Cross-Modal Learning with 3D Deformable Attention for Action Recognition
基于3D可变形注意力(3D Deformable Attention)的跨模态学习在动作识别中的应用
Abstract
摘要
An important challenge in vision-based action recognition is the embedding of s patio temporal features with two or more heterogeneous modalities into a single feature. In this study, we propose a new 3D deformable transformer for action recognition with adaptive s patio temporal receptive fields and a cross-modal learning scheme. The 3D deformable transformer consists of three attention modules: 3D deform ability, local joint stride, and temporal stride attention. The two cross-modal tokens are input into the $3D$ deformable attention module to create a cross-attention token with a reflected s patio temporal correlation. Local joint stride attention is applied to spatially combine attention and pose tokens. Temporal stride attention temporally reduces the number of input tokens in the attention module and supports temporal expression learning without the simultaneous use of all tokens. The deformable transformer iterates L-times and combines the last cross-modal token for classification. The proposed 3D deformable transformer was tested on the NTU60, NTU120, FineGYM, and PennAction datasets, and showed results better than or similar to pretrained state-of-the-art methods even without a pre-training process. In addition, by visualizing important joints and correlations during action recognition through spatial joint and temporal stride attention, the possibility of achieving an explain able potential for action recognition is presented.
基于视觉的动作识别面临一个重要挑战:如何将两种或多种异构模态的时空特征嵌入到单一特征中。本研究提出了一种新型3D可变形Transformer (3D deformable transformer) ,通过自适应时空感受野和跨模态学习方案进行动作识别。该架构包含三个注意力模块:3D可变形注意力、局部关节步幅注意力和时间步幅注意力。两个跨模态token被输入到$3D$可变形注意力模块,生成具有反射时空相关性的交叉注意力token。局部关节步幅注意力在空间维度上融合注意力与姿态token,时间步幅注意力则通过减少注意力模块的输入token数量来支持时序表达学习,无需同时使用所有token。该可变形Transformer经过L次迭代后,将最终的跨模态token组合用于分类。在NTU60、NTU120、FineGYM和PennAction数据集上的测试表明,即使没有预训练过程,所提出的3D可变形Transformer性能也优于或持平预训练的先进方法。此外,通过空间关节注意力和时间步幅注意力可视化动作识别过程中的关键关节及其相关性,展现了实现可解释性动作识别的潜力。
1. Introduction
1. 引言
S patio temporal feature learning is a crucial part of action recognition, which aims to fuse not only the spatial features of each frame but also the temporal correlation between input sequences. Previous studies on action recognition [19, 6, 5, 42, 9, 48] investigated the application of 3D convolutional kernels with an additional temporal space beyond the 2D spatial feature space. Since then, 3D convolutional neural networks (CNN) have achieved a promising performance and have eventually become the de facto standard for various action recognition tasks using sequential data. Vision transformers (ViTs) for action recognition, which have peaked in popularity, have recently been used to explore a 3D token embedding to fuse the temporal space within a single token. However, ViTs-based action recognition methods [1, 34] are limited in that they can only conduct s patio temporal feature learning within restricted receptive fields.
时空特征学习是动作识别的关键部分,其目标不仅是融合每帧的空间特征,还要捕捉输入序列间的时间相关性。早期关于动作识别的研究 [19, 6, 5, 42, 9, 48] 探索了在二维空间特征基础上引入时间维度的3D卷积核应用。此后,3D卷积神经网络 (CNN) 展现出优异性能,逐渐成为处理序列数据的动作识别任务的事实标准。近期流行的视觉Transformer (ViT) 通过3D Token嵌入来融合时间维度,但基于ViT的动作识别方法 [1, 34] 存在局限性——它们只能在有限的感受野内进行时空特征学习。
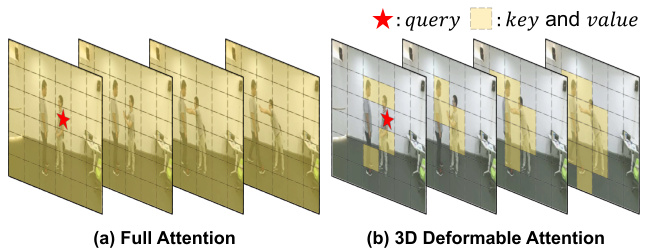
Figure 1: Comparison between (a) Full attention and (b) the proposed 3D deformable attention. Full attention considers all tokens against a specific query in a complete sequence. By contrast, 3D deformable attention considers only intense tokens with adaptive receptive fields.
图 1: (a) 全注意力机制与 (b) 提出的3D可变形注意力机制对比。全注意力机制在完整序列中考虑所有token与特定查询的关系。相比之下,3D可变形注意力机制仅关注具有自适应感受野的显著token。
To avoid this problem, several studies [15, 57, 47] have been conducted to allow more flexible receptive fields for deep learning models. Deformable CNN leverages dynamic kernels to capture the intense object regions. First, they determine the deformable coordinates using embedded features. The kernel is then applied to the features extracted from the deformable coordinates. Deformable ViTs [47, 57] encourage the use of an existing attention module to learn deformable features. The query tokens are projected onto the coordinates to obtain deformable regions from the key and value tokens. The deformed value tokens are then applied to the attention map, which is generated through a scaled dot product of the input query and deformed key tokens. These methods suggest a new approach that can overcome the limitations of existing standardized feature learning. However, despite some impressive results, these studies are still limited in that they are only compatible with the spatial dimensions. Therefore, as a primary challenge, there is a need for the development of novel and deformable
为避免这一问题,多项研究[15, 57, 47]致力于为深度学习模型提供更灵活的感受野。可变形CNN (Deformable CNN) 利用动态核捕捉显著目标区域:首先通过嵌入特征确定可变形坐标,再将核函数应用于这些坐标提取的特征。可变形ViT[47, 57]则倡导利用现有注意力模块学习可变形特征——将查询Token投影到坐标空间,从键Token和值Token中获取可变形区域,随后将形变后的值Token应用于通过输入查询与形变键Token的缩放点积生成的注意力图。这些方法突破了标准化特征学习的固有局限,但尽管取得显著成果,现有研究仍受限于仅适用于空间维度。因此,开发新型可变形
ViTs that can learn s patio temporal features from image sequences.
能够从图像序列中学习时空特征的ViTs。
Another challenge is the efficient application of multimodal input features to an action recognition model. Action recognition is classified into three categories based on the feature type. The first is a video-based approach [56, 4, 46, 29, 20, 43, 33], which has traditionally been used for action recognition. This approach is limited by a degraded performance caused by noise, such as varying object sizes, occlusions, or different camera angles. The second is a skeleton-based approach [51, 25, 12, 13, 11], which mainly converts poses into graphs for recognizing actions through a graph neural network (GNN). Although this approach is robust against noise, its performance is highly dependent on the pose extraction method. To overcome the shortcomings of the previous two approaches, the third method aims to simultaneously fuse heterogeneous domain features using multimodal or cross-modal learning. With this approach, video and skeleton features are jointly trained simultaneously. However, because most related studies use a separate model composed of a $\mathrm{GNN+CNN}$ or $\mathrm{CNN+}$ CNN for each modality, there is a limit in constructing an effective single model.
另一个挑战是如何将多模态输入特征高效应用于动作识别模型。动作识别根据特征类型可分为三类:第一类是基于视频的方法 [56, 4, 46, 29, 20, 43, 33],这是动作识别的传统方法。该方法会因物体尺寸变化、遮挡或不同摄像机角度等噪声导致性能下降。第二类是基于骨架的方法 [51, 25, 12, 13, 11],主要通过图神经网络 (GNN) 将姿态转换为图结构进行动作识别。虽然该方法对噪声具有鲁棒性,但其性能高度依赖姿态提取方法。为克服前两种方法的缺陷,第三类方法旨在通过多模态或跨模态学习同时融合异构域特征,实现视频与骨架特征的联合训练。但由于多数相关研究采用由 $\mathrm{GNN+CNN}$ 或 $\mathrm{CNN+}$ CNN 组成的独立模型处理各模态,构建有效单一模型存在局限性。
To alleviate the drawbacks stated above, we propose the use of transformer with 3D deformable attention for dynamically utilizing the s patio temporal features for action recognition. In this way, the proposed model applies flexible cross-modal learning, which handles the skeletons and video frames in a single transformer model. The skeletons are projected onto sequential joint tokens, and each joint token contains an activation at every joint coordinate. To provide effective cross-modal learning between each modality, the proposed method adopts a cross-modal token that takes the role of mutually exchanging contextual information. Therefore, the proposed model is capable of achieving a boosted performance without an auxiliary submodel for the cross-modalities. Figure 1 shows a comparison between the previous full attention and the proposed 3D deformable attention. In the case of the full attention shown in Fig. 1 (a), all tokens within a s patio temporal space are covered against a specific query token. By contrast, our proposed 3D deformable attention scheme, shown in Fig. 1 (b), considers only tokens with high relevance within the entire spatio temporal space. The main contributions of this study are as follows:
为缓解上述缺陷,我们提出采用带3D可变形注意力机制的Transformer模型,动态利用时空特征进行动作识别。该方法通过单一Transformer模型实现灵活的跨模态学习,同时处理骨骼序列与视频帧数据。骨骼数据被投影为连续的关节Token,每个关节Token包含各关节坐标的激活值。为实现模态间的有效交互,本方法引入跨模态Token来双向传递上下文信息,从而无需额外子模型即可提升跨模态性能。图1对比了传统全注意力机制与本文提出的3D可变形注意力机制:(a) 全注意力机制需计算时空范围内所有Token与查询Token的关系;(b) 我们的3D可变形注意力仅筛选高相关性的Token进行计算。本研究的主要贡献包括:
• We propose the first 3D deformable attention that adaptively considers the s patio temporal correlation within a transformer as shown in Fig. 1 (b), breaking away from previous studies that consider all tokens against a specific query in a complete sequence. • We propose a cross-modal learning scheme based on complementary cross-modal tokens. Each cross-modal token delivers contextual information between the different modalities. This approach can support a simple yet effective cross-modal learning within a singletransformer model structure.
• 我们提出了首个3D可变形注意力机制,如图1(b)所示,该机制能自适应地考虑Transformer中的时空相关性,突破了以往研究在完整序列中针对特定查询考虑所有Token的做法。
• 我们提出了一种基于互补跨模态Token的跨模态学习方案。每个跨模态Token在不同模态间传递上下文信息。该方法能在单一Transformer模型结构中实现简单而有效的跨模态学习。
• We present qualitative evidence for 3D deformable attention with visual explanations and prove that the proposed model outperforms several previous state-ofthe-art (SoTA) methods.
• 我们通过可视化解释为3D可变形注意力 (3D deformable attention) 提供了定性证据,并证明所提出的模型优于之前的多种最先进 (SoTA) 方法。
2. Related Works
2. 相关工作
S patio temporal learning for action recognition. Early studies in this area focused primarily on employing a 3D CNN, which is an extension of a 2D CNN. This has become a central remedy in vision-based action recognition in recent years. PoseC3D [19] combines 3D volumetric heatmaps from the skeletons and frames of the input video. SlowFast [21] makes a significant contribution to the field by providing a frame-fusion scheme be- tween different frame rates. There are also related methods [22, 42, 43, 44, 9, 48, 4, 20, 24] that explore the use of a 3D CNN architecture for action recognition. STDA [24] applies a 3D deformable CNN that captures substantial intense regions for s patio temporal learning. Over the last few years, focus has shifted toward skeleton-based action recognition with respect to the emergence of a GNN. ST-GCN [51] has become a baseline adopting separate spatial and temporal representation modules for s patio temporal modeling. In addition, ViTs have attracted considerable attention owing to their superior performance in sequential tasks. STAR [1] applies cross-attention for the fusing of temporal correlations between spatial representations. ViViT [2] embeds an input video with a 3D tokenizer to compose the spatiotemporal features in a single token. Other studies [7, 1, 31] have adopted a temporal stride to capture the diversity between different time steps. However, the concept of a 3D deformation, despite its excellent performance, cannot be applied to the attention of ViTs owing to various structural constraints. Cross-modal learning for action recognition. Most current action recognition methods use various modalities with video frames and skeletons. Several methods [17, 6, 5, 16] employ a graph convolutional network (GCN) to handle a raw skeleton input and a CNN for the video frames. VPN [17] applies GCN sub networks to support the CNN. The footages of GCN networks are linearly combined with the CNN feature maps. MMNet [6] introduced a multimodal network with two GCN sub networks and CNNs. Each subnetwork embeds the features separately, and these features are then summed at the end of the network. Other studies [14, 49, 3, 1, 19, 39] transformed graphical skeletons into the heatmaps. PoseC3D [19] uses dual 3D CNN branches for video frames and 3D volumetric heatmaps. It does not explicitly consider the spatial relationships between joints in the skeleton. This may limit its ability to capture complex and subtle movements, or to distinguish between similar actions that involve different joint configurations. STAR [1] proposed joint tokens generated by combining CNN feature maps with 2D joint heatmaps. To fuse the two modalities, they concatenated multiclass tokens by combining different modal tokens. Despite the improved performance of cross-modal learning, video frames and skeleton modalities are merely integrated, thus neglecting a careful design. We propose an effective feature fusion method called a crossmodal token. To exchange contextual information, each token is dispatched to another modality.
时空学习用于动作识别。该领域的早期研究主要集中在使用3D CNN(三维卷积神经网络),这是2D CNN的扩展。近年来,这已成为基于视觉的动作识别的核心解决方案。PoseC3D [19] 结合了来自输入视频骨骼和帧的3D体积热图。SlowFast [21] 通过提供不同帧率之间的帧融合方案,对该领域做出了重要贡献。还有一些相关方法 [22, 42, 43, 44, 9, 48, 4, 20, 24] 探索了使用3D CNN架构进行动作识别。STDA [24] 应用了3D可变形CNN,用于捕获时空学习中的重要区域。过去几年,随着GNN(图神经网络)的出现,研究重点转向了基于骨骼的动作识别。ST-GCN [51] 已成为采用独立空间和时间表示模块进行时空建模的基准方法。此外,ViTs(Vision Transformers)因其在序列任务中的卓越性能而备受关注。STAR [1] 应用交叉注意力来融合空间表示之间的时间相关性。ViViT [2] 使用3D tokenizer嵌入输入视频,将时空特征组合到单个token中。其他研究 [7, 1, 31] 采用时间步幅来捕获不同时间步之间的多样性。然而,尽管3D变形概念性能优异,但由于各种结构限制,无法应用于ViTs的注意力机制。
动作识别的跨模态学习。目前大多数动作识别方法使用视频帧和骨骼等多种模态。一些方法 [17, 6, 5, 16] 使用图卷积网络(GCN)处理原始骨骼输入,并使用CNN处理视频帧。VPN [17] 应用GCN子网络来支持CNN。GCN网络的输出与CNN特征图线性结合。MMNet [6] 引入了具有两个GCN子网络和CNN的多模态网络。每个子网络单独嵌入特征,然后在网络末端将这些特征相加。其他研究 [14, 49, 3, 1, 19, 39] 将图形骨骼转换为热图。PoseC3D [19] 使用双3D CNN分支处理视频帧和3D体积热图。它没有明确考虑骨骼中关节之间的空间关系,这可能限制其捕获复杂细微动作或区分涉及不同关节配置的相似动作的能力。STAR [1] 提出了通过结合CNN特征图和2D关节热图生成的联合token。为了融合这两种模态,他们通过组合不同模态的token来连接多类token。尽管跨模态学习性能有所提高,但视频帧和骨骼模态只是简单集成,忽略了精心设计。我们提出了一种称为跨模态token的有效特征融合方法。为了交换上下文信息,每个token被分发到另一个模态。
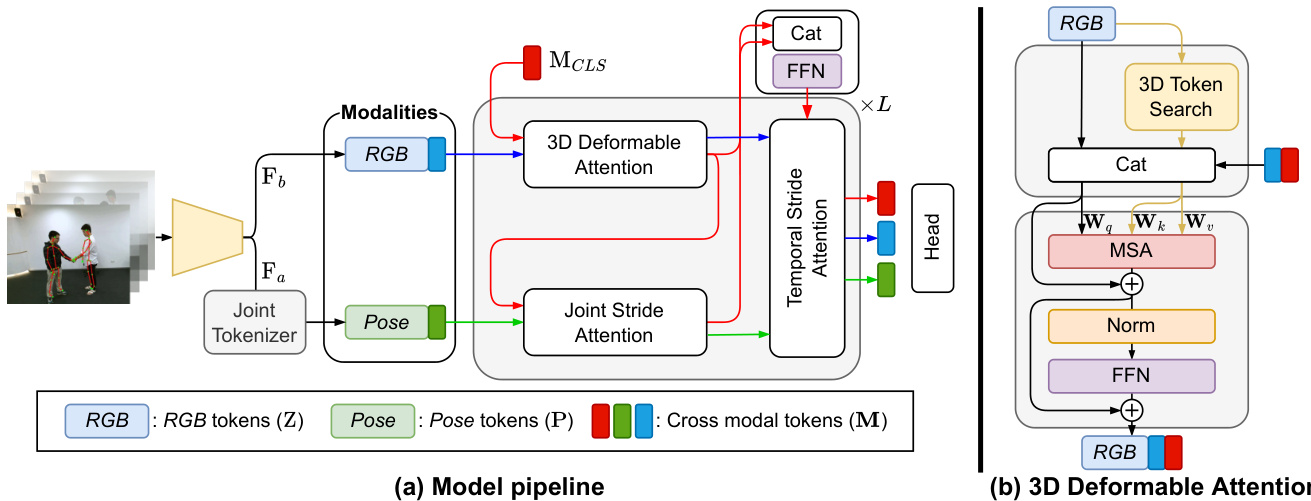
Figure 2: Overview of our 3D deformable transformer. (a) Our model consists of a backbone and a series of transformer blocks. Each transformer block uses different modality tokens to process intrinsic properties from various domains and fuse the modalities with cross-modal tokens. The proposed model includes joint stride and temporal stride attention to reduce computational costs. (b) The proposed 3D deformable attention includes the 3D token search (3DTS) and the attention block. The input RGB token Z is embedded as query token after concatenating with modal tokens. The deformable token from the 3DTS is also concatenated with modal tokens, then it is multiplied with key $(\mathbf{W}{k})$ and value $(\mathbf{W}{v})$ weights. These are then fed to the multi-head self-attention (MSA) to interact with the query token.
图 2: 我们的3D可变形Transformer概述。(a) 模型由主干网络和一系列Transformer块组成。每个Transformer块使用不同的模态Token处理来自各领域的固有属性,并通过跨模态Token融合多模态信息。该模型包含联合步长注意力与时序步长注意力以降低计算成本。(b) 提出的3D可变形注意力包含3D Token搜索(3DTS)和注意力块。输入RGB Token Z在与模态Token拼接后作为查询Token嵌入。从3DTS获取的可变形Token同样与模态Token拼接,随后与键$(\mathbf{W}{k})$和值$(\mathbf{W}{v})$权重相乘,最终输入多头自注意力(MSA)模块与查询Token进行交互。
Transformer with deformable attention. The idea of a 2D deformable CNN for the learning of deformable features has been applied to the attention module of a ViT, achieving an excellent performance in various applications, including image classification. Deformable DETR [57] was applied to object detection and demonstrated its ability to accurately detect objects of various sizes. A deformable attention transformer (DAT) [47] with an improved numerical stability and a robust performance was recently proposed. In terms of action recognition, 3D deformable CNNs [24, 26] for s patio temporal learning showed a better performance than a 2D deformable CNN but were not applied to a transformer owing to the structural constraints of an attention optimized for spatial feature embedding. Therefore, in this study, we propose a new 3D deformable transformer capable of fusing cross-modal features using cross-modal tokens. The proposed deformable method enables 3D deformable feature embedding based on local joint stride and temporal stride attention. The remainder of this paper is organized as follows. Section 3 provides a detailed explanation of the proposed approach. Section 4 provides an experimental analysis of several benchmarks as well as visual descriptions. Finally, Section 5 provides some concluding remarks regarding this research.
可变形注意力Transformer。将2D可变形CNN(Convolutional Neural Network)用于学习可变形特征的思想已应用于ViT(Vision Transformer)的注意力模块,在图像分类等多种任务中表现出色。Deformable DETR [57] 在目标检测领域展现了精准检测多尺度物体的能力。近期提出的可变形注意力Transformer(DAT)[47] 在数值稳定性和鲁棒性方面均有提升。在动作识别领域,面向时空学习的3D可变形CNN [24, 26] 虽表现优于2D版本,但由于空间特征嵌入优化的注意力结构限制,尚未与Transformer结合。为此,本研究提出新型3D可变形Transformer,通过跨模态Token实现多模态特征融合。该可变形方法支持基于局部关节步长与时序步长注意力的3D特征嵌入。本文结构如下:第3节详述研究方法;第4节进行多基准实验分析与可视化说明;第5节给出研究结论。
3. Approach
3. 方法
We propose a 3D deformable transformer for action recognition with adaptive s patio temporal receptive fields and a cross-modal learning scheme. The overall architecture of the proposed model is shown in Fig. 2 and is described in detail in the following sections.
我们提出了一种用于动作识别的3D可变形Transformer (Transformer),具有自适应时空感受野和跨模态学习方案。该模型的整体架构如图 2 所示,并将在以下章节中详细描述。
3.1. Cross-modal learning
3.1. 跨模态学习
In action recognition, cross-modal learning has been the mainstream, leveraging various modalities such as video frames and skeletons. Several successful studies [19, 6, 5, 17, 23, 16] have employed sub networks that handle different domain features. However, these designs eventually increase the redundancy and complexity owing to the domain-specific sub networks. We propose simple yet effective cross-modal learning for mutually exchanging contextual information. Our cross-modal learning method consists of a backbone [45], which provides intermediate feature maps and sequential tasks. When the image has a height $H$ , width $W$ , temporal dimension $T$ , and feature dimension $C$ , the backbone network feeds visual feature maps $\mathrm{F}{a}\in\dot{\mathbb{R}}^{C\times T\times\frac{H}{2}\times\frac{W}{2}}$ and $\mathrm{F}{b}\in\mathbb{R}^{4C\times T\times\frac{H}{8}\times\frac{W}{8}}$ , extracted from intermediate layers. In the case of $\mathrm{F}{b}$ , we consider it as the $R G B$ modality input for visual representation learning, whereas the local level feature map, $\mathrm{F}_{a}$ , is regarded as the pose modality input by combining with skeletons. To fuse both modalities, we apply the following concepts:
在动作识别领域,跨模态学习已成为主流方法,通过利用视频帧和骨骼等多种模态信息。多项成功研究[19, 6, 5, 17, 23, 16]采用了处理不同领域特征的子网络结构。然而这些设计最终会因领域专用子网络而增加冗余和复杂性。我们提出了一种简单高效的跨模态学习方法,通过双向交换上下文信息实现模态互补。该跨模态学习方法包含一个主干网络[45],可提供中间特征图和时序任务处理能力。当图像高度为$H$、宽度为$W$、时间维度为$T$、特征维度为$C$时,主干网络会输出从中间层提取的视觉特征图$\mathrm{F}{a}\in\dot{\mathbb{R}}^{C\times T\times\frac{H}{2}\times\frac{W}{2}}$和$\mathrm{F}{b}\in\mathbb{R}^{4C\times T\times\frac{H}{8}\times\frac{W}{8}}$。对于$\mathrm{F}{b}$,我们将其视为视觉表征学习的RGB模态输入,而局部层级特征图$\mathrm{F}_{a}$则通过与骨骼数据结合被视为姿态模态输入。为融合两种模态,我们应用了以下概念:
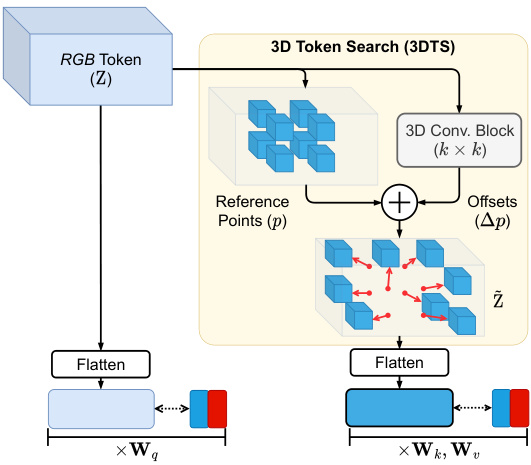
Figure 3: Illustration of proposed 3D deformable attention for adaptive s patio temporal learning. Using 3DTS, an offset vector $(\Delta p)$ from a 3D conv block finds the deformed tokens by moving the reference points $(p)$ scattered on the input $R G B$ tokens Z. The 3D deformable tokens $\tilde{\mathrm{Z}}$ have the same number of tokens as the reference points $(p)$ .
图 3: 提出的自适应时空学习3D可变形注意力机制示意图。通过3DTS (3D Temporal Shift) 模块,从3D卷积块获得的偏移向量 $(\Delta p)$ 通过移动散布在输入 $RGB$ token Z上的参考点 $(p)$ 来定位变形后的token。3D可变形token $\tilde{\mathrm{Z}}$ 与参考点 $(p)$ 具有相同数量的token。
Pose modality. To design a cross-modal learning scheme with an alleviated redundancy, we propose visual featureoriented pose tokens combined with joint heatmaps, such as [19, 1]. First, the sequential skeletons are decomposed into single-joint units. Each joint is then recomposed into a joint heatmap $\begin{array}{r}{\mathcal{H}\in\mathbb{R}^{T\times R\times\frac{H}{2}\times\frac{W}{2}}}\end{array}$ by projecting the joints toward an empty voxel at the corresponding coordinates $(x_{t,r},y_{t,r})$ . Here, $R$ is the number of joints, and spatial dimension follows feature map size of $\mathrm{F}{a}$ . Finally, pose tokens $\mathrm{P}$ using the joint tokenizer shown in Fig. 2 (a) using the multiplication of $\mathrm{F}_{a}$ and the Gaussian blur output at time $t$ as follows:
姿态模态。为设计一种减轻冗余的跨模态学习方案,我们提出结合关节热图的视觉特征导向姿态token,如[19,1]所示。首先,将连续骨骼分解为单关节单元,随后通过将关节投影至对应坐标$(x_{t,r},y_{t,r})$的空体素,将每个关节重构成关节热图$\begin{array}{r}{\mathcal{H}\in\mathbb{R}^{T\times R\times\frac{H}{2}\times\frac{W}{2}}}\end{array}$。其中$R$表示关节数量,空间维度与$\mathrm{F}{a}$的特征图尺寸一致。最终如图2(a)所示,使用关节token生成器,通过$\mathrm{F}_{a}$与时间$t$的高斯模糊输出相乘得到姿态token $\mathrm{P}$:
$$
\mathrm{P}{t}=|{r}\sum_{j}^{\frac{H}{2}}\sum_{i}^{\frac{W}{2}}\mathrm{F}{a,t}(i,j)\mathcal{H}_{t,r}(i,j)
$$
$$
\mathrm{P}{t}=|{r}\sum_{j}^{\frac{H}{2}}\sum_{i}^{\frac{W}{2}}\mathrm{F}{a,t}(i,j)\mathcal{H}_{t,r}(i,j)
$$
$$
\mathcal{H}{t,r}(i,j)=e^{-\frac{(i-x_{t,r})^{2}+(j-y_{t,r})^{2}}{2\sigma^{2}}}
$$
where $\mathrm{P~}\in\mathbb{R}^{C\times T\times R}$ consists of $R$ pose tokens for every skeleton sequence with $C$ feature dimensions. $||$ indicates concatenation. To meet the feature dimensions with $R G B$ modality, $\mathrm{F}_{b}$ , linear projection is applied to pose tokens, resulting in P ∈ R4C×T ×R.
其中 $\mathrm{P~}\in\mathbb{R}^{C\times T\times R}$ 由 $R$ 个姿态token组成,每个骨架序列具有 $C$ 个特征维度。$||$ 表示拼接操作。为匹配 $RGB$ 模态的特征维度 $\mathrm{F}_{b}$,对姿态token进行线性投影得到 P ∈ R4C×T ×R。
RGB modality. With $R G B$ modality, the extracted visual feature map $\mathrm{F}_{b}$ is regarded as $R G B$ tokens ${\mathrm{\textsf~{Z~}~}}\in$ R4C×T × H8 × W8 and is fused with the position embedding.
RGB模态。在RGB模态下,提取的视觉特征图$\mathrm{F}_{b}$被视为RGB token ${\mathrm{\textsf~{Z~}~}}\in$ R4C×T × H8 × W8,并与位置嵌入进行融合。
3.2. 3D deformable transformer
3.2. 3D可变形Transformer
Cross-modal tokens. An intuitive method is to concatenate all tokens from both modalities, considering the charact eris tics of each token, and then combining information through the transformer stacks. However, to combine different modalities in a single transformer, a deliberate design is required, and the modalities must be cooperative and complementary. Similarly, in STAR [1], the authors employ multi-class tokens for cross-modal learning. Despite a simple yet effective approach, on par with other trans- formers, it is aimed only at an information fusion for all tokens without considering the intrinsic properties and comple ment ari ties of various modalities. Therefore, we propose a cross-modal token that effectively combines the different modalities within the transformer. The cross-modal token $\mathbf{M}\in\mathbb{R}^{4C\times T\times3}$ is a set of three trainable tokens: CLS, RGB and pose modal tokens. In previous studies [18, 41], CLS tokens were used as the final embeddings fusing information by interacting with other tokens. We consider the CLS token $\mathrm{M}{C L S}\in\bar{\mathbb{R}}^{4C\times T\times1}$ as a ‘modality-mixer’ compiling the remaining two modal tokens, which are dispatched to mutual modalities to trade their domain knowledge. The first $\mathrm{M}{R G B}$ and $\mathrm{M}{C L S}$ tokens are fed to the 3D deformable attention. Then, the output $R G B$ and $C L S$ modal tokens, $\mathrm{M}{R G B}$ and $\mathrm{M}_{C L S}$ of a 3D deformable attention, reflect information from their own domains through separated transformer blocks cooperating with the dispatched $C L S$ tokens. Hereafter, we introduce the 3D deformable attention shown in Fig. 2 (b), which is the core of the proposed transformer. 3D deformable attention. Although transformers have recently become a new standard in vision tasks, relatively few studies have been conducted on action recognition tasks. Because the nature of a transformer considers long-term relations between the input tokens, it may lead to an expone nti ally increasing computational complexity with the time steps. In addition, to solve the problem of static transformers, DAT [47] that flexibly selects the key and value positions in a self-attention has been proposed; however, it is unsuitable for an action recognition that has to deal with cross-modalities and s patio temporal features. To alleviate the complexity while maintaining the nature of the transformer, inspired by [47], we propose the use of 3D deformable attention for action recognition, as shown in Fig. 2 (b). 3D deformable attention can adaptively capture spatio temporal features on the $R G B$ modality.
跨模态Token。一种直观的方法是根据每个Token的特性,将两种模态的所有Token拼接起来,然后通过Transformer堆栈整合信息。然而,要在单个Transformer中融合不同模态,需要精心设计,且各模态必须具有协同互补性。类似地,STAR[1]采用多类别Token进行跨模态学习。尽管这种方法简单有效且与其他Transformer性能相当,但其仅针对所有Token的信息融合,未考虑不同模态的内在特性与互补关系。因此,我们提出一种能在Transformer内部有效融合多模态的跨模态Token。该跨模态Token $\mathbf{M}\in\mathbb{R}^{4C\times T\times3}$ 包含三个可训练Token:CLS、RGB和姿态模态Token。在先前研究[18,41]中,CLS Token作为最终嵌入表征,通过与其他Token交互实现信息融合。我们将CLS Token $\mathrm{M}{C L S}\in\bar{\mathbb{R}}^{4C\times T\times1}$ 视为"模态混合器",负责整合另外两个模态Token,后者被分配到相互模态中以交换领域知识。首先将 $\mathrm{M}{R G B}$ 和 $\mathrm{M}{C L S}$ 输入3D可变形注意力模块,随后输出的RGB与CLS模态Token $\mathrm{M}{R G B}$ 和 $\mathrm{M}_{C L S}$ 通过独立的Transformer块与分配的CLS Token协作,反映各自领域的信息。下文将介绍图2(b)所示的3D可变形注意力机制,这是所提Transformer的核心组件。
3D可变形注意力。尽管Transformer近期已成为视觉任务的新标准,但在动作识别任务中的研究相对较少。由于Transformer本质考虑输入Token间的长期关系,随着时间步长增加可能导致计算复杂度指数级上升。此外,为解决静态Transformer的问题,DAT[47]提出在自注意力中灵活选择键值位置的方法,但其不适用于需要处理跨模态和时空特征的动作识别任务。为在保持Transformer特性的同时降低复杂度,受[47]启发,我们提出如图2(b)所示的3D可变形注意力机制用于动作识别。该机制能自适应捕获RGB模态上的时空特征。
The 3D deformable attention module consists of a 3D token search (3DTS) and multi-head self-attention (MSA) with a feed-forward network (FFN), as shown in Fig. 2 (b). First, the input of the module, RGB token Z, is fed to the 3DTS, which contains a two-layered Conv3D with kernel $k$ . After the first Conv3D, layer normalization (LN) and GELU non-linearity are applied. The last Conv3D generates offsets $(\Delta p)$ that contain flow fields against the reference points $(p)$ . The reference points are defined as being regularly scattered within a 3D space. The offsets guide the reference points to find disc rim i native token coordinates in the s patio temporal tokens Z, as shown in Fig. 3. 3D deformable tokens $\tilde{\mathrm{Z}}$ are configured by selecting the tokens from the adjusted coordinates taken from the offsets.
3D可变形注意力模块由3D Token搜索(3DTS)和带前馈网络(FFN)的多头自注意力(MSA)组成,如图2(b)所示。首先,模块的输入RGB Token Z被送入3DTS,该部分包含一个核大小为$k$的双层Conv3D。经过第一层Conv3D后,会应用层归一化(LN)和GELU非线性激活。最后一层Conv3D生成包含相对于参考点$(p)$的流场偏移量$(\Delta p)$。参考点被定义为在3D空间中规则散布的点。如图3所示,这些偏移量引导参考点在时空Token Z中找到判别性Token坐标。通过从偏移量调整后的坐标中选择Token,最终配置出3D可变形Token$\tilde{\mathrm{Z}}$。
$$
\tilde{\mathrm{Z}}=3\mathrm{DTS}(\mathrm{Z};\omega)
$$
$$
\tilde{\mathrm{Z}}=3\mathrm{DTS}(\mathrm{Z};\omega)
$$
where $\mathrm{Z}\in\mathbb{R}^{4C\times T\times\frac{H}{8}\times\frac{W}{8}}$ and $\tilde{\boldsymbol{\mathrm{Z}}}\in\mathbb{R}^{4C\times\tilde{T}\times\tilde{H}\times\tilde{W}}$ are the input and selected $R G B$ tokens respectively. The size of $\tilde{T}$ , $\tilde{H}^{\cdot}$ and $\tilde{W}$ are determined based on the kernel size $k$ . In our case, we set the $k$ as 7 without padding for sparsely extracting deformable tokens and increasing the efficiency. In addition, $\mathbf{W}_{q}\in\mathbb{R}^{4C\times4C}$ and $\omega$ are trainable weight and model parameters for the MSA and 3D conv block in the 3DTS, respectively. It should be noted that while query tokens are composed in the same manner as the transformer, the key and value tokens are composed of selected tokens from the 3DTS. Further details on our implementation are in Appendix B.
其中 $\mathrm{Z}\in\mathbb{R}^{4C\times T\times\frac{H}{8}\times\frac{W}{8}}$ 和 $\tilde{\boldsymbol{\mathrm{Z}}}\in\mathbb{R}^{4C\times\tilde{T}\times\tilde{H}\times\tilde{W}}$ 分别是输入和选定的 $RGB$ token。$\tilde{T}$、$\tilde{H}^{\cdot}$ 和 $\tilde{W}$ 的大小由核尺寸 $k$ 决定。在本研究中,我们将 $k$ 设为7且不填充,以稀疏提取可变形token并提升效率。此外,$\mathbf{W}_{q}\in\mathbb{R}^{4C\times4C}$ 和 $\omega$ 分别是3DTS中MSA和3D卷积块的可训练权重与模型参数。需注意的是,虽然查询token的组成方式与transformer相同,但键token和值token由3DTS选定的token构成。更多实现细节见附录B。
These tokens are then embedded into the key and value tokens using $\mathbf{W}{k}$ and $\mathbf{W}{v}$ , respectively. Herein, we aim to make the $\mathrm{M}{R G B}$ token faithfully learn the $R G B$ modality features, and $\mathrm{M}{C L S}$ trades domain knowledge between the $R G B$ and pose modalities. To fuse cross-modal tokens with the $R G B$ modality, three tokens, $\mathrm{M}{R G B}$ , $\mathrm{M}_{C L S}$ and s patio temporal feature tokens Z, are concatenated to token $\mathbf{X}$ .
这些Token随后分别通过$\mathbf{W}{k}$和$\mathbf{W}{v}$嵌入到键和值Token中。在此,我们的目标是让$\mathrm{M}{RGB}$ Token真实学习$RGB$模态特征,而$\mathrm{M}{CLS}$则在$RGB$和姿态模态之间交换领域知识。为了将跨模态Token与$RGB$模态融合,将$\mathrm{M}{RGB}$、$\mathrm{M}_{CLS}$和时空特征Token Z三个Token拼接为Token $\mathbf{X}$。
$$
\mathbf{X}=[\boldsymbol{\mathrm{Z}}||\mathbf{M}{R G B}||\mathbf{M}_{C L S}]
$$
$$
\mathbf{X}=[\boldsymbol{\mathrm{Z}}||\mathbf{M}{R G B}||\mathbf{M}_{C L S}]
$$
where $\mathrm{M}{R G B}$ and $\mathrm{M}_{C L S}$ are obtained from a portion of the proposed cross-modal tokens representing the $R G B$ modality and modality head, respectively.
其中 $\mathrm{M}{R G B}$ 和 $\mathrm{M}_{C L S}$ 分别从代表 $R G B$ 模态和模态头的部分跨模态 token 中获取。
Similarly, the selected deformable tokens $\tilde{\mathrm{Z}}$ are coupled with two cross-modal tokens to produce $\tilde{\bf X}$ .
同样,选定的可变形Token $\tilde{\mathrm{Z}}$ 与两个跨模态Token耦合生成 $\tilde{\bf X}$。
$$
\tilde{\mathbf{X}}=[\tilde{Z}||\mathbf{M}{R G B}||\mathbf{M}_{C L S}]
$$
$$
\tilde{\mathbf{X}}=[\tilde{Z}||\mathbf{M}{R G B}||\mathbf{M}_{C L S}]
$$
Then, $\mathbf{X}$ is multiplied with query weight $\mathbf{W}{q}$ and, $\tilde{\mathbf{X}}$ is multiplied with $k e y$ and value weights, $\mathbf{W}{k}$ and $\mathbf{W}_{v}$ , respectively. Those recomposed tokens are fed into multi-head self-attention as a query, key and value for each.
然后,$\mathbf{X}$ 与查询权重 $\mathbf{W}{q}$ 相乘,而 $\tilde{\mathbf{X}}$ 则分别与键 (key) 权重 $\mathbf{W}{k}$ 和值 (value) 权重 $\mathbf{W}_{v}$ 相乘。这些重组后的 token 作为查询 (query)、键和值输入到多头自注意力机制中。
$$
\mathbf{X}=\mathbf{X}+\mathrm{MSA}(\mathbf{XW}{q},\tilde{\mathbf{X}}\mathbf{W}{k},\tilde{\mathbf{X}}\mathbf{W}_{v})
$$
$$
\mathbf{X}=\mathbf{X}+\mathrm{MSA}(\mathbf{XW}{q},\tilde{\mathbf{X}}\mathbf{W}{k},\tilde{\mathbf{X}}\mathbf{W}_{v})
$$
The output $\mathbf{X}$ of 3D deformable attention is finally obtained by applying a LN and FFN.
输出 $\mathbf{X}$ 最终通过应用 LN 和 FFN 获得 3D 可变形注意力 (3D deformable attention) 的结果。
$$
[\mathrm{Z},\mathrm{M}{R G B},\mathrm{M}_{C L S}^{'}]=\mathbf{X}+\mathrm{FFN}(\mathrm{LN}(\mathbf{X}))
$$
$$
[\mathrm{Z},\mathrm{M}{R G B},\mathrm{M}_{C L S}^{'}]=\mathbf{X}+\mathrm{FFN}(\mathrm{LN}(\mathbf{X}))
$$
We visualized the attention scores of the selected tokens from the proposed 3D deformable attention shown in Fig. 5.
我们在图5所示提出的3D可变形注意力机制中,对选定Token的注意力分数进行了可视化。
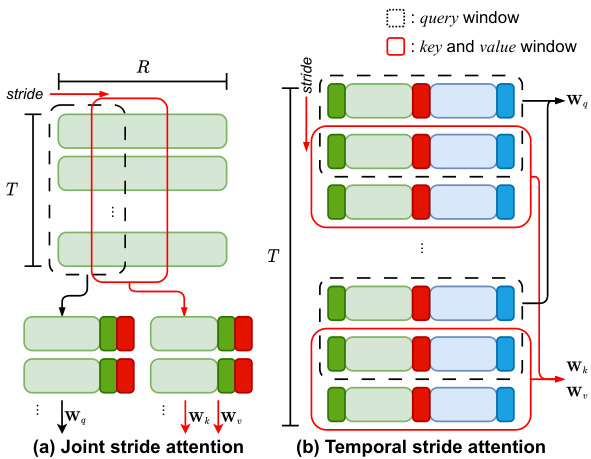
Figure 4: Proposed stride attention modules. (a) Joint stride attention, where a series of joint tokens are grouped into query, key, and value including all temporal dimensions with a stride window. (b) Temporal stride attention where tokens are bundled with temporal stride windows to fuse the changes with the time steps.
图 4: 提出的跨步注意力模块。(a) 联合跨步注意力,其中一系列联合token被分组为查询、键和值,包含所有时间维度的跨步窗口。(b) 时序跨步注意力,其中token与时序跨步窗口捆绑,以融合时间步长的变化。
As indicated in Fig. 5, our proposed 3DTS faithfully identifies the fundamental intense regions with adaptive receptive fields against entire sequences.
如图 5 所示,我们提出的 3DTS 方法能够准确识别整个序列中具有自适应感受野的基础强响应区域。
Local joint stride attention. In action recognition, there are often multiple people appearing in a scene; therefore, the number of joint tokens increases with the number of people. To reduce the computational complexity, we concatenate the joints of multiple people into a series of joint tokens. Although this approach is an efficient way to process multiple people in the same scene simultaneously without significantly increasing the complexity, it still results in a problem in that the size of the joint token increases exponentially as the number of people increases. To avoid this problem, we configure the query, key, and value tokens using a sliding window on the joint tokens, as shown in Fig. 4 (a). All tokens in each sliding window are flattened and then concatenated with $\mathrm{M}{p o s e}$ and $\mathrm{M}{C L S}^{'}$ dispatched from a 3D deformable attention to apply a scaled-dot product. This is more efficient than calculating all tokens at once and maintaining the relations with each other. The output of the joint stride attention is the pose token $\mathrm{P}$ and modal tokens $\mathrm{M}_{p o s e}$ and M∗CLS.
局部关节滑动注意力机制。在动作识别场景中,同一画面常出现多个人物,导致关节token数量随人数增加而增长。为降低计算复杂度,我们将多人的关节连接为连续的关节token序列。虽然这种方法能高效处理同场景多人动作而不显著增加复杂度,但随着人数增加,关节token规模仍会呈指数级膨胀。为解决该问题,我们采用滑动窗口机制在关节token上配置查询(query)、键(key)和值(value)token,如图4(a)所示。每个滑动窗口内的所有token会先展平,再与来自3D可变形注意力的$\mathrm{M}{pose}$和$\mathrm{M}{CLS}^{'}$进行拼接,最后执行缩放点积运算。相比一次性计算所有token并维护相互关系,这种方法效率更高。关节滑动注意力机制的输出是姿态token $\mathrm{P}$以及模态token $\mathrm{M}_{pose}$和M∗CLS。
The calculated $R G B$ tokens Z and pose tokens $\mathrm{P}$ are fed to the temporal stride attention module. Before this step, to fuse contextual information from each modality, M′CLS memorized from the 3D deformable attention and $\mathrm{M}{C L S}^{*}$ calculated from the joint stride attention are projected together into a new single $\mathrm{M}_{C L S}$ as shown in Fig. 2 (a). Subsequently, the temporal stride attention module learns the correlations between temporal changes against tokens concatenated with cross-modal tokens.
计算得到的 $R G B$ token Z 和姿态 token $\mathrm{P}$ 被输入到时序跨步注意力模块。在此之前,为了融合来自各模态的上下文信息,将从3D可变形注意力中记忆的 M′CLS 与通过联合跨步注意力计算得到的 $\mathrm{M}{C L S}^{*}$ 一起投影为新的单一 $\mathrm{M}_{C L S}$,如图 2(a) 所示。随后,时序跨步注意力模块学习与跨模态 token 拼接后的 token 之间的时序变化相关性。
Temporal stride attention. Several limitations of an attention module exist when the transformer handles the input tokens. In general, the attention module covers all input tokens with scaled-dot products. Thus, the complexity of the attention module is highly dependent on the number of input tokens. In the case of sequential data, this problem is more serious because the input tokens grow with the sizes of the temporal dimensions. Ahn et al. [1] divided temporal dimensions into two groups that contain regularly interleaved tokens. Despite the halved temporal dimensions, the complexity was only slightly reduced, and the temporal correlations of the neighborhood were decoupled. Unlike Ahn et al. [1], we propose a temporal stride with mitigated complexity and an enhanced temporal correlation for crossattention. When building input query, key, and value tokens, the temporal dimensions are split into regularly increasing strides to couple various sequential relationships with reduced complexity. As shown in Fig. 4 (b), we first set a local time window for a given stride. This window traverses all tokens and specifies the query, key, and value tokens. It not only reduces the number of input tokens of the attention module but also supports temporal representation learning without using all tokens at once.
时间跨度注意力 (Temporal stride attention)。当Transformer处理输入token时,注意力模块存在若干局限性。通常,注意力模块通过缩放点积覆盖所有输入token,因此其复杂度高度依赖于输入token的数量。对于时序数据,这个问题更为严重,因为输入token会随时间维度增长而增加。Ahn等人 [1] 将时间维度划分为两组包含规则交错token的组别。尽管时间维度减半,但复杂度仅略微降低,且相邻区域的时间相关性被解耦。与Ahn等人 [1] 不同,我们提出了一种时间跨度方法,在降低复杂度的同时增强了交叉注意力的时间相关性。构建查询(query)、键(key)和值(value) token时,时间维度被分割为规则递增的跨度,从而以更低复杂度耦合多种时序关系。如图4(b)所示,我们首先为给定跨度设置局部时间窗口。该窗口会遍历所有token并指定查询、键和值token。这种方法不仅减少了注意力模块的输入token数量,还支持无需一次性使用所有token的时间表征学习。
Table 1: Accuracy comparisons with SoTA approaches on NTU60 and NTU120. P and R denote pose and RGB modalities, respectively. $\dagger$ indicates estimated pose.
表 1: NTU60 和 NTU120 数据集上与当前最优方法 (SoTA) 的准确率对比。P 和 R 分别表示姿态和 RGB 模态。$\dagger$ 表示估计姿态。
| 方法 | 模态 | 预训练 | NTU60-XSub (%) | NTU60-XView (%) | NTU120-XSub (%) | NTU120-XSet (%) |
|---|---|---|---|---|---|---|
| 3s-AimCLR [40] | P | 86.9 | 92.8 | 80.1 | 80.9 | |
| PoseC3D [19] | Pt | 93.7 | 96.6 | 86.0 | 89.6 | |
| VPN [17] | R+P | 95.5 | 98.0 | 86.3 | 87.8 | |
| VPN++ (3D pose) [16] | R+P | 96.6 | 99.1 | 90.7 | 92.5 | |
| MMNet [6] | R+P | 96.0 | 98.8 | 92.9 | 94.4 | |
| PoseC3D [19] | R+Pt | 97.0 | 99.6 | 95.3 | 96.4 | |
| ST-GCN [51] | P | 81.5 | 88.3 | |||
| DualHead-Net [10] | P | 92.0 | 96.6 | 88.8 | 89.3 | |
| Skeletal GNN [52] | P | 91.6 | 96.7 | 87.5 | 89.2 | |
| CTR-GCN [11] | P | 92.4 | 96.8 | 88.8 | 90.6 | |
| InfoGCN [13] | P | 93.0 | 97.1 | 89.8 | 91.2 | |
| KA-AGTN [30] | P | 90.4 | 96.1 | 86.1 | 88.0 | |
| PoseMap [28] | R+Pt | 91.7 | 95.2 | |||
| MMTM [23] | R+P | 91.9 | ||||
| STAR [1] | R+P | 92.0 | 96.5 | 90.3 | 92.7 | |
| TSMF [5] | R+P | 92.5 | 97.4 | 87.0 | 89.1 | |
| Ours | R+P | 94.3 | 97.9 | 90.5 | 91.4 |
All of the deformable transformers stated above are repeated $L$ -times, as shown in Fig. 2 (a). To make the final logits, we concatenate the cross-modal tokens only along with the channel dimension and then feed them to the classification head.
上述所有可变形Transformer均重复$L$次,如图2(a)所示。为生成最终逻辑值(logits),我们仅沿通道维度拼接跨模态Token,然后将其输入分类头。
4. Experiments
4. 实验
Datasets. We conducted experiments using several represent at ive benchmark datasets: FineGYM [36], NTU60 [35], NTU120 [27], and PennAction [54]. FineGYM contains 29K videos with 99 fine-grained action labels collected from gymnastic video clips. NTU60 and NTU120 are representative multimodal datasets that are used for human action recognition. NTU60 consists of 57K videos of 60 action labels collected in a controlled environment. NTU120, which is a superset of NTU60, contains 114K videos of 120 action labels. The NTU datasets use three types of validation protocols following the action subjects and camera settings, i.e., cross-subject (XSub), cross-view (XView), and cross-setup (XSet). In addition, we validated our proposed model with a smaller dataset, PennAction, which contains 2K videos for 15 action labels.
数据集。我们使用多个代表性基准数据集进行实验:FineGYM [36]、NTU60 [35]、NTU120 [27] 和 PennAction [54]。FineGYM 包含 29K 个视频,具有 99 个细粒度动作标签,采集自体操视频片段。NTU60 和 NTU120 是用于人体动作识别的代表性多模态数据集。NTU60 包含 57K 个视频,涵盖 60 个动作标签,采集于受控环境。NTU120 作为 NTU60 的超集,包含 114K 个视频,涵盖 120 个动作标签。NTU 数据集采用三种验证协议,基于动作主体和摄像机设置:跨主体 (XSub)、跨视角 (XView) 和跨配置 (XSet)。此外,我们使用较小的数据集 PennAction 验证所提模型,该数据集包含 2K 个视频,涵盖 15 个动作标签。
Settings. We adopted an AdamW optimizer for 90 epochs with a cosine scheduler with a 5-epoch warm-up. A batch consisted of randomly cropped videos with a pixel resolution of $224\times224$ for training and center-cropped videos for testing. Training and testing were conducted using four NVIDIA Tesla V100 32GB GPUs with APEX.
设置。我们采用AdamW优化器进行90个周期的训练,使用带5周期预热阶段的余弦调度器。训练批次由随机裁剪至$224\times224$像素分辨率的视频组成,测试时则采用中心裁剪视频。整个训练和测试过程在四块NVIDIA Tesla V100 32GB GPU上通过APEX加速完成。
4.1. Comparison with state-of-the-art approaches
4.1. 与最先进方法的比较
NTU60 & 120. In action recognition, pre-training for feature extraction and pose information for recognition have a great impact on performance. To obtain objective results in action recognition, it is desirable to use pose information given in the dataset without pre-training. As shown in Table 1, PoseC3D [19] shows the best performance at NTU60 and 120, but unlike other methods, it used an estimated pose optimized for recognition models. Therefore, in the experiment, we exclude PoseC3D from quantitative comparison and analysis with SoTA methods.
NTU60 和 120。在动作识别中,用于特征提取的预训练和用于识别的姿态信息对性能有很大影响。为了在动作识别中获得客观结果,最好使用数据集中提供的姿态信息而不进行预训练。如表 1 所示,PoseC3D [19] 在 NTU60 和 120 上表现出最佳性能,但与其他方法不同,它使用了针对识别模型优化的估计姿态。因此,在实验中,我们将 PoseC3D 排除在与 SoTA 方法的定量比较和分析之外。
Table 2: Accuracy comparisons with other SoTA approaches on FineGYM.
表 2: FineGYM数据集上与其他SoTA方法的准确率对比
| 方法 | 模态 | 预训练 | 均值 (%) |
|---|---|---|---|
| ST-GCN [51] | Pt | 25.2 | |
| TQN [53] | R | √ | 90.6 |
| PoseC3D [19] | R+Pt | 95.6 | |
| Ours | R+Pt | 90.3 |
Table 3: Accuracy comparisons with other SoTA approaches on PennAction.
表 3: PennAction数据集上与其他SoTA方法的准确率对比
| 方法 | 模态 | 预训练 | Top-1 (%) |
|---|---|---|---|
| Pr-VIPE [37] | P | 97.5 | |
| UNIK [50] | P | 97.9 | |
| HDM-BG [55] | P | 93.4 | |
| 3D Deep [8] | R+P | 98.1 | |
| PoseMap [28] | R+P | 98.2 | |
| Multitask CNN [32] | R+P | 98.6 | |
| STAR [1] | R+P | 98.7 | |
| Ours | R+P | 99.7 |
In Table 1, we first compare the top-1 accuracy with various SoTA action recognition methods for the NTU60 dataset. When compared with the TSMF and STAR models trained under fair conditions, our model shows a $0.5%$ - $2.5%$ higher performance, respectively. Among the GNNbased methods, InfoGCN ranks remarkably even when it is trained with a single modality; nonetheless, our model shows higher performance of $94.3%$ and $97.9%$ , respectively.
在表1中,我们首先比较了NTU60数据集上各种SoTA动作识别方法的top-1准确率。与公平条件下训练的TSMF和STAR模型相比,我们的模型分别显示出 $0.5%$ 至 $2.5%$ 的性能提升。在基于GNN的方法中,InfoGCN即使仅使用单一模态训练也表现突出;尽管如此,我们的模型仍分别达到了 $94.3%$ 和 $97.9%$ 的更高性能。
We also provide benchmark results against the NTU120 dataset, which has double the number of videos and action labels compared to NTU60. With this result in Table 1, the GNN-based SoTA method, InfoGCN, achieved accuracy of $89.8%$ and $91.2%$ for both protocols. In the case of the multimodal trained method, PoseC3D, it achieved accuracy of $95.3%$ and $96.4%$ with pre-training and estimated poses. Unlike PoseC3D, the scratch-trained multimodal method, STAR, showed accuracy of $90.3%$ and $92.7%$ . Finally, our proposed method showed a promising performance under similar conditions, i.e., multimodal and scratch training, with accuracy of $90.5%$ and $91.4%$ , respectively.
我们还提供了针对NTU120数据集的基准测试结果,该数据集的视频数量和动作标签数量是NTU60的两倍。如表1所示,基于GNN的SoTA方法InfoGCN在两个协议下的准确率分别达到$89.8%$和$91.2%$。对于多模态训练方法PoseC3D,在使用预训练和估计姿态的情况下,其准确率达到$95.3%$和$96.4%$。与PoseC3D不同,从头开始训练的多模态方法STAR的准确率为$90.3%$和$92.7%$。最后,我们提出的方法在类似条件下(即多模态和从头开始训练)表现出色,准确率分别为$90.5%$和$91.4%$。
FineGYM. In the case of the FineGYM dataset, which is harsher than other datasets because clips have dynamic motions and camera movements from sports games. This dataset has rarely been used for multimodal action recognition, because it does not contain ground-truth skeletons. We used the estimated skeletons from HRNet [38] to apply it to cross-modal learning. Table 2 shows the results of the comparison experiments with other SoTA methods for the FineGYM. In the case of a single modality, ST-GCN showed relatively low accuracy because it used the estimated skeletons as our approach. The TQN achieved $90.6%$ with the $R G B$ single modality. Cross-modality-based methods, including PoseC3D and our approach, showed a relatively high performance compared to other methods. Pre-trained PoseC3D demonstrated a SoTA performance of $95.6%$ ; however, our method showed promising accuracy despite not applying a pre-training step.
FineGYM。FineGYM数据集比其他数据集更具挑战性,因为其片段包含体育比赛中的动态动作和摄像机移动。该数据集很少用于多模态动作识别,因为它不包含真实骨架数据。我们使用HRNet [38]估计的骨架数据应用于跨模态学习。表2展示了FineGYM数据集上与其他SoTA方法的对比实验结果。在单模态情况下,ST-GCN由于使用估计骨架(与我们方法相同)表现出较低准确率。TQN在$R G B$单模态下达到$90.6%$。基于跨模态的方法(包括PoseC3D和我们的方法)相比其他方法展现出较高性能。预训练的PoseC3D实现了$95.6%$的SoTA性能,而我们的方法虽未使用预训练步骤,仍表现出令人期待的准确率。
PennAction. We validated our method by applying smaller datasets with clearly recorded videos as shown in Table 3. In the GNN regime using the single-pose modality, Pr-VIPE and UNIK achieved high performance of $97.5%$ and $97.9%$ , respectively. Among cross-modality-based methods, Multitask CNN and STAR show the best performances among the CNN and transformer approaches at $98.6%$ and $98.7%$ , respectively. Our proposed method outperforms above SoTAs by a large margin of $1.0%-6.3%$ . This result indicates that the proposed method can achieve a good performance regardless of whether small or large datasets are applied.
PennAction。我们通过在清晰记录视频的小型数据集上验证了所提方法,如表 3 所示。在使用单姿态模态的 GNN 方案中,Pr-VIPE 和 UNIK 分别取得了 $97.5%$ 和 $97.9%$ 的高性能。在基于跨模态的方法中,Multitask CNN 和 STAR 分别在 CNN 和 Transformer 方案中以 $98.6%$ 和 $98.7%$ 的表现位居榜首。我们提出的方法以 $1.0%-6.3%$ 的显著优势超越上述 SOTA。该结果表明,无论应用于小型还是大型数据集,所提方法均能实现优异性能。
4.2. Qualitative analysis
4.2. 定性分析
Visualization of 3D deformable attention. We propose a 3D deformable attention mechanism supporting an adaptive receptive field for action recognition. To demonstrate its effec ti ve ness, we provide qualitative evaluations that show the visualized attention values of selected tokens against different video sequences. As shown in Fig. 5, the proposed method finds intensive regions through a 3D token search of the entire sequence. The activation is relatively low in inactive scenes, but, on the contrary, high activation occurs at a large transition among sequences. In particular, activations appear finely in joints used for actual action and do not appear coarsely. We can confirm that the proposed method not only properly finds tokens that are practically required for recognition in the entire sequence but also shows that strong activation appears in those tokens.
3D可变形注意力机制的可视化。我们提出了一种支持自适应感受野的3D可变形注意力机制用于动作识别。为验证其有效性,我们提供了定性评估,展示选定token在不同视频序列中的可视化注意力值。如图5所示,该方法通过全序列的3D token搜索定位到关键区域:静态场景中激活值较低,而在序列间发生显著变化时则出现高激活。特别值得注意的是,激活精准出现在实际动作涉及的关节部位,而非粗略分布。实验表明,该方法不仅能准确识别整个序列中实际需要用于识别的token,还能在这些token上呈现出强激活特征。
Visualization of joint stride attention. To make the proposed model independent of the number of input joints, we propose a local joint stride attention by grouping joint tokens with a sliding window. This approach provides improved efficiency in attention, but we need to verify whether the configured tokens with overlapping contribute to the attention module without full attention. In this experiment, we charted the attention levels of each joint according to sequence frames, as shown in Fig. 6. In practical terms, the joints that move the most when the ball is pitched in the sample video are the head, right hand, and right leg. The chart shows that the attention was largely activated according to this action flow. From this experiment, it is clear that the proposed local joint attention maintains the correlations between the entire joint token and the efficiency.
关节跨步注意力可视化。为了使所提模型不受输入关节数量的限制,我们通过滑动窗口对关节token进行分组,提出了一种局部关节跨步注意力机制。这种方法提高了注意力效率,但需要验证配置的重叠token是否能在不完全注意力的情况下对注意力模块产生贡献。在本实验中,我们根据序列帧绘制了各关节的注意力水平,如图6所示。在实际样本视频中,投球时运动幅度最大的关节是头部、右手和右腿。图表显示注意力主要根据这一动作流被激活。实验证明,所提局部关节注意力机制在保持整个关节token间相关性的同时兼顾了效率。

Figure 5: Visualized 3D deformable attentions. The proposed 3D deformable attention found disc rim i native tokens with strong attention among entire frame sequences. In particular, strong attentions are discovered at only noticeable changes in action.
图 5: 可视化的3D可变形注意力机制。提出的3D可变形注意力能够在整个帧序列中发现具有强注意力的判别性token。特别值得注意的是,仅在动作发生显著变化时才会检测到强注意力。

Figure 6: Visualized joint stride attentions. The proposed 3D deformable attention activates the attention score of each joint differently depending on the size of the ‘pitching’ action for each frame (shown in color).
图 6: 可视化关节步幅注意力。所提出的3D可变形注意力机制会根据每帧"投掷"动作的幅度 (以颜色显示) 差异性地激活各关节的注意力分数。
Table 4: Ablation study with attention blocks on PennAction.
表 4: PennAction数据集上注意力模块的消融实验
| 3D def. | Joint | Temp. | Top-1 (%) | |
|---|---|---|---|---|
| √ | √ | 94.8 | ||
| ② | 97.9 | |||
| ③ | √ | 98.2 | ||
| ④ | √ | √ | 98.5 | |
| Ours | √ | 99.7 |
4.3. Ablation studies
4.3. 消融实验
Attention modules. We provide ablation studies on three types of attention modules with PennAction dataset. According to the Table 4, when $\textcircled{1}$ 3D deformable attention is eliminated from the model, it is confirmed that the accuracy is abruptly degraded $(4.9%)$ . Conversely, $\textcircled{2}-\textcircled{4}$ other attention modules are found to have relatively less impact. The proposed 3D deformable attention is pivotal for achieving high accuracy in action recognition tasks.
注意力模块。我们在PennAction数据集上对三种注意力模块进行了消融实验。根据表4,当 $\textcircled{1}$ 从模型中移除3D可变形注意力 (3D deformable attention) 时,准确率会急剧下降 $(4.9%)$。相反,$\textcircled{2}-\textcircled{4}$ 其他注意力模块的影响相对较小。所提出的3D可变形注意力对于在动作识别任务中实现高精度至关重要。
Table 5: Comparison of the Top-1 accuracies for different modal token configurations on PennAction.
表 5: PennAction数据集上不同模态Token配置的Top-1准确率对比
| ModalTokens | Top-1 (%) |
|---|---|
| Notokens | 92.2 |
| Single token | 97.0 |
| Cross-modal tokens | 99.7 |
Cross-modal Tokens. To analyze the impact of the crossmodal tokens, we conducted ablation studies as shown in Table 5. In the ‘No tokens’ scenario, averaging the last RGB and pose tokens led to a performance drop to $92.2%$ . Using a single token for all modalities resulted in a slight decrease to $97.0%$ . However, our approach achieved the best performance, highlighting the effectiveness of learning multiple modalities in a single transformer design.
跨模态Token。为了分析跨模态Token的影响,我们进行了消融实验,如表5所示。在"无Token"场景中,对最后一个RGB和姿态Token取平均导致性能下降至$92.2%$。使用单一Token处理所有模态时,性能略微降至$97.0%$。而我们的方法取得了最佳性能,这凸显了在单一Transformer架构中学习多模态的有效性。
Temporal stride. To solve the limitations of complexity dependent on the number of tokens in an attention module, we propose a local window cross attention using a temporal stride. In this experiment, to evaluate the validity of the proposed approach, we observe the changes in performance by applying various strides to a fixed-sized window using the PennAction dataset. As shown in Fig. 7 (a), the best performance is obtained when the stride is about half the size of the window, regardless of the window size. This is because more overlap between temporal tokens fuels the temporal correlations with enhanced efficiency. Therefore, the proposed method faithfully maintains the correlations, even when tokens are divided into local windows.
时间步长。为解决注意力模块中复杂度随token数量增加而提升的局限,我们提出采用时间步长的局部窗口交叉注意力机制。本实验使用PennAction数据集,通过在固定尺寸窗口上应用不同步长来评估该方法的有效性。如图7(a)所示,无论窗口尺寸如何,当步长约为窗口尺寸一半时性能最佳。这是因为时间token间更大的重叠区域能以更高效率强化时序相关性。因此,即使token被划分到局部窗口,该方法仍能可靠地保持相关性。

Figure 7: (a) Ablation study with different stride on various window (wnd) sizes on PennAction. (b) Ablation study with different numbers of input frames during the training phase on PennAction.
图 7: (a) 在PennAction数据集上对不同窗口(wnd)大小进行不同步长的消融研究。(b) 在PennAction数据集上对训练阶段输入帧数进行消融研究。
Number of input frames. One of the important factors to determine in the learning of sequential data is the number of input frames. If the number of frames is sufficiently large, better feature representation learning is possible, although the computational cost significantly increases. We therefore empirically determined the optimal number of input frames using the PennAction dataset, as illustrated in Fig. 7 (b). In our model, the best performance was achieved using 12 input frames. When the number of frames is smaller than 12, the performance drops slightly, and there is a limit to learning the continuity of the actions.
输入帧数。在序列数据学习中需要确定的重要因素之一是输入帧数。若帧数足够大,虽然计算成本显著增加,但能实现更好的特征表示学习。因此我们基于PennAction数据集通过实验确定了最优输入帧数,如图7(b)所示。本模型使用12帧输入时达到最佳性能。当帧数少于12时,性能略有下降,且难以充分学习动作的连续性。
5. Conclusion
5. 结论
ViTs have become the mainstream in various vision tasks, achieving an overwhelming performance; however, it has been used relatively little in action recognition tasks. Therefore, we first proposed a 3D deformable attention consisting of stride window cross attention for better spatiotemporal feature learning, as well as a cross-modal framework for action recognition. The proposed method achieved a newly demonstrated SoTA performance on representative action recognition datasets. Based on the results of qualitative experiments, we can confirm that our proposed method has a strong s patio temporal feature learning capability for action recognition.
ViTs 已成为各类视觉任务的主流方法,展现出压倒性性能;然而在动作识别任务中的应用相对较少。为此,我们首次提出包含跨步窗口交叉注意力 (stride window cross attention) 的 3D 可变形注意力机制以增强时空特征学习能力,并构建了跨模态动作识别框架。该方法在代表性动作识别数据集上实现了当前最优 (SoTA) 性能。定性实验结果表明,我们提出的方法对动作识别任务具有强大的时空特征学习能力。
Acknowledgments
致谢
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Educa- tion(2022R1I1A3058128).
本研究由韩国国家研究基金会(NRF)资助的基础科学研究计划(2022R1I1A3058128)支持。
References
参考文献
A. Detailed Description of Stride Attentions
A. 步长注意力机制详细说明
In general, most of the time complexity of transformers is highly related to the attention operation. We offer stride attentions for efficient correlation learning between disc ret i zed tokens. In this section, we describe details of the proposed joint stride attention and temporal stride attention.
通常来说,Transformer的时间复杂度大多与注意力操作高度相关。我们提出了跨度注意力(stride attention)机制来实现离散化token之间的高效关联学习。本节将详细阐述所提出的联合跨度注意力(joint stride attention)和时间跨度注意力(temporal stride attention)。
A.1. Joint Stride Attention
A.1. 联合步幅注意力
The number of pose tokens (P) can grow dynamically based on the number of joints $(R)$ and people appeared in a scene. Since this is directly related to the amount of computation required for attention, we propose joint stride attention dividing pose tokens into several sliding windows. Algorithm A1 describes detailed operation of the proposed joint stride attention. According to the notations used in the Algorithm A1, we can organize comparisons of time complexity between full attention and joint stride attention as described in Table A1.
姿态Token (P) 的数量会根据场景中出现的关节数 $(R)$ 和人数动态增长。由于这直接关系到注意力机制所需的计算量,我们提出了关节滑动窗口注意力 (joint stride attention),将姿态Token划分为多个滑动窗口。算法A1详细描述了所提出的关节滑动窗口注意力的操作流程。根据算法A1使用的符号,我们可以整理出全注意力与关节滑动窗口注意力之间的时间复杂度对比,如表A1所示。
Table A1: Complexity comparisons between full attention and joint stride attention
表 A1: 全注意力机制与联合步幅注意力机制的复杂度对比
| 方法 | 复杂度 |
|---|---|
| 全注意力 (Full attention) | O(T² R²) |
| 联合步幅注意力 (Joint stride attention) | O(T² 2wnd?) |
In joint stride attention, we decompose pose tokens using sliding window (wnd) with a stride having halved size of wnd. If pose tokens $\mathrm{P}\in\mathbb{R}^{4C\times T\times R}$ are fed to full attention, the time complexity per layer becomes $O(T^{2}R^{2})$ and the equation is as follows:
在联合步长注意力中,我们使用滑动窗口(wnd)对姿态token进行分解,步长为窗口大小的一半。若将姿态token $\mathrm{P}\in\mathbb{R}^{4C\times T\times R}$ 输入全注意力层,每层时间复杂度将变为 $O(T^{2}R^{2})$ ,公式如下:
$$
{\bf O}=[{\bf P}||\mathrm{M}{p o s e}||\mathrm{M}_{C L S}^{'}]
$$
$$
{\bf O}=[{\bf P}||\mathrm{M}{p o s e}||\mathrm{M}_{C L S}^{'}]
$$
$$
\mathbf{\Sigma}=\sum_{t}^{T}{\sum_{r}^{R}\mathrm{softmax}(\frac{\mathbf{OW}{q}^{t,r}\mathbf{OW}{k}^{t,r}}{\sqrt{d_{h}}})\mathbf{OW}_{v}^{t,r}}
$$
$$
\mathbf{\Sigma}=\sum_{t}^{T}{\sum_{r}^{R}\mathrm{softmax}(\frac{\mathbf{OW}{q}^{t,r}\mathbf{OW}{k}^{t,r}}{\sqrt{d_{h}}})\mathbf{OW}_{v}^{t,r}}
$$
However, when pose tokens are fed to joint stride attention, the time complexity per layer becomes $O(T^{2}w n d^{2})$ and the equation is as follows:
然而,当姿态token被输入到联合步幅注意力中时,每层的时间复杂度变为 $O(T^{2}w n d^{2})$ ,公式如下:
$$
\begin{array}{r l}&{\mathrm{JointStrideAttention}(\mathbf{OW}{q},\tilde{\mathbf{OW}}{k},\tilde{\mathbf{OW}}{v})}\ &{\quad\quad\quad=\displaystyle\sum_{t}\sum_{w}\mathop{w n d}{w}\mathrm{Softmax}(\frac{\mathbf{OW}{q}^{t,w}\tilde{\mathbf{O}}\mathbf{W}{k}^{t,w}}{\sqrt{d_{h}}})\tilde{\mathbf{O}}\mathbf{W}_{v}^{t,w}}\end{array}
$$
$$
\begin{array}{r l}&{\mathrm{JointStrideAttention}(\mathbf{OW}{q},\tilde{\mathbf{OW}}{k},\tilde{\mathbf{OW}}{v})}\ &{\quad\quad\quad=\displaystyle\sum_{t}\sum_{w}\mathop{w n d}{w}\mathrm{Softmax}(\frac{\mathbf{OW}{q}^{t,w}\tilde{\mathbf{O}}\mathbf{W}{k}^{t,w}}{\sqrt{d_{h}}})\tilde{\mathbf{O}}\mathbf{W}_{v}^{t,w}}\end{array}
$$
where $\mathbf{O}$ and $\tilde{\mathbf{O}}$ from Algorithm A1. In Eq. A3, since wnd is always less than $R$ , the overall time complexity of joint stride attention is smaller than full attention.
其中 $\mathbf{O}$ 和 $\tilde{\mathbf{O}}$ 来自算法 A1。在公式 A3 中,由于 wnd 始终小于 $R$,联合跨度注意力 (joint stride attention) 的总体时间复杂度低于完全注意力 (full attention)。
Input: Pose tokens P, Memorized CLS modal token $\mathrm{M}{C L S}^{\bar{\prime}}$ , Pose modal token $\mathrm{M}{p o s e}$ , window size wnd, query weight $\mathbf{W}{q}$ , key weight $\mathbf{W}{k}$ , value weight $\mathbf{W}_{v}$
输入: 姿态Token P, 记忆化CLS模态Token $\mathrm{M}{C L S}^{\bar{\prime}}$ , 姿态模态Token $\mathrm{M}{p o s e}$ , 窗口大小wnd, 查询权重 $\mathbf{W}{q}$ , 键权重 $\mathbf{W}{k}$ , 值权重 $\mathbf{W}_{v}$
$\begin{array}{l}{s t r i d e\gets\lfloor w n d/2\rfloor}\ {\hat{\mathbf{P}}{q}\gets\emptyset}\ {\hat{\mathbf{P}}_{k v}\gets\emptyset}\end{array}$ \triangle right query set \triangle right key and value set
$\begin{array}{l}{s t r i d e\gets\lfloor w n d/2\rfloor}\ {\hat{\mathbf{P}}{q}\gets\emptyset}\ {\hat{\mathbf{P}}_{k v}\gets\emptyset}\end{array}$ 三角右查询集 三角右键值集
end while
end while
$$
\begin{array}{r l r}{D_{q}\gets|\hat{\mathbf{P}}{q}|}&{{}\qquad}&{\triangleright\hat{\mathbf{P}}{q}\in\mathbb{R}^{D_{q}\times4C\times T\times w n d}}\ {D_{k v}\gets|\hat{\mathbf{P}}{k v}|}&{{}\qquad}&{\triangleright\hat{\mathbf{P}}{k v}\in\mathbb{R}^{D_{k v}\times4C\times T\times w n d}}\end{array}
$$
$$
\begin{array}{r l r}{D_{q}\gets|\hat{\mathbf{P}}{q}|}&{{}\qquad}&{\triangleright\hat{\mathbf{P}}{q}\in\mathbb{R}^{D_{q}\times4C\times T\times w n d}}\ {D_{k v}\gets|\hat{\mathbf{P}}{k v}|}&{{}\qquad}&{\triangleright\hat{\mathbf{P}}{k v}\in\mathbb{R}^{D_{k v}\times4C\times T\times w n d}}\end{array}
$$
$$
\begin{array}{r}{\begin{array}{r l}&{\mathrm{\i}\mathrm{\Gamma}{0o s e},\mathrm{M}{C L S}^{'}\in\mathbb{R}^{4C\times T\times1}}\ &{\mathrm{\i}\mathrm{\Gamma}{0}\gets[\hat{\mathbf{P}}{q}||\mathrm{expand}(\mathrm{M}{p o s e},D_{q})||\mathrm{expand}(\mathrm{M}{C L S}^{'},D_{q})]}\ &{\mathrm{\i}\hat{\mathbf{\Gamma}}{0}\gets[\hat{\mathbf{P}}{k v}||\mathrm{expand}(\mathrm{M}{p o s e},D_{k v})||\mathrm{expand}(\mathrm{M}{C L S}^{'},D_{k v})]}\ &{\mathrm{\i}\mathbf{\Gamma}{0}\gets\mathbf{O}+\mathrm{MSA}(\mathbf{OW}{q},\hat{\mathbf{O}}\mathbf{W}{k},\hat{\mathbf{O}}\mathbf{W}_{v})}\ &{\mathbf{O}\gets\mathbf{O}+\mathrm{FFN}(\mathrm{LN}(\mathbf{O}))}\end{array}}\end{array}
$$
$$
\begin{array}{r}{\begin{array}{r l}&{\mathrm{\i}\mathrm{\Gamma}{0o s e},\mathrm{M}{C L S}^{'}\in\mathbb{R}^{4C\times T\times1}}\ &{\mathrm{\i}\mathrm{\Gamma}{0}\gets[\hat{\mathbf{P}}{q}||\mathrm{expand}(\mathrm{M}{p o s e},D_{q})||\mathrm{expand}(\mathrm{M}{C L S}^{'},D_{q})]}\ &{\mathrm{\i}\hat{\mathbf{\Gamma}}{0}\gets[\hat{\mathbf{P}}{k v}||\mathrm{expand}(\mathrm{M}{p o s e},D_{k v})||\mathrm{expand}(\mathrm{M}{C L S}^{'},D_{k v})]}\ &{\mathrm{\i}\mathbf{\Gamma}{0}\gets\mathbf{O}+\mathrm{MSA}(\mathbf{OW}{q},\hat{\mathbf{O}}\mathbf{W}{k},\hat{\mathbf{O}}\mathbf{W}_{v})}\ &{\mathbf{O}\gets\mathbf{O}+\mathrm{FFN}(\mathrm{LN}(\mathbf{O}))}\end{array}}\end{array}
$$
A.2. Temporal Stride Attention
A.2. 时间跨度注意力 (Temporal Stride Attention)
Temporal stride attention is proposed to capture temporal changes between each sequential frame and joint. The overall procedure is described in Algorithm A2. The number of input tokens $D_{n}$ is sum of the number of $R G B$ , pose and cross modal tokens. To decompose these tokens into small temporal windows, we apply sliding windows along with the temporal dimension. The complexity comparison result between full attention and temporal stride attention is described in Table A2.
提出了时间跨度注意力(temporal stride attention)来捕捉每个连续帧和关节之间的时序变化。整体流程如算法A2所述。输入token数 $D_{n}$ 是 $RGB$、姿态和跨模态token数量的总和。为了将这些token分解为小时序窗口,我们沿时间维度应用滑动窗口。全注意力和时间跨度注意力的复杂度对比结果如表A2所示。
In the case of full attention, the time complexity of attention against the concatenated tokens N ∈ R4C×T ×Dn becomes $O(T^{2}D_{n}^{2})$ and the equation is as follows:
在全注意力机制下,针对拼接后的 token 序列 N ∈ R4C×T ×Dn 的注意力时间复杂度变为 $O(T^{2}D_{n}^{2})$ ,其计算公式如下:
Table A2: Complexity comparisons between full attention and temporal stride attention
表 A2: 全注意力机制与时间跨度注意力机制的复杂度对比
| 方法 | 复杂度 |
|---|---|
| 全注意力机制 (Full attention) | O(T² D²) |
| 时间跨度注意力机制 (Temporal stride attention) | O(wnd² D²) |
$$
\mathbf{N}=[\mathrm{Z}||\mathrm{P}||\mathrm{M}{R G B}||\mathrm{M}{p o s e}||\mathrm{M}_{C L S}]
$$
$$
\mathbf{N}=[\mathrm{Z}||\mathrm{P}||\mathrm{M}{R G B}||\mathrm{M}{p o s e}||\mathrm{M}_{C L S}]
$$
$$
=\sum_{t}^{T}\sum_{n}^{D_{n}}\mathrm{softmax}(\frac{\mathbf{N}\mathbf{W}{q}^{t,n}\mathbf{N}\mathbf{W}{k}^{t,n}}{\sqrt{d_{h}}})\mathbf{N}\mathbf{W}_{v}^{t,n}
$$
$$
=\sum_{t}^{T}\sum_{n}^{D_{n}}\mathrm{softmax}(\frac{\mathbf{N}\mathbf{W}{q}^{t,n}\mathbf{N}\mathbf{W}{k}^{t,n}}{\sqrt{d_{h}}})\mathbf{N}\mathbf{W}_{v}^{t,n}
$$
On the contrary, when the concatenated tokens are decomposed into several sliding windows, the time complexity per layer becomes $O(w n d^{2}D_{n}^{2})$ and the equation is as follows:
相反,当将拼接的Token分解为多个滑动窗口时,每层的时间复杂度变为 $O(w n d^{2}D_{n}^{2})$ ,公式如下:
$$
\begin{array}{r l}&{\mathrm{TemporalStrideAttention}(\hat{\mathbf{N}}{q}\mathbf{W}{q},\hat{\mathbf{N}}{k v}\mathbf{W}{k},\hat{\mathbf{N}}{k v}\mathbf{W}{v})}\ &{=\displaystyle\sum_{w}\sum_{n}\mathrm{softmax}(\frac{\hat{\mathbf{N}}{q}\mathbf{W}{q}^{w,n}\hat{\mathbf{N}}{k v}\mathbf{W}{k}^{w,n}}{\sqrt{d_{h}}})\hat{\mathbf{N}}{k v}\mathbf{W}_{v}^{w,n}}\end{array}
$$
$$
\begin{array}{r l}&{\mathrm{TemporalStrideAttention}(\hat{\mathbf{N}}{q}\mathbf{W}{q},\hat{\mathbf{N}}{k v}\mathbf{W}{k},\hat{\mathbf{N}}{k v}\mathbf{W}{v})}\ &{=\displaystyle\sum_{w}\sum_{n}\mathrm{softmax}(\frac{\hat{\mathbf{N}}{q}\mathbf{W}{q}^{w,n}\hat{\mathbf{N}}{k v}\mathbf{W}{k}^{w,n}}{\sqrt{d_{h}}})\hat{\mathbf{N}}{k v}\mathbf{W}_{v}^{w,n}}\end{array}
$$
where $\hat{\bf N}{q}$ and $\hat{\bf N}_{k v}$ from Algorithm A2. In this case, because wnd is always less than $T$ , the overall time complexity of temporal stride attention is smaller than full attention.
其中 $\hat{\bf N}{q}$ 和 $\hat{\bf N}_{k v}$ 来自算法 A2。在这种情况下,由于 wnd 始终小于 $T$,因此时间跨度注意力 (temporal stride attention) 的总体时间复杂度低于完全注意力 (full attention)。
B. Detailed Description of 3D Deformable Attention
B. 3D可变形注意力的详细描述
In this study, we proposed the 3D deformable attention to adaptively capture not only long-term temporal relations but also spatial relations simultaneously. Inspired by Xia et al. [47], we rebuilt a deformable attention transformer (DAT) applicable with various video tasks including action recognition. Our proposed method finds disc rim i native tokens across 3D space while the DAT leverages only 2D space tokens. Details are described in Algorithm A3.
在本研究中,我们提出了3D可变形注意力机制,能够自适应地同时捕获长期时间关系和空间关系。受Xia等人[47]的启发,我们重建了一个适用于动作识别等多种视频任务的可变形注意力Transformer (DAT)。我们提出的方法能在3D空间中寻找判别性token,而DAT仅利用2D空间token。具体细节如算法A3所述。
C. On the fly frames in test phase.
C. 测试阶段的动态帧
The proposed method showed a good performance on several benchmarks using the suggested modules for capturing temporal changes. According to the Fig. 5 (b) in the paper, it was observed that the performance has a high relevance for the number of input frames in training phase. For that reason, we assumed that if the model well captures spatio temporal relations on dense frame condition in training,
所提方法在使用建议模块捕捉时序变化时,在多个基准测试中表现出色。根据论文中的图5(b) ,可观察到模型性能与训练阶段输入帧数高度相关。因此我们假设:若模型在训练阶段能充分捕捉密集帧条件下的时空关联性,
Algorithm A2 Temporal stride attention
算法 A2 时间跨度注意力机制
Input: RGB tokens Z, Pose tokens $\mathrm{P}$ , CLS modal token $\mathrm{M}{C L S}$ , $R G B$ modal token $\mathrm{M}{R G B}$ , Pose modal token $\mathrm{M}{p o s e}$ , window size wnd, query weight $\mathbf{W}{q}$ , key weight $\mathbf{W}{k}$ , value weight $\mathbf{W}_{v}$
输入: RGB Token Z, 姿态 Token $\mathrm{P}$, CLS模态 Token $\mathrm{M}{C L S}$, RGB模态 Token $\mathrm{M}{R G B}$, 姿态模态 Token $\mathrm{M}{p o s e}$, 窗口大小 wnd, 查询权重 $\mathbf{W}{q}$, 键权重 $\mathbf{W}{k}$, 值权重 $\mathbf{W}_{v}$
$$
\begin{array}{r l}&{s t r i d e\gets\lfloor w n d/2\rfloor}\ &{\hat{\bf N}{q}\gets\emptyset}\ &{\hat{\bf N}_{k v}\gets\emptyset}\end{array}
$$
$$
\begin{array}{r l}&{s t r i d e\gets\lfloor w n d/2\rfloor}\ &{\hat{\bf N}{q}\gets\emptyset}\ &{\hat{\bf N}_{k v}\gets\emptyset}\end{array}
$$
\triangle right query set \triangle right key and value set
△右查询集 △右键值集
$\mathrm{N}\gets[\mathrm{Z}||\mathrm{P}||\mathrm{M}{R G B}||\mathrm{M}{p o s e}||\mathrm{M}_{C L S}]$ D n ←← (| |H8 ||× W8 + |R| + 3) | \triangle right The number of tokens
$\mathrm{N}\gets[\mathrm{Z}||\mathrm{P}||\mathrm{M}{R G B}||\mathrm{M}{p o s e}||\mathrm{M}_{C L S}]$ D n ←← (| |H8 ||× W8 + |R| + 3) | \triangle right Token数量
end while
end while
$$
\begin{array}{r l}&{{\bf N}\gets\hat{\bf N}{q}+\mathrm{MSA}(\hat{\bf N}{q}{\bf W}{q},\hat{\bf N}{k v}{\bf W}{k},\hat{\bf N}{k v}{\bf W}_{v})}\ &{{\bf N}\gets{\bf N}+\mathrm{FFN}(\mathrm{LN}({\bf N}))}\end{array}
$$
$$
\begin{array}{r l}&{{\bf N}\gets\hat{\bf N}{q}+\mathrm{MSA}(\hat{\bf N}{q}{\bf W}{q},\hat{\bf N}{k v}{\bf W}{k},\hat{\bf N}{k v}{\bf W}_{v})}\ &{{\bf N}\gets{\bf N}+\mathrm{FFN}(\mathrm{LN}({\bf N}))}\end{array}
$$

Figure A1: Ablation study with different numbers of frames during test phase against model trained with 12 frames.
图 A1: 测试阶段使用不同帧数与训练阶段12帧模型的消融对比研究。
then it will be able to defense degradation of performance on sparse test frames. In practical application, some models may have to be run in sparse frames due to environmental limitations. We provided the evaluation results by diversifying the number of input frames in a model trained using 12 frames. The results verify the power of the s patio temporal feature learning of the proposed method. In Fig. A1, the proposed method shows a uniform performance for various numbers of input frames. Therefore, the proposed method is robust in learning s patio temporal features, even if the number of testing frames is sparse.
那么它将能够抵御稀疏测试帧上的性能退化。在实际应用中,由于环境限制,某些模型可能不得不在稀疏帧上运行。我们通过变化输入帧数量(使用12帧训练的模型)提供了评估结果。这些结果验证了所提方法在时空特征学习方面的强大能力。在图A1中,所提方法对不同数量的输入帧表现出一致的性能。因此,即使测试帧数量稀疏,所提方法在学习时空特征方面也具有鲁棒性。
输入: RGB tokens Z, CLS模态token McLs, RGB模态token MRGB, 查询权重Wq, 键权重Wk, 值权重Wu, 卷积核尺寸k, 3D卷积块foff, 双线性采样函数g, 可训练参数w
函数3DTS(Z; w):
Z ← 重塑(Z)
Z ∈ R4C×Tx×
△p ← tanh(foff(Z; w))
△p ∈ R3×Tx×H×W
p ← 从3D网格获取参考点
p ∈ R3×Tx×H×W
初始化 Z ∈ R4C×Tx×
对于 (px, Py, Pz) ∈ p + △p 执行:
← 0
获取时空坐标 r(x,y,z)
Φ ← g(px, rx)g(Py, ry)g(pz, rz)
← + ΦZ[, rz, ry, rx]
结束循环
Z[, pz, Py, Px] ←
结束循环
返回 fat(Z)
结束函数
初始化3D卷积参数(w) 带k
Z ← 3DTS(Z; w)
D. Additional Qualitative Results
D. 其他定性结果
D.1. Additional Joint Stride Attention Visualization
D.1. 额外的联合步幅注意力可视化
We present the result of analyzing the role of each pose token in cross-modal learning. The visualization s of each pose token for more diverse actions are shown in Fig. A2.
我们展示了分析每个姿态token在跨模态学习中所起作用的结果。针对更多样化动作的各姿态token可视化如图 A2所示。
D.2. Additional 3D Deformable Attention Visualization
D.2. 额外3D可变形注意力可视化
In this section, we provide additional visualization of 3D deformable attention for more diverse actions on each dataset. In the case of PennAction, attention is accurately appeared to the person who is the subject of the action even in complex backgrounds as shown in Fig. A3, and it can be seen that attention is occurring intensively in the frame representing the action. In terms of FineGYM, it consists of fine-grained gymnastic frames with dynamic camera moving. Our proposed 3D deformable attention accurately tracks gymnasts performing dynamic movements as shown in Fig. A4, and clearly understands the differences in each fine-grained actions, even for actions using the same equipment but with different labels. In the case of NTU120, which has a relatively simple background, the proposed method accurately finds key elements for various actions. The interaction between two people is also well tracked, especially in the case of the ‘pick up’ action label, the actor’s action is important, but the fact that there is a dropped object may be more important to accurately classify this action as shown in Fig. A5.
在本节中,我们针对各数据集中的多样化动作提供了3D可变形注意力机制的补充可视化结果。对于PennAction数据集,如图A3所示,即使在复杂背景下,注意力也能精准聚焦于动作主体人物,并密集分布于表征动作的关键帧上。在FineGYM数据集方面,该数据集包含动态摄像机移动拍摄的细粒度体操动作帧。我们提出的3D可变形注意力机制能准确追踪运动员的动态运动轨迹(图A4),清晰区分使用相同器械但标签不同的细粒度动作差异。对于背景相对简单的NTU120数据集,本方法能精准定位各类动作的关键要素。双人交互动作同样得到有效追踪,以"拾取"动作为例(图A5),演员动作虽重要,但地面掉落物体的存在对该动作的准确分类可能更具决定性意义。

Figure A2: Visualization of joint stride attention on PennAction
图 A2: PennAction 上的联合步幅注意力可视化


