Investigating the Effects of Sparse Attention on Cross-Encoders
探究稀疏注意力对交叉编码器的影响
Ferdinand Schlatt, Maik Frobe, and Matthias Hagen
Ferdinand Schlatt, Maik Frobe, Matthias Hagen
Friedrich-Schiller-Universit t Jena
弗里德里希·席勒大学耶拿
Abstract Cross-encoders are effective passage and document re-rankers but less efficient than other neural or classic retrieval models. A few previous studies have applied windowed self-attention to make crossencoders more efficient. However, these studies did not investigate the potential and limits of different attention patterns or window sizes. We close this gap and systematically analyze how token interactions can be reduced without harming the re-ranking effectiveness. Experimenting with asymmetric attention and different window sizes, we find that the query tokens do not need to attend to the passage or document tokens for effective re-ranking and that very small window sizes suffice. In our experiments, even windows of 4 tokens still yield effectiveness on par with previous cross-encoders while reducing the memory requirements by at least $22%\mathrm{/}59%$ and being $1%%43%$ faster at inference time for passages / documents. Our code is publicly available.1
摘要
交叉编码器(Cross-encoder)是高效的段落和文档重排序器,但效率低于其他神经或经典检索模型。先前少数研究尝试通过窗口自注意力机制提升交叉编码器效率,但未深入探究不同注意力模式与窗口尺寸的潜力边界。本研究填补这一空白,系统分析如何在保持重排序效果的前提下减少token交互。通过非对称注意力与多窗口尺寸实验,我们发现:查询token无需关注文档token即可实现有效重排序,且极小窗口尺寸已足够。实验表明,仅4个token的窗口仍能保持与传统交叉编码器相当的效果,同时内存需求降低22%~59%,段落/文档推理速度提升1%~43%。代码已开源。
Keywords: Cross-encoder $\cdot$ Re-ranking $\cdot$ Windowed attention $\cdot$ Cross-attention
关键词:交叉编码器 (Cross-encoder) $\cdot$ 重排序 (Re-ranking) $\cdot$ 窗口注意力 (Windowed attention) $\cdot$ 交叉注意力 (Cross-attention)
1 Introduction
1 引言
Pre-trained transformer-based language models (PLMs) are important components of modern retrieval and re-ranking pipelines as they help to mitigate the vocabulary mismatch problem of lexical systems [61, 84]. Especially cross-encoders are effective [52, 55, 57, 81] but less efficient than bi-encoders or other classic machine learning-based approaches with respect to inference run time, memory footprint, and energy consumption [68]. The run time issue is particularly problematic for practical applications as searchers often expect results after a few hundred milliseconds [2]. To increase the efficiency but maintain the effectiveness of cross-encoders, previous studies have, for instance, investigated reducing the number of token interactions by applying sparse attention patterns [44, 70].
基于Transformer的预训练语言模型(PLM)是现代检索与重排序流程的关键组成部分,它们能有效缓解词法系统的词汇不匹配问题[61, 84]。特别是交叉编码器(cross-encoder)展现出卓越效果[52, 55, 57, 81],但在推理耗时、内存占用和能耗方面,其效率低于双编码器(bi-encoder)或其他经典机器学习方法[68]。对于实际应用场景,运行时间问题尤为突出,因为用户通常期望在几百毫秒内获得结果[2]。为提升交叉编码器效率同时保持其效果,先前研究探索了多种方案,例如通过应用稀疏注意力模式来减少token交互次数[44, 70]。
Sparse attention PLMs restrict the attention of most tokens to local windows, thereby reducing token interactions and improving efficiency [72]. Which tokens have local attention is a task-specific decision. For instance, cross-encoders using the Longformer model [3] apply normal global attention to query tokens but local attention to document tokens. The underlying idea is that a document token does not require the context of the entire document to determine whether it is relevant to a query—within a document, most token interactions are unnecessary, and a smaller context window suffices (cf. Figure 1 (b) for a visualization).
稀疏注意力预训练语言模型(PLM)通过将大多数token的注意力限制在局部窗口内,从而减少token交互并提升效率[72]。哪些token采用局部注意力是任务相关的决策。例如,使用Longformer模型[3]的交叉编码器对查询token采用常规全局注意力,而对文档token采用局部注意力。其核心思想是:文档token不需要整个文档的上下文来判断其与查询的相关性——在文档内部,大多数token交互是不必要的,较小的上下文窗口就已足够(可视化效果参见图1(b))。
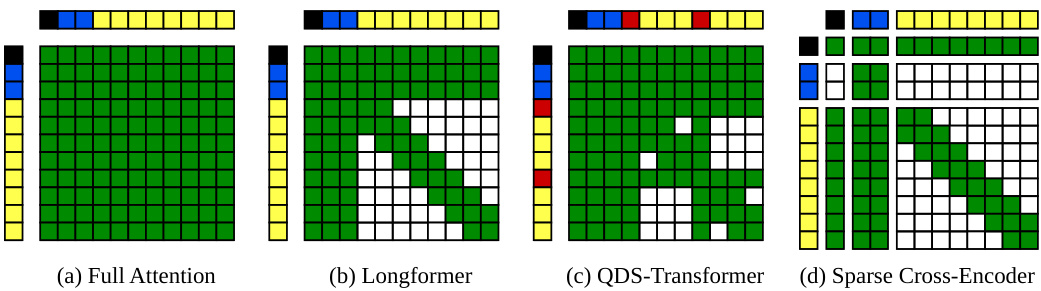
Figure 1: Previous cross-encoder attention patterns (a, b, and c) and our newly proposed sparse cross-encoder (d). The marginal boxes denote input tokens (black: [CLS], blue: query, yellow: passage / document, red: start of sentence). The inner green boxes indicate token attention. Our new pattern considers the sub-sequences separately (indicated by the added spacing) and is asymmetric.
图 1: 传统交叉编码器注意力模式 (a、b、c) 与我们新提出的稀疏交叉编码器 (d)。外框表示输入token (黑色: [CLS], 蓝色: 查询语句, 黄色: 段落/文档, 红色: 句子起始符)。内部绿色框表示token注意力机制。我们的新范式采用非对称设计,并对子序列进行分离处理 (通过间距示意)。
Previously, sparse attention has been applied to cross-encoders to be able to re-rank long documents without cropping or splitting them [44, 70]. However, the impact of sparsity on effectiveness has not been investigated in detail. To close this gap, we explore the limits of sparse cross-encoders and try to clarify which token interactions are (un)necessary. As mechanisms to reduce token interactions, we investigate local attention window sizes and disabling attention between sub-sequences (e.g., between the query and the passage or document). Our analyses are based on the following two assumptions.
此前,稀疏注意力 (sparse attention) 已被应用于交叉编码器 (cross-encoders) ,使其能够在不截断或分割的情况下对长文档进行重排序 [44, 70] 。然而,稀疏性对效果的影响尚未得到详细研究。为填补这一空白,我们探索了稀疏交叉编码器的极限,并试图厘清哪些 token 交互是(非)必要的。作为减少 token 交互的机制,我们研究了局部注意力窗口大小以及禁用子序列间(例如查询与段落或文档之间)的注意力。我们的分析基于以下两个假设。
(1) Cross-encoders create contextual i zed embeddings that encode query and passage or document semantics. We hypothesize that the contextual i zed embeddings of passage or document tokens do not actually need to encode fine-grained semantics. Rather, an overall “gist” in the form of small local context windows is sufficient to estimate relevance well.
(1) 交叉编码器 (Cross-encoders) 会生成上下文嵌入,用于编码查询与段落或文档的语义。我们假设段落或文档 token 的上下文嵌入实际上无需编码细粒度语义,仅需通过小型局部上下文窗口形成的整体"主旨"即可有效估算相关性。
(2) Cross-encoders allow queries and documents to exchange information via symmetric attention. We hypothesize that full symmetry is unnecessary as we view the query–document relevance relationship as asymmetric: for ranking, it should suffice to determine whether a result is relevant to a query, not vice versa. To further reduce token interactions, we propose a novel configurable asymmetric cross-attention pattern with varying amounts of interaction between [CLS], query, and passage or document tokens (cf. Figure $1(\mathrm{d})$ ).
(2) 交叉编码器 (cross-encoders) 允许查询和文档通过对称注意力机制交换信息。我们认为完全对称是不必要的,因为查询-文档的相关性关系本质上是非对称的:对于排序任务,只需判断结果是否与查询相关,反之则无必要。为了进一步减少 token 交互,我们提出了一种新颖的可配置非对称交叉注意力模式,其中 [CLS]、查询、段落或文档 token 之间的交互程度各不相同 (参见图 $1(\mathrm{d})$ )。
In experiments on re-ranking tasks from the TREC Deep Learning tracks [26– 29] and the TIREx benchmark [36], our new model’s effectiveness is consistently on par with previous (sparse) cross-encoder models, even with a local window size of only four tokens and asymmetric attention. Further efficiency analyses for sequences with 174 / 4096 tokens show that our spars if i cation techniques reduce the memory requirements by at least 22% / 59% and yield inference times that are at least 1% / 43% faster.
在TREC深度学习赛道[26–29]和TIREx基准测试[36]的重新排序任务实验中,即使仅使用四个token的局部窗口和不对称注意力机制,我们新模型的效果始终与之前的(稀疏)交叉编码器模型相当。针对174/4096个token序列的进一步效率分析表明,我们的稀疏化技术将内存需求降低了至少22%/59%,并使推理速度提升了至少1%/43%。
2 Related Work
2 相关工作
One strategy for using PLMs in ranking is to separate the encoding of queries and documents (or passages) [45, 46, 61, 67]. Such bi-encoder models are efficient retrievers as the document encodings can be indexed, so only the query needs to be encoded at retrieval time. However, the good efficiency of bi-encoders comes at reduced effectiveness compared to cross-encoders [40], especially in out-of-domain scenarios [66]. Consequently, bi-encoders are often used for firststage retrieval, while the more effective but less efficient cross-encoders serve as second-stage re-rankers [52, 55, 57, 81]. We focus on improving the efficiency of cross-encoders while maintaining their effectiveness.
在排序任务中使用预训练语言模型 (PLM) 的一种策略是将查询和文档 (或段落) 的编码分开处理 [45, 46, 61, 67]。这种双编码器模型 (bi-encoder) 作为检索器非常高效,因为文档编码可以被索引化,检索时只需对查询进行编码。然而,与交叉编码器 (cross-encoder) 相比 [40],双编码器的高效性是以降低效果为代价的,尤其是在域外场景中 [66]。因此,双编码器通常用于第一阶段的检索,而效果更好但效率较低的交叉编码器则作为第二阶段的重新排序器 [52, 55, 57, 81]。我们专注于在保持交叉编码器效果的同时提高其效率。
One strategy to make cross-encoders more efficient is to reduce the model size via knowledge distillation [41, 42, 50]. During knowledge distillation, a smaller and more efficient model aims to mimic a larger “teacher” model. The distilled models can often match the effectiveness of the teacher model at only a fraction of the computational costs [79], indicating that PLMs can be “over parameterized” for re-ranking [40]. We follow a similar idea and try to reduce token interactions in cross-encoders using sparse attention techniques to substantially lower computational costs at comparable effectiveness.
提升交叉编码器效率的一种策略是通过知识蒸馏 (knowledge distillation) [41, 42, 50] 缩小模型规模。在知识蒸馏过程中,更小更高效的模型会尝试模仿较大的"教师"模型。蒸馏后的模型通常能以教师模型几分之一的计算成本达到相近的效果 [79],这表明预训练语言模型 (PLM) 在重排序任务中可能存在"参数过量"问题 [40]。我们采用类似思路,尝试通过稀疏注意力技术减少交叉编码器的token交互,从而在保持效果相当的前提下显著降低计算成本。
Previously, sparse attention PLMs aimed to increase the process able input length [72]. Instead of full attention across the entire input, a sparse PLM restricts attention to neighboring tokens. For instance, the Sparse Transformer [12] uses a block-sparse kernel, splitting the input into small blocks where tokens only attend to tokens in their block. Additional strided attention allows for attention between blocks. The Longformer [3], BigBird [83], and ETC [1] use a different approach. Tokens can attend to a fixed window of neighboring tokens, with additional global attention tokens that can attend to the entire sequence.
此前,稀疏注意力预训练语言模型 (PLM) 旨在提升可处理输入长度 [72]。与对整个输入进行全局注意力不同,稀疏 PLM 将注意力限制在相邻 token 上。例如,Sparse Transformer [12] 采用块稀疏核 (block-sparse kernel),将输入分割为小块,使 token 仅关注其所在块内的 token。通过额外的跨步注意力 (strided attention) 实现块间注意力交互。Longformer [3]、BigBird [83] 和 ETC [1] 则采用不同策略:token 可关注固定窗口内的邻近 token,同时设置能关注整个序列的全局注意力 token。
For efficient windowed self-attention, the Longformer, BigBird, and ETC use block-sparse matrices. However, block-sparse techniques often make concessions on the flexibility of window sizes or incur additional overhead that does not affect the resulting predictions. We compare several previously proposed windowed selfattention implementations and find them inefficient in terms of time or space compared to the reduction in operations. Therefore, we implement a custom CUDA kernel and compare it to other implementations (cf. Section 4.2).
为实现高效的窗口化自注意力机制,Longformer、BigBird和ETC采用了块稀疏矩阵技术。然而,块稀疏方法通常需要牺牲窗口尺寸的灵活性,或引入不影响最终预测结果的额外开销。我们对比了先前提出的多种窗口化自注意力实现方案,发现其在时间或空间效率上相比计算量减少的收益并不理想。为此,我们实现了定制化的CUDA内核,并与其他实现方案进行对比(参见第4.2节)。
Sparse attention PLMs have also been applied to document re-ranking. For example, the Longformer without global attention was used as a cross-encoder to re-rank long documents [70]. However, effectiveness was not convincing as later-appearing document tokens were unable to attend to query tokens. The QDS-Transformer [44] fixed this problem by correctly applying global attention to query tokens and achieved better retrieval effectiveness than previous crossencoder strategies that split documents [30, 82]. While the QDS-Transformer was evaluated with different window sizes, the effectiveness results were inconclusive. A model fine-tuned on a window size of 64 tokens was tested with smaller (down to 16 tokens) and larger window sizes (up to 512)—always yielding worse effectiveness. We hypothesize that models specifically fine-tuned for smaller window sizes will be as effective as models fine-tuned for larger window sizes.
稀疏注意力预训练语言模型 (PLM) 也被应用于文档重排序。例如,不带全局注意力的 Longformer 被用作交叉编码器对长文档进行重排序 [70]。但由于文档后部 token 无法关注查询 token,其效果并不理想。QDS-Transformer [44] 通过正确地对查询 token 应用全局注意力解决了这个问题,其检索效果优于之前采用文档分割策略的交叉编码器方法 [30, 82]。虽然 QDS-Transformer 在不同窗口尺寸下进行了评估,但效果结果并不明确。使用 64 token 窗口微调的模型在更小(低至 16 token)和更大(高达 512)窗口测试时,效果始终更差。我们推测:专门针对较小窗口微调的模型,其效果将与针对较大窗口微调的模型相当。
Besides analyzing models fine-tuned for different window sizes, we hypothesize that token interactions between some input sub-sequences are unnecessary. For example, bi-encoder models show that independent contextual iz ation of query and document tokens can be effective [45, 46, 61, 67]. However, the symmetric attention mechanisms of previous sparse PLM architectures do not accommodate asymmetric attention patterns. We develop a new cross-encoder variant that combines windowed self-attention from sparse PLMs with asymmetric cross-attention. Cross-attention allows a sequence to attend to an arbitrary other sequence and is commonly used in transformer architectures for machine translation [73], computer vision [35, 59, 71], and in multi-modal settings [43].
除了分析针对不同窗口大小进行微调的模型外,我们假设某些输入子序列之间的token交互是不必要的。例如,双编码器模型表明,查询和文档token的独立上下文化可能有效 [45, 46, 61, 67]。然而,先前稀疏PLM架构的对称注意力机制无法适应非对称注意力模式。我们开发了一种新的交叉编码器变体,将稀疏PLM的窗口自注意力与非对称交叉注意力相结合。交叉注意力允许一个序列关注任意其他序列,并常用于机器翻译 [73]、计算机视觉 [35, 59, 71] 以及多模态场景 [43] 的Transformer架构中。
3 Sparse Asymmetric Attention Using Cross-Encoders
3 基于交叉编码器的稀疏非对称注意力机制
We propose a novel sparse asymmetric attention pattern for re-ranking documents (and passages) with cross-encoders. Besides combining existing windowed self-attention and cross-attention ideas, our pattern also flexibly allows for asymmetric query–document interactions (e.g., allowing a document to attend to the query but not vice versa). To this end, we partition the input sequence into the [CLS] token, query tokens, and document tokens, with customizable attention between these groups and local attention windows around document tokens.
我们提出了一种新颖的稀疏非对称注意力模式,用于通过交叉编码器对文档(及段落)进行重排序。该模式不仅融合了现有的窗口化自注意力和交叉注意力思想,还能灵活支持非对称的查询-文档交互(例如允许文档关注查询,但反之则不行)。为此,我们将输入序列划分为[CLS]标记、查询标记和文档标记,并支持这些分组之间的可定制注意力机制,同时在文档标记周围设置局部注意力窗口。
Figure 1 depicts our and previous cross-encoder attention patterns. In full attention, each token can attend to every other token. Instead, Longformerbased cross-encoders apply windowed self-attention to document tokens to which the QDS-Transformer adds global attention tokens per sentence. Our pattern is similar to the Longformer but deactivates attention from query tokens to [CLS] and document tokens. But, [CLS] and document tokens still have access to query tokens. Our hypothesis is that cross-encoders do not need symmetric query–document attention for re-ranking as a one-sided relationship suffices.
图 1: 展示了我们与先前交叉编码器 (cross-encoder) 的注意力模式。在全注意力 (full attention) 中,每个 Token 可关注其他所有 Token。而基于 Longformer 的交叉编码器对文档 Token 采用窗口化自注意力 (windowed self-attention),QDS-Transformer 在此基础上为每个句子添加全局注意力 Token。我们的模式与 Longformer 类似,但禁用了从查询 Token 到 [CLS] 和文档 Token 的注意力。不过,[CLS] 和文档 Token 仍可访问查询 Token。我们的假设是:重排序任务中交叉编码器不需要对称的查询-文档注意力机制,单向关系已足够。
3.1 Preliminaries
3.1 预备知识
The transformer encoder internally uses a dot-product attention mechanism [73]. For a single transformer layer, three separate linear transformations map the embedding matrix $O^{\prime}$ of the previous layer to three vector-lookup matrices $Q$ , $K$ , and $V$ . An $s\times s$ attention probability matrix that contains the probabilities of a token attending to another is obtained by softmaxing the $\sqrt{h}$ - normalized product $Q K^{T}$ . The attention probabilities are then used as weights for the vector-lookup matrix $V$ to obtain the layer’s output embedding matrix:
Transformer编码器内部采用了点积注意力机制[73]。对于单个Transformer层,通过三个独立的线性变换将前一层的嵌入矩阵$O^{\prime}$映射为三个向量查找矩阵$Q$、$K$和$V$。通过将$\sqrt{h}$归一化后的乘积$Q K^{T}$进行softmax运算,可得到一个$s\times s$的注意力概率矩阵,该矩阵包含了一个token关注另一个token的概率。随后,这些注意力概率被用作向量查找矩阵$V$的权重,以获取该层的输出嵌入矩阵:
$$
{\cal O}=\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{Q K^{T}}{\sqrt{h}}\right)V.
$$
$$
{\cal O}=\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{Q K^{T}}{\sqrt{h}}\right)V.
$$
3.2 Windowed Self-Attention
3.2 窗口自注意力 (Windowed Self-Attention)
Windowed self-attention was proposed for more efficient sparse PLM architectures [1, 3, 83]. The idea is that a token does not attend to the entire input sequence of length $s$ , but only to a local window of $w$ tokens, with $w\ll s$ (e.g., $w=4$ means that a token attends to $2\cdot4+1$ tokens: to the 4 tokens before itself, to itself, and to the 4 tokens after itself). For a window size $w$ , windowed self-attention changes the dot-products of the transformer attention mechanism to windowed variants $\boxdot$ and $\odot_{w}$ :
窗口自注意力 (windowed self-attention) 被提出用于更高效的稀疏PLM架构 [1, 3, 83]。其核心思想是:一个token不需要关注长度为$s$的整个输入序列,而只需关注包含$w$个token的局部窗口 (其中$w\ll s$,例如$w=4$表示一个token会关注$2\cdot4+1$个token:自身之前的4个token、自身以及自身之后的4个token)。对于窗口大小$w$,窗口自注意力将transformer注意力机制的点积运算替换为窗口化变体$\boxdot$和$\odot_{w}$:
$$
\begin{array}{l}{{\displaystyle{\cal O}=\mathrm{Attention}_ {w}(Q,K,V)=\mathrm{softmax}\left(\frac{Q\boxdot{\Xi}_ {w}K^{T}}{\sqrt{h}}\right)\odot_{w}V,\mathrm{with}~}}\ {{\displaystyle Q_{(s\times h)}\boxdot{\Xi}_ {w}K_{(h\times s)}^{T}\to A_{(s\times2w+1)},\quad\mathrm{where}a_{i,j}=\sum_{l=1}^{h}q_{i,l}\cdot k_{l,i+j-w-1},}}\ {{\displaystyle\qquad\quad}}\ {{P_{(s\times2w+1)}\odot_{w}V_{(s\times h)}\to{\cal O}_ {(s\times h)},\qquad\mathrm{where}o_{i,l}=\sum_{j=1}^{2w+1}p_{i,j}\cdot v_{i+j-w-1,l}.}}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle{\cal O}=\mathrm{Attention}_ {w}(Q,K,V)=\mathrm{softmax}\left(\frac{Q\boxdot{\Xi}_ {w}K^{T}}{\sqrt{h}}\right)\odot_{w}V,\mathrm{with}~}}\ {{\displaystyle Q_{(s\times h)}\boxdot{\Xi}_ {w}K_{(h\times s)}^{T}\to A_{(s\times2w+1)},\quad\mathrm{where}a_{i,j}=\sum_{l=1}^{h}q_{i,l}\cdot k_{l,i+j-w-1},}}\ {{\displaystyle\qquad\quad}}\ {{P_{(s\times2w+1)}\odot_{w}V_{(s\times h)}\to{\cal O}_ {(s\times h)},\qquad\mathrm{where}o_{i,l}=\sum_{j=1}^{2w+1}p_{i,j}\cdot v_{i+j-w-1,l}.}}\end{array}
$$
Thus, $\left\vert\cdot\right\vert_{w}$ outputs a band matrix subset of the standard matrix–matrix multiplication, stored in a space-efficient form (non-band entries omitted), and $\odot_{w}$ multiplies a space-efficiently stored band matrix and a standard matrix. To ensure correctness, we zero-pad windows exceeding the sequence bounds: when either $i+j-w\le0$ or $i+j-w>s$ , we set $k_{l,i+j-w-1}=v_{i+j-w-1,l}=0$ .
因此,$\left\vert\cdot\right\vert_{w}$ 输出标准矩阵乘法的带状矩阵子集,并以节省空间的形式存储(非带状条目被省略),而 $\odot_{w}$ 则将节省空间存储的带状矩阵与标准矩阵相乘。为确保正确性,我们对超出序列边界的窗口进行零填充:当 $i+j-w\le0$ 或 $i+j-w>s$ 时,设 $k_{l,i+j-w-1}=v_{i+j-w-1,l}=0$。
For a visual impression of windowed attention, consider the lower right document-to-document attention matrix in Figure $1(\mathrm{d})$ . Only the diagonal band is computed: in Figure $1(\mathrm{d})$ for $w=1$ .
为了直观感受窗口注意力机制,请观察图 1(d) 右下角的文档间注意力矩阵。仅计算对角带状区域:在图 1(d) 中对应 $w=1$ 的情况。
Compared to full self-attention, in theory, windowed self-attention reduces the space complexity from $\mathcal{O}(s^{2})$ to $\mathcal{O}(s\cdot(2w+1))$ and the (naive) computa tional complexity from $\mathcal{O}(s^{2}\cdot h)$ to $\mathcal{O}(s\cdot(2w+1)\cdot h)$ . However, fully achieving these improvements is difficult in practice. Previous windowed self-attention imple ment at ions avoided writing hardware-specific kernels and made concessions regarding flexibility, time efficiency, or space efficiency [3, 83]. Therefore, we implement our own CUDA kernel for windowed self-attention; Section 4.2 compares our implementation’s efficiency to previous implementations.
与全自注意力机制相比,理论上窗口自注意力将空间复杂度从 $\mathcal{O}(s^{2})$ 降至 $\mathcal{O}(s\cdot(2w+1))$ ,并将(朴素)计算复杂度从 $\mathcal{O}(s^{2}\cdot h)$ 降至 $\mathcal{O}(s\cdot(2w+1)\cdot h)$ 。然而实践中完全实现这些改进存在困难。先前的窗口自注意力实现方案为避免编写硬件专用内核,在灵活性、时间效率或空间效率上做出了妥协 [3, 83]。因此我们实现了自研的窗口自注意力CUDA内核,第4.2节将我们的实现效率与先前方案进行对比。
3.3 Cross-Attention
3.3 交叉注意力 (Cross-Attention)
Cross-attention is a type of attention where a token sequence does not attend to itself, as in self-attention, but to a different sequence. We use cross-attention to configure attention between different token types. Instead of representing a crossencoder’s input as a single sequence, we split it into three disjoint sub sequences: the [CLS] token, the query tokens, and the document tokens (Figure 1 (d) visually represents this for our proposed pattern by splitting the marginal vectors; the [SEP] tokens are part of “their” respective sub sequence). Each sub sequence can then have its own individual attention function Attention $(Q,K,V)$ .
交叉注意力 (cross-attention) 是一种注意力机制,其中 token 序列不像自注意力那样关注自身,而是关注另一个不同的序列。我们使用交叉注意力来配置不同 token 类型之间的注意力关系。与将交叉编码器输入表示为单一序列不同,我们将其拆分为三个互不相交的子序列:[CLS] token、查询 token 和文档 token (图 1(d) 通过分割边缘向量直观展示了我们提出的模式;[SEP] token 属于它们各自对应的子序列)。每个子序列都可以拥有独立的注意力函数 Attention $(Q,K,V)$。
We split the vector-lookup matrices column-wise into [CLS], query, and document token-specific sub matrices $Q_{c}$ , $Q_{q}$ , $Q_{d}$ , etc. These matrices are precomputed and shared between the different attention functions for efficiency. Restricting attention between sub sequences then means to call the attention function for a sub sequence’s $Q$ -matrix and the respective $K$ - and $V$ -matrices of the attended-to sub sequences. For example, to let a document attend to itself and the query, the function call is $\mathrm{Attention}(Q_{d},[K_{q},K_{d}],[V_{q},V_{d}])$ , where $[\cdot,\cdot]$ denotes matrix concatenation by columns (i.e., $[M,M^{\prime}]$ yields a matrix whose “left” columns come from $M$ and the “right” columns from $M^{\prime}$ ).
我们将向量查找矩阵按列分割为[CLS]、查询和文档token特定的子矩阵$Q_{c}$、$Q_{q}$、$Q_{d}$等。为提高效率,这些矩阵会预先计算并在不同注意力函数间共享。限制子序列间的注意力意味着调用某个子序列的$Q$矩阵与被关注子序列对应的$K$和$V$矩阵的注意力函数。例如,若要让文档关注自身及查询,函数调用为$\mathrm{Attention}(Q_{d},[K_{q},K_{d}],[V_{q},V_{d}])$,其中$[\cdot,\cdot]$表示按列拼接矩阵(即$[M,M^{\prime}]$生成的矩阵其"左侧"列来自$M$,"右侧"列来自$M^{\prime}$)。
3.4 Locally Windowed Cross-Attention
3.4 局部窗口化交叉注意力 (Locally Windowed Cross-Attention)
The above-described cross-attention mechanism using concatenation is not directly applicable in our case, as we want to apply windowed self-attention to document tokens and asymmetric attention to query tokens. Instead of concatenating the matrices $K$ and $V$ , our mechanism uses tuples $\mathcal{N}$ and $\nu$ of matrices and a tuple $\mathcal{W}$ of window sizes to assign different attention window sizes $w\in\mathcal{W}$ to each attended-to sub sequence. As a result, we can combine windowed selfattention with asymmetric attention based on token types. Formally, given $j$ - tuples $\mathcal{N}$ and $\nu$ of matrices $K_{i}$ and $V_{i}$ and a $j$ -tuple $\mathcal{W}$ of window sizes $w_{i}$ , our generalized windowed cross-attention mechanism works as follows:
上述使用拼接操作的交叉注意力机制并不直接适用于我们的场景,因为我们需要对文档token应用窗口化自注意力,而对查询token实施非对称注意力。我们的机制不拼接矩阵$K$和$V$,而是采用矩阵元组$\mathcal{N}$和$\nu$以及窗口尺寸元组$\mathcal{W}$,为每个被关注的子序列分配不同的注意力窗口大小$w\in\mathcal{W}$。这使得我们能基于token类型,将窗口化自注意力与非对称注意力相结合。具体而言,给定$j$维矩阵元组$\mathcal{N}$和$\nu$(包含$K_{i}$和$V_{i}$)以及$j$维窗口尺寸元组$\mathcal{W}$(包含$w_{i}$),广义窗口化交叉注意力机制运作流程如下:
$$
\begin{array}{l}{{\displaystyle\mathrm{Attention}_ {\mathcal{W}}(Q,K,\mathcal{V}) = \sum_{i=1}^{j}P_{i}\odot_{w_{i}}V_{i}\mathrm{, where}}}\ {{\displaystyle[P_{1},\ldots,P_{j}]=\mathrm{softmax}\left(\frac{\left[A_{1},\ldots,A_{j}\right]}{\sqrt{h}}\right) \mathrm{and} A_{i}=Q\boxtimes_{w_{i}}K_{i}.}}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle\mathrm{Attention}_ {\mathcal{W}}(Q,K,\mathcal{V}) = \sum_{i=1}^{j}P_{i}\odot_{w_{i}}V_{i}\mathrm{, where}}}\ {{\displaystyle[P_{1},\ldots,P_{j}]=\mathrm{softmax}\left(\frac{\left[A_{1},\ldots,A_{j}\right]}{\sqrt{h}}\right) \mathrm{and} A_{i}=Q\boxtimes_{w_{i}}K_{i}.}}\end{array}
$$
Our proposed attention pattern (visualization in Figure $1(\mathrm{d})$ ) is then formally defined as follows. The [CLS] token has full attention over all subsequences (Equation 1; for notation convenience, we use $w=\infty$ to refer to full self-attention), the query tokens can only attend to query tokens (Equation 2), and the document tokens can attend to all sub sequences but use windowed selfattention on their own sub sequence (Equation 3):
我们提出的注意力模式(可视化见图1(d))正式定义如下。[CLS] token对所有子序列具有完整注意力(公式1;为便于表示,我们使用$w=\infty$表示完整的自注意力),查询token只能关注查询token(公式2),而文档token可以关注所有子序列,但在其自身子序列上使用窗口化自注意力(公式3):
$$
\begin{array}{r l}&{O_{c}=\mathrm{Attention}_ {(\infty,\infty,\infty)}(Q_{c},(K_{c},K_{q},K_{d}),(V_{c},V_{q},V_{d})),}\ &{O_{q}=\mathrm{Attention}_ {(\infty)}(Q_{q},(K_{q}),(V_{q})),}\ &{O_{d}=\mathrm{Attention}_ {(\infty,\infty,w)}(Q_{d},(K_{c},K_{q},K_{d}),(V_{c},V_{q},V_{d})).}\end{array}
$$
$$
\begin{array}{r l}&{O_{c}=\mathrm{Attention}_ {(\infty,\infty,\infty)}(Q_{c},(K_{c},K_{q},K_{d}),(V_{c},V_{q},V_{d})),}\ &{O_{q}=\mathrm{Attention}_ {(\infty)}(Q_{q},(K_{q}),(V_{q})),}\ &{O_{d}=\mathrm{Attention}_ {(\infty,\infty,w)}(Q_{d},(K_{c},K_{q},K_{d}),(V_{c},V_{q},V_{d})).}\end{array}
$$
3.5 Experimental Setup
3.5 实验设置
We fine-tune various models using the Longformer and our proposed attention pattern with window sizes $w\in{\infty,64,16,4,1,0}$ ( $\infty$ : full self-attention). We start from an already fine-tuned and distilled cross-encoder mode $^2$ which also serves as our baseline [62]. We additionally fine-tune a QDS-Transformer model with its default $w=64$ window for comparison. All models are fine-tuned for 100,000 steps with 1,000 linear warm-up steps and a batch size of 32 (16 document pairs) with margin MSE loss using MS MARCO-based knowledge distillation triples [40]. For documents, we extend the models fine-tuned on passages using positional interpolation [10] and further fine-tune them on document pairs from MS MARCO Document [54] for 20,000 steps using RankNet loss [8]. Negative documents are sampled from the top 200 documents retrieved by BM25 [65]. We use a learning rate of $7\cdot10^{-6}$ , an AdamW optimizer [51], and a weight decay of 0.01. We truncate passages and documents to a maximum sequence length of 512 and 4096 tokens, respectively. All models were implemented in PyTorch [58] and Py Torch Lightning [34] and fine-tuned on a single NVIDIA A100 40GB GPU.
我们使用Longformer和提出的注意力模式(窗口大小$w\in{\infty,64,16,4,1,0}$)($\infty$表示完全自注意力)对各种模型进行微调。我们从已微调并蒸馏的交叉编码器模型$^2$开始,该模型也作为我们的基线[62]。此外,我们还微调了一个QDS-Transformer模型(默认窗口$w=64$)以进行比较。所有模型均使用基于MS MARCO的知识蒸馏三元组[40],通过margin MSE损失进行100,000步微调,包含1,000步线性预热,批量大小为32(16个文档对)。对于文档,我们通过位置插值[10]扩展了在段落上微调的模型,并进一步使用RankNet损失[8]在MS MARCO Document[54]的文档对上进行了20,000步微调。负样本文档从BM25[65]检索的前200篇文档中采样。我们使用学习率$7\cdot10^{-6}$、AdamW优化器[51]和0.01的权重衰减。段落和文档的最大序列长度分别截断为512和4096个token。所有模型均在PyTorch[58]和PyTorch Lightning[34]中实现,并在单个NVIDIA A100 40GB GPU上完成微调。
We evaluate the models on the TREC 2019–2022 Deep Learning (DL) passage and document retrieval tasks [26–29] and the TIREx benchmark [36]. For each TREC DL task, we re-rank the top 100 passages / documents retrieved by BM25 using pyserini [49]. For TIREx, we use the official first-stage retrieval files retrieved by BM25 and ChatNoir [4, 60] and also re-rank the top 100 documents. We measure nDCG $@10$ and access all corpora and tasks via ir datasets [53], using the default text field for passages and documents.
我们在TREC 2019-2022深度学习(DL)段落和文档检索任务[26-29]以及TIREx基准测试[36]上评估模型性能。针对每个TREC DL任务,我们使用pyserini[49]对BM25检索出的前100个段落/文档进行重排序。对于TIREx基准,我们采用官方提供的BM25和ChatNoir[4,60]第一阶段检索结果,同样对前100篇文档进行重排序。我们通过ir datasets[53]访问所有语料库和任务,使用默认文本字段处理段落和文档,并以nDCG $@10$ 作为评估指标。
To evaluate time and space efficiency, we generate random data with a query length of 10 tokens and passage / document lengths from 54 to 4086 tokens. For the QDS-Transformer, we set global sentence attention at every 30th token, corresponding to the average sentence length in MS MARCO documents. We use the largest possible batch size per model, but up to a maximum of 100.
为评估时间和空间效率,我们生成了查询长度为10个token、段落/文档长度从54到4086个token的随机数据。对于QDS-Transformer,我们在每30个token处设置全局句子注意力,这与MS MARCO文档的平均句子长度相对应。我们为每个模型使用尽可能大的批次大小,但最多不超过100。
4 Empirical Evaluation
4 实证评估
We compare our sparse cross-encoder’s re-ranking effectiveness and efficiency to full attention and previous sparse cross-encoder implementations. We also examine the impact of different small window sizes and of our attention deactivation pattern—analyses that provide further insights into how cross-encoders work.
我们比较了稀疏交叉编码器 (sparse cross-encoder) 在重排序效果和效率方面与全注意力机制及先前稀疏交叉编码器实现的差异。同时研究了不同小窗口尺寸和注意力停用模式的影响,这些分析为理解交叉编码器工作机制提供了更深层次的见解。
4.1 Effectiveness Results
4.1 有效性结果
In-domain Effectiveness Table 1 reports the nDCG@10 of various models with different attention patterns and window sizes on the TREC Deep Learning passage and document re-ranking tasks. We group Full Attention and Longformer models into the same category because they have the same pattern but different window sizes in our framework. We fine-tune separate models for passage and document re-ranking (cf. Section 3.5) except models with $w=\infty$ . Their lack of efficiency prevents training on long sequences, and we only fine-tune them on passages but include their MaxP scores [30] for documents (in gray).
领域内有效性
表1报告了在TREC深度学习段落和文档重排序任务中,不同注意力模式和窗口大小的各模型nDCG@10指标。我们将Full Attention和Longformer模型归为同一类别,因为它们在我们的框架中具有相同模式但窗口大小不同。除窗口大小$w=\infty$的模型外,我们分别针对段落和文档重排序任务微调了独立模型(参见第3.5节)。由于效率不足,这些模型无法在长序列上训练,因此我们仅对段落进行微调,但包含其文档MaxP分数30。
Table 1: Re-ranking effectiveness as nDCG@10 on TREC Deep Learning [26– 29]. The highest score per task is given in bold. Scores obtained using a MaxP strategy are grayed out. † denotes significant equivalence within $\pm0.02$ (paired TOST [69], $p<0.003$ ), compared to Full Attention $w=\infty$ for passage tasks and Longformer $w=64$ for document tasks.
| Task w= | Full Att./ Longformer | Sparse | Cross-Encoder | QDS 64 | |||||||||||
| 8 | 64 | 16 | 4 1 | 0 | 8 | 64 | 16 | 4 | 1 | 0 | |||||
| a ass P | 2019 | .724 | .719t .725t | .719 | .714 | .694 | .722 | .717 | .724 | .728 | .715 | .696 | .720t | ||
| 2020 | .674 | .681.680 | .684 | .676 | .632 | .666 | .672 | .661 | .665 | .649 | .605 | .682 | |||
| 2021 2022 | .656 .496 | .653.650 .494.487 | .645 .486 | .629 .481 | .602 | .656 | .650 .492t | .639 | .647 | .625 | .593 | .656 | |||
| Avg. | .619 | .619t .616t .615t | .607 | .441 .572 | .490 .615t | .615t | .479 .607 | .484 | .471 | .427 | .495t | ||||
| ent um C O | 2019 | .658 | .683 | .678 | .667 | .638 | .672 | .612t | .596 | .560 | .620 | ||||
| .622 | .640 | .639 | .661 | .689 .655 | .663 | .636 | .638 | .685 .650 | .669 .642 | .692 | .646 | .697 | |||
| 2020 | .678 | .671 | .681 | .683 | .683 | .644 .629 | .677 | .681 | .681 | .670 | .657 .679 | .638 .644 | .639 | ||
| 2021 | .424 | .425 | .431 | .425 | .409 | .389 | .421 | .446 | .443 | .417 | .424 | .405 | .676 | ||
| 2022 | .428 | ||||||||||||||
| Avg. | .575 | .582 .586t.587 | .584t | .556 | .573 | .590 | .594 | .577 | .589 | .561 | .587t | ||||
表 1: TREC深度学习[26–29]数据集上nDCG@10的重新排序效果。每项任务的最高分以粗体显示。使用MaxP策略获得的分数以灰色显示。†表示在段落任务中与Full Attention $w=\infty$、文档任务中与Longformer $w=64$相比具有显著等效性( $\pm0.02$ ) (配对TOST[69], $p<0.003$ )。
| Task w= | Full Att./ Longformer | Sparse | Cross-Encoder | QDS 64 |
|---|---|---|---|---|
| 8 | 64 | 16 | 4 1 | |
| a ass P | 2019 | .724 | .719t .725t | |
| 2020 | .674 | .681.680 | ||
| 2021 2022 | .656 .496 | .653.650 .494.487 | ||
| Avg. | .619 | .619t .616t .615t | ||
| ent um C O | 2019 | .658 | .683 | .678 |
| .622 | .640 | .639 | ||
| 2020 | .678 | .671 | .681 | |
| 2021 | .424 | .425 | .431 | |
| 2022 | ||||
| Avg. | .575 | .582 .586t.587 |
Since we hypothesize that sparse attention will not substantially affect the re-ranking effectiveness, we test for significant equivalence instead of differences. Therefore, we cannot use the typical t-test, but instead use a paired TOST procedure (two one-sided t-tests [69]; $p<0.003$ , multiple test correction [47]) to determine if the difference between two models is within $\pm0.02$ . We deem $\pm0.02$ a reasonable threshold for equivalence since it is approximately the difference between the top two models in the different TREC Deep Learning tasks.
由于我们假设稀疏注意力不会显著影响重排序效果,因此我们测试的是显著性等价而非差异。为此,我们无法使用常规t检验,而是采用配对TOST程序(双单侧t检验[69];$p<0.003$,多重检验校正[47])来判断两个模型间的差异是否在$\pm0.02$范围内。我们将$\pm0.02$视为合理的等价阈值,因为该数值约等于不同TREC深度学习任务中前两名模型间的差异。
We consider two different reference models for the passage and document re-ranking tasks. The Full Attention cross-encoder has complete information access in the passage re-ranking setting and serves as the reference model for the passage tasks. Since the models without windowed attention ( $w=\infty$ ) only process a limited number of tokens in the document re-ranking setting, we use the standard Longformer ( $w=64$ ) as the reference model for document tasks.
我们为段落和文档重排序任务考虑两种不同的参考模型。在段落重排序场景中,全注意力交叉编码器 (Full Attention cross-encoder) 拥有完整的信息访问权限,因此作为段落任务的参考模型。由于无窗口注意力 ( $w=\infty$ ) 模型在文档重排序场景中仅处理有限数量的 token,我们采用标准 Longformer ( $w=64$ ) 作为文档任务的参考模型。
We first examine the effectiveness of the QDS-Transformer. In contrast to the original work [44], it does not improve re-ranking effectiveness despite having more token interactions. The reference models are statistically equivalent to the QDS-Transformer within $\pm0.02$ for both passage and document re-ranking.
我们首先检验QDS-Transformer的有效性。与原始研究[44]相比,尽管具有更多token交互,它并未提升重排序效果。在段落和文档重排序任务中,参考模型与QDS-Transformer的统计差异均保持在$\pm0.02$范围内。
Next, we examine the effect of independent query contextual iz ation on effec ti ve ness. We compare the reference models for the passage and document tasks with our sparse cross-encoder with window size $w=\infty$ and $w=64$ , respectively. This comparison is a type of ablation test, as the two models being compared have identical configurations, except that our sparse cross-encoders independent ly contextual ize the query. Our model is statistically equivalent within $\pm0.02$ to the reference model on average across all passage tasks. The same does not hold for the document task, but our sparse cross-encoder is slightly more effective, achieving an 0.008 higher nDCG $@$ 10. We conclude that independent query contextual iz ation only marginally affects re-ranking effectiveness.
接下来,我们研究独立查询上下文化对效果的影响。将段落和文档任务的参考模型与我们窗口大小分别为$w=\infty$和$w=64$的稀疏交叉编码器进行对比。这种比较属于消融测试,因为两个对比模型配置完全相同,唯一的区别是我们的稀疏交叉编码器对查询进行了独立上下文化处理。在所有段落任务中,我们的模型与参考模型在统计上平均差异不超过$\pm0.02$。文档任务的情况略有不同,但我们的稀疏交叉编码器效果稍优,nDCG$@$10提高了0.008。由此得出结论:独立查询上下文化对重排序效果的影响微乎其微。
Finally, we examine the effect of decreasing window size on effectiveness. For the Longformer, the window sizes 64, 16, and 4 are all significantly equivalent within $\pm0.02$ on average across passage tasks. Even reducing the window size to just a single token, meaning a passage token can only attend to its immediate left and right neighboring tokens, reduces effectiveness by only 0.012 but is no longer statistically equivalent. The results are similar for the document tasks, with the window sizes 16 and 1 being statistically equivalent to the reference model. Furthermore, deactivating attention for passage or document tokens to its own sub sequence ( $w=0$ ) does not yield statistically equivalent effectiveness but only drops effectiveness by 0.047 and 0.026 nDCG $@$ 10, respectively.
最后,我们研究了减小窗口大小对效果的影响。对于Longformer模型,在段落任务中,窗口大小为64、16和4时的平均效果差异均在±0.02范围内,统计上无显著差异。即使将窗口大小缩减至单个token(即段落token仅能关注其左右相邻token),效果仅下降0.012,但此时统计显著性消失。文档任务的结果与之相似,窗口大小为16和1时与参考模型统计等效。此外,若关闭段落或文档token对其自身子序列的关注(w=0),虽统计不等效,但nDCG@10分别仅下降0.047和0.026。
The effect of decreasing window sizes is similar for our sparse cross-encoder model. Window sizes 64 and 4 are statistically equivalent for passage tasks. Window sizes 16 and 1 are not statistically equivalent but only drop effectiveness by 0.012 and 0.023 nDCG@10, respectively. On the document tasks, our sparse cross-encoder models with smaller window sizes are never statistically equivalent within $\pm0.02$ compared to the reference Longformer with window size 64. However, window sizes 64, 16, and 1 slightly improve over the reference model, and window size 4 is slightly less effective.
窗口尺寸减小对我们稀疏交叉编码器模型的影响类似。在段落任务中,窗口尺寸64和4在统计上等效。窗口尺寸16和1虽未达到统计等效,但nDCG@10仅分别下降0.012和0.023。在文档任务中,较小窗口尺寸的稀疏交叉编码器模型与窗口尺寸64的基准Longformer相比,始终未能在±0.02范围内达到统计等效。不过,窗口尺寸64、16和1的表现略优于基准模型,而窗口尺寸4的效果稍逊。
In summary, both independent query contextual iz ation and windowed selfattention do not substantially affect re-ranking effectiveness, confirming our initial assumptions. That is, symmetric modeling of the query–passage relationship is unnecessary, and very small window sizes suffice to determine a passage’s or document’s relevance to the query. Interestingly, we find a window size of $0$ to still feature competitive effectiveness. In this case, a document (or passage) token cannot attend to other tokens from its sub-sequence, making it similar to a lexical or bag-of-words model. We leave a more in-depth investigation into the implications of these results for future work.
总之,独立查询上下文化和窗口自注意力机制都不会显著影响重排序的效果,这证实了我们最初的假设。也就是说,查询-段落关系的对称建模是不必要的,极小的窗口大小足以确定段落或文档与查询的相关性。有趣的是,我们发现窗口大小为$0$时仍能保持竞争力。在这种情况下,文档(或段落)token无法关注其子序列中的其他token,使其类似于词袋模型。我们将对这些结果影响的更深入研究留待未来工作。
Out-of-domain Effectiveness Table 2 reports nDCG $@$ 10 on all out-of-domain tasks from the TIREx [36] benchmark of our sparse cross-encoder compared to two other cross-encoders of various sizes: monoT5 [56] and monoBERT [55]. Our model uses a window size of 4 tokens, and all models use a maximum sequence length of 512 token except for our sparse cross-encoder trained on documents, which has access to a maximum of 4096 tokens. Overall, the out-of-domain reranking effectiveness of all cross-encoders is lower than in-domain. Only the monoT5 large and 3b variants and our sparse cross-encoder trained on passages can improve the ranking of the first-stage retrieval on average across all corpora.
域外有效性
表 2 报告了我们的稀疏交叉编码器 (sparse cross-encoder) 在 TIREx [36] 基准测试中所有域外任务上的 nDCG $@$ 10 值,并与另外两种不同规模的交叉编码器进行对比:monoT5 [56] 和 monoBERT [55]。我们的模型采用 4 token 的窗口大小,除基于文档训练的稀疏交叉编码器(最大支持 4096 token)外,所有模型的最大序列长度均为 512 token。总体而言,所有交叉编码器的域外重排序效果均低于域内表现。只有 monoT5 large 和 3b 变体以及我们基于段落训练的稀疏交叉编码器能在所有语料库上平均提升第一阶段检索的排序效果。
Our model trained solely on passages (512-token sequence length) features competitive effectiveness despite having substantially fewer parameters. On average over all corpora, it slightly outperforms both the base and large monoBERT variants and the base variant of monoT5. We emphasize that our model only has about 24 million parameters, making it around four times smaller than the base variant of monoBERT, nine times smaller than the base variant of monoT5, and fourteen times smaller than monoBERT-large. It is slightly less effective than the monoT5 large variant, and the largest model, monoT5 3b, is the most effective.
我们的模型仅基于段落(512个token的序列长度)训练,尽管参数数量显著减少,但仍具备竞争力。在所有语料库上的平均表现略优于monoBERT的基础版和大版变体,以及monoT5的基础版变体。需要强调的是,我们的模型仅有约2400万个参数,规模比monoBERT基础版小约四倍,比monoT5基础版小九倍,比monoBERT-large小十四倍。其效果略逊于monoT5大版变体,而规模最大的monoT5 3b模型表现最优。
Table 2: Re-ranking effectiveness as nDCG $@10$ on TIREx [36]. The average document length per corpus and first-stage (FS) effectiveness are listed for context. We report micro-averaged scores across all queries from a corpus and macroaverage these in the “Average” row. The highest score per corpus is given in bold. Our sparse cross-encoder models use a window size of 4.
| Corpus | Doc. Len. | FS | monoT5 | monoBERT | Sparse CE | ||||
| Base | Large | 3b | Base | Large | 512 | 4096 | |||
| Antique [37] | 49.9 | .510 | .505 | .527 | .537 | .507 | .484 | .540 | .174 |
| Args.me [5, 6] | 435.5 | .405 | .305 | .338 | .392 | .314 | .371 | .313 | .180 |
| CW09 [14-17] | 1132.6 | .178 | .186 | .182 | .201 | .192 | .134 | .198 | .212 |
| CW12 [5, 6, 21, 22] | 5641.7 | .364 | .260 | .266 | .279 | .263 | .251 | .312 | .338 |
| CORD-19 [78] | 3647.7 | .586 | .688 | .636 | .603 | .690 | .625 | .673 | .642 |
| Cranfield [19, 20] | 234.8 | .008 | .006 | .007 | .007 | .006 | .006 | .009 | .003 |
| Disks4+5 [74-77] | 749.3 | .429 | .516 | .548 | .555 | .514 | .494 | .487 | .293 |
| GOV [23-25] | 2700.5 | .266 | .320 | .327 | .351 | .318 | .292 | .316 | .292 |
| GOV2 [9,13,18] | 2410.3 | .467 | .486 | .513 | .514 | .489 | .474 | .503 | .460 |
| MED.[38, 39,63,64] | 309.1 | .366 | .264 | .318 | .350 | .267 | .298 | .237 | .180 |
| NFCorpus [7] | 364.6 | .268 | .295 | .296 | .308 | .295 | .288 | .284 | .151 |
| Vaswani | 51.3 | .447 | .306 | .414 | .458 | .321 | .476 | .436 | .163 |
| WaPo | 713.0 | .364 | .451 | .492 | .476 | .449 | .438 | .434 | .296 |
| Average | .358 | .353 | .374 | .387 | .356 | .356 | .365 | .260 | |
表 2: TIREx [36] 数据集上 nDCG $@10$ 的重排序效果。上下文列出了每个语料库的平均文档长度和第一阶段 (FS) 效果。我们报告了语料库所有查询的微观平均分数,并在"Average"行中进行了宏观平均。每个语料库的最高分数以粗体显示。我们的稀疏交叉编码器模型使用窗口大小为4。
| Corpus | Doc. Len. | FS | monoT5 Base | monoT5 Large | monoT5 3b | monoBERT Base | monoBERT Large | Sparse CE 512 | Sparse CE 4096 |
|---|---|---|---|---|---|---|---|---|---|
| Antique [37] | 49.9 | .510 | .505 | .527 | .537 | .507 | .484 | .540 | .174 |
| Args.me [5, 6] | 435.5 | .405 | .305 | .338 | .392 | .314 | .371 | .313 | .180 |
| CW09 [14-17] | 1132.6 | .178 | .186 | .182 | .201 | .192 | .134 | .198 | .212 |
| CW12 [5, 6, 21, 22] | 5641.7 | .364 | .260 | .266 | .279 | .263 | .251 | .312 | .338 |
| CORD-19 [78] | 3647.7 | .586 | .688 | .636 | .603 | .690 | .625 | .673 | .642 |
| Cranfield [19, 20] | 234.8 | .008 | .006 | .007 | .007 | .006 | .006 | .009 | .003 |
| Disks4+5 [74-77] | 749.3 | .429 | .516 | .548 | .555 | .514 | .494 | .487 | .293 |
| GOV [23-25] | 2700.5 | .266 | .320 | .327 | .351 | .318 | .292 | .316 | .292 |
| GOV2 [9,13,18] | 2410.3 | .467 | .486 | .513 | .514 | .489 | .474 | .503 | .460 |
| MED.[38, 39,63,64] | 309.1 | .366 | .264 | .318 | .350 | .267 | .298 | .237 | .180 |
| NFCorpus [7] | 364.6 | .268 | .295 | .296 | .308 | .295 | .288 | .284 | .151 |
| Vaswani | 51.3 | .447 | .306 | .414 | .458 | .321 | .476 | .436 | .163 |
| WaPo | 713.0 | .364 | .451 | .492 | .476 | .449 | .438 | .434 | .296 |
| Average | .358 | .353 | .374 | .387 | .356 | .356 | .365 | .260 |
In contrast, our model trained on documents is substantially less effective in out-of-domain retrieval. Across all corpora, it is 0.105 nDCG $@$ 10 less effective than our model trained on passages. However, it can take advantage of its longer context length on the corpora containing long documents. For example, on the ClueWeb corpora it is the most effective of all cross-encoder models and features competitive effectiveness on CORD-19, GOV, and GOV2.
相比之下,我们基于文档训练的模型在跨领域检索中效果明显较差。在所有语料库中,其nDCG@10指标比基于段落训练的模型低0.105。不过,在包含长文档的语料库中,该模型能利用其更长的上下文优势。例如,在ClueWeb语料库上,它成为所有交叉编码器模型中效果最佳的,同时在CORD-19、GOV和GOV2上也展现出竞争力。
4.2 Efficiency Results
4.2 效率结果
Finally, we study how the various attention patterns affect efficiency. We first compare our custom windowed matrix multiplication kernel with previous imple ment at ions. We then compare the efficiency of our proposed cross-encoder model to the reference cross-encoder, Longformer, and QDS-Transformer.
最后,我们研究了不同注意力模式如何影响效率。首先将我们自定义的窗口矩阵乘法核与之前的实现方案进行对比。随后将我们提出的交叉编码器模型与参考交叉编码器、Longformer以及QDS-Transformer的效率进行对比。
Windowed Matrix Multiplication Figure 2a compares our windowed matrix multip li cation kernel with PyTorch’s built-in matrix multiplication kernel (Full Attention), Longformer’s TVM-based [11] implementation, and the two PyTorchbased block-sparse implementations from BigBird and Longformer. All implementations are intended as drop-in replacements for matrix multiplication but use different ways to interface with CUDA and add varying levels of overhead.
窗口化矩阵乘法
图 2a: 将我们的窗口化矩阵乘法内核与 PyTorch 内置矩阵乘法内核 (Full Attention)、Longformer 基于 TVM [11] 的实现,以及 BigBird 和 Longformer 的两种基于 PyTorch 的块稀疏实现进行对比。所有实现均设计为矩阵乘法的即插即用替代方案,但采用不同的 CUDA 交互方式并引入不同程度的开销。

Figure 2: Comparison of windowed matrix multiplication kernels (a) and sparse cross-encoder models (b) in terms of efficiency. Time (ms / Document) and space (GB) efficiency are reported for window sizes $w\in{4,64}$ . All plots use a logarithmic scale with base 2 on the x-axis and base 10 on the y-axis.
图 2: 窗口化矩阵乘法核 (a) 与稀疏交叉编码器模型 (b) 在效率上的对比。报告了窗口大小 $w\in{4,64}$ 下的时间效率 (ms/文档) 和空间效率 (GB)。所有图表均采用对数刻度,x轴以2为底,y轴以10为底。
We observe similar behavior as Beltagy et al. [3] for a window size of 64 tokens. Both block-sparse matrix implementations are time-efficient but sacrifice space efficiency. The opposite is true for the TVM-based kernel. For window size 4, the TVM implementation fairs better, achieving similar time efficiency as the PyTorch-based kernels for short sequence lengths and outperforming them at longer sequences. At the same time, it upholds its space efficiency. However, previous kernels are vastly slower compared to full matrix multiplication for shorter sequences. Our custom kernel achieves optimal space efficiency and is faster than all previous windowed matrix multiplication kernels for both window sizes. Compared to full matrix multiplication, our kernel is only slower for the edge case when the window size exceeds the sequence length.
我们观察到与 Beltagy 等人 [3] 类似的 64 token 窗口大小行为。两种块稀疏矩阵实现方式时间效率高但牺牲了空间效率。基于 TVM 的内核则相反。对于窗口大小 4,TVM 实现表现更优,在短序列长度下达到与基于 PyTorch 的内核相近的时间效率,在长序列中表现更优,同时保持空间效率。然而,对于较短序列,先前内核相比全矩阵乘法速度明显较慢。我们的自定义内核实现了最佳空间效率,且在两种窗口大小下都比所有先前的窗口矩阵乘法内核更快。与全矩阵乘法相比,仅当窗口大小超过序列长度这一边缘情况时,我们的内核速度较慢。
Cross-Encoders Models Lastly, we compare the efficiency of our sparse crossencoder model with a standard cross-encoder, the Longformer, and the QDSTransformer. We use the default implementations from Hugging face [80] but omit BigBird, as it does not support task-specific global attention. Note that the QDS-Transformer is based on the Longformer and uses the same model architecture with a different global attention pattern.
跨编码器模型 (Cross-Encoders Models)
最后,我们将稀疏跨编码器模型与标准跨编码器、Longformer 以及 QDS-Transformer 的效率进行对比。我们使用 Hugging Face [80] 的默认实现,但排除了 BigBird,因为它不支持任务特定的全局注意力。需要注意的是,QDS-Transformer 基于 Longformer,采用相同的模型架构,但使用了不同的全局注意力模式。
Figure 2b gives a visual overview of the efficiency of the models for windows sizes 4 and 64. Table 3 reports the time and memory used per sequence for passages of length 164 and documents of length 4086. These lengths correspond to the average of the longest passage / document per top-100 ranking of a TREC Deep Learning query, i.e., the setup simulates re-ranking a batch of 100 sequences. For ablation analyses, Table 3 additionally reports the efficiency of our model without our custom kernel and independent query contextual iz ation.
图 2b 直观展示了窗口大小为4和64时各模型的效率对比。表3 报告了长度为164的段落和长度为4086的文档在每序列处理时消耗的时间与内存。这些长度对应TREC深度学习查询前100名结果中最长段落/文档的平均值,即该设置模拟了对100个序列批次进行重排序的场景。为进行消融分析,表3 还额外报告了移除自定义内核(custom kernel)和独立查询上下文化(independent query contextualization)组件后我们模型的效率数据。
Table 3: Time and space efficiency of cross-encoder models, including our sparse cross-encoder without our kernel and independent query contextual iz ation. Relative differences to baseline models (underlined) are given in parentheses.
| Unit m | Full Att. 8 | Longf. 64 | QDS. 64 | Sp. CE 64 | Sp.CE 4 | Kernel 4 | Query 4 |
| Query length 10, Passage length 164 | |||||||
| μs | 368 | 980 (+166%) | 995 (+170%) | 527(+43%) | 364 (-1%) | 404(+10%) | 403 (+10%) |
| MB | 9 | 15 (+67%) | 15 (+67%) | (%0+)6 | 7(-22%) | 8 (-11%) | 7(-22%) |
| Query length 10,Document length 4086 | |||||||
| ms | 49 (+250%) | 14 | 18 (+29%) | 12 (-14%) | 8 (-43%) | 9 (-36%) | 8(-43%) |
| MB | 1608 (+905%) | 160 | 192 (+20%) | 111 (-31%) | 66 (-59%) | 84 (-48%) | 66 (-59%) |
表 3: 交叉编码器模型的时间和空间效率,包括不带我们内核的稀疏交叉编码器和独立查询上下文化。括号中给出了与基线模型(下划线标注)的相对差异。
| Unit m | Full Att. 8 | Longf. 64 | QDS. 64 | Sp. CE 64 | Sp.CE 4 | Kernel 4 | Query 4 |
|---|---|---|---|---|---|---|---|
| Query length 10, Passage length 164 | |||||||
| μs | 368 | 980 (+166%) | 995 (+170%) | 527(+43%) | 364 (-1%) | 404(+10%) | 403 (+10%) |
| MB | 9 | 15 (+67%) | 15 (+67%) | (%0+)6 | 7(-22%) | 8 (-11%) | 7(-22%) |
| Query length 10, Document length 4086 | |||||||
| ms | 49 (+250%) | 14 | 18 (+29%) | 12 (-14%) | 8 (-43%) | 9 (-36%) | 8(-43%) |
| MB | 1608 (+905%) | 160 | 192 (+20%) | 111 (-31%) | 66 (-59%) | 84 (-48%) | 66 (-59%) |
Figure 2b shows our model outperforms the other two sparse cross-encoders for time and space efficiency for both window sizes. The QDS-Transformer is the least efficient due to its additional global sentence attention. The Longformer lies between the QDS-Transformer and our sparse cross-encoder. The efficiency improvements can be attributed to two sources. The first is our improved windowed matrix multiplication kernel, and the second is our cross-attention mechanism. The Listformer uses a similar mechanism but extracts the matrices required for global attention in each transformer layer. Our sparse cross-encoder model splits the sub-sequences once and reuses the extracted matrices for all layers, avoiding repeating the expensive extraction and splitting step.
图 2b 显示我们的模型在时间和空间效率上均优于其他两种稀疏交叉编码器(无论窗口大小如何)。QDS-Transformer由于额外的全局句子注意力机制效率最低,Longformer性能介于QDS-Transformer与我们的稀疏交叉编码器之间。效率提升主要源于两方面:改进的窗口矩阵乘法内核,以及我们的交叉注意力机制。Listformer采用类似机制,但需要在每个transformer层提取全局注意力所需的矩阵。我们的稀疏交叉编码器模型只需分割一次子序列,即可在所有层复用提取的矩阵,避免了重复执行高开销的提取和分割操作。
Table 3 underlines the efficiency improvements of our model. With a 64 token window size, our sparse cross-encoder is almost twice as fast and uses 40% less memory than the Longformer on passages. On documents, the difference is less pronounced but still substantial. Our model is $14%$ faster and uses $31%$ less memory. However, our sparse cross-encoder achieves the largest efficiency improvements when reducing the window size. Compared to the Longformer with a 64-token window size, our sparse cross-encoder with a 4-token window size is $63%$ faster and uses $53%$ less memory on passages. On documents, our model is 43% faster and uses 59% less memory. Despite the different window sizes, we deem this a fair comparison because the Longformer was previously not successfully used for re-ranking with smaller window sizes. It acts as the previous sparse cross-encoder efficiency standard.
表 3 展示了我们模型的效率提升。在 64 token 窗口大小下,我们的稀疏交叉编码器 (sparse cross-encoder) 在段落处理上比 Longformer 快近两倍,内存占用减少 40%。在文档处理上差异虽较小但仍显著:我们的模型速度快 14%,内存占用少 31%。
当缩小窗口大小时,我们的稀疏交叉编码器实现了最大效率提升。与 64-token 窗口的 Longformer 相比,采用 4-token 窗口的稀疏交叉编码器在段落处理上速度快 63%,内存占用少 53%;在文档处理上速度快 43%,内存占用少 59%。尽管窗口大小不同,我们仍认为这是合理对比,因为 Longformer 此前无法成功用于较小窗口的重新排序任务,它代表了先前稀疏交叉编码器的效率基准。
Ablation tests show that our custom kernel and independent query contextu aliz ation both contribute to our model’s improved efficiency. Using a Pytorchbased block-sparse windowed matrix multiplication kernel, our model is less time and space-efficient and loses between 9% and $11%$ percent of its time and space-efficiency improvements. Independent query contextual iz ation only has a marginal effect on space efficiency and a noticeable effect on time efficiency only for passages. The query is generally not long enough compared to passages or documents to substantially impact efficiency in practice.
消融实验表明,我们的自定义内核和独立查询上下文化都提升了模型效率。使用基于PyTorch的块稀疏窗口矩阵乘法内核时,模型的时间和空间效率会降低,损失约9%至11%的改进幅度。独立查询上下文化对空间效率影响微弱,仅在段落处理时对时间效率有显著提升。由于查询长度通常远小于段落或文档,实践中对整体效率影响有限。
Comparing our sparse cross-encoder to the standard cross-encoder reveals that there is still room for improvement. Time and space efficiency on documents is orders of magnitude better, and our model uses $22%$ less memory on passages. But, regarding inference time, our model is on par with the standard crossencoder for passages. The root cause is that the cross-attention incurs additional overhead. Each sub-sequence uses its own attention function. Multiple smaller attention functions are executed sequentially, while full attention uses a single large attention function for the entire sequence. Recent work on fused-attention kernels [31, 32, 48] has shown that moving the entire attention function to the GPU substantially improves efficiency. At the time of writing, fused-attention kernels do not support asymmetric attention patterns. We leave investigating their applicability to our model to future work.
将我们的稀疏交叉编码器与标准交叉编码器进行比较,可以发现仍有改进空间。在文档处理的时间与空间效率上提升了数个数量级,且我们的模型在段落处理上减少了22%的内存占用。但在推理时间方面,我们的模型与标准交叉编码器在段落处理上表现相当。根本原因在于交叉注意力会带来额外开销:每个子序列使用独立的注意力函数,多个小型注意力函数需顺序执行,而完整注意力则对整个序列使用单一大型注意力函数。近期关于融合注意力内核的研究[31, 32, 48]表明,将整个注意力函数移至GPU可显著提升效率。截至本文撰写时,融合注意力内核尚不支持非对称注意力模式,其在本模型中的适用性研究将留待未来工作。
5 Conclusion
5 结论
We have investigated the impact of sparse attention on the re-ranking effectiveness of cross-encoders by combining windowed self-attention and token-specific cross-attention to analyze (1) decreasing context sizes for document tokens and (2) deactivating attention from the query to the [CLS] and document tokens.
我们通过结合窗口自注意力 (windowed self-attention) 和特定token交叉注意力 (token-specific cross-attention) 研究了稀疏注意力对交叉编码器重排序效果的影响,分析了以下两种情况:(1) 减少文档token的上下文大小,(2) 停用从查询到[CLS]和文档token的注意力。
In passage and document re-ranking experiments, we find a window size down to four tokens to be as effective as larger window sizes or full attention (significantly equivalent effectiveness within $\pm0.02$ nDCG $@$ 10 compared to previous cross-encoders), and we find that deactivating attention from the query to the [CLS] and document tokens does not impact effectiveness. At the same time, combining the spars if i cation techniques substantially improves efficiency of passage and document re-ranking. For these efficiency improvements, our custom CUDA kernel and asymmetric cross-attention play substantial roles but the largest gains are achieved using small window sizes.
在段落和文档重排序实验中,我们发现窗口大小低至4个token时,其效果与更大窗口或完整注意力机制相当(与先前交叉编码器相比,nDCG@10差异在±0.02范围内具有统计等效性),同时发现停用查询对[CLS]和文档token的注意力不会影响效果。此外,结合稀疏化技术可显著提升段落和文档重排序效率。这些效率提升中,我们的定制CUDA内核和非对称交叉注意力发挥了重要作用,但最大增益来自使用小窗口尺寸。
Sparse attention thus is a viable option for decreasing computational effort without substantially affecting effectiveness. To further increase efficiency, integrating asymmetric cross-attention and windowed self-attention into newly developed fused attention kernels [31, 32, 48] seems to be a promising direction. The flexibility and efficiency of our custom attention pattern also allow for further research into the direction of listwise re-ranking by passing multiple documents to the cross-encoder at once.
稀疏注意力 (sparse attention) 因此成为降低计算量而不显著影响效果的有效选择。为进一步提升效率,将非对称交叉注意力 (asymmetric cross-attention) 和窗口化自注意力 (windowed self-attention) 整合到新开发的融合注意力内核 [31, 32, 48] 中似乎是一个有前景的方向。我们定制注意力模式的灵活性和效率还支持通过一次性向交叉编码器传递多篇文档来进一步研究列表式重排序 (listwise re-ranking) 方向。
Acknowledgments
致谢
This work has received funding from the European Union’s Horizon Europe research and innovation programme under grant agreement No 101070014 (OpenWebSearch.EU, https://doi.org/10.3030/101070014).
本研究获得了欧盟"地平线欧洲"科研创新计划资助 (资助协议编号 101070014, OpenWebSearch.EU项目, https://doi.org/10.3030/101070014)。