Boots trapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
通过松弛共同命运与视觉分组从视频中自举提取物体性
Abstract
摘要
We study learning object segmentation from unlabeled videos. Humans can easily segment moving objects without knowing what they are. The Gestalt law of common fate, i.e., what move at the same speed belong together, has inspired unsupervised object discovery based on motion segmentation. However, common fate is not a reliable indicator of objectness: Parts of an articulated / deformable object may not move at the same speed, whereas shadows / reflections of an object always move with it but are not part of it.
我们研究从无标签视频中学习物体分割。人类无需知道物体是什么就能轻松分割运动物体。基于共同命运 (common fate) 的格式塔定律——即以相同速度运动的物体属于同一整体——启发了基于运动分割的无监督物体发现方法。但共同命运并非物体性的可靠指标:铰接/可变形物体的部件可能不以相同速度运动,而物体的阴影/反射虽始终随之移动却不属于物体本身。
Our insight is to bootstrap objectness by first learning image features from relaxed common fate and then refining them based on visual appearance grouping within the image itself and across images statistically. Specifically, we learn an image segmenter first in the loop of approximating optical flow with constant segment flow plus small withinsegment residual flow, and then by refining it for more coherent appearance and statistical figure-ground relevance.
我们的核心思路是通过分阶段学习来引导物体感知能力:首先从宽松的共命运关系中学习图像特征,然后基于图像内部及跨图像统计的视觉外观分组进行细化。具体而言,我们首先在光学流近似循环中训练图像分割器(使用恒定分割流加分割内残差流),随后通过优化外观一致性和统计层面的图形-背景关联性来精炼分割效果。
On unsupervised video object segmentation, using only ResNet and convolutional heads, our model surpasses the state-of-the-art by absolute gains of $7/9/5%$ on DAVIS16 / STv2 / FBMS59 respectively, demonstrating the effectiveness of our ideas. Our code is publicly available.
在无监督视频目标分割任务中,仅使用ResNet和卷积头结构,我们的模型在DAVIS16/STv2/FBMS59数据集上分别以7%/9%/5%的绝对优势超越现有最佳方法,验证了方案的有效性。代码已开源。
1. Introduction
1. 引言
Object segmentation from videos is useful to many vision and robotics tasks [1, 20, 31, 33]. However, most methods rely on pixel-wise human annotations [4,5,14,21,24,26, 27, 30, 34, 36, 50, 51], limiting their practical applications.
从视频中进行物体分割对许多视觉和机器人任务非常有用 [1, 20, 31, 33]。然而,大多数方法依赖于像素级人工标注 [4,5,14,21,24,26,27,30,34,36,50,51],这限制了它们的实际应用。
We focus on learning object segmentation from entirely unlabeled videos (Fig. 1). The Gestalt law of common fate, i.e., what move at the same speed belong together, has inspired a large body of unsupervised object discovery based on motion segmentation [6, 19, 23, 29, 44, 47, 49].
我们专注于从完全未标注的视频中学习物体分割(图1)。共同命运格式塔法则(即相同速度运动的物体属于同一整体)启发了大量基于运动分割的无监督物体发现研究[6,19,23,29,44,47,49]。
There are three main types of unsupervised video object segmentation (UVOS) methods. 1) Motion segmentation methods [19,29,44,47] use motion signals from a pretrained optical flow estimator to segment an image into foreground objects and background (Fig. 1). OCLR [44] achieves stateof-the-art performance by first synthesizing a dataset with arbitrary objects moving and then training a motion segmentation model with known object masks. 2) Motionguided image segmentation methods such as GWM [6] use motion segmentation loss to guide appearance-based segmentation. Motion between video frames is only required during training, not during testing. 3) Joint appearance segmentation and motion estimation methods such as AMD [23] learn motion and segmentation simultaneously in a self-supervised fashion by reconstructing the next frame based on how segments of the current frame move.
无监督视频目标分割(UVOS)方法主要有三种类型。1) 运动分割方法[19,29,44,47]使用预训练光流估计器获取的运动信号,将图像分割为前景目标和背景(图1)。OCLR[44]通过首先生成包含任意运动物体的合成数据集,然后使用已知物体掩码训练运动分割模型,实现了最先进的性能。2) 运动引导的图像分割方法(如GWM[6])利用运动分割损失来指导基于外观的分割。这类方法仅在训练时需要视频帧间的运动信息,测试时则不需要。3) 联合外观分割与运动估计方法(如AMD[23])通过基于当前帧分割区域的运动来重建下一帧,以自监督的方式同时学习运动和分割。
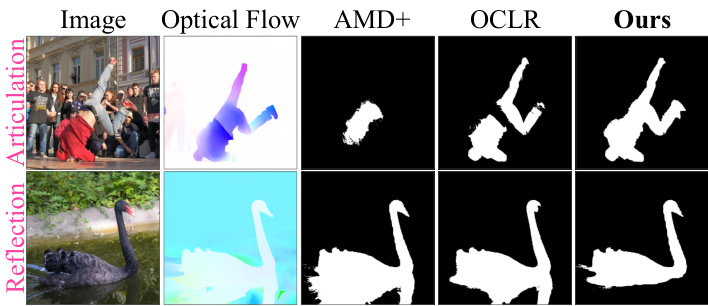
Figure 1. We study how to discover objectness from unlabeled videos based on common motion and appearance. AMD [23] and OCLR [44] rely on common fate, i.e., what move at the same speed belong together, which is not always a reliable indicator of objectness. Top: Articulation of a human body means that object parts may not move at the same speed; common fate thus leads to partial objectness. Bottom: Reflection of a swan in water always moves with it but is not part of it; common fate thus leads to excessive objectness. Our method discovers full objectness by relaxed common fate and visual grouping. $\mathrm{AMD+}$ refers to AMD with RAFT flows as motion supervision for fair comparison.
图 1: 我们研究如何基于共运动与外观从无标注视频中发现物体性。AMD [23] 和 OCLR [44] 依赖共命运原则 (即相同速度运动的物体属于同一整体) ,但这并非总是可靠的物体性指标。上:人体关节运动意味着物体部件可能不以相同速度移动,共命运原则导致部分物体性识别。下:水中天鹅倒影始终与其同步移动却不属于其本体,共命运原则导致过度物体性识别。我们的方法通过松弛共命运原则与视觉分组实现完整物体性发现。$\mathrm{AMD+}$ 表示采用 RAFT 光流作为运动监督的 AMD 方法 (公平对比基准) 。
However, while common fate is effective at binding parts of heterogeneous appearances into one whole moving object, it is not a reliable indicator of objectness (Fig. 1).
然而,尽管共同命运能有效将异质外观的部分绑定成一个整体运动对象,但它并非物体性的可靠指标 (图 1)。
- Articulation: Parts of an articulated or deformable object may not move at the same speed; common fate thus leads to partial objectness containing the major moving part only. In Fig.1 top, AMD $^+$ discovers only the middle torso of the street dancer since it moves the most, whereas OCLR misses the exposed belly which is very different from the red hoodie and the gray jogger.
- 关节运动:可关节化或可变形物体的各部分可能不会以相同速度移动;因此共同命运仅导致包含主要移动部位的部分物体性。在图1顶部,AMD$^+$仅发现街舞者的中间躯干,因为该部位移动最多,而OCLR则漏掉了与红色连帽衫和灰色慢跑裤差异极大的裸露腹部。
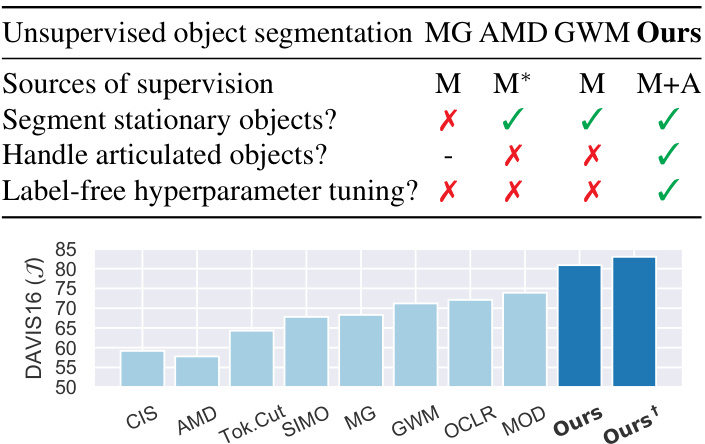
Figure 2. Advantages over leading unsupervised object segmentation methods MG [47]/AMD [23]/GWM [6]: 1) With motion supervision instead of motion input, we can segment stationary objects. 2) With both motion (M) and appearance (A) as supervision, we can discover full objectness from noisy motion cues. $\mathbf{M}^{*}$ refers to implicit motion via image warping. 3) By modeling relative motion within an object, we can handle articulated objects. 4) By comparing motion-based segmentation with appearance-based segmentation, we can tune hyper parameters without labels. Our performance gain is substantial, more with post-processing (†).
图 2: 相较于主流无监督物体分割方法MG [47]/AMD [23]/GWM [6]的优势:1) 采用运动监督而非运动输入,可分割静止物体。2) 同时以运动(M)和外观(A)作为监督,能从噪声运动线索中发现完整物体性。$\mathbf{M}^{*}$表示通过图像扭曲的隐式运动。3) 通过建模物体内部相对运动,可处理铰接物体。4) 通过对比基于运动的分割与基于外观的分割,可在无标签情况下调整超参数。我们的性能提升显著,经后处理(†)后效果更佳。
- Reflection: Shadows or reflections of an object always move with the object but are not part of the object; common fate thus leads to excessive objectness that covers more than the object. In Fig.1 bottom, $\mathrm{AMD+}$ or OCLR cannot separate the swan from its reflection in water.
- 反射:物体的阴影或反射总是随物体移动,但不属于物体本身;因此共同命运会导致过度的物体性,覆盖范围超出物体本身。在图1底部,$\mathrm{AMD+}$ 或 OCLR 无法将天鹅与其在水中的倒影分离。
We have two insights to bootstrap full objectness from common fate in unlabeled videos. 1) To detect an articulated object, we allow various parts of the same object to assume different speeds that deviate slightly from the object’s overall speed. 2) To detect an object from its reflections, we rely on visual appearance grouping within the image itself and statistical figure-ground relevance. For example, swans tend to have distinctive appearances from the water around them, and reflections may be absent in some swan images.
我们从无标签视频的共运现象中得出两个实现完整物体性检测的洞见:1) 为检测铰接物体,允许同一物体的不同部位以略微偏离整体运动速度的多变速度运动;2) 为通过反光检测物体,需结合图像内部的视觉外观分组与统计层面的图形-背景相关性。例如天鹅通常与周围水体形成鲜明外观差异,且部分天鹅图像中可能不存在倒影。
Specifically, we learn unsupervised object segmentation in two stages: Stage 1 learns to discover objects from motion supervision with relaxed common fate, whereas Stage 2 refines the segmentation model based on image appearance.
具体来说,我们通过两个阶段学习无监督物体分割:第一阶段通过宽松共命运 (common fate) 的运动监督学习发现物体,第二阶段基于图像外观优化分割模型。
At Stage 1, we discover objectness by computing the optical flow and learning an image segmenter in the loop of approximating the optical flow with constant segment flow plus small within-segment residual flow, relaxing common fate from the strict same-speed assumption. At Stage 2, we refine our model by image appearance based on low-level visual coherence within the image itself and usual figureground distinction learned statistically across images.
在第1阶段,我们通过计算光流并在近似光流的循环中学习图像分割器(用恒定分段流加分段内残差流来近似光流),从而发现物体性,这放宽了"共同命运"对严格同速假设的要求。在第2阶段,我们基于图像本身的低层视觉连贯性以及跨图像统计学习的常规图形-背景区分,通过图像外观来精炼模型。
Existing UVOS methods have hyper parameters that significantly impact the quality of segmentation. For example, the number of segmentation channels is a critical parameter for AMD [23], and it is usually chosen according to an annotated validation set in the downstream task, defeating the claim of unsupervised objectness discovery.
现有的UVOS方法存在显著影响分割质量的关键超参数。例如,分割通道数量是AMD [23] 的核心参数,通常需根据下游任务中的标注验证集进行选择,这违背了无监督目标发现的初衷。
We propose unsupervised hyper parameter tuning that does not require any annotations. We examine how well our motion-based segmentation aligns with appearance-based affinity on DINO [2] features self-supervised ly learned on ImageNet [35], which is known to capture semantic objectness. Our idea is also model-agnostic and applicable to other UVOS methods.
我们提出了一种无需任何标注的无监督超参数调优方法。通过研究基于运动的分割与在ImageNet [35]上自监督学习的DINO [2]特征所呈现的表观亲和性之间的对齐程度(已知该特征能捕捉语义对象性),我们的方法还具有模型无关性,可适用于其他无监督视频目标分割(UVOS)方法。
Built on the novel concept of Relaxed Common Fate (RCF), our method has several advantages over leading UVOS methods (Fig. 2): It is the only one that uses both motion and appearance to supervise learning; it can segment stationary and articulated objects in single images, and it can tune hyper parameters without external annotations.
基于创新的松弛共同命运 (RCF) 概念,我们的方法相比主流无监督视频目标分割 (UVOS) 方法具有多项优势 (图 2):这是唯一同时利用运动与外观信息监督学习的方法;能够在单幅图像中分割静止和铰接物体,且无需外部标注即可调整超参数。
On UVOS benchmarks, using only standard ResNet [13] backbone and convolutional heads, our RCF surpasses the state-of-the-art by absolute gains of $7.0%/9.1%/4.5%$ $(6.3%/12.0%/5.8%)$ without (with) post-processing on DAVIS16 [33] / STv2 [20] / FBMS59 [31] respectively, validating the effectiveness of our ideas.
在UVOS基准测试中,仅使用标准ResNet [13]主干网络和卷积头,我们的RCF方法在DAVIS16 [33]/STv2 [20]/FBMS59 [31]数据集上分别实现了$7.0%/9.1%/4.5%$ $(6.3%/12.0%/5.8%)$的绝对性能提升(未使用/使用后处理),验证了我们方法的有效性。
2. Related Work
2. 相关工作
Unsupervised video object segmentation (UVOS) requires segmenting prominent objects from videos without human annotations. Mainstream benchmarks [1, 20, 31, 33] define the task as a binary figure-ground segmentation problem, where salient objects are the foreground. Despite the name, several previous UVOS methods require supervised (pre-)training on other data such as large-scale images or videos with manual annotations [11,17,21,26,34,48,50,51]. In contrast, we focus on UVOS methods which do not rely on any labels at either training or inference time.
无监督视频目标分割 (UVOS) 需要在无人为标注的情况下从视频中分割显著目标。主流基准测试 [1, 20, 31, 33] 将该任务定义为二值图像-背景分割问题,其中显著目标作为前景。尽管名为无监督,先前部分 UVOS 方法仍需在其他数据上进行监督(预)训练,例如带人工标注的大规模图像或视频 [11,17,21,26,34,48,50,51]。相比之下,我们关注的是在训练和推理阶段均不依赖任何标注的无监督视频目标分割方法。
Motion segmentation separates figure from ground based on motion, which is typically optical flow computed from a pre-trained model. FTS [32] utilizes motion boundaries for segmentation. SAGE [40] additionally considers edges and saliency priors jointly with motion. CIS [49] uses independence between foreground and background motion as the goal for foreground segmentation. However, this assumption does not always hold in real-world motion patterns. MG [47] leverages attention mechanisms to group pixels with similar motion patterns. SIMO [19] and OCLR [44] generate synthetic data for segmentation supervision, with the latter supporting individual segmentation of multiple objects. Nevertheless, both rely on human-annotated sprites for realistic shapes in artificial data synthesis. Motion segmentation fails when objects do not move.
运动分割 (motion segmentation) 基于运动信息(通常是由预训练模型计算的光流)将前景与背景分离。FTS [32] 利用运动边界进行分割。SAGE [40] 进一步结合边缘和显著性先验与运动信息。CIS [49] 将前景与背景运动的独立性作为前景分割目标,但这一假设在真实运动模式中并不总是成立。MG [47] 通过注意力机制对具有相似运动模式的像素进行分组。SIMO [19] 和 OCLR [44] 生成合成数据用于分割监督,其中后者支持多物体的独立分割,但两者都依赖人工标注的精灵图 (sprites) 来实现合成数据中物体的真实形状。当物体静止时,运动分割方法会失效。
Motion-guided image segmentation treats motion computed by a pre-trained optical flow model such as RAFT [39] as ground-truth and uses it to supervise appearancebased image segmentation. GWM [6] assumes smooth flows within an object and learns appearance-based segmentation by seeking the best segment-wise affine flows that fit RAFT flows. Such methods can discover stationary objects in videos and single images.
运动引导的图像分割将预训练光流模型(如RAFT [39])计算出的运动视为真实值,并用于监督基于外观的图像分割。GWM [6]假设物体内部光流平滑,通过寻找与RAFT光流最匹配的分段仿射流来学习基于外观的分割。这类方法能够发现视频和单幅图像中的静止物体。
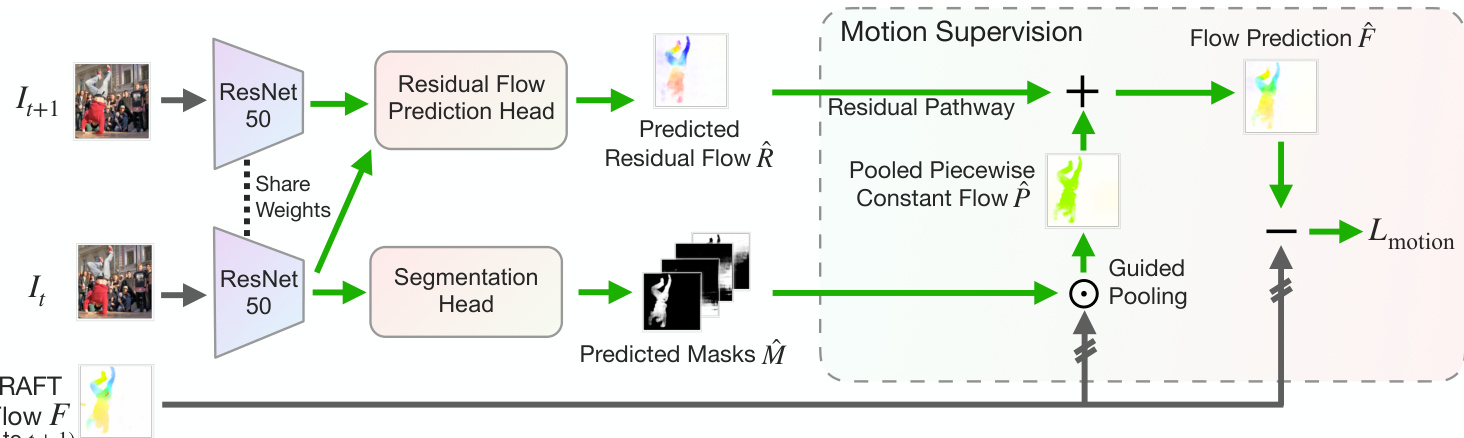
Figure 3. Our object discovery stage uses motion as supervision and follows the principle of relaxed common fate, in which training signals are obtained by reconstructing the reference RAFT flow with the sum from the two pathways: 1) a piecewise constant flow pathway, which is created from pooling the RAFT flow with the predicted masks in order to model object-level motion; 2) a predicted pixel-wise residual flow pathway, which models intra-object motion for articulated and deformable objects. Green arrows indicate gradient backprop.
图 3: 我们的物体发现阶段以运动作为监督信号,遵循宽松共同命运原则。训练信号通过以下两条路径的叠加来重建参考 RAFT 光流:1) 分段恒定光流路径,通过对 RAFT 光流与预测掩码进行池化来建模物体级运动;2) 预测的逐像素残差光流路径,用于建模铰接物体和可变形物体的内部运动。绿色箭头表示梯度反向传播。
Joint appearance segmentation and motion estimation methods such as AMD [23] learn motion and segmentation simultaneously in a self-supervised manner such that their outputs can be used to successfully reconstruct the next frame based on how segments of the current frame move.
诸如AMD [23]这样的联合外观分割与运动估计方法,以自监督方式同时学习运动和分割,使得它们的输出能够基于当前帧各分段的运动情况成功重建下一帧。
AMD is unique in that it has no preconception of optical flow or visual saliency. Since our model considers bootstrapping objectness from optical flow, for fair comparisons, we consider $\mathrm{AMD+}$ , a version of AMD with motion supervision from RAFT flows [39] instead.
AMD 的独特之处在于它对光流 (optical flow) 或视觉显著性 (visual saliency) 没有任何先入为主的观念。由于我们的模型考虑了从光流中引导物体性 (objectness) , 为了公平比较, 我们考虑 $\mathrm{AMD+}$ , 这是一个使用 RAFT 光流 [39] 进行运动监督的 AMD 版本。
Existing UVOS methods, whether they examine motion only or together with appearance, assume that objectness is revealed through common fate of motion: What move at the same speed belong together. We show that this notion fails for objects with articulation and reflection (Fig. 1). Our RCF first bootstraps objectness by relaxed common fate and then improves it by visual appearance grouping.
现有UVOS方法无论单独考察运动还是结合外观分析,都默认物体属性通过运动的共同命运显现:相同速度移动的物体属于同一整体。我们证明这一假设对具有铰接和反射特性的物体失效 (图 1)。我们的RCF方法首先通过松弛共同命运原则初始化物体属性,再通过视觉外观聚类进行优化。
3. Objectness from Relaxed Common Fate
3. 基于松弛共同命运 (Relaxed Common Fate) 的物体性
Our RCF consists of two stages: a motion-supervised object discovery stage (Fig. 3) and an appearance-supervised refinement stage (Fig. 4). Stage 1 formalizes relaxed common fate and learns segmentation by fitting RAFT flow with both object-level motion and intra-object motion. Stage 2 refines Stage 1’s motion-based segmentation s by appearance-based visual grouping and then use them to further supervise segmentation learning. Neither stage requires any annotation, making RCF fully unsupervised. We also present motion-appearance alignment as a model-agnostic label-free hyper parameter tuner.
我们的RCF包含两个阶段:运动监督的目标发现阶段(图3)和外观监督的优化阶段(图4)。第一阶段通过拟合包含目标级运动和对象内运动的RAFT光流,形式化松弛共同命运准则并学习分割。第二阶段基于外观视觉分组优化第一阶段运动分割结果,进而监督分割学习。两个阶段均无需任何标注,使RCF完全无监督。我们还提出了运动-外观对齐作为模型无关的无标签超参数调谐器。
3.1. Problem Setting
3.1. 问题设定
Let $I_{t}\in\mathbb{R}^{3\times h\times w}$ be the $t^{\mathrm{th}}$ frame from a sequence of $T$ RGB frames, where $h$ and $w$ are the height and width of the image respectively. We will omit the subscript $t$ except for input images for clarity. The goal of UVOS is to produce a binary segmentation mask $M\in{0,1}^{h\times w}$ for each time step $t$ , with 1 (0) indicating the foreground (background).
设 $I_{t}\in\mathbb{R}^{3\times h\times w}$ 为从 $T$ 帧RGB序列中提取的第 $t^{\mathrm{th}}$ 帧,其中 $h$ 和 $w$ 分别表示图像的高度和宽度。为简洁起见,除输入图像外我们将省略下标 $t$。无监督视频目标分割(UVOS)的目标是为每个时间步 $t$ 生成二值分割掩码 $M\in{0,1}^{h\times w}$,其中1(0)代表前景(背景)。
To evaluate a method on UVOS, we compute the mean Jaccard index $\mathcal{I}$ (i.e., mean IoU) between the predicted segmentation mask $M$ and the ground truth $G$ . In UVOS, the ground truth mask $G$ is not available, and no humanannotations are used throughout training and inference.
为了评估UVOS方法,我们计算预测分割掩码$M$与真实掩码$G$之间的平均Jaccard指数$\mathcal{I}$(即平均IoU)。在UVOS中,真实掩码$G$不可获取,且整个训练和推理过程均未使用人工标注。
3.2. Object Discovery with Motion Supervision
3.2. 基于运动监督的目标发现
As shown in Fig. 3, during training, our method takes a pair of consecutive frames and RAFT flow between them as inputs. To instantiate the idea of common fate, our method begins by pooling the RAFT Flow with respect to the predicted masks, creating the piecewise constant flow pathway. As a relaxation, the predicted residual flow, which models intra-object motion for articulated and deformable objects, is added to the piecewise constant flow. The composite flow prediction is then supervised by the RAFT flow to train the model. At test time, only the backbone and the segmentation head are utilized to perform inference per frame.
如图 3 所示,在训练过程中,我们的方法以连续帧对及其间的 RAFT 光流作为输入。为实现共同运动原理的实例化,该方法首先根据预测掩码对 RAFT 光流进行池化,生成分段恒定流路径。作为松弛处理,预测残差流(用于建模铰接和可变形物体的内部运动)被叠加到分段恒定流上。最终通过 RAFT 光流监督复合流预测来训练模型。在测试阶段,仅需使用主干网络和分割头逐帧执行推理。
Specifically, let $f(I_{t})\in\mathbb{R}^{K\times H\times W}$ be the feature of $I_{t}$ extracted from backbone $f(\cdot)$ , where $K,H$ , and $W$ are the number of channels, height, and width of the feature. Let $\hat{M}=g(f(I_{t}))\in\mathbb{R}^{C\times\breve{H}\times W}$ be $C$ soft segmentation masks extracted with a lightweight fully convolutional segmentation head $g(\cdot)$ taking the image feature from $f(\cdot)$ . Softmax is taken across channels inside $g(\cdot)$ so that the $C$ soft masks sum up to 1 for each of the $H\times W$ positions. Following [23], although there are $C$ segmentation masks competing for each pixel (i.e., $C$ output channels in $\hat{M},$ ), only one corresponds to the foreground, with the rest capturing background patches. We define $c_{o}$ as the object channel index with value obtained in Sec. 3.4.
具体来说,设 $f(I_{t})\in\mathbb{R}^{K\times H\times W}$ 为从主干网络 $f(\cdot)$ 提取的图像 $I_{t}$ 特征,其中 $K,H$ 和 $W$ 分别表示特征的通道数、高度和宽度。设 $\hat{M}=g(f(I_{t}))\in\mathbb{R}^{C\times\breve{H}\times W}$ 为通过轻量级全卷积分割头 $g(\cdot)$ 从 $f(\cdot)$ 提取的 $C$ 个软分割掩码,$g(\cdot)$ 内部沿通道维度进行Softmax操作,使得 $H\times W$ 个位置上的 $C$ 个软掩码之和为1。根据[23],虽然每个像素有 $C$ 个分割掩码竞争(即 $\hat{M}$ 中的 $C$ 个输出通道),但仅有一个对应前景,其余捕获背景区域。我们将 $c_{o}$ 定义为对象通道索引,其取值方法见第3.4节。
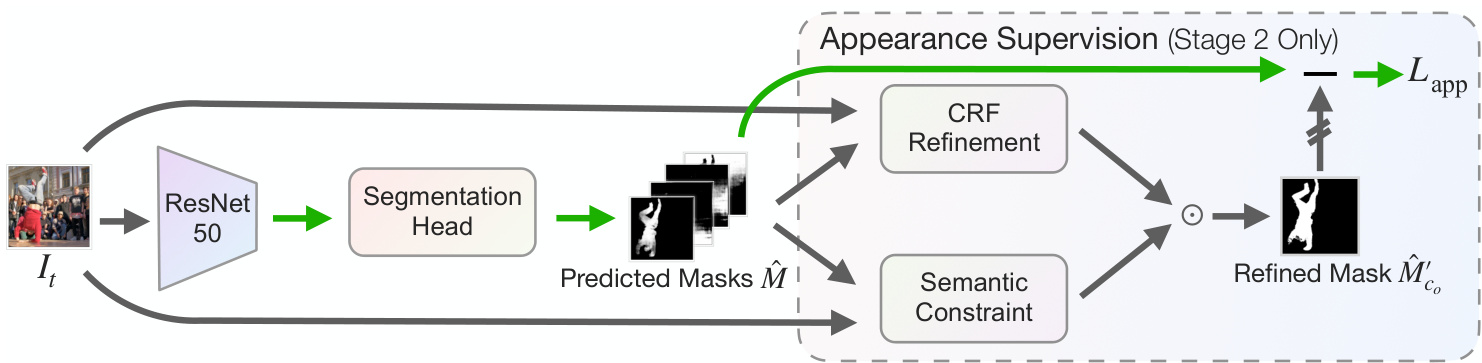
Figure 4. Our appearance refinement stage corrects misconceptions from motion supervision. The predicted mask is supervised by a refined mask based on both the CRF that enforces low-level appearance consistency (e.g., color and texture) and the semantic constraint that enforces high-level semantic consistency. External frozen image features used to enforce the semantic constraint are omitted for clarity.
图 4: 我们的外观细化阶段修正了运动监督产生的误解。预测掩膜通过基于CRF (强制保持低级外观一致性,如颜色和纹理) 和语义约束 (强制保持高级语义一致性) 的细化掩膜进行监督。为清晰起见,省略了用于实施语义约束的外部冻结图像特征。
Following [6,19,44,47], we use off-the-shelf optical flow model RAFT [39] trained on synthetic datasets [10, 28] to provide motion cues between consecutive frames. Let $F\in$ $\mathbb{R}^{2\times H\times W}$ be the flow output from RAFT from $I_{t}$ to $I_{t+1}$ . Piecewise constant pathway. We first pool the flow according to each mask to form $C$ flow vectors $\hat{P}_{c}\in\mathbb{R}^{2}$ :
遵循 [6,19,44,47] 的做法,我们使用现成的光流模型 RAFT [39](在合成数据集 [10,28] 上训练)来提供连续帧之间的运动线索。设 $F\in$ $\mathbb{R}^{2\times H\times W}$ 为 RAFT 从 $I_{t}$ 到 $I_{t+1}$ 输出的光流。分段恒定路径:首先根据每个掩码对光流进行池化,形成 $C$ 个光流向量 $\hat{P}_{c}\in\mathbb{R}^{2}$:
$$
\begin{array}{l l}{\hat{P}{c}=\phi_{2}(\mathrm{GuidedPool}(\phi_{1}(F),\hat{M}{c}))}\ {\mathrm{GuidedPool}(F,M)=\displaystyle\frac{\sum_{p=1}^{H W}(F\odot M)[p]}{\sum_{p=1}^{H W}M[p]}}\end{array}
$$
$$
\begin{array}{l l}{\hat{P}{c}=\phi_{2}(\mathrm{GuidedPool}(\phi_{1}(F),\hat{M}{c}))}\ {\mathrm{GuidedPool}(F,M)=\displaystyle\frac{\sum_{p=1}^{H W}(F\odot M)[p]}{\sum_{p=1}^{H W}M[p]}}\end{array}
$$
where $[p]$ denotes the pixel index and $\odot$ element-wise multiplication. Following [23], $\phi_{1}$ and $\phi_{2}$ are two-layer lightweight MLPs that transform each of the motion vectors independently before and after pooling, respectively. We then construct predicted flow $\hat{P}\in\mathbb{R}^{2\times\breve{H}\times W}$ according to the soft segmentation mask:
其中 $[p]$ 表示像素索引,$\odot$ 表示逐元素乘法。根据 [23],$\phi_{1}$ 和 $\phi_{2}$ 是两层轻量级 MLP (多层感知机) ,分别在池化前后独立转换每个运动向量。随后我们根据软分割掩码构建预测流 $\hat{P}\in\mathbb{R}^{2\times\breve{H}\times W}$:
$$
\begin{array}{l}{{\displaystyle\hat{P}=\sum_{c=1}^{C}\mathrm{Broadcast}(\hat{P}_{c},\hat{M}_{c})}}\ {{\mathrm{Broadcast}(\hat{P}_{c},\hat{M}_{c})[p]=\hat{P}_{c}\odot(\hat{M}_{c}[p]).}}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle\hat{P}=\sum_{c=1}^{C}\mathrm{Broadcast}(\hat{P}_{c},\hat{M}_{c})}}\ {{\mathrm{Broadcast}(\hat{P}_{c},\hat{M}_{c})[p]=\hat{P}_{c}\odot(\hat{M}_{c}[p]).}}\end{array}
$$
As the mask prediction $\hat{M}_{c}$ approaches binary during training, the flow prediction approaches a piecewise-constant function with respect to each segmentation mask, capturing common fate. Previous methods either directly supervise P with an image warping for self-supervised learning [23] or matches $\hat{P}$ and $F$ by minimizing the discrepancies up to an affine factor (i.e., up to first order) [6].
随着训练过程中掩模预测 $\hat{M}_{c}$ 逐渐接近二值化,光流预测会趋近于相对于每个分割掩模的分段常数函数,从而捕捉共同运动趋势。先前方法要么直接通过图像扭曲监督P进行自监督学习 [23] ,要么通过最小化 $\hat{P}$ 和 $F$ 之间的差异(至多相差一个仿射因子,即一阶近似)来进行匹配 [6] 。
Nonetheless, hand-crafted non-learnable motion models, while capturing the notion of common fate, underfit complex optical flow in real-world videos, which often put object parts into different segmentation channels in order to minimize the loss, despite similar color or texture. [6] uses two mask channels as a remedy, still falling short for scenes with complex backgrounds.
尽管如此,手工制作的非学习型运动模型虽然捕捉到了共同命运的概念,但在现实世界视频中无法充分拟合复杂的光流,这些模型通常会将物体部分分配到不同的分割通道中以最小化损失,尽管这些部分具有相似的颜色或纹理。[6] 使用了两个掩码通道作为补救措施,但对于具有复杂背景的场景仍然效果不佳。
Learnable residual pathway. Rather than using more complicated hand-crafted motion models to model the motion patterns in videos, we employ relaxed common fate by separately fitting object-level and intra-object motion by adding a learnable residual pathway R in addition to the piecewise constant pathway P to form the final fow prediction $\hat{F}$ . The residual pathway models relative intra-object motion such as the relative motion of the dancer’s feet to the body in Fig. 3.
可学习的残差路径。我们不再使用更复杂的手工运动模型来模拟视频中的运动模式,而是通过添加一个可学习的残差路径R与分段恒定路径P相结合,形成最终的光流预测$\hat{F}$,从而分别拟合物体级和物体内部运动,实现松弛的共同命运。残差路径模拟物体内部的相对运动,例如图3中舞者脚部相对于身体的运动。
Let $h(\cdot)$ be a lightweight module with three Conv-BNReLU blocks that take the concatenated feature of a pair of frames ${I_{t},I_{t+1}}$ as input and predicts $\hat{R}^{\prime}\in\mathbb{R}^{C\times2\times^{\cdot}H\times W}$ , which includes $C$ flows with per-pixel upper bound $\lambda$ :
设 $h(\cdot)$ 为一个轻量级模块,包含三个 Conv-BNReLU 块,以帧对 ${I_{t},I_{t+1}}$ 的拼接特征作为输入,并预测 $\hat{R}^{\prime}\in\mathbb{R}^{C\times2\times^{\cdot}H\times W}$,其中包含 $C$ 个像素级上限为 $\lambda$ 的流:
$$
\hat{R}^{\prime}=\lambda\operatorname{tanh}(h(\operatorname{concat}(f(I_{t}),f(I_{t+1})))
$$
$$
\hat{R}^{\prime}=\lambda\operatorname{tanh}(h(\operatorname{concat}(f(I_{t}),f(I_{t+1})))
$$
where the upper bound $\lambda$ is set to 10 pixels unless stated otherwise. The $C$ residual flows form aggregated residual flow R using mask predictions, which sums up with the piecewise constant pathway to form the final fow prediction F:
其中上限 $\lambda$ 设为10像素(除非另有说明)。$C$ 个残差流通过掩码预测形成聚合残差流 R,与分段恒定路径相加得到最终流预测 F:
$$
\begin{array}{l}{\displaystyle\hat{R}=\sum_{c=1}^{C}\hat{R}_{c}^{\prime}\odot\hat{M}_{c}}\ {\displaystyle\hat{F}=\hat{P}+\hat{R}}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\hat{R}=\sum_{c=1}^{C}\hat{R}_{c}^{\prime}\odot\hat{M}_{c}}\ {\displaystyle\hat{F}=\hat{P}+\hat{R}}\end{array}
$$
In this way, $\hat{F}$ additionally takes into account relative motion that is within $(-\lambda,\lambda)$ for each spatial location. The added residual pathway provides greater flexibility by allowing the model to relax from common fate that does not take intra-object motion into account. This leads to better segmentation results for articulated and deformable objects.
通过这种方式,$\hat{F}$额外考虑了每个空间位置在$(-\lambda,\lambda)$范围内的相对运动。增加的残差通路通过允许模型从不考虑物体内部运动的共运中松弛,提供了更大的灵活性。这为铰接和可变形物体带来了更好的分割结果。
At stage 1, we minimize the L1 loss between the predicted reconstruction flow $\hat{F}$ and target flow $F$ in order to learn segmentation by predicting the correct flow:
在第1阶段,我们最小化预测重建流 $\hat{F}$ 与目标流 $F$ 之间的L1损失,从而通过预测正确的流来学习分割:
$$
L_{\mathrm{stage1}}=L_{\mathrm{motion}}={\frac{1}{H W}}\sum_{p=1}^{H W}||\hat{F}[p]-F[p]||_{1}
$$
$$
L_{\mathrm{stage1}}=L_{\mathrm{motion}}={\frac{1}{H W}}\sum_{p=1}^{H W}||\hat{F}[p]-F[p]||_{1}
$$
3.3. Refinement with Appearance Supervision
3.3. 外观监督下的优化
A primary focus of self-supervised learning is to find sources of useful training signals. While the residual pathway greatly improves segmentation quality, the supervision still primarily comes from motion. This single source of supervision can lead to predictions that are optimal for flow prediction but often suboptimal from an appearance perspective. For instance, in Fig. 4, the segmentation prediction before refinement ignores a part of the dancer’s leg, despite the ignored part sharing a very similar color and texture with the included parts. Furthermore, the RAFT flow tends to be noisy in areas where nearby pixels move very differently, which leads to segmentation ambiguity.
自监督学习的一个主要关注点是寻找有用的训练信号来源。虽然残差路径大大提高了分割质量,但监督仍然主要来自运动。这种单一的监督来源可能导致预测结果在光流预测方面是最优的,但从外观角度来看往往不够理想。例如,在图4中,细化前的分割预测忽略了舞者腿部的一部分,尽管被忽略的部分与包含的部分具有非常相似的颜色和纹理。此外,RAFT光流在附近像素运动差异较大的区域往往存在噪声,这会导致分割模糊性。

Figure 5. Semantic constraint mitigates false positives from naturally-occurring misleading motion signals. The reflection has semantics distinct from the main object and is thus filtered out. The refined mask is then used as supervision to disperse the misconception in stage 2. Best viewed in color and zoom in.
图 5: 语义约束缓解了自然产生的误导性运动信号导致的误检。反射区域与主体具有不同的语义特征因而被过滤。优化后的掩码随后被用作监督信号,在第二阶段消除这一错误认知。建议彩色放大查看。
To address these issues, we propose to incorporate lowand high-level appearance signals as another source of supervision to correct the misconceptions from motion.
为解决这些问题,我们提出将低层次和高层次外观信号作为另一种监督来源,以纠正运动带来的误解。
Appearance supervision with low-level intra-image cues. With the model in stage 1, we obtain the mask prediction $\hat{M}{c_{o}}$ of $I_{t}$ , where $c_{o}$ is the objectness channel that could be found without annotation (Sec. 3.4). We then apply fullyconnected conditional random field (CRF) [18], a trainingfree technique that refines the value of each prediction based on other pixels with an appearance and a smoothness kernel. The refined masks $\hat{M}{c{o}}^{\prime}$ are then used as supervision to provide appearance signals in training:
基于低层次图像内部线索的外观监督。通过第一阶段模型,我们获得目标图像 $I_{t}$ 的掩码预测 $\hat{M}{c_{o}}$ ,其中 $c_{o}$ 为无需标注即可识别的物体性通道(见第3.4节)。随后采用全连接条件随机场 (CRF) [18]——一种基于外观平滑性核函数、通过其他像素值优化预测结果的免训练技术。优化后的掩码 $\hat{M}{c{o}}^{\prime}$ 将作为监督信号为训练提供外观信息:
$$
\begin{array}{l}{{\hat{M}{c_{o}}^{\prime}=\mathrm{\bfCRF}(\hat{M}{c_{o}})}}\ {{\displaystyle{\cal L}{\mathrm{app}}=\frac{1}{H W}\sum_{p=1}^{H W}||\hat{M}{c_{o}}[p]-\hat{M}_{c_{o}}^{\prime}[p]||_{2}^{2}}}\end{array}
$$
$$
\begin{array}{l}{{\hat{M}{c_{o}}^{\prime}=\mathrm{\bfCRF}(\hat{M}{c_{o}})}}\ {{\displaystyle{\cal L}{\mathrm{app}}=\frac{1}{H W}\sum_{p=1}^{H W}||\hat{M}{c_{o}}[p]-\hat{M}{c_{o}}^{\prime}[p]||_{2}^{2}}}\end{array}
$$
The total loss in stage 2 is a weighted sum of both motion and appearance loss:
阶段2的总损失是运动损失和外观损失的加权和:
$$
L_{\mathrm{stage}2}=w_{\mathrm{app}}L_{\mathrm{app}}+w_{\mathrm{motion}}L_{\mathrm{motion}}
$$
$$
L_{\mathrm{stage}2}=w_{\mathrm{app}}L_{\mathrm{app}}+w_{\mathrm{motion}}L_{\mathrm{motion}}
$$
where $w_{\mathrm{app}}$ and $w_{\mathrm{motion}}$ are weights for loss terms.
其中 $w_{\mathrm{app}}$ 和 $w_{\mathrm{motion}}$ 为损失项的权重。
The CRF in our method for appearance supervision is different with the traditional CRF used in postprocessing [6,49], as our refined masks provide the supervision for training the network. Furthermore, we show empirically that our method is orthogonal to the traditional CRF in the ablation (Sec. 4.4).
我们方法中用于外观监督的CRF (Conditional Random Field) 与传统后处理中使用的CRF [6,49] 不同,因为我们的优化掩码为网络训练提供了监督。此外,消融实验 (第4.4节) 表明我们的方法与传统CRF具有正交性。
Appearance supervision with semantic constraint. Lowlevel appearance is still insufficient to address misleading motion signals from naturally occurring con founders with similar motion patterns. For example, the reflections share similar motion as the swan in Fig. 5, which is confirmed by low-level appearance. However, humans could recognize that the swan and the reflection have distinct semantics, with the reflection’s semantics much closer to the background.
语义约束下的外观监督。仅靠低层次外观仍不足以解决来自自然环境中具有相似运动模式的干扰因素所产生的误导性运动信号。例如,图5中天鹅的倒影与其自身运动模式相似,这一点已通过低层次外观得到验证。然而,人类能够识别天鹅与倒影具有截然不同的语义特征,其中倒影的语义更接近于背景。
Inspired by this, we incorporate the statistically learned feature map from a frozen auxiliary DINO ViT [2,9] trained with self-supervised learning across ImageNet [35] without human annotation, to create a semantic constraint for mask prediction. We begin by taking the key features from the last transformer layer, denoted as $f_{\mathrm{aux}}(I_{t})$ , inspired by [43]. Next, we compute and iterative ly optimize the normalized cut [37] with respect to the mask to refine the mask.
受此启发,我们引入了一个通过自监督学习在ImageNet [35]上训练、无需人工标注的冻结辅助DINO ViT [2,9]所统计学习到的特征图,为掩码预测创建语义约束。首先,我们借鉴[43]的方法,从最后一个Transformer层提取关键特征,记为$f_{\mathrm{aux}}(I_{t})$。接着,我们计算并迭代优化关于掩码的归一化割[37]以优化掩码。
Specifically, we initialize a 1-D vector $\mathbf{x}$ with a flattened and resized $\hat{M}{c_{o}}$ with shape $H W$ . Then we build an appearance-based affinity matrix $A$ , where:
具体来说,我们用一个展平并调整尺寸的 $\hat{M}{c_{o}}$ 初始化一个一维向量 $\mathbf{x}$ ,其形状为 $H W$ 。然后构建一个基于外观的亲和矩阵 $A$ ,其中:
$$
A_{i j}=\mathbb{1}(\sin(f_{\mathrm{aux}}(I_{t}){i},f_{\mathrm{aux}}(I_{t})_{j})\geq0.2)
$$
$$
A_{i j}=\mathbb{1}(\sin(f_{\mathrm{aux}}(I_{t}){i},f_{\mathrm{aux}}(I_{t})_{j})\geq0.2)
$$
Next, we compute $\operatorname{NCut}(A,\mathbf{x})$ :
接下来,我们计算 $\operatorname{NCut}(A,\mathbf{x})$:
$$
\begin{array}{r l}&{~\mathrm{Cut}(A,\mathbf{x})=(1-\mathbf{x})A\mathbf{x}}\ &{\mathrm{NCut}(A,\mathbf{x})=\frac{\mathrm{Cut}(A,\mathbf{x})}{\sum_{i=1}^{H W}(A\mathbf{x}){i}}+\frac{\mathrm{Cut}(A,\mathbf{x})}{\sum_{i=1}^{H W}(A(1-\mathbf{x}))_{i}}}\end{array}
$$
$$
\begin{array}{r l}&{~\mathrm{Cut}(A,\mathbf{x})=(1-\mathbf{x})A\mathbf{x}}\ &{\mathrm{NCut}(A,\mathbf{x})=\frac{\mathrm{Cut}(A,\mathbf{x})}{\sum_{i=1}^{H W}(A\mathbf{x}){i}}+\frac{\mathrm{Cut}(A,\mathbf{x})}{\sum_{i=1}^{H W}(A(1-\mathbf{x}))_{i}}}\end{array}
$$
where $\mathrm{sim}(\cdot,\cdot)$ cosine similarity. Since $\operatorname{NCut}(A,\mathbf{x})$ is diffe rent i able with respect to $\mathbf{x}$ , we use Adam [16] to minimize $\operatorname{NCut}(A,\mathbf{x})$ in order to refine $\mathbf{x}$ for $k=10$ iterations. We denote the optimized vector as $\mathbf{x}^{(k)}$ , which is thus the refined version of the mask that carries consistent semantics, thus decoupling the objects from their shadows and reflections. With the semantic constraint, Eq. (9) changes to:
其中 $\mathrm{sim}(\cdot,\cdot)$ 表示余弦相似度。由于 $\operatorname{NCut}(A,\mathbf{x})$ 对 $\mathbf{x}$ 可微,我们使用 Adam [16] 通过 $k=10$ 次迭代最小化 $\operatorname{NCut}(A,\mathbf{x})$ 来优化 $\mathbf{x}$。将优化后的向量记为 $\mathbf{x}^{(k)}$,即具有一致语义的精细化掩码版本,从而将物体与其阴影和反射分离。加入语义约束后,式 (9) 变为:
$$
\hat{M}{c_{o}}^{\prime}=\mathrm{CRF}(\hat{M}{c_{o}})\odot\mathrm{CRF}(\mathbf{x}^{(k)})
$$
$$
\hat{M}{c_{o}}^{\prime}=\mathrm{CRF}(\hat{M}{c_{o}})\odot\mathrm{CRF}(\mathbf{x}^{(k)})
$$
where $\mathbf{x}^{(k)}$ is reshaped to 2D and resized to match the mask sizes prior to CRF. Since stage 2 is mainly misconception correction and thus much shorter than stage 1, we generate the NCut refined masks only once and use the same refined masks for efficient supervision.
其中 $\mathbf{x}^{(k)}$ 在 CRF 前被重塑为二维并调整大小以匹配掩码尺寸。由于第二阶段主要是修正错误概念,因此比第一阶段短得多,我们仅生成一次 NCut 精修掩码,并使用相同的精修掩码进行高效监督。
Because the semantic constraint introduces an additional frozen model $f_{\mathrm{aux}}(\cdot)$ , we benchmark both with and without the semantic constraint for a fair comparison with previous methods. We use $R C F~(w/o~S C)$ to denote RCF without the semantic constraint. Our method is still fully unsupervised even with the semantic constraint.
由于语义约束引入了额外的冻结模型 $f_{\mathrm{aux}}(\cdot)$ ,我们同时对有无语义约束的情况进行基准测试,以便与之前的方法进行公平比较。使用 $R C F~(w/o~S C)$ 表示无语义约束的RCF。即使加入语义约束,我们的方法仍保持完全无监督。
3.4. Label-free Hyper parameter Tuner
3.4. 无标签超参数调优器
Following previous appearance-based UVOS work, our method also requires several tunable hyper parameters for high-quality segmentation. The most critical ones are the number of segmentation channels $C$ and the object channel index $c_{o}$ . [6, 23] tune both hyper parameters either with a large labeled validation set or a hand-crafted metric tailored to a specific hyper parameter, limiting the capability towards other hyper parameters in a real-world setting.
遵循先前基于外观的无监督视频目标分割(UVOS)工作,我们的方法也需要若干可调超参数来实现高质量分割。最关键的两个参数是分割通道数$C$和目标通道索引$c_{o}$。[6,23]通过大量标注验证集或针对特定超参数手工设计的评估指标来调整这两个参数,这限制了该方法在现实场景中对其他超参数的适应能力。
We propose motion-appearance alignment as a metric to quantify the segmentation quality. The steps for tuning are: 1. Train a model with each hyper parameter setting. 2. Export the predicted mask $\hat{M}{c_{o}}$ for each image in the unlabeled validation set. 3. Compute the negative normalized cuts $-\mathrm{NCut}(A,\hat{M}{c_{o}})$ w.r.t. $\hat{M}{c_{o}}$ and the appearance-based affinity matrix $A$ as the metric quantifying motion-appearance alignment. 4. Take the mean metric across all validation images. 5. Select the setting with the highest mean metric.
我们提出运动-外观对齐作为量化分割质量的指标。调优步骤如下:
- 使用每个超参数设置训练模型。
- 为未标注验证集中的每张图像导出预测掩码 $\hat{M}{c_{o}}$。
- 计算关于 $\hat{M}{c_{o}}$ 和基于外观的亲和矩阵 $A$ 的负归一化割 $-\mathrm{NCut}(A,\hat{M}{c_{o}})$,作为量化运动-外观对齐的指标。
- 取所有验证图像的平均指标。
- 选择平均指标最高的设置。
Our hyper parameter tuning method is model-agnostic and applicable to other UVOS methods. We also demonstrate its effectiveness in tuning weight decay and present the pseudo-code in the supp. mat.
我们的超参数调优方法不依赖于特定模型,适用于其他无监督视频目标分割(UVOS)方法。我们还在补充材料中展示了该方法在调整权重衰减(weight decay)方面的有效性,并提供了伪代码。
4. Experiments
4. 实验
4.1. Datasets
4.1. 数据集
We evaluate our methods using three datasets commonly used to benchmark UVOS, following previous works [6, 23, 44, 47, 49]. DAVIS2016 [33] contains 50 video sequences with 3,455 frames in total. Performance is evaluated on a validation set that includes 20 videos with annotations at 480p resolution. SegTrackv2 (STv2) [20] contains 14 videos of different resolutions, with 976 annotated frames and lower image quality than [33]. FBMS59 [31] contains 59 videos with a total of 13,860 frames, 720 frames of which are annotated with a roughly fixed interval. We follow previous work to merge multiple foreground objects in STv2 and FBMS59 into one mask and train on all unlabeled videos. We adopt mean Jaccard index $\mathcal{I}$ (mIoU) as the primary evaluation metric.
我们采用三种常用于无监督视频目标分割(UVOS)基准测试的数据集来评估方法,延续先前研究[6,23,44,47,49]的做法。DAVIS2016[33]包含50个视频序列共3,455帧,在包含20个480p分辨率标注视频的验证集上评估性能。SegTrackv2(STv2)[20]包含14个不同分辨率视频共976标注帧,其图像质量低于[33]。FBMS59[31]包含59个视频共13,860帧,其中720帧按大致固定间隔进行标注。我们沿袭先前工作,将STv2和FBMS59中的多个前景对象合并为单一掩膜,并在所有未标注视频上进行训练。采用平均杰卡德指数$\mathcal{I}$(mIoU)作为主要评估指标。
4.2. Unsupervised Video Object Segmentation
4.2. 无监督视频目标分割
Setup. Our architecture is simple and straightforward. We use a ResNet50 [13] backbone followed by a segmentation head and a residual prediction head. Both heads only consist of three Conv-BN-ReLU layers with 256 hidden units. This standard design allows efficient implementation in real-world applications. Unless otherwise stated, we use $C=4$ object channels, which we determine without human annotation in Sec. 4.3. We also determine the object channel index $c_{o}$ using the same approach. The RAFT [39] model we use is only trained on synthetic Flying Chairs [10] and Flying Things [28] dataset without human annotation. For more details, please refer to supplementary materials.
设置。我们的架构简单直接。使用ResNet50 [13]作为主干网络,后接分割头和残差预测头。两个头均仅包含三个具有256个隐藏单元的Conv-BN-ReLU层。这种标准设计可实现实际应用中的高效部署。除非另有说明,我们使用$C=4$个物体通道(该数值通过第4.3节的无人工标注方法确定),并采用相同方法确定物体通道索引$c_{o}$。所用的RAFT [39]模型仅在合成数据集Flying Chairs [10]和Flying Things [28]上训练,未使用人工标注。更多细节请参阅补充材料。
Results. As shown in Tab. 1, RCF outperforms previous methods under fair comparison, often by a large margin.
结果。如表 1 所示,在公平比较下,RCF 超越了先前的方法,且优势通常十分显著。
| 方法 | 后处理 DAVIS16 | STv2 | FBMS59 |
|---|---|---|---|
| SAGE [40] | 42.6 57.6 55.2 54.3 | 61.2 | |
| CUT [15] FTS [32] | 57.2 | ||
| EM [29] | 55.8 47.8 69.8 | 47.7 | |
| CIS [49] | 59.2 45.6 | 36.8 | |
| MG [47] | 68.3 58.6 | 53.1 | |
| AMD [23] | 57.8 57.0 | 47.5 | |
| SIMO [19] | 67.8 62.0 | — | |
| 71.2 66.7 | 60.9 | ||
| GWM [6] GWM* [6] | 71.2 69.0 | 66.9 | |
| OCLRt [44] | 72.1 67.6 | 65.4 | |
| MOD [8] | 64.3 73.9 | 59.6 62.2 | 60.2 |
| RCF | 80.9 (+7.0) | 76.7 | 61.3 69.9 |
| CIS [49] TokenCut [43] | CRF+ SP 71.5 | (+9.1) 62.0 | (+4.5) |
| CRF only 76.7 | 61.6 | 63.6 66.6 | |
| GWM* [6] | CRF + SP+ 73.4 DINO-based+ 78.9 | 72.0 | 68.6 |
| OCLR+ [44] MOD [8] | DINO-based+ | 71.6 | 68.7 |
| RCF (w/o SC) | 79.2 69.4 | 66.9 | |
| CRF only | 78.7 | 71.9 | |
| 82.0 | |||
| RCF | CRF only 83.0 | 79.6 | 72.4 |
| (+6.3) | (+12.0) | (+5.8) |
Table 1. Our method achieves significant improvements over previous methods on common UVOS benchmarks. RCF (w/o SC) indicates low-level refinement only (no $f_{\mathrm{aux}}$ used). $^*$ : uses Swin-Transformer w/ MaskFormer [3, 25] segmentation head orthogonal to VOS method and thus is not a fair comparison with us. $\dagger$ leverages manually annotated shapes from large-scale YoutubeVOS [46] to generate synthetic data. $\ddagger$ : $S P$ : significant postprocessing (e.g., multi-step flow, multi-crop ensemble, and temporal smoothing). DINO-based: performs contrastive learning or mask propagation on a pretrained DINO ViT model [2, 9] at test time; not a fair comparison with us. Our post-processing is a $C R F$ pass only. CIS results are from [24].
表 1: 我们的方法在常见UVOS基准测试中相比之前方法取得了显著提升。RCF (w/o SC) 表示仅进行低级优化 (未使用 $f_{\mathrm{aux}}$)。$^*$: 使用Swin-Transformer结合MaskFormer [3,25]分割头(与VOS方法正交),因此与我们的方法不具备公平可比性。$\dagger$ 利用了大规模YoutubeVOS [46]中人工标注的形状来生成合成数据。$\ddagger$: $S P$: 采用了显著的后处理(如多步光流、多裁剪集成和时间平滑)。基于DINO的方法: 在测试时对预训练的DINO ViT模型 [2,9] 进行对比学习或掩码传播;与我们的方法不具备公平可比性。我们的后处理仅包含一次 $C R F$ 处理。CIS结果来自[24]。
On DAVIS16, RCF surpasses the previous state-of-the-art method by $7.0%$ without post-processing (abbreviated as pp.). With CRF as the only pp., RCF improves on previous methods by $6.3%$ without techniques such as multi-step flow, multi-crop ensemble, and temporal smoothing. RCF also outperforms GWM [6] that employs more complex Swin $\boldsymbol{\cdot}\boldsymbol{\mathrm{T}}+\boldsymbol{\mathrm{M}}$ askFormer architecture [3, 25] by $9.7%$ w/o pp. Furthermore, RCF achieves significantly better results compared with TokenCut [43] that also uses normalized cuts on DINO features [2] $16.6%$ better w/o pp.). Despite the varying image quality in STv2 and FBMS59, RCF improves over past methods under fair comparison, by $9.1%$ and $4.5%$ without pp, respectively. Semantic constraint (SC) could be included if additional gains are desired. However, RCF still outperforms previous works without the semantic constraint $(5.3%$ improvement on DAVIS16 w/o SC), thus not relying on external frozen features.
在DAVIS16数据集上,RCF无需后处理(简写为pp.)即以7.0%的优势超越先前最优方法。仅采用CRF作为后处理时,RCF在不使用多步光流、多裁剪集成和时间平滑等技术的情况下,仍比先前方法提升6.3%。RCF还以9.7%的优势(无需后处理)超越了采用更复杂Swin $\boldsymbol{\cdot}\boldsymbol{\mathrm{T}}+\boldsymbol{\mathrm{M}}$ askFormer架构[3,25]的GWM[6]。相较于同样对DINO特征[2]进行归一化切割的TokenCut[43],RCF在无后处理时取得显著更好的结果(提升16.6%)。尽管STv2和FBMS59数据集图像质量参差不齐,RCF在公平比较下分别以9.1%和4.5%的优势(无后处理)超越以往方法。若需进一步提升性能,可加入语义约束(SC),但RCF在不依赖外部冻结特征的情况下,即使不加语义约束仍优于先前工作(DAVIS16无SC时提升5.3%)。
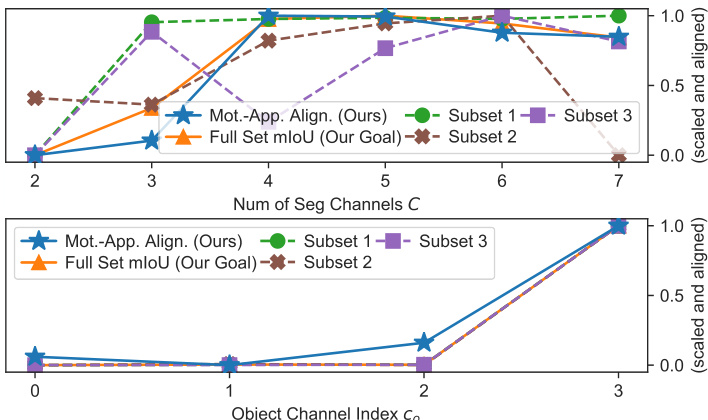
Figure 6. Our proposed label-free motion-appearance metric aligns well with mIoU on the full validation set. Top: When tuning the number of segmentation channels $C$ , our method follows full validation set mIoU better than mIoU on validation subsets with $25%$ of the sequences labeled. Bottom: Our method correctly determines the object channel $c_{o}=3$ for this run, without any human labels. Although $c_{o}$ varies in each training run by design [23], our tuning method has negligible overhead and can be performed after training ends to find $c_{o}$ within seconds.
图 6: 我们提出的无标签运动-外观指标与完整验证集上的 mIoU 高度吻合。上: 当调整分割通道数 $C$ 时,我们的方法比仅标注 $25%$ 序列的验证子集 mIoU 更贴近完整验证集 mIoU。下: 我们的方法在无需人工标注的情况下,正确判定该次训练的对象通道为 $c_{o}=3$。尽管 $c_{o}$ 会因训练设计而每次变化 [23],但我们的调参方法开销可忽略不计,且可在训练结束后数秒内确定 $c_{o}$。
4.3. Label-free Hyper parameter Tuning
4.3. 无标签超参数调优
We use motion-appearance alignment as a metric to tune two key hyper parameters: the number of segmentation masks $C$ and the object channel index $c_{o}$ . To simulate the real-world scenario that we only have limited labeled validation data, we also randomly sample $25%$ sequences three times to create three labeled subsets of the validation set to evaluate mIoU on. As shown in Fig. 6, for the number of mask channels $C$ , despite not using any manual annotation, our label-free motion-appearance alignment closely follows the validation mIoU compared to mIoU on validation subsets, showing the effectiveness of our metric on hy- per parameter tuning. Although increasing the number of channels improves the segmentation quality of our model by increasing its fitting power, such an increase saturates at $C=4$ . Therefore, we use $C=4$ unless otherwise stated. Regarding the object channel index $c_{o}$ , since it changes with each random initialization [23], optimal $c_{o}$ needs to be obtained at the end of each training run. We propose to use only the first frame of each video sequence for finding $c_{o}$ . With this adjustment, our tuning method completes within only 3 seconds for each candidate channel, which enables our tuning method to be performed after the whole training run with negligible overhead.
我们使用运动-外观对齐作为指标来调整两个关键超参数:分割掩码数量 $C$ 和物体通道索引 $c_{o}$。为了模拟现实场景中仅有有限标注验证数据的情况,我们还随机采样 $25%$ 序列三次,创建验证集的三个标注子集用于评估 mIoU。如图 6 所示,对于掩码通道数量 $C$,尽管未使用任何人工标注,我们的无标签运动-外观对齐指标与验证子集上的 mIoU 高度一致,证明了该指标在超参数调优中的有效性。虽然增加通道数量能通过提升模型拟合能力来改善分割质量,但这种提升在 $C=4$ 时达到饱和。因此,除非另有说明,我们默认使用 $C=4$。关于物体通道索引 $c_{o}$,由于该参数会随每次随机初始化而变化 [23],最优 $c_{o}$ 需要在每次训练结束时重新获取。我们提出仅使用每段视频序列的首帧来确定 $c_{o}$。经此调整后,我们的调优方法对每个候选通道仅需 3 秒即可完成,使得该调优过程可在完整训练结束后以可忽略的开销执行。
4.4. Ablation Study
4.4. 消融实验
Contributions of each component. As shown in Tab. 2, residual pathway allows more flexibility and contributes $7.8%$ mIoU. The appearance refinement in the second stage boosts the performance to $80.9%$ , resulting in a $9.8%$ gain in total. The CRF post-processing leads to $83.0%$ mIoU, an $11.9%$ increase over the baseline.
各组件贡献分析。如表 2 所示,残差路径提供了更高灵活性,贡献了 7.8% mIoU。第二阶段的外观细化将性能提升至 80.9%,总体增益达 9.8%。CRF后处理最终实现 83.0% mIoU,较基线提升 11.9%。
Table 2. Effect of each component of our method (DAVIS16). Residual pathway on its own provides the most improvement in our method. All components together contribute to an $11.9%$ gain.
表 2: 本方法各组件效果 (DAVIS16)。残差路径 (Residual pathway) 单独贡献最大提升。所有组件共同带来 11.9% 的性能增益。
| 残差路径 (Residual pathway) | 低层级优化 (Low-level refinement) | 语义约束 (Semantic constraint) | CRF | J (↑) |
|---|---|---|---|---|
| 71.1 → 78.9 (+7.8) | ||||
| →79.9 (+8.8) | ||||
| →80.9 (+9.8) | ||||
| →83.0 (+11.9) |
Table 3. Ablations on additional pathway confirm our design choice of residual pathway. We benchmark without the refinement stage to show the raw performance gain.
表 3: 额外路径的消融实验验证了我们残差路径的设计选择。我们移除了精炼阶段以展示原始性能提升。
| 变体 | DAVIS16J (↑) |
|---|---|
| 无 | 71.1 |
| 无 (使用鲁棒损失 [38]) | 74.0 |
| 缩放 | 73.8 |
| 残差 (仿射) | 76.3 |
| 残差 | 78.9 |
Table 4. The refinement CRF in our stage 2 is orthogonal to upsampling CRF in post-processing, since the latter still gives significant improvements even with CRF in stage 2.
表 4: 我们第二阶段中的精炼CRF与后处理中的上采样CRF是正交的,因为即使第二阶段使用了CRF,后者仍能带来显著提升。
| DAVIS16 J (↑) | 仅第一阶段 | 第一阶段 & 第二阶段 |
|---|---|---|
| 无后处理 | 78.9 | 80.9 |
| 使用CRF后处理 | 81.4 | 83.0 |
| △ | +2.5 | +2.1 |
Designing additional pathway. In Tab. 3, we show that robustness loss [22,38] does not effectively reduce the impact of misleading motion. We also implemented a pixel-wise scaling pathway, which multiplies each value of the motion vector by a predicted value. Furthermore, we fit an affine transformation per segmentation channel as the residual. In our setting, the pixel-wise residual performs the best and is selected for our model, showing the effectiveness of a learnable and flexible motion model inspired by relative motion. Orthogonality of our appearance supervision with postprocessing. The supervision from refined masks after appearance-based refinement has the same resolution as the original exported masks. Therefore, the refinement CRF in stage 2 has an orthogonal effect to the upsampling CRF in post-processing mainly used to create high-resolution masks. As shown in Tab. 4, the gains that come from postprocessing remain comparable after applying appearancebased refinement in stage 2, which also shows our orthogonality to post-processing.
设计额外通路。在表3中,我们表明鲁棒性损失 [22,38] 并不能有效减少误导性运动的影响。我们还实现了一个逐像素缩放通路,将运动向量的每个值乘以预测值。此外,我们为每个分割通道拟合了一个仿射变换作为残差。在我们的设置中,逐像素残差表现最佳并被选入模型,这体现了受相对运动启发的可学习灵活运动模型的有效性。
外观监督与后处理的正交性。经过基于外观的优化后,来自精细化掩模的监督与原始输出掩模具有相同分辨率。因此,第二阶段中的精细化CRF与主要用于生成高分辨率掩模的后处理上采样CRF具有正交效应。如表4所示,在第二阶段应用基于外观的优化后,后处理带来的增益仍保持相当水平,这也证明了我们方法与后处理的正交性。
Modeling camera motion? RCF does not explicitly model the flow from camera motion. To investigate whether modeling camera motion could further benefit RCF, we estimate it with the planar homography and RANSAC [12] and remove it as a preprocessing step prior to training our method. Despite the relatively accurate estimation when visualized, Tab. 5 shows that it is ineffective in improving the segmentation quality. We hypothesize that it is because 3D camera motion is equivalent to 3D scene motion in an opposite direction and thus additional modeling is unnecessary.
建模相机运动?RCF并未显式建模相机运动产生的光流。为探究建模相机运动能否进一步提升RCF性能,我们采用平面单应性矩阵和RANSAC [12] 进行运动估计,并将其作为预处理步骤在训练前剔除。尽管可视化显示运动估计相对准确,但表5表明该操作对分割质量提升无效。我们推测这是由于3D相机运动等同于反向的3D场景运动,因此无需额外建模。

Figure 7. Our method delivers great performance in challenging scenes. Our method shows significant improvements compared to OCLR [44] and AMD [23] in scenes with complex foreground motion (a)(b), distracting background motion (a)(c), motion parallax from camera motion (c). In the failure case (d), neither motion nor appearance information is informative, leading to the front legs being missed from the segmentation. However, our method still outperforms previous works and segments most of the cow’s hind legs. (e) shows that the piecewise-constant pathway and the residual pathway work together to fit the reference flow, resulting in high-quality segmentation. The symbol $^\dagger$ denotes AMD with RAFT flow [39] as motion supervision. More visualization s are available in the supp. mat.
图 7: 我们的方法在复杂场景中表现优异。相较于OCLR [44]和AMD [23],本方法在以下场景展现出显著提升:复杂前景运动(a)(b)、干扰性背景运动(a)(c)、摄像机运动导致的运动视差(c)。失败案例(d)中,由于运动和外观信息均不足,导致前腿未被分割。但我们的方法仍优于先前工作,成功分割了牛的大部分后腿。(e)显示分段恒定路径与残差路径协同拟合参考光流,从而获得高质量分割结果。符号$^\dagger$表示采用RAFT光流[39]作为运动监督的AMD版本。更多可视化结果详见补充材料。
Table 5. Modeling camera motion does not improve our method. Lower segmentation quality results from removing camera motion as preprocessing. Only stage 1 is used in both settings.
表 5: 相机运动建模未改进我们的方法。移除相机运动作为预处理会导致分割质量下降。两种设置均仅使用第一阶段。
| 相机运动建模 | 否 | 是 |
|---|---|---|
| DAVIS16 J (↑) | 78.9 | 77.9 |
4.5. Visualization s and Discussions
4.5. 可视化与讨论
Fig. 7 compares RCF with [23, 44] and shows its ability to handle challenging cases such as complex non-uniform foreground motion, distracting background motion, and camera motion including rotation. However, when neither motion nor appearance provides informative signals, RCF may suffer from the lack of information. For instance, in the absence of relative motion, RCF is misled by the similarity between the color of the cow’s front legs and the color of the ground in Fig. 7(d). Although RCF has the ability to recognize multiple foreground objects with similar motion, it sometimes captures only one object when the objects move in very different patterns. Finally, RCF is not designed to separate multiple foreground objects. More visualization s and discussions are available in the supp. mat.
图 7 将 RCF 与 [23, 44] 进行对比,展示了其处理复杂非均匀前景运动、干扰性背景运动以及包含旋转的相机运动等挑战性案例的能力。然而,当运动和外观均未提供有效信息时,RCF 可能会因信息不足而表现不佳。例如,在没有相对运动的情况下,图 7(d) 中奶牛前腿颜色与地面颜色的相似性会误导 RCF。尽管 RCF 能够识别具有相似运动的多个前景物体,但当物体运动模式差异较大时,有时仅能捕捉到一个物体。最后,RCF 并非为分离多个前景物体而设计。更多可视化结果和讨论详见补充材料。
5. Summary
5. 总结
We present RCF, an unsupervised video object segmentation method based on relaxed common fate and appearance grouping. Our approach includes a motion-supervised object discovery stage with a learnable residual pathway, a refinement stage with appearance supervision, and using motion-appearance alignment as a label-free hyperparameter tuning method. Extensive experiments show our method’s effectiveness and utility in challenging scenarios. Acknowledgements. The authors would like to thank Zilin
我们提出RCF,一种基于松弛共命运 (relaxed common fate) 和外观分组的无监督视频目标分割方法。该方法包含三个核心阶段:采用可学习残差通路的运动监督目标发现阶段、外观监督的优化阶段,以及将运动-外观对齐作为无标签超参数调优方法。大量实验表明,该方法在复杂场景中具有显著的有效性和实用性。致谢。作者感谢Zilin
Wang for proofreading this paper.
Wang 为本文进行了校对。
6. Additional Visualization s and Discussions
6. 其他可视化与讨论
We present additional visualization s on the three main datasets that we benchmark our method on [1, 20, 31, 33]. We demonstrate high-quality segmentation in several challenging cases and discuss some limitations of our method with examples.
我们在三个主要基准数据集[1, 20, 31, 33]上展示了更多可视化结果。通过多个具有挑战性的案例,我们展示了高质量的分割效果,并通过示例讨论了方法的若干局限性。
6.1. Visualization s of the Residual Pathway
6.1. 残差路径的可视化
As shown in Fig. 8, the introduction of the residual pathway allows our segmentation prediction to better fit the flow of deformable and articulated objects. In addition, it also relieves our segmentation module from strictly fitting the flow from 3D rotation and changing depth in a piecewise constant manner. By modeling relative motion in 2D flow, the residual pathway makes our method flexible and robust to objects with complex motion.
如图 8 所示,残差路径(residual pathway)的引入使我们的分割预测能更好地适应可变形和铰接物体的运动。此外,它还减轻了分割模块对分段恒定方式下严格拟合3D旋转和深度变化的依赖。通过2D光流中的相对运动建模,残差路径使我们的方法对具有复杂运动物体的处理更加灵活和鲁棒。
6.2. DAVIS2016, SegTrackv2, and FBMS59
6.2. DAVIS2016、SegTrackv2 和 FBMS59
We visualize our methods on DAVIS2016, SegTrackv2, and FBMS59 in Fig. 9, Fig. 10, and Fig. 11, respectively. Our method shows great robustness in challenging scenes where there is insufficient motion information, due to its ability to leverage both motion and appearance.
我们在图 9、图 10 和图 11 中分别展示了在 DAVIS2016、SegTrackv2 和 FBMS59 数据集上的方法可视化效果。由于能够同时利用运动和外观信息,我们的方法在运动信息不足的挑战性场景中表现出极强的鲁棒性。
7. Additional Experiments
7. 补充实验
Unless otherwise stated, all the ablation experiments in this section include only stage 1, as the ablations in this section are not relevant to the appearance supervision. Results are without post-processing.
除非另有说明,本节所有消融实验仅包含第一阶段,因为本节消融内容与外观监督无关。结果均未经过后处理。
7.1. Abltion on Different Optical Flow Estimation Methods
7.1. 不同光流估计方法的消融实验
As listed in Tab. 6, almost all recent UVOS works rely on a separate optical flow model pretrained on synthetic data. We use RAFT [39] flow by default, following previous works in UVOS. AMD trains [38] from scratch but achieves much lower mIoU.
如表 6 所示,几乎所有最近的 UVOS 工作都依赖于在合成数据上预训练的单独光流模型。我们默认使用 RAFT [39] 光流,遵循之前 UVOS 的研究。AMD 从头开始训练 [38],但获得的 mIoU 要低得多。
To evaluate our method’s robustness to optical flow estimation methods, we evaluate our method on PWCNet [38], GMFlow [45], and self-supervised ARFlow [22], in addition to RAFT [39].
为了评估我们的方法对光流估计方法的鲁棒性,除了 RAFT [39] 之外,我们还在 PWCNet [38]、GMFlow [45] 和自监督 ARFlow [22] 上进行了测试。
As shown in Tab. 7, our method suffers from a mild drop with noisier optical flow. However, our performance is largely retained without tuning the hyper parameters when employing other optical flow methods. We believe the performance gap between different optical flow estimation methods will be reduced further with additional hyperparameter tuning on each flow estimation method.
如表 7 所示,我们的方法在光流噪声较大时会出现轻微的性能下降。然而,在使用其他光流方法时,即使不调整超参数,我们的性能也能基本保持。我们相信,通过对每种光流估计方法进行额外的超参数调优,不同光流估计方法之间的性能差距将进一步缩小。
| 方法 | CIS | MG | EM | SIMO | Tok.Cut | GWMOCLR | RCF | |
|---|---|---|---|---|---|---|---|---|
| FlowModelPWCNetRAFT | RAFT | RAFT | RAFT | RAFT | RAFT |
Table 6. Optical flow methods that each UVOS approach employs by default. All methods in the table use pretrained weights for flow estimation. We utilize RAFT flow with pretrained weights from synthetic data, which is common among all the UVOS methods. Other than the methods listed in the table, AMD trains PWCNet [38] architecture from scratch but achieves much lower performance compared to RCF.
表 6: 各UVOS方法默认采用的光流方法。表中所有方法均使用预训练权重进行光流估计。我们采用基于合成数据预训练的RAFT光流,这是所有UVOS方法的共同选择。除表列方法外,AMD从头训练PWCNet [38]架构,但其性能远低于RCF。
Table 7. Our method with different optical flow estimation methods. We use pretrained optical flow on synthetic data for supervised optical flow methods. We benchmark stage 1 only since we leverage motion supervision mostly in stage 1.
表 7: 采用不同光流估计方法的实验结果。对于有监督光流方法,我们使用在合成数据上预训练的光流。由于主要在阶段1利用运动监督,因此仅对阶段1进行基准测试。
| 方法 | ARFlow[22] | PWCNet[38] | GMFlow[45] | RAFT[39] |
|---|---|---|---|---|
| DAVIS16 7(↑) | 70.3 | 74.8 | 76.6 | 78.9 |
7.2. Preventing Trivial Solutions for Residual Flow Prediction
7.2. 防止残差流预测的平凡解
There are two factors that prevent trivial solutions: 1) Regular iz ation with upper bound $\lambda$ limits the residual prediction to only capturing small relative motion (10 pixels by default). 2) The residual flow branch is initialized to be small, which favors the solution to be simple motion patterns.
防止出现简单解的两个因素:1) 使用上界 $\lambda$ 的正则化将残差预测限制为仅捕获较小的相对运动(默认为10像素)。2) 残差流分支初始化为较小值,这有利于形成简单运动模式的解。
As shown in Tab. 8, the results (mIoU on DAVIS16) show that small residual initialization allows RCF to be insensitive to a large range of $\lambda$ against performance degradation or collapses, even though setting $\lambda$ too large will still cause instability in the form of large mIoU fluctuations. With small residual initialization, $\lambda$ is relatively stable to tune.
如表 8 所示,结果(DAVIS16 上的 mIoU)表明,小残差初始化使 RCF 对较大范围的 $\lambda$ 不敏感,即使 $\lambda$ 设置过大仍会导致 mIoU 大幅波动形式的不稳定性。采用小残差初始化时,$\lambda$ 的调节相对稳定。
7.3. Applying Motion-appearance Alignment to Non-method Specific Hyper parameters
7.3. 运动-外观对齐在非方法特定超参数中的应用
To explore the possibility of using our proposed labelfree hyper parameter tuning method to tune hyper para meters that are non-method specific, we evaluate our metric on runs with three different weight decay values: $10^{-6}$ and $10^{-2}$ in addition to our default value of $10^{-4}$ . We choose this range of hyper parameter values since we observed that varying the weight decay by smaller amounts had a negligible impact on the final mIoU. As in other hyper parameter tuning experiments, we randomly sample $25%$ of the sequences from the validation set three times and evaluate the effect of using a smaller labeled validation subset for comparison. Shown in Tab. 9, while the mIoU values from the labeled validation subsets vary significantly between samplings, with one of the three runs missing the optimal value, our metric follows the full validation mIoU trend and selects the best hyper parameter values among the three.
为了探索使用我们提出的无标签超参数调优方法来调整非方法特定超参数的可能性,我们在三种不同权重衰减值($10^{-6}$、$10^{-2}$以及默认值$10^{-4}$)的运行中评估了该指标。选择这一超参数范围是因为我们观察到,更小幅度的权重衰减变化对最终mIoU的影响可以忽略不计。与其他超参数调优实验类似,我们从验证集中随机抽取$25%$的序列进行三次采样,并评估使用较小标注验证子集的效果以作对比。如表9所示,虽然标注验证子集的mIoU值在采样间存在显著波动(三次运行中有一次未命中最优值),但我们的指标始终遵循完整验证mIoU的趋势,并在三者中选出最佳超参数值。
Table 8. Using a small initialization and upper bound is important for the residual flow pathway in our method. Ours Init refers to an initialization scheme which is $10\mathrm{x}$ smaller than PyTorch default init. Red color indicates collapses.
表 8: 采用较小的初始值和上限对我们的残差流路径方法至关重要。Ours Init 指比 PyTorch 默认初始化小 $10\mathrm{x}$ 的初始化方案。红色标注表示崩溃情况。
| 上限 λ | 1 | 5 | 10 | 20 | 50 | 100 | 200 | 400 |
|---|
Table 9. Applying motion-appearance alignment provides the optimal weight decay without using labels. In contrast, using subset mIoU misses the optimal value in one of the three runs. Higher metric values indicate higher segmentation quality for all metrics.
表 9: 应用运动-外观对齐可在不使用标签的情况下获得最佳权重衰减值。相比之下,使用子集mIoU在三次实验中有一次未能达到最优值。所有指标中,数值越高代表分割质量越好。
| WeightDecay | 10-6 | 10-4 | 10-2 |
|---|---|---|---|
| Motion-app. Alignment | -0.672 | -0.670 | -0.768 |
| Subset1mloU | 77.2 | 77.6 | 75.7 |
| Subset2mIoU | 77.0 | 80.5 | 72.0 |
| Subset3mloU | 77.3 | 76.8 | 76.2 |
| FullvalmIoU | 77.2 | 78.9 | 74.8 |
8. Pseudo-code for Hyper parameter Tuning With Motion-appearance Alignment
8. 基于运动-外观对齐的超参数调优伪代码
We present the pseudo-code for hyper parameter tuning with motion-appearance alignment in Algorithm 1.
我们在算法1中给出了运动-外观对齐的超参数调优伪代码。
9. Additional Implementation Details
9. 其他实现细节
Our setting mostly follows previous works [6, 23]. Following the official implementation in [23], we treat the video frame pair ${t,t+1}$ as both a forward action from time $t$ to time $t+1$ and a backward action from time $t+1$ and $t$ , since they follow similar rules for visual grouping. Therefore, we use this to implement a symmetric loss that applies the loss function on both forward and backward. We then sum the forward loss and backward loss up to obtain the final loss. Note that this could be understood as a data augmentation technique that always supplies a pair in forward and backward to the training batch. However, since our ResNet shares weights for each image input, the feature for each input is reused by the forward and backward action. Furthermore, our residual prediction head has four times the number of channels of the segmentation head to separately predict the forward/backward flow in horizontal/vertical directions, due to its better performance. Thus, the symmetric loss only adds marginal computation and is included in our implementation as well.
我们的设置主要遵循先前的工作 [6, 23]。按照 [23] 中的官方实现,我们将视频帧对 ${t,t+1}$ 同时视为从时间 $t$ 到时间 $t+1$ 的前向动作和从时间 $t+1$ 到时间 $t$ 的后向动作,因为它们遵循相似的视觉分组规则。因此,我们利用这一点实现了一个对称损失函数,在前向和后向同时应用损失函数。随后,我们将前向损失和后向损失相加得到最终损失。需要注意的是,这可以理解为一种数据增强技术,始终为训练批次提供前向和后向的帧对。然而,由于我们的 ResNet 对每个图像输入共享权重,每个输入的特征会被前向和后向动作复用。此外,由于性能更优,我们的残差预测头的通道数是分割头的四倍,以便分别预测水平/垂直方向的前向/后向光流。因此,对称损失仅增加了少量计算量,也被纳入我们的实现中。
Furthermore, following [23], for DAVIS16, we use random crop augmentation during training to crop a square image from the original image. At test time, we directly input the original image, which is non-square. It is worth noting that the augmentation makes the image size different for training and testing, but as ResNet [13] takes images of different sizes, this does not pose a problem empirically. In STv2 and FBMS59, the images have very different aspect ratios (some having a height lower than the width), and thus we resize the images to $480\mathrm{p}$ as a preprocessing before the standard pipeline. We additionally use pixel-wise photometric transformation [7] for augmentation with the default hyper parameters for this augmentation.
此外,遵循[23]的方法,对于DAVIS16数据集,我们在训练期间使用随机裁剪增强技术,从原始图像中裁剪出正方形区域。测试时则直接输入非正方形的原始图像。值得注意的是,这种增强方式会导致训练和测试阶段的图像尺寸不同,但由于ResNet[13]能够处理不同尺寸的输入,实验表明这不会造成问题。在STv2和FBMS59数据集中,图像的长宽比差异较大(部分图像高度小于宽度),因此我们在标准流程前将图像统一缩放到$480\mathrm{p}$作为预处理步骤。此外,我们还采用默认超参数的像素级光度变换[7]进行数据增强。
算法 1: 基于运动-外观对齐的超参数调优伪代码
输入: 包含N帧的图像序列{I}
输入: 不同超参数值的设置集合{s}
输出: 根据运动-外观对齐选择的最优设置S*
对于{s}中的每个设置S:
- 使用设置S训练模型
- 通过训练好的模型获取预测掩码{M}
- 对于{I}和{M}中的每帧-掩码对(I, M):
- 从冻结的ViT特征计算亲和度A:
Aij = 1(sim(faux(It)i, faux(It)j) ≥ 0.2) - 计算预测前景与背景间的割(Cut):
x ← 展平(M)
Cut(A,x) = (1 - x)Ax - 计算预测前景与背景间的归一化割(NCut)
- 从冻结的ViT特征计算亲和度A:
As for the architecture, we found that simply taking the feature from the last ResNet stage provides insufficient detailed information for high-quality output. Instead of incorporating a more complicated segmentation head (e.g., [3] in [6]), we chose to keep our architecture easy to implement by only changing the head in a simple fashion. Following the standard approach of multi-scale feature fusion, we resized and concatenated the feature from the first residual block and the last residual block in ResNet, which allows the feature to jointly capture high-level information and low-level details. Note that such fusion is only applied to the segmentation head, and residual prediction is simply bilinearly upsampled. Due to lower image resolution, no feature merging is performed for STv2 in stage 1. Following [6], we load self-supervised ImageNet pretrained weights learned without annotation, since the training video datasets are too small for learning general iz able feature (e.g., DAVIS16/STv2/FBMS59 has only 3,455/976/13,860 frames), with DenseCL weights [35, 42] on ResNet50 for our method. This can be replaced by training on uncurated Youtube-VOS [46] with our training process, as in [23], so that one implementation can be used throughout training for simplicity in real-world applications.
在架构方面,我们发现直接从ResNet最后一阶段提取特征无法为高质量输出提供足够的细节信息。与采用更复杂的分割头(如[6]中的[3])不同,我们选择仅以简单方式修改头部来保持架构易于实现。遵循多尺度特征融合的标准方法,我们对ResNet中第一个残差块和最后一个残差块的特征进行尺寸调整并拼接,使特征能同时捕获高层语义和底层细节。需注意此类融合仅应用于分割头,残差预测仅通过双线性上采样实现。由于图像分辨率较低,STv2在第一阶段不进行特征合并。参照[6],我们加载了无需标注的自监督ImageNet预训练权重(因训练视频数据集规模过小,难以学习通用特征,例如DAVIS16/STv2/FBMS59分别仅有3,455/976/13,860帧),本方法采用ResNet50上的DenseCL权重[35,42]。如[23]所示,可通过在未筛选的Youtube-VOS[46]上使用我们的训练流程替代该步骤,从而在实际应用中简化实现流程。
In our training, we follow [23] and use a batch size of 16 (with two images in a pair, and thus 32 images processed in each forward pass). Stage 1 and stage 2 take 200 and 40 epochs, respectively, for DAVIS16. We use a learning rate of $1\times10^{-4}$ with Adam optimizer [16] and polynomial decay (factor of 0.9, min learning rate of $1\times10^{-6}$ ). We set weight decay to $1\times10^{-4}$ for DAVIS and $1\times10^{-6}$ for STv2 and FBMS59. Due to the fact that normalized cuts is slow to optimize, we split stage 2 into two sub-stages: one with the CRF followed by one with normalized cuts optimization, each of the stage has the same number of training steps. In the CRF substage in stage 2, we set $w_{\mathrm{motion}}=1$ and $w_{\mathrm{app}}=10$ to balance the two losses. However, we observe training instability if we supervise the network directly by its output refined by the CRF. Therefore, we apply exponential moving averaging (EMA) to the model weights and supervise the network by the output from the EMA model, with momentum $m=0.999$ . In the normalized cuts substage, we pre-generate the network’s outputs and use the refinement as described in the methods section, which involves running CRF before and after normalized cuts refinement and multiplying the refined masks from the two CRF runs. This is equivalent to applying such refinement with EMA with $m=1.0$ . In this substage, we set $w_{\mathrm{motion}}=0.1$ and $w_{\mathrm{app}}=2.0$ .
在我们的训练中,遵循[23]的方法,使用批量大小为16(每对包含两张图像,因此每次前向传播处理32张图像)。对于DAVIS16数据集,阶段1和阶段2分别训练200和40个周期。我们采用Adam优化器[16],初始学习率为$1\times10^{-4}$,并应用多项式衰减(衰减因子0.9,最小学习率$1\times10^{-6}$)。权重衰减设置为:DAVIS数据集$1\times10^{-4}$,STv2和FBMS59数据集$1\times10^{-6}$。由于归一化割(normalized cuts)优化速度较慢,我们将阶段2拆分为两个子阶段:先进行CRF优化,再进行归一化割优化,每个子阶段的训练步数相同。在阶段2的CRF子阶段,设置$w_{\mathrm{motion}}=1$和$w_{\mathrm{app}}=10$以平衡两项损失。但发现直接通过CRF精修后的输出监督网络会导致训练不稳定,因此对模型权重采用指数移动平均(EMA)(动量$m=0.999$),通过EMA模型的输出监督网络。在归一化割子阶段,预生成网络输出后按方法章节所述进行精修:先在归一化割精修前后运行CRF,再将两次CRF得到的精修掩码相乘。这等效于采用$m=1.0$的EMA精修方式。该子阶段设置$w_{\mathrm{motion}}=0.1$和$w_{\mathrm{app}}=2.0$。
eral objects with motion and appearance input to provide signals to train the model. Another potential approach is to over-split the scene with many object channels and use other unsupervised methods such as FreeSOLO [41, 42] to obtain coarse segmentation proposals to merge the channels to form object instance segmentation.
通过输入运动与外观信息的多个对象为模型训练提供信号。另一种潜在方法是利用FreeSOLO [41, 42]等无监督方法对场景进行过度分割,生成大量对象通道后合并通道以获得粗粒度分割提案,最终形成对象实例分割。
10. Per-sequence Results
10. 单序列结果
We list our per-sequence results on DAVIS16 [33], STv2 [20], FBMS59 [1, 31] in Tab. 10, Tab. 11, and Tab. 12, respectively. The results are with post-processing.
我们在表 10、表 11 和表 12 中分别列出了在 DAVIS16 [33]、STv2 [20] 和 FBMS59 [1, 31] 上的逐序列结果。这些结果均经过后处理。
11. Future Directions
11. 未来方向
As our method does not impose temporal consistency, it does not effectively leverage information redundancy from neighboring frames. Using such information could make our method more robust in dealing with frames that provide insufficient motion and appearance information. Temporal consistency measures, such as matching warped predictions, could be incorporated as an additional loss term or as post-processing, as in [49].
由于我们的方法未施加时间一致性约束,因此无法有效利用相邻帧的信息冗余。利用这类信息可使我们的方法在处理运动与外观信息不足的帧时更具鲁棒性。时间一致性度量(如匹配变形预测结果)可作为额外损失项或后处理步骤引入,如[49]所述。
Furthermore, our method currently does not support segmenting multiple parts of the foreground or identifying each object instance. To address this, methods such as normalized cuts [37] could be used to split the foreground into sev
此外,我们当前的方法不支持分割前景的多个部分或识别每个对象实例。为解决这一问题,可采用归一化切割 [37] 等方法将前景分割为多个部分。
Table 10. Per sequence Jaccard index $\mathcal{I}$ on DAVIS16 [33].
表 10. DAVIS16 [33] 数据集上各序列的 Jaccard 指数 $\mathcal{I}$。
| 序列 | J |
|---|---|
| blackswan | 76.2 |
| bmx-trees | 78.3 |
| breakdance | 86.1 |
| camel | 92.7 |
| car-roundabout | 80.7 |
| car-shadow | 80.4 |
| cows | 88.0 |
| dance-twirl | 90.4 |
| sop | 91.7 |
| drift-chicane | 94.1 |
| drift-straight | 65.6 |
| goat | 81.6 |
| horsejump-high | 93.4 |
| kite-surf | 53.1 |
| libby | 96.6 |
| motocross-jump | 57.0 |
| paragliding-launch | 26.0 |
| parkour | 95.8 |
| scooter-black | 72.4 |
| soapbox | 86.1 |
| Frame Avg | 83.0 |
Table 11. Per sequence Jaccard index $\mathcal{I}$ on STv2 [20].
表 11. STv2数据集[20]上每段序列的Jaccard指数$\mathcal{I}$。
| 序列 | J |
|---|---|
| bird of paradise | 91.7 |
| birdfall | 60.4 |
| bmx | 76.6 |
| cheetah | 52.4 |
| 86.3 | |
| frog | 82.2 |
| girl | 80.6 |
| hummingbird | 67.6 |
| monkey | 82.5 |
| monkeydog | 55.5 |
| parachute | 93.2 |
| penguin | 66.2 |
| soldier | 79.8 |
| worm | 85.6 |
| 帧平均 | 79.6 |
Table 12. Per sequence Jaccard index $\mathcal{I}$ on FBMS59 [1, 31].
表 12. FBMS59 [1, 31] 数据集上每段序列的 Jaccard 指数 $\mathcal{I}$。
| 序列 | J |
|---|---|
| camel01 | 88.3 |
| cars1 | 86.4 |
| cars10 | 38.2 |
| cars4 | 70.3 |
| cars5 | 79.3 |
| cats01 | 88.2 |
| cats03 | 82.0 |
| cats06 | 59.7 |
| dogs01 | 74.4 |
| dogs02 | 91.6 |
| farm01 | 82.6 |
| giraffes01 | 65.9 |
| goats01 | 89.8 |
| horses02 | 86.2 |
| horses04 | 88.6 |
| horses05 | 71.6 |
| lion01 | 84.9 |
| marple12 | 79.3 |
| marple2 | 73.7 |
| marple4 | 87.8 |
| marple6 | 50.8 |
| marple7 | 32.1 |
| marple9 people03 | 38.4 42.9 |
| peoplel | 86.1 |
| people2 | 88.0 |
| rabbits02 | 93.8 |
| rabbits03 | 85.9 |
| rabbits04 | |
| 20.2 | |
| tennis | 78.6 |
| 帧平均 | 72.4 |

Figure 8. Visualization s for both the piecewise constant and the residual pathways show that the introduction of the residual pathway allows our segmentation prediction to better fit the flow of deformable and articulated objects. In addition, it also relieves our segmentation module from strictly fitting the flow from 3D rotation and changing depth in a piecewise constant manner. By modeling relative motion in 2D flow, the residual pathway makes our method flexible and robust to objects with complex motion.
图 8: 分段常数路径与残差路径的可视化对比表明,残差路径的引入使我们的分割预测能更好地适应可变形和铰接物体的运动轨迹。此外,该设计还避免分割模块以分段常数方式严格拟合三维旋转和深度变化产生的光流。通过二维光流中的相对运动建模,残差路径使我们的方法对复杂运动物体具有灵活性和鲁棒性。

Figure 9. Additional visualization s on DAVIS16 [33]. Our method remains robust in scenes where there is insufficient motion information, in which cases our method leverages appearance cues to learn high-quality segmentation in (a) to (e). Our method accurately segments multiple foreground objects as foreground when they move together, which is consistent with human perception in (b). However, our method may exclude a portion of an object in (f), since the motion misses part of the front wheel of the bicycle and the structure is too small for appearance to capture.
图 9: DAVIS16 [33] 上的额外可视化结果。我们的方法在运动信息不足的场景中仍保持稳健,如 (a) 至 (e) 所示,此时方法通过外观线索学习高质量分割。当多个前景物体共同移动时,我们的方法能准确将其识别为前景,这与 (b) 中的人类感知一致。但在 (f) 中,由于自行车前轮部分缺失运动信息且结构过于微小难以通过外观捕捉,方法可能会遗漏物体的局部区域。

Figure 10. Additional visualization s on STv2 [20]. Our method, with the residual flow, could model non-uniform 2D flow resulting from object rotation in 3D in (a), as long as the rotation flow falls within our upper bound constraint for the residual flow. Our method also captures multiple objects in a foreground group in (b), (c), and (e). Our method is robust to camera motion that leads to non-uniform background flow in (c) and misleading common motion (reflections) in (d). However, due to the relatively low image resolution, our method may miss some details of the object. For example, the legs of both animals in (f) and the wings of the bird in (g).
图 10. STv2 [20] 上的额外可视化结果。我们的方法通过残差流能够建模 (a) 中由 3D 物体旋转导致的非均匀 2D 流,只要旋转流落在残差流的上界约束范围内。该方法还能在 (b)、(c) 和 (e) 中捕捉前景组中的多个物体。对于 (c) 中导致非均匀背景流的相机运动以及 (d) 中具有误导性的共同运动(反射),我们的方法表现出鲁棒性。但由于图像分辨率较低,该方法可能会遗漏部分物体细节,例如 (f) 中两只动物的腿部以及 (g) 中鸟类的翅膀。

Figure 11. Additional visualization s on FBMS59 [1, 31]. Our method is robust in scenes with complicated and distracting appearances in (a). Our method also works with fine details in (b) and (e). Our method accurately segments multiple foreground objects in (c) and (d). However, when multiple objects or object parts exist in one scene and exhibit different motion patterns, our method may be confused in (f) and (g).
图 11: FBMS59 [1, 31] 上的补充可视化结果。(a) 在具有复杂干扰外观的场景中,我们的方法表现稳健。(b) 和 (e) 展示了我们的方法对精细细节的处理能力。(c) 和 (d) 中,我们的方法能准确分割多个前景目标。然而,当场景中存在多个运动模式不同的物体或物体部件时,如 (f) 和 (g) 所示,我们的方法可能会出现混淆。