Gallery Filter Network for Person Search
用于行人搜索的图库过滤网络
Abstract
摘要
In person search, we aim to localize a query person from one scene in other gallery scenes. The cost of this search operation is dependent on the number of gallery scenes, making it beneficial to reduce the pool of likely scenes. We describe and demonstrate the Gallery Filter Network (GFN), a novel module which can efficiently discard gallery scenes from the search process, and benefit scoring for persons detected in remaining scenes. We show that the GFN is robust under a range of different conditions by testing on different retrieval sets, including cross-camera, occluded, and low-resolution scenarios. In addition, we develop the base SeqNeXt person search model, which improves and simplifies the original SeqNet model. We show that the SeqNeX $^{\cdot}+$ GFN combination yields significant performance gains over other state-of-the-art methods on the standard PRW and CUHK-SYSU person search datasets. To aid experi ment ation for this and other models, we provide standardized tooling for the data processing and evaluation pipeline typically used for person search research.
在行人搜索任务中,我们的目标是从一个场景中定位查询人物在其他图库场景中的位置。该搜索操作的成本取决于图库场景的数量,因此减少可能场景池的规模是有益的。我们提出并展示了图库过滤网络(Gallery Filter Network,GFN),这是一个新颖的模块,可以高效地从搜索过程中剔除图库场景,并提升在剩余场景中检测到的人物的评分。通过在不同检索集(包括跨摄像头、遮挡和低分辨率场景)上的测试,我们证明了GFN在一系列不同条件下都具有鲁棒性。此外,我们开发了基础的SeqNeXt行人搜索模型,该模型改进并简化了原始的SeqNet模型。我们展示了SeqNeXt$^{\cdot}+$GFN组合在标准PRW和CUHK-SYSU行人搜索数据集上的性能显著优于其他最先进的方法。为了支持该模型及其他模型的实验,我们提供了用于行人搜索研究的数据处理和评估流程的标准化工具。
1. Introduction
1. 引言
In the person search problem, a query person image crop is used to localize co-occurrences in a set of scene images, known as a gallery. The problem may be split into two parts: 1) person detection, in which all person bounding boxes are localized within each gallery scene and 2) person re-identification (re-id), in which detected gallery person crops are compared against a query person crop. Twostep person search methods [6,10,14,20,36,44] tackle each of these parts explicitly with separate models. In contrast, end-to-end person search methods [3–5, 7, 9, 13, 15, 19, 21, 22, 26, 29, 38–43, 45] use a single model, typically sharing backbone features for detection and re-identification.
在行人搜索问题中,查询图像裁剪区域用于定位一组场景图像(称为图库)中的共现目标。该问题可分为两部分:1) 行人检测,即在每个图库场景中定位所有行人边界框;2) 行人重识别(re-id),将检测到的图库行人裁剪区域与查询行人裁剪区域进行比对。两步式行人搜索方法 [6,10,14,20,36,44] 使用独立模型分别处理这两个部分。相比之下,端到端行人搜索方法 [3–5, 7, 9, 13, 15, 19, 21, 22, 26, 29, 38–43, 45] 采用单一模型,通常共享检测和重识别的骨干网络特征。
For both model types, the same steps are needed: 1) computation of detector backbone features, 2) detection of person bounding boxes, and 3) computation of feature embeddings for each bounding box, to be used for retrieval. Improvement of person search model efficiency is typically
对于两种模型类型,都需要执行相同的步骤:1) 计算检测器主干特征,2) 检测人物边界框,3) 为每个边界框计算特征嵌入以用于检索。提升人物搜索模型效率通常
1b. Query-scene scores are computed using cosine similarity of extracted embeddings.
1b. 查询场景分数通过提取嵌入向量的余弦相似度计算。
2a. Detection is performed on highscoring scenes.
2a. 检测在高分场景中进行。
2b. Embeddings are extracted from detected boxes.
2b. 从检测到的边界框中提取嵌入向量 (embeddings)。
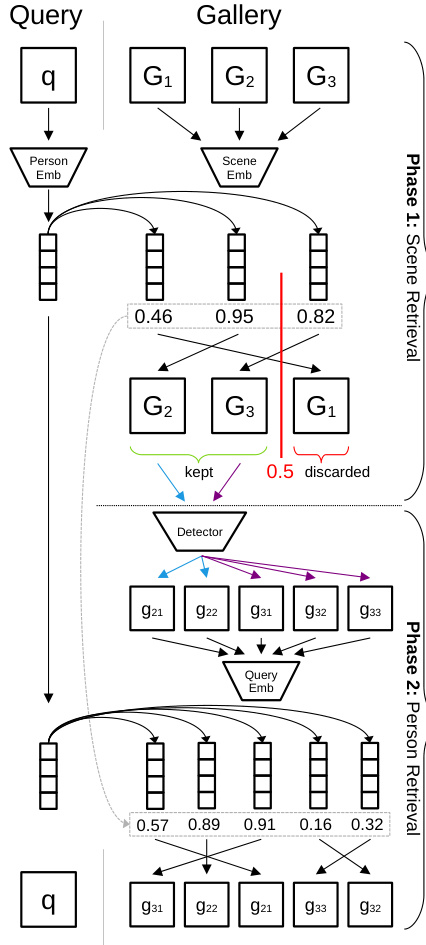
1a. Person and scene embeddings are extracted using embedding (Emb) modules. 1c. Using a hard threshold, low-scoring scenes are discarded: no need to perform detection. 2c. Query-detect similarity scores are computed and combined with queryscene scores. 2d. Combined scores are sorted to determine final ranking. Figure 1: An illustration of our proposed two-phase retrieval inference pipeline. In the first phase, the Gallery Filter Network discards scenes unlikely to contain the query person. The second phase is the standard person retrieval process, in which persons are detected, corresponding embeddings extracted, and these embeddings are compared to the query to produce a ranking.
图 1: 我们提出的两阶段检索推理流程示意图。第一阶段,Gallery Filter Network 会过滤掉不太可能包含查询人物的场景。第二阶段是标准的人物检索流程,包括人物检测、对应嵌入向量的提取,以及这些嵌入向量与查询的比对以生成排名。
1a. 使用嵌入 (Emb) 模块提取人物和场景的嵌入向量。
1c. 通过硬阈值过滤低分场景:无需执行检测。
2c. 计算查询-检测相似度分数,并与查询-场景分数结合。
2d. 对综合分数排序以确定最终排名。
focused on reducing the cost of one or more of these steps. We propose the second and third steps can be avoided altogether for some subset of gallery scenes by splitting the retrieval process into two phases: scene retrieval, followed by typical person retrieval. This two-phase process is visualized in Figure 1. We call the module implementing scene retrieval the Gallery Filter Network (GFN), since its function is to filter scenes from the gallery.
我们致力于降低其中一步或多步的成本。针对部分场景库子集,我们提出可完全跳过第二和第三步,将检索过程分为两个阶段:场景检索,随后是常规的人物检索。图 1 展示了这一两阶段流程。我们将实现场景检索的模块称为场景库过滤网络 (Gallery Filter Network, GFN) ,因其功能是从场景库中筛选场景。
By performing the cheaper query-scene comparison before detection is needed, the GFN allows for a modular computational pipeline for practical systems, in which one process can determine which scenes are of interest, and another can detect and extract person embeddings only for interesting scenes. This could serve as an efficient filter for video frames in a high frame rate context, or to cheaply reduce the search space when querying large image databases.
通过在执行检测前进行成本较低的查询-场景比对,GFN为实际系统提供了一种模块化计算流程:一个流程可确定哪些场景值得关注,另一个流程则仅针对这些关键场景进行人物嵌入向量的检测与提取。该机制可作为高帧率视频场景下的高效筛选方案,或在查询大型图像数据库时低成本地缩减搜索空间。
The GFN also provides a mechanism to incorporate global context into the gallery ranking process. Instead of combining global context features with intermediate model features as in [10, 21], we explicitly compare global scene embeddings to query embeddings. The resulting score can be used not only to filter out gallery scenes using a hard threshold, but also to weight predicted box scores for remaining scenes.
GFN还提供了一种将全局上下文整合到图库排序流程中的机制。不同于[10, 21]中将全局上下文特征与中间模型特征相结合的做法,我们显式地将全局场景嵌入(embedding)与查询嵌入进行比对。生成的分数不仅能通过硬阈值过滤图库场景,还可用于对剩余场景的预测框分数进行加权。
We show that both the hard-threshold ing and scoreweighting mechanisms are effective for the benchmark PRW and CUHK-SYSU datasets, resulting in state-of-theart retrieval performance $(+2.7%$ top-1 accuracy on the PRW dataset over previous best model), with improved efficiency (over $50%$ per-query cost savings on the CUHKSYSU dataset vs. same model without the GFN). Additionally, we make contributions to the data processing and evaluation frameworks that are used by most person search methods with publicly available code. That work is described in Supplementary Material Section A.
我们证明,硬阈值和分数加权机制在基准PRW和CUHK-SYSU数据集上均有效,实现了最先进的检索性能(PRW数据集的top-1准确率比之前最佳模型提升+2.7%),同时提高了效率(CUHK-SYSU数据集上每个查询成本比未使用GFN的相同模型节省超过50%)。此外,我们对多数采用公开代码的行人搜索方法所使用的数据处理和评估框架做出了改进,相关细节见补充材料A节。
1.1. Contributions
1.1. 贡献
Our contributions are as follows:
我们的贡献如下:
All of our code and model configurations are made publicly available1.
我们所有的代码和模型配置均已公开1。
2. Related Work
2. 相关工作
Person Search. Beginning with the release of two benchmark person search datasets, PRW [44] and CUHK-SYSU [39], there has been continual development of new deep learning models for person search. Most methods utilize the Online Instance Matching (OIM) Loss from [39] for the re-id feature learning objective. Several methods [21,40,43] enhance this objective using variations of a triplet loss [33].
人物搜索。随着PRW [44]和CUHK-SYSU [39]两个基准人物搜索数据集的发布,针对人物搜索的新深度学习模型不断发展。大多数方法采用[39]提出的在线实例匹配(OIM)损失函数作为重识别特征学习目标。部分方法[21,40,43]通过改进三元组损失[33]的变体来增强这一目标。
Many methods make modifications to the object detection sub-module. In [3, 21, 40], a variation of the Feature Pyramid Network (FPN) [24] is used to produce multi-scale feature maps for detection and re-id. Models in [3, 40] are based on the Fully-Convolutional One-Stage (FCOS) detector [34]. In COAT [42], a Cascade R-CNN-style [2] transformer-augmented [35] detector is used to refine box predictions. We use a variation of the single-scale two-stage Faster R-CNN [31] approach from the SeqNet model [22]. Query-Based Search Space Reduction. In [4, 26], query information is used to iterative ly refine the search space within a gallery scene until the query person is localized. In [10], Region Proposal Network (RPN) proposals are filtered by similarity to the query, reducing the number of proposals for expensive RoI-Pooled feature computations. Our method uses query features to perform a coarser-grained but more efficient search space reduction by filtering out full scenes before expensive detector features are computed.
许多方法对目标检测子模块进行了改进。在[3, 21, 40]中,使用了一种改进的特征金字塔网络(FPN)[24]来生成用于检测和重识别的多尺度特征图。[3, 40]中的模型基于全卷积单阶段(FCOS)检测器[34]。COAT[42]采用级联R-CNN风格[2]的Transformer增强[35]检测器来优化边界框预测。我们使用来自SeqNet模型[22]的单尺度两阶段Faster R-CNN[31]方法的改进版本。
基于查询的搜索空间缩减。在[4, 26]中,查询信息被用于迭代优化图库场景内的搜索空间,直到定位到查询目标。[10]中通过查询相似性过滤区域提议网络(RPN)生成的提议,减少了需要昂贵RoI池化特征计算的提议数量。我们的方法使用查询特征进行更粗粒度但更高效的搜索空间缩减,即在计算昂贵的检测器特征之前过滤掉整个场景。
Query-Scene Prediction. In the Instance Guided Proposal Network (IGPN) [10], a global relation branch is used for binary prediction of query presence in a scene image. This is similar in principal to the GFN prediction, but it is done using expensive intermediate query-scene features, in contrast to our cheaper modular approach to the task.
查询场景预测。在实例引导提案网络 (IGPN) [10] 中,全局关系分支用于对场景图像中查询存在的二元预测。这与 GFN 预测在原理上类似,但它是通过昂贵的中间查询-场景特征完成的,相比之下,我们对该任务采用了成本更低的模块化方法。
Backbone Variation. While the original ResNet50 [17] backbone used in SeqNet and most other person search models has been effective to date, many newer architectures have since been introduced. With the recent advent of vision transformers (ViT) [11] and a cascade of improvements including the Swin Transformer [27] and the Pyramid Vision Transformer (v2) [37], used by the PSTR person search model [3], transformer-based feature extraction has increased in popularity. However, there is still an efficiency gap with CNN models, and newer CNNs including ConvNeXt [28] have closed the performance gap with ViT-based models, while retaining the inherent efficiency of convolutional layers. For this reason, we explore ConvNeXt for our model backbone as an improvement to ResNet50, which is more efficient than ViT alternatives.
主干网络变体。尽管SeqNet和大多数其他行人搜索模型最初采用的ResNet50 [17] 主干网络至今仍表现优异,但近年来涌现了许多新架构。随着视觉Transformer (ViT) [11] 的兴起,以及Swin Transformer [27]、金字塔视觉Transformer (v2) [37](被PSTR行人搜索模型 [3] 采用)等系列改进,基于Transformer的特征提取方法日益流行。然而其效率仍落后于CNN模型,而ConvNeXt [28] 等新型CNN在保持卷积层固有效率的同时,已缩小了与ViT模型的性能差距。因此,我们选择ConvNeXt作为模型主干网络来替代ResNet50,这比ViT方案更具效率优势。
3. Methods
3. 方法
3.1. Base Model
3.1. 基础模型
Our base person search model is an end-to-end architecture based on SeqNet [22]. We make modifications to the model backbone, simplify the two-stage detection pipeline, and improve the training recipe, resulting in superior performance. Since the model inherits heavily from SeqNet, and uses a ConvNeXt base, we refer to it simply as SeqNeXt to distinguish it from the original model. Our model, combined with the GFN module, is shown in Figure 2.
我们的基础人物搜索模型是基于SeqNet [22]的端到端架构。我们对模型主干进行了修改,简化了两阶段检测流程,并改进了训练方案,从而实现了更优的性能。由于该模型在很大程度上继承了SeqNet,并使用了ConvNeXt基础架构,我们将其简称为SeqNeXt以区别于原始模型。结合GFN模块的模型如图2所示。
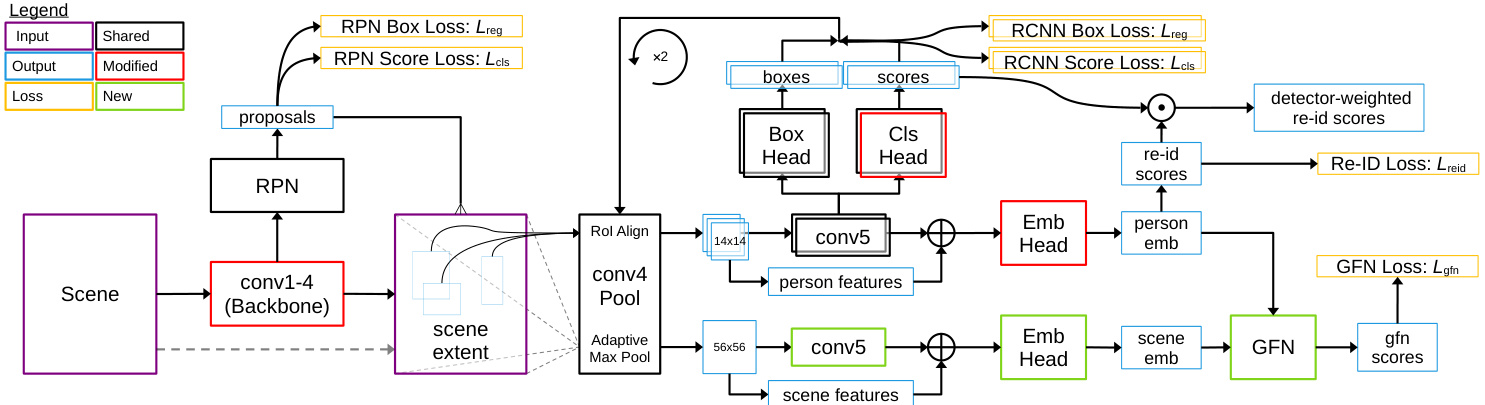
Figure 2: Architecture of the SeqNeXt person search model augmented with the GFN. Modules modified from SeqNet are colored red, and new modules, related to the GFN, are colored green. The model follows the standard Faster R-CNN paradigm, with backbone features from conv4 being used to generate proposals via the RPN. conv4 features are pooled for RPN proposals and passed through the conv5 head to generate refined proposals. This process is repeated with the refined proposals to generate the final boxes. conv4 features are also used to generate both person embeddings and scene embeddings in the same way: the person box or scene passes through the pooling block and then a duplicated conv5 head, and conv4, conv5 features are concatenated and passed through an embedding (Emb) head. In the pooling block, RoI Align [16] is used for person and proposal features, while adaptive max pooling is used for scene features. GFN scores are generated using person and scene embeddings from the same or different scenes. Person re-id scores are combined with the score output of the second R-CNN stage to produce detector-weighted scores.
图 2: 采用GFN增强的SeqNeXt人员搜索模型架构。从SeqNet修改的模块标为红色,与GFN相关的新模块标为绿色。该模型遵循标准Faster R-CNN范式,使用conv4的主干特征通过RPN生成候选框。对RPN候选框进行conv4特征池化后,经conv5头部生成优化候选框。该过程在优化候选框上重复以生成最终检测框。conv4特征还以相同方式生成人员嵌入和场景嵌入:人员框或场景通过池化块后,经复制的conv5头部处理,最终将conv4和conv5特征拼接并通过嵌入(Emb)头部。池化块中,人员及候选框特征采用RoI Align [16],场景特征采用自适应最大池化。GFN分数通过同场景或跨场景的人员与场景嵌入生成。人员重识别分数与第二阶段R-CNN的输出分数结合,形成检测器加权分数。
Backbone Features. Following SeqNet’s usage of the first four CNN blocks (conv1-4) from ResNet50 for backbone features, we use the analogous layers in terms of downsampling from ConvNeXt, also referred to as conv1-4 for convenience.
骨干特征。遵循SeqNet使用ResNet50前四个CNN块(conv1-4)作为骨干特征的做法,我们采用ConvNeXt中具有相同下采样层级的对应层,为方便起见同样称为conv1-4。
Multi-Stage Refinement and Inference. We simplify the detection pipeline of SeqNet by duplicating the Faster RCNN head [31] in place of the Norm-Aware Embedding (NAE) head from [7]. We still weight person similarity scores using the output of the detector, but use the secondstage class score instead of the first-stage as in SeqNet. This is depicted in Figure 2 as “detector-weighted re-id scores”.
多阶段优化与推理。我们通过用 Faster RCNN 头 [31] 复制替换 [7] 中的 Norm-Aware Embedding (NAE) 头,简化了 SeqNet 的检测流程。虽然仍使用检测器输出对行人相似度得分进行加权,但采用第二阶段的类别分数而非 SeqNet 使用的第一阶段分数。如图 2 所示,这部分标记为"检测器加权重识别分数"。
Additionally during inference, we do not use the Context Bipartite Graph Matching (CBGM) algorithm from SeqNet, discussed in Supplementary Material Section E.
此外在推理过程中,我们未使用SeqNet中提出的上下文二分图匹配 (CBGM) 算法,该算法在补充材料E节中有讨论。
Augmentation. Following resizing images to $900\times1500$ (Window Resize) at training time, we employ one of two random cropping methods with equal probability: 1) Random Focused Crop (RFC): randomly take a $512\times512$ crop in the original image resolution which contains at least one known person, 2) Random Safe Crop (RSC): randomly crop the image such that all persons are contained, then resize to $512\times512$ . This cropping strategy allowed us to train with larger batch sizes, while benefiting performance with improved regular iz ation. At inference time, we resize to $900\times1500$ , as in other models. We also consider a variant of Random Focused Crop (RFC2), which resizes images so the “focused” person box is not clipped.
增强。在训练时将图像尺寸调整为$900\times1500$(窗口调整)后,我们以同等概率采用两种随机裁剪方法之一:1) 随机聚焦裁剪 (RFC):在原始图像分辨率中随机截取一个包含至少一个已知人物的$512\times512$区域;2) 随机安全裁剪 (RSC):随机裁剪图像以确保包含所有人物,然后调整至$512\times512$。这种裁剪策略使我们能够以更大的批量进行训练,同时通过改进的正则化提升性能。推理时与其他模型一致,我们将尺寸调整为$900\times1500$。我们还考虑了随机聚焦裁剪的变体 (RFC2),该方式会调整图像尺寸以避免"聚焦"人物框被裁剪。
Objective. As in other person search models, we employ the Online Instance Matching (OIM) Loss [39], represented as $\mathcal{L}_{\mathrm{reid}}$ . This is visualized in Figure 3a. For all diagrams in Figure 3, we borrow from the spring analogy for metric learning used in DrLIM [12], with the concept of attractions and repulsions.
目标。与其他行人搜索模型类似,我们采用在线实例匹配(Online Instance Matching,OIM)损失函数 [39],表示为$\mathcal{L}_{\mathrm{reid}}$。如图3a所示。对于图3中的所有示意图,我们借鉴了DrLIM [12]中用于度量学习的弹簧类比概念,包含吸引力和排斥力。
The full loss is the sum of the detector, re-id, and GFN losses:
总损失是检测器损失、重识别损失和GFN损失之和:
$$
{\mathcal{L}}={\mathcal{L}}{\mathrm{det}}+{\mathcal{L}}{\mathrm{reid}}+{\mathcal{L}}_{\mathrm{gfn}}
$$
$$
{\mathcal{L}}={\mathcal{L}}{\mathrm{det}}+{\mathcal{L}}{\mathrm{reid}}+{\mathcal{L}}_{\mathrm{gfn}}
$$
3.2. Gallery Filter Network
3.2. 图库过滤网络 (Gallery Filter Network)
Our goal is to design a module which removes lowscoring scenes, and reweights boxes from higher-scoring scenes. Let $s_{\mathrm{reid}}$ be the cosine similarity of a predicted gallery box embedding with the query embedding, $s_{\mathrm{det}}$ be the detector box score, $s_{\mathrm{gfn}}$ be the cosine similarity for the corresponding gallery scene from the GFN, $\begin{array}{r}{\sigma(x)=\frac{e^{-x}}{1+e^{-x}}}\end{array}$ $\alpha$ be a temperature constant, and $\lambda_{\mathrm{gfn}}$ be the GFN score threshold. At inference time, scenes scoring below $\lambda_{\mathrm{gfn}}$ are removed, and detection is performed for remaining scenes, with the final score for detected boxes given by $s_{\mathrm{final}}=s_{\mathrm{reid}}\cdot s_{\mathrm{det}}\cdot\sigma(s_{\mathrm{gfn}}/\alpha)$ .
我们的目标是设计一个模块,用于移除低分场景并重新加权高分场景的检测框。设 $s_{\mathrm{reid}}$ 为预测图库框嵌入与查询嵌入的余弦相似度,$s_{\mathrm{det}}$ 为检测器框得分,$s_{\mathrm{gfn}}$ 为GFN对应图库场景的余弦相似度,$\begin{array}{r}{\sigma(x)=\frac{e^{-x}}{1+e^{-x}}}\end{array}$,$\alpha$ 为温度常数,$\lambda_{\mathrm{gfn}}$ 为GFN得分阈值。在推理阶段,得分低于 $\lambda_{\mathrm{gfn}}$ 的场景将被移除,并对剩余场景执行检测,最终检测框得分由 $s_{\mathrm{final}}=s_{\mathrm{reid}}\cdot s_{\mathrm{det}}\cdot\sigma(s_{\mathrm{gfn}}/\alpha)$ 计算得出。
The module should discriminate as many scenes below $\lambda_{\mathrm{gfn}}$ as possible, while positively impacting the scores of boxes from any remaining scenes. To this end, we consider three variations of the standard contrastive objective [8, 30] in Sections 3.2.1-3.2.3, in addition to a number of architectural and optimization considerations in Section 3.2.4.
该模块应尽可能区分低于 $\lambda_{\mathrm{gfn}}$ 的场景,同时对剩余场景中检测框的得分产生积极影响。为此,我们在第3.2.1-3.2.3节中考虑了标准对比目标 [8, 30] 的三种变体,并在第3.2.4节中讨论了若干架构和优化方面的考量。
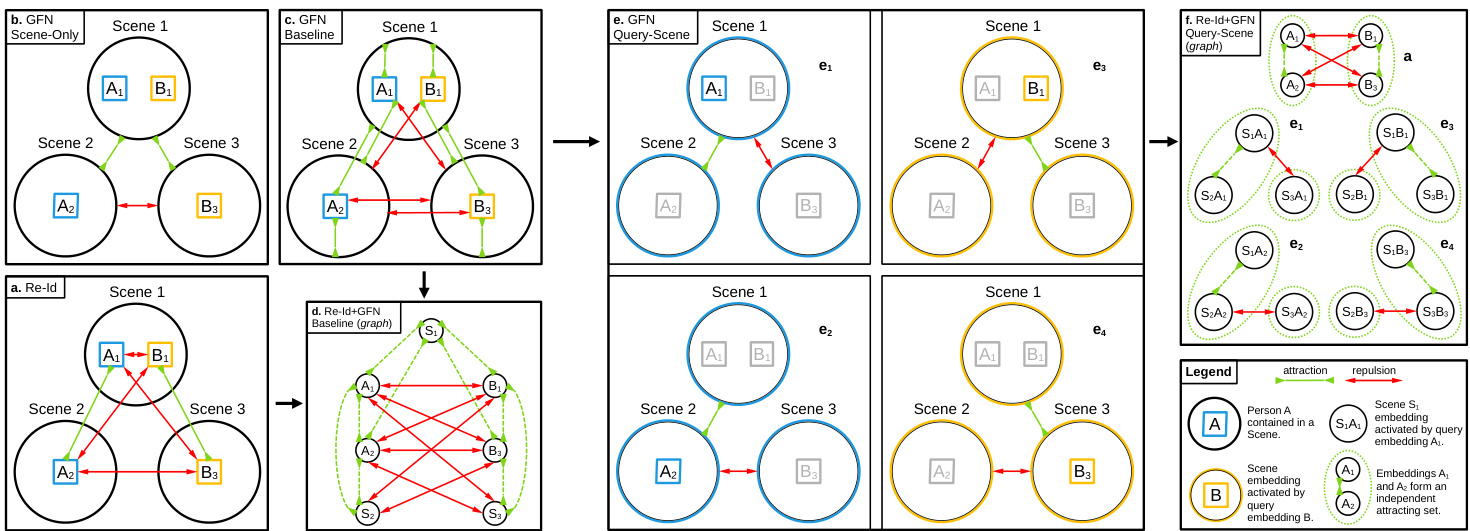
Figure 3: Visual representation of the re-id and GFN optimization objectives. In a), b), c), e), circles represent scene images which contain one or more different person identities, labeled A and B. We show a system of three scenes with two unique person identities. Green connectors represent attraction, meaning two embeddings are pushed together by an objective, and red connectors represent repulsion, meaning two embeddings are pulled apart by an objective. In a) we show the standard re-id loss objective. In b) we show the scene-only GFN objective. In c) we show the baseline GFN objective, and in e) we show the combined query-scene GFN objective. In d) we show the graph form of the baseline GFN objective and re-id objective together, and in f) we show the graph form of the combined query-scene GFN objective and re-id objective together, with green ellipses surrounding independent sets in each multi part it e component.
图 3: 重识别(re-id)与图因子网络(GFN)优化目标的视觉表示。a) b) c) e)中的圆圈代表包含一个或多个不同人员身份(标记为A和B)的场景图像,展示了包含两个独特人员身份的三种场景系统。绿色连接线表示吸引力(即两个嵌入向量被目标函数拉近),红色连接线表示排斥力(即两个嵌入向量被目标函数推远)。a)展示了标准重识别损失目标;b)展示了仅场景的GFN目标;c)展示了基线GFN目标;e)展示了查询-场景联合GFN目标。d)以图形式展示了基线GFN目标与重识别目标的组合;f)以图形式展示了查询-场景联合GFN目标与重识别目标的组合,其中绿色椭圆包围了每个多部件独立集。
3.2.1 Baseline Objective
3.2.1 基线目标
The goal of the baseline GFN optimization is to push person embeddings toward scene embeddings when a person is contained within a scene, and to pull them apart when the person is not in the scene, shown in Figure 3c.
基线GFN优化的目标是当人物处于场景中时,将人物嵌入向量推向场景嵌入向量,当人物不在场景中时则将两者分离,如图3c所示。
Let $x_{i}\in\mathbb{R}^{d}$ denote the embedding extracted from person $q_{i}$ located in some scene $s_{j}$ . Let $y_{j}\in\mathbb{R}^{d}$ denote the embedding extracted from scene $s_{j}$ . Let $X$ be the set of all person embeddings $x_{i}$ , and $Y$ the set of all scene embeddings $y_{j}$ , with $N=|X|,M=|Y|$ .
设 $x_{i}\in\mathbb{R}^{d}$ 表示从位于场景 $s_{j}$ 中的人物 $q_{i}$ 提取的嵌入向量,$y_{j}\in\mathbb{R}^{d}$ 表示从场景 $s_{j}$ 提取的嵌入向量。设 $X$ 为所有人物嵌入向量 $x_{i}$ 的集合,$Y$ 为所有场景嵌入向量 $y_{j}$ 的集合,其中 $N=|X|,M=|Y|$。
We define the query-scene indicator function to denote positive query-scene pairs as
我们定义查询场景指示函数来表示正查询场景对为
We then define a set to denote indices for a specific positive pair and all negative pairs:
然后我们定义一个集合来表示特定正样本对和所有负样本对的索引:
$\bar{K_{i,j}^{Q}}\hat{=}{k~\in1,\bar{}\hat{}\cdot\cdot,\bar{M}|k~=~j$ or $\mathcal{I}_{i,j}^{Q}=0}$ . Define $\sin(u,v)=u^{\top}v/|u||v|$ , the cosine similarity between two $u,v\in\mathbb{R}^{d}$ , and $\tau$ is a temperature constant. Then the loss for a positive query-scene pair is the cross-entropy loss
$\bar{K_{i,j}^{Q}}\hat{=}{k~\in1,\bar{}\hat{}\cdot\cdot,\bar{M}|k~=~j$ 或 $\mathcal{I}_{i,j}^{Q}=0}$。定义 $\sin(u,v)=u^{\top}v/|u||v|$ 为两个向量 $u,v\in\mathbb{R}^{d}$ 的余弦相似度,$\tau$ 为温度常数。正查询-场景对的损失函数采用交叉熵损失。
$$
\ell_{i,j}^{Q}=-\log\frac{\exp{(\sin(x_{i},y_{j})/\tau)}}{\sum_{k\in K_{i,j}^{Q}}\exp{(\sin(x_{i},y_{k})/\tau)}}
$$
$$
\ell_{i,j}^{Q}=-\log\frac{\exp{(\sin(x_{i},y_{j})/\tau)}}{\sum_{k\in K_{i,j}^{Q}}\exp{(\sin(x_{i},y_{k})/\tau)}}
$$
The baseline Gallery Filter Network loss sums positive pair losses over all query-scene pairs:
基线 Gallery Filter Network 损失对所有查询-场景对的正样本对损失求和:
$$
\mathcal{L}{\mathrm{gfn}}^{Q}=\sum_{i=1}^{N}\sum_{j=1}^{M}\mathcal{I}{i,j}^{Q}\ell_{i,j}^{Q}
$$
$$
\mathcal{L}{\mathrm{gfn}}^{Q}=\sum_{i=1}^{N}\sum_{j=1}^{M}\mathcal{I}{i,j}^{Q}\ell_{i,j}^{Q}
$$
3.2.2 Combined Query-Scene Objective
3.2.2 联合查询-场景目标
While it is possible to train the GFN directly with person and scene embeddings using the loss in Equation 5, we show that this objective is ill-posed without modification. The problem is that we have constructed a system of opposing attractions and repulsions. We can formalize this concept by interpreting the system as a graph $G(V,E)$ , visualized in Figure 3d. Let the vertices $V$ correspond to person, scene, and/or combined person-scene embeddings, where an edge in $E$ (red arrow) connecting any two nodes in $V$ represents a negative pair used in the optimization objective. Let any group of nodes connected by green dashed arrows (not edges in $G$ ) be an independent set, representing positive pairs in the optimization objective. Then, each connected component of $G$ must be multi part it e, or the optimization problem will be ill-posed by design, as in the baseline objective.
虽然可以直接使用方程5中的损失函数来训练GFN(Generative Flow Network)与人物和场景嵌入,但我们证明这一目标若不经过修改是不适定的。问题在于我们构建了一个包含相互对立吸引力和排斥力的系统。我们可以通过将该系统解释为图$G(V,E)$(如图3d所示)来形式化这一概念。设顶点$V$对应人物、场景和/或组合的人物-场景嵌入,其中$E$中的边(红色箭头)连接$V$中的任意两个节点,代表优化目标中的负样本对。设任何由绿色虚线箭头连接的节点组(非$G$中的边)为一个独立集,代表优化目标中的正样本对。那么,$G$的每个连通分量必须是多部图,否则优化问题将因设计而成为不适定问题,如基线目标所示。
To learn whether a person is contained within a scene while preventing this conflict of attractions and repulsions, we need to apply some unique transformation to query and scene embeddings before the optimization. One such option is to combine a query person embedding separately with the query scene and gallery scene embeddings to produce fused representations. This allows us to disentangle the web of interactions between query and scene embeddings, while still learning the desired relationship, visualized in Figure 3e. The person embedding used to fuse with each scene embedding in a pair is left colored, and the corresponding scenes are colored according to that person embedding. Person embeddings present in scenes which are not used are grayed out.
为了判断一个人是否包含在场景中,同时避免吸引与排斥的冲突,我们需要在优化前对查询和场景嵌入(embedding)应用独特的变换。一种可行方案是将查询人物嵌入分别与查询场景及图库场景嵌入结合,生成融合表征。这种方法能解耦查询与场景嵌入间的复杂交互网络,同时仍能学习目标关联关系(如图3e所示)。用于与每对场景嵌入融合的人物嵌入保留原色显示,对应场景则根据该人物嵌入着色。未使用的人物嵌入在场景中以灰色显示。
In the graph-based presentation, shown in Figure 3f, this modified scheme using query-scene embeddings will always result in a graph comprising some number of star graph connected components. Since these star graph components are multi part it e by design, the issue of conflicting attractions and repulsions is avoided.
在图 3f 所示的基于图的表示中,这种使用查询场景嵌入 (query-scene embeddings) 的改进方案总会生成由若干星图连通分量组成的图。由于这些星图分量在设计上就是多部分的,因此避免了吸引和排斥冲突的问题。
To combine a query and scene embedding into a single query-scene embedding, we define a function $f:\mathbb{R}^{d},\mathbb{R}^{d}\rightarrow$ $\mathbb{R}^{d}$ , such that $z_{i,j}=f(x_{i},y_{j})$ and $w_{i}=f(x_{i},y^{x_{i}})$ , where $y^{x_{i}}$ is the embedding of the scene that person $i$ is present in. Borrowing from SENet [18] and QEEPS [29], we choose a sigmoid-activated element wise excitation, with $\odot$ used for element wise product. “BN” is a Batch Normalization layer, to mirror the architecture of the other embedding heads, and $\beta$ is a temperature constant.
为了将查询和场景嵌入结合成单一的查询-场景嵌入,我们定义了一个函数 $f:\mathbb{R}^{d},\mathbb{R}^{d}\rightarrow$ $\mathbb{R}^{d}$,使得 $z_{i,j}=f(x_{i},y_{j})$ 且 $w_{i}=f(x_{i},y^{x_{i}})$,其中 $y^{x_{i}}$ 表示人物 $i$ 所在场景的嵌入。借鉴 SENet [18] 和 QEEPS [29] 的设计,我们选择了经过 sigmoid 激活的逐元素激励机制,并用 $\odot$ 表示逐元素乘积。“BN” 是一个批归一化层,以匹配其他嵌入头的架构,$\beta$ 为温度常数。
$$
f(x,y)=\mathtt{B N}(\sigma(x/\beta)\odot y)
$$
$$
f(x,y)=\mathtt{B N}(\sigma(x/\beta)\odot y)
$$
Other choices are possible for $f$ , but the element wiseproduct is critical, because it excites the features most relevant to a given query within a scene, eliciting the relationship shown in Figure 3e.
对于函数 $f$ 还有其他选择,但逐元素乘积(element wise product)是关键,因为它能激发场景中与给定查询最相关的特征,从而引出图 3e 所示的关系。
The loss for a positive query-scene pair is the crossentropy loss
正查询-场景对的损失是交叉熵损失
$$
\ell_{i,j}^{C}=-\log\frac{\exp{(\sin(w_{i},z_{i,j})/\tau)}}{\sum_{k\in K_{i,j}^{Q}}\exp{(\sin(w_{i},z_{i,k})/\tau)}}
$$
$$
\ell_{i,j}^{C}=-\log\frac{\exp{(\sin(w_{i},z_{i,j})/\tau)}}{\sum_{k\in K_{i,j}^{Q}}\exp{(\sin(w_{i},z_{i,k})/\tau)}}
$$
The query-scene combined Gallery Filter Network loss sums positive pair losses over all query-scene pairs:
查询-场景组合图库过滤网络损失对所有查询-场景正样本对的损失求和:
$$
\mathcal{L}{\mathrm{gfn}}^{C}=\sum_{i=1}^{N}\sum_{j=1}^{M}\mathcal{I}{i,j}^{Q}\ell_{i,j}^{C}
$$
$$
\mathcal{L}{\mathrm{gfn}}^{C}=\sum_{i=1}^{N}\sum_{j=1}^{M}\mathcal{I}{i,j}^{Q}\ell_{i,j}^{C}
$$
3.2.3 Scene-Only Objective
3.2.3 仅场景目标
As a control for the query-scene objective, we also define a simpler objective which uses scene embeddings only, depicted in Figure 3b. This objective attempts to learn the less disc rim i native concept of whether two scenes share any persons in common, and has the same optimization issue of conflicting attractions and repulsions as the baseline objective. At inference time, it is used in the same way as the other GFN methods.
作为查询-场景目标的对照,我们还定义了一个仅使用场景嵌入的简化目标,如图 3b 所示。该目标试图学习两个场景是否共享任何共同人物的区分性较低的概念,并且与基线目标存在相同的吸引力和排斥力冲突优化问题。在推理时,其使用方式与其他 GFN 方法相同。
We define the scene-scene indicator function to denote positive scene-scene pairs as
我们定义场景-场景指示函数来表示正例场景-场景对
Similar to Section 3.2.1, we define an index set: $K_{i,j}^{S}={k\in1,\ldots,M|k=j$ or $\mathcal{I}_{i,j}^{S}=0}$ . Then the loss for a positive scene-scene pair is the cross-entropy loss
与第3.2.1节类似,我们定义一个索引集:$K_{i,j}^{S}={k\in1,\ldots,M|k=j$ 或 $\mathcal{I}_{i,j}^{S}=0}$。正样本场景对的损失为交叉熵损失
$$
\ell_{i,j}^{S}=-\log\frac{\exp{(\sin(y_{i},y_{j})/\tau)}}{\sum_{k\in K_{i,j}^{S}}\exp{(\sin(y_{i},y_{k})/\tau)}}
$$
$$
\ell_{i,j}^{S}=-\log\frac{\exp{(\sin(y_{i},y_{j})/\tau)}}{\sum_{k\in K_{i,j}^{S}}\exp{(\sin(y_{i},y_{k})/\tau)}}
$$
The scene-only Gallery Filter Network loss sums positive pair losses over all scene-scene pairs:
场景专用图库过滤网络损失将所有场景-场景配对的正样本损失相加:
$$
\mathcal{L}{\mathrm{gfn}}^{S}=\sum_{i=1}^{M}\sum_{j=1}^{M}[i\neq j]\mathcal{L}{i,j}^{S}\ell_{i,j}^{S}
$$
$$
\mathcal{L}{\mathrm{gfn}}^{S}=\sum_{i=1}^{M}\sum_{j=1}^{M}[i\neq j]\mathcal{L}{i,j}^{S}\ell_{i,j}^{S}
$$
where $[i\neq j]$ is 1 if $i\neq j$ else 0.
其中 $[i\neq j]$ 在 $i\neq j$ 时为 1,否则为 0。
3.2.4 Architecture and Optimization
3.2.4 架构与优化
We consider a number of design choices for the architecture and optimization strategy of the GFN to improve its performance.
我们考虑了GFN架构和优化策略的多种设计选择以提升其性能。
Architecture. Scene embeddings are extracted in the same way as person embeddings, except that a larger $56\times56$ pooling size with adaptive max pooling is used vs. the person pooling size of $14\times14$ with RoI Align. This larger scene pooling size is needed to adequately summarize scene information, since the scene extent is much larger than a typical person bounding box. In addition, the scene conv5 head and Emb Head are duplicated from the corresponding person modules (no weight-sharing), shown in Figure 2.
架构。场景嵌入的提取方式与人物嵌入相同,只是采用了更大的 $56\times56$ 自适应最大池化尺寸(相比人物检测使用的 $14\times14$ RoI Align 池化尺寸)。由于场景范围远大于典型的人物检测框,需要更大的池化尺寸来充分概括场景信息。此外,场景卷积头(conv5 head)和嵌入头(Emb Head)是从对应的人物模块复制而来(不共享权重),如图 2 所示。
Lookup Table. Similar to the methodology used for the OIM objective [39], we use a lookup table (LUT) to store scene and person embeddings from previous batches, refreshing the LUT fully during each epoch. We compare the person and scene embeddings in each batch, which have gradients, with some subset of the embeddings in the LUT, which do not have gradients. Therefore only comparisons of embeddings within the batch, or between the batch and the LUT, have gradients.
查找表 (Lookup Table)。与OIM目标[39]所采用的方法类似,我们使用查找表(LUT)存储来自先前批次的场景和人物嵌入,并在每个训练周期完全刷新该表。我们将每个批次中带有梯度的人物和场景嵌入,与查找表中不带梯度的部分嵌入子集进行对比。因此,只有批次内部的嵌入比较,或批次与查找表之间的嵌入比较会产生梯度。
Query Prototype Embeddings. Rather than using person embeddings directly from a given batch, we can use the identity prototype embeddings stored in the OIM LUT, similar to [19]. To do so, we lookup the corresponding identity for a given batch person identity in the OIM LUT during training, and substitute that into the objective. In doing so, we discard gradients from batch person embeddings, meaning that we only pass gradients through scene embeddings, and therefore only update the scene embedding module. This choice is examined in an ablation in Section 4.4.
查询原型嵌入。与直接使用给定批次中的人物嵌入不同,我们可以采用类似[19]的方法,使用存储在OIM查找表(OIM LUT)中的身份原型嵌入。具体而言,在训练过程中,我们会根据批次人物身份从OIM查找表中检索对应的身份嵌入,并将其代入目标函数。通过这种方式,我们舍弃了来自批次人物嵌入的梯度,意味着仅通过场景嵌入传递梯度,因此只更新场景嵌入模块。第4.4节的消融实验将验证这一选择。
4. Experiments and Analysis
4. 实验与分析
4.1. Datasets and Evaluation
4.1. 数据集与评估
Datasets. For our experiments, we use the two standard person search datasets, CUHK-SYSU [39], and Person Reidentification in the Wild (PRW) [44]. CUHK-SYSU comprises a mixture of imagery from hand-held cameras, and shots from movies and TV shows, resulting in significant visual diversity. It contains 18,184 scene images annotated with 96,143 person bounding boxes from tracked (known) and untracked (unknown) persons, with 8,432 known identities. PRW comprises video frames from six surveillance cameras at Tsinghua University in Hong Kong. It contains 11,816 scene images annotated with 43,110 person bounding boxes from known and unknown persons, with 932 known identities.
数据集。我们实验采用两个标准人物搜索数据集:CUHK-SYSU [39] 和野外行人重识别(PRW) [44]。CUHK-SYSU包含手持摄像机拍摄的图像以及影视剧截图,具有显著的视觉多样性。该数据集包含18,184张场景图像,标注了来自追踪(已知)和未追踪(未知)人物的96,143个行人边界框,涵盖8,432个已知身份。PRW数据集由香港清华大学六台监控摄像头采集的视频帧组成,包含11,816张场景图像,标注了来自已知和未知人物的43,110个行人边界框,涵盖932个已知身份。
The standard test retrieval partition for the CUHK-SYSU dataset has 2,900 query persons, with a gallery size of 100 scenes per query. The standard test retrieval partition for the PRW dataset has 2,057 query persons, and uses all 6,112 test scenes in the gallery, excluding the identity. For a more robust analysis, we additionally divide the given train set into separate train and validation sets, further discussed in Supplementary Material Section A.
CUHK-SYSU数据集的标准测试检索分区包含2,900个查询人物,每个查询对应的图库规模为100个场景。PRW数据集的标准测试检索分区包含2,057个查询人物,并使用图库中全部6,112个测试场景(排除身份信息)。为进行更稳健的分析,我们还将给定训练集划分为独立的训练集和验证集,具体讨论见补充材料A节。
Evaluation Metrics. As in other works, we use the standard re-id metrics of mean average precision (mAP), and top-1 accuracy (top-1). For detection metrics, we use recall and average precision at $0.5\mathrm{IoU}$ (Recall, AP).
评估指标。与其他工作一致,我们采用平均精度均值(mAP)和首位准确率(top-1)作为标准行人重识别指标。对于检测指标,我们使用$0.5\mathrm{IoU}$阈值下的召回率(Recall)和平均精度(AP)。
In addition, we show GFN metrics mAP and top-1, which are computed as metrics of scene retrieval using GFN scores. To calculate these values, we compute the GFN score for each scene, and consider a gallery scene a match to the query if the query person is present in it.
此外,我们还展示了GFN指标mAP和top-1,这些指标是使用GFN分数作为场景检索的度量标准计算得出的。为了计算这些值,我们为每个场景计算GFN分数,并在查询人物出现在其中时,认为图库场景与查询匹配。
4.2. Implementation Details
4.2. 实现细节
We use SGD optimizer with momentum for ResNet models, with starting learning rate 3e-3, and Adam for ConvNeXt models, with starting learning rate 1e-4. We train all models for 30 epochs, reducing the learning rate by a factor of 10 at epochs 15 and 25. Gradients are clipped to norm 10 for all models.
我们使用带动量的SGD优化器训练ResNet模型,初始学习率为3e-3;对ConvNeXt模型采用Adam优化器,初始学习率为1e-4。所有模型均训练30个周期,在第15和25周期时将学习率降至十分之一。所有模型的梯度裁剪阈值设为10。
Models are trained on a single Quadro RTX 6000 GPU (24 GB VRAM), and 30 epoch training time using the final model configuration takes 11 hours for the PRW dataset, and 21 hours for the CUHK-SYSU dataset.
模型在单个Quadro RTX 6000 GPU (24 GB显存) 上进行训练,使用最终模型配置时,PRW数据集的30轮训练耗时11小时,CUHK-SYSU数据集则需21小时。
Our baseline model used for ablation studies has a ConvNeXt Base backbone, embedding dimension 2,048, scene embedding pool size $56\times56$ , and is trained with $512\times512$ image crops using the combined cropping strategy $(\mathrm{RSC}{+}\mathrm{RFC})$ . It uses the combined prototype feature version of the GFN objective. The final model configuration, used for comparison to other state-of-the-art models, is trained with $640\times640$ image crops using the altered combined cropping strategy $({\mathrm{RSC}}{\mathrm{+RFC2}}$ ). It uses the combined batch feature version of the GFN objective.
我们用于消融实验的基线模型采用ConvNeXt Base主干网络,嵌入维度为2,048,场景嵌入池化尺寸为$56\times56$,并使用$512\times512$图像裁剪配合组合裁剪策略$(\mathrm{RSC}{+}\mathrm{RFC})$进行训练。该模型采用GFN目标的组合原型特征版本。最终用于与其他先进模型对比的配置采用$640\times640$图像裁剪配合改进版组合裁剪策略$({\mathrm{RSC}}{\mathrm{+RFC2}})$进行训练,并使用GFN目标的组合批次特征版本。
| 遮挡情况 | mAP | top-1 |
|---|---|---|
| SeqNeXt | 91.1 | 89.8 |
| SeqNeXt+GFN | 92.0 | 90.9 |
| 低分辨率情况 | mAP | top-1 |
|---|---|---|
| SeqNeXt | 91.4 | 92.4 |
| SeqNeXt+GFN | 92.0 | 93.1 |
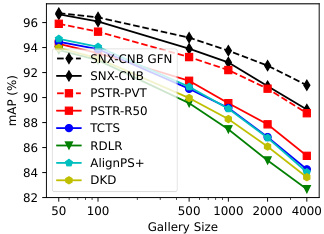
Figure 4: Effect of gallery size Table 1: Performance metrics on mAP for the CUHK-SYSU on two CUHK-SYSU retrieval dataset. SNX-CNB $=$ SeqNeXt partitions using either Occluded ConvNeXt Base. GFN helps (top) or Low-Resolution (botmore as gallery size increases. tom) query persons.
图 4: 图库规模的影响
表 1: CUHK-SYSU检索数据集上mAP性能指标。SNX-CNB $=$ 使用遮挡ConvNeXt Base分区的SeqNeXt。GFN在图库规模增大时提升效果更明显 (上) 或低分辨率 (下) 查询人物。
Additional implementation details are given in Supplementary Material Section B.
补充材料B节提供了更多实现细节。
4.3. Comparison to State-of-the-art
4.3. 与最先进技术的对比
We show a comparison of state-of-the-art methods on the standard benchmarks in Table 2. The GFN benefits all metrics, especially top-1 accuracy for the PRW dataset, which improves by $4.6%$ for the ResNet50 backbone, and $2.9%$ for the ConvNeXt Base backbone. Our best model, Se $\mathrm{qNeXt{+}G F N}$ with ConvNext Base, improves mAP by $1.8%$ on PRW and $1.2%$ on CUHK-SYSU over the previous best PSTR model. This benefit extends to larger gallery sizes for CUHK-SYSU, shown in Figure 4. In fact, the GFN scoreweighting helps more as gallery size increases. This is expected, since the benefit of down-weighting con textuallyunlikely scenes, vs. discriminating between persons within a single scene, has a greater effect when there are more scenes compared against.
我们在表2中展示了标准基准上最先进方法的对比结果。GFN (Generative Flow Networks) 在所有指标上均带来提升,尤其在PRW数据集上的top-1准确率表现突出:ResNet50骨干网络提升4.6%,ConvNeXt Base骨干网络提升2.9%。我们采用ConvNext Base的最佳模型SeqNeXt+GFN,在PRW数据集上mAP指标较此前最优的PSTR模型提升1.8%,在CUHK-SYSU数据集上提升1.2%。如图4所示,这种优势在CUHK-SYSU更大的图库规模中持续存在。实际上,随着图库规模增大,GFN的分数加权机制会发挥更大作用——这与预期一致,因为相较于在单一场景中区分人物,降低上下文不相关场景权重的策略在对比场景增多时会产生更显著的影响。
The GFN benefits CUHK-SYSU retrieval scenarios with occluded or low-resolution query persons, as shown in Table 1. This shows that high quality query person views are not essential to the function of the GFN.
如表 1 所示,GFN 对存在遮挡或低分辨率查询行人的 CUHK-SYSU 检索场景具有优势。这表明高质量查询行人视图并非 GFN 运行的必要条件。
The GFN also benefits both cross-camera and samecamera retrieval, as shown in Table 3. Strong cross-camera performance shows that the GFN can generalize to varying locations, and does not simply pick the scene which is the most visually similar. Strong same-camera performance shows that the GFN is able to use query information, even when all gallery scenes are con textually similar.
如表3所示,GFN (Generative Feature Network) 在跨摄像头和同摄像头检索任务中均表现优异。优异的跨摄像头性能表明GFN能泛化至不同地理位置,而非仅选择视觉上最相似的场景;出色的同摄像头性能则证明即使所有候选场景在上下文层面高度相似,GFN仍能有效利用查询信息。
To showcase these benefits, we provide some qualitative results in Supplementary Material Section C. These examples show that the GFN uses local person information combined with global context to improve retrieval ranking, even in the presence of difficult confusers.
为展示这些优势,我们在补充材料C节提供了部分定性结果。这些案例表明,即使存在高混淆项,GFN仍能通过结合局部人物信息与全局上下文来提升检索排序效果。
4.4. Ablation Studies
4.4. 消融研究
We conduct a series of ablations using the PRW dataset to show how detection, re-id, and GFN performance are each impacted by variations in model architecture, data augmentation, and GFN design choices.
我们使用PRW数据集进行了一系列消融实验,以展示检测、重识别和GFN性能如何分别受到模型架构、数据增强和GFN设计选择变化的影响。
Table 4: Comparison of different options for the GFN optimization objective. “None” does not use the GFN, Scene-Only uses the objective in Section 3.2.3, Base uses the baseline objective in Section 3.2.1, Combined (Comb.) uses the query-scene objective in Section 3.2.2, Batch indicates that batch query embeddings are used, Proto indicates that prototype query embeddings are used. Baseline model is marked with $\dagger$ , final model is highlighted gray.
表 4: GFN优化目标的不同选项对比。"None"表示不使用GFN,"Scene-Only"使用第3.2.3节的目标,"Base"使用第3.2.1节的基线目标,"Combined (Comb.)"使用第3.2.2节的查询-场景目标,"Batch"表示使用批量查询嵌入,"Proto"表示使用原型查询嵌入。基线模型用$\dagger$标记,最终模型以灰色高亮显示。
| 方法 | 主干网络 | CUHK-SYSU | PRW |
|---|---|---|---|
| mAP | top-1 | ||
| 两步法 | |||
| IDE [44] | ResNet50 | - | - |
| MGTS [6] | VGG16 | 83.0 | 83.7 |
| CLSA [20] | ResNet50 | 87.2 | 88.5 |
| IGPN [10] | ResNet50 | 90.3 | 91.4 |
| RDLR [14] | ResNet50 | 93.0 | 94.2 |
| TCTS [36] | ResNet50 | 93.9 | 95.1 |
| 端到端 | |||
| OIM [39] | ResNet50 | 75.5 | 78.7 |
| IAN [38] | ResNet50 | 76.3 | 80.1 |
| NPSM [26] | ResNet50 | 77.9 | 81.2 |
| RCAA [4] | ResNet50 | 79.3 | 81.3 |
| CTXG [41] | ResNet50 | 84.1 | 86.5 |
| QEEPS [29] | ResNet50 | 88.9 | 89.1 |
| APNet [45] | ResNet50 | 88.9 | 89.3 |
| HOIM [5] | ResNet50 | 89.7 | 90.8 |
| BINet [9] | ResNet50 | 90.0 | 90.7 |
| NAE+ [7] | ResNet50 | 92.1 | 92.9 |
| PGSFL [19] | ResNet50 | 92.3 | 94.7 |
| DKD [43] | ResNet50 | 93.1 | 94.2 |
| DMRN [15] | ResNet50 | 93.2 | 94.2 |
| AGWF [13] | ResNet50 | 93.3 | 94.2 |
| AlignPS [40] | ResNet50 | 94.0 | 94.5 |
| SeqNet [22] | ResNet50 | 93.8 | 94.6 |
| SeqNet+CBGM [22] | ResNet50 | 94.8 | 95.7 |
| COAT [42] | ResNet50 | 94.2 | 94.7 |
| COAT+CBGM [42] | ResNet50 | 94.8 | 95.2 |
| MHGAM [21] | ResNet50 | 94.9 | 95.9 |
| PSTR [3] | ResNet50 | 94.2 | 95.2 |
| PSTR [3] | PVTv2-B2 | 95.2 | 96.2 |
| SeqNeXt (本文) | ResNet50 | 94.1 | 94.7 |
| SeqNeXt+GFN (本文) | ResNet50 | 94.7 | 95.3 |
| SeqNeXt (本文) | ConvNeXt | 96.1 | 96.5 |
| SeqNeXt+GFN (本文) | ConvNeXt | 96.4 | 97.0 |
Table 2: Standard performance metrics mAP and top-1 accuracy on the benchmark CUHK-SYSU and PRW datasets are compared for state-of-the-art two-step and end-to-end models. ConvNeXt backbone $=$ ConvNeXt Base. Table 3: Performance on the PRW test set for query and gallery scenes from the same camera (Same Cam ID) or different cameras (Cross Cam ID).
表 2: 在基准数据集 CUHK-SYSU 和 PRW 上比较了最先进的两阶段和端到端模型的标准性能指标 mAP 和 top-1 准确率。ConvNeXt 骨干网络 $=$ ConvNeXt Base。
表 3: PRW 测试集上查询场景和图库场景来自相同摄像头 (Same Cam ID) 或不同摄像头 (Cross Cam ID) 的性能表现。
| 方法 | SameCamID | CrossCamID |
|---|---|---|
| mAP | top-1 | |
| HOIM [5] NAE+ [7] SeqNet [22] SeqNet+CBGM[22] AGWF [13] | ||
| 1 | 43.6 | |
| 1 1 | 1 | 44.3 48.0 |
| COAT+CBGM[42] SeqNeXt(ours) SeqNeXt+GFN(ours) | 1 | 1 |
| - | - | 51.7 |
| 82.9 85.1 | 98.5 98.6 | 55.3 56.4 |
In the corresponding metrics tables, we show re-id results by presenting the GFN-modified scores as mAP and top-1, and the difference between unmodified mAP and top1 with $\Delta\mathrm{mAP}$ and ∆top-1. This highlights the change in reid performance specifically from the GFN score-weighting. To indicate the baseline configuration in a table, we use the $\dagger$ symbol, and the final model configuration is highlighted in gray.
在对应的指标表中,我们通过展示GFN修正后的mAP和top-1分数,以及未修正mAP/top-1与$\Delta\mathrm{mAP}$、∆top-1之间的差值来呈现重识别结果。这突出了GFN分数加权对重识别性能的具体影响。表格中用$\dagger$符号标注基线配置,最终模型配置以灰色高亮显示。
| 检测 | 重识别 | GFN | ||||||
|---|---|---|---|---|---|---|---|---|
| GFN目标 | 召回率 | AP | mAP | top-1 | mAP | △ top-1 | mAP | top-1 |
| 无 | 96.0 | 93.6 | 58.6 | 88.7 | ! | |||
| 仅场景 | 96.0 | 93.4 | 56.5 | 91.9 | -0.9 | +2.8 | 16.1 | 73.3 |
| 基础批次 | 95.7 | 93.1 | 53.9 | 86.6 | -2.6 | -2.0 | 23.8 | 58.4 |
| 基础原型 | 96.0 | 93.6 | 55.0 | 86.2 | -3.0 | -2.7 | 22.9 | 57.8 |
| 组合批次 | 96.2 | 93.6 | 59.5 | 92.2 | +1.1 | +2.9 | 20.5 | 78.8 |
| 组合原型↑ | 96.0 | 93.4 | 58.8 | 92.3 | +1.1 | +3.5 | 20.4 | 78.5 |
Results for most of the ablations are shown in Supplementary Material Section D, including model modifications, image augmentation, scene pooling size, embedding dimension, and GFN sampling.
大多数消融实验的结果展示在补充材料D节中,包括模型修改、图像增强、场景池大小、嵌入维度和GFN采样。
GFN Objective. We analyze the impact of the various GFN objective choices discussed in Section 3.2. Comparisons are shown in Table 4. Most importantly, the re-id mAP performance without the GFN is relatively high, but the re-id top1 performance is much lower than the best GFN methods. Conversely, the Scene-Only method achieves competitive re-id top-1 performance, but reduced re-id mAP.
GFN目标。我们分析了第3.2节讨论的各种GFN目标选择的影响。比较结果如表4所示。最重要的是,不使用GFN时的重识别(re-id) mAP性能相对较高,但重识别top1性能远低于最佳GFN方法。相反,仅场景(Scene-Only)方法实现了具有竞争力的重识别top-1性能,但降低了重识别mAP。
The Base methods were found to be significantly worse than all other methods, with GFN score-weighting actually reducing GFN performance. The Combined methods were the most effective, better than the Base and Scene-Only methods for both re-id and GFN-only stats, showcasing the improvements discussed in Section 3.2.2. In addition, the success of the Combined objective can be explained by two factors: 1) similarity relationship between scene embeddings and 2) query information given by query-scene embeddings. The Scene-Only objective, which uses only similarity between scene embeddings, is functional but not as effective as the Combined objective, which uses both scene similarity and query information. Since the Scene-Only objective incorporates background information, and does not use query information, we reason that the provided additional benefit of the Combined objective comes from the described mechanism of query excitation of scene features, and not from e.g., simple matching of the query background with the gallery scene image.
研究发现,基础方法 (Base) 显著劣于其他所有方法,其中 GFN 分数加权反而降低了 GFN 性能。组合方法 (Combined) 效果最佳,在重识别 (re-id) 和纯 GFN 统计指标上均优于基础方法和仅场景方法 (Scene-Only),这印证了第 3.2.2 节讨论的改进机制。组合目标的成功可归因于两个因素:(1) 场景嵌入 (scene embeddings) 之间的相似性关系;(2) 查询-场景嵌入 (query-scene embeddings) 提供的查询信息。仅场景目标虽然通过场景嵌入相似性实现了基本功能,但由于缺乏查询信息,其效果不及同时利用场景相似性和查询信息的组合目标。由于仅场景目标已包含背景信息却未使用查询信息,我们认为组合目标的额外优势源自所述"场景特征查询激发机制",而非简单的查询背景与图库场景图像匹配。
Finally, the Batch and Proto modifiers to the Combined and Base methods were found to be relatively similar in performance. Since the Proto method is simpler and more efficient, we use it for the baseline model configuration.
最后发现,对 Combined 和 Base 方法应用 Batch 和 Proto 修饰符的性能相对接近。由于 Proto 方法更简单高效,我们将其用于基线模型配置。

Figure 5: GFN score histograms for the CUHK-SYSU and PRW test sets. Matches and non-matches (Diffs) are shown for queries in the gallery size 4,000 set for CUHK-SYSU, and the full gallery for PRW.
图 5: CUHK-SYSU和PRW测试集的GFN分数直方图。对于CUHK-SYSU图库规模为4,000的查询集和PRW完整图库,分别展示了匹配与非匹配(Diffs)情况。
4.5. Filtering Analysis
4.5. 过滤分析
GFN Score Threshold. We consider selection of the GFN score threshold value to use for filtering out gallery scenes during retrieval. In Figure 5, we show histograms of GFN scores for both CUHK-SYSU and PRW. We introduce another metric to help analyze computation savings from the filtering operation: the fraction of negative gallery scenes which can be filtered out (negative predictive value) when using a threshold which keeps $99%$ of positive gallery scenes (recall). For the histograms shown, this value is $91.4%$ for CUHK-SYSU, and only $11.5%$ for PRW.
GFN分数阈值。我们探讨了在检索过程中用于过滤图库场景的GFN分数阈值选择。图5展示了CUHK-SYSU和PRW数据集的GFN分数分布直方图。我们引入另一个指标来分析过滤操作带来的计算节省:当使用保留99%正样本图库场景(召回率)的阈值时,可过滤掉的负样本图库场景比例(阴性预测值)。对于所示直方图,CUHK-SYSU的该值为91.4%,而PRW仅为11.5%。
In short, this is because there is greater variation in scene appearance in CUHK-SYSU than PRW. This results in most query-gallery comparisons for CUHK-SYSU evaluation occurring between scenes from clearly different environments (e.g., two different movies). While the GFN score-weighting improves performance for both samecamera and cross-camera retrieval, shown in Table 3, queryscene scores used for hard threshold ing may be less discriminative for nearly-identical scenes as in PRW vs. CUHKSYSU, shown in Figure 5. Still, the GFN top-1 score for the final PRW model was $78.4%$ , meaning that $78.4%$ of queries resulted in the correct gallery scene being ranked first using only the GFN score.
简而言之,这是因为CUHK-SYSU数据集的场景外观差异比PRW更大。这导致CUHK-SYSU评估中的大多数查询-图库比对发生在明显不同环境下的场景之间(例如两部不同的电影)。如表3所示,虽然GFN(Gallery-Feature Network)的分数加权提升了同摄像头和跨摄像头检索的性能,但用于硬阈值处理的查询场景分数对PRW与CUHK-SYSU中近乎相同的场景区分度可能较低(如图5所示)。尽管如此,最终PRW模型的GFN top-1得分达到$78.4%$,这意味着仅凭GFN分数就有$78.4%$的查询能将正确的图库场景排在首位。
Compute Cost. In Table 5, we show the breakdown of percent time spent on shared computation, GFN-only computation, and detector-only computation. Since most computation time $(\sim60%)$ is spent on detection, with only $(\sim5%)$ of time spent on GFN-related tasks, there is a large cost savings from using the GFN to avoid detection by filtering gallery scenes. Exactly how much time is saved in practice depends on the relative number of queries vs. the gallery size, and how densely populated the gallery scenes are with persons of interest.
计算成本。在表5中,我们展示了共享计算、仅GFN计算和仅检测器计算的时间占比细分。由于大部分计算时间 $(\sim60%)$ 用于检测,而仅 $(\sim5%)$ 的时间用于GFN相关任务,因此通过GFN过滤图库场景来避免检测可大幅节省成本。实际节省的时间取决于查询数量与图库规模的相对比例,以及图库场景中目标人物的密集程度。
To give an understanding of compute savings for a single query, we show some example calculations using the conservative recall requirement of $99%$ . For CUHK-SYSU, we have $99.9%$ of gallery scenes negative, $91.4%$ of negative gallery scenes filtered, and $61.0%$ of time spent doing detection on gallery scenes, resulting in $55.7%$ computation saved using the GFN compared to the same model without the GFN. For PRW, the same calculation yields $6.6%$ computation saved using the GFN.
为了说明单次查询的计算节省情况,我们以保守召回率要求$99%$为例进行演示计算。在CUHK-SYSU数据集中,图库场景负样本占比$99.9%$,其中$91.4%$的负样本图库场景被过滤,且图库场景检测耗时占比$61.0%$,因此采用GFN (Generative Filtering Network) 相比原模型可节省$55.7%$的计算量。而在PRW数据集中,相同计算条件下GFN可节省$6.6%$的计算量。
Table 5: Percent computation time averaged per query of shared feature extraction, GFN, and detection on the CUHK-SYSU (gallery size 4,000) and PRW (gallery size full) test sets.
表 5: CUHK-SYSU (图库规模 4,000) 和 PRW (图库规模完整) 测试集上共享特征提取、GFN 及检测的每查询平均计算时间百分比。
| 共享 | GFN | 检测 | ||||
|---|---|---|---|---|---|---|
| Backbone | Query Emb. | SceneEmb. | GFNScores | RPN | R-CNN(×2) | |
| CUHK Time (%) | 33.7 | <0.1 | 5.3 | <0.1 | 19.2 | 41.8 |
| 33.7 | 5.3 | 61.0 | ||||
| PRW Time (%) | 36.9 | <0.1 | 5.3 | <0.1 | 16.1 | 41.7 |
| 36.9 | 5.3 | 57.8 |
5. Conclusion
5. 结论
We describe and demonstrate the Gallery Filter Network, a novel module for improving accuracy and efficiency of person search models. We show that the GFN can efficiently filter gallery scenes under certain conditions, and that it benefits scoring for detects in scenes which are not filtered. We show that the GFN is robust under a range of different conditions by testing on different retrieval sets, including cross-camera, occluded, and low-resolution scenarios. In addition, we show that the benefit given by GFN score-weighting increases as gallery size increases.
我们介绍并演示了Gallery Filter Network(GFN),这是一种用于提高人员搜索模型准确性和效率的新型模块。我们证明GFN能在特定条件下高效过滤图库场景,并对未过滤场景中的检测结果评分有所提升。通过在不同检索集(包括跨摄像头、遮挡和低分辨率场景)上的测试,我们验证了GFN在多种条件下的鲁棒性。此外,我们还发现随着图库规模增大,GFN评分加权带来的优势会相应增强。
Separately, we develop the base SeqNeXt person search model, which has significant performance gains over the original SeqNet model. We offer a corresponding training recipe to train efficiently with improved regular iz ation, using an aggressive cropping strategy. Taken together, the Se $\mathrm{qNeXt{+}G F N}$ combination yields a significant improvement over other state-of-the-art methods. Finally, we note that the GFN is not specific to SeqNeXt, and can be easily combined with other person search models.
我们单独开发了基础版SeqNeXt行人搜索模型,其性能较原始SeqNet模型有显著提升。我们提供了配套训练方案,通过改进的正则化(regularization)和激进的裁剪策略实现高效训练。Se $\mathrm{qNeXt{+}G F N}$ 组合方案相较其他前沿方法取得了显著改进。最后需要说明,GFN并非SeqNeXt专用模块,可轻松与其他行人搜索模型结合使用。
Societal Impact. It is important to consider the potential negative impact of person search models, since they are ready-made for surveillance applications. This is highlighted by the PRW dataset being entirely composed of surveillance imagery, and the CUHK-SYSU dataset containing many street-view images of pedestrians.
社会影响。由于人员搜索模型可直接用于监控应用,考虑其潜在负面影响至关重要。这一点在PRW数据集完全由监控图像构成、CUHK-SYSU数据集包含大量行人街景图像的情况下尤为突出。
We consider two potential advantages of advancing person search research, and doing so in an open format. First, that person search models can be used for beneficial applications, including aiding in finding missing persons, and for newly-emerging autonomous systems that interact with humans, e.g., automated vehicles. Second, it allows the research community to understand how the models work at a granular level, and therefore benefits the potential for counteracting negative uses when the technology is abused.
我们考虑推进人员搜索研究并以开放形式开展的两大潜在优势。首先,人员搜索模型可用于有益应用,包括协助寻找失踪人员,以及应用于与人类交互的新兴自主系统(如自动驾驶车辆)。其次,它让研究社区能够从细粒度层面理解模型工作原理,从而在技术被滥用时增强抵御负面应用的能力。
Acknowledgements
致谢
The authors would like to thank Wesam Sakla and Michael Goldman for helpful discussions and feedback.
作者感谢Wesam Sakla和Michael Goldman的有益讨论和反馈。
References
参考文献
Supplementary Material
补充材料
A. Data Processing and Evaluation
A. 数据处理与评估
We make publicly available our codebase2, which includes instructions and config files needed to replicate all main experiments of the paper. For com par it ive purposes, we implicitly refer in the following subsections to the public codebases of $\mathrm{OIM}^{3}$ [39], $\mathrm{NAE^{4}}$ [7], SeqNet5 [22], COAT6 [42], AlignPS7 [40], and $\mathrm{PSTR}^{8}$ [3].
我们公开了代码库2,其中包含复现论文所有主要实验所需的说明和配置文件。为便于比较,我们在以下小节中隐式引用了$\mathrm{OIM}^{3}$[39]、$\mathrm{NAE^{4}}$[7]、SeqNet5[22]、COAT6[42]、AlignPS7[40]和$\mathrm{PSTR}^{8}$[3]的公开代码库。
A.1. Standardized Data Format
A.1. 标准化数据格式
We produce an intermediate COCO-style [25] format for all partitions of the CUHK-SYSU and PRW datatsets. In addition to standard COCO object metadata, we include person_id and is_known fields for persons, and a cam_id image field for performing cross-camera evaluation.
我们为CUHK-SYSU和PRW数据集的所有分区生成了中间COCO格式[25]。除了标准的COCO对象元数据外,我们还为人物添加了person_id和is_known字段,并为执行跨摄像头评估添加了cam_id图像字段。
This standardization process made it straightforward to prepare new partitions of the data. In particular, we split the standard training sets into separate training and validation sets, and created some additional smaller debugging sets. This allowed us to pick hyper parameters without fitting to the test data.
这一标准化流程使得准备新的数据分区变得简单直接。具体而言,我们将标准训练集划分为独立的训练集和验证集,并创建了一些额外的较小调试集。这样我们就能在不拟合测试数据的情况下选择超参数。
We also standardize the format of retrieval partitions into three categories: 1) fully-specified format which encodes the exact gallery scenes to be used for each query 2) format which specifies queries only, and uses all scenes in the partition as the gallery and 3) format which uses all possible queries, and all possible scenes as the gallery. We create the second and third formats because it is otherwise inefficient to fully-specify the “all” cases.
我们还对检索分区的格式进行了标准化,分为三类:1) 完全指定格式,明确编码每个查询要使用的图库场景;2) 仅指定查询的格式,使用分区中的所有场景作为图库;3) 使用所有可能查询和所有可能场景作为图库的格式。我们创建第二和第三种格式是因为完全指定"所有"情况效率较低。
A.2. Training and Validation Sets
A.2. 训练集与验证集
For both datasets, known identity sets between the train and test partitions are disjoint, making the standard evaluation an open-set retrieval problem. To construct the training and validation sets to mirror the open-set retrieval problem of the standard train-test divide, we build a graph based on which scenes share common person identities. Two nodes (scenes) have an edge between them if they share at least one person identity in common. In this way, we can easily split the CUHK-SYSU dataset into a set of connected components, and divide those components into two groups for train $(\sim80%)$ and val $(\sim20%)$ .
对于这两个数据集,训练集和测试集之间已知的身份集合互不相交,使得标准评估成为一个开放集检索问题。为了构建与标准训练-测试划分的开放集检索问题相一致的训练集和验证集,我们基于场景共享共同人物身份的关系构建了一个图。若两个节点(场景)共享至少一个相同的人物身份,则它们之间存在一条边。通过这种方式,我们可以轻松将CUHK-SYSU数据集划分为一组连通组件,并将这些组件分为训练组$(\sim80%)$和验证组$(\sim20%)$。
Since the PRW dataset comprises video surveillance footage, this graph has the property that nearly every scene
由于PRW数据集包含视频监控片段,该图具有几乎每个场景的特性
| CUHK-SYSU | PRW | |||||||
|---|---|---|---|---|---|---|---|---|
| Metadata | trainval | test | train | val | trainval | test | train | val |
| Scenes | 11,206 | 6,978 | 8,964 | 2,242 | 5,704 | 6,112 | 4,563 | 1,141 |
| Boxes | 55,272 | 40,871 | 44,244 | 11,028 | 18,048 | 25,062 | 14,897 | 3,151 |
| Known IDs | 5,532 | 2,900 | 4,296 | 1,236 | 483 | 544 | 424 | 158 |
| KnownBoxes | 15,085 | 8,345 | 11,623 | 3,462 | 14,907 | 19,127 | 12,125 | 2,782 |
| UnknownBoxes | 40,187 | 32,526 | 32,621 | 7,566 | 3,141 | 5,935 | 2,772 | 369 |
Table 6: Dataset metadata showing how many scenes, boxes, and person IDs are in each partition.
表 6: 数据集元信息,展示每个分区中的场景数、包围框数和人物ID数量。
is connected to another scene via some common person identity. Therefore, we ignore the top 100 most common person identities when constructing the graph for PRW, resulting in a partition which is not quite open-set, but should exhibit similar generalization properties for the purpose of model development. For PRW, we also divide components into two groups for train $(\sim80%)$ and val $(\sim20%)$ .
通过某个共同的人物身份连接到另一个场景。因此,在构建PRW的图结构时,我们忽略了前100个最常见的人物身份,这样产生的划分虽然不是完全开放集,但对于模型开发的目的应具有相似的泛化特性。对于PRW,我们还将组件分为训练组 $(\sim80%)$ 和验证组 $(\sim20%)$ 。
We rename the original train set to “trainval”, and all of our final experimental results in this paper are from models trained on the full trainval set, and tested on the full test set using the standard retrieval scenarios.
我们将原始训练集重命名为“trainval”,本文中所有最终实验结果均基于完整trainval集训练的模型,并使用标准检索场景在完整测试集上进行测试。
A.3. Partition Information
A.3. 分区信息
Metadata for the exact breakdown of known and unknown identities and boxes for each partition is given in Table 6.
表6中提供了每个分区已知和未知身份及边界框的详细分类元数据。
A.4. Evaluation Functions
A.4. 评估函数
Using these standardized partitions, we are able to use just one function for detection evaluation and one for retrieval evaluation, as opposed to separate functions for each dataset. This also makes it easier to add in method-specific metrics that can be immediately tested for all partitions.
利用这些标准化分区,我们能够仅用一个函数进行检测评估,另一个函数进行检索评估,而无需为每个数据集单独编写函数。这也使得添加特定方法指标变得更加容易,这些指标可以立即在所有分区上进行测试。
We note that the current dataset releases for PRW and CUHK-SYSU have a small number (5 or less) of the following errors: duplicate bounding boxes in a single scene, repeated person ids in a single scene, and repeated gallery scenes in a retrieval partition. Although these issues are not handled correctly by the standard evaluation function, we exactly replicate the previous erroneous behavior in our new evaluation function to be certain the comparison against other methods is fair. We leave correction of the underlying data and evaluation function to future work.
我们注意到,当前发布的PRW和CUHK-SYSU数据集中存在少量(5个或更少)以下错误:单个场景中的重复边界框、单个场景中重复的人物ID以及检索分区中重复的图库场景。虽然标准评估函数无法正确处理这些问题,但我们在新的评估函数中完全复现了之前的错误行为,以确保与其他方法的比较是公平的。我们将基础数据和评估函数的修正留给未来工作。
A.5. Augmentation Code Structure
A.5. 增强代码结构
To make use of augmentation strategies in the albumentations library [1], we refactor evaluation to occur on the augmented data instead of the original data. This allows for easy inclusion of different resizing and cropping strategies which we make use of, in addition to a wealth of other augmentations, experimenting with which we leave to future work.
为了利用albumentations库[1]中的增强策略,我们重构了评估流程,使其基于增强后的数据而非原始数据进行。这样不仅能方便地集成我们所采用的不同尺寸调整和裁剪策略,还能利用该库提供的丰富增强功能,其余增强效果的实验验证将留待未来工作完成。
A.6. Config Format and Ray Tune
A.6. 配置格式与Ray Tune
For running experiments with our code, we provide a YAML config format which is compatible with the Ray Tune library [23]. We specifically support the tune.grid search functionality by parsing lists in the YAML file as inputs to this function. This makes it easy to run ablations with many variations using a single config file.
为了使用我们的代码运行实验,我们提供了一种与Ray Tune库[23]兼容的YAML配置文件格式。我们通过解析YAML文件中的列表作为该函数的输入,专门支持tune.grid搜索功能。这使得使用单个配置文件轻松运行包含多种变体的消融实验成为可能。
B. Additional Implementation Details
B. 其他实现细节
Model Details. We set the OIM scalar (inverse temperature) parameter to 30.0 as in [22], with an OIM circular queue size of 5,000 for CUHK-SYSU and 500 for PRW. The OIM momentum parameter is also left at 0.5. For the GFN, the training temperature parameter is 0.1, and the GFN excitation function temperature parameter is 0.2. During training, we use a batch size of 12 for ResNet50 backbone models, and a batch size of 8 for ConvNeXt backbone models.
模型细节。我们将OIM标量(逆温度)参数设置为30.0,与[22]中一致,其中CUHK-SYSU的OIM循环队列大小为5,000,PRW的为500。OIM动量参数也保持为0.5。对于GFN,训练温度参数为0.1,GFN激励函数温度参数为0.2。训练过程中,使用ResNet50骨干网络时批大小为12,使用ConvNeXt骨干网络时批大小为8。
For the ResNet50 backbone, we freeze all batch norm layers, and all weights through the conv1 layer of the model. For ConvNeXt backbones, we freeze only the conv1 layer of the model. All backbones are initialized using weights from pre-training on ImageNet1k [32].
对于ResNet50主干网络,我们冻结所有批归一化层,以及模型conv1层的所有权重。对于ConvNeXt主干网络,仅冻结模型的conv1层。所有主干网络均使用ImageNet1k [32]预训练的权重进行初始化。
We use automatic-mixed precision (AMP), which significantly reduces all training and inference times. To avoid float16 overflow, we refactor all loss functions to divide before summation when computing mean reduction. This increases likelihood of underflow, but results in more stable training overall.
我们使用自动混合精度 (automatic-mixed precision, AMP),这显著减少了所有训练和推理时间。为避免 float16 溢出,我们重构了所有损失函数,在计算均值归约时先进行除法再求和。这会增加下溢的可能性,但总体上能带来更稳定的训练。
GFN Sampling Strategies. Since we are unable to use the entire GFN LUT to form loss pairs in any given batch due to memory limitations, we have a choice about which LUT embeddings to select for the GFN optimization. By default, for each query person present in the current batch, we sample one matching scene embedding and the person embeddings for all persons in that scene. In addition, we consider sampling a “hard negative” scene, defined as a scene which shares at least one person identity in common with the query scene, but that does not contain the query person identity. An ablation for related choices is considered in Section D.
GFN采样策略。由于内存限制,我们无法在单个批次中使用完整的GFN查找表(LUT)来构建损失对,因此需要选择哪些LUT嵌入用于GFN优化。默认情况下,对于当前批次中的每个查询人物,我们会采样一个匹配场景嵌入及该场景中所有人物的嵌入。此外,我们还考虑采样"困难负样本"场景,即与查询场景共享至少一个相同人物身份但不包含查询人物身份的场景。相关选择的消融实验详见附录D部分。
C. Qualitative Analysis
C. 定性分析
Qualitative examples are shown for both CUHK-SYSU and PRW in Figure 6. All examples show cases where the baseline model top-1 match is incorrect, but the GFNmodified match for the same example is correct. We highlight examples where global scene context has an obvious vs. a more subtle impact, and where the query and scene camera ID are the same or different.
图 6 展示了 CUHK-SYSU 和 PRW 的定性示例。所有案例均显示基线模型 top-1 匹配错误,而相同示例的 GFN 修正匹配正确。我们重点展示了全局场景上下文具有明显影响与较微妙影响的案例,以及查询图像与场景相机 ID 相同或不同的案例。
| | 检测 | | 重识别 | | | GFN | |
Table 7: Comparison of model backbone (RN50=ResNet50, CNB $:=$ ConvNeXt Base), NAE vs. R-CNN head for the second detector stage, and first (stage) classifier score (FCS) or second (stage) classifier score (SCS) used at inference time. Baseline model is marked with $\dagger$ , final model is highlighted gray.
表 7: 模型主干对比 (RN50=ResNet50, CNB $:=$ ConvNeXt Base)、第二检测器阶段采用NAE与R-CNN头的对比,以及推理时使用第一(阶段)分类器分数(FCS)或第二(阶段)分类器分数(SCS)的对比。基准模型用 $\dagger$ 标记,最终模型以灰色高亮显示。
D. Additional Ablations
D. 额外消融实验
Model Modifications. We consider how changes to the SeqNet architecture impact performance, including usage of a second Faster R-CNN head instead of the NAE head, and usage of the second detector stage score instead of the first stage score during inference. Results are shown in Table 7.
模型修改。我们探讨了SeqNet架构调整对性能的影响,包括用第二个Faster R-CNN头替代NAE头,以及在推理阶段使用第二检测器阶段分数替代第一阶段分数。结果如表7所示。
Using the ConvNeXt Base backbone instead of ResNet50 does not improve detection performance, but it significantly improves re-id performance, especially mAP, by $7-8%$ . Using the first stage score significantly helps detection performance, but it reduces re-id performance.
使用 ConvNeXt Base 主干网络替代 ResNet50 并未提升检测性能,但显著提高了重识别性能,尤其是 mAP 提升了 $7-8%$。采用第一阶段分数对检测性能有明显帮助,但会降低重识别性能。
Image Augmentation. Shown in Table 8, we compare the Window Resize augmentation to the two cropping methods used, and a strategy combining the two. We find that the Window Resize method achieves comparable re-id performance with other methods, but much lower detection performance. This may be attributed to the regularizing effect of random cropping for detector training.
图像增强 (Image Augmentation)。如表 8 所示,我们将 Window Resize 增强方法与使用的两种裁剪方法以及两者结合的策略进行了比较。我们发现 Window Resize 方法在重识别 (re-id) 性能上与其他方法相当,但检测性能要低得多。这可能归因于随机裁剪对检测器训练的正则化效果。
In addition, we find that Random Safe Cropping alone results in better detection performance than Random Focused Cropping alone, but worse re-id performance. This shows that the regularizing effect of random crops that may be in the wrong scale is more important for detection, and having features in the target scene scale is more important for re-id. Combining the two results in better performance than either alone for both detection and re-id.
此外,我们发现仅使用随机安全裁剪 (Random Safe Cropping) 比仅使用随机聚焦裁剪 (Random Focused Cropping) 能带来更好的检测性能,但重识别性能较差。这表明随机裁剪可能产生错误尺度的正则化效应对检测更重要,而特征处于目标场景尺度对重识别更重要。将两种方法结合使用时,检测和重识别性能均优于单独使用任一方法。
Scene Pooling Size and Embedding Dimension. We analyze choices for the RoI Align pooling size for the scene embedding head, and choices for the embedding dimension for both the query and scene embedding heads. Comparisons are shown in Table 9.
场景池化尺寸与嵌入维度。我们分析了场景嵌入头中RoI Align池化尺寸的选择,以及查询头和场景嵌入头中嵌入维度的选择。对比结果如表9所示。
GFN performance increases nearly-monotonically with scene pooling size, with diminishing returns for GFN scoreweighted re-id performance. We also note that larger scene pooling size results in a significant increase in memory consumption, so we use $56\times56$ by default, which captures most of the performance gain, with some memory savings.
GFN性能几乎随场景池大小单调递增,而GFN分数加权重识别性能的收益递减。我们还注意到,较大的场景池大小会导致内存消耗显著增加,因此默认使用$56\times56$,在捕获大部分性能提升的同时节省部分内存。
It is clear that the scene pooling size should be larger than the query pooling size to ensure that all person information in a scene is adequately captured. The relationship between person box size distribution vs. scene size, with the ratio of respective pooling sizes could be further investigated.
显然,场景池化尺寸应大于查询池化尺寸,以确保充分捕捉场景中的所有人员信息。人员框尺寸分布与场景尺寸的关系,以及各自池化尺寸的比值,值得进一步研究。

Figure 6: Retrieval examples (CUHK-SYSU left, PRW right) from the baseline model where application of the GFN score corrected the top-1 result. The query box is shown in yellow, a false positive gallery match in red, and a true positive gallery match in blue. In each scene, the white box in the lower right duplicates the person of interest for easier comparison between scenes. In the top-left and middleleft, subtle contextual clues (formal wear) help correct the predicted box. In the bottom-left, an obvious contextual clue (interior of same building) corrects the prediction, despite a $180^{\circ}$ change in viewpoint of the person. In the top-right, the false positive and correct match look nearly identical, and the correct box is from the same camera view. In the middle-right, the false positive and correct match have the same shirt and hairstyle, and the correct box is from a different camera view. In the lower-right, the false positive appears to be a mistake in the ground truth (should be true positive), but the GFN “helped” by up-weighting a more con textually similar scene.
图 6: 基线模型的检索示例(左为CUHK-SYSU,右为PRW),其中GFN分数修正了top-1结果。查询框以黄色显示,错误匹配的图库样本为红色,正确匹配的图库样本为蓝色。每个场景右下角的白色方框重复显示目标人物以便跨场景对比。左上和中左示例中,细微的上下文线索(正装)帮助修正了预测框。左下示例中,明显的上下文线索(同一建筑内部)修正了预测结果,尽管人物视角发生了180°变化。右上示例中,错误匹配与正确匹配外观几乎相同,且正确匹配来自同一摄像头视角。中右示例中,错误匹配与正确匹配具有相同衬衫和发型,但正确匹配来自不同摄像头视角。右下示例中,错误匹配似乎是标注错误(本应为正确匹配),但GFN通过提升上下文更相似场景的权重起到了"帮助"作用。
| 方法 | 召回率 | AP | mAP | top-1 | mAP | top-1 | mAP | top-1 |
|---|---|---|---|---|---|---|---|---|
| WRS | 89.3 | 87.7 | 57.3 | 91.1 | +0.9 | +4.7 | 19.6 | 78.3 |
| RSC | 95.9 | 93.1 | 55.8 | 91.0 | +0.7 | +3.7 | 18.5 | 77.6 |
| RFC | 95.0 | 92.7 | 58.4 | 91.2 | +1.4 | +3.4 | 20.8 | 77.8 |
| RFC2 | 95.4 | 93.1 | 58.2 | 91.1 | +1.4 | +3.8 | 21.1 | 78.4 |
| RSC+RFC+ | 96.0 | 93.4 | 58.8 | 92.3 | +1.1 | +3.5 | 20.4 | 78.5 |
| RSC+RFC2 | 96.1 | 93.8 | 58.7 | 92.3 | +1.3 | +3.3 | 20.8 | 78.9 |
| 裁剪尺寸 | 召回率 | AP | mAP | top-1 | mAP | top-1 | mAP | top-1 |
|---|---|---|---|---|---|---|---|---|
| 256x256 | 95.3 | 91.9 | 51.4 | 90.1 | 0.1 | 3.3 | 16.7 | 78.0 |
| 384×384 | 96.3 | 93.6 | 56.7 | 92.0 | 0.6 | 3.0 | 19.6 | 79.2 |
| 512×512 | 96.0 | 93.4 | 58.8 | 92.3 | 1.1 | 3.5 | 20.4 | 78.5 |
| 640×640 | 95.3 | 92.9 | 59.6 | 92.3 | 1.4 | 3.4 | 21.8 | 79.6 |
Table 8: Comparison of image augmentation methods (top), and image crop sizes (bottom). Augmentation methods include WRS (Window Resize to $900\times1500\rangle$ ), RSC (Random Safe Crop to square crop size), RFC (Random Focused Crop to square crop size), RFC2 (variant of RFC), and $\mathsf{R S C}\mathsf{+R F C}(2)$ which performs either cropping method randomly with equal probability. Baseline model is marked with $\dagger$ , final model is highlighted gray.
表 8: 图像增强方法对比(上) 和图像裁剪尺寸(下)。增强方法包括 WRS (窗口调整至 $900\times1500\rangle$)、RSC (随机安全裁剪为方形尺寸)、RFC (随机聚焦裁剪为方形尺寸)、RFC2 (RFC变体) 以及 $\mathsf{R S C}\mathsf{+R F C}(2)$ (以等概率随机执行任一种裁剪方法)。基线模型标记为 $\dagger$,最终模型以灰色高亮显示。
For the embedding dimension, performance also increases nearly-monotonically with size, for both re-id and the GFN-only stats. Although there are diminishing returns in performance, like with the scene pooling size, we choose the relatively large value of 2,048 because it results in little additional memory consumption or compute time.
对于嵌入维度(embedding dimension),无论是重识别(re-id)还是仅使用GFN的统计量,性能都几乎随尺寸增加而单调提升。虽然性能提升存在边际递减效应(类似于场景池化尺寸的情况),但我们仍选择了较大的2048维,因为该维度带来的额外内存消耗和计算时间几乎可以忽略不计。
GFN Sampling. We analyze choices for the GFN sampling procedure, with comparisons shown in Table 10. Critically, we find that all sampling options with the LUT are better than not using the LUT at all, as shown by both the large increase in GFN stats, and the contribution of GFN scoreweighting to re-id stats. This is expected but important, be
GFN采样。我们分析了GFN采样过程的选择,比较结果如表10所示。关键发现是,所有使用LUT(查找表)的采样选项都优于完全不使用LUT,这体现在GFN统计量的大幅提升以及GFN分数加权对重识别统计的贡献上。这一结果虽在预期之中,但具有重要意义。
| 检测 | 重识别 | GFN | ||||||
|---|---|---|---|---|---|---|---|---|
| 池化尺寸 | 召回率 | AP | mAP | top-1 | mAP | △ top-1 | mAP | top-1 |
| 14×14 | 96.1 | 93.5 | 58.1 | 91.6 | +0.1 | +3.3 | 18.2 | 77.9 |
| 28×28 | 95.9 | 93.4 | 58.5 | 92.3 | +0.7 | +3.6 | 19.7 | 79.2 |
| 56×56 | 96.0 | 93.4 | 58.8 | 92.3 | +1.1 | +3.5 | 20.4 | 78.5 |
| 112×112 | 96.1 | 93.6 | 58.8 | 92.4 | +1.2 | +3.6 | 22.1 | 79.8 |
| 嵌入维度 | 召回率 | AP | mAP | top-1 | △1 mAP | △ top-1 | mAP | top-1 |
| 128 | 96.1 | 93.6 | 58.0 | 91.6 | 0.7 | 3.8 | 19.6 | 77.9 |
| 256 | 95.9 | 93.4 | 58.2 | 92.0 | 1.0 | 4.3 | 20.1 | 78.3 |
| 512 | 96.1 | 93.5 | 58.7 | 91.8 | 1.0 | 4.0 | 20.0 | 77.6 |
| 1024 | 96.2 | 93.6 | 59.3 | 92.2 | 1.1 | 3.5 | 20.0 | 78.0 |
| 2048 | 96.0 | 93.4 | 58.8 | 92.3 | 1.1 | 3.5 | 20.4 | 78.5 |
Table 9: Comparison of pooling sizes for the RoI Align block used to compute scene embeddings (top) and comparison of the embedding dimension used for both query and scene embeddings (bottom). Baseline model is marked with $^\dagger$ , final model is highlighted gray.
表 9: 用于计算场景嵌入的 RoI Align 块池化大小对比 (上) 以及查询和场景嵌入维度对比 (下)。基线模型标记为 $^\dagger$,最终模型以灰色高亮显示。
cause it shows that batch-only query-scene comparisons are insufficient (usually just comparing a query to the scene it is present in), and that LUT comparisons are needed despite no gradients flowing through the LUT.
因为它表明仅进行批量查询-场景比较是不够的(通常只是将查询与其所在的场景进行比较),并且尽管没有梯度流经LUT (Look-Up Table),但仍需要进行LUT比较。
Among sampling mechanisms that use the LUT, results for GFN score-weighted re-id stats were relatively similar, and more trials with more samples per trial are likely needed to distinguish a standout method.
在使用LUT的采样机制中,GFN分数加权重识别统计结果相对接近,可能需要更多试验(每轮增加样本量)才能区分出优势方法。
E. Comparison with CBGM
E. 与CBGM的对比
The GFN module is similar to the Context Bipartite Graph Matching (CBGM) method from [22] in that both methods use context from the query and gallery scenes to improve prediction ranking, although the GFN is used
GFN模块与[22]中的上下文二分图匹配(Context Bipartite Graph Matching,CBGM)方法类似,两者都利用查询场景和图库场景的上下文信息来改进预测排序,不过GFN模块用于...
| 检测 | 重识别 | GFN | |||||
|---|---|---|---|---|---|---|---|
| 采样方式 | 召回率 (Recall) | 平均精度 (AP) | 平均精度均值 (mAP) | top-1 | mAP | top-1 | mAP |
| NoLUT | 96.2 | 93.7 | 57.5 | 90.8 | -0.3 | +2.1 | 13.3 |
| P1NO | 96.1 | 93.6 | 59.5 | 91.9 | +1.3 | +2.4 | 21.0 |
| PIN1t | 96.0 | 93.4 | 58.8 | 92.3 | +1.1 | +3.5 | 20.4 |
| P2NO | 96.2 | 93.7 | 59.1 | 91.9 | +1.2 | +3.6 | 20.9 |
| P2N1 | 96.0 | 93.6 | 59.1 | 91.7 | +1.2 | +3.4 | 21.1 |
Table 10: Comparison of different sampling options for optimization of the GFN. $\mathrm{P}x\mathrm{N}y$ indicates that $_x$ positive scenes and $y$ hard negative scenes are sampled for each person in the batch. No LUT means we use only batch query and scene embeddings, and no LUT is used. Baseline model is marked with $^\dagger$ , final model is highlighted gray.
表 10: GFN优化中不同采样方案的对比。$\mathrm{P}x\mathrm{N}y$表示每个批次中为每个人采样$_x$个正样本场景和$y$个困难负样本场景。"No LUT"表示仅使用批次查询和场景嵌入,未使用LUT。基线模型标注为$^\dagger$,最终模型以灰色高亮显示。
at inference-time only, and does not need to be trained. CBGM is more explicit, in that it directly attempts to match detected person boxes in the query and gallery scenes, at the expense of requiring sensitive hyper parameters: the number of boxes to use from each scene for the matching. The authors found that very different values for these parameters were optimal for the CUHK-SYSU vs. PRW datasets, and did not provide a clear methodology for their selection besides test set performance. In contrast, we use the exact same GFN configuration for both datasets during training and inference, selected separately based on validation data, and found it to robustly improve performance for both.
在推理时仅需使用,无需训练。CBGM方法更为显式,它直接尝试匹配查询场景和图库场景中检测到的人物边界框,但代价是需要调整敏感的超参数:即每个场景中用于匹配的边界框数量。作者发现,CUHK-SYSU和PRW数据集对这些参数的最优值差异极大,且除了测试集性能外未提供明确的参数选择方法。相比之下,我们在训练和推理阶段对两个数据集采用完全相同的GFN配置(基于验证数据独立选定),并发现该方法能稳定提升两个数据集的性能。