Image as a Foreign Language: BEIT Pre training for All Vision and Vision-Language Tasks
图像作为外语:面向所有视觉与视觉-语言任务的BEIT预训练
Abstract
摘要
A big convergence of language, vision, and multimodal pre training is emerging. In this work, we introduce a general-purpose multimodal foundation model BEIT-3, which achieves state-of-the-art transfer performance on both vision and visionlanguage tasks. Specifically, we advance the big convergence from three aspects: backbone architecture, pre training task, and model scaling up. We introduce Multiway Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked “language” modeling on images (Imglish), texts (English), and image-text pairs (“parallel sentences”) in a unified manner. Experimental results show that BEIT-3 obtains state-of-the-art performance on object detection (COCO), semantic segmentation (ADE20K), image classification (ImageNet), visual reasoning (NLVR2), visual question answering (VQAv2), image captioning (COCO), and cross-modal retrieval (Flickr30K, COCO).
语言、视觉和多模态预训练的大融合正在兴起。本文提出了一种通用多模态基础模型BEIT-3,在视觉和视觉-语言任务上均实现了最先进的迁移性能。具体而言,我们从三个维度推进大融合:主干架构、预训练任务和模型扩展。我们引入了通用建模的多路Transformer (Multiway Transformers),其模块化架构同时支持深度融合和模态专用编码。基于共享主干网络,我们以统一方式对图像(Imglish)、文本(English)和图文对("平行句")进行掩码"语言"建模。实验结果表明,BEIT-3在目标检测(COCO)、语义分割(ADE20K)、图像分类(ImageNet)、视觉推理(NLVR2)、视觉问答(VQAv2)、图像描述(COCO)和跨模态检索(Flickr30K, COCO)等任务上均取得最先进性能。
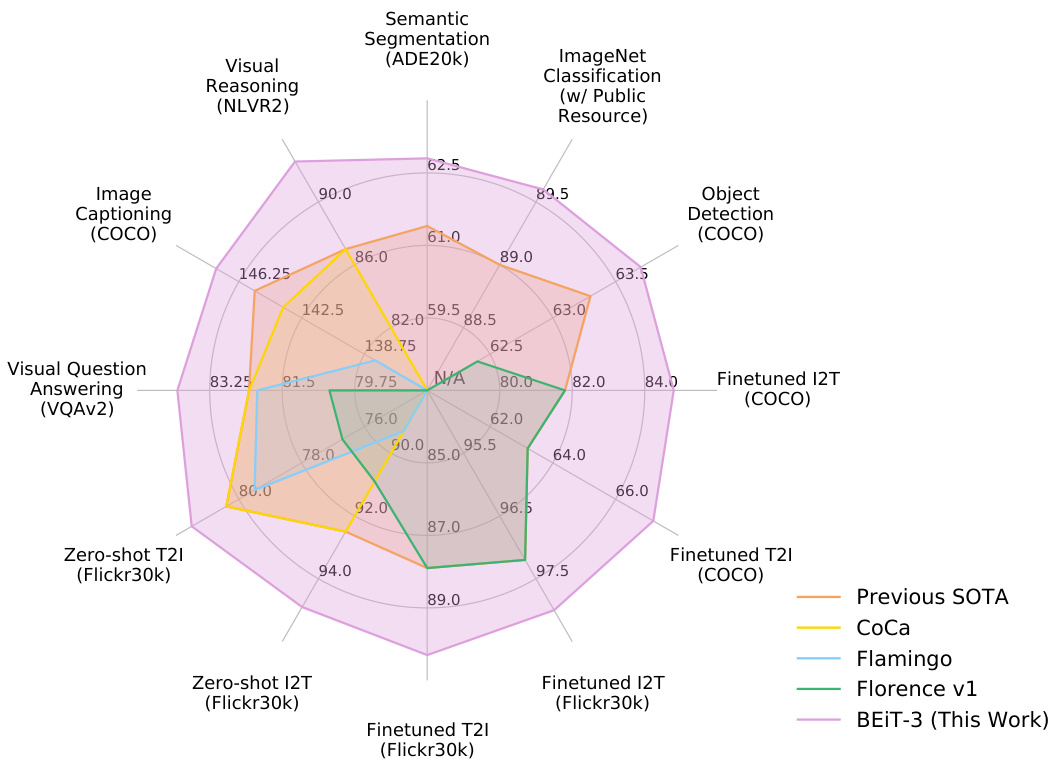
Figure 1: BEIT-3 achieves state-of-the-art performance on a broad range of tasks compared with other customized or foundation models. I2T/T2I is short for image-to-text/text-to-image retrieval.
图 1: BEIT-3 在广泛任务上相比其他定制或基础模型实现了最先进的性能。I2T/T2I 是图像到文本/文本到图像检索的缩写。
| 类别 | 任务 | 数据集 | 指标 | 先前SOTA | BE1T-3 |
|---|---|---|---|---|---|
| 视觉 | 语义分割 | ADE20K | mIoU | 61.4 (FD-SwinV2) | 62.8 (+1.4) |
| 目标检测 | COCO | AP | 63.3 (DINO) | 63.7 (+0.4) | |
| 实例分割 | COCO | AP | 54.7 (Mask DINO) | 54.8 (+0.1) | |
| 图像分类 | ImageNet | Top-1准确率 | 89.0 (FD-CLIP) | 89.6 (+0.6) | |
| 视觉-语言 | 视觉推理 | NLVR2 | 准确率 | 87.0 (CoCa) | 92.6 (+5.6) |
| 视觉问答 | VQAv2 | VQA准确率 | 82.3 (CoCa) | 84.0 (+1.7) | |
| 图像描述生成 | COCO | CIDEr | 145.3 (OFA) | 147.6 (+2.3) | |
| 微调检索 | COCO Flickr30K | R@1 | 72.5 (Florence) 92.6 (Florence) | 76.0 (+3.5) 94.2 (+1.6) | |
| 零样本检索 | Flickr30K | R@1 | 86.5 (CoCa) | 88.2 (+1.7) |
Table 1: Overview of BEIT-3 results on various vision and vision-language benchmarks. We compare with previous state-of-the-art models, including FD-SwinV2 $[\mathbf{W}\mathbf{H}\bar{\mathbf{X}}^{+}22]$ , DINO $[\mathrm{ZLL^{+}}22]$ ], Mask DINO $[\mathrm{ZLL^{+}}22]$ , FD-CLIP $[\mathbf{W}\mathbf{H}\mathbf{X}^{+}22]$ , CoCa $\mathbf{\bar{[}Y W V^{+}22]}$ , OFA $[\mathbf{W}\mathbf{Y}\mathbf{M}^{+}22]$ , Florence $[\mathrm{YCC}^{+}21]$ . We report the average of top-1 image-to-text and text-to-image results for retrieval tasks. “†” indicates ImageNet results only using publicly accessible resources. $\yen123,456$ indicates image captioning results without CIDEr optimization.
表 1: BEIT-3 在各种视觉与视觉语言基准测试中的结果概览。我们与包括 FD-SwinV2 $[\mathbf{W}\mathbf{H}\bar{\mathbf{X}}^{+}22]$、DINO $[\mathrm{ZLL^{+}}22]$、Mask DINO $[\mathrm{ZLL^{+}}22]$、FD-CLIP $[\mathbf{W}\mathbf{H}\mathbf{X}^{+}22]$、CoCa $\mathbf{\bar{[}Y W V^{+}22]}$、OFA $[\mathbf{W}\mathbf{Y}\mathbf{M}^{+}22]$、Florence $[\mathrm{YCC}^{+}21]$ 在内的先前最先进模型进行了比较。对于检索任务,我们报告了图像到文本和文本到图像检索结果的 top-1 平均值。"†"表示仅使用公开可访问资源的 ImageNet 结果。$\yen123,456$ 表示未经 CIDEr 优化的图像描述结果。
1 Introduction: The Big Convergence
1 引言:大融合
Recent years have featured a trend toward the big convergence of language [RNSS18, DCLT19, $\mathrm{DYW^{+}i9]}$ , vision [BDPW22, $\mathrm{PDB}^{+}22]$ , and multimodal [WBDW21, $\mathrm{RKH^{+}}21$ , $\mathrm{YWV}^{+}22]$ pretraining. By performing large-scale pre training on massive data, we can easily transfer the models to various downstream tasks. It is appealing that we can pretrain a general-purpose foundation model that handles multiple modalities. In this work, we advance the convergence trend for vision-language pre training from the following three aspects.
近年来,语言 [RNSS18, DCLT19, $\mathrm{DYW^{+}i9]}$、视觉 [BDPW22, $\mathrm{PDB}^{+}22]$ 以及多模态 [WBDW21, $\mathrm{RKH^{+}}21$, $\mathrm{YWV}^{+}22]$ 预训练呈现出大融合趋势。通过对海量数据进行大规模预训练,我们可以轻松将模型迁移至各类下游任务。预训练一个能处理多模态的通用基础模型 (foundation model) 极具吸引力。本工作从以下三个方面推进了视觉语言预训练的融合趋势。
First, the success of Transformers $[\mathrm{VSP^{+}}17]$ is translated from language to vision $[\mathrm{DBK^{+}}20]$ and multimodal [KSK21, WBDW21] problems. The unification of network architectures enables us to seamlessly handle multiple modalities. For vision-language modeling, there are various ways to apply Transformers due to the different natures of downstream tasks. For example, the dual-encoder architecture is used for efficient retrieval $[\mathrm{RKH^{+}}21]$ , encoder-decoder networks for generation tasks $[\mathbf{WYY^{+}}21]$ , and the fusion-encoder architecture for image-text encoding [KSK21]. However, most foundation models have to manually convert the end-task formats according to the specific architectures. Moreover, the parameters are usually not effectively shared across modalities. In this work, we adopt Multiway Transformers [WBDW21] for general-purpose modeling, i.e., one unified architecture shared for various downstream tasks. The modular network also comprehensively considers modality-specific encoding and cross-modality fusion.
首先,Transformer [VSP+17] 的成功从语言领域扩展到视觉 [DBK+20] 和多模态 [KSK21, WBDW21] 问题。网络架构的统一使我们能够无缝处理多种模态。针对视觉-语言建模,由于下游任务性质不同,存在多种应用Transformer的方式。例如:双编码器架构用于高效检索 [RKH+21],编码器-解码器网络用于生成任务 [WYY+21],融合编码器架构用于图文编码 [KSK21]。然而,大多数基础模型仍需根据特定架构手动转换终端任务格式。此外,参数通常无法跨模态有效共享。本文采用多路Transformer [WBDW21] 进行通用建模,即通过单一统一架构处理各类下游任务。该模块化网络还全面考虑了模态特定编码与跨模态融合。
Second, the pre training task based on masked data modeling has been successfully applied to various modalities, such as texts [DCLT19], images [BDPW22, $\mathrm{PD}\bar{\mathbf{B}}^{+}22]$ ], and image-text pairs [BWDW22]. Current vision-language foundation models usually multitask other pre training objectives (such as image-text matching), rendering scaling-up unfriendly and inefficient. In contrast, we only use one pre training task, i.e., mask-then-predict, to train a general-purpose multimodal foundation model. By regarding the image as a foreign language (i.e., Imglish), we handle texts and images in the same manner without fundamental modeling differences. Con sequentially, image-text pairs are utilized as “parallel sentences” in order to learn the alignments between modalities. We also show that the simple yet effective method learns strong transferable representations, achieving state-of-the-art performance on both vision and vision-language tasks. The prominent success demonstrates the superiority of generative pre training [DCLT19, BDPW22].
其次,基于掩码数据建模的预训练任务已成功应用于多种模态,如文本 [DCLT19]、图像 [BDPW22, $\mathrm{PD}\bar{\mathbf{B}}^{+}22$] 以及图文对 [BWDW22]。当前的视觉-语言基础模型通常需要多任务处理其他预训练目标(如图文匹配),导致扩展不友好且效率低下。相比之下,我们仅使用一种预训练任务(即掩码预测)来训练通用多模态基础模型。通过将图像视为外语(即 Imglish),我们以相同方式处理文本和图像,无需根本性建模差异。因此,图文对被用作“平行句子”以学习模态间的对齐。我们还证明,这种简单而有效的方法能学习到强可迁移表征,在视觉和视觉-语言任务上均达到最先进性能。这一显著成功证明了生成式预训练 [DCLT19, BDPW22] 的优越性。
Third, scaling up the model size and data size universally improves the generalization quality of foundation models, so that we can transfer them to various downstream tasks. We follow the philosophy and scale up the model size to billions of parameters. Moreover, we scale up the pre training data size in our experiments while only using publicly accessible resources for academic reproducibility. Although without using any private data, our method outperforms state-of-the-art foundation models that rely on in-house data by a decent margin. In addition, the scaling up benefits from treating images as a foreign language, as we can directly reuse the pipeline developed for large-scale language model pre training.
第三,扩大模型规模和数据规模普遍提升了基础模型的泛化能力,使其能够迁移到各种下游任务中。我们遵循这一理念,将模型参数量级提升至数十亿。同时,在实验中仅使用公开可获取资源以保证学术可复现性的前提下,我们大幅增加了预训练数据规模。尽管未使用任何私有数据,我们的方法仍以明显优势超越了依赖内部数据的最先进基础模型。此外,这种规模化优势得益于将图像视为"外语"的处理方式——这使我们能直接复用为大语言模型预训练开发的流程。
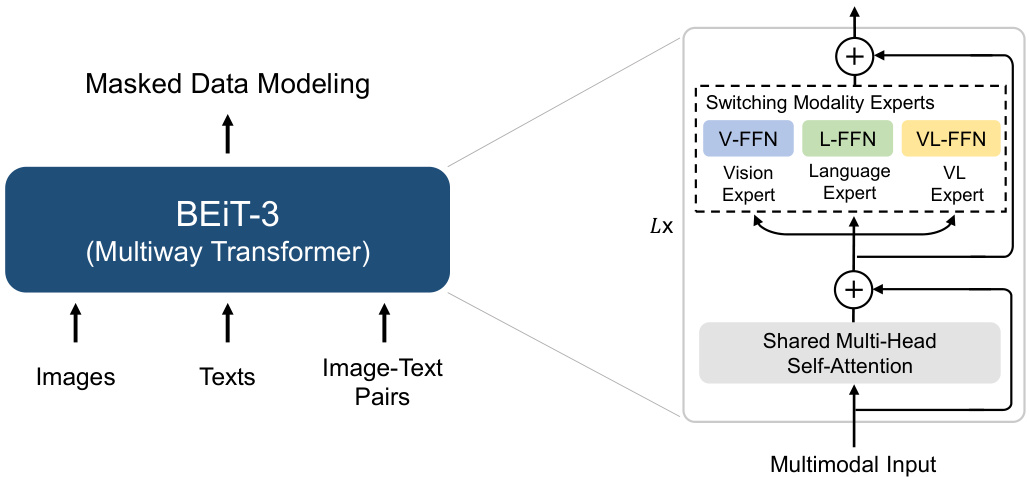
Figure 2: Overview of BEIT-3 pre training. We perform masked data modeling on monomodal (i.e., images, and texts) and multimodal (i.e., image-text pairs) data with a shared Multiway Transformer as the backbone network.
图 2: BEIT-3预训练概述。我们使用共享的Multiway Transformer作为骨干网络,在单模态(即图像和文本)和多模态(即图文对)数据上执行掩码数据建模。
In this work, we take advantage of the above ideas to pretrain a general-purpose multimodal foundation model BEIT-3. We pretrain a Multiway Transformer by performing masked data modeling on images, texts, and image-text pairs. During pre training, we randomly mask some proportion of text tokens or image patches. The self-supervised learning objective is to recover the original tokens (i.e., text tokens, or visual tokens) given corrupted inputs. The model is general-purpose in the sense that it can be repurposed for various tasks regardless of input modalities, or output formats.
在本工作中,我们利用上述思想预训练了一个通用多模态基础模型BEIT-3。我们通过对图像、文本和图文对进行掩码数据建模,预训练了一个多路Transformer。在预训练期间,我们随机掩码一定比例的文本token或图像块。自监督学习的目标是根据损坏的输入恢复原始token(即文本token或视觉token)。该模型的通用性体现在:无论输入模态或输出格式如何,它都能适应各种任务。
2 BEIT-3: A General-Purpose Multimodal Foundation Model
2 BEIT-3: 通用多模态基础模型
As shown in Figure 2, BEIT-3 is pretrained by masked data modeling on monomodal and multimodal data, using a shared Multiway Transformer network. The model can be transferred to various vision and vision-language downstream tasks.
如图 2 所示,BEIT-3 通过单模态和多模态数据的掩码数据建模 (masked data modeling) 进行预训练,使用共享的多路 Transformer (Multiway Transformer) 网络。该模型可迁移至各类视觉和视觉-语言下游任务。
2.1 Backbone Network: Multiway Transformers
2.1 主干网络:多路Transformer
We use Multiway Transformers [WBDW21] as the backbone model to encode different modalities. As shown in Figure 2, each Multiway Transformer block consists of a shared self-attention module, and a pool of feed-forward networks (i.e., modality experts) used for different modalities. We route each input token to the experts depending on its modality. In our implementation, each layer contains a vision expert and a language expert. Moreover, the top three layers have vision-language experts designed for fusion encoders. Refer to Figure 3 (a)(b)(c) for more detailed modeling layouts. Using a pool of modality experts encourages the model to capture more modality-specific information. The shared self-attention module learns the alignment between different modalities and enables deep fusion for multimodal (such as vision-language) tasks.
我们采用Multiway Transformer [WBDW21]作为主干模型来编码不同模态。如图2所示,每个Multiway Transformer块包含一个共享的自注意力模块,以及一组用于不同模态的前馈网络(即模态专家)。我们根据每个输入token的模态将其路由到相应的专家模块。在具体实现中,每层包含一个视觉专家和一个语言专家。此外,顶层三个层还设有专为融合编码器设计的视觉-语言专家。更详细的建模布局请参见图3(a)(b)(c)。通过使用模态专家池,模型能够更好地捕捉特定模态的信息。共享的自注意力模块则学习不同模态间的对齐关系,并为多模态(如视觉-语言)任务实现深度融合。
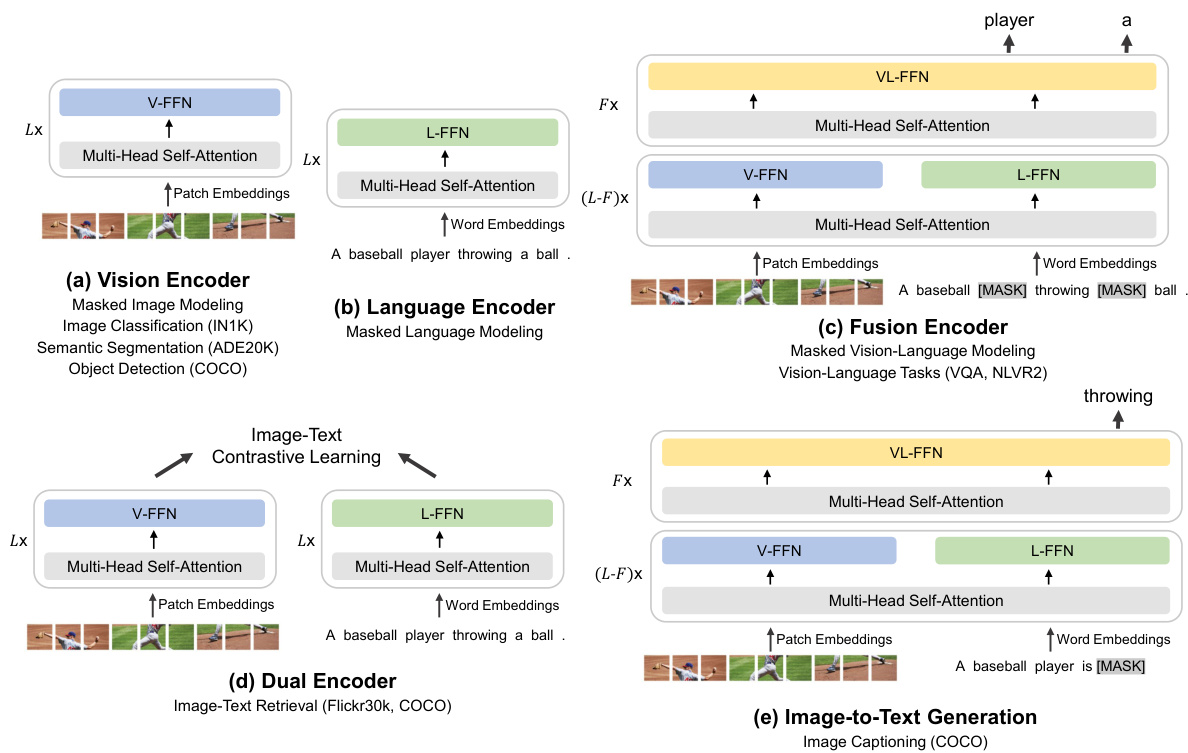
Figure 3: BEIT-3 can be transferred to various vision and vision-language downstream tasks. With a shared Multiway Transformer, we can reuse the model as (a)(b) vision or language encoders; (c) fusion encoders that jointly encode image-text pairs for deep interaction; (d) dual encoders that separately encode modalities for efficient retrieval; (e) sequence-to-sequence learning for image-totext generation.
图 3: BEIT-3 可迁移至多种视觉及视觉-语言下游任务。通过共享的多路 Transformer (Multiway Transformer),我们可以将模型复用为:(a)(b) 视觉或语言编码器;(c) 融合编码器(联合编码图文对以实现深度交互);(d) 双编码器(分别编码不同模态以实现高效检索);(e) 序列到序列学习(用于图像到文本生成)。
As shown in Figure 3, the unified architecture enables BEIT-3 to support a wide range of downstream tasks. For example, BEIT-3 can be used as an image backbone for various vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. It can also be finetuned as a dual encoder for efficient image-text retrieval, and a fusion model for multimodal understanding and generation tasks.
如图 3 所示,统一架构使 BEIT-3 能够支持广泛的下游任务。例如,BEIT-3 可作为各类视觉任务的图像主干网络,包括图像分类、目标检测、实例分割和语义分割。它还能微调为高效的图文检索双编码器,或用于多模态理解与生成任务的融合模型。
2.2 Pre training Task: Masked Data Modeling
2.2 预训练任务:掩码数据建模 (Masked Data Modeling)
We pretrain BEIT-3 via a unified masked data modeling [BWDW22] objective on monomodal (i.e., images, and texts) and multimodal data (i.e., image-text pairs). During pre training, we randomly mask some percentage of text tokens or image patches and train the model to recover the masked tokens. The unified mask-then-predict task not only learns representations but also learns the alignment of different modalities. Specifically, text data is tokenized by a Sentence Piece tokenizer [KR18]. Image data is tokenized by the tokenizer of BEIT v2 $[\mathrm{PDB^{+}}2\dot{2}]$ ] to obtain the discrete visual tokens as the reconstructed targets. We randomly mask $15%$ tokens of monomodal texts and $50%$ tokens of texts from image-text pairs. For images, we mask $40%$ of image patches using a block-wise masking strategy as in BEIT [BDPW22, $\bar{\mathrm{PDB}}^{+}22^{\cdot}$ ].
我们通过统一的掩码数据建模 [BWDW22] 目标在单模态(即图像和文本)和多模态数据(即图文对)上预训练 BEIT-3。在预训练过程中,我们随机掩码一定比例的文本 token 或图像块,并训练模型恢复被掩码的 token。这种统一的"掩码-预测"任务不仅学习表征,还学习不同模态的对齐。具体而言,文本数据通过 Sentence Piece tokenizer [KR18] 进行 token 化,图像数据则通过 BEIT v2 的 tokenizer $[\mathrm{PDB^{+}}2\dot{2}]$ 获得离散视觉 token 作为重建目标。我们随机掩码单模态文本中 $15%$ 的 token 和图文对中文本的 $50%$ token。对于图像,我们采用 BEIT [BDPW22, $\bar{\mathrm{PDB}}^{+}22^{\cdot}$] 中的分块掩码策略掩码 $40%$ 的图像块。
We only use one pre training task, which makes the training process scaling-up friendly. In contrast, previous vision-language models $[\mathrm{LYL^{+}}20$ , $\mathrm{ZLH^{+}}2\mathrm{i}$ , KSK21, $\mathrm{LS}\bar{\mathrm{G}}^{+}\bar{2}1$ , WBDW21, LLXH22, usually employ multiple pre training tasks, such as image-text contrast, imagetext matching, and word-patch/region alignment. We show that a much smaller pre training batch size can be used with the mask-then-predict task. In comparison, contrastive-based models $[\mathrm{RKH^{+}}21$ , $\mathbf{J}\mathbf{Y}\mathbf{X}^{+}21$ , $\mathrm{YCC}^{+}21$ , $\mathrm{YWV}^{+}2\bar{2}\mathrm{]}$ usually need a very large batch size2 for pre training, which brings more engineering challenges, such as GPU memory cost.
我们仅采用一种预训练任务,这使得训练过程更易于扩展。相比之下,以往的视觉语言模型 [LYL+20, ZLH+21, KSK21, LSG+21, WBDW21, LLXH22, ΔYWV+22] 通常采用多种预训练任务,如图文对比 (image-text contrast) 、图文匹配 (image-text matching) 和词块/区域对齐 (word-patch/region alignment) 。我们证明掩码预测任务 (mask-then-predict) 可以使用更小的预训练批次规模。而基于对比的模型 [RKH+21, JYX+21, YCC+21, YWV+22] 通常需要非常大的预训练批次规模,这会带来更多工程挑战,例如 GPU 内存开销。
Table 2: Model configuration of BEIT-3. The architecture layout follows ViT-giant [ZKHB21].
表 2: BEIT-3的模型配置。架构布局遵循ViT-giant [ZKHB21]。
| Model | #Layers | Hidden Size | MLP Size | V-FFN | L-FFN | VL-FFN | Shared Attention | Total |
|---|---|---|---|---|---|---|---|---|
| BE1T-3 | 40 | 1408 | 6144 | 692M | 692M | 52M | 317M | 1.9B |
Table 3: Pre training data of BEIT-3. All the data are academically accessible.
| 数据 | 来源 | 规模 |
|---|---|---|
| 图文对 (Image-Text Pair) | CC12M、CC3M、SBU、C0CO、VG | 2100万组 |
| 图像 (Image) | ImageNet-21K | 1400万张 |
| 文本 (Text) | 英文维基百科、BookCorpus、Open WebText、CC-News、Stories | 160GB文档 |
表 3: BEIT-3的预训练数据。所有数据均可在学术领域公开获取。
2.3 Scaling Up: BEIT-3 Pre training
2.3 规模化:BEIT-3 预训练
Backbone Network BEIT-3 is a giant-size foundation model following the setup of ViTgiant [ZKHB21]. As shown in Table 2, the model consists of a 40-layer Multiway Transformer with 1408 hidden size, 6144 intermediate size, and 16 attention heads. All layers contain both vision experts and language experts. Vision-language experts are also employed in the top three Multiway Transformer layers. The self-attention module is shared across different modalities. BEIT-3 consists of 1.9B parameters in total, including 692M parameters for vision experts, 692M parameters for language experts, 52M parameters for vision-language experts, and 317M parameters for the shared self-attention module. Notice that only vision-related parameters (i.e., comparable size as ViT-giant; about 1B) are activated when the model is used as a vision encoder.
骨干网络
BEIT-3 是一个遵循 ViTgiant [ZKHB21] 架构设计的超大规模基础模型。如表 2 所示,该模型由 40 层 Multiway Transformer 组成,隐藏层维度为 1408,中间层维度为 6144,并配备 16 个注意力头。所有层均包含视觉专家模块和语言专家模块,其中顶层三个 Multiway Transformer 层还引入了视觉-语言联合专家模块。自注意力模块在不同模态间共享。BEIT-3 总参数量达 19 亿,包含 6.92 亿视觉专家参数、6.92 亿语言专家参数、5200 万视觉-语言专家参数以及 3.17 亿共享自注意力模块参数。需注意的是,当模型作为视觉编码器使用时,仅激活视觉相关参数(即与 ViT-giant 相当的约 10 亿参数)。
表 2:
Pre training Data BEIT-3 is pretrained on both monomodal and multimodal data shown in Table 3. For multimodal data, there are about 15M images and 21M image-text pairs collected from five public datasets: Conceptual 12M (CC12M) [CSDS21], Conceptual Captions (CC3M) [SDGS18], SBU Captions (SBU) [OKB11], COCO $[\mathrm{LMB^{+}}14]$ and Visual Genome (VG) $[\mathrm{KZG^{+}}17]$ . For monomodal data, we use 14M images from ImageNet-21K and 160GB text corpora $[\mathrm{BDW}^{+}20]$ from English Wikipedia, BookCorpus $[Z\mathrm{K}Z^{+}15]$ , Open Web Text 3, CC-News $\mathrm{[LOG^{+}19]}$ , and Stories [TL18].
预训练数据
BEIT-3 在表 3 所示的单模态和多模态数据上进行预训练。多模态数据包含约 1500 万张图像和 2100 万图文对,采集自五个公开数据集:Conceptual 12M (CC12M) [CSDS21]、Conceptual Captions (CC3M) [SDGS18]、SBU Captions (SBU) [OKB11]、COCO [LMB+14] 和 Visual Genome (VG) [KZG+17]。单模态数据包含 ImageNet-21K 的 1400 万张图像,以及来自英文维基百科、BookCorpus [ZKZ+15]、Open Web Text 3、CC-News [LOG+19] 和 Stories [TL18] 的 160GB 文本语料 [BDW+20]。
Pre training Settings We pretrain BEIT-3 for 1M steps. Each batch contains 6144 samples in total, including 2048 images, 2048 texts and 2048 image-text pairs. The batch size is much smaller than contrastive models $[\mathrm{RKH^{+}}21$ , $\mathrm{JYX^{+}}21$ , $\mathrm{YWV}^{+}22]$ . BEIT-3 uses $14\times14$ patch size and is pretrained at resolution $224\times224$ . We use the same image augmentation as in BEIT [BDPW22], including random resized cropping, horizontal flipping, and color jittering [WXYL18]. A SentencePiece tokenizer [KR18] with 64k vocab size is employed to tokenize the text data. We use the AdamW [LH19] optimizer with $\beta_{1}=0.9$ , $\beta_{2}=0.98$ and $\epsilon=1\mathrm{e}{-6}$ for optimization. We use a cosine learning rate decay scheduler with a peak learning rate of 1e-3 and a linear warmup of 10k steps. The weight decay is 0.05. Stochastic depth $[\mathrm{HSL^{+}}1\bar{6}]$ with a rate of 0.1 is used. The BEiT initialization algorithm4 [BDPW22] is used to stabilize Transformer training.
预训练设置
我们预训练BEIT-3共100万步。每批次包含6144个样本,其中2048张图像、2048段文本和2048个图文对。该批次规模远小于对比模型 $[\mathrm{RKH^{+}}21$, $\mathrm{JYX^{+}}21$, $\mathrm{YWV}^{+}22]$。BEIT-3采用 $14\times14$ 的块大小,并在 $224\times224$ 分辨率下进行预训练。我们使用与BEIT [BDPW22]相同的图像增强方法,包括随机缩放裁剪、水平翻转和色彩抖动 [WXYL18]。文本数据采用词汇量为64k的SentencePiece tokenizer [KR18]进行分词。优化器选用AdamW [LH19],参数设为 $\beta_{1}=0.9$, $\beta_{2}=0.98$ 和 $\epsilon=1\mathrm{e}{-6}$。学习率调度采用余弦衰减,峰值学习率为1e-3,并配合10k步的线性预热。权重衰减为0.05。使用随机深度 $[\mathrm{HSL^{+}}1\bar{6}]$,比例为0.1。通过BEiT初始化算法4 [BDPW22]来稳定Transformer训练。
3 Experiments on Vision and Vision-Language Tasks
3 视觉与视觉-语言任务实验
We extensively evaluate BEIT-3 on major public benchmarks for both vision-language and vision tasks. Table 1 presents the overview of results. BEIT-3 obtains state-of-the-art performance on a wide range of vision and vision-language tasks.
我们在视觉语言和视觉任务的主要公共基准上对BEIT-3进行了广泛评估。表1展示了结果概览。BEIT-3在广泛的视觉和视觉语言任务中取得了最先进的性能。
Table 4: Results of visual question answering, visual reasoning, and image captioning tasks. We report vqa-score on VQAv2 test-dev and test-standard splits, accuracy for NLVR2 development set and public test set (test-P). For COCO image captioning, we report BLEU $\ @4$ $(\mathrm{B}@4)$ , METEOR (M), CIDEr (C), and SPICE (S) on the Karpathy test split. For simplicity, we report captioning results without using CIDEr optimization.
表 4: 视觉问答、视觉推理和图像描述任务的结果。我们在 VQAv2 的 test-dev 和 test-standard 划分上报告 vqa-score,在 NLVR2 开发集和公开测试集 (test-P) 上报告准确率。对于 COCO 图像描述任务,我们在 Karpathy 测试划分上报告 BLEU $\ @4$ $(\mathrm{B}@4)$、METEOR (M)、CIDEr (C) 和 SPICE (S)。为简化起见,我们报告的描述结果未使用 CIDEr 优化。
| 模型 | VQAv2 test-dev | VQAv2 test-std | NLVR2 dev | NLVR2 test-P | COCO Captioning B@4 | COCO Captioning M | COCO Captioning C | COCO Captioning S |
|---|---|---|---|---|---|---|---|---|
| Oscar [LYL+20] | 73.61 | 73.82 | 79.12 | 80.37 | 37.4 | 30.7 | 127.8 | 23.5 |
| VinVL [ZLH+21] | 76.52 | 76.60 | 82.67 | 83.98 | 38.5 | 30.4 | 130.8 | 23.4 |
| ALBEF [LSG+21] | 75.84 | 76.04 | 82.55 | 83.14 | ||||
| BLIP [LLXH22] | 78.25 | 78.32 | 82.15 | 82.24 | 40.4 | 136.7 | ||
| SimVLM [WYY+21] | 80.03 | 80.34 | 84.53 | 85.15 | 40.6 | 33.7 | 143.3 | 25.4 |
| Florence [YCC+21] | 80.16 | 80.36 | ||||||
| OFA [WYM+22] | 82.00 | 82.00 | 43.9 | 31.8 | 145.3 | 24.8 | ||
| Flamingo [ADL+22] | 82.00 | 82.10 | 138.1 | |||||
| CoCa [YWV+22] | 82.30 | 82.30 | 86.10 | 87.00 | 40.9 | 33.9 | 143.6 | 24.7 |
| BE1T-3 | 84.19 | 84.03 | 91.51 | 92.58 | 44.1 | 32.4 | 147.6 | 25.4 |
3.1 Vision-Language Downstream Tasks
3.1 视觉语言下游任务
We evaluate the capabilities of BEIT-3 on the widely used vision-language understanding and generation benchmarks, including visual question answering $[\mathrm{GKS^{+}}17]$ , visual reasoning $[\mathrm{SZ}\bar{Z}^{+}19]$ , image-text retrieval $\mathrm{[PWC^{+}}15$ , $\bar{\mathrm{LMB}}^{+}1\bar{4}\bar{]}$ , and image captioning $[\mathrm{LMB^{+}}14]$ .
我们在广泛使用的视觉语言理解和生成基准上评估BEIT-3的能力,包括视觉问答 $[\mathrm{GKS^{+}}17]$ 、视觉推理 $[\mathrm{SZ}\bar{Z}^{+}}19]$ 、图文检索 $\mathrm{[PWC^{+}}15$ 和 $\bar{\mathrm{LMB}}^{+}1\bar{4}\bar{]}$ ,以及图像描述 $[\mathrm{LMB^{+}}14]$ 。
Visual Question Answering (VQA) The task requires the model to answer natural language questions about input images. Following previous work $[\mathrm{AHB^{+}}18$ , $\mathrm{ZLH^{+}21}$ , KSK21], we conduct finetuning experiments on the VQA $\mathrm{v}2.0$ dataset $[\mathrm{GKS^{+}}17]$ and formulate the task as a classification problem. The model is trained to predict answers from the 3129 most frequent answer candidates in the training set. BEIT-3 is finetuned as a fusion encoder to model deep interactions of images and questions for the VQA task. We concatenate the embeddings of a given question and an image, and then feed the input embeddings into Multiway Transformers to jointly encode the image-question pair. The final pooled output is fed into a classifier layer to predict the answer. The results are present in Table 4, BEIT-3 outperforms all previous models by a large margin (more than 1.7 points), pushing the state of the art to 84.03 with a single model.
视觉问答 (Visual Question Answering, VQA)
该任务要求模型回答关于输入图像的自然语言问题。遵循先前工作 [AHB+18, ZLH+21, KSK21],我们在 VQA v2.0 数据集 [GKS+17] 上进行了微调实验,并将该任务定义为分类问题。模型被训练用于从训练集中 3129 个最常见候选答案中预测答案。BEIT-3 作为融合编码器进行微调,以建模图像和问题在 VQA 任务中的深度交互。我们将给定问题和图像的嵌入向量拼接后,输入到 Multiway Transformer 中联合编码图像-问题对。最终的池化输出被送入分类层以预测答案。结果如 表 4 所示,BEIT-3 以显著优势(超过 1.7 分)超越所有先前模型,将单模型性能推升至 84.03,刷新了当前最优水平。
Visual Reasoning The task needs models to perform joint reasoning about images and natural language descriptions. We evaluate the model on the popular NLVR2 $[\bar{\mathrm{SZZ^{+}}}19]$ benchmark, which is to determine whether a textual description is true about a pair of images. Following previous work $[\mathrm{ZLH^{+}}21$ , KSK21], we construct two image-text pairs based on the triplet input. We finetune BEIT-3 as a fusion encoder to jointly encode the image-text pairs. The final pooled outputs of the two pairs are concatenated and then fed into a classifier layer to predict the label. As shown in Table 4, BEIT-3 achieves a new state-of-the-art result for visual reasoning, outperforming CoCa by about 5.6 points. The performance on NLVR2 reaches above $90%$ for the first time.
视觉推理
该任务要求模型对图像和自然语言描述进行联合推理。我们在流行的NLVR2 $[\bar{\mathrm{SZZ^{+}}}19]$ 基准上评估模型性能,该任务需判断文本描述是否与一对图像相符。遵循先前工作 $[\mathrm{ZLH^{+}}21$ , KSK21],我们基于三元组输入构建两个图文对。通过微调BEIT-3作为融合编码器来联合编码图文对,将两个图文对的最终池化输出拼接后送入分类层进行预测。如表4所示,BEIT-3在视觉推理任务上创造了新纪录,以约5.6分的优势超越CoCa,首次在NLVR2上实现超过 $90%$ 的准确率。
Image Captioning The task aims to generate a natural language caption for the given image. We use the COCO $[\mathrm{L}\mathrm{MB^{+}}14]$ benchmark, finetune and evaluate the model on Karpathy split [KF15]. Following UNILM $[\mathrm{DYW^{+}19}]$ and $\mathrm{s}2\mathrm{s}$ -ft $[\mathrm{BDW}^{+}21]$ , BEIT-3 is used as a conditional generation model via masked finetuning. To be more specific, a special self-attention mask is employed for the image captioning task. Image tokens (i.e., image patches) can only attend to each other bidirectional ly within the image sequence. Tokens of the caption can attention to image tokens, their leftward caption tokens, and themselves. During finetuning, we randomly mask some percentage of caption tokens. The model is trained to recover these tokens based on the clues of the image and its leftward caption context. We also mask the special boundary token [SEP] to help the model learn to terminate the generation. For simplicity, BEIT-3 is trained with simple cross-entropy loss, without using CIDEr optimization. During inference, we generate the caption tokens one by one in an auto regressive manner. Table 4 presents the results on COCO captioning. BEIT-3 outperforms all previous models trained with cross-entropy loss, creating a new state-of-the-art image captioning result. The results demonstrate the superiority of BEIT-3 for vision-language generation.
图像描述生成
该任务旨在为给定图像生成自然语言描述。我们使用COCO $[\mathrm{L}\mathrm{MB^{+}}14]$ 基准,在Karpathy分割数据集 [KF15] 上进行模型微调和评估。遵循UNILM $[\mathrm{DYW^{+}19}]$ 和 $\mathrm{s}2\mathrm{s}$-ft $[\mathrm{BDW}^{+}21]$ 的方法,BEIT-3通过掩码微调作为条件生成模型使用。具体而言,图像描述任务采用特殊的自注意力掩码机制:图像token(即图像块)仅能在图像序列内部进行双向注意力交互,而描述文本的token可关注图像token、其左侧的描述token及自身。微调过程中,我们随机掩码部分描述token,模型根据图像线索及左侧上下文恢复被掩码内容。同时掩码特殊边界token [SEP]以帮助模型学习终止生成。为简化流程,BEIT-3仅使用交叉熵损失训练,未采用CIDEr优化。推理阶段以自回归方式逐token生成描述。
表4展示了COCO描述生成任务的结果。BEIT-3超越所有基于交叉熵损失的现有模型,创造了图像描述生成的新标杆。这些结果证明了BEIT-3在视觉-语言生成领域的优越性。
Table 5: Finetuning results of image-to-text retrieval and text-to-image retrieval on COCO and Flickr30K. Notice that dual-encoder models are more efficient than fusion-encoder-based models for the retrieval tasks.
表 5: COCO 和 Flickr30K 上图像到文本检索和文本到图像检索的微调结果。注意,对于检索任务,双编码器模型比基于融合编码器的模型更高效。
| Model | MSCOCO (5K test set) | Flickr30K (1K test set) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Image → Text | Text → Image | Image → Text | Text → Image | |||||||||
| Fusion-encoder models | ||||||||||||
| UNITER [CLY+20] | 65.7 | 88.6 | 93.8 | 52.9 | 79.9 | 88.0 | 87.3 | 98.0 | 99.2 | 75.6 | 94.1 | 96.8 |
| VILLA [GCL+20] | - | 87.9 | 97.5 | 98.8 | 76.3 | 94.2 | 96.8 | |||||
| Oscar [LYL+20] | 73.5 | 92.2 | 96.0 | 57.5 | 82.8 | 89.8 | ||||||
| VinVL [ZLH+21] | 75.4 | 92.9 | 96.2 | 58.8 | 83.5 | 90.3 | ||||||
| Dual encoder + Fusion encoder reranking | ||||||||||||
| ALBEF [LSG+21] | 77.6 | 94.3 | 97.2 | 60.7 | 84.3 | 90.5 | 95.9 | 99.8 | 100.0 | 85.6 | 97.5 | 98.9 |
| BLIP [LLXH22] | 82.4 | 95.4 | 97.9 | 65.1 | 86.3 | 91.8 | 97.4 | 99.8 | 99.9 | 87.6 | 97.7 | 99.0 |
| Dual-encoder models | ||||||||||||
| ALIGN [JYX+21] | 77.0 | 93.5 | 96.9 | 59.9 | 83.3 | 89.8 | 95.3 | 99.8 | 100.0 | 84.9 | 97.4 | 98.6 |
| FILIP [YHH+21] | 78.9 | 94.4 | 97.4 | 61.2 | 84.3 | 90.6 | 96.6 | 100.0 | 100.0 | 87.1 | 97.7 | 99.1 |
| Florence [YCC+21] | 81.8 | 95.2 | - | 63.2 | 85.7 | - | 97.2 | 99.9 | 87.9 | 98.1 | ||
| BE1T-3 | 84.8 | 96.5 | 98.3 | 67.2 | 87.7 | 92.8 | 98.0 | 100.0 | 100.0 | 90.3 | 98.7 | 99.5 |
Table 6: Zero-shot image-to-text retrieval and text-to-image retrieval on Flickr30K.
| 模型 | Flickr30K (1K测试集) | |||
|---|---|---|---|---|
| 图像→文本 | 文本→图像 | |||
| R@1 R@5 | R@10 | R@1 R@5 | R@10 | |
| FLAVA [SHG+21] | 67.7 94.0 | 65.2 89.4 | ||
| CLIP [RKH+21] | 88.0 98.7 | 99.4 | 68.7 | 90.6 95.2 |
| ALIGN [JYX+21] | 88.6 98.7 | 99.7 | 75.7 | 93.8 96.8 |
| FILIP [YHH+21] | 89.8 99.2 | 99.8 | 75.0 93.4 | 96.3 |
| Florence [YCC+21] | 90.9 99.1 | 76.7 | 93.6 | |
| Flamingo [ADL+22] | 89.3 98.8 | 99.7 | 79.5 | 95.3 97.9 |
| CoCa [YWV+22] | 92.5 99.5 | 99.9 | 80.4 | 95.7 97.7 |
| BE1T-3 | 94.9 99.9 | 100.0 | 81.5 | 95.6 |
表 6: Flickr30K上的零样本图像到文本检索和文本到图像检索结果。
Image-Text Retrieval The task is to measure the similarity between images and texts. There are two directions depending on the modality of the retrieved target: image-to-text retrieval, and text-to-image retrieval. Two popular retrieval benchmarks, i.e., COCO $[\mathrm{LMB^{+}}14]$ , and Flickr30K $[\mathrm{PWC}^{+}1\bar{5}]$ , are used to evaluate the model. Following previous work $[\mathrm{ZLH^{+}}21$ , KSK21], we use the Karpathy split [KF15] for the two benchmarks. BEIT-3 is finetuned as a dual encoder for efficient image-text retrieval. Dual-encoder models separately encode images and texts to obtain their representations. Then we calculate the cosine similarity scores of these representations. Dual-encoder models are more efficient than fusion-encoder models. Because they do not have to jointly encode all possible image-text pairs.
图文检索
该任务旨在衡量图像与文本之间的相似度。根据检索目标的模态可分为两个方向:图像到文本检索和文本到图像检索。我们采用两个主流检索基准数据集——COCO $[\mathrm{LMB^{+}}14]$ 和 Flickr30K $[\mathrm{PWC}^{+}1\bar{5}]$ 进行模型评估。遵循先前工作 $[\mathrm{ZLH^{+}}21$, KSK21] 的方法,我们对这两个基准采用 Karpathy 划分 [KF15]。
BEIT-3 通过微调成为高效图文检索的双编码器 (dual encoder) 架构。双编码器模型分别对图像和文本进行编码以获取其表征,随后计算这些表征的余弦相似度得分。相较于融合编码器 (fusion-encoder) 模型,双编码器模型具有更高效率优势,因其无需对所有可能的图文组合进行联合编码。
We directly finetune BEIT-3 on COCO and Flickr30K, although the model is not pretrained with image-text contrastive loss. Surprisingly, BEIT-3 outperforms previous state-of-the-art models only using a small amount of contrastive training. The results demonstrate that BEIT-3 effectively learns alignments between images and texts via masked data modeling. In order to improve the performance, we perform intermediate finetuning with an image-text contrastive objective on the pre training image-text pairs. We finetune the model with much fewer steps than pre training. Then we use the model to evaluate zero-shot and finetuned image-text retrieval. The finetuned results are present in Table 5, dual-encoder BEIT-3 outperforms prior models by a large margin, achieving $3.0/4.0$ absolute improvement on COCO top-1 image-to-text/text-to-image retrieval, and $0.8/2.4$ absolute improvement on Flickr30K top-1 image-to-text/text-to-image retrieval. BEIT-3 also significantly outperforms fusion-encoder-based models, which require more computation cost for inference. As present in Table 6, BEIT-3 also achieves better performance than previous models on Flickr30K zero-shot retrieval.
我们直接在COCO和Flickr30K上微调BEIT-3,尽管该模型未经过图像-文本对比损失的预训练。令人惊讶的是,BEIT-3仅使用少量对比训练就超越了之前的先进模型。结果表明,BEIT-3通过掩码数据建模有效学习了图像与文本的对齐关系。为了提升性能,我们在预训练图像-文本对上采用图像-文本对比目标进行中间微调,其训练步数远少于预训练阶段。随后评估该模型在零样本和微调后的图像-文本检索任务上的表现。微调结果如 表 5 所示,双编码器BEIT-3以显著优势超越先前模型:在COCO top-1图像到文本/文本到图像检索上分别实现$3.0/4.0$的绝对提升,在Flickr30K top-1图像到文本/文本到图像检索上分别实现$0.8/2.4$的绝对提升。BEIT-3也大幅优于基于融合编码器的模型(这些模型需要更高的推理计算成本)。如 表 6 所示,BEIT-3在Flickr30K零样本检索任务上也优于先前模型。
Table 7: Results of object detection and instance segmentation on COCO benchmark. BEIT-3 uses Cascade Mask R-CNN [CV21] as the detection head. Our results are reported with multiscale evaluation. We report the maximum image size used for training. FLOD-9M and FourODs also contain Object365. The results of the comparison systems are from the papers with code.com leader board (timestamp: 08/22/2022).
表 7: COCO基准上的目标检测和实例分割结果。BEIT-3采用Cascade Mask R-CNN [CV21]作为检测头。我们的结果采用多尺度评估报告。我们报告了训练时使用的最大图像尺寸。FLOD-9M和FourODs也包含Object365数据。对比系统的结果来自papers with code.com排行榜(时间戳: 2022/08/22)。
| 模型 | 额外目标检测数据 | 最大图像尺寸 | COCO test-dev APbox | APmask |
|---|---|---|---|---|
| ViT-Adapter [CDW+22] | 1600 | 60.1 | 52.1 | |
| DyHead [DCX+21] | ImageNet伪标签 | 2000 | 60.6 | |
| Soft Teacher [XZH+21] | Object365 | 61.3 | 53.0 | |
| GLIP [LZZ+21] | FourODs | 61.5 | ||
| GLIPv2 [ZZH+22] | FourODs | 62.4 | ||
| Florence [YCC+21] | FLOD-9M | 2500 | 62.4 | |
| SwinV2-G [LHL+21] | Object365 | 1536 | 63.1 | 54.4 |
| Mask DINO [LZX+22] | Object365 | 1280 | 54.7 | |
| DINO [ZLL+22] | Object365 | 2000 | 63.3 | |
| BE1T-3 | Object365 | 1280 | 63.7 | 54.8 |
3.2 Vision Downstream Tasks
3.2 视觉下游任务
In addition to vision-language downstream tasks, BEIT-3 can be transferred to a wide range of vision downstream tasks, including object detection, instance segmentation, semantic segmentation, and image classification. The number of effective parameters is comparable to ViT-giant [ZKHB21], i.e., about 1B, when BEIT-3 is used as a vision encoder.
除了视觉-语言下游任务,BEIT-3还能迁移到多种视觉下游任务,包括目标检测、实例分割、语义分割和图像分类。当BEIT-3作为视觉编码器时,其有效参数量与ViT-giant [ZKHB21]相当,约为10亿。
Object Detection and Instance Segmentation We conduct finetuning experiments on the COCO 2017 benchmark $[\mathrm{LMB^{+}}14]$ , which consists of 118k training, 5k validation, and $20\mathrm{k\Omega}$ test-dev images. We use BEIT-3 as the backbone and follow ViTDet [LMGH22], including a simple feature pyramid and window attention, for the object detection and instance segmentation tasks. Following common practices $[\mathrm{LHL^{+}}21$ , $\mathrm{ZLL^{+}}22]$ , we first conduct intermediate finetuning on the Objects365 $\bar{[}\mathrm{SLZ^{+}}19]$ dataset. Then we finetune the model on the COCO dataset. Soft-NMS [BSCD17] is used during inference. Table 7 compares BEIT-3 with previous state-of-the-art models on COCO object detection and instance segmentation. BEIT-3 achieves the best results on the COCO test-dev set with a smaller image size used for finetuning, reaching up to 63.7 box AP and 54.8 mask AP.
目标检测与实例分割
我们在COCO 2017基准测试[LMB+14]上进行了微调实验,该数据集包含11.8万张训练图像、5000张验证图像和20kΩ测试开发图像。采用BEIT-3作为主干网络,并遵循ViTDet[LMGH22]的方案(包括简单特征金字塔和窗口注意力机制)来处理目标检测和实例分割任务。按照常规实践[LHL+21, ZLL+22],我们首先在Objects365[SLZ+19]数据集上进行中间微调,随后在COCO数据集上完成模型微调。推理阶段采用Soft-NMS[BSCD17]方法。表7展示了BEIT-3与先前最优模型在COCO目标检测和实例分割任务上的对比结果:在使用更小微调图像尺寸的情况下,BEIT-3在COCO test-dev集上达到63.7边界框AP和54.8掩码AP的最高性能。
Semantic Segmentation Semantic segmentation aims to predict the label for each pixel of the given image. We evaluate BEIT-3 on the challenging ADE20K dataset $[Z Z^{+}19]$ , which includes 150 semantic categories. ADE20K contains $20\mathrm{k\Omega}$ images for training and 2k images for validation. We directly follow the task transfer settings of ViT-Adapter $[\mathrm{CDW^{+}}2\bar{2}]$ . We use a dense prediction task adapter and employ Mask 2 Former $[\mathrm{C}\mathrm{\bar{M}S^{+}}21]$ as the segmentation framework. As shown in Table 8, BEIT-3 creates a new state-of-the-art result with $62.8\mathrm{mIoU}$ , outperforming FD-SwinV2 $[\mathbf{W}\mathbf{H}\mathbf{X}^{+}22]$ giant model with 3B parameters by 1.4 points. It shows that BEIT-3 achieves superior performance on the dense prediction task.
语义分割
语义分割旨在预测给定图像每个像素的标签。我们在具有挑战性的ADE20K数据集[ZZ+19]上评估BEIT-3,该数据集包含150个语义类别。ADE20K包含20kΩ训练图像和2k验证图像。我们直接沿用ViT-Adapter[CDW+22]的任务迁移设置,使用密集预测任务适配器,并采用Mask2Former[CMS+21]作为分割框架。如表8所示,BEIT-3以62.8 mIoU创造了新的最先进结果,比拥有30亿参数的FD-SwinV2[WHX+22]巨型模型高出1.4个百分点。这表明BEIT-3在密集预测任务上实现了卓越性能。
Image Classification We evaluate the model on ImageNet-1K $[\mathrm{RDS^{+}}15]$ , which contains 1.28M training images and $50\mathrm{k\Omega}$ validation images in 1k classes. Rather than appending a task layer to the vision encoder $[\mathrm{DBK^{+}}20\$ , BDPW22], we formulate the task as an image-to-text retrieval task. We use the category names as texts to construct image-text pairs. BEIT-3 is trained as a dual encoder to find the most relevant label for an image. During inference, we first compute the feature embeddings of possible class names and the feature embedding of the image. Their cosine similarity scores are then calculated to predict the most probable label for each image. Table 9 reports the results on ImageNet-1K. We first perform intermediate finetuning on ImageNet-21K, then we train the model on ImageNet-1K. For a fair comparison, we compare with the previous models only using public image-tag data. BEIT-3 outperforms prior models, creating a new state-of-the-art result when only using public image-tag data.
图像分类
我们在 ImageNet-1K [RDS+15] 上评估模型,该数据集包含 128 万张训练图像和 5 万张验证图像,涵盖 1k 个类别。与在视觉编码器 [DBK+20, BDPW22] 上附加任务层不同,我们将该任务定义为图像到文本的检索任务。使用类别名称作为文本来构建图像-文本对。BEIT-3 被训练为双编码器,以寻找图像最相关的标签。在推理过程中,我们首先计算可能类别名称的特征嵌入和图像的特征嵌入,然后计算它们的余弦相似度分数,以预测每张图像最可能的标签。
表 9 报告了 ImageNet-1K 上的结果。我们首先在 ImageNet-21K 上进行中间微调,然后在 ImageNet-1K 上训练模型。为公平比较,我们仅使用公开的图像标签数据与先前模型进行对比。BEIT-3 优于先前模型,仅使用公开图像标签数据时创造了新的最先进结果。
Table 8: Results of semantic segmentation on ADE20K. “MS” is short for multi-scale. The results of the comparison systems are from the papers with code.com leader board (timestamp: 08/22/2022).
表 8: ADE20K语义分割结果。"MS"是多尺度(multi-scale)的缩写。对比系统的结果来自papers with code.com排行榜(时间戳: 2022年8月22日)。
| 模型 | 裁剪尺寸 | ADE20K mIoU | +MS |
|---|---|---|---|
| HorNet[RZT+22] | 6402 | 57.5 | 57.9 |
| SeMask[JSO+21] | 6402 | 57.0 | 58.3 |
| SwinV2-G [LHL+21] | 8962 | 59.3 | 59.9 |
| ViT-Adapter[CDW+22] | 8962 | 59.4 | 60.5 |
| Mask DINO [LZX+22] | 59.5 | 60.8 | |
| FD-SwinV2-G[WHX+22] | 8962 | 61.4 | |
| BE1T-3 | 8962 | 62.0 | 62.8 |
Table 9: Top-1 accuracy on ImageNet-1K.
表 9: ImageNet-1K 上的 Top-1 准确率。
| 模型 | 额外数据 | 图像尺寸 | ImageNet |
|---|---|---|---|
| 使用额外私有图像标签数据 | |||
| SwinV2-G [LHL+21] | IN-22K-ext-70M | 640² | 90.2 |
| ViT-G [ZKHB21] | JFT-3B | 518² | 90.5 |
| CoAtNet-7 [DLLT21] | JFT-3B | 512² | 90.9 |
| Model Soups [WIG+22] | JFT-3B | 500² | 91.0 |
| CoCa [YWV+22] | JFT-3B | 576² | 91.0 |
| 仅使用公开图像标签数据 | |||
| BE1T [BDPW22] | IN-21K | 512² | 88.6 |
| CoAtNet-4 [DLLT21] | IN-21K | 512² | 88.6 |
| MaxViT [TTZ+22] | IN-21K | 512² | 88.7 |
| MViTv2 [LWF+22] | IN-21K | 512² | 88.8 |
| FD-CLIP [WHX+22] | IN-21K | 336² | 89.0 |
| BE1T-3 | IN-21K | 336² | 89.6 |
4 Conclusion
4 结论
In this paper, we present BEIT-3, a general-purpose multimodal foundation model, which achieves state-of-the-art performance across a wide range of vision and vision-language benchmarks. The key idea of BEIT-3 is that image can be modeled as a foreign language, so that we can conduct masked “language” modeling over images, texts, and image-text pairs in a unified way. We also demonstrate that Multiway Transformers can effectively model different vision and vision-language tasks, making it an intriguing option for general-purpose modeling. BEIT-3 is simple and effective, and is a promising direction for scaling up multimodal foundation models. For future work, we are working on pre training multilingual BEIT-3 and including more modalities (e.g., audio) in BEIT-3 to facilitate the cross-lingual and cross-modality transfer, and advance the big convergence of large-scale pre training across tasks, languages, and modalities. We are also interested in enabling in-context learning capability for multimodal foundation models by combining the strength of BEIT-3 and MetaLM $[\bar{\mathrm{HSD}}^{+}22]$ .
本文提出了一种通用多模态基础模型BEIT-3,该模型在广泛的视觉与视觉-语言基准测试中实现了最先进的性能。BEIT-3的核心思想是将图像建模为一种外语,从而能以统一方式对图像、文本和图文对进行掩码"语言"建模。我们还证明了Multiway Transformers能有效建模不同视觉与视觉-语言任务,使其成为通用建模的理想选择。BEIT-3简单高效,为扩展多模态基础模型提供了有前景的方向。未来工作将聚焦于预训练多语言版BEIT-3,并纳入更多模态(如音频)以实现跨语言跨模态迁移,推动跨任务、跨语言、跨模态的大规模预训练大融合。我们还将结合BEIT-3与MetaLM $[\bar{\mathrm{HSD}}^{+}22]$ 的优势,探索多模态基础模型的上下文学习能力。