OmniPose: A Multi-Scale Framework for Multi-Person Pose Estimation
OmniPose: 一种用于多人姿态估计的多尺度框架
Abstract
摘要
We propose OmniPose, a single-pass, end-to-end trainable framework, that achieves state-of-the-art results for multi-person pose estimation. Using a novel waterfall module, the OmniPose architecture leverages multi-scale feature representations that increase the effectiveness of backbone feature extractors, without the need for postprocessing. OmniPose incorporates contextual information across scales and joint localization with Gaussian heatmap modulation at the multi-scale feature extractor to estimate human pose with state-of-the-art accuracy. The multi-scale representations, obtained by the improved waterfall module in OmniPose, leverage the efficiency of progressive filtering in the cascade architecture, while maintaining multiscale fields-of-view comparable to spatial pyramid configurations. Our results on multiple datasets demonstrate that OmniPose, with an improved HRNet backbone and waterfall module, is a robust and efficient architecture for multiperson pose estimation that achieves state-of-the-art results.
我们提出OmniPose——一个单次前向、端到端可训练的框架,在多人体姿态估计任务中实现了最先进的性能。该架构通过创新的瀑布模块(waterfall module)利用多尺度特征表示,在无需后处理的情况下显著提升了主干特征提取器的效能。OmniPose在多尺度特征提取器中整合了跨尺度上下文信息,并通过高斯热图调制进行关节定位,以前所未有的精度实现人体姿态估计。改进版瀑布模块生成的多尺度表示,既保持了空间金字塔配置级别的多尺度视野,又继承了级联架构中渐进式过滤的高效特性。在多个数据集上的实验表明:采用优化HRNet主干网络和瀑布模块的OmniPose,是兼具鲁棒性与高效性的多人体姿态估计架构,其性能达到当前最优水平。
1. Introduction
1. 引言
Human pose estimation is an important task in computer vision that has generated high interest for methods on 2D pose estimation [33], [23], [34], [4], [31] and 3D [29], [41], [1]; on a single frame [5] or a video sequence [13]; for a single [34] or multiple subjects [6]. The main challenges of pose estimation, especially in multi-person settings, are due the large number of degrees of freedom in the human body mechanics and the occurrence of joint occlusions. To overcome the difficulty of detecting joints under occlusion, it is common for methods to rely on statistical and geometric models to estimate occluded joints [26], [24]. Anchor poses are also used as a resource to overcome occlusion [29], but this could limit the generalization power of the model and its ability to handle unforeseen poses.
人体姿态估计是计算机视觉领域的一项重要任务,引发了学界对2D姿态估计方法 [33]、[23]、[34]、[4]、[31] 和3D姿态估计 [29]、[41]、[1] 的高度关注;研究场景涵盖单帧图像 [5] 或视频序列 [13];目标对象包括单人 [34] 或多人物 [6]。姿态估计的主要挑战(尤其在多人场景中)源于人体运动学的高自由度特性以及关节遮挡现象。为应对遮挡条件下的关节检测难题,现有方法通常依赖统计与几何模型来估计被遮挡关节 [26]、[24]。锚定姿态(anchor poses)也被用作克服遮挡的手段 [29],但这可能限制模型的泛化能力及处理未知姿态的灵活性。
Inspired by recent advances in the use of multi-scale approaches for semantic segmentation [9], [37], and expanding upon state-of-the-art results on 2D pose estimation by HRNet [31] and UniPose [4], we propose OmniPose, an expanded single-stage network that is end-to-end trainable and generates state-of-the-art results without requiring multiple iterations, intermediate supervision, anchor poses or postprocessing. A main aspect of our novel architecture is an expanded multi-scale feature representation that combines an improved HRNet feature extractor with advanced Waterfall Atrous Spatial Pooling (WASPv2) module. Our improved WASPv2 module combines the cascaded approach for atrous convolution with larger Field-of-View (FOV) and is integrated with the network decoder offering significant improvements in accuracy.
受多尺度方法在语义分割领域最新进展的启发 [9][37],并基于HRNet [31] 和 UniPose [4] 在二维姿态估计上的最先进成果,我们提出了OmniPose——一个可端到端训练的扩展单阶段网络,无需多次迭代、中间监督、锚点姿态或后处理即可生成最先进的结果。我们新架构的主要特点是扩展的多尺度特征表示,它将改进的HRNet特征提取器与先进的瀑布式空洞空间金字塔 (WASPv2) 模块相结合。我们改进的WASPv2模块将级联空洞卷积方法与更大的视场 (FOV) 相结合,并与网络解码器集成,显著提高了精度。

Figure 1. Pose estimation examples with our OmniPose method.
图 1: 采用我们的OmniPose方法进行姿态估计的示例。
Our OmniPose framework predicts the location of multiple people’s joints based on contextual information due to the multi-scale feature representation used in our network. The contextual approach allows our network to include the information from the entire frame, and consequently does not require post analysis based on statistical or geometric methods. In addition, the waterfall atrous module, allows a better detection of shapes, resulting in a more accurate estimation of occluded joints. Examples of pose estimation
我们的OmniPose框架基于网络采用的多尺度特征表示,能够利用上下文信息预测多人关节位置。这种上下文方法使网络能够整合整个帧的信息,因此无需依赖统计或几何方法进行后处理分析。此外,瀑布式空洞模块可更好地检测形状,从而更准确地估计被遮挡关节。姿态估计示例如下
2. Related Work
2. 相关工作
In recent years, deep learning methods relying on Convolutional Neural Networks (CNNs) have achieved superior results in human pose estimation [33], [34], [6], [31], [29] over early works [28], [36]. The popular Convolu- tional Pose Machine (CPM) [34] proposed an architecture that refined joint detection via a set of stages in the network. Building upon [34], Yan et al. integrated the concept of Part Affinity Fields (PAF) resulting in the OpenPose method [6].
近年来,基于卷积神经网络 (CNN) 的深度学习方法在人体姿态估计任务中取得了超越早期研究 [28], [36] 的优异成果 [33], [34], [6], [31], [29]。经典的卷积姿态机 (CPM) [34] 提出了一种通过多级网络结构逐步优化关节点检测的架构。在 [34] 的基础上,Yan 等人引入部件亲和场 (PAF) 概念,最终提出了 OpenPose 方法 [6]。
Multi-scale representations have been successfully used in backbone structures for pose estimation. Stacked hourglass networks [23] use cascaded structures of the hourglass method for pose estimation. Expanding on the hourglass structure, the multi-context approach in [14] relies on an hourglass backbone to perform pose estimation. The original backbone is augmented by the Hourglass Residual Units (HRU) with the goal of increasing the receptive FOV. Postprocessing with Conditional Random Fields (CRFs) is used to assemble the relations between detected joints. However, the drawback of CRFs is increased complexity that requires high computational power and reduces speed.
多尺度表征已成功应用于姿态估计的骨干网络结构中。堆叠沙漏网络 [23] 采用级联沙漏结构进行姿态估计。基于沙漏结构的扩展,文献 [14] 中的多上下文方法依托沙漏骨干网络实现姿态估计。原始骨干网络通过沙漏残差单元 (HRU) 进行增强,旨在扩大感受野 (FOV)。采用条件随机场 (CRFs) 后处理来整合检测关节间的关系,但 CRFs 的缺点在于复杂度较高,需要强大算力且会降低速度。
The High-Resolution Network (HRNet) [31] includes both high and low resolution representations. HRNet benefits from the larger FOV of multi resolution, a capability that we achieve in a simpler fashion with our WASPv2 module. An analogous approach to HRNet is used by the Multi
高分辨率网络 (HRNet) [31] 同时包含高分辨率和低分辨率表示。HRNet 受益于多分辨率的大视野 (FOV) ,而我们通过 WASPv2 模块以更简单的方式实现了这一能力。Multi 采用了与 HRNet 类似的方法。
Stage Pose Network (MSPN) [19], where the HRNet structure is combined with cross-stage feature aggregation and coarse-to-fine supervision.
阶段姿态网络 (MSPN) [19],其中 HRNet 结构结合了跨阶段特征聚合和由粗到精的监督机制。
UniPose [4] combined the bounding box generation and pose estimation in a single one-pass network. This was achieved by the use of WASP module that increases significantly the multi-scale representation and FOV of the network, allowing the method to extract a greater amount of contextual information.
UniPose [4] 将边界框生成和姿态估计结合到一个单次前向网络中。这是通过使用WASP模块实现的,该模块显著提升了网络的多尺度表示和视野(FOV),使方法能够提取更多上下文信息。
More recently, the HRNet structure was combined with multi-resolution pyramids in [12] to further explore multiscale features. The Distribution-Aware coordinate Representation of Keypoints (DARK) method [38] aims to reduce loss during the inference processing of the decoder stage when using an HRNet backbone.
最近,[12]中将HRNet结构与多分辨率金字塔相结合,以进一步探索多尺度特征。基于关键点分布感知的坐标表示方法(DARK) [38]旨在减少使用HRNet主干网络时解码器阶段推理过程中的损失。
Aiming to use contextual information for pose estimation, the Cascade Prediction Fusion (CPF) [39] uses graphical components in order to exploit the context for pose estimation. Similarly, the Cascade Feature Aggregation (CFA) [30] uses semantic information for pose with a cascade approach. In a related context, Generative Adversarial Networks (GANs) were used in [7] to learn dependencies and contextual information for pose.
旨在利用上下文信息进行姿态估计,Cascade Prediction Fusion (CPF) [39] 采用图形化组件来挖掘上下文信息。类似地,Cascade Feature Aggregation (CFA) [30] 通过级联方式融合语义信息进行姿态估计。相关研究中,生成对抗网络 (GANs) 被应用于 [7] 来学习姿态的依赖关系和上下文信息。
2.1. Multi-Scale Feature Representations
2.1. 多尺度特征表示
A challenge with CNN-based pose estimation, as well as semantic segmentation methods, is a significant reduction of resolution caused by pooling. Fully Convolutional Networks (FCN) [21] addressed this problem by deploying upsampling strategies across de convolution layers that increase the size of feature maps back to the dimensions of the input image. In DeepLab, dilated or atrous convolutions [8] were used to increase the size of the receptive fields in the network and avoid down sampling in a multi-scale framework. The Atrous Spacial Pyramid Pooling (ASPP) approach assembles atrous convolutions in four parallel branches with different rates, that are combined by fast bilinear interpolation with an additional factor of eight. This configuration recovers the feature maps in the original image resolution. The increase in resolution and FOV in the ASPP network can be beneficial for a contextual detection of body parts during pose estimation.
基于CNN的姿态估计方法以及语义分割方法面临的一个挑战是池化操作导致的分辨率显著下降。全卷积网络(FCN) [21]通过在反卷积层采用上采样策略,将特征图尺寸恢复至输入图像大小来解决这一问题。DeepLab采用扩张卷积(atrous convolutions) [8]来增大网络感受野,并在多尺度框架中避免下采样操作。空洞空间金字塔池化(ASPP)方法通过四条并行分支整合不同膨胀率的空洞卷积,再通过快速双线性插值配合额外的八倍因子进行特征融合。这种配置能恢复原始图像分辨率的特征图。ASPP网络中分辨率和视野范围的提升,有助于姿态估计过程中对身体部位的上下文检测。
Improving upon [8], the waterfall architecture of the WASP module incorporates multi-scale features without immediately parallel i zing the input stream [3], [4]. Instead, it creates a waterfall flow by first processing through a filter and then creating a new branch. The WASP module goes beyond the cascade approach by combining the streams from all its branches and average pooling of the original input to achieve a multi-scale representation.
在[8]的基础上改进,WASP模块的瀑布式架构融合了多尺度特征,但并未立即并行化输入流[3][4]。相反,它通过先经过滤波器处理再创建新分支的方式形成瀑布流。WASP模块通过合并所有分支流并对原始输入进行平均池化,实现了超越级联方法的多尺度表征。
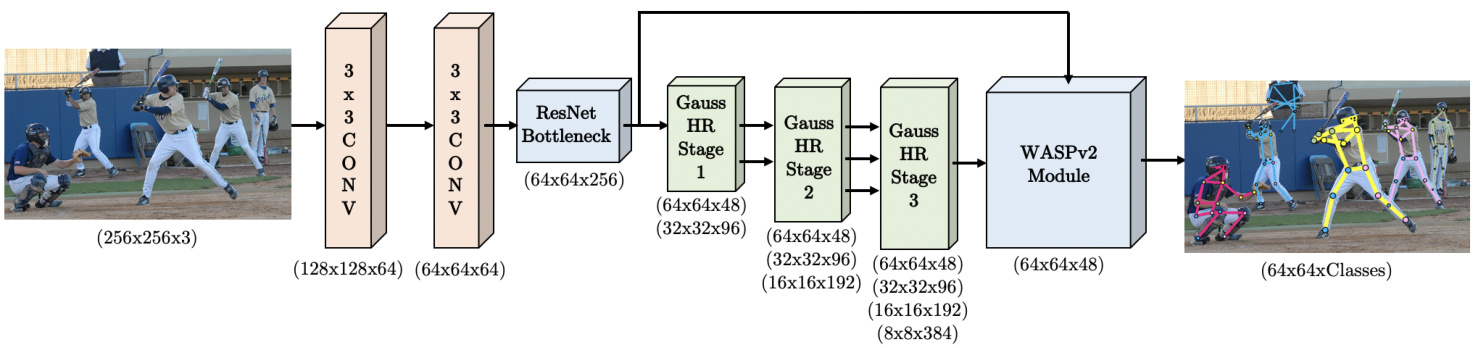
Figure 2. OmniPose framework for multi-person pose estimation. The input color image is fed through the improved HRNet backbone and WASPv2 module to generate one heatmap per joint or class.
图 2: 用于多人姿态估计的OmniPose框架。输入彩色图像通过改进的HRNet主干网络和WASPv2模块处理,为每个关节或类别生成一个热力图。
3. OmniPose Architecture
3. OmniPose 架构
The proposed OmniPose framework, illustrated in Figure 2, is a single-pass, single output branch network for pose estimation of multiple people instances. OmniPose incorporates improvements in feature representation from multi-scale approaches [31], [38] and an encoder-decoder structure combined with spatial pyramid pooling [10] and our proposed advanced waterfall module (WASPv2).
提出的OmniPose框架如图2所示,是一个单次前传、单输出分支网络,用于多人实例的姿态估计。OmniPose融合了多尺度方法[31][38]在特征表示方面的改进,采用编码器-解码器结构结合空间金字塔池化[10]和我们提出的进阶瀑布模块(WASPv2)。
The processing pipeline of the OmniPose architecture is shown in Figure 2. The input image is initially fed into a deep CNN backbone, consisting of our modified version of HRNet [31]. The resultant feature maps are processed by our WASPv2 decoder module that generates K heatmaps, one for each joint, with the corresponding confidence maps. The integrated WASPv2 decoder in our network generates detections for both visible and occluded joints while maintaining the image high resolution through the network.
OmniPose架构的处理流程如图2所示。输入图像首先输入到深度CNN主干网络(由我们改进版的HRNet [31]构成)。生成的特征图通过我们的WASPv2解码器模块处理,该模块会为每个关节生成K个热力图及对应的置信度图。我们网络中集成的WASPv2解码器能够同时检测可见和被遮挡的关节,并在整个网络中保持图像的高分辨率。
Our architecture includes several innovations to increase accuracy. The first is the application of atrous convolutions and waterfall architecture of the WASPv2 module, that increases the network’s capacity to compute multi-scale contextual information. This is accomplished by the probing of feature maps at multiple rates of dilation during convolutions, resulting in a larger FOV in the encoder. Our architecture integrates the decoding process within the WASPv2 module without requiring a separate decoder. Additionally, our network demonstrates good ability to detect shapes by the use of spatial pyramids combined with our modified HRNet feature extraction, as indicated by state-of-the-art (SOTA) results. Finally, the modularity of the OmniPose framework enables easy implementation and training.
我们的架构包含多项创新以提高准确性。首先是应用了空洞卷积 (atrous convolutions) 和WASPv2模块的瀑布式架构,增强了网络计算多尺度上下文信息的能力。这通过在卷积过程中以多种膨胀率探测特征图来实现,从而在编码器中获得更大的视野 (FOV)。我们的架构将解码过程集成在WASPv2模块内,无需单独的解码器。此外,如最先进 (SOTA) 结果表明,我们的网络通过结合空间金字塔和改进版HRNet特征提取,展现出良好的形状检测能力。最后,OmniPose框架的模块化设计使其易于实现和训练。
OmniPose leverages the large number of feature maps at multiple scales in the proposed WASPv2 module. In addition, we improved the results of the backbone network by incorporating gaussian modulated de convolutions in place of the upsampling operations during transition stages of the original HRNet architecture. The modified HRNet feature extractor is followed by the improved and integrated multi-scale waterfall configuration of the WASPv2 decoder, which further improves the efficiency of the joint detection with the incorporation of Gaussian heatmap modula- tion of the decoder stage, and full integration with the de- coder module.
OmniPose利用所提出的WASPv2模块中多尺度的大量特征图。此外,我们通过在原始HRNet架构过渡阶段采用高斯调制反卷积替代上采样操作,提升了主干网络的性能。改进后的HRNet特征提取器后接优化集成的WASPv2解码器多尺度瀑布结构,该结构通过引入解码器阶段的高斯热图调制技术并与解码器模块完全集成,进一步提升了关节检测效率。
Targeting the reduction of computational cost and number of parameters, we implement separable convolutions replacing the initial two layers of strided convolutions in our model and the atrous convolutions in the WASPv2 module. Figure 3 demonstrates the implementation of the strided convolution that consists of a spatial (or depth-wise) convolution through the individual channels of the feature maps, followed by a rectified linear unit (ReLU) activation function, and a point-wise convolution to incorporate all the lay- ers of the feature maps.
以降低计算成本和参数量为目标,我们采用可分离卷积替代模型中的初始两层跨步卷积以及WASPv2模块中的空洞卷积。图3展示了跨步卷积的实现方式:先对特征图的各通道进行空间(或深度)卷积,接着通过修正线性单元(ReLU)激活函数,最后执行点卷积以整合特征图的所有层级。
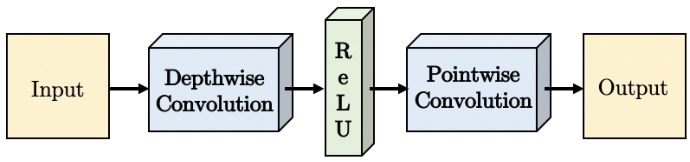
Figure 3. Implementation of our separable convolution. The cascade of depth-wise convolution, ReLU activation, and point-wise convolution replace the standard convolution in order to reduce the number of parameters and computations in the network.
图 3: 我们提出的可分离卷积实现方案。通过级联深度卷积 (depth-wise convolution) 、ReLU激活函数和逐点卷积 (point-wise convolution) 来替代标准卷积,从而减少网络中的参数量和计算量。
3.1. WASPv2 Module
3.1. WASPv2 模块
The proposed advanced “Waterfall Atrous Spatial Pyramid” module, or WASPv2, shown in Figure 4, generates an efficient multi-scale representation that helps OmniPose achieve SOTA results. Our improved WASPv2 module expands the feature extraction through its multi-level architecture. It increases the FOV of the network with consistent high resolution processing of the feature maps in all its branches, which contributes to higher accuracy. In addition, WASPv2 generates the final heatmaps for joint localization without the requirement of an additional decoder module, interpolation or pooling operations.
提出的先进"Waterfall Atrous Spatial Pyramid"模块(简称WASPv2)如图4所示,它能生成高效的多尺度表征,帮助OmniPose取得最先进(SOTA)成果。我们改进的WASPv2模块通过其多层次架构扩展了特征提取能力。该模块在所有分支中对特征图保持高分辨率处理,从而扩大网络的视野(FOV),这有助于提高精度。此外,WASPv2无需额外的解码器模块、插值或池化操作,就能直接生成用于关节定位的最终热图。
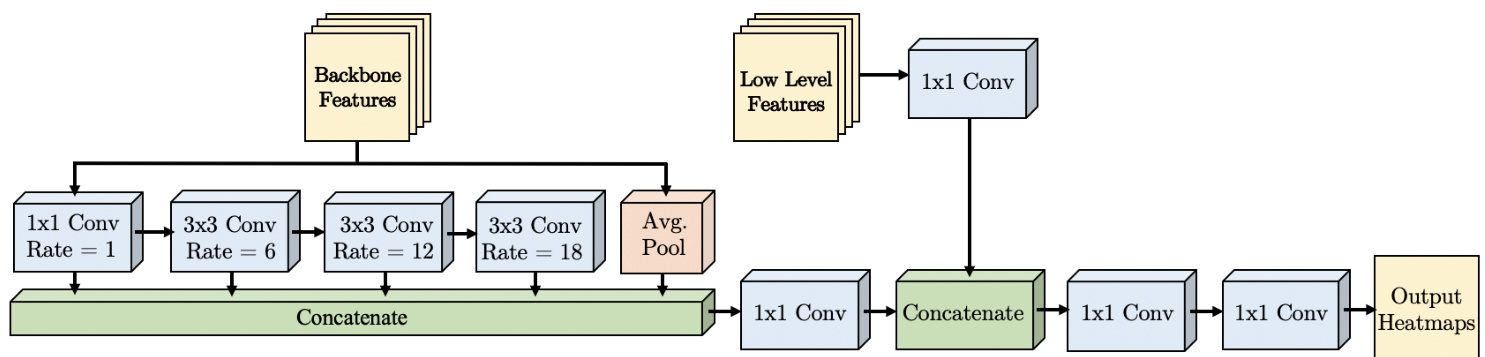
Figure 4. The proposed WASPv2 advanced waterfall module. The inputs are 48 features maps from the modified HRNet backbone and low-level features from the initial layers of the framework.
图 4: 提出的 WASPv2 高级瀑布模块。输入包括来自改进版 HRNet 骨干网络的 48 个特征图,以及框架初始层的低级特征。
The WASPv2 architecture relies on atrous convolutions to maintain a large FOV, performing a cascade of atrous convolutions at increasing rates to gain efficiency. In contrast to ASPP [10], WASPv2 does not immediately parallelize the input stream. Instead, it creates a waterfall flow by first processing through a filter and then creating a new branch. In addition, WASPv2 goes beyond the cascade approach by combining the streams from all its branches and average pooling of the original input to achieve a multiscale representation.
WASPv2架构依靠空洞卷积(dilated convolution)来保持大视场(FOV),通过以递增速率执行级联空洞卷积来提高效率。与ASPP [10]不同,WASPv2不会立即并行化输入流,而是先通过滤波器处理创建瀑布流,再生成新分支。此外,WASPv2通过组合所有分支流与原始输入的平均池化,实现了超越级联方法的多尺度表征。
Expanding upon the original WASP module [4], WASPv2 incorporates the decoder in an integrated unit shown in Figure 4, and processes both of the waterfall branches with different dilation rates and low-level features in the same higher resolution, resulting in a more accurate and refined response. The WASPv2 module output $f_{W A S P v2}$ is described as follows:
在原有WASP模块[4]的基础上,WASPv2将解码器整合为图4所示的集成单元,并以相同更高分辨率处理具有不同扩张率和低层级特征的两个瀑布分支,从而产生更精确细致的响应。WASPv2模块输出$f_{W A S P v2}$描述如下:
$$
f_{W a t e r f a l l}=K_{1}\circledast(\sum_{i=1}^{4}(K_{d_{i}}\circledast f_{i-1})+A P(f_{0}))
$$
$$
f_{W a t e r f a l l}=K_{1}\circledast(\sum_{i=1}^{4}(K_{d_{i}}\circledast f_{i-1})+A P(f_{0}))
$$
$$
f_{W A S P v2}=K_{1}\circledast\left(K_{1}\circledast f_{L L F}+f_{W a t e r f a l l}\right)
$$
$$
f_{W A S P v2}=K_{1}\circledast\left(K_{1}\circledast f_{L L F}+f_{W a t e r f a l l}\right)
$$
where $\circledast$ represents convolution, $f_{0}$ is the input feature map, $f_{i}$ is the feature map resulting from the $i^{t h}$ atrous convolution, $A P$ is the average pooling operation, $f_{L L F}$ are the low-level feature maps, $K_{1}$ and $K_{d_{i}}$ represent convolutions of kernel size $1\times1$ and $3\times3$ with dilations of $d_{i}=[1,6,12,18]$ , as shown in Figure 4. After concatenation, the feature maps are combined with low level features. The last $1\times1$ convolution brings the number of feature maps down to the final number of joints for the pose estimation.
其中 $\circledast$ 表示卷积运算,$f_{0}$ 是输入特征图,$f_{i}$ 是第 $i^{t h}$ 个空洞卷积输出的特征图,$AP$ 是平均池化操作,$f_{LLF}$ 是低级特征图,$K_{1}$ 和 $K_{d_{i}}$ 分别表示核尺寸为 $1\times1$ 和 $3\times3$、膨胀率为 $d_{i}=[1,6,12,18]$ 的卷积运算 (如 图 4 所示)。拼接后的特征图会与低级特征相结合,最后的 $1\times1$ 卷积将特征图通道数降至姿态估计所需的关键点数量。
Differently than the previous version of WASP, our $\mathbf{WASP}\mathbf{v}2$ integrates in the same resolution the feature maps from the low-level features and the first part of the waterfall module, converting the score maps from the WASPv2 module to heatmaps corresponding to body joints. Due to the higher resolution afforded by the modified HRNet backbone, the WASPv2 module directly outputs the final heatmaps without requiring an additional decoder module or need for bilinear interpolations to resize the output to the original input size.
与上一版WASP不同,我们的$\mathbf{WASP}\mathbf{v}2$在同一分辨率下集成了低级特征和瀑布模块第一部分的特征图,将WASPv2模块的得分图转换为对应人体关节的热力图。由于改进后的HRNet主干网络提供了更高分辨率,WASPv2模块无需额外解码器模块或双线性插值来调整输出至原始输入尺寸,可直接生成最终热力图。
Aiming to reduce the computational complexity and size of the network, and inspired by [10], our WASPv2 module implements separable atrous convolutions to its feature extraction waterfall branches. The inclusion of separable atrous convolutions in the WASPv2 module further reduces the number of parameters and computation cost of the framework.
为了降低计算复杂度和网络规模,并受[10]启发,我们的WASPv2模块在特征提取瀑布分支中实现了可分离空洞卷积 (separable atrous convolutions)。WASPv2模块引入可分离空洞卷积后,进一步减少了框架的参数数量和计算成本。
3.2. Gaussian Heatmap Modulation
3.2. 高斯热图调制
Conventional interpolation or upsampling methods during the decoding stage of the network result in an inevitable loss in resolution and consequently accuracy, limiting the potential of the network. Motivated by recent results with distribution aware modulation [38], we include Gaussian heatmap modulation to all interpolation stages of our network, resulting in a more accurate and robust network that diminishes the localization error due to interpolation.
在网络解码阶段采用传统插值或上采样方法会导致分辨率及精度不可避免的损失,从而限制网络潜力。受分布感知调制[38]最新研究成果启发,我们在网络所有插值阶段引入高斯热图调制,由此构建出更精准、更鲁棒的网络架构,有效降低了插值导致的定位误差。
Gaussian interpolation allows the network to achieve sub-pixel resolution for peak localization following the anticipated Gaussian pattern of the feature response. This method results in a smoother response and more accurate peak prediction for joints, by eliminating false positives in noisy responses during the joint detection.
高斯插值使网络能够按照特征响应预期的高斯模式,实现亚像素精度的峰值定位。该方法通过消除关节检测过程中噪声响应造成的误报,可获得更平滑的响应和更精确的关节峰值预测。
Figure 5 demonstrates the modular iz ation of a feature map response in our improved HRNet feature extractor. We utilize a transposed convolution operation of the feature map $f_{D}$ with a Gaussian kernel $K$ , shown in Equation (2), aiming to approximate the response shape to the expected label of the dataset during training. The feature maps $f_{G}$ after the Gaussian convolution operation are:
图 5: 展示了我们改进版HRNet特征提取器中特征图响应的模块化过程。我们使用特征图$f_{D}$与高斯核$K$的转置卷积操作(如公式(2)所示),旨在训练期间使响应形状逼近数据集的预期标签。经过高斯卷积操作后的特征图$f_{G}$为:
$$
f_{G}=K\circledast f_{D}
$$
$$
f_{G}=K\circledast f_{D}
$$
This behavior is learned and reproduced by the network during all parts of training, validation, and testing.
这种行为在网络训练、验证和测试的所有阶段都被学习并复现。
Following convolution with the Gaussian kernel, the modulation of the interpolation output is scaled to $f_{G_{s}}$ by
经过高斯核卷积处理后,插值输出的调制幅度被缩放至 $f_{G_{s}}$
mapping $f_{G}$ to the range of the response of the original feature map $f_{D}$ using:
将映射 $f_{G}$ 调整至原始特征图 $f_{D}$ 的响应范围,采用:
$$
f_{G_{s}}=\frac{f_{G}-m i n(f_{G})}{m a x(f_{G})-m i n(f_{G})}*m a x(f_{D})
$$
$$
f_{G_{s}}=\frac{f_{G}-m i n(f_{G})}{m a x(f_{G})-m i n(f_{G})}*m a x(f_{D})
$$
Our Gaussian heatmap modulation approach allows for better localization of the coordinates during the transposed convolutions, by overcoming the quantization error naturally inherited from the increase in resolution.
我们的高斯热图调制方法通过克服分辨率提升过程中自然产生的量化误差,能够在转置卷积过程中更精准地定位坐标。
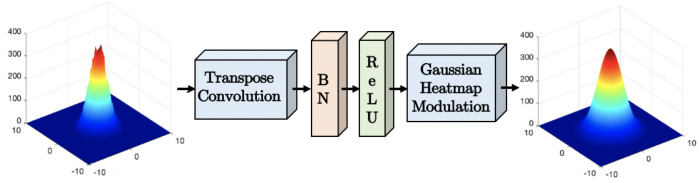
Figure 5. Illustration of the proposed transpose convolution with Gaussian modulation replacing upsampling stages of the network.
图 5: 采用高斯调制的转置卷积替代网络上采样阶段的示意图。
3.3. OmniPose-Lite
3.3. OmniPose-Lite
We introduce OmniPose-Lite, a lightweight version of OmniPose that is suitable for mobile and embedded platforms, as it achieves a drastic reduction in memory requirements and operations required for computation. The proposed OmniPose-Lite leverages the reduced computational complexity and size of separable convolutions, inspired by results obtained by MobileNet [17].
我们推出OmniPose-Lite,这是OmniPose的轻量级版本,适用于移动和嵌入式平台,因为它大幅降低了内存需求和计算所需的操作。受MobileNet [17] 成果启发,所提出的OmniPose-Lite利用了可分离卷积 (separable convolutions) 降低的计算复杂度和尺寸。
We implemented separable strided convolutions, as shown in Figure 3, for all convolutional layers of the original HRNet backbone, and implemented atrous separable convolutions in the WASPv2 decoder, resulting in a reduction of $74.3%$ of the network GFLOPs, from 22.6 GFLOPs to 5.8 GFLOPs required to process an image of size $256\mathrm{x}256$ . In addition, OmniPose-Lite also reduces the number of parameters by $71.4%$ , from $67.9\mathrm{M}$ to $19.4\mathbf{M}$ .
我们在原始HRNet骨干网络的所有卷积层中实现了可分离的跨步卷积(如图 3所示),并在WASPv2解码器中实现了空洞可分离卷积,使处理256x256尺寸图像所需的网络GFLOPs从22.6 GFLOPs降至5.8 GFLOPs,减少了74.3%。此外,OmniPose-Lite还将参数量从67.9M减少到19.4M,降低了71.4%。
The small size of the proposed OmniPose-Lite architecture, in combination with the reduced number of parameters allows the implementation of the OmniPose architecture for mobile applications without a large computational burden.
所提出的OmniPose-Lite架构体积小巧,加之参数数量减少,使得OmniPose架构能够在移动应用中实现,而不会带来较大的计算负担。
4. Datasets
4. 数据集
We performed multi-person experiments on two datasets: Common Objects in Context (COCO) [20] and MPII [2]. The COCO dataset [20] is composed of over 200K images containing over 250K instances of the person class. The labelled poses contain 17 keypoints. The dataset is considered a challenging dataset due to the large number of images in a diverse set of scales and occlusion for poses in the wild.
我们在两个数据集上进行了多人实验:Common Objects in Context (COCO) [20] 和 MPII [2]。COCO数据集 [20] 包含超过20万张图像,涵盖超过25万个人物类实例,标注姿态包含17个关键点。由于该数据集包含大量不同尺度的野外姿态图像及遮挡情况,被视为具有挑战性的基准。
The MPII dataset [2] contains approximately 25K images of annotated body joints of over 40K subjects. The images are collected from YouTube videos in 410 everyday activities. The dataset contains frames with joints annotations, head and torso orientations, and body part occlusions.
MPII数据集 [2] 包含约2.5万张图像,标注了超过4万人的身体关节。这些图像采集自410种日常活动的YouTube视频。该数据集提供带有关节标注、头部与躯干朝向以及身体部位遮挡情况的帧。
In order to better train our network for joint detection, ideal Gaussian maps were generated at the joint locations in the ground truth. These maps are more effective for training than single points at the joint locations, and were used to train our network to generate Gaussian heatmaps corresponding to the location of each joint. Gaussians with different $\sigma$ values were considered and a value of $\sigma=3$ was adopted, resulting in a well defined Gaussian curve for both the ground truth and predicted outputs. This value of $\sigma$ also allows enough separation between joints in the image.
为了更好地训练我们的网络进行联合检测,在真实标注的关节位置生成了理想的高斯(Gaussian)图。这些图比关节位置的单点标注更有效,用于训练网络生成与每个关节位置对应的高斯热图。我们考虑了不同$\sigma$值的高斯分布,最终采用$\sigma=3$,使得真实标注和预测输出都能形成清晰的高斯曲线。该$\sigma$值还能确保图像中关节之间有足够的区分度。
5. Experiments
5. 实验
OmniPose experiments were based on the metrics set by each dataset, and procedures applied by [31], [12], and [38].
OmniPose实验基于各数据集设定的指标,并采用了[31]、[12]和[38]所应用的方法。
5.1. Metrics
5.1. 指标
For the evaluation of OmniPose, various metrics were used depending on previously reported results and the available ground truth for each dataset. The first metric used is the Percentage of Correct Keypoints (PCK). This metric considers the prediction of a keypoint correct when a joint detection lies within a certain threshold distance of the ground truth. The commonly used threshold of $\mathrm{PCKh}@0.5$ was adopted for the MPII dataset, which refers to a threshold of $50%$ of the head diameter.
为评估OmniPose性能,根据不同数据集已报告结果和可用真实标注数据采用了多种指标。首选指标是关键点正确率 (PCK),当预测关节位置与真实标注的距离小于特定阈值时即判定为正确预测。针对MPII数据集采用通用阈值$\mathrm{PCKh}@0.5$,该阈值设定为头部直径的$50%$。
In the case of the COCO dataset, the evaluation is done based on the Object Keypoint Similarity metric (OKS).
在COCO数据集的评估中,采用物体关键点相似度指标 (OKS) 进行衡量。
$$
O K S=\frac{(\sum_{i}e^{-d_{i}^{2}/2s^{2}k_{i}^{2}})\delta(v_{i}>0)}{\sum_{i}\delta(v_{i}>0)}
$$
$$
O K S=\frac{(\sum_{i}e^{-d_{i}^{2}/2s^{2}k_{i}^{2}})\delta(v_{i}>0)}{\sum_{i}\delta(v_{i}>0)}
$$
where, $d_{i}$ is the Euclidian distance between the estimated keypoint and its ground truth, $v_{i}$ indicates if the keypoint is visible, $s$ is the scale of the corresponding target, and $k_{i}$ is the falloff control constant.
其中,$d_{i}$ 是估计关键点与其真实值之间的欧氏距离,$v_{i}$ 表示该关键点是否可见,$s$ 是对应目标的尺度,$k_{i}$ 是衰减控制常数。
Since OKS is measured in an analogous form as the intersection over the union (IOU), and following the evaluation framework set by [20], we report OKS as the Average Precision (AP) for the IOUs for all instances between 0.5 and 0.95 $(A P)$ , at $0.5(A P^{50})$ and 0.75 $(A P^{75})$ , as well as instances of medium $(A P^{M})$ and large size $(A P^{L})$ . We also report the Average Recall between 0.5 and 0.95 (AR).
由于OKS的测量方式类似于交并比(IOU),并遵循[20]设定的评估框架,我们报告OKS作为所有实例在0.5至0.95区间IOU的平均精度(AP) $(A P)$,以及在0.5 $(A P^{50})$ 和0.75 $(A P^{75})$ 时的值,还包括中等尺寸 $(A P^{M})$ 和大尺寸 $(A P^{L})$ 的实例。我们还报告了0.5至0.95区间内的平均召回率(AR)。
5.2. Parameter Selection
5.2. 参数选择
We process the input image in a set of different resolutions, reporting the trade-off of network size and accuracy performance. For that reason, the batch size varied depending on the size of the dataset images. We considered different rates of dilation on the WASP module and found that larger rates result in better prediction. A set of dilation rates of $r={1,6,12,18}$ was selected for the WASPv2 module.
我们在不同分辨率下处理输入图像,以权衡网络规模与准确率表现。为此,批量大小会根据数据集图像的尺寸而变化。我们测试了WASP模块的不同扩张率,发现较大的扩张率能带来更好的预测效果。最终为WASPv2模块选定了一组扩张率 $r={1,6,12,18}$。

Figure 6. Pose estimation examples using OmniPose with the MPII dataset.
Table 1. OmniPose results and comparison with SOTA methods for the MPII dataset for validation.
图 6: 使用 OmniPose 在 MPII 数据集上的姿态估计示例。
| 方法 | 参数量 (M) | GFLOPs | 头部 | 肩部 | 肘部 | 手腕 | 髋部 | 膝盖 | 脚踝 | PCKh @0.2 |
|---|---|---|---|---|---|---|---|---|---|---|
| OmniPose(WASPv2) | 68.1 | 22.6 | 97.4% | 97.1% | 92.4% | 88.7% | 91.2% | 89.9% | 85.8% | 92.3% |
| OmniPose(WASP) | 68.2 | 23.0 | 97.4% | 96.6% | 91.9% | 87.2% | 90.1% | 88.0% | 83.9% | 91.2% |
| DarkPose [38] | 63.6 | 19.5 | 97.2% | 95.9% | 91.2% | 86.7% | 89.7% | 86.7% | 84.0% | 90.6% |
| HRNet [31] | 63.6 | 19.5 | 97.1% | 95.9% | 90.3% | 86.5% | 89.1% | 87.1% | 83.3% | 90.3% |
| OmniPose-Lite | 19.4 | 5.8 | 96.6% | 95.8% | 89.1% | 84.3% | 89.0% | 84.1% | 79.6% | 89.0% |
| CMU Pose [6] | - | - | 92.4% | 90.4% | 80.9% | 70.8% | 79.5% | 73.1% | 66.5% | 79.1% |
| SPM [25] | - | - | 92.0% | 88.5% | 78.6% | 69.4% | 77.7% | 73.8% | 63.9% | 77.7% |
| RMPE [15] | - | - | 88.4% | 86.5% | 78.6% | 70.4% | 74.4% | 73.0% | 65.8% | 76.7% |
表 1: OmniPose 在 MPII 验证数据集上的结果与 SOTA 方法的对比。
We calculate the learning rate based on the step method, where the learning rate started at $10^{-3}$ and was reduced in two steps by an order of magnitude at each steps at 170 and 200 epochs, following procedures set by [38]. All experiments were performed using PyTorch on Ubuntu 16.04. The workstation has an Intel i5-2650 2.20GHz CPU with 16GB of RAM and an NVIDIA Tesla V100 GPU.
我们基于步进法计算学习率,初始学习率为 $10^{-3}$,并在170和200周期时按[38]设定的流程分两步逐步降低一个数量级。所有实验均在Ubuntu 16.04系统上使用PyTorch进行。工作站配置为Intel i5-2650 2.20GHz CPU、16GB内存及NVIDIA Tesla V100 GPU。
6. Results
6. 结果
We present OmniPose results on two large datasets and provide comparisons with state-of-the art methods.
我们在两个大型数据集上展示了OmniPose的结果,并与最先进的方法进行了比较。
6.1. Experimental results on the MPII dataset
6.1. MPII数据集上的实验结果
During our experiments on the MPII dataset, we performed a series of ablation studies to analyze the gains due to different aspects of our method. Table 2 demonstrates the results for the inclusion of the Gaussian de convolution modulation (GDM) in the HRNet backbone, and improvements gained by initially using the original WASP module
在对MPII数据集进行实验时,我们进行了一系列消融研究以分析方法各组成部分的增益效果。表2展示了在HRNet主干网络中加入高斯反卷积调制(GDM)的效果,以及初始使用原始WASP模块带来的改进。
[3], [4], and then our proposed advanced WASPv2 in combination with the improved HRNet feature extractor.
[3]、[4],以及我们提出的结合改进版HRNet特征提取器的高级WASPv2。
| 方法 | GDM WASP | WASPv2 | PCKh @0.2 |
|---|---|---|---|
| DarkPose [38] OmniPose OmniPose | √ √ √ | √ | 90.6% 91.0% 91.2% 92.3% |
Table 2. Results using different versions of OmniPose and comparison with SOTA for the MPII dataset for validation. GDM represents the use of Gaussian De convolution Modulation in the modified HRNet backbone, and WASP and WASPv2 indicates the use of the waterfall modules in the network.
表 2: 不同版本 OmniPose 在 MPII 验证集上的结果及与 SOTA 的对比。GDM 表示在改进版 HRNet 骨干网络中使用高斯解卷积调制 (Gaussian Deconvolution Modulation) ,WASP 和 WASPv2 表示在网络中使用瀑布模块 (waterfall modules) 。
Our OmniPose method progressively increases its performance with the addition of innovations, resulting in $1.9%$ improvement over DarkPose [38]. Most significantly, the integration of the enhanced multi-scale extraction with WASPv2 substantially increases the keypoints detection, particularly for occluded joints.
我们的OmniPose方法通过逐步引入创新技术持续提升性能,最终比DarkPose [38]提高了1.9%。最关键的是,增强型多尺度提取与WASPv2的结合显著提升了关键点检测能力,尤其针对被遮挡关节的识别。
Following our experiments evaluating the individual contributions of this work, we compared the results of OmniPose with other methods, as shown in Table 1. OmniPose achieved a overall $\mathrm{PCKh}@0.2$ of $92.3%$ , showing significant gains in comparison to state-of-the-art. It is significant that OmniPose results in a improvement to previous SOTA methods in all individuals groups of joints for pose estimation, demonstrating the robustness and performance of our framework, particularly to harder to detect joints such as ankles ( $2.1%$ improvement from previous state-of-the-art)
在我们评估本工作各项独立贡献的实验之后,我们将OmniPose与其他方法的结果进行了对比,如表1所示。OmniPose在$\mathrm{PCKh}@0.2$指标上达到了$92.3%$的整体准确率,相比现有最优技术展现出显著优势。值得注意的是,OmniPose在所有关节分组的人体姿态估计任务中都实现了对先前SOTA方法的提升,这证明了我们框架的鲁棒性和性能表现,特别是在检测难度较高的关节(如脚踝)方面(较先前最优技术提升$2.1%$)。

Figure 7. Pose estimation examples using OmniPose with the COCO dataset.
图 7: 使用OmniPose在COCO数据集上的姿态估计示例。
| 方法 | 输入尺寸 | 参数量 (M) | GFLOPs | AP | AP50 | AP75 | APM | APL | AR |
|---|---|---|---|---|---|---|---|---|---|
| OmniPose (WASPv2) | 384x288 | 68.1 | 37.9 | 79.5% | 93.6% | 85.9% | 76.0% | 84.6% | 81.9% |
| OmniPose(WASP) | 384x288 | 68.2 | 38.6 | 79.2% | 93.6% | 85.7% | 75.9% | 84.2% | 81.6% |
| DarkPose [38] | 384x288 | 63.6 | 32.9 | 76.8% | 90.6% | 83.2% | 72.8% | 84.0% | 81.7% |
| HRNet [31] | 384x288 | 63.6 | 32.9 | 76.3% | 90.8% | 82.9% | 72.3% | 83.4% | 81.2% |
| EvoPose2D [22] | 384x288 | 7.3 | 5.6 | 75.1% | 90.2% | 81.9% | 71.5% | 81.7% | 81.0% |
| Simple Baseline [35] | 384x288 | 68.6 | 35.6 | 74.3% | 89.6% | 81.1% | 70.5% | 79.7% | 79.7% |
Table 3. OmniPose results and comparison with SOTA methods for the COCO dataset for validation.
Table 4. OmniPose results and comparison with SOTA methods for the COCO dataset for test.
表 3. OmniPose 在 COCO 验证集上的结果与 SOTA 方法对比。
| 方法 | 输入尺寸 | 参数量 (M) | GFLOPs | AP | AP50 | AP75 | APM | APL | AR |
|---|---|---|---|---|---|---|---|---|---|
| OmniPose (WASPv2) DarkPose [38] | 384x288 | 68.1 | 37.9 | 76.4% | 92.6% | 83.7% | 72.6% | 82.6% | 81.2% |
| 384x288 | 63.6 | 32.9 | 76.2% | 92.5% | 83.6% | 72.5% | 82.4% | 81.1% | |
| MSPN [19] | 384x288 | 120 | 19.9 | 76.1% | 93.4% | 83.8% | 72.3% | 81.5% | 81.6% |
| HRNet [31] | 384x288 | 63.6 | 32.9 | 75.5% | 92.5% | 83.3% | 71.9% | 81.5% | 80.5% |
| Simple Baseline [35] | 384x288 | 68.6 | 35.6 | 73.7% | 91.9% | 70.3% | 81.1% | 80.0% | 79.0% |
| RMPE [15] | 320x256 | 28.1 | 26.7 | 72.3% | 89.2% | 79.1% | 68.0% | 78.6% | |
| CPN [11] | 384x288 | - | 72.1% | 91.4% | 80.0% | 68.7% | 77.2% | 78.5% | |
| IPR [32] | 256x256 | 45.1 | 11.0 | 67.8% | 88.2% | 74.8% | 63.9% | 74.0% | |
| G-RMI [27] | 256x256 | 42.6 | 57.0 | 64.9% | 85.5% | 71.3% | 62.3% | 70.0% | 69.7 |
| Mask-RCNN [16] | 63.1% | 87.3% | 68.7% | 57.8% | 71.4% | ||||
| CMU Pose [6] | 61.8% | 84.9% | 57.1% | 67.5% | 68.2% | 66.5% |
表 4. OmniPose 在 COCO 测试集上的结果与 SOTA 方法对比。
and wrists $2.3%$ above previous state-of-the-art). Figure 6 demonstrates successful detections on the main person in MPII images. These examples illustrate that OmniPose deals effectively with occlusion, e.g. in the case of the skier.
以及手腕 $2.3%$ 超越先前最优水平)。图6展示了在MPII图像中对主体人物的成功检测。这些示例表明OmniPose能有效处理遮挡情况,例如滑雪者的案例。
OmniPose-Lite achieves accuracy of $89.0%$ while reducing computational cost by $74.3%$ for the MPII validation dataset (Table 1). This demonstrates its ability to significantly reduce size and computational cost, while maintaining good performance compared to heavier SOTA methods.
OmniPose-Lite 在 MPII 验证数据集上实现了 $89.0%$ 的准确率,同时将计算成本降低了 $74.3%$ (表 1)。这表明与更重的 SOTA (State-of-the-Art) 方法相比,它能够在保持良好性能的同时显著减小模型规模和计算成本。
6.2. Experimental results on the COCO dataset
6.2. COCO数据集上的实验结果
We next performed training and testing on the COCO dataset, which is more challenging due to the large number of diverse images with multiple people in close proximity, as well as images lacking a person instance.
接下来我们在COCO数据集上进行了训练和测试,该数据集更具挑战性,因为包含大量密集人群的多样化图像,以及没有人实例的图像。
We performed experiment to compare the proposed improvements of OmniPose with the original HRNet framework. OmniPose outperforms HRNet in terms of average precision for different input resolutions, as shown in Figure 8 for 3 different versions of OmniPose: small $(128\times96)$ , medium $(256\times192)$ , and large $(384\times288)$ ; as well as lower resolution versions of OmniPose-Lite. OmniPose demonstrates an increase in performance for all resolutions compared with the original HRNet architecture. The accuracy of the OmniPose framework steadily increases with the increase of the input resolution, but there is a trade-off with processing time due to the larger number of image pixels that are processed in the network.
我们进行了实验,将OmniPose的改进方案与原始HRNet框架进行对比。如图8所示,针对3种不同版本的OmniPose(小尺寸$(128\times96)$、中尺寸$(256\times192)$和大尺寸$(384\times288)$)以及低分辨率版本的OmniPose-Lite,OmniPose在不同输入分辨率下的平均精度均优于HRNet。与原始HRNet架构相比,OmniPose在所有分辨率下均表现出性能提升。OmniPose框架的精度随着输入分辨率的提高而稳步上升,但由于网络中处理的图像像素数量增加,会带来处理时间上的权衡。

Figure 8. Average Precision comparison of OmniPose to the original HRNet method for different input resolutions.
图 8: OmniPose 与原始 HRNet 方法在不同输入分辨率下的平均精度 (Average Precision) 对比。
OmniPose was compared with SOTA methods for the validation set of the COCO dataset. The results in Table 3 demonstrate that OmniPose shows significant improvement over the previous SOTA. The modification of the HRNet backbone, combined with the WASPv2 module results in an improved accuracy of $79.5%$ , a significant increase of $4.2%$ compared with the original HRNet, and $7.0%$ compared with the baseline model.
将OmniPose与COCO数据集验证集的SOTA方法进行了比较。表3中的结果表明,OmniPose相比之前的SOTA方法有显著提升。对HRNet主干网络的修改,结合WASPv2模块,使准确率提升至$79.5%$,相比原始HRNet显著提高了$4.2%$,相比基线模型提升了$7.0%$。
OmniPose improves accuracy for all detection metric sizes and IOU for COCO, as was the case for MPII. Most significantly, in harder detections the AP for person instances of medium size obtained by OmniPose shows an increase of $4.4%$ over the previous state-of-the-art. These results demonstrate the increased capability of OmniPose to estimate harder poses using a reduced number of pixels due to the multi-scale features from the WASPv2 module.
OmniPose 在 COCO 数据集上提升了所有检测指标尺寸的准确率和 IOU(交并比),与 MPII 数据集的表现一致。最显著的是,在中等尺寸人体实例的困难检测中,OmniPose 的 AP(平均精度)比之前的最先进方法提高了 $4.4%$。这些结果表明,得益于 WASPv2 模块的多尺度特征,OmniPose 能够以更少的像素数量更准确地估计困难姿态。
Comparing OmniPose-Lite to lightweight architectures, OmniPose-Lite shows a reduction of size of $12%$ while increasing the performance on the COCO validation set by $8.7%$ compared to the popular Mobile Ne tV 2 [17], as shown in Table 5. This establishes a significant improvement for lightweight pose estimation methods.
将OmniPose-Lite与轻量级架构进行对比时,如表5所示,相较于流行的MobileNetV2 [17],OmniPose-Lite在模型体积上减少了12%,同时在COCO验证集上的性能提升了8.7%。这标志着轻量级姿态估计方法的重大改进。
Table 5. Lightweight comparison for the COCO validation dataset.
表 5: COCO验证数据集的轻量级对比。
| 方法 | 输入尺寸 | GFLOPs | AP |
|---|---|---|---|
| OmniPose-Lite MobileNetV2 [17] | 256x192 256x192 | 4.4 5.0 | 71.4% 65.7% |
Example results for the validation COCO dataset are shown in Figure 7. It is noticeable from these examples that our method identifies the location of symmetric body joints with high precision, providing high accuracy for challenging scenarios, that include multiple instances of people in near proximity and occluded joints, such as ankles and wrists, that are harder to detect. Challenging conditions include the detection of joints when limbs are not sufficiently separated or occlude each other, where OmniPose demonstrates a robust ability to detect.
验证COCO数据集的示例结果如图7所示。从这些示例中可以明显看出,我们的方法能以高精度识别对称身体关节的位置,即使在具有挑战性的场景下也能提供高准确度,这些场景包括近距离多人物实例以及较难检测的被遮挡关节(如脚踝和手腕)。挑战性条件包括肢体未充分分离或相互遮挡时的关节检测,而OmniPose展现出强大的检测能力。
We also compared OmniPose with SOTA methods using the COCO test-dev dataset, which contains a significantly larger number of images. OmniPose achieved a new state-of-the-art performance compared with other methods without the use of additional training data or post processing, achieving an average precision of $76.4%$ . Confirming our findings from previous datasets, OmniPose shows the most significant improvements in smaller targets.
我们还使用包含更多图像的COCO test-dev数据集将OmniPose与其他SOTA方法进行了对比。在不使用额外训练数据或后处理的情况下,OmniPose以76.4%的平均精度实现了新的最优性能。与先前数据集的研究结果一致,OmniPose在较小目标上展现出最显著的性能提升。
6.3. Single person and video datasets
6.3. 单人及视频数据集
We further tested OmniPose on the Leeds Sports Pose (LSP) [18] dataset, for single person pose estimation. OmniPose achieved a significant improvement of $5%$ from the previous state-of-the-art achieved by UniPose [4], resulting in a $\mathrm{PCK}@0.2$ of $99.5%$ and saturating the pose estimation performance for the LSP dataset. Similarly, running OmniPose on the PennAction dataset for pose estimation in short sports videos [40] shows saturation in performance by achieving state-of-the-art accuracy of $99.4%$ PCK.
我们进一步在Leeds Sports Pose (LSP) [18]数据集上测试了OmniPose的单人姿态估计性能。相比UniPose [4]先前保持的最先进水平,OmniPose实现了5%的显著提升,达到99.5%的$\mathrm{PCK}@0.2$指标,使LSP数据集的姿态估计性能趋于饱和。同样地,在PennAction数据集上运行OmniPose进行短视频运动姿态估计[40]时,以99.4%的PCK准确率达到了当前最优水平,表明性能已趋饱和。
7. Conclusion
7. 结论
We presented the OmniPose framework for multi-person pose estimation. The OmniPose pipeline utilizes the improved WASPv2 module that features a waterfall flow with a cascade of atrous convolutions and multi-scale representations. The OmniPose framework achieves state-of-theart performance, with an improved HRNet feature extractor utilizing transposed convolutions with Gaussian heatmap modulation, replacing interpolations. Omnipose is an endto-end trainable architecture that does not require anchor poses or post processing. The results of the OmniPose framework demonstrated state-of-the-art performance on several datasets using various metrics.
我们提出了用于多人姿态估计的OmniPose框架。该框架采用改进的WASPv2模块,其特点是具有级联空洞卷积和多尺度表示的瀑布流结构。OmniPose框架通过改进的HRNet特征提取器(使用转置卷积配合高斯热图调制替代插值操作)实现了最先进的性能。该端到端可训练架构无需锚定姿态或后处理步骤。实验结果表明,OmniPose框架在多个数据集上采用不同评估指标均展现出当前最优性能。
References
参考文献
Pattern Analysis and Machine Intelligence, 41(4):901–914, 2018. 1
模式分析与机器智能,41(4):901–914,2018。1