CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model
CLIP4STR: 基于预训练视觉语言模型的场景文本识别简单基线
Abstract—Pre-trained vision-language models (VLMs) are the de-facto foundation models for various downstream tasks. However, scene text recognition methods still prefer backbones pretrained on a single modality, namely, the visual modality, despite the potential of VLMs to serve as powerful scene text readers. For example, CLIP can robustly identify regular (horizontal) and irregular (rotated, curved, blurred, or occluded) text in images. With such merits, we transform CLIP into a scene text reader and introduce CLIP4STR, a simple yet effective STR method built upon image and text encoders of CLIP. It has two encoderdecoder branches: a visual branch and a cross-modal branch. The visual branch provides an initial prediction based on the visual feature, and the cross-modal branch refines this prediction by addressing the discrepancy between the visual feature and text semantics. To fully leverage the capabilities of both branches, we design a dual predict-and-refine decoding scheme for inference. We scale CLIP4STR in terms of the model size, pre-training data, and training data, achieving state-of-the-art performance on 13 STR benchmarks. Additionally, a comprehensive empirical study is provided to enhance the understanding of the adaptation of CLIP to STR. Our method establishes a simple yet strong baseline for future STR research with VLMs.
摘要—预训练的视觉语言模型 (VLM) 已成为各类下游任务实际采用的基础模型。然而,尽管VLM具备成为强大场景文本阅读器的潜力,现有场景文本识别 (STR) 方法仍倾向于使用单模态 (视觉模态) 预训练的主干网络。例如,CLIP能稳健识别图像中的规则 (水平) 和不规则 (旋转、弯曲、模糊或遮挡) 文本。基于这一优势,我们将CLIP改造为场景文本阅读器,提出CLIP4STR——一种基于CLIP图像与文本编码器的简单高效STR方法。该方法包含双编码器-解码器分支:视觉分支和跨模态分支。视觉分支基于视觉特征生成初始预测,跨模态分支则通过消除视觉特征与文本语义间的差异来优化预测结果。为充分发挥双分支能力,我们设计了双预测-优化解码方案用于推理。我们在模型规模、预训练数据和训练数据三个维度扩展CLIP4STR,在13个STR基准测试中达到最先进性能。此外,本文通过全面实验研究深化了CLIP在STR任务中适配机制的理解。本方法为未来基于VLM的STR研究建立了简单而强大的基线。
Index Terms—Vision-Language Model, Scene Text Recognition, CLIP
索引术语—视觉语言模型 (Vision-Language Model)、场景文本识别 (Scene Text Recognition)、CLIP
I. INTRODUCTION
I. 引言
ISION-LANGUAGE models (VLMs) pre-trained on web-scale data like CLIP [1] and ALIGN [2] shows remarkable zero-shot capacity across different tasks. Researchers also successfully transfer the knowledge from pre-trained VLMs to diverse tasks in a zero-shot or fine-tuning manner, e.g., visual question answering [3], information retrieval [4], [5], referring expression comprehension [6], and image captioning [7]. VLM is widely recognized as a foundational model and an important component of artificial intelligence [8].
视觉语言模型 (Vision-Language Model, VLM) 通过CLIP [1]和ALIGN [2]等网络规模数据预训练后,在不同任务中展现出卓越的零样本能力。研究者们还成功地将预训练VLM的知识以零样本或微调方式迁移至多种任务,例如视觉问答 [3]、信息检索 [4][5]、指代表达理解 [6] 以及图像描述生成 [7]。VLM被广泛认为是基础模型和人工智能的重要组成部分 [8]。
Scene text recognition (STR) is a critical technique and an essential process in many vision and language applications, e.g., document analysis, autonomous driving, and augmented reality. Similar to the aforementioned cross-modal tasks, STR involves two different modalities: image and text. However,
场景文本识别 (Scene Text Recognition, STR) 是一项关键技术,也是许多视觉与语言应用(如文档分析、自动驾驶和增强现实)中的核心流程。与前述跨模态任务类似,STR 涉及图像和文本两种不同模态。然而,
This work was partially supported by the Earth System Big Data Platform of the School of Earth Sciences, Zhejiang University. Corresponding author: Ruijie Quan
本研究部分由浙江大学地球科学学院地球系统大数据平台支持。通讯作者:Ruijie Quan
Shuai Zhao is with the ReLER Lab, Australian Artificial Intelligence Institute, University of Technology Sydney, Ultimo, NSW 2007, Australia. Part of this work is done during an internship at Baidu Inc. Email: zhao shuai m cc $@$ gmail.com. Linchao Zhu, Ruijie Quan, Yi Yang are with ReLER Lab, CCAI, Zhejiang University, Zhejiang, China. E-mail: {zhulinchao, quanruijie, yangyics}@zju.edu.cn.
帅钊就职于悉尼科技大学澳大利亚人工智能研究所ReLER实验室,地址:澳大利亚新南威尔士州Ultimo NSW 2007。部分工作完成于百度公司实习期间。邮箱:zhaoshuaimcc@gmail.com。林超柱、权锐杰、杨易同属浙江大学CCAI研究院ReLER实验室。邮箱:{zhulinchao, quanruijie, yangyics}@zju.edu.cn。

Fig. 1: Zero-shot classification results of CLIP-ViT-B/32. CLIP can perceive and understand text in images, even for irregular text with noise, rotation, and occlusion. CLIP is potentially a powerful scene text recognition expert.
图 1: CLIP-ViT-B/32 的零样本分类结果。CLIP 能够感知并理解图像中的文本,即使对于带有噪声、旋转和遮挡的不规则文本也是如此。CLIP 可能是一位强大的场景文本识别专家。
unlike the popularity of pre-trained VLMs in other crossmodal tasks, STR methods still tend to rely on backbones pre-trained on single-modality data [9], [10], [11], [12]. In this work, we show that VLM pre-trained on image-text pairs possess strong scene text perception abilities, making them superior choices as STR backbones.
与其他跨模态任务中预训练视觉语言模型(VLM)的流行不同,场景文本识别(STR)方法仍倾向于依赖单模态数据预训练的骨干网络[9][10][11][12]。本研究表明,基于图像-文本对预训练的VLM具有强大的场景文本感知能力,是更优的STR骨干网络选择。
STR methods generally struggle with irregular text like rotated, curved, blurred, or occluded text [13], [14]. However, irregular text is prevalent in real-life scenarios [15], [16], making it necessary for STR models to effectively handle these challenging cases. Interestingly, we observe that the VLM (e.g., CLIP [1]) can robustly perceive irregular text in arbitrary orders without relying on specific sequence order assumptions. During training, the visual branch provides an initial prediction based on the visual feature, which is then refined by the cross-modal branch to address possible discrepancies between the visual feature and text semantics of the prediction. The cross-modal branch functions as a semanticaware spell checker, similar to modern STR methods [9], [12]. For inference, we design a dual predict-and-refine decoding scheme to fully utilize the capabilities of both encoder-decoder branches for improved character recognition.
STR方法通常难以处理旋转、弯曲、模糊或被遮挡的不规则文本 [13], [14]。然而,不规则文本在现实场景中十分普遍 [15], [16],因此STR模型必须有效应对这些挑战性情况。有趣的是,我们发现视觉语言模型(VLM,如CLIP [1])无需依赖特定序列顺序假设,就能稳健感知任意排列的不规则文本。训练过程中,视觉分支基于视觉特征提供初始预测,随后跨模态分支通过修正视觉特征与预测文本语义间的潜在偏差来优化结果。该跨模态分支类似于现代STR方法 [9], [12] 中的语义感知拼写检查器。推理阶段,我们设计了双预测-优化解码方案,充分融合两个编码器-解码器分支的能力以提升字符识别性能。

Fig. 2: Attention of CLIP-ViT-B/32 for STR images.
图 2: CLIP-ViT-B/32 对 STR (Scene Text Recognition) 图像的注意力机制可视化
We scale CLIP4STR across different model sizes, pretraining data, and training data to investigate the effectiveness of large-scale pre-trained VLMs as STR backbones. CLIP4STR achieves state-of-the-art performance on 13 STR benchmarks, encompassing regular and irregular text. Additionally, we present a comprehensive empirical study on adapting CLIP to STR. CLIP4STR provides a simple yet strong baseline for future STR research with VLMs.
我们通过调整不同模型规模、预训练数据和训练数据来研究大规模预训练视觉语言模型(VLM)作为STR(场景文本识别)主干的有效性。CLIP4STR在13个STR基准测试(包括规则和不规则文本)上实现了最先进的性能。此外,我们对CLIP模型在STR任务上的适配进行了全面的实证研究。CLIP4STR为未来基于VLM的STR研究提供了一个简单而强大的基线。
II. RELATED WORK
II. 相关工作
natural images. In Fig. 1, we put different text stickers on a natural image, use CLIP to classify it1, and visualize the attention of CLIP via Grad-CAM [19]. It is evident that CLIP pays high attention to the text sticker and accurately understands the meaning of the word, regardless of text variations 2. CLIP is trained on massive natural images collected from the web, and its text perception ability may come from the natural images containing scene texts [20]. Will CLIP perceive the text in common STR images [21], [22], [16], which are cropped from a natural image? Fig. 2 presents the visualization results of CLIP-ViT-B/32 for STR images. Although the text in these STR images is occluded, curved, blurred, and rotated, CLIP can still perceive them. From Fig. 1&2, we can see CLIP possesses an exceptional capability to perceive and comprehend various text in images. This is exactly the desired quality for a robust STR backbone.
自然图像。在图1中,我们在自然图像上放置不同的文字贴纸,使用CLIP对其进行分类1,并通过Grad-CAM[19]可视化CLIP的注意力。显然,无论文字如何变化2,CLIP都对文字贴纸高度关注并准确理解单词含义。CLIP是基于从网络收集的海量自然图像训练的,其文本感知能力可能源自包含场景文字的自然图像[20]。那么CLIP能否感知常见STR图像[21][22][16]中的文字?这些图像是从自然图像中裁剪得到的。图2展示了CLIP-ViT-B/32对STR图像的可视化结果。尽管这些STR图像中的文字存在遮挡、弯曲、模糊和旋转,CLIP仍能感知它们。从图1和图2可以看出,CLIP具有感知和理解图像中各类文字的卓越能力,这正是稳健STR骨干网络所需的特质。
In this work, we aim to leverage the text perception capability of CLIP for STR and build a strong baseline for future STR research with VLMs. To this end, we introduce CLIP4STR, a simple yet effective STR framework built upon CLIP. CLIP4STR consists of two encoder-decoder branches: the visual branch and the cross-modal branch. The image and text encoders inherit from CLIP, while the decoders employ the transformer decoder [23]. To enable the decoder to delve deep into word structures (dependency relationship among characters in a word), we incorporate the permuted sequence modeling technique proposed by PARSeq [24]. This allows the decoder to perform sequence modeling of characters in
在本工作中,我们旨在利用CLIP的文本感知能力进行场景文本识别(STR),并为基于视觉语言模型(VLM)的未来STR研究建立强大基线。为此,我们提出了CLIP4STR——一个基于CLIP构建的简单而有效的STR框架。CLIP4STR包含视觉分支和跨模态分支两个编码器-解码器分支:图像和文本编码器继承自CLIP,而解码器采用Transformer解码器[23]。为使解码器能深入探究单词结构(单词内字符间的依赖关系),我们引入了PARSeq[24]提出的置换序列建模技术,该技术使得解码器能够对字符序列进行建模...
A. Vision-Language Models and Its Application
A. 视觉语言模型及其应用
Large-scale pre-trained vision-language models learning under language supervision such as CLIP [1], ALIGN [2], and Florence [25] demonstrate excellent generalization abilities. This encourages researchers to transfer the knowledge of these pre-trained VLMs to different downstream tasks in a finetuning or zero-shot fashion. For instance, [4], [26], [27] tune CLIP on videos and make CLIP specialized in text-video retrieval, CLIPScore [7] uses CLIP to evaluate the quality of generated image captions, and [28], [29] use CLIP as the reward model during test time or training. The wide application of VLMs also facilitates the research on different pre-training models, e.g., ERNIE-ViLG [30], CoCa [31], OFA [32], DeCLIP [33], FILIP [34], and ALBEF [35]. Researchers also explore the power of scaling up the data, e.g., COYO-700M [36] and LAION-5B [37]. Generally, more data brings more power for large VLMs [38].
大规模预训练的视觉语言模型(如CLIP [1]、ALIGN [2]和Florence [25])在语言监督下学习,展现出卓越的泛化能力。这促使研究者们将这些预训练VLM的知识通过微调或零样本方式迁移到不同下游任务中。例如,[4]、[26]、[27]对CLIP进行视频微调使其专精于文本-视频检索,CLIPScore [7]利用CLIP评估生成图像描述的质量,而[28]、[29]则在测试或训练阶段将CLIP作为奖励模型。VLM的广泛应用也推动了不同预训练模型的研究,如ERNIE-ViLG [30]、CoCa [31]、OFA [32]、DeCLIP [33]、FILIP [34]和ALBEF [35]。研究者还探索了数据规模化的潜力,例如COYO-700M [36]和LAION-5B [37]。通常,更多数据会为大型VLM带来更强性能[38]。
VLMs pre-trained on large-scale image-text pairs possess many fascinating attributes [1], [20], [39]. For instance, some neurons in CLIP can perceive the visual and text signals corresponding to the same concept. [20] finds particular neurons in CLIP-RN $I50\times4$ respond to both photos of Spiderman and the text ‘‘spider’’ in an image. This also leads to Typographic Attacks, namely, VLMs focus on the text rather than natural objects in an image as shown in Figure 1. In this work, we leverage the text perception ability of multi-modal neurons and make CLIP specialize in scene text recognition.
在大规模图文对上预训练的视觉语言模型(VLM)具有许多引人入胜的特性[1]、[20]、[39]。例如,CLIP中的某些神经元能够感知同一概念对应的视觉和文本信号。[20]发现CLIP-RN $I50\times4$ 中的特定神经元会对蜘蛛侠照片和图像中的"spider"文本同时产生响应。这也导致了排版攻击(Typographic Attacks),即如图1所示,视觉语言模型会聚焦于图像中的文字而非自然物体。本研究利用多模态神经元的文本感知能力,使CLIP专门用于场景文本识别。
B. Scene Text Recognition
B. 场景文本识别
Scene text recognition methods can be broadly divided into two categories: context-free and context-aware. Context-free STR methods only utilize the visual features of images, such as CTC-based [40] methods [41], [42], [43], [10], segmentationbased methods [44], [45], [46], and attention-based methods with an encoder-decoder mechanism [47], [48]. Since contextfree STR methods lack the understanding of text semantics, they are less robust against occluded or incomplete text.
场景文本识别方法大致可分为两类:无上下文(context-free)和上下文感知(context-aware)。无上下文STR方法仅利用图像的视觉特征,例如基于CTC (Connectionist Temporal Classification)的方法[40][41][42][43][10]、基于分割的方法[44][45][46]以及采用编码器-解码器机制的基于注意力机制的方法[47][48]。由于无上下文STR方法缺乏对文本语义的理解,它们在处理遮挡或不完整文本时鲁棒性较差。
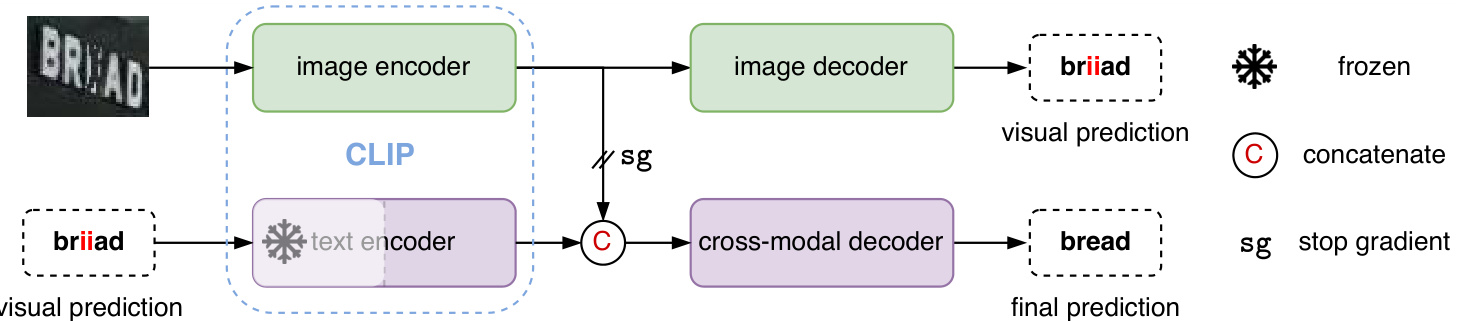
Fig. 3: The framework of CLIP4STR. It has a visual branch and a cross-modal branch. The cross-modal branch refines the prediction of the visual branch for the final output. The text encoder is partially frozen.
图 3: CLIP4STR框架。它包含视觉分支和跨模态分支。跨模态分支对视觉分支的预测进行优化以生成最终输出。文本编码器部分参数被冻结。
Context-aware STR methods are the mainstream approach, leveraging text semantics to enhance recognition performance. For example, ABINet [9], LevOCR [49], MATRN [50], and TrOCR [12] incorporate an external language model to capture text semantics. Other methods achieve similar goals with built-in modules, such as RNN [51], [52], GRU [53], transformer [54], [24], [55]. The context information is interpreted as the relations of textual primitives by Zhang et al. [56], who proposes a relational contrastive self-supervised learning STR framework. Besides the context-free and context-aware methods, some efforts aim to enhance the explain ability of STR. For instance, STRExp [57] utilizes local individual character explanations to deepen the understanding of STR methods. Moreover, training data plays a vital role in STR. Traditionally, synthetic data [58], [59] are used for training due to the ease of generating a large number of samples. However, recent research suggests that using realistic training data can lead to better outcomes compared to synthetic data [60], [24], [61], [62]. Motivated by these findings, we primarily employ realistic training data in this work.
上下文感知的场景文本识别 (STR) 方法已成为主流技术,它们通过利用文本语义来提升识别性能。例如 ABINet [9]、LevOCR [49]、MATRN [50] 和 TrOCR [12] 都引入了外部语言模型来捕获文本语义。其他方法则通过内置模块实现类似目标,如 RNN [51][52]、GRU [53]、Transformer [54][24][55]。Zhang 等人 [56] 将上下文信息解释为文本基元之间的关系,并提出了一种关系对比自监督学习 STR 框架。
除上下文无关和上下文感知方法外,部分研究致力于提升 STR 的可解释性。例如 STRExp [57] 通过局部单字符解释来深化对 STR 方法的理解。此外,训练数据对 STR 至关重要。传统方法因易于生成大量样本而采用合成数据 [58][59] 进行训练,但最新研究表明,相比合成数据,使用真实训练数据能获得更好效果 [60][24][61][62]。受此启发,本研究主要采用真实训练数据。
The success of VLMs also spreads to the STR area. For example, TrOCR [12] adopts separate pre-trained language and vision models plus post-pre training on STR data in an auto-regressive manner [63], MATRN [50] uses a popular multi-modal fusion manner in VLMs such as ALBEF [35] and ViLT [64]. CLIPTER [65] enhances the character recognition performance by utilizing the CLIP features extracted from the global image. CLIP-OCR [66] leverages both visual and linguistic knowledge from CLIP through feature distillation. In contrast, we directly transfer CLIP to a robust scene text reader, eliminating the need for CLIP features from the global image or employing an additional CLIP model as a teacher for the STR reader. We hope our method can be a strong baseline for future STR research with VLMs.
视觉语言模型(VLM)的成功也延伸到了场景文本识别(STR)领域。例如,TrOCR [12]采用预训练的语言和视觉模型分离架构,并以自回归方式在STR数据上进行后预训练[63];MATRN [50]使用了ALBEF [35]和ViLT [64]等VLM中流行的多模态融合方法。CLIPTER [65]通过利用从全局图像提取的CLIP特征来增强字符识别性能。CLIP-OCR [66]则通过特征蒸馏同时利用CLIP的视觉和语言知识。相比之下,我们直接将CLIP迁移为鲁棒的场景文本阅读器,无需从全局图像获取CLIP特征,也无需额外使用CLIP模型作为STR阅读器的教师模型。我们希望该方法能成为未来基于VLM的STR研究的强基线。
III. METHOD
III. 方法
A. Preliminary
A. 初步准备
Before illustrating the framework of CLIP4STR, we first introduce CLIP [1] and the permuted sequence modeling (PSM) technique proposed by PARSeq [24]. CLIP serves as the backbone, and the PSM is used for sequence modeling.
在阐述CLIP4STR框架之前,我们首先介绍CLIP [1] 和PARSeq [24] 提出的置换序列建模 (permuted sequence modeling, PSM) 技术。CLIP作为主干网络,PSM用于序列建模。
- CLIP: CLIP consists of a text encoder and an image encoder. CLIP is pre-trained on 400 million image-text pairs using contrastive learning. The text and image features from
- CLIP: CLIP由文本编码器和图像编码器组成。该模型通过对比学习在4亿个图文对上进行了预训练,能提取文本与图像特征。
TABLE I: Examples of attention mask $\mathcal{M}$ . The sequences with [B] and [E] represent the input context and output sequence, respectively. The entry $\mathcal{M}_{i,j}=-\infty$ (negative infinity) indicates that the dependency of output $i$ on input context $j$ is removed.
表 1: 注意力掩码 $\mathcal{M}$ 示例。带有 [B] 和 [E] 的序列分别表示输入上下文和输出序列。条目 $\mathcal{M}_{i,j}=-\infty$ (负无穷) 表示输出 $i$ 对输入上下文 $j$ 的依赖关系被移除。
| [B] | y1 | y2 | y3 | [B] | y1 | y2 | y3 | [B] | y1 | y2 | y3 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| y1 y2 y3 | 0 | 181818 | y1 | 0 | 18 | 0 | 0 | y1 | 0 | 18 | 0 | 0 | ||
| 0 | 0 | 18丨8 | y2 | 0 | 0 | 18 | 0 | y2 | 0 | 181818 | ||||
| 0 | 0 | 0 | 18 | y3 | 0 | 0 | 0 | 18 | y3 | 0 18 | 0 | 18 | ||
| 0 | 0 | 0 | 0 | [E] | 0 | 0 | 0 | 0 | [E] | 0 | 0 | 0 | ||
| (a) AR掩码 | (b) 完形掩码 | (c) 随机掩码 | 0 |
CLIP are aligned in a joint image-text embedding space. i) The image encoder of CLIP is a vision transformer (ViT) [69]. Given an image, ViT introduces a visual tokenizer (convolution) to convert non-overlapped image patches into a discrete sequence. A [CLASS] token is then prepended to the beginning of the image sequence. Initially, CLIP image encoder only returns the feature of the [CLASS] token, but in this work, we return features of all tokens. The rationale behind this choice is that character-level recognition requires fine-grained detail, and local features from all patches are necessary. These features are normalized and linearly projected into the joint image-text embedding space. ii) The text encoder of CLIP is a transformer encoder [23], [70]. The text tokenizer is a lower-cased byte pair encoding – BPE [71] with vocabulary size 49,152. The beginning and end of the text sequence are padded with [SOS] and [EOS] tokens, respectively. Linguistic features of all tokens are utilized for character recognition. These features are also normalized and linearly projected into the joint image-text embedding space.
CLIP在联合图文嵌入空间中对齐。i) CLIP的图像编码器采用视觉Transformer (ViT) [69]。给定图像时,ViT通过视觉分词器(卷积操作)将非重叠图像块转换为离散序列,并在序列开头添加[CLASS]标记。原始CLIP图像编码器仅返回[CLASS]标记的特征,但本研究返回所有标记的特征——因为字符级识别需要细粒度细节,必须利用所有图像块的局部特征。这些特征经归一化后线性投影至联合图文嵌入空间。ii) CLIP的文本编码器采用Transformer编码器[23][70],其文本分词器使用小写字节对编码(BPE)[71](词表大小49,152),文本序列首尾分别添加[SOS]和[EOS]标记。字符识别任务会利用所有文本标记的语言特征,这些特征同样经过归一化后线性投影至联合图文嵌入空间。
- Permuted sequence modeling: Traditionally, STR methods use a left-to-right or right-to-left order to model character sequences [9]. However, the characters in a word do not strictly follow such directional dependencies. For instance, to predict the letter “o” in the word “model”, it is sufficient to consider only the context “m_de” rather than relying solely on the left-to-right context “m_” or the right-to-left context “led_”. The dependencies between characters in a word can take various forms. To encourage the STR method to explore these structural relationships within words, PARSeq [24] introduces a permuted sequence modeling (PSM) technique. This technique uses a random attention mask $\mathcal{M}$ for attention operations [23] to generate random dependency relationships between the input context and the output. Table I illustrates three examples of mask $\mathcal{M}$ . We will delve further into this mechanism in $\S\mathrm{III-C}$ .
- 置换序列建模 (Permuted sequence modeling): 传统STR方法采用从左到右或从右到左的顺序建模字符序列[9]。但单词中的字符并不严格遵循这种方向性依赖关系。例如预测单词"model"中的字母"o"时,仅需考虑上下文"m_de",而非单纯依赖从左到右的"m_"或从右到左的"led_"上下文。单词内字符间的依赖关系可呈现多种形式。为促使STR方法探索单词内部的结构关系,PARSeq[24]引入了置换序列建模(PSM)技术,该技术通过随机注意力掩码$\mathcal{M}$进行注意力运算[23],从而在输入上下文与输出之间生成随机依赖关系。表I展示了三种掩码$\mathcal{M}$的示例,我们将在$\S\mathrm{III-C}$章节深入探讨该机制。

Fig. 4: The decoder of CLIP4STR. [B], [E], and [P] are the beginning, end, and padding tokens, respectively. ‘[· · · ]’ in prediction represents the ignored outputs. Layer normalization [67] and dropout [68] in the decoder are ignored.
图 4: CLIP4STR的解码器结构。[B]、[E]和[P]分别表示起始token、结束token和填充token。预测中的"[···]"代表被忽略的输出。解码器中的层归一化[67]和dropout[68]未在图中显示。
B. Encoder
B. 编码器
The framework of CLIP4STR is illustrated in Fig. 3. CLIP4STR employs a dual encoder-decoder design, consisting of a visual branch and a cross-modal branch. The text and image encoders utilize the architectures and pre-trained weights from CLIP. The visual branch generates an initial prediction based on the visual features extracted by the image encoder. Subsequently, the cross-modal branch refines the initial prediction by addressing the discrepancy between the visual features and the textual semantics of the prediction. Since the image and text features are aligned in a joint imagetext embedding space during pre-training, it becomes easy to identify this discrepancy. The cross-modal branch acts as a semantic-aware spell checker.
CLIP4STR的框架如图3所示。CLIP4STR采用双编码器-解码器设计,包含视觉分支和跨模态分支。文本和图像编码器使用CLIP的架构和预训练权重。视觉分支基于图像编码器提取的视觉特征生成初始预测。随后,跨模态分支通过解决视觉特征与预测文本语义之间的差异来优化初始预测。由于图像和文本特征在预训练期间被对齐到联合图像-文本嵌入空间,因此很容易识别这种差异。跨模态分支充当语义感知的拼写检查器。
The text encoder is partially frozen. This freezing operation retains the learned text understanding ability of the language model and reduces training costs. It is a common practice in transfer learning of large language models [72]. In contrast, the visual branch is fully trainable due to the domain gap between STR data (cropped word images) and CLIP training data (collected from the web, often natural images). Additionally, we block the gradient flow from the cross-modal decoder to the visual encoder to enable autonomous learning of the visual branch, resulting in improved refined cross-modal predictions.
文本编码器部分冻结。这种冻结操作保留了语言模型已学习的文本理解能力,并降低了训练成本,这是大语言模型迁移学习中的常见做法 [72]。相比之下,由于STR数据(裁剪后的单词图像)与CLIP训练数据(从网络收集的通常是自然图像)之间存在领域差距,视觉分支是完全可训练的。此外,我们阻断了从跨模态解码器到视觉编码器的梯度流,使视觉分支能够自主学习,从而改进优化后的跨模态预测。
For the text encoder $g(\cdot)$ and the image encoder $h(\cdot)$ , given the input text $\pmb{t}$ and image $_{x}$ , the text, image, and cross-modal features are computed as:
对于文本编码器 $g(\cdot)$ 和图像编码器 $h(\cdot)$,给定输入文本 $\pmb{t}$ 和图像 $_{x}$,其文本特征、图像特征及跨模态特征的计算方式为:
$$
\begin{array}{r l}&{{\boldsymbol{F}}{t}={\boldsymbol{g}}(t)\in\mathbb{R}^{L_{t}\times D},}\ &{{\boldsymbol{F}}{i}={\boldsymbol{h}}({\boldsymbol{x}})\in\mathbb{R}^{L_{i}\times D},}\ &{{\boldsymbol{F}}{c}=[{\boldsymbol{F}}{i}^{T}{\boldsymbol{F}}{t}^{T}]^{T}\in\mathbb{R}^{L_{c}\times D},}\end{array}
$$
$$
\begin{array}{r l}&{{\boldsymbol{F}}{t}={\boldsymbol{g}}(t)\in\mathbb{R}^{L_{t}\times D},}\ &{{\boldsymbol{F}}{i}={\boldsymbol{h}}({\boldsymbol{x}})\in\mathbb{R}^{L_{i}\times D},}\ &{{\boldsymbol{F}}{c}=[{\boldsymbol{F}}{i}^{T}{\boldsymbol{F}}{t}^{T}]^{T}\in\mathbb{R}^{L_{c}\times D},}\end{array}
$$
where $L_{t}$ represents the text sequence length, $L_{i}$ is the sequence length of image tokens, $D$ denotes the dimension of the joint image-text embedding space, and the cross-modal sequence length $L_{c}=L_{i}+L_{t}$ .
其中 $L_{t}$ 表示文本序列长度,$L_{i}$ 表示图像token序列长度,$D$ 表示图文联合嵌入空间的维度,跨模态序列长度 $L_{c}=L_{i}+L_{t}$。
C. Decoder
C. 解码器
The decoder aims to extract the character information from the visual feature $F_{i}$ or cross-modal feature $F_{c}$ . The decoder framework is shown in Fig. 4. It adopts the design of the transformer decoder [23] plus the PSM technique mentioned in $\S$ III-A2, enabling a predicted character to have arbitrary dependencies on the input context during training.
解码器旨在从视觉特征 $F_{i}$ 或跨模态特征 $F_{c}$ 中提取字符信息。解码器框架如图 4 所示。它采用了 Transformer 解码器 [23] 的设计,并结合了 $\S$ III-A2 中提到的 PSM 技术,使得训练期间预测字符能够对输入上下文具有任意依赖性。
The visual and cross-modal decoders have the same architecture but differ in the input. They receive the following inputs: a learnable position query $\textbf{}\in\mathbb{R}^{N\times D}$ , an input context c ∈ RN×D, and a randomly generated attention mask $\mathcal{M}\in\mathbb{R}^{N\times N}$ . $N$ represents the length of characters. The decoder outputs the prediction $\textbf{}\in\mathbf{\bar{\mathbb{R}}}^{N\times C}$ , where $C$ is the number of character classes. The decoding stage can be denoted as: $\pmb{y}=\mathrm{DEC}(\pmb{p},\pmb{c},\pmb{\mathcal{M}},\pmb{F})$ . The first Multi-Head Attention (MHA) in Fig. 4 performs context-position attention:
视觉解码器和跨模态解码器结构相同但输入不同。它们接收以下输入:可学习的位置查询 $\textbf{}\in\mathbb{R}^{N\times D}$ 、输入上下文 c ∈ RN×D,以及随机生成的注意力掩码 $\mathcal{M}\in\mathbb{R}^{N\times N}$ 。$N$ 表示字符长度。解码器输出预测 $\textbf{}\in\mathbf{\bar{\mathbb{R}}}^{N\times C}$ ,其中 $C$ 是字符类别数。解码阶段可表示为:$\pmb{y}=\mathrm{DEC}(\pmb{p},\pmb{c},\pmb{\mathcal{M}},\pmb{F})$ 。图4中第一个多头注意力(MHA)执行上下文-位置注意力:
$$
m_{1}=\mathsf{s o f t m a x}(\frac{p c^{T}}{\sqrt{D}}+\mathcal{M})c+p.
$$
$$
m_{1}=\mathsf{s o f t m a x}(\frac{p c^{T}}{\sqrt{D}}+\mathcal{M})c+p.
$$
The second MHA focuses on feature-position attention:
第二个 MHA 专注于特征-位置注意力:
$$
m_{2}={\mathsf{s o f t m a x}}({\frac{m_{1}F^{T}}{\sqrt{D}}})F+m_{1}.
$$
$$
m_{2}={\mathsf{s o f t m a x}}({\frac{m_{1}F^{T}}{\sqrt{D}}})F+m_{1}.
$$
For simplicity, we ignore the input and output linear transformations in the attention operations of Eq. (4) and Eq. (5). Then $m_{2}\in\mathbb{R}^{N\times D}$ is used for the final prediction $\pmb{y}$ :
为简化起见,我们忽略式(4)和式(5)注意力操作中的输入输出线性变换。随后用 $m_{2}\in\mathbb{R}^{N\times D}$ 进行最终预测 $\pmb{y}$ :
$$
\pmb{y}=\mathrm{Linear}\big(\mathrm{MLP}\big(m_{2}\big)+m_{2}\big).
$$
$$
\pmb{y}=\mathrm{Linear}\big(\mathrm{MLP}\big(m_{2}\big)+m_{2}\big).
$$
During training, the output of the decoder depends on the randomly permuted input context. This encourages the decoder to analyze the word structure beyond the traditional leftto-right or right-to-left sequence modeling assumptions [9]. The inclusion of a random attention mask $\mathcal{M}$ in Eq.(4) enables this capability [24]. Table I presents examples of generated attention masks, including a left-to-right autoregressive (AR) mask, a cloze mask, and a random mask. Following PARSeq [24], we employ $K=6$ masks per input context during training. The first two masks are left-to-right and right-to-left masks, and others are randomly generated. CLIP4STR is optimized to minimize the sum of cross-entropy losses $\left(\mathrm{CE}\left(\cdot\right)\right)$ of the visual branch and the cross-modal branch:
训练过程中,解码器的输出依赖于随机置换的输入上下文。这促使解码器能够分析单词结构,而不仅限于传统的从左到右或从右到左的序列建模假设 [9]。在公式(4) 中加入随机注意力掩码 $\mathcal{M}$ 实现了这一能力 [24]。表 I 展示了生成的注意力掩码示例,包括从左到右的自回归 (AR) 掩码、填空掩码和随机掩码。遵循 PARSeq [24] 的方法,我们在训练时为每个输入上下文使用 $K=6$ 个掩码。前两个掩码是左到右和右到左掩码,其余为随机生成。CLIP4STR 通过最小化视觉分支和跨模态分支的交叉熵损失 $\left(\mathrm{CE}\left(\cdot\right)\right)$ 之和进行优化:
$$
\mathcal{L}=\mathbb{C}\mathbb{E}(\pmb{y}^{i},\hat{\pmb{y}})+\mathbb{C}\mathbb{E}(\pmb{y},\hat{\pmb{y}}),
$$
$$
\mathcal{L}=\mathbb{C}\mathbb{E}(\pmb{y}^{i},\hat{\pmb{y}})+\mathbb{C}\mathbb{E}(\pmb{y},\hat{\pmb{y}}),
$$
where ${\hat{y}},{y}^{i}$ , and $\textit{\textbf{y}}$ indicate ground truth, prediction of the visual branch, and prediction of the cross-modal branch.
其中 ${\hat{y}},{y}^{i}$ 和 $\textit{\textbf{y}}$ 分别表示真实值、视觉分支预测值和跨模态分支预测值。
Algorithm 1: Inference decoding scheme $(\S\mathrm{A})$
算法 1: 推理解码方案 $(\S\mathrm{A})$
| 模型 | 参数量 | 训练数据 | 批次大小 | 训练轮数 | 耗时 |
|---|---|---|---|---|---|
| CLIP4STR-B | 158M | Real(3.3M) | 1024 | 16 | 12.8h |
| CLIP4STR-L | 446M | Real(3.3M) | 1024 | 10 | 23.4h |
| CLIP4STR-H | 1B | RBU(6.5M) | 1024 | 4 | 48.0h |
TABLE II: Model sizes and optimization hyper-parameter. The learning rate for CLIP encoders is $8.4\mathrm{e}{-5}\times\frac{\mathrm{batch}}{512}$ [73]. For models trained from scratch (decoders), the learning rate is multiplied by 19.0. Params is the total parameters in a model, and non-trainable parameters in three models are $44.3\mathbf{M}$ , $80.5\mathbf{M}$ , and 126M, respectively. Training time is measured on 8 NVIDIA RTX A6000 GPUs.
表 II: 模型规模与优化超参数。CLIP编码器的学习率为 $8.4\mathrm{e}{-5}\times\frac{\mathrm{batch}}{512}$ [73]。对于从头训练的模型(解码器),学习率需乘以19.0。Params表示模型总参数量,三个模型的不可训练参数量分别为 $44.3\mathbf{M}$、$80.5\mathbf{M}$ 和126M。训练时长基于8块NVIDIA RTX A6000 GPU测得。
- Decoding scheme: CLIP4STR consists of two branches: a visual branch and a cross-modal branch. To fully exploit the capacity of both branches, we design a dual predict-and-refine decoding scheme for inference, inspired by previous STR methods [9], [24]. Alg. 1 illustrates the decoding process. The visual branch first performs auto regressive decoding, where the future output depends on previous predictions. Subsequently, the cross-modal branch addresses possible discrepancies between the visual feature and the text semantics of the visual prediction, aiming to improve recognition accuracy. This process is also auto regressive. Finally, the previous predictions are utilized as the input context for refining the output in a cloze-filling manner. The refinement process can be iterative. After iterative refinement, the output of the cross-modal branch serves as the final prediction.
- 解码方案:CLIP4STR包含两个分支:视觉分支和跨模态分支。为充分发挥两个分支的能力,我们受先前STR方法[9][24]启发,设计了一种双预测-精调的解码方案进行推理。算法1展示了该解码流程。视觉分支首先执行自回归解码,其未来输出取决于先前的预测结果。随后,跨模态分支会处理视觉特征与视觉预测文本语义之间可能存在的差异,旨在提升识别准确率。此过程同样采用自回归方式。最终,先前预测结果将作为填空式精调的输入上下文,该精调过程可迭代进行。经过迭代精调后,跨模态分支的输出将作为最终预测结果。
IV. EXPERIMENT
IV. 实验
A. Experimental Details
A. 实验细节
We instantiate CLIP4STR with CLIP-ViT-B/16, CLIP-ViTL/14, and CLIP-ViT-H/14 [38]. Table II presents the main hyper-parameters of CLIP4STR. A reproduction of CLIP4STR is at https://github.com/VamosC/CLIP4STR.
我们使用CLIP-ViT-B/16、CLIP-ViTL/14和CLIP-ViT-H/14 [38]实例化CLIP4STR。表II展示了CLIP4STR的主要超参数。CLIP4STR的复现代码位于https://github.com/VamosC/CLIP4STR。
Test benchmarks The evaluation benchmarks include IIIT5K [74], CUTE80 [75], Street View Text (SVT) [76], SVTPerspective (SVTP) [77], ICDAR 2013 (IC13) [21], ICDAR 2015 (IC15) [22], and three occluded datasets – HOST,
测试基准
评估基准包括IIIT5K [74]、CUTE80 [75]、街景文本(SVT) [76]、透视街景文本(SVTP) [77]、ICDAR 2013(IC13) [21]、ICDAR 2015(IC15) [22]以及三个遮挡数据集——HOST、
WOST [78], and OCTT [14]. Additionally, we utilize 3 recent large benchmarks: COCO-Text (low-resolution, occluded text) [79], ArT (curved and rotated text) [15], and UberText (vertical and rotated text) [16].
WOST [78]和OCTT [14]。此外,我们使用了3个近期的大型基准数据集:COCO-Text(低分辨率、遮挡文本)[79]、ArT(弯曲和旋转文本)[15]以及UberText(垂直和旋转文本)[16]。
Training dataset 1) $\mathbf{MJ+SJ}$ : MJSynth (MJ, 9M samples) [58] and SynthText (ST, 6.9M samples) [59]. 2) Real(3.3M): COCO-Text (COCO) [79], RCTW17 [80], UberText (Uber) [16], ArT [15], LSVT [81], MLT19 [82], ReCTS [83], TextOCR [84], Open Images [85] annotations from the OpenVINO toolkit [86]. These real datasets have 3.3M images in total. 3) RBU(6.5M): A dataset provided by [62]. It combines the Real(3.3M), benchmark datsets (training data of SVT, IIIT5K, IC13, and IC15), and part of Union14M-L [61].
训练数据集
- $\mathbf{MJ+SJ}$:MJSynth(MJ,900万样本)[58] 和 SynthText(ST,690万样本)[59]。
- Real(330万):COCO-Text(COCO)[79]、RCTW17 [80]、UberText(Uber)[16]、ArT [15]、LSVT [81]、MLT19 [82]、ReCTS [83]、TextOCR [84]、Open Images [85](来自 OpenVINO 工具包 [86] 的标注)。这些真实数据集总计包含 330 万张图像。
- RBU(650万):由 [62] 提供的数据集,整合了 Real(330万)、基准数据集(SVT、IIIT5K、IC13 和 IC15 的训练数据)以及部分 Union14M-L [61]。
Learning strategies We apply a warm up and cosine learning rate decay policy. The batch size is kept to be close to 1024. For large models, this is achieved by gradient accumulation. For synthetic data, we train CLIP4STR-B for 6 epochs and CLIP4STR-L for 5 epochs. For RBU(6.5M) data, we train 11, 5, and 4 epochs for CLIP4STR-B, CLIP4STR-L, and CLIP4STR-H, respectively. AdamW [87] optimizer is adopted with a weight decay value 0.2. All experiments are performed with mixed precision [88].
学习策略
我们采用预热和余弦学习率衰减策略。批量大小保持在接近1024。对于大型模型,这是通过梯度累积实现的。对于合成数据,我们训练CLIP4STR-B 6个周期,CLIP4STR-L 5个周期。对于RBU(6.5M)数据,我们分别训练CLIP4STR-B、CLIP4STR-L和CLIP4STR-H 11、5和4个周期。采用AdamW [87]优化器,权重衰减值为0.2。所有实验均使用混合精度 [88]进行。
Data and label processing Rand Augment [97] excludes sharpness and invert is used with layer depth 3 and magnitude 5. The image size is $224\times224$ . The sequence length of the text encoder is 16. The maximum length of the character sequence is 25. Considering an extra [B] or [E] token, we set $N=26$ . During training, the number of character classes $C=94$ , i.e., mixed-case alphanumeric characters and punctuation marks are recognized. During inference, we only use a lowercase alphanumeric charset, i.e., $C=36$ . The iterative refinement times $T_{i}=1$ . The evaluation metric is word accuracy.
数据和标签处理
Rand Augment [97] 排除了锐度和反转操作,采用层深度3和幅度5。图像尺寸为 $224\times224$。文本编码器的序列长度为16。字符序列的最大长度为25。考虑到额外的[B]或[E] token,我们设定 $N=26$。训练时字符类别数 $C=94$(即识别大小写字母数字及标点符号),推理时仅使用小写字母数字字符集($C=36$)。迭代优化次数 $T_{i}=1$。评估指标为单词准确率。
B. Comparison to State-of-the-art
B. 与最先进技术的对比
We compare CLIP4STR with previous SOTA methods on 10 common STR benchmarks in Table III. CLIP4STR surpasses the previous methods by a significant margin, achieving new SOTA performance. Notably, CLIP4STR performs exceptionally well on irregular text datasets, such as IC15 (incidental scene text), SVTP (perspective scene text), CUTE (curved text line images), HOST (heavily occluded scene text), and WOST (weakly occluded scene text). This aligns with the examples shown in Fig. 1&2 and supports our motivation for adapting CLIP as a scene text reader, as CLIP demonstrates robust identification of regular and irregular text. CLIP4STR exhibits excellent reading ability on occluded datasets, surpassing the previous SOTA by $7.8%$ and $5.4%$ in the best case on HOST and WOST, respectively. This ability can be attributed to the pre-trained text encoder and cross-modal decoder, which can infer missing characters using text semantics or visual features. The performance of CLIP4STR is also much better than CLIP-OCR [66] and CLIPTER [65], both of which work in a similar direction as CLIP4STR. This demonstrates that directly transferring CLIP into a STR reader is more effective than the distillation method [66] or utilizing CLIP features of the global image as auxiliary context [65].
我们在表 III 中将 CLIP4STR 与之前的 SOTA (State-of-the-Art) 方法在 10 个常见 STR (Scene Text Recognition) 基准上进行了比较。CLIP4STR 以显著优势超越先前方法,实现了新的 SOTA 性能。值得注意的是,CLIP4STR 在不规则文本数据集上表现尤为突出,例如 IC15 (自然场景文本)、SVTP (透视场景文本)、CUTE (弯曲文本行图像)、HOST (严重遮挡场景文本) 和 WOST (轻微遮挡场景文本)。这与图 1&2 所示的示例一致,并支持我们将 CLIP 适配为场景文本阅读器的动机,因为 CLIP 展现出对规则和不规则文本的鲁棒识别能力。CLIP4STR 在遮挡数据集上表现出卓越的阅读能力,在 HOST 和 WOST 的最佳情况下分别超越先前 SOTA 方法 $7.8%$ 和 $5.4%$。这种能力可归因于预训练的文本编码器和跨模态解码器,它们能利用文本语义或视觉特征推断缺失字符。CLIP4STR 的性能也远优于 CLIP-OCR [66] 和 CLIPTER [65],这两种方法与 CLIP4STR 的研究方向类似。这表明直接将 CLIP 迁移为 STR 阅读器比蒸馏方法 [66] 或利用全局图像的 CLIP 特征作为辅助上下文 [65] 更有效。
TABLE III: Word accuracy on 10 common benchmarks. The best and second-best results are highlighted. Benchmark datasets (B) - SVT, IIIT5K, IC13, and IC15. ‘N/A’ for not applicable. ♯Reproduced by PARSeq [24].
表 III: 10个常见基准测试的词准确率。最佳和次佳结果已高亮显示。基准数据集 (B) - SVT、IIIT5K、IC13和IC15。"N/A"表示不适用。♯由PARSeq [24]复现。
| 方法 | 预训练数据 | 训练数据 | IIIT5K 3,000 | SVT 647 | IC13 1,015 | IC15 1,811 | IC15 2,077 | SVTP 645 | CUTE 288 | HOST 2,416 | WOST 2,416 | OCTT 1,911 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 零样本 CLIP [1] | WIT 400M [1] | N/A | 90.0 | — | — | — | — | — | — | — | — | — |
| SRN [89] | ImageNet-1K | MJ+ST | 94.8 | 91.5 | — | 82.7 | — | 85.1 | 87.8 | — | — | — |
| TextScanner [45] | N/A | MJ+ST | 95.7 | 92.7 | 94.9 | — | 83.5 | 84.8 | 91.6 | — | — | — |
| RCEED [90] | N/A | MJ+ST+B | 94.9 | 91.8 | — | — | 82.2 | 83.6 | 91.7 | — | — | — |
| TRBA [60] | N/A | MJ+ST | 92.1 | 88.9 | — | 86.0 | — | 89.3 | 89.2 | — | — | — |
| VisionLAN [78] | 从头训练 | MJ+ST | 95.8 | 91.7 | — | 83.7 | — | 86.0 | 88.5 | 50.3 | 70.3 | — |
| ABINet [9] | WikiText-103 | MJ+ST | 96.2 | 93.5 | — | 86.0 | — | 89.3 | 89.2 | — | — | — |
| ViTSTR-B [10] | ImageNet-1K | MJ+ST | 88.4 | 87.7 | 92.4 | 78.5 | 72.6 | 81.8 | 81.3 | — | — | — |
| LevOCR [49] | WikiText-103 | MJ+ST | 96.6 | 92.9 | — | 86.4 | — | 88.1 | 91.7 | — | — | — |
| MATRN [50] | WikiText-103 | MJ+ST | 96.6 | 95.0 | 95.8 | 86.6 | 82.8 | 90.6 | 93.5 | — | — | — |
| PETR [91] | N/A | MJ+ST | 95.8 | 92.4 | 97.0 | 83.3 | — | 86.2 | 89.9 | — | — | — |
| DiG-ViT-B [11] | Textimages-33M | MJ+ST | 96.7 | 94.6 | 96.9 | 87.1 | — | 91.0 | 91.3 | 74.9 | 82.3 | — |
| PARSeqA [24] | 从头训练 | MJ+ST | 97.0 | 93.6 | 96.2 | 86.5 | 82.9 | 88.9 | 92.2 | — | — | — |
| TrOCRLarge [12] | Textlines-684M | MJ+ST+B | 94.1 | 96.1 | 97.3 | 88.1 | 84.1 | 93.0 | 95.1 | — | — | — |
| SIGAT [92] | ImageNet-1K | MJ+ST | 96.6 | 95.1 | 96.8 | 86.6 | 83.0 | 90.5 | 93.1 | — | — | — |
| CLIP-OCR [66] | 从头训练 | MJ+ST | 97.3 | 94.7 | — | 87.2 | — | 89.9 | 93.1 | — | — | — |
| LISTER-B [93] | N/A | MJ+ST | 96.9 | 93.8 | — | 87.2 | — | 87.5 | 93.1 | — | — | — |
| CLIPTER [65] | N/A | Real(1.5M) | — | 96.6 | — | — | 85.9 | — | — | — | — | — |
| DiG-ViT-B [11] | Textimages-33M | Real(2.8M) | 97.6 | 96.5 | 97.6 | 88.9 | — | 92.9 | 96.5 | 62.8 | 79.7 | — |
| CCD-ViT-B [94] | Textimages-33M | Real(2.8M) | 98.0 | 97.8 | 98.3 | 91.6 | — | 96.1 | 98.3 | — | — | — |
| ViTSTR-S [10]# | ImageNet-1K | Real(3.3M) | 97.9 | 96.0 | 97.8 | 89.0 | 87.5 | 91.5 | 96.2 | 64.5 | 77.9 | 64.2 |
| ABINet [9]# | 从头训练 | Real(3.3M) | 98.6 | 98.2 | 98.0 | 90.5 | 88.7 | 94.1 | 97.2 | 72.2 | 85.0 | 70.1 |
| PARSeqA [24] | 从头训练 | Real(3.3M) | 99.1 | 97.9 | 98.4 | 90.7 | 89.6 | 95.7 | 98.3 | 74.4 | 85.4 | 73.1 |
| MAERec-B [61] | Union14M-U | Union14M-L | 98.5 | 97.8 | 98.1 | — | 89.5 | 94.4 | 98.6 | — | — | — |
| CLIP4STR-B | — | MJ+ST | 97.7 | 95.2 | 96.1 | 87.6 | 84.2 | 91.3 | 95.5 | 79.8 | 87.0 | 57.1 |
| CLIP4STR-L | WIT 400M | MJ+ST | 98.0 | 95.2 | 96.9 | 87.7 | 84.5 | 93.3 | 95.1 | 82.7 | 88.8 | 59.2 |
| CLIP4STR-B | — | Real(3.3M) | 99.2 | 98.3 | 98.3 | 91.4 | 90.6 | 97.2 | 99.3 | 77.5 | 87.5 | 81.8 |
| CLIP4STR-L | — | Real(3.3M) | 99.5 | 98.5 | 98.5 | 91.3 | 90.8 | 97.4 | 99.0 | 79.8 | 89.2 | 84.9 |
| CLIP4STR-B | DataComp-1B [95] | Real(3.3M) | 99.4 | 98.6 | 98.3 | 90.8 | 90.3 | 97.8 | 99.0 | 77.6 | 87.9 | 83.1 |
| CLIP4STR-B | — | RBU(6.5M) | 99.5 | 98.3 | 98.6 | 91.4 | 91.1 | 98.0 | 99.0 | 79.3 | 88.8 | 83.5 |
| CLIP4STR-L | — | RBU(6.5M) | 99.6 | 98.6 | 99.0 | 91.9 | 91.4 | 98.1 | 99.7 | 81.1 | 90.6 | 85.9 |
| CLIP4STR-H | DFN-5B [96] | RBU(6.5M) | 99.5 | 99.1 | 98.9 | 91.7 | 91.0 | 98.0 | 99.0 | 82.6 | 90.9 | 86.5 |
In addition to the small-scale common benchmarks, we also evaluate CLIP4STR on 3 larger and more challenging benchmarks. These benchmarks primarily consist of irregular texts with various shapes, low-resolution images, rotation, etc. The results, shown in Table IV, further demonstrate the strong generalization ability of CLIP4STR. CLIP4STR substantially outperforms the previous SOTA methods on these three large and challenging benchmarks. At the same time, we observe that scaling CLIP4STR to 1B parameters does not bring much improvement in performance. CLIP4STR-L is comparable to CLIP4STR-H in most cases, while CLIP4STR-H is superior in recognizing occluded characters (WOST, HOST, OCTT).
除了小规模通用基准测试外,我们还在3个更大、更具挑战性的基准上评估了CLIP4STR。这些基准主要包含各种形状的不规则文本、低分辨率图像、旋转等情况。表IV所示结果进一步证明了CLIP4STR强大的泛化能力。在这三个大型挑战性基准上,CLIP4STR显著优于之前的SOTA方法。同时我们观察到,将CLIP4STR扩展到10亿参数并未带来明显的性能提升。CLIP4STR-L在大多数情况下与CLIP4STR-H相当,而CLIP4STR-H在识别遮挡字符(WOST、HOST、OCTT)方面表现更优。
TABLE IV: Word accuracy on 3 large benchmarks. ♯Reproduced by PARSeq [24].
表 IV: 三大基准测试的词准确率。♯由 PARSeq [24] 复现。
| 方法 | 训练数据 | COCO 9,825 | ArT 35,149 | Uber 80,551 |
|---|---|---|---|---|
| ViTSTR-S [10]# TRBA [60]# ABINet [9]# PARSeqA [24] MPSTRA [98] | MJ+ST MJ+ST MJ+ST MJ+ST MJ+ST | 56.4 61.4 57.1 64.0 | 66.1 68.2 65.4 70.7 | 37.6 38.0 34.9 42.0 |
| CLIP-OCR [66] CLIP4STR-B CLIP4STR-L | MJ+ST MJ+ST MJ+ST | 64.5 66.5 66.3 | 69.9 70.5 72.8 | 42.8 42.4 43.4 |
| DiG-ViT-B [11] ViTSTR-S [10]# | Real(2.8M) Real(3.3M) Real(3.3M) | 67.0 75.8 73.6 | 73.7 | 44.5 |
| TRBA [60]# | 77.5 | 81.0 82.5 | 78.2 81.2 | |
| ABINet [9]# PARSeqA [24] | Real(3.3M) | 76.5 | 81.2 | 71.2 |
| MPSTRA [98] CLIP4STR-B CLIP4STR-L | Real(3.3M) Real(3.3M) Real(3.3M) | 79.8 80.3 81.1 | 84.5 84.4 | 84.1 84.9 |
V. EMPIRICAL STUDY
V. 实证研究
This section presents our empirical study on adapting CLIP to STR. Without mention, the models are all trained on $3.3\mathbf{M}$
本节介绍我们在将CLIP模型适配到STR任务上的实证研究。除非特别说明,所有模型均在$3.3\mathbf{M}$数据量上训练。
TABLE V: Ablation study of different components of CLIP4STR. PSM is short for the permuted sequence modeling technique [24]. Recipe represents the training recipe for CLIP4STR in $\S\mathrm{IV}{-}\mathrm{A}$ . Cross denotes the cross-modal branch. [CLASS] with a ✓mark means the decoders only use the [CLASS] and [EOS] of CLIP encoders rather than features of all tokens (refer to $\S\mathrm{III{-A},}$ .
表 V: CLIP4STR 不同组件的消融研究。PSM 是排列序列建模技术 (permuted sequence modeling technique) [24] 的缩写。Recipe 表示 CLIP4STR 在 $\S\mathrm{IV}{-}\mathrm{A}$ 中的训练方案。Cross 表示跨模态分支。带 ✓ 标记的 [CLASS] 表示解码器仅使用 CLIP 编码器的 [CLASS] 和 [EOS] 而非所有 token 的特征 (参见 $\S\mathrm{III{-A},}$)。
| 参考方法 | 平均 | |||||
|---|---|---|---|---|---|---|
| ABINet [9] | 89.1 | |||||
| PARSeqA[24] | (先前SOTA) | 89.9 | ||||
| Base | PSM ViT-B | Recipe | Cross | [CLASS] | ViT-L | 平均 |
| 89.2 | ||||||
| 89.9 | ||||||
| ← | 90.0 | |||||
| √ | 90.8 | |||||
| × | √ | 90.0 | ||||
| < | 90.6 | |||||
| √ | 91.2 | |||||
| 91.9 |
real data, and the IC15 dataset here contains 2,077 samples. The average accuracy reported in this section is calculated over the first 9 benchmarks (14,315 samples) in Table III.
真实数据,此处使用的IC15数据集包含2077个样本。本节报告的平均准确率是基于表III中前9个基准测试(14315个样本)计算得出。
A. Ablation Study of CLIP4STR
A. CLIP4STR 消融研究
Table III&IV show that CLIP4STR achieves SOTA performance on 11 STR benchmarks. What are the sources of this high performance? We conduct ablation studies of different components in Table V, starting with the visual branch in Fig. 3 as the baseline (accuracy $89.2%$ ). The encoder is a ViTS without pre-training. Then we apply the permuted sequence modeling (PSM) technique [24] to the visual decoder and follow the training recipe of PARSeq: $4\times8$ patch size, the same learning rate for the encoder and decoder, and 20 training epochs. This brings a $0.7%$ improvement in accuracy. Next, we replace the encoder with the image encoder of CLIPViT-B/16. However, no significant gain is observed without adaptations. To unleash the potential of CLIP, we adjust the training recipe: using $16\times16$ patch size, a small learning rate for CLIP encoders, a relatively large learning rate for decoders, and fewer training epochs — 16 (§IV-A). The learning rate is searched automatically by Ray [99], and the best number of training epochs is decided by manual test. CLIP makes the model converge easier and faster, so the training recipe should change accordingly. To better grasp the contribution of PSM, we conducted an experiment where we removed PSM and achieved an accuracy of $90.0%$ .
表 III 和表 IV 显示,CLIP4STR 在 11 个 STR 基准测试中达到了 SOTA (state-of-the-art) 性能。这种高性能的来源是什么?我们在表 V 中对不同组件进行了消融研究,以图 3 中的视觉分支作为基线(准确率 $89.2%$)。编码器是一个未经预训练的 ViTS。然后,我们将置换序列建模 (PSM) 技术 [24] 应用于视觉解码器,并遵循 PARSeq 的训练方案:$4\times8$ 的补丁大小、编码器和解码器相同的学习率以及 20 个训练周期。这使得准确率提高了 $0.7%$。接下来,我们将编码器替换为 CLIPViT-B/16 的图像编码器。然而,在没有调整的情况下,没有观察到显著的增益。为了释放 CLIP 的潜力,我们调整了训练方案:使用 $16\times16$ 的补丁大小、对 CLIP 编码器使用较小的学习率、对解码器使用相对较大的学习率以及更少的训练周期——16 个(§IV-A)。学习率通过 Ray [99] 自动搜索,最佳训练周期数通过手动测试确定。CLIP 使模型更容易且更快地收敛,因此训练方案应相应调整。为了更好地理解 PSM 的贡献,我们进行了一项实验,移除了 PSM 并达到了 $90.0%$ 的准确率。
Although the performance of the visual branch is already very high $(90.8%)$ , the cross-modal branch further improves the accuracy by $0.4%$ , demonstrating its effectiveness. It is worth noting that utilizing CLIP features of all patches is crucial for character recognition. Only using the [CLASS] and [EOS] results in inferior performance – $90.6%$ . Moreover, the use of a large model — CLIP-ViT-L/14 further increases the accuracy by $0.7%$ . The large CLIP-ViT-L/14 converges faster than CLIP-ViT-B/16 for STR. It only requires 10 epochs of training on the Real(3.3M) data, much less than the training epochs of CLIP-ViT-B/16.
尽管视觉分支的性能已经非常高 $(90.8%)$ ,但跨模态分支进一步将准确率提升了 $0.4%$ ,证明了其有效性。值得注意的是,利用所有图像块 (patch) 的 CLIP 特征对字符识别至关重要。仅使用 [CLASS] 和 [EOS] 会导致性能下降至 $90.6%$ 。此外,使用大模型 CLIP-ViT-L/14 还能将准确率提高 $0.7%$ 。对于 STR 任务,大型 CLIP-ViT-L/14 比 CLIP-ViT-B/16 收敛更快,仅需在 Real(3.3M) 数据上训练 10 个周期,远少于 CLIP-ViT-B/16 所需的训练周期。
TABLE VI: Freezing options in CLIP4STR-B. #Params means the number of learnable parameters of encoders in CLIP4STR-B. One decoder in CLIP4STR-B has 4.3M parameters. token means we only use pre-trained token embeddings of CLIP text encoder as text features.
表 VI: CLIP4STR-B 中的冻结选项。#Params 表示 CLIP4STR-B 中编码器的可学习参数量。CLIP4STR-B 的一个解码器有 4.3M 参数。token 表示我们仅使用 CLIP 文本编码器的预训练 token 嵌入作为文本特征。
| 冻结层数 | 文本层数 | 参数量 | IC15 | WOST | HOST | COCO | Uber |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 149 M | 90.8 | 87.5 | 76.4 | 80.8 | 87.0 |
| 0 | 3 | 114 M | 90.4 | 88.1 | 76.9 | 81.2 | 86.8 |
| 0 | 6 | 104 M | 90.6 | 87.5 | 77.5 | 81.1 | 86.8 |
| 0 | 9 | 95 M | 90.3 | 86.8 | 74.9 | 80.9 | 86.3 |
| 0 | 12 | 86 M | 90.3 | 86.1 | 74.9 | 80.9 | 86.4 |
| 0 | token | 86 M | 90.7 | 87.3 | 77.0 | 80.9 | 86.7 |
| 0 | 6 | 95 M | 90.6 | 87.5 | 77.5 | 81.1 | 86.8 |
| 3 | 6 | 84 M | 90.4 | 88.5 | 76.5 | 81.3 | 86.4 |
| 6 | 6 | 62 M | 89.5 | 86.7 | 72.8 | 80.3 | 83.8 |
| 9 | 6 | 41 M | 87.8 | 80.0 | 64.0 | 75.3 | 72.8 |
| 12 | 6 | 19 M | 61.2 | 55.8 | 40.4 | 49.5 | 20.6 |
B. Parameter Freezing Options
B. 参数冻结选项
In CLIP4STR, we freeze half of the layers in the CLIP text encoder, which is a common practice when transferring a large language model to new tasks [72]. Table VI illustrates the influence of different parameter freezing options. The results indicate that freezing the language model has a lesser impact compared to freezing the image model. Despite using the fixed pre-trained token embeddings of the CLIP text encoder, the system can still achieve satisfactory performance. This demonstrates that semantic understanding in STR is relatively easier compared to general language understanding. In STR, text mainly consists of words and phrases, which simplifies the task compared to the general language case. On the other hand, freezing the image models has a significant impact on performance. The substantial domain gap between the data in STR and the pre-trained data of the CLIP image encoder possibly contributes to this discrepancy. CLIP is pretrained on web images, which are primarily natural images. In contrast, the scene text recognition data comprises cropped word images. Such a disparity may necessitate a fully trainable image encoder in CLIP4STR to bridge the domain gap.
在CLIP4STR中,我们冻结了CLIP文本编码器的一半层数,这是将大语言模型迁移至新任务时的常见做法[72]。表VI展示了不同参数冻结方案的影响。结果表明,与冻结图像模型相比,冻结语言模型的影响较小。尽管使用了CLIP文本编码器固定的预训练token嵌入,系统仍能取得令人满意的性能。这说明STR中的语义理解相比通用语言理解相对更容易。在STR中,文本主要由单词和短语构成,相比通用语言场景简化了任务。另一方面,冻结图像模型会对性能产生显著影响。STR数据与CLIP图像编码器预训练数据之间的显著领域差异可能是造成这种差距的原因。CLIP是在网络图像(主要是自然图像)上预训练的,而场景文本识别数据由裁剪后的单词图像组成。这种差异可能需要CLIP4STR中完全可训练的图像编码器来弥合领域差距。
C. Comparison to Single-modality Pre-trained Model
C. 与单模态预训练模型的对比
In previous empirical studies, we see the effectiveness of CLIP as a STR backbone. Is VLM better than models pre-trained on single-modality data? To further clarify this question, Table VII presents the results of replacing the visual encoder in Fig. 3 with a random initialized ViT, an ImageNet1K [100] pre-trained ViT via DeiT $[101]^{3}$ , and an ImageNet21K pre-trained ViT provided by Ridnik et al. [102]. The training schedules including the learning rate and training epochs are kept the same as CLIP4STR. In Table VII, the ImageNet pre-trained models even perform worse than the model trained from scratch. Previous works also support this finding. PARSeq [24] trains its vision transformer from scratch rather than using a pre-trained model. TrOCR [12] uses pre-trained transformers from DeiT [101], BEiT [103],
在之前的实证研究中,我们观察到CLIP作为STR(场景文本识别)骨干网络的有效性。那么,视觉语言模型(VLM)是否优于单模态数据预训练的模型?为了进一步阐明这个问题,表VII展示了将图3中的视觉编码器替换为随机初始化的ViT、通过DeiT $[101]^{3}$ 预训练的ImageNet1K [100] ViT,以及Ridnik等人[102]提供的ImageNet21K预训练ViT的结果。训练计划(包括学习率和训练周期)与CLIP4STR保持一致。在表VII中,ImageNet预训练模型的表现甚至不如从头开始训练的模型。先前的研究也支持这一发现:PARSeq [24]选择从头训练其视觉Transformer而非使用预训练模型,TrOCR [12]则采用了来自DeiT [101]和BEiT [103]的预训练Transformer。
TABLE VII: Different pre-training strategies. #Params means the learnable parameters in the visual encoder. For a fair comparison, only the results of the visual branch in CLIP4STR-B are shown.
表 VII: 不同预训练策略对比。#Params 表示视觉编码器中的可学习参数量。为公平比较,仅展示 CLIP4STR-B 视觉分支的结果。
| Pre-train | #Params | IC15 | WOST | HOST | COCO | Uber |
|---|---|---|---|---|---|---|
| Scratch | 86 M | 90.1 | 84.9 | 74.8 | 80.7 | 86.6 |
| ImageNet-1K | 86 M | 89.7 | 82.7 | 68.7 | 80.0 | 84.0 |
| ImageNet-21K | 86 M | 89.3 | 83.1 | 69.1 | 79.6 | 82.9 |
| Image-text pairs | 86 M | 90.3 | 87.4 | 76.3 | 80.9 | 86.6 |
TABLE VIII: Parameter-efficient adaptations. #Params means the learnable parameters in the visual encoder. $r$ is the feature reduction ratio in LST. Here we only show the results of the visual branch in CLIP4STR-B, and the crossmodal branch is ignored.
表 VIII: 参数高效适配方案。#Params 表示视觉编码器中的可学习参数。$r$ 是 LST 中的特征降维比率。此处仅展示 CLIP4STR-B 视觉分支的结果,跨模态分支未列入统计。
| 方法 | 参数量 | IC15 | WOST | HOST | COCO | Uber |
|---|---|---|---|---|---|---|
| Frozen | 0 | 60.9 | 54.8 | 39.9 | 48.9 | 20.1 |
| CLIP-Adapter | 262 K | 63.6 | 57.2 | 41.1 | 50.9 | 22.7 |
| LST (r = 4) | 4.1M | 88.2 | 82.8 | 66.1 | 77.1 | 78.7 |
| LST (r = 2) | 13.1M | 89.6 | 86.0 | 70.8 | 79.6 | 80.6 |
| Fine-tune | 86 M | 90.3 | 87.4 | 76.3 | 80.9 | 86.6 |
and RoBERTa [104], but it still post-pretrains them on $684\mathbf{M}$ textlines from publicly available PDF files on the Internet.
RoBERTa [104],但仍对来自互联网公开PDF文件的6.84亿文本行进行了后预训练。
ImageNet classification pre-training does not align well with STR. Classifying objects in an image does not help the model learn specific information about the text within the image. For example, two images – one of a cat and one of a dog – both containing the text “park” cause the model to learn contradictory information about the same text. In contrast, the vision encoders in CLIP can accurately perceive text signals due to the presence of multi-modal neurons [20] (§II-A), making CLIP a strong backbone for STR.
ImageNet分类预训练与STR(场景文本识别)任务匹配度不高。图像中的物体分类无法帮助模型学习图片内文本的特定信息。例如两张分别包含猫和狗的图片若都带有"park"文字,会导致模型对相同文本学习到矛盾信息。相比之下,CLIP中的视觉编码器由于具备多模态神经元20,能准确感知文本信号,这使CLIP成为STR任务的强效主干网络。
D. Parameter-efficient Adaptations
D. 参数高效适配
CLIP4STR fine-tunes the whole pre-trained CLIP model to transfer the knowledge of CLIP to the STR task. Besides such a fully fine-tuning manner, the parameter-efficient finetuning (PEFT) methods for large pre-trained models are also popular. For example, CoOp [105] only trains several learnable prefix prompts for efficiency, and CLIP-Adapter [106] incorporates tunable linear layers on top of frozen VLMs. These PEFT methods achieve pretty good performance on a few tasks, so we wonder if such PEFT methods work for STR.
CLIP4STR对整个预训练的CLIP模型进行微调,将CLIP的知识迁移到STR任务中。除了这种完全微调方式外,针对大型预训练模型的参数高效微调(PEFT)方法也颇受欢迎。例如CoOp [105]仅训练少量可学习的前缀提示词以提升效率,CLIP-Adapter [106]则在冻结的视觉语言模型(VLM)顶部加入可调线性层。这些PEFT方法在少量任务上取得了相当好的性能,因此我们想知道此类方法是否适用于STR任务。
We test CLIP with two PEFT methods in this work, i.e., CLIP-Adapter [106] and Ladder Side-Tuning (LST) adapter [107]. Fig. 5 shows the design of the two adapters. CLIP-Adapter adds two linear layers on the top of the frozen pre-trained VLM. We use the same architecture as [106]: a residual addition ratio $\lambda=0.2$ , which means that the original CLIP feature is multiplied by 0.8. Ladder Side-Tuning (LST) uses a ladder side network as shown in Fig. 5. Following [107], we use the structure-pruned [108] CLIP model as the ladder side network. The CLIP features are down sampled by a factor of $1/r$ before entering the ladder side network to reduce the computation cost, and then upsampled by a factor of $r$ before output to match the original feature dimension. We also use the layer-dropping strategy in LST, which connects only the layers $[2,4,6,8,10,12]$ to the ladder side network, namely, the depth of LST is 6. This reduces the training cost.
我们在本工作中测试了CLIP与两种参数高效微调(PEFT)方法的结合效果,即CLIP-Adapter [106]和阶梯侧调(LST)适配器[107]。图5展示了两种适配器的设计结构。CLIP-Adapter在冻结的预训练VLM顶部添加了两个线性层,采用与[106]相同的架构:残差叠加比例$\lambda=0.2$,表示原始CLIP特征会乘以0.8。阶梯侧调(LST)采用如图5所示的阶梯侧边网络结构,依照[107]的做法,我们使用结构剪枝[108]后的CLIP模型作为阶梯侧边网络。CLIP特征在进入阶梯侧边网络前会经过$1/r$倍降采样以降低计算成本,输出时再通过$r$倍上采样恢复原始特征维度。LST中还采用了层级丢弃策略,仅将$[2,4,6,8,10,12]$层连接到阶梯侧边网络,即LST深度为6,这有效降低了训练成本。

Fig. 5: CLIP-Adapter (left) and LST (right).
图 5: CLIP-Adapter (左) 和 LST (右)。
The results of using the two adapters with CLIP in STR are presented in Table VIII. CLIP-Adapter outperforms the frozen model but falls short of the performance achieved by the fully fine-tuned model. The addition of a few learnable parameters on top of the CLIP model alone is insufficient to bridge the domain gap between scene text data and the pretraining data of CLIP. On the other hand, LST achieves notably improved performance but still lags behind the fine-tuned model. However, when the parameters of LST are increased, it approaches the performance of the fine-tuned model. Overall, LST can serve as an alternative option when computational resources are limited for training.
表 VIII 展示了在STR任务中使用两种适配器与CLIP结合的效果。CLIP-Adapter表现优于冻结模型,但未达到全微调模型的水平。仅在CLIP模型顶部添加少量可学习参数,不足以弥合场景文本数据与CLIP预训练数据之间的领域差距。另一方面,LST取得了显著提升的性能,但仍落后于微调模型。不过当增加LST参数规模时,其性能接近微调模型。总体而言,在计算资源有限的情况下,LST可作为训练备选方案。
E. Inference Time
E. 推理时间
Despite the good performance, adapting the pre-trained CLIP model introduces extra training and inference costs due to its large size. Table IX presents the inference time of CLIP4STR. The large transformer models slow down the inference speed of CLIP4STR. However, using a large ViT does not always improve accuracy, as Table VII shows, because of different pre-training strategies. The cross-modal branch also increases the inference time, but slightly ${(0.49\mathrm{ms)}}$ , since the input sequence length of the text encoder is small (16, as explained in $\S_{\mathrm{{IV-A})}}$ . Moreover, we can reduce the inference time of the cross-modal branch by replacing line $10{\sim}13$ in Alg. 1 with
尽管性能良好,但由于预训练 CLIP 模型体积庞大,对其进行适配会引入额外的训练和推理成本。表 IX 展示了 CLIP4STR 的推理时间。大型 Transformer 模型降低了 CLIP4STR 的推理速度。然而,如表 VII 所示,由于预训练策略不同,使用大型 ViT 并不总能提高准确率。跨模态分支也略微增加了推理时间 ${(0.49\mathrm{ms)}}$ ,因为文本编码器的输入序列长度较短 (如 $\S_{\mathrm{{IV-A})}}$ 所述,长度为 16)。此外,我们可以通过将算法 1 中第 $10{\sim}13$ 行替换为...来减少跨模态分支的推理时间。
$$
\pmb{y}\leftarrow\mathsf{D e c}^{c}(\pmb{p}^{c},\pmb{c},\mathcal{M}^{a},\pmb{F}_{c}).
$$
$$
\pmb{y}\leftarrow\mathsf{D e c}^{c}(\pmb{p}^{c},\pmb{c},\mathcal{M}^{a},\pmb{F}_{c}).
$$
Eq. (8) uses the prediction of the visual branch as the input context instead of the previous prediction of the cross-modal
式 (8) 使用视觉分支的预测作为输入上下文,而不是跨模态的先前预测。
TABLE IX: Inference time of CLIP4STR. AR stands for auto regressive decoding, and cloze stands for cloze-filling decoding manner (refer to Table I). Iter. is the number of refinement steps during decoding. Time is the average inference time per sample on a single NVIDIA A100 40GB.
表 IX: CLIP4STR的推理时间。AR表示自回归解码,cloze表示填空式解码方式(参见表 I)。Iter.是解码过程中的细化步骤数。Time是单个NVIDIA A100 40GB上每个样本的平均推理时间。
| 方法 | 主干网络 | 解码方式 | Iter. | 平均 | 时间(ms) |
|---|---|---|---|---|---|
| ABINet [9] | ResNet-45 | Cloze | 1 | 89.1 | 1.30 |
| PARSeq [24] | ViT-S | AR | 1 | 89.9 | 1.32 |
| PARSeq[24] | ViT-B | AR | 1 | 90.0 | 2.81 |
| CLIP4STR-B (Visual) | ViT-B | Cloze | 1 | 89.8 | 2.73 |
| CLIP4STR-B (Visual) | ViT-B | AR | 1 | 90.8 | 3.03 |
| CLIP4STR-B (Cross) | ViT-B | AR | 1 | 91.2 | 3.52 |
| CLIP4STR-B (Cross) | ViT-B | AR + Eq. (8) | 1 | 91.1 | 3.41 |
| CLIP4STR-B (Cross) | ViT-B | AR | 2 | 91.2 | 3.72 |
| CLIP4STR-B (Cross) | ViT-B | AR | 3 | 91.2 | 3.85 |
| CLIP4STR-L (Cross) | ViT-L | AR | 1 | 91.9 | 6.52 |
TABLE X: Word accuracy on cleaned benchmarks. Mislabeled samples in blue benchmarks are cleaned by Yang et al. [98]. All methods are trained on $3.3\mathbf{M}$ real samples. The best results are highlighted.
表 X: 清洗后基准测试的词准确率。蓝色基准测试中误标记样本由Yang等人[98]清洗。所有方法均在 $3.3\mathbf{M}$ 个真实样本上训练。最佳结果已高亮标注。
| 方法 | IIIT5K 3,000 | SVT 647 | IC13 1,015 | IC15 1,811 | IC15 2,077 | SVTP 645 | CUTE 288 |
|---|---|---|---|---|---|---|---|
| ABINet [9]# | 98.6 | 97.8 | 98.0 | 93.2 | 91.4 | 94.7 | 97.2 |
| PARSeqA [24] | 98.9 | 97.5 | 98.5 | 93.8 | 92.6 | 95.7 | 98.6 |
| MPSTRA [98] | 99.2 | 98.5 | 98.3 | 93.9 | 92.7 | 96.1 | 99.0 |
| CLIP4STR-B | 99.2 | 97.8 | 98.4 | 94.1 | 93.3 | 97.4 | 99.3 |
| CLIP4STR-L | 99.4 | 97.8 | 98.6 | 94.0 | 93.5 | 97.4 | 99.0 |
branch, avoiding repeated runs of the cross-modal decoder. However, this slightly decreases the performance. The ViTL backbone also increases the inference time. Clearly, for CLIP4STR, there is a trade-off between recognition accuracy and inference speed. Besides, Table IX also shows that more iterative refinement times (a large $T_{i}$ at line 14 in Alg. 1) will not bring further improvement in accuracy, so we just set $T_{i}=1$ in practice.
分支,避免了跨模态解码器的重复运行。然而,这会略微降低性能。ViTL主干网络也会增加推理时间。显然,对于CLIP4STR来说,识别准确率和推理速度之间存在权衡。此外,表IX还显示,更多的迭代细化次数(算法1第14行中的较大$T_{i}$)不会带来进一步的准确率提升,因此我们在实践中仅设置$T_{i}=1$。
F. Qualitative results
F. 定性结果
Fig. 6 shows qualitative results of CLIP4STR on IC15 (incidental text), SVTP (perspective text), CUTE (curved text), and HOST (heavily occluded). CLIP4STR can robustly read scene text that is curved, occluded, blurred, or rotated, showing its great robustness. Meanwhile, we find that CLIP4STR has a strong ability to complement incomplete characters. In the last two cases in Fig. 6, CLIP4STR predicts an additional “n” character. This capability may stem from the semantic understanding of the pre-trained CLIP model. However, the accuracy of this complement is uncertain, and we currently cannot control this behavior in CLIP4STR.
图 6: 展示了 CLIP4STR 在 IC15 (场景文本)、SVTP (透视文本)、CUTE (弯曲文本) 和 HOST (严重遮挡文本) 上的定性结果。CLIP4STR 能够稳健地识别弯曲、遮挡、模糊或旋转的场景文本,展现出极强的鲁棒性。同时,我们发现 CLIP4STR 具备补全不完整字符的强大能力。在图 6 的最后两个案例中,CLIP4STR 额外预测了一个字母 "n"。这种能力可能源于预训练 CLIP 模型的语义理解能力。然而,这种补全的准确性尚不确定,且目前我们无法在 CLIP4STR 中控制这一行为。
G. Results on Cleaned Benchmarks
G. 基准测试清洗后的结果
Recently, Yang et al. [98] correct the ground truth of mislabeled samples and present cleaned versions of IIIT5K, SVT, IC13, IC15, SVTP, and CUTE. Table X shows the results of CLIP4STR on these cleaned benchmarks. CLIP4STR still achieves SOTA performance on these cleaned benchmarks.
最近,Yang等人[98]修正了错误标注样本的真实标签,并提供了IIIT5K、SVT、IC13、IC15、SVTP和CUTE的清洗版本。表X展示了CLIP4STR在这些清洗后基准测试上的结果。CLIP4STR在这些清洗后的基准上仍保持了最先进的性能。

Fig. 6: Qualitative results of CLIP4STR-B.
图 6: CLIP4STR-B的定性结果
VI. CONCLUSION
VI. 结论
We present CLIP4STR, a method that leverages CLIP for STR. It has a dual encoder-decoder architecture: a visual branch for initial prediction and a cross-modal branch for refinement. CLIP4STR achieves state-of-the-art results on 13 STR benchmarks, showing that CLIP is a powerful scene text reader and that vision-language pre-training benefits STR. We also conduct a comprehensive empirical study to explain how CLIP adapts to STR. We hope CLIP4STR can serve as a simple but strong baseline for future STR research with VLMs.
我们提出了CLIP4STR方法,该方法利用CLIP进行场景文本识别(STR)。它采用双编码器-解码器架构:视觉分支用于初始预测,跨模态分支用于结果优化。CLIP4STR在13个STR基准测试中取得了最先进的结果,表明CLIP是强大的场景文本阅读器,且视觉语言预训练对STR有益。我们还进行了全面的实证研究,以解释CLIP如何适应STR任务。我们希望CLIP4STR能作为未来基于视觉语言模型(VLM)的STR研究的简单而强大的基线。
APPENDIX A DETAIL EXPLANATION OF THE INFERENCE PROCESS
附录 A 推理过程的详细说明
Here we provide an explanation of the inference process in Alg. 1. Given an image ${x}$ , the initial step involves obtaining the image feature $\begin{array}{r}{F_{i}\gets h(\pmb{x})}\end{array}$ . This image feature $F_{i}$ is then forwarded to the visual decoder to generate the visual prediction ${\pmb y}^{i}$ , with the blank context (denoted as token [B]) serving as the initial condition (line 1). Subsequently, the visual decoder operates in an auto regressive manner, utilizing previous predictions as context for subsequent ones (lines 4- 7). Once the prediction is obtained from the visual branch, the linguistic feature is derived by inputting the visual prediction ${\pmb y}^{i}$ along with the cross-model feature $F_{c}$ into the text encoder (line 8). Similar to the decoding process of the visual decoder, the cross-modal decoder generates predictions $\pmb{y}$ in an auto regressive fashion (lines 10–13). Upon acquiring predictions ${\boldsymbol y}^{i}$ and $\pmb{y}$ , they are employed to update the context $_c$ during the refinement process (lines 15 and 18). Notably, while the decoder previously produced ${\pmb y}^{i}$ and $\pmb{y}$ in an auto regressive manner, a different approach is adopted in lines 14–20, where a cloze mask is utilized. This entails providing information about other characters in the word as context when predicting a certain character. For further insights into the workings of auto regressive and cloze masks, please refer to Table I.
此处对算法1中的推理过程进行说明。给定图像$x$,首先获取图像特征$\begin{array}{r}{F_{i}\gets h(\pmb{x})}\end{array}$。该图像特征$F_{i}$被送入视觉解码器生成视觉预测${\pmb y}^{i}$,并以空白上下文(标记为token [B])作为初始条件(第1行)。随后视觉解码器以自回归(auto regressive)方式运行,将先前的预测结果作为后续预测的上下文(第4-7行)。从视觉分支获得预测后,通过将视觉预测${\pmb y}^{i}$与跨模态特征$F_{c}$输入文本编码器来获取语言特征(第8行)。与视觉解码过程类似,跨模态解码器以自回归方式生成预测$\pmb{y}$(第10-13行)。获得预测${\boldsymbol y}^{i}$和$\pmb{y}$后,它们被用于在精炼过程中更新上下文$_c$(第15和18行)。值得注意的是,虽然解码器先前以自回归方式生成${\pmb y}^{i}$和$\pmb{y}$,但在第14-20行采用了不同的方法——使用完形填空掩码(cloze mask)。该方法在预测某个字符时,会提供单词中其他字符的信息作为上下文。关于自回归和完形填空掩码的详细说明,请参阅表1。
TABLE XI: Comparison with auto regressive pre-training methods. Rang et al. [62] train CLIP4STR on RBEUSyn(23.8M). The best and second-best results are highlighted.
表 XI: 自回归预训练方法对比。Rang等[62]在RBEUSyn(23.8M)上训练CLIP4STR。最优与次优结果已高亮。
| 方法 | 预训练数据 | IIIT5K 3,000 | SVT 647 | IC13 1,015 | IC15 1,811 | IC15 2,077 | SVTP 645 | CUTE 288 |
|---|---|---|---|---|---|---|---|---|
| TrOCR [12] | Textlines-684M | 94.1 | 96.1 | 97.3 | 88.1 | 84.1 | 93.0 | 95.1 |
| DTrOCR [55] | Textlines-6B | 99.6 | 98.9 | 99.4 | 93.5 | 93.2 | 98.6 | 99.1 |
| CLIP4STR-B [62] | WIT-400M | 99.0 | 98.8 | - | 92.3 | - | 97.8 | 99.7 |
| CLIP4STR-L[62] | WIT-400M | 99.1 | 98.6 | - | 92.6 | - | 98.1 | 99.7 |
| CLIP4STR-B | DataComp-1B | 99.5 | 98.3 | 98.6 | 91.4 | 91.1 | 98.0 | 99.0 |
| CLIP4STR-L | DataComp-1B | 99.6 | 98.6 | 99.0 | 91.9 | 91.4 | 98.1 | 99.7 |
| CLIP4STR-H | DFN-5B | 99.5 | 99.1 | 98.9 | 91.7 | 91.0 | 98.0 | 99.0 |
APPENDIX B DISCUSSION WITH AUTO REGRESSIVE PRE-TRAINING
附录 B 自回归预训练的讨论
Another pre-training task for STR is auto regressive language modeling, such as TrOCR [12] and DTrOCR [55]. These models take the image as input and are optimized by predicting the next tokens based on the previous context during pre-training, similar to the GPT language models [109]. Table XI presents a comparison between CLIP4STR and auto regressive pre-training methods. DTrOCR, pre-trained on 6B textlines, surpasses CLIP4STR on IC13, IC15, and SVTP, demonstrating the effectiveness of large-scale auto regressive pre-training. However, the difference between performance on these three benchmarks is trivial, and CLIP4STR performs better on III5K, SVT, and CUTE. Overall, CLIP4STR and DTrOCR are two comparable methods. In such a case, CLIP4STR has two additional merits to be a more practical STR method: 1) Numerous large-scale pre-trained VLMs are publicly available, eliminating the cost of pre-training for CLIP4STR. Additionally, the cost of transferring CLIP into a STR reader is affordable, as shown in Table II. In contrast, the cost of pre-training DTrOCR on 6 billion textlines is prohibitive. 2) CLIP4STR is open-sourced and easy to reproduce, while DTrOCR is closed-sourced. Moreover, CLIP4STR offers a thorough empirical study on adapting CLIP to STR, which is valuable for subsequent STR methods based on VLMs.
STR的另一项预训练任务是自回归语言建模,例如TrOCR [12]和DTrOCR [55]。这些模型以图像作为输入,在预训练期间通过基于先前上下文预测下一个token进行优化,类似于GPT语言模型 [109]。表XI展示了CLIP4STR与自回归预训练方法的对比。在60亿文本行上预训练的DTrOCR在IC13、IC15和SVTP上超越了CLIP4STR,证明了大尺度自回归预训练的有效性。然而,这三个基准测试的性能差异微乎其微,而CLIP4STR在III5K、SVT和CUTE上表现更优。总体而言,CLIP4STR和DTrOCR是两种可比的方法。在这种情况下,CLIP4STR具有两个额外优势,使其成为更实用的STR方法:1) 大量大规模预训练视觉语言模型(VLM)已公开可用,消除了CLIP4STR的预训练成本。此外,如表II所示,将CLIP迁移为STR阅读器的成本可控。相比之下,在60亿文本行上预训练DTrOCR的成本令人望而却步。2) CLIP4STR已开源且易于复现,而DTrOCR未开源。更重要的是,CLIP4STR提供了关于将CLIP适配到STR的全面实证研究,这对后续基于VLM的STR方法具有重要价值。