UniNet: A Contrastive Learning-guided Unified Framework with Feature Selection for Anomaly Detection
UniNet: 基于对比学习的特征选择统一异常检测框架
Abstract
摘要
Anomaly detection $(A D)$ is a crucial visual task aimed at recognizing abnormal pattern within samples. However, most existing $A D$ methods suffer from limited generalizability, as they are primarily designed for domain-specific applications, such as industrial scenarios, and often perform poorly when applied to other domains. This challenge largely stems from the inherent discrepancies in features across domains. To bridge this domain gap, we introduce UniNet, a generic unified framework that incorporates effective feature selection and contrastive learning-guided anomaly discrimination. UniNet comprises student-teacher models and a bottleneck, featuring several vital innovations: First, we propose domain-related feature selection, where the student is guided to select and focus on representative features from the teacher with domain-relevant priors, while restoring them effectively. Second, a similarity contrastive loss function is developed to strengthen the correlations among homogeneous features. Meanwhile, a margin loss function is proposed to enforce the separation between the similarities of abnormality and normality, effectively improving the model’s ability to discriminate anomalies. Third, we propose a weighted decision mechanism for dynamically evaluating the anomaly score to achieve robust AD. Large-scale experiments on 11 datasets from various domains show that UniNet surpasses existing methods1.
异常检测(AD)是一项关键的视觉任务,旨在识别样本中的异常模式。然而,现有大多数AD方法泛化能力有限,因为它们主要针对特定领域(如工业场景)设计,在其他领域表现往往不佳。这一挑战主要源于跨领域特征的内在差异。为弥合领域差距,我们提出了通用统一框架UniNet,它融合了有效特征选择和对比学习引导的异常判别。UniNet包含师生模型和瓶颈结构,具有以下关键创新:首先,我们提出领域相关特征选择机制,通过领域先验知识指导学生模型从教师模型中选择并聚焦代表性特征,同时高效恢复这些特征。其次,开发了相似性对比损失函数以增强同类特征间的关联性,同时提出边界损失函数来扩大异常与正常样本相似度的分离度,有效提升模型异常判别能力。第三,我们提出加权决策机制来动态评估异常分数,实现稳健的异常检测。在11个跨领域数据集的大规模实验中,UniNet超越了现有方法[1]。
1. Introduction
1. 引言
Visual anomaly detection (AD) has gained significant traction in recent years, with applications spanning across various fields, such as medical image diagnosis [7, 37, 48], industrial defect inspection [9, 25, 33, 50], and video surveillance [1, 39, 44]. Prior AD paradigms typically develop separate models tailored to each domain (see Fig. 1(a)). Despite considerable advancements in domain-specific applications, these approaches often suffer from limited crossdomain applicability. This limitation primarily arises from domain differences and inherent discrepancies in features. For instance, in industrial AD, some self-supervised methods [29, 43, 55] employ external data [10] or data augmentation technologies to synthesize anomalies and learn anoma- lous feature distribution. However, the anomalies generated in this manner can differ substantially from those encountered in other domains, e.g., medical imaging [11, 26, 45] or video surveillance [30], potentially resulting in insufficient learning of the anomalous distribution. In fact, beyond the stark differences in visual appearance of anomalies–such as defects on industrial products vs. polyps on the intestine or anomalous behavior like cyclist in video surveillance–there are also notable differences in the normal features across different domains. This variability further complicates their cross-domain applications. Moreover, another main challenge hindering the effective application of most methods across other domains is their reliance on pre-trained networks–trained on source domains such as ImageNet [13]–for feature extraction. Recent studies [17, 23, 57] have demonstrated that pre-trained features often bear little resemblance to those needed to the target domain owing to inherent biases in these pre-trained networks, adversely affecting performance (see Fig. 1(c)). In light of these challenges, this paper explores the problem of how to develop a unified framework capable of adapting to diverse domains while achieving accurate AD (see Fig. 1(b)).
视觉异常检测 (AD) 近年来受到广泛关注,其应用涵盖医疗影像诊断 [7, 37, 48]、工业缺陷检测 [9, 25, 33, 50] 和视频监控 [1, 39, 44] 等多个领域。传统AD范式通常针对每个领域开发独立模型(见图1(a))。尽管在特定领域应用中取得了显著进展,但这些方法往往缺乏跨领域适用性。这一局限主要源于领域差异和特征固有差异。例如在工业AD中,部分自监督方法 [29, 43, 55] 通过外部数据 [10] 或数据增强技术合成异常并学习异常特征分布,但这种方式生成的异常与其他领域(如医疗影像 [11, 26, 45] 或视频监控 [30])的真实异常可能存在显著差异,导致异常分布学习不充分。事实上,除了异常视觉表现的明显差异(如工业产品缺陷与肠道息肉,或视频中骑行者等异常行为),不同领域的正常特征也存在显著差异,这进一步增加了跨领域应用的复杂性。此外,多数方法依赖源领域(如ImageNet [13])预训练网络进行特征提取,这种预训练特征由于网络固有偏差往往与目标领域需求特征不符 [17, 23, 57],从而影响性能(见图1(c))。针对这些挑战,本文探索如何构建能适应多领域并实现精准AD的统一框架(见图1(b))。
Recently, ReContrast [17] introduces contrastive learning (CL) elements to optimize its framework for adaptation to different target domains, showing good transfer abil- ity. Nevertheless, two limitations restrict its further development. First, it struggles to capture representative features relevant to the target domain, which impacts its ability to understand domain-related information. Second, it still faces a significant challenge in effectively discriminating between abnormality and normality, even after being trained on some anomalous samples, which limits its applicability in supervised settings [2, 6, 24, 46].
最近,ReContrast [17] 引入了对比学习 (contrastive learning, CL) 元素来优化其框架以适应不同的目标域,展现出良好的迁移能力。然而,其进一步发展受到两个限制。首先,它难以捕获与目标域相关的代表性特征,这影响了其理解领域相关信息的能力。其次,即使在训练了一些异常样本后,它仍然面临有效区分异常与正常的重大挑战,这限制了其在监督设置中的适用性 [2, 6, 24, 46]。
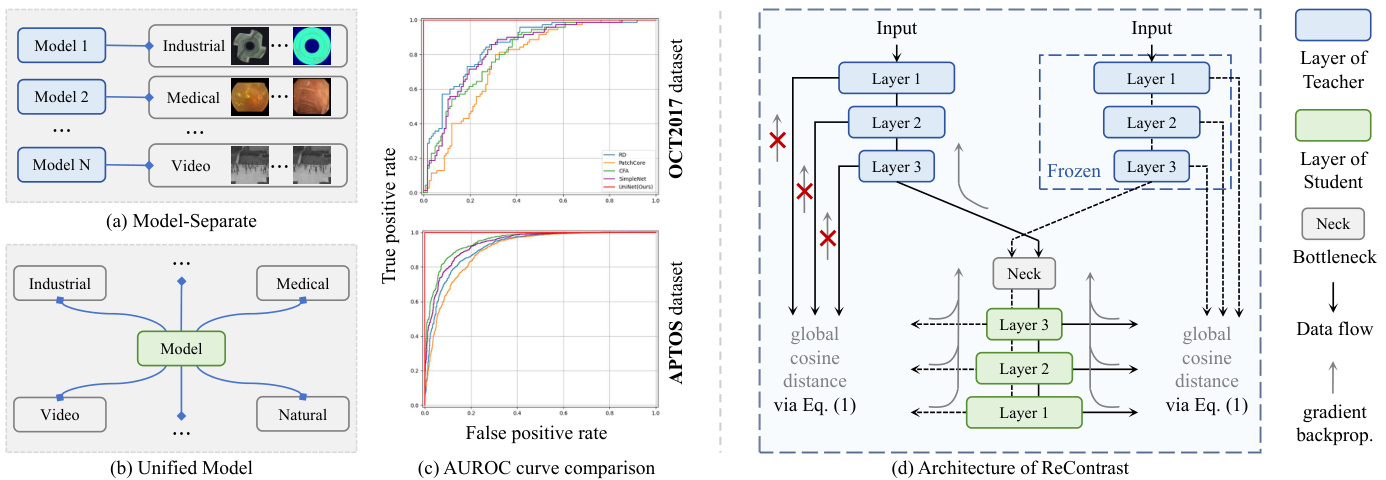
Figure 1. (a) One-model-one-domain setting. (b) One-model multi-domain setting. (c) AUROC curve comparison of UniNet and competing AD methods (reliance on pre-trained features) on medical datasets. (d) Architecture of ReContrast.
图 1: (a) 单模型单领域设置。 (b) 单模型多领域设置。 (c) UniNet与依赖预训练特征的竞争性异常检测方法在医学数据集上的AUROC曲线对比。 (d) ReContrast架构。
In respond to these problems, we propose a novel generic unified framework based on ReContrast, termed UniNet. It consists of student-teacher (S-T) models along with a bottleneck. Concretely, UniNet first develop a lightweightyet-powerful multi-scale embedding module (MEM) within the bottleneck to better capture the contextual relationships among features provided to the student. We then propose domain-related feature selection, a method that prompts the student to select crucial features from the teacher with prior knowledge to learn domain-related information. To effectively distinguish anomalies, a similarity-contrastive loss is first proposed to strengthen the correlations among homogeneous features. Followed this, a margin loss is developed to enhance the similarity of normal features, ensuring they are separated from anomalous ones with low similarity. Finally, considering the similarity between the outputs of S-T networks, we propose a weighted decision mechanism to adaptively calculate the anomaly score for improved AD performance. Notably, unlike ReContrast [17] that mainly focuses on unsupervised AD, our UniNet can be suited for unsupervised and supervised settings simultaneously. In summary, our contributions are as follows:
针对这些问题,我们提出了一种基于ReContrast的新型通用统一框架UniNet。该框架由师生(S-T)模型和瓶颈结构组成。具体而言,UniNet首先在瓶颈结构中开发了一个轻量级但强大的多尺度嵌入模块(MEM),以更好地捕获提供给学生的特征之间的上下文关系。接着我们提出领域相关特征选择方法,通过先验知识指导学生从教师模型中选择关键特征来学习领域相关信息。为有效区分异常,首次提出相似性对比损失来强化同类特征间的相关性;随后开发边界损失来增强正常特征的相似性,确保其与相似度较低的异常特征分离。最后,考虑到S-T网络输出的相似性,我们提出加权决策机制来自适应计算异常分数以提升异常检测(AD)性能。值得注意的是,与主要关注无监督AD的ReContrast [17]不同,我们的UniNet可同时适用于无监督和有监督场景。本文的主要贡献如下:
• This paper presents UniNet, a generic unified framework that can be oriented towards a wider range of domains, applicable to both unsupervised and supervised settings. • We design MEM to capture contextual information and propose domain-related feature selection to guide the student in selecting and learning target-oriented representative features from the teacher. • A similarity-contrastive loss is developed to enhance the relationships among homogeneous features and we then employ a margin loss to enhance the similarity of normal features for better anomaly discrimination. We implement a weighted decision mechanism to achieve superior AD performance during inference.
• 本文提出UniNet,一种面向更广泛领域的通用统一框架,适用于无监督和有监督场景。
• 我们设计MEM (Contextual Information Capture Module) 来捕获上下文信息,并提出领域相关特征选择机制,指导学生从教师网络中选择和学习目标导向的代表性特征。
• 开发了相似性对比损失函数以增强同类特征间的关系,并采用边界损失提升正常特征的相似性以实现更好的异常判别。推理阶段通过加权决策机制实现卓越的异常检测(AD)性能。
• Large-scale experiments conducted on 11 datasets from industrial, medical and video domains manifest that UniNet achieves superior results across different metrics.
• 在来自工业、医疗和视频领域的11个数据集上进行的大规模实验表明,UniNet在不同指标上均取得了优异结果。
2. Related work
2. 相关工作
Unsupervised methods. Unsupervised AD methods rely solely on available anomaly-free samples to learn their distribution due to the scarcity of anomalous data. Conse- quently, numerous promising methods [17, 25, 33, 39, 41, 47, 50, 58] have been continuously proposed. AST [41] employs an asymmetric S-T framework, minimizing the distance between their outputs to identify anomalies with large deviations. THF [25] proposes a new flow-based method that prevents the overlap of distribution between normal and anomalous features. Other attempts explore the use of memory banks to store additional normal prototypes to effectively detect anomalies, such as PatchCore [40] and MemKD [16]. The aforementioned methods are typically classified as one-class AD methods, as they train a separate model for each class. Recently, some efforts [17, 18, 53] have shifted toward multi-class AD, aiming to use one unified model to detect anomalies across different classes concurrently. UniAD [53] pioneers this approach, solving the problem that a growing number of training categories often leads to increased computational time. MambaAD [18] further advances this idea by exploring state space models, achieving outstanding performance while maintaining low complexity and computational overheads.
无监督方法。由于异常数据稀缺,无监督异常检测(AD)方法仅依赖可用的正常样本来学习其分布。因此,不断涌现出许多有前景的方法[17,25,33,39,41,47,50,58]。AST[41]采用非对称S-T框架,通过最小化输出间距来识别具有较大偏差的异常。THF[25]提出了一种新的基于流(flow-based)的方法,防止正常与异常特征分布重叠。其他尝试则探索使用记忆库存储额外正常原型以有效检测异常,例如PatchCore[40]和MemKD[16]。上述方法通常被归类为一类异常检测方法,因为它们为每个类别训练独立模型。最近,一些研究[17,18,53]转向多类异常检测,旨在使用统一模型同时检测不同类别的异常。UniAD[53]开创了这一方向,解决了训练类别增长导致计算时间增加的问题。MambaAD[18]通过探索状态空间模型进一步推进该理念,在保持低复杂度和计算开销的同时实现了卓越性能。
Supervised methods. Unlike unsupervised AD methods, supervised AD approaches can train a model on anomalous samples, thereby improving the accuracy of class boundaries [42]. DevNet [38] utilizes some labeled anomalous samples and prior probabilities to enforce that the anomaly scores of the anomalous samples significantly deviate from those of the normal samples in the upper tail. FCDD [34] employs a fully convolutional neural network architecture to map normal samples towards the center of the feature space, effectively distancing anomalous samples from this central region. DRA [14] generalizes to unknown anomalies by learning disentangled anomalous representations for different types of anomalies. Due to the scarcity of available supervised datasets, these methods are primarily trained on the widely used MVTec AD dataset [4], where the labeled anomalous samples are generally derived from the test set. However, they still face challenge in having adequate anomalous samples. Consequently, they often employ anomaly synthesis strategy [29, 43, 55] to generate anomalous samples, but these anomalies hardly conform to the real-world anomaly distribution. To tackle the issue of limited supervised datasets, Baitieva et al. [2] recently introduced a new industrial supervised AD benchmark, which features a wider array of complex anomalies and substantial intra-class variability among anomalous-free images. Given that conventional AD methods struggle with this benchmark, they further incorporated a segmentation-based anomaly detector to enhance AD performance.
监督方法。与无监督异常检测 (AD) 方法不同,监督式异常检测方法可利用异常样本训练模型,从而提升类别边界精度 [42]。DevNet [38] 利用标记异常样本和先验概率,强制使异常样本的异常分数显著偏离正常样本的上尾分布。FCDD [34] 采用全卷积神经网络架构,将正常样本映射至特征空间中心区域,同时使异常样本远离该中心。DRA [14] 通过学习不同异常类型的解耦表征,实现对未知异常的泛化检测。由于可用监督数据集稀缺,这些方法主要在广泛使用的 MVTec AD 数据集 [4] 上训练,其中标记异常样本通常来自测试集。但它们仍面临异常样本不足的挑战,因此常采用异常合成策略 [29, 43, 55] 生成异常样本,但这些合成异常往往不符合真实异常分布。为解决监督数据有限的问题,Baitieva 等人 [2] 近期提出了新型工业监督异常检测基准,其特点是包含更复杂的异常类型,且正常图像存在显著的类内差异。鉴于传统异常检测方法在该基准上表现不佳,研究者进一步引入基于分割的异常检测器以提升性能。
In this paper, our work seeks to develop a unified solution for AD across different domains, in contrast to most current mainstream methods, which design separate models for domain-specific AD.
本文旨在开发一种适用于不同领域的统一异常检测(AD)解决方案,这与当前主流方法形成鲜明对比——现有方法通常为特定领域设计独立模型。
3. Preliminaries
3. 预备知识
The prototype of ReContrast [17] is composed of a pretrained teacher model, a bottleneck, and a learnable student model. ReContrast aims to optimize the entire framework to the target domain through CL elements. Let $F_{T}^{i},F_{S}^{i}\in$ $\mathbb{R}^{C_{i}\times H_{i}\times\bar{W}{i}}$ respectively represent the output of $i^{t h}$ layer of the teacher and student models, where $C_{i},H_{i}$ , and $W_{i}$ are the channels, height, width of the corresponding output. To optimize the student model, ReContrast first proposes global cosine distance to better maintain global consistency between feature points and avoid instability during training:
ReContrast [17] 的原型由一个预训练的教师模型、一个瓶颈层和一个可学习的学生模型组成。ReContrast 旨在通过对比学习 (Contrastive Learning, CL) 元素将整个框架优化到目标域。设 $F_{T}^{i},F_{S}^{i}\in$ $\mathbb{R}^{C_{i}\times H_{i}\times\bar{W}{i}}$ 分别表示教师模型和学生模型第 $i^{t h}$ 层的输出,其中 $C_{i},H_{i}$ 和 $W_{i}$ 是对应输出的通道数、高度和宽度。为了优化学生模型,ReContrast 首先提出全局余弦距离,以更好地保持特征点之间的全局一致性,并避免训练过程中的不稳定性:
$$
\mathcal{L}{g}=\sum_{i=1}^{n}d(F_{T}^{i},F_{S}^{i})=\sum_{i=1}^{n}1-\frac{\mathcal{F}(F_{T}^{i})^{\top}}{\big|\mathcal{F}(F_{T}^{i})\big|}\cdot\frac{\mathcal{F}(F_{S}^{i})}{\big|\mathcal{F}(F_{S}^{i})\big|},
$$
$$
\mathcal{L}{g}=\sum_{i=1}^{n}d(F_{T}^{i},F_{S}^{i})=\sum_{i=1}^{n}1-\frac{\mathcal{F}(F_{T}^{i})^{\top}}{\big|\mathcal{F}(F_{T}^{i})\big|}\cdot\frac{\mathcal{F}(F_{S}^{i})}{\big|\mathcal{F}(F_{S}^{i})\big|},
$$
where $n$ represents the number of layers, $d(:,:)$ is the cosine distance, $\left\Vert\cdot\right\Vert$ is $\ell_{2}$ norm, and $\mathcal{F}(\cdot){\mathrm{:}}\mathbb{R}^{C\times H\times W}\rightarrow\mathbb{R}^{C H W}$ denotes a flattening operation. Subsequently, ReContrast optimizes the pre-trained teacher model to adapt it to the target domain. However, prior works suggested that this would result in pattern collapse. Inspired by CL for selfsupervised learning [8], the stop gradient operation is introduced to mitigate pattern collapse by modifying Eq. (1):
其中 $n$ 表示层数,$d(:,:)$ 为余弦距离,$\left\Vert\cdot\right\Vert$ 是 $\ell_{2}$ 范数,$\mathcal{F}(\cdot){\mathrm{:}}\mathbb{R}^{C\times H\times W}\rightarrow\mathbb{R}^{C H W}$ 表示展平操作。随后,ReContrast 通过优化预训练教师模型使其适应目标域。但先前研究表明这会导致模式坍塌 [8]。受自监督学习中对比学习 (CL) 的启发,我们引入停止梯度操作来缓解模式坍塌,并将公式 (1) 修改为:
$$
\mathcal{L}{g}=\sum_{i=1}^{n}1-\frac{\mathrm{SG}(\mathcal{F}(F_{T}^{i}))^{\top}}{\left|\mathrm{SG}(\mathcal{F}(F_{T}^{i}))\right|}\cdot\frac{\mathcal{F}(F_{S}^{i})}{\left|\mathcal{F}(F_{S}^{i})\right|},
$$
$$
\mathcal{L}{g}=\sum_{i=1}^{n}1-\frac{\mathrm{SG}(\mathcal{F}(F_{T}^{i}))^{\top}}{\left|\mathrm{SG}(\mathcal{F}(F_{T}^{i}))\right|}\cdot\frac{\mathcal{F}(F_{S}^{i})}{\left|\mathcal{F}(F_{S}^{i})\right|},
$$
where $\mathrm{SG}(\cdot)$ is the stop gradient operation. To prevent “identical shortcut” caused by no contrastive pairs, ReContrast introduces an additional frozen teacher model without any optimization during training. In this way, two teacher models can produce two views from one image, i.e., a target domain view and a source domain view, to achieve image augmentations, similar to a CL paradigm (see Fig. 1(d)).
其中 $\mathrm{SG}(\cdot)$ 是停止梯度操作。为避免因缺少对比对而导致的"相同捷径"问题,ReContrast引入了一个额外的冻结教师模型,在训练期间不进行任何优化。这样,两个教师模型可以从一张图像生成两种视图,即目标域视图和源域视图,以实现图像增强,类似于CL范式(见图1(d))。
4. Methodology
4. 方法论
4.1. Approach overview
4.1. 方法概述
With inspiration from ReContrast [17], this paper proposes UniNet, a generic unified framework for different domains, as illustrated in Fig. 2. The goal of UniNet is to optimize the entire framework towards the target domain, while enabling domain-relevant feature selection and learning, along with effective anomaly discrimination.
受ReContrast [17]启发,本文提出了UniNet这一适用于不同领域的通用统一框架,如图 2 所示。UniNet的目标是针对目标领域优化整个框架,同时实现领域相关特征的选择与学习,以及有效的异常判别。
To capture the contextual relationships among features, UniNet first develops a lightweight-yet-effective MEM within the bottleneck (Sec. 4.2). Then, we propose domainrelated feature selection, guiding the student to select targetoriented features from the teacher with prior knowledge and prompting its learning (Sec. 4.3). Besides, a similaritycontrastive loss is proposed to enhance the correlations among homogeneous features, followed by the development of a margin loss to preserve the distinction between the similarities of normal and anomalous features, thereby enhancing disc rim inability (Sec. 4.4). Based on the similarity between the outputs of S-T network, a weighted decision mechanism is proposed to achieve robust AD performance during inference (Sec. 4.5).
为捕捉特征间的上下文关系,UniNet首先在瓶颈层开发了轻量高效的MEM模块(见第4.2节)。随后,我们提出基于先验知识的领域相关特征选择方法,指导学生网络从教师网络中筛选目标导向特征以促进学习(见第4.3节)。此外,通过设计相似性对比损失来增强同质特征间的关联性,并引入边界损失以保持正常特征与异常特征相似度的区分度,从而提升判别能力(见第4.4节)。基于师生网络输出的相似性,我们提出加权决策机制以实现推理阶段稳健的异常检测性能(见第4.5节)。
4.2. Multi-Scale Embedding Module
4.2. 多尺度嵌入模块
Motivation. Some prior approaches [12, 25] struggle to capture the contextual relationships among features, impeding enhancement in feature correlations and redundancy reduction. These methods typically employ a set of small kernels to mitigate increased computational overheads, but recent research [15] has demonstrated that fittingly using a few larger kernels can be helpful for vision tasks. Propelled by this insight, we design a simple yet powerful Multi-Scale Embedding Module (MEM) within the bottleneck for feature extraction across various contexts while maintaining low memory consumption, as visualized in Fig. 2.
动机。现有方法[12, 25]难以捕捉特征间的上下文关联,阻碍了特征相关性增强与冗余降低。这些方法通常采用一组小卷积核来缓解计算开销增长,但近期研究[15]表明,合理使用少量大卷积核反而有利于视觉任务。受此启发,我们在瓶颈层设计了一个简洁高效的多尺度嵌入模块(Multi-Scale Embedding Module, MEM),可在低内存消耗下提取多上下文特征,如图2所示。
Module design. Considering the multi-scale features, we first split the input as two parts along the channel dimensions, with two different size of kernels to capture global and local information, thus enriching the contextual relationships among features. These two parts are respectively fed into a $k\times k$ (where $k$ is 3 or 7) kernel convolution layer, followed by a batch normalization (BN) layer and a ReLU activation (ReLU). Similarly, they are further fed into a $k\times k$ kernel convolution layer and a BN layer to enhance feature extraction. Then, these two parts are concatenated to compress channel dimensions by a $1\times1$ kernel convolution layer and a BN layer. Finally, to achieve better regular iz ation, a residual connection is conducted before ReLU.
模块设计。考虑到多尺度特征,我们首先沿通道维度将输入分为两部分,采用两种不同大小的卷积核来捕获全局和局部信息,从而丰富特征间的上下文关系。这两部分分别输入一个$k\times k$(其中$k$为3或7)的卷积核层,后接批量归一化(BN)层和ReLU激活函数(ReLU)。类似地,它们会进一步输入一个$k\times k$卷积核层和BN层以增强特征提取。随后,这两部分通过一个$1\times1$卷积核层和BN层进行通道维度压缩并拼接。最后,为实现更好的正则化效果,在ReLU前执行残差连接。
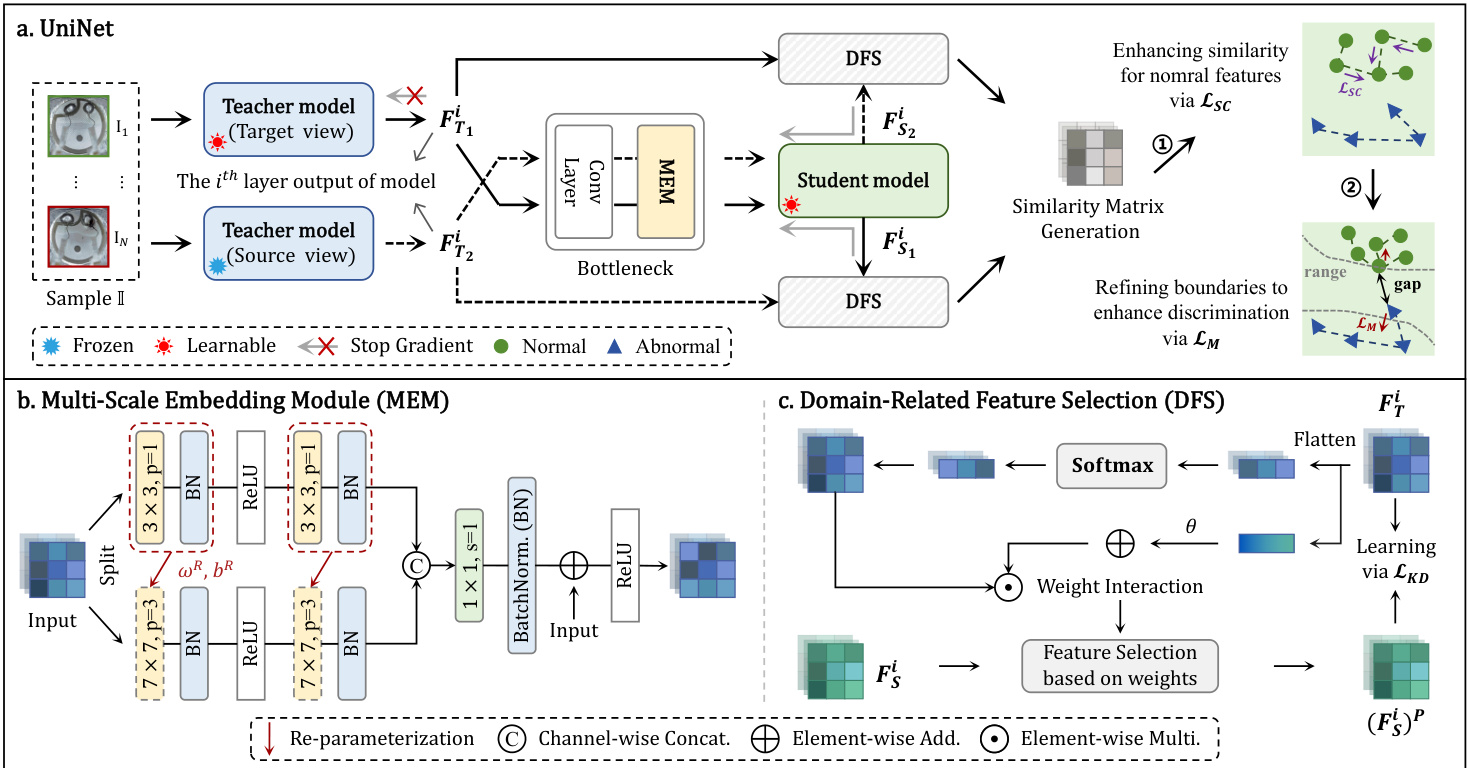
Figure 2. Overall framework of the proposed UniNet. It consists of a pair of teachers models, a bottleneck, and a student model, with several key components: MEM, DFS, Similarity-Contrastive loss $\mathcal{L}{S C}$ and Margin loss $\mathcal{L}_{M}$ .
图 2: 提出的UniNet整体框架。它由一对教师模型、一个瓶颈层和一个学生模型组成,包含几个关键组件:MEM、DFS、相似性对比损失 $\mathcal{L}{S C}$ 和边界损失 $\mathcal{L}_{M}$。
Due to the use of large kernels, the number of parameters and inference time would increase. To mitigate this, we reparameterized the large kernel convolutional layers through the small kernel convolutional layers and BN layers:
由于使用大核卷积,参数量和推理时间会增加。为缓解这一问题,我们通过小核卷积层和BN层对大型核卷积层进行重参数化:
$$
\omega^{R}=\omega\cdot\frac{\gamma}{\sqrt{\sigma^{2}+\epsilon}},b^{R}=b-\frac{\mu\cdot\gamma}{\sqrt{\sigma^{2}+\epsilon}},
$$
$$
\omega^{R}=\omega\cdot\frac{\gamma}{\sqrt{\sigma^{2}+\epsilon}},b^{R}=b-\frac{\mu\cdot\gamma}{\sqrt{\sigma^{2}+\epsilon}},
$$
where $\omega$ is the weight of small kernel convolutional layer, while $\omega^{R}$ and $b^{R}$ are the weight and bias of large kernel convolutional layer after re-parameter iz ation. $\mu,\sigma^{2},\gamma$ , and $b$ denote the mean, variance, weight, and bias of BN layers, respectively. $\epsilon$ is a small constant. In this way, $7\times7$ kernel convolution layers can be viewed as equivalent to $3\times3$ kernel convolution layers, thus decreasing computational costs.
其中 $\omega$ 是小核卷积层的权重,$\omega^{R}$ 和 $b^{R}$ 是重参数化后大核卷积层的权重和偏置。$\mu,\sigma^{2},\gamma$ 和 $b$ 分别表示 BN (Batch Normalization) 层的均值、方差、权重和偏置。$\epsilon$ 是一个小常数。通过这种方式,$7\times7$ 核卷积层可视为等效于 $3\times3$ 核卷积层,从而降低计算成本。
4.3. Domain-Related Feature Selection
4.3. 领域相关特征选择
Motivation. Despite its great transfer ability across different domains, ReContrast [17] still suffer from an insufficient capture of feature representations relevant to the target domain, resulting in the loss of crucial information. To solve this challenge, we propose Domain-Related Feature Selection (DFS), which encourages the student to selectively concentrate on target-oriented features from the teacher and well restore them, thereby avoiding the inclusion of unimportant information. Particularly, the student is required to learn only representative information pertaining to the target domain, rather than all available information.
动机。尽管ReContrast [17]在不同领域间展现出卓越的迁移能力,但其对目标领域相关特征表征的捕捉仍不充分,导致关键信息丢失。为解决这一挑战,我们提出领域相关特征选择(Domain-Related Feature Selection, DFS)方法,促使学生模型从教师模型中选择性聚焦目标导向特征并充分还原,从而避免引入无关信息。具体而言,学生模型仅需学习与目标域相关的代表性信息,而非全部可用信息。
Selection and learning. Introducing information from target-oriented domain into the student is crucial for enabling it to understand and generate the feature representations required for that domain. To achieve it, we utilize the weight to control how much representative information should be selected from the teacher with prior knowledge. Concretely, let the features from the teacher and student models be $F_{T}^{i},F_{S}^{i}\in\mathbb{R}^{C_{i}\times H_{i}\times W_{i}}$ , and the teacher feature is flattened to $\widehat{F}{T}^{i}\in\mathbb{R}^{C_{i}\times H_{i}W_{i}}$ . The weight can be generated as follows:
选择与学习。将目标领域的信息引入学生模型对于使其理解和生成该领域所需的特征表示至关重要。为此,我们利用权重来控制应从具备先验知识的教师模型中选择多少代表性信息。具体而言,设教师模型和学生模型的特征分别为 $F_{T}^{i},F_{S}^{i}\in\mathbb{R}^{C_{i}\times H_{i}\times W_{i}}$ ,并将教师特征展平为 $\widehat{F}{T}^{i}\in\mathbb{R}^{C_{i}\times H_{i}W_{i}}$ 。权重可按如下方式生成:
$$
w_{i}=\frac{\exp(\widehat{F}{T}^{i}-\varrho)}{\sum_{j=1}^{H_{i}W_{i}}\exp(\widehat{F}_{T}^{i}(:,j)-\varrho)},
$$
$$
w_{i}=\frac{\exp(\widehat{F}{T}^{i}-\varrho)}{\sum_{j=1}^{H_{i}W_{i}}\exp(\widehat{F}_{T}^{i}(:,j)-\varrho)},
$$
where $w_{i}\in\mathbb{R}^{C_{i}\times H_{i}W_{i}}$ and $\varrho=\operatorname*{max}(\widehat{F}_{T}^{i})$ . To avoid relying on local information only, we integ rbate global informa- tion to ensure weight interaction, enhancing aware ability.
其中 $w_{i}\in\mathbb{R}^{C_{i}\times H_{i}W_{i}}$ ,且 $\varrho=\operatorname*{max}(\widehat{F}_{T}^{i})$ 。为避免仅依赖局部信息,我们整合全局信息以确保权重交互,从而增强感知能力。
The global information $F_{i}^{g}$ can be obtained as follows:
全局信息 $F_{i}^{g}$ 可通过以下方式获取:
$$
F_{i}^{g}=\frac{1}{H_{i}\cdot W_{i}}\sum_{h=1}^{H_{i}}\sum_{w=1}^{W_{i}}F_{T}^{i}(:,h,w),
$$
$$
F_{i}^{g}=\frac{1}{H_{i}\cdot W_{i}}\sum_{h=1}^{H_{i}}\sum_{w=1}^{W_{i}}F_{T}^{i}(:,h,w),
$$
where $F_{i}^{g}\in\mathbb{R}^{C_{i}\times1\times1}$ . Let the weight $w_{i}$ be further reshaped to $(w_{i})^{R}\in\mathbb{R}^{C_{i}\times H_{i}\times W_{i}}$ . The interacted weight can be obtained through the fusion of global and local information, and the student can then select domain-related feature information based on the interacted weight to generate domain-related features $(F_{S_{i}})^{P}$ :
其中 $F_{i}^{g}\in\mathbb{R}^{C_{i}\times1\times1}$。将权重 $w_{i}$ 进一步重塑为 $(w_{i})^{R}\in\mathbb{R}^{C_{i}\times H_{i}\times W_{i}}$。通过全局和局部信息的融合可获得交互权重,学生网络随后可根据该交互权重选择与领域相关的特征信息,生成领域相关特征 $(F_{S_{i}})^{P}$:
$$
(F_{S}^{i})^{P}=F_{S}^{i}\odot{(w_{i})^{R}\odot(\theta+F_{i}^{g})},
$$
$$
(F_{S}^{i})^{P}=F_{S}^{i}\odot{(w_{i})^{R}\odot(\theta+F_{i}^{g})},
$$
where $\theta$ is a learnable parameter flexibly controlling the domain-related feature selection and $\odot$ represents elementwise multiplication. To ensure that the student effectively learns the prior knowledge, we aim to minimize the distance between its output and that of the teacher during training:
其中 $\theta$ 是可学习参数,用于灵活控制与领域相关的特征选择,$\odot$ 表示逐元素相乘。为确保学生模型有效学习先验知识,我们旨在训练期间最小化其输出与教师模型输出之间的距离:
$$
\mathcal{L}{K D}=\sum_{i=1}^{n}d(\mathrm{SG}(F_{T}^{i}),(F_{S}^{i})^{P}).
$$
$$
\mathcal{L}{K D}=\sum_{i=1}^{n}d(\mathrm{SG}(F_{T}^{i}),(F_{S}^{i})^{P}).
$$
4.4. Comparing similarity and enhancing discrimination
4.4. 相似性比较与区分度增强
Motivation. Most unsupervised methods [12, 17, 33, 40] may fail to establish class boundaries [38] due to the absence of anomalous samples. However, even when trained with some anomalous samples, these methods still face challenge in effectively discriminating anomalies, particularly unseen ones [14]. To overcome this limitation, we propose a similarity-contrastive loss and a margin loss. The similarity-contrastive loss is first employed to enhance the correlations among normal features, ensuring they remain tightly clustered. Yet, since anomalous features are not expected to exhibit high similarity to normal ones, this encourages a clear gap between them. Thus, we then use the margin loss to enforce a greater separation between their similarity, further enhancing the model’s discrimination ability.
动机。大多数无监督方法 [12, 17, 33, 40] 由于缺乏异常样本,可能无法有效建立类别边界 [38]。然而,即使使用部分异常样本进行训练,这些方法仍难以有效区分异常,尤其是未见过的异常 [14]。为突破这一局限,我们提出了相似性对比损失 (similarity-contrastive loss) 和边界损失 (margin loss)。首先采用相似性对比损失增强正常特征间的相关性,确保它们紧密聚集;同时由于异常特征不应与正常特征高度相似,这促使二者形成明显间隔。随后通过边界损失进一步扩大相似性差异,从而提升模型的判别能力。
Mechanism. The learned student feature $(F_{S}^{i})^{P}$ is flattened and reshaped to $(\widehat{F}{S}^{i})^{P}\in\mathbb{R}^{H_{i}W_{i}\times C_{i}}$ . The similarity matrix $m_{i}$ between the obutputs of S-T models is obtained:
机制。学习到的学生特征 $(F_{S}^{i})^{P}$ 被展平并重塑为 $(\widehat{F}{S}^{i})^{P}\in\mathbb{R}^{H_{i}W_{i}\times C_{i}}$。通过计算S-T模型输出之间的相似度矩阵 $m_{i}$ 得到:
$$
m_{i}=\frac{(\widehat{F}{S}^{i})^{P}\cdot(\widehat{F}{T}^{i})}{\left|(\widehat{F}{S}^{i})^{P}\right|\cdot\left|\widehat{F}_{T}^{i}\right|\cdot\mathcal{T}},
$$
$$
m_{i}=\frac{(\widehat{F}{S}^{i})^{P}\cdot(\widehat{F}{T}^{i})}{\left|(\widehat{F}{S}^{i})^{P}\right|\cdot\left|\widehat{F}_{T}^{i}\right|\cdot\mathcal{T}},
$$
where $\tau$ is a temperature parameter which controls the dis- tribution of similarity. With the similarity matrix, the normalized similarity matrix can be then obtained by:
其中 $\tau$ 是控制相似度分布的温度参数。通过相似度矩阵,归一化相似度矩阵可通过以下方式获得:
$$
\widehat{m}{i}=\frac{\exp(m_{i})}{\sum_{k=1}^{H_{i}W_{i}}\exp(m_{i}(:,k))+\epsilon}.
$$
$$
\widehat{m}{i}=\frac{\exp(m_{i})}{\sum_{k=1}^{H_{i}W_{i}}\exp(m_{i}(:,k))+\epsilon}.
$$
Each diagonal element of $\widehat{m}_{i}$ is the similarity between the features of S-T pairs. Tob strengthen the relationships among normal features within these pairs, we employ the similarity-contrastive loss to maximize their similarity:
$\widehat{m}_{i}$ 的每个对角元素表示 S-T 对特征之间的相似度。为了增强这些对中正常特征之间的关系,我们采用相似性对比损失 (similarity-contrastive loss) 来最大化它们的相似性:
$$
\mathcal{L}{S C}=-\frac{1}{n}\sum_{i=1}^{n}\sum_{j=1}^{N_{1}}\log(\mathrm{{diag}}((\widehat{m}{i})_{j})+\epsilon),
$$
$$
\mathcal{L}{S C}=-\frac{1}{n}\sum_{i=1}^{n}\sum_{j=1}^{N_{1}}\log(\mathrm{{diag}}((\widehat{m}{i})_{j})+\epsilon),
$$
where $N_{1}(N_{1}\leq N)$ is the number of normal samples and diag $(\cdot)$ is the operation of selecting diagonal elements.
其中 $N_{1}(N_{1}\leq N)$ 是正常样本的数量,diag $(\cdot)$ 是选择对角线元素的操作。
where $\tau$ is a hyper-parameter controlling the boundary. In this way, homogeneous features can be grouped together.
其中 $\tau$ 是控制边界的超参数。通过这种方式,同质特征可以被分组在一起。
During training, the overall losses are measured as:
训练期间,总体损失计算为:
$$
\mathcal{L}{U}=\lambda\mathcal{L}{K D}+(1-\lambda)\mathcal{L}{S C}+\mathcal{L}_{M},
$$
$$
\mathcal{L}{U}=\lambda\mathcal{L}{K D}+(1-\lambda)\mathcal{L}{S C}+\mathcal{L}_{M},
$$
where $\lambda$ is a balancing hyper-parameter. In supervised settings, Eq.(12) can be modified based on its task:
其中 $\lambda$ 是一个平衡超参数。在有监督的设置中,方程 (12) 可以根据其任务进行修改:
$$
\mathcal{L}=\mathcal{L}{U}+\sum_{i=1}^{n-1}\mathcal{L}{S}(\Phi(F_{S}^{i}),l),
$$
$$
\mathcal{L}=\mathcal{L}{U}+\sum_{i=1}^{n-1}\mathcal{L}{S}(\Phi(F_{S}^{i}),l),
$$
where $\mathcal{L}_{S}(:,:)$ denotes a Binary Cross-Entropy loss or a Dice loss, $\Phi(\cdot)$ is a flattening or upsampling operation, and $l$ is a label or a ground-truth mask.
其中 $\mathcal{L}_{S}(:,:)$ 表示二元交叉熵损失 (Binary Cross-Entropy loss) 或 Dice 损失 (Dice loss),$\Phi(\cdot)$ 为展平或上采样操作,$l$ 为标签或真实掩码。
4.5. Anomaly detection
4.5. 异常检测
Motivation. Some efforts [22, 38] use top $K$ or top-ranked values from the anomaly map to evaluate the anomaly score. Nevertheless, they rely on a fixed value (e.g., $K=3%$ ) for score calculation, which does not ensure robust AD. To remedy this, we propose a weighted decision mechanism that dynamically calculates image-level anomaly score for each sample, where anomaly score is determined by weight.
动机。一些研究[22, 38]采用异常图中前 $K$ 个或最高排名的值来评估异常分数。然而,它们依赖固定值(如 $K=3%$)进行分数计算,这无法确保稳健的异常检测(AD)。为此,我们提出一种加权决策机制,动态计算每个样本的图像级异常分数,其中异常分数由权重决定。
Weighted decision mechanism. Formally, we begin with obtaining the pixel-level anomaly map for each sample. With a pair of teacher models and one student model, two anomaly maps can be generated from each layer by $d(\cdot)$ in Eq. (1), with in total of $2n$ anomaly maps. Then, we obtain $2n$ low similarity values by taking the maximum value in each anomaly map. These low similarity values are further transformed into a probability distribution $\mathcal{N}$ via a Softmax activation. The values from $\mathcal{N}$ higher than the average of $\mathcal{N}$ are added to a set $\mathcal{P}$ to dynamically calculate the weight. The weight is defined as follows:
加权决策机制。具体而言,我们首先获取每个样本的像素级异常图。通过一对教师模型和一个学生模型,可利用公式(1)中的 $d(\cdot)$ 从每层生成两张异常图,共计 $2n$ 张异常图。随后,通过提取每张异常图中的最大值,得到 $2n$ 个低相似度值。这些低相似度值通过Softmax激活函数转换为概率分布 $\mathcal{N}$ ,将 $\mathcal{N}$ 中高于其均值的数值加入集合 $\mathcal{P}$ 以动态计算权重。权重定义如下:
(a) MVTec AD
(a) MVTec AD
| 方法 | I-AUROC | P-AUROC | PRO |
|---|---|---|---|
| RD++ [47] | 99.44 | 98.25 | 94.99 |
| DMAD [32] | 99.50 | 98.21 | — |
| GLAD [52] | 99.30 | 98.62 | 95.31 |
| ReConPacth [23] | 99.56 | 98.18 | — |
| RealNet [57] | 99.65 | 99.03 | 93.07 |
| ReContrast [17] | 99.46 | 98.41 | 95.20 |
| UniNet (Ours) | 99.90 | 98.81 | 96.00 |
(b) BTAD (c) MVTec 3D-AD
(b) BTAD (c) MVTec 3D-AD
| 方法 | I-AUROC | PRO |
|---|---|---|
| PatchCore[40] | 81.14 | 91.03 |
| AST [41] | 88.00 | — |
| M3DM[50] | 85.03 | 94.22 |
| Shape-Guided[9] | 81.51 | 93.30 |
| BTF [20] | 78.52 | 87.63 |
| ReContrast[17] | 88.63 | 95.20 |
| UniNet(我们的方法) | 95.76 | 95.55 |
Table 1. Quantitative results on industrial datasets, including (a) MVTec AD, (b) BTAD, and (c) MVTec 3D-AD. We report the Image-level AUROC (I-AUROC), Pixel-level AUROC (P-AUROC), and PRO. Best and second-best results are highlighted in red and blue, respectively.
表 1: 工业数据集上的定量结果,包括 (a) MVTec AD, (b) BTAD, 和 (c) MVTec 3D-AD。我们报告了图像级AUROC (I-AUROC)、像素级AUROC (P-AUROC) 和 PRO。最佳和次佳结果分别用红色和蓝色标出。
| 方法 | I-AUROC | P-AUROC |
|---|---|---|
| PatchCore[40] | 93.13 | 97.27 |
| RD++ [47] | 95.63 | 97.41 |
| PyramidFlow[28] | 95.83 | 97.70 |
| ReConPacth[23] | 95.80 | 97.47 |
| RealNet[57] | 96.07 | 97.90 |
| ReContrast[17] | 95.06 | 97.50 |
| UniNet(Ours) | 97.73 | 97.70 |
$$
v_{w}=\operatorname*{max}{\alpha(\frac{1}{L}\sum_{p_{j}\in\mathcal{P}}^{L}p_{j}),\beta}
$$
$$
v_{w}=\operatorname*{max}{\alpha(\frac{1}{L}\sum_{p_{j}\in\mathcal{P}}^{L}p_{j}),\beta}
$$
where $\mathcal{P}={p_{j}}{j=1}^{L}$ contains $L$ high probability values and $L\in[n-1,n+\bar{1}]$ . $\alpha$ controls its upper limit and $\beta$ decides the lower limit. After obtaining weight, $2n$ anomaly maps are upsampled and accumulated to form the final pixel-level anomaly map $M_{A S}$ . Finally, our method adaptively selects the largest $v_{w}$ values from $M_{A S}$ and averages them to obtain the final image-level anomaly score for AD. More details can be found in Appendix.
其中 $\mathcal{P}={p_{j}}{j=1}^{L}$ 包含 $L$ 个高概率值,且 $L\in[n-1,n+\bar{1}]$。$\alpha$ 控制其上限,$\beta$ 决定下限。获得权重后,将 $2n$ 个异常图上采样并累积,形成最终的像素级异常图 $M_{A S}$。最后,我们的方法自适应地从 $M_{A S}$ 中选取最大的 $v_{w}$ 个值并取平均,得到用于异常检测 (AD) 的最终图像级异常分数。更多细节见附录。
For the segmentation task, the anomaly map $M_{A S}$ is employed, where higher values in it indicate the presence of anomalies at that corresponding positions.
在分割任务中,使用异常图 $M_{A S}$,其中数值较高的位置表示该处存在异常。
5. Experiments
5. 实验
5.1. Experimental setup
5.1. 实验设置
Datasets. To demonstrate the superiority of UniNet, extensive experiments were conducted across 11 datasets from various domains, including industrial defect inspection, medical imaging analysis, and video surveillance. In industrial AD, we considered three unsupervised benchmarks (MVTec AD [4], BTAD [36], and MVTec AD-3D [5]) and one recently published supervised benchmark, VAD [2]. For medical diagnosis, we utilized three unsupervised datasets (APTOS [45], OCT2017 [26], and ISIC2018 [11]) alongside three supervised datasets (Kvasir [24], CVCClinicDB [6], and CVC-ColonDB [46]). In video surveillance, we considered one popular unsupervised dataset, Ped2 [30]. Further details can be found in Appendix.
数据集。为证明UniNet的优越性,我们在工业缺陷检测、医学影像分析和视频监控等领域的11个数据集上进行了广泛实验。在工业异常检测(AD)领域,我们采用了三个无监督基准(MVTec AD [4]、BTAD [36]和MVTec AD-3D [5])以及一个新近发布的有监督基准VAD [2]。针对医学诊断,我们使用了三个无监督数据集(APTOS [45]、OCT2017 [26]和ISIC2018 [11])和三个有监督数据集(Kvasir [24]、CVCClinicDB [6]和CVC-ColonDB [46])。在视频监控方面,我们选用了一个流行的无监督数据集Ped2 [30]。更多细节详见附录。
Evaluation metrics. Following [2, 17, 37, 50, 51, 57], appropriate metrics are selected for each task. The imagelevel Area Under the Receiver Characteristic Curve (AUROC) and Average precision (AP) are employed to evaluate AD performance. For anomaly segmentation, both the pixel-level AUROC and Per-Region Overlap (PRO) are used. In medical datasets, F1-score (F1) and accuracy (ACC) are used for AD, while Dice Similarity Coefficient (DSC) and mean Intersection over Union (mIoU) are applied for anomaly segmentation.
评估指标。参照 [2, 17, 37, 50, 51, 57],为每项任务选择合适的指标。图像级别的受试者工作特征曲线下面积 (AUROC) 和平均精度 (AP) 用于评估异常检测 (AD) 性能。对于异常分割,则同时采用像素级 AUROC 和区域重叠度 (PRO)。在医学数据集中,异常检测使用 F1分数 (F1) 和准确率 (ACC),而异常分割采用戴斯相似系数 (DSC) 和平均交并比 (mIoU)。

Figure 3. Qualitative results of UniNet on MVTec AD dataset. Each group from left to right: the anomalous images, our segmentation results, and ground-truths.
图 3: UniNet 在 MVTec AD 数据集上的定性结果。每组从左到右依次为:异常图像、我们的分割结果和真实标注。
Implementation details. Following [12, 17], we used the publicly available Wide Res Net 50 as backbone in S-T models. AdamW [35] was employed as the optimizer with a learning rate of 5e-3 and 1e-6 for the learnable student and teacher, respectively. The batch size was 8. All images were resized into $256\times256$ . For MVTec 3D-AD dataset, only RGB data were used for training. Hyper-parameters $n$ , ${\mathcal{T}},\tau,\lambda,\alpha$ , and $\beta$ were set to 3, 2, 1, 0.7, 0.01, and 0.03, respectively. More details can be found in Appendix.
实现细节。遵循[12, 17],我们在S-T模型中采用公开可用的Wide Res Net 50作为主干网络。使用AdamW[35]作为优化器,可学习学生模型和教师模型的学习率分别设为5e-3和1e-6。批处理大小为8。所有图像均调整至$256\times256$分辨率。对于MVTec 3D-AD数据集,仅使用RGB数据进行训练。超参数$n$、${\mathcal{T}},\tau,\lambda,\alpha$和$\beta$分别设为3、2、1、0.7、0.01和0.03。更多细节见附录。
5.2. Comparison with state-of-the-art methods
5.2. 与先进方法的对比
We compared UniNet against the state-of-the-art (SOTA) methods on each dataset, selecting ReContrast [17] as baseline model. Further details can be found in Appendix.
我们在每个数据集上将UniNet与最先进(SOTA)方法进行对比,选择ReContrast [17]作为基线模型。更多细节详见附录。
5.2.1. Results under the unsupervised setting
5.2.1. 无监督设置下的结果
MVTec AD. Five leading methods were considered: RealNet [57], ReConPatch [23], GLAD [52], DMAD [32], and $\scriptstyle\mathrm{RD}++$ [47]. The comparison results are presented in Table 1(a). UniNet achieves superior performance across multiple metrics, except for the pixel-level AUROC slightly lower than that of RealNet by $0.22%$ . UniNet yields the significant results in terms of both image-level AUROC and pixel
MVTec AD。我们比较了五种主流方法:RealNet [57]、ReConPatch [23]、GLAD [52]、DMAD [32] 和 $\scriptstyle\mathrm{RD}++$ [47]。对比结果如表 1(a) 所示。UniNet 在多数指标上表现优异,仅在像素级 AUROC 上略低于 RealNet ($0.22%$)。该模型在图像级 AUROC 和像素级指标上均取得显著提升。
(a) Medical anomaly detection
(a) 医学异常检测
| 方法← | I-AUROC | F1 | ACC | I-AUROC | F1 | ACC | I-AUROC | F1 | ACC |
|---|---|---|---|---|---|---|---|---|---|
| RD4AD [12] | 92.43 | 90.65 | 86.44 | 99.25 | 97.79 | 96.70 | 85.09 | 74.53 | 78.76 |
| PatchCore[40] | 90.45 | 90.18 | 85.57 | 99.61 | 98.34 | 97.50 | 78.94 | 68.57 | 71.50 |
| AE-flow[58] | 98.15 | 96.36 | 94.42 | 87.79 | 80.56 | 84.97 | |||
| CFA [27] | 94.21 | 94.39 | 92.03 | 98.01 | 96.40 | 94.70 | 81.31 | 72.31 | 74.61 |
| SimpleNet[33] | 93.42 | 91.16 | 87.27 | 98.50 | 96.91 | 95.40 | 82.17 | 69.82 | 73.59 |
| ReContrast[17] | 97.51 | 95.27 | 93.35 | 99.60 | 98.53 | 97.80 | 90.15 | 81.12 | 86.01 |
| UniNet(Ours) | 100.0 | 99.60 | 99.44 | 100.0 | 99.60 | 99.40 | 100.0 | 100.0 | 100.0 |
(b) Video anomaly detection Table 3. Quantitative results on three medical datasets (Kvasir, CVC-ClinicDB, and CVC-ColonDB) and one industrial dataset (VAD). For the medical datasets, we report the DSC and mIOS metrics, while for the VAD dataset, we provide the I-AUROC, F1, and ACC. The values in parentheses indicate results after using SegAD [2]. Best and second-best results are highlighted in red and blue, respectively.
(b) 视频异常检测
表 3. 三个医学数据集 (Kvasir、CVC-ClinicDB 和 CVC-ColonDB) 和一个工业数据集 (VAD) 的定量结果。对于医学数据集,我们报告了 DSC 和 mIOS 指标,而对于 VAD 数据集,我们提供了 I-AUROC、F1 和 ACC。括号中的值表示使用 SegAD [2] 后的结果。最佳和次佳结果分别用红色和蓝色标出。
| 方法 | I-AUROC |
|---|---|
| zx VAD [1] | 96.9 |
| SLM [44] | 97.6 |
| PDM-Net [21] | 97.7 |
| Ristea et al. [39] | 95.4 |
| AnomalyRuler [51] | 97.9 |
| ReContrast [17] | 95.2 |
| UniNet (Ours) | 97.9 |
Table 2. Quantitative results on three medical datasets (APTOS, OCT2017, and ISIC2018) and one video dataset (VAD). We report the I-AUROC, F1, and ACC. Best and second-best results are highlighted in red and blue, respectively.
表 2: 三个医学数据集 (APTOS、OCT2017 和 ISIC2018) 和一个视频数据集 (VAD) 的量化结果。我们报告了 I-AUROC、F1 和 ACC 指标,最优和次优结果分别用红色和蓝色标出。
(a) Industrial anomaly detection (b) Medical anomaly detection
(a) 工业异常检测
(b) 医疗异常检测
| 数据集→ | VAD | | | 数据集→ | Kvasir | | CVC-ClinicDB | | CVC-ColonDB | |
| 方法√ | I-AUROC | F1 | ACC | 方法 | DSC | mIOU | DSC | mIOU | DSC | mIOU |
| DevNet[38] | 87.00 | 80.05 | 84.53 | KDAS [49] | 91.3 | 84.8 | 92.5 | 87.2 | 91.2 | 83.3 |
| DRA [14] | 87.53 | 80.46 | 84.87 | HarDNet-CPS[54] | 91.1 | 85.6 | 91.7 | 88.7 | 91.0 | 83.6 |
| RD4AD [12] | 87.40(90.23) | 80.33 | 84.56 | SAM-EG[48] | 91.5 | 86.2 | 93.1 | 87.9 | 91.5 | 84.3 |
| PatchCore[40] | 88.52(91.70) | 81.43 | 85.12 | MEGANet[7] | 91.3 | 86.3 | 93.8 | 89.4 | | |
| EfficientAD[3] | 88.01(91.75) | 81.55 | 85.31 | MADGNet[37] | 90.7 | 85.3 | 93.9 | 89.5 | | |
| ReContrast[17] | 84.52(88.31) | 74.03 | 78.23 | ReContrast[17] | 87.3 | 80.5 | 90.3 | 84.0 | 87.3 | 79.2 |
| UniNet(我们的) | 99.95 | 98.60 | 98.60 | UniNet(我们的) | 91.5 | 85.7 | 94.2 | 89.5 | 91.9 | 85.6 |
level PRO compared to SOTA methods, particularly excelling in image-level AUROC with an average of $99.90%$ . Our UniNet improves the baseline model by $0.44%$ and $0.40%$ AUROC, and $0.80%$ PRO. Besides, the anomalous regions segmented by UniNet are identical to ground-truths, as shown in Fig. 3. We also evaluated UniNet under the multi-class AD setting, with results provided in Appendix.
与现有最优方法 (SOTA) 相比,我们的 PRO 级别表现尤为突出,图像级 AUROC 平均值达到 $99.90%$。UniNet 将基线模型的 AUROC 提升了 $0.44%$ 和 $0.40%$,PRO 提升了 $0.80%$。此外,如图 3 所示,UniNet 分割的异常区域与真实标注完全一致。我们还在多类别异常检测 (AD) 设置下评估了 UniNet,相关结果见附录。
BTAD. We compared UniNet with five SOTA methods: ReConPatch [23], RealNet [57], Pyramid Flow [28], $\mathrm{RD}{+}{+}$ [47], and PatchCore [40]. As shown in Table 1(b), UniNet surpasses all methods in terms of image-level AUROC, outperforming the recent two top methods, RealNet and ReConPatch, by a large margin of $1.66%$ and $1.93%$ , respectively. Meanwhile, UniNet achieves comparable segmentation performance compared to RealNet. Besides, UniNet improves the baseline by both $2.67%$ and $0.20%$ AUROC.
BTAD。我们将UniNet与五种SOTA方法进行了比较:ReConPatch [23]、RealNet [57]、Pyramid Flow [28]、$\mathrm{RD}{+}{+}$[47]和PatchCore [40]。如表1(b)所示,UniNet在图像级AUROC指标上超越了所有方法,分别以$1.66%$和$1.93%$的显著优势领先于近期两种顶级方法RealNet和ReConPatch。同时,UniNet的分割性能与RealNet相当。此外,UniNet将基线AUROC分别提升了$2.67%$和$0.20%$。
MTVec 3D-AD. We also evaluated UniNet on a more challenging 3D dataset and compared it with SOTA methods, including M3DM [50], AST [41], Shape-Guided [9], BTF [20], and PatchCore [40]. Table 1(c) shows the comparison results. Despite only RGB data used, UniNet still achieves $95.76%$ image-level AUROC, surpassing other methods and the baseline model by significant gains of $7.76%$ and $7.13%$ , respectively. Additionally, UniNet also enhances PRO metric compared to competing methods.
MTVec 3D-AD。我们还在更具挑战性的3D数据集上评估了UniNet,并与包括M3DM [50]、AST [41]、Shape-Guided [9]、BTF [20]和PatchCore [40]在内的SOTA方法进行了比较。表1(c)展示了对比结果。尽管仅使用RGB数据,UniNet仍实现了95.76%的图像级AUROC,分别以7.76%和7.13%的显著优势超越其他方法和基线模型。此外,与竞争方法相比,UniNet还提升了PRO指标。
Medical datasets. UniNet was evaluated on three medical datasets: APTOS, OCT2017, and ISIC2018. Following [17], we compared UniNet with five recent methods: SimpleNet [33], CFA [27], AE-flow [58], PatchCore [40], and RD4AD [12]. Detailed results are presented in Table 2(a). UniNet achieves exceptional performance across all three evaluation metrics, with $100.0%$ image-level AUROC on all three datasets. UniNet improves other methods and the baseline model by $12.21%$ AUROC and $9.85%$ AUROC on the more challenging ISIC2018 dataset, respectively.
医学数据集。UniNet在三个医学数据集上进行了评估:APTOS、OCT2017和ISIC2018。参照[17],我们将UniNet与五种最新方法进行了比较:SimpleNet [33]、CFA [27]、AE-flow [58]、PatchCore [40]和RD4AD [12]。详细结果如表 2(a) 所示。UniNet在所有三个评估指标上均表现出色,在三个数据集上的图像级AUROC均达到$100.0%$。在更具挑战性的ISIC2018数据集上,UniNet分别将其他方法和基线模型的AUROC提升了$12.21%$和$9.85%$。
Ped2. We compared UniNet with SOTA methods, including [39], Anomaly Ruler [51], PDM-Net [21], SLM [44], and zxVAD [1]. As reported in Table 2(b), UniNet also achieves comparable performance to Anomaly Ruler in video domain and surpasses the baseline by $2.7%$ AUROC.
Ped2. 我们将UniNet与最先进方法进行了比较,包括[39]、Anomaly Ruler [51]、PDM-Net [21]、SLM [44]和zxVAD [1]。如表2(b)所示,UniNet在视频领域与Anomaly Ruler表现相当,并以2.7%的AUROC优势超越基线。
5.2.2. Results under the supervised setting
5.2.2. 监督设置下的结果
VAD. UniNet was compared with methods reported in [2], including three unsupervised methods (Efficient AD [3], PatchCore [40], and RD4AD[12]) and two supervised methods (DevNet [38], DRA[14]). The results are summarized in Table 3(a). Even without SegAD, UniNet still achieves $99.95%$ AUROC on this new and challenging dataset and improves the competing methods that equip with SegAD by $8.20%$ AUROC. It is noted that the unsupervised methods struggle without SegAD, as they face difficulty in distinguish anomalies. Additionally, supervised methods also perform poorly, as this dataset contains unseen anomalies, and they are biased by the seen anomalies.
VAD。UniNet 与 [2] 中报告的方法进行了比较,包括三种无监督方法 (Efficient AD [3]、PatchCore [40] 和 RD4AD[12]) 和两种有监督方法 (DevNet [38]、DRA[14])。结果总结在表 3(a) 中。即使不使用 SegAD,UniNet 仍在这个新颖且具有挑战性的数据集上实现了 $99.95%$ 的 AUROC,并将配备 SegAD 的竞争方法的 AUROC 提高了 $8.20%$。值得注意的是,无监督方法在没有 SegAD 的情况下表现不佳,因为它们难以区分异常。此外,有监督方法也表现不佳,因为该数据集包含未见过的异常,并且它们会受到已见过异常的偏差影响。
Table 4. Ablation study on the key components of UniNet on the MVTec AD dataset. Best results are highlighted in bold.
表 4: UniNet 关键组件在 MVTec AD 数据集上的消融实验。最佳结果以粗体标出。
| MEM | DFS | CsC | CM | M | I-AUROC | P-AUROC | PRO |
|---|---|---|---|---|---|---|---|
| 98.42 | 98.13 | 94.89 | |||||
| √ | 99.01 | 98.20 | 95.06 | ||||
| 99.23 | 98.29 | 95.13 | |||||
| √ | 99.36 | 98.34 | 95.40 | ||||
| √ | √ | 99.40 | 98.59 | 95.30 | |||
| √ | √ | 99.42 | 98.64 | 95.52 | |||
| √ | √ | √ | 99.77 | 98.76 | 95.73 | ||
| √ | √ | √ | 99.90 | 98.81 | 96.00 |
Table 5. Study on the effect of $v_{m}$ on AD performance. ${\mathrm{Max}}{=}{\frac{100%}{H\times W}}$ denotes using the maximum value in the anomaly map. Best results are highlighted in bold.
表 5: 研究 $v_{m}$ 对 AD (Anomaly Detection) 性能的影响。 ${\mathrm{Max}}{=}{\frac{100%}{H\times W}}$ 表示使用异常图中的最大值。最佳结果以粗体标出。
| 数据集 | Max | 3% | 5% | 10% | M(Ours) |
|---|---|---|---|---|---|
| MVTec3D-AD | 90.30 | 94.42 | 94.90 | 93.68 | 95.76 |
| APTOS | 99.53 | 99.87 | 99.95 | 99.98 | 100.0 |
| VAD | 99.35 | 99.36 | 99.38 | 99.37 | 99.95 |
Medical datasets. UniNet was compared with several SOTA supervised methods (MADGNet [37], HarDNet-CPS [54], SAM-EG [48], MEGANet [7], and KDAS [49]) on three datasets, including Kvasir, CVC-ClinicDB, and CVCColonDB. Table 3(b) shows the detailed results. UniNet demonstrates promising performance on both the DSC and mIoU evaluation metrics, except for a $0.6%$ lower mIoU on the Kvasir dataset compared to MEGANet. Notably, although these methods are specifically designed for medical polyp segmentation, UniNet still outperforms them.
医学数据集。在Kvasir、CVC-ClinicDB和CVCColonDB三个数据集上,将UniNet与多种SOTA监督方法(MADGNet [37]、HarDNet-CPS [54]、SAM-EG [48]、MEGANet [7]和KDAS [49])进行了比较。表3(b)展示了详细结果。除在Kvasir数据集上mIoU比MEGANet低0.6%外,UniNet在DSC和mIoU评估指标上均表现出色。值得注意的是,尽管这些方法专为医学息肉分割设计,UniNet仍优于它们。
5.3. Ablation study
5.3. 消融研究
To demonstrate the effectiveness of UniNet, we conducted comprehensive ablation studies on datasets from different domains. More details can be found in Appendix.
为验证UniNet的有效性,我们在不同领域的数据集上进行了全面的消融实验。更多细节详见附录。
Study on key elements. The key components of UniNet include MEM, DFS, similarity-contrastive loss $\mathcal{L}{S C}$ , margin loss $\mathcal{L}{M}$ , and weighted decision mechanism $\mathcal{M}$ . The numerical results on the MVTec AD dataset are presented in Table 4. With MEM, UniNet can capture richer contextual relationships among features, which is help for visual tasks. By incorporating DFS, UniNet obtains domainrelated information and thus enhances performance. When only employing $\mathcal{L}{S C}$ , the performance is lower than using both $\mathcal{L}{S C}$ and $\mathcal{L}_{M}$ since the similarity for some normal features is inadequately high. Besides, the use of $\mathcal{M}$ substantially contributes to AD performance. Finally, combining all these elements, UniNet yields superior anomaly detection and segmentation performance.
关键要素研究。UniNet的核心组件包括MEM、DFS、相似性对比损失$\mathcal{L}{S C}$、边界损失$\mathcal{L}{M}$以及加权决策机制$\mathcal{M}$。表4展示了在MVTec AD数据集上的数值结果。通过MEM,UniNet能够捕捉更丰富的特征间上下文关系,这对视觉任务有所帮助。引入DFS后,UniNet获得了与领域相关的信息,从而提升了性能。当仅使用$\mathcal{L}{S C}$时,由于某些正常特征的相似性不足够高,其性能低于同时使用$\mathcal{L}{S C}$和$\mathcal{L}_{M}$的情况。此外,$\mathcal{M}$的使用显著提升了异常检测(AD)性能。最终,结合所有这些要素,UniNet实现了卓越的异常检测与分割性能。
Study on loss functions. To validate the effectiveness of $\mathcal{L}{S C}$ and $\mathcal{L}{M}$ , we conducted experiments on two unsupervised datasets (MTVec AD and MTVec 3D-AD) and a supervised dataset (VAD). Without $\mathcal{L}{S C}$ and $\mathcal{L}_{M}$ , UniNet struggles to improve class boundaries in unsupervised setting. Instead, integrating them to UniNet enhances the correlations among normal features and maintains higher similarity for them, enabling effective anomaly discrimination (see Fig. 4(a) and (b)). In supervised setting, normal features are clustered, while anomalous features are repelled and their similarity are further constrained, which is helpful for the model to distinguish anomalies, including unseen anomalies (see Fig. 4(c)).
损失函数研究。为验证 $\mathcal{L}{S C}$ 和 $\mathcal{L}{M}$ 的有效性,我们在两个无监督数据集 (MTVec AD 和 MTVec 3D-AD) 和一个有监督数据集 (VAD) 上进行了实验。未引入 $\mathcal{L}{S C}$ 和 $\mathcal{L}_{M}$ 时,UniNet 在无监督场景下难以改善类别边界。而将其整合至 UniNet 后,能增强正常特征间的相关性并保持更高相似度,从而实现有效异常判别 (见图 4(a) 和 (b))。在有监督场景中,正常特征会聚集成簇,异常特征则被排斥且其相似度受到进一步约束,这有助于模型区分包括未见异常在内的各类异常 (见图 4(c))。

Figure 4. Feature distributions visualized using t-SNE across three datasets.
图 4: 使用t-SNE可视化三个数据集中的特征分布。
Study on weighted decision mechanism. During inference, the precise calculation of weight $v_{w}$ is crucial for the image-level anomaly score. Table 5 investigates the effects of different $v_{w}$ on AD performance. As reported in Table 5, our weighted decision mechanism $\mathcal{M}$ achieves the best results across three datasets. Notably, compared to recent methods [22, 38] that select the fixed largest $v_{w}$ (e.g., $ v_{w}=3%$ ) values from the anomaly map to calculate the anomaly score, our method dynamically determines the optimal $v_{w}$ for more accurate AD, achieving a notable improvement of $0.86%$ on the MVTec 3D-AD dataset.
加权决策机制研究。在推理过程中,权重$v_{w}$的精确计算对图像级异常得分至关重要。表5探究了不同$v_{w}$对异常检测(AD)性能的影响。如表5所示,我们的加权决策机制$\mathcal{M}$在三个数据集上均取得最佳结果。值得注意的是,相较于近期方法[22, 38]从异常图中选取固定最大值$v_{w}$(如$v_{w}=3%$)来计算异常得分,我们的方法能动态确定最优$v_{w}$以实现更精准的异常检测,在MVTec 3D-AD数据集上实现了$0.86%$的显著提升。
6. Conclusion
6. 结论
In this paper, we present UniNet, a generic unified anomaly detection framework designed for diverse domains. UniNet comprises student-teacher models and a bottleneck. The key innovations of UniNet are threefold: domain-related feature selection, similarity-contrastive loss and margin loss, and weighted decision mechanism. These components collectively enhance UniNet’s ability to effectively select and learn domain-relevant feature information, distinguish abnormality and normality, and achieve robust AD performance during inference. Extensive experiments across 11 datasets from various domains demonstrate UniNet’s superiority over SOTA methods.
本文提出UniNet,一种面向多领域的通用统一异常检测框架。该框架由师生模型和瓶颈模块构成,其核心创新点包含三部分:领域相关特征选择、相似度对比损失与边界损失、加权决策机制。这些组件共同提升了UniNet在推理过程中有效筛选和学习领域相关特征信息、区分异常与正常状态的能力,从而实现稳健的异常检测性能。在11个跨领域数据集上的大量实验表明,UniNet性能优于当前最先进方法。