的实际跟踪性能,其MOTA和IDF1均显著提升,展现出更高水平的跟踪能力。
BDD100K-MOT. In BDD100K-MOT dataset, the offi- cial evaluation provides two object classification schemes. The first is a fine-grained classification with eight categories: pedestrian, rider, car, truck, bus, train, motorcycle, and bicycle. The second is a coarse-grained classification, grouping objects into three categories: human, vehicle, and bike.
BDD100K-MOT。在BDD100K-MOT数据集中,官方评估提供了两种物体分类方案。第一种是细粒度分类,包含八个类别:行人(pedestrian)、骑行者(rider)、汽车(car)、卡车(truck)、公交车(bus)、火车(train)、摩托车(motorcycle)和自行车(bicycle)。第二种是粗粒度分类,将物体分为三类:人(human)、车辆(vehicle)和自行车(bike)。
Table 1. Comparison with other popular MOT methods on DanceTrack test set.
表 1: DanceTrack测试集上与其他流行MOT方法的对比
| 方法 | 发表会议 | HOTA↑ | MOTA↑ | IDF1↑ | AssA↑ | DetA↑ |
|---|---|---|---|---|---|---|
| SORT[2] | ICIP2016 | 47.9 | 91.8 | 50.8 | 31.2 | 72.0 |
| DeepSORT[26] | ICIP2017 | 45.6 | 87.8 | 47.9 | 29.7 | 71.0 |
| FairMOT[39] | IJCV2021 | 39.7 | 82.2 | 40.8 | 23.8 | 66.7 |
| CenterTrack[42] | ECCV2020 | 41.8 | 86.8 | 35.7 | 22.6 | 78.1 |
| QDTrack[10] | CVPR2021 | 45.7 | 83.0 | 44.8 | 29.2 | 72.1 |
| GTR[43] | CVPR2022 | 48.0 | 84.7 | 50.3 | 31.9 | 72.5 |
| ByteTrack[40] | ECCV2022 | 47.3 | 89.5 | 52.5 | 31.4 | 71.6 |
| MOTR[38] | ECCV2022 | 54.2 | 79.7 | 51.5 | 40.2 | 73.5 |
| SUSHI[5] | CVPR2023 | 63.3 | 88.7 | 63.4 | 50.1 | 80.1 |
| MOTRv2[41] | CVPR2022 | 69.9 | 91.9 | 71.7 | 59.0 | 83.0 |
| ColTrack[16] | ICCV2023 | 72.6 | 92.1 | 74.0 | 62.3 | - |
| FineTrack[21] | CVPR2023 | 52.7 | 89.9 | 59.8 | 38.5 | 72.4 |
| OC-SORT[4] | CVPR2023 | 54.6 | 89.6 | 54.6 | 40.2 | 80.4 |
| DiffMOT[18] | CVPR2024 | 62.3 | 92.8 | 63.0 | 47.2 | 82.5 |
| Hybrid-SORT[34] | AAAI2024 | 65.7 | 91.8 | 67.4 | - | - |
| AED[9] | arXiv2024 | 66.6 | 92.2 | 69.7 | 54.3 | 82.0 |
| MOTIP[12] | arXiv2024 | 73.7 | 92.7 | 79.4 | 65.9 | 82.6 |
| Co-DINO-l, 无微调 | ||||||
| SAM2MOT | 本文 | 75.5 | 89.2 | 83.4 | 71.3 | 80.3 |
| Grounding-DINO-l, 无微调 | ||||||
| SAM2MOT | 本文 | 75.8 | 88.5 | 83.9 | 72.2 | 79.7 |
Table 2. Comparison with other popular MOT methods on UAVDT-MOT test set. Methods in blue block are specifically designed for the drone.
表 2: 在UAVDT-MOT测试集上与其他流行MOT方法的对比。蓝色区块中的方法是专为无人机设计的。
| 方法 | 发表年份 | MOTA↑ | IDF1↑ | ↑NH | FP↓ | IDSW↓ | MT↑ | ML↓ |
|---|---|---|---|---|---|---|---|---|
| DeepSORT[26] | ICIP2017 | 40.7 | 58.2 | 155290 | 44868 | 2061 | 595 | 338 |
| SiamMOT[23] | CVPR2021 | 39.4 | 61.4 | 176164 | 46903 | 190 | ||
| OC-SORT[4] | CVPR2023 | 47.5 | 64.9 | 148378 | 47681 | 288 | ||
| UAVMOT[15] | CVPR2022 | 46.4 | 67.3 | 115940 | 66352 | 456 | 624 | 221 |
| FOLT[35] | MM2023 | 48.5 | 68.3 | 155696 | 36429 | 338 | ||
| GLOA[22] | J-STARS2023 | 49.6 | 68.9 | 115567 | 55822 | 433 | 626 | 220 |
| DroneMOT[27] | ICRA2024 | 50.1 | 69.6 | 112548 | 57411 | 129 | 638 | 178 |
| Co-DINO-l,nofine-tuning | ||||||||
| SAM2MOT-iou0.5 | Ours | 55.6 | 74.4 | 92504 | 58610 | 141 | 742 | 161 |
| SAM2MOT-iou0.4 | Ours | 66.1 | 79.3 | 74586 | 40692 | 136 | 816 | 147 |
| Grounding-DINO-l,nofine-tuning | ||||||||
| SAM2MOT-iou0.5 | Ours | 51.0 | 71.7 | 103977 | 62906 | 139 | 694 | 189 |
| SAM2MOT-iou0.4 | Ours | 60.9 | 76.6 | 87003 | 45932 | 155 | 767 | 171 |
Table 3. Comparison with other popular MOT methods on BDD100K-MOT val set.
表 3: BDD100K-MOT验证集上与其他流行多目标跟踪(MOT)方法的对比
| 方法 | 发表 | MOTA↑ | IDF1↑ | IDSW← |
|---|---|---|---|---|
| QDtrack10 Unicorn31 | TPAMI2023 ECCV2022 | 63.5 66.6 | 71.5 71.3 | 6262 10876 |
| MOTRv241 UNINEXT32 MASA14 | CVPR2022 CVPR2023 | 65.6 67.1 | 72.7 69.9 | 10222 |
| CVPR2024 | 71.7 | |||
| Co-DINO-l,nofine-tuning | ||||
| SAM2MOT(cls-8) | 本工作 | 57.5 | 70.8 | 5587 |
| SAM2MOT(cls-3) | 本工作 | 63.0 | 73.7 | 5755 |
| Grounding-DINO-l,nofine-tuning | ||||
| SAM2MOT(cls-8) | 本工作 | 44.1 | 63.6 | |
| SAM2MOT(cls-3) | 本工作 | 58.0 | 71.0 | 5184 5464 |
We report SAM2MOT’s results on UAVDT-MOT test set in Table 3, and compare them with other popular methods. When using Co-DINO-l as the detector, SAM2MOT achieves MOTA of 57.5 and IDF1 of 70.8 under the eightcategory classification scheme. Under the three-category scheme, MOTA and IDF1 improve to 63.0 and 73.7, respectively.
我们在表3中报告了SAM2MOT在UAVDT-MOT测试集上的结果,并与其他流行方法进行了比较。当使用Co-DINO-l作为检测器时,SAM2MOT在八分类方案下取得了57.5的MOTA和70.8的IDF1。在三分类方案下,MOTA和IDF1分别提升至63.0和73.7。
This improvement is mainly attributed to Co-DINO-l not being fine-tuned on the BDD100K-MOT training set, leading to suboptimal classification performance and increased confusion between similar categories. When using Grounding-DINO-l as the detector, the results are similar to those obtained with Co-DINO-l. The experimental results demonstrate that, compared to state-of-the-art methods, SAM2MOT achieves superior performance in IDF1 while significantly reducing ID switches, further validating its strong object association capabilities.
这一改进主要归因于Co-DINO-l未在BDD100K-MOT训练集上进行微调,导致分类性能欠佳且相似类别间混淆增加。使用Grounding-DINO-l作为检测器时,结果与Co-DINO-l相近。实验结果表明,相比前沿方法,SAM2MOT在IDF1指标上表现更优,同时显著减少了ID切换次数,进一步验证了其强大的目标关联能力。
4.4. Ablation Study and Analysis
4.4. 消融研究与分析
Unified Detector Comparison. To evaluate the dependency of SAM2MOT on detection accuracy, we conduct experiments using the same detector for both SAM2MOT and ByteTrack. This ensures a fair comparison and highlights the advantages of SAM2MOT in scenarios with varying detection performance.
统一检测器对比。为了评估SAM2MOT对检测精度的依赖性,我们使用相同的检测器对SAM2MOT和ByteTrack进行实验。这确保了公平比较,并突显了SAM2MOT在不同检测性能场景下的优势。
Table 4. Comparison with ByteTrack using the same detector on DanceTrack test set.
表 4: 在DanceTrack测试集上使用相同检测器与ByteTrack的对比。
| Methods | HOTA↑ | MOTA↑ | IDF1↑ | AssA↑ | DetA↑ | TP↑ | FN↓ | FP↓ | IDSW↓ | MT↑ | ML↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Co-DINO-l,nofine-tuning | |||||||||||
| ByteTrack | 56.1 | 87.2 | 56.6 | 40.3 | 78.2 | 259793 | 29373 | 6028 | 1650 | 240 | 7 |
| SAM2MOT | 75.5 | 89.2 | 83.4 | 71.3 | 80.3 | 274582 | 14584 | 15653 | 854 | 273 | 2 |
| Grounding-DINO-l,nofine-tuning | |||||||||||
| ByteTrack | 53.3 | 86.8 | 53.7 | 37.0 | 77.0 | 260160 | 29006 | 7281 | 1864 | 233 | 5 |
| SAM2MOT | 75.8 | 88.5 | 83.9 | 72.2 | 79.7 | 271472 | 17694 | 14650 | 879 | 264 | 3 |
Table 5. Comparison with ByteTrack using the same detector on UAVDT-MOT test set.
表 5. 在UAVDT-MOT测试集上使用相同检测器与ByteTrack的对比。
| Methods | MOTA↑ | IDF1↑ | FN↓ | FP↓ | IDSW↓ | MT↑ | ML↓ |
|---|---|---|---|---|---|---|---|
| Co-DINO-l,nofine-tuning | |||||||
| ByteTrack-iou0.5 | 52.4 | 67.8 | 136586 | 25081 | 452 | 588 | 250 |
| ByteTrack-iou0.4 | 55.4 | 69.1 | 131603 | 20098 | 482 | 607 | 240 |
| SAM2MOT-iou0.5 | 55.6 | 74.4 | 92504 | 58610 | 141 | 742 | 161 |
| SAM2MOT-iou0.4 | 66.1 | 79.4 | 74586 | 40692 | 136 | 816 | 147 |
| Grounding-DINO-l,nofine-tuning | |||||||
| ByteTrack-iou0.5 | 44.3 | 61.6 | 168086 | 21533 | 414 | 465 | 318 |
| ByteTrack-iou0.4 | 46.4 | 62.8 | 164399 | 17846 | 477 | 488 | 306 |
| SAM2MOT-iou0.5 | 51.0 | 71.7 | 103977 | 62906 | 139 | 694 | 189 |
| SAM2MOT-iou0.4 | 61.0 | 76.7 | 87003 | 45932 | 155 | 767 | 171 |
Table 6. Comparison with ByteTrack using the same detector on BDD100K-MOT val set.
表 6. 在BDD100K-MOT验证集上使用相同检测器与ByteTrack的对比。
| 方法 | MOTA↑ | IDF1↑ | IDSW↓ | FN↓ | FP↓ |
|---|---|---|---|---|---|
| Co-DINO-l, no fine-tuning | |||||
| ByteTrack(cls-8) | 50.0 | 58.2 | 26562 | 159596 | 35365 |
| SAM2MOT(cls-8) | 57.5 | 70.8 | 5587 | 137460 | 45247 |
| ByteTrack(cls-3) | 54.7 | 60.7 | 24832 | 149852 | 25710 |
| SAM2MOT(cls-3) | 63.0 | 73.7 | 5755 | 125064 | 32965 |
| Grounding-DINO-l, no fine-tuning | |||||
| ByteTrack(cls-8) | 33.8 | 49.0 | 25506 | 201737 | 65988 |
| SAM2MOT(cls-8) | 44.1 | 63.6 | 5184 | 169420 | 72833 |
| ByteTrack(cls-3) | 44.8 | 55.6 | 21680 | 179103 | 43437 |
| SAM2MOT(cls-3) | 58.0 | 71.0 | 5464 | 138491 | 42070 |
Table 7. Ablation study on different strategies, and evaluation metrics on DanceTrack test set.
表 7. 不同策略的消融研究,以及 DanceTrack 测试集上的评估指标。
| Baseline | Add | Col | Q-R | B-R | HOTA | MOTA | IDF1 |
|---|---|---|---|---|---|---|---|
| Co-DINO-1 | |||||||
| 62.9 | 55.6 | 69.6 | |||||
| √ | 67.9 | 69.7 | 74.4 | ||||
| √ | √ | 69.1 | 69.2 | 76.0 | |||
| 73.8 | 87.4 | 80.9 | |||||
| √ | √ | 75.1 | 88.1 | 83.0 | |||
| √ | √ | 75.6 | 89.2 | 83.4 | |||
| Grounding-DINO-1 | |||||||
| 60.9 | 50.1 | 66.5 | |||||
| √ | 67.4 | 67.2 | 74.0 | ||||
| 69.0 | 68.7 | 76.2 | |||||
| √ | 73.6 | 86.5 | 81.2 | ||||
| 75.1 | 87.4 | 83.1 | |||||
| √ | 75.8 | 88.5 | 83.9 |
The experiments are conducted on DanceTrack, UAVDT-MOT, and BDD100K-MOT datasets, following the same experimental settings as described above. As shown in Table 4, on DanceTrack, SAM2MOT consistently outperforms ByteTrack across different detectors, with HOTA and IDF1 improving by approximately 20.0 and 30.0, respectively. This significant margin underscores SAM2MOT’s superior association capability.
实验在DanceTrack、UAVDT-MOT和BDD100K-MOT数据集上进行,采用与上述相同的实验设置。如表4所示,在DanceTrack数据集上,SAM2MOT在不同检测器下均优于ByteTrack,HOTA和IDF1分别提升约20.0和30.0。这一显著差距凸显了SAM2MOT卓越的关联能力。
Similarly, Table 5 presents results on UAVDT-MOT, where it exhibits substantial gains in MOTA and IDF1. Table 6 further demonstrates SAM2MOT’s advantages on BDD100K-MOT, where it achieves notable improvements in both MOTA and IDF1 across both the 8-category and 3-category classification settings, while also reducing ID switches (IDSW).
同样地,表5展示了UAVDT-MOT数据集上的结果,该方法在MOTA和IDF1指标上均取得显著提升。表6进一步验证了SAM2MOT在BDD100K-MOT数据集上的优势,无论是8类别还是3类别分类设置下,其MOTA和IDF1均有明显改进,同时减少了ID切换(IDSW)次数。
The experimental results on BDD100K-MOT and UAVDT-MOT demonstrate that SAM2MOT not only enhances object association but also recovers additional true positives (TP) by leveraging its self-generated bounding boxes, thereby reducing reliance on precise detection.
在BDD100K-MOT和UAVDT-MOT上的实验结果表明,SAM2MOT不仅增强了目标关联能力,还通过利用其自生成的边界框恢复了额外的真阳性样本(TP),从而降低了对精确检测的依赖。
The visualized comparison results between ByteTrack and SAM2MOT are shown in Figure 4.
图 4: ByteTrack 与 SAM2MOT 的可视化对比结果
Component Ablation. We evaluated the contribution of each module in SAM2MOT on DanceTrack test set, with experimental results presented in Table 7. The evaluation primarily focuses on three core components: Object Addition(Add), Cross-object Interaction(CoI), and Quality Reconstruction(Q-R). Among them, Cross-object Interaction contributes the most significantly to tracking associa- tion performance, enabling SAM2MOT to achieve a break- through improvement in object correlation.
组件消融实验。我们在DanceTrack测试集上评估了SAM2MOT各模块的贡献,实验结果如表7所示。评估主要关注三个核心组件:目标新增模块(Add)、跨目标交互模块(CoI)和质量重建模块(Q-R)。其中,跨目标交互模块对跟踪关联性能提升最为显著,使SAM2MOT在目标关联性方面实现了突破性提升。

Figure 4. Sample tracking results visualization of ByteTrack and SAM2MOT using the same detector on DanceTrack, BDD100K-MOT and UAVDT-MOT. The results indicate that SAM2MOT significantly outperforms ByteTrack in association performance under scenarios involving camera motion, detector degradation, and occlusion.
图 4: 在DanceTrack、BDD100K-MOT和UAVDT-MOT数据集上使用相同检测器时,ByteTrack与SAM2MOT的跟踪结果可视化对比。结果表明,在相机运动、检测器性能下降及遮挡场景下,SAM2MOT在关联性能上显著优于ByteTrack。
SAM2MOT generates tracking bounding boxes using masks, which only cover the visible parts of objects, lead to mismatches with ground truth (GT), increasing the false positive rate. To mitigate this issue, we reconstructed the quality of the bounding box. However, this method is not universally applicable to all datasets and is therefore not elaborated in this paper. Notably, even without bounding box reconstruction(B-R), SAM2MOT still achieves the best tracking accuracy on DanceTrack.
SAM2MOT通过掩码生成跟踪边界框,这些掩码仅覆盖物体的可见部分,导致与真实标注(GT)不匹配,增加了误报率。为缓解该问题,我们重构了边界框的质量。但此方法并非适用于所有数据集,因此本文不作详细阐述。值得注意的是,即使不进行边界框重构(B-R),SAM2MOT仍在DanceTrack上实现了最佳跟踪精度。
5. Conclusion
5. 结论
We propose SAM2MOT, a novel multi-object tracking paradigm—Tracking by Segmentation. By decoupling detection from tracking, it improves adaptability, stability, and zero-shot generalization while enhancing object association. Moreover, SAM2MOT mitigates performance limi- tations from data scarcity, contributing to practical applications.
我们提出SAM2MOT,一种新颖的多目标跟踪范式——基于分割的跟踪(Tracking by Segmentation)。通过将检测与跟踪解耦,该方法提升了适应性、稳定性及零样本(Zero-shot)泛化能力,同时强化了目标关联。此外,SAM2MOT缓解了数据稀缺导致的性能限制,有助于实际应用。
SAM2MOT currently exhibits limitations in FPS performance. In future work, we will optimize this aspect to enhance efficiency and real-time applicability.
SAM2MOT目前在FPS(帧率)性能上存在局限。后续工作中我们将对此进行优化,以提升效率和实时性。