Augmentation-Adapted Retriever Improves Generalization of Language Models as Generic Plug-In
增强适配检索器作为通用插件提升语言模型的泛化能力
Zichun $\mathbf{Y}\mathbf{u}^{1}$ Chenyan Xiong2 Shi $\mathbf{Y}\mathbf{u}^{1}$ Zhiyuan Liu13
Zichun $\mathbf{Y}\mathbf{u}^{1}$ Chenyan Xiong2 Shi $\mathbf{Y}\mathbf{u}^{1}$ Zhiyuan Liu13
1Dept. of Comp. Sci. & Tech., Institute for AI, Tsinghua University, Beijing, China 2Microsoft Research, Redmond, USA 3Beijing National Research Center for Information Science and Technology, Beijing, China {yuzc19, yus21}@mails.tsinghua.edu.cn; chenyan.xiong@microsoft.com liuzy@tsinghua.edu.cn
1清华大学计算机科学与技术系,人工智能研究院,中国北京 2微软研究院,美国雷德蒙 3北京信息科学与技术国家研究中心,中国北京 {yuzc19, yus21}@mails.tsinghua.edu.cn; chenyan.xiong@microsoft.com liuzy@tsinghua.edu.cn
Abstract
摘要
Retrieval augmentation can aid language models (LMs) in knowledge-intensive tasks by supplying them with external information. Prior works on retrieval augmentation usually jointly fine-tune the retriever and the LM, making them closely coupled. In this paper, we explore the scheme of generic retrieval plug-in: the retriever is to assist target LMs that may not be known beforehand or are unable to be fine-tuned together. To retrieve useful documents for unseen target LMs, we propose augmentation-adapted retriever (AAR), which learns LM’s preferences obtained from a known source LM. Experiments on the MMLU and PopQA datasets demonstrate that our AAR trained with a small source LM is able to significantly improve the zero-shot generalization of larger target LMs ranging from 250M Flan-T5 to 175B Instruct GP T. Further analysis indicates that the preferences of different LMs overlap, enabling AAR trained with a single source LM to serve as a generic plug-in for various target LMs. Our code is open-sourced at https://github.com/OpenMatch/AugmentationAdapted-Retriever.
检索增强能够通过提供外部信息,辅助语言模型(LM)完成知识密集型任务。现有检索增强研究通常联合微调检索器与语言模型,导致二者紧密耦合。本文探索通用检索插件的实现方案:检索器需辅助可能预先未知或无法联合微调的目标语言模型。为给未知目标语言模型检索有效文档,我们提出适配增强的检索器(AAR),通过学习已知源语言模型获得的偏好来优化检索。在MMLU和PopQA数据集上的实验表明,使用小型源语言模型训练的AAR能显著提升250M参数Flan-T5至175B参数InstructGPT等不同规模目标模型的零样本泛化能力。进一步分析表明,不同语言模型的偏好存在重叠,使得基于单一源模型训练的AAR可作为通用插件服务于各类目标模型。代码已开源:https://github.com/OpenMatch/AugmentationAdapted-Retriever。
1 Introduction
1 引言
Large language models (LMs) that possess billions of parameters are able to capture a significant amount of human knowledge, leading to consistent improvements on various downstream tasks (Brown et al., 2020; Kaplan et al., 2020; Roberts et al., 2020). However, the undeniable drawback of large LMs lies in their high computational cost, which negatively impacts their efficiency (Strubell et al., 2019; Bender et al., 2021). Furthermore, the knowledge memorized from pretraining and the implicit reasoning process of LMs can be inaccurate and intractable sometimes, hindering their applications on knowledge-intensive tasks (Guu et al., 2020; Lewis et al., 2020; Mallen et al., 2022; Wei et al., 2022).
拥有数十亿参数的大语言模型(LM)能够捕获大量人类知识,从而在各种下游任务上持续取得进步 (Brown et al., 2020; Kaplan et al., 2020; Roberts et al., 2020)。然而,大语言模型不可否认的缺点在于其高昂的计算成本,这会影响其效率 (Strubell et al., 2019; Bender et al., 2021)。此外,从预训练中记忆的知识和语言模型的隐式推理过程有时可能不准确且难以处理,阻碍了其在知识密集型任务中的应用 (Guu et al., 2020; Lewis et al., 2020; Mallen et al., 2022; Wei et al., 2022)。
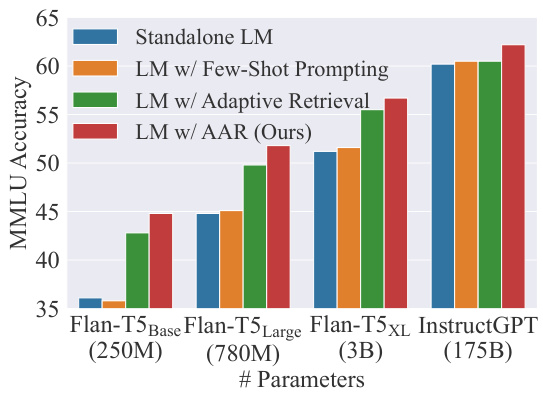
Figure 1: Performance of LM w/ AAR (Ours).
图 1: 采用AAR的LM性能(本研究)。
Instead of leveraging the knowledge and reasoning abilities embedded within the parameters of the LMs, retrieval augmentation (Guu et al., 2020; Lewis et al., 2020; Borgeaud et al., 2022) enhances the LM with a retriever that can retrieve knowledge from an external corpus. On the other hand, prior retrieval augmentation methods (Izacard and Grave, 2021a; Izacard et al., 2022) necessitate fine-tuning the backbone LM to adjust to the retriever and tackle specific downstream tasks. This kind of fine-tuning can be expensive when more and more unique demands emerge (Maro nikola k is and Schütze, 2021). More importantly, many toptier LMs can only be accessed through black-box APIs (Ouyang et al., 2022; OpenAI, 2023). These APIs allow users to submit queries and receive responses but typically do not support fine-tuning.
检索增强 (retrieval augmentation) (Guu et al., 2020; Lewis et al., 2020; Borgeaud et al., 2022) 并非利用大语言模型参数中内嵌的知识与推理能力,而是通过检索器从外部语料库获取知识来增强模型性能。另一方面,现有检索增强方法 (Izacard and Grave, 2021a; Izacard et al., 2022) 需要对骨干大语言模型进行微调以适应检索器并处理特定下游任务。当出现越来越多独特需求时 (Maro nikola k is and Schütze, 2021),此类微调成本会变得高昂。更重要的是,许多顶级大语言模型仅能通过黑盒API访问 (Ouyang et al., 2022; OpenAI, 2023),这些API允许用户提交查询并获取响应,但通常不支持微调。
In this paper, we introduce AugmentationAdapted Retriever (AAR) to assist black-box LMs with downstream tasks as generic plug-in. To retrieve valuable documents for many unseen LMs, we propose to leverage a small source LM to provide LM-preferred signals for retriever’s training. The retriever after training (i.e., AAR) can be directly utilized to assist a large target LM by plugging in the retrieved documents.
本文介绍了增强适应检索器 (AugmentationAdapted Retriever, AAR) ,作为通用插件协助黑盒大语言模型完成下游任务。为了为众多未见过的模型检索有价值文档,我们提出利用一个小型源模型提供模型偏好的信号来训练检索器。训练后的检索器 (即AAR) 可直接通过插入检索到的文档来辅助大型目标模型。
Specifically, we choose a small encoder-decoder LM as the source LM and utilize its fusionin-decoder attention scores (Izacard and Grave, 2021a) to annotate LM-preferred documents. The LM-preferred documents are then combined with human-preferred documents to form the positive document set. Negative documents are mined by the retriever itself using the ANCE (Xiong et al., 2021) technique. After fine-tuning the retriever with LM’s preferences, it can directly assist unseen target LMs in the zero-shot task generalization.
具体来说,我们选择一个小型编码器-解码器大语言模型作为源模型,并利用其解码器融合注意力分数 (Izacard and Grave, 2021a) 来标注模型偏好的文档。这些模型偏好的文档随后与人类偏好的文档结合,形成正例文档集。负例文档则通过检索器自身使用ANCE技术 (Xiong et al., 2021) 进行挖掘。在用模型的偏好微调检索器后,它可以直接在零样本任务泛化中协助未见过的目标大语言模型。
We evaluate AAR on a multi-task language understanding dataset MMLU (Hendrycks et al., 2021) and an entity-centric question answering dataset PopQA (Mallen et al., 2022). For the target LMs, we choose Flan-T5 (Chung et al., 2022) series as our backbone for encoder-decoder LMs and Instruct GP T (Ouyang et al., 2022) as our backbone for decoder-only LMs. Figure 1 shows that assisted with a generic AAR, LMs of different sizes and architectures can consistently outperform the standalone LMs; the performance of smaller LMs can sometimes surpass the standalone counterparts of significantly larger sizes (e.g., Flan-T5Large w/ AAR outperforms standalone Flan $.\mathrm{T}5_{\mathrm{XL}}$ by $0.6%$ ). AAR also demonstrates advantages over other augmentation approaches such as few-shot prompting and adaptive retrieval (Mallen et al., 2022).
我们在多任务语言理解数据集MMLU (Hendrycks et al., 2021) 和以实体为中心的问答数据集PopQA (Mallen et al., 2022) 上评估AAR。对于目标大语言模型,我们选择Flan-T5 (Chung et al., 2022) 系列作为编码器-解码器架构的基准模型,并选用Instruct GPT (Ouyang et al., 2022) 作为纯解码器架构的基准模型。图1显示,在通用AAR的辅助下,不同规模和架构的大语言模型都能持续超越独立运行的大语言模型;较小模型的性能有时甚至能显著超越规模大得多的独立运行模型 (例如配备AAR的Flan-T5Large比独立运行的Flan-T5XL高出0.6%)。AAR也展现出相对于少样本提示 (few-shot prompting) 和自适应检索 (adaptive retrieval) (Mallen et al., 2022)) 等其他增强方法的优势。
Further analysis reveals that the preferences obtained from different-sized source LMs are similar, and LMs with near capacities tend to yield closer preferred document sets. As a result, our AAR model trained from a small source LM can be considered as a generic plug-in to enhance the zeroshot generalization of a significantly larger target LM. We also discover that the documents preferred by LMs can provide assistance to the model from alternative perspectives, rather than relying solely on the full information favored by search users.
进一步分析表明,不同规模源大语言模型获得的偏好具有相似性,且容量相近的模型往往会产生更接近的偏好文档集。因此,我们基于小型源大语言模型训练的AAR模型,可作为通用插件来显著增强大型目标大语言模型的零样本泛化能力。研究还发现,大语言模型偏好的文档能从替代视角为模型提供辅助,而非仅依赖搜索用户青睐的完整信息。
2 Related Work
2 相关工作
Retrieval Augmentation. Augmenting LMs with retrieved information from external memories has shown effective on diverse knowledge-intensive tasks (Guu et al., 2020). Prior works explore novel ways to train the whole retriever-LM system in an end-to-end fashion, using retrievalaugmented sequence log-likelihood (Lewis et al., 2020; Borgeaud et al., 2022), fusion-in-decoder attention distillation (Izacard and Grave, 2021a; Izacard et al., 2022), or knowledge graph (Ju et al., 2022). To decouple the retriever from LM, Rubin et al. (2022) train an independent prompt retriever for in-context learning, and Lin et al. (2022) only fine-tune the LM via the retrieved data that is similar to few-shot unsupervised samples.
检索增强 (Retrieval Augmentation)。通过从外部记忆库中检索信息来增强大语言模型,已在多种知识密集型任务中展现出有效性 (Guu et al., 2020)。先前研究探索了端到端训练整个检索器-语言模型系统的新方法,包括使用检索增强序列对数似然 (Lewis et al., 2020; Borgeaud et al., 2022)、解码器融合注意力蒸馏 (Izacard and Grave, 2021a; Izacard et al., 2022) 或知识图谱 (Ju et al., 2022)。为解耦检索器与语言模型,Rubin et al. (2022) 训练了独立的提示检索器用于上下文学习,而 Lin et al. (2022) 仅通过类似于少样本无监督样本的检索数据对语言模型进行微调。
Recent researches adopt zero-shot retrieval augmentation that does not fine-tune the LM on InstructGPT (Ouyang et al., 2022). It can benefit entity-centric question answering (Mallen et al., 2022), chain-of-thought reasoning (He et al., 2022), and multi-hop question answering (Khattab et al., 2022). Parallel work (Shi et al., 2023) uses LM likelihood to train the retriever for satisfying blackbox LM’s preferences, and they adopt GPT-3 Curie (Brown et al., 2020) to provide the supervision signals. In this work, we devise the retriever that can be used as a generic plug-in to assist a variety of unseen LMs.
近期研究采用零样本检索增强技术,该技术无需在InstructGPT (Ouyang等人,2022) 上对语言模型进行微调。这种方法可提升以实体为中心的问答 (Mallen等人,2022) 、思维链推理 (He等人,2022) 以及多跳问答 (Khattab等人,2022) 的效果。并行研究 (Shi等人,2023) 利用语言模型似然性训练检索器以满足黑盒语言模型的偏好,并采用GPT-3 Curie (Brown等人,2020) 提供监督信号。本工作设计的检索器可作为通用插件辅助各类未知语言模型。
Zero-shot Learning and Reasoning. Largescale unsupervised pre-trained LMs like GPT3 (Brown et al., 2020), GPT-4 (OpenAI, 2023), and PaLM (Chowdhery et al., 2022) are able to perform zero-shot learning on many downstream tasks with a task description provided at inference time. Instruction-finetuned LMs (Sanh et al., 2022; Chung et al., 2022; Ouyang et al., 2022), which are pre-trained on multiple supervised tasks using human instructions, also also exhibit robust zeroshot learning capabilities. Yu et al. (2023) propose a new scheme of zero-shot reasoning, which first prompts large LMs to generate relevant documents and then perform reading comprehension on the generated contents. Recently, there has been a growing trend of utilizing plug-and-play knowledge injection to enhance the zero-shot performance of LMs, which is achieved through mapping network (Zhang et al., 2023) or document encoding (Xiao et al., 2023). Our work improves the zero-shot generalization of LMs by utilizing the retrieved information. We demonstrate that identifying LMs’ preferences to train the retriever can in turn bring additional evidence texts for LMs.
零样本学习与推理。像GPT-3 (Brown等人,2020)、GPT-4 (OpenAI,2023) 和PaLM (Chowdhery等人,2022) 这样的大规模无监督预训练大语言模型,能够在推理时通过任务描述对许多下游任务进行零样本学习。基于指令微调的大语言模型 (Sanh等人,2022;Chung等人,2022;Ouyang等人,2022) 通过人类指令对多个监督任务进行预训练后,同样展现出强大的零样本学习能力。Yu等人 (2023) 提出了一种新的零样本推理方案,先提示大语言模型生成相关文档,再对生成内容进行阅读理解。近期,越来越多研究通过即插即用的知识注入来增强大语言模型的零样本性能,具体实现方式包括映射网络 (Zhang等人,2023) 或文档编码 (Xiao等人,2023)。我们的工作通过利用检索信息提升了大语言模型的零样本泛化能力。实验表明,通过识别大语言模型的偏好来训练检索器,能够为其提供额外的证据文本。
3 Method
3 方法
In this section, we first introduce the preliminaries of the dense retrieval and the retrieval-augmented LM $(\S\enspace3.1)$ , then propose our augmentationadapted retriever $(\S3.2)$ .
在本节中,我们首先介绍密集检索 (dense retrieval) 和检索增强语言模型 (retrieval-augmented LM) 的基础知识 (第3.1节),然后提出我们的自适应增强检索器 (第3.2节)。
3.1 Preliminaries
3.1 预备知识
Retrieval-augmented LM (Guu et al., 2020; Lewis et al., 2020) is a type of LM that leverages external information to improve its performance. It retrieves relevant documents from a corpus using a retriever, and then utilizes the documents to enhance its language generation capabilities.
检索增强型大语言模型 (Retrieval-augmented LM) (Guu et al., 2020; Lewis et al., 2020) 是一种利用外部信息提升性能的大语言模型。它通过检索器从语料库中获取相关文档,并利用这些文档来增强其语言生成能力。
The objective of the retriever is to find an augmentation document set $D^{a}$ from a corpus $C$ that helps the LM handle a given query $q$ . Previous researches (Karpukhin et al., 2020; Xiong et al., 2021) concentrate primarily on the dense retrieval system that searches in the dense vector space since dense retrieval usually performs more accurately and efficiently than sparse one.
检索器的目标是从语料库 $C$ 中找到一个有助于大语言模型处理给定查询 $q$ 的增强文档集 $D^{a}$。先前的研究 [20][21] 主要集中于在稠密向量空间中进行搜索的稠密检索系统,因为稠密检索通常比稀疏检索更准确高效。
A dense retrieval model first represents $q$ and the document $d$ into an embedding space using a pre-trained encoder $g$ ,
密集检索模型首先使用预训练的编码器 $g$ 将查询 $q$ 和文档 $d$ 映射到嵌入空间,
$$
\pmb{q}=q(q);\pmb{d}=g(d),d\in C,
$$
$$
\pmb{q}=q(q);\pmb{d}=g(d),d\in C,
$$
and match their embeddings by dot product function $f$ , which supports fast approximate nearest neighbor search (ANN) (André et al., 2016; Johnson et al., 2021). We then define $D^{a}$ that contains top $N$ retrieved documents as:
并通过点积函数 $f$ 匹配它们的嵌入向量,支持快速近似最近邻搜索 (ANN) (André et al., 2016; Johnson et al., 2021)。随后我们将包含前 $N$ 个检索文档的集合定义为 $D^{a}$:
$$
D^{a}={d_{1}^{a}...d_{N}^{a}}=\mathrm{ANN}_{f(q,\circ)}^{N}.
$$
$$
D^{a}={d_{1}^{a}...d_{N}^{a}}=\mathrm{ANN}_{f(q,\circ)}^{N}.
$$
For the LM backbones, the decoder-only and the encoder-decoder models are the two primary choices of the retrieval-augmented LMs (Izacard and Grave, 2021b; Yu et al., 2023).
在检索增强的大语言模型架构选择上,主要存在两种核心范式:仅解码器(decoder-only)模型和编码器-解码器(encoder-decoder)模型 (Izacard and Grave, 2021b; Yu et al., 2023)。
Given a decoder-only LM like GPT-3 (Brown et al., 2020), the LM input can be a simple concatenation of the query and all the augmentation documents ${d_{1}^{a}\cdot\cdot\cdot d_{N}^{a}}$ . Then, the LM will generate the answer based on the inputs auto-regressive ly.
给定一个仅解码器的大语言模型(如GPT-3 [20]),模型输入可以是查询与所有增强文档${d_{1}^{a}\cdot\cdot\cdot d_{N}^{a}}$的简单拼接。随后,该模型将以自回归方式基于输入生成答案。
For an encoder-decoder LM like T5 (Raffel et al., 2020), taking simple concatenation as the encoder input may still be effective. However, this method may not scale to a large volume of documents due to the quadratic self-attention computation associated with the number of documents. To aggregate multiple documents more efficiently, Izacard and Grave (2021b) propose the fusion-in-decoder (FiD) mechanism, which soon becomes the mainstream in the development of encoder-decoder retrievalaugmented LMs. It first encodes each concatenation of the $(d_{i}^{a},q)$ pair separately and then lets the decoder attend to all parts:
对于像T5 (Raffel et al., 2020) 这样的编码器-解码器大语言模型,采用简单拼接作为编码器输入可能仍然有效。但由于文档数量会导致自注意力计算呈平方级增长,这种方法难以扩展到海量文档场景。为更高效聚合多文档,Izacard和Grave (2021b) 提出了解码器融合 (FiD) 机制,该方案迅速成为编码器-解码器检索增强大语言模型开发的主流范式。其核心是先将每个$(d_{i}^{a},q)$ 对分别编码,再让解码器关注所有片段:
$$
\mathrm{FiD}(q)=\mathrm{Dec}(\mathrm{Enc}(d_{1}^{a}\oplus q)\cdot\cdot\cdot\mathrm{Enc}(d_{N}^{a}\oplus q)).
$$
$$
\mathrm{FiD}(q)=\mathrm{Dec}(\mathrm{Enc}(d_{1}^{a}\oplus q)\cdot\cdot\cdot\mathrm{Enc}(d_{N}^{a}\oplus q)).
$$
In this way, the encoder computes self-attention over one document at a time so that the computational cost can grow linearly with the number of documents. Furthermore, FiD cross-attention is found effective in estimating the relative importance of the augmentation documents from the LM’s perspective (Izacard and Grave, 2021a). Therefore, soft FiD distillation (Izacard and Grave, 2021a; Izacard et al., 2022; Shi et al., 2023), which minimizes the KL-divergence between retrieval likelihood and LM likelihood, is often used to train the retriever and the LM end-to-end.
通过这种方式,编码器每次仅计算单个文档的自注意力(self-attention),使得计算成本随文档数量线性增长。此外,研究发现FiD交叉注意力(FiD cross-attention)能有效评估增强文档在大语言模型视角下的相对重要性(Izacard and Grave, 2021a)。因此,通常采用软FiD蒸馏(soft FiD distillation)(Izacard and Grave, 2021a; Izacard et al., 2022; Shi et al., 2023)来端到端训练检索器与大语言模型,该方法通过最小化检索似然与语言模型似然之间的KL散度实现。
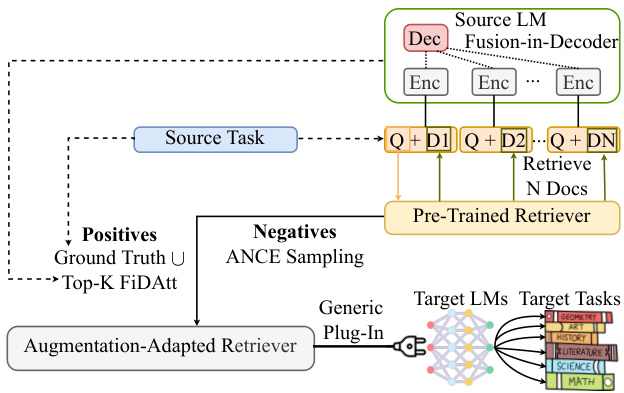
Figure 2: Illustration of augmentation-adapted retriever.
图 2: 增强适配检索器示意图。
3.2 Augmentation-adapted Retriever
3.2 适应增强的检索器
Due to the emerging real-world demands and the limitations of black-box APIs, fine-tuning retrieval-augmented LM for each possible downstream task can be infeasible. Hence, we introduce Augmentation-Adapted Retriever (AAR) as a generic plug-in for black-box LMs. As illustrated in Figure 2, AAR can learn the preferences of LMs without the need for fine-tuning them.
由于现实需求不断涌现以及黑盒API的局限性,为每个潜在的下游任务微调检索增强的大语言模型可能并不可行。因此,我们引入了适配增强的检索器 (AAR) 作为黑盒大语言模型的通用插件。如图 2 所示,AAR 无需微调即可学习大语言模型的偏好。
Specifically, we utilize an encoder-decoder LM as source LM $(L_{s})$ to provide LM-preferred signals on a source task $(T_{s})$ for fine-tuning a pre-trained retriever. Then, we plug the fine-tuned retriever into unseen target LM $(L_{t})$ on a set of target tasks $(T_{t})$ non-intersecting with $T_{s}$ .
具体而言,我们采用编码器-解码器架构的大语言模型作为源模型 $(L_{s})$ ,通过在源任务 $(T_{s})$ 上提供模型偏好信号来微调预训练的检索器。随后,我们将微调后的检索器部署到未见过的目标模型 $(L_{t})$ 上,用于处理与 $T_{s}$ 不相交的一系列目标任务 $(T_{t})$ 。
Our training method starts from a source task $T_{s}$ , where we aggregate the source LM $L_{s}$ ’s average FiD cross-attention (FiDAtt) scores $S_{i}^{a}$ corresponding to document $d_{i}^{a}$ from the first decoder token over all the layers, all the heads and all the input tokens $t$ of $d_{i}^{a}\oplus q$ :
我们的训练方法从一个源任务 $T_{s}$ 开始,在此我们聚合源大语言模型 $L_{s}$ 的平均FiD交叉注意力(FiDAtt)分数 $S_{i}^{a}$,这些分数对应于文档 $d_{i}^{a}$,来自所有层、所有注意力头以及 $d_{i}^{a}\oplus q$ 的所有输入token $t$ 的第一个解码器token:
$$
S_{i}^{a}=\frac{1}{\ln*\ln*\tan}\sum_{\mathrm{layers}}\sum_{\mathrm{heads}}\sum_{{t}\in d_{i}^{a}\oplus{q}}\mathrm{FiDAtt}(\mathrm{FiD}(q)).
$$
$$
S_{i}^{a}=\frac{1}{\ln*\ln*\tan}\sum_{\mathrm{layers}}\sum_{\mathrm{heads}}\sum_{{t}\in d_{i}^{a}\oplus{q}}\mathrm{FiDAtt}(\mathrm{FiD}(q)).
$$
where ln, hn, tn are the numbers of the layers, the heads and the input tokens.
其中 ln、hn、tn 分别表示层数、头数和输入 token 数。
To make the training process more robust, we utilize the FiDAtt scores to annotate the LM-preferred positive documents in a discrete way:
为了使训练过程更加稳健,我们利用FiDAtt分数以离散方式标注LM偏好的正向文档:
$$
D^{a+}=D^{h+}\cup\mathrm{Top}{-}K_{S_{i}^{a},D^{a}},
$$
$$
D^{a+}=D^{h+}\cup\mathrm{Top}{-}K_{S_{i}^{a},D^{a}},
$$
where $D^{h+}$ is the human-preferred positive document set (i.e., ground truth) on $T_{s}$ . Top $K_{S_{i}^{a},D^{a}}$ means the documents with the top $\mathbf{\nabla\cdot}\mathbf{k}$ average FiDAtt scores $S_{i}^{a}$ in the retrieved document set $D^{a}$ .
其中 $D^{h+}$ 是 $T_{s}$ 上人类偏好的正文档集(即真实值)。Top $K_{S_{i}^{a},D^{a}}$ 表示在检索文档集 $D^{a}$ 中具有前 $\mathbf{\nabla\cdot}\mathbf{k}$ 平均FiDAtt分数 $S_{i}^{a}$ 的文档。
Then, we sample hard negatives following ANCE (Xiong et al., 2021) and formulate the training loss $\mathcal{L}$ of the retriever as:
然后,我们按照ANCE (Xiong et al., 2021)的方法采样困难负例,并将检索器的训练损失$\mathcal{L}$表示为:
$$
\begin{array}{r l}&{D^{-}=\mathrm{ANN}_ {f(q,\circ)}^{M}\backslash D^{a+},}\ &{\mathcal{L}=\displaystyle\sum_{q}\sum_{d^{+}\in D^{a+}}\sum_{d^{-}\in D^{-}}l(f(q,d^{+}),f(q,d^{-})),}\end{array}
$$
$$
\begin{array}{r l}&{D^{-}=\mathrm{ANN}_ {f(q,\circ)}^{M}\backslash D^{a+},}\ &{\mathcal{L}=\displaystyle\sum_{q}\sum_{d^{+}\in D^{a+}}\sum_{d^{-}\in D^{-}}l(f(q,d^{+}),f(q,d^{-})),}\end{array}
$$
where $M$ is the hyper parameter of the negative sampling depth and $l$ is the standard cross entropy loss. After fine-tuning the retriever, we directly use it to augment unseen target LM $L_{t}$ on each task from target task set $T_{t}$ .
其中 $M$ 是负采样深度的超参数,$l$ 是标准交叉熵损失。在对检索器进行微调后,我们直接使用它来增强目标任务集 $T_{t}$ 中每个任务上未见过的目标语言模型 $L_{t}$。
4 Experimental Methodologies
4 实验方法
In this section, we discuss our main experimental setup. More details can be found in Appendix A.
在本节中,我们将讨论主要的实验设置。更多细节详见附录A。
4.1 Target Tasks
4.1 目标任务
Following prior works (Chung et al., 2022; Mallen et al., 2022), we choose MMLU (Hendrycks et al., 2021) and PopQA (Mallen et al., 2022) as target tasks $T_{t}$ .
遵循先前研究 (Chung et al., 2022; Mallen et al., 2022) ,我们选择 MMLU (Hendrycks et al., 2021) 和 PopQA (Mallen et al., 2022) 作为目标任务 $T_{t}$ 。
MMLU is a multitask language understanding dataset, which includes 57 multi-choice question answering subtasks. These subtasks can be generally classified into four categories: humanities, social sciences, STEM, and other. We average the accuracy of the subtasks in each category to obtain the final score. We report the accuracy of the evaluation set in our main experiments.
MMLU是一个多任务语言理解数据集,包含57个多选题问答子任务。这些子任务大致可分为四类:人文、社会科学、STEM(科学/技术/工程/数学)和其他领域。我们通过计算每个类别中子任务的平均准确率来获得最终得分。在主要实验中,我们报告了评估集的准确率。
PopQA is an entity-centric question answering dataset that mainly concentrates on long-tail questions. We report the accuracy of the test set in our main experiments.
PopQA是一个以实体为中心的问题回答数据集,主要关注长尾问题。我们在主要实验中报告了测试集的准确率。
4.2 Our Method
4.2 我们的方法
Retrievers. We adopt two widely used retrievers to initialize AAR: ANCE initialized from $\mathrm{T}5_{\mathrm{Base}}$ (Raffel et al., 2020; Ge et al., 2023) and Contriever (Izacard et al., 2021) initialized from $\mathrm{BERT_{Base}}$ (Devlin et al., 2019). Both of them have been fine-tuned on MS MARCO (Bajaj et al., 2016) previously. For the retrieval corpus, we choose the MS MARCO (Bajaj et al., 2016) for MMLU and the KILT-Wikipedia (Petroni et al.) for PopQA.
检索器。我们采用两种广泛使用的检索器来初始化AAR:基于$\mathrm{T}5_{\mathrm{Base}}$ (Raffel et al., 2020; Ge et al., 2023)初始化的ANCE,以及基于$\mathrm{BERT_{Base}}$ (Devlin et al., 2019)初始化的Contriever (Izacard et al., 2021)。两者此前均在MS MARCO (Bajaj et al., 2016)上进行过微调。对于检索语料库,我们选择MS MARCO (Bajaj et al., 2016)用于MMLU任务,选择KILT-Wikipedia (Petroni et al.)用于PopQA任务。
Language Models. We adopt Flan-T5 (Chung et al., 2022) series as our backbone for encoderdecoder LMs and Instruct GP T 1 (Ouyang et al., 2022) as our backbone for decoder-only LMs. These models have been multi-task instructionfinetuned and are widely utilized for assessing zeroshot generalization (Zhou et al., 2023).
语言模型。我们采用 Flan-T5 (Chung et al., 2022) 系列作为编码器-解码器大语言模型的骨干,并选用 Instruct GPT (Ouyang et al., 2022) 作为仅解码器大语言模型的骨干。这些模型经过多任务指令微调,被广泛用于评估零样本泛化能力 (Zhou et al., 2023)。
Implementation Details. We utilize the MS MARCO (Bajaj et al., 2016) as our source task $T_{s}$ since it is the common choice to train the retriever (Xin et al., 2022). This dataset consists of high-quality questions that require real-world knowledge to answer, which aligns strongly with our target tasks $T_{t}$ and possesses no overlap with them. Considering the implementation efficiency, we take the Flan $\mathrm{T}5_{\mathrm{Base}}$ as the source LM $L_{s}$ and treat the larger model as the target LM $L_{t}$ . We directly set the total document number $N=10$ , LMpreferred document number $K=2$ , and the negative mining depth $M=100$ in the augmentationadapted training. We run all experiments on a single A100 GPU (40G).
实现细节。我们采用MS MARCO (Bajaj et al., 2016) 作为源任务 $T_{s}$,因为这是训练检索器 (Xin et al., 2022) 的常见选择。该数据集包含需要现实世界知识才能回答的高质量问题,与我们的目标任务 $T_{t}$ 高度契合且无重叠。考虑到实现效率,我们选用Flan $\mathrm{T}5_{\mathrm{Base}}$ 作为源大语言模型 $L_{s}$,并将更大模型设为目标大语言模型 $L_{t}$。在适配增强训练中直接设置总文档数 $N=10$、大语言模型优选文档数 $K=2$ 以及负样本挖掘深度 $M=100$。所有实验均在单张A100 GPU (40G) 上运行。
4.3 Baselines
4.3 基线方法
Zero-shot Setting. We compare our method with the state-of-the-art zero-shot baselines. Standalone LMs, including Flan-T5 (Chung et al., 2022), InstructGPT (Ouyang et al., 2022), GAL (Taylor et al., 2022) and OPT-IML-Max (Iyer et al., 2022), are prompted by a natural language instruction that describes the desired task and question. Adaptive retrieval (Mallen et al., 2022) selectively utilizes non-parametric memory (retrieval augmentation) and parametric memory (the knowledge obtained from pre-training) based on questions’ popularity. In our main experiment, we select the optimal combination in their paper, which consists of Contriever as the non-parametric memory and GenRead (Yu et al., 2023) as the parametric memory.
零样本设置。我们将本方法与最先进的零样本基线进行比较。独立的大语言模型包括 Flan-T5 (Chung et al., 2022)、InstructGPT (Ouyang et al., 2022)、GAL (Taylor et al., 2022) 和 OPT-IML-Max (Iyer et al., 2022),这些模型通过描述目标任务和问题的自然语言指令进行提示。自适应检索 (Mallen et al., 2022) 根据问题的流行度选择性利用非参数记忆(检索增强)和参数记忆(预训练获得的知识)。在我们的主要实验中,我们选择了其论文中的最优组合,即 Contriever 作为非参数记忆,GenRead (Yu et al., 2023) 作为参数记忆。
Few-shot Setting. We also include the results of previous few-shot models for reference. Flan-T5, Instruct GP T, Chinchilla (Hoffmann et al., 2022) and OPT-IML-Max adopt few-shot demonstrations, which provide the LMs with a limited number of task examples. This enables the models to generalize from these examples and generate accurate responses (Gao et al., 2021). Atlas (Izacard et al., 2022) is a state-of-the-art retrieval-augmented LM, which jointly pre-trains the retriever with the LM using unsupervised data and fine-tunes the retriever via the attention distillation on few-shot data.
少样本设置。我们还包含了以往少样本模型的结果以供参考。Flan-T5、InstructGPT、Chinchilla (Hoffmann et al., 2022) 和 OPT-IML-Max 采用了少样本演示,为语言模型提供了有限数量的任务示例。这使得模型能够从这些示例中泛化并生成准确的响应 (Gao et al., 2021)。Atlas (Izacard et al., 2022) 是一种最先进的检索增强语言模型,它使用无监督数据联合预训练检索器和语言模型,并通过少样本数据上的注意力蒸馏对检索器进行微调。
| Settings Methods | #Parameters | MMLU | PopQA All | |||||
| All | Hum. | Soc. Sci. | STEM | Other | ||||
| Base Setting: T5 Base Size | ||||||||
| Few-shot | Flan-T5Base (Chung et al., 2022) | 250M | 35.8 | 39.6 | 39.8 | 26.3 | 41.2 | 8.0 |
| Flan-T5Base | 250M | 36.1 | 40.4 | 39.8 | 27.0 | 40.6 | 8.8 | |
| Flan-T5Base w/ AR (Mallen et al., 2022) | 250M | 42.8 | 43.5 | 44.0 | 35.8 | 50.0 | 29.4 | |
| Flan-T5Base W/ AARContriever (Ours) | 250M | 44.4 | 44.7 | 47.7 | 35.8 | 52.2 | 31.9 | |
| Flan-T5Base w/ AARANCE (Ours) | 250M | 44.8 | 42.2 | 46.4 | 39.0 | 53.2 | 37.7 | |
| Large Setting: T5 Large Size Few-shot | ||||||||
| AtlasLarge FT (Izacard et al., 2022) | 770M | 38.9 | 37.3 | 41.7 | 32.3 | 44.9 | n.a. | |
| Zero-shot | Flan-T5Large | 780M | 45.1 | 47.7 | 53.5 | 34.4 | 49.2 | 9.3 |
| Flan-T5Large | 780M | 44.8 | 46.3 | 51.4 | 34.8 | 50.6 | 7.2 | |
| Flan-T5Large w/ AR | 780M | 49.8 | 50.0 | 55.6 | 38.4 | 59.5 | 29.6 | |
| Flan-T5Large W/ AARContriever (Ours) | 780M | 51.8 | 50.8 | 59.7 | 39.4 | 61.8 | 33.4 | |
| XL Setting: T5 XL Size | Flan-T5Large w/ AARANCE (Ours) | 780M | 50.4 | 48.0 | 58.1 | 39.3 | 60.2 | 39.3 |
| AtlasxL FT | ||||||||
| Few-shot | 3B | 42.3 | 40.0 | 46.8 | 35.0 | 48.1 | n.a. | |
| Flan-T5xL | 3B | 51.6 | 55.0 | 61.1 | 36.8 | 59.5 | 11.1 | |
| Flan-T5xL | 3B | 51.2 | 55.5 | 57.4 | 38.1 | 58.7 | 11.3 | |
| Zero-shot | Flan-T5xL w/ AR | 3B | 55.5 | 56.7 | 64.5 | 43.0 | 62.6 | 33.7 |
| Flan-T5xL w/ AARContriever (Ours) | 3B | 56.7 | 57.7 | 65.4 | 43.6 | 65.1 | 31.5 | |
| Flan-T5xL w/ AARANCE (Ours) | 3B | 56.2 | 59.4 | 64.8 | 41.5 | 64.9 | 38.0 | |
| Giant Setting: Over 70B Size | ||||||||
| Few-shot | Chinchilla (Hoffmann et al., 2022) | 70B | 67.5 | 63.6 | 79.3 | 55.0 | 73.9 | n.a. |
| OPT-IML-Max (Iyer et al., 2022) | 175B | 47.1 | n.a. | n.a. | n.a. | n.a. | n.a. | |
| InstructGPT (Ouyang et al., 2022) | 175B | 60.5 | 62.0 | 71.8 | 44.3 | 70.1 | 35.2 | |
| GAL (Taylor et al., 2022) | 120B | 52.6 | ||||||
| OPT-IML-Max | 175B | 49.1 | n.a. | n.a. | n.a. | n.a. | n.a. | |
| InstructGPT | 175B | 60.2 | n.a. 65.7 | n.a. | n.a. 46.1 | n.a. | n.a. | |
| Zero-shot | InstructGPT w/ AR | 68.0 | 66.5 | 34.7 | ||||
| 175B | 60.5 | 62.2 | 71.3 | 44.7 | 69.7 | 43.3 | ||
| InstructGPT w/ AARContriever (Ours) | 175B | 61.5 | 64.5 | 73.1 | 45.0 | 69.9 | 43.9 | |
| InstructGPT w/ AARANCE (Ours) | 175B | 62.2 | 62.0 | 72.0 | 49.2 | 70.7 | 52.0 | |
Table 1: Our main results on MMLU and PopQA dataset. We group the methods mainly by the parameters. Our $L_{s}$ is Flan-$\mathrm{T5_{Base}}$ . A ARC on tri ever: AAR initialized from Contriever; $\mathrm{AAR}_{\mathrm{ANCE}}$ : AAR initialized from ANCE; FT: fine-tuning; AR: adaptive retrieval. Unspecified methods represent direct prompting. The score marked as bold means the best performance among the models in the zero-shot setting.
| 设置方法 | 参数量 | MMLU | PopQA全部 | |||||
|---|---|---|---|---|---|---|---|---|
| 全部 | 人文 | 社科 | STEM | 其他 | ||||
| 基础设置: T5基础尺寸 | ||||||||
| 少样本 | Flan-T5Base (Chung et al., 2022) | 250M | 35.8 | 39.6 | 39.8 | 26.3 | 41.2 | 8.0 |
| Flan-T5Base | 250M | 36.1 | 40.4 | 39.8 | 27.0 | 40.6 | 8.8 | |
| Flan-T5Base w/ AR (Mallen et al., 2022) | 250M | 42.8 | 43.5 | 44.0 | 35.8 | 50.0 | 29.4 | |
| Flan-T5Base W/ AARContriever (Ours) | 250M | 44.4 | 44.7 | 47.7 | 35.8 | 52.2 | 31.9 | |
| Flan-T5Base w/ AARANCE (Ours) | 250M | 44.8 | 42.2 | 46.4 | 39.0 | 53.2 | 37.7 | |
| 大型设置: T5大型尺寸 少样本 | ||||||||
| AtlasLarge FT (Izacard et al., 2022) | 770M | 38.9 | 37.3 | 41.7 | 32.3 | 44.9 | n.a. | |
| 零样本 | Flan-T5Large | 780M | 45.1 | 47.7 | 53.5 | 34.4 | 49.2 | 9.3 |
| Flan-T5Large | 780M | 44.8 | 46.3 | 51.4 | 34.8 | 50.6 | 7.2 | |
| Flan-T5Large w/ AR | 780M | 49.8 | 50.0 | 55.6 | 38.4 | 59.5 | 29.6 | |
| Flan-T5Large W/ AARContriever (Ours) | 780M | 51.8 | 50.8 | 59.7 | 39.4 | 61.8 | 33.4 | |
| XL设置: T5 XL尺寸 | Flan-T5Large w/ AARANCE (Ours) | 780M | 50.4 | 48.0 | 58.1 | 39.3 | 60.2 | 39.3 |
| AtlasxL FT | ||||||||
| 少样本 | 3B | 42.3 | 40.0 | 46.8 | 35.0 | 48.1 | n.a. | |
| Flan-T5xL | 3B | 51.6 | 55.0 | 61.1 | 36.8 | 59.5 | 11.1 | |
| Flan-T5xL | 3B | 51.2 | 55.5 | 57.4 | 38.1 | 58.7 | 11.3 | |
| 零样本 | Flan-T5xL w/ AR | 3B | 55.5 | 56.7 | 64.5 | 43.0 | 62.6 | 33.7 |
| Flan-T5xL w/ AARContriever (Ours) | 3B | 56.7 | 57.7 | 65.4 | 43.6 | 65.1 | 31.5 | |
| Flan-T5xL w/ AARANCE (Ours) | 3B | 56.2 | 59.4 | 64.8 | 41.5 | 64.9 | 38.0 | |
| 巨型设置: 超过70B尺寸 | ||||||||
| 少样本 | Chinchilla (Hoffmann et al., 2022) | 70B | 67.5 | 63.6 | 79.3 | 55.0 | 73.9 | n.a. |
| OPT-IML-Max (Iyer et al., 2022) | 175B | 47.1 | n.a. | n.a. | n.a. | n.a. | n.a. | |
| InstructGPT (Ouyang et al., 2022) | 175B | 60.5 | 62.0 | 71.8 | 44.3 | 70.1 | 35.2 | |
| GAL (Taylor et al., 2022) | 120B | 52.6 | ||||||
| OPT-IML-Max | 175B | 49.1 | n.a. | n.a. | n.a. | n.a. | n.a. | |
| InstructGPT | 175B | 60.2 | n.a. 65.7 | n.a. | n.a. 46.1 | n.a. | n.a. | |
| 零样本 | InstructGPT w/ AR | 68.0 | 66.5 | |||||
| 175B | 60.5 | 62.2 | 71.3 | 44.7 | 69.7 | 43.3 | ||
| InstructGPT w/ AARContriever (Ours) | 175B | 61.5 | 64.5 | 73.1 | 45.0 | 69.9 | 43.9 | |
| InstructGPT w/ AARANCE (Ours) | 175B | 62.2 | 62.0 | 72.0 | 49.2 | 70.7 | 52.0 |
表 1: 我们在MMLU和PopQA数据集上的主要结果。我们主要根据参数量对方法进行分组。我们的 $L_{s}$ 是Flan-$\mathrm{T5_{Base}}$。AARC on tri ever: 从Contriever初始化的AAR; $\mathrm{AAR}_{\mathrm{ANCE}}$: 从ANCE初始化的AAR;FT: 微调;AR: 自适应检索。未指定的方法代表直接提示。加粗的分数表示在零样本设置中模型的最佳性能。
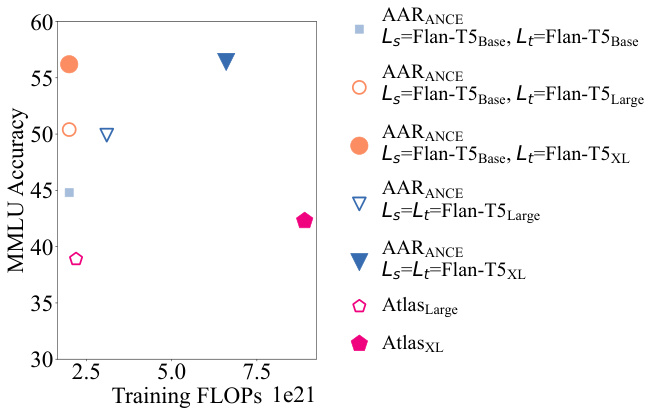
Figure 3: Training FLOPs of retrieval augmentation methods.
图 3: 检索增强方法的训练FLOPs。
5 Evaluation Results
5 评估结果
In this section, we discuss our main results on MMLU and PopQA datasets $(\S5.1)$ and conduct
在本节中,我们将讨论在MMLU和PopQA数据集上的主要结果 $(\S5.1)$ ,并进行
comprehensive studies about how $(\S5.2,\S5.3.$ $\S\S.4)$ and when $(\S5.5,\S5.6)$ AAR helps.
关于AAR如何 $(\S5.2,\S5.3.$ $\S\S.4)$ 以及何时 $(\S5.5,\S5.6)$ 发挥作用的全面研究。
5.1 Overall Performance
5.1 整体性能
Table 1 demonstrates that, with the assistance of a generic AAR, target LMs of different sizes and architectures can significantly outperform their standalone baselines in the zero-shot setting. Notably, AAR even improves powerful Instruct GP T by $2%$ on MMLU and by nearly $20%$ on PopQA. We hypothesize that the PopQA dataset mainly comprises long-tail questions and thus necessitates more augmentation information to attain high accuracy. AAR outperforms other augmentation methods like few-shot prompting and adaptive retrieval, as they may not offer as extensive evidence text as AAR does.
表 1: 结果表明,在通用AAR的辅助下,不同规模和架构的目标大语言模型在零样本设置中均能显著超越其独立基线水平。值得注意的是,AAR甚至将强大的InstructGPT在MMLU上的表现提升了$2%$,在PopQA上提升了近$20%$。我们推测PopQA数据集主要由长尾问题构成,因此需要更多增强信息以实现高准确率。AAR优于少样本提示和自适应检索等其他增强方法,因为这些方法可能无法提供像AAR那样广泛的证据文本。
Meanwhile, AAR is a highly efficient augmentation approach since it only relies on a small source
同时,AAR是一种高效的增强方法,因为它仅依赖于少量源
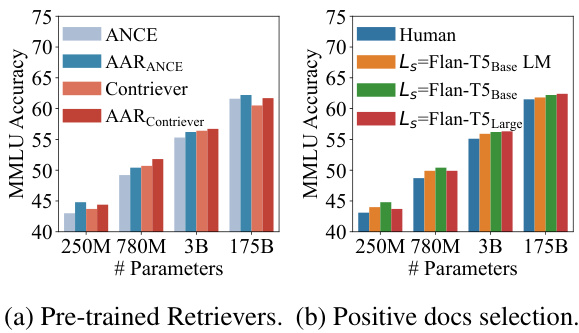
Figure 4: AAR’s performance when (a) using different pre-trained retrievers and (b) trained with different positive documents, using Flan-$\mathrm{T5}_ {\mathrm{Base}}$ (250M), Flan-$\mathrm{T5}_ {\mathrm{Large}}$ (780M), Flan-$\mathrm{{T}}5_{\mathrm{{XL}}}$ (3B), Instruct GP T (175B) as $L_{t}$ . The retriever in (b) is initialized from ANCE.
图 4: AAR在不同情况下的性能表现:(a) 使用不同预训练检索器时,(b) 使用不同正样本文档训练时。实验采用 Flan-$\mathrm{T5}_ {\mathrm{Base}}$ (250M)、Flan-$\mathrm{T}5_{\mathrm{Large}}$ (780M)、Flan-$\mathrm{{T}}5_{\mathrm{{XL}}}$ (3B) 和 Instruct GPT (175B) 作为 $L_{t}$。(b) 中的检索器基于ANCE初始化。
LM Flan-$\mathrm{T5_{Base}}$ (250M) to provide training signals and can generalize well to target LMs of larger capacities. Figure 3 illustrates that solely setting the source LM as the target LM (represented by the inverted triangles) does not significantly enhance the MMLU accuracy. However, it may triple the training budget required. Only using a small source LM is able to outperform the powerful Atlas by large margins with fewer training FLOPs.
LM Flan-$\mathrm{T5_{Base}}$ (250M) 来提供训练信号,并能很好地泛化到更大容量的目标大语言模型。图 3 表明,仅将源大语言模型设为目标大语言模型 (以倒三角形表示) 并不会显著提升 MMLU 准确率,反而可能使训练预算增加三倍。仅使用小型源大语言模型就能以更少的训练 FLOPs 大幅超越强大的 Atlas。
5.2 Ablation Study
5.2 消融研究
In this experiment, we conduct the ablation study of augmentation-adapted training and analyze model behaviors during the training process.
在本实验中,我们进行了数据增强适应训练 (augmentation-adapted training) 的消融研究,并分析了训练过程中的模型行为。
Figure 4a illustrates that augmentation-adapted training can bring additional improvements compared to the pre-trained retrievers. In general, ANCE benefits more from augmentation-adapted training than Contriever. This may be due to the fact that Contriever has been already intensively pre-trained on massive data augmentations as well as MS MARCO whereas ANCE is trained only on MS MARCO. We provide exact numbers in Table 7 and PopQA results in Figure 8, which yield similar observations as MMLU.
图 4a 表明,相较于预训练的检索器,适应增强训练能带来额外提升。总体而言,ANCE 从适应增强训练中获益多于 Contriever。这可能是因为 Contriever 已在海量数据增强和 MS MARCO 上进行了密集预训练,而 ANCE 仅基于 MS MARCO 训练。具体数值见表 7,PopQA 结果见图 8,其结论与 MMLU 实验结果一致。
In Figure 4b, we compare retrievers trained with different positive documents, including humanpreferred documents annotated by search users (the blue bar), LM-preferred documents obtained by the source LM (the orange bar), and their combinations (the green bar and the red bar). Since the retriever has been pre-trained on user-annotated MS MARCO, simply using human-preferred documents to train it may be meaningless and therefore performs the worst among all approaches. Only using LM-preferred documents demonstrates notable gains over only using human-preferred documents, and merging both human-preferred and LM-preferred documents (our main setup) further enhances the retriever’s performance. Finally, using Flan- $\mathrm{T5}_{\mathrm{Base}}$ as source LM yields better results compared to using Flan-T5Large when the target LMs are relatively small. However, as the target LM’s size increases, both approaches achieve comparable performance. Hence, our choice to utilize a small source LM in the augmentation-adapted training is reasonable and effective.
在图4b中,我们比较了使用不同正向文档训练的检索器,包括搜索用户标注的人类偏好文档(蓝色柱)、源大语言模型获得的模型偏好文档(橙色柱)及其组合(绿色柱和红色柱)。由于检索器已在用户标注的MS MARCO数据集上进行了预训练,仅使用人类偏好文档进行训练可能没有意义,因此在所有方法中表现最差。仅使用模型偏好文档相比仅使用人类偏好文档显示出显著提升,而合并人类偏好和模型偏好文档(我们的主要设置)则进一步提高了检索器性能。最后,当目标大语言模型较小时,使用Flan-$\mathrm{T5}_ {\mathrm{Base}}$作为源模型比使用Flan-T5Large获得更好结果;但随着目标模型规模增大,两种方法达到相当性能。因此,我们在适应增强训练中选择使用小型源模型是合理且有效的。
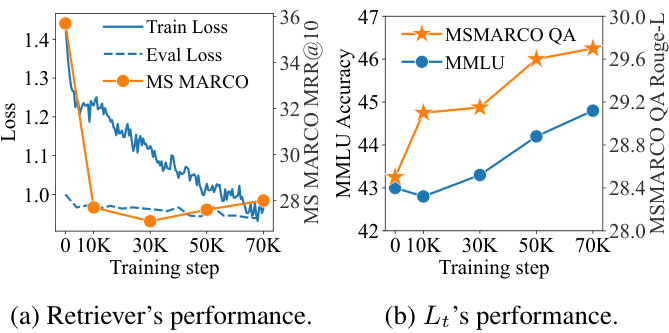
Figure 5: AAR’s training process. (a) exhibits the retriever’s (ANCE) performance on MS MARCO. (b) presents the $L_{t}$ ’s (Flan $\cdot\mathrm{T}5_{\mathrm{Base}}$ ) performance on MSMARCO QA and MMLU.
图 5: AAR的训练过程。(a)展示了检索器(ANCE)在MS MARCO上的性能。(b)展示了$L_{t}$(Flan $\cdot\mathrm{T}5_{\mathrm{Base}}$)在MSMARCO QA和MMLU上的性能。
Figure 5a and Figure 5b plot the retriever’s and LM’s performance during augmentation-adapted training, respectively. At the beginning of the training, the retriever’s $\mathrm{MRR}@10$ on the MS MARCO drops dramatically, indicating a large distribution gap between human-preferred and LM-preferred documents. As the retriever’s train and dev loss continually decline, the retrieval-augmented LM gradually performs better on MSMARCO QA and eventually, on MMLU. This result implies that LMs on different task may share common preferences, making AAR generalize well from single source task to heterogeneous target tasks.
图 5a 和图 5b 分别展示了增强适应训练过程中检索器和语言模型的性能表现。训练初期,检索器在 MS MARCO 数据集上的 $\mathrm{MRR}@10$ 指标急剧下降,表明人类偏好文档与语言模型偏好文档之间存在显著分布差异。随着检索器训练损失和验证损失持续降低,检索增强的语言模型在 MSMARCO QA 任务上的表现逐步提升,并最终在 MMLU 任务中取得进步。这一结果表明,不同任务的语言模型可能具有共同偏好,使得自适应增强检索 (AAR) 能够从单一源任务良好泛化到异构目标任务。
5.3 Analysis of LM-preferred Documents
5.3 大语言模型偏好文档分析
We highlight the necessity of adapting existing retrievers to LMs by comparing the preferred documents between search users and LMs. In general, we discover that LM-preferred documents can assist LM from alternative perspectives rather than the full information favored by search users.
我们通过比较搜索用户和大语言模型偏好的文档,强调了调整现有检索器以适应大语言模型的必要性。总体而言,我们发现大语言模型偏好的文档能从不同于搜索用户青睐的完整信息的替代视角为其提供帮助。
First, we define the set overlap $O$ between two positive documents set $D_{1}^{+}$ and $D_{2}^{+}$ as:
首先,我们定义两个正文档集 $D_{1}^{+}$ 和 $D_{2}^{+}$ 之间的集合重叠度 $O$ 为:
$$
O=\frac{D_{1}^{+}\cap D_{2}^{+}}{D_{1}^{+}\cup D_{2}^{+}}.
$$
$$
O=\frac{D_{1}^{+}\cap D_{2}^{+}}{D_{1}^{+}\cup D_{2}^{+}}.
$$
As illustrated in Figure 6a, the set overlaps of the positive document sets annotated by human users $(D^{h+})$ and LMs (Top $-K_{S_{i}^{a},D^{a}})$ are quite low (near $13%)$ , demonstrating their distinct tendencies in selecting valuable documents. On the contrary, the overlaps between different LMs are relatively high (over $55%$ ). This evidence provides a strong rationale for the generalization ability of AAR since LMs with different sizes tend to annotate similar positive documents. Furthermore, LMs whose sizes are closer generally possess higher overlaps. This implies a better generalization ability of the AAR to the LMs whose capacity is near the source LM. The findings further validate the results illustrated in Figure 4b.
如图6a所示,人工标注的正文档集$(D^{h+})$与大语言模型标注的Top$-K_{S_{i}^{a},D^{a}}$集合重叠率极低(约$13%$),表明两者在筛选有价值文档时存在显著差异。相反,不同大语言模型间的标注重叠率较高(超过$55%$)。这一现象为AAR的泛化能力提供了有力依据,因为不同规模的模型倾向于标注相似的正文档。此外,模型规模越接近,其标注重叠率通常越高,说明AAR对与源模型容量相近的大语言模型具有更好的泛化能力。该发现进一步验证了图4b所示的结果。
Table 2: Cases study on MSMARCO QA dataset. We show Top-1 document annotated by human users and FiDAt scores. Red texts are the gold answer spans.
| Question | Human-preferred Document | LM-preferred Document |
| what happens if you miss your cruise ship | If you domiss the ship,gointo the cruiseterminal andtalkwiththeport agents, who are in contact with both shipboardandshoresidepersonnel They can help you decide the best way to meet your ... | The cruise line is not financially respon- sible for getting passengers to the next port if they miss the ship.Your travel to the subsequent port, or home, is on your dime, as are any necessary hotel stays and meals... |
| what is annexation? | Annexation isan activityinwhichtwo things arejoined together,usuallywith a subordinateorlesser thingbeingat- tached to a larger thing. In strict legal terms, annexation simply involves... | Annexation (Latin ad,to,and nexus, joining) is the administrative action and concept in international law relating to theforcibletransitionof onestate's ter- ritory by another state. It is generally held to be an illegal act.. |
表 2: MSMARCO QA数据集案例研究。展示人工标注的Top-1文档及FiDAt评分,红色文本为黄金答案片段。
| 问题 | 人工偏好文档 | 大语言模型偏好文档 |
|---|---|---|
| 错过邮轮会怎样 | 若错过登船,请前往邮轮码头与港口代理沟通,他们与船上及岸上人员保持联系,可协助制定最佳方案... | 邮轮公司不承担乘客因误船产生的后续港口或返程费用,包括必要住宿及餐饮开支... |
| 什么是领土兼并 | 兼并指将两个事物结合的活动,通常较小部分依附于较大部分。严格法律意义上,兼并仅涉及... | 领土兼并(拉丁语ad表示"至",nexus表示"连接")是国际法中关于一国领土被另一国强制转移的行政行为概念,通常被视为非法行为... |
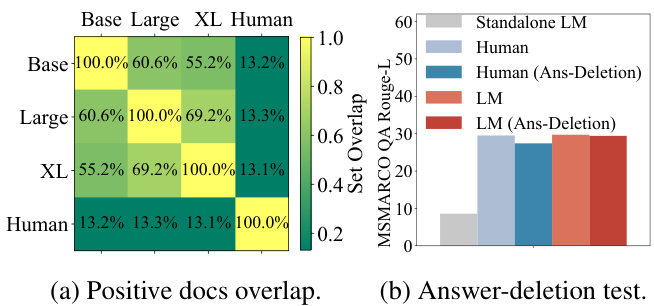
Figure 6: Analysis of LM-preferred documents. (a) shows the overlaps of positive document sets, where used LMs are Flan-T5 series. (b) presents the answerdeletion experiments on the MSMARCO QA dataset. The retriever is initialized from ANCE.
图 6: LM偏好文档分析。(a) 展示了正文档集的重叠情况,使用的LM为Flan-T5系列。(b) 呈现了在MSMARCO QA数据集上进行的答案删除实验。检索器基于ANCE初始化。
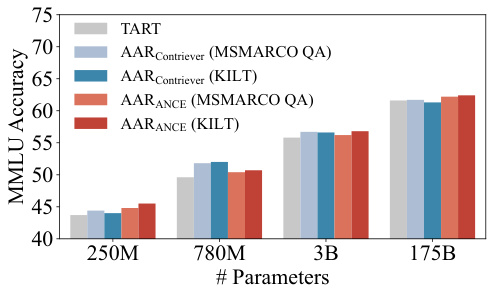
Figure 7: Comparison between single-task (MSMARCO QA) and multi-task (KILT) trained AAR. TART (Asai et al., 2022) is a multi-task instructionfinetuned retriever that has not been finetuned with LMpreferred signals.
图 7: 单任务 (MSMARCO QA) 与多任务 (KILT) 训练的 AAR 对比。TART (Asai et al., 2022) 是一个未经 LM 偏好信号微调的多任务指令微调检索器。
To give an in-depth analysis of how humanpreferred and LM-preferred documents differ, we show two representative cases sampled from the MSMARCO QA in Table 2. We observe that the human-preferred document can always present the gold answer at the beginning of the text, while the LM-preferred document may not contain the exact answer. However, an LM-preferred document can (1) deliver a new perspective to answer the given question, e.g., “the cruise line’s resp on sibi lity if you miss your cruise ship” and (2) give a specific explanation instead of an abstract definition, e.g., “forcible transition of one state’s territory by another state”, These characteristics differ from search users who want the full information and can further assist LMs in knowledge-based reasoning.
为了深入分析人类偏好和大语言模型偏好的文档差异,我们从MSMARCO QA数据集中选取了两个典型案例展示在表2中。研究发现,人类偏好的文档总是能在开头就呈现正确答案,而大语言模型偏好的文档可能不包含确切答案。但后者具有以下优势:(1) 能提供回答问题的新视角,例如"邮轮公司对乘客误船应承担的责任";(2) 能给出具体解释而非抽象定义,例如"一国对另一国领土的强制性占领"。这些特点不同于搜索用户追求完整信息的需求,但能辅助大语言模型进行知识推理。
We further examine the unique characteristics of LM-preferred documents through the answerdeletion test (i.e., deleting the exact answer span from the retrieved documents). As shown in Figure 6b, the retriever trained by either humanpreferred (i.e., human-preferred retriever) or LMpreferred documents (i.e., LM-preferred retriever) can help LM answer the given question. Nevertheless, after the answer-deletion, the performance of LM with the human-preferred retriever declines more significantly than with the LM-preferred retriever. Despite having fewer exact match answers ( $0.6%$ for LM-preferred documents vs. $13.0%$ for human-preferred documents), LM-preferred documents provide helpful information from alternative perspectives. Therefore, adapting retrievers with LM-preferred documents can in turn make retrievalaugmented LM perform better.
我们通过答案删除测试(即从检索文档中删除精确答案片段)进一步研究了LM偏好文档的独特特征。如图6b所示,无论是通过人类偏好(即人类偏好检索器)还是LM偏好文档(即LM偏好检索器)训练的检索器,都能帮助LM回答给定问题。然而,在答案删除后,使用人类偏好检索器的LM性能下降幅度明显大于使用LM偏好检索器的情况。尽管LM偏好文档的精确匹配答案较少(LM偏好文档为0.6%,人类偏好文档为13.0%),但它们能从其他角度提供有用信息。因此,使用LM偏好文档调整检索器反而能使检索增强的LM表现更好。
Table 3: Ablation of the retrieval corpus, with Flan $\mathrm{T}5_{\mathrm{Base}}$ as LM and AARANCE as retriever.
| Corpora | MMLU | PopQA All | ||||
| All | Hum. | Soc.Sci. | STEM | Other | ||
| MSMARCO | 44.8 | 42.2 | 46.4 | 39.0 | 53.2 | 13.6 |
| KILT-Wikipedia | 42.6 | 42.5 | 45.9 | 34.3 | 50.5 | 37.7 |
| StandaloneLM | 36.1 | 40.4 | 39.8 | 27.0 | 40.6 | 8.8 |
表 3: 检索语料库的消融实验,使用 Flan $\mathrm{T}5_{\mathrm{Base}}$ 作为语言模型 (LM) 和 AARANCE 作为检索器。
| Corpora | MMLU All | Hum. | Soc.Sci. | STEM | Other | PopQA All |
|---|---|---|---|---|---|---|
| MSMARCO | 44.8 | 42.2 | 46.4 | 39.0 | 53.2 | 13.6 |
| KILT-Wikipedia | 42.6 | 42.5 | 45.9 | 34.3 | 50.5 | 37.7 |
| StandaloneLM | 36.1 | 40.4 | 39.8 | 27.0 | 40.6 | 8.8 |
5.4 Multi-task Training of AAR
5.4 AAR的多任务训练
In this section, we explore if the multi-task training of AAR can endow the retriever with better generalization to the target task. Specifically, we choose KILT (Petroni et al.) as our multi-task data source, which consists of 5 categories (Fact Checking, Entity Linking, Slot Filling, Open Domain QA, and Dialogue). We take one representative subtask per category to form a mixture of multiple source tasks.
在本节中,我们探讨AAR的多任务训练能否使检索器对目标任务具有更好的泛化能力。具体而言,我们选择KILT (Petroni等人)作为多任务数据源,它包含5个类别(事实核查、实体链接、槽填充、开放域问答和对话)。我们从每个类别中选取一个代表性子任务,组成多源任务的混合体。
Figure 7 illustrates that ANCE trained with multi-task KILT can consistently outperform the single-task MSMARCO QA, proving the better generalization ability brought by multi-task augmentation-adapted training. It is possible that LMs may vary slightly in preferred documents for different tasks and AAR can switch more smoothly to the target task with the help of multi-task training. Contriever does not benefit greatly from multitask training. We conjecture that this is because Contriever has been pre-trained with multiple formats of data augmentations and thus generalizes better to new data distribution than ANCE. Interestingly, multi-task instruction-finetuned retriever TART (Asai et al., 2022) has an overall worse performance compared to AAR, highlighting the benefits of having LM-preferred documents during the multi-task training. A more detailed analysis about the selection of source tasks is in Appendix B.
图 7: 采用多任务KILT训练的ANCE模型持续优于单任务MSMARCO QA,证明多任务增强适应性训练能带来更好的泛化能力。这可能是因为语言模型对不同任务的偏好文档存在细微差异,而AAR通过多任务训练能更顺畅地切换至目标任务。Contriever未能从多任务训练中获得显著提升,我们推测这是由于Contriever已通过多种数据增强形式进行预训练,因此比ANCE对新数据分布具有更好的泛化能力。值得注意的是,经过多任务指令微调的检索器TART (Asai et al., 2022) 整体表现逊于AAR,这突显了在多任务训练期间采用语言模型偏好文档的优势。关于源任务选择的更详细分析见附录B。
5.5 Effect of Retrieval Corpus
5.5 检索语料库的影响
Table 3 demonstrates that regardless of the retrieval corpus, AAR results in consistent and substantial performance gains over the standalone LM.
表 3: 表明无论检索语料库如何,AAR都能比独立大语言模型带来持续且显著的性能提升。
On MMLU, using MS MARCO as the retrieval corpus improves the LM more compared to KILTWikipedia. We hypothesize that the retriever has been trained with MS MARCO corpus and thus holds better retrieval performance on it.
在MMLU任务中,使用MS MARCO作为检索语料相比KILTWikipedia更能提升语言模型性能。我们推测这是由于检索器在MS MARCO语料上训练过,因此对其具有更好的检索表现。
Table 4: Results of OPT and GPT-neo. We use their 1.3B version. The score marked as bold means the best performance in the zero-shot setting.
| Settings | Methods | MMLU All | PopQA All |
| Few-shot | OPT (Zhang et al.,2022) GPT-neo(Black etal.,2021) OPT | 26.0 28.7 | 12.3 11.3 12.0 |
| Zero-shot | GPT-neo OPTGenRead GPT-neoGenRead OPT w/ AARContriever (Ours) GPT-neo w/AARContriever (Ours) OPT w/ AARANCE (Ours) | 22.7 25.3 22.3 24.4 23.2 25.2 23.7 26.6 | 9.9 12.2 11.9 29.1 27.8 32.9 |
表 4: OPT 和 GPT-neo 的结果。我们使用它们的 1.3B 版本。加粗分数表示零样本设置下的最佳性能。
| Settings | Methods | MMLU All | PopQA All |
|---|---|---|---|
| Few-shot | OPT (Zhang et al., 2022) GPT-neo (Black et al., 2021) OPT | 26.0 28.7 | 12.3 11.3 12.0 |
| Zero-shot | GPT-neo OPTGenRead GPT-neoGenRead OPT w/ AARContriever (Ours) GPT-neo w/AARContriever (Ours) OPT w/ AARANCE (Ours) | 22.7 25.3 22.3 24.4 23.2 25.2 23.7 26.6 | 9.9 12.2 11.9 29.1 27.8 32.9 |
On PopQA, model performance will drop by large margins if we use MS MARCO as the retrieval corpus instead of KILT-Wikipedia. The primary reason is that the PopQA dataset is sampled from Wikidata and designed for long-tail questions. Partial long-tail knowledge can be only found in KILT-Wikipedia (Mallen et al., 2022) while MS MARCO lacks the indispensable evidence that should be utilized for answer prediction. For instance, given the question “Who is the mother of Melissa Benn?”, there is no document in MS MARCO containing the answer “Caroline Benn”. Under such circumstances, aligning the retrieval corpus with the data source can be necessary to leverage AAR’s ability.
在PopQA数据集上,若使用MS MARCO作为检索语料而非KILT-Wikipedia,模型性能会大幅下降。主要原因在于PopQA是从Wikidata采样的长尾问题数据集,部分长尾知识仅存在于KILT-Wikipedia (Mallen et al., 2022) ,而MS MARCO缺乏答案预测所需的关键证据。例如对于问题"Who is the mother of Melissa Benn?",MS MARCO中没有包含正确答案"Caroline Benn"的文档。这种情况下,将检索语料与数据源对齐对于发挥AAR的能力至关重要。
5.6 Application Scenarios of AAR
5.6 AAR的应用场景
To examine if AAR works for unseen LMs that lack zero-shot generalization ability, we also report the results of OPT (Zhang et al., 2022) and GPTneo (Black et al., 2021). These models may have poor zero-shot performance due to the lack of multitask instruction tuning.
为了验证AAR是否适用于缺乏零样本泛化能力的未见过的大语言模型,我们还报告了OPT (Zhang et al., 2022) 和GPTneo (Black et al., 2021) 的结果。由于缺少多任务指令微调,这些模型的零样本性能可能较差。
From Table 4, we find that our AAR improves both LMs marginally on MMLU while achieving significant gains on PopQA. We conjecture that LMs can benefit more easily from retrieval augmentation on the knowledge-probing task like PopQA, where the answer span can be directly acquired from the retrieved documents. MMLU requires the LM to not only comprehend the retrieved pieces of evidence but also perform knowledge-based reasoning over them. OPT and GPT-neo may not possess such abilities in zero-shot scenarios.
从表4中我们发现,我们的AAR在MMLU上略微提升了两种大语言模型,同时在PopQA上取得了显著提升。我们推测,在PopQA这类知识探测任务中,大语言模型能更轻松地从检索增强中受益,因为答案片段可以直接从检索到的文档中获取。而MMLU要求模型不仅要理解检索到的证据片段,还需要基于这些知识进行推理。OPT和GPT-neo在零样本场景下可能不具备这种能力。
In summary, although AAR perfectly fits the multi-task instruction-finetuned LMs such as the Flan-T5 series and Instruct GP T, it may not bring significant gains for LMs whose zero-shot performance is sometimes poor, especially on knowledgebased reasoning. However, we believe that multitask instruction-finetuned models will be the foundation of future work due to their outstanding zeroshot generalization capabilities, ensuring the wideranging application scenarios of AAR.
总之,虽然AAR完美适配Flan-T5系列和InstructGPT等多任务指令微调的大语言模型,但对于零样本表现欠佳(尤其在知识推理任务上)的模型可能收益有限。但我们认为,凭借卓越的零样本泛化能力,多任务指令微调模型将成为未来研究的基础,这也确保了AAR具有广泛的应用场景。
6 Discussions
6 讨论
LM-preferred Documents. Acquiring discrete feedback signals from LMs is challenging as it requires superior labeling ability, which is not the designed purpose of LMs. Inspired by ADist (Izacard and Grave, 2021a) and Atlas (Izacard et al., 2022), we utilize the FiDAtt scores to select LM-preferred documents for the augmentation-adapted training. However, FiDAtt scores may not reflect the actual contribution of each document faithfully since LM may prefer attending to readable rather than informative documents. Furthermore, the quality of LM-preferred documents depends heavily on the initial performance of the retrieval-augmented LM. Parallel work (Shi et al., 2023) computes the KL divergence between retrieval likelihood and LM likelihood to train the retriever. Nevertheless, they require a larger source LM, Curie (6.7B), to provide accurate LM likelihood signals. In the future, reinforcement learning could serve as an alternative method to train the retriever, as it optimizes the retriever by directly leveraging LM’s signals without relying on the devised rule.
大语言模型偏好的文档。从大语言模型中获取离散反馈信号具有挑战性,因为这需要卓越的标注能力,而这并非大语言模型的设计初衷。受ADist (Izacard and Grave, 2021a) 和Atlas (Izacard et al., 2022) 的启发,我们利用FiDAtt分数为适配增强的训练选择大语言模型偏好的文档。然而,FiDAtt分数可能无法真实反映每个文档的实际贡献,因为大语言模型可能更倾向于关注可读性而非信息量。此外,大语言模型偏好文档的质量很大程度上依赖于检索增强大语言模型的初始性能。并行研究 (Shi et al., 2023) 通过计算检索似然与大语言模型似然之间的KL散度来训练检索器,但该方法需要更大的源大语言模型Curie (6.7B) 来提供准确的大语言模型似然信号。未来,强化学习可作为训练检索器的替代方法,因为它通过直接利用大语言模型的信号来优化检索器,而无需依赖设计的规则。
Generic Retrieval Plug-in. Chatgpt-retrieval- plugin2 has recently gained attention in the NLP community as a generic retrieval plug-in. It retrieves the most relevant document from users’ data sources and tailor ChatGPT’s response to meet their specific needs. We believe that techniques such as AAR will enhance the ability of black-box ChatGPT to generate more reasonable responses based on the retrieved information, thereby promoting the development of human-centered LM design.
通用检索插件。Chatgpt-retrieval-plugin2 作为通用检索插件近期在 NLP 领域受到关注。它能从用户数据源中检索最相关文档,并定制 ChatGPT 的响应以满足特定需求。我们认为 AAR 等技术将增强黑盒 ChatGPT 基于检索信息生成更合理响应的能力,从而推动以人为中心的大语言模型设计发展。
7 Conclusion and Future Work
7 结论与未来工作
This paper introduces generic retrieval plug-in that utilizes a generic retriever to enhance target LMs that may be unknown in advance or are unable to be fine-tuned jointly. Our proposed retriever, AAR, can directly support black-box LMs without requiring any fine-tuning of the LMs. This is accomplished by building the AAR’s training data with preferred documents from a small source LM together with the ground truth.
本文介绍了一种通用检索插件,它利用通用检索器来增强可能预先未知或无法联合微调的目标大语言模型。我们提出的检索器AAR无需对目标模型进行任何微调,即可直接支持黑盒大语言模型。这一功能是通过使用小型源大语言模型中的优选文档及真实标注数据来构建AAR训练集实现的。
Empirical results on MMLU and PopQA demonstrate that AAR-assisted LMs greatly outperform the standalone ones in zero-shot scenarios, and AAR generalizes well to LMs of different sizes and structures. Analytical results reveal that LMpreferred and human-preferred documents complement each other; LM-preferred documents from different LMs overlap significantly, and LMs with similar sizes tend to yield closer document sets.
在MMLU和PopQA上的实证结果表明,AAR辅助的大语言模型在零样本场景中显著优于独立模型,且AAR能良好适配不同规模和结构的模型。分析结果显示:模型偏好文档与人类偏好文档具有互补性;不同模型选择的偏好文档存在显著重叠,且规模相近的模型倾向于生成更相似的文档集。
We leave a more detailed explanation of how different LMs interact with augmentation documents and a more reasonable selection of LM-preferred documents for future work. We hope our work shed light on a path to a generic way of treating large LMs as black boxes and adapting retrievers to augment them.
我们将对不同大语言模型如何与增强文档交互以及如何更合理地选择模型偏好文档的详细解释留待未来工作。希望本研究能为将大语言模型视为黑箱并改进检索器以增强其性能的通用方法开辟道路。
Limitations
局限性
Due to the limitation of computational resources, we have not evaluated the Flan-$\mathrm{T5_{XXL}}$ whose number of parameters is 11B, and the OPT whose number of parameters is greater than 1.3B.
由于计算资源限制,我们未评估参数量为11B的Flan-$\mathrm{T5_{XXL}}$ 以及参数量超过1.3B的OPT模型。
Since OPT and GPT-neo perform poorly in the zero-shot setting and separating attention scores of each document in the input is tedious for decoderonly models, we choose not to use them as source LMs. However, we prove that taking the encoderdecoder model Flan-$\mathrm{T5_{Base}}$ as our source LM is also robust to augment decoder-only models. We will explore new methods to annotate LM-preferred documents of decoder-only models based on their inherent signals.
由于OPT和GPT-neo在零样本(Zero-shot)设置下表现不佳,且为仅解码器(decoder-only)模型分离输入中每个文档的注意力分数十分繁琐,我们决定不将它们作为源大语言模型(LLM)使用。但实验证明,采用编码器-解码器(encoder-decoder)架构的Flan-$\mathrm{T5_{Base}}$ 作为源大语言模型同样能有效增强仅解码器模型。我们将基于仅解码器模型的固有信号,探索新方法来标注其偏好的文档。
Acknowledgement
致谢
Zichun Yu, Shi Yu, and Zhiyuan Liu are supported by Institute Guo Qiang at Tsinghua University, Beijing Academy of Artificial Intelligence (BAAI). All authors proposed the original idea together. Zichun Yu conducted the experiments. Zichun Yu, Chenyan Xiong, Shi Yu, and Zhiyuan Liu wrote the paper. Chenyan Xiong and Zhiyuan Liu provided valuable suggestions for the research. We thank Suyu Ge for sharing the ANCE checkpoint initialized from T5Base.
Zichun Yu、Shi Yu和Zhiyuan Liu的研究得到了清华大学国强研究院和北京智源人工智能研究院(BAAI)的支持。所有作者共同提出了原始构想。Zichun Yu负责实验实施。Zichun Yu、Chenyan Xiong、Shi Yu和Zhiyuan Liu共同撰写了论文。Chenyan Xiong与Zhiyuan Liu为研究提供了宝贵建议。我们感谢Suyu Ge分享了基于T5Base初始化的ANCE模型检查点。
References
参考文献
Fabien André, Anne-Marie Kermarrec, and Nicolas Le Scouarnec. 2016. Cache locality is not enough: High-performance nearest neighbor search with product quantization fast scan. In VLDB, page 12.
Fabien André、Anne-Marie Kermarrec 和 Nicolas Le Scouarnec。2016. 缓存局部性不足:基于乘积量化快速扫描的高性能最近邻搜索。见 VLDB,第 12 页。
Akari Asai, Timo Schick, Patrick Lewis, Xilun Chen, Gautier Izacard, Sebastian Riedel, Hannaneh Hajishirzi, and Wen-tau Yih. 2022. Task-aware retrieval with instructions. arXiv preprint arXiv:2211.09260.
Akari Asai、Timo Schick、Patrick Lewis、Xilun Chen、Gautier Izacard、Sebastian Riedel、Hannaneh Hajishirzi 和 Wen-tau Yih。2022。面向任务的指令检索。arXiv预印本 arXiv:2211.09260。
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. 2016. Ms marco: A human generated machine reading comprehension dataset. In CoCo@NeurIPS.
Payal Bajaj、Daniel Campos、Nick Craswell、Li Deng、Jianfeng Gao、Xiaodong Liu、Rangan Majumder、Andrew McNamara、Bhaskar Mitra、Tri Nguyen等。2016. MS MARCO:人工生成的机器阅读理解数据集。发表于CoCo@NeurIPS。
Emily M. Bender, Timnit Gebru, Angelina McMillan- Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of ACM FAccT, pages 610–623.
Emily M. Bender、Timnit Gebru、Angelina McMillan-Major和Shmargaret Shmitchell。2021。随机鹦鹉的危险:语言模型会不会太大?载于《ACM FAccT会议论文集》,第610-623页。
Sid Black, Gao Leo, Phil Wang, Connor Leahy, and Stella Biderman. 2021. Gpt-neo: Large scale autore- gressive language modeling with mesh-tensorflow.
Sid Black、Gao Leo、Phil Wang、Connor Leahy和Stella Biderman。2021。GPT-Neo:基于Mesh-Tensorflow的大规模自回归语言建模。
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack Rae, Erich Elsen, and Laurent Sifre. 2022. Improving language models by retrieving from trillions of tokens. In ICML, pages 2206–2240.
Sebastian Borgeaud、Arthur Mensch、Jordan Hoffmann、Trevor Cai、Eliza Rutherford、Katie Millican、George Bm Van Den Driessche、Jean-Baptiste Lespiau、Bogdan Damoc、Aidan Clark、Diego De Las Casas、Aurelia Guy、Jacob Menick、Roman Ring、Tom Hennigan、Saffron Huang、Loren Maggiore、Chris Jones、Albin Cassirer、Andy Brock、Michela Paganini、Geoffrey Irving、Oriol Vinyals、Simon Osindero、Karen Simonyan、Jack Rae、Erich Elsen和Laurent Sifre。2022。通过从数万亿token中检索改进语言模型。发表于ICML,第2206–2240页。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. In NeurIPS, pages 1877–1901.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell等. 2020. 大语言模型是少样本学习者. 收录于NeurIPS, 页码1877–1901.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, and et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
Aakanksha Chowdhery、Sharan Narang、Jacob Devlin、Maarten Bosma、Gaurav Mishra、Adam Roberts、Paul Barham、Hyung Won Chung、Charles Sutton、Sebastian Gehrmann、Parker Schuh 等。2022。PaLM: 基于Pathways扩展语言建模。arXiv预印本 arXiv:2204.02311。
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
Hyung Won Chung、Le Hou、Shayne Longpre、Barret Zoph、Yi Tay、William Fedus、Eric Li、Xuezhi Wang、Mostafa Dehghani、Siddhartha Brahma、Albert Webson、Shixiang Shane Gu、Zhuyun Dai、Mirac Suzgun、Xinyun Chen、Aakanksha Chowdhery、Sharan Narang、Gaurav Mishra、Adams Yu、Vincent Zhao、Yanping Huang、Andrew Dai、Hongkun Yu、Slav Petrov、Ed H. Chi、Jeff Dean、Jacob Devlin、Adam Roberts、Denny Zhou、Quoc V. Le 和 Jason Wei。2022。扩展指令微调语言模型。arXiv预印本 arXiv:2210.11416。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL, pages 4171– 4186.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019. BERT: 用于语言理解的深度双向Transformer预训练。见《NAACL论文集》,第4171-4186页。
Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Proceedings of ACL, pages 3816–3830.
Tianyu Gao、Adam Fisch 和 Danqi Chen。2021。让预训练语言模型成为更好的少样本学习器。见《ACL 会议论文集》,第 3816–3830 页。
Suyu Ge, Chenyan Xiong, Corby Rosset, Arnold Overwijk, Jiawei Han, and Paul Bennett. 2023. Augmenting zero-shot dense retrievers with plug-in mixture- of-memories. arXiv preprint arXiv:2302.03754.
Suyu Ge、Chenyan Xiong、Corby Rosset、Arnold Overwijk、Jiawei Han 和 Paul Bennett。2023。基于插件混合记忆增强的零样本密集检索器 (Augmenting zero-shot dense retrievers with plug-in mixture-of-memories)。arXiv预印本 arXiv:2302.03754。
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. Realm: Retrievalaugmented language model pre-training. In ICML, pages 3929–3938.
Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat 和 Ming-Wei Chang。2020. REALM:检索增强的语言模型预训练。见 ICML,第 3929-3938 页。
Hangfeng He, Hongming Zhang, and Dan Roth. 2022. Rethinking with retrieval: Faithful large language model inference. arXiv preprint arXiv:2301.00303.
Hangfeng He, Hongming Zhang, and Dan Roth. 2022. 基于检索的反思:可信大语言模型推理. arXiv preprint arXiv:2301.00303.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In ICLR.
Dan Hendrycks、Collin Burns、Steven Basart、Andy Zou、Mantas Mazeika、Dawn Song 和 Jacob Steinhardt。2021。大规模多任务语言理解评估。发表于 ICLR。
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buch at s kaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Jo- hannes Welbl, Aidan Clark, Thomas Hennigan, Eric Noland, Katherine Millican, George van den Driess- che, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karén Simonyan, Erich Elsen, Oriol Vinyals, Jack Rae, and Laurent Sifre. 2022. An empirical analysis of compute-optimal large language model training. In NeurIPS, pages 30016–30030.
Jordan Hoffmann、Sebastian Borgeaud、Arthur Mensch、Elena Buch at s kaya、Trevor Cai、Eliza Rutherford、Diego de Las Casas、Lisa Anne Hendricks、Johannes Welbl、Aidan Clark、Thomas Hennigan、Eric Noland、Katherine Millican、George van den Driessche、Bogdan Damoc、Aurelia Guy、Simon Osindero、Karén Simonyan、Erich Elsen、Oriol Vinyals、Jack Rae 和 Laurent Sifre。2022。计算最优大语言模型训练的实证分析。发表于 NeurIPS,页码 30016–30030。
Srinivasan Iyer, Xi Victoria Lin, Ramakanth Pasunuru, Todor Mihaylov, Daniel Simig, Ping Yu, Kurt Shuster, Tianlu Wang, Qing Liu, Punit Singh Koura, Xian Li, Brian O’Horo, Gabriel Pereyra, Jeff Wang, Christopher Dewan, Asli Cel i kyi l maz, Luke Z ett le moyer, and Ves Stoyanov. 2022. Opt-iml: Scaling language model instruction meta learning through the lens of generalization. arXiv preprint arXiv:2212.12017.
Srinivasan Iyer、Xi Victoria Lin、Ramakanth Pasunuru、Todor Mihaylov、Daniel Simig、Ping Yu、Kurt Shuster、Tianlu Wang、Qing Liu、Punit Singh Koura、Xian Li、Brian O'Horo、Gabriel Pereyra、Jeff Wang、Christopher Dewan、Asli Celikyilmaz、Luke Zettlemoyer 和 Ves Stoyanov。2022年。Opt-IML:通过泛化视角扩展语言模型指令元学习。arXiv预印本 arXiv:2212.12017。
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2021. Unsupervised dense information retrieval with contrastive learning. TMLR.
Gautier Izacard、Mathilde Caron、Lucas Hosseini、Sebastian Riedel、Piotr Bojanowski、Armand Joulin 和 Edouard Grave。2021。基于对比学习的无监督密集信息检索。TMLR。
Gautier Izacard and Edouard Grave. 2021a. Distilling knowledge from reader to retriever for question answering. In ICLR.
Gautier Izacard和Edouard Grave。2021a。从阅读器到检索器的知识蒸馏用于问答。发表于ICLR。
Gautier Izacard and Edouard Grave. 2021b. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of EACL, pages 874–880.
Gautier Izacard 和 Edouard Grave. 2021b. 利用生成式模型结合段落检索实现开放域问答. 载于 EACL 会议论文集, 第 874–880 页.
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and
Gautier Izacard、Patrick Lewis、Maria Lomeli、Lucas Hosseini、Fabio Petroni、Timo Schick、Jane Dwivedi-Yu、Armand Joulin、Sebastian Riedel
Edouard Grave. 2022. Few-shot Learning with Retrieval Augmented Language Models. arXiv preprint arXiv:2208.03299.
Edouard Grave. 2022. 基于检索增强语言模型的少样本学习. arXiv预印本 arXiv:2208.03299.
Jeff Johnson, Matthijs Douze, and Herve Jegou. 2021. Billion-scale similarity search with gpus. IEEE TBD, 7(3):535–547.
Jeff Johnson、Matthijs Douze 和 Herve Jegou. 2021. 基于 GPU 的十亿级相似性搜索. IEEE TBD, 7(3):535–547.
Mingxuan Ju, Wenhao Yu, Tong Zhao, Chuxu Zhang, and Yanfang Ye. 2022. Grape: Knowledge graph enhanced passage reader for open-domain question answering. In Findings of EMNLP.
Mingxuan Ju、Wenhao Yu、Tong Zhao、Chuxu Zhang和Yanfang Ye。2022。Grape:开放域问答的知识图谱增强段落阅读器。见EMNLP的研究发现。
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
Jared Kaplan、Sam McCandlish、Tom Henighan、Tom B Brown、Benjamin Chess、Rewon Child、Scott Gray、Alec Radford、Jeffrey Wu 和 Dario Amodei。2020。神经语言模型的缩放定律。arXiv预印本 arXiv:2001.08361。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of EMNLP, pages 6769–6781.
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. 开放域问答的密集段落检索. 载于EMNLP会议论文集, 第6769–6781页.
Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. 2022. Demonstrate-searchpredict: Composing retrieval and language models for knowledge-intensive nlp. arXiv preprint arXiv:2212.14024.
Omar Khattab、Keshav Santhanam、Xiang Lisa Li、David Hall、Percy Liang、Christopher Potts 和 Matei Zaharia。2022。演示-搜索-预测:结合检索与语言模型实现知识密集型自然语言处理。arXiv预印本 arXiv:2212.14024。
Patrick Lewis, Ethan Perez, Aleksandar a Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledgeintensive NLP tasks. In NeurIPS, pages 9459–9474.
Patrick Lewis、Ethan Perez、Aleksandar a Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rock-täschel、Sebastian Riedel 和 Douwe Kiela。2020。面向知识密集型 NLP 任务的检索增强生成。收录于 NeurIPS,第 9459–9474 页。
Bill Yuchen Lin, Kangmin Tan, Chris Miller, Beiwen Tian, and Xiang Ren. 2022. Unsupervised crosstask generalization via retrieval augmentation. In NeurIPS, pages 22003–22017.
Bill Yuchen Lin、Kangmin Tan、Chris Miller、Beiwen Tian 和 Xiang Ren。2022。基于检索增强的无监督跨任务泛化。载于 NeurIPS,第 22003–22017 页。
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Hannaneh Hajishirzi, and Daniel Khashabi. 2022. When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories. arXiv preprint arXiv:2212.10511.
Alex Mallen、Akari Asai、Victor Zhong、Rajarshi Das、Hannaneh Hajishirzi 和 Daniel Khashabi。2022。何时不信任语言模型:探究参数化与非参数化记忆的有效性与局限性。arXiv预印本 arXiv:2212.10511。
Antonis Maro nikola k is and Hinrich Schütze. 2021. Multidomain pretrained language models for green NLP. In Proceedings of AdaptNLP, pages 1–8.
Antonis Maro nikola k 和 Hinrich Schütze. 2021. 面向绿色 NLP 的多领域预训练语言模型. 载于《AdaptNLP 会议论文集》, 第 1-8 页.
OpenAI. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
OpenAI. 2023. GPT-4技术报告. arXiv预印本 arXiv:2303.08774.
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In NeurIPS, pages 27730–27744.
龙傲阳、Jeffrey Wu、徐江、Diogo Almeida、Carroll Wainwright、Pamela Mishkin、张冲、Sandhini Agarwal、Katarina Slama、Alex Gray、John Schulman、Jacob Hilton、Fraser Kelton、Luke Miller、Maddie Simens、Amanda Askell、Peter Welinder、Paul Christiano、Jan Leike 和 Ryan Lowe。2022。通过人类反馈训练语言模型遵循指令。发表于NeurIPS,页码27730–27744。
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate nearest neigh- bor negative contrastive learning for dense text retrieval. In ICLR.
Lee Xiong、Chenyan Xiong、Ye Li、Kwok-Fung Tang、Jialin Liu、Paul N. Bennett、Junaid Ahmed 和 Arnold Overwijk。2021. 密集文本检索的近似最近邻负对比学习。发表于 ICLR。
Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, and Meng Jiang. 2023. Generate rather than retrieve: Large language models are strong context generators. In ICLR.
Wenhao Yu、Dan Iter、Shuohang Wang、Yichong Xu、Mingxuan Ju、Soumya Sanyal、Chenguang Zhu、Michael Zeng 和 Meng Jiang。2023。生成而非检索:大语言模型是强大的上下文生成器。发表于ICLR。
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher De- wan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Z ett le moyer. 2022. Opt: Open pretrained transformer language models. arXiv preprint arXiv:2205.01068.
Susan Zhang、Stephen Roller、Naman Goyal、Mikel Artetxe、Moya Chen、Shuohui Chen、Christopher Dewan、Mona Diab、Xian Li、Xi Victoria Lin、Todor Mihaylov、Myle Ott、Sam Shleifer、Kurt Shuster、Daniel Simig、Punit Singh Koura、Anjali Sridhar、Tianlu Wang 和 Luke Zettlemoyer。2022。OPT:开放预训练Transformer语言模型。arXiv预印本 arXiv:2205.01068。
Zhengyan Zhang, Zhiyuan Zeng, Yankai Lin, Huadong Wang, Deming Ye, Chaojun Xiao, Xu Han, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. 2023. Plug-and-play knowledge injection for pre-trained language models. In Proceedings of ACL.
张正彦、曾志远、林彦凯、王华东、叶德明、肖朝君、韩旭、刘知远、李鹏、孙茂松和周杰。2023。预训练语言模型的即插即用知识注入。载于ACL会议论文集。
Ce Zhou, Qian Li, Chen Li, Jun Yu, Yixin Liu, Guangjing Wang, Kai Zhang, Cheng Ji, Qiben Yan, Lifang He, Hao Peng, Jianxin Li, Jia Wu, Ziwei Liu, Pengtao Xie, Caiming Xiong, Jian Pei, Philip S. Yu, and Lichao Sun. 2023. A comprehensive survey on pretrained foundation models: A history from bert to chatgpt. arXiv preprint arXiv:2302.09419.
周策、李倩、李晨、余俊、刘一鑫、王广景、张凯、纪程、严启奔、何丽芳、彭浩、李建新、吴佳、刘子维、谢鹏涛、熊才明、裴健、Philip S. Yu、孙立超。2023。预训练基础模型全面综述:从BERT到ChatGPT的发展历程。arXiv预印本 arXiv:2302.09419。
A Experimental Settings
实验设置
A.1 Training Hyper parameters
A.1 训练超参数
We take the ANCE initialized from $\mathrm{T}5_{\mathrm{Base}}^{3}$ 3 (Xiong et al., 2021; Ge et al., 2023) and Con tri ever 4 (Izacard et al., 2021)’s hyper parameters in the augmentation-adapted training. Specifically, we fix batch size as 8, learning rate as 5e-6, and epochs as 6 for ANCE while taking batch size as 8, learning rate as 1e-5, and epochs as 3 for Contriever. We choose their best checkpoints based on the performance of the development set. The information about our source tasks and target tasks are listed in Table 6.
我们采用从$\mathrm{T}5_{\mathrm{Base}}^{3}$ [3] (Xiong et al., 2021; Ge et al., 2023)初始化的ANCE,并在增强适应训练中使用Contriever [4] (Izacard et al., 2021)的超参数。具体而言,ANCE的批次大小固定为8,学习率为5e-6,训练轮数为6;而Contriever的批次大小为8,学习率为1e-5,训练轮数为3。我们根据开发集的性能选择它们的最佳检查点。源任务和目标任务的相关信息列于表6。
A.2 Number of Augmentation Documents
A.2 增强文档数量
LMs of different sizes, facing various target tasks, may require indefinite numbers of augmentation documents to achieve their best performance.
不同规模的大语言模型在面对各类目标任务时,可能需要不定量的增强文档才能达到最佳性能。
For MMLU, we analyze how the number of augmentation documents affects LMs’ performance. As illustrated in Figure 9, we discover that LMs of larger capacity generally benefit more from more augmentation documents. A possible explanation is that larger LMs are more capable of integrating information from multiple documents and performing complicated reasoning based on them.
对于MMLU,我们分析了增强文档数量如何影响大语言模型的性能。如图9所示,我们发现更大规模的模型通常能从更多增强文档中获得更多收益。一个可能的解释是,更大规模的模型更擅长整合来自多个文档的信息,并基于这些信息进行复杂推理。
For PopQA, using 3 augmentation documents achieves the best performance across all LMs.
对于PopQA,使用3份增强文档在所有大语言模型中实现了最佳性能。
A.3 Prompt Templates
A.3 提示模板
The prompt template for MMLU is:
MMLU的提示模板为:
Here’s a problem to solve: {question} Among the 4 following options, which is the correct answer?
需要解决的问题: {question} 在以下4个选项中,哪个是正确答案?
- A: {choice_A} - B: {choice_B} - C: {choice_C} - D: {choice_D}
- A: {choice_A} - B: {choice_B} - C: {choice_C} - D: {choice_D}
The prompt template for PopQA is: Q: {question} A:
PopQA的提示模板为:Q: {question} A:
B Selection of Source Task
B 源任务选择
We provide a detailed selection of the source tasks here, using a variety of source and target tasks to analyze. MSMARCO QA, KILT-TriviaQA, and NQ belong to Open Domain QA, while KILT-T-REx and zsRE belong to Slot Filling. MMLU belongs to Multi-task Language Understanding, which is closer to the Open Domain QA in terms of the task objective. As shown in Table 5, when we align the category of the source task with the target task, the LM w/ AAR can generally achieve the best results. We suppose that this is because LM may share similar document preferences on the tasks from the same dataset category, making AAR easier to generalize. Furthermore, taking MSMARCO QA as the source task performs the best on MMLU. This validates the rationality to set $T_{s}$ as MSMARCO QA in our main experimental settings.
我们在此详细筛选了源任务,通过多种源任务与目标任务组合进行分析。MSMARCO QA、KILT-TriviaQA和NQ属于开放域问答任务,而KILT-T-REx和zsRE属于槽位填充任务。MMLU属于多任务语言理解任务,其任务目标更接近开放域问答。如表5所示,当源任务与目标任务类别一致时,采用AAR的大语言模型通常能取得最佳效果。我们推测这是因为同类数据集中的任务可能具有相似的文档偏好,使得AAR更易于泛化。此外,以MSMARCO QA作为源任务时,在MMLU上表现最优,这验证了我们在主要实验设置中将$T_{s}$设为MSMARCO QA的合理性。
Table 5: Relationship between the selection of source task $T_{s}$ and the performance of target task $T_{t}$ . The model is Flan $\mathrm{^{T5}B a s e}$ w/ AARANCE. As NQ and zsRE are included in the Flan-T5 training data, we only report their F1 results here for reference.
| Tt Ts | MMLU | NQ | zsRE |
| MSMARCOQA | 44.8 | 46.7 | 75.1 |
| KILT-TriviaQA | 43.6 | 46.4 | 74.9 |
| KILT-T-REx | 44.1 | 45.9 | 77.2 |
表 5: 源任务 $T_{s}$ 选择与目标任务 $T_{t}$ 性能的关系。模型为 Flan $\mathrm{^{T5}B a s e}$ w/ AARANCE。由于 NQ 和 zsRE 包含在 Flan-T5 训练数据中,此处仅列出它们的 F1 结果作为参考。
| Tt Ts | MMLU | NQ | zsRE |
|---|---|---|---|
| MSMARCOQA | 44.8 | 46.7 | 75.1 |
| KILT-TriviaQA | 43.6 | 46.4 | 74.9 |
| KILT-T-REx | 44.1 | 45.9 | 77.2 |

C AAR’s Improvements on PopQA Figure 8: AAR’s improvements on PopQA, using Flan $\mathrm{T}5_{\mathrm{Base}}$ (250M), Flan $\cdot\mathrm{T}5_{\mathrm{Large}}$ (780M), Flan $\cdot\mathrm{T}5_{\mathrm{XL}}$ (3B), Instruct GP T (175B) as target LMs.
图 8: AAR在PopQA上的改进效果,使用Flan $\mathrm{T}5_{\mathrm{Base}}$ (250M)、Flan $\cdot\mathrm{T}5_{\mathrm{Large}}$ (780M)、Flan $\cdot\mathrm{T}5_{\mathrm{XL}}$ (3B)和Instruct GPT (175B)作为目标大语言模型。
D Fine-tuning Results
D 微调结果
We also report the fine-tuning results of Flan $\mathrm{T}5_{\mathrm{Base}}$ and Flan $\cdot\mathrm{T}5_{\mathrm{Large}}$ on MMLU auxiliary training data (Hendrycks et al., 2021) in Table 7. Due to the limitation of the computational resources, we do not include the fine-tuning result of Flan $.\mathrm{T}5_{\mathrm{XL}}$ . We take batch size as 32, learning rate as 5e-5, and epochs as 3 in fine-tuning. In general, the LM that has already been massively multi-task instructionfinetuned, such as Flan-T5, improves little from fine-tuning on extra tasks but benefits greatly from our AAR. The results further validate the power of zero-shot retrieval augmentation.
我们还报告了 Flan $\mathrm{T}5_{\mathrm{Base}}$ 和 Flan $\cdot\mathrm{T}5_{\mathrm{Large}}$ 在 MMLU 辅助训练数据 (Hendrycks et al., 2021) 上的微调结果,如表 7 所示。由于计算资源限制,我们未包含 Flan $.\mathrm{T}5_{\mathrm{XL}}$ 的微调结果。微调时我们设置批量大小为 32、学习率为 5e-5、训练轮数为 3。总体而言,像 Flan-T5 这样已经经过大规模多任务指令微调的大语言模型,在额外任务上微调带来的提升有限,但能从我们的 AAR 中获益良多。这些结果进一步验证了零样本检索增强的有效性。

Figure 9: Relationship between LM’s performance and the number of augmentation documents.
图 9: 大语言模型 (LM) 性能与增强文档数量的关系
Table 6: Configurations of our source tasks and target tasks.
| Category | Number | ||
| Ts | MSMARCOQA KILT-FEVER KILT-WNED KILT-T-REx KILT-TriviaQA KILT-WizardofWikipedia | Open Domain QA Fact Checking Entity Linking Slot Filling Open Domain QA Dialogue | 148122 10444 3396 5000 5359 3054 |
| Tt | MMLU PopQA | Multi-task Language Understanding Open Domain 1QA | 1531 14267 |
表 6: 源任务与目标任务的配置。
| 类别 | 数量 | ||
|---|---|---|---|
| Ts | MSMARCOQA KILT-FEVER KILT-WNED KILT-T-REx KILT-TriviaQA KILT-WizardofWikipedia | 开放域问答 事实核查 实体链接 槽填充 开放域问答 对话 | 148122 10444 3396 5000 5359 3054 |
| Tt | MMLU PopQA | 多任务语言理解 开放域问答 | 1531 14267 |
Table 7: Fine-tuning results on MMLU. We use the official auxiliary training data of MMLU to fine-tune the LM.
| Methods | MMLU | ||||
| All | Hum. | Soc. Sci. | STEM | Other | |
| Flan-T5Base | 36.1 | 40.4 | 39.8 | 27.0 | 40.6 |
| Flan-T5Base Fine-tuning | 36.1 | 38.9 | 41.2 | 27.9 | 39.9 |
| Flan-T5Base w/ Contriever | 43.7 | 44.4 | 45.0 | 36.4 | 51.1 |
| Flan-T5Base w/ ANCE | 43.0 | 44.2 | 44.3 | 34.5 | 51.9 |
| Flan-T5Base W/ AARContriever (Ours) | 44.4 | 44.7 | 47.7 | 35.8 | 52.2 |
| Flan-T5Base w/ AARANCE (Ours) | 44.8 | 42.2 | 46.4 | 39.0 | 53.2 |
| Flan-T5Large | 45.1 | 47.7 | 53.5 | 34.4 | 49.2 |
| Flan-T5Large Fine-tuning | 45.3 | 47.6 | 54.1 | 35.2 | 48.7 |
| Flan-T5Large w/ Contriever | 50.7 | 50.5 | 56.4 | 38.9 | 61.1 |
| Flan-T5Large w/ ANCE | 49.2 | 49.3 | 56.7 | 38.1 | 57.2 |
| Flan-T5Large W/ AARContriever (Ours) | 51.8 | 50.8 | 59.7 | 39.4 | 61.8 |
| Flan-T5Large W/ AARANCE (Ours) | 50.4 | 48.0 | 58.1 | 39.3 | 60.2 |
| Flan-T5xL | 51.2 | 55.5 | 57.4 | 38.1 | 58.7 |
| Flan-T5xL w/ Contriever | 56.4 | 57.3 | 66.1 | 43.9 | 63.2 |
| Flan-T5xL w/ ANCE | 55.3 | 55.9 | 64.0 | 41.5 | 64.9 |
| Flan-T5xL w/ AARContriever (Ours) | 56.7 | 57.7 | 65.4 | 43.6 | 65.1 |
| Flan-T5xL w/ AARANCE (Ours) | 56.2 | 59.4 | 64.8 | 41.5 | 64.9 |
| InstructGPT | 60.2 | 65.7 | 68.0 | 46.1 | 66.5 |
| InstructGPT w/ Contriever | 60.5 | 62.0 | 71.8 | 44.3 | 70.1 |
| InstructGPTw/ANCE | 61.6 | 62.4 | 73.4 | 47.6 | 68.6 |
| InstructGPT w/ AARContriever (Ours) | 61.5 | 64.5 | 73.1 | 45.0 | 69.9 |
| InstructGPT w/ AARANCE (Ours) | 62.2 | 62.0 | 72.0 | 49.2 | 70.7 |
表 7: MMLU微调结果。我们使用MMLU官方辅助训练数据对语言模型进行微调。
| 方法 | MMLU | 人文 | 社科 | STEM | 其他 |
|---|---|---|---|---|---|
| Flan-T5Base | 36.1 | 40.4 | 39.8 | 27.0 | 40.6 |
| Flan-T5Base微调 | 36.1 | 38.9 | 41.2 | 27.9 | 39.9 |
| Flan-T5Base w/ Contriever | 43.7 | 44.4 | 45.0 | 36.4 | 51.1 |
| Flan-T5Base w/ ANCE | 43.0 | 44.2 | 44.3 | 34.5 | 51.9 |
| Flan-T5Base w/ AARContriever (Ours) | 44.4 | 44.7 | 47.7 | 35.8 | 52.2 |
| Flan-T5Base w/ AARANCE (Ours) | 44.8 | 42.2 | 46.4 | 39.0 | 53.2 |
| Flan-T5Large | 45.1 | 47.7 | 53.5 | 34.4 | 49.2 |
| Flan-T5Large微调 | 45.3 | 47.6 | 54.1 | 35.2 | 48.7 |
| Flan-T5Large w/ Contriever | 50.7 | 50.5 | 56.4 | 38.9 | 61.1 |
| Flan-T5Large w/ ANCE | 49.2 | 49.3 | 56.7 | 38.1 | 57.2 |
| Flan-T5Large w/ AARContriever (Ours) | 51.8 | 50.8 | 59.7 | 39.4 | 61.8 |
| Flan-T5Large w/ AARANCE (Ours) | 50.4 | 48.0 | 58.1 | 39.3 | 60.2 |
| Flan-T5xL | 51.2 | 55.5 | 57.4 | 38.1 | 58.7 |
| Flan-T5xL w/ Contriever | 56.4 | 57.3 | 66.1 | 43.9 | 63.2 |
| Flan-T5xL w/ ANCE | 55.3 | 55.9 | 64.0 | 41.5 | 64.9 |
| Flan-T5xL w/ AARContriever (Ours) | 56.7 | 57.7 | 65.4 | 43.6 | 65.1 |
| Flan-T5xL w/ AARANCE (Ours) | 56.2 | 59.4 | 64.8 | 41.5 | 64.9 |
| InstructGPT | 60.2 | 65.7 | 68.0 | 46.1 | 66.5 |
| InstructGPT w/ Contriever | 60.5 | 62.0 | 71.8 | 44.3 | 70.1 |
| InstructGPT w/ ANCE | 61.6 | 62.4 | 73.4 | 47.6 | 68.6 |
| InstructGPT w/ AARContriever (Ours) | 61.5 | 64.5 | 73.1 | 45.0 | 69.9 |
| InstructGPT w/ AARANCE (Ours) | 62.2 | 62.0 | 72.0 | 49.2 | 70.7 |