GAN-BERT: Generative Adversarial Learning for Robust Text Classification with a Bunch of Labeled Examples
GAN-BERT:基于生成对抗学习的鲁棒文本分类方法(仅需少量标注样本)
Abstract
摘要
Recent Transformer-based architectures, e.g., BERT, provide impressive results in many Natural Language Processing tasks. However, most of the adopted benchmarks are made of (sometimes hundreds of) thousands of examples. In many real scenarios, obtaining highquality annotated data is expensive and timeconsuming; in contrast, unlabeled examples characterizing the target task can be, in general, easily collected. One promising method to enable semi-supervised learning has been proposed in image processing, based on SemiSupervised Generative Adversarial Networks. In this paper, we propose GAN-BERT that extends the fine-tuning of BERT-like architectures with unlabeled data in a generative adversarial setting. Experimental results show that the requirement for annotated examples can be drastically reduced (up to only 50-100 annotated examples), still obtaining good performances in several sentence classification tasks.
基于Transformer的最新架构(如BERT)在众多自然语言处理任务中展现出卓越性能。然而现有基准测试大多依赖(有时多达数十万)标注样本。实际场景中,获取高质量标注数据往往成本高昂且耗时,而目标任务的未标注数据通常易于收集。半监督生成对抗网络已在图像处理领域展现出解决这一问题的潜力。本文提出GAN-BERT,通过在生成对抗框架中结合未标注数据来扩展类BERT架构的微调方法。实验表明,该方法在多个句子分类任务中仅需极少量标注样本(50-100个)即可保持优异性能。
1 Introduction
1 引言
In recent years, Deep Learning methods have become very popular in Natural Language Processing (NLP), e.g., they reach high performances by relying on very simple input representations (for example, in (Kim, 2014; Goldberg, 2016; Kim et al., 2016)). In particular, Transformer-based architectures, e.g., BERT (Devlin et al., 2019), provide representations of their inputs as a result of a pre-training stage. These are, in fact, trained over large scale corpora and then effectively finetuned over a targeted task achieving state-of-the-art results in different and heterogeneous NLP tasks. These achievements are obtained when thousands of annotated examples exist for the final tasks. As experimented in this work, the quality of BERT fine-tuned over less than 200 annotated instances shows significant drops, especially in classification tasks involving many categories. Unfortunately, obtaining annotated data is a time-consuming and costly process. A viable solution is adopting semisupervised methods, such as in (Weston et al., 2008; Chapelle et al., 2010; Yang et al., 2016; Kipf and Welling, 2016) to improve the generalization capability when few annotated data is available, while the acquisition of unlabeled sources is possible.
近年来,深度学习(Deep Learning)方法在自然语言处理(NLP)领域变得非常流行,例如,它们通过依赖非常简单的输入表示就能达到高性能(如(Kim, 2014; Goldberg, 2016; Kim et al., 2016))。特别是基于Transformer的架构,如BERT(Devlin et al., 2019),通过预训练阶段生成输入表示。这些模型实际上是在大规模语料库上进行训练,然后针对特定任务进行有效微调,在各种异构NLP任务中取得最先进的结果。这些成就是在最终任务存在数千个标注样本的情况下获得的。正如本实验所示,在少于200个标注实例上微调的BERT质量会出现显著下降,尤其是在涉及多类别的分类任务中。遗憾的是,获取标注数据是一个耗时且昂贵的过程。一个可行的解决方案是采用半监督方法(如(Weston et al., 2008; Chapelle et al., 2010; Yang et al., 2016; Kipf and Welling, 2016)),在标注数据较少但可以获取未标注数据源的情况下提高泛化能力。
One effective semi-supervised method is implemented within Semi-Supervised Generative Adversarial Networks (SS-GANs). Usually, in GANs (Goodfellow et al., 2014) a “generator” is trained to produce samples resembling some data distribution. This training process “adversarial ly” depends on a “disc rim in at or”, which is instead trained to distinguish samples of the generator from the real instances. SS-GANs (Salimans et al., 2016) are an extension to GANs where the disc rim in at or also assigns a category to each example while discriminating whether it was automatically generated or not.
一种有效的半监督方法是在半监督生成对抗网络 (SS-GANs) 中实现的。通常,在 GANs (Goodfellow et al., 2014) 中,"生成器"被训练用于生成与某些数据分布相似的样本。这一训练过程"对抗性"依赖于一个"判别器",后者则被训练用于区分生成器的样本与真实实例。SS-GANs (Salimans et al., 2016) 是 GANs 的扩展,其中判别器在判断样本是否为自动生成的同时,还会为每个样本分配一个类别。
In SS-GANs, the labeled material is thus used to train the disc rim in at or, while the unlabeled examples (as well as the ones automatically generated) improve its inner representations. In image processing, SS-GANs have been shown to be effective: exposed to few dozens of labeled examples (but thousands of unlabeled ones), they obtain performances competitive with fully supervised settings.
在SS-GAN中,标注数据用于训练判别器 (discriminator),而未标注样本(以及自动生成的样本)则用于提升其内部表征。在图像处理领域,SS-GAN已被证明具有显著效果:仅需接触数十个标注样本(但配合数千个未标注样本),其性能便可媲美全监督场景下的模型表现。
In this paper, we extend the BERT training with unlabeled data in a generative adversarial setting. In particular, we enrich the BERT fine-tuning process with an SS-GAN perspective, in the so-called GAN-BERT1 model. That is, a generator produces “fake” examples resembling the data distribution, while BERT is used as a disc rim in at or. In this way, we exploit both the capability of BERT to produce high-quality representations of input texts and to adopt unlabeled material to help the network in generalizing its representations for the final tasks. At the best of our knowledge, using SS-GANs in NLP has been investigated only by (Croce et al., 2019) with the so-called Kernel-based GAN. In that work, authors extend a Kernel-based Deep Architecture (KDA, (Croce et al., 2017)) with an SS-GAN perspective. Sentences are projected into low-dimensional embeddings, which approximate the implicit space generated by using a Semantic Tree Kernel function. However, it only marginally investigated how the GAN perspective could extend deep architecture for NLP tasks. In particular, a KGAN operates in a pre-computed embedding space by approximating a kernel function (Annesi et al., 2014). While the SS-GAN improves the quality of the Multi-layered Perceptron used in the KDA, it does not affect the input representation space, which is statically derived by the kernel space approximation. In the present work, all the parameters of the network are instead considered during the training process, in line with the SSGAN approaches.
本文提出了一种在生成对抗环境下利用无标注数据扩展BERT训练的方法。具体而言,我们在BERT微调过程中引入SS-GAN框架,构建了名为GAN-BERT1的模型。该模型通过生成器合成符合数据分布的"伪"样本,同时将BERT作为判别器使用。这种方法既发挥了BERT生成高质量文本表征的能力,又能利用无标注数据帮助网络泛化最终任务的表征能力。据我们所知,NLP领域仅有(Croce et al., 2019)通过基于核的GAN(Kernel-based GAN)探索过SS-GAN的应用。该研究在基于核的深度架构(KDA,(Croce et al., 2017))中引入SS-GAN视角,将句子投影到低维嵌入空间来近似语义树核函数生成的隐空间。但其对GAN如何扩展NLP深度架构的探索较为有限:KGAN通过近似核函数在预计算的嵌入空间中操作(Annesi et al., 2014),虽然SS-GAN提升了KDA中多层感知机的性能,但并未改变由核空间近似静态生成的输入表征空间。本研究则遵循SSGAN范式,在训练过程中优化网络全部参数。
We empirically demonstrate that the SS-GAN schema applied over BERT, i.e., GAN-BERT, reduces the requirement for annotated examples: even with less than 200 annotated examples it is possible to obtain results comparable with a fully supervised setting. In any case, the adopted semisupervised schema always improves the result obtained by BERT.
我们通过实验证明,基于BERT应用SS-GAN框架(即GAN-BERT)能降低对标注数据的需求:即使使用少于200个标注样本,仍可获得与全监督设置相当的结果。无论何种情况,采用的半监督框架始终能提升BERT的表现。
In the rest of this paper, section 2 provides an introduction to SS-GANs. In sections 3 and 4, GAN-BERT and the experimental evaluations are presented. In section 5 conclusions are derived.
在本文的其余部分中,第2节介绍了SS-GANs。第3节和第4节分别介绍了GAN-BERT和实验评估。第5节得出了结论。
2 Semi-supervised GANs
2 半监督生成对抗网络 (Semi-supervised GANs)
SS-GANs (Salimans et al., 2016) enable semi- supervised learning in a GAN framework. A discriminator is trained over a $(k+1)$ -class objective: “true” examples are classified in one of the target $(1,...,k)$ classes, while the generated samples are classified into the $k+1$ class.
SS-GANs (Salimans et al., 2016) 实现了GAN框架中的半监督学习。判别器通过一个 $(k+1)$ 类目标进行训练:真实样本被分类到目标 $(1,...,k)$ 类别之一,而生成的样本则被归类到第 $k+1$ 类。
More formally, let $\mathcal{D}$ and $\mathcal{G}$ denote the discriminator and generator, and $p_{d}$ and $p\boldsymbol{\mathscr{G}}$ denote the real data distribution and the generated examples, respectively. In order to train a semi-supervised $k$ -class classifier, the objective of $\mathcal{D}$ is extended as follows. Let us define $p_{m}(\hat{y}=y|x,y=k+1)$ the probability provided by the model $m$ that a generic example $x$ is associated with the fake class and $p_{m}(\hat{y}=y|x,y\in(1,...,k))$ that $x$ is considered real, thus belonging to one of the target classes. The loss function of $\mathcal{D}$ is defined as: LD = LDsup. + LDunsup. where:
更正式地说,令 $\mathcal{D}$ 和 $\mathcal{G}$ 分别表示判别器 (discriminator) 和生成器 (generator),$p_{d}$ 和 $p\boldsymbol{\mathscr{G}}$ 分别表示真实数据分布和生成样本分布。为了训练一个半监督的 $k$ 类分类器,$\mathcal{D}$ 的目标被扩展如下:定义 $p_{m}(\hat{y}=y|x,y=k+1)$ 为模型 $m$ 将样本 $x$ 判定为伪造类别的概率,$p_{m}(\hat{y}=y|x,y\in(1,...,k))$ 为 $x$ 被判定为真实样本(即属于某个目标类别)的概率。判别器 $\mathcal{D}$ 的损失函数定义为:LD = LDsup. + LDunsup. 其中:
$$
\begin{array}{c}{L_{\mathcal{D}_ {\mathrm{sup.}}=-\mathbb{E}_ {x,y\sim p_{d}}}\mathrm{log}\left[p_{\mathrm{m}}(\hat{y}=y|x,y\in(1,...,k))\right]}\ {L_{\mathcal{D}_{\mathrm{unsup.}}=-\mathbb{E}_{x\sim p_{d}}}\mathrm{log}\left[1-p_{\mathrm{m}}\left(\hat{y}=y|x,y=k+1\right)\right]}\ {-\mathbb{E}_ {x\sim\mathcal{G}}\mathrm{log}\left[p_{\mathrm{m}}(\hat{y}=y|x,y=k+1)\right]}\end{array}
$$
$$
\begin{array}{c}{L_{\mathcal{D}_ {\mathrm{sup.}}=-\mathbb{E}_ {x,y\sim p_{d}}}\mathrm{log}\left[p_{\mathrm{m}}(\hat{y}=y|x,y\in(1,...,k))\right]}\ {L_{\mathcal{D}_ {\mathrm{unsup.}}=-\mathbb{E}_ {x\sim p_{d}}}\mathrm{log}\left[1-p_{\mathrm{m}}\left(\hat{y}=y|x,y=k+1\right)\right]}\ {-\mathbb{E}_ {x\sim\mathcal{G}}\mathrm{log}\left[p_{\mathrm{m}}(\hat{y}=y|x,y=k+1)\right]}\end{array}
$$
$L_{\mathcal{D}_ {\mathrm{sup.}}}$ measures the error in assigning the wrong class to a real example among the original $k$ categories. $L_{D_{\mathrm{unsup}}}$ . measures the error in incorrectly recognizing a real (unlabeled) example as fake and not recognizing a fake example.
$L_{\mathcal{D}_ {\mathrm{sup.}}}$ 衡量在原始 $k$ 个类别中为真实样本分配错误类别的误差。$L_{D_{\mathrm{unsup}}}$ 衡量将真实(未标注)样本误判为伪造样本,以及未能识别伪造样本的误差。
At the same time, $\mathcal{G}$ is expected to generate examples that are similar to the ones sampled from the real distribution $p_{d}$ . As suggested in (Salimans et al., 2016), $\mathcal{G}$ should generate data approximating the statistics of real data as much as possible. In other words, the average example generated in a batch by $\mathcal{G}$ should be similar to the real prototypical one. Formally, let’s $f(x)$ denote the activation on an intermediate layer of $\mathcal{D}$ . The feature matching loss of $\mathcal{G}$ is then defined as:
同时,$\mathcal{G}$ 需要生成与从真实分布 $p_{d}$ 中采样的样本相似的示例。如 (Salimans et al., 2016) 所述,$\mathcal{G}$ 应尽可能生成接近真实数据统计特性的数据。换言之,$\mathcal{G}$ 在批次中生成的平均样本应与真实原型样本相似。形式上,设 $f(x)$ 表示 $\mathcal{D}$ 中间层的激活值,则 $\mathcal{G}$ 的特征匹配损失定义为:
$$
L_{G_{\mathrm{featurematching}}=\left|\left|\mathbb{E}_ {x}\sim p_{d}f(x)-\mathbb{E}_ {x}\sim\varsigma f(x)\right|\right|_{2}^{2}}
$$
$$
L_{G_{\mathrm{featurematching}}=\left|\left|\mathbb{E}_ {x}\sim p_{d}f(x)-\mathbb{E}_ {x}\sim\varsigma f(x)\right|\right|_{2}^{2}}
$$
that is, the generator should produce examples whose intermediate representations provided in input to $\mathcal{D}$ are very similar to the real ones. The $\mathcal{G}$ loss also considers the error induced by fake examples correctly identified by $\mathcal{D}$ , i.e.,
即生成器应产生这样的示例:其提供给判别器 $\mathcal{D}$ 的中间表示与真实样本高度相似。生成器 $\mathcal{G}$ 的损失还包含被 $\mathcal{D}$ 正确识别的伪造样本所导致的误差,也就是说,
$$
L_{{\mathcal{G}}_ {u n s u p.}}{=}{-}\mathbb{E}_ {x\sim{\mathcal{G}}}\log[1-p_{m}({\hat{y}}=y|x,y=k+1)]
$$
$$
L_{{\mathcal{G}}_ {u n s u p.}}{=}{-}\mathbb{E}_ {x\sim{\mathcal{G}}}\log[1-p_{m}({\hat{y}}=y|x,y=k+1)]
$$
The G loss is LG = LGfeature matching $L_{\mathcal{G}}=L_{\mathcal{G}_ {\mathrm{featurematching}}}+L_{\mathcal{G}_{u n s u p.}}$ .
G损失为LG = LG特征匹配 $L_{\mathcal{G}}=L_{\mathcal{G}_ {\mathrm{featurematching}}}+L_{\mathcal{G}_{u n s u p.}}$ 。
While SS-GANs are usually used with image inputs, we will show that they can be adopted in combination with BERT (Devlin et al., 2019) over inputs encoding linguistic information.
虽然SS-GAN通常用于图像输入,但我们将展示它们可以与BERT (Devlin et al., 2019)结合使用,处理编码语言信息的输入。
3 GAN-BERT: Semi-supervised BERT with Adversarial Learning
3 GAN-BERT: 基于对抗学习的半监督BERT
Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2019) belongs to the family of the so-called transfer learning methods, where a model is first pre-trained on general tasks and then fine-tuned on the final target tasks. In Computer Vision, transfer learning has been shown beneficial in many different tasks, i.e., pre-training a neural network model on a known task, followed by a fine-tuning stage on a (different) target task (see, for example, (Girshick et al., 2013)). BERT is a very deep model that is pre-trained over large corpora of raw texts and then is fine-tuned on target annotated data. The building block of BERT is the Transformer (Vaswani et al., 2017), an attentionbased mechanism that learns contextual relations between words (or sub-words, i.e., word pieces, (Schuster and Nakajima, 2012)) in a text.
基于Transformer的双向编码器表征 (BERT) (Devlin et al., 2019) 属于迁移学习方法家族,这类方法首先在通用任务上对模型进行预训练,然后在最终目标任务上进行微调。在计算机视觉领域,迁移学习已被证明对许多不同任务有益,即在已知任务上预训练神经网络模型,然后在(不同的)目标任务上进行微调阶段 (例如参见 (Girshick et al., 2013))。BERT是一个非常深的模型,它在大型原始文本语料库上进行预训练,然后在目标标注数据上进行微调。BERT的基本构建模块是Transformer (Vaswani et al., 2017),这是一种基于注意力的机制,用于学习文本中单词(或子词,即word pieces, (Schuster and Nakajima, 2012))之间的上下文关系。
BERT provides contextual i zed embeddings of the words composing a sentence as well as a sentence embedding capturing sentence-level semantics: the pre-training of BERT is designed to capture such information by relying on very large corpora. After the pre-training, BERT allows encoding (i) the words of a sentence, (ii) the entire sentence, and (iii) sentence pairs in dedicated embeddings. These can be used in input to further layers to solve sentence classification, sequence labeling or relational learning tasks: this is achieved by adding task-specific layers and by fine-tuning the entire architecture on annotated data.
BERT能够为句子中的单词提供上下文嵌入,同时也能捕捉句子层面的语义信息:其预训练过程依赖大规模语料库来捕获此类信息。预训练完成后,BERT可以对(i)句子中的单词、(ii)整句以及(iii)句子对进行专用嵌入编码。这些嵌入可作为后续层的输入,用于解决句子分类、序列标注或关系学习等任务:具体实现方式是通过添加任务特定层,并在标注数据上对整个架构进行微调。
In this work, we extend BERT by using SSGANs for the fine-tuning stage. We take an already pre-trained BERT model and adapt the fine-tuning by adding two components: i) task-specific layers, as in the usual BERT fine-tuning; ii) SS-GAN layers to enable semi-supervised learning. Without loss of generality, let us assume we are facing a sentence classification task over $k$ categories. Given an input sentence $s=(t_{1},...,t_{n})$ BERT produces in output $n+2$ vector representations in $R^{d}$ , i.e., $(h_{C L S},h_{t_{1}},...,h_{t_{n}},h_{S E P})$ . As suggested in (Devlin et al., 2019), we adopt the $h_{C L S}$ representation as a sentence embedding for the target tasks.
在本工作中,我们通过使用SSGANs对BERT进行微调阶段的扩展。我们采用一个已预训练的BERT模型,并通过添加两个组件来调整微调过程:i) 任务特定层,与常规BERT微调相同;ii) SS-GAN层以实现半监督学习。不失一般性,假设我们面临一个包含$k$个类别的句子分类任务。给定输入句子$s=(t_{1},...,t_{n})$,BERT会输出$n+2$个在$R^{d}$中的向量表示,即$(h_{C L S},h_{t_{1}},...,h_{t_{n}},h_{S E P})$。如(Devlin et al., 2019)所建议,我们采用$h_{C L S}$表示作为目标任务的句子嵌入。
As shown in figure 1, we add on top of BERT the SS-GAN architecture by introducing i) a discriminator $\mathcal{D}$ for classifying examples, and ii) a generator $\mathcal{G}$ acting adversarial ly. In particular, $\mathcal{G}$ is a Multi Layer Perceptron (MLP) that takes in input a 100-dimensional noise vector drawn from $N(\mu,\sigma^{2})$ and produces in output a vector $h_{f a k e}\in R^{d}$ . The disc rim in at or is another MLP that receives in input a vector $h_{ * }\in R^{d}$ ; $h_{*}$ can be either $\boldsymbol{h}_ {f a k e}$ produced by the generator or $h_{C L S}$ for unlabeled or labeled examples from the real distribution. The last layer of $\mathcal{D}$ is a softmax-activated layer, whose output is a $k+1$ vector of logits, as discussed in section 2.
如图 1 所示,我们在 BERT 基础上引入 SS-GAN 架构:i) 添加用于样本分类的判别器 $\mathcal{D}$,ii) 加入对抗操作的生成器 $\mathcal{G}$。具体而言,$\mathcal{G}$ 是一个多层感知机 (MLP),其输入为从 $N(\mu,\sigma^{2})$ 采样的 100 维噪声向量,输出为向量 $h_{f a k e}\in R^{d}$。判别器是另一个 MLP,其输入向量 $h_{*}\in R^{d}$ 可以是生成器产生的 $\boldsymbol{h}_ {f a k e}$,也可以是来自真实分布的未标注/已标注样本的 $h_{C L S}$。如第 2 节所述,$\mathcal{D}$ 的最后一层是 softmax 激活层,输出为 $k+1$ 维 logits 向量。
During the forward step, when real instances are sampled (i.e., $h_{ * }=h_{C L S},$ ), $\mathcal{D}$ should classify them in one of the $k$ categories; when $\begin{array}{r}{h_{*}=h_{f a k e}}\end{array}$ , it should classify each example in the $k+1$ category. As discussed in section 2, the training process tries to optimize two competing losses, i.e., $L_{D}$ and $L_{G}$ .
在前向步骤中,当采样到真实实例时(即 $h_{ * }=h_{C L S},$ ),$\mathcal{D}$ 应将其分类到 $k$ 个类别之一;当 $\begin{array}{r}{h_{*}=h_{f a k e}}\end{array}$ 时,则应将其分类到第 $k+1$ 个类别。如第2节所述,训练过程需要优化两个相互竞争的损失函数,即 $L_{D}$ 和 $L_{G}$。
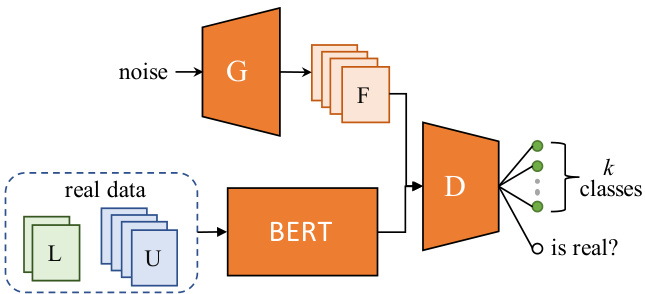
Figure 1: GAN-BERT architecture: $\mathcal{G}$ generates a set of fake examples F given a random distribution. These, along with unlabeled U and labeled $\mathrm{L}$ vector representations computed by BERT are used as input for the disc rim in at or $\mathcal{D}$ .
图 1: GAN-BERT架构:给定随机分布,$\mathcal{G}$生成一组伪样本F。这些伪样本与未标记数据U和已标记数据$\mathrm{L}$的BERT向量表示共同作为判别器$\mathcal{D}$的输入。
During back-propagation, the unlabeled examples contribute only to $L_{D_{u n s u p.}}$ , i.e., they are considered in the loss computation only if they are erroneously classified into the $k+1$ category. In all other cases, their contribution to the loss is masked out. The labeled examples thus contribute to the supervised loss $L_{D_{s u p.}}$ . Finally, the examples generated by $\mathcal{G}$ contribute to both $L_{D}$ and $L_{G}$ , i.e., $\mathcal{D}$ is penalized when not finding examples generated by $\mathcal{G}$ and vice-versa. When updating $\mathcal{D}$ , we also change the BERT weights in order to fine-tune its inner representations, so considering both the labeled and the unlabeled data2.
在反向传播过程中,未标注样本仅对 $L_{D_{u n s u p.}}$ 产生贡献,即只有当它们被错误分类至 $k+1$ 类别时才会参与损失计算。其余情况下,这些样本对损失的贡献会被屏蔽。标注样本则作用于监督损失 $L_{D_{s u p.}}$。最终,由 $\mathcal{G}$ 生成的样本会同时影响 $L_{D}$ 和 $L_{G}$,即当 $\mathcal{D}$ 未能识别 $\mathcal{G}$ 生成的样本时会受到惩罚,反之亦然。更新 $\mathcal{D}$ 时,我们也会调整 BERT 权重以微调其内部表征,从而同时利用标注和未标注数据[2]。
After training, $\mathcal{G}$ is discarded while retaining the rest of the original BERT model for inference. This means that there is no additional cost at inference time with respect to the standard BERT model. In the following, we will refer to this architecture as GAN-BERT.
训练完成后,$\mathcal{G}$ 被丢弃,同时保留原始 BERT 模型的其余部分用于推理。这意味着在推理时相对于标准 BERT 模型不会产生额外成本。在下文中,我们将此架构称为 GAN-BERT。
4 Experimental Results
4 实验结果
In this section, we assess the impact of GAN-BERT over sentence classification tasks characterized by different training conditions, i.e., number of examples and number of categories. We report measures of our approach to support the development of deep learning models when exposed to few labeled examples over the following tasks: Topic Classification over the 20 News Group (20N) dataset (Lang, 1995), Question Classification (QC) on the UIUC dataset (Li and Roth, 2006), Sentiment Analysis over the $S S\mathbb{T}-5$ dataset (Socher et al., 2013). We will also report the performances over a sentence pair task, i.e., over the MNLI dataset (Williams et al., 2018). For each task, we report the performances with the metric commonly used for that specific dataset, i.e., accuracy for $S S\mathbb{T}-5$ and QC, while F1 is used for 20N and MNLI datasets. As a comparison, we report the performances of the BERT-base model fine-tuned as described in (Devlin et al., 2019) on the available training material. We used BERT-base as the starting point also for the training of our approach. GAN-BERT is implemented in Tensorflow by extending the original BERT implementation 3.
在本节中,我们评估了GAN-BERT在不同训练条件(即样本数量和类别数量)下的句子分类任务中的表现。我们通过以下任务报告了该方法在少标签样本场景下对深度学习模型开发的支持效果:基于20 News Group (20N)数据集的主题分类(Lang, 1995)、UIUC数据集的问题分类(QC)(Li and Roth, 2006)、$S S\mathbb{T}-5$数据集的情感分析(Socher et al., 2013)。同时我们还报告了在句子对任务(即MNLI数据集(Williams et al., 2018))上的性能表现。针对每个任务,我们采用该数据集常用评估指标:$S S\mathbb{T}-5$和QC使用准确率,20N和MNLI使用F1值。作为对比,我们展示了BERT-base模型(Devlin et al., 2019)在相同训练数据上的微调结果。我们的方法同样以BERT-base为初始模型进行训练,GAN-BERT通过扩展原始BERT实现3在Tensorflow中完成部署。
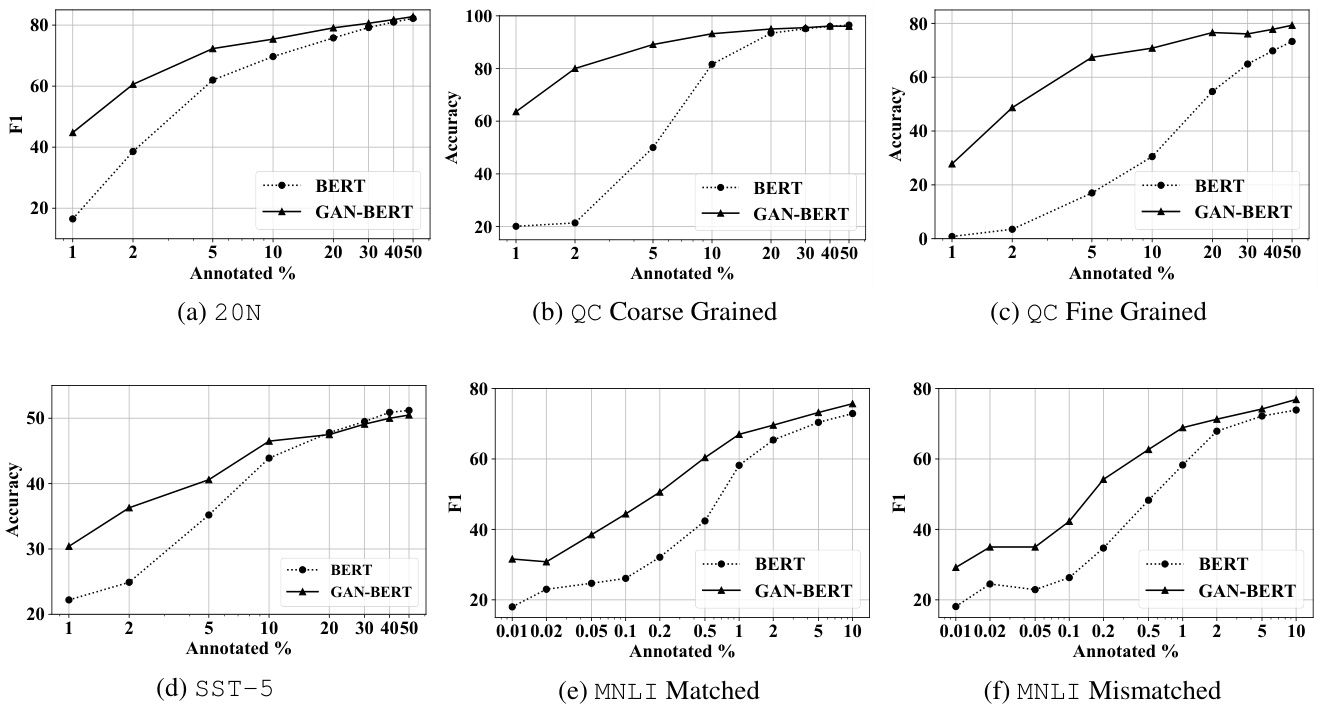
Figure 2: Learning curves for the six tasks. We run all the models for 3 epochs except for $_ {20\mathrm{N}}$ (15 epochs). The sequence length we used is: 64 for QC coarse, QC fine, and $S S\mathbb{T}-5$ ; 128 for both MNLI settings; 256 for $_{20\mathrm{N}}$ . Learning rate was set for all to 2e-5, except for $20\mathrm{N}$ (5e-6).
图 2: 六个任务的学习曲线。除 $_ {20\mathrm{N}}$ (15个周期) 外,所有模型均运行3个周期。使用的序列长度为:QC coarse、QC fine和 $S S\mathbb{T}-5$ 为64;两种MNLI设置为128;$_{20\mathrm{N}}$ 为256。除 $20\mathrm{N}$ (5e-6) 外,所有任务的学习率均设为2e-5。
In more detail, $\mathcal{G}$ is implemented as an MLP with one hidden layer activated by a leaky-relu function. $\mathcal{G}$ inputs consist of noise vectors drawn from a normal distribution $N(0,1)$ . The noise vectors pass through the MLP and finally result in 768-dimensional vectors, that are used as fake examples in our architecture. $\mathcal{D}$ is, also, an MLP with one hidden layer activated by a leaky-relu function followed by a softmax layer for the final prediction. For both $\mathcal{G}$ and $\mathcal{D}$ we used dropout $=0.1$ after the hidden layer. We repeated the training of each model with an increasing set of annotated material $(L)$ , starting by sampling only $0.01%$ or $1%$ of the training set, in order to measure the performances starting with very few labeled examples (about 50- 70 instances). GAN-BERT is also provided with a set of unlabeled examples $U$ coming from the unused annotated material for each training set sample $|U|=100|L|$ , when available). We replicated the labeled examples of a factor $l o g(|U|/|L|)$ : this guarantees the presence of some labeled instances in each batch to avoid divergences due to the unsupervised component of the adversarial training. All the reported results are averaged over 5 different shuffles of the training material.
具体来说,$\mathcal{G}$ 是一个带有单隐藏层的多层感知机 (MLP),采用 leaky-relu 函数激活。其输入为从正态分布 $N(0,1)$ 采样的噪声向量,这些向量经 MLP 处理后生成 768 维向量,作为我们架构中的伪造样本。$\mathcal{D}$ 同样为带单隐藏层的 MLP,使用 leaky-relu 激活函数,并通过 softmax 层进行最终预测。$\mathcal{G}$ 和 $\mathcal{D}$ 的隐藏层后均采用 $=0.1$ 的 dropout 率。
为测量极少量标注样本 (约 50-70 个实例) 下的性能,我们从仅采样训练集 $0.01%$ 或 $1%$ 开始,逐步增加标注材料 $(L)$ 的规模进行模型训练。GAN-BERT 还配备了来自未使用标注材料的无标签样本集 $U$ (当可用时,满足 $|U|=100|L|$)。我们将标注样本复制 $log(|U|/|L|)$ 倍,以确保每个批次都包含部分标注实例,避免对抗训练中无监督成分导致的发散问题。所有报告结果均为训练材料 5 次不同随机打乱后的平均值。
The $20\mathrm{N}$ classification results are shown in figure 2a. The training and testing datasets are made of 11, 314 and 7, 531 documents classified in 20 categories 4, respectively. The plot shows F1 scores of the models: when $1%$ of data is used (i.e., about 110 examples) BERT almost diverges while GAN-BERT achieves more than $40%$ of F1. This trend is confirmed until $40%$ of labeled documents are used (i.e., about 5, 000 examples).
20N分类结果如图2a所示。训练和测试数据集分别由11,314份和7,531份文档组成,这些文档被分为20个类别[4]。图中展示了模型的F1分数:当使用1%的数据时(即约110个样本),BERT几乎无法收敛,而GAN-BERT的F1分数超过了40%。这一趋势在使用40%标注文档时(即约5,000个样本)仍保持一致。
In the QC task we observe similar outcomes. The training dataset is made of about 5, 400 question. In the coarse-grained setting (figure 2b) 6 classes are involved; in the fine-grained scenario (figure 2c) the number of classes is 50. In both cases, BERT diverges when only $1%$ of labeled questions are used, i.e., about 50 questions. It starts to compensate when using about $20%$ of the data in the coarse setting (about 1, 000 labeled examples). In the fine-grained scenario, our approach is performing better until $50%$ of the labeled examples. It seems that, when a large number of categories is involved, i.e., the classification task is more complex, the semi-supervised setting is even more beneficial.
在QC任务中,我们观察到类似的结果。训练数据集由约5,400个问题组成。在粗粒度设置(图2b)中涉及6个类别;在细粒度场景(图2c)中类别数量为50。在这两种情况下,BERT仅使用$1%$的标注问题(约50个)时就会发散。在粗粒度设置中使用约$20%$的数据(约1,000个标注样本)时,它开始有所改善。在细粒度场景中,我们的方法在使用$50%$的标注样本之前表现更优。这表明,当涉及大量类别(即分类任务更复杂)时,半监督设置的优势更为明显。
The results are confirmed in sentiment analysis over the $S S\mathbb{T}-5$ dataset (figure 2d), i.e., sentence classification involving 5 polarity categories. Also in this setting, we observe that GAN-BERT is beneficial when few examples are available. This is demonstrated by the difference in accuracy at $1%$ of the data (about 85 labeled examples), where BERT accuracy is $22.2%$ while GAN-BERT reaches $30.4%$ in accuracy. This trend is confirmed until about $20%$ of labeled examples (about 1, 700), where BERT achieves comparable results.
结果在情感分析任务中得到了验证,该任务基于 $S S\mathbb{T}-5$ 数据集 (图 2d),即包含5种极性类别的句子分类。在此设置下,我们同样观察到当可用样本较少时,GAN-BERT具有优势。这一点通过使用 $1%$ 数据量(约85个标注样本)时的准确率差异得到证明:BERT准确率为 $22.2%$,而GAN-BERT达到 $30.4%$。这一优势趋势持续到约 $20%$ 标注样本量(约1,700个)时,此时BERT才能取得相当的结果。
Finally, we report the performances on Natural Language Inference on the MNLI dataset. We observe (in figures 2e and 2f) a systematic improvement starting from $0.01%$ labeled examples (about 40 instances): GAN-BERT provides about $6-10$ additional points in F1 with respect to BERT $18.09%$ vs. $29.19%$ and $18.01%$ vs. $31.64%$ , for mismatched and matched settings, respectively). This trend is confirmed until $0.5%$ of annotated material (about 2, 000 annotated examples): GAN-BERT reaches $62.67%$ and $60.45%$ while BERT reaches $48.35%$ and $42.41%$ , for mismatched and matched, respectively. Using more annotated data results in very similar performances with a slight advantage in using GAN-BERT. Even if acquiring unlabeled examples for sentence pairs is not trivial, these results give a hint about the potential benefits on similar tasks (e.g., questionanswer classification).
最后,我们报告了在MNLI数据集上进行自然语言推理的性能表现。我们观察到(如图2e和2f所示),从$0.01%$标注样本(约40个实例)开始出现系统性提升:在F1分数上,GAN-BERT相比BERT分别提升了$6-10$个百分点(不匹配设置下$18.09%$ vs. $29.19%$,匹配设置下$18.01%$ vs. $31.64%$)。这一趋势持续到标注数据达到$0.5%$(约2000个标注样本)时:在不匹配和匹配设置下,GAN-BERT分别达到$62.67%$和$60.45%$,而BERT为$48.35%$和$42.41%$。使用更多标注数据时两者性能非常接近,但GAN-BERT仍保持微弱优势。尽管获取句子对的未标注样本并非易事,这些结果仍暗示了该方法在类似任务(如问答分类)上的潜在优势。
5 Conclusion
5 结论
In this paper, we extended the limits of Transformed-based architectures (i.e., BERT) in poor training conditions. Experiments confirm that fine-tuning such architectures with few labeled examples lead to unstable models whose performances are not acceptable. We suggest here to adopt adversarial training to enable semisupervised learning Transformer-based architectures. The evaluations show that the proposed variant of BERT, namely GAN-BERT, systematically improves the robustness of such architectures, while not introducing additional costs to the inference. In fact, the generator network is only used in training, while at inference time only the discriminator is necessary.
本文突破了Transformer架构(如BERT)在训练条件不足时的性能极限。实验证实,仅用少量标注样本微调此类架构会导致模型不稳定且性能不佳。我们提出采用对抗训练来实现基于Transformer架构的半监督学习。评估表明,改进后的BERT变体(命名为GAN-BERT)能系统性提升架构鲁棒性,且不会增加推理成本。实际上生成器网络仅用于训练阶段,推理时仅需判别器即可。
This first investigation paves the way to several extensions including adopting other architectures, such as GPT-2 (Radford et al., 2019) or DistilBERT (Sanh et al., 2019) or other tasks, e.g., Sequence Labeling or Question Answering. Moreover, we will investigate the potential impact of the adversarial training directly in the BERT pre-training. From a linguistic perspective, it is worth investigating what the generator encodes in the produced representations.
这项初步研究为多项扩展工作铺平了道路,包括采用其他架构(如 GPT-2 [Radford et al., 2019] 或 DistilBERT [Sanh et al., 2019])或其他任务(例如序列标注或问答)。此外,我们将研究对抗训练在 BERT 预训练中的潜在影响。从语言学角度,值得探究生成器在所产生表征中编码了哪些信息。
Acknowledgments
致谢
We would like to thank Carlo Gaibisso, Bruno Luigi Martino and Francis Farrelly of the Istituto di Analisi dei Sistemi ed In format ica “Antonio Ruberti” (IASI) for supporting the early experimentations through access to dedicated computing resources made available by the Artificial Intelligence & High-Performance Computing laboratory.
我们要感谢Istituto di Analisi dei Sistemi ed Informatica "Antonio Ruberti" (IASI) 的Carlo Gaibisso、Bruno Luigi Martino和Francis Farrelly,他们通过人工智能与高性能计算实验室提供的专用计算资源支持了早期实验工作。
References
参考文献
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019. BERT:面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会人类语言技术会议论文集(长文与短文)》第1卷,第4171–4186页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Ross B. Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. 2013. Rich feature hierarchies for accurate object detection and semantic segmentation. CoRR, abs/1311.2524.
Ross B. Girshick、Jeff Donahue、Trevor Darrell 和 Jitendra Malik。2013. 用于精确目标检测和语义分割的丰富特征层次结构。CoRR, abs/1311.2524。
Yoav Goldberg. 2016. A primer on neural network models for natural language processing. J. Artif. Int. Res., 57(1):345–420.
Yoav Goldberg. 2016. 自然语言处理神经网络模型入门. J. Artif. Int. Res., 57(1):345–420.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc.
Ian Goodfellow、Jean Pouget-Abadie、Mehdi Mirza、Bing Xu、David Warde-Farley、Sherjil Ozair、Aaron Courville 和 Yoshua Bengio。2014. 生成对抗网络 (Generative Adversarial Nets)。见 Z. Ghahramani、M. Welling、C. Cortes、N. D. Lawrence 和 K. Q. Weinberger 编,《神经信息处理系统进展 27》,第 2672–2680 页。Curran Associates 公司。
Yoon Kim. 2014. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL, pages 1746–1751.
Yoon Kim. 2014. 基于卷积神经网络的句子分类. 载于《2014年自然语言处理经验方法会议论文集》(EMNLP 2014), 2014年10月25-29日, 卡塔尔多哈, ACL下属特殊兴趣小组SIGDAT主办, 第1746–1751页.
Yoon Kim, Yacine Jernite, David Sontag, and Alexander M. Rush. 2016. Character-aware neural language models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, February 12- 17, 2016, Phoenix, Arizona, USA., pages 2741– 2749.
Yoon Kim、Yacine Jernite、David Sontag 和 Alexander M. Rush。2016. 基于字符感知的神经语言模型。载于《第三十届AAAI人工智能会议论文集》,2016年2月12-17日,美国亚利桑那州凤凰城,第2741–2749页。
Thomas N. Kipf and Max Welling. 2016. Semisupervised classification with graph convolutional networks. CoRR, abs/1609.02907.
Thomas N. Kipf 和 Max Welling. 2016. 基于图卷积网络的半监督分类. CoRR, abs/1609.02907.
Ken Lang. 1995. Newsweeder: Learning to filter netnews. In Machine Learning Proceedings 1995, pages 331–339. Elsevier.
Ken Lang. 1995. Newsweeder: 网络新闻过滤学习。In Machine Learning Proceedings 1995, pages 331–339. Elsevier.
Xin Li and Dan Roth. 2006. Learning question classifiers: the role of semantic information. Natural Language Engineering, 12(3):229–249.
Xin Li 和 Dan Roth。2006。学习问题分类器:语义信息的作用。《自然语言工程》,12(3):229–249。
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. Technical report, OpenAI.
Alec Radford、Jeff Wu、Rewon Child、David Luan、Dario Amodei 和 Ilya Sutskever。2019。语言模型是无监督多任务学习者。技术报告,OpenAI。
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, Xi Chen, and Xi Chen. 2016. Improved techniques for training gans. In D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems 29, pages 2234–2242. Cur- ran Associates, Inc.
Tim Salimans、Ian Goodfellow、Wojciech Zaremba、Vicki Cheung、Alec Radford、Xi Chen和Xi Chen。2016. 改进训练GAN的技术。见D. D. Lee、M. Sugiyama、U. V. Luxburg、I. Guyon和R. Garnett编辑的《神经信息处理系统进展29》,第2234–2242页。Curran Associates公司。
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter. CoRR, abs/1910.01108.
Victor Sanh、Lysandre Debut、Julien Chaumond和Thomas Wolf。2019。DistilBERT(蒸馏版BERT):更小、更快、更经济、更轻量。CoRR, abs/1910.01108。
Mike Schuster and Kaisuke Nakajima. 2012. Japanese and korean voice search. In International Conference on Acoustics, Speech and Signal Processing, pages 5149–5152.
Mike Schuster和Kaisuke Nakajima。2012。日语和韩语语音搜索。载于《声学、语音与信号处理国际会议》,第5149–5152页。
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositional it y over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington, USA. Association for Computational Linguistics.
Richard Socher、Alex Perelygin、Jean Wu、Jason Chuang、Christopher D. Manning、Andrew Ng 和 Christopher Potts。2013. 基于情感树库的语义组合性递归深度模型。载于《2013年自然语言处理实证方法会议论文集》,第1631–1642页,美国华盛顿州西雅图。计算语言学协会。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanath an, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 5998–6008. Curran Associates, Inc.
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。2017。Attention is all you need。载于 I. Guyon、U. V. Luxburg、S. Bengio、H. Wallach、R. Fergus、S. Vishwanathan 和 R. Garnett 编,《神经信息处理系统进展 30》,第 5998–6008 页。Curran Associates 公司。
Jason Weston, Frédéric Ratle, and Ronan Collobert. 2008. Deep learning via semi-supervised embedding. In Proceedings of the 25th International Conference on Machine Learning, ICML $\ '_{08}$ , pages 1168–1175, New York, NY, USA. ACM.
Jason Weston、Frédéric Ratle 和 Ronan Collobert。2008. 通过半监督嵌入进行深度学习。见《第25届国际机器学习会议论文集》(ICML '08),第1168–1175页,美国纽约州纽约市。ACM。
Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics.
Adina Williams、Nikita Nangia 和 Samuel Bowman。2018. 面向广泛覆盖的句子理解推理挑战语料库。载于《2018年北美计算语言学协会人类语言技术会议论文集》第1卷(长论文),第1112–1122页。计算语言学协会。
Zhilin Yang, William W. Cohen, and Ruslan Salakhutdinov. 2016. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, pages 40–48. JMLR.org.
Zhilin Yang、William W. Cohen 和 Ruslan Salakhutdinov。2016。基于图嵌入的半监督学习再探索。载于《第33届国际机器学习会议论文集》第48卷,ICML'16,第40-48页。JMLR.org。