SLOWFAST NETWORK FOR CONTINUOUS SIGN LANGUAGE RECOGNITION
用于连续手语识别的SLOWFAST网络
ABSTRACT
摘要
The objective of this work is the effective extraction of spatial and dynamic features for Continuous Sign Language Recognition (CSLR). To accomplish this, we utilise a two-pathway SlowFast network, where each pathway operates at distinct temporal resolutions to separately capture spatial (hand shapes, facial expressions) and dynamic (movements) information. In addition, we introduce two distinct feature fusion methods, carefully designed for the characteristics of CSLR: (1) Bi-directional Feature Fusion (BFF), which facilitates the transfer of dynamic semantics into spatial semantics and vice versa; and (2) Pathway Feature Enhancement (PFE), which enriches dynamic and spatial representations through auxiliary sub networks, while avoiding the need for extra inference time. As a result, our model further strengthens spatial and dynamic representations in parallel. We demonstrate that the proposed framework outperforms the current state-of-the-art performance on popular CSLR datasets, including PHOENIX14, PHOENIX14-T, and CSL-Daily.
本工作的目标是为连续手语识别(CSLR)有效提取空间和动态特征。为此,我们采用双路径SlowFast网络,每条路径以不同时间分辨率运行,分别捕捉空间(手形、面部表情)和动态(运动)信息。此外,我们针对CSLR特性精心设计了两种特征融合方法:(1) 双向特征融合(BFF),促进动态语义向空间语义的转换,反之亦然;(2) 路径特征增强(PFE),通过辅助子网络丰富动态和空间表征,同时避免增加额外推理时间。最终,我们的模型并行强化了空间与动态表征。实验表明,该框架在PHOENIX14、PHOENIX14-T和CSL-Daily等主流CSLR数据集上超越了当前最优性能。
Index Terms— Continuous sign language recognition, SlowFast network, temporal modelling, bi-directional fusion
关键词 - 连续手语识别, SlowFast网络, 时序建模, 双向融合
1. INTRODUCTION
1. 引言
Sign language serves a pivotal role as a mode of communication for the deaf community in their daily interactions. However, due to the challenging nature of sign languages, there are obstacles to direct communication between hard-of-hearing and normal hearing people. In response to this issue, the field of automatic sign language recognition has received increasing attention with the advances in deep learning techniques. Automatic sign language recognition can be divided into two strands: Isolated Sign Language Recognition (ISLR) and Continuous Sign Language Recognition (CSLR). The former aims to categorise isolated video segments into distinct glosses1. On the other hand, the latter progressively transforms video frames into a sequence of glosses, hence being more applicable to real-world scenarios.
手语作为听障人士日常交流的重要沟通方式发挥着关键作用。然而由于手语的特殊性,听障人士与健听人士之间存在直接沟通障碍。针对这一问题,随着深度学习技术的发展,自动手语识别领域受到越来越多的关注。自动手语识别可分为孤立手语识别(Isolated Sign Language Recognition,ISLR)和连续手语识别(Continuous Sign Language Recognition,CSLR)两个方向:前者旨在将孤立的视频片段分类为特定手势词汇1;后者则将视频帧逐步转化为手势词汇序列,因而更适用于现实场景。
To understand continuous sign language and recognise it as meaningful words, it is important to consider spatially meaningful gestures, such as hand direction, finger shape, mouth shape, and facial expression, as well as dynamically meaningful gestures, including arm movements and body gesture. For example, sign language’s alphabet can be depicted through distinct hand shapes in a single frame. Here, the crucial aspect lies in identifying spatially meaningful attributes to translate these images into alphabet letters. On the other hand, certain words can be portrayed through changes in hand positions over multiple frames. In this instance, the essential task involves identifying dynamically significant attributes to interpret the video into the corresponding word. However, the prevailing CSLR methods [1–6] predominantly extract features on a frame-by-frame basis, which constrains their ability to capture dynamically significant actions. Specifically, these methods commonly employ shared 2D Convolutional Neural Networks (CNNs) to capture spatial features. This approach results in independent processing of frames without considering interactions with neighbouring frames, consequently limiting their capacity to identify and capitalise on awareness of local temporal patterns that convey sign meanings. To overcome the inherent limitation of 2D CNNs, some recent studies [7–10] adopt 3D CNNs [11, 12] as their backbone networks. However, these approaches still encounter a notable limitation in consolidating spatially distinct information. This stems from the fact that the extracted features primarily emphasise only the most crucial regions within spatio-temporal receptive fields. Most recent works have aimed to expand both the spatial and temporal receptive fields by computing correlation maps between adjacent frames [13]. However, calculating correlation maps comes with a significant computational burden, posing difficulties in applying this module to high-resolution features.
要理解连续手语并将其识别为有意义的词汇,必须同时考虑空间维度上有意义的手势(如手部方向、手指形状、口型及面部表情)和时间维度上有意义的动作(包括手臂运动与身体姿态)。例如,手语字母可通过单帧图像中的独特手形来呈现——此时关键在于识别空间特征属性以将图像转换为字母;而某些词汇则需要通过多帧画面中手部位置的变化来表现——这种情况下,核心任务在于识别动态特征属性以将视频解析为对应词汇。然而当前主流的连续手语识别方法[1-6]仍以逐帧特征提取为主,这限制了其捕捉动态动作的能力。具体而言,这些方法通常采用共享的二维卷积神经网络(2D CNN)来捕获空间特征,导致各帧被独立处理而忽略了相邻帧间的交互关系,因而难以识别和利用传达手语含义的局部时序模式。为克服2D CNN的固有局限,近期研究[7-10]开始采用三维卷积神经网络(3D CNN)[11,12]作为主干网络,但这些方法在整合空间差异信息方面仍存在明显缺陷——因为提取的特征主要聚焦于时空感受野中最关键的区域。最新研究尝试通过计算相邻帧间的相关性图谱[13]来扩大时空感受野,但相关性图谱的计算会带来巨大算力开销,导致该模块难以应用于高分辨率特征。
To tackle these aforementioned problems, we adopt the architecture of the SlowFast network [14], which is composed of two distinct pathways: (1) Slow pathway, operating at low frame rate to capture spatial semantics, and (2) Fast pathway, operating at high frame rate to capture motion with finer temporal resolution. The most notable difference between previous literature is that we intentionally extract spatial and dynamic features separately by using two independent sub networks. This is achieved by employing distinct models specialised in capturing either spatial or dynamic aspects. Given the nature of CSLR where single frame or sequences represent meaningful characters, we introduce the Bi-directional Feature Fusion (BFF) method. This approach efficiently transfers important features to both Slow and Fast pathways with only a minimal increase in computational overhead and model parameters. Furthermore, since the contents of the Slow and Fast pathways have different characteristics, we also propose Pathway Feature Enhancement (PFE). This method enhances sequence features from each pathway, enabling a comprehensive understanding of sign language’s spatial and dynamic context. We evaluate our method on three widely used datasets, PHOENIX14 [15], PHOENIX14-T [16], and CSL-Daily [17]. Through comprehensive ablation experiments for CSLR, we showcase the effectiveness of the proposed feature fusion methods. Our model establishes state-of-the-art performances across all datasets with notable improvement over the previous works.
为解决上述问题,我们采用SlowFast网络[14]架构,该架构由两条独立路径组成:(1) 慢速路径(Slow pathway)以低帧率运行捕捉空间语义,(2) 快速路径(Fast pathway)以高帧率运行获取更精细时间分辨率的动作特征。与先前研究最显著的不同在于,我们通过两个独立子网络实现空间与动态特征的刻意分离提取,这得益于专门捕获空间或动态特性的差异化模型设计。针对CSLR任务中单帧或序列均可表征有效字符的特性,我们提出双向特征融合(Bi-directional Feature Fusion, BFF)方法,该方法能以极小的计算开销和参数增长为代价,将重要特征高效传递至慢速与快速路径。此外,鉴于两条路径内容的特性差异,我们还提出路径特征增强(Pathway Feature Enhancement, PFE),通过增强各路径的序列特征来实现对手语空间与动态上下文的全方位理解。我们在PHOENIX14[15]、PHOENIX14-T[16]和CSL-Daily[17]三个主流数据集上评估方法效果,通过针对CSLR的全面消融实验验证了所提特征融合方法的有效性。我们的模型在所有数据集上均达到最先进性能,较先前工作有显著提升。
2. METHOD
2. 方法
CSLR and action recognition are distinct tasks. Action recognition categorises short video clips into predefined action classes, whereas CSLR is a more intricate task focused on mapping an entire video into a continuous sequence of glosses. In particular, CSLR requires simultaneous capture of detailed spatial features such as hand shape and facial expressions, as well as dynamic features such as arm movements and body gestures. This highlights the importance of employing a distinct feature extraction process for different types of actions that convey meaningful signs.
CSLR和动作识别是两个不同的任务。动作识别将短视频片段分类到预定义的动作类别中,而CSLR则是一项更复杂的任务,专注于将整个视频映射为连续的手语词序列。具体而言,CSLR需要同时捕捉手形和面部表情等细节空间特征,以及手臂运动和身体姿态等动态特征。这凸显了对传递有意义信号的不同类型动作采用独特特征提取过程的重要性。
In this paper, we introduce a novel CSLR framework that enables the extraction of spatial and dynamic features in parallel, based on the analysis of CSLR characteristics. As illustrated in Fig. 1, our framework comprises (1) the Slow and Fast pathways, (2) Bi-directional Feature Fusion (BFF), and (3) Pathway Feature Enhancement (PFE). Each pathway serves as an expert in extracting either spatial or dynamic features from sign videos. The BFF module facilitates the exchange of complementary information between pathways through a simple adding operation. Finally, the PFE fuses sequence features obtained from different frame rates.
本文提出了一种新颖的连续手语识别(CSLR)框架,基于CSLR特性分析实现了空间与动态特征的并行提取。如图1所示,该框架包含:(1) 慢速与快速路径(Slow and Fast pathways),(2) 双向特征融合(BFF),以及(3) 路径特征增强(PFE)。每条路径专门负责从手语视频中提取空间或动态特征,BFF模块通过简单加法运算实现路径间互补信息交换,PFE则融合来自不同帧率的序列特征。
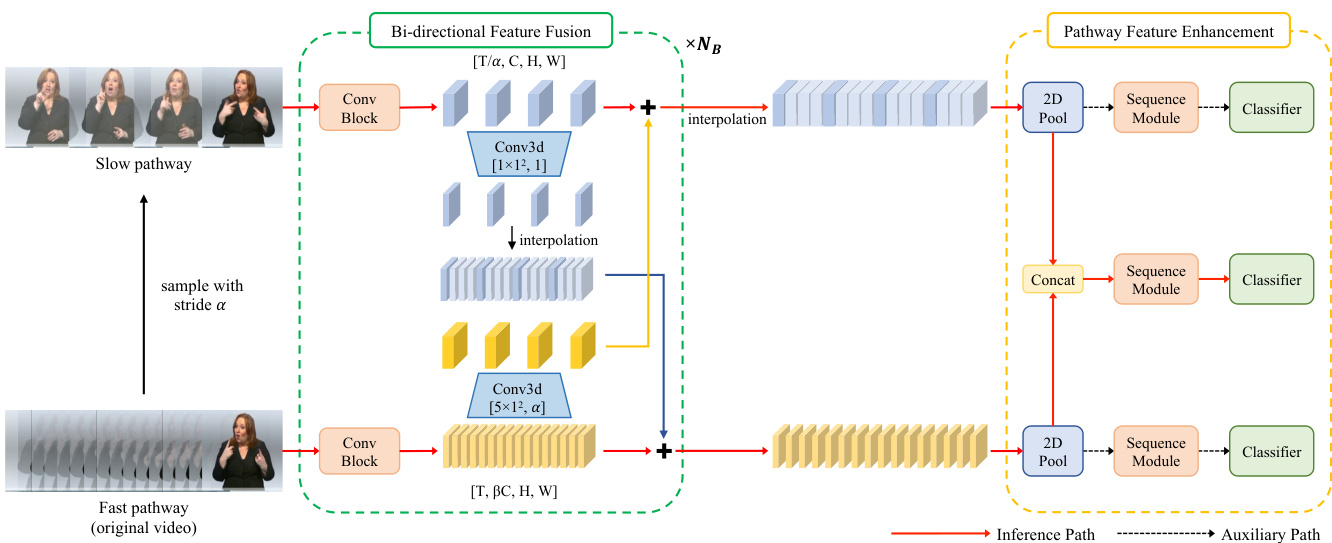
Fig. 1. Overall Architecture. Our framework extracts spatial and dynamic features in parallel using the Slow and Fast pathways. Bi-directional Feature Fusion (BFF) facilitates the exchange of rich information between two pathways. Pathway Feature Enhancement (PFE) amplifies the sequence feature of each pathway by utilising characteristics sourced from different sample rates. $\alpha$ and $\beta$ represent the temporal sampling stride and channel reduction ratio, respectively, while $N_{B}$ stands for the number of blocks in the backbone network.
图 1: 整体架构。我们的框架通过Slow和Fast双通路并行提取空间与动态特征。双向特征融合 (BFF) 促进两条通路间的丰富信息交换。通路特征增强 (PFE) 通过利用不同采样率来源的特征来放大每条通路的序列特征。$\alpha$ 和 $\beta$ 分别表示时序采样步长与通道缩减比率,$N_{B}$ 代表主干网络中的块数量。
2.1. Slow Pathway
2.1. 慢通路
The Slow pathway extracts spatially important features in sign languages, such as hand shape and facial expressions, from the video data while using a larger temporal stride on input frames. The reason for adopting a larger temporal stride lies in the fact that CSLR datasets frequently consist of videos with long durations, necessitating a more efficient approach to processing them. An illustrative instance is that the PHOENIX14-T dataset exhibits a maximum frame length of approximately 500 frames. Nevertheless, using a large stride is not always the optimal choice. For instance, action recognition often relies on a large temporal stride of 8, but this can lead to the issue of overlooking rapid and continuous movements, which are essential for conveying meaning in sign language. Hence, the primary key solution lies in identifying an optimal temporal stride that is both adequately dense to capture essential movements and capable of reducing computational costs. Through an ablation study, we select a temporal stride of $\alpha=4$ , striking a balance that ensures both performance and computational efficiency.
慢速通道从视频数据中提取手语中空间上重要的特征,例如手形和面部表情,同时对输入帧采用较大的时间步长。采用较大时间步长的原因在于,CSLR数据集通常包含持续时间较长的视频,需要更高效的处理方式。例如,PHOENIX14-T数据集的最大帧长度约为500帧。然而,使用大步长并非总是最优选择。以动作识别为例,通常采用8的大时间步长,但这可能导致忽略快速连续的动作,而这些动作对手语表意至关重要。因此,关键在于找到一个最优时间步长,既能足够密集地捕捉关键动作,又能降低计算成本。通过消融实验,我们选择时间步长$\alpha=4$,在性能与计算效率之间取得了平衡。
2.2. Fast Pathway
2.2. 快速通路
The Fast pathway extracts temporally important dynamics, such as arm movements and body gestures, from the video data with a smaller stride. It clearly denotes that the two pathways operate at distinct temporal speeds, resulting in the special is ation of two sub networks in different types of feature extraction. As sign language relies on rapid and intricate movements to convey meaning, it is essential to track these movements. To make sure our model captures all these crucial motions, we set the sampling interval in our Fast pathway to 1. This indicates that the frame rate of our Fast pathway is four times denser than that of the Slow pathway. However, as we mentioned earlier, processing all frames of sign video is heavy. In response to this, following [14], we use significantly lower channel capacity in the Fast pathway, amounting to only $\beta{=}1/8$ of the Slow pathway’s channel size, C. This approach results in a more lightweight model, allowing us to increase the depth of the model effectively. Furthermore, the limited channel capacity encourages the Fast pathway to focus on temporal modelling by attenuating the ability to represent spatial features.
快速通路 (Fast pathway) 以较小步幅从视频数据中提取时间维度的重要动态特征,例如手臂运动和身体姿态。这明确表明两条通路以不同的时间速度运行,从而实现了两种子网络在不同类型特征提取上的专门化。由于手语依赖快速复杂的动作传递信息,追踪这些动作至关重要。为确保模型捕获所有关键动作,我们将快速通路的采样间隔设为1,这意味着其帧率是慢速通路 (Slow pathway) 的4倍。但如前所述,处理手语视频的所有帧计算量巨大。为此,我们遵循[14]的方案,在快速通路中采用显著更低的通道容量,仅为慢速通路通道数C的$\beta{=}1/8$。这种方法实现了更轻量化的模型,使我们能有效增加模型深度。此外,有限的通道容量通过抑制空间特征表征能力,促使快速通路专注于时序建模。
2.3. Bi-directional Feature Fusion
2.3. 双向特征融合
By dividing our model into two sub networks, we specialise each network for its own purpose. However, to better understand comprehensive signs, it is necessary for each pathway to be aware of the representation learned by the other pathway. To accomplish this objective, we introduce the Bi-directional Feature Fusion (BFF) module, which facilitates the transfer of information between each pathway.
通过将我们的模型划分为两个子网络,我们为每个网络专门设计了特定用途。然而,为了更好地理解综合特征,需要让每条通路都能感知另一条通路学习到的表征。为实现这一目标,我们引入了双向特征融合 (BFF) 模块,以促进通路间的信息传递。
Fast to Slow. In the original SlowFast architecture, information from the Fast pathway is integrated into the Slow pathway by concatenating their respective features. However, this approach requires the allocation of larger channel sizes for the subsequent convolutional layers. To address this limitation, we devise a Fast to Slow pathway fusion mechanism employing addition, instead of concatenation. At first, we project the Fast pathway’s features by $\alpha$ -strided 3D convolution of a $5{\bar{\times}}1^{2}$ kernel with $C$ output channel size. This mapping procedure allows the model to learn which information from the Fast pathway is most beneficial for enhancing the Slow pathway’s features. Finally, we introduce a learnable parameter to weight the importance of the projected features. Note that this parameter is initial is ed to 0, allowing the fusion to initially perform an identity mapping and then gradually adapt during training.
快慢融合。在原始的SlowFast架构中,快速路径(Fast pathway)的信息通过特征拼接(concatenation)方式融入慢速路径(Slow pathway),但这种方法需要为后续卷积层分配更大的通道尺寸。为解决这一限制,我们设计了采用加法(additive)而非拼接的快速到慢速路径融合机制。首先,我们通过步长为$\alpha$的3D卷积(核尺寸$5{\bar{\times}}1^{2}$,输出通道数$C$)对快速路径特征进行投影。该映射过程使模型能学习快速路径中哪些信息最有利于增强慢速路径特征。最后,我们引入可学习参数来加权投影特征的重要性。需注意该参数初始化为0,使融合初始执行恒等映射(identity mapping),随后在训练过程中逐步调整。
Slow to Fast. We introduce the Slow to Fast fusion pathway, which is not included in the SlowFast baseline [14]. The primary objective of this process is to propagate a guide indicating visually important locations on a screen to the Fast pathway. This guide facilitates the extraction of temporal dynamics that constitute meaningful sign motions. Similar to the Fast to Slow pathway fusion, we project the Slow pathway’s features by 1-strided 3D convolution of a $1\times\bar{1}^{2}$ kernel with $\beta C$ output channel size. Here, we employ a straightforward temporal interpolation to extend the temporal dimension to match the size of the Fast pathway’s features. The interpolated features are added to the Fast features to transfer spatial information that assists the Fast pathway in capturing both spatially and dynamically meaningful features. Note that we use a learnable parameter and initialise it to 0 with the same purpose as the Fast to Slow fusion.
慢速到快速融合路径。我们引入了慢速到快速融合路径,该路径未包含在SlowFast基线[14]中。该过程的主要目标是将屏幕视觉重要位置的引导信息传递至快速路径。该引导有助于提取构成有意义手语动作的时序动态特征。与快速到慢速路径融合类似,我们通过步长为1的3D卷积(核大小为$1\times\bar{1}^{2}$,输出通道数为$\beta C$)对慢速路径特征进行投影。此处采用简单的时间插值方法扩展时序维度,使其与快速路径特征尺寸匹配。插值后的特征会叠加至快速路径特征,从而传递空间信息以辅助快速路径捕获具有空间和动态意义的特征。需注意,我们使用可学习参数并将其初始化为0,其目的与快速到慢速融合相同。
2.4. Pathway Feature Enhancement
2.4. 路径特征增强
Unlike action recognition, which maps an output of the backbone network to a single action class using a fully-connected layer, CSLR tasks require the model to predict the gloss sequence in a weakly-supervised manner without access to frame-level gloss labels. For this reason, most recent CSLR models integrate a sequence module on top of the feature extractor. This module aims to identify potential alignments between the visual features and their corresponding labels. Subsequently, these models are optimised by Connection is t Temporal Classification (CTC) loss [18].
与动作识别不同(后者通过全连接层将主干网络的输出映射到单一动作类别),连续手语识别(CSLR)任务要求模型在无法获取帧级别手语标注的弱监督条件下预测手语词序列。为此,最新的大多数CSLR模型都在特征提取器之上集成了序列模块。该模块旨在识别视觉特征与对应标签之间的潜在对齐关系,随后通过连接时序分类(CTC)损失函数 [18] 对这些模型进行优化。
Feature enhancement. Given that the Slow pathway’s output possesses a smaller temporal resolution, we perform interpolation to align it with the same temporal resolution as that of the Fast pathway’s output. The outputs from both pathways are concatenated and subsequently used as input to the main sequence module, as depicted in Fig. 1. To delve deeper into the capabilities of the dual pathway encoder structure, we introduce a novel Pathway Feature Enhancement (PFE) method. We design two auxiliary sequence modules with the same architecture as the main sequence module. This design choice offers two significant advantages: (1) it boosts the representation capacity of each encoder, which aids in temporal alignment by propagating CTC loss, and (2) it ensures that the inference speed is not compromised.
特征增强。鉴于慢速路径(Slow pathway)的输出具有较小的时间分辨率,我们通过插值操作将其与快速路径(Fast pathway)输出的时间分辨率对齐。两条路径的输出被拼接后作为主序列模块的输入,如图1所示。为了深入探索双路径编码器结构的能力,我们提出了一种新颖的路径特征增强(PFE)方法。我们设计了两个与主序列模块结构相同的辅助序列模块,这种设计带来两个显著优势:(1) 通过传播CTC损失来提升每个编码器的表征能力,有助于时间对齐;(2) 确保推理速度不受影响。
2.5. Training Details.
2.5. 训练细节
We employ a state-of-the-art architecture for sequence module that includes a 1D CNN followed by two BiLSTM layers. The 1D CNN component is configured as a sequence of ${K5,P2,K5,P2}$ layers, where $K\sigma$ and $P\sigma$ denote a 1D convolutional layer and a pooling layer with kernel size of $\sigma$ , respectively. Since the output channel sizes of the Slow and Fast pathway encoders are 2048 and 256, respectively, the input channel size for the main sequence module is 2304. Both the main and auxiliary sequence modules have a hidden size of 1024. All pathways are basically trained with CTC loss $(\mathcal{L}{C T C})$ . In addition, following VAC [19], we incorporate the Visual Alignment loss $(\mathcal{L}{V A})$ and Visual Enhancement loss $(\mathcal{L}_{V E})$ for visual supervision. We formulate the overall loss as follows:
我们采用了一种先进的序列模块架构,包含一个一维卷积神经网络 (1D CNN) 和两个双向长短期记忆网络 (BiLSTM) 层。一维 CNN 组件配置为 ${K5,P2,K5,P2}$ 层序列,其中 $K\sigma$ 和 $P\sigma$ 分别表示核大小为 $\sigma$ 的一维卷积层和池化层。由于慢速路径和快速路径编码器的输出通道大小分别为 2048 和 256,主序列模块的输入通道大小为 2304。主序列模块和辅助序列模块的隐藏层大小均为 1024。所有路径基本都使用 CTC 损失 $(\mathcal{L}{C T C})$ 进行训练。此外,遵循 VAC [19],我们引入了视觉对齐损失 $(\mathcal{L}{V A})$ 和视觉增强损失 $(\mathcal{L}_{V E})$ 进行视觉监督。整体损失函数如下:
$$
\begin{array}{r l}&{\mathcal{L}{m a i n}=\mathcal{L}{C T C}+\lambda_{V A}\mathcal{L}{V A}+\lambda_{V E}\mathcal{L}{V E},}\ &{\mathcal{L}{s l o w}=\mathcal{L}{C T C s}+\lambda_{V A}\mathcal{L}{V A_{s}}+\lambda_{V E}\mathcal{L}{V E_{s}},}\ &{\mathcal{L}{f a s t}=\mathcal{L}{C T C_{f}}+\lambda_{V A}\mathcal{L}{V A_{f}}+\lambda_{V E}\mathcal{L}{V E_{f}},}\ &{\mathcal{L}{t o t a l}=\mathcal{L}{m a i n}+\lambda_{s l o w}\mathcal{L}{s l o w}+\lambda_{f a s t}\mathcal{L}_{f a s t}.}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{m a i n}=\mathcal{L}{C T C}+\lambda_{V A}\mathcal{L}{V A}+\lambda_{V E}\mathcal{L}{V E},}\ &{\mathcal{L}{s l o w}=\mathcal{L}{C T C s}+\lambda_{V A}\mathcal{L}{V A_{s}}+\lambda_{V E}\mathcal{L}{V E_{s}},}\ &{\mathcal{L}{f a s t}=\mathcal{L}{C T C_{f}}+\lambda_{V A}\mathcal{L}{V A_{f}}+\lambda_{V E}\mathcal{L}{V E_{f}},}\ &{\mathcal{L}{t o t a l}=\mathcal{L}{m a i n}+\lambda_{s l o w}\mathcal{L}{s l o w}+\lambda_{f a s t}\mathcal{L}_{f a s t}.}\end{array}
$$
Here, $\lambda_{s l o w}$ and $\lambda_{f a s t}$ represent the loss weights for the two auxiliary losses. $\lambda_{V A}$ and $\lambda_{V E}$ are set to 25 and 1, respectively, following VAC methodology.
这里,$\lambda_{s l o w}$ 和 $\lambda_{f a s t}$ 表示两个辅助损失的损失权重。根据 VAC 方法,$\lambda_{V A}$ 和 $\lambda_{V E}$ 分别设置为 25 和 1。
3. EXPERIMENTS
3. 实验
3.1. Experimental Setup
3.1. 实验设置
Datasets and evaluation metric. The PHOENIX14 dataset contains German weather forecast recordings by 9 actors, comprising 6,841 sentences with 1,295 signs, split into 5,672 training, 540 development, and 629 testing samples. The PHOENIX14-T dataset, designed for CSLR and sign language translation tasks, consists of 8,247 sentences with 1,085 signs, divided into 7,096 training, 519 development, and 642 test instances. The CSL-Daily dataset covers daily life activities by 10 signers, featuring 20,654 sentences distributed among 18,401 training, 1,077 development, and 1,176 test samples. For evaluation, we adopt Word Error Rate (WER)2 [15] for evaluation.
数据集与评估指标。PHOENIX14数据集包含9位演员录制的德语天气预报,共6,841个句子和1,295个手语符号,划分为5,672个训练样本、540个开发样本和629个测试样本。专为连续手语识别(CSLR)和手语翻译任务设计的PHOENIX14-T数据集包含8,247个句子和1,085个手语符号,分为7,096个训练样本、519个开发样本和642个测试样本。CSL-Daily数据集涵盖10位手语者的日常生活场景,包含20,654个句子,划分为18,401个训练样本、1,077个开发样本和1,176个测试样本。评估采用词错误率(WER)2 [15]作为指标。
Table 1. Comparison with state-of-the-art methods on PHOENIX14 and PHOENIX14-T. Our model achieves new state-of-the-art performance on both datasets.
表 1. PHOENIX14 和 PHOENIX14-T 数据集上与其他先进方法的对比。我们的模型在这两个数据集上都实现了新的最优性能。
| 方法 | PHOENIX14 | PHOENIX14-T | ||
|---|---|---|---|---|
| Dev | Test | Dev | Test | |
| 仅RGB | ||||
| SFL [2] | 26.2 | 26.8 | 25.1 | 26.1 |
| FCN [3] | 23.7 | 23.9 | 23.3 | 25.1 |
| Joint-SLRT [20] | - | - | 24.6 | 24.5 |
| VAC [19] | 21.2 | 22.3 | - | - |
| LCSA [21] | 21.4 | 21.9 | - | - |
| CMA [22] | 21.3 | 21.9 | - | - |
| SignBT [17] | - | - | 22.7 | 23.9 |
| MMTLB [23] | - | - | 21.9 | 22.5 |
| SMKD [24] | 20.8 | 21.0 | 20.8 | 22.4 |
| SEN [25] | 19.5 | 21.0 | 19.3 | 20.7 |
| SSSLR [26] | 20.9 | 20.8 | 20.5 | 22.3 |
| TLP [27] | 19.7 | 20.8 | 19.4 | 21.2 |
| Corrnet [13] | 18.8 | 19.4 | 18.9 | 20.5 |
| SlowFastSign (Ours) | 18.0 | 18.3 | 17.7 | 18.7 |
| 附加模态 | ||||
| DNF (RGB+光流) [4] | 23.1 | 22.9 | - | - |
| SOS (RGB+场景) [28] | 20.6 | 21.5 | - | - |
| STMC (RGB+关键点) [5] | 21.1 | 20.7 | 19.6 | 21.0 |
| C2SLR (RGB+关键点) [6] | 20.5 | 20.4 | 20.2 | 20.4 |
| TwoStream-SLR (RGB+关键点) [29] | 18.4 | 18.8 | 17.7 | 19.3 |
Implementation details. We adopt Slow Fast 101 [14] as our baseline with Kinetics-600 [30] pretrained weights. All the input frames are initially resized to $256\times256$ . To augment training data, we perform random cropping to achieve a final resolution of $224\times224$ . We apply horizontal flipping with a probability of $50%$ and $20%$ temporal rescaling. During inference, we only apply center cropping with a size of $224\times224$ Our model is optimised by Adam [31] optimiser with a weight decay of $10^{-4}$ and a batch size of 2. Our model is trained on the PHOENIX datasets for 80 epochs, and on the CSL-Daily dataset for 50 epochs. The initial learning rate is $10^{-4}$ for the PHOENIX datasets and reduced by 5 at the 40th and 60th epochs. For the CSL-Daily dataset, we initialise the learning rate with $5\times\dot{1}0^{-5}$ and is halved every 5 epochs starting from 25th epoch. We empirically set $\lambda_{s l o w}$ and $\lambda_{f a s t}$ to 0.25 and 0.25 for PHOENIX datasets and 0.1 and 0.4 for CSL-Daily dataset.
实现细节。我们采用Slow Fast 101 [14]作为基线模型,并使用Kinetics-600 [30]预训练权重。所有输入帧初始尺寸调整为$256\times256$。为增强训练数据,我们执行随机裁剪以获得$224\times224$的最终分辨率。采用概率为$50%$的水平翻转和$20%$的时间尺度缩放。推理阶段仅应用$224\times224$的中心裁剪。模型通过Adam [31]优化器进行优化,权重衰减为$10^{-4}$,批量大小为2。在PHOENIX数据集上训练80轮次,CSL-Daily数据集上训练50轮次。PHOENIX初始学习率为$10^{-4}$,并在第40和60轮次时降至1/5;CSL-Daily初始学习率为$5\times\dot{1}0^{-5}$,从第25轮次开始每5轮次减半。经验性设置$\lambda_{slow}$和$\lambda_{fast}$:PHOENIX数据集为0.25和0.25,CSL-Daily数据集为0.1和0.4。
3.2. Experimental Results
3.2. 实验结果
PHOENIX14 and PHOENIX14-T. We compare the proposed framework, named Slow Fast Sign, with previous methods on the PHOENIX14 and PHOENIX14-T datasets. As shown in Table 1, our model achieves new state-of-the-art performance on both datasets, surpassing the previous best RGB-based method, Corrnet [13], by a margin of $1.1%$ and $1.8%$ on PHOENIX14 and PHOENIX14-T test splits, respectively. We also compare our method with recent works that require additional modalities, such as keypoints and optical flow, for training. Our model outperforms every multimodal-based CSLR model. Specifically, our model exhibits better performance than TwoStream-SLR [29] network, which leverages human keypoints. The margins of improvement are $0.5%$ on PHOENIX14 and $0.6%$ on PHOENIX14-T, respectively. We highlight that the proposed method does not require additional modalities or annotations to identify spatially important regions.
PHOENIX14 和 PHOENIX14-T。我们将提出的框架 Slow Fast Sign 与之前的方法在 PHOENIX14 和 PHOENIX14-T 数据集上进行了比较。如表 1 所示,我们的模型在两个数据集上均实现了新的最先进性能,在 PHOENIX14 和 PHOENIX14-T 测试集上分别以 $1.1%$ 和 $1.8%$ 的优势超越了之前最佳的基于 RGB 的方法 Corrnet [13]。我们还与需要额外模态 (如关键点和光流) 进行训练的最新工作进行了对比。我们的模型优于所有基于多模态的 CSLR 模型。具体而言,我们的模型表现优于利用人体关键点的 TwoStream-SLR [29] 网络,提升幅度分别为 PHOENIX14 上的 $0.5%$ 和 PHOENIX14-T 上的 $0.6%$。我们强调,所提出的方法无需额外模态或标注即可识别空间重要区域。
CSL-Daily. We also compare our framework on the CSL-Daily dataset to demonstrate its general is ability. As reported in Table 2, the proposed framework outperforms all the previous state-of-the-art methods. Notably, our method shows a $5.2%$ improvement compared to the RGB-based Corrnet. Furthermore, our model excels the TwoStream-SLR network, which incorporates additional supervision, by a $0.4%$ margin on test split.
CSL-Daily。我们还在CSL-Daily数据集上比较了我们的框架,以展示其通用能力。如表2所示,所提出的框架优于所有先前的最先进方法。值得注意的是,与基于RGB的Corrnet相比,我们的方法显示出5.2%的改进。此外,我们的模型在测试集上比采用额外监督的TwoStream-SLR网络高出0.4%。
Table 2. Comparison with state-of-the-art methods on CSL-Daily dataset. † indicates the reproduced results in [17]. Our model achieves new state-of-the-art performance.
表 2: CSL-Daily数据集上与最先进方法的对比。†表示文献[17]中复现的结果。我们的模型实现了新的最先进性能。
| 方法 | WER (%)↓ | |
|---|---|---|
| Dev | Test | |
| 仅RGB | ||
| LS-HAN+ [32] | 39.0 | 39.4 |
| SignBT [17] | 33.6 | 33.1 |
| FCNt [3] | 33.2 | 32.5 |
| DNF (RGB) [4] | 32.8 | 32.4 |
| Joint-SLRTt [20] | 33.1 | 32.0 |
| Corrnet [13] | 30.6 | 30.1 |
| SlowFastSign(我们的) | 25.5 | 24.9 |
| 附加模态 | ||
| TwoStream-SLR (RGB+关键点)[29] | 25.4 | 25.3 |
Table 3. Effect of temporal stride $\alpha.$ . We observe that a denser temporal resolution achieved by lower $\alpha$ in the Slow pathway steadily improves the CSLR performance.
表 3: 时间步长 $\alpha$ 的影响。我们观察到,通过降低 $\alpha$ 实现的更密集时间分辨率能够持续提升 CSLR (Continuous Sign Language Recognition) 性能。
| WER(%)√ | 最大内存使用量 (MB) | GFLOPs (G) | ||
|---|---|---|---|---|
| Dev | Test | |||
| 8 | 20.9 | 21.5 | 13,829 | 283.9 |
| 4 | 18.0 | 18.3 | 21,418 | 521.2 |
| 2 | 17.4 | 17.9 | 39,521 | 995.8 |
3.3. Ablation Study
3.3. 消融实验
Effect of temporal stride $\alpha$ in Slow pathway. In order to investigate the impact of temporal stride $\alpha$ in the Slow pathway, we ablate the value of $\alpha$ in Table 3. As we increase the input temporal resolution of the Slow pathway, we observe a consistent improvement in our model’s performance. However, this leads to higher memory usage and computational overhead, which hinders real-world applications and deployment of CSLR. For fair comparisons with previous works considering computational costs and memory usage, we use $\alpha{=}4$ in all of our experiments.
Slow通路中时间步长$\alpha$的影响。为研究Slow通路中时间步长$\alpha$的作用,我们在表3中对$\alpha$取值进行了消融实验。随着Slow通路输入时间分辨率的提高,模型性能呈现持续提升趋势。但这也导致了更高的内存占用和计算开销,制约了CSLR在实际场景中的应用部署。出于与现有工作公平对比(考虑计算成本和内存占用),我们在所有实验中均采用$\alpha{=}4$的设置。
Design choice of Bi-directional Feature Fusion. As shown in Table 4, the BFF module utilising concatenation yields a $0.4%$ improvement in test performance compared to the baseline, demonstrating the effectiveness of the bi-directional fusion approach. However, this comes at the cost of an additional 8 GFLOPs to process 200-frame video. On the other hand, with the addition method, our BFF module not only reduces the computational cost by 3 GFLOPs compared to the previous method but also shows the best performance among the three methods. Additionally, our model has even fewer parameters than the uni-directional baseline.
双向特征融合(Bi-directional Feature Fusion)的设计选择。如表 4 所示,采用拼接(concatenation)的 BFF 模块相比基线在测试性能上提升了 $0.4%$,证明了双向融合方法的有效性。但这种方法处理 200 帧视频需要额外增加 8 GFLOPs 计算量。另一方面,采用加法(addition)方法的 BFF 模块不仅比前一种方法减少了 3 GFLOPs 计算成本,还在三种方法中展现出最佳性能。此外,我们的模型参数量甚至比单向基线更少。
Component analysis. To establish the effectiveness of all components within our framework, we systematically conduct ablation experiments by progressively incorporating the proposed components into the baseline model in Table 5. Initially, we assess the performance of the individual Slow and Fast networks separately. The model using only the Slow pathway exhibits superior recognition performance compared to the model using only the Fast pathway. This emphasises that the extraction of spatial semantics is crucial in CSLR tasks. However, when both Slow and Fast pathways are employed (utilising the same architecture as the original SlowFast network, which includes only Fast-to-Slow feature fusion), it becomes evident that the temporal information extracted from the Fast pathway plays a pivotal role in capturing motion. With the incorporation of the BFF module, it surpasses the performance of the vanilla SlowFast network, affirming the effectiveness of propagating spatial information to the Fast pathway in CSLR. In the end, by integrating all proposed components, we attain the highest score, showing a performance improvement of $0.6%$ on the both dev and test sets in comparison to the SlowFast baseline.
组件分析。为了验证框架中所有组件的有效性,我们通过逐步将提出的组件加入基线模型(表5)进行了系统性的消融实验。首先,我们分别评估了Slow和Fast网络的独立性能。仅使用Slow通路的模型展现出比仅使用Fast通路更优的识别性能,这强调了空间语义提取在CSLR任务中的关键作用。然而,当同时采用Slow和Fast通路(采用与原始SlowFast网络相同的架构,仅包含Fast到Slow的特征融合)时,可以明显看出从Fast通路提取的时间信息对动作捕捉起着关键作用。通过引入BFF模块,其性能超越了原始SlowFast网络,证实了在CSLR任务中将空间信息传递至Fast通路的有效性。最终,通过整合所有提出的组件,我们取得了最高分数,与SlowFast基线相比,在开发集和测试集上均实现了$0.6%$的性能提升。
Table 4. Design choice on Bi-directional Feature Fusion. We design BFF module with a projector and an adding operation to minimise the computational costs and modal parameters.
表 4: 双向特征融合的设计选择。我们设计了带有投影器和加法操作的BFF模块,以最小化计算成本和模态参数。
| 方法 | Dev | Test | #Params (M) | GFLOPs (G) |
|---|---|---|---|---|
| SlowFast | 18.6 | 18.9 | 52.9 | 515.9 |
| SlowFast+BFF(concat) | 18.6 | 18.5 | 53.1 | 524.0 |
| SlowFast+BFF(add) | 18.4 | 18.3 | 52.5 | 521.2 |

Table 5. Analysis of the proposed components. Each component consistently contributes to boosting performance. The best result is achieved when all components are combined.
表 5: 所提出组件的分析。每个组件均能持续提升性能,所有组件组合时达到最佳效果。

Fig. 2. GradCAM visualisation. The Slow pathway emphasises hand and face regions, which are crucial components in sign language, while the Fast pathway captures dynamic movements.
图 2: GradCAM可视化。慢速通路(Slow pathway)着重于手部和面部区域(这些是手语的关键组成部分),而快速通路(Fast pathway)则捕捉动态动作。
GradCAM Visualisation. To demonstrate that the Slow and Fast pathways capture different types of features, we visualise each pathway’s feature maps using GradCAM [33]. As shown in Fig. 2, the Slow pathway highlights both hand and face regions, which are essential for sign language. On the other hand, as shown in the figure, the Fast pathway focuses heavily on the dynamically moving hand of the signer. This implies that our framework is capable of capturing both spatial and dynamic features in parallel within a screen.
GradCAM 可视化。为了证明慢速和快速路径捕捉不同类型的特征,我们使用 GradCAM [33] 对每条路径的特征图进行可视化。如图 2 所示,慢速路径同时突出手部和面部区域,这些区域对手语至关重要。另一方面,如图所示,快速路径则高度关注手语者动态移动的手部。这表明我们的框架能够在一个屏幕内并行捕捉空间和动态特征。
4. CONCLUSION
4. 结论
In this paper, we aim to extract both spatial and dynamic features for Continuous Sign Language Recognition (CSLR). To accomplish this goal, we employ the SlowFast network, which captures spatial and dynamic features with two expert networks operating at different temporal resolutions. To the best of our knowledge, we are the first to separately extract distinct types of features, tailored to the specific characteristics of sign language. Additionally, we introduce two novel methods that improve the capacity of each pathway: (1) Bi-directional Feature Fusion (BFF), which facilitates the exchange of temporal and spatial semantics, and (2) Pathway Feature Enhancement (PFE), which enhances dynamic and spatial representations through auxiliary sub networks, while avoiding the need for additional inference time. The experimental results show that our framework achieves state-of-the-art performance on three large-scale benchmarks.
本文旨在为连续手语识别(CSLR)同时提取空间和动态特征。为实现这一目标,我们采用SlowFast网络,该网络通过两个以不同时间分辨率运行的专家网络来捕获空间和动态特征。据我们所知,我们是首个针对手语特性分别提取不同类型特征的方法。此外,我们提出了两种创新方法来提升各路径的能力:(1) 双向特征融合(BFF),促进时空语义交换;(2) 路径特征增强(PFE),通过辅助子网络增强动态和空间表征,且无需额外推理时间。实验结果表明,我们的框架在三个大规模基准测试中达到了最先进性能。