Learning Symmetry Consistent Deep CNNs for Face Completion
学习对称一致的深度CNN用于人脸补全

Figure 1: Completion results of face images with synthetic and real occlusions.
图 1: 合成与真实遮挡下的人脸图像补全结果。
Abstract
摘要
1. Introduction
1. 引言
Deep convolutional networks (CNNs) have achieved great success in face completion to generate plausible facial structures. These methods, however, are limited in maintaining global consistency among face components and recovering fine facial details. On the other hand, reflection al symmetry is a prominent property of face image and benefits face recognition and consistency modeling, yet remaining un investigated in deep face completion. In this work, we leverage two kinds of symmetry-enforcing subnets to form a symmetry-consistent CNN model (i.e., SymmFCNet) for effective face completion. For missing pixels on only one of the half-faces, an illumination-reweighted warping subnet is developed to guide the warping and illumination re weighting of the other half-face. As for missing pixels on both of half-faces, we present a generative reconstruction subnet together with a perceptual symmetry loss to enforce symmetry consistency of recovered structures. The SymmFCNet is constructed by stacking generative reconstruction subnet upon illumination-reweighted warping subnet, and can be end-to-end learned from training set of unaligned face images. Experiments show that SymmFCNet can generate high quality results on images with synthetic and real occlusion, and performs favorably against state-of-the-arts.
深度卷积网络(CNN)在人脸补全任务中取得了显著成功,能够生成合理的面部结构。然而,这些方法在保持面部组件全局一致性及恢复精细面部细节方面仍存在局限。另一方面,反射对称性是人脸图像的显著特性,有助于人脸识别和一致性建模,但在深度人脸补全领域尚未得到充分研究。本研究通过整合两种对称增强子网络,构建了具有对称一致性的CNN模型(即SymmFCNet)以实现高效人脸补全。针对单侧半脸缺失像素的情况,我们开发了光照重加权变形子网络,用于引导对侧半脸的形变与光照调整。对于双侧半脸均存在缺失的情况,我们提出生成式重建子网络并结合感知对称损失函数,以强化复原结构的对称一致性。SymmFCNet通过将生成式重建子网络堆叠在光照重加权变形子网络之上构建而成,能够从未对齐人脸图像训练集中进行端到端学习。实验表明,SymmFCNet在合成遮挡和真实遮挡图像上均能生成高质量结果,其性能优于当前最先进方法。
The task of face completion is to fill in missing facial pixels with visually plausible hypothesis [19, 31]. The generated solutions for missing parts aim to restore semantic facial structures and realistic fine details, but are not required to exactly approximate the unique ground-truth. Unlike images of natural scene, face images usually contain little repetitive structures [33], which further increases the difficulties of face completion. Moreover, face completion can also be used in many real world face-related applications such as unwanted content removal (e.g., glasses, scarf, and HMD in interactive AR/VR), interactive face editing, and occluded face recognition.
人脸补全任务旨在用视觉上合理的假设填充缺失的面部像素 [19, 31]。针对缺失部分生成的解决方案需要恢复语义化的面部结构及逼真的细节,但无需精确还原唯一真实值。与自然场景图像不同,人脸图像通常缺乏重复结构 [33],这进一步增加了人脸补全的难度。此外,该技术可应用于多种现实场景的人脸相关任务,例如:交互式AR/VR中的遮挡物移除(如眼镜、围巾、头戴显示器)、交互式人脸编辑以及遮挡人脸识别。
Recently, along with the development of deep learning, significant progress has been made in image inpainting [24, 26, 28, 29, 33] and face completion [11, 19, 20, 33]. The existing methods generally adopt the generative adversarial network (GAN) [7] framework which involves a generator and a disc rim in at or. On one hand, contextual attention [33] and shift-connection [26,28] have been introduced into the baseline generator (i.e., context-encoder) [24] to exploit surrounding repetitive structures for generating visually plausible content with fine details. On the other hand, global and local disc rim in at or s are incorporated to obtain globally consistent result with locally realistic details [11, 19], and semantic parsing loss is also adopted to enhance the consistency of face completion result [19].
近年来,随着深度学习的发展,图像修复 [24, 26, 28, 29, 33] 和人脸补全 [11, 19, 20, 33] 领域取得了显著进展。现有方法普遍采用生成对抗网络 (GAN) [7] 框架,包含生成器和判别器。一方面,研究者在基线生成器 (即上下文编码器) [24] 中引入了上下文注意力 [33] 和位移连接 [26, 28],通过利用周围重复结构来生成具有精细细节的视觉合理内容。另一方面,通过结合全局和局部判别器 [11, 19] 来获得全局一致且局部真实的细节,并采用语义解析损失来增强人脸补全结果的一致性 [19]。
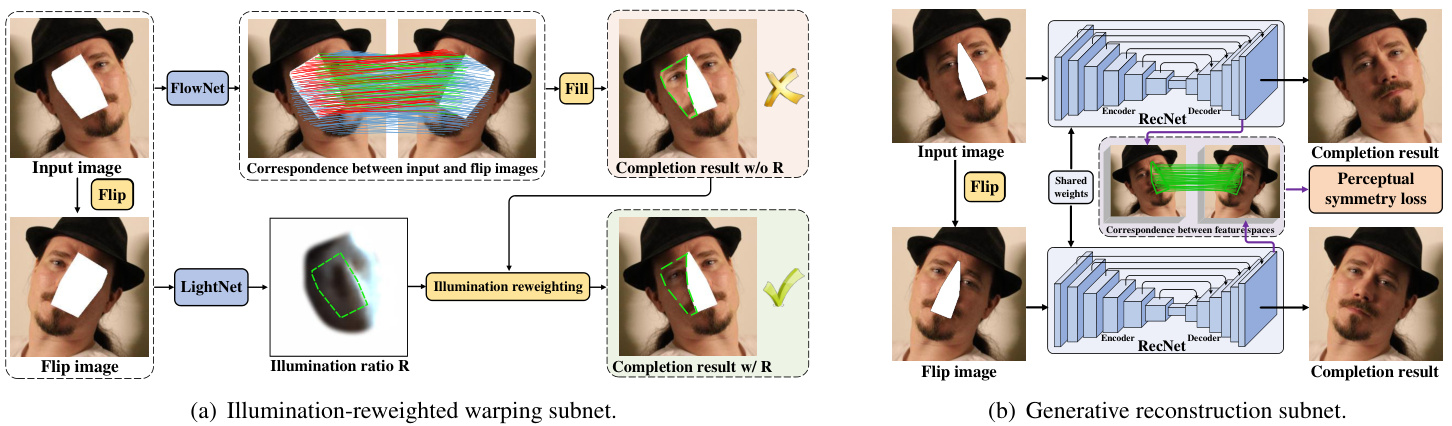
Figure 2: Overview of our SymmFCNet. Red, green and blue lines represent the pixel-wise correspondence between the input and the flip image. Red: missing pixels (input) to non-occluded pixels (flip); Green: missing pixels (input) to missing pixels (flip); Blue: remaining pixels (input) to remaining pixels (flip).
图 2: SymmFCNet 架构概览。红、绿、蓝三色线条分别表示输入图像与翻转图像的像素级对应关系。红色: 缺失像素(输入)对应非遮挡像素(翻转); 绿色: 缺失像素(输入)对应缺失像素(翻转); 蓝色: 保留像素(输入)对应保留像素(翻转)。
However, face completion is not a simple application of image inpainting, and remains not well solved. Fig. 1 illustrates the results by state-of-the-art CNN-based methods, including Iizuka et al. [11], Li et al. [19], Yu et al. [33], and Liu et al. [20]. Because face images are generally of nonrepetitive structures, blurry results remain inevitable in the methods [11, 19, 33] based on auto-encoder and contextual attention. Furthermore, from the top image in Fig. 1(e), although the generated right eye by [20] is locally satisfying, it is globally inconsistent with the left eye.
然而,人脸补全并非图像修复的简单应用,至今仍未得到很好解决。图 1 展示了基于CNN的先进方法的结果,包括Iizuka等人 [11]、Li等人 [19]、Yu等人 [33] 以及Liu等人 [20] 的研究。由于人脸图像通常具有非重复性结构,基于自编码器和上下文注意力的方法 [11, 19, 33] 仍不可避免地产生模糊结果。此外,从图 1(e) 顶部图像可见,虽然 [20] 生成的右眼局部效果令人满意,但与左眼存在全局不一致性。
In this work, we present a deep symmetry-consistent face completion network (SymmFCNet), which leverages face symmetry to improve the global consistency and local fine details of face completion result. The reflection al symmetry of face images, which has been widely adopted to face recognition and consistency modeling [4, 8, 27], remains a non-trivial issue to exploit the symmetry property in face completion due to the effect of illumination and pose. Nonsymmetric lighting causes the pixel value not equal to the corresponding pixel value in the other half-face. The deviation from frontal face further breaks the reflection al symme- try and makes the pixel correspondence between two halffaces much more complicated.
在本工作中,我们提出了一种深度对称一致的人脸补全网络(SymmFCNet),该网络利用人脸对称性来提升补全结果的全局一致性与局部细节。尽管人脸图像的反射对称性已被广泛应用于人脸识别与一致性建模[4,8,27],但由于光照和姿态的影响,如何在人脸补全中有效利用对称性仍是一个重要问题。非对称光照会导致像素值与另半侧脸的对应像素值不相等。而偏离正面角度的姿态会进一步破坏反射对称性,使得两侧脸部的像素对应关系更加复杂。
As shown in Fig. 2, the correspondence between two half-faces can be divided into three types: (1) The missing pixels in input image correspond to non-occluded pixels in flip image (red lines in Fig. 2(a)), which indicates that these missing pixels can be filled by their symmetric ones. (2) The missing pixels in input image correspond to missing pixels in flip image (green lines in Fig. 2(a)), which indicates that these missing pixels can only be filled by generation. (3) The remaining pixels in input image correspond to other pixels in flip image (blue lines in Fig. 2(a)). Based on this, we present two mechanisms to leverage symmetric consistency for filling in two types of missing pixels.
如图 2 所示,两个半脸之间的对应关系可分为三种类型:(1) 输入图像中缺失的像素对应于翻转图像中未遮挡的像素(图 2(a)中的红线),表明这些缺失像素可通过其对称像素填补。(2) 输入图像中缺失的像素对应于翻转图像中同样缺失的像素(图 2(a)中的绿线),表明这些缺失像素只能通过生成填补。(3) 输入图像中剩余的像素对应于翻转图像中的其他像素(图 2(a)中的蓝线)。基于此,我们提出两种机制来利用对称一致性填补两类缺失像素。
For missing pixels happened on only one of the halffaces (see Fig. 2(a)), it is natural to fill them by reweighting the illumination of the corresponding pixels in the other half-face (the red correspondence in Fig. 2(a)). To cope with pose and illumination variation between half-faces, we suggest an illumination-reweighted warping subnet of two parts: (i) a FlowNet to establish the correspondence map between two half-faces, and (ii) a LightNet to indicate the ratio of illumination between two half-faces. For missing pixels happened on both of the half-faces (see Fig. 2(b)), perceptual symmetry loss is incorporated with a generative reconstruction subnet (RecNet) for symmetry-consistent completion. Based on the correspondence map established by FlowNet, the perceptual symmetry loss is defined on the decoder feature layer to alleviate the effect of illumination inconsistency between two half-faces. To sum up, our full SymmFCNet can be constructed by stacking generative reconstruction subnet upon illumination-reweighted warping subnet. Perceptual symmetry, reconstruction and adversarial losses are deployed on RecNet to end-to-end train the full SymmFCNet. While illumination consistency loss, landmark loss and total variation (TV) regular iz ation are employed to illumination-reweighted warping subnet for improving the training stability of FlowNet and LightNet.
对于仅发生在半张脸上的缺失像素(见图2(a)),自然可以通过重新加权另一侧半脸对应像素(图2(a)中红色对应区域)的照明来填充。为处理半脸间的姿态与光照差异,我们提出由两部分组成的光照重加权变形子网:(i)用于建立两侧半脸对应关系的FlowNet;(ii)用于标定两侧光照比率的LightNet。当两侧半脸均存在像素缺失时(见图2(b)),将感知对称损失与生成式重建子网(RecNet)结合以实现对称一致性补全。基于FlowNet建立的对应图,感知对称损失定义在解码器特征层上以减轻两侧光照不一致的影响。综上所述,完整SymmFCNet可通过在光照重加权变形子网上堆叠生成式重建子网构建。感知对称损失、重建损失和对抗损失部署于RecNet以实现端到端训练,而光照一致性损失、关键点损失和全变分(TV)正则化则用于光照重加权变形子网以提升FlowNet与LightNet的训练稳定性。
Experiments show that illumination-reweighted warping is effective in filling in missing pixels happened on only one of the half-faces. In contrast, the RecNet can not only generate symmetry-consistent result for missing pixels happened on both of the half-faces, but also benefit the refinement of the result by illumination-reweighted warping. In terms of quantitative metrics and visual quality, our SymmFCNet performs favorably against state-of-the-arts [11, 19, 20, 33], and achieves high quality results on face images with real occlusions. The contributions of this work include:
实验表明,光照重加权扭曲能有效填补仅发生在半侧脸部的缺失像素。相比之下,RecNet不仅能对双侧脸部同时缺失像素的情况生成对称一致的结果,还能通过光照重加权扭曲优化生成效果。在量化指标和视觉质量方面,我们的SymmFCNet优于现有技术[11, 19, 20, 33],并在真实遮挡的人脸图像上实现了高质量修复。本工作的贡献包括:
2. Related Work
2. 相关工作
In this section, we briefly review the relevant work of three sub-fields: deep image inpainting, deep face completion and the applications of symmetry in face analysis.
本节简要回顾三个子领域的相关工作:深度图像修复 (deep image inpainting)、深度人脸补全 (deep face completion) 以及对称性在人脸分析中的应用。
Deep Image Inpainting. Image inpainting aims to fill in missing pixels in a seamless manner [2], which has wide applications, such as restoration of damaged image and unwanted content removal. Recently, motivated by the unprecedent ed success of GAN in many vision tasks like style transfer [10,16], image-to-image translation [12,39], image super-resolution [15] and face attribute manipulation [17], deep CNNs have also greatly facilitated the development of image inpainting. Originally, Pathak et al. [24] present an encoder-decoder (i.e., context encoder) network to learn the image semantic structure for the recovery of the missing pixels, and an adversarial loss is deployed to enhance the visual quality of the inpainting result. Subsequently, global and local disc rim in at or s [11] are adopted for better discrimination between real images and inpainting results. In addition, dilated convolution [11] and partial convolution [20] are introduced to improve the training of generator. To exploit the repetitive structures in surrounding contexts, multiscale neural patch synthesis (MNPS) [29] is suggested, and contextual attention [33] and shift-connection [26, 28] are further presented to overcome the inefficiency of MNPS. Unlike natural images, face images generally exhibit nonrepetitive structures and are more sensitive to semantic consistency and visual artifacts, making it difficult to directly apply general-purposed inpainting models.
深度图像修复。图像修复旨在无缝填充缺失像素[2],其应用广泛,如受损图像恢复和内容移除。近年来,受GAN在风格迁移[10,16]、图像转换[12,39]、超分辨率[15]和人脸属性编辑[17]等视觉任务中的空前成功启发,深度CNN也极大推动了图像修复的发展。最初,Pathak等人[24]提出编码器-解码器(即上下文编码器)网络来学习图像语义结构以恢复缺失像素,并采用对抗损失提升修复结果的视觉质量。随后,全局与局部判别器[11]被用于更好区分真实图像与修复结果。此外,扩张卷积[11]和部分卷积[20]被引入以改进生成器训练。为利用周围上下文中的重复结构,多尺度神经块合成(MNPS)[29]被提出,上下文注意力[33]和移位连接[26,28]进一步解决了MNPS的低效问题。与自然图像不同,人脸图像通常呈现非重复结构且对语义一致性和视觉伪影更敏感,使得通用修复模型难以直接适用。
Deep Face Completion. Apart from the aforementioned image inpainting methods, Yeh et al. [31] develop a semantic face completion method, which exploits the trained GAN to find the closest encoding and then fill the missing pixels by considering both context disc rim in at or and corrupted input image. Li et al. [19] learn a generative model to recover missing pixels by minimizing the combination of reconstruction loss, local and global adversarial losses as well as semantic parsing loss. For better recovery of facial details, Zhao et al. [37] suggest a guidance image from the extra non-occluded face image to facilitate identity-aware completion. However, the introduction of guidance image certainly limits its wide applications, and its performance degrades remarkably when the guidance and occluded images are of different poses. Instead of guidance image, we leverage the symmetry of face images to establish the corresponden ce between two half-faces, which is then used to guide the generation of high quality completion result.
深度人脸补全。除上述图像修复方法外,Yeh等人[31]提出了一种语义人脸补全方法,该方法利用训练好的GAN(生成对抗网络)寻找最接近的编码,并通过同时考虑上下文判别器和受损输入图像来填充缺失像素。Li等人[19]通过学习生成模型,通过最小化重建损失、局部与全局对抗损失以及语义解析损失的组合来恢复缺失像素。为更好地恢复面部细节,Zhao等人[37]提出从额外的未遮挡人脸图像中提取引导图像,以实现身份感知的补全。然而引导图像的引入必然限制其广泛应用,且当引导图像与遮挡图像姿态不同时性能显著下降。我们摒弃引导图像方案,转而利用人脸图像的对称性建立两侧半脸的对应关系,进而指导生成高质量补全结果。
Face Symmetry. Symmetry is closely related to the human perception, understanding and discovery of images, and also has received upsurging interests in computer vision [4, 5, 8, 21, 23, 27]. In computational symmetry, numerous methods have been proposed to detect reflection, rotation, translation and medial-axis-like symmetries from images [5, 21]. Reflection al symmetry is also an important characteristic of face images, which has been used to assist 3D face reconstruction [4], 3D face alignment [23] and face recognition [8, 27]. In addition, Huang et al. [9] adopt symmetry loss on pixel and Laplacian space for identitypreserving face front aliz ation. Unlike [9], we present a more general scheme for modeling face symmetry for face completion.
面部对称性。对称性与人类对图像的感知、理解和发现密切相关,也在计算机视觉领域引发了日益高涨的研究兴趣[4,5,8,21,23,27]。在计算对称性领域,已有大量方法被提出用于从图像中检测反射、旋转、平移及类中轴对称性[5,21]。反射对称性同样是面部图像的重要特征,已被用于辅助三维人脸重建[4]、三维人脸对齐[23]及人脸识别[8,27]。此外,Huang等人[9]在像素空间和拉普拉斯空间采用对称性损失函数来实现身份保持的人脸正面化。与[9]不同,我们提出了一种更通用的方案来建模面部对称性以完成人脸补全任务。
3. Method
3. 方法
Face completion aims at learning a mapping from occluded face $I^{o}$ as well as its binary indicator mask $M$ to a desired completion result $\hat{I}$ (i.e., an estimation of the ground-truth $I$ ). Here, the images $I^{o}$ , $M$ , and $\hat{I}$ are of the same size $h\times w$ , and $M(i,j)=0$ indicates the pixel at $(i,j)$ is missing. To exploit face symmetry, we present our twostage SymmFCNet to generate symmetry-consistent completion result. In the first stage, an illumination-reweighted warping subnet is deployed to fill in missing pixels happened on only one of the half-faces (see Fig. 2(a)), where a FlowNet is included to establish the correspondence between two half-faces. In the second stage, a generative reconstruction subnet is used to handle missing pixels happened on both of the half-faces and further refine the inpainting result (see Fig. 2(b)). Using the output of FlowNet, we define a perceptual symmetry loss on the decoder feature layer to enforce symmetry consistent completion. In this section, we first detail the architecture of SymmFCNet and then define the learning objective.
人脸补全旨在学习从遮挡人脸图像$I^{o}$及其二值指示掩码$M$到理想补全结果$\hat{I}$(即对真实图像$I$的估计)的映射。其中,$I^{o}$、$M$和$\hat{I}$均为$h\times w$尺寸,当$M(i,j)=0$时表示$(i,j)$处像素缺失。为利用人脸对称性,我们提出两阶段对称人脸补全网络SymmFCNet:第一阶段部署光照重加权变形子网,通过内置的FlowNet建立半脸间对应关系,填补仅单侧半脸缺失的像素(见图2(a));第二阶段采用生成式重建子网处理双侧半脸缺失像素并优化修复结果(见图2(b))。基于FlowNet输出,我们在解码器特征层定义感知对称损失以强化对称一致性补全。本节将首先详述SymmFCNet架构,随后定义学习目标。
3.1. Illumination-reweighted warping
3.1. 光照重加权变形
Unlike general-purposed image inpainting, face is a highly structured object with prominent reflection al symmetric characteristic. Thus, when the missing pixels are within only half of the face, it is reasonable to fill them based on the corresponding pixels in the other half-face. To this end, we should solve the illumination in consist en ce and create correspondence between the pixels from two half-faces. For example, given a missing pixel $(i,j)$ , if its corresponding pixel $(i^{\prime},j^{\prime})$ in the other half-face and their illumination ratio $\begin{array}{r}{\begin{array}{c c}{\overline{{R(i,j)}}}\end{array}=\frac{I(i,j)}{I(i^{\prime},j^{\prime})}}\end{array}$ is known, the value $\scriptstyle{\hat{I}}(i,j)$ can then be computed by $I^{o}(i^{\prime},j^{\prime})R(i,j)$ (Note that ${\cal I}^{o}(i^{\prime},j^{\prime})~=~{\cal I}(i^{\prime},j^{\prime}))$ . In the following, we introduce a FlowNet and a LightNet for computing pixel correspondence and illumination ratio, respectively.
与通用图像修复不同,人脸是高度结构化的对象,具有显著的反射对称特性。因此,当缺失像素仅位于半张脸时,基于另半张脸的对应像素进行填充是合理的。为此,我们需要解决光照不一致性并建立两半脸像素间的对应关系。例如,给定缺失像素$(i,j)$,若其在另半脸的对应像素$(i^{\prime},j^{\prime})$及其光照比$\begin{array}{r}{\begin{array}{c c}{\overline{{R(i,j)}}}\end{array}=\frac{I(i,j)}{I(i^{\prime},j^{\prime})}}\end{array}$已知,则可通过$I^{o}(i^{\prime},j^{\prime})R(i,j)$计算出$\scriptstyle{\hat{I}}(i,j)$值(注意${\cal I}^{o}(i^{\prime},j^{\prime})~=~{\cal I}(i^{\prime},j^{\prime})$)。下文将分别介绍用于计算像素对应关系的FlowNet和计算光照比的LightNet。
3.1.1 FlowNet
3.1.1 FlowNet
One may establish the correspondence between the pixels from two half-faces by direct matching. However such approach is computational costly and the annotation of dense correspondence is also practically infeasible. Instead, we introduce the flip image $I^{o^{\prime}}\left(M^{'}\right)$ of occluded face (mask) $I^{o}\left(M\right)$ , and adopt a FlowNet which takes both $I^{o^{\prime}}$ and $I^{o}$ to predict the flow field $\Phi=\left(\Phi^{x},\Phi^{y}\right)$ ,
可以通过直接匹配来建立两个半脸像素之间的对应关系。然而这种方法计算成本高昂,且密集对应的标注在实际中也难以实现。为此,我们引入被遮挡面部(掩模) $I^{o}\left(M\right)$ 的翻转图像 $I^{o^{\prime}}\left(M^{'}\right)$ ,并采用FlowNet同时接收 $I^{o^{\prime}}$ 和 $I^{o}$ 来预测流场 $\Phi=\left(\Phi^{x},\Phi^{y}\right)$ 。

where $\Theta_{w}$ denotes the FlowNet model parameters. Given a pixel $(i,j)$ in $I^{o}$ , $(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$ indicates the position of its corresponding pixel in $I^{o^{\prime}}$ . Note that $I^{o^{\prime}}$ is the flip image of $I^{o}$ . Thus, $I^{o}(i,j)$ and $I^{o^{\prime}}(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$ are a pair of corresponding pixels from different half-faces, and the correspondence between two half-faces is then constructed.
其中$\Theta_{w}$表示FlowNet模型参数。给定$I^{o}$中的像素$(i,j)$,$(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$表示其在翻转图像$I^{o^{\prime}}$中的对应像素位置。因此,$I^{o}(i,j)$与$I^{o^{\prime}}(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$构成来自不同半脸的一对对应像素,从而建立两个半脸之间的对应关系。
With $\Phi$ , the pixel value at $(i,j)$ of the warped image $I^{w}$ is defined as the pixel value at $(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$ of the flipped image $I^{o^{\prime}}$ . Since $\Phi_{i,j}^{x}$ and $\Phi_{i,j}^{y}$ are real numbers, then I(o′Φix,j,Φiy,j) can be bilinear interpolated by its 4 surrounding neighboring pixels. Thus, the warped image $I_{i,j}^{w}$ can be computed as the interpolation result:
通过 $\Phi$,变形图像 $I^{w}$ 在 $(i,j)$ 处的像素值定义为翻转图像 $I^{o^{\prime}}$ 在 $(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$ 处的像素值。由于 $\Phi_{i,j}^{x}$ 和 $\Phi_{i,j}^{y}$ 为实数,因此 $I^{o^{\prime}}(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$ 可通过其周围4个相邻像素进行双线性插值计算。因此,变形图像 $I_{i,j}^{w}$ 可表示为插值结果:
$$
I_{i,j}^{w}=\sum_{(h,w)\in\mathcal{N}}I_{h,w}^{o^{\prime}}\operatorname*{max}(0,1-|\Phi_{i,j}^{y}-h|)\operatorname*{max}(0,1-|\Phi_{i,j}^{x}-w|),
$$
$$
I_{i,j}^{w}=\sum_{(h,w)\in\mathcal{N}}I_{h,w}^{o^{\prime}}\operatorname*{max}(0,1-|\Phi_{i,j}^{y}-h|)\operatorname*{max}(0,1-|\Phi_{i,j}^{x}-w|),
$$
where $\mathcal{N}$ denotes the 4-pixel neighbors of $(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$ Analogously, the warped mask image $M^{w}$ of $M^{'}$ can be given by:
其中 $\mathcal{N}$ 表示 $(\Phi_{i,j}^{x},\Phi_{i,j}^{y})$ 的4像素邻域。类似地,$M^{'}$ 的扭曲掩膜图像 $M^{w}$ 可表示为:
$$
M_{i,j}^{w}=\sum_{(h,w)\in\mathcal{N}}M_{h,w}^{'}\operatorname*{max}(0,1-|\Phi_{i,j}^{y}-h|)\operatorname*{max}(0,1-|\Phi_{i,j}^{x}-w|).
$$
$$
M_{i,j}^{w}=\sum_{(h,w)\in\mathcal{N}}M_{h,w}^{'}\operatorname*{max}(0,1-|\Phi_{i,j}^{y}-h|)\operatorname*{max}(0,1-|\Phi_{i,j}^{x}-w|).
$$
By defining $M^{s1}=M^{w}\odot(1-M)$ , we can then identify the missing pixels $(i,j)$ within only half of the face as $M_{i,j}^{s1}=$ 1. Here, $\odot$ represents the element-wise product operation.
通过定义 $M^{s1}=M^{w}\odot(1-M)$ ,我们可以将仅存在于半张脸内的缺失像素 $(i,j)$ 标识为 $M_{i,j}^{s1}=$ 1。其中 $\odot$ 表示逐元素乘积运算。
The FlowNet adopts the encoder-decoder architecture which is the same as pix2pix [12] except that the inputs contain 6 channels rather than 3 ones. As for the last activation function, we employ tanh to normalize the two channels coordinates to the range $[-1,1]$ . Please refer to the appendix for more details of FlowNet.
FlowNet采用了与pix2pix [12]相同的编码器-解码器架构,不同之处在于输入包含6个通道而非3个。至于最后的激活函数,我们使用tanh将两个通道的坐标归一化到范围$[-1,1]$。更多FlowNet的细节请参阅附录。
Because it is un practical to annotate the dense correspondence between left and right half-faces, alternative losses are required to train FlowNet. In [6, 30, 38], the losses are enforced on the warped images. For face completion, however, the ground-truth of warped image is unknown, and the two half-faces may be of different illumination, making it unsuitable to use $I^{o}$ as the ground-truth.
由于标注左右半脸之间的密集对应关系不切实际,训练FlowNet需要采用替代损失函数。在[6, 30, 38]中,损失函数作用于扭曲后的图像上。然而对于人脸补全任务,扭曲图像的真实值未知,且两个半脸可能存在光照差异,因此不适合将$I^{o}$作为真实值。
Following [18], we train FlowNet in a semi-supervised manner by incorporating landmark loss with a TV regularizer. Given the ground-truth image $I$ , we detect its 68 facial landmarks $left{(bar{x}{i}^{g},y{i}^{g})left|{i=1}^{68}right.right}$ through [36]. Denote by $I^{'}$ the horizontal flip of $I$ . Landmarks of $I^{'}$ , denoted by $left{(x{i}^{g^{prime}},y{i}^{g^{prime}})left|{i=1}^{68}right.right}$ , can be obtained by horizontal flip of $(x^{g},y^{g})$ . In order to align $I^{o^{\prime}}$ to the pose of $I^{o}$ , it is natural to require $(\Phi{x{i}^{g^{\prime}},y{i}^{g^{\prime}}}^{x},\Phi{x{i}^{g^{\prime}},y{i}^{g^{\prime}}}^{y})$ be close to $(x{i}^{g},y{i}^{g})$ , and we thus define the landmark loss as:
遵循[18]的研究,我们通过结合地标损失与TV正则化器以半监督方式训练FlowNet。给定真实图像$I$,我们通过[36]检测其68个面部关键点$left{(bar{x}{i}^{g},y{i}^{g})left|{i=1}^{68}right.right}$。设$I^{'}$为$I$的水平翻转图像,其关键点$left{(x{i}^{g^{prime}},y{i}^{g^{prime}})left|{i=1}^{68}right.right}$可通过$(x^{g},y^{g})$的水平翻转获得。为使$I^{o^{\prime}}$与$I^{o}$的姿态对齐,自然要求$(Phi{x{i}^{g^{prime}},y{i}^{g^{prime}}}^{x},Phi{x{i}^{g^{prime}},y{i}^{g^{prime}}}^{y})$接近$(x{i}^{g},y{i}^{g})$,因此将地标损失定义为:
$$
\ell_{l m}=\sum_{i=1}^{68}(\Phi_{x_{i}^{g^{\prime}},y_{i}^{g^{\prime}}}^{x}-x_{i}^{g})^{2}+(\Phi_{x_{i}^{g^{\prime}},y_{i}^{g^{\prime}}}^{y}-y_{i}^{g})^{2}.
$$
Furthermore, TV regular iz ation is deployed to constrain the spatial smoothness of flow field $\Phi$ . Given the 2D dense flow field $(\Phi^{x},\Phi^{y})$ , the TV regular iz ation is defined as:
此外,采用TV正则化(Total Variation regularization)约束流场$\Phi$的空间平滑性。给定二维稠密流场$(\Phi^{x},\Phi^{y})$,其TV正则化定义为:
$$
\ell_{T V}=|\nabla_{x}\Phi^{x}|^{2}+|\nabla_{y}\Phi^{x}|^{2}+|\nabla_{x}\Phi^{y}|^{2}+|\nabla_{y}\Phi^{y}|^{2},
$$
$$
\ell_{T V}=|\nabla_{x}\Phi^{x}|^{2}+|\nabla_{y}\Phi^{x}|^{2}+|\nabla_{x}\Phi^{y}|^{2}+|\nabla_{y}\Phi^{y}|^{2},
$$
where $\nabla_{x}$ and $\nabla_{y}$ denote the gradient operators along $x$ and $y$ coordinates, respectively.
其中 $\nabla_{x}$ 和 $\nabla_{y}$ 分别表示沿 $x$ 和 $y$ 坐标的梯度算子。
3.1.2 LightNet
3.1.2 LightNet
Generally, the left and right half-faces are lighting inconsistent, therefore, we cannot fill in missing pixels directly by $I^{w}$ . In order to compensate the illumination variation, we add the light adjustment module (LightNet) to make the completion result more harmonious. LightNet takes $I^{o}$ and $I^{o^{\prime}}$ as inputs, and adopts the same network architecture of FlowNet but it predicts the illumination ratio $R$ as shown in the start of Sec. 3.1 as follows:
通常,左右半脸的照明条件不一致,因此无法直接通过 $I^{w}$ 填充缺失像素。为了补偿光照变化,我们添加了光照调整模块 (LightNet) 使补全结果更协调。LightNet 以 $I^{o}$ 和 $I^{o^{\prime}}$ 作为输入,采用与 FlowNet 相同的网络架构,但预测的是如第 3.1 节开头所示的照明比例 $R$:

where $\Theta_{l}$ denotes the LightNet model parameters.
其中 $\Theta_{l}$ 表示 LightNet 模型参数。
Given the illumination ratio $R$ , warped image $I^{w}$ , the inpainting result for missing pixels within only one of the half-face can be given by $M^{s1}\odot I^{w}\odot R$ . Taking the surrounding context into account, the completion result in the first stage can be obtained by:
给定光照比例 $R$ 和扭曲图像 $I^{w}$ ,仅针对半脸缺失像素的修复结果可通过 $M^{s1}\odot I^{w}\odot R$ 计算得出。结合周围上下文信息,第一阶段补全结果可通过下式获得:
$$
\hat{I}^{1}=M^{s1}\odot I^{w}\odot R+I^{o}\odot(1-M^{s1}).
$$
$$
\hat{I}^{1}=M^{s1}\odot I^{w}\odot R+I^{o}\odot(1-M^{s1}).
$$
Here, $\odot$ represents the element-wise product operation.
这里,$\odot$ 表示逐元素乘积运算。
We note that illumination reweighted warping cannot handle missing pixels happened on both of the half-faces, which will be addressed in the second stage.
我们注意到,光照重加权扭曲无法处理两个半脸同时出现的像素缺失问题,这将在第二阶段解决。
For training LightNet, we introduce an illumination consistency loss. Denote by $I^{w^{\prime}}$ the warped version of the flip ground-truth $I^{'}$ . Then, the illumination reweighted $I^{w^{\prime}}$ is required to approximate the original ground-truth $I$ . And we thus define the illumination consistency loss as:
为训练LightNet,我们引入了光照一致性损失。设$I^{w^{\prime}}$为翻转真值$I^{'}$经形变后的版本,则需使光照重加权后的$I^{w^{\prime}}$逼近原始真值$I$。据此定义光照一致性损失为:
$$
\mathcal{L}_{l}=|I^{w^{\prime}}\odot R-I|^{2}.
$$
$$
\mathcal{L}_{l}=|I^{w^{\prime}}\odot R-I|^{2}.
$$
3.2. Generative reconstruction
3.2. 生成式重建
We further present a generative reconstruction subnet for the inpainting of missing pixels happened on both of the half-faces. Let $M^{s2}=1-M-M^{s1}$ . When $M_{i,j}^{s2}=1$ , it indicates that pixel at location $(i,j)$ is missing. Thus, generative reconstruction subnet (RecNet) takes $\hat{I}^{1}$ (the completion result in the first stage) and $M^{s2}$ as input to generate the final completion result.
我们进一步提出了一个生成式重建子网络(RecNet),用于修复两个半脸上缺失的像素。令$M^{s2}=1-M-M^{s1}$。当$M_{i,j}^{s2}=1$时,表示位置$(i,j)$处的像素缺失。因此,生成式重建子网络以$\hat{I}^{1}$(第一阶段完成结果)和$M^{s2}$作为输入,生成最终的修复结果。

where $\Theta_{r}$ represents the RecNet model parameters. For RecNet, we adopt the U-Net architecture [25] which has the same structure with FlowNet. Moreover, skip connections are included to concatenate each $l$ -th layer to the $(L-l)$ -th layer, where $L$ is the network depth.
其中$\Theta_{r}$表示RecNet模型参数。对于RecNet,我们采用与FlowNet结构相同的U-Net架构[25],并通过跳跃连接(skip connections)将第$l$层与第$(L-l)$层相连接,其中$L$为网络深度。
The flow field $\Phi$ is further utilized to enforce the symmetry consistency on the completion results of missing pixels on both of the half-faces. RecNet also takes the flip versions of $\hat{I}^{1}$ and $M^{s2}$ as input to generate $\hat{I}^{'}$ . We define $\Omega_{l}(\Omega_{l}^{'})$ as the $(L-l)$ -th layer of decoder feature map for $\hat{I}^{1}$ and $M^{s2}$ (their flip versions). By down sampling $\Phi(M^{s2})$ to $\Phi_{\downarrow}(M_{\downarrow}^{s2})$ which has the same size with $\Omega_{l}$ , the perceptual symmetry loss can then be defined as:
流场 $\Phi$ 被进一步用于在两侧半脸缺失像素的补全结果上施加对称一致性约束。RecNet 还将 $\hat{I}^{1}$ 和 $M^{s2}$ 的翻转版本作为输入以生成 $\hat{I}^{'}$。我们定义 $\Omega_{l}(\Omega_{l}^{'})$ 为 $\hat{I}^{1}$ 和 $M^{s2}$ (及其翻转版本) 的解码器第 $(L-l)$ 层特征图。通过将 $\Phi(M^{s2})$ 下采样至与 $\Omega_{l}$ 尺寸相同的 $\Phi_{\downarrow}(M_{\downarrow}^{s2})$ ,感知对称损失可定义为:

where $C_{l}$ denotes the channel number of the feature map $\Omega_{l}$ . In our implementation, we set $l=1$ with feature size $128\times128$ . Benefited from $\mathcal{L}_{s}$ , we can maintain symmetric consistency even for filling in the missing pixels on both of the half-faces.
其中 $C_{l}$ 表示特征图 $\Omega_{l}$ 的通道数。在我们的实现中,设置 $l=1$ 对应的特征尺寸为 $128\times128$。得益于 $\mathcal{L}_{s}$,我们即使在填补两侧半脸的缺失像素时也能保持对称一致性。
Reconstruction loss is introduced to require the final completion result Iˆ be close to the ground-truth $I$ , which involves two terms. The first one, $\ell_{2}$ loss, is defined as the squared Euclidean distance between Iˆ and $I$ ,
重建损失 (reconstruction loss) 用于约束最终修复结果 Iˆ 与真实值 $I$ 的接近程度,包含两项:第一项 $\ell_{2}$ 损失定义为 Iˆ 与 $I$ 之间的欧氏距离平方,
$$
\ell_{2}=|\hat{I}-I|^{2}.
$$
$$
\ell_{2}=|\hat{I}-I|^{2}.
$$
Inspired by [13], the second term adopts the perceptual loss defined on pre-trained VGG-Face [22]. Denote by $\Psi$ the VGG-Face model, and $\Psi_{k}$ the $k$ -th layer (i.e., $k=5$ ) of feature map. The perceptual loss is then defined as,
受[13]启发,第二项采用基于预训练VGG-Face[22]定义的感知损失。设$\Psi$为VGG-Face模型,$\Psi_{k}$为第$k$层特征图(即$k=5$),感知损失定义为
$$
\ell_{p e r c e p t u a l}=\frac{1}{C_{k}H_{k}W_{k}}|\Psi_{k}(\hat{I})-\Psi_{k}(I)|^{2},
$$
$$
\ell_{p e r c e p t u a l}=\frac{1}{C_{k}H_{k}W_{k}}|\Psi_{k}(\hat{I})-\Psi_{k}(I)|^{2},
$$
where the $C_{k},H_{k}$ and $W_{k}$ denote the channel number, height and width of feature maps, respectively. Then, the reconstruction loss is defined as,
其中 $C_{k},H_{k}$ 和 $W_{k}$ 分别表示特征图的通道数、高度和宽度。重构损失定义为,
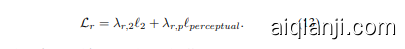
where $\lambda_{r,2}$ and $\lambda_{r,p}$ are the tradeoff parameters.
其中 $\lambda_{r,2}$ 和 $\lambda_{r,p}$ 为权衡参数。
Finally, adversarial loss is deployed to generate photorealistic completion result. In [11, 19], global and local discri minato rs are exploited, where local disc rim in at or is defined on the inpainting result of a hole. Considering that the hole may be irregular, it is inconvenient to define and learn local disc rim in at or. Instead, we apply local discrim- inators to four specific facial parts, i.e., left/right eye, nose and mouth. Thus, local disc rim in at or s are consistent for any images with any missing masks, and facilitate the learning process of SymmFCNet. For each part, we define its local adversarial loss as,
最后,采用对抗损失来生成逼真的修复结果。在[11, 19]中,使用了全局和局部判别器,其中局部判别器是针对孔洞修复结果定义的。考虑到孔洞可能不规则,定义和学习局部判别器并不方便。因此,我们将局部判别器应用于四个特定的面部部位,即左/右眼、鼻子和嘴巴。这样,无论图像缺失何种掩码,局部判别器都能保持一致,并促进SymmFCNet的学习过程。对于每个部位,我们将其局部对抗损失定义为,

where $p{d a t a}(I{p{i}})$ and $p{r e c}(\hat{I}{p{i}})$ stands for the distributions of the $i$ -th part from $I$ and $\hat{I}$ , respectively. $D{p{i}}$ denotes the $i$ -th part disc rim in at or. To sum up, the overall adversarial loss is defined as,
其中 $p{d a t a}(I{p{i}})$ 和 $p{r e c}(\hat{I}{p{i}})$ 分别表示 $I$ 和 $\hat{I}$ 中第 $i$ 个部分的分布,$D{p{i}}$ 代表第 $i$ 个部分判别器。综上所述,整体对抗损失定义为:
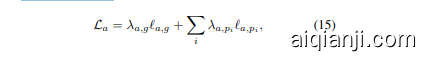
where $\ell_{a,g}$ represents the global adversarial loss [7] working on the whole image rather than parts, $\lambda_{a,g}$ and $\lambda_{a,p_{i}}$ are the tradeoff parameters for the global and local adversarial losses, respectively. Here, left eye, right eye, nose, and mouth denote the first, second, third and fourth parts, respectively. For each part cropped from face images, we employ bi-linear interpolation to resize it to $128\times128$ .
其中 $\ell_{a,g}$ 表示作用于整张图像而非局部的全局对抗损失 [7],$\lambda_{a,g}$ 和 $\lambda_{a,p_{i}}$ 分别是全局与局部对抗损失的权衡参数。此处左眼、右眼、鼻子和嘴巴分别对应第一、第二、第三和第四局部区域。对于从人脸图像中裁剪的每个局部区域,我们采用双线性插值将其尺寸调整为 $128\times128$。
3.3. Learning Objective
3.3. 学习目标
Taking all the losses on FlowNet, LightNet and RecNet into account, the overall objective of SymmFCNet can be defined as,
综合考虑FlowNet、LightNet和RecNet的所有损失,SymmFCNet的整体目标可定义为,
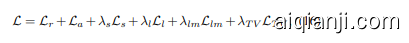
where $\lambda_{s},\lambda_{l},\lambda_{l m}$ and $\lambda_{T V}$ are the tradeoff parameters for symmetry consistency loss, illumination consistency loss, landmark loss and TV regular iz ation, respectively. Note that our SymmFCNet is constructed by stacking generative reconstruction subnet upon illumination reweighted warping subnet and can be trained in an end-to-end manner. Thus, FlowNet and LightNet can also be learned by minimizing $\mathcal{L}{r}$ , $\mathcal{L}{a}$ and $\mathcal{L}{s}$ even they are defined on RecNet.
其中 $\lambda_{s},\lambda_{l},\lambda_{l m}$ 和 $\lambda_{T V}$ 分别为对称一致性损失、光照一致性损失、关键点损失和TV正则化的权衡参数。需要注意的是,我们的SymmFCNet通过在光照重加权变形子网络上叠加生成重建子网络构建而成,并能以端到端方式进行训练。因此,FlowNet和LightNet也可以通过最小化 $\mathcal{L}{r}$ 、 $\mathcal{L}{a}$ 和 $\mathcal{L}{s}$ 来学习,尽管这些损失函数是在RecNet上定义的。
4. Experiments
4. 实验
In this section, experiments are conducted to assess our SymmFCNet and compare it with the state-of-the-art image inpainting and face completion methods [11,19,20,33]. For comprehensive evaluation, quantitative and qualitative results as well as user study are reported. In addition, we test the completion performance on both images with synthetic missing pixels and images with real occlusion. Testing code is available at: https://github.com/ csxmli2016/SymmFCNet.
在本节中,我们通过实验评估SymmFCNet,并将其与最先进的图像修复和人脸补全方法[11,19,20,33]进行对比。为全面评估,我们报告了定量与定性结果以及用户调研数据。此外,我们测试了模型在合成缺失像素图像和真实遮挡图像上的补全性能。测试代码已开源:https://github.com/csxmli2016/SymmFCNet。
4.1. Dataset and Setting
4.1. 数据集与设置
The VGGFace2 dataset [3] is used to train our SymmFCNet. The dataset contains 9,131 identities and each has an average of 362 images, from which we manually select 19,000 images to constitute our training set by excluding images with low quality and large occlusions. A validation set is also built by selecting another 400 images from VGGFace2 for guiding the settings of model and learning parameters. We adopt two test sets to assess SymmFCNet. The first one involves 1,200 images from VGGFace2, and the other includes 1,200 images from WebFace [32] to verify generalization performance across datasets. The identities of face images from training, validation and test sets are non-overlapped. Using bounding box detected by MTCNN [34], each face image is cropped and resized to $256\times256$ .
VGGFace2数据集[3]用于训练我们的SymmFCNet。该数据集包含9,131个身份,每个身份平均有362张图像,我们从中手动筛选出19,000张图像构成训练集,排除了低质量和严重遮挡的图像。另外从VGGFace2中选取400张图像构建验证集,用于指导模型和学习参数的设置。我们采用两个测试集评估SymmFCNet:第一个包含VGGFace2的1,200张图像,另一个包含WebFace[32]的1,200张图像以验证跨数据集的泛化性能。训练集、验证集和测试集的人脸图像身份均无重叠。使用MTCNN[34]检测的边界框对每张人脸图像进行裁剪并调整至$256\times256$分辨率。
4.2. Results on Images with Synthetic Missing Pixels
4.2. 合成缺失像素图像的实验结果
Quantitative and qualitative results are reported on our SymmFCNet and four state-of-the-art methods [11, 19, 20, 33]. Among them, Li et al. [19] and Iizuka et al. [11] can only handle $128\times128$ images, and we use bicubic interpolation to upsample the output to the size of $256\times256$ . For
在我们的SymmFCNet和四种先进方法[11, 19, 20, 33]上报告了定量和定性结果。其中,Li等人[19]和Iizuka等人[11]只能处理$128\times128$图像,我们使用双三次插值将输出上采样至$256\times256$尺寸。
Table 1: Quantitative results. Here, $\uparrow(\downarrow)$ indicates higher (lower) is better.
| Methods | VggFace2[3] | WebFace[32] | |||||||
| PSNR↑SSIM↑LPIPS↓Dis.↓PSNR↑SSIM↑LPIPS↓Dis.↓ | |||||||||
| State-of- the-arts | Iizukaetal.[i1] | 18.62 | .688 | .513 | 1.325 | 19.04 | .683 | .504 | 1.462 |
| Liet al.[19] | 25.05 | .932 | .397 | 0.932 | 25.65 | .959 | .371 | 1.116 | |
| Yuetal.[33] PlainRecNet | 25.53 | .963 | .292 | 0.788 | 25.96 25.81 | .965 | .270 | 0.965 | |
| Ablation|SymmFcNet(-GLO) | 24.99 | .957 | .279 | 0.864 | .959 | .310 | 1.035 | ||
| study | 25.54 | .959 | .260 | 0.830 | 25.94 | .963 | .294 | 0.987 | |
| SymmFcNet(-L) SymmFCNet(-S) | 26.43 | .967 | .226 | 0.622 | 26.43 | .968 | .258 | 0.852 | |
| SymmFCNet(Full) | 26.33 27.81 | .962 .970 | .232 .219 | 0.714 0.617 | 26.17 27.22 | .961 .969 | .266 .252 | 0.945 0.849 | |
表 1: 定量结果。其中 $\uparrow(\downarrow)$ 表示数值越高(低)越好。
| Methods | VggFace2[3] PSNR↑ | SSIM↑ | LPIPS↓ | Dis.↓ | WebFace[32] PSNR↑ | SSIM↑ | LPIPS↓ | Dis.↓ |
|---|---|---|---|---|---|---|---|---|
| State-of-the-arts | ||||||||
| Iizukaetal.[i1] | 18.62 | .688 | .513 | 1.325 | 19.04 | .683 | .504 | 1.462 |
| Li et al.[19] | 25.05 | .932 | .397 | 0.932 | 25.65 | .959 | .371 | 1.116 |
| Ablation study | ||||||||
| Yuetal.[33] PlainRecNet | 25.53 | .963 | .292 | 0.788 | 25.96/25.81 | .965 | .270 | 0.965 |
| SymmFcNet(-GLO) | 24.99 | .957 | .279 | 0.864 | - | .959 | .310 | 1.035 |
| SymmFcNet(-L) | 25.54 | .959 | .260 | 0.830 | 25.94 | .963 | .294 | 0.987 |
| SymmFCNet(-S) | 26.43 | .967 | .226 | 0.622 | 26.43 | .968 | .258 | 0.852 |
| SymmFCNet(Full) | 26.33/27.81 | .962/.970 | .232/.219 | 0.714/0.617 | 26.17/27.22 | .961/.969 | .266/.252 | 0.945/0.849 |
Iizuka et al. [11], we exploit the alignment tool suggested by the authors to pre-process the input image. For Liu et al. [20], it upsamples the input to $512\times512$ and we downsample the output to $256\times256$ . Online manual specification of missing masks is required to obtain the results by Liu et al. [20], and we thus do not report its quantitative metrics (e.g., PSNR) because it is exhausted to manually edit the masks for thousands of images.
Iizuka等人[11]利用作者建议的对齐工具对输入图像进行预处理。对于Liu等人[20]的方法,其将输入上采样至$512\times512$,而我们则将输出下采样至$256\times256$。使用Liu等人[20]的方法需在线手动指定缺失掩膜以获取结果,因此我们未报告其定量指标(如PSNR),因为手动编辑数千张图像的掩膜过于耗时。
4.2.1 Quantitative Results
4.2.1 定量结果
Table 1 lists the PSNR, SSIM, identity distance (Dis.) by OpenFace toolbox [1], and perceptual similarity (LPIPS) [35] on the the two test sets (i.e., VGGFace and WebFace). In comparison with the competing methods, notable PSNR gain (i.e., ${>}1$ dB) is achieved by our SymmFCNet. In terms of SSIM, our SymmFCNet also performs favorably. LPIPS [35] is a recently proposed perceptual similarity which is more consistent with human perception. Again our SymmFCNet achieves the best LPIPS performance in comparison to the competing methods. In addition, identity distance measures whether the result and ground-truth have the same identity, and thus can be used to assess the coherence of the completion result with surrounding context. From Table 1, it can be seen that SymmFCNet exhibits better identity-preserving ability than the competing methods.
表1列出了在两个测试集(即VGGFace和WebFace)上的PSNR、SSIM(通过OpenFace工具箱[1]计算的身份距离(Dis.))以及感知相似度(LPIPS)[35]。与竞争方法相比,我们的SymmFCNet实现了显著的PSNR提升(即${>}1$ dB)。在SSIM指标上,SymmFCNet同样表现优异。LPIPS[35]是近期提出的更符合人类感知的相似度度量方法,SymmFCNet在该指标上仍优于其他对比方法。此外,身份距离用于衡量生成结果与真实图像是否具有相同身份特征,可评估补全结果与周围上下文的一致性。由表1可见,SymmFCNet展现出优于对比方法的身份保持能力。
4.2.2 Qualitative Results
4.2.2 定性结果
The solutions for face completion are neither unique nor required to exactly approximate the ground-truth. Thus, qualitative comparison is conducted to show the effective nss of our methods. Figs. 3 and 4 show the completion results on rectangular and irregular holes, respectively. The results by Liu et al. [20] are also included for comparison. Benefited from the joint effectiveness of illumination reweighted warping and perceptual symmetric loss, our SymmFCNet can achieve very promising inpainting results which preserve visually pleasing symmetry consistent details for missing pixels within only one half-faces and both half-faces. In comparison, the methods [11,19,33] fail to recover rich details and even semantic facial structures, while Liu et al. [20] is still limited in maintaining global symmetry consistency and sometimes fails in generating plausible results with large occlusions.
面部补全的解决方案既非唯一,也无需严格逼近真实值。因此,我们通过定性对比来展示方法的有效性。图3和图4分别展示了矩形缺损与不规则缺损的补全效果,同时纳入Liu等人[20]的结果作为对比。得益于光照重加权变形与感知对称损失的联合作用,我们的SymmFCNet能实现优异的修复效果——即使缺失区域仅涉及单侧或双侧半脸,仍能保持视觉上和谐的对称细节。相比之下,方法[11,19,33]难以恢复丰富细节甚至语义层面的面部结构,而Liu等人[20]在维持全局对称一致性方面仍有局限,面对大面积遮挡时可能生成不合理结果。

Figure 3: Completion results on regular holes.
图 3: 规则孔洞的补全结果
Table 2: Voting results for three types of missing pixels.
| Methods | RegularMask | Irregular Mask | Real Image |
| lizukaetal.[11] | 2.04% | 3.52% | 2.56% |
| Lietal.[19] | 0.24% | 0.16% | 0.48% |
| Yuetal.[33] | 0.40% | 0.64% | 2.40% |
| Liuetal.[20] | 16.80% | 1.68% | 15.04% |
| SymmFCNet | 80.52% | 94.00% | 79.52% |
表 2: 三种缺失像素类型的投票结果。
| Methods | RegularMask | Irregular Mask | Real Image |
|---|---|---|---|
| lizukaetal.[11] | 2.04% | 3.52% | 2.56% |
| Lietal.[19] | 0.24% | 0.16% | 0.48% |
| Yuetal.[33] | 0.40% | 0.64% | 2.40% |
| Liuetal.[20] | 16.80% | 1.68% | 15.04% |
| SymmFCNet | 80.52% | 94.00% | 79.52% |
4.2.3 User Study
4.2.3 用户研究
User study is conducted on a crowd sourcing platform for three types of missing pixels, i.e., regular mask, irregular mask and real occlusions, which contain 50, 25 and $25\mathrm{im}.$ - ages, respectively. For each image, we display the results by our SymmFCNet and the methods [11,19,20,33] in random order to 50 workers who are required to choose the one with the best global consistency and perception quality. We use the percent of the votes of one particular algorithm against all votes to evaluate the performance of the algorithm in Table. 2. The result by SymmFCNet has $84.68%$ probability on average to be selected as the best one.
用户研究在众包平台上针对三种缺失像素类型(规则掩模、不规则掩模和真实遮挡)进行,分别包含50、25和25张图像。每张图像向50名工作人员随机展示SymmFCNet与文献[11,19,20,33]方法的结果,要求其选择全局一致性和感知质量最佳者。采用各算法得票数占总票数的百分比评估性能(表2)。SymmFCNet结果平均以84.68%的概率被选为最佳。
4.2.4 Running Time
4.2.4 运行时间
All the experiments are conducted on a computer equipped with Intel Xeon E3 CPU and NVIDIA GeForce GTX 1080Ti GPU. And the model is trained and tested with Torch. Our SymmFCNet takes $36.29m s$ on average for completing a $256\times256$ image.
所有实验均在一台配备Intel Xeon E3 CPU和NVIDIA GeForce GTX 1080Ti GPU的计算机上进行。模型使用Torch框架进行训练和测试。我们的SymmFCNet平均耗时$36.29m s$完成一张$256\times256$尺寸的图像处理。
4.3. Results on Images with Real Occlusions
4.3. 真实遮挡图像上的结果
By manually specifying the missing masks, Fig. 5 shows the completion results on two face images with real occlusions. For the first image, even the occlusion is large and nearly symmetric, SymmFCNet still performs favorably, validating the effectiveness of perceptual symmetry loss. As for the second image, the occlusion is mainly in one half-face, and the result by SymmFCNet is globally more symmetry consistent in comparison to Liu et al. [20].
通过手动指定缺失的掩码,图5展示了在两张真实遮挡的人脸图像上的补全结果。对于第一张图像,即使遮挡区域较大且接近对称,SymmFCNet仍表现优异,验证了感知对称损失(perceptual symmetry loss)的有效性。至于第二张图像,遮挡主要集中于半侧人脸,与Liu等人[20]的方法相比,SymmFCNet的结果在全局上更具对称一致性。
4.4. Ablation Study
4.4. 消融研究
Two groups of experiments are conducted to assess the contributions of main components in our SymmFCNet. In the first group of experiments, Fig. 6 shows the intermediate results of SymmFCNet, including warped images, and the completion results after FlowNet, LightNet, and RecNet. From Fig. 6, we have the following observations: (i) FlowNet can correctly align the flip image with the original one, and construct the correspondence between left and right half-faces. (ii) Although the correspondence can be used to fill in missing pixels within only one half-face, the result suffers from illumination inconsistency, and can be improved via the introduction of LightNet. (iii) RecNet not only can fill in missing pixels on both of the half-faces, but also is effective in further refining the result of illuminationreweighted warping.
我们进行了两组实验来评估SymmFCNet中主要组件的贡献。在第一组实验中,图6展示了SymmFCNet的中间结果,包括变形后的图像,以及经过FlowNet、LightNet和RecNet处理后的补全结果。从图6可以得出以下观察:(i) FlowNet能正确将翻转图像与原图对齐,并建立左右半脸的对应关系。(ii) 虽然这种对应关系仅能用于填充单个半脸的缺失像素,但结果存在光照不一致问题,通过引入LightNet可得到改善。(iii) RecNet不仅能填补两个半脸的缺失像素,还能有效优化光照重加权变形后的结果。

Figure 4: Completion results on irregular holes.
图 4: 不规则孔洞的补全结果
In the second group of experiments, we further assess the effect of perceptual symmetry loss, FlowNet, and LightNet. To this end, we consider five variants of SymmFCNet: (i) SymmFCNet (Full), (ii) SymmFCNet (-S): removing perceptual symmetry loss, (iii) SymmFCNet $(-L)$ : removing LightNet, (iv) SymmFCNet (-GL0): removing Light- Net and applying the predicted flow field only in perceptual symmetry loss, (v) plain RecNet: removing FlowNet, LightNet and perceptual symmetry loss. Table 1 and Fig. 7 report the quantitative and qualitative results of these variants. By removing FlowNet, LightNet and perceptual symmetry loss, plain RecNet only performs on par with Li et al. [19] (Table 1) and is prone to symmetry-inconsistent completion results (Fig. 7 (b)).
在第二组实验中,我们进一步评估了感知对称性损失(perceptual symmetry loss)、FlowNet和LightNet的效果。为此,我们考虑了SymmFCNet的五个变体:(i) SymmFCNet(完整版)、(ii) SymmFCNet(-S):去除感知对称性损失、(iii) SymmFCNet(-L):去除LightNet、(iv) SymmFCNet(-GL0):去除LightNet并仅在感知对称性损失中应用预测流场、(v)基础RecNet:去除FlowNet、LightNet和感知对称性损失。表1和图7展示了这些变体的定量与定性结果。当去除FlowNet、LightNet和感知对称性损失后,基础RecNet的表现仅与Li等人[19]相当(表1),且容易产生对称性不一致的补全结果(图7(b))。
FlowNet. The flow field by FlowNet can be exploited for (i) guiding the completion of missing pixels within only one half-face and (ii) incorporating with $\mathscr{L}_{s}$ to train RecNet. Here we only focus on (i) and compare SymmFCNet $(-L)$ and SymmFCNet (-GL0). By using FlowNet to complete missing pixels within only one half-face, notable gains on PSNR, LPIPS and identity distance can be attained by SymmFCNet $(-L)$ (see Table 1). From Fig. 7(c) andFig. 7(d), SymmFCNet (-GL0) is still limited in preserving the symmetry consistency of result, while it can be well addressed by SymmFCNet $(-L)$ .
FlowNet。FlowNet 生成的流场可用于:(i) 仅在半脸范围内指导缺失像素的补全,(ii) 与 $\mathscr{L}_{s}$ 结合训练 RecNet。本文仅聚焦(i),并对比 SymmFCNet $(-L)$ 与 SymmFCNet (-GL0)。通过 FlowNet 实现单侧半脸缺失像素补全时,SymmFCNet $(-L)$ 在 PSNR、LPIPS 和身份距离指标上均取得显著提升(见表 1)。如图 7(c) 和图 7(d) 所示,SymmFCNet (-GL0) 在保持结果对称一致性方面仍存在局限,而 SymmFCNet $(-L)$ 能有效解决该问题。
Perceptual symmetry loss. The contribution of perceptual symmetry loss can be assessed by both SymmFCNet (- GL0) vs RecNet and SymmFCNet (Full) vs SymmFCNet (- S). In comparison to plain RecNet, SymmFCNet (-GL0) can achieve moderate gains on quantitative metrics (see Table 1) and more symmetry consistent results (see Fig. 7(b)(c)). It is worth to note that, compared with SymmFCNet (-S), much more gains (e.g., 1.1 dB by PSNR) can be obtained by SymmFCNet (Full). From Fig. 7 (e) and (f), SymmFCNet (Full) is also able to correct the artifacts and illumination inconsistency produced in the first stage. Thus, RecNet with perceptual symmetry loss is helpful in filling missing pixels on both of the half-faces and refining the result of illumination-reweighted warping.
感知对称性损失。通过对比SymmFCNet (-GL0)与RecNet、SymmFCNet (Full)与SymmFCNet (-S),可以评估感知对称性损失的贡献。相较于基础RecNet,SymmFCNet (-GL0)在量化指标上取得适度提升(见表1),并生成更具对称一致性的结果(见图7(b)(c))。值得注意的是,与SymmFCNet (-S)相比,SymmFCNet (Full)能带来更显著的性能增益(如PSNR指标提升1.1 dB)。从图7(e)(f)可见,完整版网络还能修正第一阶段产生的伪影和光照不一致问题。因此,配备感知对称性损失的RecNet既能有效填补半脸缺失像素,又能优化光照重加权变形阶段的结果。

Figure 5: Completion results on images with real occlusion.
图 5: 真实遮挡图像的补全结果

Figure 6: Intermediate results of SymmFCNet, (a) occluded face $I^{o}$ , (b) warped image $I^{w}$ by FlowNet, (c) completion result in the first stage without illumination correction, (d) completion result in the first stage after illumination correction, (e) final completion result $\mathbf{\bar{\boldsymbol{I}}}$ from RecNet.
图 6: SymmFCNet的中间结果,(a)遮挡人脸$I^{o}$,(b)FlowNet生成的扭曲图像$I^{w}$,(c)未进行光照校正的第一阶段补全结果,(d)光照校正后的第一阶段补全结果,(e)RecNet生成的最终补全结果$\mathbf{\bar{\boldsymbol{I}}}$。
LightNet. We further compare SymmFCNet (Full) with SymmFCNet $(-L)$ to assess the contribution of LightNet. It can be seen that the introduction of LightNet can further improve the quantitative performance (see Table 1) and generate illumination consistent results (see Fig. 7(d)(f)). We also note that, RecNet also benefits the correction of illumination inconsistency, and SymmFCNet $(-L)$ attains the second best quantitative performance among the five SymmFCNet varaints. Even though, from the top image in Fig. 7(d), illumination inconsistency remains obvious for the result by SymmFCNet $(-L)$ , indicating that LightNet is still required and cannot be totally replaced by RecNet.
LightNet。我们进一步比较了SymmFCNet (Full)和SymmFCNet $(-L)$ 以评估LightNet的贡献。可以看出,引入LightNet能进一步提升定量性能(见 表1)并生成光照一致的结果(见图7(d)(f))。我们还注意到,RecNet也有助于修正光照不一致问题,且SymmFCNet $(-L)$ 在五个SymmFCNet变体中取得了第二佳的定量性能。尽管如此,从图7(d)顶部图像可见,SymmFCNet $(-L)$ 的结果仍存在明显的光照不一致现象,表明LightNet仍是必需且无法被RecNet完全替代的。
5. Conclusion
5. 结论
This work presents a symmetry consistent CNN model, i.e., SymmFCNet, for effective face completion. In the proposed method, a FlowNet is adopted to construct the correspondence between two half-faces. The correspondence is then combined with a LightNet for filling in missing pixels within only one half-face, and incorporated with RecNet in the form of perceptual symmetry loss for recovering missing pixels in both of half-faces. Extensive experiments show the the effectiveness of SymmFCNet on generating photorealistic results with fine details for inpainting rectangular and irregular holes and even real occlusions. In terms of quantitative metrics, perception quality and user study, our SymmFCNet performs favorably against state-of-the-arts.
本研究提出了一种对称一致性CNN模型SymmFCNet,用于高效的人脸补全。该方法采用FlowNet构建两侧半脸的对应关系,结合LightNet仅填充单侧半脸的缺失像素,并通过RecNet以感知对称损失的形式恢复双侧半脸的缺失像素。大量实验表明,SymmFCNet在修复矩形/不规则孔洞及真实遮挡时,能生成具有精细细节的逼真效果。在定量指标、感知质量和用户研究中,SymmFCNet均优于当前最优方法。

Figure 7: Results of our SymmFCNet variants. From left to right: (a) input, (b) RecNet, (c) SymmFCNet (-GL0), (d) Symm- FCNet $(-L)$ , (e) SymmFCNet (-S), (f) SymmFCNet (Full), (g) ground-truth. Best viewed by zooming in the screen.
图 7: 我们的SymmFCNet变体结果。从左至右: (a) 输入, (b) RecNet, (c) SymmFCNet (-GL0), (d) SymmFCNet $(-L)$, (e) SymmFCNet (-S), (f) SymmFCNet (完整版), (g) 真实值。建议放大屏幕查看最佳效果。
References
参考文献
Appendix
附录
Our SymmFCNet consists of three sub-networks, i.e., FlowNet, LightNet and RecNet. FlowNet and LightNet have the same structure except the channel number of the output. Architecture details are shown in Table A. Here, Conv $(d,k,s)$ and TransConv $(d,k,s)$ denote the convolutional layer and transposed convolutional layer, respectively. $d,k$ and $s$ represent output dimension, kernel size and stride, respectively. BN is batch normalization and
我们的SymmFCNet由三个子网络组成,即FlowNet、LightNet和RecNet。FlowNet和LightNet除了输出通道数外结构相同。架构细节如表A所示。其中,Conv $(d,k,s)$ 和TransConv $(d,k,s)$ 分别表示卷积层和转置卷积层。$d,k$ 和 $s$ 分别代表输出维度、核大小和步长。BN是批量归一化。
Concat indicates the concatenation from the $i$ -th layer to the $(L-i)$ -th layer via skip connetion ( $L$ is the depth of RecNet). LReLU and DropOut are equipped with parameters of 0.2 and 0.5, respectively. Besides, as for global and part discri minato rs, the architectures are demonstrated in Table B. PatchGAN is adopted to classify if each $N\times N$ patch in an image is real or fake [12].
Concat 表示通过跳跃连接 (skip connection) 从第 $i$ 层到第 $(L-i)$ 层的拼接 ( $L$ 为 RecNet 的深度)。LReLU 和 DropOut 的参数分别设置为 0.2 和 0.5。此外,全局判别器 (global discriminator) 和局部判别器 (part discriminator) 的架构如表 B 所示。采用 PatchGAN 对图像中每个 $N\times N$ 图像块进行真伪分类 [12]。
Table A: Network architecture of SymmFCNet.
| FlowNet | LightNet | RecNet |
| Input (6 x 256 × 256) Conv (64,4, 2), LReLU Conv (128,4,2),BN, LReLU Conv (256,4,2),BN, LReLU Conv (512,4,2), BN, LReLU Conv (1024,4,2), BN,LReLU Conv (1024, 4, 2), BN, LReLU Conv (1024,4,2),BN,LReLU Conv (1024,4,2), ReLU TransConv (1024, 4, 2), BN, ReLU | Input(6 × 256 × 256) Conv (64, 4, 2), LReLU Conv (128,4,2),BN, LReLU Conv (256,4,2),BN, LReLU Conv (512,4,2), BN, LReLU Conv (1024,4,2),BN,LReLU Conv (1024,4,2),BN,LReLU Conv (1024,4, 2),BN, LReLU Conv (1024,4,2), LReLU TransConv (1024,4, 2), BN, DropOut, Concat, LReLU TransConv (1024, 4, 2), BN, DropOut, Concat, LReLU TransConv (1024,4, 2), BN, DropOut, Concat, LReLU | |
| TransConv (512, 4, 2), BN, ReLU TransConv (256,4,2),BN,ReLU TransConv (128, 4, 2), BN, ReLU TransConv (64, 4, 2), BN, ReLU TransConv (2,4, 2),Tanh | TransConv (3, 4, 2), ReLU Output(3 × 256 × 256) | TransConv (512,4, 2), BN, Concat, LReLU TransConv (256,4, 2), BN, Concat, LReLU TransConv (128, 4, 2), BN, Concat, LReLU TransConv (64, 4, 2), BN, Concat, LReLU TransConv (3, 4, 2), Sigmoid Output(3 × 256 × 256) |
表 A: SymmFCNet 的网络架构。
| FlowNet | LightNet | RecNet |
|---|---|---|
| 输入 (6 x 256 × 256) Conv (64,4, 2), LReLU Conv (128,4,2),BN, LReLU Conv (256,4,2),BN, LReLU Conv (512,4,2), BN, LReLU Conv (1024,4,2), BN,LReLU Conv (1024, 4, 2), BN, LReLU Conv (1024,4,2),BN,LReLU Conv (1024,4,2), ReLU TransConv (1024, 4, 2), BN, ReLU | 输入(6 × 256 × 256) Conv (64, 4, 2), LReLU Conv (128,4,2),BN, LReLU Conv (256,4,2),BN, LReLU Conv (512,4,2), BN, LReLU Conv (1024,4,2),BN,LReLU Conv (1024,4,2),BN,LReLU Conv (1024,4, 2),BN, LReLU Conv (1024,4,2), LReLU TransConv (1024,4, 2), BN, DropOut, Concat, LReLU TransConv (1024, 4, 2), BN, DropOut, Concat, LReLU TransConv (1024,4, 2), BN, DropOut, Concat, LReLU | |
| TransConv (512, 4, 2), BN, ReLU TransConv (256,4,2),BN,ReLU TransConv (128, 4, 2), BN, ReLU TransConv (64, 4, 2), BN, ReLU TransConv (2,4, 2),Tanh | TransConv (3, 4, 2), ReLU 输出(3 × 256 × 256) | TransConv (512,4, 2), BN, Concat, LReLU TransConv (256,4, 2), BN, Concat, LReLU TransConv (128, 4, 2), BN, Concat, LReLU TransConv (64, 4, 2), BN, Concat, LReLU TransConv (3, 4, 2), Sigmoid 输出(3 × 256 × 256) |
Table B: Network architecture of global and part disc rim in at or s.
| Global Discriminator | Part Discriminator |
| Input(3 × 256 × 256) Conv(64, 4, 2), LReLU Conv(128,4,2), BN, LReLU Conv(256, 4, 2), BN, LReLU Conv(512, 4, 1), BN, LReLU Conv(1, 4, 1), Sigmoid Output(1 × 30 × 30) | Input(3 × 128 × 128) Conv(64,4, 2), LReLU Conv (128,4,2),BN,LReLU Conv (256, 4, 1), BN, LReLU Conv (1,4, 1), Sigmoid Output(1 × 30 × 30) |
表 B: 全局和局部判别器的网络架构
| 全局判别器 | 局部判别器 |
|---|---|
| 输入(3 × 256 × 256) Conv(64, 4, 2), LReLU Conv(128,4,2), BN, LReLU Conv(256, 4, 2), BN, LReLU Conv(512, 4, 1), BN, LReLU Conv(1, 4, 1), Sigmoid 输出(1 × 30 × 30) | 输入(3 × 128 × 128) Conv(64,4, 2), LReLU Conv(128,4,2), BN, LReLU Conv(256, 4, 1), BN, LReLU Conv(1,4, 1), Sigmoid 输出(1 × 30 × 30) |