DRCT: Saving Image Super-Resolution away from Information Bottleneck
DRCT: 突破图像超分辨率中的信息瓶颈
Abstract
摘要
In recent years, Vision Transformer-based approaches for low-level vision tasks have achieved widespread success. Unlike CNN-based models, Transformers are more adept at capturing long-range dependencies, enabling the reconstruction of images utilizing non-local information. In the domain of super-resolution, Swin-transformer-based models have become mainstream due to their capability of global spatial information modeling and their shiftingwindow attention mechanism that facilitates the interchange of information between different windows. Many researchers have enhanced model performance by expanding the receptive fields or designing meticulous networks, yielding commendable results. However, we observed that it is a general phenomenon for the feature map intensity to be abruptly suppressed to small values towards the network’s end. This implies an information bottleneck and a diminish ment of spatial information, implicitly limiting the model’s potential. To address this, we propose the Dense-residual-connected Transformer (DRCT), aimed at mitigating the loss of spatial information and stabilizing the information flow through dense-residual connections between layers, thereby unleashing the model’s potential and saving the model away from information bottleneck. Experiment results indicate that our approach surpasses state-of-the-art methods on benchmark datasets and performs commendably at the NTIRE-2024 Image SuperResolution $(x4)$ Challenge. Our source code is available at https://github.com/ming053l/DRCT
近年来,基于Vision Transformer的低级视觉任务方法取得了广泛成功。与基于CNN的模型不同,Transformer更擅长捕捉长距离依赖关系,从而能够利用非局部信息重建图像。在超分辨率领域,基于Swin-transformer的模型因其全局空间信息建模能力及促进不同窗口间信息交换的移位窗口注意力机制成为主流。许多研究者通过扩大感受野或设计精细网络来提升模型性能,取得了令人瞩目的成果。然而,我们观察到特征图强度在接近网络末端时突然被抑制至较小值是一种普遍现象,这意味着信息瓶颈和空间信息的衰减,隐性地限制了模型潜力。为此,我们提出稠密残差连接Transformer (DRCT),旨在通过层间稠密残差连接缓解空间信息损失并稳定信息流,从而释放模型潜力并避免信息瓶颈。实验结果表明,我们的方法在基准数据集上超越了现有最优方法,并在NTIRE-2024图像超分辨率 $(x4)$ 挑战赛中表现优异。源代码已发布于https://github.com/ming053l/DRCT
1. Introduction
1. 引言
The task of Single Image Super-Resolution (SISR) is aimed at reconstructing a high-quality image from its lowresolution version. This quest for effective and skilled super-resolution algorithms has become a focal point of research within the field of computer vision, owing to its wide range of applications.
单图像超分辨率 (Single Image Super-Resolution, SISR) 的任务旨在从低分辨率版本重建高质量图像。由于其广泛的应用范围,寻找高效且专业的超分辨率算法已成为计算机视觉领域的研究重点。
Following the foundational studies, CNN-based strategies [8, 19, 20, 35, 39, 40] have predominantly governed the super-resolution domain for an extended period. These strategies largely leverage techniques such as residual learning [12, 36, 46, 52, 61], or recursive learning [18, 21] for developing network architectures, significantly propelling the progress of super-resolution models forward.
在基础研究之后,基于CNN的策略[8, 19, 20, 35, 39, 40]长期主导了超分辨率领域。这些策略主要利用残差学习[12, 36, 46, 52, 61]或递归学习[18, 21]等技术来开发网络架构,极大地推动了超分辨率模型的发展。
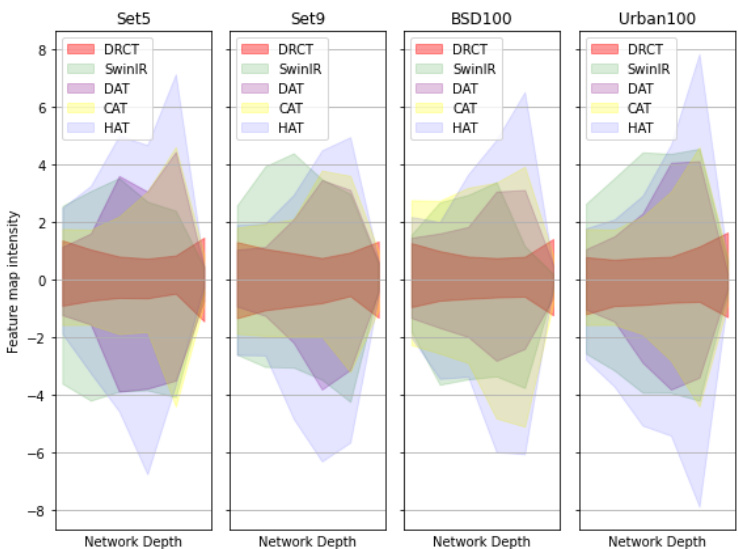
Figure 1. The feature map intensity on various benchmark datasets. We observed that feature map intensities decrease sharply at the end of SISR network, indicating potential information loss. In this paper, we propose DRCT to address this issue by enhancing receptive fields and adding dense-connections within residual blocks to mitigate information bottlenecks, thereby improving performance with a simpler model design.
图 1: 不同基准数据集上的特征图强度。我们观察到,在SISR网络末端特征图强度急剧下降,表明存在潜在信息丢失。本文提出DRCT方法,通过增强感受野并在残差块内添加密集连接来缓解信息瓶颈,从而以更简单的模型设计提升性能。
CNN-based networks have achieved notable success in terms of performance. However, the inductive bias of CNN limits SISR models capture long-range dependencies. Their inherent limitations stem from the parameterdependent scaling of the receptive field and the kernel size of convolution operator within different layers, which may neglect non-local spatial information within images.
基于CNN的网络在性能方面取得了显著成功。然而,CNN的归纳偏置限制了SISR模型捕获长程依赖关系的能力。其固有局限性源于不同层间卷积算子感受野和核大小的参数依赖性缩放,这可能会忽略图像中的非局部空间信息。
To overcome the limitations associated with CNN-based networks, researchers have introduced Transformer-based SISR networks that leverage the capability to model longrange dependencies, thereby enhancing SISR performance. Notable examples include IPT [16] and EDT [33], which utilize pre-training on large-scale dataset like ImageNet [14] to fully leverage the capabilities of Vision Transformer [9] for achieving ideal SISR results. Afterwards, SwinIR [34] incorporates Swin-Transformer [26] into SISR, marked a significant advancement in SISR performance.
为了克服基于CNN网络的局限性,研究人员引入了基于Transformer的超分辨率重建(SISR)网络,利用其建模长距离依赖关系的能力,从而提升SISR性能。典型代表包括IPT [16]和EDT [33],这些方法通过在ImageNet [14]等大规模数据集上进行预训练,充分发挥Vision Transformer [9]的潜力以获得理想的SISR效果。随后,SwinIR [34]将Swin-Transformer [26]引入SISR领域,标志着SISR性能的重大突破。
This approach significantly enhances capabilities beyond those of traditional CNN-based models across various benchmarks. Following SwinIR’s success, several works [4, 6, 32, 34, 58, 59, 63, 64] have built upon its framework. These subsequent studies leverage Transformers to innovate diverse network architectures specifically for super-resolution tasks, showcasing the evolving landscape of SISR technology through the exploration of new architectural innovations and techniques.
该方法显著提升了传统基于CNN模型在各类基准测试中的性能。继SwinIR成功后,多项研究[4, 6, 32, 34, 58, 59, 63, 64]在其框架基础上展开。这些后续研究利用Transformer创新了专为超分辨率任务设计的多样化网络架构,通过探索新的架构创新与技术,展现了单图像超分辨率(SISR)技术的演进图景。
While using Transformer-based SISR model for inference across various datasets, we observed a common phenomenon: the intensity distribution of the feature maps undergoes more substantial changes as the network depth increases. This indicates the spatial information and attention intensity learned by the model. However, there’s often sharp decrease towards the end of the network (refer to Figure 1) , shrinking to a smaller range. This phenomenon suggests that such abrupt changes might be accompanied by a loss of spatial information, indicating the presence of an information bottleneck.
在使用基于Transformer的单图像超分辨率(SISR)模型进行跨数据集推理时,我们观察到一个普遍现象:随着网络深度增加,特征图的强度分布会发生更显著的变化。这表明了模型学习到的空间信息和注意力强度。然而在网络末端经常会出现急剧下降(参见图1),收缩至更小范围。这种现象表明此类突变可能伴随着空间信息丢失,意味着存在信息瓶颈。
Inspired by a series of works by Wang et al., such as the YOLO-family [47, 50], CSPNet [48], and ELAN [49], we consider that network architectures based on SwinIR, despite significantly enlarging the receptive fields through shift-window attention mechanism to address the small receptive fields in CNNs, are prone to gradient bottlenecks due to the loss of spatial information as network depth increases. This implicitly constrains the model’s performance and potential.
受 Wang 等人一系列工作的启发,如 YOLO 系列 [47, 50]、CSPNet [48] 和 ELAN [49],我们认为基于 SwinIR 的网络架构虽然通过移位窗口注意力机制显著扩大了感受野以解决 CNN 中小感受野的问题,但随着网络深度增加,由于空间信息丢失容易导致梯度瓶颈。这隐式地限制了模型的性能和潜力。
To address the issue of spatial information loss due to an increased number of network layers, we introduce the Dense-residual-connected Transformer (DRCT), designed to stabilize the forward-propagation process and prevent information bottlenecks. This is achieved by the proposed Swin-Dense-Residual-Connected Block (SDRCB), which incorporates Swin Transformer Layers and transition layers into each Residual Dense Group (RDG). Consequently, this approach enhances the receptive field with fewer parameters and a simplified model architecture, thereby resulting in improved performance. The main contributions of this paper are summarised as follows:
为解决网络层数增加导致空间信息丢失的问题,我们提出了密集残差连接Transformer (DRCT),旨在稳定前向传播过程并防止信息瓶颈。这一目标通过提出的Swin密集残差连接块 (SDRCB) 实现,该模块将Swin Transformer层和过渡层整合到每个残差密集组 (RDG) 中。因此,该方法以更少的参数和简化的模型架构增强了感受野,从而提升了性能。本文的主要贡献总结如下:
• We observed that as the network depth increases, the intensity of the feature map will gradually increase, then abruptly drop to a smaller range. This severe oscillation may be accompanied by information loss. • We propose DRCT by adding dense-connection within residual groups to stabilize the information flow for deep feature extraction during propagation, thereby saving the
• 我们观察到,随着网络深度增加,特征图的强度会逐渐增强,然后突然降至更小范围。这种剧烈波动可能伴随信息丢失。
• 我们提出DRCT方法,通过在残差组内添加密集连接来稳定传播过程中的深度特征提取信息流,从而保留
SISR model away from the information bottleneck.
SISR模型远离信息瓶颈。
• By integrating dense connections into the SwinTransformer-based SISR model, the proposed DRCT achieves state-of-the-art performance while maintaining efficiency. This approach showcases its potential and raises the upper-bound of the SISR task.
• 通过将密集连接集成到基于SwinTransformer的SISR模型中,所提出的DRCT在保持效率的同时实现了最先进的性能。这一方法展示了其潜力,并提升了SISR任务的上限。
2. Related works
2. 相关工作
2.1. Vision Transformer-based Super-Resolution
2.1. 基于Vision Transformer的超分辨率
IPT [16], a versatile model utilizing the Transformer encoder-decoder architecture, has shown efficacy in several low-level vision tasks. SwinIR [34], building on the Swin Transformer [26] encoder, employs self-attention within local windows during feature extraction for larger receptive fields and greater performance, compared to traditional CNN-based approaches. UFormer [53] introduces an innovative local-enhancement window Transformer block, utilizing a learnable multi-scale restoration modulator within the decoder to enhance the model’s ability to detect both local and global patterns. ART [64] incorporates an attention retractable module to expand its receptive field, thereby enhancing SISR performance. CAT [5] leverages rectanglewindow self-attention for feature aggregation, achieving a broader receptive field. HAT [4] integrates channel attention mechanism [51] with overlapping cross-attention module, activating more pixels to reconstruct better SISR results, thereby setting new benchmarks in the field.
IPT [16] 是一种采用 Transformer 编码器-解码器架构的多功能模型,已在多项低级视觉任务中展现出卓越性能。SwinIR [34] 基于 Swin Transformer [26] 编码器构建,在特征提取阶段采用局部窗口自注意力机制,相比传统基于 CNN 的方法能获得更大感受野和更优性能。UFormer [53] 提出创新的局部增强窗口 Transformer 模块,通过在解码器中引入可学习的多尺度修复调制器,增强模型对局部和全局模式的检测能力。ART [64] 采用注意力可伸缩模块来扩展感受野,从而提升单图像超分辨率 (SISR) 性能。CAT [5] 利用矩形窗口自注意力进行特征聚合,实现更广阔的感受野。HAT [4] 将通道注意力机制 [51] 与重叠交叉注意力模块相结合,通过激活更多像素来重建更优的 SISR 结果,由此树立了该领域的新基准。
2.2. Auxiliary Supervision and Feature Fusion
2.2. 辅助监督与特征融合
Auxiliary Supervision. Deep supervision is a commonly used auxiliary supervision method [13, 31] that involves training by adding prediction layers at the intermediate levels of the model [47–49]. This approach is particularly prevalent in architectures based on Transformers that incorporate multi-layer decoders. Another popular auxiliary supervision technique involves guiding the feature maps produced by the intermediate layers with relevant metadata to ensure they possess attributes beneficial to the target task [11, 28, 30, 52, 61]. Choosing the appropriate auxiliary supervision mechanism can accelerate the model’s convergence speed, while also enhancing its efficiency and performance.
辅助监督。深度监督是一种常用的辅助监督方法 [13, 31],通过在模型的中间层级添加预测层进行训练 [47–49]。这种方法在基于Transformer的多层解码器架构中尤为普遍。另一种流行的辅助监督技术是利用相关元数据引导中间层生成的特征图,确保其具备对目标任务有益的属性 [11, 28, 30, 52, 61]。选择合适的辅助监督机制可以加速模型收敛速度,同时提升其效率和性能。
Feature Fusion. Many studies have explored the integration of features across varying dimensions or multi-level features, such as FPN [22], to obtain richer representations for different tasks [36, 55]. In CNNs, attention mechanisms have been applied to both spatial and channel dimensions to improve feature representation; examples of which include RTCS [10] and SwinFusion [37]. In ViT [9], spatial self-attention is used to model the long-range dependencies between pixels. Additionally, some researchers have investigated the incorporation of channel attention within Transformers [3, 62] to effectively amalgamate spatial and channel information, thereby improving model performance.
特征融合。许多研究探索了跨不同维度或多层次特征的整合,例如 FPN [22],以获取适用于不同任务的更丰富表征 [36, 55]。在 CNN 中,注意力机制被应用于空间和通道维度以提升特征表征能力,例如 RTCS [10] 和 SwinFusion [37]。在 ViT [9] 中,空间自注意力被用于建模像素间的长程依赖关系。此外,部分研究者探索了在 Transformer [3, 62] 中引入通道注意力机制,以有效融合空间与通道信息,从而提升模型性能。
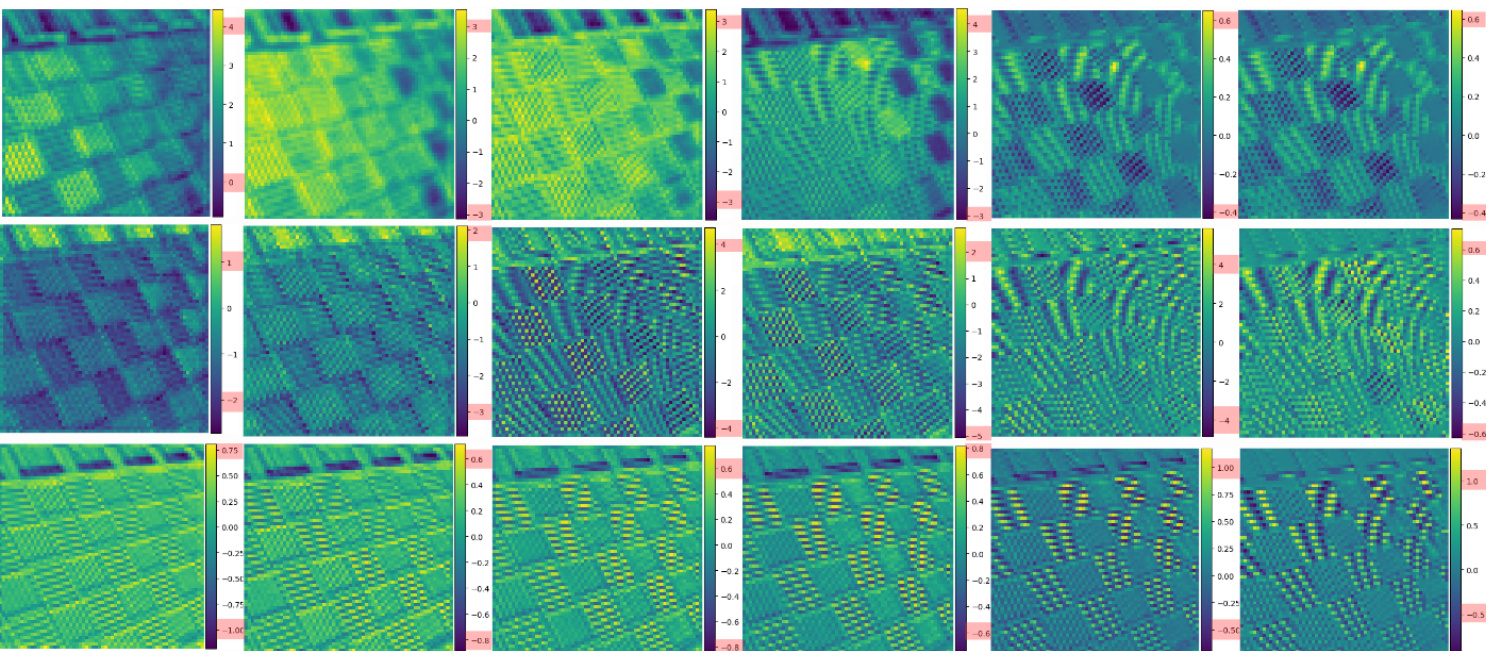
Figure 2. The feature map visualization displays, from top to bottom, SwinIR [34], HAT [4], and the proposed DRCT, with positions further to the right representing deeper layers within the network. For both SwinIR and HAT, the intensity of the feature maps is significant in the shallower layers but diminishes towards the network’s end. We consider this phenomenon implies the loss of spatial information, leading to the limitation and information bottleneck with SISR tasks. As for the proposed DRCT, the learned feature maps are gradually and stably enhanced without obvious oscillations. It represents the stability of the information flow during forward propagation, thereby yielding higher intensity in the final layer’s output. (zoom in to better observe the color-bar besides feature maps.)
图 2: 特征图可视化从上至下依次展示 SwinIR [34]、HAT [4] 和本文提出的 DRCT,越靠右的位置表示网络中的更深层。对于 SwinIR 和 HAT,特征图强度在较浅层显著,但在接近网络末端时减弱。我们认为这种现象意味着空间信息的丢失,导致 SISR (单图像超分辨率) 任务存在局限性和信息瓶颈。至于提出的 DRCT,所学得的特征图逐步且稳定地增强,没有明显波动。这表明前向传播过程中信息流的稳定性,从而在最终层输出中获得更高的强度。(放大可更清晰观察特征图旁的色条。)
3. Problem Statement
3. 问题陈述
3.1. Information Bottleneck Principle
3.1. 信息瓶颈原理
According to the information bottleneck principle [45], the given data $X$ may cause information loss when going through consecutive layers. It may lead to gradient vanish when back-propagation for fitting network parameters and predicting $Y$ , as shown in the equation below:
根据信息瓶颈原理 [45],给定数据 $X$ 在通过连续层时可能导致信息丢失。这会在反向传播拟合网络参数和预测 $Y$ 时引发梯度消失,如下式所示:
$$
I(X,X)\geq I(Y,X)\geq I(Y,f_{\theta}(X))\geq I(X,g_{\phi}(f_{\theta}(X))),
$$
$$
I(X,X)\geq I(Y,X)\geq I(Y,f_{\theta}(X))\geq I(X,g_{\phi}(f_{\theta}(X))),
$$
where $I$ indicates mutual information, $f$ and $g$ are transformation functions, and $\theta$ and $\phi$ are parameters of $f$ and $g$ , respectively.
其中 $I$ 表示互信息,$f$ 和 $g$ 是变换函数,$\theta$ 和 $\phi$ 分别是 $f$ 和 $g$ 的参数。
In deep neural networks, $f_{\theta}(\cdot)$ and $g_{\phi}(\cdot)$ respectively represent the two consecutive layers in neural network. From equation (1), we consider that as the number of network layer becomes deeper, the information flow will be more likely to be lost. In term of SISR tasks, the general goal is to find the mapping function $F$ with optimized function parameters $\theta$ to maximize the mutual information be- tween HR and SR image.
在深度神经网络中,$f_{\theta}(\cdot)$ 和 $g_{\phi}(\cdot)$ 分别表示神经网络中两个连续的层。从方程 (1) 可以看出,随着网络层数加深,信息流更可能丢失。对于单图像超分辨率 (SISR) 任务,总体目标是找到具有优化函数参数 $\theta$ 的映射函数 $F$,以最大化高分辨率 (HR) 图像与超分辨率 (SR) 图像之间的互信息。
$$
F(\mathbf{I}{L R};\theta)=\mathbf{I}{S R};\operatorname*{max}{\theta}I(\mathbf{I}{H R};F(\mathbf{I}_{L R};\theta))
$$
3.2. Spatial Information Vanish in Super-resolution
3.2. 超分辨率中的空间信息消失
Generally speaking, SISR methods [4–6, 32, 34, 58, 63, 64] can generally divided into three parts: (1) shallow feature extraction, (2) deep feature extraction, (3) image reconstruction. Among these methods, there is almost no difference between shallow feature extraction and image reconstruction. The former is composed of simple convolution layers, while the latter consists of convolution layers and upsampling layers. However, deep feature extraction differs significantly. Yet, their common ali ty lies in being composed of various residual blocks, which can be simply defined as:
一般来说,SISR方法[4–6, 32, 34, 58, 63, 64]通常可分为三部分:(1) 浅层特征提取,(2) 深层特征提取,(3) 图像重建。这些方法中,浅层特征提取与图像重建环节几乎无差异:前者由简单卷积层构成,后者则由卷积层和上采样层组成。而深层特征提取则存在显著差异,其共性在于均由各类残差块(residual block)构成,可简单定义为:
$$
X^{l+1}=X^{l}+f_{\theta}^{l+1}(X^{l}),
$$
$$
X^{l+1}=X^{l}+f_{\theta}^{l+1}(X^{l}),
$$
where $X$ indicates inputs, $f$ is a consecutive layers for $l^{:}$ th residual group , and $\theta$ represents the parameters of $f^{l}$ .
其中 $X$ 表示输入,$f$ 是第 $l^{:}$ 个残差组的连续层,$\theta$ 代表 $f^{l}$ 的参数。
Especially for SISR task, two methods of stabilizing information flow or training process are introduced:
针对SISR(单图像超分辨率)任务,特别引入了两种稳定信息流或训练过程的方法:
Residual connection to learn local feature. Adopting residual learning allows the model to only update the differences between layers, rather than output the total information from a previous layer directly [12]. This reduces the difficulty of model training and prevents gradient vanishing locally [61]. However, according to our observations, while this design effectively transmits spatial information between different residual blocks, there may still be infor
采用残差连接学习局部特征。通过残差学习,模型只需更新层间差异而非直接输出前一层全部信息[12],这降低了模型训练难度并局部避免了梯度消失问题[61]。但根据我们观察,该设计虽能有效传递不同残差块间的空间信息,仍可能存在信息...
mation loss.
信息损失
Because the information within a residual block may not necessarily maintain spatial information, this ultimately leads to non-smoothness in terms of feature map intensity (refer to Fig. 2), causing an information bottleneck at the deepest layers during forward propagation. This makes it easy for spatial information to be lost as the gradient flow reaches the deeper layers of the network, resulting in reduced data efficiency or the need for more complex network designs to achieve better performance.
由于残差块内的信息不一定能保持空间信息,这最终会导致特征图强度方面的不平滑 (参考图 2),在前向传播过程中最深层出现信息瓶颈。这使得梯度流到达网络更深层时容易丢失空间信息,导致数据效率降低或需要更复杂的网络设计来实现更好的性能。
Dense connection to stabilize information flow. Incorpora ting dense connections into the Swin-Transformer based SISR model offers two significant advantages. Firstly, global auxiliary supervision. It effectively fuses the spatial information across different residual groups [52, 61], preserving high-frequency features throughout the deep feature extraction. Secondly, saving SISR model away from information bottleneck. By leveraging the integration of spatial information, the model ensures a smooth transmission of spatial information [46], thereby mitigating the information loss and enhancing the receptive field.
密集连接稳定信息流。将密集连接融入基于Swin-Transformer的单图像超分辨率(SISR)模型具有两大优势:首先,全局辅助监督机制能有效融合不同残差组间的空间信息[52,61],在深度特征提取过程中保持高频特征;其次,规避信息瓶颈问题。通过整合空间信息,模型确保了空间信息的流畅传递[46],从而减少信息损失并扩大感受野。
4. Motivation
4. 动机
Dense-Residual Group auxiliary supervision. Motivated by RRDB-Net [52], Wang et al. suggested that incorporating dense-residual connections can aggregate multilevel spatial information and stabilize the training process [35, 41]. We consider that it is possible to stabilize the information flow within each residual-groups during propagation, thereby saving SISR model away from the information bottleneck.
密集残差组辅助监督。受RRDB-Net [52]启发,Wang等人提出密集残差连接能聚合多层级空间信息并稳定训练过程[35, 41]。我们认为该方法可稳定残差组内部信息流传播,从而避免SISR模型陷入信息瓶颈。
Dense connection with Shifting-window mechanism. Recent studies on SwinIR-based methods have concentrated on enlarging the receptive field [4–6, 64] by sophisticated WSA or enhancing the network’s capability to extract features [32, 53] for high-quality SR images. By adding dense-connections [15] within Swin-Transformerbased blocks [26, 34] in the SISR network for deep feature extraction, the proposed DRCT’s receptive field is enhanced while capturing long-range dependencies. Consequently, this approach allows for achieving outstanding performance with simpler model architectures [46], or even using shallower SISR networks.
采用移位窗口机制的密集连接。近期基于SwinIR方法的研究主要聚焦于通过复杂的窗口注意力机制(WSA)扩大感受野[4-6,64],或增强网络提取高质量超分辨率(SR)图像特征的能力[32,53]。通过在单图像超分辨率(SISR)网络的Swin-Transformer模块[26,34]中引入密集连接[15],所提出的DRCT在捕获长程依赖关系的同时增强了感受野。因此,这种方法能以更简单的模型架构[46]甚至更浅层的SISR网络实现卓越性能。
5. Methodology
5. 方法论
5.1. Network Architecture
5.1. 网络架构
As shown in Figure 3, DRCT comprises three distinct components: shallow feature extraction, deep feature extraction, and image reconstruction module, respectively.
如图 3 所示,DRCT 包含三个不同的组件:浅层特征提取、深层特征提取和图像重建模块。
Shallow and deep feature extraction. Given a lowresolution (LR) input $\mathbf{I}{L R}\in\mathbb{R}^{H\times W\times C_{i n}}$ $(H,W$ and $C_{i n}$
浅层与深层特征提取。给定低分辨率 (LR) 输入 $\mathbf{I}{L R}\in\mathbb{R}^{H\times W\times C_{i n}}$ $(H,W$ 和 $C_{i n}$
are the image height, width and input channel number, respectively), we use a $3\times3$ convolution layer $\mathrm{{Conv}(\cdot)}$ [54] to extract shallow feature $\mathbf{F}_{0}\in\mathbb{R}^{H\times W\times C}$ as
图像高度、宽度和输入通道数),我们使用一个$3\times3$卷积层$\mathrm{{Conv}(\cdot)}$ [54]来提取浅层特征$\mathbf{F}_{0}\in\mathbb{R}^{H\times W\times C}$作为
$$
{\bf F}{0}=\mathrm{Conv}({\bf I}_{L Q}),
$$
$$
{\bf F}{0}=\mathrm{Conv}({\bf I}_{L Q}),
$$
Then, we extract deep feature which contains highfrequency spatial information $\mathbf{F}{D F}\in\mathbb{R}^{H\times W\times C}$ from $\mathbf{F}_{0}$ and it can be defined as
然后,我们从 $\mathbf{F}{0}$ 中提取包含高频空间信息的深度特征 $\mathbf{F}_{D F}\in\mathbb{R}^{H\times W\times C}$ ,其定义为
$$
\mathbf{F}{D F}=H_{D F}(\mathbf{F}_{0}),
$$
$$
\mathbf{F}{D F}=H_{D F}(\mathbf{F}_{0}),
$$
where $H_{D F}(\cdot)$ is the deep feature extraction module and it contains $K$ Residual Dense Group (RDG) and single convolution layer $\mathrm{{Conv}(\cdot)}$ for feature transition. More specifically, intermediate features $\mathbf{F}{1},\mathbf{F}{2},\ldots,\mathbf{F}{K}$ and the output deep feature ${\bf F}_{D F}$ are extracted block by block as
其中 $H_{D F}(\cdot)$ 是深度特征提取模块,包含 $K$ 个残差密集组 (Residual Dense Group, RDG) 和用于特征转换的单个卷积层 $\mathrm{{Conv}(\cdot)}$。具体而言,中间特征 $\mathbf{F}{1},\mathbf{F}{2},\ldots,\mathbf{F}{K}$ 和输出的深度特征 ${\bf F}_{D F}$ 通过逐块提取得到
$$
\mathbf{F}{i}=\mathrm{RDG}{i}(\mathbf{F}_{i-1}),\quad i=1,2,\ldots,K,
$$
$$
\mathbf{F}{i}=\mathrm{RDG}{i}(\mathbf{F}_{i-1}),\quad i=1,2,\ldots,K,
$$
$$
\mathbf{F}{D F}=\mathrm{Conv}(\mathbf{F}_{K}),
$$
$$
\mathbf{F}{D F}=\mathrm{Conv}(\mathbf{F}_{K}),
$$
Image reconstruction. We reconstruct the SR image $\mathbf{I}{S R}\in\mathbf{\bar{\mathbb{R}}}^{H\times W\times C_{i n}}$ by aggregating shallow and deep features, it can be defined as:
图像重建。我们通过聚合浅层和深层特征来重建超分辨率图像 $\mathbf{I}{S R}\in\mathbf{\bar{\mathbb{R}}}^{H\times W\times C_{i n}}$,其定义如下:
$$
\mathbf{I}{S R}=H_{\mathrm{rec}}(\mathbf{F}{0}+\mathbf{F}_{D F}),
$$
$$
\mathbf{I}{S R}=H_{\mathrm{rec}}(\mathbf{F}{0}+\mathbf{F}_{D F}),
$$
where $H_{\mathrm{rec}}(\cdot)$ is the function of the reconstruction for fusing high-frequency deep feature ${\bf F}{D F}$ and low-frequency feature $\mathbf{F}_{0}$ together to obtain SR result.
其中 $H_{\mathrm{rec}}(\cdot)$ 是用于融合高频深度特征 ${\bf F}{D F}$ 和低频特征 $\mathbf{F}_{0}$ 以获取超分辨率结果的重建函数。
5.2. Deep Feature Extraction
5.2. 深度特征提取
Residual Dense Group. In developing of RDG, we take cues from RRDB-Net [52] and RDN [61], employing a residual-dense block (RDB) as the foundational unit for SISR. The reuse of feature maps emerges as the enhanced receptive field in the RDG’s feed-forward mechanism. To expound further, RDG with several SDRCB enhances the capability to integrate information across different scales, thus allowing for a more comprehensive feature extraction. RDG facilitates the information flow within residual group, capturing the local features and spatial information group by group.
残差密集组 (Residual Dense Group)。在RDG的开发过程中,我们借鉴了RRDB-Net [52]和RDN [61]的思路,采用残差密集块 (RDB) 作为SISR的基础单元。特征图的重用体现在RDG前馈机制中增强的感受野上。进一步说明,配备多个SDRCB的RDG增强了跨尺度信息整合能力,从而实现更全面的特征提取。RDG促进了残差组内的信息流动,逐组捕获局部特征和空间信息。
Swin-Dense-Residual-Connected Block. In purpose of capturing the long-range dependency, we utilize the shifting window self-attention mechanism of Swin-Transformer Layer (STL) [26, 34] for obatining adaptive receptive fields, complementing RRDB-Net by focusing on multi-level spatial information. This synergy leverages STL to dynamically adjust the focus of the model based on the global content of the input, allowing for a more targeted and efficient extraction of features. This mechanism ensures that even as the depth of the network increases, global details are preserved, effectively enlarging and enhancing the receptive field without compromising. By integrating STLs with dense-residual connections, the architecture benefits from both a vast receptive field and the capability to hone in on the most relevant information, thereby enhancing the model’s performance in SISR tasks requiring detailed and context-aware processing. For the input feature maps $\mathbf{Z}$ within RDG, the SDRCB can be defined as:
Swin-Dense-Residual-Connected Block。为了捕捉长程依赖关系,我们采用Swin-Transformer Layer (STL) [26,34]的移位窗口自注意力机制来获取自适应感受野,通过关注多层级空间信息来补充RRDB-Net。这种协同作用利用STL根据输入内容的全局信息动态调整模型关注点,实现更精准高效的特征提取。该机制确保即使网络深度增加,全局细节仍能保留,在不损失性能的前提下有效扩大并增强感受野。通过将STL与密集残差连接相结合,该架构既能获得广阔的感受野,又能聚焦最相关信息,从而提升模型在需要细节和上下文感知处理的SISR任务中的性能。对于RDG内的输入特征图$\mathbf{Z}$,SDRCB可定义为:
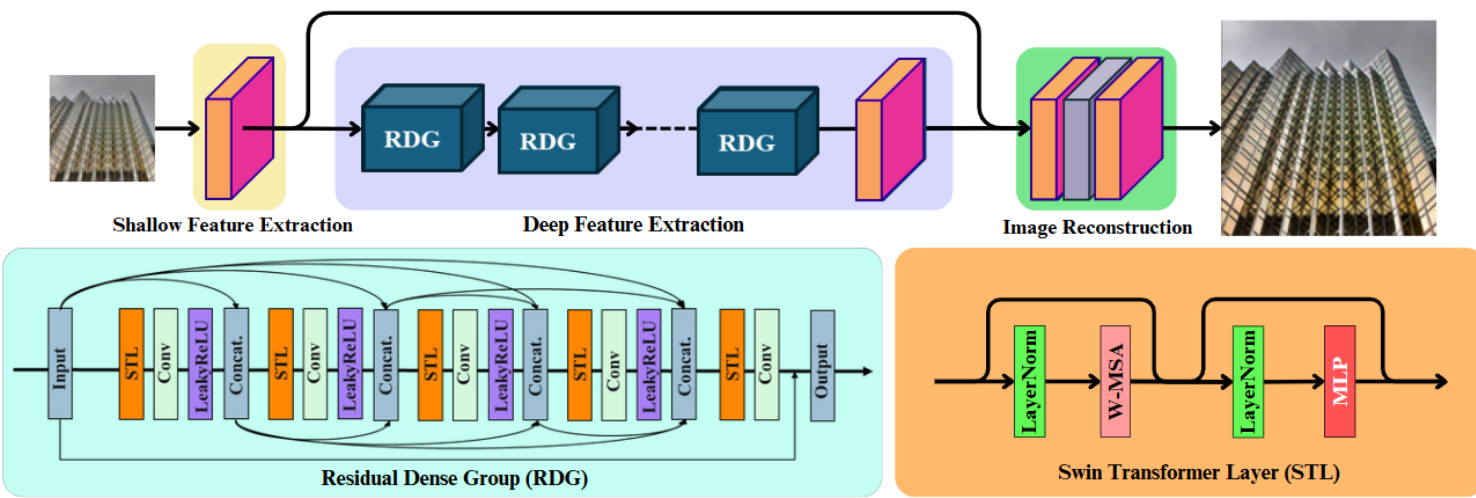
Figure 3. The overall architecture of the proposed Dense-residual-connected Transformer (DRCT) and the structure of Residual-Dense Group (RDG). Each RDG contains five consecutive Swin-Dense-Residual-Connected Blocks (SDRCBs). By integrating dense-connection [15] into SwinIR [34], the efficiency can be improved for Saving Image Super-resolution away from Information Bottleneck.
图 3: 提出的密集残差连接Transformer (DRCT) 整体架构及残差密集组 (RDG) 结构。每个RDG包含五个连续的Swin密集残差连接块 (SDRCBs)。通过将密集连接 [15] 集成到SwinIR [34] 中,可提升"远离信息瓶颈的图像超分辨率"任务效率。
$$
\mathbf{Z}{j}=H_{\operatorname{trans}}(\operatorname{STL}([\mathbf{Z},...,\mathbf{Z}_{j-1}])),j=1,2,3,4,5,
$$
$$
\mathbf{Z}{j}=H_{\operatorname{trans}}(\operatorname{STL}([\mathbf{Z},...,\mathbf{Z}_{j-1}])),j=1,2,3,4,5,
$$
$$
\mathrm{{SDRCB}}(\mathbf{Z})=\alpha\cdot\mathbf{Z}_{5}+\mathbf{Z},
$$
$$
\mathrm{{SDRCB}}(\mathbf{Z})=\alpha\cdot\mathbf{Z}_{5}+\mathbf{Z},
$$
where $[\cdot]$ denotes the concatenation of multi-level feature maps produced by the previous layers. $H_{\mathrm{trans}}(\cdot)$ refers to the convolution layer with a LeakyReLU activate function for feature transition. The negative slope of LeakyReLU is set to 0.2. $\mathrm{{Conv}_{1}}$ is the $1\times1$ convolution layer, which is used to adaptively fuse a range of features with different levels [42]. $\alpha$ represents residual scaling factor, which is set to 0.2 for stabilizing the training process [52].
其中 $[\cdot]$ 表示前几层生成的多级特征图的拼接。$H_{\mathrm{trans}}(\cdot)$ 指代带有 LeakyReLU 激活函数的卷积层,用于特征转换。LeakyReLU 的负斜率设为 0.2。$\mathrm{{Conv}_{1}}$ 是 $1\times1$ 卷积层,用于自适应融合不同层次的特征范围 [42]。$\alpha$ 表示残差缩放因子,为稳定训练过程设为 0.2 [52]。
5.3. Same-task Progressive Training Strategy
5.3. 同任务渐进式训练策略
In recent years, Progressive Training Strategy (PTS) [17, 25] has gained increased attention and can be seen as a method of fine-tuning. Compared to conventional training methods, PTS tends to converge model parameters to more desirable local minima. HAT [4] introduces the Sametask Pre-training, which aims to train the model on a large dataset like ImageNet [14] before fine-tuning it on a specific dataset, leading to improved SISR results. Lei et al. [57] proposed initially training a SISR network with L1-loss and then using L2-loss to eliminate artifacts, achieving better results on the PSNR metric. This has been widely adopted [64]. We proposed a Same-task Progressive Training Strategy (SPTS). At first, we pre-trained DRCT on ImageNet to initialize model parameters and then fine-tuned on specific datasets with L1 loss,
近年来,渐进式训练策略 (Progressive Training Strategy, PTS) [17, 25] 受到越来越多的关注,可视为一种微调方法。与传统训练方法相比,PTS 倾向于将模型参数收敛到更理想的局部最小值。HAT [4] 提出了同任务预训练 (Sametask Pre-training),旨在像 ImageNet [14] 这样的大数据集上训练模型,然后在特定数据集上进行微调,从而提升 SISR 效果。Lei 等人 [57] 提出先用 L1 损失函数训练 SISR 网络,再用 L2 损失函数消除伪影,在 PSNR 指标上取得了更好效果,该方法已被广泛采用 [64]。我们提出了同任务渐进式训练策略 (Same-task Progressive Training Strategy, SPTS):首先在 ImageNet 上预训练 DRCT 以初始化模型参数,随后在特定数据集上用 L1 损失进行微调。
$$
\ell_{L1}=\left|I_{H R}-I_{S R}\right|_{1},
$$
$$
\ell_{L1}=\left|I_{H R}-I_{S R}\right|_{1},
$$
and finally use L2 loss to eliminate singular pixels and artifacts, therefore further archiving greater performance on PSNR metric.
最后使用L2损失函数消除奇异像素和伪影,从而在PSNR指标上进一步提升性能。
$$
\ell_{L2}=\left|I_{H R}-I_{S R}\right|_{2}
$$
$$
\ell_{L2}=\left|I_{H R}-I_{S R}\right|_{2}
$$
6. Experiment Results
6. 实验结果
6.1. Dataset
6.1. 数据集
Our DRCT model is trained on DF2K, a substantial aggregated dataset that includes DIV2K [1] and Flickr2K [44]. DIV2K provides 800 images for training, while Flickr2K contributes 2650 images. For the training input, we generate LR versions of these images by applying a bicubic down sampling method with scaling factors of 2, 3, and 4, respectively. To assess the effectiveness of our model, we conduct performance evaluations using well-known SISR benchmark datasets such as Set5 [2], Set14 [56], BSD100 [38], Urban100 [29], and Manga109 [24].
我们的 DRCT 模型在 DF2K 数据集上进行训练,这是一个包含 DIV2K [1] 和 Flickr2K [44] 的大规模聚合数据集。DIV2K 提供 800 张训练图像,而 Flickr2K 贡献了 2650 张图像。对于训练输入,我们通过分别应用缩放因子为 2、3 和 4 的双三次下采样方法生成这些图像的低分辨率 (LR) 版本。为了评估模型的有效性,我们使用知名的 SISR 基准数据集进行性能评估,包括 Set5 [2]、Set14 [56]、BSD100 [38]、Urban100 [29] 和 Manga109 [24]。
6.2. Implementation Details
6.2. 实现细节
The training process can be structured into three phases, as Section 4-3 illustrates. (1) pre-trained on ImageNet [14], (2) optimize the model on the given dataset, (3) L2-loss for PSNR enhancement. Throughout the training process, we use the Adam optimizer with $\beta_{1}=0.9$ , and $\beta_{2}=0.999$ and train for $800k$ iterations in the first and second stages. The learning rate is set to $2e-4$ , and the multi-step learning scheduler is also used. The learning rate is halved at the $300k$ , $500k$ , $650k$ , $700k$ , $750k$ iterations respectively.
训练过程可分为三个阶段,如第4-3节所示:(1) 在ImageNet [14]上进行预训练,(2) 在给定数据集上优化模型,(3) 使用L2损失函数提升PSNR。整个训练过程中,我们采用Adam优化器,参数设为$\beta_{1}=0.9$和$\beta_{2}=0.999$,并在第一、二阶段进行$800k$次迭代训练。初始学习率设置为$2e-4$,同时采用多步学习率调度器:分别在$300k$、$500k$、$650k$、$700k$、$750k$次迭代时将学习率减半。
Table 1. Quantitative comparison with the several peer-methods on benchmark datasets. ”†” indicates that methods adopt pre-training strategy [4] on ImageNet. ” $\because\ddagger^{,}$ represents that methods use same-task progressive-training strategy. The top three results are marked in red, blue, and orange , respectively.
表 1: 在基准数据集上与多种同类方法的定量比较。"†"表示方法采用ImageNet预训练策略[4]。"$\because\ddagger^{,}$"代表方法使用同任务渐进式训练策略。前三名结果分别用红、蓝、橙三色标出。
| 方法 | 尺度 | 训练数据 | Set5 [2] PSNR | SSIM | Set14 [56] PSNR | SSIM | BSD100 [38] PSNR | SSIM | Urban100 [29] PSNR | SSIM | Manga109 [24] PSNR | SSIM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EDSR [35] | ×2 | DIV2K | 38.11 | 0.9602 | 33.92 | 0.9195 | 32.32 | 0.9013 | 32.93 | 0.9351 | 39.10 | 0.9773 |
| RCAN [60] | ×2 | DIV2K | 38.27 | 0.9614 | 34.12 | 0.9216 | 32.41 | 0.9027 | 33.34 | 0.9384 | 39.44 | 0.9786 |
| SAN [20] | ×2 | DIV2K | 38.31 | 0.9620 | 34.07 | 0.9213 | 32.42 | 0.9028 | 33.10 | 0.9370 | 39.32 | 0.9792 |
| IGNN [19] | ×2 | DIV2K | 38.24 | 0.9613 | 34.07 | 0.9217 | 32.41 | 0.9025 | 33.23 | 0.9383 | 39.35 | 0.9786 |
| HAN [40] | ×2 | DIV2K | 38.27 | 0.9614 | 34.16 | 0.9217 | 32.41 | 0.9027 | 33.35 | 0.9385 | 39.46 | 0.9785 |
| NLSN [39] | ×2 | DIV2K | 38.34 | 0.9618 | 34.08 | 0.9231 | 32.43 | 0.9027 | 33.42 | 0.9394 | 39.59 | 0.9789 |
| SwinIR [34] | ×2 | DF2K | 38.42 | 0.9623 | 34.46 | 0.9250 | 32.53 | 0.9041 | 33.81 | 0.9427 | 39.92 | 0.9797 |
| CAT-A [5] | ×2 | DF2K | 38.51 | 0.9626 | 34.78 | 0.9265 | 32.59 | 0.9047 | 34.26 | 0.9440 | 40.10 | 0.9805 |
| HAT [4] | ×2 | DF2K | 38.63 | 0.9630 | 34.86 | 0.9274 | 32.62 | 0.9053 | 34.45 | 0.9466 | 40.26 | 0.9809 |
| DAT [6] | ×2 | DF2K | 38.58 | 0.9629 | 34.81 | 0.9272 | 32.61 | 0.9051 | 34.37 | 0.9458 | 40.33 | 0.9807 |
| DRCT (Ours) | ×2 | DF2K | 38.62 | 0.9628 | 34.84 | 0.9272 | 32.62 | 0.9051 | 34.44 | 0.9464 | 40.31 | 0.9804 |
| IPT [16] | ×2 | ImageNet | 38.37 | - | 34.43 | - | 32.48 | - | 33.76 | - | - | - |
| EDT [33] | ×2 | DF2K | 38.63 | 0.9632 | 34.80 | 0.9273 | 32.74 | 0.9052 | 34.27 | 0.9456 | 40.37 | 0.9811 |
| HAT-L [4] | ×2 | DF2K | 38.91 | 0.9646 | 35.29 | 0.9293 | 32.76 | 0.9066 | 35.09 | 0.9505 | 41.01 | 0.9831 |
| DRCT-L (Ours) | ×2 | DF2K | 39.82 | 0.9644 | 35.24 | 0.9284 | 29.25 | 0.8093 | 35.11 | 0.9506 | 40.94 | 0.9828 |
| EDSR [35] | ×3 | DIV2K | 34.65 | 0.9280 | 30.52 | 0.8462 | - | - | - | 0.8653 | 34.17 | 0.9476 |
| RCAN [60] | ×3 | DIV2K | 34.74 | 0.9299 | 30.65 | 0.8482 | 29.32 | 0.8111 | - | - | 34.44 | 0.9499 |
| SAN [20] | ×3 | DIV2K | 34.75 | 0.9300 | 30.59 | 0.8476 | 29.33 | - | 29.09 | 0.8702 | 34.30 | 0.9494 |
| IGNN [19] | ×3 | DIV2K | 34.72 | 0.9298 | 30.66 | 0.8484 | - | 0.8112 | 28.93 | - | - | - |
| HAN [40] | ×3 | DIV2K | 34.75 | 0.9299 | 30.67 | 0.8483 | 29.31 | 0.8105 | 29.03 | 0.8696 | 34.39 | 0.9496 |
| NLSN [39] | ×3 | DIV2K | 34.85 | 0.9306 | 30.70 | 0.8485 | 29.32 | 0.8110 | 29.10 | 0.8705 | 34.48 | 0.9500 |
| SwinIR [34] | ×3 | DF2K | 34.97 | 0.9318 | - | - | 29.52 | 0.8145 | 29.75 | 0.8826 | 35.12 | 0.9537 |
| CAT-A [5] | ×3 | DF2K | 35.06 | 0.9326 | 31.04 | 0.8538 | 29.54 | 0.8167 | 30.23 | 0.8862 | 35.38 | 0.9546 |
| HAT [4] | ×3 | DF2K | 35.07 | 0.9329 | 31.08 | 0.8555 | 29.55 | 0.8169 | 30.18 | 0.8896 | 35.53 | 0.9552 |
| DAT [6] | ×3 | DF2K | 35.16 | 0.9331 | 31.11 | 0.8550 | 29.68 | 0.8182 | 30.34 | 0.8886 | 35.59 | 0.9554 |
| IPT [16] | ×3 | ImageNet | 34.87 | - | 30.85 | - | 29.38 | 0.8165 | 29.49 | - | - | 0.9575 |
| EDT [33] | ×3 | DF2K | 35.13 | 0.9328 | 31.09 | 0.8553 | 29.53 | - | 30.07 | 0.8863 | 35.47 | 0.9550 |
| HAT-L [4] | ×3 | DF2K | 35.28 | 0.9345 | 31.47 | - | 29.63 | 0.8191 | 30.92 | 0.8981 | 36.02 | 0.9576 |
| DRCT-L (Ours) | ×3 | DF2K | 35.32 | 0.9348 | 31.54 | 0.8591 | 29.68 | 0.7420 | 31.14 | 0.9004 | 36.16 | 0.9585 |
| EDSR [35] | ×4 | DIV2K | - | - | - | - | - | - | - | - | - | - |
Weight decay is not applied, and the batch size is set to 32. In the architecture of DRCT, the configuration of depth and width is maintained identically to that of HAT [4]. To elaborate, both the number of RDG and SDRCB units are established at 6, and the channel number of intermediate feature maps is designated as 180. The attention head number and window size are set to 6 and 16 for window-based multi-head self-attention (W-MSA). In terms of data preparation, HR patches with dimensions of $256~\times~256$ pixels were extracted from the HR images. To improve the genera liz ability, we apply random horizontal flips and rotation augmentation.
权重衰减未应用,批量大小设置为32。在DRCT架构中,深度和宽度的配置与HAT [4]保持一致。具体而言,RDG和SDRCB单元的数量均设为6,中间特征图的通道数指定为180。基于窗口的多头自注意力(W-MSA)的头数和窗口大小分别设置为6和16。在数据准备方面,从高分辨率(HR)图像中提取尺寸为$256~\times~256$像素的HR图像块。为提高泛化能力,我们应用了随机水平翻转和旋转增强。

Figure 4. Visual comparison on $\times4$ SISR. The patches for comparison are marked with red boxes in the original images. The higher the PSNR/SSIM metrics, the better the performance..
图 4: $\times4$ 单图像超分辨率(SISR)的视觉对比。原始图像中用红色方框标出待比较的局部区域。PSNR/SSIM指标越高表示性能越好。
6.3. Quantitative Results
6.3. 定量结果
For the evaluation, we use full RGB channels and ignore the ( $2\times\mathrm{scale})$ pixels from the border. PSNR and SSIM metrics are used to evaluation criteria. Table 1 presents the quantitative comparison of our approach and the state-ofthe-art methods, including EDSR [35], RCAN [60], SAN [20], IGN [19], HAN [40], NLSN [39], SwinIR [34], CAT- A [5], DAT [6], as well as approaches using ImageNet pretraining, such as IPT [16], EDT [33] and HAT [4]. We can see that our method outperforms the other methods significantly on all benchmark datasets. In addition, the DRCTL can bring further improvement and greatly expand the performance upper-bound on SISR tasks. Even with fewer model parameters and computational requirements, DRCT is also significantly greater than the state-of-the-art methods.
在评估中,我们使用完整的RGB通道,并忽略边界处 ( $2\times\mathrm{scale}$ ) 像素。采用PSNR和SSIM作为评价指标。表1展示了我们的方法与现有先进方法的定量对比,包括EDSR [35]、RCAN [60]、SAN [20]、IGN [19]、HAN [40]、NLSN [39]、SwinIR [34]、CAT-A [5]、DAT [6],以及使用ImageNet预训练的方法如IPT [16]、EDT [33]和HAT [4]。可以看出,我们的方法在所有基准数据集上均显著优于其他方法。此外,DRCTL能带来进一步改进,并大幅提升SISR任务的性能上限。即使模型参数量和计算需求更少,DRCT仍明显优于现有先进方法。
6.4. Visual Comparison
6.4. 视觉对比
The visual comparisons displayed in Figure 4. For the selected images from Urban100 [29], DRCT is effective in restoring structures, whereas other methods suffer from notably blurry effects. The visual results demonstrate the superiority of our approach.
图 4 展示了视觉对比结果。对于从Urban100 [29] 数据集中选取的图像,DRCT能有效恢复结构,而其他方法则存在明显的模糊效应。可视化结果证明了我们方法的优越性。

Figure 5. The LAM [27] visualization. DRCT improves performance by enhancing the receptive field to mitigate the issue of spatial information loss in deeper layers of the network.
图 5: LAM [27] 可视化效果。DRCT 通过增强感受野 (receptive field) 来缓解网络深层空间信息丢失问题,从而提升性能。
Along with providing visualization s for the LAM [27], we compute the Diffusion Index (DI), which is the attribution-based analysis. The DI reflects the range of involved pixels. A higher DI refers to a wider range of attention. In scenarios where DRCT used fewer parameters (which will be discussed in the next subsection), it achieves a higher DI. This outcome suggests that, after enhancing the receptive field through SDRCB, the model can leverage a long-range dependency and non-local information for SISR without the need for intricately designed W-MSA.
在提供LAM [27]可视化的同时,我们计算了基于归因分析的扩散指数(Diffusion Index, DI)。DI反映了所涉及像素的范围,数值越高表示注意力覆盖范围越广。当DRCT使用较少参数时(下节将讨论),其DI值反而更高。这一结果表明:通过SDRCB增强感受野后,模型无需复杂设计的W-MSA模块,即可利用长程依赖和非局部信息进行SISR任务。

Figure 6. The model complexity comparison between SwinIR, HAT, and proposed DRCT evaluated on Urban100 [29] dataset.
图 6: 在Urban100 [29]数据集上评估的SwinIR、HAT与所提DRCT模型之间的复杂度对比。
6.5. Model Complexity
6.5. 模型复杂度
To demonstrate the potential of our proposed DRCT, we conducted further analysis on model complexity and performance.
为了展示我们提出的DRCT的潜力,我们对模型复杂度和性能进行了进一步分析。
Model efficiency. In Table 2, the proposed DRCT clearly requires fewer computational resources compared to HAT in terms of parameter size, multiply-add operations, memory requirements, and FLOPs. Specifically, when scaling up the model sizes of DRCT and HAT, DRCT-L sur- passes HAT-L in all metrics.
模型效率。在表 2 中,所提出的 DRCT 在参数量、乘加运算、内存需求和 FLOPs 方面明显比 HAT 需要更少的计算资源。具体而言,当扩大 DRCT 和 HAT 的模型规模时,DRCT-L 在所有指标上都超过了 HAT-L。
Model performance. From Figure 6, we can observe that the performance curves of the HAT and SwinIR models are approaching horizontal lines, suggesting that the performance is nearing a bottleneck and its upper-bound, even if scaling up the model parameters.
模型性能。从图 6 可以看出,HAT 和 SwinIR 模型的性能曲线接近水平线,这表明即使扩大模型参数,性能也接近瓶颈和上限。
This demonstrates that the design of DRCT, which incorporates dense-connections in the residual groups within a Swin-transformer-based model to stabilize the information flow, achieves convincing results with a reduced computational burden.
这表明,DRCT的设计在基于Swin-transformer的模型中采用残差组密集连接来稳定信息流,以较低计算负担获得了令人信服的结果。
Table 2. Model complexity analysis for $(\times4)$ SISR on Urban100.
表 2: Urban100 上 $(\times4)$ SISR 的模型复杂度分析
| #参数量 | #乘加运算数 | 前向或反向传播 | FLOPs | |
|---|---|---|---|---|
| HAT [4] | 20.77M | 11.22G | 2053.42M | 42.18G |
| DRCT | 14.13M | 5.92G | 1857.55M | 7.92G |
| HAT-L[4] | 40.846M | 76.69G | 5165.39M | 79.60G |
| DRCT-L | 27.580M | 9.20G | 4278.19M | 11.07G |
6.6. NTIRE Image Super-Resolution Challenge
6.6. NTIRE 图像超分辨率 挑战赛
The dataset for the NTIRE 2024 Image Super-Resolution (x4) Challenge [7] comprises three collections: DIV2K [1], Flickr2K [44], and LSDIR [23]. Specifically, the DIV2K dataset provides 800 pairs of HR and LR images for training. The LR images are obtained from the HR images after bicubic down sampling with specific scaling factor. For validation, it offers $100\mathrm{LR}$ images for the purpose of creating SR images, with the HR versions to be made available at the challenge’s final stage. Additionally, the test dataset includes 100 varied LR images. The self-ensemble strategy is used for testing-time augmentation (TTA) [43]. Our TTA methods include random rotation, and horizontal and vertical flipping. We also conducted a model ensemble strategy for fusing different reconstructed results by HAT [4] and the proposed DRCT to eliminate the annoying artifacts and improve final SR quality. Our SISR model was entered into both the validation and testing phases of this challenge, with the detailed in Table 3.
NTIRE 2024图像超分辨率(x4)挑战赛[7]数据集包含三个子集:DIV2K[1]、Flickr2K[44]和LSDIR[23]。具体而言,DIV2K数据集提供800对高分辨率(HR)与低分辨率(LR)训练图像,其中LR图像通过双三次降采样(bicubic down sampling)特定比例因子从HR图像生成。验证集包含100张用于生成超分辨率(SR)图像的LR图像,其对应HR版本将在挑战赛最终阶段公布。测试数据集则包含100张多样化LR图像。我们采用自集成策略(self-ensemble strategy)进行测试时增强(TTA)[43],具体方法包括随机旋转、水平/垂直翻转。同时通过融合HAT[4]与所提DRCT的不同重建结果实施模型集成策略,以消除伪影并提升最终SR质量。我们的单图像超分辨率(SISR)模型参与了该挑战赛验证与测试阶段,详细配置见表3。
Table 3. NTIRE 2024 Challenge Results with $\mathbf{x}4\mathrm{SR}$ in terms of PSNR and SSIM on validation phase and testing phase.
表 3: NTIRE 2024 挑战赛使用 $\mathbf{x}4\mathrm{SR}$ 在验证阶段和测试阶段的 PSNR 与 SSIM 结果。
| 验证阶段 | 测试阶段 | |
|---|---|---|
| PSNR | 31.1820 | 31.1776 |
| SSIM | 0.8494 | 0.8620 |
7. Conclusion
7. 结论
In this paper, we introduce the phenomenon of information bottlenecks observed in SISR models, where spatial information is lost as network depth increases during forward propagation. This may lead to information loss when limiting the upper bound of model performance for the SISR task, which requires detailed spatial information and context-aware processing.
本文介绍了在单图像超分辨率(SISR)模型中观察到的信息瓶颈现象:随着网络深度增加,前向传播过程中空间信息会逐渐丢失。这种现象可能限制SISR任务模型性能的上限,而该任务恰恰需要精细的空间信息和上下文感知处理能力。
To address these issues, we present a novel Swintransformer-based model, Dense-residual-connected Transformer (DRCT). The design philosophy behind DRCT centers on stabilizing the information flow and enhancing the receptive fields by incorporating dense-connections within residual blocks, combining the shift-window attention mechanism to adaptively capture global information.
为了解决这些问题,我们提出了一种基于Swintransformer的新型模型——密集残差连接Transformer (DRCT)。DRCT的设计理念聚焦于通过残差块内密集连接来稳定信息流并增强感受野,同时结合移位窗口注意力机制以自适应捕获全局信息。
As a result, the model can better focus on global spatial information and surpass existing state-of-the-art methods without the need for designing sophisticated window attention mechanisms or increasing model parameters. The ex- periment results have demonstrated the efficacy of the proposed DRCT, indicating its effectiveness and the potential for future work related to SISR tasks.
因此,该模型能更专注于全局空间信息,无需设计复杂的窗口注意力机制或增加模型参数即可超越现有最优方法。实验结果表明了所提出的DRCT的有效性,展现了其在单图像超分辨率(SISR)任务中的潜力及未来研究方向。