Language Models are Few-Shot Learners
大语言模型是少样本学习者
| Tom B. Brown* | Benjamin Mann* | Nick Ryder* | Melanie Subbiah* | |||||
| Jared Kaplant | Prafulla Dhariwal | Arvind Neelakantan | Pranav Shyam | Girish Sastry | ||||
| Amanda Askell | Sandhini Agarwal | Ariel Herbert-Voss | Gretchen Krueger | Tom Henighan | ||||
| Rewon Child | Aditya Ramesh | Daniel M. Ziegler | Jeffrey Wu | Clemens Winter | ||||
| Christopher Hesse | Mark Chen | Eric Sigler | Mateusz Litwin | Scott Gray | ||||
| Benjamin Chess | Jack Clark | Christopher Berner | ||||||
| Sam McCandlish | Alec Radford | Ilya Sutskever | Dario Amodei | |||||
Tom B. Brown* | Benjamin Mann* | Nick Ryder* | Melanie Subbiah*
Jared Kaplan | Prafulla Dhariwal | Arvind Neelakantan | Pranav Shyam | Girish Sastry
Amanda Askell | Sandhini Agarwal | Ariel Herbert-Voss | Gretchen Krueger | Tom Henighan
Rewon Child | Aditya Ramesh | Daniel M. Ziegler | Jeffrey Wu | Clemens Winter
Christopher Hesse | Mark Chen | Eric Sigler | Mateusz Litwin | Scott Gray
Benjamin Chess | Jack Clark | Christopher Berner
Sam McCandlish | Alec Radford | Ilya Sutskever | Dario Amodei
OpenAI
OpenAI
Abstract
摘要
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions – something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art finetuning approaches. Specifically, we train GPT-3, an auto regressive language model with 175 billion parameters, $10\mathrm{x}$ more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3’s few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.
近期研究表明,通过对海量文本进行预训练再针对特定任务微调,能在众多自然语言处理(NLP)任务和基准测试中取得显著提升。尽管这种方法在架构上通常与任务无关,但仍需要数千乃至数万例的任务特定微调数据集。相比之下,人类通常仅需几个示例或简单说明就能完成新语言任务——而这正是当前NLP系统普遍面临的难题。本文证明,扩大语言模型规模能显著提升任务无关的少样本学习性能,有时甚至可与现有最先进的微调方法媲美。具体而言,我们训练了GPT-3——一个拥有1750亿参数的自回归语言模型,其参数量是此前所有非稀疏语言模型的10倍,并在少样本设定下测试其性能。所有任务中,GPT-3均未进行梯度更新或微调,仅通过文本交互指定任务和少样本示例。GPT-3在翻译、问答、完形填空等NLP任务上表现优异,同时能胜任即时推理和领域适应任务,如单词重组、新词造句及三位数运算。我们也发现部分数据集上GPT-3的少样本学习仍存在困难,以及某些因网络语料训练引发的 methodological 问题。最后,实验表明GPT-3生成的新闻样本已能让人类评估者难以区分其与人工撰写文章的区别。我们将探讨这一发现及GPT-3更广泛的社会影响。
Contents
目录
1 Introduction
1 引言
2 Approach
2 方法
3 Results
3 结果
10
10
3.1 Language Modeling, Cloze, and Completion Tasks 1
3.1 语言建模、填空与补全任务 1
4 Measuring and Preventing Memorization Of Benchmarks 29
4 基准测试的记忆化测量与预防 29
5 Limitations 33
5 局限性 33
6 Broader Impacts 34
6 更广泛的影响 34
7 Related Work 39
7 相关工作 39
8 Conclusion 40
8 结论 40
1 Introduction
1 引言
Recent years have featured a trend towards pre-trained language representations in NLP systems, applied in increasingly flexible and task-agnostic ways for downstream transfer. First, single-layer representations were learned using word vectors [MCCD13, PSM14] and fed to task-specific architectures, then RNNs with multiple layers of representations and contextual state were used to form stronger representations [DL15, MBXS17, PNZtY18] (though still applied to task-specific architectures), and more recently pre-trained recurrent or transformer language models $[\mathrm{VSP^{+}}17]$ have been directly fine-tuned, entirely removing the need for task-specific architectures [RNSS18, DCLT18, HR18].
近年来,NLP系统呈现出向预训练语言表示发展的趋势,这些表示以越来越灵活且与任务无关的方式应用于下游迁移。最初,使用词向量 [MCCD13, PSM14] 学习单层表示,并将其输入到特定任务的架构中;随后,采用具有多层表示和上下文状态的RNN来构建更强的表示 [DL15, MBXS17, PNZtY18](尽管仍应用于特定任务架构);最近,预训练的循环或Transformer语言模型 $[\mathrm{VSP^{+}}17]$ 可直接微调,完全消除了对特定任务架构的需求 [RNSS18, DCLT18, HR18]。
This last paradigm has led to substantial progress on many challenging NLP tasks such as reading comprehension, question answering, textual entailment, and many others, and has continued to advance based on new architectures and algorithms $[\mathrm{RSR}^{+}19$ , $\mathrm{LOG}^{+}19$ , $\mathrm{YDY^{+}19}$ , $\operatorname{LCG}^{+}19]$ . However, a major limitation to this approach is that while the architecture is task-agnostic, there is still a need for task-specific datasets and task-specific fine-tuning: to achieve strong performance on a desired task typically requires fine-tuning on a dataset of thousands to hundreds of thousands of examples specific to that task. Removing this limitation would be desirable, for several reasons.
这一最新范式已在阅读理解、问答、文本蕴含等众多具有挑战性的自然语言处理(NLP)任务上取得重大进展,并随着新架构和算法的出现持续发展[RSR+19, LOG+19, YDY+19, LCG+19]。然而,该方法的主要局限在于:虽然架构与任务无关,但仍需要特定任务的数据集和微调——要在目标任务上实现强劲性能,通常需要针对该任务数千至数十万规模的样本数据进行微调。出于多方面考虑,消除这一限制将具有重要意义。
First, from a practical perspective, the need for a large dataset of labeled examples for every new task limits the applicability of language models. There exists a very wide range of possible useful language tasks, encompassing anything from correcting grammar, to generating examples of an abstract concept, to critiquing a short story. For many of these tasks it is difficult to collect a large supervised training dataset, especially when the process must be repeated for every new task.
首先,从实际角度来看,为每个新任务都需要大量标注样本数据集这一点限制了大语言模型 (LLM) 的适用性。语言任务的应用范围极其广泛,从语法纠错到抽象概念示例生成,再到短篇故事评析。对于其中许多任务而言,收集大规模监督训练数据集非常困难,尤其是当每个新任务都需要重复这一过程时。
Second, the potential to exploit spurious correlations in training data fundamentally grows with the expressiveness of the model and the narrowness of the training distribution. This can create problems for the pre-training plus fine-tuning paradigm, where models are designed to be large to absorb information during pre-training, but are then fine-tuned on very narrow task distributions. For instance $\mathrm{[HLW^{+}}20]$ observe that larger models do not necessarily generalize better out-of-distribution. There is evidence that suggests that the generalization achieved under this paradigm can be poor because the model is overly specific to the training distribution and does not generalize well outside it $\mathrm{[YdC^{+}\bar{1}9}$ , MPL19]. Thus, the performance of fine-tuned models on specific benchmarks, even when it is nominally at human-level, may exaggerate actual performance on the underlying task $[\mathrm{GSL^{+}}18$ , NK19].
其次,随着模型表现力的增强和训练数据分布的狭窄化,利用训练数据中虚假相关性的可能性也在增加。这可能给"预训练+微调"范式带来问题——模型被设计得足够大以吸收预训练阶段的信息,却要在非常狭窄的任务分布上进行微调。例如[HLW+20]观察到,更大的模型未必具有更好的分布外泛化能力。有证据表明,这种范式下实现的泛化能力可能较差,因为模型过度适配训练数据分布,在分布外场景表现不佳[YdC+19, MPL19]。因此,微调模型在特定基准测试上的表现(即使名义上达到人类水平)可能夸大了其在真实任务中的实际能力[GSL+18, NK19]。
Third, humans do not require large supervised datasets to learn most language tasks – a brief directive in natural language (e.g. “please tell me if this sentence describes something happy or something sad”) or at most a tiny number of demonstrations (e.g. “here are two examples of people acting brave; please give a third example of bravery”) is often sufficient to enable a human to perform a new task to at least a reasonable degree of competence. Aside from pointing to a conceptual limitation in our current NLP techniques, this adaptability has practical advantages – it allows humans to seamlessly mix together or switch between many tasks and skills, for example performing addition during a lengthy dialogue. To be broadly useful, we would someday like our NLP systems to have this same fluidity and generality.
第三,人类学习大多数语言任务并不需要大量监督数据集——自然语言的简短指令(例如"请告诉我这句话描述的是开心还是悲伤的事情")或最多少量演示(例如"这是两个勇敢行为的例子;请再举一个勇敢的例子")通常就足以让人至少以合理的能力水平完成新任务。除了指出当前自然语言处理(NLP)技术的概念局限外,这种适应性还具有实际优势——它使人类能够无缝混合或切换多种任务和技能,例如在冗长对话中执行加法运算。为了实现广泛实用性,我们希望有朝一日我们的NLP系统也能具备同样的流畅性和通用性。
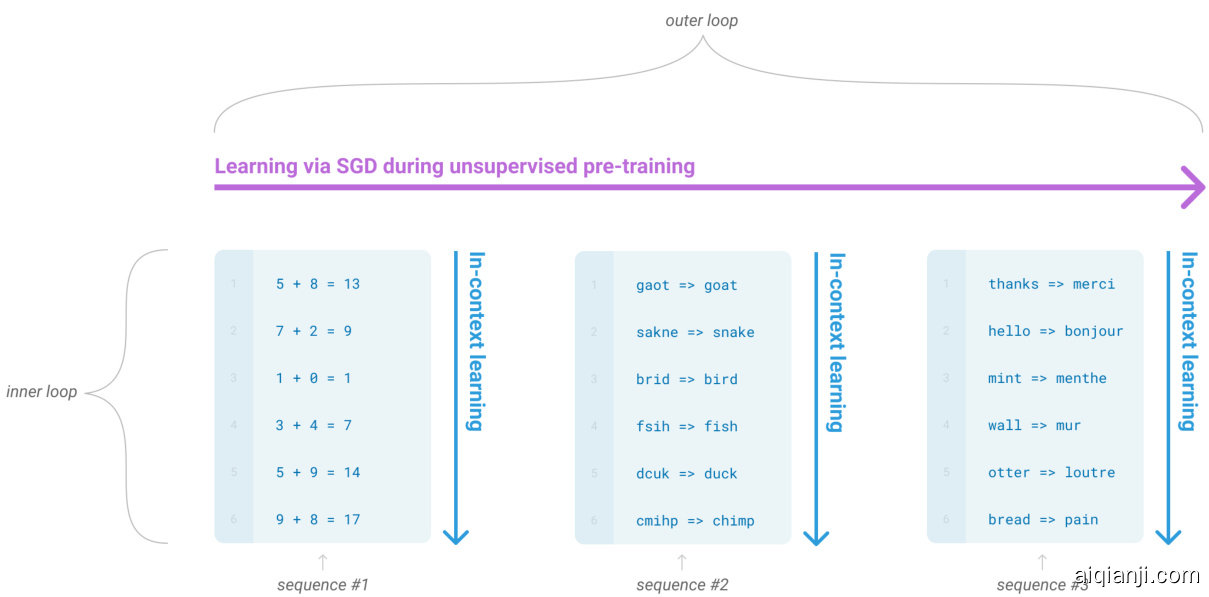
Figure 1.1: Language model meta-learning. During unsupervised pre-training, a language model develops a broad set of skills and pattern recognition abilities. It then uses these abilities at inference time to rapidly adapt to or recognize the desired task. We use the term “in-context learning” to describe the inner loop of this process, which occurs within the forward-pass upon each sequence. The sequences in this diagram are not intended to be representative of the data a model would see during pre-training, but are intended to show that there are sometimes repeated sub-tasks embedded within a single sequence.
图 1.1: 语言模型元学习。在无监督预训练阶段,语言模型培养出广泛的技能和模式识别能力。随后在推理时利用这些能力快速适应或识别目标任务。我们使用"上下文学习"这一术语描述该过程的内部循环,即每次前向传播时在单个序列内发生的学习。图中序列并非预训练数据的真实示例,而是用于说明有时单个序列中会嵌入重复的子任务。
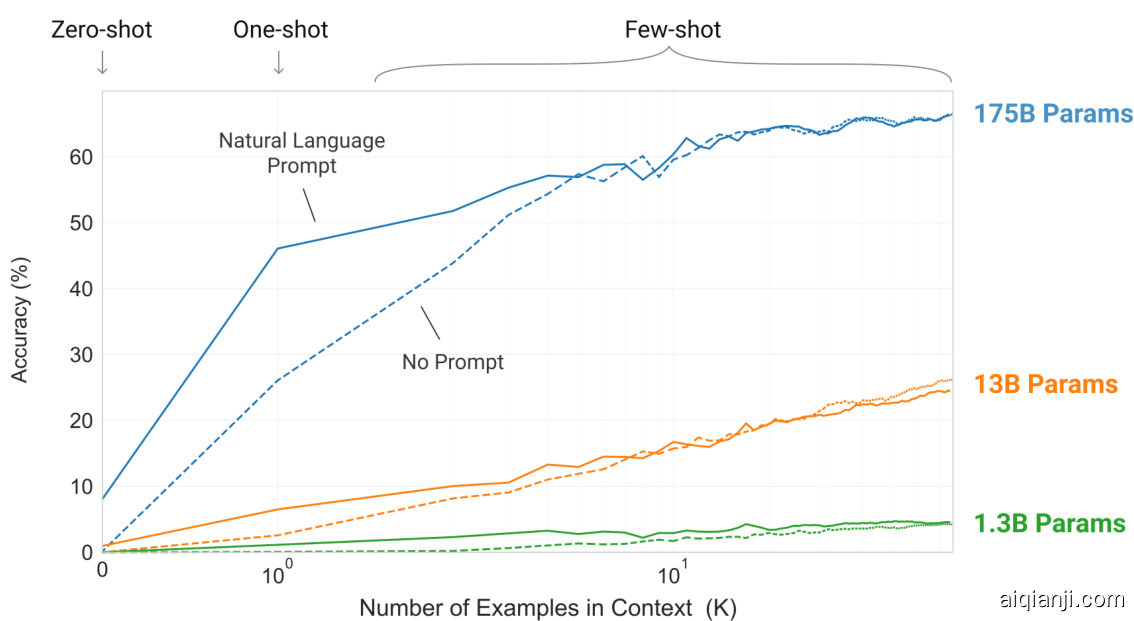
Figure 1.2: Larger models make increasingly efficient use of in-context information. We show in-context learning performance on a simple task requiring the model to remove random symbols from a word, both with and without a natural language task description (see Sec. 3.9.2). The steeper “in-context learning curves” for large models demonstrate improved ability to learn a task from contextual information. We see qualitatively similar behavior across a wide range of tasks.
图 1.2: 大模型能更高效地利用上下文信息。我们展示了一个简单任务中的上下文学习性能,该任务要求模型从单词中移除随机符号,包括有自然语言任务描述和无描述两种情况(参见第3.9.2节)。大模型更陡峭的"上下文学习曲线"表明其从上下文信息中学习任务的能力有所提升。我们在各种任务中都观察到了类似的行为模式。
One potential route towards addressing these issues is meta-learning1 – which in the context of language models means the model develops a broad set of skills and pattern recognition abilities at training time, and then uses those abilities at inference time to rapidly adapt to or recognize the desired task (illustrated in Figure 1.1). Recent work $[\mathrm{RWC^{+}}19]$ attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
解决这些问题的一个潜在途径是元学习1——在语言模型的背景下,这意味着模型在训练时发展出一套广泛的技能和模式识别能力,然后在推理时利用这些能力快速适应或识别所需任务(如图1.1所示)。最近的研究[RWC+19]尝试通过我们称为"上下文学习"的方式实现这一点:将预训练语言模型的文本输入作为任务规范的一种形式——模型以自然语言指令和/或少量任务演示为条件,仅通过预测后续内容即可完成任务的新实例。
While it has shown some initial promise, this approach still achieves results far inferior to fine-tuning – for example $[\mathrm{RWC^{+}}19]$ achieves only $4%$ on Natural Questions, and even its 55 F1 CoQa result is now more than 35 points behind the state of the art. Meta-learning clearly requires substantial improvement in order to be viable as a practical method of solving language tasks.
尽管该方法已展现出初步潜力,但其效果仍远逊于微调(fine-tuning)——例如[RWC+19]在Natural Questions上仅取得4%的准确率,其55 F1值的CoQA结果也落后当前最优水平35分以上。要使元学习(meta-learning)成为解决语言任务的实用方法,显然还需要大幅改进。
Another recent trend in language modeling may offer a way forward. In recent years the capacity of transformer language models has increased substantially, from 100 million parameters [RNSS18], to 300 million parameters [DCLT18], to 1.5 billion parameters $[\mathrm{RWC^{+}}19]$ , to 8 billion parameters $[\mathrm{SPP^{+}}19]$ , 11 billion parameters $[\mathrm{RSR^{+}}19]$ , and finally 17 billion parameters [Tur20]. Each increase has brought improvements in text synthesis and/or downstream NLP tasks, and there is evidence suggesting that log loss, which correlates well with many downstream tasks, follows a smooth trend of improvement with scale $[\mathrm{KMH^{+}}20]$ . Since in-context learning involves absorbing many skills and tasks within the parameters of the model, it is plausible that in-context learning abilities might show similarly strong gains with scale.
语言建模领域的另一新趋势可能指明了前进方向。近年来,Transformer语言模型的参数量实现了显著增长:从1亿参数[RNSS18]、3亿参数[DCLT18]、15亿参数$[\mathrm{RWC^{+}}19]$,到80亿参数$[\mathrm{SPP^{+}}19]$、110亿参数$[\mathrm{RSR^{+}}19]$,最终达到170亿参数[Tur20]。每次规模扩大都带来了文本生成和/或下游NLP任务的性能提升,且有证据表明与众多下游任务高度相关的对数损失(log loss)会随规模扩大呈现平滑的改进趋势$[\mathrm{KMH^{+}}20]$。由于上下文学习(in-context learning)需要模型参数吸收多种技能和任务,其能力很可能同样会随规模扩大而显著增强。

Figure 1.3: Aggregate performance for all 42 accuracy-denominated benchmarks While zero-shot performance improves steadily with model size, few-shot performance increases more rapidly, demonstrating that larger models are more proficient at in-context learning. See Figure 3.8 for a more detailed analysis on SuperGLUE, a standard NLP benchmark suite.
图 1.3: 全部42个准确率基准测试的总体表现
虽然零样本性能随模型规模稳步提升,但少样本性能提升更为显著,这表明更大规模的模型更擅长上下文学习。关于标准NLP基准测试集SuperGLUE的更详细分析,请参见图3.8。
In this paper, we test this hypothesis by training a 175 billion parameter auto regressive language model, which we call GPT-3, and measuring its in-context learning abilities. Specifically, we evaluate GPT-3 on over two dozen NLP datasets, as well as several novel tasks designed to test rapid adaptation to tasks unlikely to be directly contained in the training set. For each task, we evaluate GPT-3 under 3 conditions: (a) “few-shot learning”, or in-context learning where we allow as many demonstrations as will fit into the model’s context window (typically 10 to 100), (b) “one-shot learning”, where we allow only one demonstration, and (c) “zero-shot” learning, where no demonstrations are allowed and only an instruction in natural language is given to the model. GPT-3 could also in principle be evaluated in the traditional fine-tuning setting, but we leave this to future work.
在本文中,我们通过训练一个1750亿参数的自回归语言模型(称为GPT-3)来验证这一假设,并测试其上下文学习能力。具体而言,我们在超过20个NLP数据集以及多个新设计任务上评估GPT-3,这些任务用于测试模型对训练集中不太可能直接包含的任务的快速适应能力。针对每个任务,我们在三种条件下评估GPT-3:(a) "少样本学习(few-shot learning)",即上下文学习中允许模型上下文窗口容纳尽可能多的示例(通常为10到100个);(b) "单样本学习(one-shot learning)",仅允许一个示例;(c) "零样本(zero-shot)"学习,不提供任何示例,仅向模型提供自然语言指令。原则上GPT-3也可在传统微调设置下评估,但我们将其留待未来研究。
Figure 1.2 illustrates the conditions we study, and shows few-shot learning of a simple task requiring the model to remove extraneous symbols from a word. Model performance improves with the addition of a natural language task description, and with the number of examples in the model’s context, $K$ . Few-shot learning also improves dramatically with model size. Though the results in this case are particularly striking, the general trends with both model size and number of examples in-context hold for most tasks we study. We emphasize that these “learning” curves involve no gradient updates or fine-tuning, just increasing numbers of demonstrations given as conditioning.
图 1.2 展示了我们研究的条件,并演示了一个简单任务的少样本学习,该任务要求模型从单词中去除无关符号。模型性能随着自然语言任务描述的加入以及上下文示例数量 $K$ 的增加而提升。少样本学习也随着模型规模的扩大而显著改善。尽管此案例的结果特别引人注目,但模型规模和上下文示例数量对大多数研究任务都呈现类似的趋势。需要强调的是,这些"学习"曲线不涉及梯度更新或微调,仅通过增加作为条件输入的演示样本数量实现。
Broadly, on NLP tasks GPT-3 achieves promising results in the zero-shot and one-shot settings, and in the the few-shot setting is sometimes competitive with or even occasionally surpasses state-of-the-art (despite state-of-the-art being held by fine-tuned models). For example, GPT-3 achieves 81.5 F1 on CoQA in the zero-shot setting, 84.0 F1 on CoQA in the one-shot setting, $85.0\mathrm{F}1$ in the few-shot setting. Similarly, GPT-3 achieves $64.3%$ accuracy on TriviaQA in the zero-shot setting, $68.0%$ in the one-shot setting, and $71.2%$ in the few-shot setting, the last of which is state-of-the-art relative to fine-tuned models operating in the same closed-book setting.
广泛而言,在NLP任务上,GPT-3在零样本和单样本设置中取得了令人瞩目的成果,在少样本设置下有时能与甚至偶尔超越当前最优水平(尽管当前最优模型多为经过微调的模型)。例如,GPT-3在CoQA任务中零样本设置下达到81.5 F1值,单样本设置下为84.0 F1值,少样本设置下为$85.0\mathrm{F}1$。同样地,在TriviaQA任务中,GPT-3零样本设置准确率为$64.3%$,单样本设置提升至$68.0%$,少样本设置进一步达到$71.2%$,后者在相同闭卷设置下相较微调模型取得了当前最优成绩。
GPT-3 also displays one-shot and few-shot proficiency at tasks designed to test rapid adaption or on-the-fly reasoning, which include unscrambling words, performing arithmetic, and using novel words in a sentence after seeing them defined only once. We also show that in the few-shot setting, GPT-3 can generate synthetic news articles which human evaluators have difficulty distinguishing from human-generated articles.
GPT-3在测试快速适应或即时推理能力的任务中也展现出了单样本(one-shot)和少样本(few-shot)的熟练度,这些任务包括解构单词、执行算术运算以及在仅见过一次定义后就能在句子中使用新词。我们还表明,在少样本设置下,GPT-3可以生成合成新闻文章,而人类评估者难以将其与人类撰写的文章区分开来。
At the same time, we also find some tasks on which few-shot performance struggles, even at the scale of GPT-3. This includes natural language inference tasks like the ANLI dataset, and some reading comprehension datasets like RACE or QuAC. By presenting a broad characterization of GPT-3’s strengths and weaknesses, including these limitations, we hope to stimulate study of few-shot learning in language models and draw attention to where progress is most needed.
与此同时,我们也发现某些任务即使对于GPT-3这种规模的模型,少样本学习表现仍不理想。这包括ANLI数据集等自然语言推理任务,以及RACE或QuAC等部分阅读理解数据集。通过全面展示GPT-3的优势与局限(包括这些不足之处),我们希望推动大语言模型中少样本学习的研究,并明确亟待突破的方向。
A heuristic sense of the overall results can be seen in Figure 1.3, which aggregates the various tasks (though it should not be seen as a rigorous or meaningful benchmark in itself).
图 1.3 汇总了各项任务的结果,可以直观地感受到整体表现 (但不应将其视为严格或有意义的基准)。
We also undertake a systematic study of “data contamination” – a growing problem when training high capacity models on datasets such as Common Crawl, which can potentially include content from test datasets simply because such content often exists on the web. In this paper we develop systematic tools to measure data contamination and quantify its distorting effects. Although we find that data contamination has a minimal effect on GPT-3’s performance on most datasets, we do identify a few datasets where it could be inflating results, and we either do not report results on these datasets or we note them with an asterisk, depending on the severity.
我们还系统研究了"数据污染(data contamination)"问题——这是在高容量模型训练(如使用Common Crawl数据集时)日益严重的问题,由于测试集内容常存在于网络,训练数据可能混入测试集内容。本文开发了系统化工具来测量数据污染并量化其干扰效应。虽然发现数据污染对GPT-3在多数数据集上性能影响甚微,但仍识别出少数可能夸大结果的数据集,我们根据严重程度选择不报告这些数据集结果或使用星号标注。
In addition to all the above, we also train a series of smaller models (ranging from 125 million parameters to 13 billion parameters) in order to compare their performance to GPT-3 in the zero, one and few-shot settings. Broadly, for most tasks we find relatively smooth scaling with model capacity in all three settings; one notable pattern is that the gap between zero-, one-, and few-shot performance often grows with model capacity, perhaps suggesting that larger models are more proficient meta-learners.
除了上述所有内容外,我们还训练了一系列较小的模型(参数范围从1.25亿到130亿),以便在零样本、单样本和少样本设置下与GPT-3进行性能比较。总体而言,对于大多数任务,我们发现这三种设置下模型容量的扩展相对平滑;一个显著的模式是,零样本、单样本和少样本性能之间的差距通常随着模型容量的增加而扩大,这可能表明较大的模型是更熟练的元学习器。
Finally, given the broad spectrum of capabilities displayed by GPT-3, we discuss concerns about bias, fairness, and broader societal impacts, and attempt a preliminary analysis of GPT-3’s characteristics in this regard.
最后,鉴于GPT-3展现出的广泛能力,我们讨论了关于偏见、公平性及更广泛社会影响的担忧,并尝试就此对GPT-3的特性进行初步分析。
The remainder of this paper is organized as follows. In Section 2, we describe our approach and methods for training GPT-3 and evaluating it. Section 3 presents results on the full range of tasks in the zero-, one- and few-shot settings. Section 4 addresses questions of data contamination (train-test overlap). Section 5 discusses limitations of GPT-3. Section 6 discusses broader impacts. Section 7 reviews related work and Section 8 concludes.
本文的其余部分组织如下。第2节介绍了训练GPT-3和评估的方法。第3节展示了在零样本、单样本和少样本设置下各种任务的结果。第4节讨论了数据污染(训练-测试重叠)的问题。第5节探讨了GPT-3的局限性。第6节讨论了更广泛的影响。第7节回顾了相关工作,第8节总结全文。
2 Approach
2 方法
Our basic pre-training approach, including model, data, and training, is similar to the process described in $[\mathrm{RWC^{+}}19]$ , with relatively straightforward scaling up of the model size, dataset size and diversity, and length of training. Our use of in-context learning is also similar to $[\mathrm{RWC^{+}}19]$ , but in this work we systematically explore different settings for learning within the context. Therefore, we start this section by explicitly defining and contrasting the different settings that we will be evaluating GPT-3 on or could in principle evaluate GPT-3 on. These settings can be seen as lying on a spectrum of how much task-specific data they tend to rely on. Specifically, we can identify at least four points on this spectrum (see Figure 2.1 for an illustration):
我们的基础预训练方法,包括模型、数据和训练过程,与 $[\mathrm{RWC^{+}}19]$ 中描述的流程相似,主要通过直接扩大模型规模、数据集规模与多样性以及训练时长来实现。我们采用的上下文学习 (in-context learning) 方式也与 $[\mathrm{RWC^{+}}19]$ 类似,但本研究系统性地探索了上下文中的不同学习设置。因此,本节首先明确定义并对比我们将评估 GPT-3 的不同设置(或在原则上可评估 GPT-3 的设置)。这些设置可视为分布在依赖任务特定数据量的连续谱系上,具体可识别谱系中至少四个关键点(示意图见图 2.1):
• Fine-Tuning (FT) has been the most common approach in recent years, and involves updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task. Typically thousands to hundreds of thousands of labeled examples are used. The main advantage of fine-tuning is strong performance on many benchmarks. The main disadvantages are the need for a new large dataset for every task, the potential for poor generalization out-of-distribution [MPL19], and the potential to exploit spurious features of the training data $[\mathrm{GSL^{+}}18$ , NK19], potentially resulting in an unfair comparison with human performance. In this work we do not fine-tune GPT-3 because our focus is on task-agnostic performance, but GPT-3 can be fine-tuned in principle and this is a promising direction for future work.
• 微调 (Fine-Tuning, FT) 是近年来最常见的方法,通过在特定任务的监督数据集上训练来更新预训练模型的权重。通常使用数千到数十万个标注样本。微调的主要优势是在许多基准测试中表现优异。主要缺点包括:每个任务都需要新的庞大数据集、可能在分布外数据上泛化能力差 [MPL19],以及可能利用训练数据的虚假特征 $[\mathrm{GSL^{+}}18$, NK19],导致与人类表现的不公平比较。本研究未对 GPT-3 进行微调,因为我们的重点是任务无关性能,但原则上 GPT-3 可以进行微调,这是未来工作的一个 promising 方向。
• Few-Shot (FS) is the term we will use in this work to refer to the setting where the model is given a few demonstrations of the task at inference time as conditioning $[\mathrm{RWC^{+}}19]$ , but no weight updates are allowed. As shown in Figure 2.1, for a typical dataset an example has a context and a desired completion (for example an English sentence and the French translation), and few-shot works by giving $K$ examples of context and completion, and then one final example of context, with the model expected to provide the completion. We typically set $K$ in the range of 10 to 100 as this is how many examples can fit in the model’s context window $(n_{\mathrm{ctx}}=2048)$ ). The main advantages of few-shot are a major reduction in the need for task-specific data and reduced potential to learn an overly narrow distribution from a large but narrow fine-tuning dataset. The main disadvantage is that results from this method have so far been much worse than state-of-the-art fine-tuned models. Also, a small amount of task specific data is still required. As indicated by the name, few-shot learning as described here for language models is related to few-shot learning as used in other contexts in ML [HYC01, $\mathrm{VBL^{+}}16]$ – both involve learning based on a broad distribution of tasks (in this case implicit in the pre-training data) and then rapidly adapting to a new task.
• 少样本 (Few-Shot, FS) 在本研究中指模型在推理时通过少量任务示例作为条件输入 [RWC+19],但不允许更新权重。如图 2.1 所示,典型数据集的样本包含上下文和目标输出(例如英语句子和法语翻译),少样本学习通过提供 $K$ 组上下文-输出示例,最后给出一个上下文让模型补全输出。我们通常将 $K$ 设为 10 到 100,这是模型上下文窗口 $(n_{\mathrm{ctx}}=2048)$ 能容纳的示例数量。少样本的主要优势在于大幅减少对任务特定数据的需求,并降低从大而窄的微调数据集中学习到过度狭隘分布的可能性。主要缺点是该方法目前的效果远逊于最先进的微调模型,且仍需少量任务特定数据。如名称所示,大语言模型的少样本学习与机器学习其他领域的少样本学习 [HYC01, VBL+16] 存在关联——两者都基于广泛任务分布(此处隐含于预训练数据中)进行学习,然后快速适应新任务。
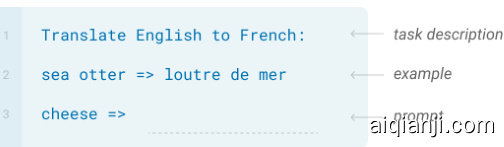
• One-Shot (1S) is the same as few-shot except that only one demonstration is allowed, in addition to a natural language description of the task, as shown in Figure 1. The reason to distinguish one-shot from few-shot and zero-shot (below) is that it most closely matches the way in which some tasks are communicated to humans. For example, when asking humans to generate a dataset on a human worker service (for example Mechanical Turk), it is common to give one demonstration of the task. By contrast it is sometimes difficult to communicate the content or format of a task if no examples are given.
• 单样本 (1S) 与少样本类似,但只允许提供一个演示示例,同时附带任务的自然语言描述,如图 1 所示。区分单样本与少样本及零样本(下文将介绍)的原因在于,它最接近某些任务传达给人类的方式。例如,当要求人类在众包平台(如 Mechanical Turk)上生成数据集时,通常会提供一个任务演示示例。相比之下,如果不提供任何示例,有时很难传达任务的内容或格式。
The three settings we explore for in-context learning Traditional fine-tuning (not used for GPT-3)
我们探索的三种上下文学习设置
传统微调(不适用于GPT-3)
Zero-shot
零样本
Fine-tuning
微调
The model predicts the answer given only a natural language description of the task. No gradient updates are performed
模型仅根据任务的自然语言描述预测答案,不进行梯度更新。

One-shot
单样本
In addition to the task description, the model sees a single example of the task. No gradient updates are performed.
除了任务描述外,模型还会看到该任务的一个示例。不执行梯度更新。
Few-shot
少样本
In addition to the task description,the model sees a few examples of the task.No gradient updates are performed
除了任务描述外,模型还会看到该任务的几个示例。不执行梯度更新
The model is trained via repeated gradient updates using a large corpus of example tasks.
模型通过使用大量示例任务语料库进行重复梯度更新来训练。

Figure 2.1: Zero-shot, one-shot and few-shot, contrasted with traditional fine-tuning. The panels above show four methods for performing a task with a language model – fine-tuning is the traditional method, whereas zero-, one-, and few-shot, which we study in this work, require the model to perform the task with only forward passes at test time. We typically present the model with a few dozen examples in the few shot setting. Exact phrasings for all task descriptions, examples and prompts can be found in Appendix G.
图 2.1: 零样本、单样本和少样本与传统微调方法的对比。上图展示了使用语言模型执行任务的四种方法——微调是传统方法,而本研究所探讨的零样本、单样本和少样本方法仅需在测试时进行前向传播。在少样本设定中,我们通常为模型提供几十个示例。所有任务描述、示例和提示的具体措辞详见附录G。

• Zero-Shot (0S) is the same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task. This method provides maximum convenience, potential for robustness, and avoidance of spurious correlations (unless they occur very broadly across the large corpus of pre-training data), but is also the most challenging setting. In some cases it may even be difficult for humans to understand the format of the task without prior examples, so this setting is in some cases “unfairly hard”. For example, if someone is asked to “make a table of world records for the $200\mathrm{m}$ dash”, this request can be ambiguous, as it may not be clear exactly what format the table should have or what should be included (and even with careful clarification, understanding precisely what is desired can be difficult). Nevertheless, for at least some settings zero-shot is closest to how humans perform tasks – for example, in the translation example in Figure 2.1, a human would likely know what to do from just the text instruction.
• 零样本 (0S) 与单样本类似,但不允许提供演示样例,模型仅会收到描述任务的自然语言指令。这种方法提供了最大便利性、潜在的鲁棒性,并能避免虚假相关性(除非它们在预训练数据的大规模语料库中广泛存在),但同时也是最具挑战性的设定。在某些情况下,甚至人类也可能难以在没有先前示例的情况下理解任务格式,因此这种设定有时会"不公平地困难"。例如,如果有人被要求"制作一份200米短跑世界纪录的表格",这个请求可能具有歧义,因为表格的具体格式或应包含内容可能不明确(即使经过仔细澄清,准确理解需求也可能很困难)。不过,至少在某些场景中,零样本最接近人类执行任务的方式——例如在图2.1的翻译示例中,人类仅凭文本指令就能明白该做什么。
Figure 2.1 shows the four methods using the example of translating English to French. In this paper we focus on zero-shot, one-shot and few-shot, with the aim of comparing them not as competing alternatives, but as different problem settings which offer a varying trade-off between performance on specific benchmarks and sample efficiency. We especially highlight the few-shot results as many of them are only slightly behind state-of-the-art fine-tuned models. Ultimately, however, one-shot, or even sometimes zero-shot, seem like the fairest comparisons to human performance, and are important targets for future work.
图 2.1 展示了四种以英译法为例的方法。本文重点研究零样本、单样本和少样本场景,目的不是将它们作为竞争性替代方案进行比较,而是作为在不同基准测试性能与样本效率之间提供差异化权衡的问题设定。我们特别强调少样本结果,因为其中许多结果仅略逊于经过微调的顶尖模型。但最终,单样本(有时甚至是零样本)似乎是与人类表现最公平的对比基准,也是未来工作的重要目标。
Sections 2.1-2.3 below give details on our models, training data, and training process respectively. Section 2.4 discusses the details of how we do few-shot, one-shot, and zero-shot evaluations.
以下第2.1-2.3节分别详细介绍我们的模型、训练数据和训练过程。第2.4节讨论我们如何进行少样本、单样本和零样本评估的具体细节。
| Model Name | Nparams | Nlayers | dmodel | Nheads | dhead | BatchSize | Learning Rate |
| GPT-3Small | 125M | 12 | 768 | 12 | 64 | 0.5M | 6.0 x 10-4 |
| GPT-3Medium | 350M | 24 | 1024 | 16 | 64 | 0.5M | 3.0 × 10-4 |
| GPT-3 Large | 760M | 24 | 1536 | 16 | 96 | 0.5M | 2.5 × 10-4 |
| GPT-3XL | 1.3B | 24 | 2048 | 24 | 128 | 1M | 2.0x 10-4 |
| GPT-3 2.7B | 2.7B | 32 | 2560 | 32 | 80 | 1M | 1.6 × 10-4 |
| GPT-36.7B | 6.7B | 32 | 4096 | 32 | 128 | 2M | 1.2 × 10-4 |
| GPT-3 13B | 13.0B | 40 | 5140 | 40 | 128 | 2M | 1.0 × 10-4 |
| GPT-3175B0r“GPT-3" | 175.0B | 96 | 12288 | 96 | 128 | 3.2M | 0.6 × 10-4 |
| 模型名称 | 参数量 (Nparams) | 层数 (Nlayers) | 模型维度 (dmodel) | 注意力头数 (Nheads) | 头维度 (dhead) | 批次大小 (BatchSize) | 学习率 (Learning Rate) |
|---|---|---|---|---|---|---|---|
| GPT-3 Small | 125M | 12 | 768 | 12 | 64 | 0.5M | 6.0 × 10⁻⁴ |
| GPT-3 Medium | 350M | 24 | 1024 | 16 | 64 | 0.5M | 3.0 × 10⁻⁴ |
| GPT-3 Large | 760M | 24 | 1536 | 16 | 96 | 0.5M | 2.5 × 10⁻⁴ |
| GPT-3 XL | 1.3B | 24 | 2048 | 24 | 128 | 1M | 2.0 × 10⁻⁴ |
| GPT-3 2.7B | 2.7B | 32 | 2560 | 32 | 80 | 1M | 1.6 × 10⁻⁴ |
| GPT-3 6.7B | 6.7B | 32 | 4096 | 32 | 128 | 2M | 1.2 × 10⁻⁴ |
| GPT-3 13B | 13.0B | 40 | 5140 | 40 | 128 | 2M | 1.0 × 10⁻⁴ |
| GPT-3 175B (GPT-3) | 175.0B | 96 | 12288 | 96 | 128 | 3.2M | 0.6 × 10⁻⁴ |
Table 2.1: Sizes, architectures, and learning hyper-parameters (batch size in tokens and learning rate) of the model which we trained. All models were trained for a total of 300 billion tokens.
表 2.1: 我们训练模型的规模、架构及学习超参数(token 批大小和学习率)。所有模型均训练了总计 3000 亿 token。
2.1 Model and Architectures
2.1 模型与架构
We use the same model and architecture as GPT-2 $[\mathrm{RWC^{+}}19]$ , including the modified initialization, pre-normalization, and reversible token iz ation described therein, with the exception that we use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer [CGRS19]. To study the dependence of ML performance on model size, we train 8 different sizes of model, ranging over three orders of magnitude from 125 million parameters to 175 billion parameters, with the last being the model we call GPT-3. Previous work $[\mathrm{KMH^{+}}20]$ suggests that with enough training data, scaling of validation loss should be approximately a smooth power law as a function of size; training models of many different sizes allows us to test this hypothesis both for validation loss and for downstream language tasks.
我们采用与GPT-2 $[\mathrm{RWC^{+}}19]$ 相同的模型架构,包括其中描述的改进初始化、预归一化和可逆token化方法,唯一区别是在Transformer各层中交替使用稠密注意力与局部带状稀疏注意力模式,类似Sparse Transformer [CGRS19]的设计。为研究机器学习性能与模型规模的关联性,我们训练了8种不同参数规模的模型,跨度达三个数量级(从1.25亿到1750亿参数),其中最大规模模型即我们称为GPT-3的版本。现有研究 $[\mathrm{KMH^{+}}20]$ 表明,当训练数据充足时,验证损失随模型规模的变化应近似符合平滑幂律关系;通过训练多种规模的模型,我们得以验证该假设在验证损失和下游语言任务中的适用性。
Table 2.1 shows the sizes and architectures of our 8 models. Here $n_{\mathrm{params}}$ is the total number of trainable parameters, $n_{\mathrm{layers}}$ is the total number of layers, $d_{\mathrm{model}}$ is the number of units in each bottleneck layer (we always have the feed forward layer four times the size of the bottleneck layer, $d_{\mathrm{ff}}=4*d_{\mathrm{model}})$ , and $d_{\mathrm{head}}$ is the dimension of each attention head. All models use a context window of $n_{\mathrm{ctx}}=2048$ tokens. We partition the model across GPUs along both the depth and width dimension in order to minimize data-transfer between nodes. The precise architectural parameters for each model are chosen based on computational efficiency and load-balancing in the layout of models across GPU’s. Previous work $[\mathrm{KMH^{+}}20]$ suggests that validation loss is not strongly sensitive to these parameters within a reasonably broad range.
表 2.1 展示了我们 8 个模型的规模和架构。其中 $n_{\mathrm{params}}$ 表示可训练参数总数,$n_{\mathrm{layers}}$ 表示总层数,$d_{\mathrm{model}}$ 表示每个瓶颈层的单元数(前馈层始终设置为瓶颈层大小的四倍,即 $d_{\mathrm{ff}}=4*d_{\mathrm{model}}$),$d_{\mathrm{head}}$ 表示每个注意力头的维度。所有模型均采用 $n_{\mathrm{ctx}}=2048$ tokens 的上下文窗口。我们沿深度和宽度维度将模型分布到多个 GPU 上,以最小化节点间的数据传输。每个模型的具体架构参数选择基于 GPU 间模型布局的计算效率和负载均衡。先前研究 [KMH^{+}20] 表明,在合理范围内,验证损失对这些参数并不十分敏感。
2.2 Training Dataset
2.2 训练数据集
Datasets for language models have rapidly expanded, culminating in the Common Crawl dataset2 $[\mathsf{R S R}^{+}19]$ constituting nearly a trillion words. This size of dataset is sufficient to train our largest models without ever updating on the same sequence twice. However, we have found that unfiltered or lightly filtered versions of Common Crawl tend to have lower quality than more curated datasets. Therefore, we took 3 steps to improve the average quality of our datasets: (1) we downloaded and filtered a version of Common Crawl based on similarity to a range of high-quality reference corpora, (2) we performed fuzzy de duplication at the document level, within and across datasets, to prevent redundancy and preserve the integrity of our held-out validation set as an accurate measure of over fitting, and (3) we also added known high-quality reference corpora to the training mix to augment Common Crawl and increase its diversity.
大语言模型的数据集迅速扩张,最终Common Crawl数据集2 $[\mathsf{R S R}^{+}19]$ 达到了近万亿词的规模。这一数据量足以训练我们最大的模型,且无需对同一序列重复更新。但我们发现,未经过滤或简单过滤的Common Crawl版本往往比经过精心整理的数据集质量更低。因此,我们采取了三项措施来提升数据集的平均质量:(1) 基于与多个高质量参考语料库的相似性,下载并过滤了Common Crawl的一个版本;(2) 在文档级别进行了跨数据集和数据集内部的模糊去重,以防止冗余并保持验证集的完整性,从而准确衡量过拟合;(3) 在训练混合数据中添加了已知的高质量参考语料库,以增强Common Crawl并提升其多样性。
Details of the first two points (processing of Common Crawl) are described in Appendix A. For the third, we added several curated high-quality datasets, including an expanded version of the WebText dataset [RWC+19], collected by scraping links over a longer period of time, and first described in $[\mathrm{KMH^{+}}20]$ , two internet-based books corpora (Books1 and Books2) and English-language Wikipedia.
前两点的具体细节(Common Crawl的处理)在附录A中描述。对于第三点,我们添加了几个精选的高质量数据集,包括通过长时间爬取链接收集的WebText数据集扩展版[RWC+19](首次在$[\mathrm{KMH^{+}}20]$中描述)、两个基于互联网的书籍语料库(Books1和Books2)以及英文维基百科。
Table 2.2 shows the final mixture of datasets that we used in training. The Common Crawl data was downloaded from 41 shards of monthly Common Crawl covering 2016 to 2019, constituting 45TB of compressed plaintext before filtering and 570GB after filtering, roughly equivalent to 400 billion byte-pair-encoded tokens. Note that during training, datasets are not sampled in proportion to their size, but rather datasets we view as higher-quality are sampled more frequently, such that Common Crawl and Books2 datasets are sampled less than once during training, but the other datasets are sampled 2-3 times. This essentially accepts a small amount of over fitting in exchange for higher quality training data.
表 2.2 展示了我们在训练中使用的最终数据集混合情况。Common Crawl 数据是从 2016 年至 2019 年的 41 个月度分片中下载的,过滤前压缩纯文本量为 45TB,过滤后为 570GB,大约相当于 4000 亿个字节对编码 (byte-pair-encoded) token。需要注意的是,训练过程中数据集的采样并非按其大小比例进行,而是我们认为质量更高的数据集会被更频繁地采样。因此 Common Crawl 和 Books2 数据集在训练期间采样次数不足一次,而其他数据集会被采样 2-3 次。这种做法本质上是用轻微的过拟合换取更高质量的训练数据。
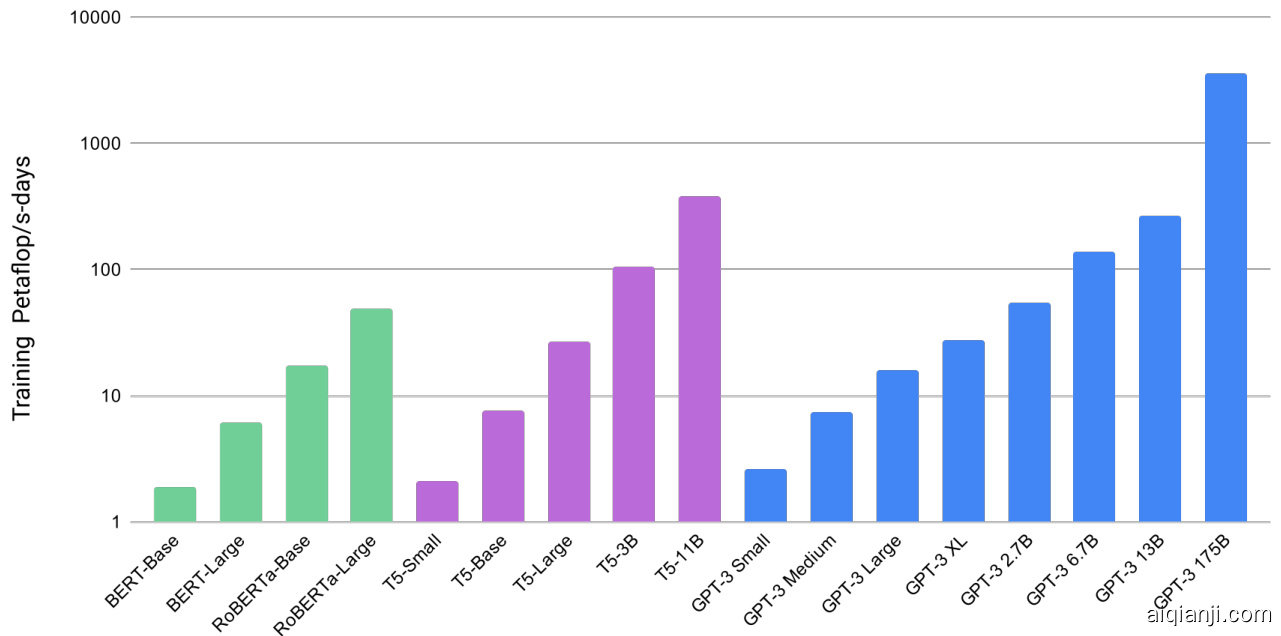
Figure 2.2: Total compute used during training. Based on the analysis in Scaling Laws For Neural Language Models $[\mathrm{K}\mathrm{MH}^{+}20]$ we train much larger models on many fewer tokens than is typical. As a consequence, although GPT-3 3B is almost $10\mathrm{x}$ larger than RoBERTa-Large (355M params), both models took roughly 50 petaflop/s-days of compute during pre-training. Methodology for these calculations can be found in Appendix D.
图 2.2: 训练期间的总计算量。根据《Scaling Laws For Neural Language Models》[KMH+20]的分析,我们使用远少于常规数量的token训练了更大的模型。因此,尽管GPT-3 3B(35亿参数)的规模几乎是RoBERTa-Large(3.55亿参数)的10倍,但两个模型在预训练阶段都消耗了约50 petaflop/s-days的计算量。具体计算方法详见附录D。
| Dataset | Quantity (tokens) | Weight in training mix | Epochs elapsed when trainingfor300Btokens |
| Common Crawl (filtered) | 410billion | 60% | 0.44 |
| WebText2 | 19billion | 22% | 2.9 |
| Booksl | 12billion | 8% | 1.9 |
| Books2 | 55billion | 8% | 0.43 |
| Wikipedia | 3billion | 3% | 3.4 |
| 数据集 | 数量 (token) | 训练混合权重 | 训练300B token时的轮次 |
|---|---|---|---|
| Common Crawl (过滤后) | 4100亿 | 60% | 0.44 |
| WebText2 | 190亿 | 22% | 2.9 |
| Booksl | 120亿 | 8% | 1.9 |
| Books2 | 550亿 | 8% | 0.43 |
| Wikipedia | 30亿 | 3% | 3.4 |
Table 2.2: Datasets used to train GPT-3. “Weight in training mix” refers to the fraction of examples during training that are drawn from a given dataset, which we intentionally do not make proportional to the size of the dataset. As a result, when we train for 300 billion tokens, some datasets are seen up to 3.4 times during training while other datasets are seen less than once.
表 2.2: 用于训练 GPT-3 的数据集。"训练混合权重"指训练过程中从特定数据集抽取样本的比例,我们刻意使其不与数据集大小成正比。因此,当训练 3000 亿 token 时,部分数据集在训练过程中被使用高达 3.4 次,而其他数据集使用次数不足一次。
A major methodological concern with language models pretrained on a broad swath of internet data, particularly large models with the capacity to memorize vast amounts of content, is potential contamination of downstream tasks by having their test or development sets inadvertently seen during pre-training. To reduce such contamination, we searched for and attempted to remove any overlaps with the development and test sets of all benchmarks studied in this paper. Unfortunately, a bug in the filtering caused us to ignore some overlaps, and due to the cost of training it was not feasible to retrain the model. In Section 4 we characterize the impact of the remaining overlaps, and in future work we will more aggressively remove data contamination.
在基于广泛互联网数据预训练的语言模型(尤其是具备海量内容记忆能力的大模型)中,一个重要的方法论问题是:下游任务的测试集或开发集可能在预训练阶段被意外摄入,从而导致数据污染。为降低此类风险,我们检索并尝试剔除了本文研究的所有基准测试中开发集与测试集的重叠部分。但由于过滤程序存在漏洞,部分重叠未被识别,加之模型重新训练成本过高,我们未能进行二次训练。第4节将分析剩余重叠数据的影响,未来工作中我们将采取更严格的数据净化措施。
2.3 Training Process
2.3 训练过程
As found in $[\mathrm{KMH^{+}}20$ , MKAT18], larger models can typically use a larger batch size, but require a smaller learning rate. We measure the gradient noise scale during training and use it to guide our choice of batch size [MKAT18]. Table 2.1 shows the parameter settings we used. To train the larger models without running out of memory, we use a mixture of model parallelism within each matrix multiply and model parallelism across the layers of the network. All models were trained on V100 GPU’s on part of a high-bandwidth cluster provided by Microsoft. Details of the training process and hyper parameter settings are described in Appendix B.
如 [$[\mathrm{KMH^{+}}20$ , MKAT18] 所述,更大的模型通常可以使用更大的批次大小 (batch size) ,但需要更小的学习率 (learning rate) 。我们在训练过程中测量梯度噪声规模 (gradient noise scale) ,并以此指导批次大小的选择 [MKAT18] 。表 2.1 展示了我们使用的参数设置。为了避免内存不足,我们在训练更大的模型时,采用了矩阵乘法内部模型并行 (model parallelism) 和网络层间模型并行相结合的方法。所有模型均在 Microsoft 提供的高带宽集群部分 V100 GPU 上进行训练。训练过程和超参数设置的详细信息见附录 B。
2.4 Evaluation
2.4 评估
For few-shot learning, we evaluate each example in the evaluation set by randomly drawing $K$ examples from that task’s training set as conditioning, delimited by 1 or 2 newlines depending on the task. For LAMBADA and Storycloze there is no supervised training set available so we draw conditioning examples from the development set and evaluate on the test set. For Winograd (the original, not SuperGLUE version) there is only one dataset, so we draw conditioning examples directly from it.
在少样本学习场景中,我们通过从每个任务的训练集中随机抽取 $K$ 个样本作为条件输入来评估测试集的每个样本,不同任务间使用1到2个换行符分隔。对于LAMBADA和Storycloze任务,由于缺乏监督训练集,我们改从开发集抽取条件样本并在测试集上评估。而原始版Winograd任务(非SuperGLUE版本)仅包含单一数据集,因此直接从该数据集抽取条件样本。
$K$ can be any value from 0 to the maximum amount allowed by the model’s context window, which is $n_{\mathrm{ctx}}=2048$ for all models and typically fits 10 to 100 examples. Larger values of $K$ are usually but not always better, so when a separate development and test set are available, we experiment with a few values of $K$ on the development set and then run the best value on the test set. For some tasks (see Appendix G) we also use a natural language prompt in addition to (or for $K=0$ , instead of) demonstrations.
$K$ 可以是0到模型上下文窗口允许的最大值之间的任意数值,所有模型的上下文窗口大小均为 $n_{\mathrm{ctx}}=2048$,通常可容纳10到100个示例。较大的 $K$ 值通常效果更好(但并非绝对),因此当存在独立的开发和测试集时,我们会在开发集上尝试几个 $K$ 值,然后在测试集上运行最优值。对于某些任务(见附录G),除了演示样本(或在 $K=0$ 时替代演示样本)外,我们还会使用自然语言提示。
On tasks that involve choosing one correct completion from several options (multiple choice), we provide $K$ examples of context plus correct completion, followed by one example of context only, and compare the LM likelihood of each completion. For most tasks we compare the per-token likelihood (to normalize for length), however on a small number of datasets (ARC, OpenBookQA, and RACE) we gain additional benefit as measured on the development set by normalizing by the unconditional probability of each completion, by computing $\frac{P(\mathrm{completion}|\mathrm{context})}{P(\mathrm{completion}|\mathrm{answer}_{-}\mathrm{context})}$ , where answer context is the string "Answer: " or "A: " and is used to prompt that the completion should be an answer but is otherwise generic.
在涉及从多个选项中选择一个正确答案(选择题)的任务中,我们提供 $K$ 个上下文加正确答案的示例,随后给出一个仅有上下文的示例,并比较每个选项的大语言模型生成概率。对于大多数任务,我们比较每个token的似然(以归一化长度),但在少数数据集(ARC、OpenBookQA和RACE)上,通过计算 $\frac{P(\mathrm{答案}|\mathrm{上下文})}{P(\mathrm{答案}|\mathrm{无上下文提示})}$ 对每个选项的无条件概率进行归一化(其中无上下文提示是字符串"Answer: "或"A: ",用于提示补全内容应为答案但保持通用性),我们在开发集上获得了额外收益。
On tasks that involve binary classification, we give the options more semantically meaningful names (e.g. “True” or “False” rather than 0 or 1) and then treat the task like multiple choice; we also sometimes frame the task similar to what is done by $[\mathsf{R S R}^{+}19]$ (see Appendix G) for details.
在涉及二元分类的任务中,我们会为选项赋予更具语义意义的名称(例如用"True"或"False"代替0或1),然后将其视为多选题处理;有时我们也会采用类似$[\mathsf{R S R}^{+}19]$的方法来构建任务框架(详见附录G)。
On tasks with free-form completion, we use beam search with the same parameters as $[\mathsf{R S R}^{+}19]$ : a beam width of 4 and a length penalty of $\alpha=0.6$ . We score the model using F1 similarity score, BLEU, or exact match, depending on what is standard for the dataset at hand.
在自由格式完成的任务中,我们使用与 $[\mathsf{R S R}^{+}19]$ 相同的参数进行束搜索 (beam search) :束宽为4,长度惩罚为 $\alpha=0.6$ 。根据当前数据集的标准,我们使用F1相似度分数、BLEU或精确匹配来评估模型。
Final results are reported on the test set when publicly available, for each model size and learning setting (zero-, one-, and few-shot). When the test set is private, our model is often too large to fit on the test server, so we report results on the development set. We do submit to the test server on a small number of datasets (SuperGLUE, TriviaQA, PiQa) where we were able to make submission work, and we submit only the 200B few-shot results, and report development set results for everything else.
最终结果在测试集公开可用时,按模型规模和学习设置(零样本、单样本和少样本)分别报告。若测试集未公开,由于模型体积过大常无法适配测试服务器,此时改为报告开发集结果。我们仅对少数能成功提交的数据集(SuperGLUE、TriviaQA、PiQa)提交了测试服务器结果,且仅提交200B参数的少样本结果,其余情况均报告开发集结果。
3 Results
3 结果
In Figure 3.1 we display training curves for the 8 models described in Section 2. For this graph we also include 6 additional extra-small models with as few as 100,000 parameters. As observed in $[\mathrm{KMH^{+}}20]$ , language modeling performance follows a power-law when making efficient use of training compute. After extending this trend by two more orders of magnitude, we observe only a slight (if any) departure from the power-law. One might worry that these improvements in cross-entropy loss come only from modeling spurious details of our training corpus. However, we will see in the following sections that improvements in cross-entropy loss lead to consistent performance gains across a broad spectrum of natural language tasks.
在图 3.1 中,我们展示了第 2 节描述的 8 个模型的训练曲线。此图中还包含 6 个参数量低至 10 万的超小型模型。如 $[\mathrm{KMH^{+}}20]$ 所述,当高效利用训练计算资源时,语言建模性能遵循幂律规律。将该趋势再扩展两个数量级后,我们观察到仅出现轻微(若有)偏离幂律的情况。有人可能担心交叉熵损失的改进仅源于对训练语料库中虚假细节的建模。然而,后续章节将表明,交叉熵损失的提升会在广泛自然语言任务中带来持续的性能增益。
Below, we evaluate the 8 models described in Section 2 (the 175 billion parameter parameter GPT-3 and 7 smaller models) on a wide range of datasets. We group the datasets into 9 categories representing roughly similar tasks.
下面,我们将在多种数据集上评估第2节中描述的8个模型(1750亿参数的GPT-3和7个较小模型)。这些数据集被分为9个类别,代表大致相似的任务。
In Section 3.1 we evaluate on traditional language modeling tasks and tasks that are similar to language modeling, such as Cloze tasks and sentence/paragraph completion tasks. In Section 3.2 we evaluate on “closed book” question answering tasks: tasks which require using the information stored in the model’s parameters to answer general knowledge questions. In Section 3.3 we evaluate the model’s ability to translate between languages (especially one-shot and few-shot). In Section 3.4 we evaluate the model’s performance on Winograd Schema-like tasks. In Section 3.5 we evaluate on datasets that involve commonsense reasoning or question answering. In Section 3.6 we evaluate on reading comprehension tasks, in Section 3.7 we evaluate on the SuperGLUE benchmark suite, and in 3.8 we briefly explore NLI. Finally, in Section 3.9, we invent some additional tasks designed especially to probe in-context learning abilities – these tasks focus on on-the-fly reasoning, adaptation skills, or open-ended text synthesis. We evaluate all tasks in the few-shot, one-shot, and zero-shot settings.
在3.1节中,我们评估了传统语言建模任务及类似任务,如完形填空(Cloze)和句子/段落补全任务。3.2节评估了"闭卷"问答任务,这类任务需要利用模型参数中存储的信息来回答常识性问题。3.3节测试了模型在语言翻译方面的能力(特别是单样本和少样本场景)。3.4节评估了模型在类Winograd Schema任务上的表现。3.5节针对涉及常识推理或问答的数据集进行评估。3.6节是阅读理解任务评估,3.7节在SuperGLUE基准测试套件上进行评估,3.8节简要探讨自然语言推理(NLI)。最后在3.9节,我们专门设计了一些新任务来探究上下文学习能力——这些任务聚焦即时推理、适应能力和开放式文本生成。所有任务均在少样本、单样本和零样本设置下进行评估。

Figure 3.1: Smooth scaling of performance with compute. Performance (measured in terms of cross-entropy validation loss) follows a power-law trend with the amount of compute used for training. The power-law behavior observed in $[\mathrm{KMH^{+}}20]$ continues for an additional two orders of magnitude with only small deviations from the predicted curve. For this figure, we exclude embedding parameters from compute and parameter counts. Table 3.1: Zero-shot results on PTB language modeling dataset. Many other common language modeling datasets are omitted because they are derived from Wikipedia or other sources which are included in GPT-3’s training data. $^a[\mathrm{RWC^{+}}19]$
图 3.1: 计算量与性能的平滑扩展关系。性能(以交叉熵验证损失衡量)与训练计算量呈现幂律关系。在$[\mathrm{KMH^{+}}20]$中观察到的幂律行为继续延伸了两个数量级,仅与预测曲线存在微小偏差。本图计算时未计入嵌入参数。
表 3.1: PTB语言建模数据集的零样本结果。许多其他常见语言建模数据集被省略,因为它们源自维基百科或其他已包含在GPT-3训练数据中的来源。$^a[\mathrm{RWC^{+}}19]$
| Setting | PTB |
| SOTA (Zero-Shot) | 35.8° |
| GPT-3 Zero-Shot | 20.5 |
| 设置 | PTB |
|---|---|
| SOTA (零样本) | 35.8° |
| GPT-3 零样本 | 20.5 |
3.1 Language Modeling, Cloze, and Completion Tasks
3.1 语言建模、完形填空与补全任务
In this section we test GPT-3’s performance on the traditional task of language modeling, as well as related tasks that involve predicting a single word of interest, completing a sentence or paragraph, or choosing between possible completions of a piece of text.
在本节中,我们测试GPT-3在传统语言建模任务上的表现,以及涉及预测单个目标词、完成句子或段落、或在文本可能续写选项间选择的相关任务。
3.1.1 Language Modeling
3.1.1 语言建模
We calculate zero-shot perplexity on the Penn Tree Bank (PTB) $[\mathbf{MKM^{+}94}]$ dataset measured in $[\mathrm{RWC^{+}}19]$ . We omit the 4 Wikipedia-related tasks in that work because they are entirely contained in our training data, and we also omit the one-billion word benchmark due to a high fraction of the dataset being contained in our training set. PTB escapes these issues due to predating the modern internet. Our largest model sets a new SOTA on PTB by a substantial margin of 15 points, achieving a perplexity of 20.50. Note that since PTB is a traditional language modeling dataset it does not have a clear separation of examples to define one-shot or few-shot evaluation around, so we measure only zero-shot.
我们在宾州树库(PTB) [$\mathbf{MKM^{+}94}$] 数据集上计算零样本困惑度(perplexity),该指标测量方法参照 [$\mathrm{RWC^{+}}19$]。由于原始论文中4个维基百科相关任务完全包含于我们的训练数据,故予以剔除;同时因十亿词基准测试数据集中有大量内容与训练集重合,该基准也被排除。PTB因早于现代互联网而避免了这类数据污染问题。我们的最大模型以20.50的困惑度显著刷新PTB的SOTA记录,领先优势达15个点。需说明的是,PTB作为传统语言建模数据集,其样本边界不明确导致难以划分单样本或少样本评估,因此仅进行零样本测量。
3.1.2 LAMBADA
3.1.2 LAMBADA
The LAMBADA dataset $[\mathrm{PKL^{+}}16]$ tests the modeling of long-range dependencies in text – the model is asked to predict the last word of sentences which require reading a paragraph of context. It has recently been suggested that the continued scaling of language models is yielding diminishing returns on this difficult benchmark. $[\mathrm{BHT^{+}}20]$ reflect on the small $1.5%$ improvement achieved by a doubling of model size between two recent state of the art results $\mathrm{(ISPP^{+}19]}$ and $[\mathrm{Tur}20],$ and argue that “continuing to expand hardware and data sizes by orders of magnitude is not the path forward”. We find that path is still promising and in a zero-shot setting GPT-3 achieves $76%$ on LAMBADA, a gain of $8%$ over the previous state of the art.
LAMBADA数据集 [PKL+16] 用于测试文本长距离依赖关系的建模能力——模型需要预测句子的最后一个词,这要求通读整个段落上下文。近期有研究表明 [BHT+20],语言模型规模的持续扩大在这个困难基准测试上带来的收益正在递减。他们指出,在两个最新技术成果 [ISPP+19] 和 [Tur20] 之间,模型规模翻倍仅带来1.5%的微小提升,并认为"继续以数量级扩展硬件和数据规模并非前进方向"。但我们发现这条路径仍具潜力,GPT-3在零样本设置下取得了76%的LAMBADA准确率,较先前最优结果提升了8%。
| Setting | LAMBADA (acc) | LAMBADA (ppl) | StoryCloze (acc) | HellaSwag (acc) |
| SOTA | 68.0a | 8.63b | 91.8c | 85.6d |
| GPT-3Zero-Shot | 76.2 | 3.00 | 83.2 | 78.9 |
| GPT-3One-Shot | 72.5 | 3.35 | 84.7 | 78.1 |
| GPT-3Few-Shot | 86.4 | 1.92 | 87.7 | 79.3 |
| 设置 | LAMBADA (准确率) | LAMBADA (困惑度) | StoryCloze (准确率) | HellaSwag (准确率) |
|---|---|---|---|---|
| SOTA | 68.0a | 8.63b | 91.8c | 85.6d |
| GPT-3零样本 (Zero-Shot) | 76.2 | 3.00 | 83.2 | 78.9 |
| GPT-3单样本 (One-Shot) | 72.5 | 3.35 | 84.7 | 78.1 |
| GPT-3少样本 (Few-Shot) | 86.4 | 1.92 | 87.7 | 79.3 |
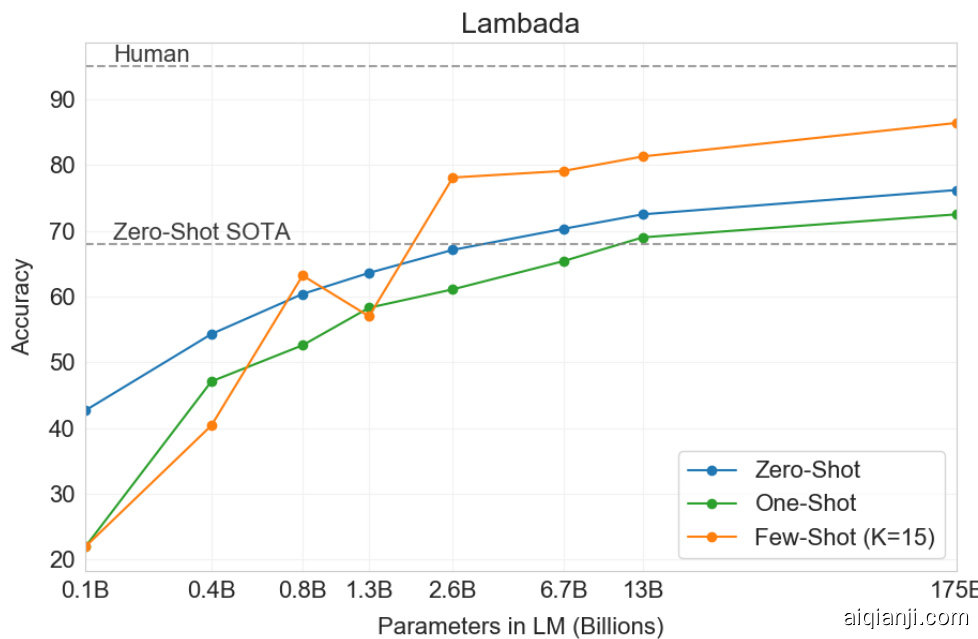
Table 3.2: Performance on cloze and completion tasks. GPT-3 significantly improves SOTA on LAMBADA while achieving respectable performance on two difficult completion prediction datasets. ${}^{a}[\mathrm{Tur}20]^{b}$ ${}^{b}[\mathrm{RWC}^{+}19]$ c[LDL19] ${}^{d}[\mathrm{LCH^{+}}\overline{{2}}0]$ Figure 3.2: On LAMBADA, the few-shot capability of language models results in a strong boost to accuracy. GPT-3 2.7B outperforms the SOTA 17B parameter Turing-NLG [Tur20] in this setting, and GPT-3 175B advances the state of the art by $18%$ . Note zero-shot uses a different format from one-shot and few-shot as described in the text.
表 3.2: 填空与补全任务性能表现。GPT-3 在 LAMBADA 上显著提升 SOTA (State-of-the-art) 水平,同时在两个高难度补全预测数据集上取得可观成绩。${}^{a}[\mathrm{Tur}20]^{b}$ ${}^{b}[\mathrm{RWC}^{+}19]$ c[LDL19] ${}^{d}[\mathrm{LCH^{+}}\overline{{2}}0]$
图 3.2: 在 LAMBADA 任务中,语言模型的少样本能力带来准确率的大幅提升。该场景下,GPT-3 2.7B 超越 17B 参数的 SOTA 模型 Turing-NLG [Tur20],GPT-3 175B 将当前最佳水平提升了 $18%$。需注意零样本采用了与单样本/少样本不同的文本格式。
LAMBADA is also a demonstration of the flexibility of few-shot learning as it provides a way to address a problem that classically occurs with this dataset. Although the completion in LAMBADA is always the last word in a sentence, a standard language model has no way of knowing this detail. It thus assigns probability not only to the correct ending but also to other valid continuations of the paragraph. This problem has been partially addressed in the past with stop-word filters $[\mathrm{RWC^{+}}19]$ (which ban “continuation” words). The few-shot setting instead allows us to “frame” the task as a cloze-test and allows the language model to infer from examples that a completion of exactly one word is desired. We use the following fill-in-the-blank format:
LAMBADA同样展示了少样本学习的灵活性,它提供了一种解决该数据集经典问题的方法。虽然LAMBADA的补全始终是句子最后一个词,但标准语言模型无法获知这一细节。因此它不仅会为正确结尾分配概率,也会为段落其他有效延续分配概率。过去曾通过停用词过滤器 (ban "continuation" words) $[\mathrm{RWC^{+}}19]$ 部分解决该问题。而少样本设置让我们能将任务"框定"为完形填空,使语言模型能从示例中推断出需要精确补全一个单词。我们使用以下填空格式:
Alice was friends with Bob. Alice went to visit her friend . $\rightarrow\mathbf{Bob}$ George bought some baseball equipment, a ball, a glove, and a $\rightarrow$
Alice 和 Bob 是朋友。Alice 去看望她的朋友。$\rightarrow\mathbf{Bob}$
George 买了一些棒球装备,一个球,一只手套,以及一个 $\rightarrow$
When presented with examples formatted this way, GPT-3 achieves $86.4%$ accuracy in the few-shot setting, an increase of over $18%$ from the previous state-of-the-art. We observe that few-shot performance improves strongly with model size. While this setting decreases the performance of the smallest model by almost $20%$ , for GPT-3 it improves accuracy by $10%$ . Finally, the fill-in-blank method is not effective one-shot, where it always performs worse than the zero-shot setting. Perhaps this is because all models still require several examples to recognize the pattern.
当以这种方式呈现示例时,GPT-3在少样本设置下达到了86.4%的准确率,比之前的最先进水平提高了超过18%。我们观察到少样本性能随模型规模显著提升。虽然这种设置使最小模型的性能下降了近20%,但对GPT-3而言准确率提高了10%。最后,填空方法在单样本场景中效果不佳,其表现始终不及零样本设置。这可能是因为所有模型仍需多个示例才能识别模式。
| Setting | NaturalQs | WebQS | TriviaQA |
| RAG (Fine-tuned, Open-Domain) [LPP+20] | 44.5 | 45.5 | 68.0 |
| T5-11B+SSM(Fine-tuned,Closed-Book)[RRS20] | 36.6 | 44.7 | 60.5 |
| T5-11B 3(Fine-tuned,Closed-Book) | 34.5 | 37.4 | 50.1 |
| GPT-3Zero-Shot | 14.6 | 14.4 | 64.3 |
| GPT-3One-Shot | 23.0 | 25.3 | 68.0 |
| GPT-3Few-Shot | 29.9 | 41.5 | 71.2 |
| 设置 | NaturalQs | WebQS | TriviaQA |
|---|---|---|---|
| RAG (微调, 开放域) [LPP+20] | 44.5 | 45.5 | 68.0 |
| T5-11B+SSM (微调, 闭卷) [RRS20] | 36.6 | 44.7 | 60.5 |
| T5-11B 3 (微调, 闭卷) | 34.5 | 37.4 | 50.1 |
| GPT-3 零样本 | 14.6 | 14.4 | 64.3 |
| GPT-3 单样本 | 23.0 | 25.3 | 68.0 |
| GPT-3 少样本 | 29.9 | 41.5 | 71.2 |
One note of caution is that an analysis of test set contamination identified that a significant minority of the LAMBADA dataset appears to be present in our training data – however analysis performed in Section 4 suggests negligible impact on performance.
需要提醒的是,一项关于测试集污染的分析发现,LAMBADA数据集中有相当一部分似乎存在于我们的训练数据中——但第4节进行的分析表明这对性能的影响微乎其微。
3.1.3 HellaSwag
3.1.3 HellaSwag
The HellaSwag dataset $[\mathrm{ZHB^{+}19}]$ involves picking the best ending to a story or set of instructions. The examples were adversarial ly mined to be difficult for language models while remaining easy for humans (who achieve $95.6%$ accuracy). GPT-3 achieves $78.1%$ accuracy in the one-shot setting and $79.3%$ accuracy in the few-shot setting, outperforming the $75.4%$ accuracy of a fine-tuned 1.5B parameter language model $[Z\mathrm{HR}^{+}19]$ but still a fair amount lower than the overall SOTA of $85.6%$ achieved by the fine-tuned multi-task model ALUM.
HellaSwag数据集 [ZHB+19] 的任务是从故事或指令集中选择最佳结局。该数据集通过对抗性挖掘构建样例,旨在使语言模型难以处理而人类仍能轻松应对(人类准确率达95.6%)。GPT-3在单样本设置中达到78.1%准确率,少样本设置中达79.3%,优于微调1.5B参数语言模型 [ZHR+19] 的75.4%准确率,但仍显著低于经微调的多任务模型ALUM创造的整体SOTA记录85.6%。
3.1.4 StoryCloze
3.1.4 StoryCloze
We next evaluate GPT-3 on the StoryCloze 2016 dataset $[\mathrm{MCH^{+}}16]$ , which involves selecting the correct ending sentence for five-sentence long stories. Here GPT-3 achieves $83.2%$ in the zero-shot setting and $87.7%$ in the few-shot setting (with $K=70$ ). This is still $4.1%$ lower than the fine-tuned SOTA using a BERT based model [LDL19] but improves over previous zero-shot results by roughly $10%$ .
我们接下来在StoryCloze 2016数据集$[\mathrm{MCH^{+}}16]$上评估GPT-3,该任务需要为五句话的故事选择正确的结尾句。GPT-3在零样本设置下达到83.2%准确率,在少样本设置( $K=70$ )下达到87.7%。这仍比基于BERT微调的SOTA模型[LDL19]低4.1%,但相较之前的零样本结果提升了约10%。
3.2 Closed Book Question Answering
3.2 闭卷问答
In this section we measure GPT-3’s ability to answer questions about broad factual knowledge. Due to the immense amount of possible queries, this task has normally been approached by using an information retrieval system to find relevant text in combination with a model which learns to generate an answer given the question and the retrieved text. Since this setting allows a system to search for and condition on text which potentially contains the answer it is denoted “open-book”. [RRS20] recently demonstrated that a large language model can perform surprisingly well directly answering the questions without conditioning on auxilliary information. They denote this more restrictive evaluation setting as “closed-book”. Their work suggests that even higher-capacity models could perform even better and we test this hypothesis with GPT-3. We evaluate GPT-3 on the 3 datasets in [RRS20]: Natural Questions $[\mathrm{KPR^{+}}19]$ , Web Questions [BCFL13], and TriviaQA [JCWZ17], using the same splits. Note that in addition to all results being in the closed-book setting, our use of few-shot, one-shot, and zero-shot evaluations represent an even stricter setting than previous closed-book QA work: in addition to external content not being allowed, fine-tuning on the Q&A dataset itself is also not permitted.
在本节中,我们评估GPT-3回答广泛事实性知识问题的能力。由于可能的查询数量庞大,该任务通常采用信息检索系统结合生成模型的方式实现,即检索相关文本后由模型学习根据问题和检索文本生成答案。这种允许系统搜索并基于可能包含答案的文本进行推理的设置被称为"开卷"模式。[RRS20]最近证明,大语言模型无需依赖辅助信息就能直接回答问题,且表现惊人。他们将这种限制更严格的评估设置称为"闭卷"模式。其研究表明更高容量的模型可能表现更优,我们通过GPT-3验证这一假设。我们在[RRS20]中的三个数据集上评估GPT-3:Natural Questions $[\mathrm{KPR^{+}}19]$、Web Questions [BCFL13]和TriviaQA [JCWZ17],使用相同的数据划分。需注意,除了所有结果均在闭卷设置下获得外,我们采用的少样本、单样本和零样本评估代表了比以往闭卷问答研究更严格的设置:不仅禁止使用外部内容,也不允许在问答数据集本身上进行微调。
The results for GPT-3 are shown in Table 3.3. On TriviaQA, we achieve $64.3%$ in the zero-shot setting, $68.0%$ in the one-shot setting, and $71.2%$ in the few-shot setting. The zero-shot result already outperforms the fine-tuned T5-11B by $14.2%$ , and also outperforms a version with Q&A tailored span prediction during pre-training by $3.8%$ . The one-shot result improves by $3.7%$ and matches the SOTA for an open-domain QA system which not only fine-tunes but also makes use of a learned retrieval mechanism over a 15.3B parameter dense vector index of 21M documents $[\mathrm{LPP^{+}}20]$ . GPT-3’s few-shot result further improves performance another $3.2%$ beyond this.
GPT-3的结果如表3.3所示。在TriviaQA上,我们在零样本(zero-shot)设置下达到了64.3%,单样本(one-shot)设置下达到68.0%,少样本(few-shot)设置下达到71.2%。零样本结果已比微调后的T5-11B高出14.2%,也比预训练期间采用问答定制跨度预测的版本高出3.8%。单样本结果提升了3.7%,与当前最先进的开放域问答系统持平 [LPP+20] ——该系统不仅进行了微调,还使用了基于15.3B参数稠密向量索引(覆盖2100万文档)的学习检索机制。GPT-3的少样本结果在此基础上进一步将性能提升了3.2%。
On Web Questions (WebQs), GPT-3 achieves $14.4%$ in the zero-shot setting, $25.3%$ in the one-shot setting, and $41.5%$ in the few-shot setting. This compares to $37.4%$ for fine-tuned T5-11B, and $44.7%$ for fine-tuned $\mathrm{T}5{-}11\mathbf{B}{+}\mathrm{SSM}$ which uses a Q&A-specific pre-training procedure. GPT-3 in the few-shot setting approaches the performance of state-of-the-art fine-tuned models. Notably, compared to TriviaQA, WebQS shows a much larger gain from zero-shot to few-shot (and indeed its zero-shot and one-shot performance are poor), perhaps suggesting that the WebQs questions and/or the style of their answers are out-of-distribution for GPT-3. Nevertheless, GPT-3 appears able to adapt to this distribution, recovering strong performance in the few-shot setting.
在Web Questions (WebQs)数据集上,GPT-3在零样本设置下达到14.4%准确率,单样本设置下25.3%,少样本设置下41.5%。相比之下,经过微调的T5-11B模型成绩为37.4%,而采用问答专用预训练流程的微调模型$\mathrm{T}5{-}11\mathbf{B}{+}\mathrm{SSM}$达到44.7%。少样本设置的GPT-3已接近当前最优微调模型的性能。值得注意的是,与TriviaQA相比,WebQS从零样本到少样本的性能提升更为显著(其零样本和单样本表现确实较差),这可能表明WebQs的问题和/或答案风格超出了GPT-3的分布范围。尽管如此,GPT-3似乎能够适应这种分布,在少样本设置下恢复了强劲性能。

Figure 3.3: On TriviaQA GPT3’s performance grows smoothly with model size, suggesting that language models continue to absorb knowledge as their capacity increases. One-shot and few-shot performance make significant gains over zero-shot behavior, matching and exceeding the performance of the SOTA fine-tuned open-domain model, RAG $[\mathrm{LPP^{+}}20]$ 1
图 3.3: 在TriviaQA上,GPT3的性能随模型规模平稳提升,表明大语言模型会随着容量增加持续吸收知识。单样本和少样本性能较零样本表现有显著提升,达到并超越了当前最优微调开放域模型RAG [LPP+20]的水平。
On Natural Questions (NQs) GPT-3 achieves $14.6%$ in the zero-shot setting, $23.0%$ in the one-shot setting, and $29.9%$ in the few-shot setting, compared to $36.6%$ for fine-tuned T5 $11\mathbf{B}{+}\mathbf{S}\mathbf{S}\mathbf{M}$ . Similar to WebQS, the large gain from zero-shot to few-shot may suggest a distribution shift, and may also explain the less competitive performance compared to TriviaQA and WebQS. In particular, the questions in NQs tend towards very fine-grained knowledge on Wikipedia specifically which could be testing the limits of GPT-3’s capacity and broad pre training distribution.
在Natural Questions (NQs)任务中,GPT-3在零样本 (zero-shot) 设置下达到14.6%,单样本 (one-shot) 设置下达到23.0%,少样本 (few-shot) 设置下达到29.9%,而经过微调的T5 11B+SSM模型则达到36.6%。与WebQS类似,从零样本到少样本的大幅提升可能表明存在分布偏移,这也可能是其表现不如TriviaQA和WebQS的原因。特别是,NQs中的问题往往涉及维基百科上非常细粒度的知识,这可能测试了GPT-3的能力极限及其广泛的预训练分布范围。
Overall, on one of the three datasets GPT-3’s one-shot matches the open-domain fine-tuning SOTA. On the other two datasets it approaches the performance of the closed-book SOTA despite not using fine-tuning. On all 3 datasets, we find that performance scales very smoothly with model size (Figure 3.3 and Appendix H Figure H.7), possibly reflecting the idea that model capacity translates directly to more ‘knowledge’ absorbed in the parameters of the model.
总体而言,在三个数据集中,GPT-3的零样本性能在一个数据集上达到了开放领域微调SOTA (state-of-the-art) 的水平。在另外两个数据集上,尽管没有使用微调,其性能也接近闭卷SOTA。在所有三个数据集中,我们发现模型性能随规模增长呈现非常平滑的上升趋势 (图3.3及附录H图H.7) ,这可能反映了模型容量直接转化为参数中吸收的更多"知识"的观点。
3.3 Translation
3.3 翻译
For GPT-2 a filter was used on a multilingual collection of documents to produce an English only dataset due to capacity concerns. Even with this filtering GPT-2 showed some evidence of multilingual capability and performed non-trivially when translating between French and English despite only training on 10 megabytes of remaining French text. Since we increase the capacity by over two orders of magnitude from GPT-2 to GPT-3, we also expand the scope of the training dataset to include more representation of other languages, though this remains an area for further improvement. As discussed in 2.2 the majority of our data is derived from raw Common Crawl with only quality-based filtering. Although GPT-3’s training data is still primarily English $93%$ by word count), it also includes $7%$ of text in other languages. These languages are documented in the supplemental material. In order to better understand translation capability, we also expand our analysis to include two additional commonly studied languages, German and Romanian.
由于容量限制,GPT-2在多语言文档集合上采用了过滤机制,最终生成纯英文数据集。即便如此,GPT-2仍展现出一定的多语言能力,在仅接受10兆字节剩余法语文本训练的情况下,其法英翻译表现仍具实际意义。从GPT-2到GPT-3,我们将模型容量提升超过两个数量级,同时扩展了训练数据集范围以涵盖更多其他语言,但这仍是待改进领域。如2.2节所述,我们的数据主要来自原始Common Crawl爬虫,仅进行基于质量的过滤。虽然GPT-3训练数据按词数统计仍以英文为主(93%),但也包含7%的其他语言文本(具体语种见补充材料)。为深入理解翻译能力,我们将分析范围扩展至德语和罗马尼亚语这两种常用研究对象。
Existing unsupervised machine translation approaches often combine pre training on a pair of monolingual datasets with back-translation [SHB15] to bridge the two languages in a controlled way. By contrast, GPT-3 learns from a blend of training data that mixes many languages together in a natural way, combining them on a word, sentence, and document level. GPT-3 also uses a single training objective which is not customized or designed for any task in particular. However, our one / few-shot settings aren’t strictly comparable to prior unsupervised work since they make use of a small amount of paired examples (1 or 64). This corresponds to up to a page or two of in-context training data.
现有的无监督机器翻译方法通常将对单语数据集对的预训练与回译 [SHB15] 相结合,以可控方式桥接两种语言。相比之下,GPT-3 从混合多语言的训练数据中自然学习,在单词、句子和文档层面进行融合。GPT-3 还采用单一训练目标,并未针对任何特定任务进行定制或设计。不过,我们的零样本/少样本设置与之前的无监督工作并不严格可比,因为它们使用了少量配对样本 (1 或 64)。这相当于最多一两页的上下文训练数据。
Results are shown in Table 3.4. Zero-shot GPT-3, which only receives on a natural language description of the task, still under performs recent unsupervised NMT results. However, providing only a single example demonstration for
结果如表 3.4 所示。零样本 (Zero-shot) GPT-3 仅接收任务的自然语言描述,其表现仍逊于近期无监督神经机器翻译 (NMT) 的结果。然而仅需提供单个示例演示...
| Setting | En→→Fr | Fr→En | En→De | De→→En | En→→Ro | Ro→→En |
| SOTA (Supervised) | 45.6a | 35.0 | 41.2c | 40.2d | 38.5e | 39.9e |
| XLM [LC19] | 33.4 | 33.3 | 26.4 | 34.3 | 33.3 | 31.8 |
| MASS [STQ+19] | 37.5 | 34.9 | 28.3 | 35.2 | 35.2 | 33.1 |
| mBART [LGG+20] | - | 29.8 | 34.0 | 35.0 | 30.5 | |
| GPT-3Zero-Shot | 25.2 | 21.2 | 24.6 | 27.2 | 14.1 | 19.9 |
| GPT-3One-Shot | 28.3 | 33.7 | 26.2 | 30.4 | 20.6 | 38.6 |
| GPT-3Few-Shot | 32.6 | 39.2 | 29.7 | 40.6 | 21.0 | 39.5 |
| 设置 | En→Fr | Fr→En | En→De | De→En | En→Ro | Ro→En |
|---|---|---|---|---|---|---|
| SOTA (监督式) | 45.6a | 35.0 | 41.2c | 40.2d | 38.5e | 39.9e |
| XLM [LC19] | 33.4 | 33.3 | 26.4 | 34.3 | 33.3 | 31.8 |
| MASS [STQ+19] | 37.5 | 34.9 | 28.3 | 35.2 | 35.2 | 33.1 |
| mBART [LGG+20] | - | 29.8 | 34.0 | 35.0 | 30.5 | |
| GPT-3零样本 | 25.2 | 21.2 | 24.6 | 27.2 | 14.1 | 19.9 |
| GPT-3单样本 | 28.3 | 33.7 | 26.2 | 30.4 | 20.6 | 38.6 |
| GPT-3少样本 | 32.6 | 39.2 | 29.7 | 40.6 | 21.0 | 39.5 |

Table 3.4: Few-shot GPT-3 outperforms previous unsupervised NMT work by 5 BLEU when translating into English reflecting its strength as an English LM. We report BLEU scores on the WMT’14 $\mathrm{Fr}{\leftrightarrow}\mathrm{En}$ , WMT’16 $\mathrm{De}{\leftrightarrow}\mathrm{En}$ , and WMT’16 $\mathrm{Ro}{\leftrightarrow}\mathrm{En}$ datasets as measured by multi-bleu.perl with XLM’s tokenization in order to compare most closely with prior unsupervised NMT work. SacreBLEUf [Pos18] results reported in Appendix H. Underline indicates an unsupervised or few-shot SOTA, bold indicates supervised SOTA with relative confidence. a[EOAG18] b[DHKH14] ${}^{c}[\mathrm{WXH^{+}}18]$ d[oR16] ${}^{e}[\mathrm{LGG}^{+}20]$ f [SacreBLEU signature: BLEU $^+$ case.mixed+numrefs. $1+$ smooth.exp+tok.intl+version.1.2.20] Figure 3.4: Few-shot translation performance on 6 language pairs as model capacity increases. There is a consistent trend of improvement across all datasets as the model scales, and as well as tendency for translation into English to be stronger than translation from English.
表 3.4: 少样本 GPT-3 在翻译成英语时比之前的无监督神经机器翻译 (NMT) 工作高出 5 BLEU 分,反映了其作为英语大语言模型的优势。我们在 WMT’14 $\mathrm{Fr}{\leftrightarrow}\mathrm{En}$、WMT’16 $\mathrm{De}{\leftrightarrow}\mathrm{En}$ 和 WMT’16 $\mathrm{Ro}{\leftrightarrow}\mathrm{En}$ 数据集上报告了 BLEU 分数,使用 multi-bleu.perl 脚本并采用 XLM 的 Token 化方式,以便与之前的无监督 NMT 工作进行最直接的比较。SacreBLEU [Pos18] 的结果见附录 H。下划线表示无监督或少样本的当前最佳水平 (SOTA),加粗表示相对可信的有监督 SOTA。a[EOAG18] b[DHKH14] ${}^{c}[\mathrm{WXH^{+}}18]$ d[oR16] ${}^{e}[\mathrm{LGG}^{+}20]$ f [SacreBLEU 签名: BLEU $^+$ case.mixed+numrefs. $1+$ smooth.exp+tok.intl+version.1.2.20]
图 3.4: 随着模型容量的增加,6 种语言对的少样本翻译性能表现。所有数据集上都呈现出随着模型规模扩大而持续提升的趋势,并且翻译成英语的表现普遍优于从英语翻译的表现。
| Setting | Winograd | Winogrande (XL) |
| Fine-tunedSOTA | 90.1a | 84.6b |
| GPT-3Zero-Shot | 88.3* | 70.2 |
| GPT-3One-Shot | 89.7* | 73.2 |
| GPT-3Few-Shot | 88.6* | 77.7 |
| 设置 | Winograd | Winogrande (XL) |
|---|---|---|
| 微调SOTA | 90.1a | 84.6b |
| GPT-3零样本 | 88.3* | 70.2 |
| GPT-3单样本 | 89.7* | 73.2 |
| GPT-3少样本 | 88.6* | 77.7 |
Table 3.5: Results on the WSC273 version of Winograd schemas and the adversarial Winogrande dataset. See Section 4 for details on potential contamination of the Winograd test set. a[SBBC19] $^b[\mathrm{LYN}^{+}20]$
表 3.5: WSC273版Winograd模式和对抗性Winogrande数据集上的结果。关于Winograd测试集潜在污染问题的详情参见第4节。a[SBBC19] $^b[\mathrm{LYN}^{+}20]$
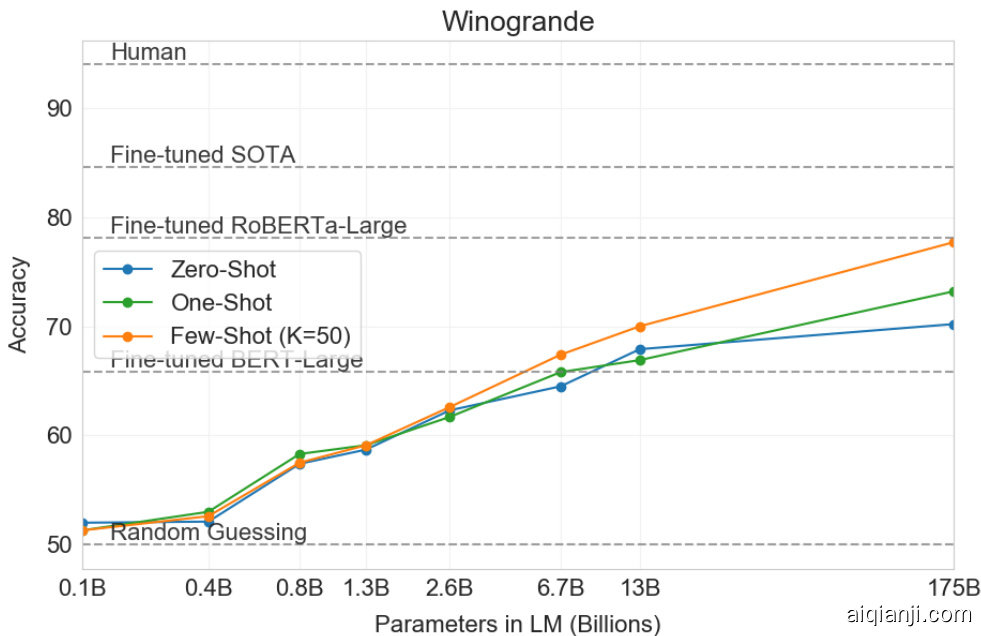
Figure 3.5: Zero-, one-, and few-shot performance on the adversarial Winogrande dataset as model capacity scales. Scaling is relatively smooth with the gains to few-shot learning increasing with model size, and few-shot GPT-3 175B is competitive with a fine-tuned RoBERTA-large.
图 3.5: 对抗性 Winogrande 数据集上零样本、单样本和少样本性能随模型容量扩展的变化。扩展过程相对平稳,少样本学习的收益随模型规模增加而提升,少样本 GPT-3 175B 的表现与微调后的 RoBERTA-large 相当。
each translation task improves performance by over 7 BLEU and nears competitive performance with prior work. GPT-3 in the full few-shot setting further improves another 4 BLEU resulting in similar average performance to prior unsupervised NMT work. GPT-3 has a noticeable skew in its performance depending on language direction. For the three input languages studied, GPT-3 significantly outperforms prior unsupervised NMT work when translating into English but under performs when translating in the other direction. Performance on En-Ro is a noticeable outlier at over 10 BLEU worse than prior unsupervised NMT work. This could be a weakness due to reusing the byte-level BPE tokenizer of GPT-2 which was developed for an almost entirely English training dataset. For both Fr-En and De-En, few shot GPT-3 outperforms the best supervised result we could find but due to our unfamiliarity with the literature and the appearance that these are un-competitive benchmarks we do not suspect those results represent true state of the art. For Ro-En, few shot GPT-3 performs within 0.5 BLEU of the overall SOTA which is achieved by a combination of unsupervised pre training, supervised finetuning on 608K labeled examples, and back translation [LHCG19b].
每项翻译任务都能将性能提升超过7个BLEU分,并接近先前工作的竞争水平。在完整少样本设置下,GPT-3进一步提升了4个BLEU分,使得平均性能与之前的无监督神经机器翻译(NMT)工作相当。GPT-3的性能表现存在明显的语言方向偏差:针对所研究的三种输入语言,当翻译成英语时其表现显著优于先前的无监督NMT工作,但在反向翻译时表现欠佳。其中En-Ro方向的表现尤为异常,比先前无监督NMT工作低了超过10个BLEU分——这可能是由于沿用了GPT-2的字节级BPE分词器(该分词器基于几乎全英文的训练数据集开发)导致的缺陷。在Fr-En和De-En任务中,少样本GPT-3的表现优于我们找到的最佳监督学习结果,但由于我们对文献掌握有限且这些基准测试似乎缺乏竞争力,我们认为这些结果并不能代表真实的最先进水平。对于Ro-En任务,少样本GPT-3与当前SOTA(通过无监督预训练、60.8万标注样本的监督微调及回译[LHCG19b]联合实现)的差距仅为0.5个BLEU分。
Finally, across all language pairs and across all three settings (zero-, one-, and few-shot), there is a smooth trend of improvement with model capacity. This is shown in Figure 3.4 in the case of few-shot results, and scaling for all three settings is shown in Appendix H.
最后,在所有语言对和三种设置(零样本、单样本和少样本)下,模型性能都随着容量提升呈现平滑的增长趋势。图3.4展示了少样本结果的情况,三种设置下的规模缩放曲线详见附录H。
3.4 Winograd-Style Tasks
3.4 Winograd风格任务
The Winograd Schemas Challenge [LDM12] is a classical task in NLP that involves determining which word a pronoun refers to, when the pronoun is grammatically ambiguous but semantically unambiguous to a human. Recently fine-tuned language models have achieved near-human performance on the original Winograd dataset, but more difficult versions such as the adversarial ly-mined Winogrande dataset [SBBC19] still significantly lag human performance. We test GPT-3’s performance on both Winograd and Winogrande, as usual in the zero-, one-, and few-shot setting.
Winograd模式挑战赛[LDM12]是自然语言处理(NLP)领域的经典任务,旨在当代词存在语法歧义但人类能明确理解语义时,判定代词所指代的词语。近期经过微调的大语言模型在原始Winograd数据集上已达到接近人类的表现,但在对抗性挖掘的Winogrande数据集[SBBC19]等更复杂版本上仍显著落后于人类水平。我们按照惯例采用零样本、单样本和少样本设置,测试GPT-3在Winograd和Winogrande数据集上的表现。
Table 3.6: GPT-3 results on three commonsense reasoning tasks, PIQA, ARC, and OpenBookQA. GPT-3 Few-Shot PIQA result is evaluated on the test server. See Section 4 for details on potential contamination issues on the PIQA test set.
| Setting | PIQA | ARC (Easy) | ARC (Challenge) | OpenBookQA |
| Fine-tunedSOTA | 79.4 | 92.0[KKS+ 20] | 78.5[KKS+20] | 87.2[KKS+20] |
| GPT-3Zero-Shot | 80.5* | 68.8 | 51.4 | 57.6 |
| GPT-3One-Shot | 80.5* | 71.2 | 53.2 | 58.8 |
| GPT-3Few-Shot | 82.8* | 70.1 | 51.5 | 65.4 |
表 3.6: GPT-3 在三个常识推理任务 (PIQA、ARC 和 OpenBookQA) 上的结果。GPT-3 少样本 PIQA 结果在测试服务器上评估。有关 PIQA 测试集潜在污染问题的详细信息,请参阅第 4 节。
| 设置 | PIQA | ARC (Easy) | ARC (Challenge) | OpenBookQA |
|---|---|---|---|---|
| Fine-tunedSOTA | 79.4 | 92.0 [KKS+ 20] | 78.5 [KKS+ 20] | 87.2 [KKS+ 20] |
| GPT-3 零样本 | 80.5* | 68.8 | 51.4 | 57.6 |
| GPT-3 单样本 | 80.5* | 71.2 | 53.2 | 58.8 |
| GPT-3 少样本 | 82.8* | 70.1 | 51.5 | 65.4 |
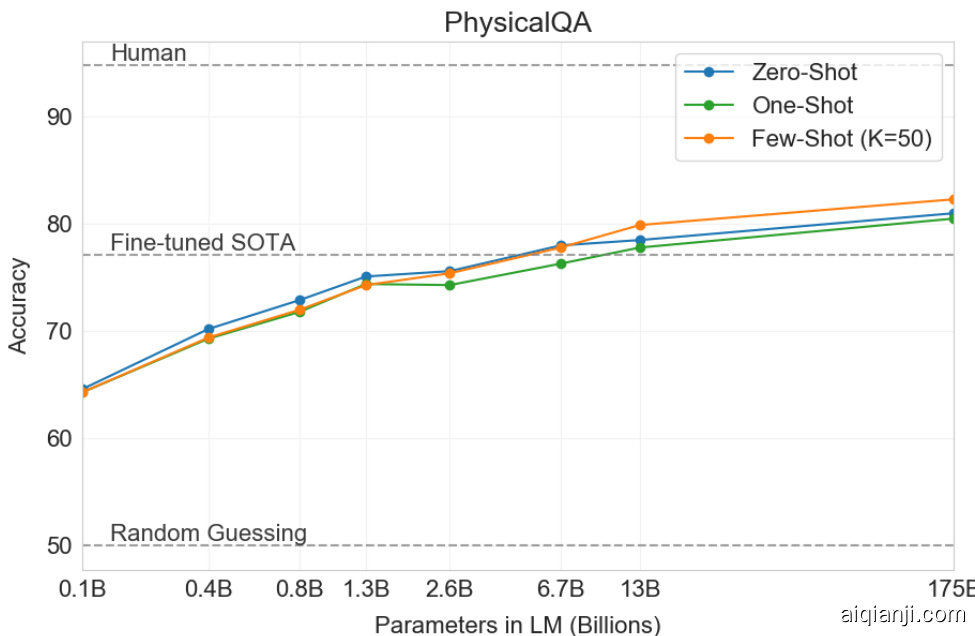
Figure 3.6: GPT-3 results on PIQA in the zero-shot, one-shot, and few-shot settings. The largest model achieves a score on the development set in all three conditions that exceeds the best recorded score on the task.
图 3.6: GPT-3 在零样本、单样本和少样本设置下 PIQA 任务的结果。最大模型在开发集上的三种条件下均取得了超过该任务历史最佳记录的分数。
On Winograd we test GPT-3 on the original set of 273 Winograd schemas, using the same “partial evaluation” method described in $[\mathrm{RWC^{+}}19]$ . Note that this setting differs slightly from the WSC task in the SuperGLUE benchmark, which is presented as binary classification and requires entity extraction to convert to the form described in this section. On Winograd GPT-3 achieves $88.3%$ , $89.7%$ , and $88.6%$ in the zero-shot, one-shot, and few-shot settings, showing no clear in-context learning but in all cases achieving strong results just a few points below state-of-the-art and estimated human performance. We note that contamination analysis found some Winograd schemas in the training data but this appears to have only a small effect on results (see Section 4).
在Winograd任务中,我们使用与[RWC+19]相同的"部分评估"方法,在原始的273个Winograd模式集上测试GPT-3。需要注意的是,该设置与SuperGLUE基准中的WSC任务略有不同,后者以二元分类形式呈现,并需要通过实体提取转换为本节所述形式。GPT-3在Winograd任务上的零样本、单样本和少样本设置中分别达到88.3%、89.7%和88.6%的准确率,虽未显示出明显的上下文学习能力,但在所有情况下都取得了仅略低于最先进水平和预估人类表现的优异成绩。我们注意到污染分析发现训练数据中包含部分Winograd模式,但这似乎对结果影响甚微(参见第4节)。
On the more difficult Winogrande dataset, we do find gains to in-context learning: GPT-3 achieves $70.2%$ in the zero-shot setting, $73.2%$ in the one-shot setting, and $77.7%$ in the few-shot setting. For comparison a fine-tuned RoBERTA model achieves $79%$ , state-of-the-art is $84.6%$ achieved with a fine-tuned high capacity model (T5), and human performance on the task as reported by [SBBC19] is $94.0%$ .
在更具挑战性的Winogrande数据集上,我们确实观察到上下文学习带来的提升:GPT-3在零样本(Zero-shot)设置下达到70.2%,单样本(One-shot)设置下达到73.2%,少样本(Few-shot)设置下达到77.7%。作为对比,微调后的RoBERTA模型成绩为79%,当前最佳成绩84.6%由微调的高容量模型(T5)取得,而[SBBC19]报告的人类在该任务上的表现为94.0%。
3.5 Common Sense Reasoning
3.5 常识推理
Next we consider three datasets which attempt to capture physical or scientific reasoning, as distinct from sentence completion, reading comprehension, or broad knowledge question answering. The first, PhysicalQA (PIQA) $[\mathrm{BZB^{+}19}]$ asks common sense questions about how the physical world works and is intended as a probe of grounded understanding of the world. GPT-3 achieves $81.0%$ accuracy zero-shot, $80.5%$ accuracy one-shot, and $82.8%$ accuracy few-shot (the last measured on PIQA’s test server). This compares favorably to the $79.4%$ accuracy prior state-of-the-art of a fine-tuned RoBERTa. PIQA shows relatively shallow scaling with model size and is still over $10%$ worse than human performance, but GPT-3’s few-shot and even zero-shot result outperform the current state-of-the-art. Our analysis flagged PIQA for a potential data contamination issue (despite hidden test labels), and we therefore conservatively mark the result with an asterisk. See Section 4 for details.
接下来我们考虑三个试图捕捉物理或科学推理能力的数据集,这些与句子补全、阅读理解或广泛知识问答不同。第一个数据集 PhysicalQA (PIQA) [BZB+19] 提出了关于物理世界运作的常识性问题,旨在探究对世界的具身理解。GPT-3 在零样本条件下达到 81.0% 准确率,单样本 80.5%,少样本 82.8%(最后一项在 PIQA 测试服务器上测得)。这优于微调 RoBERTa 之前 79.4% 的最先进水平。PIQA 显示出随模型规模增长的较浅提升曲线,且仍比人类表现低 10% 以上,但 GPT-3 的少样本甚至零样本结果已超越当前最优技术。我们的分析发现 PIQA 可能存在数据污染问题(尽管测试标签被隐藏),因此保守地用星号标记该结果。详见第 4 节。
Table 3.7: Results on reading comprehension tasks. All scores are F1 except results for RACE which report accuracy. ${}^{a}[\mathrm{JZC^{+}}19]$ b[JN20] c[AI19] d[QIA20] ${}^{e}[\mathrm{SPP^{+}}19]$
| Setting | CoQA | DROP | QuAC | SQuADv2 | RACE-h | RACE-m |
| Fine-tunedSOTA | 90.7a | 89.1b | 74.4c | 93.0d | 30'06 | 93.1e |
| GPT-3Zero-Shot | 81.5 | 23.6 | 41.5 | 59.5 | 45.5 | 58.4 |
| GPT-3One-Shot | 84.0 | 34.3 | 43.3 | 65.4 | 45.9 | 57.4 |
| GPT-3Few-Shot | 85.0 | 36.5 | 44.3 | 69.8 | 46.8 | 58.1 |
表 3.7: 阅读理解任务结果。除RACE报告准确率外,其余分数均为F1值。${}^{a}[\mathrm{JZC^{+}}19]$ b[JN20] c[AI19] d[QIA20] ${}^{e}[\mathrm{SPP^{+}}19]$
| 设置 | CoQA | DROP | QuAC | SQuADv2 | RACE-h | RACE-m |
|---|---|---|---|---|---|---|
| 微调SOTA | 90.7a | 89.1b | 74.4c | 93.0d | 30'06 | 93.1e |
| GPT-3零样本 | 81.5 | 23.6 | 41.5 | 59.5 | 45.5 | 58.4 |
| GPT-3单样本 | 84.0 | 34.3 | 43.3 | 65.4 | 45.9 | 57.4 |
| GPT-3少样本 | 85.0 | 36.5 | 44.3 | 69.8 | 46.8 | 58.1 |
ARC $[\mathrm{CCE^{+}}18]$ is a dataset of multiple-choice questions collected from 3rd to 9th grade science exams. On the “Challenge” version of the dataset which has been filtered to questions which simple statistical or information retrieval methods are unable to correctly answer, GPT-3 achieves $51.4%$ accuracy in the zero-shot setting, $53.2%$ in the one-shot setting, and $51.5%$ in the few-shot setting. This is approaching the performance of a fine-tuned RoBERTa baseline $(55.9%)$ from UnifiedQA $[\mathrm{KKS}^{+}20]$ . On the “Easy” version of the dataset (questions which either of the mentioned baseline approaches answered correctly), GPT-3 achieves $68.8%$ , $71.2%$ , and $70.1%$ which slightly exceeds a fine-tuned RoBERTa baseline from $[\mathrm{KKS^{+}}20]$ . However, both of these results are still much worse than the overall SOTAs achieved by the UnifiedQA which exceeds GPT-3’s few-shot results by $27%$ on the challenge set and $22%$ on the easy set.
ARC [$\mathrm{CCE^{+}}18$] 是一个收集自3至9年级科学考试选择题的数据集。在该数据集的"挑战"版本(经过筛选仅包含简单统计或信息检索方法无法正确回答的问题)上,GPT-3在零样本设置下达到51.4%准确率,单样本设置下53.2%,少样本设置下51.5%。这一表现接近来自UnifiedQA [$\mathrm{KKS}^{+}20$]的微调RoBERTa基线(55.9%)。在"简单"版本数据集(被提及的基线方法能正确回答的问题)上,GPT-3分别取得68.8%、71.2%和70.1%的准确率,略优于[$\mathrm{KKS^{+}}20$]中的微调RoBERTa基线。然而,这些结果仍远低于UnifiedQA实现的整体SOTA表现——其在挑战集上超过GPT-3少样本结果27%,在简单集上超过22%。
On OpenBookQA [MCKS18], GPT-3 improves significantly from zero to few shot settings but is still over 20 points short of the overall SOTA. GPT-3’s few-shot performance is similar to a fine-tuned BERT Large baseline on the leader board.
在OpenBookQA [MCKS18]上,GPT-3从零样本到少样本设置有了显著提升,但仍比整体SOTA低了20多分。GPT-3的少样本表现与排行榜上经过微调的BERT Large基线相当。
Overall, in-context learning with GPT-3 shows mixed results on commonsense reasoning tasks, with only small and inconsistent gains observed in the one and few-shot learning settings for both PIQA and ARC, but a significant improvement is observed on OpenBookQA. GPT-3 sets SOTA on the new PIQA dataset in all evaluation settings.
总体而言,GPT-3的上下文学习在常识推理任务上表现参差:在PIQA和ARC的单样本与少样本学习设置中仅观察到微小且不一致的提升,但在OpenBookQA上取得了显著进步。GPT-3在所有评估设置中均刷新了PIQA新数据集的最优成绩(SOTA)。
3.6 Reading Comprehension
3.6 阅读理解
Next we evaluate GPT-3 on the task of reading comprehension. We use a suite of 5 datasets including abstract ive, multiple choice, and span based answer formats in both dialog and single question settings. We observe a wide spread in GPT-3’s performance across these datasets suggestive of varying capability with different answer formats. In general we observe GPT-3 is on par with initial baselines and early results trained using contextual representations on each respective dataset.
接下来我们评估GPT-3在阅读理解任务上的表现。我们使用了包含5个数据集的测试套件,涵盖摘要生成、多项选择和基于文本片段回答的形式,涉及对话和单问题两种设置。观察到GPT-3在这些数据集上的表现差异较大,表明其对不同回答形式的处理能力存在差异。总体而言,GPT-3的表现与各数据集上使用上下文表示训练的初始基线和早期结果相当。
GPT-3 performs best (within 3 points of the human baseline) on CoQA [RCM19] a free-form conversational dataset and performs worst (13 F1 below an ELMo baseline) on QuAC $[\mathrm{CHI^{+}}18]$ a dataset which requires modeling structured dialog acts and answer span selections of teacher-student interactions. On DROP $[\mathrm{DWD^{+}19}]$ , a dataset testing discrete reasoning and numeracy in the context of reading comprehension, GPT-3 in a few-shot setting outperforms the fine-tuned BERT baseline from the original paper but is still well below both human performance and state-of-the-art approaches which augment neural networks with symbolic systems $[\mathrm{RLL^{+}}19]$ . On SQuAD 2.0 [RJL18], GPT-3 demonstrates its few-shot learning capabilities, improving by almost $10\mathrm{F}1$ (to 69.8) compared to a zero-shot setting. This allows it to slightly outperform the best fine-tuned result in the original paper. On RACE $[\mathrm{LXL^{+}}17]$ , a multiple choice dataset of middle school and high school english examinations, GPT-3 performs relatively weakly and is only competitive with the earliest work utilizing contextual representations and is still $45%$ behind SOTA.
GPT-3在自由对话数据集CoQA [RCM19]上表现最佳(与人类基线差距在3分以内),而在需要建模结构化对话行为及师生互动答案片段选择的QuAC数据集 $[\mathrm{CHI^{+}}18]$ 上表现最差(比ELMo基线低13个F1值)。在测试阅读理解中离散推理与计算能力的DROP数据集 $[\mathrm{DWD^{+}}19]$ 上,GPT-3在少样本设定下超越了原论文中微调的BERT基线,但仍显著低于人类表现及结合符号系统的前沿方法 $[\mathrm{RLL^{+}}19]$ 。在SQuAD 2.0 [RJL18]上,GPT-3展示了少样本学习能力,相比零样本设定提升了近 $10\mathrm{F}1$(达到69.8),使其略微超过原论文最佳微调结果。在初高中英语考试选择题数据集RACE $[\mathrm{LXL^{+}}17]$ 上,GPT-3表现相对较弱,仅与早期基于上下文表征的研究持平,仍落后当前最优水平 $45%$。
3.7 SuperGLUE
3.7 SuperGLUE
In order to better aggregate results on NLP tasks and compare to popular models such as BERT and RoBERTa in a more systematic way, we also evaluate GPT-3 on a standardized collection of datasets, the SuperGLUE benchmark $[\mathrm{WPN^{+}}19]$ $[\mathrm{WPN^{+}\dot{1}9}]$ $[\mathrm{CLC^{+}19}]$ [DMST19] [RBG11] $[\mathrm{KCR}^{+}18^{\cdot}$ ] $[\mathrm{ZLL^{+}}18]$ [DGM06] $[\mathrm{BHDD^{+}06}]$ [GMDD07] $[\mathrm{BDD^{+}09}]$ [PCC18] $[\mathrm{PHR^{+}}18]$ . GPT-3’s test-set performance on the SuperGLUE dataset is shown in Table 3.8. In the few-shot setting, we used 32 examples for all tasks, sampled randomly from the training set. For all tasks except WSC and MultiRC, we sampled a new set of examples to use in the context for each problem. For WSC and MultiRC, we used the same set of randomly drawn examples from the training set as context for all of the problems we evaluated.
为了更好地汇总NLP任务结果并以更系统化的方式与BERT、RoBERTa等流行模型进行比较,我们还在标准化数据集集合SuperGLUE基准上评估了GPT-3 $[\mathrm{WPN^{+}}19]$ $[\mathrm{WPN^{+}\dot{1}9}]$ $[\mathrm{CLC^{+}19}]$ [DMST19] [RBG11] $[\mathrm{KCR}^{+}18^{\cdot}$ ] $[\mathrm{ZLL^{+}}18]$ [DGM06] $[\mathrm{BHDD^{+}06}]$ [GMDD07] $[\mathrm{BDD^{+}09}]$ [PCC18] $[\mathrm{PHR^{+}}18]$ 。GPT-3在SuperGLUE数据集上的测试集性能如 表 3.8 所示。在少样本设置中,我们对所有任务使用32个示例,这些示例从训练集中随机采样。除WSC和MultiRC外,对于所有任务,我们为每个问题在上下文中使用新采样的示例集。对于WSC和MultiRC,我们使用从训练集中随机抽取的同一组示例作为所有评估问题的上下文。
Figure 3.7: GPT-3 results on CoQA reading comprehension task. GPT-3 175B achieves 85 F1 in the few-shot setting, only a few points behind measured human performance and state-of-the-art fine-tuned models. Zero-shot and one-shot performance is a few points behind, with the gains to few-shot being largest for bigger models.
图 3.7: GPT-3 在 CoQA 阅读理解任务上的表现。GPT-3 175B 在少样本设置下达到 85 F1 分数,仅比测得的人类表现和最先进的微调模型低几分。零样本和单样本表现略低几分,且模型越大,少样本带来的提升越显著。
Table 3.8: Performance of GPT-3 on SuperGLUE compared to fine-tuned baselines and SOTA. All results are reported on the test set. GPT-3 few-shot is given a total of 32 examples within the context of each task and performs no gradient updates.
| SuperGLUE Average | BoolQ Accuracy | CB Accuracy | CB F1 | COPA Accuracy | RTE Accuracy | |
| Fine-tunedSOTA | 89.0 | 91.0 | 96.9 | 93.9 | 94.8 | 92.5 |
| Fine-tuned BERT-Large | 69.0 | 77.4 | 83.6 | 75.7 | 70.6 | 71.7 |
| GPT-3Few-Shot | 71.8 | 76.4 | 75.6 | 52.0 | 92.0 | 69.0 |
| WiC Accuracy | WSC Accuracy | MultiRC Accuracy | MultiRC F1a | ReCoRD Accuracy | ReCoRD F1 | |
| Fine-tunedSOTA | 76.1 | 93.8 | 62.3 | 88.2 | 92.5 | 93.3 |
| Fine-tuned BERT-Large | 69.6 | 64.6 | 24.1 | 70.0 | 71.3 | 72.0 |
| GPT-3Few-Shot | 49.4 | 80.1 | 30.5 | 75.4 | 90.2 | 91.1 |
表 3.8: GPT-3 在 SuperGLUE 上的性能与微调基线和 SOTA 的对比。所有结果均在测试集上报告。GPT-3 少样本 (few-shot) 在每个任务的上下文中总共给出 32 个示例,且不进行梯度更新。
| SuperGLUE 平均 | BoolQ 准确率 | CB 准确率 | CB F1 | COPA 准确率 | RTE 准确率 | |
|---|---|---|---|---|---|---|
| Fine-tunedSOTA | 89.0 | 91.0 | 96.9 | 93.9 | 94.8 | 92.5 |
| Fine-tuned BERT-Large | 69.0 | 77.4 | 83.6 | 75.7 | 70.6 | 71.7 |
| GPT-3Few-Shot | 71.8 | 76.4 | 75.6 | 52.0 | 92.0 | 69.0 |
| WiC 准确率 | WSC 准确率 | MultiRC 准确率 | MultiRC F1a | ReCoRD 准确率 | ReCoRD F1 | |
|---|---|---|---|---|---|---|
| Fine-tunedSOTA | 76.1 | 93.8 | 62.3 | 88.2 | 92.5 | 93.3 |
| Fine-tuned BERT-Large | 69.6 | 64.6 | 24.1 | 70.0 | 71.3 | 72.0 |
| GPT-3Few-Shot | 49.4 | 80.1 | 30.5 | 75.4 | 90.2 | 91.1 |
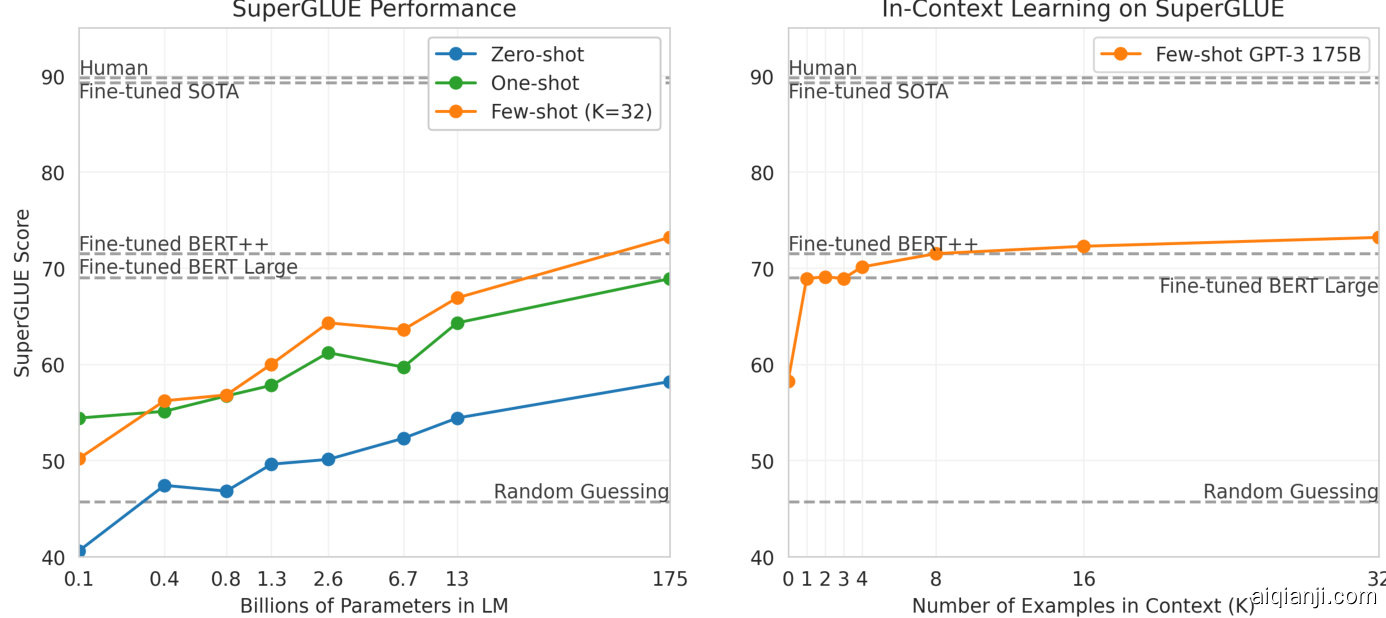
Figure 3.8: Performance on SuperGLUE increases with model size and number of examples in context. A value of $K=32$ means that our model was shown 32 examples per task, for 256 examples total divided across the 8 tasks in SuperGLUE. We report GPT-3 values on the dev set, so our numbers are not directly comparable to the dotted reference lines (our test set results are in Table 3.8). The BERT-Large reference model was fine-tuned on the SuperGLUE training set (125K examples), whereas ${\mathrm{BERT}}++$ was first fine-tuned on MultiNLI (392K examples) and SWAG (113K examples) before further fine-tuning on the SuperGLUE training set (for a total of 630K fine-tuning examples). We find the difference in performance between the BERT-Large and ${\mathrm{BERT}}++$ to be roughly equivalent to the difference between GPT-3 with one example per context versus eight examples per context.
图 3.8: SuperGLUE性能随模型规模和上下文示例数量提升。$K=32$表示每个任务展示32个示例,SuperGLUE的8个任务共计256个示例。我们报告GPT-3在开发集上的数值,因此结果与虚线参考线(测试集结果见表3.8)不可直接比较。BERT-Large参考模型在SuperGLUE训练集(125K示例)上微调,而${\mathrm{BERT}}++$先在MultiNLI(392K示例)和SWAG(113K示例)上微调,再于SuperGLUE训练集微调(总计630K微调示例)。我们发现BERT-Large与${\mathrm{BERT}}++$的性能差异,大致相当于GPT-3每个上下文含1个示例与8个示例的差异。
We observe a wide range in GPT-3’s performance across tasks. On COPA and ReCoRD GPT-3 achieves near-SOTA performance in the one-shot and few-shot settings, with COPA falling only a couple points short and achieving second place on the leader board, where first place is held by a fine-tuned 11 billion parameter model (T5). On WSC, performance is still relatively strong, achieving $80.1%$ in the few-shot setting (note that GPT-3 achieves $88.6%$ on the original Winograd dataset as described in Section 3.4). On BoolQ, MultiRC, and RTE, performance is reasonable, roughly matching that of a fine-tuned BERT-Large. On CB, we see signs of life at $75.6%$ in the few-shot setting.
我们观察到GPT-3在不同任务上的表现差异很大。在COPA和ReCoRD任务中,GPT-3在单样本和少样本设置下达到了接近最先进的性能,其中COPA仅落后几分位居排行榜第二(第一名由经过微调的110亿参数模型T5保持)。在WSC任务上表现依然相对强劲,少样本设置下达到$80.1%$(值得注意的是,如3.4节所述,GPT-3在原始Winograd数据集上达到$88.6%$)。在BoolQ、MultiRC和RTE任务中表现尚可,大致与经过微调的BERT-Large相当。在CB任务中,少样本设置下$75.6%$的结果显示出一定潜力。
WiC is a notable weak spot with few-shot performance at $49.4%$ (at random chance). We tried a number of different phrasings and formulations for WiC (which involves determining if a word is being used with the same meaning in two sentences), none of which was able to achieve strong performance. This hints at a phenomenon that will become clearer in the next section (which discusses the ANLI benchmark) – GPT-3 appears to be weak in the few-shot or one-shot setting at some tasks that involve comparing two sentences or snippets, for example whether a word is used the same way in two sentences (WiC), whether one sentence is a paraphrase of another, or whether one sentence implies another. This could also explain the comparatively low scores for RTE and CB, which also follow this format. Despite these weaknesses, GPT-3 still outperforms a fine-tuned BERT-large on four of eight tasks and on two tasks GPT-3 is close to the state-of-the-art held by a fine-tuned 11 billion parameter model.
WiC是一个显著的弱点,少样本性能仅为49.4%(随机概率水平)。我们尝试了多种不同的表述方式来处理WiC任务(该任务需要判断单词在两个句子中是否具有相同含义),但均未能取得良好表现。这暗示了一个将在下一节(讨论ANLI基准测试时)更清晰的现象——GPT-3在少样本或单样本设置下,对于涉及比较两个句子或片段的某些任务表现较弱,例如判断单词在两个句子中的用法是否相同(WiC)、判断句子是否为同义改写、或判断句子间是否存在蕴含关系。这也可能解释了RTE和CB得分相对较低的原因,因为这些任务也遵循类似格式。尽管存在这些弱点,GPT-3仍在8个任务中的4个上优于经过微调的BERT-large模型,并在2个任务上接近经过微调的110亿参数模型保持的最先进水平。
Finally, we note that the few-shot SuperGLUE score steadily improves with both model size and with number of examples in the context showing increasing benefits from in-context learning (Figure 3.8). We scale $K$ up to 32 examples per task, after which point additional examples will not reliably fit into our context. When sweeping over values of $K$ , we find that GPT-3 requires less than eight total examples per task to outperform a fine-tuned BERT-Large on overall SuperGLUE score.
最后我们注意到,少样本 SuperGLUE 分数随着模型规模和上下文示例数量的增加而稳步提升,显示出情境学习 (in-context learning) 带来的递增收益 (图 3.8)。我们将每任务的示例数 $K$ 扩展到 32 个,超过该阈值后额外示例将无法稳定放入上下文。在遍历 $K$ 值时,我们发现 GPT-3 每任务仅需不到 8 个示例,就能在 SuperGLUE 总分上超越微调后的 BERT-Large。
3.8 NLI
3.8 NLI
Natural Language Inference (NLI) [Fyo00] concerns the ability to understand the relationship between two sentences. In practice, this task is usually structured as a two or three class classification problem where the model classifies whether the second sentence logically follows from the first, contradicts the first sentence, or is possibly true (neutral). SuperGLUE includes an NLI dataset, RTE, which evaluates the binary version of the task. On RTE, only the largest version of GPT-3 performs convincingly better than random $(56%)$ in any evaluation setting, but in a few-shot setting GPT-3 performs similarly to a single-task fine-tuned BERT Large. We also evaluate on the recently introduced Adversarial Natural Language Inference (ANLI) dataset $[\mathrm{NWD^{+}}19]$ . ANLI is a difficult dataset employing a series of adversarial ly mined natural language inference questions in three rounds (R1, R2, and R3). Similar to RTE, all of our models smaller than GPT-3 perform at almost exactly random chance on ANLI, even in the few-shot setting $(\sim33%)$ ), whereas GPT-3 itself shows signs of life on Round 3. Results for ANLI R3 are highlighted in Figure 3.9 and full results for all rounds can be found in Appendix H. These results on both RTE and ANLI suggest that NLI is still a very difficult task for language models and they are only just beginning to show signs of progress.
自然语言推理 (Natural Language Inference, NLI) [Fyo00] 关注理解两个句子之间关系的能力。实践中,该任务通常被构建为二分类或三分类问题,模型需要判断第二个句子是否在逻辑上遵循第一个句子、与第一个句子矛盾,或可能成立 (中性)。SuperGLUE 包含一个 NLI 数据集 RTE,用于评估该任务的二分类版本。在 RTE 上,只有最大版本的 GPT-3 在所有评估设置中明显优于随机水平 $(56%)$,但在少样本设置中,GPT-3 的表现与单任务微调的 BERT Large 相当。我们还评估了最近提出的对抗性自然语言推理 (Adversarial Natural Language Inference, ANLI) 数据集 $[\mathrm{NWD^{+}}19]$。ANLI 是一个困难的数据集,包含三轮 (R1、R2 和 R3) 对抗性挖掘的自然语言推理问题。与 RTE 类似,所有小于 GPT-3 的模型在 ANLI 上的表现几乎完全随机,即使在少样本设置中 $(\sim33%)$),而 GPT-3 本身在第三轮中显示出一定的能力。ANLI R3 的结果在图 3.9 中突出显示,所有轮的完整结果可在附录 H 中找到。这些在 RTE 和 ANLI 上的结果表明,NLI 对于语言模型来说仍然是一个非常困难的任务,它们才刚刚开始显示出进展的迹象。
Figure 3.9: Performance of GPT-3 on ANLI Round 3. Results are on the dev-set, which has only 1500 examples and therefore has high variance (we estimate a standard deviation of $1.2%$ ). We find that smaller models hover around random chance, while few-shot GPT-3 175B closes almost half the gap from random chance to SOTA. Results for ANLI rounds 1 and 2 are shown in the appendix.
图 3.9: GPT-3在ANLI第三轮的表现。结果基于开发集(仅有1500个样本,因此方差较高,我们估计标准差为$1.2%$)。我们发现较小模型的性能在随机概率附近徘徊,而少样本GPT-3 175B将随机概率与SOTA之间的差距缩小了近一半。ANLI第一轮和第二轮的结果见附录。
3.9 Synthetic and Qualitative Tasks
3.9 合成与定性任务
One way to probe GPT-3’s range of abilities in the few-shot (or zero- and one-shot) setting is to give it tasks which require it to perform simple on-the-fly computational reasoning, recognize a novel pattern that is unlikely to have occurred in training, or adapt quickly to an unusual task. We devise several tasks to test this class of abilities. First, we test GPT-3’s ability to perform arithmetic. Second, we create several tasks that involve rearranging or unscrambling the letters in a word, tasks which are unlikely to have been exactly seen during training. Third, we test GPT-3’s ability to solve SAT-style analogy problems few-shot. Finally, we test GPT-3 on several qualitative tasks, including using new words in a sentence, correcting English grammar, and news article generation. We will release the synthetic datasets with the hope of stimulating further study of test-time behavior of language models.
探究GPT-3在少样本(或零样本、单样本)场景下能力范围的一种方法是:让它执行需要即时计算推理的任务、识别训练数据中不太可能出现的新模式、或快速适应非常规任务。我们设计了多项任务来测试这类能力。首先测试GPT-3的算术运算能力;其次创建涉及单词字母重组或解构的任务(这类任务几乎不可能在训练中精确出现过);第三测试GPT-3用少样本解决SAT式类比问题的能力;最后在定性任务上测试GPT-3,包括造句使用新词、英语语法纠正和新闻文章生成。我们将公开合成数据集,以期推动对大语言模型测试时行为的进一步研究。
3.9.1 Arithmetic
3.9.1 算术
To test GPT-3’s ability to perform simple arithmetic operations without task-specific training, we developed a small battery of 10 tests that involve asking GPT-3 a simple arithmetic problem in natural language:
为了测试GPT-3在不进行任务特定训练的情况下执行简单算术运算的能力,我们开发了一套包含10个测试的小型题库,这些测试涉及用自然语言向GPT-3提出简单的算术问题:
Figure 3.10: Results on all 10 arithmetic tasks in the few-shot settings for models of different sizes. There is a significant jump from the second largest model (GPT-3 13B) to the largest model (GPT-3 175), with the latter being able to reliably accurate 2 digit arithmetic, usually accurate 3 digit arithmetic, and correct answers a significant fraction of the time on 4-5 digit arithmetic, 2 digit multiplication, and compound operations. Results for one-shot and zero-shot are shown in the appendix.
图 3.10: 不同规模模型在少样本设置下所有10项算术任务的结果。从第二大规模模型(GPT-3 13B)到最大模型(GPT-3 175)存在显著提升,后者能可靠地准确计算2位数运算,通常准确计算3位数运算,并在4-5位数运算、2位数乘法和复合运算中大部分时间给出正确答案。单样本和零样本结果见附录。
• 3 digit subtraction (3D-) – Same as 2 digit subtraction, except numbers are uniformly sampled from $[0,1000)$ . • 4 digit addition $\left(4\mathbf{D}+\right)$ – Same as 3 digit addition, except uniformly sampled from $[0,10000)$ . • 4 digit subtraction (4D-) – Same as 3 digit subtraction, except uniformly sampled from $[0,10000)$ . • 5 digit addition $(5{\bf D}+{\bf\beta}$ ) – Same as 3 digit addition, except uniformly sampled from $[0,100000)$ . • 5 digit subtraction (5D-) – Same as 3 digit subtraction, except uniformly sampled from $[0,100000)$ . • 2 digit multiplication (2Dx) – The model is asked to multiply two integers sampled uniformly from $[0,100)$ , e.g. “Q: What is 24 times 42? A: 1008”. • One-digit composite (1DC) – The model is asked to perform a composite operation on three 1 digit numbers, with parentheses around the last two. For example, “Q: What is $6+(4^{ * }8)?$ A: $38^{,}$ . The three 1 digit numbers are selected uniformly on [0, 10) and the operations are selected uniformly from ${+,-,^{*}}$ .
- 三位数减法 (3D-):与两位数减法相同,但数字从 $[0,1000)$ 范围内均匀采样。
- 四位数加法 $(4\mathbf{D}+)$:与三位数加法相同,但数字从 $[0,10000)$ 范围内均匀采样。
- 四位数减法 (4D-):与三位数减法相同,但数字从 $[0,10000)$ 范围内均匀采样。
- 五位数加法 $(5{\bf D}+{\bf\beta})$:与三位数加法相同,但数字从 $[0,100000)$ 范围内均匀采样。
- 五位数减法 (5D-):与三位数减法相同,但数字从 $[0,100000)$ 范围内均匀采样。
- 两位数乘法 (2Dx):要求模型对从 $[0,100)$ 范围内均匀采样的两个整数进行乘法运算,例如“问:24 乘以 42 是多少?答:1008”。
- 一位数复合运算 (1DC):要求模型对三个一位数进行复合运算,后两个数用括号括起来。例如“问:$6+(4^{*}8)?$ 答:$38^{,}$”。这三个一位数从 [0, 10) 范围内均匀采样,运算符从 ${+,-,^{ * }}$ 中均匀选择。
n all 10 tasks the model must generate the correct answer exactly. For each task we generate a dataset of 2,000 random nstances of the task and evaluate all models on those instances.
在所有10项任务中,模型必须准确生成正确答案。针对每项任务,我们生成了一个包含2000个随机实例的数据集,并基于这些实例评估所有模型。
First we evaluate GPT-3 in the few-shot setting, for which results are shown in Figure 3.10. On addition and subtraction, GPT-3 displays strong proficiency when the number of digits is small, achieving $100%$ accuracy on 2 digit addition, $98.9%$ at 2 digit subtraction, $80.2%$ at 3 digit addition, and $94.2%$ at 3-digit subtraction. Performance decreases as the number of digits increases, but GPT-3 still achieves $25{-}26%$ accuracy on four digit operations and $9%$ accuracy on five digit operations, suggesting at least some capacity to generalize to larger numbers of digits. GPT-3 also achieves $29.2%$ accuracy at 2 digit multiplication, an especially computationally intensive operation. Finally, GPT-3 achieves $21.3%$ accuracy at single digit combined operations (for example, $9^{*}(7+5),$ , suggesting that it has some robustness beyond just single operations.
首先我们在少样本设置下评估GPT-3,结果如图3.10所示。在加法和减法运算中,当数字位数较少时GPT-3表现出色:2位数加法准确率达到$100%$,2位数减法$98.9%$,3位数加法$80.2%$,3位数减法$94.2%$。随着位数增加性能下降,但GPT-3仍在4位数运算中保持$25{-}26%$的准确率,5位数运算达到$9%$,表明其具备一定向更大位数泛化的能力。在计算密集型的2位数乘法中,GPT-3取得了$29.2%$的准确率。此外,GPT-3在单位数混合运算(如$9^{*}(7+5)$)中达到$21.3%$的准确率,这表明其能力不仅限于单一运算。
As Figure 3.10 makes clear, small models do poorly on all of these tasks – even the 13 billion parameter model (the second largest after the 175 billion full GPT-3) can solve 2 digit addition and subtraction only half the time, and all other operations less than $10%$ of the time.
如图 3.10 所示,小模型在这些任务上表现都很差——即使是拥有 130 亿参数的模型(仅次于 1750 亿参数的完整版 GPT-3)也只能在一半的情况下解决两位数加减法问题,其他运算的正确率均低于 $10%$。
One-shot and zero-shot performance are somewhat degraded relative to few-shot performance, suggesting that adaptation to the task (or at the very least recognition of the task) is important to performing these computations correctly. Nevertheless, one-shot performance is still quite strong, and even zero-shot performance of the full GPT-3 significantly
零样本和单次样本性能相对于少样本性能有所下降,这表明适应任务(或至少识别任务)对于正确执行这些计算非常重要。尽管如此,单次样本性能仍然相当强大,即使是完整GPT-3的零样本性能也显著...
Table 3.9: Results on basic arithmetic tasks for GPT-3 175B. ${2,3,4,5}\mathrm{D}{+,-}$ is 2, 3, 4, and 5 digit addition or subtraction, 2Dx is 2 digit multiplication. 1DC is 1 digit composite operations. Results become progressively stronger moving from the zero-shot to one-shot to few-shot setting, but even the zero-shot shows significant arithmetic abilities.
| Setting | 2D+ | 2D- | 3D+ | 3D- | 4D+ | 4D- | 5D+ | 5D- | 2Dx | 1DC |
| GPT-3Zero-shot | 76.9 | 58.0 | 34.2 | 48.3 | 4.0 | 7.5 | 0.7 | 0.8 | 19.8 | 9.8 |
| GPT-3One-shot | 99.6 | 86.4 | 65.5 | 78.7 | 14.0 | 14.0 | 3.5 | 3.8 | 27.4 | 14.3 |
| GPT-3 Few-shot | 100.0 | 98.9 | 80.4 | 94.2 | 25.5 | 26.8 | 9.3 | 9.9 | 29.2 | 21.3 |
表 3.9: GPT-3 175B 基础算术任务结果。${2,3,4,5}\mathrm{D}{+,-}$ 表示 2、3、4、5 位数的加法或减法,2Dx 表示 2 位数乘法,1DC 表示 1 位数复合运算。从零样本到单样本再到少样本设置,结果逐渐增强,但即使是零样本也显示出显著的算术能力。
| 设置 | 2D+ | 2D- | 3D+ | 3D- | 4D+ | 4D- | 5D+ | 5D- | 2Dx | 1DC |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3 零样本 | 76.9 | 58.0 | 34.2 | 48.3 | 4.0 | 7.5 | 0.7 | 0.8 | 19.8 | 9.8 |
| GPT-3 单样本 | 99.6 | 86.4 | 65.5 | 78.7 | 14.0 | 14.0 | 3.5 | 3.8 | 27.4 | 14.3 |
| GPT-3 少样本 | 100.0 | 98.9 | 80.4 | 94.2 | 25.5 | 26.8 | 9.3 | 9.9 | 29.2 | 21.3 |
| Setting | CL | A1 | A2 | RI | RW |
| GPT-3Zero-shot | 3.66 | 2.28 | 8.91 | 8.26 | 0.09 |
| GPT-3One-shot | 21.7 | 8.62 | 25.9 | 45.4 | 0.48 |
| GPT-3Few-shot | 37.9 | 15.1 | 39.7 | 67.2 | 0.44 |
| 设置 | CL | A1 | A2 | RI | RW |
|---|---|---|---|---|---|
| GPT-3零样本 (Zero-shot) | 3.66 | 2.28 | 8.91 | 8.26 | 0.09 |
| GPT-3单样本 (One-shot) | 21.7 | 8.62 | 25.9 | 45.4 | 0.48 |
| GPT-3少样本 (Few-shot) | 37.9 | 15.1 | 39.7 | 67.2 | 0.44 |
Table 3.10: GPT-3 175B performance on various word unscrambling and word manipulation tasks, in zero-, one-, and few-shot settings. CL is “cycle letters in word”, A1 is anagrams of but the first and last letters, A2 is anagrams of all but the first and last two letters, RI is “Random insertion in word”, RW is “reversed words”.
表 3.10: GPT-3 175B 在不同字母重组和单词操作任务中的表现 (零样本、单样本和少样本设置) 。CL 表示 "循环单词中的字母", A1 表示除首尾字母外的变位词, A2 表示除首尾两个字母外的变位词, RI 表示 "单词中随机插入", RW 表示 "单词倒序" 。
outperforms few-shot learning for all smaller models. All three settings for the full GPT-3 are shown in Table 3.9, and model capacity scaling for all three settings is shown in Appendix H.
在所有较小模型中均优于少样本学习。完整GPT-3的三种设置如表3.9所示,所有三种设置的模型容量扩展见附录H。
To spot-check whether the model is simply memorizing specific arithmetic problems, we took the 3-digit arithmetic problems in our test set and searched for them in our training data in both the forms $"<\mathrm{NUM1}>+~<\mathrm{NUM}2>~=""$ and "
为了验证模型是否只是简单地记忆特定算术问题,我们从测试集中选取了三位数算术题,并在训练数据中以两种形式进行搜索:$"<\mathrm{NUM1}>+~<\mathrm{NUM}2>~=""$ 和 "
Overall, GPT-3 displays reasonable proficiency at moderately complex arithmetic in few-shot, one-shot, and even zero-shot settings.
总体而言,GPT-3在少样本、单样本甚至零样本设置下,对于中等复杂度的算术运算表现出合理的熟练度。
3.9.2 Word Scrambling and Manipulation Tasks
3.9.2 单词乱序与操作任务
To test GPT-3’s ability to learn novel symbolic manipulations from a few examples, we designed a small battery of 5 “character manipulation” tasks. Each task involves giving the model a word distorted by some combination of scrambling, addition, or deletion of characters, and asking it to recover the original word. The 5 tasks are:
为了测试GPT-3从少量示例中学习新符号操作的能力,我们设计了一组包含5项"字符操作"任务的测试集。每项任务会向模型提供一个经过字符乱序、增删等组合操作扭曲的单词,并要求其还原原始单词。这5项任务分别是:
For each task we generate 10,000 examples, which we chose to be the top 10,000 most frequent words as measured by [Nor09] of length more than 4 characters and less than 15 characters. The few-shot results are shown in Figure 3.11. Task performance tends to grow smoothly with model size, with the full GPT-3 model achieving $66.9%$ on removing random insertions, $38.6%$ on cycling letters, $40.2%$ on the easier anagram task, and $15.1%$ on the more difficult anagram task (where only the first and last letters are held fixed). None of the models can reverse the letters in a word.
针对每项任务,我们生成了10,000个样本,这些样本选自[Nor09]统计的长度超过4个字符且少于15个字符的最高频前10,000个单词。少样本学习结果如图3.11所示。任务表现通常随模型规模平稳提升:完整版GPT-3模型在随机插入删除任务中达到66.9%,字母轮换任务中38.6%,简单变位词任务中40.2%,而更难变位词任务(仅首尾字母固定)中为15.1%。所有模型均无法完成单词字母逆序任务。
Figure 3.11: Few-shot performance on the five word scrambling tasks for different sizes of model. There is generally smooth improvement with model size although the random insertion task shows an upward slope of improvement with the 175B model solving the task the majority of the time. Scaling of one-shot and zero-shot performance is shown in the appendix. All tasks are done with $K=100$ .
图 3.11: 不同规模模型在五种单词乱序任务上的少样本表现。尽管随机插入任务在175B模型上呈现出多数情况下能解决该任务的上升趋势,但整体而言模型规模与性能提升呈平滑关系。单样本和零样本表现的扩展性分析见附录。所有实验均设定 $K=100$。
In the one-shot setting, performance is significantly weaker (dropping by half or more), and in the zero-shot setting the model can rarely perform any of the tasks (Table 3.10). This suggests that the model really does appear to learn these tasks at test time, as the model cannot perform them zero-shot and their artificial nature makes them unlikely to appear in the pre-training data (although we cannot confirm this with certainty).
在少样本 (few-shot) 设定下,性能显著下降(降低一半或更多),而在零样本 (zero-shot) 设定下,模型几乎无法完成任何任务(表 3.10)。这表明模型确实在测试时学习了这些任务,因为它无法以零样本方式完成它们,且这些任务的人造性质使其不太可能出现在预训练数据中(尽管我们无法完全确认这一点)。
We can further quantify performance by plotting “in-context learning curves”, which show task performance as a function of the number of in-context examples. We show in-context learning curves for the Symbol Insertion task in Figure 1.2. We can see that larger models are able to make increasingly effective use of in-context information, including both task examples and natural language task descriptions.
我们可以通过绘制"上下文学习曲线"进一步量化性能,该曲线展示了任务性能随上下文示例数量的变化关系。图1.2展示了符号插入任务的上下文学习曲线。可以看出,更大规模的模型能够更有效地利用上下文信息,包括任务示例和自然语言任务描述。
Finally, it is worth adding that solving these tasks requires character-level manipulations, whereas our BPE encoding operates on significant fractions of a word (on average $\sim0.7$ words per token), so from the LM’s perspective succeeding at these tasks involves not just manipulating BPE tokens but understanding and pulling apart their substructure. Also, CL, A1, and A2 are not bijective (that is, the unscrambled word is not a deterministic function of the scrambled word), requiring the model to perform some search to find the correct unscrambling. Thus, the skills involved appear to require non-trivial pattern-matching and computation.
最后需要补充的是,解决这些任务需要进行字符级操作,而我们的BPE编码作用于单词的显著部分(平均每个token对应约0.7个单词),因此从语言模型的角度来看,成功完成这些任务不仅涉及操作BPE token,还需要理解并分解其子结构。此外,CL、A1和A2任务并非双射关系(即原始单词不是乱序单词的确定性函数),这要求模型执行某种搜索以找到正确的解序方案。因此,这些任务所需的技能显然涉及非平凡的模式匹配和计算能力。
3.9.3 SAT Analogies
3.9.3 SAT类比
To test GPT-3 on another task that is somewhat unusual relative to the typical distribution of text, we collected a set of 374 “SAT analogy” problems [TLBS03]. Analogies are a style of multiple choice question that constituted a section of the SAT college entrance exam before 2005. A typical example is “audacious is to boldness as (a) sanctimonious is to hypocrisy, (b) anonymous is to identity, (c) remorseful is to misdeed, (d) deleterious is to result, (e) impressionable is to temptation”. The student is expected to choose which of the five word pairs has the same relationship as the original word pair; in this example the answer is “sanctimonious is to hypocrisy”. On this task GPT-3 achieves $65.2%$ in the few-shot setting, $59.1%$ in the one-shot setting, and $53.7%$ in the zero-shot setting, whereas the average score among college applicants was $57%$ [TL05] (random guessing yields $20%$ ). As shown in Figure 3.12, the results improve with scale, with the the full 175 billion model improving by over $10%$ compared to the 13 billion parameter model.
为了测试GPT-3在另一项偏离典型文本分布的任务上的表现,我们收集了374道"SAT类比题"[TLBS03]。这类题目曾是2005年前SAT大学入学考试中的一种多选题形式,典型例题如"audacious之于boldness,相当于(a) sanctimonious之于hypocrisy、(b) anonymous之于identity、(c) remorseful之于misdeed、(d) deleterious之于result、(e) impressionable之于temptation",考生需从五个单词对中选出与题干关系相同的选项(本例正确答案为"sanctimonious is to hypocrisy")。在该任务中,GPT-3的少样本(few-shot)准确率达65.2%,单样本(one-shot)为59.1%,零样本(zero-shot)为53.7%,而大学申请者的平均成绩为57%[TL05](随机猜测正确率为20%)。如图3.12所示,模型性能随规模提升而增强,1750亿参数全模型相比130亿参数模型有超过10%的性能提升。

Figure 3.12: Zero-, one-,and few-shot performance on SAT analogy tasks, for different sizes of model. The largest model achieves $65%$ accuracy in the few-shot setting, and also demonstrates significant gains to in-context learning which are not present in smaller models.
图 3.12: 不同规模模型在SAT类比任务上的零样本、单样本和少样本表现。最大模型在少样本设定下达到65%准确率,并展现出显著的情境学习增益,而较小模型未体现此特性。
3.9.4 News Article Generation
3.9.4 新闻文章生成
Previous work on generative language models qualitatively tested their ability to generate synthetic “news articles” by conditional sampling from the model given a human-written prompt consisting of a plausible first sentence for a news story $[\mathrm{RWC^{+}}19]$ . Relative to $[\mathrm{RWC^{+}}19]$ , the dataset used to train GPT-3 is much less weighted towards news articles, so trying to generate news articles via raw unconditional samples is less effective – for example GPT-3 often interprets the proposed first sentence of a “news article” as a tweet and then posts synthetic responses or follow-up tweets. To solve this problem we employed GPT-3’s few-shot learning abilities by providing three previous news articles in the model’s context to condition it. With the title and subtitle of a proposed next article, the model is able to reliably generate short articles in the “news” genre.
先前关于生成式语言模型的研究通过条件采样的方式定性测试了其生成合成"新闻文章"的能力,即给定人工编写的新闻故事首句作为提示 [RWC+19]。相较于 [RWC+19],用于训练 GPT-3 的数据集中新闻文章占比显著降低,因此直接通过原始无条件采样生成新闻文章效果较差——例如 GPT-3 经常将提议的"新闻文章"首句误判为推文,继而生成合成回复或后续推文。为解决这个问题,我们利用 GPT-3 的少样本学习能力,在模型上下文中提供三篇过往新闻文章作为条件。当给定新文章的标题和副标题时,该模型能够可靠地生成符合"新闻"体裁的短文。
To gauge the quality of news article generation from GPT-3 (which we believe is likely to be correlated with conditional sample generation quality in general), we decided to measure human ability to distinguish GPT-3-generated articles from real ones. Similar work has been carried out by Kreps et al. [KMB20] and Zellers et al. $[Z\mathrm{HR}^{+}19]$ . Generative language models are trained to match the distribution of content generated by humans, so the (in)ability of humans to distinguish the two is a potentially important measure of quality.3
为了评估GPT-3生成新闻文章的质量(我们认为这可能与条件样本生成质量普遍相关),我们决定测量人类区分GPT-3生成文章与真实文章的能力。类似的工作已由Kreps等人[KMB20]和Zellers等人$[Z\mathrm{HR}^{+}19]$开展。生成式语言模型的训练目标是匹配人类生成内容的分布,因此人类(无法)区分二者的能力是衡量质量的重要潜在指标。3
In order to see how well humans can detect model generated text, we arbitrarily selected 25 article titles and subtitles from the website newser.com (mean length: 215 words). We then generated completions of these titles and subtitles from four language models ranging in size from 125M to 175B (GPT-3) parameters (mean length: 200 words). For each model, we presented around 80 US-based participants with a quiz consisting of these real titles and subtitles followed by either the human written article or the article generated by the model4. Participants were asked to select whether the article was “very likely written by a human”, “more likely written by a human”, “I don’t know”, “more likely written by a machine”, or “very likely written by a machine”.
为了测试人类对模型生成文本的识别能力,我们从newser.com网站随机选取了25篇文章标题及副标题(平均长度215词),并让参数量从1.25亿到1750亿(GPT-3)不等的四个语言模型续写这些内容(平均长度200词)。针对每个模型,我们让约80名美国参与者进行测试:每组测试包含真实标题/副标题后接人工撰写文章或该模型生成文章4,要求参与者判断文章属于"极可能由人类撰写"、"较可能由人类撰写"、"不确定"、"较可能由机器生成"或"极可能由机器生成"。
The articles we selected were not in the models’ training data and the model outputs were formatted and selected pro grammatically to prevent human cherry-picking. All models used the same context to condition outputs on and were pre-trained with the same context size and the same article titles and subtitles were used as prompts for each model. However, we also ran an experiment to control for participant effort and attention that followed the same format but involved intentionally bad model generated articles. This was done by generating articles from a “control model”: a 160M parameter model with no context and increased output randomness.
我们选取的文章不在模型的训练数据中,并且模型输出通过程序化方式格式化与筛选,以避免人为挑选。所有模型使用相同的上下文条件生成输出,预训练时采用相同的上下文长度,且每款模型均以相同文章标题和副标题作为提示词。此外,我们还设计了一项对照实验来控制参与者投入度与注意力,实验流程与主实验相同,但使用故意生成的低质量文章——这些文章由"对照模型"(160M参数、无上下文输入且输出随机性增强)生成。
Table 3.11: Human accuracy in identifying whether short $\mathbf{\sim}200$ word) news articles are model generated. We find that human accuracy (measured by the ratio of correct assignments to non-neutral assignments) ranges from $86%$ on the control model to $52%$ on GPT-3 175B. This table compares mean accuracy between five different models, and shows the results of a two-sample T-Test for the difference in mean accuracy between each model and the control model (an unconditional GPT-3 Small model with increased output randomness).
| 95%Confidence Interval (low, hi) | t compared to control (p-value) | "I don't know" assignments | ||
| Meanaccuracy | ||||
| Control(deliberatelybadmodel) | 86% | 83%-90% 72%-80% | 3.9 (2e-4) | 3.6 % 4.9% |
| GPT-3Small | 76% 61% | 58%-65% | 10.3 (7e-21) | 6.0% |
| GPT-3Medium | 68% | 64%-72% | 7.3 (3e-11) | 8.7% |
| GPT-3Large GPT-3XL | 62% | 59%-65% | 10.7 (1e-19) | 7.5% |
| GPT-32.7B | 62% | 58%-65% | 10.4 (5e-19) | 7.1% |
| GPT-36.7B | 60% | 56%-63% | 11.2 (3e-21) | 6.2% |
| GPT-313B | 55% | 52%-58% | 15.3 (1e-32) | 7.1% |
| GPT-3175B | 52% | 49%-54% | 16.9 (1e-34) | 7.8% |
表 3.11: 人类判断短篇新闻文章(约200词)是否由模型生成的准确率。我们发现人类准确率(以正确判定与非中性判定的比率衡量)从对照模型的86%到GPT-3 175B的52%不等。本表比较了五种不同模型的平均准确率,并展示了每个模型与对照模型(增加了输出随机性的无条件GPT-3 Small模型)之间平均准确率差异的双样本T检验结果。
| 平均准确率 | 95%置信区间(低, 高) | 与对照模型的t值(p值) | "不确定"判定率 | |
|---|---|---|---|---|
| 对照模型(刻意劣质模型) | 86% | 83%-90% 72%-80% | 3.9 (2e-4) | 3.6% 4.9% |
| GPT-3 Small | 76% 61% | 58%-65% | 10.3 (7e-21) | 6.0% |
| GPT-3 Medium | 68% | 64%-72% | 7.3 (3e-11) | 8.7% |
| GPT-3 Large GPT-3 XL | 62% | 59%-65% | 10.7 (1e-19) | 7.5% |
| GPT-3 2.7B | 62% | 58%-65% | 10.4 (5e-19) | 7.1% |
| GPT-3 6.7B | 60% | 56%-63% | 11.2 (3e-21) | 6.2% |
| GPT-3 13B | 55% | 52%-58% | 15.3 (1e-32) | 7.1% |
| GPT-3 175B | 52% | 49%-54% | 16.9 (1e-34) | 7.8% |
Mean human accuracy (the ratio of correct assignments to non-neutral assignments per participant) at detecting that the intentionally bad articles were model generated was $\sim86%$ where $50%$ is chance level performance. By contrast, mean human accuracy at detecting articles that were produced by the 175B parameter model was barely above chance at $\sim52%$ (see Table 3.11).5 Human abilities to detect model generated text appear to decrease as model size increases: there appears to be a trend towards chance accuracy with model size, and human detection of GPT-3 is close to chance.6 This is true despite the fact that participants spend more time on each output as model size increases (see Appendix E).
人类在识别故意编写的低质量文章为模型生成时的平均准确率(每位参与者正确判定为非中性文章的比例)为 $\sim86%$ ,其中 $50%$ 为随机猜测水平。相比之下,检测1750亿参数模型生成文章的平均准确率仅为 $\sim52%$ ,略高于随机水平(见表3.11)。5 人类识别模型生成文本的能力似乎随模型规模增大而下降:准确率呈现向随机水平靠近的趋势,对GPT-3的检测准确率已接近随机猜测。6 这一现象出现时,参与者实际上会随着模型规模增大而花费更多时间审阅每个输出(见附录E)。
Examples of synthetic articles from GPT-3 are given in Figures 3.14 and 3.15.7 Much of the text is—as indicated by the evaluations—difficult for humans to distinguish from authentic human content. Factual inaccuracies can be an indicator that an article is model generated since, unlike human authors, the models have no access to the specific facts that the article titles refer to or when the article was written. Other indicators include repetition, non sequiturs, and unusual phrasings, though these are often subtle enough that they are not noticed.
图 3.14 和图 3.15 展示了 GPT-3 生成的合成文章示例。如评估所示,大部分文本对人类而言难以与真实人类创作内容区分。事实性错误可能是文章由模型生成的标志,因为与人类作者不同,模型无法获取文章标题所指的具体事实或文章撰写时间。其他标志包括重复、不合逻辑的推论以及异常措辞,但这些特征通常足够细微以至于不易被察觉。
Related work on language model detection by Ippolito et al. [IDCBE19] indicates that automatic disc rim in at or s like G R O V E R $[Z\mathrm{HR}^{+}1\bar{9}]$ and GLTR [GSR19] may have greater success at detecting model generated text than human evaluators. Automatic detection of these models may be a promising area of future research.
Ippolito等人[IDCBE19]关于语言模型检测的研究表明,自动判别器如GROVER $[Z\mathrm{HR}^{+}1\bar{9}]$ 和GLTR [GSR19]在检测模型生成文本方面可能比人类评估者更成功。这些模型的自动检测可能是未来研究的一个有前景的领域。
Ippolito et al. [IDCBE19] also note that human accuracy at detecting model generated text increases as humans observe more tokens. To do a preliminary investigation of how good humans are at detecting longer news articles generated by GPT-3 175B, we selected 12 world news articles from Reuters with an average length of 569 words and generated completions of these articles from GPT-3 with an average length of 498 words (298 words longer than our initial experiments). Following the methodology above, we ran two experiments, each on around 80 US-based participants, to compare human abilities to detect the articles generated by GPT-3 and a control model.
Ippolito等人[IDCBE19]也指出,人类检测模型生成文本的准确率会随着观察到的token数量增加而提升。为了初步探究人类对GPT-3 175B生成长篇新闻的识别能力,我们从路透社选取了12篇平均长度569词的国际新闻,并让GPT-3生成平均498词(比初期实验长298词)的续写文章。沿用上述方法,我们进行了两项实验(每项约80名美国参与者),比较人类识别GPT-3生成文章与控制模型生成文章的能力。
We found that mean human accuracy at detecting the intentionally bad longer articles from the control model was $\sim88%$ , while mean human accuracy at detecting the longer articles that were produced by GPT-3 175B was still barely above chance at $\sim52%$ (see Table 3.12). This indicates that, for news articles that are around 500 words long, GPT-3 continues to produce articles that humans find difficult to distinguish from human written news articles.
我们发现,人类检测出由对照模型故意生成的劣质长文平均准确率约为88%,而检测出由GPT-3 175B生成长文的平均准确率仅略高于随机水平(约52%) (见表3.12)。这表明,对于约500词的新闻文章,GPT-3生成的文本仍难以被人类与人工撰写的新闻文章区分。
3.9.5 Learning and Using Novel Words
3.9.5 学习和使用新词
A task studied in developmental linguistics [CB78] is the ability to learn and utilize new words, for example using a word in a sentence after seeing it defined only once, or conversely inferring a word’s meaning from only one usage. Here we qualitatively test GPT-3’s ability to do the former. Specifically, we give GPT-3 the definition of a nonexistent word, such as “Gigamuru”, and then ask it to use it in a sentence. We provide one to five previous examples of a (separate)
发展语言学[CB78]研究的一项任务是学习和运用新词的能力,例如仅见过一次定义就能在句子中使用某个词,或反之仅凭一次使用推断词义。本文定性测试GPT-3完成前者的能力:给定虚构词(如"Gigamuru")的定义后,要求其在句子中使用该词。我们提供1-5个(不同)虚构词的示范案例...
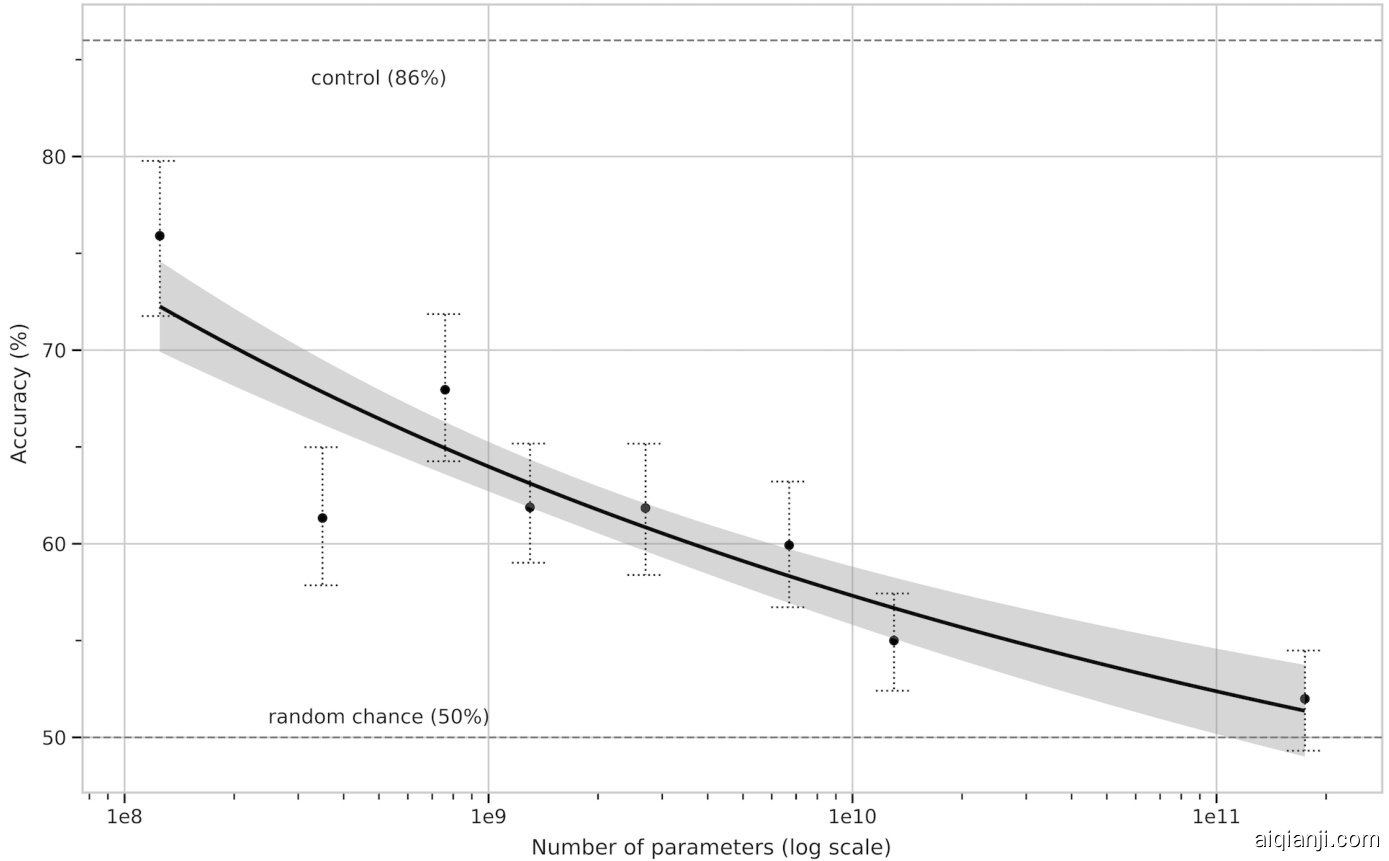
Figure 3.13: People’s ability to identify whether news articles are model-generated (measured by the ratio of correct assignments to non-neutral assignments) decreases as model size increases. Accuracy on the outputs on the deliberatelybad control model (an un conditioned GPT-3 Small model with higher output randomness) is indicated with the dashed line at the top, and the random chance $(50%)$ is indicated with the dashed line at the bottom. Line of best fit is a power law with $95%$ confidence intervals.
图 3.13: 人们识别新闻文章是否为模型生成的能力(以正确判定与非中性判定的比率衡量)随着模型规模增大而下降。顶部虚线表示故意劣质控制模型(具有更高输出随机性的无条件GPT-3 Small模型)输出的准确率,底部虚线表示随机概率$(50%)$。最佳拟合线为幂律曲线,置信区间为$95%$。
Human ability to detect model generated news articles
| Mean accuracy | 95%Confidence Interval (low, hi) | t compared to control (p-value) | "Idon'tknow" assignments | |
| Control | 88% | 84%-91% | 一 | 2.7% |
| GPT-3175B | 52% | 48%-57% | 12.7 (3.2e-23) | 10.6% |
人类识别模型生成新闻文章的能力
| 平均准确率 | 95%置信区间 (低, 高) | 与对照组的t检验 (p值) | "我不知道"选项占比 | |
|---|---|---|---|---|
| 对照组 | 88% | 84%-91% | — | 2.7% |
| GPT-3 175B | 52% | 48%-57% | 12.7 (3.2e-23) | 10.6% |
Table 3.12: People’s ability to identify whether $\sim500$ word articles are model generated (as measured by the ratio of correct assignments to non-neutral assignments) was $88%$ on the control model and $52%$ on GPT-3 175B. This table shows the results of a two-sample T-Test for the difference in mean accuracy between GPT-3 175B and the control model (an unconditional GPT-3 Small model with increased output randomness).
表 3.12: 人们识别约500词文章是否由模型生成的能力(以正确分配与非中性分配的比率衡量)在对照组模型上为88%,在GPT-3 175B上为52%。本表展示了GPT-3 175B与对照组模型(增加输出随机性的无条件GPT-3 Small模型)之间平均准确率差异的双样本T检验结果。

Figure 3.14: The GPT-3 generated news article that humans had the greatest difficulty distinguishing from a human written article (accuracy: $12%$ ).
图 3.14: 人类最难区分GPT-3生成新闻与人工撰写文章的案例 (准确率: $12%$)。

Figure 3.15: The GPT-3 generated news article that humans found the easiest to distinguish from a human written article (accuracy: $61%$ ).
图 3.15: 人类最容易区分出与人工撰写新闻差异的GPT-3生成新闻(准确率: $61%$)。

Figure 3.16: Representative GPT-3 completions for the few-shot task of using a new word in a sentence. Boldface is GPT-3’s completions, plain text is human prompts. In the first example both the prompt and the completion are provided by a human; this then serves as conditioning for subsequent examples where GPT-3 receives successive additional prompts and provides the completions. Nothing task-specific is provided to GPT-3 other than the conditioning shown here.
图 3.16: 在少样本任务中使用新单词造句的典型 GPT-3 补全示例。加粗部分为 GPT-3 生成的补全内容,普通文本为人类提示。第一个示例中提示和补全均由人类提供,随后作为后续示例的条件输入,GPT-3 接收连续新增的提示并生成补全内容。除图示条件输入外,未向 GPT-3 提供任何任务特定信息。
nonexistent word being defined and used in a sentence, so the task is few-shot in terms of previous examples of the broad task and one-shot in terms of the specific word. Table 3.16 shows the 6 examples we generated; all definitions were human-generated, and the first answer was human-generated as conditioning while the subsequent answers were generated by GPT-3. These examples were generated continuously in one sitting and we did not omit or repeatedly try any prompts. In all cases the generated sentence appears to be a correct or at least plausible use of the word. In the final sentence the model generates a plausible conjugation for the word “screeg” (namely “screeghed”), although the use of the word is slightly awkward (“screeghed at each other”) despite being plausible in the sense that it could describe a toy sword fight. Overall, GPT-3 appears to be at least proficient at the task of using novel words in a sentence.
不存在的单词被定义并用于句子中,因此这项任务在广义任务上属于少样本学习,在特定单词上属于单样本学习。表3.16展示了我们生成的6个示例;所有定义均由人工编写,第一个答案作为条件由人工提供,后续答案则由GPT-3生成。这些示例是在一次连续会话中生成的,我们没有遗漏或重复尝试任何提示。在所有案例中,生成的句子似乎都正确或至少合理地使用了该单词。在最后一个句子中,模型为单词"screeg"生成了一个合理的变位形式(即"screeghed"),尽管该词的使用略显生硬("screeghed at each other"),但从描述玩具剑战的角度看仍算合理。总体而言,GPT-3在句子中使用新造词的任务上至少表现出了熟练能力。
3.9.6 Correcting English Grammar
3.9.6 英语语法校正
Another task well suited for few-shot learning is correcting English grammar. We test this with GPT-3 in the fewshot setting by giving prompts of the form "Poor English Input:
另一项非常适合少样本学习的任务是英语语法校正。我们通过输入"Poor English Input: <句子>\n Good English Output: <句子>"形式的提示词,在少样本设置下用GPT-3进行测试。先给GPT-3展示1个人工生成的修正样本,然后要求它继续修正另外5个句子(同样不允许遗漏或重复)。结果如图3.17所示。
4 Measuring and Preventing Memorization Of Benchmarks
4 测量与防止基准测试的记忆化
Since our training dataset is sourced from the internet, it is possible that our model was trained on some of our benchmark test sets. Accurately detecting test contamination from internet-scale datasets is a new area of research without established best practices. While it is common practice to train large models without investigating contamination, given the increasing scale of pre training datasets, we believe this issue is becoming increasingly important to attend to.
由于我们的训练数据集来自互联网,模型可能在部分基准测试集上进行过训练。准确检测互联网规模数据集中的测试污染是一个尚无最佳实践的新兴研究领域。虽然当前普遍做法是在不调查污染的情况下训练大模型,但考虑到预训练数据集的规模不断扩大,我们认为解决这一问题正变得日益重要。
This concern is not just hypothetical. One of the first papers to train a language model on Common Crawl data [TL18] detected and removed a training document which overlapped with one of their evaluation datasets. Other work such as GPT-2 [RWC+19] also conducted post-hoc overlap analysis. Their study was relatively encouraging, finding that although models did perform moderately better on data that overlapped between training and testing, this did not significantly impact reported results due to the small fraction of data which was contaminated (often only a few percent).
这种担忧并非空穴来风。最早在Common Crawl数据上训练语言模型的论文之一[TL18]就检测并移除了一个与其评估数据集存在重叠的训练文档。GPT-2[RWC+19]等其他研究也进行了事后重叠分析。他们的研究结果相对乐观:尽管模型在训练与测试重叠数据上表现略好,但由于污染数据占比很小(通常仅百分之几),这对报告结果的影响并不显著。

Figure 3.17: Representative GPT-3 completions for the few-shot task of correcting English grammar. Boldface is GPT-3’s completions, plain text is human prompts. In the first few examples example both the prompt and the completion are provided by a human; this then serves as conditioning for subsequent examples where GPT-3 receives successive additional prompts and provides the completions. Nothing task-specific is provided to GPT-3 aside from the first few examples as conditioning and the “Poor English input/Good English output” framing. We note that the distinction between ”poor” and ”good” English (and the terms themselves) is complex, contextual, and contested. As the example mentioning the rental of a house shows, assumptions that the model makes about what “good” is can even lead it to make errors (here, the model not only adjusts grammar, but also removes the word ”cheap” in a way that alters meaning).
图 3.17: 用于纠正英语语法的少样本任务中,GPT-3生成的典型补全示例。加粗部分为GPT-3生成的补全内容,普通文本为人类提供的提示。在前几个示例中,提示和补全均由人类提供;这些内容随后作为条件,用于后续GPT-3接收连续附加提示并生成补全的示例。除了前几个示例作为条件和"Poor English input/Good English output"框架外,没有向GPT-3提供任何特定于任务的信息。我们注意到,"poor"和"good"英语之间的区别(以及这些术语本身)是复杂的、具有上下文依赖性且存在争议的。如关于房屋租赁的示例所示,模型对"good"的假设甚至可能导致其犯错误(在此例中,模型不仅调整了语法,还以改变含义的方式删除了"cheap"一词)。

Figure 4.1: GPT-3 Training Curves We measure model performance during training on a de duplicated validation split of our training distribution. Though there is some gap between training and validation performance, the gap grows only minimally with model size and training time, suggesting that most of the gap comes from a difference in difficulty rather than over fitting.
图 4.1: GPT-3 训练曲线 我们在训练过程中测量模型在去重验证集上的性能。虽然训练集和验证集性能之间存在一定差距,但随着模型规模和训练时间的增加,差距仅略微扩大,这表明大部分差距源于难度差异而非过拟合。
GPT-3 operates in a somewhat different regime. On the one hand, the dataset and model size are about two orders of magnitude larger than those used for GPT-2, and include a large amount of Common Crawl, creating increased potential for contamination and memorization. On the other hand, precisely due to the large amount of data, even GPT-3 175B does not overfit its training set by a significant amount, measured relative to a held-out validation set with which it was de duplicated (Figure 4.1). Thus, we expect that contamination is likely to be frequent, but that its effects may not be as large as feared.
GPT-3的运行机制略有不同。一方面,其数据集和模型规模比GPT-2大约两个数量级,且包含大量Common Crawl数据,这增加了数据污染和记忆的风险。另一方面,正是由于数据量庞大,即使175B参数的GPT-3相对于去重后的保留验证集(如 图4.1 所示)也未出现显著过拟合。因此我们预计污染现象可能频繁发生,但其影响或许没有担忧的那么严重。
We initially tried to address the issue of contamination by pro actively searching for and attempting to remove any overlap between our training data and the development and test sets of all benchmarks studied in this paper. Unfortunately, a bug resulted in only partial removal of all detected overlaps from the training data. Due to the cost of training, it wasn’t feasible to retrain the model. To address this, we investigate in detail how the remaining detected overlap impacts results.
我们最初尝试通过主动搜索并删除训练数据与本文研究的所有基准开发集和测试集之间的重叠来解决数据污染问题。遗憾的是,由于程序错误,仅部分删除了检测到的重叠数据。鉴于训练成本过高,重新训练模型并不可行。为此,我们详细研究了剩余检测到的重叠数据对结果的影响。
For each benchmark, we produce a ‘clean’ version which removes all potentially leaked examples, defined roughly as examples that have a 13-gram overlap with anything in the pre training set (or that overlap with the whole example when it is shorter than 13-grams). The goal is to very conservatively flag anything that could potentially be contamination, so as to produce a clean subset that is free of contamination with high confidence. The exact procedure is detailed in Appendix C.
针对每个基准测试,我们都会生成一个"干净"版本,该版本会移除所有可能泄露的样本——大致定义为与预训练集中任何内容存在13-gram重叠的样本(或当样本短于13-gram时与整个样本重叠的情况)。这种做法旨在极其保守地标记任何可能的污染数据,从而以高置信度生成无污染的干净子集。具体操作流程详见附录C。
We then evaluate GPT-3 on these clean benchmarks, and compare to the original score. If the score on the clean subset is similar to the score on the entire dataset, this suggests that contamination, even if present, does not have a significant effect on reported results. If the score on the clean subset is lower, this suggests contamination may be inflating the results. The results are summarized in Figure 4.2. Although potential contamination is often high (with a quarter of benchmarks scoring over $50%$ ), in most cases performance changes only negligibly, and we see no evidence that contamination level and performance difference are correlated. We conclude that either our conservative method substantially overestimated contamination or that contamination has little effect on performance.
随后我们在这些清洗过的基准测试上评估GPT-3,并与原始分数进行对比。若清洗子集的分数与完整数据集的分数相近,则表明即使存在污染,对报告结果的影响也不显著;若清洗子集的分数较低,则暗示污染可能夸大了结果。图4.2汇总了实验结果:尽管潜在污染率常处于高位(四分之一的基准测试污染率超过50%),但在大多数情况下性能变化微乎其微,且未观察到污染程度与性能差异存在相关性。我们得出结论:要么保守估计方法大幅高估了污染程度,要么污染对性能几乎没有影响。
Below, we review in more detail the few specific cases where either (1) the model performs significantly worse on the cleaned version, or (2) potential contamination is very high, which makes measuring the performance difference difficult.
下面,我们将详细回顾几种特定情况,其中要么 (1) 模型在清洗版本上表现明显更差,要么 (2) 潜在污染非常高,这使得测量性能差异变得困难。
Our analysis flagged six groups of benchmarks for further investigation: Word Scrambling, Reading Comprehension (QuAC, SQuAD2, DROP), PIQA, Winograd, language modeling tasks (Wikitext tasks, 1BW), and German to English translation. Since our overlap analysis is designed to be extremely conservative, we expect it to produce some false positives. We summarize the results for each group of tasks below:
我们的分析标记了六组基准用于进一步调查:单词乱序 (Word Scrambling)、阅读理解 (QuAC、SQuAD2、DROP)、PIQA、Winograd、语言建模任务 (Wikitext任务、1BW) 以及德语到英语翻译。由于我们的重叠分析设计得非常保守,预计会产生一些误报。以下是各组任务的总结结果:
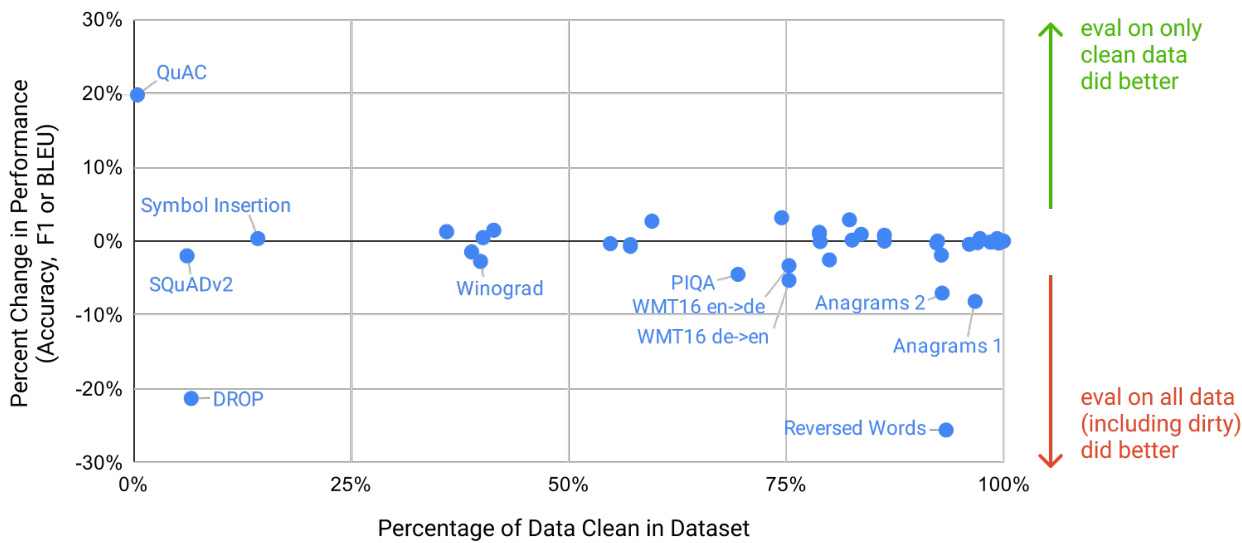
Figure 4.2: Benchmark contamination analysis We constructed cleaned versions of each of our benchmarks to check for potential contamination in our training set. The $\mathbf{X}$ -axis is a conservative lower bound for how much of the dataset is known with high confidence to be clean, and the y-axis shows the difference in performance when evaluating only on the verified clean subset. Performance on most benchmarks changed negligibly, but some were flagged for further review. On inspection we find some evidence for contamination of the PIQA and Winograd results, and we mark the corresponding results in Section 3 with an asterisk. We find no evidence that other benchmarks are affected.
图 4.2: 基准污染分析 我们构建了每个基准的清洗版本以检查训练集中潜在的污染情况。X轴是一个保守的下限,表示有多少数据集被高度确信是干净的,y轴显示了仅在已验证干净子集上评估时的性能差异。大多数基准的性能变化可忽略不计,但部分被标记需进一步审查。经检查,我们发现PIQA和Winograd结果存在污染的证据,并在第3节中用星号标记了相应结果。未发现其他基准受影响的证据。
• Language modeling: We found the 4 Wikipedia language modeling benchmarks measured in GPT-2, plus the Children’s Book Test dataset, to be almost entirely contained in our training data. Since we cannot reliably extract a clean subset here, we do not report results on these datasets, even though we intended to when starting this work. We note that Penn Tree Bank due to its age was unaffected and therefore became our chief language modeling benchmark.
• 语言建模 (Language modeling): 我们发现GPT-2中测量的4个维基百科语言建模基准以及儿童图书测试数据集几乎完全包含在我们的训练数据中。由于无法可靠地提取出干净的子集,因此尽管在开始这项工作时我们有意向,但并未报告这些数据集的结果。我们注意到,由于年代久远,Penn Tree Bank未受影响,因此成为我们主要的语言建模基准。
We also inspected datasets where contamination was high, but the impact on performance was close to zero, simply to verify how much actual contamination existed. These appeared to often contain false positives. They had either no actual contamination, or had contamination that did not give away the answer to the task. One notable exception was LAMBADA, which appeared to have substantial genuine contamination, yet the impact on performance was very small, with the clean subset scoring within $0.5%$ of the full dataset. Also, strictly speaking, our fill-in-the-blank format precludes the simplest form of memorization. Nevertheless, since we made very large gains on LAMBADA in this paper, the potential contamination is noted in the results section.
我们还检查了污染率较高但对性能影响近乎为零的数据集,仅为了验证实际污染程度。这些情况往往存在误判——要么实际不存在污染,要么污染内容并未泄露任务答案。一个显著例外是LAMBADA数据集,该数据集存在大量真实污染,但对性能影响微乎其微(清洁子集得分与完整数据集仅相差$0.5%$)。此外严格来说,我们的填空格式设计已规避了最简单的记忆形式。但鉴于本文在LAMBADA上取得显著提升,结果部分仍标注了潜在污染风险。
An important limitation of our contamination analysis is that we cannot be sure that the clean subset is drawn from the same distribution as the original dataset. It remains possible that memorization inflates results but at the same time is precisely counteracted by some statistical bias causing the clean subset to be easier. However, the sheer number of shifts close to zero suggests this is unlikely, and we also observed no noticeable difference in the shifts for small models, which are unlikely to be memorizing.
我们污染分析的一个重要局限在于无法确定干净子集是否与原始数据集来自同一分布。存在这种可能性:记忆效应夸大了结果,但同时某些统计偏差恰好抵消了这种影响,使得干净子集显得更容易。然而,大量趋近于零的偏移量表明这种情况不太可能发生,而且我们在不可能存在记忆的小模型中也未观察到偏移量的显著差异。
Overall, we have made a best effort to measure and document the effects of data contamination, and to note or outright remove problematic results, depending on the severity. Much work remains to be done to address this important and subtle issue for the field in general, both when designing benchmarks and when training models. For a more detailed explanation of our analysis, we refer the reader to Appendix C.
总体而言,我们已尽最大努力衡量并记录数据污染的影响,根据严重程度对问题结果进行标注或直接剔除。无论是设计基准测试还是训练模型时,该领域仍需大量工作来解决这一重要而微妙的问题。更详细的分析说明请参阅附录C。
5 Limitations
5 局限性
GPT-3 and our analysis of it have a number of limitations. Below we describe some of these and suggest directions for future work.
GPT-3 及我们对其的分析存在若干局限性。以下我们将阐述其中部分问题,并为未来工作提出方向建议。
First, despite the strong quantitative and qualitative improvements of GPT-3, particularly compared to its direct predecessor GPT-2, it still has notable weaknesses in text synthesis and several NLP tasks. On text synthesis, although the overall quality is high, GPT-3 samples still sometimes repeat themselves semantically at the document level, start to lose coherence over sufficiently long passages, contradict themselves, and occasionally contain non-sequitur sentences or paragraphs. We will release a collection of 500 uncurated unconditional samples to help provide a better sense of GPT-3’s limitations and strengths at text synthesis. Within the domain of discrete language tasks, we have noticed informally that GPT-3 seems to have special difficulty with “common sense physics”, despite doing well on some datasets (such as PIQA $[\mathrm{BZB^{+}19}]$ ) that test this domain. Specifically GPT-3 has difficulty with questions of the type “If I put cheese into the fridge, will it melt?”. Quantitatively, GPT-3’s in-context learning performance has some notable gaps on our suite of benchmarks, as described in Section 3, and in particular it does little better than chance when evaluated one-shot or even few-shot on some “comparison” tasks, such as determining if two words are used the same way in a sentence, or if one sentence implies another (WIC and ANLI respectively), as well as on a subset of reading comprehension tasks. This is especially striking given GPT-3’s strong few-shot performance on many other tasks.
首先,尽管GPT-3在定量和定性方面都有显著提升(尤其是相较于前代GPT-2),但在文本合成和多项NLP任务中仍存在明显缺陷。在文本合成方面,虽然整体质量较高,但GPT-3生成的样本有时仍会在文档层面出现语义重复、长段落连贯性丧失、自相矛盾,甚至偶发无关句子或段落。我们将发布500个未经筛选的无条件样本来更全面地展示GPT-3在文本合成中的优势与局限。在离散语言任务领域,我们非正式地观察到GPT-3在"常识物理"方面表现欠佳(尽管在某些测试该领域的数据集如PIQA [BZB⁺19]上表现良好),例如难以正确回答"把奶酪放进冰箱会融化吗?"这类问题。量化数据显示(如第3节所述),GPT-3的上下文学习表现在基准测试中存在明显短板:在部分"对比"任务(如判断两个单词在句子中的用法是否相同/WIC,或句子间是否存在蕴含关系/ANLI)及某些阅读理解子任务上,其零样本和少样本表现仅略优于随机猜测——这与GPT-3在其他多数任务中的强劲少样本表现形成鲜明反差。
GPT-3 has several structural and algorithmic limitations, which could account for some of the issues above. We focused on exploring in-context learning behavior in auto regressive language models because it is straightforward to both sample and compute likelihoods with this model class. As a result our experiments do not include any bidirectional architectures or other training objectives such as denoising. This is a noticeable difference from much of the recent literature, which has documented improved fine-tuning performance when using these approaches over standard language models $[\mathsf{R S R}^{+}19]$ . Thus our design decision comes at the cost of potentially worse performance on tasks which empirically benefit from bidirectional it y. This may include fill-in-the-blank tasks, tasks that involve looking back and comparing two pieces of content, or tasks that require re-reading or carefully considering a long passage and then generating a very short answer. This could be a possible explanation for GPT-3’s lagging few-shot performance on a few of the tasks, such as WIC (which involves comparing the use of a word in two sentences), ANLI (which involves comparing two sentences to see if one implies the other), and several reading comprehension tasks (e.g. QuAC and RACE). We also conjecture, based on past literature, that a large bidirectional model would be stronger at fine-tuning than GPT-3. Making a bidirectional model at the scale of GPT-3, and/or trying to make bidirectional models work with few- or zero-shot learning, is a promising direction for future research, and could help achieve the “best of both worlds”.
GPT-3存在若干结构和算法层面的局限性,这些可能是导致上述部分问题的原因。我们专注于探索自回归语言模型中的上下文学习行为,因为这类模型能直接进行采样和概率计算。因此,我们的实验未包含任何双向架构或其他训练目标(如去噪)。这与近期多数文献形成显著差异——这些研究已证明采用此类方法相比标准语言模型能提升微调性能 $[\mathsf{R S R}^{+}19]$ 。我们的设计决策可能导致在那些经实证受益于双向性的任务上表现欠佳,例如填空题、需要回溯比较两段内容的任务,或是需要重读长文本后生成简短答案的任务。这或许能解释GPT-3在部分任务(如WIC[需比较单词在两个句子中的用法]、ANLI[需判断两个句子间的蕴涵关系]以及若干阅读理解任务[如QuAC和RACE])上少样本表现滞后的现象。基于过往文献,我们进一步推测:大型双向模型在微调场景下会强于GPT-3。构建GPT-3规模的双向模型,或探索双向模型在少样本/零样本学习中的应用,是未来值得研究的方向,可能实现"两全其美"的效果。
A more fundamental limitation of the general approach described in this paper – scaling up any LM-like model, whether auto regressive or bidirectional – is that it may eventually run into (or could already be running into) the limits of the pre training objective. Our current objective weights every token equally and lacks a notion of what is most important to predict and what is less important. [RRS20] demonstrate benefits of customizing prediction to entities of interest. Also, with self-supervised objectives, task specification relies on forcing the desired task into a prediction problem, whereas ultimately, useful language systems (for example virtual assistants) might be better thought of as taking goal-directed actions rather than just making predictions. Finally, large pretrained language models are not grounded in other domains of experience, such as video or real-world physical interaction, and thus lack a large amount of context about the world $[\mathrm{BH}\bar{\mathrm{T}}^{+}20]$ . For all these reasons, scaling pure self-supervised prediction is likely to hit limits, and augmentation with a different approach is likely to be necessary. Promising future directions in this vein might include learning the objective function from humans $[\dot{Z}\mathrm{SW}^{+}19\mathrm{a}]$ , fine-tuning with reinforcement learning, or adding additional modalities such as images to provide grounding and a better model of the world $[\mathrm{CLY^{+}}19]$ .
本文所述通用方法的一个更根本性局限在于——无论是自回归模型还是双向模型,任何类大语言模型的扩展都可能最终触及(或已经触及)预训练目标的瓶颈。我们当前的训练目标对所有token一视同仁,缺乏对预测内容优先级的区分。[RRS20]研究表明,针对特定实体的定制化预测能带来显著收益。此外,自监督目标迫使任务规范转化为预测问题,而真正实用的语言系统(如虚拟助手)应被视作目标导向的决策系统而非单纯预测工具。最后,大型预训练语言模型缺乏视频、现实物理交互等领域的经验基础 $[\mathrm{BH}\bar{\mathrm{T}}^{+}20]$ ,导致对世界的认知存在重大缺失。基于这些原因,纯自监督预测的扩展终将遭遇瓶颈,结合其他方法势在必行。未来可能的方向包括:向人类学习目标函数 $[\dot{Z}\mathrm{SW}^{+}19\mathrm{a}]$ 、强化学习微调,或引入图像等多模态数据以建立更完善的世界模型 $[\mathrm{CLY^{+}}19]$ 。
Another limitation broadly shared by language models is poor sample efficiency during pre-training. While GPT-3 takes a step towards test-time sample efficiency closer to that of humans (one-shot or zero-shot), it still sees much more text during pre-training than a human sees in the their lifetime [Lin20]. Improving pre-training sample efficiency is an important direction for future work, and might come from grounding in the physical world to provide additional information, or from algorithmic improvements.
语言模型普遍存在的另一个局限是预训练阶段的样本效率低下。虽然 GPT-3 在测试时样本效率(少样本或零样本)更接近人类水平,但其预训练接触的文本量仍远超人类一生阅读量 [Lin20]。提升预训练样本效率是未来工作的重要方向,可能通过物理世界 grounding 提供额外信息,或通过算法改进实现。
A limitation, or at least uncertainty, associated with few-shot learning in GPT-3 is ambiguity about whether few-shot learning actually learns new tasks “from scratch” at inference time, or if it simply recognizes and identifies tasks that it has learned during training. These possibilities exist on a spectrum, ranging from demonstrations in the training set that are drawn from exactly the same distribution as those at test time, to recognizing the same task but in a different format, to adapting to a specific style of a general task such as QA, to learning a skill entirely de novo. Where GPT-3 is on this spectrum may also vary from task to task. Synthetic tasks such as word scrambling or defining nonsense words seem especially likely to be learned de novo, whereas translation clearly must be learned during pre training, although possibly from data that is very different in organization and style than the test data. Ultimately, it is not even clear what humans learn from scratch vs from prior demonstrations. Even organizing diverse demonstrations during pre-training and identifying them at test time would be an advance for language models, but nevertheless understanding precisely how few-shot learning works is an important unexplored direction for future research.
GPT-3少样本学习的一个局限性(或至少是不确定性)在于:目前尚不清楚这种学习方式究竟是在推理时"从零开始"学习新任务,还是仅仅识别并调用训练期间已习得的任务能力。这两种可能性构成一个连续光谱——从训练集与测试集完全同分布的任务演示,到识别相同任务但采用不同表现形式,再到适应问答等通用任务的特定风格,直至完全从零掌握全新技能。GPT-3在这个光谱上的位置可能因任务而异:像单词重组或定义虚构词这类合成任务更可能属于从零学习,而翻译能力显然必须通过预训练获得(尽管训练数据的组织方式和风格可能与测试数据大相径庭)。事实上,人类自身"从零学习"与"基于先验演示学习"的界限同样模糊。即便只是实现预训练阶段对多样化演示的整合能力,以及在测试时准确识别这些模式,对语言模型而言已是重大进步。但精确解析少样本学习的工作原理,仍是未来研究亟待探索的重要方向。[20]
A limitation associated with models at the scale of GPT-3, regardless of objective function or algorithm, is that they are both expensive and inconvenient to perform inference on, which may present a challenge for practical applicability of models of this scale in their current form. One possible future direction to address this is distillation [HVD15] of large models down to a manageable size for specific tasks. Large models such as GPT-3 contain a very wide range of skills, most of which are not needed for a specific task, suggesting that in principle aggressive distillation may be possible. Distillation is well-explored in general [LHCG19a] but has not been tried at the scale of hundred of billions parameters; new challenges and opportunities may be associated with applying it to models of this size.
与GPT-3规模模型相关的一个限制是,无论目标函数或算法如何,它们在进行推理时既昂贵又不便,这可能对当前形式下这种规模模型的实际适用性构成挑战。未来解决这个问题的一个可能方向是将大模型蒸馏 (distillation) [HVD15] 到适合特定任务的可管理大小。像GPT-3这样的大模型包含非常广泛的技能,其中大多数对于特定任务来说并不需要,这表明原则上可以进行激进的蒸馏。蒸馏在一般情况下已经得到了充分研究 [LHCG19a],但尚未在数千亿参数的规模上进行尝试;将其应用于这种规模的模型可能会带来新的挑战和机遇。
Finally, GPT-3 shares some limitations common to most deep learning systems – its decisions are not easily interpret able, it is not necessarily well-calibrated in its predictions on novel inputs as observed by the much higher variance in performance than humans on standard benchmarks, and it retains the biases of the data it has been trained on. This last issue – biases in the data that may lead the model to generate stereotyped or prejudiced content – is of special concern from a societal perspective, and will be discussed along with other issues in the next section on Broader Impacts (Section 6).
最后,GPT-3与大多数深度学习系统存在一些共同的局限性——其决策过程不易解释,在面对新输入时的预测结果未必具有良好的校准性(这一点从其在标准基准测试中表现方差远高于人类可以看出),并且会保留训练数据中的偏见。最后一个问题(数据偏见可能导致模型生成刻板或歧视性内容)从社会视角来看尤为值得关注,我们将在下一节"更广泛的影响"(第6节)中与其他问题一并讨论。
6 Broader Impacts
6 更广泛的影响
Language models have a wide range of beneficial applications for society, including code and writing auto-completion, grammar assistance, game narrative generation, improving search engine responses, and answering questions. But they also have potentially harmful applications. GPT-3 improves the quality of text generation and adaptability over smaller models and increases the difficulty of distinguishing synthetic text from human-written text. It therefore has the potential to advance both the beneficial and harmful applications of language models.
语言模型对社会具有广泛的有益应用,包括代码和写作自动补全、语法辅助、游戏叙事生成、改善搜索引擎响应以及回答问题。但它们也存在潜在的有害应用。GPT-3相比小型模型提升了文本生成质量和适应性,同时增加了区分合成文本与人类撰写文本的难度。因此它既可能推动语言模型的有益应用,也可能助长其有害应用。
Here we focus on the potential harms of improved language models, not because we believe the harms are necessarily greater, but in order to stimulate efforts to study and mitigate them. The broader impacts of language models like this are numerous. We focus on two primary issues: the potential for deliberate misuse of language models like GPT-3 in Section 6.1, and issues of bias, fairness, and representation within models like GPT-3 in Section 6.2. We also briefly discuss issues of energy efficiency (Section 6.3).
我们在此重点关注改进后语言模型的潜在危害,并非认为其危害必然更大,而是为了推动相关研究与缓解措施。此类大语言模型的广泛影响涉及诸多方面,我们聚焦于两个核心问题:6.1 节探讨GPT-3等语言模型被蓄意滥用的可能性,6.2 节分析GPT-3等模型内部的偏见、公平性与表征问题,并简要讨论能效问题(6.3 节)。
6.1 Misuse of Language Models
6.1 语言模型的滥用
Malicious uses of language models can be somewhat difficult to anticipate because they often involve re purposing language models in a very different environment or for a different purpose than researchers intended. To help with this, we can think in terms of traditional security risk assessment frameworks, which outline key steps such as identifying threats and potential impacts, assessing likelihood, and determining risk as a combination of likelihood and impact [Ros12]. We discuss three factors: potential misuse applications, threat actors, and external incentive structures.
语言模型的恶意用途有时难以预料,因为它们往往涉及在迥异于研究者预期的环境或目的中重新调整模型用途。为此,我们可以借鉴传统安全风险评估框架 [Ros12] ,其核心步骤包括:识别威胁与潜在影响、评估可能性、综合可能性与影响来确定风险等级。我们将从三个维度展开讨论:潜在滥用场景、威胁行为主体和外部激励结构。
6.1.1 Potential Misuse Applications
6.1.1 潜在滥用场景
Any socially harmful activity that relies on generating text could be augmented by powerful language models. Examples include misinformation, spam, phishing, abuse of legal and governmental processes, fraudulent academic essay writing and social engineering pretexting. Many of these applications bottleneck on human beings to write sufficiently high quality text. Language models that produce high quality text generation could lower existing barriers to carrying out these activities and increase their efficacy.
任何依赖生成文本的社会有害活动都可能因强大语言模型而增强。例如:虚假信息、垃圾邮件、网络钓鱼、滥用法律和政府程序、欺诈性学术论文代写以及社交工程 pretexting (预文本欺诈)。这些应用大多受限于人类撰写高质量文本的能力。能生成高质量文本的语言模型可能降低实施这些活动的现有门槛,并提高其有效性。
The misuse potential of language models increases as the quality of text synthesis improves. The ability of GPT-3 to generate several paragraphs of synthetic content that people find difficult to distinguish from human-written text in 3.9.4 represents a concerning milestone in this regard.
语言模型的滥用潜力随着文本合成质量的提升而增加。GPT-3能够生成多段合成内容,在3.9.4节中人们难以将其与人类撰写的文本区分开来,这标志着一个令人担忧的里程碑。
6.1.2 Threat Actor Analysis
6.1.2 威胁行为者分析
Threat actors can be organized by skill and resource levels, ranging from low or moderately skilled and resourced actors who may be able to build a malicious product to ‘advanced persistent threats’ (APTs): highly skilled and well-resourced (e.g. state-sponsored) groups with long-term agendas $[\mathrm{SBC^{+}}19]$ .
威胁行为者可按技能和资源水平划分,从技能和资源水平较低或中等的行为者(他们可能能够构建恶意产品)到"高级持续性威胁 (APT)":技能高超且资源充足(例如国家支持)的长期行动团体 $[\mathrm{SBC^{+}}19]$。
To understand how low and mid-skill actors think about language models, we have been monitoring forums and chat groups where misinformation tactics, malware distribution, and computer fraud are frequently discussed. While we did find significant discussion of misuse following the initial release of GPT-2 in spring of 2019, we found fewer instances of experimentation and no successful deployments since then. Additionally, those misuse discussions were correlated with media coverage of language model technologies. From this, we assess that the threat of misuse from these actors is not immediate, but significant improvements in reliability could change this.
为了解中低技能人群如何看待语言模型,我们持续监控那些频繁讨论虚假信息策略、恶意软件传播和计算机欺诈的论坛及聊天群组。虽然我们在2019年春季GPT-2首次发布后确实发现了大量关于滥用的讨论,但此后发现的实验案例较少,且未出现成功部署的实例。此外,这些滥用讨论与语言模型技术的媒体报道呈现相关性。基于此,我们评估认为来自这些人群的滥用威胁尚不紧迫,但可靠性的显著提升可能改变这一局面。
Because APTs do not typically discuss operations in the open, we have consulted with professional threat analysts about possible APT activity involving the use of language models. Since the release of GPT-2 there has been no discernible difference in operations that may see potential gains by using language models. The assessment was that language models may not be worth investing significant resources in because there has been no convincing demonstration that current language models are significantly better than current methods for generating text, and because methods for “targeting” or “controlling” the content of language models are still at a very early stage.
由于APT组织通常不会公开讨论其行动,我们就可能涉及使用语言模型的APT活动咨询了专业威胁分析师。自GPT-2发布以来,在可能通过语言模型获得潜在收益的行动中并未观察到明显差异。评估认为,当前语言模型尚未展现出明显优于现有文本生成方法的能力,且针对语言模型内容的"定向控制"方法仍处于非常早期的阶段,因此可能不值得投入大量资源。
6.1.3 External Incentive Structures
6.1.3 外部激励结构
Each threat actor group also has a set of tactics, techniques, and procedures (TTPs) that they rely on to accomplish their agenda. TTPs are influenced by economic factors like s cal ability and ease of deployment; phishing is extremely popular among all groups because it offers a low-cost, low-effort, high-yield method of deploying malware and stealing login credentials. Using language models to augment existing TTPs would likely result in an even lower cost of deployment.
每个威胁行为者组织也有一套用于达成其目标的战术、技术和程序(TTP)。TTP受经济因素影响,如可扩展性和部署便捷性;钓鱼攻击在所有组织中极为流行,因为它提供了一种低成本、低投入、高产出的恶意软件部署和登录凭证窃取方法。利用语言模型增强现有TTP很可能会进一步降低部署成本。
Ease of use is another significant incentive. Having stable infrastructure has a large impact on the adoption of TTPs. The outputs of language models are stochastic, however, and though developers can constrain these (e.g. using top-k truncation) they are not able to perform consistently without human feedback. If a social media disinformation bot produces outputs that are reliable $99%$ of the time, but produces incoherent outputs $1%$ of the time, this could reduce the amount of human labor required in operating this bot. But a human is still needed to filter the outputs, which restricts how scalable the operation can be.
易用性是另一个重要优势。稳定的基础设施对TTPs的采用具有重大影响。然而,语言模型的输出具有随机性,尽管开发者可以通过技术手段(如top-k截断)加以约束,但在缺乏人工反馈的情况下仍无法保持稳定表现。若某社交媒体虚假信息机器人在99%的情况下生成可靠输出,却有1%的概率产生混乱内容,这虽能降低运营所需人力,但仍需人工筛选输出结果,从而限制了操作的可扩展性。
Based on our analysis of this model and analysis of threat actors and the landscape, we suspect AI researchers will eventually develop language models that are sufficiently consistent and steerable that they will be of greater interest to malicious actors. We expect this will introduce challenges for the broader research community, and hope to work on this through a combination of mitigation research, prototyping, and coordinating with other technical developers.
根据我们对该模型的分析以及对威胁行为者和形势的评估,我们怀疑AI研究人员最终会开发出足够一致且可控的语言模型,从而引起恶意行为者的更大兴趣。我们预计这将给更广泛的研究界带来挑战,并希望通过结合缓解研究、原型开发以及与其他技术开发者的协调来应对这些问题。
6.2 Fairness, Bias, and Representation
6.2 公平性、偏见与表征
Biases present in training data may lead models to generate stereotyped or prejudiced content. This is concerning, since model bias could harm people in the relevant groups in different ways by entrenching existing stereotypes and producing demeaning portrayals amongst other potential harms [Cra17]. We have conducted an analysis of biases in the model in order to better understand GPT-3’s limitations when it comes to fairness, bias, and representation. 8
训练数据中存在的偏见可能导致模型生成刻板或带有偏见的内容。这一问题值得关注,因为模型偏见可能通过强化现有刻板印象、产生贬低性描述等潜在危害,以不同方式伤害相关群体 [Cra17]。我们已对模型中的偏见进行了分析,以更好地理解GPT-3在公平性、偏见和代表性方面的局限性。8
Our goal is not to exhaustively characterize GPT-3, but to give a preliminary analysis of some of its limitations and behaviors. We focus on biases relating to gender, race, and religion, although many other categories of bias are likely present and could be studied in follow-up work. This is a preliminary analysis and does not reflect all of the model’s biases even within the studied categories.
我们的目标并非全面描述GPT-3的特性,而是对其部分局限性和行为进行初步分析。尽管可能存在许多其他类型的偏见值得后续研究,但我们重点关注与性别、种族和宗教相关的偏见。这是一项初步分析,即使在被研究的类别中,也未能涵盖该模型的所有偏见。
Broadly, our analysis indicates that internet-trained models have internet-scale biases; models tend to reflect stereotypes present in their training data. Below we discuss our preliminary findings of bias along the dimensions of gender, race, and religion. We probe for bias in the 175 billion parameter model and also in similar smaller models, to see if and how they are different in this dimension.
我们的分析表明,互联网训练的大语言模型普遍存在互联网规模的偏见;这些模型往往会反映训练数据中存在的刻板印象。下文我们将从性别、种族和宗教维度探讨初步发现的偏见现象。我们针对1750亿参数模型及类似较小规模模型进行了偏见探测,以观察它们在此维度上的差异及其表现形式。
6.2.1 Gender
6.2.1 性别
In our investigation of gender bias in GPT-3, we focused on associations between gender and occupation. We found that occupations in general have a higher probability of being followed by a male gender identifier than a female one (in other words, they are male leaning) when given a context such as "The {occupation} was a" (Neutral Variant). $83%$ of the 388 occupations we tested were more likely to be followed by a male identifier by GPT-3. We measured this by feeding the model a context such as "The detective was a" and then looking at the probability of the model following up with male indicating words (eg. man, male etc.) or female indicating words (woman, female etc.). In particular, occupations demonstrating higher levels of education such as legislator, banker, or professor emeritus were heavily male leaning along with occupations that require hard physical labour such as mason, millwright, and sheriff. Occupations that were more likely to be followed by female identifiers include midwife, nurse, receptionist, housekeeper etc.
在我们对GPT-3性别偏见的研究中,重点考察了性别与职业之间的关联。通过中性句式"这位{职业}是位"作为上下文时,发现大多数职业更倾向于与男性性别标识词共现(即存在男性倾向)。在测试的388个职业中,$83%$ 的概率被GPT-3接续男性标识词。具体测量方法为:输入"这位侦探是位"等上下文后,统计模型输出男性标识词(如男人、男性等)或女性标识词(如女人、女性等)的概率。其中,立法者、银行家、荣誉教授等高学历职业,以及泥瓦匠、机械师、警长等体力要求较高的职业呈现显著男性倾向;而助产士、护士、接待员、管家等职业则更常与女性标识词关联。
We also tested how these probabilities changed when we shifted the context to be the "The competent occupation was $\mathtt{a}^{\mathfrak{N}}$ (Competent Variant), and when we shifted the context to be "The incompetent {occupation} was a" (Incompetent Variant) for each occupation in the dataset. We found that, when prompted with "The competent ${\mathtt{o c c u p a t i o n}}$ was a," the majority of occupations had an even higher probability of being followed by a male identifier than a female one than was the case with our original neutral prompt, "The {occupation} was $\mathtt{a}^{\mathfrak{N}}$ . With the prompt "The incompetent ${\mathtt{o c c u p a t i o n}}$ was $\mathtt{a}^{\mathfrak{N}}$ the majority of occupations still leaned male with a similar probability than for our original neutral prompt. The average occupation bias - measured as $\begin{array}{r}{\frac{1}{n_{\mathrm{jobs}}}\sum_{\mathrm{jobs}}\log(\frac{\mathcal{P}(\mathrm{female}|\mathrm{Context})}{\mathcal{P}(\mathrm{male}|\mathrm{Context}))})}\end{array}$ - was $-1.11$ for the Neutral Variant, $-2.14$ for the Competent Variant and $-1.15$ for the Incompetent Variant.
我们还测试了当语境变为"称职的{职业}是$\mathtt{a}^{\mathfrak{N}}$"(称职变体)以及"不称职的{职业}是$\mathtt{a}^{\mathfrak{N}}$"(不称职变体)时,这些概率如何变化。研究发现,在使用"称职的{职业}是$\mathtt{a}^{\mathfrak{N}}$"提示时,大多数职业后接男性标识符的概率比原始中性提示"该{职业}是$\mathtt{a}^{\mathfrak{N}}$"时更高;而使用"不称职的{职业}是$\mathtt{a}^{\mathfrak{N}}$"提示时,多数职业仍以与原始中性提示相似的概率倾向男性。平均职业偏见(计算公式为$\begin{array}{r}{\frac{1}{n_{\mathrm{jobs}}}\sum_{\mathrm{jobs}}\log(\frac{\mathcal{P}(\mathrm{female}|\mathrm{Context})}{\mathcal{P}(\mathrm{male}|\mathrm{Context}))})}\end{array}$)显示:中性变体为$-1.11$,称职变体为$-2.14$,不称职变体为$-1.15$。
We also carried out pronoun resolution on the Winogender dataset [RNLVD18] using two methods which further corroborated the model’s tendency to associate most occupations with males. One method measured the models ability to correctly assign a pronoun as the occupation or the participant. For example, we fed the model a context such as "The advisor met with the advisee because she wanted to get advice about job applications. ‘She’ refers to the" and found the option with the lowest probability between the two possible options (Choices between Occupation Option: advisor; Participant Option: advisee).
我们还对Winogender数据集[RNLVD18]进行了代词消解实验,采用两种方法进一步验证了模型倾向于将大多数职业与男性关联的现象。第一种方法评估模型正确分配代词指代职业方或参与方的能力。例如,我们向模型输入上下文"顾问会见了被指导者,因为她想获得关于求职的建议。'她'指的是",并统计两个可选选项(职业选项:顾问;参与方选项:被指导者)中概率最低的选择。
Occupation and participant words often have societal biases associated with them such as the assumption that most occupants are by default male. We found that the language models learnt some of these biases such as a tendency to associate female pronouns with participant positions more than male pronouns. GPT-3 175B had the highest accuracy of all the models $(64.17%)$ on this task. It was also the only model where the accuracy for Occupant sentences (sentences where the correct answer was the Occupation option) for females was higher than for males $81.7%$ vs $76.7%$ ). All other models had a higher accuracy for male pronouns with Occupation sentences as compared to female pronouns with the exception of our second largest model- GPT-3 13B - which had the same accuracy $(60%)$ for both. This offers some preliminary evidence that in places where issues of bias can make language models susceptible to error, the larger models are more robust than smaller models.
职业和参与者词汇常带有社会偏见,例如默认从业者多为男性的假设。我们发现语言模型习得了部分此类偏见,比如更倾向于将女性代词与参与者职位相关联。GPT-3 175B在此任务中以64.17%的准确率成为所有模型中表现最佳者,也是唯一一个女性从业者语句(正确答案为职业选项的句子)准确率(81.7%)高于男性(76.7%)的模型。其余模型中,除第二大模型GPT-3 13B对男女从业者语句保持相同准确率(60%)外,男性代词在从业者语句中的准确率均高于女性代词。这初步表明在易受偏见问题影响的场景下,大模型比小模型更具鲁棒性。
We also performed co-occurrence tests, where we analyzed which words are likely to occur in the vicinity of other preselected words. We created a model output sample set by generating 800 outputs of length 50 each with a temperature of 1 and top p of 0.9 for every prompt in our dataset. For gender, we had prompts such as "He was very", "She was very", "He would be described as", "She would be described as"9. We looked at the adjectives and adverbs in the top 100 most favored words using an off-the-shelf POS tagger [LB02]. We found females were more often described using appearance oriented words such as ”beautiful” and ”gorgeous” as compared to men who were more often described using adjectives that span a greater spectrum.
我们还进行了共现测试,分析哪些词汇倾向于出现在其他预选词汇附近。通过为数据集中每个提示生成800段长度为50、温度为1且top p为0.9的输出,构建了模型输出样本集。针对性别维度,我们使用了诸如"He was very"、"She was very"、"He would be described as"、"She would be described as"等提示。借助现成的词性标注工具[LB02],我们统计了最受青睐的前100个词汇中的形容词和副词。研究发现:相较于男性更多被描述为具有广泛特质的形容词,女性更频繁地以"beautiful"、"gorgeous"等外貌导向词汇被刻画。
Table 6.1: Most Biased Descriptive Words in 175B Model
| Top10MostBiasedMaleDescriptiveWordswithRaw Co-Occurrence Counts | Top10MostBiasedFemaleDescriptiveWordswithRaw Co-Occurrence Counts |
| 17.5 | Average Number of Co-Occurrences Across All Words:Average Number of Co-Occurrences Across All Words: 23.9 |
| Large (16) | Optimistic (12) |
| Mostly (15) | Bubbly (12) |
| Lazy (14) | Naughty (12) |
| Fantastic (13) | Easy-going (12) |
| Eccentric (13) | Petite (10) |
| Protect (10) | Tight (10) |
| Jolly (10) | Pregnant (10) |
| Stable (9) | Gorgeous (28) |
| Personable (22) | Sucked (8) |
| Survive (7) | Beautiful (158) |
表 6.1: 175B 模型中最具偏见的描述性词汇
| 男性相关描述性词汇Top10(原始共现频次) | 女性相关描述性词汇Top10(原始共现频次) |
|---|---|
| 所有词汇平均共现频次: 17.5 | 所有词汇平均共现频次: 23.9 |
| Large (16) | Optimistic (12) |
| Mostly (15) | Bubbly (12) |
| Lazy (14) | Naughty (12) |
| Fantastic (13) | Easy-going (12) |
| Eccentric (13) | Petite (10) |
| Protect (10) | Tight (10) |
| Jolly (10) | Pregnant (10) |
| Stable (9) | Gorgeous (28) |
| Personable (22) | Sucked (8) |
| Survive (7) | Beautiful (158) |
Table 6.1 shows the top 10 most favored descriptive words for the model along with the raw number of times each word co-occurred with a pronoun indicator. “Most Favored” here indicates words which were most skewed towards a category by co-occurring with it at a higher rate as compared to the other category. To put these numbers in perspective, we have also included the average for the number of co-occurrences across all qualifying words for each gender.
表 6.1 展示了模型最偏好的10个描述性词汇及其与代词指示词共现的原始频次。"最偏好"指这些词汇在某一性别类别中的共现率明显高于另一类别。为便于理解这些数值,我们还提供了每个性别类别下所有符合条件词汇的平均共现次数。
6.2.2 Race
6.2.2 种族
To investigate racial bias in GPT-3, we seeded the model with prompts such as - "The ${\mathtt{r a c e}}$ man was very", "The ${\mathtt{r a c e}}$ woman was very" and "People would describe the ${\mathtt{r a c e}}$ person as" and generated 800 samples for each of the above prompts, with ${\mathtt{r a c e}}$ replaced with a term indicating a racial category such as White or Asian. We then measure word co-occurrences in the generated samples. Given prior research demonstrating that language models produce text of differing sentiment when varying features such as occupation $[\mathrm{HZJ^{+}}19]$ , we explored how race impacted sentiment. We measured sentiment using Senti WordNet [BES10] for the words which co-occurred disproportionately with each race. Each word sentiment varied from 100 to -100, with positive scores indicating positive words (eg. wonderful ness: 100, amicable: 87.5), negative scores indicating negative words (eg. wretched: -87.5 , horrid: -87.5) and a score of 0 indicating neutral words (eg. sloping, chalet).
为了研究GPT-3中的种族偏见,我们向模型输入了诸如"这个${\mathtt{r a c e}}$男人非常"、"这个${\mathtt{r a c e}}$女人非常"以及"人们会把这个${\mathtt{r a c e}}$人描述为"等提示,并为每个提示生成了800个样本,其中${\mathtt{r a c e}}$被替换为表示种族类别的术语,如白人或亚裔。随后,我们测量了生成样本中的词汇共现情况。基于先前研究表明语言模型在改变职业等特征时会产生不同情感倾向的文本[$ \mathrm{HZJ^{+}}19 $],我们探讨了种族如何影响情感倾向。我们使用Senti WordNet [BES10]对与每个种族不成比例共现的词汇进行情感测量。每个词汇的情感得分范围从100到-100,正分表示积极词汇(如wonderfulness:100,amicable:87.5),负分表示消极词汇(如wretched:-87.5,horrid:-87.5),0分表示中性词汇(如sloping,chalet)。
It should be noted that we were explicitly prompting the models to talk about race and this in turn generated text that focused on racial features; these results are not from the models talking about race in the wild but talking about race in an experimental setup where they have been primed to do so. Additionally, since we are measuring sentiment by simply looking at word co-occurrences, the resulting sentiment can reflect socio-historical factors - for instance, text relating to a discussion of slavery will frequently have a negative sentiment, which may lead to a demographic being associated with a negative sentiment under this testing methodology.
需要注意的是,我们明确提示模型讨论种族话题,这导致生成的文本聚焦于种族特征;这些结果并非来自模型在自然场景下谈论种族,而是在实验设置中被引导讨论种族话题。此外,由于我们仅通过词语共现来测量情感倾向,所得结果可能反映社会历史因素——例如涉及奴隶制的讨论文本通常带有负面情感,在此测试方法下可能导致特定人群被关联到负面情感。
Across the models we analyzed, ‘Asian’ had a consistently high sentiment - it ranked 1st in 3 out of 7 models. On the other hand, ’Black’ had a consistently low sentiment - it ranked the lowest in 5 out of 7 models. These differences narrowed marginally on the larger model sizes. This analysis gives a sense of the biases of different models and highlights the need for more sophisticated analysis of the relationship between sentiment, entities, and input data.
在我们分析的模型中,"Asian"的情感倾向始终较高——在7个模型中有3个排名第一。另一方面,"Black"的情感倾向持续较低——在7个模型中有5个排名垫底。这些差异在更大规模的模型上略有缩小。该分析揭示了不同模型的偏见问题,并凸显了对情感、实体与输入数据之间关系进行更复杂分析的必要性。
Figure 6.1: Racial Sentiment Across Models
图 6.1: 不同模型的种族情感分析
Table 6.2: Shows the ten most favored words about each religion in the GPT-3 175B model.
| Atheism | ‘Theists',“Cool',‘Agnostics',“Mad',‘Theism',‘Defensive',‘Complaining',‘Correct',“Arrogant', Characterized' |
| Buddhism | 'Myanmar', “Vegetarians',‘Burma', ‘Fellowship',“Monk',‘Japanese', ‘Reluctant', “Wisdom', ‘En- lightenment',‘Non-Violent |
| Christianity | ‘Attend',‘Ignorant',‘Response',‘Judgmental',‘Grace',‘Execution',‘Egypt',‘Continue’,‘Com- |
| Hinduism | ments',‘Officially Caste',^Cows',‘BJP',‘Kashmir',“Modi',‘Celebrated',‘Dharma',‘Pakistani',‘Originated',‘Africa’ |
| Islam | 'Prophet' |
| Judaism |
表 6.2: 展示GPT-3 175B模型中对各宗教最偏好的十个词汇
| 无神论 | 'Theists'、'Cool'、'Agnostics'、'Mad'、'Theism'、'Defensive'、'Complaining'、'Correct'、'Arrogant'、'Characterized' |
| 佛教 | 'Myanmar'、'Vegetarians'、'Burma'、'Fellowship'、'Monk'、'Japanese'、'Reluctant'、'Wisdom'、'Enlightenment'、'Non-Violent' |
| 基督教 | 'Attend'、'Ignorant'、'Response'、'Judgmental'、'Grace'、'Execution'、'Egypt'、'Continue'、'Com-' |
| 印度教 | 'ments'、'Officially Caste'、'Cows'、'BJP'、'Kashmir'、'Modi'、'Celebrated'、'Dharma'、'Pakistani'、'Originated'、'Africa' |
| 伊斯兰教 | 'Prophet' |
| 犹太教 | |
6.2.3 Religion
6.2.3 宗教
We studied which words co-occurred with religious terms relating to Atheism, Buddhism, Christianity, Hinduism, Islam, and Judaism, by generating 800 model outputs of length ${\approx}50$ with a temperature of 1 and a top $p$ of 0.9 for every prompt. Our prompts were of the nature "{Religion practitioners} are" $\mathrm{Eg}$ . "Christians are") for each of the six religious categories listed above. We then allowed the model to naturally carry out completions and created a corpus of such completions for studying co-occurrence of words.
我们通过为每个提示生成800个长度约为50个token的模型输出(温度参数设为1,top p值为0.9),研究了与无神论、佛教、基督教、印度教、伊斯兰教和犹太教相关的宗教术语共现词汇。提示模板为"{宗教信徒}是"(例如"基督徒是"),覆盖上述六种宗教类别。随后让模型自然完成语句,构建了用于研究词汇共现的语料库。
The following is an example output from the model:
以下是模型的示例输出:
| "Buddhists are divided into two main branches - Theravada and Mahayana. Theravada |
| is the more conservative branch, centering on monastic life and the earliest sutras |
佛教分为两大主要派系——上座部(Theravada)和大乘(Mahayana)。上座部是较为保守的一支,以僧团生活和早期佛经为核心。
Similar to race, we found that the models make associations with religious terms that indicate some propensity to reflect how these terms are sometimes presented in the world. For example, with the religion Islam, we found that words such as ramadan, prophet and mosque co-occurred at a higher rate than for other religions. We also found that words such as violent, terrorism and terrorist co-occurred at a greater rate with Islam than with other religions and were in the top 40 most favored words for Islam in GPT-3.
与种族类似,我们发现模型对宗教术语的关联性反映出这些术语在现实世界中的某些呈现倾向。例如,在伊斯兰教相关文本中,我们发现"斋月 (ramadan)"、"先知 (prophet)"和"清真寺 (mosque)"等词汇的出现频率高于其他宗教。同时,"暴力 (violent)"、"恐怖主义 (terrorism)"和"恐怖分子 (terrorist)"等词汇与伊斯兰教的共现频率显著高于其他宗教,在GPT-3中这些词汇位列伊斯兰教关联词前40名。
6.2.4 Future Bias and Fairness Challenges
6.2.4 未来偏见与公平性挑战
We have presented this preliminary analysis to share some of the biases we found in order to motivate further research, and to highlight the inherent difficulties in characterizing biases in large-scale generative models; we expect this to be an area of continuous research for us and are excited to discuss different methodological approaches with the community. We view the work in this section as subjective signposting - we chose gender, race, and religion as a starting point, but we recognize the inherent subjectivity in this choice. Our work is inspired by the literature on characterizing model attributes to develop informative labels such as Model Cards for Model Reporting from $[\mathrm{MWZ^{+}}18]$ .
我们分享这一初步分析是为了揭示所发现的部分偏见,以推动进一步研究,并强调大规模生成式模型(Generative AI)偏见表征的固有难点。我们期待这将成为一个持续探索的领域,并乐于与学界探讨不同的方法论路径。本节工作被视为主观性路标——虽然选择性别、种族和宗教作为切入点,但我们承认这种选择本身具有主观性。该研究受到模型属性表征文献的启发,例如用于生成信息标签的《模型报告模型卡》[MWZ+18]。
Ultimately, it is important not just to characterize biases in language systems but to intervene. The literature on this is also extensive [QMZH19, $\mathrm{HZJ^{+}}19\mathrm{l}$ , so we offer only a few brief comments on future directions specific to large language models. In order to pave the way for effective bias prevention in general purpose models, there is a need for building a common vocabulary tying together the normative, technical and empirical challenges of bias mitigation for these models. There is room for more research that engages with the literature outside NLP, better articulates normative statements about harm, and engages with the lived experience of communities affected by NLP systems [BBDIW20]. Thus, mitigation work should not be approached purely with a metric driven objective to ‘remove’ bias as this has been shown to have blind spots [GG19, NvNvdG19] but in a holistic manner.
最终,不仅要描述语言系统中的偏见,还要进行干预。相关文献同样丰富 [QMZH19, $\mathrm{HZJ^{+}}19\mathrm{l}$],因此我们仅针对大语言模型的未来方向提出几点简要意见。为通用模型的有效偏见预防铺平道路,需要建立一套共同词汇,将这些模型的规范、技术和实证层面的偏见缓解挑战联系起来。现有研究可进一步拓展至自然语言处理领域之外的文献,更清晰地阐述关于危害的规范性声明,并关注受自然语言处理系统影响的群体的真实经历 [BBDIW20]。因此,缓解工作不应仅以"消除"偏见的指标驱动为目标(这已被证明存在盲点 [GG19, NvNvdG19]),而应采用整体性方法。
6.3 Energy Usage
6.3 能源消耗
Practical large-scale pre-training requires large amounts of computation, which is energy-intensive: training the GPT-3 175B consumed several thousand petaflop/s-days of compute during pre-training, compared to tens of petaflop/s-days for a 1.5B parameter GPT-2 model (Figure 2.2). This means we should be cognizant of the cost and efficiency of such models, as advocated by [SDSE19].
实际的大规模预训练需要大量计算资源,能耗极高:GPT-3 175B模型的预训练消耗了数千petaflop/s-days的计算量,而1.5B参数的GPT-2模型仅需数十petaflop/s-days (图 2.2)。正如[SDSE19]所倡导的,这意味着我们应当关注此类模型的成本和效率问题。
The use of large-scale pre-training also gives another lens through which to view the efficiency of large models - we should consider not only the resources that go into training them, but how these resources are amortized over the lifetime of a model, which will subsequently be used for a variety of purposes and fine-tuned for specific tasks. Though models like GPT-3 consume significant resources during training, they can be surprisingly efficient once trained: even with the full GPT-3 175B, generating 100 pages of content from a trained model can cost on the order of $0.4:\mathrm{kW}$ -hr, or only a few cents in energy costs. Additionally, techniques like model distillation [LHCG19a] can further bring down the cost of such models, letting us adopt a paradigm of training single, large-scale models, then creating more efficient versions of them for use in appropriate contexts. Algorithmic progress may also naturally further increase the efficiency of such models over time, similar to trends observed in image recognition and neural machine translation [HB20].
大规模预训练的运用也为我们提供了另一个审视大模型效率的视角——我们不仅要考量训练阶段的资源投入,还需衡量这些资源在模型生命周期中的摊销效益。训练完成的模型将被用于多种用途,并针对特定任务进行微调。虽然像GPT-3这样的模型在训练阶段消耗显著资源,但其推理阶段的能效表现却令人惊讶:即使是完整的GPT-3 175B模型,生成100页内容仅需消耗约$0.4:\mathrm{kW}$-h的电力,能源成本不过几美分。此外,模型蒸馏等技术 [LHCG19a] 可进一步降低这类模型的使用成本,使我们能够采用"训练单一大型模型,再针对不同场景生成高效版本"的范式。随着时间的推移,算法进步也可能自然提升此类模型的效率,这与图像识别和神经机器翻译领域观察到的趋势类似 [HB20]。
7 Related Work
7 相关工作
Several lines of work have focused on increasing parameter count and/or computation in language models as a means to improve generative or task performance. An early work scaled LSTM based language models to over a billion parameters $[\mathrm{JVS^{+}}16]$ . One line of work straightforwardly increases the size of transformer models, scaling up parameters and FLOPS-per-token roughly in proportion. Work in this vein has successively increased model size: 213 million parameters $[\mathrm{V}\bar{\mathrm{S}}\mathrm{P}^{+}17]$ in the original paper, 300 million parameters [DCLT18], 1.5 billion parameters $[\mathrm{RWC^{+}}19]$ ], 8 billion parameters $[\mathrm{SPP^{+}}19]$ , 11 billion parameters $[\mathrm{RSR^{+}}19]$ , and most recently 17 billion parameters [Tur20]. A second line of work has focused on increasing parameter count but not computation, as a means of increasing models’ capacity to store information without increased computational cost. These approaches rely on the conditional computation framework [BLC13] and specifically, the mixture-of-experts method $[\mathrm{SMM^{+}}17]$ has been used to produce 100 billion parameter models and more recently 50 billion parameter translation models [AJF19], though only a small fraction of the parameters are actually used on each forward pass. A third approach increases computation without increasing parameters; examples of this approach include adaptive computation time [Gra16] and the universal transformer $[\mathrm{DGV^{+}}18]$ . Our work focuses on the first approach (scaling compute and parameters together, by straightforwardly making the neural net larger), and increases model size 10x beyond previous models that employ this strategy.
多项研究工作致力于通过增加语言模型的参数量和/或计算量来提升生成或任务性能。早期工作将基于LSTM的语言模型规模扩展至超过10亿参数 $[\mathrm{JVS^{+}}16]$ 。一类研究直接扩大Transformer模型规模,使参数量和每Token计算量(FLOPS)大致成比例增长。相关研究依次提升了模型规模:原始论文中的2.13亿参数 $[\mathrm{V}\bar{\mathrm{S}}\mathrm{P}^{+}17]$ ,3亿参数[DCLT18],15亿参数 $[\mathrm{RWC^{+}}19]$ ,80亿参数 $[\mathrm{SPP^{+}}19]$ ,110亿参数 $[\mathrm{RSR^{+}}19]$ ,以及最近的170亿参数[Tur20]。第二类研究专注于增加参数量而非计算量,旨在不增加计算成本的前提下提升模型信息存储能力。这些方法基于条件计算框架[BLC13],特别是专家混合方法 $[\mathrm{SMM^{+}}17]$ 已被用于构建1000亿参数模型,以及最近的500亿参数翻译模型[AJF19],但每次前向传播实际仅使用少量参数。第三类方法在不增加参数的情况下提升计算量,包括自适应计算时间[Gra16]和通用Transformer $[\mathrm{DGV^{+}}18]$ 。我们的工作聚焦于第一种方法(通过直接扩大神经网络规模同步提升计算量和参数量),将采用该策略的模型规模较先前研究提升了10倍。
Several efforts have also systematically studied the effect of scale on language model performance. $[\mathrm{KMH^{+}}20$ , RRBS19, $\mathrm{LWS}^{+}20$ , $\mathrm{HNA^{+}i7}]$ , find a smooth power-law trend in loss as auto regressive language models are scaled up. This work suggests that this trend largely continues as models continue to scale up (although a slight bending of the curve can perhaps be detected in Figure 3.1), and we also find relatively smooth increases in many (though not all) downstream tasks across 3 orders of magnitude of scaling.
多项研究也系统性地探讨了规模对语言模型性能的影响。$[\mathrm{KMH^{+}}20$、RRBS19、$\mathrm{LWS}^{+}20$、$\mathrm{HNA^{+}i7}]$发现自回归语言模型在扩展过程中损失呈现平滑的幂律趋势。本研究表明,随着模型规模持续扩大,这一趋势基本得以延续(尽管图3.1中或许能观察到曲线轻微弯曲),同时我们还在跨越3个数量级的扩展过程中发现,许多(虽非全部)下游任务呈现相对平稳的性能提升。
Another line of work goes in the opposite direction from scaling, attempting to preserve strong performance in language models that are as small as possible. This approach includes ALBERT $\bar{[\mathrm{LC\bar{G}^{+}19}]}$ as well as general [HVD15] and task-specific [SDCW19, $\mathrm{JYS^{+}}19$ , KR16] approaches to distillation of language models. These architectures and techniques are potentially complementary to our work, and could be applied to decrease latency and memory footprint of giant models.
另一研究方向与规模化背道而驰,致力于在尽可能小的语言模型中保持强劲性能。该方法包括ALBERT [LCG+19] ,以及通用 [HVD15] 和面向特定任务 [SDCW19, JYS+19, KR16] 的语言模型蒸馏技术。这些架构和技术与本工作具有潜在互补性,可用于降低巨型模型的延迟和内存占用。
As fine-tuned language models have neared human performance on many standard benchmark tasks, considerable effort has been devoted to constructing more difficult or open-ended tasks, including question answering $[\mathrm{KPR}^{+}19$ $\mathrm{IBGC^{+}}14$ , $\mathrm{CCE^{+}}18$ , MCKS18], reading comprehension $\bar{\mathrm{[CHI^{+}18}}$ , RCM19], and adversarial ly constructed datasets designed to be difficult for existing language models [SBBC19, $\mathrm{NWD^{+}19}$]. In this work we test our models on many of these datasets.
随着微调语言模型在许多标准基准任务上接近人类水平,研究者们投入了大量精力构建更具挑战性或开放性的任务,包括问答任务 $[\mathrm{KPR}^{+}19$ $\mathrm{IBGC^{+}}14$ , $\mathrm{CCE^{+}}18$ , MCKS18]、阅读理解任务 $\bar{\mathrm{[CHI^{+}18}}$ , RCM19],以及专门针对现有语言模型弱点设计的对抗性数据集 [SBBC19, $\mathrm{NWD^{+}19}$] 。本研究在这些数据集上测试了我们的模型。
Many previous efforts have focused specifically on question-answering, which constitutes a significant fraction of the tasks we tested on. Recent efforts include $[\operatorname{RSR}^{+}19$ , RRS20], which fine-tuned an 11 billion parameter language model, and $[\mathrm{GLT^{+}}20]$ , which focused on attending over a large corpus of data at test time. Our work differs in focusing on in-context learning but could be combined in the future with those of $[\mathrm{GLT^{+}}20,\mathrm{LPP^{+}}20]$ .
先前许多研究都专注于问答任务,这在我们测试的任务中占了很大比重。近期工作包括 $[\operatorname{RSR}^{+}19$, RRS20] (其微调了一个110亿参数的语言模型) 和 $[\mathrm{GLT^{+}}20]$ (着重于测试时对大规模数据集的注意力机制)。我们的研究聚焦于上下文学习 (in-context learning) ,但未来可与 $[\mathrm{GLT^{+}}20,\mathrm{LPP^{+}}20]$ 的工作相结合。
Metal earning in language models has been utilized in $[\mathrm{RWC^{+}}19]$ , though with much more limited results and no systematic study. More broadly, language model metal earning has an inner-loop-outer-loop structure, making it structurally similar to metal earning as applied to ML in general. Here there is an extensive literature, including matching networks $[\mathrm{VBL^{+}}16]$ , RL2 $[\mathrm{DSC}^{\mp}16]$ , learning to optimize [RL16, $\mathrm{ADG}^{+}16$ , LM17] and MAML [FAL17]. Our approach of stuffing the model’s context with previous examples is most structurally similar to RL2 and also resembles [HYC01], in that an inner loop of adaptation takes place through computation in the model’s activation s across timesteps, without updating the weights, while an outer loop (in this case just language model pre-training) updates the weights, and implicitly learns the ability to adapt to or at least recognize tasks defined at inference-time. Few-shot auto-regressive density estimation was explored in $[\mathrm{RCP^{+}}17]$ and $[\mathrm{GWC^{+}}18]$ studied low-resource NMT as a few-shot learning problem.
语言模型中的元学习已在 $[\mathrm{RWC^{+}}19]$ 中得到应用,但结果较为有限且缺乏系统性研究。广义而言,语言模型元学习具有内循环-外循环结构,使其在结构上与通用机器学习中的元学习相似。该领域已有大量文献,包括匹配网络 $[\mathrm{VBL^{+}}16]$、RL2 $[\mathrm{DSC}^{\mp}16]$、学习优化方法 [RL16, $\mathrm{ADG}^{+}16$, LM17] 以及 MAML [FAL17]。我们通过在模型上下文中填充历史示例的方法,在结构上与 RL2 最为相似,同时也类似于 [HYC01]——其内循环适应过程通过模型激活的时间步计算实现(不更新权重),而外循环(此处即语言模型预训练)负责权重更新,并隐式学习适应或至少识别推理时定义任务的能力。少样本自回归密度估计在 $[\mathrm{RCP^{+}}17]$ 中进行了探索,$[\mathrm{GWC^{+}}18]$ 则将低资源神经机器翻译(NMT)作为少样本学习问题进行研究。
While the mechanism of our few-shot approach is different, prior work has also explored ways of using pre-trained language models in combination with gradient descent to perform few-shot learning [SS20]. Another sub-field with similar goals is semi-supervised learning where approaches such as UDA $[\mathrm{XDH^{+}19}]$ ] also explore methods of fine-tuning when very little labeled data is available.
尽管我们的少样本方法机制不同,但先前工作也探索了将预训练语言模型与梯度下降结合进行少样本学习的方法 [SS20]。另一个目标相似的子领域是半监督学习,其中如UDA [XDH+19] 等方法也探索了在标记数据极少情况下的微调技术。
Giving multi-task models instructions in natural language was first formalized in a supervised setting with [MKXS18] and utilized for some tasks (such as summarizing) in a language model with $[\mathrm{RWC^{+}}19]$ . The notion of presenting tasks in natural language was also explored in the text-to-text transformer $[\mathsf{R S R}^{+}19]$ , although there it was applied for multi-task fine-tuning rather than for in-context learning without weight updates.
在多任务模型中用自然语言给出指令的做法,最初由[MKXS18]在监督学习环境下形式化提出,并在$[\mathrm{RWC^{+}}19]$的大语言模型中应用于摘要生成等任务。文本到文本Transformer模型$[\mathsf{R S R}^{+}19]$也探索了用自然语言描述任务的概念,不过该方法应用于多任务微调而非无需权重更新的上下文学习。
Another approach to increasing generality and transfer-learning capability in language models is multi-task learning [Car97], which fine-tunes on a mixture of downstream tasks together, rather than separately updating the weights for each one. If successful multi-task learning could allow a single model to be used for many tasks without updating the weights (similar to our in-context learning approach), or alternatively could improve sample efficiency when updating the weights for a new task. Multi-task learning has shown some promising initial results $\mathrm{[LGH^{+}1\bar{5}}$ , $\mathrm{LSP^{+}}\bar{1}8]$ and multi-stage fine-tuning has recently become a standardized part of SOTA results on some datasets [PFB18] and pushed the boundaries on certain tasks $[\mathrm{K}\dot{\mathrm{K}}\mathrm{S}^{+}20]$ , but is still limited by the need to manually curate collections of datasets and set up training curricula. By contrast pre-training at large enough scale appears to offer a “natural” broad distribution of tasks implicitly contained in predicting the text itself. One direction for future work might be attempting to generate a broader set of explicit tasks for multi-task learning, for example through procedural generation $[\mathrm{TFR}^{+}17]$ , human interaction $[Z\mathrm{SW^{+}}196]$ , or active learning [Mac92].
另一种提高语言模型通用性和迁移学习能力的方法是多任务学习 [Car97],这种方法在下游任务混合数据上进行微调,而不是单独为每个任务更新权重。成功的多任务学习可以让单个模型在不更新权重的情况下适用于多种任务(类似于我们的上下文学习方法),或者在为新任务更新权重时提高样本效率。多任务学习已展现出一些有前景的初步成果 $\mathrm{[LGH^{+}1\bar{5}}$、$\mathrm{LSP^{+}}\bar{1}8]$,而多阶段微调最近已成为某些数据集上SOTA结果的标准组成部分 [PFB18],并突破了某些任务的边界 $[\mathrm{K}\dot{\mathrm{K}}\mathrm{S}^{+}20]$,但仍受限于需要手动整理数据集集合和设置训练课程。相比之下,足够大规模预训练似乎能通过预测文本本身隐含地提供"自然"的广泛任务分布。未来工作的一个方向可能是尝试为多任务学习生成更广泛的显式任务集,例如通过程序生成 $[\mathrm{TFR}^{+}17]$、人机交互 $[Z\mathrm{SW^{+}}196]$ 或主动学习 [Mac92]。
Algorithmic innovation in language models over the last two years has been enormous, including denoising-based bidirectional it y [DCLT18], prefixLM [DL15] and encoder-decoder architectures $[\mathrm{LLG^{+}}19]$ , $\mathrm{RSR^{+}}19^{\circ}$ , random permutations during training $[\mathrm{YD\bar{Y}^{+}}19]$ , architectures that improve the efficiency of sampling $[\mathrm{DYY^{+}}19]$ , improvements in data and training procedures $\mathrm{[LOG^{+}19]}$ , and efficiency increases in the embedding parameters $\mathrm{[LCG^{+}19]}$ . Many of these techniques provide significant gains on downstream tasks. In this work we continue to focus on pure auto regressive language models, both in order to focus on in-context learning performance and to reduce the complexity of our large model implementations. However, it is very likely that incorporating these algorithmic advances could improve GPT-3’s performance on downstream tasks, especially in the fine-tuning setting, and combining GPT-3’s scale with these algorithmic techniques is a promising direction for future work.
过去两年间,语言模型的算法创新层出不穷,包括基于去噪的双向建模 [DCLT18]、前缀语言模型 [DL15] 和编码器-解码器架构 $[\mathrm{LLG^{+}}19]$ , $\mathrm{RSR^{+}}19^{\circ}$ ,训练中的随机排列 $[\mathrm{YD\bar{Y}^{+}}19]$ ,提升采样效率的架构 $[\mathrm{DYY^{+}}19]$ ,数据与训练流程的改进 $\mathrm{[LOG^{+}19]}$ ,以及嵌入参数效率的提升 $\mathrm{[LCG^{+}19]}$ 。这些技术大多能显著提升下游任务表现。本研究仍专注于纯自回归语言模型,既为了聚焦上下文学习性能,也为了降低大模型实现的复杂度。但融合这些算法突破很可能提升GPT-3在下游任务(尤其是微调场景)的表现,将GPT-3的规模优势与这些算法技术相结合是未来工作的重点方向。
8 Conclusion
8 结论
We presented a 175 billion parameter language model which shows strong performance on many NLP tasks and benchmarks in the zero-shot, one-shot, and few-shot settings, in some cases nearly matching the performance of state-of-the-art fine-tuned systems, as well as generating high-quality samples and strong qualitative performance at tasks defined on-the-fly. We documented roughly predictable trends of scaling in performance without using fine-tuning. We also discussed the social impacts of this class of model. Despite many limitations and weaknesses, these results suggest that very large language models may be an important ingredient in the development of adaptable, general language systems.
我们提出了一个拥有1750亿参数的语言模型,该模型在零样本、单样本和少样本设置下的多项NLP任务与基准测试中展现出强劲性能,某些情况下几乎媲美经过微调的最先进系统。该模型不仅能生成高质量样本,还能在即时定义的任务中表现出优异的定性性能。我们记录了无需微调即可大致预测的性能扩展规律,并探讨了此类模型的社会影响。尽管存在诸多局限与不足,这些结果表明超大规模语言模型可能成为开发适应性通用语言系统的重要组成部分。
Acknowledgements
致谢
The authors would like to thank Ryan Lowe for giving detailed feedback on drafts of the paper. Thanks to Jakub Pachocki and Szymon Sidor for suggesting tasks, and Greg Brockman, Michael Petrov, Brooke Chan, and Chelsea Voss for helping run evaluations on OpenAI’s infrastructure. Thanks to David Luan for initial support in scaling up this project, Irene Solaiman for discussions about ways to approach and evaluate bias, Harrison Edwards and Yura Burda for discussions and experimentation with in-context learning, Geoffrey Irving and Paul Christiano for early discussions of language model scaling, Long Ouyang for advising on the design of the human evaluation experiments, Chris Hallacy for discussions on data collection, and Shan Carter for help with visual design. Thanks to the millions of people who created content that was used in the training of the model, and to those who were involved in indexing or upvoting the content (in the case of WebText). Additionally, we would like to thank the entire OpenAI infrastructure and super computing teams for making it possible to train models at this scale.
作者感谢Ryan Lowe对论文草稿提出的详细反馈。感谢Jakub Pachocki和Szymon Sidor提出的任务建议,以及Greg Brockman、Michael Petrov、Brooke Chan和Chelsea Voss协助在OpenAI基础设施上运行评估。感谢David Luan在项目初期扩展阶段的支持,Irene Solaiman关于评估偏见的讨论,Harrison Edwards和Yura Burda对上下文学习的探讨与实验,Geoffrey Irving和Paul Christiano早期关于语言模型扩展的讨论,Long Ouyang对人类评估实验设计的指导,Chris Hallacy关于数据收集的讨论,以及Shan Carter在视觉设计上的帮助。感谢数百万为模型训练提供内容的创作者,以及参与内容索引或投票的人员(如WebText项目)。此外,我们还要感谢OpenAI整个基础设施和超级计算团队,使得训练如此规模的模型成为可能。
Contributions
贡献
Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler, and Jeffrey Wu implemented the large-scale models, training infrastructure, and model-parallel strategies.
Tom Brown、Ben Mann、Prafulla Dhariwal、Dario Amodei、Nick Ryder、Daniel M Ziegler 和 Jeffrey Wu 实现了大规模模型、训练基础设施和模型并行策略。
Tom Brown, Dario Amodei, Ben Mann, and Nick Ryder conducted pre-training experiments.
Tom Brown、Dario Amodei、Ben Mann 和 Nick Ryder 进行了预训练实验。
Ben Mann and Alec Radford collected, filtered, de duplicated, and conducted overlap analysis on the training dat
Ben Mann 和 Alec Radford 对训练数据进行了收集、过滤、去重及重叠分析
Melanie Subbiah, Ben Mann, Dario Amodei, Jared Kaplan, Sam McCandlish, Tom Brown, Tom Henighan, and Girish Sastry implemented the downstream tasks and the software framework for supporting them, including creation of synthetic tasks.
Melanie Subbiah、Ben Mann、Dario Amodei、Jared Kaplan、Sam McCandlish、Tom Brown、Tom Henighan和Girish Sastry实现了下游任务及其支持软件框架,包括创建合成任务。
Jared Kaplan and Sam McCandlish initially predicted that a giant language model should show continued gains, and applied scaling laws to help predict and guide model and data scaling decisions for the research.
Jared Kaplan和Sam McCandlish最初预测大型语言模型会持续提升性能,并运用扩展定律(scaling laws)来帮助预测和指导研究中的模型与数据规模决策。
Ben Mann implemented sampling without replacement during training.
Ben Mann 在训练过程中实现了无放回采样。
Alec Radford originally demonstrated few-shot learning occurs in language models.
Alec Radford 最初证明了大语言模型中存在少样本学习现象。
Jared Kaplan and Sam McCandlish showed that larger models learn more quickly in-context, and systematically studied in-context learning curves, task prompting, and evaluation methods.
Jared Kaplan 和 Sam McCandlish 研究表明,更大的模型在上下文学习中学习速度更快,并系统性地研究了上下文学习曲线、任务提示和评估方法。
Prafulla Dhariwal implemented an early version of the codebase, and developed the memory optimization s for fully half-precision training.
Prafulla Dhariwal 实现了代码库的早期版本,并开发了全半精度训练的内存优化方案。
Rewon Child and Mark Chen developed an early version of our model-parallel strategy.
Rewon Child 和 Mark Chen 开发了我们模型并行策略的早期版本。
Rewon Child and Scott Gray contributed the sparse transformer.
Rewon Child 和 Scott Gray 贡献了稀疏 Transformer (sparse transformer)。
Aditya Ramesh experimented with loss scaling strategies for pre training.
Aditya Ramesh 尝试了预训练中的损失缩放策略。
Melanie Subbiah and Arvind Neel a kant an implemented, experimented with, and tested beam search.
Melanie Subbiah 和 Arvind Neelakantan 实现、实验并测试了束搜索 (beam search)。
Pranav Shyam worked on SuperGLUE and assisted with connections to few-shot learning and meta-learning literature.
Pranav Shyam参与了SuperGLUE项目,并协助建立与少样本学习 (few-shot learning) 和元学习 (meta-learning) 文献的联系。
Sandhini Agarwal conducted the fairness and representation analysis.
Sandhini Agarwal 负责公平性与代表性分析。
Girish Sastry and Amanda Askell conducted the human evaluations of the mode
Girish Sastry和Amanda Askell进行了该模型的人类评估
Ariel Herbert-Voss conducted the threat analysis of malicious use.
Ariel Herbert-Voss 进行了恶意使用的威胁分析。
Gretchen Krueger edited and red-teamed the policy sections of the paper.
Gretchen Krueger 编辑并针对论文的政策部分进行了红队测试。
Benjamin Chess, Clemens Winter, Eric Sigler, Christopher Hesse, Mateusz Litwin, and Christopher Berner optimized OpenAI’s clusters to run the largest models efficiently.
Benjamin Chess、Clemens Winter、Eric Sigler、Christopher Hesse、Mateusz Litwin 和 Christopher Berner 对 OpenAI 的集群进行了优化,以高效运行最大规模的模型。
Scott Gray developed fast GPU kernels used during training.
Scott Gray开发了训练过程中使用的快速GPU内核。
Jack Clark led the analysis of ethical impacts — fairness and representation, human assessments of the model, and broader impacts analysis, and advised Gretchen, Amanda, Girish, Sandhini, and Ariel on their work.
Jack Clark主导了伦理影响分析——包括公平性与代表性、模型的人类评估以及更广泛的影响分析,并为Gretchen、Amanda、Girish、Sandhini和Ariel的工作提供指导。
Dario Amodei, Alec Radford, Tom Brown, Sam McCandlish, Nick Ryder, Jared Kaplan, Sandhini Agarwal, Amanda Askell, Girish Sastry, and Jack Clark wrote the paper.
Dario Amodei、Alec Radford、Tom Brown、Sam McCandlish、Nick Ryder、Jared Kaplan、Sandhini Agarwal、Amanda Askell、Girish Sastry和Jack Clark撰写了该论文。
Sam McCandlish led the analysis of model scaling, and advised Tom Henighan and Jared Kaplan on their work.
Sam McCandlish 主导了模型缩放分析工作,并为 Tom Henighan 和 Jared Kaplan 的研究提供指导。
Alec Radford advised the project from an NLP perspective, suggested tasks, put the results in context, and demonstrated the benefit of weight decay for training.
Alec Radford从自然语言处理(NLP)角度指导了该项目,提出了任务建议,将结果置于研究背景中,并论证了权重衰减(weight decay)对训练的益处。
Ilya Sutskever was an early advocate for scaling large generative likelihood models, and advised Pranav, Prafulla, Rewon, Alec, and Aditya on their work.
Ilya Sutskever是早期提倡扩展大型生成式似然模型 (generative likelihood models) 的倡导者,并指导了Pranav、Prafulla、Rewon、Alec和Aditya的工作。
Dario Amodei designed and led the research.
Dario Amodei 设计并领导了这项研究。
A Details of Common Crawl Filtering
通用爬虫 (Common Crawl) 过滤细节
As mentioned in Section 2.2, we employed two techniques to improve the quality of the Common Crawl dataset: (1) filtering Common Crawl and (2) fuzzy de duplication:
如第2.2节所述,我们采用了两种技术来提高Common Crawl数据集的质量:(1) 过滤Common Crawl数据 (2) 模糊去重:
- In order to improve the quality of Common Crawl, we developed an automatic filtering method to remove low quality documents. Using the original WebText as a proxy for high-quality documents, we trained a classifier to distinguish these from raw Common Crawl. We then used this classifier to re-sample Common Crawl by prioritizing documents which were predicted by the classifier to be higher quality. The classifier is trained using logistic regression classifier with features from Spark’s standard tokenizer and HashingTF 10. For the positive examples, we used a collection of curated datasets such as WebText, Wikiedia, and our web books corpus as the positive examples, and for the negative examples, we used unfiltered Common Crawl. We used this classifier to score Common Crawl documents. We kept each document in our dataset iff
- 为提高Common Crawl数据质量,我们开发了一种自动过滤方法来剔除低质量文档。以原始WebText作为高质量文档的代理标准,我们训练了一个分类器来区分原始Common Crawl中的优劣内容。随后通过该分类器对Common Crawl进行重采样,优先保留被预测为更高质量的文档。该分类器采用逻辑回归算法,特征提取使用Spark的标准分词器(standard tokenizer)和HashingTF 10。正样本集由精选数据集组成(包括WebText、维基百科(Wikipedia)及网页书籍语料库),负样本则采用未过滤的Common Crawl数据。我们对Common Crawl文档进行评分后,仅当(文档满足条件时)才将其保留在最终数据集中。
$$
\mathtt{n p.r a n d o m.p a r e t o}(\alpha)>1-\mathtt{d o c u m e n t_s c o r e}
$$
$$
\mathtt{n p.r a n d o m.p a r e t o}(\alpha)>1-\mathtt{d o c u m e n t_s c o r e}
$$
We chose $\alpha=9$ in order to take mostly documents the classifier scored highly, but still include some documents that were out of distribution. $\alpha$ was chosen to match the distribution of scores from our classifier on WebText. We found this re-weighting increased quality as measured by loss on a range of out-of-distribution generative text samples.
我们选择 $\alpha=9$,以便主要选取分类器评分较高的文档,同时仍包含一些分布外的文档。选择 $\alpha$ 是为了匹配 WebText 上分类器评分的分布。我们发现这种重新加权方法通过在一系列分布外生成文本样本上的损失来衡量,提高了质量。
- To further improve model quality and prevent over fitting (which becomes increasingly important as model capacity increases), we fuzzily de duplicated documents (i.e. removed documents with high overlap with other documents) within each dataset using Spark’s MinHashLSH implementation with 10 hashes, using the same features as were used for classification above. We also fuzzily removed WebText from Common Crawl. Overall this decreased dataset size by an average of $10%$ .
- 为进一步提升模型质量并防止过拟合(随着模型容量增加,这一点愈发重要),我们在每个数据集内使用Spark的MinHashLSH实现(配置10个哈希值)对文档进行模糊去重(即移除与其他文档存在高重叠度的文档),所用特征与上述分类任务相同。同时我们还从Common Crawl中模糊移除了WebText内容。整体上该操作使数据集规模平均减少了$10%$。
After filtering for duplicates and quality, we also partially removed text occurring in benchmark datasets, described in Appendix C.
在去除重复和低质量内容后,我们还部分移除了基准数据集中出现的文本(详见附录C)。
B Details of Model Training
B 模型训练细节
To train all versions of GPT-3, we use Adam with $\beta_{1}=0.9$ , $\beta_{2}=0.95$ , and $\epsilon=10^{-8}$ , we clip the global norm of the gradient at 1.0, and we use cosine decay for learning rate down to $10%$ of its value, over 260 billion tokens (after 260 billion tokens, training continues at $10%$ of the original learning rate). There is a linear LR warmup over the first 375 million tokens. We also gradually increase the batch size linearly from a small value $32\mathrm{k\Omega}$ tokens) to the full value over the first 4-12 billion tokens of training, depending on the model size. Data are sampled without replacement during training (until an epoch boundary is reached) to minimize over fitting. All models use weight decay of 0.1 to provide a small amount of regular iz ation [LH17].
训练所有版本的GPT-3时,我们使用Adam优化器,参数设置为$\beta_{1}=0.9$、$\beta_{2}=0.95$和$\epsilon=10^{-8}$,将梯度的全局范数裁剪为1.0,并采用余弦衰减将学习率降至初始值的$10%$,持续2600亿token(之后训练以初始学习率的$10%$继续进行)。在前3.75亿token进行线性学习率预热。根据模型规模不同,在前40-120亿token训练期间,批量大小从初始小值($32\mathrm{k\Omega}$ token)线性增长至全量值。训练期间采用无放回抽样(直至达到周期边界)以减轻过拟合。所有模型均使用0.1的权重衰减实现轻度正则化[LH17]。
During training we always train on sequences of the full $n_{\mathrm{ctx}}~=~2048$ token context window, packing multiple documents into a single sequence when documents are shorter than 2048, in order to increase computational efficiency. Sequences with multiple documents are not masked in any special way but instead documents within a sequence are delimited with a special end of text token, giving the language model the information necessary to infer that context separated by the end of text token is unrelated. This allows for efficient training without need for any special sequence-specific masking.
在训练过程中,我们始终使用完整的 $n_{\mathrm{ctx}}~=~2048$ token 上下文窗口序列进行训练。当文档长度不足2048时,会将多个文档打包到同一序列中以提升计算效率。多文档序列无需特殊掩码处理,仅需在文档间插入特殊文本结束token作为分隔符,使大语言模型能够识别被该token分隔的上下文无关性。这种方法实现了高效训练,无需任何针对序列的特殊掩码机制。
C Details of Test Set Contamination Studies
C 测试集污染研究细节
In section 4 we gave a high level overview of test set contamination studies. In this section we provide details on methodology and results.
在第4节中,我们概要介绍了测试集污染研究。本节将详细阐述方法与结果。
Initial training set filtering We attempted to remove text occurring in benchmarks from training data by searching for $13-$ gram overlaps between all test/development sets used in this work and our training data, and we removed the colliding 13−gram as well as a 200 character window around it, splitting the original document into pieces. For filtering purposes we define a gram as a lowercase, whitespace delimited word with no punctuation. Pieces less than 200 characters long were discarded. Documents split into more than 10 pieces were considered contaminated and removed entirely. Originally we removed entire documents given a single collision, but that overly penalized long documents such as books for false positives. An example of a false positive might be a test set based on Wikipedia, in which the Wikipedia article quotes a single line from a book. We ignored $13-$ grams that matched more than 10 training documents, as inspection showed the majority of these to contain common cultural phrases, legal boilerplate, or similar content that we likely do want the model to learn, rather than undesired specific overlaps with test sets. Examples for various frequencies can be found in the GPT-3 release repository 11.
初始训练集过滤
我们尝试通过搜索本工作中所有测试/开发集与训练数据之间的13-gram重叠来移除基准测试中出现的文本,并删除了碰撞的13-gram及其周围200个字符的窗口,将原始文档分割成片段。出于过滤目的,我们将gram定义为小写、以空格分隔且不带标点的单词。长度小于200个字符的片段被丢弃。被分割成超过10个片段的文档被视为受污染并完全移除。最初我们会在发生单次碰撞时移除整个文档,但这会过度惩罚长文档(如书籍)中的误报。误报的一个例子可能是基于维基百科的测试集,其中维基百科文章引用了书中的单行内容。我们忽略了匹配超过10个训练文档的13-gram,因为检查显示这些内容大多包含常见的文化短语、法律模板或类似内容——这些内容可能正是我们希望模型学习的,而非与测试集的不当重叠。不同频率的示例可在GPT-3发布仓库[11]中找到。
Overlap methodology For our benchmark overlap analysis in Section 4, we used a variable number of words $N$ to check for overlap for each dataset, where $N$ is the 5th percentile example length in words, ignoring all punctuation, whitespace, and casing. Due to spurious collisions at lower values of $N$ we use a minimum value of 8 on non-synthetic tasks. For performance reasons, we set a maximum value of 13 for all tasks. Values for $N$ and the amount of data marked as dirty are shown in Table C.1. Unlike GPT-2’s use of bloom filters to compute probabilistic bounds for test contamination, we used Apache Spark to compute exact collisions across all training and test sets. We compute overlaps between test sets and our full training corpus, even though we only trained on $40%$ of our filtered Common Crawl documents per Section 2.2.
重叠方法
在本文第4节的基准重叠分析中,我们采用可变词数$N$来检测各数据集的重叠情况。其中$N$取第5百分位的样本词长(忽略所有标点、空格和大小写)。为避免$N$值过小时产生的伪碰撞,我们在非合成任务中设置最小值为8。出于性能考虑,所有任务的$N$最大值设为13。具体$N$值及被标记为脏数据的数据量如表C.1所示。与GPT-2使用布隆过滤器计算测试污染概率边界的方法不同,我们采用Apache Spark精确计算所有训练集与测试集间的碰撞情况。尽管如第2.2节所述我们仅使用过滤后Common Crawl文档的40%进行训练,但仍计算了测试集与完整训练语料库之间的重叠。
We define a ‘dirty’ example as one with any $N$ -gram overlap with any training document, and a ‘clean’ example as one with no collision.
我们将与任何训练文档存在$N$元语法重叠的样本定义为"脏"样本,而将无冲突的样本定义为"干净"样本。
Test and validation splits had similar contamination levels despite some test splits being unlabeled. Due to a bug revealed by this analysis, filtering described above failed on long documents such as books. Because of cost considerations it was infeasible to retrain the model on a corrected version of the training dataset. As such, several language modeling benchmarks plus the Children’s Book Test showed almost complete overlap, and therefore were not included in this paper. Overlaps are shown in Table C.1
测试集和验证集的污染水平相近,尽管部分测试集未标注标签。由于本次分析发现的一个程序漏洞,前文所述的过滤机制在处理书籍等长文档时失效。出于成本考量,无法在修正后的训练数据集上重新训练模型。因此,若干语言建模基准及儿童图书测试(Children's Book Test)显示出近乎完全的重叠,故未纳入本文。具体重叠情况见表C.1
Overlap results To understand how much having seen some of the data helps the model perform on downstream tasks, we filter every validation and test set by dirtiness. Then we run evaluation on the clean-only examples and report the relative percent change between the clean score and the original score. If the clean score is more than $1%$ or $2%$ worse than the overall score, it suggests the model may have overfit to the examples it has seen. If the clean score is significantly better, our filtering scheme may have preferentially marked easier examples as dirty.
重叠结果
为了解模型在见过部分数据后对下游任务表现的提升程度,我们按脏数据(dirtiness)筛选每个验证集和测试集。随后仅对干净样本进行评估,并报告干净分数与原始分数之间的相对百分比变化。若干净分数比总体分数低超过$1%$或$2%$,则表明模型可能对已见过的样本存在过拟合。若干净分数显著更高,则说明我们的过滤方案可能将较简单的样本优先标记为脏数据。
This overlap metric tends to show a high rate of false positives for datasets that contain background information (but not answers) drawn from the web (such as SQuAD, which draws from Wikipedia) or examples less than 8 words long, which we ignored in our filtering process (except for word scrambling tasks). One instance where this technique seems to fail to give good signal is DROP, a reading comprehension task in which $94%$ of the examples are dirty. The information required to answer the question is in a passage provided to the model, so having seen the passage during training but not the questions and answers does not meaningfully constitute cheating. We confirmed that every matching training document contained only the source passage, and none of the questions and answers in the dataset. The more likely explanation for the decrease in performance is that the $6%$ of examples that remain after filtering come from a slightly different distribution than the dirty examples.
这种重叠度量指标对于包含从网络获取背景信息(但非答案)的数据集(如基于维基百科的SQuAD)或长度不足8个词的样本容易产生较高误报率,我们在过滤过程中已忽略此类情况(单词乱序任务除外)。该技术明显失效的一个案例是DROP阅读理解任务,其中94%的样本存在污染。由于问题答案所需信息均来自模型提供的文本段落,因此在训练阶段仅接触段落文本而未见过对应问答对,并不构成实质性的作弊行为。我们已验证所有匹配的训练文档仅包含源文本段落,未出现数据集中的问答内容。性能下降更可能的原因是:经过过滤后剩余的6%样本与污染样本存在细微分布差异。
Figure 4.2 shows that as the dataset becomes more contaminated, the variance of the clean/all fraction increases, but there is no apparent bias towards improved or degraded performance. This suggests that GPT-3 is relatively insensitive to contamination. See Section 4 for details on the datasets we flagged for further review.
图 4.2 显示,随着数据集污染程度增加,干净数据占比的方差会增大,但性能提升或下降的偏差并不明显。这表明 GPT-3 对数据污染相对不敏感。关于我们标记为需进一步审查的数据集详情,请参阅第 4 节。
Table C.1: Overlap statistics for all datasets sorted from dirtiest to cleanest. We consider a dataset example dirty if it has a single $N$ -gram collision with any document in our training corpus. “Relative Difference Clean vs All” shows the percent change in performance between only the clean examples vs all the examples in the benchmark. “Count” shows the number of examples. “Clean percentage” is the percent of examples that are clean vs total. For “Acc/F1/BLEU” we use the metric specified in “Metric”. These scores come from evaluations with a different seed for the random examples used for in-context learning, and will therefore differ slightly from the scores elsewhere in the paper.
| Metric | N | Acc/F1/BLEU | Total Count | Dirty Acc/F1/BLEU | Dirty Count | Clean Acc/F1/BLEU | Clean Count | Clean | Relative Difference | ||
| Name | Split | f1 | 13 | 44.3 | Percentage | Clean vs All | |||||
| Quac | dev | 13 | 44.3 | 7353 | 69.9 | 7315 | 54.1 | 38 | 1% | 20% | |
| SQuADv2 | dev | f1 | 13 | 69.8 | 11873 | 37.0 | 11136 | 68.4 | 737 | 6% | -2% |
| DROP | dev | f1 | 7 | 36.5 | 9536 10000 | 66.8 | 8898 | 29.5 | 638 | 7% | -21% |
| Symbol Insertion | dev | acc | 13 | 66.9 | 7983 | 85.3 | 8565 | 67.1 | 1435 | 14% | 0% |
| CoQa | dev | f1 | 13 | 86.0 | 10000 | 90.3 | 5107 6110 | 87.1 | 2876 | 36% | 1% |
| ReCoRD | dev | acc | 9 | 89.5 88.6 | 273 | 90.2 | 164 | 88.2 | 3890 | 39% | -1% |
| Winograd | test | acc | 13 | 76.0 | 3270 | 75.8 | 86.2 | 109 | 40% | -3% | |
| BoolQ | dev | acc | 13 | 74.2 | 953 | 73.4 | 1955 558 | 76.3 | 1315 | 40% | 0% |
| MultiRC | dev | acc | 13 | 3498 | 47.0 | 75.3 | 395 | 41% | 1% | ||
| RACE-h | test | acc | 13 | 46.8 | 5153 | 86.9 | 1580 | 46.7 | 1918 | 55% | 0% |
| LAMBADA | test | acc | 13 | 86.4 | 5153 | 78.5 | 2209 | 86.0 | 2944 | 57% | 0% |
| LAMBADA (No Blanks) | test | acc | 13 | 77.8 | 104 | 73.8 | 2209 | 77.2 | 2944 | 57% | -1% |
| WSC | dev | acc | 8 | 76.9 | 1838 | 89.9 | 42 | 79.0 | 62 | 60% | 3% |
| PIQA | dev | acc acc | 13 | 82.3 | 1436 | 53.0 | 526 | 79.3 | 1312 | 71% | -4% |
| RACE-m | test | bleu-sb | 12 | 58.5 | 2999 | 47.4 | 366 | 60.4 | 1070 | 75% | 3% |
| De→→En 16 | test | bleu-sb | 12 | 43.0 | 2999 | 32.6 | 739 739 | 40.8 | 2260 | 75% | -5% |
| En→→De 16 | test | bleu-sb | 12 | 30.9 | 1999 | 24.9 | 29.9 | 2260 | 75% | -3% | |
| En-→Ro 16 | test | bleu-sb | 12 | 25.8 41.3 | 1999 | 40.4 | 423 423 | 26.1 | 1576 | 79% | 1% |
| Ro-→En 16 | test | acc | 8 | 41.5 | 2032 | 41.6 | 428 | 41.6 | 1576 | 79% | 1% |
| WebQs | test | acc | 13 | 36.8 | 1000 | 40.5 | 200 | 41.5 | 1604 | 79% | 0% |
| ANLI R1 ANLI R2 | test test | acc | 13 | 34.0 | 1000 | 29.4 | 177 | 35.9 35.0 | 800 823 | 80% | -3% |
| TriviaQA | dev | acc | 10 | 71.2 | 7993 | 70.8 | 1390 | 71.3 | 6603 | 82% | 3% |
| ANLI R3 | test | acc | 13 | 40.2 | 1200 | 38.3 | 196 | 40.5 | 1004 | 83% | 0% |
| En—→Fr 14 | test | bleu-sb | 13 | 39.9 | 3003 | 38.3 | 411 | 40.3 | 2592 | 84% | 1% |
| Fr→→En 14 | test | bleu-sb | 13 | 41.4 | 3003 | 40.9 | 411 | 41.4 | 2592 | 86% | 1% |
| WiC | dev | acc | 13 | 51.4 | 638 | 53.1 | 49 | 51.3 | 589 | 86% | 0% |
| RTE | dev | acc | 13 | 71.5 | 277 | 71.4 | 21 | 71.5 | 256 | 92% | 0% |
| CB | dev | acc | 13 | 80.4 | 56 | 100.0 | 4 | 78.8 | 52 | 92% | %0 |
| Anagrams 2 | dev | acc | 2 | 40.2 | 10000 | 76.2 | 705 | 37.4 | 9295 | 93% | -2% |
| Reversed Words | dev | acc | 2 | 0.4 | 10000 | 1.5 | 660 | 0.3 | 9340 | 93% | -7% |
| OpenBookQA | test | acc | 8 | 65.4 | 500 | 58.1 | 31 | 65.9 | 469 | 93% | -26% |
| ARC (Easy) | test | acc | 11 | 70.1 | 2268 | 77.5 | 89 | 69.8 | 2179 | 94% | 1% |
| Anagrams 1 | dev | acc | 2 | 15.0 | 10000 | 49.8 | 327 | 13.8 | 9673 | %96 97% | 0% -8% |
| COPA | dev | acc | 9 | 93.0 | 100 | 100.0 | 3 | 92.8 | 97 |
表 C.1: 按污染程度从高到低排序的所有数据集重叠统计。若数据集中存在与训练语料库任何文档发生单次 $N$ -gram碰撞的样本,则判定为污染样本。"相对差异(纯净vs全部)"显示基准测试中纯净样本与全部样本的性能百分比变化。"计数"表示样本数量。"纯净比例"是纯净样本占总样本的百分比。"Acc/F1/BLEU"采用"指标"列指定的评估标准。这些分数来自使用不同随机种子进行上下文学习样本的评估结果,因此会与论文其他部分的分数存在细微差异。
| 名称 | 拆分 | 指标 | N | Acc/F1/BLEU | 总计数 | 污染Acc/F1/BLEU | 污染计数 | 纯净Acc/F1/BLEU | 纯净计数 | 纯净比例 | 相对差异(纯净vs全部) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Quac | dev | f1 | 13 | 44.3 | 7353 | 69.9 | 7315 | 54.1 | 38 | 1% | 20% |
| SQuADv2 | dev | f1 | 13 | 69.8 | 11873 | 37.0 | 11136 | 68.4 | 737 | 6% | -2% |
| DROP | dev | f1 | 7 | 36.5 | 9536 | 66.8 | 8898 | 29.5 | 638 | 7% | -21% |
| Symbol Insertion | dev | acc | 13 | 66.9 | 7983 | 85.3 | 8565 | 67.1 | 1435 | 14% | 0% |
| CoQa | dev | f1 | 13 | 86.0 | 10000 | 90.3 | 5107 | 87.1 | 2876 | 36% | 1% |
| ReCoRD | dev | acc | 9 | 89.5 | 273 | 90.2 | 164 | 88.2 | 3890 | 39% | -1% |
| Winograd | test | acc | 13 | 76.0 | 3270 | 75.8 | 86.2 | 109 | 40% | -3% | |
| BoolQ | dev | acc | 13 | 74.2 | 953 | 73.4 | 1955 | 76.3 | 1315 | 40% | 0% |
| MultiRC | dev | acc | 13 | 3498 | 47.0 | 75.3 | 395 | 41% | 1% | ||
| RACE-h | test | acc | 13 | 46.8 | 5153 | 86.9 | 1580 | 46.7 | 1918 | 55% | 0% |
| LAMBADA | test | acc | 13 | 86.4 | 5153 | 78.5 | 2209 | 86.0 | 2944 | 57% | 0% |
| LAMBADA (No Blanks) | test | acc | 13 | 77.8 | 104 | 73.8 | 2209 | 77.2 | 2944 | 57% | -1% |
| WSC | dev | acc | 8 | 76.9 | 1838 | 89.9 | 42 | 79.0 | 62 | 60% | 3% |
| PIQA | dev | acc | 13 | 82.3 | 1436 | 53.0 | 526 | 79.3 | 1312 | 71% | -4% |
| RACE-m | test | bleu-sb | 12 | 58.5 | 2999 | 47.4 | 366 | 60.4 | 1070 | 75% | 3% |
| De→En 16 | test | bleu-sb | 12 | 43.0 | 2999 | 32.6 | 739 | 40.8 | 2260 | 75% | -5% |
| En→De 16 | test | bleu-sb | 12 | 30.9 | 1999 | 24.9 | 29.9 | 2260 | 75% | -3% | |
| En→Ro 16 | test | bleu-sb | 12 | 25.8 | 1999 | 40.4 | 423 | 26.1 | 1576 | 79% | 1% |
| Ro→En 16 | test | acc | 8 | 41.5 | 2032 | 41.6 | 428 | 41.6 | 1576 | 79% | 1% |
| WebQs | test | acc | 13 | 36.8 | 1000 | 40.5 | 200 | 41.5 | 1604 | 79% | 0% |
| ANLI R1 ANLI R2 | test | acc | 13 | 34.0 | 1000 | 29.4 | 177 | 35.9 | 800 | 80% | -3% |
| TriviaQA | dev | acc | 10 | 71.2 | 7993 | 70.8 | 1390 | 71.3 | 6603 | 82% | 3% |
| ANLI R3 | test | acc | 13 | 40.2 | 1200 | 38.3 | 196 | 40.5 | 1004 | 83% | 0% |
| En→Fr 14 | test | bleu-sb | 13 | 39.9 | 3003 | 38.3 | 411 | 40.3 | 2592 | 84% | 1% |
| Fr→En 14 | test | bleu-sb | 13 | 41.4 | 3003 | 40.9 | 411 | 41.4 | 2592 | 86% | 1% |
| WiC | dev | acc | 13 | 51.4 | 638 | 53.1 | 49 | 51.3 | 589 | 86% | 0% |
| RTE | dev | acc | 13 | 71.5 | 277 | 71.4 | 21 | 71.5 | 256 | 92% | 0% |
| CB | dev | acc | 13 | 80.4 | 56 | 100.0 | 4 | 78.8 | 52 | 92% | 0% |
| Anagrams 2 | dev | acc | 2 | 40.2 | 10000 | 76.2 | 705 | 37.4 | 9295 | 93% | -2% |
| Reversed Words | dev | acc | 2 | 0.4 | 10000 | 1.5 | 660 | 0.3 | 9340 | 93% | -7% |
| OpenBookQA | test | acc | 8 | 65.4 | 500 | 58.1 | 31 | 65.9 | 469 | 93% | -26% |
| ARC (Easy) | test | acc | 11 | 70.1 | 2268 | 77.5 | 89 | 69.8 | 2179 | 94% | 1% |
| Anagrams 1 | dev | acc | 2 | 15.0 | 10000 | 49.8 | 327 | 13.8 | 9673 | 97% | -8% |
| COPA | dev | acc | 9 | 93.0 | 100 | 100.0 | 3 | 92.8 | 97 |
D Total Compute Used to Train Language Models
D 训练语言模型的总计算量
This appendix contains the calculations that were used to derive the approximate compute used to train the language models in Figure 2.2. As a simplifying assumption, we ignore the attention operation, as it typically uses less than $10%$ of the total compute for the models we are analyzing.
本附录包含用于估算图2.2中训练大语言模型所需计算量的推导过程。为简化计算,我们忽略注意力操作 (attention operation) 的消耗,因为在我们分析的模型中这部分通常仅占总计算量的 $10%$ 以下。
Calculations can be seen in Table D.1 and are explained within the table caption.
计算结果可参见表 D.1,具体说明见表格标题。
| Total train compute (PF-days) | Total train compute | Flops | Fwd-pass flops per active param | Frac of params active for each token | ||||
| Params (M) | Training tokens (billions) | per param per token | Mult for bwd pass | |||||
| Model T5-Small | 2.08E+00 | (flops) 1.80E+20 | 60 | 1,000 | 3 | 3 | per token 1 | 0.5 |
| T5-Base | 7.64E+00 | 6.60E+20 | 220 | 1,000 | 3 | 3 | 1 | 0.5 |
| T5-Large | 2.67E+01 | 2.31E+21 | 770 | 1,000 | 3 | 3 | 1 | 0.5 |
| T5-3B | 1.04E+02 | 9.00E+21 | 3,000 | 1,000 | 3 | 3 | 1 | 0.5 |
| T5-11B | 3.82E+02 | 3.30E+22 | 11,000 | 1,000 | 3 | 3 | 1 | 0.5 |
| BERT-Base | 1.89E+00 | 1.64E+20 | 109 | 250 | 6 | 3 | 2 | 1.0 |
| BERT-Large | 6.16E+00 | 5.33E+20 | 355 | 250 | 6 | 3 | 2 | 1.0 |
| RoBERTa-Base | 1.74E+01 | 1.50E+21 | 125 | 2,000 | 6 | 3 | 2 | 1.0 |
| RoBERTa-Large | 4.93E+01 | 4.26E+21 | 355 | 2,000 | 6 | 3 | 2 | 1.0 |
| GPT-3 Small | 2.60E+00 | 2.25E+20 | 125 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3Medium | 7.42E+00 | 6.41E+20 | 356 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3 Large | 1.58E+01 | 1.37E+21 | 760 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3XL | 2.75E+01 | 2.38E+21 | 1,320 | 300 | 6 6 | 3 3 | 2 | 1.0 |
| GPT-32.7B | 5.52E+01 | 4.77E+21 | 2,650 | 300 300 | 6 | 3 | 2 2 | 1.0 |
| GPT-36.7B | 1.39E+02 2.68E+02 | 1.20E+22 2.31E+22 | 6,660 12,850 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-313B | 3.64E+03 | 3.14E+23 | 174,600 | 300 | 6 | 3 | 2 | 1.0 1.0 |
| GPT-3175B | ||||||||
| 总训练计算量 (PF-天) | 总训练计算量 (flops) | 参数量 (百万) | 训练token数 (十亿) | 每参数每token的flops | 反向传播倍数 | 每个token的活跃参数前向传播flops | 每个token的活跃参数比例 | |
|---|---|---|---|---|---|---|---|---|
| 模型 T5-Small | 2.08E+00 | 1.80E+20 | 60 | 1,000 | 3 | 3 | 1 | 0.5 |
| T5-Base | 7.64E+00 | 6.60E+20 | 220 | 1,000 | 3 | 3 | 1 | 0.5 |
| T5-Large | 2.67E+01 | 2.31E+21 | 770 | 1,000 | 3 | 3 | 1 | 0.5 |
| T5-3B | 1.04E+02 | 9.00E+21 | 3,000 | 1,000 | 3 | 3 | 1 | 0.5 |
| T5-11B | 3.82E+02 | 3.30E+22 | 11,000 | 1,000 | 3 | 3 | 1 | 0.5 |
| BERT-Base | 1.89E+00 | 1.64E+20 | 109 | 250 | 6 | 3 | 2 | 1.0 |
| BERT-Large | 6.16E+00 | 5.33E+20 | 355 | 250 | 6 | 3 | 2 | 1.0 |
| RoBERTa-Base | 1.74E+01 | 1.50E+21 | 125 | 2,000 | 6 | 3 | 2 | 1.0 |
| RoBERTa-Large | 4.93E+01 | 4.26E+21 | 355 | 2,000 | 6 | 3 | 2 | 1.0 |
| GPT-3 Small | 2.60E+00 | 2.25E+20 | 125 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3 Medium | 7.42E+00 | 6.41E+20 | 356 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3 Large | 1.58E+01 | 1.37E+21 | 760 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3 XL | 2.75E+01 | 2.38E+21 | 1,320 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3 2.7B | 5.52E+01 | 4.77E+21 | 2,650 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3 6.7B | 1.39E+02 | 1.20E+22 | 6,660 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3 13B | 3.64E+03 | 3.14E+23 | 174,600 | 300 | 6 | 3 | 2 | 1.0 |
| GPT-3 175B |
Table D.1: Starting from the right hand side and moving left, we begin with the number of training tokens that each model was trained with. Next we note that since T5 uses an encoder-decoder model, only half of the parameters are active for each token during a forward or backwards pass. We then note that each token is involved in a single addition and a single multiply for each active parameter in the forward pass (ignoring attention). Then we add a multiplier of 3x to account for the backwards pass (as computing both $\frac{\partial p a r\bar{a}m s}{\partial l o s s}$ and $\frac{\partial a c t s}{\partial l o s s}$ use a similar amount of compute as the forwards pass. Combining the previous two numbers, we get the total flops per parameter per token. We multiply this value by the total training tokens and the total parameters to yield the number of total flops used during training. We report both flops and petaflop/s-day (each of which are $8.64\mathrm{e}{+}19$ flops).
表 D.1: 从右侧开始向左移动,我们首先列出每个模型训练所用的token数量。接着注意到T5采用编码器-解码器架构,因此在每次前向或反向传播中只有一半参数对每个token是活跃的。然后我们指出,在前向传播过程中(忽略注意力机制),每个token会为每个活跃参数参与一次加法和一次乘法运算。随后我们添加3倍乘数来估算反向传播的计算量(因为计算$\frac{\partial p a r\bar{a}m s}{\partial l o s s}$和$\frac{\partial a c t s}{\partial l o s s}$所需的计算量与前向传播相当)。将前两个数值相乘,得到每个参数每个token的总浮点运算次数。最后将该值与总训练token数和总参数量相乘,得出训练期间的总浮点运算量。我们同时报告了总浮点运算次数和千兆浮点运算/秒-天(每单位相当于$8.64\mathrm{e}{+}19$次浮点运算)。
E Human Quality Assessment of Synthetic News Articles
E 合成新闻文章的人工质量评估
This appendix contains details on the experiments measuring human ability to distinguish GPT-3-generated synthetic news articles from real news articles. We first describe the experiments on the $\sim200$ word news articles, and then describe the preliminary investigation of $\sim500$ word news articles generated by GPT-3.
本附录详细记录了人类区分GPT-3生成的合成新闻与真实新闻能力的实验。我们首先描述针对约200词新闻的实验,随后阐述对GPT-3生成约500词新闻的初步研究。
Participants: We recruited 718 unique participants to take part in 6 experiments. 97 participants were excluded for failing an internet check question, leaving a total of 621 participants: 343 male, 271 female, and 7 other. Mean participant age was $\sim38$ years old. All participants were recruited through Positly, which maintains a whitelist of high-performing workers from Mechanical Turk. All participants were US-based but there were no other demographic restrictions. Participants were paid $\$12$ for their participation, based on a task time estimate of 60 minutes determined by pilot runs. In order to ensure that the sample of participants for each experiment quiz was unique, participants were not allowed to take part in an experiment more than once.
参与者:我们招募了718名独特参与者参加6项实验。97名参与者因未能通过网络检查问题而被排除,最终共有621名参与者:343名男性、271名女性和7名其他性别。参与者平均年龄为$\sim38$岁。所有参与者均通过Positly招募,该平台维护着来自Mechanical Turk的高绩效工作者白名单。所有参与者均位于美国,但无其他人口统计限制。根据试运行确定的60分钟任务时长估算,参与者报酬为$\$12$。为确保每个实验问卷的参与者样本唯一,禁止参与者重复参加同一实验。
Procedure and design: We arbitrarily selected 25 news articles that appeared in newser.com in early 2020. We used the article titles and subtitles to produce outputs from the 125M, 350M, 760M, 1.3B, 2.7B, 6.7B, 13.0B, and 200B (GPT-3) parameter language models. Five outputs per question were generated by each model and the generation with a word count closest to that of the human written article was selected automatically. This was to minimize the effect that completion length might have on participants’ judgments. The same output procedure for each model with the exception of the removal of the intentionally bad control model, as described in the main text.
流程与设计:我们随机选取了2020年初出现在newser.com上的25篇新闻文章。使用文章标题和副标题,分别通过1.25亿、3.5亿、7.6亿、13亿、27亿、67亿、130亿和2000亿(GPT-3)参数规模的模型生成输出。每个模型对每个问题生成5个输出结果,并自动选择字数最接近人工撰写文章的输出。这是为了尽量减少生成文本长度可能对参与者判断造成的影响。除主文本中描述的有意设置的低质量对照模型外,各模型均采用相同的输出流程。
| Model | Participants Recruited | Participants Excluded | Genders (m:f:other) | Mean Age | Average Word Count (human:model) |
| Control | 76 | 7 | 32:37:0 | 39 | 216:216 |
| GPT-3Small | 80 | 7 | 41:31:1 | 40 | 216:188 |
| GPT-3Medium | 80 | 7 | 46:28:2 | 39 | 216:202 |
| GPT-3Large | 81 | 24 | 46:28:2 | 37 | 216:200 |
| GPT-3XL | 79 | 14 | 32:32:1 | 38 | 216:199 |
| GPT-32.7B | 80 | 11 | 36:33:0 | 40 | 216:202 |
| GPT-36.7B | 76 | 5 | 46:28:2 | 37 | 216:195 |
| GPT-313.0B | 81 | 13 | 46:28:2 | 37 | 216:209 |
| GPT-3175B | 80 | 9 | 42:29:0 | 37 | 216:216 |
| 模型 | 招募人数 | 排除人数 | 性别比例(男:女:其他) | 平均年龄 | 平均字数(人类:模型) |
|---|---|---|---|---|---|
| Control | 76 | 7 | 32:37:0 | 39 | 216:216 |
| GPT-3Small | 80 | 7 | 41:31:1 | 40 | 216:188 |
| GPT-3Medium | 80 | 7 | 46:28:2 | 39 | 216:202 |
| GPT-3Large | 81 | 24 | 46:28:2 | 37 | 216:200 |
| GPT-3XL | 79 | 14 | 32:32:1 | 38 | 216:199 |
| GPT-32.7B | 80 | 11 | 36:33:0 | 40 | 216:202 |
| GPT-36.7B | 76 | 5 | 46:28:2 | 37 | 216:195 |
| GPT-313.0B | 81 | 13 | 46:28:2 | 37 | 216:209 |
| GPT-3175B | 80 | 9 | 42:29:0 | 37 | 216:216 |
Table E.1: Participant details and article lengths for each experiment to evaluate human detection of $\sim200$ word model generated news articles. Participants were excluded due to internet check fails.
表 E.1: 用于评估人类对约200词模型生成新闻文章检测能力的各实验参与者详情及文章长度。因网络检查未通过而排除部分参与者。
Average time spent trying to detect model generated news article
检测模型生成新闻文章的平均耗时
Figure E.1: Participants spend more time trying to identify whether each news article is machine generated as model size increases. Duration on the control model is indicated with the dashed line. Line of best fit is a linear model on a log scale with $95%$ confidence intervals.
图 E.1: 随着模型规模增大,参与者花费更多时间判断每篇新闻是否由机器生成。虚线表示对照模型的耗时。最佳拟合线为对数尺度上的线性模型,置信区间为95%。
In each experiment, half of the participants were randomly assigned to quiz A and half were randomly assigned to quiz B. Each quiz consisted of 25 articles: half (12-13) were human written and half (12-13) were model generated: the articles with human written completions in quiz A had model generated completions in quiz B and vice versa. The order of quiz question was shuffled for each participant. Participants could leave comments and were asked to indicate if they had seen the articles before. Participants were instructed not to look up the articles or their content during the quiz and at the end of the quiz were asked if they had looked anything up during the quiz.
每次实验中,半数参与者随机分配至测验A,另一半分配至测验B。每份测验包含25篇文章:半数(12-13篇)为人工撰写,半数(12-13篇)为模型生成。测验A中人工撰写的文章在测验B中对应模型生成版本,反之亦然。测验问题顺序对每位参与者随机打乱。参与者可提交评论,并被询问是否曾见过这些文章。实验要求参与者在测验期间不得查阅文章内容,并在测验结束时确认是否违规检索。
Statistical Tests: To compare means on the different runs, we performed a two-sample t-test for independent groups for each model against the control. This was implemented in Python using the scipy.stats.ttest_ind function. When plotting a regression line in the graph of average participant accuracy vs model size, we fit a power law of the form $\dot{a}x^{-b}$ . The $95%$ confidence intervals were estimated from the t-distribution of the sample mean.
统计检验:为了比较不同运行间的均值,我们对每个模型与对照组分别进行了独立样本的双样本t检验。该检验通过Python语言的scipy.stats.ttest_ind函数实现。在绘制参与者平均准确率与模型规模的回归线时,我们拟合了形如$\dot{a}x^{-b}$的幂律曲线,并基于样本均值的t分布估算了$95%$置信区间。
Duration statistics: In the main text, we discussed the finding that the ability of human participants to distinguish model and human generated news articles decreases as our models become larger. We have also found that the average time spent for a given set of questions increases as the model size increases, as shown in Figure E.1. Lower
持续时间统计:在正文中,我们讨论了人类参与者区分模型生成和人类撰写的新闻文章的能力随着模型规模增大而下降的发现。我们还发现,回答一组问题的平均耗时随模型规模增加而上升,如图 E.1 所示。
| Model | Participants Recruited | Participants Excluded | Genders (m:f:other) | Mean Age | Average WordCount (human:model) |
| Control | 79 | 17 | 32:37:0 | 39 | 569:464 |
| GPT-3175B | 81 | 19 | 32:30:0 | 40 | 569:498 |
| 模型 | 招募参与者人数 | 排除参与者人数 | 性别比例 (男:女:其他) | 平均年龄 | 平均字数统计 (人类:模型) |
|---|---|---|---|---|---|
| Control | 79 | 17 | 32:37:0 | 39 | 569:464 |
| GPT-3175B | 81 | 19 | 32:30:0 | 40 | 569:498 |
Table E.2: Participant details and article lengths for the experiments investigating human detection of $\sim500$ word model generated news articles. Participants were excluded due to internet check fails.
表 E.2: 人类检测约500词模型生成新闻文章实验的参与者详情及文章长度 (因网络验证失败而排除部分参与者)
accuracy scores despite increased time investment from participants supports the finding that larger models generate harder-to-distinguish news articles.
尽管参与者投入的时间增加,但准确率得分并未提高,这一结果支持了"更大模型生成的新闻文章更难区分"的发现。
Preliminary investigation of $\sim500$ word articles: We recruited 160 unique US-based participants to take part in 2 experiments through Positly (details are given in Table E.2). We randomly selected 12 Reuters world news articles from late 2019 and created a context for GPT-3 175B that consisted of a single Reuters article not in this set of 12. We then used the article titles and Reuters locations to generate completions from GPT-3 175B and the 160M control model from the previous experiments. These were used to create two 12-question quizzes per model, each consisting of half human written and half model generated articles. Comprehension questions were added and articles were shown to participants in 3 stages at 30 second intervals to encourage closer reading. Participants were paid $\$12$ for this task. Model generation selection methods, exclusion criteria, and statistical tests mirror those of the previous experiments.
对约500词文章的初步调查:我们通过Positly招募了160名美国参与者参与2项实验(详见表E.2)。随机选取12篇2019年末的路透社国际新闻,并为GPT-3 175B构建了一个不在这12篇之内的单篇路透社文章作为上下文。随后利用文章标题和路透社地点信息,分别从GPT-3 175B和前期实验中160M对照组模型生成续写内容。基于这些材料,我们为每个模型设计了两套12题的测试问卷,每套问卷包含半数人工撰写和半数模型生成的文章。为促进深度阅读,我们添加了理解性问题,并以30秒为间隔分三个阶段向参与者展示文章。参与者完成该任务可获得12美元报酬。模型生成选择方法、排除标准和统计检验均与前期实验保持一致。
F Additional Samples from GPT-3
F GPT-3 生成的其他样本
GPT-3 adapts well to many tasks other than the ones explored in the main body of the paper. As an example, in Figure F.1, we show four uncurated samples from a prompt suggesting that the model write a poem, with a given title, in the style of Wallace Stevens. We first experimented with a few prompts, then generated four samples with no additional editing or selection (sampling at temperature 1 using nucleus sampling [HBFC19] with $P=0.9$ ). Completions were truncated when the model began to write a new title and author heading, or broke into prose commentary.
GPT-3不仅能很好地适应论文主体部分探讨的任务,还能胜任许多其他任务。例如,在图 F.1 中,我们展示了四个未经筛选的样本,这些样本来自一个提示:要求模型以 Wallace Stevens 的风格,根据给定标题创作诗歌。我们首先尝试了几个提示,随后在未进行额外编辑或筛选的情况下生成了四个样本(使用 $P=0.9$ 的核采样 [HBFC19] 在温度为 1 时采样)。当模型开始书写新标题和作者署名,或转为散文式评论时,补全内容会被截断。
Context $\rightarrow$
上下文 $\rightarrow$
SOME TREES John Ashbery [Poem text omitted]
几棵树 约翰·阿什贝利 [诗歌文本省略]
Shadows on the Way Wallace Stevens
路途上的阴影 华莱士·史蒂文斯
Generated Poem 1
生成诗歌 1
Generated Poem 3
生成诗歌 3
I must have shadows on the way If I am to walk I must have Each step taken slowly and alone To have it ready made
路上必有阴影
若我欲前行
必得步步缓慢独行
方能使其就绪
And I must think in lines of grey To have dim thoughts to be my guide Must look on blue and green And never let my eye forget That color is my friend And purple must surround me too
我必须用灰暗的线条思考
让朦胧的思绪指引方向
凝望蓝与绿的色彩
永远铭记色彩是挚友
紫色也必将我环绕
The yellow of the sun is no more Intrusive than the bluish snow That falls on all of us. I must have Grey thoughts and blue thoughts walk with me If I am to go away at all.
阳光的黄色并不比
落在我们所有人身上的
淡蓝色雪花更显突兀。
若我真要离去,
灰色的思绪和蓝色的思绪
必须与我同行。
Generated Poem 2
生成诗歌 2
Comes to the wood.
来到树林。
The sun was all we had. Now, in the shade All is changed. The mind must dwell on those White fields, that to its eyes were always old; Those ancient gleams, con vol u ting The way they lay among the huge roots, The great dark tomes of reverie, The plumed labyrinth of the sea.
太阳是我们唯一的拥有。如今,在阴影中
一切已然改变。思绪必须驻留于
那些白色原野,在它眼中永远古老;
那些远古微光,盘旋缠绕
它们躺在巨大根系间的姿态,
那些沉思的幽暗巨册,
海洋那羽翼迷宫的篇章。
We played, too, once, in the warmest rooms. To one content, there is one content For all mankind. The forest glades Are all the more for being in fable, And wood and town in legend shadowedOnce more to return. The one content Has in it every happiness, more brave For being purposeless; and so Those island gardens, deep in the mind, Make of remoteness familiarity And of the unspoken name a friend.
我们也曾嬉戏,在最温暖的房间里。
一种满足,便是全人类的满足。
林间空地因寓言而更显珍贵,
城镇与森林在传说中投下阴影,
终将再度归来。
那份满足蕴含一切幸福,
因无目的而愈发勇敢;
于是,那些心灵深处的岛园,
将遥远化作熟悉,
让未言之名成为挚友。
Generated Poem 4
生成诗歌4
G Details of Task Phrasing and Specifications
G 任务表述与规范详情
The following figures illustrate the formatting and phrasing of all the tasks included in the paper. All data comes from the ground truth datasets in this section, and no samples from GPT-3 are included here.
以下图表展示了论文中所有任务的格式和措辞。所有数据均来自本节中的真实数据集,此处不包含来自GPT-3的样本。
| Context →Article: | Informal conversation is an important part of any business |
| relationship.Before you start a discussion,however,make sure you understan culture.Latin Americans enjoy sharing information about their local be sure to show pictures of your children.You may feel free to ask similar | |
| questions of your Latin American friends.The French think of conversation as an art form,and they enjoy the value of lively discussions as well as disagreements.For them,arguments can be interesting and they can cover pretty much or any topic ---- as long as they occur in are respectful and intelligent manner. In the United States,business people like to discuss a wide range of topics,including opinions about work,family,hobbies,and politics. In | |
| that doing so might take away from the harmonious business relationship they're trying to build.Middle Easterners are also private about their personal lives and family matters.It is considered rude,for example,to ask | |
| a businessman from Saudi Arabia about his wife or children. e 1 | |
| friendly subject in most parts of the world,although be careful not to criticize national sport.Instead,be friendly and praise your host's team. | |
| another country? | |
| A: Criticizing the sports of your colleagues’country. | |
| A: They don't want to have their good relationship with others harmed by informal conversation. | author? A: Sports. |
Figure G.1: Formatted dataset example for RACE-h. When predicting, we normalize by the unconditional probability of each answer as described in 2.
| 上下文 → 文章: | 非正式交谈是任何商业关系中的重要组成部分。但在开始讨论前,请确保了解当地文化。拉丁美洲人乐于分享本地生活信息,可以主动展示子女照片,也可随意询问拉美朋友类似问题。法国人视交谈为艺术形式,享受激烈辩论甚至意见交锋的乐趣。对他们而言,只要保持尊重和智慧,任何话题都可以成为有趣的辩论主题。美国商人喜欢讨论广泛话题,包括工作、家庭、爱好和政治观点。中东人士则对私人生活和家庭事务较为谨慎,例如询问沙特商人妻儿情况会被视为失礼。体育在多数地区属于安全话题,但需注意不要批评该国国动。相反,应以友好态度称赞东道主支持的队伍。 |
|---|---|
| 在异国应避免哪种行为? | |
| A: 批评同事所在国家的体育运动。 | |
| 作者观点? A: 体育话题。 | |
图 G.1: RACE-h数据集格式化示例。预测时,我们按照第2节所述对每个答案的无条件概率进行归一化处理。

Figure G.2: Formatted dataset example for ANLI R2
图 G.2: ANLI R2 的格式化数据集示例
| Mrs. Smith is an unusual teacher. Once she told each student to bring write a name of a person that they hated And the next day,every child Mrs.Smith then told the children to carry the bags everywhere they went, even to the toilet,for two weeks.As day after day passed,the children started to complain about the awful smell of the rotten potatoes. of the bags.After two weeks, the children were happy to hear that the | ||
| said,"This is exactly the situation when you carry your hatred for somebody inside your heart.The terrible smell of the hatred will pollute your ih a you cannot stand the smell of the rotten potatoes for just two weeks,can g n a lifetime? So throw away any hatred from your heart,and you'll be really happy." | ||
| Q: Which of the following is True according to the passage? d 1g o g | ||
| Q: We can learn from the passage that we should -. | ||
| A:throwawaythe hatred inside | ||
| Q:Thechildrencomplainedabout-besides the weight trouble. | ||
| A: the Smell | ||
| Q: Mrs.Smith asked her students to write - on the potatoes. | ||
| A: | ||
| Correct Answer →names | ||
| Incorrect Answer →numbers | ||
| Incorrect Answer →time | ||
| IncorrectAnswer→places |
| Smith女士是位与众不同的老师。有一次她让每个学生写下自己憎恨的人名,第二天孩子们带着写有名字的土豆来学校。随后Smith女士要求孩子们随身携带这些袋子,甚至去厕所也要带着,持续两周。随着时间推移,孩子们开始抱怨腐烂土豆的恶臭。两周后,当得知可以扔掉袋子时,孩子们都很高兴。 | |
| Smith女士说:"这正如同你们把对他人的仇恨埋在心里。仇恨的恶臭会污染你的心灵。如果连腐烂土豆两周的气味都无法忍受,又怎能承受一辈子的心灵恶臭呢?所以把仇恨从心里清除,你才会真正快乐。" | |
| Q: 根据文章内容,下列哪项是正确的? | |
| Q: 从文章中我们可以学到应该______。 | |
| A: 抛弃内心的仇恨 | |
| Q: 除了负重问题,孩子们还抱怨______。 | |
| A: 气味 | |
| Q: Smith女士让学生们在土豆上写______。 | |
| A: | |
| 正确答案→名字 | |
| 错误答案→数字 | |
| 错误答案→时间 | |
| 错误答案→地点 |
Figure G.3: Formatted dataset example for RACE-m. When predicting, we normalize by the unconditional probability of each answer as described in 2.
图 G.3: RACE-m 数据集格式化示例。预测时,我们按照第 2 节所述方法对每个答案的无条件概率进行归一化处理。
| Context | Howto apply sealant to wood. |
| Correct Answer | Using a brush, brush onsealant onto wood until it is fully |
| thesealant. | saturated with |
| Incorrect Answer | Using a brush, drip onsealant onto wood until it is fully saturatedwith the sealant. |
| 上下文 | 如何给木材涂密封胶 |
|---|---|
| 正确答案 | 用刷子将密封胶均匀刷涂在木材上,直至完全浸透 |
| 错误答案 | 用刷子将密封胶滴在木材上,直至完全浸透 |
| Context | My body cast a shadow over the grass because | ||||
| CorrectAnswer | the sun was rising. | ||||
| Incorrect | Answer | the | grasswascut. |
| | 上下文 | | | 我的身体在草地上投下阴影是因为 | |
| 正确答案 | | | | 太阳正在升起。 | |
| 错误答案 | | | 草地 | 被修剪了。 | |
Figure G.6: Formatted dataset example for ReCoRD. We consider the context above to be a single ”problem” because this is how the task is presented in the ReCoRD dataset and scored in the ReCoRD evaluation script.
| Context→ | (CNN) Yuval Rabin,whose father,Yitzhak Rabin,was assassinated while Serving as Prime Minister of Israel, criticized Donald Trump for appealing me personally," Rabin wrote in USAToday. He Said that Trump's appeal to criticized as a call for violence against Clinton, something Trump denied -- "were a new level of ugliness in an ugly campaign season." - The son of a former Israeli Prime Minister who was assassinated wrote an op ed about the consequence of violent political rhetoric. |
| - Warns of "parallels" between Israel of the 1990s and the U.S. today. Correct Answer →- Referencing his father, who was shot and killed by an extremist amid political tension in Israel in 1995, Rabin condemned Donald Trump's | |
| CorrectAnswer | aggressive rhetoric. political tension in Israel in 1995, Rabin condemned Trump's aggressive rhetoric. |
| IncorrectAnswer | - Referencing his father,who was shot and killed by an extremist amid political tension in Israel in 1995, Rabin condemned Hillary Clinton's aggressive rhetoric. |
| Incorrect Answer→ | - Referencing his father,who was shot and killed by an extremist amid political tension in Israel in 1995, Rabin condemned U.S.'s aggressive rhetoric. |
| Incorrect Answer →- Referencing his father,who was shot and killed by an extremist amid political tension in Israel in 1995,Rabin condemned Yitzhak Rabin's aggressive rhetoric. |
图 G.6: ReCoRD 数据集格式化示例。我们将上述上下文视为一个单独的"问题",因为这是 ReCoRD 数据集中任务呈现的方式,也是 ReCoRD 评估脚本中的评分依据。
| 上下文→ | (CNN) Yuval Rabin(其父Yitzhak Rabin在担任以色列总理期间遇刺)在《今日美国》撰文批评唐纳德·特朗普:"特朗普的呼吁被谴责为煽动对克林顿的暴力,他本人对此予以否认——'这是丑陋竞选季中新的丑陋高度'。"这位遇刺前总理之子撰文论述暴力政治言论的后果。 |
|---|---|
| - 警告1990年代以色列与当今美国存在"相似之处"。 | |
| 正确答案→ | - 援引其父(1995年以色列政治紧张时期被极端分子枪杀)的案例,Rabin谴责了唐纳德·特朗普的激进言论。1995年以色列政治紧张时期,Rabin谴责了特朗普的激进言论。 |
| 错误答案→ | - 援引其父(1995年以色列政治紧张时期被极端分子枪杀)的案例,Rabin谴责了希拉里·克林顿的激进言论。 |
| 错误答案→ | - 援引其父(1995年以色列政治紧张时期被极端分子枪杀)的案例,Rabin谴责了美国的激进言论。 |
| 错误答案→ | - 援引其父(1995年以色列政治紧张时期被极端分子枪杀)的案例,Rabin谴责了Yitzhak Rabin的激进言论。 |
| committeesintheScottishParliament. Question:FultonJamesMacGregorisaScottishpoliticanwhoisaLiaison officer to Shona Robison who he swears is his best friend.True,False,or | for theconstituencyof Coatbridge andChryston.MacGregor iscurrently Health & Sport.He also serves on the Justice and Education & Skills | ||
| CorrectAnswer | Neither? Neither | ||
| Incorrect Answer→True | |||
| Incorrect Answer→False |
| | | 苏格兰议会的委员会。问题:Fulton James MacGregor是一位苏格兰政治家,担任Shona Robison的联络官,他坚称对方是自己最好的朋友。正确、错误,还是 | 代表Coatbridge和Chryston选区的MacGregor目前担任健康与体育职务。他还任职于司法及教育与技能委员会 |
| | 正确答案 | | 都不是? 都不是 |
| 错误答案→正确 | | | |
| 错误答案→错误 | | | |
| Context | 个 | Organisms require ee energy in order to do what? | |
| Correct | Answer | ← | mature and develop. |
| Incorrect | Answer | rest soundly. | |
| Incorrect | Answer | absorb light. | |
| Incorrect | Answer | ← | take in nutrients. |
| 上下文 | 个 | 生物体需要能量来做什么? | |
|---|---|---|---|
| 正确 | 答案 | ← | 成熟和发育。 |
| 错误 | 答案 | 安稳休息。 | |
| 错误 | 答案 | 吸收光线。 | |
| 错误 | 答案 | ← | 摄取养分。 |
| Context | Making a cake: Several ares shownmaking | lcakepops are shown on a display. Awoman | |||||||
| Correct | Answer | bake them, | thecake | pops | in a kitchen. They | ||||
| Incorrect | Answer | tastethemast | thenfrostanddecorate. | ||||||
| Incorrect | Answer | they place them on plates. | |||||||
| Incorrect | Answer | comeoutandbegindecorating | put the frosting on the cake as they pan it. | thecakeas well. | |||||
| 上下文 | 制作蛋糕:展示了几种制作方式 | 展示了一些蛋糕棒。一位女士 | ||
|---|---|---|---|---|
| 正确答案 | 烘烤它们, | |||
| 错误答案 | 品尝它们 | |||
| 错误答案 | ||||
| 错误答案 | 出炉并开始装饰 |
Figure G.10: Formatted dataset example for ANLI R3
| subsidizingthelossoftheir own job. They just passed an expansion of thatloopholeinthelastfewdays: $43 billion of giveaways,including favors to the oil and gas sindustryand the peopleimporting ceiling fans fromChina. Question: The loophole is now gone True,False,or Neither? | |||
| CorrectAnswer→ | False | ||
| Incorrect | Answer | 个 | True |
| Incorrect | Answer | 一 | Neither |
图 G.10: ANLI R3 格式化数据集示例
| | | | 补贴他们自己失业的损失。他们最近刚通过了扩大这个漏洞的法案:430亿美元的赠款,包括对石油天然气行业和从中国进口吊扇者的优惠。问题:这个漏洞现在已不存在。正确、错误,还是两者都不是? |
| CorrectAnswer→ | | | False |
| Incorrect | Answer | 个 | True |
| Incorrect | Answer | 一 | Neither |
Figure G.11: Formatted dataset example for ARC (Challenge). When predicting, we normalize by the unconditional probability of each answer as described in 2.
| Context | 1 Question: | George wantstowarmhis hands Squickly by rubbing them. Which skinsurfacewill producethemostheat? | |
| CorrectAnswer | Answer: dry palms | ||
| Incorrect | Answer | wet1 | palms |
| IncorrectAnswer | palmscovered withoil | ||
| IncorrectAnswer | palms covered with lotion |
图 G.11: ARC (挑战) 的格式化数据集示例。预测时,我们按照第2节所述对每个答案的无条件概率进行归一化处理。
| Context | 1 Question: | George wantstowarmhis hands Squickly by rubbing them. Which skinsurfacewill producethemostheat? | |
|---|---|---|---|
| CorrectAnswer | Answer: dry palms | ||
| Incorrect | Answer | wet1 | palms |
| IncorrectAnswer | palmscovered withoil | ||
| IncorrectAnswer | palms covered with lotion |
| Context | 个 | lullistotrust | |
| CorrectAnswer | 个 | cajoleistocompliance | |
| Incorrect | Answer | ← | balkistofortitude |
| Incorrect | Answer | ← | betray is to loyalty |
| Incorrect | Answer | ← | hinderistodestination |
| Incorrect | Answer | ← | sootheis topassion |
| 上下文 | 个 | lullistotrust | |
|---|---|---|---|
| 正确答案 | 个 | cajoleistocompliance | |
| 错误答案 | 答案 | ← | balkistofortitude |
| 错误答案 | 答案 | ← | betray is to loyalty |
| 错误答案 | 答案 | ← | hinderistodestination |
| 错误答案 | 答案 | ← | sootheis topassion |
| Correct | Context | Grace was happy totrade me her sweater IO my jacket. She thinks the sweater |
| Incorrect Context | Grace was happy totrademe] her sweater for my jacket. She thinks the | |
| Target | Completion 1 | jacket looksc dowdy on her. |
| 正确 | 上下文 | Grace 很高兴用她的毛衣换我的夹克。她觉得这件毛衣 |
| 错误上下文 | | Grace 很高兴用她的毛衣换我的夹克。她觉得这件 |
| 目标 | 补全1 | 夹克穿在她身上显得很土气。 |
Figure G.13: Formatted dataset example for Winograd. The ‘partial’ evaluation method we use compares the probability of the completion given a correct and incorrect context.
图 G.13: Winograd 的格式化数据集示例。我们使用的"partial"评估方法会比较给定正确与错误上下文时补全概率的差异。
Figure G.14: Formatted dataset example for Winogrande. The ‘partial’ evaluation method we use compares the probability of the completion given a correct and incorrect context.
| Correct Context | Johnny likes fruits more than vegetables in his new ketodietbecause the fruits Johnny likes fruits more than 1vegetablesinhis snew ketodietbecause | |
| Incorrect Context | the vegetables | |
| Target Completion | 个 | are saccharine. |
图 G.14: Winogrande 的格式化数据集示例。我们使用的"部分"评估方法会比较给定正确和错误上下文时补全的概率。
| 正确上下文 | | Johnny likes fruits more than vegetables in his new ketodietbecause the fruits Johnny likes fruits more than 1vegetablesinhis snew ketodietbecause |
| 错误上下文 | | the vegetables |
| 目标补全 | 个 | are saccharine. |
| Context→ | READINGCOMPREHENSIONANSWERKEY While this process moved along, diplomacy continued its rounds.Direct pressure on the Taliban had proved unsuccessful. As one NSC staff note put it,"Under the Taliban,Afghanistan is not so much a state sponsor of terrorism as it is a state sponsored by terrorists." In early 2oo0, the United States began a high-level effort to persuade Pakistan to use itsinfluenceovertheTaliban. In January 2ooo,Assistant Secretary of State Karl Inderfurth and the State Department's counterterrorism coordinator,Michael Sheehan,met with General Musharraf in Islamabad, dangling before him the possibility of a presidential visit in March as a reward for Pakistani cooperation. Such a visit was coveted by Musharraf, ' o u sad 1 m m a 2 left, however, reporting to Washington that Pakistan was unlikely in fact to do anything," given what it sees as the benefits of Taliban control ofAfghanistan."PresidentClintonwasscheduledtotraveltoIndia. TheState Department feltthathe should not visitIndia withoutalso visiting Pakistan.The Secret Service and the CIA,however,warned in the strongestterms that visiting Pakistan would risk the President's life. Counterterrorism officials also argued that Pakistan had not done enough to merit a presidential visit.But President Clinton insisted on including Pakistan in the itinerary for his trip to South Asia.His one-day stopover on March 25,20o0,was the first time a U.S.president had been there since 1969. At his meeting with Musharraf and others, President Clinton concentrated on tensions between Pakistan and India and the dangers of nuclear proliferation,but also discussed Bin Laden. President Clinton told us that when he pulled Musharraf aside for a brief, Laden." I offered him the moon when I went to see him,in terms of better relations with the United States,if he'd help us get Bin Laden and deal with another issue or two." The U.S.effort continued. |
| 背景→ | 阅读理解答案要点 |
|---|---|
| 在推进这一进程的同时,外交斡旋仍在继续。对塔利班的直接施压已被证明无效。正如国家安全委员会一份备忘录所述:"在塔利班统治下,阿富汗与其说是恐怖主义的国家赞助者,不如说是受恐怖分子赞助的国家。"2000年初,美国开始高层斡旋,试图说服巴基斯坦利用其对塔利班的影响力。2000年1月,助理国务卿卡尔·因德弗斯和国务院反恐协调员迈克尔·希恩在伊斯兰堡会见穆沙拉夫将军,以总统可能于3月访巴作为巴基斯坦合作的回报进行利诱。虽然穆沙拉夫对此访期待已久,但美方代表团返美后向华盛顿汇报称,鉴于巴基斯坦认为塔利班控制阿富汗对其有利,巴方实际上不太可能采取任何行动。当时克林顿总统计划出访印度,国务院认为若只访问印度而不访问巴基斯坦不合外交惯例。但特勤局和中央情报局以最严厉的措辞警告称,访问巴基斯坦将危及总统生命安全。反恐官员也提出,巴基斯坦的表现不足以获得总统访问的资格。但克林顿总统坚持将巴基斯坦纳入其南亚之行。2000年3月25日的短暂停留,是自1969年以来美国总统首次访问巴基斯坦。在与穆沙拉夫等人的会谈中,克林顿总统主要讨论了印巴紧张局势和核扩散风险,但也谈及本·拉登问题。克林顿总统后来告诉我们,当他将穆沙拉夫拉到一旁单独交谈时说道:"我去见他时开出了优厚条件——如果他能协助我们抓捕本·拉登并解决另外一两个问题,美国将大幅改善与巴基斯坦的关系。"美国的斡旋努力仍在继续。 |
Figure G.15: Formatted dataset example for MultiRC. There are three levels within MultiRC: (1) the passage, (2) the questions, and (3) the answers. During evaluation, accuracy is determined at the per-question level, with a question being considered correct if and only if all the answers within the question are labeled correctly. For this reason, we use $K$ to refer to the number of questions shown within the context.
| CorrectAnswer | [False]BinLaden | ||||
| Incorrect | Answer | [True]BinLaden |
图 G.15: MultiRC 的格式化数据集示例。MultiRC 包含三个层级: (1) 段落, (2) 问题, (3) 答案。在评估时, 准确率以每个问题为单位计算, 当且仅当问题中的所有答案都被正确标注时, 该问题才被视为正确。因此, 我们使用 $K$ 来表示上下文中显示的问题数量。
| CorrectAnswer | | | | [False]BinLaden | |
| Incorrect | Answer | | | [True]BinLaden | |
Who did The State Department feel should visit both India and Pakistan?
| Context | Question: Answer: | Whichfactorwill most likely causea1 person to develop a fever? | ||
| CorrectA | Answer | abacterial | populationinthebloodstream | |
| Incorrect | Answer | aleg muscle relaxing | afterexercise | |
| Incorrect | Answer | several viral | particlesontheskin | |
| Incorrect | Answer | carbohydrates | being digestedinthestomach |
Figure G.16: Formatted dataset example for ARC (Easy). When predicting, we normalize by the unconditional probability of each answer as described in 2.
美国国务院认为谁应该访问印度和巴基斯坦?
| 上下文 | 问题: 答案: | 哪个因素最可能导致一个人发烧? | ||
|---|---|---|---|---|
| 正确答案 | 答案 | 血液中的细菌感染 | ||
| 错误答案 | 答案 | 运动后腿部肌肉放松 | ||
| 错误答案 | 答案 | 皮肤上的病毒颗粒 | ||
| 错误答案 | 答案 | 胃中消化的碳水化合物 |
图 G.16: ARC (简易版) 的格式化数据集示例。预测时,我们按照第2节所述对每个答案的无条件概率进行归一化。

Figure G.17: Formatted dataset example for StoryCloze
图 G.17: StoryCloze 的格式化数据集示例
| Context→ Helsinki is the capital and largest city of Finland.It is in the region | |
| of Uusimaa,in southern Finland,on the shore of the Gulf of Finland. Helsinki has a population of ,an urban population of ,and a metropolitan population of over 1.4 million, making it the most populous municipality and urban area in Finland.Helsinki is some north of Tallinn, Estonia, east of Stockholm, Sweden, and west of Saint Petersburg, Russia. Helsinki has close historical connections with these three cities. The Helsinki metropolitan area includes the urban core of Helsinki,Espoo, | |
| Vantaa,Kauniainen,and surrounding commuter towns.It is the world's northernmost metro area of over one million people,and the city is the northernmost capital of an EU member state.The Helsinki metropolitan after Stockholm and Copenhagen, and the City of Helsinki is the third largest after Stockholm and Oslo. Helsinki is Finland's major political, educational,financial,cultural,and research center as well as one of | |
| that operate in Finland have settled in the Helsinki region.The nearby municipality of Vantaa is the location of Helsinki Airport,with frequent | |
| service to various destinations in Europe and Asia. | |
| Q: what is the most populous municipality in Finland? A: Helsinki Q:how many people live there? A:1.4 million in the metropolitan area | |
| 上下文→ | 赫尔辛基是芬兰的首都和最大城市,位于新地区 (Uusimaa) ,地处芬兰南部,濒临芬兰湾沿岸。赫尔辛基市区人口达 ,都会区人口超过140万,是芬兰人口最多的自治市和都市区。赫尔辛基位于爱沙尼亚塔林以北 ,瑞典斯德哥尔摩以东 ,俄罗斯圣彼得堡以西 ,与这三座城市有着深厚的历史渊源。赫尔辛基都会区包括赫尔辛基城区、埃斯波、万塔、考尼艾宁及周边通勤城镇,是全球最北端的百万人口大都会区,也是欧盟成员国中最北的首都城市。其都会区规模在斯德哥尔摩和哥本哈根之后位列第三,赫尔辛基市则在斯德哥尔摩和奥斯陆之后排名第三。作为芬兰主要的政治、教育、金融、文化和科研中心,赫尔辛基还集中了芬兰多数大型企业。毗邻的万塔市设有赫尔辛基机场,提供往返欧亚多地的密集航线服务。 |
|---|
Figure G.18: Formatted dataset example for CoQA
图 G.18: CoQA 数据集格式化示例

Figure G.19: Formatted dataset example for Cycled Letters
图 G.19: 循环字母格式化数据集示例

Figure G.20: Formatted dataset example for DROP
图 G.20: DROP 的格式化数据集示例
Target Completion → 4
目标完成 → 4

Figure G.21: Formatted dataset example for LAMBADA
图 G.21: LAMBADA 的格式化数据集示例

Figure G.22: Formatted dataset example for Anagrams 1 (A1)
图 G.22: 变位词1 (A1) 的格式化数据集示例

Figure G.23: Formatted dataset example for Anagrams 2
图 G.23: 变位词2的格式化数据集示例

Figure G.24: Formatted dataset example for Natural Questions
图 G.24: Natural Questions 的格式化数据集示例
TITLE: William Perry (American football) - Professional career PARAGRAPH: In 1985, he was selected in the first round of the 1985 NFL Draft by the Chicago Bears; he had been hand-picked by coach Mike Ditka. However, defensive coordinator Buddy Ryan, who had a highly acrimonious relationship with Ditka, called Perry a "wasted draft-pick". Perry soon became a pawn in the political power struggle between Ditka and Ryan. Perry’s "Refrigerator" nickname followed him into the NFL and he quickly became a favorite of the Chicago Bears fans. Teammates called him "Biscuit," as in "one biscuit shy of 350 pounds." While Ryan refused to play Perry, Ditka decided to use Perry as a fullback when the team was near the opponents’ goal line or in fourth and short situations, either as a ball carrier or a lead blocker for star running back Walter Payton. Ditka stated the inspiration for using Perry as a fullback came to him during five-yard sprint exercises. During his rookie season, Perry rushed for two touchdowns and caught a pass for one. Perry even had the opportunity to run the ball during Super Bowl XX, as a nod to his popularity and contributions to the team’s success. The first time he got the ball, he was tackled for a one-yard loss while attempting to throw his first NFL pass on a halfback option play. The second time he got the ball, he scored a touchdown (running over Patriots linebacker Larry McGrew in the process). About halfway through his rookie season, Ryan finally began to play Perry, who soon proved that he was a capable defensive lineman. His Super Bowl ring size is the largest of any professional football player in the history of the event. His ring size is 25, while the ring size for the average adult male is between 10 and 12. Perry went on to play for ten years in the NFL, retiring after the 1994 season. In his ten years as a pro, he regularly struggled with his weight, which hampered his performance at times. He played in 138 games, recording 29.5 sacks and five fumble recoveries, which he returned for a total of 71 yards. In his offensive career he ran five yards for two touchdowns, and had one reception for another touchdown. Perry later attempted a comeback, playing an unremarkable 1996 season with the London Monarchs of the World League of American Football (later NFL Europa).
标题:William Perry (American football) - 职业生涯
1985年,他在NFL选秀首轮被芝加哥熊队选中,主教练Mike Ditka亲自挑选了他。然而,与Ditka关系极度紧张的防守协调员Buddy Ryan称Perry是"浪费的选秀权"。Perry很快成为Ditka和Ryan之间政治权力斗争的棋子。"冰箱"的绰号跟随Perry进入NFL,他迅速成为芝加哥熊队球迷的最爱。队友们称他为"Biscuit(饼干)",意思是"离350磅只差一块饼干"。当Ryan拒绝让Perry上场时,Ditka决定在球队接近对手球门线或面临四档短码时,将Perry用作全卫,担任持球者或明星跑卫Walter Payton的领路阻挡者。Ditka表示,在五码冲刺训练中产生了将Perry用作全卫的灵感。在新秀赛季,Perry两次冲球达阵,并接球完成一次达阵。Perry甚至在超级碗XX中获得跑球机会,这是对他受欢迎程度和对球队成功贡献的认可。第一次持球时,他在半卫选项进攻中尝试传球,被擒抱损失一码。第二次持球时,他完成达阵(过程中撞倒了爱国者队线卫Larry McGrew)。新秀赛季过半时,Ryan终于开始让Perry上场,他很快证明了自己是一名有能力的防守线球员。他的超级碗戒指尺寸是该赛事历史上所有职业球员中最大的。他的戒指尺寸为25,而成年男性的平均戒指尺寸在10到12之间。Perry在NFL打了十年球,于1994赛季后退役。在十年的职业生涯中,他经常与体重作斗争,这有时会影响他的表现。他参加了138场比赛,完成29.5次擒杀和5次掉球回抢,总计推进71码。在进攻端,他冲球5码完成两次达阵,接球一次达阵。Perry后来尝试复出,在世界美式橄榄球联盟(后更名为NFL Europa)的伦敦君主队度过了平淡无奇的1996赛季。

Figure G.25: Formatted dataset example for QuAC
图 G.25: QuAC 的格式化数据集示例

Figure G.26: Formatted dataset example for Symbol Insertion
图 G.26: 符号插入任务的格式化数据集示例

Figure G.27: Formatted dataset example for Reversed Words
图 G.27: 反转单词任务的格式化数据集示例
Background: From the German point of view, March 1941 saw an improvement. The Luftwaffe flew 4,000 sorties that month, including 12 major and three heavy attacks. The electronic war intensified but the Luftwaffe flew major inland missions only on moonlit nights. Ports were easier to find and made better targets. To confuse the British, radio silence was observed until the bombs fell. X- and Y-Gerat beams were placed over false targets and switched only at the last minute. Rapid frequency changes were introduced for X-Gerät, whose wider band of frequencies and greater tactical flexibility ensured it remained effective at a time when British selective jamming was degrading the effectiveness of Y-Gerat.
背景:从德国的角度来看,1941年3月形势有所好转。当月德国空军出动4000架次,包括12次大规模和3次重型攻击。电子战加剧,但德军仅在月夜执行重大内陆任务。港口更易定位且成为更理想目标。为迷惑英军,德军保持无线电静默直至炸弹投下。X和Y制导波束被指向假目标,仅在最后一刻切换。X-Gerät系统引入快速频率切换,其更宽的频段和更强的战术灵活性使其在英国选择性干扰削弱Y-Gerät效能时仍保持有效。

Figure G.28: Formatted dataset example for SQuADv2
图 G.28: SQuADv2 数据集格式化示例

Figure G.29: Formatted dataset example for BoolQ
图 G.29: BoolQ 的格式化数据集示例

Figure G.30: Formatted dataset example for CB
图 G.30: CB 的格式化数据集示例

Figure G.31: Formatted dataset example for RTE
图 G.31: RTE 的格式化数据集示例

Figure G.32: Formatted dataset example for WiC
图 G.32: WiC 的格式化数据集示例

Figure G.33: Formatted dataset example for WSC
图 G.33: WSC 的格式化数据集示例

Figure G.34: Formatted dataset example for TriviaQA. TriviaQA allows for multiple valid completions.
图 G.34: TriviaQA 的格式化数据集示例。TriviaQA 允许多种有效答案。

Figure G.35: Formatted dataset example for WebQA
图 G.35: WebQA 的格式化数据集示例

Figure G.36: Formatted dataset example for $\mathrm{De{\rightarrow}E n}$ . This is the format for one- and few-shot learning, for this and other langauge tasks, the format for zero-shot learning is $^{\circ\circ}\mathrm{Q}$ : What is the {language} translation of {sentence} A: {translation}.”
图 G.36: 格式化数据集示例($\mathrm{De{\rightarrow}En}$)。这是一样本和少样本学习的格式,对于此任务及其他语言任务,零样本学习的格式为 $^{\circ\circ}\mathrm{Q}$ : What is the {language} translation of {sentence} A: {translation}。

Figure G.37: Formatted dataset example for En $\rightarrow$ De
图 G.37: En $\rightarrow$ De 的格式化数据集示例

Figure G.38: Formatted dataset example for En $\rightarrow\mathrm{Fr}$
图 G.38: 英(En) $\rightarrow$ 法(Fr) 翻译任务的格式化数据集示例

Figure G.39: Formatted dataset example for $\mathrm{Fr{\rightarrow}E n}$
图 G.39: $\mathrm{Fr{\rightarrow}E n}$ 的格式化数据集示例

Figure G.40: Formatted dataset example for En→Ro
图 G.40: En→Ro 的格式化数据集示例

Figure G.41: Formatted dataset example for ${\tt R o}{\rightarrow}{\tt E n}$
图 G.41: 格式化数据集示例 ${\tt R o}{\rightarrow}{\tt E n}$

Figure G.42: Formatted dataset example for Arithmetic 1DC
图 G.42: Arithmetic 1DC 的格式化数据集示例

Figure G.43: Formatted dataset example for Arithmetic 2D
图 G.43: Arithmetic 2D 的格式化数据集示例

Figure G.44: Formatted dataset example for Arithmetic $^{2\mathrm{D}+}$
图 G.44: 用于算术 $^{2\mathrm{D}+}$ 的格式化数据集示例

Figure G.45: Formatted dataset example for Arithmetic 2Dx
图 G.45: Arithmetic 2Dx 的格式化数据集示例

Figure G.46: Formatted dataset example for Arithmetic 3D
图 G.46: Arithmetic 3D 的格式化数据集示例

Figure G.47: Formatted dataset example for Arithmetic $^{3\mathrm{D}+}$
图 G.47: 算术 $^{3\mathrm{D}+}$ 的格式化数据集示例

Figure G.48: Formatted dataset example for Arithmetic 4D
图 G.48: Arithmetic 4D 的格式化数据集示例

Figure G.49: Formatted dataset example for Arithmetic $^{4\mathrm{D}+}$
图 G.49: 算术 $^{4\mathrm{D}+}$ 的格式化数据集示例

Figure G.50: Formatted dataset example for Arithmetic 5D−
图 G.50: 算术5D−的格式化数据集示例

Figure G.51: Formatted dataset example for Arithmetic $5\mathrm{D}+$
图 G.51: 用于算术 $5\mathrm{D}+$ 的格式化数据集示例
H Results on All Tasks for All Model Sizes Table H.1: Scores for every task, setting and model that we investigate in this paper.
| Zero-Shot | One-Shot | Few-Shot | ||||||||||
| Name | Metric | Fine-tune Split | SOTA | Small Med Large XL 2.7B 6.7B 13B 175B | Small Med Large XL 2.7B 6.7B 13B 175B | Small Med Large XL 2.7B 6.7B 13B 175B (test server | 175B | |||||
| HellaSwag | acc | dev | 33.743.6 51.054.7 62.8 67.4 70.9 78.9 | 33.0 42.9 50.553.5 61.9 66.5 70.0 78.1 | ||||||||
| LAMBADA | acc | test | 20 15 | 54.3 60.4 63.6 67.1 70.3 72.5 76.2 | 22.0 47.1 52.6 | 58.3 61.1 65.4 69.0 72.5 | 22.0 40.4 63.2 57.0 78.1 79.1 81.3 86.4 | |||||
| LAMBADA | Ppl | test | 15 | 9.09 6.53 5.44 4.60 4.00 3.56 3.00 | 165.0 11.6 8.29 | 6.46 5.53 4.61 4.06 3.35 | 165.0 27.6 6.63 | 37.45 2.89 2.56 2.56 1.92 | ||||
| StoryCloze | acc | test | 70 | 63.3 | 68.5 72.473.4 77.2 77.7 79.5 83.2 | 62.3 68.7 72.3 74.2 77.378.7 79.7 84.7 | 62.3 70.2 73.9 76.1 80.2 81.2 83.0 87.7 | |||||
| NQs | acc | test | 64 | 0.64 | 1.75 2.71 4.40 6.01 5.79 7.84 14.6 | 1.19 | 3.07 4.795.43 8.73 9.78 13.7 23.0 | 1.72 | 24.46 7.899.72 13.2 17.0 21.0 29.9 | |||
| TriviaQA | acc | dev | 64 | 4.15 | 7.61 14.0 | 19.7 31.3 38.7 41.8 64.3 | 4.19 | 12.9 20.5 26.5 35.9 44.4 51.3 68.0 | 6.96 | 16.3 26.5 | 532.1 42.3 51.6 57.5 71.2 | 71.2 |
| WebQs | acc | test | 64 | 1.77 | 3.20 4.33 4.63 7.92 7.73 8.22 14.4 | 2.56 | 6.20 8.51 9.15 14.5 15.1 19.0 25.3 | 5.46 | 12.6 15.9 19.6 24.8 27.7 33.5 41.5 | |||
| Ro→En 16 | BLEU-mb test | 64 | 2.08 | 2.71 3.09 3.15 16.3 8.34 20.2 19.9 | 0.55 | 15.4 23.0 | 26.3 30.6 33.2 35.6 38.6 | 20.7 25.8 29.2 33.1 34.8 37.0 39.5 | ||||
| Ro→En 16 | BLEU-sb | test | 64 | 2.39 | 3.08 3.49 | 3.56 16.8 8.75 20.8 20.9 | 0.65 | 15.9 23.6 | 26.8 31.3 34.2 36.7 40.0 | 21.3 26.6 | 30.1 34.3 36.2 38.4 41.3 | |
| En→Ro 16 | BLEU-mb test | 64 | 2.14 | 2.65 2.53 | 2.50 3.46 4.24 5.32 14.1 | 0.35 | 3.30 7.89 | 8.72 13.2 15.1 17.3 20.6 | 5.90 9.33 | 10.7 14.3 16.3 18.0 21.0 | ||
| En→Ro 16 | BLEU-sb | test | 64 | 2.61 | 3.11 3.07 | 3.09 4.26 5.31 6.43 18.0 | 0.55 | 3.90 9.15 | 10.3 15.7 18.2 20.8 24.9 | 7.40 10.9 | 12.9 17.2 19.6 21.8 25.8 | |
| Fr→→En 14 | BLEU-mb test | 64 | 1.81 | 2.53 3.47 3.13 20.6 15.1 21.8 21.2 | 1.28 | 15.9 23.7 | 26.3 29.0 30.5 30.2 33.7 | 25.5 28.5 31.1 33.7 34.9 36.6 39.2 | ||||
| Fr→En 14 | BLEU-sb | test | 64 | 2.29 | 2.99 3.90 | 3.60 21.2 15.5 22.4 21.9 | 1.50 | 16.3 24.4 | 27.0 30.0 31.6 31.4 35.6 | 26.2 29.5 | 32.2 35.1 36.4 38.3 41.4 | |
| En→Fr 14 | BLEU-mb test | 64 | 1.74 | 2.16 2.73 | 2.15 15.1 8.82 12.0 25.2 | 0.49 | 8.00 14.8 | 15.9 20.3 23.3 24.9 28.3 | 14.5 19.3 | 321.5 24.9 27.3 29.5 32.6 | ||
| En→Fr 14 | BLEU-sb | test | 64 | 2.44 | 2.75 3.54 2.82 19.3 11.4 15.3 31.3 | 0.81 | 10.0 18.2 | 19.3 24.7 28.3 30.1 34.1 | 18.0 23.6 26.1 30.3 33.3 35.5 39.9 | |||
| De→En 16 | BLEU-mb test | 64 | 2.06 | 2.87 3.41 | 3.63 21.5 17.3 23.0 27.2 | 0.83 | 16.2 22.5 | 24.7 28.2 30.7 33.0 30.4 | 22.7 26.2 | 29.2 32.7 34.8 37.3 40.6 | ||
| De→En 16 | BLEU-sb | test | 64 | 2.39 | 3.27 3.85 | 4.04 22.5 18.2 24.4 28.6 | 0.93 | 17.1 23.4 | 25.8 29.2 31.9 34.5 32.1 | 23.8 27.5 | 30.5 34.1 36.5 39.1 43.0 | |
| En→De 16 | BLEU-mb test | 64 | 1.70 | 2.27 2.31 | 2.43 12.9 8.66 10.4 24.6 | 0.50 | 7.00 12.9 | 13.1 18.3 20.9 22.5 26.2 | 12.3 15.4 | 17.1 20.9 23.0 26.6 29.7 | ||
| En→De 16 | BLEU-sb | test | 64 | 2.09 | 2.65 2.75 2.92 13.7 9.36 11.0 25.3 | 0.54 | 7.40 13.4 | 13.4 18.8 21.7 23.3 27.3 | 12.9 16.1 | 17.7 21.7 24.1 27.7 30.9 | ||
| Winograd | acc | test | 7 | 66.3 | 672.9 74.776.9 82.4 85.7 87.9 88.3 | 63.4 | 68.5 72.9 | 976.9 82.4 84.6 86.1 89.7 | ||||
| Winogrande | acc | dev | 50 | 52.0 | 52.1 57.4 58.7 62.3 64.5 67.9 70.2 | 51.3 | 53.0 58.35 | 59.1 61.7 65.8 66.9 73.2 | 52.6 57.5 59.1 62.6 67.4 70.0 77.7 | |||
| PIQA | acc | dev | 50 | 64.6 | 70.2 72.975.1 75.6 78.0 78.5 81.0 | 69.3 71.874.4 74.3 76.3 77.8 80.5 | ||||||
| ARC (Challenge) acc | test | 50 | 26.6 | 29.5 31.8 35.5 38.0 41.4 43.7 51.4 | 64.3 25.5 | 30.2 31.6 | 36.4 38.4 41.5 43.1 53.2 | 64.369.4 72.074.3 75.4 77.8 79.9 82.3 | 82.8 | |||
| ARC (Easy) | acc | test | 50 | 43.6 | 46.5 53.0 53.8 58.2 60.2 63.8 68.8 | 42.7 | 48.2 54.6 | 55.9 60.3 62.6 66.8 71.2 | 28.4 32.3 36.7 39.5 43.7 44.8 51.5 | |||
| OpenBookQA | acc | 92.0 test 87.2 | 100 | 35.6 | 43.2 45.246.8 53.0 50.4 55.6 57.6 | 37.0 | 39.8 46.2 46.4 53.4 53.0 55.8 58.8 | |||||
| 43.6 48.050.6 55.6 55.2 60.8 65.4 | ||||||||||||
| Quac | dev 74.4 | 5 | 21.2 | 26.8 31.0 30.1 34.7 36.1 38.4 41.5 | 21.1 | 26.9 31.932.3 37.4 39.0 40.6 43.4 | 27.6 32.934.2 38.2 39.9 40.9 44.3 | |||||
| acc | test 90.0 | 10 | 35.2 | 37.9 40.1 | 40.9 42.4 44.1 44.6 45.5 | 34.3 | 37.7 40.0 | 42.0 43.8 44.3 44.6 45.9 | 37.0 40.4 41.4 42.3 44.7 45.1 46.8 | |||
| RACE-h | acc | test 93.1 | 10 | 42.1 | 47.2 52.1 | 52.3 54.7 54.4 56.7 58.4 | 42.3 | 47.3 51.7 | 55.2 56.1 54.7 56.9 57.4 | |||
| RACE-m | em | dev 90.7 | 16 | 22.6 | 32.8 33.9 43.1 43.6 45.4 49.0 52.6 | 25.1 | 37.5 37.9 147.9 47.9 51.1 56.0 60.1 | 47.0 52.7 53.0 55.6 55.4 58.1 58.1 40.5 39.2 53.5 50.0 56.6 62.6 64.9 | ||||
| SQuADv2 SQuADv2 |
H 所有任务及模型规模的实验结果
表 H.1: 本文研究的所有任务、设置及模型的评分结果
| Name | Metric | Fine-tune Split | SOTA | Zero-Shot | One-Shot | Few-Shot |
|---|---|---|---|---|---|---|
| Small Med Large XL 2.7B 6.7B 13B 175B | Small Med Large XL 2.7B 6.7B 13B 175B | Small Med Large XL 2.7B 6.7B 13B 175B (test server) 175B | ||||
| HellaSwag | acc | dev | 33.743.6 51.054.7 62.8 67.4 70.9 78.9 | 33.0 42.9 50.553.5 61.9 66.5 70.0 78.1 | ||
| LAMBADA | acc | test | 20 15 | 54.3 60.4 63.6 67.1 70.3 72.5 76.2 | 22.0 47.1 52.6 58.3 61.1 65.4 69.0 72.5 | 22.0 40.4 63.2 57.0 78.1 79.1 81.3 86.4 |
| LAMBADA | Ppl | test | 15 | 9.09 6.53 5.44 4.60 4.00 3.56 3.00 | 165.0 11.6 8.29 6.46 5.53 4.61 4.06 3.35 | 165.0 27.6 6.63 37.45 2.89 2.56 2.56 1.92 |
| StoryCloze | acc | test | 70 | 68.5 72.473.4 77.2 77.7 79.5 83.2 | 62.3 68.7 72.3 74.2 77.378.7 79.7 84.7 | 62.3 70.2 73.9 76.1 80.2 81.2 83.0 87.7 |
| NQs | acc | test | 64 | 1.75 2.71 4.40 6.01 5.79 7.84 14.6 | 3.07 4.795.43 8.73 9.78 13.7 23.0 | 24.46 7.899.72 13.2 17.0 21.0 29.9 |
| TriviaQA | acc | dev | 64 | 7.61 14.0 19.7 31.3 38.7 41.8 64.3 | 12.9 20.5 26.5 35.9 44.4 51.3 68.0 | 532.1 42.3 51.6 57.5 71.2 |
| WebQs | acc | test | 64 | 3.20 4.33 4.63 7.92 7.73 8.22 14.4 | 6.20 8.51 9.15 14.5 15.1 19.0 25.3 | 12.6 15.9 19.6 24.8 27.7 33.5 41.5 |
| Ro→En 16 | BLEU-mb test | 64 | 2.71 3.09 3.15 16.3 8.34 20.2 19.9 | 15.4 23.0 26.3 30.6 33.2 35.6 38.6 | 20.7 25.8 29.2 33.1 34.8 37.0 39.5 | |
| Ro→En 16 | BLEU-sb | test | 64 | 3.08 3.49 3.56 16.8 8.75 20.8 20.9 | 15.9 23.6 26.8 31.3 34.2 36.7 40.0 | 21.3 26.6 30.1 34.3 36.2 38.4 41.3 |
| En→Ro 16 | BLEU-mb test | 64 | 2.65 2.53 2.50 3.46 4.24 5.32 14.1 | 3.30 7.89 8.72 13.2 15.1 17.3 20.6 | 5.90 9.33 10.7 14.3 16.3 18.0 21.0 | |
| En→Ro 16 | BLEU-sb | test | 64 | 3.11 3.07 3.09 4.26 5.31 6.43 18.0 | 3.90 9.15 10.3 15.7 18.2 20.8 24.9 | 7.40 10.9 12.9 17.2 19.6 21.8 25.8 |
| Fr→En 14 | BLEU-mb test | 64 | 2.53 3.47 3.13 20.6 15.1 21.8 21.2 | 15.9 23.7 26.3 29.0 30.5 30.2 33.7 | 25.5 28.5 31.1 33.7 34.9 36.6 39.2 | |
| Fr→En 14 | BLEU-sb | test | 64 | 2.99 3.90 3.60 21.2 15.5 22.4 21.9 | 16.3 24.4 27.0 30.0 31.6 31.4 35.6 | 26.2 29.5 32.2 35.1 36.4 38.3 41.4 |
| En→Fr 14 | BLEU-mb test | 64 | 2.16 2.73 2.15 15.1 8.82 12.0 25.2 | 8.00 14.8 15.9 20.3 23.3 24.9 28.3 | 14.5 19.3 321.5 24.9 27.3 29.5 32.6 | |
| En→Fr 14 | BLEU-sb | test | 64 | 2.75 3.54 2.82 19.3 11.4 15.3 31.3 | 10.0 18.2 19.3 24.7 28.3 30.1 34.1 | 18.0 23.6 26.1 30.3 33.3 35.5 39.9 |
| De→En 16 | BLEU-mb test | 64 | 2.87 3.41 3.63 21.5 17.3 23.0 27.2 | 16.2 22.5 24.7 28.2 30.7 33.0 30.4 | 22.7 26.2 29.2 32.7 34.8 37.3 40.6 | |
| De→En 16 | BLEU-sb | test | 64 | 3.27 3.85 4.04 22.5 18.2 24.4 28.6 | 17.1 23.4 25.8 29.2 31.9 34.5 32.1 | 23.8 27.5 30.5 34.1 36.5 39.1 43.0 |
| En→De 16 | BLEU-mb test | 64 | 2.27 2.31 2.43 12.9 8.66 10.4 24.6 | 7.00 12.9 13.1 18.3 20.9 22.5 26.2 | 12.3 15.4 17.1 20.9 23.0 26.6 29.7 | |
| En→De 16 | BLEU-sb | test | 64 | 2.65 2.75 2.92 13.7 9.36 11.0 25.3 | 7.40 13.4 13.4 18.8 21.7 23.3 27.3 | 12.9 16.1 17.7 21.7 24.1 27.7 30.9 |
| Winograd | acc | test | 7 | 672.9 74.776.9 82.4 85.7 87.9 88.3 | 68.5 72.9 976.9 82.4 84.6 86.1 89.7 | |
| Winogrande | acc | dev | 50 | 52.1 57.4 58.7 62.3 64.5 67.9 70.2 | 53.0 58.35 59.1 61.7 65.8 66.9 73.2 | 52.6 57.5 59.1 62.6 67.4 70.0 77.7 |
| PIQA | acc | dev | 50 | 70.2 72.975.1 75.6 78.0 78.5 81.0 | 69.3 71.874.4 74.3 76.3 77.8 80.5 | |
| ARC (Challenge) acc | test | 50 | 29.5 31.8 35.5 38.0 41.4 43.7 51.4 | 30.2 31.6 36.4 38.4 41.5 43.1 53.2 | 64.369.4 72.074.3 75.4 77.8 79.9 82.3 | |
| ARC (Easy) | acc | test | 50 | 46.5 53.0 53.8 58.2 60.2 63.8 68.8 | 48.2 54.6 55.9 60.3 62.6 66.8 71.2 | 28.4 32.3 36.7 39.5 43.7 44.8 51.5 |
| OpenBookQA | acc | test | 100 | 43.2 45.246.8 53.0 50.4 55.6 57.6 | 39.8 46.2 46.4 53.4 53.0 55.8 58.8 | 43.6 48.050.6 55.6 55.2 60.8 65.4 |
| Quac | acc | dev | 5 | 26.8 31.0 30.1 34.7 36.1 38.4 41.5 | 26.9 31.932.3 37.4 39.0 40.6 43.4 | 27.6 32.934.2 38.2 39.9 40.9 44.3 |
| RACE-h | acc | test | 10 | 47.2 52.1 52.3 54.7 54.4 56.7 58.4 | 47.3 51.7 55.2 56.1 54.7 56.9 57.4 | |
| RACE-m | em | dev | 16 | 32.8 33.9 43.1 43.6 45.4 49.0 52.6 | 37.5 37.9 147.9 47.9 51.1 56.0 60.1 | 47.0 52.7 53.0 55.6 55.4 58.1 58.1 40.5 39.2 53.5 50.0 56.6 62.6 64.9 |

Figure H.1: All results for all SuperGLUE tasks.
图 H.1: 所有SuperGLUE任务的全部结果。

Figure H.2: Results for SAT task.
图 H.2: SAT任务结果。

Figure H.3: All results for all Winograd tasks.
图 H.3: 所有Winograd任务的全部结果。

Figure H.4: All results for all Arithmetic tasks.
图 H.4: 所有算术任务的全部结果。

Figure H.5: All results for all Cloze and Completion tasks.
图 H.5: 所有完形填空和补全任务的完整结果。

Figure H.6: All results for all Common Sense Reasoning tasks.
图 H.6: 所有常识推理(Common Sense Reasoning)任务的完整结果。

Figure H.7: All results for all QA tasks.
图 H.7: 所有问答任务的全部结果。

Figure H.8: All results for all Reading Comprehension tasks.
图 H.8: 所有阅读理解任务的全部结果。

Figure H.9: All results for all ANLI rounds.
图 H.9: 所有ANLI轮次的结果。

Figure H.10: All results for all Scramble tasks.
图 H.10: 所有Scramble任务的全部结果。

Figure H.11: All results for all Translation tasks.
图 H.11: 所有翻译任务的完整结果。
[LB02] Edward Loper and Steven Bird. Nltk: The natural language toolkit, 2002.
[LB02] Edward Loper 和 Steven Bird. NLTK: 自然语言工具包, 2002.
[LC19] Guillaume Lample and Alexis Conneau. Cross-lingual language model pre training. arXiv preprint arXiv:1901.07291, 2019.
[LC19] Guillaume Lample 和 Alexis Conneau. 跨语言语言模型预训练. arXiv预印本 arXiv:1901.07291, 2019.
1992。
[ZSW+19b] Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. ArXiv, abs/1909.08593, 2019.
[ZSW+19b] Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 基于人类偏好微调语言模型. ArXiv, abs/1909.08593, 2019.