Multimodal Abstract ive Sum mari z ation for How2 Videos
面向How2视频的多模态摘要生成
Abstract
摘要
In this paper, we study abstract ive summarization for open-domain videos. Unlike the tra- ditional text news sum mari z ation, the goal is less to “compress” text information but rather to provide a fluent textual summary of information that has been collected and fused from different source modalities, in our case video and audio transcripts (or text). We show how a multi-source sequence-to-sequence model with hierarchical attention can integrate information from different modalities into a coherent output, compare various models trained with different modalities and present pilot experiments on the How2 corpus of instructional videos. We also propose a new evaluation metric (Content F1) for abstract ive sum mari z ation task that measures semantic adequacy rather than fluency of the summaries, which is covered by metrics like ROUGE and BLEU.
本文研究了开放领域视频的抽象摘要生成任务。与传统文本新闻摘要不同,该任务的目标并非简单"压缩"文本信息,而是基于从多源模态(本研究中指视频和音频转录文本)收集融合的信息,生成流畅的文本摘要。我们展示了具有分层注意力机制的多源序列到序列模型如何将不同模态信息整合为连贯输出,比较了基于不同模态训练的多种模型,并在How2教学视频语料库上进行了初步实验。针对抽象摘要任务,我们还提出了一种新的评估指标Content F1,该指标侧重衡量摘要的语义充分性而非流畅度(ROUGE和BLEU等指标已涵盖流畅度评估)。
1 Introduction
1 引言
In recent years, with the growing popularity of video sharing platforms, there has been a steep rise in the number of user-generated instructional videos shared online. With the abundance of videos online, there has been an increase in demand for efficient ways to search and retrieve relevant videos (Song et al., 2011; Wang et al., 2012; Otani et al., 2016; Torabi et al., 2016). Many cross-modal search applications rely on text associated with the video such as description or title to find relevant content. However, often videos do not have text meta-data associated with them or the existing ones do not provide clear information of the video content and fail to capture subtle differences between related videos (Wang et al., 2012). We address this by aiming to generate a short text summary of the video that describes the most salient content of the video. Our work benefits users through better contextual information and user experience, and video sharing platforms with increased user engagement by retrieving or suggesting relevant videos to users and capturing their attention.
近年来,随着视频分享平台的日益普及,用户生成的在线教学视频数量急剧增长。面对海量的在线视频,人们对高效搜索和检索相关视频的需求也随之增加 (Song et al., 2011; Wang et al., 2012; Otani et al., 2016; Torabi et al., 2016)。许多跨模态搜索应用依赖视频关联文本(如描述或标题)来查找相关内容。然而,视频往往缺乏关联的文本元数据,或现有元数据无法清晰反映视频内容,难以捕捉相关视频间的细微差异 (Wang et al., 2012)。我们通过生成描述视频核心内容的简短文本来解决这一问题。这项工作通过提供更优质的上下文信息和用户体验使终端用户受益,同时帮助视频分享平台通过精准检索/推荐相关视频来提升用户参与度和注意力。
Sum mari z ation is a task of producing a shorter version of the content in the document while preserving its information and has been studied for both textual documents (automatic text summarization) and visual documents such as images and videos (video sum mari z ation). Automatic text summarization is a widely studied topic in natural language processing (Luhn, 1958; Kupiec et al., 1995; Mani, 1999); given a text document the task is to generate a textual summary for applications that can assist users to understand large documents. Most of the work on text sum mari z ation has focused on single-document sum mari z ation for domains such as news (Rush et al., 2015; Nallapati et al., 2016; See et al., 2017; Narayan et al., 2018) and some on multi-document sum mari z ation (Goldstein et al., 2000; Lin and Hovy, 2002; Woodsend and Lapata, 2012; Cao et al., 2015; Yasunaga et al., 2017).
摘要生成是一项在保留文档信息的同时生成更简洁版本内容的任务,已针对文本文档(自动文本摘要)和图像、视频等视觉文档(视频摘要)展开研究。自动文本摘要是自然语言处理领域广泛研究的课题 (Luhn, 1958; Kupiec et al., 1995; Mani, 1999),其任务是为帮助用户理解大型文档的应用生成文本摘要。大多数文本摘要研究集中在新闻等领域的单文档摘要 (Rush et al., 2015; Nallapati et al., 2016; See et al., 2017; Narayan et al., 2018),部分研究涉及多文档摘要 (Goldstein et al., 2000; Lin and Hovy, 2002; Woodsend and Lapata, 2012; Cao et al., 2015; Yasunaga et al., 2017)。
Video sum mari z ation is the task of producing a compact version of the video (visual summary) by encapsulating the most informative parts (Money and Agius, 2008; Lu and Grauman, 2013; Gygli et al., 2014; Song et al., 2015; Sah et al., 2017). Multimodal sum mari z ation is the combination of textual and visual modalities by summarizing a video document with a text summary that summarizes the content of the video. Multimodal summarization is a more recent challenge with no benchmarking datasets yet. Li et al. (2017) collected a multimodal corpus of 500 English news videos and articles paired with manually annotated summaries. The dataset is small-scale and has news articles with audio, video, and text summaries, but there are no human annotated audio-transcripts.
视频摘要 (Video summarization) 的任务是通过封装最具信息量的部分来生成视频的紧凑版本(视觉摘要)(Money and Agius, 2008; Lu and Grauman, 2013; Gygli et al., 2014; Song et al., 2015; Sah et al., 2017)。多模态摘要 (Multimodal summarization) 是通过结合文本和视觉模态,用文本摘要来概括视频文档的内容。多模态摘要是一个较新的挑战,目前还没有基准数据集。Li 等人 (2017) 收集了一个包含 500 个英语新闻视频和文章的多模态语料库,并配有人工标注的摘要。该数据集规模较小,包含带有音频、视频和文本摘要的新闻文章,但没有人工标注的音频转录文本。
Transcript
转录文本
today we are going to show you how to make spanish omelet . i 'm going to dice a little bit of peppers here . $\mathrm{i} \mathrm{m}$ not going to use a lot , $\mathrm{i}~\mathrm{m}$ going to use very very little . a little bit more then this maybe . you can use red peppers if you like to get a little bit color in your omelet . some people do and some people do n't …. t is the way they make there spanish omelets that is what she says . i loved it , it actually tasted really good . you are going to take the onion also and dice it really small . you do n't want big chunks of onion in there cause it is just pops out of the omelet . so we are going to dice the up also very very small . so we have small pieces of onions and peppers ready to go .
今天我们将向大家展示如何制作西班牙煎蛋卷。我要在这里切一些甜椒丁。$\mathrm{i} \mathrm{m}$ 不会用太多,$\mathrm{i}~\mathrm{m}$ 只用非常非常少的量。可能比这个再多一点点。如果你喜欢煎蛋卷带点颜色,也可以用红甜椒。有些人这样做,有些人不这样做……这就是他们制作西班牙煎蛋卷的方式,她是这么说的。我很喜欢,味道确实很棒。你还需要把洋葱也切成非常小的丁。煎蛋卷里不想要大块的洋葱,因为那样会突出来。所以我们也要把洋葱切得非常非常小。现在我们已经准备好了小块的洋葱和甜椒。

Video Figure 1: How2 dataset example with different modalities. “Cuban breakfast” and “free cooking video” is not mentioned in the transcript, and has to be derived from other sources.
图 1: How2数据集示例展示多模态信息。"Cuban breakfast"和"free cooking video"未在文本转录中出现,需通过其他模态数据推断。
Summary
摘要
how to cut peppers to make a spanish omelette; get expert tips and advice on making cuban breakfast recipes in this free cooking video .
如何切辣椒制作西班牙煎蛋卷;在这个免费烹饪视频中获取制作古巴早餐食谱的专家建议和技巧。
Related tasks include image or video captioning and description generation, video story generation, procedure learning from instructional videos and title generation which focus on events or activities in the video and generating descriptions at various levels of granularity from single sentence to multiple sentences (Das et al., 2013; Regneri et al., 2013; Rohrbach et al., 2014; Zeng et al., 2016; Zhou et al., 2018; Zhang et al., 2018; Gella et al., 2018). A closely related task to ours is video title generation where the task is to describe the most salient event in the video in a compact title that is aimed at capturing users attention (Zeng et al., 2016). Zhou et al. (2018) present the YouCookII dataset containing instructional videos, specifically cooking recipes, with temporally localized annotations for the procedure which could be viewed as a sum mari z ation task as well although localized with time alignments between video segments and procedures.
相关任务包括图像或视频字幕生成、描述生成、视频故事生成、教学视频中的流程学习以及标题生成,这些任务聚焦于视频中的事件或活动,并生成从单句到多句不同粒度的描述 (Das et al., 2013; Regneri et al., 2013; Rohrbach et al., 2014; Zeng et al., 2016; Zhou et al., 2018; Zhang et al., 2018; Gella et al., 2018)。与我们任务密切相关的是视频标题生成,其目标是用简洁标题描述视频中最突出的事件以吸引用户注意 (Zeng et al., 2016)。Zhou et al. (2018) 提出的 YouCookII 数据集包含教学视频(特别是烹饪食谱),其中带有时间定位的流程标注,这也可视为一种摘要任务,尽管是通过视频片段与流程间的时间对齐来实现定位的。
2 Multimodal Abstract ive Sum mari z ation
2 多模态摘要生成
In this work, we study multimodal summarization with various methods to summarize the intent of open-domain instructional videos stating the exclusive and unique features of the video, irrespective of modality. We study this task in detail using the new How2 dataset (Sanabria et al., 2018) which contains human annotated video summaries for a varied range of topics. Our models generate natural language descriptions for video content using the transcriptions (both user-generated and output of automatic speech recognition systems) as well as visual features extracted from the video. We also introduce a new evaluation metric (Content F1) that suits this task and present detailed results to understand the task better.
在本研究中,我们采用多种方法研究多模态摘要生成任务,旨在提炼开放域教学视频的核心意图,突出视频独有的跨模态特征。我们基于How2数据集(Sanabria等人,2018)对该任务进行深入分析,该数据集包含涵盖广泛主题的人工标注视频摘要。我们的模型通过视频转录文本(包括用户生成内容和自动语音识别系统输出)及视频视觉特征,生成描述视频内容的自然语言文本。同时,我们提出了适用于该任务的新评估指标(Content F1),并通过详实实验结果深化对该任务的理解。
The How2 dataset (Sanabria et al., 2018) contains about 2,000 hours of short instructional videos, spanning different domains such as cooking, sports, indoor/outdoor activities, music, etc. Each video is accompanied by a human-generated transcript and a 2 to 3 sentence summary is available for every video written to generate interest in a potential viewer.
How2数据集 (Sanabria et al., 2018) 包含约2000小时的简短教学视频,涵盖烹饪、体育、室内/外活动、音乐等多个领域。每个视频都附有人工生成的文字记录,并为每个视频编写了2到3句的摘要,旨在激发潜在观众的兴趣。
The example in Figure 1 shows the transcript describes instructions in detail, while the summary is a high-level overview of the entire video, mentioning that the peppers are being “cut”, and that this is a “Cuban breakfast recipe”, which is not mentioned in the transcript. We observe that text and vision modalities both contain complementary information, thereby when fused, helps in generating richer and more fluent summaries. Additionally, we can also leverage the speech modality by using the output of a speech recognizer as input to a summarization model instead of a human-annotated transcript.
图1中的示例显示,转录本详细描述了操作步骤,而摘要则是对整个视频的高度概括,提到辣椒被"切碎",以及这是一道"古巴早餐食谱"(这些信息在转录本中并未提及)。我们观察到文本和视觉模态都包含互补信息,因此当它们融合时,有助于生成更丰富、更流畅的摘要。此外,我们还可以通过将语音识别器的输出(而非人工标注的转录本)作为摘要模型的输入,来利用语音模态的优势。
The How2 corpus contains 73,993 videos for training, 2,965 for validation and 2,156 for testing. The average length of transcripts is 291 words and of summaries is 33 words. A more general comparison of the How2 dataset for sum mari z ation as compared with certain common datasets is given in (Sanabria et al., 2018).
How2语料库包含73,993个训练视频、2,965个验证视频和2,156个测试视频。转录文本的平均长度为291个单词,摘要的平均长度为33个单词。关于How2数据集与其他常见摘要数据集的综合对比分析可参考 (Sanabria et al., 2018)。
Video-based Sum mari z ation. We represent videos by features extracted from a pre-trained action recognition model: a ResNeXt-101 3D Convolutional Neural Network (Hara et al., 2018)
基于视频的摘要。我们使用从预训练动作识别模型(ResNeXt-101 3D卷积神经网络 (Hara et al., 2018))中提取的特征来表示视频。
trained to recognize 400 different human actions in the Kinetics dataset (Kay et al., 2017). These features are 2048 dimensional, extracted for every 16 non-overlapping frames in the video. This results in a sequence of feature vectors per video rather than a single/global one. We use these sequential features in our models described in Section 3. 2048-dimensional feature vector representing all text a single video.
经过训练可识别Kinetics数据集(Kay等人,2017)中的400种不同人类动作。这些特征为2048维,从视频中每16个非重叠帧提取一次,从而为每个视频生成特征向量序列而非单一全局向量。如第3节所述,我们将在模型中使用这些时序特征。2048维特征向量代表单个视频的全部文本信息。
Speech-based Sum mari z ation. We leverage the speech modality by using the outputs from a pretrained speech recognizer that is trained with other data, as inputs to a text sum mari z ation model. We use the state-of-the-art models for distantmicrophone conversational speech recognition, ASpIRE (Peddinti et al., 2015) and EESEN (Miao et al., 2015; Le Franc et al., 2018). The word error rate of these models on the How2 test data is $35.4%$ This high error mostly stems from normalization issues in the data. For example, recognizing and labeling $\ '20'$ as “twenty” etc. Handling these effectively will reduce the word error rates significantly. We accept these as is for this task.
基于语音的摘要生成。我们利用语音模态,将预训练语音识别器(使用其他数据训练)的输出作为文本摘要模型的输入。采用远场对话语音识别的先进模型ASpIRE (Peddinti et al., 2015)和EESEN (Miao et al., 2015; Le Franc et al., 2018),这些模型在How2测试数据上的词错误率为$35.4%$。高错误率主要源于数据规范化问题,例如将$\ '20'$识别标注为"twenty"等。有效处理这些问题可显著降低词错误率,但本任务中我们直接接受原始输出。
Transfer Learning. Our parallel work Sanabria et al. (2019) demonstrates the use of sum mari z ation models trained in this paper for a transfer learning based sum mari z ation task on the Charades dataset (Sigurdsson et al., 2016) that has audio, video, and text (summary, caption and question-answer pairs) modalities similar to the How2 dataset. Sanabria et al. (2019) observe that pre-training and transfer learning with the How2 dataset led to significant improvements in unimodal and multimodal adaptation tasks on the Charades dataset.
迁移学习。我们的并行工作Sanabria等人(2019)展示了使用本文训练的摘要模型在Charades数据集(Sigurdsson等人, 2016)上执行基于迁移学习的摘要任务,该数据集具有与How2数据集相似的音频、视频和文本(摘要、字幕及问答对)模态。Sanabria等人(2019)发现,使用How2数据集进行预训练和迁移学习显著提升了在Charades数据集上的单模态与多模态适应任务性能。
3 Sum mari z ation Models
3 摘要模型 (Summari z ation Models)
We study various sum mari z ation models. First, we use a Recurrent Neural Network (RNN) Sequenceto-Sequence (S2S) model (Sutskever et al., 2014) consisting of an encoder RNN to encode (text or video features) with the attention mechanism (Bahdanau et al., 2014) and a decoder RNN to generate summaries. Our second model is a Pointer-Generator (PG) model (Vinyals et al., 2015; Gülçehre et al., 2016) that has shown strong performance for abstract ive sum mari z ation (Nallapati et al., 2016; See et al., 2017). As our third model, we use hierarchical attention approach of Libovický and Helcl 2017 originally proposed for multimodal machine translation to combine textual and visual modalities to generate text. The model first computes the context vector independently for each of the input modalities (text and video). In the next step, the context vectors are treated as states of another encoder, and a new vector is computed. When using a sequence of action features instead of a single averaged vector for a video, the RNN layer helps capture context. In Figure 2 we present the building block of our models.
我们研究了多种摘要生成模型。首先,我们采用基于循环神经网络(RNN)的序列到序列(S2S)模型(Sutskever等人,2014),该模型包含一个带注意力机制(Bahdanau等人,2014)的编码器RNN用于编码(文本或视频特征),以及一个解码器RNN用于生成摘要。我们的第二个模型是指针生成器(PG)模型(Vinyals等人,2015;Gülçehre等人,2016),该模型在抽象摘要任务(Nallapati等人,2016;See等人,2017)中表现出色。作为第三个模型,我们采用Libovický和Helcl 2017提出的层级注意力方法(原用于多模态机器翻译),通过结合文本和视觉模态来生成文本。该模型首先为每个输入模态(文本和视频)独立计算上下文向量,随后将这些上下文向量视为另一个编码器的状态并计算新向量。当使用动作特征序列而非单一平均向量表示视频时,RNN层有助于捕获上下文信息。图2展示了我们模型的核心构建模块。
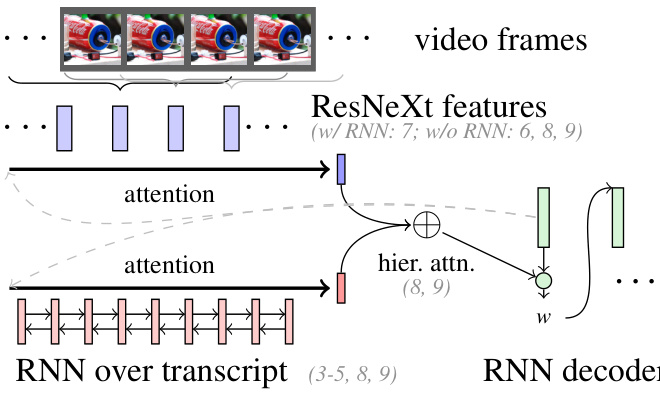
Figure 2: Building blocks of the sequence-to-sequence models, gray numbers in brackets indicate which components are utilized in which experiments.
图 2: 序列到序列模型的构建模块,括号中的灰色数字表示各组件在哪些实验中被使用。
4 Evaluation
4 评估
We evaluate the summaries using the standard metric for abstract ive sum mari z ation ROUGE-L (Lin and Och, 2004) that measures the longest common sequence between the reference and the generated summary. Additionally, we introduce the Content F1 metric that fits the template-like structure of the summaries. We analyze the most frequently occurring words in the transcription and summary. The words in transcript reflect the conversational and spontaneous speech while the words in the summaries reflect their descriptive nature. For examples, see Table A1 in Appendix A.2.
我们采用摘要生成的标准评估指标ROUGE-L (Lin and Och, 2004)来衡量参考摘要与生成摘要之间的最长公共子序列。此外,针对模板化结构的摘要,我们引入了Content F1指标。我们分析了转录文本和摘要中出现频率最高的词汇:转录文本中的词汇反映了对话式自发语言特征,而摘要词汇则体现描述性特质。具体示例参见附录A.2中的表A1。
Content F1. This metric is the F1 score of the content words in the summaries based over a monolingual alignment, similar to metrics used to evaluate quality of monolingual alignment (Sultan et al., 2014). We use the METEOR toolkit (Banerjee and Lavie, 2005; Denkowski and Lavie, 2014) to obtain the alignment. Then, we remove function words and task-specific stop words that appear in most of the summaries (see Appendix A.2) from the reference and the hypothesis. The stop words are easy to predict and thus increase the ROUGE score. We treat remaining content words from the reference and the hypothesis as two bags of words and compute the F1 score over the alignment. Note that the score ignores the fluency of output.
内容F1。该指标是基于单语对齐的摘要中内容词的F1分数,类似于用于评估单语对齐质量的指标[20]。我们使用METEOR工具包[5][9]获取对齐结果,然后从参考摘要和生成摘要中移除功能词及大多数摘要中出现的任务特定停用词(见附录A.2)。这些停用词容易预测,因此会提高ROUGE分数。我们将参考摘要和生成摘要中剩余的内容词视为两个词袋,并计算对齐后的F1分数。需注意该指标不考虑输出流畅性。
Table 1: ROUGE-L and Content F1 for different sum mari z ation models: random baseline (1), rule-based extracted summary (2a), nearest neighbor summary (2b), different text-only (3,4,5a), pointer-generator (5b), ASR output transcript (5c), video-only (6-7) and text-and-video models (8-9).
表 1: 不同摘要模型的 ROUGE-L 和内容 F1 分数:随机基线 (1)、基于规则的抽取式摘要 (2a)、最近邻摘要 (2b)、纯文本模型 (3,4,5a)、指针生成器 (5b)、ASR 输出转录文本 (5c)、纯视频模型 (6-7) 以及文本-视频融合模型 (8-9)。
| 模型编号 | 描述 | ROUGE-L | 内容 F1 |
|---|---|---|---|
| 1 | 使用语言模型的随机基线 | 27.5 | 8.3 |
| 2a | 基于规则的抽取式摘要 | 16.4 | 18.8 |
| 2b | 最近邻摘要 | 31.8 | 17.9 |
| 3 | 仅使用 2a 抽取的句子(纯文本) | 46.4 | 36.0 |
| 4 | 前 200 个 token(纯文本) | 40.3 | 27.5 |
| 5a | S2S 完整转录文本(纯文本,650 token) | 53.9 | 47.4 |
| 5b | PG 完整转录文本(纯文本) | 50.2 | 42.0 |
| 5c | ASR 输出完整转录文本(纯文本) | 46.1 | 34.7 |
| 6 | 仅动作特征(视频) | 38.5 | 24.8 |
| 7 | 动作特征 + RNN(视频) | 46.3 | 34.9 |
| 8 | 真实转录文本 + 分层注意力动作特征 | 54.9 | 48.9 |
| 9 | ASR 输出 + 分层注意力动作特征 | 46.3 | 34.7 |
Table 2: Human evaluation scores on 4 different measures of Informative ness (INF), Relevance (REL), Coherence (COH), Fluency (FLU).
表 2: 人类评估在信息量 (INF)、相关性 (REL)、连贯性 (COH)、流畅性 (FLU) 四个不同指标上的得分。
| 模型 (编号) | INF | REL | COH | FLU |
|---|---|---|---|---|
| 纯文本 (5a) | 3.86 | 3.78 | 3.78 | 3.92 |
| 纯视频 (7) | 3.58 | 3.30 | 3.71 | 3.80 |
| 文本加视频 (8) | 3.89 | 3.74 | 3.85 | 3.94 |
Human Evaluation. In addition to automatic evaluation, we perform a human evaluation to understand the outputs of this task better. Following the abstract ive sum mari z ation human annotation work of Grusky et al. (2018), we ask our annotators to label the generated output on a scale of $1-5$ on informative ness, relevance, coherence, and fluency. We perform this on randomly sampled 500 videos from the test set.
人工评估。除自动评估外,我们还进行了人工评估以更好地理解该任务的输出结果。参照Grusky等人(2018)的摘要生成人工标注工作,我们要求标注者以$1-5$分为生成输出的信息量(informativeness)、相关性(relevance)、连贯性(coherence)和流畅性(fluency)进行评分。该评估在测试集中随机抽取的500个视频上进行。
We evaluate three models: two unimodal (textonly (5a), video-only (7)) and one multimodal (text-and-video (8)). Three workers annotated each video on Amazon Mechanical Turk. More details about human evaluation are in the Appendix A.5.
我们评估了三种模型:两种单模态(纯文本 (5a)、纯视频 (7))和一种多模态(文本加视频 (8))。三名工作人员在Amazon Mechanical Turk上对每个视频进行了标注。关于人工评估的更多细节见附录A.5。
5 Experiments and Results
5 实验与结果
As a baseline, we train an RNN language model (Sutskever et al., 2011) on all the summaries and randomly sample tokens from it. The output obtained is fluent in English leading to a high ROUGE score, but the content is unrelated which leads to a low Content F1 score in Table 1. As another baseline, we replace the target summary with a rule-based extracted summary from the transcription itself. We used the sentence containing words “how to” with predicates learn, tell, show, discuss or explain, usually the second sentence in the transcript. Our final baseline was a model trained with the summary of the nearest neighbor of each video in the Latent Dirichlet Allocation (LDA; Blei et al., 2003) based topic space as a target. This model achieves a similar Content F1 score as the rulebased model which shows the similarity of content and further demonstrates the utility of the Content F1 score.
作为基线,我们在所有摘要上训练了一个RNN语言模型 (Sutskever et al., 2011) 并从中随机采样token。生成的输出在英语表达上流畅,因此获得了较高的ROUGE分数,但其内容不相关,导致表1中的Content F1分数较低。另一个基线方法是用基于规则从转录文本中提取的摘要替换目标摘要。我们使用包含"how to"及谓语动词learn、tell、show、discuss或explain的句子(通常是转录文本中的第二句话)。最终基线模型采用基于潜在狄利克雷分配 (LDA; Blei et al., 2003) 主题空间中每个视频最近邻的摘要作为训练目标。该模型取得了与基于规则模型相近的Content F1分数,表明内容相似性,进一步验证了Content F1分数的实用性。
We use the transcript (either ground-truth transcript or speech recognition output) and the video action features to train various models with different combinations of modalities. The text-only model performs best when using the complete transcript in the input (650 tokens). This is in contrast to prior work with news-domain sum mari z ation (Nallapati et al., 2016). We also observe that PG networks do not perform better than S2S models on this data which could be attributed to the abstractive nature of our summaries and also the lack of common $n$ -gram overlap between input and output which is the important feature of PG networks. We also use the automatic transcriptions obtained from a pretrained automatic speech recognizer as input to the sum mari z ation model. This model achieves competitive performance with the video-only models (described below) but degrades noticeably than ground-truth transcription sum mari z ation model. This is as expected due to the large margin of ASR errors in distant-microphone open-domain speech recognition.
我们使用文本转录(包括真实转录文本和语音识别输出)和视频动作特征来训练不同模态组合的多种模型。纯文本模型在输入完整转录文本(650个token)时表现最佳,这与新闻领域摘要研究的先前工作形成对比 [20]。我们还观察到,在该数据集上,指针生成网络(PG)的性能并未优于序列到序列(S2S)模型,这可能归因于我们摘要的抽象性质,以及输入输出间缺乏共现n元语法重叠——而这正是PG网络的关键特征。我们还使用预训练语音识别器生成的自动转录文本作为摘要模型的输入,该模型取得了与纯视频模型(下文详述)相当的性能,但明显逊于真实转录文本的摘要模型。这是由于远场麦克风开放领域语音识别存在较高错误率所致,符合预期。
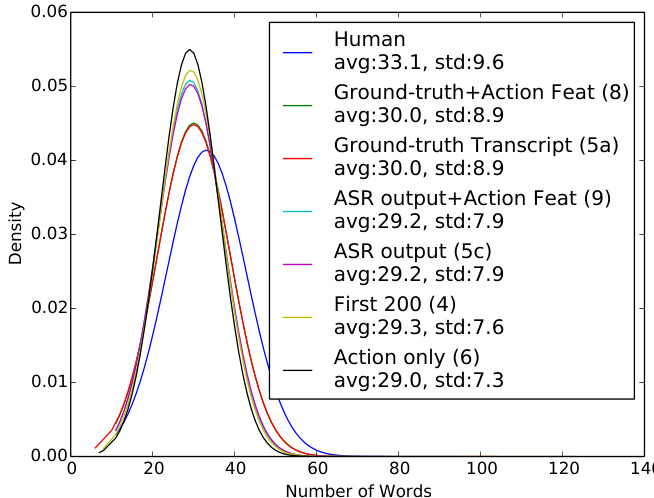
Figure 3: Word distribution in comparison with the human summaries for different unimodal and multimodal models. Density curves show the length distributions of human annotated and system produced summaries.
图 3: 不同单模态与多模态模型生成摘要与人工摘要的词汇分布对比。密度曲线展示了人工标注摘要与系统生成摘要的长度分布。
We trained two video-only models: the first one uses a single mean-pooled feature vector representation for the entire video, while the second one applies a single layer RNN over the vectors in time.
我们训练了两个纯视频模型:第一个模型对整个视频使用单一的平均池化特征向量表示,而第二个模型在时间维度上对向量应用单层RNN。
Note that using only the action features in input reaches almost competitive ROUGE and Content F1 scores compared to the text-only model showing the importance of both modalities in this task. Finally, the hierarchical attention model that combines both modalities obtains the highest score.
需要注意的是,仅使用输入中的动作特征就能达到与纯文本模型几乎相当的ROUGE和Content F1分数,这表明了两种模态在此任务中的重要性。最终,结合两种模态的分层注意力模型获得了最高分。
In Table 2, we report human evaluation scores on our best text-only, video-only and multimodal models. In three evaluation measures, the multimodal models with the hierarchical attention reach the best scores. Model hyper parameter settings, attention analysis and example outputs for the models described above are available in the Appendix.
在表2中,我们报告了纯文本、纯视频和多模态最佳模型的人类评估分数。在三个评估指标中,采用分层注意力机制的多模态模型获得了最高分。上述模型的超参数设置、注意力分析和输出示例详见附录。
In Figure 3, we analyze the word distributions of different system generated summaries with the human annotated reference. The density curves show that most model outputs are shorter than human annotations with the action-only model (6) being the shortest as expected. Interestingly, the two different uni-modal and multimodal systems with groundtruth text and ASR output text features are very similar in length showing that the improvements in Rouge-L and Content-F1 scores stem from the difference in content rather than length. Example presented in Table A2 Section A.3 shows how the outputs vary.
在图 3 中,我们分析了不同系统生成的摘要与人工标注参考之间的词分布。密度曲线显示,大多数模型输出比人工标注更短,其中仅动作模型 (6) 的篇幅最短,符合预期。有趣的是,采用真实文本和 ASR (Automatic Speech Recognition) 输出文本特征的两种单模态与多模态系统在长度上非常相似,这表明 Rouge-L 和 Content-F1 分数的提升源于内容差异而非长度差异。表 A2 第 A.3 节展示的示例说明了输出结果的多样性。
6 Conclusions
6 结论
We present several baseline models for generating abstract ive text summaries for the open-domain videos in How2 data. Our presented models include a video-only sum mari z ation model that performs competitively with a text-only model. In the future, we would like to extend this work to generate multidocument (multi-video) summaries and also build end-to-end models directly from audio in the video instead of text-based output from pretrained ASR. We define and show the quality of a new metric, Content F1, for evaluation of the video summaries that are designed as teasers or highlights for viewers, instead of a condensed version of the input like traditional text summaries.
我们提出了几种基线模型,用于为How2数据集中的开放域视频生成抽象文本摘要。我们展示的模型包括仅使用视频的摘要模型,其性能与仅使用文本的模型相当。未来,我们希望扩展这项工作以生成多文档(多视频)摘要,并直接从视频中的音频构建端到端模型,而非依赖预训练ASR的文本输出。我们定义并展示了一种新指标Content F1的质量,该指标用于评估视频摘要,这些摘要设计为吸引观众观看的预告片或精彩片段,而非传统文本摘要那样的输入浓缩版本。
Acknowledgements
致谢
This work was mostly conducted at the 2018 Frederick Jelinek Memorial Summer Workshop on Speech and Language Technologies,1 hosted and sponsored by Johns Hopkins University. Shruti Palaskar received funding from Facebook and Amazon grants. Jindrich Libovicky received funding from the Czech Science Foundation, grant no. 19- 26934X. This work used the Extreme Science and Engineering Discovery Environment (XSEDE) supported by NSF grant ACI-1548562 and the Bridges system supported by NSF award ACI-1445606, at the Pittsburgh Super computing Center.
本研究主要于2018年Frederick Jelinek纪念暑期语音与语言技术研讨会期间完成,该研讨会由约翰霍普金斯大学主办并资助。Shruti Palaskar的研究经费来自Facebook和Amazon的资助。Jindrich Libovicky的研究经费来自捷克科学基金会资助项目(编号19-26934X)。本研究使用了美国国家科学基金会(NSF)资助ACI-1548562支持的极限科学与工程发现环境(XSEDE),以及NSF奖项ACI-1445606支持的匹兹堡超级计算中心Bridges系统。
References
参考文献
Ozan Caglayan, Mercedes García-Martínez, Adrien Bardet, Walid Aransa, Fethi Bougares, and Loïc Bar- rault. 2017. Nmtpy: A flexible toolkit for advanced neural machine translation systems. The Prague Bulletin of Mathematical Linguistics, 109:15–28.
Ozan Caglayan、Mercedes García-Martínez、Adrien Bardet、Walid Aransa、Fethi Bougares 和 Loïc Barrault。2017。Nmtpy:一个用于高级神经机器翻译系统的灵活工具包。《布拉格数学语言学公报》109:15–28。
Ziqiang Cao, Furu Wei, Li Dong, Sujian Li, and Ming Zhou. 2015. Ranking with recursive neural networks and its application to multi-document summarization. In Twenty-ninth AAAI conference on artificial intelligence.
曹子强、韦福如、董力、李素建、周明。2015。基于递归神经网络的排序及其在多文档摘要中的应用。载于第二十九届AAAI人工智能会议。
Kyunghyun Cho, Bart van Merrie n boer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).
Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio. 2014. 基于RNN编码器-解码器的短语表征学习在统计机器翻译中的应用. 见《2014年自然语言处理实证方法会议论文集》(EMNLP).
P. Das, C. Xu, R. F. Doell, and J. J. Corso. 2013. A thousand frames in just a few words: Lingual description of videos through latent topics and sparse object stitching. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.
P. Das, C. Xu, R. F. Doell, and J. J. Corso. 2013. 寥寥数语描述千帧画面:基于潜在主题与稀疏目标拼接的视频语言描述。见:IEEE计算机视觉与模式识别会议论文集。
Michael Denkowski and Alon Lavie. 2014. Meteor universal: Language specific translation evaluation for any target language. In Proceedings of the ninth workshop on statistical machine translation, pages 376–380. Association for Computational Linguistics.
Michael Denkowski 和 Alon Lavie. 2014. Meteor universal: 面向任意目标语言的特定语言翻译评估. 见《第九届统计机器翻译研讨会论文集》, 第376-380页. 计算语言学协会.
Spandana Gella, Mike Lewis, and Marcus Rohrbach. 2018. A dataset for telling the stories of social media videos. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 968–974.
Spandana Gella、Mike Lewis和Marcus Rohrbach。2018。社交媒体视频叙事数据集。载于《2018年自然语言处理实证方法会议论文集》,第968–974页。
Jade Goldstein, Vibhu Mittal, Jaime Carbonell, and Mark Kantrowitz. 2000. Multi-document summarization by sentence extraction. In Proceedings of the 2000 NAACL-ANLP Workshop on Automatic sum mari z ation, pages 40–48. Association for Computational Linguistics.
Jade Goldstein、Vibhu Mittal、Jaime Carbonell和Mark Kantrowitz。2000。基于句子抽取的多文档摘要生成。载于《2000年NAACL-ANLP自动摘要研讨会论文集》(Proceedings of the 2000 NAACL-ANLP Workshop on Automatic summarization),第40-48页。计算语言学协会(Association for Computational Linguistics)。
Max Grusky, Mor Naaman, and Yoav Artzi. 2018. Newsroom: A dataset of 1.3 million summaries with diverse extractive strategies. CoRR.
Max Grusky、Mor Naaman 和 Yoav Artzi。2018. Newsroom: 一个包含130万篇摘要及多样化抽取策略的数据集。CoRR。
Çaglar Gülçehre, Sungjin Ahn, Ramesh Nallapati, Bowen Zhou, and Yoshua Bengio. 2016. Pointing the unknown words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, Volume 1: Long Papers.
Çaglar Gülçehre, Sungjin Ahn, Ramesh Nallapati, Bowen Zhou, and Yoshua Bengio. 2016. 指向未知词. 见: 第54届计算语言学协会年会论文集, ACL 2016, 第1卷: 长论文.
Michael Gygli, Helmut Grabner, Hayko Rie mensch nei- der, and Luc Van Gool. 2014. Creating summaries from user videos. In European conference on computer vision, pages 505–520. Springer.
Michael Gygli、Helmut Grabner、Hayko Riemenschneider 和 Luc Van Gool。2014. 从用户视频中创建摘要。载于欧洲计算机视觉会议 (European conference on computer vision),第505–520页。Springer。
Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. 2018. Can s patio temporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6546–6555.
Kensho Hara、Hirokatsu Kataoka和Yutaka Satoh。2018。时空3D CNN能否重走2D CNN与ImageNet的发展之路?见《IEEE计算机视觉与模式识别会议论文集》(CVPR),第6546–6555页。
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action video dataset. CoRR.
Will Kay、Joao Carreira、Karen Simonyan、Brian Zhang、Chloe Hillier、Sudheendra Vijayanarasimhan、Fabio Viola、Tim Green、Trevor Back、Paul Natsev 等。2017。Kinetics人类动作视频数据集。CoRR。
Diederik P. Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. CoRR, abs/1412.6980.
Diederik P. Kingma 和 Jimmy Ba. 2014. Adam: 一种随机优化方法. CoRR, abs/1412.6980.
Julian Kupiec, Jan Pedersen, and Francine Chen. 1995. A trainable document summarizer. In Proceedings of the 18th annual international ACM SIGIR conference on Research and development in information retrieval, pages 68–73. ACM.
Julian Kupiec、Jan Pedersen 和 Francine Chen。1995. 一种可训练的文档摘要生成器。见《第18届国际ACM SIGIR信息检索研究与发展会议论文集》,第68-73页。ACM。
Adrien Le Franc, Eric Riebling, Julien Karadayi, W Yun, Camila Scaff, Florian Metze, and Alejandrina Cristia. 2018. The aclew divime: An easy-to- use di ari z ation tool. In Inter speech, pages 1383– 1387. Inter speech, ISCA.
Adrien Le Franc、Eric Riebling、Julien Karadayi、W Yun、Camila Scaff、Florian Metze 和 Alejandrina Cristia。2018. ACLEW DIVIME:一款易用的方言转录工具。收录于《Inter speech》,第1383-1387页。Inter speech,ISCA。
Haoran Li, Junnan Zhu, Cong Ma, Jiajun Zhang, and Chengqing Zong. 2017. Multi-modal summarization for asynchronous collection of text, image, au- dio and video. In Proceedings of the 2017 Con- ference on Empirical Methods in Natural Language Processing, pages 1092–1102.
Haoran Li、Junnan Zhu、Cong Ma、Jiajun Zhang 和 Chengqing Zong。2017. 面向异步采集文本、图像、音频和视频的多模态摘要生成。载于《2017年自然语言处理实证方法会议论文集》,第1092–1102页。
Jindrich Libovicky and Jindrich Helcl. 2017. Attention strategies for multi-source sequence-to-sequence learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 196–202.
Jindrich Libovicky 和 Jindrich Helcl。2017。多源序列到序列学习的注意力策略。载于《第55届计算语言学协会年会论文集(第二卷:短论文)》,第196–202页。
Chin-Yew Lin and Eduard Hovy. 2002. From single to multi-document sum mari z ation. In Proceedings of 40th Annual Meeting of the Association for Computational Linguistics, pages 457–464.
Chin-Yew Lin和Eduard Hovy。2002。从单文档到多文档摘要生成。见《第40届计算语言学协会年会论文集》,第457–464页。
Chin-Yew Lin and Franz Josef Och. 2004. Automatic evaluation of machine translation quality using longest common sub sequence and skip-bigram statistics. In Proceedings of the 42nd Meeting of the Association for Computational Linguistics, pages 605–612. Association for Computational Linguistics.
Chin-Yew Lin和Franz Josef Och。2004。基于最长公共子序列和跳跃二元组统计的机器翻译质量自动评估。载于《第42届计算语言学协会年会论文集》,第605–612页。计算语言学协会。
Zheng Lu and Kristen Grauman. 2013. Story-driven sum mari z ation for egocentric video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2714–2721.
郑璐和Kristen Grauman。2013。以故事驱动的第一人称视频摘要方法。见《IEEE计算机视觉与模式识别会议论文集》,第2714–2721页。
Hans Peter Luhn. 1958. The automatic creation of literature abstracts. IBM Journal of research and development, 2(2):159–165.
Hans Peter Luhn. 1958. 文献摘要的自动生成. IBM Journal of research and development, 2(2):159–165.
Inderjeet Mani. 1999. Advances in automatic text summarization. MIT press.
Inderjeet Mani. 1999. 自动文本摘要的进展. MIT press.
Yajie Miao, Mohammad Gowayyed, and Florian Metze. 2015. Eesen: End-to-end speech recognition us- ing deep rnn models and wfst-based decoding. In Automatic Speech Recognition and Understanding (ASRU), 2015 IEEE Workshop on, pages 167–174. IEEE.
Yajie Miao, Mohammad Gowayyed和Florian Metze. 2015. Eesen: 基于深度RNN模型和WFST解码的端到端语音识别. 收录于《2015年IEEE自动语音识别与理解研讨会(ASRU)》, 第167-174页. IEEE.
Arthur G Money and Harry Agius. 2008. Video summarisation: A conceptual framework and survey of the state of the art. Journal of Visual Communication and Image Representation, 19(2):121–143.
Arthur G Money 和 Harry Agius. 2008. 视频摘要: 概念框架与前沿技术综述. Journal of Visual Communication and Image Representation, 19(2):121–143.
Ramesh Nallapati, Bowen Zhou, Cicero dos Santos, Ça glar Gulçehre, and Bing Xiang. 2016. Abstrac- tive text sum mari z ation using sequence-to-sequence rnns and beyond. CoNLL 2016, page 280.
Ramesh Nallapati、Bowen Zhou、Cicero dos Santos、Çağlar Gulçehre 和 Bing Xiang。2016。基于序列到序列 RNN 及其扩展模型的抽象文本摘要。CoNLL 2016,第 280 页。
Shashi Narayan, Shay B Cohen, and Mirella Lapata. 2018. Ranking sentences for extractive summarization with reinforcement learning. CoRR.
Shashi Narayan、Shay B Cohen 和 Mirella Lapata。2018. 基于强化学习的句子排序用于抽取式摘要。CoRR。
Mayu Otani, Yuta Nakashima, Esa Rahtu, Janne Heikkilä, and Naokazu Yokoya. 2016. Learning joint representations of videos and sentences with web image search. In European Conference on Computer Vision, pages 651–667. Springer.
Mayu Otani、Yuta Nakashima、Esa Rahtu、Janne Heikkilä 和 Naokazu Yokoya。2016。利用网络图像搜索学习视频与句子的联合表征。载于《欧洲计算机视觉会议》,第651–667页。Springer。
Vijay aditya Peddinti, Guoguo Chen, Vimal Manohar, Tom Ko, Daniel Povey, and Sanjeev Khudanpur. 2015. Jhu aspire system: Robust lvcsr with tdnns, ivector adaptation and rnn-lms. In Automatic Speech Recognition and Understanding (ASRU), 2015 IEEE Workshop on, pages 539–546. IEEE.
Vijay aditya Peddinti、Guoguo Chen、Vimal Manohar、Tom Ko、Daniel Povey 和 Sanjeev Khudanpur。2015. JHU ASPIRE 系统:采用 TDNNS、IVECTOR 自适应和 RNN-LMS 的鲁棒 LVCSR。收录于《2015 IEEE 自动语音识别与理解研讨会 (ASRU)》,第 539-546 页。IEEE。
Michaela Regneri, Marcus Rohrbach, Dominikus Wet- zel, Stefan Thater, Bernt Schiele, and Manfred Pinkal. 2013. Grounding action descriptions in videos. TACL, 1:25–36.
Michaela Regneri、Marcus Rohrbach、Dominikus Wetzel、Stefan Thater、Bernt Schiele 和 Manfred Pinkal。2013. 基于视频的动作描述关联。TACL, 1:25–36。
Anna Rohrbach, Marcus Rohrbach, Wei Qiu, An- nemarie Friedrich, Manfred Pinkal, and Bernt Schiele. 2014. Coherent multi-sentence video de- scription with variable level of detail. In Pattern Recognition - 36th German Conference, GCPR 2014, pages 184–195.
Anna Rohrbach、Marcus Rohrbach、Wei Qiu、An-nemarie Friedrich、Manfred Pinkal和Bernt Schiele。2014. 具有可变细节级别的连贯多句视频描述。见《模式识别-第36届德国会议,GCPR 2014》,第184-195页。
Alexander M. Rush, Sumit Chopra, and Jason Weston. 2015. A neural attention model for abstract ive sentence sum mari z ation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 379–389. Association for Computational Linguistics.
Alexander M. Rush、Sumit Chopra 和 Jason Weston。2015. 基于神经注意力模型的抽象式句子摘要生成。载于《2015年自然语言处理实证方法会议论文集》,第379-389页。计算语言学协会。
Shagan Sah, Sourabh Kulhare, Allison Gray, Subhashini Ven u gopalan, Emily Prud’Hommeaux, and Raymond Ptucha. 2017. Semantic text summarization of long videos. In Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on, pages 989–997. IEEE.
Shagan Sah、Sourabh Kulhare、Allison Gray、Subhashini Venugopalan、Emily Prud'Hommeaux 和 Raymond Ptucha。2017. 长视频的语义文本摘要。见《计算机视觉应用 (WACV)》,2017年IEEE冬季会议论文集,第989–997页。IEEE。
Ramon Sanabria, Ozan Caglayan, Shruti Palaskar, Desmond Elliott, Loïc Barrault, Lucia Specia, and Florian Metze. 2018. How2: a large-scale dataset for multimodal language understanding. In Proceedings of the Workshop on Visually Grounded Interaction and Language (ViGIL). NIPS.
Ramon Sanabria、Ozan Caglayan、Shruti Palaskar、Desmond Elliott、Loïc Barrault、Lucia Specia和Florian Metze。2018. How2: 一个用于多模态语言理解的大规模数据集。见《视觉基础交互与语言研讨会论文集》(ViGIL)。NIPS。
Ramon Sanabria, Shruti Palaskar, and Florian Metze. 2019. Cmu sinbad’s submission for the dstc7 avsd challenge. In Proc. 7th Dialog System Technology Challenges Workshop at AAAI, Honolulu, Hawaii, USA.
Ramon Sanabria、Shruti Palaskar和Florian Metze。2019. CMU SINBAD团队在DSTC7 AVSD挑战赛的参赛方案。见《第七届对话系统技术挑战赛论文集》(AAAI会议), 美国夏威夷檀香山。
Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. Get to the point: Sum mari z ation with pointergenerator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073– 1083.
Abigail See、Peter J. Liu 和 Christopher D. Manning。2017. 切中要点:基于指针生成器网络的摘要生成。载于《第55届计算语言学协会年会论文集(第一卷:长论文)》,第1073–1083页。
Rico Sennrich, Orhan Firat, Kyunghyun Cho, Alexan- dra Birch, Barry Haddow, Julian Hitschler, Marcin Junczys-Dowmunt, Samuel Läubli, Antonio Vale- rio Miceli Barone, Jozef Mokry, and Maria Nadejde. 2017. Nematus: a toolkit for neural machine translation. In Proceedings of the Software Demonstrations of the 15th Conference of the European Chap- ter of the Association for Computational Linguistics, pages 65–68. Association for Computational Linguistics.
Rico Sennrich、Orhan Firat、Kyunghyun Cho、Alexandra Birch、Barry Haddow、Julian Hitschler、Marcin Junczys-Dowmunt、Samuel Läubli、Antonio Valerio Miceli Barone、Jozef Mokry 和 Maria Nadejde。2017。Nematus:神经机器翻译工具包。载于《第15届欧洲计算语言学协会会议软件演示论文集》,第65-68页。计算语言学协会。
Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. 2016. Hollywood in homes: Crowd sourcing data collection for activity understanding. In European Conference on Computer Vision.
Gunnar A. Sigurdsson、Gül Varol、Xiaolong Wang、Ali Farhadi、Ivan Laptev 和 Abhinav Gupta。2016. 家庭中的好莱坞:众包数据收集以理解活动。载于欧洲计算机视觉会议。
Jingkuan Song, Yi Yang, Zi Huang, Heng Tao Shen, and Richang Hong. 2011. Multiple feature hashing for real-time large scale near-duplicate video retrieval. In Proceedings of the 19th ACM international conference on Multimedia, pages 423–432. ACM.
Jingkuan Song、Yi Yang、Zi Huang、Heng Tao Shen 和 Richang Hong。2011. 面向实时大规模近似重复视频检索的多特征哈希方法。载于《第19届ACM国际多媒体会议论文集》,第423-432页。ACM。
Yale Song, Jordi Vall mit jana, Amanda Stent, and Ale- jandro Jaimes. 2015. Tvsum: Summarizing web videos using titles. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5179–5187.
Yale Song、Jordi Vall mit jana、Amanda Stent 和 Alejandro Jaimes。2015. Tvsum:使用标题总结网络视频。在《IEEE计算机视觉与模式识别会议论文集》中,第5179–5187页。
Md Arafat Sultan, Steven Bethard, and Tamara Sumner. 2014. Back to basics for monolingual alignment: Exploiting word similarity and contextual evidence. Transactions of the Association for Computational Linguistics, 2:219–230.
Md Arafat Sultan、Steven Bethard 和 Tamara Sumner。2014。单语对齐回归基础:利用词汇相似度与上下文证据。计算语言学协会汇刊,2:219-230。
Ilya Sutskever, James Martens, and Geoffrey E Hinton. 2011. Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), pages 1017–1024. JMLR.org.
Ilya Sutskever、James Martens 和 Geoffrey E Hinton。2011。使用循环神经网络生成文本。载于《第28届国际机器学习会议论文集》(ICML-11),第1017–1024页。JMLR.org。
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems 27, pages 3104–3112. Curran Associates, Inc.
Ilya Sutskever、Oriol Vinyals 和 Quoc V Le. 2014. 使用神经网络进行序列到序列学习. 发表于《神经信息处理系统进展》第27卷, 第3104–3112页. Curran Associates公司出版.
Atousa Torabi, Niket Tandon, and Leonid Sigal. 2016. Learning language-visual embedding for movie understanding with natural-language. CoRR, abs/1609.08124.
Atousa Torabi、Niket Tandon 和 Leonid Sigal。2016。基于自然语言的电影理解语言-视觉嵌入学习。CoRR,abs/1609.08124。
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015. Pointer networks. In Advances in Neural Information Processing Systems, pages 2692–2700. Curran Associates, Inc.
Oriol Vinyals、Meire Fortunato 和 Navdeep Jaitly。2015. Pointer networks。在《神经信息处理系统进展》中,第2692–2700页。Curran Associates公司。
Meng Wang, Richang Hong, Guangda Li, Zheng-Jun Zha, Shuicheng Yan, and Tat-Seng Chua. 2012. Event driven web video sum mari z ation by tag localization and key-shot identification. IEEE Transactions on Multimedia, 14(4):975–985.
王萌、洪日昌、李广达、查正军、颜水成、Chua Tat-Seng。2012。基于标签定位与关键镜头识别的事件驱动网络视频摘要技术。IEEE Transactions on Multimedia,14(4):975–985。
Kristian Woodsend and Mirella Lapata. 2012. Multiple aspect sum mari z ation using integer linear programming. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 233–243.
Kristian Woodsend和Mirella Lapata。2012。基于整数线性规划的多角度摘要生成。载于《2012年自然语言处理经验方法及计算自然语言学习联合会议论文集》,第233–243页。
Michihiro Yasunaga, Rui Zhang, Kshitijh Meelu, Ayush Pareek, Krishnan Srinivasan, and Dragomir R. Radev. 2017. Graph-based neural multi-document sum mari z ation. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 452–462.
Michihiro Yasunaga、Rui Zhang、Kshitijh Meelu、Ayush Pareek、Krishnan Srinivasan 和 Dragomir R. Radev。2017。基于图神经网络的多元文档摘要。载于《第21届计算自然语言学习会议论文集》(CoNLL 2017),第452–462页。
Kuo-Hao Zeng, Tseng-Hung Chen, Juan Carlos Niebles, and Min Sun. 2016. Generation for user generated videos. In European conference on computer vision, pages 609–625. Springer.
Kuo-Hao Zeng, Tseng-Hung Chen, Juan Carlos Niebles, and Min Sun. 2016. 用户生成视频的生成方法. In European conference on computer vision, pages 609–625. Springer.
Jianguo Zhang, Pengcheng Zou, Zhao Li, Yao Wan, Ye Liu, Xiuming Pan, Yu Gong, and Philip S Yu. 2018. Product title refinement via multi-modal generative adversarial learning. arXiv preprint arXiv:1811.04498.
Jianguo Zhang, Pengcheng Zou, Zhao Li, Yao Wan, Ye Liu, Xiuming Pan, Yu Gong, and Philip S Yu. 2018. 基于多模态生成对抗学习的商品标题优化. arXiv preprint arXiv:1811.04498.
Luowei Zhou, Chenliang Xu, and Jason J. Corso. 2018. Towards automatic learning of procedures from web instructional videos. In Proceedings of the ThirtySecond AAAI Conference on Artificial Intelligence, (AAAI-18), pages 7590–7598.
Luowei Zhou、Chenliang Xu 和 Jason J. Corso。2018. 基于网络教学视频的程序自动学习研究。载于《第三十二届 AAAI 人工智能会议论文集》(AAAI-18),第 7590–7598 页。
A Appendix
附录
A.1 Experimental Setup
A.1 实验设置
In all our experiments, the text encoder consists of 2 bidirectional layers of the encoder with 256 Gated Recurrent Units (GRU; Cho et al. 2014) and 2 layers of the decoder with Conditional Gated Recurrent Units (CGRU; Sennrich et al. 2017). We optimize the models with the Adam Optimizer (Kingma and Ba, 2014) with learning rate $4\cdot10^{-4}$ halved after each epoch when the validation performance does not increase for maximum 50 epochs.
在我们所有的实验中,文本编码器由2层双向编码器(每层包含256个门控循环单元(GRU; Cho等人2014))和2层条件门控循环单元解码器(CGRU; Sennrich等人2017)组成。我们使用Adam优化器(Kingma和Ba,2014)进行模型优化,初始学习率为$4\cdot10^{-4}$,当验证性能在最多50个周期内未提升时,学习率会减半。
We restrict the input length to 600 tokens for all experiments except the best text-only model in the section Experiments and Results. We use vocabulary the 20,000 most frequently occurring words which showed best results in our experiments, largely outperforming models using subword-based vocabularies. We ran all experiments with the nmtpytorch toolkit (Caglayan et al., 2017).
除实验与结果部分表现最佳的纯文本模型外,我们在所有实验中均将输入长度限制为600个token。采用实验效果最优的20,000个高频词作为词表,其表现显著优于基于子词的词表方案。所有实验均通过nmtpytorch工具包(Caglayan et al., 2017)完成。
Table A1: Most frequently occurring words in Transcript and Summaries.
表 A1: 转录文本和摘要中出现频率最高的单词。
| 集合 | 单词 |
|---|---|
| 转录文本 | the, to, and, you, a, it, that, of, is, i, going, we, in, your, this, 's, so, on |
| 摘要 | in, a, this, to, free, the, video, and. learn, from, on, with, how, tips, for, of, expert, an |
A.2 Frequent Words in Transcripts and Summaries
A.2 转录文本与摘要中的高频词
Table A1 shows the frequent words in transcripts (input) and summaries (output). The words in transcripts reflect conversational and spontaneous speech while words in the summary reflect their descriptive nature.
表 A1 展示了转录文本(输入)和摘要(输出)中的高频词。转录文本中的词汇反映了对话性和自发性的口语特征,而摘要中的词汇则体现了描述性特质。
A.3 Output Examples from Different Models
A.3 不同模型的输出示例
Table A2 shows example outputs from our different text-only and text-and-video models. The text-only model produces a fluent output which is close to the reference. The action features with the RNN model, which sees no text in the input, produces an in-domain (“fly tying”’ and “fishing”) abstract ive summary that involves more details like “equipment” which is missing from the text-based models but is relevant. The action features without RNN model belongs to the relevant domain but contains fewer details. The nearest neighbor model is related to “knot tying” but not related to “fishing”. The scores for each of these models reflect their respective properties. The random baseline output shows the output of sampling from the random language model based baseline. Although it is a fluent output, the content is incorrect. Observing other outputs of the model we noticed that although predictions were usually fluent leading to high scores, there is scope to improve them by predicting all details from the ground truth summary, like the subtle selling point phrases, or by using the visual features in a different adaptation model.
表 A2 展示了我们不同纯文本模型及文本-视频模型的输出示例。纯文本模型生成的输出流畅且接近参考内容。采用 RNN 模型的动作特征(输入不含文本)会生成领域内摘要(如"飞蝇绑制"和"钓鱼"),其中包含更多细节(如"装备"),这些细节在纯文本模型中缺失但与主题相关。未使用 RNN 模型的动作特征输出属于相关领域但细节较少。最近邻模型输出与"绳结绑制"相关但与"钓鱼"无关。各模型的评分反映了其特性。随机基线输出展示了基于随机语言模型采样的结果,虽然语句流畅但内容错误。通过观察模型的其他输出,我们注意到尽管预测结果通常因流畅性获得高分,但仍可通过预测真实摘要中的所有细节(如微妙的卖点短语)或在不同适配模型中利用视觉特征来改进。
A.4 Attention Analysis
A.4 注意力分析
Figure A1 shows an analysis of the attention distributions using the hierarchical attention model in an example video of painting. The vertical axis denotes the output summary of the model, and the horizontal axis denotes the input time-steps (from the transcript). We observe less attention in the first
图 A1: 展示了绘画示例视频中使用分层注意力模型的注意力分布分析。纵轴表示模型的输出摘要,横轴表示输入时间步(来自转录文本)。我们观察到在前
| No. Model | Reference | R-LC-F1Output | 观看学习如何将线绑在钩上以辅助飞蝇绑制技巧。 | |
|---|---|---|---|---|
| 8 | Ground-truth text +54.9 48.9 Action Feat. | 在本免费飞蝇绑制技巧教学视频中,向专家学习如何为飞蝇钓绑制线材。 | ||
| 5a | Text-only (Ground-53.947.4 truth) | 在本免费飞蝇绑制技巧教学视频中,向专家学习如何为飞蝇钓绑制线材。 | ||
| 9 | ASR output + Ac- 46.3 34.7 tion Feat. | 飞蝇绑制技巧。 | ||
| 5c | ASR output | 46.1 34.7 | 在本免费钓鱼视频中学习飞蝇钓技巧,了解制作飞蝇若虫的方法。 | |
| 7 | Action Features +46.334.9 RNN | 在本免费飞蝇绑制技巧教学视频中,向专家学习飞蝇绑制所需装备及其他飞蝇钓技巧。 | ||
| 6 | Action only | Features 38.524.8 | 在本免费视频片段中向专家学习如何打双半结,了解飞蝇钓技巧。 | |
| 2b | Next Neighbor | 31.8 | 17.9 | 使用羊角结缩短长绳。向鹰级童子军学习技巧视频。 |
| 1 | Random Baseline | 27.5 | 8.3 | 这段免费视频片段涉及乐理知识与吉他课程。 |
Table A2: Example outputs of ground-truth text-and-video with hierarchical attention (8), text-only with groundtruth (5a), text-only with ASR output (5c), ASR output text-andv-video with hierarchical attention (9), action features with RNN (7) and action features only (6) models compared with the reference, the topic-based next neighbor (2b) and random baseline (1). Arranged in the order of best to worst summary in this table.
表 A2: 真实文本-视频分层注意力模型 (8) 、纯文本真实输入模型 (5a) 、纯文本ASR输出模型 (5c) 、ASR输出文本-视频分层注意力模型 (9) 、RNN动作特征模型 (7) 和纯动作特征模型 (6) 的示例输出,与参考结果、基于主题的最近邻模型 (2b) 和随机基线 (1) 的对比。本表按摘要质量从优到劣排列。

Figure A1: Visualizing Attention over Video Features.
图 A1: 视频特征注意力可视化。
part of the video where the speaker is introducing the task and preparing the brush. In the middle half, the camera focuses on the close-up of brush strokes with hand, to which the model pays higher attention over consecutive frames. Towards the end, the close up does not contain the hand but only the paper and brush, where the model again pays less attention which could be due to unrecognized actions in the close-up. There are black frames in the very end of the video where the model learns not to pay any attention. In the middle of the video, there are two places with a cut in the video when the camera shifts angle. The model has learned to identify these areas and uses it effectively. From this particular example, we see the model using both modalities very effectively in this task of the sum mari z ation of open-domain videos.
视频中演讲者介绍任务并准备画笔的部分。中间半段镜头聚焦于手部特写笔触,模型对此连续帧给予了更高关注度。临近结尾时,特写画面不再包含手部而仅有纸张和画笔,此时模型关注度再次降低,可能是由于特写中动作未被识别所致。视频末尾出现黑帧时,模型已学会完全忽略。影片中部存在两处镜头角度切换的剪辑点,模型能有效识别并利用这些区域。通过这个典型案例,我们观察到模型在开放域视频摘要任务中实现了对双模态的高效运用。
A.5 Human Evaluation Details
A.5 人工评估细节
To understand the outputs generated for this task better, we ask workers on Amazon Mechanical Turk to compare outputs of unimodal and multimodal models with the ground-truth summary and assign a score between 1 (lowest) and 5 (highest) for four metrics: informative ness, relevance, coherence and fluency of generated summary. The annotators were shown the ground-truth summary and a candidate summary (without knowledge of the type of modality used to generate it). Each example was annotated by three workers. Annotation was restricted to English speaking countries. 129 annotators participated in this task.
为了更好地理解该任务的生成结果,我们请Amazon Mechanical Turk的工作人员将单模态和多模态模型的输出与真实摘要进行对比,并为四个指标打分(1分最低,5分最高):生成摘要的信息量、相关性、连贯性和流畅性。标注者在不知晓生成模态类型的情况下,会看到真实摘要和候选摘要。每个示例由三名标注者进行标注,且标注工作仅限于英语国家。共有129名标注者参与了此项任务。