Evaluating surgical skills from kinematic data using convolutional neural networks
基于运动学数据和卷积神经网络的手术技能评估
Abstract. The need for automatic surgical skills assessment is increasing, especially because manual feedback from senior surgeons observing junior surgeons is prone to subjectivity and time consuming. Thus, automating surgical skills evaluation is a very important step towards improving surgical practice. In this paper, we designed a Convolutional Neural Network (CNN) to evaluate surgeon skills by extracting patterns in the surgeon motions performed in robotic surgery. The proposed method is validated on the JIGSAWS dataset and achieved very competitive results with $100%$ accuracy on the suturing and needle passing tasks. While we leveraged from the CNNs efficiency, we also managed to mitigate its black-box effect using class activation map. This feature allows our method to automatically highlight which parts of the surgical task influenced the skill prediction and can be used to explain the classification and to provide personalized feedback to the trainee.
摘要。自动手术技能评估的需求日益增长,尤其是因为资深外科医生观察初级外科医生时提供的手动反馈容易受主观影响且耗时。因此,自动化手术技能评估是改善外科实践的重要一步。本文设计了一种卷积神经网络 (CNN) ,通过提取机器人手术中外科医生动作的模式来评估其技能。所提方法在 JIGSAWS 数据集上进行了验证,在缝合和穿针任务中取得了极具竞争力的结果,准确率达到 $100%$ 。在利用 CNN 高效性的同时,我们还通过类别激活图减轻了其黑箱效应。这一特性使我们的方法能自动突出显示手术任务中影响技能预测的部分,既可用于解释分类结果,也能为学员提供个性化反馈。
Keywords: kinematic data, RMIS, deep learning, CNN
关键词:运动学数据、RMIS、深度学习、CNN
1 Introduction
1 引言
Over the past one hundred years, the classical training program of Dr. William Halsted has governed surgical training in different parts of the world [15]. His teaching philosophy of “see one, do one, teach one” is still one of the most practiced methods to this day [1]. The idea is that the trainee could become an expert surgeon by watching and assisting in mentored surgeries [15]. These training methods, although broadly used, lack of an objective surgical skill evaluation technique [9]. Conventional surgical skill assessment is currently based on checklists that are filled by an expert surgeon observing the surgery [14]. In an attempt to evaluate surgical skills without relying on an expert’s opinion, Objective Structured Assessment of Technical Skills (OSATS) has been proposed and is used in clinical practice [12]. Unfortunately, this type of observational evaluation is still prone to several external and subjective variables: the checklists’ development process, the inter-rater reliability and the evaluator bias [7].
在过去的一百年间,William Halsted博士创立的经典外科培训体系主导了全球各地的外科教学实践[15]。其"观摩一例、操作一例、教学一例"的理念至今仍是应用最广泛的教学方法之一[1]。该体系认为学员通过观察和协助指导手术即可成长为优秀外科医生[15]。然而这些传统培训方法普遍缺乏客观的手术技能评估技术[9]。现行常规外科技能评估主要依赖专家观察手术过程后填写的检查清单[14]。为建立不依赖专家意见的评估体系,技术技能客观结构化评估(OSATS)被提出并应用于临床实践[12]。但此类观察性评估仍易受多重外部和主观变量影响:检查表制定流程、评估者间信度以及评价者偏见等[7]。
Other studies showed that a strong relationship exists between the postoperative outcomes and the technical skill of a surgeon [2]. This type of approach suffers from the fact that a surgery’s outcome also depends on the patient’s physiological characteristics [9]. In addition, acquiring such type of data is very difficult, which makes these skill evaluation methods difficult to apply for surgical training. Recent advances in surgical robotics such as the da Vinci surgical robot (Intuitive Surgical Inc. Sunnyvale, CA) enabled the collection of motion and video data from different surgical activities. Hence, an alternative for checklists and outcome-based methods is to extract, from these motion data, global movement features such as the surgical task’s time completion, speed, curvature, motion smoothness and other holistic features [3,19,9]. Although most of these methods are efficient, it is not clear how they could be used to provide a detailed and constructive feedback for the trainee to go beyond the simple classification into a category (i.e. novice, expert, etc.). This is problematic as studies [8] showed that feedback on medical practice allows surgeons to improve their performance and reach higher skill levels.
其他研究表明,术后结果与外科医生的技术能力存在强相关性 [2]。但这类方法的局限性在于手术结果还取决于患者的生理特征 [9]。此外,此类数据获取难度大,导致这些技能评估方法难以应用于手术培训。达芬奇手术机器人 (Intuitive Surgical Inc. Sunnyvale, CA) 等手术机器人技术的最新进展,实现了从不同手术活动中采集运动数据和视频数据。因此,除检查表和基于结果的方法外,还可从这些运动数据中提取全局运动特征,如手术任务完成时间、速度、曲率、运动平滑度等整体特征 [3,19,9]。尽管这些方法大多有效,但尚不清楚如何利用它们为学员提供详细且具有建设性的反馈,而非简单归类(如新手、专家等)。这成为显著问题,因为研究 [8] 表明医疗实践中的反馈能帮助外科医生提升表现并达到更高技能水平。
Recently, a new field named Surgical Data Science [11] has emerged thanks to the increasing access to large amounts of complex data which pertain to the patient, the staff and sensors for perceiving the patient and procedure related data such as videos and kinematic variables [5]. As an alternative to extracting global movement features, recent studies tend to break down surgical tasks into smaller segments called surgical gestures, manually before the training phase, and assess the performance of the surgical task based on the assessment of these gestures [13]. Although these methods obtained very accurate and promising results in terms of surgical skill evaluation, they require a huge amount of labeled gestures for the training phase [13]. We have identified two main limits in the existing approaches that classify a surgeon’s skill level based on the kinematic data. First is the lack of an interpret able result of skill evaluation usable by the trainee to achieve higher skill levels. Additionally current state of the art Hidden Markov Models require gesture boundaries that are pre-defined by human annotators which is time consuming and prone to inter-annotator reliability [16].
近来,随着可获取的患者、医护人员及感知患者相关数据的传感器(如视频和运动学变量) [5] 等复杂数据量不断增加,一个名为外科数据科学(Surgical Data Science) [11] 的新领域应运而生。与提取全局运动特征不同,近期研究倾向于在训练阶段前将外科任务手动分解为更小的片段(称为外科手势),并根据这些手势的评估来衡量手术任务表现 [13]。尽管这些方法在外科技能评估方面取得了非常准确且有前景的结果,但训练阶段需要大量标注手势数据 [13]。我们发现现有基于运动学数据评估外科医生技能水平的方法存在两个主要局限:一是缺乏可供受训者用于提升技能的可解释性评估结果;二是当前最先进的隐马尔可夫模型(Hidden Markov Models)需要人工标注预定义手势边界,这种方法耗时且易受标注者间可靠性影响 [16]。
In this paper, we propose a new architecture of Convolutional Neural Networks (CNN) dedicated to surgical skill evaluation (Figure 1). By using one dimensional filters over the kinematic data, we mitigate the need to pre-define sensitive and unreliable gesture boundaries. The original hierarchical structure of our deep learning model enables us to represent the gestures in latent low-level variables (first and second layers), as well as capturing global information related to the surgical skill level (third layer). To provide interpret able feedback, instead of using a final fully-connected layer like most traditional approaches [18], we place a Global Average Pooling (GAP) layer which enables us to benefit from the Class Activation Map [18] (CAM) to visualize which parts of the surgical task contributed the most to the surgical skill classification (Figure 2). We demonstrate the accuracy of our approach using a standardized experimental setup on the largest publicly available dataset for surgical data analysis: the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) [5]. The main contribution of our work is to show that deep learning can be used to understand the latent and complex structures of what constitutes a surgical skill, especially that there is still much to be learned on what is exactly a surgical skill [9].
本文提出了一种专用于手术技能评估的新型卷积神经网络 (CNN) 架构 (图 1)。通过在运动学数据上使用一维滤波器,我们减少了对敏感且不可靠手势边界预定义的需求。深度学习模型的原始分层结构使我们能够在潜在低层变量 (第一层和第二层) 中表示手势,同时捕获与手术技能水平相关的全局信息 (第三层)。为了提供可解释的反馈,与大多数传统方法 [18] 不同,我们没有使用最终的全连接层,而是采用了全局平均池化 (GAP) 层,这使我们能够利用类别激活图 [18] (CAM) 来可视化手术任务的哪些部分对手术技能分类贡献最大 (图 2)。我们在最大的公开手术数据分析数据集 JHU-ISI 手势与技能评估工作集 (JIGSAWS) [5] 上使用标准化实验设置验证了该方法的准确性。本研究的主要贡献在于证明深度学习可用于理解构成手术技能的潜在复杂结构,特别是考虑到目前对手术技能的准确定义仍存在大量未知 [9]。
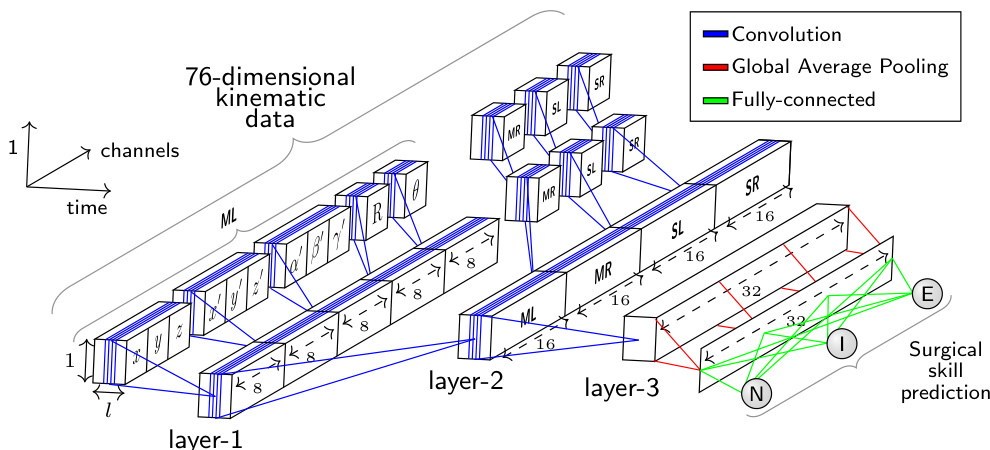
Fig. 1: The network architecture whose input is a surgical task with variable length $\imath$ recorded by the four manipulators (ML: master left, MR: master right, SL: slave left, SR: slave right) of the da Vinci surgical system. The output is a surgical skill prediction (N: Novice, I: Intermediate and E: Expert).
图 1: 网络架构的输入是由达芬奇手术系统的四个机械臂 (ML: 主左, MR: 主右, SL: 从左, SR: 从右) 记录的可变长度手术任务 $\imath$。输出为手术技能预测 (N: 新手, I: 中级, E: 专家)。
2 Method
2 方法
2.1 Dataset
2.1 数据集
We first present briefly the dataset used in this paper as we rely on features definition to describe our method. The JIGSAWS [5] dataset has been collected from eight right-handed subjects with three different skill levels (Novice (N), Intermediate (I) and Expert (E)) performing three different surgical tasks (suturing, needle passing and knot tying) using the da Vinci surgical system. Each subject performed five trials of each task. For each trial the kinematic and video data were recorded.
我们首先简要介绍本文使用的数据集,因为我们的方法依赖于特征定义来描述。JIGSAWS [5] 数据集收集自八名右利手受试者,他们具有三种不同的技能水平(新手 (N)、中级 (I) 和专家 (E)),使用达芬奇手术系统执行三种不同的外科手术任务(缝合、穿针和打结)。每位受试者对每项任务进行了五次试验,每次试验均记录了运动学和视频数据。
In our work, we only focused on kinematic data which are numeric variables of four manipulators: left and right masters (controlled directly by the subject’s hands) and left and right slaves (controlled indirectly by the subject via the master manipulators). These kinematic variables (76 in total) are captured at a frequency equal to 30 frames per second for each trial. We considered each trial as a multivariate time series (MTS) and designed a one dimensional CNN dedicated to learn automatically useful features for surgical skill classification.
在我们的工作中,我们仅关注四种机械臂的数值型运动学数据:左右主控臂(由受试者双手直接操控)和左右从动臂(受试者通过主控臂间接操控)。这些运动学变量(共76个)以每秒30帧的频率在每次试验中采集。我们将每次试验视为多元时间序列(MTS),并设计了一维CNN(卷积神经网络)来自动学习用于手术技能分类的有效特征。
2.2 Architecture
2.2 架构
Our approach takes inspiration of the recent success of CNN for time series classification [17]. The proposed architecture (Figure 1) has been specifically designed to classify surgical skills using kinematic data. The input of the CNN is a MTS with variable length $\it l$ and 76 channels. The output layer contains the surgical skill level (N, I, E). Comparing to CNNs for image classification, where usually the network’s input has two dimensions (width and height) and 3 channels (RGB), our network’s input is a time series with one dimension (length $\textit{l}$ of the surgical task) and 76 channels (the kinematic variables $x,y,z,x^{\prime}$ , etc.).
我们的方法受到近期CNN(卷积神经网络)在时间序列分类领域成功应用的启发[17]。所提出的架构(图1)专为利用运动学数据对手术技能进行分类而设计。该CNN的输入是一个可变长度$\it l$、76通道的多变量时间序列(MTS),输出层包含手术技能等级(N, I, E)。与通常处理二维输入(宽度和高度)及3通道(RGB)图像的图像分类CNN相比,我们的网络输入是一个单维时间序列(手术任务长度$\textit{l}$)和76个通道(运动学变量$x,y,z,x^{\prime}$等)。
The main challenge we encountered when designing our network was the huge number of input channels (76) compared to the RGB channels (3) for the image classification task. Therefore, instead of applying the convolutions over the 76 channels, we proposed to carry out different convolutions for each cluster and sub-cluster of channels. In order to decide which channels should be grouped together, we used domain knowledge when clustering the channels.
在设计网络时遇到的主要挑战是,与图像分类任务的RGB通道(3)相比,输入通道数量巨大(76)。因此,我们没有对这76个通道直接进行卷积运算,而是提出对每个通道簇及其子簇分别执行不同的卷积操作。在确定通道分组方案时,我们运用领域知识对通道进行聚类。
First we divide the 76 variables into four different clusters, such as each cluster contains the variables from one of the four manipulators: the $1^{s t},2^{n d},3^{r d}$ and $4^{t h}$ clusters correspond respectively to the four manipulators (ML: master left, MR: master right, SL: slave left and SR: slave right) of the da Vinci surgical system. Thus, each cluster contains 19 of the 76 total kinematic variables.
首先我们将76个变量划分为四个不同的集群,每个集群包含来自四个机械臂之一的变量:$1^{s t}$、$2^{n d}$、$3^{r d}$和$4^{t h}$集群分别对应达芬奇手术系统的四个机械臂 (ML: 主左臂, MR: 主右臂, SL: 从左臂, SR: 从右臂) 。因此,每个集群包含76个运动学变量中的19个。
Next, each cluster of 19 variables is split into five different sub-clusters such as each sub-cluster contains variables that we hypothesize are highly correlated. For each cluster, the variables are grouped into five sub-clusters: $1^{s t}$ sub-cluster with 3 variables for the Cartesian coordinates $(x,y,z)$ ; $2^{n d}$ sub-cluster with 3 variables for the linear velocity $(x^{\prime},y^{\prime},z^{\prime})$ ; $3^{r d}$ sub-cluster with 3 variables for the rotational velocity $(\alpha^{\prime},\beta^{\prime},\gamma^{\prime})$ ; $4^{t h}$ sub-cluster with 9 variables for the rotation matrix R; $5^{t h}$ sub-cluster with 1 variable for the gripper angular velocity $(\theta)$ .
接下来,每组19个变量被划分为五个不同的子集群,每个子集群包含我们假设高度相关的变量。具体分组方式为:$1^{st}$子集群包含3个笛卡尔坐标变量$(x,y,z)$;$2^{nd}$子集群包含3个线性速度变量$(x^{\prime},y^{\prime},z^{\prime})$;$3^{rd}$子集群包含3个旋转速度变量$(\alpha^{\prime},\beta^{\prime},\gamma^{\prime})$;$4^{th}$子集群包含9个旋转矩阵R变量;$5^{th}$子集群包含1个夹爪角速度变量$(\theta)$。
Figure 1 shows how the convolutions in the first layer are different for each sub-cluster of channels. Following the same reasoning, the convolutions in the second layer are different for each cluster of channels (ML, MR, SL and SR). However, in the third layer, the same convolutions are applied for all channels.
图 1: 展示了第一层中每个子通道群的卷积操作如何各不相同。同理,第二层的卷积操作对每个通道群 (ML、MR、SL 和 SR) 也各不相同。然而在第三层中,所有通道都应用相同的卷积操作。
In order to reduce the number of parameters in our model and benefit from the CAM method [18], we replaced the fully-connected layer with a GAP operation after the third convolutional layer. This results in a summarized MTS that shrinks from a length $\it l$ to 1, while preserving the same number of channels in the third layer. As for the output layer, we use a fully-connected softmax layer with three neurons, one for each class (N, I, E).
为了减少模型参数量并利用CAM方法[18]的优势,我们在第三卷积层后使用全局平均池化(GAP)操作替代全连接层。这使得多时间序列(MTS)的表示长度从$\it l$缩减为1,同时保持第三层的通道数不变。输出层采用包含三个神经元(分别对应N、I、E三类)的全连接softmax层。
Without any cross-validation, we choose to use 8 filters at the first convolutional layer, then we increase the number of filters (by a factor of 2), thus balancing the number of parameters for each layer while going deeper into the network. The Rectified Linear Unit (ReLU) activation function is employed for the three convolutional layers with a filter size of 3 and a stride of 1.
不进行任何交叉验证的情况下,我们选择在第一卷积层使用8个滤波器,随后逐层增加滤波器数量(以2为倍数),从而在加深网络的同时平衡各层参数规模。三个卷积层均采用ReLU激活函数(ReLU),滤波器尺寸为3,步长为1。
2.3 Training & Testing
2.3 训练与测试
To train the network, we used the multi no mi al cross-entropy as our objective cost function. The network’s parameters were optimized using Adam [10]. Following [17], without any fine-tuning, the learning rate was set to 0.001 and the exponential decay rates of the first and second moment estimates were set to 0.9 and 0.999 respectively. Each trial was used in a forward-pass followed by a back-propagation update of the weights which were initialized using Glorot’s uniform initialization [6]. Before each training epoch, the train set was randomly shuffled. We trained the network for 1000 epochs, then by saving the model at each training epoch, we chose the one that minimized the objective cost function on a random (non-seen) split from the training set. Thus, we only validate the number of epochs since no extra-computation is needed to perform this step. Finally, to avoid over fitting, we added a $l2$ regular iz ation parameter equal to $10^{-5}$ . Since we did not fine-tune the model’s hyper-parameters, the same network architecture with the same hyper-parameters was trained on each surgical task resulting in three different models1.
为训练网络,我们采用多项式交叉熵作为目标损失函数。网络参数使用Adam优化器[10]进行优化。参照[17]的做法,在未进行任何微调的情况下,学习率设为0.001,一阶和二阶矩估计的指数衰减率分别设为0.9和0.999。每个试验样本均执行前向传播和反向传播权重更新,权重初始化采用Glorot均匀初始化方法[6]。每个训练周期开始前对训练集进行随机打乱。网络训练1000个周期后,通过保存每个训练周期的模型,我们选择在训练集随机划分(未见过的)子集上使目标损失函数最小的模型。因此仅需验证训练周期数,无需额外计算步骤。最后为防止过拟合,我们添加了$l2$正则化参数(值为$10^{-5}$)。由于未对模型超参数进行微调,相同网络架构和超参数被用于各项手术任务训练,最终得到三个独立模型1。
To evaluate our approach we adopted the standard benchmark configuration, Leave One Super Trial Out (LOSO) [1]: for each iteration of cross-validation (five in total), one trial of each subject was left out for the test and the remaining trials were used for training.
为评估我们的方法,我们采用了标准基准配置——留一超级试验交叉验证 (LOSO) [1]:在每次交叉验证迭代(共五次)中,每个受试者的一项试验数据留作测试集,其余试验数据用于训练集。
2.4 Class Activation Map
2.4 类激活图 (Class Activation Map)
By employing a GAP layer, we benefit from the CAM [18] method, which makes it possible to identify which regions of the surgical task contributed the most to a certain class identification. Let $A_{k}(t)$ be the result of the third convolutional layer which is a MTS with $K$ channels (in our case $K$ is equal to 32 filters and $t$ denotes the time dimension). Let $w_{k}^{c}$ be the weight between the output neuron of class $c$ and the $k^{t h}$ filter. Since a GAP layer is used, the input to the output neuron of class $c$ ( $z_{c}$ ) and the CAM ( $M_{c}(t),$ can be defined as:
通过采用GAP层,我们受益于CAM [18]方法,这使得识别手术任务中哪些区域对特定类别识别贡献最大成为可能。设$A_{k}(t)$为第三卷积层的结果,它是一个具有$K$个通道的MTS(在我们的案例中,$K$等于32个滤波器,$t$表示时间维度)。设$w_{k}^{c}$为类别$c$的输出神经元与第$k^{th}$个滤波器之间的权重。由于使用了GAP层,类别$c$的输出神经元($z_{c}$)和CAM($M_{c}(t)$可以定义为:
$$
z_{c}=\sum_{k}w_{k}^{c}\sum_{t}A_{k}(t)=\sum_{t}\sum_{k}w_{k}^{c}A_{k}(t)\quad;\quad M_{c}(t)=\sum_{k}w_{k}^{c}A_{k}(t)
$$
$$
z_{c}=\sum_{k}w_{k}^{c}\sum_{t}A_{k}(t)=\sum_{t}\sum_{k}w_{k}^{c}A_{k}(t)\quad;\quad M_{c}(t)=\sum_{k}w_{k}^{c}A_{k}(t)
$$
In order to avoid upsampling the CAM, we padded the input of each convolution with zeros, thus preserving the initial MTS length $\textit{l}$ throughout the convolutions.
为了避免对CAM(类激活映射)进行上采样,我们在每个卷积的输入周围补零,从而在整个卷积过程中保持初始多变量时间序列(MTS)的长度$\textit{l}$。
3 Results
3 结果
3.1 Surgical skill classification
3.1 手术技能分类
Table 1 reports the micro and macro measures (defined in [1]) of four different methods for the surgeons’ skill classification of the three surgical tasks. For our approach (CNN), we report the average of 40 runs to eliminate any bias due to the random seed. From these results, it appears that the CNN method is much more accurate than the other approaches with $100%$ accuracy for the suturing and needle passing tasks. As for the knot tying task, we report $92.1%$ and $93.2%$ respectively for the micro and macro configurations. Indeed, for knot tying, the model is less accurate compared to the other two. This is due to the complexity of this task, which is in compliance with the results of the other approaches.
表1报告了四种不同方法在三种外科手术任务中对医生技能分类的微观和宏观指标(定义见[1])。对于我们的方法(CNN),我们报告了40次运行的平均值以消除随机种子带来的偏差。从这些结果来看,CNN方法比其他方法准确得多,在缝合和穿针任务中达到了100%的准确率。至于打结任务,我们报告的微观和宏观配置准确率分别为92.1%和93.2%。实际上,与其他两项任务相比,该模型在打结任务上的准确性较低,这是由于该任务的复杂性所致,这一结果与其他方法的研究结论一致。
In [13], the authors designed Sparse Hidden Markov Models (S-HMM) to evaluate the surgical skills. Although the latter method utilizes the gesture boundaries during the training phase, our approach achieves much higher accuracy while still providing the trainee with interpret able skill evaluation.
在[13]中,作者设计了稀疏隐马尔可夫模型(S-HMM)来评估手术技能。虽然后一种方法在训练阶段利用了手势边界,但我们的方法在保持可解释性技能评估的同时,实现了更高的准确率。
Approximate Entropy (ApEn) is used to extract features from each trial [19], which are then fed to a nearest neighbor classifier. Although both methods (ApEn and CNN) achieve state of the art results with $100%$ accuracy for the suturing and needle passing surgical tasks, it is not clear how ApEn could be extended to provide feedback for the trainee. In addition, we hypothesize that by doing cross-validation and hyper-parameters fine tuning, we could squeeze higher accuracy from the CNN, especially for the knot tying task.
近似熵 (Approximate Entropy, ApEn) 用于从每次试验中提取特征 [19],这些特征随后被输入到最近邻分类器中。尽管两种方法 (ApEn 和 CNN) 在缝合和穿针手术任务中都达到了 100% 准确率的最先进水平,但尚不清楚如何扩展 ApEn 来为学员提供反馈。此外,我们假设通过交叉验证和超参数微调,可以从 CNN 中榨取更高的准确率,特别是在打结任务中。
Finally, in [4], the authors introduce a sliding window technique with a disc ret iz ation method to transform the MTS into bag of words. Then, they build a vector for each class from the frequency of the words, which is compared to vectors of the MTS in the test set to identify the nearest neighbor with a cosine similarity metric. The authors emphasized the need to obtain interpret able surgical skill evaluation, which justified their relatively low accuracy. On contrast, our approach does not trade off accuracy for feedback: CNN is much more accurate and equally interpret able.
最后,在[4]中,作者引入了一种滑动窗口技术结合离散化方法,将多变量时间序列(MTS)转化为词袋模型。随后,他们根据词频为每个类别构建特征向量,并通过余弦相似度度量与测试集中MTS向量的匹配程度,以此识别最近邻。作者强调需要获得可解释的手术技能评估,这解释了其相对较低的准确率。相比之下,我们的方法无需牺牲准确率来换取反馈:卷积神经网络(CNN)在保持同等可解释性的同时,显著提升了预测精度。
Table 1: Surgical skill classification results (%)
表 1: 手术技能分类结果 (%)
| 方法 | Suturing MicroMacro | Micro | NeedlePassing Macro | Knot Tying MicroMacro |
|---|---|---|---|---|
| S-HMM [13] | 97.4 n/a | 96.2 | n/a | 94.4 n/a |
| ApEn [19] Sax-Vsm [4] | 100 n/a | 100 | n/a | 99.9 n/a |
| CNN (proposed) | 89.7 86.7 100 100 | 96.3 100 | 95.8 100 | 61.1 53.3 92.1 93.2 |
3.2 Feedback visualization
3.2 反馈可视化
The CAM technique allows us to visualize which parts of the trial contributes the most to a certain skill classification. Patterns in movements could be understood by identifying for example disc rim i native behaviors specific to a novice or an expert. We can also pinpoint to the trainees their good/bad movements in order to improve themselves and achieve potentially higher skill levels.
CAM技术能让我们直观看到试验中哪些部分对特定技能分类贡献最大。通过识别新手或专家特有的动作模式(例如飞盘边缘操控),可以理解运动规律。我们还能精准指出学员动作的优劣,帮助他们改进并可能达到更高技能水平。
Figure 2 gives an example on how to visualize the feedback for the trainee by constructing a heatmap from the CAM. A trial of a novice subject is studied: its last frame is shown in Figure 2a and its corresponding heatmap is illustrated in Figure 2b. In the latter, the model was able to detect which movements (red area) were the main reason behind subject H’s classification (as a novice). This feedback could be used to explain to a young surgeon which movements are classifying him/her as a novice and which ones are classifying another subject as an expert. Thus, the feedback could guide the novices into becoming experts.
图 2: 展示了如何通过从CAM构建热图来可视化对学员的反馈。研究了一名新手受试者的试验:其最后一帧如图2a所示,对应的热图如图2b所示。在后者中,模型能够检测出哪些动作(红色区域)是受试者H被分类为新手的主要原因。这种反馈可用于向年轻外科医生解释哪些动作导致其被归类为新手,而哪些动作使其他受试者被归类为专家。因此,该反馈可以引导新手成长为专家。

Fig. 2: Example of feedback using Class Activation Map (a video illustrating this feedback is available on https://germain-forestier.info/src/ miccai2018/).
图 2: 使用类别激活图 (Class Activation Map) 的反馈示例 (演示视频详见 https://germain-forestier.info/src/miccai2018/)。
4 Conclusion
4 结论
In this paper, we presented a new method for classifying surgical skills. By designing a specific CNN, we achieved $100%$ accuracy, while providing interpret ability that justifies a certain skill evaluation, which reduces the CNN’s black-box effect.
本文提出了一种新的手术技能分类方法。通过设计特定的CNN (Convolutional Neural Network) ,我们实现了100%的准确率,同时提供了可解释性来证明特定技能评估的合理性,从而降低了CNN的黑箱效应。
In our future work, due to the natural extension of CNNs to image classification, we aim at developing a unified CNN framework that uses both video and kinematic data to classify surgical skills accurately and to provide highly interpret able feedback for the trainee.
在我们的未来工作中,由于CNN(卷积神经网络)在图像分类上的自然扩展,我们旨在开发一个统一的CNN框架,同时利用视频和运动学数据来准确分类手术技能,并为学员提供高度可解释的反馈。