LANGUAGE MODELS ARE OPEN KNOWLEDGE GRAPHS
语言模型即开放知识图谱
ABSTRACT
摘要
This paper shows how to construct knowledge graphs (KGs) from pre-trained language models (e.g., BERT, GPT-2/3), without human supervision. Popular KGs (e.g, Wikidata, NELL) are built in either a supervised or semi-supervised manner, requiring humans to create knowledge. Recent deep language models automatically acquire knowledge from large-scale corpora via pre-training. The stored knowledge has enabled the language models to improve downstream NLP tasks, e.g., answering questions, and writing code and articles. In this paper, we propose an unsupervised method to cast the knowledge contained within language models into KGs. We show that KGs are constructed with a single forward pass of the pretrained language models (without fine-tuning) over the corpora. We demonstrate the quality of the constructed KGs by comparing to two KGs (Wikidata, TAC KBP) created by humans. Our KGs also provide open factual knowledge that is new in the existing KGs. Our code and KGs will be made publicly available.
本文展示了如何从预训练语言模型(如BERT、GPT-2/3)中无监督地构建知识图谱(KG)。主流知识图谱(如Wikidata、NELL)通常通过监督或半监督方式构建,依赖人工创建知识。而近期深度语言模型通过预训练从大规模语料中自动获取知识,这些存储的知识提升了语言模型在下游NLP任务(如问答、代码生成和文章撰写)中的表现。本文提出一种无监督方法,将语言模型内蕴的知识转化为知识图谱。研究表明,仅需对预训练语言模型(无需微调)执行一次前向传播即可构建知识图谱。通过与人构建的两个知识图谱(Wikidata、TAC KBP)对比,验证了所构建知识图谱的质量。我们的知识图谱还提供了现有图谱中未涵盖的开放事实知识。代码与知识图谱将公开提供。
1 INTRODUCTION
1 引言
Knowledge graphs (KGs) are an important resource for both humans and machines. Factual knowledge in KGs is injected into AI applications to imitate important skills possessed by humans, e.g., reasoning and understanding. KG construction is mainly supervised, requiring humans to handwrite every fact, such as Freebase (Bollacker et al., 2008) and Wikidata. KGs can also be constructed in a semi-supervised way, in which a semi-automatic extractor is used to obtain the facts from web corpora (e.g., NELL (Carlson et al., 2010) and Knowledge Vault (Dong et al., 2014)). Humans however still need to interact with the extractor to improve the quality of the discovered facts. Therefore, human supervision, which is often expensive, is required in constructing KGs.
知识图谱 (Knowledge Graph, KG) 是人类和机器的重要资源。KG中的事实知识被注入AI应用,以模仿人类具备的关键能力,例如推理和理解。KG构建主要采用监督方式,需要人工编写每条事实,如Freebase (Bollacker et al., 2008) 和Wikidata。KG也可以通过半监督方式构建,使用半自动提取器从网络语料中获取事实 (例如NELL (Carlson et al., 2010) 和Knowledge Vault (Dong et al., 2014))。但人类仍需与提取器交互以提升发现事实的质量。因此,构建KG需要昂贵的人工监督。
Recent progress in language models (LMs), such as BERT (Devlin et al., 2018) and GPT-2/3 (Radford et al., 2019; Brown et al., 2020), has led to superior results even outperforming humans in a wide range of tasks, e.g., sentence classification (Wang et al., 2018), question answering (Brown et al., 2020). Pre-trained LMs are also capable to write poetry, music, and code, while such tasks often require we human to spend a significant amount of time in learning the relevant knowledge to work well. In fact, these pre-trained LMs automatically acquire factual knowledge from large-scale corpora (e.g., BookCorpus (Zhu et al., 2015), Common Crawl (Brown et al., 2020)) via pre-training. The learned knowledge in pre-trained LMs is the key to the current success. We therefore consider the following question: instead of using the manually created knowledge, can we use the knowledge stored in pre-trained LMs to construct KGs?
语言模型(如BERT [20] 和GPT-2/3 [21][22])的最新进展,已在句子分类 [23]、问答 [22] 等广泛任务中取得超越人类的表现。预训练语言模型还能创作诗歌、音乐和代码,而这些任务通常需要人类花费大量时间学习相关知识才能胜任。事实上,这些预训练语言模型通过大规模语料(如BookCorpus [24]、Common Crawl [22])自动获取事实性知识,其内化的知识正是当前成功的关键。由此我们思考:能否利用预训练语言模型中存储的知识来构建知识图谱(KG),而非依赖人工构建的知识?
In this paper, we design an unsupervised approach called MAMA that successfully recovers the factual knowledge stored in LMs to build KGs from scratch. MAMA constructs a KG with a single forward pass of a pre-trained LM (without fine-tuning) over a textual corpus. As illustrated in Figure 1, MAMA has two stages: Match and Map. Match stage generates a set of candidate facts by matching the facts in the textual corpus with the knowledge in the pre-trained LM. General or world knowledge from large-scale corpora is embedded in the LM, thus candidate facts in the target corpus are often covered by the knowledge in the LM. The candidate facts are matched through an efficient beam search in the attention weight matrices of the pre-trained LM without fine-tuning. Map stage produces an open KG via mapping the matched candidate facts from Match stage to both fixed KG schema and open schema. If the schema of candidate facts exists in the KG schema, we map the candidate facts directly to the fixed KG schema. Otherwise, we reserve the unmapped candidate facts in the open schema. This results in a new type of KG, open KG, with a mixture of mapped facts in fixed KG schema and unmapped facts in the open schema.
本文设计了一种名为MAMA的无监督方法,成功从大语言模型中提取事实知识来从头构建知识图谱。MAMA通过预训练大语言模型(无需微调)对文本语料库进行单次前向传播来构建知识图谱。如图1所示,MAMA包含匹配和映射两个阶段:匹配阶段通过将文本语料中的事实与预训练大语言模型中的知识进行匹配,生成候选事实集。由于大规模语料中的通用或世界知识已嵌入大语言模型,目标语料中的候选事实通常能被模型知识覆盖。这些候选事实通过预训练大语言模型注意力权重矩阵的高效束搜索完成匹配(无需微调)。映射阶段通过将匹配的候选事实同时映射到固定知识图谱模式和开放模式,生成开放知识图谱。若候选事实的模式存在于知识图谱模式中,则直接映射至固定模式;否则将未映射的候选事实保留在开放模式中。由此产生的新型开放知识图谱,同时包含固定模式中已映射的事实和开放模式中未映射的事实。
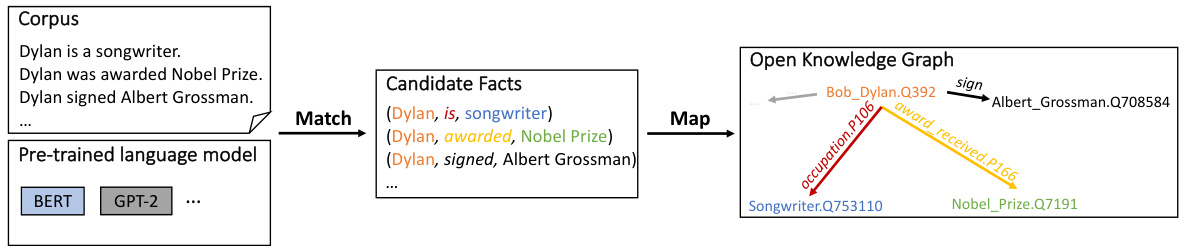
Figure 1: Overview of the proposed approach MAMA. MAMA constructs an open knowledge graph (KG) with a single forward pass of the pre-trained language model (LM) (without fine-tuning) over the corpus. Given the input: a textual corpus containing passages and sentences, e.g., English Wikipedia, and a pre-trained LM, e.g., BERT, GPT-2/3, MAMA (1) generates a set of candidate facts via matching the knowledge in the pretrained LM with facts in the textual corpus, e.g., a candidate fact (Dylan, is, songwriter) from the sentence “Dylan is a songwriter.”, and (2) produces an open KG by mapping the matched candidate facts to both an existing KG schema, e.g., (Bob Dylan.Q392, occupation.P106, Songwriter.Q753110) in Wikidata schema, and an open schema, e.g., (Bob Dylan.Q392, sign, Albert Grossman.Q708584).
图 1: 所提方法MAMA的概述。MAMA通过预训练语言模型(LM)(未经微调)对语料库的单次前向传递构建开放知识图谱(KG)。给定输入:包含段落和句子的文本语料库(如英文维基百科)及预训练LM(如BERT、GPT-2/3),MAMA(1)通过将预训练LM中的知识与文本语料库中的事实进行匹配生成候选事实集,例如从句子"Dylan is a songwriter."中提取候选事实(Dylan, is, songwriter);(2)通过将匹配的候选事实映射到现有KG模式(如Wikidata模式中的(Bob Dylan.Q392, occupation.P106, Songwriter.Q753110))和开放模式(如(Bob Dylan.Q392, sign, Albert Grossman.Q708584))来生成开放KG。
Our contributions are as follows:
我们的贡献如下:
2 MAMA
2 MAMA
We introduce an unsupervised end-to-end approach Match and Map (MAMA) as illustrated in Figure 1 to construct open knowledge graphs (KGs) from language models (LMs). MAMA constructs the KGs with a single forward pass of the pre-trained LMs (without fine-tuning) over the corpora. The two stages of MAMA are:
我们提出了一种无监督的端到端方法Match and Map (MAMA),如图1所示,用于从语言模型(LMs)构建开放知识图谱(KGs)。MAMA通过预训练LMs(无需微调)对语料库进行单次前向传递来构建KGs。MAMA的两个阶段是:
Match generates a set of candidate facts from a textual corpus. LMs contain global or world knowledge learned from large-scale corpora, which often does not perfectly match the knowledge in the target corpus. The goal of this stage is to match the knowledge stored in pre-trained LMs with facts in the corpus. Each fact is represented as a triplet (head, relation, tail) 1, in short, $(h,r,t)$ , and passed to Map stage. Match procedure is detailed in Sec. 2.1.
Match从文本语料库中生成一组候选事实。大语言模型包含从大规模语料库中学到的全局或世界知识,这些知识通常与目标语料库中的知识并不完全匹配。此阶段的目标是将预训练大语言模型中存储的知识与语料库中的事实进行匹配。每个事实以三元组(头实体, 关系, 尾实体)表示,简记为$(h,r,t)$,并传递给Map阶段。匹配流程详见第2.1节。
Map produces an open KG using the matched candidate facts from Match stage. The constructed open KG has two portions: (a) mapped candidate facts that are in a fixed KG schema, e.g., (Dylan, is, songwriter) is mapped to (Bob Dylan.Q392, occupation.P106, Songwriter.Q753110) according to Wikidata schema; and (b) unmapped candidate facts that are in an open schema, e.g., a candidate fact (Dylan, signed, Albert Grossman) is partially mapped to (Bob Dylan.Q392, sign, Albert Grossman.Q708584) in the open schema. This stage is described in Sec. 2.2.
Map阶段利用Match阶段匹配的候选事实生成一个开放知识图谱。构建的开放知识图谱包含两部分:(a) 按固定知识图谱模式映射的候选事实,例如根据Wikidata模式将(Dylan, is, songwriter)映射为(Bob Dylan.Q392, occupation.P106, Songwriter.Q753110);(b) 采用开放模式的部分映射候选事实,例如候选事实(Dylan, signed, Albert Grossman)在开放模式中被部分映射为(Bob Dylan.Q392, sign, Albert Grossman.Q708584)。该阶段具体描述见第2.2节。
(b) Attention matrix for matching degree calculation.
| Step | Action | Intermediate candidates | Matching degrees |
| 0 | START | (Dylan, | 0 |
| 1 | YIELD | (Dylan, is | 0.3 |
| 2 | YIELD | (Dylan,issongwriter | 0.7 |
| 3 | STOP | (Dylan,is,songwriter) | 0.7 |
(b) 用于匹配度计算的注意力矩阵。
| 步骤 | 动作 | 中间候选 | 匹配度 |
|---|---|---|---|
| 0 | START | (Dylan, | 0 |
| 1 | YIELD | (Dylan, is | 0.3 |
| 2 | YIELD | (Dylan,issongwriter | 0.7 |
| 3 | STOP | (Dylan,is,songwriter) | 0.7 |
| Query: | ||||
| Key: Dylan | Dylan X | is X | a | songwrite |
| is | 0.3 | X | X X | X X |
| a | 0.1 | 0.2 | X | X |
| songwriter | 0.1 | 0.4 | 0.2 | X |
| 查询: | ||||
|---|---|---|---|---|
| 关键词: Dylan | Dylan X | is X | a | songwriter |
| is | 0.3 | X | X X | X X |
| a | 0.1 | 0.2 | X | X |
| songwriter | 0.1 | 0.4 | 0.2 | X |
(a) Matching example.
(a) 匹配示例。
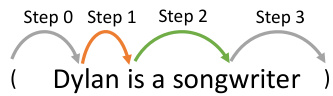
Figure 2: Illustration of Match stage. The upper part of (a) represents the general matching steps of generating the best matched candidate fact (Dylan, is, songwriter) from the sentence “Dylan is a songwriter.” The lower portion shows the corresponding step-by-step process. Given a head-tail pair (Dylan, songwriter), at each step, the search chooses one of the actions, i.e., START, YIELD, STOP to produce an intermediate candidate fact. The search starts by adding the head “Dylan” as an initial candidate (step 0). The matching degree of the candidate is initialized as 0. Next, a new candidate is yielded if the candidate has not reached the tail “songwriter”, by appending the next largest attended token (with the largest score from the attention matrix (b) of the sentence) to the end of the current candidate, and the corresponding matching degrees are increased by the associated attention scores (step 1 and step 2). Otherwise, the search stops, and the candidate fact with the best matching degree is returned for the head-tail pair (step 3). The attention matrix (b) is from the forward pass of the LM without fine-tuning over the sentence. “x” marks the tokens to prevent searching backward.
图 2: 匹配阶段示意图。(a) 图上半部分展示了从句子"Dylan is a songwriter"生成最佳匹配候选事实(Dylan, is, songwriter)的通用匹配步骤,下半部分呈现了对应的分步流程。给定头尾对(Dylan, songwriter),在每一步搜索中会从START、YIELD、STOP三个动作中选择其一,生成中间候选事实。搜索开始时将头部"Dylan"作为初始候选(步骤0),该候选的匹配度初始化为0。若当前候选未抵达尾部"songwriter",则通过追加注意力矩阵(b)中得分最高的下一个关注token来生成新候选,并累加相应注意力分数以提升匹配度(步骤1和步骤2)。当抵达尾部时停止搜索,返回该头尾对中匹配度最优的候选事实(步骤3)。注意力矩阵(b)来自语言模型前向计算过程,未经句子微调。"x"标记表示禁止向后搜索的token。
2.1 MATCH
2.1 MATCH
We frame the matching procedure as a search problem. To obtain the best matched candidate facts of an input sentence, the candidates with the top matching degrees are returned from a search process. The matching degree is derived from the search in the attention weight matrices of the pre-trained LM, since the attention weight matrices are the container of the knowledge in the pre-trained LM. The attention weight matrices are simply from the forward pass of the LM without fine-tuning over the sentence.
我们将匹配过程构建为一个搜索问题。为了获取输入句子最匹配的候选事实,搜索过程会返回匹配度最高的候选结果。匹配度源自预训练语言模型 (LM) 注意力权重矩阵的搜索,因为这些矩阵是预训练语言模型中知识的载体。注意力权重矩阵直接来自语言模型的前向传播过程,无需对句子进行微调。
2.1.1 BEAM SEARCH
2.1.1 束搜索 (BEAM SEARCH)
We design a simple-yet-effective beam search to find the best matched candidate facts. For every head-tail pair $(h,t)$ in a sentence, the search maintains the $k$ -best matched candidate facts of the pair. Let’s first consider the search from left to right with beam size equals to 1. An example search process is shown in Figure 2. Given a head-tail pair (Dylan, songwriter), at each step, the search performs one of the following actions:
我们设计了一种简单而有效的束搜索(beam search)方法来寻找最佳匹配的候选事实。对于句子中的每个头尾对$(h,t)$,搜索会保留该对的$k$个最佳匹配候选事实。首先考虑从左到右、束宽(beam size)为1的搜索过程。图2展示了一个示例搜索过程:给定头尾对(Dylan, songwriter),在每一步中,搜索会执行以下操作之一:
START the search from the head. The head $h$ is added as an initial candidate into the beam. For simplicity, we use $S\mathbb{T}\mathbb{A}\mathbb{R}\mathbb{T}(h)$ to denote the action, which returns a candidate ( $h.$ . In Figure 2(a), at step 0, the head “Dylan” is added as (Dylan, into the beam. The matching degree is initialized to 0.
从头节点开始搜索。头节点 $h$ 被作为初始候选加入搜索束。为简化表示,我们使用 $S\mathbb{T}\mathbb{A}\mathbb{R}\mathbb{T}(h)$ 表示该操作,该操作返回一个候选节点 ( $h.$ 。在图 2(a) 的第 0 步,头节点 "Dylan" 作为 (Dylan, 被加入搜索束,其匹配度初始化为 0。
YIELD a new intermediate candidate in the beam if the current candidate has not reached the tail. The next largest attended token (with the largest score from the attention matrix) is appended to the end of the current candidate to yield the new candidate. The corresponding matching degrees are increased by the associated attention scores. At step 1 (orange arrow in Figure 2(a)), “is” is appended to the current candidate to yield (Dylan, is, , since “is” has the largest attention score with “Dylan” in the attention matrix. The attention score is 0.3 as highlighted in orange in Figure 2(b). The multi-head attention is reduced to a single head so that every two tokens of the sentence are associated with one attention weight. We experiment with different reduction setups in Sec. A.3. “x” marks the tokens (prior to the current token) that are not considered in the search to prevent searching backward. Step 2 similarly takes YIELD action to produce (Dylan, is songwriter, . We use YIELD $\left(c,s,\mathbf{A}_ {s}\right)$ to denote the action, where $c$ is a current candidate, $s$ represents the sentence, and ${\bf A}_{s}$ is the
若当前候选序列未到达尾部,则在搜索束中生成一个新的中间候选序列。将注意力矩阵中得分最高的下一个被关注token附加到当前候选序列末尾,从而产生新候选序列。对应的匹配度会随相应注意力分数增加而提升。在第1步(图2(a)橙色箭头)中,由于"is"在注意力矩阵中与"Dylan"的注意力得分最高(0.3分,如图2(b)橙色标注),将其附加到当前候选序列后得到(Dylan, is, 。为简化处理,我们将多头注意力机制降为单头注意力,使得句子中每两个token对应一个注意力权重。不同降维设置的实验详见附录A.3节。"x"标记表示搜索过程中不考虑该token(位于当前token之前)以避免回溯。第2步同理执行YIELD操作生成(Dylan, is songwriter, 。我们用YIELD $\left(c,s,\mathbf{A}_ {s}\right)$ 表示该操作,其中 $c$ 为当前候选序列, $s$ 代表句子, ${\bf A}_{s}$ 是注意力矩阵。
Algorithm 1 Beam search for matching candidate facts.
算法 1: 用于匹配候选事实的束搜索 (Beam Search)
attention matrix from the forward pass of the pre-trained LM over $s$ , which yields a new candidate.
预训练语言模型前向传播过程中对 $s$ 生成的注意力矩阵,从而产生新的候选结果。
STOP the search step if the candidate has reached the tail, then add the candidate as a valid candidate fact into the beam. As beam size equals to 1, (Dylan, is, songwriter) is the only returned candidate fact for the given pair. We denote this step using $\operatorname{STOP}\left(c,t\right)$ , which returns a valid fact.
如果候选事实已到达尾部,则停止搜索步骤,并将该候选事实作为有效候选事实加入集束。由于集束大小为1,(Dylan, is, songwriter) 是给定实体对唯一返回的候选事实。我们用 $\operatorname{STOP}\left(c,t\right)$ 表示这一步骤,该函数会返回一个有效事实。
The details of the proposed beam search are in Algorithm 1. The inputs of the search algorithm are a head-tail pair $(h,t)$ , a sentence $s$ , an attention matrix ${\bf A}_ {s}$ of $s$ . Both $h$ and $t$ are identified by the noun chunk in $s$ . ${\bf A}_{s}$ is the attention matrix associated with $s$ from the forward pass of LM without fine-tuning. The search gets started by adding the head $h$ as the initial candidate in the beam (line 1). While there are still new candidates waiting to be yielded (line 2), the search continues, and the top $k$ candidates sorted by the matching degrees are maintained (line 3-11) in the beam. In practice, we implement an action manager $\mathcal{O}$ to decide which action to take at each step. Given a candidate $c$ in the beam, $\mathcal{O}(c)=\mathrm{START}$ always happens at the beginning of the search. If $c$ has not reached the tail $t$ yet, $\mathcal{O}(c)=\Upsilon\Sigma\Sigma\Sigma\mathsf{D}.$ . Otherwise, $\bar{\boldsymbol{\mathcal{O}}}(c)=\mathrm{STOP}$ . We also notice some facts are in reverse order in the sentence, e.g., “· · · said Jason Forcier , a vice president at battery maker A123 Systems Inc.” for facts of relation “org:top members employees”, thus enable bidirectional it y by running the algorithm in both directions (left to right and right to left). The beam search is implemented by the breadth-first search, which is efficient as the time complexity is $O(k\cdot d)$ , where $d$ is the maximum depth of the search tree.
所提出的束搜索(beam search)细节如算法1所示。该搜索算法的输入为一个头尾实体对$(h,t)$、句子$s$以及句子$s$的注意力矩阵${\bf A}_ {s}$。其中$h$和$t$通过句子$s$中的名词短语确定,${\bf A}_{s}$是未经微调的语言模型前向传播过程中产生的注意力矩阵。搜索过程首先将头实体$h$作为初始候选加入束中(第1行)。当存在待扩展的新候选时(第2行),算法持续运行,并在束中维护按匹配度排序的前$k$个候选(第3-11行)。实际操作中,我们通过动作管理器$\mathcal{O}$决定每一步采取的动作:对于束中的候选$c$,$\mathcal{O}(c)=\mathrm{START}$始终出现在搜索初始阶段;若$c$尚未抵达尾实体$t$,则执行$\mathcal{O}(c)=\Upsilon\Sigma\Sigma\Sigma\mathsf{D}.$;否则触发$\bar{\boldsymbol{\mathcal{O}}}(c)=\mathrm{STOP}$。我们还发现部分事实在句中呈逆序出现(例如关系"org:top_members/employees"的事实"··· said Jason Forcier, a vice president at battery maker A123 Systems Inc."),因此通过双向(从左到右和从右到左)运行算法实现双向搜索。该束搜索采用广度优先实现,时间复杂度为$O(k\cdot d)$(其中$d$为搜索树的最大深度),具有较高效率。
2.1.2 FILTER
2.1.2 滤波器 (FILTER)
Although the basic functionality provided by beam search is sufficient for finding useful candidate facts, we have found a few constraints useful. Given a candidate fact $(h,r,t)$ from beam search result $\mathbb{T}_{(h,t)}$ , it remains as a fact if satisfying all the following constraints.
虽然束搜索 (beam search) 提供的基本功能足以找到有用的候选事实,但我们发现一些约束条件很有帮助。给定来自束搜索结果 $\mathbb{T}_{(h,t)}$ 的候选事实 $(h,r,t)$ ,若满足以下所有约束条件,则该候选事实将保留为事实。
Constraint #1 The matching degree of $(h,r,t)$ is above a threshold. We compare the matching degrees corpus-wide to only reserve the facts that are matched better with the knowledge in LMs. For example, MAMA extracts a fact (Rolling Stone, wrote, pop song) from “Rolling Stone wrote: “No other pop song has so thoroughly challenged artistic conventions””, which is not an accurate fact based on the sentence. We observe the associated matching degree is below a proper threshold, while the matching degrees of high-quality facts from the same documents, e.g., (Dylan, is, songwriter), or confident facts from the other documents are beyond the threshold.
约束条件 #1 $(h,r,t)$ 的匹配度需高于阈值。我们通过全语料库范围的匹配度比较,仅保留与语言模型 (LM) 中知识匹配更优的事实。例如,MAMA 从句子 "Rolling Stone wrote: 'No other pop song has so thoroughly challenged artistic conventions'" 中提取出事实 (Rolling Stone, wrote, pop song) ,但根据上下文判断该事实并不准确。我们观察到其关联匹配度低于合理阈值,而来自同一文档的高质量事实(如 (Dylan, is, songwriter) )或其他文档中高置信度事实的匹配度均超过该阈值。
Constraint #2 The distinct frequency of $r$ is above a threshold. To avoid facts to be over-specified, e.g., (Dylan, signed to Sam Peckinpah’s film, Pat Garrett and Billy the Kid), we require $r$ should take many distinct head-tail pairs in the corpus.
约束条件2:关系 $r$ 的不同出现频率需高于阈值。为避免事实被过度特化(例如 (Dylan, signed to Sam Peckinpah's film, Pat Garrett and Billy the Kid)),我们要求 $r$ 在语料库中应涵盖大量不同的头尾实体对。
Constraint #3 Relation $r$ is a contiguous sequence in the sentence. We can avoid $r$ that has no meaningful interpretation (Fader et al., 2011), e.g., (Rolling Stone, wrote challenged, conventions) from the above sentence.
约束 #3 关系 $r$ 是句子中的连续序列。我们可以避免那些没有意义解释的 $r$ (Fader et al., 2011) ,例如上述句子中的 (Rolling Stone, wrote challenged, conventions) 。
2.2 MAP
2.2 MAP
The objective of Map stage is to generate an open KG. The open KG contains (a) mapped facts in a KG schema (Sec. 2.2.1), e.g., Wikidata schema, if the schema of the candidate facts is within the existing KG schema; and (b) unmapped facts from (a) in an open schema (Sec. 2.2.2).
Map阶段的目标是生成一个开放知识图谱(Open KG)。该开放知识图谱包含:(a) 若候选事实的模式属于现有知识图谱模式(如Wikidata模式),则将其映射为知识图谱模式中的事实(见2.2.1节);(b) 将(a)中未映射的事实以开放模式呈现(见2.2.2节)。
2.2.1 MAPPED FACTS IN KG SCHEMA
2.2.1 知识图谱模式中的映射事实
The goal is to map a candidate fact $(h,r,t)$ to a fact $(h_{k},r_{k},t_{k})$ in the KG schema. The reason for mapping to an existing KG schema is to make use of the high-quality schema designed by experts (to avoid duplicated efforts of building from scratch) and enable evaluating the candidate facts with oracle KG facts contributed by human volunteers. We first map both entities $h,t$ to $h_{k},t_{k}$ , then map the relation $r$ to $r_{k}$ in the reference KG schema.
目标是将候选事实 $(h,r,t)$ 映射到知识图谱(KG)模式中的事实 $(h_{k},r_{k},t_{k})$。映射到现有KG模式的原因是为了利用专家设计的高质量模式(避免从零构建的重复工作),并能够通过人类志愿者贡献的标准KG事实来评估候选事实。我们首先将实体 $h,t$ 映射到 $h_{k},t_{k}$,然后将关系 $r$ 映射到参考KG模式中的 $r_{k}$。
Entity linking to KG schema We leverage an unsupervised entity linker based on a mentionto-entity dictionary (Spitkovsky & Chang, 2012) to link the entities for s cal ability consideration. Besides, contextual information is crucial to link the entities correctly, we use the word embedding of the context to disambiguate the entities, which means we only link the entities with high contextual similarities based on the word embedding. We adopt the entity linker to map $h,t$ to $h_{k},t_{k}$ .
基于知识图谱模式的实体链接
我们采用基于提及-实体词典的无监督实体链接器(Spitkovsky & Chang, 2012)进行实体链接以兼顾扩展性。此外,上下文信息对正确链接实体至关重要,我们通过上下文词向量进行实体消歧,即仅链接词向量上下文相似度高的实体。该链接器将$h,t$映射为$h_{k},t_{k}$。
Relation mapping with KG schema We largely follow the relation mapping method proposed by Angeli et al. (2015) to construct an offline relation map between KG relation and relation phrases of the candidate facts. The basic idea is that the more often linked head-tail pairs (i.e., entities are with type information from the entity linking step) co-occur between the candidate facts and KG facts, the more likely the corresponding relations are mapped to each other. In addition, we normalize each relation phrase of the candidate facts by lemma ti z ation, and removing inflection, auxiliary verbs, adjectives, adverbs. After the relation mapping is constructed, one author manually checks whether the top 15 relation phrases are true mappings for each KG relation. We only reserve the true ones in the final relation mapping. This process takes approximately one day. Later, $r$ is mapped to $r_{k}$ with an efficient look-up operation in the relation mapping.
基于知识图谱模式的关系映射
我们主要遵循Angeli等人(2015)提出的关系映射方法,构建知识图谱关系与候选事实关系短语之间的离线关系映射。其核心思想是:候选事实与知识图谱事实中共同出现的头尾实体对(即经过实体链接步骤后带有类型信息的实体)频率越高,对应关系相互映射的可能性越大。此外,我们对候选事实的每个关系短语进行词形还原(lemmatization)处理,去除变体形式、助动词、形容词和副词。完成关系映射构建后,由一位作者人工核验每个知识图谱关系对应的前15个关系短语是否为真实映射,最终仅保留正确的映射关系。该过程耗时约一天。随后,通过关系映射中的高效查找操作将$r$映射到$r_{k}$。
2.2.2 UNMAPPED FACTS IN OPEN SCHEMA
2.2.2 开放模式中的未映射事实
An unmapped candidate fact $(h,r,t)$ means at least one of $h,r$ , and $t$ is not mapped to the KG schema based on the method in Sec. 2.2.1. There are two types of unmapped candidate facts:
未映射候选事实 $(h,r,t)$ 表示根据第2.2.1节的方法,$h$、$r$ 和 $t$ 中至少有一个未被映射到知识图谱模式上。未映射候选事实分为两种类型:
Partially unmapped facts represent at least one of $h,r_{\mathrm{}}$ , and $t$ are mapped to the KG schema. It can be $h$ or $t$ mapped to $h_{k}$ or $t_{k}$ based on the entity linker in Sec. 2.2.1. It can also be $r$ that mapped to $r_{k}$ using the relation mapping in Sec. 2.2.1. This actually results in unmapped facts that are in a mixture of the KG schema and the open schema. As the overall schema of the unmapped facts is not in the KG schema, we use open schema to denote such unmapped facts in the rest of the paper for simplicity. An example is (Dylan, signed, Albert Grossman) in Figure 1, where both head and tail are linked to Wikidata schema based on the entity linker in Sec. 2.2.1, but the relation cannot be mapped since there is no relation mapping from “signed” to a KG relation in Wikidata schema.
部分未映射事实表示 $h$、$r_{\mathrm{}}$ 和 $t$ 中至少有一个被映射到知识图谱 (KG) 模式。根据第2.2.1节的实体链接器,可能是 $h$ 或 $t$ 被映射到 $h_{k}$ 或 $t_{k}$;也可能是通过第2.2.1节的关系映射将 $r$ 映射到 $r_{k}$。这实际上导致未映射事实同时混合了知识图谱模式和开放模式。由于未映射事实的整体模式不属于知识图谱模式,为简化表述,本文后续统一用开放模式指代此类未映射事实。例如图1中的 (Dylan, signed, Albert Grossman),其头尾实体通过第2.2.1节的实体链接器关联到Wikidata模式,但关系"sign"无法映射,因为Wikidata模式中不存在从"sign"到知识图谱关系的映射。
Completely unmapped facts indicate all $h,r$ , and $t$ are not mapped to the KG schema. This means neither the entity linker nor the relation mapping is able to map $h,r$ , and $t$ to $h_{k}$ , $r_{k}$ , $t_{k}$ respectively. The resulting unmapped candidate facts stay in the open schema, e.g., a candidate fact (Jacob, was, A Registered Mennonite) stays the same in the open schema from a sentence “Jacob was a registered Mennonite in Amsterdam.”.
完全未映射的事实表明所有 $h,r$ 和 $t$ 都未映射到知识图谱 (KG) 模式。这意味着实体链接器和关系映射都无法将 $h,r$ 和 $t$ 分别映射到 $h_{k}$, $r_{k}$, $t_{k}$。由此产生的未映射候选事实保留在开放模式中,例如,从句子"Jacob was a registered Mennonite in Amsterdam."中提取的候选事实 (Jacob, was, A Registered Mennonite) 在开放模式中保持不变。
The resulting open KG is a new type of KG that mixes the fixed KG schema with the flexible open schema, suggesting new directions for the next generation of KGs. The open KG not only contains existing knowledge in the reference KGs, but also extends the fixed KG schema with an additional open schema to improve the coverage of the KGs, that benefits the downstream KG based applications, e.g., QA and commonsense reasoning (Wang et al., 2019; Brown et al., 2020).
最终形成的开放知识图谱(Open KG)是一种新型知识图谱,它融合了固定模式与灵活开放模式,为下一代知识图谱的发展指明了新方向。这种开放知识图谱不仅包含参考知识图谱中的现有知识,还通过附加开放模式扩展了固定模式,从而提升了知识图谱的覆盖范围,使基于知识图谱的下游应用受益,例如问答系统(QA)和常识推理(Wang et al., 2019; Brown et al., 2020)。
3 EXPERIMENTS
3 实验
How well can language models generate knowledge graphs? We experimentally explore how well can MAMA answer the question in the section. To measure the ability of LMs in generating KGs, we directly measure the quality of resulting open KGs. The open KG (see an example in Figure 3) contains two types of facts: mapped facts in the fixed KG schema; and unmapped facts in the
语言模型生成知识图谱的能力如何?我们通过实验探究MAMA在该问题上的表现。为评估大语言模型生成知识图谱的能力,我们直接测量生成开放知识图谱的质量。开放知识图谱(示例见图3)包含两类事实:遵循固定图谱模式的映射事实;以及未映射事实
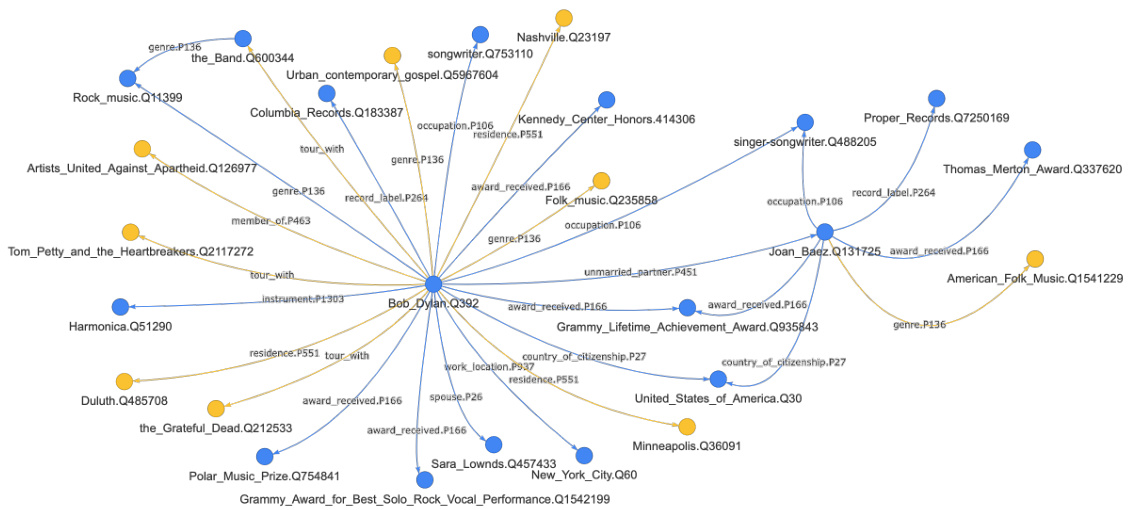
Figure 3: A snapshot subgraph of the open KG generated by MAMA using BERTLARGE from Wikipedia pages neighboring “Bob Dylan”. The blue node and arrow represent the mapped facts in the Wikidata schema, while the yellow node and arrow denote the unmapped facts in the open schema. We also visualize the correct facts that are new in Wikidata in yellow.
图 3: 使用 BERTLARGE 从维基百科"Bob Dylan"相关页面生成的开放知识图谱快照子图,由 MAMA 构建。蓝色节点和箭头表示 Wikidata 模式中已映射的事实,黄色节点和箭头表示开放模式中未映射的事实。我们同时用黄色高亮标注了 Wikidata 中新增的正确事实。
| KG | #oforaclefacts | #of documents |
| TACKBP | 27,6553 | 3,877,207 |
| Wikidata | 27,368,562 | 6,047,494 |
| KG | #oforaclefacts | #of documents |
|---|---|---|
| TACKBP | 27,6553 | 3,877,207 |
| Wikidata | 27,368,562 | 6,047,494 |
Table 1: Dataset statistics of two knowledge graphs: TAC KBP and Wikidata. TAC KBP refers to TAC KBP Slot Filling 2013 challenge. # of oracle facts for TAC KBP is the number of oracle facts in the 2013 task. # of documents for TAC KBP is the number of the documents in the 2013 task. # of oracle facts for Wikidata is the total number of oracle facts in Wikidata. # of documents for Wikidata is the size of English Wikipedia.
表 1: 两个知识图谱 TAC KBP 和 Wikidata 的数据集统计信息。TAC KBP 指代 TAC KBP Slot Filling 2013 挑战赛。TAC KBP 的基准事实数量是 2013 年任务中的基准事实总数。TAC KBP 的文档数量是 2013 年任务中的文档总数。Wikidata 的基准事实数量是 Wikidata 中的基准事实总数。Wikidata 的文档数量是英文维基百科的规模。
open schema. We first quantitatively evaluate MAMA by comparing the mapped facts to oracle KGs annotated by humans in Sec. 3.1, then conduct an in-depth analysis of the unmapped facts in Sec. 3.2.
开放模式。我们首先在第3.1节通过将映射事实与人工标注的基准知识图谱进行定量比较来评估MAMA,然后在第3.2节对未映射事实进行深入分析。
3.1 RESULTS ON MAPPED FACTS
3.1 映射事实结果
We first study the quality of the mapped facts. As the candidate facts have been mapped to the schema of oracle KGs, we are able to quant it iv ely compare the candidate facts with the oracle facts in the reference KGs.
我们首先研究映射事实的质量。由于候选事实已映射到参考知识图谱(oracle KGs)的模式上,我们能够定量比较候选事实与参考知识图谱中的标准事实。
3.1.1 DATASETS
3.1.1 数据集
We compare the mapped facts from MAMA with the facts in two KGs:
我们将MAMA映射的事实与两个知识图谱(KG)中的事实进行对比:
TAC KBP TAC Knowledge Base Population (KBP) Slot Filling is a task to search a document collection to fill in the tail/object entity for predefined relations (slots) for a given head/subject entity in a reference KG. We experiment with the reference KG in the 2013 challenge. We use the document collection and oracle facts of the 2013 task. The statistic of the dataset is shown in Table 1.
TAC KBP
TAC知识库填充(KBP)槽填充任务旨在通过搜索文档集合,为参考知识图谱(KG)中给定头/主体实体的预定义关系(槽)填充尾/客体实体。我们采用2013年挑战赛的参考知识图谱进行实验,使用该年度任务的文档集合和基准事实数据。数据集统计信息如表1所示。
表1:
Wikidata We use popular Wikidata as another KG. We use all the oracle facts in Wikidata. We use the English Wikipedia as the text corpus, since a large amount of facts in Wikidata is from English Wikipedia. The statistic is in Table 1.
Wikidata
我们选用广受欢迎的Wikidata作为另一个知识图谱(KG)。采用Wikidata中所有权威事实作为数据源,并以英文维基百科作为文本语料库,因为Wikidata中大量事实源自英文维基百科。统计数据见表1:
表1:
To evaluate the mapped facts, we first use Match stage of MAMA to run over the corresponding documents to generate the candidate facts. Then Map stage is leveraged to map the candidate facts to the schema of TAC KBP and Wikidata respectively. The parameter settings, such as beam size in Algorithm 1, are shared across TAC KBP and Wikidata based on the parameter study in Sec. A.3.
为了评估映射事实,我们首先使用MAMA的匹配阶段(Match stage)遍历相应文档以生成候选事实。随后利用映射阶段(Map stage)将这些候选事实分别映射到TAC KBP和Wikidata的架构上。根据A.3节的参数研究,算法1中的束宽(beam size)等参数设置均在TAC KBP和Wikidata之间共享。
3.1.2 TAC KBP
3.1.2 TAC KBP
To verify the ability to produce correct facts, we compare candidate facts from MAMA to the outputs of two open information systems, which also produce triplets in the form of $(h,r,t)$ .
为验证生成正确事实的能力,我们将MAMA生成的候选事实与两个开放信息系统输出的$(h,r,t)$形式三元组进行对比。
| Method | Precision% | Recall% | F1% |
| OpenIE5.12 Stanford OpenIE (Angeli et al.,2015) MAMA-BERTBASE | 56.98 61.55 | 14.54 17.35 | 23.16 27.07 |
| (ours MAMA-BERTLARGE (ours MAMA-GPT-2(ours) MAMA-GPT-2MEDIUM (ours) MAMA-GPT-2LARGE (ours) | 61.57 61.69 61.62 62.10 62.38 | 18.79 18.99 18.17 18.65 19.00 | 28.79 29.05 28.07 28.69 29.12 |
Table 2: Compare the quality of mapped facts on TAC KBP.
| 方法 | 精确率% | 召回率% | F1值% |
|---|---|---|---|
| OpenIE5.12 Stanford OpenIE (Angeli et al., 2015) MAMA-BERTBASE | 56.98 61.55 | 14.54 17.35 | 23.16 27.07 |
| (ours) MAMA-BERTLARGE (ours) MAMA-GPT-2 (ours) MAMA-GPT-2MEDIUM (ours) MAMA-GPT-2LARGE (ours) | 61.57 61.69 61.62 62.10 62.38 | 18.79 18.99 18.17 18.65 19.00 | 28.79 29.05 28.07 28.69 29.12 |
表 2: TAC KBP上映射事实的质量对比
Stanford OpenIE leverages POS tag and dependency parser, and generates self-contained clauses from long sentences to extract the triplets, which is the best open information extraction system (Angeli et al., 2015) on TAC KBP (Surdeanu, 2013). After collecting the triplets from the system, we use the same Map procedure with MAMA (Sec. 2.2.1) to map the triplets to the corresponding KG schema.
斯坦福OpenIE利用词性标注 (POS tag) 和依存句法分析器 (dependency parser),通过从长句中生成自包含子句来抽取三元组,该系统是TAC KBP (Surdeanu, 2013) 评测中表现最优的开源信息抽取系统 (Angeli et al., 2015)。从该系统收集三元组后,我们采用与MAMA相同的映射流程 (第2.2.1节) 将三元组映射至对应的知识图谱 (KG) 模式。
OpenIE 5.1 2 is the successor to Ollie (Schmitz et al., 2012), and it improves extractions from noun relations, numerical sentences, and conjunctive sentences depending on the linguistic patterns. Similarly, the same Map procedure (Sec. 2.2.1) is leveraged to map the triplets from the system to the KG schema.
OpenIE 5.1 2是Ollie (Schmitz et al., 2012) 的继任者,它根据语言模式改进了名词关系、数字句和并列句的抽取。同样地,该系统沿用相同的映射流程 (第2.2.1节) 将三元组映射至知识图谱模式。
We use two families of pre-trained LMs with MAMA. We use BERTBASE and BERTLARGE from Devlin et al. (2018) with MAMA, namely MAMA-BERTBASE and MAMA-BERTLARGE. Besides, GPT-2s from Radford et al. (2019) are used, i.e., MAMA-GPT-2, MAMA-GPT-2MEDIUM, MAMA-GPT-2LARGE, and MAMA-GPT $\mathbf{\boldsymbol{\cdot}}\mathbf{\boldsymbol{2}}_{\mathrm{XL}}$ .
我们采用两种预训练语言模型(LM)与MAMA结合使用。首先是Devlin等人(2018)提出的BERTBASE和BERTLARGE,分别命名为MAMA-BERTBASE和MAMA-BERTLARGE。此外还使用了Radford等人(2019)提出的GPT-2系列模型,包括MAMA-GPT-2、MAMA-GPT-2MEDIUM、MAMA-GPT-2LARGE以及MAMA-GPT $\mathbf{\boldsymbol{\cdot}}\mathbf{\boldsymbol{2}}_{\mathrm{XL}}$。
Table 2 shows the results on TAC KBP. We use the official scorer of TAC KBP Slot Filling 2013 to evaluate precision, recall, and F1 on TAC KBP 3.
表 2: 展示了在 TAC KBP 上的结果。我们使用 TAC KBP Slot Filling 2013 的官方评分器来评估 TAC KBP 3 的精确率 (precision)、召回率 (recall) 和 F1 值。
MAMA constructs improved KGs. From the results, we find that all our methods achieve competitive precision, which is greater than $60%$ , given the unsupervised nature of MAMA. All the proposed methods outperform the two open IE systems. This shows that MAMA is able to produce high-quality knowledge directly from pre-trained LMs by a single forward pass without human supervision. The results show the effectiveness of MAMA in generating candidate facts from Match stage, and producing high-quality KGs through Map stage. We also find that MAMA-GPT $2_{\mathrm{XL}}$ performs the best. MAMA-GPT $2_{\mathrm{XL}}$ outperforms the previous state-of-the-art Stanford OpenIE by over $2.6%$ in F1. This shows the proposed end-to-end MAMA is able to recover the knowledge stored in pre-trained LMs without relying on any extra linguistic features, such as POS tag and dependency parser used in open IE systems. The main reason leading to the moderate results of OpenIE 5.1 is that the system generates objects of the triplets with extraneous words, which hurt the performance in slot filling tasks. Even though the proposed methods all outperform the two open IE systems in the recall, however improving recall is clearly the future direction to further improve the performance of MAMA. We find that the main cause of the moderate recall is the incorrect entities caused by spaCy noun chunk as summarized in Sec. A.2.
MAMA构建了改进的知识图谱(KG)。结果显示,鉴于MAMA的无监督特性,我们提出的所有方法都取得了超过60%的竞争性准确率。所有方法均优于两个开放信息抽取系统,这表明MAMA能通过单次前向传播直接从预训练语言模型中生成高质量知识,无需人工监督。实验结果证明了MAMA在匹配阶段生成候选事实的有效性,以及通过映射阶段构建高质量知识图谱的能力。其中,MAMA-GPT 2$_{\mathrm{XL}}$表现最佳,其F1分数比之前最先进的Stanford OpenIE系统高出2.6%。这表明端到端的MAMA能够在不依赖任何额外语言特征(如开放信息抽取系统使用的词性标注和依存句法分析器)的情况下,有效提取预训练语言模型中的知识。OpenIE 5.1表现平庸的主要原因是其生成的三元组对象包含冗余词汇,影响了槽填充任务的性能。虽然我们提出的方法在召回率上都优于两个开放信息抽取系统,但提升召回率仍是未来改进MAMA性能的主要方向。如A.2节所述,召回率受限的主要原因是spaCy名词块识别导致的错误实体。
Larger/deeper LMs produce KGs of higher quality. BERTLARGE outperforms BERTBASE since the doubling parameter size. GPT-2s share similar trends, where we observe performance increases when the model size increases. This complies with our intuition on more knowledge is stored in deeper and larger models. Such increases in performance seem subtle on TAC KBP, we find this might due to the relatively small number of oracle facts by noticing a more significant improvement on Wikidata in Sec. 3.1.3. We plan to further improve the results with larger pre-trained LMs, e.g., GPT-3 (Brown et al., 2020), Megatron-LM (Shoeybi et al., 2019).
更大/更深的大语言模型能生成更高质量的知识图谱(KG)。BERTLARGE由于参数量翻倍而优于BERTBASE。GPT-2系列也呈现相似趋势,我们观察到模型规模扩大时性能随之提升。这与"更深更大的模型存储更多知识"的直觉相符。虽然在TAC KBP数据集上性能提升较微弱,我们通过第3.1.3节发现这可能是由于标注事实数量较少所致——在Wikidata上观察到了更显著的改进。我们计划采用更大型的预训练大语言模型(如GPT-3 [20]、Megatron-LM [19])来进一步提升结果。
BERT LMs outperform GPT-2 LMs under similar model sizes. More specifically, BERTBASE performs better than MAMA-GPT-2 in F1, and MAMA-BERTLARGE outperforms MAMA-GPT2MEDIUM in F1. BERTBASE and MAMA-GPT-2 are similar in size, while MAMA-BERTLARGE and MAMA-GPT-2MEDIUM are similar in model size as well. This is mainly because that the recall of BERT LMs is higher than that of corresponding GPT-2 LMs. The result indicates that the Cloze-style loss function (i.e., masked language model) of BERT is more effective and flexible in recovering more knowledge than the auto regressive LM objective. We also notice that the precision of GPT-2 LMs is higher than that of according BERT LMs. The reason is that the auto regressive LM objective captures more accurate knowledge than Cloze-style loss does by not introducing extra noise (e.g., masked tokens) during pre-training.
在相近模型规模下,BERT语言模型表现优于GPT-2语言模型。具体而言,BERTBASE在F1分数上超越MAMA-GPT-2,而MAMA-BERTLARGE的F1分数高于MAMA-GPT2MEDIUM。BERTBASE与MAMA-GPT-2模型规模相当,MAMA-BERTLARGE与MAMA-GPT-2MEDIUM的参数量也相近。这主要得益于BERT语言模型的召回率高于对应GPT-2语言模型,表明BERT采用的完形填空式损失函数(即掩码语言模型)比自回归语言模型目标能更有效、更灵活地恢复知识。我们也注意到GPT-2语言模型的精确度普遍高于对应BERT语言模型,这是因为自回归语言模型目标通过避免预训练时引入额外噪声(如掩码token),能够捕捉更准确的知识。
Table 3: Compare the quality of mapped facts on Wikidata.
| Method | Precision% | Recall% | F1% |
| Stanford OpenlE (Angeli et al., 2015) | 23.32 | 13.09 | 16.77 |
| MAMA-BERTLARGE ours | 29.52 | 16.56 | 21.22 |
| MAMA-GPT-2xL (ours | 31.32 | 17.42 | 22.39 |
表 3: 对比 Wikidata 上映射事实的质量
| 方法 | 准确率% | 召回率% | F1值% |
|---|---|---|---|
| Stanford OpenlE (Angeli et al., 2015) | 23.32 | 13.09 | 16.77 |
| MAMA-BERTLARGE (ours) | 29.52 | 16.56 | 21.22 |
| MAMA-GPT-2xL (ours) | 31.32 | 17.42 | 22.39 |
3.1.3 WIKIDATA
3.1.3 WIKIDATA
We select our best BERT based method MAMA-BERTLARGE, and GPT-2 based method MAMAGPT $2_{\mathrm{XL}}$ on TAC KBP to compare with Stanford OpenIE (the best open IE system on TAC KBP) for s cal ability experiments on Wikidata. We follow the same definition as the slot filling task to calculate precision, recall, and F1 on Wikidata. Table 3 summarizes the results.
我们选用基于BERT的最佳方法MAMA-BERTLARGE和基于GPT-2的方法MAMAGPT $2_{\mathrm{XL}}$,在TAC KBP上与斯坦福OpenIE(TAC KBP上最佳开放信息抽取系统)进行维基数据可扩展性实验。参照槽填充任务的定义计算维基数据上的精确率、召回率和F1值。表3汇总了实验结果。
MAMA is scalable to larger corpora. Similar to the trends on TAC KBP, MAMA-GPT $2_{\mathrm{XL}}$ performs the best in precision, recall, and F1. The results show the effectiveness of MAMA in generating candidate facts and high-quality KGs. We also find that MAMA-GPT $2_{\mathrm{XL}}$ outperforms MAMA-BERTLARGE by over $1%$ in F1. This shows that the larger model $(\mathrm{GPT}-2_{\mathrm{XL}}$ has ${5}\mathbf{{X}}$ more parameters compared to BERTLARGE) contains more knowledge, and MAMA is able to restore the knowledge. When larger or deeper models (e.g., GPT-3) are used with MAMA, we can expect more gains of the KG quality. Thanks to the efficient nature of MAMA, which relies only on the forward pass of the LMs without fine-tuning, the results suggest that MAMA is scalable to large KGs.
MAMA可扩展至更大规模语料库。与TAC KBP上的趋势类似,MAMA-GPT $2_{\mathrm{XL}}$ 在精确率、召回率和F1值上表现最佳。结果表明MAMA在生成候选事实和高质量知识图谱(KG)方面的有效性。我们还发现MAMA-GPT $2_{\mathrm{XL}}$ 的F1值比MAMA-BERTLARGE高出超过 $1%$ ,这表明更大规模的模型 $(\mathrm{GPT}-2_{\mathrm{XL}}$ 参数量是BERTLARGE的 ${5}\mathbf{{X}}$ 倍)蕴含更多知识,而MAMA能够还原这些知识。当使用更大或更深度的模型(如GPT-3)配合MAMA时,可预期知识图谱质量会获得更大提升。得益于MAMA仅依赖语言模型前向传播(无需微调)的高效特性,结果表明该方法具备扩展至大型知识图谱的能力。
Larger corpora embed more complete KGs. In particular, MAMA-GPT $2_{\mathrm{XL}}$ outperforms Stanford OpenIE by $5.6%$ in F1. MAMA-BERTLARGE outperforms Stanford OpenIE by approximately $4.4%$ in F1. Both F1 gains are larger compared to that on TAC KBP. This is because that the LMs contain world knowledge from pre-training corpora, e.g. Wikipedia and Common Crawl. The larger the textual corpora are, the more knowledge our method is able to recover and match to the knowledge stored in LMs. The finding is particularly important, since we are now able to construct larger KGs of high quality from scratch when larger datasets are used, such as WebText2 and Common Crawl (Raffel et al., 2019; Brown et al., 2020). Similar to the observations on TAC KBP, the precision is higher compared to recall. Wikidata is not fully built from Wikipedia, MAMA could improve the recall by running on those larger corpora to collect more facts.
更大的语料库能嵌入更完整的知识图谱(KG)。具体而言,MAMA-GPT $2_{\mathrm{XL}}$ 在F1值上比Stanford OpenIE高出$5.6%$,MAMA-BERTLARGE则领先约$4.4%$。相比TAC KBP上的表现,这两个F1提升幅度更大。这是因为语言模型(LM)包含来自预训练语料库(如Wikipedia和Common Crawl)的世界知识。文本语料规模越大,我们的方法就能恢复并匹配更多存储在语言模型中的知识。这一发现尤为重要——当使用WebText2和Common Crawl等更大规模数据集时(Raffel et al., 2019; Brown et al., 2020),我们能够从头构建更高质量的大型知识图谱。与TAC KBP的观察结果类似,精确率仍高于召回率。由于Wikidata并非完全基于Wikipedia构建,MAMA可以通过在更大语料库上运行来收集更多事实,从而提升召回率。
3.2 ANALYSIS OF UNMAPPED FACTS
3.2 未映射事实分析
As illustrated in Figure 3, the open KG constructed by MAMA is a new type of KG combining the fixed KG schema with the flexible open schema. We turn to study the quality of the candidate facts that are not mapped to the above reference KG schema, but are in the open schema generated by MAMA. We manually judge such unmapped facts generated by our best method MAMA-GPT $2_{\mathrm{XL}}$ from 100 sampled documents in Wikidata and TAC KBP respectively.
如图 3 所示,由 MAMA 构建的开放知识图谱 (KG) 是一种结合固定 KG 模式与灵活开放模式的新型知识图谱。我们转而研究未被映射到上述参考 KG 模式、但属于 MAMA 生成的开放模式的候选事实质量。我们手动评估了最佳方法 MAMA-GPT $2_{\mathrm{XL}}$ 在 Wikidata 和 TAC KBP 各 100 篇抽样文档中生成的此类未映射事实。
The quality of unmapped facts is verified. We find $35.3%$ of the unmapped facts are true on Wikidata. We find $83.2%$ of those true facts are partially unmapped facts as defined in Sec. 2.2.2, e.g., (Bob Dylan.Q392, tour with, the Grateful Dead.Q212533), whose relation is not within the schema of Wikidata, while both head and tail are in the schema. The remaining true facts are completely unmapped facts (Sec. 2.2.2), e.g., a candidate fact (Jacob, was, A Registered Mennonite) stays the same in the open schema.
未映射事实的质量经过验证。我们发现$35.3%$的未映射事实在Wikidata上为真。其中$83.2%$的真实事实属于第2.2.2节定义的部分未映射事实,例如 (Bob Dylan.Q392, tour with, the Grateful Dead.Q212533) ,其关系不在Wikidata模式中,但头尾实体均属于该模式。其余真实事实为完全未映射事实(第2.2.2节),例如候选事实 (Jacob, was, A Registered Mennonite) 在开放模式中保持不变。
Accurate entity detection is desired. We also notice $45.5%$ of the untrue unmapped facts on Wikidata are due to the incorrect entities detected by the spaCy. Incorrect or missing entity linking (to either head or tail) in Sec. 2.2.1 causes additional $9.1%$ errors in the unmapped facts. $4.5%$ of the untrue unmapped facts are caused by the missing relation mapping in Sec. 2.2.1. The rest errors made by MAMA-GPT $2_{\mathrm{XL}}$ are incorrect relation phrases, such as uninformative relation phrases, e.g., (Dylan, made, his breakthrough), which is similar to the errors made by open IE systems (Fader et al., 2011). Both entity linking and relation mapping of Map stage rely heavily on the accuracy of entity detection from the spaCy noun chunk. We conclude that the main root cause of the untrue unmapped facts is due to the errors made by the spaCy noun chunk.
需要精准的实体检测。我们还发现,Wikidata上45.5%未映射的错误事实是由于spaCy检测到的实体不正确所致。第2.2.1节中头尾实体链接错误或缺失,导致未映射事实中额外增加了9.1%的错误。另有4.5%的未映射错误事实源于第2.2.1节中关系映射缺失。MAMA-GPT 2XL造成的剩余错误属于不正确的关系短语,例如无信息量的关系短语(如(Dylan, made, his breakthrough)),这与开放信息抽取系统(Fader等人,2011)所犯错误类似。映射阶段的实体链接和关系映射都高度依赖spaCy名词块实体检测的准确性。我们得出结论:未映射错误事实的主要根源在于spaCy名词块造成的错误。
We observe similar trends on TAC KBP. We plan to leverage crowd sourcing platforms, e.g., Mechanical Turk, to conduct quantitative evaluations over the unmapped facts to better understand the strengths and shortage of MAMA. We plan to identify more accurate entities by relying on attention weights in LMs (Clark et al., 2019; Hewitt & Manning, 2019) instead of using extra resources. We will also investigate stronger entity linkers (Kolitsas et al., 2018) and learn a more robust relation mapping through weak or distant supervision (Mintz et al., 2009; Ratner et al., 2017). We will investigate more sophisticated approaches, such as graph neural networks (Kipf & Welling, 2016), to generate more accurate relation phrases from the attention weight matrices by considering structural information.
我们在TAC KBP上也观察到类似的趋势。我们计划利用众包平台(如Mechanical Turk)对未映射事实进行定量评估,以更好地理解MAMA的优势与不足。我们计划通过依赖大语言模型中的注意力权重(Clark et al., 2019; Hewitt & Manning, 2019)来识别更准确的实体,而非使用额外资源。我们还将研究更强的实体链接器(Kolitsas et al., 2018),并通过弱监督或远程监督(Mintz et al., 2009; Ratner et al., 2017)学习更稳健的关系映射。我们将研究更复杂的方法(如图神经网络(Kipf & Welling, 2016)),通过考虑结构信息从注意力权重矩阵生成更准确的关系短语。
4 RELATED WORK
4 相关工作
Knowledge graph construction can be generally categorized into two groups, 1) supervised approaches. Wikidata, Freebase (Bollacker et al., 2008), YAGO (Suchanek et al., 2007), YAGO2 (Hof- fart et al., 2013), DBpedia (Auer et al., 2007) are built based on human supervision from Wikipedia infoboxes and other structured data sources; 2) semi-supervised approaches. Open information extraction systems, e.g., OLLIE (Schmitz et al., 2012), Reverb (Fader et al., 2011), Stanford OpenIE (Angeli et al., 2015), and OpenIE 5.1 2 aim to leverage carefully-designed patterns based on linguistic features (e.g., dependencies and POS tags), to extract triplets from web corpora for open schema KG. Besides, NELL (Carlson et al., 2010), DeepDive (Niu et al., 2012), Knowledge Vault (Dong et al., 2014) extract information based on a fixed schema or ontology, where humans help improve the accuracy of the extractions. Probase (Wu et al., 2012) produces taxonomies instead of rich typed relations in general KGs. MAMA instead uses learned knowledge stored in pre-trained LMs without human supervision to construct an open KG, which is a mixture of fixed schema and open schema.
知识图谱构建通常可分为两类:1) 监督方法。Wikidata、Freebase (Bollacker et al., 2008)、YAGO (Suchanek et al., 2007)、YAGO2 (Hof-fart et al., 2013)、DBpedia (Auer et al., 2007) 基于维基百科信息框和其他结构化数据源的人工监督构建;2) 半监督方法。开放信息抽取系统(如 OLLIE (Schmitz et al., 2012)、Reverb (Fader et al., 2011)、Stanford OpenIE (Angeli et al., 2015) 和 OpenIE 5.1)旨在利用基于语言特征(如依存关系和词性标注)精心设计的模式,从网络语料中抽取三元组以构建开放模式知识图谱。此外,NELL (Carlson et al., 2010)、DeepDive (Niu et al., 2012)、Knowledge Vault (Dong et al., 2014) 基于固定模式或本体抽取信息,并通过人工干预提高抽取准确性。Probase (Wu et al., 2012) 生成分类体系而非通用知识图谱中的丰富类型关系。MAMA 则利用预训练语言模型中存储的学习知识,无需人工监督即可构建混合固定模式和开放模式的知识图谱。
Language models, e.g., BERT (Devlin et al., 2018), GPT (Radford et al., 2018), GPT-2/3 (Radford et al., 2019; Brown et al., 2020), ELMo (Peters et al., 2018), Transformer-XL (Dai et al., 2019), ALBERT (Lan et al., 2019), RoBERTa (Liu et al., 2019), XLNet (Yang et al., 2019) and MegatronLM (Shoeybi et al., 2019) contain factual knowledge obtained via pre-training on large-scale corpora such as Wikipedia and BookCorpus (Zhu et al., 2015). Studies have leveraged the pre-trained LMs as virtual KGs, and show reasonable performance in QA tasks (Dhingra et al., 2020; Guu et al., 2020), and language modeling (Khandelwal et al., 2019). LMs are further enhanced by KGs (Zhang et al., 2019; Peters et al., 2019) to improve knowledge-driven tasks. While the existing work utilizes knowledge in an implicit way, the main difference is that our approach explicitly extracts knowledgeable facts from the LMs. Compare to LAMA (Petroni et al., 2019; 2020), instead of conducting fact recall in cloze statements, MAMA directly generates the whole fact in the form of a triplet $(h,r,t)$ from a sentence. Besides, the benchmark datasets used with MAMA are larger compared to the LAMA benchmark, e.g., Wikidata is 3 orders of magnitude larger compared to the largest dataset in the LAMA benchmark.
语言模型,例如BERT (Devlin et al., 2018)、GPT (Radford et al., 2018)、GPT-2/3 (Radford et al., 2019; Brown et al., 2020)、ELMo (Peters et al., 2018)、Transformer-XL (Dai et al., 2019)、ALBERT (Lan et al., 2019)、RoBERTa (Liu et al., 2019)、XLNet (Yang et al., 2019)和MegatronLM (Shoeybi et al., 2019),通过在大规模语料库(如Wikipedia和BookCorpus (Zhu et al., 2015))上进行预训练,获得了事实性知识。研究利用预训练的语言模型作为虚拟知识图谱(KG),在问答任务(Dhingra et al., 2020; Guu et al., 2020)和语言建模(Khandelwal et al., 2019)中表现出合理性能。知识图谱进一步增强了语言模型(Zhang et al., 2019; Peters et al., 2019),以改进知识驱动任务。现有工作以隐式方式利用知识,而我们的方法主要区别在于显式地从语言模型中提取知识性事实。与LAMA (Petroni et al., 2019; 2020)相比,MAMA不是在填空语句中进行事实回忆,而是直接从句子中以三元组$(h,r,t)$的形式生成完整事实。此外,MAMA使用的基准数据集比LAMA基准更大,例如Wikidata比LAMA基准中最大的数据集大3个数量级。
Neural network interpretation here specifically refers to pre-trained deep language model analysis. There has been a lot of work to understand what the neural networks learn (Linzen et al., 2016; Adi et al., 2016; Tenney et al., 2019). With regards to analyzing Transformer (Vaswani et al., 2017) based language models (e.g., BERT and GPT-3), substantial recent work focuses on both visualizing and analyzing the attention (Vig, 2019; Jain & Wallace, 2019; Clark et al., 2019; Michel et al., 2019; Vig et al., 2020; Ramsauer et al., 2020; Hendrycks et al., 2020). Instead of analyzing or visualizing, we use LMs to generate structured KGs to directly recover what LMs learn from the corpora.
神经网络解释在此特指预训练的深度语言模型分析。已有大量工作致力于理解神经网络学习到的内容 (Linzen et al., 2016; Adi et al., 2016; Tenney et al., 2019)。针对基于Transformer (Vaswani et al., 2017) 的语言模型(如BERT和GPT-3),近期研究主要集中在注意力机制的可视化与分析 (Vig, 2019; Jain & Wallace, 2019; Clark et al., 2019; Michel et al., 2019; Vig et al., 2020; Ramsauer et al., 2020; Hendrycks et al., 2020)。不同于分析或可视化方法,我们直接利用语言模型生成结构化知识图谱(KG)来还原其从语料中学到的知识。
5 CONCLUSION
5 结论
We show that the knowledge graphs can be constructed by a single forward pass of the language models over textual corpora. We propose a two-stage unsupervised approach MAMA to first match the facts in the corpus with the internal knowledge of the language model, and then map the matched facts to produce a knowledge graph. We demonstrate the quality of the resultant open knowledge graphs by comparing to two knowledge graphs (Wikidata and TAC KBP). The open knowledge graph also features new facts in the open schema, which could have broad implications for knowledge graphs and their downstream applications. The results also suggest that larger language models store richer knowledge than existing knowledge graphs, and generating on even larger high-quality text corpora could continue improving knowledge graphs. Additionally, the knowledge graphs generated by our approach can help researchers to look into what the language models learn, so our interpret able knowledge graphs establish a bridge between the deep learning and knowledge graph communities.
我们证明知识图谱可通过语言模型对文本语料库的单次前向传递构建而成。提出名为MAMA的两阶段无监督方法:首先将语料事实与语言模型内部知识进行匹配,随后映射匹配事实以生成知识图谱。通过对比Wikidata和TAC KBP两个知识图谱,验证了所得开放知识图谱的质量。该开放知识图谱还具备开放模式下的新增事实特征,这对知识图谱及其下游应用具有广泛意义。结果表明,更大规模的语言模型比现有知识图谱存储更丰富的知识,且在更高质量文本语料上生成可持续改进知识图谱。此外,本方法生成的知识图谱有助于研究者探究语言模型的学习内容,因此我们可解释的知识图谱在深度学习与知识图谱领域间架设了桥梁。
ACKNOWLEDGEMENTS
致谢
We would like to thank Xinyun Chen, Yu Gai, Dan Hendrycks, Qingsong Lv, Yangqiu Song, Jie Tang, and Eric Wallace for their helpful inputs. We also thank Gabor Angeli, Christopher D. Manning for their timely help in replicating the results in Angeli et al. (2015). This material is in part based upon work supported by Berkeley DeepDrive and Berkeley Artificial Intelligence Research.
我们要感谢Xinyun Chen、Yu Gai、Dan Hendrycks、Qingsong Lv、Yangqiu Song、Jie Tang和Eric Wallace提供的宝贵意见。同时感谢Gabor Angeli和Christopher D. Manning在复现Angeli等人(2015)研究成果时给予的及时协助。本研究部分工作得到了Berkeley DeepDrive和Berkeley Artificial Intelligence Research的支持。
A ADDITIONAL DETAILS AND ANALYSIS OF MAMA
MAMA 的额外细节与分析
A.1 IMPLEMENTATION DETAILS
A.1 实现细节
To evaluate the mapped facts, we first use Match stage of MAMA to run over the corresponding documents to generate the candidate facts. For Map stage on TAC KBP, we link to the oracle annotation of the entities or spans in the TAC KBP corpus. On Wikidata, the entity linking method described in Sec. 2.2.1 is first leveraged to link entities in the candidate facts to Wikipedia anchors. Then a Wikipedia anchor to the Wikidata item dictionary is used to further link the entities to Wikidata. If the head or tail is a pronoun, we further use neural core f 4 for co reference resolution. We use GloVe (Pennington et al., 2014) embedding for disambiguation. The relation mapping is constructed offline for TAC KBP and Wikidata respectively using the method in Sec. 2.2.1. For oracle facts in Wikidata, we only preserve those facts describing relations that could be linked to a corresponding Wikipedia anchor. We rule out facts of attributes about entities and facts of auxiliary relations (such as topic’s main category.P901) and finally results in 27,368,562 oracle facts.
为评估映射事实,我们首先使用MAMA的匹配(Match)阶段遍历对应文档生成候选事实。在TAC KBP数据集上执行映射(Map)阶段时,我们链接至该语料库中实体或文本片段的标注真值。对于Wikidata,先采用第2.2.1节所述的实体链接方法将候选事实中的实体关联至维基百科锚点,再通过维基百科锚点到Wikidata条目的字典进行二次链接。若头尾实体为代词,则使用神经共指消解系统coref4进行处理,并采用GloVe (Pennington et al., 2014) 嵌入向量进行消歧。关系映射分别针对TAC KBP和Wikidata离线构建(方法见第2.2.1节)。对于Wikidata中的标注事实,仅保留可关联至维基百科锚点的关系描述事实,剔除实体属性类事实及辅助关系类事实(如主题主分类P901),最终获得27,368,562条标注事实。
For Wikidata, at Match stage, we randomly split the English Wikipedia data into 20 partitions, and map the data partitions to 20 distributed servers to run. Each server is configured with four Tesla K80 12Gs. We set the max sequence length to 256, and batch size as 32 for MAMA-BERTLARGE and 4 for MAMA-GPT $2_{\mathrm{XL}}$ . We use implementations of pre-trained LMs in Transformers package 5. We use spaCy sent en cize r 6 to segment the documents into sentences. MAMA-BERTLARGE takes approximately 48 hours, and MAMA-GPT $2_{\mathrm{XL}}$ costs around 96 hours. The resulting candidate facts of Match stage from the 20 servers are then reduced a data server, where a MongoDB database is maintained to store the oracle Wikidata and entity linking results to enable the efficient Map stage. To produce the open KGs, Map stage takes around 18 hours. The setup is similar to TAC KBP. Match stage is done within 48 hours for all the settings. The batch sizes of MAMA-BERTBASE, MAMA-GPT-2, MAMA-GPT-2MEDIUM, MAMA-GPT $^{2_{\mathrm{L}}}$ ARGE are 64, 32, 16, 8 respectively.
对于Wikidata,在匹配阶段,我们将英文维基百科数据随机分为20个分区,并将数据分区映射到20台分布式服务器上运行。每台服务器配置四块Tesla K80 12G显卡。我们将最大序列长度设为256,MAMA-BERTLARGE的批次大小设为32,MAMA-GPT $2_{\mathrm{XL}}$ 设为4。我们使用Transformers软件包5中的预训练语言模型实现,并采用spaCy sent en cize r 6将文档分割为句子。MAMA-BERTLARGE耗时约48小时,MAMA-GPT $2_{\mathrm{XL}}$ 耗时约96小时。匹配阶段产生的候选事实从20台服务器汇总至数据服务器,该服务器维护着存储原始Wikidata和实体链接结果的MongoDB数据库,以实现高效的映射阶段。生成开放知识图谱时,映射阶段耗时约18小时。TAC KBP的设置与之类似。所有配置下的匹配阶段均在48小时内完成。MAMA-BERTBASE、MAMA-GPT-2、MAMA-GPT-2MEDIUM和MAMA-GPT $^{2_{\mathrm{L}}}$ ARGE的批次大小分别为64、32、16和8。
The parameter settings are shared across TAC KBP and Wikidata. All the choices are based on the parameter study in Sec. A.3. The beam size of Algorithm 1 is set to 6. The matching degree threshold of Constraint #1 (Sec. 2.1.2) is set to 0.005, and the number of distinct head-tail pairs of Constraint #2 (Sec. 2.1.2) is set to 10. To generate the attention weight matrix ${\bf A}_{s}$ of a sentence, we reduce the weights of every attention head in the last layer of pre-trained LMs using the mean operator.
参数设置在TAC KBP和Wikidata中共享。所有选择均基于A.3节的参数研究。算法1的束大小(beam size)设置为6。约束条件#1(第2.1.2节)的匹配度阈值设为0.005,约束条件#2(第2.1.2节)的独特头尾对数量设为10。为生成句子的注意力权重矩阵${\bf A}_{s}$,我们使用均值算子降低预训练语言模型最后一层中每个注意力头的权重。
A.2 ERROR ANALYSIS
A.2 错误分析
There is still significant room to improve MAMA. To further understand the shortage of MAMA, we conduct an error analysis of the errors in precision (i.e., incorrect facts returned by MAMA) of Table 2 and Table 3. We choose our best method MAMA-GPT $2_{\mathrm{XL}}$ for the study. We sample 100 documents from the Wikidata dataset, and manually check the reasons for the errors. We find $33.1%$ of the errors are caused by incorrect entities, while the relation phrases are correct. The errors are due to the incorrect noun chunk detected by the spaCy 7. $18.3%$ of the errors are due to the missing relation mapping created in Sec. 2.2.1. Note that we find approximately $23.8%$ of the errors are actually correct facts that are new in the reference KGs. e.g., (Bob Dylan.Q392, residence. $.P551$ , Nashville.Q23197) (in Figure 3) is not an existing fact in Wikidata, but it is a correct mapped fact based on our annotation. The rest errors made by MAMA-GPT $2_{\mathrm{XL}}$ are incorrect relation phrases, such as uninformative relation phrases. We find similar errors are made by MAMA-GPT $2_{\mathrm{XL}}$ on TAC KBP. Similar to Sec. 3.2, enhancing the entity detection, entity linker, relation mapping, and relation generation are helpful. We also plan to leverage lifelong learning (Carlson et al., 2010) to add true facts to the reference KGs to improve the evaluation.
MAMA仍有很大的改进空间。为进一步理解MAMA的不足,我们对表2和表3中的精度错误(即MAMA返回的错误事实)进行了错误分析。我们选择最佳方法MAMA-GPT $2_{\mathrm{XL}}$ 进行研究,从Wikidata数据集中抽样100份文档并人工核查错误原因。发现 $33.1%$ 的错误源于实体识别错误(但关系短语正确),这些错误是由spaCy 7的错误名词块检测导致。 $18.3%$ 的错误源于第2.2.1节创建的关系映射缺失。值得注意的是,约 $23.8%$ 的错误实际上是参考知识图谱中新增的正确事实,例如( Bob Dylan.Q392, residence.P551, Nashville.Q23197 )(图3所示)在Wikidata中虽不存在,但根据我们的标注属于正确映射事实。其余错误来自MAMA-GPT $2_{\mathrm{XL}}$ 生成的不正确关系短语(如信息量不足的关系短语)。在TAC KBP数据集上也观察到类似错误。与第3.2节类似,增强实体检测、实体链接、关系映射和关系生成模块将有所助益。我们还计划采用终身学习(Carlson et al., 2010)技术将真实事实添加到参考知识图谱中以改进评估。

Figure 4: Parameter study with MAMA-BERTBASE on TAC KBP hold-out subset.
图 4: 采用 MAMA-BERTBASE 在 TAC KBP 保留子集上的参数研究。
A.3 PARAMETER STUDY
A.3 参数研究
We study the effects of the parameters using MAMA-BERTBASE on TAC KBP. We randomly sample $20%$ of the oracle query entities as a hold-out dataset to tune the parameters, and use the best parameter setting achieved for both TAC KBP and Wikidata experiments. When studying the effect of a certain parameter, we keep the remaining parameters as default described in Sec. A.1. We use F1 to measure the effects.
我们研究了在TAC KBP上使用MAMA-BERTBASE时参数的影响。随机抽取20%的基准查询实体作为调参验证集,并将最优参数设置同时应用于TAC KBP和Wikidata实验。研究特定参数影响时,其余参数保持A.1节所述的默认值,采用F1值作为评估指标。
Effects of beam size Figure 4(a) illustrates the effects of various beam sizes in Algorithm 1. We find that in general, the larger the beam size is, the better F1 the setting achieves. This is because that MAMA is able to reserve more potentially correct facts when more candidates are allowed in the Match stage. However, F1 improvement gradually becomes subtle, while the computation costs increase more significantly. For sake of the efficiency, we do not explore larger beam sizes. We set the beam size as 6.
光束尺寸的影响
图 4(a) 展示了算法1中不同光束尺寸的效果。我们发现,通常情况下,光束尺寸越大,该设置实现的F1值越好。这是因为在匹配阶段允许更多候选时,MAMA能够保留更多潜在正确的事实。然而,F1的提升逐渐变得细微,而计算成本却显著增加。出于效率考虑,我们未探索更大的光束尺寸,最终将其设定为6。
Effects of search constraints Figure 4(b) compares the effect of different thresholds of the matching degree of Constraint #1 in Sec. 2.1.2. We set the threshold as 0.005 since it achieves the best result. Note that the summed attention score is normalized by the length of the fact to penalize the cumbersome facts. Figure 4(c) shows the impact of the number of distinct head-tail pairs in identifying common relations of Constraint #2 in Sec. 2.1.2. The best result is achieved when it equals 10. This shows that while MAMA mostly identifies frequent relations, it is also able to capture some rare relations for the open schema.
搜索约束的影响
图4(b)比较了第2.1.2节中约束条件#1不同匹配度阈值的效果。我们将阈值设为0.005,因为此时效果最佳。需注意,汇总注意力分数会通过事实长度进行归一化,以惩罚冗长事实。图4(c)展示了第2.1.2节中约束条件#2在识别常见关系时,不同头尾对数量的影响。当该数值为10时效果最优。这表明虽然MAMA主要识别高频关系,但也能为开放模式捕获一些罕见关系。
Effects of attention weights Figure 4(d) shows the comparison between attention weights of the last layer and the mean of all layers. The attention weights of the last layer perform better. This is due to the attention weights in lower layers are low-level linguistic knowledge according to (Clark et al., 2019; Ramsauer et al., 2020), which are less relevant to the factual knowledge for the KG construction. Figure 4(e) compares the impact of different attention reduction, i.e., mean, max, over the attention heads of the last layer. We find the “mean” perform better. The reason is that the token often intensively attends to several specific tokens in the sequence (Michel et al., 2019), and the “mean” operator is more sensitive to such information.
注意力权重的影响
图4(d)展示了最后一层注意力权重与所有层平均值的对比。最后一层的注意力权重表现更优。这是因为根据 (Clark et al., 2019; Ramsauer et al., 2020) 的研究,较低层的注意力权重属于底层语言学知识,与知识图谱(KG)构建所需的事实知识关联性较低。图4(e)比较了最后一层不同注意力头聚合方式(均值与最大值)的效果,发现"均值"操作表现更好。原因是token通常会集中关注序列中的某些特定token (Michel et al., 2019),而"均值"算子对此类信息更为敏感。
B SAMPLES FROM MAMA ON TAC KBP
B 来自 MAMA 关于 TAC KBP 的样本
B.1 MAPPED FACTS
B.1 映射事实
We randomly sample 100 documents from TAC KBP corpus, then randomly sample sentences from those documents. The uncurated candidate facts and the corresponding mapped facts of the sampled sentences based on our best methods MAMA-BERTLARGE and MAMA-GPT $^{\cdot2_{\mathrm{XL}}}$ are shown in Figure 5 and Figure 6 respectively. We also randomly sample several sentences in which MAMABERTLARGE differs from MAMA-GPT $2_{\mathrm{XL}}$ in the resulting facts for comparison, which is illustrated in Figure 7. In each table, “ID” represents the document ID of a sampled sentence in TAC KBP corpus. “Sentence” indicates the sampled sentence. “Candidate facts to mapped facts” column contains the candidate facts (on the left side of $^{66}\rightarrow^{,55}$ ) and their corresponding mapped facts (on the right side of $\mathbf{\omega}^{66}\rightarrow\mathbf{\omega}^{55}$ ).
我们从TAC KBP语料库中随机抽取100份文档,并从中随机选取句子。基于最佳方法MAMA-BERTLARGE和MAMA-GPT$^{\cdot2_{\mathrm{XL}}}$,这些抽样句子的未筛选候选事实及对应映射事实分别展示在图5和图6中。此外,我们还随机选取了若干MAMA-BERTLARGE与MAMA-GPT$2_{\mathrm{XL}}$在生成事实上存在差异的句子进行对比,如图7所示。各表中,"ID"代表TAC KBP语料库中抽样句子的文档编号,"Sentence"为抽样句子,"Candidate facts to mapped facts"列包含候选事实(位于$^{66}\rightarrow^{,55}$左侧)及其对应映射事实(位于$\mathbf{\omega}^{66}\rightarrow\mathbf{\omega}^{55}$右侧)。
B.2 UNMAPPED FACTS
B.2 未映射事实
We randomly sample 100 documents from TAC KBP corpus. From those documents, we show unmapped facts from the sampled sentences from those documents. We manually check the correctness of the unmapped facts according to Sec. 3.2, and show the correct ones. The original candidate facts with the corresponding unmapped facts of the sampled sentences generated by MAMABERTLARGE and MAMA-GPT $2_{\mathrm{XL}}$ are shown in Figure 8 and Figure 9. A further comparison of the unmapped candidate facts is illustrated in Figure 10. In each table, “ID” represents the document ID of a sampled sentence in TAC KBP corpus. “Sentence” indicates the sampled sentence. “Candidate facts to unmapped facts” column contains the candidate facts (on the left side of $\ "\rightarrow"$ ) and their corresponding unmapped facts (on the right side of $\ "\rightarrow"$ ).
我们从TAC KBP语料库中随机抽取100份文档,展示这些文档采样句子中未映射的事实。根据3.2节标准人工核验未映射事实的正确性,并展示正确结果。图8和图9分别呈现了MAMABERTLARGE与MAMA-GPT $2_{\mathrm{XL}}$ 生成的采样句子原始候选事实及其对应未映射事实。未映射候选事实的进一步对比见图10。各表中"ID"代表TAC KBP语料库采样句子的文档编号,"Sentence"为采样句子,"Candidate facts to unmapped facts"列左侧为候选事实( $"\rightarrow"$ 右侧为对应未映射事实( $\ "\rightarrow"$ )。
C SAMPLES FROM MAMA ON WIKIDATA
来自维基数据MAMA的C样本
C.1 MAPPED FACTS
C.1 映射事实
Similar to TAC KBP, we randomly sample 100 documents from the Wikidata corpus (i.e., English Wikipedia), then randomly sample sentences from those documents. The uncurated candidate facts and the corresponding mapped facts of the sampled sentences based on our best methods MAMABERTLARGE and MAMA-GPT $2_{\mathrm{XL}}$ are shown in Figure 11 and Figure 12 respectively. We also randomly sample several sentences in which MAMA-BERTLARGE differs from MAMA-GPT $\cdot2_{\mathrm{XL}}$ in the resulting facts for comparison, which is illustrated in Figure 13. In each table, “ID” represents the Wikipedia page’s title of a sampled sentence. “Sentence” indicates the sampled sentence. “Candidate facts to mapped facts” column contains the candidate facts (on the left side of $\ "\rightarrow"$ ) and their corresponding mapped facts (on the right side of $\ "\rightarrow"$ ).
与TAC KBP类似,我们从Wikidata语料库(即英文维基百科)中随机抽取100篇文档,然后从这些文档中随机抽取句子。基于我们的最佳方法MAMABERTLARGE和MAMA-GPT $2_{\mathrm{XL}}$,这些抽样句子的未筛选候选事实及对应映射事实分别展示在图11和图12中。我们还随机抽取了若干MAMA-BERTLARGE与MAMA-GPT $\cdot2_{\mathrm{XL}}$在生成事实上存在差异的句子进行对比,如图13所示。各表中"ID"代表抽样句子所属维基百科页面的标题,"Sentence"表示被抽样的句子,"Candidate facts to mapped facts"列包含候选事实(位于$\ "\rightarrow"$左侧)及其对应映射事实(位于$\ "\rightarrow"$右侧)。
C.2 UNMAPPED FACTS
C.2 未映射事实
Similar to TAC KBP, we randomly sample 100 documents from the Wikidata corpus. From those documents, we show unmapped facts from several sampled sentences from those documents. We manually check the correctness of the unmapped facts according to Sec. 3.2, and show the correct ones. The original candidate facts with the corresponding unmapped facts of the sampled sentences generated by MAMA-BERTLARGE and MAMA-GPT $2_{\mathrm{XL}}$ are shown in Figure 14 and Figure 15. A further comparison of the unmapped candidate facts is illustrated in Figure 16. In each table, “ID” represents the Wikipedia page’s title of a sampled sentence. “Sentence” indicates the sampled sentence. “Candidate facts to unmapped facts” column contains the candidate facts (on the left side of $\ "\rightarrow"$ ) and their corresponding unmapped facts (on the right side of $\ "\rightarrow"$ ).
类似于TAC KBP,我们从Wikidata语料库中随机抽取了100份文档,并展示这些文档中若干抽样句子的未映射事实。根据第3.2节,我们人工核验未映射事实的正确性,并展示正确部分。由MAMA-BERTLARGE和MAMA-GPT $2_{\mathrm{XL}}$ 生成的抽样句子原始候选事实及其对应未映射事实如图14和图15所示。未映射候选事实的进一步对比见图16。各表中"ID"代表抽样句子对应的维基百科页面标题,"Sentence"为抽样句子,"Candidate facts to unmapped facts"列左侧 $\ "\rightarrow"$ 为候选事实,右侧 $\ "\rightarrow"$ 为对应未映射事实。
D ADDITIONAL OPEN KG SUBGRAPHS FROM MAMA ON WIKIDATA
D 来自维基数据MAMA的额外开放知识图谱子图
We sample several documents from the Wikidata corpus. We visualize the mapped facts and unmapped facts from those documents as examples of subgraphs in the resulting open KGs. We show the snapshots of the subgraphs generated by MAMA-BERTLARGE from Figure 17 to Figure 24. We similarly illustrate the snapshots of the subgraphs constructed by MAMA-GPT $2_{\mathrm{XL}}$ from Figure 25 to Figure 32. In each figure, the blue node and arrow represent the mapped facts in the Wikidata schema, while the yellow node and arrow denote the unmapped facts in the open schema. We additionally visualize the correct facts that are new in Wikidata according to Sec. A.2 in yellow.
我们从维基数据语料库中抽取若干文档,将其中已映射事实与未映射事实可视化为开放知识图谱中的子图示例。图17至图24展示了MAMA-BERTLARGE生成的子图快照,图25至图32则呈现了MAMA-GPT $2_{\mathrm{XL}}$ 构建的子图快照。各图中蓝色节点与箭头表示符合维基数据模式(schema)的已映射事实,黄色节点与箭头代表开放模式中的未映射事实。根据附录A.2章节,我们额外用黄色标注了维基数据中新增的正确事实。

Figure 5: Mapped facts: MAMA-BERTLARGE on TAC KBP.
图 5: 映射事实: TAC KBP数据集上的MAMA-BERTLARGE模型。

Figure 6: Mapped facts: MAMA-GPT- $2\mathrm{xL}$ on TAC KBP.
图 6: 映射事实:MAMA-GPT-$2\mathrm{xL}$在TAC KBP上的表现

Figure 7: Mapped facts: MAMA-BERTLARGE vs. MAMA-GPT $2_{\mathrm{XL}}$ on TAC KBP.
图 7: 映射事实对比: MAMA-BERTLARGE 与 MAMA-GPT $2_{\mathrm{XL}}$ 在 TAC KBP 上的表现









Figure 16: Unmapped facts: MAMA-BERTLARGE vs. MAMA-GPT $\boldsymbol{\cdot}2_{\mathrm{XL}}$ on Wikidata.
图 16: 未映射事实:MAMA-BERTLARGE 与 MAMA-GPT $\boldsymbol{\cdot}2_{\mathrm{XL}}$ 在 Wikidata 上的对比。

Figure 17: A snapshot subgraph of the open KG generated by MAMA-BERTLARGE from the Wikipedia page “Douglas Bader”.
图 17: 由MAMA-BERTLARGE从维基百科页面"Douglas Bader"生成的开放知识图谱快照子图。

图 1:

Figure 18: A snapshot subgraph of the open KG generated by MAMA-BERTLARGE from the Wikipedia page “Helen Storrow”.
图 18: 由MAMA-BERTLARGE从维基百科页面"Helen Storrow"生成的开放知识图谱快照子图。

Figure 19: A snapshot subgraph of the open KG generated by MAMA-BERTLARGE from the Wikipedia page “Jacob van Ruisdael”. Figure 20: A snapshot subgraph of the open KG generated by MAMA-BERTLARGE from the Wikipedia page “John Maynard Keynes”.
图 19: MAMA-BERTLARGE 从维基百科页面 "Jacob van Ruisdael" 生成的知识图谱子图快照。
图 20: MAMA-BERTLARGE 从维基百科页面 "John Maynard Keynes" 生成的知识图谱子图快照。

Figure 21: A snapshot subgraph of the open KG generated by MAMA-BERTLARGE from the Wikipedia page “Liaquat Ali Khan”.
图 21: 由MAMA-BERTLARGE从维基百科页面"Liaquat Ali Khan"生成的开放知识图谱快照子图。

Figure 22: A snapshot subgraph of the open KG generated by MAMA-BERTLARGE from the Wikipedia page “Neville Southall”.
图 22: 由MAMA-BERTLARGE从维基百科页面"Neville Southall"生成的开放知识图谱快照子图。

Figure 23: A snapshot subgraph of the open KG generated by MAMA-BERTLARGE from the Wikipedia page “Pauline Baynes”.
图 23: MAMA-BERTLARGE 从维基百科页面"Pauline Baynes"生成的开放知识图谱快照子图。

Figure 24: A snapshot subgraph of the open KG generated by MAMA-BERTLARGE from the Wikipedia page “Thor Heyerdahl’.
图 24: MAMA-BERTLARGE 从维基百科页面 "Thor Heyerdahl" 生成的开放知识图谱快照子图。

Figure 25: A snapshot subgraph of the open KG generated by MAMA-GPT $2\mathrm{xL}$ from the Wikipedia page “Douglas Bader”.
图 25: 由MAMA-GPT $2\mathrm{xL}$从维基百科页面"Douglas Bader"生成的开放知识图谱快照子图

Figure 26: A snapshot subgraph of the open KG generated by MAMA-GPT $2_{\mathrm{XL}}$ from the Wikipedia page “Helen Storrow”.
图 26: MAMA-GPT $2_{\mathrm{XL}}$ 从维基百科页面"Helen Storrow"生成的开放知识图谱快照子图。

Figure 27: A snapshot subgraph of the open KG generated by MAMA-GPT $2_{\mathrm{XL}}$ from the Wikipedia page “Jacob van Ruisdael”.
图 27: 由MAMA-GPT $2_{\mathrm{XL}}$从维基百科页面"Jacob van Ruisdael"生成的开放知识图谱快照子图。

Figure 28: A snapshot subgraph of the open KG generated by MAMA-GPT $2_{\mathrm{XL}}$ from the Wikipedia page “John Maynard Keynes”.
图 28: 由 MAMA-GPT $2_{\mathrm{XL}}$ 从维基百科页面 "John Maynard Keynes" 生成的开放知识图谱快照子图。

Figure 29: A snapshot subgraph of the open KG generated by MAMA-GPT $2_{\mathrm{XL}}$ from the Wikipedia page “Liaquat Ali Khan”.
图 29: 由MAMA-GPT $2_{\mathrm{XL}}$从维基百科页面"Liaquat Ali Khan"生成的开放知识图谱快照子图。

Figure 30: A snapshot subgraph of the open KG generated by MAMA-GPT $2_{\mathrm{XL}}$ from the Wikipedia page “Neville Southall”.
图 30: 由MAMA-GPT $2_{\mathrm{XL}}$从维基百科页面"Neville Southall"生成的开放知识图谱快照子图。

Figure 31: A snapshot subgraph of the open KG generated by MAMA-GPT $2_{\mathrm{XL}}$ from the Wikipedia page “Pauline Baynes”.
图 31: 由MAMA-GPT $2_{\mathrm{XL}}$从维基百科页面"Pauline Baynes"生成的开放知识图谱快照子图

Figure 32: A snapshot subgraph of the open KG generated by MAMA-GPT $2\mathrm{xL}$ from the Wikipedia page “Thor Heyerdahl”.
图 32: 由MAMA-GPT $2\mathrm{xL}$从维基百科页面"Thor Heyerdahl"生成的开放知识图谱快照子图。