AUTO-AVSR: AUDIO-VISUAL SPEECH RECOGNITION WITH AUTOMATIC LABELS
AUTO-AVSR: 基于自动标注的视听语音识别
ABSTRACT
摘要
Audio-visual speech recognition has received a lot of attention due to its robustness against acoustic noise. Recently, the performance of automatic, visual, and audio-visual speech recognition (ASR, VSR, and AV-ASR, respectively) has been substantially improved, mainly due to the use of larger models and training sets. However, accurate labelling of datasets is time-consuming and expensive. Hence, in this work, we investigate the use of automatically-generated transcriptions of unlabelled datasets to increase the training set size. For this purpose, we use publicly-available pre-trained ASR models to automatically transcribe unlabelled datasets such as AVSpeech and VoxCeleb2. Then, we train ASR, VSR and AV-ASR models on the augmented training set, which consists of the LRS2 and LRS3 datasets as well as the additional automatically-transcribed data. We demonstrate that increasing the size of the training set, a recent trend in the literature, leads to reduced WER despite using noisy transcriptions. The proposed model achieves new state-of-the-art performance on AV-ASR on LRS2 and LRS3. In particular, it achieves a WER of $0.9%$ on LRS3, a relative improvement of $30%$ over the current state-of-the-art approach, and outperforms methods that have been trained on non-publicly available datasets with 26 times more training data.
视听语音识别因其对声学噪声的鲁棒性而备受关注。近期,自动、视觉及视听语音识别(分别为ASR、VSR和AV-ASR)性能显著提升,主要得益于更大模型和训练集的使用。然而,数据集的精确标注耗时且昂贵。因此,本研究探索利用未标注数据集的自动生成转录来扩充训练集规模。我们采用公开可用的预训练ASR模型(如AVSpeech和VoxCeleb2)进行自动转录,随后在由LRS2、LRS3数据集及新增自动转录数据构成的增强训练集上训练ASR、VSR和AV-ASR模型。实验表明,尽管使用含噪声的转录文本,扩大训练集规模(当前学界趋势)仍能降低词错误率(WER)。所提模型在LRS2和LRS3上实现了AV-ASR的新最优性能:LRS3上WER达$0.9%$,较现有最优方法相对提升$30%$,且优于使用26倍非公开训练数据的方法。
Index Terms— audio-visual speech recognition, unlabelled audio-visual data, automatically generated transcriptions
索引术语 - 视听语音识别 (audio-visual speech recognition), 未标注视听数据 (unlabelled audio-visual data), 自动生成转录文本 (automatically generated transcriptions)
1. INTRODUCTION
1. 引言
In the human perceptual system, the visual and audio streams often complement each other, yielding a unified robust response. It is also known that using visual signals along with audio signals leads to higher model robustness than using a single modality, especially in the presence of high levels of acoustic noise [1–4].
在人类感知系统中,视觉和听觉信息流通常相互补充,产生统一而稳健的响应。已知结合视觉信号与音频信号能比单一模态获得更高的模型鲁棒性,特别是在存在高强度声学噪声的情况下 [1-4]。
In this paper, we tackle Audio-Visual Automatic Speech Recognition (AV-ASR, or AVSR), which aims to transcribe continuous spoken sentences from both audio and visual streams. Recent audio(ASR), video- (VSR) and audio-visual-based models have relied heavily on large-scale and well-labelled transcriptions to achieve convincing performance. However, accurate transcriptions require manual labelling, which is time-consuming and prohibitively expensive. In order to address this issue, several works have been proposed to build advanced ASR and VSR models by leveraging large-scale unlabelled audio-visual datasets. Popular approaches pre-train ASR and VSR models using self-supervised learning, where the goal is to learn audio and visual representations from large unlabelled datasets [5–8]. The pre-trained models are then fine-tuned on smaller labelled datasets. Alternatively, another line of work solves the task using knowledge distillation [9, 10]. For example, Afouras et al. [9] use a pre-trained ASR model - acting as a teacher - to provide an extra supervisory signal to the target VSR model, where the goal is to force the posterior distribution of the VSR network to match the teacher. Similarly, Ren et al. [10] further improve the performance of visual-only models by distilling knowledge from pre-trained models with multiple modalities.
本文研究音视频自动语音识别 (AV-ASR 或 AVSR) 技术,旨在通过音频和视觉双模态流转录连续口语语句。当前基于音频 (ASR)、视频 (VSR) 和音视频的模型高度依赖大规模精准标注文本才能达到理想性能,但人工标注存在耗时耗力的瓶颈。为解决该问题,已有研究尝试利用大规模无标注音视频数据集构建先进 ASR 和 VSR 模型。主流方法采用自监督学习预训练模型,目标是从海量无标注数据中学习音频与视觉表征 [5-8],再通过小规模标注数据微调模型。另一类研究采用知识蒸馏技术 [9,10],如 Afouras 等人 [9] 使用预训练 ASR 模型作为教师网络,为目标 VSR 模型提供额外监督信号,迫使 VSR 网络的后验分布与教师网络对齐。Ren 等人 [10] 则通过多模态预训练模型的知识蒸馏进一步提升纯视觉模型的性能。
In this work, we propose a different approach to leverage large unlabelled datasets which does not require a two-step training approach used in self-supervised learning (SSL) (but it can easily be combined with any state-of-the-art SSL approach). In particular, we take advantage of the availability of good publicly-available pretrained ASR models [5, 8, 11, 12] to automatically annotate largescale audio-visual datasets. This approach is broadly related to selftraining [13–15], where a model is first trained on annotated data and then used to generate pseudo-labels for the unlabelled data. A new model is trained with all the annotated data, and this process is repeated for a few iterations. This iterative process might be necessary in other domains for which a high-quality pre-trained model does not exist, but this is not the case for ASR, where accurate pre-trained models are relatively abundant. Thus, we sidestep the need for a costly iterative procedure. Moreover, we incorporate the automatically-transcribed unlabelled data into the training set rather than using the pre-trained ASR model for distillation [9]. As a result, we can easily train a large-scale AV-ASR system by simplifying the implementation and reducing both the computational and memory costs of using a teacher during training. We also find similarities with [3, 16], but instead of using owner-uploaded transcriptions or a production-quality ASR system, all models and datasets we use are publicly accessible.
在本工作中,我们提出了一种利用大规模未标注数据集的不同方法,该方法不需要自监督学习 (SSL) 中使用的两步训练流程(但可以轻松与任何前沿 SSL 方法结合)。具体而言,我们利用现有优质公开预训练ASR模型 [5, 8, 11, 12] 来自动标注大规模视听数据集。该方法与自训练 [13–15] 有广泛关联性——自训练先使用标注数据训练模型,再生成未标注数据的伪标签,最后用全部标注数据训练新模型并迭代数次。这种迭代流程在其他缺乏高质量预训练模型的领域可能是必要的,但ASR领域存在大量准确预训练模型,因此我们规避了高成本的迭代过程。此外,我们将自动转写的未标注数据直接纳入训练集,而非使用预训练ASR模型进行蒸馏 [9],从而通过简化实现方式并降低训练时使用教师模型的计算/内存成本,轻松训练大规模AV-ASR系统。虽然与 [3, 16] 存在相似性,但我们使用的所有模型和数据集均公开可获取,而非依赖用户上传的转录文本或生产级ASR系统。
Our main contributions can be summarised as follows: 1) we automatically generate transcriptions for more than 2 000 hours of videos by utilising publicly-available ASR models. We then train ASR, VSR and AV-ASR models with these transcriptions and achieve state-of-the-art performance on the LRS2 and LRS3 datasets. Concretely, the proposed approach leads to a WER of $0.9%$ for AV-ASR on the LRS3 dataset, which outperforms models trained on much larger training sets; 2) We show that the accuracy of the pretrained ASR models used to automatically transcribe the unlabelled datasets is not highly correlated with the performance of the ASR and VSR models trained with these transcriptions; 3) We observe that an increase in the number of hours of automatically-transcribed data used in the training set results in reduced WER, especially for the VSR models. On the other hand, the performance of the ASR models seems to saturate beyond 1500 hours.
我们的主要贡献可总结如下:1) 利用公开可用的自动语音识别(ASR)模型为超过2000小时的视频自动生成转录文本。随后使用这些转录训练ASR、视觉语音识别(VSR)和视听语音识别(AV-ASR)模型,在LRS2和LRS3数据集上实现了最先进性能。具体而言,所提方法在LRS3数据集上实现AV-ASR的单词错误率(WER)为$0.9%$,优于使用更大规模训练集训练的模型;2) 研究表明,用于自动转录未标注数据集的预训练ASR模型准确率,与基于这些转录训练的ASR和VSR模型性能之间不存在高度相关性;3) 观察到训练集中自动转录数据时长的增加会降低WER,对VSR模型尤为明显。而ASR模型性能在超过1500小时后趋于饱和。

Stage 1: Leverage pre-trained ASR for automated transcripts of unlabelled data and combination with LRS2 and LRS3
图 1:
阶段 1: 利用预训练ASR(自动语音识别)生成未标注数据的自动转录文本 并与LRS2和LRS3数据集结合
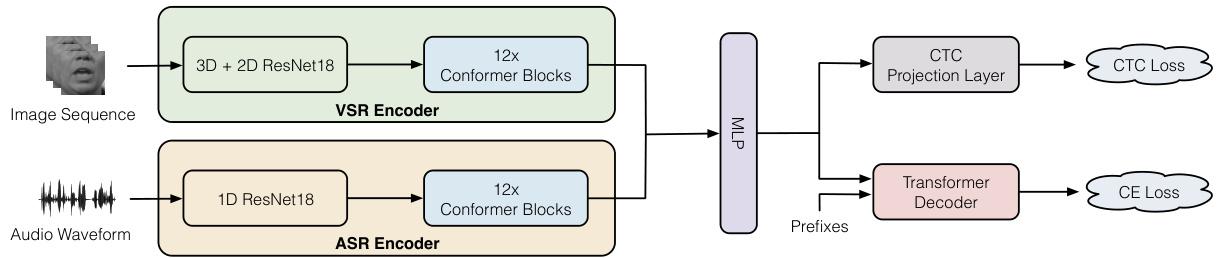
Stage 2: Training an audio-visual automatic speech recognition model Fig. 1. AV-ASR architecture overview. In the first stage, a pre-trained ASR model is leveraged to produce automatically-generated transcriptions for unlabelled audio-visual datasets. And then these unlabelled datasets are combined with the labelled training sets, including LRS2 and LRS3, for training. The frame rate of audio and visual features from the ASR and VSR encoders is 25 frames per second (fps).
图 1: AV-ASR架构概览。第一阶段利用预训练的ASR模型为未标注的音频-视觉数据集生成自动转录文本。随后将这些未标注数据集与已标注训练集(包括LRS2和LRS3)合并用于训练。来自ASR和VSR编码器的音频与视觉特征帧率为每秒25帧(25 fps)。
2. AUTO-AVSR
2. AUTO-AVSR
2.3. Architecture
2.3. 架构
2.1. Leveraging pre-trained models to produce automaticallygenerated transcriptions for unlabelled audio-visual datasets
2.1. 利用预训练模型为未标注的视听数据集生成自动转录
In order to investigate the impact of the size of training data on the performance of audio-only, visual-only and audio-visual models, we scale the training sources by including publicly-available audiovisual clips into the training set. An overview of our label generation pipeline can be found at the top of Fig. 1. To be specific, audio waveforms from the unlabelled audio-visual datasets are fed into a pretrained ASR model to produce automatic transcriptions. For the purpose of this study, we use two unlabelled datasets: VoxCeleb2 [17] and AVSpeech [18]. In particular, AVSpeech [18] contains 4 700 hours of YouTube video segments in multiple languages, and VoxCeleb2 [17] consists of 2 300 hours of video segments from more than 6 000 people. However, we are interested in training models in English. Thus, we use the Vox Lingua 107 language classifier [19] to filter the AVSpeech dataset, resulting in a total of 1 323 hours; the list of English data we use for VoxCeleb2 is obtained from [7], and comprises 1 307 data hours. Next, we leverage publicly-available ASR models to produce automatically generated transcriptions. It is worth pointing out that our work facilitates reproduction and comparison since all datasets and models used are publicly accessible.
为了研究训练数据规模对纯音频、纯视觉及视听模型性能的影响,我们通过将公开可用的视听片段纳入训练集来扩展训练资源。标签生成流程概述见图 1 顶部。具体而言,我们将未标注视听数据集中的音频波形输入预训练的自动语音识别 (ASR) 模型以生成自动转录文本。本研究使用了两个未标注数据集:VoxCeleb2 [17] 和 AVSpeech [18]。其中 AVSpeech [18] 包含 4700 小时的多语言 YouTube 视频片段,VoxCeleb2 [17] 则包含来自 6000 多人共计 2300 小时的视频片段。由于我们专注于英语模型训练,因此使用 Vox Lingua 107 语言分类器 [19] 过滤 AVSpeech 数据集,最终获得 1323 小时数据;VoxCeleb2 的英语数据清单引自 [7],共计 1307 小时。随后,我们利用公开可用的 ASR 模型生成自动转录文本。需要指出的是,由于所用数据集和模型均为公开资源,本研究有利于成果复现与对比。
2.2. Automatic speech recognition models
2.2. 自动语音识别模型
We investigate the impact of the automatic transcriptions given by four different ASR models on the performance of audio-only and visual-only models, i.e. Whisper [11], wav2vec2.0 [5], Hidden unit BERT (HuBERT) [8] and Conformer-Transducer [12, 20]. In particular, wav2vec 2.0 [5] and HuBERT [8] are self-supervised learning methods for learning speech representations from unlabelled audio. In contrast, Conformer-Transducer [12] is a conformer-based model trained with recurrent neural network transducers (RNN-T) loss that uses the NeMo ASRSET dataset, consisting of 12 000 hours of English speech. Finally, Whisper [11] is a transformerbased model [21] trained with a total of 680 000 hours of labelled audio. In this work, we access the ASR models from the Hugging Face community, “nvidia/stt en conformer transducer xlarge”, “facebook/hubert-large-ls960-ft”, “facebook/wav2vec2-base-960h”, and “openai/whisper-medium.en”, respectively.
我们研究了四种不同ASR模型提供的自动转录对纯音频和纯视觉模型性能的影响,即Whisper [11]、wav2vec2.0 [5]、隐单元BERT (HuBERT) [8]和Conformer-Transducer [12, 20]。特别地,wav2vec 2.0 [5]和HuBERT [8]是从无标注音频中学习语音表征的自监督学习方法。相比之下,Conformer-Transducer [12]是基于Conformer的模型,使用循环神经网络传感器(RNN-T)损失进行训练,并采用了包含12,000小时英语语音的NeMo ASRSET数据集。最后,Whisper [11]是基于Transformer的模型[21],训练时使用了总计680,000小时的标注音频。在本工作中,我们通过Hugging Face社区获取了这些ASR模型,分别是"nvidia/stt_en_conformer_transducer_xlarge"、"facebook/hubert-large-ls960-ft"、"facebook/wav2vec2-base-960h"和"openai/whisper-medium.en"。
We adopt the off-the-shelf architecture presented in [22], which has achieved state-of-the-art performance on the LRS2 and LRS3 datasets without the use of external data. The architecture is shown at the bottom of Fig. 1. In particular, the VSR front-end is based on a modified ResNet-18 [23, 24], where the first layer is a spatiotemporal convolutional layer with a kernel size of $5\times7\times7$ and a stride of $1\times2\times2$ . The temporal back-end, which follows the frontend, is a Conformer [20]. Similarly, the ASR encoder consists of a 1D ResNet-18 [25] followed by a Conformer. The ASR and VSR encoder outputs are fused via a multi-layer perceptron (MLP). The rest of the network consists of a projection layer and a Transformer decoder for joint CTC/attention training [26].
我们采用[22]中提出的现成架构,该架构在不使用外部数据的情况下在LRS2和LRS3数据集上实现了最先进的性能。该架构如图1底部所示。具体而言,VSR前端基于改进的ResNet-18 [23, 24],其中第一层是时空卷积层,内核大小为$5\times7\times7$,步长为$1\times2\times2$。紧随前端的时序后端是一个Conformer [20]。同样,ASR编码器由一维ResNet-18 [25]和Conformer组成。ASR和VSR编码器的输出通过多层感知机(MLP)进行融合。网络的其余部分包括一个投影层和一个用于联合CTC/注意力训练[26]的Transformer解码器。
3. EXPERIMENTAL SETUP
3. 实验设置
3.1. Datasets
3.1. 数据集
We conduct experiments on LRS2 [27] and LRS3 [28], which are the two largest publicly available datasets for audio-visual speech recognition in English. LRS2, collected from BBC programs, contains 144 482 video clips with a total of 225 hours. Specifically, the pre-training, training, validation and test set contains 96 318 (195 hours), 45 839 (28 hours), 1 082 (0.6 hours) and 1 243 (0.5 hours) video clips, respectively. LRS3 consists of 151 819 video clips from TED talks with a total of 439 hours. It contains 118 516 (408 hours), 31 982 (30 hours) and 1 321 clips (0.9 hours) in the pretraining, training-validation, and test set, respectively. For training, we also use the English-speaking videos from AVSpeech (1 323 hours) and VoxCeleb2 (1 307 hours) as the additional training data together with automatically-generated transcriptions.
我们在LRS2 [27]和LRS3 [28]这两个最大的公开英语视听语音识别数据集上进行实验。LRS2采集自BBC节目,包含144 482个视频片段,总时长225小时。具体而言,预训练集、训练集、验证集和测试集分别包含96 318段(195小时)、45 839段(28小时)、1 082段(0.6小时)和1 243段(0.5小时)视频。LRS3包含来自TED演讲的151 819个视频片段,总时长439小时,其预训练集、训练-验证集和测试集分别包含118 516段(408小时)、31 982段(30小时)和1 321段(0.9小时)视频。训练过程中,我们还使用了来自AVSpeech(1 323小时)和VoxCeleb2(1 307小时)的英语视频作为附加训练数据,并配以自动生成的转录文本。
3.2. Pre-processing
3.2. 预处理
For the visual stream, we follow previous work [22] to pre-process the datasets. We crop the mouth region of interests (ROIs) using a bounding box of $96\times96$ . Each frame is normalised by subtracting the mean and dividing by the standard deviation of the training set. For audio streams, we only perform $z$ -normalisation per utterance.
对于视觉流,我们遵循先前工作[22]对数据集进行预处理。使用$96\times96$的边界框裁剪出嘴部感兴趣区域(ROIs)。每帧图像通过减去训练集均值并除以其标准差进行归一化。对于音频流,我们仅对每条语音进行$z$归一化处理。
Table 1. Impact of the pre-trained ASR models used to generate automatic transcriptions from unlabelled data on the performance of VSR/ASR models on the LRS3 dataset. † and †† denote the word error rate (WER) reported on Libri speech test-clean set [33] and LRS3 test set [28], respectively. “CM” denotes Conformer. “V” and “A” denote the visual-only and audio-only models trained on LRW, LRS2, LRS3, VoxCeleb2 and AVSpeech (using the automaticallygenerated transcriptions from the corresponding pre-trained ASR model), with a total of 3 448 hours.
表 1: 用于从未标注数据生成自动转录的预训练ASR模型对LRS3数据集上VSR/ASR模型性能的影响。†和††分别表示在Libri speech test-clean集[33]和LRS3测试集[28]上报告的词错误率(WER)。"CM"表示Conformer。"V"和"A"表示仅在视觉和仅在音频上训练的模型,训练数据包括LRW、LRS2、LRS3、VoxCeleb2和AVSpeech(使用相应预训练ASR模型生成的自动转录),总计3 448小时。
3.3. Implementation details
3.3. 实现细节
For our audio- and visual-only ASR models, we use a ResNetbased front-end module pre-trained on LRW [29], followed by a Conformer encoder with 12 layers, 768 input dimensions, 3 072 feed-forward dimensions, and 16 attention heads. The decoder is a 6-layer Transformer with the same dimensions and number of heads as the encoder, resulting in a total of $243.1\mathrm{M}$ and $250.4\mathrm{M}$ parameters for the audio- and visual-only models, respectively. More specifically, the ASR front-end, VSR front-end, Conformer back-end, Transformer decoder and the projection layer of the CTC have $3.9\mathbf{M}$ , $11.2\mathbf{M}$ , $170.9\mathrm{M}$ , $64.5\mathrm{M}$ and $3.9\mathrm{M}$ parameters, respectively. For the audio-visual models, we concatenate the audio-visual encoder outputs and feed them to a 2-layer multi-layer perceptron (MLP) with hidden and output sizes of 8 192 and 768, respectively.
对于仅音频和仅视觉的ASR (Automatic Speech Recognition) 模型,我们采用了基于ResNet的前端模块,该模块已在LRW [29] 上进行了预训练,随后是一个Conformer编码器,包含12层、768个输入维度、3072个前馈维度和16个注意力头。解码器是一个6层Transformer,其维度和头数与编码器相同,最终仅音频和仅视觉模型的总参数量分别为$243.1\mathrm{M}$和$250.4\mathrm{M}$。具体而言,ASR前端、VSR前端、Conformer后端、Transformer解码器以及CTC的投影层分别拥有$3.9\mathbf{M}$、$11.2\mathbf{M}$、$170.9\mathrm{M}$、$64.5\mathrm{M}$和$3.9\mathrm{M}$个参数。对于视听模型,我们将视听编码器的输出拼接后输入到一个2层多层感知机 (MLP) ,其隐藏层和输出层的维度分别为8192和768。
Table 2. Impact of the size of additional training data (from AVSpeech and VoxCeleb2) on the WER $(%)$ of audio-only and visual-only models evaluated on LRS3. All models are initial is ed from a model pre-trained on LRW and trained on LRS2, LRS3 plus $X%$ hours of VoxCeleb2 and AVSpeech. “P” and “U” denote the amount of additional data in percentages and in hours, respectively. “T” denotes the total amount of training data (hours).
表 2: 额外训练数据 (来自 AVSpeech 和 VoxCeleb2) 的规模对纯音频和纯视觉模型在 LRS3 上评估的 WER $(%)$ 的影响。所有模型均从 LRW 预训练模型初始化,并在 LRS2、LRS3 加上 $X%$ 小时的 VoxCeleb2 和 AVSpeech 数据上进行训练。"P"和"U"分别表示额外数据的百分比和小时数。"T"表示训练数据总量 (小时)。
| 方法 | WER[%] | ||
|---|---|---|---|
| At | Att | ||
| CM-Transducer [12] | 1.62 | 19.1 | 0.99 |
| HuBERT [8] | 1.90 | 19.8 | 1.12 |
| Wav2vec 2.0 [5] | 3.40 | 19.1 | 1.06 |
| Whisper [11] | 4.10 | 11.22 19.0 | 1.04 |
For data augmentation, we apply horizontal flipping, random cropping, and adaptive time masking [30] to the visual inputs, while we only use adaptive time masking for the audio stream. For both streams, we choose a number of masks that is proportional to the utterance length and a maximum masking length of up to 0.4 seconds. For the target vocabulary, we use Sentence Piece [31] subword units with a vocabulary size of 5 000. We train the model for 75 epochs with the AdamW [32] optimizer, a cosine learning rate scheduler, and a warm-up of 5 epochs. The peak learning rate is 1e-3. The maximal number of frames in each batch is $1800$ frames. Following [30], our visual-only models are incorporated with a transformerbased language model trained on a corpus of 166 million characters † whereas language models are not included for ASR and AV-ASR models since no further improvements are observed.
在数据增强方面,我们对视觉输入应用了水平翻转、随机裁剪和自适应时间掩码 [30],而音频流仅使用自适应时间掩码。对于两个数据流,我们选择与语音长度成比例的掩码数量,最大掩码长度不超过0.4秒。目标词汇表采用Sentence Piece [31]子词单元,词汇量为5000。模型使用AdamW [32]优化器训练75个周期,采用余弦学习率调度器并预热5个周期,峰值学习率为1e-3。每批次最大帧数为$1800$帧。遵循[30]的方法,我们的纯视觉模型整合了基于Transformer的语言模型(训练语料包含1.66亿字符†),而ASR和AV-ASR模型由于未观察到进一步改进未包含语言模型。
4. RESULTS
4. 结果
4.1. Do better Libri speech ASR models provide better transcriptions for VSR?
4.1. 更好的Libri语音ASR模型能否为VSR提供更好的转录?
Given that several publicly-available ASR models are available, we use performance on Libri speech as a criterion for model selection. We use models that have achieved state-of-the-art performance on the test-clean set of Libri speech, i.e., Conformer-Transducer [12] and HuBERT [8]. We also use ASR models that are widely used in the speech community, wav2vec 2.0 [5] and Whisper [11]. Performance of ASR models on Libri speech clean-test set is shown in the first column of Table 1. Results of the ASR and VSR models trained with the automatically-generated transcriptions on the LRS3 dataset are shown in the third and fourth columns, respectively, of Table 1. We observe that overall the WER on Libri speech is not highly correlated with the performance of the ASR and VSR models trained with the automatically-generated transcriptions from the corresponding pre-trained ASR models. The same conclusion is also true when we measure the WER on the LRS3 test. We show that using the transcriptions from most ASR models (i.e., wav2vec 2.0 [5], Whisper [11], and Conformer-Transducer [12]) results in very similar WER for both audio-only and visual-only models. The only exception is the use of automatically-generated transcriptions from HuBERT [8] which results in slightly worse performance despite being one of the best performing models on Libri speech. In this work, we rely on the automatically-generated transcriptions from the Conformer-Transducer [12] since on average it leads to the best performance for both ASR and VSR models.
考虑到目前已有多个公开可用的自动语音识别 (ASR) 模型,我们采用 LibriSpeech 数据集上的性能表现作为模型筛选标准。我们选用了在 LibriSpeech 测试集 (test-clean) 上达到当前最优性能的 Conformer-Transducer [12] 和 HuBERT [8] 模型,同时选取了语音领域广泛使用的 wav2vec 2.0 [5] 和 Whisper [11] 模型。各 ASR 模型在 LibriSpeech clean-test 测试集上的性能表现如 表 1 第一列所示。
使用这些预训练 ASR 模型自动生成的转录文本,在 LRS3 数据集上训练的 ASR 与视觉语音识别 (VSR) 模型性能分别展示在 表 1 第三、四列。我们发现:LibriSpeech 上的词错率 (WER) 与使用对应 ASR 模型自动生成文本训练的 ASR/VSR 模型性能之间并不存在强相关性,这一结论在 LRS3 测试集上的 WER 评估中同样成立。
实验表明,当采用大多数 ASR 模型 (包括 wav2vec 2.0 [5]、Whisper [11] 和 Conformer-Transducer [12]) 的自动转录文本时,纯音频模型与纯视觉模型取得的 WER 非常接近。唯一的例外是 HuBERT [8] 生成的转录文本——尽管该模型在 LibriSpeech 上表现最佳,但其生成的文本却导致模型性能轻微下降。本研究最终选用 Conformer-Transducer [12] 的自动转录文本,因为其平均能为 ASR 和 VSR 模型带来最优性能。
| P U T | 0% Oh 818h | 20% 526h 1344h | 40% 1052h 1870h | 60% 1578h 2396h | 80% 2104h 2922h | 100% 2630h 3448h |
|---|---|---|---|---|---|---|
| A | 1.5 | 1.3 | 1.3 | 1.1 | 1.0 | |
| 33.0 | 26.6 | 23.6 | 21.9 | 20.0 | 19.1 |
4.2. Impact of the number of hours of unlabelled data
4.2. 未标注数据小时数的影响
Table 2 shows the impact of varying the numbers of hours of unlabelled data on the performance of ASR and VSR models on LRS3. An absolute improvement of $1.7%$ in WER is observed for VSR by using only labelled data from LRS2 and LRS3 (818 hours) compared to [30]. This gain is likely due to the increase in model capacity. When including $20%$ (526 hours) of AVSpeech [18] and VoxCeleb2 [17], the performance of audio- and visual-only models can be further improved to $1.3%$ and $26.6%$ WER, respectively. Increasing further the number of training hours leads to a further reduction of the WER especially for the VSR model. This is in line with the recent trend observed in the literature [30], where using larger training sets substantially improves performance. In this experiment, we also show that the WER can be improved even by adding data that have been automatically transcribed and inevitably have noisy labels. We also notice that the improvement for the ASR model is marginal when using more than 1 578 hours of unlabelled training data, indicating that the ASR performance may have saturated.
表 2 展示了未标注数据时长变化对 LRS3 数据集上 ASR 和 VSR 模型性能的影响。与 [30] 相比,仅使用 LRS2 和 LRS3 (818 小时) 的标注数据时,VSR 的 WER 绝对值提升了 1.7%,这可能是模型容量增加所致。当加入 20% (526 小时) 的 AVSpeech [18] 和 VoxCeleb2 [17] 数据后,纯音频和纯视觉模型的 WER 可进一步分别提升至 1.3% 和 26.6%。继续增加训练时长会进一步降低 WER,对 VSR 模型尤为明显。这与文献 [30] 中观察到的近期趋势一致,即更大规模的训练集能显著提升性能。本实验还表明,即使添加自动转录且必然带有噪声标签的数据,WER 仍能获得改善。我们还注意到,当使用超过 1,578 小时的未标注训练数据时,ASR 模型的改进幅度趋缓,表明其性能可能已达饱和。
4.3. Comparison with the state-of-the-art
4.3. 与现有最优技术的对比
Results on LRS2 and LRS3 are presented in Tables 3 and 4, respectively. For LRS2, it is clear that our visual-only, audio-only and audio-visual models further push the state-of-the-art performance to a WER of $14.6%$ , $1.5%$ and $1.5%$ respectively. For LRS3, the best visual-only model has a WER of $19.1%$ , which is outperformed only by [16] ( $17.0%$ WER) which uses $26\times$ more training data. Similarly, our audio-only model establishes a new state-of-the-art [7] by achieving a WER of $1.0%$ when using 1 921 hours of training data from LRW, LRS3 and VoxCeleb2 datasets. However, when further introducing AVSpeech for training, no further improvement is observed, suggesting that the ASR performance may have reached saturation. State-of-the-art performance is also achieved for AV-ASR with a WER of $0.9%$ .
LRS2和LRS3的结果分别展示在表3和表4中。对于LRS2,我们的纯视觉、纯音频和视听模型将当前最优性能分别提升至14.6%、1.5%和1.5%的词错误率(WER)。在LRS3上,最佳纯视觉模型的WER为19.1%,仅被[16]以17.0%的WER超越(该研究使用了26倍以上的训练数据)。同样地,我们的纯音频模型在使用来自LRW、LRS3和VoxCeleb2数据集的1921小时训练数据时,取得了1.0%的WER,创造了新纪录[7]。然而,当进一步引入AVSpeech进行训练时,未观察到性能提升,这表明语音识别性能可能已达到饱和。视听语音识别(AV-ASR)也实现了0.9%WER的当前最优性能。
Table 3. WER $(%)$ of our audio-only, visual-only and audio-visual models on the LRS2 dataset. † The total hours are counted by including the datasets used for both pre-training and training. Our model trained on 818 hours uses LRW, LRS2 and LRS3. Our model trained on 3 448 hours uses LRW, LRS2, LRS3, VoxCeleb2 and AVSpeech.
表 3. 我们的纯音频、纯视觉和视听模型在 LRS2 数据集上的词错误率 (WER $(%)$)。† 总时长统计包含预训练和训练所用的数据集。在 818 小时数据上训练的模型使用了 LRW、LRS2 和 LRS3。在 3 448 小时数据上训练的模型使用了 LRW、LRS2、LRS3、VoxCeleb2 和 AVSpeech。
| 方法 | 类型 | 额外数据 | 总时长† | WER (%) |
|---|---|---|---|---|
| MV-WAS [27] TDNN [36] CM-seq2seq [22] CM-aux [30] CTC/Attention [2] | A | × | 223 | 70.4 48.9 39.1 32.9 |
| KD + CTC [9] KD-seq2seq [10] TM-seq2seq [1] CTC/Attention [37] | A | 380 995 818 1391 60 000 | 63.5 51.3 49.2 48.3 43.2 | |
| CM-aux [30] VTP [38] Ours Ours | A | 1459 2676 818 3448 | 25.5 22.6 27.9 | |
| TDNN [36] CM-seq2seq [22] | A | 223 | 14.6 6.7 4.3 | |
| CTC/Attention [37] Ours Ours | A | 60000 818 | 2.7 2.6 | |
| TDNN [36] CM-seq2seq [22] TM-seq2seq [1] CTC/Attention [2] | A+V | 3448 223 | 1.5 5.9 | |
| A+V | 1391 380 | 4.2 8.3 7.0 3.9 |
4.4. Noise experiments
4.4. 噪声实验
Results of ASR and AV-ASR models, when tested with different acoustic noise levels, are shown in Table. 5. During training we use the babble noise from the NOISEX dataset [39], while the SNR level is selected from [-5 dB, 0 dB, 5 dB, 10 dB, 15 dB, $20\mathrm{dB}$ , $\infty$ dB] with a uniform distribution. For evaluation, we test three types of noise: babble noise [39], pink and white noise from the Speech Commands dataset [40]. We show that, overall, the results are consistent with those presented in [1, 3, 4, 22], i.e. the performance of audio-only models is closer to the audio-visual counterpart in the presence of low levels of noise, whereas the performance gap becomes larger as the noise levels increase. We notice that when using babble noise for evaluation, the performance of either audio-only or audio-visual models has a WER lower than $10%$ at $-7.5\mathrm{dB}$ . This is likely mainly a consequence of the overlapping noise type in the training and testing phases (despite mismatched levels of noise).
表 5 展示了不同声学噪声水平下 ASR 和 AV-ASR 模型的测试结果。训练阶段我们使用 NOISEX 数据集 [39] 的混叠噪声,信噪比 (SNR) 水平从 [-5 dB, 0 dB, 5 dB, 10 dB, 15 dB, $20\mathrm{dB}$, $\infty$ dB] 中均匀采样。评估阶段测试了三种噪声类型:混叠噪声 [39]、Speech Commands 数据集 [40] 的粉红噪声和白噪声。结果表明,整体趋势与 [1, 3, 4, 22] 的研究一致:在低噪声环境下,纯音频模型的性能更接近视听联合模型;随着噪声水平升高,性能差距逐渐扩大。值得注意的是,当使用混叠噪声评估时,无论是纯音频还是视听模型,在 $-7.5\mathrm{dB}$ 信噪比下的词错误率 (WER) 均低于 $10%$,这主要源于训练与测试阶段噪声类型的重叠(尽管噪声水平存在差异)。
5. CONCLUSIONS
5. 结论
In this work, we propose a simple and efficient method for scaling up audio-visual data for speech recognition. We present a detailed study on the performance of LRS3 in terms of the amount of unlabelled training data. By leveraging publicly-available ASR models to produce automatically-generated transcriptions, we train an AV-ASR system and achieve state-of-the-art performance on both publiclyavailable audio-visual benchmarks, LRS2 and LRS3. Furthermore, we show that our audio-visual model is more robust against different levels of noise than its audio-only counterpart.
在本研究中,我们提出了一种简单高效的方法来扩展语音识别中的视听数据规模。我们针对LRS3数据集在不同规模未标注训练数据下的性能表现进行了详细研究。通过利用公开可用的自动语音识别(ASR)模型生成自动转录文本,我们训练出一个视听语音识别(AV-ASR)系统,并在LRS2和LRS3这两个公开视听基准测试上取得了最先进的性能表现。此外,实验表明我们的视听模型比纯音频模型对不同噪声水平具有更强的鲁棒性。
Table 4. WER $(%)$ of our audio-only, visual-only and audio-visual models on the LRS3 dataset. ‡ The total hours are counted by including the datasets used for both pre-training and training. Our model trained on 818 hours uses LRW, LRS2 and LRS3. Our model trained on 1 902 hours uses LRW, LRS3 and VoxCeleb2. Our model trained on 3 448 hours uses LRW, LRS2, LRS3, VoxCeleb2 and AVSpeech.
表 4: 我们的纯音频、纯视觉和视听模型在LRS3数据集上的词错误率(WER) $(%)$ 。‡ 总时长统计包含预训练和训练所用的数据集。我们基于818小时训练的模型使用了LRW、LRS2和LRS3数据集;基于1,902小时训练的模型使用了LRW、LRS3和VoxCeleb2数据集;基于3,448小时训练的模型使用了LRW、LRS2、LRS3、VoxCeleb2和AVSpeech数据集。
| 方法 | 类型 | 额外数据 | 总时长* | WER (%) |
|---|---|---|---|---|
| CM-seq2seq [22] | × | 438 | 46.9 37.9 36.3 | |
| CM-aux [30] | ||||
| Ours | ||||
| KD +CTC [9] | 772 | 59.8 | ||
| KD-seq2seq [10] | 818 | 59.0 | ||
| TM-seq2seq [1] | 1362 | 58.9 | ||
| AVHuBERT [7] | 1759 | 26.9 33.6 | ||
| RNN-T [3] | 31000 | 30.7 | ||
| VTP [38] | 2676 | 90000 | 17.0 | |
| ViT3D-CM [16] | ||||
| Ours | 818 | 33.0 | ||
| Ours | 1902 | 23.5 | ||
| Ours | 3448 | 19.1 | ||
| CM-seq2seq [22] | 438 | 2.3 4.5 | ||
| RNN-T [3] | 31000 | |||
| AV-HuBERT [7] | A | 1759 | 1.3 | |
| Ours | 818 | 1.5 | ||
| Ours | 1902 | 1.0 | ||
| Ours | 3448 | 1.0 | ||
| CM-seq2seq [22] | 438 | |||
| RNN-T [3] | 31000 | 2.3 | ||
| AV-HuBERT [7] | A+V | 1759 | 1.4 | |
| ViT3D-CM [16] | 90000 | 1.6 | ||
| Ours | 1902 | 1.0 | ||
| Ours | 3448 | 0.9 |
Table 5. WER $(%)$ of our audio-only and audio-visual models as a function of the noise levels on the LRS3 dataset. The babble noise from the NOISEX dataset [39] is used for training while one of SNR levels from [-5 dB, 0 dB, 5 dB, $10\mathrm{dB}$ , 15 dB, $20\mathrm{dB}$ , $\infty$ dB] is selected with a uniform distribution. For testing, the pink and white noise from the Speech Commands dataset [40] is added to the raw audio waveforms with a specific SNR level. $^\ddag$ denotes the noise type used in both training and test set.
表 5. 我们的纯音频和视听模型在 LRS3 数据集上随噪声水平变化的词错误率 (WER) $(%)$。训练时使用 NOISEX 数据集 [39] 的混叠噪声,测试时从 [-5 dB, 0 dB, 5 dB, $10\mathrm{dB}$, 15 dB, $20\mathrm{dB}$, $\infty$ dB] 中均匀选择一个信噪比 (SNR) 水平。测试时,将 Speech Commands 数据集 [40] 的粉红噪声和白噪声以特定 SNR 水平添加到原始音频波形中。$^\ddag$ 表示训练集和测试集都使用的噪声类型。
| 类型 | 噪声 | 12.5 7.5 | SNR 水平 [dB] 2.5 -2.5 |
|---|---|---|---|
| A | Babble+ | 1.1 1.2 | 1.6 2.7 8.3 |
| A+V | Babble+ | 1.0 | 1.5 2.2 5.6 |
| A | Pink | 1.0 1.4 | 1.9 4.3 13.1 56.8 |
| A+V | Pink | 1.2 | 6.0 16.2 |
| A | White | 1.4 2.1 | 4.0 2.3 10.4 30.2 |
| A+V | White | 1.4 | 9.5 |