Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Hiera: 一种去芜存菁的层级化视觉Transformer
Abstract
摘要
Modern hierarchical vision transformers have added several vision-specific components in the pursuit of supervised classification performance. While these components lead to effective accuracies and attractive FLOP counts, the added complexity actually makes these transformers slower than their vanilla ViT counterparts. In this paper, we argue that this additional bulk is unnecessary. By pre training with a strong visual pretext task (MAE), we can strip out all the bells-and-whistles from a state-of-the-art multi-stage vision transformer without losing accuracy. In the process, we create Hiera, an extremely simple hierarchi- cal vision transformer that is more accurate than previous models while being significantly faster both at inference and during training. We evaluate Hiera on a variety of tasks for image and video recognition. Our code and models are available at https://github.com/facebook research/hiera.
现代分层视觉Transformer在追求监督分类性能时引入了多种视觉专用组件。虽然这些组件带来了高准确率和诱人的FLOPs数值,但增加的复杂性实际上使其速度落后于原始ViT模型。本文论证了这些附加结构实属多余——通过采用强视觉预训练任务(MAE),我们能够从最先进的多阶段视觉Transformer中剔除所有冗余设计,同时保持精度不变。在此过程中,我们提出了Hiera:一个极其简洁的分层视觉Transformer架构,其不仅精度超越前代模型,在推理和训练速度上更是显著提升。我们在图像与视频识别的多项任务上评估了Hiera性能。代码与模型已开源:https://github.com/facebookresearch/hiera。
1. Introduction
1. 引言
Since their introduction by Do sov it ski y et al. (2021) a few years ago, Vision Transformers (ViTs) have dominated several tasks in computer vision. While architecturally simple, their accuracy (Touvron et al., 2022) and ability to scale (Zhai et al., 2021) make them still a popular choice today. Moreover, their simplicity unlocks the use of powerful pretraining strategies such as MAE (He et al., 2022), which make ViTs computationally and data efficient to train.
自Dosovitskiy等人(2021) 提出视觉Transformer (ViT) 以来,这类架构已在计算机视觉多个任务中占据主导地位。尽管结构简洁,但其准确度 (Touvron等人, 2022) 和扩展能力 (Zhai等人, 2021) 使其至今仍是热门选择。此外,这种简洁性使得MAE (He等人, 2022) 等高效预训练策略得以应用,显著提升了ViT的训练计算效率和数据利用率。
However, this simplicity comes at a cost: by using the same spatial resolution and number of channels throughout the network, ViTs make inefficient use of their parameters. This is in contrast to prior “hierarchical” or “multi-scale” models (e.g., Krizhevsky et al. (2012); He et al. (2016)), which use fewer channels but higher spatial resolution in early stages with simpler features, and more channels but lower spatial resolution later in the model with more complex features.
然而,这种简洁性是有代价的:由于在整个网络中使用了相同的空间分辨率和通道数,ViTs 对参数的利用效率较低。这与之前的分层或多尺度模型 (例如 Krizhevsky et al. (2012); He et al. (2016)) 形成鲜明对比,后者在早期阶段使用较少的通道但更高的空间分辨率来处理简单特征,而在模型后期处理更复杂特征时使用更多的通道但更低的空间分辨率。
Several domain specific vision transformers have been introduced that employ this hierarchical design, such as Swin (Liu et al., 2021) or MViT (Fan et al., 2021). However, in the pursuit of state-of-the-art results using fully supervised training on ImageNet-1K (an area where ViT has historically struggled), these models have become more and more complicated as they add specialized modules (e.g., crossshaped windows in CSWin (Dong et al., 2022), decomposed relative position embeddings in MViTv2 (Li et al., 2022c)). While these changes produce effective models with attractive floating point operation (FLOP) counts, under the hood the added complexity makes these models slower overall.
目前已经出现了多个采用这种分层设计的领域专用视觉Transformer,例如Swin (Liu等人, 2021) 或 MViT (Fan等人, 2021)。然而,为了在ImageNet-1K全监督训练(这是ViT历来表现欠佳的领域)中追求最先进的结果,这些模型通过添加专用模块变得越来越复杂(例如CSWin (Dong等人, 2022)中的十字形窗口,MViTv2 (Li等人, 2022c)中的分解相对位置嵌入)。虽然这些改进产生了具有诱人浮点运算(FLOP)数量的高效模型,但底层增加的复杂性使得这些模型的整体速度变慢。
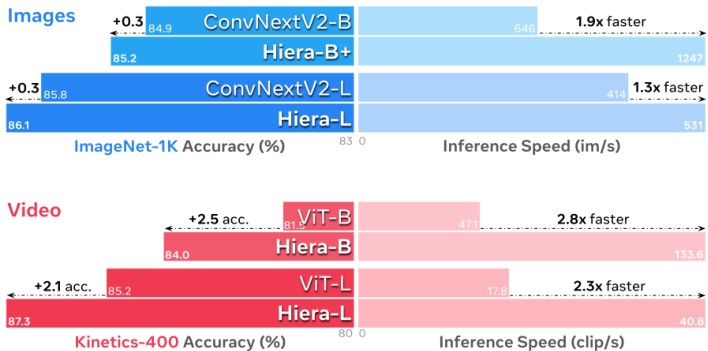
Figure 1. Hiera cuts out expensive specialized operations (e.g., convs) from hierarchical transformers to create a simple, efficient, and accurate model that is fast across many image and video tasks. Above we compare to recent MAE-based works (Woo et al., 2023; Fei chten hofer et al., 2022). All speeds measured with A100, fp16.
图 1: Hiera通过从分层Transformer中剔除昂贵的专用操作(如卷积),创建了一个简单、高效且精确的模型,在多种图像和视频任务中都能快速运行。上图展示了与近期基于MAE的研究(Woo等人, 2023; Feichtenhofer等人, 2022)的对比结果。所有速度测试均在A100显卡、fp16精度下完成。
We argue that a lot of this bulk is actually unnecessary. Because ViTs lack inductive bias after their initial patchify operation, many of the changes proposed by subsequent vision specific transformers serve to manually add spatial biases. But why should we slow down our architecture to add these biases, if we could just train the model to learn them instead? In particular, MAE pre training has shown to be a very effective tool to teach ViTs spatial reasoning, allowing pure vision transformers to obtain good results on detection (Li et al., 2022b), which was a task previously dominated by models like Swin or MViT. Moreover, MAE pre training is sparse and can be $4-10\times$ as fast as normal supervised training, making it an already desirable alternative across many domains for more than just accuracy (He et al., 2022; Fei chten hofer et al., 2022; Huang et al., 2022b).
我们认为这些冗余设计大多是不必要的。由于视觉Transformer (ViT) 在初始分块操作后缺乏归纳偏置,后续许多针对视觉设计的改进方案本质上是人为添加空间偏置。但既然可以通过训练让模型自主习得这些偏置,为何要牺牲架构效率来手动引入?特别是MAE预训练已被证明能有效教会ViT空间推理能力——纯视觉Transformer在检测任务上已能取得优异效果 (Li等, 2022b),而这类任务此前一直被Swin或MViT等模型主导。此外,MAE预训练具有稀疏特性,其训练速度可达常规监督学习的$4-10倍$,这使其不仅因精度优势,更因效率成为多领域的理想选择 (He等, 2022; Feichtenhofer等, 2022; Huang等, 2022b)。
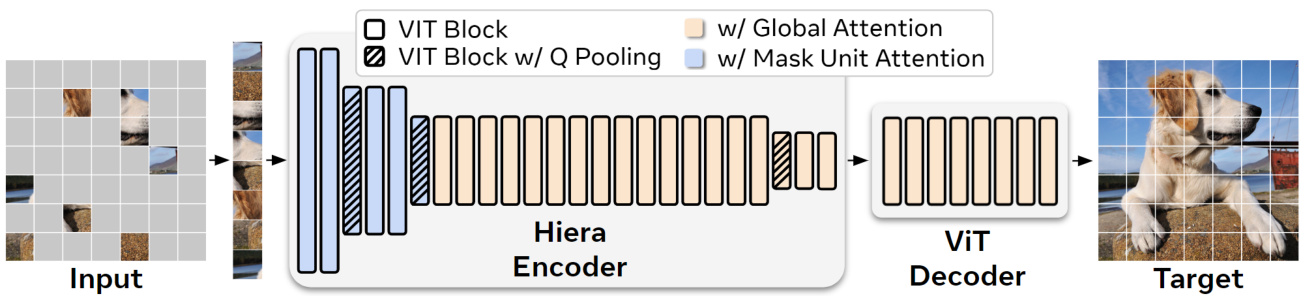
Figure 2. Hiera Setup. Modern hierarchical transformers like Swin (Liu et al., 2021) or MViT (Li et al., 2022c) are more parameter efficient than vanilla ViTs (Do sov it ski y et al., 2021), but end up slower due to overhead from adding spatial bias through vision-specific modules like shifted windows or convs. In contrast, we design Hiera to be as simple as possible. To add spatial bias, we opt to teach it to the model using a strong pretext task like MAE (pictured here) instead. Hiera consists entirely of standard ViT blocks. For efficiency, we use local attention within “mask units” (Fig. 4, 5) for the first two stages and global attention for the rest. At each stage transition, $Q$ and the skip connection have their features doubled by a linear layer and spatial dimension pooled by a $2\times2$ maxpool. Hiera-B is shown here (see Tab. 2 for other configs).
图 2: Hiera架构。现代分层Transformer如Swin (Liu等人, 2021)或MViT (Li等人, 2022c)比原始ViT (Dosovitskiy等人, 2021)更具参数效率,但由于通过视觉专用模块(如移位窗口或卷积)添加空间偏置的开销,最终速度较慢。相比之下,我们将Hiera设计得尽可能简单。为了添加空间偏置,我们选择通过强预训练任务(如这里所示的MAE)将其教给模型。Hiera完全由标准ViT块组成。为了提高效率,我们在前两个阶段使用"掩码单元"(图4、5)内的局部注意力,其余阶段使用全局注意力。在每个阶段过渡时,$Q$和跳跃连接的特征通过线性层加倍,空间维度通过$2\times2$最大池化进行下采样。这里展示的是Hiera-B架构(其他配置见表2)。
We test this hypothesis with a simple strategy: using some implementation tricks (Fig. 4), take an existing hierarchical ViT (e.g., MViTv2) and carefully remove non-essential components while training with MAE (Tab. 1). After tuning the MAE task to this new architecture (Tab. 3), we find that we can actually simplify or remove all of the non-transformer components, while increasing in accuracy. The result is an extremely efficient model with no bells-and-whistles: no convolutions, no shifted or cross-shaped windows, no decomposed relative position embeddings. Just a pure, simple hierarchical ViT that is both faster and more accurate than prior work across several model sizes, domains, and tasks.
我们通过一个简单策略验证这一假设:运用若干实现技巧(图4),选取现有的分层ViT(如MViTv2),在使用MAE训练时谨慎移除非必要组件(表1)。在针对新架构调整MAE任务后(表3),发现实际上可以简化或移除所有非Transformer组件,同时提升准确率。最终得到一个极致高效的"无修饰"模型:没有卷积、没有移位或十字形窗口、没有分解的相对位置嵌入。仅保留纯粹简单的分层ViT,在多种模型规模、领域和任务中,其速度与精度均超越先前工作。
Our Simple Hierarchical Vision Transformer (Hiera) outperforms the SotA on images and far exceeds prior work on video while being much faster (Fig. 1) at every model scale (Fig. 3) and across extensive datasets and tasks (Sec. 5, 6).
我们的简单分层视觉Transformer (Hiera) 在图像任务上超越了当前最优水平 (SotA),并在视频任务上远超先前工作,同时在不同模型规模 (图 3)、广泛数据集和任务 (第 5、6 节) 中保持显著速度优势 (图 1)。
2. Related Work
2. 相关工作
Vision transformers (ViTs) have attracted attention because of their massive success on several vision tasks including image classification (Do sov it ski y et al., 2021), video classification (Fan et al., 2021; Arnab et al., 2021; Bertasius et al., 2021), semantic segmentation (Ranftl et al., 2021), object detection (Carion et al., 2020; Li et al., 2022b), video object segmentation (Duke et al., 2021), 3D object detection (Misra et al., 2021) and 3D reconstruction (Bozic et al., 2021). The key difference between vanilla ViT (Dosovitskiy et al., 2021) and prior convolutional neural networks (CNNs) (LeCun et al., 1998) is that ViT partitions images into, e.g., $16\times16$ pixel, non-overlapping patches and flattens the spatial grid into a 1D sequence, whereas CNNs maintain this grid over multiple stages of the model, reducing the resolution in each stage and introducing inductive biases such as shift e qui variance. Recently, the field has shown an increased interest in hybrid methods (Fan et al., 2021;
视觉Transformer (ViT) 因其在多项视觉任务中的卓越表现而备受关注,包括图像分类 (Dosovitskiy et al., 2021)、视频分类 (Fan et al., 2021; Arnab et al., 2021; Bertasius et al., 2021)、语义分割 (Ranftl et al., 2021)、目标检测 (Carion et al., 2020; Li et al., 2022b)、视频目标分割 (Duke et al., 2021)、3D目标检测 (Misra et al., 2021) 和3D重建 (Bozic et al., 2021)。原始ViT (Dosovitskiy et al., 2021) 与传统卷积神经网络 (CNN) (LeCun et al., 1998) 的关键区别在于,ViT将图像分割为例如 $16\times16$ 像素的非重叠块,并将空间网格展平为一维序列,而CNN在模型的多个阶段中保持这种网格结构,逐步降低分辨率并引入平移等变性等归纳偏置。近期,该领域对混合方法 (Fan et al., 2021;
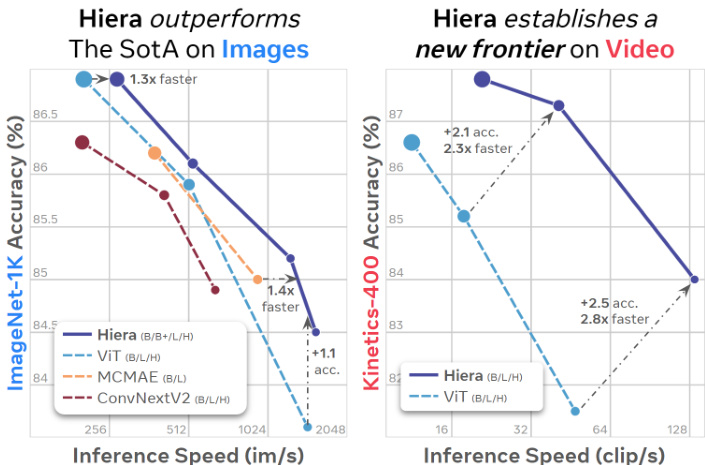
Figure 3. Performance vs. prior work. Hiera compared to B, L, and H variants of SotA models that use MAE-like pre training. On images, Hiera is faster and more accurate than even the most recent SotA (He et al., 2022; Gao et al., 2022; Woo et al., 2023), offering $30{-}40%$ speed-up compared to the best model at every scale. On video, Hiera represents a new class of performance, significantly improving accuracy, while being over $2\times$ faster than popular ViT models. Marker size is proportional to FLOP count.
图 3: 性能对比先前工作。Hiera 与采用类似 MAE 预训练的 SotA 模型 B、L、H 变体进行比较。在图像任务中,Hiera 比最新 SotA 模型 (He et al., 2022; Gao et al., 2022; Woo et al., 2023) 更快更准确,在所有规模上相比最佳模型实现 $30{-}40%$ 的速度提升。在视频任务中,Hiera 代表了全新的性能级别,在显著提升精度的同时,速度比主流 ViT 模型快 $2\times$ 以上。标记点大小与 FLOP 计算量成正比。
Liu et al., 2021; Li et al., 2022c; Dong et al., 2022; Wang et al., 2021) that combine transformers with convolutionlike operations and the hierarchical stage structure of prior CNNs. This direction has shown success and has achieved state-of-the-art on various vision tasks. However, in practice these models are actually slower than their vanilla ViT counterparts and convs are not easily compatible with popular self-supervised tasks such as masked image modeling. We address both of these issues in the creation of Hiera.
Liu et al., 2021; Li et al., 2022c; Dong et al., 2022; Wang et al., 2021) 将Transformer与类卷积操作及传统CNN的分层阶段结构相结合。这一方向已取得显著成功,并在多项视觉任务中达到最先进水平。然而实际应用中,这些模型的速度往往不及原始ViT架构,且卷积操作难以适配掩码图像建模等主流自监督任务。Hiera的构建正是为了解决这两大问题。
Masked pre training has emerged as a powerful selfsupervised learning pretext task for learning visual representations (Vincent et al., 2010; Pathak et al., 2016; Chen et al., 2020; He et al., 2022; Bao et al., 2022; Xie et al., 2022; Hou et al., 2022). Among previous works, Masked Auto Encoder (MAE, He et al. (2022)) takes advantage of vanilla ViTs, which allow any length of input, and thereby derives an efficient training regime using the sparsity of masked images. This greatly improves the training efficiency of masked pretraining, but adapting sparse training to hierarchical models is nontrivial, because the input is no longer laid out in a rigid 2D grid. There have been several attempts to enable hierarchical ViTs to use masked pre training. MaskFeat (Wei et al., 2022) and SimMIM (Xie et al., 2022) replace masked patches with [mask] tokens, meaning most computation is wasted on non-visible tokens and training is incredibly slow. Huang et al. (2022a) introduce several techniques to enable sparsity in every component of the network, in the end creating a much more complicated model that doesn’t improve much in accuracy. UM-MAE (Li et al., 2022a) uses a special masking strategy to allow for sparsity, but this restriction significantly hurts accuracy. MCMAE (Gao et al., 2022) uses masked convolution in the first couple of stages which obtains high accuracy but significantly reduces the efficiency of the model overall. We bypass all of these complicated techniques and restrictions by designing our architecture specifically for sparse MAE pre training, thereby creating a powerful yet simple model.
掩码预训练已成为学习视觉表征的一种强大自监督学习前置任务 (Vincent et al., 2010; Pathak et al., 2016; Chen et al., 2020; He et al., 2022; Bao et al., 2022; Xie et al., 2022; Hou et al., 2022)。在先前工作中,掩码自编码器 (MAE, He et al. (2022)) 利用原生ViT可接受任意长度输入的特性,通过掩码图像的稀疏性实现了高效训练范式。这极大提升了掩码预训练效率,但将稀疏训练适配到层级模型却非易事,因其输入不再严格遵循二维网格排列。现有若干尝试使层级ViT支持掩码预训练:MaskFeat (Wei et al., 2022) 和SimMIM (Xie et al., 2022) 用[mask] token替换掩码块,导致大量计算浪费在不可见token上,训练速度极慢;Huang et al. (2022a) 为网络各组件引入稀疏化技术,最终构建的复杂模型精度提升有限;UM-MAE (Li et al., 2022a) 采用特殊掩码策略实现稀疏性,但这种限制严重损害精度;MCMAE (Gao et al., 2022) 在前几阶段使用掩码卷积获得高精度,却显著降低整体模型效率。我们通过专为稀疏MAE预训练设计的架构,绕过了所有这些复杂技术与限制,最终构建出强大而简洁的模型。
3. Approach
3. 方法
Our goal is to create a powerful and efficient multiscale vision transformer that is, above all, simple. We argue that we do not need any specialized modules like convolution (Fan et al., 2021), shifted windows (Liu et al., 2021), or attention bias (Graham et al., 2021; Li et al., 2022c) to obtain high accuracy on vision tasks. This may seem difficult, as these techniques add much needed spatial (and temporal) biases that vanilla transformers (Do sov it ski y et al., 2021) lack. However, we employ a different strategy. While prior work adds spatial bias through complicated architectural changes, we opt to keep the model simple and learn these biases through a strong pretext task instead. To show the efficacy of this idea, we devise a simple experiment: take an existing hierarchical vision transformer and ablate its bells-and-whistles while training with a strong pretext task.
我们的目标是创建一个强大且高效的多尺度视觉Transformer (vision transformer),最重要的是保持简洁。我们认为,不需要任何专门模块(如卷积 [Fan et al., 2021]、移位窗口 [Liu et al., 2021] 或注意力偏置 [Graham et al., 2021; Li et al., 2022c])就能在视觉任务上实现高精度。这看似困难,因为这些技术弥补了原始Transformer [Dosovitskiy et al., 2021] 所缺乏的关键空间(和时间)偏置。然而,我们采用了不同策略:前人工作通过复杂的架构改动引入空间偏置,而我们选择保持模型简洁,通过强预训练任务学习这些偏置。为验证这一理念,我们设计了一个简单实验:选取现有分层视觉Transformer,在强预训练任务下移除其复杂模块。
For the pretext task, we use Masked Auto encoders (MAE, He et al. (2022)), which has been shown effective in teaching ViTs localization capabilities for downstream tasks (e.g., detection (Li et al., 2022b)) by having the network reconstruct masked input patches (Fig. 2). Note that MAE pretraining is sparse—that is, masked tokens are deleted instead of being overwritten like in other masked image modeling approaches (Wei et al., 2022; Xie et al., 2022). This makes pre training efficient, but poses a problem for existing hierarchical models as it breaks the 2D grid that they rely on (Fig. 4b). Moreover, MAE masks out individual tokens, which are large $16\times16$ patches for ViT, but only small $4\times4$ patches for most hierarchical models (Fig. 4a).
在预训练任务中,我们采用掩码自编码器 (MAE, He等人 (2022)),该方法通过让网络重建被掩码的输入图像块 (图2),已被证明能有效为下游任务 (如检测 (Li等人, 2022b)) 教授视觉Transformer (ViT) 的定位能力。需要注意的是,MAE预训练是稀疏的——即被掩码的token会被删除,而非像其他掩码图像建模方法 (Wei等人, 2022; Xie等人, 2022) 那样被覆盖。这使得预训练更高效,但对现有分层模型造成了问题,因为它破坏了这些模型所依赖的二维网格结构 (图4b)。此外,MAE掩码的是单个token,这对ViT来说是较大的$16\times16$图像块,但对大多数分层模型而言只是较小的$4\times4$图像块 (图4a)。
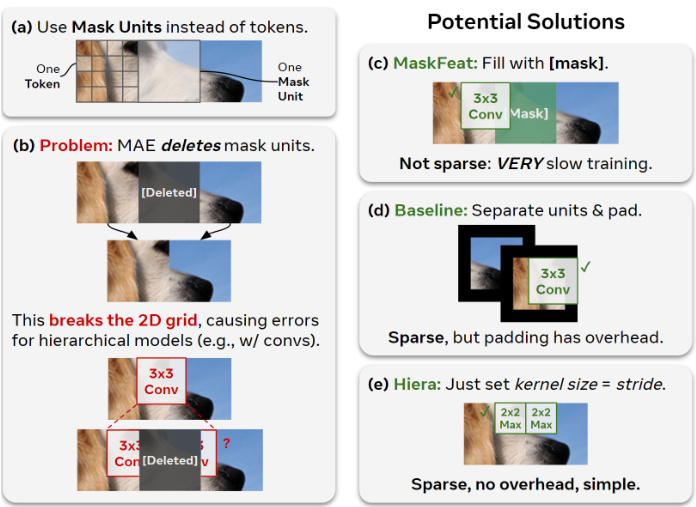
Figure 4. MAE for Hierarchical Models. MAE is not compatible with multi-stage models, but we can apply some simple tricks to remedy this. While MAE masks individual tokens, tokens in multistage transformers start very small (e.g., $4\times4$ pixels), doubling size in each stage. (a) Thus, we mask coarser “mask units” $(32\times32$ pixels) instead of tokens directly. (b) For efficiency, MAE is sparse, meaning it deletes what it masks (a problem for spatial modules like convs). (c) Keeping masked tokens fixes this, but gives up the potential $4-10\times$ training speed-up of MAE. (d) As a baseline, we introduce a trick that treats mask units as a separate entities for convs, solving the issue but requiring undesirable padding. (e) In Hiera, we side-step the problem entirely by changing the architecture so the kernels can’t overlap between mask units.
图 4: 分层模型的MAE。MAE与多阶段模型不兼容,但我们可以通过一些简单技巧解决这一问题。MAE对单个token进行掩码,而多阶段transformer中的token初始尺寸极小(如$4\times4$像素),每阶段尺寸翻倍。(a)因此我们改为掩码更粗粒度的"掩码单元"$(32\times32$像素)而非直接掩码token。(b)出于效率考虑,MAE采用稀疏处理,即删除被掩码内容(这对卷积等空间模块会造成问题)。(c)保留被掩码token可解决该问题,但会牺牲MAE原本$4-10\times$的训练加速优势。(d)作为基线方案,我们引入将掩码单元视为卷积独立实体的技巧,虽解决问题但需额外填充。(e)在Hiera中,我们通过调整架构使卷积核无法跨越掩码单元边界,从而彻底规避该问题。
To address both of these issues, we opt to distinguish tokens from “mask units”. As described in Fig. 4a, mask units are at the resolution we apply MAE masking, while tokens are the internal resolution of the model (like in Wei et al. (2022); Xie et al. (2022)). In our case, we mask $32\times32$ pixel regions, meaning one mask unit is $8\times8$ tokens at the start of the network. Once we have made this distinction, we can use a clever trick (Fig. 4d) to evaluate hierarchical models by treating mask units as contiguous, separate from other tokens. Thus, we can continue with our experiments and use MAE with an existing hierarchical vision transformer.
为了解决这两个问题,我们选择将token与"掩码单元"区分开来。如图4a所示,掩码单元是我们应用MAE掩码的分辨率,而token是模型的内部分辨率(如Wei et al. (2022);Xie et al. (2022)所述)。在我们的案例中,我们对$32\times32$像素区域进行掩码,这意味着在网络开始时一个掩码单元是$8\times8$个token。一旦做出这种区分,我们就可以使用一个巧妙的技巧(图4d)来评估分层模型,将掩码单元视为连续的、与其他token分离的部分。因此,我们可以继续实验,并在现有的分层视觉Transformer中使用MAE。
3.1. Preparing MViTv2
3.1. 准备 MViTv2
We choose MViTv2 as our base architecture, as its small $3\times3$ kernels are affected the least by the separate-andpad trick described in Fig. 4d, though we likely could have chosen a different transformer and obtained a similar end result. We briefly review MViTv2 below.
我们选择MViTv2作为基础架构,因为其小型$3\times3$卷积核受图4d所述分离填充技巧的影响最小(尽管选用其他Transformer架构也可能获得相似结果)。以下简要回顾MViTv2特性。
MViTv2 (Li et al., 2022c) is a hierarchical model. That is, it learns multi-scale representations over its four stages. It starts by modeling low level features with a small channel capacity but high spatial resolution, and then in each stage trades channel capacity for spatial resolution to model more complex high-level features in deeper layers.
MViTv2 (Li et al., 2022c) 是一种分层模型。它通过四个阶段学习多尺度表征:初期以较小通道容量和高空间分辨率建模低级特征,随后每个阶段通过牺牲空间分辨率换取通道容量,从而在更深层级建模更复杂的高级特征。

Figure 5. Mask Unit Attention. MViTv2 uses pooling attention (a) which performs global attention with a pooled version of $K$ and $V$ . This can get expensive for large inputs (e.g., for video), so we opt to replace this with “Mask Unit Attention” (b) which performs local attention within mask units (Fig. 4a). This has no overhead because we already group tokens into units for masking. We do not have to worry about shifting like in Swin (Liu et al., 2021), because we use global attention in stages 3 and 4 (Fig. 2).
图 5: 掩码单元注意力。MViTv2采用池化注意力机制(a),通过池化版本的$K$和$V$进行全局注意力计算。对于大尺寸输入(如视频)可能计算量较大,因此我们改用"掩码单元注意力"(b),在掩码单元内执行局部注意力计算(图4a)。由于我们已将token分组为掩码单元,该方法不会引入额外开销。无需像Swin (Liu et al., 2021)那样考虑位移问题,因为我们在第3和第4阶段使用全局注意力机制(图2)。
A key feature of MViTv2 is pooling attention (Fig. 5a), wherein features are locally aggregated—typically using $3\times3$ convolution, before computing self-attention. In pooling attention, $K$ and $V$ are pooled to decrease computation in the first two stages, while $Q$ is pooled to transition from one stage to the next by reducing spatial resolution. MViTv2 also features decomposed relative position embeddings instead of absolute ones and a residual pooling connection to skip between pooled $Q$ tokens inside the attention blocks. Note that by default, pooling attention in MViTv2 contain convs with stride 1 even if no down sampling is required.
MViTv2的一个关键特性是池化注意力 (图 5a),其中特征在计算自注意力前会先进行局部聚合——通常使用 $3\times3$ 卷积。在池化注意力中,$K$ 和 $V$ 会被池化以减少前两个阶段的计算量,而 $Q$ 则通过降低空间分辨率来实现阶段间的过渡。MViTv2还采用了分解的相对位置嵌入 (relative position embeddings) 而非绝对位置嵌入,并在注意力块内部通过残差池化连接来跳过被池化的 $Q$ token。需要注意的是,默认情况下,MViTv2中的池化注意力即使无需下采样也会包含步长为1的卷积操作。
Applying MAE. Since MViTv2 down samples by $2\times2$ a total of three times (Fig. 2) and because it uses a token size of $4\times4$ pixels, we employ a mask unit of size $32\times32$ This ensures that each mask unit corresponds to $8^{2},4^{2},2^{2}$ , $1^{2}$ tokens in stages 1, 2, 3, 4 respectively, allowing each mask unit to cover at least one distinct token in each stage. Then as described in Fig. 4d, to make sure conv kernels do not bleed into deleted tokens, we shift the mask units to the batch dimension to separate them for pooling (effectively treating each mask unit as an “image”) and then undo the shift afterward to ensure that self-attention is still global.
应用MAE。由于MViTv2总共进行了三次$2\times2$下采样(图2),并且使用了$4\times4$像素的token尺寸,我们采用$32\times32$的掩码单元。这确保每个掩码单元分别对应第1、2、3、4阶段的$8^{2},4^{2},2^{2}$和$1^{2}$个token,使得每个掩码单元在各阶段至少覆盖一个独立token。如图4d所述,为防止卷积核渗入被删除的token,我们将掩码单元移至批次维度以分离它们进行池化(实质上是将每个掩码单元视为一个"图像"),随后撤销移位以确保自注意力仍保持全局性。
3.2. Simplifying MViTv2
3.2. 简化 MViTv2
In this section we remove non-essential components of MViTv2 while training with MAE. In Tab. 1, we find that we can remove or otherwise simplify all of them and still maintain high accuracy for image classification on ImageNet-1K. We use MViTv2-L to ensure our changes work at scale.
在本节中,我们在使用MAE训练时移除了MViTv2的非必要组件。表1显示,我们可以移除或简化所有非必要组件,同时仍在ImageNet-1K图像分类任务中保持高准确率。我们采用MViTv2-L架构来验证这些改动在大规模场景下的有效性。
Relative Position Embeddings. MViTv2 swaps the absolute position embeddings in Do sov it ski y et al. (2021) for more powerful relative ones added to attention in each block. Technically, we could implement a version of this that is compatible with sparse pre training, but doing so would add
相对位置嵌入。MViTv2将Dosovitskiy等人(2021)中的绝对位置嵌入替换为更强大的相对位置嵌入,并将其添加到每个注意力块中。从技术上讲,我们可以实现一个与稀疏预训练兼容的版本,但这样做会增加
| Image | Video | |||
| Setting | acc. | im/s | acc. | clip/s |
| MViTv2-LSupervised | 85.3 | 219.8 | 80.5 | 20.5 |
| Hiera-LMAE | ||||
| a.replace rel pos with absolute | 85.6 | 253.3 | 85.3 | 20.7 |
| b. replace convs with maxpools * | 84.4 | 99.9t | 84.1 | 10.4t |
| c.delete stride=1maxpools | 85.4 | 309.2 | 84.3 | 26.2 |
| d.set kernel size equal to stride | 85.7 | 369.8 | 85.5 | 29.4 |
| e.deleteqattention residuals | 85.6 | 374.3 | 85.5 | 29.8 |
| f. replace kv pooling with MU attn | 85.6 | 531.4 | 85.5 | 40.8 |
| 图像 | 视频 | |||
|---|---|---|---|---|
| 设置 | 准确率 (%) | 帧/秒 | 准确率 (%) | 段/秒 |
| MViTv2-L监督式 | 85.3 | 219.8 | 80.5 | 20.5 |
| Hiera-LMAE | ||||
| a. 用绝对位置替换相对位置 | 85.6 | 253.3 | 85.3 | 20.7 |
| b. 用最大池化替换卷积* | 84.4 | 99.9t | 84.1 | 10.4t |
| c. 删除步幅=1的最大池化 | 85.4 | 309.2 | 84.3 | 26.2 |
| d. 设置卷积核大小等于步幅 | 85.7 | 369.8 | 85.5 | 29.4 |
| e. 删除注意力残差连接 | 85.6 | 374.3 | 85.5 | 29.8 |
| f. 用多头注意力替换KV池化 | 85.6 | 531.4 | 85.5 | 40.8 |
Table 1. Simplifying MViTv2. MViTv2 employs several architectural tweaks to perform well on supervised training. By progressively removing them in Sec. 3.2, we find these bells-and-whistles are unnecessary when training with a strong pretext task (MAE). In the process, we create an extremely simple model (Fig. 2) that is accurate while being significantly faster. We report fp16 inference speed for ImageNet-1K and Kinetics-400 on an A100. Our final Hiera-L in gray . ∗Requires the separate-and-pad trick described in Fig. 4d. †PyTorch’s maxpool3d interacts unfavorably with this.
表 1: MViTv2简化方案。MViTv2通过多项架构调整在监督训练中表现优异。在第3.2节逐步移除这些组件后,我们发现当配合强预训练任务(MAE)时,这些装饰性设计实非必要。在此过程中,我们构建了一个极其简洁的模型(图2),在保持高精度的同时大幅提升速度。数据基于A100显卡的ImageNet-1K和Kinetics-400 fp16推理速度测试。最终版Hiera-L以灰色标注。*需配合图4d所述的分隔填充技巧。†PyTorch的maxpool3d与此存在兼容性问题。
a lot of complexity. Instead, we opt to start our study here by undoing this change and using absolute position embeddings instead. As shown in Tab. 1a, these relative position embeddings are not necessary when training with MAE. Further, absolute position embeddings are much faster.
我们选择撤销这一改动,转而采用绝对位置嵌入 (absolute position embeddings) 来简化研究。如表 1a 所示,在使用 MAE (Masked Autoencoder) 训练时,这些相对位置嵌入并非必需。此外,绝对位置嵌入的速度明显更快。
Removing Convolutions. Next, we aim to remove the convs in the model, which are vision specific modules and add potentially unnecessary overhead. We first attempt to replace every conv layer with maxpools (shown by Fan et al. (2021) to be the next best option), which itself is fairly costly. The result (Tab. 1b) drops accuracy by over $1%$ on images, but this is to be expected: we’ve also replaced all of the extra stride=1 convs with maxpools, which impacts the features significantly (with padding and small mask units, this in effect performs a relu on every feature map). Once we delete those additional stride=1 maxpools (Tab. 1c), we nearly return to the accuracy we had before, while speeding up the model by $22%$ for images and $27%$ for video. At this point, the only pooling layers that remain are for $Q$ at stage transitions and for $K V$ pooling in the first two stages.
移除卷积层。接下来,我们的目标是移除模型中的卷积层(convs),这些是视觉专用模块,会带来潜在的不必要开销。我们首先尝试用最大池化(maxpools)替换每个卷积层(Fan等人(2021)证明这是次优选择),但该方法本身成本较高。结果(表1b)显示图像准确率下降超过$1%$,但这在预期之中:我们还把所有额外stride=1的卷积替换为最大池化,这会显著影响特征(由于填充和小型掩码单元,实际上相当于对每个特征图执行了ReLU操作)。当我们删除这些额外的stride=1最大池化层后(表1c),准确率几乎恢复到之前水平,同时图像处理速度提升$22%$,视频处理速度提升$27%$。此时,仅剩的池化层用于阶段转换时的$Q$以及前两个阶段的$K V$池化。
Removing Overlap. The remaining maxpool layers still have a kernel size of $3\times3$ , necessitating the use of the separate-and-pad trick in Fig. 4d during both training and inference. However, as shown in Fig. 4e, we can avoid this problem entirely if we just do not let these maxpool kernels overlap. That is, if we set the kernel size equal to stride for each maxpool, we can use sparse MAE pre training without the separate-and-pad trick. As shown in Tab. 1d, this speeds up the model by $20%$ on image and $12%$ on video while increasing accuracy, likely due to not having to pad.
去除重叠。剩余的 maxpool 层仍保持 $3\times3$ 的核大小,因此在训练和推理期间都需要使用图 4d 中的分离填充技巧。然而,如图 4e 所示,如果我们直接不让这些 maxpool 核重叠,就能完全避免这一问题。也就是说,若将每个 maxpool 的核大小设为与步长相等,即可在不使用分离填充技巧的情况下进行稀疏 MAE 预训练。表 1d 显示,这一改动使模型在图像任务上提速 $20%$,视频任务上提速 $12%$,同时准确率有所提升——这很可能是因为无需填充所致。
Removing the Attention Residual. MViTv2 adds a residual connection in the attention layer between $Q$ and the output to assist in learning its pooling attention. However, so far we’ve minimized the number of layers, making attention easier to learn. Thus, we can safely remove it (Tab. 1e).
移除注意力残差连接。MViTv2 在注意力层的 $Q$ 和输出之间添加了残差连接以辅助学习其池化注意力。但当前我们已将层数降至最少,使得注意力更易学习。因此可以安全移除该连接 (表 1e)。

Figure 6. Mask Unit Attn vs. Window Attn. Window attention (a) performs local attention within a fixed size window. Doing so would potentially overlap with deleted tokens during sparse MAE pre training. In contrast, Mask Unit attention (b) performs local attention within individual mask units, no matter their size.
图 6: 掩码单元注意力 vs. 窗口注意力。窗口注意力 (a) 在固定大小的窗口内执行局部注意力。这种做法可能在稀疏 MAE 预训练期间与已删除的 token 重叠。相比之下,掩码单元注意力 (b) 在单个掩码单元内执行局部注意力,无论其大小如何。
Mask Unit Attention. At this point, the only specialized module left is pooling attention. Pooling $Q$ is necessary to maintain a hierarchical model, but $K V$ pooling is only there to reduce the size of the attention matrix in the first two stages. We can remove this outright, but it would considerably increase the computational cost of the network. Instead, in Tab. 1f we replace it with an implementation ally trivial alternative: local attention within a mask unit.
掩码单元注意力。至此,唯一剩下的专用模块是池化注意力。对$Q$进行池化是维持层次化模型的必要操作,但$K V$池化仅用于在前两个阶段缩减注意力矩阵的尺寸。我们可以直接移除该模块,但这会显著增加网络的计算成本。作为替代方案,我们在表1f中采用了一种实现上更简单的方案:掩码单元内的局部注意力。
During MAE pre training, we already have to separate out mask units at the start of the network (see Fig. 2). Thus the tokens are already neatly grouped by units once they arrive at attention. We can then simply perform local attention within these units with no overhead. While this “Mask Unit attention” is local instead of global like pooling attention (Fig. 5), $K$ and $V$ were only pooled in the first two stages, where global attention isn’t as useful. Thus, as shown in Tab. 1, this change has no impact on accuracy but increases throughput by quite a lot—up to $32%$ on video.
在MAE预训练过程中,我们必须在网络起始阶段分离出掩码单元(见图2)。因此当这些token到达注意力层时,已经按单元整齐分组。我们可以直接在这些单元内执行局部注意力计算,无需额外开销。虽然这种"掩码单元注意力"是局部而非全局的(如图5所示的池化注意力),但$K$和$V$仅在前两个阶段进行池化,而这两个阶段的全局注意力作用有限。如表1所示,这一改动在保持精度的同时显著提升了吞吐量——视频任务最高可提升$32%$。
Note that mask unit attention is distinct from window attention because it adapts the window size to the size of mask units at the current resolution. Window attention would have a fixed size throughout the network, which would leak into deleted tokens after a downsample (see Fig. 6).
注意,掩码单元注意力 (mask unit attention) 与窗口注意力 (window attention) 不同,因为它会根据当前分辨率下掩码单元的大小调整窗口尺寸。窗口注意力在整个网络中保持固定尺寸,这会在下采样后泄露到已删除的 token 中 (见图 6)。
Hiera. The result of these changes is an extremely simple and efficient model, which we denote “Hiera”. Hiera is $2.4\times$ faster on images and $5.l\times$ faster on video than the MViTv2 we started with and is actually more accurate because of MAE. Furthermore, because Hiera supports sparse pretraining, the results in Tab. 1 are extremely fast to obtain. In fact, to obtain superior accuracy on images, Hiera-L is $3\times$ faster to train than a supervised MViTv2-L (Fig. 7). For video, Wei et al. (2022) report $80.5%$ using a cut down version of MViTv2 with double the $K V$ stride in the first 3 stages. Compared to this model, our Hiera-L obtains $85.5%$ in 800 pretrain epochs while being $2.l\times$ faster to train (Fig. 7). All benchmarks in this paper are on an A100 with fp16 (as this setting is most useful in practice) unless noted otherwise.
Hiera。这些改进的结果是一个极其简单高效的模型,我们将其命名为"Hiera"。在图像任务上,Hiera比初始的MViTv2快2.4倍;在视频任务上快5.1倍,并且由于采用了MAE(Masked Autoencoder)技术,其准确率反而更高。此外,由于Hiera支持稀疏预训练,表1中的结果可以极快地获得。实际上,要在图像任务上达到更高的准确率,Hiera-L的训练速度比监督式MViTv2-L快3倍(见图7)。在视频任务方面,Wei等人(2022)报告使用精简版MViTv2(前3个阶段的KV步幅加倍)获得了80.5%的准确率。与之相比,我们的Hiera-L在800个预训练周期内达到了85.5%的准确率,同时训练速度快2.1倍(见图7)。除非另有说明,本文所有基准测试均在A100显卡上使用fp16精度进行(该设置在实际应用中最具实用价值)。
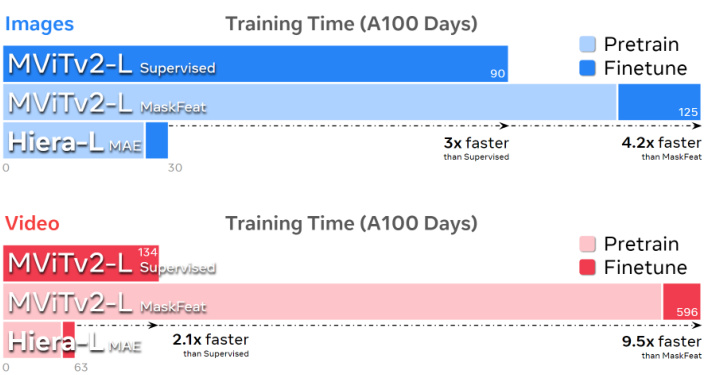
Figure 7. Training time. Measured in half precision A100 days. Our Hiera is significantly faster to train than MViTv2 due to being more efficient and benefiting from sparse pre training (as opposed to MaskFeat). Here, supervised uses 300 epochs for ImageNet-1K and 200 for Kinetics-400, while MaskFeat and MAE use 400 for pre training on images and 800 on video followed by 50 epochs of finetuning for both. Note that Hiera-L at 200 epochs of pre training (81.8) already outperforms MViTv2-L supervised (80.5) on video, making it $5.6\times$ faster to obtain higher accuracy.
图 7: 训练时间。以半精度A100天为单位测量。由于效率更高且受益于稀疏预训练(与MaskFeat相反),我们的Hiera训练速度明显快于MViTv2。其中,监督式方法在ImageNet-1K上使用300个周期,在Kinetics-400上使用200个周期;而MaskFeat和MAE在图像预训练中使用400个周期,视频预训练中使用800个周期,随后进行50个周期的微调。值得注意的是,Hiera-L仅需200个预训练周期(81.8)就能在视频任务上超越MViTv2-L监督式训练(80.5)的精度,这意味着以$5.6\times$更快的速度获得更高准确率。
While we used Hiera-L for the experiments in this section, we can of course instantiate it in different sizes, e.g. Tab. 2.
| model | #Channels | #Blocks | #Heads | FLOPsParam |
| Hiera-T | [96-192-384-768] | [1-2-7-2] | [1-2-4-8] | 5G 28M |
| Hiera-S | [96-192-384-768] | [1-2-11-2] | [1-2-4-8] | 6G 35M |
| Hiera-B | [96-192-384-768] | [2-3-16-3] | [1-2-4-8] | 9G 52M |
| Hiera-B+ | [112-224-448-896] | [2-3-16-3] | [2-4-8-16] | 13G 70M |
| Hiera-L | [144-288-576-1152] | [2-6-36-4 | [2-4-8-16] | 40G214M |
| Hiera-H | [256-512-1024-2048][2-6-36-4] | [4-8-16-32] | 125G673M |
虽然本节实验使用的是Hiera-L模型,但我们也可以实例化不同规模的版本,如 表 2 所示。
| 模型 | 通道数 | 块数 | 头数 | FLOPs/参数 |
|---|---|---|---|---|
| Hiera-T | [96-192-384-768] | [1-2-7-2] | [1-2-4-8] | 5G/28M |
| Hiera-S | [96-192-384-768] | [1-2-11-2] | [1-2-4-8] | 6G/35M |
| Hiera-B | [96-192-384-768] | [2-3-16-3] | [1-2-4-8] | 9G/52M |
| Hiera-B+ | [112-224-448-896] | [2-3-16-3] | [2-4-8-16] | 13G/70M |
| Hiera-L | [144-288-576-1152] | [2-6-36-4] | [2-4-8-16] | 40G/214M |
| Hiera-H | [256-512-1024-2048] | [2-6-36-4] | [4-8-16-32] | 125G/673M |
Table 2. Configuration for Hiera variants. #Channels, #Blocks and #Heads specify the channel width, number of Hier a blocks and heads in each block for the four stages, respectively. FLOPs are measured for image classification with $224\times224$ input. The stage resolutions are $[56^{2},28^{2},14^{2},7^{2}]$ . We introduce $\mathrm{B+}$ for more direct comparison against prior work with slower B models.
表 2: Hiera变体的配置。#Channels、#Blocks和#Heads分别指定了四个阶段中每个阶段的通道宽度、Hier a块数量和头数。FLOPs是针对输入尺寸为$224\times224$的图像分类任务测量的。各阶段分辨率分别为$[56^{2},28^{2},14^{2},7^{2}]$。我们引入$\mathrm{B+}$以便更直接地与先前速度较慢的B模型进行比较。
4. MAE Ablations
4. MAE消融实验
In this section, we ablate MAE pre training settings in Hiera for both images and video, using ImageNet-1K (IN1K, Deng et al. (2009)) and Kinetics-400 (K400, Kay et al. (2017)). Like in He et al. (2022); Fei chten hofer et al. (2022), we ablate using our large model, Hiera-L, to ensure that our method works at scale. We evaluate performance by finetuning. All metrics are top-1 accuracies using standard evaluation protocols—a single (resized) center crop on IN1K and 3 spatial $\times5$ temporal views on K400.
在本节中,我们针对Hiera在图像和视频上的MAE预训练设置进行消融实验,使用ImageNet-1K (IN1K, Deng et al. (2009))和Kinetics-400 (K400, Kay et al. (2017))数据集。参照He et al. (2022)和Feichtenhofer et al. (2022)的做法,我们采用大型模型Hiera-L进行消融,以确保方法在大规模场景下的有效性。通过微调评估性能,所有指标均为采用标准评估协议得到的top-1准确率——IN1K使用单次(缩放)中心裁剪,K400使用3个空间$\times5$时序视图。
Multi-Scale decoder. While He et al. (2022); Fei chten hofer et al. (2022) use the tokens from the last block of the encoder as the input to the decoder, Hiera being hierarchical permits more flexibility: as in Gao et al. (2022), we can use multiscale information by fusing representations from all stages, which brings large gains in both modalities (Tab. 3a).
多尺度解码器。虽然He等人(2022)和Feichtenhofer等人(2022)使用编码器最后一个块的token作为解码器输入,但Hiera的分层特性允许更灵活的方案:如Gao等人(2022)所述,我们可以通过融合所有阶段的表征来利用多尺度信息,这在两种模态上都带来了显著提升(表3a)。
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
| multi-scale | image | video |
| 85.0 | 83.8 | |
| 85.6 | 85.5 |
Hiera: 一个没有花哨功能的分层视觉Transformer
| multi-scale | image | video |
|---|---|---|
| 85.0 | 83.8 | |
| 85.6 | 85.5 |
| mask | image | mask | video |
| 0.5 | 85.5 | 0.75 | 84.9 |
| 0.6 | 85.6 | 0.9 | 85.5 |
| 0.7 | 85.3 | 0.95 | 84.4 |
| mask | image | mask | video |
|---|---|---|---|
| 0.5 | 85.5 | 0.75 | 84.9 |
| 0.6 | 85.6 | 0.9 | 85.5 |
| 0.7 | 85.3 | 0.95 | 84.4 |
(a) Multi-Scale Decoder. Hiera being hierarchical, using multi-scale information for decoding brings significant gains.
(a) 多尺度解码器。Hiera作为分层架构,利用多尺度信息进行解码可带来显著性能提升。
(c) Reconstruction target. Both pixel and HOG targets result in strong performance.
| target | image | video |
| pixel | 85.6 | 85.5 |
| HOG | 85.7 | 86.1 |
(c) 重建目标。像素(pixel)和HOG目标都能带来强劲性能表现。
| 目标 | 图像 | 视频 |
|---|---|---|
| pixel | 85.6 | 85.5 |
| HOG | 85.7 | 86.1 |
(b) Mask ratio. High masking ratios lead to good performance, with video benefiting from higher masking than image modality.
(b) 掩码比例。高掩码比例带来良好性能,视频模态比图像模态更能受益于更高的掩码比例。
| dpr | image | video |
| 0.0 | 85.2 | 84.5 |
| 0.1 | 85.6 | 85.4 |
| 0.2 | 85.6 | 85.5 |
| 0.3 | 85.5 | 85.2 |
| dpr | image | video |
|---|---|---|
| 0.0 | 85.2 | 84.5 |
| 0.1 | 85.6 | 85.4 |
| 0.2 | 85.6 | 85.5 |
| 0.3 | 85.5 | 85.2 |
| depth | image | video |
| 4 | 85.5 | 84.8 |
| 8 | 85.6 | 85.5 |
| 12 | 85.5 | 85.4 |
| depth | image | video |
|---|---|---|
| 4 | 85.5 | 84.8 |
| 8 | 85.6 | 85.5 |
| 12 | 85.5 | 85.4 |
(d) Drop path rate. Surprisingly, we find drop path important during MAE pretraining, especially for video, unlike in He et al. (2022); Feichtenhofer et al. (2022).
(d) Drop path率。出乎意料的是,我们发现drop path在MAE预训练过程中非常重要,尤其是对于视频任务,这与He等人 (2022) 和Feichtenhofer等人 (2022) 的研究结论不同。
(f) Pre training schedule. Our pretraining follows the same trend as He et al. (2022), benefiting significantly from longer training.
| epochs | image | video |
| 400 | 85.6 | 84.0 |
| 800 | 85.8 | 85.5 |
| 1600 | 86.1 | 86.4 |
| 3200 | 86.1 | 87.3 |
(f) 预训练计划。我们的预训练遵循与He等人(2022)相同的趋势,从更长时间的训练中获益显著。
| 训练轮数 | 图像 | 视频 |
|---|---|---|
| 400 | 85.6 | 84.0 |
| 800 | 85.8 | 85.5 |
| 1600 | 86.1 | 86.4 |
| 3200 | 86.1 | 87.3 |
(e) Decoder depth. We find that a deeper decoder than in Fei chten hofer et al. (2022) works better for video.
(e) 解码器深度。我们发现比Feichtenhofer等人 (2022) 更深的解码器在视频任务上表现更好。
Table 3. Ablating MAE pre training with Hiera-L. For each ablation, we use 400 (800) epochs of sparse MAE pre training for IN1K (K400) and 50 epochs of dense finetuning unless otherwise noted. Our default† settings are marked in gray . For design choices not ablated here, we find the defaults in (He et al., 2022; Fei chten hofer et al., 2022) to be appropriate. $^\dagger$ default pre training length for the rest of the paper is 1600 (3200) epochs, unless otherwise noted.
表 3: 基于 Hiera-L 的 MAE 预训练消融实验。每组消融实验中,我们默认使用 400 (800) 轮稀疏 MAE 预训练处理 IN1K (K400) 数据集,并进行 50 轮密集微调 (除非特别说明)。标灰的†项表示我们的默认配置。对于未列出的设计选项,我们发现 (He et al., 2022; Feichtenhofer et al., 2022) 中的默认设置较为合适。$^\dagger$ 本文其余部分的默认预训练时长为 1600 (3200) 轮 (除非特别说明)。
Masking ratio. Fei chten hofer et al. (2022) find video to require a much higher masking ratio than images, suggesting higher information redundancy. We observe a similar trend in Tab. 3b with optimal masking ratios of 0.6 for images but 0.9 for video. Our optimal ratio for images, 0.6, is slightly lower than the 0.75 used in He et al. (2022). We expect this is due to increased difficulty of the pretext task from using a $32~\times32$ mask unit instead of $16\times~16$ as in He et al. (2022). Interestingly, we find the same 0.9 masking ratio to be appropriate for video as in Fei chten hofer et al. (2022). This could be because they actually find 0.95 to work optimally if allowed to train twice as long. With our increased task difficulty, 0.9 works out to be best.
掩码比例。Feichtenhofer等人 (2022) 发现视频需要比图像高得多的掩码比例,表明其信息冗余度更高。我们在表3b中观察到类似趋势:图像的最佳掩码比例为0.6,而视频为0.9。我们得出的图像最佳比例0.6略低于He等人 (2022) 使用的0.75,推测这是由于我们将掩码单元从原文的$16~\times16$改为$32\times~32$,导致预训练任务难度增加。值得注意的是,我们发现与Feichtenhofer等人 (2022) 相同的0.9掩码比例也适用于视频数据。这可能是因为他们的研究表明,若训练时长翻倍,0.95才是最优解。由于我们的任务难度更高,0.9被证实为最佳选择。
Reconstruction target. We find (Tab. 3c) that both pixel (w/ norm) and HOG (Dalal & Triggs, 2005) targets result in strong performance. While HOG targets results in slightly better performance for the default number of pre training epochs we use in ablations, we found that with longer training HOG targets achieve the same performance as pixel targets for video, but slightly worse for images.
重建目标。我们发现 (Tab. 3c) ,像素 (带归一化) 和 HOG (Dalal & Triggs, 2005) 目标都能带来强劲性能。虽然在消融实验默认使用的预训练周期数下,HOG 目标表现略优,但延长训练后,HOG 目标在视频任务上能达到与像素目标相当的水平,但在图像任务上仍稍逊一筹。
Droppath rate. The original MAE pre training recipes (He et al., 2022; Fei chten hofer et al., 2022) explicitly do not use drop path (Huang et al., 2016) during pre training, instead opting to only do so while finetuning. However, our HieraL has twice the depth of a ViT-L model: 48 for Hiera-L vs. 24 for ViT-L. While each layer individually has a lower parameter count, due to the sheer depth of Hiera, there could be a significant benefit from drop path.
丢弃路径率。原始MAE预训练方案(He et al., 2022; Feichtenhofer et al., 2022)明确表示在预训练期间不使用drop path(Huang et al., 2016),仅在微调阶段采用。但我们的Hiera-L模型深度是ViT-L的两倍:Hiera-L为48层,而ViT-L为24层。虽然每层参数量较少,但由于Hiera的极深架构,采用drop path可能带来显著收益。
In Tab. 3d, we ablate applying drop path during pre training (finetuning employs drop path by default) and find significant gains. This is surprising because it means that without drop path, Hiera can overfit to the MAE task.
在表 3d 中,我们对比了在预训练阶段应用 drop path (默认在微调阶段使用 drop path) 的效果,发现性能显著提升。这一结果令人意外,因为表明不使用 drop path 时 Hiera 会对 MAE 任务产生过拟合。
Decoder depth. We find a significant benefit from a deeper decoder than previous work use for video (Fei chten hofer et al., 2022), see Tab. 3e. This brings the decoder for video in line with images (He et al., 2022).
解码器深度。我们发现使用比以往视频研究 (Feichtenhofer et al., 2022) 更深的解码器能带来显著优势 (参见表 3e)。这使得视频解码器与图像解码器 (He et al., 2022) 保持一致。
Pre training schedule. Several masked image modeling approaches (He et al., 2022; Wei et al., 2022) have found benefits from longer pre training schedules, often using up to 1600 epochs. In Tab. 3f, we observe the same trend for Hiera, increasing $+0.5%$ over 400 epochs on IN1K. In fact, Hiera’s accuracy at 400ep is $+0.7%$ higher than ViTL MAE $(84.9%)$ at the same number of epochs but only $+0.2%$ higher at 1600 epochs—suggesting that Hiera is a more efficient learner. On K400, even with only 800 epochs of pre training, Hiera outperforms the previous SotA result that uses 1600 epochs $(85.2%)$ . Gains from longer training saturate less quickly on video, with a large $0.9%$ gain from 800 epochs to 1600 epochs and beyond.
预训练计划。多项掩码图像建模方法(He et al., 2022; Wei et al., 2022)发现延长预训练周期(通常高达1600轮次)能带来收益。在表3f中,我们观察到Hiera同样呈现这一趋势,在IN1K上经过400轮次训练后精度提升$+0.5%$。实际上,Hiera在400轮次时的准确率$(85.6%)$比ViTL MAE$(84.9%)$高出$+0.7%$,但在1600轮次时仅高出$+0.2%$——这表明Hiera具有更高效的学习能力。在K400上,即使仅进行800轮次预训练,Hiera仍超越之前采用1600轮次训练的SotA结果$(85.2%)$。视频任务中长周期训练的收益饱和较慢,从800轮次到1600轮次及以上仍有显著$0.9%$提升。
5. Video Results
5. 视频结果
We report our results on video recognition. All models input 16 frames of $224^{2}$ pixels unless otherwise specified. For video, mask units are $2\times32\times32\mathrm{px}$ (i.e., $1\times8\times8$ tokens as before). The rest of the model is the same as for images.
我们报告了在视频识别上的结果。除非另有说明,所有模型均输入16帧224²像素的画面。对于视频,掩码单元为2×32×32像素(即与之前相同的1×8×8 token)。模型其余部分与图像处理时保持一致。
Kinetics-400,-600,-700. In Tab. 4, we compare Hiera trained with MAE to the SotA on Kinetics-400 (Kay et al., 2017) at a system level. We compare to MViTv2-L (Li et al., 2022c) pretrained with MaskFeat (Wei et al., 2022) and ViT (Do sov it ski y et al., 2021) pretrained with MAE on video (Fei chten hofer et al., 2022; Tong et al., 2022). Hiera-L brings large gains $(+2.1%)$ over previous SotA (Fei chten hofer et al., 2022; Tong et al., 2022), while using ${\sim}45%$ fewer flops, being ${\sim}43%$ smaller and ${\bf2.3\times}$ faster (Fig. 3). In fact, Hiera-L significantly outperforms $(+0.7%)$ models one tier higher, while being ${\mathfrak{3}}\times$ smaller and $3.5\times$ faster. Hiera-L achieves a gain of $+6.8%$ over the corresponding MViTv2-L supervised baseline. Going one tier up in size, Hiera-H improves performance over previous SotA by $+1.2%$ , establishing a new SotA for $224^{2}$ without external data. We show similarly large improvements over the art on K600 $(+1.9%)$ and K700 $(+2.8%)$ in Tab. 5, with our H models bringing even further gains.
Kinetics-400、-600、-700。在表4中,我们在系统级别上将使用MAE训练的Hiera与Kinetics-400 (Kay等人,2017)上的SotA进行了比较。我们对比了使用MaskFeat (Wei等人,2022)预训练的MViTv2-L (Li等人,2022c)以及使用MAE在视频上预训练的ViT (Dosovitskiy等人,2021) (Feichtenhofer等人,2022; Tong等人,2022)。Hiera-L相比之前的SotA (Feichtenhofer等人,2022; Tong等人,2022)带来了大幅提升 $(+2.1%)$,同时减少了 ${\sim}45%$ 的浮点运算量,模型体积缩小了 ${\sim}43%$,速度提升了 ${\bf2.3\times}$ (图3)。实际上,Hiera-L显著优于 $(+0.7%)$ 更高一级的模型,同时体积缩小了 ${\mathfrak{3}}\times$,速度提升了 $3.5\times$。Hiera-L相比对应的监督式MViTv2-L基线实现了 $+6.8%$ 的提升。在更大规模的层级上,Hiera-H将性能比之前的SotA提高了 $+1.2%$,为 $224^{2}$ 分辨率(不使用外部数据)建立了新的SotA。我们在表5中展示了在K600 $(+1.9%)$ 和K700 $(+2.8%)$ 上同样显著的改进,而我们的H模型带来了更大的提升。
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
| Param | ||||
| backbone | pretrain | acc. | FLOPs (G) | |
| ViT-B | MAE | 81.5 | 180×3×5 | 87M |
| Hiera-B Hiera-B+ | MAE | 84.0 | 102×3x5 | 51M |
| MAE | 85.0 | 133×3x5 | 69M | |
| MViTv2-L | 80.5 | 377×1×10 | 218M | |
| MViTv2-L | MaskFeat | 84.3 | 377×1×10 | 218M |
| ViT-L | MAE | 85.2 | 597×3x5 | 305M |
| Hiera-L | MAE | 87.3 | 413x3x5 | 213M |
| ViT-H | MAE | 86.6 | 1192x3x5 | 633M |
| Hiera-H | MAE | 87.8 | 1159×3×5 | 672M |
Hiera: 一种去芜存菁的层次化视觉Transformer
| backbone | pretrain | acc. | FLOPs (G) | Param |
|---|---|---|---|---|
| ViT-B | MAE | 81.5 | 180×3×5 | 87M |
| Hiera-B Hiera-B+ | MAE | 84.0 | 102×3×5 | 51M |
| MAE | 85.0 | 133×3×5 | 69M | |
| MViTv2-L | 80.5 | 377×1×10 | 218M | |
| MViTv2-L | MaskFeat | 84.3 | 377×1×10 | 218M |
| ViT-L | MAE | 85.2 | 597×3×5 | 305M |
| Hiera-L | MAE | 87.3 | 413×3×5 | 213M |
| ViT-H | MAE | 86.6 | 1192×3×5 | 633M |
| Hiera-H | MAE | 87.8 | 1159×3×5 | 672M |
Table 4. K400 results. Hiera improves on previous SotA by a large amount, while being lighter and faster. FLOPs are reported as inference FLOPs $\times$ spatial crops $\times$ temporal clips. Table 5. K600 and K700 results. Hiera improves over SotA by a large margin. FLOPs reported as inference $\mathrm{FLOPs}\times$ spatial crops $\times$ temporal clips. Approaches using extra data are de-emphasized.
| backbone | pretrain | acc. | FLOPs (G) | Param |
| MViTv2-L | Sup, IN-21K | 85.8 | 377x1x10 | 218M |
| MViTv2-L | MaskFeat | 86.4 | 377x1x10 | 218M |
| Hiera-L | MAE | 88.3 | 413×3x5 | 213M |
| Hiera-H | MAE | 88.8 | 1159×3×5 | 672M |
| (a)Kinetics-600 video classification | ||||
| backbone | pretrain | acc. | FLOPs (G) | Param |
| MViTv2-L | Sup, IN-21K | 76.7 | 377×1x10 | 218M |
| MViTv2-L | MaskFeat | 77.5 | 377x1x10 | 218M |
| Hiera-L | MAE | 80.3 | 413×3x5 | 213M |
| Hiera-H | MAE | 81.1 | 1159×3×5 | 672M |
(b) Kinetics-700 video classification
表 4: K400 结果。Hiera 在显著提升之前 SotA (State of the Art) 性能的同时,模型更轻量且速度更快。FLOPs 报告为推理 FLOPs $\times$ 空间裁剪 $\times$ 时序片段。
表 5: K600 和 K700 结果。Hiera 大幅超越 SotA。FLOPs 报告为推理 $\mathrm{FLOPs}\times$ 空间裁剪 $\times$ 时序片段。使用额外数据的方法被弱化标注。
| backbone | pretrain | acc. | FLOPs (G) | Param |
|---|---|---|---|---|
| MViTv2-L | Sup, IN-21K | 85.8 | 377x1x10 | 218M |
| MViTv2-L | MaskFeat | 86.4 | 377x1x10 | 218M |
| Hiera-L | MAE | 88.3 | 413×3x5 | 213M |
| Hiera-H | MAE | 88.8 | 1159×3×5 | 672M |
| (a) Kinetics-600 视频分类 | ||||
| backbone | pretrain | acc. | FLOPs (G) | Param |
| MViTv2-L | Sup, IN-21K | 76.7 | 377×1x10 | 218M |
| MViTv2-L | MaskFeat | 77.5 | 377x1x10 | 218M |
| Hiera-L | MAE | 80.3 | 413×3x5 | 213M |
| Hiera-H | MAE | 81.1 | 1159×3×5 | 672M |
(b) Kinetics-700 视频分类
Something-Something-v2 (SSv2). In Tab. 6, we compare our Hiera with the current art on SSv2 (Goyal et al., 2017b) at a system level: MViTv2-L (Li et al., 2022c) pretrained with MaskFeat (Wei et al., 2022) and ViT (Do sov it ski y et al., 2021) pretrained with MAE on video (Tong et al., 2022). When pretrained on K400, Hiera-L outperforms the runnerup method MaskFeat by $+0.6%$ , but Hiera is dramatically more efficient, using 16 frames at $224^{2}$ resolution vs. 40 frames at $312^{2}$ resolution in MaskFeat, effectively using $phantom{-}3.4times$ fewer FLOPs. When pretrained on SSv2, Hiera-L achieves $75.1%$ , outperforming ViT-L pretrained with MAE, by $+0.8%$ , while using $sim45%$ fewer flops and being ${sim}43%$ smaller. Our Hiera ${cdotL{32}}$ model further achieves $76.5%$ , SotA among approaches trained only on SSv2.
Something-Something-v2 (SSv2)。在表6中,我们在系统级别上将Hiera与当前SSv2 (Goyal et al., 2017b) 上的先进方法进行了比较:包括采用MaskFeat (Wei et al., 2022) 预训练的MViTv2-L (Li et al., 2022c) 以及采用视频MAE (Tong et al., 2022) 预训练的ViT (Dosovitskiy et al., 2021)。在K400上预训练时,Hiera-L以$+0.6%$的优势超越第二名方法MaskFeat,但Hiera的效率显著更高——仅使用16帧$224^{2}$分辨率输入,而MaskFeat需要40帧$312^{2}$分辨率,实际计算量减少$phantom{-}3.4times$ FLOPs。在SSv2上预训练时,Hiera-L达到$75.1%$准确率,以$+0.8%$超越MAE预训练的ViT-L,同时计算量减少$sim45%$,模型体积缩小${sim}43%$。我们的Hiera ${cdotL{32}}$模型进一步达到$76.5%$准确率,成为仅使用SSv2训练方法中的最先进(SotA)水平。
Table 6. SSv2 results pretrained on Kinetics-400 and SSv2. Hiera improves over SotA by a large margin. We report inference FLOPs $\times$ spatial crops $\times$ temporal clips.
表 6: 基于 Kinetics-400 和 SSv2 预训练的 SSv2 结果。Hiera 大幅超越当前最优水平 (SotA)。我们报告的推理 FLOPs $\times$ 空间裁剪 $\times$ 时序片段。
| backbone | pretrain | acc. | FLOPs (G) | Param |
|---|---|---|---|---|
| K400pretrain | ||||
| ViT-L MViTv2-L40,312 ViT-L | supervised MaskFeat MAE | 55.7 74.4 74.0 | 598×3×1 2828×3×1 597×3×2 | 304M 218M 305M |
| Hiera-L Hiera-L | MAE MAE | 74.7 75.0 | 413×3×1 413×3×2 | 213M 213M |
| SSv2pretrain | ||||
| ViT-L Hiera-L | MAE MAE | 74.3 74.9 | 597×3×2 413×3×1 | 305M 213M |
| Hiera-L | MAE | 75.1 | 413×3×2 | 213M |
| ViT-L32 | MAE | 75.4 | 1436×3×1 | 305M |
| Hiera-L32 | MAE | 76.5 | 1029×3×1 | 213M |
Transferring to action detection (AVA). We evaluate transfer learning of K400/K600/K700 pretrained Hiera on action detection using AVA $\mathrm{v}2.2$ dataset (Gu et al., 2018). In Tab. 7 we compare the pretrained Hiera with SotA methods, MViTv2 with MaskFeat (Wei et al., 2022) and ViT with MAE on video (Tong et al., 2022; Fei chten hofer et al., 2022) at system level, and report mean average precision (mAP). Our K400 pretrained Hiera-L outperforms an MAE pretrained ViT-L by $+2.8%$ and an MViTv2-L40,312 Mask- Feat by $+1.3%$ mAP while Hiera-L has fewer FLOPs and parameters. Our Hiera-H outperforms an MAE pretrained ViT-H by $+3.0%$ mAP. We observe similar performance improvement of the K600/K700 pretrained Hiera as well. Specifically, the K700 pretrained Hiera-H outperforms an MAE pretrained ViT-H by $+3.2$ , establishing a new SotA.
迁移到动作检测任务 (AVA)。我们在 AVA v2.2 数据集 (Gu et al., 2018) 上评估了基于 K400/K600/K700 预训练的 Hiera 在动作检测中的迁移学习性能。表 7 展示了在系统级别将预训练的 Hiera 与当前最优方法 (包括采用 MaskFeat 的 MViTv2 (Wei et al., 2022) 和基于视频 MAE 的 ViT (Tong et al., 2022; Feichtenhofer et al., 2022)) 进行对比的平均精度均值 (mAP) 结果。在 FLOPs 和参数量更少的情况下,基于 K400 预训练的 Hiera-L 比 MAE 预训练的 ViT-L 高出 +2.8% mAP,比 MViTv2-L40x312 MaskFeat 高出 +1.3% mAP。我们的 Hiera-H 比 MAE 预训练的 ViT-H 高出 +3.0% mAP。基于 K600/K700 预训练的 Hiera 也表现出类似的性能提升,特别是 K700 预训练的 Hiera-H 以 +3.2 mAP 的优势超越 MAE 预训练的 ViT-H,创造了新的性能标杆。
6. Image Results
6. 图像结果
We first evaluate performance on IN1K and then transfer to other image recognition, detection, and segmentation tasks.
我们首先在IN1K上评估性能,然后迁移到其他图像识别、检测和分割任务。
6.1. Performance on ImageNet-1K
6.1. ImageNet-1K 上的性能
In Tab. 8, we perform a system-level comparison of Hiera trained with MAE to relevant prior work. First, we observe that the supervised MViTv2 baselines are already quite strong, with MViTv2-B (L) reaching 84.4 (85.3) top1 accuracy—better than several approaches that use pretraining (e.g. ViT-B MAE). This showcases the significant benefits that convolutions give in the supervised setting, especially at the base model size and lower. Remarkably, even at this size, Hiera-B without using any bells-and-whistles (e.g., convs), is able to reach $84.5%$ (slightly) outperforming MViTv2-B; MCMAE-B achieves a higher accuracy, but the model is significantly heavier. Our Hiera $\mathbf{\nabla}\cdot\mathbf{B}+$ model handily outperforms it in both speed (Fig. 3) and accuracy. Going even smaller, Hiera-S, -T demonstrate remarkably strong performance - in a scale regime where convolutions have historically dominated, consistent with our core premise that good spatial biases can be learned.
在表8中,我们对采用MAE训练的Hiera与相关先前工作进行了系统级比较。首先观察到监督式MViTv2基线已具备较强性能,MViTv2-B (L)分别达到84.4 (85.3)的top1准确率——优于部分采用预训练的方法(如ViT-B MAE)。这证明了卷积在监督式场景下的显著优势,尤其在基础模型尺寸及更小规模时。值得注意的是,即使在这个尺寸下,未使用任何附加组件(如卷积)的Hiera-B仍能达到$84.5%$ (略微)超越MViTv2-B;MCMAE-B实现了更高准确率,但模型复杂度显著增加。我们的Hiera $\mathbf{\nabla}\cdot\mathbf{B}+$模型在速度(图3)和准确率上均轻松超越它。在更小尺寸的Hiera-S和-T上,其表现出色性能——在这个历来由卷积主导的规模区间,印证了我们关于良好空间偏置可被学习的核心前提。
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
| backbone | pretrain | mAP | FLOPs (G) | Param |
| K400 pretrain | ||||
| ViT-L | supervised | 22.2 | 598 | 304M |
| MViTv2-L40,312 ViT-L | MaskFeat MAE | 38.5 37.0 | 2828 597 | 218M 305M |
| Hiera-L | MAE | 39.8 | 413 | 213M |
| ViT-H | MAE | 39.5 | 1192 | 633M |
| Hiera-H | MAE | 42.5 | 1158 | 672M |
| K600 pretrain | ||||
| ViT-L | MAE | 38.4 | 598 | 304M |
| MViTv2-L40,312 | MaskFeat | 39.8 | 2828 | 218M |
| Hiera-L | MAE | 40.7 | 413 | 213M |
| ViT-H | MAE | 40.3 | 1193 | 632M |
| Hiera-H | MAE | 42.8 | 1158 | 672M |
| K700 pretrain | ||||
| ViT-L | MAE | 39.5 | 598 | 304M |
| Hiera-L | MAE | 41.7 | 413 | 213M |
| ViT-H | MAE | 40.1 | 1193 | 632M |
| Hiera-H | MAE | 43.3 | 1158 | 672M |
Table 7. AVA v2.2 results pretrained on Kinetics. Hiera improves over SotA by a large margin. All inference FLOPs reported with a center crop strategy following Fan et al. (2021).
Hiera: 一种没有花哨技巧的层次化视觉Transformer
| backbone | pretrain | mAP | FLOPs (G) | Param |
|---|---|---|---|---|
| K400 pretrain | ||||
| ViT-L | supervised | 22.2 | 598 | 304M |
| MViTv2-L40,312 ViT-L | MaskFeat MAE | 38.5 37.0 | 2828 597 | 218M 305M |
| Hiera-L | MAE | 39.8 | 413 | 213M |
| ViT-H | MAE | 39.5 | 1192 | 633M |
| Hiera-H | MAE | 42.5 | 1158 | 672M |
| K600 pretrain | ||||
| ViT-L | MAE | 38.4 | 598 | 304M |
| MViTv2-L40,312 | MaskFeat | 39.8 | 2828 | 218M |
| Hiera-L | MAE | 40.7 | 413 | 213M |
| ViT-H | MAE | 40.3 | 1193 | 632M |
| Hiera-H | MAE | 42.8 | 1158 | 672M |
| K700 pretrain | ||||
| ViT-L | MAE | 39.5 | 598 | 304M |
| Hiera-L | MAE | 41.7 | 413 | 213M |
| ViT-H | MAE | 40.1 | 1193 | 632M |
| Hiera-H | MAE | 43.3 | 1158 | 672M |
表 7: 基于Kinetics预训练的AVA v2.2结果。Hiera大幅超越当前最优技术(SotA)。所有推理FLOPs数据采用Fan等人(2021)提出的中心裁剪策略报告。
At our default scale, Hiera-L MAE reaches an accuracy of $86.1%$ , a significant $+0.8%$ gain over MViTv2-L; it also (slightly) outperforms ViT-L MAE, which is $42%$ larger and has $1.6\times$ the FLOPs, by $+0.2%$ . Note that while we adopted the MAE pre training in this work due to its efficient sparse pre training, Hiera-L is readily compatible with complementary, orthogonal approaches, e.g. using an EMA teacher (El-Nouby et al., 2021; Baevski et al., 2022).
在我们的默认规模下,Hiera-L MAE达到了86.1%的准确率,比MViTv2-L显著提升了+0.8%;同时它以+0.2%的微弱优势超过了体积大42%、计算量(FLOPs)多1.6倍的ViT-L MAE。需要注意的是,虽然本研究采用了MAE预训练方法(因其高效的稀疏预训练特性),但Hiera-L也能兼容其他互补的正交方法,例如使用EMA教师模型 (El-Nouby et al., 2021; Baevski et al., 2022)。
6.2. Transfer learning experiments
6.2. 迁移学习实验
Here, we perform transfer learning experiments on downstream classification, detection, and segmentation tasks.
在此,我们对下游分类、检测和分割任务进行迁移学习实验。
Classification on i Naturalists and Places. In Tab. 9 we evaluate transfer learning performance on downstream iNaturalist (Van Horn et al., 2018) and Places (Zhou et al., 2014) datasets. We finetune the ImageNet-1K pretrained Hiera on i Naturalist 2017, 2018, and 2019, and Places 365. Hiera consistently outperforms ViT pretrained with MAE (He et al., 2022), indicating that our Hiera-L and Hiera-H architectures are effective outside of just ImageNet.
iNaturalist和Places分类任务。在表9中,我们评估了在下游iNaturalist (Van Horn et al., 2018) 和Places (Zhou et al., 2014) 数据集上的迁移学习性能。我们在iNaturalist 2017、2018、2019以及Places 365上对基于ImageNet-1K预训练的Hiera进行微调。Hiera始终优于采用MAE预训练的ViT (He et al., 2022),这表明我们的Hiera-L和Hiera-H架构在ImageNet之外的其他领域同样有效。
Table 8. ImageNet-1K comparison to previous MIM approaches. We de-emphasize approaches using extra data and indicate the source of extra data.
| backbone | pretrain | acc. | FLOPs (G) | Param |
| Swin-T | 81.3 | 5 | 29M | |
| MViTv2-T | 82.3 | 5 | 24M | |
| Hiera-T | MAE | 82.8 | 5 | 28M |
| Swin-S | 83.0 | 9 | 50M | |
| MViTv2-S | 83.6 | 7 | 35M | |
| Hiera-S | MAE | 83.8 | 6 | 35M |
| ViT-B | 82.3 | 18 | 87M | |
| Swin-B | 83.3 | 15 | 88M | |
| MViTv2-B | 84.4 | 10 | 52M | |
| ViT-B | BEiT, DALLE | 83.2 | 18 | 87M |
| ViT-B | MAE | 83.6 | 18 | 87M |
| ViT-B | MaskFeat | 84.0 | 18 | 87M |
| Swin-B | SimMIM | 83.8 | 15 | 88M |
| MCMAE-B | MCMAE | 85.0 | 28 | 88M |
| Hiera-B | MAE | 84.5 | 9 | 52M |
| Hiera-B+ | MAE | 85.2 | 13 | 70M |
| ViT-L | 82.6 | 62 | 304M | |
| MViTv2-L | 85.3 | 42 | 218M | |
| ViT-L | BEiT, DALLE | 85.2 | 62 | 304M |
| ViT-L | MAE | 85.9 | 62 | 304M |
| ViT-L | MaskFeat | 85.7 | 62 | 304M |
| Swin-L | SimMIM | 85.4 | 36 | 197M |
| MCMAE-L | MCMAE | 86.2 | 94 | 323M |
| Hiera-L | MAE | 86.1 | 40 | 214M |
| ViT-H | 83.1 | 167 | 632M | |
| ViT-H | MAE | 86.9 | 167 | 632M |
| Hiera-H | MAE | 86.9 | 125 | 673M |
表 8: ImageNet-1K 与先前 MIM 方法的对比。我们弱化了使用额外数据的方法,并标注了额外数据来源。
| backbone | pretrain | acc. | FLOPs (G) | Param |
|---|---|---|---|---|
| Swin-T | 81.3 | 5 | 29M | |
| MViTv2-T | 82.3 | 5 | 24M | |
| Hiera-T | MAE | 82.8 | 5 | 28M |
| Swin-S | 83.0 | 9 | 50M | |
| MViTv2-S | 83.6 | 7 | 35M | |
| Hiera-S | MAE | 83.8 | 6 | 35M |
| ViT-B | 82.3 | 18 | 87M | |
| Swin-B | 83.3 | 15 | 88M | |
| MViTv2-B | 84.4 | 10 | 52M | |
| ViT-B | BEiT, DALLE | 83.2 | 18 | 87M |
| ViT-B | MAE | 83.6 | 18 | 87M |
| ViT-B | MaskFeat | 84.0 | 18 | 87M |
| Swin-B | SimMIM | 83.8 | 15 | 88M |
| MCMAE-B | MCMAE | 85.0 | 28 | 88M |
| Hiera-B | MAE | 84.5 | 9 | 52M |
| Hiera-B+ | MAE | 85.2 | 13 | 70M |
| ViT-L | 82.6 | 62 | 304M | |
| MViTv2-L | 85.3 | 42 | 218M | |
| ViT-L | BEiT, DALLE | 85.2 | 62 | 304M |
| ViT-L | MAE | 85.9 | 62 | 304M |
| ViT-L | MaskFeat | 85.7 | 62 | 304M |
| Swin-L | SimMIM | 85.4 | 36 | 197M |
| MCMAE-L | MCMAE | 86.2 | 94 | 323M |
| Hiera-L | MAE | 86.1 | 40 | 214M |
| ViT-H | 83.1 | 167 | 632M | |
| ViT-H | MAE | 86.9 | 167 | 632M |
| Hiera-H | MAE | 86.9 | 125 | 673M |
Object detection and segmentation on COCO. We finetune Mask R-CNN (He et al., 2017) with different pretrained backbones on the COCO dataset (Lin et al., 2014). We report $\mathrm{AP^{box}}$ and $\mathrm{AP^{mask}}$ for object detection and instance segmentation. We utilize the training recipe following ViTDet (Li et al., 2022b) and incorporate multi-scale features from Hiera with a Feature Pyramid Network (FPN, Lin et al. (2017)) as described in the original paper.
在COCO数据集上进行目标检测与分割。我们采用不同预训练骨干网络在COCO数据集(Lin等人,2014)上微调Mask R-CNN(He等人,2017)。报告目标检测的$\mathrm{AP^{box}}$和实例分割的$\mathrm{AP^{mask}}$指标。实验沿用ViTDet(Li等人,2022b)的训练方案,并如原论文所述,通过特征金字塔网络(FPN,Lin等人(2017))整合Hiera的多尺度特征。
In Tab. 10, our Hiera with MAE pre training demonstrates a strong scaling behavior when compared models with supervised pre training such as MViTv2 (Li et al., 2022c), while being consistently faster. For example, Hiera-L is $\mathbf{+1.8~AP^{\mathrm{box}}}$ higher than MViTv2-L (55.0 vs. 53.2) with a $24%$ reduction in inference time. Even when compared to MViTv2 using ImageNet-21K pre training, Hiera-L still performs $\mathbf{+1.4\mathrm{AP^{box}}}$ better than MViTv2-L.
在表 10 中,我们采用 MAE 预训练的 Hiera 模型与监督预训练模型 (如 MViTv2 [Li et al., 2022c]) 相比展现出优异的扩展性,同时始终保持更快的推理速度。例如,Hiera-L 在目标检测框 AP (AP^box) 指标上比 MViTv2-L 高出 $\mathbf{+1.8}$ (55.0 vs. 53.2),推理时间减少 $24%$。即使与采用 ImageNet-21K 预训练的 MViTv2 相比,Hiera-L 仍以 $\mathbf{+1.4\mathrm{AP^{box}}}$ 的优势领先 MViTv2-L。
When compared to the state-of-the-art method, ViTDet, our Hiera models achieve comparable results while having faster inference and a lower operation count. For example, HieraB shows $+0.6$ higher $\mathrm{AP^{box}}$ than ViTDet-B with $34%$ fewer parameters and $15%$ lower inference time. Additionally, Hiera $\mathbf{\nabla}\cdot\mathbf{B}+$ achieves $\mathbf{+1.9}$ boxAP improvements while having lower inference time and model complexity vs. ViTDetB. For the large model, Hiera-L is consistently faster than ViTDet-L with only a slightly lower accuracy.
与当前最先进的方法ViTDet相比,我们的Hiera模型在保持相当结果的同时,实现了更快的推理速度和更低的运算量。例如,HieraB的$\mathrm{AP^{box}}$比ViTDet-B高出$+0.6$,同时参数减少$34%$,推理时间降低$15%$。此外,Hiera $\mathbf{\nabla}\cdot\mathbf{B}+$相比ViTDetB实现了$\mathbf{+1.9}$的boxAP提升,同时推理时间和模型复杂度更低。对于大型模型,Hiera-L始终比ViTDet-L更快,仅精度略低。
Table 9. Transfer learning on i Naturalists and Places datasets.
| backbone | iNat17 | iNat18 | iNat19 | Places365 |
| ViT-B | 70.5 | 75.4 | 80.5 | 57.9 |
| Hiera-B | 73.3 | 77.9 | 83.0 | 58.9 |
| Hiera-B+ | 74.7 | 79.9 | 83.1 | 59.2 |
| ViT-L | 75.7 | 80.1 | 83.4 | 59.4 |
| Hiera-L | 76.8 | 80.9 | 84.3 | 59.6 |
| ViT-H | 79.3 | 83.0 | 85.7 | 59.8 |
| Hiera-H | 79.6 | 83.5 | 85.7 | 60.0 |
| ViT-H448 | 83.4 | 86.8 | 88.3 | 60.3 |
| Hiera-H448 | 83.8 | 87.3 | 88.5 | 60.6 |
表 9. iNaturalist 和 Places 数据集上的迁移学习。
| backbone | iNat17 | iNat18 | iNat19 | Places365 |
|---|---|---|---|---|
| ViT-B | 70.5 | 75.4 | 80.5 | 57.9 |
| Hiera-B | 73.3 | 77.9 | 83.0 | 58.9 |
| Hiera-B+ | 74.7 | 79.9 | 83.1 | 59.2 |
| ViT-L | 75.7 | 80.1 | 83.4 | 59.4 |
| Hiera-L | 76.8 | 80.9 | 84.3 | 59.6 |
| ViT-H | 79.3 | 83.0 | 85.7 | 59.8 |
| Hiera-H | 79.6 | 83.5 | 85.7 | 60.0 |
| ViT-H448 | 83.4 | 86.8 | 88.3 | 60.3 |
| Hiera-H448 | 83.8 | 87.3 | 88.5 | 60.6 |
Table 10. COCO object detection and segmentation using MaskRCNN. All methods are following the training recipe from Li et al. (2022b) and pretrained on ImageNet-1K by default. Methods using ImageNet-21K pre training are de-emphasized. Test time is measured on a single V100 GPU with full precision.
| backbone | pretrain | APbox | Apmask | FLOPs | params | time |
| Swin-B | Sup,21K | 51.4 | 45.4 | 0.7T | 109M | 164ms |
| MViTv2-B | Sup,21K | 53.1 | 47.4 | 0.6T | 73M | 208ms |
| Swin-B | Sup | 50.1 | 44.5 | 0.7T | 109M | 164ms |
| MViTv2-B | Sup | 52.4 | 46.7 | 0.6T | 73M | 208ms |
| ViTDet-B | MAE | 51.6 | 45.9 | 0.8T | 111M | 201ms |
| Hiera-B | MAE | 52.2 | 46.3 | 0.6T | 73M | 173ms |
| Hiera-B+ | MAE | 53.5 | 47.3 | 0.6T | 92M | 192ms |
| Swin-L | Sup,21K | 52.4 | 46.2 | 1.1T | 218M | 243ms |
| MViTv2-L | Sup,21K | 53.6 | 47.5 | 1.3T | 239M | 447ms |
| MViTv2-L | Sup | 53.2 | 47.1 | 1.3T | 239M | 447ms |
| ViTDet-L | MAE | 55.6 | 49.2 | 1.9T | 331M | 396ms |
| Hiera-L | MAE | 55.0 | 48.6 | 1.2T | 236M | 340ms |
表 10: 使用MaskRCNN的COCO目标检测与分割结果。所有方法默认采用Li等人 (2022b) 的训练方案并在ImageNet-1K上进行预训练。使用ImageNet-21K预训练的方法已作淡化处理。测试时间是在单块V100 GPU上以全精度测量的。
| backbone | pretrain | APbox | Apmask | FLOPs | params | time |
|---|---|---|---|---|---|---|
| Swin-B | Sup,21K | 51.4 | 45.4 | 0.7T | 109M | 164ms |
| MViTv2-B | Sup,21K | 53.1 | 47.4 | 0.6T | 73M | 208ms |
| Swin-B | Sup | 50.1 | 44.5 | 0.7T | 109M | 164ms |
| MViTv2-B | Sup | 52.4 | 46.7 | 0.6T | 73M | 208ms |
| ViTDet-B | MAE | 51.6 | 45.9 | 0.8T | 111M | 201ms |
| Hiera-B | MAE | 52.2 | 46.3 | 0.6T | 73M | 173ms |
| Hiera-B+ | MAE | 53.5 | 47.3 | 0.6T | 92M | 192ms |
| Swin-L | Sup,21K | 52.4 | 46.2 | 1.1T | 218M | 243ms |
| MViTv2-L | Sup,21K | 53.6 | 47.5 | 1.3T | 239M | 447ms |
| MViTv2-L | Sup | 53.2 | 47.1 | 1.3T | 239M | 447ms |
| ViTDet-L | MAE | 55.6 | 49.2 | 1.9T | 331M | 396ms |
| Hiera-L | MAE | 55.0 | 48.6 | 1.2T | 236M | 340ms |
7. Conclusion
7. 结论
In this work, we create a simple hierarchical vision transformer by taking an existing one and removing all its bellsand-whistles while supplying the model with spatial bias through MAE pre training. The resulting architecture, Hiera, is more effective than current work on image recognition tasks and surpasses the state-of-the-art on video tasks. We hope Hiera can allow future work to do more, faster.
在这项工作中,我们通过采用现有的Transformer架构,去除其所有复杂设计,并通过MAE预训练为模型提供空间偏置,创建了一个简单的分层视觉Transformer。由此产生的架构Hiera在图像识别任务上比当前工作更有效,并在视频任务上超越了最先进水平。我们希望Hiera能让未来的工作更快地取得更多成果。
A. Implementation Details
A. 实现细节
A mask unit for video corresponds to a block of 2 frames $\times$ $32\mathrm{px}\times32\mathrm{px}$ (as opposed to images which use $1\times32\times$ 32). Following Fei chten hofer et al. (2022), each token in Hiera on video corresponds to 2 frames of the input. Since the mask units also span 2 frames, the window sizes for Mask Unit Attention do not change for video (i.e., $1\times8\times8$ tokens in the first stage, $1\times4\times4$ tokens in the second stage)—meaning we use exactly the same implementation for images and video (just the mask unit size is changed). We use learned spatial (separable spatio-temporal) position embeddings for images (video). These are all the differences between Hiera for images and for video. The rest of the encoder is completely agnostic to spatio-temporal structure.
视频中的掩码单元对应于一个由2帧$\times$ $32\mathrm{px}\times32\mathrm{px}$组成的块(相比之下,图像使用的是$1\times32\times$32)。根据Feichtenhofer等人(2022)的研究,Hiera在视频中的每个token对应输入的两帧。由于掩码单元也跨越2帧,因此视频的掩码单元注意力(Mask Unit Attention)窗口大小保持不变(即第一阶段为$1\times8\times8$个token,第二阶段为$1\times4\times4$个token)——这意味着我们对图像和视频使用完全相同的实现(仅改变掩码单元大小)。对于图像(视频),我们使用学习到的空间(可分离时空)位置嵌入。这些就是Hiera在图像和视频之间的全部差异。编码器的其余部分完全不受时空结构影响。
As in Wei et al. (2022), we remove $Q$ -pooling before the last stage for MAE pre training only. This is done so that MAE settings from prior work using ViT also work for Hiera with minimal modifications. This introduces little extra computation as stage 4 is small. If desired, by design, pre training with Hiera can also work without removal of query pooling during pre training, since a mask unit of $1\times$ $8\times8$ tokens would correspond to 1 distinct token in the last stage.
如Wei等人(2022)所述,我们仅在MAE预训练时移除了最后阶段前的$Q$-pooling。这样做是为了使先前使用ViT的MAE设置也能以最小修改适用于Hiera。由于第4阶段规模较小,这几乎不会引入额外计算量。根据设计,如果需要,Hiera预训练也可以在保留查询池化的情况下进行,因为$1\times$$8\times8$ token的掩码单元将对应最后阶段的1个独立token。
A.1. Video Experiments
A.1. 视频实验
Kinetics-400, -600, -700. Our settings mainly follow Fei chten hofer et al. (2022). We report the pre training and finetuning settings for our main results on the Kinetics-400 (Kay et al., 2017), -600 (Carreira et al., 2018) and -700 (Carreira et al., 2019) human action datasets in Tab. 11. Epochs are always reported as effective epochs (Fei chten hofer et al., 2022), i.e. accounting for repeated sampling. We use $16\times4$ sampling as in Fei chten hofer et al. (2022).
Kinetics-400、-600、-700。我们的设置主要遵循Feichtenhofer等人 (2022) 的方法。我们在表11中报告了Kinetics-400 (Kay等人, 2017) 、-600 (Carreira等人, 2018) 和-700 (Carreira等人, 2019) 人体动作数据集上主要结果的预训练和微调设置。epoch数始终以有效epoch数 (Feichtenhofer等人, 2022) 报告,即考虑重复采样。我们采用与Feichtenhofer等人 (2022) 相同的$16\times4$采样策略。
Something-Something-v2 (SSv2). We evaluate Hiera-L on the SSv2 dataset (Goyal et al., 2017b). SSv2 is a dataset focusing on human-object interaction classification. We pretrain Hiera-L on either Kinetics 400 or SSv2 and finetune on SSv2. We report the top-1 classification accuracy in Tab. 6. We provide further details about the pre training and finetuning settings on SSv2 in Tab. 12.
Something-Something-v2 (SSv2)。我们在SSv2数据集(Goyal et al., 2017b)上评估Hiera-L。该数据集专注于人物-物体交互分类任务。我们分别在Kinetics 400或SSv2上预训练Hiera-L后,在SSv2上进行微调。表6展示了top-1分类准确率,表12提供了SSv2预训练与微调的具体参数设置。
AVA v2.2. We perform transferring experiments on AVA v2.2 (Gu et al., 2018) for human action localization in video. We adopt a detection framework following (Fei chten hofer et al., 2019) for human action localization. We extract ROI features from the feature map of the last layer in Hiera and pool the ROI features via spatial max-pooling. We then use a linear classifier trained with cross entropy loss to predict the action class. We use the center crop for Hiera in the evaluation and report the mAP in Tab. 7. We use Kinetics pretrained and finetuned Hiera in the experiments. We provide details about the finetuning setting on AVA v2.2 in Tab. 13.
AVA v2.2。我们在AVA v2.2 (Gu et al., 2018) 上进行了视频中人体动作定位的迁移实验。采用(Feichtenhofer et al., 2019) 提出的检测框架进行人体动作定位,从Hiera最后一层特征图中提取ROI特征,并通过空间最大池化汇聚ROI特征。随后使用交叉熵损失训练的线性分类器预测动作类别。评估时对Hiera采用中心裁剪,并在表7中报告mAP结果。实验中使用了Kinetics预训练及微调的Hiera模型,AVA v2.2微调设置详见表13。
A.2. Image Experiments
A.2. 图像实验
ImageNet-1K. Our settings mainly follow He et al. (2022). We report the pre training and finetuning settings for our main results in Tab. 14.
ImageNet-1K。我们的设置主要遵循He等人 (2022) 的研究。我们在表14中报告了主要结果的预训练和微调设置。
Transfer learning on i Naturalists and Places. We conduct transfer learning experiments on classification datasets including i Naturalist 2017, i Naturalist 2018, iNatura list 2019 (Van Horn et al., 2018) and Places365 (Zhou et al., 2014). Following (He et al., 2022), we adjust learning rate, training epochs on each dataset. We search the layer-wise decay among 0.875, 0.9 and 0.925, drop path rate between 0.1 to 0.5, and the dropout rate among 0.1, 0.2 and 0.3. For Hiera $\mathrm{\cdotH}_{448}$ , we set the learning rate decay of the positional embedding to 0.5 instead of following the layer-wise decay rule.
在iNaturalist和Places上的迁移学习。我们在包括iNaturalist 2017、iNaturalist 2018、iNaturalist 2019 (Van Horn等人, 2018) 和Places365 (Zhou等人, 2014) 在内的分类数据集上进行了迁移学习实验。遵循(He等人, 2022)的方法,我们调整了每个数据集上的学习率和训练周期。我们在0.875、0.9和0.925之间搜索分层衰减率,在0.1到0.5之间搜索路径丢弃率,以及在0.1、0.2和0.3之间搜索丢弃率。对于Hiera $\mathrm{\cdotH}_{448}$,我们将位置嵌入的学习率衰减设置为0.5,而不是遵循分层衰减规则。
(a) Pre training
| config | value |
| optimizer | AdamW(Loshchilov&Hutter,2019) |
| optimizer momentum | β1,β2=0.9,0.95 |
| weight decay | 0.05 |
| learningrate | 8e-4(B,B+,L);-/8e-4/3.2e-4 (H) |
| learning rate sch. | cosine decay (Loshchilov & Hutter, 2017) |
| warmup epochs (Goyal et al., 2017a) epochs | 120 800/1600/3200 |
| repeated sampling (Hoffer et al.,2020) | 4 |
| augmentation | hflip, crop [0.5, 1] |
| batch size | 512 |
| num.decoderblocks | |
| num.decoderheads | 8 |
| 8 | |
| mask ratio | 0.9 |
| drop path (Huang et al., 2016) | 0.1 (B); 0.2 (B+, L); - / 0.3 / 0.4 (H) |
(a) 预训练
| config | value |
|---|---|
| optimizer | AdamW (Loshchilov & Hutter, 2019) |
| optimizer momentum | β1, β2 = 0.9, 0.95 |
| weight decay | 0.05 |
| learning rate | 8e-4 (B, B+, L); -/8e-4/3.2e-4 (H) |
| learning rate sch. | cosine decay (Loshchilov & Hutter, 2017) |
| warmup epochs (Goyal et al., 2017a) epochs | 120 800/1600/3200 |
| repeated sampling (Hoffer et al., 2020) | 4 |
| augmentation | hflip, crop [0.5, 1] |
| batch size | 512 |
| num.decoder blocks | |
| num.decoder heads | 8 |
| 8 | |
| mask ratio | 0.9 |
| drop path (Huang et al., 2016) | 0.1 (B); 0.2 (B+, L); - / 0.3 / 0.4 (H) |
COCO. We use the Mask R-CNN (He et al., 2017) framework in Detectron2 (Wu et al., 2019) for object detection and instance segmentation experiments on the COCO dataset. Similar to ViTDet (Li et al., 2022b), we use 2 hidden convolution layers for the RPN and 4 hidden convolution layers for the RoI heads for Hiera and all comparison detection methods. These layers are followed by LayerNorm layers.
COCO。我们在Detectron2 (Wu等人,2019) 中使用Mask R-CNN (He等人,2017) 框架进行COCO数据集上的目标检测和实例分割实验。与ViTDet (Li等人,2022b) 类似,我们为Hiera及所有对比检测方法的RPN使用2个隐藏卷积层,为RoI头部使用4个隐藏卷积层。这些层后接LayerNorm层。
Table 12. Settings for SSv2. Notation: setting corresponding to Hiera-L / L32.
| config | value |
| optimizer | Adamw |
| optimizer momentum | β1, β2=0.9,0.999 0.05 |
| weight decay learning rate | 8e-4 (B, B+, L), 4e-4 (H) |
| learningrateschedule | cosine decay |
| warmupepochs epochs | 10 |
| repeated sampling | 150 (B, B+), 100 (L, H) 2 |
| augmentation | |
| batch size | RandAug (7, 0.5) (Cubuk et al., 2020) |
| 256 | |
| gradient clipping | 5.0 |
| mixup (Zhang et al., 2018) | 0.8 |
| cutmix (Yun et al., 2019) | 1.0 |
| label smoothing (Szegedy et al., | 0.1 |
| 2016) drop path | 0.2 (B,B+,L),0.3 (H) |
| dropout (Srivastava et al., 2014) | 0.3 (B,B+),0.5 (L,H) |
| layer-wise decay (Clark et al., | - / 0.85 /0.8 (B,B+); 0.925 /0.9/ |
| 2020) | 0.875 (L, H) |
| (b)Finetuning |
表 12. SSv2的设置。注:Hiera-L/L32对应的设置。
| 配置 | 值 |
|---|---|
| 优化器 | Adamw |
| 优化器动量 | β1, β2=0.9,0.999 0.05 |
| 权重衰减学习率 | 8e-4 (B, B+, L), 4e-4 (H) |
| 学习率计划 | 余弦衰减 |
| 预热周期 | 10 |
| 重复采样 | 150 (B, B+), 100 (L, H) 2 |
| 数据增强 | RandAug (7, 0.5) (Cubuk et al., 2020) |
| 批量大小 | 256 |
| 梯度裁剪 | 5.0 |
| Mixup (Zhang et al., 2018) | 0.8 |
| CutMix (Yun et al., 2019) | 1.0 |
| 标签平滑 (Szegedy et al., 2016) | 0.1 |
| Drop path | 0.2 (B,B+,L),0.3 (H) |
| Dropout (Srivastava et al., 2014) | 0.3 (B,B+),0.5 (L,H) |
| 分层衰减 (Clark et al., 2020) | - / 0.85 /0.8 (B,B+); 0.925 /0.9/0.875 (L, H) |
| (b)微调 |
| config optimizer optimizer momentum | value AdamW |
| weight decay learning rate learning rate schedule warmup epochs epochs augmentation batch size gradient clipping num. decoder blocks num.decoder heads mask ratio drop path (a) Pretraining config | β1,β2=0.9,0.95 0.05 8e-4 cosine decay 30 1600 crop [0.5, 1] 1024 0.02 8 8 0.9 0.2 |
| optimizer weight decay learning rate learning rate schedule warmupepochs epochs augmentation batch size mixup cutmix label smoothing drop path | values SGD 1e-4 |
| dropout layer-wise decay | 0.16/ 0.08 cosine decay 3 40 RandAug (7, 0.5) 256/128 0.8 / - 1.0 / - 0.1 / - 0.1/ 0.2 0.5 0.875 |
(b) Finetuning
| 配置项 | 优化器动量 | 值 |
|---|---|---|
| 优化器 (optimizer) | AdamW | - |
| 权重衰减 (weight decay) | β1,β2=0.9,0.95 | 0.05 |
| 学习率 (learning rate) | 8e-4 | - |
| 学习率调度 (learning rate schedule) | 余弦衰减 (cosine decay) | - |
| 预热周期 (warmup epochs) | 30 | - |
| 训练周期 (epochs) | 1600 | - |
| 数据增强 (augmentation) | 随机裁剪 [0.5, 1] | - |
| 批量大小 (batch size) | 1024 | - |
| 梯度裁剪 (gradient clipping) | 0.02 | - |
| 解码器块数 (num. decoder blocks) | 8 | - |
| 解码器头数 (num.decoder heads) | 8 | - |
| 掩码比例 (mask ratio) | 0.9 | - |
| 路径丢弃率 (drop path) | 0.2 | - |
(a) 预训练配置
| 配置项 | 值 |
|---|---|
| 优化器 (optimizer) | SGD |
| 权重衰减 (weight decay) | 1e-4 |
| 学习率 (learning rate) | 0.16/0.08 |
| 学习率调度 (learning rate schedule) | 余弦衰减 (cosine decay) |
| 预热周期 (warmup epochs) | 3 |
| 训练周期 (epochs) | 40 |
| 数据增强 (augmentation) | RandAug (7, 0.5) |
| 批量大小 (batch size) | 256/128 |
| MixUp | 0.8 / - |
| CutMix | 1.0 / - |
| 标签平滑 (label smoothing) | 0.1 / - |
| 路径丢弃率 (drop path) | 0.1/0.2 |
| Dropout | 0.5 |
| 分层衰减 (layer-wise decay) | 0.875 |
(b) 微调配置
Table 13. Settings for AVA. Hiera-L and Hiera-H finetuning settings on AVA.
| config | values |
| optimizer | SGD |
| weight decay | 1e-8 |
| learning rate | 3.6 |
| learning rate schedule | cosine decay |
| warmup epochs | 5 |
| epochs | 30 |
| batch size | 128 |
| drop path | 0.4 |
| dropout | 0.5 |
| layer-wise decay | 0.875 |
表 13: AVA 的设置。Hiera-L 和 Hiera-H 在 AVA 上的微调设置。
| config | values |
|---|---|
| optimizer | SGD |
| weight decay | 1e-8 |
| learning rate | 3.6 |
| learning rate schedule | cosine decay |
| warmup epochs | 5 |
| epochs | 30 |
| batch size | 128 |
| drop path | 0.4 |
| dropout | 0.5 |
| layer-wise decay | 0.875 |
For the training recipe, we follow ViTDet to use input size as $1024\times1024$ with large-scale jittering (LSJ) (Ghiasi et al., 2021). We don’t use the layer-wise decay during training. Additional hyper paramters can be found in Tab. 15.
在训练方案上,我们遵循ViTDet,采用1024×1024的输入尺寸,并应用大规模抖动(LSJ) (Ghiasi et al., 2021)。训练过程中未使用分层衰减策略。其他超参数详见表15。
A.3. Speed Benchmarking
A.3. 速度基准测试
We use an NVIDIA A100 40GB GPU, PyTorch v1.12.1 and CUDA 11.4 to benchmark speed for all baselines and our approach, unless otherwise mentioned. Note that we did not use Flash Attention (Dao et al., 2022) or any other attention speed-up mechanism in this paper, though they can be used to further increase speed. For each of the methods, we measure purely the model inference throughput. We compute the throughput with various batch sizes, and report the throughput with the optimal batch size. We use half precision (fp16) to run speed benchmarking unless otherwise specified. We set the input resolution to $224\times224\times3$ for image benchmarking, and $224\times224\times3$ with 16 frames as a clip for video benchmarking. To measure the training time, we measure the speed of a forward-backward pass on a single gpu and extrapolate the total training time according to the size of the dataset and the number of training epochs, ignoring data loading and communication overheads when training with multiple GPUs.
我们使用NVIDIA A100 40GB GPU、PyTorch v1.12.1和CUDA 11.4对所有基线方法和我们的方法进行速度基准测试,除非另有说明。需要注意的是,本文未采用Flash Attention (Dao et al., 2022) 或其他注意力加速机制,但这些技术可进一步提升速度。针对每种方法,我们仅测量模型推理吞吐量。通过不同批次大小计算吞吐量,并报告最优批次大小下的吞吐量结果。除非特别说明,所有速度基准测试均采用半精度(fp16)运行。图像基准测试的输入分辨率设为$224\times224\times3$,视频基准测试则采用16帧组成的片段(分辨率$224\times224\times3$)。训练时间的测量方式为:在单GPU上记录一次前向-反向传播耗时,根据数据集规模和训练轮次推算总训练时间,多GPU训练时的数据加载和通信开销不计入统计。
(a) Pre training
| config | value |
| optimizer | AdamW |
| optimizermomentum | β1,β2=0.9,0.95 |
| weight decay | 0.05 |
| learningrate | 8e-4 |
| learning rate sch. | cosine decay |
| warmup epochs | 40 |
| epochs | 400/1600 |
| augmentation | hflip, crop [0.2, 1] |
| batch size | 4096 |
| num.decoderblocks | 8 |
| num.decoderheads | 16 |
| mask ratio | 0.6 |
| drop path | 0.0 (T, S); 0.2 (B, B+, L); 0.3 |
| (H) |
(a) 预训练 (Pre training)
| config | value |
|---|---|
| optimizer | AdamW |
| optimizermomentum | β1,β2=0.9,0.95 |
| weight decay | 0.05 |
| learningrate | 8e-4 |
| learning rate sch. | cosine decay |
| warmup epochs | 40 |
| epochs | 400/1600 |
| augmentation | hflip, crop [0.2, 1] |
| batch size | 4096 |
| num.decoderblocks | 8 |
| num.decoderheads | 16 |
| mask ratio | 0.6 |
| drop path | 0.0 (T, S); 0.2 (B, B+, L); 0.3 |
| (H) |
Table 14. Settings for ImageNet-1K. Notation: setting corresponding to $400/1600$ epochs of pre training.
| config | value |
| optimizer optimizer momentum weight decay | Adamw β1, β2=0.9,0.999 0.05 |
| learning rate learning rate schedule warmup epochs epochs augmentation | 2e-3 (T, S,B);1e-3 (B+,L,H) cosine decay 5 300 (T);200 (S);100 (B,B+); 50 (L,H) |
| batch size mixup cutmix label smoothing drop path | RandAug (9, 0.5) 1024 0.8 1.0 0.1 0.1 (T, S, B,B+); 0.2 / 0.1 (L); |
表 14: ImageNet-1K 参数设置。注:设置对应 $400/1600$ 轮预训练。
| 配置项 | 值 |
|---|---|
| 优化器 (optimizer) 优化器动量 (optimizer momentum) 权重衰减 (weight decay) | Adamw β1, β2=0.9,0.999 0.05 |
| 学习率 (learning rate) 学习率调度 (learning rate schedule) 预热轮数 (warmup epochs) 训练轮数 (epochs) 数据增强 (augmentation) | 2e-3 (T, S,B);1e-3 (B+,L,H) 余弦退火 (cosine decay) 5 300 (T);200 (S);100 (B,B+); 50 (L,H) RandAug (9, 0.5) |
| 批量大小 (batch size) MixUp CutMix 标签平滑 (label smoothing) 路径丢弃 (drop path) | 1024 0.8 1.0 0.1 0.1 (T, S, B,B+); 0.2 / 0.1 (L) |
Table 15. Settings for COCO. Hiera finetuning settings on COCO.
| config | values |
| optimizer | AdamW |
| optimizer momentum | β1,β2=0.9,0.999 |
| weightdecay | 0.1 |
| learning rate | 3.5e-5 (B, B+), 3e-5 (L) |
| learning rate schedule | step-wise decay |
| epochs | 100 |
| augmentation | LSJ [0.1,2.0] |
| batch size | 64 |
| drop path | 0.2 (B,B+),0.4 (L) |
表 15: COCO 数据集上的 Hiera 微调设置
| 配置项 | 值 |
|---|---|
| 优化器 | AdamW |
| 优化器动量 | β1,β2=0.9,0.999 |
| 权重衰减 | 0.1 |
| 学习率 | 3.5e-5 (B, B+), 3e-5 (L) |
| 学习率调度 | 阶梯式衰减 |
| 训练轮数 | 100 |
| 数据增强 | LSJ [0.1,2.0] |
| 批次大小 | 64 |
| 路径丢弃率 | 0.2 (B,B+),0.4 (L) |
Table 17. Video speed benchmarking on A100 fp16 (clip/s).
| size | ViT | MCMAE | ConvNextV2 | Hiera |
| T | 1 | 1 | 1381 | 2758 |
| S | - | 2211 | ||
| B | 1448 | 1069 | 646 | 1556 |
| B+ | - | 936 | - | 1247 |
| L | 514 | 381 | 414 | 531 |
| H | 205 | 194 | 202 | 274 |
表 17: A100 fp16 上的视频速度基准测试 (clip/s)。
| size | ViT | MCMAE | ConvNextV2 | Hiera |
|---|---|---|---|---|
| T | 1 | 1 | 1381 | 2758 |
| S | - | 2211 | ||
| B | 1448 | 1069 | 646 | 1556 |
| B+ | - | 936 | - | 1247 |
| L | 514 | 381 | 414 | 531 |
| H | 205 | 194 | 202 | 274 |
Table 16. Image speed benchmarking on A100 fp16 (im/s).
| size | ViT | Hiera |
| B | 47.1 | 133.6 |
| B+ | 84.1 | |
| L | 17.8 | 40.8 |
| H | 11.3 | 20.9 |
表 16. A100 fp16 上的图像速度基准测试 (im/s)。
| size | ViT | Hiera |
|---|---|---|
| B | 47.1 | 133.6 |
| B+ | 84.1 | |
| L | 17.8 | 40.8 |
| H | 11.3 | 20.9 |
We report the image benchmarking results on NVIDIA A100 with fp16 and compared with in ViT (Do sov it ski y et al., 2021), ConvNextV2 (Woo et al., 2023) and MCMAE (Gao et al., 2022) in Tab. 16. We provide video benchmarking results in Tab. 17.
我们在NVIDIA A100上使用fp16报告了图像基准测试结果,并与ViT (Do sov it ski y等人, 2021)、ConvNextV2 (Woo等人, 2023)和MCMAE (Gao等人, 2022)进行了对比,如 表16 所示。视频基准测试结果见 表17。
B. From Scratch Supervised Training
B. 从零开始的监督训练
In the main paper, we show that we can replace the spatial biases offered by specialized modules in a hierarchical vision transformer with a strong pretext task like MAE (He et al., 2022), thereby teaching these spatial biases instead. This renders these bells-and-whistles unnecessary, and we remove them to construct an extremely fast and accurate vision transformer: Hiera.
在主论文中,我们证明了可以用类似MAE (He et al., 2022)这样的强预训练任务替代分层视觉Transformer (hierarchical vision transformer)中专有模块提供的空间偏置,从而通过训练学习这些空间偏置。这使得这些附加组件变得多余,我们将其移除后构建了一个极其快速且准确的视觉Transformer:Hiera。
However, we do not claim that these modules are unnecessary in general. In fact, here we intend to show the opposite: the reason these spatial biases were necessary in the first place is because they are required when training a vision transformer from scratch with classification. In Fig. 8, we show this by repeating the ablations in Tab. 1 on ImageNet1K starting from an MViT-B model and ending at Hiera-B, but this time training on classification from scratch.
然而,我们并不认为这些模块在一般情况下是多余的。实际上,我们想表明相反的观点:这些空间偏置最初之所以必要,是因为在从头开始训练视觉Transformer (Vision Transformer) 进行分类时需要它们。在图8中,我们通过在ImageNet1K上重复表1的消融实验来展示这一点,从MViT-B模型开始,最终到Hiera-B模型,但这次是从头开始进行分类训练。
As expected, we see the opposite trend as we did when training with a strong pretext task: the bells-and-whistles are necessary when training in a classical supervised setting. This reiterates the fact that, by training with MAE, we are replacing the need to explicitly build spatial biases into the network’s architecture itself.
正如预期,我们观察到的趋势与使用强前置任务训练时相反:在经典监督训练设置中,这些附加功能是必要的。这再次印证了一个事实——通过MAE (Masked Autoencoder) 训练,我们无需在网络架构中显式构建空间偏置。
Note that this also has ramifications for downstream tasks:
需要注意的是,这也会对下游任务产生影响:

Figure 8. Training on classification from scratch. Here we repeat the experiment in Tab. 1 but without MAE pre training, using MViTv2’s supervised recipe instead. As expected, the bells-andwhistles that Hiera removes are actually necessary when training from scratch—hence their introduction in prior work in the first place. Hiera learns spatial biases instead.
图 8: 从头开始分类训练。这里我们重复表 1 的实验,但不使用 MAE (Masked Autoencoder) 预训练,而是采用 MViTv2 的监督式训练方案。正如预期,当从头训练时,Hiera 移除的那些附加组件实际上是必要的——这也正是它们最初被引入先前工作的原因。Hiera 转而学习空间偏置。
while prior specialized Vision Transformers like MViT or Swin act like convnets (e.g., you can just use a normal Mask R-CNN (He et al., 2017) head for detection), Hiera acts like a ViT. Thus, we recommend using transformer-based solutions for downstream tasks such as ViTDet (Li et al., 2022b) for detection instead of Mask R-CNN.
虽然之前的专用视觉Transformer (Vision Transformers) 如MViT或Swin表现得像卷积网络(例如可以直接使用常规的Mask R-CNN (He et al., 2017) 头进行检测),但Hiera的表现更接近ViT。因此,我们建议在下游任务(如检测)中使用基于Transformer的解决方案,例如ViTDet (Li et al., 2022b),而非Mask R-CNN。