https://arxiv.org/pdf/2006.11149v3# Compositional Learning of Image-Text Query for Image Retrieval
图像检索中图文查询的组合学习
Abstract
摘要
In this paper, we investigate the problem of retrieving images from a database based on a multi-modal (imagetext) query. Specifically, the query text prompts some modification in the query image and the task is to retrieve images with the desired modifications. For instance, a user of an E-Commerce platform is interested in buying a dress, which should look similar to her friend’s dress, but the dress should be of white color with a ribbon sash. In this case, we would like the algorithm to retrieve some dresses with desired modifications in the query dress. We propose an auto encoder based model, ComposeAE, to learn the composition of image and text query for retrieving images. We adopt a deep metric learning approach and learn a metric that pushes composition of source image and text query closer to the target images. We also propose a rotational symmetry constraint on the optimization problem. Our approach is able to outperform the state-of-the-art method TIRG [23] on three benchmark datasets, namely: MIT-States, Fashion 200 k and Fashion IQ. In order to ensure fair comparison, we introduce strong baselines by enhancing TIRG method. To ensure reproducibility of the results, we publish our code here: https://github. com/ecom-research/ComposeAE.
本文研究基于多模态(图像文本)查询从数据库中检索图像的问题。具体而言,查询文本提示对查询图像进行某些修改,任务则是检索具有所需修改的图像。例如,电子商务平台用户想购买一件与她朋友裙子相似但需改为白色并配腰带款的连衣裙。此时,我们希望算法能检索出对查询裙子进行所需修改后的若干款式。我们提出基于自动编码器的模型ComposeAE,通过学习图像和文本查询的组合来检索图像。采用深度度量学习方法,学习使源图像与文本查询的组合更接近目标图像的度量标准。同时提出优化问题的旋转对称约束。我们的方法在三个基准数据集(MIT-States、Fashion 200k和Fashion IQ)上优于当前最先进的TIRG[23]方法。为确保公平比较,我们通过增强TIRG方法引入强基线。为保障结果可复现性,代码已开源:https://github.com/ecom-research/ComposeAE。
1. Introduction
1. 引言
One of the peculiar features of human perception is multi-modality. We unconsciously attach attributes to objects, which can sometimes uniquely identify them. For instance, when a person says apple it is quite natural that an image of an apple, which may be green or red in color, forms in their mind. In information retrieval, the user seeks information from a retrieval system by sending a query. Traditional information retrieval systems allow a unimodal query, i.e., either a text or an image. Advanced information retrieval systems should enable the users in expressing the concept in their mind by allowing a multi-modal query.
人类感知的一个独特特征是多模态性。我们会无意识地为物体附加属性,这些属性有时能唯一标识它们。例如,当有人说"苹果"时,脑海中很自然地会浮现出一个可能是绿色或红色的苹果图像。在信息检索中,用户通过向检索系统发送查询来寻找信息。传统的信息检索系统只允许单模态查询,即仅支持文本或图像。先进的信息检索系统应支持多模态查询,使用户能更准确地表达心中的概念。
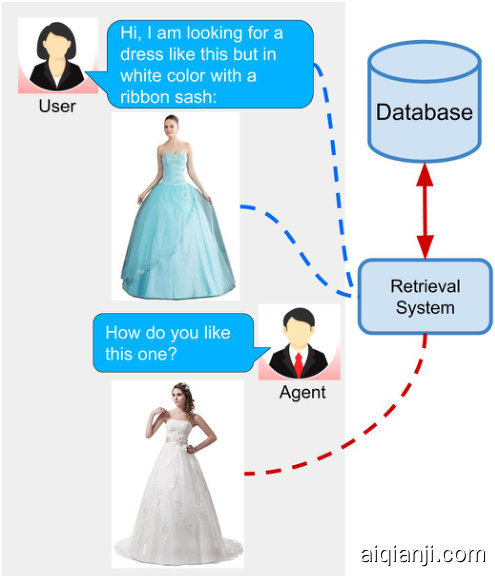
Figure 1. Potential application scenario of this task
图 1: 该任务的潜在应用场景
In this work, we consider such an advanced retrieval system, where users can retrieve images from a database based on a multi-modal query. Concretely, we have an image retrieval task where the input query is specified in the form of an image and natural language expressions describing the desired modifications in the query image. Such a retrieval system offers a natural and effective interface [18]. This task has applications in the domain of E-Commerce search, surveillance systems and internet search. Fig. 1 shows a potential application scenario of this task.
在本工作中,我们考虑这样一种高级检索系统:用户可以通过多模态查询从数据库中检索图像。具体而言,我们设定了一个图像检索任务,其输入查询由图像和自然语言描述共同构成,后者用于指定对查询图像的期望修改。这种检索系统提供了自然高效的交互界面 [18]。该任务可应用于电子商务搜索、监控系统和互联网搜索领域。图 1 展示了该任务的潜在应用场景。
Recently, Vo et al. [23] have proposed the Text Image Residual Gating (TIRG) method for composing the query image and text for image retrieval. They have achieved state-of-the-art (SOTA) results on this task. However, their approach does not perform well for real-world application scenarios, i.e. with long and detailed texts (see Sec. 4.4). We think the reason is that their approach is too focused on changing the image space and does not give the query text its due importance. The gating connection takes elementwise product of query image features with image-text represent ation after passing it through two fully connected layers. In short, TIRG assigns huge importance to query image features by putting it directly in the final composed representation. Similar to [19, 22], they employ LSTM for extracting features from the query text. This works fine for simple queries but fails for more realistic queries.
最近,Vo等人[23]提出了文本图像残差门控(TIRG)方法,用于组合查询图像和文本以进行图像检索。他们在这项任务上取得了最先进(SOTA)的结果。然而,他们的方法在现实应用场景(即长文本和详细文本)中表现不佳(见第4.4节)。我们认为原因是他们的方法过于专注于改变图像空间,而没有给予查询文本应有的重要性。门控连接在通过两个全连接层后,将查询图像特征与图像文本表示进行逐元素乘积。简而言之,TIRG通过直接将查询图像特征放入最终组合表示中,赋予了查询图像特征极大的重要性。与[19, 22]类似,他们使用LSTM从查询文本中提取特征。这对于简单查询效果良好,但对于更真实的查询则失效。
In this paper, we attempt to overcome these limitations by proposing ComposeAE, an auto encoder based approach for composing the modalities in the multi-modal query. We employ a pre-trained BERT model [1] for extracting text features, instead of LSTM. We hypothesize that by jointly conditioning on both left and right context, BERT is able to give better representation for the complex queries. Similar to TIRG [23], we use a pre-trained ResNet-17 model for extracting image features. The extracted image and text features have different statistical properties as they are extracted from independent uni-modal models. We argue that it will not be beneficial to fuse them by passing through a few fully connected layers, as typically done in image-text joint embeddings [24].
本文试图通过提出ComposeAE来克服这些限制,这是一种基于自动编码器的方法,用于组合多模态查询中的模态。我们采用预训练的BERT模型[1]来提取文本特征,而非LSTM。我们假设,通过同时考虑左右上下文,BERT能够为复杂查询提供更好的表征。与TIRG[23]类似,我们使用预训练的ResNet-17模型来提取图像特征。由于提取自独立的单模态模型,图像和文本特征具有不同的统计特性。我们认为,像图像-文本联合嵌入[24]中常见的那样,仅通过几个全连接层进行融合并不会带来益处。
We adopt a novel approach and map these features to a complex space. We propose that the target image representation is an element-wise rotation of the representation of the source image in this complex space. The information about the degree of rotation is specified by the text features. We learn the composition of these complex vectors and their mapping to the target image space by adopting a deep metric learning (DML) approach. In this formulation, text features take a central role in defining the relationship between query image and target image. This also implies that the search space for learning the composition features is restricted. From a DML point of view, this restriction proves to be quite vital in learning a good similarity metric.
我们采用了一种新颖的方法,将这些特征映射到一个复数空间。我们提出,目标图像的表征是该复数空间中源图像表征的逐元素旋转。旋转角度的信息由文本特征指定。通过采用深度度量学习 (DML) 方法,我们学习这些复数向量的组合及其到目标图像空间的映射。在这一公式中,文本特征在定义查询图像与目标图像关系时起着核心作用。这也意味着学习组合特征的搜索空间受到了限制。从 DML 的角度来看,这种限制对于学习良好的相似性度量至关重要。
We also propose an explicit rotational symmetry constraint on the optimization problem based on our novel formulation of composing the image and text features. Specifically, we require that multiplication of the target image features with the complex conjugate of the query text features should yield a representation similar to the query image features. We explore the effectiveness of this constraint in our experiments (see Sec. 4.5).
我们还基于图像和文本特征组合的新颖表述,在优化问题上提出了明确的旋转对称约束。具体而言,我们要求目标图像特征与查询文本特征的复共轭相乘后,应产生与查询图像特征相似的表示。我们在实验中探索了这一约束的有效性(参见第4.5节)。
We validate the effectiveness of our approach on three datasets: MIT-States, Fashion 200 k and Fashion IQ. In Sec. 4, we show empirically that ComposeAE is able to learn a better composition of image and text queries and outperforms SOTA method. In DML, it has been recently shown that improvements in reported results are exaggerated and performance comparisons are done unfairly [11]. In our experiments, we took special care to ensure fair comparison. For instance, we introduce several variants of TIRG. Some of them show huge improvements over the original TIRG. We also conduct several ablation studies to quantify the contribution of different modules in the improvement of the ComposeAE performance.
我们在三个数据集上验证了方法的有效性:MIT-States、Fashion 200k和Fashion IQ。在第4节中,我们通过实验证明ComposeAE能够学习更好的图像和文本查询组合,并优于SOTA方法。DML领域近期研究表明,已报道结果的改进程度被夸大,且性能对比存在不公平性[11]。实验中我们特别注重确保公平比较,例如引入了TIRG的多个变体,其中部分变体较原始TIRG展现出显著提升。我们还进行了多项消融实验,以量化不同模块对ComposeAE性能提升的贡献。
Our main contributions are summarized below:
我们的主要贡献如下:
• We propose a ComposeAE model to learn the composed representation of image and text query. • We adopt a novel approach and argue that the source image and the target image lie in a common complex space. They are rotations of each other and the degree of rotation is encoded via query text features. • We propose a rotational symmetry constraint on the optimization problem. • ComposeAE outperforms the SOTA method TIRG by a huge margin, i.e., $30.12%$ on Fashion $200\mathrm{k\Omega}$ and $11.13%$ on MIT-States on the Recall $@10$ metric. • We enhance SOTA method TIRG [23] to ensure fair comparison and identify its limitations.
• 我们提出ComposeAE模型来学习图像和文本查询的组合表征。
• 采用创新方法论证源图像与目标图像处于同一复杂空间,二者通过查询文本特征编码的旋转角度相互关联。
• 在优化问题上提出旋转对称约束。
• ComposeAE以显著优势超越SOTA方法TIRG:在Fashion 200k数据集Recall@10指标提升30.12%,在MIT-States数据集提升11.13%。
• 改进SOTA方法TIRG [23]以确保公平对比,并揭示其局限性。
2. Related Work
2. 相关工作
Deep metric learning (DML) has become a popular technique for solving retrieval problems. DML aims to learn a metric such that the distances between samples of the same class are smaller than the distances between the samples of different classes. The task where DML has been employed extensively is the cross-modal retrieval, i.e. retrieving images based on text query and getting captions from the database based on the image query [24, 9, 28, 2, 8, 26].
深度度量学习 (DML) 已成为解决检索问题的流行技术。DML 旨在学习一种度量,使得同类样本之间的距离小于不同类样本之间的距离。DML 广泛应用的场景是跨模态检索,例如基于文本查询检索图像,或基于图像查询从数据库中获取描述 [24, 9, 28, 2, 8, 26]。
In the domain of Visual Question Answering (VQA), many methods have been proposed to fuse the text and image inputs [19, 17, 16]. We review below a few closely related methods. Relationship [19] is a method based on relational reasoning. Image features are extracted from CNN and text features from LSTM to create a set of relationship features. These features are then passed through a MLP and after averaging them the composed representation is obtained. FiLM [17] method tries to “influence” the source image by applying an affine transformation to the output of a hidden layer in the network. In order to perform complex operations, this linear transformation needs to be applied to several hidden layers. Another prominent method is parameter hashing [16] where one of the fully-connected layers in a CNN acts as the dynamic parameter layer.
在视觉问答 (Visual Question Answering, VQA) 领域,已有许多方法被提出用于融合文本和图像输入 [19, 17, 16]。下面我们回顾几种密切相关的方法。Relationship [19] 是一种基于关系推理的方法,通过 CNN 提取图像特征和 LSTM 提取文本特征,生成一组关系特征。这些特征经过 MLP 处理后,通过平均操作获得组合表征。FiLM [17] 方法试图通过对网络中隐藏层输出应用仿射变换来"影响"源图像。为了实现复杂操作,这种线性变换需要应用于多个隐藏层。另一个重要方法是参数哈希 [16],其中 CNN 的某个全连接层作为动态参数层。
In this work, we focus on the image retrieval problem based on the image and text query. This task has been studied recently by Vo et al. [23]. They propose a gated feature connection in order to keep the composed representation of query image and text in the same space as that of the target image. They also incorporate a residual connection which learns the similarity between concatenation of image-text features and the target image features. Another simple but effective approach is Show and Tell[22]. They train a LSTM to predict the next word in the sequence after it has seen the image and previous words. The final state of this LSTM is considered the composed representation. Han et al. [6] presents an interesting approach to learn spatiallyaware attributes from product description and then use them to retrieve products from the database. But their text query is limited to a predefined set of attributes. Nagarajan et al. [12] proposed an embedding approach, “Attribute as Operator”, where text query is embedded as a transformation matrix. The image features are then transformed with this matrix to get the composed representation.
在本工作中,我们专注于基于图像和文本查询的图像检索问题。Vo等人[23]近期对此任务进行了研究,他们提出了一种门控特征连接方法,使查询图像与文本的组合表征与目标图像保持在同一空间。该方法还引入了残差连接,用于学习图像-文本特征拼接与目标图像特征之间的相似性。另一种简单有效的方法是Show and Tell[22],该方法训练LSTM模型在观察图像及前序词汇后预测序列中的下一个词,并将LSTM的最终状态作为组合表征。Han等人[6]提出了一种创新方法,从商品描述中学习空间感知属性,进而用于数据库商品检索,但其文本查询仅限于预定义的属性集。Nagarajan等人[12]提出了"属性即运算符"的嵌入方法,将文本查询嵌入为变换矩阵,再通过该矩阵转换图像特征以获得组合表征。
This task is also closely related with interactive image retrieval task [4, 21] and attribute-based product retrieval task [27, 23]. These approaches have their limitations such as that the query texts are limited to a fixed set of relative attributes [27], require multiple rounds of natural language queries as input [4, 21] or that query texts can be only one word i.e. an attribute [6]. In contrast, the input query text in our approach is not limited to a fixed set of attributes and does not require multiple interactions with the user. Different from our work, the focus of these methods is on modeling the interaction between user and the agent.
该任务也与交互式图像检索任务 [4, 21] 和基于属性的产品检索任务 [27, 23] 密切相关。这些方法存在局限性,例如查询文本仅限于一组固定的相对属性 [27]、需要多轮自然语言查询作为输入 [4, 21],或查询文本只能是单个词(即属性)[6]。相比之下,我们的方法中输入的查询文本不受限于固定属性集,也不需要与用户进行多次交互。与我们的工作不同,这些方法的重点在于建模用户与AI智能体之间的交互。
3. Methodology
3. 方法论
3.1. Problem Formulation
3.1. 问题描述
Let $\mathcal{X}={x_{1},x_{2},\cdot\cdot\cdot,x_{n}}$ denote the set of query images, $\mathcal{T}={t_{1},t_{2},\cdot\cdot\cdot,t_{n}}$ denote the set of query texts and $y={y_{1},y_{2},\cdot\cdot\cdot,y_{n}}$ denote the set of target images. Let $\psi(\cdot)$ denote the pre-trained image model, which takes an image as input and returns image features in a $d\cdot$ - dimensional space. Let $\kappa(\cdot,\cdot)$ denote the similarity kernel, which we implement as a dot product between its inputs. The task is to learn a composed representation of the imagetext query, denoted by $g(x,t;\Theta)$ , by maximising
设 $\mathcal{X}={x_{1},x_{2},\cdot\cdot\cdot,x_{n}}$ 表示查询图像集,$\mathcal{T}={t_{1},t_{2},\cdot\cdot\cdot,t_{n}}$ 表示查询文本集,$y={y_{1},y_{2},\cdot\cdot\cdot,y_{n}}$ 表示目标图像集。设 $\psi(\cdot)$ 表示预训练图像模型,该模型以图像为输入并返回 $d\cdot$ 维空间中的图像特征。设 $\kappa(\cdot,\cdot)$ 表示相似性核函数,我们将其实现为输入之间的点积。该任务的目标是通过最大化 $g(x,t;\Theta)$ 来学习图文查询的组合表示。
$$
\operatorname*{max}_{\Theta}\kappa(g(x,t;\Theta),\psi(y)),
$$
$$
\operatorname*{max}_{\Theta}\kappa(g(x,t;\Theta),\psi(y)),
$$
3.2. Motivation for Complex Projection
3.2. 复杂投影的动机
In deep learning, researchers aim to formulate the learning problem in such a way that the solution space is restricted in a meaningful way. This helps in learning better and robust representations. The objective function (Equation 1) maximizes the similarity between the output of the composition function of the image-text query and the target image features. Thus, it is intuitive to model the query image, query text and target image lying in some common space. One drawback of TIRG is that it does not emphasize the importance of text features in defining the relationship between the query image and the target image.
在深度学习中,研究人员的目标是以一种有意义的方式限制解空间来构建学习问题。这有助于学习更好且稳健的表征。目标函数(公式1)最大化图文查询组合函数输出与目标图像特征之间的相似性。因此,将查询图像、查询文本和目标图像建模在某个共同空间中是直观的。TIRG的一个缺点是它没有强调文本特征在定义查询图像与目标图像之间关系时的重要性。
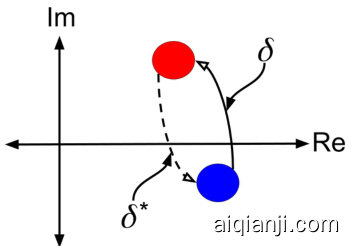
Figure 2. Conceptual Diagram of Rotation of the Images in Complex Space. Blue and Red Circle represent the query and the target image respectively. $\delta$ represents the rotation in the complex space, learned from the query text features. $\delta^{*}$ represents the complex conjugate of the rotation in the complex space.
图 2: 复数空间图像旋转概念示意图。蓝色和红色圆圈分别代表查询图像和目标图像。$\delta$表示从查询文本特征学习到的复数空间旋转。$\delta^{*}$表示复数空间旋转的共轭复数。
where $\Theta$ denotes all the network parameters.
其中 $\Theta$ 表示所有网络参数。
Based on these insights, we restrict the compositional learning of query image and text features in such a way that: (i) query and target image features lie in the same space, (ii) text features encode the transition from query image to target image in this space and (iii) transition is symmetric, i.e. some function of the text features must encode the reverse transition from target image to query image.
基于这些观察,我们对查询图像和文本特征的组合学习施加以下限制:(i) 查询图像与目标图像特征位于同一空间,(ii) 文本特征编码了从查询图像到目标图像在该空间中的转移,(iii) 转移具有对称性,即文本特征的某种函数必须能编码从目标图像返回查询图像的逆向转移。
In order to incorporate these characteristics in the composed representation, we propose that the query image and target image are rotations (transitions) of each other in a complex space. The rotation is determined by the text features. This enables incorporating the desired text information about the image in the common complex space. The reason for choosing the complex space is that some function of text features required for the transition to be symmetric can easily be defined as the complex conjugate of the text features in the complex space (see Fig. 2).
为了将这些特性融入组合表征中,我们提出查询图像与目标图像在复数空间中互为旋转(变换)。该旋转由文本特征决定,从而能在公共复数空间中融入所需的图像文本信息。选择复数空间的原因是:某些实现对称变换所需的文本特征函数,可以简单地定义为复数空间中文本特征的共轭复数(见图 2)。
Choosing such projection also enables us to define a constraint on the optimization problem, referred to as rotational symmetry constraint (see Equations 12, 13 and 14). We will empirically verify the effectiveness of this constraint in learning better composed representations. We will also explore the effect on performance if we fuse image and text information in the real space. Refer to Sec. 4.5.
选择这种投影方式还能让我们在优化问题上定义一个约束条件,称为旋转对称约束 (rotational symmetry constraint) (见公式12、13和14)。我们将通过实验验证该约束在学习更优组合表征方面的有效性。同时会探究在实数空间融合图像和文本信息对性能的影响。具体参见第4.5节。
An advantage of modelling the reverse transition in this way is that we do not require captions of query image. This is quite useful in practice, since a user-friendly retrieval system will not ask the user to describe the query image for it. In the public datasets, query image captions are not always available, e.g. for Fashion IQ dataset. In addition to that, it also forces the model to learn a good “internal” representation of the text features in the complex space.
以这种方式建模反向转换的优势在于,我们不需要查询图像的描述文本。这在实际应用中非常有用,因为用户友好的检索系统不会要求用户为查询图像提供描述。在公开数据集中,查询图像的描述文本并非总是可用(例如 Fashion IQ 数据集)。此外,这种方式还能迫使模型在复杂空间中学习文本特征的优质"内部"表示。
Interestingly, such restrictions on the learning problem serve as implicit regular iz ation. e.g., the text features only influence angles of the composed representation. This is in line with recent developments in deep learning theory [14, 13]. Neyshabur et al. [15] showed that imposing simple but global constraints on the parameter space of deep networks is an effective way of analyzing learning theoretic properties and aids in decreasing the generalization error.
有趣的是,这类对学习问题的限制起到了隐式正则化 (regularization) 的作用。例如,文本特征仅影响组合表征的角度。这与深度学习理论的最新进展 [14, 13] 相吻合。Neyshabur 等人 [15] 表明,对深度网络参数空间施加简单但全局的约束,是分析学习理论特性的有效方法,并有助于降低泛化误差。
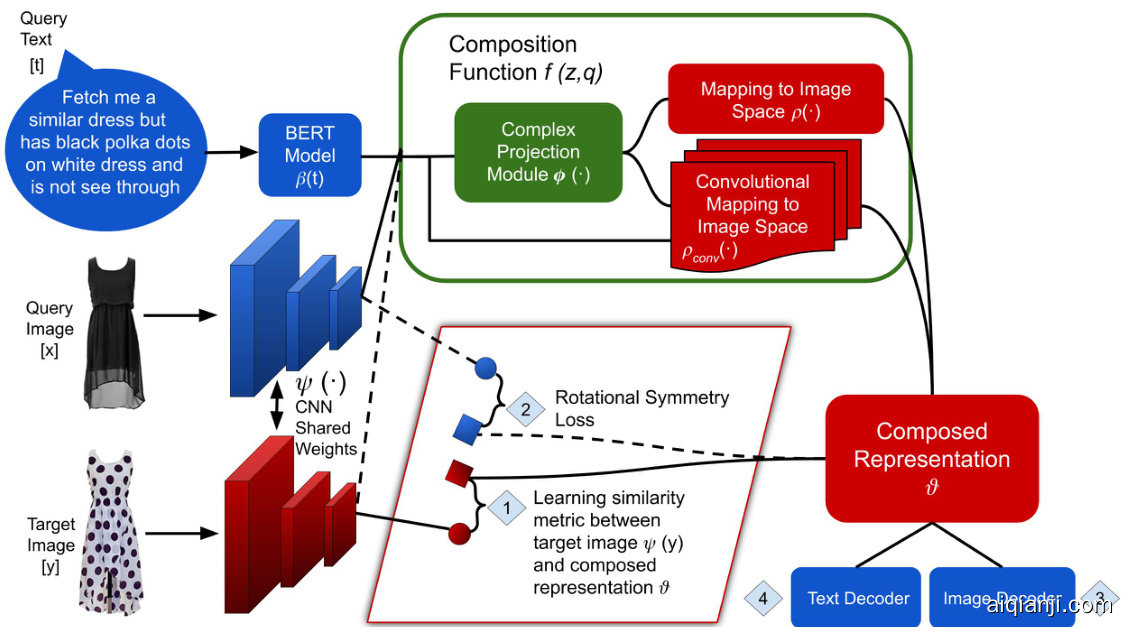
Figure 3. ComposeAE Architecture: Image retrieval using text and image query. Dotted lines indicate connections needed for calculating rotational symmetry loss (see Equations 12, 13 and 14). Here 1 refers to $L_{B A S E}$ , 2 refers to $L_{S Y M}^{B A S E}$ , 3 refers to $L_{R I}$ and 4 refers to $L_{R T}$
图 3: ComposeAE架构:使用文本和图像查询进行图像检索。虚线表示计算旋转对称损失所需的连接 (参见公式12、13和14)。其中1表示 $L_{B A S E}$ ,2表示 $L_{S Y M}^{B A S E}$ ,3表示 $L_{R I}$ ,4表示 $L_{R T}$
3.3. Network Architecture
3.3. 网络架构
Now we describe ComposeAE, an auto encoder based approach for composing the modalities in the multi-modal query. Figure 3 presents the overview of the ComposeAE architecture.
现在我们介绍ComposeAE,这是一种基于自动编码器的方法,用于组合多模态查询中的模态。图3展示了ComposeAE架构的概览。
For the image query, we extract the image feature vector living in a $d$ -dimensional space, using the image model $\psi(\cdot)$ (e.g. ResNet-17), which we denote as:
对于图像查询,我们使用图像模型 $\psi(\cdot)$ (例如 ResNet-17) 提取存在于 $d$ 维空间中的图像特征向量,记为:
$$
\psi(x)=z\in\mathbb{R}^{d}.
$$
$$
\psi(x)=z\in\mathbb{R}^{d}.
$$
Similarly, for the text query $t$ , we extract the text feature vector living in an $h$ -dimensional space, using the BERT model [1], $\beta(\cdot)$ as:
同样,对于文本查询 $t$,我们使用 BERT 模型 [1] 提取位于 $h$ 维空间中的文本特征向量 $\beta(\cdot)$:
$$
\beta(t)=q\in\mathbb{R}^{h}.
$$
$$
\beta(t)=q\in\mathbb{R}^{h}.
$$
Since the image features $z$ and text features $q$ are extracted from independent uni-modal models; they have different statistical properties and follow complex distributions. Typically in image-text joint embeddings [23, 24], these features are combined using fully connected layers or gating mechanisms.
由于图像特征 $z$ 和文本特征 $q$ 是从独立的单模态模型中提取的,它们具有不同的统计特性并遵循复杂的分布。通常在图像-文本联合嵌入 [23, 24] 中,这些特征会通过全连接层或门控机制进行组合。
In contrast to this we propose that the source image and target image are rotations of each other in some complex space, say, $\mathbb{C}^{k}$ . Specifically, the target image representation is an element-wise rotation of the representation of the source image in this complex space. The information of how much rotation is needed to get from source to target image is encoded via the query text features. During training, we learn the appropriate mapping functions which give us the composition of $z$ and $q$ in $\mathbb{C}^{k}$ .
与此相反,我们提出源图像和目标图像是某个复杂空间(例如 $\mathbb{C}^{k}$)中的相互旋转。具体而言,目标图像的表征是该复杂空间中源图像表征的逐元素旋转。从源图像到目标图像所需旋转的信息通过查询文本特征进行编码。在训练过程中,我们学习适当的映射函数,从而得到 $\mathbb{C}^{k}$ 中 $z$ 和 $q$ 的组合。
More precisely, to model the text features $q$ as specifying element-wise rotation of source image features, we learn a mapping $\gamma\colon\mathbb{R}^{k}\to{D\in\mathbb{R}^{k\times k}\mid D$ is diagonal $}$ and obtain the coordinate-wise complex rotations via
更准确地说,为了将文本特征 $q$ 建模为指定源图像特征的逐元素旋转,我们学习一个映射 $\gamma\colon\mathbb{R}^{k}\to{D\in\mathbb{R}^{k\times k}\mid D$ 是对角矩阵 $}$,并通过以下方式获得坐标方向的复数旋转:
$$
\delta=\mathcal{E}{j\gamma(q)},
$$
$$
\delta=\mathcal{E}{j\gamma(q)},
$$
where $\mathcal{E}$ denotes the matrix exponential function and $j$ is square root of $-1$ . The mapping $\gamma$ is implemented as a multilayer perceptron (MLP) i.e. two fully-connected layers with non-linear activation.
其中 $\mathcal{E}$ 表示矩阵指数函数,$j$ 是 $-1$ 的平方根。映射 $\gamma$ 通过多层感知机 (MLP) 实现,即两个带有非线性激活函数的全连接层。
Next, we learn a mapping function, $\eta:\mathbb{R}^{d}\rightarrow\mathbb{C}^{k}$ , which maps image features $z$ to the complex space. $\eta$ is also implemented as a MLP. The composed representation denoted by $\phi\in\mathbb{C}^{k}$ can be written as:
接下来,我们学习一个映射函数 $\eta:\mathbb{R}^{d}\rightarrow\mathbb{C}^{k}$,它将图像特征 $z$ 映射到复数空间。$\eta$ 同样由多层感知机 (MLP) 实现。组合后的表示记为 $\phi\in\mathbb{C}^{k}$,其表达式为:
$$
\phi=\delta\eta(z)
$$
$$
\phi=\delta\eta(z)
$$
The optimization problem defined in Eq. 1 aims to maximize the similarity between the composed features and the target image features extracted from the image model. Thus, we need to learn a mapping function, $\rho:\mathbb{C}^{k}\mapsto\mathbb{R}^{d}$ , from the complex space $\mathbb{C}^{k}$ back to the $d$ -dimensional real space where extracted target image features exist. $\rho$ is implemented as MLP.
式 (1) 中定义的优化问题旨在最大化组合特征与从图像模型中提取的目标图像特征之间的相似性。因此,我们需要学习一个映射函数 $\rho:\mathbb{C}^{k}\mapsto\mathbb{R}^{d}$ ,将复数空间 $\mathbb{C}^{k}$ 映射回存在提取目标图像特征的 $d$ 维实数空间。 $\rho$ 通过多层感知机 (MLP) 实现。
In order to better capture the underlying cross-modal similarity structure in the data, we learn another mapping, denoted as $\rho_{c o n v}$ . The convolutional mapping is implemented as two fully connected layers followed by a single convolutional layer. It learns 64 convolutional filters and adaptive max pooling is applied on them to get the representation from this convolutional mapping. This enables learning effective local interactions among different features. In addition to $\phi,\rho_{c o n v}$ also takes raw features $z$ and $q$ as input. $\rho_{c o n v}$ plays a really important role for queries where the query text asks for a modification that is spatially localized. e.g., a user wants a t-shirt with a different logo on the front (see second row in Fig. 4).
为了更好地捕捉数据中潜在的跨模态相似性结构,我们学习了另一个映射,记为 $\rho_{conv}$。该卷积映射由两个全连接层和一个卷积层实现,通过64个卷积滤波器学习特征,并应用自适应最大池化获取表征。这种方法能有效学习不同特征间的局部交互关系。除了 $\phi$,$\rho_{conv}$ 同样以原始特征 $z$ 和 $q$ 作为输入。对于需要空间局部修改的查询(例如用户想要改变T恤正面的Logo,见图4第二行),$\rho_{conv}$ 发挥着关键作用。
Let $f(z,q)$ denote the overall composition function which learns how to effectively compose extracted image and text features for target image retrieval. The final representation, $\vartheta\in\mathbb{R}^{d}$ , of the composed image-text features can be written as follows:
设 $f(z,q)$ 表示通过学习如何有效组合提取的图像和文本特征以进行目标图像检索的整体组合函数。组合后的图像-文本特征的最终表示 $\vartheta\in\mathbb{R}^{d}$ 可表示为:
$$
\vartheta=f(z,q)=a\rho(\phi)+b\rho_{c o n v}(\phi,z,q),
$$
$$
\vartheta=f(z,q)=a\rho(\phi)+b\rho_{c o n v}(\phi,z,q),
$$
where $a$ and $b$ are learnable parameters.
其中 $a$ 和 $b$ 是可学习参数。
In auto encoder terminology, the encoder has learnt the composed representation of image and text query, $\vartheta$ . Next, we learn to reconstruct the extracted image $z$ and text features $q$ from $\vartheta$ . Separate decoders are learned for each modality, i.e., image decoder and text decoder denoted by $d_{i m g}$ and $d_{t x t}$ respectively. The reason for using the decoders and reconstruction losses is two-fold: first, it acts as regularize r on the learnt composed representation and secondly, it forces the composition function to retain relevant text and image information in the final representation. Empirically, we have seen that these losses reduce the variation in the performance and aid in preventing over fitting.
在自编码器术语中,编码器已学会图像和文本查询的组合表示 $\vartheta$。接下来,我们学习从 $\vartheta$ 重构提取的图像 $z$ 和文本特征 $q$。为每种模态分别学习解码器,即图像解码器和文本解码器,分别表示为 $d_{img}$ 和 $d_{txt}$。使用解码器和重构损失的原因有两个:首先,它对学习到的组合表示起到正则化作用;其次,它迫使组合函数在最终表示中保留相关的文本和图像信息。根据经验,我们发现这些损失减少了性能波动,并有助于防止过拟合。
3.4. Training Objective
3.4. 训练目标
We adopt a deep metric learning (DML) approach to train ComposeAE. Our training objective is to learn a similarity metric, $\kappa(\cdot,\cdot):\mathbb{R}^{d}\times\mathbb{R}^{d}\mapsto\mathbb{R}$ , between composed image-text query features $\vartheta$ and extracted target image features $\psi(y)$ . The composition function $f(z,q)$ should learn to map semantically similar points from the data manifold in $\mathbb{R}^{d}\times\mathbb{R}^{h}$ onto metrically close points in $\mathbb{R}^{d}$ . Analogously, $f(\cdot,\cdot)$ should push the composed representation away from non-similar images in $\mathbb{R}^{d}$ .
我们采用深度度量学习(DML)方法来训练ComposeAE。训练目标是学习一个相似性度量函数 $\kappa(\cdot,\cdot):\mathbb{R}^{d}\times\mathbb{R}^{d}\mapsto\mathbb{R}$ ,用于衡量组合图文查询特征 $\vartheta$ 与目标图像特征 $\psi(y)$ 之间的距离。组合函数 $f(z,q)$ 需要学会将数据流形 $\mathbb{R}^{d}\times\mathbb{R}^{h}$ 中语义相似的样本映射到 $\mathbb{R}^{d}$ 空间中的邻近点,同时将不相似图像的组合表征推离。
For sample $i$ from the training mini-batch of size $N$ , let $\vartheta_{i}$ denote the composition feature, $\psi(y_{i})$ denote the target image features and $\psi(\tilde{y}_{i})$ denote the randomly selected negative image from the mini-batch. We follow TIRG [23] in choosing the base loss for the datasets.
对于训练小批量中大小为 $N$ 的样本 $i$,设 $\vartheta_{i}$ 表示组合特征,$\psi(y_{i})$ 表示目标图像特征,$\psi(\tilde{y}_{i})$ 表示从小批量中随机选择的负样本图像。我们遵循 TIRG [23] 的方法选择数据集的基准损失函数。
So, for MIT-States dataset, we employ triplet loss with soft margin as a base loss.
因此,对于 MIT-States 数据集,我们采用带软间隔的三元组损失 (triplet loss with soft margin) 作为基础损失。
where $M$ denotes the number of triplets for each training sample $i$ . In our experiments, we choose the same value as mentioned in the TIRG code, i.e. 3.
其中 $M$ 表示每个训练样本 $i$ 的三元组数量。在我们的实验中,我们选择与 TIRG 代码中提到的相同值,即 3。
For Fashion 200 k and Fashion IQ datasets, the base loss is the softmax loss with similarity kernels, denoted as $L_{S M A X}$ . For each training sample $i$ , we normalize the similarity between the composed query-image features $(\vartheta_{i})$ and target image features by dividing it with the sum of similarities between $\vartheta_{i}$ and all the target images in the batch. This is equivalent to the classification based loss in [23, 3, 20, 10].
对于Fashion 200k和Fashion IQ数据集,基础损失是带有相似性核的softmax损失,记为$L_{S M A X}$。对于每个训练样本$i$,我们通过将组合查询-图像特征$(\vartheta_{i})$与目标图像特征之间的相似度除以$\vartheta_{i}$与批次中所有目标图像相似度之和来进行归一化。这等同于[23, 3, 20, 10]中基于分类的损失。
In addition to the base loss, we also incorporate two reconstruction losses in our training objective. They act as regularize rs on the learning of the composed representation. The image reconstruction loss is given by:
除了基础损失函数外,我们还在训练目标中加入了两个重构损失。它们对组合表征的学习起到正则化作用。图像重构损失由以下公式给出:
$$
L_{R I}=\frac{1}{N}\sum_{i=1}^{N}{\left\Vert{z_{i}-\hat{z_{i}}}\right\Vert_{2}^{2}},
$$
$$
L_{R I}=\frac{1}{N}\sum_{i=1}^{N}{\left\Vert{z_{i}-\hat{z_{i}}}\right\Vert_{2}^{2}},
$$
where $\hat{z}{i}=d_{i m g}(\vartheta_{i})$ .
其中 $\hat{z}{i}=d_{i m g}(\vartheta_{i})$。
Similarly, the text reconstruction loss is given by:
文本重建损失由下式给出:
$$
L_{R T}=\frac{1}{N}\sum_{i=1}^{N}\Big\lVert q_{i}-\hat{q}{i}\Big\rVert_{2}^{2},
$$
$$
L_{R T}=\frac{1}{N}\sum_{i=1}^{N}\Big\lVert q_{i}-\hat{q}{i}\Big\rVert_{2}^{2},
$$
where $\hat{q}{i}=d_{t x t}(\vartheta_{i})$ .
其中 $\hat{q}{i}=d_{t x t}(\vartheta_{i})$。
3.4.1 Rotational Symmetry Loss
3.4.1 旋转对称性损失 (Rotational Symmetry Loss)
As discussed in subsection 3.2, based on our novel formulation of learning the composition function, we can include a rotational symmetry loss in our training objective. Specifically, we require that the composition of the target image features with the complex conjugate of the text features should be similar to the query image features. In concrete terms, first we obtain the complex conjugate of the text features projected in the complex space. It is given by:
如第3.2节所述,基于我们提出的学习组合函数的新颖公式,可以在训练目标中加入旋转对称性损失。具体而言,我们要求目标图像特征与文本特征在复数空间中的共轭组合应与查询图像特征相似。具体来说,首先获取投影到复数空间的文本特征的共轭复数,其表达式为:
$$
\delta^{*}=\mathcal{E}{-j\gamma(q)}.
$$
$$
\delta^{*}=\mathcal{E}{-j\gamma(q)}.
$$
Let $\tilde{\phi}$ denote the composition of $\delta^{*}$ with the target image features $\psi(y)$ in the complex space. Concretely:
设 $\tilde{\phi}$ 表示复空间中目标图像特征 $\psi(y)$ 与 $\delta^{*}$ 的复合。具体而言:
$$
\tilde{\phi}=\delta^{*}\eta(\psi(y))
$$
$$
\tilde{\phi}=\delta^{*}\eta(\psi(y))
$$
Finally, we compute the composed representation, denoted by $\vartheta^{*}$ , in the following way:
最后,我们通过以下方式计算组合表示 $\vartheta^{*}$:
$$
\vartheta^{*}=f(\psi(y),q)=a\rho(\tilde{\phi})+b\rho_{c o n v}(\tilde{\phi},\psi(y),q)
$$
$$
\vartheta^{*}=f(\psi(y),q)=a\rho(\tilde{\phi})+b\rho_{c o n v}(\tilde{\phi},\psi(y),q)
$$
The rotational symmetry constraint translates to maximizing this similarity kernel: $\kappa(\vartheta^{*},z)$ . We incorporate this
旋转对称约束转化为最大化相似性核函数:$\kappa(\vartheta^{*},z)$。我们将其纳入
constraint in our training objective by employing softmax loss or soft-triplet loss depending on the dataset.
在训练目标中通过根据数据集采用softmax损失或soft-triplet损失来施加约束。
The total loss is computed by the weighted sum of above mentioned losses. It is given by:
总损失通过上述损失的加权和计算得出,其表达式为:
$$
{\cal L}{T}={\cal L}{B A S E}+\lambda_{S Y M}{\cal L}{S Y M}^{B A S E}+\lambda_{R I}{\cal L}{R I}+\lambda_{R T}{\cal L}_{R T},
$$
$$
{\cal L}{T}={\cal L}{B A S E}+\lambda_{S Y M}{\cal L}{S Y M}^{B A S E}+\lambda_{R I}{\cal L}{R I}+\lambda_{R T}{\cal L}_{R T},
$$
where $B A S E\in{S M A X,S T}$ depending on the dataset.
其中 $BASE\in{SMAX,ST}$ 取决于数据集。
4. Experiments
4. 实验
4.1. Experimental Setup
4.1. 实验设置
We evaluate our approach on three real-world datasets, namely: MIT-States[7], Fashion 200 k [6] and Fashion IQ [5]. For evaluation, we follow the same protocols as other recent works [23, 6, 17]. We use recall at rank $k$ , denoted as $R@k$ , as our evaluation metric. We repeat each experiment 5 times in order to estimate the mean and the standard deviation in the performance of the models.
我们在三个真实世界数据集上评估了我们的方法,分别是:MIT-States[7]、Fashion 200k[6]和Fashion IQ[5]。评估时,我们遵循与其他近期工作[23,6,17]相同的协议。我们使用排名k的召回率(记为$R@k$)作为评估指标。为了估计模型性能的均值和标准差,每个实验重复进行了5次。
To ensure fair comparison, we keep the same hyperparameters as TIRG [23] and use the same optimizer (SGD with momentum). Similar to TIRG, we use ResNet-17 for image feature extraction to get 512-dimensional feature vector. In contrast to TIRG, we use pretrained BERT [1] for encoding text query. Concretely, we employ BERT-asservice [25] and use Uncased BERT-Base which outputs a 768-dimensional feature vector for a text query. Further implementation details can be found in the code: https: //github.com/ecom-research/ComposeAE.
为确保公平比较,我们保持与TIRG [23]相同的超参数,并使用相同的优化器(带动量的SGD)。与TIRG类似,我们使用ResNet-17进行图像特征提取,得到512维特征向量。不同于TIRG,我们采用预训练的BERT [1]对文本查询进行编码。具体而言,我们使用BERT-as-service [25]并选择Uncased BERT-Base模型,该模型可为文本查询输出768维特征向量。更多实现细节可参阅代码库:https://github.com/ecom-research/ComposeAE。
4.2. Baselines
4.2. 基线方法
We compare the results of ComposeAE with several methods, namely: Show and Tell, Parameter Hashing, Attribute as Operator, Relationship, FiLM and TIRG. We explained them briefly in Sec. 2.
我们将ComposeAE的结果与以下几种方法进行了比较:Show and Tell、Parameter Hashing、Attribute as Operator、Relationship、FiLM和TIRG。这些方法在第2节中已简要说明。
In order to identify the limitations of TIRG and to ensure fair comparison with our method, we introduce three variants of TIRG. First, we employ the BERT model as a text model instead of LSTM, which will be referred to as TIRG with BERT. Secondly, we keep the LSTM but text query contains full target captions. We refer to it as TIRG with Complete Text Query. Thirdly, we combine these two variants and get TIRG with BERT and Complete Text Query. The reason for complete text query baselines is that the original TIRG approach generates text query by finding one word difference in the source and target image captions. It disregards all other words in the target captions.
为了识别TIRG的局限性并确保与我们的方法进行公平比较,我们引入了TIRG的三种变体。首先,我们使用BERT模型替代LSTM作为文本模型,称为TIRG with BERT。其次,我们保留LSTM但文本查询包含完整的目标描述,称为TIRG with Complete Text Query。第三,我们将这两种变体结合,得到TIRG with BERT and Complete Text Query。引入完整文本查询基线的原因是原始TIRG方法通过寻找源图像描述与目标图像描述之间的一个单词差异来生成文本查询,忽略了目标描述中的所有其他单词。
Table 1. Dataset statistics
表 1: 数据集统计
| MIT-States | Fashion200k | FashionIQ | |
|---|---|---|---|
| 总图像数 | 53753 | 201838 | 62145 |
| 训练查询数 | 43207 | 172049 | 46609 |
| 测试查询数 | 82732 | 33480 | 15536 |
| 完整文本查询的平均长度 | 2 | 4.81 | 13.5 |
| 每查询的目标图像平均数 | 26.7 | 3 | 1 |
While such formulation of queries may be effective on some datasets, but the restriction on the specific form (or length) of text query largely constrain the information that a user can convey to benefit the retrieval process. Thus, such an approach of generating text query has limited applications in real life scenarios, where a user usually describes the modification text with multiple words. This argument is also supported by several recent studies [5, 4, 21]. In our experiments, Fashion IQ dataset contains queries asked by humans in natural language, with an average length of 13.5 words. (see Table 1). Due to this reason, we can not get results of original TIRG on this dataset.
虽然这种查询表述方式在某些数据集上可能有效,但对文本查询特定形式(或长度)的限制极大制约了用户能为检索过程提供的信息量。因此,这种生成文本查询的方法在现实场景中应用有限——用户通常会用多个词语来描述修改需求。这一观点也得到了近期多项研究的支持 [5, 4, 21]。在我们的实验中,Fashion IQ数据集包含人类用自然语言提出的查询,平均长度为13.5个单词(见表1)。由于这个原因,我们无法在该数据集上获得原始TIRG模型的结果。
4.3. Datasets
4.3. 数据集
Table 1 summarizes the statistics of the datasets. The train-test split of the datasets is the same for all the methods. MIT-States [7] dataset consists of ${\sim}60\mathrm{k}$ diverse real-world images where each image is described by an adjective (state) and a noun (categories), e.g. “ripe tomato”. There are 245 nouns in the dataset and 49 of them are reserved for testing. This split ensures that the algorithm is able to learn the composition on the unseen nouns (categories). The input image (say “unripe tomato”) is sampled and the text query asks to change the state to ripe. The algorithm is considered successful if it retrieves the correct target image (“ripe tomato”) from the pool of all test images.
表 1: 数据集统计信息摘要。所有方法的数据集训练-测试划分方式相同。MIT-States [7] 数据集包含约 6 万张多样化真实场景图像,每张图像通过形容词 (状态) 和名词 (类别) 组合描述,例如"成熟番茄"。该数据集包含 245 个名词,其中 49 个专用于测试。这种划分方式确保算法能够学习未见名词 (类别) 的组合关系。输入图像 (如"未成熟番茄") 被采样后,文本查询要求将其状态改为成熟。若算法能从所有测试图像中检索出正确目标图像 ("成熟番茄"),则视为成功。
Fashion 200 k [6] consists of ${\sim}200\mathrm{k}$ images of 5 different fashion categories, namely: pants, skirts, dresses, tops and jackets. Each image has a human annotated caption, e.g. “blue knee length skirt”.
Fashion 200k [6] 包含约20万张图像,涵盖5种不同的时尚类别:裤子、裙子、连衣裙、上衣和夹克。每张图像都配有标注人员编写的内容描述,例如"蓝色及膝裙"。
Fashion IQ[5] is a challenging dataset consisting of 77684 images belonging to three categories: dresses, top-tees and shirts. Fashion IQ has two human written annotations for each target image. We report the performance on the validation set as the test set labels are not available.
Fashion IQ[5]是一个包含77684张图像的挑战性数据集,涵盖连衣裙、上衣T恤和衬衫三个类别。每张目标图像配有两条人工标注文本。由于测试集标签未公开,我们仅在验证集上报告性能指标。
Table 2. Model performance comparison on MIT-States. The best number is in bold and the second best is underlined.
表 2. MIT-States数据集上的模型性能对比。最佳数值以粗体显示,次佳数值以下划线标注。
| 方法 | R@1 | R@5 | R@10 |
|---|---|---|---|
| Show and Tell Att.as Operator Relationship FiLM TIRG | 11.9±0.1 8.8±0.1 12.3±0.5 10.1±0.3 12.2±0.4 | 31.0±0.5 27.3±0.3 31.9±0.7 27.7±0.7 31.9±0.3 | 42.0±0.8 39.1±0.3 42.9±0.9 38.3±0.7 43.1±0.3 |
| TIRGwithBERT TIRG with Complete Text Query | 12.3±0.6 7.9±1.9 | 31.8±0.3 28.7±2.5 | 42.6±0.8 34.1±2.9 |
| TIRGwithBERTand Complete Text Query | 13.3±0.6 | 34.5±1.0 | 46.8±1.1 |
| ComposeAE | 13.9±0.5 | 35.3±0.8 | 47.9±0.7 |
4.4. Discussion of Results
4.4. 结果讨论
Tables 2, 3 and 4 summarize the results of the performance comparison. In the following, we discuss these results to gain some important insights into the problem.
表 2、表 3 和表 4 总结了性能对比的结果。接下来,我们将讨论这些结果,以获取关于该问题的一些重要见解。
First, we note that our proposed method ComposeAE outperforms other methods by a significant margin. On Fashion $200\mathrm{k\Omega}$ , the performance improvement of ComposeAE over the original TIRG and its enhanced variants is most significant. Specifically, in terms of $\mathrm{\mathbf{R}}\ @10$ metric, the performance improvement over the second best method is $6.96%$ and $30.12%$ over the original TIRG method . Similarly on $\mathrm{R}\ @10$ , for MIT-States, ComposeAE outperforms the second best method by $2.35%$ and by $11.13%$ over the original TIRG method. For the Fashion IQ dataset , ComposeAE has $2.61%$ and $3.82%$ better performance than the second best method in terms of $\mathrm{\mathbf{R}}\ @10$ and $\mathrm{R}@100$ respectively.
首先,我们注意到所提出的ComposeAE方法显著优于其他方法。在Fashion $200\mathrm{k\Omega}$数据集上,ComposeAE相较于原始TIRG及其增强变体的性能提升最为显著。具体而言,在$\mathrm{\mathbf{R}}\ @10$指标上,其性能比第二名方法高出$6.96%$,比原始TIRG方法高出$30.12%$。同样在$\mathrm{R}\ @10$指标上,对于MIT-States数据集,ComposeAE比第二名方法高出$2.35%$,比原始TIRG方法高出$11.13%$。在Fashion IQ数据集上,ComposeAE在$\mathrm{\mathbf{R}}\ @10$和$\mathrm{R}@100$指标上分别比第二名方法高出$2.61%$和$3.82%$。
Second, we observe that the performance of the methods on MIT-States and Fashion $200\mathrm{k\Omega}$ datasets is in a similar range as compared to the range on the Fashion IQ. For instance, in terms of $\mathrm{\mathbf{R}}\ @10$ , the performance of TIRG with BERT and Complete Text Query is 46.8 and 51.8 on MITStates and Fashion 200 k datasets while it is 11.5 for Fashion IQ. The reasons which make Fashion IQ the most challenging among the three datasets are: (i) the text query is quite complex and detailed and (ii) there is only one target image per query (See Table 1). That is even though the algorithm retrieves semantically similar images but they will not be considered correct by the recall metric. For instance, for the first query in Fig.4, we can see that the second, third and fourth image are semantically similar and modify the image as described by the query text. But if the third image which is the labelled target image did not appear in top-5, then $\mathtt{R@5}$ would have been zero for this query. This issue has also been discussed in depth by Nawaz et al.[?].
其次,我们注意到这些方法在MIT-States和Fashion $200\mathrm{k\Omega}$数据集上的性能表现与Fashion IQ处于相近区间。例如,在$\mathrm{\mathbf{R}}\ @10$指标上,采用BERT和完整文本查询的TIRG模型在MIT-States和Fashion 200k数据集上的得分分别为46.8和51.8,而在Fashion IQ上仅为11.5。导致Fashion IQ成为三个数据集中最具挑战性的原因在于:(i) 文本查询非常复杂且细节丰富;(ii) 每个查询仅对应一张目标图像(见表1)。这意味着即使算法检索到语义相似的图像,召回率指标也不会将其判定为正确结果。例如图4中的第一个查询,我们可以看到第二、第三和第四张图像在语义上相似,并且按照查询文本修改了图像。但如果标记为目标图像的第三张图未出现在top-5结果中,则该查询的$\mathtt{R@5}$值将为零。Nawaz等人[?]对此问题也进行过深入讨论。
Table 3. Model performance comparison on Fashion 200 k. The best number is in bold and the second best is underlined.
表 3: Fashion 200k数据集上的模型性能对比。最优数值加粗显示,次优数值带下划线。
| 方法 | R@1 | R@10 | R@50 |
|---|---|---|---|
| Han et al. [6] Show and Tell Param Hashing Relationship FiLM TIRG | 6.3 12.3±1.1 12.2±1.1 13.0±0.6 12.9±0.7 14.1±0.6 | 19.9 40.2±1.7 40.0±1.1 40.5±0.7 39.5±2.1 42.5±0.7 | 38.3 61.8±0.9 61.7±0.8 62.4±0.6 61.9±1.9 63.8±0.8 |
| TIRGwithBERT TIRG with Complete Text Query | 14.2±1.0 18.1±1.9 | 41.9±1.0 52.4±2.7 | 63.3±0.9 73.1±2.1 |
| TIRG with BERT and Complete Text Query | 19.9±1.0 | 51.7±1.5 | 71.8±1.3 |
| ComposeAE | 22.8±0.8 | 55.3±0.6 | 73.4±0.4 |
Table 4. Model performance comparison on Fashion IQ. The best number is in bold and the second best is underlined.
表 4: Fashion IQ数据集上的模型性能对比。最优数值以粗体显示,次优数值带下划线。
| 方法 | R@10 | R@50 | R@100 |
|---|---|---|---|
| TIRGwith Complete Text Query | 3.34±0.6 | 9.18±0.9 | 9.45±0.8 |
| TIRGwithBERTand Complete Text Query | 11.5±0.8 | 28.8±1.5 | 28.8±1.6 |
| ComposeAE | 11.8±0.9 | 29.4±1.1 | 29.9±1.3 |
Third, for MIT-States and Fashion 200 k datasets, we observe that the TIRG variant which replaces LSTM with BERT as a text model results in slight degradation of the performance. On the other hand, the performance of the TIRG variant which uses complete text (caption) query is quite better than the original TIRG. However, for the Fashion IQ dataset which represents a real-world application scenario, the performance of TIRG with complete text query is significantly worse. Concretely, TIRG with complete text query performs $253%$ worse than ComposeAE on $\mathrm{\mathbf{R}}\ @10$ . The reason for this huge variation is that the average length of complete text query for MIT-States and Fashion200k datasets is 2 and 3.5 respectively. Whereas average length of complete text query for Fashion IQ is 12.4. It is because TIRG uses the LSTM model and the composition is done in a way which underestimates the importance of the text query. This shows that TIRG approach does not perform well when the query text description is more realistic and complex.
第三,对于MIT-States和Fashion 200k数据集,我们观察到用BERT替换LSTM作为文本模型的TIRG变体会导致性能轻微下降。另一方面,使用完整文本(描述)查询的TIRG变体性能明显优于原始TIRG。然而,在代表真实应用场景的Fashion IQ数据集中,完整文本查询的TIRG性能显著更差。具体而言,完整文本查询的TIRG在$\mathrm{\mathbf{R}}\ @10$上的表现比ComposeAE差$253%$。这种巨大差异的原因是:MIT-States和Fashion200k数据集的完整文本查询平均长度分别为2和3.5,而Fashion IQ的完整文本查询平均长度达12.4。由于TIRG使用LSTM模型并以低估文本查询重要性的方式进行组合,这表明当查询文本描述更真实和复杂时,TIRG方法表现不佳。
Fourth, one of the baselines (TIRG with BERT and Complete Text Query) that we introduced shows significant improvement over the original TIRG. Specifically, in terms of $\mathrm{\mathbf{R}}\ @10$ , the performance gain over original TIRG is $8.58%$ and $21.65%$ on MIT-States and Fashion 200 k respectively. This method is also the second best performing method on all datasets. We think that with more detailed text query, BERT is able to give better representation of the query and this in turn helps in the improvement of the performance.
第四,我们引入的一个基线方法(结合BERT和完整文本查询的TIRG)相比原始TIRG展现出显著提升。具体而言,在$\mathrm{\mathbf{R}}\ @10$指标上,该方法在MIT-States和Fashion 200k数据集上分别比原始TIRG提高了$8.58%$和$21.65%$。该方法在所有数据集上均为第二优性能方案。我们认为,更详细的文本查询使BERT能生成更优质的查询表征,从而推动性能提升。

Figure 4. Qualitative Results: Retrieval examples from FashionIQ Dataset
图 4: 定性结果:FashionIQ数据集中的检索示例
Qualitative Results: Fig.4 presents some qualitative retrieval results for Fashion IQ. For the first query, we see that all images are in “blue print” as requested by text query. The second request in the text query was that the dress should be “short sleeves”, four out of top-5 images fulfill this requirement. For the second query, we can observe that all retrieved images share the same semantics and are visually similar to the target images. Qualitative results for other two datasets are given in the supplementary material.
定性结果:图4展示了Fashion IQ的一些定性检索结果。对于第一个查询,我们看到所有图像都符合文本查询要求的"蓝色印花"。文本查询的第二个要求是裙子应为"短袖",前5张图像中有4张满足这一条件。在第二个查询中,我们可以观察到所有检索到的图像都具有相同的语义,并且在视觉上与目标图像相似。另外两个数据集的定性结果见补充材料。
Table 5. Retrieval performance $(\mathbf{R}\ @10)$ of ablation studies.
表 5: 消融实验的检索性能 $(\mathbf{R}\ @10)$
| 方法 | Fashion200k | MIT-States | FashionIQ |
|---|---|---|---|
| ComposeAE | 55.3 | 47.9 | 11.8 |
| -withoutLsYM | 51.6 | 47.6 | 10.5 |
| -Concatin realspace | 48.4 | 46.2 | 09.8 |
| -withoutpconu | 52.8 | 47.1 | 10.7 |
| -withoutp | 52.2 | 45.2 | 11.1 |
4.5. Ablation Studies
4.5. 消融研究
We have conducted various ablation studies, in order to gain insight into which parts of our approach helps in the high performance of ComposeAE. Table 5 presents the quantitative results of these studies.
我们进行了多项消融研究,以深入了解ComposeAE方法中哪些部分对其高性能表现起到了关键作用。表5展示了这些研究的定量结果。
Impact of $L_{S Y M}$ : on the performance can be seen on Row 2. For Fashion 200 k and Fashion IQ datasets, the decrease in performance is quite significant: $7.17%$ and $12.38%$ respectively. While for MIT-States, the impact of incorporating $L_{S Y M}$ is not that significant. It may be because the text query is quite simple in the MIT-states case, i.e. 2 words. This needs further investigation.
$L_{S Y M}$ 的影响:性能表现可从第2行看出。在Fashion 200k和Fashion IQ数据集上,性能下降较为显著,分别为 $7.17%$ 和 $12.38%$。而对于MIT-States数据集,引入 $L_{S Y M}$ 的影响并不显著,这可能是因为MIT-States案例中的文本查询较为简单(仅2个单词),该现象有待进一步研究。
Efficacy of Mapping to Complex Space: ComposeAE has a complex projection module, see Fig. 3. We removed this module to quantify its effect on the performance. Row 3 shows that there is a drop in performance for all three datasets. This strengthens our hypothesis that it is better to map the extracted image and text features into a common complex space than simple concatenation in real space.
映射到复数空间的有效性:ComposeAE 包含一个复数投影模块(参见图 3)。我们移除了该模块以量化其对性能的影响。第 3 行数据显示,三个数据集的性能均出现下降。这进一步验证了我们的假设:与实数空间的简单拼接相比,将提取的图像和文本特征映射到公共复数空间更具优势。
Convolutional versus Fully-Connected Mapping: ComposeAE has two modules for mapping the features from complex space to target image space, i.e., $\rho(\cdot)$ and the second with an additional convolutional layer $\rho_{c o n v}(\cdot)$ . Rows 4 and 5 show that the performance is quite similar for fashion datasets. While for MIT-States, ComposeAE without $\rho_{c o n v}(\cdot)$ performs much better. Overall, it can be observed that for all three datasets both modules contribute in improving the performance of ComposeAE.
卷积映射与全连接映射对比:ComposeAE 包含两个将特征从复数空间映射到目标图像空间的模块,即 $\rho(\cdot)$ 和带额外卷积层的 $\rho_{conv}(\cdot)$。第4、5行数据显示,在时尚数据集上两者性能相近。而在 MIT-States 数据集上,未使用 $\rho_{conv}(\cdot)$ 的 ComposeAE 表现更优。总体而言,可观察到这两个模块对提升 ComposeAE 在三个数据集上的性能均有贡献。
5. Conclusion
5. 结论
In this work, we propose ComposeAE to compose the representation of source image rotated with the modification text in a complex space. This composed representation is mapped to the target image space and a similarity metric is learned. Based on our novel formulation of the problem, we introduce a rotational symmetry loss in our training objective. Our experiments on three datasets show that ComposeAE consistently outperforms SOTA method on this task. We enhance SOTA method TIRG [23] to ensure fair comparison and identify its limitations.
在本工作中,我们提出ComposeAE方法,通过在复数空间组合旋转后的源图像表示与修改文本。该组合表示被映射至目标图像空间,并学习相似性度量。基于我们对问题的新颖表述,我们在训练目标中引入了旋转对称损失。在三个数据集上的实验表明,ComposeAE在此任务上持续优于SOTA方法。我们改进了SOTA方法TIRG [23]以确保公平比较,并指出其局限性。