Exploring Self-Attention Mechanisms for Speech Separation
探索自注意力机制在语音分离中的应用
Abstract—Transformers have enabled impressive improvements in deep learning. They often outperform recurrent and convolutional models in many tasks while taking advantage of parallel processing. Recently, we proposed the SepFormer, which obtains state-of-the-art performance in speech separation with the WSJ0-2/3 Mix datasets. This paper studies in-depth Transformers for speech separation. In particular, we extend our previous findings on the SepFormer by providing results on more challenging noisy and noisy-reverb e rant datasets, such as LibriMix, WHAM!, and WHAMR!. Moreover, we extend our model to perform speech enhancement and provide experimental evidence on denoising and de reverberation tasks. Finally, we investigate, for the first time in speech separation, the use of efficient self-attention mechanisms such as Linformers, Lonformers, and ReFormers. We found that they reduce memory requirements significantly. For example, we show that the Reformerbased attention outperforms the popular Conv-TasNet model on the WSJ0-2Mix dataset while being faster at inference and comparable in terms of memory consumption.
摘要—Transformer 在深度学习领域实现了显著进步。在许多任务中,其表现往往优于循环和卷积模型,同时还能利用并行处理优势。近期,我们提出的 SepFormer 在 WSJ0-2/3 Mix 数据集上实现了语音分离的最先进性能。本文深入研究了语音分离领域的 Transformer 模型,特别通过 LibriMix、WHAM! 和 WHAMR! 等更具挑战性的含噪及含噪混响数据集扩展了 SepFormer 的先前研究成果。此外,我们将模型扩展至语音增强任务,并在去噪和去混响实验中提供了实证。最后,我们首次在语音分离领域探索了高效自注意力机制(如 Linformer、Longformer 和 Reformer)的应用,发现其能显著降低内存需求。例如,基于 Reformer 的注意力机制在 WSJ0-2Mix 数据集上优于流行的 Conv-TasNet 模型,且推理速度更快,内存消耗相当。
Index Terms—speech separation, source separation, transformer, attention, deep learning.
索引术语—语音分离,源分离,Transformer,注意力机制,深度学习。
I. INTRODUCTION
I. 引言
deep learning [1]. They contributed to a paradigm shift in sequence learning and made it possible to achieve unprecedented performance in many Natural Language Processing (NLP) tasks, such as language modeling [2], machine translation [3], and various applications in computer vision [4], [5]. Transformers enable more accurate modeling of longer-term dependencies, which makes them suitable for speech and audio processing as well. They have indeed been recently adopted for speech recognition, speaker verification, speech enhancement, and other tasks [6], [7].
深度学习 [1]。它们推动了序列学习的范式转变,使得在自然语言处理 (NLP) 任务中实现前所未有的性能成为可能,例如语言建模 [2]、机器翻译 [3] 以及计算机视觉中的各种应用 [4], [5]。Transformer 能够更准确地建模长期依赖关系,因此也适用于语音和音频处理。近年来,它们确实已被应用于语音识别、说话人验证、语音增强等任务 [6], [7]。
Powerful sequence modeling is central to source separation as well, where long-term modeling turned out to impact performance significantly [8], [9]. However, speech separation typically involves long sequences in the order of tens of thousands of frames, and using Transformers poses a challenge because of the quadratic complexity of the standard selfattention mechanism [1]. For a sequence of length $N$ , it needs to compare $N^{2}$ elements, leading to a computational bottleneck that emerges more clearly when processing long signals. Mitigating the memory bottleneck of Transformers has been the object of intense research in the last years [10]–[13]. A popular way to address the problem consists of attending to a subset of elements only. For instance, Sparse Transformer [10] employs local and dilated sliding windows over a fixed number of elements to learn short and long-term dependencies. LongFormer [11] augments the Sparse Transformer by adding global attention heads. Linformers [12], approximate the full sparse attention with low-rank matrix multiplication, while Reformers [13] cluster the elements to attend through an efficient locality-sensitive hashing function.
强大的序列建模同样是源分离的核心,其中长期建模对性能有显著影响 [8], [9]。然而,语音分离通常涉及数万帧量级的长序列,由于标准自注意力机制 (self-attention) 的二次方复杂度 [1],使用 Transformer 带来了挑战。对于长度为 $N$ 的序列,需要比较 $N^{2}$ 个元素,导致计算瓶颈在处理长信号时更为明显。近年来,缓解 Transformer 的内存瓶颈成为密集研究的焦点 [10]–[13]。解决该问题的常用方法之一是仅关注元素的子集。例如,稀疏 Transformer (Sparse Transformer) [10] 通过局部和扩张滑动窗口在固定数量的元素上学习短期和长期依赖关系。LongFormer [11] 通过添加全局注意力头扩展了稀疏 Transformer。Linformers [12] 通过低秩矩阵乘法近似完整的稀疏注意力,而 Reformers [13] 则通过高效的局部敏感哈希函数对元素进行聚类以实现注意力计算。
To address this issue in speech separation, we recently proposed the SepFormer [14], a Transformer specifically designed for speech separation that inherits the dual-path processing pipeline proposed originally in [8] for recurrent neural networks (RNN). Dual-path processing splits long sequences into chunks, thus naturally alleviating the quadratic complexity issue. Moreover, it combines short-term and long-term modeling by adding a cascade of two distinct stages, making it particularly appealing for audio processing. Differently from its predecessors, SepFormer employs a Masking Network composed of Transformer encoder layers only. This property significantly improves the parallel iz ation and inference speed of the SepFormer compared to previous RNN-based methods.
为了解决语音分离中的这一问题,我们近期提出了SepFormer [14],这是一种专为语音分离设计的Transformer,它继承了最初在[8]中为循环神经网络(RNN)提出的双路径处理流程。双路径处理将长序列分割成块,从而自然缓解了二次复杂度问题。此外,它通过添加两个不同阶段的级联,结合了短期和长期建模,使其特别适用于音频处理。与之前的方法不同,SepFormer采用仅由Transformer编码器层组成的掩码网络。这一特性显著提高了SepFormer的并行化能力和推理速度,相比之前基于RNN的方法。
This paper extends our previous studies on Transformerbased architectures for speech separation. In our previous work [14], for instance, we focused on the standard WSJ0- 2/3Mix benchmark datasets only. Here, we propose additional experiments and insights on more realistic and challenging datasets such as Libri2/3-Mix [15], which includes long mixtures, WHAM! [16] and WHAMR! [17], which feature noisy and noisy and reverb e rant conditions, respectively. Moreover, we adapted the SepFormer to perform speech enhancement and provide experimental evidence on VoiceBank-DEMAND, WHAM!, and WHAMR! datasets. Another contribution of this paper is investigating different types of self-attention mechanisms for speech separation. We explore, for the first time in speech separation, three efficient self-attention mechanisms [8], namely Longformer [11], Linformer [12], and Reformer [13] attention, all found to yield comparable or even better results than standard self-attention in natural language processing (NLP) applications.
本文扩展了我们先前基于Transformer的语音分离架构研究。在我们之前的工作[14]中,例如,我们仅关注标准的WSJ0-2/3Mix基准数据集。在此,我们针对更现实且更具挑战性的数据集提出了更多实验和见解,例如包含长混合音频的Libri2/3-Mix[15]、分别具有噪声和噪声加混响条件的WHAM![16]和WHAMR![17]。此外,我们调整了SepFormer以执行语音增强,并在VoiceBank-DEMAND、WHAM!和WHAMR!数据集上提供了实验证据。本文的另一贡献是研究了不同类型的自注意力机制在语音分离中的应用。我们首次在语音分离中探索了三种高效的自注意力机制[8],即Longformer[11]、Linformer[12]和Reformer[13]注意力,这些机制在自然语言处理(NLP)应用中均表现出与标准自注意力相当甚至更优的效果。
We found that Reformer and Longformer attention mechanisms exhibit a favorable trade-off between performance and memory requirements. For instance, the Reformer-based model turned out to be even more efficient in terms of memory usage and inference speed than the popular Conv-TasNet model while yielding significantly better performance than the latter ( $16.7\mathrm{dB}$ versus 15.3 dB SI-SNR improvement). Despite the impressive improvements in the memory footprint and inference time, we found that the best performance, in speech separation, is still achieved, by far, with the regular selfattention mechanism used in the original SepFormer model, confirming the importance of full self-attention mechanisms.
我们发现Reformer和Longformer的注意力机制在性能和内存需求之间展现出良好的平衡。例如,基于Reformer的模型在内存占用和推理速度上甚至比流行的Conv-TasNet模型更高效,同时性能显著优于后者(SI-SNR提升16.7dB对比15.3dB)。尽管在内存占用和推理时间方面取得了显著改进,但我们发现迄今为止,语音分离的最佳性能仍由原始SepFormer模型中使用的常规自注意力机制实现,这证实了完整自注意力机制的重要性。
The training recipes for the main experiments are available in the Speech brain [18] toolkit. Moreover, the pretrained models for the WSJ0-2/3Mix datasets, Libri2/3Mix datasets, WHAM!/WHAMR! datasets are available on the Speech Brain Hugging face page1.
主要实验的训练方案可在SpeechBrain[18]工具包中获取。此外,WSJ0-2/3Mix数据集、Libri2/3Mix数据集以及WHAM!/WHAMR!数据集的预训练模型已发布于SpeechBrain的Hugging Face页面。
The contributions in this paper are summarized as follows,
本文的贡献总结如下:
The paper is organized as follows. In Section III, we introduce the building blocks of Transformers and also describe the three efficient attention mechanisms (Longformer, Linformer, and Reformer) explored in this work. In Section IV, we describe the SepFormer model in detail with a focus on the dual-path processing pipeline employed by the model. Finally, in Section VI, we present the results on speech separation, speech enhancement, and experimental analysis of different types of self-attention.
本文组织结构如下。在第三节中,我们介绍了Transformer的基础模块,并详细阐述了本研究中探索的三种高效注意力机制 (Longformer、Linformer和Reformer)。第四节重点描述了SepFormer模型采用的双路径处理流程。最后,第六节展示了语音分离、语音增强的实验结果,以及不同类型自注意力的对比分析。
II. RELATED WORKS
II. 相关工作
A. Deep learning for source separation
A. 源分离的深度学习
Thanks to the advances in deep learning, tremendous progress has been made in the source separation domain. Notable early works include Deep Clustering [19], where a recurrent neural network is trained on an affinity matrix in order to estimate embeddings for each source from the magnitude spectra of the mixture. TasNet and Conv-TasNet [20], [21] achieved impressive performance by introducing time-domain processing, combined with utterance level and permutation-invariant training [22].
得益于深度学习的进步,源分离领域取得了巨大进展。早期重要工作包括Deep Clustering [19],该方法通过训练循环神经网络处理亲和矩阵,从混合信号的幅度谱中估计各声源的嵌入表示。TasNet与Conv-TasNet [20][21] 通过引入时域处理技术,结合语句级和置换不变训练 [22],实现了令人瞩目的性能突破。
More recent works include Sudo rm -rf [23], which uses a U-Net type architecture to reduce computational complexity, and Dual-Path Recurrent Neural Network (DPRNN) [8]. The latter first introduced the extremely effective dual-path processing framework adopted in this work. Other works focused more on training strategies, such as [24], which proposed to split the learning of the encoder-decoder pair and the masking network into two steps in time domain separation. [25] reports impressive performance with a modified DPRNN model using a technique to determine the number of speakers. In [26] Wavesplit was proposed and it further improved over [25] by leveraging speaker-id information.
近期的工作包括 Sudo rm -rf [23],它采用 U-Net 架构来降低计算复杂度,以及双路径循环神经网络 (DPRNN) [8]。后者首次引入了本文采用的极其高效的双路径处理框架。其他研究更侧重于训练策略,例如 [24] 提出将编码器-解码器对和掩码网络的学习分两步进行时域分离。[25] 报告了采用改进版 DPRNN 模型的出色性能,该模型使用了一种确定说话人数量的技术。[26] 提出了 Wavesplit,它通过利用说话人 ID 信息进一步改进了 [25] 的性能。
At the time of the writing, only a few papers exist on Transformers for source separation. These works include DPTNet [9], which adopts an architecture similar to DPRNN but adds
在撰写本文时,仅有少数关于Transformer用于音源分离的论文。这些工作包括采用类似DPRNN架构但增加了Transformer模块的DPTNet [9]
B. Transformers for source separation
B. 用于源分离的Transformer
a multi-head-attention layer plus layer normalization in each block before the RNN part. SepFormer, on the contrary, uses multiple Transformer encoder blocks without any RNN in each dual-path processing block. Our results in Section VI indicate that SepFormer outperforms DPTNet, and is faster and more parallel iz able at inference time due to the absence of recurrent operations.
多头注意力层加上层归一化,每个模块在RNN部分之前。相反,SepFormer在每个双路径处理模块中使用多个Transformer编码器块,没有任何RNN。我们在第六部分的结果表明,SepFormer优于DPTNet,并且由于没有循环操作,在推理时更快且更易于并行化。
In [27], the authors propose Transformers to deal with a multi-microphone meeting-like scenario, where the amount of overlapping speech is low and a powerful separation might not be needed. The system’s main feature is adapting the number of transformer layers according to the complexity of the input mixture. In [28], a multi-scale transformer is proposed. As shown in Section VI, the SepFormer outperforms this method. Other Transformer-based source separation works include [29], which uses a similar architecture as SepFormer but uses RNNs before the self-attention blocks (like DPTNet). There also exists methods that leverage Transformers for continuous speech separation, which aim to do source separation on long, meeting-like audio recordings. Prominent examples include [27], [30], [31]. Moreover, there have been recent concurrent works exploring efficient attention mechanisms for speech separation [32], [33]. We note that, the architectures of the separation networks that we explore for this purpose are different from these aforementioned works.
在[27]中,作者提出用Transformer处理多麦克风会议场景,该场景下语音重叠率较低且可能不需要强分离能力。该系统主要特性是根据输入混合音的复杂度自适应调整Transformer层数。[28]提出了一种多尺度Transformer,如第六节所示,SepFormer性能优于该方法。其他基于Transformer的语音分离工作包括[29],其采用与SepFormer相似的架构,但在自注意力模块前使用RNN(类似DPTNet)。另有方法利用Transformer进行连续语音分离,旨在对会议式长音频进行音源分离,典型代表包括[27]、[30]、[31]。此外,近期有并行研究探索语音分离的高效注意力机制[32]、[33]。需要说明的是,本文研究的分离网络架构与上述工作均不相同。
III. TRANSFORMERS
III. TRANSFORMER
In this paper, we utilize the encoder part of the Transformer architecture, which is depicted in Fig. 1. The encoder turns an input sequence $X={x_{1},\dots,x_{T}}\in\mathbb{R}^{F\times T}$ (where $F$ denotes the number of features, and $T$ denotes the signal length) into an output sequence $Y~={y_{0},\dots,y_{T}}\in~\mathbb{R}^{F\times T}$ using a pipeline of computations that involve positional embedding, multi-head self-attention, normalization, feed-forward layers, and residual connections.
本文采用Transformer架构的编码器部分,其结构如图1所示。编码器通过包含位置嵌入 (positional embedding)、多头自注意力 (multi-head self-attention)、归一化 (normalization)、前馈层 (feed-forward layers) 和残差连接 (residual connections) 的计算流程,将输入序列 $X={x_{1},\dots,x_{T}}\in\mathbb{R}^{F\times T}$(其中 $F$ 表示特征数量,$T$ 表示信号长度)转换为输出序列 $Y~={y_{0},\dots,y_{T}}\in~\mathbb{R}^{F\times T}$。
A. Multi-head self-attention
A. 多头自注意力 (Multi-head self-attention)
The multi-head self-attention mechanism allows the Transformer to model dependencies across all the elements of the sequence. The first step calculates the Query, Key, and Value matrices from the input sequence $X$ of length $T$ . This operation is performed by multiplying the input vector by weight matrices: $Q=W_{Q}X$ , $K=W_{K}X$ , $V=W_{V}X$ , where $W_{Q},W_{K},W_{V}\in\mathbb{R}^{d_{\mathrm{model}}\times\dot{F}}$ . The attention layer consists of the following operations:
多头自注意力机制使Transformer能够建模序列中所有元素之间的依赖关系。第一步从长度为$T$的输入序列$X$中计算查询(Query)、键(Key)和值(Value)矩阵。该操作通过将输入向量与权重矩阵相乘实现:$Q=W_{Q}X$,$K=W_{K}X$,$V=W_{V}X$,其中$W_{Q},W_{K},W_{V}\in\mathbb{R}^{d_{\mathrm{model}}\times\dot{F}}$。注意力层包含以下运算:
$$
{\mathrm{Attention}}(Q,K,V)={\mathrm{SoftMax}}\left({\frac{Q^{\top}K}{\sqrt{d_{k}}}}\right)V^{\top},
$$
$$
{\mathrm{Attention}}(Q,K,V)={\mathrm{SoftMax}}\left({\frac{Q^{\top}K}{\sqrt{d_{k}}}}\right)V^{\top},
$$
where $d_{k}$ represents the latent dimensionality of the $Q$ and $K$ matrices. The attention weights are obtained from a scaled dot-product between queries and keys: closer queries and key vectors will have higher dot products. The softmax function ensures that the attention weights range between 0 and 1. The attention mechanism produces $T$ weights for each input element (i.e., $T^{2}$ attention weights). All in all, the softmax part of the attention layer computes relative importance weights, and then we multiply this attention map with the input value sequence $V$ . Multi-head attention consists of several parallel attention layers. More in detail, it is computed as follows:
其中 $d_{k}$ 表示 $Q$ 和 $K$ 矩阵的潜在维度。注意力权重通过查询(query)和键(key)之间的缩放点积获得:越接近的查询向量和键向量会产生更高的点积值。softmax函数确保注意力权重范围在0到1之间。该注意力机制为每个输入元素生成 $T$ 个权重(即 $T^{2}$ 个注意力权重)。总体而言,注意力层的softmax部分计算相对重要性权重,然后将该注意力图与输入值序列 $V$ 相乘。多头注意力由多个并行的注意力层组成,具体计算方式如下:
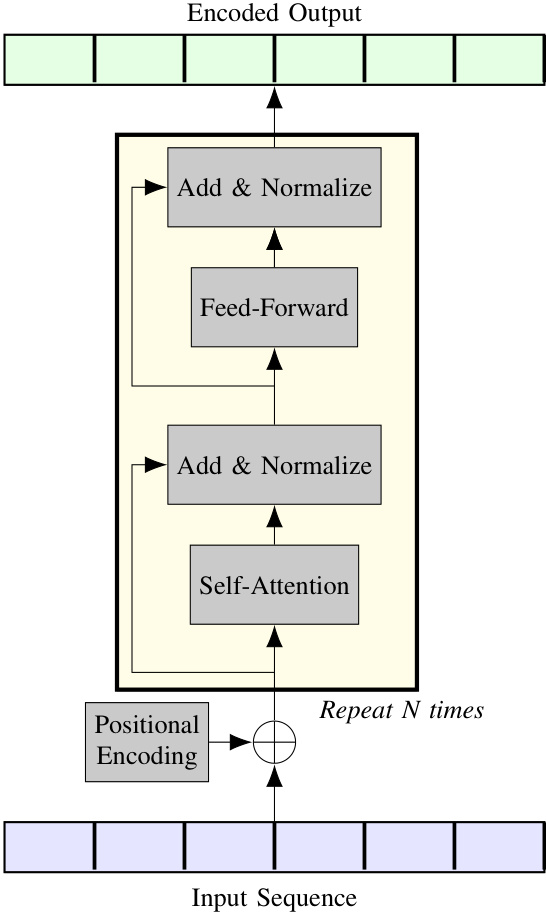
Fig. 1. The encoder of a standard Transformer. Positional embeddings are added to the input sequence. Then, N encoding layers based on multihead self-attention, normalization, feed-forward transformations, and residual connections process it to generate an output sequence.
图 1: 标准 Transformer 的编码器结构。位置编码 (positional embeddings) 被添加到输入序列中,随后经过基于多头自注意力 (multihead self-attention)、归一化、前馈变换和残差连接的 N 个编码层处理,最终生成输出序列。
$$
\begin{array}{r l}&{\mathrm{MultiHeadAttention}(Q,K,V)}\ &{=\mathrm{Concat}(\mathrm{Head}{1},...,\mathrm{Head}{h})W^{O},}\ &{\mathrm{whereHead}{i}=\mathrm{Attention}(Q_{i},K_{i},V_{i}),}\end{array}
$$
$$
\begin{array}{r l}&{\mathrm{MultiHeadAttention}(Q,K,V)}\ &{=\mathrm{Concat}(\mathrm{Head}{1},...,\mathrm{Head}{h})W^{O},}\ &{\mathrm{whereHead}{i}=\mathrm{Attention}(Q_{i},K_{i},V_{i}),}\end{array}
$$
where $h$ is the number of parallel attention heads and $W^{O}\in~\mathbb{R}^{d_{\mathrm{model}}\times h F}$ is the matrix that combines the parallel attention heads, and $d_{\mathrm{model}}$ denotes the latent dimensionality of this combined model.
其中 $h$ 是并行注意力头 (parallel attention heads) 的数量,$W^{O}\in~\mathbb{R}^{d_{\mathrm{model}}\times h F}$ 是组合并行注意力头的矩阵,$d_{\mathrm{model}}$ 表示该组合模型的潜在维度。
B. Feed-Forward Layers
B. 前馈层
The feed-forward component of the Transformer architecture consists of a two-layer perceptron. The exact definition of it is the following:
Transformer架构的前馈组件由一个两层感知机构成。其具体定义如下:
$$
\mathrm{Feed-Forward}(x)=\mathrm{ReLU}(x W_{1}+b_{1})W_{2}+b_{2},
$$
$$
\mathrm{Feed-Forward}(x)=\mathrm{ReLU}(x W_{1}+b_{1})W_{2}+b_{2},
$$
where $x$ is the input. In the context of sequences, this feedforward transformation is applied to each time point separately. $W_{1}$ , and $W_{2}$ are learnable matrices, and $b_{1}$ , and $b_{2}$ are learnable bias vectors.
其中 $x$ 是输入。在序列处理场景中,该前馈变换会独立作用于每个时间点。$W_{1}$ 和 $W_{2}$ 是可学习矩阵,$b_{1}$ 和 $b_{2}$ 是可学习偏置向量。
C. Positional encoding
C. 位置编码
As the self-attention layer and feed-forward layers do not embed any notion of order, the transformer uses a positional
由于自注意力层和前馈层不包含任何顺序概念,Transformer使用了位置编码
encoding scheme for injecting sequence ordering information. The positional encoding is defined as follows:
用于注入序列排序信息的编码方案。位置编码定义如下:
$$
\begin{array}{r}{P E_{t,2i}=\mathrm{Sin}(t/10000^{2i/d_{\mathrm{model}}})}\ {P E_{t,2i+1}=\mathrm{Cos}(t/10000^{2i/d_{\mathrm{model}}})}\end{array}
$$
$$
\begin{array}{r}{P E_{t,2i}=\mathrm{Sin}(t/10000^{2i/d_{\mathrm{model}}})}\ {P E_{t,2i+1}=\mathrm{Cos}(t/10000^{2i/d_{\mathrm{model}}})}\end{array}
$$
This encoding relies on sinusoids of different frequencies in each latent dimension to encode positional information [1].
这种编码方式利用每个潜在维度中不同频率的正弦波来编码位置信息 [1]。
D. Reducing the memory bottleneck
D. 缓解内存瓶颈
Many alternative architectures have been proposed in the literature. Popular variations for mitigating the quadratic memory issues are described in the following.
文献中提出了许多替代架构。以下是缓解二次内存问题的常见变体。
- Longformer: Longformer [11] aims to reduce the quadratic complexity by replacing the full self-attention structure with a combination of local and global attention. Specifically, Longformer relies on local attention that captures dependencies from nearby elements and global attention that globally captures dependencies from all the elements. To keep the computational requirements manageable, global attention is performed for a few special elements in the sequence.
- Longformer: Longformer [11] 旨在通过用局部和全局注意力相结合的方式替代完整的自注意力结构,从而降低二次复杂度。具体来说,Longformer 依赖于局部注意力(捕捉附近元素的依赖关系)和全局注意力(全局捕捉所有元素的依赖关系)。为了保持计算需求可控,全局注意力仅针对序列中的少数特殊元素执行。
- Linformer: Linformer [12] avoids the quadratic complexity by reducing the size of the time dimension of the matrices $K,V\in\mathbb{R}^{d_{\mathrm{model}}\times T}$ . This is done by projecting the time dimension $T$ to a smaller dimensionality $k$ by using projection matrices $P,F\in\mathbb{R}^{T\times k}$ . The multi-head attention equation, therefore, becomes the following:
- Linformer: Linformer [12] 通过缩减矩阵 $K,V\in\mathbb{R}^{d_{\mathrm{model}}\times T}$ 的时间维度规模来避免二次复杂度。具体实现方式是使用投影矩阵 $P,F\in\mathbb{R}^{T\times k}$ 将时间维度 $T$ 映射到更小的维度 $k$。因此,多头注意力方程变为如下形式:
$$
\mathrm{ention}\left(Q,K,V\right)=\mathrm{SoftMax}\left(\frac{Q^{\top}(K P)}{\sqrt{d_{k}}}\right)(V F)^{\top},
$$
$$
\mathrm{ention}\left(Q,K,V\right)=\mathrm{SoftMax}\left(\frac{Q^{\top}(K P)}{\sqrt{d_{k}}}\right)(V F)^{\top},
$$
which effectively limits the complexity of the matrix product between the softmax output and the $V$ matrix.
这有效地限制了softmax输出与$V$矩阵之间矩阵乘积的复杂度。
- Reformer: Reformer [13] uses locality-sensitive hashing (LSH) to reduce the complexity of self-attention. LSH is used to find the vector pairs $(q,k),q\in Q,k\in K$ that are closer. The intuition is that those pairs will have a bigger dot product and contribute the most to the attention matrix. Because of this, the authors limit the attention computation to the close pairs $(q,k)$ , while ignoring the others (saving time and memory). In addition, the Reformer, inspired by [34], implements reversible Transformer layers that avoid the linear memory complexity scaling with respect to the number of layers. An example usage of Reformer in speech is in Text-to-Speech [35].
- Reformer: Reformer [13] 使用局部敏感哈希 (LSH) 来降低自注意力 (self-attention) 的复杂度。LSH 用于寻找向量对 $(q,k),q\in Q,k\in K$ 中距离较近的组合。其核心思想是这些组合的点积会更大,对注意力矩阵的贡献也最显著。因此,作者将注意力计算限制在相近的 $(q,k)$ 对上,同时忽略其他组合(从而节省时间和内存)。此外,受 [34] 启发,Reformer 实现了可逆的 Transformer 层,避免了内存复杂度随层数线性增长的问题。Reformer 在语音领域的应用案例包括文本转语音 (Text-to-Speech) [35]。
IV. SEPARATION TRANSFORMER (SEPFORMER)
IV. 分离Transformer (SEPFORMER)
The SepFormer relies on the masking-based source separation framework popularized by [20], [21] (Figure 2). An input mixture $x\in\mathbb{R}^{T}$ feeds the architecture. An encoder learns a latent representation $h\in\mathbb{R}^{F\times T^{\prime}}$ . Afterwards, a masking network estimates the masks $m_{1},m_{2}\in\mathbb{R}^{F\times T^{\prime}}$ . The separated time domain signals for source 1 and source 2 are obtained by passing the $hm_{1}$ , and $hm_{2}$ through the decoder, where $^*$ denotes element-wise multiplication. In the following, we explain in detail each block separately.
SepFormer基于[20]、[21]提出的掩码分离框架(图2)。输入混合信号$x\in\mathbb{R}^{T}$进入架构后,编码器学习潜在表示$h\in\mathbb{R}^{F\times T^{\prime}}$。随后掩码网络估计出掩码$m_{1},m_{2}\in\mathbb{R}^{F\times T^{\prime}}$。通过将$hm_{1}$和$hm_{2}$输入解码器(其中$^*$表示逐元素相乘),可获得源1和源2的分离时域信号。下文将分别详解各模块。
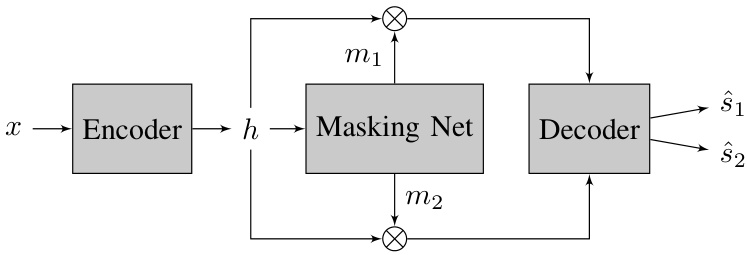
Fig. 2. The high-level description of the masking-based source separation pipeline: The encoder block learns a latent representation for the input signal. The masking network estimates optimal masks to separate the sources in the mixtures. The decoder finally reconstructs the estimated sources in the time domain using these masks. The self-attention-based modeling is applied inside the masking network.
图 2: 基于掩码的源分离流程概览:编码器模块学习输入信号的潜在表征。掩码网络估计最优掩码以分离混合信号中的各源信号。解码器最终利用这些掩码在时域中重建估计的源信号。基于自注意力(self-attention)的建模应用于掩码网络内部。
A. Encoder
A. 编码器
The encoder takes the time-domain mixture-signal $x\in\mathbb{R}^{T}$ as input. It learns a time-frequency latent representation $h\in$ $\mathbb{R}^{F\times\mathbf{\dot{T}}^{\prime}}$ using a single convolutional layer:
编码器以时域混合信号 $x\in\mathbb{R}^{T}$ 作为输入,通过单层卷积学习到时频潜在表示 $h\in\mathbb{R}^{F\times\mathbf{\dot{T}}^{\prime}}$:
$$
h=\operatorname{ReLU}(\operatorname{Conv1d}(x)).
$$
$$
h=\operatorname{ReLU}(\operatorname{Conv1d}(x)).
$$
As we will describe in Section VI-A, the stride factor of this convolution impacts significantly the performance, speed, and memory of the model.
正如我们将在第 VI-A 节中所述,该卷积的步长因子 (stride factor) 会显著影响模型的性能、速度和内存占用。
B. Decoder
B. 解码器
The decoder uses a simple transposed convolutional layer with the same stride and kernel size as the encoder. Its input is the element-wise multiplication between the mask of the $k$ -th source $m_{k}$ and the output of the encoder $h$ . The transformation operated by the decoder is the following:
解码器使用与编码器相同步长和核大小的简单转置卷积层。其输入是第 $k$ 个源掩码 $m_{k}$ 与编码器输出 $h$ 之间的逐元素乘积。解码器执行的变换如下:
$$
\widehat{s}{k}=\mathrm{Conv1dTranspose}(m_{k}\odot h),
$$
$$
\widehat{s}{k}=\mathrm{Conv1dTranspose}(m_{k}\odot h),
$$
where $\widehat{s}_{k}\in\mathbb{R}^{T}$ denotes the separated source $k$ , and $\odot$ denotes eleme nbt-wise multiplication.
其中 $\widehat{s}_{k}\in\mathbb{R}^{T}$ 表示分离出的源信号 $k$ ,$\odot$ 表示逐元素乘法。
C. Masking Network
C. 掩码网络
Figure 3 (top) shows the detailed architecture of the masking network (Masking Net). The masking network is fed by the encoded representations $\boldsymbol{h}\in\mathbb{R}^{F\times T^{\gamma}}$ and estimates a mask ${m_{1},\dots,m_{N s}}$ for each of the $N s$ speakers in the mixture.
图 3 (top) 展示了掩码网络 (Masking Net) 的详细架构。该网络以编码表示 $\boldsymbol{h}\in\mathbb{R}^{F\times T^{\gamma}}$ 作为输入,并为混合音频中的 $N s$ 个说话人分别估计掩码 ${m_{1},\dots,m_{N s}}$。
As in [21], the encoded input $h$ is normalized with layer normalization [36] and processed by a linear layer (with dimensionality $F$ ). Following the dual-path framework introduced in [8], we create overlapping chunks of size $C$ by chopping up $h$ on the time axis with an overlap factor of $50%$ . We denote the output of the chunking operation with $h^{\prime}\in\mathbb{R}^{F\times C\times N c}$ , where $C$ is the length of each chunk, and $N c$ is the resulting number of chunks.
如[21]所述,编码输入 $h$ 经过层归一化[36]处理,并通过一个维度为 $F$ 的线性层。根据[8]提出的双路径框架,我们在时间轴上以 $50%$ 的重叠因子将 $h$ 切分为大小为 $C$ 的重叠块。用 $h^{\prime}\in\mathbb{R}^{F\times C\times N c}$ 表示分块操作的输出,其中 $C$ 为每个块的长度,$N c$ 为最终生成的块数。
The representation $h^{\prime}$ feeds the SepFormer separator block, which is the main component of the masking network. This block, which will be described in detail in Section IV-D, employs a pipeline composed of two Transformers able to learn short and long-term dependencies. We pictorially describe the overall pipeline of the SepFormer separator block in Figure 4. We would like to note that, for graphical convenience, nonoverlapping chunks were used in the figure. However, in the experiments in this paper, we used $50%$ overlapping chunks.
表示 $h^{\prime}$ 输入到 SepFormer 分离器模块,这是掩码网络的核心组件。该模块将在第 IV-D 节详细描述,它采用由两个 Transformer 组成的管道,能够学习短期和长期依赖关系。我们在图 4 中直观展示了 SepFormer 分离器模块的整体流程。需要说明的是,出于图示便利性,图中使用了非重叠分块,但在本文实验中我们采用了 $50%$ 重叠分块。
The output of the SepFormer $h^{\prime\prime}\in\mathbb{R}^{F\times C\times N c}$ is processed by PReLU activation s followed by a linear layer. We denote the output of this module by $h^{\prime\prime\prime}\in\dot{\mathbb{R}}^{(F\times N s)\times C\times N c}$ , where $N s$ is the number of speakers. Afterward, we apply the overlapadd scheme described in [8] and obtain h′′′′ ∈ RF ×Ns×T ′. We pass this representation through two feed-forward layers and a ReLU activation at the end to obtain a mask $m_{k}$ for each one of the speakers.
SepFormer的输出$h^{\prime\prime}\in\mathbb{R}^{F\times C\times N c}$经过PReLU激活函数处理后接入线性层。该模块的输出记为$h^{\prime\prime\prime}\in\dot{\mathbb{R}}^{(F\times N s)\times C\times N c}$,其中$N s$代表说话者数量。随后应用[8]中描述的重叠相加方案,得到h′′′′ ∈ RF ×Ns×T ′。将该表征通过两个前馈层,并在末端使用ReLU激活函数,最终为每位说话者生成掩码$m_{k}$。
D. Dual-Path Processing Pipeline and SepFormer
D. 双路径处理流程与SepFormer
The dual-path processing pipeline [8] (shown in Fig. 4) enables a combination of short and long-term modeling while making long sequence processing feasible with a self-attention block. In the context of the masking-based end-to-end source separation shown in Fig. 2, the latent representation $h\in$ RF ×T ′ is divided into overlapping chunks.
双路径处理流程 [8] (如图 4 所示) 实现了短期与长期建模的结合,同时通过自注意力模块使长序列处理成为可能。在图 2 所示的基于掩码的端到端音源分离场景中,潜在表示 $h\in$ RF ×T ′ 被划分为重叠区块。
A Transformer encoder is applied to each chunk separately. We call this block Intra Transformer (IntraT) and denote it with $f_{\mathrm{intra}}(.)$ . This block effectively operates as a block diagonal attention structure, modeling the interaction between all elements in each chunk separately so that the attention memory requirements are bounded. Another transformer encoder is applied to model the inter-chunk interactions, i.e. between each chunk element. We call this block Inter Transformer (InterT) and denote with $f_{\mathrm{inter}}(.)$ . Because this block attends to all elements that occupy the same position in each chunk, it effectively operates as a strided-attention structure. Mathematically, the overall transformation can be summarized as follows:
对每个分块单独应用一个Transformer编码器。我们称该模块为块内Transformer (IntraT),用$f_{\mathrm{intra}}(.)$表示。该模块通过块对角注意力结构有效建模各分块内部元素间的交互,从而限制注意力内存需求。另一个Transformer编码器用于建模分块间交互(即各分块对应位置元素间的交互),我们称该模块为块间Transformer (InterT),用$f_{\mathrm{inter}}(.)$表示。由于该模块关注所有分块中相同位置的元素,实际上形成了跨步注意力结构。整体变换可数学表述为:
$$
h^{\prime\prime}=f_{\mathrm{inter}}(f_{\mathrm{intra}}(h^{\prime})).
$$
$$
h^{\prime\prime}=f_{\mathrm{inter}}(f_{\mathrm{intra}}(h^{\prime})).
$$
In the standard SepFormer model defined in [14], $f_{\mathrm{inter}}$ and $f_{\mathrm{intra}}$ are chosen to be full self-attention blocks. In Section IV-E, we describe the full self-attention block employed in SepFormer in detail.
在[14]中定义的标准SepFormer模型中,$f_{\mathrm{inter}}$和$f_{\mathrm{intra}}$被选为完整的自注意力块。在第四节E部分,我们将详细描述SepFormer中采用的完整自注意力块。
E. Full Self-Attention Transformer Encoder
E. 全自注意力 Transformer 编码器
The architecture for the full self-attention transformer encoder layers follows the original Transformer architecture [1]. Figure 3 (Bottom) shows the architecture used for the Intra Transformer and Inter Transformer blocks.
完整自注意力Transformer编码器层的架构遵循原始Transformer架构[1]。图3 (Bottom)展示了用于Intra Transformer和Inter Transformer模块的架构。
We use the variable $z$ to denote the input to the Transformer. First of all, sinusoidal positional encoding $e$ is added to the input $z$ , such that,
我们使用变量 $z$ 表示Transformer的输入。首先,将正弦位置编码 $e$ 添加到输入 $z$ 中,使得
$$
z^{\prime}=z+e.
$$
$$
z^{\prime}=z+e.
$$
We follow the positional encoding definition in [1]. We then apply multiple Transformer layers. Inside each Transformer layer $g(.)$ , we first apply layer normalization, followed by multi-head attention (MHA):
我们遵循[1]中的位置编码定义,随后应用多个Transformer层。在每个Transformer层 $g(.)$ 内部,首先进行层归一化,接着执行多头注意力机制 (MHA):
$$
z^{\prime\prime}=\mathrm{MultiHeadAttention}(\mathrm{LayerNorm}(z^{\prime})).
$$
$$
z^{\prime\prime}=\mathrm{MultiHeadAttention}(\mathrm{LayerNorm}(z^{\prime})).
$$
As proposed in [1], each attention head computes the scaled dot-product attention between all the sequence elements. The Transformer finally employs a feed-forward network (FFW), which is applied to each position independently:
如[1]所提出的,每个注意力头会计算所有序列元素之间的缩放点积注意力。Transformer最终采用一个前馈网络(FFW),该网络独立应用于每个位置:
$$
z^{\prime\prime\prime}=\operatorname{Feed-Forward}(\operatorname{LayerNorm}(z^{\prime\prime}+z^{\prime}))+z^{\prime\prime}+z^{\prime}.
$$
$$
z^{\prime\prime\prime}=\operatorname{Feed-Forward}(\operatorname{LayerNorm}(z^{\prime\prime}+z^{\prime}))+z^{\prime\prime}+z^{\prime}.
$$
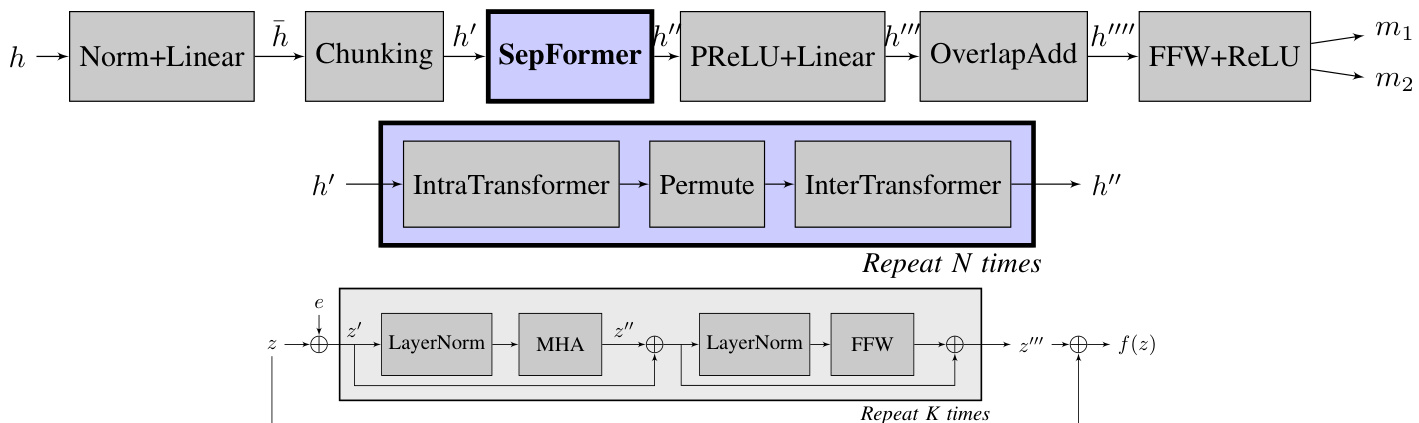
Fig. 3. (Top) The overall architecture proposed for the masking network. (Middle) The SepFormer Block. (Bottom) The transformer architecture $f(.)$ that is used both in the Intra Transformer block and in the Inter Transformer block.
图 3: (上) 提出的掩码网络整体架构。(中) SepFormer模块。(下) 同时用于Intra Transformer模块和Inter Transformer模块的Transformer架构 $f(.)$。
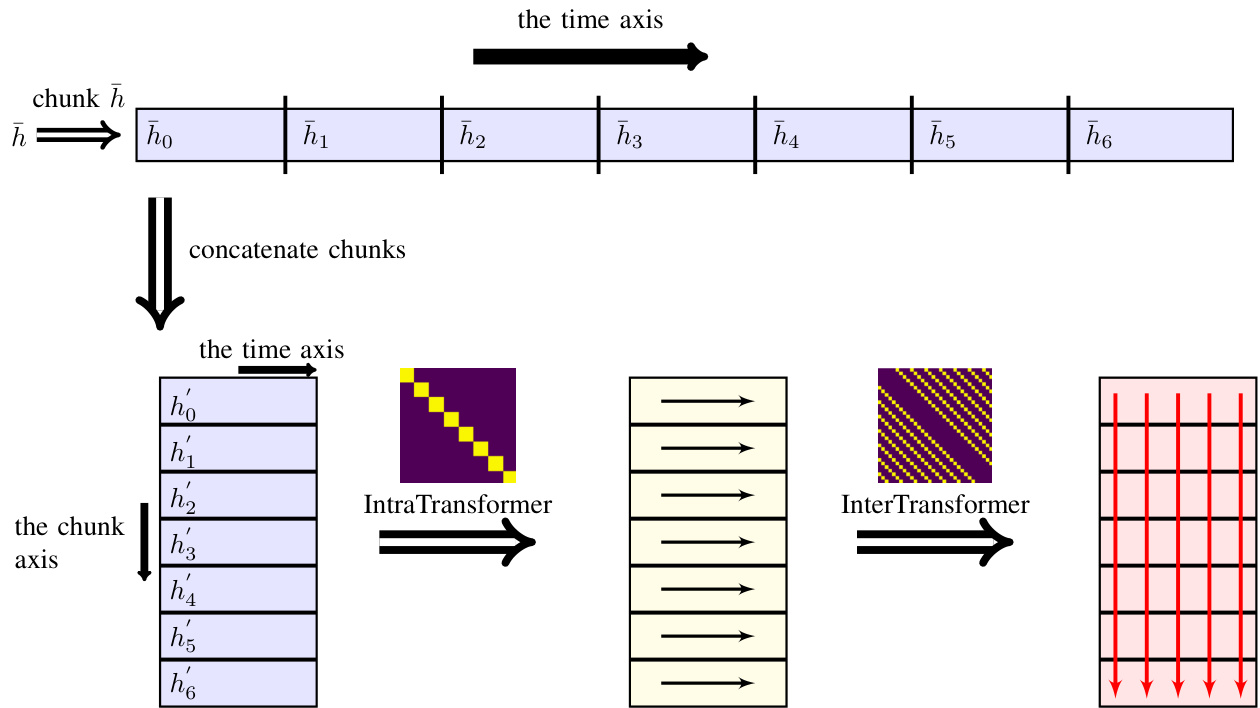
Fig. 4. The dual-path processing employed in the SepFormer masking network. The input representation $\bar{h}$ is first of all chunked to get the chunks $\bar{h}{0}$ , $\bar{h}{1}$ , $\therefore,\bar{h}_{6}$ . Then the chunks are concatenated on another dimension (chunk dimension). Afterward, we apply the Intra Transformer along the time dimension of each chunk and the Inter Transformer along the chunk dimension. As mentioned in IV-C, for graphical convenience, non-overlapping chunks are used in the figure. However, for the experiments in this paper, we used chunks with $50%$ overlap. The attention maps show how elements of the input feature vectors are interconnected sequentially inside the Intra and Inter blocks.
图 4: SepFormer掩码网络采用的双路径处理流程。输入表征$\bar{h}$首先被分块处理,得到分块序列$\bar{h}{0}$、$\bar{h}{1}$、$\therefore,\bar{h}_{6}$。随后这些分块在另一个维度(分块维度)上进行拼接。接着,我们沿每个分块的时间维度应用Intra Transformer,并沿分块维度应用Inter Transformer。如第IV-C节所述,为图示清晰,图中使用了非重叠分块。但本文实验实际采用$50%$重叠的分块方案。注意力图谱展示了输入特征向量元素在Intra和Inter模块内部的序列化关联方式。
The overall transformer block is therefore defined as follows:
整体 Transformer 模块定义如下:
$$
f(z)=g^{K}(z+e)+z,
$$
$$
f(z)=g^{K}(z+e)+z,
$$
where $g^{K}(.)$ denotes $K$ layers of transformer layer $g(.)$ . We use $K=N_{\mathrm{{intra}}}$ layers for the IntraT, and $K=N_{\mathrm{{inter}}}$ layers for the InterT. As shown in Figure 3 (Bottom) and Eq. (13), we add residual connections across the transformer layers and across the transformer architecture to improve gradient back propagation. We would like to note that, in the experiments presented in this paper, a non-causal attention mechanism was utilized.
其中 $g^{K}(.)$ 表示 $K$ 层 Transformer 层 $g(.)$。我们使用 $K=N_{\mathrm{{intra}}}$ 层作为 IntraT,$K=N_{\mathrm{{inter}}}$ 层作为 InterT。如图 3 (底部) 和公式 (13) 所示,我们在 Transformer 层之间以及 Transformer 架构中添加了残差连接以改善梯度反向传播。需要说明的是,本文实验中采用了非因果注意力机制。
V. EXPERIMENTAL SETUP
V. 实验设置
A. Datasets
A. 数据集
In our experiments, we use the popular WSJ0-2mix and WSJ0-3mix datasets [19], where mixtures of two speakers and three speakers are created by randomly mixing utterances in the WSJ0 corpus. The relative levels for the sources are sampled uniformly between 0 dB to 5 dB. Respectively, 30, 10, and 5 hours of speech are used for training (20k utterances), validation $\mathrm{5k}$ utterances), and testing $3\mathrm{k}$ utterances). The training and test sets are created with different sets of speakers. We use the 8kHz version of the dataset, with the ‘min’ version where the added waveforms are clipped to the shorter signal’s length. These datasets have become the de-facto standard benchmark for source separation algorithms.
在我们的实验中,使用了流行的WSJ0-2mix和WSJ0-3mix数据集[19],其中通过随机混合WSJ0语料库中的话语创建了两人和三人混合语音。源信号的相对电平在0 dB至5 dB之间均匀采样。训练集(20k条话语)、验证集($\mathrm{5k}$条话语)和测试集($3\mathrm{k}$条话语)分别使用了30小时、10小时和5小时的语音数据。训练集和测试集由不同的说话人组成。我们使用8kHz版本的"min"数据集,其中添加的波形被截断为较短信号的长度。这些数据集已成为源分离算法的事实标准基准。
In addition to the WSJ0-2/3 Mix we also provide experimental evidence on WHAM! [16], and WHAMR! datasets [17] which are essentially derived from the WSJ0-2Mix dataset by adding environmental noise and environmental noise plus reverberation respectively. In WHAM! and WHAMR! datasets the environmental noises contain ambient noise from coffee shops, restaurants, and bars, which is collected by the authors of the original paper [16]. In WHAMR! the reverberation time RT60 is randomly uniformly sampled from three categories– low, medium, and high, which respectively have the distributions $\mathcal{U}(0.1,0.3)$ , $\mathcal{U}(0.2,0.4)$ , $\mathcal{U}(0.4,1.0)$ . More details regarding the $R T_{60}$ distribution of the WHAMR! dataset is given in the original paper [17].
除了WSJ0-2/3 Mix数据集外,我们还提供了在WHAM! [16]和WHAMR!数据集[17]上的实验证据。这两个数据集本质上是通过分别在WSJ0-2Mix数据集上添加环境噪声(环境噪声加混响)衍生而来。WHAM!和WHAMR!数据集中的环境噪声包含咖啡馆、餐厅和酒吧的 ambient noise(环境噪声),这些噪声由原论文作者[16]采集。在WHAMR!数据集中,混响时间RT60从低、中、高三类中随机均匀采样,其分布分别为$\mathcal{U}(0.1,0.3)$、$\mathcal{U}(0.2,0.4)$和$\mathcal{U}(0.4,1.0)$。关于WHAMR!数据集$R T_{60}$分布的更多细节详见原论文[17]。
The popular speech enhancement VoiceBank-DEMAND dataset [37] is also used to compare the SepFormer architecture with other state-of-the-art denoising models. We also provide experimental results on the LibriMix dataset [15], which contains longer and more challenging mixtures than the WSJ0-Mix dataset.
流行的语音增强 VoiceBank-DEMAND 数据集 [37] 也被用于比较 SepFormer 架构与其他最先进的降噪模型。我们还提供了 LibriMix 数据集 [15] 上的实验结果,该数据集包含比 WSJ0-Mix 数据集更长且更具挑战性的混合音频。
B. Architecture Details
B. 架构细节
The SepFormer encoder employs 256 convolutional filters with a kernel size of 16 samples and a stride factor of 8. The decoder uses the same kernel size and the stride factors of the encoder.
SepFormer编码器采用256个卷积滤波器,卷积核大小为16个样本,步长因子为8。解码器使用相同的卷积核大小和编码器的步长因子。
In our best models, the masking network processes chunks of size $C~=~250$ with a $50%$ overlap between them and employs 8 layers of Transformer encoder in both IntraTransformer and Inter Transformer. The dual-path processing pipeline is repeated $N=2$ times. We used 8 parallel attention heads and 1024-dimensional positional feed-forward networks within each Transformer layer. The model has a total of 25.7 million parameters.
在我们最佳模型中,掩码网络处理大小为 $C~=~250$ 的数据块,块间重叠率为 $50%$,并在IntraTransformer和Inter Transformer中均采用8层Transformer编码器。这种双路径处理流程重复 $N=2$ 次。每个Transformer层使用8个并行注意力头和1024维位置前馈网络。该模型总参数量为2570万。
C. Training Details
C. 训练细节
We use dynamic mixing (DM) data augmentation [26], which consists of an on-the-fly creation of new mixtures from single speaker sources. In this work, we expanded this powerful technique by applying speed perturbation before mixing the sources. The speed randomly changes between 95 $%$ slow-down and $105%$ speed-up.
我们采用动态混音 (dynamic mixing, DM) 数据增强技术 [26],该方法通过实时混合单说话人音源生成新混合物。本研究在混音前引入速度扰动对该技术进行扩展,速度随机变化范围为降速95%至加速105%。
We use the Adam algorithm [38] as an optimizer, with a learning rate of $1.5e^{-4}$ . After epoch 65 (after epoch 85 with DM), the learning rate is annealed by halving it if we do not observe any improvement of the validation performance for 3 successive epochs (5 epochs for DM). Gradient clipping is employed to limit the $l^{2}$ -norm of the gradients to 5. During training, we used a batch size of 1, and used the scaleinvariant signal-to-noise ratio (SI-SNR) [39] via utterancelevel permutation invariant loss [22], with clipping at $30\mathrm{dB}$ [26]. The SI-SNR measures the energy of the signal over the energy of the noise by using a zero mean signal estimate and the ground truth signal. We also use SDR (Signal to Distortion Ratio) which measures the energy of the signal over the energy of the noise, artifacts, and interference, as defined in [40]. In our tables, we report SI-SNRi, and SDRi values that denote the SI-SNR and SDR improvement values from the baseline results obtained when SI-SNR and SDR are computed with the mixture as the source estimate.
我们采用Adam算法[38]作为优化器,学习率为$1.5e^{-4}$。在第65个epoch后(使用DM时为第85个epoch后),若连续3个epoch(DM为5个epoch)未观察到验证性能提升,则将学习率减半。采用梯度裁剪将梯度的$l^{2}$-范数限制为5。训练时使用批量大小为1,并通过语句级排列不变损失[22]采用尺度不变信噪比(SI-SNR)[39],以$30\mathrm{dB}$[26]为裁剪阈值。SI-SNR通过零均值信号估计和真实信号,衡量信号能量与噪声能量的比值。我们还使用信号失真比(SDR)[40]来度量信号能量与噪声、伪影及干扰能量的比值。在表格中,我们报告SI-SNRi和SDRi值,这些值表示以混合信号作为源估计时,SI-SNR和SDR相对于基线结果的改进量。
We use automatic mixed precision to speed up training. Each model is trained for a maximum of 200 epochs. Each epoch takes approximately 1.5 hours on a single NVIDIA V100 GPU with 32 GB of memory with automatic mixed precision. The training recipes for SepFormer on WSJ0-2/3Mix datasets, Libri2/3Mix datasets, WHAM! and WHAMR! datasets can found in Speech brain 2.
我们使用自动混合精度 (automatic mixed precision) 来加速训练。每个模型最多训练200个周期,在配备32GB内存的NVIDIA V100 GPU上,使用自动混合精度时每个周期约需1.5小时。SepFormer在WSJ0-2/3Mix数据集、Libri2/3Mix数据集、WHAM!和WHAMR!数据集上的训练方案可在Speech brain 2中找到。
TABLE I BEST RESULTS ON THE WSJ0-2MIX DATASET (TEST-SET). DM STANDS FOR DYNAMIC MIXING.
*only SI-SNR and SDR (without improvement) are reported. **our experimentation ***uses speaker-ids as additional info.
表 1: WSJ0-2MIX 数据集(测试集)上的最佳结果 (DM 代表动态混合)
| 模型 | SI-SNRi | SDRi | #参数 | 步长 |
|---|---|---|---|---|
| Tasnet [20] | 10.8 | 11.1 | n.a. | 20 |
| SignPredictionNet[41] | 15.3 | 15.6 | 55.2M | 8 |
| Conv-TasNet [21] | 15.3 | 15.6 | 5.1M | 10 |
| Two-Step CTN[24] | 16.1 | n.a. | 8.6M | 10 |
| MGST[28] | 17.0 | 17.3 | n.a. | n.a. |
| DeepCASA [42] | 17.7 | 18.0 | 12.8M | 1 |
| FurcaNeXt [43] | n.a. | 18.4 | 51.4M | n.a. |
| DualPathRNN[8] | 18.8 | 19.0 | 2.6M | 1 |
| sudo rm -rf [23] | 18.9 | n.a. | 2.6M | 10 |
| VSUNOS[25] | 20.1 | 20.4 | 7.5M | 2 |
| DPTNet* [9] | 20.2 | 20.6 | 2.6M | 1 |
| DPTNet + DM** [9] | 20.6 | 20.8 | 26.2M | 8 |
| DPRNN + DM** [8] | 21.8 | 22.0 | 27.5M | 8 |
| SepFormer-CF+DM** | 21.9 | 22.1 | 38.5M | 8 |
| Wavesplit*** [26] | 21.0 | 21.2 | 29M | 1 |
| Wavesplit*** + DM [26] SepFormer | 22.2 20.4 | 22.3 20.5 | 29M 25.7M | 1 8 |
*仅报告了SI-SNR和SDR(无改进值)
**我们的实验
***使用说话人ID作为附加信息
TABLE II ABLATION OF THE SEPFORMER ON WSJ0-2MIX (VALIDATION SET).
表 2 WSJ0-2MIX 验证集上 SEPFORMER 的消融实验
| SI-SNRi | N | Nintra | Ninter | #Heads | DFF | PosEnc | DM |
|---|---|---|---|---|---|---|---|
| 22.3 | 2 | 8----8 | 8 | 1024 | Yes | Yes | |
| 20.5 | 2 | 8 | 8 | 8 | 1024 | Yes | No |
| 19.9 | 2 | 4 | 4 | 8 | 2048 | Yes | No |
| 19.4 | 2 | 4---4 | 8 | 2048 | No | No | |
| 19.2 | 2 | 4 | 1 | 8 | 2048 | Yes | No |
| 18.3 | 2 | 1 | 4 | 8 | 2048 | Yes | No |
| 19.1 | 2 | 3 | 3 | 8 | 2048 | Yes | No |
| 19.0 | 2 | 3 | 3 | 8 | 2048 | No | No |
VI. RESULTS
VI. 结果
A. Results on WSJ0-2/3 Mix datasets
A. WSJ0-2/3 Mix 数据集上的结果
WSJ0-2/3 Mix datasets are standard benchmarks in the source-separation literature. In Table I, we compare the performance achieved by the proposed SepFormer with the best results reported in the literature on the WSJ0-2mix dataset. The SepFormer achieves an SI-SNR improvement (SI-SNRi) of $22.3\mathrm{dB}$ and a Signal-to-Distortion Ratio [40] (SDRi) improvement of $22.4\mathrm{dB}$ on the test-set with dynamic mixing. When using dynamic mixing, the proposed architecture achieves stateof-the-art performance. The SepFormer outperforms previous systems without dynamic mixing, except for Wavesplit, which leverages speaker identity as additional information.
WSJ0-2/3混合数据集是源分离文献中的标准基准。表1比较了所提出的SepFormer在WSJ0-2mix数据集上取得的性能与文献报道的最佳结果。采用动态混合时,SepFormer在测试集上实现了22.3dB的SI-SNR提升(SI-SNRi)和22.4dB的信号失真比40提升。使用动态混合时,该架构达到了最先进的性能。除利用说话人身份作为额外信息的Wavesplit外,SepFormer在非动态混合条件下均优于先前系统。
In Table II, we also study the effect of various hyperparameters and data augmentations strategies (the reported performance is computed on the validation set). We observe that the number of InterT and IntraT blocks has an important impact on the performance. The best performance is reached with 8 layers for both blocks replicated two times. We also would like to point out that a respectable performance of $19.2\mathrm{dB}$ is obtained even when we use a single-layer transformer for the Inter Transformer. In contrast, when a single layer Transformer is used for Intra Transformer the performance drops to 18.3 dB. This suggests that the Intra Transformer, and thus local processing, has a greater influence on the final performance. It also emerges that positional encoding is helpful (e.g. see lines 3-4, and 7-8 of Table II). A similar outcome has been observed in [44] for speech enhancement. As for the number of attention heads, we observe a slight performance difference between 8 and 16 heads. Finally, as expected, we observed that dynamic mixing improves the performance.
在表 II 中,我们还研究了各种超参数和数据增强策略的影响(报告的性能是在验证集上计算的)。我们观察到 InterT 和 IntraT 块的数量对性能有重要影响。当两个块各使用 8 层并重复两次时,性能达到最佳。我们还想指出,即使 Inter Transformer 使用单层 Transformer,也能获得 19.2dB 的不错性能。相比之下,当 Intra Transformer 使用单层 Transformer 时,性能下降到 18.3 dB。这表明 Intra Transformer(即局部处理)对最终性能的影响更大。此外,位置编码也被证明是有帮助的(例如参见表 II 的第 3-4 行和第 7-8 行)。在语音增强任务中,[44] 也观察到了类似的结果。至于注意力头的数量,我们观察到 8 头和 16 头之间的性能差异较小。最后,正如预期的那样,动态混合提高了性能。
TABLE III BEST RESULTS ON THE WSJ0-3MIX DATASET.
表 III WSJ0-3MIX 数据集上的最佳结果
| 模型 | SI-SNRi | SDRi | 参数量 |
|---|---|---|---|
| Conv-TasNet [21] | 12.7 | 13.1 | 5.1M |
| 2.6M | |||
| DualPathRNN [8] | 14.7 | n.a | |
| VSUNOS [25] Wavesplit [26] | 16.9 17.3 | n.a 17.6 | 7.5M 29M |
| Wavesplit [26] + DM | 17.8 | 18.1 | 29M |
| SepFormer | 17.6 | 17.9 | 26M |
| SepFormer + DM | 19.5 | 19.7 | 26M |
To ascertain that SepFormer has better performance because of architectural choices (and not just because it has more parameters or dynamic mixing), we have compared the SepFormer with DPTNet, DPRNN, and with a SepFormer that utilizes a Conformer [7] block in the Intra Transformer. These three models are trained under the same conditions (with dynamic mixing, and $k e r n e l s i z e=16$ , kernel stride $=8$ as SepFormer). The results of this experiment in terms of SISNR on the test are as follows (shown in Table I) $20.6\mathrm{dB}$ for DPTNet (26.2M parameters), $21.8\mathrm{dB}$ for DPRNN (27.5M parameters), and 21.9 dB for SepFormer with Conformer block as intra block (38.5M parameters) (SepFormer-CF in Table I). We, therefore, observe that the better performance of SepFormer is due to the architectural differences, and not just because it has more parameters or is trained with dynamic mixing.
为了确认SepFormer的优越性能源于架构选择(而非仅因参数量更多或动态混音技术),我们将其与DPTNet、DPRNN以及采用Conformer [7] 模块替代Intra Transformer的SepFormer变体进行对比。这三个模型在相同条件下训练(均采用动态混音技术,卷积核尺寸$kernelsize=16$,步长$=8$,与SepFormer一致)。测试集的SISNR指标结果如下(见表1):DPTNet(2620万参数)为$20.6\mathrm{dB}$,DPRNN(2750万参数)为$21.8\mathrm{dB}$,而采用Conformer模块的SepFormer(3850万参数,表1中标记为SepFormer-CF)达到21.9 dB。由此可证,SepFormer的性能优势主要来自架构差异,而非单纯依赖参数量或动态混音技术。
Table III showcases the best-performing models on the WSJ0-3mix dataset. SepFormer obtains state-of-the-art performance with an SI-SNRi of $19.5\mathrm{dB}$ and an SDRi of $19.7\mathrm{dB}$ . We here used the best architecture found for the WSJ0-2mix dataset in Table II. The only difference is that the decoder has three outputs now. It is worth noting that the SepFormer outperforms all previously proposed systems on this corpus.
表 III 展示了在 WSJ0-3mix 数据集上表现最佳的模型。SepFormer 以 SI-SNRi 为 $19.5\mathrm{dB}$ 和 SDRi 为 $19.7\mathrm{dB}$ 的性能达到了当前最优水平。此处我们采用了表 II 中针对 WSJ0-2mix 数据集找到的最佳架构,唯一区别是解码器现在有三个输出。值得注意的是,SepFormer 在该语料库上的表现优于所有先前提出的系统。
Our results on $\mathrm{WSJ0–2mix}$ and $\mathrm{WSJ0–3mix}$ show that we can achieve state-of-the-art performance in separation with an RNN-free Transformer-based model. The major advantage of SepFormer over RNN-based systems like [8], [9], [25] is the possibility to parallel ize the computations over different time steps. This feature leads to faster training and inference, as described in the following section.
我们在 $\mathrm{WSJ0–2mix}$ 和 $\mathrm{WSJ0–3mix}$ 上的结果表明,基于 Transformer 的无 RNN 模型能实现最先进的分离性能。与 [8]、[9]、[25] 等基于 RNN 的系统相比,SepFormer 的主要优势在于能够并行化不同时间步的计算。如下节所述,这一特性可加速训练和推理过程。
B. Speed and Memory Comparison
B. 速度与内存对比
We now compare the training and inference speed of our model with DPRNN [8] and DPTNet [9]. Figure 5 (left) shows the performance achieved on the validation set in the first 48 hours of training versus the wall-clock time (on the WSJ0-2mix dataset). For a fair comparison, we used the same machine with the same GPU (a single NVIDIA V100-32GB) for all the models. Moreover, all the systems are trained with a batch size of 1 and employ automatic mixed precision. We observe that the SepFormer is faster than DPRNN and DPTNeT. Figure 5 (left), highlights that SepFormer reaches above $17\mathrm{dB}$ levels only after a full day of training, whereas the DPRNN model requires two days of training to achieve the same level of performance.
我们现在将我们的模型与DPRNN [8]和DPTNet [9]的训练和推理速度进行比较。图5 (左) 显示了在WSJ0-2mix数据集上,前48小时训练中验证集上的性能表现与挂钟时间的关系。为了公平比较,我们为所有模型使用了相同的机器和GPU (单个NVIDIA V100-32GB)。此外,所有系统都以批量大小为1进行训练,并采用自动混合精度。我们观察到SepFormer比DPRNN和DPTNeT更快。图5 (左) 突出显示,SepFormer仅需一天训练就能达到17dB以上水平,而DPRNN模型需要两天训练才能达到相同的性能水平。
Figure 5 (middle&right) compares the average computation time (in ms) and the total memory allocation (in GB) during inference when single precision is used. We analyze the speed of our best model for both WSJ0-2Mix and WSJ0-3Mix datasets. We compare our models against DP-RNN, DPTNet, and Wavesplit. All the models run in the same NVIDIA RTX8000-48GB GPU using the PyTorch profiler [45].
图 5 (中&右) 对比了使用单精度时推理过程中的平均计算时间 (单位: 毫秒) 和总内存分配量 (单位: GB)。我们分析了最佳模型在 WSJ0-2Mix 和 WSJ0-3Mix 数据集上的速度,并将我们的模型与 DP-RNN、DPTNet 和 Wavesplit 进行对比。所有模型均使用 PyTorch profiler [45] 在同一块 NVIDIA RTX8000-48GB GPU 上运行。
From this analysis, it emerges that the SepFormer is faster and less memory-demanding than DPTNet, DPRNN, and Wavesplit. We observed the same behavior using the CPU for inference. Such a level of computational efficiency is achieved even though the proposed SepFormer employs more parameters than the other RNN-based methods (see Table I). This is not only due to the superior parallel iz ation capabilities of the proposed model, but also because the best performance is achieved with a stride factor of 8 samples, against a stride of 1 for DPRNN and DPTNet. Increasing the stride of the encoder results in down sampling the input sequence, and therefore the model processes fewer data. In [8], the authors showed that the DPRNN performance degrades significantly when increasing the stride factor. The SepFormer, instead, reaches competitive results even with a relatively large stride, leading to the aforementioned speed and memory advantages. We also compare the required Multiply-Accumulate Operations (MACs) for SepFormer, DPRNN, DPTNet, and Wavesplit in Figure 6. We see that SepFormer, DPRNN, and DPTNet have roughly the same MACs requirements. Despite that, due to the better parallel iz ability of SepFormer, the inference time (forward-pass time) is faster for SepFormer (and less memory demanding). We also observe that Wavesplit has a significantly larger requirement in terms of MACs. We could not obtain MACs for sequences longer than 4 seconds due to out-ofmemory errors for Wavesplit.
通过分析发现,SepFormer在速度和内存占用上均优于DPTNet、DPRNN和Wavesplit。使用CPU进行推理时也观察到相同现象。值得注意的是,尽管SepFormer比其他基于RNN的方法使用了更多参数(见表1),仍能实现如此高的计算效率。这既得益于该模型优异的并行化能力,也因其在8样本步长下就能达到最佳性能(而DPRNN和DPPTNet需要1样本步长)。增大编码器步长会降低输入序列采样率,从而减少模型处理的数据量。文献[8]指出,DPRNN在增大步长时性能显著下降,而SepFormer即使采用较大步长仍能保持竞争力,由此获得前述的速度和内存优势。
图6对比了SepFormer、DPRNN、DPTNet和Wavesplit所需的乘积累加运算量(MACs)。可见SepFormer、DPRNN和DPTNet的MACs需求基本相当,但由于SepFormer具备更好的并行化能力,其推理时间(前向传播时间)更快(且内存需求更低)。值得注意的是,Wavesplit的MACs需求显著更高——因其存在内存溢出问题,我们无法获取超过4秒音频序列的MACs数据。
C. Results on WHAM! and WHAMR! datasets
C. WHAM! 和 WHAMR! 数据集上的结果
WHAM! [16] and WHAMR! [17] datasets are versions of the WSJ0-2Mix dataset with noise and noise+reverberation, respectively. We use the same model configuration as the WSJ0-2/3Mix dataset for WHAM! and WHAMR!. For both datasets, we train the model so that it does source separation and speech enhancement at the same time. With the WHAM! dataset the model learns to denoise while also separating. With WHAMR!, the model jointly learns to denoise and de reverberation in addition to separating. In this case, we augment the mixtures by randomly choosing a room-impulse response from the training set of the WHAMR! dataset.
WHAM! [16] 和 WHAMR! [17] 数据集分别是带有噪声以及噪声加混响的 WSJ0-2Mix 数据集版本。对于 WHAM! 和 WHAMR!,我们采用与 WSJ0-2/3Mix 数据集相同的模型配置。针对这两个数据集,我们训练模型使其同时进行源分离和语音增强。使用 WHAM! 数据集时,模型学习在分离的同时进行去噪;而使用 WHAMR! 时,模型除了分离外还联合学习去噪和去混响。在此情况下,我们通过从 WHAMR! 数据集的训练集中随机选择房间脉冲响应来增强混合音频。

Fig. 5. (Left) The training curves of SepFormer, DPRNN, and DPTNeT on the WSJ0-2mix dataset. (Middle & Right) The comparison of forward-pass speed and memory usage in the GPU on inputs ranging 1-5 seconds long sampled at 8kHz.
图 5: (左) SepFormer、DPRNN和DPTNeT在WSJ0-2mix数据集上的训练曲线。(中 & 右) 在8kHz采样率下,对1-5秒长度输入的GPU前向传播速度和内存使用情况比较。

Fig. 6. Comparing the required Multiply Accumulate Operations (MACs) for SepFormer, DPRNN, DPTNet and Wavesplit.
图 6: 比较SepFormer、DPRNN、DPTNet和Wavesplit所需的乘积累加运算(MACs)量。
TABLE IV BEST RESULTS ON THE WHAM DATASET.
表 IV WHAM数据集上的最佳结果
| 模型 | SI-SNRi | SDRi |
|---|---|---|
| Conv-TasNet | 12.7 | |
| Learnablefbank | 12.9 | - |
| MGST [28] | 13.1 | |
| Wavesplit + DM [26] | 16.0 | 16.5 |
| SepFormer | 14.7 | 15.1 |
| SepFormer + SpeedA. | 16.3 | 16.7 |
| SepFormer + DM | 16.4 | 16.7 |
In Tables IV, V, we provide results with SepFormer on the WHAM! and WHAMR! datasets compared to the other methods in the literature. We observe that on both WHAM! and WHAMR! datasets SepFormer outperforms the previously proposed methods even without using DM, which further improves the performance.
在表 IV、表 V 中,我们展示了 SepFormer 在 WHAM! 和 WHAMR! 数据集上与其他文献方法的对比结果。我们观察到,即使不使用 DM (Deep Module),SepFormer 在这两个数据集上的表现仍优于先前提出的方法,而 DM 的引入进一步提升了性能。
D. Results on Libri-2/3Mix datasets
D. Libri-2/3Mix数据集结果
LibriMix [15] is proposed as an alternative to WSJ0-2/3Mix with more diverse and longer utterances. Table VI shows results achieved with the Libri-2/3Mix datasets (both for cleaning any noisy versions). We use here the same model configuration found on WSJ0-2mix in Table II. Similar to the WHAM! dataset, for Libri-2/3 Mix datasets the network is trained to separate and denoise at the same time. We train the models on the train-360 set, both with and without dynamic mixing. In addition to providing the performance of the models trained on LibriMix, we also report the performance of the model pre-trained on the WSJ0-Mix dataset. One common criticism of the WSJ0-Mix is that the models trained on it do not generalize well to other tasks. Here, we showcase that SepFormer can obtain respectable performance on Libri 2/3 Mix clean versions even when trained on WSJ0-2/3Mix, surpassing the performance of a Conv-TasNet model trained on LibriMix as shown in row SepFormer PT of Table VI. We also report the performance obtained with a model pretrained on WHAM! dataset.
LibriMix [15] 被提出作为WSJ0-2/3Mix的替代方案,具有更多样化和更长的语音片段。表 VI 展示了在Libri-2/3Mix数据集上取得的结果(包括干净和含噪版本)。此处我们采用与表 II 中WSJ0-2mix相同的模型配置。与WHAM!数据集类似,针对Libri-2/3Mix数据集,网络被训练同时进行语音分离和降噪。我们在train-360集合上训练模型,分别采用动态混合和静态混合两种方式。除了提供在LibriMix上训练模型的性能外,我们还报告了在WSJ0-Mix数据集上预训练模型的性能。对WSJ0-Mix的一个常见批评是,基于它训练的模型难以泛化到其他任务。本文证明,即使仅在WSJ0-2/3Mix上训练,SepFormer仍能在Libri 2/3Mix干净版本上取得可观性能(如表 VI 中SepFormer PT行所示),超越了在LibriMix上训练的Conv-TasNet模型。我们还报告了在WHAM!数据集上预训练模型的性能表现。
TABLE V BEST RESULTS ON THE WHAMR DATASET.
表 5: WHAMR数据集上的最佳结果
| 模型 | SI-SNRi | SDRi |
|---|---|---|
| Conv-TasNet | 8.3 | |
| BiLSTM Tasnet | 9.2 | |
| Wavesplit + DM 1[26] | 13.2 | 12.2 |
| SepFormer | 11.4 | 10.4 |
| SepFormer + SpeedA. | 13.7 | 12.7 |
| SepFormer + DM | 14.0 | 13.0 |

Fig. 7. Comparison of memory usage and forward-pass time on the SepFormer architecture with several different self-attention types.
图 7: SepFormer架构中几种不同自注意力(self-attention)类型的内存占用和前向传播时间对比。
When trained directly on Libri2/3-Mix with dynamic mixing, SepFormer obtains the state-of-the-art performance as shown in row SepFormer $\mathbf{\Delta}+\mathbf{DM}$ of Table VI. We also show the case where we fine-tune a pretrained SepFormer model on LibriMix in the row SepFormer $^+$ DM PT+FT of Table VI.
当直接在Libri2/3-Mix数据集上采用动态混合(dynamic mixing)训练时,SepFormer获得了表VI中SepFormer $\mathbf{\Delta}+\mathbf{DM}$ 行所示的最先进性能。我们还在表VI的SepFormer $^+$ DM PT+FT行展示了在LibriMix上微调预训练SepFormer模型的情况。
TABLE VI RESULTS ON LIBRI2MIX AND LIBRI3MIX DATASETS. SEPFORMER $^+$ PT INDICATES PRE TRAINING ON WSJ0-2/3 MIX OR WHAM! DATASET ACCORDING TO THE CASE. SEPFORMER $^+$ DM $\mathrm{PT}{+}\mathrm{FT}$ IS THE CASE WHERE THE PRETRAINED SEPFORMER MODEL IS FINE-TUNED ON LIBRIMIX.
表 6 LIBRI2MIX 和 LIBRI3MIX 数据集上的结果。SEPFORMER $^+$ PT 表示根据情况在 WSJ0-2/3 MIX 或 WHAM! 数据集上进行预训练。SEPFORMER $^+$ DM $\mathrm{PT}{+}\mathrm{FT}$ 表示预训练的 SEPFORMER 模型在 LIBRIMIX 上进行微调的情况。
| Libri2Mix-Clean | Libri2Mix-Noisy | Libri3Mix-Clean | Libri3Mix-Noisy | |
|---|---|---|---|---|
| Model | SI-SNRi | SDRi | SI-SNRi | SDRi |
| Conv-TasNet | 14.7 | 二 | 12.0 | |
| SepFormer PT | 17.0 | 17.5 | 11.2 | 13.1 |
| Wavesplit[26] | 19.5 | 20.0 | 15.1 | 15.8 |
| Wavesplit + DM [26] | 20.5 | 20.0 | 15.2 | 15.9 |
| SepFormer | 19.2 | 19.4 | 14.9 | 15.4 |
| SepFormer + DM | 20.2 | 20.5 | 15.9 | 16.5 |
| SepFormer + DM PT+FT | 20.6 | 20.8 | 15.9 | 16.5 |
TABLE VII COMPARISON OF DIFFERENT TYPES OF SELF-ATTENTION (WSJ0-2MIX, TEST SET).
表 VII: 不同自注意力类型的对比 (WSJ0-2MIX, 测试集)
| Model | C=250v1 SI-SNRi | C=250v1 SDRi | C=250v2 SI-SNRi | C=250v2 SDRi | C=1000 SI-SNRi | C=1000 SDRi | No Chunking SI-SNRi | No Chunking SDRi |
|---|---|---|---|---|---|---|---|---|
| Longformer | 19.44 | 19.66 | 19.32 | 19.54 | 18.17 | 18.39 | 13.11 | 13.36 |
| Linformer | 2.75 | 3.01 | 6.04 | 6.30 | 4.74 | 5.02 | 6.39 | 6.68 |
| Reformer | 20.09 | 20.28 | 20.34 | 20.52 | 19.42 | 19.61 | 16.66 | 16.86 |
| Transformer (SepFormer) | 21.61 | 21.79 | 21.61 | 21.79 | 21.48 | 21.66 | 12.40 | 12.60 |
E. Ablations on the type of Self-Attention
E. 自注意力 (Self-Attention) 类型的消融实验
Table VII compares the WSJ0-2Mix test set performance of four different architectural choices for Full (regular), LongFormer, Linformer, and Reformer self-attention. We train all models using only speed augment (no dynamic mixing), using 4-second long training segments. The architectural choices in this ablation experiment given in Table VII are summarized as follows:
表 VII 比较了四种不同自注意力架构 (Full (常规)、LongFormer、Linformer 和 Reformer) 在 WSJ0-2Mix 测试集上的性能表现。所有模型仅使用速度增强 (无动态混合) 进行训练,训练片段长度为 4 秒。表 VII 中列出的消融实验架构选择总结如下:
We observe from Table VII that the architectural choices adopted in the original SepFormer paper lead to the best overall performance in terms of SI-SNR and SDR improvement. We also show the memory usage and forward pass time (in CPU using Pytorch profiler [45]) for some of the relevant models in Figure 7. The chunking/dual-path mechanism in the SepFormer architecture reduces the memory footprint significantly compared to the architecture where no chunking is applied. From Figure 7, we also see that using the Longformer or Reformer blocks on the whole sequence without applying chunking is an efficient alternative to dual-path processing. Furthermore from Figure 7, we observe that compared to Conv-TasNet, Reformer without chunking results in almost equivalent memory usage, and faster forward pass time, while yielding slightly better performance, namely 16.7 dB SI-SNRi on the test set of WSJ0-2Mix, compared to 15.3 dB SI-SNRi obtained with Conv-TasNet [21].
从表 VII 中我们观察到,原始 SepFormer 论文采用的架构选择在 SI-SNR 和 SDR 提升方面实现了最佳整体性能。图 7 还展示了部分相关模型的内存使用情况和前向传播时间 (在 CPU 上使用 Pytorch profiler [45])。与未应用分块的架构相比,SepFormer 架构中的分块/双路径机制显著降低了内存占用。从图 7 中还可以看出,在不应用分块的情况下对整个序列使用 Longformer 或 Reformer 模块是双路径处理的有效替代方案。此外,从图 7 中我们观察到,与 Conv-TasNet 相比,未分块的 Reformer 实现了几乎相当的内存使用量和更快的前向传播时间,同时获得了略优的性能,即在 WSJ0-2Mix 测试集上达到 16.7 dB SI-SNRi,而 Conv-TasNet [21] 为 15.3 dB SI-SNRi。
We also observe that full attention is more efficient than using a reformer inside the dual-path pipeline in terms of forwarding pass time and memory usage, and full attention is not significantly more expensive than Longformer in terms of memory. Another observation is the fact that Linformer does not yield competitive performance. We suspect that this stems from the fact that Linformer has a reduced modeling capacity since it projects the time dimension inside the attention mechanism to a lower dimensionality, thereby losing time resolution, which is essential for effective source separation.
我们还观察到,在前向传播时间和内存使用方面,完全注意力机制比在双路径管道中使用reformer更高效,且其内存消耗与Longformer相比并未显著增加。另一个观察结果是Linformer未能展现出有竞争力的性能。我们推测这源于Linformer因在注意力机制中将时间维度投影至更低维度而降低了建模能力,从而丢失了对源分离至关重要的时间分辨率。
To showcase the reduction of computational requirements when using efficient self-attention mechanisms (namely Longformer and Reformer), we report the total MACs (MultiplyAccumulate Operations) for a 4-seconds input sequence in Figure 8. We notice a significant reduction in the required MACs for Longformer and Reformer compared to the full-attention case. In the case where no-chunking is applied, from Table VII we also observe that the performance is significantly better with Reformer compared to the full-attention case. However, another important conclusion to make from this ablation study is that even though the Longformer and Reformer provide a reduction in computational requirements the best performance is obtained in the SepFormer architecture (that is the case where we use full-self attention in Intra and Inter transformer blocks).
为展示使用高效自注意力机制(即 Longformer 和 Reformer)时计算需求的降低,我们在图 8 中报告了 4 秒输入序列的总 MACs (乘加运算) 。我们注意到,与全注意力情况相比,Longformer 和 Reformer 所需的 MACs 显著减少。在未应用分块的情况下,从表 VII 中我们还观察到,Reformer 的性能明显优于全注意力情况。然而,这项消融研究的另一个重要结论是,尽管 Longformer 和 Reformer 降低了计算需求,但最佳性能仍出现在 SepFormer 架构中(即在 Intra 和 Inter transformer 块中使用全自注意力的情况)。

Fig. 8. Multiply-Accumulate Operations for $C=250v1$ , $C=1000$ , and no chunking, obtained on a 4 seconds input signal. Reformer and Longformer provide significant reduction in MACs for the no-chunking option.
图 8: 在4秒输入信号上获得的 $C=250v1$ 、 $C=1000$ 以及无分块情况下的乘加运算量。Reformer和Longformer在无分块选项下显著降低了MACs运算量。
F. Speech Enhancement
F. 语音增强
We trained the SepFormer for speech enhancement on the WHAM! and WHAMR! datasets for noisy and noisyreverb e rant mixtures with one speaker. The obtained enhancement performances in terms of SI-SNR, SDR, and PESQ [46] are presented in Table VIII, and Table IX respectively. Note that in WHAM! dataset the model is trained to denoise and on the WHAMR! dataset the model is trained to both derever be ration and denoising at the same time. The SepFormer models are trained to maximize the output SI-SNR between the estimated and the ground truth signals in the time domain.
我们在WHAM!和WHAMR!数据集上训练了SepFormer模型,用于单说话人场景下的含噪及含噪混响语音增强。表VIII和表IX分别展示了在SI-SNR(信号与干扰噪声比)、SDR(信号与失真比)和PESQ [46]指标上取得的增强性能。需要注意的是,WHAM!数据集训练模型仅进行降噪处理,而WHAMR!数据集则同时训练模型进行去混响和降噪。SepFormer模型通过最大化时域中估计信号与真实信号之间的输出SI-SNR进行优化训练。
In addition to training SepFormer, we also trained a Bidirectional LSTM, CNN Transformer, and 2D-CNN models from Speech brain [18], which are trained to minimize the Euclidean distance of the estimated magnitude spec tr ogram and the spec tr ogram of the clean signals. We observe that SepFormer outperforms these methods by a large margin in terms of SISNR, SDR, and PESQ.
除了训练SepFormer,我们还从Speech brain[18]中训练了一个双向LSTM、CNN Transformer和2D-CNN模型,这些模型的训练目标是最小化估计的幅度谱与干净信号谱之间的欧氏距离。我们观察到,SepFormer在SISNR、SDR和PESQ指标上大幅优于这些方法。
Other than WHAM! and WHAMR! datasets, we have also trained a SepFormer on the Voicebank-DEMAND speech enhancement dataset for denoising. In this case, the SepFormer estimates a mask applied on the magnitude of Short-time Fourier Transform (STFT) representation. This allows a direct comparison with most state-of-the-art VoiceBank-DEMAND models, which also employ a mask on magnitude spectra, and compare directly the architectures. The results are given in Table X. We observe that SepFormer outperforms most of the recent methods, except for the MetricGAN+ [47], and AIAT [48]. Note that MetricGAN+ is optimized specifically on PESQ and, therefore, the performance in terms of the STOI metric is not reported. We note that SepFormer obtains the same performance as AIAT (Magnitude version) in terms of the STOI metric [49]. These speech enhancement experiments, therefore, demonstrate that SepFormer is competitive also with respect to state-of-the-art denoising models.
除了WHAM!和WHAMR!数据集外,我们还使用Voicebank-DEMAND语音增强数据集训练了一个用于降噪的SepFormer。在这种情况下,SepFormer估计一个应用于短时傅里叶变换(STFT)表示幅度的掩码。这使得我们可以与大多数同样采用幅度谱掩码的最先进VoiceBank-DEMAND模型进行直接比较,并直接对比架构差异。结果如表X所示。我们观察到SepFormer优于大多数最新方法,除了MetricGAN+ [47]和AIAT [48]。需要注意的是,MetricGAN+专门针对PESQ进行了优化,因此未报告其在STOI指标上的性能。我们注意到SepFormer在STOI指标[49]上与AIAT(幅度版本)取得了相同性能。这些语音增强实验表明,SepFormer在最先进的降噪模型中也具有竞争力。
VII. CONCLUSION
VII. 结论
In this paper, we studied in-depth Transformers for speech separation. In particular, we built upon our previously proposed SepFormer, an attention-only masking network based on dual-path processing. We extended our previous findings by performing additional experiments on more challenging and realistic datasets, such as LibriMix, WHAM!, WHAMR!. With all these datasets, the SepFormer achieves competitive or state-of-the-art performance. We also analyzed the computational resources needed by popular separation models, and we showed that the SepFormer excels in terms of memory usage and forward-pass time given the state-of-the-art performance. As another contribution, we compared more efficient selfattention mechanisms such as Longformer, Linformer, and Reformer. Our results suggest that Longformer and especially Reformer are suitable for speech separation applications and obtain a highly favorable trade-off between performance and computational requirements. Finally, we adapted the SepFormer to perform speech enhancement and showed competitive performance in this context as well.
本文深入研究了用于语音分离的Transformer。具体而言,我们在先前提出的仅基于注意力掩码的双路径处理网络SepFormer基础上进行了扩展,通过在更具挑战性和真实性的数据集(如LibriMix、WHAM!、WHAMR!)上进行额外实验验证了先前发现。在所有数据集中,SepFormer均取得具有竞争力或最先进的性能表现。我们还分析了主流分离模型所需的计算资源,结果表明在保持最先进性能的同时,SepFormer在内存占用和前向传播时间方面表现优异。作为另一项贡献,我们比较了更高效的自注意力机制(如Longformer、Linformer和Reformer)。实验结果表明,Longformer尤其是Reformer非常适合语音分离应用,在性能和计算需求之间实现了极佳的平衡。最后,我们将SepFormer适配于语音增强任务,同样展现出具有竞争力的性能。
TABLE VIII SPEECH ENHANCEMENT RESULTS ON WHAM! DATASET (DENOISING)
表 8: WHAM! 数据集上的语音增强 (降噪) 结果
| Model | SI-SNR | SDR | PESQ |
|---|---|---|---|
| 2D-CNN | 7.90 | 8.70 | 2.36 |
| 2D-CNN+BLSTM | 7.09 | 7.89 | 2.32 |
| BLSTM | 5.15 | 6.2 | 2.11 |
| CNNTransformer | 8.3 | 8.9 | 2.52 |
| SepFormer | 14.35 | 15.04 | 3.07 |
TABLE IX SPEECH ENHANCEMENT RESULTS ON WHAMR! DATASET (DENOISING $^+$ DE REVERBERATION)
表 IX WHAMR! 数据集上的语音增强结果 (去噪 $^+$ 去混响)
| 模型 | SI-SNR | SDR | PESQ |
|---|---|---|---|
| 2D-CNN | 6.84 | 7.75 | 2.18 |
| 2D-CNN+BLSTM | 5.87 | 6.82 | 2.15 |
| BLSTM | 5.58 | 6.49 | 2.11 |
| CNNTransformer | 7.38 | 8.21 | 2.27 |
| SepFormer | 10.58 | 12.29 | 2.84 |
TABLE X SPEECH ENHANCEMENT RESULTS ON THE VOICEBANK-DEMAND DATASET (DENOISING)
表 X VOICEBANK-DEMAND 数据集语音增强(降噪)结果
| 模型 | PESQ | STOI |
|---|---|---|
| CNNTransformer [18] | 2.65 | 91.5 |
| MetricGAN[50] | 2.86 | |
| CRGAN[51] | 2.92 | 94.0 |
| DeepMMSE[52] | 2.95 | 二 |
| YinPHASEN[53] | 2.99 | 二 |
| MetricGAN+[47] | 3.15 | - |
| AIAT (Magnitude)[48] | 3.11 | 94.9 |
| SepFormer | 3.03 | 94.9 |
REFERENCES
参考文献

Cem Subakan is an Assistant Professor at Universite Laval in the Computer Science and Software Engineering department. He is also currently an Affiliate Assistant Professor in the Concordia University Computer Science and Software Engineering Department, and an invited researcher at
Cem Subakan 是拉瓦尔大学 (Universite Laval) 计算机科学与软件工程系的助理教授。他目前还兼任康考迪亚大学 (Concordia University) 计算机科学与软件工程系的客座助理教授,并担任......
Mila-Quebec AI Institue. He received his PhD in Computer Science from University of Illinois at Urbana-Champaign (UIUC), and did a postdoc in Mila Quebec AI Institute and Université de Sherbrooke.He serves as reviewer in several conferences including NeurIPS, ICML, ICLR, ICASSP, MLSP and journals such as IEEE Signal Processing Letters (SPL), IEEE Transactions on Audio, Speech, and Language Processing (TASL). His research interests include Deep learning for Source Separation and Speech Enhancement under realistic conditions, Neural Network Interpret ability, and Latent Variable Modeling. He is a recipient of best paper award in the 2017 version IEEE Machine Learning for Signal Processing Conference (MLSP), as well as the Sabura Muroga Fellowship from the UIUC CS department. He’s a core contributor to the Speech Brain project, leading the speech separation part.
Mila-Quebec AI Institue。他获得了伊利诺伊大学厄巴纳-香槟分校 (UIUC) 的计算机科学博士学位,并在Mila Quebec AI Institute和舍布鲁克大学从事博士后研究。他担任多个会议(包括NeurIPS、ICML、ICLR、ICASSP、MLSP)及期刊(如IEEE Signal Processing Letters (SPL)、IEEE Transactions on Audio, Speech, and Language Processing (TASL))的审稿人。他的研究兴趣包括现实条件下的深度学习用于源分离和语音增强、神经网络可解释性以及潜变量建模。他是2017年IEEE机器学习信号处理会议 (MLSP) 最佳论文奖得主,并获得了UIUC计算机科学系的Sabura Muroga奖学金。他是Speech Brain项目的核心贡献者,负责领导语音分离部分的工作。

Mirco Ravanelli is an assistant professor at Concordia University, an adjunct professor at Université de Montréal, and Mila associate member. His main research interests are deep learning and Conversational AI. He is the author or co-author of more than 60 papers on these research topics.
Mirco Ravanelli是康考迪亚大学助理教授、蒙特利尔大学兼职教授及Mila附属成员,主要研究方向为深度学习与对话式AI (Conversational AI)。他在相关领域发表论文60余篇。
He received his Ph.D. (with cum laude distinction) from the University of Trento in December 2017. Mirco is an active member of the speech and machine learning communities. He is the founder and leader of the Speech Brain project which aim to build an open-source toolkit for conversational AI and speech processing.
他于2017年12月以优等成绩获得特伦托大学博士学位。Mirco是语音和机器学习社区的活跃成员,同时也是Speech Brain项目的创始人和领导者,该项目旨在构建一个用于对话式AI (Conversational AI) 和语音处理的开源工具包。
Samuele Cornell received a Master degree in Electronic Engineering at Universita Polite c nica delle Marche (UnivPM) in 2019. He is currently a doctoral candidate at UnivPM Department of Information Engineering. His current research interests are in the area of front-end preprocessing techniques for Automatic Speech Recognition applications such as: Source Separation, Speech Enhancement, Speech Segmentation and Beam forming.
Samuele Cornell于2019年在马尔凯理工大学(UnivPM)获得电子工程硕士学位,现为该校信息工程系博士研究生。目前研究方向聚焦自动语音识别(ASR)的前端预处理技术,包括:源分离(Speech Separation)、语音增强(Speech Enhancement)、语音分割(Speech Segmentation)和波束成形(Beamforming)。


Francois Grondin received the B.Sc. degree in electrical engineering from McGill University, Montreal, QC, Canada, in 2009, and the M.Sc. and Ph.D. degrees in electrical engineering from the Université de Sherbrooke, Sherbrooke, QC, Canada, in 2011 and 2017, respectively. After completing postdoctoral work with the Computer
Francois Grondin于2009年在加拿大魁北克省蒙特利尔的麦吉尔大学获得电气工程学士学位,并于2011年和2017年分别在加拿大魁北克省舍布鲁克的舍布鲁克大学获得电气工程硕士和博士学位。在完成计算机领域的博士后工作后
Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, MA, USA, in 2019, he became a Faculty Member with the Department of Electrical Engineering and Computer Engineering, Université de Sherbrooke. He is a member of the Ordre des ingenieurs du Québec. His research interests include robot audition, sound source localization, speech enhancement, sound classification, and machine learning.
科学与人工智能实验室,麻省理工学院,剑桥,美国马萨诸塞州,2019年成为舍布鲁克大学电气工程与计算机工程系教员。他是魁北克工程师协会成员,研究方向包括机器人听觉、声源定位、语音增强、声音分类及机器学习。

Mirko Bronzi is an Senior Applied Research Scientist at Mila-Quebec AI Institute. He completed his Ph.D. in Rome (University of Roma Tre) working on techniques for extracting and integrating information from different web sources, in an automatic way. During his career he worked on NLU systems for virtual assistants for cars, on CLU (clinical language understanding), as well as in other domains of machine learning. His research interests are in the NLP area and in the audio domain for machine learning. He is also interested in computer vision, and in the intersection of Engineering and machine learning.
Mirko Bronzi是Mila-Quebec人工智能研究所的高级应用研究科学家。他在罗马(罗马第三大学)完成了博士学位,致力于以自动化方式从不同网络来源提取和整合信息的技术研究。职业生涯中,他从事过汽车虚拟助手的自然语言理解(NLU)系统开发、临床语言理解(CLU)以及机器学习其他领域的工作。其研究兴趣集中于自然语言处理(NLP)领域及机器学习中的音频技术,同时对计算机视觉以及工程与机器学习的交叉领域也有涉猎。