UCPhrase: Unsupervised Context-aware Quality Phrase Tagging
UCPhrase: 无监督上下文感知的高质量短语标注
ABSTRACT
摘要
Identifying and understanding quality phrases from context is a fundamental task in text mining. The most challenging part of this task arguably lies in uncommon, emerging, and domain-specific phrases. The infrequent nature of these phrases significantly hurts the performance of phrase mining methods that rely on sufficient phrase occurrences in the input corpus. Context-aware tagging models, though not restricted by frequency, heavily rely on domain experts for either massive sentence-level gold labels or handcrafted gazetteers. In this work, we propose UCPhrase, a novel unsupervised context-aware quality phrase tagger. Specifically, we induce high-quality phrase spans as silver labels from consistently co-occurring word sequences within each document. Compared with typical context-agnostic distant supervision based on existing knowledge bases (KBs), our silver labels root deeply in the input domain and context, thus having unique advantages in preserving contextual completeness and capturing emerging, out-of-KB phrases. Training a conventional neural tagger based on silver labels usually faces the risk of over fitting phrase surface names. Alternatively, we observe that the contextual i zed attention maps generated from a Transformer-based neural language model effectively reveal the connections between words in a surface-agnostic way. Therefore, we pair such attention maps with the silver labels to train a lightweight span prediction model, which can be applied to new input to recognize (unseen) quality phrases regardless of their surface names or frequency. Thorough experiments on various tasks and datasets, including corpus-level phrase ranking, document-level keyphrase extraction, and sentence-level phrase tagging, demonstrate the superiority of our design over state-of-the-art pre-trained, unsupervised, and distantly supervised methods.
从上下文中识别和理解高质量短语是文本挖掘的一项基础任务。该任务最具挑战性的部分在于罕见、新兴和领域特定短语的识别。这些短语的低频特性严重影响了依赖语料库中充分出现次数的传统短语挖掘方法性能。虽然基于上下文感知的标注模型不受频率限制,但其严重依赖领域专家提供大量句子级黄金标注或手工编纂的术语表。
本研究提出UCPhrase——一种新型无监督上下文感知高质量短语标注器。具体而言,我们通过文档内部持续共现的词语序列诱导出高质量短语跨度作为银标注。相比传统基于现有知识库(KB)的上下文无关远程监督方法,我们的银标注深度扎根于输入领域和上下文,在保持上下文完整性和捕捉新兴、知识库外短语方面具有独特优势。
基于银标注训练常规神经标注器通常面临过度拟合短语表面形式的风险。我们观察到,基于Transformer的神经语言模型生成的上下文注意力图能以表面无关的方式有效揭示词语关联。因此,我们将此类注意力图与银标注结合,训练了一个轻量级跨度预测模型。该模型可应用于新输入数据,实现不受表面形式或频率影响的(未见过)高质量短语识别。
在包括语料库级短语排序、文档级关键词抽取和句子级短语标注等多项任务和数据集上的全面实验表明,我们的设计优于当前最先进的预训练、无监督和远程监督方法。
1 INTRODUCTION
1 引言
Quality phrases refer to informative multi-word sequences that “appear consecutively in the text, forming a complete semantic unit in certain contexts or the given document” [10]. Identifying and understanding quality phrases from context is a fundamental task in text mining. Automated quality phrase tagging serves as a cornerstone in a broad spectrum of downstream applications, including but not limited to entity recognition [35], text classification [1], and information retrieval [5].
优质短语 (quality phrases) 指那些"在文本中连续出现,在特定语境或给定文档中形成完整语义单元" [10] 的信息性多词序列。从上下文中识别和理解优质短语是文本挖掘的基础任务。自动化优质短语标注作为众多下游应用的基石,包括但不限于实体识别 [35]、文本分类 [1] 和信息检索 [5]。
The most challenging open problem in this task is how to recognize uncommon, emerging phrases, especially in specific domains. These phrases are essential in the sense of their significant semantic meanings and the large volume—following a typical Zipfian distribution, uncommon phrases can add up to a significant portion of quality phrases [37]. Moreover, emerging phrases are critical in understanding domain-specific documents, such as scientific papers, since new terminologies often come along with transformative innovations. However, mining such sparse long-tail phrases is nontrivial, since a frequency threshold has long ruled them out in traditional phrase mining methods [6, 8, 23, 25, 34] due to the lack of reliable frequency-related corpus-level signals (e.g., the mutual information of its sub-ngrams). For instance, AutoPhrase [34] only recognizes phrases with at least 10 occurrences by default.
该任务中最具挑战性的开放性问题是如何识别不常见的新兴短语,尤其在特定领域内。这些短语的重要性体现在其显著的语义含义和庞大的数量上——根据典型的齐夫分布 (Zipfian distribution) ,不常见短语可能占据高质量短语的很大比例 [37]。此外,新兴短语对于理解领域特定文档(如科学论文)至关重要,因为新术语往往伴随着变革性创新出现。然而,挖掘这类稀疏的长尾短语并非易事,由于缺乏可靠的频率相关语料库级信号(例如其子n-gram的互信息),传统短语挖掘方法 [6, 8, 23, 25, 34] 长期通过频率阈值将其排除在外。例如,AutoPhrase [34] 默认仅识别出现至少10次的短语。
For infrequent phrases, the tagging process largely relies on local context. Recent advances in neural language models have unleashed the power of sentence-level contextual i zed features in building chunking- and tagging-based models [27, 36]. These contextaware models can even recognize unseen phrases from new input texts, thus being no longer restricted by frequency. However, training a domain-specific tagger of reasonably high quality requires expensive, hard-to-scale effort from domain experts for massive sentence-level gold labels or handcrafted gazetteers.
对于低频短语,标注过程主要依赖局部上下文。近年来,神经语言模型的进展释放了句子级上下文特征在构建基于分块和标注模型中的潜力 [27, 36]。这些上下文感知模型甚至能识别新输入文本中未出现的短语,从而不再受频率限制。然而,训练一个质量尚可的领域专用标注器,需要领域专家付出昂贵且难以扩展的努力,以获取大量句子级黄金标注或手工编纂的词典。
In this work, we propose UCPhrase, a novel unsupervised contextaware quality phrase tagger. It first induces high-quality silver labels directly from the corpus under the unsupervised setting, and then trains a tailored Transformer-based neural model that can recognize quality phrases in new sentences. Figure 1 presents an overview of UCPhrase. The two major steps are detailed as follows.
在本工作中,我们提出了UCPhrase,一种新型的无监督上下文感知质量短语标注器。它首先在无监督设置下直接从语料库中生成高质量的银标签,然后训练一个定制的基于Transformer的神经模型,用于识别新句子中的质量短语。图1展示了UCPhrase的概览。两个主要步骤如下。
By imitating the reading process of humans, we derive supervision directly from the input corpus. Given a document, human readers can quickly recognize new phrases or terminologies from the consistently used word sequences within the document. The “document” here refers to a collection of sentences centered on the same topic, such as sentences from an abstract of a scientific paper and tweets mentioning the same hashtag. Inspired by this observation, we propose to extract core phrases from each document, which are maximal contiguous word sequences that appear in the document more than once. The “maximal” here means that if one expands this word sequence further towards the left or right, its frequency within this document will drop. To avoid uninformative phrases (e.g., “of a”), we conduct simple filtering of stopwords before finalizing the silver labels. Note that our proposed silver label generation follows a per-document manner. Therefore, compared with typical context-agnostic distant supervision based on existing knowledge bases or dictionaries [34–36], our supervision roots deeply in the input domain and context, thus having unique advantages in preserving contextual completeness of matched spans and capturing much more emerging phrases.
通过模仿人类的阅读过程,我们直接从输入语料中获取监督信号。给定一篇文档,人类读者能快速从文档中反复出现的连贯词序列里识别出新短语或术语。这里的"文档"指围绕同一主题的句子集合,例如科学论文摘要中的句子、提及同一话题标签的推文等。受此启发,我们提出从每篇文档中提取核心短语——这些是在文档中出现超过一次的极大连续词序列。"极大"意味着若向左右任意方向扩展该词序列,其在当前文档中的出现频率就会下降。为避免无意义短语(如"of a"),我们在确定银标签前进行了简单的停用词过滤。值得注意的是,我们提出的银标签生成遵循逐文档处理方式。因此,相比基于现有知识库或词典的典型上下文无关远程监督[34-36],我们的监督信号深植于输入领域和上下文环境,在保持匹配文本片段上下文完整性、捕获更多新兴短语方面具有独特优势。

Figure 1: An overview of our UCPhrase: unsupervised context-aware quality phrase tagging.
图 1: 我们的 UCPhrase 方法概览:无监督上下文感知质量短语标注。
We further design a tailored neural tagger to fit our silver labels better. Training a conventional neural tagger based on silver labels usually faces a high risk of over fitting the observed labels [24]. With access to the word-identifiable embedding features, it is easy for the model to achieve nearly zero training error by rigidly memorizing the surface names of training labels. Alternatively, we find that the contextual i zed attention distributions generated from a Transformer-based neural language model could capture the connections between words in a surface-agnostic way [19]. Intuitively, the attention maps of quality phrases should reveal distinct patterns from ordinary word spans. Moreover, attention-based features block the direct access to the surface names of training labels, and force the model to learn about more general context patterns. Therefore, we pair such surface-agnostic features based on attention maps with the silver labels to train a neural tagging model, which can be applied to new input to recognize (unseen) quality phrases. Specifically, given an unlabeled sentence of $N$ words, we first encode the sentence with a pre-trained Transformer-based language model and obtain the attention maps as features. The $N\times N$ matrices from different Transformer layers and attention heads can be viewed as images to be classified with multiple channels. A lightweight CNN-based classifier is then trained to distinguish quality phrases from randomly sampled negative spans.
我们进一步设计了一个定制的神经标注器,以更好地适配我们的银标签。基于银标签训练传统神经标注器通常会面临过拟合已观测标签的高风险 [24]。借助词可识别的嵌入特征,模型很容易通过死记硬背训练标签的表面名称来实现近乎零的训练误差。相反,我们发现基于Transformer的神经语言模型生成的上下文注意力分布能以表面无关的方式捕捉词间关联 [19]。直观上,优质短语的注意力图应展现出与普通词跨度截然不同的模式。此外,基于注意力的特征阻断了直接访问训练标签表面名称的途径,迫使模型学习更通用的上下文模式。因此,我们将这种基于注意力图的表面无关特征与银标签配对,训练了一个可应用于新输入以识别(未见过的)优质短语的神经标注模型。具体而言,给定一个包含$N$个词的未标注句子,我们首先用预训练的基于Transformer的语言模型编码该句子,并获取注意力图作为特征。来自不同Transformer层和注意力头的$N×N$矩阵可视为待分类的多通道图像。随后训练一个轻量级基于CNN的分类器,用于从随机采样的负跨度中区分优质短语。
Thorough experiments on various tasks and datasets, including corpus-level phrase ranking, document-level keyphrase extraction, and sentence-level phrase tagging, demonstrate the superiority of our design over state-of-the-art unsupervised, distantly supervised methods, and pre-trained off-the-shelf tagging models. It is noteworthy that our trained model is robust to the noise in the core phrases—our case studies in Section 4.7 show that the model can identify inferior training labels by assigning extremely low scores.
在多种任务和数据集上的全面实验,包括语料库级短语排序、文档级关键词抽取和句子级短语标注,证明了我们的设计优于当前最先进的无监督方法、远程监督方法以及预训练的现成标注模型。值得注意的是,我们训练的模型对核心短语中的噪声具有鲁棒性——第4.7节的案例研究表明,该模型能通过分配极低分数来识别劣质训练标签。
Efficiency wise, thanks to the rich semantic and syntactic knowledge in the pre-trained language model, we can simply use the generated attention maps as informative features without fine-tuning the language model. Hence we only need to update the lightweight classification model during training, making the training process as fast as one inference pass of the language model through the corpus with limited resource consumption.
效率方面,得益于预训练语言模型中丰富的语义和句法知识,我们可以直接使用生成的注意力图作为信息特征,无需微调语言模型。因此训练过程中只需更新轻量级分类模型,使得训练过程与语言模型在语料库上的一次推理过程同样快速,且资源消耗有限。
To the best of our knowledge, UCPhrase is the first unsupervised context-aware quality phrase tagger. It enjoys the rich knowledge from the pre-trained neural language models. The learned phrase tagger works efficiently and effectively without reliance on human annotations, existing knowledge bases, or phrase dictionaries. We summarize our key contributions as follows:
据我们所知,UCPhrase 是首个无监督上下文感知的高质量短语标注工具。它充分利用了预训练神经语言模型中的丰富知识。学习得到的短语标注器无需依赖人工标注、现有知识库或短语词典即可高效且有效地工作。我们的主要贡献总结如下:
• We propose to mine silver labels that root deeply in the input domain and context by recognizing core phrases, i.e., maximal word sequences that occur consistently in a per-document manner. • We propose to replace the conventional contextual i zed word representations with surface-agnostic attention maps generated by pre-trained Transformer-based language models to alleviate the risk of over fitting silver labels. • We conduct extensive experiments, ablation studies, and case studies to compare UCPhrase with state-of-the-art unsupervised, distantly supervised methods, and pre-trained off-the-shelf tagging models. The results verify the superiority of our method .
• 我们提出通过识别核心短语(即每篇文档中持续出现的最大词序列)来挖掘深植于输入领域和上下文中的银标签。
• 我们提出用预训练基于Transformer的语言模型生成的与表面形式无关的注意力图替代传统的上下文词表示,以减轻过拟合银标签的风险。
• 我们进行了大量实验、消融研究和案例分析,将UCPhrase与最先进的无监督方法、远程监督方法以及预训练现成标注模型进行对比。结果验证了我们方法的优越性。
2 PROBLEM DEFINITION
2 问题定义
Given a sequence of words $\left[w_{1},\ldots,w_{N}\right]$ , a quality phrase is a contiguous span of words $[w_{i},\dots,w_{i+k}]$ that form a complete and informative semantic unit in context. Though some studies also view unigrams as potential phrases, in this work, we focus on multi-word phrases $(k>0)$ , which are more informative, yet more challenging to get due to both diversity and sparsity.
给定一个词序列 $\left[w_{1},\ldots,w_{N}\right]$,质量短语是指构成完整且信息丰富语义单元的连续词跨度 $[w_{i},\dots,w_{i+k}]$。尽管部分研究也将单字词视为潜在短语,但本工作专注于多词短语 $(k>0)$,这类短语信息量更大,却因多样性和稀疏性而更难获取。
To effectively capture phrases with potential overlaps, e.g., “information extraction” in “information extraction systems”, we adopt the span prediction framework, where each possible span in the sentence is assigned a binary label. To avoid a quadratic growth of the size of candidate spans, we follow previous work [25, 34] to set a maximum span length $K$ . We also explore alternative class if i ers based on the sequence labeling framework in Section 3.
为有效捕捉可能存在重叠的短语(例如“信息抽取系统”中的“信息抽取”),我们采用跨度预测框架,为句子中每个可能的跨度分配二元标签。为避免候选跨度数量呈二次增长,我们遵循先前研究 [25, 34] 设置最大跨度长度 $K$。第3节还将探讨基于序列标注框架的替代分类器。
3 UCPHRASE: METHODOLOGY
3 UCPHRASE: 方法论
Figure 1 presents an overview of UCPhrase. As an unsupervised method, UCPhrase first mines core phrases directly from each document as silver labels and extracts surface-agnostic attention features with a pre-trained language model. A lightweight classifier is then trained with silver labels and randomly sampled negative labels. Algorithm 1 shows the detailed training process.
图 1: UCPhrase 概述。作为一种无监督方法,UCPhrase 首先直接从每篇文档中挖掘核心短语作为银标签 (silver labels) ,并使用预训练语言模型提取与表面形式无关的注意力特征。随后通过银标签和随机采样的负标签 (negative labels) 训练一个轻量级分类器。算法 1 展示了详细的训练流程。
3.1 Silver Label Generation
3.1 银标签生成
As the first step, we seek to collect high-quality phrases in the input corpus following an unsupervised way, which will be our silver labels for the tagging model training. A common practice for automated label fetching is to conduct a context-agnostic matching between the corpus and a given quality phrase list, either mined
第一步,我们尝试以无监督方式从输入语料库中收集高质量短语,这些短语将作为标注模型训练的银标准标签。自动获取标签的常见做法是在语料库与给定质量短语列表之间进行上下文无关匹配,这些短语列表可通过挖掘...
Distant Supervision based on Wiki Entities
基于维基实体的远程监督
Doc1: … study about heat [island effect] … The heat [island effect] arises because the buildings…of their heat [island effect]…
Doc1: … 关于热岛效应 (heat island effect) 的研究 … 热岛效应的产生是由于建筑物…的热岛效应…
Doc2: … propose to extract core phrases … robust to potential noise in core phrases … the surface names of core phrases…
Doc2: …提出提取核心短语…对核心短语中的潜在噪声具有鲁棒性…核心短语的表面名称…
Core Phrase Mining
核心短语挖掘
Doc1: …a study about [heat island effect]… The [heat island effect] arises because the buildings…of their [heat island effect]…
Doc1: …一项关于[热岛效应]的研究… [热岛效应]的产生是由于建筑物…的[热岛效应]…
Doc2: …propose to extract [core phrases]… robust to potential noise in [core phrases]… the surface names of [core phrases]…
文档2:…提出提取[核心短语]…对[核心短语]中的潜在噪声具有鲁棒性…[核心短语]的表面名称…
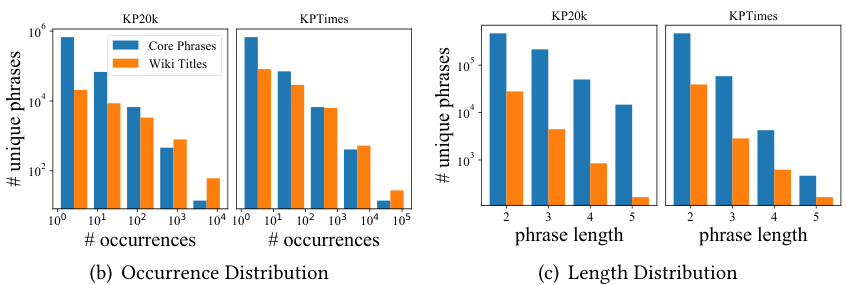
Figure 2: Comparing core phrases with context-agnostic distant supervision. (a) An illustrative example with context. Our core phrases preserve better contextual completeness and discover emerging new concepts introduced in the document. (b) Distributions of the generated silver labels with their occurrences in the corpus. The X-axis represents bins of phrase occurrences in the corpus. The Y-axis (exponential) represents the number of unique phrases in each bin. (c) Distributions of the generated silver labels with their lengths (# of words).
图 2: 核心短语与上下文无关的远距离监督对比。(a) 带上下文的示例。我们的核心短语保持了更好的上下文完整性,并发现了文档中引入的新兴概念。(b) 生成的银标签在语料库中出现次数的分布。X轴表示短语在语料库中出现次数的区间。Y轴(指数)表示每个区间内独特短语的数量。(c) 生成的银标签长度(单词数)的分布。
Algorithm 1: UCPhrase: unsupervised model training
算法 1: UCPhrase: 无监督模型训练
with unsupervised models or collected from an existing knowledge base (KB). Such methods, as we show later, can suffer from incomplete labels due to the negligence of context.
使用无监督模型或从现有知识库(KB)收集。正如我们稍后展示的,这类方法可能因忽略上下文而导致标签不完整。
On the contrary, based on the definition of phrases, we look for consistently used word sequences in context. We propose to treat documents as context and collect high-quality phrases directly from each document. The “document” here refers to a collection of sentences centered on the same topic, such as sentences from an abstract of a scientific paper and tweets mentioning the same hashtag. This way, we expect to preserve better contextual completeness that reflects the original writing intention.
相反,基于短语的定义,我们在上下文中寻找一致使用的词序列。我们建议将文档视为上下文,并直接从每篇文档中收集高质量短语。这里的"文档"指围绕同一主题的句子集合,例如科学论文摘要中的句子和提及相同话题标签的推文。通过这种方式,我们期望保留更好的上下文完整性,以反映原始写作意图。
We view a document $d_{m}$ as a contiguous word sequence $[w_{1},\ldots,$ $w_{N}]$ and then mine max contiguous sequential patterns. A valid pattern here is a word span $[w_{i},\dots,w_{j}]$ that appear more than once in the input sequence. One can easily adjust the frequency threshold to balance the quality and quantity of valid patterns. In this work, we simply use the minimum requirement of two occurrences without further tuning, and find it works well for both short documents like paper abstracts and long documents like news reports. To preserve completeness, we only leave max patterns that are not sub-patterns of any other valid patterns. Uninformative patterns like “of $\alpha^{\mathfrak{s}}$ are removed with a stopword list widely used by previous work [25, 34]. We treat the remaining max patterns as core phrases of document $d_{m}$ , and add them to the positive training samples $\mathcal{P}{m}^{+}$ . An equal number of negative samples are randomly drawn from the remaining spans in $d_{m}$ , denoted as $\mathcal{P}_{m}^{-}$ .
我们将文档 $d_{m}$ 视为连续的词序列 $[w_{1},\ldots,$ $w_{N}]$,然后挖掘最大连续序列模式。这里的有效模式是指词片段 $[w_{i},\dots,w_{j}]$ 在输入序列中出现超过一次。可以轻松调整频率阈值以平衡有效模式的质量和数量。在本工作中,我们简单地使用最低要求两次出现而不进行进一步调整,发现它对于论文摘要等短文档和新闻报道等长文档都效果良好。为了保持完整性,我们只保留那些不是其他有效模式子模式的最大模式。通过使用先前工作广泛采用的停用词列表 [25, 34],我们移除了诸如“of $\alpha^{\mathfrak{s}}$”之类的无信息模式。我们将剩余的最大模式视为文档 $d_{m}$ 的核心短语,并将它们添加到正训练样本 $\mathcal{P}{m}^{+}$ 中。从 $d_{m}$ 的剩余片段中随机抽取同等数量的负样本,记为 $\mathcal{P}_{m}^{-}$。
Figure 2 compares the silver labels generated by our core phrases with those by distant supervision, which follows a context-agnostic string matching from the Wikipedia entities. From the real example in Figure 2(a), “heat island effect” is not a Wikipedia entity, but “island effect” is one. Distant supervision hence generates a flawed label by partially matching the real phrase. Similar examples are quite common especially when it comes to compound phrases, like “biomedical data mining”. Distant supervision would tend to favor those popular phrases and generate incomplete matches in context. On the contrary, our core phrase mining can generate labels with better contextual completeness. Core phrase mining can also dynamically capture concepts or expressions newly introduced in each document, such as the “core phrases” in this paper. Figure 2(b) confirms this by showing the distribution of unique phrases of the two types of silver labels, mined from the KP20k CS publication corpus and the KPTimes news corpus, with respect to their frequency. In particular, core phrase mining discovers more unique phrases with less than 10 occurrences in the corpus (30x on KP20k, 9x on KPTimes). As Figure 2(c) demonstrates, core phrases outnumber matched Wiki titles on all length ranges. Overall, core phrase mining discovers much more unique phrases than distant supervision (20x on KP20k, 6x on KPTimes).
图 2: 将我们生成的核心短语银标签与远程监督生成的标签进行对比。远程监督采用与上下文无关的维基百科实体字符串匹配方式。从图 2(a)的实际案例可见,"heat island effect"并非维基百科实体,但"island effect"是。因此远程监督通过部分匹配生成了错误标签。这种案例在复合短语(如"biomedical data mining")中尤为常见——远程监督会倾向流行短语并产生上下文不完整的匹配。相反,我们的核心短语挖掘能生成上下文更完整的标签,还能动态捕捉每篇文档新引入的概念或表述(如本文的"core phrases")。图 2(b)通过KP20k学术文献库和KPTimes新闻语料中两类银标签的唯一短语分布验证了这一点:核心短语挖掘在出现次数少于10次的低频短语上具有显著优势(KP20k语料30倍,KPTimes语料9倍)。如图 2(c)所示,核心短语在所有长度区间均超过匹配的维基标题数量。总体而言,核心短语挖掘发现的唯一短语数量远超远程监督(KP20k语料20倍,KPTimes语料6倍)。
Of course, there also inevitably exist noises in mined core phrases due to random word combinations consistently used in some documents, e.g., “countries including”. Fortunately, since we collected core phrases from each document independently, such noisy labels will not spread and be amplified to the entire corpus. In fact, among the tagged core phrases randomly sampled from two datasets, the overall proportion of high-quality labels is over $90%$ . The large volume of reasonably high-quality silver labels provides a robust foundation for us to train a span classifier that learns about general context patterns to distinguish noisy spans. As Section 4.7 shows, the final classifier can assign extremely low scores to false-positive phrases in training labels.
当然,由于某些文档中持续使用的随机词汇组合(例如“countries including”),挖掘出的核心短语中也不可避免地存在噪声。幸运的是,由于我们独立地从每篇文档中收集核心短语,此类噪声标签不会扩散并放大到整个语料库。事实上,在从两个数据集中随机抽样的已标注核心短语中,高质量标签的总体占比超过$90%$。大量合理的高质量银标签为我们训练一个学习通用上下文模式以区分噪声片段的跨度分类器奠定了坚实基础。如第4.7节所示,最终分类器可以为训练标签中的假阳性短语分配极低分数。
In summary, document-level core phrase mining provides a simple and effective way to automatically fetch abundant contextaware silver labels of reasonably good quality without relying on external KBs. In ablation studies (Section 4.6) we show that models trained with such free silver labels can outperform the same models
总之,文档级核心短语挖掘提供了一种简单有效的方法,无需依赖外部知识库(KB)即可自动获取大量质量尚可的上下文感知银标签。消融研究(第4.6节)表明,使用这类免费银标签训练的模型性能可超越同等模型。

Figure 3: Illustration of the attention map generated by one of the pre-trained RoBERTa layers, averaged over all attention heads.
图 3: 预训练 RoBERTa 某一层生成的平均注意力图 (attention map) 可视化结果 (对所有注意力头取平均)。
trained with distant supervision.
通过远监督训练。
3.2 Surface-agnostic Feature Extraction
3.2 表面无关的特征提取
To build an effective context-aware tagger for quality phrases, in addition to labels, we need to figure out the contextual i zed feature representation for each span. Traditional word-identifiable features (e.g., contextual i zed embedding) make it easy for a classification model to overfit the silver labels by rigidly memorizing the surface names of training labels. A degenerated name-matching model can easily achieve zero training error without really learning about any useful, general iz able features.
为了构建一个有效的上下文感知标签器来识别优质短语,除了标签外,我们还需要为每个文本片段提取上下文特征表示。传统的可识别词特征(例如上下文嵌入)容易导致分类模型通过死记硬背训练标签的表面名称而过拟合银标签。一个退化的名称匹配模型即使没有学习到任何有用且可泛化的特征,也能轻松实现零训练误差。
In principle, the recognition of a phrase should depend on the role that it plays in the sentence. Kim et al. [19] show that the structure information of a sentence can be largely captured by its attention distribution. Therefore, we propose to obtain surfaceagnostic features from the attention distributions generated by a pre-trained Transformer-based language model encoder (LM), such as BERT [7] and RoBERTa [26].
原则上,短语的识别应取决于其在句子中的作用。Kim等人[19]表明,句子的结构信息很大程度上可以通过其注意力分布来捕捉。因此,我们提出从预训练的基于Transformer的语言模型编码器(LM)(如BERT[7]和RoBERTa[26])生成的注意力分布中获取表面无关特征。
Given a sentence $\left[w_{1},\dots,w_{N}\right]$ , we encode it with a language model pre-trained on a massive, unlabeled corpus from the same domain (e.g., general domain and scientific domain). Suppose this language model has $L$ layers, and each layer has $H$ attention heads. Each attention head $h$ from layer $l$ produces an attention map $\mathbf{A}^{l,h}\in\mathbb{R}^{N\times N}$ of the sentence. The aggregated attention map from attention heads of all layers is denoted as $\mathbf{\dot{A}}\in\mathbb{R}^{N\times N\times(H\cdot L)}$ , where $\mathbf{A}{i,j}\in\mathbb{R}^{H\cdot L}$ is a vector that contains the attention scores from $w_{i}$ to $w_{j}$ . Finally, for each candidate span $\boldsymbol{p}=\left[w_{i},\ldots,w_{j}\right]$ , we denote its feature as X𝑝 = A𝑖...𝑗,𝑖...𝑗 .
给定一个句子 $\left[w_{1},\dots,w_{N}\right]$ ,我们使用在相同领域(例如通用领域和科学领域)的大规模未标注语料上预训练的语言模型对其进行编码。假设该语言模型有 $L$ 层,每层有 $H$ 个注意力头。层 $l$ 中的每个注意力头 $h$ 会生成该句子的注意力图 $\mathbf{A}^{l,h}\in\mathbb{R}^{N\times N}$ 。所有层注意力头的聚合注意力图表示为 $\mathbf{\dot{A}}\in\mathbb{R}^{N\times N\times(H\cdot L)}$ ,其中 $\mathbf{A}{i,j}\in\mathbb{R}^{H\cdot L}$ 是一个包含从 $w_{i}$ 到 $w_{j}$ 注意力分数的向量。最后,对于每个候选片段 $\boldsymbol{p}=\left[w_{i},\ldots,w_{j}\right]$ ,我们将其特征表示为 X𝑝 = A𝑖...𝑗,𝑖...𝑗 。
Ideally, the attention maps of quality phrases should reveal distinct patterns of word connections. Figure 3 shows a real example of the generated attention map of a sentence. The chunks on the attention map lead to a clear separation of different parts of the sentence. From all chunks, our final span classifier (Section 3.3) accurately distinguishes the quality phrases (“coal mine”, “heat island effects”) from ordinary spans (e.g., “We can”), indicating the informative ness of the attention features.
理想情况下,质量短语的注意力图应呈现清晰的词语关联模式。图 3 展示了一个句子生成的注意力图实例,图中区块能清晰区分句子的不同部分。通过所有区块分析,我们的最终跨度分类器 (第 3.3 节) 能准确区分质量短语 ("coal mine", "heat island effects") 与普通片段 (如 "We can"),这证明了注意力特征的信息有效性。
Efficient Implementation. Thanks to the rich syntactic and semantic knowledge in the pre-trained language model, the generated attention maps are already informative enough for phrase tagging.
高效实现。得益于预训练语言模型中丰富的句法和语义知识,生成的注意力图已经足够丰富,可用于短语标注。
Figure 4: An alternative classifier based on attention-level LSTM.
图 4: 基于注意力级别 LSTM 的替代分类器。
In this work, we adopt the RoBERTa model [26], one of the state-ofthe-art Transformer-based language models, as a feature extractor without the need for further fine-tuning. We only need to apply the pre-trained RoBERTa model for one inference pass through the target corpus for feature extraction.
在本工作中,我们采用RoBERTa模型[26]作为特征提取器,无需进一步微调。该模型是基于Transformer的先进语言模型之一。我们只需将预训练的RoBERTa模型对目标语料库进行一次推理遍历即可完成特征提取。
The overall efficiency now mainly depends on the size of the attention map, which is $N{\times}N{\times}(H{\cdot}L).N$ is restricted to the length of each span during training, and for inference, we apply sentencelevel encoding, with each sentence restricted to at most 64 tokens. Depth wise, existing studies have observed considerable redundancy in the outputs of different Transformer layers, including attention distributions [14, 15]. For this reason, as the default setting of UCPhrase, we only preserve attention maps from the first 3 layers in RoBERTa (i.e., $L=3$ ). As RoBERTa has 12 layers in total, this saves $75%$ of resource consumption. We have quantitatively compared the final tagging performance of using 3 layers vs. using all 12 layers in Section 4.6. As the experimental results suggest, using 3 layers exhibits comparable performance with the full model.
整体效率现在主要取决于注意力图的大小,即 $N{\times}N{\times}(H{\cdot}L)$。训练时 $N$ 受限于每个跨度的长度,而在推理阶段,我们采用句子级编码,每句最多限制为64个token。在深度方面,现有研究发现不同Transformer层的输出存在显著冗余,包括注意力分布 [14, 15]。因此,UCPhrase默认设置仅保留RoBERTa前3层的注意力图(即 $L=3$)。由于RoBERTa共有12层,这一设定可节省 $75%$ 的资源消耗。我们在4.6节定量比较了使用3层与全部12层的最终标注性能,实验结果表明:3层配置与完整模型具有相当的表现力。
3.3 Lightweight Span Classifier
3.3 轻量级跨度分类器
With the labels and features in-house, we are ready to build a classifier to recognize spans of quality phrases. Our framework is general and compatible with various classification models. For the sake of efficiency, we wish to find a lightweight classifier.
有了内部的标签和特征,我们就可以构建一个分类器来识别质量短语的范围。我们的框架具有通用性,兼容多种分类模型。出于效率考虑,我们希望找到一个轻量级的分类器。
Given the attention map of a $k$ -word span, an accurate classifier should effectively capture inter-word relationships from different LM layers and at different ranges. Naturally, the attention map can be viewed as a square image of $k$ pixels for both height and width, with $H\cdot L$ channels. We can now transform the phrase classification problem into an image classification problem: given a multi-channel image (attention map), we want to predict whether the corresponding word span is a quality phrase. Specifically, we apply a two-layer convolutional neural network (CNN) model on the multi-channel attention map. The output is then fed to a logistic regression layer to assign a binary label for the corresponding span. During the training process, the classification model $f(\cdot;\theta)$ parameterized by $\theta$ is learned by minimizing the loss over the training set ${\mathbf{X}\varphi,{\mathcal{P}}}$ :
给定一个 $k$ 词跨度的注意力图,一个准确的分类器应能有效捕捉来自不同大语言模型层和不同范围的词间关系。自然地,注意力图可视为高度和宽度均为 $k$ 像素的方形图像,具有 $H\cdot L$ 个通道。现在我们可以将短语分类问题转化为图像分类问题:给定一个多通道图像(注意力图),我们需要预测对应的词跨度是否为优质短语。具体而言,我们在多通道注意力图上应用一个双层卷积神经网络(CNN)模型,其输出随后被送入逻辑回归层,为对应跨度分配二元标签。在训练过程中,通过最小化训练集 ${\mathbf{X}\varphi,{\mathcal{P}}}$ 上的损失,学习由参数 $\theta$ 定义的分类模型 $f(\cdot;\theta)$:
$$
\hat{\theta}=\underset{\theta}{\operatorname{argmin}}\frac{1}{|\mathcal{P}|}\sum_{i=1}^{|\mathcal{P}|}\ell(p_{i},f(\mathbf{X}{p_{i}};\theta)),
$$
$$
\hat{\theta}=\underset{\theta}{\operatorname{argmin}}\frac{1}{|\mathcal{P}|}\sum_{i=1}^{|\mathcal{P}|}\ell(p_{i},f(\mathbf{X}{p_{i}};\theta)),
$$
where $p_{i}\in\mathcal{P}=\bigcup_{m=1}^{M}{\mathcal{P}{m}^{-},\mathcal{P}_{m}^{+}}$ represents the $i$ -th labeled span, and $\ell$ is the binary cross entropy loss function. The model is updated with minibatch-based stochastic gradient descent.
其中 $p_{i}\in\mathcal{P}=\bigcup_{m=1}^{M}{\mathcal{P}{m}^{-},\mathcal{P}_{m}^{+}}$ 表示第 $i$ 个标注片段,$\ell$ 为二元交叉熵损失函数。模型采用基于小批量的随机梯度下降法进行更新。
Note that $\theta$ here only includes the parameters in the two CNN layers and the logistic regression layer during training, which makes
请注意,这里的 $\theta$ 仅在训练期间包含两个 CNN 层和逻辑回归层中的参数,这使得
Corpus
语料库
Task I. Corpus-level Phrase Ranking
任务 I. 语料库级短语排序

Task II. Document-level Keyphrase Extraction
任务 II. 文档级关键词抽取
Doc1 Gold Keyphrases: - Richard Healing - Transportation Safety Board
Doc1 黄金关键词: - Richard Healing - Transportation Safety Board
Tagged phrases as candidates -- fRo irc mh a err d m Hee mal bien rg Rec. = 100% - Transportation Safety Board
标记短语作为候选 -- fRo irc mh a err d m Hee mal bien rg 召回率 = 100% - 运输安全委员会
Ranked by TF-IDF
按TF-IDF排序
- Transportation Safety Board - Richard Healing - safety consultant $F_{I}@3=80%$
- 运输安全委员会 - Richard Healing - 安全顾问 $F_{I}@3=80%$
Task III. Sentence-level Phrase Tagging
任务 III. 句子级短语标注
Human Annotators (* 3):
人工标注员 (* 3):
[Support Vector Machine] is a member of [supervised class if i ers] widely used in [information extraction systems] .
[支持向量机]是[信息抽取系统]中广泛使用的[监督分类器]之一。
System Prediction:
系统预测:
[Support Vector Machine] is a [member of] [supervised class if i ers] widely used in [information extraction] systems.
支持向量机 (Support Vector Machine) 是信息抽取 (information extraction) 系统中广泛使用的监督分类器 (supervised classifiers) 成员之一。
Rec. = 66.7%, Prec. $=50%$ , $F_{I}=57.2%$ (average over all annotators)
Rec. = 66.7%, Prec. $=50%$, $F_{I}=57.2%$ (所有标注者的平均值)
Fine-grained
细粒度
the training process efficient in terms of resource consumption. In fact, the checkpoint of training parameters from each epoch can be stored in a 22 KB file on disk.
训练过程在资源消耗方面非常高效。实际上,每个训练周期的参数检查点可以存储在磁盘上22 KB的文件中。
Another bidirectional LSTM layer is built upon the word representations $\mathbf{R}$ to extract the feature F, i.e.,
另一个双向 LSTM 层基于词表示 $\mathbf{R}$ 构建,用于提取特征 F,即
$$
\begin{array}{r}{\begin{array}{l}{\overrightarrow{\mathbf{F}}{1,2,\ldots,N}=\mathrm{LSTM}(\mathbf{R}{1},\mathbf{R}{2},\ldots,\mathbf{R}{N}),}\ {\overleftarrow{\mathbf{F}}{N,N-1,\ldots,1}=\mathrm{LSTM}(\mathbf{R}{N},\mathbf{R}{N-1},\ldots,\mathbf{R}_{1}).}\end{array}}\end{array}
$$
$$
\begin{array}{r}{\begin{array}{l}{\overrightarrow{\mathbf{F}}{1,2,\ldots,N}=\mathrm{LSTM}(\mathbf{R}{1},\mathbf{R}{2},\ldots,\mathbf{R}{N}),}\ {\overleftarrow{\mathbf{F}}{N,N-1,\ldots,1}=\mathrm{LSTM}(\mathbf{R}{N},\mathbf{R}{N-1},\ldots,\mathbf{R}_{1}).}\end{array}}\end{array}
$$
Scheme wise, there are two popular labeling schemes in sequence labeling: (1) Tie-or-Break, which is predicting whether each consecutive pair of words belong to the same phrase, and (2) BIO Tagging, which is tagging phrases in the sentence through a Begin-InsideOutside scheme [32]. We are not using BIOES [33] as we focus on multi-word phrases. For the Tie-or-Break tagging scheme, we apply a 2-layer Multi-layer Perceptron followed by a Sigmoid classification function to predict whether the $[\overrightarrow{\textbf{F}}{i},\overleftarrow{\textbf{F}}{i+1}]$ representation corresponds to a tie between word $i$ and word $i+1$ or a break. For the BIO tagging scheme, in a word-wise manner, we concatenate the represent at ions $\vec{\textbf{F}}{1,2,...,N}$ and $\overleftarrow{\mathbf{F}}_{N,N-1,...,1}$ into $N$ representations for each sentence, and then send them through a Conditional Random Field (CRF) layer [18, 22] to predict the BIO tags for phrases.
在序列标注中,有两种流行的标注方案:(1) Tie-or-Break,用于预测每对相邻单词是否属于同一短语;(2) BIO标注,通过Begin-Inside-Outside方案对句子中的短语进行标注[32]。由于我们关注多词短语,因此不使用BIOES[33]。对于Tie-or-Break标注方案,我们采用2层多层感知机(MLP)和Sigmoid分类函数来预测$[\overrightarrow{\textbf{F}}{i},\overleftarrow{\textbf{F}}{i+1}]$表示是否对应单词$i$与单词$i+1$之间的连接或断开。对于BIO标注方案,我们以逐词方式将表示$\vec{\textbf{F}}{1,2,...,N}$和$\overleftarrow{\mathbf{F}}_{N,N-1,...,1}$拼接为$N$个句子表示,然后通过条件随机场(CRF)层[18,22]预测短语的BIO标签。
Other training procedures for both of the class if i ers are the same as the aforementioned default span classifier. These alternative classifiers have comparable performance, as confirmed in Section 4.6.
两类分类器的其他训练流程与前述默认跨度分类器相同。这些替代分类器具有可比性能,如第4.6节所验证。
4 EXPERIMENTS
4 实验
We compare our UCPhrase with previous studies on multi-word phrase mining tasks on two datasets and three tasks at different granularity: corpus-level phrase ranking, document-level keyphrase extraction, and sentence-level phrase tagging.
我们在两个数据集和三个不同粒度的任务上,将UCPhrase与以往的多词短语挖掘研究进行对比:语料库级短语排序、文档级关键词抽取以及句子级短语标注。
Figure 5: Illustration of the Three Evaluation Tasks and their Evaluation Metrics. Table 1: Dataset statistics on KP20k and KPTimes.
图 5: 三项评估任务及其评估指标示意图。
表 1: KP20k 和 KPTimes 数据集统计信息。
| Statistics | KP20k | KPTimes |
|---|---|---|
| TrainSet | TrainSet | |
| #documents | 527,090 | 259,923 |
| #words per document | 176 | 907 |
| TestSet | TestSet | |
| #documents | 20,000 | 20,000 |
| #multi-word keyphrases | 37,289 | 24,920 |
| #unique | 24,626 | 8,970 |
| #absent in training corpus | 4,171 | 2,940 |
4.1 Evaluation Tasks and Metrics
4.1 评估任务与指标
We evaluate all methods on the following three tasks. Figure 5 illustrates the tasks and evaluation metrics with some examples.
我们在以下三个任务上评估所有方法。图5: 用示例展示了任务和评估指标。
Task I: Phrase Ranking is a popular evaluation task in previous statistics-based phrase mining work [6, 8, 23, 25, 34]. Specifically, it evaluates the “global” rank list of phrases that a method finds from the input corpus. Since UCPhrase does not explicitly compute a “global” score for each phrase, we use the average logits of all occurrences of a predicted phrase to rank phrases.
任务 I: 短语排序是先前基于统计的短语挖掘工作中常见的评估任务 [6, 8, 23, 25, 34]。具体而言,它评估方法从输入语料库中发现的短语的"全局"排名列表。由于 UCPhrase 并未显式计算每个短语的"全局"分数,我们使用预测短语所有出现位置的平均 logits 值对短语进行排序。
In our experiments, for each method2 on each dataset, we quantitatively evaluate the precision of the phrases found in the topranked 5,000 and 50,000 phrases, denoted as $\mathbf{P}{a}5\mathbf{K}$ and $\mathbf{P}@50\mathbf{K}$ . Since it is expensive to hire annotators to annotate all these phrases, we estimate the precision scores by randomly sampling 200 phrases from rank lists. Extracted phrases from different methods are shuffled and mixed before presenting to the annotators.
在我们的实验中,对于每个数据集上的每种方法2,我们定量评估了排名前5,000和50,000个短语的准确率,分别表示为$\mathbf{P}{a}5\mathbf{K}$和$\mathbf{P}@50\mathbf{K}$。由于雇佣标注人员标注所有这些短语成本高昂,我们通过从排名列表中随机抽取200个短语来估算准确率分数。不同方法提取的短语在呈现给标注人员之前会被打乱并混合。
Task II: Keyphrase Extraction is a classic task to extract salient phrases that best summarize a document [9], which essentially has two stages: candidate generation and keyphrase ranking. At the first stage, we treat all compared methods as candidate phrase extractors and evaluate the recall of generated candidates. In each document, the recall measures how many gold keyphrases are extracted in the candidate list. For fair comparison, we preserve the same number of candidates from the rank list of each method for evaluation.
任务二:关键词提取是一项经典任务,旨在提取最能概括文档的显著短语 [9],主要包含两个阶段:候选生成和关键词排序。第一阶段,我们将所有对比方法视为候选短语提取器,评估生成候选的召回率。在每篇文档中,召回率衡量候选列表中提取到的黄金关键词数量。为保证公平比较,我们从每种方法的排序列表中保留相同数量的候选进行评估。
For the end-the-end performance, we apply the classic TF-IDF model to rank the candidate phrases extracted by different methods. In each document, we follow the standard evaluation method [13] to calculate the $F_{1}$ score of the top-10 ranked phrases $(\mathbf{F}{1}@\mathbf{10})$ . The reported recall and $F_{1}$ scores are averaged in a macro way across all documents in the same dataset.
对于端到端性能评估,我们采用经典的TF-IDF模型对各类方法提取的候选短语进行排序。在每个文档中,我们遵循标准评估方法[13],计算排名前10短语的$F_{1}$分数$(\mathbf{F}{1}@\mathbf{10})$。最终报告的召回率和$F_{1}$分数采用宏观平均法,对同一数据集中所有文档的得分进行平均。
Task III: Phrase Tagging is a fine-grained task that aims to find all occurrences of phrases in sentences. Specifically, it evaluates the extracted phrase spans for each sentence. We treat each phrase mining method as a sentence tagger that identifies starting and ending boundaries of phrases in a sentence. We randomly sample 200 sentences on each dataset and ask three annotators to tag all spans of multi-word phrases. Each sentence is annotated by all annotators independently, and the agreement between human annotations is around $90%$ . We then pool all annotations together, evaluate the predicted spans, and report the overall precision, recall and ${\bf F}_{1}$ scores. Note that these scores are computed in a micro average fashion following previous work on entity recognition [35].
任务三:短语标注是一项细粒度任务,旨在识别句子中所有短语实例。具体而言,该任务评估每个句子中提取的短语跨度范围。我们将每种短语挖掘方法视为句子标注器,用于识别句子中短语的起始和结束边界。我们在每个数据集中随机抽取200个句子,并邀请三位标注员标注所有多词短语的跨度范围。每个句子均由所有标注员独立标注,人工标注间的一致性约为$90%$。随后汇总所有标注结果,评估预测跨度范围,并报告整体精确率、召回率和${\bf F}_{1}$值。需注意,这些分数遵循实体识别领域先前工作[35]的做法,采用微观平均方式计算。
Table 2: Evaluation results $(%)$ of three tasks for all compared methods on datasets on two domains.
表 2: 两个领域数据集上所有对比方法在三个任务中的评估结果 $(%)$
| MethodType | MethodName | TaskI:PhraseRanking | TaskII:KPExtract. | Task IHI: Phrase Tagging |
|---|---|---|---|---|
| KP20k | KPTimes | KP20K | ||
| Pre-trained | PKE [3] | |||
| Pre-trained | Spacy [17] | |||
| Pre-trained | StanfordNLP [27] | |||
| DistantlySupervised | AutoPhrase[34] | 97.5 | 96.0 | 96.5 |
| DistantlySupervised | Wiki+RoBERTa | 100.0 | 98.5 | 99.0 |
| Unsupervised | TopMine [8] | 81.5 | 78.0 | 85.5 |
| Unsupervised | UCPhrase (ours) | 96.5 | 96.5 | 96.5 |
4.2 Datasets
4.2 数据集
We adopt two commonly used datasets from different domains to evaluate all different methods.
我们采用两个不同领域的常用数据集来评估所有不同方法。
• KP20k [29] is a collection of titles & abstracts from Computer Science papers—527,090 for training and 20,000 for testing. • KPTimes [12] consists of news articles on New York Times from 2006 to 2017, supplemented with 10,000 more news articles from Japan Times. In total, there are 259,923 articles for training, and 20,000 articles for testing.
• KP20k [29] 是一个计算机科学论文标题与摘要的集合,包含527,090篇训练数据和20,000篇测试数据。
• KPTimes [12] 包含2006年至2017年《纽约时报》的新闻文章,并补充了来自《日本时报》的10,000篇新闻。总计有259,923篇训练文章和20,000篇测试文章。
Following Gururangan et al. [16], sentence separation and tokenization is conducted with Spacy [17] for post processing. All three tasks are evaluated on the test sets. Statistics of the two datasets are shown in Table 1. Note that $17%$ unique keyphrases in the test of KP20k never occur in the corresponding training corpus. On KPTimes the absence ratio is $33%$ . Hence, the task can be challenging for models relying on phrase frequencies and models rigidly memorizing training phrases.
根据Gururangan等人[16]的研究,我们使用Spacy[17]进行句子分割和Token化以进行后处理。所有三项任务均在测试集上评估。两个数据集的统计信息如表1所示。需要注意的是,KP20k测试集中17%的独特关键词从未在对应训练语料中出现,而KPTimes的这一缺失比例为33%。因此,对于依赖短语频率或机械记忆训练短语的模型而言,这项任务可能具有挑战性。
4.3 Compared Methods
4.3 对比方法
We compare the proposed method with existing methods under the same scenario, where no gold annotations for training are available. This leads to three categories: unsupervised phrase mining methods, distantly supervised methods with an existing KB, and pre-trained off-the-shelf toolkits. For each method that requires training (i.e., all the unsupervised and distantly supervised ones), we use the unlabeled documents from the training set for model learning.
我们在相同场景下将所提方法与现有方法进行比较,该场景中不存在用于训练的黄金标注数据。这形成了三类方法:无监督短语挖掘方法、基于现有知识库的远程监督方法,以及预训练即用工具包。对于需要训练的每种方法(即所有无监督和远程监督方法),我们使用训练集中的未标注文档进行模型学习。
For unsupervised methods we consider:
对于无监督方法,我们考虑:
• ToPMine [8], the state-of-the-art unsupervised phrase mining method building upon statistical features. • UCPhrase, the proposed method in this work.
• ToPMine [8],基于统计特征的最先进无监督短语挖掘方法。
• UCPhrase,本文提出的方法。
For distantly supervised methods, we use silver labels generated from the Wiki Entities, which is firstly used in [34].
对于远程监督方法,我们使用从Wiki Entities生成的银标签,该方法首次在[34]中使用。
• AutoPhrase [34] leverages statistics-based phrase classifier and further enhances it with a POS-guided phrasal segmentation model for sentence tagging and phrase frequency rectification.
• AutoPhrase [34] 采用基于统计的短语分类器,并通过词性标注 (POS) 引导的短语分割模型进一步增强,用于句子标注和短语频率校正。
• Wiki+RoBERTa is a strong baseline that we propose here. It can be viewed as a variant of UCPhrase with the same span prediction framework and the same pre-trained LM as our method but following distant supervision. Also, it uses the output states from the last layer of the pre-trained RoBERTa as feature instead of attention maps. As shown in [24], stopping the model training early is an essential intervention for distantly supervised tagging models. To fully unleash the potential of the Wiki $^+$ RoBERTa baseline, we manually stop its training process after the first epoch to avoid over fitting. This indeed achieves a better test performance than stopping after more epochs.
• Wiki+RoBERTa是我们在此提出的强基线模型。可将其视为UCPhrase的变体:采用相同的跨度预测框架和预训练语言模型,但遵循远程监督机制。该基线使用预训练RoBERTa最后一层的输出状态作为特征(而非注意力图)。如[24]所示,提前终止训练对远程监督标注模型至关重要。为充分释放Wiki$^+$RoBERTa基线的潜力,我们手动在首个训练周期后终止训练以避免过拟合,此举确实比多周期训练获得了更优的测试性能。
For off-the-shelf toolkits we consider the linguistic-based methods that are pre-trained with labeled pos-tagging or parsing data.
对于现成的工具包,我们考虑基于语言学的方法,这些方法已使用带有标注的词性标注或解析数据进行预训练。
• PKE [3] is a widely used toolkit for keyphrase extraction. Its phrase mining module is a chunking model based on a supervised POS-tagging model from NLTK [2] and a set of grammar rules. • Spacy [17] is an industrial library with a pre-trained phrase chunking model based on supervised POS tagging and parsing. • Stanford Core NLP [27] is a long recognized NLP package whose chunking model is based on dependency parsing.
- PKE [3] 是一个广泛使用的关键词提取工具包。其短语挖掘模块基于 NLTK [2] 的监督式词性标注模型和一组语法规则构建的分块模型。
- Spacy [17] 是一个工业级库,提供了基于监督式词性标注和解析的预训练短语分块模型。
- Stanford Core NLP [27] 是一个长期公认的自然语言处理工具包,其分块模型基于依存句法分析。
4.4 Reproduction Details
4.4 复现细节
For KPTimes, we use the official RoBERTa model pre-trained on documents from the general domain. On the $\mathrm{KP20k}$ dataset, we use the “allenai/cs roberta base” RoBERTa model [16] . The model is based on the standard pre-trained RoBERTa model, and then trained on unlabeled Computer Science publications. This domainadapted model performs slightly better on the KP20k dataset than the original model. We adopt the Adam [20] optimizer with the default parameters for model training. The learning rate is set to 0.001. As described in Algorithm 1, we train the classifier until its performance on the $10%$ hold-out validation set $\mathcal{D}_{v a l i d}$ drops. Other details have been covered in Section 3. We will publish our data and code base for reproduction.
对于KPTimes,我们使用在通用领域文档上预训练的官方RoBERTa模型。在KP20k数据集上,我们采用"allenai/cs roberta base" RoBERTa模型[16]。该模型基于标准预训练RoBERTa模型,并在未标注的计算机科学出版物上进行了二次训练。这个经过领域适配的模型在KP20k数据集上表现略优于原始模型。我们采用Adam[20]优化器进行模型训练,使用默认参数设置,学习率为0.001。如算法1所述,当分类器在10%保留验证集$\mathcal{D}_{valid}$上的性能开始下降时停止训练。其他细节已在第3节说明。我们将公开数据和代码库以供复现。
4.5 Evaluation Results
4.5 评估结果
From Table 2 we can see that UCPhrase achieves the best overall performance on all the three evaluation tasks. The performance gap becomes more vivid as the task becomes more fine-grained.
从表2可以看出,UCPhrase在所有三项评估任务中都取得了最佳整体性能。随着任务粒度变细,性能差距愈发显著。
Table 4: Comparison of attention feature aggregated from different numbers of Transformer layers, evaluated on KP20k $(%)$ .
表 4: 不同 Transformer 层数聚合注意力特征的对比,在 KP20k 上评估 $(%)$
| KPExtract. | Phrase Tagging | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 设计选择 | KP20k | KPTimes | KP20k | KPTimes | |||||||||
| 监督方式 | 特征 | 微调 | Rec. | F1@10 | Rec. | F1@10 | Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| UCPhrase | 核心 | 注意力 | 否 | 72.9 | 19.7 | 83.4 | 10.9 | 69.9 | 78.3 | 73.9 | 69.1 | 78.9 | 73.5 |
| Variants | Wiki | 注意力 | 否 | 68.7 | 17.7 | 79.4 | 10.7 | 72.1 | 71.9 | 72.0 | 64.1 | 67.6 | 65.8 |
| Wiki | 嵌入 | 否 | 73.0 | 19.2 | 64.5 | 9.4 | 60.9 | 65.6 | 63.2 | 60.9 | 65.6 | 63.2 | |
| 核心 | 嵌入 | 否 | 79.3 | 19.7 | 78.7 | 10.2 | 68.4 | 74.6 | 71.4 | 55.7 | 64.8 | 59.9 | |
| 核心 | 嵌入 | 是 | 80.3 | 19.7 | 73.9 | 9.9 | 68.6 | 74.8 | 71.6 | 53.3 | 64.5 | 59.0 |
Table 3: Ablation study of UCPhrase model variants $(%)$
表 3: UCPhrase 模型变体的消融研究 $(%)$
| #Layers | KP Extract. | Phrase Tagging |
|---|---|---|
| Rec. | F1@10 | |
| 3 | 72.9 | 19.7 |
| 12 | 81.8 | 20.6 |
In the corpus-level phrase ranking task, most methods show very high precision (i.e., $\geq95%$ ) on the top 50,000 mined phrases from each dataset. Notably, UCPhrase significantly outperforms the only other unsupervised method ToPMine and is able to perform on par with distantly supervised methods.
在语料库级别的短语排序任务中,大多数方法在从每个数据集中挖掘出的前50,000个短语上表现出非常高的准确率(即 $\geq95%$)。值得注意的是,UCPhrase显著优于其他唯一的无监督方法ToPMine,并且能够与远程监督方法相媲美。
In the document-level keyphrase extraction task, UCPhrase has better recall than most compared methods, demonstrating a coverage of high-quality phrases. Wik $^{+}$ RoBERTa has slightly better recall on the KP20k dataset $(0.1%)$ within a reasonable range, considering Wik $^{+}$ RoBERTa has access to hundreds of thousands keyphrases from Wiki Entities. Note that UCPhrase outperforms all the compared methods on the end-to-end performance (i.e., $F_{1}@10)$ , which verifies its value to the application of keyphrase extraction.
在文档级关键词提取任务中,UCPhrase相比大多数方法具有更高的召回率,展现出对高质量短语的覆盖能力。Wik$^{+}$RoBERTa在KP20k数据集上的召回率略高$(0.1%)$,考虑到Wik$^{+}$RoBERTa能够访问Wiki Entities中的数十万条关键短语,这一差异在合理范围内。值得注意的是,UCPhrase在端到端性能指标(即$F_{1}@10$)上优于所有对比方法,验证了其在关键词提取应用中的价值。
In the sentence-level phrase tagging task, UCPhrase achieves $F_{1}$ scores of more than $73%$ on both datasets, showing significant advantages (i.e., $>10%$ in $F_{1}$ ) over all the compared methods. This is truly encouraging given the facts that (1) UCPhrase is an unsupervised phrase mining model that requires no human effort, and (2) even human annotators cannot fully agree with each other on some particular phrases, and have around $10%$ disagreement on this task. This phrase tagging task makes clear that UCPhrase is able to find phrases much more accurately than compared methods. In Section 4.6 we apply comprehensive comparison between different models on real examples, for a more straightforward visualization of the pros and cons of compared methods.
在句子级短语标注任务中,UCPhrase在两个数据集上的$F_{1}$分数均超过$73%$,相比所有对比方法展现出显著优势(即$F_{1}$值提升$>10%$)。这一结果尤其令人鼓舞,因为:(1) UCPhrase是无监督短语挖掘模型,无需人工标注;(2) 即使人类标注员对某些特定短语也无法完全达成一致,在该任务上存在约$10%$的分歧。该短语标注任务清晰表明,UCPhrase能比对比方法更准确地发现短语。在第4.6节中,我们将通过实际案例对不同模型进行全面比较,更直观地展示各对比方法的优缺点。
4.6 Ablation studies
4.6 消融实验
To gain deeper insights, we apply extensive ablation studies to test model variants from several aspects, as summarized in Table 3. For supervision, we compare the silver labels generated by unsupervised core phrase mining (core), and those generated by distant supervision with Wikipedia entities (Wiki). For the type of features, we compare the attention map features (attention), and the output states of RoBERTa (embedding).
为深入分析,我们对模型变体进行了多方面的消融实验,结果总结如表 3。在监督信号方面,我们对比了无监督核心短语挖掘生成的核心标签 (core) 和基于维基百科实体远程监督生成的维基标签 (Wiki)。在特征类型方面,我们比较了注意力图特征 (attention) 和 RoBERTa 输出状态特征 (embedding)。
Supervision: Core Phrase vs. Distant Supervision. When using the same type of feature, unsupervised models with core phrases as supervision significantly outperform distantly supervised models on most metrics by a clear gap. The better completeness and larger volume of core phrases bring unique advantages in training context-aware tagging models, not to mention the labels are fetched from the corpus for free without relying on an external KB. Moreover, the better diversity of core phrases effectively alleviates the risk of over fitting. It is also worth mentioning that different from the distantly supervised embedding model, the embedding-based model trained with core phrases does not require any manual early stopping to achieve satisfying performance.
监督方法:核心短语 vs. 远程监督。当使用相同类型的特征时,以核心短语作为监督的无监督模型在大多数指标上显著优于远程监督模型,且优势明显。核心短语更好的完整性和更大的规模为训练上下文感知的标记模型带来了独特优势,更不用说这些标签是从语料库中免费获取的,无需依赖外部知识库 (KB)。此外,核心短语更好的多样性有效缓解了过拟合风险。值得一提的是,与远程监督的嵌入模型不同,基于核心短语训练的嵌入模型无需任何人工早停即可达到满意性能。
Table 5: Exploring LSTM-based class if i ers as alternatives based on Tie-or-Break and BIO labeling schemes, evaluated on KP20k $(%)$ .
表 5: 基于 Tie-or-Break 和 BIO 标注方案探索 LSTM 分类器作为替代方案,在 KP20k 上的评估结果 $(%)$。
| 分类器 | KPExtract. | Phrase Tagging | |||
|---|---|---|---|---|---|
| Rec. | F1@10 | Prec. | Rec. | F1 | |
| CNN (UCPhrase 默认) | 68.1 | 18.7 | 69.9 | 78.3 | 73.9 |
| LSTM w/Tie-or-Break | 72.4 | 19.3 | 68.1 | 72.3 | 70.1 |
| LSTM w/BIO | 66.2 | 18.1 | 71.0 | 76.7 | 73.7 |
Features: Attention vs. Embedding. When using the same type of supervision, models with attention features are almost always better than embedding-based features. This verifies our intuition that word-identifiable embeddings allow the classifier to easily overfit silver labels, while the surface-agnostic attention features force the model to learn about informative contextual features, and thus having a better ability of generalization.
特征:注意力机制 vs 嵌入表示。在使用相同监督方式时,采用注意力特征的模型几乎始终优于基于嵌入的特征。这验证了我们的直觉:具有单词可识别性的嵌入会使分类器容易对伪标签过拟合,而与表层形式无关的注意力特征会迫使模型学习信息丰富的上下文特征,从而具备更强的泛化能力。
Attention: First Few Layers vs. Full Layers. Table 4 compares UCPhrase trained with attention features aggregated from the first 3 layers of RoBERTa and those aggregated from all 12 layers, with intuitions explained in Section 3.2. The two models achieve comparable performance, while the small model only requires $25%$ resource consumption.
注意:前几层与全层的对比。表4比较了使用RoBERTa前3层注意力特征聚合训练的UCPhrase与使用全部12层特征聚合训练的模型效果差异,相关原理已在3.2节说明。两个模型性能相当,而小模型仅需消耗$25%$的计算资源。
Alternative Class if i ers. Table 5 compares our model with the the Tie-or-Break classifier and the BIO classifier as introduced in Section 3.3. Overall, the alternative class if i ers have comparable performances, indicating the ability of our proposed method to generalize to different tagging schemes and model architectures.
替代分类器。表5将我们的模型与第3.3节介绍的Tie-or-Break分类器和BIO分类器进行了比较。总体而言,替代分类器具有相当的性能,这表明我们提出的方法能够泛化到不同的标记方案和模型架构。
4.7 Case Studies
4.7 案例研究
In spite of the reasonably high quality of the silver labels, we are curious about whether our final span classifier is robust to the noisy silver labels. To this end, we feed the silver labels to the span classifier and investigate the predicted probability scores. Table 7 presents the silver labels with probabilities below $1%$ and above $99%$ respectively. As it shows, our classifier successfully distinguishes high-quality core phrases from noisy spans, including typos (italic font) that happen to be used consistently in some document. The classifier draws a clear line between these two kinds of spans based on their attention features, which reflect their distinct roles in sentences. We have attempted to remove the low-score ones from the silver labels and re-train the classifier, however, the final performance changes little. This further verifies the robustness of our model, and its ability to capture general context features rather than rigid memorization.
尽管银标签的质量相当高,我们仍好奇最终的跨度分类器是否能抵抗噪声银标签的干扰。为此,我们将银标签输入跨度分类器并分析预测概率分数。表7分别展示了概率低于$1%$和高于$99%$的银标签。结果显示,分类器能有效区分高质量核心短语与噪声跨度(包括某些文档中偶然一致使用的拼写错误(斜体))。基于注意力特征(反映其在句子中的不同作用),分类器清晰划分了这两类跨度。我们尝试从银标签中移除低分样本并重新训练分类器,但最终性能变化甚微。这进一步验证了模型的鲁棒性及其捕捉通用上下文特征(而非机械记忆)的能力。
Table 6: Sentences tagged with different methods described in Section 4.3.
表 6: 使用第4.3节中描述的不同方法标记的句子。
Table 6 presents sentences tagged with representative methods from each category. As it shows, pre-trained models like Spacy can hardly adapt to a new domain without human annotations. For instance, it fails to recognize “Varshamov bound” as a phrase for recognizing “bound” as a verb. Statistics-based methods like AutoPhrase tend to miss uncommon phrases in the corpus, such as “Varshamov graphs”, “finite values”, and “global profiles”. The widely used distantly supervised methods based on word representations from a pre-trained language model (e.g., RoBERTa) can easily overfit the phrases in the KB, even though we have applied manual early stopping. The consequence of rigid memorization comes in two folds. First, the model can miss a lot of out-of-KB phrases, such as the terminologies in KP20k. Second, it can recognize false phrases just because they have similar surface names with real phrases. In the example from KPTimes, the model recognizes “taxes companies” and “but companies” as two phrases, while “taxes” is used as a verb in this sentence, and “but” is a conjunction word. Overall, the results generated by UCPhrase are more accurate. There is also an interesting case in the example from KPTimes, where RoBERTa and UCPhrase recognize “pharmaceutical companies” as a complete phrase, while Spacy and AutoPhrase think “technology and” is also part of the phrase. It is debatable which one is better: both results can contribute to a high-quality phrase vocabulary. In fact, even human annotators cannot achieve perfect agreement in their independent annotations. Dynamically adjusting the granularity of tagged phrases according to different end tasks remains a valuable research problem for further studies.
表 6: 展示了各类别代表性方法标注的句子。如表格所示,Spacy等预训练模型在没有人工标注的情况下难以适应新领域。例如,它无法将"Varshamov bound"识别为短语,而错误地将"bound"判断为动词。基于统计的方法(如AutoPhrase)往往会遗漏语料库中的罕见短语,例如"Varshamov graphs"、"finite values"和"global profiles"。广泛使用的基于预训练语言模型(如RoBERTa)词表示的远程监督方法容易过拟合知识库中的短语——尽管我们已采用人工早停策略。这种机械记忆会带来双重影响:首先模型可能遗漏大量知识库外短语(如KP20k中的术语);其次会因表面名称相似而误判假短语。在KPTimes的示例中,模型将"taxes companies"和"but companies"识别为短语,而实际上"taxes"是动词,"but"是连词。总体而言,UCPhrase生成的结果更准确。KPTimes示例中有个有趣案例:RoBERTa和UCPhrase将"pharmaceutical companies"识别为完整短语,而Spacy和AutoPhrase认为"technology and"也属于该短语。哪种结果更优存在争议——两者都能为高质量短语库做出贡献。事实上,即使人工标注者在独立标注时也无法完全达成一致。根据不同终端任务动态调整短语标注粒度,仍是值得深入研究的课题。
Table 7: Examples from silver training labels with extremely high and low quality scores $f(\cdot;\theta)$ estimated by UCPhrase. The results show that UCPhrase is robust to noises in training labels.
表 7: UCPhrase 估计的极高和极低质量分数 $f(\cdot;\theta)$ 的银训练标签示例。结果表明 UCPhrase 对训练标签中的噪声具有鲁棒性。
| KP20k | KPTimes | |
|---|---|---|
| Spacy | 我们有兴趣改进长度为 n 且[最小距离]d 的[有限值]的[Varshamov界]。为此我们采用了一个[计数引理],发现它对于Varshamov图特别有用。 | [美国]至少在理论上对公司的[全球利润]征税。但拥有大量[知识产权]的公司——尤其是[技术和制药公司]——只需支付其中的一小部分。 |
| AutoPhrase | 我们有兴趣改进长度为 n 且[最小距离]d 的[有限值]的[Varshamov界]。为此我们采用了一个[计数引理],发现它对于Varshamov图特别有用。 | [美国],至少在理论上,对公司的全球利润征税。但拥有大量[知识产权]的公司——特别是[技术和制药公司]——只需支付其中的一小部分。 |
| RoBERTa | 我们有兴趣改进长度为 n 且最小距离 d 的有限值的[Varshamov界]。为此我们采用了一个[计数引理],发现它对于Varshamov图特别有用。 | [美国],至少在理论上,[对公司征税]基于它们的[全球利润]。[制药公司]只需支付其中的一小部分。 |
| UCPhrase | 我们有兴趣改进长度为 n 且[最小距离]d 的[有限值]的[Varshamov界]。为此我们采用了一个[计数引理],发现它对于Varshamov图特别有用。 | [美国],至少在理论上,对公司的[全球利润]征税。但拥有大量[知识产权]的公司——特别是技术和[制药公司]——只需支付其中的一小部分。 |
5 RELATED WORK
5 相关工作
Phrase mining is a long studied task [6, 8, 11, 25, 34]. Due to the broad applicability of phrases to text-associated tasks, supervision signals would be expensive to obtain for vast domains. Unsupervised approaches have been proposed to extract phrases from many different angles, most importantly, language grammar [17, 27, 31] and text statistics [8]. Our work utilizes contextual i zed features from Transformer-based language models [7, 26], therefore, lifts the unnecessary requirement of frequency in statistics-based methods and alleviates requirements of expert-crafted grammar rules. Through experiments of three different tasks (i.e., corpus-level phrase ranking, document-level keyphrase extraction, and sentencelevel phrase tagging), our method shows great performance improvement over previous methods.
短语挖掘是一项长期研究的任务 [6, 8, 11, 25, 34]。由于短语在文本相关任务中的广泛适用性,获取大规模领域的监督信号成本高昂。已有研究从多个角度提出了无监督的短语提取方法,最重要的是基于语言语法 [17, 27, 31] 和文本统计 [8] 的方法。我们的工作利用了基于 Transformer 的语言模型 [7, 26] 的上下文特征,因此摆脱了基于统计方法对词频的不必要要求,并降低了对专家编写语法规则的依赖。通过在三个不同任务(即语料库级短语排序、文档级关键词抽取和句子级短语标注)上的实验,我们的方法相比先前方法展现出显著的性能提升。
KP20k f(·:0)>99% f(-:0)<1%
模型识别、数据结构、发布日期、VLSI设计、产品开发、网络流、有限精度、水印检测、模型选择、路径规划、网络安全、数据中心、源代码...
次数更少、处方意味着、算法需要估计、显著提升性能、包括不连续性、显著降低功耗、因素包括、Titterington考虑...
KPTimes f(·:0)>99% f(-:0)<1%
戴维斯杯、常春藤联盟、禁飞区、巡回锦标赛、纳税申报表、市政厅、本垒打、拘留中心、操作系统、莱德杯、空间站、冰袋、白宫、泽西市、棋盘游戏、减税...
百分比、第11个冠军、部门开始告知官员、类别包括工人、包括袭击、第74次职业胜利、包括政治、包括西班牙在内的国家、包括银行业、包括移动设备...
Another line of research studies on distant supervision signals, such as existing knowledge bases [34, 36]. They typically use knowledge base entries (e.g., Wiki Entities from [34]) to string-match a corpus to obtain supervision signals in their first step. Such matching does not take into account how n-grams exist in the corpus, and as we show, could lead to partial matching of phrases, thus bringing bias to the phrase mining tool trained (e.g., “heat island effect” is usually matched into “island effect”). Our core phrase mining method, while being unsupervised, looks into the context of each n-gram to find max patterns and is able to find more complete phrases that serve as a better supervision signal to UCPhrase contextual i zed feature based classifier.
另一研究方向关注远距离监督信号,例如利用现有知识库[34, 36]。这类方法通常先通过字符串匹配(如[34]采用的维基实体条目)从语料库获取监督信号。此类匹配未考虑n元词组在语料中的实际存在形式,正如我们所示,可能导致短语的部分匹配(例如将"heat island effect"误匹配为"island effect"),从而给训练的短语挖掘工具带来偏差。我们的核心短语挖掘方法虽属无监督,但会分析每个n元词组的上下文以发现最大模式,能识别更完整的短语,为UCPhrase基于上下文特征分类器提供更优质的监督信号。
We use attention maps from pre-trained Transformer-based language models to identify phrases since they carry inter-relation information of tokens [4, 19]. Clark et al. [4] showed that a sufficient amount of linguistic knowledge, such as noun determiners and objects of verbs and prepositions, are captured by attention maps of BERT. Moreover, using only attention maps, one can train a model to perform dependency parsing [4] and constituency tree construction [19] relatively well. Our work utilizes this powerful nature of attention maps and treats them as the only feature to identify quality phrases. Furthermore, through comparing with the output states of RoBERTa, we show that using attention is less likely to overfit and has a more robust generalization.
我们利用预训练基于Transformer的语言模型中的注意力图(attention maps)来识别短语,因为它们携带了token间的关联信息[4,19]。Clark等人[4]研究表明,BERT的注意力图能捕获大量语言学知识,例如名词限定词、动词和介词的宾语等。仅使用注意力图,就能训练出表现较好的依存句法分析模型[4]和成分树构建模型[19]。本研究利用注意力图的这一强大特性,将其作为识别优质短语的唯一特征。此外,通过与RoBERTa输出状态的对比,我们发现使用注意力机制更不易过拟合,且具有更强的泛化能力。
6 CONCLUSIONS
6 结论
We explore phrase tagging in an unsupervised and context-aware manner. Our proposed method, UCPhrase, shows clear improvement on performance for three quality-measuring tasks on two datasets in different domains. Further experimental studies reveal the strength of our two major components: our unsupervised core phrase mining finds more diverse, complete phrases in context than string-matching from some knowledge bases; our use of attention features unleashes the rich linguistic knowledge contained in pretrained neural language models. By leveraging surface-agnostic context features, our model removes the frequency requirement in statistics-based models and alleviates the over fitting issue in embedding-based models.
我们探索了一种无监督且上下文感知的短语标注方法。提出的UCPhrase方法在跨领域两个数据集的三项质量评估任务中均表现出明显的性能提升。进一步实验研究表明:我们的无监督核心短语挖掘相比知识库字符串匹配,能在上下文中发现更多样、更完整的短语;注意力特征的使用释放了预训练神经语言模型中丰富的语言学知识。通过利用与表层无关的上下文特征,该模型消除了基于统计方法的频率限制,并缓解了基于嵌入方法的过拟合问题。
We plan to explore the following directions in future studies. First, our study shows that the combination of silver labels and attention is robust and contains sufficient linguistic knowledge. This idea of unsupervised learning is worth exploring in other text mining tasks, such as co reference resolution [28], dependency parsing [21], and named entity recognition [30]. Second, the imperfection of distant supervision calls for a more effective way to incorporate large-scale unlabeled corpus with existing knowledge bases for more accurate prediction and more intelligent reasoning.
我们计划在未来的研究中探索以下方向。首先,我们的研究表明,银标签 (silver labels) 与注意力机制的结合具有鲁棒性且包含充足的语言学知识。这种无监督学习思路值得在其他文本挖掘任务中探索,例如共指消解 [28]、依存句法分析 [21] 和命名实体识别 [30]。其次,远程监督的不完善性要求开发更有效的方法,将大规模无标注语料库与现有知识库结合,以实现更精准的预测和更智能的推理。