On Evolving Attention Towards Domain Adaptation
论领域自适应中注意力机制的演进
Abstract
摘要
Towards better unsupervised domain adaptation (UDA), recently, researchers propose various domain-conditioned attention modules and make promising progresses. However, considering that the configuration of attention, i.e., the type and the position of attention module, affects the performance significantly, it is more generalized to optimize the attention configuration automatically to be specialized for arbitrary UDA scenario. For the first time, this paper proposes EvoADA: a novel framework to evolve the attention configuration for a given UDA task without human in- tervention. In particular, we propose a novel search space containing diverse attention configurations. Then, to evaluate the attention configurations and make search procedure UDA-oriented (transfer ability $+$ discrimination), we apply a simple and effective evaluation strategy: 1) training the network weights on two domains with off-the-shelf domain adaptation methods; 2) evolving the attention configurations under the guide of the disc rim i native ability on the target domain. Experiments on various kinds of cross-domain benchmarks, i.e., Office-31, Office-Home, CUB-Paintings, and Duke-Market-1510, reveal that the proposed EvoADA consistently boosts multiple state-of-the-art domain adaptation approaches, and the optimal attention configurations help them achieve better performance.
为提升无监督域适应 (UDA) 性能,近期研究者提出了多种域条件注意力模块并取得显著进展。然而考虑到注意力配置 (即注意力模块的类型和位置) 会显著影响性能,自动优化注意力配置以适配任意UDA场景将更具普适性。本文首次提出EvoADA框架:一种无需人工干预即可为给定UDA任务进化注意力配置的新方法。具体而言,我们设计了一个包含多样化注意力配置的新型搜索空间。为评估注意力配置并使搜索过程面向UDA特性 (迁移能力 $+$ 判别能力),采用简单有效的评估策略:1) 使用现成域适应方法在双域上训练网络权重;2) 在目标域判别能力指导下进化注意力配置。在Office-31、Office-Home、CUB-Paintings和Duke-Market-1510等跨域基准测试中,EvoADA持续提升了多种前沿域适应方法的性能,最优注意力配置帮助它们实现了更优表现。
1. Introduction
1. 引言
Unsupervised domain adaptation (UDA) [15, 33, 23, 42] aims at exploiting the meaningful knowledge from a labelled source domain to facilitate learning on another unlabelled target domain. Generally, researchers focus on learning domain-general features. For better performance in the target domain, researchers propose domain-conditioned spatial or channel attention mechanisms [24, 48, 50, 25] to mitigate negative transfer and enhance the insufficient domain-specific features. However, these works design the attention module by hand and may fall to a sub-optimal solution in real world application. For example, in Figure 1, we observe that on a given UDA task and a pre-defined backbone network, different configurations of the attention module focus on various visual patterns and thus may come out with different accuracies. Therefore, given one arbitrary UDA task, a more generalized manner is to automatically find the optimal attention configuration.
无监督域适应 (UDA) [15, 33, 23, 42] 旨在利用带标签源域的有意义知识来促进另一个无标签目标域的学习。通常,研究人员专注于学习域通用特征。为了在目标域获得更好的性能,研究人员提出了域条件空间或通道注意力机制 [24, 48, 50, 25] 以减轻负迁移并增强不足的域特定特征。然而,这些工作手动设计注意力模块,在实际应用中可能陷入次优解。例如,在图 1 中,我们观察到在给定的 UDA 任务和预定义骨干网络下,注意力模块的不同配置会关注不同的视觉模式,从而可能产生不同的准确率。因此,对于任意一个 UDA 任务,更通用的方式是自动找到最优的注意力配置。
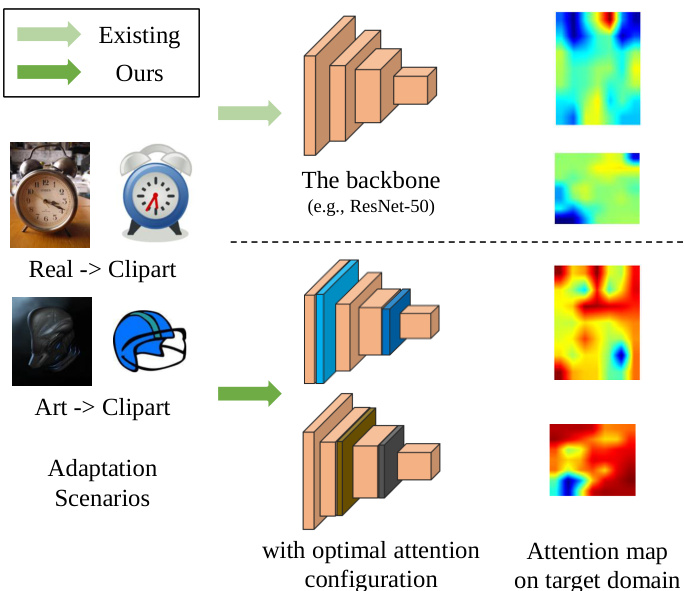
Figure 1. Why Attention Configuration Matters. Intuitively, different configurations of attention work differently. Given one UDA scenario, our EvoADA finds which and where to add the attention modules and achieves better domain adaptation performance.
图 1: 注意力配置的重要性。直观来看,不同的注意力配置会产生不同效果。在给定一个无监督域适应(UDA)场景时,我们的EvoADA方法能自动发现需要添加注意力模块的位置及类型,从而获得更优的域适应性能。
One natural and widely-used solution is neural architecture search (NAS) [31, 57, 38, 19]. The goal of NAS is to automatically seek for effective architectures [57, 26]. Nevertheless, [13, 26] point out that existing NAS algorithms rarely consider the topic of transfer learning and are vulnerable to large domain shift, resulting in inferior performance for UDA tasks. We speculate the reasons as follows. The first challenge is the design of search space. Existing popular search spaces (e.g., NASNet [57] or DARTS [31]) are not specialized to refine the attention module and maybe ineffective in generating optimal architectures for domain adaptation. The second challenge is how to evaluate the searched architectures, which is an open question. In a conventional NAS setting, we have labelled data on both the training and validation partitions, which are assumed to have little domain shift [37]. It means that the architectures optimized on the training domain can be directly evaluated on the validation domain with ground-truth labels. But in an UDA scenario, no manual annotations are available in the target domain, and the relatively larger domain shift between the source and the target domains make it ineffective to evaluate the models only on the source domain.
一种自然而广泛使用的解决方案是神经架构搜索(NAS) [31, 57, 38, 19]。NAS的目标是自动寻找有效的架构[57, 26]。然而,[13, 26]指出现有的NAS算法很少考虑迁移学习主题,且容易受到大域偏移的影响,导致在无监督域适应(UDA)任务中表现不佳。我们推测原因如下:第一个挑战是搜索空间的设计。现有流行的搜索空间(如NASNet[57]或DARTS[31])并非专门用于优化注意力模块,可能在生成域适应的最优架构方面效果不佳。第二个挑战是如何评估搜索到的架构,这是一个开放性问题。在传统NAS设置中,训练集和验证集都带有标注数据,且假设两者间域偏移较小[37]。这意味着在训练域优化的架构可以直接用验证域的真实标签进行评估。但在UDA场景中,目标域没有人工标注,且源域与目标域之间较大的域偏移使得仅基于源域评估模型效果不佳。

Figure 2. UDA result comparisons on Office-Home datasets.
图 2: Office-Home数据集上的UDA结果对比。
In this paper, for the first time, we propose a novel NAS algorithm, termed EvoADA. It automatically searches attention configurations, i.e., the type and position of attention module, for different UDA scenarios. Specifically, different from existing search spaces [57, 31] on the basic CNN operations, we design a novel search space on diverse configurations of typical attention modules [52, 21, 16]. To evaluate the attention configuration effectively and make the configuration optimization UDA-oriented, we further propose a simple yet effective evaluation strategy: train the network weights on both the two domains with arbitrary UDA methods to learn transferable knowledge and then evaluate the attention configurations by our pseudo-labeling discrimination in target domain to check how the learned knowledge are disc rim i native on target domain. We find that the estimated qualities are strongly correlates with the final accuracy in the target domain. Eventually, we propose a new UDA-oriented NAS scheme based on a typical evolutionbased NAS algorithm. Building on extensive experiments on 4 cross-domain benchmarks, we verify that the searched attention configuration via our EvoADA benefits multiple state-of-the-art methods [27, 17, 47] and lead to better performance in the target domain (Figure 2). The experiments also provide practical insights for further research.
本文首次提出了一种新颖的神经架构搜索(NAS)算法EvoADA,该算法能针对不同无监督域适应(UDA)场景自动搜索注意力配置(即注意力模块的类型和位置)。具体而言,与现有基于基础CNN操作的搜索空间[57,31]不同,我们在典型注意力模块[52,21,16]的多样化配置上设计了新型搜索空间。为有效评估注意力配置并使配置优化面向UDA任务,我们进一步提出简单而高效的评估策略:先用任意UDA方法在双域上训练网络权重以学习可迁移知识,再通过目标域的伪标签判别机制评估注意力配置,检验所学知识在目标域的判别性。我们发现这种质量评估与目标域最终准确率高度相关。最终,我们在典型进化式NAS算法基础上提出了新型UDA导向的NAS方案。通过在4个跨域基准上的大量实验验证,经EvoADA搜索的注意力配置能提升多种前沿方法[27,17,47]的性能,并在目标域获得更优表现(图2)。实验还为后续研究提供了实践启示。
The main contributions are summarized as follows:
主要贡献总结如下:
• We propose a new search space with a set of effective attention modules to cover diverse attention configurations and reinforce representations for UDA tasks.
• 我们提出了一个新的搜索空间,包含一组高效的注意力模块,用于覆盖多样化的注意力配置并增强UDA任务的表征能力。
• We propose a simple yet effective strategy to evaluate the UDA performance of attention configurations. Empirically, the measure of pseudo-labeling in the target domain is effective to seek for optimal attention configurations.
• 我们提出了一种简单而有效的策略来评估注意力配置的无监督域适应(UDA)性能。实验表明,目标域中的伪标签(pseudo-labeling)度量能有效寻找最优注意力配置。
• Experiments on four benchmarks verify that our algorithm successfully consolidates various state-of-theart methods and largely promote their performance.
• 在四个基准测试上的实验验证了我们的算法成功整合了多种最先进方法,并大幅提升了它们的性能。
2. Related Work
2. 相关工作
Unsupervised Domain Adaptation (UDA) [15, 33, 7] aims to facilitate the learning on one unlabelled target domain with the knowledge from one labelled source domain, and has practical value in many tasks [17, 47, 10]. There are three typical settings: closed-set UDA, partial-set UDA (PDA), and open-set UDA (ODA). Technically, two fundamental problems lie in the core of UDA: 1) how to diminish the domain discrepancy on representation spaces of two domains; 2) how to deal with negative transfer and promote discrimination on target domains. To solve the problems, researchers propose different methods that can be divided into three mainstreams: 1) feature disentanglement methods [48, 25]; 2) domain alignment methods [43, 32]; and 3) discrimination-aware methods [58, 12, 27]. More recently, novel loss designs (e.g., [55, 42] for universal domain adaptation; [11] for a progressive method) and advanced network modules (e.g., [48] for normalization module; [51] for convolution module; [50, 24, 25] for attention module) are proposed for better domain adaptation performance. Different from TADA [50], CADA [24], and DCAN [25] that combines a handcrafted attention module with an elaborate loss design, we solely investigate the improvement brought by an automatically searched attention module, which may benefit most of the state-of-theart UDA methods in a more flexible way.
无监督域适应 (Unsupervised Domain Adaptation, UDA) [15, 33, 7] 旨在利用带标注的源域知识促进无标注目标域的学习,在许多任务中具有实用价值 [17, 47, 10]。其包含三种典型设定:闭集UDA、部分集UDA (Partial-set UDA, PDA) 和开集UDA (Open-set UDA, ODA)。从技术角度看,UDA的核心存在两个基本问题:1) 如何缩小两个域在表征空间上的差异;2) 如何处理负迁移并增强目标域的判别性。针对这些问题,研究者提出了可分为三大主流的方法:1) 特征解耦方法 [48, 25];2) 域对齐方法 [43, 32];3) 判别感知方法 [58, 12, 27]。近期还涌现了新型损失函数设计(如通用域适应的 [55, 42];渐进式方法的 [11])和先进网络模块(如归一化模块的 [48];卷积模块的 [51];注意力模块的 [50, 24, 25])以提升域适应性能。与TADA [50]、CADA [24] 和DCAN [25] 将手工设计的注意力模块与精心构造的损失函数相结合不同,我们仅研究通过自动搜索的注意力模块带来的改进,这种方式可能以更灵活的机制惠及多数先进UDA方法。
Neural Architecture Search (NAS) aims to automate architecture engineering procedure given one certain problem. There are five NAS mainstreams: random search, Bayesian-based method [14], reinforcement-learning approach, evolutionary scheme [1], and surrogate-based framework (e.g., gradient-based and predictor-based). Represent at ive approaches include DARTS [31], P-DARTS [8], AmoebaNet [38], one-shot NAS [2, 19], path-level NAS [3], NASNet [57], and AdaptNAS [26]. Recently, NAS technique has found its value in wide tasks, such as detection [9], segmentation [29], and person re-ID [36]. Different from the existing literature, in this paper, we investigate the possibility and an effective solution to search for optimal archi tec ture s towards better domain adaptation. Concurrently, we find that Li et al. [26] and Robbiano et al. [40] have investigated a similar topic: the generalization abilities of architectures cross domains. The differences are two-fold: 1) we propose a novel search space for diverse attention configurations, which is different from the search space of AdaptNAS [26] (akin to NASNet [57]) and ABAS [40] (just change the architecture of the auxiliary adversarial branch); 2) we focus on an effective NAS protocol to search for optimal attention configuration towards UDA tasks.
神经架构搜索 (Neural Architecture Search, NAS) 旨在针对特定问题自动化架构设计流程。当前主流NAS方法包含五类:随机搜索、基于贝叶斯的方法 [14]、强化学习方法、进化算法 [1] 以及基于代理的框架(如梯度优化和预测器引导)。代表性工作包括DARTS [31]、P-DARTS [8]、AmoebaNet [38]、一次性NAS [2,19]、路径级NAS [3]、NASNet [57] 和 AdaptNAS [26]。近年来,NAS技术已在检测 [9]、分割 [29] 和行人重识别 [36] 等广泛任务中展现价值。与现有研究不同,本文探索了通过搜索最优架构来提升域适应性能的可能性及有效方案。我们发现Li等人 [26] 和Robbiano等人 [40] 同期研究了类似课题——架构的跨域泛化能力,主要差异在于:1) 我们提出了面向多样化注意力配置的新型搜索空间,不同于AdaptNAS [26](类似NASNet [57])和ABAS [40](仅修改辅助对抗分支架构)的搜索空间;2) 我们专注于开发有效的NAS协议以搜索适用于无监督域适应 (UDA) 任务的最优注意力配置。
3. Methodology
3. 方法论
3.1. Preliminary
3.1. 初步准备
Unsupervised Domain Adaptation. Formally, in one UDA task, we have a labeled dataset ${x_{i}^{S},y_{i}^{S}}{i=1}^{\stackrel{.}{N}^{S}}$ of $N^{S}$ image-annotation pairs from source domain $s$ and an unlabeled dataset ${x_{i}^{\bar{T}}}_{i=1}^{N^{T}}$ of $N^{\mathcal{T}}$ images from target domain $\tau$ . Considering that the two domains $s$ and $\tau$ are semantically related, UDA aims to facilitate the learning on $\tau$ by exploiting the meaningful knowledge learned from $s$ and try to handle the challenges of large domain shift between source domain $s$ and target domain $\tau$ .
无监督域自适应 (Unsupervised Domain Adaptation)。形式上,在一个UDA任务中,我们有一个来自源域 $s$ 的带标签数据集 ${x_{i}^{S},y_{i}^{S}}{i=1}^{\stackrel{.}{N}^{S}}$,包含 $N^{S}$ 个图像-标注对;以及一个来自目标域 $\tau$ 的无标签数据集 ${x_{i}^{\bar{T}}}_{i=1}^{N^{T}}$,包含 $N^{\mathcal{T}}$ 个图像。考虑到两个域 $s$ 和 $\tau$ 在语义上相关,UDA旨在通过利用从 $s$ 学习到的有意义知识来促进 $\tau$ 上的学习,并尝试处理源域 $s$ 与目标域 $\tau$ 之间的大域偏移挑战。
Neural Architecture Search. Given one certain task, its goal to search optimal network architectures automatically. Without loss of generality, we formulate the search procedure in a bi-level optimization process:
神经架构搜索 (Neural Architecture Search)。给定特定任务,其目标是自动搜索最优网络架构。不失一般性,我们将搜索过程表述为双层优化过程:
$$
\begin{array}{r}{\alpha=\underset{\alpha\in\cal{A}}{\arg\operatorname*{min}}\mathcal{L}{v a l}(y,F(x;\alpha,\theta^{}(\alpha))),}\ {s.t.,\theta^{}(\alpha)=\underset{\theta}{\arg\operatorname*{min}}\mathcal{L}_{t r}(y,F(x;\alpha,\theta)),}\end{array}
$$
where $\alpha$ is the architecture parameter, $\mathcal{A}$ denotes the search space that contains all possible architectures, $\theta$ is the network weights, and $F(;\alpha,\theta)$ is the function of neural network. In Eq. (1), we optimize $\alpha$ with one certain loss or evaluation function on validation partition $L{v a l}$ under the constraint that its weight parameter $^{*}(\alpha)$ is optimal for another loss function on training dataset $\mathcal{L}_{t r}$ . Researchers propose several effective NAS algorithms [38, 57, 31] to seek for optimal architectures $\alpha$ among $\mathcal{A}$ .
其中 $\alpha$ 是架构参数,$\mathcal{A}$ 表示包含所有可能架构的搜索空间,$\theta$ 是网络权重,$F(;\alpha,\theta)$ 是神经网络函数。在式(1)中,我们在权重参数 $\theta^{*}(\alpha)$ 对训练数据集 $L{t r}$ 的另一个损失函数最优的约束下,通过验证集 $L_{v a l}$ 上的特定损失或评估函数来优化 $\alpha$。研究者们提出了几种有效的神经架构搜索(NAS)算法[38, 57, 31],用于在 $\mathcal{A}$ 中寻找最优架构 $alpha$。
3.2. EvoADA
3.2. EvoADA
Our goal is to investigate a more generalized UDA framework from the perspective of attention mechanism: automatically optimizing the configuration of attention in backbone networks for one arbitrary UDA scenario. To this end, we propose a new UDA-oriented NAS scheme, termed EvoADA, which searches the optimal attention in the attention configuration search space by employing our search algorithm and evaluation method. The overall illustration of the proposed method is shown in Figure 3.
我们的目标是从注意力机制的角度研究一个更通用的无监督域适应 (UDA) 框架:针对任意UDA场景自动优化主干网络中的注意力配置。为此,我们提出了一种新的面向UDA的神经架构搜索 (NAS) 方案,称为EvoADA,该方案通过我们的搜索算法和评估方法在注意力配置搜索空间中寻找最优注意力。所提方法的整体示意图如图3所示。
Search Space for Diverse Attention Configuration. Inspired by recent domain-conditioned attention mechanisms in UDA tasks [48, 25, 51], we propose a novel and effective search space that consists of diverse attention configurations, we define our search space in two aspects: the type and the position of attention module.
多样化注意力配置的搜索空间。受近期UDA任务中领域条件注意力机制[48, 25, 51]的启发,我们提出了一个由多样化注意力配置组成的新型高效搜索空间,该空间从注意力模块的类型和位置两个维度进行定义。

Figure 3. The pipeline of the proposed evolutionary framework to seek for optimal attention configurations towards domain adaptation. Given an pre-defined backbone, we sample several possible attention configurations from our search space, and then conduct an UDA-oriented performance estimation: train the network weights on the two domains with arbitrary domain adaptation method to learn transferable knowledge and evaluate the pseudolabel discrimination on target domain.
图 3: 面向领域自适应的进化框架流程示意图。在给定预定义主干网络的情况下,我们从搜索空间中采样若干可能的注意力配置,随后执行面向无监督领域适应(UDA)的性能评估:通过任意领域适应方法在双域上训练网络权重以学习可迁移知识,并评估目标域上的伪标签判别性。
Table 1. The basic element to make up various attention modules. The element can also be easily extended with other kinds of attention operations for practical usages.
| AttentionModule Parameter | ||
| Attentionon Module | ||
| spatial position channel | Choices | |
| SE [21] | #channel | |
| GSoP [16] | #channel | |
| CBAM [52] | #channel | |
| Identity | 1 | |
| GroupStrategy | ||
| Group [49] | #group | |
表 1: 构成各种注意力模块的基本元素。该元素还可轻松扩展为其他类型的注意力操作以适应实际用途。
| AttentionModule Parameter | ||
|---|---|---|
| Attentionon Module | ||
| spatial position channel | Choices | |
| SE [21] | #channel | |
| GSoP [16] | #channel | |
| CBAM [52] | #channel | |
| Identity | 1 | |
| GroupStrategy | ||
| Group [49] | #group |
▷ Type. Based on the function, there are two basic types of attention: spatial type and channel type, where spatial attention aims to exploit spatial interdependence and the channel one aims to make use of channel interdependence. When it comes to the choice of its parameter, there are two extra hyper-parameters, #channel and #group, where the #channel and the #group denote the number of channels and groups of intermediate features within attention layers. To produce a diverse search space towards UDA problems, we summarize the types and parameter choices of the widely-used attention modules in Table 1 and make up various types of attention modules with these basic elements. On sampling one type of attention, the procedure is: i) choose among 4 kinds of basic types (SE [21], GSoP [16], and CBAM [52]) or Identity; ii) when we select the first 3 modules, we have two additional choices to make: #channel and #group. In our implementation, #channel is 4 ({256, 512, 1024, 2048}) and #group is 4 ({1, 2, 4, 8}). Thus, the number of possible attention modules is $(3\times4\times4+1)$ . It should be noticed that the diversity and completeness of Table 1 works well to produce optimal attention configurations for UDA scenarios, as validated later in Section 4.
▷ 类型。根据功能划分,注意力机制有两种基本类型:空间型 (spatial type) 和通道型 (channel type),其中空间注意力旨在利用空间相互依赖性,通道注意力则用于挖掘通道相互依赖性。参数选择方面存在两个额外超参数:#channel 和 #group,分别表示注意力层中间特征的通道数和分组数。为构建面向UDA问题的多样化搜索空间,我们在表1中总结了常用注意力模块的类型与参数选择,并用这些基础元素组合出多种注意力模块。采样某类注意力时的流程为:i) 从4种基础类型(SE [21]、GSoP [16]、CBAM [52]或Identity)中选择;ii) 若选择前3种模块,需额外确定#channel和#group参数。本实现中#channel取4种值({256, 512, 1024, 2048}),#group取4种值({1, 2, 4, 8}),因此可能的注意力模块数量为$(3\times4\times4+1)$。值得注意的是,如表1所示,这种多样性和完备性能够为UDA场景生成最优注意力配置,第4节的实验将验证这一点。
$\triangleright$ Position. We also need to consider the position in a backbone network to introduce attention modules, since features from different intermediate layers have different transfer ability [54]. Suppose there are $L$ intermediate layers in the backbone network (e.g., $\cal L\mit=\mathrm{50}$ in ResNet50 [20]), we then have $L$ possible position choices. Given that low-level features generally have better transfer ability, we choose the deeper $L/2$ layers to cut-off unnecessary attempts. For the shallower $L/2$ layers, we apply weight sharing strategy on the backbone, akin to one-shot NAS algorithms [2, 19]. To further simplify the search space, on each intermediate layer within the backbone, we only select one attention module, instead of applying parallel block design.
$\triangleright$ 位置。我们还需要考虑在骨干网络中引入注意力模块的位置,因为不同中间层的特征具有不同的迁移能力 [54]。假设骨干网络中有 $L$ 个中间层 (例如 ResNet50 [20] 中 $\cal L\mit=\mathrm{50}$),那么我们有 $L$ 种可能的位置选择。鉴于低层特征通常具有更好的迁移能力,我们选择较深的 $L/2$ 层来减少不必要的尝试。对于较浅的 $L/2$ 层,我们在骨干网络上应用权重共享策略,类似于一次性 NAS 算法 [2, 19]。为了进一步简化搜索空间,在骨干网络的每个中间层上,我们只选择一个注意力模块,而不是采用并行块设计。
$\triangleright$ Overall complexity. Put the type and the position together, we then formulate the attention configuration parameter $\alpha$ as: $\alpha=[\alpha_{1},\alpha_{2},\cdot\cdot\cdot\alpha_{L/2}]$ . $\alpha_{i}$ indicates the attention configuration on layer $i$ of the backbone network. The overall complexity of our search space $\mathcal{A}$ is $|\alpha_{i}|^{L/2}=$ $(3\times4\times4+1)^{25}=49^{25}\approx1\times10^{42}$ .
$\triangleright$ 总体复杂度。将类型和位置结合起来,我们将注意力配置参数 $\alpha$ 表示为:$\alpha=[\alpha_{1},\alpha_{2},\cdot\cdot\cdot\alpha_{L/2}]$。$\alpha_{i}$ 表示主干网络第 $i$ 层的注意力配置。我们搜索空间 $\mathcal{A}$ 的总体复杂度为 $|\alpha_{i}|^{L/2}=$ $(3\times4\times4+1)^{25}=49^{25}\approx1\times10^{42}$。
UDA-oriented Evaluation Strategy. Considering that the core of the UDA task (transfer ability and discrimination), we train the network weights with a certain attention configuration $\theta(\alpha)$ on the two domains to learn transferable representation and evaluate the discrimination of the models on target domain, which in our case is mainly determined by the attention configuration $\alpha$ . Formally, we re-write the typical NAS formulation Eq. (1) 。
面向UDA的评估策略。考虑到UDA任务的核心(迁移能力和判别能力),我们在两个域上以特定注意力配置$\theta(\alpha)$训练网络权重以学习可迁移表示,并在目标域上评估模型的判别能力,这主要取决于注意力配置$\alpha$。形式上,我们将典型NAS公式(1)。
where DA denotes one certain loss function for the domain adaptation task from $s$ to $\tau$ (e.g., CDAN [32] or SHOT [27]); $\mathcal{L}_{\mathcal{T}}^{P E}$ is the evaluation function to measure the discrimination of models in target domain and based on the information maximization loss [18, 22], we propose a pseudo-label discrimination term to measure the desirable properties of ideal representations on target domain:
其中 DA 表示从 $s$ 到 $\tau$ 的领域适应任务的某种损失函数 (例如 CDAN [32] 或 SHOT [27]);$\mathcal{L}_{\mathcal{T}}^{P E}$ 是衡量模型在目标域中判别性的评估函数,基于信息最大化损失 [18, 22],我们提出了一个伪标签判别项来衡量理想表示在目标域上的期望特性:
$$
L{T}^{P E}=L{T}^{e n t}+L_{T}^{d i v}+L_{T}^{p s e},
$$
where $\mathcal{L}{T}^{e n t}$ is the information entropy of each output pre- diction on target domain, $\mathcal{L}{\mathcal{T}}^{d i v}$ is to measure the diversity of output predictions on target domain (e.g., the negative information entropy of the average output predictions), and $\mathcal{L}_{\mathcal{T}}^{p s e}$ is the cross-entropy based on pseudo-labels $\hat{y}$ via existing self-training methods (e.g., Deep Cluster [6]). For the detailed implementation, please refer to the supplementary.
其中 $\mathcal{L}{T}^{e n t}$ 是目标域上每个输出预测的信息熵,$\mathcal{L}{\mathcal{T}}^{d i v}$ 用于衡量目标域输出预测的多样性(例如平均输出预测的负信息熵),而 $\mathcal{L}_{\mathcal{T}}^{p s e}$ 是基于伪标签 $\hat{y}$ 通过现有自训练方法(如 Deep Cluster [6])计算的交叉熵。具体实现请参阅补充材料。
Algorithm 1: EvoADA
算法 1: EvoADA
Data: ${x_{i}^{S},y_{i}^{S}}{i=1}^{N^{S}}$ , ${x_{i}^{\mathcal{T}}}{i=1}^{N^{\mathcal{T}}}$ , population size $K$ Result: A list of optimal architectures and corresponding network weights for the DA task from $s$ to $\tau$ 1 Seed Initialization: sample $\mathrm{K}$ seeds from the search space $\mathcal{A}$ as $\mathcal{G}{s e e d}$ , initialize their weights, and assign various seed numbers for each seed; 2 $\mathcal{G}{b e s t}=[]$ , $\mathfrak{t}=1$ ; 3 while $t\leq T$ do 4 train $\mathcal{G}_{s e e d}$ ; 5 inference the performance of $\mathcal{G}_{s e e d}$ ; $\mathbf{6}$ crossover top seeds to get $\mathcal{G}{c r o s s o v e r}$ ; 7 mutate the bottom seeds to get $\mathcal{G}{m u t a t e}$ ; 8 record mature seeds in $\mathcal{G}{c r o s s o v e r}$ with $\mathcal{G}{b e s t}$ ; 9 pop poor seeds from $\mathcal{G}{m u t a t e}$ ; 10 $\mathcal{G}{s e e d}=\mathcal{G}{c r o s s o v e r}+\mathcal{G}{m u t a t e}$ ; 11 if $|\mathcal{G}{s e e d}|<K$ then 12 initialize another $\left(K-|\mathcal{G}{s e e d}|\right)$ seeds $\mathcal{G}{r a n d}$ ; 13 $\mathcal{G}{s e e d}=\mathcal{G}{s e e d}+\mathcal{G}{r a n d}$ ; 14 end 15 $\mathfrak{t}+=1$ ; 16 end 17 return $\mathcal{G}_{b e s t}$ ;
数据:${x_{i}^{S},y_{i}^{S}}{i=1}^{N^{S}}$,${x_{i}^{\mathcal{T}}}{i=1}^{N^{\mathcal{T}}}$,种群规模 $K$
结果:从 $s$ 到 $\tau$ 的DA任务最优架构列表及对应网络权重
1 种子初始化:从搜索空间 $\mathcal{A}$ 中采样 $\mathrm{K}$ 个种子作为 $\mathcal{G}{s e e d}$,初始化其权重,并为每个种子分配不同种子编号;
2 $\mathcal{G}{b e s t}=[]$,$\mathfrak{t}=1$;
3 while $t\leq T$ do
4 训练 $\mathcal{G}{s e e d}$;
5 推断 $\mathcal{G}{s e e d}$ 的性能;
6 交叉顶级种子得到 $\mathcal{G}{c r o s s o v e r}$;
7 变异底部种子得到 $\mathcal{G}{m u t a t e}$;
8 将 $\mathcal{G}{c r o s s o v e r}$ 中的成熟种子记录至 $\mathcal{G}{b e s t}$;
9 从 $\mathcal{G}{m u t a t e}$ 中剔除劣质种子;
10 $\mathcal{G}{s e e d}=\mathcal{G}{c r o s s o v e r}+\mathcal{G}{m u t a t e}$;
11 if $|\mathcal{G}{s e e d}|<K$ then
12 初始化另外 $\left(K-|\mathcal{G}{s e e d}|\right)$ 个种子 $\mathcal{G}{r a n d}$;
13 $\mathcal{G}{s e e d}=\mathcal{G}{s e e d}+\mathcal{G}{r a n d}$;
14 end
15 $\mathfrak{t}+=1$;
16 end
17 return $\mathcal{G}_{b e s t}$;
Overall Search Algorithm. To make the architecture optimization effective, we integrate the search space and the performance evaluation with an evolutionary algorithm [1] and propose our EvoADA (elaborated in Algorithm 1):
总体搜索算法。为了使架构优化更有效,我们将搜索空间和性能评估与进化算法 [1] 相结合,并提出了我们的 EvoADA (详细见算法 1):
• Sample Seed. We sample $K$ possible attention configurations of $\alpha$ as initial seeds, initialize weights of the backbone on ImageNet, randomly initialize the weights of introduced attention modules, and assign each seed with different random seed numbers (e.g., random(seed)) to reduce uncertainty in training procedure. • Inference.With initialized seeds, we then run several training epochs in each population in a parallel way, update their network weights, and evaluate their UDA performance $\mathcal{L}{\mathcal{T}}^{P E}$ in the target domain. • Crossover and Mutation. We conduct crossover to get even better performance in the next generation. On those poor ones, we perform two mutation strategies to explore for better seeds: 1) drop the seed and initialize another one randomly; 2) change $\alpha$ by introducing another attention module or shifting to different layers. • Update and Early Stop. To promote training efficiency and mitigate the discord between the estimated performance and the final UDA performance, we adopt several early-stopping criteria: i) when the accuracy in source domain is higher than $t r_{a c c}$ (e.g., 0.95), it generally indicates the model may suffer from negative transfer; ii) when the seed finishes $T$ evolution iterations; iii) when pseudo-label accuracy in target domain keeps being poor for over $T_{d}$ (e.g., 5 in our implementation) iterations.
• 样本种子。我们采样 $K$ 种可能的注意力配置 $\alpha$ 作为初始种子,在ImageNet上初始化主干网络权重,随机初始化引入的注意力模块权重,并为每个种子分配不同的随机种子数(例如random(seed))以减少训练过程中的不确定性。
• 推理。通过初始化的种子,我们以并行方式在每个种群中运行若干训练周期,更新其网络权重,并评估其在目标域中的UDA性能 $\mathcal{L}{\mathcal{T}}^{P E}$。
• 交叉与变异。我们执行交叉操作以获得下一代更优性能。对于表现较差的种子,采用两种变异策略探索更好的种子:1)丢弃该种子并随机初始化另一个;2)通过引入另一个注意力模块或切换到不同层来改变 $\alpha$。
• 更新与早停。为提高训练效率并缓解估计性能与最终UDA性能之间的差异,我们采用以下早停标准:i) 当源域准确率高于 $tr_{acc}$(例如0.95)时,通常表明模型可能遭受负迁移;ii) 当种子完成 $T$ 次进化迭代;iii) 当目标域伪标签准确率持续低于阈值超过 $T_{d}$(例如我们实现中的5)次迭代时。
We end up with several populations that contain optimal attention configurations. To report the final performance, we re-train the optimal architectures on the two domains from scratch with one certain domain adaptation approaches. It should be noticed that we can also apply other architecture search algorithms, such as neural networkbased reinforcement learning NAS [57]. Thanks to the flexibility of evolution-based NAS scheme, the proposed EvoADA can be easily applied on arbitrary domain adaptation methods and is compatible with two typical training modes of existing UDA methods: 1) single-stage mode trains on two domains simultaneously (e.g., [32, 47]); 2) two-stage mode trains first in the source domain and then in the target domain (e.g., [27, 17]).
我们最终得到了多个包含最优注意力配置的种群。为了报告最终性能,我们使用某种特定的域适应方法,在两个领域上从头开始重新训练这些最优架构。需要注意的是,我们也可以应用其他架构搜索算法,例如基于神经网络的强化学习NAS [57]。得益于基于进化的NAS方案的灵活性,所提出的EvoADA可以轻松应用于任意域适应方法,并且兼容现有UDA方法的两种典型训练模式:1) 单阶段模式同时在两个领域进行训练 (例如 [32, 47]);2) 两阶段模式先在源领域训练,然后在目标领域训练 (例如 [27, 17])。
Differences from Concurrent Methods. Concurrently, Liet al. [26] and Robbianoet al. [40] also propose to seek for better transferable network architectures. The differences between our EvoADA and them are: 1) on the design of search space: AdaptNAS [26] adopted the search space of NASNet [57] that includes basic operations in CNNs (e.g., different pooling or convolution operations) and seeks for optimal structures in a cell perspective, ABAS [40] only changes the structure of the auxiliary branch. In EvoADA, we design a new space to produce diverse attention configurations and apply different modules on various intermediate layers of the backbone network, which is a more generalized manner; 2) on the architecture search process: AdaptNAS adopts a gradient-based differentiable scheme [31], which might result in sub-optimal solutions; ABAS leverages the BOHB [14], a Bayesian-based hyperparameter optimization method, which is not suitable for a high-dimensional optimization problem. We adopt an Evolution based NAS framework [1], which is a more flexible and stable test-bed for the propose of implementation. Experiments in Section 4 demonstrate the effectiveness and versatility of EvoADA in various UDA scenarios.
与现有方法的差异。与此同时,Li等人[26]和Robbiano等人[40]也提出了寻找更具可迁移性的网络架构。我们的EvoADA与它们的区别在于:1) 搜索空间设计方面:AdaptNAS[26]采用NASNet[57]的搜索空间(包含CNN基础操作如不同池化或卷积运算),以单元视角寻找最优结构;ABAS[40]仅修改辅助分支结构。而EvoADA设计了能生成多样化注意力配置的新空间,并在主干网络不同中间层应用多种模块,具有更高通用性;2) 架构搜索过程方面:AdaptNAS采用基于梯度的可微分方案[31],可能陷入次优解;ABAS使用贝叶斯超参优化方法BOHB[14],不适用于高维优化问题。我们采用基于进化的NAS框架[1],为实现目标提供了更灵活稳定的实验平台。第4节实验证明了EvoADA在各种UDA场景中的有效性和通用性。
4. Experiments
4. 实验
4.1. Setup
4.1. 设置
Implementation details. To check the effectiveness and versatility of our NAS algorithm, we experiment on 5 scenarios: closed-set UDA, PDA, ODA, UDA in fine-grained classification (FGDA), and UDA in person re-ID. Without loss of generality, we select 3 state-of-the-art methods as baselines: SHOT [27] for UDA, PDA, and ODA; PAN [47] for FGDA; and MMT [17] for UDA in person re-ID. For fair comparisons, i) we use the same backbone, i.e., ResNet50 [20], which is prevailing in domain adaptation literature [32, 12, 47, 17]; 2) in PDA and ODA, we follow the same data pipeline as [4, 5, 30, 27]; 3) in FGDA, we use the data pipeline of PAN [47]; 4) to reduce the uncertainty from random seeds, we train the searched architectures with baseline methods three times using different random seeds and report the average results. On these baselines, we adopt our EvoADA to investigate whether the searched architectures help boost classification performance on the target domain. Experimental results also verify the versatility of our method in various domain adaptation tasks.
实现细节。为验证我们NAS算法的有效性和通用性,我们在5种场景下进行实验:闭集UDA、PDA、ODA、细粒度分类中的UDA (FGDA) 以及行人重识别中的UDA。不失一般性,我们选择3种前沿方法作为基线:SHOT [27] 用于UDA、PDA和ODA;PAN [47] 用于FGDA;MMT [17] 用于行人重识别中的UDA。为保证公平比较:i) 采用相同骨干网络ResNet50 [20],该网络在域适应文献 [32, 12, 47, 17] 中被广泛使用;ii) 在PDA和ODA中遵循与 [4, 5, 30, 27] 相同的数据流程;iii) 在FGDA中使用PAN [47] 的数据流程;iv) 为降低随机种子带来的不确定性,使用不同随机种子对搜索到的架构进行三次训练并报告平均结果。在这些基线上,我们采用EvoADA来探究搜索到的架构是否能提升目标域的分类性能。实验结果也验证了我们方法在各种域适应任务中的通用性。
To train the network weights $\theta$ , we use the same settings (including data augmentation, learning-rate schedule, batch-size, etc.) as the aforementioned UDA baseline methods. EvoADA run $T=100$ epochs and $K=20$ different seeds evolve. We implement the proposed EvoADA with pytorch platform [35]. We adopt 8 NVIDIA Tesla V100 GPUs and it takes approximately 20 hours to finish the search procedure on one UDA task on average.
为了训练网络权重 $\theta$,我们采用了与前述UDA基线方法相同的设置(包括数据增强、学习率调度、批处理大小等)。EvoADA运行了 $T=100$ 个周期和 $K=20$ 个不同的种子演化。我们基于PyTorch平台[35]实现了所提出的EvoADA方法。实验使用8块NVIDIA Tesla V100 GPU,平均每个UDA任务的搜索过程耗时约20小时。
Datasets. We experiment on multiple benchmarks:
数据集。我们在多个基准测试上进行实验:
Benchmark I: Office-Home & Office-31. OfficeHome [45] is one challenging medium-sized dataset. It contains 12 adaptation tasks from 4 distinct domains: Artistic (Ar), Clip Art (Cl), Product $(\mathrm{Pr})$ , and Real-World (Rw). Office31 [41] is a popular small-scale domain adaptation benchmark with 4, 110 images and 31 classes. It consists of 6 cross-domain tasks from 3 distinct domains: Amazon (A), Webcam (W), and DSLR (D). Follow the practice, we report classification accuracy on each adaptation task.
基准测试I:Office-Home与Office-31
OfficeHome [45] 是一个具有挑战性的中等规模数据集,包含来自4个不同领域的12项迁移任务:艺术图像 (Ar)、剪贴画 (Cl)、商品图像 (Pr) 和真实场景 (Rw)。Office31 [41] 是流行的小规模域适应基准数据集,包含4,110张图像和31个类别,涵盖来自3个不同领域(亚马逊商品 (A)、网络摄像头 (W) 和数码单反 (D))的6项跨领域任务。按照惯例,我们报告每项迁移任务的分类准确率。
Benchmark II: FGDA. CUB-200-2011 [46] and CUB200-Paintings [47] are datasets for fine-grained UDA. CUB-200-2011 [46] is a fine-grained visual categorization dataset with 12K bird images in 200 species. CUB-200- Paintings is a dataset of 3K bird paintings collected by Wang et al. [47] and its class lists are identical to CUB200-2011. We follow the same data pipeline as PAN [47] and report classification accuracy on the two tasks.
基准测试II:FGDA。CUB-200-2011 [46] 和 CUB200-Paintings [47] 是用于细粒度无监督域适应 (UDA) 的数据集。CUB-200-2011 [46] 是一个细粒度视觉分类数据集,包含200个物种的1.2万张鸟类图像。CUB-200-Paintings 是由 Wang 等人 [47] 收集的3000幅鸟类绘画数据集,其类别列表与 CUB200-2011 完全相同。我们采用与 PAN [47] 相同的数据处理流程,并报告两项任务的分类准确率。
Benchmark III: UDA in person Re-ID. Duke [39] and Market1501 [56] are two widely-used person re-ID datasets. Market-1501 [56] consists of 32K labelled images of 1, 501 identities shot from 6 cameras. 13K images of 751 identities are used for training and 19.7 images of 750 identities are used for inference. Duke [39] contains $16.5\mathrm{K}$ photos of 702 identities for training, and photos out of additional 702 identities for testing. We follow the same pipeline on these benchmarks as Ge et al. [17] and report mean average precision (mAP) to evaluate the performance.
基准测试 III: 人员重识别中的无监督域适应 (UDA)。Duke [39] 和 Market1501 [56] 是两个广泛使用的人员重识别数据集。Market-1501 [56] 包含由6个摄像头拍摄的1,501个身份的32K标注图像,其中751个身份的13K图像用于训练,750个身份的19.7K图像用于推理。Duke [39] 包含702个身份的$16.5\mathrm{K}$训练照片,以及额外702个身份的测试照片。我们遵循与Ge等人[17]相同的流程,并报告平均精度均值(mAP)以评估性能。
Baselines. We compare with multiple state-of-the-art approaches: DANN [15], JAN [33], OSBP [44], CDAN [32], IBN-Net [34], MCD [43], SAN [4], TADA [50], BSP [7], SAFN [53], STA [30], CADA-A [24], ETN [5], CRST [58], $\mathrm{{BA}^{3}U S}$ [28], DCAN [25], MMT [17], PAN [47], SHOT [27], and ABAS [40]. Among them, TADA [50], CADA-A [24], DCAN [25] are the competitive approaches of better attention module design towards domain adaptation and ABAS [40] (one current work) also adopts NAS to search optimal architectures for domain adaptation, which provide a good counterpart to investigate the effect of network design in the topic of domain adaptation.
基线方法。我们与多种先进方法进行比较:DANN [15]、JAN [33]、OSBP [44]、CDAN [32]、IBN-Net [34]、MCD [43]、SAN [4]、TADA [50]、BSP [7]、SAFN [53]、STA [30]、CADA-A [24]、ETN [5]、CRST [58]、$\mathrm{{BA}^{3}U S}$ [28]、DCAN [25]、MMT [17]、PAN [47]、SHOT [27] 和 ABAS [40]。其中,TADA [50]、CADA-A [24]、DCAN [25] 是面向领域自适应 (domain adaptation) 的注意力模块设计方面的竞争性方法,而 ABAS [40] (一项近期工作) 也采用神经架构搜索 (NAS) 来寻找领域自适应的最优架构,这为研究网络设计在领域自适应主题中的效果提供了良好对照。
Table 2. Accuracy $(%)$ on Office-Home for UDA, PDA, and ODA methods (ResNet-50).
表 2. Office-Home数据集上UDA、PDA和ODA方法的准确率 $(%)$ (ResNet-50)。
| 方法 | Ar→Cl | Ar→Pr | Ar→Rw | Cl→Ar | Cl→Pr | Cl→Rw | Pr→Ar | Pr→Cl | Pr→Rw | Rw→Ar | Rw→Cl | Rw→Pr | AVG |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 [20] | 34.9 | 50.0 | 58.0 | 37.4 | 41.9 | 46.2 | 38.5 | 31.2 | 60.4 | 53.9 | 41.2 | 59.9 | 46.1 |
| DANN [15] | 45.6 | 59.3 | 70.1 | 47.0 | 58.5 | 60.9 | 46.1 | 43.7 | 68.5 | 63.2 | 51.8 | 76.8 | 57.6 |
| JAN [33] | 45.9 | 61.2 | 68.9 | 50.4 | 59.7 | 61.0 | 45.8 | 43.4 | 70.3 | 63.9 | 52.4 | 76.8 | 58.3 |
| CDAN [32] | 50.7 | 70.6 | 76.0 | 57.6 | 70.0 | 70.0 | 57.4 | 50.9 | 77.3 | 70.9 | 56.7 | 81.6 | 65.8 |
| ABAS [40] | 51.5 | 71.7 | 75.5 | 59.8 | 69.4 | 69.5 | 59.8 | 47.1 | 77.7 | 70.6 | 55.2 | 80.2 | 65.7 |
| TADA [50] | 53.1 | 72.3 | 77.2 | 59.1 | 71.2 | 72.1 | 59.7 | 53.1 | 78.4 | 72.4 | 60.0 | 82.9 | 67.6 |
| CADA-A [24] | 56.9 | 75.4 | 80.2 | 61.7 | 74.6 | 74.9 | 62.9 | 54.4 | 80.9 | 74.3 | 61.1 | 84.4 | 70.1 |
| DCAN [25] | 54.5 | 75.7 | 81.2 | 67.4 | 74.0 | 76.3 | 67.4 | 52.7 | 80.6 | 74.1 | 59.1 | 83.5 | 70.5 |
| SHOT [27] | 56.9 | 78.1 | 81.0 | 67.9 | 78.4 | 78.1 | 67.0 | 54.6 | 81.8 | 73.4 | 58.1 | 84.5 | 71.6 |
| SHOT+Ours | 60.0 | 78.0 | 83.5 | 74.0 | 77.9 | 79.8 | 71.2 | 56.3 | 82.8 | 77.5 | 59.0 | 86.2 | 73.9 |
| 方法 | Ar→Cl | Ar→Pr | Ar→Rw | Cl→Ar | Cl→Pr | Cl→Rw | Pr→Ar | Pr→Cl | Pr→Rw | Rw→Ar | Rw→Cl | Rw→Pr | AVG |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 [20] | 46.3 | 67.5 | 75.9 | 59.1 | 59.9 | 62.7 | 58.2 | 41.8 | 74.9 | 67.4 | 48.2 | 74.2 | 61.3 |
| DANN [15] | 35.5 | 48.2 | 51.6 | 35.2 | 35.4 | 41.4 | 34.8 | 31.7 | 46.2 | 47.5 | 34.7 | 49.0 | 40.9 |
| SAN [4] | 44.4 | 68.7 | 74.6 | 67.5 | 65.0 | 77.8 | 59.8 | 44.7 | 80.1 | 72.2 | 50.2 | 78.7 | 65.3 |
| ETN [5] | 59.2 | 77.0 | 79.5 | 62.9 | 65.7 | 75.0 | 68.3 | 55.4 | 84.4 | 75.7 | 57.7 | 84.5 | 70.5 |
| SAFN[53] | 58.9 | 76.3 | 81.4 | 70.4 | 73.0 | 77.8 | 72.4 | 55.3 | 80.4 | 75.8 | 60.4 | 79.9 | 71.8 |
| BA3US [28] | 60.6 | 83.2 | 88.4 | 71.8 | 72.8 | 83.4 | 75.5 | 61.6 | 86.5 | 79.3 | 62.8 | 86.1 | 76.0 |
| SHOT [27] | 62.8 | 84.2 | 92.3 | 75.1 | 76.3 | 86.4 | 78.5 | 62.3 | 89.6 | 80.9 | 63.8 | 87.1 | 78.3 |
| SHOT+Ours | 66.5 | 84.7 | 89.8 | 80.3 | 80.9 | 86.3 | 83.3 | 64.1 | 90.1 | 85.5 | 61.4 | 89.9 | 80.2 |
| 方法 | Ar→Cl | Ar→Pr | Ar→Rw | Cl→Ar | Cl→Pr | Cl→Rw | Pr→Ar | Pr→Cl | Pr→Rw | Rw→Ar | Rw→Cl | Rw→Pr | AVG |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 [20] | 53.4 | 69.3 | 78.7 | 61.4 | 61.8 | 71.0 | 64.0 | 52.7 | 74.9 | 70.0 | 51.9 | 74.1 | 65.3 |
| DANN [15] | 54.6 | 69.5 | 80.2 | 61.9 | 63.5 | 71.7 | 63.3 | 49.7 | 74.2 | 71.3 | 51.9 | 72.9 | 65.4 |
| OSBP [44] | 56.7 | 67.5 | 80.6 | 62.5 | 65.5 | 74.7 | 64.8 | 51.5 | 71.5 | 69.3 | 49.2 | 74.0 | 65.7 |
| STA [30] | 58.1 | 71.6 | 85.0 | 63.4 | 69.3 | 75.8 | 65.2 | 53.1 | 80.8 | 74.9 | 54.4 | 81.9 | 69.5 |
| ETN [5] | 58.2 | 79.9 | 85.5 | 67.7 | 70.9 | 79.6 | 66.2 | 54.8 | 81.2 | 76.8 | 60.7 | 81.7 | 71.9 |
| SHOT [27] | 60.5 | 59.2 | 69.5 | 63.4 | 73.6 | 61.8 | 54.7 | 80.4 | 81.8 | 82.3 | 82.6 | 77.2 | 70.6 |
| SHOT+Ours | 62.1 | 60.2 | 79.2 | 69.4 | 73.6 | 63.7 | 58.1 | 82.7 | 87.0 | 87.4 | 86.5 | 79.3 | 74.1 |
Table 3. Accuracy $(%)$ on Office-31 for UDA (ResNet-50).
表 3. Office-31数据集上UDA (ResNet-50)的准确率 $(%)$
| 方法 | A→W | D→W | W→D | A→D | D→A | W→A | AVG |
|---|---|---|---|---|---|---|---|
| ResNet-50 [20] | 68.4 | 96.7 | 99.3 | 68.9 | 62.5 | 60.7 | 76.1 |
| 82.0 | 96.9 | 99.1 | 79.7 | 68.2 | 67.4 | 82.2 | |
| DANN [15] | 86.0 | 96.7 | 99.7 | 85.1 | 69.2 | - | - |
| JAN [33] | 70.7 | 84.6 | 88.6 | 98.5 | 100.0 | 92.2 | 69.5 |
| 69.7 | - | - | - | - | - | 86.5 | |
| MCD [43] | 89.4 | 98.9 | 100.0 | 88.7 | 72.6 | 70.9 | 86.8 |
| CRST [58] | - | - | - | - | - | - | - |
| CDAN [32] | 94.1 | 98.6 | 100.0 | 92.9 | 71.0 | 69.3 | 87.7 |
| TADA [50] | 94.3 | 98.7 | 99.8 | 91.6 | 72.9 | 73.0 | 88.4 |
| BSP [7] | 93.3 | 98.2 | 100.0 | 93.0 | 73.6 | 72.6 | 88.5 |
| CADA-A [24] | 96.8 | 99.0 | 99.8 | 93.4 | 71.7 | 70.5 | 88.5 |
| SHOT [27] | 90.9 | 98.8 | 99.9 | 93.1 | 74.5 | 74.8 | 88.7 |
| SHOT+Ours | 94.0 | 97.9 | 100.0 | 94.2 | 74.6 | 74.9 | 89.3 |
4.2. Results on Office-Home & Office-31
4.2. Office-Home和Office-31数据集上的结果
Experiments on Office-Home benchmark in Table 2 include 3 typical settings: closed-set UDA, PDA, and ODA 1. As we can observe that, in term of average accuracy, the proposed NAS algorithm helps SHOT achieve better performance: $+2.3%$ on closed-set UDA tasks, $+1.9%$ on PDA tasks, and $+3.5%$ on ODA tasks. We also notice that sometimes, optimal performances can be obtained when only one GSoP [16] attention layer is put at Layer3 for ResNet-50. These observations encourage advanced development of the attention mechanism in domain adaptation problems.
表 2 中的 Office-Home 基准测试实验包含 3 种典型设置:闭集 UDA、PDA 和 ODA 1。我们可以观察到,在平均准确率方面,提出的 NAS 算法帮助 SHOT 取得了更好的性能:闭集 UDA 任务提升 $+2.3%$,PDA 任务提升 $+1.9%$,ODA 任务提升 $+3.5%$。我们还注意到,有时仅在 ResNet-50 的 Layer3 放置一个 GSoP [16] 注意力层即可获得最佳性能。这些发现为注意力机制在域适应问题中的进一步发展提供了启示。
Numerical results on Office-31 dataset are listed in Table 3. Again, the proposed EvoADA generally helps SHOT promote its classification performance on target domain. These results indicate the importance of optimal attention configuration and the effectiveness of our EvoADA in typical domain adaptation scenarios.
Office-31数据集上的数值结果列于表3。同样,提出的EvoADA方法普遍帮助SHOT提升了其在目标域的分类性能。这些结果表明了最优注意力配置的重要性,以及我们的EvoADA在典型域适应场景中的有效性。
4.3. Results on FGDA and UDA in Person Re-ID
4.3. 行人重识别中的FGDA与UDA结果
We also experiment on two additional cross-domain applications: FGDA tasks and UDA tasks of person re-ID. Results are listed in Table 4. On FGDA: The performance gains from the searched attention configurations are generally large on both FGDA scenarios. In terms of average accuracy, our EvoADA helps PAN achieve $4.1%$ gains. Similar to the observations previously, we find that the gains can be achieved by automatically introducing 2 or 3 attention modules at proper layers of the backbone network. On UDA in Person Re-ID: For full comparisons, we experiment with different configurations of MMT [17]: MMT-500 and MMT-700 means that in the MMT framework, 500 and
我们还针对两个额外的跨域应用进行了实验:FGDA任务和人员重识别的UDA任务。结果如表4所示。在FGDA方面:搜索到的注意力配置在两种FGDA场景下通常都能带来较大的性能提升。就平均准确率而言,我们的EvoADA帮助PAN实现了4.1%的提升。与之前的观察类似,我们发现通过在主干网络的适当层级自动引入2或3个注意力模块即可实现这些提升。在人员重识别的UDA方面:为了进行全面比较,我们测试了MMT [17]的不同配置:MMT-500和MMT-700表示在MMT框架中分别使用500和700个...
Table 4. Accuracy $(%)$ on CUB-Paintings (ResNet-50) and mAP (%) Market-1501-Duke (ResNet-50 vs IBN-Net-50 vs ours).
表 4. CUB-Paintings (ResNet-50) 和 Market-1501-Duke (ResNet-50 vs IBN-Net-50 vs 我们的方法) 的准确率 $(%)$ 和 mAP (%)。
| FGDA | CUB-200-2011→ CUB-200-Paintin | CUB-200-Paintings →→CUB-200-2011 | AVG |
|---|---|---|---|
| ResNet-50 [20] | 47.9 | 36.6 | 42.3 |
| DANN [15] | 57.5 | 43.0 | 50.3 |
| JAN [33] | 62.4 | 40.4 | 51.4 |
| MCD [43] | 63.4 | 43.6 | 53.5 |
| CDAN [32] | 63.2 | 45.4 | 54.3 |
| BSP [7] | 63.3 | 46.6 | 55.0 |
| SAFN [53] | 61.4 | 48.9 | 55.2 |
| PAN [47] | 67.4 | 50.9 | 59.2 |
| PAN+Ours | 70.5 | 56.0 | 63.3 |
| UDA in Person ReID | Market1501 →Duke | Duke-→ Market-1501 | AVG |
|---|---|---|---|
| MMT-500 [17] | 63.1 | 71.2 | 67.2 |
| + IBN-Net-50 [34] | 65.7 | 76.5 | 71.1 |
| + Ours | 69.6 | 79.9 | 74.8 |
| MMT-700 [17] | 65.1 | 69.0 | 67.1 |
| + IBN-Net-50 [34] | 68.7 | 74.5 | 71.6 |
| + Ours | 71.0 | 78.5 | 74.8 |
| MMT-DBSCAN [17] | 64.3 | 75.6 | 70.0 |
| + IBN-Net-50 [34] | 68.8 | 80.5 | 74.7 |
| + Ours | 71.4 | 84.3 | 77.9 |
Table 5. Comparison of the proposed search space and two existing typical ones. The Experiments are conducted on the four closedset UDA settings on Office-Home dataset.
表 5: 提出的搜索空间与两种现有典型方法的对比。实验在Office-Home数据集的四种闭集UDA设置下进行。
| Settings | NASNet [57] | DARTS[31] | ABAS[40] | Ours |
|---|---|---|---|---|
| Ar→C1 | 57.1 | 56.8 | 51.5 | 60.0 |
| C1→→Pr | 78.1 | 77.3 | 69.4 | 77.9 |
| PrRw | 81.3 | 80.7 | 77.7 | 82.8 |
| Rw→→Ar | 73.0 | 74.6 | 70.6 | 77.5 |
| AVG | 72.6 | 72.3 | 67.3 | 74.6 |
700 centroids are adopted when $\mathrm{k}$ -means clustering is used, and MMT-DBSCAN means DBSCAN clustering is adopted for pseudo-labels. As listed in Table 4, the architecture searched by our EvoADA generally outperforms the other two competitive baselines, i.e., ResNet-50 [20] and IBNNet-50 [34], over different configurations of MMT method and two UDA person re-ID task scenarios.
当使用 $\mathrm{k}$ 均值聚类时采用700个中心点,MMT-DBSCAN表示对伪标签采用DBSCAN聚类。如表4所示,在不同MMT方法配置和两个UDA行人重识别任务场景下,我们的EvoADA搜索出的架构通常优于其他两个竞争基线,即ResNet-50 [20]和IBNNet-50 [34]。
Together, we verify the effectiveness and versatility of the proposed NAS scheme in searching for optimal attention configurations for various domain adaptation scenarios.
我们共同验证了所提出的NAS方案在搜索适用于各种领域适应场景的最佳注意力配置时的有效性和多功能性。
4.4. Ablation Study & Insight Analysis
4.4. 消融研究与洞察分析
Comparison with Other Search Spaces. To demonstrate the effectiveness of the proposed search space in the topic of domain adaptation, we also compare with two typical search spaces in NAS methods: the search space of NASNet [57] and that of DARTS [31]. Both of them are based on basic operations in convolutional neural networks (e.g., dilated convolution, pooling, and skip connection). We randomly select 4 close-set UDA settings from Office-Home dataset and alternate our search space with the two to investigate how their performance in the context of domain adaptation. For full comparison, we also report the results from ABAS [40]. As listed in Table 5 the proposed attentionbased search space does outperform other existing alternatives and yields the best domain adaptation results.
与其他搜索空间的对比。为证明所提出搜索空间在领域自适应主题中的有效性,我们还将该方法与NAS方法中两种典型搜索空间进行对比:NASNet [57] 的搜索空间和DARTS [31] 的搜索空间。二者均基于卷积神经网络中的基础操作(如空洞卷积、池化和跳跃连接)。我们从Office-Home数据集中随机选取4个闭集UDA设置,将我们的搜索空间与这两种方案交替使用,以探究它们在领域自适应场景下的性能表现。为全面对比,我们还列出了ABAS [40] 的结果。如表5所示,所提出的基于注意力机制的搜索空间确实优于其他现有方案,并取得了最佳领域自适应效果。

Figure 4. The comparison of EvoADA and random search on the partial UDA task $\scriptstyle\mathrm{Pr}\to\mathrm{Rw}$ on Office-Home dataset. The prevailing backbone, ResNet-50, is denoted as the dashed horizontal bar.
图 4: EvoADA 与随机搜索在 Office-Home 数据集部分 UDA 任务 $Pr{Rw}$ 上的对比。主流骨干网络 ResNet-50 以虚线水平条表示。
Comparison with Random Search. The search curves of our EvoADA and one random search algorithm are shown in Figure 4. As we can observe that our EvoADA is more effective in optimizing the attention configurations for domain adaptation settings. We find similar observations on Office-Home benchmark with two additional baseline methods (random search v.s. ours): CDAN [32] $66.4%$ v.s. $69.8%)$ ) and SHOT [27] $(71.9%$ v.s. $73.9%$ ). Therefore, the results of random search demonstrate the necessity of an effective NAS algorithm towards domain adaptation tasks.
与随机搜索的对比。我们的EvoADA与一种随机搜索算法的搜索曲线如图4所示。可以观察到,EvoADA在优化领域自适应场景的注意力配置方面更为高效。在Office-Home基准测试中,我们对比了两种基线方法(随机搜索 vs. 我们的方法)并得到相似结论:CDAN [32] ($66.4%$ vs. $69.8%$) 和 SHOT [27] ($71.9%$ vs. $73.9%$)。因此,随机搜索的结果印证了有效的神经架构搜索(NAS)算法对领域自适应任务的必要性。
Hyper-parameter Sensitivity. We investigate the sensitivity to 3 hyper-parameters, $t r_{a c c}$ , $T$ , $T_{d}$ . Empirically, we observe that: When $t_{a c c}=0.98$ , the results go worse; when $t_{a c c}\in{0.9,0.93,0.95}$ , the results are similar; when $t_{a c c}\in{0.8,0.85}$ , the results become worse again. ii) When $T\geq100$ , the results are slightly better but the cost also arises. iii) When $T_{d}>5$ , the results are relatively worse; when $T_{d}\leq5$ , the results are similar. Thus, our EvoADA is relatively robust to these hyper-parameters.
超参数敏感性。我们研究了三个超参数的敏感性:$t r_{a c c}$、$T$、$T_{d}$。实验观察发现:i) 当 $t_{a c c}=0.98$ 时结果变差;当 $t_{a c c}\in{0.9,0.93,0.95}$ 时结果相近;当 $t_{a c c}\in{0.8,0.85}$ 时结果再次变差。ii) 当 $T\geq100$ 时结果略优但计算成本上升。iii) 当 $T_{d}>5$ 时结果相对较差;当 $T_{d}\leq5$ 时结果相近。因此,我们的EvoADA对这些超参数具有相对鲁棒性。
Effectiveness of Performance Estimation. To further demonstrate the rationale of our performance estimation strategy, we show the rank correlation, i.e., Spearman $\rho$ , between our estimation results and the final accuracy in the target domain. For comparison, we also show the rank correlation between the accuracy in the source domain and that in the target domain. The results are shown in Table 6. Obvious, the rank correlation between the accuracy in the source domain and that in the target domain is relatively low, due to the large domain shift between two domains. The estimation results via our evaluation strategy, on the other hand, are highly correlated with the accuracy in the target domain and are effective to guide search procedures to seek optimal architectures for domain adaptation.
性能估计的有效性。为进一步验证我们性能估计策略的合理性,我们展示了估计结果与目标域最终准确率之间的秩相关性(即Spearman $\rho$)。作为对比,我们还展示了源域准确率与目标域准确率之间的秩相关性,结果如表6所示。显然,由于两域间存在较大领域偏移,源域与目标域准确率的秩相关性较低。而通过我们的评估策略得到的估计结果,与目标域准确率高度相关,能有效指导搜索程序寻找适合领域适应的最优架构。
Table 6. Comparison of the rank correlation between the estimation results via the accuracy on source domain and that via our evaluation protocol.
表 6. 源域准确率与我们的评估协议所得估计结果的秩相关性对比
| 标准 | Office-31 | Office-Home |
|---|---|---|
| 源域准确率 | 0.40 | 0.23 |
| 我们的评估协议 | 0.68 | 0.54 |

Figure 5. (a) Histogram of the accuracies for 500 random populations on the FGDA task of CUB-200-Painting to CUB-200-2011. The dashed vertical line indicates the result of ResNet-50. (b) Some seeds on the PDA task of $\mathbf{R}\mathbf{w}\rightarrow\mathbf{A}\mathbf{r}$ on Office-Home. The numbers indicate their corresponding accuracies on target domain.
图 5: (a) CUB-200-Painting到CUB-200-2011的FGDA任务中500个随机种群准确率直方图。虚线垂直线表示ResNet-50的结果。 (b) Office-Home数据集上 $\mathbf{R}\mathbf{w}\rightarrow\mathbf{A}\mathbf{r}$ PDA任务的部分种子示例。数字表示其在目标域上的对应准确率。
Good and Bad Case Analysis. Finally, we take a closer look at the searched attention configurations. Figure 5 displays the accuracies of 500 randomly sampled populations on the FGDA task of CUB-200-Painting $\begin{array}{r}{\gamma\mathbf{CUB}\cdot}\end{array}$ 200-2011. The histogram verifies the benefit from refining the attention configurations and the effectiveness of the proposed attention configuration. For better understanding the searched optimal architectures, we also visualize some attention configurations with good and sub-optimal UDA results (Figure 5(b)), and the training curves of the optimal networks (Figure 6). Experiments indicate that Layer 3 and Layer 4 seem to be optimal positions to introduce attention modules, and we achieve the gains in accuracy when only moderate amounts of parameters and #FLOPs are introduced. All these numerical results can help and encourage researchers to cast a new light on designing novel attention modules towards better domain adaptation.
优劣案例分析。最后,我们深入研究了搜索到的注意力配置。图5展示了在CUB-200-Painting $\begin{array}{r}{\gamma\mathbf{CUB}\cdot}\end{array}$ 200-2011的FGDA任务上随机抽取的500个种群的准确率分布。直方图验证了优化注意力配置带来的收益以及所提注意力配置方案的有效性。为更好理解搜索到的最优架构,我们还可视化了一些具有优良和次优UDA结果的注意力配置(图5(b)),以及最优网络的训练曲线(图6)。实验表明,第3层和第4层似乎是引入注意力模块的最佳位置,且仅需引入适量参数和#FLOPs即可实现精度提升。这些数值结果有助于启发研究者以新视角设计更优的注意力模块来提升域适应性能。

Figure 6. (a) and (b): The curves of three backbone networks on UDA tasks over person re-ID benchmarks. The $\mathbf{X}$ -axis is training epochs and the y-axis is the accuracy $(%)$ on target domain. (c) and (d): The differences between ResNet-50 and ours on fine-grained UDA tasks over CUB-Paintings. The $\mathbf{X}$ -axis indicates training iterations. The y-axis indicates the training loss.
图 6: (a) 和 (b): 三种骨干网络在行人重识别基准上的无监督域适应(UDA)任务曲线。X轴为训练周期,Y轴为目标域准确率(%)。(c) 和 (d): ResNet-50与本文方法在CUB-Paintings细粒度UDA任务上的差异对比。X轴表示训练迭代次数,Y轴表示训练损失值。
5. Conclusion
5. 结论
In this paper, we devise a novel and effective NAS algorithm for UDA problems. We propose a more generalized way to apply the attention module for domain adaptation: to automatically optimize the attention configuration for one arbitrary UDA dataset. We propose a new search space with a set of attention modules and their positions in the backbone network. To be consonant with UDA settings, we propose a UDA-oriented estimation strategy: train the weights on two domains and evaluate the attention configurations in the target domain with a self-training pseudo-label strategy. We implement the EvoADA framework based on an evolution-based NAS algorithm. Extensive experiments on multiple cross-domain benchmarks and typical adaptation scenarios verify that our scheme generally promotes popular domain adaptation methods.
本文针对无监督领域自适应(UDA)问题设计了一种新颖高效的神经架构搜索(NAS)算法。我们提出了一种更通用的注意力模块应用方法:为任意UDA数据集自动优化注意力配置。通过构建包含多种注意力模块及其在主干网络中位置的新搜索空间,配合面向UDA的评估策略(在双域训练权重,采用自训练伪标签策略在目标域评估注意力配置),开发了基于进化算法的EvoADA框架。跨域基准测试和典型适应场景的大量实验表明,该方案能有效提升主流领域自适应方法的性能。
For future work, we will investigate the transfer ability of various architectures and study the topic in other scenarios, e.g., object detection and semantic segmentation.
在未来的工作中,我们将研究不同架构的迁移能力,并在其他场景(如目标检测和语义分割)中探索该主题。