Extracting Training Data from Large Language Models
从大语言模型中提取训练数据
Nicholas Carlini1 Florian Tramèr2 Eric Wallace3 Matthew Jagielski4 Ariel Herbert-Voss5,6 Katherine Lee1 Adam Roberts1 Tom Brown5 Dawn Song3 Úlfar Erling s son 7 Alina Oprea4 Colin Raffel1 1Google 2Stanford 3UC Berkeley 4 Northeastern University 5OpenAI 6Harvard 7Apple
Nicholas Carlini1 Florian Tramèr2 Eric Wallace3 Matthew Jagielski4 Ariel Herbert-Voss5,6 Katherine Lee1 Adam Roberts1 Tom Brown5 Dawn Song3 Úlfar Erling s son 7 Alina Oprea4 Colin Raffel1 1谷歌 2斯坦福大学 3加州大学伯克利分校 4东北大学 5OpenAI 6哈佛大学 7苹果公司
Abstract
摘要
It has become common to publish large (billion parameter) language models that have been trained on private datasets. This paper demonstrates that in such settings, an adversary can perform a training data extraction attack to recover individual training examples by querying the language model.
在私有数据集上训练的大型(数十亿参数)语言模型已变得普遍。本文证明,在此类场景下,攻击者可通过查询语言模型执行训练数据提取攻击,以恢复单个训练样本。
We demonstrate our attack on GPT-2, a language model trained on scrapes of the public Internet, and are able to extract hundreds of verbatim text sequences from the model’s training data. These extracted examples include (public) personally identifiable information (names, phone numbers, and email addresses), IRC conversations, code, and 128-bit UUIDs. Our attack is possible even though each of the above sequences are included in just one document in the training data.
我们以GPT-2(一个基于公开互联网数据训练的大语言模型)为攻击对象进行演示,成功从模型训练数据中提取出数百条逐字文本序列。这些被提取的样本包含:(公开的)个人身份信息(姓名、电话号码和电子邮件地址)、IRC聊天记录、代码片段以及128位UUID。值得注意的是,即便上述每条序列在训练数据中仅出现于单个文档,我们的攻击依然能够实现。
We comprehensively evaluate our extraction attack to understand the factors that contribute to its success. Worryingly, we find that larger models are more vulnerable than smaller models. We conclude by drawing lessons and discussing possible safeguards for training large language models.
我们全面评估了提取攻击以了解其成功的关键因素。令人担忧的是,我们发现模型规模越大越容易受到攻击。最后我们总结了经验教训,并探讨了大语言模型训练中可能的安全防护措施。
1 Introduction
1 引言
Language models (LMs)—statistical models which assign a probability to a sequence of words—are fundamental to many natural language processing tasks. Modern neural-networkbased LMs use very large model architectures (e.g., 175 billion parameters [7]) and train on massive datasets (e.g., nearly a terabyte of English text [55]). This scaling increases the ability of LMs to generate fluent natural language [53, 74, 76], and also allows them to be applied to a plethora of other tasks [29, 39, 55], even without updating their parameters [7].
语言模型 (LMs) ——为词序列分配概率的统计模型——是许多自然语言处理任务的基础。现代基于神经网络的LMs采用超大规模模型架构 (例如1750亿参数 [7]) 并在海量数据集上训练 (例如近1TB英文文本 [55])。这种规模化提升了LMs生成流畅自然语言的能力 [53, 74, 76],还使其能够应用于众多其他任务 [29, 39, 55],甚至无需更新参数 [7]。
At the same time, machine learning models are notorious for exposing information about their (potentially private) training data—both in general [47, 65] and in the specific case of language models [8, 45]. For instance, for certain models it is known that adversaries can apply membership inference attacks [65] to predict whether or not any particular example was in the training data.
与此同时,机器学习模型因泄露其(可能涉及隐私的)训练数据信息而臭名昭著——无论是普遍情况 [47, 65] 还是大语言模型 [8, 45] 的特殊案例。例如,已知某些模型可能遭受成员推理攻击 [65],攻击者可借此推断特定样本是否存在于训练数据中。
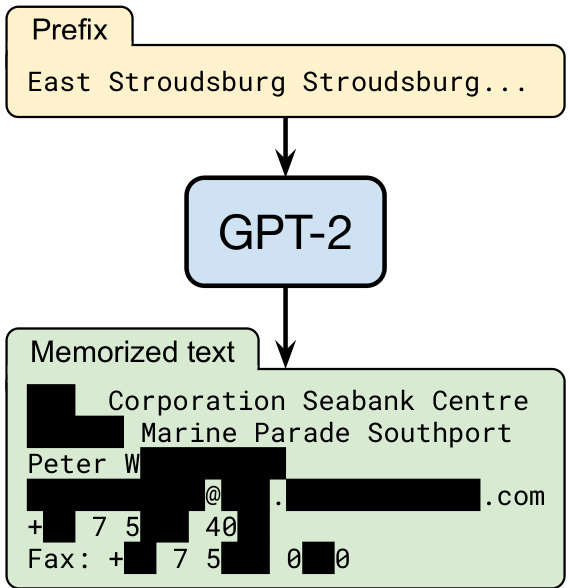
Figure 1: Our extraction attack. Given query access to a neural network language model, we extract an individual person’s name, email address, phone number, fax number, and physical address. The example in this figure shows information that is all accurate so we redact it to protect privacy.
图 1: 我们的提取攻击。在获得对神经网络语言模型的查询权限后,我们提取了个人的姓名、电子邮件地址、电话号码、传真号码和实际地址。本图示例显示的信息均属真实,因此我们进行了脱敏处理以保护隐私。
Such privacy leakage is typically associated with over fitting [75]—when a model’s training error is significantly lower than its test error—because over fitting often indicates that a model has memorized examples from its training set. Indeed, over fitting is a sufficient condition for privacy leakage [72] and many attacks work by exploiting over fitting [65].
这种隐私泄露通常与过拟合 [75] 有关——当模型的训练误差显著低于测试误差时——因为过拟合往往表明模型已记忆了训练集中的样本。事实上,过拟合是隐私泄露的充分条件 [72],许多攻击正是通过利用过拟合来实现的 [65]。
The association between over fitting and memorization has— erroneously—led many to assume that state-of-the-art LMs will not leak information about their training data. Because these models are often trained on massive de-duplicated datasets only for a single epoch [7, 55], they exhibit little to no over fitting [53]. Accordingly, the prevailing wisdom has been that “the degree of copying with respect to any given work is likely to be, at most, de minimis” [71] and that models do not significantly memorize any particular training example.
过拟合与记忆之间的关联——错误地——导致许多人认为最先进的大语言模型(LM)不会泄露其训练数据的信息。由于这些模型通常仅在一个周期内对大规模去重数据集进行训练[7,55],它们表现出极少甚至没有过拟合[53]。因此,普遍观点认为"对于任何特定作品的复制程度最多是微不足道的"[71],并且模型不会显著记忆任何特定的训练样本。
Contributions. In this work, we demonstrate that large language models memorize and leak individual training examples. In particular, we propose a simple and efficient method for extracting verbatim sequences from a language model’s training set using only black-box query access. Our key insight is that, although training examples do not have noticeably lower losses than test examples on average, certain worstcase training examples are indeed memorized.
贡献。在这项工作中,我们证明了大语言模型会记忆并泄露单个训练样本。具体而言,我们提出了一种仅通过黑盒查询访问即可从语言模型训练集中提取逐字序列的简单高效方法。我们的核心发现是:虽然训练样本的平均损失与测试样本相比并无明显差异,但某些最差情况的训练样本确实被模型记忆了。
In our attack, we first generate a large, diverse set of highlikelihood samples from the model, using one of three generalpurpose sampling strategies. We then sort each sample using one of six different metrics that estimate the likelihood of each sample using a separate reference model (e.g., another LM), and rank highest the samples with an abnormally high likelihood ratio between the two models.
在我们的攻击中,首先采用三种通用采样策略之一从模型中生成大量多样化高概率样本。随后使用六种不同指标之一对每个样本进行排序,这些指标通过独立参考模型(例如另一个大语言模型)估算各样本概率,并优先筛选出在两模型间具有异常高似然比的样本。
Our attacks directly apply to any language model, including those trained on sensitive and non-public data [10,16]. We use the GPT-2 model [54] released by OpenAI as a representative language model in our experiments. We choose to attack GPT-2 to minimize real-world harm—the GPT-2 model and original training data source are already public.
我们的攻击方法直接适用于任何语言模型,包括那些基于敏感和非公开数据训练的模型 [10,16]。实验中,我们使用OpenAI发布的GPT-2模型 [54] 作为代表性大语言模型。选择攻击GPT-2是为了尽可能减少现实危害——该模型及其原始训练数据源已公开。
To make our results quantitative, we define a testable definition of memorization. We then generate 1,800 candidate memorized samples, 100 under each of the $3\times6$ attack configurations, and find that over 600 of them are verbatim samples from the GPT-2 training data (confirmed in collaboration with the creators of GPT-2). In the best attack configuration, $67%$ of candidate samples are verbatim training examples. Our most obviously-sensitive attack extracts the full name, physical address, email address, phone number, and fax number of an individual (see Figure 1). We comprehensively analyze our attack, including studying how model size and string frequency affects memorization, as well as how different attack configurations change the types of extracted data.
为了使我们的结果具有可量化性,我们定义了记忆的可测试定义。随后生成了1,800个候选记忆样本(每种 $3\times6$ 攻击配置下各100个),发现其中超过600个样本与GPT-2训练数据完全一致(经与GPT-2创建者合作确认)。在最佳攻击配置下, $67%$ 的候选样本为逐字复制的训练示例。我们最敏感的攻撃案例提取了个人的全名、物理地址、电子邮箱、电话号码及传真号码(见图1)。我们对攻撃进行了全面分析,包括研究模型规模和字符串频率如何影响记忆,以及不同攻撃配置如何改变提取的数据类型。
We conclude by discussing numerous practical strategies to mitigate privacy leakage. For example, differential ly-private training [1] is theoretically well-founded and guaranteed to produce private models if applied at an appropriate record level, but it can result in longer training times and typically degrades utility. We also make recommendations, such as carefully de-duplicating documents, that empirically will help to mitigate memorization but cannot prevent all attacks.
我们最后讨论了多种减轻隐私泄露的实用策略。例如,差分隐私训练 (differentially private training) [1] 在理论上有良好基础,若在适当的记录级别应用可确保生成隐私模型,但会导致训练时间延长且通常降低效用。我们还提出了一些建议,例如仔细去重文档,这些方法经实证有助于减轻记忆效应,但无法防范所有攻击。
2 Background & Related Work
2 背景与相关工作
To begin, we introduce the relevant background on large (billion-parameter) neural network-based language models (LMs) as well as data privacy attacks.
首先,我们介绍基于大规模(数十亿参数)神经网络的大语言模型(LM)以及数据隐私攻击的相关背景。
2.1 Language Modeling
2.1 语言建模
Language models are a fundamental building block of current state-of-the-art natural language processing pipelines [12, 31, 50, 52, 55]. While the unsupervised objectives used
语言模型是当前最先进自然语言处理流程的基础构建模块[12, 31, 50, 52, 55]。尽管使用的无监督目标
to train these models vary, one popular choice is a “next-step prediction” objective [5, 31, 44, 52]. This approach constructs a generative model of the distribution
训练这些模型的目标各不相同,一种流行的选择是"下一步预测"目标 [5, 31, 44, 52]。这种方法构建了一个生成式分布模型
$$
\mathbf{Pr}(x_{1},x_{2},\ldots,x_{n}),
$$
$$
\mathbf{Pr}(x_{1},x_{2},\ldots,x_{n}),
$$
where $x_{1},x_{2},\ldots,x_{n}$ is a sequence of tokens from a vocabulary $\mathcal{V}$ by applying the chain rule of probability
其中 $x_{1},x_{2},\ldots,x_{n}$ 是通过应用概率链式法则从词汇表 $\mathcal{V}$ 中提取的token序列
$$
\mathbf{Pr}(x_{1},x_{2},\ldots,x_{n})=\Pi_{i=1}^{n}\mathbf{Pr}(x_{i}\mid x_{1},\ldots,x_{i-1}).
$$
$$
\mathbf{Pr}(x_{1},x_{2},\ldots,x_{n})=\Pi_{i=1}^{n}\mathbf{Pr}(x_{i}\mid x_{1},\ldots,x_{i-1}).
$$
State-of-the-art LMs use neural networks to estimate this probability distribution. We let $f_{\boldsymbol{\Theta}}(x_{i}\mid x_{1},\dots,x_{i-1})$ denote the likelihood of token $x_{i}$ when evaluating the neural network $f$ with parameters θ. While recurrent neural networks (RNNs) [26, 44] used to be a common choice for the neural network architecture of LMs, attention-based models [4] have recently replaced RNNs in state-of-the-art models. In particular, Transformer LMs [70] consist of a sequence of attention layers and are the current model architecture of choice. Because we believe our results are independent of the exact architecture used, we will not describe the Transformer architecture in detail here and instead refer to existing work [3].
最先进的大语言模型使用神经网络来估计这一概率分布。我们用$f_{\boldsymbol{\Theta}}(x_{i}\mid x_{1},\dots,x_{i-1})$表示在评估参数为θ的神经网络$f$时token$x_{i}$的似然度。虽然循环神经网络(RNNs)[26,44]曾是大语言模型神经网络架构的常见选择,但基于注意力机制的模型[4]最近已在最先进模型中取代了RNNs。特别是Transformer大语言模型[70]由一系列注意力层组成,是目前首选模型架构。由于我们认为研究结果与具体架构无关,此处不再详细描述Transformer架构,相关细节请参阅现有文献[3]。
Training Objective. A language model is trained to maximize the probability of the data in a training set $\chi$ . In this paper, each training example is a text document—for example, a specific news article or webpage from the internet. Formally, training involves minimizing the loss function
训练目标。语言模型的训练目标是最大化训练集 $\chi$ 中数据的概率。本文中,每个训练样本均为文本文档(例如互联网上的特定新闻文章或网页)。形式上,训练过程需最小化损失函数
$$
\mathcal{L}(\boldsymbol{\Theta})=-\log\Pi_{i=1}^{n}f_{\boldsymbol{\Theta}}(x_{i}\mid x_{1},\ldots,x_{i-1})
$$
$$
\mathcal{L}(\boldsymbol{\Theta})=-\log\Pi_{i=1}^{n}f_{\boldsymbol{\Theta}}(x_{i}\mid x_{1},\ldots,x_{i-1})
$$
over each training example in the training dataset $\chi$ . Because of this training setup, the “optimal” solution to the task of language modeling is to memorize the answer to the question “what token follows the sequence $x_{1},\ldots,x_{i-1}?^{\gamma}$ for ev- ery prefix in the training set. However, state-of-the-art LMs are trained with massive datasets, which causes them to not exhibit significant forms of memorization: empirically, the training loss and the test loss are nearly identical [7, 53, 55].
在训练数据集$\chi$中对每个训练样本进行遍历。由于这种训练设置,语言建模任务的"最优"解是记住训练集中每个前缀序列$x_{1},\ldots,x_{i-1}?^{\gamma}$后接哪个token的答案。然而,最先进的大语言模型使用海量数据进行训练,这使得它们不会表现出明显的记忆行为:实证研究表明,训练损失和测试损失几乎相同[7, 53, 55]。
Generating Text. A language model can generate new text (potentially conditioned on some prefix $x_{1},\ldots,x_{i})$ by iterative ly sampling $\hat{x}_ {i+1}\sim f_{\boldsymbol{\theta}}(x_{i+1}|x_{1},\dots,x_{i})$ and then feeding $\hat{x}_ {i+1}$ back into the model to sample $\hat{x}_ {i+2}\sim$ $f_{\Theta}(x_{i+2}|x_{1},\dots,\hat{x}_{i+1})$ . This process is repeated until a desired stopping criterion is reached. Variations of this text generation method include deterministic ally choosing the most-probable token rather than sampling (i.e., “greedy” sampling) or setting all but the top $n$ probabilities to zero and re normalizing the probabilities before sampling (i.e., top $\mathbf{\nabla}\cdot n$ sampling1 [18]).
生成文本。语言模型可以通过迭代采样 $\hat{x}_ {i+1}\sim f_{\boldsymbol{\theta}}(x_{i+1}|x_{1},\dots,x_{i})$ 生成新文本(可能以某些前缀 $x_{1},\ldots,x_{i})$ 为条件),然后将 $\hat{x}_ {i+1}$ 反馈给模型以采样 $\hat{x}_ {i+2}\sim$ $f_{\Theta}(x_{i+2}|x_{1},\dots,\hat{x}_{i+1})$。重复此过程直到达到所需的停止标准。这种文本生成方法的变体包括确定性地选择概率最高的token而非采样(即"贪婪"采样),或在采样前将所有非前$n$个概率设为零并重新归一化概率(即top $\mathbf{\nabla}\cdot n$采样[18])。
GPT-2. Our paper focuses on the GPT variant of Transformer LMs [7,52,54]. Specifically, we demonstrate our training data extraction attacks on GPT-2, a family of LMs that were all trained using the same dataset and training algorithm, but with varying model sizes. GPT-2 uses a word-pieces [61] vocabulary with a byte pair encoder [22].
GPT-2。我们的论文聚焦于Transformer语言模型的GPT变体[7,52,54]。具体而言,我们在GPT-2上演示了训练数据提取攻击,该系列大语言模型均采用相同数据集和训练算法,但模型规模各异。GPT-2使用基于字节对编码器[22]的word-pieces词汇表[61]。
GPT-2 XL is the largest model with 1.5 billion parameters. For the remainder of this paper, the “GPT-2” model refers to this 1.5 billion parameter model or, when we specifically indicate this, its Small and Medium variants with 124 million and 334 million parameters, respectively.
GPT-2 XL是参数量达15亿的最大模型。本文后续提到的"GPT-2"模型均指这个15亿参数的版本,或特别说明时的1.24亿参数(Small)与3.34亿参数(Medium)变体。
The GPT-2 model family was trained on data scraped from the public Internet. The authors collected a dataset by following outbound links from the social media website Reddit. The webpages were cleaned of HTML, with only the document text retained, and then de-duplicated at the document level. This resulted in a final dataset of 40GB of text data, over which the model was trained for approximately 12 epochs.2 As a result, GPT-2 does not overfit: the training loss is only roughly $10%$ smaller than the test loss across all model sizes.
GPT-2模型家族是在从公开互联网抓取的数据上进行训练的。作者通过跟踪社交媒体网站Reddit的外链收集了一个数据集。这些网页经过HTML清理,仅保留文档文本,并在文档级别进行去重处理。最终得到一个40GB文本数据的训练集,模型在其上训练了约12个周期。因此GPT-2不会过拟合:在所有模型规模下,训练损失仅比测试损失低约$10%$。
2.2 Training Data Privacy
2.2 训练数据隐私
It is undesirable for models to remember any details that are specific to their (potentially private) training data. The field of training data privacy develops attacks (to leak training data details) and defenses (to prevent leaks).
模型不应记住任何与其(可能涉及隐私的)训练数据相关的具体细节。训练数据隐私领域发展出了攻击手段(用于泄露训练数据细节)和防御措施(用于防止泄露)。
Privacy Attacks. When models are not trained with privacy-preserving algorithms, they are vulnerable to numerous privacy attacks. The least revealing form of attack is the membership inference attack [28, 47, 65, 67]: given a trained model, an adversary can predict whether or not a particular example was used to train the model. Separately, model inversion attacks [21] reconstruct representative views of a subset of examples (e.g., a model inversion attack on a face recognition classifier might recover a fuzzy image of a particular person that the classifier can recognize).
隐私攻击。当模型未采用隐私保护算法进行训练时,容易遭受多种隐私攻击。其中信息泄露最少的攻击形式是成员推断攻击[28, 47, 65, 67]:给定一个训练好的模型,攻击者可以预测特定样本是否被用于训练该模型。此外,模型反演攻击[21]能重构部分样本的代表性视图(例如,针对人脸识别分类器的模型反演攻击可能恢复出分类器可识别的特定人物的模糊图像)。
Training data extraction attacks, like model inversion attacks, reconstruct training datapoints. However, training data extraction attacks aim to reconstruct verbatim training examples and not just representative “fuzzy” examples. This makes them more dangerous, e.g., they can extract secrets such as verbatim social security numbers or passwords. Training data extraction attacks have until now been limited to small LMs trained on academic datasets under artificial training setups (e.g., for more epochs than typical) [8, 66, 68, 73], or settings where the adversary has a priori knowledge of the secret they want to extract (e.g., a social security number) [8, 27].
训练数据提取攻击(Training data extraction attacks)与模型反转攻击类似,旨在重建训练数据点。但训练数据提取攻击的目标是逐字重建训练样本,而不仅仅是具有代表性的"模糊"样本。这使得此类攻击更加危险,例如能直接提取社保号码或密码等机密信息。目前这类攻击仅局限于以下场景:(1) 在人工训练设置(如超常规训练周期)下针对学术数据集训练的小型大语言模型 [8, 66, 68, 73];(2) 攻击者预先知晓待提取机密信息(如特定社保号码)的特殊情境 [8, 27]。
Protecting Privacy. An approach to minimizing memorization of training data is to apply differential ly-private training techniques [1, 9, 43, 60, 64]. Unfortunately, training models with differential ly-private mechanisms often reduces accuracy [34] because it causes models to fail to capture the long tails of the data distribution [19,20,67]. Moreover, it increases training time, which can further reduce accuracy because current LMs are limited by the cost of training [35, 38, 55]. As a result, state-of-the-art LMs such as GPT-2 [53], GPT-3 [7], and T5 [55] do not apply these privacy-preserving techniques.
保护隐私。最小化训练数据记忆的一种方法是应用差分隐私(differential privacy)训练技术[1,9,43,60,64]。遗憾的是,使用差分隐私机制训练模型通常会降低准确性[34],因为这会导致模型无法捕捉数据分布的长尾部分[19,20,67]。此外,这会增加训练时间,由于当前大语言模型受限于训练成本[35,38,55],可能进一步降低准确性。因此,最先进的大语言模型如GPT-2[53]、GPT-3[7]和T5[55]都没有采用这些隐私保护技术。
3 Threat Model & Ethics
3 威胁模型与伦理
Training data extraction attacks are often seen as theoretical or academic and are thus unlikely to be exploit able in practice [71]. This is justified by the prevailing intuition that privacy leakage is correlated with over fitting [72], and because stateof-the-art LMs are trained on large (near terabyte-sized [7]) datasets for a few epochs, they tend to not overfit [53].
训练数据提取攻击常被视为理论性或学术性的,因此在实践中不太可能被利用[71]。这一观点的合理性在于普遍认为隐私泄露与过拟合相关[72],而由于最先进的大语言模型是在大型(接近TB级别[7])数据集上训练几个周期,它们往往不会出现过拟合[53]。
Our paper demonstrates that training data extraction attacks are practical. To accomplish this, we first precisely define what we mean by “memorization”. We then state our threat model and our attack objectives. Finally, we discuss the ethical considerations behind these attacks and explain why they are likely to be a serious threat in the future.
我们的论文证明训练数据提取攻击是切实可行的。为此,我们首先明确定义了"记忆"的含义,接着阐述了威胁模型和攻击目标,最后探讨了这类攻击背后的伦理考量,并解释了为何它们未来可能构成严重威胁。
3.1 Defining Language Model Memorization
3.1 定义语言模型的记忆能力
There are many ways to define memorization in language modeling. As mentioned earlier, memorization is in many ways an essential component of language models because the training objective is to assign high overall likelihood to the training dataset. LMs must, for example, “memorize” the correct spelling of individual words.
在语言建模中,定义记忆(memorization)的方式有很多种。如前所述,记忆在诸多方面都是语言模型的关键组成部分,因为训练目标就是为训练数据集赋予较高的整体似然值。例如,大语言模型必须"记住"单个单词的正确拼写。
Indeed, there is a research direction that analyzes neural networks as repositories of (memorized) knowledge [51, 59]. For example, when GPT-2 is prompted to complete the sentence “My address is 1 Main Street, San Francisco CA”, it generates $\mathbf{\tilde{\gamma}}^{\mathrm{q}}4107\mathbf{\tilde{\gamma}}$ : a correct zip code for San Francisco, CA. While this is clearly memorization in some abstract form,we aim to formalize our definition of memorization in order to restrict it to cases that we might consider “unintended” [8].
确实存在一个研究方向,将神经网络视为(记忆性)知识的存储库[51, 59]。例如,当提示GPT-2补全句子"My address is 1 Main Street, San Francisco CA"时,它会生成$\mathbf{\tilde{\gamma}}^{\mathrm{q}}4107\mathbf{\tilde{\gamma}}$:一个正确的加州旧金山邮编。虽然这显然是以某种抽象形式进行的记忆,但我们旨在形式化记忆的定义,以将其限制在我们可能认为"非预期"的情况[8]。
3.1.1 Eidetic Memorization of Text
3.1.1 文本的精确记忆
We define eidetic memorization as a particular type of memorization.3 Informally, eidetic memorization is data that has been memorized by a model despite only appearing in a small set of training instances. The fewer training samples that contain the data, the stronger the eidetic memorization is.
我们将"精确记忆"(eidetic memorization)定义为一种特定类型的记忆。非正式地说,精确记忆是指那些尽管只在少量训练样本中出现、却被模型记住的数据。包含该数据的训练样本越少,精确记忆的表现就越强。
To formalize this notion, we first define what it means for a model to have knowledge of a string $s$ . Our definition is loosely inspired by knowledge definitions in interactive proof systems [24]: a model $f_{\theta}$ knows a string s if s can be extracted by interacting with the model. More precisely, we focus on black-box interactions where the model generates $s$ as the most likely continuation when prompted with some prefix $c$ :
为了形式化这一概念,我们首先定义一个模型对字符串$s$的"知识"意味着什么。该定义松散地借鉴了交互式证明系统中的知识定义[24]:若通过与模型$\quad f_{\theta}$交互能提取出字符串s,则认为该模型知晓s。更准确地说,我们关注黑盒交互场景——当给定某个前缀$c$作为提示时,模型将$s$生成为其最可能的延续序列:
Definition 1 (Model Knowledge Extraction) $A$ string s is extract able 4 from an LM fθ if there exists a prefix c such that:
定义 1 (模型知识提取) 若存在前缀 c 使得字符串 s 可从大语言模型 fθ 中提取,则称 s 是可提取的:
$$
s\gets\arg\operatorname*{max}_ {s^{\prime}\mid s^{\prime}\mid=N}f_{\Theta}(s^{\prime}\mid c)
$$
$$
s\gets\arg\operatorname*{max}_ {s^{\prime}\mid s^{\prime}\mid=N}f_{\Theta}(s^{\prime}\mid c)
$$
We abuse notation slightly here to denote by $f_{\boldsymbol{\Theta}}(s^{\prime}\mid c)$ the likelihood of an entire sequence $s^{\prime}$ . Since computing the most likely sequence $s$ is intractable for large $N$ , the arg max in Definition 1 can be replaced by an appropriate sampling strategy (e.g., greedy sampling) that reflects the way in which the model $\quad f_{\theta}$ generates text in practical applications. We then define eidetic memorization as follows:
我们在此略微滥用符号,用$f_{\boldsymbol{\Theta}}(s^{\prime}\mid c)$表示整个序列$s^{\prime}$的似然。由于对于较大的$N$,计算最可能的序列$s$是难以处理的,定义1中的arg max可以用适当的采样策略(例如贪婪采样)替代,以反映模型$\quad f_{\theta}$在实际应用中生成文本的方式。然后我们如下定义精确记忆:
Definition 2 ( $k$ -Eidetic Memorization) A string s is $k$ eidetic memorized (for $k\geq1$ ) by an LM fθ if s is extract able from $\quad f_{\theta}$ and s appears in at most $k$ examples in the training data $X$ : $|{x\in X:s\subseteq x}|\leq k$ .
定义 2 ($k$-Eidetic Memorization) 若字符串 s 可从 $\quad f_{\theta}$ 中提取, 且在训练数据 $X$ 中最多出现在 $k$ 个样本中 (即 $|{x\in X:s\subseteq x}|\leq k$), 则称大语言模型 $\quad f_{\theta}$ 对 s 实现了 $k$-Eidetic Memorization (其中 $k\geq1$)。
Key to this definition is what “examples” means. For GPT2, each webpage is used (in its entirety) as one training example. Since this definition counts the number of distinct training examples containing a given string, and not the total number of times the string occurs, a string may appear multiple times on one page while still counting as $k=1$ memorization.
该定义的关键在于“样本”的含义。对于GPT2,每个网页(作为一个整体)被视作一个训练样本。由于该定义统计的是包含特定字符串的不同训练样本数量,而非该字符串出现的总次数,因此一个字符串可能在单个页面中出现多次,但仍计为$k=1$的记忆。
This definition allows us to define memorization as a spectrum. While there is no definitive value of $k$ at which we might say that memorization is unintentional and potentially harmful, smaller values are more likely to be so. For any given $k$ , memorizing longer strings is also “worse” than shorter strings, although our definition omits this distinction for simplicity.
该定义让我们能够将记忆视为一个连续谱。虽然无法确定一个明确的$k$值来判定记忆是否无意且可能有害,但较小的$k$值更可能属于这种情况。对于任意给定的$k$,记忆较长字符串的行为也比记忆较短字符串"更糟糕",尽管为简化起见,我们的定义忽略了这一区别。
For example, under this definition, memorizing the correct spellings of one particular word is not severe if the word occurs in many training examples (i.e., $k$ is large). Memorizing the zip code of a particular city might be eidetic memorization, depending on whether the city was mentioned in many training examples (e.g., webpages) or just a few. Referring back to Figure 1, memorizing an individual person’s name and phone number clearly (informally) violates privacy expectations, and also satisfies our formal definition: it is contained in just a few documents on the Internet—and hence the training data.
例如,根据这一定义,如果某个单词出现在许多训练样本中(即$k$值较大),那么记住该单词的正确拼写并不算严重问题。而记住某个特定城市的邮编可能属于精准记忆,具体取决于该城市在训练样本(如网页)中出现的频率高低。回顾图1,记忆某个人的姓名和电话号码显然(非正式地)违反了隐私预期,同时也符合我们的正式定义:这些信息在互联网(因而训练数据)中仅存在于少数文档中。
3.2 Threat Model
3.2 威胁模型
Adversary’s Capabilities. We consider an adversary who has black-box input-output access to a language model. This allows the adversary to compute the probability of arbitrary sequences $f_{\boldsymbol{\Theta}}(x_{1},\dots,x_{n})$ , and as a result allows the adversary to obtain next-word predictions, but it does not allow the adversary to inspect individual weights or hidden states (e.g., attention vectors) of the language model.
对手能力。我们考虑一个对语言模型具有黑盒输入输出访问权限的对手。这使得对手能够计算任意序列的概率 $f_{\boldsymbol{\Theta}}(x_{1},\dots,x_{n})$ ,从而获得下一个词的预测,但无法检查语言模型的单个权重或隐藏状态(例如注意力向量)。
This threat model is highly realistic as many LMs are available through black-box APIs. For example, the GPT3 model [7] created by OpenAI is available through black-box API access. Auto-complete models trained on actual user data have also been made public, although they reportedly use privacy-protection measures during training [10].
该威胁模型极具现实性,因为许多大语言模型可通过黑盒API获取。例如,OpenAI开发的GPT3模型[7]便通过黑盒API接口开放使用。基于真实用户数据训练的自动补全模型虽据称在训练阶段采用了隐私保护措施[10],但同样已公开可用。
Adversary’s Objective. The adversary’s objective is to extract memorized training data from the model. The strength of an attack is measured by how private (formalized as being $k$ -eidetic memorized) a particular example is. Stronger attacks extract more examples in total (both more total sequences, and longer sequences) and examples with lower values of $k$ .
攻击者的目标。攻击者的目标是从模型中提取记忆的训练数据。攻击强度通过特定样本的隐私程度(形式化为$k$-eidetic记忆)来衡量。更强的攻击能提取更多样本(包括更多序列和更长序列)以及$k$值更低的样本。
We do not aim to extract targeted pieces of training data, but rather indiscriminately extract training data. While targeted attacks have the potential to be more adversarial ly harmful, our goal is to study the ability of LMs to memorize data generally, not to create an attack that can be operational i zed by real adversaries to target specific users.
我们不旨在提取特定的训练数据片段,而是无差别地提取训练数据。虽然针对性攻击可能更具对抗性危害,但我们的目标是研究大语言模型(LM)对数据的普遍记忆能力,而非创建一种可被真实攻击者利用来针对特定用户的操作性攻击。
Attack Target. We select GPT-2 [54] as a representative LM to study for our attacks. GPT-2 is nearly a perfect target. First, from an ethical standpoint, the model and data are public, and so any memorized data that we extract is already public.5 Second, from a research standpoint, the dataset (despite being collected from public sources) was never actually released by OpenAI. Thus, it is not possible for us to unintentionally “cheat” and develop attacks that make use of knowledge of the GPT-2 training dataset.
攻击目标。我们选择GPT-2 [54]作为代表性大语言模型进行研究。GPT-2近乎是理想的研究对象:首先,从伦理角度看,该模型和数据都是公开的,因此我们提取的任何记忆数据本就属于公开信息;其次,从研究角度而言,虽然数据集来自公开渠道,但OpenAI从未实际发布过原始训练数据,这确保了我们不可能无意间"作弊"或利用GPT-2训练数据集知识来开发攻击方法。
3.3 Risks of Training Data Extraction
3.3 训练数据提取的风险
Training data extraction attacks present numerous privacy risks. From an ethical standpoint, most of these risks are mitigated in our paper because we attack GPT-2, whose training data is public. However, since our attacks would apply to any LM, we also discuss potential consequences of future attacks on models that may be trained on private data.
训练数据提取攻击存在诸多隐私风险。从伦理角度来看,由于我们攻击的是训练数据公开的GPT-2,本文已规避了大部分风险。但鉴于我们的攻击方法适用于所有大语言模型,我们也探讨了未来针对可能使用私有数据训练的模型实施攻击时的潜在后果。
Data Secrecy. The most direct form of privacy leakage occurs when data is extracted from a model that was trained on confidential or private data. For example, GMail’s autocomplete model [10] is trained on private text communications between users, so the extraction of unique snippets of training data would break data secrecy.
数据保密性。最直接的隐私泄露形式发生在从训练于机密或私人数据的模型中提取数据时。例如,GMail的自动补全模型[10]基于用户间的私人文本通信训练,因此提取独特的训练数据片段会破坏数据保密性。
Contextual Integrity of Data. The above privacy threat corresponds to a narrow view of data privacy as data secrecy.
数据的情境完整性。上述隐私威胁对应的是将数据隐私狭义理解为数据保密性的观点。
A broader view of the privacy risks posed by data extraction stems from the framework of data privacy as contextual integrity [48]. That is, data memorization is a privacy infringement if it causes data to be used outside of its intended context. An example violation of contextual integrity is shown in Figure 1. This individual’s name, address, email, and phone number are not secret—they were shared online in a specific context of intended use (as contact information for a software project)—but are reproduced by the LM in a separate context. Due to failures such as these, user-facing applications that use LMs may inadvertently emit data in inappropriate contexts, e.g., a dialogue system may emit a user’s phone number in response to another user’s query.
关于数据提取带来的隐私风险,更广泛的视角源于将数据隐私视为情境完整性(contextual integrity)的框架[48]。也就是说,如果数据记忆导致数据在预期情境之外被使用,就构成隐私侵犯。图1展示了一个违反情境完整性的示例:此人的姓名、地址、电子邮箱和电话号码并非机密——它们是在特定使用情境(作为软件项目联系信息)下在线分享的——但被大语言模型在另一个情境中复现。由于这类失误,面向用户的大语言模型应用可能会在不恰当的情境中无意泄露数据,例如对话系统可能在响应用户查询时泄露另一用户的电话号码。
Small $k$ Eidetic Risks. We nevertheless focus on $k$ -eidetic memorization with a small $k$ value because it makes extraction attacks more impactful.While there are cases where large $\cdot k$ memorization may still matter (for example, a company may refer to the name of an upcoming product multiple times in private—and even though it is discussed often the name itself may still be sensitive) we study the small $k$ case.
小$k$值的记忆风险。尽管如此,我们仍聚焦于小$k$值的记忆现象,因其能使提取攻击更具破坏性。尽管存在大$k$值记忆仍具重要性的情况(例如某公司可能在内部多次提及未发布产品名称——即使频繁讨论,该名称本身仍可能敏感),本研究主要探讨小$k$值场景。
Moreover, note that although we frame our paper as an “attack”, LMs will output memorized data even in the absence of an explicit adversary. We treat LMs as black-box generative functions, and the memorized content that we extract can be generated through honest interaction with the LM. Indeed, we have even discovered at least one memorized training example among the 1,000 GPT-3 samples that OpenAI originally released in its official repository [49].
此外,需要注意的是,尽管我们将本文定位为一种"攻击",但即使没有明确的对抗者,大语言模型也会输出记忆数据。我们将大语言模型视为黑盒生成函数,而我们提取的记忆内容可以通过与模型的正常交互产生。事实上,我们甚至在OpenAI官方代码库[49]最初发布的1000个GPT-3样本中发现了至少一个记忆训练样本。
3.4 Ethical Considerations
3.4 伦理考量
In this paper, we will discuss and carefully examine specific memorized content that we find in our extraction attacks. This raises ethical considerations as some of the data that we extract contains information about individual users.
在本文中,我们将讨论并仔细检查从提取攻击中发现的具体记忆内容。这引发了伦理考量,因为我们提取的部分数据包含个体用户的信息。
As previously mentioned, we minimize ethical concerns by using data that is already public. We attack the GPT-2 model, which is available online. Moreover, the GPT-2 training data was collected from the public Internet [54], and is in principle available to anyone who performs the same (documented) collection process as OpenAI, e.g., see [23].
如前所述,我们通过使用已公开的数据来最小化伦理问题。我们针对在线可用的GPT-2模型进行攻击。此外,GPT-2的训练数据是从公开互联网收集的[54],原则上任何执行与OpenAI相同(有文档记录的)收集流程的人都可以获取这些数据,例如参见[23]。
However, there are still ethical concerns even though the model and data are public. It is possible—and indeed we find it is the case—that we might extract personal information for individuals from the training data. For example, as shown in Figure 1, we recovered a person’s full name, address, and phone number. In this paper, whenever we succeed in extracting personally-identifying information (usernames, phone numbers, etc.) we partially mask out this content with the token . We are aware of the fact that this does not provide complete mediation: disclosing that the vulnerability exists allows a malicious actor to perform these attacks on their own to recover this personal information.
然而,即便模型和数据是公开的,伦理问题依然存在。我们有可能(事实上也确实发现)从训练数据中提取出个人的隐私信息。例如,如图1所示,我们还原出了一个真实人物的全名、地址和电话号码。在本文中,每当成功提取出个人身份信息(用户名、电话号码等)时,我们会用
Just as responsible disclosure still causes some (limited) harm, we believe that the benefits of publicizing these attacks outweigh the potential harms. Further, to make our attacks public, we must necessarily reveal some sensitive information. We contacted the individual whose information is partially shown in Figure 1 to disclose this fact to them in advance and received permission to use this example. Our research findings have also been disclosed to OpenAI.
正如负责任的披露仍会造成某些(有限的)伤害,我们认为公开这些攻击的益处大于潜在危害。此外,为公开攻击方法,我们不得不透露部分敏感信息。我们已联系图1中部分信息涉及的个人,提前向其披露此事并获准使用该示例。研究结果也已向OpenAI披露。
Unfortunately, we cannot hope to contact all researchers who train large LMs in advance of our publication. We thus hope that this publication will spark further discussions on the ethics of memorization and extraction among other companies and research teams that train large LMs [2, 36, 55, 63].
遗憾的是,我们无法在论文发表前联系所有训练大语言模型的研究者。因此,我们希望本文能引发其他训练大语言模型的公司和研究团队就记忆与提取的伦理问题展开进一步讨论 [2, 36, 55, 63]。
4 Initial Training Data Extraction Attack
4 初始训练数据提取攻击
We begin with a simple strawman baseline for extracting training data from a language model in a two-step procedure.
我们首先采用一个简单的稻草人基线方法,通过两步流程从语言模型中提取训练数据。
• Generate text. We generate a large quantity of data by unconditionally sampling from the model (Section 4.1). • Predict which outputs contain memorized text. We next remove the generated samples that are unlikely to contain memorized text using a membership inference attack (Section 4.2).
• 生成文本。我们通过无条件从模型中采样生成大量数据(第4.1节)。
• 预测哪些输出包含记忆文本。接着,我们使用成员推断攻击移除不太可能包含记忆文本的生成样本(第4.2节)。
These two steps correspond directly to extracting model knowledge (Definition 1), and then predicting which strings might be $k$ -eidetic memorization (Definition 2).
这两步直接对应于提取模型知识(Definition 1),然后预测哪些字符串可能是$k$-eidetic记忆(Definition 2)。
4.1 Initial Text Generation Scheme
4.1 初始文本生成方案
To generate text, we initialize the language model with a onetoken prompt containing a special start-of-sentence token and then repeatedly sample tokens in an auto regressive fashion from the model (see Section 2.1 for background). We hope that by sampling according to the model’s assigned likelihood, we will sample sequences that the model considers “highly likely”, and that likely sequences correspond to memorized text. Concretely, we sample exactly 256 tokens for each trial using the top $\boldsymbol{\cdot}n$ strategy from Section 2.1 with $n=40$ .
为生成文本,我们用一个包含特殊句子起始token的单token提示初始化大语言模型,随后以自回归方式从模型中重复采样token(背景知识参见第2.1节)。我们希望通过根据模型分配的概率进行采样,能够获取模型认为"高概率"的序列,而这些概率高的序列对应着被记忆的文本。具体而言,每次试验我们严格采样256个token,采用第2.1节所述的top $\boldsymbol{\cdot}n$策略(设$n=40$)。
4.2 Initial Membership Inference
4.2 初始成员推理
Given a set of samples from the model, the problem of training data extraction reduces to one of membership inference: predict whether each sample was present in the training data [65]. In their most basic form, past membership inference attacks rely on the observation that models tend to assign higher confidence to examples that are present in the training data [46]. Therefore, a potentially high-precision membership inference classifier is to simply choose examples that are assigned the highest likelihood by the model.
给定一组来自模型的样本,训练数据提取问题可简化为成员推理问题:预测每个样本是否存在于训练数据中 [65]。最基本的成员推理攻击依赖于一个观察结果:模型往往对训练数据中存在的样本赋予更高的置信度 [46]。因此,一种潜在高精度的成员推理分类器就是简单地选择模型赋予最高似然的样本。
Since LMs are probabilistic generative models, we follow prior work [8] and use a natural likelihood measure: the perplexity of a sequence measures how well the LM “predicts” the tokens in that sequence. Concretely, given a sequence of tokens $x_{1},\ldots,x_{n}$ , the perplexity is defined as
由于大语言模型是概率生成模型,我们遵循先前工作 [8] 采用自然似然度量:序列的困惑度 (perplexity) 衡量模型对该序列 token 的"预测"能力。具体而言,给定 token 序列 $x_{1},\ldots,x_{n}$,困惑度定义为
$$
\mathcal P=\exp\left(-\frac1n\sum_{i=1}^{n}\log f_{\boldsymbol\theta}(x_{i}|x_{1},\dots,x_{i-1})\right)
$$
$$
\mathcal P=\exp\left(-\frac1n\sum_{i=1}^{n}\log f_{\boldsymbol\theta}(x_{i}|x_{1},\dots,x_{i-1})\right)
$$
That is, if the perplexity is low, then the model is not very “surprised” by the sequence and has assigned on average a high probability to each subsequent token in the sequence.
也就是说,如果困惑度较低,那么模型对该序列不会感到非常"意外",并且对序列中每个后续token的平均分配了较高的概率。
4.3 Initial Extraction Results
4.3 初始提取结果
We generate 200,000 samples using the largest version of the GPT-2 model (XL, 1558M parameters) following the text generation scheme described in Section 4.1. We then sort these samples according to the model’s perplexity measure and investigate those with the lowest perplexity.
我们使用GPT-2最大版本(XL版,15.58亿参数)按照第4.1节描述的文本生成方案生成了20万个样本。随后根据模型的困惑度指标对这些样本进行排序,并重点分析困惑度最低的样本。
This simple baseline extraction attack can find a wide variety of memorized content. For example, GPT-2 memorizes the entire text of the MIT public license, as well as the user guidelines of Vaughn Live, an online streaming site. While this is “memorization”, it is only $k$ -eidetic memorization for a large value of $k$ —these licenses occur thousands of times.
这种简单的基线提取攻击能够发现各种被记忆的内容。例如,GPT-2完整记忆了MIT公共许可证的全文,以及在线流媒体网站Vaughn Live的用户指南。虽然这是"记忆",但仅针对较大的$k$值形成$k$-完全记忆——这些许可证出现了数千次。
The most interesting (but still not eidetic memorization for low values of $k$ ) examples include the memorization of popular individuals’ Twitter handles or email addresses (omitted to preserve user privacy). In fact, all memorized content we identify in this baseline setting is likely to have appeared in the training dataset many times.
最有趣(但在$k$值较低时仍非完全记忆)的例子包括对名人推特账号或电子邮箱的记忆(出于用户隐私保护已省略)。事实上,我们在该基线设置中识别的所有记忆内容,很可能已在训练数据集中多次出现。
This initial approach has two key weaknesses that we can identify. First, our sampling scheme tends to produce a low diversity of outputs. For example, out of the 200,000 samples we generated, several hundred are duplicates of the memorized user guidelines of Vaughn Live.
我们初步的方法存在两个明显缺陷。首先,采样方案容易导致输出多样性不足。例如,在生成的20万份样本中,有数百份是重复记忆的Vaughn Live用户指南内容。
Second, our baseline membership inference strategy suffers from a large number of false positives, i.e., content that is assigned high likelihood but is not memorized. The majority of these false positive samples contain “repeated” strings (e.g., the same phrase repeated multiple times). Despite such text being highly unlikely, large LMs often incorrectly assign high likelihood to such repetitive sequences [30].
其次,我们的基线成员推断策略存在大量误报,即被赋予高可能性但未被记忆的内容。这些误报样本大多包含"重复"字符串(例如同一短语多次重复)。尽管此类文本极不可能出现,但大语言模型常常错误地为这类重复序列分配高可能性 [30]。
5 Improved Training Data Extraction Attack
5 改进的训练数据提取攻击
The proof-of-concept attack presented in the previous section has low precision (high-likelihood samples are not always in the training data) and low recall (it identifies no $k$ -memorized content for low $k$ ). Here, we improve the attack by incorporating better methods for sampling from the model (Section 5.1) and membership inference (Section 5.2).
上一节提出的概念验证攻击存在精度低(高概率样本并不总是在训练数据中)和召回率低(对于低$k$值无法识别任何$k$记忆内容)的问题。我们通过改进模型采样方法(第5.1节)和成员推理方法(第5.2节)来优化该攻击方案。
5.1 Improved Text Generation Schemes
5.1 改进的文本生成方案
The first step in our attack is to randomly sample from the language model. Above, we used top $n$ sampling and conditioned the LM on the start-of-sequence token as input. This strategy has clear limitations [32]: it will only generate sequences that are likely from beginning to end. As a result, top $\cdot n$ sampling from the model will cause it to generate the same (or similar) examples several times. Below we describe two alternative techniques for generating more diverse samples from the LM.
我们攻击的第一步是从语言模型中随机采样。上文我们使用了 top $n$ 采样方法,并以序列起始token作为输入条件。这种策略存在明显局限性 [32]:它只会生成从头到尾都高概率的序列。因此,使用 top $\cdot n$ 采样会导致模型反复生成相同(或相似)的示例。下面我们介绍两种从大语言模型中生成更多样化样本的替代技术。
5.1.1 Sampling With A Decaying Temperature
5.1.1 采用衰减温度进行采样
As described in Section 2.1, an LM outputs the probability of the next token given the prior tokens $\mathbf{Pr}(x_{i}\mid x_{1},\ldots,x_{i-1})$ . In practice, this is achieved by evaluating the neural network $z=$ $f_{\boldsymbol{\Theta}}(x_{1},\dots,x_{i-1})$ to obtain the “logit” vector $z$ , and then computing the output probability distribution as $y=\operatorname{softmax}(z)$ defined by softma $\begin{array}{r}{\mathbf{\boldsymbol{x}}(z)_ {i}=\exp{(z_{i})}/\sum_{j=1}^{n}\exp{(z_{j})}}\end{array}$ .
如第2.1节所述,大语言模型 (LLM) 在给定先前token序列时输出下一个token的概率 $\mathbf{Pr}(x_{i}\mid x_{1},\ldots,x_{i-1})$ 。实际实现中,通过神经网络计算 $z=f_{\boldsymbol{\Theta}}(x_{1},\dots,x_{i-1})$ 得到"logit"向量 $z$,再通过softmax函数 $\begin{array}{r}{\mathbf{\boldsymbol{x}}(z)_ {i}=\exp{(z_{i})}/\sum_{j=1}^{n}\exp{(z_{j})}}\end{array}$ 计算出概率分布 $y=\operatorname{softmax}(z)$ 。
One can artificially “flatten” this probability distribution to make the model less confident by replacing the output softmax $(z)$ with softmax $(z/t)$ , for $t>1$ . Here, $t$ is called the temperature. A higher temperature causes the model to be less confident and more diverse in its output.
可以通过人为“展平”概率分布来降低模型的置信度,具体方法是将输出softmax $(z)$ 替换为softmax $(z/t)$ ,其中 $t>1$ 。这里的 $t$ 称为温度 (temperature) 。温度越高,模型的输出置信度越低,多样性越高。
However, maintaining a high temperature throughout the generation process would mean that even if the sampling process began to emit a memorized example, it would likely randomly step off the path of the memorized output. Thus, we use a softmax temperature that decays over time, starting at $t=10$ and decaying down to $t=1$ over a period of the first 20 tokens $(\approx10%$ of the length of the sequence). This gives a sufficient amount of time for the model to “explore” a diverse set of prefixes while also allowing it to follow a high-confidence paths that it finds.
然而,在整个生成过程中保持高温意味着即使采样过程开始输出记忆样本,也很可能随机偏离记忆内容的路径。因此,我们采用随时间衰减的softmax温度策略,初始值设为$t=10$,并在前20个token(约序列长度的10%)内逐步衰减至$t=1$。这为模型提供了足够时间"探索"多样化的前缀组合,同时允许其跟随已发现的高置信度路径。
5.1.2 Conditioning on Internet Text
5.1.2 基于互联网文本的条件化
Even when applying temperature sampling, there are still some prefixes that are unlikely to be sampled but nevertheless occur in actual data. As a final strategy, our third sampling strategy seeds the model with prefixes from our own scrapes of the Internet. This sampling strategy ensures that we will generate samples with a diverse set of prefixes that are similar in nature to the type of data GPT-2 was trained on.
即使在应用温度采样时,仍有一些前缀不太可能被采样,但在实际数据中确实存在。作为最终策略,我们的第三种采样策略从我们自己抓取的互联网数据中提取前缀作为模型种子。这种采样策略确保我们能生成具有多样化前缀的样本,这些前缀本质上与训练GPT-2所用的数据类型相似。
We follow a different data collection process as used in GPT-2 (which follows Reddit links) in order to reduce the likelihood that our dataset has any intersection with the model’s training data. In particular, we select samples from a subset of Common Crawl6 to feed as context to the model.7
我们采用了与GPT-2(通过Reddit链接收集)不同的数据收集流程,以降低数据集与模型训练数据存在交集的可能性。具体而言,我们从Common Crawl6的子集中选取样本作为模型的上下文输入。7
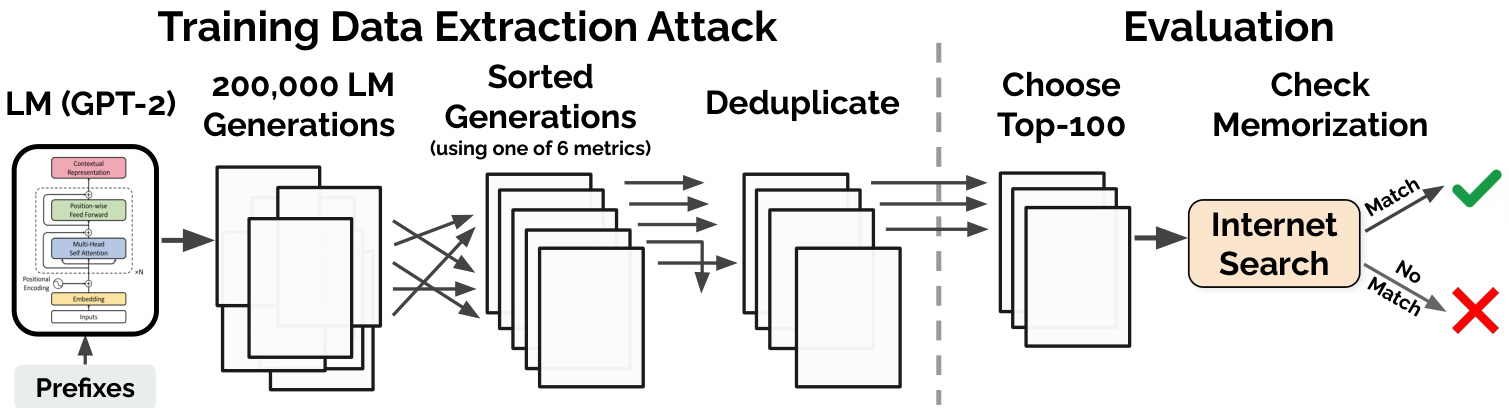
Figure 2: Workflow of our extraction attack and evaluation. 1) Attack. We begin by generating many samples from GPT-2 when the model is conditioned on (potentially empty) prefixes. We then sort each generation according to one of six metrics and remove the duplicates. This gives us a set of potentially memorized training examples. 2) Evaluation. We manually inspect 100 of the top-1000 generations for each metric. We mark each generation as either memorized or not-memorized by manually searching online, and we confirm these findings by working with OpenAI to query the original training data. An open-source implementation of our attack process is available at https://github.com/ftramer/LM Memorization.
图 2: 提取攻击与评估流程。1) 攻击阶段。首先通过GPT-2在(可能为空的)前缀条件下生成大量样本,随后根据六种指标之一对生成内容进行排序并去重,从而获得可能被记忆的训练数据集合。2) 评估阶段。针对每个指标的前1000条生成结果,人工检查其中100条。通过在线手动检索标记每条内容是否被记忆,并与OpenAI合作查询原始训练数据以确认结果。攻击过程的开源实现详见 https://github.com/ftramer/LM_Memorization。
As in prior work [55], we perform basic data-san it iz ation by removing HTML and JavaScript from webpages, and we de-duplicate data on a line-by-line basis. This gives us a dataset of 50MB of text. We randomly sample between 5 and 10 tokens of context from this scraped data and then continue LM generation with top $\cdot n$ sampling as in Section 4.1.
与先前工作[55]类似,我们通过移除网页中的HTML和JavaScript进行基础数据清洗,并以逐行方式去重。最终获得50MB的文本数据集。从该爬取数据中随机抽取5至10个token的上下文,随后按照第4.1节所述采用top-$\cdot n$采样方法继续大语言模型生成。
5.2 Improved Membership Inference
5.2 改进的成员推断攻击
Performing membership inference by filtering out samples with low likelihood has poor precision due to failures in the underlying language model: there are many samples that are assigned spuriously high likelihood. There are predominantly two categories of such samples:
通过过滤掉低似然样本进行成员推理时,由于底层语言模型的缺陷会导致精度低下:存在大量被错误赋予高似然的样本。这类样本主要分为两类:
• Trivial memorization. We identify many cases where GPT-2 outputs content that is uninteresting because of how common the text is. For example, it repeats the numbers from 1 to 100 with high probability. • Repeated substrings. One common failure mode of LMs is their propensity to repeatedly emit the same string over and over [30, 37]. We found many of the high-likelihood samples that are not memorized are indeed repeated texts (e.g., “I love you. I love you. . . ”).
- 简单记忆。我们发现许多情况下,GPT-2输出的内容因文本过于常见而显得无趣。例如,它大概率会重复输出1到100的数字。
- 重复子串。语言模型(LMs)的一个常见故障模式是倾向于反复输出相同的字符串[30, 37]。我们发现许多未被记忆的高概率样本确实包含重复文本(例如“我爱你。我爱你……”)。
Our insight is that we can filter out these uninteresting (yet still high-likelihood samples) by comparing to a second LM. Given a second model that accurately captures text likelihood, we should expect it will also assign high likelihood to these forms of memorized content. Therefore, a natural strategy for finding more diverse and rare forms of memorization is to filter samples where the original model’s likelihood is “unexpectedly high” compared to a second model. Below we discuss four methods for achieving this.
我们的思路是,可以通过与第二个大语言模型对比来过滤这些无趣(但仍是高概率)的样本。假设第二个模型能准确捕捉文本概率,它同样会为这类记忆内容分配高概率值。因此,寻找更多样化、更罕见记忆形式的自然策略是:筛选出原始模型概率值相比第二个模型"异常偏高"的样本。下文将讨论四种实现方法。
Comparing to Other Neural Language Models. Assume that we have access to a second LM that memorizes a different set of examples than GPT-2. One way to achieve this would be to train a model on a disjoint set of training data, in which case it is unlikely that the two models will memorize the same data for small $k$ . An alternate strategy is to take a much smaller model trained on the same underlying dataset: because smaller models have less capacity for memorization, we conjecture that there are samples that are $k$ -eidetic memorized (for small $k$ ) by the largest GPT-2 model, but which are not memorized by smaller GPT-2 models. Specifically, we use the Small (117M parameters) and Medium (345M parameters) models.
与其他神经语言模型的比较。假设我们拥有另一个大语言模型,其记忆的样本集与GPT-2不同。实现方式之一是在不相交的训练数据上训练模型,这种情况下两个模型不太可能对小$k$值记忆相同数据。另一种策略是采用基于相同底层数据集训练的更小模型:由于小模型记忆容量有限,我们推测存在某些样本会被最大GPT-2模型进行$k$值精准记忆(小$k$值),但不会被较小GPT-2模型记忆。具体而言,我们使用Small(1.17亿参数)和Medium(3.45亿参数)版本模型。
Comparing to zlib Compression. It is not necessary that we compare to another neural LM; any technique that quantifies some notion of “surprise” for a given sequence can be useful. As a simple baseline method, we compute the zlib [41] entropy of the text: the number of bits of entropy when the sequence is compressed with zlib compression. We then use the ratio of the GPT-2 perplexity and the zlib entropy as our membership inference metric. Although text compressors are simple, they can identify many of the examples of trivial memorization and repeated patterns described above (e.g., they are excellent at modeling repeated substrings).
与zlib压缩的对比。我们无需将神经语言模型与其他技术进行比较;任何能够量化给定序列"意外性"的技术都可能有用。作为简单基线方法,我们计算文本的zlib [41]熵:即使用zlib压缩时序列的熵位数。然后将GPT-2困惑度与zlib熵的比值作为我们的成员推理指标。尽管文本压缩器很简单,但它们能识别上述许多简单记忆和重复模式的实例(例如,它们非常擅长建模重复子字符串)。
Comparing to Lowercased Text. Instead of detecting memorization by comparing one model to another model, another option detects memorization by comparing the perplexity of the model to the perplexity of the same model on a “canonical i zed” version of that sequence. Specifically, we measure the ratio of the perplexity on the sample before and after lower casing it, which can dramatically alter the perplexity of memorized content that expects a particular casing.
与小写文本对比。不同于通过比较一个模型与另一个模型来检测记忆,另一种方法是通过比较模型在序列上的困惑度与其在"规范化"版本上的困惑度来检测记忆。具体而言,我们测量样本在小写转换前后的困惑度比值——这一操作会显著改变那些依赖特定大小写形式的记忆内容的困惑度。
Perplexity on a Sliding Window. Sometimes a model is not confident when the sample contains one memorized substring surrounded by a block of non-memorized (and high perplexity) text. To handle this, we use the minimum perplexity when averaged over a sliding window of 50 tokens.8
滑动窗口困惑度。有时当样本中包含一个被记忆子串,周围环绕着未被记忆(且高困惑度)的文本块时,模型会缺乏信心。为此,我们采用50个token滑动窗口平均后的最小困惑度值。8
6 Evaluating Memorization
6 评估记忆能力
We now evaluate the various data extraction methods and study common themes in the resulting memorized content.
我们现在评估各种数据提取方法,并研究所得记忆内容中的常见主题。
6.1 Methodology
6.1 方法论
An overview of our experimental setup is shown in Figure 2. We first build three datasets of 200,000 generated samples (each of which is 256 tokens long) using one of our strategies:
我们的实验设置概览如图 2 所示。我们首先使用以下策略之一构建三个包含 20 万个生成样本的数据集 (每个样本长度为 256 token):
We order each of these three datasets according to each of our six membership inference metrics:
我们根据六种成员推理指标对这三个数据集分别进行排序:
• Perplexity: the perplexity of the largest GPT-2 model. • Small: the ratio of log-perplexities of the largest GPT-2 model and the Small GPT-2 model. • Medium: the ratio as above, but for the Medium GPT-2. • zlib: the ratio of the (log) of the GPT-2 perplexity and the zlib entropy (as computed by compressing the text). • Lowercase: the ratio of perplexities of the GPT-2 model on the original sample and on the lowercased sample. • Window: the minimum perplexity of the largest GPT-2 model across any sliding window of 50 tokens.
• 困惑度 (Perplexity): 最大GPT-2模型的困惑度。
• 小模型 (Small): 最大GPT-2模型与小GPT-2模型的对数困惑度比值。
• 中模型 (Medium): 同上,但针对中GPT-2模型。
• zlib: GPT-2对数困惑度与zlib熵(通过文本压缩计算)的比值。
• 小写化 (Lowercase): GPT-2模型在原始样本与小写样本上的困惑度比值。
• 滑动窗口 (Window): 最大GPT-2模型在50个token滑动窗口中的最小困惑度。
For each of these $3\times6=18$ configurations, we select 100 samples from among the top-1000 samples according to the chosen metric.9 This gives us 1,800 total samples of potentially memorized content. In real-world attacks, adversaries will look to uncover large amounts of memorized content and thus may generate many more samples. We focus on a smaller set as a proof-of-concept attack.
对于这 $3\times6=18$ 种配置,我们根据所选指标从前1000个样本中各选取100个样本。这样我们总共获得了1800个可能被记忆内容的样本。在实际攻击中,攻击者会试图揭露大量被记忆的内容,因此可能会生成更多样本。我们专注于较小规模的样本集,作为概念验证攻击。
Data De-Duplication. To avoid “double-counting” memorized content, we apply an automated fuzzy de-duplication step when we select the 100 samples for each configuration.
数据去重。为避免对记忆内容进行"重复计数",我们在为每种配置选择100个样本时应用了自动化模糊去重步骤。
Given a sample $s$ , we define the trigram-multiset of $s$ , denoted $\mathtt{t r i}(s)$ as a multiset of all word-level trigrams in $s$ (with words split on whitespace and punctuation characters). For example, the sentence “my name my name my name” has two trigrams (“my name my” and ”name my name”) each of multiplicity 2. We mark a sample $s_{1}$ as a duplicate of another sample $s_{2}$ , if their trigram multisets are similar, specifically if $|\mathtt{t r i}(s_{1})\cap\mathtt{t r i}(s_{2})|\geq|\mathtt{t r i}(s_{1})|/2$ .
给定样本 $s$,我们定义其三元组多重集 $\mathtt{t r i}(s)$ 为 $s$ 中所有词级三元组的集合(按空格和标点符号分割单词)。例如,句子"my name my name my name"包含两个三元组("my name my"和"name my name"),每个重复出现2次。当两个样本 $s_{1}$ 和 $s_{2}$ 的三元组多重集相似时(具体指 $|\mathtt{t r i}(s_{1})\cap\mathtt{t r i}(s_{2})|\geq|\mathtt{t r i}(s_{1})|/2$),我们将 $s_{1}$ 标记为 $s_{2}$ 的重复样本。
Evaluating Memorization Using Manual Inspection. For each of the 1,800 selected samples, one of four authors manually determined whether the sample contains memorized text. Since the training data for GPT-2 was sourced from the public Web, our main tool is Internet searches. We mark a sample as memorized if we can identify a non-trivial substring that returns an exact match on a page found by a Google search.
通过人工检查评估记忆程度。针对选定的1800个样本,四位作者之一会人工判断样本是否包含记忆文本。由于GPT-2的训练数据来自公共网络,我们的主要工具是互联网搜索。当我们通过谷歌搜索找到的页面上存在完全匹配的非平凡子字符串时,就将该样本标记为被记忆内容。
Validating Results on the Original Training Data. Finally, given the samples that we believe to be memorized, we work with the original authors of GPT-2 to obtain limited query access to their training dataset. To do this we sent them all 1, 800 sequences we selected for analysis. For efficiency, they then performed a fuzzy 3-gram match to account for memorization with different possible token iz at ions. We marked samples as memorized if all 3-grams in the memorized sequence occurred in close proximity in the training dataset. This approach eliminates false negatives, but has false positives. It can confirm that our samples are memorized but cannot detect cases where we missed memorized samples. In some experiments below, we report exact counts for how often a particular sequence occurs in the training data. We obtained these counts by asking the GPT-2 authors to perform a separate grep over the entire dataset to get an exact count.
在原训练数据上验证结果。最后,针对我们认为是记忆样本的数据,我们与GPT-2的原作者合作,获得了对其训练数据集的有限查询权限。为此,我们向他们发送了所有选作分析的1,800条序列。为了提高效率,他们随后执行了模糊3-gram匹配,以考虑不同可能的token化方式导致的记忆现象。如果记忆序列中的所有3-gram在训练数据集中紧密相邻出现,我们就将该样本标记为被记忆。这种方法可以消除假阴性,但存在假阳性。它能确认我们的样本是被记忆的,但无法检测我们遗漏的记忆样本。在下面的一些实验中,我们报告了特定序列在训练数据中出现的精确次数。这些计数是通过请求GPT-2作者对整个数据集执行单独的grep搜索来获取的。
6.2 Results
6.2 结果
In total across all strategies, we identify 604 unique memorized training examples from among the 1,800 possible candidates, for an aggregate true positive rate of $33.5%$ (our best variant has a true positive rate of $67%$ ). Below, we categorize what types of content is memorized by the model, and also study which attack methods are most effective.
在所有策略中,我们从1800个候选样本中识别出604个独特的被记忆训练样本,总体真阳性率为$33.5%$(我们最佳变体的真阳性率达到$67%$)。接下来,我们对模型记忆的内容类型进行分类,并研究哪些攻击方法最有效。
Categories of Memorized Content. We manually grouped the memorized samples into different categories (a description of these categories is in Appendix A). The results are shown in Table 1. Most memorized content is fairly canonical text from news headlines, log files, entries from forums or wikis, or religious text. However, we also identify a significant amount of unique data, containing 128-bit UUIDs, (correctlyresolving) URLs containing random substrings, and contact information of individual people and corporations. In Section 6.3, we study these cases in more detail.
记忆内容的分类。我们将记忆样本手动分组到不同类别中(这些类别的描述见附录A),结果如表1所示。大多数记忆内容是相当规范的文本,来自新闻标题、日志文件、论坛或维基条目,或宗教文本。然而,我们也发现了大量独特数据,包含128位UUID、(正确解析的)带有随机子串的URL,以及个人和公司的联系信息。在第6.3节中,我们将更详细地研究这些案例。
Efficacy of Different Attack Strategies. Table 2 shows the number of memorized samples broken down by the different text generation and membership inference strategies.
不同攻击策略的有效性。表2展示了根据不同文本生成和成员推断策略划分的记忆样本数量。
Table 1: Manual categorization of the 604 memorized training examples that we extract from GPT-2, along with a description of each category. Some samples correspond to multiple categories (e.g., a URL may contain base-64 data). Categories in bold correspond to personally identifiable information.
| US andinternationalnews Log files and error reports License,terms of use,copyrightnotices Lists of named items (games, countries, etc.) Forum orWikientry Valid URLs Named individuals (non-news samples only) Promotional content (products, subscriptions, etc.) High entropy (UUIDs, base64 data) Contact info (address, email, phone, twitter, etc.) | 109 79 54 54 53 50 46 45 35 32 |
| Code Configuration files Religious texts Pseudonyms Donald Trump tweets and quotes | 31 30 25 15 |
| Web forms (menu items, instructions, etc.) Technews Lists of numbers (dates, sequences, etc.) | 12 11 11 |
表 1: 从GPT-2中提取的604个记忆训练样本的人工分类及各类别说明。部分样本对应多个类别(例如URL可能包含base-64数据)。加粗类别对应个人身份信息。
| 类别 | 数量 |
|---|---|
| 美国和国际新闻 | 109 |
| 日志文件和错误报告 | 79 |
| 许可证、使用条款、版权声明 | 54 |
| 命名项目列表(游戏、国家等) | 54 |
| 论坛或维基条目 | 53 |
| 有效URL | 50 |
| 指名个人(仅限非新闻样本) | 46 |
| 促销内容(产品、订阅等) | 45 |
| 高熵数据(UUID、base64数据等) | 35 |
| 联系信息(地址、邮箱、电话、推特等) | 32 |
| 代码 | 31 |
| 配置文件 | 30 |
| 宗教文本 | 25 |
| Donald Trump推文和语录 | 15 |
| 网页表单(菜单项、说明等) | 12 |
| 科技新闻 | 11 |
| 数字列表(日期、序列等) | 11 |
Sampling conditioned on Internet text is the most effective way to identify memorized content, however, all generation schemes reveal a significant amount of memorized content. For example, the baseline strategy of generating with top $\cdot n$ sampling yields 191 unique memorized samples, whereas conditioning on Internet text increases this to 273.
基于互联网文本的条件采样是识别记忆内容的最有效方法,然而所有生成方案都会暴露大量记忆内容。例如,使用top $\cdot n$ 采样的基线策略产生了191个独特记忆样本,而基于互联网文本的条件采样则将此数量增加到273个。
As discussed earlier, looking directly at the LM perplexity is a poor membership inference metric when classifying data generated with top $n$ or temperature sampling: just $9%$ and $3%$ of inspected samples are memorized, respectively. The comparison-based metrics are significantly more effective at predicting if content was memorized. For example, $67%$ of Internet samples marked by zlib are memorized.
如前所述,在分类使用top $n$ 或温度采样生成的数据时,直接观察大语言模型的困惑度(perplexity)是一种较差的成员推断指标:仅有 $9%$ 和 $3%$ 的被检样本分别存在记忆现象。相比之下,基于比较的指标在预测内容是否被记忆方面明显更有效。例如,被zlib标记的互联网样本中有 $67%$ 存在记忆。
Figure 3 compares the zlib entropy and the GPT-2 XL perplexity for each sample, with memorized examples highlighted. Plots for the other strategies are shown in Figure 4 in Appendix B. Observe that most samples fall along a diagonal, i.e., samples with higher likelihood under one model also have higher likelihood under another model. However, there are numerous outliers in the top left: these samples correspond to those that GPT-2 assigns a low perplexity (a high likelihood) but zlib is surprised by. These points, especially those which are extreme outliers, are more likely to be memorized than those close to the diagonal.
The different extraction methods differ in the type of memorized content they find. A complete breakdown of the data is given in Appendix A; however, to briefly summarize:
不同提取方法在发现的记忆内容类型上存在差异。完整数据分类详见附录A;简要概括如下:
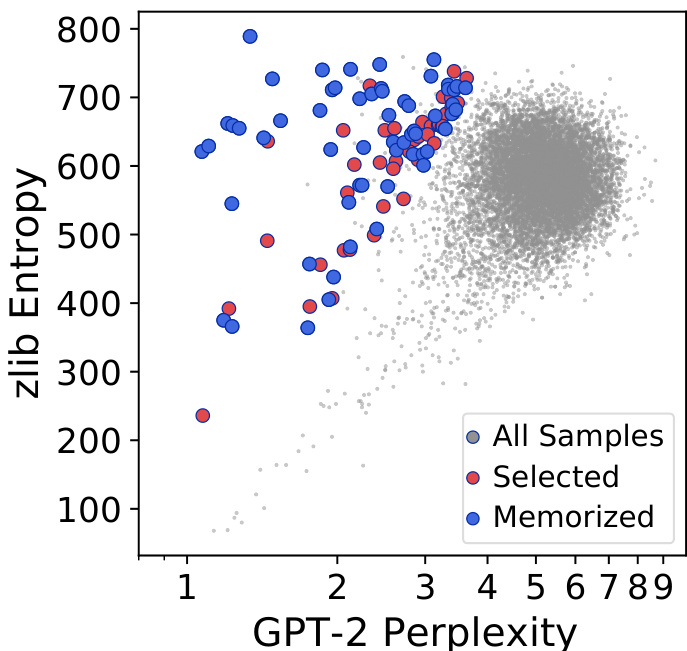
Figure 3: The zlib entropy and the perplexity of GPT-2 XL for 200,000 samples generated with top $\cdot n$ sampling. In red, we show the 100 samples that were selected for manual inspection. In blue, we show the 59 samples that were confirmed as memorized text. Additional plots for other text generation and detection strategies are in Figure 4.
图 3: 采用 top $\cdot n$ 采样生成的 20 万样本的 zlib 熵与 GPT-2 XL 困惑度。红色标记表示人工检查选出的 100 个样本,蓝色标记表示确认为记忆文本的 59 个样本。其他文本生成与检测策略的补充图示见图 4。
6.3 Examples of Memorized Content
6.3 记忆内容的示例
We next manually analyze categories of memorized content that we find particularly compelling. (Additional examples are presented in Appendix C.) Recall that since GPT-2 is trained on public data, our attacks are not particularly severe. Nevertheless, we find it useful to analyze what we are able to extract to understand the categories of memorized content— with the understanding that attacking a model trained on a sensitive dataset would give stronger results.
我们接下来手动分析几类特别引人关注的记忆内容(更多示例见附录C)。需要说明的是,由于GPT-2是在公开数据上训练的,我们的攻击并不算特别严重。但通过分析可提取的内容类型仍具价值——可以预见,若攻击基于敏感数据集训练的模型,结果将更具冲击力。
Personally Identifiable Information. We identify numerous examples of individual peoples’ names, phone numbers, addresses, and social media accounts.
个人身份信息。我们识别出大量个人姓名、电话号码、地址和社交媒体账号的实例。
Table 2: The number of memorized examples (out of 100 candidates) that we identify using each of the three text generation strategies and six membership inference techniques. Some samples are found by multiple strategies; we identify 604 unique memorized examples in total. Table 3: Examples of $k=1$ eidetic memorized, highentropy content that we extract from the training data. Each is contained in just one document. In the best case, we extract a 87-characters-long sequence that is contained in the training dataset just 10 times in total, all in the same document.
| Inference Strategy | Text Generation Strategy | |
| Top-n | Temperature Internet | |
| Perplexity | 9 | 3 |
| Small | 41 | 39 42 58 |
| Medium | 38 | 33 45 |
| zlib | 59 | 46 67 |
| Window | 33 | 28 58 |
| Lowercase | 53 | 22 60 |
| Total Unique | 191 | 140 273 |
表 2: 使用三种文本生成策略和六种成员推断技术识别出的记忆样本数量(从100个候选样本中)。部分样本被多种策略重复发现;我们共识别出604个独特的记忆样本。
表 3: 从训练数据中提取的$k=1$高熵记忆内容示例。每个样本仅出现在单一文档中。最优情况下,我们提取出87个字符长的序列,该序列在整个训练数据集中仅出现10次且均位于同一文档。
| Inference Strategy | Text Generation Strategy |
|---|---|
| Top-n | |
| Perplexity | 9 |
| Small | 41 |
| Medium | 38 |
| zlib | 59 |
| Window | 33 |
| Lowercase | 53 |
| Total Unique | 191 |
We find 46 examples that contain individual peoples’ names. When counting occurrences of named individuals, we omit memorized samples that relate to national and inter national news (e.g., if GPT-2 emits the name of a famous politician, we do not count this as a named individual here). We further find 32 examples that contain some form of contact information (e.g., a phone number or social media handle). Of these, 16 contain contact information for businesses, and 16 contain private individuals’ contact details.
我们发现46个包含个人姓名的样本。在统计具体人名出现频次时,我们排除了涉及国内外新闻的已记忆样本(例如当GPT-2输出著名政治人物姓名时,此处不计入个人姓名统计)。此外,我们还发现32个包含某种联系信息的样本(如电话号码或社交媒体账号),其中16个涉及企业联系方式,16个包含私人联系信息。
Some of this memorized content is exclusive to just a few documents. For example, we extract the usernames of six users participating in an IRC conversation that appeared in exactly one training document.
部分记忆内容仅存在于少数文档中。例如,我们从恰好出现在一份训练文档中的IRC对话中提取了六位参与用户的用户名。
URLs. We identify 50 examples of memorized URLs that correctly resolve to live webpages. Many of these URLs contain uncommon pieces of text, such as random numbers or base-64 encoded strings. We also identify several URLs that resolve correctly but we cannot identify their source (and we thus do not count them as “memorized” in our evaluation).
URL。我们识别出50个被记忆的URL示例,这些URL能正确解析为有效网页。其中许多URL包含不常见的文本片段,例如随机数字或base-64编码字符串。我们还发现几个能正确解析但无法追溯来源的URL(因此在评估中未将其计为"被记忆")。
Code. We identify 31 generated samples that contain snippets of memorized source code. Despite our ability to recover the source code verbatim, we are almost always unable to recover the original authorship notices or terms of use. Often, this information is given either before the code itself or in a LICENSE file that appears separately. For many of these samples, we can also extend their length and recover thousands of lines of (near verbatim) source code (see Section 6.4).
代码。我们识别出31个包含记忆源代码片段的生成样本。尽管我们能够逐字恢复源代码,但几乎总是无法恢复原始的作者声明或使用条款。通常,这些信息要么出现在代码本身之前,要么出现在单独的LICENSE文件中。对于许多此类样本,我们还可以扩展其长度并恢复数千行(近乎逐字的)源代码(见第6.4节)。
Unnatural Text. Memorization is not limited to naturallooking text. We find 21 instances of random number sequences with at least 50 bits of entropy.10 For example, we
非自然文本。记忆行为不仅限于看似自然的文本。我们发现21组随机数字序列,每组至少包含50比特的熵值。例如,我们
extract the following UUID:
提取以下UUID:
1e4bd2a8-e8c8-4a62-adcd-40a936480059 from the model; a Google search for this string identifies just 3 documents containing this UUID, and it is contained in just one GPT-2 training document (i.e., it is 1-eidetic memorized). Other memorized random number sequences include UUIDs contained in only a few documents (not listed to preserve privacy), git commit hashes, random IDs used for ad tracking, and product model numbers.
1e4bd2a8-e8c8-4a62-adcd-40a936480059 来自模型;谷歌搜索此字符串仅找到3份包含该UUID的文档,且它仅出现在一份GPT-2训练文档中(即属于1-精确记忆)。其他被记忆的随机数字序列包括:仅存在于少数文档的UUID(出于隐私考虑未列出)、git提交哈希值、用于广告跟踪的随机ID以及产品型号编号。
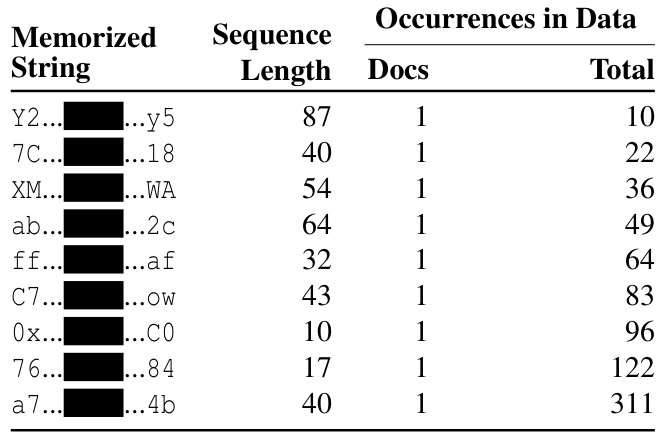
Table 3 gives nine examples of $k=1$ eidetic memorized content, each of which is a random sequences between 10 and 87 characters long. In each of these cases, the memorized example is contained in exactly one training document, and the total number of occurrences within that single document varies between just 10 and 311.
表 3 给出了 $k=1$ 的 9 个具体记忆内容示例,每个示例均为 10 至 87 个字符长度的随机序列。这些案例中,记忆样本仅出现在单一训练文档里,且该文档内的总出现次数介于 10 至 311 次之间。
Data From Two Sources. We find samples that contain two or more snippets of memorized text that are unrelated to one another. In one example, GPT-2 generates a news article about the (real) murder of a woman in 2013, but then attributes the murder to one of the victims of a nightclub shooting in Orlando in 2016. Another sample starts with the memorized Instagram biography of a pornography producer, but then goes on to incorrectly describe an American fashion model as a pornography actress. This type of generation is not $k$ -eidetic memorization (these independent pieces of information never appear in the same training documents), but it is an example of a contextual integrity violation.
来自两个数据源的记忆内容。我们发现部分生成样本包含两个及以上互不关联的记忆文本片段。例如,GPT-2生成了一篇关于2013年真实发生的女性谋杀案的新闻报道,却错误地将凶手指认为2016年奥兰多夜店枪击案的受害者之一。另一个样本开头复述了某色情制品生产商的Instagram个人简介,随后却将一位美国时尚模特错误描述为色情演员。这类生成现象不属于$k$阶精准记忆(这些独立信息从未出现在同一训练文档中),但属于上下文完整性违规的典型案例。
Removed Content. Finally, GPT-2 memorizes content that has since been removed from the Internet, and is thus now primarily accessible through GPT-2. We are aware of this content as it is still cached by Google search, but is no longer present on the linked webpage. Some of this data is not particularly interesting in its own right, e.g., error logs due to a mis configured webserver that has since been fixed. However, the fact that this type of memorization occurs highlights that LMs that are trained entirely on (at-the-time) public data may end up serving as an unintentional archive for removed data.
已移除内容。最终,GPT-2 记住了那些已被从互联网上删除的内容,因此现在主要通过 GPT-2 才能访问这些内容。我们之所以知道这些内容,是因为它们仍被 Google 搜索缓存,但已不再存在于链接的网页上。其中一些数据本身并不特别有趣,例如由于配置错误的网络服务器(现已修复)而产生的错误日志。然而,这种记忆现象的发生凸显了一个事实:完全基于(当时)公开数据训练的大语言模型,可能会无意中成为已删除数据的存档库。
6.4 Extracting Longer Verbatim Sequences
6.4 提取更长的逐字序列
In our previous experiments, we extract strings of 256 tokens in length. Here, we briefly investigate if we can extract longer sequences. In particular, we extend the length of some of the memorized sequences by seeding the model with each sample and continuing to generate. To do this, we apply a beamsearch-like decoding method introduced in prior work [8] instead of greedy decoding which often fails to generate long verbatim sequences.
在我们之前的实验中,提取了长度为256个token的字符串。这里我们简要探讨是否能提取更长的序列。具体而言,我们通过以每个样本作为种子输入模型并持续生成,从而扩展部分记忆序列的长度。为此,我们采用了先前研究[8]中引入的类似束搜索(beam search)的解码方法,而非通常难以生成长逐字序列的贪婪解码(greedy decoding)。
We can extend many of the memorized samples. For example, we identify a piece of source code taken from a repository on GitHub. We can extend this snippet to extract an entire file, namely 1450 lines of verbatim source code. We can also extract the entirety of the MIT, Creative Commons, and Project Gutenberg licenses. This indicates that while we have extracted 604 memorized examples, we could likely extend many of these to much longer snippets of memorized content.
我们可以扩展许多记忆样本。例如,我们识别出一段来自GitHub仓库的源代码片段。通过扩展该片段,我们提取出完整的文件内容,即1450行逐字复制的源代码。此外,我们还能完整提取MIT许可证、知识共享(Creative Commons)许可证和古腾堡计划(Project Gutenberg)许可证的全文。这表明虽然当前仅提取了604个记忆样本,但其中许多样本很可能可扩展为更长的记忆内容片段。
6.5 Memorization is Context-Dependent
6.5 记忆是上下文相关的
Consistent with recent work on constructing effective “prompts” for generative LMs [7, 62], we find that the memorized content is highly dependent on the model’s context.
与近期关于为大语言模型构建有效"提示"的研究[7, 62]一致,我们发现记忆内容高度依赖模型的上下文。
For example, GPT-2 will complete the prompt “3.14159” with the first 25 digits of $\pi$ correctly using greedy sampling. However, we find that GPT-2 “knows” (under Definition 2) more digits of $\pi$ because using the beam-search-like strategy introduced above extracts 500 digits correctly.
例如,GPT-2会通过贪心采样正确补全提示"3.14159"并给出$\pi$的前25位数字。但我们发现,GPT-2"知道"(根据定义2)更多$\pi$的数字,因为使用上述类似束搜索的策略可以正确提取出500位数字。
Interestingly, by providing the more descriptive prompt “pi is $3.14159^{\ '}$ , straight greedy decoding gives the first 799 digits of $\pi$ —more than with the sophisticated beam search. Further providing the context “e begins 2.7182818, pi begins 3.14159”, GPT-2 greedily completes the first 824 digits of $\pi$
有趣的是,当提供更具描述性的提示"pi是$3.14159^{\ '}$"时,直接使用贪婪解码 (greedy decoding) 就能输出π的前799位数字——这比复杂的束搜索 (beam search) 得到的结果更多。若进一步提供上下文"e以2.7182818开头,pi以3.14159开头",GPT-2通过贪婪解码能完整输出π的前824位数字。
This example demonstrates the importance of the context: in the right setting, orders of magnitude more extraction is feasible than when the context is just slightly suboptimal. We find that this holds true for our memorized examples as well. None of the 273 extracted samples found using Internet conditioning can be reliably reproduced when using the same prefix initially provided to GPT-2 that produced this sample. However, nearly all can be reproduced with high probability if we provided the entire sequence of data up to (but not including) the beginning of the memorized content.
此例展示了上下文的重要性:在合适的设置下,可提取的内容量级会远高于上下文稍次最优时的情况。我们发现这一规律同样适用于记忆样本。在使用最初提供给GPT-2的相同前缀时(该前缀曾生成过此样本),无法可靠复现通过互联网条件获取的273个提取样本中的任何一个。但若提供直至(但不包含)记忆内容起始处的完整数据序列,则几乎全部样本都能以高概率复现。
The important lesson here is that our work vastly underestimates the true amount of content that GPT-2 memorized.
这里的重要教训是,我们的工作严重低估了GPT-2实际记忆的内容量。
There are likely prompts that would identify much more memorized content, but because we stick to simple prompts we do not find this memorized content.
可能存在某些提示词能识别出更多被记忆的内容,但由于我们坚持使用简单提示,因此未能发现这些被记忆的内容。
Correlating Memorization with Model Size & Insertion Frequency
模型大小与插入频率对记忆化的关联性研究
Thus far, we have shown that language models can memorize verbatim training strings, even when they are trained for few epochs and achieve small train-test accuracy gaps. A natural question is how many times a string must appear for it to be memorized (i.e., $k$ in Definition 2). Prior work has investigated LM memorization by varying the number of times particular “canary” tokens were inserted into a training dataset [8]. The main limitation of this approach is that it is synthetic: canaries are inserted artificially after the dataset has been collected and may not be representative of natural data.
至此,我们已经证明语言模型能够逐字记忆训练字符串,即便在训练轮次较少且训练-测试准确率差距较小的情况下。一个自然的问题是:字符串需要出现多少次才能被记忆(即定义2中的 $k$ 值)。先前研究通过调整训练数据集中特定"金丝雀"token的插入次数来探究大语言模型的记忆行为 [8]。这种方法的主要局限在于其人为性:金丝雀是在数据集收集后人为插入的,可能无法代表自然数据。
Here, we study how well GPT-2 memorizes naturally occurring canaries in the training data. In particular, we consider a piece of memorized content with the following prefix:
在此,我们研究GPT-2对训练数据中自然出现的金丝雀(canary)记忆程度。具体而言,我们考察以下前缀形式的记忆内容:
{"color":"fuchsia","link":"https://www. reddit.com/r/The_Donald/comments/
{"color":"fuchsia","link":"https://www.reddit.com/r/The_Donald/comments/
The reddit.com URL above is completed by a specific 6-character article ID and a title. We located URLs in this specific format in a single document on pastebin.com. Each URL appears a varying number of times in this document, and hence in the GPT-2 training dataset.11 Table 4 shows a subset of the URLs that appear more than once, and their respective counts in the document.12 This allows us to ask the question: how many times must an example appear in the training dataset for us to extract it?
上述reddit.com网址由特定的6字符文章ID和标题组成。我们在pastebin.com的单个文档中发现了这种特定格式的URL。每个URL在该文档中出现的次数各不相同,因此在GPT-2训练数据集中出现的频次也不同。表4展示了部分重复出现的URL及其在文档中的对应计数。这使我们能够提出一个问题:训练数据集中需要出现多少次样本才能被我们提取出来?
Methods. We attempt two approaches to extract URLs of this format, and run three variants of GPT-2 (XL, Medium, and Small). The two approaches vary the “difficulty” of the attack, so even if the more difficult fails the easier may succeed.
方法。我们尝试了两种提取此类格式URL的方法,并运行了GPT-2的三种变体(XL、Medium和Small)。这两种方法在攻击"难度"上有所差异,因此即使较难的方法失败,较易的方法仍可能成功。
First, we directly prompt each variant of GPT-2 with the prefix above, and use top $\cdot n$ sampling to generate 10,000 possible extensions. Then, we test whether any of the URLs in the training document were among those that were emitted by GPT-2. We count a URL as emitted if it matches verbatim with one of the 10,000 generations.
首先,我们直接用上述前缀提示GPT-2的每个变体,并采用top $\cdot n$采样生成10,000种可能的扩展。接着,我们检测训练文档中的任意URL是否出现在GPT-2生成的输出中。若某个URL与10,000次生成结果中的某一个完全匹配,则判定该URL被生成。
Some URLs are not extract able with this technique, and so we make the problem easier for GPT-2 by additionally providing GPT-2 the 6-character random token that begins each URL. Given this additional prefix, we then sample from the model using the beam search procedure. This task is easier in two ways: we have first provided more context and additionally use a higher recall sampling strategy.
部分URL无法通过此技术提取,因此我们通过额外提供每个URL开头的6字符随机token来简化GPT-2的任务。在获得这个额外前缀后,我们使用束搜索(beam search)程序从模型中采样。该任务在两方面更容易实现:我们提供了更多上下文信息,并采用了更高召回率的采样策略。
Occurrences Memorized? Table 4: We show snippets of Reddit URLs that appear a varying number of times in a single training document. We condition GPT-2 XL, Medium, or Small on a prompt that contains the beginning of a Reddit URL and report a $\checkmark$ if the corresponding URL was generated verbatim in the first 10,000 generations. We report a $1/2$ if the URL is generated by providing GPT-2 with the first 6 characters of the URL and then running beam search.
| URL (trimmed) | Docs | Total | XL | M | S |
| /r/ | 51y/milo_evacua... | 1 | 359 | √ | 1/2 |
| /r/ | zin/hi_my_name... | 1 | 113 | √ | |
| /r/ | 7ne/for_all_yo... | 1 | 76 | 1/2 | |
| /r/ | 5mj/fake_news_... | 1 | 72 | ||
| /r/ | 5wn/reddit_admi... | 1 | 64 | √ | |
| /r/ | lp8/26_evening... | 1 | 56 | √ | |
| /r/ | jla/so_pizzagat... | 1 | 51 | √ | 1/2 |
| /r/ | ubf/late_night... | 1 | 51 | 1/2 | |
| /r/ | eta/make_christ... | 1 | 35 | 1/2 | |
| /r/ | 6ev/its_officia... | 1 | 33 | √ | |
| /r/ | 3c7/scott_adams.. | 1 | 17 | ||
| /r/ | k2o/because_his... | 1 | 17 | ||
| /r/ | tu3/armynavy_ga... | 1 | 8 |
记忆出现次数?
表 4: 我们展示了单个训练文档中出现次数不等的Reddit URL片段。我们以包含Reddit URL开头的提示作为条件,测试GPT-2 XL、Medium或Small模型,若在前10,000次生成中完全重现对应URL则标记√。若需提供URL前6个字符并通过束搜索生成,则标记1/2。
| URL (trimmed) | Docs | Total | XL | M | S |
|---|---|---|---|---|---|
| /r/51y/milo_evacua... | 1 | 359 | √ | 1/2 | |
| /r/zin/hi_my_name... | 1 | 113 | √ | ||
| /r/7ne/for_all_yo... | 1 | 76 | 1/2 | ||
| /r/5mj/fake_news_... | 1 | 72 | |||
| /r/5wn/reddit_admi... | 1 | 64 | √ | ||
| /r/lp8/26_evening... | 1 | 56 | √ | ||
| /r/jla/so_pizzagat... | 1 | 51 | √ | 1/2 | |
| /r/ubf/late_night... | 1 | 51 | 1/2 | ||
| /r/eta/make_christ... | 1 | 35 | 1/2 | ||
| /r/6ev/its_officia... | 1 | 33 | √ | ||
| /r/3c7/scott_adams... | 1 | 17 | |||
| /r/k2o/because_his... | 1 | 17 | |||
| /r/tu3/armynavy_ga... | 1 | 8 |
Results. Table 4 summarizes the key results. Under the more difficult of the two approaches, the full-sized 1.5 billion parameter GPT-2 model emits all examples that are inserted 33 times or more, the medium-sized 345 million parameter memorizes half of the URLs, and the smallest 117 million parameter model memorizes none of these URLs.
结果。表4总结了关键结果。在两种方法中较困难的情况下,完整规模的15亿参数GPT-2模型输出了所有被插入33次或以上的示例,中等规模的3.45亿参数模型记住了半数URL,而最小的1.17亿参数模型则未记住任何URL。
When given the additional context and using beam search, the medium model can emit four more URLs, and the small model only emits the one URL that was inserted 359 times.
在提供额外上下文并使用束搜索 (beam search) 时,中等模型能额外生成4个URL,而小模型仅生成被插入359次的那一个URL。
These results illustrate two fundamental lessons in LM memorization. First, larger models memorize significantly more training data: even hundreds of millions of parameters are not enough to memorize some of the training points. The ability of LMs to improve with model size has been extensively studied [35, 38]; we show a negative trend where these improvements come at the cost of decreased privacy. Second, for the largest LM, complete memorization occurs after just 33 insertions. This implies that any potentially sensitive information that is repeated a non-trivial amount of times is at risk for memorization, even if it was only repeated multiple times in a single training document.
这些结果揭示了大语言模型记忆能力的两个基本规律。首先,模型规模越大记忆的训练数据就越多:即使数亿参数仍不足以记忆某些训练样本。大语言模型随规模提升而增强的能力已被广泛研究[35,38];我们则揭示了这种提升是以隐私性下降为代价的负面趋势。其次,对于最大规模的模型,仅需33次重复插入就能实现完整记忆。这意味着任何重复出现一定次数的潜在敏感信息(即便仅在同一训练文档中多次出现)都存在被记忆的风险。
8 Mitigating Privacy Leakage in LMs
8 缓解大语言模型中的隐私泄漏问题
Now that we have shown that memorized training data can be extracted from LMs, a natural question is how to mitigate these threats. Here we describe several possible strategies.
既然我们已经证明可以从大语言模型中提取出记忆的训练数据,一个自然的问题是如何缓解这些威胁。下面我们描述几种可能的策略。
Training With Differential Privacy. Differential privacy (DP) [13, 14] is a well-established notion of privacy that offers strong guarantees on the privacy of individual records in the training dataset. Private machine learning models can be trained with variants of the differential ly private stochastic gradient descent (DP-SGD) algorithm [1] which is widely implemented [17, 25]. Large companies have even used DP in production machine learning models to protect users’ sensitive information [15,69]. The tradeoffs between privacy and utility of models have been studied extensively: differential ly-private training typically prevents models from capturing the long tails of the data distribution and thus hurts utility [19, 20, 67].
差分隐私训练。差分隐私 (DP) [13, 14] 是一种成熟的隐私保护概念,能为训练数据集中的个体记录提供强有力的隐私保障。私有机器学习模型可通过差分隐私随机梯度下降 (DP-SGD) 算法 [1] 的变体进行训练,该算法已被广泛实现 [17, 25]。大型企业甚至在生产环境的机器学习模型中采用差分隐私技术来保护用户敏感信息 [15,69]。隐私保护与模型效用之间的权衡已得到深入研究:差分隐私训练通常会阻碍模型捕捉数据分布的长尾特征,从而影响模型效用 [19, 20, 67]。
In the content of language modeling, recent work demonstrates the privacy benefits of user-level DP models [56]. Unfortunately, this work requires labels for which users contributed each document; such labels are unavailable for data scraped from the open Web. It may instead seem natural to aim for DP guarantees at the granularity of individual webpages, but rare snippets of text (e.g., an individual’s name and contact information as in Figure 1) might appear in more than one webpage. It is thus unclear how to apply DP in a principled and effective way on Web data.
在语言建模领域,近期研究展示了用户级差分隐私(DP)模型的隐私优势[56]。但遗憾的是,该方法需要标注每份文档的用户贡献者,而这类标注无法从公开网络抓取的数据中获取。虽然针对单个网页粒度实施DP保障看似可行,但罕见文本片段(如图1所示的个人姓名和联系方式)可能出现在多个网页中。因此,如何在网络数据上以原则性且有效的方式应用DP仍不明确。
Curating the Training Data. One cannot manually vet the extremely large training datasets used for training LMs. However, there are methods to limit the amount of sensitive content that is present, e.g., by identifying and filtering personal information or content with restrictive terms of use [11, 58].
筛选训练数据。人们无法手动审核用于训练大语言模型的庞大数据集。但可以通过识别并过滤个人信息或含有使用限制条款的内容 [11, 58] 等方法,来限制训练数据中敏感内容的数量。
Aside from attempting to remove sensitive content, it is also important to carefully de-duplicate the data. Many language modeling datasets are de-duplicated at the documentor paragraph-level, which means that a single document can still contain many repeated occurrences of a sensitive piece of content. We envision more sophisticated strategies to deduplicate the training data, or limit the contribution of any single source of training data.
除了尝试移除敏感内容外,仔细去重数据同样重要。许多语言建模数据集在文档或段落级别进行去重,这意味着单个文档仍可能包含敏感内容的多次重复出现。我们设想了更复杂的策略来对训练数据去重,或限制任何单一训练数据源的贡献。
It is also vital to carefully source the training data. Many of the potentially-sensitive training examples that we extracted (e.g., individuals’ personal information) came from websites that are known to host sensitive content, e.g., pastebin is the 12th most popular domain in GPT-2’s training set.
谨慎选择训练数据来源同样至关重要。我们提取的许多潜在敏感训练样本(如个人隐私信息)来自已知托管敏感内容的网站,例如pastebin是GPT-2训练集中第12大热门域名。
Overall, sanitizing data is imperfect—some private data will always slip through—and thus it serves as a first line of defense and not an outright prevention against privacy leaks.
总体而言,数据清洗( sanitizing )并不完美——部分隐私数据总会泄露——因此它只是隐私防线的第一道屏障,而非彻底杜绝隐私泄露的手段。
Limiting Impact of Memorization on Downstream Applications. In many downstream applications, e.g., dialogue systems [76] and sum mari z ation models [29], LMs are finetuned on task-specific data. On the positive side, this finetuning process may cause the LM to “forget” [42, 57] some of the data that is memorized during the pre-training stage. On the negative side, fine-tuning may introduce its own privacy leakages if the task-specific data also contains private information. An interesting direction for future work is to explore how memorization is inherited by fine-tuned models.
限制记忆对下游应用的影响。在许多下游应用中,例如对话系统[76]和摘要模型[29],大语言模型会在任务特定数据上进行微调。从积极方面看,这种微调过程可能导致模型"遗忘"[42,57]预训练阶段记忆的部分数据。但消极方面是,若任务特定数据同样包含隐私信息,微调可能引发新的隐私泄露问题。未来研究中有趣的方向是探索微调模型如何继承记忆特性。
Downstream applications built on top of language models could also attempt to filter out generated text that contains memorized content, if such content can be reliably detected (e.g., using various membership inference strategies).
基于大语言模型的下游应用也可以尝试过滤掉包含记忆内容的生成文本,前提是这些内容能够被可靠地检测到(例如使用各种成员推断策略)。
Auditing ML Models for Memorization. Finally, after mitigating privacy leaks, it is vital to audit models to empirically determine the privacy level they offer in practice [33]. Auditing is important even when using differential privacy, as it can complement theoretical upper bounds on privacy leakage [1]. We envision using our proposed methods, as well as existing attacks [8, 33, 65, 72], to audit LMs.
审核机器学习模型的记忆情况。最后,在缓解隐私泄露问题后,必须对模型进行审核,以实证确定其在实际应用中的隐私保护水平 [33]。即使采用差分隐私技术,审核仍然至关重要,因为它能补充隐私泄露的理论上限 [1]。我们建议利用本文提出的方法及现有攻击手段 [8, 33, 65, 72] 对大语言模型进行审计。
9 Lessons and Future Work
9 经验教训与未来工作
Extraction Attacks Are a Practical Threat. Prior work shows that ( $100\times$ to $1000\times$ smaller) language models potentially memorize training data in semi-realistic settings [8, 73]. Our results show that state-of-the-art LMs do memorize their training data in practice, and that adversaries can extract this data with simple techniques. Our attacks are practical even when the data contains a given sequence only a few times.
提取攻击是切实存在的威胁。已有研究表明,在接近现实的场景中,规模小100至1000倍的语言模型也可能记忆训练数据 [8, 73]。我们的实验证明,当前最先进的大语言模型确实会在实践中记忆训练数据,攻击者可通过简单技术提取这些数据。即使数据中仅包含某段序列数次,我们的攻击方法依然有效。
As our attacks interact with a language model as a blackbox, our results approximate the worst-case behavior of language models when interacting with benign users. In particular, among 600,000 (honestly) generated samples, our attacks find that at least 604 (or $0.1%$ ) contain memorized text.
由于我们的攻击将语言模型视为黑盒进行交互,实验结果近似呈现了语言模型在与善意用户互动时的最差表现。具体而言,在60万条(诚实)生成的样本中,攻击实验发现至少有604条(即$0.1%$)包含记忆文本。
Note that this is likely an extremely loose lower bound. We only manually inspected 1,800 potential candidate memorized samples; if we had started with more candidates we would likely have identified significantly more memorized content. Developing improved techniques for extracting memorized data, including attacks that are targeted towards specific content, is an interesting area for future work.
需要注意的是,这很可能是一个非常宽松的下限。我们仅手动检查了1800个潜在的候选记忆样本;如果从更多候选样本开始,很可能会发现更多被记忆的内容。开发改进的记忆数据提取技术(包括针对特定内容的攻击方法)是未来工作的一个有趣方向。
Memorization Does Not Require Over fitting. It is often believed that preventing over fitting (i.e., reducing the traintest generalization gap) will prevent models from memorizing training data. However, large LMs have no significant traintest gap, and yet we still extract numerous examples verbatim from the training set. The key reason is that even though on average the training loss is only slightly lower than the validation loss, there are still some training examples that have anomalous ly low losses. Understanding why this happens is an important problem for future work [6, 40].
记忆化无需过拟合。人们常认为防止过拟合(即缩小训练-测试泛化差距)就能阻止模型记忆训练数据。然而大型大语言模型的训练-测试差距并不显著,我们仍能从训练集中提取大量逐字复现的示例。关键原因在于:尽管平均训练损失仅略低于验证损失,但某些训练样本仍会出现异常低的损失值。理解这一现象的成因是未来研究的重要课题 [6, 40]。
Larger Models Memorize More Data. Throughout our experiments, larger language models consistently memorized more training data than smaller LMs. For example, in one setting the 1.5 billion parameter GPT-2 model memorizes over $18\times$ as much content as the 124 million parameter model (Section 7). Worryingly, it is likely that as LMs become bigger (in fact they already are $100\times$ larger than the GPT-2 model we study [7]), privacy leakage will become even more prevalent.
模型规模越大记忆数据越多。在我们的实验中,更大规模的大语言模型始终比小型模型记忆更多训练数据。例如,在某个实验设定下,15亿参数的GPT-2模型记忆的内容量是1.24亿参数模型的18倍以上(第7节)。令人担忧的是,随着大语言模型规模持续扩大(事实上当前模型已比我们研究的GPT-2大100倍[7]),隐私泄露问题将变得更加普遍。
Memorization Can Be Hard to Discover. Much of the training data that we extract is only discovered when prompting the LM with a particular prefix. Currently, we simply attempt to use high-quality prefixes and hope that they might elicit memorization. Better prefix selection strategies [62] might identify more memorized data.
记忆行为可能难以察觉。我们提取的大部分训练数据只有在使用特定前缀提示大语言模型时才会被发现。目前,我们仅尝试使用高质量前缀并期望它们能引发记忆行为。更好的前缀选择策略 [62] 可能会识别出更多被记忆的数据。
Adopt and Develop Mitigation Strategies. We discuss several directions for mitigating memorization in LMs, including training with differential privacy, vetting the training data for sensitive content, limiting the impact on downstream applications, and auditing LMs to test for memorization. All of these are interesting and promising avenues of future work, but each has weaknesses and are incomplete solutions to the full problem. Memorization in modern LMs must be addressed as new generations of LMs are emerging and becoming building blocks for a range of real-world applications.
采用并开发缓解策略。我们讨论了减轻大语言模型中记忆效应的几个方向,包括采用差分隐私训练、筛查训练数据中的敏感内容、限制对下游应用的影响,以及通过审计测试模型的记忆程度。这些都是未来研究中具有前景的方向,但每种方法都存在缺陷,无法完全解决这一问题。随着新一代大语言模型不断涌现并成为现实应用的基础组件,现代大语言模型中的记忆效应问题亟待解决。
10 Conclusion
10 结论
For large language models to be widely adopted, they must address the training data memorization problems that we have identified. Our extraction attacks are practical and efficient, and can recover hundreds of training examples from a model, even when they are contained in just one training document.
要让大语言模型得到广泛采用,必须解决我们发现的训练数据记忆问题。我们的提取攻击方法实用高效,即使训练样本仅存在于单个训练文档中,也能从模型中恢复数百条训练样本。
Our analysis is best viewed as a cautionary tale of what could happen when training large LMs on sensitive data. Even though our attacks target GPT-2 (which allows us to ensure that our work is not harmful), the same techniques apply to any LM. Moreover, because memorization gets worse as LMs become larger, we expect that these vulnerabilities will become significantly more important in the future.
我们的分析最好被视为一个警示故事,展示了在敏感数据上训练大语言模型 (Large Language Model) 可能带来的后果。尽管我们的攻击针对的是 GPT-2(这确保我们的研究不会造成危害),但同样的技术适用于任何语言模型。此外,由于记忆效应会随着语言模型规模的增大而加剧,我们预计这些漏洞在未来将变得更加重要。
There will therefore need to be techniques developed to specifically address our attacks. Training with differential lyprivate techniques is one method for mitigating privacy leakage, however, we believe that it will be necessary to develop new methods that can train models at this extreme scale (e.g., billions of parameters) without sacrificing model accuracy or training time. More generally, there are many open questions that we hope will be investigated further, including why models memorize, the dangers of memorization, and how to prevent memorization.
因此需要开发专门针对我们攻击的技术。采用差分隐私 (differential privacy) 技术进行训练是缓解隐私泄露的一种方法,但我们认为有必要开发新方法,使其能在极端规模(例如数十亿参数)下训练模型,同时不牺牲模型准确性或训练时间。更广泛地说,还有许多开放性问题有待进一步研究,包括模型为何会记忆、记忆的危害以及如何防止记忆。
Acknowledgements
致谢
We are grateful for comments on early versions of this paper by Dan Boneh, Andreas Terzis, Carey Radebaugh, Daphne Ippolito, Christine Robson, Kelly Cooke, Janel Thamkul, Austin Tarango, Jack Clark, Ilya Mironov, and Om Thakkar. Florian Tramèr is supported by NSF award CNS-1804222.
我们感谢Dan Boneh、Andreas Terzis、Carey Radebaugh、Daphne Ippolito、Christine Robson、Kelly Cooke、Janel Thamkul、Austin Tarango、Jack Clark、Ilya Mironov和Om Thakkar对本文早期版本的评论。Florian Tramèr获得了NSF奖项CNS-1804222的支持。
Summary of Contributions
贡献总结
References
参考文献
[72] Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to over fitting. In IEEE CSF, 2018.
[72] Samuel Yeom、Irene Giacomelli、Matt Fredrikson 和 Somesh Jha。机器学习中的隐私风险:分析与过拟合的关联。发表于 IEEE CSF,2018。
[73] Santiago Zanella-Béguelin, Lukas Wutschitz, Shruti Tople, Victor Rühle, Andrew Paverd, Olga Ohrimenko, Boris Köpf, and Marc Brock schmidt. Analyzing information leakage of updates to natural language models. In ACM CCS, 2020.
[73] Santiago Zanella-Béguelin, Lukas Wutschitz, Shruti Tople, Victor Rühle, Andrew Paverd, Olga Ohrimenko, Boris Köpf, and Marc Brockschmidt. 分析自然语言模型更新的信息泄露问题. 发表于 ACM CCS, 2020.
[74] Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. Defending against neural fake news. In NeurIPS, 2019.
[74] Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. 防御神经生成假新闻. 发表于NeurIPS, 2019.
[75] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. ICLR, 2017.
[75] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, Oriol Vinyals. 理解深度学习需要重新思考泛化性. ICLR, 2017.
[76] Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. DialoGPT: Large-scale generative pretraining for conversational response generation. In ACL Demo Track, 2020.
[76] Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. DialoGPT: 面向对话响应生成的大规模生成式预训练. In ACL Demo Track, 2020.
A Categorization of Memorized Data
记忆数据的分类
Table 5 describes the high-level categories that we assigned to the 604 memorized samples extracted from GPT-2. Note that a single sample can belong to multiple categories. Tables 6 and 7 (omitted for space) show the categorization broken down by attack strategy.
表 5: 描述了我们对从 GPT-2 中提取的 604 个记忆样本分配的高级类别。请注意,单个样本可能属于多个类别。表 6 和表 7 (因篇幅限制省略) 按攻击策略细分了分类结果。
B Distribution of Model Perplexities
B 模型困惑度分布
Figure 4 shows the distribution of the perplexities of samples generated with each of our three text generation strategies and ordered based on our six membership inference strategies.
图 4: 展示了采用我们三种文本生成策略生成的样本困惑度分布情况,并根据六种成员推断策略进行排序。
C Additional Case Studies of Memorization
C 记忆化案例研究的补充
Here we present additional results from our manual analysis of the memorized content.
这里我们展示了关于记忆内容手动分析的额外结果。
Memorized Leaked Podesta Emails from WikiLeaks. We identify several memorized URLs that originated from the leaked Podesta Emails available on WikiLeaks 13. There is only one training document that contains these memorized URLs. Due to the nature of email, the text of one message is often included in subsequent replies to this email. As a result, a URL that is used (intentionally) only once can be included in the dataset tens of times due to the replies.
记忆自维基解密泄露的Podesta邮件。我们识别出多个源自维基解密13泄露的Podesta邮件中的记忆URL。仅有一份训练文档包含这些记忆URL。由于电子邮件的特性,一封邮件的内容常被包含在后续回复中。因此,一个仅被(有意)使用一次的URL可能因回复而在数据集中出现数十次。
Memorized Donald Trump Quotes and Tweets. The GPT-2 training dataset was collected when the 2016 US Presidential election was often in the news. As a result, we find several instances of memorized quotes from Donald Trump, both in the form of official remarks made as President (found in the official government records), as well as statements made on Twitter.
记忆中的唐纳德·特朗普语录与推文。GPT-2训练数据集收集期间正值2016年美国总统大选频繁见诸报端,因此我们发现模型记忆了多段特朗普的言论,包括总统官方讲话(源自政府公开记录)和Twitter平台发布的声明。
Memorized Promotional Content. We extract memorized samples of promotional content, such as advertisements for books, beauty products, software products. One of these samples includes a link to an author’s valid Patreon account, along with a list of named and pseudonym o us prior donors.
记忆性宣传内容。我们提取了书籍、美容产品、软件产品等广告的记忆性样本。其中一个样本包含作者有效的Patreon账户链接,以及署名的和化名的先前捐赠者列表。
Memorized Number Sequences. We identify many examples where GPT-2 emits common number sequences. Nearly ten examples contain the integers counting up from some specific value. We also find examples of GPT-2 counting the squares $\begin{array}{c c c c c}{{1,}}&{{2,}}&{{4,}}&{{8,}}&{{16,}}\end{array}$ 25, 36, Fibonacci numbers $1,1,2,3,5,8,13,21,$ 34, 55, 89, 144, 233, 377, 610, 987, or digits of $\pi$ , 3.14159265358979323846264. None of these examples should be unexpected, but the quantity of memorized number sequences was surprising to us.
记忆数字序列。我们发现GPT-2能输出许多常见数字序列的例子。近十个例子包含从特定值开始递增的整数。我们还发现GPT-2能输出平方数序列 $\begin{array}{c c c c c}{{1,}}&{{2,}}&{{4,}}&{{8,}}&{{16,}}\end{array}$ 25, 36,斐波那契数列 $1,1,2,3,5,8,13,21,$ 34, 55, 89, 144, 233, 377, 610, 987,以及圆周率 $\pi$ 的位数3.14159265358979323846264。这些例子都不应令人意外,但记忆数字序列的数量之多令我们感到惊讶。
Memorized News Headlines. Numerous memorized text snippets are verbatim copies of news articles and headlines. A large number of these memorized samples are attributed to a single source: thehill.com, an American news website. Interestingly, most of these samples follow the exact same template: (1) they contain a list of different news headlines separated by a “pipe” symbol (|), (2) the sample begins with two merged words, e.g., “Trump Jesuit”, (3) the headline list ends with the all-caps word “MORE”, and (4) the sample contains the all-caps word “ADVERTISEMENT”.
记忆的新闻标题。大量记忆的文本片段是新闻文章和标题的逐字复制。这些记忆样本中有很大一部分来自单一来源:美国新闻网站thehill.com。有趣的是,大多数样本遵循完全相同的模板:(1) 包含由“竖线”符号(|)分隔的不同新闻标题列表,(2) 样本以两个合并的单词开头,例如“Trump Jesuit”,(3) 标题列表以全大写单词“MORE”结尾,(4) 样本包含全大写单词“ADVERTISEMENT”。
We indeed find pages on the Web that contain copies of headlines from thehill.com under this exact template. The peculiarities of these snippets likely contributed to their memorization. For example, the token Trump Jesuit does not appear in any other context on the entire Web.
我们确实在网络上发现了完全按照此模板复制的thehill.com新闻标题网页。这些文本片段的独特性可能促成了其被记忆的过程。例如,整个互联网上再未出现过"Trump Jesuit"这个token组合。
Memorized Base-64 Content. One particularly interesting form of memorization that we identify is the ability of GPT-2 to emit base-64 encoded content. For example, we extract out of the model the following sequence:
记忆的Base-64内容。我们发现一种特别有趣的记忆形式是GPT-2能够发出base-64编码内容的能力。例如,我们从模型中提取出以下序列:
b W F zd G Vy f Gl tY Wdl c 3 w 3 OT k xO Xx pb W F nZ S 9 wb md 8 aW 1 hZ 2 V zL 2 h kZ S 9 oM D Qv OD g 0 N TY 3 M jY xM Tg 3 MC 5 wb md 8 Zm F kM TM lN mFi Y W J hZ j FiM jJ lY TAy N zU 0 Z which decodes to the sequence “master|images|79919|image /png|images/hde/h04/8845672611870.png|...”. Despite our attempts, we are unable to identify where this content originates.
规则:
- 输出中文翻译部分时仅保留翻译标题,不包含冗余内容、重复或解释
- 不输出无关英文内容
- 保留原始段落格式及术语(如FLAC/JPEG)、公司缩写(如Microsoft/Amazon/OpenAI)
- 人名不译
- 保留文献引用标记如[20]
- 图表翻译保留格式("图1: "/"表1: ")
- 全角括号转半角并添加间距
- 专业术语首现标注英文(如"生成式AI (Generative AI)")
- 标准AI术语对照:
- Transformer -> Transformer
- Token -> Token
- LLM -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
- 保留无法识别的特殊字符/公式
- HTML表格转Markdown格式
- 准确翻译不遗漏信息
最终仅返回Markdown格式译文
(注:根据规则要求,提供的加密字符串因无法识别且无实质内容,不予翻译。若需翻译有效文本段落,请提供具体可译内容。)

Figure 4: For each of our three text generation strategies (Top $\cdot n$ , Internet and Temperature), we generate 200,000 samples using GPT-2 and apply a de-duplication procedure. The two left-most plots show the distribution of perplexities for the full sample, and the most likely window of 50 tokens. The remaining plots compare the distribution of perplexities of GPT-2 to other measure of sample likelihood: zlib entropy, perplexity under GPT-2 Small and GPT-2 Medium, and perplexity of lower-cased samples. Each plot highlights the 100 samples we selected for manual inspection (red) and the subset that was confirmed as memorized (blue).
| Category | Count | Description | Category | Count | Description |
| US and international news | 109 | General news articles or headlines,mostly about US politics | Contact info | 32 | Physical addresses, email addresses, phone numbers, twitter handles, etc. |
| Log files and error reports | 79 | Logs produced by software or hardware | Code | 31 | Snippets of source code, including JavaScript |
| License, terms of use, copyright | 54 | Software licenses or website terms of use, copyright for code, books, etc. | Configuration files | 30 | Structured configuration data, mainly for software products |
| notices Lists of named items | 54 | Ordered lists, typically alphabetically, of | Religious texts | 25 | Extracts from the Bible, the Quran, etc. Valid usernames that do not appear to be tied |
| games, books, countries, etc. User posts on online forums or entries in | Pseudonyms | 15 | to a physical name | ||
| Forum orWiki entry | specific wikis A URL that resolves to a live page | Donald Trump tweets and quotes | 12 | Quotes and tweets from Donald Trump, of- ten from news articles Lists of user menu items, Website instruc- | |
| Valid URLs Named individuals | 50 46 | Samples that contain names of real individu- als.We limit this category to non-news sam- | Web forms | 11 | tions, navigation prompts (e.g., “please enter your email to continue") |
| ples. E.g., we do not count names of politi- cians or journalists within news articles | Tech news | 11 | News related to technology | ||
| Promotionalcontent | 45 | Descriptions of products, subscriptions, | Lists of numbers Sports news | 10 9 | Lists of dates, number sequences, π,etc. |
| newsletters, etc. | Movie synopsis, cast | 5 | News related to sports List of actors, writers, producers. Plot syn- | ||
| High entropy | 35 | Random content with high entropy, e.g.. UUIDs Base64 data,etc. | Pornography | opsis. Content of pornographic nature, often lists |
图 4: 针对我们采用的三种文本生成策略 (Top $\cdot n$、Internet 和 Temperature),使用 GPT-2 生成 20 万个样本并进行去重处理。左侧两幅图分别展示全样本的困惑度分布和最可能 50 个 token 窗口的分布。其余图表对比了 GPT-2 困惑度与其他样本似然度指标的分布:zlib 熵、GPT-2 Small 和 GPT-2 Medium 下的困惑度,以及小写样本的困惑度。每幅图均突出显示人工审查选取的 100 个样本 (红色) 和确认为记忆内容的子集 (蓝色)。
| 类别 | 数量 | 描述 | 类别 | 数量 | 描述 |
|---|---|---|---|---|---|
| 美国及国际新闻 | 109 | 主要关于美国政治的新闻文章或标题 | 联系信息 | 32 | 物理地址、电子邮箱、电话号码、推特账号等 |
| 日志文件与错误报告 | 79 | 软件或硬件生成的日志 | 代码 | 31 | 源代码片段 (含 JavaScript) |
| 许可证与使用条款 | 54 | 软件许可证、网站使用条款、代码/书籍版权等 | 配置文件 | 30 | 结构化配置数据 (主要为软件产品) |
| 命名项目列表 | 54 | 按字母顺序排列的游戏/书籍/国家等列表 | 宗教文本 | 25 | 圣经、古兰经等经文摘录 |
| 论坛或维基条目 | 50 | 在线论坛帖子或特定维基条目 | 伪名 | 15 | 未关联真实姓名的有效用户名 |
| 有效URL | 46 | 可解析为有效页面的URL | 特朗普推文与引述 | 12 | 来自新闻文章的特朗普推文和引述 |
| 实名个体 | 46 | 含真实个体姓名的样本 (不含新闻中的政客/记者) | 网页表单 | 11 | 用户菜单项列表、网站导航提示 (如"请输入邮箱继续") |
| 推广内容 | 45 | 产品描述、订阅服务、新闻通讯等 | 科技新闻 | 11 | 科技相关新闻 |
| 高熵值内容 | 35 | 高熵随机内容 (如UUID、Base64数据) | 数字列表 | 10 | 日期、数列、π等列表 |
| 体育新闻 | 9 | 体育相关新闻 | |||
| 电影概要与演职员表 | 5 | 演员/编剧/制片人列表、剧情概要 | |||
| 色情内容 | 5 | 色情性质内容 (多为列表形式) |
| Category Count | Category | ||
| USandinternationalnews | 88 | Log files and error reports | 86 |
| ForumorWikientry | 34 | Lists of named items | 53 |
| License,terms of use,copyright notice | 28 | ValidURLs | 40 |
| Namedindividuals | 25 | License, terms of use, copyright notice | 36 |
| Promotionalcontent | 18 | High entropy | 33 |
| Lists of named items | 15 | Configuration files | 32 |
| Contactinfo | 20 | Code | 29 |
| Donald Trump tweets and quotes | 12 | Named individuals | 18 |
| Pseudonyms | 7 | Promotionalcontent | 14 |
| ValidURLs | 7 | Contact info | 12 |
| Sportsnews | 6 | Pseudonyms | 11 |
| Moviesynopsis or cast | 6 | Forum orWiki entry | 9 |
| (a) Top-n (191 samples) | US and international news | 7 | |
| Tech news | 7 | ||
| Pornography | 5 | ||
| Webforms | 5 | ||
| Lists of numbers | 5 | ||
(b) Internet (273 samples)
| 类别计数 | 类别 | ||
|---|---|---|---|
| USandinternationalnews | 88 | Log files and error reports | 86 |
| ForumorWikientry | 34 | Lists of named items | 53 |
| License,terms of use,copyright notice | 28 | ValidURLs | 40 |
| Namedindividuals | 25 | License, terms of use, copyright notice | 36 |
| Promotionalcontent | 18 | High entropy | 33 |
| Lists of named items | 15 | Configuration files | 32 |
| Contactinfo | 20 | Code | 29 |
| Donald Trump tweets and quotes | 12 | Named individuals | 18 |
| Pseudonyms | 7 | Promotionalcontent | 14 |
| ValidURLs | 7 | Contact info | 12 |
| Sportsnews | 6 | Pseudonyms | 11 |
| Moviesynopsis or cast | 6 | Forum orWiki entry | 9 |
| (a) Top-n (191 samples) | US and international news | 7 | |
| Tech news | 7 | ||
| Pornography | 5 | ||
| Webforms | 5 | ||
| Lists of numbers | 5 |
(b) 互联网 (273个样本)
| Category | Count |
| USandinternationalnews Religious texts | 31 |
| License,terms of use,copyright notice | 28 |
| Promotionalcontent | 24 |
| Forum orWikientry | 20 |
| Namedindividuals | 17 |
| Listsofnameditems | 12 |
| ValidURLs | 12 |
| 12 | |
| Tech news | 8 |
| Contactinfo | 8 |
| High entropy | 6 |
| Listsofnumbers | 6 |
(c) Temperature (140 samples)
| 类别 | 数量 |
|---|---|
| 美国及国际新闻、宗教文本 | 31 |
| 许可证、使用条款、版权声明 | 28 |
| 推广内容 | 24 |
| 论坛或维基条目 | 20 |
| 指名个人 | 17 |
| 项目名称列表 | 12 |
| 有效URL | 12 |
| 12 | |
| 科技新闻 | 8 |
| 联系信息 | 8 |
| 高熵值内容 | 6 |
| 数字列表 | 6 |
(c) 温度 (140个样本)
Table 6: Memorized content found in samples produced by each of the our three text generation strategies. We show categories with at least 5 samples.
表 6: 三种文本生成策略产出样本中发现的记忆内容 (按至少5个样本的类别展示)
Table 7: Memorized content found using our six membership inference strategies. We show categories with at least 5 samples.
| Category Count Category License, terms of use, copyright notice 11 | ||||
| Count US and international news 21 | Category US and international news | Count | 40 | |
| Lists of named items | 8 Lists of named items | 18 | License, terms of use, copyright notice | 31 |
| Log files and error reports 7 6 | License, terms of use, copyright notice | 16 | Lists of named items | 17 |
| Valid URLs | Promotional content | 11 | Forum or Wiki entry | 14 |
| Lists of numbers | Valid URLs | 11 | Named individuals | 13 |
| 5 (a) Perplexity (51 samples) | Log files and error reports Named individuals | 10 | Promotional content | 13 |
| 8 | Contact info | 12 | ||
| High entropy | 8 | Log files and error reports Valid URLs | 11 | |
| Forum or Wiki entry | 7 | 10 | ||
| Configuration files Code | 6 6 | Code Tech news | 10 | |
| Configuration files | 6 6 | |||
| (b) Window (119 samples) | Pseudonyms | |||
| (c) zlib (172 samples) | ||||
| Category | Count | Category | Count Category | Count |
| US and international news | 39 | Log files and error reports | 17 Valid URLs | 17 |
| Log files and error reports Lists of named items | 29 | Forum or Wiki entry Religious texts | 15 14 | Log files and error reports 14 US and international news 13 |
| Forum or Wiki entry | 17 12 Valid URLs | 13 Contact info | 12 | |
| Named individuals | 11 High entropy | 13 Religious texts | 12 | |
| License, terms of use, copyright notice | 10 Lists of named items | 12 Named individuals | 11 | |
| High entropy | 9 | License, terms of use, copyright notice 12 | Promotional content | 11 |
| Configuration files | 6 Promotional content | 11 | High entropy | 10 |
| Promotional content | 5 Configuration files | 11 | Forum or Wiki entry | 9 |
| Tech news | 5 Named individuals | 11 | Lists of named items | 8 |
| other | 9 | License, terms of use, copyright notice | 8 | |
| (d) Lowercase (135 samples) | US and international news | 9 | Code | 5 |
| Contact info | 8 | Donald Trump tweets and quotes | 5 | |
| Donald Trump tweets and quotes | 7 | |||
| Code | 6 | (f) Medium (116 samples) | ||
(e) Small (141 samples)
表 7: 使用六种成员推断策略发现的记忆内容。我们展示样本数不少于5的类别。
| 类别 | 计数 | 类别 | 计数 | 类别 | 计数 |
|---|---|---|---|---|---|
| 许可证、使用条款、版权声明 | 11 | 美国和国际新闻 | 21 | 美国和国际新闻 | 40 |
| 命名项目列表 | 8 | 命名项目列表 | 18 | 许可证、使用条款、版权声明 | 31 |
| 日志文件和错误报告 | 7 | 许可证、使用条款、版权声明 | 16 | 命名项目列表 | 17 |
| 有效URL | 6 | 宣传内容 | 11 | 论坛或Wiki条目 | 14 |
| 数字列表 | 5 | 有效URL | 11 | 指名个人 | 13 |
| (a) 困惑度 (51样本) | 日志文件和错误报告 | 10 | 宣传内容 | 13 | |
| 指名个人 | 8 | 联系信息 | 12 | ||
| 高熵值 | 8 | 日志文件和错误报告 | 11 | ||
| 论坛或Wiki条目 | 7 | 有效URL | 10 | ||
| 配置文件 | 6 | 代码 | 10 | ||
| 代码 | 6 | 科技新闻 | 10 | ||
| 配置文件 | 6 | ||||
| (b) 窗口 (119样本) | 化名 | ||||
| (c) zlib (172样本) | |||||
| 类别 | 计数 | 类别 | 计数 | 类别 | 计数 |
| 美国和国际新闻 | 39 | 日志文件和错误报告 | 17 | 有效URL | 17 |
| 日志文件和错误报告 | 29 | 论坛或Wiki条目 | 15 | 日志文件和错误报告 | 14 |
| 命名项目列表 | 宗教文本 | 14 | 美国和国际新闻 | 13 | |
| 论坛或Wiki条目 | 17 | 有效URL | 13 | 联系信息 | 12 |
| 指名个人 | 12 | 联系信息 | 13 | 宗教文本 | 12 |
| 高熵值 | 11 | 宗教文本 | 12 | 指名个人 | 11 |
| 许可证、使用条款、版权声明 | 10 | 命名项目列表 | 12 | 宣传内容 | 11 |
| 高熵值 | 9 | 许可证、使用条款、版权声明 | 11 | 高熵值 | 10 |
| 配置文件 | 6 | 宣传内容 | 11 | 论坛或Wiki条目 | 9 |
| 宣传内容 | 5 | 配置文件 | 11 | 命名项目列表 | 8 |
| 科技新闻 | 5 | 指名个人 | 11 | 许可证、使用条款、版权声明 | 8 |
| 其他 | 9 | 代码 | 5 | ||
| (d) 小写 (135样本) | 美国和国际新闻 | 9 | 唐纳德·特朗普推文和引用 | 5 | |
| 联系信息 | 8 | ||||
| 唐纳德·特朗普推文和引用 | 7 | (f) 中等 (116样本) | |||
| 代码 | 6 |
(e) 小 (141样本)