VISUALBERT: A SIMPLE AND PERFORMANT BASELINE FOR VISION AND LANGUAGE
VISUALBERT: 一种简单高效的视觉与语言基线模型
ABSTRACT
摘要
We propose VisualBERT, a simple and flexible framework for modeling a broad range of vision-and-language tasks. VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an associated input image with self-attention. We further propose two visually-grounded language model objectives for pre-training VisualBERT on image caption data. Experiments on four vision-and-language tasks including VQA, VCR, $\mathrm{NLVR^{2}}$ , and Flickr30K show that VisualBERT outperforms or rivals with state-of-the-art models while being significantly simpler. Further analysis demonstrates that VisualBERT can ground elements of language to image regions without any explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between verbs and image regions corresponding to their arguments.
我们提出VisualBERT,一个简单灵活的框架,用于建模广泛的视觉与语言任务。VisualBERT由一系列Transformer层组成,通过自注意力机制隐式对齐输入文本元素和关联输入图像区域。我们进一步提出两种视觉基础的语言模型目标,用于在图像描述数据上预训练VisualBERT。在VQA、VCR、$\mathrm{NLVR^{2}}$和Flickr30K等四个视觉与语言任务上的实验表明,VisualBERT在显著简化的同时,性能优于或媲美最先进模型。进一步分析显示,VisualBERT能在没有任何显式监督的情况下将语言元素关联到图像区域,甚至对句法关系敏感,例如追踪动词与其论元对应图像区域之间的关联。
1 INTRODUCTION
1 引言
Tasks combining vision and natural language serve as a rich test-bed for evaluating the reasoning capabilities of visually informed systems. Beyond simply recognizing what objects are present (Russakovsky et al., 2015; Lin et al., 2014), vision-and-language tasks, such as captioning (Chen et al., 2015), visual question answering (Antol et al., 2015), and visual reasoning (Suhr et al., 2019; Zellers et al., 2019), challenge systems to understand a wide range of detailed semantics of an image, including objects, attributes, parts, spatial relationships, actions and intentions, and how all of these concepts are referred to and grounded in natural language.
结合视觉与自然语言的任务为评估视觉系统的推理能力提供了丰富的测试平台。这些任务不仅限于识别图像中存在哪些物体 (Russakovsky et al., 2015; Lin et al., 2014),还包括图像描述生成 (Chen et al., 2015)、视觉问答 (Antol et al., 2015) 和视觉推理 (Suhr et al., 2019; Zellers et al., 2019) 等,它们挑战系统去理解图像中广泛的细节语义,包括物体、属性、部件、空间关系、动作与意图,以及所有这些概念如何通过自然语言进行指代和关联。
In this paper, we propose VisualBERT, a simple and flexible model designed for capturing rich semantics in the image and associated text. VisualBERT integrates BERT (Devlin et al., 2019), a recent Transformer-based model (Vaswani et al., 2017) for natural language processing, and pretrained object proposals systems such as Faster-RCNN (Ren et al., 2015) and it can be applied to a variety of vision-and-language tasks. In particular, image features extracted from object proposals are treated as unordered input tokens and fed into VisualBERT along with text. The text and image inputs are jointly processed by multiple Transformer layers in VisualBERT (See Figure 2). The rich interaction among words and object proposals allows the model to capture the intricate associations between text and image.
本文提出VisualBERT,这是一种简单灵活的模型,旨在捕捉图像及相关文本中的丰富语义。VisualBERT整合了BERT (Devlin et al., 2019) —— 一种基于Transformer (Vaswani et al., 2017) 的最新自然语言处理模型,以及预训练的目标检测系统(如Faster-RCNN (Ren et al., 2015)),可应用于多种视觉-语言任务。具体而言,从目标检测框提取的图像特征被视为无序输入token,与文本一起输入VisualBERT。文本和图像输入通过VisualBERT中的多个Transformer层进行联合处理(见图2)。单词与目标检测框之间的丰富交互使模型能够捕捉文本与图像之间的复杂关联。
Similar to BERT, pre-training VisualBERT on external resource can benefit downstream applications. In order to learn associations between images and text, we consider pre-training VisualBERT on image caption data, where detailed semantics of an image are expressed in natural language. We propose two visually-grounded language model objectives for pre-training: (1) part of the text is masked and the model learns to predict the masked words based on the remaining text and visual context; (2) the model is trained to determine whether the provided text matches the image. We show that such pre-training on image caption data is important for VisualBERT to learn transferable text and visual representations.
与BERT类似,在外部资源上对VisualBERT进行预训练可以提升下游应用性能。为了让模型学习图像与文本之间的关联,我们考虑在图像描述数据上对VisualBERT进行预训练,这类数据通过自然语言详细表达了图像语义。我们提出两种基于视觉的语言模型预训练目标:(1) 对部分文本进行掩码处理,模型根据剩余文本和视觉上下文预测被掩码词汇;(2) 训练模型判断给定文本是否与图像匹配。实验表明,这种基于图像描述数据的预训练对VisualBERT学习可迁移的文本与视觉表征至关重要。
We conduct comprehensive experiments on four vision-and-language tasks: (1) visual question answering (VQA 2.0, Goyal et al. (2017)), (2) visual commonsense reasoning (VCR, Zellers et al.
我们在四项视觉与语言任务上进行了全面实验:(1) 视觉问答 (VQA 2.0, Goyal et al. (2017)),(2) 视觉常识推理 (VCR, Zellers et al.
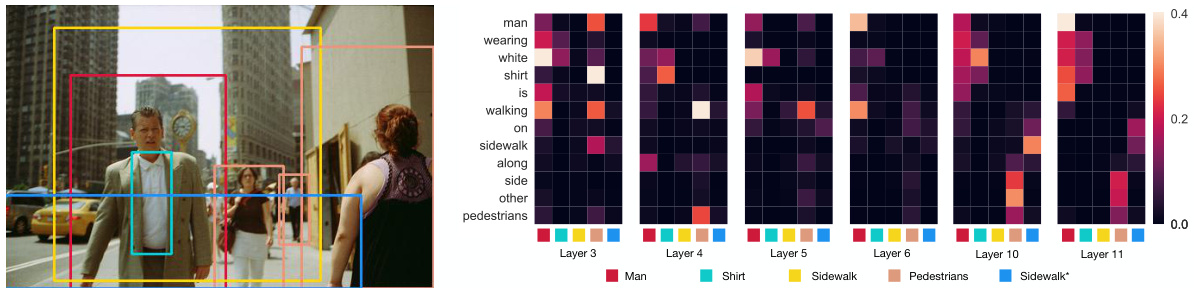
Figure 1: Attention weights of some selected heads in VisualBERT. In high layers (e.g., the 10- th and 11-th layer), VisualBERT is capable of implicitly grounding visual concepts (e.g., “other pedestrians” and “man wearing white shirt”). The model also captures certain syntactic dependency relations (e.g., “walking” is aligned to the man region in the 6-th layer). The model also refines its understanding over the layers, incorrectly aligning “man” and “shirt” in the 3-rd layer but correcting them in higher layers. (See more details in §5.3.)
图 1: VisualBERT中部分选定注意力头的权重分布。在高层(如第10层和第11层),VisualBERT能够隐式地关联视觉概念(例如"其他行人"和"穿白衬衫的男子")。该模型还捕获了某些句法依赖关系(如第6层中"行走"与男子区域的对齐)。模型还会随着层数加深而修正理解,例如在第3层错误对齐"男子"和"衬衫",但在更高层中进行了修正。(详见§5.3节)
(2019)), (3) natural language for visual reasoning $\mathrm{(NLVR^{2}}$ , Suhr et al. (2019)), and (4) regionto-phrase grounding (Flickr30K, Plummer et al. (2015)). Results demonstrate that by pre-training VisualBERT on the COCO image caption dataset (Chen et al., 2015), VisualBERT outperforms or rivals with the state-of-the-art models. We further provide detailed ablation study to justify our design choices. Further quantitative and qualitative analysis reveals how VisualBERT allocates attention weights to align words and image regions internally. We demonstrate that through pre-training, VisualBERT learns to ground entities and encode certain dependency relationships between words and image regions, which attributes to improving the model’s understanding on the detailed semantics of an image (see an example in Figure 1).
(2019)), (3) 视觉推理自然语言任务 (NLVR², Suhr等人 (2019)), 以及 (4) 区域到短语定位任务 (Flickr30K, Plummer等人 (2015))。实验结果表明,通过在COCO图像标题数据集 (Chen等人, 2015) 上对VisualBERT进行预训练,其性能超越或匹敌当前最先进的模型。我们进一步提供了详细的消融研究以验证设计选择。定量与定性分析揭示了VisualBERT如何通过分配注意力权重来实现词语与图像区域的内在对齐。研究表明,通过预训练,VisualBERT能够学习实体定位并编码词语与图像区域间的特定依赖关系,这有助于提升模型对图像细节语义的理解 (示例见图1)。
2 RELATED WORK
2 相关工作
There is a long research history of bridging vision and language. Various tasks such as visual question answering (Antol et al., 2015; Goyal et al., 2017), textual grounding (Kazemzadeh et al., 2014; Plummer et al., 2015), and visual reasoning (Suhr et al., 2019; Zellers et al., 2019) have been proposed and various models (Yang et al., 2016; Anderson et al., 2018; Jiang et al., 2018) have been developed to solve them. These approaches often consist of a text encoder, an image feature extractor, a multi-modal fusion module (typically with attention), and an answer classifier. Most models are designed for specific tasks, while VisualBERT is general and can be easily adapted to new tasks or incorporated into other task-specific models.
连接视觉与语言的研究由来已久。视觉问答 (Antol et al., 2015; Goyal et al., 2017)、文本定位 (Kazemzadeh et al., 2014; Plummer et al., 2015) 和视觉推理 (Suhr et al., 2019; Zellers et al., 2019) 等多种任务相继被提出,并开发了各类模型 (Yang et al., 2016; Anderson et al., 2018; Jiang et al., 2018) 来解决这些问题。这些方法通常包含文本编码器、图像特征提取器、多模态融合模块(通常带有注意力机制)和答案分类器。大多数模型专为特定任务设计,而 VisualBERT 具有通用性,能轻松适配新任务或整合到其他任务专用模型中。
Understanding detailed semantics depicted in an image is critical for visual understanding (Johnson et al., 2015) and prior studies show that modeling such semantics can benefit visual-an-language models. For instance, attribute annotations in Visual Genome (Krishna et al., 2017) are used to enhance the object detector in VQA systems (Anderson et al., 2018). Santoro et al. (2017), NorcliffeBrown et al. (2018), and Cadene et al. (2019) explore using an attention module to implicitly model the relations between objects in the image. Li et al. (2019) take a further step and explicitly build a graph to encode object relations. In VisualBERT, the self-attention mechanism allows the model to capture the implicit relations between objects. Furthermore, we argue that pre-training on image caption data is an effective way to teach the model how to capture such relations.
理解图像中描绘的细节语义对于视觉理解至关重要 (Johnson et al., 2015)。先前研究表明,建模此类语义能提升视觉-语言模型的性能。例如,Visual Genome (Krishna et al., 2017) 中的属性标注被用于增强VQA系统中的目标检测器 (Anderson et al., 2018)。Santoro et al. (2017)、NorcliffeBrown et al. (2018) 和 Cadene et al. (2019) 探索了使用注意力模块隐式建模图像中物体间关系的方法。Li et al. (2019) 更进一步,显式构建图结构来编码物体关系。在VisualBERT中,自注意力机制使模型能够捕捉物体间的隐式关联。此外,我们认为在图像描述数据上进行预训练是教会模型捕获此类关系的有效方式。
Our work is inspired by BERT (Devlin et al., 2019), a Transformer-based representation model for natural language. It falls into a line of works (Peters et al., 2018; Radford et al., 2018; 2019) that learn a universal language encoder by pre-training with language modeling objective (i.e., predicting words that are masked out from the input based on the remaining context). Two concurrent studies resemble this paper. VideoBERT (Sun et al., 2019) transforms a video into spoken words paired with a series of images and applies a Transformer to learn joint representations. Their model architecture is similar to ours. However, VideoBERT is evaluated on captioning for cooking videos, while we conduct comprehensive analysis on a variety of vision-and-language tasks. Concurrently with our work, ViLBERT (Jiasen et al., 2019) proposes to learn joint representation of images and text using a BERT-like architecture but has separate Transformers for vision and language that can only attend to each-other (resulting in twice the parameters). They use a slightly different pre-training process on Conceptual Captions (Sharma et al., 2018) and conduct evaluation on four datasets, two of which are also considered in our work. Our results are consistent with theirs (our model outperforms on one out of the two intersecting tasks), but the methods are not wholly comparable because different visual representation and pre-training resource are used.
我们的工作受到BERT (Devlin et al., 2019) 的启发,这是一种基于Transformer的自然语言表征模型。它属于一系列通过语言建模目标(即根据剩余上下文预测输入中被遮蔽的单词)进行预训练来学习通用语言编码器的工作线 (Peters et al., 2018; Radford et al., 2018; 2019)。有两项同期研究与本文相似。VideoBERT (Sun et al., 2019) 将视频转换为与一系列图像配对的语音文字,并应用Transformer学习联合表征。他们的模型架构与我们的类似,但VideoBERT仅在烹饪视频的字幕生成任务上进行评估,而我们对多种视觉与语言任务进行了全面分析。与我们同期的工作ViLBERT (Jiasen et al., 2019) 提出使用类BERT架构学习图像和文本的联合表征,但采用视觉和语言分离的Transformer(导致参数量翻倍),两者仅能互相关注。他们在Conceptual Captions (Sharma et al., 2018) 上使用了稍有不同的预训练流程,并在四个数据集上进行评估,其中两个也在我们的工作中涉及。我们的结果与其一致(在两个交叉任务中我们的模型在一个任务上表现更优),但由于使用了不同的视觉表征和预训练资源,方法并不完全可比。
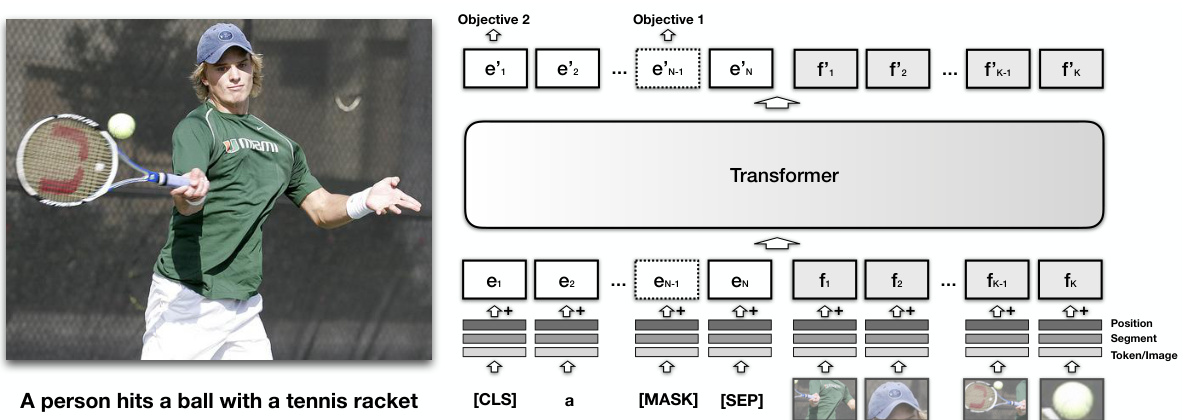
Figure 2: The architecture of VisualBERT. Image regions and language are combined with a Transformer to allow the self-attention to discover implicit alignments between language and vision. It is pre-trained with a masked language modeling (Objective 1), and sentence-image prediction task (Objective 2), on caption data and then fine-tuned for different tasks. See $\S3.3$ for more details.
图 2: VisualBERT架构。图像区域和语言通过Transformer结合,使自注意力机制能够发现语言与视觉之间的隐式对齐关系。该模型在字幕数据上通过掩码语言建模(目标1)和句子-图像预测任务(目标2)进行预训练,随后针对不同任务进行微调。更多细节参见$\S3.3$。
3 A JOINT REPRESENTATION MODEL FOR VISION AND LANGUAGE
3 一种视觉与语言的联合表征模型
In this section we introduce VisualBERT, a model for learning joint contextual i zed representations of vision and language. First we give background on BERT (§3.1), then summarize the adaptations we made to allow processing images and text jointly (§3.2), as seen in Figure 2, and finally explain our training procedure $(\S3.3)$ .
在本节中,我们将介绍 VisualBERT,这是一个用于学习视觉与语言联合上下文表征的模型。首先我们回顾 BERT 的背景 (第3.1节),然后总结我们为联合处理图像和文本所做的适配 (第3.2节),如图 2 所示,最后解释我们的训练流程 (第3.3节)。
3.1 BACKGROUND
3.1 背景
BERT (Devlin et al., 2019) is a Transformer (Vaswani et al., 2017) with subwords (Wu et al., 2016) as input and trained using language modeling objectives. All of the subwords in an input sentence are mapped to a set of embeddings, $E$ . Each embedding $e\in E$ is computed as the sum of 1) a token embedding $e_{t}$ , specific to the subword, 2) a segment embedding $e_{s}$ , indicating which part of text the token comes from (e.g., the hypothesis from an entailment pair) and 3) a position embedding $e_{p}$ , indicating the position of the token in the sentence. The input embeddings $E$ are then passed through a multi-layer Transformer that builds up a contextual i zed representation of the subwords.
BERT (Devlin et al., 2019) 是一种基于 Transformer (Vaswani et al., 2017) 的模型,以子词 (Wu et al., 2016) 作为输入,并通过语言建模目标进行训练。输入句子中的所有子词都被映射为一组嵌入向量 $E$。每个嵌入向量 $e\in E$ 由三部分相加计算得到:1) 特定于子词的 token 嵌入 $e_{t}$;2) 段嵌入 $e_{s}$,表示该 token 所属的文本部分(例如蕴含对中的假设);3) 位置嵌入 $e_{p}$,表示 token 在句子中的位置。输入嵌入 $E$ 随后通过多层 Transformer 处理,逐步构建子词的上下文表示。
BERT is commonly trained with two steps: pre-training and fine-tuning. Pre-training is done using a combination of two language modeling objectives: (1) masked language modeling, where some parts of the input tokens are randomly replaced with a special token (i.e., [MASK]), and the model needs to predict the identity of those tokens and (2) next sentence prediction, where the model is given a sentence pair and trained to classify whether they are two consecutive sentences from a document. Finally, to apply BERT to a particular task, a task-specific input, output layer, and objective are introduced, and the model is fine-tuned on the task data from pre-trained parameters.
BERT通常通过两个步骤进行训练:预训练和微调。预训练结合了两种语言建模目标:(1) 掩码语言建模(masked language modeling),即随机将输入token的部分内容替换为特殊token(如[MASK]),模型需预测这些token的原始内容;(2) 下一句预测(next sentence prediction),即给定句子对,模型需判断它们是否为文档中的连续句子。最终,为将BERT应用于特定任务,会引入任务相关的输入、输出层及目标函数,并基于预训练参数对任务数据进行微调。
3.2 VISUALBERT
3.2 VISUALBERT
The core of our idea is to reuse the self-attention mechanism within the Transformer to implicitly align elements of the input text and regions in the input image. In addition to all the components of BERT, we introduce a set of visual embeddings, $F$ , to model an image. Each $f\in F$ corresponds to a bounding region in the image, derived from an object detector.
我们方法的核心在于复用Transformer中的自注意力机制(self-attention),隐式对齐输入文本元素与输入图像区域。除了BERT的所有组件外,我们引入了一组视觉嵌入(visual embeddings) $F$ 来建模图像。每个 $f\in F$ 对应图像中由目标检测器(object detector)生成的边界区域。
Each embedding in $F$ is computed by summing three embeddings: (1) $f_{o}$ , a visual feature representation of the bounding region of $f$ , computed by a convolutional neural network, (2) $f_{s}$ , a segment embedding indicating it is an image embedding as opposed to a text embedding, and (3) $f_{p}$ , a position embedding, which is used when alignments between words and bounding regions are provided as part of the input, and set to the sum of the position embeddings corresponding to the aligned words (see VCR in $\S4_{,}$ ). The visual embeddings are then passed to the multi-layer Transformer along with the original set of text embeddings, allowing the model to implicitly discover useful alignments between both sets of inputs, and build up a new joint representation.1
$F$ 中的每个嵌入通过求和三个嵌入计算得到:(1) $f_{o}$,即 $f$ 边界区域的视觉特征表示,由卷积神经网络计算;(2) $f_{s}$,表示图像嵌入(与文本嵌入相对)的分段嵌入;(3) $f_{p}$,位置嵌入,当输入中提供单词与边界区域的对齐关系时使用,并设置为对齐单词对应位置嵌入的总和(参见 $\S4_{,}$ 中的 VCR)。随后,视觉嵌入与原始文本嵌入集合一起输入多层 Transformer,使模型能够隐式发现两组输入之间的有效对齐关系,并构建新的联合表示。1
3.3 TRAINING VISUALBERT
3.3 训练 VisualBERT
We would like to adopt a similar training procedure as BERT but VisualBERT must learn to accommodate both language and visual input. Therefore we reach to a resource of paired data: COCO (Chen et al., 2015) that contains images each paired with 5 independent captions. Our training procedure contains three phases:
我们计划采用与BERT类似的训练流程,但VisualBERT需要学会同时处理语言和视觉输入。为此,我们选择了成对数据资源:COCO (Chen et al., 2015),其中每张图像都配有5条独立描述文本。我们的训练流程包含三个阶段:
Task-Agnostic Pre-Training Here we train VisualBERT on COCO using two visually-grounded language model objectives. (1) Masked language modeling with the image. Some elements of text input are masked and must be predicted but vectors corresponding to image regions are not masked. (2) Sentence-image prediction. For COCO, where there are multiple captions corresponding to one image, we provide a text segment consisting of two captions. One of the caption is describing the image, while the other has a $50%$ chance to be another corresponding caption and a $50%$ chance to be a randomly drawn caption. The model is trained to distinguish these two situations.
任务无关的预训练
我们使用两个基于视觉的语言模型目标在COCO上训练VisualBERT。(1) 带图像的掩码语言建模。文本输入的部分元素被掩码并需要预测,但对应图像区域的向量不被掩码。(2) 句子-图像预测。对于一张图像对应多个描述的COCO数据集,我们提供一个包含两个描述的文本片段。其中一个描述与图像匹配,另一个描述有50%概率是另一条对应描述,50%概率是随机抽取的描述。模型需要学会区分这两种情况。
Task-Specific Pre-Training Before fine-tuning VisualBERT to a downstream task, we find it beneficial to train the model using the data of the task with the masked language modeling with the image objective. This step allows the model to adapt to the new target domain.
任务特定预训练
在将 VisualBERT 微调到下游任务之前,我们发现使用任务数据结合掩码语言建模 (masked language modeling) 和图像目标对模型进行训练是有益的。这一步骤使模型能够适应新的目标领域。
Fine-Tuning This step mirrors BERT fine-tuning, where a task-specific input, output, and objective are introduced, and the Transformer is trained to maximize performance on the task.
微调
这一步与 BERT 微调类似,会引入任务特定的输入、输出和目标,并训练 Transformer 以最大化任务性能。
4 EXPERIMENT
4 实验
We evaluate VisualBERT on four different types of vision-and-language applications: (1) Visual Question Answering (VQA 2.0) (Goyal et al., 2017), (2) Visual Commonsense Reasoning (VCR) (Zellers et al., 2019), (3) Natural Language for Visual Reasoning $\mathrm{(NLVR^{2}})$ ) (Suhr et al., 2019), and (4) Region-to-Phrase Grounding (Flickr30K) (Plummer et al., 2015), each described in more details in the following sections and the appendix. For all tasks, we use the Karpathy train split (Karpathy & Fei-Fei, 2015) of COCO for task-agnostic pre-training, which has around 100k images with 5 captions each. The Transformer encoder in all models has the same configuration as BERTBASE: 12 layers, a hidden size of 768, and 12 self-attention heads. The parameters are initialized from the pre-trained BERTBASE parameters released by Devlin et al. (2019).
我们在四种不同类型的视觉与语言应用上评估VisualBERT:(1) 视觉问答 (VQA 2.0) (Goyal et al., 2017) 、(2) 视觉常识推理 (VCR) (Zellers et al., 2019) 、(3) 视觉推理自然语言理解 $\mathrm{(NLVR^{2}})$ (Suhr et al., 2019) ,以及 (4) 区域到短语定位 (Flickr30K) (Plummer et al., 2015) ,每个任务的具体细节将在后续章节和附录中详细说明。对于所有任务,我们使用COCO的Karpathy训练集 (Karpathy & Fei-Fei, 2015) 进行任务无关的预训练,该数据集包含约10万张图像,每张图像配有5条描述。所有模型中的Transformer编码器均采用与BERTBASE相同的配置:12层网络结构,隐藏层维度为768,配备12个自注意力头。模型参数初始化采用Devlin等人 (2019) 发布的预训练BERTBASE参数。
For the image representations, each dataset we study has a different standard object detector to generate region proposals and region features. To compare with them, we follow their settings, and as a result, different image features are used for different tasks (see details in the subsections). 2 For consistency, during task-agnostic pre-training on COCO, we use the same image features as in the end tasks. For each dataset, we evaluate three variants of our model:
对于图像表征,我们研究的每个数据集都采用不同的标准物体检测器来生成区域提议和区域特征。为了与它们进行比较,我们遵循其设置,因此不同任务使用了不同的图像特征(详见各小节说明)。为保持一致性,在COCO数据集进行任务无关预训练时,我们采用与最终任务相同的图像特征。针对每个数据集,我们评估了模型的三个变体:
VisualBERT: The full model with parameter initialization from BERT that undergoes pre-training on COCO, pre-training on the task data, and fine-tuning for the task.
VisualBERT: 完整模型,参数初始化自BERT,经过COCO预训练、任务数据预训练和任务微调。
VisualBERT w/o Early Fusion: VisualBERT but where image representations are not combined with the text in the initial Transformer layer but instead at the very end with a new Transformer layer. This allows us to test whether interaction between language and vision throughout the whole Transformer stack is important to performance.
VisualBERT 无早期融合:VisualBERT 的一种变体,其图像表征不在初始 Transformer 层与文本结合,而是在最后通过一个新的 Transformer 层进行融合。这使我们能够测试语言和视觉在整个 Transformer 堆栈中的交互是否对性能至关重要。
VisualBERT w/o COCO Pre-training: VisualBERT but where we skip task-agnostic pre-training on COCO captions. This allows us to validate the importance of this step.
VisualBERT 无COCO预训练:指跳过COCO字幕任务无关预训练步骤的VisualBERT版本,用于验证该步骤的重要性。
Following Devlin et al. (2019), we optimize all models using SGD with Adam (Kingma & Ba, 2015). We set the warm-up step number to be $10%$ of the total training step count unless specified otherwise. Batch sizes are chosen to meet hardware constraints and text sequences whose lengths are longer than 128 are capped. Experiments are conducted on Tesla V100s and GTX 1080Tis, and all experiments can be replicated on at most 4 Tesla V100s each with 16GBs of GPU memory. Pre-training on COCO generally takes less than a day on 4 cards while task-specific pre-training and fine-tuning usually takes less. Other task-specific training details are in the corresponding sections.
遵循 Devlin 等人 (2019) 的方法,我们使用带有 Adam (Kingma & Ba, 2015) 的 SGD 优化所有模型。除非另有说明,否则我们将预热步数设置为总训练步数的 $10%$。选择批量大小以满足硬件限制,并将长度超过 128 的文本序列截断。实验在 Tesla V100 和 GTX 1080Ti 上进行,所有实验最多可在 4 块 16GB 显存的 Tesla V100 上复现。在 COCO 上的预训练通常只需不到一天(4 卡),而任务特定的预训练和微调通常耗时更短。其他任务特定的训练细节见相应章节。
4.1 VQA
4.1 视觉问答 (VQA)
Given an image and a question, the task is to correctly answer the question. We use the VQA 2.0 (Goyal et al., 2017), consisting of over 1 million questions about images from COCO. We train the model to predict the 3,129 most frequent answers and use image features from a ResNeXt-based Faster RCNN pre-trained on Visual Genome (Jiang et al., 2018). More details are in Appendix A.
给定一张图像和一个问题,任务是根据图像正确回答问题。我们采用VQA 2.0数据集 (Goyal et al., 2017),该数据集包含超过100万个关于COCO图像的提问。模型被训练用于预测3,129个最常见答案,并使用了基于ResNeXt的Faster RCNN提取的图像特征 (该模型在Visual Genome数据集上预训练 (Jiang et al., 2018))。更多细节详见附录A。
We report the results in Table 1, including baselines using the same visual features and number of bounding region proposals as our methods (first section), our models (second section), and other incomparable methods (third section) that use external question-answer pairs from Visual Genome $(+\mathrm{V}\mathrm{G})$ , multiple detectors (Yu et al., 2019a) (+Multiple Detectors) and ensembles of their models. In comparable settings, our method is significantly simpler and outperforms existing work.
我们在表1中报告了结果,包括使用与我们方法相同视觉特征和边界区域提议数量的基线方法(第一部分)、我们的模型(第二部分)以及其他不可比方法(第三部分)。这些不可比方法使用了来自Visual Genome $(+\mathrm{V}\mathrm{G})$ 的外部问答对、多个检测器 (Yu et al., 2019a) (+Multiple Detectors) 以及它们的模型集成。在可比较的设置下,我们的方法明显更简单且优于现有工作。
Table 1: Model performance on VQA. VisualBERT outperforms Pythia $\mathrm{v}0.1$ and v0.3, which are tested under a comparable setting.
表 1: VQA任务上的模型性能。VisualBERT在可比设置下优于Pythia $\mathrm{v}0.1$ 和v0.3。
| 模型 | Test-Dev | Test-Std |
|---|---|---|
| Pythia v0.1 (Jiang et al., 2018) | 68.49 | |
| Pythia v0.3 (Singh et al., 2019) | 68.71 | |
| VisualBERTw/oEarlyFusion | 68.18 | |
| VisualBERTw/oCOCOPre-training | 70.18 | |
| VisualBERT | 70.80 | 71.00 |
| Pythia v0.1 + VG + Other Data Augmentation (Jiang et al., 2018) | 70.01 | 70.24 |
| MCAN+VG (Yu et al., 2019b) | 70.63 | 70.90 |
| MCAN + VG + Multiple Detectors (Yu et al., 2019b) | 72.55 | |
| MCAN+VG +Multiple Detectors +BERT (Yu et al., 2019b) | 72.80 | |
| MCAN + VG + Multiple Detectors + BERT + Ensemble (Yu et al., 2019b) | 75.00 | 75.23 |
4.2 VCR
4.2 VCR
VCR consists of 290k questions derived from $110\mathrm{k\Omega}$ movie scenes, where the questions focus on visual commonsense. The task is decomposed into two multi-choice sub-tasks wherein we train individual models: question answering $(\mathrm{Q}\rightarrow\mathrm{A})$ ) and answer justification $(\mathrm{QA}\rightarrow\mathrm{R})$ ). Image features are obtained from a ResNet50 (He et al., 2016) and “gold” detection bounding boxes and segmentations provided in the dataset are used3. The dataset also provides alignments between words and bounding regions that are referenced to in the text, which we utilize by using the same position embeddings for matched words and regions. More details are in Appendix B.
VCR包含源自$110\mathrm{k\Omega}$电影场景的29万个问题,这些问题聚焦于视觉常识。该任务被分解为两个多选子任务,我们分别训练独立模型:问答任务$(\mathrm{Q}\rightarrow\mathrm{A})$和答案论证任务$(\mathrm{QA}\rightarrow\mathrm{R})$。图像特征通过ResNet50 (He et al., 2016)提取,并使用了数据集中提供的"黄金"检测边界框和分割结果。该数据集还提供了文本中提及的词语与边界区域的对齐关系,我们通过为匹配的词语和区域使用相同的位置嵌入来利用这一特性。更多细节见附录B。
Results on VCR are presented in Table 2. We compare our methods against the model released with the dataset which builds on BERT (R2C) and list the top performing single model on the leader board (B2T2). Our ablated VisualBERT w/o COCO Pre-training enjoys the same resource as R2C, and despite being significantly simpler, outperforms it by a large margin. The full model further improves the results. Despite substantial domain difference between COCO and VCR, with VCR covering scenes from movies, pre-training on COCO still helps significantly.
VCR数据集上的结果如表2所示。我们将本方法与基于BERT构建的基准模型R2C进行了对比,并列出了排行榜上性能最佳的单一模型B2T2。未经过COCO预训练的消融版VisualBERT模型与R2C使用相同资源,尽管结构大幅简化,却以显著优势超越后者。完整模型进一步提升了性能。虽然COCO与VCR存在显著领域差异(VCR包含电影场景),但COCO预训练仍带来显著提升。
Table 2: Model performance on VCR. VisualBERT w/o COCO Pre-training outperforms R2C, which enjoys the same resource while VisualBERT further improves the results.
表 2: VCR任务上的模型性能。未经COCO预训练的VisualBERT优于R2C,两者使用相同资源,而VisualBERT进一步提升了结果。
| 模型 | Q→A Dev | Test | QA→R Dev | Test | Q→AR Dev | Test |
|---|---|---|---|---|---|---|
| R2C (Zellers et al.,2019) | 63.8 | 65.1 | 67.2 | 67.3 | 43.1 | 44.0 |
| B2T2 (Leaderboard; Unpublished) | 72.6 | 75.7 | 55.0 | |||
| VisualBERTw/oEarlyFusion | 70.1 | 71.9 | 50.6 | |||
| VisualBERTw/oCOCOPre-training | 67.9 | 69.5 | 47.9 | |||
| VisualBERT | 70.8 | 71.6 | 73.2 | 73.2 | 52.2 | 52.4 |
4.3 NLVR2
4.3 NLVR2
$\mathrm{NLVR^{2}}$ is a dataset for joint reasoning about natural language and images, with a focus on semantic diversity, compositional it y, and visual reasoning challenges. The task is to determine whether a natural language caption is true about a pair of images. The dataset consists of over $100\mathrm{k}$ examples of English sentences paired with web images. We modify the segment embedding mechanism in VisualBERT and assign features from different images with different segment embeddings. We use an off-the-shelf detector from Detectron (Girshick et al., 2018) to provide image features and use 144 proposals per image.4 More details are in Appendix C.
$\mathrm{NLVR^{2}}$ 是一个用于联合推理自然语言与图像的数据集,其核心关注语义多样性、组合性和视觉推理挑战。该任务要求判断自然语言描述是否与一对图像内容相符。数据集包含超过 $100\mathrm{k}$ 个英语句子与网络图像的配对样本。我们改进了 VisualBERT 中的片段嵌入机制,为不同图像的特征分配不同的片段嵌入。使用 Detectron (Girshick et al., 2018) 提供的现成检测器提取图像特征,每张图像生成 144 个候选区域。更多细节详见附录 C。
Results are in Table 3. VisualBERT w/o Early Fusion and VisualBERT w/o COCO Pre-training surpass the previous best model MaxEnt by a large margin while VisualBERT widens the gap.
结果如表3所示。VisualBERT w/o Early Fusion和VisualBERT w/o COCO Pre-training以较大优势超越之前的最佳模型MaxEnt,而VisualBERT进一步扩大了这一差距。
| 模型 | Dev | Test-P | Test-U | Test-U(Cons) |
|---|---|---|---|---|
| MaxEnt (Suhr et al., 2019) | 54.1 | 54.8 | 53.5 | 12.0 |
| VisualBERT w/o Early Fusion | 64.6 | - | - | - |
| VisualBERT w/o COCO Pre-training | 63.5 | - | - | - |
| VisualBERT | 67.4 | 67.0 | 67.3 | 26.9 |
Table 3: Comparison with the state-of-the-art model on $\mathrm{NLVR^{2}}$ . The two ablation models significantly outperform MaxEnt while the full model widens the gap.
表 3: 在 $\mathrm{NLVR^{2}}$ 上与最先进模型的对比。两个消融模型显著优于 MaxEnt,而完整模型进一步扩大了优势。
4.4 FLICKR30K ENTITIES
4.4 FLICKR30K ENTITIES
Flickr30K Entities dataset tests the ability of systems to ground phrases in captions to bounding regions in the image. The task is, given spans from a sentence, selecting the bounding regions they correspond to. The dataset consists of $30\mathrm{k\Omega}$ images and nearly $250\mathrm{k}$ annotations. We adapt the setting of BAN (Kim et al., 2018), where image features from a Faster R-CNN pre-trained on Visual Genome are used. For task specific fine-tuning, we introduce an additional self-attention block and use the average attention weights from each head to predict the alignment between boxes and phrases. For a phrase to be grounded, we take whichever box receives the most attention from the last sub-word of the phrase as the model prediction. More details are in Appendix D.
Flickr30K Entities数据集测试系统将描述中的短语定位到图像边界区域的能力。该任务要求根据句子中的文本片段选择对应的边界区域。数据集包含$30\mathrm{k\Omega}$张图像和近$250\mathrm{k}$条标注。我们采用BAN (Kim et al., 2018)的设置,使用基于Visual Genome预训练的Faster R-CNN提取图像特征。针对任务特定微调,我们引入额外的自注意力模块,利用各注意力头的平均权重预测边界框与短语的对齐关系。对于待定位短语,模型将最后一个子词注意力权重最高的边界框作为预测结果。更多细节见附录D。
Results are listed in Table 4. VisualBERT outperforms the current state-of-the-art model BAN. In this setting, we do not observe a significant difference between the ablation model without early fusion and our full model, arguing that perhaps a shallower architecture is sufficient for this task.
结果如表 4 所示。VisualBERT 超越了当前最先进的模型 BAN。在此设置中,我们没有观察到去除早期融合的消融模型与完整模型之间存在显著差异,这表明或许较浅的架构就足以完成该任务。
5 ANALYSIS
5 分析
In this section we conduct extensive analysis on what parts of our approach are important to VisualBERT’s strong performance $(\S5.1)$ . Then we use Flickr30K as a diagnostic dataset to understand whether VisualBERT’s pre-training phase actually allows the model to learn implicit alignments between bounding regions and text phrases. We show that many attention heads within VisualBERT accurately track grounding information and that some are even sensitive to syntax, attending from verbs to the bounding regions corresponding to their arguments within a sentence $(\S_{\S}5.2)$ . Finally, we show qualitative examples of how VisualBERT resolves ambiguous groundings through multiple layers of the Transformer (§ 5.3).
在本节中,我们对VisualBERT优异性能的关键组成部分进行了全面分析(§5.1)。随后以Flickr30K作为诊断数据集,探究预训练阶段是否真正使模型学会边界框与文本短语的隐式对齐。实验表明,VisualBERT中许多注意力头能精确追踪视觉定位信息,部分甚至对句法敏感——例如从动词关注到句子中对应论元的边界区域(§5.2)。最后通过Transformer多层处理的定性示例,展示了VisualBERT如何解决歧义性视觉定位问题(§5.3)。
Table 4: Comparison with the state-of-the-art model on the Flickr30K. VisualBERT holds a clear advantage over BAN.
表 4: Flickr30K数据集上最新模型的对比结果。VisualBERT相比BAN具有明显优势。
| 模型 | R@1 | R@1 | R@5 | R@5 | R@10 | R@10 | UpperBound | UpperBound |
|---|---|---|---|---|---|---|---|---|
| Dev | Test | Dev | Test | Dev | Test | Dev | Test | |
| BAN (Kim et al., 2018) | 69.69 | 84.22 | 86.35 | 86.97 | 87.45 | |||
| VisualBERTw/oEarlyFusion | 70.33 | 84.53 | 86.39 | |||||
| VisualBERTw/oCOCOPre-training | 68.07 | 83.98 | 86.24 | 86.97 | 87.45 | |||
| VisualBERT | 70.40 | 71.33 | 84.49 | 84.98 | 86.31 | 86.51 |
Table 5: Performance of the ablation models on $\mathrm{NLVR^{2}}$ . Results confirm that task-agnostic pretraining (C1) and early fusion of vision and language (C2) are essential for VisualBERT.
表 5: 消融模型在 $\mathrm{NLVR^{2}}$ 上的性能。结果证实,任务无关的预训练 (C1) 以及视觉与语言的早期融合 (C2) 对 VisualBERT 至关重要。
| 模型 | Dev |
|---|---|
| VisualBERT | 66.7 |
| VisualBERT w/o Grounded Pre-training C1 | 63.9 |
| VisualBERT w/o COCO Pre-training | 62.9 |
| C2 VisualBERT w/o Early Fusion | 61.4 |
| C3 VisualBERT w/o BERT Initialization | 64.7 |
| C4 VisualBERT w/o Objective 2 | 64.9 |

Figure 3: Entity grounding accuracy of the attention heads of VisualBERT. The rule-based base- line is dawn as the grey line. We find that certain heads achieves high accuracy while the accuracy peaks at higher layers.
图 3: VisualBERT注意力头的实体接地(Entity Grounding)准确率。基于规则的基线用灰色线表示。我们发现某些注意力头能实现较高准确率,且准确率在更高层达到峰值。
5.1 ABLATION STUDY
5.1 消融实验
We conduct our ablation study on $\mathrm{NLVR^{2}}$ and include two ablation models in $\S4$ and four additional variants of VisualBERT for comparison. For ease of computations, all these models are trained with only 36 features per image (including the full model). Our analysis (Table 5) aims to investigate the contributions of the following four components in VisualBERT:
我们在 $\mathrm{NLVR^{2}}$ 上进行了消融研究,并在 $\S4$ 中包含了两个消融模型以及四个额外的 VisualBERT 变体进行比较。为了简化计算,所有模型均仅使用每张图像 36 个特征进行训练(包括完整模型)。我们的分析(表 5)旨在探究 VisualBERT 中以下四个组件的贡献:
C1: Task-agnostic Pre-training. We investigate the contribution of task-agnostic pre-training by entirely skipping such pre-training (VisualBERT w/o COCO Pre-training) and also by pre-training with only text but no images from COCO (VisualBERT w/o Grounded Pre-training). Both variants under perform, showing that pre-training on paired vision and language data is important.
C1: 任务无关预训练。我们通过完全跳过此类预训练(VisualBERT 无 COCO 预训练)以及仅使用文本但无 COCO 图像进行预训练(VisualBERT 无基础预训练)来研究任务无关预训练的贡献。两种变体性能均不佳,表明在配对视觉和语言数据上进行预训练十分重要。
C2: Early Fusion. We include VisualBERT w/o Early Fusion introduced in $\S4$ to verify the importance of allowing early interaction between image and text features, confirming again that multiple interaction layers between vision and language are important.
C2: 早期融合 (Early Fusion)。我们在 $\S4$ 中引入了不带早期融合的 VisualBERT 来验证图像与文本特征早期交互的重要性,再次确认视觉与语言之间的多层交互至关重要。
C3: BERT Initialization. All the models discussed so far are initialized with parameters from a pre-trained BERT model. To understand the contributions of the BERT initialization, we introduce a variant with randomly initialized parameters. The model is then trained as the full model. While it does seem weights from language-only pre-trained BERT are important, performance does not degrade as much as we expect, arguing that the model is likely learning many of the same useful aspects about grounded language during COCO pre-training.
C3: BERT初始化。目前讨论的所有模型都使用预训练BERT模型的参数进行初始化。为了理解BERT初始化的贡献,我们引入了一个随机初始化参数的变体。该模型随后会像完整模型一样进行训练。虽然仅基于语言预训练的BERT权重似乎很重要,但性能下降幅度没有预期那么大,这表明模型可能在COCO预训练期间学习了许多关于基础语言(grounded language)的有用方面。
C4: The sentence-image prediction objective. We introduce a model without the sentence-image prediction objective during task-agnostic pre-training (VisualBERT w/o Objective 2). Results suggest that this objective has positive but less significant effect, compared to other components.
C4: 句子-图像预测目标。我们在任务无关预训练阶段引入了一个不包含句子-图像预测目标的模型 (VisualBERT w/o Objective 2) 。结果表明,与其他组件相比,该目标具有积极但相对次要的影响。
Overall, the results confirm that the most important design choices are task-agnostic pre-training (C1) and early fusion of vision and language (C2). In pre-training, both the inclusion of additional COCO data and using both images and captions are paramount.
总体而言,结果证实最重要的设计选择是任务无关的预训练 (C1) 以及视觉与语言的早期融合 (C2) 。在预训练中,额外加入 COCO 数据以及同时使用图像和标题都至关重要。
5.2 DISSECTING ATTENTION WEIGHTS
5.2 剖析注意力权重
In this section we investigate which bounding regions are attended to by words, before VisualBERT is fine-tuned on any task.
在本节中,我们研究在VisualBERT针对任何任务进行微调之前,哪些边界区域会被词语关注到。
Entity Grounding First, we attempt to find attention heads within VisualBERT that could perform entity grounding, i.e., attending to the corresponding bounding regions from entities in the sentence. Specifically, we use the ground truth alignments from the evaluation set of Flickr30K. For each entity in the sentence and for each attention head in VisualBERT, we look at the bounding region which receives the most attention weight. Because a word is likely to attend to not only the image regions but also words in the text, for this evaluation, we mask out the head’s attention to words and keep only attention to the image regions. Then we compute the how often the attention of a particular head agrees with the annotations in Flickr30K.
实体接地
首先,我们尝试在VisualBERT中寻找能够执行实体接地的注意力头,即关注句子中实体对应的边界区域。具体来说,我们使用Flickr30K评估集中的真实对齐数据。对于句子中的每个实体和VisualBERT中的每个注意力头,我们观察接收最多注意力权重的边界区域。由于一个词可能不仅关注图像区域,还会关注文本中的其他词,因此在本次评估中,我们屏蔽了注意力头对文本词的关注,仅保留对图像区域的注意力。接着,我们计算特定注意力头的关注与Flickr30K标注一致的概率。
We report this accuracy5, for all 144 attention heads in VisualBERT, organized by layer, in Figure 3. We also consider a baseline that always chooses the region with the highest detection confidence. We find that VisualBERT achieves a remarkably high accuracy though it is not exposed to any direct supervision for entity grounding. The grounding accuracy also seems to improve in higher layers, showing the model is less certain when synthesizing the two inputs in lower layers, but then becomes increasingly aware of how they should align. We show examples of this behavior in $\S5.3$ .
我们在图3中按层展示了VisualBERT中全部144个注意力头(attention head)的准确率数据。同时设置了始终选择检测置信度最高区域的基线方法。研究发现,尽管未接受任何实体接地的直接监督,VisualBERT仍展现出惊人的高准确率。更高网络层中的接地准确率呈现上升趋势,表明模型在底层融合两种输入时较为不确定,但随着层级提升会逐渐学习到正确的对齐方式。具体案例展示见$\S5.3$章节。
Syntactic Grounding Given that many have observed that the attention heads of BERT can discover syntactic relationships (Voita et al., 2019; Clark et al., 2019), we also analyze how grounding information is passed through syntactic relationships that VisualBERT may have discovered. In particular, given two words that are connected with a dependency relation, $w_{1}\xrightarrow{r}w_{2}$ , we would like to know how often the attention heads at $w_{2}$ attend to the regions corresponding to $w_{1}$ , and vice-versa. For example, in Figure 1, we would like to know if there is an attention head that, at the word “walking”, is systematically attending to the region corresponding to the “man”, because “man” and “walking” are related through a “nsubj” relation, under the Stanford Dependency Parsing formalism (De Marneffe & Manning, 2008).
句法基础
鉴于许多研究者已观察到BERT的注意力头能发现句法关系 (Voita et al., 2019; Clark et al., 2019),我们同样分析了VisualBERT可能发现的句法关系如何传递基础信息。具体而言,给定两个通过依存关系相连的词语 $w_{1}\xrightarrow{r}w_{2}$ ,我们想探究 $w_{2}$ 处的注意力头有多大频率会关注与 $w_{1}$ 对应的区域,反之亦然。例如在图1中,我们想知道是否存在一个注意力头,在"walking"这个词上系统性地关注与"man"对应的区域,因为根据斯坦福依存句法体系 (De Marneffe & Manning, 2008) ,"man"和"walking"通过"nsubj"关系相关联。
To evaluate such syntactic sensitivity in VisualBERT, we first parse all sentences in Flickr30K using AllenNLP’s dependency parser (Dozat & Manning, 2017; Gardner et al., 2018). Then, for each attention head in VisualBERT, given that two words have a particular dependency relationship, and one of them has a ground-truth grounding in Flickr30K, we compute how accurately the head attention weights predict the ground-truth grounding. Examination of all dependency relationships shows that in VisualBERT, there exists at least one head for each relationship that significantly outperforms guessing the most confident bounding region. We highlight a few particularly interesting dependency relationships in Figure 4. Many heads seem to accurately associate arguments with verbs (i.e. “pobj”, “nsub”, and “dobj” dependency relations), arguing that VisualBERT is resolving these arguments, implicitly and without supervision, to visual elements.
为评估VisualBERT中的这种句法敏感性,我们首先使用AllenNLP的依存句法解析器 (Dozat & Manning, 2017; Gardner et al., 2018) 解析Flickr30K中的所有句子。接着,针对VisualBERT中的每个注意力头,在给定两个词存在特定依存关系且其中一个词在Flickr30K中有真实标注的情况下,我们计算该注意力头权重预测真实标注的准确率。对所有依存关系的检测表明,VisualBERT中每个关系至少存在一个注意力头显著优于直接猜测最高置信度边界框的表现。我们在图4中重点展示了几组特别有趣的依存关系。许多注意力头能准确关联动词与论元 (如"pobj"、"nsub"和"dobj"依存关系),这表明VisualBERT正在隐式且无监督地将这些论元解析为视觉元素。
5.3 QUALITATIVE ANALYSIS
5.3 定性分析
Finally, we showcase several interesting examples of how VisualBERT changes its attention over the layers when processing images and text, in Figure 1 and Figure 5. To generate these examples, for each ground-truth box, we show a predicted bounding region closest to it and manually group the bounding regions into different categories. We also include regions that the model is actively attending to, even if they are not present in the ground-truth annotation (marked with an asterisk). We then aggregate the attention weights from words to those regions in the same category. We show the best heads of 6 layers that achieve the highest entity grounding accuracy.
最后,我们在图1和图5中展示了VisualBERT在处理图像和文本时如何在不同层间改变注意力分布的若干有趣案例。为生成这些示例,我们针对每个真实标注框,显示与之最接近的预测边界区域,并手动将这些边界区域分组到不同类别。同时纳入了模型主动关注的区域(标有星号),即使它们未出现在真实标注中。随后,我们聚合了从词语到同类别区域的注意力权重,并展示了6个层中实现最高实体定位准确度的最佳注意力头。

Figure 4: Accuracy of attention heads of VisualBERT for predicting four specific dependency relationships (“pobj”, “amod”, “nsubj”, and “dobj”) across modality. The grey lines denote a baseline that always chooses the region with the highest detection confidence. We observe that VisualBERT is capable of detecting these dependency relationships without direct supervision.
图 4: VisualBERT 注意力头在跨模态预测四种特定依存关系 ("pobj", "amod", "nsubj", 和 "dobj") 时的准确率。灰色线条表示始终选择检测置信度最高区域的基线。我们观察到 VisualBERT 能够在没有直接监督的情况下检测这些依存关系。
Overall, we observe that VisualBERT seems to refine alignments through successive Transformer layers. For example, in the bottom left image in Figure 5, initially the word “husband” and the word “woman” both have significant attention weight on regions corresponding to the woman. By the end of the computation, VisualBERT has disentangled the woman and man, correctly aligning both. Furthermore, there are many examples of syntactic alignments. For example, in the same image, the word “teased” aligns to both the man and woman while “by” aligns to the man. Finally, some co reference seems to be resolved, as, in the same image, the word “her” is resolved to the woman.
总体来看,我们发现 VisualBERT 似乎通过连续的 Transformer 层逐步优化对齐效果。例如,在图 5 左下角的图像中,初始时单词 "husband" 和 "woman" 都在女性对应区域具有显著的注意力权重。经过计算后,VisualBERT 成功区分了女性和男性,并正确对齐了两者。此外,还存在许多句法对齐的示例。例如,在同一张图像中,单词 "teased" 同时对齐到男性和女性,而 "by" 则对齐到男性。最后,部分共指关系似乎得到了解决,如同张图像中的单词 "her" 被解析为指向女性。
6 CONCLUSION AND FUTURE WORK
6 结论与未来工作
In this paper, we presented VisualBERT, a pre-trained model for joint vision and language representation. Despite VisualBERT is simple, it achieves strong performance on four evaluation tasks. Further analysis suggests that the model uses the attention mechanism to capture information in an interpret able way. For future work, we are curious about whether we could extend VisualBERT to image-only tasks, such as scene graph parsing and situation recognition. Pre-training VisualBERT on larger caption datasets such as Visual Genome and Conceptual Caption is also a valid direction.
本文介绍了VisualBERT,一个用于视觉与语言联合表征的预训练模型。尽管VisualBERT结构简单,但在四项评测任务中均表现出色。进一步分析表明,该模型通过注意力机制以可解释的方式捕获信息。未来工作中,我们关注能否将VisualBERT扩展至纯图像任务(如图场景图解析和情境识别)。在更大规模的标注数据集(如Visual Genome和Conceptual Caption)上对VisualBERT进行预训练也是可行的研究方向。