LaMI-DETR: Open-Vocabulary Detection with Language Model Instruction
LaMI-DETR: 基于语言模型指令的开放词汇检测
Abstract. Existing methods enhance open-vocabulary object detection by leveraging the robust open-vocabulary recognition capabilities of VisionLanguage Models (VLMs), such as CLIP. However, two main challenges emerge: (1) A deficiency in concept representation, where the category names in CLIP’s text space lack textual and visual knowledge. (2) An over fitting tendency towards base categories, with the open vocabulary knowledge biased towards base categories during the transfer from VLMs to detectors. To address these challenges, we propose the Language Model Instruction (LaMI) strategy, which leverages the relationships between visual concepts and applies them within a simple yet effective DETR-like detector, termed LaMI-DETR. LaMI utilizes GPT to construct visual concepts and employs T5 to investigate visual similarities across categories. These inter-category relationships refine concept representation and avoid over fitting to base categories. Comprehensive experiments validate our approach’s superior performance over existing methods in the same rigorous setting without reliance on external training resources. LaMI-DETR achieves a rare box AP of 43.4 on OV-LVIS, surpassing the previous best by 7.8 rare box AP.
摘要。现有方法通过利用视觉语言模型(VLMs)(如CLIP)强大的开放词汇识别能力来增强开放词汇目标检测。然而存在两个主要挑战:(1)概念表征不足,CLIP文本空间中的类别名称缺乏文本和视觉知识;(2)对基类别的过拟合倾向,在从VLM迁移到检测器时,开放词汇知识会偏向基类别。为解决这些挑战,我们提出语言模型指令(LaMI)策略,利用视觉概念间的关系,并将其应用于简单高效的类DETR检测器LaMI-DETR中。LaMI使用GPT构建视觉概念,并采用T5研究跨类别视觉相似性。这些类别间关系能优化概念表征并避免对基类别的过拟合。综合实验表明,在不依赖外部训练资源的同等严格设置下,我们的方法性能优于现有方案。LaMI-DETR在OV-LVIS上取得43.4的稀有框AP,较之前最佳结果提升7.8稀有框AP。
Keywords: Inter-category Relationships $\cdot$ Language Model · DETR
关键词:跨类别关系 $\cdot$ 大语言模型 (Large Language Model) · DETR
1 Introduction
1 引言
Open-vocabulary object detection (OVOD) aims to identify and locate objects from a wide range of categories, including base and novel categories during inference, even though it is only trained on a limited set of base categories. Existing works $[6,9,13,29,33,35,36,40]$ in open-vocabulary object detection have been focusing on the development of sophisticated modules within detectors. These modules are tailored to effectively adapt the zero-shot and few-shot learning capabilities inherent in Vision-Language Models (VLMs) to the context of object detection.
开放词汇目标检测 (OVOD) 旨在识别和定位来自广泛类别的物体,包括推理过程中的基类和新类,尽管它仅在有限的基类集合上进行训练。现有工作 [6,9,13,29,33,35,36,40] 在开放词汇目标检测领域主要聚焦于开发检测器内部的复杂模块。这些模块专门设计用于有效适配视觉语言模型 (VLMs) 中固有的零样本和少样本学习能力至目标检测场景。
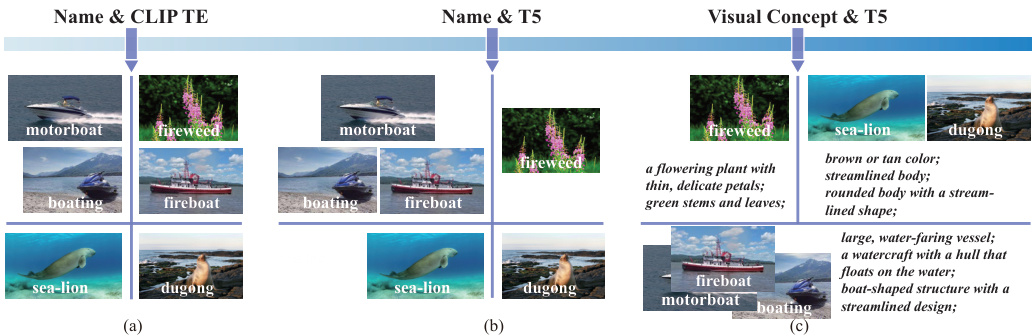
Fig. 1: Illustration of the concept representation challenge. The clustering results are from (a) name embeddings by CLIP text encoder, (b) name embeddings by T5, and (c) visual description embeddings by T5, respectively. (a) CLIP text encoder struggles to distinguish between category names that are composition ally similar in letters, such as "fireboat" and "fireweed". (b) T5 fails to cluster categories that are visually comparable but composition ally different in name around the same cluster center, such as "sealion" and "dugong". (c) Marrying T5’s textual semantic knowledge with visual insights achieves reasonable cluster results.
图 1: 概念表征挑战示意图。聚类结果分别来自 (a) CLIP文本编码器的名称嵌入, (b) T5的名称嵌入, 以及 (c) T5的视觉描述嵌入。(a) CLIP文本编码器难以区分字母组合相似的类别名称, 如"fireboat"和"fireweed"。(b) T5无法将视觉相似但名称构成不同的类别(如"sealion"和"dugong")聚类到同一中心。(c) 结合T5的文本语义知识与视觉理解后获得了合理的聚类结果。
However, there are two challenges in most existing methods: (1) Concept Represent ation. Most existing methods represent concepts using name embeddings from CLIP text encoder. However, this approach of concept representation has a limitation in capturing the textual and visual semantic similarities between categories, which could aid in discriminating visually confusable categories and exploring potential novel objects; (2) Overfit to base categories. Although VLMs can perform well on novel categories, only base detection data is used in open vocabulary detectors’ optimization, resulting in detectors’ over fitting to base categories. As a result, novel objects are easily regarded as background or base categories.
然而,现有方法存在两个挑战:(1) 概念表征 (Concept Representation)。多数方法采用CLIP文本编码器的名称嵌入来表征概念,但这种方式难以捕捉类别间的文本与视觉语义相似性,而这种相似性有助于区分视觉易混淆类别并探索潜在新物体;(2) 对基类过拟合 (Overfit to base categories)。尽管视觉语言模型 (VLMs) 在新类别上表现良好,但开放词汇检测器的优化仅使用基类检测数据,导致检测器对基类过拟合,从而使新物体易被误判为背景或基类。
Firstly, the issue of concept representation. Category names within CLIP’s textual space are deficient in both textual depth and visual information.
首先,概念表示的问题。CLIP文本空间中的类别名称在文本深度和视觉信息方面都存在不足。
(1) The VLM’s text encoder lacks textual semantic knowledge compared with language model. As depicted in Figure 1(a), relying solely on name representations from CLIP concentrates on the similarity of letter composition, neglecting the hierarchical and common-sense understanding behind language. This method is disadvantageous for categorizing clustering as it fails to consider the conceptual relationships between categories. (2) Existing concept representations based on abstract category names or definitions fail to account for visual characteristics. Figure 1(b) demonstrates this problem, where sea lions and dugongs, despite their visual similarity, are allocated to separate clusters. Representing concept only with category name overlooks the rich visual context that language provides, which can facilitate the discovery of potential novel objects.
(1) 与语言模型相比,VLM的文本编码器缺乏文本语义知识。如图1(a)所示,仅依赖CLIP的名称表示会聚焦于字母组合的相似性,而忽略了语言背后的层次结构和常识理解。这种方法不利于聚类分类,因为它未能考虑类别之间的概念关联。(2) 现有基于抽象类别名称或定义的概念表示未能考虑视觉特征。图1(b)展示了这个问题:海狮和儒艮尽管视觉相似,却被划分到不同聚类中。仅用类别名称表示概念,忽视了语言提供的丰富视觉上下文,而这些上下文有助于发现潜在的新对象。
Secondly, the issue of over fitting to base categories. To leverage the open vocabulary capabilities of VLMs, we employ a frozen CLIP image encoder as the backbone and utilize category embeddings from the CLIP text encoder as classification weights. We regard that detector training should serve two main functions: firstly, to differentiate foreground from background; and secondly, to maintain the open vocabulary classification capability of CLIP. However, training solely on base category annotations, without incorporating additional strategies, often results in over fitting: novel objects are commonly mis classified as either background or base categories. This problem has been further elucidated in prior research [29, 32].
其次,基础类别过拟合问题。为利用视觉语言模型(VLM)的开放词汇能力,我们采用冻结的CLIP图像编码器作为主干网络,并使用CLIP文本编码器的类别嵌入作为分类权重。我们认为检测器训练应实现两个主要功能:一是区分前景与背景;二是保持CLIP的开放词汇分类能力。但若仅基于基础类别标注进行训练且未引入额外策略,往往会导致过拟合现象:新物体常被误判为背景或基础类别。该问题在先前研究[29, 32]中已得到进一步阐释。
We pinpoint the exploration of inter-category relationships as pivotal in tackling the aforementioned challenges. By cultivating a nuanced understanding of these relationships, we can develop a concept representation method that integrates both textual and visual semantics. This approach can also identify visually similar categories, guiding the model to focus more on learning generalized foreground features and preventing over fitting to base categories. Consequently, in this paper, we introduce LaMI-DETR (Frozen CLIP-based DETR with Language Model Instruction), a simple but effective DETR-based detector that leverages language model insights to extract inter-category relationships, aiming to solve the aforementioned challenges.
我们指出,探索类别间关系是解决上述挑战的关键。通过深入理解这些关系,我们可以开发一种融合文本和视觉语义的概念表征方法。这种方法还能识别视觉相似的类别,引导模型更专注于学习通用前景特征,防止对基础类别的过拟合。因此,本文提出LaMI-DETR(基于冻结CLIP且带有语言模型指令的DETR),这是一种简单但有效的基于DETR的检测器,它利用语言模型的洞察力来提取类别间关系,旨在解决上述挑战。
To tackle the concept representation, we first adopt the Instructor Embedding [31], a T5 language model, to re-evaluate category similarities. As we find that language models exhibit a more refined semantic space compared to the CLIP text encoder. As shown in Figure 1(b), "fireweed" and "fireboat" are categorized into separate clusters, mirroring human recognition more closely. Next, we introduce the use of GPT-3.5 [2] to generate visual descriptions for each category. This includes detailing aspects such as shape, color, and size, effectively converting these categories into visual concepts. Figure 1(c) shows that, with similar visual descriptions, sea lions and dugongs are now grouped into the same cluster. To mitigate the over fitting issue, we cluster visual concepts into groups based on visual description embeddings from T5. This clustering result enables the identification and sampling of negative classes that are visually different from ground truth categories in each iteration. This relaxes the optimization of classification and focuses the model on deriving more generalized foreground features rather than over fitting to base categories. Consequently, this approach enhances the model’s general iz ability by reducing over training on base categories while preserving CLIP image backbone’s ability to categorize.
为了解决概念表征问题,我们首先采用Instructor Embedding [31](一种T5语言模型)重新评估类别相似性。我们发现语言模型相比CLIP文本编码器能展现出更精细的语义空间。如图1(b)所示,"fireweed"和"fireboat"被划分到不同聚类簇,更贴近人类认知模式。接着,我们引入GPT-3.5 [2]为每个类别生成视觉描述,包括形状、颜色、尺寸等细节特征,从而将这些类别有效转化为视觉概念。图1(c)显示,在获得相似视觉描述后,海狮和儒艮被归入同一聚类簇。为缓解过拟合问题,我们基于T5生成的视觉描述嵌入向量对视觉概念进行聚类分组。该聚类结果可在每次迭代时识别并采样与真实类别视觉差异大的负类,从而放宽分类优化目标,使模型更专注于学习泛化性强的前景特征而非过度拟合基类。该方法通过减少基类过训练同时保留CLIP图像骨干的分类能力,有效提升了模型的泛化性能。
In summary, we introduce a novel approach, LaMI, to enhance base-to-novel generalization in OVOD. LaMI harnesses large language models to extract intercategory relationships, utilizing this information to sample easy negative categories and avoid over fitting to base categories, while also refining concept represent at ions to enable effective classification between visually similar categories. We propose a simple but effective end-to-end LaMI-DETR framework, enabling the effective transfer of open vocabulary knowledge from pretrained VLMs to detectors. We demonstrate the superiority of our LaMI-DETR framework through rigorous testing on large vocabulary OVOD benchmark, including +7.8 AP $\mathbf{r}$ on OV-LVIS and $+2.9\mathrm{AP_{r}}$ on VG-dedup(fair comparison with OWL [20,22]). Code is available at https://github.com/eternal dolphin/LaMI-DETR.
总之,我们提出了一种名为LaMI的新方法,用于增强开放词汇目标检测(OVOD)中基础类别到新类别的泛化能力。LaMI利用大语言模型提取类别间关系,通过该信息采样简单负类别以避免对基础类别的过拟合,同时优化概念表示以实现视觉相似类别间的有效分类。我们提出了一种简单但有效的端到端LaMI-DETR框架,能够将预训练视觉语言模型(VLM)中的开放词汇知识有效迁移至检测器。通过在大型词汇OVOD基准测试上的严格验证,包括OV-LVIS上+7.8 AP $\mathbf{r}$ 和VG-dedup上 $+2.9\mathrm{AP_{r}}$ (与OWL [20,22]的公平对比),我们证明了LaMI-DETR框架的优越性。代码已开源:https://github.com/eternal dolphin/LaMI-DETR。
2 Related Work
2 相关工作
Open-vocabulary object detection (OVOD) leverages the image and language alignment knowledge stored in image-level dataset, e.g., Conceptual Captions [28], or large pre-trained VLMs, e.g., CLIP [25], to incorporate the openvocabulary information into object detectors. One group of OVOD utilizes largescale image-text pairs to expand detection vocabulary [7, 19, 26, 41, 44–46] However, based on VLMs’ proven strong zero-shot recognition abilities, most openvocabulary object detectors leverage VLM-derived knowledge to handle open vocabularies. The methods for object detectors to obtain open vocabulary knowledge from VLM can be divided into three categories: pseudo labels [26, 40, 45], distillation [6, 9, 33, 35] or parameter transfer [15, 36]. Despite its utility, performances of these methods are arguably restricted by the teacher VLM, which is shown to be largely unaware of inter-category visual relationship. Our method is orthogonal to all the aforementioned approaches in the sense that it not only explicitly models region-word correspondences, but also leverages visual correspondences across categories to help localize novel categories, which greatly improves the performance, especially in the DETR-based architecture [3, 11, 42, 43].
开放词汇目标检测 (OVOD) 利用存储在图像级数据集 (如 Conceptual Captions [28]) 或大型预训练视觉语言模型 (如 CLIP [25]) 中的图文对齐知识,将开放词汇信息融入目标检测器。一类 OVOD 方法通过大规模图文对扩展检测词汇表 [7, 19, 26, 41, 44-46]。然而,基于视觉语言模型已被证实的强大零样本识别能力,大多数开放词汇目标检测器都利用视觉语言模型衍生的知识来处理开放词汇。目标检测器从视觉语言模型获取开放词汇知识的方法可分为三类:伪标签 [26, 40, 45]、蒸馏 [6, 9, 33, 35] 或参数迁移 [15, 36]。尽管这些方法有效,但其性能仍受限于教师视觉语言模型——研究表明该模型很大程度上缺乏对类别间视觉关系的认知。我们的方法与上述所有方法正交,不仅显式建模区域-单词对应关系,还利用跨类别视觉对应关系来帮助定位新类别,这显著提升了性能,特别是在基于 DETR 的架构中 [3, 11, 42, 43]。
Zero-shot object detection (ZSD) addresses the challenge of detecting novel, unseen classes by leveraging language features for generalization. Traditional approaches utilize word embeddings, such as GloVe [23], as classifier weights to project region features into a pre-computed text embedding space [1,5]. This enables ZSD models to recognize unseen objects by their names during inference. However, the primary limitation of ZSD lies in its training on a constrained set of seen classes, failing to adequately align the vision and language feature spaces. Some methods attempt to mitigate this issue by generating feature representations of novel classes using Generative Adversarial Networks [8, 30] or through data augmentation strategies for synthesizing unseen classes [48]. Despite these efforts, ZSD still faces significant performance gaps compared to supervised detection methods, highlighting the difficulty in extending detection capabilities to entirely unseen objects without access to relevant resources.
零样本目标检测 (ZSD) 通过利用语言特征实现泛化,解决了检测新颖未见类别的挑战。传统方法使用词嵌入 (例如 GloVe [23]) 作为分类器权重,将区域特征映射到预计算的文本嵌入空间 [1,5]。这使得 ZSD 模型能够在推理时通过名称识别未见物体。然而,ZSD 的主要局限在于其训练仅基于有限的已知类别集,未能充分对齐视觉与语言特征空间。部分方法尝试通过生成对抗网络 [8, 30] 生成新类别特征表示,或采用数据增强策略合成未见类别 [48] 来缓解该问题。尽管存在这些努力,与监督检测方法相比,ZSD 仍存在显著性能差距,这凸显了在缺乏相关资源的情况下将检测能力扩展到完全未见物体的困难性。
Large Language Model (LLM) Language data has increasingly played a pivotal role in open-vocabulary research, with recent Large Language Models (LLMs) showcasing vast knowledge applicable across various Natural Language Processing tasks. Works such as [21,24,37] have leveraged language insights from LLMs to generate descriptive labels for visual categories, thus enriching VLMs without necessitating further training or labeling. Nonetheless, there are gaps in current methodologies: firstly, the potential of disc rim i native LLMs for enhancing VLMs is frequently overlooked; secondly, the inter-category relationships remain under explored. We propose a novel, straightforward clustering approach that employs GPT and Instructor Embeddings to investigate visual similarities among concepts, addressing these oversights.
大语言模型 (LLM)
语言数据在开放词汇研究中日益发挥关键作用,近期的大语言模型展现出适用于各类自然语言处理任务的广泛知识。研究如[21,24,37]利用LLM的语言洞察力为视觉类别生成描述性标签,从而无需额外训练或标注即可增强视觉语言模型(VLM)。然而当前方法存在不足:首先,判别式LLM提升VLM的潜力常被忽视;其次,类别间关联性尚未充分探索。我们提出一种新颖简洁的聚类方法,采用GPT和Instructor Embeddings来探究概念间的视觉相似性,以解决这些遗漏问题。
3 Method
3 方法
In this section, we begin with an introduction to open-vocabulary object detection (OVOD) in Section 3.1. Following this, we describe our proposed architecture of LaMI-DETR, a straightforward and efficient OVOD baseline, detailed in Section 3.2. Finally, we provide a detailed explanation of Language Model Instruction (LaMI) in Section 3.3.
在本节中,我们首先在第3.1节介绍开放词汇目标检测 (open-vocabulary object detection, OVOD) 。接着,在第3.2节详细描述我们提出的LaMI-DETR架构——一种简单高效的OVOD基线方法。最后,在第3.3节对语言模型指令 (Language Model Instruction, LaMI) 进行详细说明。
3.1 Preliminaries
3.1 预备知识
Given an image $I R^{H W3}$ as input to an open-vocabulary ob ject detector, two primary outputs are typically generated: (1) Classification, wherein a class label, $c_{j}\in\mathcal{C}{\mathrm{{test}}}$ , is assigned to the $j^{\mathrm{th}}$ predicted object in the image, with $\mathcal{C}{\mathrm{test}}$ ect representing the set of categories targeted during inference. (2) Localization, which involves determining the bounding box coordinates, $\mathbf{b}{j}\in\mathbb{R}^{4}$ , that identify the location of the $j^{\mathrm{th}}$ predicted object. Following the framework established by OVR-CNN [41], there is a detection dataset, $\mathcal{D}{\mathrm{det}}$ , comprising bounding box coordinates, class labels, and corresponding images, and addressing a category vocabulary, $\mathcal{C}_{\mathrm{det}}$ .
给定一张图像 $\mathbf{I}\in\mathbb{R}^{H\times W\times3}$ 作为开放词汇目标检测器的输入,通常会生成两个主要输出:(1) 分类,其中为图像中第 $j^{\mathrm{th}}$ 个预测对象分配一个类别标签 $c_{j}\in\mathcal{C}{\mathrm{{test}}}$ ,$\mathcal{C}{\mathrm{test}}$ 表示推理过程中目标类别的集合;(2) 定位,涉及确定边界框坐标 $\mathbf{b}{j}\in\mathbb{R}^{4}$ ,以标识第 $j^{\mathrm{th}}$ 个预测对象的位置。遵循 OVR-CNN [41] 建立的框架,存在一个检测数据集 $\mathcal{D}{\mathrm{det}}$ ,包含边界框坐标、类别标签和对应图像,并处理一个类别词汇表 $\mathcal{C}_{\mathrm{det}}$ 。
In line with the conventions of OVOD, we denote the category spaces of $\mathcal{C}{\mathrm{test}}$ ect and $\mathcal{C}{\mathrm{det}}$ as $\mathcal{C}$ and ${\mathit{C}}{\mathrm{B}}$ rotect respectively. Typically, $\mathcal{C}{\mathrm{B}}\subset\mathcal{C}$ . The categories within ${\mathit{C}}{\mathrm{B}}$ are known as base categories, whereas those exclusively appearing in $\mathcal{C}{\mathrm{test}}$ are identified as novel categories. The set of novel categories is expressed as ${\mathcal{C}}{\mathrm{N}}={\mathcal{C}}\setminus{\mathcal{C}}{\mathrm{B}}\neq\emptyset$ . For each category $c\in{\mathcal{C}}$ , we utilize CLIP to encode its text embedding $t_{c}\in\mathbb{R}^{d}$ , and $\mathcal{T}{\mathrm{CLS}}=~{t_{c}}_{c=1}^{C}$ ( $C$ is the size of the category vocabulary).
按照 OVOD 的惯例,我们将 $\mathcal{C}{\mathrm{test}}$ 和 $\mathcal{C}{\mathrm{det}}$ 的类别空间分别表示为 $\mathcal{C}$ 和 $\mathcal{C}{\mathrm{B}}$。通常,$\mathcal{C}{\mathrm{B}}\subset\mathcal{C}$。$\mathcal{C}{\mathrm{B}}$ 中的类别称为基类 (base categories),而仅出现在 $\mathcal{C}{\mathrm{test}}$ 中的类别则被识别为新类 (novel categories)。新类集合表示为 $\mathcal{C}{\mathrm{N}}=\mathcal{C}\setminus\mathcal{C}{\mathrm{B}}\neq\emptyset$。对于每个类别 $c\in\mathcal{C}$,我们使用 CLIP 编码其文本嵌入 $t_{c}\in\mathbb{R}^{d}$,且 $\mathcal{T}{\mathrm{CLS}}=~{t_{c}}_{c=1}^{C}$($C$ 为类别词汇表大小)。
3.2 Architecture of LaMI-DETR
3.2 LaMI-DETR架构
The overall framework of LaMI-DETR is illustrated in Figure 2. Given an image input, we obtain the spatial feature map using the ConvNext backbone from the pre-trained CLIP image encoder $\phi_{\mathrm{BACKBONE}}$ , which remains frozen during training. Then the feature map is sequentially subjected to a series of operations: a transformer encoder $\left(\varPhi_{\mathrm{ENC}}\right)$ to refine the feature map; a transformer decoder $\phi_{\mathrm{DEC}}$ , producing a set of query features ${f_{j}}{j=1}^{N}$ ; The query features are then processed by a bounding box module \ $\cdot\varPhi_{\mathrm{BBOX.}}$ to infer the positions of objects, denoted as ${\mathbf{b}{j}}{j=1}^{N}$ . We follow the inference pipeline of F-VLM [15] and use VLM score $S^{v l m}$ to calibrate detection score $S^{d e t}$ .
LaMI-DETR的整体框架如图2所示。给定图像输入,我们使用预训练CLIP图像编码器中的ConvNext主干网络$\phi_{\mathrm{BACKBONE}}$ 获取空间特征图,该主干网络在训练期间保持冻结状态。随后对特征图依次执行以下操作:通过Transformer编码器$\left(\varPhi_{\mathrm{ENC}}\right)$ 细化特征图;通过Transformer解码器$\phi_{\mathrm{DEC}}$ 生成一组查询特征${f_{j}}{j=1}^{N}$;这些查询特征随后由边界框模块$\cdot\varPhi_{\mathrm{BBOX.}}$ 处理以推断物体位置,记为${\mathbf{b}{j}}{j=1}^{N}$ {\mathbf {b}j\right }_{j=1}^{N}。我们遵循F-VLM[15]的推理流程,使用VLM分数$S^{v l m}$校准检测分数$S^{d e t}$。
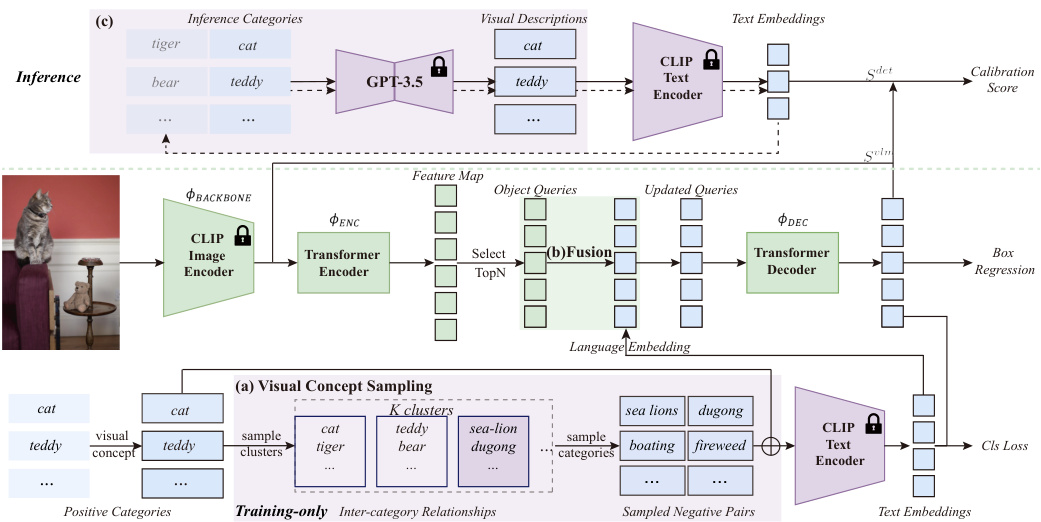
Fig. 2: An overview of LaMI-DETR Framework. LaMI-DETR adapts the DETR model by incorporating a frozen CLIP image encoder as the backbone and replacing the final classification layer with CLIP text embeddings. (a) Visual Concept Sampling, applied only during the training phase, leverages pre-extracted inter-category relationships to sample easy negative categories that are visually distinct from ground truth classes. This encourages the detector to derive more generalized foreground features rather than over fitting to base categories. (b) Language embeddings selected are integrated into the object queries for enhanced classification accuracy. (c) During inference, confusing categories are identified to improve VLM score.
图 2: LaMI-DETR框架概览。该框架通过引入冻结的CLIP图像编码器作为主干网络,并将最终分类层替换为CLIP文本嵌入来改进DETR模型。(a) 视觉概念采样(仅训练阶段使用)利用预提取的类别间关系,从与真实类别视觉差异较大的负类别中采样简单样本,促使检测器学习更具泛化性的前景特征而非过拟合基类。(b) 精选的语言嵌入被整合至对象查询中以提升分类精度。(c) 推理阶段通过识别易混淆类别来优化VLM评分。
Comparison with other Open-Vocabulary DETR. CORA [36] and EdaDet [29] also propose to use a frozen CLIP image encoder in DETR for extracting image features. However, LaMI-DETR significantly differs from these two approaches in the following aspects.
与其他开放词汇DETR的对比。CORA [36] 和 EdaDet [29] 也提出在DETR中使用冻结的CLIP图像编码器来提取图像特征。然而,LaMI-DETR在以下方面与这两种方法有显著差异。
Firstly, regarding the number of backbones used, both LaMI-DETR and CORA employ a single backbone. In contrast, EdaDet utilizes two backbones: a learnable backbone and a frozen CLIP image encoder.
首先,关于使用的骨干网络数量,LaMI-DETR和CORA都采用单一骨干网络。相比之下,EdaDet使用了两个骨干网络:一个可学习的骨干网络和一个冻结的CLIP图像编码器。
Secondly, both CORA and EdaDet adopt an architecture that decouples classification and regression tasks. While this method addresses the issue of failing to recall novel classes, it necessitates extra post-processing steps, such as NMS, disrupting DETR’s original end-to-end structure.
其次,CORA和EdaDet都采用了分类与回归任务解耦的架构。虽然这种方法解决了无法召回新类别的问题,但需要额外的后处理步骤(如NMS),破坏了DETR原有的端到端结构。
Furthermore, both CORA and EdaDet require RoI-Align operations during training. In CORA, the DETR only predicts objectness, necessitating RoIAlign on the CLIP feature map during anchor pre-matching to determine the specific categories of proposals. EdaDet minimizes the cross-entropy loss based on each proposal’s classification scores, obtained through a pooling operation. Consequently, CORA and EdaDet require multiple pooling operations during inference. In contrast, LaMI-DETR simplifies this process, needing only a single pooling operation at the inference stage.
此外,CORA和EdaDet在训练过程中都需要RoI-Align操作。在CORA中,DETR仅预测物体性(objectness),因此在锚框预匹配阶段需要对CLIP特征图进行RoIAlign以确定提案的具体类别。EdaDet则基于每个提案的分类分数(通过池化操作获得)最小化交叉熵损失。因此,CORA和EdaDet在推理阶段需要多次池化操作。相比之下,LaMI-DETR简化了这一流程,在推理阶段仅需单次池化操作。
3.3 Language Model Instruction
3.3 大语言模型指令
Unlike previous methods that only rely on the vision-language alignment of VLMs, we aim to improve open-vocabulary detectors by enhancing concept represent ation and investigating inter-category relationships. To achieve this, we first explain the process of constructing visual concepts and delineating their rela tion ships. In Language Embedding Fusion and Confusing Category sections, we describe methods for more accurately representing concepts during the training and inference processes. The Visual Concept Sampling section addresses how to mitigate over fitting issue through the use of inter-category relationships. Finally, we detail the distinctions with other research effort.
与以往仅依赖视觉语言模型(VLM)对齐的方法不同,我们致力于通过增强概念表征(concept representation)和探究类别间关系来改进开放词汇检测器。为此,我们首先阐释了视觉概念构建及其关系界定的流程。在"语言嵌入融合"和"混淆类别"章节中,我们描述了在训练与推理过程中更精准表征概念的方法。"视觉概念采样"章节则探讨如何利用类别间关系缓解过拟合问题。最后,我们详述了与其他研究的区别。
Inter-category Relationships Extraction. Based on the problem identified in Figure 1, we employ visual descriptions to establish visual concepts, refining concept representation. Furthermore, we utilize T5, which possesses extensive textual semantic knowledge, to measure similarity relationships among visual concepts, thereby extracting inter-category relationships.
跨类别关系提取。基于图 1 中识别的问题,我们采用视觉描述来建立视觉概念,优化概念表征。此外,我们利用具有丰富文本语义知识的 T5 来度量视觉概念之间的相似性关系,从而提取跨类别关系。
As illustraed in Figure 3, given a category name $c\in{\mathcal{C}}$ , we extract its finegrained visual feature descriptors $d$ using the method described in [21]. We define $\mathcal{D}$ as the visual description space for categories in $\mathcal{C}$ . These visual descriptions $d\in\mathcal{D}$ are then sent to the T5 model to obtain the visual description embeddings $e\in\mathcal{E}$ . Consequently, we construct an open set of visual concepts $\mathcal{D}$ and their corresponding embeddings $\mathcal{E}$ . To identify visually similar concepts, we propose clustering the visual description embeddings $\mathcal{E}$ into $K$ cluster centroids. Concepts grouped under the same cluster centroid are deemed to possess similar visual characteristics. The extracted inter-category relationships are then applied in the visual concept sampling as shown in Figure 2(a).
如图 3 所示,给定类别名称 $c\in{\mathcal{C}}$ ,我们使用 [21] 中描述的方法提取其细粒度视觉特征描述符 $d$ 。我们将 $\mathcal{D}$ 定义为 $\mathcal{C}$ 中类别的视觉描述空间。这些视觉描述 $d\in\mathcal{D}$ 随后被输入 T5 模型以获得视觉描述嵌入 $e\in\mathcal{E}$ 。因此,我们构建了一个开放的视觉概念集合 $\mathcal{D}$ 及其对应的嵌入 $\mathcal{E}$ 。为了识别视觉相似的概念,我们提出将视觉描述嵌入 $\mathcal{E}$ 聚类为 $K$ 个聚类中心。被归入同一聚类中心下的概念被认为具有相似的视觉特征。提取的类别间关系随后被应用于视觉概念采样,如图 2(a) 所示。

Fig. 3: Illustration of Inter-category Relationships Extraction. Visual descriptions generated by GPT-3.5 are processed by T5 to cluster categories with visual similarities.
图 3: 跨类别关系提取示意图。GPT-3.5生成的视觉描述通过T5处理,将具有视觉相似性的类别进行聚类。
Language Embedding Fusion. As shown in Figure 2(b), after transformer encoder, each pixel on the feature map ${f_{i}}{i=1}^{M}$ \lbrace \else \text brace left \fi f_i}{i=1}^{M} is interpreted as an ob ject query, with each directly predicting a bounding box. To select the top $N$ scoring bounding boxes as region proposals, the process can be encapsulated as follows:
语言嵌入融合。如图 2(b) 所示,经过 Transformer 编码器后,特征图 ${f_{i}}_{i=1}^{M}$ 上的每个像素被解释为一个对象查询 (object query),每个查询直接预测一个边界框。为了选择得分最高的 $N$ 个边界框作为区域提议 (region proposals),该过程可概括如下:
$$
{q_{j}}_{j=1}^{N}=\operatorname{Top}_{N}\bigl({\mathcal{T}_{\mathrm{cLs}}\cdot f_{i}}_{i=1}^{M}\bigr).
$$
$$
{q_{j}}_{j=1}^{N}=\operatorname{Top}_{N}\bigl({\mathcal{T}_{\mathrm{cLs}}\cdot f_{i}}_{i=1}^{M}\bigr).
$$
In LaMI-DETR, we fuse each query ${q_{j}}_{j=1}^{N}$ with its closest text embedding, resulting in:
在LaMI-DETR中,我们将每个查询${q_{j}}_{j=1}^{N}$与其最接近的文本嵌入进行融合,得到:
$$
{q_{j}}_{j=1}^{N}={q_{j}\oplus t_{j}}_{j=1}^{N},
$$
$$
{q_{j}}_{j=1}^{N}={q_{j}\oplus t_{j}}_{j=1}^{N},
$$
where $\bigoplus$ denotes element-wise addition.
其中 $\bigoplus$ 表示逐元素相加。
On one hand, the visual descriptions are sent to the T5 model to cluster visually similar categories, as previously described. On the other hand, the visual descriptions $d_{j}\in{\mathcal{D}}$ are forwarded to the text encoder of the CLIP model to update the classification weights, denoted as $\mathcal{T}{\mathrm{CLS}}={t{c}^{\prime}}{c=1}^{C}$ , where $t{c}^{\prime}$ represents the text embedding of $d$ in the CLIP text encoder space. Consequently, the text embeddings used in the language embedding fusion process are updated accordingly:
一方面,视觉描述被送入T5模型以聚类视觉相似的类别,如前所述。另一方面,视觉描述 $d_{j}\in{\mathcal{D}}$ 被传递到CLIP模型的文本编码器来更新分类权重,记为 $\mathcal{T}{\mathrm{CLS}}={t{c}^{\prime}}{c=1}^{C}$ ,其中 $t{c}^{\prime}$ 表示 $d$ 在CLIP文本编码器空间中的文本嵌入。因此,语言嵌入融合过程中使用的文本嵌入也相应更新:
$$
{q_{j}}_{j=1}^{N}={q_{j}\oplus t_{j}^{\prime}}_{j=1}^{N}
$$
$$
{q_{j}}_{j=1}^{N}={q_{j}\oplus t_{j}^{\prime}}_{j=1}^{N}
$$
Confusing Category. Due to similar visual concepts often sharing common features, nearly identical visual descriptors can be generated for these categories. This similarity poses challenges in distinguishing similar visual concepts during the inference process.
混淆类别。由于具有相似视觉概念的类别通常共享共同特征,这些类别可能生成几乎相同的视觉描述符。这种相似性在推理过程中对区分相似视觉概念提出了挑战。
To distinguish easily confusable categories during the inference process, we initially identify the most similar category $c^{\mathrm{conf}}\in{\mathcal{C}}$ for each class $c\in{\mathcal{C}}$ within the CLIP text encoder semantic space, based on $\tau_{\mathrm{crs}}$ . We then modify the prompt for generating visual descriptions $d^{\prime}\in\mathcal{D}^{\prime}$ for category $c$ to emphasize the features that differentiate $c$ from $c^{\mathrm{conf}}$ ext {conf}}. Let $t^{\prime\prime}$ be the text embedding of $d^{\prime}$ in the CLIP text encoder space. As shown in Figure 2(c), We update the inference pipeline as follows:
为在推理过程中区分易混淆类别,我们首先基于$\tau_{\mathrm{crs}}$,在CLIP文本编码器语义空间内为每个类别$c\in{\mathcal{C}}$确定最相似类别$c^{\mathrm{conf}}\in{\mathcal{C}}$。随后修改生成视觉描述$d^{\prime}\in\mathcal{D}^{\prime}$的提示词,以突出$c$与$c^{\mathrm{conf}}$的区分特征。设$t^{\prime\prime}$为$d^{\prime}$在CLIP文本编码器空间中的文本嵌入。如图2(c)所示,我们按以下方式更新推理流程:
$$
\begin{array}{r l}&{\mathcal{T}{\mathrm{cLs}}^{\prime}={t_{c}^{\prime\prime}}{c=1}^{C},}\ &{S_{j}^{v l m}=\mathcal{T}{\mathrm{cLs}}^{\prime}\cdot\boldsymbol{\varPhi}{\mathrm{pooling}}\left(b_{j}\right).}\end{array}
$$
Visual Concept Sampling. To address the challenges posed by incomplete annotations in open-vocabulary detection datasets, we employ Federated Loss [47], originally introduced for long-tail datasets [10]. This approach involves randomly selecting a set of categories to calculate detection losses for each minibatch, effectively minimizing issues related to missing annotations in certain classes. Given category occurrence frequency $p=[p_{1},p_{2},\ldots,p_{C}]$ ldots , p_C], where $p_{c}$ denotes the occurrence frequency in training data of the $c^{\mathrm{th}}$ visual concept and $C$ represents the total number of categories. We randomly draw $\boldsymbol{C}{\mathrm{fed}}$ samples based on the probability distribution $p$ . The likelihood of selecting the $c^{\mathrm{th}}$ sample $x_{c}$ is proportional to its corresponding weight $p_{c}$ . This method facilitates the transfer of visual similarity knowledge, extracted by the language model, to the detector, thereby reducing the issue of over fitting:
视觉概念采样。为解决开放词汇检测数据集中标注不完整带来的挑战,我们采用最初为长尾数据集[10]提出的联邦损失(Federated Loss)[47]。该方法通过随机选择一组类别计算每个小批量的检测损失,有效缓解某些类别缺失标注的问题。给定类别出现频率$p=[p_{1},p_{2},\ldots,p_{C}]$,其中$p_{c}$表示第$c^{\mathrm{th}}$个视觉概念在训练数据中的出现频率,$C$为类别总数。我们基于概率分布$p$随机抽取$\boldsymbol{C}{\mathrm{fed}}$个样本,第$c^{\mathrm{th}}$个样本$x_{c}$的选取概率与其对应权重$p_{c}$成正比。该方法能促进语言模型提取的视觉相似性知识向检测器迁移,从而缓解过拟合问题:
$$
P(X=c)=p_{c},\quad{\mathrm{for~}}c=1,2,\ldots,C
$$
$$
P(X=c)=p_{c},\quad{\mathrm{对于~}}c=1,2,\ldots,C
$$
Incorporating federated loss, the classification weight is reformulated as $\tau_{\mathrm{cLs}}=$ ${t_{c}^{\prime\prime}}{c=1}^{\bar{C}{\mathrm{fed}}}$ , where $\mathcal{C}{\mathrm{FED}}$ denotes the categories engaged in the loss calculation of each iteration, and $\boldsymbol{C}{\mathrm{fed}}$ text {fed}} is the count of $\mathcal{C}_{\mathrm{FED}}$ .
结合联邦损失,分类权重被重新表述为 $\tau_{\mathrm{cLs}}=$ ${t_{c}^{\prime\prime}}{c=1}^{\bar{C}{\mathrm{fed}}}$ ,其中 $\mathcal{C}{\mathrm{FED}}$ 表示每次迭代参与损失计算的类别,$\boldsymbol{C}{\mathrm{fed}}$ text {fed}} 是 $\mathcal{C}_{\mathrm{FED}}$ 的计数。
We utilize a frozen CLIP with strong open vocabulary capabilities as LaMIDETR’s backbone. However, due to the limited categories in detection datasets, over fitting to base classes is inevitable after training. To mitigate over training on base categories, we aim to sample straightforward negative categories based on the results of visual concepts clustering. In LaMI-DETR, let the clusters containing the ground truth categories be denoted by $\kappa_{G}$ in a given iteration. We denote all the categories within $K_{G}$ rotect \mathcal {K}G as $\mathcal{C}{g}$ . Specifically, we aim to exclude $\mathcal{C}{g}$ from being sampled in the current iteration. To achieve this, we set the frequency of occurrence for categories within $\mathcal{C}_{g}$ to zero.
我们采用具有强大开放词汇能力的冻结CLIP作为LaMIDETR的骨干网络。然而由于检测数据集的类别有限,训练后对基类的过拟合不可避免。为缓解基类过训练问题,我们基于视觉概念聚类结果采样简单负类别。在LaMI-DETR中,设当前迭代中包含真实类别的聚类为$\kappa_{G}$,将$\mathcal{K}G$内所有类别记为$\mathcal{C}{g}$。
where $p_{c}^{c a l}$ indicates the frequency of occurrence of category $c$ after language model calibration, ensuring visually similar categories are not sampled during this iteration. This process is shown in Figure $2(\mathrm{a})$ .
其中 $p_{c}^{c a l}$ 表示经过语言模型校准后类别 $c$ 的出现频率,确保在此次迭代中不会采样视觉上相似的类别。该过程如图 $2(\mathrm{a})$ 所示。
Comparison with concept enrichment. The visual concept description is different from the concept enrichment employed in DetCLIP [39]. The visual descriptions used in LaMI place more emphasis on the visual attributes inherent to the object itself. In DetCLIP, category label is supplemented with definitions, which may include concepts not present in the pictures to rigorously characterize a class.
与概念增强的对比。视觉概念描述与DetCLIP [39] 中采用的概念增强不同。LaMI使用的视觉描述更侧重于物体本身固有的视觉属性。在DetCLIP中,类别标签会补充定义,这些定义可能包含图片中未出现的概念,以严格表征某个类别。
4 Experiments
4 实验
Section 4.1 introduces the standard dataset and benchmarks commonly utilized in the field, as detailed in [9]. Section 4.2 outlines the implementation and training details of our LaMI-DETR, which leverages knowledge of visual character istics from language models. We present a comparison of our models with existing works in Section 4.3, showcasing state-of-the-art performance. Additionally, Section 4.3 includes results on cross-dataset transfer to demonstrate the genera liz ability of our approach. Finally, Section 4.4 conducts ablation studies to examine the impact of our design decisions.
4.1 节介绍了该领域常用的标准数据集和基准测试,具体细节见 [9]。4.2 节概述了我们 LaMI-DETR 的实现和训练细节,该方法利用了语言模型中视觉特征的知识。4.3 节展示了我们的模型与现有工作的对比,呈现了最先进的性能表现。此外,4.3 节还包含跨数据集迁移的结果,以证明我们方法的泛化能力。最后,4.4 节进行了消融实验,以检验我们设计决策的影响。
4.1 Datasets
4.1 数据集
LVIS. Our experiments are conducted on the LVIS dataset, which includes annotations for $1,203$ object categories. These categories are divided into three groups—rare, common, and frequent—based on the number of training images containing a given class. Following the approach of previous studies, we categorize them into 866 base classes, encompassing frequent and common categories, and 337 novel classes, consisting of rare categories. To create an open-vocabulary scenario, we exclude annotations for novel classes from the training images. In line with standard practice, we report the mean average precision (mAP) for predicted boxes specifically for the rare classes, denoted as AP $\mathbf{r}$ . Additionally, we present the box AP averaged across all classes to reflect overall performance, denoted as mAP.
LVIS。我们的实验在LVIS数据集上进行,该数据集包含1,203个物体类别的标注。这些类别根据包含特定类的训练图像数量分为三组——稀有、常见和频繁。沿用先前研究的方法,我们将它们分为866个基类(包含频繁和常见类别)和337个新类(由稀有类别构成)。为构建开放词汇场景,我们从训练图像中移除了新类别的标注。按照标准做法,我们专门针对稀有类别报告预测框的平均精度均值(mAP)(记为AP r),同时给出所有类别的平均框AP(记为mAP)以反映整体性能。
Object365 and Visual Genome. For a fair comparison with OWL-ViT [20, 22], we adopt the same training settings, utilizing data from Object365 and VisualGenome. To conserve training time, we employ only a $1/3$ random sample of Object365 in our study. With respect to Visual Genome, we meticulously replicate OWL-ViT’s preprocessing steps by eliminating all detection annotations that correspond to the names of LVIS’s rare categories. The resulting curated dataset is referred to as VG dedup.
为与OWL-ViT [20, 22]进行公平比较,我们采用相同的训练设置,使用Object365和VisualGenome的数据。为节省训练时间,本研究仅随机抽取Object365的$1/3$样本。针对VisualGenome,我们严格复现OWL-ViT的预处理流程:剔除所有与LVIS稀有类别名称对应的检测标注,最终处理后的数据集称为VG dedup。
4.2 Implementation Details
4.2 实现细节
Training is conducted on 8 40G A100 GPUs with a total batch size of 32. For the OV-LVIS setting, we train the model for 12 epochs. In the VG-dedup benchmark, to ensure a fair comparison with OWL-ViT, we initially pretrain LaMI-DETR on a randomly sampled $1/3$ of the Object365 dataset for 12 epochs. Subsequently, LaMI-DETR is finetuned on the VG dedup dataset for an additional 12 epochs.
训练在8块40G显存的A100 GPU上进行,总批次大小为32。针对OV-LVIS场景,模型训练12个周期。在VG-dedup基准测试中,为确保与OWL-ViT的公平对比,我们首先在随机采样的Object365数据集$1/3$子集上对LaMI-DETR进行12周期的预训练,随后在VG去重数据集上继续微调12个周期。
The detector utilizes ConVNext-Large [18] from OpenCLIP [12] as its backbone, which remains frozen throughout the training process. LaMI-DETR, building upon DINO, employs 900 queries as specified in detrex [27]. We adhere closely to the original training configurations detailed in detrex, with the exception of employing an exponential moving average (EMA) strategy to enhance training stability. To balance the distribution of training samples, we apply repeat factor sampling [10] using the default hyper parameters. For federated loss, the numbers of categories $\boldsymbol{C}_{\mathrm{fed}}$ text {fed}} are set to 100 and 700 for OV-LVIS and VG dedup datasets, respectively.
该检测器采用OpenCLIP [12]中的ConVNext-Large [18]作为主干网络,并在整个训练过程中保持冻结。基于DINO框架的LaMI-DETR按照detrex [27]的设定使用900个查询向量。我们严格遵循detrex中的原始训练配置,仅额外采用指数移动平均(EMA)策略以提升训练稳定性。为平衡训练样本分布,我们使用默认超参数实施重复因子采样[10]。在联邦损失方面,OV-LVIS和VG去重数据集的类别数$\boldsymbol{C}_{\mathrm{fed}}$分别设置为100和700。
To explore a broader range of visual concepts for more effective clustering, we compile a comprehensive category collection from LVIS, Object365, VisualGenome, Open Images, and ImageNet-21K. Redundant concepts are filtered out using WordNet hypernyms, resulting in a visual concept dictionary comprising 26, 410 unique concepts. During the visual concept grouping phase, this dictionary is clustered into $K$ centers, with $K$ being 128 for OV-LVIS and 256 for VG dedup, respectively.
为了探索更广泛的视觉概念以实现更有效的聚类,我们从LVIS、Object365、VisualGenome、Open Images和ImageNet-21K中整理了一个全面的类别集合。通过WordNet上位词过滤冗余概念后,最终得到一个包含26,410个独特概念的视觉概念词典。在视觉概念分组阶段,该词典被聚类为$K$个中心,其中OV-LVIS的$K$值为128,VG dedup的$K$值为256。
4.3 Open-Vocabulary Detection Results
4.3 开放词汇检测结果
Table 1: LVIS open-vocabulary detection (box AP). LaMI-DETR outperforms the best existing approach by $+7.8$ box $\mathrm{AP}_{r}$ in the standard benchmark. All methods use the same instance-level supervision from LVIS base categories for detection training. †: reports mask AP. $\star$ : uses the image-level data in pre training. We calculate the backbone’s parameters based on models released by CLIP except RN50, which may vary slightly from their actual sizes.
表 1: LVIS开放词汇检测 (边界框AP)。LaMI-DETR在标准基准测试中以边界框 $\mathrm{AP}_{r}$ $+7.8$ 的优势超越现有最佳方法。所有方法均使用LVIS基础类别提供的相同实例级监督数据进行检测训练。†: 报告掩膜AP。 $\star$ : 在预训练阶段使用了图像级数据。除RN50外,我们基于CLIP发布的模型计算骨干网络参数量,可能与实际尺寸存在微小差异。
| 方法 | 预训练模型 | 检测器骨干网络 | 骨干参数量 | 图像级数据集 | APr AP | |
|---|---|---|---|---|---|---|
| VL-PLM [44] | ViT-B/32 | R-50 | 26M | IN-L | 17.2t 27.0t | |
| OV-DETR [40] | ViT-B/32 | R-50 | 26M | × | 17.4t 26.6t | |
| DetPro-Cascade [6] | ViT-B/32 | R-50 | 26M | × | 21.7 | 30.5 |
| Rasheed [26] | ViT-B/32 | R-50 | 26M | IN-L | 21.1t 25.9t | |
| PromptDet [7] | ViT-B/32 | R-50 | 26M | LAION-novel 21.4f 25.3t | ||
| OADP [33] | ViT-B/32 | R-50 | 26M | 21.9 | 28.7 | |
| RegionCLIP [45] | R-50x4 | R-50x4 | 87M | CC3M | 22.0t 32.3t | |
| CORA [36] | R-50x4 | R-50x4 | 87M | × | 22.2 | |
| BARON [35] | ViT-B/32 | R-50 | 26M | CC3M | 23.2 | 29.5 |
| CondHead [34] | R-50x4 | R-50x4 | 87M | CC3M | 25.1 | 33.7 |
| Detic-CN2 [46] | ViT-B/32 | R-50 | 26M | IN-L | 24.6t 32.4t | |
| ViLD-Ens [9] | ViT-B/32 | R-50 | 26M | × | 16.727.8 | |
| F-VLM [15] | R-50x64 | R-50x64 | 420M | 32.8t 34.9t | ||
| OWL-ViT [22] | ViT-L/14 | ViT-L/14 | 306M | × | 25.6 | 34.7 |
| RO-ViT [14] | ViT-B/16 | ViT-B/16 | 86M | ALIGN* | 28.4 | 31.9 |
| RO-ViT [14] | ViT-L/16 | ViT-L/16 | 303M | ALIGN* | 33.6 | 36.2 |
| CFM-ViT [13] | ViT-B/16 | ViT-B/16 | 86M | ALIGN* | 29.6 | 33.8 |
| CFM-ViT [13] | ViT-L/16 | ViT-L/16 | 303M | ALIGN* | 35.6 | 38.5 |
| ours | ConVNext-L ConVNext-L | 196M | × | 43.4 41.3 |
OV-LVIS. We compare our LaMI-DETR framework with the other state-ofthe-art OVOD methods in Table 1. We report overall box AP performance and box AP for "rare" classes only. The latter metric is the key measure of OVOD performance. Our method obtain the best performance on both AP $\mathbf{r}$ and overall mAP compared to existing approaches for open-vocabulary object detection, while utilizing a more challenging strictly open-vocabulary training paradigm without additional data. LaMI-DETR, with a backbone of only 196M parameters significantly less than CFM-ViT’s 303M achieves superior performance. Moreover, LaMI-DETR does not utilize additional image-level datasets. The results demonstrate that LaMI-DETR has lower computational requirements and higher accuracy.
OV-LVIS。我们在表1中将LaMI-DETR框架与其他最先进的OVOD方法进行了比较。我们报告了整体边界框AP性能以及仅针对"稀有"类别的边界框AP。后者是衡量OVOD性能的关键指标。在采用更具挑战性的严格开放词汇训练范式且不引入额外数据的情况下,我们的方法在AP$\mathbf{r}$和整体mAP上均优于现有开放词汇目标检测方案。LaMI-DETR的主干网络仅含1.96亿参数,远低于CFM-ViT的3.03亿参数,却实现了更优性能。此外,LaMI-DETR未使用额外的图像级数据集。结果表明LaMI-DETR具有更低的计算需求和更高的准确度。
Zero-shot LVIS. We evaluate the model’s ability to recognize diverse and rare objects on LVIS in a zero-shot setting. We replace VG-dedup with LVIS vocabulary embeddings for zero-shot detection without finetuning. We assume all categories are novel and set $\alpha,\beta$ =(0.0, 0.25) in Eq 2. We use OWL as the baseline for our models. The results are shown in Table 2. LaMI-DETR outperforms OWLs under the same settings.
零样本 LVIS。我们在零样本设置下评估模型识别 LVIS 中多样化和稀有物体的能力。我们将 VG-dedup 替换为 LVIS 词汇嵌入,以实现无需微调的零样本检测。假设所有类别都是新类别,并在公式 2 中设置 $\alpha,\beta$ =(0.0, 0.25)。我们使用 OWL 作为模型的基线,结果如表 2 所示。在相同设置下,LaMI-DETR 的表现优于 OWL。
Table 2: LVIS zero-shot detection (box AP). §: The models only report fixed AP [4] on LVIS-val. The models depicted in this figure utilize multiple detection datasets, excluding LVIS; therefore, we refer to this configuration as the zero-shot setting.
表 2: LVIS 零样本检测 (box AP)。§: 这些模型仅在 LVIS-val 上报告固定 AP [4]。本图中展示的模型使用了多个检测数据集 (不包括 LVIS),因此我们将此配置称为零样本设置。
| 方法 | 检测器主干网络 | 数据集 | APrAP |
|---|---|---|---|
| GLIP-L [16] | Swin-L | O365, GoldG, Cap4M | 17.1 26.9 |
| GroundingDINO [17] | Swin-L | O365, GoldG, OI, Cap4M, COCO, ReC | 22.0 32.3 |
| DetCLIP [39] | Swin-L | O365, GoldG, YFCC1M | 27.6 31.2 |
| DetCLIPv2* [38] | Swin-L | O365, GoldG, CC15M | 33.3 36.6 |
| OWL-ViT [22] | ViT-L/14 | O365, VG-dedup | 31.2 34.6 |
| OWL-ST [20] | ViT-L/14 | O365, VG-dedup | 34.9 933.5 |
| ours | ConVNext-L | O365, VG-dedup | 37.8 35.4 |
Cross-dataset Transfer. To evaluate the general iz ability of our method in a cross-dataset transfer detection setting, we conduct experiments on the COCO and Objects365-v1 validation split. Specifically, we directly applies the detector trained on the LVIS base categories, while replacing the LVIS class embeddings with those of COCO/Objects365 for transfer detection without further finetuning. All categories were treated as novel. Our best-performing model achieved 42.8 AP on COCO and 21.9 AP on Object365, outperforming CoDet by +3.7 AP on COCO and CFM by +3.2 AP on Object365 according to Table 3.
跨数据集迁移。为评估本方法在跨数据集迁移检测场景中的泛化能力,我们在COCO和Objects365-v1验证集上开展实验。具体而言,直接使用基于LVIS基础类别训练的检测器,仅将LVIS类别嵌入替换为COCO/Objects365的嵌入进行迁移检测(无需微调),所有类别均视为新类别。如表3所示,我们的最佳模型在COCO上达到42.8 AP,在Objects365上达到21.9 AP,较CoDet在COCO指标提升+3.7 AP,较CFM在Objects365指标提升+3.2 AP。
Table 3: Cross-datasets transfer detection from OV-LVIS to COCO and Objects365. F-VLM adopts RN50 in CLIP as backbone, which is larger than standard RN50.
表 3: 从 OV-LVIS 到 COCO 和 Objects365 的跨数据集迁移检测结果。F-VLM 采用 CLIP 中的 RN50 作为主干网络,其规模大于标准 RN50。
| 方法 | 主干网络 | 参数量 | COCO | Objects365 | ||
|---|---|---|---|---|---|---|
| AP | AP50 AP75 | AP | AP50 AP75 | |||
| ViLD [6] | RN50 | 26M | 36.6 | 55.6 39.8 | 11.8 | 18.2 12.6 |
| DetPro [6] | RN50 | 26M | 34.9 | 53.8 37.4 | 12.1 | 18.8 12.9 |
| F-VLM [15] | RN50 | 38M | 32.5 | 53.1 34.6 | 11.9 | 19.2 12.6 |
| BARON [35] | RN50 | 26M | 36.2 | 55.7 39.1 | 13.6 | 21.0 14.5 |
| CoDet [19] | EVA02-L | 304M | 39.1 | 57.0 42.3 | 14.2 | 20.5 15.3 |
| CFM [13] | ViT-L/16 | 303M | — | — | 18.7 | 28.9 20.3 |
| ours | ConvNext-L | 196M | 42.8 57.6 | 46.9 | 21.9 | 30.0 23.5 |
Table 4: Ablations for our model. Language Model Instruction consists of visual concepts sampling, embedding update and confusing categories distinguish. Below the horizontal line are the results with the class factor. See Table 7 for details.
表 4: 模型消融实验结果。语言模型指令包含视觉概念采样、嵌入更新和易混淆类别区分三部分。横线下方为加入类别因子后的结果,详见表 7。
| 联邦损失 (Eq.8) | 嵌入融合 (Eq.4) | 视觉概念采样 (Eq.9) | 嵌入更新 (Eq.5) | 易混淆类别 (Eq.6) | AP | |
|---|---|---|---|---|---|---|
| 1 | 32.2 | |||||
| 7 | 33.0 | |||||
| 3 4 | 40.1 42.5 | |||||
| 5 | ||||||
| 43.4 |
4.4 Ablation Study
4.4 消融实验
To study the advantages of LaMI-DETR, we provide ablation studies on the OV-LVIS benchmark.
为了研究LaMI-DETR的优势,我们在OV-LVIS基准上进行了消融实验。
LaMI-DETR. Table 4 demonstrates the impact of incorporating language model guidance into our LaMI-DETR framework. The version without LaMI module achieves an AP $\mathbf{r}$ of 33.0. By integrating our proposed LaMI module, the model achieves an $\mathrm{AP_{r}}$ of 43.4. The top two rows in Table 4 shows language embedding fusion in Eq.4 brings a $0.8~\mathrm{AP_{r}}$ gain. The $3^{\mathrm{nd}}$ to $5^{\mathrm{th}}$ row in Table 4 adds Visual Concept Sampling, embedding update and Confusing Category dist ingui shing to baseline gradually.
LaMI-DETR。表4展示了将语言模型引导融入LaMI-DETR框架的效果。未搭载LaMI模块的版本取得了33.0的AP $\mathbf{r}$。通过集成我们提出的LaMI模块,模型获得了43.4的$\mathrm{AP_{r}}$。表4前两行显示,公式4中的语言嵌入融合带来了$0.8~\mathrm{AP_{r}}$的提升。表4第$3^{\mathrm{nd}}$至$5^{\mathrm{th}}$行逐步向基线添加了视觉概念采样、嵌入更新和混淆类别区分模块。
Table 5: Ablation study on the confusing category. Zero-shot proposal classification performance on LVIS minival datasets.
表 5: 混淆类别的消融研究。在LVIS minival数据集上的零样本提案分类性能。
| Model | mAccr | mAccc | mAccf | mAcc |
|---|---|---|---|---|
| CLIP | 43.8 | 44.1 | 37.8 | 41.0 |
| visual desc.[21] | 49.5 | 45.8 | 40.2 | 43.4 |
| ours | 52.7 | 46.1 | 41.4 | 44.4 |
Confusing Category. We demonstrate the effectiveness of Confusing Category in Table 5. Given the ground truth bounding boxes, we use different text embeddings to classify their region features. To evaluate the performance, we compute "Mean Accuracy" (accuracy for each category independently with equal weights). For the following strategies, we use RoI-Align to directly extract features from CLIP. The table validates that the CLIP text encoder can discriminate categories from confusing ones with our refined concept representation.
混淆类别。我们在表5中展示了混淆类别的有效性。给定真实边界框,我们使用不同的文本嵌入对其区域特征进行分类。为评估性能,我们计算"平均准确率"(各品类独立计算准确率后等权平均)。针对以下策略,我们使用RoI-Align直接从CLIP提取特征。该表验证了CLIP文本编码器能够通过我们优化的概念表示区分易混淆品类。
Table 6: Ablation study on the cluster designs. For fair comparison, all detectors use classification weights from CLIP text encoder name embeddings. †: Results with class factor. See Table 7 for details.
表 6: 聚类设计的消融研究。为公平比较,所有检测器均使用CLIP文本编码器名称嵌入的分类权重。†: 含类别因子的结果,详见表7。
| Model | ClusterEncoder | ClusterText | APr ARr |
|---|---|---|---|
| baseline | 33.0 40.3 | ||
| baseline+VCS | CLIPTextEncoder | name | 33.5 41.4 |
| baseline+VCS Instructor Embedding | name | 34.1 39.5 | |
| baseline+VCSInstructor Embedding | name+definition | 31.53 37.3 | |
| baseline+VCS Instructor Embedding | name+visual desc. 40.1f 57.0t |
The Cluster Design. Visual Concept Sampling aims to sample negative categories with large visual differences from the positive class, enabling the detector to utilize inter-class relationships by penalizing categories with large visual differences, thus achieving generalization to visually close classes. We validate this claim through the enhancements detailed in Table 6.
集群设计。视觉概念采样旨在从正类中采样视觉差异较大的负类,使检测器能够通过惩罚视觉差异较大的类别来利用类间关系,从而实现视觉相近类别的泛化。我们通过表6中的增强细节验证了这一主张。
Our experimental results in Table 6 demonstrate the effectiveness of our sampling negtive classes method. The first row shows results of baseline. Rows $2^{\mathrm{nd}}{-}5^{\mathrm{th}}$ employ the Visual Concept Sampling module but vary the clustering method. Specifically, the second row clusters category name embeddings from a CLIP text encoder, corresponding to (a) in Figure 1. The third row clusters category name embeddings from the T5 space, corresponding to Figure 1(b). The fourth row aims to match DetCLIP’s concept enrichment by clustering definition embeddings in the T5 space. Finally, the last row presents our full method, clustering category visual description embeddings from the T5 space as Figure 1(c). This systematic ablation analyzes how different semantics and grouping strategies within the Visual Concept Sampling module affect downstream detection performance, validating the importance of visual similarity-based concept sampling for our task.
表6中的实验结果表明了我们采样负类方法的有效性。首行显示基线结果。第2-5行采用视觉概念采样模块但使用不同聚类方法:第二行聚类CLIP文本编码器的类别名称嵌入,对应图1(a);第三行聚类T5空间的类别名称嵌入,对应图1(b);第四行通过聚类T5空间的定义嵌入来匹配DetCLIP的概念增强;最后一行展示我们的完整方法,即如图1(c)所示聚类T5空间的类别视觉描述嵌入。该系统消融实验分析了视觉概念采样模块中不同语义和分组策略如何影响下游检测性能,验证了基于视觉相似性的概念采样对本任务的重要性。
5 Conclusion
5 结论
In this paper, we undertake the first effort to explore inter-category relationships for generalization in OVOD. We introduce LaMI-DETR, a framework that effectively utilize the visual concepts similarity to sample negtive categories during training for learning general iz able object localization and retaining open vocabulary knowledge of VLMs. Additionally, the refined concepts enable effective object classification especially between confusing categoris. Experiments show that LaMI-DETR achieves state-of-the-art performance across various OVOD benchmarks. On the other hand, our method utilizes the CLIP ConvNext-L architecture as the visual backbone. Exploring alternative pre-trained VLMs such as those based on ViT is under-explored here. We leave this for further investigation.
本文首次探索了开放词汇目标检测(OVOD)中跨类别关系对泛化能力的影响。我们提出了LaMI-DETR框架,该框架通过利用视觉概念相似性在训练过程中采样负类别,从而学习可泛化的目标定位能力并保持视觉语言模型(VLM)的开放词汇知识。此外,经过优化的概念表示能有效提升目标分类性能,特别是在易混淆类别之间。实验表明,LaMI-DETR在多个OVOD基准测试中达到了最先进的性能。另一方面,本方法采用CLIP ConvNext-L架构作为视觉主干网络。基于ViT等其他预训练视觉语言模型的探索尚未充分展开,我们将此留待未来研究。
Acknowledgements
致谢
This research is supported in part by National Science and Technology Major Project (2022 ZD 0115502), National Natural Science Foundation of China (NO. 62122010, U23B2010), Zhejiang Provincial Natural Science Foundation of China (Grant No. LD T 23 F 02022 F 02), and Beijing Natural Science Foundation (NO. L231011). We thank the authors of LW-DETR [3]: Qiang Chen and Xinyu Zhang, the author of OADP [33]: Yi Liu and the author of DetPro [6]: Yu Du for their helpful discussions.
本研究部分得到国家科技重大专项(2022ZD0115502)、国家自然科学基金(62122010、U23B2010)、浙江省自然科学基金(LDT23F02022F02)和北京市自然科学基金(L231011)资助。感谢LW-DETR[3]作者Qiang Chen与Xinyu Zhang、OADP[33]作者Yi Liu以及DetPro[6]作者Yu Du的有益讨论。
References
参考文献
18 P. Du, Y. Wang et al.
18 P. Du, Y. Wang 等
6 Supplementary Material
6 补充材料
6.1 Visualization
6.1 可视化
We visualize detection results of LaMI-DETR on LVIS novel categories (Figure 4).
我们在LVIS新类别上可视化了LaMI-DETR的检测结果(图4)。

Fig. 4: Visualization of results by LaMI-DETR on OV-LVIS. For better clarity, we only display the prediction results for novel categories.
图 4: LaMI-DETR 在 OV-LVIS 数据集上的可视化结果。为清晰起见,我们仅展示新类别的预测结果。
6.2 Ablation
6.2 消融实验
In the OVD setting, there exist both base and novel categories during inference. The logits for novel classes are usually lower than those for base categories. This issue is commonly alleviated by rescoring novel categories [36]. We multiply the logit of novel classes by a factor of 5.0 during inference. We include results related to the factor in Table 7.
在OVD设置中,推理阶段同时存在基础类别和新类别。新类别的logits通常低于基础类别。这一问题通常通过重新评分新类别[36]来缓解。我们在推理时将新类别的logit乘以5.0倍。相关因子结果见 表7: 。
Table 7: Novel classes factor. †: results with factor.
表 7: 新类别因子。†: 带因子的结果。
| Model | ClusterEncoder | Cluster Text | APr AP |
|---|---|---|---|
| baseline | 33.0 40.6 | ||
| baseline+VCS | Instructor Embedding | name+visualdesc.34.2 41.7 | |
| baseline+VCst | InstructorEmbedding | name+visual desc. 40.1 40.5 | |
| baseline+LaMI | InstructorEmbedding | name+visual desc.41.7 41.1 | |
| baseline+LaMIt | InstructorEmbedding | name+visualdesc.43.4 41.3 |
6.3 Further Analysis on generalization of LaMI
6.3 LaMI 泛化能力的进一步分析
Figure 5 illustrates the base-to-novel generalization capability of LaMI. Specifically, it employs models trained on the OV-LVIS benchmark to generate proposals. We visualize proposals having an IoU $>0.5$ with the nearest ground-truth box for novel categories in the LVIS validation set.
图 5: 展示了LaMI的基类到新类的泛化能力。具体而言,它采用在OV-LVIS基准上训练的模型来生成候选框。我们可视化了LVIS验证集中与新类别最近真实框IoU $>0.5$ 的候选框。

Fig. 5: Visualization of proposals generated by the model with and without LaMI. Sequentially from top to bottom, each row displays the results for the ground-truth, LaMI-DETR, and the baseline, respectively. For detailed examination, please zoom in.
图 5: 展示模型在使用LaMI与未使用LaMI时生成的提案可视化效果。从上至下各行依次为:真实标注、LaMI-DETR及基线模型的输出结果。建议放大查看细节。
6.4 Confusing Category Details
6.4 混淆类别细节
We provide a detailed description of the Confusing Category module pipeline in LaMI. Based on text embeddings from the CLIP text encoder, we identify visually similar categories for each inference category. Our method then constructs tailored prompts for GPT by incorporating disambiguating context about the confusable categories.
我们详细描述了LaMI中的混淆类别模块流程。基于CLIP文本编码器的文本嵌入 (text embeddings),我们为每个推理类别识别视觉上相似的类别。随后,该方法通过整合关于易混淆类别的消歧上下文,为GPT构建定制化的提示。

Fig. 6: Illustration of Confusing Category module.
图 6: 混淆类别模块示意图。
20 P. Du, Y. Wang et al.
20 P. Du, Y. Wang 等
6.5 Inference Time
6.5 推理时间
Table 8: Zero-shot Evaluation on LVIS-minival. The FPS is evaluated on NVIDIA V100 GPU. To highlight our model’s efficiency, we compare with methods using lighter backbones like Swin-T.
表 8: LVIS-minival 上的零样本评估。FPS 在 NVIDIA V100 GPU 上评估。为突出我们模型的高效性,我们与使用 Swin-T 等轻量级主干网络的方法进行了比较。
| 方法 | 主干网络 | FPS↑ |
|---|---|---|
| GLIP-T | Swin-T | 0.12 |
| GLIPv2-T | Swin-T | 0.12 |
| Grounding DINO-T | Swin-T | 1.5 |
| DetCLIP-T | Swin-T | 2.3 |
| LaMI-DETR | ConvNext-L | 4.5 |
During inference, confusing categories are first selected using cosine similarity with sklearn. Next, API calls regenerate descriptions, followed by updating classifier weights. Finally, the model runs at 4.5 FPS. We report FPS reflecting wall-clock time in tab 8.
在推理过程中,首先使用sklearn的余弦相似度筛选易混淆类别。接着通过API调用重新生成描述,随后更新分类器权重。最终模型以4.5 FPS的速度运行。我们在表8中报告了反映实际运行时间的FPS指标。