In-Context Retrieval-Augmented Language Models
上下文检索增强型语言模型
Ori Ram∗ Yoav Levine∗ Itay Dalmedigos Dor Muhlgay Amnon Shashua Kevin Leyton-Brown Yoav Shoham AI21 Labs
Ori Ram∗ Yoav Levine∗ Itay Dalmedigos Dor Muhlgay Amnon Shashua Kevin Leyton-Brown Yoav Shoham AI21 Labs
{orir,yoavl,itayd,dorm,amnons,kevinlb,yoavs}@ai21.com
{orir,yoavl,itayd,dorm,amnons,kevinlb,yoavs}@ai21.com
Abstract
摘要
Retrieval-Augmented Language Modeling (RALM) methods, which condition a language model (LM) on relevant documents from a grounding corpus during generation, were shown to significantly improve language modeling performance. In addition, they can mitigate the problem of factually inaccurate text generation and provide natural source attribution mechanism. Existing RALM approaches focus on modifying the LM architecture in order to facilitate the incorporation of external information, significantly complicating deployment. This paper considers a simple alternative, which we dub In-Context RALM: leaving the LM architecture unchanged and prepending grounding documents to the input, without any further training of the LM. We show that In-Context RALM that builds on off-the-shelf general purpose retrievers provides surprisingly large LM gains across model sizes and diverse corpora. We also demonstrate that the document retrieval and ranking mechanism can be specialized to the RALM setting to further boost performance. We conclude that In-Context RALM has considerable potential to increase the prevalence of LM grounding, particularly in settings where a pretrained LM must be used without modification or even via API access.1
检索增强语言建模 (Retrieval-Augmented Language Modeling, RALM) 方法通过在生成过程中基于语料库中的相关文档对语言模型 (Language Model, LM) 进行条件约束,被证明能显著提升语言建模性能。此外,该方法还能缓解生成文本事实性错误的问题,并提供自然的来源归因机制。现有RALM方法主要侧重于修改LM架构以整合外部信息,这大幅增加了部署复杂度。本文提出了一种名为"上下文RALM"的简单替代方案:保持LM架构不变,仅将相关文档前置到输入中,无需对LM进行额外训练。实验表明,基于现成通用检索器的上下文RALM能在不同模型规模和多样语料库上带来惊人的性能提升。我们还证实,通过针对RALM场景定制文档检索和排序机制可进一步提升效果。研究得出结论:上下文RALM具有极大潜力来提升语言模型的基础应用普及度,特别是在必须使用未经修改的预训练模型或仅通过API访问的场景中。[1]
1 Introduction
1 引言
Recent advances in language modeling (LM) have dramatically increased the usefulness of machinegenerated text across a wide range of use-cases and domains (Brown et al., 2020). However, the mainstream paradigm of generating text with LMs bears inherent limitations in access to external knowledge. First, LMs are not coupled with any source attribution, and must be trained in order to incorporate up-to-date information that was not seen during training. More importantly, they tend to produce factual inaccuracies and errors (Lin et al., 2022; Maynez et al., 2020; Huang et al., 2020). This problem is present in any LM generation scenario, and is exacerbated when generation is made in uncommon domains or private data. A promising approach for addressing the above is Retrieval-Augmented Language Modeling (RALM), grounding the LM during generation by conditioning on relevant documents retrieved from an external knowledge source. RALM systems include two high level components: (i) document selection, selecting the set of documents upon which to condition; and (ii) document reading, determining how to incorporate the selected documents into the LM generation process.
语言建模 (LM) 领域的最新进展显著提升了机器生成文本在各类应用场景和领域中的实用性 (Brown et al., 2020)。然而,当前主流的大语言模型文本生成范式在获取外部知识方面存在固有局限:首先,模型缺乏来源归因机制,必须通过重新训练才能整合训练时未接触的最新信息;更重要的是,它们容易产生事实性错误 (Lin et al., 2022; Maynez et al., 2020; Huang et al., 2020)。这一问题存在于所有大语言模型生成场景中,在非常规领域或私有数据上的生成任务中尤为突出。
检索增强语言建模 (Retrieval-Augmented Language Modeling, RALM) 是解决上述问题的有效方案,该方法通过在生成过程中锚定外部知识源检索的相关文档来增强模型可靠性。RALM 系统包含两个核心组件:(i) 文档选择模块——确定用于生成的条件文档集;(ii) 文档阅读模块——决定如何将选定文档整合到语言模型生成流程中。

Figure 1: Our framework, dubbed In-Context RALM, provides large language modeling gains on the test set of WikiText-103, without modifying the LM. Adapting the use of a BM25 retriever (Robertson and Zaragoza, 2009) to the LM task (§5) yields significant gains, and choosing the grounding documents via our new class of Predictive Rerankers (§6) provides a further boost. See Table 1 for the full results on five diverse corpora.
图 1: 我们的框架In-Context RALM在WikiText-103测试集上实现了大语言模型性能提升,且无需修改语言模型。将BM25检索器 (Robertson and Zaragoza, 2009) 适配至语言模型任务 (§5) 带来显著增益,而通过我们提出的预测性重排序器 (§6) 选取基础文档可进一步提升效果。完整结果参见表 1 中五个不同语料库的数据。
Leading RALM systems introduced recently tend to be focused on altering the language model architecture (Khandelwal et al., 2020; Borgeaud et al., 2022; Zhong et al., 2022; Levine et al., $2022\mathrm{c}$ ; Li et al., 2022). Notably, Borgeaud et al. (2022) introduced RETRO, featuring document reading via nontrivial modifications that require further training to the LM architecture, while using an off-theshelf frozen BERT retriever for document selection. Although the paper’s experimental findings showed impressive performance gains, the need for changes in architecture and dedicated retraining has hindered the wide adoption of such models.
近期提出的领先 RALM 系统往往侧重于改变语言模型架构 [20][5][28][17][16]。值得注意的是,Borgeaud 等人 [5] 提出的 RETRO 通过非平凡架构修改实现文档读取功能,这需要对语言模型进行额外训练,同时采用现成的冻结 BERT 检索器进行文档选择。尽管实验结果显示其性能提升显著,但由于需要修改架构并进行专门训练,这类模型的广泛采用仍受到限制。

Figure 2: An example of In-Context RALM: we simply prepend the retrieved document before the input prefix.
图 2: 上下文检索增强语言模型 (In-Context RALM) 示例:我们只需在输入前缀前添加检索到的文档。
In this paper, we show that a very simple document reading mechanism can have a large impact, and that substantial gains can also be made by adapting the document selection mechanism to the task of language modeling. Thus, we show that many of the benefits of RALM can be achieved while working with off-the-shelf LMs, even via API access. Specifically, we consider a simple but powerful RALM framework, dubbed In-Context RALM (presented in Section 3), which employs a zero-effort document reading mechanism: we simply prepend the selected documents to the LM’s input text (Figure 2).
本文表明,一种极其简单的文档读取机制能产生显著影响,同时通过使文档选择机制适配语言建模任务也能实现大幅性能提升。我们证明,即使通过API调用现成大语言模型(LM),也能获得检索增强语言模型(RALM)的大部分优势。具体而言,我们提出了一种简单但强大的RALM框架——上下文检索增强语言模型(In-Context RALM) (详见第3节),该框架采用零干预文档读取机制:直接将选定文档预置至大语言模型的输入文本前 (图2)。
Section 4 describes our experimental setup. To show the wide applicability of our framework, we performed LM experiments on a suite of five diverse corpora: WikiText-103 (Merity et al., 2016), RealNews (Zellers et al., 2019), and three datasets from The Pile (Gao et al., 2021): ArXiv, Stack Exchange and FreeLaw. We use open-source LMs ranging from 110M to 66B parameters (from the GPT-2, GPT-Neo, OPT and LLaMA model families).
第4节描述了我们的实验设置。为展示框架的广泛适用性,我们在五个多样化语料库上进行了大语言模型实验:WikiText-103 (Merity等人, 2016)、RealNews (Zellers等人, 2019)以及来自The Pile (Gao等人, 2021)的三个数据集(ArXiv、Stack Exchange和FreeLaw)。实验使用了参数量从1.1亿到660亿不等的开源大语言模型(涵盖GPT-2、GPT-Neo、OPT和LLaMA模型系列)。
In Section 5 we evaluate the application of offthe-shelf retrievers to our framework. In this minimal-effort setting, we found that In-Context RALM led to LM performance gains equivalent to increasing the LM’s number of parameters by $2-$ $3\times$ across all of the text corpora we examined. In Section 6 we investigate methods for adapting document ranking to the LM task, a relatively underexplored RALM degree of freedom. Our adaptation methods range from using a small LM to per- form zero-shot ranking of the retrieved documents, up to training a dedicated bidirectional reranker by employing self-supervision from the LM signal. These methods lead to further gains in the LM task corresponding to an additional size increase of $2\times$ in the LM architecture. As a concrete example of the gains, a 345M parameter GPT-2 enhanced by In-Context RALM outperforms a 762M parameter GPT-2 when employing an off-the-shelf BM25 retriever (Robertson and Zaragoza, 2009), and outperforms a 1.5B parameter GPT-2 when employing our trained LM-oriented reranker (see Figure 1). For large model sizes, our method is even more effective: In-Context RALM with an off-the-shelf retriever improved the performance of a 6.7B parameter OPT model to match that of a 66B parameter parameter OPT model (see Figure 4).
在第5节中,我们评估了现成检索器在本框架中的应用。在这种最小化人工干预的设置下,我们发现上下文检索增强语言模型(In-Context RALM)带来的性能提升,相当于将大语言模型的参数量增加$2-$ $3\times$(基于我们测试的所有文本语料)。第6节探讨了如何使文档排序适应大语言模型任务的方法,这是当前检索增强语言模型中研究较少的自由度方向。我们的适配方法包括:使用小型语言模型对检索文档进行零样本排序,以及通过大语言模型信号进行自监督训练专用双向重排序器。这些方法可带来相当于模型规模再扩大$2\times$的性能提升。具体而言:当采用现成BM25检索器(Robertson and Zaragoza, 2009)时,经过In-Context RALM增强的3.45亿参数GPT-2模型性能超越7.62亿参数GPT-2;而使用我们训练的语言模型导向重排序器时,其性能更超越15亿参数GPT-2(见图1)。对于大型模型,本方法效果更为显著:使用现成检索器的In-Context RALM将67亿参数OPT模型的性能提升至匹配660亿参数OPT模型的水平(见图4)。
In Section 7 we demonstrate the applicability of In-Context RALM to downstream open-domain questions answering (ODQA) tasks.
在第7节中,我们展示了上下文检索增强语言模型(In-Context RALM)在下游开放域问答(ODQA)任务中的适用性。
In a concurrent work, Shi et al. (2023) also suggest to augment off-the-shelf LMs with retrieved texts by prepending them to the input. Their results are based on training a dedicated retriever for language modeling. In contrast, we focus on the gains achievable in using off-the-shelf retrievers for this task. We show strong gains of this simpler setting by investigating: (1) which off-the-shelf retriever is best suited for language modeling, (2) the frequency of retrieval operations, and (3) the optimal query length. In addition, we boost the offthe-shelf retrieval performance by introducing two reranking methods that demonstrate further gains in perplexity.
在同期研究中,Shi等人(2023)同样建议通过将检索文本前置输入的方式增强现成大语言模型(Large Language Model)性能。他们的研究基于训练专用检索器来优化语言建模,而我们的重点在于探索使用现成检索器所能实现的性能提升。通过研究以下三个方面,我们证明了这种更简单设置带来的显著增益:(1)哪种现成检索器最适合语言建模,(2)检索操作的执行频率,(3)最优查询长度。此外,我们通过引入两种重排序方法进一步提升了现成检索器的性能,这些方法在困惑度指标上展现了额外改进。
We believe that In-Context RALM can play two important roles in making RALM systems more powerful and more prevalent. First, given its simple reading mechanism, In-Context RALM can serve as a clean probe for developing document retrieval methods that are specialized for the LM task. These in turn can be used to improve both In-Context RALM and other more elaborate RALM methods that currently leverage general purpose retrievers. Second, due to its compatibility with off-the-shelf LMs, In-Context RALM can help drive wider deployment of RALM systems.
我们相信,上下文检索增强语言模型 (In-Context RALM) 能在增强RALM系统能力与普及度方面发挥双重作用。首先,凭借其简洁的阅读机制,该模型可作为开发面向大语言模型任务的专用文档检索方法的理想探针,这些方法不仅能优化上下文RALM,也能改进当前依赖通用检索器的其他复杂RALM方案。其次,由于与现成大语言模型的兼容性,该技术有望推动检索增强语言模型系统更广泛落地。
2 Related Work
2 相关工作
RALM approaches can be roughly divided into two families of models: (i) nearest-neighbor language models (also called kNN-LM), and (ii) retrieve and read models. Our work belongs to the second family, but is distinct in that it involves no further training of the LM.
RALM方法大致可分为两类模型:(i) 最近邻语言模型 (也称为kNN-LM),以及 (ii) 检索阅读模型。我们的工作属于第二类,但不同之处在于它不涉及对大语言模型的进一步训练。
Nearest Neighbor Language Models The $k\mathbf{NN}.$ LM approach was first introduced in Khandelwal et al. (2020). The authors suggest a simple inference-time model that interpolates between two next-token distributions: one induced by the LM itself, and one induced by the $k$ neighbors from the retrieval corpus that are closest to the query token in the LM embedding space. Zhong et al. (2022) suggest a framework for training these models. While they showed significant gains from $k\mathbf{NN-LM}$ , the approach requires storing the representations for each token in the corpus, an expensive requirement even for a small corpus like Wikipedia. Although numerous approaches have been suggested for alleviating this issue (He et al., 2021; Alon et al., 2022), scaling any of them to large corpora remains an open challenge.
最近邻语言模型
$k\mathbf{NN}$-LM方法由Khandelwal等人(2020)首次提出。作者提出了一种简单的推理时模型,该模型对两种下一token分布进行插值:一种由大语言模型本身生成,另一种由检索语料库中与查询token在嵌入空间最接近的$k$个邻居生成。Zhong等人(2022)提出了训练这些模型的框架。虽然$k\mathbf{NN-LM}$显示出显著优势,但该方法需要存储语料库中每个token的表示,即使对于维基百科这样的小型语料库也是昂贵的要求。尽管已有多种方法被提出以缓解此问题(He等人,2021;Alon等人,2022),但将其扩展到大型语料库仍是一个开放挑战。
Retrieve and Read Models This family of RALMs creates a clear division between document selection and document reading components. All prior work involves training the LM. We begin by describing works that use this approach for tackling downstream tasks, and then mention works oriented towards RALM. Lewis et al. (2020) and Izacard and Grave (2021) fine tuned encoder–decoder architectures for downstream knowledge-intensive tasks. Izacard et al. (2022b) explored different ways of pre training such models, while Levine et al. (2022c) pretrained an auto regressive LM on clusters of nearest neighbors in sentence embedding space. Levine et al. (2022a) showed competitive open domain question-answering performance by prompt-tuning a frozen LM as a reader. Guu et al. (2020) pretrained REALM, a retrieval augmented bidirectional, masked LM, later fine-tuned for open-domain question answering. The work closest to this paper—with a focus on the language modeling task—is RETRO (Borgeaud et al., 2022), which modifies an auto regressive LM to attend to relevant documents via chunked cross-attention, thus introducing new parameters to the model. OurIn-Context RALM differs from prior work in this family of models in two key aspects:
检索与阅读模型
这类检索增强型大语言模型(RALM)明确划分了文档选择与文档阅读组件。所有先前研究都涉及对大语言模型的训练。我们首先描述将该方法应用于下游任务的研究,再介绍面向RALM的研究。Lewis等人(2020)和Izacard与Grave(2021)针对知识密集型下游任务微调了编码器-解码器架构。Izacard等人(2022b)探索了此类模型的不同预训练方法,而Levine等人(2022c)则在句子嵌入空间的最近邻簇上预训练了自回归大语言模型。Levine等人(2022a)通过提示调优冻结的大语言模型作为阅读器,展现了具有竞争力的开放域问答性能。Guu等人(2020)预训练了REALM——一种检索增强的双向掩码大语言模型,后针对开放域问答任务进行微调。与本论文最接近的研究是专注于语言建模任务的RETRO(Borgeaud等人,2022),该研究通过分块交叉注意力机制使自回归大语言模型关注相关文档,从而为模型引入新参数。我们的上下文检索增强型大语言模型(In-Context RALM)与该类模型先前研究有两个关键区别:
• We use off-the-shelf LMs for document reading without any further training of the LM. • We focus on how to choose documents for improved LM performance.
• 我们直接使用现成的大语言模型 (LLM) 进行文档阅读,无需对模型进行额外训练。
• 我们重点研究如何通过优化文档选择策略来提升大语言模型性能。
3 Our Framework
3 我们的框架
3.1 In-Context RALM
3.1 上下文相关RALM
Language models define probability distributions over sequences of tokens. Given such a sequence $x_{1},...,x_{n}$ , the standard way to model its probability is via next-token prediction: $p(x_{1},...,x_{n})=$ $\textstyle\prod_{i=1}^{n}p(x_{i}|x_{<i})$ , where $x_{<i}:=x_{1},...,x_{i-1}$ is the sequence of tokens preceding $x_{i}$ , also referred to as its prefix. This auto regressive model is usually implemented via a learned transformer network (Vaswani et al., 2017) parameterized by the set of parameters $\theta$ :
语言模型定义了token序列的概率分布。给定一个序列 $x_{1},...,x_{n}$ ,建模其概率的标准方法是通过下一个token预测: $p(x_{1},...,x_{n})=$ $\textstyle\prod_{i=1}^{n}p(x_{i}|x_{<i})$ ,其中 $x_{<i}:=x_{1},...,x_{i-1}$ 是 $x_{i}$ 的前缀序列。这种自回归模型通常通过参数为 $\theta$ 的Transformer网络 (Vaswani et al., 2017) 实现:
$$
p(x_{1},...,x_{n})=\prod_{i=1}^{n}p_{\theta}(x_{i}|x_{<i}),
$$
$$
p(x_{1},...,x_{n})=\prod_{i=1}^{n}p_{\theta}(x_{i}|x_{<i}),
$$
where the conditional probabilities are modeled by employing a causal self-attention mask (Radford et al., 2018). Notably, leading LMs such as GPT-2 (Radford et al., 2019), GPT-3 (Brown et al., 2020), OPT (Zhang et al., 2022) or Jurassic- 1 (Lieber et al., 2021) follow this simple parameterization.
其中条件概率通过采用因果自注意力掩码 (causal self-attention mask) 建模 (Radford et al., 2018) 。值得注意的是,主流大语言模型如 GPT-2 (Radford et al., 2019)、GPT-3 (Brown et al., 2020)、OPT (Zhang et al., 2022) 和 Jurassic-1 (Lieber et al., 2021) 均采用这种简单参数化方式。
Retrieval augmented language models (RALMs) add an operation that retrieves one or more documents from an external corpus $\mathcal{C}$ , and condition the above LM predictions on these documents. Specifically, for predicting $x_{i}$ , the retrieval operation from $\mathcal{C}$ depends on its prefix: $\mathcal{R}_ {\mathcal{C}}(x_{<i})$ , so the most general RALM decomposition is: $p(x_{1},...,x_{n})=$ $\begin{array}{r}{\prod_{i=1}^{n}p(x_{i}|\boldsymbol x_{<i},\mathcal{R}c(\boldsymbol x_{<i}))}\end{array}$ . In order to condition the LM generation on the retrieved document, previous RALM approaches used specialized architectures or algorithms (see $\S2$ ). Inspired by the success of In-Context Learning (Brown et al., 2020; Dong et al., 2023), In-Context RALM refers to the following specific, simple method of concatenating the retrieved documents2 within the Transformer’s input prior to the prefix (see Figure 2), which does not involve altering the LM weights $\theta$ :
检索增强语言模型 (RALM) 通过从外部语料库 $\mathcal{C}$ 检索一个或多个文档的操作,并基于这些文档调整上述语言模型的预测。具体来说,为预测 $x_{i}$ ,从 $\mathcal{C}$ 的检索操作依赖于其前缀: $\mathcal{R}_ {\mathcal{C}}(x_{<i})$ ,因此最通用的 RALM 分解为: $p(x_{1},...,x_{n})=$ $\begin{array}{r}{\prod_{i=1}^{n}p(x_{i}|\boldsymbol x_{<i},\mathcal{R}c(\boldsymbol x_{<i}))}\end{array}$ 。为了使语言模型生成基于检索到的文档,以往的 RALM 方法使用了专门的架构或算法(见 $\S2$ )。受上下文学习 (In-Context Learning) 成功的启发 (Brown et al., 2020; Dong et al., 2023),上下文 RALM 指的是以下具体而简单的方法:在 Transformer 的输入中,将检索到的文档2与前缀拼接(见图 2),这种方法不涉及修改语言模型权重 $\theta$ :
$$
[
p(\boldsymbol{x}_ 1, \dots, \boldsymbol{x}_ n) = \prod_{i=1}^n p_{\theta}\left( \boldsymbol{x}_ i \mid \left[ \mathcal{R}_ {\mathcal{C}}(\boldsymbol{x}_ {<i}); \boldsymbol{x}_{<i} \right] \right)
]
$$
$$
[
p(\boldsymbol{x}_ 1, \dots, \boldsymbol{x}_ n) = \prod_{i=1}^n p_{\theta}\left( \boldsymbol{x}_ i \mid \left[ \mathcal{R}_ {\mathcal{C}}(\boldsymbol{x}_ {<i}); \boldsymbol{x}_{<i} \right] \right)
]
$$
where $[a;b]$ denotes the concatenation of strings $a$ and $b$ .
其中 $[a;b]$ 表示字符串 $a$ 和 $b$ 的拼接。
Since common Transformer-based LM implementations support limited length input sequences, when the concatenation of the document and the input sequence exceed this limit we remove tokens from the beginning of $x$ until the overall input length equals that allowed by the model. Because our retrieved documents are passages of limited length, we always have enough context left from $x$ (see $\S4.3)$ .
由于常见的基于Transformer的大语言模型实现支持有限长度的输入序列,当文档和输入序列的拼接超过此限制时,我们会从$x$的开头移除token,直到整体输入长度等于模型允许的长度。由于我们检索的文档是有限长度的段落,因此总能从$x$中保留足够的上下文(参见$\S4.3$)。
3.2 RALM Design Choices
3.2 RALM 设计选择
We detail below two practical design choices often made in RALM systems. In $\S5$ , we investigate the effect of these in the setting of In-Context RALM.
我们在下面详细介绍了RALM系统中常见的两种实用设计选择。在$\S5$中,我们研究了这些选择在上下文RALM环境中的影响。
Retrieval Stride While in the above formulation a retrieval operation can occur at each generation step, we might want to perform retrieval only once every $s>1$ tokens due to the cost of calling the retriever, and the need to replace the documents in the LM prefix during generation. We refer to $s$ as the retrieval stride. This gives rise to the following In-Context RALM formulation (which reduces back to Eq. (2) for $s=1$ ):
检索步长
在上述设定中,每次生成步骤都可能触发检索操作,但由于调用检索器的成本较高,且需要在生成过程中替换大语言模型前缀中的文档,我们可能希望每生成 $s>1$ 个token才执行一次检索。我们将 $s$ 称为检索步长。由此得到以下上下文检索增强大语言模型(In-Context RALM)的公式化表达(当 $s=1$ 时,该表达式会退化为式(2)):
$$
\begin{array}{r l}&{p(x_{1},...,x_{n})=}\ &{\quad\prod_{j=0}^{n_{s}-1}\prod_{i=1}^{s}p_{\theta}\left(x_{s\cdot j+i}\vert\left[\mathcal{R}_ {\mathcal{C}}(x_{\leq s\cdot j});x_{<(s\cdot j+i)}\right]\right),}\end{array}
$$
$$
\begin{array}{r l}&{p(x_{1},...,x_{n})=}\ &{\quad\prod_{j=0}^{n_{s}-1}\prod_{i=1}^{s}p_{\theta}\left(x_{s\cdot j+i}\vert\left[\mathcal{R}_ {\mathcal{C}}(x_{\leq s\cdot j});x_{<(s\cdot j+i)}\right]\right),}\end{array}
$$
where $n_{s}=n/s$ is the number of retrieval strides.
其中 $n_{s}=n/s$ 为检索步长数。
Notably, in this framework the runtime costs of each retrieval operation is composed of (a) applying the retriever itself, and (b) re computing the embeddings of the prefix. In $\S5.2$ we show that using smaller retrieval strides, i.e., retrieving as often as possible, is superior to using larger ones (though In-Context RALM with larger strides already provides large gains over vanilla LM). Thus, choosing the retrieval stride is ultimately a tradeoff between runtime and performance.
值得注意的是,在该框架中,每次检索操作的运行时成本由两部分组成:(a) 应用检索器本身,(b) 重新计算前缀的嵌入向量。在$\S5.2$中我们证明,使用较小的检索步长(即尽可能频繁地检索)优于使用较大步长(尽管采用较大步长的上下文检索增强大语言模型(In-Context RALM)已比原始大语言模型带来显著提升)。因此,检索步长的选择本质上是运行时间与性能之间的权衡。
Retrieval Query Length While the retrieval query above in principle depends on all prefix tokens $x_{\leq s\cdot j}$ , the information at the very end of the prefix is typically the most relevant to the generated tokens. If the retrieval query is too long then this information can be diluted. To avoid this, we restrict the retrieval query at stride $j$ to the last $\ell$ tokens of the prefix, i.e., we use qj $q_{j}^{s,\ell}:=x_{s\cdot j-\ell+1},...,x_{s\cdot j}$ . We refer to $\ell$ as the retrieval query length. Note that prior RALM work couples the retrieval stride $s$ and the retrieval query length $\ell$ (Borgeaud et al., 2022). In $\S5$ , we show that enforcing $s=\ell$ degrades LM performance. Integrating these hyper-parameters into the In-Context RALM formulation gives
检索查询长度
虽然上述检索查询原则上依赖于所有前缀token $x_{\leq s\cdot j}$,但前缀末尾的信息通常与生成的token最相关。如果检索查询过长,这些信息可能会被稀释。为避免这种情况,我们将步长$j$处的检索查询限制为前缀的最后$\ell$个token,即使用$q_{j}^{s,\ell}:=x_{s\cdot j-\ell+1},...,x_{s\cdot j}$。我们将$\ell$称为检索查询长度。
需要注意的是,先前RALM研究将检索步长$s$与检索查询长度$\ell$耦合处理 (Borgeaud et al., 2022)。在$\S5$中,我们将证明强制$s=\ell$会降低语言模型性能。将这些超参数整合到上下文RALM公式中可得:
$$
\begin{array}{r l}&{p(x_{1},...,x_{n})=}\ &{\quad\prod_{j=0}^{n_{s}-1}\prod_{i=1}^{s}p_{\theta}\left(x_{s\cdot j+i}\vert\left[\mathcal{R}_ {\mathcal{C}}(q_{j}^{s,\ell});x_{<(s\cdot j+i)}\right]\right).}\end{array}
$$
$$
\begin{array}{r l}&{p(x_{1},...,x_{n})=}\ &{\quad\prod_{j=0}^{n_{s}-1}\prod_{i=1}^{s}p_{\theta}\left(x_{s\cdot j+i}\vert\left[\mathcal{R}_ {\mathcal{C}}(q_{j}^{s,\ell});x_{<(s\cdot j+i)}\right]\right).}\end{array}
$$
4 Experimental Details
4 实验细节
We now describe our experimental setup, including all models we use and their implementation details.
我们现在描述实验设置,包括使用的所有模型及其实现细节。
4.1 Datasets
4.1 数据集
We evaluated the effectiveness of In-Context RALM across five diverse language modeling datasets and two common open-domain question answering datasets.
我们在五个不同的语言建模数据集和两个常见的开放域问答数据集上评估了In-Context RALM的有效性。
Language Modeling The first LM dataset is WikiText-103 (Merity et al., 2016), which has been extensively used to evaluate RALMs (Khandelwal et al., 2020; He et al., 2021; Borgeaud et al., 2022; Alon et al., 2022; Zhong et al., 2022). Second, we chose three datasets spanning diverse subjects from The Pile (Gao et al., 2021): ArXiv, Stack Exchange and FreeLaw. Finally, we also investigated RealNews (Zellers et al., 2019), since The Pile lacks a corpus focused only on news (which is by nature a knowledge-intensive domain).
语言建模
首个语言模型数据集是WikiText-103 (Merity et al., 2016),该数据集被广泛用于评估检索增强语言模型(RALMs) (Khandelwal et al., 2020; He et al., 2021; Borgeaud et al., 2022; Alon et al., 2022; Zhong et al., 2022)。其次,我们从The Pile (Gao et al., 2021)中选取了涵盖多个学科的三个数据集:ArXiv、Stack Exchange和FreeLaw。最后,我们还研究了RealNews (Zellers et al., 2019),因为The Pile缺乏专注于新闻的语料库(新闻本质上是知识密集型领域)。
Open-Domain Question Answering In order to evaluate In-Context RALM on downstream tasks as well, we use the Natural Questions (NQ; Kwiatkowski et al. 2019) and TriviaQA (Joshi et al., 2017) open-domain question answering datasets.
开放域问答
为了在下游任务中评估上下文相关RALM,我们使用了Natural Questions (NQ; Kwiatkowski et al. 2019)和TriviaQA (Joshi et al., 2017)这两个开放域问答数据集。
4.2 Models
4.2 模型
Language Models We performed our experiments using the four models of GPT-2 (110M– 1.5B; Radford et al. 2019), three models of GPTNeo and GPT-J (1.3B–6B; Black et al. 2021; Wang and Komatsu zak i 2021), eight models of OPT (125M–66B; Zhang et al. 2022) and three models of LLaMA (7B–33B; Touvron et al. 2023). All models are open source and publicly available.3
语言模型
我们使用 GPT-2 的四个模型 (110M–1.5B; Radford et al. 2019)、GPTNeo 和 GPT-J 的三个模型 (1.3B–6B; Black et al. 2021; Wang and Komatsuzaki 2021)、OPT 的八个模型 (125M–66B; Zhang et al. 2022) 以及 LLaMA 的三个模型 (7B–33B; Touvron et al. 2023) 进行了实验。所有模型均为开源且公开可用。
We elected to study these particular models for the following reasons. The first four (GPT-2) models were trained on WebText (Radford et al., 2019), with Wikipedia documents excluded from their training datasets. We were thus able to evaluate our method’s “zero-shot” performance when retrieving from a novel corpus (for WikiText-103). The rest of the models brought two further benefits. First, they allowed us to investigate how our methods scale to models larger than GPT-2. Second, the fact that Wikipedia was part of their training data allowed us to investigate the usefulness of In-Context RALM for corpora seen during training. The helpfulness of such retrieval has been demonstrated for previous RALM methods (Khandelwal et al., 2020) and has also been justified theoretically by Levine et al. (2022c).
我们选择研究这些特定模型的原因如下。前四个 (GPT-2) 模型是在 WebText (Radford et al., 2019) 上训练的,其训练数据集中排除了维基百科文档。因此,我们能够评估从新语料库 (WikiText-103) 检索时方法的"零样本"性能。其余模型带来了两个额外优势:首先,它们让我们能研究该方法如何扩展到比 GPT-2 更大的模型;其次,由于维基百科是其训练数据的一部分,这使我们能研究 In-Context RALM 对训练期间见过的语料库的有效性。此类检索的效用已在先前 RALM 方法 (Khandelwal et al., 2020) 中得到证实,并得到 Levine 等人 (2022c) 的理论支持。
We ran all models with a maximum sequence length of 1,024, even though GPT-Neo, OPT and LLaMA models support a sequence length of 2,048.4
我们将所有模型的最大序列长度设为1,024运行,尽管GPT-Neo、OPT和LLaMA模型支持2,048的序列长度。
Retrievers We experimented with both sparse (word-based) and dense (neural) retrievers. We used BM25 (Robertson and Zaragoza, 2009) as our sparse model. For dense models, we experimented with (i) a frozen BERT-base (Devlin et al., 2019) followed by mean pooling, similar to Borgeaud et al. (2022); and (ii) the Contriever (Izacard et al., 2022a) and Spider (Ram et al., 2022) models, which are dense retrievers that were trained in unsupervised manners.
检索器
我们尝试了稀疏(基于词)和稠密(基于神经网络)两种检索器。使用BM25 (Robertson和Zaragoza, 2009)作为稀疏模型。对于稠密模型,我们测试了:(i) 固定参数的BERT-base (Devlin等人, 2019)结合均值池化,类似Borgeaud等人 (2022)的方法;(ii) Contriever (Izacard等人, 2022a)和Spider (Ram等人, 2022)模型,这些是通过无监督方式训练的稠密检索器。
Reranking When training rerankers (Section 6.2), we initialized from RoBERTa-base (Liu et al., 2019).
重排序
训练重排序器时(第6.2节),我们从RoBERTa-base (Liu et al., 2019)初始化。
4.3 Implementation Details
4.3 实现细节
We implemented our code base using the Transformers library (Wolf et al., 2020). We based our dense retrieval code on the DPR repository (Karpukhin et al., 2020).
我们使用Transformers库(Wolf等人, 2020)实现了代码库。我们的密集检索代码基于DPR代码库(Karpukhin等人, 2020)。

Figure 3: The performance of four off-the-shelf retrievers used for In-Context RALM on the development set of WikiText-103. All RALMs are run with $s=4$ (i.e., retrieval is applied every four tokens). For each RALM, we report the result of the best query length $\ell$ (see Figures 6, 9, 10).
图 3: 四种现成检索器在WikiText-103开发集上用于上下文RALM (In-Context RALM) 的性能表现。所有RALM均以 $s=4$ 运行 (即每4个token执行一次检索)。对于每个RALM,我们报告了最佳查询长度 $\ell$ 的结果 (参见图6、图9、图10)。
Retrieval Corpora For WikiText-103 and ODQA datasets, we used the Wikipedia corpus from Dec. 20, 2018, standardized by Karpukhin et al. (2020) using the preprocessing from Chen et al. (2017). To avoid contamination, we found and removed all 120 articles of the development and test set of WikiText-103 from the corpus. For the remaining datasets, we used their training data as the retrieval corpus. Similar to Karpukhin et al. (2020), our retrieval corpora consist of non-overlapping passages of 100 words (which translate to less than 150 tokens for the vast majority of passages). Thus, we truncate our retrieved passages at 256 tokens when input to the models, but they are usually much smaller.
WikiText-103和ODQA数据集的检索语料库采用Karpukhin等人(2020)基于Chen等人(2017)预处理流程标准化的2018年12月20日维基百科语料。为避免数据污染,我们移除了该语料库中与WikiText-103开发集及测试集重合的120篇文章。其余数据集则直接使用其训练数据作为检索语料库。参照Karpukhin等人(2020)的做法,我们的检索语料库由100词长度的非重叠段落构成(绝大多数段落对应的token数少于150个)。因此输入模型时会将检索段落截断至256个token,但实际长度通常远小于该值。
Retrieval For sparse retrieval, we used the Pyserini library (Lin et al., 2021). For dense retrieval, we applied exact search using FAISS (Johnson et al., 2021).
检索
对于稀疏检索 (sparse retrieval),我们使用了 Pyserini 库 (Lin et al., 2021)。对于稠密检索 (dense retrieval),我们采用 FAISS (Johnson et al., 2021) 进行精确搜索。
5 The Effectiveness of In-Context RALM with Off-the-Shelf Retrievers
5 现成检索器在上下文 RALM 中的有效性
We now empirically show that despite its simple document reading mechanism, In-Context RALM leads to substantial LM gains across our diverse evaluation suite. We begin in this section by investigating the effectiveness of off-the-shelf retrievers for In-Context RALM; we go on in $\S6$ to show that further LM gains can be made by tailoring document ranking functions to the LM task.
我们现在通过实证表明,尽管采用了简单的文档读取机制,上下文检索增强型大语言模型(In-Context RALM)在我们的多样化评估体系中仍能带来显著的语言模型性能提升。本节首先研究现成检索器在上下文检索增强型大语言模型中的有效性;随后在$\S6$章节将展示,通过针对语言模型任务定制文档排序函数,可以进一步获得性能提升。
The experiments in this section provided us with a recommended configuration for applying In
本节实验为我们提供了应用In的推荐配置
Table 1: Perplexity on the test set of WikiText-103, RealNews and three datasets from the Pile. For each LM, we report: (a) its performance without retrieval, (b) its performance when fed the top-scored passage by BM25 (§5), and (c) its performance when applied on the top-scored passage of each of our two suggested rerankers (§6). All models share the same vocabulary, thus token-level perplexity (token ppl) numbers are comparable. For WikiText we follow prior work and report word-level perplexity $(w o r d p p l)$ .
| Model | Retrieval | Reranking | WikiText-103 | RealNews | ArXiv | Stack Exch. | FreeLaw |
| word ppl | token ppl | token ppl | token ppl | token ppl | |||
| GPT-2 S | 一 | 37.5 | 21.3 | 12.0 | 12.8 | 13.0 | |
| BM25 §5 | 一 | 29.6 | 16.1 | 10.9 | 11.3 | 9.6 | |
| BM25 | Zero-shot §6.1 | 28.6 | 15.5 | 10.1 | 10.6 | 8.8 | |
| BM25 | Predictive §6.2 | 26.8 | 一 | 一 | 一 | ||
| GPT-2 M | 一 | 26.3 | 15.7 | 9.3 | 8.8 | 9.6 | |
| BM25§5 | 一 | 21.5 | 12.4 | 8.6 | 8.1 | 7.4 | |
| BM25 | Zero-shot §6.1 | 20.8 | 12.0 | 8.0 | 7.7 | 6.9 | |
| BM25 | Predictive §6.2 | 19.7 | 一 | 一 | 一 | ||
| GPT-2 L | 22.0 | 13.6 | 8.4 | 8.5 | 8.7 | ||
| BM25 §5 | 18.1 | 10.9 | 7.8 | 7.8 | 6.8 | ||
| BM25 | Zero-shot §6.1 | 17.6 | 10.6 | 7.3 | 7.4 | 6.4 | |
| BM25 | Predictive §6.2 | 16.6 | 一 | 一 | |||
| GPT-2XL | 一 | 一 | 20.0 | 12.4 | 7.8 | 8.0 | 8.0 |
| BM25§5 | 16.6 | 10.1 | 7.2 | 7.4 | 6.4 | ||
| BM25 | Zero-shot §6.1 | 16.1 | 9.8 | 6.8 | 7.1 | 6.0 | |
| BM25 | Predictive §6.2 | 15.4 |
表 1: WikiText-103、RealNews 和 Pile 中三个数据集的测试集困惑度。对于每个大语言模型,我们报告: (a) 无检索时的性能, (b) 输入 BM25 最高分段落时的性能 (§5), 以及 (c) 应用我们建议的两个重排序器最高分段落时的性能 (§6)。所有模型共享相同词汇表,因此 token 级困惑度 (token ppl) 数值可比较。WikiText 遵循先前工作报告词级困惑度 $(word ppl)$。
| 模型 | 检索 | 重排序 | WikiText-103word ppl | RealNewstoken ppl | ArXivtoken ppl | Stack Exch.token ppl | FreeLawtoken ppl |
|---|---|---|---|---|---|---|---|
| GPT-2 S | 一 | 37.5 | 21.3 | 12.0 | 12.8 | 13.0 | |
| BM25 §5 | 一 | 29.6 | 16.1 | 10.9 | 11.3 | 9.6 | |
| BM25 | 零样本 §6.1 | 28.6 | 15.5 | 10.1 | 10.6 | 8.8 | |
| BM25 | Predictive §6.2 | 26.8 | 一 | 一 | 一 | ||
| GPT-2 M | 一 | 26.3 | 15.7 | 9.3 | 8.8 | 9.6 | |
| BM25 §5 | 一 | 21.5 | 12.4 | 8.6 | 8.1 | 7.4 | |
| BM25 | 零样本 §6.1 | 20.8 | 12.0 | 8.0 | 7.7 | 6.9 | |
| BM25 | Predictive §6.2 | 19.7 | 一 | 一 | 一 | ||
| GPT-2 L | 22.0 | 13.6 | 8.4 | 8.5 | 8.7 | ||
| BM25 §5 | 18.1 | 10.9 | 7.8 | 7.8 | 6.8 | ||
| BM25 | 零样本 §6.1 | 17.6 | 10.6 | 7.3 | 7.4 | 6.4 | |
| BM25 | Predictive §6.2 | 16.6 | 一 | 一 | |||
| GPT-2 XL | 一 | 一 | 20.0 | 12.4 | 7.8 | 8.0 | 8.0 |
| BM25 §5 | 16.6 | 10.1 | 7.2 | 7.4 | 6.4 | ||
| BM25 | 零样本 §6.1 | 16.1 | 9.8 | 6.8 | 7.1 | 6.0 | |
| BM25 | Predictive §6.2 | 15.4 |
Table 2: The performance of models from the LLaMA family, measured by word-level perplexity on the test set of WikiText-103.
| Model | Retrieval | WikiText-103 |
| word ppl | ||
| LLaMA-7B | 9.9 | |
| BM25,§5 | 8.8 | |
| LLaMA-13B | 8.5 | |
| BM25,§5 | 7.6 | |
| LLaMA-33B | 6.3 | |
| BM25,§5 | 6.1 |
表 2: LLaMA系列模型在WikiText-103测试集上的词级困惑度表现
| Model | Retrieval | WikiText-103 |
|---|---|---|
| LLaMA-7B | 9.9 | |
| BM25,§5 | 8.8 | |
| LLaMA-13B | 8.5 | |
| BM25,§5 | 7.6 | |
| LLaMA-33B | 6.3 | |
| BM25,§5 | 6.1 |
Context RALM: applying a sparse BM25 retriever that receives $\ell=32$ query tokens and is applied as frequently as possible. Practically, we retrieve every $s=4$ tokens ( $\ell$ and $s$ are defined in $\S3$ ). Table 1 shows for the GPT-2 models that across all the examined corpora, employing In-Context RALM with an off-the-shelf retriever improved LM perplexity to a sufficient extent that it matched that of a $2{-}3\times$ larger model. Figure 4 and Tables 2 and 5 show that this trend holds across model sizes up to 66B parameters, for both WikiText-103 and
上下文RALM:应用一个稀疏BM25检索器,接收$\ell=32$个查询token,并尽可能频繁地应用。实际上,我们每$s=4$个token检索一次($\ell$和$s$的定义见$\S3$)。表1显示,对于GPT-2模型,在所有检查的语料库中,使用现成检索器的上下文RALM将语言模型的困惑度提升到足以匹配$2{-}3\times$更大模型的程度。图4及表2和表5表明,这一趋势在模型规模高达660亿参数的情况下,对于WikiText-103和...
RealNews.
RealNews
5.1 BM25 Outperforms Off-the-Shelf Neural Retrievers in Language Modeling
5.1 BM25 在语言建模中优于现成的神经检索器
We experimented with different off-the-shelf general purpose retrievers, and found that the sparse (lexical) BM25 retriever (Robertson and Zaragoza, 2009) outperformed three popular dense (neural) retrievers: the self-supervised retrievers Contriever (Izacard et al., 2022a) and Spider (Ram et al., 2022), as well as a retriever based on the average pooling of BERT embeddings that was used in the RETRO system (Borgeaud et al., 2022). We conducted a minimal hyper-parameter search on the query length $\ell$ for each of the retrievers, and found that $\ell=32$ was optimal for BM25 (Figure 6), and $\ell=64$ worked best for dense retrievers (Figures 9, 10).
我们尝试了多种现成的通用检索器,发现稀疏(词法)BM25检索器(Robertson和Zaragoza,2009)优于三种流行的稠密(神经)检索器:自监督检索器Contriever(Izacard等,2022a)和Spider(Ram等,2022),以及基于BERT嵌入平均池化的RETRO系统(Borgeaud等,2022)所用检索器。我们对每种检索器的查询长度$\ell$进行了最小超参数搜索,发现$\ell=32$对BM25最优(图6),而$\ell=64$对稠密检索器效果最佳(图9、10)。
Figure 3 compares the performance gains of InContext RALM with these four general-purpose retrievers. The BM25 retriever clearly outperformed all dense retrievers. This outcome is consistent with prior work showing that BM25 outperforms neural retrievers across a wide array of tasks, when applied in zero-shot settings (Thakur et al., 2021). This result renders In-Context RALM even more appealing since applying a BM25 retriever is significantly cheaper than the neural alternatives.
图 3 对比了 InContext RALM 与这四种通用检索器的性能提升。BM25 检索器明显优于所有密集检索器。这一结果与先前研究一致 (Thakur et al., 2021) ,表明在零样本设置下,BM25 在多种任务中表现优于神经检索器。由于 BM25 检索器的应用成本显著低于神经检索方案,这一结果使得 In-Context RALM 更具吸引力。
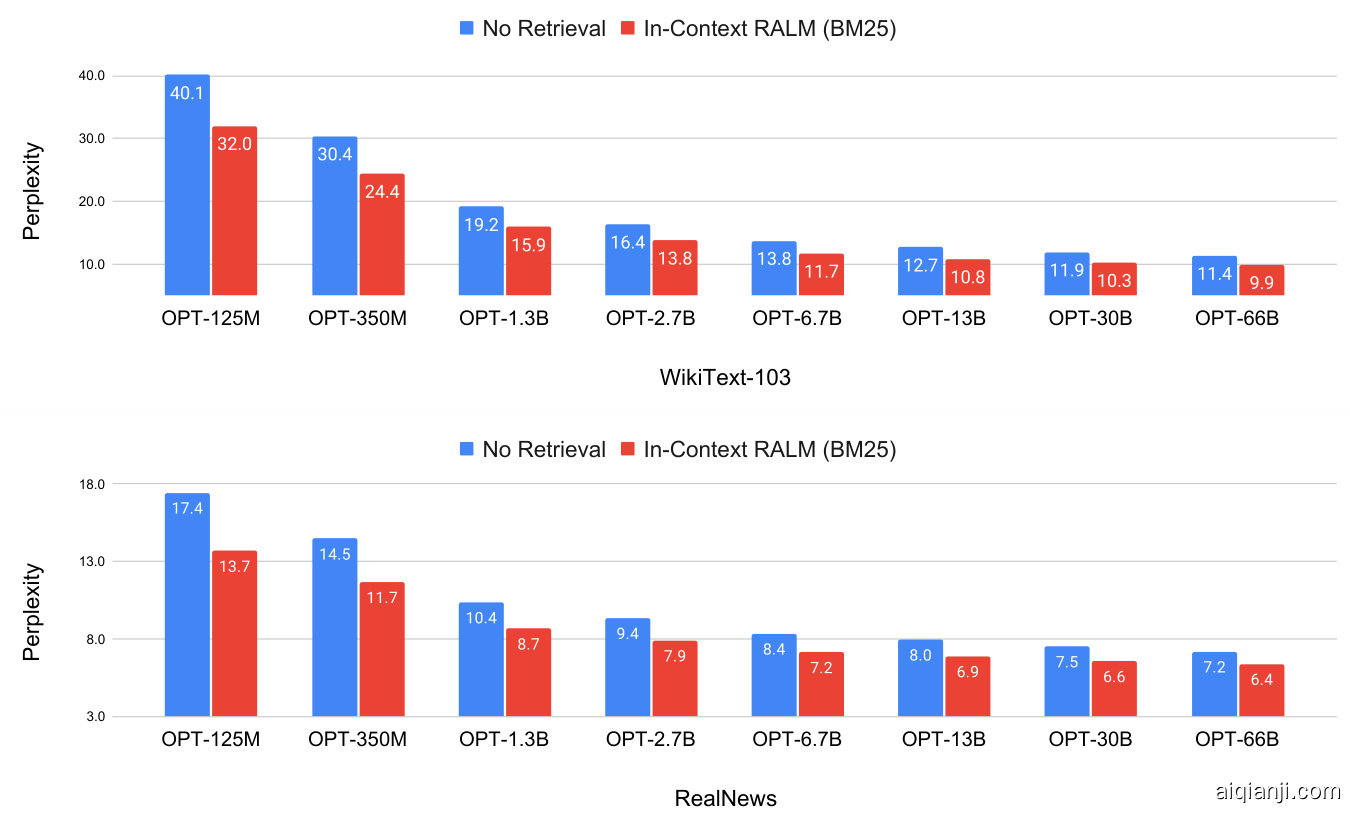
Figure 4: Results of OPT models (Zhang et al., 2022) on the test set of WikiText-103 (word-level perplexity) and the development set of RealNews (token-level perplexity). In-Context RALM models use a BM25 retriever with $s=4$ (i.e., the retriever is called every four tokens) and $\ell=32$ (i.e., the retriever query is comprised of the last 32 tokens of the prefix). In-Context RALM with an off-the-shelf retriever improved the performance of a 6.7B parameter OPT model to match that of $a66B$ parameter OPT model.
图 4: OPT模型 (Zhang et al., 2022) 在WikiText-103测试集 (词级困惑度) 和RealNews开发集 (token级困惑度) 上的结果。上下文检索增强语言模型 (In-Context RALM) 使用BM25检索器,参数为$s=4$ (即每4个token调用一次检索器) 和$\ell=32$ (即检索查询由前缀的最后32个token组成)。采用现成检索器的上下文检索增强语言模型将6.7B参数OPT模型的性能提升至与$a66B$参数OPT模型相当的水平。
5.2 Frequent Retrieval Improves Language Modeling
5.2 频繁检索提升语言建模能力
We investigated the effect of varying the retrieval stride s (i.e., the number of tokens between consecutive retrieval operations). Figure 5 shows that LM performance improved as the retrieval operation became more frequent. This supports the intuition that retrieved documents become more relevant the closer the retrieval query becomes to the generated tokens. Of course, each retrieval operation imposes a runtime cost. To balance performance and runtime, we used $s=4$ in our experiments. For comparison, RETRO employed a retrieval frequency of $s=64$ (Borgeaud et al., 2022), which leads to large degradation in perplexity. Intuitively, retrieving with high frequency (low retrieval stride) allows to ground the LM in higher resolution.
我们研究了检索步长s(即连续检索操作之间的token数)变化的影响。图5显示,随着检索操作频率提高,大语言模型性能随之提升。这印证了直觉判断:检索查询位置越接近生成token时,检索到的文档相关性越高。当然,每次检索操作都会带来运行时开销。为平衡性能与耗时,我们在实验中采用$s=4$。作为对比,RETRO采用的检索频率为$s=64$(Borgeaud et al., 2022),这会导致困惑度显著上升。直观而言,高频检索(低检索步长)能使大语言模型基于更细粒度信息进行生成。
5.3 A Contextual iz ation vs. Recency Tradeoff in Query Length
5.3 查询长度中的情境化与时效性权衡
We also investigated the effect of varying $\ell$ , the length of the retrieval query for BM25. Figure 6 reveals an interesting tradeoff and a sweet spot around a query length of 32 tokens. Similar experiments for dense retrievers are given in App. A. We conjecture that when the retriever query is too short, it does not include enough of the input context, decreasing the retrieved document’s relevance. Conversely, excessively growing the retriever query de emphasizes the tokens at the very end of the prefix, diluting the query’s relevance to the LM task.
我们还研究了改变BM25检索查询长度$\ell$的影响。图6揭示了一个有趣的权衡点:查询长度为32个token时达到最佳效果。关于稠密检索器的类似实验见附录A。我们推测当检索查询过短时,无法包含足够的输入上下文,从而降低检索文档的相关性;反之,过度增加检索查询长度会弱化前缀末尾token的重要性,稀释查询与大语言模型任务的相关性。
6 Improving In-Context RALM with LM-Oriented Reranking
6 通过面向大语言模型的重新排序改进上下文检索增强的大语言模型
Since In-Context RALM uses a fixed document reading component by definition, it is natural to ask whether performance can be improved by specializing its document retrieval mechanism to the LM task. Indeed, there is considerable scope for improvement: the previous section considered conditioning the model only on the first document retrieved by the BM25 retriever. This permits very limited semantic understanding of the query, since BM25 is based only on the bag of words signal. Moreover, it offers no way to accord different degrees of importance to different retrieval query tokens, such as recognizing that later query tokens are more relevant to the generated text.
由于上下文相关检索增强语言模型 (In-Context RALM) 根据定义使用了固定的文档读取组件,自然会产生一个问题:能否通过针对大语言模型任务专门优化其文档检索机制来提升性能?事实上,改进空间相当大:上一节仅考虑了基于BM25检索器返回的首个文档来调节模型。这种方式对查询的语义理解非常有限,因为BM25仅基于词袋信号。此外,该方法无法为不同的检索查询token分配不同权重,例如识别到后续查询token与生成文本具有更高相关性。
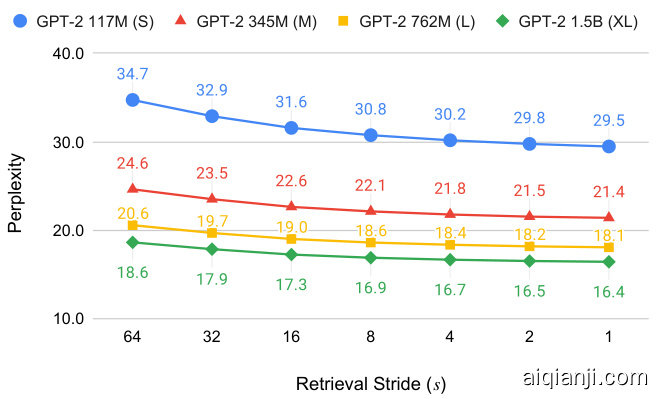
Figure 5: An analysis of perplexity as a function of $s$ , the retrieval stride, i.e., the number of tokens between consecutive retrieval operations, on the development set of WikiText-103. Throughout the paper, we use $s=4$ to balance perplexity and runtime.
图 5: 困惑度随检索步长 $s$ (即连续检索操作之间的token数量)的变化分析,基于WikiText-103开发集。本文统一采用 $s=4$ 以平衡困惑度与运行时间。
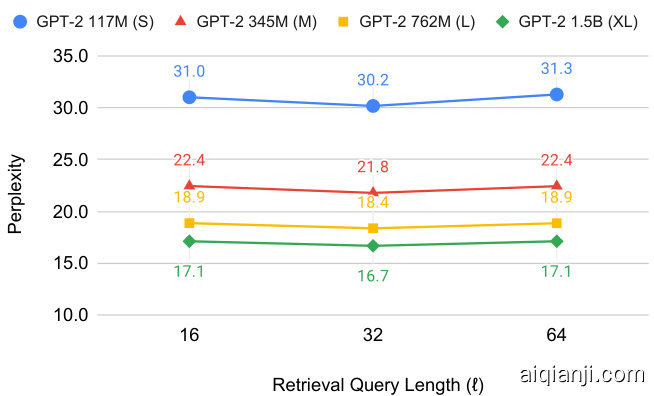
Figure 6: An analysis of perplexity as a function of the number of tokens in the query $\ell$ for BM25 on the development set of WikiText-103. In the appendix, we show similar trade-offs for dense retrievers within WikiText-103. Throughout the paper, we use a query length of $\ell=32$ tokens.
图 6: 在WikiText-103开发集上分析BM25的困惑度随查询token数量$\ell$的变化关系。附录中展示了WikiText-103内稠密检索器的类似权衡。本文统一采用$\ell=32$个token的查询长度。
In this section, we focus on choosing which document to present to the model, by reranking the top $k$ documents returned by the BM25 retriever.5 We use Figure 7 as motivation: it shows the large potential for improvement among the top-16 documents returned by the BM25 retriever. We act upon this motivation by using two rerankers. Specifically, in $\S6.1$ we show performance gains across our evaluation suite obtained by using an LM to perform zero-shot reranking of the top $k$ BM25 retrieved documents (results in third row for each of the models in Table 1). Then, in $\S6.2$ we show that training a specialized bidirectional reranker of the top $k$ BM25 retrieved documents in a selfsupervised manner via the LM signal can provide further LM gains (results in forth row for each of the models in Table 1).
在本节中,我们重点讨论如何通过重新排序BM25检索器返回的前$k$篇文档来选择呈现给模型的文档。图7展示了这一动机:它表明BM25检索器返回的前16篇文档存在巨大的改进空间。我们采用两种重新排序器来实现这一目标。具体而言,在$\S6.1$中,我们展示了使用大语言模型对BM25检索到的前$k$篇文档进行零样本重新排序所获得的性能提升(结果见表1中每个模型的第三行)。接着,在$\S6.2$中,我们证明了通过LM信号以自监督方式训练一个专门针对BM25检索前$k$篇文档的双向重新排序器,可以带来进一步的LM性能提升(结果见表1中每个模型的第四行)。
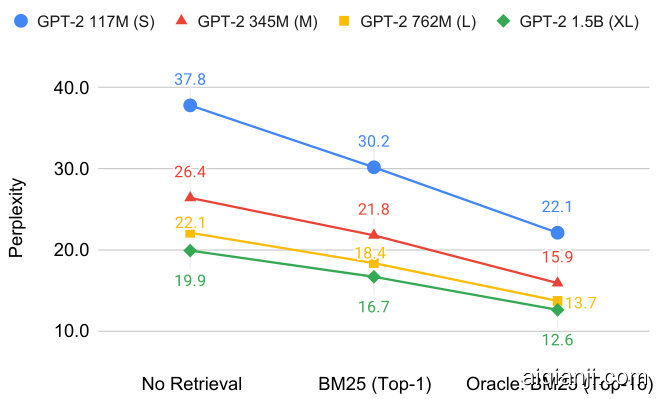
Figure 7: Potential for gains from reranking: perplexity improvement (on the development set of WikiText-103) from an oracle that takes the best of the top-16 documents retrieved by BM25 rather than the first.
图 7: 重排序带来的潜在收益:在WikiText-103开发集上,通过选择BM25检索的前16篇文档中的最佳文档而非首篇文档,困惑度(perplexity)的改进情况。
6.1 LMs as Zero-Shot Rerankers
6.1 大语言模型作为零样本重排器
First, we used off-the-shelf language models as document rerankers for the In-Context RALM setting. Formally, for a query $q$ consisting of the last $\ell$ tokens in the prefix of the LM input $x$ , let ${d_{1},...,d_{k}}$ be the top $k$ documents returned by BM25. For retrieval iteration $j$ , let the text for generation be $y:=x_{s\cdot j+1},...,x_{s\cdot j+s}$ . Ideally, we would like to find the document $d_{i^{*}}$ that maximizes the probability of the text for generation, i.e.,
首先,我们采用现成的语言模型作为文档重排序器,用于上下文相关检索增强语言模型 (In-Context RALM) 场景。具体而言,对于由大语言模型输入 $x$ 前缀中最后 $\ell$ 个 token 组成的查询 $q$,设 ${d_{1},...,d_{k}}$ 为 BM25 返回的前 $k$ 篇文档。在第 $j$ 次检索迭代中,设待生成文本为 $y:=x_{s\cdot j+1},...,x_{s\cdot j+s}$。理想情况下,我们希望找到能最大化待生成文本概率的文档 $d_{i^{*}}$,即
$$
i^{* }=\arg\operatorname*{max}_ {i\in[k]}p_{\theta}(y|[d_{i};x_{\leq s\cdot j}]).
$$
$$
i^{* }=\arg\operatorname*{max}_ {i\in[k]}p_{\theta}(y|[d_{i};x_{\leq s\cdot j}]).
$$
However, at test time we do not have access to the tokens of $y$ . Instead, we used the last $p r e-$ $f\boldsymbol{a}\boldsymbol{x}$ tokens (which are available at test time), denoted by $y^{\prime}$ , for reranking. Formally, let $s^{\prime}$ be a hyper-parameter that determines the number of the prefix tokens by which to rerank. We define $y^{\prime}:=x_{s\cdot j-s^{\prime}+1},...,x_{s\cdot j}$ (i.e., the stride of length $s^{\prime}$ that precedes $y$ ) and choose the document $d_{\hat{i}}$ such
然而,在测试时我们无法获取 $y$ 的 token。为此,我们改用测试时可用的最后 $pre$-$f\boldsymbol{a}\boldsymbol{x}$ 个 token(记为 $y^{\prime}$)进行重排序。具体而言,设 $s^{\prime}$ 为决定用于重排序的前缀 token 数量的超参数。我们定义 $y^{\prime}:=x_{s\cdot j-s^{\prime}+1},...,x_{s\cdot j}$(即 $y$ 之前长度为 $s^{\prime}$ 的滑动窗口),并选择文档 $d_{\hat{i}}$ 使得
| Model | Reranking Model | WikiText-103 | RealNews |
| word ppl | token ppl | ||
| GPT-2 345M (M) | GPT-2 110M (S) | 20.8 | 12.1 |
| GPT-2 345M (M) | 20.8 | 12.0 | |
| GPT-2 762M (L) | GPT-2 110M (S) | 17.7 | 10.7 |
| GPT-2 762M (L) | 17.6 | 10.6 | |
| GPT-2 1.5B (XL) | GPT-2 110M (S) | 16.2 | 9.9 |
| GPT-2 1.5B (XL) | 16.1 | 9.8 |
| 模型 | 重排序模型 | WikiText-103 | RealNews |
|---|---|---|---|
| 词困惑度 | token困惑度 | ||
| GPT-2 345M (M) | GPT-2 110M (S) | 20.8 | 12.1 |
| GPT-2 345M (M) | 20.8 | 12.0 | |
| GPT-2 762M (L) | GPT-2 110M (S) | 17.7 | 10.7 |
| GPT-2 762M (L) | 17.6 | 10.6 | |
| GPT-2 1.5B (XL) | GPT-2 110M (S) | 16.2 | 9.9 |
| GPT-2 1.5B (XL) | 16.1 | 9.8 |
Table 3: Perplexity for zero-shot reranking $(\S6.1)$ where the reranking models is smaller than the LM, or the LM itself. Reranking is performed on the top 16 documents retrieved by BM25. Using a GPT-2 110M (S) instead of a larger language model as a reranker leads to only a minor degradation.
表 3: 零样本重排困惑度 $(\S6.1)$ 其中重排模型小于语言模型或使用语言模型本身。重排基于BM25检索的前16篇文档进行。使用GPT-2 110M (S) 而非更大的语言模型作为重排器仅导致性能轻微下降。
that
那
$$
\hat{i}=\arg\operatorname*{max}_ {i\in[k]}p_{\phi}(y^{\prime}|\left[d_{i};x_{\leq(s\cdot j-s^{\prime})}\right]).
$$
$$
\hat{i}=\arg\operatorname*{max}_ {i\in[k]}p_{\phi}(y^{\prime}|\left[d_{i};x_{\leq(s\cdot j-s^{\prime})}\right]).
$$
The main motivation is that since BM25 is a lexical retriever, we want to incorporate a semantic signal induced by the LM. Also, this reranking shares conceptual similarities with the reranking framework of Sachan et al. (2022) for open-domain question answering, where $y^{\prime}$ (i.e., the last prefix tokens) can be thought of as their “question”.
主要动机在于,由于BM25是一种基于词法的检索器,我们希望融入由大语言模型 (LM) 产生的语义信号。此外,这种重排序与Sachan等人 (2022) 在开放域问答中提出的重排序框架具有概念上的相似性,其中 $y^{\prime}$(即最后的前缀token)可被视为他们的“问题”。
Note that our zero-shot reranking does not require that the LM used for reranking is the same model as the LM used for generation (i.e., the LM in Eq. (6), parameterized by $\phi$ , does not need to be the LM in Eq. (2), parameterized by $\theta$ ). This observation unlocks the possibility of reranking with smaller (and thus faster) models, which is important for two main reasons: (i) Reranking $k$ documents requires $k$ forward passes; and (ii) it allows our methods to be used in cases where the actual LM’s log probabilities are not available (for example, when the LM is accessed through an API).6
需要注意的是,我们的零样本重排序并不要求用于重排序的大语言模型与生成阶段使用的大语言模型相同 (即式 (6) 中由 $\phi$ 参数化的模型不必是式 (2) 中由 $\theta$ 参数化的模型) 。这一发现使得采用更小 (因而更快) 的模型进行重排序成为可能,其重要性主要体现在两方面:(i) 对 $k$ 个文档进行重排序需要进行 $k$ 次前向传播;(ii) 该方法适用于无法获取原始大语言模型对数概率的场景 (例如通过API调用模型时) 。6
Results A minimal hyper-parameter search on the development set of WikiText-103 revealed that the optimal query length is $s^{\prime}=16$ , so we proceed with this value going forward. Table 1 shows the results of letting the LM perform zero-shot reranking on the top-16 documents retrieved by BM25 (third row for each of the models). It is evident that reranking yielded consistently better results than simply taking the first result returned by the retriever.
结果 在WikiText-103开发集上进行的最小超参数搜索显示,最优查询长度为 $s^{\prime}=16$ ,因此后续实验均采用该值。表1展示了让大语言模型对BM25检索出的前16篇文档进行零样本重排的结果(每个模型对应的第三行数据)。显然,重排后的结果始终优于直接采用检索器返回的首个结果。
Table 3 shows that a small LM (GPT-2 117M) can be used to rerank the documents for all larger GPT-2 models, with roughly the same performance as having each LM perform reranking for itself, supporting the applicability of this method for LMs that are only accessible via an API.
表 3: 小型大语言模型 (GPT-2 117M) 可用于为所有更大的 GPT-2 模型重新排序文档,其性能与每个大语言模型自行重新排序大致相同,这支持了该方法仅通过 API 访问的大语言模型的适用性。
6.2 Training LM-dedicated Rerankers
6.2 训练专用大语言模型的重排序器
Next, we trained a reranker to choose one of the top $k$ documents retrieved by BM25. We refer to this approach as Predictive Reranking, since the reranker learns to choose which document will help in “predicting” the upcoming text. For this process, we assume availability of training data from the target corpus. Our reranker is a classifier that gets a prefix $x_{\leq s\cdot j}$ and a document $d_{i}$ (for $i\in[k])$ , and produces a scalar $f(x_{\le s\cdot j},d_{i})$ that should resemble the relevance of di for the continuation of x s j.
接下来,我们训练了一个重排序器 (reranker) 从 BM25 检索到的前 $k$ 个文档中选择一个。我们将这种方法称为预测性重排序 (Predictive Reranking),因为重排序器通过学习来选择哪个文档有助于"预测"接下来的文本。在此过程中,我们假设可以从目标语料库中获得训练数据。我们的重排序器是一个分类器,它接收一个前缀 $x_{\leq s\cdot j}$ 和一个文档 $d_{i}$ (对于 $i\in[k])$,并输出一个标量 $f(x_{\le s\cdot j},d_{i})$,该标量应反映 $d_{i}$ 对于继续生成 $x_{s j}$ 的相关性。
We then normalize these relevance scores:
然后我们对这些相关性分数进行归一化处理:
$$
p_{\mathrm{rank}}(d_{i}|\boldsymbol x{<\boldsymbol s\cdot\boldsymbol j}_ {\mathrm{}})=\frac{\exp(f(\boldsymbol x{<\boldsymbol s\cdot\boldsymbol j}_ {\mathrm{}},d_{i}))}{\sum_{i^{\prime}=1}^{k}\exp(f(\boldsymbol x{<\boldsymbol s\cdot\boldsymbol j}_ {\mathrm{}},d_{i^{\prime}}))},
$$
$$
p_{\mathrm{rank}}(d_{i}|\boldsymbol x{<\boldsymbol s\cdot\boldsymbol j}_ {\mathrm{}})=\frac{\exp(f(\boldsymbol x{<\boldsymbol s\cdot\boldsymbol j}_ {\mathrm{}},d_{i}))}{\sum_{i^{\prime}=1}^{k}\exp(f(\boldsymbol x{<\boldsymbol s\cdot\boldsymbol j}_ {\mathrm{}},d_{i^{\prime}}))},
$$
and choose the document $d_{\hat{i}}$ such that
并选择文档 $d_{\hat{i}}$ 使得
$$
\hat{i}=\mathop{\mathrm{arg}}_ {i\in[k]}p_{\mathrm{rank}}(d_{i}|x\leq s\cdot j).
$$
$$
\hat{i}=\mathop{\mathrm{arg}}_ {i\in[k]}p_{\mathrm{rank}}(d_{i}|x\leq s\cdot j).
$$
Collecting Training Examples To train our predictive reranker, we collected training examples as follows. Let $x_{\leq s\cdot j}$ be a prefix we sample from the training data, and $y:=x_{s\cdot j+1},...,x_{s\cdot j+s}$ be the text for generation upcoming in its next stride. We run BM25 on the query qjs, $q_{j}^{\bar{s,\ell}}$ derived from x s j (see $\S3.2)$ and get $k$ documents ${d_{1},...,d_{k}}$ . For each document $d_{i}$ , we then run the LM to compute $p_{\theta}(y|[d_{i};x_{\leq s\cdot j}])$ similar to Eq. (4).
收集训练样本
为训练我们的预测性重排序模型,我们按以下方式收集训练样本。设 $x_{\leq s\cdot j}$ 为从训练数据中采样的前缀,$y:=x_{s\cdot j+1},...,x_{s\cdot j+s}$ 为接下来要生成的文本。我们在查询 $q_{j}^{\bar{s,\ell}}$ (源自 $x_{s j}$,参见 $\S3.2$) 上运行 BM25,并获取 $k$ 个文档 ${d_{1},...,d_{k}}$。对于每个文档 $d_{i}$,我们运行语言模型计算 $p_{\theta}(y|[d_{i};x_{\leq s\cdot j}])$,类似于公式 (4)。

Figure 8: Zero-shot performance of In-Context RALM on the development set of Natural Questions and TriviaQA, when varying the number of documents (retrieved by DPR) shown in-context.
图 8: In-Context RALM 在 Natural Questions 和 TriviaQA 开发集上的零样本性能 (当改变上下文显示的 DPR 检索文档数量时)。
Training Our reranker was a fine-tuned RoBERTa-base (Liu et al., 2019) that trained for 10,000 steps with a peak learning rate of $10^{-5}$ and a batch size of 32. Overall, we created 300,000 examples from the training set of WikiText-103 as explained above. The loss function we use to train the reranker follows previous work (Guu et al., 2020; Lewis et al., 2020):
训练我们的重排序器是一个经过微调的RoBERTa-base模型(Liu等人, 2019),该模型训练了10,000步,峰值学习率为$10^{-5}$,批量大小为32。总体而言,我们按照上述方法从WikiText-103的训练集中创建了300,000个示例。用于训练重排序器的损失函数遵循先前的工作(Guu等人, 2020;Lewis等人, 2020):
$$
-\log\sum_{i=1}^{k}p_{\mathrm{rank}}(d_{i}|\boldsymbol x\leq\boldsymbol s\cdot\boldsymbol j)\cdot p_{\boldsymbol\theta}(\boldsymbol y|[d_{i};\boldsymbol x\leq\boldsymbol s\cdot\boldsymbol j]).
$$
$$
-\log\sum_{i=1}^{k}p_{\mathrm{rank}}(d_{i}|\boldsymbol x\leq\boldsymbol s\cdot\boldsymbol j)\cdot p_{\boldsymbol\theta}(\boldsymbol y|[d_{i};\boldsymbol x\leq\boldsymbol s\cdot\boldsymbol j]).
$$
Note that unlike those works, we train only the reranker $(p_{\mathrm{rank}})$ , keeping the LM weights $\theta$ frozen.
注意,与这些工作不同,我们仅训练重排序器 $(p_{\mathrm{rank}})$ ,保持语言模型权重 $\theta$ 冻结。
Results Table 1 shows the result of our predictive reranker, trained on WikiText-103. Specifically, we trained it with data produced by GPT-2 110M (S), and tested its effectiveness for all GPT-2 models. We observed significant gains obtained from Predictive Reranking. For example, the perplexity of GPT2 110M (S) improved from 29.6 to 26.8, and that of GPT-2 1.5B (XL) improved from 16.6 to 15.4. This trend held for the other two models as well. Overall, these results demonstrate that training a reranker with domain-specific data was more effective than zero-shot reranking (Section 6.1). Note that these results—while impressive—still leave room for further improvements, compared to the top-16 BM25 oracle results (see Figure 7). Moreover, the oracle results themselves can be improved by retrieving $k>16$ documents via a BM25 retriever, or by training stronger retrievers dedicated to the RALM task. We leave this direction for future work.
结果 表1展示了我们在WikiText-103上训练的预测性重排序器( Predictive Reranker )的结果。具体而言,我们使用GPT-2 110M (S)生成的数据进行训练,并测试了其对所有GPT-2模型的有效性。我们观察到预测性重排序带来了显著提升:例如GPT-2 110M (S)的困惑度从29.6降至26.8,GPT-2 1.5B (XL)从16.6降至15.4。这一趋势在其他两个模型上也保持一致。总体而言,这些结果表明使用领域特定数据训练的重排序器比零样本重排序更有效( 见第6.1节 )。值得注意的是,虽然这些结果令人印象深刻,但与top-16 BM25基准结果相比( 见图7 )仍有提升空间。此外,通过BM25检索器获取$k>16$个文档,或训练专门针对RALM任务的更强检索器,还可以进一步提升基准结果本身。我们将这一方向留作未来工作。
| Model | Retrieval | NQ | TriviaQA |
| LLaMA-7B | 10.3 | 47.5 | |
| DPR | 28.0 | 56.0 | |
| LLaMA-13B | 12.0 | 54.8 | |
| DPR | 31.0 | 60.1 | |
| LLaMA-33B | 13.7 | 58.3 | |
| DPR | 32.3 | 62.7 |
| 模型 | 检索方式 | NQ | TriviaQA |
|---|---|---|---|
| LLaMA-7B | 无 | 10.3 | 47.5 |
| LLaMA-7B | DPR | 28.0 | 56.0 |
| LLaMA-13B | 无 | 12.0 | 54.8 |
| LLaMA-13B | DPR | 31.0 | 60.1 |
| LLaMA-33B | 无 | 13.7 | 58.3 |
| LLaMA-33B | DPR | 32.3 | 62.7 |
Table 4: Zero-shot results of In-Context RALM on the test set of Natural Questions and TriviaQA measured by exact match. In the open-book setting, we include the top two documents returned by DPR.
表 4: In-Context RALM 在 Natural Questions 和 TriviaQA 测试集上的零样本 (Zero-shot) 结果(基于精确匹配指标)。在开卷 (open-book) 设置中,我们包含了 DPR 返回的前两份文档。
7 In-Context RALM for Open-Domain Question Answering
7 开放领域问答中的上下文相关 RALM
So far, we evaluated our framework on language modeling benchmarks. To test its efficacy in additional scenarios, and specifically downstream tasks, we now turn to evaluate In-Context RALM on opendomain question answering (ODQA; Chen et al. 2017). This experiment is intended to verify, in a controlled environment, that LMs can leverage retrieved documents without further training and without any training examples. Specifically, we use the LLaMA family (Touvron et al., 2023) with and without In-Context RALM (often referred to in ODQA literature as open-book and closed-book settings, respectively). In contrast to most prior work on ODQA (e.g., Izacard and Grave 2021; Fajcik et al. 2021; Izacard et al. 2022b; Levine et al. 2022b), our “reader” (i.e., the model that gets the question along with its corresponding retrieved documents, and returns the answer) is simply a frozen large LM: not pretrained, fine-tuned or prompted to be retrieval-augmented. For the closed-book setting, we utilize the prompt of Touvron et al. (2023). For the open-book setting, we extend this prompt to include retrieved documents (see App. C). We use DPR (Karpukhin et al., 2020) as our retriever.
目前,我们已在语言建模基准上评估了该框架。为了测试其在其他场景(尤其是下游任务)中的有效性,我们转向在开放域问答(ODQA;Chen等人2017)任务中评估In-Context RALM。本实验旨在受控环境中验证:大语言模型无需额外训练或任何训练样本即可利用检索文档。具体而言,我们对比了使用与不使用In-Context RALM的LLaMA系列模型(Touvron等人2023)(在ODQA文献中常分别称为开卷与闭卷设置)。与大多数先前ODQA研究(如Izacard和Grave 2021;Fajcik等人2021;Izacard等人2022b;Levine等人2022b)不同,我们的"阅读器"(即接收问题及其对应检索文档并返回答案的模型)仅是一个冻结的大语言模型:未经预训练、微调或提示进行检索增强。闭卷设置采用Touvron等人(2023)的提示模板,开卷设置则扩展该模板以包含检索文档(见附录C)。我们使用DPR(Karpukhin等人2020)作为检索器。
Varying the Number of Documents To investigate the the effect of the number of documents shown to the model, we performed a minimal analysis on the development set of NQ and TriviaQA. Figure 8 demonstrates that showing documents incontext significantly improves the model’s performance. In addition, most of the gain can be obtained by using only two documents (or even a single one in some cases).
调整文档数量
为了研究向模型展示的文档数量对效果的影响,我们对NQ和TriviaQA的开发集进行了简要分析。图8表明,在上下文中展示文档能显著提升模型性能。此外,仅使用两个文档(某些情况下甚至一个文档)即可获得大部分性能提升。
Results Table 4 gives the results of In-Context RALM on the test set of Natural Questions and TriviaQA. Motivated by our previous findings, we used two retrieved documents. It is evident that showing the model relevant documents significantly boosted its performance. For example, adding retrieved documents improved LLaMA13B in the zero-shot setting by more than 18 points on NQ (from $12.0%$ to $31.0%$ ) and more than 5 points on TriviaQA (from $54.8%$ to $60.1%$ ).
结果 表4给出了In-Context RALM在Natural Questions和TriviaQA测试集上的结果。基于我们之前的发现,我们使用了两个检索到的文档。显然,向模型展示相关文档显著提升了其性能。例如,在零样本设置下,添加检索到的文档使LLaMA13B在NQ上的表现提高了18个百分点以上(从$12.0%$提升至$31.0%$),在TriviaQA上提高了5个百分点以上(从$54.8%$提升至$60.1%$)。
8 Discussion
8 讨论
Retrieval from external sources has become a common practice in knowledge-intensive tasks (such as factual question answering, fact checking, and more; Petroni et al. 2021). In parallel, recent breakthroughs in LM generation capabilities has led to LMs that can generate useful long texts. However, factual inaccuracies remain a common way in which machine-generated text can fall short, and lack of direct provenance makes it hard to trust machine generated text. This makes language modeling both a promising and an urgent new application area for knowledge grounding, and motivates promoting RALM approaches. Prior research has already investigated RALM, of course, but it is not yet widely deployed. One likely reason is that existing approaches rely upon fine-tuning the LM, which is typically difficult and costly, and is even impossible for LMs accessible only via an API.
在知识密集型任务(如事实问答、事实核查等;Petroni等人2021)中,从外部来源检索已成为常见做法。与此同时,大语言模型生成能力的近期突破使其能够产出有用的长文本。然而,事实性错误仍是机器生成文本的主要缺陷,且缺乏直接来源导致其可信度存疑。这使语言建模既成为知识落地极具前景的新应用领域,也凸显了推动检索增强语言模型(RALM)方法的紧迫性。尽管已有研究探索过RALM,但其尚未广泛部署。一个重要原因是现有方法依赖对大语言模型的微调,而微调通常困难且成本高昂,对于仅通过API访问的模型更是无法实现。
This paper presented the framework of InContext RALM, enabling frozen, off-the-shelf LMs to benefit from retrieval. We demonstrated that substantial performance gains can be achieved by using general purpose retrievers, and showed that additional gains can be achieved by tailoring the document selection to the LM setting. A recent work by Muhlgay et al. (2023) demonstrates that In-Context RALM is indeed able to improve the factuality of large LMs.
本文提出了InContext RALM框架,使现成的冻结大语言模型能够通过检索获益。我们证明使用通用检索器可显著提升性能,并表明通过针对大语言模型设置定制文档选择策略能获得额外增益。Muhlgay等人 (2023) 的最新研究表明,In-Context RALM确实能提升大语言模型的事实准确性。
Several directions for further improvement remain for future work. First, this paper considers only the case of prepending a single external document to the context; adding more documents could drive further gains (for example, using the framework of Ratner et al. 2022). Second, we retrieved documents every fixed interval of $s$ tokens, but see potential for large latency and cost gains by retrieving more sparsely, such as only when a specialized model predicts that retrieval is needed.
未来工作仍有多个改进方向。首先,本文仅考虑在上下文前添加单个外部文档的情况;增加更多文档可能带来进一步收益(例如采用Ratner等人2022年提出的框架)。其次,我们每固定间隔$s$个token检索一次文档,但发现通过更稀疏的检索(如仅在专用模型预测需要检索时执行)可能显著降低延迟和成本。
We release the code used in this work, for the community to use and improve over. We hope it will drive further research of RALM, which will enable its wider adoption.
我们发布了本工作中使用的代码,供社区使用和改进。我们希望这将推动检索增强语言模型(RALM)的进一步研究,从而促进其更广泛的应用。
Acknowledgements
致谢
We would like to thank the reviewers and the Action Editor for their valuable feedback.
感谢审稿人和执行编辑的宝贵反馈。
References
参考文献
Uri Alon, Frank Xu, Junxian He, Sudipta Sengupta, Dan Roth, and Graham Neubig. 2022. Neurosymbolic language modeling with automatonaugmented retrieval. In ICML.
Uri Alon、Frank Xu、Junxian He、Sudipta Sengupta、Dan Roth 和 Graham Neubig。2022。基于自动机增强检索的神经符号语言建模。收录于ICML。
Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. 2021. GPT-Neo: Large Scale Auto regressive Language Modeling with Mesh-Tensorflow.
Sid Black、Leo Gao、Phil Wang、Connor Leahy 和 Stella Biderman。2021. GPT-Neo: 基于 Mesh-Tensorflow 的大规模自回归语言建模。
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean- Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Si- monyan, Jack Rae, Erich Elsen, and Laurent Sifre. 2022. Improving language models by retrieving from trillions of tokens. In ICML.
Sebastian Borgeaud、Arthur Mensch、Jordan Hoffmann、Trevor Cai、Eliza Rutherford、Katie Millican、George Bm Van Den Driessche、Jean-Baptiste Lespiau、Bogdan Damoc、Aidan Clark、Diego De Las Casas、Aurelia Guy、Jacob Menick、Roman Ring、Tom Hennigan、Saffron Huang、Loren Maggiore、Chris Jones、Albin Cassirer、Andy Brock、Michela Paganini、Geoffrey Irving、Oriol Vinyals、Simon Osindero、Karen Simonyan、Jack Rae、Erich Elsen 和 Laurent Sifre。2022。通过从数万亿token中检索改进语言模型。发表于ICML。
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhari- wal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems.
Tom B. Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell、Sandhini Agarwal、Ariel Herbert-Voss、Gretchen Krueger、Tom Henighan、Rewon Child、Aditya Ramesh、Daniel Ziegler、Jeffrey Wu、Clemens Winter、Christopher Hesse、Mark Chen、Eric Sigler、Mateusz Litwin、Scott Gray、Benjamin Chess、Jack Clark、Christopher Berner、Sam McCandlish、Alec Radford、Ilya Sutskever 和 Dario Amodei。2020。大语言模型是少样本学习者。《神经信息处理系统进展》。
Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading Wikipedia to answer open-domain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long
Danqi Chen、Adam Fisch、Jason Weston和Antoine Bordes。2017年。通过阅读维基百科回答开放域问题。收录于第55届计算语言学协会年会论文集(第一卷:长篇论文)
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019。BERT:面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会人类语言技术会议论文集(长文与短文)》第1卷,第4171–4186页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiy- ong Wu, Baobao Chang, Xu Sun, Jingjing Xu, Lei Li, and Zhifang Sui. 2023. A survey on in-context learning.
董清秀、李磊、戴大迈、郑策、吴志勇、常宝宝、孙旭、徐晶晶、李磊、隋志芳。2023。上下文学习综述。
Martin Fajcik, Martin Docekal, Karel Ondrej, and Pavel Smrz. 2021. R2-D2: A modular baseline for open-domain question answering. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 854–870, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Martin Fajcik、Martin Docekal、Karel Ondrej 和 Pavel Smrz。2021。R2-D2: 开放域问答的模块化基线。载于《计算语言学协会发现:EMNLP 2021》,第854–870页,多米尼加共和国蓬塔卡纳。计算语言学协会。
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. 2021. The pile: An $800\mathrm{gb}$ dataset of diverse text for lan- guage modeling.
Leo Gao、Stella Biderman、Sid Black、Laurence Golding、Travis Hoppe、Charles Foster、Jason Phang、Horace He、Anish Thite、Noa Nabeshima、Shawn Presser 和 Connor Leahy。2021。The Pile: 一个用于语言建模的800GB多样化文本数据集。
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. REALM: Retrieval-augmented language model pretraining. In ICML.
Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat 和 Ming-Wei Chang。2020. REALM:检索增强的语言模型预训练。收录于ICML。
Junxian He, Graham Neubig, and Taylor BergKirkpatrick. 2021. Efficient nearest neighbor language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5703–5714, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Junxian He、Graham Neubig 和 Taylor BergKirkpatrick。2021. 高效最近邻语言模型。载于《2021年自然语言处理实证方法会议论文集》,第5703-5714页,线上会议及多米尼加共和国蓬塔卡纳。计算语言学协会。
Minlie Huang, Xiaoyan Zhu, and Jianfeng Gao. 2020. Challenges in building intelligent opendomain dialog systems. ACM Trans. Inf. Syst., 38(3).
Minlie Huang、Xiaoyan Zhu和Jianfeng Gao。2020。构建智能开放域对话系统的挑战。ACM Trans. Inf. Syst., 38(3)。
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand
Joulin, and Edouard Grave. 2022a. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research.
Joulin 和 Edouard Grave. 2022a. 基于对比学习的无监督密集信息检索. Transactions on Machine Learning Research.
Gautier Izacard and Edouard Grave. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, Online. Association for Computational Linguistics.
Gautier Izacard 和 Edouard Grave. 2021. 利用生成模型结合段落检索实现开放域问答. 载于《第16届欧洲计算语言学协会会议论文集: 主卷》, 第874–880页, 线上会议. 计算语言学协会.
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2022b. Atlas: Few-shot learning with retrieval augmented language models.
Gautier Izacard、Patrick Lewis、Maria Lomeli、Lucas Hosseini、Fabio Petroni、Timo Schick、Jane Dwivedi-Yu、Armand Joulin、Sebastian Riedel 和 Edouard Grave。2022b. Atlas: 基于检索增强语言模型的少样本学习。
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2021. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547.
Jeff Johnson、Matthijs Douze和Hervé Jégou。2021。基于GPU的十亿级相似性搜索。《IEEE大数据汇刊》7(3):535–547。
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Z ett le moyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the $55t h$ Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada. Association for Computational Linguistics.
Mandar Joshi、Eunsol Choi、Daniel Weld和Luke Zettlemoyer。2017. TriviaQA: 一个大规模远程监督的阅读理解挑战数据集。见《第55届计算语言学协会年会论文集》(第1卷: 长论文), 第1601-1611页, 加拿大温哥华。计算语言学协会。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online. Association for Computational Linguistics.
Vladimir Karpukhin、Barlas Oguz、Sewon Min、Patrick Lewis、Ledell Wu、Sergey Edunov、Danqi Chen和Wen-tau Yih。2020。开放域问答的密集段落检索。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第6769–6781页,线上。计算语言学协会。
Urvashi Khandelwal, Omer Levy, Dan Juraf-sky, Luke Z ett le moyer, and Mike Lewis. 2020. Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations.
Urvashi Khandelwal、Omer Levy、Dan Jurafsky、Luke Zettlemoyer 和 Mike Lewis。2020。通过记忆实现泛化:最近邻语言模型。In International Conference on Learning Representations。
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and
Tom Kwiatkowski、Jennimaria Palomaki、Olivia Redfield、Michael Collins、Ankur Parikh、Chris Alberti、Danielle Epstein、Illia Polosukhin、Jacob Devlin、Kenton Lee、Kristina Toutanova、Llion Jones、Matthew Kelcey、Ming-Wei Chang、Andrew M. Dai、Jakob Uszkoreit、Quoc Le
Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466.
Slav Petrov. 2019. 自然问题:问答研究基准。《计算语言学协会汇刊》7:452–466。
Yoav Levine, Itay Dalmedigos, Ori Ram, Yoel Zeldes, Daniel Jannai, Dor Muhlgay, Yoni Osin, Opher Lieber, Barak Lenz, Shai Shalev-Shwartz, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2022a. Standing on the shoulders of giant frozen language models.
Yoav Levine、Itay Dalmedigos、Ori Ram、Yoel Zeldes、Daniel Jannai、Dor Muhlgay、Yoni Osin、Opher Lieber、Barak Lenz、Shai Shalev-Shwartz、Amnon Shashua、Kevin Leyton-Brown 和 Yoav Shoham。2022a。站在巨人的肩膀上:冻结大语言模型的应用。
Yoav Levine, Ori Ram, Daniel Jannai, Barak Lenz, Shai Shalev-Shwartz, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2022b. Huge frozen language models as readers for opendomain question answering. In ICML 2022 Workshop on Knowledge Retrieval and Language Models.
Yoav Levine、Ori Ram、Daniel Jannai、Barak Lenz、Shai Shalev-Shwartz、Amnon Shashua、Kevin Leyton-Brown和Yoav Shoham。2022b。将超大规模冻结语言模型作为开放域问答的阅读器。收录于ICML 2022知识检索与语言模型研讨会。
Yoav Levine, Noam Wies, Daniel Jannai, Dan Navon, Yedid Hoshen, and Amnon Shashua. 2022c. The inductive bias of in-context learning: Rethinking pre training example design. In International Conference on Learning Representations.
Yoav Levine、Noam Wies、Daniel Jannai、Dan Navon、Yedid Hoshen 和 Amnon Shashua。2022c。上下文学习的归纳偏置:重新思考预训练示例设计。见于国际学习表征会议。
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock t s chel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems, pages 9459–9474.
Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel、Sebastian Riedel 和 Douwe Kiela。2020。面向知识密集型 NLP 任务的检索增强生成。载于《神经信息处理系统进展》,第9459-9474页。
Zonglin Li, Ruiqi Guo, and Sanjiv Kumar. 2022. Decoupled context processing for context augmented language modeling. In Advances in Neural Information Processing Systems.
Zonglin Li, Ruiqi Guo, 和 Sanjiv Kumar. 2022. 面向上下文增强语言建模的解耦上下文处理. 见《神经信息处理系统进展》.
Opher Lieber, Or Sharir, Barak Lenz, and Yoav Shoham. 2021. Jurassic-1: Technical details and evaluation.
Opher Lieber、Or Sharir、Barak Lenz 和 Yoav Shoham。2021. Jurassic-1:技术细节与评估
Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021. Pyserini: A python toolkit for reproducible information retrieval research with sparse and dense representations. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’21, page 2356–2362, New York, NY, USA. Association for Computing Machinery.
Jimmy Lin、Xueguang Ma、Sheng-Chieh Lin、Jheng-Hong Yang、Ronak Pradeep 和 Rodrigo Nogueira。2021。Pyserini: 一个基于Python语言的稀疏与稠密表示可复现信息检索研究工具包。见《第44届国际ACM SIGIR信息检索研究与发展会议论文集》(SIGIR '21),第2356–2362页,美国纽约州纽约市。ACM出版社。
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland. Association for Computational Linguistics.
Stephanie Lin、Jacob Hilton和Owain Evans。2022。TruthfulQA:衡量模型如何模仿人类谬误。载于《第60届计算语言学协会年会论文集(第一卷:长论文)》,第3214–3252页,爱尔兰都柏林。计算语言学协会。
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Z ett le moyer, and Veselin Stoyanov. 2019. RoBERTa: A robustly optimized bert pre training approach.
Yinhan Liu、Myle Ott、Naman Goyal、Jingfei Du、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zettlemoyer 和 Veselin Stoyanov。2019。RoBERTa: 一种稳健优化的BERT预训练方法。
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On faithfulness and factuality in abstract ive sum mari z ation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, Online. Association for Computational Linguistics.
Joshua Maynez、Shashi Narayan、Bernd Bohnet和Ryan McDonald。2020。论摘要生成中的忠实性与事实性。载于《第58届计算语言学协会年会论文集》,第1906-1919页,线上。计算语言学协会。
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2016. Pointer sentinel mixture models.
Stephen Merity、Caiming Xiong、James Bradbury 和 Richard Socher。2016. 指针哨兵混合模型。
Dor Muhlgay, Ori Ram, Inbal Magar, Yoav Levine, Nir Ratner, Yonatan Belinkov, Omri Abend, Kevin Leyton-Brown, Amnon Shashua, and Yoav Shoham. 2023. Generating benchmarks for factuality evaluation of language models.
Dor Muhlgay、Ori Ram、Inbal Magar、Yoav Levine、Nir Ratner、Yonatan Belinkov、Omri Abend、Kevin Leyton-Brown、Amnon Shashua 和 Yoav Shoham。2023。为大语言模型的事实性评估生成基准。
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, Vassilis Plachouras, Tim Rock t s chel, and Sebastian Riedel. 2021. KILT: a benchmark for knowledge intensive language tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2523–2544, Online. Association for Computational Linguistics.
Fabio Petroni、Aleksandra Piktus、Angela Fan、Patrick Lewis、Majid Yazdani、Nicola De Cao、James Thorne、Yacine Jernite、Vladimir Karpukhin、Jean Maillard、Vassilis Plachouras、Tim Rocktäschel 和 Sebastian Riedel。2021。KILT:知识密集型语言任务基准测试。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第2523–2544页,线上会议。计算语言学协会。
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.
Alec Radford、Karthik Narasimhan、Tim Salimans 和 Ilya Sutskever。2018. 通过生成式预训练提升语言理解能力。
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
Alec Radford、Jeff Wu、Rewon Child、David Luan、Dario Amodei 和 Ilya Sutskever。2019。语言模型是无监督多任务学习器。
Ori Ram, Gal Shachaf, Omer Levy, Jonathan Be- rant, and Amir Globerson. 2022. Learning to retrieve passages without supervision. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo- gies, pages 2687–2700, Seattle, United States. Association for Computational Linguistics.
Ori Ram、Gal Shachaf、Omer Levy、Jonathan Berant 和 Amir Globerson。2022。无监督学习检索段落。载于《2022年北美计算语言学协会人类语言技术会议论文集》(Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies),第2687–2700页,美国西雅图。计算语言学协会。
Nir Ratner, Yoav Levine, Yonatan Belinkov, Ori Ram, Omri Abend, Ehud Karpas, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2022. Parallel context windows improve in-context learning of large language models.
Nir Ratner、Yoav Levine、Yonatan Belinkov、Ori Ram、Omri Abend、Ehud Karpas、Amnon Shashua、Kevin Leyton-Brown 和 Yoav Shoham。2022。并行上下文窗口提升大语言模型的上下文学习能力。
Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389.
Stephen Robertson 和 Hugo Zaragoza. 2009. 概率相关性框架: BM25 及后续发展. 信息检索基础与趋势, 3(4):333–389.
Devendra Sachan, Mike Lewis, Mandar Joshi, Armen Aghajanyan, Wen-tau Yih, Joelle Pineau, and Luke Z ett le moyer. 2022. Improving passage retrieval with zero-shot question generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3781–3797, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Devendra Sachan、Mike Lewis、Mandar Joshi、Armen Aghajanyan、Wen-tau Yih、Joelle Pineau 和 Luke Zettlemoyer。2022。通过零样本问题生成改进段落检索。载于《2022年自然语言处理实证方法会议论文集》,第3781–3797页,阿拉伯联合酋长国阿布扎比。计算语言学协会。
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen tau Yih. 2023. REPLUG: Retrieval-augmented black-box language models.
Weijia Shi、Sewon Min、Michihiro Yasunaga、Minjoon Seo、Rich James、Mike Lewis、Luke Zettlemoyer 和 Wen tau Yih。2023。REPLUG:检索增强的黑盒语言模型。
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1.
Nandan Thakur、Nils Reimers、Andreas Rücklé、Abhishek Srivastava和Iryna Gurevych。2021。BEIR:一个用于信息检索模型零样本评估的异构基准。收录于《神经信息处理系统数据集与基准跟踪会议论文集》第1卷。
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and efficient foundation language models.
Hugo Touvron、Thibaut Lavril、Gautier Izacard、Xavier Martinet、Marie-Anne Lachaux、Timo-thée Lacroix、Baptiste Rozière、Naman Goyal、Eric Hambro、Faisal Azhar、Aurelien Rodriguez、Armand Joulin、Edouard Grave 和 Guillaume Lample。2023。LLaMA:开放高效的基础语言模型。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez,
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez
Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30, pages 5998– 6008.
Ł ukasz Kaiser 和 Illia Polosukhin。2017。注意力就是一切。在《神经信息处理系统进展》第30卷,第5998-6008页。
Ben Wang and Aran Komatsu zak i. 2021. GPT-J6B: A 6 Billion Parameter Auto regressive Language Model.
Ben Wang 和 Aran Komatsu zak i. 2021. GPT-J6B: 一个 60 亿参数的自回归语言模型。
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pierric Cistac、Tim Rault、Remi Louf、Morgan Funtowicz、Joe Davison、Sam Shleifer、Patrick von Platen、Clara Ma、Yacine Jernite、Julien Plu、Canwen Xu、Teven Le Scao、Sylvain Gugger、Mariama Drame、Quentin Lhoest 和 Alexander Rush。2020。Transformer:最先进的自然语言处理技术。载于《2020年自然语言处理实证方法会议:系统演示论文集》,第38-45页,线上。计算语言学协会。
Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. 2019. Defending against neural fake news. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
Rowan Zellers、Ari Holtzman、Hannah Rashkin、Yonatan Bisk、Ali Farhadi、Franziska Roesner和Yejin Choi。2019。防御神经假新闻。收录于《神经信息处理系统进展》第32卷。Curran Associates公司。
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Z ett le moyer. 2022. OPT: Open pre-trained transformer language models.
Susan Zhang、Stephen Roller、Naman Goyal、Mikel Artetxe、Moya Chen、Shuohui Chen、Christopher Dewan、Mona Diab、Xian Li、Xi Victoria Lin、Todor Mihaylov、Myle Ott、Sam Shleifer、Kurt Shuster、Daniel Simig、Punit Singh Koura、Anjali Sridhar、Tianlu Wang和Luke Zettlemoyer。2022。OPT:开放预训练Transformer语言模型。
Zexuan Zhong, Tao Lei, and Danqi Chen. 2022. Training language models with memory augmentation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5657–5673, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Zexuan Zhong、Tao Lei和Danqi Chen。2022。基于记忆增强的语言模型训练。载于《2022年自然语言处理实证方法会议论文集》,第5657–5673页,阿拉伯联合酋长国阿布扎比。计算语言学协会。
A Query Length Ablations
查询长度消融实验
Figure 9 and Figure 10 show ablations on the optimal query length $\ell$ for off-the-shelf dense retrievers (BERT and Contriever respectively). We omit the results of Spider as they are almost identical to those of Contriever. Consistently, using $\ell=64$ (tokens) is optimal. This is in contrast to similar experiments we conducted for BM25 (cf. Figure 6), where $\ell=32$ is optimal.
图 9 和图 10 展示了针对现成密集检索器 (分别为 BERT 和 Contriever) 的最优查询长度 $\ell$ 的消融实验。我们省略了 Spider 的结果,因为它们与 Contriever 几乎相同。一致地,使用 $\ell=64$ (token) 是最优的。这与我们在 BM25 上进行的类似实验 (参见图 6) 形成对比,后者最优值为 $\ell=32$。
B GPT-Neo Results
B GPT-Neo 实验结果
Table 5 gives the results of applying In-Context RALM to the models from the GPT-Neo model family on WikiText-103 and RealNews.
表 5: GPT-Neo 模型家族在 WikiText-103 和 RealNews 数据集上应用上下文检索增强语言模型 (In-Context RALM) 的结果
Open-Domain Question Answering Experiments: Further Details
开放域问答实验:更多细节
Closed-Book Setting For the closed-book setting, we adopt the prompt of Touvron et al. (2023):
闭卷设置
对于闭卷设置,我们采用Touvron等人 (2023) 的提示模板:
Answer these questions: Q: Who got the first nobel prize in physics? A:
回答以下问题:Q: 谁获得了第一个诺贝尔物理学奖?A:
| Model | Retrieval | Wiki-103 | RealNews |
| word ppl | token ppl | ||
| GPT-Ne01.3B | 17.5 | 12.3 | |
| BM25,§5 | 14.6 | 9.9 | |
| GPT-Ne02.7B | 15.1 | 11.0 | |
| BM25,§5 | 12.8 | 9.0 | |
| GPT-J 6B | 11.6 | 9.2 | |
| BM25,§5 | 10.0 | 7.7 |
| 模型 | 检索 | Wiki-103 (词级困惑度) | RealNews (Token级困惑度) |
|---|---|---|---|
| GPT-Neo 1.3B | - | 17.5 | 12.3 |
| BM25, §5 | 14.6 | 9.9 | |
| GPT-Neo 2.7B | - | 15.1 | 11.0 |
| BM25, §5 | 12.8 | 9.0 | |
| GPT-J 6B | - | 11.6 | 9.2 |
| BM25, §5 | 10.0 | 7.7 |
Table 5: The performance of models from the GPTNeo family, measured by word-level perplexity on the test set of WikiText-103 and token-level perplexity on the development set of RealNews.
表 5: GPTNeo系列模型在WikiText-103测试集上的词级困惑度(perplexity)及RealNews开发集上的token级困惑度表现。
Open-Book Setting For the open-book setting, we extend the above prompt as follows:
开卷设置
对于开卷设置,我们将上述提示扩展如下:
Nobel Prize
诺贝尔奖
A group including 42 Swedish writers, artists, and literary critics protested against this decision, having expected Leo Tolstoy to be awarded. Some, including Burton Feldman, have criticised this prize because they...
包括42名瑞典作家、艺术家和文学评论家在内的团体抗议这一决定,他们原本期望列夫·托尔斯泰获奖。包括Burton Feldman在内的一些人批评该奖项,因为他们...
Nobel Prize in Physiology or Medicine
诺贝尔生理学或医学奖
In the last half century there has been an increasing tendency for scientists to work as teams, resulting in controversial exclusions. Alfred Nobel was born on 21 October 1833 in Stockholm, Sweden, into a family of engineers...
近半个世纪以来,科学家们越来越倾向于以团队形式开展工作,这导致了一些有争议的排除现象。Alfred Nobel于1833年10月21日出生在瑞典斯德哥尔摩的一个工程师家庭...
Based on these texts, answer these questions: Q: Who got the first nobel prize in physics? A:
根据这些文本,回答以下问题:Q: 谁获得了第一个诺贝尔物理学奖?A:

Figure 9: An analysis of perplexity as a function of the number of tokens in the query for an offthe-shelf BERT retriever on the development set of WikiText-103.
图 9: 针对WikiText-103开发集上现成BERT检索器的困惑度随查询token数量变化的分析。

Figure 10: An analysis of perplexity as a function of the number of tokens in the query for Contriever on the development set of WikiText-103.
图 10: 在WikiText-103开发集上分析Contriever查询中token数量与困惑度(perplexity)的关系。