Abstract
摘要
1. Introduction
1. 引言
Indoor scenes are essential to urban environments. Current urban studies necessitate understanding indoor scene semantic information for tasks like emergency evacuation [38], robotic navigation [36], and virtual reality [43]. The dynamic nature of indoor scenes demands perception of env iron mental changes in real time for tasks such as emergency evacuation [38], stressing the importance of algorithms’ real-time capabilities. Existing real-time semantic segmentation methods often falter when applied to the complex semantic information of indoor scenes, usually requiring a sacrifice in accuracy [40]. This often requires a trade-off between inference speed and increased network complexity to achieve adequate segmentation accuracy indoors. Consequently, a critical research question is how to improve the accuracy of semantic segmentation in indoor environments without substantially increasing complexity, while ensuring real-time performance.
室内场景是城市环境的重要组成部分。当前的城市研究需要理解室内场景的语义信息,以支持应急疏散[38]、机器人导航[36]和虚拟现实[43]等任务。室内场景的动态特性要求实时感知环境变化,例如应急疏散场景[38],这凸显了算法实时能力的重要性。现有的实时语义分割方法在处理室内场景复杂语义信息时往往表现不佳,通常需要以牺牲精度为代价[40]。这常常需要在推理速度与增加网络复杂度之间进行权衡,以实现室内场景的充分分割精度。因此,一个关键的研究问题是如何在不显著增加复杂度的前提下提升室内环境语义分割的准确性,同时确保实时性能。
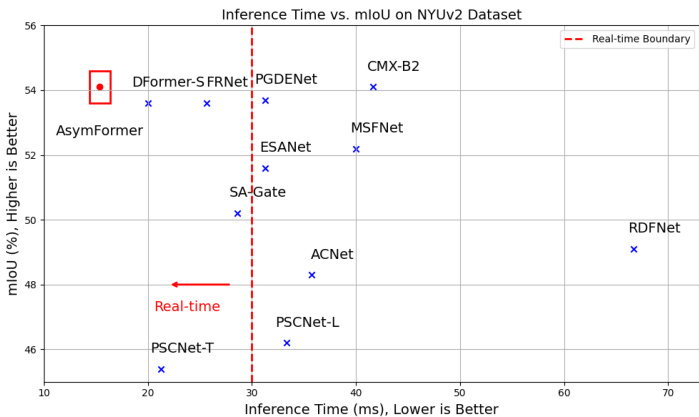
Figure 1. The AsymFormer has 33.0 million parameters and 36.0 GFLOPs computational cost, and it can achieve 65 FPS inference speed on RTX 3090, $54.1%$ mIoU on NYUv2.
图 1: AsymFormer 拥有 3300 万参数和 36.0 GFLOPs 计算量,在 RTX 3090 上可实现 65 FPS 的推理速度,在 NYUv2 数据集上达到 54.1% mIoU。
Aside from increasing the complexity of the network, introducing additional information, such as RGB-D data, is also an effective way to improve the accuracy of semantic segmentation networks. RGB-D cameras are widely used devices for indoor information acquisition. RGB-D information consists of RGB (color, texture and shape) and
除了增加网络复杂度外,引入RGB-D数据等额外信息也是提升语义分割网络精度的有效方法。RGB-D相机是广泛应用的室内信息采集设备,其数据包含RGB(色彩、纹理和形状)与深度信息。
Depth (boundaries and relative location) features, which are somewhat complementary [42]. Several studies have explored how to improve indoor scene semantic segmentation performance by integrating RGB-D information [26, 42, 50].
深度(边界和相对位置)特征,这些特征在某种程度上是互补的[42]。多项研究探讨了如何通过整合RGB-D信息来提升室内场景语义分割的性能[26, 42, 50]。
Existing research has explored the implementation of attention mechanisms to extract valuable information from RGB-D features without significantly increasing computational complexity. However, due to the additional feature extraction branch for depth features and the lack of discussion on how to allocate computational resources based on feature importance, these methods often introduce a substantial amount of redundant parameters, significantly reducing their computational efficiency [9].
现有研究探索了通过注意力机制从RGB-D特征中提取有价值信息而不显著增加计算复杂度的实现方式。然而,由于深度特征需要额外的特征提取分支,且缺乏关于如何根据特征重要性分配计算资源的讨论,这些方法通常会引入大量冗余参数,显著降低计算效率 [9]。
To address this issue, this paper introduces AsymFormer, a high-performance real-time network for RGB-D semantic segmentation that employs an asymmetric backbone design. This includes a larger parameter backbone for important RGB features and a smaller backbone for the Depth branch. Regarding framework selection, at the same computational complexity, Transformer often achieves higher accuracy but has a slower inference speed compared to CNN [19]. In order to speed up the main branch, this paper employ a hardware-friendly CNN [21] for the RGB branch and a light-weight Transformer [35] for the Depth branch to further compress the parameters. Considering the differences between different modal representation, to effectively select and fuse asymmetric features, this paper proposes a learnable method for feature information compression and constructs a Local Attention Guided Feature Selection (LAFS) module. Additionally, a Cross-Modal Attention (CMA) module is introduced to embed cross-modal information into pixel-wise fused features. Finally, we employ a lightweight MLP-Decoder[35] to decode semantic information from shallow features.
为解决这一问题,本文提出了AsymFormer,一种采用非对称主干设计的高性能实时RGB-D语义分割网络。该设计包含一个参数较多的主干用于处理重要RGB特征,以及一个较小的主干用于深度分支。在框架选择方面,在相同计算复杂度下,Transformer通常能达到更高精度但推理速度慢于CNN [19]。为加速主分支,本文为RGB分支采用了硬件友好的CNN [21],为深度分支采用轻量级Transformer [35]以进一步压缩参数量。考虑到不同模态表征的差异,为有效选择和融合非对称特征,本文提出了一种可学习的特征信息压缩方法,并构建了局部注意力引导的特征选择(LAFS)模块。此外,还引入了跨模态注意力(CMA)模块,将跨模态信息嵌入到逐像素融合特征中。最后,我们采用轻量级MLP解码器[35]从浅层特征解码语义信息。
This paper evaluates AsymFormer on two classic indoor scene semantic segmentation datasets: NYUv2 and SUNRGBD. Meanwhile, the inference speed test is also preformed on Nvidia RTX 3090 platform. The AsymFormer achieves $54.1%$ mIoU on NYUv2 and 49.1 mIoU on SUNRGBD, with 65 FPS inference speed (79 FPS with mixed precision quantization using the TensorRT). Our experiments highlight AsymFormer’s ability to acquire high accuracy and efficiency at the same time. The main contributions are summarized as follows:
本文在NYUv2和SUNRGBD两个经典室内场景语义分割数据集上评估了AsymFormer性能,并在Nvidia RTX 3090平台进行了推理速度测试。AsymFormer在NYUv2上达到54.1% mIoU,在SUNRGBD上达到49.1 mIoU,推理速度为65 FPS (使用TensorRT混合精度量化后可达79 FPS)。实验结果表明AsymFormer能够同时实现高精度与高效率。主要贡献总结如下:
features, validating its capability to enhance network accuracy with minimal additional model parameters.
特征,验证了其能以最少的额外模型参数提升网络精度的能力。
2. Related Works
2. 相关工作
2.1. Indoor Scene Understanding
2.1. 室内场景理解
Current research in indoor scene understanding leverages diverse data sources, including RGB images [2], RGB-D images [42], point clouds [51], and mesh data [45]. Each of these sources provides unique insights and benefits for analyzing and interpreting indoor environments. For instance, RGB images are accessible and straightforward for visual representations, whereas point clouds and meshes offer intricate 3D spatial data. However, when considering the simultaneous use of both 2D and 3D information to optimize efficiency and effectiveness in scene understanding, RGB-D images emerge as the optimal choice.
当前室内场景理解研究利用多种数据源,包括RGB图像[2]、RGB-D图像[42]、点云数据[51]和网格数据[45]。每种数据源都为分析和解读室内环境提供了独特的视角与优势。例如,RGB图像易于获取且适合视觉呈现,而点云和网格则能提供精细的三维空间数据。然而,当需要同时运用2D与3D信息以优化场景理解的效率与效果时,RGB-D图像成为最佳选择。
2.2. RGB-D Representation Learning
2.2. RGB-D 表征学习
One of the earliest works on RGB-D semantic segmentation, FCN [22], treated RGB-D information as a single input and processed it with a single backbone. However, subsequent works have recognized the need to extract features from RGB and Depth information separately, as they have different properties. Therefore, most of them have adopted two symmetric backbones for RGB and Depth feature extraction [5, 26, 27, 42]. Primarily, asymmetric backbones doubles the overall computational complexity [9]. However, it is generally observed that for semantic segmentation, RGB information typically plays a more prominent role than Depth information, as indicated by [9]. Using a asymmetric backbone for feature extraction will obviously lead to redundant parameters on the less important side, reducing the efficiency of the network.
RGB-D语义分割的早期工作之一FCN [22]将RGB-D信息视为单一输入并用单一主干网络处理。但后续研究认识到需要分别从RGB和深度信息中提取特征,因其特性不同。因此多数方法采用两个对称主干网络分别进行RGB和深度特征提取[5, 26, 27, 42]。非对称主干网络主要会使整体计算复杂度翻倍[9]。然而研究表明,对于语义分割任务,RGB信息通常比深度信息起更重要作用[9]。使用非对称主干网络进行特征提取显然会在重要性较低的一侧产生冗余参数,降低网络效率。
2.3. RGB-D feature fusion
2.3. RGB-D特征融合
The performance and efficiency of different frameworks depends largely on how they fuse RGB and Depth features. Some early works, such as RedNet [17], fused RGB and Depth feature maps pixel-wise in the backbone. Later, ESANet series [26, 27] proposed channel attention to select features from different channels, as RGB and Depth feature maps may not align well on the corresponding channels. PSCNet [9] further extended channel attention to both spatial and channel directions and achieved better performance. Recently, more complex models have been proposed to exploit cross-modal information and select features for RGBD fusion. For example, SAGate [5] proposed a gated attention mechanism that can leverage cross-modal information for feature selection. CANet [47] extended non-local attention [32] to cross-modal semantic information and achieved significant improvement. CMX [42] extended SA-Gate to spatial and channel directions and proposed a novel crossmodal attention with global receptive field. However, integrating cross-modal information and learning cross-modal similarity is still an open question in vision tasks.
不同框架的性能和效率很大程度上取决于它们如何融合RGB和深度特征。早期工作如RedNet [17]在主干网络中采用像素级方式融合RGB与深度特征图。随后,ESANet系列[26, 27]提出通道注意力机制,从不同通道选择特征,因为RGB和深度特征图在对应通道上可能无法很好对齐。PSCNet [9]进一步将通道注意力扩展到空间和通道两个维度,取得了更好的性能。近期,更复杂的模型被提出以利用跨模态信息并进行RGBD融合的特征选择。例如,SAGate [5]提出了一种门控注意力机制,能够利用跨模态信息进行特征选择。CANet [47]将非局部注意力[32]扩展到跨模态语义信息,实现了显著提升。CMX [42]将SA-Gate扩展到空间和通道维度,并提出具有全局感受野的新型跨模态注意力机制。然而,在视觉任务中整合跨模态信息并学习跨模态相似性仍是一个开放性问题。
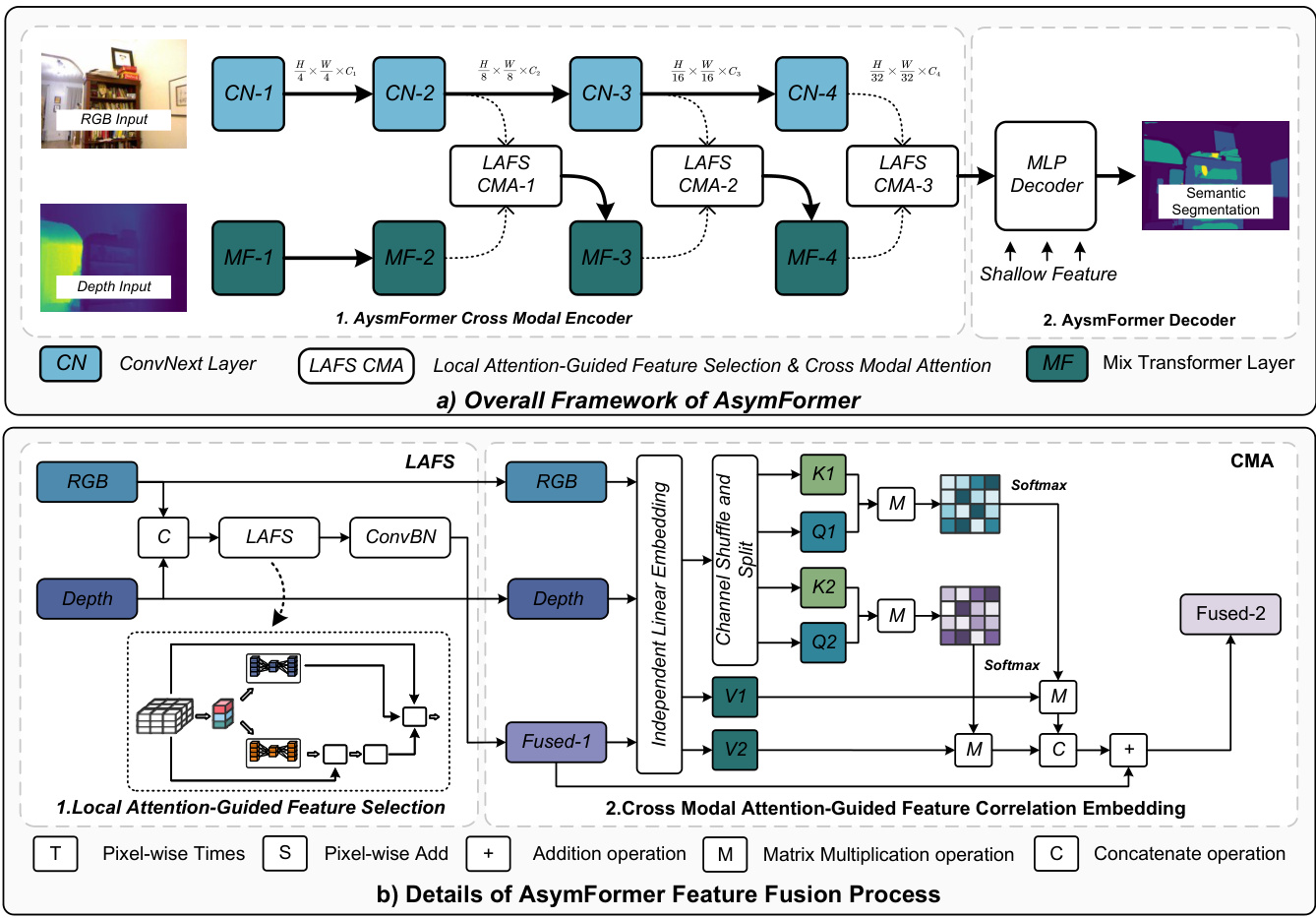
Figure 2. Overview of AsymFormer.
图 2: AsymFormer 架构概览
3. Method
3. 方法
3.1. Framework Overview
3.1. 框架概述
This paper develops a high-accuracy real-time semantic segmentation method, AsymFormer, which leverages an asymmetric backbone network to mine multimodal representations. A hardware friendly convolution network ConvNext [21] is used for RGB feature extraction and a lightweight Mix-Transformer [35]is used for processing Depth feature. To effectively fuse RGB-D features, the study introduces a Local Attention Guided Multimodal Feature Selection (LAFS) module, which uses learnable strategy to extract global information and selects multimodal features in both spatial and channel dimensions. Moreover, to further mine the information contained in multimodal features, the study embeds the information contained in multimodal features through a novel Cross-Modal Attention (CMA) module. The overall framework of AsymFormer is shown in Fig.2.
本文提出了一种高精度实时语义分割方法AsymFormer,该方法利用非对称主干网络挖掘多模态表征。研究采用硬件友好的卷积网络ConvNext [21]提取RGB特征,使用轻量级Mix-Transformer [35]处理深度特征。为有效融合RGB-D特征,研究提出了局部注意力引导的多模态特征选择(LAFS)模块,该模块通过可学习策略提取全局信息,并在空间和通道维度上选择多模态特征。此外,为深度挖掘多模态特征中的信息,研究通过新型跨模态注意力(CMA)模块嵌入多模态特征信息。AsymFormer的整体框架如图2所示。
3.2. Local Attention Guided Feature Selection
3.2. 局部注意力引导的特征选择
Studies have shown that attention mechanisms can effectively select complementary features from RGB and Depth features, thereby improving the efficiency of feature extraction and the performance of semantic segmentation [9, 16, 40, 42]. However, existing attention mechanisms usually adopt a non-learnable, fixed strategy for feature information compression [34], which may overlook the differences among various modal features, causing insufficient use of information.
研究表明,注意力机制能有效从RGB和深度特征中选择互补特征,从而提升特征提取效率和语义分割性能 [9, 16, 40, 42]。但现有注意力机制通常采用不可学习的固定策略进行特征信息压缩 [34],可能忽略不同模态特征的差异性,导致信息利用不足。
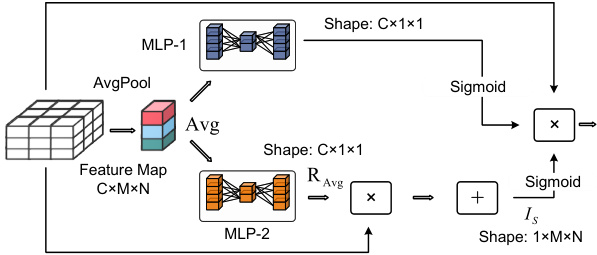
Figure 3. LAFS.
图 3: LAFS
In response to this issue, this paper proposes a learnable method for feature information compression and constructs a Local Attention Guided Feature Selection (LAFS) module. The core design of LAFS is a learnable method for spatial information compression. Inspired by SE [14] attention,
针对这一问题,本文提出了一种可学习的特征信息压缩方法,并构建了局部注意力引导特征选择(LAFS)模块。LAFS的核心设计是一种可学习的空间信息压缩方法,其灵感来源于SE [14]注意力机制。
LAFS abandons traditional fixed strategies and employs a feed forward neural network to learn a set of dynamic spatial information compression rules.
LAFS摒弃了传统的固定策略,采用前馈神经网络来学习一组动态空间信息压缩规则。
The Fig. 3 demonstrates details of the LAFS module. The input features to the LAFS module are the tensor concatenation of $R G B$ and Depth features. For computing attention weights, the study first extracts a global information vector $A v g$ through Adaptive Average Pooling. For channel attention, its structure is the same as SE [14].
图 3: 展示了LAFS模块的细节。LAFS模块的输入特征是将RGB和深度(Depth)特征张量拼接而成的。为了计算注意力权重,该研究首先通过自适应平均池化(Adaptive Average Pooling)提取全局信息向量$Avg$。在通道注意力方面,其结构与SE [14]相同。
On spatial attention computation, which is the primary improvement, the LAFS first processes global information $A v g$ through another feed forward neural network with a squeeze-excitation structure, producing the output vector $R_{A v g}$ , representing pixel space similarity descriptions. Then, by computing the dot product similarity between $R_{A v g}$ and input feature map, the global spatial information $I_{S}$ is extracted (this equates to a weighted sum of the channel features, dynamically varying with $A v g$ changes). Subsequently, spatial attention weights $W_{S}$ are calculated through sigmoid normalization.
在空间注意力计算这一主要改进点上,LAFS首先通过另一个带有压缩激励结构的前馈神经网络处理全局信息 $A v g$,生成输出向量 $R_{A v g}$,表示像素空间相似性描述。接着,通过计算 $R_{A v g}$ 与输入特征图之间的点积相似度,提取全局空间信息 $I_{S}$(这相当于通道特征的加权求和,随 $A v g$ 变化动态调整)。随后,通过sigmoid归一化计算出空间注意力权重 $W_{S}$。
$$
W_{S}={\mathrm{Sigmoid}}({\frac{{\mathrm{Dot}}(I n p u t.{\mathrm{Reshape}}(C,H\times W)^{T},R_{A v g})}{C^{2}}})
$$
$$
W_{S}={\mathrm{Sigmoid}}({\frac{{\mathrm{Dot}}(I n p u t.{\mathrm{Reshape}}(C,H\times W)^{T},R_{A v g})}{C^{2}}})
$$
Here, all results are divided by $C^{2}$ to prevent sigmoid overflow. Finally, input features are selected based on the pixelwise multiplication of feature maps with spatial and channel attention weights.
此处将所有结果除以 $C^{2}$ 以防止sigmoid函数溢出。最终,基于特征图与空间及通道注意力权重的逐像素相乘来选择输入特征。
3.3. Cross-Attention Guided Feature Embedding
3.3. 跨注意力引导的特征嵌入
Aside from selecting existing features, it is necessary to mine new information from fused features. Existing MultiHead Self-Attention (MHSA) in Transformer [31] is limited to learning self-similarity within a single modality, whereas mining information from multi-modal jointly is a new goal in representation learning. In this paper, a new Cross-Modal Attention (CMA) module is constructed. The key to CMA is defining cross-modal self-similarity using a linear sum, and embedding its result into the fused features.
除了选择现有特征外,还需从融合特征中挖掘新信息。Transformer [31] 中现有的多头自注意力 (MHSA) 仅能学习单模态内的自相似性,而联合多模态挖掘信息是表征学习的新目标。本文构建了一个新的跨模态注意力 (CMA) 模块,其核心是通过线性求和定义跨模态自相似性,并将结果嵌入融合特征中。
3.3.1 Definition of Cross-Modal Self-Similarity:
3.3.1 跨模态自相似性定义:
Suppose $R G B$ and Depth features are seamlessly embedded into $K e y$ and Query, then for a pixel $(i_{0},j_{0})$ , its crossmodal self-similarity with other pixels $(i,j)$ can be defined as:
假设 $RGB$ 和深度 (Depth) 特征被无缝嵌入到 $Key$ 和 $Query$ 中,那么对于像素 $(i_{0},j_{0})$ ,其与其他像素 $(i,j)$ 的跨模态自相似性可定义为:
$$
W(i,j)=\sum_{n=1}^{N}(K r_{n,i,j}.Q r_{n,i_{0},j_{0}})+\sum_{n=1}^{N}(K d_{n,i,j}.Q d_{n,i_{0},j_{0}})
$$
$$
W(i,j)=\sum_{n=1}^{N}(K r_{n,i,j}.Q r_{n,i_{0},j_{0}})+\sum_{n=1}^{N}(K d_{n,i,j}.Q d_{n,i_{0},j_{0}})
$$
where $K r_{n,i,j}$ represents the nth feature value of the pixel $K e y_{R G B}$ , and $Q r_{n,i,j}$ represents the nth feature value of the pixel $Q u e r y_{R G B}$ . Similarly, $K d_{1,i,j}$ and $Q d_{1,i,j}$ represent the nth feature value of the pixel $K e y_{D e p t h}$ and QueryDepth respectively.
其中 $K r_{n,i,j}$ 表示像素 $K e y_{R G B}$ 的第n个特征值,$Q r_{n,i,j}$ 表示像素 $Q u e r y_{R G B}$ 的第n个特征值。同理,$K d_{1,i,j}$ 和 $Q d_{1,i,j}$ 分别表示像素 $K e y_{D e p t h}$ 和 QueryDepth 的第n个特征值。
3.3.2 Feature Embedding
3.3.2 特征嵌入
The CMA has three input features, namely $R G B$ features, Depth features, and the fused features F used selected by LAFS. In the calculation process of CMA, the first step is to embed the input features RGB, Depth, and F used into vector space.
CMA具有三个输入特征,即$R G B$特征、深度(Depth)特征以及由LAFS选择使用的融合特征F。在CMA的计算过程中,首先将输入特征RGB、Depth和F used嵌入到向量空间。
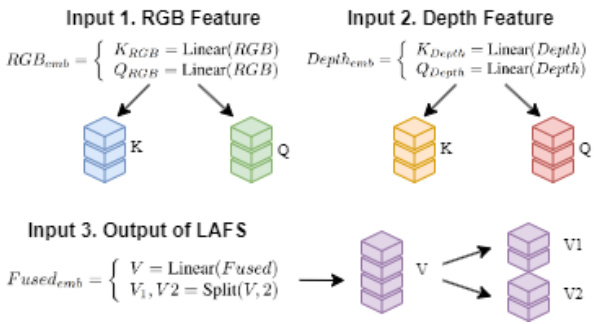
Figure 4. Feature Embedding.
图 4: 特征嵌入 (Feature Embedding)。
Simultaneously, the output V alue split into two independent vectors $V_{1}$ and $V_{2}$ in the channel direction.
同时,输出值V在通道方向上分裂为两个独立向量$V_{1}$和$V_{2}$。
3.3.3 Splitting and Mixing of Multimodal Information
3.3.3 多模态信息的分割与混合
To learn features from multiple subspaces, the embedded features $K_{R G B}$ , $K_{D e p t h}$ , $Q_{R G B}$ , and $Q_{D e p t h}$ are split into two independent vectors.The study first concatenates $K e y_{R G B+D e p t h}$ with $Q u e r y_{R G B+D e p t h}$ in the channel direction, obtaining Key and Query:
为了从多个子空间学习特征,嵌入特征$K_{R G B}$、$K_{D e p t h}$、$Q_{R G B}$和$Q_{D e p t h}$被拆分为两个独立向量。研究首先在通道方向上拼接$Key_{R G B+D e p t h}$与$Query_{R G B+D e p t h}$。
It can be noted that if the vectors are directly split and self-similarity is calculated in different subspaces, it might result in the inability to simultaneously include RGB and Depth features in different subspaces. Therefore, we introduce a Shuffle mechanism to ensure each $K1,K2,Q1$ , and $Q2$ contain information from both modalities. As shown in Figure 4.
可以注意到,如果直接分割向量并在不同子空间中计算自相似性,可能导致无法同时在不同子空间中包含RGB和Depth特征。因此,我们引入了一种Shuffle机制,以确保每个$K1,K2,Q1$和$Q2$都包含来自两种模态的信息。如图4所示。
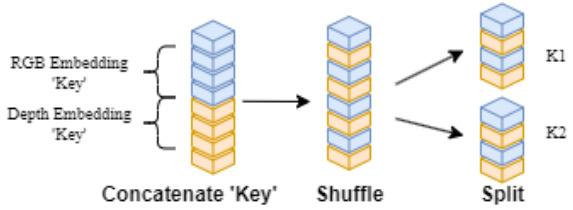
Figure 5. Splitting and Mixing of Multimodal Information.
图 5: 多模态信息的分割与混合。
After channel shuffle, CMA can ensure that both RGB and Depth information can be utilized simultaneously when calculating self-similarity.
通道混洗后,CMA能确保在计算自相似性时同时利用RGB和深度信息。
3.3.4 Representation Learning in Multiple Subspaces
3.3.4 多子空间表征学习
Finally, CMA calculates the cross-modal similarity and embeds the calculation result into the fused feature V alue,
最后,CMA计算跨模态相似度并将计算结果嵌入到融合特征V alue中,
similar to operations in [8, 31, 32]. Specifically, the study computes the dot products $K_{1},Q_{1}$ and $K_{2},Q_{2}$ to derive two representations of subspaces $W_{1}$ and $W_{2}$ :
类似于[8, 31, 32]中的操作。具体而言,该研究计算点积$K_{1},Q_{1}$和$K_{2},Q_{2}$,以推导出子空间$W_{1}$和$W_{2}$的两种表示:
$$
\begin{array}{r}{W_{1}=\mathrm{Softmax}(\frac{Q_{1}\cdot K_{1}^{T}}{\sqrt{C_{1}/4}})}\ {W_{2}=\mathrm{Softmax}(\frac{Q_{2}\cdot K_{2}^{T}}{\sqrt{C_{1}/4}})}\end{array}
$$
$$
\begin{array}{r}{W_{1}=\mathrm{Softmax}(\frac{Q_{1}\cdot K_{1}^{T}}{\sqrt{C_{1}/4}})}\ {W_{2}=\mathrm{Softmax}(\frac{Q_{2}\cdot K_{2}^{T}}{\sqrt{C_{1}/4}})}\end{array}
$$
Then, $W_{1}$ and $W_{2}$ embed information into $V_{1}$ and $V_{2}$ through dot products. The fused feature $F u s e d_{2}$ is the concatenation of $V_{1}$ and $V_{2}$ in the channel dimension:
接着,$W_{1}$ 和 $W_{2}$ 通过点积将信息嵌入到 $V_{1}$ 和 $V_{2}$ 中。融合特征 $Fused_{2}$ 是 $V_{1}$ 和 $V_{2}$ 在通道维度上的拼接:
$$
F u s e d=\mathbf{Cat}[W_{1}\cdot V_{1},W_{2}\cdot V_{2}]
$$
$$
F u s e d=\mathbf{Cat}[W_{1}\cdot V_{1},W_{2}\cdot V_{2}]
$$
Finally, CMA converts $F u s e d_{2}$ into output channels $C_{2}$ using a linear layer and connects it with the residual connection F used, resulting in CMA’s output feature.
最后,CMA通过线性层将$Fused_{2}$转换为输出通道$C_{2}$,并与残差连接Fused相连,生成CMA的输出特征。
4. EXPERIMENT RESULTS
4. 实验结果
4.1. Implementation Details
4.1. 实现细节
To evaluate our Real-Time semantic segmentation network design, we conduct a series of experiments on two widelyused datasets NYUv2[28] (795 training and 654 testing RGB-D images) and SUNRGBD[30] (5825 training and 5050 testing RGB-D images). We conduct the model training and testing on different platforms. For the training, we use Nvidia A100-40G GPU. For the evaluation and inference speed testing, we use Nvidia RTX 3090 GPU, Ubuntu 20.04, CUDA 12.0 and Pytorch 2.0.1. We apply data augmentation to all datasets by randomly flipping $(\mathtt{p}{=}0.5)$ , random scales between 1.0 and 2.0, random crop $480\times640$ and random HSV. We adopt ConvNext-T [21] backbones pretrained on ImageNet-1k[6]. For the Mix TransformerB0 [35], no pre-trained weight has been used. The MLPdecoder in AsymFormer has the same structure as Segformer and an embedding dimension of 256. We choose AdamW optimizer with a weight decay of 0.01. The initial learning rate is $5e^{-5}$ and we use a poly learning rate schedule $\textstyle(1-{\frac{i t e r}{m a x_{i}t e r}})^{0.9}$ aitxerter )0.9 with a warm-up of 10 epochs. We train with a batch size of 8 for NYUv2 (500 epochs) and SUNRGBD (200 epochs). We employ cross-entropy as the loss function and do not use any auxiliary loss during training process. The evaluation metric is mean Intersection over Union (mIoU).
为了评估我们的实时语义分割网络设计,我们在两个广泛使用的数据集NYUv2[28](795张训练和654张测试RGB-D图像)和SUNRGBD[30](5825张训练和5050张测试RGB-D图像)上进行了一系列实验。我们在不同平台上进行模型训练和测试。训练使用Nvidia A100-40G GPU,评估和推理速度测试使用Nvidia RTX 3090 GPU、Ubuntu 20.04、CUDA 12.0和Pytorch 2.0.1。
我们对所有数据集应用数据增强,包括随机翻转 $(\mathtt{p}{=}0.5)$、1.0到2.0之间的随机缩放、随机裁剪 $480\times640$ 以及随机HSV变换。采用在ImageNet-1k[6]上预训练的ConvNext-T[21]主干网络,而Mix TransformerB0[35]未使用预训练权重。AsymFormer中的MLP解码器结构与Segformer相同,嵌入维度为256。
我们选择AdamW优化器,权重衰减为0.01,初始学习率为 $5e^{-5}$,并采用多项式学习率调度 $\textstyle(1-{\frac{i t e r}{m a x_{i}t e r}})^{0.9}$,预热10个周期。NYUv2(500周期)和SUNRGBD(200周期)的批量大小均为8。使用交叉熵作为损失函数,训练过程中未使用任何辅助损失。评估指标为平均交并比(mIoU)。
4.2. Ablation Experiment
4.2. 消融实验
We conduct a series of ablation experiments on NYUv2 dataset to evaluate the effectiveness of the LAFS and CMA module. We set two common feature fusion methods as our comparative baseline: 1. Cat: This method directly concatenates two features and then uses convolution layers to adjust the channel numbers. Essentially, it is a pixelwise fusion without feature selection. 2. $\mathbf{SE{+}M H S A}$ : This method combines the popular SE attention [14] and MHSA attention [31] for feature fusion. Here, SE is used for feature selection in the channel direction, while MHSA is employed for further feature extraction on the fused features.
我们在NYUv2数据集上进行了一系列消融实验,以评估LAFS和CMA模块的有效性。我们设置了两种常见的特征融合方法作为对比基线:
- Cat:该方法直接将两个特征拼接,然后使用卷积层调整通道数。本质上是一种无特征选择的逐像素融合。
- SE+M HSA:该方法结合了流行的SE注意力[14]和MHSA注意力[31]进行特征融合。其中,SE用于通道方向的特征选择,而MHSA用于对融合后的特征进一步提取。
In our experiments, the Cat fusion method, used as a baseline, achieved a segmentation accuracy of $47.0\mathrm{mIoU}$ and an inference speed of 77.5 FPS. When using LAFS alone, we achieved a performance improvement of $2.1%$ while sacrificing only 1.8 FPS of inference speed. This demonstrates that LAFS provides performance gains without significantly impacting inference speed. In comparison to the other baseline, using $\mathrm{Cat+MHSA}$ , which resulted in a reduction of inference speed by 11.8 FPS, an improvement of only $2.9%$ in mIoU was achieved. This further highlights the efficiency of LAFS. Furthermore, when using CMA alone, we observed a $2.6%$ improvement in seg- mentation accuracy but encountered a significant decrease in inference speed of 10.1 FPS. Compared to LAFS, CMA showed a more noticeable reduction in inference speed.
在我们的实验中,作为基线的Cat融合方法实现了$47.0\mathrm{mIoU}$的分割精度和77.5 FPS的推理速度。单独使用LAFS时,我们获得了$2.1%$的性能提升,而仅牺牲了1.8 FPS的推理速度。这表明LAFS在不显著影响推理速度的情况下提供了性能增益。与另一个基线$\mathrm{Cat+MHSA}$相比,后者导致推理速度降低11.8 FPS,仅实现了$2.9%$的mIoU提升,这进一步凸显了LAFS的高效性。此外,单独使用CMA时,我们观察到分割精度提高了$2.6%$,但推理速度显著下降了10.1 FPS。与LAFS相比,CMA在推理速度上表现出更明显的下降。
Finally, we combined LAFS with CMA $(\mathrm{LAFS+CMA})$ . Since LAFS had minimal impact on inference speed and served a different purpose than CMA, the network’s inference speed decreased by only 2 FPS. This change achieved a significant improvement of $7.1%$ in segmentation accuracy compared to the baseline Cat. At this point, the inference speed of $\mathrm{LAFS{+}C M A}$ was similar to $\mathrm{SE{+}M H S A}$ , but with a $4.2%$ performance improvement. This validates our experimental hypothesis: by re-modeling feature selection and mining cross-modal self-similarity, we can enhance the segmentation performance of the network without sacrificing inference speed compared to existing models. This demonstrates that we have indeed improved the efficiency of the network.
最后,我们将LAFS与CMA结合使用 $(\mathrm{LAFS+CMA})$ 。由于LAFS对推理速度影响极小且与CMA功能不同,网络推理速度仅下降2 FPS。这一改动使分割准确率较基线Cat显著提升 $7.1%$ 。此时 $\mathrm{LAFS{+}C M A}$ 的推理速度与 $\mathrm{SE{+}M H S A}$ 相近,但性能提高了 $4.2%$ 。这验证了我们的实验假设:通过重新建模特征选择并挖掘跨模态自相似性,我们能在不牺牲推理速度的前提下提升网络分割性能,证明确实提高了网络效率。
4.3. Comparison With State-of-The-Arts
4.3. 与现有最优方法的比较
4.3.1 NYUv2 Comparison Results
4.3.1 NYUv2对比结果
According to Table 2, despite the lack of ImageNet-1k pre training—a common practice among competing methods—our AsymFormer still achieves leading scores in RealTime semantic segmentation. Th AsymFormer achieves $54.1%$ mIoU, demonstrating competitive accuracy compared to those high-performance heavy designs. AsymFormer also has faster inference speed than other methods. For instance, AsymFormer outperforms PSCNet-T[9] by $8.7%$ mIoU and 18 FPS inference speed improvement. Similarly, AsymFormer is two times faster than ESANet[26] and three times faster than CMX-B2 [42] with the same performance. Finally, by using multi-scale inference strategy, the AsymFormer achieves $55.3%$ mIoU on NYUv2. In terms of semantic segmentation accuracy, AsymFormer does not show a significant disadvantage compared to those high-performance methods, such as Omnivore, included in the comparison. This validates the effectiveness of our various efforts in reducing network redundancy parameters and improving inference speed.
根据表2,尽管缺少ImageNet-1k预训练(竞争方法的常见做法),我们的AsymFormer仍在实时语义分割中取得领先分数。AsymFormer达到54.1% mIoU,与那些高性能复杂设计相比展现出竞争力。AsymFormer还具有更快的推理速度,例如:mIoU指标超越PSCNet-T[9] 8.7%,推理速度提升18 FPS;在同等性能下,速度是ESANet[26]的2倍、CMX-B2[42]的3倍。采用多尺度推理策略时,AsymFormer在NYUv2数据集达到55.3% mIoU。与Omnivore等高性能方法相比,AsymFormer在语义分割精度方面未显现明显劣势,这验证了我们减少网络冗余参数和提升推理速度各项措施的有效性。
Table 1. Ablation experiment results for different multi-modal feature fusion method.
表 1: 不同多模态特征融合方法的消融实验结果。
| 模型 | 特征融合方法 | 指标 | Params/M | mIoU(%) | Inf.Speed(FPS) |
|---|---|---|---|---|---|
| Baseline | Cat SE+MHSA | 31.9 | 47.0 | 77.5 | |
| 32.6(+0.7M) | 49.9 (+2.9%) | 65.7 | |||
| Ours | LAFS CMA | 32.4 (+0.5M) | 49.1 (+2.1%) | 75.7 | |
| 32.5 (+0.6M) | 49.6 (+2.6%) | 67.4 | |||
| Cat SE+MHSA + 人 | 33.0 (+1.1M) | 54.1 (+7.1%) | 65.5 |
Table 2. Comparison Results on NYUv2. The inference speed is tested on RTX 3090 platform, $(480\times640)$ inputs. MS denotes MultiScale inference strategy.
表 2: NYUv2数据集对比结果。推理速度测试平台为RTX 3090,输入尺寸$(480\times640)$。MS表示多尺度推理策略。
| 方法 | 年份 | 骨干网络 | 参数量/M | mIoU (%) | 实时性 | 速度/FPS | 速度 (%) |
|---|---|---|---|---|---|---|---|
| CMX-B2 [42] | 2022 | Segformer-B2 | 67 | 54.1 | 24 | 36.9% | |
| Token-Fusion[33] | 2022 | Token-Fusion(S) | 54.2 | × | |||
| CMX-B2(MS)[42] | 2022 | Segformer-B2 | 67 | 54.4 | × | ||
| Multi-MAE[1] | 2022 | Vit-B | 56.0 | × | |||
| CMX-B4 (MS) [42] | 2022 | Segformer-B4 | 140 | 56.3 | × | ||
| Omnivore [10] | 2022 | Swin-L | 56.8 | × | |||
| CMX-B5(MS)[42] | 2022 | Segformer-B5 | 181 | 56.9 | × | - | - |
| SA-Gate [5] | 2021 | Res50 | 65 | 50.2 | 35 | 53.8% | |
| ESANet [26] | 2022 | Res34-Nbt1D | 34 | 51.6 | 32 | 49.2% | |
| PSCNet-L [9] | 2022 | Res50 | 52 | 46.2 | 30 | 46.2% | |
| PSCNet-T [9] | 2022 | Res50 | 40 | 45.4 | 47 | 72.3% | |
| PGDENet [49] | 2022 | Res34 | 101 | 53.7 | 32 | 49.2% | |
| FRNet [50] | 2022 | Res34 | 86 | 53.6 | 39 | 60.0% | |
| DFormer-S [37] | 2023 | DFormer-S | 18.7 | 53.6 | 50 | 76.9% | |
| AsymFormer | 2024 | BO+T | 33 | 54.1 | 65 | 100.0% | |
| AsymFormer (FP16) | 2024 | BO+T | 33 | 54.1 | 79 | 121.5% | |
| AsymFormer (MS) | 2024 | BO+T | 33 | 55.3 | × | - |
4.3.2 SUNRGBD Comparison Results
4.3.2 SUNRGBD对比结果
Table 3 reports the performance of AsymFormer on the SUNRGBD dataset. AsymFormer achieves competitive accuracy with $49.1%$ mIoU. The advantage of AsymFormer is not as significant as in NYUv2 experiment. For example, AsymFormer improves 3.9 mIoU over SA-Gate[5] in NYUv2 dataset $(54.1%$ vs $50.2%$ mIoU), but decreases 0.3 mIoU in SUNRGBD dataset $(49.1%$ vs $49.4%$ mIoU). A similar performance degradation can be observed in CMXB2 result which also uses Transformer based backbone. We conjecture that this phenomenon may be caused by low quality depth images in SUNRGBD dataset. The aim of our research is not to construct a state-of-the-art method that has a marginal mIoU improvement over other methods, but to construct a method that has a better performancespeed balance and is more suitable for robot platform. Given that AsymFormer still has faster inference speed than other methods, we consider this performance acceptable for AsymFormer.
表 3 报告了 AsymFormer 在 SUNRGBD 数据集上的性能表现。AsymFormer 以 49.1% mIoU 取得了具有竞争力的准确率,但其优势不如在 NYUv2 实验中显著。例如,AsymFormer 在 NYUv2 数据集上比 SA-Gate[5] 提高了 3.9 mIoU (54.1% vs 50.2% mIoU),但在 SUNRGBD 数据集上却降低了 0.3 mIoU (49.1% vs 49.4% mIoU)。类似性能下降现象也出现在同样采用 Transformer 架构的 CMXB2 结果中。我们推测该现象可能源于 SUNRGBD 数据集中低质量的深度图像。本研究的目标并非构建一个较其他方法仅有边际 mIoU 提升的尖端算法,而是开发具备更优性能-速度平衡、更适配机器人平台的方法。鉴于 AsymFormer 仍保持快于其他方法的推理速度,我们认为该性能表现是可接受的。
Table 3. Comparison Results on SUNRGBD. MS denotes MultiScale inference strategy.
表 3: SUNRGBD数据集上的对比结果。MS表示多尺度推理策略。
| 方法 | 像素准确率 (%) | mIoU (%) |
|---|---|---|
| RDFNet [25] | 81.5 | 47.7 |
| ESANet [26] | 48.0 | |
| ACNet [16] | - | 48.1 |
| SA-Gate [5] | 82.5 | 49.4 |
| CMX-B2 (MS) [42] | 82.8 | 49.7 |
| DFormer-S [37] | 50.0 | |
| MSFNet [18] | - | 50.3 |
| FRNet [50] | 87.4 | 51.8 |
| PGDENet [49] | 87.7 | 51.0 |
| CMX-B4 (MS) [42] | 83.5 | 52.1 |
| CMX-B5 (MS) [42] | 83.8 | 52.4 |
| AsymFormer | 81.9 | 49.1 |
4.4. Visualization
4.4. 可视化
4.4.1 LAFS Attention Map
4.4.1 LAFS 注意力图
As shown in Figure 6, to demonstrate that LAFS performs better than CBAM [34] in selecting features in the spatial dimension, we visualized the spatial attention weights of both methods. It can be observed that LAFS provides better coverage of informative regions in the image while maintaining consistency within objects and preserving the integrity of edges.
如图6所示,为证明LAFS在空间维度特征选择上优于CBAM [34],我们可视化对比了两种方法的空间注意力权重。可观察到LAFS能更全面地覆盖图像中的信息区域,同时保持物体内部一致性并保留边缘完整性。

Figure 6. Difference between CBAM and LAFS.
图 6: CBAM 与 LAFS 的区别。
4.4.2 Semantic Segmentation Results
4.4.2 语义分割结果
The Figure 7 demonstrates the segmentation results of AsymFormer on the NYUv2 dataset. As observed, while maintaining a significantly faster inference speed compared to other methods, AsymFormer achieves comparable semantic segmentation accuracy to mainstream approaches.
图 7: 展示了AsymFormer在NYUv2数据集上的分割结果。如图所示,在保持比其他方法快得多的推理速度的同时,AsymFormer实现了与主流方法相当的语义分割精度。

Figure 7. Visualization of AsymFormer Semantic Segmentation Results.
图 7: AsymFormer 语义分割结果可视化。
5. CONCLUSIONS
5. 结论
In this work, we proposed AsymFormer, which aims to construct a less-redundant real-time indoor scene under standing network. To enhance efficiency and reduce redundant parameters, we implemented the following improvement: 1. the asymmetric backbone that compressed the parameters of the Depth feature extraction branch, thus reducing redundancy. 2. the LAFS module for feature selection, utilizing learnable strategy for global information compressing and improving spatial attention calculations
在本工作中,我们提出了AsymFormer,旨在构建一个低冗余的实时室内场景理解网络。为提升效率并减少冗余参数,我们实现了以下改进:(1) 采用非对称主干网络压缩深度特征提取分支参数量,从而降低冗余;(2) 设计LAFS模块进行特征选择,通过可学习策略压缩全局信息并优化空间注意力计算。
- the self-similarity in multi-modal features, validating its capability to enhance network accuracy with minimal additional model parameters. The experiments demonstrated that the AsymFormer achieves a balance between accuracy and speed. Moving forward, we will continue to optimize the modules and address issues such as self-supervised pre-training of the model, aiming for further improvements.
- 多模态特征中的自相似性,验证了其能以最少的额外模型参数提升网络精度的能力。实验表明,AsymFormer在精度与速度之间实现了平衡。未来我们将持续优化模块,并解决模型自监督预训练等问题,以追求进一步改进。